
Análisis Cualitativo de Datos Textuales con AnSWRdiploeio/documentos/answr.pdf · AnSWR,...
46
Análisis Cualitativo de Datos Textuales con AnSWR Analysis Software for Word-Based Records Juan Muñoz Justicia Universitat Autònoma de Barcelona junio de 2003 Versión 2.1
-
Upload
truongtram -
Category
Documents
-
view
213 -
download
0
Transcript of Análisis Cualitativo de Datos Textuales con AnSWRdiploeio/documentos/answr.pdf · AnSWR,...

Análisis Cualitativo de Datos Textuales con AnSWR
Analysis Software for Word-Based Records
Juan Muñoz JusticiaUniversitat Autònoma de Barcelona
junio de 2003
Versión 2.1

© 2003 Juan Manuel Muñoz Justicia. Se permite la copia literal y la distribución de este documento completo, en cualquier soporte, siempre que no se realice con fines comerciales y que se mantenga copia de este aviso
AnsWR
IBM-compatible Qualitative Data Analysis Software Programfor Managing and Analyzing Large, Complex Team-BasedProjects that Integrates Qualitative and QuantitativeTechniques
Produced By:
Centers for Disease Control and Prevention
Division of HIV/AIDS Prevention, NCHSTP
Atlanta, Georgia, U.S.A
Ver 6.4.17
http://www.cdc.gov/nchstp/hiv_aids/software/answr.htm

AnSWR - Introducción
ÍNDICE
Introducción ..........................................................................................1
CAQDAS..........................................................................................................................1 Empezar a trabajar...........................................................................................................2 Datos................................................................................................................................2 Usuarios/Analistas ...........................................................................................................3
Estudios y Proyectos ............................................................................4
Creación de un Estudio....................................................................................................4 Creación de un Proyecto..................................................................................................5 Datos del estudio .............................................................................................................7
Fuentes y Códigos................................................................................9
Definición de Fuentes ......................................................................................................9 Definición de códigos.....................................................................................................11 Relaciones entre elementos...........................................................................................14
Codificación ........................................................................................20
Introducción....................................................................................................................20 Codificar .........................................................................................................................22
Definición de citas ......................................................................................................22 Asignación de Fuentes y Códigos ..............................................................................23 Visualización de la codificación..................................................................................25
Codificar otros tipos de documentos..............................................................................25 Sustitución de frases sensibles......................................................................................28 Recuento de palabras....................................................................................................29
Informes y Formularios .......................................................................31
Formularios ....................................................................................................................31 Archivos externos.......................................................................................................32
Informes .........................................................................................................................33 Opciones generales....................................................................................................34
Opciones de administración ...............................................................38
Preferencias ...................................................................................................................38 System Utilities...............................................................................................................39
Frases sensibles.........................................................................................................39 Recuento de palabras ................................................................................................40
System Administration ...................................................................................................41


AnSWR - Introducción
1
Introducción
El auge que han experimentado en los últimos años las metodologías cualitativas, se ha reflejado no sólo en su utilización por cada vez más investigador@s de diferentes disciplinas y en el incremento del número de publicaciones "cualitativas", sino que también ha venido acompañado, desde hace no demasiados años, de la aparición de toda una serie de herramientas informáticas que tienen como objetivo facilitar el arduo trabajo de la investigación cualitativa.
Como nos recuerda Anselm Strauss, la investigación cualitativa no se ha caracterizado precisamente por la sofisticación de las herramientas de que han dispuesto l@s investigadores para facilitar su trabajo.
"In my graduate student days, there were no tape recorders for making an interviewer's life easier: these arrived after World War II, passing first through the wire recorder stage. These were ponderous machines, only gradually slimming down to today's light models. Many years lafter, following our dreams of computers that would ease our lives as qualitative social researchers, software was devised for us." (Strauss, 1996, 11)
Mientras que la investigación cuantitativa se ha venido beneficiando desde hace años de la revolución informática, no sólo por la posibilidad de disponer de ordenadores personales con cada vez mayores capacidades de procesamiento y almacenamiento de información, sino también por la existencia de potentes programas para el análisis de datos numéricos, el investigador cualitativo ha tenido que conformarse a utilizar los ordenadores en su faceta de procesadores de texto, gestores de bases de datos, o herramientas de representación gráfica. No es hasta inicios de la década de los 80 que empiezan a aparecer los primeros programas informáticos de ayuda al análisis cualitativo (Fielding y Lee, 19982) y tenemos que esperar a mediados y finales de esa década para la aparición de las primeras versiones de los programas más populares hoy en día (The Ethnographer, Nud·ist, Atlas/ti, y más recientemente Nvivo o QUALRUS)
Hoy en día la oferta de este tipo de programas, conocidos con el nombre genérico de CAQDAS (Computer Assisted Qualitative Data Análisis Software), es amplia, ofreciendo prácticamente todos ellos las suficientes herramientas para facilitar el trabajo del analista. Entre esa oferta figura, desde hace unos años, el programa que presento en este manual, AnSWR, desarrollado por la “División of HIV/AIDS Prevention” del “Center for Disease Control and Prevention” (de los Estados Unidos de América) y que presenta, frente a los programas principales, la ventaja de distribuirse de forma gratuita. A cambio, probablemente no tenga la “potencia” de esos otros programas, pero considero que es una opción interesante.
1 Strauss, A. (1996). Introduction. En Mühr, T. Atlas/ti short user manual. London: Scolari. 2 Fielding, N.G. & Lee, R.M. (1998). Computer analysis and qualitative research. London: Sage.
CAQDAS

Juan Muñoz Justicia
2
El desarrollo de un análisis con AnSWR seguirá los pasos mínimos que podemos ver en la Ilustración 1. Éste será el esquema que seguiré de aquí en adelante, ilustrando los diferentes pasos con un ejemplo de una investigación real3.
El programa acepta como entrada de datos para ser codificados datos textuales en formato RTF, TXT y HTML, aunque permite también incluir cualquier otro tipo de datos para su visualización y vinculación con ciertos elementos del programa (ver sección Archivos externos en pág. 32)
3 Íñiguez, L.; Martínez,M.; Muñoz,J.M.; Pallarés,S. y Vázquez,F., 1999. La donació de sang a Catalunya. Bellaterra: Universitat Autònoma de Barcelona
Empezar a trabajar
Ilustración 1. Proceso de análisis
Datos

AnSWR - Introducción
3
Una de las características de AnSWR es el trabajo en equipo, la posibilidad de que diferentes personas trabajen de forma independiente los mismos datos, por lo tanto, cada vez que iniciemos una sesión de trabajo, el programa nos pedirá que identifiquemos al usuario (analista, codificador) con un identificador de usuario y un password4. De esta forma, todo el trabajo que se realice posteriormente quedará relacionado con la persona que lo lleve a cabo.
Si queremos definir un nuevo usuario, simplemente tenemos que introducir el nombre de usuario que queremos utilizar en el futuro y utilizar (obligatoriamente) como password la palabra "NEWUSER". La pantalla que aparecerá a continuación (Ilustración 2) mostrará el identificador que hayamos utilizado (Coder ID), y permitirá introducir los datos del nuevo usuario, incluyendo el nombre completo y el password que utilizará en el futuro.
4 Podemos obviar esta pantalla en las siguientes sesiones activando la casilla “remember password”
Usuarios/Analistas
Ilustración 2. Login. Nuevo usuario

Juan Muñoz Justicia
4
Estudios y Proyectos
AnSWR organiza el trabajo de análisis en Estudios y Proyectos. El Estudio es el "contenedor" principal de una investigación, y en él se incluyen todos los datos relacionados con la misma —transcripción de entrevistas, diarios de campo, notas de trabajo, cuestionarios, datos sobre las fuentes— Cada Estudio debe incluir un mínimo de un Proyecto, el cuál hará uso de todos o parte de los datos incluidos en el Estudio, y en
el que se desarrollará, por ejemplo, el análisis relacionado con algún objetivo concreto de la investigación general. Una investigación que incluya diferentes objetivos, diferentes fases de análisis, o diferentes agrupaciones de datos, estaría compuesta, por lo tanto, de un Estudio y varios Proyectos.
La primera tarea, por lo tanto, consistirá en crear un Estudio. Si al iniciar el programa no existe ninguno, aparecerá automáticamente la ventana Create New Study (Ilustración 4), en la que daremos nombre a nuestro Estudio (sin utilizar espacios en blanco, letras acentuadas ni la letra ñ). A continuación haremos clic en el icono Save Study.
Creación de un Estudio
Ilustración 4. Crear Estudio
ESTUDIO
Proyecto 1 Proyecto 2 Proyecto 3
Objetivo 1 Objetivo 2 Objetivo 3
Entrevista individual 1Entrevista individual 2Entrevista individual 3Entrevista individual 4
Diario de campo 1Diario de campo 2Diario de campo 3
Entrevista grupal 1Entrevista grupal 2
Entrevista individual 1Entrevista grupal 1Diario de campo 1
Objetivo 4
Proyecto 4
ESTUDIO
Proyecto 1 Proyecto 2 Proyecto 3
Objetivo 1 Objetivo 2 Objetivo 3
Entrevista individual 1Entrevista individual 2Entrevista individual 3Entrevista individual 4
Diario de campo 1Diario de campo 2Diario de campo 3
Entrevista grupal 1Entrevista grupal 2
Entrevista individual 1Entrevista grupal 1Diario de campo 1
Objetivo 4
Proyecto 4
Ilustración 3. Estudios y Proyectos

AnSWR - Estudios y Proyectos
5
El usuario que haya creado el estudio quedará definido como "propietario del estudio", y le será asignado automáticamente el estatus de "administrador del estudio", el resto de usuarios que utilicen el estudio tendrán diferente estatus, y por lo tanto diferentes privilegios, que podrán ser cambiados por el administrador (ver sección Opciones de administración en pág. 38)
En la misma ventana de creación del Estudio, Study Location indica el directorio donde se guardarán los datos5 referidos al estudio; si deseamos cambiar su ubicación, podemos utilizar el botón Set Location. Hay que tener presente que el proceso de creación de un nuevo estudio implica la creación automática por parte de AnSWR de una nueva carpeta (directorio), con el mismo nombre que hayamos dado a nuestro estudio, en la dirección que hayamos especificado6.
Por ejemplo, si creamos un nuevo estudio al que identificamos con el nombre de "Donacion", y especificamos como Location la dirección "C:\Mis trabajos\Answr", el resultado será la creación de la carpeta "C:\Mis trabajos\Answr\Donacion\" en la que AnSWR almacenará los datos relativos al estudio "Donacion".
Puesto que se trata de un nuevo Estudio, que no contiene ningún Proyecto, la siguiente pantalla que nos aparecerá será la del Project Wizard (Ilustración 5), que nos irá guiando en los pasos necesarios para crear un nuevo Proyecto. La primera información que se nos solicitará sobre el Proyecto servirá para identificarlo con una etiqueta descriptiva
5 En este caso “datos” hace referencia a los datos internos del programa, no a los datos utilizados para el análisis. 6 Si como estrategia de organización queremos ubicar los archivos de datos en la misma carpeta/directorio en la que tendremos los “datos” del análisis (carpeta del estudio), es
Creación de un Proyecto
Ilustración 5. Crear Proyecto: Definición Proyecto

Juan Muñoz Justicia
6
(New Project Name), una descripción amplia (Project Description), y la descripción de los objetivos de análisis (Analysis Objective).
En nuestro ejemplo, crearemos un proyecto con los siguientes datos:
New Project Name: Donacion_1999
Project Description: Estudio sobre la donación de sangre en Catalunya
Analysis Objective: Identificar los factores que inciden en la disminución de la hemocaptación en Catalunya
De nuevo hay que tener en cuenta que el nombre que demos al Proyecto será utilizado por AnSWR para crear una nueva carpeta "hija" de la carpeta creada anteriormente con el nombre del Estudio. Cada nuevo Proyecto del Estudio Donacion se convertirá en una carpeta subordinada a la carpeta Donacion. Por lo tanto, en nuestro caso el programa creará una carpeta
“Donacion_1999” dentro de la carpeta “Donación”
Una vez identificado el Proyecto, la siguiente pantalla del Project Wizard nos pedirá que identifiquemos los archivos de texto (RTF o TXT) que serán utilizados como datos en ese Proyecto. La adición de archivos al Proyecto se realiza con el botón Add File to Project. Una vez asignados los ficheros, en la pantalla nos aparecerá el nombre de los archivos y la dirección completa (la que hayamos especificado) donde están almacenados. Podemos añadirles una descripción con la opción View/Add/Save File Description or Alias.
conveniente crear primero el estudio y posteriormente copiar los archivos de datos en la carpeta que el programa genera automáticamente)
Ilustración 6. Crear Proyecto: Definir datos
AnSWR - Estudios y Proyectos
7
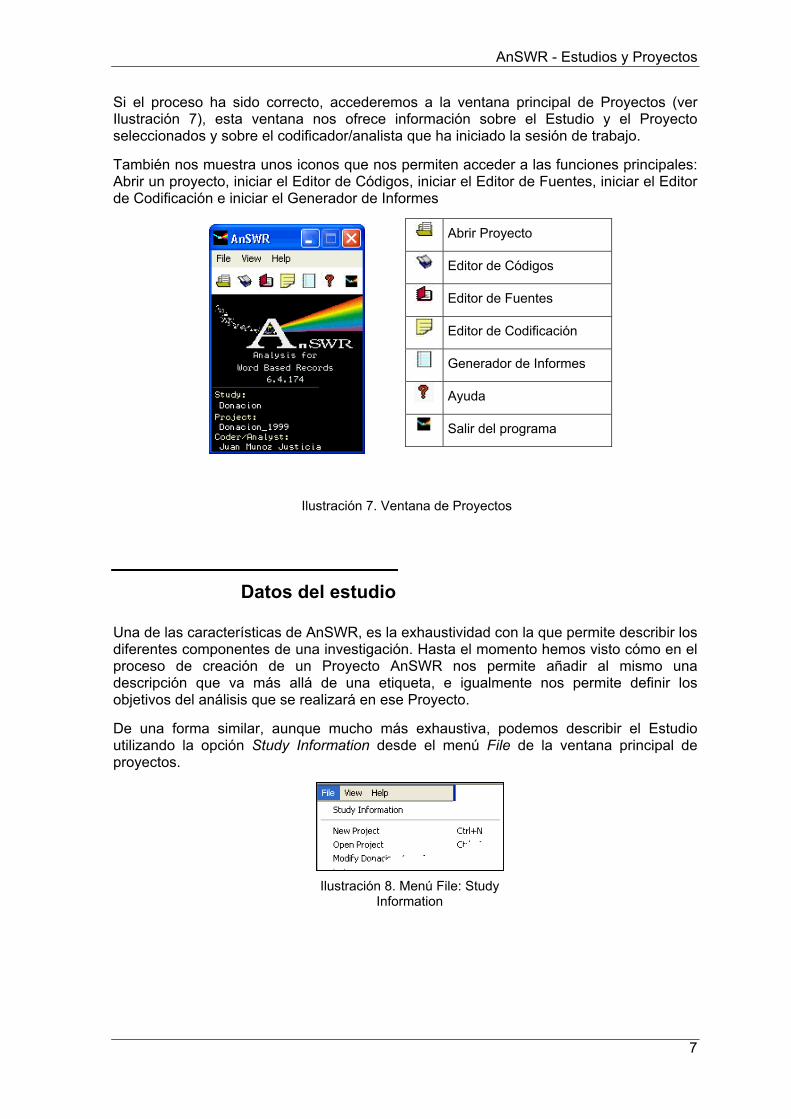
Si el proceso ha sido correcto, accederemos a la ventana principal de Proyectos (ver Ilustración 7), esta ventana nos ofrece información sobre el Estudio y el Proyecto seleccionados y sobre el codificador/analista que ha iniciado la sesión de trabajo.
También nos muestra unos iconos que nos permiten acceder a las funciones principales: Abrir un proyecto, iniciar el Editor de Códigos, iniciar el Editor de Fuentes, iniciar el Editor de Codificación e iniciar el Generador de Informes
Abrir Proyecto
Editor de Códigos
Editor de Fuentes
Editor de Codificación
Generador de Informes
Ayuda
Salir del programa
Una de las características de AnSWR, es la exhaustividad con la que permite describir los diferentes componentes de una investigación. Hasta el momento hemos visto cómo en el proceso de creación de un Proyecto AnSWR nos permite añadir al mismo una descripción que va más allá de una etiqueta, e igualmente nos permite definir los objetivos del análisis que se realizará en ese Proyecto.
De una forma similar, aunque mucho más exhaustiva, podemos describir el Estudio utilizando la opción Study Information desde el menú File de la ventana principal de proyectos.
Ilustración 7. Ventana de Proyectos
Datos del estudio
Ilustración 8. Menú File: Study Information
Juan Muñoz Justicia
8
Nos aparecerá la ventana Study Information Manager (Ilustración 9), en la que se nos ofrece la posibilidad de incluir información sobre
1. Información general sobre el estudio 2. Objetivos de la investigación 3. Preparación de los datos: a) Procedimientos; b) Preparación adicional 4. Equipo de analistas: a) Investigador principal; b) equipo 5. Plan de codificación 6. Convenciones de codificación 7. Miscelánea: a) Fuentes de datos primarios; b) Códigos usados para reducción de
datos
Parece evidente que completar toda esta información supone un esfuerzo importante de tiempo, lo que podría llevar al analista a considerar que esta inversión supone un retraso innecesario para conseguir el resultado deseado con la utilización del programa, es decir, la realización de un análisis.
Creo no obstante que esa inversión puede, en muchos casos, ser positiva, sobre todo en aquellos casos en que el trabajo es realizado por un equipo de analistas, puesto que permitirá tener una información común sobre diferentes aspectos de la investigación (lo cual no siempre es evidente)
Por otra parte, aunque el tipo de información que solicita AnSWR puede que no sea aplicable exactamente a un Estudio concreto, eso no impide que podamos aprovechar la posibilidad del “espacio” que nos ofrece para aportar otro tipo de información que consideremos necesaria.
Ilustración 9. Información del Estudio

AnSWR - Fuentes y Códigos
9
Fuentes y Códigos
Antes de poder iniciar el trabajo de codificación, AnSWR necesita que suministremos información sobre las Fuentes, es decir sobre quiénes nos han proporcionado la información (p.ej. las personas que han sido entrevistadas); e información sobre los
Códigos que utilizaremos con posterioridad en el tratamiento de nuestros datos.
Haciendo un símil con el viejo esquema de la comunicación, podríamos decir que parte del trabajo a desarrollar consistirá en identificar en el texto quién dice qué y cómo. En nuestro caso, quién son las fuentes de información (entrevistados, entrevistadores/observadores, documentos...), qué serían los códigos que utilizamos para conceptualizar el texto, mientras que el texto (o fragmentos de
texto) sería en este caso el cómo.
Haciendo doble click en el icono Sourcebook Editor, accederemos a la pantalla de edición de fuentes, en la que podremos definir las fuentes que participan en nuestro estudio.
Definición de Fuentes
Ilustración 10. Editor de Fuentes
Quién Qué
CómoFuentesFuentes CódigosCódigos
DocumentosDocumentos
Quién Qué
CómoFuentesFuentes CódigosCódigos
DocumentosDocumentos

Juan Muñoz Justicia
10
La pantalla está dividia en dos panales. En el de la izquierda, identificado como Source ID, aparecerán los identificadores de las Fuentes que vayamos añadiendo (botón Add Source); en el de la derecha, identificado como Network for aparecerá nuevamente el identificador de la Fuente seleccionada en ese momento en el panel izquierdo.
El concepto de Network, aplicable tanto a Fuentes como a Códigos, implica la posibilidad de definir estructuras jerárquicas de organización de Fuentes y Códigos. Si en nuestra investigación sobre la donación de sangre hemos realizado, por ejemplo, entrevistas a profesionales de la salud (médicos, enfermeras, PAS), a promotores, voluntari@s y donantes, podemos definir, junto a las fuentes concretas (las personas que han participado específicamente en las entrevistas individuales o grupales), categorías o familias de Fuentes que podemos identificar como Enfermeras, Medicos, Donantes y Promotores. De esta forma, podemos agrupar, bajo la etiqueta Enfermeras a todas las enfermeras entrevistadas, y lo mismo con el resto de categorías. Igualmente, médicos, enfermeras y PAS podríamos agruparlos en la categoría Profesionales, que a su vez podría formar parte, junto con promotores, voluntarios y donantes de una categoría de rango superior, por ejemplo, Entrevistados (Ver Ilustración 10)
Esta agrupación implica no sólo una forma de organizar la información de Fuentes (o Códigos), sino que también será la base a partir de la cual podremos establecer otro tipo de relaciones más complejas entre los diferentes elementos incluidos en un Network (ver Relaciones entre elementos en pág. 14)
La creación de la estructura jerárquica la hacemos arrastrando elementos desde el panel izquierdo al derecho. Para asignar los elementos subordinados de Entrevistadores, por ejemplo, seleccionaremos esta Fuente de forma que aparezca en el panel derecho, a continuación hacemos clik7 en el panel izquierdo, sobre el elemento que queramos ubicar como subordinado (el puntero del ratón cambiará) y lo arrastramos hacia el panel derecho. Este proceso lo realizaríamos, en nuestro ejemplo, con todos los entrevistadores (ENT01, ENT02 y ENT03). A continuación seleccionaríamos la categoría Participantes y arrastraríamos hasta ella la categoría Entrevistadores, y así sucesivamente hasta completar la estructura de relaciones deseada. Una misma fuente puede formar parte de varias estructuras (familias)
Posteriormente, en el proceso de asignación de Fuentes a los datos, podremos asignar tanto los elementos particulares como las categorías que los agrupan, es decir, en nuestro ejemplo, podríamos relacionar un fragmento de texto con la Fuente Entrevistadores: ENT01 o con la Fuente Entrevistadores. Hay que tener en cuenta que la asignación de una fuente al texto diferenciará en función de que escojamos la fuente original o la fuente que forma parte de una estructura. Es decir, un fragmento de texto lo podemos relacionar con la fuente ENT01 y con la fuente Entrevistadores: ENT01, con lo cual habremos asignado dos fuentes a un mismo fragmento de texto (ver más adelante: Codificar)
En algunos casos, puede que prefiramos que la categoría general no pueda ser asignada a fragmentos de texto, para ello, tenemos que darle el carácter de “simple” contenedor de Fuentes con la opción Network Holder del menú Edit. Cuando lo hagamos, la etiqueta de la Fuente cambiará de color (Ilustración 11).
Hay que tener en cuenta que aunque a esta pantalla accedemos desde la pantalla principal de proyectos, y que tenemos un proyecto
7 Sin soltar el ratón, si lo hacemos ese elemento pasará a ser el que aparecerá en el panel derecho
Ilustración 11. Network holder

AnSWR - Fuentes y Códigos
11
activado, las Fuentes que definamos serán Fuentes del Estudio, no del Proyecto. Para que un Proyecto utilice una Fuente, es necesario seleccionar la casilla situada a la izquierda del nombre de la Fuente. Si queremos que todas las Fuentes del Estudio forman parte del proyecto, podemos agilizar el proceso utilizando la opción Add ALL Netowrks to Project del menú Edit.
El proceso de definición de códigos es básicamente similar al de definición de fuentes en cuanto a la forma de creación de los elementos y en cuanto a la forma de creación de las estructuras o familias de códigos. En este caso, llegaremos a la pantalla de definición de códigos utilizando el icono correspondiente o con la opción Codebook Editor del menú File.
La principal diferencia entre ambos tipos de definiciones estriba en que mientras que la definición que hemos realizado de las diferentes Fuentes se ha limitado (por el momento) a identificarlas con una etiqueta, en el caso de los Códigos, siguiendo en la línea de exhaustividad de documentación que hemos visto con los estudios, podemos/debemos
Ilustración 12. Sourcebook Editor. Menú Edit
Definición de códigos
Ilustración 13. Descripción de códigos

Juan Muñoz Justicia
12
ofrecer una descripción más amplia de cada uno de ellos. Para ello, una vez creado el código, (de la misma forma que las fuentes) utilizaremos la opción Edit Network del menú Edit para describirlo.
La pantalla que nos aparece (Ilustración 13) nos permitirá ofrecer una descripción (breve y amplia) del código; especificar cómo lo usaremos, es decir, qué condiciones deben cumplirse para que un fragmento de texto sea codificado con este código en concreto, y en qué condiciones no debe hacerse; y nos permite también ofrecer un ejemplo de texto codificado con este código. En la tabla siguiente podemos ver un ejemplo de definición de un código8.
Código MARGIN
Definición breve
Miembros marginalizados de la comunidad
Definición amplia
Grupos que son percibidos negativamente como social y/o físicamente outsiders a la estructura comunitaria principal. En los grupos marginal izados las fronteras son impuestas por los otros para evitar que los grupos “no favorables” participen o interactúen con los grupos dominantes
Cuándo usar Aplicar este código a todas las referencias a grupos de personas que ha marginal izado el resto de la comunidad. Esas personas o grupos pueden ser descritos como parias, extremistas, radicales, o explícitamente descritos como periféricos, extranjeros, outsiders, estrafalarios, etc.
Cuándo no usar
No usar este código para referirse a grupos institucionalizados por motivos de salud o criminales (ver INSTIT) o para grupos que se han ubicado voluntariamente alejados de la vida de la comunidad (ver SELMFAR)
Ejemplo “Entonces tienes a los parias negros -camellos, yonquis, prostitutas.”
Por último, existe también la posibilidad de definir una "estructura de valores" relacionada con el código, es decir, considerar el código como si fuera una variable de tipo nominal de forma que en el proceso de codificación podamos asignar al texto uno de los valores definidos para la variable.
La definición de los valores de un código está activa únicamente cuando se ha seleccionado la casilla "Code Network Uses Value Structure". Al seleccionar la "pestaña" Values nos aparecerá una pantalla (Ilustración 14) en la que podremos realizar la definición siguiendo los pasos siguientes. En primer lugar especificaremos el rango que tomarán los valores de la variable; a continuación, para cada uno de los valores, haremos click en el botón New Value, lo que nos permitirá escoger el valor, describirlo, y salvarlo. Podríamos, por ejemplo, definir el código Miedo como si fuera una variable con valores del uno al cinco para definir diferentes niveles de miedo a la donación expresados por los participantes en las entrevistas. 8 Adaptado de MacQueen, K., M., McLellan, E., Kay, Kelly & Milstein, B. (1998). Codebook development for team-based qualitative analysis. Cultural Anthropology Methods, 10 (2), 31-36. (accesible en http://www.cdc.gov/hiv/software/pubs/codebook.pdf). Tabla 1 disponible en http://www.cdc.gov/hiv/software/pubs/codetab1.pdf
Tabla 1. Códigos: ejemplo de definición

AnSWR - Fuentes y Códigos
13
Igual que con las Fuentes, podemos definir una estructura jerárquica (Network) de códigos (a la cual también nos referiremos como “familia”), que posteriormente será la base para el establecimiento de relaciones entre códigos.
En la Ilustración 15 podemos ver un ejemplo de la estructuración de los códigos de nuestro estudio. Se ha creado un código que agrupa a diferentes razones que, según los encuestados, pueden favorecer que se realice la donación. Entre ellas se encuentran toda una serie de recompensas que recibe el donante, desde la institución, por el hecho de realizar la donación (agradecimiento, un análisis de sangre gratuito, etc.). Por lo tanto, se ha creado una estructura/familia para el código Recompensa que a su vez se ha incluido como elemento de la estructura/familia Razon_Si.
Lo mismo lo podemos hacer con las razones para no donar sangre, creando una estructura/familia para el código Razon_No. En esa estructura estará incluida, en este
Ilustración 14. Definición de valores de código
Ilustración 15. Jerarquía de códigos

Juan Muñoz Justicia
14
caso, otra familia de códigos que hacen referencia a los diferentes tipos de miedos que pueden dificultar que se realice la donación.
También podemos observar (Ilustración 15) que un mismo código puede pertenecer a dos familias diferentes. En este caso, el código Tiempo ha sido asignado tanto a la jerarquía Razon_Si como a la jerarquía Razon_No, lo cual nos permitirá posteriormente codificar como Razon_Si: Tiempo las intervenciones de los encuestados en las que se hace referencia, por ejemplo, a cómo las Unidades Móviles de recaptación implican una menor inversión de tiempo para realizar la donación; y codificar como Razon_No: Tiempo aquellas en las que se alude al excesivo gasto de tiempo que implica el proceso de donación (por ejemplo en los Bancos de Sangre).
Como hemos visto, tanto en el caso de las Fuentes como para el de los Códigos, podemos definir estructuras de relaciones que permiten agruparlos formando jerarquías de fuentes o de relaciones. En el momento de su creación, esas relaciones son simplemente eso, relaciones que no tienen ninguna otra característica aparte de definir un vínculo entre dos o más elementos.
AnSWR nos ofrece, sin embargo, la posibilidad de definir de una forma mucho más precisa las características de esas relaciones, permitiendo, por ejemplo, “definir que “el código1 es el resultado del código2” o que “el código1 es usado para el código2”. Se trata, por lo tanto, de un trabajo de tipo conceptual que va más allá de la “simple” definición de códigos y que podemos realizar tanto en el momento de su definición, antes de iniciar el trabajo de codificación, como en fases posteriores del análisis, es decir, una vez que hemos iniciado nuestro trabajo de codificación.
Para definir las relaciones, tenemos que seleccionar, desde el editor de códigos o fuentes, el elemento para el que queremos definirlas, hacer clic sobre él con el botón derecho del ratón, y seleccionar la opción Set Relationship/Connection”. En la Ilustración 16 podemos ver cómo, por ejemplo, podemos iniciar el proceso de definición de relaciones para el código Cantidad, miembro de la estructura de códigos Razon_No.
Relaciones entre elementos
Ilustración 16. Definición de relaciones

AnSWR - Fuentes y Códigos
15
A continuación nos aparecerá la primera ventana de definición de relaciones (Ilustración 17, en la que podremos ver, en el caso de que ya existan, las relaciones existentes para el elemento escogido, y/o definir nuevas relaciones.
Los apartados de la ventana del Editor de relaciones son los siguientes:
1) En esta parte de la ventana podremos ver los elementos con los que está relacionado el item seleccionado (en este caso veríamos los códigos con los que está relacionado el código Cantidad).
2) Tipo de relación definida entre el código seleccionado y el código que esté en ese momento seleccionado en (1)
3) Para cada elemento podemos definir dos tipos de relaciones, primarias y secundarias. Este icono permite cambiar la visualización para ver unos u otros tipos de relaciones.
4) Icono para añadir nuevas relaciones
5) Edición de relaciones existentes
6) Borrar la relación seleccionada en 1.
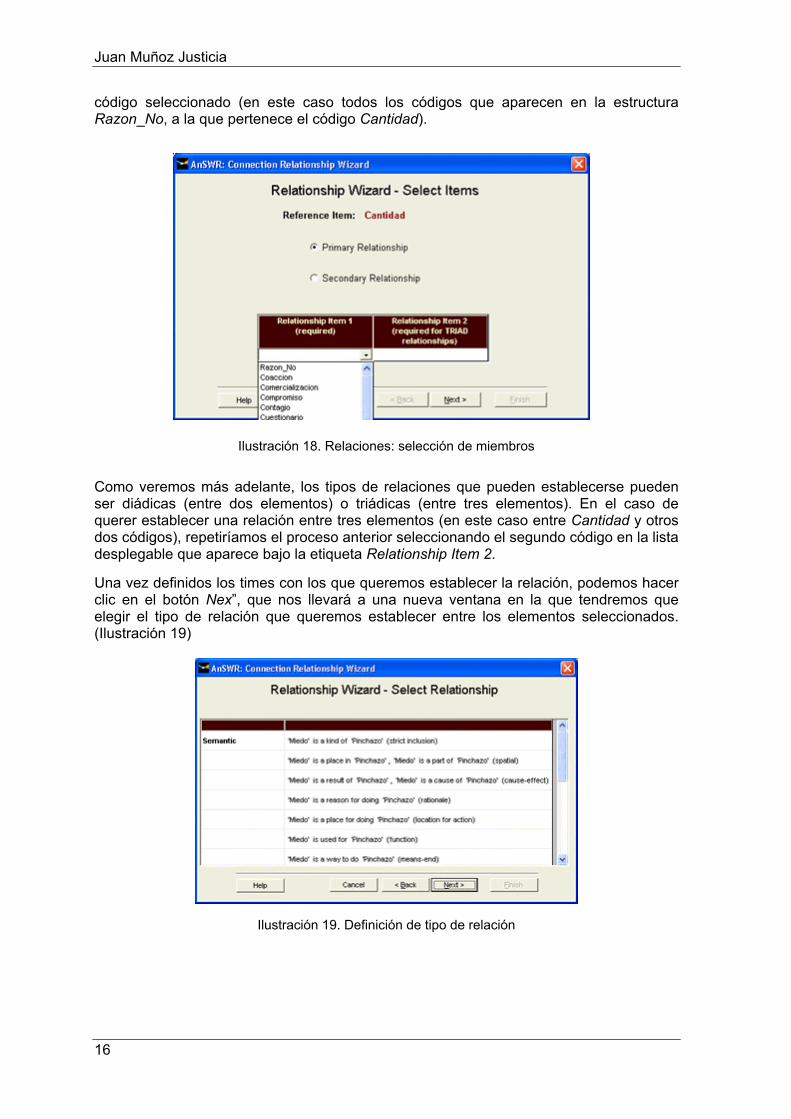
Puesto que hasta el momento no hemos definido ninguna relación, lo primero que haremos será seleccionar el icono de añadir nuevas relaciones (4), lo que hará que nos aparezca una nueva ventana como la que aparece en la Ilustración 18, en la que podremos seleccionar el/los códigos con los que queremos relacionar el código Cantidad.
Como podemos ver en la ilustración, en primer lugar podemos seleccionar entre definición de relaciones primarias o secundarias (por defecto estará seleccionada la opción de definición de relaciones primarias). A continuación tendremos que seleccionar el item con el que queremos establecer la relación. Para ello, haremos clic en la flecha de la lista desplegable que aparece bajo la etiqueta Relationship Item 1 (required), que hará que nos aparezcan la lista de códigos que forman parte de la misma estructura que el
Ilustración 17. Editor de relaciones
Juan Muñoz Justicia
16
código seleccionado (en este caso todos los códigos que aparecen en la estructura Razon_No, a la que pertenece el código Cantidad).
Como veremos más adelante, los tipos de relaciones que pueden establecerse pueden ser diádicas (entre dos elementos) o triádicas (entre tres elementos). En el caso de querer establecer una relación entre tres elementos (en este caso entre Cantidad y otros dos códigos), repetiríamos el proceso anterior seleccionando el segundo código en la lista desplegable que aparece bajo la etiqueta Relationship Item 2.
Una vez definidos los times con los que queremos establecer la relación, podemos hacer clic en el botón Nex”, que nos llevará a una nueva ventana en la que tendremos que elegir el tipo de relación que queremos establecer entre los elementos seleccionados. (Ilustración 19)
Ilustración 18. Relaciones: selección de miembros
Ilustración 19. Definición de tipo de relación

AnSWR - Fuentes y Códigos
17
El tipo de relación que podremos escoger variará en función de si nuestra selección previa es diádica (únicamente entre dos elementos) o triádica (entre tres elementos). Podemos ver los tipos de relaciones en la Tabla 2 y en la Tabla 3, en las que se ilustra un ejemplo de relación entre el código Cantidad y el código Razon_No (en el caso de una relación diádica) y entre el código Cantidad, el código Miedo y el código Razon_No (relación triádica)9.
‘Cantidad’ is a kind of ‘Razon_No’(strict inclusion)
‘Cantidad’ is a place in ‘Razon_No’, ‘Cantidad’ is a part of ‘Razon_No’ (spatial)
‘Cantidad’ is a result of ‘Razon_No’, ‘Cantidad’ is a cause of ‘Razon_No’ (cause-effect)
‘Cantidad’ is a reason for doing ‘Razon_No’ (rationale)
‘Cantidad’ is a place for doing ‘Razon_No’ (location for action)
‘Cantidad’ is used for ‘Razon_No’ (function)
‘Cantidad’ is a way to do ‘Razon_No’ (means-end)
‘Cantidad’ is a step/stage in ‘Razon_No’ (sequence)
Semantic
‘Cantidad’ is an attribute/characteristic of ‘Razon_No’ (attribution)
evaluation of one person by another (e.g., friends, likes, dislikes)
transfer/exchange of material resources (e.g., pigs for yams)
association or affiliation (e.g., same social club, age grade)
behavioral interaction (e.g., talk to one another)
movement between places or statues (e.g. migration, social or physical mobility)
physical connection (e.g., a road, river, or bride connecting two points)
formal relations (e.g., authority)
Relational Tie
biological relationships (e.g., kinship or descent)
symmetrical-bi-directional; mutual reciprocity; ‘Cantidad’ is to ‘Razon_No’ as ‘Razon_No’ is to ‘Cantidad’ ( ‘Cantidad’ <---> ‘Razon_No’)
Dyad
asymmetrical - unidirectional; ‘Cantidad’ is to ‘Razon_No’, but ‘Razon_No’ is not to (‘Cantidad’ ---> ‘Razon_No’or 'Razon_No' ---> 'Razon_No' )
9 Existe la posibilidad de modificar las etiquetas de las relaciones (por ejemplo para que aparezcan en castellano). Para ello, habrá que modificar los valores de la tabla “ConnectionValues” de la base de datos “study30.mdb” que se encuentra en la carpeta del estudio.
Tabla 2. Relaciones diádicas

Juan Muñoz Justicia
18
Para finalizar, una vez seleccionada la relación podemos hacer clic en el botón Next, lo que nos permitirá dar el último paso (opcional) en la definición de las relaciones, añadir un comentario a la relación definida.
Si hemos realizado todos los pasos correctamente, el resultado final será como el que podemos ver en la Ilustración 20, en la que podemos ver cómo hemos definido una relación entre el código Cantidad y el código Razon_No del tipo “es un tipo de” y a la que hemos añadido un comentario que ilustra la relación.
A partir de aquí, podemos cerrar el editor de relaciones o seguir añadiendo relaciones al código origen (Cantidad)
Otros programas de CAQDAS, como por ejemplo Atlas/ti permiten también definir relaciones entre elementos como las que hemos visto aquí, con la diferencia de que probablemente el tipo de relaciones que se pueden establecer son mucho más flexibles, y con la diferencia fundamental de que una vez se han definido relaciones entre elementos éstas pueden visualizarse gráficamente en formas de mapas conceptuales que ilustran perfectamente el trabajo de relación llevado a cabo. Esta opción no existe en AnSWR (espero que sólo por el momento), y la única forma que tenemos de visualizar las relaciones definidas es en forma de listado.
transitive - if ‘Cantidad’ is to ‘Miedo’ and ‘Miedo’ is to 'Razon_No' , then ‘Cantidad’ is to 'Razon_No'
Triad
intransitive ‘Cantidad’ is to ‘Miedo’ and ‘Miedo’ is to 'Razon_No' , but ‘Cantidad’ is not to 'Razon_No'
Tabla 3. Relaciones triádicas
Ilustración 20. Editor de relaciones. Relación definida

AnSWR - Fuentes y Códigos
19
Aunque no pretendo exponer los diferentes modelos de listados, haré una excepción en este caso para mostrar este tipo de listado10. El informe que tendremos que seleccionar es el definido como Study/Project Network Code”, que se encuentra en el grupo Data/Table List Reports (ver los diferentes tipos de informes en la Tabla 4, pág.35). Este informe permite, a su vez, generar un informe simple de los códigos existentes en el proyecto o el informe que nos interesa en este caso, con las relaciones entre códigos (Connection/Relationships Report).
En la Ilustración 21 podemos ver un ejemplo de listado de relaciones, en el que se muestran en este caso las establecidas entre el código Miedo y otros códigos (el listado completo incluirá, a no ser que se haya especificado algún filtro, la lista de todos los códigos para los que se han definido relaciones).
Evidentemente, dado que las relaciones pueden establecerse tanto entre Códigos como entre Fuentes, podemos generar un informe similar para mostrar las relaciones entre Fuentes. Para ello, tendremos que seleccionar el modelo de informe Study/Project Sources, seleccionando de nuevo la opción Connection/Relationships Report”
10 Ver la sección Informes (en pág. 33) para una descripción general de las opciones relacionadas con los informes.
Ilustración 21. Informe de relaciones entre códigos

Juan Muñoz Justicia
20
Codificación
Una vez llegados a este punto podemos por fin empezar a codificar nuestros datos. Para ello abriremos la ventana Coding Editor, utilizando el icono correspondiente o la opción Coding Editor del menú File.
Como podemos ver en la Ilustración 22, la ventana se encuentra dividida en varias secciones: 1) Iconos de control, 2) Iconos de segmentación, 3) Documento activo, 4) visualización de códigos, fuentes y fragmentos definidos, y 5) Selección de documentos.
1) Iconos de control de elementos
Abre el Project Wizard para añadir nuevos documentos al Proyecto
Visualiza en (4) las fuentes previamente definidas (ver Ilustración 23)
Visualiza en (4) los códigos previamente definidos (ver Ilustración 23)
Visualiza en (4) los segmentos de texto definidos en el documento activo (ver Ilustración 23)
Introducción
Ilustración 22. Coding Editor

AnSWR - Codificación
21
Abre el Codebook Editor
Abre el Sourcebook Editor
2) Iconos de creación de segmentos de texto (en adelante “citas”)
Convierte en “cita” el fragmento de texto previamente seleccionado.
Establece el punto de inicio de una cita.
Establece el punto final de una cita
Elimina la cita previamente seleccionada
3) Documento activo
En esta parte de la pantalla podemos visualizar el documento activo (seleccionándolo en [5]). También será aquí donde realizaremos el trabajo de codificación. Los documentos disponibles serán los que previamente hemos asignado al proyecto en la fase de definición del mismo (ver Creación de un Proyecto en pág. 5), aunque también podremos añadir nuevos documentos desde esta ventana haciendo clic en el icono Add File, que abrirá el Project Wizard para añadir nuevos documentos siguiendo los mismos pasos que anteriormente.
Los documentos que podemos añadir siguiendo este procedimiento serán única y exclusivamente documentos TXT (sólo texto) o documentos RTF (texto con formato), aunque como veremos más adelante (ver Relaciones entre elementos en pág. 14) existe la posibilidad de añadir otros tipos de documentos sobre los que podremos realizar el mismo trabajo de codificación que sobre los documentos “propios” del proyecto.
4) Visualización de códigos, fuentes y fragmentos definidos
Como hemos visto anteriormente, en esta parte de la pantalla podemos visualizar los códigos, fuentes y “citas” previamente definidos.
Ilustración 23. Ventanas de información

Juan Muñoz Justicia
22
5) Selección de documentos
Informa de los documentos activos en el proyecto y permite seleccionar el documento de trabajo que se visualizará en (3)
El trabajo de codificación implicará tres pasos: 1) crear o seleccionar una cita, 2) asignar un código a la cita, 3) asignar una fuente a la cita.
Como hemos visto más arriba, para la creación de una cita podemos seguir dos procedimientos
equivalentes, podemos seleccionar un fragmento de texto y hacer clic en el icono Select Segment, o podemos seleccionar el punto de inicio del fragmento de texto, hacer clic en el icono Open Segment y a continuación hacer seleccionar el punto final del fragmento de texto que queremos convertir en cita y hacer clic en el icono Close Segment.
Si la cita se ha creado con éxito, el programa le asignará una etiqueta (un número de orden) y nos recordará que tenemos que relacionar la cita tanto con códigos como con fuentes (ver Ilustración 24). A partir de ese momento, el fragmento de texto que hemos convertido en cita cambiará de color, con lo que podremos reconocerlo como “cita” en la ventana de visualización de documentos. También podremos seleccionar la cita haciendo clic en cualquier parte de la misma o bien seleccionándola en la ventana de información11.
Si una vez que hemos creado una cita seleccionamos un fragmento de texto incluido en la misma y creamos una nueva cita, el programa creará una estructura anidada similar a las que hemos visto anteriormente en el caso de las fuentes y los códigos.
Codificar
Definición de citas
Ilustración 24. Confirmación de segmento
Ilustración 25. Citas anidadas

AnSWR - Codificación
23
Si, por ejemplo, hemos creado una cita seleccionando como fragmento de texto un párrafo completo (y ésta ha sido etiquetada como “1”) y posteriormente seleccionamos una frase que forma parte de ese párrafo y creamos una nueva cita, esta será etiquetada como “1.1”. En la Ilustración 25 podemos ver un ejemplo de citas anidadas: En primer lugar se ha creado una cita seleccionando todo el párrafo (cita 1, en rojo en la imagen), posteriormente se han creado dos nuevas cita seleccionando una de las frase identificadas en azul en la imagen (citas 1.1 y 1.2), y posteriormente se ha creado una nueva cita para el fragmento “perjuicio físico” (identificado en verde en la imagen) que el programa ha etiquetado automáticamente como 1.1.1, puesto que “está dentro” de la cita 1.112.
Una vez que hemos creado una cita, y siguiendo una vez más en la línea de documentación de los elementos creados, podemos añadir “notas de segmento” (Tools Coding Tools Coding Notes, o “F2”), es decir, comentarios específicos para el fragmento seleccionado.
En esta misma ventana podemos añadir “notas de codificación del analista”, que no estarán relacionadas con ninguna cita en particular, sino que serán genéricas del proyecto13.
Es muy importante tener en cuenta que, una vez creadas citas, no debe modificarse el documento original, puesto que esto
impediría que el programa las reconociera correctamente y perderíamos, por lo tanto, todo el trabajo realizado hasta ese momento.
Una vez que hemos definidas citas, podemos pasar a relacionarlas tanto con fuentes como con códigos.
El proceso será idéntico en ambos casos, e implicará 1) seleccionar una cita, 2) seleccionar el código o la fuente en la ventana Code Networks o Source Networks, y 3) arrastrar el código o la fuente sobre la cita seleccionada.
Una vez creada la relación, al seleccionar una cita podremos saber si esta está relacionada con una fuente y/o con un código, puesto que en la parte superior de la
ventana aparecerá seleccionada la casilla de verificación correspondiente. Igualmente, al seleccionar una cita, los códigos o las fuentes relacionados con la misma, aparecerán al inicio de la lista de la ventana correspondiente resaltadas con un color diferente.
11 Como hemos visto anteriormente, la eliminación de una cita la realizamos seleccionándolo y haciendo clic en el botón Delete Segment 12 Si el proceso lo realizamos en forma inversa, es decir, creando primero los “segmentos interiores” y posteriormente el texto que los incluye, el programa reasignará las etiquetas de citas de forma que se mantenga la estructura jerárquica en su identificación. 13 Si una cita tiene asociado un comentario, el icono de la ventana de información (“coded segment) cambiará a
Ilustración 26. Ventana de notas
Asignación de Fuentes y Códigos

Juan Muñoz Justicia
24
Aunque la asignación de Fuentes a los segmentos no es algo imprescindible, puesto que podemos relacionarlos únicamente Códigos, hay que tener presente que en el momento de obtener listados de los fragmentos codificados (por ejemplo el modelo de listado Text-Based Analysis Reports Coded text report) sólo aparecerán en el mismo los fragmentos que tienen asignados Código y Fuente. Para solventar este problema y no necesitar relacionar cada fragmento de texto con una Fuente, podemos utilizar la opción de asignación automática de Fuente, disponible en el menú File de la ventana de codificación (Always apply default Source to coded segments) o bien, en el momento de definición del proyecto, seleccionar la opción Always apply default source when coding en la primera pantalla del Project Wizard (ver Ilustración 5 en pág. 5). Eso hará que en el momento de creación de un fragmento a éste se le asigne la “fuente por defecto”, es decir, “AnSWR”. Podemos cambiarla con la opción Tools Coding Tools View/Change Default Source (también podemos definir la fuente por defecto desde el Editor de Fuentes)
Como recordaremos, en el momento de definición de fuentes y códigos hemos tenido la opción de crear estructuras jerárquicas de códigos y/o fuentes relacionados entre sí. Por ejemplo, como podemos ver en la Ilustración 28, el código “Razon_Si” lo hemos relacionado con otros códigos que recogen las diferentes razones para donar sangre (Acto_Social, Beneficio_Propio, Experiencia...) Uno de esos códigos relacionados (Recompensa) ha sido relacionado a su vez con otros códigos que hacen referencia a los diferentes tipos de recompensas que puede recibir un donante, como por ejemplo Agradecimiento, Análisis, Carnet, Carta y Trato.
Si seleccionamos uno de estos códigos o fuentes, el proceso de relacionarlos con una cita será diferente. En este caso nos aparecerá una ventana como la de la Ilustración 28 en la que se representará la estructura del código o fuente seleccionado y en la que
Ilustración 27. Opciones de asignación automática de fuente
Ilustración 28. Vinculación de estructuras

AnSWR - Codificación
25
podremos relacionar con la cita uno o varios de los elementos de la estructura (haciendo clic en el icono Add Network item to Family). En el ejemplo de la Ilustración 28 podemos ver como se han relacionado con una cita los códigos “Acto social”, “Recompensa” y “Agradecimiento” de la estructura “Razon Si” (el signo más en el icono indica que el código está relacionado con una cita)
Es evidente que a medida que vamos avanzando en nuestro proceso de codificación (relación de citas con
códigos y fuentes), será más difícil “visualizar” y gestionar el trabajo realizado. Una posibilidad para tener un mayor control de ese trabajo es la de generar alguno de los diferentes tipos de informes que ofrece el programa (ver la sección Informes y Formularios en pág. 31), pero también es evidente que no sería nada práctico tener que generar continuamente informes para “ver nuestro trabajo”.
AnSWR ofrece la posibilidad de visualizar, en la misma ventana de codificación, un “sumario” del trabajo realizado hasta ese momento (ver Ilustración 29), en el que se nos informa, para cada cita, de los códigos y fuentes que tiene asignados14. La forma de acceder al mismo es con la opción Display Summary Window del menú Edit (o con la combinación de teclas ctrl.+s)15
Como hemos comentado anteriormente, existe también la posibilidad de codificar documentos que tengan un formato diferente a TXT o RTF. En concreto, podemos codificar documentos HTML e incluso archivos gráficos o de sonido. Para ello, es 14 Una de las opciones del sumario es la de obtener, además, una copia impresa. 15 En el caso de los códigos a los que se les han definido valores “nominales”, la única forma que tenemos de ver los valores asignados a una cita es a través de la ventana de sumario.
Visualización de la codificación
Ilustración 29. Ventana de sumario
Codificar otros tipos de documentos

Juan Muñoz Justicia
26
necesario que esté activada la opción Codificación HTML (ver Preferencias en pág.38). Si hemos activado esa opción, en el menú Tools del Coding Editor tendremos una nueva opción: HTML Coding (ver Ilustración 30)
Al seleccionar la opción Code a HTML document (o utilizando la tecla F4), la ventana principal de codificación cambiará ligeramente (ver Ilustración 31) para permitirnos, en primer lugar, escribir la dirección URL del documento HTML que queremos codificar16. Una vez que veamos el documento en la pantalla, para poder iniciar el proceso de codificación tenemos que hacer clic sobre el icono Add File, lo que hará que dicho documento quede asignado al proyecto en el que estamos trabajando17 (Si la asignación ha sido correcta, aparecerá un mensaje de confirmación)
Una nueva diferencia con el procedimiento utilizado para la codificación de otros tipos de documentos consiste en que para la creación de citas primero tenemos que seleccionar el texto que queremos convertir en cita (igual que antes) para a continuación hacer clic con el botón derecho del ratón sobre la zona seleccionada y seleccionar la opción “copiar”. Sólo entonces podremos hacer clic sobre el icono Select Segment para crear la cita.
También, la visualización de las citas será diferente para este tipo de documentos, pues mientras que en los documentos TXT o RTF al hacer clic sobre alguna etiqueta de cita (en la lista de citas que aparecen en la sección Coded Segment) se accederá
16 También podemos codificar un documento HTML almacenado en nuestro disco duro, para ello simplemente tenemos que escribir la dirección de nuestro disco donde está ubicado dicho documento (p.ej. “c:\mis documentos\documento.htm”) 17 Recuerdo que la asignación de documentos de tipo TXT o RTF se realizaba en el momento de definición del proyecto (Project Wizard) o en cualquier otro momento utilizando la opción “Add File”, sin embargo, este otro tipo de documentos no pueden asignarse directamente al proyecto, tienen que realizarse previamente los pasos que acabo de describir.
Ilustración 30. Menú HTML Coding
Ilustración 31. Codificación HTML

AnSWR - Codificación
27
directamente a la misma (queda seleccionado el documento correspondiente y la cita aparece resaltada en el mismo), en el caso de los documentos HTML la selección de la cita hará igualmente que se seleccione el documento correspondiente pero no quedará seleccionada, sino que aparecerá en una pequeña ventana en la parte inferior de la pantalla. En la Ilustración 32 podemos ver cómo se ha seleccionado la cita 11, correspondiente a un documento HTML que aparece en pantalla, pero en el que no accedemos directamente a la zona del documento en la que se encuentra la cita, sino que la vemos en la parte inferior de la pantalla.
Como hemos podido ver en la Ilustración 30, una de las opciones de codificación cuando nos encontramos en modo de codificación HTML es la de codificar archivos gráficos. Esos archivos pueden ser imágenes existentes en el documento HTML o archivos independientes18, pero en cualquier caso antes de poder proceder a su codificación será necesario guardarlos en disco (si se trata de un documento HTML en línea tendremos que seleccionar la imagen que deseamos codificar, hacer clic sobre ella con el botón derecho del ratón y seleccionar la opción Guardar imagen como...). Una vez que tenemos el archivo gráfico almacenado en disco podemos seleccionar la opción Tools HTML Coding Code Graphic/Sound File; se nos pedirá entonces que seleccionemos el archivo gráfico (previamente archivado) que queremos utilizar y este (toda la imagen) quedará definido como cita.
Igual que ocurría con las citas de texto de los documentos HTML, la selección de la cita no nos permitirá visualizar el archivo gráfico relacionado con la misma, únicamente aparecerá, igual que antes, una referencia al mismo en la parte inferior de la pantalla con el formato siguiente:
ANALYSIS TEXT FOR ID: ~PICTURE:~ C:\Mis trabajos\Soft analisis\Answr\borrar2\Washburn-graph3.gif
18 En este caso, en la zona donde escribimos la dirección del documento HTML escribiremos la dirección del archivo gráfico.
Ilustración 32. Visualización de citas: Documentos HTML

Juan Muñoz Justicia
28
No obstante, si aplicamos códigos y fuentes al gráfico, podremos visualizarlo en el listado Text-Based Análisis Reports Coded Text Report.
Una vez dados estos pasos, podemos proceder a la asignación de fuentes y códigos (tanto para citas de texto HTML como para citas de archivos gráficos) siguiendo el mismo procedimiento que el utilizado para los otros tipos de documentos.
Una característica muy interesante de AnSWR es la posibilidad de definir lo que el programa denomina “Sustitución de frases sensibles”, es decir, la posibilidad de definir texto que por cualquier motivo no queremos que aparezca en los listados y que en su lugar aparezca algún otro texto alternativo. Esto nos permitirá que si queremos ocultar cierta información (nombres de personas por ejemplo) no tengamos que realizar cambios en el documento original, es decir, no tener que hacer la sustitución “físicamente” en el documento que estamos codificando, lo que repercutirá en un mayor nivel de información para el analista.
En la Ilustración 33 podemos ver un ejemplo de listado en el que la palabra “[Ciudad]” está sustituyendo a un nombre de ciudad que ha sido definido como frase sensible. En ese mismo ejemplo, tampoco aparece el nombre del hospital al que se está haciendo referencia (en su lugar aparece “X”), pero en este caso “X” no es una etiqueta que sustituye a una frase sensible. La diferencia entre definir o no frases sensibles la podemos apreciar mejor si vemos cómo en la pantalla de codificación (Ilustración 34) el analista no puede saber directamente a qué hospital se está refiriendo el entrevistado pero sí a qué población.
La definición de frases sensibles la podemos hacer seleccionando el texto, haciendo clic sobre él con el botón derecho del ratón y seleccionar la opción Add text phrase to Substitución Phrase Table del menú contextual que aparecerá. El resto de opciones relacionadas con la sustitución de frases sensibles podrás encontrarlas en el apartado System Utilities, en la pág. 39.
Sustitución de frases sensibles
Ilustración 33. Listado con frase sensible sustituida
Ilustración 34. Cita con y sin "frases sensibles"

AnSWR - Codificación
29
Otra de las opciones disponibles en la ventana de codificación consiste en el recuento de palabras. El recuento puede realizarse sobre un segmento o cita particular o sobre el proyecto en su totalidad, aunque esta última opción consumirá una gran cantidad de tiempo.
Si la opción de recuento de palabras está activada19, ésta se realizará cada vez que creemos un nuevo segmento de nivel superior (es decir, no se realizará si se trata de un segmento incluido dentro de otro), aunque también podemos realizarla seleccionando la opción Proccess Word Count for current ID del menú Tools Word Count Tools (Ilustración 35).
En el caso de que el recuento se realice automáticamente, también aparecerá automáticamente una nueva ventana (Ilustración 36) con la información del número total de palabras y del número de palabras diferentes. Junto a cada palabra aparece un recuadro de confirmación de recuento, de forma que si lo desactivamos, esa palabra no
19 La activación se realiza desde el menú de administración del sistema (ver System Administration en pág. 41)
Recuento de palabras
Ilustración 35. Menú de recuento de palabras
Ilustración 36. Recuento de palabras de segmento

Juan Muñoz Justicia
30
será incluida. Otra acción que podemos realizar sobre este recuento es la de definir “sinónimos”, es decir, hacer que una palabra “recoja” el recuento de otras (que dejarían de aparecer en la lista). Para ello, tenemos que seleccionar la palabra que queremos “borrar” y mantener apretado el botón izquierdo del ratón hasta que el cursor cambie de forma, y entonces hacer clic sobre la palabra “principal”. Estas opciones, eliminar de la lista y creación de sinónimos afectarán única y exclusivamente al segmento seleccionado. Si queremos realizar cambios que afecten a todo un proyecto, tendremos que realizarlos desde el editor de Lista de Exclusiones y Alias de Palabras, una de las opciones de las Utilidades del Sistema (ver System Utilities en pág. 39)
Como podemos ver en la Ilustración 36, la ventana también informa de las fuentes asignadas al segmento. Los cambios anteriores (palabras no activas o sinónimos) afectan únicamente a la fuente seleccionada en el momento de realizarlos, por lo que si una vez realizados los cambios seleccionamos otra fuente, cambiará el recuento que aparece en la parte inferior de la pantalla.

AnSWR - Informes y Formularios
31
Informes y Formularios
Tanto en el caso del Estudio como en el de los Códigos, hemos visto cómo su documentación, su descripción, constituye una fase importante en el proceso de análisis. Siguiendo en esa dirección, otra de las posibilidades que ofrece AnSWR es la de que el usuario pueda definir sus propios formularios de datos para algunos de los elementos que hemos visto hasta el momento. Esto significa que podemos optar por definir tipos de información adicional –referente al codificador/analista, a las fuentes, al estudio y al proyecto– y darle forma de formulario de datos que podremos imprimir posteriormente. A la definición de todos estos formularios podemos acceder mediante la opción System Utilities del menú File.
La pantalla de estas utilidades (Ilustración 37) aparecerá dividida en dos paneles. El situado a la izquierda (Data fields) muestra las variables definidas para el formulario, mientras que el situado a la derecha muestra las variables incluidas en el formulario. En el ejemplo de la Ilustración 37, podemos ver cómo el formulario tiene definidas cuatro variables (Data Fields), Apellido, Location, Nombre y Speaker. Dos de ellas son variables del sistema (Location y Speaker), mientras que las otras dos han sido definidas por el analista. Como podemos ver en la ilustración, las cuatro se incluirán en el formulario, por lo que podremos añadir como información referente a la fuente (en este caso) su nombre y apellidos.
Formularios
Ilustración 37. Creación de Formularios

Juan Muñoz Justicia
32
Los iconos situados debajo del panel Data Fields (Ilustración 38) permiten añadir variables a la lista de variables o al formulario.
Las funciones a las que podemos acceder con los iconos de edición de formulario son las siguientes:
1) Añadir una nueva variable a la lista de variables (aparecerá la pantalla Add New Field)
2) Eliminar variable de la lista de variables
3) Añadir la variable seleccionada al formulario
4) Página siguiente/anterior del formulario
La definición de una nueva variable (icono 1 en Ilustración 38) implicará identificarla con un nombre; elegir el tipo de variable (Textual, numérica, fecha, anotación, sí/no); y el número de caracteres permitidos (Ilustración 39).
Una vez definidos los campos y añadidos al formulario, podemos añadir información a los diferentes codificadores, fuentes...; para cambiar de un codificador/fuente a otro utilizaremos las flechas de dirección, teniendo cuidado que hay que salvar previamente la información introducida.
De entre las informaciones que podemos añadir a los formularios, una especialmente interesante es la
posibilidad de relacionar ficheros externos, de cualquier tipo, con los diferentes codificadores/usuarios, fuentes, etc. Esta opción nos permitiría, por ejemplo, poder acceder fácilmente a un fichero Word en el que tenemos información (relacionada con una fuente), que no queremos analizar y por lo tanto no la incluimos como datos del estudio, pero a la que queremos poder acceder de una forma rápida. Por ejemplo, si nuestra investigación analiza entrevistas a estudiantes y profesores, con esta opción podríamos ver fácilmente los modelos de examen utilizados por los diferentes docentes. Si tuviéramos fotografías digitalizadas de los diferentes participantes (o codificadores), también podríamos “verlos” de una forma fácil y rápida.
Ilustración 38. Iconos Formulario
Ilustración 39. Definir variables en Formularios
Archivos externos

AnSWR - Informes y Formularios
33
En el estudio que venimos trabajando hasta el momento, junto con la transcripción de entrevistas y observaciones se disponía de información documental relacionada con el proceso de donación (folletos, carteles, croquis de la ubicación de los bancos de sangre en los hospitales, señalización, etc....) Aunque no sea necesario analizarla, esa información puede servirnos de ayuda para interpretar algunas intervenciones de los participantes, por lo que una posibilidad sería relacionar esos documentos con el estudio o con el proyecto, de forma que la tengamos fácilmente accesible. Igualmente, podríamos relacionar con el Estudio el guión utilizado en las entrevistas, o incluso el fichero de sonido con la grabación de las entrevistas20.
Al acceder a la ventana de Archivos Relacionados21 (ver Ilustración 40), se nos ofrecerá información (nombre y ubicación) de los archivos relacionados con el Estudio, el Proyecto, el codificador y la Fuente (1) junto a una descripción de los mismos (2) Para añadir relaciones (a ficheros o a direcciones internet [URL]), sólo tenemos que hacer clic sobre el botón Add New External File o Add New External HTML URL (3). Una vez definidas las relaciones, podremos acceder a los ficheros simplemente seleccionándolos y haciendo clic en Open Selected External File (4), lo que hará que se abra el archivo seleccionado con el programa adecuado (con el programa que en la configuración del ordenador esté relacionado con ese tipo de archivos)
Además de los formularios, AnSWR ofrece una gran variedad de posibilidades de informes, por lo que en esta sección no intentaré describirlos, limitándome a ofrecer información genérica sobre cómo podemos generarlos22.
20 Las posibilidades de tipos de archivos que podemos relacionar están limitadas únicamente por la configuración de nuestro ordenador. Podremos acceder a cualquier archivo que podamos ver con los programas que tengamos instalados. 21 A esta ventana podemos acceder desde el editor de formularios haciendo clic en el icono External Files (ver Ilustración 37) o desde el menú principal con la opción File System Utilities External File Utility. 22 Desde la ventana de informes puede accederse fácilmente a la ayuda específica para el informe seleccionado (ver Ilustración 41)
Ilustración 40. Asociar documentos externos
Informes

Juan Muñoz Justicia
34
Para acceder a los diferentes modelos de informes, haremos clic en el icono System Reports. Nos
aparecerá una pantalla (Ilustración 41) en la que se nos irá guiando en los pasos para la selección del informe. En primer lugar (1), elegiremos el Estudio y Proyecto sobre el que queremos realizar el informe. A continuación seleccionaremos el modelo de informe que queremos realizar (2). Una vez seleccionado el tipo de informe, podemos cambiarle el título que AnSWR sugiere por defecto (3). Para que aparezca definitivamente el informe seleccionado, haremos clic en el botón Next (5).
Si en vez de querer crear un nuevo informe queremos acceder a un informe archivado previamente, hemos de seleccionar la casilla Display/Print a saved report (4) antes de hacer clic en Next (5).
Como podemos ver en la sección 2 de la Ilustración 41, existen siete categorías, que nos darán la posibilidad de acceder hasta a un total de 46 diferentes modelos de informe. En la Tabla 4 podemos ver el listado de los diferentes modelos agrupados por categoría.
Data / Table List Reports 1 Study/Project Network Codes 2 Study/Project Coder/Analysts 3 Study/Project Sources 4 Advanced Utility Report 5 Sensitive Phrase Substitution 6 Study Information 7 Project File Information 8 Code Network Tree Report 9 Source Network Tree Report
Opciones generales
Ilustración 41. Informes

AnSWR - Informes y Formularios
35
10 Direct Text Input Report 11 Source Text Listing 12 External File Report
Text-based Analysis Reports 13 Coded Text Report 14 Coding Notes Report
Numeric-based Analysis Reports 15 Network Code Frequency Report 16 Binary Matrix Report 17 Value Matrix Report 18 Coding Combination Reports 19 Salient Coding Pattern Report
Cross-Tab Analysis Reports 20 Source/Source Cross-tab Report 21 Source/Source Cross-tab Report (by Code Network) 22 Code/Source Cross-tab Report (Value-based Fields) 23 Code/Source Cross-tab Report (Boolean-based Fields) 24 Code/Source Cross-tab Report (Text-based Fields) 25 Code/Code Cross-tab Report (Segment Based) 26 Code/Code Cross-tab Report (Source Based)
Coder / InterCoder Analysis Reports 27 Intercoder Text Segment Comparisons ver 1 28 Intercoder Text Segment Comparisons ver 2 29 Intercoder File Summary Comparisons 30 Intercoder Source Kappa Statistics 31 Intercoder File Kappa Statistics 32 Intercoder Segment Kappa Statistics 33 Coder/Analyst Summary Report
Word Count Analysis Reports 34 Word Exclusion/Alias Reports 35 Project-Based Word Counts Report 36 Segment-Based Word Counts
Quality Assurance Reports 37 Coding Segmentation Display 38 Coding Assignment Report 39 Coding Summary Report 40 Code Check Report 41 Code/Coder/Source Usage Report 42 Code Network Check 43 Source Text Assessment 44 Source Check Report 45 Source Network Check 46 ID Code/Source Check Report
Tabla 4. Tipos de informes

Juan Muñoz Justicia
36
Según el tipo de informe seleccionado, lo siguiente que aparecerá será la ventana de Selección de criterios (Ilustración 42), es decir, una ventana en la que se podrán especificar el/los filtro(s) a aplicar al informe. Por lo general, en cada una de las columnas que nos aparecerán (ver Ilustración 43) dispondremos de una lista desplegable con las diferentes posibilidades de selección, que pueden variar en función de los criterios previamente seleccionados.
Por ejemplo, si hemos seleccionado el informe Study/Project Networks Codes, la única posibilidad de selección de tabla (Report Tables) será Codebook, la tabla en la que se almacena toda la información sobre los códigos. Si la seleccionamos, podremos seleccionar el campo sobre el queremos realizar el filtro (Table Fields), el operador lógico para realizarlo (igual, diferente…), y finalmente la condición que queremos que se cumpla (Selection Criteria). En el ejemplo de la Ilustración 43, el filtro definido sería: Informe de códigos en el que se cumpla la condición Código = CódigoA_3.
Si no queremos definir ningún filtro, o si hemos terminado su definición (lo cual puede incluir varias condiciones (líneas de criterios) unidas entre sí con los conectores lógicos Y/O), podemos hacer clic en el botón Next para visualizar el informe.
Ilustración 42. Criterios de selección
Ilustración 43. Elementos de los criterios de selección

AnSWR - Informes y Formularios
37
La pantalla que aparecerá a continuación (Ilustración 44) puede variar según el tipo de informe que estemos realizando, aunque siempre tendrá una estructura similar. La parte izquierda de la ventana (1) variará según el modelo de informe, y en ella se nos ofrecerán diferentes opciones de visualización. En la parte derecha de la ventana tendremos una visualización previa, en formato reducido, del informe (2), junto a opciones de navegación por el mismo, cambio de tamaño, e impresión (3).
También encontraremos en la parte derecha una serie de botones (4) que permitirán la visualización del informe a pantalla completa, la creación del informe (puesto que en algunos tipos el cambio de las opciones de visualización hace necesario generarlo de nuevo), y salvar el informe o cargar uno previamente generado.
Hay que tener en cuenta que la opción salvar/recuperar informes utiliza un formato “propio” (archivo con extensión “vsr”), es decir, que un informe archivado con esta opción no podremos verlo en los editores de texto habituales (Word, WordPerfect…), sólo será legible/visible desde AnSWR. Si lo que queremos es tener una versión del informe en un formato diferente, legible por otros programas, tenemos que, en primer lugar, seleccionar la casilla Create HTML or RTF document (5) (también podemos generar el informe en formato ASCII), seleccionar uno de los formatos disponibles y a continuación hacer clic en el botón Create Report. AnSWR pedirá que le demos un nombre al archivo y lo salvará con el formato deseado.
Por último, existe también la interesante opción de salvar el informe en formato PDF (5).
Ilustración 44. Visualización informes

Juan Muñoz Justicia
38
Opciones de administración
El programa ofrece diferentes opciones que permiten administrar el Estudio y/o el Proyecto, aunque no todas estarán siempre disponibles, puesto que algunas sólo son accesibles para el Administrador del Estudio, es decir, para la persona que lo ha creado. Es por lo tanto muy importante que en el momento de creación de un Estudio prestemos especial atención al nombre de usuario y al password que hemos utilizado en el momento de la creación, puesto que si posteriormente queremos hacer cambios que requieran nivel de administrador, sólo podremos hacerlos si hemos iniciado el programa conectándonos (Login) con los mismos.
Desde el menú File podemos acceder a la ventana Preferences, la cual se encuentra organizada en dos secciones. En la primera, Preferences, podemos modificar algunas opciones generales, mientras que en la segunda, Coder/Analyst Information se nos ofrecerá la información relacionada con el codificador/analista conectado en ese momento, junto con la posibilidad de cambiar su password.
Sólo comentaré algunas de las opciones que considero más interesantes de la primera ventana de preferencias.
Como podemos ver en la Ilustración 45, nos encontramos con un primer apartado de opciones bajo el rótulo Study codebook minimum field preferences, que permiten seleccionar el nivel de exhaustividad que exigirá el programa en la definición de códigos. Como habíamos visto anteriormente (ver Definición de códigos en pág. 11), el programa ofrece la posibilidad de aportar una gran cantidad de información en la definición de los códigos (definición breve, amplia, cuándo usar, cuando no usar...), información que será obligatorio introducir en el caso de dejar desactivadas las casillas de esta sección de preferencias.
Otra opción interesante es la que se sitúa junto a la etiqueta Coding Editor Style. En este caso, se nos ofrece la posibilidad de poder utilizar o no la opción de codificación de documentos HTML. Aunque en apartados anteriores habíamos comentado que el
Preferencias
Ilustración 45. Ventanas de Preferencias

AnSWR - Opciones de administración
39
programa ofrece la posibilidad de trabajar con documentos TXT o RTF, existe también la posibilidad de codificar datos de archivos HTM, e incluso de archivos gráficos o de sonido, aunque no de forma tan directa como los otros tipos de documentos (ver seccón Codificar otros tipos de documentos en pág. 25).
En el menú File System Utilities encontramos las opciones de administración de Frases sensibles y de recuento de palabras.
La opción de Sustitución de Frases Sensibles sólo estará activa si el usuario actual tiene privilegios de
administración. Como vimos anteriormente, esta función permite ocultar determinada información en el momento de generar listados. Si, por ejemplo, no queremos que en los listados puedan aparecer datos “sensibles” como nombres propios de personas (o lugares), podemos con esta función definir un texto alternativo que aparecerá en su lugar en los listados. En el ejemplo de la Ilustración 46 se han definido dos “frases” sensibles, Girona y Joseph Trueta. La primera de ellas sería sustituida en los listados por Nombre ciudad 01 (el texto que aparece en la sección Substitution Phrase. Para añadir nuevas palabras a la lista sólo tenemos que hacer clic en el icono situado a la izquierda en la barra de iconos23.
23 También podemos añadir palabras o frases a la lista directamente desde la ventana Coding Editor.
System Utilities
Ilustración 46. Sustitución de frases sensibles
Frases sensibles

Juan Muñoz Justicia
40
Hay que tener en cuenta que, aunque se haya realizado la definición de frases sensibles, estas no se aplicarán a no ser que el documento o los documentos sobre los que queremos que se apliquen tengan activada esta función. Para ello, en la pantalla de asignación de ficheros al proyecto (a la que accedemos en el momento de definir el proyecto o posteriormente con la opción File Modify xxx Project) tendremos que seleccionar la opción Set File’s SPS Status (para cada uno de los ficheros) que hará aparecer una ventana como la de la Ilustración 48 en la que llevaremos a cabo la definición.
La opción Word Count Administration permite modificar la forma en que el programa procesará el recuento de
palabras (recuerda que el recuento de palabras se realiza desde el Codign Editor, ver Recuento de palabras en pág. 29). La ventana que aparece (ver Ilustración 47) presenta, una vez más dos posibilidades, administrar la lista de exclusión de palabras y administrar la lista de “alias” de palabras.
Ilustración 47. Administración de recuento de palabras
Ilustración 48. Definición de archivos para aplicar SPS
Recuento de palabras

AnSWR - Opciones de administración
41
La administración de la lista de exclusión, permite definir las palabras que no serán incluidas en el recuento, de forma que evitemos que sean contados artículos, pronombres, o cualquier otro tipo de palabra que por sus características no sea de interés para el recuento. La lista predefinida que nos ofrece el programa está en inglés, por lo que si queremos tener nuestra propia lista en otro idioma necesitaremos eliminar las palabras existentes e ir añadiendo las nuestras propias.
En cuanto a la opción de administración de alias de palabras, nos permite definir listas de palabras que serán consideradas como sinónimos de otras a la hora de realizar el recuento. Por ejemplo, para la palabra donación podríamos definir como ‘sinónimos’ donar, donaciones u otra palabras, de forma que, a la hora de realizar el recuento, obtendremos un único resultado para la aparición de todas ellas, es decir, el total de donación será el número de veces que aparezca esa palabra más el número de veces que aparezca donar más el número de veces que aparezca donaciones.
Podemos llegar a las opciones de administración del sistema desde el menú File System Administration. Como es lógico, estas opciones sólo estarán accesibles si el usuario conectado tiene privilegios de administración.
La ventana que aparece (ver Ilustración 49) está organizada en dos secciones. En la primera (Master Code Administration), podemos definir una lista de códigos que no podrán ser modificados por los usuarios (Locked Codes), y que por lo tanto permanecerán invariables a lo largo del análisis a no ser que el administrador vuelva a definirlos como códigos “abiertos” (Unlocked Codes).
La segunda sección (Study Administration) permite definir una palabra de paso necesaria para poder acceder al Estudio, de forma que incluso un usuario registrado con derechos para acceder al programa no pueda acceder a un estudio determinado (para que la definición de password tenga efecto hay que hacer clic en el icono Apply Study
System Administration
Ilustración 49. System Administration

Juan Muñoz Justicia
42
Password Settings). Al intentar abrir un estudio para el que se ha definido un password, aparecerá una nueva ventana de identificación, y sólo se tendrá acceso al Estudio si se introduce el password correcto.
Dentro de esta misma ventana, encontramos también las opciones de gestión de usuarios/analistas. En este caso, podremos elegir en la lista desplegable alguno de los usuarios definidos y modificar su nivel de acceso a los datos, desde el nivel máximo de administrador del estudio al mínimo de “simple” codificador/analista.
Por último, podemos también activar la posibilidad de utilizar la función de recuento de palabras que, como recordaremos, es una opción a la que tendremos acceso desde el Coding Editor pero que sólo estará disponible si previamente hemos seleccionado la casilla correspondiente en esta ventana.











![Sistema LOGÍSTICO Informativa 007 - protocol… · CJ HIV/AIDS - Adulto HIV/AIDS • Criança Gestante HIV+ 3 - Este formulário tem a validade de: Cl 30 dias C] 60 dias Cl 90 dias](https://static.fdocuments.es/doc/165x107/5f2fc6808008175fd648641c/sistema-logstico-informativa-007-protocol-cj-hivaids-adulto-hivaids-a.jpg)






