
5 Contrastes
153
276 "CONTRASTES DE HIPÓTESIS" 4.4 Parte básica
-
Upload
wilmar-jose-gonzalez-palomino -
Category
Documents
-
view
246 -
download
0
Transcript of 5 Contrastes

276
"CONTRASTES DE HIPÓTESIS"
4.4 Parte básica

277
4.4.1 Introducción a los contrastes de hipótesis
La Inferencia Estadística consta de dos partes: Estimación y Contrastes de Hipótesis. La primera se ha estudiado en la unidad anterior y estaba destinada a tratar de determinar el valor de un parámetro poblacional, a partir de lo observado en la muestra. La técnica de Contraste de Hipótesis es preciso para establecer procedimientos para aceptar o rechazar hipótesis estadísticas emitidas acerca de un parámetro, u otra característica de la población.
La única forma de saber con certeza absoluta que una hipótesis estadística es verdadera, es examinar toda la población. Pero esto, en la mayoría de los casos resulta, imposible (por falta de medios económicos, imposibilidades técnicas, etc.). Por lo tanto, la decisión debe adoptarse a partir de los resultados de una muestra de la población (supuesta representativa), que nos inducirá a tomar la decisión sobre la verdad o falsedad de la hipótesis. Pero es difícil ésta decisión, porque aunque sepamos exactamente el valor del parámetro de la población, en las muestras es muy difícil que se verifique ese valor exacto, por lo que debemos decidir unos límites de valores del parámetro en la muestra, que nos puedan llevar a la decisión de aceptar el valor del parámetro poblacional.
Por ejemplo, si una población es normal N(150, 30), en todas las muestras de
tamaño 36, aproximadamente en un 2% de ellas, la media muestral superará las 160
unidades, y en otro 2% aproximadamente será inferior a las 140 unidades.
El problema, es pues, decidir a partir de qué valores de la media muestral
podemos aceptar que la media poblacional es de 150 unidades, y todo ello siempre con
un margen de error.

278
4.4.2Conceptos básicos4.4.2.1 Hipótesis nula e Hipótesis
alternativaA la hipótesis que se desea contrastar la denominaremos Hipótesis nula, y la
denotaremos por Ho.
Esta hipótesis nula es la que se somete a comprobación, y es la que se
acepta o rechaza, como la conclusión final de un contraste.
Puede surgir de diversos modos (Por discusiones teóricas, ó como modelo teórico,
ó por la experiencia, ó por intuición, etc.).
Esta hipótesis nula lleva consigo una hipótesis alternativa, denotada por Ha o
H1.
La hipótesis alternativa será la que se acepta si se rechaza Ho y viceversa
En el ejemplo del párrafo anterior, si tratamos de determinar la media poblacional
(supuesta desconocida), la hipótesis nula podría ser:
Ho: Media poblacional = 150.
En éste caso, la hipótesis alternativa tendría la siguiente expresión:
Ha: Media poblacional ≠ 150.
4.4.2.2 Estadígrafo de contrasteEl contraste de hipótesis, es pues, un mecanismo mediante el cual se rechaza la
hipótesis nula cuando existan diferencias significativas entre los valores muestrales y los valores teóricos, y se acepte en caso contrario. Estas variables se medirán mediante una variable denominada estadígrafo de contraste, o estadístico de contraste, que sigue una distribución determinada conocida, y que para cada muestra tomará un valor particular.

279
En el ejemplo anterior, el estadístico de contraste puede ser la media muestral,
pero según hemos visto en unidades anteriores, conocemos que la variable
Z = x ! µ con n > 30∀
n
sigue una distribución normal N(0,1), por lo que puede utilizarse ésta variable como un
estadístico de contraste, ya que se conoce su distribución.
4.4.2.3 Región crítica y región de aceptaciónDenominaremos región crítica, al conjunto de valores del estadístico de
contraste que nos lleva a rechazar la hipótesis nula.
La región crítica es el conjunto de valores del estadístico de contraste que
nos induce a rechazar la hipótesis nula
En el ejemplo anterior, si tomamos la media muestral como estadístico de
contraste, la región crítica serían los valores de la media muestral superiores a 159.8, o
inferiores a 140.2. Pero si tomamos el estadístico Z, la región crítica serían los valores
de Z cuyo valor absoluto sea mayor que 1.96.
Llamaremos región de aceptación, al conjunto de los valores del estadístico
que nos llevan a aceptar la hipótesis nula.
La región de aceptación es el conjunto de los valores del estadístico que nos
induce a aceptar la hipótesis nula.
4.4.2.4 Error tipo I y Error tipo IIObviamente la conclusión tras un contraste de hipótesis puede ser cierta o no, ya
que no sabemos con certeza cuál es la situación verdadera. Esto nos puede llevar a las
situaciones reflejadas en el siguiente cuadro:

280
Decisión
Aceptar Ho Rechazar HoHipótesis
HoCorrecta Error tipo I
ciertaH1
Error tipo II Correcta
O bien reflejadas en la siguiente forma:
. Si la hipótesis nula es cierta y se acepta, la decisión es correcta.
. Si la hipótesis nula es cierta y se rechaza ésta, se comete un error; a este error
le denominaremos error de tipo I.
. Si la hipótesis alternativa es cierta y se acepta la hipótesis nula, se comete un
error; a éste error le denominaremos error de tipo II.
. Si la hipótesis alternativa es falsa y se rechaza la hipótesis nula, la decisión es
correcta.
4.4.2.5 Nivel de significación y potencia del contraste
Nivel de significación del contraste es la probabilidad de cometer
un error del tipo I, es decir, de rechazar la hipótesis nula siendo
cierta, y se acostumbra a denotar por α
α = P(cometer error tipo I) = P(rechazar Ho siendo cierta)
La interpretación estadística del error tipo I es la siguiente:
Si el experimento se repitiera un gran número de veces, sobre una población con
media de 150 unidades, en el 100(1 - a)% de los casos, ese experimento llevaría a la
conclusión verdadera de que µ = 150, y en el 100 a% de las veces conduciría a la
decisión falsa de que µ ≠ 150.

281
La probabilidad de cometer error del tipo II se denota por β
β = P(cometer error tipo II) = P(aceptar Ho siendo falsa)
Su complementario hasta uno es lo que se llama potencia del contraste
La potencia del contraste, es la probabilidad de rechazar la hipótesis nula
siendo ésta falsa., es decir, aceptar la hipótesis alternativa siendo cierta.
La interpretación estadística del error tipo II es la siguiente:
Si el experimento se repitiera un gran número de veces, sobre una población con
media de 150 unidades, en el 100β% de los casos, ese experimento llevaría a la
conclusión falsa de que µ = 150, y en el 100 (1 - β)% de las veces conduciría a la
decisión verdadera de que µ ≠ 150.
Estas probabilidades se pueden conocer:
Si en el ejemplo de una población normal N(µ, 30) tomamos una muestra de 36
elementos, y contrastamos Ho (µ=150) contra la hipótesis alternativa Ha (µ=165), yconsideramos como región de aceptación el intervalo (140, 160), entonces la
probabilidad de cometer error tipo I, es la probabilidad de que la media muestral
pertenezca a la región crítica; es decir, sea mayor que 160, o menor que 140 unidades, y
la hipótesis nula sea cierta. Así
α = P(cometer error tipo I) = P( x ≥ 160/N(150,30))+P( x ≤ 140/N(150,30))=
=P(Z ≥ 2) + P(Z ≤ -2) = 0.0228 + 0.0228 = 0.0456
lo que nos da cierta información sobre la posibilidad de acertar en nuestra decisión,
aunque no sepamos el verdadero valor del parámetro poblacional.
Análogamente se puede calcular la probabilidad de cometer error tipo II, es decir,
de que la media muestral pertenezca al intervalo (140, 160) y sea cierta la hipótesis
alternativa:
β = P(cometer error tipo II) = P(140 ≤ x ≤ 160/N(165,30))= P(-5
≤ Z ≤ -1) = P(Z ≤ -1) - P(Z ≤ -5) = 0.1687 - 0.00001 = 0.168699.

282
4.4.2.6 Tipo de contrasteSegún que la región crítica contenga una o dos regiones, diremos que el contraste
es unilateral, o bilateral.
Estos son los conceptos iniciales que deben tenerse en cuenta en un contraste de
hipótesis.
4.4.2.7 Pasos en un contraste de hipótesisVeamos ahora los pasos que son convenientes seguir para realizar el contraste de
hipótesis:
1º Determinar, claramente, la hipótesis nula Ho y la hipótesis alternativa
Ha.
2º Elegir el nivel de significación.
3º Seleccionar un estadístico cuya distribución muestral sea conocida en el
caso de que la hipótesis nula sea cierta.
4º Determinar la región crítica.
5º Calcular el valor del estadístico de contraste para la muestra elegida.
6º Sacar las conclusiones estadísticas del contraste (aceptar o rechazar Ho).
7º Sacar las conclusiones no estadísticas (biológicas, médicas, económicas,
etc.) a que nos llevan los resultados estadísticos.

283
4.4.3 Contraste para la media de una población normal4.4.3.1 Contraste para la media de una población normal, con varianza poblacional conocida
Supongamos que queremos contrastar la hipótesis de que la media µ de una
población normal, toma un valor específico µo , cuando la varianza σ2 de la poblaciónes conocida.
En éste caso, la hipótesis nula será, en general: Ho (µ = µo )
Mientras que la hipótesis alternativa puede tener diversas expresiones:
Ha (µ = µ1 ) , o bien, Ha (µ < µo ), Ha (µ > µo ), o bien Ha (µ ≠ µo ). Estadígrafo de contraste: El contraste se efectuará tomando muestras
aleatorias de tamaño n. Conocemos que la distribución de la media muestral sigue una distribución normal N(µ, σ/√n). Entonces, si x es la media de una muestra de tamaño n, entonces la variable
Z = x
! µ
o
n
seguirá, cuando la hipótesis nula sea cierta una distribución normal estándar N(0,1). Se
puede utilizar así pues ésta variable como estadístico de contraste en éste caso.
Nivel de significación: El nivel de significación será α, que, generalmente
tomará los valores 0.1, 0.05 ó 0.01.
Región crítica:
Si la hipótesis nula fuese cierta y µ = µo , cabe esperar que la media muestral x se
distribuya en torno al valor µo, es decir, x - µo tendrá un valor elevado para que existan evidencias de que la hipótesis nula sea falsa, es decir, la variable Z tomará un valor absoluto grande; así pues, la región crítica estará formada por los valores de Z elevados, tanto positivos como negativos. Para especificar cuando se consideran


284
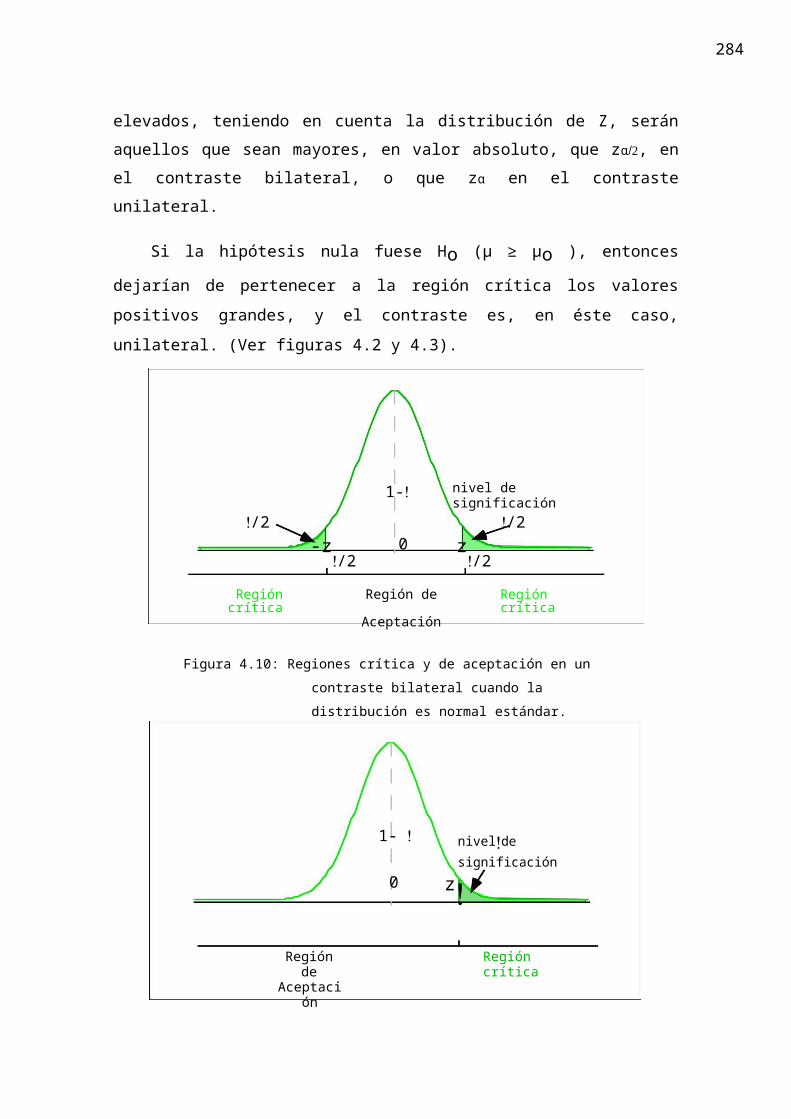
elevados, teniendo en cuenta la distribución de Z, serán aquellos que sean mayores, en valor absoluto, que zα/2, en el contraste bilateral, o que zα en el contraste unilateral.
Si la hipótesis nula fuese Ho (µ ≥ µo ), entonces dejarían de pertenecer a la región
crítica los valores positivos grandes, y el contraste es, en éste caso, unilateral. (Ver figuras 4.2 y 4.3).
1-! nivel de significación
!/2 !/2-z!/2
0 z!/2
Región crítica Región de Región críticaAceptación
Figura 4.10: Regiones crítica y de aceptación en un contraste bilateral cuando la distribución es normal estándar.
1- ! nivel!de significación
0 z!
Región de Región críticaAceptación
Figura 4.11: Regiones crítica y de aceptación en un contraste unilateral cuando
la distribución es normal estándar.

285
4.4.3.2 Contraste para la media de una población normal, con varianza poblacional desconocida
MUESTRAS GRANDES
Estadígrafo de contraste:
En el mismo caso que en el párrafo anterior, y con las mismas hipótesis, si el tamaño de la muestra es suficientemente grande (n > 30), aunque sea desconocida la varianza poblacional, se consiguen buenos resultados utilizando como estimador de la varianza poblacional la cuasi-varianza muestral y, por lo tanto, se puede tomar como estadístico de contraste el mismo que se tomó cuando la varianza poblacional era conocida; es decir
Z = x
! µ
o
n
es una variable que sigue una distribución normal estándar N(0,1), por lo que el
razonamiento es idéntico al caso anterior.
MUESTRAS PEQUEÑAS
Estadígrafo de contraste:
Si el tamaño de la muestra es pequeño (n < 30), sabemos de unidades anteriores que la variable
t = x
s ! µ o
n!1
difiere sensiblemente de una distribución normal, aproximándose bastante mejor por
una distribución t de Student, con n-1 grados de libertad, por lo que ésta variable t puede
utilizarse con un estadístico de contraste.
Región crítica:

La región crítica, en éste caso, estará determinada por los valores de la variable t
que sean excesivamente grandes en valor absoluto, si el contraste es bilateral, y para
especificar el nivel de cuando pueden considerarse grandes, teniendo en cuenta la

286
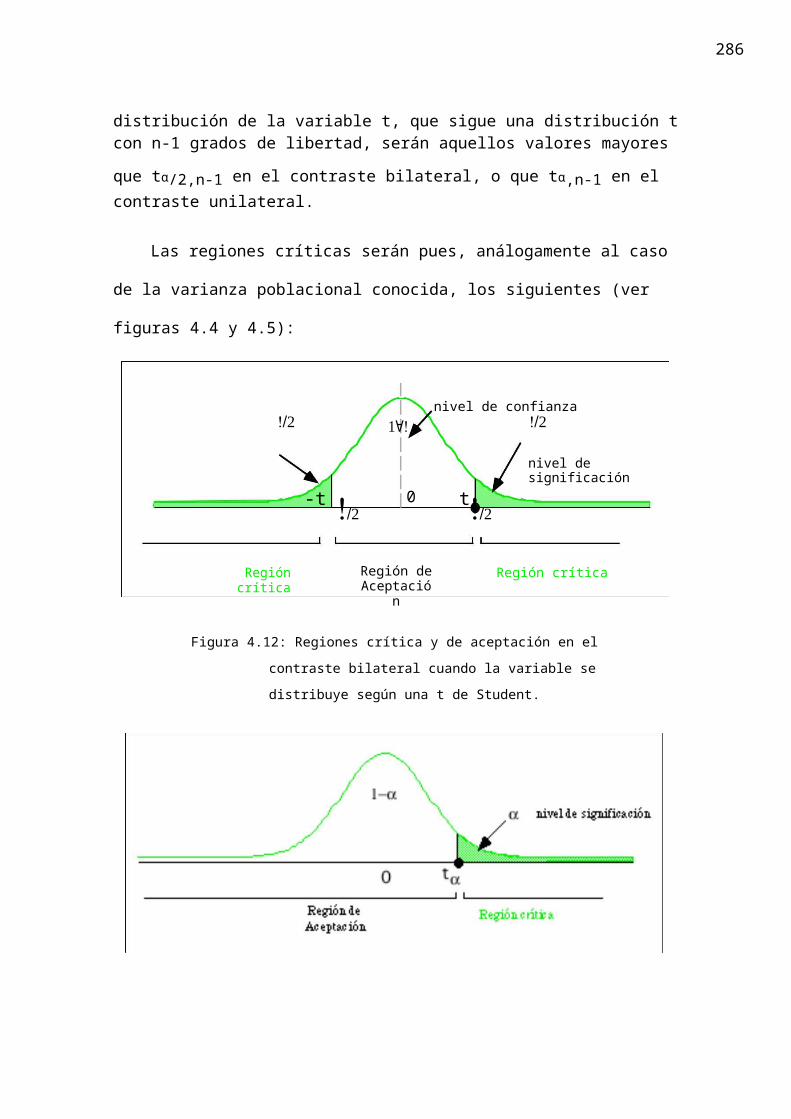
distribución de la variable t, que sigue una distribución t con n-1 grados de libertad,
serán aquellos valores mayores que tα/2,n-1 en el contraste bilateral, o que tα,n-1 en elcontraste unilateral.
Las regiones críticas serán pues, análogamente al caso de la varianza poblacional
conocida, los siguientes (ver figuras 4.4 y 4.5):
nivel de confianza!/2 1∀! !/2
nivel de significación-t !/2 0 t!/2
Región crítica Región de Región críticaAceptación
Figura 4.12: Regiones crítica y de aceptación en el contraste bilateral cuando
la variable se distribuye según una t de Student.
Figura 4.13: Regiones crítica y de aceptación en el contraste unilateral
cuando la variable se distribuye según una t de Student.

287
4.4.4 Contraste de hipótesis para la igualdad de medias de dos poblaciones normales
En este apartado consideraremos dos poblaciones con distribuciones normales con medias µ1 y µ2 y varianzas !1
2 y !
22 respectivamente, de las cuales extraemos muestras
aleatorias independientes de tamaños n1 y n2 respectivamente. El objetivo de éste apartado será determinar si las dos poblaciones pueden considerarse con la misma
media poblacional, es decir, la hipótesis nula será Ho (µ 1 = µ2 ), mientras que la
hipótesis alternativa puede tener diversas expresiones: Ha (µ 1 < µ2 ), o bien, Ha (µ1 >
µ2 ), o bien Ha (µ1 ≠ µ2 ).
Estas hipótesis son equivalentes a las siguientes: la hipótesis nula será Ho (µ1 - µ2 = 0), mientras que la hipótesis alternativa tendrá éstas expresiones: Ha (µ1 - µ2 < 0), o bien,
Ha (µ1 - µ2 > 0), o bien Ha (µ1 - µ2 ≠ 0).
4.4.4.1 Contraste de hipótesis para la igualdad de medias de dos poblaciones normales con varianzas poblacionales conocidas.
Estadígrafo de contraste:
Conocemos del tema relacionado con las distribuciones normales, que la diferencia de dos distribuciones normales se distribuye también normalmente con media la diferencia de las medias, y varianza la suma de las varianzas, por lo que la variable
# &∀ 2 ∀ 2
x 1 !x 2 será una variable que se distribuye normalmente N% µ1 ! µ2 , 1 + 2 ( , por∃ n1
n2 ∋
lo que en el caso particular de conocer las varianzas poblacionales, podemos utilizar como estadístico de contraste la variable
Z =x
1 ! x2
∀12 + ∀ 2 2
n1
n2

288
que, en el caso de que la hipótesis nula sea cierta (µ1 = µ2 ), se distribuye como una
distribución normal estándar N(0,1), y, por lo tanto, puede utilizarse como estadístico de contraste, dado que conocemos su distribución.
Región crítica:
La región crítica estará formada por los valores de Z elevados, tanto positivos
como negativos. Para especificar cuando se consideran elevados, teniendo en cuenta la
distribución de Z, serán aquellos que sean mayores, en valor absoluto, que Zα/2, en el
contraste bilateral, o que zα en el contraste unilateral.
4.4.4.2 Contraste de hipótesis para la igualdad de medias de dos poblaciones normales con varianzas poblacionales desconocidas pero iguales
MUESTRAS GRANDES
Estadígrafo de contraste:
Supongamos ahora que las varianzas son desconocidas pero iguales (σ1 = σ2 = σ). Si las muestras tienen tamaño grande, aunque no se conozca la varianza poblacional, se trabaja como si se conociese utilizando en lugar de la varianza poblacional, su estimador la cuasivarianza muestral, por lo que la distribución de la diferencia de
∀ %
medias muestrales es ahora 1 1 ,N∃ µ1 ! µ2 ,sˆ + ∋
# n1 n2 &ˆ ˆ 2 ˆ 2
(n1 ! 1)s1 + (n2 ! 1)s 2
siendos = n1 + n2 ! 2 , por lo que la variable tipificada es una normal
estándar
Z = (x1 ! x
2) ! (µ1
! µ
2 )Sˆ
1 +
1
n1 n2
Entonces, si ha hipótesis nula es cierta, (µ1 =µ2 ), la variable
Z = (x1 ! x
2)Sˆ
1 +
1
n1 n
2
289
se distribuye como una distribución normal estándar, por lo que se puede utilizar como
un estadístico de contraste.
Región crítica:
La región crítica se determina igual que en el párrafo anterior, es decir, para los valores de Z mayores, en valor absoluto, que zα/2 (contraste bilateral), o que zα
(contraste unilateral).
MUESTRAS PEQUEÑAS
Estadígrafo de contraste
Pero, si las muestras son pequeñas (n1 + n2 < 30), entonces la variable siguiente
t = (x1 ! x2) ! (µ1 ! µ2)ˆ 1 + 1S n1 n2
ˆ ˆ 2 ˆ 2
con (n1 ! 1)S1 + (n2 ! 1)S 2 , sigue una distribución t de Student con n1+n2-2S = n1 + n2 ! 2grados de libertad.
Si la hipótesis nula es cierta, el estadígrafo de contraste que utilizaremos es
t = (x1 ! x2)ˆ 1 + 1S n1 n2
porque se distribuye como una t de Student con n1+n2-2.
Región crítica:
La región crítica viene determinada por los valores de esta variable t, que son
mayores en valor absoluto que tα/2 en el contraste bilateral, o bien los valores de t, que
son mayores en valor absoluto que tα en el contraste unilateral.

290
4.4.5 Contraste para distribuciones binomiales
Estudiaremos sólo contrastes en los que sea posible aproximaciones de la
binomial mediante la normal, por lo que estudiaremos sólo los casos de muestras
grandes, de tamaño > 30.
4.4.5.1 Contraste para el parámetro p de una distribución Binomial
Partimos de una población que se ajuste al modelo binomial B(n, p), siendo p la probabilidad de "éxito"; denotaremos por p a la proporción muestral de casos
favorables y por po el valor hipotético con el que queremos contrastar el valor delparámetro p.
Hipótesis de partida
En éste caso, la hipótesis nula será:
Ho : p = po
y la hipótesis alternativa puede ser:
Ha : p ≠ po en el contraste bilateral,
o bien Ha : p > po , en el contraste unilateral (también Ha : p < po).
Estadígrafo de contraste:
Como conocemos que la distribución binomial B(n, p) se aproxima mediante una
variable normal N(np, npq ), entonces, se verifica que la variable
Z = pˆ
! p
o pˆ(1 ! pˆ)
n

se distribuye como una distribución normal estándar N(0,1).

291
Región crítica:
La región crítica, ahora, será la determinada por los valores de la variable Z que
son mayores en valor absoluto que zα/2 , en el contraste bilateral, o bien, mayores que zα
, en el contraste unilateral.
4.4.5.2 Contraste para la igualdad de los parámetros de dos distribuciones binomiales
Partimos, en éste caso, de dos distribuciones binomiales B(n1, p1) y B(n2, p2)
respectivamente. En las muestras los parámetros muestrales serán ˆp1 y ˆp2 respectivamente.
Hipótesis de partida:
La hipótesis nula será:
Ho : p1 = p2
mientras que la hipótesis alternativa puede ser :
Ha : p 1 ≠ p2
Estadígrafo de contraste:
Ahora, teniendo en cuenta las propiedades de las distribuciones normales, por las que se
aproximan las binomiales, se verifica que la variable
p ! pZ = ! ! 1 !2 !
p1(1 ! p1) +p2(1 ! p 2)
n1 n2
se distribuye, cuando la hipótesis nula es cierta, como una distribución normal estándar
N(0,1)
Región crítica:

292
La región crítica será análoga a todas aquéllas en el que el estadístico de contraste
sigue una distribución normal.

293
"CONTRASTES DE HIPÓTESIS"

4.5 Ampliación

294
4.5.1 Introducción y motivaciónAntes de comenzar con el desarrollo del tema se supone que el lector conoce los
conceptos fundamentales de muestreo, los principales estimadores de los parámetros de
distribuciones normales y sus correspondientes distribuciones muestrales, y los
conceptos básicos asociados a los contrastes de hipótesis como son el riesgo tipo I, tipo
II, potencia del contraste, etc....
Aunque muchos de los conceptos han sido ya explicados en la parte básica, se
repiten aquí encuadrados en el problema general de la investigación aplicada añadiendo
una posible guía para la explicación de los mismos en contextos aplicados a las ciencias
experimentales.
Comenzaremos ilustrando las ideas generales sobre el contraste más simple, el de la media de una población Normal, para ir extendiendo progresivamente las ideas a dos poblaciones, a la comparación de proporciones y a las poblaciones no normales. Analizaremos la problemática de realizar un número elevado de contrastes sobre el mismo conjunto de datos, y extenderemos las ideas fundamentales al diseño de experimentos con varios grupos experimentales.
4.5.2 Contraste para la media de una población Normal4.5.2.1 Planteamiento general
Consideremos un caso muy simple mediante un ejemplo concreto.
Supongamos que pertenecemos al consejo regulador de la denominación de
origen de los vinos de Ribera de Duero. Sabemos que los vinos jóvenes de
años anteriores tienen un grado alcohólico medio de 12.5 grados, tal y como
aparece en la etiqueta. Para el año actual, el consejo regulador, de acuerdo
con todos sus miembros, ha decidido cambiar algunos de los pasos del

proceso de fabricación. El primer problema que se plantea es: ¿Se ha
modificado el grado alcohólico al modificar el proceso de fabricación?.

295
La definición del problema a estudiar nos permite determinar la población que
queremos estudiar, los vinos jóvenes de ribera de Duero en el año actual; la variable que
queremos medir, el grado alcohólico de los mismos, y la hipótesis de trabajo inicial ¿Se
ha modificado el grado alcohólico?.
El paso siguiente consiste en suponer un modelo de comportamiento teórico para la población (a priori). Suponemos que la variable que estamos midiendo en la población a estudiar sigue una distribución Normal. La suposición de normalidad la haremos de acuerdo con el conocimiento previo que tengamos sobre la población objeto de estudio tratando de que las características de la distribución reflejen en la mayor medida posible las de la población, se trata simplemente de buscar un modelo probabilístico que aproxime la variable a estudiar. En el caso que nos ocupa, parece razonable suponer, a priori, que el grado alcohólico se concentra de forma simétrica alrededor de un valor medio. Si consideráramos, por ejemplo, los salarios de una empresa la hipótesis de normalidad no es plausible puesto que cabe esperar que la distribución de los mismos sea marcadamente asimétrica debido a los altos salarios de un grupo reducido de ejecutivos.
Formularemos ahora la hipótesis de trabajo en términos de los parámetros del modelo (media y/o desviación típica en el caso de la Normal). La hipótesis principal la
denominamos hipótesis nula (H0).
H0 = µ = µ0 = 12.5
La hipótesis nula suele ser la de igualdad del parámetro a un único valor concreto
µo procedente de la hipótesis de trabajo.
Junto con la hipótesis nula planteamos la que denominamos hipótesis alternativa
(Ha o H1) que será aceptada cuando se rechace la nula y viceversa. Por el momento tomaremos la más sencilla, la hipótesis e que la media es diferente de 12 que resultará en un contraste bilateral.
Ha = µ ! µ0 = 12.5
Trataremos de diseñar un procedimiento para decidir entre ambas hipótesis a
partir de la información contenida en una muestra de tamaño n, por ejemplo 14
observaciones.

296
Supongamos que la muestra ha sido seleccionada al azar de la población y que se
han obtenido los resultados siguientes.
RIBERA DE DUERO12,8 12,8 12,5 11,9 12,5 12,1 12,2 12,6 13,0 12,4 12,6 12,2 12,8 13,0
Tabla 4.1: Grado alcohólico de 14 vinos de la denominación de Ribera de Duero.
La primera cuestión que hemos de tener en cuenta es que la decisión por una
hipótesis concreta ha de tomarse con un cierto riesgo de equivocarse al no disponer de
la información de todos los individuos de la población. Trabajaremos con la media
muestral como estimador de la media poblacional desconocida. En el ejemplo la media
muestral es de 12,529, que como ya sabemos no coincide con la media poblacional.
Trataremos de decidir entre las dos hipótesis a partir del valor de la media muestral pero, si la media muestral no coincide con la media poblacional, ¿será la diferencia entre el valor observado y el teórico lo suficientemente grande como para rechazar la hipótesis nula? o ¿la diferencia observada es lo suficientemente pequeña como para ser debida simplemente al azar o al desconocimiento de la población?. Daremos respuesta a ambas preguntas utilizando los conceptos sobre distribuciones aprendidos en temas anteriores.
4.5.2.2 Varianza (desviación típica conocida)Supondremos, por el momento, que la varianza de la población es !
2 = 0.5
2
conocida. Sabemos que la media muestral para distintas muestras sigue una distribución
Normal N(µ, !n ) , luego, cuando la hipótesis nula es cierta
∀x ! N(µ0, n )
En la práctica, este resultado tiene implicaciones importantes. Veámoslo con un
dibujo (figura 4.7).

297
x ! N(µ , ∀
)0 n
µ0 x
Figura 4.14: Distribución de la media muestral.
El dibujo muestra cómo, aunque los valores de la media muestral no coinciden
con la media poblacional, se concentran en torno a ella y por tanto es muy probable que
sean cercanos aunque, con el modelo supuesto puede tomar cualquier valor. Obsérvese
también que cuanto mayor es el tamaño muestral más se concentran los valores de la
media muestral en torno a la media poblacional.
Intuitivamente, aceptaremos la hipótesis nula cuando la media muestral sea
próxima a µ0 y la rechazaremos (aceptando la alternativa) cuando la media muestral sea
muy diferente de µ0 , es decir, utilizamos la media muestral como estadístico, o estadígrafo, de contraste. Nos queda por determinar cual es el criterio para decidir si la media muestral está próxima o no al valor teórico propuesto utilizando el concepto de riesgo tipo I definido previamente. Fijamos el riesgo tipo Y en α (por ejemplo en 0.05 o el 5%)
Nos plantearemos el contraste como un juicio en el que la media muestral es
inocente (procede de una población con media µ0 ) y no la declararemos culpable (no
procede de una población con media µ0 ) hasta que no se demuestre claramente lo contrario.
Sobre la distribución de la media seleccionamos dos puntos µ0 ! a y µ0 + a ,
simétricos alrededor de µ0 de forma que si la hipótesis nula cierta en el (1-α)100% (por ejemplo el 95%) de las muestras la media muestral esté entre esos dos valores (figura 4.8).
P(µ0 ! a ∀ x ∀ µ0 + a) = 1 ! #

298
Figura 4.15: Procedimiento de contraste a partir de la media muestral
Aceptaremos la hipótesis nula si la media muestral está dentro del intervalo seleccionado y la rechazaremos en caso contrario. Es claro que si la media está fuera del intervalo seleccionado hay una clara evidencia de que la hipótesis no es cierta ya que toma los valores correspondientes solo en el 5% de los casos en los que la hipótesis nula es cierta. Por supuesto, estamos asumiendo un riesgo del 5% de equivocarnos y rechazar indebidamente.
Como ya es conocido, al conjunto de valores que nos llevan a aceptar la hipótesis
nula lo denominamos Región de Aceptación, y al conjunto de valores que nos llevan a
rechazarla Región Crítica. En este caso la región crítica se ha dividido en las dos colas
de la distribución por lo que se dice que el contraste es bilateral o de dos colas.
En la práctica no se trabaja directamente con la media muestral y su distribución
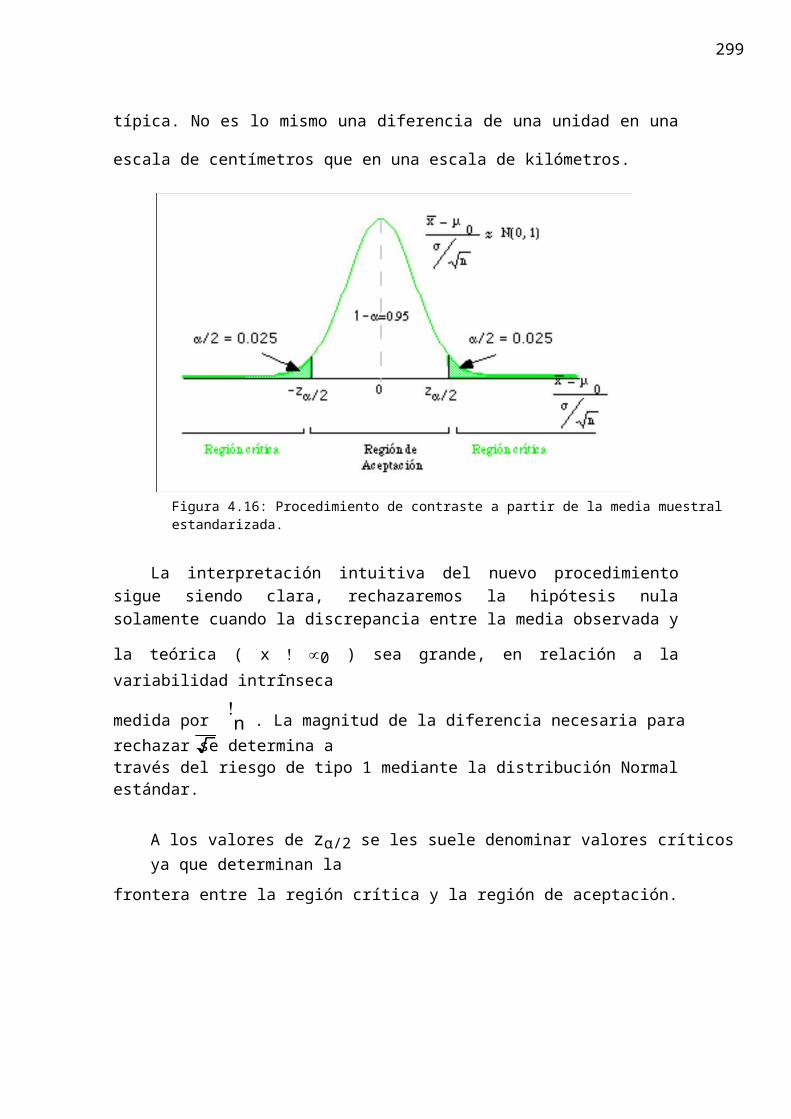
asociada sino con la distribución Normal estándar. Teniendo en cuenta las
propiedades de la Normal podemos escribir
P(µ0 ! a ∀ x ∀ µ0 + a) = P(!z# /2 ∀ x∃! µ0 ∀ z#/2) = 1 ! #
n
de forma que el procedimiento descrito se convierte ahora en el que se muestra en la
figura 4.9. El estadígrafo de contraste es ahora x∀! µ0 y mide la discrepancia entre el
nvalor observado de la media l valor teórico de la misma, en la escala de la desviación

299
típica. No es lo mismo una diferencia de una unidad en una escala de centímetros que en
una escala de kilómetros.
Figura 4.16: Procedimiento de contraste a partir de la media muestral estandarizada.
La interpretación intuitiva del nuevo procedimiento sigue siendo clara, rechazaremos la hipótesis nula solamente cuando la discrepancia entre la media
observada y la teórica ( x ! µ0 ) sea grande, en relación a la variabilidad intrínseca
medida por !n . La magnitud de la diferencia necesaria para rechazar se determina a
través del riesgo de tipo 1 mediante la distribución Normal estándar.
A los valores de zα/2 se les suele denominar valores críticos ya que determinan la
frontera entre la región crítica y la región de aceptación.
El cuadro 4.2 muestra el procedimiento completo con los pasos que se siguen
habitualmente en la construcción de cualquier contraste.

300
Hipótesis
H0:µ = µ0Ha :µ ! µ0
Nivel de significación: α
Estadígrafo de contraste: Z = x∀! µ0
nDistribución del estadígrafo cuando la hipótesis nula es cierta: N(0,1)
Región de aceptación: {Z / Z ! z∀/2}Región critica: {Z / Z > z!/2}
Cuadro 4.2: Contraste para la media de una población Normal con varianza conocida.
Una vez que hemos determinado la forma general del contraste pasamos a
aplicarlo a los datos del problema inicial que nos ocupa (ver cuadro 4.3).
Hipótesis:
H0:µ = 12.5Ha :µ ! 12.5
Nivel de significación: 5% y 1%.Estadígrafo de contraste: Z =
x ! µ 0 = 12.529 ! 12.5 = 0.217∀ 0.
n 14Valores críticos : para el 5% z0.025= 1,96 para el 1% z0.005= 2,57Decisión estadística: El valor del estadígrafo de contraste pertenece a la región de aceptación, por tanto aceptamos la hipótesis nula.Conclusión no estadística: La modificación en el proceso de fabricación no ha modificado significativamente el grado alcohólico.
Cuadro 4.3: Aplicación del contraste para la media de una población Normal con varianza conocida al
problema de la modificación en el grado alcohólico del vino de Ribera de Duero
Una vez que hemos tomado la decisión final, no sabemos si es correcta o no, simplemente esperamos que sea del 95% de las muestras en las que aceptamos la hipótesis correctamente. Si aceptamos la hipótesis nula no quiere decir que sea cierta y el grado medio sea exactamente de 12.5 grados (probablemente no lo es), sería más correcto interpretar que, con la información de la que disponemos no hemos encontrado evidencia suficiente de que la media sea distinta de 12.5. Evidentemente, los valores muestrales son compatibles con muchos otros posibles valores teóricos.

Si aumentamos el tamaño de muestra indefinidamente, la variabilidad de la media

301
sería cada vez menor y conseguiríamos que la pequeña diferencia observada sea lo suficientemente grande como para considerarla significativa. Es por esto por lo que en Estadística decimos que es tan malo tener un tamaño de muestra demasiado alto como tenerlo demasiado bajo ya que en el primer caso cualquier pequeña diferencia es considerada como significativa mientras que en el segundo no se declara significación incluso en el caso en el que la diferencia sea elevada.
4.5.2.3 La potencia de un contrasteEn todo el proceso descrito hasta el momento solamente se ha utilizado el riesgo
de tipo I en el desarrollo del contraste. Sabemos que esta asociado con el riesgo de tipo
II de forma que cuando uno aumenta, el otro disminuye. Tampoco hemos hecho
ninguna afirmación acerca de un concepto importante como es el de potencia del
contraste (probabilidad de rechazar la hipótesis nula cuando es falsa).
No es posible calcular la potencia del contraste porque para ello necesitaríamos un
único valor en la hipótesis alternativa (revísese el ejemplo de los cirróticos utilizado
como aplicación de la distribución Normal), aunque si podemos realizar el cálculo para
distintos valores en la alternativa (función de potencia) y analizar lo que ocurre.
Veámoslo con un ejemplo.
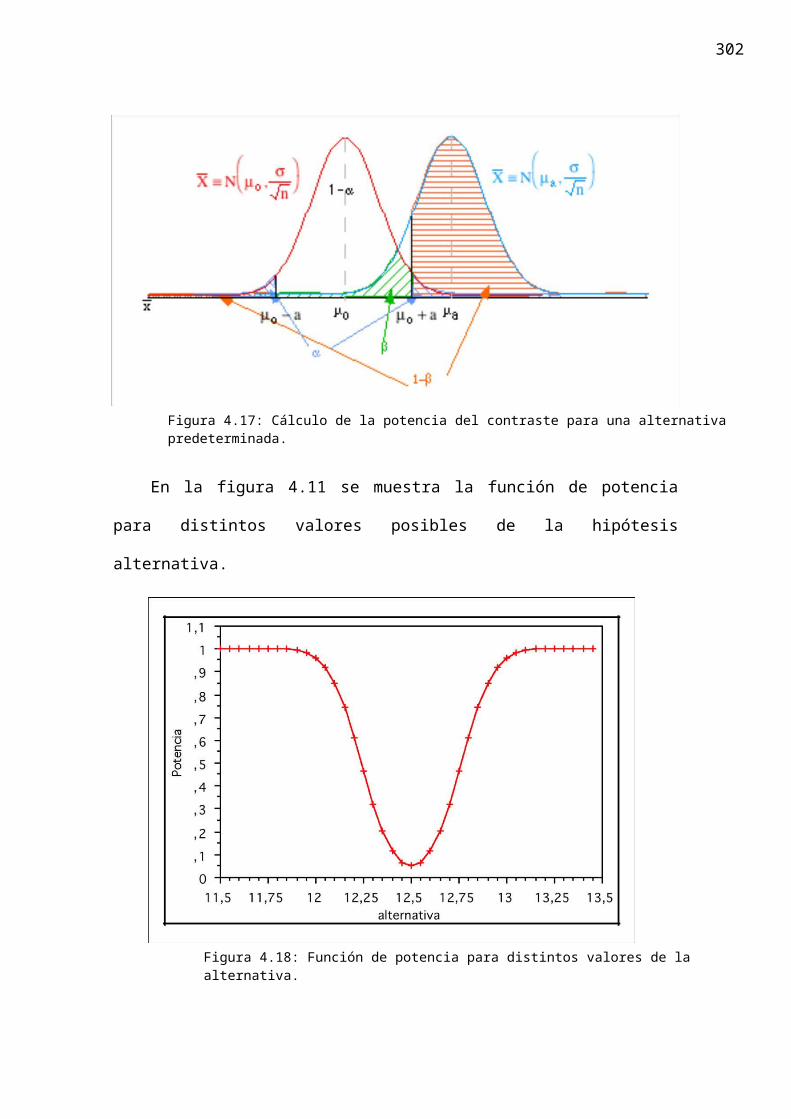
Cual sería la potencia del contraste obtenido para detectar que la media no es 12.5
si en realidad la media fuera 13 (y suponiendo un nivel de significación del 5%).
En términos de la media muestral el procedimiento de contraste consiste en aceptar la hipótesis nula si la media muestral está entre 12.238 y 12.762. La probabilidad de cometer un error de tipo 2 (aceptar indebidamente) si la media real fuera de 13 se podría calcular como P(12.382 ! X ! 12.762) en una Normal de media 13 y
desviación típica 014
.5 . Esta probabilidad es 0.037 de forma que la potencia es 1 -
0.037 = 0.963. La situación esquematizada aparece en la figura 4.10.

302
Figura 4.17: Cálculo de la potencia del contraste para una alternativa predeterminada.
En la figura 4.11 se muestra la función de potencia para distintos valores posibles
de la hipótesis alternativa.
Figura 4.18: Función de potencia para distintos valores de la alternativa.
El gráfico muestra como la potencia es mayor cuando los valores de la alternativa se alejan del valor para la hipótesis nula. En la práctica este hecho tiene una implicación obvia: es más fácil detectar diferencias o efectos experimentales de gran magnitud.
Aunque no es posible un control directo de la potencia, a la vista de la figura 4.10

303
es claro que la potencia puede modificarse modificando el nivel de significación o el
tamaño muestral ya que la forma de las curvas depende de éste. Cuanto mayor sea el
tamaño muestral más concentrada es la curva Normal y, por tanto, mayor es la potencia
para el mismo nivel de significación.
En la práctica suele hacerse un estudio de potencia para los contrastes no
significativos, calculando cual sería el tamaño muestral necesario para que la diferencia
observada en los datos sea significativa. Si este tamaño es muy grande es difícil declarar
la significación por lo que consideraremos que estamos haciendo lo correcto, si el
tamaño muestral necesario es pequeño, sería conveniente revisar el experimento.

El cálculo es muy simple cuando
hipótesis nula se rechaza cuando x
! µ0
n
sea significativa el valor de n será
se trabaja con distribuciones normales. La
> z#/2 de forma que, para que la diferencia

n> z2
!/2∀2
x
# µ0
para el ejemplo del grado alcohólico, n> 1141,97, es decir, para que la diferencia
observada fuera significativa tendríamos que haber recogido más de 1142 observaciones
lo que da una idea de que la diferencia observada es muy pequeña y, por tanto es muy
probable que la hipótesis nula sea cierta.
4.5.2.4 El p-valor del contrasteUna forma habitual de medir la significación en los contrastes de hipótesis es el
denominado p-valor del contraste. Su utilización en la investigación aplicada es debida
a que es la forma de presentación de los resultados de un contraste usada por la mayor
parte de los programas de ordenador.
Se puede definir el p-valor de un contraste como la probabilidad de obtener un
valor muestral más extremo que el obtenido en nuestro caso particular (cuando H0 escierta). Si el p-valor es muy pequeño rechazaremos la hipótesis nula ya que el valor
experimental es muy extremo, mientras que si el p-valor es grande aceptaremos la
hipótesis nula ya que el valor es compatible con la misma.

304
De forma general, el p-valor para el contraste actual se puede calcular como# ! µ &
xP%
Z > 0 ( en una distribución Normal estándar.∀
∃ ∋n
Para el ejemplo anterior el p-valor es 1-P(-0.217 < Z < 0.217) = 2 P(Z > 0.217) =
0.8285, es decir el p-valor puede considerarse grande. En la práctica se suele adoptar el
criterio de aceptar la hipótesis cuando el p-valor es mayor que el nivel de significación
fijado en el procedimiento de contraste.
Figura 4.19: El p-valor de un contraste bilateral.
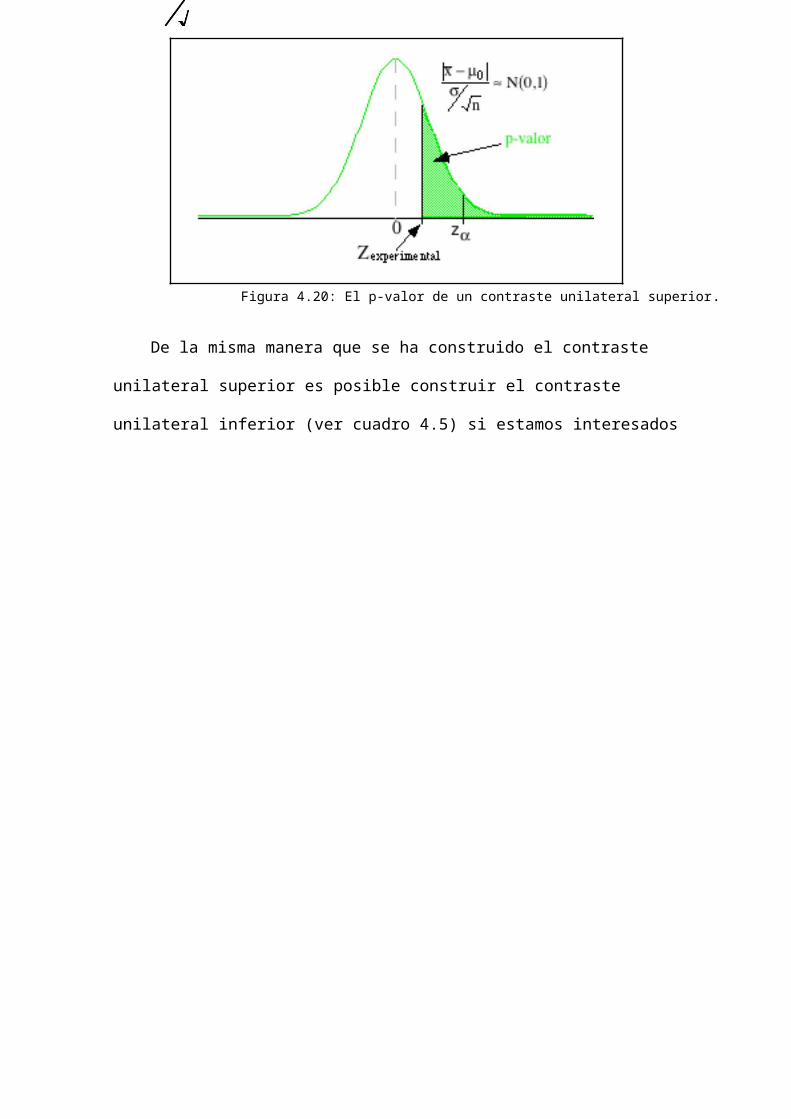
4.5.2.5 Los contrastes unilateralesEn algunas situaciones concretas no estamos interesados en todos los posibles
valores de la hipótesis alternativa propuesta en un contraste bilateral. Supongamos, por ejemplo, que en el caso práctico anterior sospechamos a priori que la modificación en el procedimiento de fabricación produce un incremento en el contenido alcohólico. En este
caso sería conveniente modificar la hipótesis alternativa para que sea de la forma Ha :µ
> µ0. El procedimiento de contraste es muy similar al anterior y se muestra en el cuadro 4.4.

305
Hipótesis
H0:µ = µ0Ha :µ > µ0
Nivel de significación: α
Estadígrafo de contraste: Z = x∀! µ0
nDistribución del estadígrafo cuando la hipótesis nula es cierta: N(0,1)
Región de aceptación: {Z / Z ! z∀/2}Región critica: {Z / Z > z!/2}
Cuadro 4.4: Contraste unilateral superior para la media de una población Normal con varianza conocida.
El contraste así obtenido se denomina contraste unilateral superior ya que solo
estamos interesados en las desviaciones positivas. La diferencia fundamental con el
contraste bilateral es que se produce un incremento en la potencia para detectar
diferencias positivas de la hipótesis nula y un decremento drástico para detectar las
negativas.
El p-valor sigue teniendo la misma interpretación aunque ahora se calcula como# x !
µ&
0
P% Z >
( .∀
∃ n ∋
Figura 4.20: El p-valor de un contraste unilateral superior.

De la misma manera que se ha construido el contraste unilateral superior es
posible construir el contraste unilateral inferior (ver cuadro 4.5) si estamos interesados

306
exclusivamente en detectar diferencias negativas con respecto a la hipótesis nula. La
construcción del contraste es completamente análoga con la correspondiente
modificación de la hipótesis alternativa. El contraste unilateral inferior incrementa la
potencia para detectar diferencias negativas aunque no tiene potencia para detectar las
positivas.
Hipótesis
H0:µ = µ0Ha :µ < µ0
Nivel de significación: α
Estadígrafo de contraste: Z = x∀! µ0
nDistribución del estadígrafo cuando la hipótesis nula es cierta: N(0,1)
Región de aceptación: {Z / Z ! z∀/2}Región critica: {Z / Z < z!/2}
# x ! µ
&p-valor: P% Z >
0 (∀∃ ∋
nCuadro 4.5: Contraste unilateral inferior para la media de una población Normal con varianza conocida.
Figura 4.21: El p-valor de un contraste unilateral inferior.
La decisión por el tipo de contraste debe hacerse a priori, antes de tomar los datos.
Supongamos, por ejemplo, que sospechamos, antes de realizar el experimento, que la
modificación en el proceso de fabricación, aumenta el grado alcohólico. El
procedimiento de contraste para los datos de la tabla 1 se muestra en el cuadro 4.6.

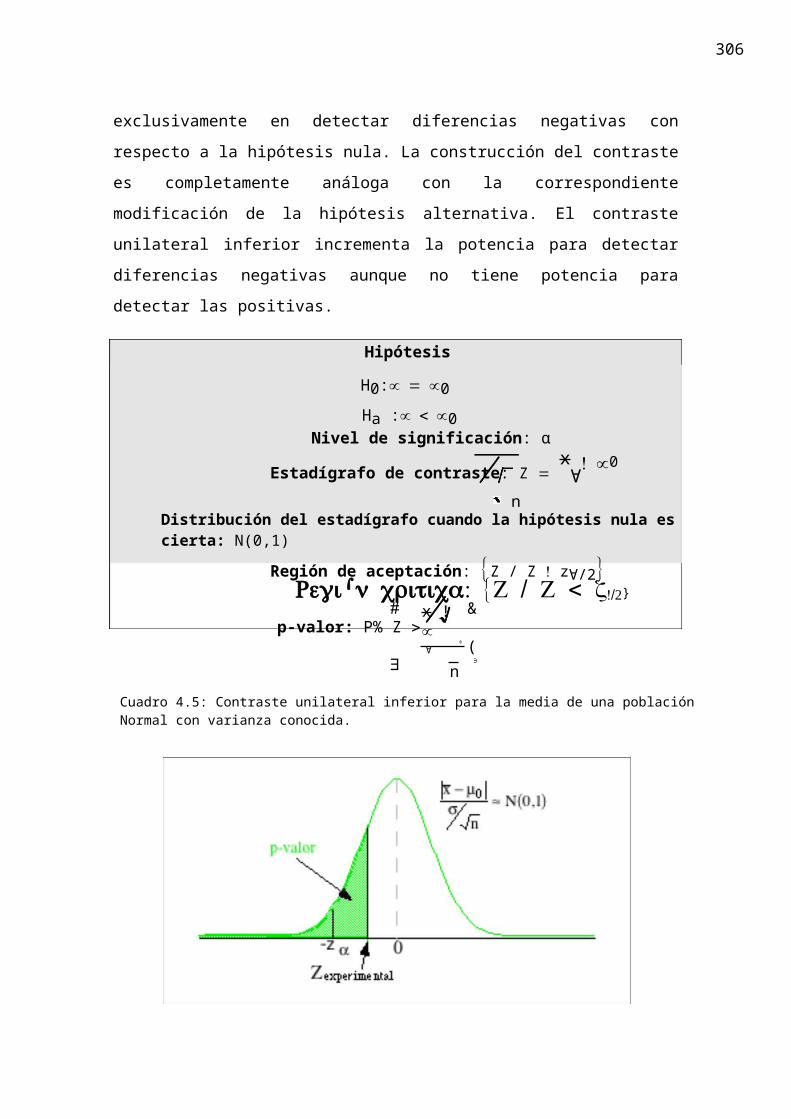
307
Hipótesis:
H0:µ = 12.5Ha :µ > µ0
Nivel de significación: 5% y 1%.x ! µ0 12.529 ! 12.5
Estadígrafo de contraste: Z = ∀
= = 0.217 0.n 14
Valores críticos : para el 5% z0.025= 1,65 para el 1% z0.005= 2,33p-valor: 0.4129
Decisión estadística: El valor del estadígrafo de contraste pertenece a la región de aceptación, por tanto aceptamos la hipótesis nula.Conclusión no estadística: La modificación en el proceso de fabricación no ha aumentado significativamente el grado alcohólico.
Cuadro 4.6: Aplicación del contraste para la media de una población Normal con varianza conocida al
problema de la modificación en el grado alcohólico del vino de Ribera de Duero
La función de potencia para distintos valores de la alternativa aparece en la figura
4.15. Obsérvese como el contraste no tiene ninguna potencia para detectar valores a la
izquierda de la hipótesis nula.
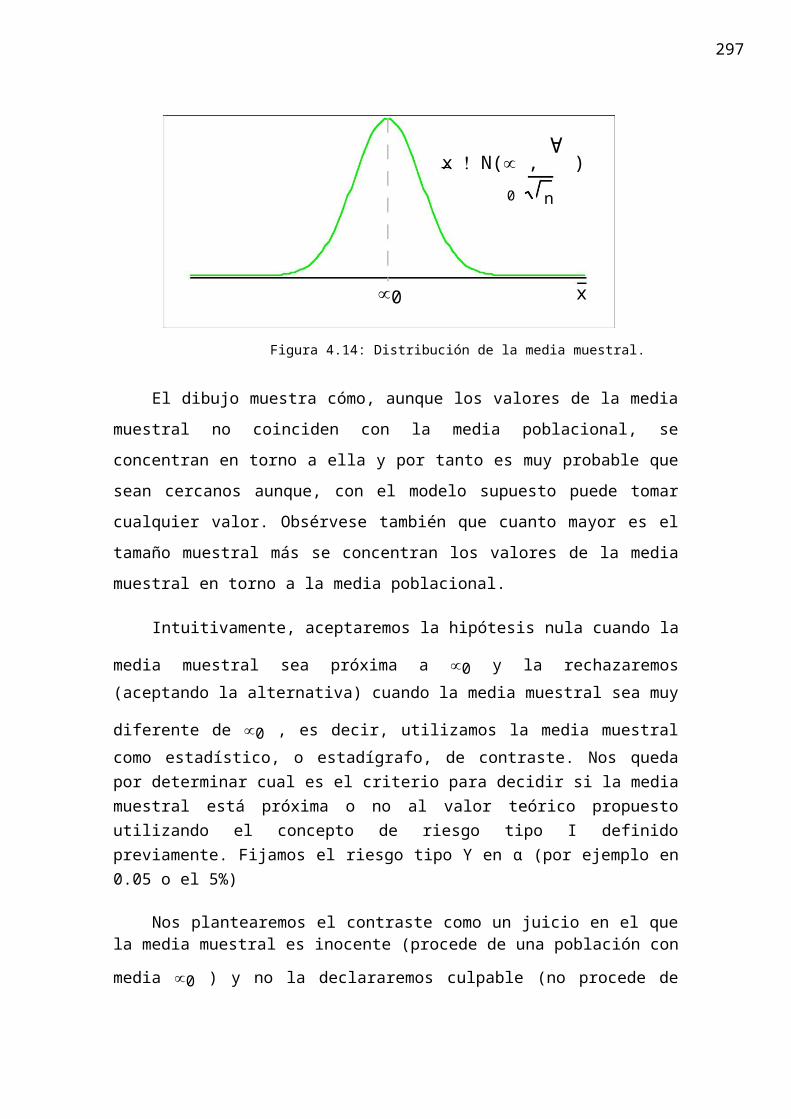
Figura 4.22: Función de potencia para un contraste unilateral superior.

308
4.5.2.6 Varianza desconocidaEn la mayor parte de las aplicaciones prácticas la varianza de la distribución es
también desconocida y ha de ser estimada a partir de los datos. El problema es que ya no es posible seguir utilizando la distribución Normal para el procedimiento de
contraste ya que es necesario eliminar el parámetro σ del estadígrafo de contraste.
De acuerdo con la teoría, además de la distribución muestral de la media sabemosˆ 2
que (n ! 1)S sigue una distribución ji-cuadrado con n-1 grados de libertad. Si∀2
suponemos que media y varianza son independientes* , es posible combinar las correspondientes distribuciones muestrales para obtener una distribución t de Student y eliminar el parámetro σ.
Utilizando la definición de distribución t de Student con n-1 grados de libertad como el cociente
entre una Normal estándar y la raíz cuadrada de una ji-cuadrado con n-1 grados de libertad dividida por
sus grados de libertad, y ambas independientes, obtenemos que la variable aleatoria
x ! µ0∀
x ! µ0t = n =ˆˆ 2
(n ! 1)S
n∀2
(n ! 1)
sigue una distribución t de Student con n-1 grados de libertad.
El procedimiento de contraste en este caso es análogo al anterior pero
sustituyendo la distribución Normal por la distribución t. El cuadro 4.7 muestra el
procedimiento de contraste completo.

* La demostración completa no se realiza aquí.

309
Hipótesis
H0:µ = µ0Ha :µ ! µ0
Nivel de significación: αEstadígrafo de contraste: t =
x ! µ0
ˆn
Distribución del estadígrafo cuando la hipótesis nula es cierta: tn-1
Región de aceptación: {t / t ! tn∀1,#}Región critica: {t / t > tn!1,∀}*
Cuadro 4.7: Contraste para la media de una población Normal con varianza desconocida.
En la práctica, la sustitución de la distribución Normal por la distribución t de
Student implica un aumento de la dispersión por lo que es más difícil detectar
diferencias. La situación se muestra el la figura 4.16 en la que se comparan la
distribución Normal estándar (en línea discontinua) y la distribución t (en línea
continua).
t = x ∀ µ 0 # tn∀1ˆ 1∀!
n!/2 !/2
-t ! 0t!
Figura 4.23: Diferencia entra la distribución Normal y la distribución t de Student.
Es posible construir contrastes unilaterales de la misma manera que en el caso de
varianza conocida. El cuadro 4.8 muestra el contraste unilateral superior, el contraste
unilateral inferior se deja como ejercicio al lector.
* tn-1,α es el valor crítico de la t de Student tal que P(-tn-1,α ≤ tn-1 ≤ tn-1,α ) = 1-α. Se ha denotado con
el subíndice α porque es el que se utiliza para buscar el valor correspondiente en la tabla.
310
Hipótesis
H0:µ = µ0Ha :µ > µ0
Nivel de significación: αEstadígrafo de contraste: t =
x ! µ0
ˆn
Distribución del estadígrafo cuando la hipótesis nula es cierta: tn-1
Región de aceptación: {t / t ! tn∀1,2# }*
Región critica: {t / t > tn!1,2∀ }Cuadro 4.8: Contraste para la media de una población Normal con varianza desconocida.
Para el ejemplo del grado alcohólico de los vinos de la denominación de origen de
Ribera de Duero los resultados del contraste bilateral se muestran en el cuadro 4.9
Hipótesis:
H0:µ = 12.5Ha :µ ! 12.5
Nivel de significación: 5% y 1%.Estadígrafo de contraste: Z = x ! µ0 = 12.529 ! 12.5 = 0.316
ˆ 0.
n 14
Valores críticos : para el 5% t0.05= 1,96 para el 1% t0.01= 2,57p-valor : 0,7571Decisión estadística: El valor del estadígrafo de contraste pertenece a la región de aceptación, por tanto aceptamos la hipótesis nula.Conclusión no estadística: La modificación en el proceso de fabricación no ha modificado significativamente el grado alcohólico.
Cuadro 4.9: Aplicación del contraste para la media de una población Normal con varianza conocida al
problema de la modificación en el grado alcohólico del vino de Ribera de Duero
Todos los conceptos explicados para el contraste de la media de una población
Normal con varianza conocida siguen siendo válidos aquí.
* tn-1,2α es el valor crítico de la t de Student tal que P( tn-1 > tn-1,2α ) = α. Se ha denotado con el
subíndice 2α porque es el que se utiliza para buscar el valor correspondiente en la tabla.

311
4.5.2.7 Contrastes para muestras grandesCuando las muestras de las que se dispone son muestras grandes
(aproximadamente mayores de 30 observaciones) es posible utilizar directamente la distribución Normal ya que es muy similar a la t de Student. Además el teorema central del límite permite relajar la hipótesis de normalidad ya que la normalidad de la distribución muestral de medias está garantizada, bajo ciertas condiciones de regularidad, aunque la población original no sea Normal. Hay que tener en cuenta que se trata sólo de una aproximación y, cuanto mayor es el tamaño de la muestra mejor es la aproximación Normal obtenida. El procedimiento de contraste para muestras grandes se muestra en el cuadro 4.10. Mostramos solamente el contraste bilateral ya que los unilaterales se construyen exactamente de la misma manera que en los casos anteriores.
H0:µ = µ0
Hipótesis: Ha :µ ! µ0
Nivel de significación: αEstadígrafo de contraste: Z =
x ! µ0
ˆn
Distribución del estadígrafo cuando la hipótesis nula es cierta: N(0, 1)
Región de aceptación: {Z / Z ! z∀/2}Región critica: {Z / Z > z!/2}
Cuadro 4.10: Contraste para la media de una población Normal con varianza
desconocida cuando la muestra es grande.

312
4.5.3 Contraste para la diferencia de medias de dos poblaciones normales con datos independientes4.5.3.1 Planteamiento general
En la investigación aplicada la situación más habitual es aquella en la que se
quieren comparar dos poblaciones a las que se les ha aplicado, por ejemplo, dos
tratamientos diferentes.
Pongámonos en el mismo supuesto que en el ejemplo que sirvió para ilustrar el contraste para una población, y supongamos que lo que deseamos es conocer si los vinos de nuestra denominación de origen tienen el mismo contenido alcohólico que los de otra denominación de origen, por ejemplo la de Toro. Se trata de saber si existe una clara diferenciación en los mismos ya que, debido a la proximidad geográfica de ambas regiones, es posible que haya fraudes y se intercambien vinos de ambas dependiendo del mercado de los mismos. La hipótesis de trabajo inicial es entonces ¿Existen diferencias en el grado alcohólico de ambas denominaciones?.
Procediendo de la misma manera que en el caso de una población, suponemos una distribución de probabilidad para la población que es la distribución Normal. En la primera población (Ribera de Duero) el grado alcohólico sigue una distribución Normal
N(µ1, σ1); en la segunda población (Toro) el grado alcohólico sigue un Modelo
Normal N(µ2, σ2).
Formulamos a continuación las hipótesis de trabajo en términos de los parámetros
de los modelos. Las hipótesis nula y alternativa son ahora
H0:µ1 = µ2 (µ1 ! µ2 = 0)Ha :µ1 ∀ µ2 (µ1 ! µ2 ∀ 0)
para el contraste bilateral. Vemos como el contraste de que las medias son iguales es
equivalente al contraste de que la diferencia de medias vale 0.

Supongamos que los datos obtenidos son los siguientes para muestras aleatorias

313
de tamaño n1 = 14 y n2 = 6.
Ribera de Duero
12,8 12,8 12,5 11,9 12,5 12,1 12,2 12,6 13,0 12,4 12,6 12,2 12,8 13,0Toro13,0 14,0 13,2 13,4 13,2 13,9
Tabla 4.2: Grado alcohólico de 20 vinos de las denominaciones de origen de Ribera y Toro.
Se supone que las muestras se han obtenido de forma independiente en ambas
denominaciones.
La estadística descriptiva básica para ambos grupos aparece en la tabla 4.3.
Tabla 4.3: Descriptiva básica del grado alcohólico.
Una primera aproximación a las diferencias entre los dos grupos sería la
construcción de gráficos comparativos que muestren la estructura de los mismos, por
ejemplo, un Box-Plot con los grupos separados. (Ver figura 4.17).
Una simple inspección visual del gráfico nos muestra que hay una clara diferencia entre los grados de ambas denominaciones, a pesar de que la diferencia muestral es muy evidente necesitamos un procedimiento más formal para establecer si las diferencias observadas pueden ser consideradas estadísticamente significativas. Construiremos el procedimiento de contraste en varios supuestos comenzando desde el más sencillo hasta los más complejos.

314
Figura 4.24: Box plot para la comparación del grado alcohólico de
las denominaciones de Ribera y Toro.
4.5.3.2 Varianzas conocidasSupongamos, para simplificar que las desviaciones típicas son conocidas, por
ejemplo σ1 = 0.5 y σ2 = 0.6 para las denominaciones de Ribera de Duero y Toro respectivamente. Desarrollaremos el procedimiento general para después aplicarlo a los datos de los que disponemos.
Conocemos la distribución de la media muestral en ambas poblaciones.
x1 ! N(µ1, ∀1 ) n1
x2 ! N(µ2, ∀2 ) n2
y ambas distribuciones son independientes. El estimador de la diferencia de medias
poblacionales será la diferencia de medias muestrales y, como la diferencia de normales
independientes es también una distribución Normal, tenemos que
# 2 #
2
x !x ∀ N(µ ! µ , 1 + 2 )1 2 1 2
n1 n2

315
Estandarizando se obtiene que
Z = (x
1 ! x
2) ! (µ
1 ! µ
2) # N(0,1)
∀ 2 1 + ∀ 2 2n1 n2
Cuando la hipótesis nula es cierta µ1 ! µ2 = 0 y se tiene que
Z = (x
1 ! x
2 ) # N(0,1)
∀12 + ∀ 2 2
n1 n2
luego Z será el estadígrafo de contraste que utilizaremos.
El procedimiento de contraste completo se muestra el cuadro 4.11. Solo se incluye
el contraste bilateral ya que la construcción de los correspondientes unilaterales es la
misma que en los casos previos y se deja como ejercicio al lector.
Hipótesis: H0:µ1 =
µ2
(µ1 ! µ2 = 0)
Ha :µ1 ∀ µ2 (µ1 ! µ2 ∀ 0)Nivel de significación: α
Estadígrafo de contraste: Z = (x1 !
x2 )
∀12 + ∀ 2 2
n1 n2Distribución del estadígrafo cuando la hipótesis nula es cierta: N(0, 1)
Región de aceptación: {Z / Z ! z∀/2}Región critica: {Z / Z > z!/2}
Cuadro 4.11: Contraste para la diferencia de medias de dos poblaciones normales con varianza conocida.
Si aplicamos el contraste a los datos del ejemplo, obtenemos los resultados del
cuadro 4.12.
316
Hipótesis: H0:µ1 = µ2 (µ1 ! µ2 = 0)Ha :µ1 ∀ µ2 (µ1 ! µ2 ∀ 0)
Nivel de significación: α= 0.05 (5%) ó 0.01 (1%)Estadígrafo de contraste: Z = (12.529 ! 13.450) = !10.829
0.25 +0.36
Valores críticos : para el 5% z0.025= 1,9614 6
para el 1% z0.005= 2,57Decisión estadística: El valor del estadígrafo de contraste pertenece a la región crítica, por tanto rechazamos la hipótesis nula.Conclusión no estadística: La modificación en el proceso de fabricación ha
aumentado significativamente el grado alcohólico.Cuadro 4.12: Contraste para la diferencia de medias de dos
poblaciones normales con varianza desconocida.
4.5.3.3 Varianzas desconocidas pero igualesSupongamos ahora que las varianzas son desconocidas pero iguales (σ1 = σ2 =
σ). La distribución de la diferencia de medias muestrales es ahora
Z = (x
1 ! x
2) ! (µ
1 ! µ
2) # N(0,1)
∀1 + 1
n1 n2
Tenemos que eliminar el parámetro σ, para lo cual utilizaremos las distribuciones
muestrales asociadas a las cuasi-varianzas muestrales
(n ˆ 2 (n ˆ 21 ! 1)S
# ∃n2
1 !12 ! 1)S
# ∃n2
2 !11 y 2
∀ 2 2∀
La suma de dos ji-cuadrado es también una ji-cuadrado, sumando las dos anteriores
(nˆ 2
(nˆ 2
(nˆ 2
+ (nˆ 2
1 ! 1)S 2 ! 1)S 1 ! 1)S 2 ! 1)S1
+2
=1 2 # ∃
n21 +n2 !2∀ 2 2 2
∀ ∀

317
Suponiendo que ambas distribuciones son independientes* , podemos combinarlas para
obtener una distribución t de Student. La variable aleatoria
(x1 ! x 2) ! (µ1 ! µ2 )∀ 1 + 1
(x1 ! x2) ! (µ1 ! µ2)t = n1
n2 =
ˆ 2+ (n ! ˆ 2 ˆ 1 1(n ! 1)S 1)S +1 1 2 2 S
n1 n2∀21 + n2 ! 2
ˆ ˆ 2 ˆ 2con (n1 ! 1)S1 + (n2 ! 1)S2
sigue una t de Student con n1 + n2 - 2 grados deS = n1 + n2 ! 2libertad.
Si la hipótesis nula es cierta, el estadígrafo de contraste que utilizaremos es
t = (x1 ! x2) = tn1 +n2 !2
ˆ 1 + 1S
n1 n2
Es posible considerar un estadígrafo de contraste alternativo si se utilizan las
varianzas muestrales en lugar de las cuasi-varianzas. Para ello basta tener en cuenta que
las distribuciones muestrales asociadas a las varianzas son
n1 S12 ∀ #2
n1∃1y n2 S2
2 ∀ #n2
2 ∃12 2
! !El nuevo estadígrafo de contraste es de la forma
t = (x1 ! x2) = tn1 +n2 !2
S 1 + 1
n1 n2
ˆ 2 ˆ 2
con S = n1 S1 + n2 S 2 . Los dos estadísticos toman exactamente el mismo valor por lon1 + n2 ! 2
que pueden utilizarse indistintamente. Usaremos el calculado a partir de las cuasi-varianzas porque son estimadores insesgados de la varianza poblacional.

* La demostración puede encontrarse en cualquier libro de Estadística Matemática. No se ha incluido aquí porqwue supera los propósitos de este trabajo.

318
En ambos casos lo que se ha hecho es estimar la varianza común de ambas
poblaciones mediante una media ponderada de las varianzas estimadas en cada
población, y se ha cambiado la distribución Normal por la t de Student con el
correspondiente aumento en la dispersión que hace que sea más difícil encontrar
diferencias.
En este caso es necesario que las varianzas sean iguales para poder despejarlas y
eliminarlas en el cálculo del estadígrafo de contraste. La comprobación de la igualdad
de varianzas se hará posteriormente aunque sea un paso previo a la decisión del tipo de
contraste.
Las cuestiones relacionadas con la potencia del contraste se interpretan de la misma manera que en todos los casos anteriores. Cuanto mayor sea la diferencia que queremos detectar mayor será la potencia para detectarla. Cuanto más pequeño sea el efecto que queremos detectar mayor será el tamaño de muestra necesario para hacerlo. Si aumentamos indefinidamente el tamaño muestral conseguiremos que la diferencia muestral sea siempre estadísticamente significativa por pequeña que sea.
El contraste completo se muestra en el cuadro 4.13.
Hipótesis: H0:µ1 = µ2 (µ1 ! µ2 = 0)Ha :µ1 ∀ µ2 (µ1 ! µ2 ∀ 0)
Nivel de significación: αEstadígrafo de contraste: t = (x1 ! x2) ó t = (x1 ! x 2)
ˆ 1 + 1 1 + 1S S
n1 n2 n1 n2ˆ ˆ 2 + (n2 ˆ 2 ˆ 2 ˆ 2
con (n1 ! 1)S1 ! 1)S2 ó n1 S1 + n2 S 2
S = n1 + n2 ! 2 S = n1 + n2 ! 2Distribución del estadígrafo cuando la hipótesis nula es cierta: t de Student
t n1+n2!2
Región de aceptación: {t / t
! tn1 +n2 ∀2,#}
Región critica: {t / t
> tn1 +n2 !2,∀}
Cuadro 4.13: Contraste para la diferencia de medias de dos poblaciones normales con varianzas desconocidas pero iguales.
El contraste se ha aplicado a los datos del ejemplo inicial y se han obtenido los
siguientes resultados (ver cuadro 4.14).

319
Hipótesis: H0:µ1 =
µ2
(µ1 ! µ2 = 0)
Ha :µ1 ∀ µ2 (µ1 ! µ2 ∀ 0)Nivel de significación: α= 0.05 (5%) ó 0.01 (1%)Estadígrafo de contraste: t = (12.529 ! 13.450) = !5.256
0.359 1 + 114 6
Valores críticos : para el 5% t18,0.025= 2.101 para el 1% t18,0.005= 2.878Decisión estadística: El valor del estadígrafo de contraste pertenece a la región crítica, por tanto rechazamos la hipótesis nula.Conclusión no estadística: El grado alcohólico es significativamente diferente enRibera de Duero y Toro.
Cuadro 4.14: Contraste para la diferencia de medias de dos poblaciones normales con varianzas
desconocidas pero iguales, aplicado a los datos sobre el grado alcohólico.
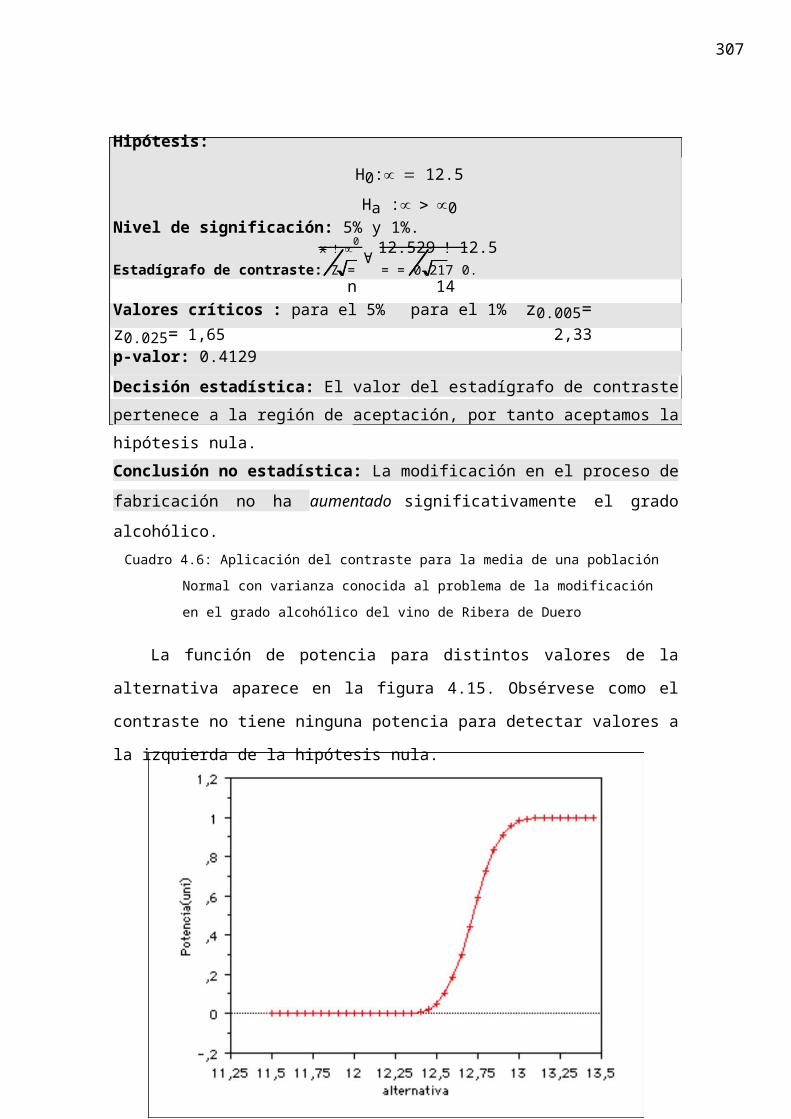
4.5.3.4 Varianzas desconocidas y distintasSupongamos ahora que las varianzas son desconocidas y distintas (σ1 ≠ σ2) de
forma que ya no es posible eliminar el parámetro en el cálculo de la t de Student. Se han propuesto diversas aproximaciones para la aproximación de la distribución del estadígrafo de contraste. Describiremos aquí la aproximación de Welch (ver cuadro 4.15). La demostración completa está fuera de los propósitos de este trabajo.
Hipótesis: H0:µ1 = µ2 (µ1 ! µ2 = 0)Ha :µ1 ∀ µ2 (µ1 ! µ2 ∀ 0)
Nivel de significación: αˆ 2 ˆ 2
Estadígrafo de contraste: t = (x 1 !x 2)S1 + S2
n1
n2
Distribución del estadígrafo cuando la hipótesis nula es cierta: t de Student tf dondef es el entero más próximo a
! ˆ 2 ˆ 2&
∃ 2#S1 + S2
f = ∀ n1 n2 % ∋ 2∃ 2 ! S ∃ 2
! S
# ̂2 & # ̂2 &1 2
∀ n
1 % + ∀ n 2 %
n1 + 1 n2 + 1
Región de aceptación: {t / t ! tf,∀ }Región critica: {t / t > tf,!}

Cuadro 4.15: Contraste para la diferencia de medias de dos poblaciones normales
con varianzas desconocidas y distintas.

320
4.5.3.5 Contrastes de comparación de medias para muestras grandes
Como ya se comentó para el caso de una única población, el teorema central del límite permite asignar distribuciones normales a las medias muestrales aunque la distribución en la población no sea Normal. Si disponemos de una muestra de tamaño grande y estimamos la varianza poblacional a través de la cuasi-varianza muestral, podemos construir un contraste aproximado de comparación de medias utilizando la distribución Normal (ver cuadro 4.16).
Hipótesis: H0:µ1 =
µ2
(µ1 ! µ2 = 0)
Ha :µ1 ∀ µ2 (µ1 ! µ2 ∀ 0)Nivel de significación: α
ˆ 2 ˆ 2
Estadígrafo de contraste: t = (x 1 !x 2) S1 +
S2
n1 n2Distribución del estadígrafo cuando la hipótesis nula es cierta: N(0,1)
Región de aceptación: {Z / Z ! z∀/2}Región critica: {Z / Z > z!/2}
Cuadro 4.16: Contraste para la diferencia de medias de dos poblaciones
normales con varianzas desconocidas y tamaños muestrales grandes.
Obsérvese que estamos suponiendo implícitamente que la cuasi-varianza muestral
es un buen estimador de la varianza poblacional, próximo al verdadero valor.
4.5.3.6 Obtención de datos para la comparación de medias.
Dos son los tipos de datos de los que es posible disponer para la comparación de las medias
- Datos procedentes de estudios observacionales.- Datos procedentes de estudios experimentales.
En el primer caso se toman muestras aleatorias en dos poblaciones. La muestra
aleatoria garantiza la representatividad . A este tipo de datos corresponde el ejemplo que
hemos utilizado como guía para la explicación.

321
Los datos experimentales se corresponden con experimentos planificados en los que se asignan dos tratamientos distintos a un grupo de individuos. En este tipo de diseños es necesario que todas las características que no intervienen en el diseño y puedan modificar la respuesta, estén controlados y sean similares en los dos grupos a comparar. Por ejemplo, si se desea hacer un ensayo clínico en el que se dispone de un grupo de pacientes de forma que a un subconjunto se le aplicará el tratamiento a comparar y el resto será utilizado como control sobre el que se utilizará un placebo (substancia no activa) con la misma apariencia que el tratamiento, los pacientes de ambos grupos han de ser similares en composición con respecto a características como la edad peso u otros factores que pudieran alterar la respuesta y que no intervienen directamente en el diseño. Se tratará de evitar sesgos de forma que los efectos puedan ser asignados a los tratamientos, por ejemplo, en un experimento con ratones de laboratorio en el que se dispone de dos camadas distintas, no sería correcto asignar un tratamiento diferente a cada una de las camadas ya que sería imposible separar los efectos del tratamiento y de la camada. En Estadística decimos que los tratamientos están confundidos.
La forma de asignar tratamientos a individuos para que no existan errores sistemáticos es hacerlo al azar, por ejemplo, sorteando cual es el tratamiento que se aplica a cada individuo. A este procedimiento se le denomina aleatorización, y juega un papel fundamental en el diseño de experimentos planificados. Hay que hacer notar que al azar no significa "de cualquier manera" o "cualquiera de los tratamientos", para conseguir una verdadera aleatorización es necesario utilizar la probabilidad.
En los experimentos diseñados es muy importante realizar estudios previos sobre
el tamaño de muestra necesario para detectar un determinado efecto. Este problema está
fuera del alcance de un curso introductorio aunque las ideas básicas fueron expuestas
cuando se trató con los intervalos de confianza.
Este tipo de experimentos se comenzó en Agricultura para extenderse después a otras aplicaciones como la Industria o la Medicina. Actualmente los ensayos clínicos controlados, basados fundamentalmente en conceptos de Estadística, forman una parte importante de la investigación médica. Todo el mundo ha oído alguna vez en las noticias los resultados de ensayos clínicos controlados antes de lanzar al mercado un nuevo medicamento.
322
4.5.3.7 Contraste para datos apareados.En el caso de datos independientes en el punto anterior, se dispone de dos
conjuntos distintos de individuos para cada una de las situaciones experimentales que se quiere compara. Una forma de controlar la variabilidad debida a los propios sujetos consiste en aplicar todos los tratamientos en estudio a todos los individuos de la muestra en dos ocasiones diferentes. A este tipo de datos lo denominaremos datos apareados, relacionados, o ligados y consisten en dos medidas tomadas sobre el mismo conjunto d individuos en dos ocasiones diferentes.
Para ilustrar los procedimientos utilizaremos datos tomados de MARTÍN
ANDRÉS y LUNA CASTILLO (1990).
Supongamos que deseamos saber si la presión sistólica de personas alcohólicas se modifica cuando dejan el hábito de beber, para ello se toma una muestra de 10 personas que ingresan en el hospital para tratar su alcoholismo y se toma una medida de la presión sistólica antes y después de dos meses de haber dejado de beber. El experimento fue diseñado de esta manera ya que aunque se espera una reducción en la presión sanguínea, esta depende del valor inicial en cada individuo.
Los resultados obtenidos para la presión sistólica medida en milímetros de
mercurio fueron los siguientes (tabla 4.4):
Individuo 1 2 3 4 5 6 7 8 9 10Antes 140 165 160 160 175 190 170 175 155 160
Después 145 150 150 160 170 175 160 165 145 170Reducción -5 15 10 0 5 15 10 10 10 -10
Tabla 4.4: datos utilizados en el ejemplo de contraste para datos apareados
Como las variables están relacionadas, todos los cálculos que realizamos en el caso de datos independientes ya no son válidos. Para evitar este problema nos centraremos en una sola variable aleatoria que es la diferencia entre los dos valores obtenidos para cada uno de los individuos estudiados que mide el efecto del tratamiento aplicado. Tenemos ahora una nueva variable D que suponemos que tiene una
distribución Normal de media µd desviación típica σd . La hipótesis de interés es ahora
que, en promedio, el tratamiento aplicado a los individuos es 0, es decir, µd = 0. El contraste es ahora exactamente igual que el descrito para la media de una población Normal (ahora la población de las diferencias.
323
Describimos a continuación el contraste para muestras pequeñas y varianza
desconocida para datos apareados. Llamaremos d , a la media muestral de las
diferencias y Sˆ d a la cuasi desviación típica. El contraste se muestra en el cuadro 4.17.
H0:µd = 0
Hipótesis: Ha :µd ! 0Nivel de significación: α
d
Estadígrafo de contraste: t = Sˆd n
Distribución del estadígrafo cuando h0 es cierta: tn-1Región de aceptación: {t / t ! tn∀1,#}
Región critica: t /t > t{ n!1, ∀}
Cuadro 4.17: Contraste para la diferencia de medias de dos poblaciones normales con datos apareados.
El resto de los contrastes se construye de la misma manera que en el caso de una
sola población. El cuadro 4.18 muestra ejemplo.
H0:µd = 0
Hipótesis: Ha :µd ! 0Nivel de significación: 5% y 1%
6Estadígrafo de contraste: t =
= 2.2508.
10Distribución del estadígrafo cuando h0 es cierta: t9
Valores críticos : para el 5% t9, 0.05= 2,262 para el 1% t9, 0.01= 3,250p-valor : 0,0510Decisión estadística: El valor del estadígrafo de contraste pertenece a la región de aceptación, por tanto aceptamos la hipótesis nula.Conclusión no estadística: Con los datos de los que disponemos no existe una evidencia significativa de que exista una diferencia entre la presión sistólica antes y después de haber dejado de beber.
Cuadro 4.18: Contraste para la diferencia de medias de dos poblaciones normales con datos
apareados aplicado al ejemplo de la reducción de la tensión arterial en alcohólicos.

324
4.5.3.8 Árbol de decisiones para la comparación de medias de dos poblaciones normales.
La figura siguiente muestra de forma esquemática el proceso de decisión por el
tipo de contraste a utilizar en poblaciones normales.
325
4.5.3.9 Contraste para la comparación de la tendencia central cuando las poblaciones no son normales
En muchas situaciones prácticas es difícil aceptar la hipótesis previa de que los datos
son normales al disponerse, por ejemplo, de distribuciones muy asimétricas. En estos
casos los contrastes anteriores no detectan claras diferencias en el comportamiento de
las poblaciones, debido a que la dispersión es muy grande o debido a que la medida de
tendencia central utilizada (la media) no es la correcta porque está afectada por los
valores extremos. Los contrastes paramétricos descritos antes son especialmente
sensibles a valores extremos de la variable.
Para solucionar el problema se utiliza la mediana en lugar de la media construyéndose
los que se denominan contrastes no paramétricos al no referirse ya a parámetros de una
distribución concreta.
Me1 x1 x2 Me2
En la figura se muestra como para distribuciones asimétricas es mucho más intuitiva la
comparación de las medianas que la comparación de las medias, ya que estas están
afectadas por los valores muy extremos de la distribución. La situación del esquema es
muy típica, por ejemplo, en problamas médicos en los que la mayoría de los controles
(curva de la izquierda) presentan valores normales de la variable, y solamente algunos
de ellos presentan valores elevados, en el grupo de los pacientes enfremos, la mayoría
presenta valores elevados y solamente alguno presenta valores normales. El problema es
particularmente crítico cuando el tamaño de muestra es pequeño pero, incluso cuando el
tamaño de muestra es grande y se utiliza erróneamente el contraste paramétrico

326
correspondiente, se subestima el tamaño del efecto a pesar de que la distribución normal
esté correctamente utilizada aplicando el Teorema Central del límite. La práctica
habitual, especialmente en el ámbito médico, de aplicar contrastes no paramétricos
cuando la muestra es pequeña y paramétricos cuando es grande es claramente errónea y
puede llevar a no encontrar efectos experimentales que aparecen claramente definidos
en los datos.
Para la comparación de medianas de dos poblaciones con datos independientes el
contraste más utilizado es el conocido como U de Mann-Withney, está basado en la
suma de los rangos de orden de las observaciones de las dos poblaciones consideradas
conjuntamente y consiste básicamente en calcular todas las ordenaciones posibles con
muestras de los mismos tamaños en el caso de que las medianas fueran iguales, para
comprobar el percentil en el que se encuentra nuestro caso particular. Cabe esperar que
si las medianas de las dos poblaciones son iguales los datos estén mezclados y las sumas
de rangos de orden sean similares en amos grupos. El resto del razonamiento es similar
al de cualquier contraste, si el valor muestral obtenido es muy probable aceptamos la
hipótesis nula y si no la rechazamos.
Para el caso de datos apareados se utiliza el test de Wilcoxon que contrasta la hipótesis
de que la mediana de las diferencias es cero. La base del contraste es similar al caso de
muestras independientes.
Comparación de medianas de dos poblaciones con datos independientes: el contraste U de Mann-Withney
Está basado en la suma de los rangos de orden de las observaciones de las dos
poblaciones consideradas conjuntamente y consiste básicamente en calcular la
distribución muestral a partir de todas las ordenaciones posibles con muestras de los
mismos tamaños en el caso de que las medianas fueran iguales. Cabe esperar que si las
medianas de las dos poblaciones son iguales los datos estén mezclados y las sumas de
rangos de orden sean similares en ambos grupos.

327
HIPOTESIS: H0 : Me1 = Me2 (Me1 ! Me2 = 0)Ha :Me1 ∀ Me2 (Me1 ! Me2 ∀ 0)
ESTADIGRAFO DE CONTRASTE: Ordenar las observaciones, asignar el rangocorrespondiente y calcular las sumas de rangos de las observaciones de cada grupo.(R1 y
R2)
U = min(U1 , U2 ) Ui = n1n 2+ ni (ni + 1) ! Ri
2
U ! n1n2
Para muestras grandes: Z = 2+ 1)n1n2 (n1 + n2
12
DISTRIBUCION DEL ESTADIGRAFO CUANDO H0 ES CIERTA: Distribuciónempírica o N(0,1) para muestras grandes.
REG. DE ACEP.: {U / U!inf
;n1,n2 ∀ U ∀ Usup
!;n1,n2 } {Z / Z ! z∀ /2 }
REGION CRITICA: {U / U ![U inf∀;n1,n2 ;U
sup∀;n1,n2 ]}{Z / Z > z!/2 }
Comparación de medianas de dos poblaciones con datos apareados: el test de Wilcoxon
Contrasta la hipótesis de que la mediana de las diferencias es cero. La base del contraste
es similar al caso de muestras independientes.
H0 : Med = 0HIPOTESIS:
Ha :Med ! 0ESTADIGRAFO DE CONTRASTE: Calcular las diferencias entre los valores de ambos grupos, Suprimir las observaciones nulas, Ordenar las observaciones en valor
absoluto, asignar el rango correspondiente y calcular las sumas de rangos de las
observaciones positivas y negativas.(T+ y T-)
T = min(T+ , T! )

328
T ! n(n + 1)Para muestras grandes: Z = 4
n(n + 1)(2n + 1)24
DISTRIBUCION DEL ESTADIGRAFO CUANDO H0 ES CIERTA: Distribuciónempírica o N(0,1) para muestras grandes.
REG. DE ACEP.: {T / T!inf
;n ∀ T ∀ T!sup
;n} {Z / Z ! z∀ /2 }
REGION CRITICA: {T / T ![T∀inf;n ;T∀sup
;n]} {Z / Z > z!/2 }
4.5.3.10 Comparación de varias poblaciones. Introducción al problema de las comparaciones múltiples.
En muchas situaciones experimentales se dispone de r >2 poblaciones a comparar.
La primera aproximación al problema es la comparación de todas la parejas de medias,
sin embargo, la propia construcción del procedimiento de contraste hace que la
probabilidad de error no se mantenga al realizar todas las comparaciones por parejas.
Supongamos que disponemos de r poblaciones y queremos contrastar la hipótesis
de que todas las medias son iguales
H0:µ1 = …= µi =…= µr
La hipótesis es cierta si y solo si las hipótesis por parejas Hi,0 j:µi = µj para todas
!r ∃ r(r & 1)las k = # = combinaciones posibles de i y de j.
∀ 2% 2
Si contrastamos la hipótesis por separado a un nivel de significación α, tenemos
P(Aceptar Hi,j /Hi, j
cierta ) = 1 ! ∀0 0
Si las comparaciones fueran independientes

329
P(Aceptar H0 / H0 cierta ) = P( !Aceptar H0i, j
/ H0 cierta ) =i! j
∀P(Aceptar H0i, j
/ H0i,j
cierta ) = (1# ∃)k
i! j
es decir, la probabilidad de cometer un error tipo I es
P(Re chazarH 0 / H0 cierta ) =
= 1 ! P(Aceptar H 0 / H 0 cierta ) = 1 ! (1 ! ∀)k
# ∀

Por ejemplo, para individuales al 5%, hay rechazar la hipótesis nula
tres poblaciones en las que se realizan comparacionesuna probabilidad de 1 ! 0.95
3 = 1! 0.8574 = 0.1426
deindebidamente. Con 5 poblaciones la probabilidad sería
1 ! 0.9510
= 1! 0.5987 = 0.4013.
Con 10 poblaciones 1 ! 0. 9545
= 1 ! 0. 0994 = 0. 9006, es decir, con 10 poblaciones, aunque todas las medias fueran iguales tendríamos una probabilidad del 90% de encontrar diferencias en alguna de las parejas.
Este problema es importante no solo en la comparación de medias por parejas sino también cuando se quieren realizar muchas comparaciones sobre el mismo conjunto de datos. Supongamos, por ejemplo, que un investigador desea demostrar que es capaz de encontrar diferencias entre personas convictas por algún tipo de delito y personas que no. A tal fin realiza 100 medidas biométricas como el perímetro torácico, el perímetro craneal, etc.... que compara en los dos grupos. En cada comparación tiene una probabilidad del 5% de rechazar indebidamente, sin embargo (si las medidas fueran independientes) tendría una probabilidad del 99,41% de encontrar diferencias en alguna de las variables. El número esperado de contrastes significativos sería de 5.
El problema de mantener el nivel de significación global en la comparación de las
medias de varios grupos se soluciona mediante la técnica denominada Análisis de la
varianza seguido de las comparaciones por parejas en las que se hace algún tipo de
corrección en el nivel de significación individual.

330
4.5.3.11 Validación de las hipótesis de partida.A lo largo de los distintos puntos de la descripción de los contrastes básicos
hemos ido haciendo una serie de suposiciones que no hemos verificado como son las
hipótesis de normalidad o de igualdad de varianzas (homocedasticidad) de las
poblaciones. La validación de estos supuestos se ha dejado para el final aunque debe
realizarse previamente a la aplicación de los procedimientos de contraste.
Existen muchos métodos que permiten la validación de la hipótesis de normalidad, desde los más formales consistentes en nuevos contrastes cuya hipótesis nula es la hipótesis de que los datos proceden de una distribución Normal, hasta simples procedimientos descriptivos como el histograma o el Box-Plot que nos permiten decidir si la distribución es aproximadamente simétrica o Normal y si la dispersión de los grupos en estudio es aproximadamente la misma.
Los procedimientos de contraste de comparación de medias suelen ser robustos
con respecto a la hipótesis de normalidad aunque muy sensibles a la presencia de
outliers (datos anormalmente grandes o pequeños). En las representaciones Box-plot de
los grupos a comparar buscaremos la simetría de lo grupos y, sobre todo, la presencia de
observaciones extrañas en los extremos de la distribución.
La figura 4.19 muestra el gráfico con los Box-Plots correspondientes al ejemplo
de las denominaciones de origen, que hemos analizado previamente

Figura 4.26: Box plot para la comparación del grado alcohólico de las

331
denominaciones de Ribera y Toro.
El gráfico muestra como no hay observaciones muy extremas, las dos
distribuciones tienen aproximadamente la misma dispersión y la correspondiente a la
denominación de origen de Toro parece más asimétrica. La asimetría podría ser debida
simplemente a que el tamaño muestral es muy pequeño en este grupo.
En líneas generales parece que las hipótesis se verifican y es posible aplicar el
contraste par la igualdad de medias de dos poblaciones normales con varianzas
desconocidas pero iguales.
Para contrastar más formalmente que las varianzas son iguales se puede construir
un contraste muy simple teniendo en cuenta la distribución del cociente de varianzas
basado en el cociente de las distribuciones ji-cuadrado asociadas.
El cociente
(n1 ! 1)∀2
1
ˆ 2 2(n1 ! 1)
F ==
= S1 ∀2
ˆ2 ˆ 2 2
(n2 ! 1)S2 S2 ∀1
∀22
(n2 ! 1)sigue una distribución F de Snedecor con n1-1 y n2-1 grados de libertad.
Si la hipótesis nula H0:!12 = !22 es cierta, el cociente de cuasi-varianzas
Sˆ2
muestrales F = 1 sigue una distribución F de Snedecor con n1-1 y n2-1 grados de
Sˆ2
2libertad.

332
El contraste completo aparece en el cuadro 4.19.
H0:!12 = !
22
Hipótesis:
Ha :!12 ∀ !
22
Nivel de significación: αSˆ2
Estadígrafo de contraste: F = 1
Sˆ2
2Distribución del estadígrafo cuando h0 es cierta: Fn1 !1, n2 !1
Región de aceptación: {F / F
![F
n1∀1,n2 ∀1,1∀#/2,F
n1∀1,n2 ∀1,1∀#/2]}
Región critica: {F / F
![F
n1∀1,n2 ∀1,1∀#/2,F
n1∀1,n2 ∀1,1∀#/2]}*
Cuadro 4.19: Contraste de comparación de las varianzas de dos poblaciones normales.
Para el ejemplo de la comparación del grado alcohólico en las dos
denominaciones de origen consideradas el contraste de comparación de varianzas se
muestra en el cuadro 4.20.
H0:!12 = !
22
Hipótesis:
Ha :!12 ∀ !
22
Nivel de significación: α = 5% y 1%Sˆ2
Estadígrafo de contraste: F = 1 = 0.686
Sˆ2
2Distribución del estadígrafo cuando h0 es cierta: Fn1 !1, n2 !1
p-valor : 0.6261
Conclusión : Se acepta la hipótesis nula.Cuadro 4.20: Contraste de comparación de las varianzas de dos poblaciones normales aplicado a la
comparación de la variabilidad del grado alcohólico.
Como se acepta la hipótesis de igualdad de varianzas, la comparación de medias
ha de hacerse en el supuesto de que las varianzas son iguales.
* El valor F n1!1,n2!1, 1!∀ /2 es el valor crítico que deja a la derecha un área de 1 ! ∀ / 2 . En la
práctica puede calcularse como F
n1!1,n2!1, 1!∀ /2 = F n2 !1, n1 !1, ∀ / 2

333
5 QuintaUnidad Didáctica
"TABLAS DE CONTINGENCIA"
5.1 Parte básica

334
5.1.1 IntroducciónLa existencia de distintas pruebas estadísticas es consecuencia, en parte, de las
distintas escalas de medida que se utilizan para tratar las variables objeto de una
determinada investigación.
Los investigadores de distintos campos utilizan de modo habitual variables medidas
en escala nominal y pasan buena parte de su tiempo clasificando y contando individuos. Así
por ejemplo cualquier individuo puede ser clasificado en categorías(varón, mujer; enfermo, sano; ausencia, presencia; soltero, casado, viudo, separado).
El resultado de tales clasificaciones da lugar a lo que en la terminología
estadística se le conoce como tablas de contingencia o tablas de frecuencias.
Tablas de contingencia son tablas de variables aleatorias cualitativas cuyos
datos están recogidos en forma de tablas de frecuencias.
El objetivo de este capítulo es:
El estudio de diversas cuestiones en relación a variables aleatorias cualitativas cuyos datos estén recogidos en forma de tablas de
frecuencias: Tablas de contingencia.
En esencia se pueden a abordar varios tipos de problemas:
1) Test de bondad de ajuste a distribuciones:Para comprobar si nuestros datos muestrales se ajustan a un determinado
modelo teórico. (Ejemplo: ¿Sigue la estatura media de los españoles una ley
normal?)
2) Test de homogeneidad de varias muestras cualitativas:Contraste para probar si varias muestras de un carácter cualitativo proceden
de igual población. (Ejemplo: ¿Es la proporción de parados en España la
misma que en el resto de los países Europeos?)

335
3) Test de asociación:Para comprobar si dos o mas características cualitativas están relacionadas
entre sí. (Ejemplo: ¿Está la intención de voto, a un determinado partido
político, relacionada con el sexo?).
En el desarrollo del capítulo nos vamos a centrar en este último tipo de contrastes.
5.1.2 Nociones generales útiles para su resolución
El denominador común a estos objetivos es que su tratamiento estadístico está
basado en la misma distribución teórica: la distribución Ji- cuadrado.
El test ji-cuadrado es el estadístico más apropiado para variables categóricas.
Antes de comenzar al desarrollo de los contrastes señalados hemos de sentar unas
ideas que nos permitirán abordar el estudio con mayor facilidad de comprensión.
En toda tabla de contingencia (sea cual sea el objetivo perseguido) podemos
distinguir varios elementos comunes:
Frecuencias observadas: número de individuos de nuestra muestra que pertenece a una de las categorías en las que hemos dividido a nuestra
variable aleatoria (Oi).
Frecuencias esperadas: Número de individuos en nuestra muestra que cabría esperar en cada categoría si alguna hipótesis nula de partida fuera
cierta (Ei).
EJEMPLO 5.1:

Supongamos una muestra de 100 individuos de una población en los que estamos
estudiando el estado civil. Esta variable aleatoria puede tener cuatro categorías: soltero,
casado, viudo y divorciado. Supongamos que el número de individuos en

336
nuestro estudio ha sido: 50 casados, 30 solteros, 15 viudos y 5 divorciados, estos
números representan nuestras frecuencias observadas.
Solución:
Nuestra hipótesis de partida (H0) podría ser que las cuatro categorías están
igualmente representadas. En este caso cabría esperar que nuestra muestra constara de
25 individuos en cada casilla, que se corresponden con nuestras frecuencias esperadas.
Solteros Casados Viudos DivorciadosfrecuenciaObservada 30 50 15 5
frecuencia 25 25 25 25Esperada

Está claro que si nuestra H0 fuera cierta
esperadas discreparían poco y, serían muy diferentes
entonces un problema:
las frecuencias observadas y las en
caso contrario. Se nos plantea
¿Cómo medir las discrepancias?. La forma más simple de medir divergencias
entre ambas magnitudes sería efectuar la diferencia entre ambas (fo i -fei ), en todas y cada
una de las casillas de la tabla y, obtener, de este modo, una magnitud que: si es grande nos
hará pensar en rechazar la hipótesis de partida, y si es pequeña en aceptarla.
En realidad el estadístico con el que vamos a trabajar se basa en esta idea, si bien tiene algunas
correcciones (no trabaja con diferencias sino con diferencias al cuadrado, para evitar problemas de signos,
y trabaja con discrepancias normalizadas, obteniéndolas en valores relativos).
Estadígrafo de contraste:
!2 = #( fo i
∀ fe i ) 2
ife
i
foi= Frecuencia observada para la i-ésima categoría
fei= Frecuencia esperada para la i-ésima categoría

337
El siguiente problema que se nos plantea: ¿qué entendemos por magnitud
grande? Necesitamos un criterio uniforme para declarar rechazos o aceptaciones.
Pearson nos soluciona este problema demostrando que el estadígrafo de
contraste propuesto seguía un modelo teórico:
Una Ji-cuadrado con (r-1)(s-1) grados de libertad, cuando la hipótesis
nula se verificaba. (Siendo r= nº de filas de la tabla y s= nº de columnas de la tabla).
De este modo el criterio de decisión ya está establecido, declararemos rechazo, es decir declararemos diferencias grandes, cuando nuestro valor del estadígrafo experimental supere al valor crítico encontrado en la tabla de la distribución Ji-cuadrado con esos grados de libertad, al nivel de significación elegido.
Recuérdese que un valor crítico no es más que un valor de la variable aleatoria que sólo es
superado por un porcentaje pequeño, preestablecido de antemano, de individuos cuando la hipótesis nula
es cierta
5.1.3 Test de asociación en tablas de contingencia
Es frecuente el problema de estudiar conjuntamente dos variables en losmismos individuos y preguntarse si existe algún tipo de relación entre ellas, es decir si los valores que tome una de ellas van a condicionar de algún modo los valores que tome la otra. Cuando las dos variables son cuantitativas hemos visto que son las técnicas de regresión y correlación las que nos permiten resolver el problema, pero estas técnicas dejan de ser válidas cuando las dos variables en estudio son cualitativas. Este apartado pretende dar solución a dicha situación. Para resolver este problema vamos a explicarlo mediante un ejemplo.

338
EJEMPLO 5.2:Supongamos cuatro tratamientos (Ai) que se piensa efectivos para curar
una determinada enfermedad, estos tratamientos se aplican a enfermos de dicha enfermedad y se anota el tipo de respuesta que presentan (Bj). La respuesta se clasifica en tres posibles clases: "peor", "igual", "mejor". Ejemplo tomado de MARTÍN ANDRÉS, A. et al. (1995).
Peor Igual mejor TOTAL
Trat 1 7 f11 28 f
12 115 f13 150 f
1.Trat 2 15 f
21 20 f22 85 f
23 120 f2.
Trat 3 10 f31 30 f
32 90 f33 130 f
3.Trat 4 5 f
41 40 f42 115 f
43 160 f4.
TOTAL 37 f.1 118 f.2 405 f.3 560 f..
fi. = Total fila i
f.j = Total columna j
f.. = Gran total
Solución:
Disponemos de nuestra tabla de frecuencias observadas, se necesita establecer una
hipótesis de partida que nos permita el cálculo de las correspondientes frecuencias
esperadas. La hipótesis de la que se parte es la hipótesis de independencia, es decir
vamos a suponer que ambos caracteres no están relacionados (no están asociados).
Si denotamos:
Ai= Suceso de que un individuo pertenezca a la clase i de A
Bj= Suceso de que un individuo pertenezca a la clase j de B
Podemos escribir las hipótesis como:
Ho: Los caracteres A y B son independientes ó bien los caracteres A y
B no están relacionados ó los caracteres A y B no están asociados
Ha: Son dependientes, relacionados, ó asociados

339
En nuestro ejemplo:
Ho: El tipo de tratamiento no condiciona la respuesta del individuo.
Ha: Si condiciona.
Si ambas características son independientes podemos escribir las hipótesis de la siguiente forma:
Ho:P(Ai ! B
j) = P(Ai)P(Bj) ∀i, j( i j) ( i) ( j) en alguna ocasión
Ha:P A ! B # P A P B
Es decir bajo el supuesto de independencia, y sólo en este supuesto, la
probabilidad de la intersección de dos sucesos es el producto de probabilidades de
ambos sucesos
Obtención de las feij: Como en todo test Ji-cuadrado necesitamos las
cantidades esperadas bajo el supuesto de que H0 se verifique. Fijémonos en una
cualquiera de ellas por ejemplo en la E21: Cantidad de individuos que habiendo recibido el tratamiento 2 empeoran supuestas ambas independientes.
Si Ho es cierta:
fe21 = f.. P(A2 )P(B1)
Para su cálculo necesitamos P(A2) , es decir la probabilidad de los individuos a
recibir el tratamiento 2, y la P(B1) es decir la probabilidad de los individuos de empeorar. Nótese que en la fórmula aparecen, ademas de estas dos probabilidades el total global. El total global es necesario para pasar de probabilidades a frecuencias
Ambas probabilidades son desconocidas pero estimables a partir de la tabla(casos favorables entre casos totales). A los correspondientes estimadores de las
probabilidades les vamos a denotar con: pˆ ij
ˆp(A2 )= 120
= f2. 560 f..
ˆp(B1)= 37
= f.1
560 f..

340
ˆ ˆ f2. f.1 f2.
f.1
fe21 = f.. P (A2 )P (B1)=
f..
= = 7.93f..
f..
f..
De donde se desprende la regla general que nos permitirá calcular la frecuencia
esperada de cualquiera de las casillas de la tabla:
feij= (Total fila i-ésima)(Total col. j-ésima)/Total global
Sin más que aplicar esta fórmula general obtendremos la tabla de frecuencias
esperadas:
Peor Igual mejor TOTALTrat 1 7 28 115 150
9.91 31.61 108.48Trat 2 15 20 85 120
7.93 25.28 86.79Trat 3 10 30 90 130
8.59 27.39 94.02Trat 4 5 40 115 160
10.57 33.72 115.71TOTAL 37 118 405 560
Obtención de la cantidad experimental: Para medir las discrepancias entre
ambas utilizamos el estadígrafo de contraste adecuado que como veíamos era:
2 ( fo ij ∀ fe ij) 2 !exp = ## fe
iji j
En nuestro ejemplo concreto este valor resulta ser:
2 ( 7 ∀ 9.91 ) 2 ( 115 ∀ 115. 71 ) 2 !exp = +...+ = 13.87
9. 91 15.71
Ya sabemos que valores grandes nos llevaran a rechazar la hipótesis de
independencia, y los pequeños a aceptarla. Sabemos también que la regla de decisión
está clara pues basta con buscar el valor crítico en la tabla de la Ji-cuadrado ( con los
grados de libertad adecuados, y al nivel de significación deseado, 5% por ejemplo), y

341
comparar nuestro valor experimental con él. Declararemos significación siempre que el valor experimental supere el valor crítico.
!exp2 H
! = (r ∀1)(s ∀ 1) = 2x3 = 6
∀∀o# !∃2 ,%
!02
.05,6 = 12. 59
12.59<13.87 , por tanto Rechazo Ho
En nuestro caso concreto son 6 los grados de libertad y 12.59 el valor crítico.
El valor experimental, 13.87, supera al valor crítico.
Conclusión: El tipo de tratamiento condiciona el tipo de respuesta encontrada en el paciente. No podemos suponer independencia de las dos variables en estudio.
En resumen, los pasos a seguir en este tipo de análisis son:
1º Cálculo individual de las frecuencias esperadas que cabría esperar si H0 fueracierta. La hipótesis de la que partiremos es siempre la de independencia entre las dos variables, ya que sólo bajo este supuesto conocemos la distribución del estadígrafo de contraste (distribución ji-cuadrado de Pearson)
2º Cálculo de los componentes individuales de ! 2 , es decir cálculo de lasdivergencias entre observadas y esperadas para cada casilla.
3º Suma de los valores obtenidos en el apartado anterior y obtención , de esta forma, del valor experimental de nuestro estadígrafo de contraste.
4º Determinación de los grados de libertad de la forma (r-1)(s-1)
5º Obtención del valor crítico en la tabla de la distribución ! 2 con los grados delibertad correspondientes y decidir si el estadístico calculado en el paso 3º excede este valor crítico con p=0.05 o bien con p=0.01
6º Concluir en consecuencia. Es decir, hablar de que existe o no asociación entre
ambas variables según el valor experimental exceda o no al valor crítico.

342
"TABLAS DE CONTINGENCIA"
5.2 Ampliación

343
5.2.1Aspectos de interés.5.2.1.1 Tipo de contraste
- Se trata de un contraste unilateral superior y esto es así siempre que trabajemos con tablas de contingencia (sea cual sea el objetivo a cubrir), se debe a la
forma del estadígrafo empleado. Si fuera bilateral rechazaríamos H0 para valores muy grandes y muy pequeños del estadígrafo de contraste, pero valores pequeños, se interpretan como gran parecido entre ambos tipos de frecuencias. Por tanto no nos interesa rechazar en los dos sentidos, sino sólo en el caso de valores anormalmente grandes.
5.2.1.2 Tablas poco ocupadas- Una problemática ampliamente tratada en los libros de texto es el de las tablas
poco ocupadas o tablas con valores de frecuencias próximos a cero. Cuando nos
encontremos en esta situación hay que estar prevenidos porque representan un problema de posible incremento en el riesgo tipo I. Se recomienda tenerlo en cuenta
para frecuencias menores o iguales a 5. Si observamos la fórmula del estadígrafo de contraste
podemos ver cómo las frecuencias esperadas van en el denominador. Frecuencias pequeñas nos darán, al ir el
en denominador, valores altos en el estadígrafo de contraste, lo que nos llevará, con mayor probabilidad, a
rechazar la Ho, aunque sea cierta. Es decir, a un serio incremento en el riesgo tipo I ó probabilidad de rechazar
indebidamente la Ho.
5.2.1.3 Causas de la significación- El test empleado nos mide discrepancias a nivel global, pero no nos informa
acerca de dónde están las discrepancias. Basta que en una sola casilla de la tabla se den
grandes discrepancias para obtener valores experimentales grandes que nos llevarán a rechazar la hipótesis, por tanto ante una magnitud grande no podremos saber si sólo una, dos o todas las casillas
discrepan. Necesitamos un procedimiento posterior que nos ponga de manifiesto dónde
están realmente las discrepancias: Búsqueda de las causas de la significación.

344
5.2.2 Búsqueda de las causas de la significación
Cuando un test ! 2 da no significativo, es decir aceptamos la H0 de independencia entre las variables, el problema acaba ahí, pero, si la significación se produce, lo inmediato es intentar localizar la causa de la misma.
La idea ahora es la descomponer la tabla original en subtablas que nos expliquen
las causas de la significación. Para ello nos basamos en la propiedad aditiva de la ! 2 .
5.2.2.1 Propiedad aditiva de la Ji-cuadradoLa propiedad aditiva de la ! 2 dice:
!∀2 + !∀
2 = !∀2+∀ 2
1 2 1
Es decir: si tenemos dos variables aleatorias que siguen respectivamente un
modelo teórico Ji-cuadrado con !1 y !2 grados de libertad, la suma de las dos nos daotra variable aleatoria que sigue un modelo Ji-cuadrado con la suma de los grados de
libertad de las de partida.
5.2.2.2 Búsqueda de las causas de la significación
El modo de partir la tabla original no es único y sólo el análisis detallado de los
datos nos dará las pautas a seguir.
Para el desarrollo de este apartado utilizaremos el ejemplo visto con los alumnos,
dado que allí la conclusión a la que se llegaba era la de relación entre ambas variables.
La primera idea que se nos ocurre para analizar la situación es saber lo que
contribuye cada casilla al valor experimental (recordar que el rechazo se obtenía para
valores grandes de éste y, que bastaba que una casilla tuviera grandes discrepancias para

producirse este hecho). De esta manera calcularemos la tabla de contribuciones, donde
los valores de cada casilla se obtienen como:

345
( fo i ! fe i) 2 fei
En nuestro caso concreto:
Tabla de contribuciones
Peor Igual mejor TOTALTrat 1 0.85 0.41 0.39 1.65Trat 2 6.31 1.11 0.04 7.46Trat 3 0.23 0.25 0.17 0.65Trat 4 2.94 1.17 0.00 4.11
13.87
Donde el primer elemento de la primera columna se ha obtenido como:
( 7 ! 9.91 ) 2 =
0.85 9.91
El primer elemento de la segunda columna como: (28
! 31.61)2 = 0.41 etc.
31.61
El análisis de la tabla nos sugiere que el principal responsable de la significación
es el tratamiento 2 con una contribución total de 7.46, superior a la de los otros 3
conjuntamente.
Esto parece sugerir que los tratamientos 1,3,4 son homogéneos
entre si (la respuesta es independiente de estos tratamientos) y difieren del 2.
De ahí que intentemos realizar estos dos contrastes:
Primero: Los tratamientos 1,3,4 son homogéneosSegundo: Los tratamientos anteriores difieren del 2
Para llevar a cabo el primero de ellos construimos una subtabla en la que
hemos de eliminar el tratamiento 2 (el aparentemente responsable de la significación):
PEOR IGUAL MEJOR TOTALT1 7 28 115 150

346
T3 10 30 90 130T4 5 40 115 160
TOTAL 22 98 320 440
En dicha tabla realizaremos el contraste de independencia del mismo modo a
como lo hicimos en la tabla original, con la esperanza de que en este caso la conclusión
sea la de aceptar la Ho (lo que sugiere la observación de los datos).
Ahora las frecuencias esperadas no van a coincidir con el primer supuesto ya que
los marginales de columnas son distintos (hemos eliminado a los enfermos tratados con
el segundo de los tratamientos), tampoco coincidirá el valor experimental ni los grados
de libertad de la tabla.
Siguiendo los pasos enunciados en el ejercicio de los alumnos obtenemos para
este caso:
! exp2
= 5. 04 que hemos de comparar con el correspondiente valor crítico de latabla en este caso con 4 grados de libertad, que resultó ser en este caso
! 4;02
.05 = 9.488
Concusión: ACEPTO Ho : HOMOGENEIDAD
Como era de esperar hemos llegado a la conclusión de que estos tres tratamientos
eran igualmente efectivos. Por tanto no se trata de tres tratamientos distintos sino de uno
sólo que llamaremos a partir de ahora tratamiento (1+3+4).
Para llevar a cabo el segundo de los contrastes, que nos ponga de manifiesto
que es el tratamiento 2 el que difiere del resto necesitamos construir otra subtabla en la
que se disponga de la información que nos interesa, es decir el tratamiento 2 y el
tratamiento (1+3+4).

347
PEOR IGUAL MEJOR TotalT2 15 20 85 120
T(1+3+4) 22 98 320 440Total 37 118 405 560
2 Realizado el contraste de independencia en esta subtabla obtenemos:
= 9.488 que hemos de comparar con un valor crítico, correspondiente a esta! exp
situación, con 2 grados de libertad. Dicho valor es: ! 2;02
.05 = 9.21
La conclusión a la que llegamos es pues: Rechazo la H0 de independenciaentre la respuesta y los dos tratamientos el 2 ó cualquiera de los otros.
Obsérvese que la descomposición realizada de la tabla original es lícita puesto que
se verifica la propiedad aditiva de la Ji-cuadrado. Hemos obtenido dos subtablas en la
que las sumas de sus grados de libertad (4 y 2 respectivamente) coinciden con los
grados de libertad de la tabla de partida (6).
En resumen lo que hemos hecho es:
Variación g.l. !exp.2 significación
tratamientos 4 5.04 No1,3,4
tratamientos 2 9.48 **2 y (1+3+4)
Sumas 6 14.52 -
tratamientos 6 13.87 **1,2,3,4
Con esta descomposición hemos probado que el tratamiento 2 difiere del
resto como parecía intuirse de la tabla de contribuciones, pero esta afirmación, aunque
válida no deja de ser incompleta ya que nada nos dice de en qué sentido es diferente, dicho
de otra forma, difiere el tratamiento 2 del resto porque es peor o porque es mejor. Faltaría,

348
pues, descomponer la última tabla que nos dio significativa, y que tenía dos grados de
libertad, en otras dos subtablas de 1 grado de libertad cada una para saber el sentido
de las diferencias.
Un esquema global de los pasos pueden verse en la figura 5.1.
P I MT1
P I M T3 NS I M
T1 T4T2 T2T3 P I M NS
T4 T2
* P (I+M)
T1+T2+T3T2
*T1+T2+T3
Figura 5.1: Esquema de descomposición de la tabla de contingencia de
partida para la búsqueda de la significación

349
5.2.3 Paradoja de SimpsonSupongamos que se realiza un experimento para comparar un nuevo tratamiento
para cierta enfermedad con el tratamiento estándar para esa enfermedad. En el experimento se tratan 80 individuos que padecen la enfermedad, 40 recibieron el nuevo tratamiento y 40 recibieron el estándar. Después de un tiempo se observa cuantos de los individuos de cada grupo han mejorado y cuantos no. Supongamos que los resultados fueron:
TODOS LOS PACIENTES MEJORAN NO MEJORANNUEVO TRATAMIENTO 20 20
TRAT. ESTÁNDAR 24 16
De acuerdo con la tabla, 20 de los 40 individuos que reciben el nuevo tratamiento
mejoraron y 24 de los 40 individuos que recibieron el estándar mejoraron. Por tanto el
50% de los individuos mejoraron con el nuevo tratamiento, mientras que el 60% de los
individuos mejoraron con el tratamiento estándar. El nuevo tratamiento parece inferior
al tratamiento estándar.
Para investigar la eficacia del nuevo tratamiento más a fondo, se podría comparar
con el tratamiento estándar sólo para los hombres de la muestra y separadamente sólo
para las mujeres. Podríamos pues desagregar esta tabla en otras dos subtablas: la de hombres y la de mujeres.
Supóngase que tenemos información suficiente para construir estas subtablas y
que el resultado es el siguiente:
SOLO HOMBRES MEJORAN NO MEJORAN
NUEVO TRATAM 12 18TRAT. ESTÁNDAR 3 7
SOLO MUJERES MEJORAN NO MEJORAN
NUEVO TRATAM 8 2TRAT. ESTÁNDAR 21 9

350
Obsérvese que si agregamos de nuevo las dos subtablas obtendríamos de nuevo la
tabla de partida.
Sin embargo, el análisis de las subtablas nos pone de manifiesto algo sorprendente, ya que el nuevo tratamiento parece ser más efectivo que el estándar tanto en hombres como en mujeres. Específicamente, el 40% de los hombres (12 de cada 30) que reciben el nuevo tratamiento mejoraron, pero sólo el 30% de los hombres (3 de cada 10) que recibieron el estándar mejoraron. Además el 80% de las mujeres (8 de cada 10) que recibieron el nuevo tratamiento mejoraron pero sólo el 70% de ellas (21 de cada 30) que recibieron el tratamiento estándar mejoraron.
Está claro que la tabla inicial y las subtablas proporcionan resultadoscontradictorios. De acuerdo con la primera el tratamiento estándar es mejor para todos pero con las subtablas, el nuevo es superior, para hombres y para mujeres. A este tipo de resultados se le conoce como paradoja de Simpson.
La paradoja de Simpson no es realmente una paradoja, sólo es un resultadoque sorprende y confunde cuando no se ha observado antes. Se puede ver en la subtabla correspondiente a mujeres que éstas tienen una tasa de recuperación de la enfermedad mayor que la de los hombres, independientemente del tratamiento que reciban. Además, entre los 40 hombres de la muestra, 30 recibieron el nuevo tratamiento y sólo 10 el estándar, mientras que para las mujeres estos números son justamente al revés. Por tanto aunque los números de hombres y de mujeres en el experimento fueron iguales, una alta proporción de mujeres y una baja proporción de hombres recibieron el tratamiento estándar. Puesto que las mujeres tienen una tasa de recuperación mayor, se encuentra en la tabla agregada que el tratamiento estándar manifiesta una mayor tasa global de recuperación que el nuevo tratamiento.
La paradoja de Simpson demuestra de una forma drástica los peligros de
realizar inferencias a partir de tablas agregadas.
Para estar seguros de que la paradoja no está presente en un experimento las
proporciones de relativas de hombres y de mujeres entre los individuos que reciben el
nuevo tratamiento debe ser aproximadamente la misma, así como las proporciones
relativas de hombres y de mujeres entre los individuos que reciben el tratamiento
estándar.
La posibilidad de la paradoja subyace en cualquier tabla de contingencia. Aún
cuando se tuviera cuidado al diseñar un experimento particular de forma que no pudiera

351
ocurrir la paradoja cuando se desagrega para hombres y mujeres, siempre es posible que
exista alguna otra variable, como la edad de los individuos o la intensidad y grado de
avance de la enfermedad, con respecto a la cual la desagregación podría conducir a una
conclusión directamente opuesta a la indicada por la tabla agregada.


















