
1 Contenido - Centro de Innovación Pública...
58
Transcript of 1 Contenido - Centro de Innovación Pública...



1 Contenido GENERALIDADES DE LA INVESTIGACIÓN 4
Contexto de la investigación 4 Información de contacto del grupo de investigación 4 Entidad Beneficiaria 4 Necesidad de la Entidad Beneficiaria 4 Reto 4 Resumen de los Resultados 4
Alcance de la investigación 5 Enfoque del proyecto de investigación 5 Cambios esperados en la entidad beneficiaria 5
RESUMEN DE INVESTIGACIÓN 5 Resumen de la investigación 5 Palabras claves 5 Objetivo de Investigación 6 Objetivo general 6 Objetivo especifico 6 Tipo de Investigación 6 Resumen de las etapas de la investigación y metodología 6 Elementos conceptuales de la investigación 7 Infraestructura del análisis de datos. 7 Sistema de visión. 7 Glosario 12 Principales logros por etapas de la investigación 13 Principales aprendizajes 15 Lo que sigue en el futuro 15 Conclusiones 16
PROCESO DE INVESTIGACIÓN 16 En qué consiste la Investigación? 16 Proceso de Investigación 16 Etapa 1: Determinación de la infraestructura para el análisis de datos 16
Sistema Distribuido para el análisis de Datos 16 Etapa 2: Determinación de los algoritmos usados en la infraestructura para el análisis de imagenes de tráfico vehicular. 17
Sistema de detección de Vehículos 17 Sistema de tracking de vehículos 18

Etapa 3: Creación del sistema: ensamble de las infraestructuras de analisis de datos y analisis de imagenes. 23 Etapa 4: Pruebas del sistema 23 Etapa 5: Entrega del sistema 24 Listado de Actores 24 Requerimietos 24 Requerimientos funcionales 24 Requerimientos no funcionales 25 Definición de Actores 25 Indentificación de Casos de Uso 26 Diagrama de Casos de Uso 26 Priorización de Casos de Uso 27 Descripción de Casos de Uso Prioritarios 28 Desarrollo del prototipo 32 Estrategia de Diseño 32
Infraestructura para el Análisis de Datos 32 Análisis de Tráfico Vehicular 33
Arquitectura Básica 34 Diagrama de Componentes 35
Cluster de Análisis de Datos 35
Sistema de Análisis de Patrones 37
Detector / Clasificador 38
Seguidor (Tracker) 39
Detector de accidentes 40
Prototipo de Aplicación para Visualización de Reportes 42 Diseño de Frontend 42 Modelo Entidad Relación (MER) 44
Despliegue de la Solución 45
Diagrama de Despliegue de la Versión Stand Alone 45
Diagrama de Despliegue de la Versión Distribuida 46 Infraestructura Física y Herramientas Software 47 Validación y Pruebas 48 Entrega 49
Manuales de usuario 49 El manual de usuario puede consultarse en el Anexo 6.1 (Guía de Uso). 49 Instalación 49

Código fuente 50
Anexos 51 Guía de uso 51
Guía de uso del sistema Stand Alone 51 Guía de uso del sistema Distribuido 55

GENERALIDADES DE LA INVESTIGACIÓN 1 Contexto de la investigación 1.1 Información de contacto del grupo de investigación Nombre del Grupo: Grupo deInvestigaciónenTelemáticaeInformáticaAplicada(GITI) Categoría Colciencias: A Coordinador del Grupo: Oscar H. Mondragón
1.2 Entidad Beneficiaria
Adlcaldía de Cali
1.3 Necesidad de la Entidad Beneficiaria
La ciudad requería de un sistema para comprender mejor los fenómenos de accidentalidad que se evidencian en la ciudad de Cali, que sirva como insumo para la toma de decisiones de los entes gubernamentales.
1.4 Reto Analizar patrones de accidentalidad de las vías de Cali a partir de imágenes de video recolectadas en sus vías.
1.5 Resumen de los Resultados El resultado principal de esta investigación, corresponde a un sistema de visión computacional que, a través de imágenes capturadas desde cámaras instaladas en la ciudad, analiza el fenómeno de la accidentalidad vial, permitiendo la mejora en la toma de decisiones frente a la reducción de dicha problemática. A continuación se listan en detalle los resultados obtenidos:
● Sistema de visión computacional para detección de eventos con alta probabilidad de generar accidentes
● Sistema de visión computacional para la detección de accidentes en las vías de la ciudad
● Código adaptado para aprovechar la infraestructura computacional distribuida de análisis de datos basada en tecnología Hadoop/Spark.

2 Alcance de la investigación 2.1 Enfoque del proyecto de investigación
Se espera que la investigación permita conocer las potencialidades de la analítica de datos y la visión inteligente basada en inteligencia artificial para que a través de imágenes capturadas desde las cámaras de tránsito de la ciudad de Cali, se pueda analizar el fenómeno de la accidentalidad vial, permitiendo la mejora en la toma de decisiones frente a la reducción de dicha problemática.
2.2 Cambios esperados en la entidad beneficiaria La entidad beneficiaria contará con una nueva herramienta que le permitirá mejorar su proceso de toma de decisiones relativas a la gestión del tráfico vehicular de la ciudad.
RESUMEN DE INVESTIGACIÓN 1. Resumen de la investigación Esta investigación aplicada abarca el desarrollo de una plataforma tecnológica consistente en un sistema distribuido para el reconocimiento de patrones en imágenes de video, enfocado principalmente en patrones que impactan de manera negativa los índices de accidentalidad en las vías de una ciudad. Basados en experiencias previas del grupo en esta área, se plantea el diseño un clúster basado en tecnologías de infraestructura de sistemas distribuidos para análisis de datos, la implementación de un algoritmo para el reconocimiento de patrones de afectación del tráco seleccionados, los mecanismos para la noticación de las alertas correspondientes y las herramientas de análisis que permitan predecir estos eventos y sirvan de apoyo a la toma de deciciones.
2. Palabras claves Visión computacional, análisis de datos, sistemas distribuidos
3. Objetivo de Investigación Generar una investigación que demuestre de forma teórica y práctica (a través de un prototipo funcional), el potencial de analizar los patrones de accidentalidad de las vías en una ciudad para generar un modelo que permita entender el comportamiento del tránsito.
3 Objetivo general

Conocer las potencialidades de la analítica de datos y la visión inteligente basada en inteligencia artificial para que a través de imágenes capturadas de una ciudad, se pueda analizar el fenómeno de la accidentalidad vial, permitiendo la mejora en la toma de decisiones frente a la reducción de dicha problemática.
4 Objetivo especifico
● Generar secuencias de datos organizados que le permitan a una ciudad, entender la dinámica de tránsito en el Municipio.
● Sacar un mayor provecho de las imágenes generadas por las cámaras instaladas en el
Municipio, frente a la reducción de los índices de accidentalidad vial.
● Prototipo en licencia libre que demuestre funcionalidad de la tecnología en la situación planteada
4. Tipo de Investigación Investigación Aplicada
5. Resumen de las etapas de la investigación y metodología Las siguientes etapas se cumplieron durante el desarrollo del proyecto: ETAPA 1: Determinación de la infraestructura para el análisis de datos ETAPA 2: Determinación de los algoritmos usados en la infraestructura para el análisis de imagenes de tráfico vehicular. ETAPA 3: Creación del sistema: ensamble de las infraestructuras de analisis de datos y analisis de imagenes. ETAPA 4: Pruebas del sistema. ETAPA 5: Entrega del sistema.
6. Elementos conceptuales de la investigación A continuación se presentan los elementos conceptuales de las dos partes que sirven de base para esta investigación: la infraestructura de análisis de datos y el sistema de vision.
a. Infraestructura del análisis de datos.
Para el correcto funcionamiento de los sistemas de análisis de datos se hace necesario contar con una infraestructura computacional adecuada que permita la asignación de recursos en

forma dinámica, adaptándose siempre a la carga actual del sistema y considerando una apropiada tolerancia a fallo. La infraestructura propuesta para esta investigación tiene como componentes basicos: Apache Hadoop, Apache Spark y MySql, los cuales se definen a continuación. Apache Hadoop. Es una plataforma software que soporta el procesamiento distribuido de grandes volúmenes de datos mediante el uso de clusters computacionales usando modelos de programación simples. Permite escalar a miles de máquinas, cada una ofreciendo servicios de computación y almacenamiento local. La plataforma incluye mecanismos de tolerancia a fallos y proporciona alta disponibilidad a los servicios que la usan. Apache Spark. Es probablemente el motor más rápido de procesamiento de datos para ambientes de Big Data. Esta herramienta ofrece diferentes componentes para streaming, machine learning y soporte SQL necesarios para la implementación de la solución que proponemos. Soporta lenguajes de programación como Python, Java, R y Scala. MySQL. Es un sistema de gestión de bases de datos relacional de codigo abierto bastante popular mundialmente sobre todo para desarrollo de entornos web.
b. Sistema de visión.
El sistema de visión usado en esta investigación utiliza como base una red neuronal convolucional y un sistema de seguimiento multiple. Los conceptos internos necesarios para el buen entendimiento de la base usada son presentados a continuación. Detector. Un detector es un sistema capaz de identificar la localización de un determinado objeto en una imagen. Existen 3 pasos fundamentales para crear un sitema de detección: el primero, es crear un algoritmo que sea capaz de generar posibles regiones de interes (ROI) dentro de la imagen completa; un segundo paso consiste en extraer caracteristicas para cada ROI, las cuales son posteriormente evaluadas para determinar cuales de estas regiones continenen el objeto buscado; debido a la alta posibilidad que partes de un mismo objeto sean detectados en distintas regiones superpuestas, el tercer paso consiste en combinar estas regiones en una sola region. Regiones de Interes (ROI). Dos de los principales algortimos usados para proponer regiones de interes son : el algoritmo de busqueda selectiva y los algoritmos de fuerza bruta. El primero, se basa en el agrupamiento de pixeles a partir de uno o más parametros previamente sintonizados a través de un nivel de umbral. El segundo, consiste en deslizar una ventana sobre la imagen a diferentes escalas creando automaticamente diferentes ROI’s (ver figura 1).

Figura 1. Tecnica de SlidingWindow para encontrar ROI’s. Fuente: Imagen modificada de la original: Minesweeper © Diciembre 2006 . Desde en-wikipedia. Extracción de caracteristicas. El analisis de cada uno de los pixeles sobre una región de interés puede llegar a ser computacionalmente costoso. Reducir este analisis a una cantidad fija de caracteristicas representativas de un objeto en particular, es la tarea de los algoritmos extractores de caracteristicas visuales. Como un ejemplo de esto, en la figura 2, se puede observar uno de los principales algoritmos usados para la extraccion de caracteristicas, el SIFT (Scale Invariant Feature Transform), basados en este algorimto se han presentado en las ultimas 2 decadas un sinnúmero de nuevos algortimos mucho mas eficientes tales como: SURF, ORB, AKAZE, HOG, etc.

Figura 2. Extracción de características usando el detector/descriptor SIFT. Se genera un descriptor con 128 datos que describen un objeto en particular. Fuente: Autor.
Combinacion de ROI’s. Los algoritmos usados para reducir el numero de detecciones de un mismo objeto sobre una imagen se basan en la técnica conocida como supresión no maxima (NMS) la cual es responsable de agrupar las detecciones pertenecientes a un mismo objeto. Dado el caracter artesanal que tiene este metodo, existen formas de garantizar un buen agrupamiento basados generalmente en una metrica conocida como mAP (mean average precision) la cual a su vez utiliza una tecnica conocida como IoU (instersection over union), para obtener una puntuacion del grado de semejanza de una determinada ROI con un objeto en particular (Ver figura 3).
Figura 3. Calculando la intersección de la unión como la división del área de intersección de áreas por el area de la union. Fuente: Autor.

Clasificador. Cuando sobre una misma imagen se tienen diferentes clases de objetos, el mismo sistema de detección se puede convertir en un sistema detector/clasificador. Redes Neuronales Convolucionales (CNN’s). CNN’s o ConvNets son una categoría de redes neuronales artificales o un modelo de aprendizaje profundo comunmente aplicado al análisis de imagenes visuales. Existen varias arquitecturas propuestas para CNN’s, sin embargo, la base de todas estas arquitecturas es similar y se fundamenta en 4 operaciones: Convolucion, No-Linealidad, Submuestreo y Clasificación. (Ver figura 4)
Figura 4. Arquitectura generica de una CNN, motrando las 4 operaciones fundamentales: convolción, no linealidad, submuestreo y clasificación. Fuente: Imagen modificada de la original: Alphex34 © Diciembre 2015 . Desde Wikimedia Commons. La operacion de convolucion permite obtener mapas de caracterisitcas de una imagen, tales como bordes, curvas, etc. mediante la aplicacion de diferentes tipos de filtros. Dado que la convolución es una operación lineal, mientras que los datos del “mundo-real” contienen no-linealidades, se hace uso de una funcion que introduzca este tipo de no-linealidades deseadas en el aprendizaje. Existen varias funciones no lineales que son usadas en CNN’s: ReLU, Tanh y Sigmoide, siendo ReLU la que ha mostrado un mejor rendimiento en diversas situaciones. Una vez aplicada esta operación, se obtienen mapas de caracteristicas rectificados. Dado que los mapas de caracteristicas rectificados son del mismo tamaño que la imagen original, se hace necesario el uso una operación de submuestreo que permita retener solo la informacion más importante. Esta operación es mejor conocida como “Spatial Pooling” y puede ser de diferentes tipos: Máximo (Max), Average (Avg), Sum, etc, siendo el “Max Pooling” el que ha mostrado trabajar de una mejor manera en la practica. Las operaciones de convolucion + ReLU forman una capa y la operación de pooling forma otra capa de la CNN. La salida de la capa de pooling puede ser de nuevo pasada por una nueva capa de convolución + ReLU, formandose n capas posibles que permiten a la CNN ser más robusta a variaciones de pequeñas transformaciones, distorsiones y traslacionaes en la imagen de entrada. La salida de la ultima capa de poolin actua como la entrada a la ultima capa conocida como FCL (Fully Connected Layer), la cual tradicionalmente es un MLP (Multi Layer PErceptron) que usa auna funcion de activación Softmax; como su nombre lo indica en esta capa cada neurona en la capa previa es conectada a cualquier neurona en la FCL. El proposito de esta capa

es entonces usar todas las caraacteristicas de alto nivel generadas en las capas anteriores para clasificar la imagen de entrada en varias clases, basado en el conjunto de datos de entrenamiento. Sistema de seguimiento. Dado que un video es una secuencia de imagenes, una vez un objeto ha sido detectado en una primera imagen, se hace necesario hacer un seguimiento del mismo sobre el resto de imagenes. Existen varios algoritmos que permiten realizar este seguimiento, sin embargo ha sido el filtro de Kalman el que ha demostrado mejores prestaciones en distintos casos donde los grados de incertidumbre son altos. El filtro de Kalman es un conjunto de ecuaciones matematicas que implementa un estimador del tipo predictor-corrector que minimiza la covarianza de error estimado sobre el estado. Asi, en forma generica, las 2 ecuaciónes en diferencia que modelan el estado y las medidas son respectivamente:
x Buxk = A k−1 + k + wk−1 xzk = H k + vk
Estas ecuaciones son entonces usadas en una forma de lazo de control realimentado: primero, basado en la informacion previa del estado, el filtro esta en su etapa de predictor, estimando el estado actual y el error de covarianza del proceso, lo cual es conocido como el estimado a priori. Esta informacion entra entonces a la etapa donde el filtro trabaja como un corrector basado en las medidas observadas del proceso, tal como es mostrado en la figura 5.
Figura 5. Modelo general del filtro de Kalman como un sistema de control realimentado de sus etapas de predicción y corrección. Fuente: Autor. En la figura 6 se muestra de una manera más detallada como las ecuaciones base son usadas en las etapas de predicción y corrección.

Figura 6. Modelo del filtro de Kalman como un sistema de control realimentado, especificando las ecuaciones usadas en sus etapas de predicción y corrección. Fuente: Imagen modificada de la original: Martin Thoma © Junio 2016 . Desde Wikimedia Commons. Como se puede intuir, el filtro de Kalman funciona como un seguidor de un solo objeto. Dado que en esta investigación es natural tener más de un objeto a ser seguido es necesario llevar al filtro a ser un multi - seguidor. La creacion de un banco de filtros de Kalman es una solución acpetable, sin embargo, para reducir la incertidumbre de cual es el objeto seguido por cada filtro se hace necesario la utilización de un algoritmo de optimización que resuelva el problema de asignación. En esta investigación fue usado el algortimo conocido como Algortimo Hungaro.
7. Glosario CNN : Convolutional Neural Network Darknet: framework de software de licencia libre para redes neuronales. Docker: tecnología de código libre para automatizar el despliegue de software usando contenedores de software Filtro de Kalman: algoritmo desarrollado para predecir el estado actual de un sistema a partir del conocimiento de los estados y observaciones previas. Hadoop: framework de software de licencia libre que soporta aplicaciones distribuidas que funcionan usando el algoritmo MapReduce

Machine Learning: Disciplina cientifica del ámbito de inteligencia artificial que crea sistemas que aprenden autónomamente. OpenCV: biblioteca libre de visión artificial y machine learning. Pooling: Función de reducción de caracteristicas previamente generadas por la capa de convolución en una red neuronal. ReLU: Es una función de activación para introducir efectos no-lineales dentro de las neuronas conformando una red neuronal artifical. ROI : Region of Interest SIFT: Scale Invariant Feature Transformation Sliding Window: algoritmo para proponer ROI´s dentro de una imagen, sobre la cual se desliza una ventana que puede cambiar de tamaño con el fin de obtener objetos a diferentes escalas. Spark: sistema de computación en clúster con soporte para aplicaciones que funcionan bajo el paradigma MapReduce SQL : Structured Query Languaje. Es un lenguaje de programación estándar par la obtención de información desde una base de datos. Vagrant: herramienta usada como gestor del ciclo de vida de máquinas virtuales y/o contenedores en entornos virtualizados VirtualBox: hipervisor usado como proveedor de vagrant en este proyecto YOLO : You Only Look Once. Es un sistema para detección de objetos en tiempo real.
8. Principales logros por etapas de la investigación ETAPA 1: Determinación de la infraestructura para el análisis de datos Logro1. Sistema distribuido de analisis de videos en paralelo construido bajo el paradigma MapReduce. Logro2. Reducción de tiempo de análisis de patrones de tráfico vehícular gracias a la infraestructura computacional distribuida implementada. ETAPA 2: Determinación de los algoritmos usados en la infraestructura para el análisis de imagenes de tráfico vehicular. Logro 1. Sistema de detección de vehículos haciendo uso de una de las arquitecturas con mejores prestaciones para la detección de objetos: YOLO Version 3.

Logro 2. Sistema multi-tracking de vehículos haciendo uso de un arreglo de Filtros de Kalman y una mejora en la probabilidad de asignamiento correcto en la detección sobre cada nuevo frame de un mismo vehiculo a través del uso de dos metodos: El IoU y el algoritmo húngaro. El primero mejora la precisión en tamaño del area conteniendo cada vehiculo previamente detectado, mejorando por ende la localización de cada vehiculo en un frame, y el segundo optimiza el problema de tiempos de asignación de nuevas detecciones en nuevos frames. Logro 3. Sistema probabilístico detector de accidentes basado en el artículo: “Accident detection system using image processing and MDR” escrito por Ki, Y. K. Dentro de este sistema se crearon nuevos metodos que permitieron un procesamiento más acelerado: un metodo para segmentación de carreteras el cual permite una detección anticipada de intersecciones y un sistema que llamamos IOOA (Intersection Over Object Area) el cual permitió emparejar con mejor precisión la ubicacion de cada vehiculo y una determinada intersección.
ETAPA 3: Creación del sistema: ensamble de las infraestructuras de analisis de datos y analisis de imagenes. Logro 1. Infraestructura Hadoop-Spark. Se diseñó y desplegó un cluster Hadoop/Spark adaptado para soportar los requerimientos de infraestructura computacional para el análisis de videos usando software especializado como OpenCV y darknet. Logro 2. Aprovisionamiento automático del software.. Se implementó la infraestructura necesaria para el aprovisionamiento automático del sistema. Logro 3. Empaquetamiento de la solución completa usando tecnologías de contenedores de software. Se realizó el aprovisionamiento automático del sistema usando Docker para la generación de contenedores de software con toda la funcionalidad incluída y Vagrant como gestor del ciclo de vida de los contenedores. ETAPA 4: Pruebas del sistema. Logro 1. Se realizaron pruebas satisfactorias los sistemas de detección de vehículos, multi-tracking y probabilistico para la detección de accidentes. Logro 2. Se realizaron pruebas satisfactorias del analisis paralelo distribuido desde videos fuente. ETAPA 5: Entrega del Sistema Logro 1. Se entrega sistema para funcionar en nodo individual empaquetado en contedores docker sobre Vagrant. Logro 1. Se entrega sistema para funcionar en cluster distribuido empaquetado en máquinas virtuales de Virtualbox sobre Vagrant.

9. Principales aprendizajes Entre los principales aprendizajes logrados con este proyecto se incluyen: Aprendizaje 1. Establecimiento preciso de las limitaciones y restricciones a tener en cuenta para la captura de imágenes desde cámaras de video para ser aprovechables por sistemas de visión computacional, en cuanto a factores cómo luminosidad, ángulos de captura, movimiento de las cámaras, etc. Aprendizaje 2. Prueba y selección de algoritmos que permitieron un mejor sistema de detección y tracking. Entre los cuales se incluyen YOLO como detector, manejo de un banco de filtros de Kalman como predictor y el algoritmo Hungaro como asignador probabilístico. Aprendizaje 3. Ajustes a los pesos asignados para cada variable dentro del algoritmo de detección de accidentes, teniendo en cuenta direcciones de movimiento reales de los vehiculos en carreteras y cambios de valores de dichas variables no instantaneas usando promedios de datos acumulados durante la trayectoria. Esto es reflejo de los cambios necesarios que se hicieron del estado del arte propuesto. Aprendizaje 4. Configuración y optimización de clusters de analisis de datos basados en Hadoop/Spark para el soporte de aplicaciones de visión computacional.
10. Lo que sigue en el futuro Los resultados de este proyecto son una primera aproximación para el desarrollo de sistemas de visión computacinal aplicados a la solución de problemas de tráfico vehicular en Colombia y se pueden aprovechar como base para desarrollos futuros. Consideramos como siguientes pasos para dar continuidad al proyecto los enumerados a continuación. De manera particular para el sistema de detección: Basados en las necesidades expresadas por los diferentes actores incluidos en este proyecto,
1. Re-entrenamiento de la CNN para obtener nuevos objetos detectados que puedan darnos màs informaciòn de las posibles causas generadoras de accidentes. Por ejemplo: semaforos, señales de tránsito, etc.
2. Sistema automatico de segmentación de carreteras. 3. Sistema automático de eliminación de la perspectiva causada por la posición de la
cámara, haciendo uso de los parametros intrinsecos y extrinsecos de esta ultima.
De manera global:
1. Desarollo de un sistema de análisis de datos a partir de la información recolectada por el sistema de visión computacional: el sistema implementado es una fuente importante de información que puede ser usada para alimentar sistemas de análisis de datos que

permitan la creación de modelos estocásticos para comprender el fenómeno de movilidad en las ciudades del país.
2. Acercamiento municipios de Colombia intersados en sistemas de apoyo para conocer más de cerca sus problemas de movilidad. Los resultados del sistema desarrollado pueden usarse para enternder de manera exploratoria el problema de movilidad en las ciudades del país, para luego formular proyectos de mayor alcance de acuerdo a necesidades particulares.
11. Conclusiones
1. El sistema de visión vial inteligente desarrollado es una primera aproximación al uso de visión computacional para estudiar fenómenos de movilidad en ciudades Colombianas. Nuevas soluciones pueden ser desarrolladas a partir de los aprendizajes adquiridos en este proyecto.
2. Los sistemas distribuidos de analisis de datos en combinación con los sistemas de visión computacional mejoran la eficiencia de estos sistemas, entregando resultados en tiempos más cortos.
3. Los grandes avances que se tienen actualmente en el area de maquinas inteligentes, ha permitido la aplicación de soluciones dadas a nivel de investigación básica en problematicas reales tal como es el caso de la detección de accidentes.
5 PROCESO DE INVESTIGACIÓN 1. En qué consiste la Investigación?
Esta investigación consiste en demuestrar de forma teórica y práctica (a través de un prototipo funcional), el potencial de analizar los patrones de accidentalidad de las vías en una ciudad para generar un modelo que permita entender el comportamiento del tránsito.
2. Proceso de Investigación
El desarrollo de la investigación se da en 5 de etapas:
a. Etapa 1: Determinación de la infraestructura para el análisis de datos
Sistema Distribuido para el análisis de Datos

Con el ánimo de desarrollar un sistema de alto desempeño, escalable, y tolerante a fallos, se estudiaron diferentes tecnologías basadas en sistemas distribuidos para la implementación de un cluster que permita procesar imágenes desde cámaras de video en paralelo. Dado su alto nivel de madurez y aceptación en el mercado, se decidió implementar un cluster basado en tecnologías Hadoop/Spark. Para ello se requiere paralelizar el código de visión computacional y escribirlo para soportar el paradigma de programación MapReduce. De esta forma el sistema soporta el análisis concurrente de videos y es escalable al incrementar el número de nodos que conforman el cluster.
b. Etapa 2: Determinación de los algoritmos usados en la infraestructura para el análisis de imagenes de tráfico vehicular.
Sistema de detección de Vehículos Depués de realizar pruebas con diferentes algoritmos de detección de OpenCV, el API de tensoflow y 6 versiones de YOLO, el algoritmo que mejores resultados arrojó fue la versión YOLO V3, la cual actualmente es uno de los algoritmos con mejores prestaciones para detección de objetos. Este algoritmo originalmente está diseñado en lenguaje C y hace uso de una librería llamada darknet. YOLO V3 es un algoritmo de Machine Learning que hace uso de un método conocido como deep learning, el cual utiliza una red neuronal convolucional (CNN) para clasificar y detectar diferentes objetos (en nuestro caso vehículos). Para usar la versión YOLO V3 fue necesario instalar darknet que a su vez depende de OpenCV y Cuda. Adicionalmente se instaló python 2.7, el cual usamos como lenguaje de programación principal para todo el proyecto. Darknet fue configurado para funcionar con las características de nuestros equipos, compilado y enlazado con python. Dentro de las configuraciones realizadas a darknet se especificó la estructura de la tarjeta de video utilizada, se configuró la red convolucional para testeo y no para entrenamiento y se configuró el tamaño de entrada de las imágenes. El sistema de detección funciona en forma general de la siguiente manera: dado que un video obtenido de una cámara puede ser percibido como un conjunto de frames (imágenes estáticas) que reproducidos en secuencia recrean el video, YOLOV3 recibe como entrada un frame y retorna todos los objetos detectados en este. Por cada objeto detectado YOLO entrega el área rectangular donde se encuentra el objeto, el tipo de objeto y un valor de certeza de la detección como se muestra en la figura 7.

Figura 7. Sistema de detección usando YOLOV3
Sistema de tracking de vehículos Después de detectados los vehículos se debe realizar un seguimiento de cada uno de ellos, el cual estará limitado por el desempeño del algoritmo YOLOV3 y este a su vez de la calidad de los videos. Para implementar el seguimiento de los vehículos se diseñó un sistema multitracking que hace uso de un algoritmo conocido como filtro de Kalman. Este filtro, se implementó para recibir dos puntos (x,y) que representan el área que encierra cada objeto detectado mediante YOLOV3 en el frame k y a partir de estos datos permite predecir la ubicación de los mismos dos puntos (x,y) en un frame futuro k+1 (ver figura 8).
Figura 8. Predicción de la posición de un vehículo en un siguiente frame mediante filtro de Kalman
Una característica importante de este proyecto es su sistema multitracking, el cual permite hacer el seguimiento a la vez de múltiples vehículos durante todo el video. Cada vehículo dentro del sistema multitracking tiene asignado una identificación (id) y un color para permitir la diferenciación entre los vehículos.

Para realizar el multitraking se utiliza un combinación entre filtro de Kalman y un método llamado intercepción sobre la unión conocido con sus siglas en inglés como IoU (ver figura 9)
Figura 9. Método intercepción sobre la unión
IoU, entonces tomará las predicciones realizadas por el filtro de Kalman en el frame inicial y las comparará con los objetos detectados en el frame final. El IoU más grande permitirá asignar la predicción del frame inicial con su respectivo vehículo detectado en un frame final (ver figura 10).
Figura 10. Secuencia realizada por el sistema muititracking para asignar la predicción de
un frame inicial con un vehiculo detectado en un frame final. El sistema multitracking se actualiza frame a frame y cuando un vehículo deja de ser detectado por YOLOV3 durante 5 frames, el vehículo es borrado del sistema multitracking. Si el vehículo es detectado después de haber sido borrado este será incluido de nuevo en el sistema pero con un id y color diferente. Cada vehículo dentro del sistema multitracking actualiza con cada frame un conjunto de variables que representan la velocidad del vehículo, el centroide del vehículo, la dirección del vehículo, la distancia entre el vehículo y las intersecciones en su camino entre otras. Sistema probabilístico detector de accidentes.

Para el sistema probabilístico se consideraron varias características del vehículo dentro de la imagen, las cuales son actualizadas frame a frame y usadas para determinar que tan alta o baja es la probabilidad de choque. Una de las características más importantes diseñadas en este proyecto es la distancia entre el vehículo y todas las intersecciones presentes en la carretera sobre la cual va el vehículo. Cuando un carro se desplaza por la carretera, una de las zonas con alta probabilidad de choque son las intersecciones, por lo tanto entre más cerca el vehículo se encuentre de una intersección más probabilidad de choque tendrá. Para encontrar la distancia entre el carro y las intersecciones se debe conocer primero la posición del carro y la posición de las intersecciones dentro de la imagen. La posición del carro es su centroide, el cual es conocido y se actualiza con el algoritmo de tracking. Para hallar la posición de las intersecciones se propusieron varios métodos automáticos; sin embargo, no fue posible la utilización de estos ya que precisan de imágenes sin perspectiva (ver figura 11), en nuestro caso particular, deberíamos contar con imágenes tomadas perpendicularmente a la carretera, lo que es completamente ilógico por la ubicación natural de las cámaras en carreteras reales.
Figura 11. Visualización de una imagen con y sin perspectiva
Existen métodos basados en las parámetros intrínsecos y extrínsecos de la cámara que permiten eliminar la perspectiva, pero dado que no contamos con ellos, se diseñó un método que de forma semiautomática permite detectar la posición de las intersecciones (ver figura 12). Para ello primero se marca de forma manual sobre un frame de cada cámara de video todas las calles que se desean analizar con nuestro sistema. Posteriormente se calculan las aéreas que se interceptan y después se calcula el centroide de cada una de estas aéreas. Cabe aclarar que como las cámaras son estáticas y están siempre apuntando hacia las mismas vías, el procedimiento manual para marcar las calles solo se realiza una sola vez por cámara y es considerado como uno de los procedimientos de configuración del sistema de análisis de patrones.

Figura 12. Selección de las calles en las cuales se reconocerán los patrones de
conducción para posterior obtención de las intersecciones
Medir la distancia entre el carro y cada intercepción sobre su vía permite conocer en cada momento que tan cerca está el carro de una posible zona con alta probabilidad de choque. Mediante la medición frame a frame de la distancia entre el carro y la zona de choque planteamos un primer modelo para determinar la probabilidad de choque de los carros, el cual asigna una probabilidad 0 o muy baja a un carro que se encuentre muy retirado de la intercepción y una probabilidad muy alta o 1 cuando un carro está muy próximo a una intercepción. En el video2 anexado se puede observar una prueba sobre algunas de las calles e intersecciones, donde las cajas que encierran a los carros cambian de color azul a rojo cuando se encuentran más cerca a una intercepción (zona de alta probabilidad de choque). Este modelo presenta resultados aceptables pero poco robustos debido a que solo considera la medición de una característica para calcular la probabilidad de choque. Por lo tanto una mejora considerada fue implementar 3 características adicionales para obtener un cálculo de probabilidad de choque más robusto. Las 3 características consideradas son el cambio de la posición del centroide, el cambio de velocidad del vehículo y el cambio de la dirección del vehículo. El cambio de la posición del centroide (CPC) de cada vehículo es una medición que permite conocer la distancia relativa de un centroide entre dos frames. Un cambio abrupto de esta distancia puede estar vinculado con un posible accidente. Por lo tanto cambios grandes en la distancia conllevan probabilidades altas de choque. El cálculo del centroide es presentado a continuación.
PC entroideF rame entroideF rame C = c F inal − c inicial
Donde:
entroideF rame C , ] c i = [ x Cy

es la distancia en x al centro de la caja que encierra el vehiculo Cx es la distancia en y al centro de la caja que encierra el vehiculo Cy
Medir frame a frame el cambio de velocidad que experimenta cada vehículo le permite al sistema conocer cuando el vehículo desacelera o cuando acelera. Una desaceleración abruptamente puede estar relacionada con una circunstancia de choque. Por lo tanto entre mayor sea la desaceleración mayor es la probabilidad de choque. Para calcular el cambio de velocidad primero se debe calcular la velocidad del carro en cada frame, la cual a su vez es calculada considerando la distancia recorrida de un centroide entre un frame y otro y el tiempo que se demora el sistema para pasar entre los frames. Una aproximación de la ecuación utilizada para calcular la velocidad de los vehículos (Vv) es presentada a continuación.
M /tEF V v = d
Donde: dM es la distancia entre metros
es el tiempo entre framesEF t
La distancia entre metros (dM) puede ser calculada como:
M P scala d = d * e
Donde: , es la distancia entre pixeles y es calculada como la resta entre centroides de dosP d
frames , es larelacion entre la medida real y la medida en pixelesscala e
El tiempo entre frames (tEF) puede ser calculada como:
EFt = f rameRateframeF inal−f rameInicial
La otra característica que se mide entre frames para cada vehículo es la dirección de este dentro de la imagen. La dirección está representada por un ángulo entre 0 y 360 grados que permite determinar si el vehículo lleva una trayectoria horizontal, vertical o en diagonal. Adicionalmente se puede conocer si el vehículo va de norte a sur, sur a norte, oriente a occidente u occidente a oriente. El conocer la dirección en cada momento del vehículo permite calcular el cambio de dirección entre frames. Si este cambio es abrupto puede estar relacionado con una acción imprudente o con un posible choque. Por lo tanto un valor grande en el cambio de dirección aumenta la probabilidad de choque. A continuación se muestra la ecuación utilizada para calcular la dirección de los vehículos a partir del angulo 𝛂.
α = C frameF inal−C frameInicialy y
C frameF inal−C frameInicialx x Finalmente considerando las 4 mediciones calculadas para cada vehículo se construye un

modelo de probabilidad de choque. El modelo recibe como entrada de cada vehículo el cambio de velocidad, cambio de posición del centroide, cambio de dirección y la distancia a las intersecciones. Cada uno de estos cambios está relacionado con una ecuación que les otorga un peso entre 0 y 1 baja y alta probabilidad respectivamente. Las 4 ecuaciones relacionadas con cada característica son mostradas a continuación junto con la ecuación de probabilidad de choque. Cada una de la 4 ecuaciones dependerán de un rango de actuación que se encuentra limitado por los 10 valores de la “a” a la “j”. Estos valores pueden ser configurados para rango de cada ecuación.
Los 4 resultados de las cuatro ecuaciones son sumados y divididos por 4 para determinar la salida del modelo, la cual toma valores entre 0 y 1, donde 0 es la más baja probabilidad de choque y 1 la más alta probabilidad de choque.
c. Etapa 3: Creación del sistema: ensamble de las infraestructuras de analisis de datos y analisis de imagenes.
Se implementó un Cluster Hadoop/Spark sobre el cual se paraleliza el análisis de los videos de tráfico vehicular. Los detalles de su desarrollo se encuentran en la sección 4 (Desarrollo del prototipo).
d. Etapa 4: Pruebas del sistema

Se probaron las soluciones stand alone y distribuida. Las pruebas realizadas se describen en la sección “Entrega e Implementación”.
e. Etapa 5: Entrega del sistema Se entregan repositorios con informe final del proyecto, código fuente y empaquetado del código. Los detalles de los entregables se describen en la sección “Entrega e Implementación”.
3. Listado de Actores
A_1: Usuario (Departamento TIC Alcaldía Cali) A_2: Administrador del Sistema A_3: Administrador Avanzado del Sistema
4. Requerimietos
a. Requerimientos funcionales
RF_1: el sistema debe permitir al usuario el análisis de videos para detectar accidentes originados por patrones de accidentalidad predefinidos
RF_2: el sistema debe permitir al usuario la fragmentación de videos en diferentes tamaños para su análisis
RF_3: el sistema deberá permitir al usuario subir los videos al sistema de archivos distribuido
RF_4: el sistema deberá permitir al usuario eliminar videos del sistema de archivos distribuido
RF_5: el sistema deberá permitir iniciar el análisis de un set de videos previamente particionado
RF_6: el sistema deberá permitir al usuario proveer el número de nodos en los cuales desea correr la aplicación de análisis
RF_7: el sistema deberá permitir al usuario la verificación del estado de los nodos que conforman el cluster
RF_8: el sistema deberá permitir al usuario la verificación del estado del análisis de videos previamente lanzados
RF_9: el sistema debe permitir la clasificación de automotores de acuerdo a sus características: motocicleta, automóvil
RF_10: el sistema debe permitir, a partir de videos de prueba suministrados ( con previa identificación manual de eventos de accidente y su tiempo de ocurrencia), asociar los patrones predefinidos con el evento de accidente sucedido
RF_11: el sistema debe permitir la detección de la ocurrencia de un patrón de accidente y su relación con un accidente a partir de un video dado
RF_12: el sistema debe permitir almacenar la ocurrencia de patrones con alta probabilidad de ocasionar accidentes
RF_13: el sistema debe permitir almacenar la ocurrencia de un accidente

RF_14: el sistema debe permitir al usuario la generación de reportes de la ocurrencia de eventos de accidente, su relación con los patrones de accidentalidad identificados (causas probables) y con el tipo de vía en que ocurrieron
b. Requerimientos no funcionales
Requerimientos Funcionales sobre los videos a recolectar
RNF_1: los videos a ser analizados deben ser videos con cámara fija, sin rotaciones de la cámara ni aproximaciones del lente
RNF_2: los videos deben ser tomados con luz del día RNF_3: los videos deben tener una duración mínima de 20 minutos
Requerimientos funcionales sobre la infraestructura computacional
RNF_4: el sistema debe desplegarse en un sistema computacional de nube (local)
sobre infraestructura computacional para el análisis de datos RNF_5: el sistema deberá soportar un sistema de archivos distribuido para
almacenamiento RNF_6: el sistema debe ofrecer mecanismos de escalabilidad horizontal (instancias)
y vertical (CPU, memoria)
5. Definición de Actores La aplicación de análisis de accidentalidad basada en visión computacional tendrá tres (3) actores que podrán interactuar con el sistema.
Figura 13. Actores Sistema de Análisis de Accidentalidad Usuario: es aquel rol de persona que puede acceder al sistema para su uso. No requiere de conocimientos especiales a nivel de software y/o programación. No tendrá posibilidad de cambiar el código fuente de la aplicación, es un usuario convencional de herramienta de autor. Administrador: es aquel rol de persona que accede al sistema para la generación del proceso de análisis de videos.

Administrador Avanzado: es aquel rol de persona que accede al sistema para tareas propias de administración del cluster distribuido.
6. Indentificación de Casos de Uso
1. Iniciar análisis de video 2. Subir videos al sistema de archivos 3. Eliminar videos del sistema de archivos 4. Analizar video 5. Clasificar automotores 6. Detectar patrón de accidentalidad 7. Reconocer accidente 8. Correlacionar Patrones a accidentes 9. Generar Reporte 10. Reportar patrones de accidentalidad 11. Generar reporte de eventos de accidentalidad 12. Correlacionar patrones de accidentalidad 13. Administrar cluster de análisis de datos 14. Iniciar cluster de análisis de datos 15. Detener cluster de análisis de datos 16. Visualizar estado del cluster 17. Visualizar estado de aplicación (análisis en curso)
1. Diagrama de Casos de Uso

Figura 14. Casos de Uso del Sistema
2. Priorización de Casos de Uso Para seleccionar los casos de usos prioritarios se han categorizado en 3 ítems: 1-corresponde a una complejidad sencilla de realizar, 2-corresponde a una complejidad media y 3-corresponde a una complejidad alta y prioritario en su realización.
Casos de Uso Dificultad Duración (semanas)
CU_01: Iniciar análisis de video 1 1 CU_02: Subir videos al sistema de archivos 1 1
CU_03: Eliminar videos del sistema de archivos 1 1
CU_04: Analizar video 3 12

CU_05: Clasificar automotores 3 3 CU_06: Detectar patrón de accidentalidad 3 3
CU_07: Reconocer accidente 3 3 CU_08: Correlacionar patrones a accidentes 3 3
CU_9: Generar Reporte 2 8 CU_10: Generar reporte de eventos de accidentalidad 2 2
CU_11: Reportar patrones de accidentalidad 2 2
CU_12: Reportar accidentes 2 2
CU_13: Reportar correlación de patrones de accidentalidad 2 2
CU_14: Administrar cluster de análisis de datos 1 1
CU_15: Iniciar cluster de análisis de datos 1 1
CU_16: Detener cluster de análisis de datos 1 1
CU_17: Visualizar estado del cluster 1 1 CU_18: Visualizar estado de aplicación 1 1
Tabla 1. Priorización casos de uso
3. Descripción de Casos de Uso Prioritarios Nombre de Caso de Uso: “Analizar Videos” Actor(es): Administrador Descripción: Este caso de uso describe cómo el administrador (ó el usuario desde el caso de uso “iniciar análisis de video”) interactúa con el sistema para realizar el análisis de un video específico, en busca de la ocurrencia de un accidente.
Flujo de Eventos Curso normal Alternativas
1. El caso de uso inicia cuando el usuario inicia el proceso de análisis de video

2. El sistema detecta, identifica y realiza una clasificación de automotores, diferenciando carros de motocicletas.
3. Iterativamente y de forma contínua, el sistema encuentra para cada automotor detectado, 4 características previamente definidas (por ejemplo: área, centroide, velocidad, y dirección). Estas características son ponderadas y comparadas con unos rangos de valores predeterminados, lo cual permite validar la ocurrencia o no de un patrón de accidentalidad.
4. El sistema correlaciona las 4 características para determinar la ocurrencia de un patrón con alta probabilidad de causar un accidente (para el prototipo los patrones se limitarán a exceso de velocidad o cambio de dirección abrupta).
5. El sistema almacena un registro en la base de datos con la descripción del patrón (timestamp, nombre del patrón, combinación de automotores involucrados, localización, probabilidad_generar_accidente, accidente=false)
6. El sistema detecta la ocurrencia de un accidente como consecuencia del patrón identificado en el paso 4.
7. El sistema modifica el registro del patrón identificado para registrar la ocurrencia del accidente (el atributo accidente se cambia a “true”)
8. Fin del caso de uso
Tabla 2. Caso de Uso Analizar Videos. Requerimientos Especiales N/A Pre-Condiciones
1. Video previamente particionado 2. Video previamente subido al sistema 3. Usuario ha iniciado sesión como “usuario” o “administrador”
Post-Condiciones

N/A Nombre de Caso de Uso: “Generar Reportes” Actor(es): Usuario Descripción: Este caso de uso describe cómo el usuario interactúa con el sistema para generar reportes sobre la ocurrencia de accidentes y su relación con patrones de accidentalidad detectados.
Flujo de Eventos Curso normal Alternativas
1. El caso de uso inicia cuando el usuario ingresa a la interfaz de generación de reportes.
2. El sistema despliega las siguientes opciones:
a. Visualizar reporte de patrones de accidentalidad detectados
b. Visualizar reporte de accidentes ocurridos
c. Visualizar reporte de correlación de patrones de accidentalidad a accidentes
3. El usuario selecciona la opción ‘a’: visualizar reporte de patrones de accidentalidad
3.1. El usuario selecciona la opción ‘b’: visualizar reporte de accidentes ocurridos
3.2. El usuario selecciona la opción ‘c’: visualizar reporte de correlación de patrones de accidentalidad a accidentes
4. El sistema presenta un listado de vías
5. El usuario selecciona la vía de su interés
6. El sistema presenta una interfaz para seleccionar las fechas de inicio y fin para la cual se desea generar el reporte
7. El usuario selecciona las fechas de generación del reporte y acepta

8. El sistema realiza una consulta en la base de datos y despliega una tabla en la cual se muestran los patrones de accidentalidad ocurridos y su información asociada.
9. Fin del caso de uso
Tabla 3. Caso de Uso Generar Reportes Requerimientos Especiales N/A Pre-Condiciones Para cada video se debe proveer una fecha/hora de inicio del mismo Iniciar sesión como ‘usuario’ Post-Condiciones N/A Nombre de Caso de Uso: “Administrar cluster de análisis de datos” Actor(es): Administrador Avanzado Descripción: Este caso de uso describe cómo el usuario avanzado interactúa con el sistema para realizar acciones de gestión y monitoreo del cluster de análisis de datos.
Flujo de Eventos Curso normal Alternativas
1. El caso de uso inicia cuando el Usuario Avanzado abre un terminal con el objetivo de administrar el cluster de análisis de datos
2. El sistema ofrece los comandos necesarios para administrar el cluster de análisis de datos
3. El usuario ingresa el comando para iniciar el cluster
3.1. el usuario ingresa el comando ó abre la página para visualizar el cluster de análisis de datos

3.2. el usuario abre la página para visualizar el estado de una aplicación corriendo en el cluster
3.3. el usuario ingresa el comando para detener el cluster
4. El sistema inicializa el cluster y muestra un mensaje confirmando el número de nodos activos
5. Fin del caso de uso
Tabla 4. Caso de Uso Administrar Cluster de Análisis de Datos Requerimientos Especiales Conocimiento de administración de sistemas Linux Pre-Condiciones Iniciar sesión como administrador avanzado. Post-Condiciones N/A
4. Desarrollo del prototipo El sistema se compondrá de dos partes fundamentales: la infraestructura distribuida de análisis de datos necesaria para soportar la aplicación de visión computacional y la solución de visión computacional en sí misma. A continuación se describen las tecnologías que serán empleadas para el desarrollo de la solución. Para todos los componentes de la solución a desarrollar se hará uso de software libre.
a. Estrategia de Diseño
a. Infraestructura para el Análisis de Datos Para el correcto funcionamiento de los sistemas de análisis de datos se hace necesario contar con infraestructura computacional adecuada. La asignación de los recursos computacionales en dichos sistemas debe ser cuidadosamente planificada y depende de múltiples factores, entre los que se cuentan la potencia eléctrica consumida en el data center, el desempeño de los servicios soportados y las relaciones de interferencia entre las cargas de trabajo que comparten dichos recursos. La asignación de recursos se debe realizar en forma dinámica, adaptándose siempre a la carga actual del sistema y considerando una apropiada tolerancia a fallos. Es necesario diseñar sistemas lo suficientemente elásticos para soportar adecuadamente servicios con demandas fluctuantes de recursos computacionales. De acuerdo a la necesidad planteada, se propone el uso de tecnologías como las que se describen a continuación:

1. Apache Hadoop. Esta plataforma permite el procesamiento distribuido de grandes volúmenes de datos mediante el uso de clusters computacionales y usando modelos de programación simples. Permite escalar a miles de máquinas, cada una ofreciendo servicios de computación y almacenamiento local. La plataforma incluye mecanismos de tolerancia a fallos y proporciona alta disponibilidad a los servicios que la usan. 2. Apache Spark. Es probablemente el motor más rápido de procesamiento de datos para ambientes de Big Data. Esta herramienta ofrece diferentes componentes para streaming, machine learning y soporte SQL necesarios para la implementación de la solución que proponemos. Soporta lenguajes de programación como Python, Java, R y Scala.
b. Análisis de Tráfico Vehicular Existen actualmente una gran cantidad de técnicas concernientes a tráfico vehicular. Estas técnicas se pueden agrupar dependiendo del problema que se quiere solucionar:
● Detección y conteo de vehículos ● Detección, clasificación y conteo de vehículos ● Detección y seguimiento de vehículos ● Detección de maniobras inseguras en vehículos
Para el objetivo particular fijado en este estudio, se hace necesario 3 componentes: detección y clasificación de vehículos, seguimiento de vehículos detectados y detección de posibles accidentes. Las soluciones a estos tipos de problemas pueden fallar, debido a que la base fundamental de dichas soluciones es el procesamiento de imágenes, y estas a su vez, son obtenidas de ambientes reales donde se presentan oclusiones causados por otros vehículos o por otros objetos tales como: arboles, señales de tránsito, condiciones climáticas,etc. Por lo tanto un buen desempeño de una solución solo es posible si se consigue un buen análisis de imágenes de tráfico que permita detectar, clasificar y seguir vehículos. Basados en las necesidades planteadas, se propone el uso de las siguientes metodologías:
● Detección y clasificación de vehículos. Para esta parte y con el fín proporcionar una mayor robustez, se propone usar una red neuronal convolucional.
● Para el seguimiento de vehículos, se propone usar un método robusto basado las detecciones previamente realizadas, utilizando para tal fín un filtro de Kalman. Para esta parte se utilizará como lenguaje de programación Python, el cual es un lenguaje de alto nivel interpretado y dos librerías para procesamiento de imágenes bastante robustas y completas como los son OpenCV y Scikit-Images.
● Detección de posibles accidentes. Basados en el seguimiento de los diferentes vehículos se calcularán algunas variables sobre estos que sumadas y ponderadas permitan definir la ocurrencia de un posible accidente.
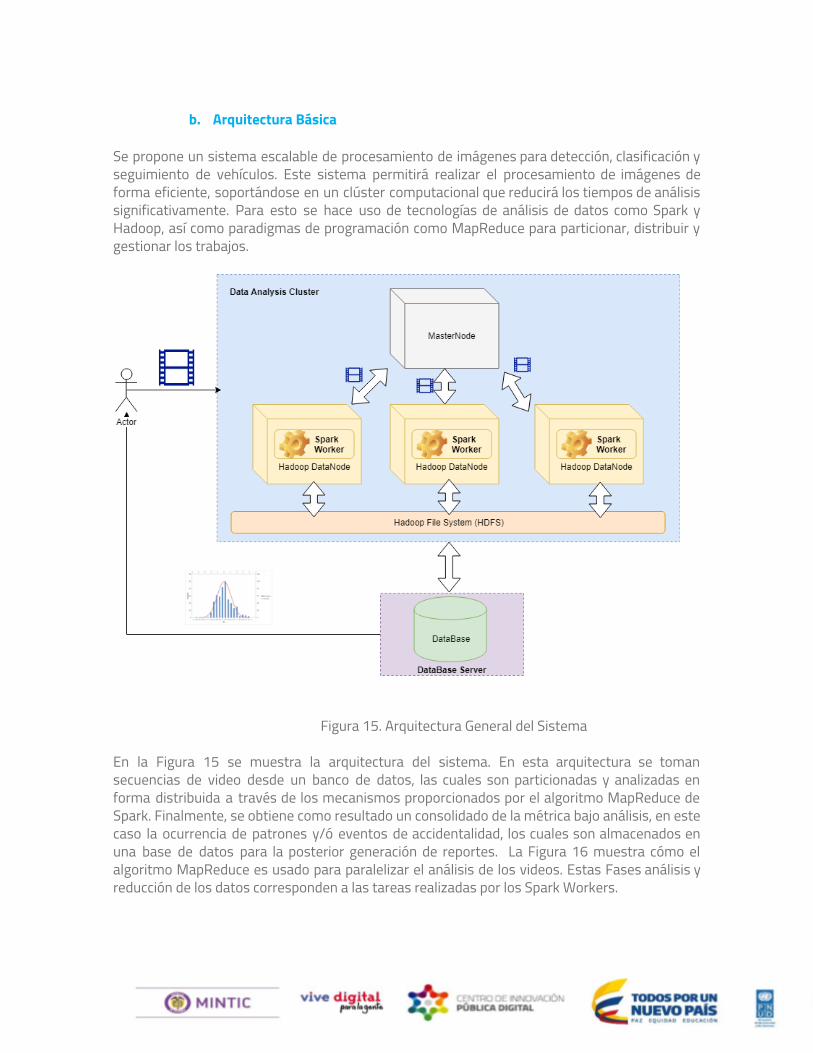
b. Arquitectura Básica Se propone un sistema escalable de procesamiento de imágenes para detección, clasificación y seguimiento de vehículos. Este sistema permitirá realizar el procesamiento de imágenes de forma eficiente, soportándose en un clúster computacional que reducirá los tiempos de análisis significativamente. Para esto se hace uso de tecnologías de análisis de datos como Spark y Hadoop, así como paradigmas de programación como MapReduce para particionar, distribuir y gestionar los trabajos.
Figura 15. Arquitectura General del Sistema En la Figura 15 se muestra la arquitectura del sistema. En esta arquitectura se toman secuencias de video desde un banco de datos, las cuales son particionadas y analizadas en forma distribuida a través de los mecanismos proporcionados por el algoritmo MapReduce de Spark. Finalmente, se obtiene como resultado un consolidado de la métrica bajo análisis, en este caso la ocurrencia de patrones y/ó eventos de accidentalidad, los cuales son almacenados en una base de datos para la posterior generación de reportes. La Figura 16 muestra cómo el algoritmo MapReduce es usado para paralelizar el análisis de los videos. Estas Fases análisis y reducción de los datos corresponden a las tareas realizadas por los Spark Workers.
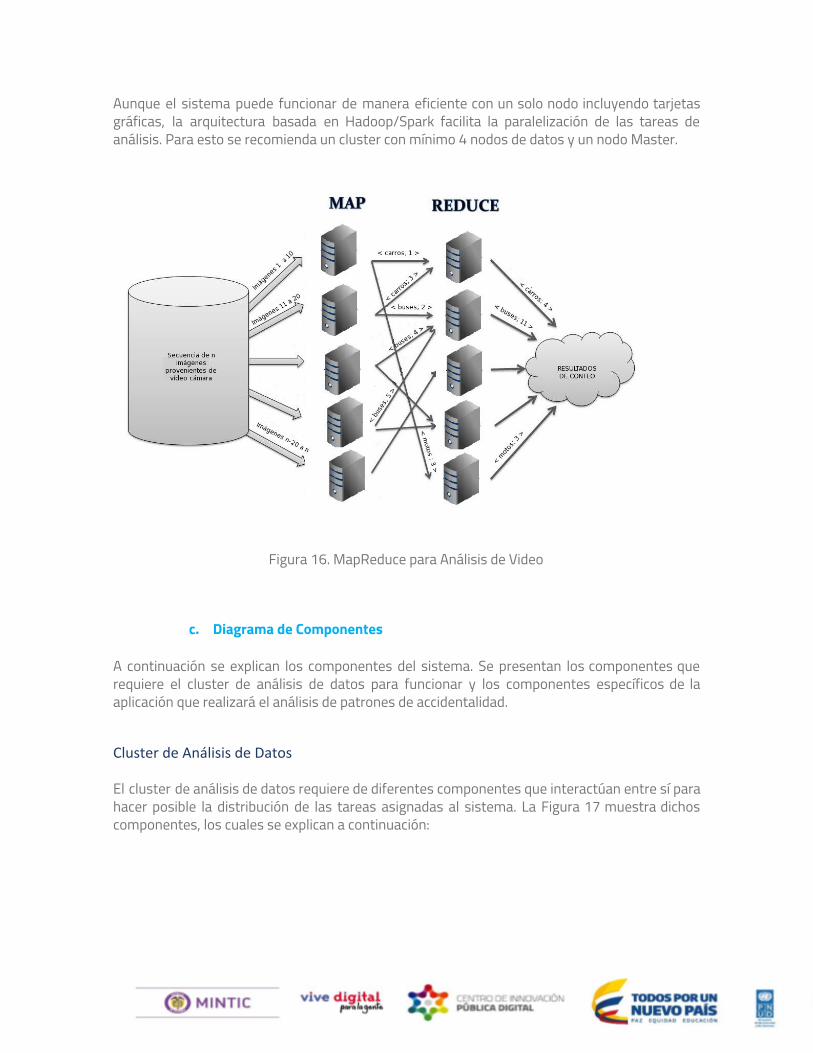
Aunque el sistema puede funcionar de manera eficiente con un solo nodo incluyendo tarjetas gráficas, la arquitectura basada en Hadoop/Spark facilita la paralelización de las tareas de análisis. Para esto se recomienda un cluster con mínimo 4 nodos de datos y un nodo Master.
Figura 16. MapReduce para Análisis de Video
c. Diagrama de Componentes A continuación se explican los componentes del sistema. Se presentan los componentes que requiere el cluster de análisis de datos para funcionar y los componentes específicos de la aplicación que realizará el análisis de patrones de accidentalidad.
Cluster de Análisis de Datos El cluster de análisis de datos requiere de diferentes componentes que interactúan entre sí para hacer posible la distribución de las tareas asignadas al sistema. La Figura 17 muestra dichos componentes, los cuales se explican a continuación:

Figura 17. Diagrama de Componentes
1. Aprovisionador: recibe peticiones de usuario sobre videos que se deseen analizar en el sistema. Dichas peticiones incluye especificaciones acerca del hardware que se desea usar y el número de partes en las cuales se desea dividir el video.
2. Sistema de Nombrado: permite identificar los nodos en la red a través de un sistema de nombres de dominio, el cual traduce nombres de dominio a direcciones IP.
3. Planificador de recursos: realiza la asignación de tareas a nodos y el mapeo de datos al sistema de almacenamiento distribuido de Hadoop (HDFS). Administra el espacio de nombres del sistema de archivos y controla el acceso a archivos por parte de los clientes
4. Sistema de Análisis de Patrones: se ocupa de la detección de patrones de accidentalidad desde imágenes de video. En general, a cada nodo de análisis del sistema se le asigna una porción de video a analizar. Los resultados del análisis son guardados en una base de datos estructurada.
5. Gestor de Reportes: genera reportes de patrones de accidentalidad detectados a partir de peticiones del usuario.

Sistema de Análisis de Patrones
El proceso de análisis realizado en cada nodo de datos (DataNode) de la Figura 15, y soportado por el sistema de análisis de patrones, consiste en la aplicación del modelo de análisis de patrones desde imágenes de video. Como se muestra en la Figura 18, el primer paso consiste en adquirir las imágenes desde las secuencias de video obtenidas desde las cámaras de video de la ciudad. Estas imágenes pasan primero por una etapa de pre-procesamiento, donde se utilizarán filtros gaussianos para eliminar el ruido. Posteriormente, se utilizará una red neuronal convolucional que permita la detección y clasificación de los vehículos. Una vez detectados y clasificados los vehículos en tres categorías: motocicletas, autos, y camiones ó buses. Un módulo probabilístico basado en el Filtro de Kalman es el encargado de describir las trayectorias de los vehículos detectados. Finalmente, la salida del modelo consiste en los siguientes datos, para cada vehículo detectado:
● Variaciones de velocidad. ● Variaciones de orientación. ● Variaciones de tamaño. ● Variaciones de posición.
El análisis de estos datos arrojará como resultado final la detección de un posible accidente.
Figura 18. Diagrama de Componentes Aplicación de Análisis de patrones de accidentalidad

Detector / Clasificador
Un detector, es un algoritmo que permite distinguir sobre una imagen o video un objeto determinado. En nuestro caso este objeto es un vehículo de ruedas genérico. El objeto detectado pasa ahora por un clasificador, el cual, es un algoritmo que permite distinguir entre diferentes tipos de objetos. En nuestro caso particular, partimos de la conjetura que nuestro objeto genérico son vehículos de ruedas y el clasificador deberá distinguir entre cuatro diferentes vehículos: motocicletas, autos y camiones o buses. Basados en el estado del arte actual en el campo de la detección y clasificación de objetos, hemos seleccionado para tal fin las redes neuronales convolucionales o CNN por sus siglas en inglés (Convolutional Neural Networks)
Figura 19. Red Neuronal Convolucional genérica. (Fuente:https://commons.wikimedia.org/wiki/File:Typical_cnn.png)
La figura 19 muestra una CNN en forma genérica. Como se puede observar, su entrada (input) consiste en una imagen la cual es pasada por diferentes capas que son las encargadas de determinar diferentes características (Feature Maps) sobre la imagen, en la última parte de la CNN se tiene una capa (Fully connected) qué es la encargada de clasificar y entregar como salida (output) los diferentes objetos dentro de una imagen. En la figura 20, podemos observar la respuesta de una CNN a una imagen que contiene diferentes tipos de vehículos y otros objetos. En este caso la CNN clasifica de forma general todos los vehículos como de tipo carro, al tiempo que otros objetos tales como los árboles o personas sobre la imagen no son detectados.

Figura 20. CNN detectando vehículos.
La misma imagen pasada por otra CNN que ha sido pre-entrenada para realizar una clasificación más precisa de vehículos es mostrada en la figura 21.
Figura 21. CNN realizando una clasificación más precisa de los tipos de vehículos sobre la
imagen de entrada.
Seguidor (Tracker)
La CNN presentada detecta objetos en un video marco a marco, un detector no es capaz de distinguir si un objeto es el mismo marco a marco (Ver figura 22a). En nuestro caso particular

donde el objetivo es detectar posibles accidentes se hace necesario detectar un objeto y poderlo seguir marco a marco (Ver figura 22b). Este seguimiento permitirá obtener datos relevantes como son: velocidad, orientación, entre otros.
Figura 22a. Marco de un video, mostrando vehículos detectados (cajas azules).
Figura 22b. Marco de un video mostrando vehículos detectados y seguidos (cajas de
diferentes colores)
Detector de accidentes
Basados en el estado del arte, cuando un accidente ocurre hay diferentes variables que pueden cambiar abruptamente de valor: la velocidad, que tiende a disminuir en el momento del impacto, la dirección de movimiento de los vehículos involucrados el área y la posición del centroide del área delimitando el vehículo. En la figura 23 se han extraído algunos marcos de un video donde ha ocurrido un accidente. Después del marco 1 se puede ver como en los marcos siguientes los dos vehículos involucrados en el accidente permanecen en la misma posición, demostrando de esta forma que las variables de posición y velocidad (0 m/seg para este caso). En la figura 24, se muestra como al momento de ocurrir un accidente (Marco 10) los vehículos involucrados pueden cambiar abruptamente su dirección (Marco 15).
Marco 1 Marco 5 Marco 6 Marco 9 Marco 20
Figura 23. Distintos marcos que demuestran la influencia de las variables de posición y velocidad en un posible accidente.

Marco 1 Marco 10 Marco 15
Figura 24. Distintos marcos que demuestran la influencia de la variable dirección en un posible
accidente No necesariamente todas las variables estudiadas deben aparecer sobre la ocurrencia de un accidente y las variables que aparezcan no ocurren en la misma proporción. Por ejemplo en la figura 23 (Marco 20) hay un cambio de dirección del carro blanco pero esta es pequeña comparada con el cambio de dirección del carro negro mostrado en la figura 24 (Marco 15). Por estas razones el sistema deberá poseer un módulo de detección de accidentes que permita definir si la ocurrencia de dichas variables han o no causado un accidente (Ver figura 25).
Figura 25. Diagrama de flujo del algoritmo de detección de accidentes.

Prototipo de Aplicación para Visualización de Reportes Aunque el alcance de este proyecto no es realizar un análisis de datos completo, se desarrolló un prototipo de aplicación para generación de reportes, de acuerdo a los casos de uso previamente definidos. A continuación se presenta el diseño de dicho prototipo.
a. Diseño de Frontend Registro y Login de Ususarios
Interfaz Principal
Dashboard

Estadísticas
b. Modelo Entidad Relación (MER)

Entrega e implementación
1. Despliegue de la Solución En esta sección se describen los nodos en los que se sugiere desplegar el sistema y los componentes que se deben asignar a cada uno de ellos. Se hace entrega de dos versiones del software implementado. La primera versión corresponde a una versión stand alone del sistema y la segunda a su versión distribuida.
Diagrama de Despliegue de la Versión Stand Alone La figura 26 muestra el diagrama de componentes de la solución stand alone. Se entrega la solución empaquetada en un Contenedor Docker gestionado usando Vagrant. 1
1 https://www.docker.com/

Figura 26. Diagrama de Componentes de la Solución Stand Alone
Diagrama de Despliegue de la Versión Distribuida La figura 27 muestra el diagrama de componentes de la solución distribuida. Se entrega la solución en Máquinas virtuales de Virtualbox gestionadas por Vagrant . 2 3
Figura 27. Diagrama de Componentes de la Solución Distribuida
2 https://www.virtualbox.org 3 https://www.vagrantup.com/

2. Infraestructura Física y Herramientas Software La siguiente tabla describe la infraestructura física recomendada para desplegar el sistema, así como las herramientas software que usa la solución desarrollada con sus correspondientes versiones.
Nodo Especificaciones Software Instalado
PC Cliente Espacio en disco duro de 32 GB ó superior RAM de 2 GB ó superior Procesador 1.4 GHz 64-bit o superior Adaptador de red Ethernet
Sistema Operativo Windows 10 o superior Cliente SSH (eg. OpenSSH, Putty, etc.) Google Chrome 60.x
MasterNode Espacio en disco duro de 40 GB ó superior RAM de 32 GB ó superior Procesador 2.4 GHz 64-bit, con 8 CPU cores o superior
Sistema Operativo Ubuntu 16.04 Java 8 Servidor SSH (eg.: OpenSSH 7.7 o superior) Python 3.4 o superior OpenCV 3.4 Yolo v3 o superior Darknet Tensorflow 1.4.0 (Opcional)
Data Node Espacio en disco duro de 100 GB ó superior RAM de 32 GB ó superior
Sistema Operativo Ubuntu 16.04 Java 8
Procesador 2.4 GHz 64-bit, con 8 CPU cores o superior GPU NVIDIA TITAN Xp 12GB (Deseable - Opcional)
Servidor SSH (ejemplo: OpenSSH 7.7 o superior) Python 3.4 o superior OpenCV 3.4 Yolo v3 o superior Darknet Tensorflow 1.4.0 (Opcional)
DNS Espacio en disco duro de 32 GB ó superior RAM de 1 GB ó superior Procesador 1.4 GHz 64-bit o superior Adaptador de red Ethernet
Sistema Operativo Ubuntu 16.04 Bind 9.12
5. Validación y Pruebas En esta sección se muestra la validación y pruebas del prototipo stand alone, los resultados para el prototipo distribuido son similares. En en el Anexo 6.1 (Guía de Uso) se describe como lanzar una prueba de ejemplo en el sistema distribuido. El sistema fue validado haciendo uso de 7 videos los cuales fueron procesados haciendo uso del aplicativo diseñado. En la parte de detección de vehiculos el sistema mostró optimos resultados en la detección de vehiculos tipo “carro” y tipo “camión o bus”. Los vehículos tipo “moto”, son detectados pero el sistema no es suficientemente robusto para hacerles seguimiento. El sistema mostró fortalezas en la detección de maniobras peligrosas como cambio de carril o dirección de vehiculos tipo carro; igualmente en la detección de colisiones “carro - carro” . El sistema muestra buenos resultados en la distinción de maniobras peligrosas y accidentes entre vehiculos tipo “carro -carro”. Todas los resultados pueden ser observados en el aplicativo generado. Los factores más importantes que impiden tener una mayor eficacia del sistema diseñado son:
● Calidad de los videos. Una gran parte de los vídeos recolectados provienen directamente de páginas web las cuales proporcioan videos de baja resolución. La baja calidad de los vídeos no permite al sistema facilmente distinguir entre personas y

persona en moto, lo que dificultó en gran medida lel seguimiento de este tipo de vehículos.
● Parametros extrínsecos e intrinsecos de la cámara. La ubicación espacial de la cámara
con respecto a la vía (párametros extrínsecos) y la distancia focal (párametro intrínseco) permite encontrar la perspectiva de la misma. Esta perspectiva es usada para cálculos de velocidad y aceleración. El no contar con estos párametros, nos obligó a usar otro tipo de metodología menos efectiva basada en visión computacional.
3. Entrega a. Manuales de usuario
El manual de usuario puede consultarse en el Anexo 6.1 (Guía de Uso).
b. Instalación Para instalar cualquiera de las dos versiones de la aplicación es suficiente seguir los siguientes pasos:
1. Descargar VirtualBox desde https://www.virtualbox.org/wiki/Downloads
2. Descargar e instalar desde http://www.vagrantup.com/downloads.html).
3. Clonar el repositorio de gitLab correspondiente
Para clonar la versión stand alone, referirse a: https://gitlab.com/oscar.mondragon/visionvial
Para clonar la versión distribuida, referirse a. https://gitlab.com/oscar.mondragon/visionvialdistribuido
4. Desde un terminal ejecutar de su maquina (CMD, command line, etc.) ejecutar:
a. vagrant up para crear el contenedor docker
b. vagrant ssh para ingresar al contenedor
5. Una vez realice las pruebas deseadas puede apagar la maquina usando vagrant halt
6. Para volver a cargar el contenedor en una proxima prueba es necesario repetir los pasos 4a y 4b y adicionalmente dentro del contenedor ejecutar:
a. service apache2 start b. service mysql start

c. Código fuente El código fuente de la aplicación en sus dos versiones está disponible en GitLab . 4
Para descargar la versión stand alone, referirse a: https://gitlab.com/oscar.mondragon/visionvial Para descargar la versión distribuida, referirse a. https://gitlab.com/oscar.mondragon/visionvialdistribuido En el mismo repositorio se encuentran las instrucciones de instalación.
4 https://gitlab.com/

6 Anexos
6.1 Guía de uso
a. Guía de uso del sistema Stand Alone En la máquina anfitriona, después de levantar el contenedor por medio de vagrant up digite http://localhost:8080 en un browser para tener acceso al frontend de la aplicacion. La primera pantalla, le permite al usuario acceder con su nombre de usuario y contraseña ( boton Login) o registrarse si es la primera vez que accesa al sistema (botón Registrarse).
En el caso de registro por primera vez, el sistema le presentará al usuario la siguiente pantalla (regsiter.html):
a modo de ejemplo hemos creado un usuario de prueba (usertest):

Una vez el usuario llena el formulario de registro y lo envía (boton Submit), el sistema le presentará la siguiente pantalla de Login (login.html):
Despues de ingresar sus datos de usuario y contraseña, el sistema le presentará al usuario una pagina de bienvenida y automaticamente presenta el Dashboard (Dashboard.html), en la cual se presenta un resumen de los últimos patrones de accidentalidad registrados.. En la parte superior serán desplegados diferentes enlaces, las cuales serán descritos a continuación.
● Videos (videoregister.html). Este enlace le presenta al usuario dos botones: procesar y procesado.
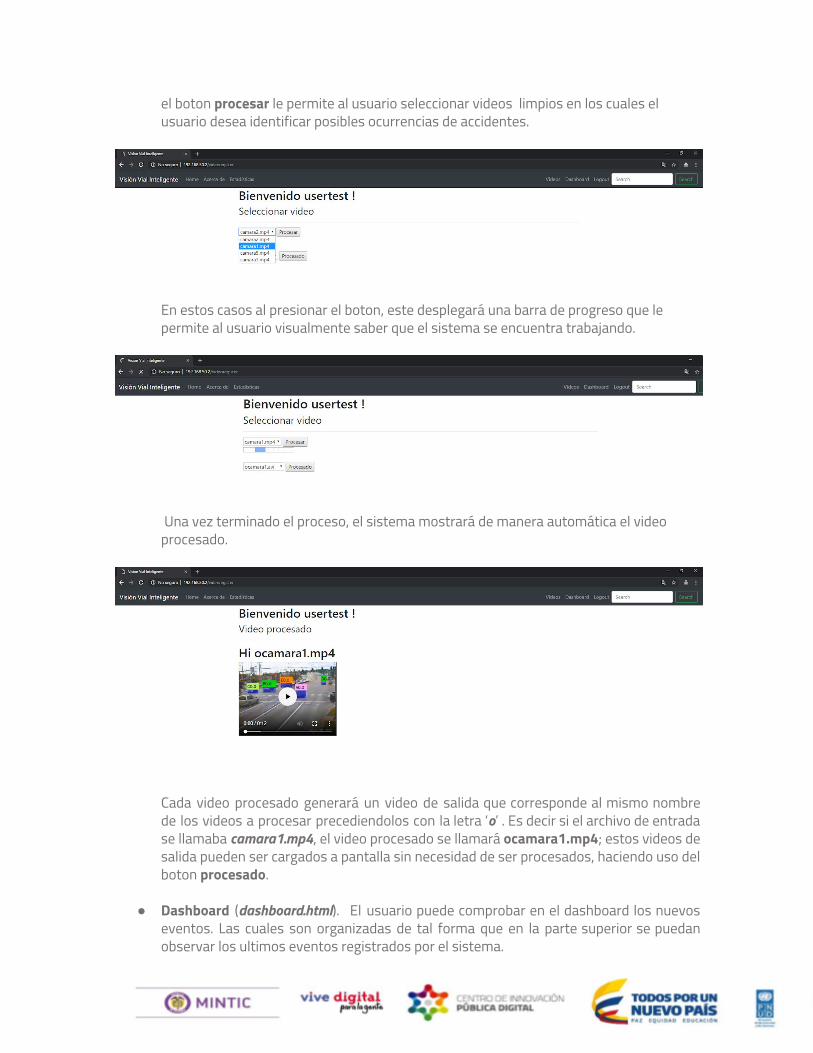
el boton procesar le permite al usuario seleccionar videos limpios en los cuales el usuario desea identificar posibles ocurrencias de accidentes.
En estos casos al presionar el boton, este desplegará una barra de progreso que le permite al usuario visualmente saber que el sistema se encuentra trabajando.
Una vez terminado el proceso, el sistema mostrará de manera automática el video procesado.
Cada video procesado generará un video de salida que corresponde al mismo nombre de los videos a procesar precediendolos con la letra ‘o’ . Es decir si el archivo de entrada se llamaba camara1.mp4, el video procesado se llamará ocamara1.mp4; estos videos de salida pueden ser cargados a pantalla sin necesidad de ser procesados, haciendo uso del boton procesado.
● Dashboard (dashboard.html). El usuario puede comprobar en el dashboard los nuevos
eventos. Las cuales son organizadas de tal forma que en la parte superior se puedan observar los ultimos eventos registrados por el sistema.
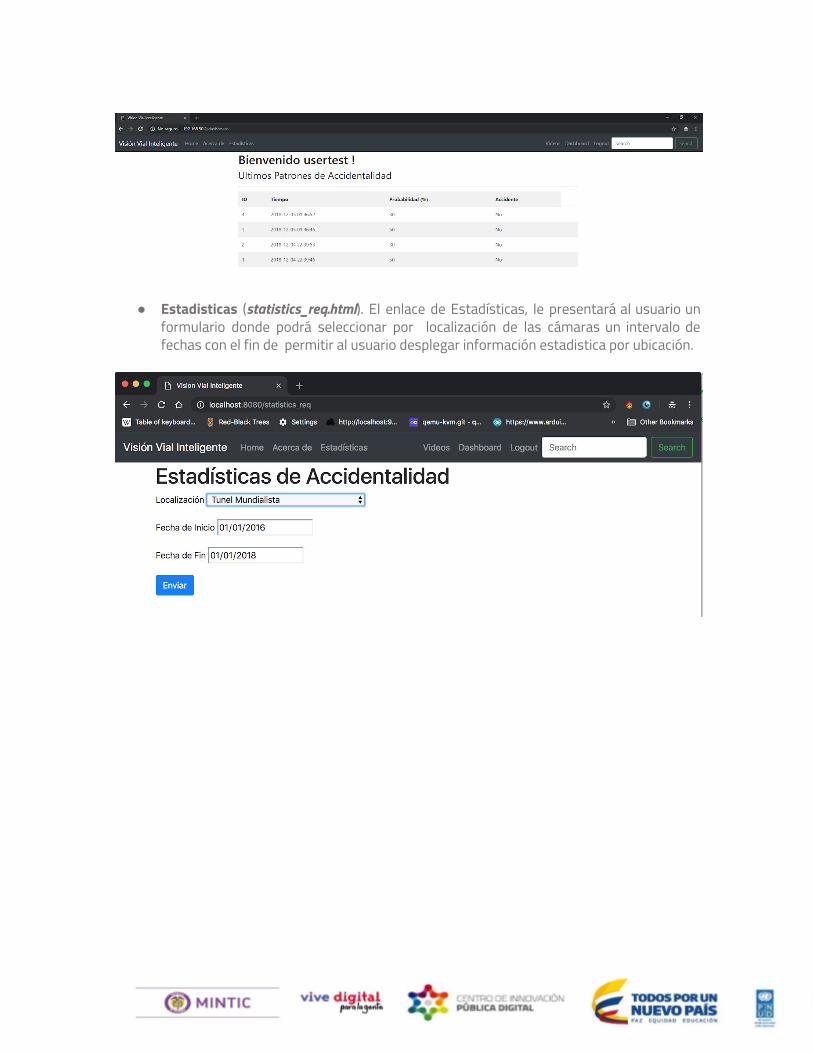
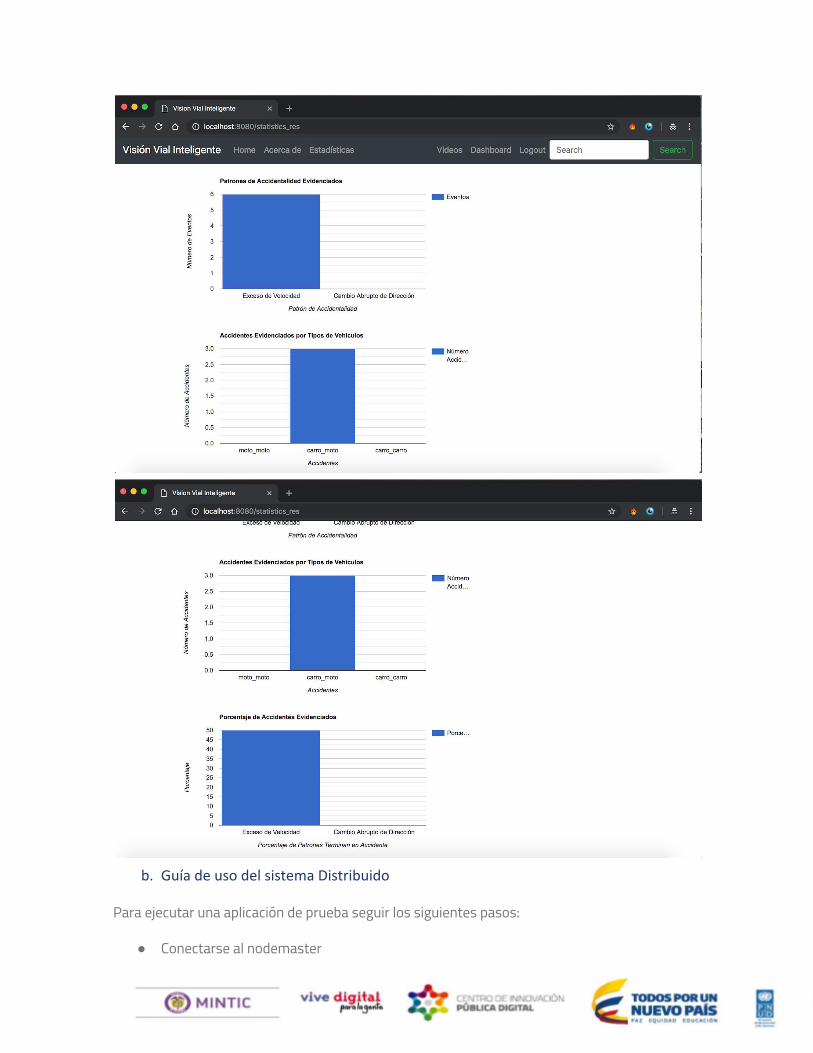
● Estadisticas (statistics_req.html). El enlace de Estadísticas, le presentará al usuario un formulario donde podrá seleccionar por localización de las cámaras un intervalo de fechas con el fin de permitir al usuario desplegar información estadistica por ubicación.
b. Guía de uso del sistema Distribuido
Para ejecutar una aplicación de prueba seguir los siguientes pasos:
● Conectarse al nodemaster

vagrant ssh nodemaster
● Cambiar a usuario hadoop
su hadoop El password solicitado es hadoop
● Subir video de prueba al sistema de archivos distribuido (HDFS)
cd /home/hadoop/vision/videoInputs hdfs dfs -put camara1.mp4 vids
● Ejecutar aplicacion de vision vial inteligente
cd /home/hadoop/vision/pythonPrograms ./run_vision.sh
● Los videos resultantes estaran en la carpeta /tmp del node1.
Ejecutar:
ssh node1 cd /tmp ls
El nombre del video original tendra un prefijo "ori" y el del resultante un prefijo "rs". Por ejemplo,
ori-4841c4fc-f3f9-11e8-8f7b-0800275f82b1.mp4 rs-4841c4fc-f3f9-11e8-8f7b-0800275f82b1.avi
Para extraer estos videos los puede copiar al directorio sincronizado de Vagrant Por ejemplo: cp /vagrant/ori-4841c4fc-f3f9-11e8-8f7b-0800275f82b1.mp4 cp /vagrant/rs-4841c4fc-f3f9-11e8-8f7b-0800275f82b1.avi De esta manera los videos quedaran disponibles en el directorio raiz del proyecto en la maquina anfitriona.


















