
10 – REGRESIÓN LINEAL SIMPLE · la naturaleza de esa relación. El análisis de regresión es la...
26
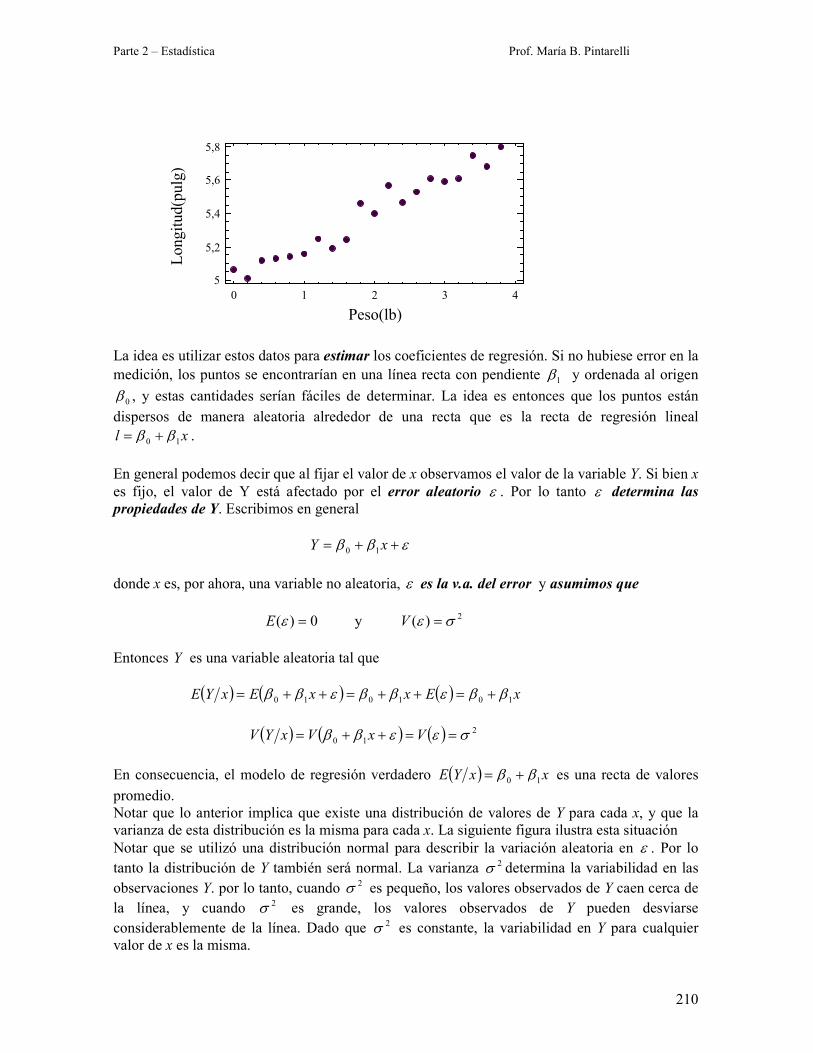
Parte 2 – Estadística Prof. María B. Pintarelli 209 10 – REGRESIÓN LINEAL SIMPLE 10.1 – Introducción En muchos problemas existe una relación entre dos o más variables, y resulta de interés estudiar la naturaleza de esa relación. El análisis de regresión es la técnica estadística para el modelado y la investigación de la relación entre dos o más variables. Veamos un ejemplo. Los resortes se usan en aplicaciones por su capacidad para alargarse (contraerse) bajo carga. La rigidez de un resorte se mide con la constante del resorte, que es la longitud del resorte que se alargará por unidad de la fuerza o de la carga. Para asegurarse de que un resorte dado funciona adecuadamente es necesario calcular la constante de resorte con exactitud y precisión. En este experimento hipotético un resorte se cuelga verticalmente con un extremo fijo, y los pesos se cuelgan uno tras otro del otro extremo. Después de colgar cada peso se mide la longitud del resorte. Sean n x x x ,..., , 2 1 los pesos, y sea i l la longitud del resorte bajo la carga i x . La ley de Hooke establece que i i x l 1 0 β β + = donde 0 β representa la longitud del resorte cuando no tiene carga y 1 β es la constante del resorte. Sea i y la longitud medida del resorte bajo la carga i x . Debido al error de medición i y será diferente de la longitud verdadera i l . Se escribe como i i i l y ε + = donde i ε es el error en la i-ésima medición. Al combinar ambas ecuaciones se obtiene i i i x y ε β β + + = 1 0 (10.1) En la ecuación (10.1), i y es la variable dependiente, i x es la variable independiente, 0 β y 1 β son los coeficientes de regresión, y i ε se denomina error. A la ecuación (10.1) se la llama modelo de regresión lineal simple. La tabla siguiente presenta los resultados del experimento y la figura el diagrama de dispersión de y contra x. Peso (lb) Longitud medida (pulg) Peso (lb) Longitud medida (pulg) x y x y 0,0 5,06 2,0 5,40 0,2 5,01 2,2 5,57 0,4 5,12 2,4 5,47 0,6 5,13 2,6 5,53 0,8 5,14 2,8 5,61 1,0 5,16 3,0 5,59 1,2 5,25 3,2 5,61 1,4 5,19 3,4 5,75 1,6 5,24 3,6 5,68 1,8 5,46 3,8 5,80
Transcript of 10 – REGRESIÓN LINEAL SIMPLE · la naturaleza de esa relación. El análisis de regresión es la...

Parte 2 – Estadística Prof. María B. Pintarelli
209
10 – REGRESIÓN LINEAL SIMPLE
10.1 – Introducción En muchos problemas existe una relación entre dos o más variables, y resulta de interés estudiar
la naturaleza de esa relación. El análisis de regresión es la técnica estadística para el modelado y
la investigación de la relación entre dos o más variables. Veamos un ejemplo.
Los resortes se usan en aplicaciones por su capacidad para alargarse (contraerse) bajo carga. La
rigidez de un resorte se mide con la constante del resorte, que es la longitud del resorte que se
alargará por unidad de la fuerza o de la carga. Para asegurarse de que un resorte dado funciona
adecuadamente es necesario calcular la constante de resorte con exactitud y precisión.
En este experimento hipotético un resorte se cuelga verticalmente con un extremo fijo, y los
pesos se cuelgan uno tras otro del otro extremo. Después de colgar cada peso se mide la longitud
del resorte. Sean nxxx ,...,, 21 los pesos, y sea il la longitud del resorte bajo la carga ix .
La ley de Hooke establece que
ii xl 10 ββ +=
donde 0β representa la longitud del resorte cuando no tiene carga y 1β es la constante del
resorte.
Sea iy la longitud medida del resorte bajo la carga
ix . Debido al error de medición iy será
diferente de la longitud verdadera il . Se escribe como
iii ly ε+=
donde iε es el error en la i-ésima medición. Al combinar ambas ecuaciones se obtiene
iii xy εββ ++= 10 (10.1)
En la ecuación (10.1), iy es la variable dependiente, ix es la variable independiente, 0β y 1β
son los coeficientes de regresión, y iε se denomina error. A la ecuación (10.1) se la llama
modelo de regresión lineal simple.
La tabla siguiente presenta los resultados del experimento y la figura el diagrama de dispersión
de y contra x.
Peso (lb) Longitud medida (pulg) Peso (lb) Longitud medida (pulg)
x y x y
0,0 5,06 2,0 5,40
0,2 5,01 2,2 5,57
0,4 5,12 2,4 5,47
0,6 5,13 2,6 5,53
0,8 5,14 2,8 5,61
1,0 5,16 3,0 5,59
1,2 5,25 3,2 5,61
1,4 5,19 3,4 5,75
1,6 5,24 3,6 5,68
1,8 5,46 3,8 5,80
Parte 2 – Estadística Prof. María B. Pintarelli
210
La idea es utilizar estos datos para estimar los coeficientes de regresión. Si no hubiese error en la
medición, los puntos se encontrarían en una línea recta con pendiente 1β y ordenada al origen
0β , y estas cantidades serían fáciles de determinar. La idea es entonces que los puntos están
dispersos de manera aleatoria alrededor de una recta que es la recta de regresión lineal
xl 10 ββ += .
En general podemos decir que al fijar el valor de x observamos el valor de la variable Y. Si bien x
es fijo, el valor de Y está afectado por el error aleatorio ε . Por lo tanto ε determina las
propiedades de Y. Escribimos en general
εββ ++= xY 10
donde x es, por ahora, una variable no aleatoria, ε es la v.a. del error y asumimos que
0)( =εE y 2)( σε =V
Entonces Y es una variable aleatoria tal que
( ) ( ) ( ) xExxExYE 101010 ββεββεββ +=++=++=
( ) ( ) ( ) 2
10 σεεββ ==++= VxVxYV
En consecuencia, el modelo de regresión verdadero ( ) xxYE 10 ββ += es una recta de valores
promedio.
Notar que lo anterior implica que existe una distribución de valores de Y para cada x, y que la
varianza de esta distribución es la misma para cada x. La siguiente figura ilustra esta situación
Notar que se utilizó una distribución normal para describir la variación aleatoria en ε . Por lo tanto la distribución de Y también será normal. La varianza 2σ determina la variabilidad en las
observaciones Y. por lo tanto, cuando 2σ es pequeño, los valores observados de Y caen cerca de
la línea, y cuando 2σ es grande, los valores observados de Y pueden desviarse
considerablemente de la línea. Dado que 2σ es constante, la variabilidad en Y para cualquier
valor de x es la misma.
Peso(lb)
Longitud(pulg)
0 1 2 3 4
5
5,2
5,4
5,6
5,8
Parte 2 – Estadística Prof. María B. Pintarelli
211
10.2 – Regresión lineal simple- Estimación de parámetros
Para estimar los coeficientes de regresión se utiliza el método de mínimos cuadrados.
Supongamos que se tienen n pares de observaciones ),();....;,();,( 2211 nn yxyxyx . Realizamos
una gráfica representativa de los datos y una recta como posible recta de regresión
Anotamos a la recta de regresión estimada con xy 10ˆˆˆ ββ +=
x
y
110 xββ +
210 xββ +
1x 2x
( ) xxYE 10 ββ +=
iy
iy
ix
Recta de regresión
estimada

Parte 2 – Estadística Prof. María B. Pintarelli
212
Las estimaciones de 0β y 1β deben dar como resultado una línea que en algún sentido se “ajuste
mejor” a los datos. El método de mínimos cuadrados consiste en estimar 0β y 1β de manera tal
que se minimice la suma de los cuadrados de las desviaciones verticales mostradas en la figura
anterior.
La suma de los cuadrados de las desviaciones de las observaciones con respecto a la recta de
regresión es
( )∑=
−−=n
i
ii xyL1
2
10ˆˆ ββ
Los estimadores de mínimos cuadrados de 0β y 1β , que anotamos 0β y 1β , deben satisfacer las
siguientes ecuaciones
( )
( )
=−−−=∂∂
=−−−=∂∂
∑
∑
=
=n
i
iii
n
i
ii
xxyL
xyL
1
10
1
1
10
0
0ˆˆ2
0ˆˆ2
βββ
βββ
(10.2)
Después de simplificar las expresiones anteriores, se llega a
=+
=+
∑ ∑ ∑
∑ ∑
= = =
= =n
i
n
i
n
i
iiii
n
i
n
i
ii
yxxx
yxn
1 1 1
2
10
1 1
10
ˆˆ
ˆˆ
ββ
ββ (10.3)
Las ecuaciones (10.3) reciben el nombre de ecuaciones normales de mínimos cuadrados.
La solución de estas ecuaciones dan como resultado las estimaciones de mínimos cuadrados 0β
y 1β
xy 10ˆˆ ββ −= (10.4)
∑∑
∑∑∑
=
=
=
==
−
−=
n
i
n
i
i
i
n
i
n
i
i
n
i
i
ii
n
x
x
n
yx
xy
1
2
12
1
11
1β (10.5)
donde n
y
y
n
i
i∑== 1 y
n
x
x
n
i
i∑== 1
Parte 2 – Estadística Prof. María B. Pintarelli
213
Las diferencias iii yye ˆ−= con ni ,...,1= se llaman residuos. El residuo ie describe el error
en el ajuste del modelo en la i-ésima observación iy .
Para agilizar la notación son útiles los siguientes símbolos
( )n
x
xxxS
n
i
in
i
n
i
iixx
2
1
1 1
22
−=−=∑
∑ ∑ =
= =
(10.6)
( )n
yx
yxxxyS
n
i
i
n
i
in
i
n
i
iiiixy
−=−=∑∑
∑ ∑ ==
= =
11
1 1
(10.7)
Entonces con esta notación podemos escribir xx
xy
S
S=1β
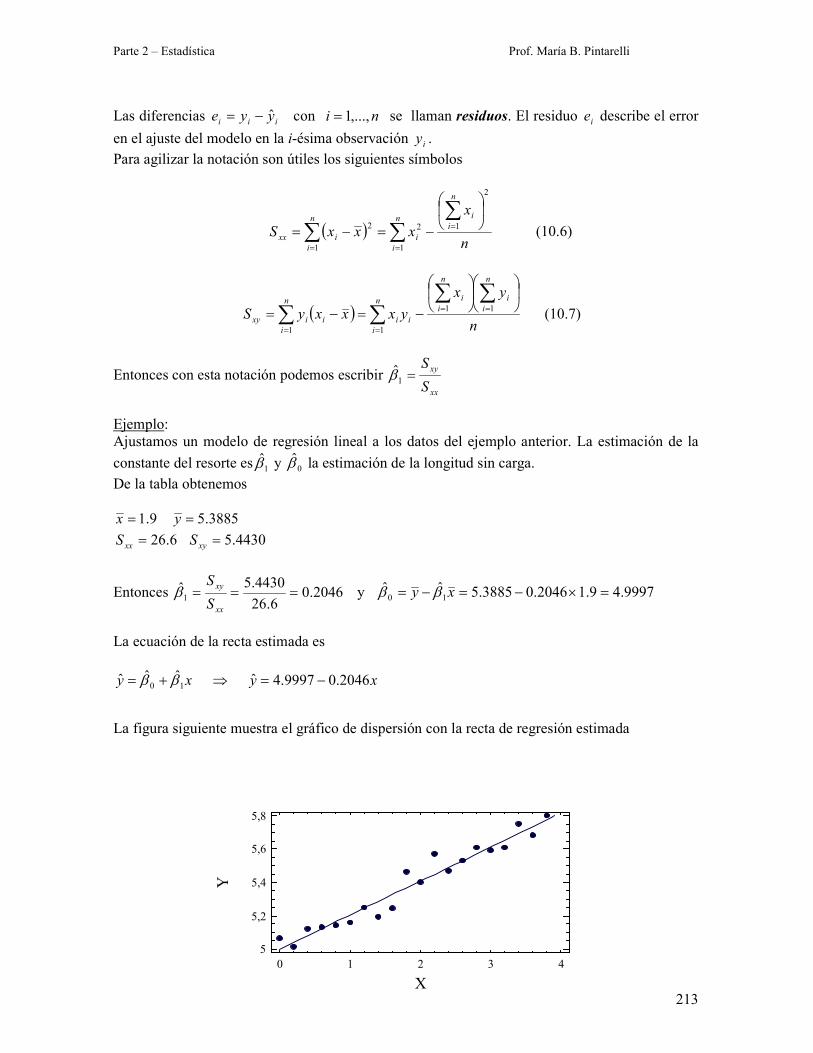
Ejemplo:
Ajustamos un modelo de regresión lineal a los datos del ejemplo anterior. La estimación de la
constante del resorte es 1β y 0β la estimación de la longitud sin carga.
De la tabla obtenemos
9.1=x 3885.5=y
6.26=xxS 4430.5=xyS
Entonces 2046.06.26
4430.5ˆ1 ===
xx
xy
S
Sβ y 9997.49.12046.03885.5ˆˆ
10 =×−=−= xy ββ
La ecuación de la recta estimada es
xyxy 2046.09997.4ˆˆˆˆ10 −=⇒+= ββ
La figura siguiente muestra el gráfico de dispersión con la recta de regresión estimada
X
Y
0 1 2 3 4
5
5,2
5,4
5,6
5,8

Parte 2 – Estadística Prof. María B. Pintarelli
214
Podemos utilizar la recta de regresión estimada para predecir la longitud del resorte bajo una
carga determinada, por ejemplo con una carga de 1.3 lb:
pulg.27.5)3.1(2046.09997.4ˆ =−=y
Podemos también estimar la longitud del resorte bajo una carga de 1.4 lb:
pulg.29.5)4.1(2046.09997.4ˆ =−=y
Notar que la longitud medida para una carga de 1.4 lb es 5.19 pulg., pero la estimación de
mínimos cuadrados de 5.29 pulg. Está basada en todos los datos y es más precisa (tiene menor
incertidumbre). Mas adelante calcularemos la varianza de estos estimadores.
Observaciones:
1- Las estimaciones de mínimos cuadrados 1β y 0β son valores de variables aleatorias y dicho
valor varía con las muestras. Los coeficientes de regresión 0β y 1β son constantes desconocidas
que estimamos con 1β y 0β .
2- Los residuos ie no son lo mismo que los errores
iε . Cada residuo es la diferencia iii yye ˆ−=
entre el valor observado y el valor ajustado, y se pueden calcular a partir de los datos. Los errores
iε representan la diferencia entre los valores medidos iy y los valores
ix10 ββ + . Como los
valores verdaderos de 0β y 1β no se conocen entonces, los errores no se pueden calcular.
3- ¿Qué sucede si se quisiera estimar la longitud del resorte bajo una carga de 100 lb? La
estimación de mínimos cuadrados es pulg.46.25)100(2046.09997.4ˆ =−=y pero esta estimación
no es confiable, pues ninguno de los pesos en el conjunto de datos es tan grande. Es probable que
el resorte se deformara, por lo que la ley de Hooke no valdría. Para muchas variables las
relaciones lineales valen dentro de cierto rango, pero no fuera de él. Si se quiere saber cómo
respondería el resorte a una carga de 100 lb se deben incluir pesos de 100 lb o mayores en el
conjunto de datos.
Por lo tanto no hay que extrapolar una recta ajustada fuera del rango de los datos. La relación
lineal puede no ser válida ahí.
10.3 – Propiedades de los estimadores de mínimos cuadrados y estimación de 2σ
Los estimadores de 1β y 0β los anotamos
xY 10ˆˆ ββ −=
( )
xx
n
i
ii
xx
xY
S
xxY
S
S∑=
−== 1
1β (10.8)
Como 1β y 0β son estimadores de 1β y 0β respectivamente, son variables aleatorias, por lo
tanto podemos calcular su esperanza y varianza. Como estamos asumiendo que x no es v.a.
entonces 1β y 0β son funciones de la v.a. Y.
Recordemos que el modelo es εββ ++= xY 10, si medimos n veces la variable Y tenemos
iii xY εββ ++= 10

Parte 2 – Estadística Prof. María B. Pintarelli
215
donde asumimos ( ) 0=iE ε ; ( ) 2σε =iV ni ,...,2,1= y nεεε ,...,, 21 independientes
Por lo tanto
( ) ( ) ( ) iiii xExxExYE 101010 ββεββεββ +=++=++=
( ) ( ) ( ) 2
10 σεεββ ==++= iiiiVxVxYV
Consideramos
( )
xx
n
i
ii
xx
xY
S
xxY
S
S∑=
−== 1
1β . Podemos ver a 1β como una combinación lineal de las
variables iY , entonces
( )( )
( ) ( )( ) =−=
−=
−
=
= ∑∑
∑==
=n
i
ii
xx
n
i
ii
xxxx
n
i
ii
xx
xyxxYE
SxxYE
SS
xxY
ES
SEE
11
11
11β
( )( ) ( ) ( ) 11
1 1
10
1
10
111ββββββ ==
−+−=−+= ∑ ∑∑= ==
xx
xx
n
i
n
i
iii
xx
n
i
ii
xx
SS
xxxxxS
xxxS
Notar que ( ) 01
111
=
−=−=−∑
∑∑∑ =
=== n
x
nxxnxxx
n
i
in
i
i
n
i
i
n
i
i
y ( ) ( )( ) xx
n
i
ii
n
i
ii Sxxxxxxx =−−=− ∑∑== 11
Por lo tanto
( )
xx
n
i
ii
xx
xy
S
xxY
S
S ∑=
−== 1
1β es un estimador insesgados de 1β
Veamos ahora la varianza de 1β
( )( )
( ) ( )( ) =−=
−=
−
=
= ∑∑
∑==
=n
i
ii
xx
n
i
ii
xxxx
n
i
ii
xx
xyxxYV
SxxYV
SS
xxY
VS
SVV
1
2
21
2
11
11β
( )xx
xx
xx
n
i
i
xxS
SS
xxS
22
21
22
2
11 σσσ ==−= ∑
=
Por lo tanto
(10.9) ( ) 11ˆ ββ =E y ( )
xxSV
2
1ˆ σβ =

Parte 2 – Estadística Prof. María B. Pintarelli
216
Con un enfoque similar calculamos la esperanza y la varianza de 0β
( ) ( ) ( ) ( ) ( ) =−=−
=−=−= ∑∑
=
= xYEn
xn
Y
ExEyExYEEn
i
i
n
i
i
1
1
11
110
1ˆˆˆ βββββ
( ) 0110110
1βββββββ =−+=−+= ∑
=
xxxxn
n
i
i
Calculamos la varianza de 0β , para esto planteamos:
( ) ( ) ( ) ( )( ) ( )xYCovxVYVxYVV 1110ˆ,2ˆˆˆ ββββ −+=−=
Tenemos que
( ) ( )nn
YVn
Yn
VYVn
i
n
i
i
n
i
i
2
1
2
21
21
111 σσ ===
= ∑∑∑
===
r
Y ( ) 0, =ji YYCov por indep.
( ) ( ) ( ) ( )( )
( ) ( ) ( ) ( ) 01
,1
,1
,1ˆ,ˆ,
1
2
1
2
1
11 1
11
=−=−=−=
=−=
−==
∑∑∑
∑∑ ∑
===
== =
n
i
i
xx
n
i
i
xx
n
i
iii
xx
n
i
iii
xx
n
i
n
i xx
iii
xxnS
xxxnS
xYYCovxxnS
x
xxYYCovnS
xS
xxYY
nCovxYCovxxYCov
σσ
ββ
Por lo tanto
( ) ( ) ( ) ( )( ) ( )
+=−+=−+=−=
xxxx S
x
nSx
nxYCovxVYVxYVV
22
22
2
12
110
10ˆ,2ˆˆˆ σ
σσββββ
Entonces
( 10.10)
Necesitamos estimar la varianza desconocida 2σ que aparece en las expresiones de ( )0βV y
( )1βV .
Los residuos iii yye ˆ−= se emplean para estimar 2σ . La suma de los cuadrados de los residuos
es
( )∑=
−=n
i
iiR yySS1
2ˆ (10.11)
( ) 00ˆ ββ =E y ( )
+=
xxS
x
nV
22
0
1ˆ σβ

Parte 2 – Estadística Prof. María B. Pintarelli
217
Puede demostrarse que 22
−=
n
SSE R
σ , en consecuencia 2
2σ=
−n
SSE R .
Entonces se toma como estimador de 2σ a
2
ˆ 2
−=n
SSRσ (10.12)
Puede obtenerse una fórmula más conveniente para el cálculo de RSS , para esto primero notar
que las ecuaciones normales (10.2) se pueden escribir como
( )
( )
=−−
=−−
∑
∑
=
=n
i
iii
n
i
ii
xxy
xy
1
10
1
10
0ˆˆ
0ˆˆ
ββ
ββ ⇒
=
=
∑
∑
=
=n
i
ii
n
i
i
xe
e
1
1
0
0
Entonces
( ) ( )( ) ( ) ( )
( ) ( ) ( ) ( )yyexyyeyexeye
xyeyyeyyyyyySS
i
n
i
ii
n
i
ii
n
i
iiii
n
i
i
ii
n
i
iii
n
i
i
n
i
iiii
n
i
iiR
−=−−=−=−−=
=−−=−=−−=−=
∑∑∑∑∑
∑∑∑∑
====
====
1
1
1
0
1
10
1
10
1111
2
ˆˆˆˆ
ˆˆˆˆˆˆ
ββββ
ββ
Por lo tanto
( ) ( )( ) ( )( )
( )( ) ( )( ) xyyyi
n
i
ii
n
i
i
i
n
i
iii
n
i
iii
n
i
iR
SSyyxxyyyy
yyxxyyyyxyyyeSS
1
1
1
1
1
11
1
10
1
ˆˆ
ˆˆˆˆ
ββ
ββββ
−=−−−−−=
=−−+−=−−−=−=
∑∑
∑∑∑
==
===
También se puede escribir
xx
xy
yyxy
xx
xy
yyxyyyRS
SSS
S
SSSSSS
2
1ˆ −=−=−= β
En resumen xx
xy
yyRxyyyRS
SSSSSSSS
2
1 ó ˆ −=−= β (10.13)
Por lo tanto 2
ˆ
2
2
−
−
=n
S
SS
xx
xy
yy
σ
Y si anotamos a la desviación estándar estimada de 0β y 1β con 0β
s y 0β
s respectivamente
entonces

Parte 2 – Estadística Prof. María B. Pintarelli
218
xxS
s2
ˆ
ˆ
1
σβ= y
+=
xxS
x
ns
22
ˆ
1ˆ
0
σβ (10.14)
Ejemplo:
En el ejemplo anterior se calculó, 9.1=x , 3885.5=y , 6.26=xxS , 4430.5=xyS .
Calculamos ahora ( ) 1733.120
1
2 =−=∑=i
iyy yyS y entonces
003307.018
6.26
4430.51733.1
2ˆ
22
2 =−
=−
−
=n
S
SS
xx
xy
yy
σ
0111.0000124.06.26
003307.0ˆ 2
ˆ1
====xxS
sσ
β
02478219.06.26
9.1
20
1003307.0
1ˆ
222
ˆ0
=
+=
+=
xxS
x
ns σβ
Observación:
La varianza de 0β y 1β se puede disminuir tomando valores ix muy dispersos con respecto a
x pues de esta forma aumenta xxS
Para construir intervalos de confianza para los coeficientes de regresión o para construir pruebas
de hipótesis con respecto a 0β o 1β necesitamos asumir que los errores iε tienen distribución
normal. Entonces ),0(~ 2σε Ni
Observación:
Si ),0(~ 2σε Ni entonces, como iii xY εββ ++= 10 , resulta que ),(~ 2
10 σββ ii xNY + . Se
pueden calcular entonces los EMV de los parámetros y llegaríamos a que son los mismos que
los encontrados usando mínimos cuadrados. De modo que la función que cumple la
suposición de normalidad de los iε no es otra que la de justificar el uso del método de
mínimos cuadrados, que es el mas sencillo de calcular.
Ya vimos que 0β y 1β pueden considerarse combinaciones lineales de las iY , por lo tanto 0β y
1β son combinación lineal de variables aleatorias independientes con distribución normal y eso
implica que
+
xxS
x
nN
22
00
1,~ˆ σββ y
xxSN
2
11 ,~ˆ σββ (10.15)

Parte 2 – Estadística Prof. María B. Pintarelli
219
Y entonces
( )1,0~
1
-ˆ
22
00N
S
x
n xx
+σ
ββ y ( )1,0~
ˆ
2
11 N
S xx
σ
ββ − (10.16)
Bajo la suposición que los errores tienen distribución normal, se puede probar que
2
2-n2~ χ
σRSS
(10.17)
Y también se puede probar que
2-n2
2
00 ~
1ˆ
-ˆt
S
x
n xx
+σ
ββ y
2-n2
11 ~ˆ
ˆt
S xx
σ
ββ − (10.18)
10.4 – Inferencias estadísticas sobre los parámetros de regresión Suponemos que los errores tiene distribución normal, con media cero, varianza 2σ y son
independientes.
Inferencias sobre 1β
Tests de hipótesis sobre 1β
Se desea probar la hipótesis de que la pendiente 1β es igual a una constante, por ejemplo 10β .
Supongamos las hipótesis
1010 : ββ =H contra 1010 : ββ ≠H
El estadístico de prueba es
xxS
T2
101
ˆ
ˆ
σ
ββ −= que bajo 0H tiene distribución Student con n-2
grados de libertad.
Por lo tanto la regla de decisión es
≤
>
−
−
2,2
0
2,´2
0
n
n
tTsiHaceptar
tTsiHrechazar
α
α
Si 1011 : ββ >H se rechaza 1010 : ββ =H si 2, −> ntT α
Si 1011 : ββ <H se rechaza 1010 : ββ =H si 2, −−< ntT α

Parte 2 – Estadística Prof. María B. Pintarelli
220
Un caso especial importante es cuando 0: 10 =βH contra 0: 10 ≠βH
Estas hipótesis están relacionadas con la significancia de la regresión.
Aceptar 0: 10 =βH es equivalente a concluir que no hay ninguna relación lineal entre x e Y.
Si 0: 10 =βH se rechaza implica que x tiene importancia al explicar la variabilidad en Y.
También puede significar que el modelo lineal es adecuado, o que aunque existe efecto lineal
pueden obtenerse mejores resultados agregando términos polinomiales de mayor grado en x.
Ejemplos:
1- El fabricante del resorte de los datos de la ley de Hooke afirma que la constante del resorte 1β
es al menos 0.23 pulg/lb. Se ha calculado que la constante del resorte es 2046.0ˆ1 =β pulg/lb. ¿Se
puede concluir que la afirmación del fabricante es falsa?
Solución:
Se requiere una prueba de hipótesis para contestar la pregunta. Las hipótesis serían
23.0: 10 =βH contra 23.0: 10 <βH
El estadístico de prueba es
xxxx SS
T2
1
2
101
ˆ
23.0ˆ
ˆ
ˆ
σ
β
σ
ββ −=
−=
Se calculó anteriormente 0111.0ˆ 2
=xxS
σ, entonces el valor
0t que toma el estadístico es
28.20111.0
23.02046.00 −=
−=t
Calculamos el p-valor recordando que bajo 23.0: 10 =βH , 2-n~ tT :
( )28.2−<=− TPvalorp
Vemos en la tabla de la distribución Student que en la fila 18=ν grados de libertad
( )( )
=>
=>
01.0552.2
025.0101.2
TP
TP ⇒ 025.001.0 <−< valorp
Por lo tanto se rechaza 23.0: 10 =βH
2- La capacidad de una unión soldada de alongarse bajo tensión está afectada por el compuesto
químico del metal de soldadura. En un experimento para determinar el efecto del contenido de
carbono (x) sobre la elongación (y) se alongaron 39 soldaduras hasta la fractura, y se midió tanto
el contenido de carbono (en partes por mil) como la elongación (en %). Se calcularon los
siguientes resúmenes estadísticos:
6561.0=xxS ; 9097.3−=xyS ; 3319.4ˆ =σ

Parte 2 – Estadística Prof. María B. Pintarelli
221
Suponiendo que x e y siguen un modelo lineal, calcular el cambio estimado en la elongación
debido a un aumento de una parte por mil en el contenido de carbono. ¿Se debe utilizar el
modelo lineal para pronosticar la elongación del contenido de carbono?
Solución:
El modelo lineal es εββ ++= xy 10 , y el cambio de elongación debido a un aumento de una
parte por mil en el contenido de carbono es 1β .
Las hipótesis serían 0: 10 =βH contra 0: 10 ≠βH
La hipótesi nula establece que incrementar el contenido de carbono no afecta la elongación,
mientras que la hipótesis alternativa establece que sí afecta la elongación.
El estadístico de prueba
xxxx SS
T2
1
2
101
ˆ
ˆ
ˆ
ˆ
σ
β
σ
ββ=
−= si 0: 10 =βH es verdadera tiene distribución
Student con 2−n gados de libertad.
Calculamos
( )959.5
6561.0
9097.3ˆ 11 −=
−=
−==∑=
xx
n
i
ii
xx
xy
S
xxy
S
Sβ
348.56561.0
3319.4ˆˆ 2
===xxxx SS
σσ
El valor que toma el estadístico de prueba es 114.1348.5
959.50 =
−=t
Y ( ) 20.010.02114.1 =×>>=− TPvalorp
Por lo tanto no hay evidencia en contra de la hipótesis nula. No se puede concluir que el modelo
lineal sea útil para pronosticar la elongación a partir del contenido de carbono.
Intervalos de confianza para 1β
Podemos construir intervalos de confianza para 1β de nivel α−1 utilizando el hecho que el
estadístico 2-n
2
11 ~ˆ
ˆt
S xx
σ
ββ −. El intervalo sería
+−
−−xx
nxx
n St
St
2
2,2
1
2
2,2
1
ˆˆ ;ˆˆ σ
βσ
β αα (10.19)

Parte 2 – Estadística Prof. María B. Pintarelli
222
Ejemplo:
Determinar un intervalo de confianza de nivel 0.95 para la constante del resorte de los datos de la
ley de Hooke.
Solución:
Se calculó antes 2046.0ˆ1 =β y 0111.0
ˆ 2
=xxS
σ
El número de grados de libertad es 18220 =− , y 05.0=α por lo tanto
101.218,025.02,
2
==−
ttn
α
Por lo tanto el intervalo es
( ) ( )[ ] [ ]228.0 ;181.00111.0101.22046.0 ;0111.0101.22046.0 =−−
Inferencias sobre 0β
De manera similar a lo visto sobre 1β , se pueden deducir intervalos de confianza y tests de
hipótesis para 0β
Específicamente, si tenemos las hipótesis
0000 : ββ =H contra 0000 : ββ ≠H
El estadístico de prueba es
+
xxS
x
n
T2
2
000
1ˆ
-ˆ
σ
ββ y bajo
0000 : ββ =H tenemos que 2-n~ tT
Por lo tanto la regla de decisión es
≤
>
−
−
2,2
0
2,´2
0
n
n
tTsiHaceptar
tTsiHrechazar
α
α
Si 0001 : ββ >H se rechaza 0000 : ββ =H si 2, −> ntT α
Si 0001 : ββ <H se rechaza
0000 : ββ =H si 2, −−< ntT α
Intervalos de confianza de nivel α−1 se deducen de manera análoga a lo visto anteriormente,
donde usamos el hecho que el estadístico 2-n2
2
00 ~
1ˆ
-ˆt
S
x
n
T
xx
+σ
ββ
El intervalo es
++
+−
−−
1ˆˆ ;
1ˆˆ
22
2,2
0
22
2,2
0xx
nxx
n S
x
nt
S
x
nt σβσβ αα (10.20)

Parte 2 – Estadística Prof. María B. Pintarelli
223
Ejemplo:
En los datos de la ley de Hooke determine un intervalo de confianza de nivel 0.99 para la
longitud del resorte no cargado.
Solución:
La longitud del resorte no cargado es 0β . Se ha calculado anteriormente 9997.4ˆ0 =β y
02478219.01
ˆ2
2ˆ0
=
+=
xxS
x
ns σβ
El número de gados de libertad es 18220 =− y como 01.0=α entonces
878.218,005.02,
2
==−
ttn
α
Por lo tanto el intervalo es
( ) ( )[ ] [ ]071023.5 ;9283.4 02478219.0878.29997.4 ;024782193.0878.29997.4 =−−
10.5 – Intervalo de confianza para la respuesta media A menudo es de interés estimar mediante un intervalo de confianza
010 xββ + , es decir estimar
la media ( )0xYE para un valor específico 0x .
Un estimador puntual razonable para 010 xββ + es 010ˆˆ xββ + .
Sabemos que ( ) 010010ˆˆ xxE ββββ +=+ .
Como de costumbre necesitamos construir un estadístico a partir de 010ˆˆ xββ + que contenga al
parámetro de interés, (en este caso 010 xββ + ) y del cual conozcamos la distribución de
probabilidad.
Pensamos en el estadístico ( )
( )010
010010
ˆˆ
ˆˆˆˆ
xV
xEx
ββ
ββββ
+
+−+
Nos falta calcular ( )010ˆˆ xV ββ + . Para esto nuevamente observamos que 010
ˆˆ xββ + es una
combinación lineal de las variables iY
( ) ( ) =−+=−+=+−=+ ∑∑==
xxS
SY
nxxY
nxxYx
xx
xYn
i
i
n
i
i 0
1
01
1
011010
1ˆ1ˆˆˆˆ βββββ
( )( ) ( ) ( )
−
−+=−
−+= ∑∑
∑=
=
=
xxS
xx
nYxx
S
xxY
Yn xx
in
i
i
xx
n
i
iin
i
i 0
1
01
1
11
Por lo tanto:
( ) ( ) ( ) ( ) ( ) ( )
( ) ( ) ( ) ( ) ( ) ( ) =
−
−+−
−+=
−
−+=
=
−
−+=
−
−+=+
∑∑
∑∑
==
==
xxnS
xxxx
S
xx
nxx
S
xx
n
xxS
xx
nYVxx
S
xx
nYVxV
xx
i
xx
in
ixx
in
i
xx
in
i
i
xx
in
i
i
0
2
02
2
21
2
2
0
1
2
2
0
1
0
1
010
211
11ˆˆ
σσ
ββ

Parte 2 – Estadística Prof. María B. Pintarelli
224
( ) ( ) ( ) ( ) =
−
−+−
−+= ∑ ∑
= =
n
i
n
i
i
xx
i
xx
xxnS
xxxx
S
xx
n1 1
02
2
2
02 21σ
Notar que ( ) 01
=−∑=
n
i
i xx y ( ) xx
n
i
i Sxx =−∑=1
2 entonces
( )
−+=
xxS
xx
n
2
02 1σ
Por lo tanto
( )
−+++
xxS
xx
nxNx
2
02
010010
1 ;~ˆˆ σββββ (10.21)
Como 2σ es desconocido lo reemplazamos por 2
ˆ 2
−=n
SSRσ , y puede probarse que
( )( )
−+
+−+
xxS
xx
n
xx
2
02
010010
1ˆ
ˆˆ
σ
ββββ tiene distribución Student con 2−n grados de libertad
Razonando como en casos anteriores, el intervalo de confianza para 010 xββ + de nivel α−1 es
( ) ( )
−+++
−+−+
−−
1ˆˆˆ ;
1ˆˆˆ
2
02
2,2
010
2
02
2,2
010
xxn
xxn S
xx
ntx
S
xx
ntx σββσββ αα (10.22)
Ejemplo:
Mediante los datos de la ley de Hooke calcular un intervalo de confianza de nivel 0.95 para la
longitud media de un resorte bajo una carga de 1.4 lb
Solución:
Para aplicar (10.22) necesitamos calcular 010ˆˆ xββ + ; 2σ ; x ; xxS .
En este caso 4.10 =x y 05.0=α , por lo tanto 101.218,025.02,
2
==−
ttn
α
Ya tenemos calculado de ejemplos anteriores:
0575.0ˆ =σ
9.1=x
6.26=xxS
9997.4ˆ0 =β y 2046.0ˆ
1 =β
De aquí ya calculamos 286.54.12046.09997.4ˆˆ010 =×+=+ xββ
Parte 2 – Estadística Prof. María B. Pintarelli
225
Entonces el intervalo es:
( ) ( )
[ ]32.5 ;26.5
6.26
9.14.1
20
10575.0101.2286.5 ;
6.26
9.14.1
20
10575.0101.2286.5
2
2
2
2
=
=
−++
−+−
Observaciones:
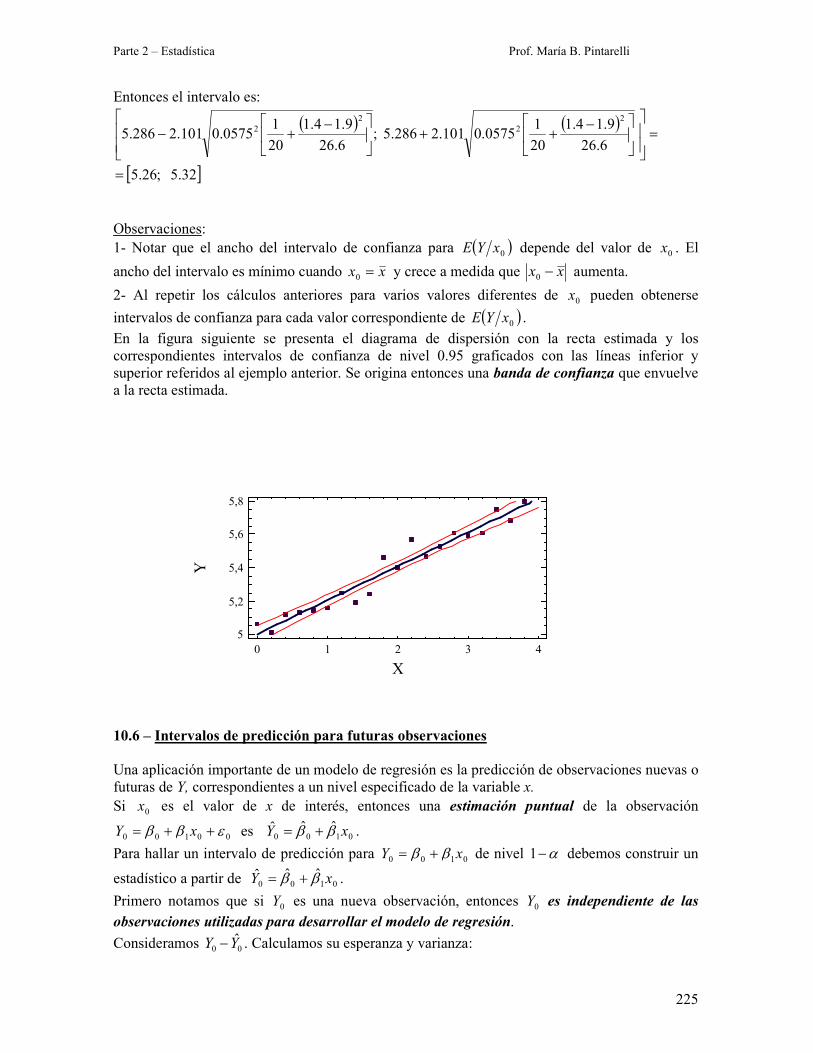
1- Notar que el ancho del intervalo de confianza para ( )0xYE depende del valor de 0x . El
ancho del intervalo es mínimo cuando xx =0 y crece a medida que xx −0 aumenta.
2- Al repetir los cálculos anteriores para varios valores diferentes de 0x pueden obtenerse
intervalos de confianza para cada valor correspondiente de ( )0xYE .
En la figura siguiente se presenta el diagrama de dispersión con la recta estimada y los
correspondientes intervalos de confianza de nivel 0.95 graficados con las líneas inferior y
superior referidos al ejemplo anterior. Se origina entonces una banda de confianza que envuelve
a la recta estimada.
10.6 – Intervalos de predicción para futuras observaciones Una aplicación importante de un modelo de regresión es la predicción de observaciones nuevas o
futuras de Y, correspondientes a un nivel especificado de la variable x.
Si 0x es el valor de x de interés, entonces una estimación puntual de la observación
00100 εββ ++= xY es 0100ˆˆˆ xY ββ += .
Para hallar un intervalo de predicción para 0100 xY ββ += de nivel α−1 debemos construir un
estadístico a partir de 0100ˆˆˆ xY ββ += .
Primero notamos que si 0Y es una nueva observación, entonces 0Y es independiente de las
observaciones utilizadas para desarrollar el modelo de regresión.
Consideramos 00 YY − . Calculamos su esperanza y varianza:
X
Y
0 1 2 3 4
5
5,2
5,4
5,6
5,8

Parte 2 – Estadística Prof. María B. Pintarelli
226
( ) ( )( ) ( ) ( ) 0ˆˆˆ0100010010001000 =+−++=+−++=− xExxxEYYE ββεββββεββ
( ) ( ) ( ) ( ) ( ) ( )
( )
−++=
=
−++=++++=+=−
xx
xx
S
xx
n
S
xx
nxVxVYVYVYYV
2
02
2
022
01000100000
11
1ˆˆˆˆ
σ
σσββεββ
Por lo tanto
( )
−++−
xxS
xx
nNYY
2
02
00
11 ;0~ˆ σ (10.23)
En consecuencia
( )
( )1 ;0~1
1
ˆ
2
02
00 N
S
xx
n
YY
xx
−++
−
σ
(10.24)
Si reemplazamos 2σ por su estimación 2σ se puede probar que
( ) 2-n2
02
00 ~1
1ˆ
ˆt
S
xx
n
YY
xx
−++
−
σ
(10.25)
Por el argumento usual llegamos al siguiente intervalo de predicción de nivel α−1 para 0Y :
( ) ( )
−+++
−++
xxxx S
xx
ntY
S
xx
ntY
2
02
2-n,2
0
2
02
2-n,2
0
11ˆˆ ;
11ˆ-ˆ σσ αα (10.26)
Ejemplo:
Calcular el intervalo de predicción con nivel 0.95 para la elongación de un resorte bajo una
carga de 1.4 lb.
Solución:
El intervalo es
( ) ( )
[ ]5.41034 ;16165.5
6.26
9.14.1
20
110575.0101.2286.5 ;
6.26
9.14.1
20
110575.0101.2286.5
2
2
2
2
=
=
−+++
−++−
Parte 2 – Estadística Prof. María B. Pintarelli
227
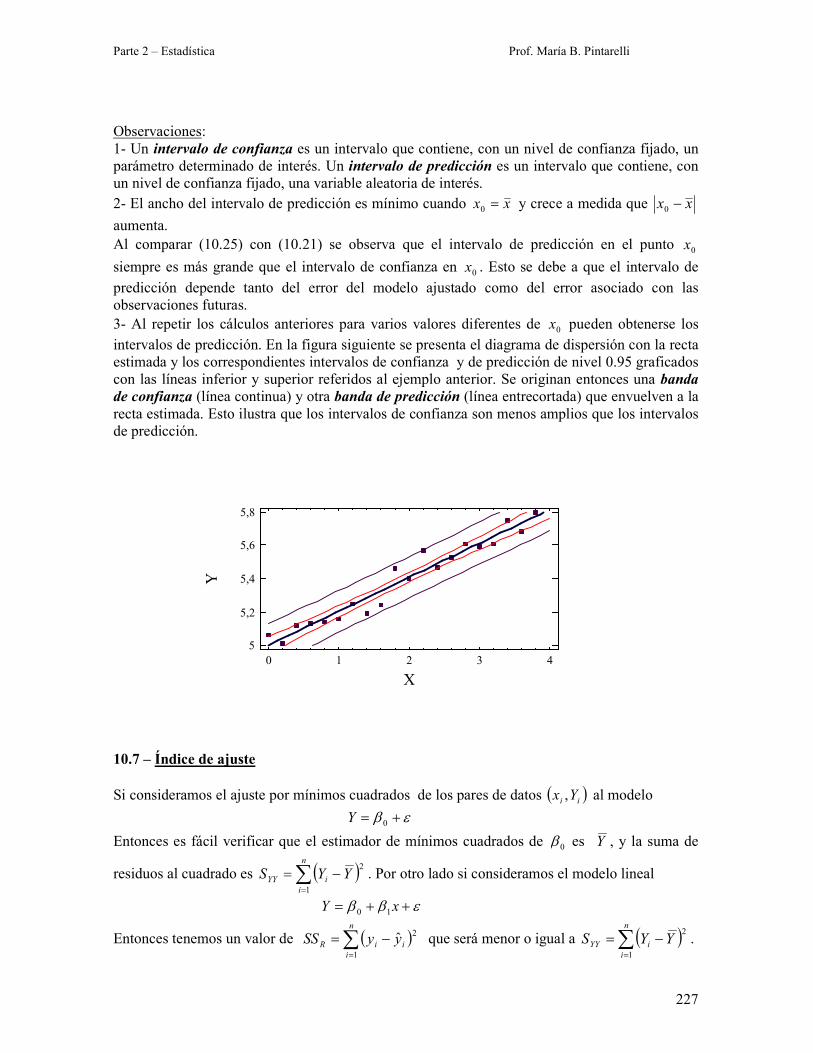
Observaciones:
1- Un intervalo de confianza es un intervalo que contiene, con un nivel de confianza fijado, un
parámetro determinado de interés. Un intervalo de predicción es un intervalo que contiene, con
un nivel de confianza fijado, una variable aleatoria de interés.
2- El ancho del intervalo de predicción es mínimo cuando xx =0 y crece a medida que xx −0
aumenta.
Al comparar (10.25) con (10.21) se observa que el intervalo de predicción en el punto 0x
siempre es más grande que el intervalo de confianza en 0x . Esto se debe a que el intervalo de
predicción depende tanto del error del modelo ajustado como del error asociado con las
observaciones futuras.
3- Al repetir los cálculos anteriores para varios valores diferentes de 0x pueden obtenerse los
intervalos de predicción. En la figura siguiente se presenta el diagrama de dispersión con la recta
estimada y los correspondientes intervalos de confianza y de predicción de nivel 0.95 graficados
con las líneas inferior y superior referidos al ejemplo anterior. Se originan entonces una banda
de confianza (línea continua) y otra banda de predicción (línea entrecortada) que envuelven a la
recta estimada. Esto ilustra que los intervalos de confianza son menos amplios que los intervalos
de predicción.
10.7 – Índice de ajuste Si consideramos el ajuste por mínimos cuadrados de los pares de datos ( )ii Yx , al modelo
εβ += 0Y
Entonces es fácil verificar que el estimador de mínimos cuadrados de 0β es Y , y la suma de
residuos al cuadrado es ( )∑=
−=n
i
iYY YYS1
2. Por otro lado si consideramos el modelo lineal
εββ ++= xY 10
Entonces tenemos un valor de ( )∑=
−=n
i
iiR yySS1
2ˆ que será menor o igual a ( )∑
=
−=n
i
iYY YYS1
2.
X
Y
0 1 2 3 4
5
5,2
5,4
5,6
5,8

Parte 2 – Estadística Prof. María B. Pintarelli
228
La cantidad 2R se define como
YY
R
S
SSR −= 12 (10.27)
y es llamado coeficiente de determinación. Vemos que 2R será cero si 01 =β y será uno si
( )∑=
=−=n
i
iiR yySS1
20ˆ , lo que significa ajuste lineal perfecto.
En general 10 2 ≤≤ R . El valor de 2R se interpreta como la proporción de variación de la
respuesta Y que es explicada por el modelo. La cantidad 2R es llamada índice de ajuste, y es
a menudo usada como un indicador de qué tan bien el modelo de regresión ajusta los datos. Pero
un valor alto de R no significa necesariamente que el modelo de regresión sea correcto.
Ejemplo:
En el ejemplo de la ley de Hooke, tenemos ( ) 1733.120
1
2 =−=∑=i
iyy yyS , y
059526.06.26
4430.51733.1
2
=−=RSS
Por lo tanto 949266.01733.1
059526.0112 =−=−=
YY
R
S
SSR
El índice de ajuste R es a menudo llamado coeficiente de correlación muestral. Si la variable
fijada x es una variable aleatoria, entonces tendríamos una v.a. bidimensional ( )YX , con una
distribución de probabilidad conjunta, y tenemos una muestra de pares ( )ii YX , ni ,...,1= .
Supongamos que estamos interesados en estimar ρ el coeficiente de correlación entre X e Y. Es
decir
( )( ) ( )( )[ ]( ) ( )YVXV
YEYXEXE −−=ρ
Es razonable estimar
( )( ) ( )( )[ ]YEYXEXE −− con ( )( )∑=
−−n
i
ii YYXXn 1
1
( )XV con ( )∑=
−n
i
i XXn 1
21 y ( )YV con ( )∑
=
−n
i
i YYn 1
1
Por lo tanto un estimador natural de ρ es
( )( )
( ) ( )R
SS
S
YYXX
YYXX
YYXX
XY
n
i
i
n
i
i
n
i
ii
==
−−
−−=
∑∑
∑
==
=
1
2
1
2
1ρ (10.28)

Parte 2 – Estadística Prof. María B. Pintarelli
229
Es decir el índice de ajuste estima la correlación entre X e Y
Si X es una variable aleatoria, entonces se observan pares independientes ( )ii YX , con ni ,...,1=
que cumplen el modelo
iii XY εββ ++= 10
Si asumimos que iX y
iε son independientes y que las iε tienen todas la misma distribución
con ( ) 0=iE ε , entonces ( ) iii XXYE 10 ββ +=
Si además suponemos que ( )2,0~ σε Ni entonces se puede probar que los estimadores de
máxima verosimilitud para los parámetros 0β y 1β son
XY 10ˆˆ ββ −=
y
( )
( ) XX
XY
n
i
i
n
i
ii
S
S
XX
XXY
=−
−=
∑
∑
=
=
1
2
1
1β
Es decir son los mismos estimadores a los dados por el método de mínimos cuadrados en el caso
de suponer que X es una variable matemática.
También se puede probar que bajo las suposiciones hechas (10.17) y (10.18) siguen siendo
válidas.
Las distribuciones de los estimadores dependen ahora de las distribuciones de las iX . Puede
probarse que siguen siendo insesgados, y que su distribución condicional en las iX es normal,
pero en general su distribución no será normal.
10.8 – Análisis de residuos El ajuste de un modelo de regresión requiere varias suposiciones. La estimación de los
parámetros del modelo requiere la suposición de que los errores son variables aleatorias
independientes con media cero y varianza constante. Las pruebas de hipótesis y la estimación de
intervalos requieren que los errores estén distribuidos de manera normal. Además se supone que
el grado del modelo es correcto, es decir, si se ajusta un modelo de regresión lineal simple,
entonces se supone que el fenómeno en realidad se comporta de una manera lineal.
Se debe considerar la validez de estas suposiciones como dudosas y examinar cuán adecuado es
el modelo que se propone. A continuación se estudian métodos que son útiles para este
propósito.
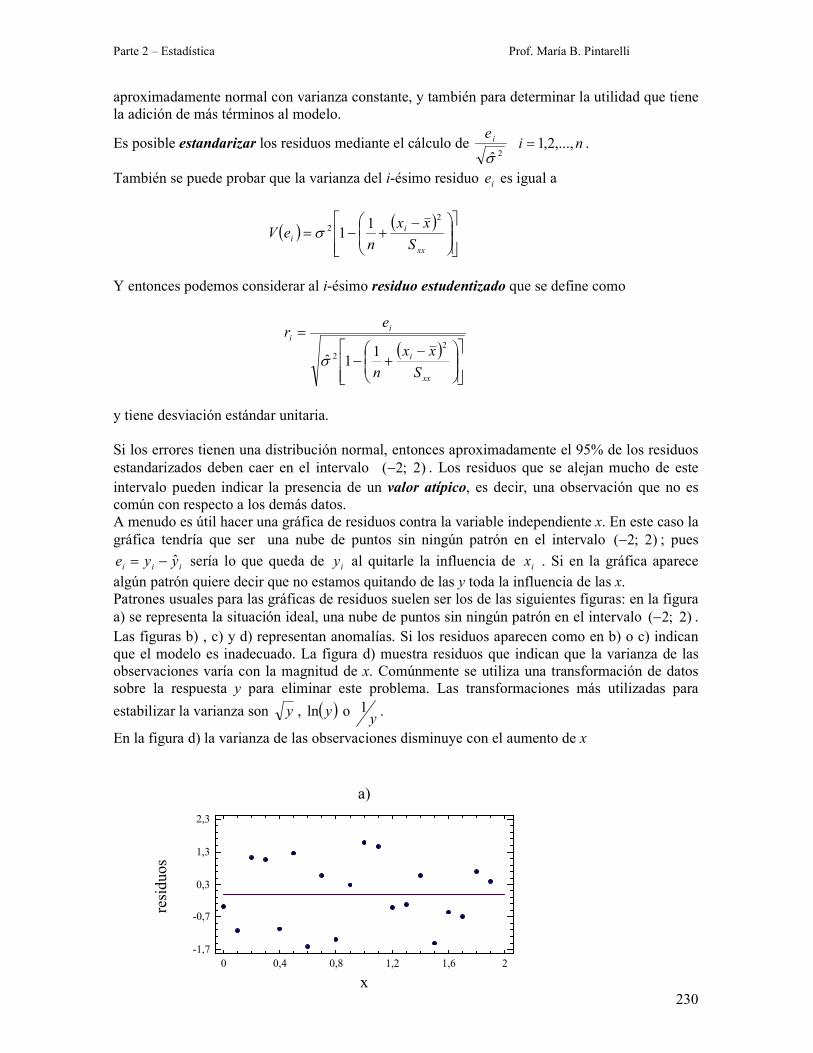
Los residuos de un modelo de regresión son iii yye ˆ−= ni ,...,2,1= . A menudo el análisis de
los residuos es útil para verificar la hipótesis de que los errores tienen una distribución que es
Parte 2 – Estadística Prof. María B. Pintarelli
230
aproximadamente normal con varianza constante, y también para determinar la utilidad que tiene
la adición de más términos al modelo.
Es posible estandarizar los residuos mediante el cálculo de 2σ
ie ni ,...,2,1= .
También se puede probar que la varianza del i-ésimo residuo ie es igual a
( ) ( )
−+−=
xx
i
iS
xx
neV
2
2 11σ
Y entonces podemos considerar al i-ésimo residuo estudentizado que se define como
( )
−+−
=
xx
i
ii
S
xx
n
er
2
2 11σ
y tiene desviación estándar unitaria.
Si los errores tienen una distribución normal, entonces aproximadamente el 95% de los residuos
estandarizados deben caer en el intervalo )2 ;2(− . Los residuos que se alejan mucho de este
intervalo pueden indicar la presencia de un valor atípico, es decir, una observación que no es
común con respecto a los demás datos.
A menudo es útil hacer una gráfica de residuos contra la variable independiente x. En este caso la
gráfica tendría que ser una nube de puntos sin ningún patrón en el intervalo )2 ;2(− ; pues
iii yye ˆ−= sería lo que queda de iy al quitarle la influencia de ix . Si en la gráfica aparece
algún patrón quiere decir que no estamos quitando de las y toda la influencia de las x.
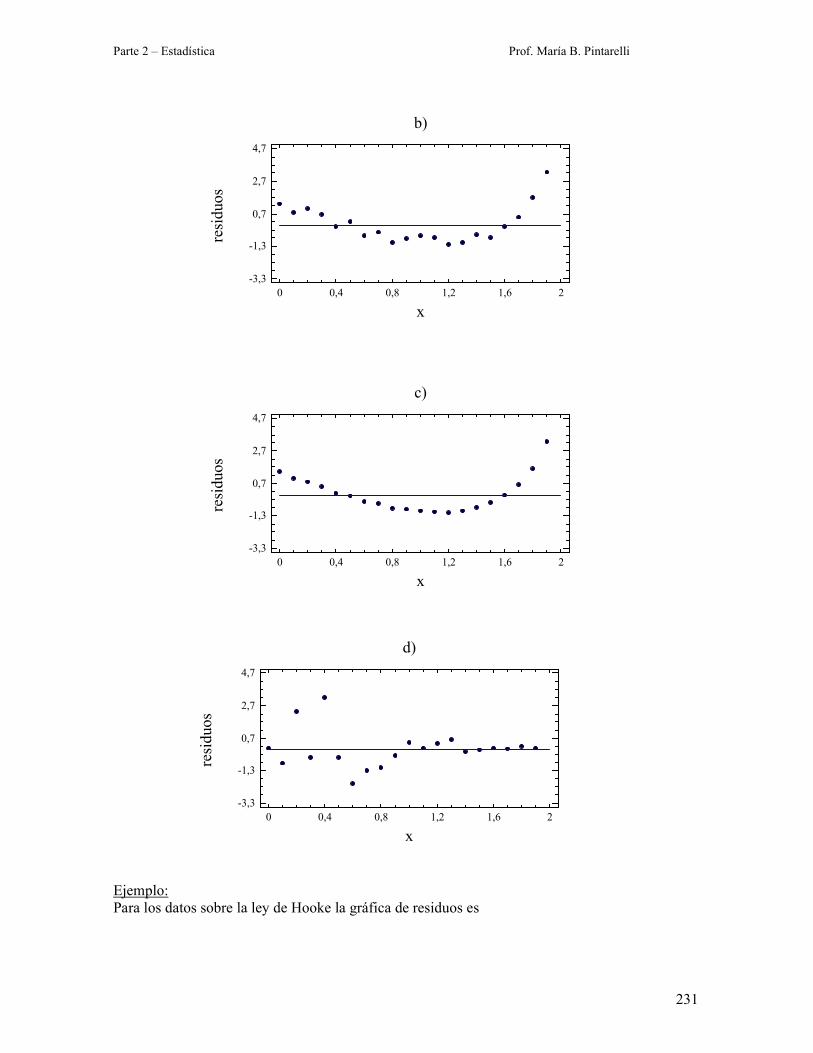
Patrones usuales para las gráficas de residuos suelen ser los de las siguientes figuras: en la figura
a) se representa la situación ideal, una nube de puntos sin ningún patrón en el intervalo )2 ;2(− .
Las figuras b) , c) y d) representan anomalías. Si los residuos aparecen como en b) o c) indican
que el modelo es inadecuado. La figura d) muestra residuos que indican que la varianza de las
observaciones varía con la magnitud de x. Comúnmente se utiliza una transformación de datos
sobre la respuesta y para eliminar este problema. Las transformaciones más utilizadas para
estabilizar la varianza son y , ( )yln o y
1 .
En la figura d) la varianza de las observaciones disminuye con el aumento de x
a)
x
residuos
0 0,4 0,8 1,2 1,6 2
-1,7
-0,7
0,3
1,3
2,3
Parte 2 – Estadística Prof. María B. Pintarelli
231
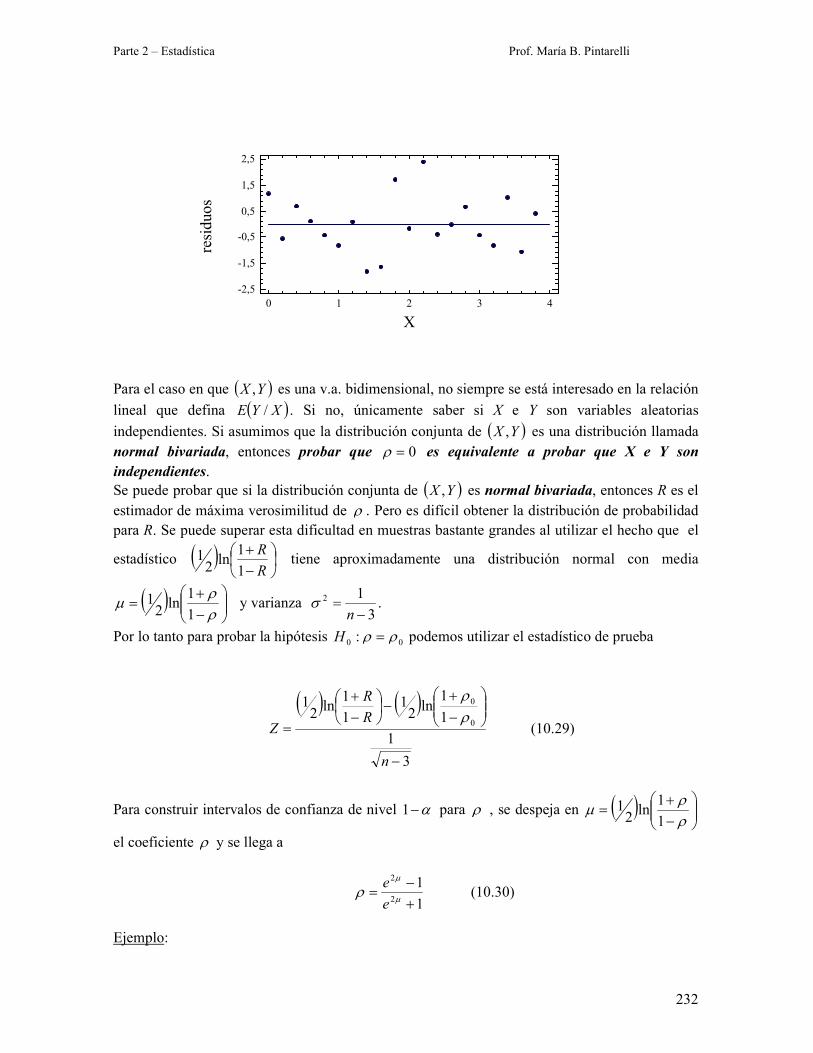
Ejemplo:
Para los datos sobre la ley de Hooke la gráfica de residuos es
b)
x
residuos
0 0,4 0,8 1,2 1,6 2
-3,3
-1,3
0,7
2,7
4,7
c)
x
residuos
0 0,4 0,8 1,2 1,6 2
-3,3
-1,3
0,7
2,7
4,7
d)
x
residuos
0 0,4 0,8 1,2 1,6 2
-3,3
-1,3
0,7
2,7
4,7
Parte 2 – Estadística Prof. María B. Pintarelli
232
Para el caso en que ( )YX , es una v.a. bidimensional, no siempre se está interesado en la relación
lineal que defina ( )XYE / . Si no, únicamente saber si X e Y son variables aleatorias
independientes. Si asumimos que la distribución conjunta de ( )YX , es una distribución llamada
normal bivariada, entonces probar que 0=ρ es equivalente a probar que X e Y son
independientes.
Se puede probar que si la distribución conjunta de ( )YX , es normal bivariada, entonces R es el
estimador de máxima verosimilitud de ρ . Pero es difícil obtener la distribución de probabilidad
para R. Se puede superar esta dificultad en muestras bastante grandes al utilizar el hecho que el
estadístico ( )
−+R
R
1
1ln
21 tiene aproximadamente una distribución normal con media
( )
−+
=ρρ
µ1
1ln
21 y varianza
3
12
−=n
σ .
Por lo tanto para probar la hipótesis 00 : ρρ =H podemos utilizar el estadístico de prueba
( ) ( )
3
1
1
1ln
21
1
1ln
21
0
0
−
−
+−
−+
=
n
R
R
Zρρ
(10.29)
Para construir intervalos de confianza de nivel α−1 para ρ , se despeja en ( )
−+
=ρρ
µ1
1ln
21
el coeficiente ρ y se llega a
1
12
2
+
−=
µ
µ
ρe
e (10.30)
Ejemplo:
X
residuos
0 1 2 3 4
-2,5
-1,5
-0,5
0,5
1,5
2,5

Parte 2 – Estadística Prof. María B. Pintarelli
233
En un estudio de los tiempos de reacción, el tiempo de respuesta a un estímulo visual (x) y el
tiempo de respuesta a un estímulo auditivo (y) se registraron para cada una de 10 personas.
Los tiempos se midieron en minutos. Se presentan en la siguiente tabla.
x 161 203 235 176 201 188 228 211 191 178
y 159 206 241 163 197 193 209 189 169 201
a) Determinar un intervalo de confianza de nivel 0.95 para la correlación entre los tiempos de
reacción.
b) Determinar el p-valor para 3.0:0 =ρH contra 3.0:1 >ρH
Solución:
a) Se calcula
( )( )
( ) ( )8159.0
1
2
1
2
1 ==
−−
−−=
∑∑
∑
==
=
YYXX
XY
n
i
i
n
i
i
n
i
ii
SS
S
YYXX
YYXX
R
Luego calcula ( ) ( ) 1444.18159.01
8159.01ln
21
1
1ln
21 =
−+
=
−+R
R
Como ( )
−+R
R
1
1ln
21 está distribuido normalmente con varianza
3
12
−=n
σ , el intervalo para
( )
−+
=ρρ
µ1
1ln
21 es
[ ]8852.1 ;4036.0 310
196.11444.1 ;
310
196.11444.1 =
−+
−−
Para hallar el intervalo para ρ aplicamos la transformación (10.30) y se obtiene
( )
( )
( )
( ) 1
1
1
18852.12
8852.12
4036.02
4036.02
+
−<<
+
−
e
e
e
eρ ⇒ 955.0383.0 << ρ
b) Si 3.0:0 =ρH es verdadera entonces el estadístico
( ) ( )
310
1
3.01
3.01ln
21
1
1ln
21
−
−+
−
−+
=R
R
Z tiene aproximadamente distribución )1,0(N
El valor observado de ( )
−+R
R
1
1ln
21 es 1.1444, por lo tanto el estadístico toma el valor

Parte 2 – Estadística Prof. María B. Pintarelli
234
2088.20 =z
Entonces ( ) 0136.02088.2 =>=− ZPvalorp . Entonces se rechaza 3.0:0 =ρH y se con-
cluye que 3.0>ρ


















