
Administracion de Sistemas Operativos
60
Administración de Sistemas Operativos Curso Académico 2003-2004 Tema 1 - Visión General de la Administración de un Sistema Operativo a) Introducción Según Tanembaum, existen dos aspectos o puntos de vista diferentes respecto de los SS. OO.: a) el S. O. es una máquina ampliada (llamada también máquina virtual) que es más fácil de programar y manejar que el propio hardware de la máquina (llamada también máquina real). b) el S. O. es un gestor de recursos que ofrece una distribución ordenada y controlada de los dispositivos de la máquina real, entre los distintos programas que compiten por esos recursos. Otra definición para el S. O. es la siguiente: '' programa cuyo objetivo es el de simplificar el manejo del ordenador, haciéndolo seguro y eficiente. Las funciones de un S. O. han sido, clásicamente, las siguientes: • la gestión de recursos, • la ejecución de servicios para los programas y • la ejecución de órdenes de usuario. Tradicionalmente, se han representado los elementos que intervienen en la comunicación hombre- ordenador, en el siguiente modelo de capas: En una primera aproximación, entendemos que el usuario se comunica con una máquina virtual ('' algo que no es lo que parece''). Si obs ervamos más de cerca, y nos centramos en el nivel más básico en el uso del ordenador, percibiremos que el usuario se comunica con un sistema operativo que, a su vez, se comunica con la máquina física o real (que en los gráficos se llama HW o hardware). Si observamos la relación entre el usuario y el ordenador a un nivel más alto, se verá que el usuario interacciona con una serie de aplicaciones que interactúan con el sistema operativo, Tema 1, página 1 Ignacio José Blanco Medina Usuario M. V. Usuario S. O. HW Usuario S. O. HW Aplicaciones
Transcript of Administracion de Sistemas Operativos

Administración de Sistemas Operativos Curso Académico 20032004
Tema 1 - Visión General de la Administración de un Sistema Operativo
a) Introducción Según Tanembaum, existen dos aspectos o puntos de vista diferentes respecto de los SS. OO.:
a) el S. O. es una máquina ampliada (llamada también máquina virtual) que es más fácil deprogramar y manejar que el propio hardware de la máquina (llamada también máquina real).
b) el S. O. es un gestor de recursos que ofrece una distribución ordenada y controlada de losdispositivos de la máquina real, entre los distintos programas que compiten por esos recursos.
Otra definición para el S. O. es la siguiente: ''programa cuyo objetivo es el de simplificar el manejodel ordenador, haciéndolo seguro y eficiente.
Las funciones de un S. O. han sido, clásicamente, las siguientes:
• la gestión de recursos,
• la ejecución de servicios para los programas y
• la ejecución de órdenes de usuario.
Tradicionalmente, se han representado los elementos que intervienen en la comunicación hombreordenador, en el siguiente modelo de capas:
En una primera aproximación, entendemos que el usuario se comunica con una máquina virtual(''algo que no es lo que parece''). Si observamos más de cerca, y nos centramos en el nivel másbásico en el uso del ordenador, percibiremos que el usuario se comunica con un sistema operativoque, a su vez, se comunica con la máquina física o real (que en los gráficos se llama HW ohardware). Si observamos la relación entre el usuario y el ordenador a un nivel más alto, se veráque el usuario interacciona con una serie de aplicaciones que interactúan con el sistema operativo,
Tema 1, página 1 Ignacio José Blanco Medina
Usuario
M. V.
UsuarioS. O.
HW
Usuario
S. O.
HW
Aplicaciones

Administración de Sistemas Operativos Curso Académico 20032004
el cual, a su vez, interacciona con la máquina física.
Para representar un rango más amplio de canales de comunicación entre el usuario y el ordenador,podemos usar el siguiente esquema:
en el caso de máquinas aisladas, o el que se muestra a continuación para el caso de máquinasconectadas mediante un red:
En este diagrama de capas, se muestra que la conexión de dos máquinas mediante una red seconcibe como una parte del hardware de las máquinas, aunque el sistema operativo provea demodos de acceso a esos recursos del sistema.
Nuestro área de interés se centrará en la zona del S. O. que aparece marcada en los gráficos.
Si descendemos a un nivel de detalle aún mayor, podemos ver el sistema operativo como dos partes
Tema 1, página 2 Ignacio José Blanco Medina
Usuario
Aplicaciones
S. O.
HW
Usuario
Aplicaciones
S. O.
HW
Usuario
Aplicaciones
S. O.
HW
Usuario
Aplicaciones
S. O.
HWNetwork

Administración de Sistemas Operativos Curso Académico 20032004
interconectadas entre sí y concordantes con la definición de Tanembaum:
1. una máquina virtual: compuesta de una serie de servicios y una shell (o intérprete de comandos)y
2. un gestor de recursos o kernel, que provee a la máquina de un funcionamiento básico y unaforma de acceder a los dispositivos.
En el tema 3, abordaremos la administración de usuarios y su entorno. Es decir, afectaremos a lafrontera entre el usuario y la shell, y entre el usuario y las aplicaciones, para establecer a qué puedenacceder qué usuarios, cuándo y cómo.
En el tema 4, trataremos el problema de cómo se guarda y recupera la información desde el usuarioy las aplicaciones en el hardware.
En el tema 5, veremos cómo hacer que un ordenador se comunique con otros, a nivel del sistemaoperativo, mediante una red.
En el tema 7, veremos cómo se administran recursos de conexión e impresión.
b) Conceptos Vamos a definir una serie de conceptos que nos serán útiles a la hora de la administración de unsistema operativo:
a) proceso : básicamente, un programa en ejecución, es decir, el conjunto formado por un programaejecutable, sus datos, su pila, su contador de programa y sus registros.
La definición provista por The Free Online Dictionary of Computing (27 SEP 03) es la
Tema 1, página 3 Ignacio José Blanco Medina
Usu
ario
(3)
AplicacionesSh
ell
Serv
icio
s Kernel
HW

Administración de Sistemas Operativos Curso Académico 20032004
siguiente: ''Secuencia de estados de un programa en ejecución. Un proceso consta de código delprograma (que puede ser compartido con otros procesos que ejecutan el mismo programa), datosprivados, y el estado del procesador, en particular, los valores de los registros. Puede tenerasociados una serie de recursos.“
b) archivo : colección de datos almacenada en memoria.
La definición más consecuente, provista por WordNet® 2.0 es: ''conjunto de registrosrelacionados (en forma escrita o electrónica) que se almacenan juntos''.
c) sistema de ficheros : la definición provista por The Free Online Dictionary of Computing (27SEP 03) es ''un sistema para organizar directorios y fichero, generalmente en términos de cómolo implementa el sistema operativo; la colección de ficheros y directorios que se almacenan enuna unidad determinada''.
d) jerarquía de directorios o árbol: jerarquía de directorios (archivos que contienen a otrosarchivos) en la que se organizan los archivos dentro de un sistema de ficheros, cuyo punto departida es el llamado directorio raíz.
La definición que provee The Free Online Dictionary of Computing (27 SEP 03) para unsistema de ficheros jerárquico es: ''sistema de ficheros en el que los archivos están organizadosen una jerarquía en la que, los nodos intermedios de la misma se llaman directorios y las hojas seconocen como archivos, comenzando por un nodo raíz.
e) shell o intérprete de comandos : programa que permite la comunicación directa entre el usuarioy el S. O. en un lenguaje más próximo al usuario que el propio lenguaje máquina o el de losservicios provistos por el núcleo (o kernel). Generalmente, consta de una línea de comandos queespera un comando introducido por el usuario, para posteriormente procesarlo y devolver elresultado proporcionado por el sistema operativo.
La definición provista por Jargon File (4.3.0, 30 APR 2001) es ''el intérprete de comandos usadopara pasar comandos a un sistema operativo; llamado de esta manera porque es la parte delsistema operativo que lo comunica con el mundo exterior (el usuario). Más generalmente, se usaeste vocablo para describir a cualquier programa de interfase que media en el acceso a cualquierrecurso o servicio por conveniencia, eficiencia o, simplemente, por seguridad''.
c) Tareas de un administrador Las principales tareas de una administrador del sistema operativo son las siguientes:
• administrar usuarios,
• configurar dispositivos,
• arranque y desconexión del sistema operativo,
• seguridad del sistema (tanto interna como externa),
• bitácora o supervisión del sistema,
• copia de seguridad,
• formación de los usuarios en el uso del sistema operativo en cuestión, y
• consejero de los usuarios en cuanto a temas relacionados con dicho sistema operativo.
Tema 1, página 4 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
Algunas normas básicas para un administrador de sistema operativo son:
• jamás conectar al sistema como administrador si no es necesario,
• evitar la administración del sistema operativo mientras haya usuarios que puedan verse afectadosen un mayor grado por dicha tarea de administración (por ejemplo, con el reinicio del equipoinformático), y
• realizar copias de seguridad en un horario no crítico.
Algunas referencias• Wordnet
• The Free OnLine Dictionary of Computing
• Jargon File
Tema 1, página 5 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
Tema 2 - Instalación de un Sistema Operativo
a) Dedicación del Sistema Operativo En primer lugar, es necesario determinar a qué se va a dedicar el ordenador que se está instalando,ya que, en última instancia, este uso determinará el tipo de sistema operativo que se deberá instalar.Esta decisión vendrá influida por el tipo de organización que se desea aplicar a la informacióndentro del sistema y al tipo de servicios que se requerirán del ordenador en cuestión.
Las posibilidades, a la hora de instalar un equipo, son las siguientes:
a) máquina independiente: un ordenador que trabaja de forma aislada y que es utilizada por uno omás usuarios. Requerirá de un espacio de disco para cada usuario, además de las aplicacionesque estos puedan necesitar.
b) máquina servidor: equipo que, usualmente, trabaja conectada a una red de ordenadores y que sededica a la atención de peticiones emitidas por otros ordenadores, conocidos como máquinascliente. Según el servicio que se desee ofrecer, habrá unas u otras restricciones sobre losrecursos, como pueden ser espacio o acceso a red. Generalmente, un ordenador servidor (host)sólo requerirá del uso de aquellos recursos relacionados de alguna forma con el servicio queofrece, ya que sólo ejecutará procesos relacionados con el núcleo del sistema operativo (kernel) ycon el servicio ofrecido. Los principales (o más conocidos) servicios que se pueden proveer, son:
servicio de disco: este tipo de servidor atiende peticiones de acceso a sus discos duros porparte de usuarios o de aplicaciones ejecutadas por estos desde ordenadores remotos (clientesde disco). Según el tipo de archivos a los que accede el usuario, podemos distinguir entre:
➢ servidores de cuenta de usuario: centralizan los archivos de cada usuario, de modo que, seacual sea el ordenador en el que se conecte el usuario, podrá manejar sus ficheros (siempreque usuario y ordenador estén autorizados para ello).
➢ servidores de aplicaciones: centralizan el software instalado en una empresa u organizaciónde modo que sólo es necesario realizar una instalación de cada programa para todos losclientes autorizados.
servicio de impresión: el ordenador dedicado a este servicio cuenta, entre su hardware, conuna o varias impresoras, en las que se imprimen los trabajos recibidos como peticiones deotros ordenadores, emitidas por usuarios o programas que trabajan sobre ordenadoresremotos. Los servidores de impresión como máquinas independiente están empezando aquedar desfasados por la aparición de impresoras que incorporan su propio procesador,memoria, disco duro, sistema operativo y hardware de red, con lo que la funcionalidad delservidor se incorpora a la propia impresora, la cual se conecta directamente a la red.
servicio de correo electrónico/noticias: atiende peticiones de envío/recepción de correoelectrónico por parte de usuarios registrados y programas que actúen en su nombre. Laresponsabilidad de la limpieza del correo recibido (en cuanto a virus) ha pasado de perteneceral usuario a estar integrada dentro del propio servidor, de modo que los correos recibidos secomprueban y limpian automáticamente antes de que el usuario pueda proceder a su lectura.
Según el tipo de servidor de correo de que estemos hablando, las restricciones sobre losrecursos serán distintas:
Tema 2, página 1 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
➢ servidor POP3: el servidor actúa como una estafeta de correo. El programa de correo, quese ejecuta en el ordenador cliente, conecta con el servidor y descarga de forma local elcorreo electrónico recibido desde la última conexión, además de proceder al envío delcorreo saliente. Este modo de comunicación se conoce como offline. La necesidad deespacio para las cuentas de correo de los usuarios estará adaptada a la cantidad de correoque el usuario puede recibir.
➢ servidor IMAP: el servidor actúa como apartado de correo. El programa de correo que seejecuta en el ordenador cliente actúa interactivamente con el servidor de correo. Loscorreos electrónicos se reciben y almacenan directamente en el servidor de correo. Lasventajas que presenta el uso del protocolo IMAP para el correo electrónico reside en que elcorreo puede ser consultado indiferentemente desde cualquier ordenador cliente con unprograma cliente de IMAP. Sin embargo, como desventajas cabe remarcar la necesidad deuna red de ordenadores con un ancho de banda suficiente y que la necesidad de espacio dedisco para almacenar las cuentas de correo de los usuarios estará adaptada a la cantidad decorreo que el usuario puede almacenar.
servicio de web hosting (o albergue de páginas web, o de web, simplemente): almacena unajerarquía de páginas web y atiende peticiones de acceso a las mismas, emitidas por programas(navegador o browser) ejecutados en ordenadores cliente. Generalmente, las páginas websuelen ser interfaces para otros servicios provistos por la misma máquina, de modo que elservidor instalado en la máquina (referido al proceso que ofrece el servicio) sólo actúa comopaso a otros servicios (portal), como pueden ser correo, bases de datos, etc.
servicio de acceso (ISP, Internet Service Provider o proveedor de servicios de Internet):proveen de servicio de acceso a una red a un ordenador que no está directamente conectada auna.
Es preciso recordar, como se verá en el tema 5, que todo ordenador conectado a una red tiene,en dicha red, un identificador único o dirección IP (dirección de Internet Protocol). De estemodo, un ordenador no conectado a una red no posee dicha dirección, que es provista por unISP para que el cliente la ostente temporalmente hasta que finalice el uso del servicio. Elproceso de conexión tiene el esquema que se muestra en la figura 1 y sigue los siguientespasos:
1º el cliente conecta con el ISP,
2º el ISP concede una dirección temporal mediante un protocolo conocido como DHCP(que se estudiará en el tema 5), y
3º el ISP actúa como router, es decir, envía toda la información emitida por el cliente através de su propia conexión a la red.
Tema 2, página 2 Ignacio José Blanco Medina
Ilustración 1. Servicio ISP
Cliente ISP Servidor ISP
Network

Administración de Sistemas Operativos Curso Académico 20032004
sigue los siguientes pasos:
➢ el cliente conecta con el ISP,
➢ el ISP concede una configuración de red de forma temporal mediante el protocolo DHCP(Dynamic Host Configuration Protocol), y
➢ el ISP actúa como un gateway y router entre el cliente y la red.
servicio de proceso: proveen a las máquinas cliente de tiempo de proceso en su/sprocesador/es. Existen dos modos de conexión a estos servidores:
➢ conexión mediante shell remota: modo texto, y
➢ conexión mediante clientes gráficos (X server): lanza un interfaz gráfico remoto, pero elgrueso del cálculo se ejecuta en el servidor.
servicios multimedia: comunmente conocidos como servidores de streaming, en los que elcliente se conecta y reproduce segmentos archivos en formatos de multimedia conforme sedescargan, para borrarlos después (WMV, RealMedia, MP3, ...).
d) clusters: conjuntos de máquinas que trabajan juntas y aparecen como una sola. Comunmente, seconectan a nivel de placa base.
En general, un servidor no tiene por qué estar dedicado a un único servicio (por ejemplo, a laimpresión), sino que puede proveer varios servicios. A partir de ahora, llamaremos ordenadorservidor a aquel ordenador que ejecuta procesos para proveer servicios y servidor al proceso quegestiona y ofrece un servicio.
Una vez establecido el tipo de instalación, que establecerá restricciones sobre el espacio necesario ysu distribución, se procederá al tratamiento del soporte de almacenamiento para la instalación.
b) Particionado del disco duro:
(i) Estructura física de un disco duro Un disco duro (comunmente representado por HD) es una pila de 1 o más platos (véase lailustración 2), cada uno de los cuales tiene dos caras recubiertas con un material magnético quepermite la representación de información. La información de cada una de las caras es leída por unacabeza lectora y escrita por una cabeza de grabación, de modo que se habla de cabeza. Un discotiene n cabezas, donde n es el número de platos multiplicado por dos.
Para aumentar la eficiencia en el acceso y aumentar la integración (reducir el tamaño), todas lascabezas están sujetas al mismo brazo mecánico, y todos los platos están sujetos al mismo brazo, demodo que hay un solo motor de giro para el disco y un solo motor para posicionar las cabezas.
Las cabezas de lectura y escritura no se mueven verticalmente, sino que flotan sobre los discos en loque se conoce como colchón de aire (la velocidad de giro del disco origina una corriente circular deaire sobre la superficie del disco, y sobre esa corriente flota la cabeza).
Físicamente, un disco tiene varios platos, cada uno de los cuales tiene dos caras (véanse lasilustraciones 3 y 4), cada una de las cuales tiene una serie de pistas circulares conocidas comopistas (circulares, que no espirales como los discos de vinilo). Cada pista se divide en una serie de
Tema 2, página 3 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
arcos o segmentos de pista conocidos como sectores. Al conjunto de todas las pistas que seencuentran en la misma vertical se le conoce como cilindro, y al conjunto de sectores que seencuentran en la misma proyección vertical se le conoce como cluster o bloque.
De la forma de disponer la información almacenada en un disco en sectores, bloques, cilindros, etc.dependerá la eficiencia del dispositivo de almacenamiento.
(ii) Estructura lógica de un disco duro Lógicamente, un disco duro se compone de:
• sector de arranque o MBR (Master Boot Record),
• espacio particionado (o espacio preparado para albergar un sistema de ficheros), y
• espacio sin particionar (espacio libre no preparado para albergar un sistema de ficheros).
El sector de arranque de un disco, conocido como sector 0 o MBR, se encuentra ubicado en lacabeza 0, cilindro 0 y sector 1. En dicha sección del disco se almacenan la tabla de particiones y un
Tema 2, página 4 Ignacio José Blanco Medina
Ilustración 2. Estructura interna de un disco duro
Ilustración 3. Estructura de los platos y caras

Administración de Sistemas Operativos Curso Académico 20032004
programa de inicialización que indica dónde se encuentra ubicado el sistema operativo que permiteceder el control a la partición activa del disco (la cual tiene su propio sector 0 o sector de arranque).En este MBR se almacena el programa conocido como cargador del sistema operativo (NTLoader,LILO, GRUB, ...).
La motivación para el uso de particiones es la siguiente:
• permite una mejor organización de la información, por ejemplo, de diversos tipos (correo, basesde datos, archivos de usuario, etc.),
• permite la instalación de múltiples sistemas operativos en el mismo ordenador, o variasinstalaciones del mismo,
• mejoran la eficiencia ya que, a veces, es preferible varias FATs (tabla de asignación dearchivos) pequeñas que una grande dado que, en particiones grandes, el tamaño de cluster esmayor y se desperdicia más espacio.
Existen dos tipos de particiones: las primarias y las extendidas.
Inicialmente, un disco duro sólo podía contener cuatro particiones primarias (debido a la estructurade su tabla de particiones, que se almacena en el MBR) como máximo. Sin embargo, la necesidadde aumentar el número de particiones posibles llevó a la introducción de un nuevo tipo departiciones llamadas extendidas, que se caracteriza por contener varias unidades lógicas(particiones independientes).
De este modo, la estructura lógica de un disco duro puede variar desde la siguiente:
MBR Partición primariahasta la siguiente:
MBR PP1 PP2 PP3 PL1 PL2 PL3 ... Pln
Para que la BIOS del ordenador pueda iniciar desde un disco duro (disco ''arrancable'' o de inicio),es necesario que una de las particiones primarias esté marcada como activa (aquella partición a laque se cede el control en el arranque).
Tema 2, página 5 Ignacio José Blanco Medina
Ilustración 4Estructura interna de una cara
Administración de Sistemas Operativos Curso Académico 20032004
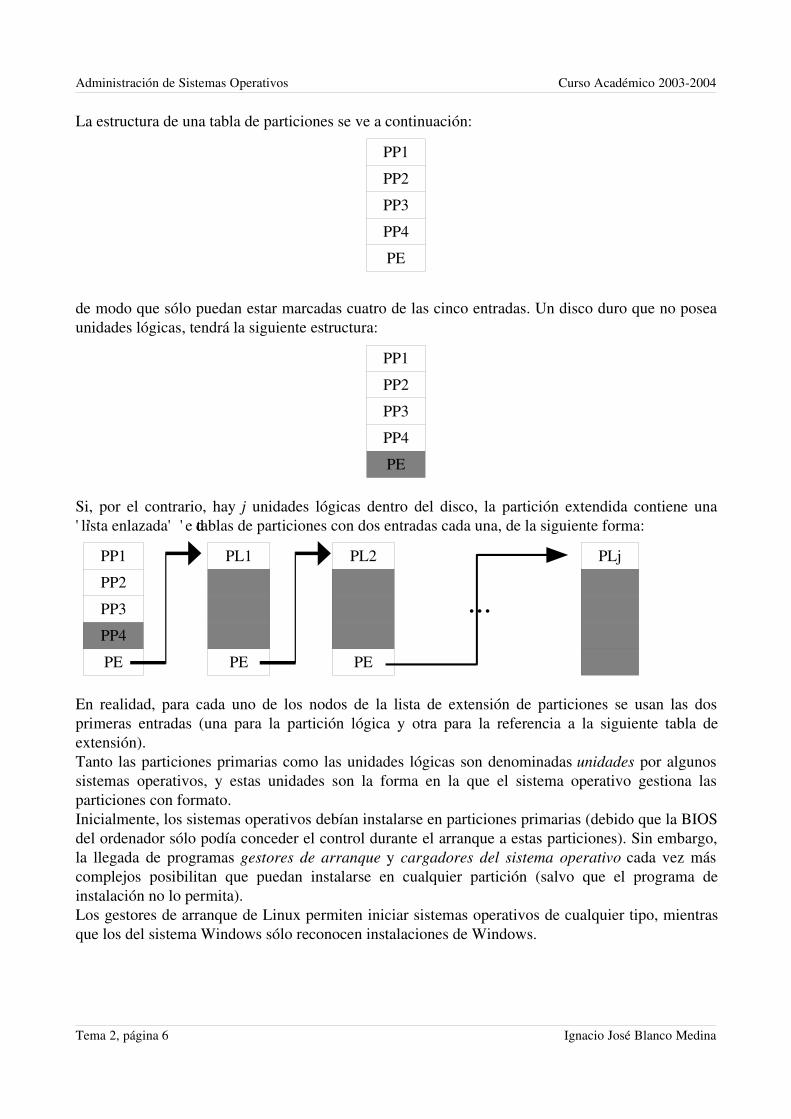
La estructura de una tabla de particiones se ve a continuación:
PP1
PP2
PP3
PP4
PE
de modo que sólo puedan estar marcadas cuatro de las cinco entradas. Un disco duro que no poseaunidades lógicas, tendrá la siguiente estructura:
PP1
PP2
PP3
PP4
PE
Si, por el contrario, hay j unidades lógicas dentro del disco, la partición extendida contiene una''lista enlazada'' de tablas de particiones con dos entradas cada una, de la siguiente forma:
PP1 PL1 PL2 PLj
PP2
PP3
PP4
PE PE PE
En realidad, para cada uno de los nodos de la lista de extensión de particiones se usan las dosprimeras entradas (una para la partición lógica y otra para la referencia a la siguiente tabla deextensión).Tanto las particiones primarias como las unidades lógicas son denominadas unidades por algunossistemas operativos, y estas unidades son la forma en la que el sistema operativo gestiona lasparticiones con formato.Inicialmente, los sistemas operativos debían instalarse en particiones primarias (debido que la BIOSdel ordenador sólo podía conceder el control durante el arranque a estas particiones). Sin embargo,la llegada de programas gestores de arranque y cargadores del sistema operativo cada vez máscomplejos posibilitan que puedan instalarse en cualquier partición (salvo que el programa deinstalación no lo permita).Los gestores de arranque de Linux permiten iniciar sistemas operativos de cualquier tipo, mientrasque los del sistema Windows sólo reconocen instalaciones de Windows.
Tema 2, página 6 Ignacio José Blanco Medina
...

Administración de Sistemas Operativos Curso Académico 20032004
(iii) Estructura lógica de una partición El concepto básico dentro de todo sistema de ficheros es el concepto de fichero, que se ha descritoanteriormente. Sin embargo, la forma de almacenar y gestionar estas estructuras dentro de lapartición varía de unos sistemas de ficheros a otros (es decir, del formato que se haya aplicado a lapartición).
Cada sistema operativo posee uno o varios sistemas de ficheros que son manejados directamentepor el núcleo del sistema operativo. Estos sistemas se llaman nativos y se ven a continuación:
DOS Win95 Win95OSR2
Win98 WinNT Win2000 WinXP Linux
FAT Acc, Nat Acc Acc Acc Acc Acc Acc Acc
VFAT Acc, Nat Acc Acc Acc Acc Acc Acc
FAT32 Acc, Nat Acc, Nat Acc Acc Acc
NTFS Acc, Nat Acc, Nat Acc, Nat Acc RO
EXT Acc, Nat
El sistema de ficheros FAT ( File Allocation Table o Tabla de Asignación de Ficheros)
La estructura lógica de una partición con este tipo de formato es la que se ve a continuación:
Sector dearranque FAT1 FAT2 Directorio
Raíz Área de datos
Este sistema de ficheros emplea un índice conocido como tabla FAT. Cada una de las entradas de latabla corresponde a un fichero en el sistema, y almacena la siguiente información con respecto almsmo:
• nombre• grupos usados• grupos libres• grupos defectuosos
Un grupo es un cluster (un conjunto de sectores consecutivos de un disco). Por ellos, el tamañoocupado del disco será siempre múltiplo del tamano del cluster, y el tamaño de este determinará elgrado de aprovechamiento del disco.
Un cluster nunca es compartido por dos ficheros y, por ello, es importante optimizar el tamaño delcluster en función de la aplicación que se vaya a dar al sistema. Por ejemplo, supónganse dosficheros con un único byte cada uno. Cada uno de ellos irá a parar a un cluster distinto. Si el clusteres de 32 KB, para el sistema operativo estarán reserados 64 KB, mientras que sólo dos de esos bytescontienen información real.
Las entradas de la tabla FAT pueden contener nombres de 8 caracteres de largo más un punto yotros tres caracteres (extensión). Cada bloque es direccionado por 16 bits, de modo que sólo puedendireccionarse 216 bloques = 65.536 bloques. Dado que el tamaño máximo del bloque es de 25 KB =
Tema 2, página 7 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
32 KB, el tamaño máximo de espacio direccionable es de 216 bloques ∙ 25 KB/bloque = 2 ∙ 220 KB =2 GB.
El sistema de ficheros VFAT (Virtual FAT)
La estructura de índice para los ficheros es la misma que la del sistema FAT, pero la entrada denombre puede contener hasta 255 caracteres (sumando los caracteres del nombre propiamentedicho, el punto y la extensión). Sin embargo, plantea el mismo problema de direccionamiento que elsistema FAT.
El sistema de ficheros FAT32 (FAT de 32 bits)
Este sistema de ficheros incorpora las características de el sistema de fichero VFAT e incrementa elnúmero de bits para el direccionamiento de bloques a 32 bits. Esto permite direccionar 232 bloques.El tamaño de bloque para las particiones grandes es, además, menor con lo que se aprovecha mejorel espacio. No obstante, este sistema de ficheros FAT32 no puede aplicarse a particiones de tamañoinferior a 512 MB.
El sistema de ficheros NTFS
El sistema de ficheros NTFS supone un cambio radical con respecto a los anteriores sistemas deficheros de Microsoft e incorpora características de seguridad y de comprobación de consistenciadel sistemas de ficheros.
El formato del sistema de ficheros resulta en la creación de una estructura denominada Master FileTable (MFT) que contiene información sobre los archivos y directorios almacenados en la partición.La estructura lógica de una partición de este tipo es la siguiente:
Partition Boot Sector MFTSector 0 Sector 16
Una partición con este sistema de ficheros se compone de:
a) Partition Boot Sector: en los sectores que van del 0 al 15, contiene los parámetros BIOS sobre lalocalización relativa de la partición en el disco y sobre las estructuras del sistema de ficheros.Además, incorpora información sobre la carga de los archivos de todos los sistemas operativosiniciables mediante el programa NTLDR.
b) MFT o Master File Table: primer fichero del sistema de ficheros. Almacena toda la informaciónsobre los ficheros y directorios del sistema de ficheros. Cuando se aplica el formato a lapartición, el sistema reserva 1 MB para los metadatos de la MFT. La MFT contiene una serie deregistros con la siguiente estructura:
Standardinformation
File or directoryname Security descriptor Data or index Other information
La MFT reserva 1024 bytes dentro de la zona de datos del registro, de modo que ficherospequeños (de menos de 1 KB) pueden quedar contenidos integramente dentro de su registrocorrespondiente de la MFT. Si el tamaño sobrepasa 1 KB, se reservan extensiones a lo largo deldisco, y se almacenan las referencias a esas extensiones en el registro de la MFT correspondiente
Tema 2, página 8 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
al archivo en cuestión.
Con algo más de detalle, pero aún a grandes rasgos, cada registro de la MFT contiene:
• información estándar: sello de tiempo, enlaces, etc.
• lista de atributos: lista de la localización de los atributos del objeto del sistema de ficheros queno se almacena dentro del MFT,
• nombre: de hasta 255 caracteres,
• descriptor de seguridad: quién posee el objeto y quién puede hacer según qué cosas.
• index root, index allocation y bitmap: para los directorios
• volume information y volume name: para registros especiales dentro de la MFT.
Los 16 primeros registros de la MFT son de uso exclusivo para ficheros del sistema, que son:
Registro 0: $MFT
Registro 1: $MFTMirror
Registro 2: $Logfile
Registro 3: $Volume
Registro 4: $AttrDef
Registro 5: $ (El directorio raíz)
Registro 6: $Bitmap (clusters usados)
Registro 7: $Boot (que incluye el BPB y el cargador)
Registro 8: $BadClus (clusters dañados)
Registro 9: $Secure (descriptores de seguridad)
Registro 10: $Upcase (tabla de conversión de caracteres)
Registro 11: $Extend (extensiones: cuota, ...)
Registro 12: $ (no usado)
Registro 13: $ (no usado)
Registro 14: $ (no usado)
Registro 15: $ (no usado)
El sistema de ficheros EXT2FS
En el almacenamiento, el sistema de ficheros ext2 no distingue entre ficheros y directorios, aunqueel tratamiento de ambos sea distinto.
Este sistema de ficheros constituye una evolución del sistema de ficheros ext, desarrollado a partirdel sistema de ficheros del sistema operativo Minix y basado en el sistema de ficheros FFS delsistema operativo UNIX.
El principal concepto en el que se basa el sistema de ficheros FFS es el de la homogeneidad, dadoque un directorio sólo es un fichero especial, pero un fichero al fin y al cabo.
Tema 2, página 9 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
Bloques y fragmentación
Normalmente el sector de disco tiene 512 bytes. Sin embargo, un bloque (cluster) mayor seríadeseable. De todos modos, y dado que el sistema operativo UNIX contiene archivos que, en sumayoría, son de tamaño pequeño, se limita el tamaño de bloque a dos sectores.
Una solución posterior pasa por definit dos tamaños de bloque (o, exactamente, un tamaño para elbloque y un tamaño para fragmentos de bloque), de modo que todos los bloques de un ficherotienen el tamaño de un bloque (por ejemplo, 8 Kbytes) excepto el último, que tiene el tamaño de unfragmento (múltiplo de un divisor de el bloque como, por ejemplo, 2 Kbytes).
Los tamaños de bloque y fragmento se establecen durante la aplicación de formato a la particiónque contendrá al sistema de ficheros. Si este sistema de ficheros estuviera pensado para contenerficheros pequeños, el tamaño del fragmento debería adaptarse al tamaño de los ficheros. Si, por elcontrario, se realizan transferencias de ficheros de gran tamaño, entonces se recomienda un tamañode bloque grande. Dichos tamaños suelen variar entre 4096:512 y 8192:1024.
I-nodos
Cualquier objeto contenido en el sistema de ficheros está representado por una estructura conocidacomo inode (Index Node) que se ve a continuación:
Tema 2, página 10 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
El uso que se da a los campos de la estructura inode son:
• mode: tipo de objeto del sistema de ficheros (fichero, directorio, enlace simbólico, dispositivo decaracteres, dispositivo de bloques o socket),
• owner info: usuario (uid) y grupo (gid),
• size: número de bloques que contienen los datos del objeto,
• timestamps: fechas de creación y última modificación,
• direct blocks: 12 direcciones de bloques físicos que permiten almacenar 12*tamaño de bloquebytes del contenido del fichero,
• indirect blocks: una dirección a un bloque físico que contiene direcciones a bloques físicos paraalmacenar 2060*tamaño de bloque bytes del contenido del fichero,
• double indirect blocks: una dirección a un bloque físico que contiene 2060 direcciones a bloquesfísicos que contienen 2060 direcciones a bloques físicos para el almacenamiento de datos,
• triple indirect blocks: ...
Directorios
El atributo mode diferencia a un fichero de un directorio. Los bloques de datos de un directoriocontienen una entrada por cada elemento contenido en el mismo, cada una de las cuales contiene lasiguiente información:
• longitud del nombre de objeto,
• nombre del objeto y
• número del inodo.
En todo directorio, hay dos entradas especiales:
• . o directorio autocontenido y
• .. o directorio contenedor (directorio padre).
El directorio raíz tiene por nombre / y no posee directorio contenedor.
Enlaces
Existen dos tipos de enlaces: duros y simbólicos.
Los enlaces duros se tratan como entradas normales de directorio. Los enlaces simbólicos han de sercontrolados para no caer en recursión infinita cuando se recorra un camino.
Algunas referencias
Tema 2, página 11 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
Tema 3 - Administración de usuarios y entornos de usuario
a) Conceptos previos
Usuario: persona autorizada para usar un sistema informático. Se autentifica mediante un nombre yuna contraseña (password). En realidad, un sistema informático no asocia el concepto deusuario con el de cuenta física, sino con un nombre de cuenta (de modo que la misma personapuede poseer varios nombre de cuenta y, por ende, varios usuarios). Del mismo modo, unacuente de usuario puede estar asociada a más de una persona (práctica no aconsejable pormotivos de seguridad).
Perfil: la definición técnica es “ fichero de control para un programa, generalmente un fichero detexto leído desde el directorio home de cada usuario y que está orientado a una modificaciónfácil por parte del mismo para personalizar el uso del programa en cuestión” . La propiaconexión del usuario al sistema, desencadena el comienzo de un proceso conocido como shell,cuyo perfil se almacena en el propio directorio home (.bashrc, .profile, .shrc, ...).
Contraseña: conjunto de caracteres alfanuméricos y especiales, conocido únicamente por el usuarioy el sistema operativo sobre el que se ha llegado a un acuerdo para que sea usado como clavede acceso al sistema.
Grupo de usuarios: agrupación de privilegios compartidos por una serie de usuarios. Cada usuariopertenece a uno o más grupos que comparten privilegios y derechos comunes. Cualquiergrupo es susceptible de obtener derechos y privilegios, de modo que cualquier usuario suscritoa ese grupo ostenta sus propios privilegios y los de los grupos a los que está adscrito.
b) Creación de cuentas Previo al proceso de creación de las cuentas de usuario, es necesario recopilar una serie de datosreferentes a las cuentas que se crearán, como son:
nombre de la cuenta del usuario,
grupo/s a el/los que pertenece,
directorio home,
shell que usa para la conexión al sistema (en el caso de sistemas del tipo UNIX),
información adicional (variada),
fecha de expiración (deshabilitación de cuenta),
dias para el bloqueo de cuenta después de la expiración de la contraseña,
contraseña y
UID (User Identifier).
(i) Gestión de cuentas de usuario en Windows ® 2000 Server
En el sistema operativo Windows® 2000 Server instalado en una máquina servidor independiente(no conectada a dominio), los usuarios se crean mediante el Administrador de Equipos (al cualpuede accederse con la opción “Admin istrar” del menú contextual de “ Mi PC” o bien a través del
Tema 3, página 1 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
“P anel de Control” y la subcategoría “Her ramientas Administrativas” ). En cambio, si el equipo seencuentra conectado a un dominio como servidor PDC o BDC, la administración de usuarios serealiza mediante la herramienta “ Usuarios y Equipos de Active Directory” ubicada en lasubcategoría “Herr amientas Administrativas” del “Pan el de Control”.
Durante el proceso de creación de cuentas, el gestor solicita del administrador información como:nombre y apellidos del usuario, nombre de la cuenta, nombre de la cuenta en sistemas operativosanteriores a Windows® 2000 suscritos al dominio, contraseña, fecha de expiración de la contraseñae información adicional.
Sin embargo, el gestor sólo solicita información genérica que puede ser ampliada manualmentedespués de la creación de la cuenta de usuario a través de las propiedades del menú contextual delusuario en cuestión.
En el caso de este sistema operativo, el UID (User Identifier) es generado y gestionadointernamente, sin intervención del administrador.
(ii) Gestión de cuentas de usuario en Linux En las últimas versiones de las distribuciones actuales del sistema operativo Linux, existen diversasherramientas para la gestión de usuarios, pero todas ellas recurren a un comando del sistemaoperativo para la gestión de cuentas. En este apartado, nos centraremos en los comandos de la shellpara la gestión, de los cuales, el que se encarga de la creación de usuarios es:
adduser [-u uid [-o]] [-g group] [-G group,...] [-d home] [-s shell]
[-c comment] [-m [-k template]] [-f inactive] [-e expire]
[-p passwd] [-M] [-n] [-r] name
Algunos de estos parámetros pueden omitirse durante la ejecución del comando. En este caso,aquellos parámetros omitidos toman valores por defecto que pueden modificarse mediante unasintaxis adicional del comando:
adduser -D [-g group] [-b base] [-s shell] [-f inactive] [-e expire]
En este sistema operativo, toda la información sobre cualquier cuenta de usuario se encuentraalmacenada en el fichero de texto /etc/passwd, que contiene una línea para cada usuario, con elsiguiente formato:
<nombre cuenta>:<contraseña>:<uid>:<gid>:<comentario>:<home>:<shell>
La información adicional sobre la seguridad, expiración de la contraseña, etc. se almacena en elfichero /etc/shadow, que contiene una línea para cada usuario, con el siguiente formato:
<nombre cuenta>:<contraseña>:<días desde el último cambio de contraseña>:
<días antes el próximo cambio posible>:
<días para el próximo cambio obligatorio>:
<días antes del aviso de expiración de contraseña>:
<días antes del bloqueo de cuenta expirada>:
<días de bloqueo>:<campo reservado>
Tema 3, página 2 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
c) Gestión de contraseñas Una contraseña se almacena cifrada mediante un algoritmo de encriptación como se ve en lasiguiente figura:
Durante el acceso, el usuario proporciona una contraseña que se encripta y se comprueba con laalmacenada en el fichero que contiene las contraseñas de usuario:
A la hora de seleccionar una contraseña existen una serie de recomendaciones, algunas de las cualesson tenidas en cuenta por el algoritmo de encriptación. Algunas de esas recomendaciones no puedenser ignoradas ya que supondrían un fallo de seguridad en el sistema. Por citar algunas de las que seaplican comunmente, están:
• longitud mínima de 6 caracteres entre los que se recomiendan caracteres alfanuméricos yespeciales,
• no se permiten palabras que aparezcan en un diccionario incorporado al sistema de encriptación,
• se recomienda el uso de palabras no relacionadas con el usuario (nombres, fechas, ...),
• no se permiten contraseñas que sólo contengan caracteres numéricos,
• se recomienda el uso de caracteres y digitos combinados en la contraseña, y
• no se permiten cambios triviales sobre palabras del diccionario o derivadas.
Tema 3, página 3 Ignacio José Blanco Medina
Contraseña Encriptación UsersFile
Contraseña Encriptación
UsersFile
Contraseñacifrada
Comparador
Acceso

Administración de Sistemas Operativos Curso Académico 20032004
Para la gestión de contraseñas en Windows® 2000 Server se usa el mismo “ Administrador deEquipos” que para la gestión de usuarios, dado que la contraseña es una propiedad del usuario sobrela que puede tener privilegios de cambio o no.
En caso de que el usuario posea privilegios para alterar su contraseña, la forma más rápida parahacerlo consiste en el uso de las teclas <Ctrl>+<Alt>+<Del> durante la ejecución de unasesión, lo cual inicia el menú de control de sesión.
El comando para la gestión de contraseñas en el sistema operativo Linux es:passwd [-l] [-u [-f]] [-d] [-n mindays] [-x maxdays] [-w warndays]
[-i inactivedays] [-S] [username]
d) Ficheros de inicialización de usuario (perfiles) Como ya se ha dicho anteriormente, un perfil es un fichero de configuración para un programa. Lashell es un programa específico que permite la comunicación entre el usuario y el sistema operativoa un nivel básico y, como tal, tiene sus propios ficheros de configuración.
El perfil de usuario en Windows® 2000 Server se compone de una serie de directorios y ficherosque almacenan toda la información sobre el usuario, así como es estado de la sesión de trabajo parael mismo (unidades conectadas desde la red, accesos a sitios en Internet, archivos personales,configuración de escritorio, etc.)
Sin embargo, los perfiles de un usuario en Windows® 2000 Server son generados por el propiosistema operativo. Lo único que puede hacer el administrador es usar un perfil genérico, totalmenteconfigurado (unidades de uso más común, configuraciones de programas, etc.) para forzar a que elsistema operativo lo copie para los usuarios que el administrador determine.
Si un ordenador se conecta a un dominio, y se prevé que los usuarios tengan la necesidad de accedera los recursos del dominio desde diversos ordenadores conectados al mismo, es recomendablealmacenar los perfiles en un directorio centralizado en uno de esos ordenadores (generalmente elque actúa como servidor de dominio), de modo que los perfiles cargados por el usuario no dependandel ordenador en el que dicho usuario inicie la sesión.
La especificación de la ubicación de los perfiles para un usuario concreto se realiza durante lacreación de un usuario.
Por el contrario, en el sistema operativo Linux, el perfil de usuario se compone principalmente deun archivo de texto que el intérprete de comandos ejecuta cuando se inicia una sesión y que puedeser fácilmente modificado por el usuario. Los ficheros de configuración más comunes para lasdiversas shells del sistema son:
Shell Perfil de sistema Perfil de usuario
/bin/bash /etc/bashrc ~/.bashrc
/bin/tcsh /etc/tcshrc ~/.tcshrc
/bin/sh /etc/profile ~/.profile
Inicialmente, las shells fueron diseñadas para ejecutar en primer lugar el perfil de sistema y,seguidamente, el perfil de usuario. Sin embargo, en la actualidad y por cuestiones de
Tema 3, página 4 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
homogeneidad, las shells ejecutan únicamente el perfil de usuario, pero se garantiza la correctaconfiguración del sistema haciendo que el perfil de usuario ejecute forzosamente el perfil desistema.
El uso de dobles perfiles permite al administrador reflejar cambios que deban afectar a la totalidaddel sistema y a todos los usuarios, sin más que modificar los ficheros de sistema que se muestran enla tabla anterior (en el directorio /etc).
Durante la creación de un usuario, se le copia, de forma automática un perfil de usuario por defectoy una serie de ficheros y directorios necesarios para el funcionamiento de la shell y de aplicacionescomo el servidor gráfico. A este conjunto de ficheros (incluido el perfil de usuario) y directorios,que se copian al usuario recien creado, se le conoce como esqueleto de la cuenta (skeleton). Pordefecto, el comando de creación de usuarios toma un esqueleto determinado (contenido en eldirectorio /etc/skel), aunque es posible especificar el esqueleto que debe usuarse tanto por defectocomo para un usuario que se desea crear, mediante el siguiente comando:
adduser -m -k <ubicación> <username>
El modificador m obliga al comando adduser a crear el directorio home si este no existe, y elmodificador k establece que directorio contiene los ficheros y directorios que se usarán comoesqueleto de la cuenta.
e) Cuentas especiales (restringidas) Las cuentas restringidas son cuentas especiales que no están asignadas a ninguna persona. Estascuentas se relacionan con algún servicio ofrecido por el sistema.
Por ejemplo, cuando un usuario accede a una página web en un servidor (máquina servidor), dichamáquina ejecuta un proceso (proceso servidor de páginas web) para satisfacer las peticiones delcliente. Este proceso servidor ha de estar adscrito a algún usuario del sistema y, dado que no sepuede crear una cuenta de usuario para cada usuario que únicamente tenga que acceder a páginasweb, existe un usuario en el sistema que inicia cada proceso servidor de páginas web.
En el caso de Windows® 2000 Server, el usuario más común para los accesos vía HTTP es elusuario IUSR_<nombre del sitio web>, que es creado de forma automática por el gestor deservicios de Internet provisto por Windows® 2000 Server: Internet Information Server (IIS).
En el caso de UNIX, exite un usuario restringido por cada uno de los servicios de red, como puedenser el usuario ftp para procesos asignados a clientes del protocolo FTP conectador mediante modoanónimo, o el usuario mail para clientes de correo que consultan tablones de noticias públicos.
f) Grupos de usuarios Un grupo de usuarios es un conjunto de usuarios con privilegios comunes.
En el sistema operativo Windows® 2000 Server, un usuario puede pertenecer a varios grupos deusuarios. En cambio, en los sistemas UNIX, un usuario pertenece forzosamente a un grupo deusuarios, conocido como grupo primario (que se almacena en la entrada del fichero /etc/passwdcorrespondiente al usuario en cuestión), y a ninguno, uno o varios grupos secundarios. La lista deusuarios que pertenecen a un grupo secundario se recoge en la entrada del fichero /etc/groupcorrespondiente al grupo en cuestión.
El formato del fichero /etc/group es el siguiente:
Tema 3, página 5 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
<nombre grupo>:<contraseña>:<gid>:<username>,<username>,...
Los parámetros tienen el siguiente significado:
• nombre grupo: nombre del grupo en cuestión,
• contraseña: de administración del grupo,
• gid: identificador numérico del grupo,
• lista de usuarios: que tienen al grupo como secundario.
Para la gestión de grupos en Windows® 2000 Server, se usa la misma aplicación que para lagestión de usuarios y se sigue el mismo proceso.
En los sistemas operativos UNIX, los comandos para gestión de grupos son:
• nuevo grupo:groupadd [-g gid [-o]] [-r] [-f] group
donde la opción g permite especificar el GID del grupo, o permite que no se pueda crear másde un grupo con el mismo GID, r permite crear el grupo como un grupo para cuenta restringiday el f fuerza a devolver un mensaje de error si ya existe un grupo con el GID especificado.
• modificación de grupo:groupmod [-g gid [-o]] [-n name] group
donde las opciones tienen el mismo significado en el caso anterior, menos la opción n quepermite cambiar el nombre de un grupo.
• borrado de grupo:groupdel group
Análogamente al fichero /etc/shadow, que almacena información acerca de la información deseguridad en contraseñas de cada usuario (tiempo de expiración, etc.) existe un fichero quealmacena información adicional para los grupos: /etc/gshadow. El formato del fichero es elsiguiente:
<nombre grupo>:<contraseña>:<gid>:<username>,<username>,...
es decir, tiene el mismo formato que el fichero /etc/group.
g) Borrado de cuentas de usuario En el caso de Windows® 2000 Server, la gestión de usuarios y contraseñas se realiza mediante lamisma aplicación que se usa para gestionar las cuentas de usuario y los grupos, aunque ladestrucción de un usuario no implica el borrado de todos los ficheros que pueda tener adscritos en elsistema de ficheros.
En los sistemas operativos UNIX, el borrado de una cuenta se realiza mediante el comando:userdel [-r] name
La opción r obliga al comando a eliminar tanto la cuenta de disco (directorio home) del usuariocomo el fichero de entrada de correo (inbox) del usuario ubicado en el directorio /var/spool/mail.
Tema 3, página 6 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
h) Algunas referencias • Páginas de manual de Linux, y
• Ayuda de Windows® 2000 Server.
Tema 3, página 7 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
Tema 4 - Gestión de ficheros y sistemas de ficheros Un sistema de ficheros es una estructura que permite el almacenamiento de información en unapartición y su posterior recuperación y modificación.
Los sistemas de ficheros de uso más extendido son:
• FAT (en sus variantes, 12, 16, V y 32),
• NTFS,
• HPFS, y
• ext (y sus extensiones ext2 y ext3).
La gestión de los sistemas de ficheros recogen una serie de operaciones que se detallarán a lo largodel desarrollo del tema, y que son:
Tareas de creación (o aplicación) de un sistema de ficheros:
Particionado de discos
Creación (o aplicación) de un sistema de ficheros
Montaje del sistema de ficheros
Comprobación del sistema de ficheros
Seguridad en el sistema de ficheros
a) Tareas de creación (o aplicación) del sistema de ficheros
(i) Particionado de disco El primer paso, anterior al de la aplicación del sistema de ficheros propiamente dicho, es el departicionado del disco, es decir, el de reserva del espacio de disco que albergará ese sistema deficheros.
La herramienta para la gestión de particiones en Windows® 2000 Server es el Administrador deDiscos Lógico, al cual se accede mediante el menú contextual del elemento Mi PC, o a través de lasubcategoría Herramientas Administrativas del Panel de Control. Esta herramienta permite lacreación de particiones, de tipos primario, extendido o lógico, especificando su tamaño ypermitiendo asignarle una letra de unidad o no.
La herramienta que permite la gestión de particiones en el sistema operativo Linux es el comandofdisk, aunque es incapaz de gestionar más de 16 particiones dentro de un mismo disco. Laalternativa a este comando, y que no posee la misma limitación, es el comando parted.
(ii) Aplicación del sistema de ficheros A esta tarea se la conoce comunmente como “f ormateo” o aplicación de formato, y consiste enincorporar a la partición las estructuras que permitirán el almacenamiento de archivos y otrasestructuras propias de un sistema de ficheros.
La herramienta para la aplicación de un sistema de ficheros en Windows® 2000 Server es elAdministrador de Discos Lógico, que se describe en el apartado anterior. Sin embargo, la operaciónde formato puede ser invocada desde el menú contextual del icono de la unidad en cuestión, que se
Tema 4, página 1 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
encuentra en el elemento Mi PC. Esta herramienta permite establecer el tipo de sistema de ficherosque se aplicará (FAT, FAT32 o NTFS) y el tamaño de la unidad de asignación (o bloque). Sinembargo, existe una alternativa a la herramienta gráfica, que puede invocarse desde una ventana decomando:
format <unidad>: <opciones>
que puede invocarse con las siguientes opciones (aunque existen más):
• /fs:[FAT|FAT32|NTFS] para el tipo de sistema de ficheros que el comando aplicará a lapartición,
• /v:<etiqueta> para fijar una etiqueta para la unidad,
• /q para aplicar un formato de forma rápida (únicamente borra el contenido de las estructuras deficheros de la partición), y
• /a:[512|1024|2048|4096|8192|16k|32k|64k|128k|256k] para el tamaño de bloque(de los cuales los dos últimos sólo son aplicables a FAT y FAT32),
En el sistema operativo UNIX, el comando para dar formato a una partición es:mkfs -V -t <fstype> <fs-options> <filesystem> [<blocks>]
Este comando es un redireccionador de comandos, es decir, dependiendo del valor del parámetro<fstype> invoca a uno u otro comando. Así, para el valor ext2, llama al comando mkfs.ext2 oe2mkfs que se encarga de aplicar el sistema de ficheros.
Algunos de los sistemas de ficheros que permite el comando fsck son: ext2, ext3 o vfat.
Cada uno de los comandos incorpora un conjunto de opciones independientes. Algunas de lasopciones más comunes para el sistema de ficheros ext2 son:
• -b [1024|2048|4096] establece el tamaño de bloque para el sistema de ficheros, y
• -f <fragment size> para fijar el tamaño para el fragmento de bloque,
La opción más común para el sistema de ficheros vfat es -F [12|16|32] para fijar el número debits de la tabla FAT.
b) Montaje del sistema de ficheros
(i) Sistema operativo LINUX Al proceso de hacer accesible una partición, con formato aplicado previamente, durante unaejecución concreta del sistema operativo, se le conoce como montaje.
En el sistema operativo UNIX, exite una única jerarquía de directorios, conocida como árbol dedirectorios. Cualquier partición accesible, contiene una estructura de ficheros y directorios quetiene que ser accesible en la jerarquía única. Al punto en el que se “ conecta” la estructura dedirectorios, contenida en una partición, con la jerarquía se le conoce como punto de montaje.
Al existir una única jerarquía de directorios, sólo existe una cima de esa jerarquía, o primerdirectorio, llamado raíz, y representado por el símbolo /. Ese directorio constituye el punto demontaje del sistema de ficheros que contiene al propio sistema operativo.
El proceso de montaje consiste en el análisis del tipo y contenido de una partición, la creación de la
Tema 4, página 2 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
estructura de directorios contenida en la partición y “c uelgue” de esa estructura en el punto demontaje establecido para la partición. Por eso, a esta operación se le conoce también como colgadode particiones o cuelgue.
La información manejada durante la ejecución del sistema operativo UNIX no tiene por qué estarubicada en una única partición, pero es necesario conectar todas las particiones necesarias. Una vezcargado el sistema operativo, se procede al montaje de las particiones predeterminadas en el fichero/etc/fstab. Este fichero almacena una línea por cada sistema de ficheros determinado en elsistema, que no contiene más que opciones para la invocación automática del comando de montajemount:
mount <options> <device> <dir>
algunas de las opciones son las siguientes:
• -r monta el sistema de ficheros de la partición para lectura solamente,
• -w monta el sistema de ficheros de la partición para lectura y escritura,
• -t <fstype> ahorra al comando la labor de identificar el tipo de sistema de ficheros, y
• -o <fsoptions> establece la lista de opciones de montaje para el sistema de ficheros encuestión, y que es propia de cada tipo de sistema de ficheros.
Esta operación de montaje se efectúa sobre cada una de las líneas del fichero /etc/fstab enfunción de su contenido. Como se ha dicho anteriormente, cada línea del fichero representa unsistema de ficheros almacenado en una partición, y contiene la siguiente información sobre dichosistema de ficheros:
<device>|LABEL=<label> <mount dir> <fstype> <fsoptions> <dumpno> <pass_no>
Recuérdese que, a partir del momento de la creación de la partición, el sistema operativo consideraque cada partición es un dispositivo independiente, creando su propio archivo de dispositivo en eldirectorio /dev. Sin embargo, durante la operación de aplicación de formato, es posible asignar unaetiqueta al sistema de ficheros contenido en la partición, la cual se almacena en la estructura dedatos contenida en el sector 0 de la partición. Desde ese momento, cualquiera de las dos referenciasa la partición (etiqueta o dispositivo) es indiferente.
La operación mount se aplica a cada una de las líneas del fichero que no incluyan la opción noautoen el campo <fsoptions>.
La operación contraria al montaje es la de desmontaje. Esta operación se encarga de volcar los datosno almacenados en la partición que se desmonta y actualizar la información sobre modificacionesen el sistema de ficheros antes de eliminar su estructura de directorios del árbol de directorios.
(ii) Sistema operativo Windows ® 2000 Server
La filosofía de directorios del sistema operativo Windows® 2000 Server es, sin embargo, distinta.En dicho sistema operativo, no existe una única jerarquía de directorios, sino una por cada particiónaccesible (unidad), de modo que es necesario identificar una de esas jerarquías de las demás,mediante lo que se conoce como letra de unidad (representada por una letra del alfabeto, seguidadel carácter :). Algunas de esas letras se reservan a unidades o dispositivos especiales: A y B (paralas unidades de floppy), o C (para la primera partición del primer disco duro, conocida como desistema).
Tema 4, página 3 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
Con estas consideraciones, hay que indicar que no existe un único directorio raíz, sino uno por cadaunidad accesible. El identificador del directorio raíz de una unidad es <unidad>:\ .
La única forma de hacer que una unidad no esté accesible consiste en retirarle la letra de unidad.Con ello, se elimina el modo de acceso a la jerarquía de directorios y ficheros que contiene, pero noes una operación de desmontaje ya que la unidad sigue estando accesible por otros medios.
c) Comprobación de la consistencia del sistema de ficheros Dado que un sistema de ficheros almacena información sobre los archivos almacenados en lasbloques de la partición, y que tanto los propios archivos como las estructuras de datos sobre lapartición son susceptibles de daño, es necesario proveer de los mecanismos de seguridad para larecuperación de fallos, siempre en la medida de los posible.
(i) Sistema operativo Windows ® 2000 Server
En Windows® 2000 Server, la integridad de un sistema de ficheros es comprobada por laherramienta Scandisk, accesible desde las Herramientas situadas en las Propiedades del menúcontextual de cada icono de unidad situado en Mi PC.
Los sistemas de ficheros FAT no incluyen información para la comprobación de la consistencia,con lo cual, la recuperación se centra en recuperar toda la información posible de los bloquesdañados, copiando su contenido en un nuevo fichero, y liberando o marcando los bloques erróneos.
Por el contrario, el sistema de ficheros NTFS es un sistema de ficheros transaccional. Este tipo desistemas de ficheros se basa en el concepto de bitácora (registro de acciones), de modo que,cualquier cambio, antes de realizarse, es registrado en la bitácora. Para cada cambio, se almacenanvarios registros:
registro REDO (rehacer): registro que contiene los cambios realizados por la operación, antes derealizarse, para volver a realizarlos en caso de que falle, y
registro UNDO (deshacer): registro que contiene los cambios que hay que deshacer para que elsistema de ficheros quede como estaba antes de realizar la operación.
Adicionalmente, se almacenan registros de operación efectuada (COMMIT) y, periódicamente, sealmacenan puntos de verificación (CHECKPOINT). El almacenamiento de un checkpoint implicadesechar todos los registros anteriores, puesto que los cambios almacenados en esos registros ya sehan realizado.
La primera vez que se accede a una partición de tipo NTFS, durante el encendido del ordenador,fuerza una ejecución del test de integridad. Si el log no está vacío, esto implica que hubotransacciones que no se completaron, y han de ser recuperadas. Para ello, se recorren los registroshacia delante. Si se encuentra un registro de COMMIT para la operación, se consideran realizadoslos cambios, y por tanto, se usan los registros REDO para realizar los cambios de nuevo y asegurarque han sido volcados al disco. Si, por el contrario, no se encuentra un registro de COMMIT, nadagarantiza que la última sentencia sea válida y que no haya más operaciones detrás para la mismatransacción, de modo que se usan los registros UNDO para fijar el estado de los bloques implicadosal estado anterior a la realización de la operación.
El registro de log se almacena en el fichero $Logfile de la estructura de datos MFT del sistema de ficheros NTFS, creada durante el proceso de aplicación de formato a una partición NTFS. El fichero
Tema 4, página 4 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
$Logfile se compone de dos secciones:
área de logging: constituida por una lista circular de registros de log, y
área de restart: que contiene información tal como la posición del área de logging dondecomienza la lista circular de registros de log y la posición en la que termina. La posición deinicio es útil para determinar la posición a partir de la cual comienzan las operaciones dudosasdel sistema transaccional. El sistema mantiene dos copias de esta área por si ocurrieran fallos.
(ii) Sistema operativo LINUX Durante la operación con un sistema de ficheros en UNIX, la información de los ficheros ydirectorios está contenida tanto en disco como en la caché de disco en memoria por motivos deeficiencia. En general, la información sobre los distintos directorios se almacena en memoria (quemantiene la copia actualizada de la información y que, periódicamente, se copia al disco).
Supongase un fallo eléctrico que provoque la desconexión del equipo informático. Ello implica quetoda la información sobre ficheros abiertos desaparecerá, dejando el sistema de ficheros en estadode inconsistencia, ya que el estado real de algunos ficheros no está descrito en las estructuras delsistema de ficheros. El comprobador de consistencia de UNIX compara los datos de la estructura dedirectorios con los bloques del disco, tratando de resolver las incongruencias detectadas.
En cuanto al tipo de errores que pueden darse en un sistema de ficheros, estos están muy ligados alos algoritmos de reserva y liberación de bloques en el disco. Por ejemplo, supongamos un sistemade ficheros con un sistema de referencias de bloques para un archivo basado en una lista de bloques(cada bloque contiene un enlace al siguiente bloque). A esta alternativa se la conoce como sistemade ficheros enlazado. Una entrada de directorio incorrecta puede resolverse recorriendosecuencialmente los bloques del fichero, siempre que no se haya perdido ningún enlace. Por elcontrario, en un sistema de ficheros indexado (en el que la información sobre los archivos sealmacena en una estructura parecida a un índice), la pérdida de una entrada de directorio haríaimposible su recuperación puesto que se ha perdido el orden y posición de los bloques.
Para evitar posibles fallos, el subsistema de gestión de disco sólo mantiene copias de los inodos deficheros abiertos para lectura. La modificación de un archivo que suponga la reserva o liberación debloques en el disco produce una escritura inmediata del inodo en el sistema de ficheros, antesincluso de la escritura del propio bloque modificado.
El comando que efectúa la comprobación de la consistencia de un sistema de ficheros es fsck, yrealiza comprobaciones a nivel de inodos, bloques, directorios y mapas de bits de reserva debloques. Las tareas de comprobación del sistema de ficheros incluyen:
• comprobar que la información almacenada en el superbloque de la partición (bloque que sealmacena en el sector 0 de la misma) concuerda con las características de la misma,
• comprobar que los mapas de bits de inodos reservados coinciden con los inodos reservadosefectivamente,
• comprobar que los mapas de bits de bloques reservados se corresponden con los bloquesreservados efectivamente en el disco, y
• comprobar en la estructura de directorios que ningún inodo está referenciado por más de undirectorio.
Tema 4, página 5 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
La comprobación del estado de los bloques se realiza en base a dos tablas. La primera de ellascontiene un número entero que representa el número de veces que un bloque es referenciado en lazona de bloques de un inodo. La segunda contiene un entero que especifica si un bloque está libreo reservado.
A la hora de la comprobación del sistema de ficheros, se carga en la segunda tabla la tabla debloques libres, y la primera se completa recorriendo la estructura de inodos del sistema de ficheros.Una vez rellenas las dos tablas, se procede a la comprobación, bloque por bloque (casilla porcasilla) de las dos tablas. Después de ello, se procede a la comprobación.
Si en una posición dada, hay un cero en una de las tablas y un uno en la otra se habla de bloquecoherente. Si todos los bloques se encuentran en este estado, se habla de sistema de ficheroscoherente.
Cuando en una posición dada hay un cero en ambas tablas (el bloque no aparece como libre ytampoco como ocupado, luego se reservó el bloque para un fichero que no lo referenció, en últimainstancia), se habla de bloque perdido. La única solución posible es la de crear un nuevo fichero quecontenga como único bloque al bloque en cuestión, fichero que se mete en el directorio lost+foundque poseen todos los sistemas de ficheros ext.
Cuando aparece un número mayor que uno en la primera tabla (un bloque tiene más de unareferencia en los inodos), se habla de bloque reutilizado. Al no ser capaz de discernir a qué ficheropertenece en realidad el bloque, esta situación se resuelve reservando un nuevo bloque, copiando eloriginal y cambiando la referencia de uno de los inodos para que “ apunte” al nuevo bloquereservado.
Cuando aparece un número mayor que uno en la segunda tabla, se habla de bloque libre repetido.Esta situación, que podría parecer irreal, puede darse en el caso de sistemas de ficheros queimplementen el mapa de bloques libres como una lista de bloques, si ocurriera un fallo en elalgoritmo de liberación de bloques. La solución a esta situación pasa por poner un uno en laposición correspondiente de la tabla de bloques libres.
El comando que se encarga de la comprobación del sistema de ficheros es fsck. Al igual que elcomando mkfs, éste actúa como redireccionador de comando.
d) Seguridad en el sistema de ficheros La mayor parte de los sistemas de ficheros actuales diseñados para máquinas multiusuario incluyenla capacidad de asignar características de seguridad a los objetos contenidos en él a distintosniveles.
(i) Windows ® 2000 Server (NTFS)
Como se vio anteriormente (tema 2), cada una de las entradas de la estructura MFT del sistema deficheros NTFS incluye información de seguridad mediante el campo Security Descriptor.
En las primeras versiones del sistema de ficheros, este campo incluía una referencia a una lista dedescriptores de seguridad asignados al objeto en cuestión. Esta implementación se reveló ineficientea la hora de asignar los mismos permisos a todo un subárbol de objetos del sistema, ya quegeneraban demasiada redundancia y ocupaban demasiado espacio.
La versión 5 del sistema de ficheros introduce un nuevo fichero en el MFT, conocido como
Tema 4, página 6 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
$SECURE, que almacena una única copia de cada descriptor de seguridad asignado en el sistema deficheros.
Este fichero se divide en tres partes:
➔ $SDH (Security Descriptors Hashing),
➔ $SDI (Security Descriptor Index) y
➔ $SDS (Security Descriptor Section).
Estás partes están relacionadas entre sí como se muestra en la siguiente figura:
Cada descriptor de seguridad posee un identificador único (asignado por el sistema) y se localizamediante el uso de un hashing simple. Sin embargo, estas funciones de hashing pueden plantearproblemas de colisión, de modo que dos descriptores puedan dar lugar al mismo valor hash.
Creación de descriptores
Cuando se introduce un nuevo descriptor de seguridad, en primer lugar se comprueba su existenciaprevia. Para ello, se calcula su valor hash y se localiza su desplazamiento en $SDH.
Si ese valor hash no tiene asignado un desplazamiento (el descriptor no ha aparecido previamente),se le asigna un desplazamiento en $SDS, se introduce el descriptor en esa zona de $SDS y sealmacena el desplazamiento en la posición hash correspondiente de $SDH. Una vez generado elnuevo descriptor es necesario generar un nuevo identificador y una entrada en $SDI.
Si, por el contrario, el valor hash tiene un desplazamiento asignado pueden ocurrir dos cosas:
1º el descriptor de seguridad almacenado en el desplazamiento de $SDS concuerda con el nuevodescriptor, luego ese descriptor ya está almacenado, o
2º el descriptor de seguridad no coincide con el introducido (se ha producido una colisión), pero nosabemos dónde puede estar el descriptor buscado, por lo cual es necesario buscarlo en todo$SDS. Esta búsqueda puede resultar en:
a) no se encuentra el descriptor en $SDS, lo cual implica que el descriptor es nuevo, luego hay
Tema 4, página 7 Ignacio José Blanco Medina
Hash1$SDS Offset
Hash2$SDS Offset
Hash0$SDS Offset
$SDH IndexSecurity
Descriptor 0
$SDS
Security Descriptor 1
Security Descriptor 2
$SDS Offset
$SDS Offset
NTFS Security ID 2
$SDS Offset
NTFS Security ID 1
NTFS Security ID 0
$SDI

Administración de Sistemas Operativos Curso Académico 20032004
que almacenarlo en un desplazamiento libre de $SDS y generar un nuevo identificador dedescriptor para almacenarlos ambos en $SDI, o
b) se encuentra el descriptor en un desplazamiento de $SDS, luego hay que buscar elidentificador que tiene ese desplazamiento en $SDI.
Un descriptor de seguridad se crea para ser asignado a un objeto, lo cual se logra almacenando elidentificador del descriptor de seguridad (localizado o generado) en el atributo Security Descriptorde la tabla MFT.
Los bloques de permisos que pueden asignarse a un descriptor de seguridad son:
control total,
modificar,
lectura y ejecución,
listado de contenidos y
lectura y escritura.
Sin embargo, estos bloques de permisos no son más que combinaciones de permisos básicos, quelogran los resultados deseados. Esos permisos básicos son:
➔ atravesar carpeta / ejecutar fichero,
➔ listar carpeta / leer fichero,
➔ leer atributos,
➔ leer atributos especiales,
➔ crear ficheros / escribir,
➔ crear carpetas / modificar,
➔ cambiar atributos,
➔ cambiar atributos especiales,
➔ borrar ficheros y subdirectorios,
➔ borrar,
➔ leer permisos,
➔ cambiar permisos,
➔ tomar posesión, y
➔ sincronizar.
Algunos de estos atributos tienen una doble semántica que depende del objeto al que se aplique(ficheros o directorios).
La modificación del descriptor de seguridad asignado a un objeto pasa por localizarlo en el sistemade ficheros mediante una ventana del navegador y acceder a la ficha de Seguridad, localizada en lasPropiedades del menú contextual del objeto en cuestión.
Tema 4, página 8 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
(ii) Sistema operativo LINUX El sistema de ficheros ext se basa en el sistema de ficheros FFS y almacena la informaciónrelacionada con la seguridad en el inodo correspondiente al objeto en cuestión.
Las operaciones controlables en un sistema de ficheros de este tipo son:
➔ lectura,
➔ escritura,
➔ ejecución,
➔ añadido,
➔ borrado y
➔ listado.
Sin embargo, existe una serie de permisos especiales que permiten abrir o cerrar accionesespecíficas:
➔ sólo ejecutar (si es un directorio) pero no pasar a través de él, o ejecutar si alguien puede ejecutar(si es un archivo, es decir, ejecutar si alguno de los otros owners tiene el permiso de ejecución),
➔ cambiar el uid o el gid (setUID) durante la ejecución, y
➔ usar el espacio de swap para almacenar texto de programa.
Los otros tipos de acciones posibles son sólo combinaciones de estos permisos básicos. Al procesode asignar seguridad a los nodos de un sistema de ficheros se le conoce como control de acceso, demodo que cada uno de los objetos tendrá una lista de accesos (pares usuariopermisos). El problemade estas listas es su longitud.
A fin de simplificar la complejidad de las listas, se crearon los conceptos de owner user (pordefecto, el usuario que crea un objeto), owner group (por defecto, el grupo primario al quepertenece el usuario que crea el objeto) y owner other. Estos tres conceptos permiten que cualquierusuario tenga permisos asignados sobre todo objeto del sistema de ficheros, ya que permite asignarpermisos distintos para el usuario que posee el objeto, para los usuarios de grupo que lo posee ypara el resto de los usuarios.
En el sistema de ficheros ext, la información de seguridad se almacena en dos campos concretos:mode y owner.
El campo owner del inodo almacena dos valores: uid (user owner identifier) y gid (group ownerid).
El campo mode se compone a su vez de 10 partes:
tipo de objeto: indicador que puede ser – (archivo), d (directorio), l (enlace), b (dispositivo debloques) o c (dispositivo carácter),
permisos de owner user: tres permisos r (lectura / listado), w (escritura / modificación) y x(ejecución / paso) que permiten establecer qué acciones puede realizar el usuario que posee elobjeto en cuestión,
permisos de owner group: tres permisos r, w y x que permiten establecer qué acciones puedenrealizar los usuarios que pertenecen al grupo que posee el objeto en cuestión, y
Tema 4, página 9 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
permisos de owner other: tres permisos r, w y x que permiten establecer qué acciones puedenrealizar los demás usuarios.
El comando que permite el cambio del owner user de un objeto es:chown [-R] <username> <object>
El comando que permite cambiar el owner group es:chgrp [-R] <username> <object>
Sin embargo, es posible cambiar ambas asignaciones simultáneamente con:chown [-R] <username>.<group name> <object>
El comando que permite cambiar el campo mode de un inodo es:chmod [<options>] <mode> <object>
donde el modo puede especificarse de dos formas distintas:
•absoluta: especificado todos los permisos mediante tres dígitos octales, uno para el owner user,otros para el owner group y otro para owner other, que reflejen los permisos de cada unotraduciendo la presencia del permiso por un uno y la ausencia del mismo por un cero; unidos lostres dan un número binario de tres cifras que puede ser leído en base octal (o sea, 777 paraacceso total de todos sería rwxrwxrwx, y acceso cerrado sería 000, o sea, ---------).
•relativa: se establece una expresión regular para cambiar sólo parte de los permisos:[ugoa...][[+-=][rwxXstugo...]...]
donde u es el usuario, g es el grupo, o es el resto de usuarios y a afecta a todos los owner porigual.
Algunas referencias
• Páginas de manual de LINUX
• http://www.qvctc.commnet.edu/classes/csc277/ntfs.html#Structure%20of%20an%20NTFS% 20Volume
Tema 4, página 10 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
Tema 5 - Administración de una red
a) Redes e interconexión de ordenadores Se define una red de ordenadores como un subsistema de comunicación compuesto por una serie decomponentes hardware y software, que proporcionan los servicios necesarios para que los procesosque se ejecutan en los distintos ordenadores que conforman la red puedan comunicarse entre sí.
Tradicionalmente, las redes se han dividido en dos tipos distintos, aunque esta división es subjetiva:
• LAN (Local Area Network, redes de área local)
• WAN (Wide Area Network, redes de área amplia)
Algunos parámetros de importancia, a la hora de evaluar una red, son:
Tasa de transferencia: velocidad de intercambio de datos, medida en kilobytes por segundo (KB/s)o en megabytes por segundo (MB/s).
Latencia: tiempo que se tarda en completar el envío y recepción de un mensaje vacío, a lo que seconoce como sobrecarga del sistema de comunicaciones.
Tiempo de transferencia: el tiempo que se tarda en enviar un mensaje:
Se recomienda una latencia baja para todo sistema de comunicaciones, al ser la quepredomina en los mensajes pequeños.
Paquetes por segundo
Capacidad de crecimiento: grado en el que se ve afectada la red cuando se añade un nuevo nodo(por ejemplo, una red de tipo ethernet se degrada cuando se introduce un nuevo nodo, ya queaumenta el número de colisiones).
Calidad de servicio: capacidad de la red para satisfacer las necesidades de un servicio determinado(ancho de banda, latencia mínima, etc.), por ejemplo, para aplicaciones multimedia.
Ancho de banda: o bandwidth, es la máxima cantidad de información, medida en bits por segundo(b/s, bps) que se puede transmitir por un canal.
Fiabilidad: posibilidad de pérdida de mensajes.
Seguridad: protección de datos en tránsito a través de la red.
b) Protocolos de comunicación En primer lugar, hay ciertos conceptos que deben ser introducidos:
Mensaje: objeto lógico intercambiado entre dos o más procesos. Los mensajes tienen que serdescompuestos en paquetes para su envío a través de la red.
Paquete: unidad de información que se intercambian dos dispositivos de comunicación. El tamañode estos suele venir limitado por el hardware.
Protocolo: conjunto de reglas e intrucciones para el gobierno del intercambio de paquetes y
Tema 5, página 1 Ignacio José Blanco Medina
latenciatamaño de mensajetasa de transferencia

Administración de Sistemas Operativos Curso Académico 20032004
mensajes.
Un protocolo fija varios parámetros en una configuración, entre los que destacan:
1º la secuencia de los mensajes y
2º el formato de los mismos.
Lo que habitualmente se conoce como protocolo de comunicación (como, por ejemplo, el protocoloTCP/IP) suele ser, a menudo, una pila de protocolos más específicos que realizan las siguientesfunciones:
• segmentación y ensamblado de paquetes,
• encapsulamiento,
• control de conexión (existen dos tipos de protocolos: orientados a conexión y no orientados aconexión),
• control de flujo (mecanismo de control mediante el cual el receptor controla la cantidad deinformación enviada por el emisor),
• control de errores y
• direccionamiento.
Los tipos de protocolo más usados son OSI y TCP/IP. En concreto, el protocolo usado para laimplementación de INTERNET es el conocido como TCP/IP. Este protocolo es un protocolo decapas (el modelo de capas permite aislar la funcionalidad de distintos niveles, estableciendo unainterfaz bien definida para comunicar un nivel con los inmediatamente superior e inferior), cuyaestructura general puede verse en la siguiente figura:
Las funciones de cada uno de los niveles de la familia de protocolos TCP/IP son:
a) Nivel de red (o interfaz de red): controla el acceso al hardware de red, por lo que está muyligado a la infraestructura concreta de dicha red.
Tema 5, página 2 Ignacio José Blanco Medina
Aplicación
Transporte
Internet
Interfaz de red
Emisor Receptor

Administración de Sistemas Operativos Curso Académico 20032004
b) Nivel de Internet (también conocido como IP): se encarga de la transmisión de paquetes entre elemisor y el receptor.
c) Nivel de transporte: transmite mensajes entre procesos. En el nivel de transporte, existen dostipos de protocolos:
(i) Protocolo UDP: protocolo no orientado a conexión que permite un tamaño máximo depaquete de 64KB, que no ofrece fiabilidad y que no considera un orden en la entrega de lospaquetes (es decir, el receptor es quien ordena los paquetes del mensaje conforme llegan).
(ii) Protocolo TCP: protocolo orientado a conexión que observa el orden en la entrega depaquetes. Un protocolo orientado a conexión tiene tres fases: establecimiento, intercambio demensajes y cierre.
d) Nivel de aplicación: nivel conformado por las aplicaciones que se comunican entre sí en losdistintos nodos en conexión (FTP, HTTP, TELNET, ...).
(i) Direccionamiento IP Un aspecto importante a la hora de la configuración y gestión del sistema operativo es eldireccionamiento dentro de la red.
Todo ordenador conectado a la red se identifica mediante un conjunto de 4 bytes (4B, 32 bits)conocido como dirección IP, de valor único y asignado por un organismo mundial conocido comoN. I. C. (Network Information Center). Cuando una red no está conectada a INTERNET, puedeestablecer su propio direccionamiento.
Los 32 bits de la dirección de red se dividen en bits de red (que identifican a la red a la que estáconectado el ordenador, red que está conectada a INTERNET) y bits de host (que identifican alordenador dentro de la red a la que está conectado). Dependiendo de cuántos bits se destinen a bitsde red y, en consecuencia, cuántos se destinen a bits de host, se habla de clases dedireccionamiento. Hay cinco clases en total:
Clase A: de los 32 bits, 1 identifica a la clase, 7 a la red y 24 al ordenador.
Las direcciones de esta clase de red van desde la 0.1.0.0 hasta la 126.0.0.0, lo cual constituye unconjunto de 126 redes de 1'6 millones de ordenadores cada una.
Clase B: de los 32 bits, 2 identifican a la clase, 14 a la red y 16 al ordenador.
A esta clase, pertenecen las direcciones que van desde la 128.0.0.1 hasta la 191.255.0.0, lo cualpermite la existencia de 16320 redes con 65024 ordenadores cada una.
Tema 5, página 3 Ignacio José Blanco Medina
0 7 bits 24 bits0 1 Network 9 Host
10 14 bits 16 bits0 2 Network 16 Host

Administración de Sistemas Operativos Curso Académico 20032004
Clase C: de los 32 bits, 3 identifican a la clase, 21 a la red y 8 al ordenador.
A esta clase pertenecen las direcciones que van desde la 192.0.1.0 hasta la 223.255.255.0, lo cualpermite la existencia de 2 millones de redes con 254 ordenadores cada una.
Clase D: de los 32 bits, 4 identifican a la clase y 28 al ordenador. Esta última se usa paradireccionamiento de difusión múltiple.
A esta clase pertenecen las direcciones que van desde la 224.0.0.0 hasta la 239.255.235.255.
Clase E: Aún no se ha establecido cómo se gestionará.
Las direcciones de esta clase van desde la 240.0.0.0 hasta la 247.255.255.255.
c) Nodos especiales de una red INTERNET no es, en sí misma, una red tal y como la concebimos, ya que en una red, los nodos sonordenadores. En el caso de INTERNET, los nodos son redes, a su vez. Por eso se la conoce como lared de redes.
En INTERNET, las redes se interconectan entre sí, pero esa interconexión puede ser más o menostrivial. Si dos redes usan los mismos protocolos, no será difícil conectar una a otra (siempre que noplanteen conflictos en el direccionamiento), ya que los mensajes de un nodo en una de ellas a otronodo en la otra se transmiten “en el mismo idioma” , por así decir. Si, por el contrario, ambas redesusan protocolos distintos, será necesario realizar una “tr aducción”.
Para conectar dos subredes se usan una serie de nodos especiales, que se diferencian entre sí en lafuncionalidad que presentan. Algunos de estos nodos son:
• router: nodo que enlaza dos o mas segmentos de red separados. Los segmentos unidos por unrouter permanecen lógicamente separados y actúan como subredes independientes. Estos nodostienen acceso a una serie de servicios al nivel de red de los protocolos OSI, lo cual les permitecalcular el camino de envío entre origen y destino en función de ciertos parámetros.
• gateway: dispositivos complejos que enlazan dos o más redes con distintas arquitecturas.
d) Arquitectura cliente-servidor: servicios comunes en una red Se define una arquitectura cliente servidor como “ un sistema distribuido entre múltiplesprocesadores donde se ejecutan programas que solicitan servicios a otros procesadores que ejecutanservidores que los proporcionan”.
En esta arquitectura, el procesamiento de los datos se realiza en distintas partes, que son: elpeticionario (cliente) y el proveedor (servidor). Un cliente envía, durante el procesamiento de losdatos, una serie de peticiones a uno o varios servidores para que estos realicen una tarea
Tema 5, página 4 Ignacio José Blanco Medina
110 21 bits 8 bits0 3 Network 25 Host
1110 28 bits0 3 Host

Administración de Sistemas Operativos Curso Académico 20032004
determinada.
Los modos básicos de comunicación en una arquitectura clienteservidor son:
• RPC (Remote Procedure Call), o
• basado en mensajes.
(i) Servicios importantes dentro de la red
DNS: (Domain Name Server, Servicio de Dominio de Nombres). El protocolo de direccionamientoIP sólo usa direcciones de 4 bytes para referenciar al emisor y al receptor en unacomunicación. Sin embargo, estas direcciones son difíciles de usar por un usuario normal, porlo que, además de la dirección IP, se asigna un nombre único a cada máquina (directamenterelacionado con dicha dirección). La estructura general del nombre suele ser:
<nombre de ordenador>.<nombre de subdominio>.<nombre de dominio>
Dado que los protocolos no entienden de nombres sino de direcciones, es necesario que algúnelemento de la red realice esa traducción, y a esos elementos se les conoce como servidores DNS.
El espacio de nombres de la red (el conjunto de todos los nombres de ordenador) se divide endominios que pueden, a su vez, dividirse en zonas y subdominios (y estos últimos pueden dividirseen nuevas zonas y subdominios, y así sucesivamente).
La estructura del espacio de nombres permite que se delegue la autoridad de un dominio en susadministradores. Estos pueden crear subdominios dentro de este dominio y delegar la gestión decada subdominio en una serie de administradores.
Cada uno de estos ámbitos es controlado por uno o varios servidores de nombres, que pueden ser:
• servidor autorizado: servidor que gestiona un dominio y está capacitado para la creación desubdominios y zonas, y para delegar la gestión de estos y aquellas en sendos servidores denombres, y
• servidor delegado: servidor en el que se delega la gestión de nombres de un subdominio o zona.
Se llama dominio a la cima de la jerarquía de nombres. El servidor de un dominio suele ser unservidor autorizado. Un dominio puede dividirse en subdominios y zonas. Un subdominio es undominio que posee un servidor delegado (es decir, es parte de un dominio más amplio con su propioservidor autorizado). Una zona es un conjunto de nombres de ordenador gestionados por unservidor de zona.
La diferencia entre un servidor de zona y uno de dominio (o subdominio) estriba en que un servidorde zona es un servidor delegado pero nunca autorizado, por lo cual, sólo contiene las relacionesnombredirección de todas las máquinas de su ámbito. Sin embargo, un servidor de dominio (osubdominio) no sólo contiene las relaciones nombredirección de las máquinas de su ámbito, sinoque delega en todos los servidores de dominio de los subdominios que contiene y en los servidores
Tema 5, página 5 Ignacio José Blanco Medina
Cliente Servidorrequest
service

Administración de Sistemas Operativos Curso Académico 20032004
de zona de las zonas que contenga, a su vez. Es decir, un servidor de zona sólo contiene direccionesde ordenadores y uno de dominio puede contener, además, direcciones de servidores delegados (desus subdominios y zonas).
Cuando un usuario intenta acceder a otro ordenador, utiliza el nombre del mismo. En ese momento,y antes de establecer la comunicación, el cliente de DNS realiza la petición de traducción alservidor de nombres correspondiente. El procedimiento de resolución de nombres es el siguiente:
1º el cliente pregunta al servidor de su zona o subdominio; si el mismo conoce la traducción, laproporciona al cliente,
2º si el servidor de zona o subdominio no la posee, el propio servidor preguntará al servidor deldominio raiz (el de la cima de la jerarquía), el cual desgranará la dirección de derecha a izquierdapara averiguar a qué servidor de dominio debe preguntar; cuando lo localice, este hará lo mismocon el subdominio y así sucesivamente hasta llegar al servidor de zona o de dominio quecontenga la traducción nombredirección.
Hay que notar que, una vez que el cliente DNS inicia la petición con su servidor de zona osubdominio, es éste el que proporciona la traducción, aunque éste haya tenido que recurrir a otrosservidores para satisfacer dicha resolución. Sin embargo, cuando un servidor realiza una petición aotro servidor y ésta es satisfecha, antes de devolver la traducción al cliente que la solicitó, sealmacena en una caché de direcciones por si el mismo cliente u otro la vuelven a solicitar (sealmacena la traducción y el servidor que la resolvió, por si se necesita acceder a un nodo de lamisma zona o subdominio que controla). Esta información permanece en dicha caché durante untiempo conocido como TTL.
Existe un último tipo de servidores, conocidos como sólocaché, que no almacenan informaciónsobre ordenadores o servidores delegados, sino que únicamente sirven para recibir peticiones ytramitarlas con otros servidores almacenando temporalmente la respuestas en la caché de nombres.
DHCP: (Dynamic Host Configuration Protocol, Protocolo de Configuración Dinámica de Nodo).Es un protocolo que provee de un medio para asignar dinámicamente un conjunto dedirecciones a un conjunto de nodos autorizados dentro de una LAN.
Este mecanismo permite optimizar el uso de un conjunto de direcciones IP adquiridas para unconjunto de máquinas que no tienen por qué tener la misma configuración de red en dos ejecucionessucesivas del sistema operativo.
El servidor posee un conjunto de direcciones (pool) que pueden ser asignadas a un conjunto deordenadores con acceso al servidor. Dichos ordenadores configuran su tarjeta de red para el envíode un paquete DHCP por la red solicitando configuración a cualquier servidor DHCP que estéescuchando. Los paquetes enviados por los ordenadores se firman con la dirección ethernet de lainterfaz de red (tarjeta de red) de modo que el servidor pueda reconocer la procedencia del paquetey autorizarlo. Una vez reconocido y autorizado el paquete, se responde al mismo con otro paqueteDHCP, cuyo destinatario es aquella interfaz de red con la dirección ethernet correspondiente, quecontendrá la configuración IP para la interfaz de red y para el sistema operativo del ordenador.Dicha configuración incluye: dirección IP, máscara de red, dirección IP del gateway, aunquepuede incluir información adicional como lista de servidores de nombres, dominio de búsqueda,nombre de ordenador, etc.
Tema 5, página 6 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
e) Instalación de un servidor (servicio) Los pasos necesarios para la instalación de un proceso servidor (o una aplicación servidor) en unordenador determinado, que actuará como servidor a partir de ese momento, son los siguientes:
1º localización de la instalación:
a) discos,
b) distribución en INTERNET, o
c) proveedor.
2º instalación del servidor,
3º asegurar que el servidor esté inactivo durante el proceso de configuración y que no se inicia deforma automática cuando se reinicia el sistema hasta que esté totalmente configurado,
4º configuración del servidor,
5º configuración del software de firewall, en caso de haberlo instalado, para permitir el paso depaquetes desde y hacia el puerto o los puertos del servidor en cuestión,
6º inicio del servidor, y
7º monitorización de uso del servidor y de accesos.
Tema 5, página 7 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
Tema 6 - Arranque y parada del Sistema Operativo Después del encendido de la máquina, se llevan a cabo una serie de procesos, entre el momento dela activación y el momento en el que la máquina entra en funcionamiento normal.
Del mismo modo, durante el proceso de apagado de la máquina, es necesario llevar a cabo una seriede tareas que protejan los datos y a la propia máquina de fallos en futuras sesiones de trabajo.
a) Arranque del Sistema Operativo Durante la puesta en funcionamiento del ordenador, los pasos que se siguen son los siguientes:
1. En primer lugar, la BIOS que se encuentra en la memoria ROM del ordenador, toma el controlde la máquina para realizar una serie de comprobaciones como son: memoria, unidades de disco,tarjeta gráfica, etc. Recuérdese que la BIOS de la tarjeta gráfica se antepone a la BIOS delordenador de modo que las comprobaciones internas de dicha tarjeta se realicen antes de todo.
2. Después de esto, se procede a la carga en memoria RAM del cargador de sistema operativosituado en el sector 0 cilindro 0 de la unidad de disco establecida como de arranque, o alcomienzo del dispositivo de almacenamiento fijado a tal efecto. Este cargador puede, a su vez,ceder el control a otros programas de carga de sistema operativo.
3. Carga en memoria RAM del núcleo del sistema operativo seleccionado e inicialización delmismo.
Veamos ahora las posibles variantes en los distintos pasos del proceso.
(i) Dispositivos de almacenamiento de arranque Originalmente, los dispositivos a los que la BIOS del sistema podía ceder el control para el arranquedel sistema operativo eran disquettes y el primer disco duro. Actualmente, los dispositivos quepermiten la inicialización del sistema operativo son:
• el disco duro maestro del bus IDE primario,
• el primer dispositivo de un bus SCSI,
• un lector de CDROM,
• una unidad ZIP,
• una unidad de cinta o
• un dispositivo de red (este último requiere el protocolo de red BOOTP, que permite lainicialización de un ordenador por descarga remota del sistema operativo).
La unidad desde la que se realizará el arranque del ordenador se establece en la configuración deBIOS. Sin embargo, lo que se proporciona durante dicha configuración es una lista de dispositivosiniciables, de modo que si no es posible encontrar el cargador en el primero de ellos, se procede alocalizarlo en el segundo, y así sucesivamente.
(ii) El programa cargador del sistema operativo Un programa cargador de sistema operativo es un programa que transfiere a memoria el núcleo delsistema operativo seleccionado para la sesión de trabajo.
Tema 6, página 1 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
NTLoader
El programa NTLoader es el cargador de los sistemas operativos de Microsoft Windows®.Inicialmente, se diseñó para el sistema Microsoft Windows NT®, aunque se aplicó después a lossistemas operativos Microsoft Windows 2000® y XP®, y se le dotó con capacidades para iniciarotros sistemas operativos de la empresa Microsoft® como pueden ser Microsoft Windows 95®,98® o Millenium®.
El archivo de configuración del cargador se ubica en la primera partición del disco duro maestro delprimer bus IDE, y se denomina boot.ini (c:\boot.ini). Un ejemplo de este archivo se muestra acontinuación:[boot loader]timeout=10default=multi(0)disk(0)rdisk(0)partition(1)\WINNT[operating systems]multi(0)disk(0)rdisk(0)partition(1)\WINNT="Practicas Generales" /fastdetectmulti(0)disk(0)rdisk(1)partition(1)\WINNT="Neurocomputacion" /fastdetectmulti(0)disk(0)rdisk(1)partition(3)\WINNT="Administracion de S.O. (Grupo1)" /fastdetectmulti(0)disk(0)rdisk(1)partition(5)\WINNT="Administracion de S.O. (Grupo2)" /fastdetect
Los parámetros que se muestran en el fichero son:
• timeout: fija el tiempo que el cargador espera, en segundos, antes de ceder el control de maneraautomática al sistema operativo seleccionado por defecto. Se cancela la cuenta atrás de arranqueautomático pulsando cualquier tecla.
• default: establece el sistema operativo que se inicia por defecto si no se pulsa ninguna tecla yexpira el tiempo fijado en timeout. La sintaxis para una ubicación de sistema operativo es una delas siguientes:
• type(x)disk(y)rdisk(z)partition(a)path• multi(x)disk(y)rdisk(z)partition(a)path
donde cada uno de los parámetros identifica lo siguiente:
• type(x) establece el tipo de dispositivo de almacenamiento cuando una máquina poseeúnicamente dispositivos SCSI o dispositivos ESDI, IDE y SCSI. Si el sistema operativo seencuentra en un disposivo conectado a un bus SCSI, el parámetro se establece como scsi(x)donde x especifica el número del controlador del tipo especificado. En el caso de tratarse deun dispositivo IDE, se usa la sintaxis multi(x).
• disk(y) donde y es siempre 0 en el caso de dispositivos multi; si se trata de otro tipo, y secalcula multiplicando x (número de bus) por 32 y sumándole el número de orden deldispositivo que contiene el sistema operativo dentro del bus.
• rdisk(z) donde z identifica si el dispositivo es el MASTER (0) o el SLAVE (1) dentro delbus; en el caso de dispositivos SCSI, z vale siempre 0.
• partition(a) donde a establece el número de la partición empezando desde 1; es necesariorecordar que la partición extendida no se cuenta como tal, de ese modo, todas las particioneslógicas se identifican por su posición menos 1.
• path establece el directorio que contiene el núcleo del sistema operativo que se desea cargar.
• La sección operating systems establece los sistemas operativos arrancables desde el cargador de
Tema 6, página 2 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
Windows NT®. Hay una línea por cada uno de dichos sistemas operativos que comienza con lamisma sintaxis que la cláusula default, seguida de una cadena de =<cadena de caracteresentre comillas dobles> que identifica el sistema operativo seleccionado y, por último, unaopción que permite el chequeo rápido del sistema operativo tras la carga.
GRUB
Programa cargador de sistemas operativos instalado por las nuevas versiones de las distribucionesde Linux. Permite la carga de sistemas operativos variados como Linux y sistemas operativosWindows®. El proceso de instalación del programa cargador GRUB tiene dos fases:
a) configuración de /etc/grub.conf e
b) instalación de grub en el dispositivo de arranque.
Fichero grub.conf
El fichero tiene una sintaxis genérica como se ve a continuación:default=0timeout=10splashimage=(hd0,1)/boot/grub/splash.xpm.gztitle Red Hat Linux (2.4.18-17.8.0) root (hd0,1) kernel /boot/vmlinuz-2.4.18-17.8.0 ro root=LABEL=/ initrd /boot/initrd-2.4.18-17.8.0.imgtitle DOS rootnoverify (hd0,0) chainloader +1
Los parámetros del fichero son los siguientes:
• default establece la entrada del fichero de configuración (contando desde 0) que se iniciará pordefecto en caso de que expire el plazo de espera,
• timeout establece el tiempo de espera (en segundos), después del cual se iniciará la opción pordefecto si no se ha pulsado ninguna tecla,
• fallback establece la entrada del fichero de configuración que se iniciará en caso de que falle lainicialización de la entrada por defecto,
• splashimage establece la imagen (en formato XPM y comprimida con GZIP) que se mostrará defondo en la lista de selección del sistema operativo, con la sintaxis (hdx,y)/ruta donde xestablece el número del bus al que está conectado el disco (empezando desde 0) e y es el númerode partición (empezando desde 0),
• cada uno de los sistemas operativos iniciables se registra con la siguiente sintaxis:
• la palabra reservada title seguida de una cadena de caracteres sin comillas que aparecerá enel menú de arranque,
• en caso de tratarse de un sistema operativo de tipo Linux, se añaden los siguentesparámetros:
• la línea root (hdx,y) establece la ubicación de la partición raíz del sistemaoperativos, con las consideraciones antes expuestas para x e y,
• la línea kernel <ruta hasta la imagen del núcleo> <parámetros>root=<partición raíz> establece la ubicación del núcleo de sistema operativo que
Tema 6, página 3 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
ha de iniciarse,
• la línea initrd <ruta> establece la ubicación del fichero de imagen que se cargapara que un núcleo preconfigurado (no compilado para la máquina concreta) puedafuncionar.
• En caso de tratarse de un sistema operativo del tipo Windows®, los parámetros son:
• rootnoverify (hdx,y) establece la partición que contiene el sistema operativo(con los valores de x e y expuestos anteriormente); este comando no trata de montarla partición,
• chainloader <file> carga el cargador de arranque del sistema operativo contenidoen el fichero <file> o en el sector 0 de la partición si se especifica +1.
Instalación de GRUB
Para instalar GRUB hay que ejecutar la orden:grub-install <dispositivo de instalación>
Por ejemplo, se puede instalar el GRUB en discos duros o, incluso en un diskette.
(iii) Crear un disco de arranque Un disco de arranque permite reiniciar el sistema en caso de un fallo del sector de arranque deldisco duro. Para que un disco se haga de arranque, es necesario transferir el núcleo del sistemaoperativo dentro de dicho disco.
El comando en Linux que crea un disco de arranque es el comando:mkbootdisk <núcleo> <dispositivo>
Este comando transfiere el núcleo (vmlinux) y el cargador (initrd) al disco. Pero un disco hecho desistema por este procedimiento, únicamente es capaz de iniciar el sistema operativo que le ha sidotransferido. Es posible instalar el cargador en el sector de arranque del disquette mediante la propiaorden de instalación:grub-install /dev/fd0
lo cual permitiría crear un disquette que pregunte qué sistema operativo desea iniciarse incluso si elsector de arranque del disco duro ha resultado dañado.
(iv) Tareas posteriores a la carga del sistema operativo Una vez que el sistema operativo reside en la memoria, se procede a:
• chequeo y montaje del sistema de ficheros raiz (que contiene al propio sistema operativo),
• inicio de los niveles de ejecución (en sistemas operativos de tipo UNIX),
• primer proceso del sistema o proceso INIT (en sistemas UNIX) y
• ficheros de inicialización.
Modos de funcionamiento
Los sistemas operativos (tanto Windows® como Linux) pueden funcionar en varios modos,atendiendo a la tarea que se desee realizar con ellos:
Tema 6, página 4 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
• modo monousuario: sólo un usuario puede conectarse al sistema operativo y además ha dehacerlo en la consola local; comunmente se usa para tareas de administración (en caso de UNIX)o de recuperación de fallos (en el caso de Windows 2000®), y
• modo multiusuario: o modo de funcionamiento normal, en el cual varios usuarios puedenconectarse a la misma máquina o requerir servicios de esta.
Niveles de ejecución
Dentro de los sistemas UNIX, se definen una serie de niveles de ejecución en los que la máquinapuede operar, y se orientan a distintos usos de la máquina. Es por ello, que en cada nivel, lamáquina se comporte de manera diferente.
Los niveles de ejecución vienen determinados en el fichero /etc/inittab, facilitan laconfiguración del sistema y es posible cambiar de un nivel de ejecución a otro sin reiniciar.
Por convenio, se establece el uso de los niveles como sigue:
• Nivel 0: estado de parada,
• Nivel 1: modo monousuario,
• Niveles 2, 3 y 5: modo multiusuario (en el caso de RedHat, el nivel 2 es para multiusuario sinNFS, el 3 para multiusuario normal y el 5 para X11) y
• Nivel 6: reinicio del sistema.
Los procesos y servicios que se inician según el nivel de ejecución asignado se pueden ver en eldirectorio /etc/rc.d/rc.<número de nivel>. Estos procesos son iniciados por el proceso init.
El proceso INIT
El proceso INIT es el primer proceso que se inicia tras la puesta en marcha del sistema, y sueletener como PID el número 1. La configuración para este proceso se encuentra en el fichero /etc/inittab que tiene el siguiente formato:<identificador de proceso>:<nivel>:<acción>:<comando>
Por ejemplo, el nivel inicial de ejecución del sistema lo establece la línea:id:5:initdefault:
la cual establece el nivel inicial en el número 5.
La línea que sigue:l5:5:wait:/etc/rc.d/rc 5
establece que debe ejecutar el proceso rc (/etc/rc.d/rc) con el parámetro 5 y esperar a que estetermine (wait) antes de continuar.
Los ficheros de inicialización
El proceso rc <número de nivel> ejecuta todos los ficheros de inicialización que se encuentrenen ese nivel de ejecución. La subestructura del sistema de archivos en la que se almacenan losfichero de inicialización puede verse en la siguiente figura:
Tema 6, página 5 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
Estos ficheros se organizan según el nivel de ejecución en el que se encuentren, se escriben en ellenguaje de la shell y tienen, como mínimo, la funcionalidad para arrancar y parar una tarea.
El nombre de los ficheros de inicialización sigue el esquema:S[0-9][0-9][a-z]*
y dentro de cada nivel, los ficheros se ejecutan según el orden alfabético de su nombre.
b) Parada del sistema operativo La parada del sistema operativo se realiza por una de las siguientes razones:
• sustitución de hardware,
• errores hardware o software o
• fallos en el entorno de operación que puedan producir disfunciones.
El proceso de parada es similar al de arranque, y sólo consiste en pasar al nivel 0 pero, al contrarioque con otros niveles, no se inicia ningún proceso.
Siempre que sea posible, la parada debe ser planificada y comunicada a los usuarios con antelaciónsuficiente.
(i) Fichero de parada Los fichero de parada siguen el mismo esquema que los de inicialización, pero su nombre seconstruye mediante la sintaxis:K[0-9][0-9][a-z]*
Estos ficheros se ejecutan en cada nivel, antes de ejecutar los ficheros de inicialización paragarantizar la entrada en un nuevo nivel de forma coherente. De este modo, el nivel 0 sólo tieneficheros K pero no S.
Tema 6, página 6 Ignacio José Blanco Medina
/etc/rc.d
rc.sysinit rc rc0.d rc6.d... rc5.d
S55sshd S90crond

Administración de Sistemas Operativos Curso Académico 20032004
Tema 7 - Gestión de la impresión
a) Fundamentos
(i) Impresión en Windows® Cuando un programa Windows® desea imprimir, crea un contexto gráfico (una página) asociada aldriver de la impresora, sobre el cual el programa realiza llamadas al sistema para trazar líneas,escribir texto con atributos y seleccionar colores. Una vez que el programa ha completado laimpresión de la página, el driver traduce la misma a un lenguaje que la impresora puedacomprender, y dicha traducción se almacena en c:\windows\spool\printer. Esta traducción estomada por el módulo conocido como spool32, que se encarga de su envío a la impresora. Algunasde las impresoras más modernas incorporan spoolers propios que se comunican directamente con laimpresora e incorporan una mayor amigabilidad y comunicación con el usuario.
(ii) Impresión en Linux Cuando un programa quiere imprimir, es responsabilidad del mismo producir una salida que laimpresora pueda comprender, aunque sistemas gráficos como el KDE incorporan infraestructurapara impresión basada en llamadas a bibliotecas.
El método más común empleado en sistemas UNIX consiste en imprimir el lenguaje Postscript, quela mayor parte de las impresoras entienden. Si, por el contrario, el programa genera una salida noPostscript, los paquetes de impresión incorporan conversores de formato que toman otros formatosde impresión y los traduce en ficheros Postscript.
El programa que se encarga de la impresión es “ lpr”, el cual copia el archivo que se desea imprimiren /var/spool/lpd y llama al demonio de impresión (proceso que se encarga de la impresión) “ lpd” .
El comportamiento de “l pr” y “ lpd” y otros programas relacionados es determinado por el fichero /etc/printcap, que almacena la configuración de las impresoras:
# Local ASCII printer lp1|printer :server :cm=Dumb printer :lp=/dev/lp1 :sd=/var/spool/lpd/lp1 :lf=log:af=acct :filter=/usr/local/libexec/filters/ifhp :mx=0
donde:
• server especifica que dicha entrada de printcap no es usadapor ningún programa, salvo por el servidor lpd
• cm=comment for status
• filter=job filter
• lf=log file
• af=accounting file
Tema 7, página 1 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
• lp=output device
• mx=maximum job size
• sd=spool directory file
Una diferencia importante entre el spooler de Windows® y el de UNIX, es que el spooler de UNIXespera a que el programa termine de generar la salida impresa, que después es copiada en eldirectorio de spooling que especifica la correspondiente entrada del archivo printcap y, una vezhecho todo, comienza la impresión. Esto enlentece el proceso de impresión pero desbloquea elprograma aunque la impresión no haya finalizado.
Algunos comandos importantes que permiten el control y configuración de la impresora en elsistema de impresión LPRng son:
• lpc: shell de control de las impresoras para manipulación de las colas de impresión, estado de laimpresora, etc. (comando importante dentro de la shell: “ help” o “?” ),
• lpr: cliente que imprime un fichero postscript en la impresora especificada,
• lpq: cliente que consulta el estado de la cola de impresión,
• lprm: cliente que elimina un trabajo de la cola de impresión,
• lpstatus: cliente que consulta el estado de una o varias impresoras.
b) El sistema de impresión CUPS (Common UNIX Printing System)
(i) Fundamentos de CUPS El sistema de impresión CUPS surgió como una extensión de IPP (Internet Printing Protocol,protocolo que extiende el HTTP para dotarlo de capacidad para servicios de impresión remota.
En CUPS, todo gira alrededor de un proceso de planificación de impresión, llamado scheduler, quegestiona y procesa los trabajos impresos, comandos administrativos de impresión, peticiónes deinformación sobre impresoras e informe de estado para los usuarios. El diagrama organizativo deCUPS se ve en el siguiente gráfico:
donde:
• scheduler: es un servidor de aplicación HTTP que admite peticiones HTTP de impresión, ademásde proveer de funcionalidad para documentación, información sobre estado y administración,
• los ficheros de configuración se dividen en:
• /etc/cups/cupsd.conf: fichero de configuración para el scheduler que incorpora
Tema 7, página 2 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
opciones para funcionalidad, operación y seguridad,
• ficheros de definición de clases e impresoras: que permiten la definición deimpresoras (/etc/cups/printers.conf) y conjuntos de impresoras iguales(/etc/cups/classes.conf) o con el mismo driver a las que mandar un trabajo,
• tipo MIME y ficheros de reglas de conversión y
• ficheros PPD (Postcript Printer Description).
• CUPS API (Advanced Program Interface): conjunto de funciones para encolar trabajos deimpresión, obtener información sobre las impresoras, acceder a recursos a través de HTTP e IPPy manipular ficheros PPD.
• Comandos Berkeley y System V: comandos en linea para invocar desde la shell en estos dossistemas de procesos que permiten enviar trabajos y comprobar el estado de las impresoras, talescomo “l pd.cups”, “l pq.cups” , “ lprm.cups” o “ lpstat.cups”.
• Filtro: programa que lee de un fichero de entrada o desde la entrada estándar y produce unasalida. Tienen un conjunto de datos comunes (nombre de impresora, ID del trabajo, username,nombre del trabajo, número de copias y opciones del trabajo). Los filtros se proveen paramuchos formatos de fichero e imágenes. Generalmente, los filtros se encadenan para conseguir elformato deseado.
• CUPS Imaging: biblioteca que proporciona funciones para gestionar imágenes de gran tamaño,relizar conversiones de color para la impresión, escarlar imágenes para la impresión y manejarflujos de página raster (salida generada por los filtros de Postscript Raster, que permitenimprimir en impresoras no postscript).
• Backend: filtro especial que envía datos de impresión a un dispositivo o conexión de red. CUPSincorpora backends para puerto paralelo, puerto serie, puerto USB, impresoras LPD, impresorasIPP e impresoras AppSocket (JetDirect).
CUPS permite buscar en la red impresoras que estén accesibles desde la máquina en concreto, demodo que se pueden enviar trabajos, e incluso gestionar impresoras remotas.
(ii) Configuración de CUPS La configuración del sistema de impresión CUPS se realiza mediante una conexión HTTP a lapropia máquina que se quiere configurar. Como se ha dicho, el “s cheduler” es un servidor HTTPque recibe peticiones de impresión, configuración, etc.
Generalmente, dicho servidor escucha en el puerto 631, aunque puede modificarse en el fichero /etc/cups/cupsd.conf.
A partir de la configuración correcta del fichero de configuración, el control de CUPS se lleva acabo a través de un navegador.
La página principal de configuración recoge todas las opciones posibles para el servidor y se ve enla imagen que aparece a continuación:
Tema 7, página 3 Ignacio José Blanco Medina
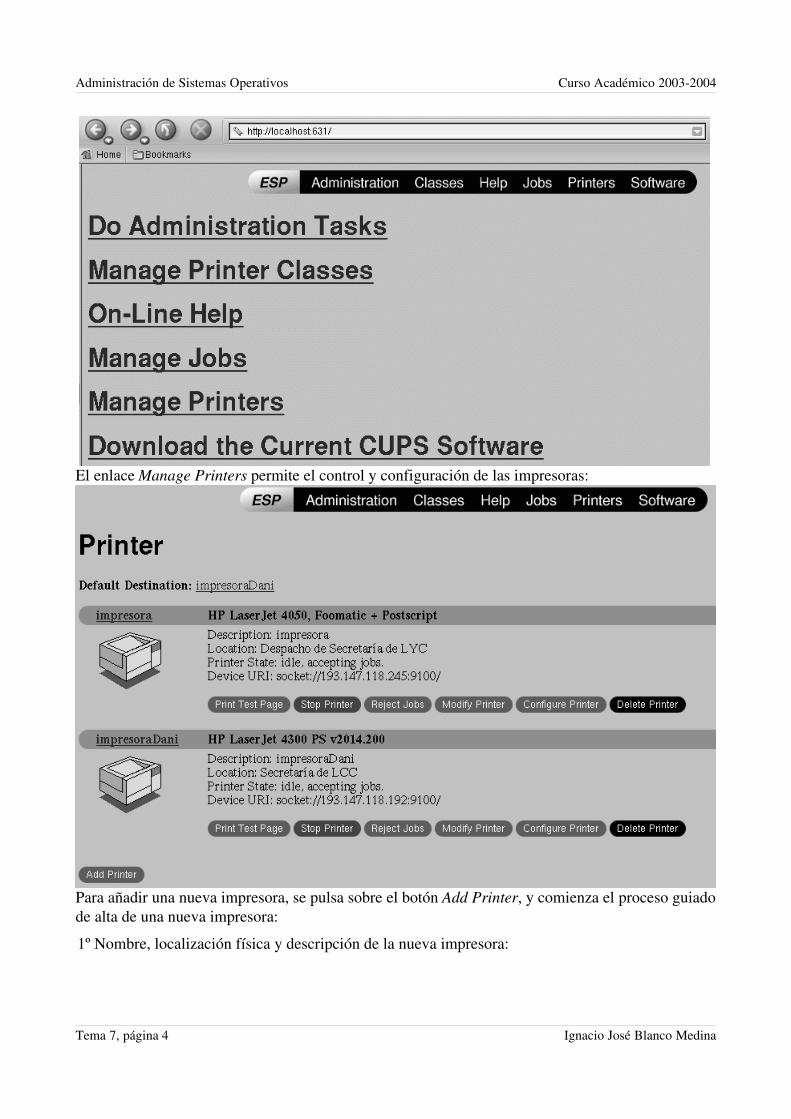
Administración de Sistemas Operativos Curso Académico 20032004
El enlace Manage Printers permite el control y configuración de las impresoras:
Para añadir una nueva impresora, se pulsa sobre el botón Add Printer, y comienza el proceso guiadode alta de una nueva impresora:
1º Nombre, localización física y descripción de la nueva impresora:
Tema 7, página 4 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
2º Tipo de conexión con el dispositivo:
y datos para la conexión:
3º Selección de marca:
Tema 7, página 5 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
4º y modelo para establecer el driver correcto:
5º Configuración de parámetros de la impresora: para ello, una vez creada la impresora, en lapágina de gestión de impresoras se usa el botón Configure Printer para la impresoraseleccionada:
y después se configuran los parámetros correspondientes a esa impresora, que dependerán deldriver que se esté empleando:
Tema 7, página 6 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
Tema 8 - Copias de seguridad
(a) Generalidades
(i) Razones para las copias de seguridad Cuando un sistema totalmente funcional sufre un desperfecto debido a:
• fallos hardware,
• fallos software,
• intervención humana (errores, intrusiones, etc.) o
• desastres naturales.
es necesario recuperar los datos de usuario y los archivos de configuración del sistema, a fin depoder ponerlo en funcionamiento en el menor tiempo posible.
Sin embargo, la propia copia de seguridad es susceptible de fallos, bien sea por:
• proceso erróneo de creación o
• fallo del soporte de la copia de seguridad,
por lo cual sería recomendable realizar copias de más de un nivel de antigüedad. De este modo,siempre podremos tener disponible la copia anterior a la fallida.
(ii) Selección del medio para la copia Antes de proveer a un sistema de un subsistema de copia de seguridad, es necesario seleccionar yadquirir el soporte sobre el cual va a realizarse. Dicha selección se centra en los siguientesparámetros:
• coste,
• fiabilidad: el uso del soporte afecta a la fiabilidad, por ejemplo, un disco duro es comúnmentefiable, aunque no si se usa como soporte de una copia de seguridad de la propia máquina,
• velocidad: aunque no suele ser importante, ya que el backup es un proceso no interactivo quesuele realizarse a horas de baja carga del sistema,
• disponibilidad y
• usabilidad: un soporte para backup debe ser de uso fácil.
Las opciones más comunes para soporte de backup suelen ser los floppies y las unidades de cinta,aunque se han incorporado a estas los CDROMs (grabables y regrabables).
(b) Respaldo de ficheros del sistema Los ficheros que debería verse afectados por el proceso de copia de seguridad, deberían ser lossiguientes:
• ficheros de configuración del sistema,
• directorios HOME de usuario,
Tema 8, página 1 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
• bandejas de correo electrónico de usuarios y
• bases de datos.
Por el contrario, no es necesario realizar una copia de seguridad integral del sistema, ya quedisponemos de la instalación para restaurar el sistema operativo en modo preconfigurado. Unacopia de seguridad integral requeriría demasiado espacio en un dispositivo de almacenamientomasivo que, generalmente, no tiene porque estar disponible.
(c) Comandos de respaldo Los comandos tradicionales de UNIX para la copia de seguridad son:
• tar y cpio: comandos creados para transferir archivos a cinta y recuperarlos de la misma; ambospueden almacenar ficheros en cualquier tipo de dispositivos (de lo que se encargan los driversincorporados al núcleo del sistema operativo),
• dump: esta herramienta está orientada a sistemas de ficheros completos y no a ficherosindividuales.
(d) Backups simples Los tipos de backups que podemos realizar son:
• Backup completo: backup que se realiza por primera vez (o todas las veces que se realice unbackup por designación del administrador).
• Backup incremental: en contraposición al backup completo, éste consiste en detectar los ficherosde la copia de seguridad anterior que hayan cambiado según algún criterio (fecha, tamaño,atributos, etc.), que hayan sido borrados, o que no aparezcan, y realizar una copia de seguridadsólo de esos ficheros.
Desde el punto de vista de la complejidad, realizar un backup completo requiere menos esfuerzopero mucho más espacio y tiempo. Sin embargo, un backup incremental requiere menos tiempo yespacio (salvando el hecho de que la primera copia debe ser completa) pero más esfuerzo.
Es necesario realizar una planificación de las copias de seguridad en función de los mediosdisponibles, la importancia de los datos, etc. pero siempre es recomendable guardar copias de másantigüedad.
El comando tar se creó para realizar copias de seguridad en un archivo secuencial almacenadocomúnmente en dispositivos secuenciales (unidades de cinta, principalmente) aunque hay querecordar que los dispositivos direccionables (discos duros, CDROMs, etc.) soportan el modo deacceso secuencial.
Para realizar una copia de seguridad incrementar con el comando tar, se usaba la siguientesentencia:tar –create –file /dev/ftape /home
el cual crea un nuevo fichero que transfiere directamente al dispositivo ftape (cinta magnética), elcual contendrá la copia de seguridad del directorio /home.
El modificador –multi-volume (o -M) habilita la copia de seguridad en varias cintas o discos (quese conectan al mismo dispositivo) en caso de que se complete uno de ellos. Este modo es
Tema 8, página 2 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
interactivo, de forma que el comando muestra un mensaje al administrador y espera a que éstesuministre otro disco o cinta.
Es recomendable, en cualquier caso, comprobar la corrección de la copia de seguridad realizada.Para ello, el comando tar provee del modificador –compare (o d) que comparará los ficherosalmacenados en la copia de seguridad con sus originales en el sistema de ficheros correspondiente.
La copia de seguridad incremental con tar se realiza mediante el modificador –newer (o -N), de lasiguiente manera:tar –-create –-newer '20 Jan 2003' –-file /dev/ftape /home
de modo que se realicen copias de seguridad de aquellos archivos que tengan fecha de accesoposterior al 20 de enero de 2003. Por desgracia, el comando tar no es capaz de determinar cambiosen los inodos de los ficheros, de modo que no se puede hacer copia de seguridad de aquellosficheros cuyos inodos hayan variado desde la última vez. Sin embargo, es posible simular estecomportamiento mediante el uso del comando find, que permite localizar aquellos ficheros quecumplan ciertas características (nombre que siga un determinado patrón, etc.) y diseñar una lista deaquellos ficheros que deben entrar en la copia de seguridad incremental.
La recuperación de una copia de seguridad realizada con tar, se realiza mediante la siguientesentencia:tar –-extract –-same-permissions –file /dev/ftape
con el modificador –extract (o -x). A este modificador se puede añadir el modificador -p quepermite la extracción de un archivo concreto o de un directorio y sus subdirectorios, de la siguientemanera:tar xpfv -–file /dev/ftape /home/usuario/.mozilla/abook.nab
También es posible listar el contenido de una copia de seguridad mediante el modificador –list, dela siguiente manera:tar –-list –-file /dev/ftape
Algunas de las acciones que pueden realizarse con el comando tar son:
• c: crea un contenedor de copia,
• x: extrae archivos de un contenedor,
• t: prueba la integridad de un contenedor,
• r: añade archivos al final de un contenedor,
• v: modo interactivo,
• f: especifica el nombre del contenedor,
• Z: comprime/descomprime mediante el/los comando/s compress/uncompress,
• z: comprime/descomprime mediante el comando gzip, o
• p: conserva los permisos de los ficheros.
(e) Backups multinivel El modo de copia de seguridad simple es un modo potente para mantener un volcado periódico delos archivos importantes pero sólo es útil en el caso de servidores pequeños o para uso personal. En
Tema 8, página 3 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
el caso de que la información sea más importante o sea necesario un sistema de copias de seguridadaltamente fiable, se recomienda un sistema de copias de seguridad multinivel.
La orden dump permite el volcado de sistemas de ficheros completos y está disponible en todos lossistemas operativos clones de UNIX. La orden de recuperación para el comando dump es restore.La sintaxis del comando es:
dump -0 -u -f /dev/cinta /dev/hda2
Las opciones más comunes para el comando son:
• 09: nivel de copia de seguridad; 0 para copia integral, nivel superior a 0 para copia de seguridadincremental,
• u: actualiza el fichero /etc/dumpdates en el que se almacena información sobre las copias deseguridad realizadas,
• f: fichero o dispositivo de volcado de la copia de seguridad, y
• A: dispositivo en el que almacenar el resultado de la copia de seguridad.
Como se ha especificado en los parámetros anteriores, el comando dump permite dos niveles decopia de seguridad:
• completa (nivel 0): se hace copia de seguridad de todo el sistema de ficheros, e
• incremental (del 1 al 9): se hace copia de seguridad de todo lo que haya cambiado en el sistemade ficheros desde la última copia de seguridad del mismo nivel o inferior.
El objetivo del uso de varios niveles permite extender la profundidad del backup (la historia) deforma barata. Por ejemplo, supóngase un dispositivo de unidad de cinta para las copias de seguridady diez soportes magnéticos para la unidad (cintas). Podemos usar las cintas 1 y 2 para las copiasmensuales (el primer viernes de cada mes), las cintas de la 3 a la 6 para las copias semanales (losotros viernes del mes que no son el primero), y las cintas de la 7 a la 10 para el resto de los días dela semana (de lunes a jueves). Esto nos permite recuperar los cambios de:
• el día anterior,
• del anterior a este,
• o así sucesivamente hasta el viernes anterior,
• o del viernes anterior,
• o así sucesivamente, hasta el primer viernes del mes,
• o del primer viernes del mes anterior.
Nótese que, comprando cuatro cintas más sería posible mantener la copia de seguridad de dossemanas completas. El sistema no es perfecto, pero mejor recuperar una versión no actualizada deun fichero borrado que ningún fichero.
Este sistema de copias de seguridad minimiza, no sólo el tamaño de las copias incrementales, sinoel tiempo de recuperación de un estado anterior a una situación de corrupción del sistema. Si seutiliza una planificación con números de nivel que se incrementan de forma monótona, se necesitarárecuperar todas las copias de seguridad si se necesitara reconstruir todo el sistema de ficheros. Paraevitarlo, se usan números de nivel que no crecen de forma monótona y se mantiene bajo el númerode backups para recuperar.
Tema 8, página 4 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
Si, por el contrario, se desea minimizar el número de cintas necesarias, se puede usar un nivelmenor para cada copia incremental. No obstante, en este caso, el tiempo para hacer las copias seincrementa (ya que cada copia incluye todos los cambios ocurridos desde la última copia integral).
Los niveles de copia de seguridad pueden combinarse para reducir los tiempos de copia yrestauración. Para las copias de seguridad diarias, las páginas de manual de dump recomiendan unasecuencia 3 2 5 4 7 6 9 8 9 9 ... En la referencia http://www.tld.org/LDP/sag/html/x2645.html,puede encontrarse una tabla que sugiere otra secuencia para más cintas y días.
Algunas referencias• http://es.tldp.org/ManualesLuCAS/GSAL/gsal19991128htm/copiasseguridad.htm
• http://es.tldp.org/ManualesLuCAS/SEGUNIX/unixsec2.1html/node100.html
• http://www.tld.org/LDP/sag/html/x2645.html
• Página de manual de dump (man dump)
Tema 8, página 5 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
Tema 9 - Monitorización del sistema
a) Introducción La monitorización de un sistema es recomendable por muchas razones, entre las cuales se incluyenmotivos legales o el seguimiento de irrupciones en el sistema.
b) Herramientas para la monitorización en Windows ® 2000 Server
En el sistema operativo Windows® 2000 Server, el propio núcleo del sistema operativo provee dela capacidad de realizar logs tanto del propio núcleo como de las aplicaciones. Esto se logramediante una serie de bibliotecas de función incorporadas al sistema operativo de modo que ofrecenuna visión unificada para la gestión de dichos eventos del sistema.
La herramienta que permite la supervisión de los logs del sistema se llama Visor de Sucesos (EventViewer) y se accede a ella a través del Panel de control y en la categoría Herramientas Avanzadas.En Windows® 2000 Server existen tres tipos de sucesos:
• Sistema: recoge sucesos registrados por el propio sistema operativo o sus subsistemas (gestiónde disco, gestión de dispositivos, gestor de red, etc.)
• Aplicación: recoge los sucesos registrados por las aplicaciones en ejecución sobre el núcleo delsistema operativo; constituyen un elemento útil a la hora de depurar el comportamiento dedeterminadas aplicaciones.
• Seguridad: recoge los sucesos registrados por el subsistema de seguridad del sistema operativo,así como de los subsistemas de seguridad que incorporan algunas de las aplicaciones.
La herramienta Event Viewer permite el filtrado de sucesos, dado que la extensión de los logs delsistema puede ser enorme. Cuando el log se satura, se informa mediante un mensaje emergente alusuario que ocupa consola local de la máquina para que el administrador efectúe una limpieza enlos logs del sistema.
c) El sistema de log en UNIX Casi todas las actividades en el sistema operativo UNIX son susceptibles de supervisión y puedenser monitorizadas, desde los intentos de acceso (fallidos o exitosos) hasta el tiempo de CPU queconsume un usuario. Esta característica plantea un beneficio claro: la capacidad de proteger lamáquina de accesos o usos indebidos, incluso de forma automática.
Una de las principales ventajas del sistema de log de UNIX radica en que los ficheros de log no sonmás que ficheros de texto que el administrador puede consultar con herramientas tan simples comoun comando cat o un less, aunque existen herramientas más complejas para esta supervisión.
Sin embargo, no se debe depositar una confianza excesiva en el sistema de log, ya que este puedeser falsificado, para lo cual se proponen algunas alternativas.
Una de los principales inconvenientes de los sistemas operativos UNIX radica en la complejidad ala hora de configurar el sistema de logs, unido a las diferencias entre los sistemas de log de lasdiversas versiones de este sistema operativo.
En UNIX existen dos grandes familias de sistemas (System V y BSD) que difierenconsiderablemente entre sí. Es, por tanto, recomendable recurrir a las páginas de ayuda antes de
Tema 9, página 1 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
proceder a la configuración del sistema de log. Una de las principales diferencias entre ellosconsiste en el process accounting, o simplemente account, que es la forma de almacenarinformación sobre los procesos ejecutados por un usuario. Evidentemente, esta información sólo esrelevante en casos muy concretos y es muy grande, por lo que no debe activarse su uso si no esnecesario.
(i) El demonio de log (sys log d) Este demonio se activa automáticamente cuando se inicia el sistema UNIX y es el encargado demantener los informes acerca del funcionamiento de la máquina. Recibe diferentes mensajes de laspartes software que se ejecutan en la máquina (núcleo, programas, controladores de dispositivo,etc.) y los almacena en diferentes localizaciones, que pueden ser locales o remotas, fijadas en elfichero de configuración /etc/syslog.conf (véase).
Este fichero contiene una serie de líneas denominadas reglas, que determinan a qué afecta la regla(selección) y qué hay que hacer con lo afectado (acción). Ambos campos se separan por comas.
A su vez, la selección se divide en dos partes separadas por un punto:
• servicio que genera el informe: que puede ser auth, authpriv, cron, daemon, kern, lpr, mail,mark, news, security (equivalente a auth), syslog, user, uucp y local0 hasta local7,
• prioridad del evento generado (importancia): que puede ser debug, info, notice, warning, warn(equivalente a warning), err, error (equivalente a err), crit, alert, emerg, y panic (equivalente aemerg).
Es posible definir reglas que afecten a todos los eventos de un determinado servicio (mail.*),afectar a mensajes sin prioridad (mail. ), afectar a una prioridad y las superiores en todos losservicios (*.info), afectar sólo a una prioridad en un servicio pero no a las superiores(mail.=info), invertir el comportamiento de un selector de prioridad (mail.!=info, seleccionatodas las prioridades del servicio mail menos la prioridad info).
Con respecto a las acciones que pueden realizarse, podemos enviar los mensajes a los siguientesdestinos:
• un fichero de texto: /var/log/messages,
• un dispositivo físico: /dev/tty12,
• al demonio syslogd en otra máquina: @lab1gw.lablyc.ual.es,
• uno o varios usuarios del sistema, en caso de estar conectados: root,aso1, y
• todos los usuarios conectados al sistema: *.
(ii) Archivos de log Algunos de los ficheros estándar de log se describen a continuación:
• /var/log/syslog: información relevante sobre la seguridad de la máquina y el acceso a servicios,
• /var/log/messages: eventos informativos del núcleo y las aplicaciones de prioridad baja,
• /var/log/wtmp: fichero binario que contiene información sobre las conexiones al sistema, informasobre el nombre de usuario de cada conexión, vía de acceso, lugar de origen de la conexión y
Tema 9, página 2 Ignacio José Blanco Medina

Administración de Sistemas Operativos Curso Académico 20032004
tiempo,
• /var/log/utmp: fichero binario que contiene información sobre los usuarios conectados en unmomento dado (se consulta con los comandos last o who),
• /var/log/lastlog: fichero que contiene información sobre la última conexión de un usuario,
• /var/log/btmp: conexiones fallidas,
• /var/log/sulog: ejecuciones del comando su, y
• /var/log/debug: eventos de depuración de todos los servicios.
Algunas referencias• http://es.tldp.org/ManualesLuCAS/GSAL/gsal19991128htm/herramientasmonitorizacion.htm
• http://es.tldp.org/ManualesLuCAS/SEGUNIX/unixsec2.1html/node86.html
Tema 9, página 3 Ignacio José Blanco Medina


















