
Alta Disponibilidad - Inicio · Alta Disponibilidad ... grado de confiabilidad del componente Los...
63
Alta Disponibilidad Alta Disponibilidad SISTEMAS DISTRIBUIDOS Departamento de Sistemas e Informática Escuela de Ingeniería Electrónica FCEIA
Transcript of Alta Disponibilidad - Inicio · Alta Disponibilidad ... grado de confiabilidad del componente Los...

Alta DisponibilidadAlta Disponibilidad
SISTEMAS DISTRIBUIDOSDepartamento de Sistemas e Informática
Escuela de Ingeniería ElectrónicaFCEIA

TemarioTemario
Disponibilidad y performance
Tolerancia a Fallas y Alta Disponibilidad
Soluciones
Clusters
Grids
Conclusión

TemarioTemario
Disponibilidad y performance
Tolerancia a Fallas y Alta Disponibilidad
Soluciones
Clusters
Grids
Conclusión

¿Qué es “Misión Crítica”?¿Qué es “Misión Crítica”?
Cuando del correcto funcionamiento de un sistema informático depende la vida, la seguridad o la propiedad de las personas
Algunos ejemplos: Controladores de tráfico aéreo Tecnología médica Control y supervisión de industrias críticas Transporte Finanzas Seguridad

Requerimientos de misión Requerimientos de misión críticacrítica
En las aplicaciones de misión crítica los sistemas informáticos deben producir las respuestas correctas en tiempos acotados
La capacidad de un SIMC de funcionar sin interrupciones se denomina “disponibilidad”
La “performance” es una medida de la capacidad de un SIMC de producir los resultados correctos en tiempos acotados

TemarioTemario
Disponibilidad y performance
Tolerancia a Fallas y Alta Disponibilidad
Soluciones
Clusters
Grids
Conclusión

Tolerancia a FallasTolerancia a Fallas
Tolerancia a Fallas es la capacidad de un sistema informático de mantener servicio ante la presencia de fallas parciales en:
Sistema: Hardware Software de base
Aplicativos Ambientales (energía, temperatura) Operaciones Infraestructura de comunicaciones

Alta DisponibilidadAlta Disponibilidad
Disponibilidad es la medida en que un sistema informático es capaz de proveer servicio ininterrumpido a sus usuarios.
Se mide como la razón entre el tiempo durante el que se provee servicio aceptable y el tiempo total de operaciones, en porcentaje.
Las aplicaciones de misión crítica requieren 99,9% o mas. Estos valores se catalogan como Alta Disponibilidad (HA, High Availability)

DisponibilidadDisponibilidad
tiempo real de funcionamiento * 100
tiempo total
D =

Clasificación de DisponibilidadClasificación de Disponibilidad
Disponibilidad Tiempo anual sin servicio
99% 87 horas 36'
99.5% 43 horas 48'
99.95% 4 horas 23'
99.99% 53'
99.999% 5'
Alta disponibi-lidad

Disponibilidad ContinuaDisponibilidad Continua
Implica un servicio sin interrupciones. Representa un estado ideal, generalmente
usado para sistemas de misión crítica en los cuales no son tolerables caídas de servicio, por ejemplo centrales telefónicas.
La disponibilidad continua se obtiene construyendo sistemas redundantes, tanto en hardware como software
Conceptualmente es diferente de la alta disponibilidad, y se denomina tolerancia a fallas

Fallas: clasificaciónFallas: clasificación
De parada: El sistema, recurso o aplicación deja de responder por completo. Son las mas fáciles de detectar -algo “no funciona”-
Bizantinas: El componente en falla no deja de funcionar pero expone comportamientos no previstos o incorrectos. Son difíciles de detectar y pueden afectar a otros componentes, provocando funcionamiento defectuoso de parte o todo el sistema.

MTBFMTBF
Mean Time Between Failures, es una medición estadística de la probabilidad de falla de un componente.
Se especifica en horas y da una idea del grado de confiabilidad del componente
Los componentes actuales de alta calidad tienen MTBF del rango del millón de horas

Punto Unico de FallaPunto Unico de Falla
Se denomina así a todo componente de un sistema informático que si falla, es capaz de impedir el funcionamiento de todo el conjunto.
Los sistemas tolerantes a fallas evitan la existencia de PUF utilizando redundancia.
Ejemplos: Fuentes de alimentación, buses, cpus, almacenamiento, discos, etc.

Punto único de falla: ejemploPunto único de falla: ejemplo
Base de Datos
El servidor es punto único de falla

DowntimeDowntime
Es el tiempo durante el cual un sistema no brinda servicio.Se divide en planeado y no planeado
DowntimeDowntimePlaneadoPlaneado
DowntimeDowntime No PlaneadoNo Planeado
ManteniemientoManteniemientode Rutinade Rutina
OperacionesOperacionesde Rutinade Rutina
ErrorErrorHumanoHumano
DesastresDesastres
Fallas Fallas del Sistemadel Sistema

DesastresDesastres
La ocurrencia de fenómenos externos -es decir, no originados en el propio sistema- puede afectar total o parcialmente su funcionamiento
Ejemplos: incendio, inundación, terremoto, robo, etc.
Los sistemas de misión crítica deben diseñarse teniendo en cuenta la probabilidad de ocurrencia de desastres

FailoverFailover
Cuando un componente de un sistema de alta disponibilidad falla produciendo pérdida de servicio, un proceso de control arranca el servicio afectado en otro componente redundante del sistema.
Implica una relocalización de servicio conocida como Failover
El tiempo que demanda esta acción es un parámetro esencial para calificar el nivel de servicio del sistema

TemarioTemario
Disponibilidad y performance
Tolerancia a Fallas y Alta Disponibilidad
Soluciones
Clusters
Grids
Conclusión

SolucionesSoluciones
Los sistemas de misión crítica se diseñan para ofrecer un nivel de disponibilidad predecible en la presencia de fallas como las mencionadas
La primera consideración de diseño es evitar puntos únicos de falla
Si además se requiere mantener el servicio en presencia de desastres, será necesario disponer de redundancia geográficamente separada, con vínculos de datos redundantes

TemarioTemario
Disponibilidad y performance
Tolerancia a Fallas y Alta Disponibilidad
Soluciones
Clusters
Grids
Conclusión

¿Qué es un Cluster?¿Qué es un Cluster?
Un cluster es un sistema distribuido consistente en una colección de computadoras autónomas
interconectadas y fuertemente acopladas, que es utilizado como un recurso computacional
unificado

Clusters: RequerimientosClusters: Requerimientos
Disponibilidad Escalabilidad vertical y horizontal Administrabilidad Calidad de Servicio Administración de cargas Seguridad

Componentes de un ClusterComponentes de un Cluster
Nodos: cada uno de los equipos participantes del cluster, aportando CPU, memoria y E/S
Interconexión Almacenamiento Conexión a la red pública Cluster Manager
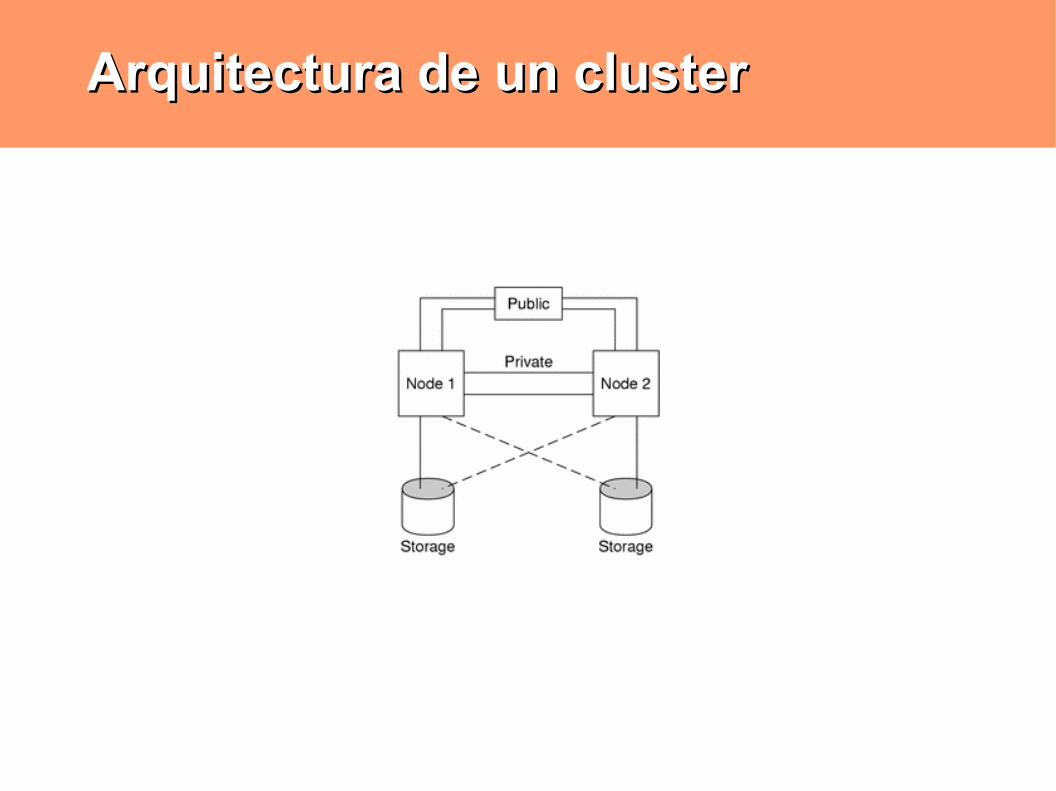
Arquitectura de un clusterArquitectura de un cluster

NodosNodos
Múltiples componentes de alta perfomance individual
Aunque pueden ser heterogéneos, habitualmente los clusters están integrados por computadores similares
La plataforma de software tambien es habitualmente la misma en todos los nodos

Sistemas OperativosSistemas Operativos
Linux (Beowulf, Rock, etc.)
MS Windows (MS Cluster Service)
Sun Solaris (Sun Cluster, Berkeley NOW)
HP-UX (Illinois Panda, HP MC)
IBM AIX pSeries (IBM SP Unix Cluster)
IBM zSeries (IBM SysPlex)
Oracle RAC

InterconexiónInterconexión
Es el vínculo de alta capacidad que enlaza a los nodos
Tecnologías: Gigabit Ethernet (1~10 Gbps) ATM Myrinet (1.2 Mbps) Infiniband (hasta 40 Gbps)
La interconexión es una red privada entre los nodos de baja latencia y alta disponibilidad, sobre enlaces redundantes
Sobre esta red circula la sincronización y el heartbeat del cluster

Red PúblicaRed Pública
Se denomina así a la red mediante la cual los usuarios del cluster acceden a sus servicios
Gigabit Ethernet, Infiniband, etc.
En esa red el cluster se muestra como un solo nodo, con una única dirección de red.

Cluster ManagerCluster Manager
Capa de software que corre en todos los nodos y provee la comunicación de procesos sobre la interconexión privada
Sobre la interconexión circula la información de sincronización del cluster, que permite que su configuración esté replicada en los nodos, y un protocolo de comunicación en grupo que permite determinar en todo momento el estado de funcionamiento de cada nodo del cluster

Cluster Manager (cont)Cluster Manager (cont)
El CM designa un nodo responsable de asumir la imagen única del sistema de cara al exterior y distribuye la carga de procesamiento sobre los nodos disponibles
Es responsable de detectar la caída de uno o mas nodos y conducir el proceso de recuperación (failover)
En caso de caída del nodo primario, el CM debe designar un nuevo primario entre los nodos sobrevivientes

Cluster RockCluster Rock
http://www.rocksclusters.org/Clusters de HPC en Linux

Cluster Cluster MiddlewareMiddleware Reside en cada nodo, entre el SO y las
aplicaciones y provee la infraestructura de soporte para:
Imágen única del cluster (Single System Image, SSI)
Control de disponibilidad del cluster (System Availability, SA)
SSI muestra a los recursos del cluster como una sola máquina -un solo IP, un solo hostname, etc.
SA provee mecanismos de checkpointing y migración de procesos en failover

Single System ImageSingle System Image
SSI provee una visión centralizada de los recursos del cluster.
Maximiza el aprovechamiento de recursos mediante resource pools y administración.
Brinda mayor escalabilidad y abstracción Un cluster puede brindar así servicios
equivalentes a un computador SMP mas costoso.

Beneficios de SSIBeneficios de SSI
Uso transparente de recursos Balanceo de cargas y migración de
procesos transparente Mas confiabilidad y mayor disponibilidad Mayor perfomance y mejor tiempo de
respuesta Simplificación de la administración

Servicios de SSIServicios de SSI
Unico punto de acceso a los servicios del cluster
Unica jerarquía de filesystems
Unico punto de control
Virtual Networking única
Unico espacio de memoria
Unica interface de usuario: CDE, MS-Windows, KDE, Gnome, Web, etc.

Servicios de DisponibilidadServicios de Disponibilidad
Espacio de E/S único: cada nodo accede a todos los periféricos independientemente de su localización.
Espacio de Procesos único: todos los procesos, independientemente del nodo en que se crean pueden comunicarse con el resto en forma transparente.
Checkpointing: salva el estado de los procesos y los resultados intermedios a disco para soportar rollback cuando el nodo falla.

Global FilesystemGlobal Filesystem

CheckpointingCheckpointing

AplicacionesAplicaciones
Un cluster puede ejecutar dos tipos de aplicaciones:
Secuenciales Paralelas (Cluster aware-apps)
Aplicaciones científicas computación-intensivas: meteorología, química cuantica, biología molecular, etc.
Web servers
Data mining

Clasificación de ClustersClasificación de Clusters
Clusters de alta perfomance (HPC)
Aplicaciones de alta carga de procesamiento. Maximizan la performance
Clusters de alta disponibilidad (HA) Aplicaciones de misión crítica Se maximiza la disponibilidad frente a la
performance

Topologias: Topologias: clustered pairsclustered pairs

Topologías: N + 1Topologías: N + 1

Topologías: Par + NTopologías: Par + N

Shared NothingShared Nothing Clusters Clusters
Cada nodo tiene recursos de almacenamiento exclusivos

Shared All Shared All ClustersClusters
Varios nodos comparten los mismos recursos de almacenamiento

MembresíaMembresía
Es el conjunto de nodos que puede comunicarse con cada uno del resto de los integrantes del grupo a través del interconnect.
Está administrada por un Cluster Membership Manager distribuido que supervisa la entrada y salida de nodos al cluster.
El CMM debe retirar del grupo a los nodos en falla, y reincorporarlos cuando están operacionales nuevamente.

Fallas de particionamientoFallas de particionamiento
Split Brain: el cluster se divide en dos o mas subgrupos autónomos, cada uno de los cuales cree ser el 'sobreviviente'
Amnesia: cuando el cluster rearranca después de una caída con información de configuración inconsistente.
Múltiples Instancias: varias copias de la misma aplicación corriendo en el cluster

Split BrainSplit Brain

Split BrainSplit Brain (cont.) (cont.)
Es una situación que se da cuando un cluster sufre una falla que resulta en la reconfiguración en múltiples particiones, cada una sin conocimiento de la existencia de la(s) otra(s).
Conceptualmente aparecen dos (o mas) clusters que se ignoran mutuamente. Esta situación puede dar lugar a colisiones en la utilización de recursos compartidos, por ejemplo, direcciones de red o almacenamiento compartido. El resultado de esta colisión puede ser catastrófico

Solución al problema “split Solución al problema “split brain”brain”
Quorum device: un dispositivo (gralmente. un disco rígido) de acceso compartido a todos los nodos del cluster, que puede ser “reservado” en forma exclusiva por un nodo. Sólo puede tomar el rol principal de SSI el nodo que detenta la reserva del QD

AmnesiaAmnesia
Es un modo de falla en el cual un nodo arranca con información de configuración del cluster incoherente. Mientras que el cluster está operacional, toda la información acerca del estado del cluster y de sus servicios es mantenida en el CCR, que es la memoria permanente del cluster.La amnesia es un error de sincronización, debido a que la información de configuración no fué propagada consistentemente a todos los nodos. Un ejemplo de esta situación se da cuando un nodo falla y el cluster es reconfigurado, excluyendo al nodo en falla. La información de configuración de este nodo no se actualiza mas, por lo que deviene incoherente con el resto. Si el nodo rearranca y trata de ingresar nuevamente en el cluster, debe resincronizar su información de configuración antes.
Una situación peor puede darse si un nodo falla, el cluster es reconfigurado, mas tarde es sacado de servicio y posteriormente el nodo en falla es reiniciado. En este caso la información de configuración contenida en este nodo se presume correcta y se construye un nuevo cluster con información incoherente.

Instancias MúltiplesInstancias Múltiples
Esta falla ocurre cuando una aplicación está diseñada para operar sobre datos asumiendo acceso exclusivo a los mismos, y se lanzan varias instancias de esa aplicación.
Cuando esto pasa en una computadora existen varias formas de prevenir el problema, usando semáforos, lock files, mutexes, etc.
En un entorno de cluster, la solución es mas dificultosa, dado que hay que chequear en cada nodo la existencia de instancias ya en ejecución.

Failover “En Frío”Failover “En Frío”
Nodo 1 Nodo 2

Failover “En Caliente”Failover “En Caliente”
Nodo 1Nodo 1Instancia ‘A’Instancia ‘A’
Nodo 2Nodo 2Instancia ‘A’Instancia ‘A’

TemarioTemario
Disponibilidad y performance
Tolerancia a Fallas y Alta Disponibilidad
Soluciones
Clusters
Grids
Conclusión

GridsGrids
La baja utilización promedio de muchas computadoras conectadas a la red y su gran difusión alentaron esfuerzos dirigidos a aprovechar el poder de cómputo ocioso
Surge así la idea de procesar grandes lotes de datos subdividiéndolos de forma de procesar cada parte en una computadora distinta, integrante de un “grid”
Un software distribuido en cada nodo permite participar del grid

ArquitecturaArquitectura
Los modelos de grids en uso constan de un nodo coordinador, encargado de la distribución de la carga, y
muchos nodos de procesamiento, que devuelven los resultados al nodo coordinador para su integración.

ConceptosConceptos
Los nodos que integran un grid son implícitamente heterogéneos, tanto en software como hardware
Tienen en común su conectividad a la red y un software que les permite participar del trabajo compartido por el grid
Los nodos pueden desconectarse y reconectarse en forma independiente y no planificada, esto no debe afectar el resultado final

Grids y ClustersGrids y Clusters
Débilmente acoplado
Nodos heterogéneos Alta performance con
bajo costo Interconexión sobre
Internet Utilizado en
aplicaciones de tratamiento masivo de datos que pueden segmentarse
Fuertemente acoplado
Nodos homogéneos
Alta disponibilidad y costo medio/alto
Interconexión de alta capacidad entre nodos
Aplicación genérica
GRIDS CLUSTERS

EjemplosEjemplos
Seti@home: proyecto pionero en los grids de Pcs, http://setiathome.berkeley.edu/ es un experimento científico que utiliza computadoras conectadas a Internet para la búsqueda de inteligencia extraterrestre en datos de radiotelescopios
BOINC de la Univ. De California en Berkeley: llega a mas de 400.000 nodos y 5800 Teraflops

TemarioTemario
Disponibilidad y performance
Tolerancia a Fallas y Alta Disponibilidad
Soluciones
Clusters
Grids
Conclusión

ConclusiónConclusión
● Los Sistemas Distribuidos son susceptibles a las fallas
● Los puntos únicos de falla pueden detener el funcionamiento de todo el SD
● La redundancia y replicación son las técnicas empleadas para atacar el problema
● Agregando sistemas independientes conectados puede conseguirse performance


















