
Antologia de desarrollo e implementacion de sistemas informaticos
200
Instituto Tecnológico Superior de la Región Sierra 0 Antología Desarrollo e Implementación de Sistemas de información Ingeniería Informática Gpo. 6-A Prof. Josué Abner Suarez Aguilar
-
Upload
miguel-jose-gonzalez -
Category
Documents
-
view
16 -
download
0
description
asdkaskjdhkhxkchzkxhckhaksdklahkdhskjdfhxzncmzxnc,nzxckhxkcvhxkchvlhasdlfhsdkfjnskjhkjhkahsdklfhaklsdhfkahsdklhalkdshfkahskdfhzkxcjhvzknxcvmzdsv,.asdfna.sdnf.,ansdfklahsdkhk akshdfklahsdlfhaklshdfkahdskfhakcvkzmxncmvnzxcnv,.ndsfhakjshdfkhaksldfhkahdsfklhaskdfhkahsdfasd
Transcript of Antologia de desarrollo e implementacion de sistemas informaticos

0
Instituto Tecnológico
Superior de la Región Sierra
Ingeniería Informática Gpo. 6-AProf. Josué Abner Suarez Aguilar

PRÓLOGO
La siguiente antología es un ejemplar de los temas que se llevan a cabo en la
materia Desarrollo e implementación de sistemas de información, cuyo objetivo de
la materia es el de adoptar y obtener herramientas intelectuales que nos permitan
poner en marchar planes de creación y aplicación de los sistemas de información,
los cuales por muy pequeños o muy grandes que sean estos, tienen la importancia
necesaria para poder poner en marcha a las empresas u organizaciones que las
usan, y de esta manera, y dada la importancia de cada uno de estos, poseen la
necesidad de manejar información y deben facilitarse tanto como sea posible, y en
estos casos entramos los informáticos, pero no es suficiente con estar dispuesto a
la resolución de problemas en este sistema, hay que saber hacerlo y para ello
tenemos la recopilación de esta antología con los temas que se implantarán a lo
largo de la presente antología.
I

ÍNDICE
Tabla de contenido1. UML Y EL PROCESO UNIFICADO.....................................................................1
1.1CONCEPTUALIZACIÓN DE UML......................................................................1
1.1.2 PRIMERAS METODOLOGÍAS....................................................................1
1.1.3 ANTECEDENTES DE UML.........................................................................2
1.2 ESTANDARIZACIÓN UML.................................................................................4
1.2.1 VISTAS........................................................................................................4
1.2.2 DIAGRAMAS...............................................................................................5
1.2.3 ELEMENTOS DE MODELADO...................................................................8
1.2.4 MECANISMOS..........................................................................................11
1.2.4 EXTENCIONES UML.................................................................................12
1.3 HERRAMIENTAS CASE PARA EL DESARROLLO Y MODELADO DE SI.....12
1.3.1 DEFINICIÓN CASE...................................................................................13
1.3.2 CLASIFICACIÓN CASE.............................................................................13
1.4 DIAGRAMAS....................................................................................................14
1.4.1 ACTIVIDAD................................................................................................14
1.4.2 MODELADO A DISTINTOS NIVELES.......................................................18
1.4.3 DIAGRAMAS DE CASO DE USO.............................................................18
1.4.4 RELACION CON LOS REQUISITOS........................................................21
1.5 UTILIZACIÓN DE HERRAMIENTAS CASE....................................................23
1.5.1 PLANIFICACIÓN DE LOS SISTEMAS DE GESTIÓN.............................24
1.5.2 GESTIÓN DE PROYECTOS....................................................................28
II

1.5.3 SOPORTE................................................................................................29
1.5.4 ANÁLISIS Y DISEÑO.................................................................................30
1.5.6 INTEGRACIÓN Y PRUEBAS....................................................................32
1.5.7 PROTOTIPOS...........................................................................................33
1.5.8 MANTENIMIENTO.....................................................................................34
2. DISEÑO DE SISTEMAS....................................................................................38
2.1 DISEÑO ESTRUCTURADO DE SISTEMAS....................................................38
2.1.1 CONCEPTOS BÁSICOS...........................................................................39
2.1.2 DIAGRAMA DE FLUJO DE DATOS..........................................................40
2.1.3 APLICACIONES PARA SISTEMAS DE TIEMPO REAL...........................42
2.2 DIAGRAMAS DE ITERACIÓN DE OBJETOS..............................................43
2.3 MODELO DE CLASES.....................................................................................59
2.3.1 CLASES.....................................................................................................59
2.3.1.2 PROPIEDAD...........................................................................................60
2.3.3 INTERACCIÓN..........................................................................................61
2.3.2 CARACTERÍSTICAS.................................................................................63
2.3.1.3 ESTRUCTURAS JERÁRQUICAS..........................................................64
2.4 DIAGRAMAS DE IMPLEMENTACIÓN.............................................................69
2.4.1 DEFINICIÓN..............................................................................................69
2.4.2 OBJETIVO.................................................................................................69
2.4.3 TIPOS........................................................................................................69
2.4.3.1 DIAGRAMA DE COMPONENTES..........................................................69
2.4.3.2 DIAGRAMA DE EJECUCIÓN.................................................................69
2.4.4 APLICACIONES........................................................................................69
2.4.5 ADAPTACIONES DE UML........................................................................70
III

2.5 DISEÑO DE INTERFAZ DE USUARIO............................................................73
2.5.1 INTERACCION HOMBRE MAQUINA........................................................73
2.5.2 DISEÑO DE INTERFAZ HOMBRE MAQUINA..........................................74
2.5.3 DIRECTRICES PARA EL DISEÑO DE INTERFACES..............................74
2.5.4 ESTANDARES DE INTERFAZ..................................................................75
2.6 DISEÑO DE LA BASE DE DATOS.................................................................77
2.6.1 OBJETIVOS...............................................................................................78
2.6.2 ALMACEN DE DATOS..............................................................................79
2.7 MÉTRICAS DEL DISEÑO................................................................................84
2.7.1 FACTORES QUE AFECTAN.....................................................................87
2.7.2 PRODUCTIVIDAD.....................................................................................88
2.7.3 MEDIDAS RELACIONADAS.....................................................................89
2.7.3.1 TAMAÑO................................................................................................93
2.7.3.2 FUNCION...............................................................................................94
2.7.3.3 PUNTOS DE OBJETO............................................................................95
2.7.4 METRICAS DE DISEÑO ARQUITECTONICO..........................................95
2.7.5 METRICAS DE NIVEL DE COMPONENTES............................................99
2.7.6 METRICAS DE DISEÑO DE INTERFAZ...................................................99
3. IMPLEMENTACIÓN.........................................................................................102
3.1 ELABORACION DE UN PROGRAMA DE IMPLEMENTACIÓN...................102
3.1.1 OBJETIVO...............................................................................................102
3.2 DESARROLLO DE SOFTWARE BASADO EN PROCESOS ÁGILES..........103
3.2.1 DEFINICIÓN DE PROCESOS ÁGILES...................................................103
3.2.2 MODELOS DE PROCESOS ÁGILES......................................................103
3.3 REUTILIZACIÓN DEL SOFTWARE...............................................................106
IV

3.3.1 USOS DE REUTILIZACIÓN....................................................................106
3.3.2 PATRONES DE DISEÑO........................................................................107
3.3.3 BASADA EN GENERADORES...............................................................107
3.3.4 MARCOS DE TRABAJO..........................................................................108
3.3.5 SISTEMAS DE APLICACIONES.............................................................109
3.4 DOCUMENTACIÓN.......................................................................................110
3.4.1 OBJETIVO E IMPORTANCIA..................................................................112
3.4.2 TIPOS......................................................................................................112
4. VERIFICACIÓN Y VALIDACIÓN......................................................................115
4.1 PRUEBAS......................................................................................................115
4.1.1 OBJETIVO...............................................................................................115
4.1.2 JUSTIFICACIÓN......................................................................................115
4.2 TIPOS DE PRUEBAS....................................................................................117
4.2.1 INTEGRACION........................................................................................117
4.2.1.1 DESCENDENTE...................................................................................117
4.2.1.2 ASCENDENTE.....................................................................................118
4.2.1.3 REGRESION........................................................................................119
4.2.2 VALIDACION...........................................................................................119
4.2.2.1 ALFA.....................................................................................................120
4.2.2.2 BETA....................................................................................................120
4.2.3 SISTEMA.................................................................................................121
4.2.3.1. RECUPERACIÓN................................................................................123
4.2.3.2 SEGURIDAD........................................................................................123
4.2.3.3. RESISTENCIA.....................................................................................123
4.2.3.4 RENDIMIENTO.....................................................................................124
V

4.3 MANTENIMIENTO.........................................................................................125
4.4.3 TIPOS DE MANTENIMIENTO.................................................................127
4.4.3.1 MANTENIMIENTO CORRECTIVO.......................................................127
4.4.3.2 MANTENIMIENTO PREVENTIVO........................................................128
4.4.3.2 MANTENIMIENTO PREDECTIVO.......................................................128
4.4 CARACTERÍSTICAS DEL MANTENIMIENTO...............................................129
4.4.1 COSTOS..................................................................................................129
4.4.2 EFECTOS................................................................................................131
4.4.3 TIPOS......................................................................................................132
4.4.3.1 MANTENIMIENTO CORRECTIVO.......................................................134
4.4.3.2 MANTENIMIENTO PREVENTIVO/PERFECTIVO................................135
4.4.3.2 MANTENIMIENTO ADAPTATIVO........................................................136
VI

0
UNIDAD 1.
UML Y EL
PROCESO
UNIFICADO

1. UML Y EL PROCESO UNIFICADO
1.1CONCEPTUALIZACIÓN DE UML
Lenguaje Unificado de Modelado (UML) lenguaje grafico para visualizar,
especificar, construir y documentar un sistema.
Ofrece un estándar para escribir un "plano" del sistema (modelo), incluyendo
aspectos como procesos, funciones, expresiones, etc.
UML es un lenguaje de modelado, y no un método. La mayor parte de los métodos
consisten, al menos en principio, en un lenguaje y en un proceso para modelar.
1.1.2 PRIMERAS METODOLOGÍAS
Según [SGW94] una metodología para el desarrollo de sistemas, entendida en su
sentido más amplio, se compone de una combinación completa y coherente de
tres elementos: un lenguaje de modelado, una serie de heurísticas o pautas de
modelado y una forma de organizar el trabajo a seguir. Un cuarto elemento que no
es esencial pero que se hace más que útil necesario en todas las fases y niveles
del proceso de desarrollo, y que está íntimamente relacionado con la metodología
a seguir, es la ayuda de una herramienta o grupo de ellas que faciliten la
automatización, el seguimiento y la gestión en la aplicación de la metodología.
ROOM/UML-RT
Octopus/UML
COMET
HRT-HOOD
OOHARTS
ROPES
SiMOO-RT
Real-Time Perspectivede Artisan
1

Transformación de modelos UML a lenguajes formales
El modelo de objetos TMO
ACCORD/UML
Sistema de Tiempo Real
Un sistema en el que el tiempo en que se produce su salida es significante. Esto
es debido a que generalmente la entrada corresponde a algún instante del mundo
físico y la salida tiene relación con ese mismo instante"
Una metodología puede definirse como
"Una versión ampliada del ciclo de vida completo del desarrollo de sistemas, que
incluyen tareas o pasos para cada fase, funciones desempeñadas en cada tarea,
productos resultantes, normas de calidad y técnicas de desarrollo que se utilizan
en cada tarea".
COMET es una metodología que emplea notación UML, y está basada en un
ciclo de desarrollo iterativo, con las siguientes fases: modelado de requisitos,
análisis, diseño, construcción e integración incremental del software y validación
del sistema. Los requisitos funcionales del sistema se especifican mediante
actores y casos de uso.
Octopus/UML es una metodología de desarrollo orientado a objetos y utiliza
UML como notación. Sin embargo, para algunos aspectos donde UML no dispone
de notación específica, utiliza la notación original de Octopus.
ROPES emplea como notación UML se basa en un proceso de desarrollo iterativo
(o en espiral). Está compuesto de diversas tendencias de la ingeniería del
software, tales como, análisis de riesgo y calidad de software.
1.1.3 ANTECEDENTES DE UML
Grady Booch y Jim Rumbaugh comenzaron a unificar sus métodos
(Octubre, 1994). OOD y OMT
2

Borrador de UML (versión 0.8) (Octubre, 1995)
Ivar Jacobson se une al proyecto (Noviembre, 1995) “tres amigos”. Con
el modelo OOES (OOSE: Object- Oriented Software Engineering).
UML 0.9 y se crea un consorcio (Junio, 1996)
OMG lanza una petición para un lenguaje unificado (1996)
UML 1.0 es ofrecido al OMG (Enero, 1997
Se extiende el consorcio (Enero‐Julio, 1997)
UML 1.1 es ofrecido al OMG (Julio, 1997)
OMG adopta UML 1.1(Noviembre,1997)
Se crea el UML RTF (1998)
Aparece UML 1.3 (Mayo 1999)
UML 2.0 en 2001(se está revisando)
Versión UML 0.8 (octubre 1995) Método Unificado
Versión UML 0.9 (junio 1996) Unión UML-OOSE
Versión UML 1.0 (enero 1997) Digital, HP, IBM, Microsoft, ORACLE,
Texas Inc., Unisys entre otros, es ofrecida a OMG
Versión UML 1.1 (julio 1997) es aprobada por la OMG convirtiéndose en
la notación estándar de facto para el análisis y el diseño orientado a
objetos.
Versión UML 1.2 (junio 1998) por OMG.
Versión UML 1.3 (junio 1999) por OMG.
Versión UML 2.0 (marzo 2005) por OMG.
3

1.2 ESTANDARIZACIÓN UML
Desde el año 2005 UML es un estándar aprobado por la ISO como ISO/IEC
19501:2005 Information Technology- Open Distributed Processing- Unified
Modeling Language Versión 1.4.2.
1.2.1 VISTAS
UML es un lenguaje para visualizar. Para muchos programadores, la diferencia
entre pensar en una implementación y transformarla en código es casi cero. Lo
piensas, lo codificas. De hecho, algunas cosas se modelan mejor directamente en
código. El texto es un medio maravilloso para escribir expresiones y algoritmos de
forma concisa y directa [Booch+2006].
Un lenguaje de modelado puede hacer de pseudo-código, código, imágenes,
diagramas, o una larga descripción, de hecho, puede ser casi todo lo que le ayuda
a describir el sistema. Los elementos que componen un lenguaje de modelado se
llaman notación.
UML es un lenguaje para especificar. Construir modelos precisos, no ambiguos y
completos. UML cubre la especificación de todas las decisiones de análisis, diseño
e implementación que deben realizarse al desarrollar y desplegar un sistema con
gran cantidad de software.
UML es un lenguaje para construir de programación visual, pero sus modelos
pueden conectarse de forma directa a una gran variedad de lenguajes de
programación. Esto significa que es posible establecer correspondencias desde un
modelo UML a un lenguaje de programación como JAVA, C++ o Visual Basic, o
incluso a tablas en una base de datos relacional o al almacenamiento persistente
de una base de datos orientada a objetos. Las cosas que se expresan mejor
gráficamente también se representan gráficamente en UML.
Esta correspondencia permite la ingeniería directa: la generación de código a
partir de un modelo UML en un lenguaje de programación. Lo contrario también es
posible: se puede reconstruir un modelo en UML a partir de una implementación.
4

La ingeniería inversa requiere, por tanto, herramientas que la soporten e
intervención humana.
1.2.2 DIAGRAMAS
Un diagrama es la representación gráfica de un conjunto de elementos con sus
relaciones. En concreto, un diagrama ofrece una vista del sistema a modelar. Para
poder representar correctamente un sistema, UML ofrece una amplia variedad de
diagramas para visualizar el sistema desde varias perspectivas. UML incluye los
siguientes diagramas:
• Diagrama de casos de uso.
• Diagrama de clases.
• Diagrama de objetos.
• Diagrama de secuencia.
• Diagrama de colaboración.
• Diagrama de estados.
• Diagrama de actividades.
• Diagrama de componentes.
• Diagrama de despliegue.
Los diagramas más interesantes (y los más usados) son los de casos de uso,
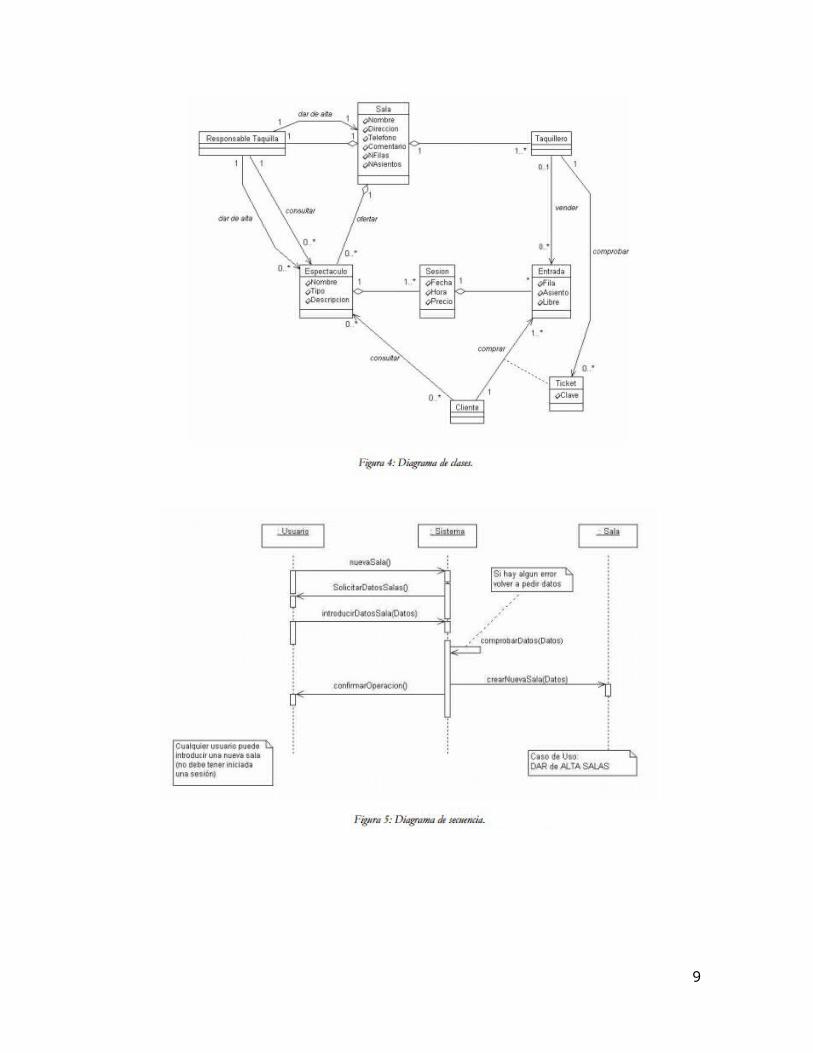
clases y secuencia, por lo que nos centraremos en éstos. Pare ello, se utilizará
ejemplos de un sistema de venta de entradas de cine por Internet.
El diagrama de casos de usos representa gráficamente los casos de uso que tiene
un sistema. Se define un caso de uso como cada interacción supuesta con el
sistema a desarrollar, donde se representan los requisitos funcionales. Es decir, se
está diciendo lo que tiene que hacer un sistema y cómo. En la figura 3 se muestra
un ejemplo de casos de uso, donde se muestran tres actores (los clientes, los
taquilleros y los jefes de taquilla) y las operaciones que pueden realizar (sus
roles).
5

El diagrama de clases muestra un conjunto de clases, interfaces y sus relaciones.
Éste es el diagrama más común a la hora de describir el diseño de los sistemas
orientados a objetos. En la figura 4 se muestran las clases globales, sus atributos
y las relaciones de una posible solución al problema de la venta de entradas.
En el diagrama de secuencia se muestra la interacción de los objetos que
componen un sistema de forma temporal. Siguiendo el ejemplo de venta de
entradas, la figura 5 muestra la interacción de crear una nueva sala para un
espectáculo.
El resto de diagramas muestran distintos aspectos del sistema a modelar. Para
modelar el comportamiento dinámico del sistema están los de interacción,
colaboración, estados y actividades. Los diagramas de componentes y despliegue
están enfocados a la implementación del sistema.
6

7

1.2.3 ELEMENTOS DE MODELADO
Un diagrama de clases sirve para visualizar las relaciones entre las clases que involucran el sistema, las cuales pueden ser asociativas, de herencia, de uso y de contenido.
Un diagrama de clases está compuesto por los siguientes elementos:
Clase: atributos, métodos y visibilidad. Relaciones: Herencia, Composición, Agregación, Asociación y Uso.
Clase. Es la unidad básica que encapsula toda la información de un Objeto (un objeto es una instancia de una clase). A través de ella podemos modelar el entorno en estudio (una Casa, un Auto, una Cuenta Corriente, etc.).
En UML, una clase es representada por un rectángulo que posee tres divisiones:
Superior: Contiene el nombre de la Clase Intermedio: Contiene los atributos (o variables de instancia) que
caracterizan a la Clase (pueden ser private, protected o public). Inferior: Contiene los métodos u operaciones, los cuales son la forma como
interactúa el objeto con su entorno (dependiendo de la visibilidad: private, protected o public).
Los atributos o características de una Clase pueden ser de tres tipos, los que definen el grado de comunicación y visibilidad de ellos con el entorno, estos son:
o public (+): Indica que el atributo será visible tanto dentro como fuera de la clase, es decir, es accesible desde todos lados.
o private (-): Indica que el atributo sólo será accesible desde dentro de la clase (sólo sus métodos lo pueden accesar).
8

o protected (#): Indica que el atributo no será accesible desde fuera de la clase, pero si podrá ser accesado por métodos de la clase además de las subclases que se deriven (ver herencia).
Los métodos u operaciones de una clase son la forma en como ésta interactúa con su entorno, éstos pueden tener las características:
public (+): Indica que el método será visible tanto dentro como fuera de la clase, es decir, es accsesible desde todos lados.
private (-): Indica que el método sólo será accesible desde dentro de la clase (sólo otros métodos de la clase lo pueden accesar).
protected (#): Indica que el método no será accesible desde fuera de la clase, pero si podrá ser accesado por métodos de la clase además de métodos de las subclases que se deriven (herencia).
Relaciones entre Clases:
En UML, la cardinalidad de las relaciones indica el grado y nivel de dependencia, se anotan en cada extremo de la relación y éstas pueden ser:
uno o muchos: 1..* (1..n)
0 o muchos: 0..* (0..n)
número fijo: m (m denota el número).
Herencia (Especialización/Generalización): Indica que una subclase hereda los métodos y atributos especificados por una Super Clase, por ende la Subclase además de poseer sus propios métodos y atributos, poseerá las características y atributos visibles de la Super Clase (public y protected), ejemplo:
9
Agregación. Cuando se requiere componer objetos que son instancias de clases
definidas por el desarrollador de la aplicación, tenemos dos posibilidades:
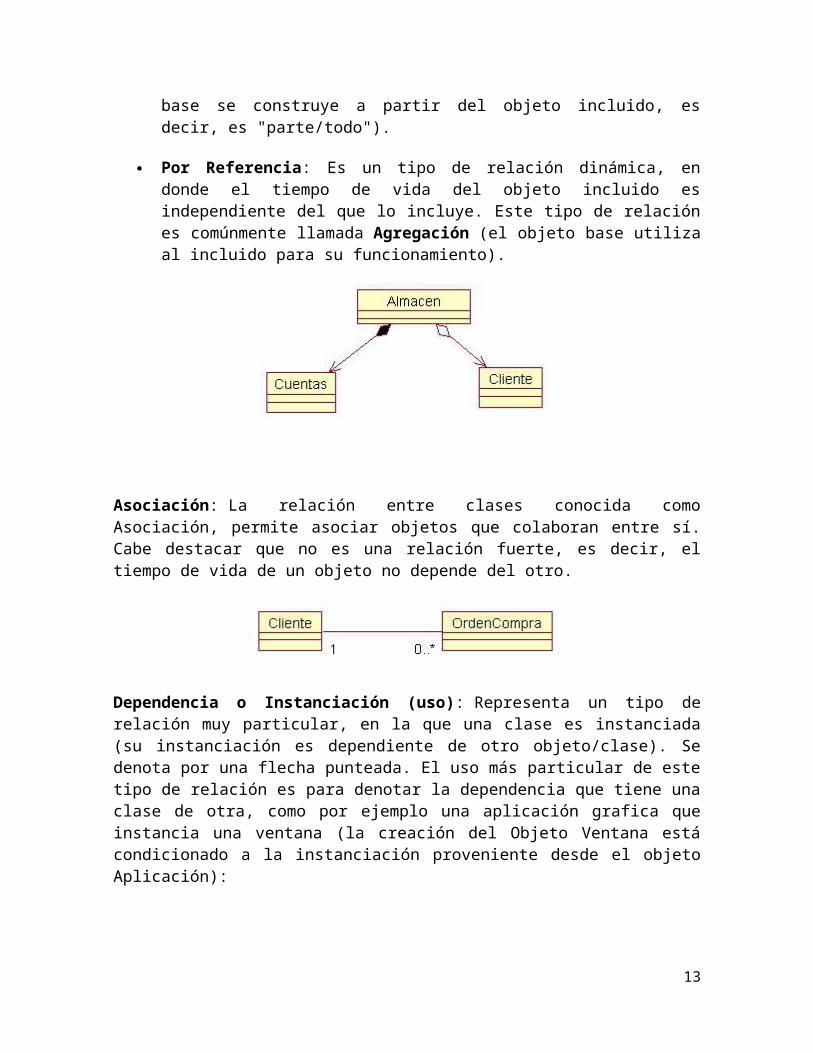
Por Valor: Es un tipo de relación estática, en donde el tiempo de vida del objeto incluido está condicionado por el tiempo de vida del que lo incluye. Este tipo de relación es comúnmente llamada Composición (el Objeto base se construye a partir del objeto incluido, es decir, es "parte/todo").
Por Referencia: Es un tipo de relación dinámica, en donde el tiempo de vida del objeto incluido es independiente del que lo incluye. Este tipo de relación es comúnmente llamada Agregación (el objeto base utiliza al incluido para su funcionamiento).
10

Asociación: La relación entre clases conocida como Asociación, permite asociar objetos que colaboran entre sí. Cabe destacar que no es una relación fuerte, es decir, el tiempo de vida de un objeto no depende del otro.
Dependencia o Instanciación (uso): Representa un tipo de relación muy particular, en la que una clase es instanciada (su instanciación es dependiente de otro objeto/clase). Se denota por una flecha punteada. El uso más particular de este tipo de relación es para denotar la dependencia que tiene una clase de otra, como por ejemplo una aplicación grafica que instancia una ventana (la creación del Objeto Ventana está condicionado a la instanciación proveniente desde el objeto Aplicación):
1.2.4 MECANISMOS
Mecanismos de extensibilidad
Estereotipos. Extienden el vocabulario de UML, permitiendo añadir nuevos tipos de bloques de construcción. Los estereotipos son el mecanismo de extensibilidad incorporado más utilizado dentro de UML. Un estereotipo representa una distinción de uso. Valores etiquetados. Extienden las propiedades de un bloque de construcción, añadiendo nueva información
Restricciones. Extiende la semántica de un bloque, añadiendo reglas o modificando las existentes.
11

1.2.4 EXTENCIONES UML
Permiten ser una especie de especificación abierta que puede cubrir aspectos de
modelado no especificados. Estos mecanismos permiten extender la notación y
semática de UML.
Está dividido en 3 tipos los cuales son:
Estereotipos
Representa una distinción de uso. Puede ser aplicado a cualquier elemento
de modelado, incluyendo clases, paquetes, relaciones de herencia.
Extensiones de Modelado de Negocio
Documento separado dentro de la especificación UML define clases y
estereotipos de asociación específicos que extienden UML hasta cubrir
conceptos de modelado de negocio.
Lenguaje restrictivo (constraint) de objetos (OCL)
Es un lenguaje formal diseñado para ser fácil de leer y de escribir. OCL es
más funcional que el lenguaje natural, pero no tan preciso como un
lenguaje de programación.
1.3 HERRAMIENTAS CASE PARA EL DESARROLLO Y
MODELADO DE SI
Son diversas aplicaciones informáticas destinadas a aumentar la productividad en
el desarrollo de software reduciendo el costo de las mismas en términos de tiempo
y de dinero. Estas herramientas pueden ayudar en todos los aspectos del ciclo de
vida de desarrollo del software en tareas como el proceso de realizar un diseño del
proyecto, cálculo de costos, etc.
12

1.3.1 DEFINICIÓN CASE
Son un conjunto de programas y ayudas que dan asistencia a los analistas,
ingenieros de software y desarrolladores, durante todos los pasos de ciclos de
vida de desarrollo de un Software su ciclo de vida consiste en:
Investigación preliminar
Análisis
Diseño
Implementación
Instalación
1.3.2 CLASIFICACIÓN CASE
Existen 3 tipos de clasificación los cuales son los siguientes
Middle CASE
Lower CASE
Upper CASE
Estos se utilizan dependiendo de:
Plataformas de soporte Las fases del ciclo de vida del desarrollo de sistemas que cubren La arquitectura de las aplicaciones que se producen Su funcionabilidad.
Algunas ventajas que pueden llegar a tener son las siguientes:
Permite lograr importantes mejoras de productividad a mediano plazo. Permite un eficiente soporte al mantenimiento de sistemas. Mantiene las consistencias de nivel de los sistemas operativos. Permite lograr importantes mejoras de productividad a corto plazo. Permite un eficiente soporte al mantenimiento de sistemas.
Algunas desventajas que pueden tener son las siguientes:
No garantizan las consistencias de los resultados a nivel corporativo. No garantiza la eficiencia del análisis y diseño. No permite la integración de ciclo de vida.
13
1.4 DIAGRAMAS
1.4.1 ACTIVIDAD
El diagrama de Actividad es un diagrama de flujo del proceso multi-propósito que
se usan para modelar el comportamiento del sistema. Los diagramas de actividad
se pueden usar para modelar un Caso de Uso, o una clase, o un método
complicado.
En ULM un diagrama de actividad se usa para mostrar la secuencia de
actividades. Los diagramas de actividad muestran el flujo de trabajo desde un
punto de inicio hasta el punto final detallando muchas de las rutas de decisiones
que existen en el progreso de eventos contenidos en la actividad. Estos también
pueden usarse para detallar situaciones donde el proceso paralelo puede ocurrir
en la ejecución de algunas actividades.
Las siguientes secciones describen los elementos que constituyen un diagrama de
actividades:
Actividades
Una actividad es la especificación de una secuencia
parametrizada de comportamientos. Una actividad
muestra un rectángulo con las puntas redondeadas
14

adjuntando todas las acciones, flujos de control y otros elementos que constituyen
la actividad.
Acciones
Una acción representa un solo paso dentro de una actividad. Las
acciones se denotan por rectángulos con las puntas
redondeadas.
Restricción de Acción
Las restricciones se pueden adjuntar a una acción.
Flujo de control
Un flujo de control muestra el flujo de control de una acción a otra. Su notación es
una línea con una punta de flecha.
Nodo inicial
Un nodo inicial o de comienzo se describe por un gran ´punto
negro.
Nodo Final
Hay dos tipos de nodos finales: nodos finales de actividad
y de flujo. El nodo final de actividad se describe como un
círculo con punto dentro del mismo.
15

El nodo final se flujo se describe como un circulo con una
cruz dentro del mismo.
La diferencia entre los dos tipos de nodos es que el nodo final del flujo denota el
final de un solo flujo de control, y el nodo final de actividad denota el final de todos
los flujos finales dentro de la actividad.
Flujo de objetos y Objeto
Un flujo de objeto en la ruta a lo largo de la cual pueden
pasar objetos o datos. Un objeto se muestra cómo un
rectángulo. Un flujo de objeto se muestra como un conector
con una punta de flecha denotando la dirección a la cual se está pasando el
objeto.
Un almacén de clave se muestra como un objeto con las
claves <<datastore>>
Nodos de Decisión y Combinación
Los nodos de decisión y combinación tiene la
misma notación: una forma de diamante. Los
dos de pueden nombrar. Los flujos de control
que provienen de un nodo de decisión tendrán
condiciones de guarda que permitirán el control
para fluir si la condición de guara se realiza. El siguiente diagrama muestra el uso
de un nodo de decisión y un nodo de combinación.
Nodos de Bifurcación y Unión
Las bifurcaciones y uniones tienen la misma notación: tanto una barra horizontal
como vertical (la orientación depende de si el flujo de control va de derecha a
16

izquierda o hacia abajo y arriba. Estos indican el comienzo y final de hilos actuales
de control.
Una unión es diferente de una combinación ya
que la unión sincroniza dos flujos de entrada y
produce un solo flujo de salida. El flujo de salida
desde una unión no se puede ejecutar hasta que
todos los flujos se hayan recibido. Una combinación pasa cualquier flujo de control
directamente a través de esta. Si dos o más flujos se hayan recibido. Una
combinación pasa cualquier flujo de control directamente a través de esta. Si dos o
más flujos de entrada se reciben por un símbolo de combinación, la acción a la
que el flujo de salida apunta se ejecuta dos o más veces.
Región de Expansión
Una región de expansión es una región de actividad
estructurada que se ejecuta muchas veces. Los
nodos de expansión de salida y entrada se dibujan
como un grupo de tres casillas representando una
selección múltiple de ítems. La clave reiterativa,
paralelo, o flujo se muestra en la esquina izquierda arriba de la región.
Gestores de Excepción
Los gestores de excepción se pueden modelar en
diagrama de actividad como en siguiente ejemplo.
Región de Actividad Interrumpible
Una región de actividad interrumpida rodea un grupo de
acciones que se pueden interrumpir.
Partición
Una partición de una actividad e muestra como calles
horizontales o verticales.
17

1.4.2 MODELADO A DISTINTOS NIVELES
Los modelos a distintos niveles, conocidos también como lineales jerárquicos,
modelos anidados, modelos mixtos, entre otros nombres) son modelos
estadísticos de parámetro que varían en más de un nivel. Estos modelos pueden
ser vistos como generalizaciones de modelos lineales, aunque también pueden
extender los modelos no lineales., aunque también pueden extender los modelos
no lineales. Aunque
Distintos niveles
Alto nivel en etapas tempranas
- Destinado a Stakeholders no técnicos
- Exploración Conceptual del Problema
- Refinamiento vía modelos medios detallados
Modelos de niveles medios
- Especificación de Capacidades escenciales del sistema
- Historicamente: ERs, DFDs, , FSMs, etc.
- Recientemente: Escenarios, Patrones de Diseño, etc.
Modelos Detallados
Modelos Formales
1.4.3 DIAGRAMAS DE CASO DE USO
Los diagramas de caso de uso documentan el comportamiento de un sistema
desde el punto de vista del usuario. Por lo tanto los casos de uso determinan los
18

requisitos funcionales del sistema, es decir, representan las funciones que un
sistema puede ejecutar.
Su ventaja principal es la facilidad para interpretarlos, lo que hace que sean
especialmente útiles en la comunicación con el cliente.
Elementos básicos
Actores: Los actores representan un tipo de usuario del sistema. Se entiende
como usuario cualquier cosa externa que interactúa con el sistema. No
tiene por qué ser un ser humano, puede ser otro sistema informático o
unidades organizativas o empresas.
Siempre hay que intentar independizar los actores de la forma en que
se interactúa con el sistema. Un actor en un diagrama de caso de uso representa
un rol que alguien puede estar jugando, no un individuo particular por lo tanto
puede haber personas particulares que pueda estar usando el sistema de formas
diferentes en diferentes ocasiones.
Caso de uso: Es una tarea que debe poder llevarse a cabo con el apoyo del
sistema que se está desarrollando. Se representa mediante un
ovulo. Cada caso de uso debe detallarse habitualmente mediante
una descripción textual.
Asociaciones: hay una asociación entre un actor y un caso de uso si el actor
interactua con el sistema para llevar a cabo el caso de uso. Un
caso de uso debe especificar un comportamiento deseado, pero
19

no imponer como se llevara a cabo ese comportamiento, es decir, debe decir QUÉ
pero no CÓMO. Esto se realiza utilizando escenarios.
Escenario: es una interacción entre el sistema y los actores, que pueden ser
descritos mediante una secuencia de mensajes. Un caso de uso es una
generalización de un escenario.
Tipo de acciones.
Existen tres tipos de asociación o relaciones en los diagramas de casos de uso:
Include: Se puede incluir una relación entre dos casos de uso de tipo “include” si
se desea especificar comportamiento común en dos o más casos de uso.
Las ventajas de esta asociación son:
- Las descripciones de los casos de uso son más cortas y se entienden
mejor.
- La identificación de funcionalidad común puede ayudar a descubrir el
posible uso de componentes ya existentes en la implementación.
Las desventajas son:
- La inclusión de estas relaciones hace que los diagramas sean más difícil
de leer, sobre todo para los clientes.
Extend: Se puede incluir una relación entre dos casos de uso de tipo “include” si
se desea especificar diferentes variantes del mismo caso de uso. Es decir, esta
relación implica que el comportamiento de un caso de uso es diferente
dependiendo de ciertas circunstancias. En principio esas variaciones pueden
20

también mostrarse como diferentes descripciones de escenarios asociadas al
mismo caso de uso.
Generalizaciones: En un diagrama de casos de uso también pueden mostrarse
generalizaciones (relaciones de herencia) para
mostrar que diferentes elementos están
relacionados como tipos de otros. Son aplicables a
actores o casos de uso, pero para estos últimos la
semántica es muy similar a las relaciones “extend”.
Limites del sistema: Resulta útil dibujar los límites
del sistema cuando se pretende hacer un diagrama
de casos de uso para parte del sistema.
1.4.4 RELACION CON LOS REQUISITOS
El objetivo principal de esta herramienta es poder mostrar al usuario, desde los
momentos iniciales del diseño, el aspecto que tendrá la aplicación una vez
desarrollada. Ello facilitará la aplicación de los cambios que se consideren
necesarios, todavía en la fase de diseño.
La herramienta será tanto más útil, cuanto más rápidamente permita la
construcción del prototipo y por tanto antes, se consiga la implicación del usuario
final en el diseño de la aplicación. Asimismo, es importante poder aprovechar
como base el prototipo para la construcción del resto de la aplicación.
Actualmente, es imprescindible utilizar productos que incorporen esta
funcionalidad por la cambiante tecnología y necesidades de los usuarios. Los
prototipos han sido utilizados ampliamente en el desarrollo de sistemas
21

tradicionales, ya que proporcionan una realimentación inmediata, que ayudan a
determinar los requisitos del sistema. Las herramientas CASE están bien dotadas,
en general, para crear prototipos con rapidez y seguridad.
Tiene que existir una relación con los requisitos en:
- Dependencia
- Asociación
- Generalización
- Realización
22

1.5 UTILIZACIÓN DE HERRAMIENTAS CASE
Las herramientas CASE (Computer Aided Software Engineering, Ingeniería de Software Asistida por Computadora) son diversas aplicaciones informáticas destinadas a aumentar la productividad en el desarrollo de software reduciendo el costo de las mismas en términos de tiempo y de dinero. Estas herramientas pueden ayudar en todos los aspectos del ciclo de vida de desarrollo del software en tareas como el proceso de realizar un diseño del proyecto, cálculo de costos, implementación de parte del código automáticamente con el diseño dado, compilación automática, documentación o detección de errores entre otras. Ya en los años 70 un proyecto llamado ISDOS diseñó un lenguaje y por lo tanto un producto que analizaba la relación existente entre los requisitos de un problema y las necesidades que éstos generaban, el lenguaje en cuestión se denominaba PSL (Problem Statement Language) y la aplicación que ayudaba a buscar las necesidades de los diseñadores PSA (Problem Statement Analyzer).
Aunque ésos son los inicios de las herramientas informáticas que ayudan a crear nuevos proyectos informáticos, la primera herramienta CASE fue Excelerator que salió a la luz en el año 1984 y trabajaba bajo una plataforma PC.
Las herramientas CASE alcanzaron su techo a principios de los años 90. En la época en la que IBM había conseguido una alianza con la empresa de software AD/Cycle para trabajar con sus mainframes, estos dos gigantes trabajaban con herramientas CASE que abarcaban todo el ciclo de vida del software. Pero poco a poco los mainframes han ido siendo menos utilizados y actualmente el mercado de las Big CASE ha muerto completamente abriendo el mercado de diversas herramientas más específicas para cada fase del ciclo de vida del software.
Objetivos
Mejorar la productividad en el desarrollo y mantenimiento del software. Aumentar la calidad del software. Reducir el tiempo y costo de desarrollo y mantenimiento de los sistemas
informáticos. Mejorar la planificación de un proyecto Aumentar la biblioteca de conocimiento informático de una empresa
ayudando a la búsqueda de soluciones para los requisitos. Automatizar el desarrollo del software, la documentación, la generación de
código, las pruebas de errores y la gestión del proyecto. Ayuda a la reutilización del software, portabilidad y estandarización de la
documentación Gestión global en todas las fases de desarrollo de software con una misma
herramienta. Facilitar el uso de las distintas metodologías propias de la ingeniería del
software.
23

Clasificación
Aunque no es fácil y no existe una forma única de clasificarlas, las herramientas CASE se pueden clasificar teniendo en cuenta los siguientes parámetros:
Las plataformas que soportan.Las fases del ciclo de vida del desarrollo de sistemas que cubren.La arquitectura de las aplicaciones que producen.Su funcionalidad.
La siguiente clasificación es la más habitual basada en las fases del ciclo de desarrollo que cubren:
Upper CASE (U-CASE), herramientas que ayudan en las fases de planificación, análisis de requisitos y estrategia del desarrollo, usando, entre otros diagramas UML.
Middle CASE (M-CASE), herramientas para automatizar tareas en el análisis y diseño de la aplicación.
Lower CASE (L-CASE), herramientas que semi-automatizan la generación de código, crean programas de detección de errores, soportan la depuración de programas y pruebas. Además automatizan la documentación completa de la aplicación. Aquí pueden incluirse las herramientas de Desarrollo rápido de aplicaciones.
1.5.1 PLANIFICACIÓN DE LOS SISTEMAS DE GESTIÓN
Un Sistema de Gestión es un conjunto de etapas unidas en un proceso continuo,
que permite trabajar ordenadamente una idea hasta lograr mejoras y su
continuidad.
Se establecen cuatro etapas en este proceso, que hacen de este sistema, un
proceso circular virtuoso, pues en la medida que el ciclo se repita recurrente y
recursivamente, se logrará en cada ciclo, obtener una mejora.
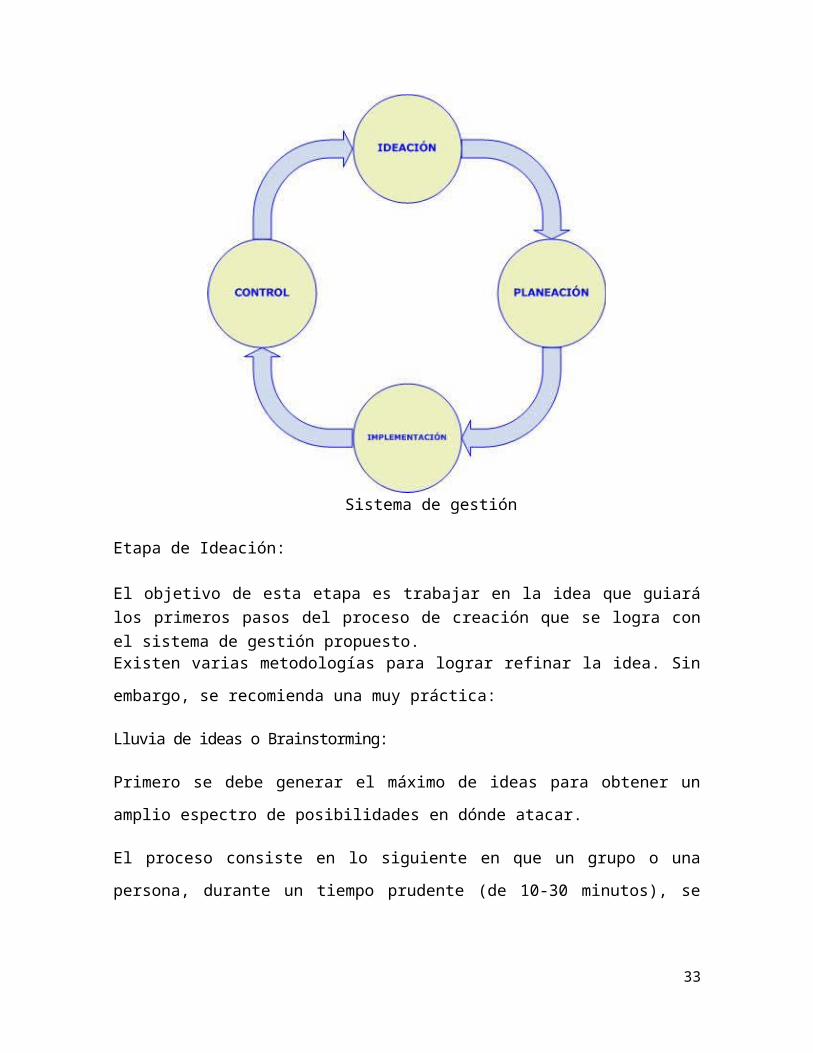
Las cuatro etapas del sistema de gestión son:1. Etapa de Ideación2. Etapa de Planeación3. Etapa de Implementación4. Etapa de Control
24

Sistema de gestión
Etapa de Ideación:
El objetivo de esta etapa es trabajar en la idea que guiará los primeros pasos del
proceso de creación que se logra con el sistema de gestión propuesto.Existen varias metodologías para lograr refinar la idea. Sin embargo, se
recomienda una muy práctica:
Lluvia de ideas o Brainstorming:
Primero se debe generar el máximo de ideas para obtener un amplio espectro de
posibilidades en dónde atacar.
El proceso consiste en lo siguiente en que un grupo o una persona, durante un
tiempo prudente (de 10-30 minutos), se enfoca en generar o “lanzar” ideas sin
restricciones, pero que tengan cercanía con el tema que se está tratando.
Una vez que se tenga un listado adecuado, se procede a analizar las ideas y a
pulir su cercanía con lo que realmente se quiere.
25

La idea central de este proceso es que aquí se debe definir claramente el objetivo
perseguido, es decir el “Qué queremos lograr?”. Una vez definido, se procede al
“Cómo lograrlo?” y pasamos a la siguiente etapa.
Etapa de Planeación (Planificación):
Dentro del proceso, la planificación constituye una etapa fundamental y el punto
de partida de la acción directiva, ya que supone el establecimiento de sub-
objetivos y los cursos de acción para alcanzarlos.
En esta etapa, se definen las estrategias que se utilizarán, la estructura
organizacional que se requiere, el personal que se asigna, el tipo de tecnología
que se necesita, el tipo de recursos que se utilizan y la clase de controles que se
aplican en todo el proceso.
Proceso Formal de Planificación
El proceso de planificación contiene un número determinado de etapas que hacen
de ella una actividad dinámica, flexible y continua. En general, estas etapas
consideran, para cada una de las perspectivas mencionadas, el examen del medio
externo (identificación de oportunidades y amenazas), la evaluación interna
26

(determinación de fortalezas y debilidades), y concluye con la definición de una
postura competitiva sugerida (objetivos y metas).
A nivel corporativo, se obtienen como resultado las directrices estratégicas y los
objetivos de desempeño de la organización. Además, se determina la asignación
de recursos, la estructura de la organización (que se necesita para poner en
práctica exitosamente la estrategia definida), los sistemas administrativos y las
directrices para la selección y promoción del personal clave.
A nivel de negocios y funcional, los resultados se enmarcan en propuestas de
programas estratégicos de acción y programación de presupuestos. Estas
propuestas son, finalmente, evaluadas y consolidadas a nivel corporativo.
Etapa de Implementación (Gestión):
En su significado más general, se entiende por gestión, la acción y efecto de
administrar. Pero, en un contexto empresarial, esto se refiere a la dirección que
toman las decisiones y las acciones para alcanzar los objetivos trazados.
Es importante destacar que las decisiones y acciones que se toman para llevar
adelante un propósito, se sustentan en los mecanismos o instrumentos
administrativos (estrategias, tácticas, procedimientos, presupuestos, etc.), que
están sistémicamente relacionados y que se obtienen del proceso de planificación.
(Véase la figura: Esquema de gestión).
Esquema de Gestión
27

Etapa de Control:
Para este concepto se han desarrollado varias definiciones (Fuente: CABRERA,
E., “Control” [En línea], Monografias.com, [citado en marzo de 2005]. Disponible
en www.monografias.com/trabajos14/control/control.shtml), a lo largo de su
evolución, sin embargo, todas se centran en la siguiente idea general:
El control es una función administrativa, esencialmente reguladora, que permite
verificar (o también constatar, palpar, medir o evaluar), si el elemento
seleccionado (es decir, la actividad, proceso, unidad, sistema, etc.), está
cumpliendo sus objetivos o alcanzando los resultados que se esperan.
Es importante destacar que la finalidad del control es la detección de errores,
fallas o diferencias, en relación a un planteamiento inicial, para su corrección y/o
prevención. Por tanto, el control debe estar relacionado con los objetivos
inicialmente definidos, debe permitir la medición y cuantificación de los resultados,
la detección de desviaciones y el establecimiento de medidas correctivas y
preventivas.
1.5.2 GESTIÓN DE PROYECTOS
La gestión de proyectos también conocida como gerencia o administración de proyectos es la disciplina que guía e integra los procesos de planificar, captar, dinamizar, organizar talentos y administrar recursos, con el fin de culminar todo el trabajo requerido para desarrollar un proyecto y cumplir con el alcance, dentro de límites de tiempo, y costo definidos: sin estrés y con buen clima interpersonal. Todo lo cual requiere liderar los talentos, evaluar y regular continuamente las acciones necesarias y suficientes.
Otras denominaciones equivalentes según los países: gerencia o gestión de proyectos, gestión integral de proyectos, dirección integrada de proyectos (España), etc. Es una disciplina de gerencia y no una herramienta ingenieril, confusión derivada a su intenso uso en proyectos civiles.
Características
Temporal significa que cada proyecto tiene un comienzo definido y un final definido. El final se alcanza cuando se ha logrado alcance y objetivos del proyecto o cuando queda claro que el alcance y objetivos del proyecto no serán o no podrán ser alcanzados, o cuando la necesidad a satisfacer –por el proyecto- ya no exista y el proyecto sea cancelado. Temporal no necesariamente significa de corta duración; muchos proyectos duran varios años.
28

Un proyecto crea productos entregables –bienes y/o servicios o resultados únicos, pudiendo crear:
• Un producto –bien o artículo producido, que es cuantificable, y que puede ser un elemento terminado o un componente o un servicio prestado.
• La capacidad de prestar un servicio como, por ejemplo, la capacidad de producción o de prestación de servicio de las funciones del negocio, que respaldan la producción, la distribución, etc.
• Un resultado como, por ejemplo, salidas, documentos, ideas… Por ejemplo, de un proyecto de investigación se obtienen conocimientos que pueden usarse para determinar si existe o no una tendencia o si un nuevo proceso beneficiará a la sociedad.
La singularidad es una característica importante de los productos o entregables de un proyecto. Por ejemplo, se han construido muchos miles de edificios de oficinas, pero cada edificio individual es único: diferente propietario, diferente diseño, diferente ubicación, diferente contratista, etc. Por otra parte se prestan miles de horas de servicio de consultoría, etc., pero cada consultoría es diferente, con diferentes clientes y diferentes consultores, resolviendo situaciones diferentes, etc., etc. La presencia de elementos repetitivos –en la producción de bienes o en la prestación de servicios- no cambia la condición fundamental de único…
Elaboración gradual
La elaboración gradual es una característica de los proyectos que acompaña a los conceptos de temporal y único. “Elaboración gradual” significa desarrollar en pasos e ir aumentando mediante incrementos. Por ejemplo, el alcance de un proyecto se define de forma general al comienzo del proyecto, y se hace más explícito y detallado a medida que el equipo del proyecto desarrolla un mejor y más completo entendimiento de los objetivos y de los productos –bienes y/o servicios- y entregables asociados. La elaboración gradual no debe confundirse con lentitud ni corrupción del alcance.
1.5.3 SOPORTE
El soporte para modelado UML e ingeniería inversa de NetBeans resulta muy útil,
especialmente en el análisis de grandes proyectos. Lamentablemente, NetBeans
ya no incluye un gestor de módulos, y -en teoría- nos tenemos que limitar a los
plugins del mismo, entre los que no se incluye dicha funcionalidad.
En ella, descargaremos el cluster UML, descomprimiendo su contenido en la raíz
del directorio de instalación de NetBeans. Una vez hecho, el directorio “uml” (que
29

contiene el cluster) debe quedar al mismo nivel que otros cluster como “java“,
“profiler“, etc. ¡Listo! Tras reiniciar NetBeans, el módulo estará listo para usar.
1.5.4 ANÁLISIS Y DISEÑO
1. Planificación y Especificación de Requisitos: Planificación, definición de
requisitos, conocer los procesos del dominio, etc.
2. Construcción: La construcción del sistema. Se subdivide en las siguientes:
Análisis: Se analiza el problema a resolver desde la perspectiva de los
usuarios y de las entidades externas que van a solicitar servicios al sistema.
Diseño: El sistema se especifica en detalle, describiendo cómo va a
funcionar internamente para satisfacer lo especificado en el análisis.
Implementación: Se lleva lo especificado en el diseño a un lenguaje de
programación.
Pruebas: Se llevan a cabo una serie de pruebas para corroborar que el
software funciona correctamente y que satisface lo especificado en la etapa
de Planificación y Especificación de Requisitos.
3. Instalación: La puesta en marcha del sistema en el entorno previsto de uso.
UML
El Unified Modeling Language (UML) define un lenguaje de modelado orientado a
objetos común para visualizar, especificar, construir y documentar los
componentes de un sistema software OO.
El UML no es una metodología, sino una notación que trata de posibilitar el
intercambio de modelos de software.
Un modelo es una simplificación de la realidad creada para comprender
mejor un sistema.
UML es un lenguaje de modelado visual, utiliza diagramas, para la
representación de los sistemas.
Diagramas para modelar el Comportamiento del Sistema:
Diagrama de Casos de Uso: Muestra un conjunto de casos de uso y actores
y sus relaciones.
30

Diagrama de Secuencia: Diagrama de interacción con la relación temporal
de los mensajes y los objetos.
Diagrama de Colaboración: Diagrama de interacción que resalta la
organización estructural de los objetos que envían y reciben mensajes.
Diagrama de Estados: Muestra una máquina de estados, que consta de
estados, transiciones, eventos y actividades. Vista dinámica del sistema.
Diagrama de Actividades: Muestra el flujo de actividades dentro de un
sistema.
Diagramas para modelar la Estructura del Sistema:
Diagrama de Clases: Muestra un conjunto de clases, interfaces y
colaboraciones, así como sus relaciones.
Diagrama de Objetos: Muestra un conjunto de objetos y sus relaciones.
Diagrama de Componentes: Muestra la organización y las dependencias
entre un conjunto de componentes.
Diagrama de Despliegue: Representa la infraestructura de un sistema en
tiempo de ejecución.
31

1.5.6 INTEGRACIÓN Y PRUEBAS
INTEGRACIÓN
En el nivel más bajo del espectro de integración está la herramienta individual
(solución puntual). Cuando las herramientas proporcionan facilidades para el
intercambio de datos (la mayoría lo hace), el nivel de integración aumenta
ligeramente. Estas herramientas generan una salida en un formato estándar
compatible con otras herramientas que puedan leer ese formato. En algunos
casos, los que construyen herramientas CASE complementarias trabajan juntos
para establecer un puente entre ellas (p. ej.: una herramienta de análisis y diseño
que se une a un generador de código). Utilizando este enfoque, la compatibilidad
entre herramientas puede generar productos finales que serían difíciles de
desarrollar utilizando cada herramienta por separado. La integración por fuente
única se da cuando un constructor de herramientas CASE integra diferentes
herramientas y las vende como un único paquete. Aunque este enfoque es
bastante efectivo, la mayoría de los entornos provenientes de una misma fuente
tienen una arquitectura cerrada que hace difícil añadir nuevas herramientas de
otros vendedores.
32

La principal ventaja de la utilización de una herramienta CASE, es la mejora de
la calidad de los desarrollos realizados y, en segundo término, el aumento de la
productividad. Para conseguir estos dos objetivos es conveniente contar con una
organización y una metodología de trabajo además de la propia herramienta.
La mejora de calidad se consigue reduciendo sustancialmente muchos de los
problemas de análisis y diseño, inherentes a los proyectos de mediano y gran
tamaño (lógica del diseño, coherencia, consolidación, etc.).
La mejora de productividad se consigue a través de la automatización de
determinadas tareas como la generación de código y la reutilización de objetos o
módulos.
PRUEBAS
Las pruebas son básicamente un conjunto de actividades dentro del desarrollo
de software. Dependiendo del tipo de pruebas, estas actividades podrán ser
implementadas en cualquier momento de dicho proceso de desarrollo.
Existen tres tipos de pruebas:
Por Programas Individuales: para realizar la prueba, se toma por separado
cada uno de éstos y se ejecutan para comprobar que hagan lo esperado.
Por Secciones del Sistema: Una vez realizadas las pruebas a programas
individuales, deben realizarse pruebas a secciones del sistema. Por ejemplo dar
de alta, dar de baja y modificaciones de la información.
Por Sistema Total: en esta última prueba, una vez corroborado que el sistema
cumple con su objetivo, se libera y pasa a la etapa de implementación.
1.5.7 PROTOTIPOS
Es un modelo a escala o facsímil de lo real, pero no tan funcional para que
equivalga a un producto final, ya que no lleva a cabo la totalidad de las funciones
33
necesarias del sistema final. Proporcionando una retroalimentación temprana por
parte de los usuarios acerca del Sistema.
El principal propósito es obtener y validar los requerimientos esenciales,
manteniendo abiertas, las opciones de implementación. Esto implica que se debe
tomar los comentarios de los usuarios, pero debemos regresar a sus objetivos
para no perder la atención.
En la fase de Diseño, su propósito, basándose en los requerimientos
previamente obtenidos, es mostrar las ventanas, su navegación, interacción,
controles y botones al usuario y obtener una retroalimentación que nos permite
mejorar el Diseño de Interfaz.
1.5.8 MANTENIMIENTO
Es importante considerar la evaluación y el monitoreo de un sistema en términos
del mantenimiento necesario y, en consecuencia, reducir o contener los costos
implícitos. El mantenimiento de sistemas puede clasificarse en cuatro grupos,
cada uno de los cuales repercute en el plan estratégico de información
institucional de diferentes maneras:
Mantenimiento correctivo. Independientemente de cuán bien diseñado,
desarrollado y probado está un sistema o aplicación, ocurrirán errores
inevitablemente. Este tipo de mantenimiento se relaciona con la solución o la
corrección de problemas del sistema. Atañe generalmente a problemas no
identificados durante la fase de ejecución. Un ejemplo de mantenimiento correctivo
es la falta de una característica requerida por el usuario, o su funcionamiento
defectuoso.
Mantenimiento para fines específicos. Este tipo de mantenimiento se refiere a la
creación de características nuevas o a la adaptación de las existentes según lo
requieren los cambios en la organización o los usuarios, por ejemplo, los cambios
en el código tributario o los reglamentos internos de la organización
Mantenimiento para mejoras. Se trata de la extensión o el mejoramiento del
desempeño del sistema, ya sea mediante el agregado de nuevas características, o
34

el cambio de las existentes. Un ejemplo de este tipo de mantenimiento es la
conversión de los sistemas de texto a GUI (interfaz gráfica de usuarios).
Mantenimiento preventivo. Este tipo de mantenimiento es probablemente uno de
los más eficaces en función de los costos, ya que si se realiza de manera oportuna
y adecuada, puede evitar serios problemas en el sistema.
3 IMPLEMENTACIÓN
Dentro del ciclo de vida se encuentra la fase de implementación de un sistema,
es la fase más costosa y que consume más tiempo, se dice que es costosa porque
muchas personas, herramientas y recursos, están involucrados en el proceso y
consume mucho tiempo porque se completa todo el trabajo realizado previamente
durante el ciclo de vida.
En la fase de implementación se instala el nuevo sistema de información para
que empiece a trabajar y se capacita a sus usuarios para que puedan utilizarlo.
La instalación puede realizarse según cuatro métodos: Directo, paralelo, piloto y
en fases.
• Método directo: Se abandona el sistema antiguo y se adopta inmediatamente
el nuevo. Esto puede ser sumamente riesgoso porque si algo marcha mal, es
imposible volver al sistema anterior, las correcciones deberán hacerse bajo la
marcha. Regularmente con un sistema nuevo suelen surgir problemas de pequeña
y gran escala. Si se trata de grandes sistemas, un problema puede significar una
catástrofe, perjudicando o retrasando el desempeño entero de la organización.
• Método paralelo: Los sistemas de información antiguo y nuevo operan juntos
hasta que el nuevo demuestra ser confiable. Este método es de bajo riesgo. Si el
sistema nuevo falla, la organización puede mantener sus actividades con el
sistema antiguo. Pero puede representar un alto costo al requerir contar con
personal y equipo para laborar con los dos sistemas, por lo que este método se
35

reserva específicamente para casos en los que el costo de una falla sería
considerable.
• Método piloto: Pone a prueba el nuevo sistema sólo en una parte de la
organización. Al comprobar su efectividad, se implementa en el resto de la
organización. El método es menos costoso que el paralelo, aunque más riesgoso.
Pero en este caso el riesgo es controlable al limitarse a ciertas áreas, sin afectar
toda la empresa.
• Método en fases: La implementación del sistema se divide en partes o fases,
que se van realizando a lo largo de un periodo de tiempo, sucesivamente. Una vez
iniciada la primera fase, la segunda no se inicia hasta que la primera se ha
completado con éxito. Así se continúa hasta que se finaliza con la última fase. Es
costoso porque se hace más lenta la implementación, pero sin duda tiene el menor
riesgo.
36

37
UNIDAD 2.
DISEÑO DE SISTEMAS

2. DISEÑO DE SISTEMAS
2.1 DISEÑO ESTRUCTURADO DE SISTEMAS
El diseño estructurado de sistemas se ocupa de la identificación, selección y
organización de los módulos y sus relaciones. Se comienza con la especificación
resultante del proceso de análisis, se realiza una descomposición del sistema en
módulos estructurados en jerarquías, con características tales que permitan la
implementación de un sistema que no requiera elevados costos de mantenimiento.
La idea original del diseño estructurado fue presentada en la década de los '70,
por Larry Constantine, y continuada posteriormente por otros autores: Myers,
Yourdon y Stevens.
El diseño estructurado es un enfoque disciplinado de la transformación de qué es
necesario para el desarrollo de un sistema, a cómo deberá ser hecha la
implementación. La definición anterior implica que: el análisis de requerimientos
del usuario (determinación del qué) debe preceder al diseño y que, al finalizar el
diseño se tendrá medios para la implementación de las necesidades del usuario
(el cómo), pero no se tendrá implementada la solución al problema. Cinco
aspectos básicos pueden ser reconocidos:
1. Permitir que la forma del problema guíe a la forma de la solución. Un concepto
básico del diseño de arquitecturas es: las formas siempre siguen funciones.
2. Intentar resolver la complejidad de los grandes sistemas a través de la
segmentación de un sistema en cajas negras, y su organización en una jerarquía
conveniente para la implementación. 3. Utilizar herramientas, especialmente
gráficas, para realizar diseños de fácil comprensión. Un diseño estructurado usa
diagramas de estructura (DE) en el diseño de la arquitectura de módulos del
sistema y adiciona especificaciones de los módulos y cumplas (entradas y salidas
de los módulos), en un Diccionario de Datos (DD).
4. Ofrecer un conjunto de estrategias para derivar el diseño de la solución,
basándose en los resultados del proceso de análisis.
38

5. Ofrecer un conjunto de criterios para evaluar la calidad de un diseño con
respecto al problema a ser resuelto, y las posibles alternativas de solución, en la
búsqueda de la mejor de ellas. El diseño estructurado produce sistemas fáciles de
entender y mantener, confiables, fácilmente desarrollados, eficientes y que
funcionan.
2.1.1 CONCEPTOS BÁSICOS
Las diversas tecnologías y métodos utilizados antiguamente para la manipulación y transmisión de comunicación visual intencionada, han ido modificando sucesivamente la actividad que hoy conocemos por diseño gráfico, hasta el extremo, de confundir el campo de actividades y competencias que debería serle propio, incluyendo por supuesto, sus lejanas fuentes originales. El desarrollo de los productos y servicios ha crecido espectacularmente, lo que les obliga a competir entre sí para ocupar un sitio en el mercado. Es en este momento cuando surge la publicidad, y con ella la evolución del diseño gráfico como forma estratégica de comunicar, atraer y ganar la batalla frente a los competidores. El cómo se transmite una determinada información es un elemento significativo trascendental para lograr persuadir, convencer, e incluso manipular a gran parte de la sociedad. El culto hacia los medios de comunicación visual utilizados en la antigüedad (como mosaicos, pinturas, lienzos...) ha permitido sobrevivir a muchos de ellos a la función temporal para la que fueron creados. Para estos objetos el medio ha acabado por convertirse en obra de arte, es decir, en el auténtico y definitivo mensaje. La función del diseñador es, transmitir una idea, un concepto o una imagen de la forma más eficaz posible.
Para ello, el diseñador debe contar con una serie de herramientas como, la información necesaria de lo que se va a transmitir, los elementos gráficos adecuados, su imaginación y todo aquello que pueda servir para su comunicación. Nuestro diseño debe constituir un todo, donde cada uno de los elementos gráficos que utilicemos posean una función específica, sin interferir en importancia y protagonismo a los elementos restantes (a no ser quesea intencionado).Un buen diseñador debe comunicar las ideas y conceptos de una forma clara y directa, por medio de los elementos gráficos.
Por tanto, la eficacia de la comunicación del mensaje visual que elabora el diseñador, dependerá de la elección de los elementos que utilice y del conocimiento que tenga de ellos. Lo primero que hay que hacer para diseñar algo ( un anuncio en revista, una tarjeta...), es saber que es lo que se quiere transmitir al público y que tipo de público es ese, en definitiva, cual es la misión que debe cumplir ese diseño. El dilema con el que se encuentra el diseñador es cómo elegir la mejor combinación de los elementos y su ubicación (texto, fotografías, líneas,
39

titulares...), con el propósito de conseguir comunicar de la forma más eficaz y atractiva posible. En esta parte empezaremos por conocer los elementos básicos del diseño, pero primero aclararemos un término que facilitará nuestra comprensión del concepto que debemos tener delos elementos.
La impresión o sensación que causan dichos elementos, es decir la información que transmiten .Los diseñadores pueden manipular los elementos siempre que tengan conocimiento de ellos y delo que en sí representan, ya que en el ámbito del diseño es muy importante el factor psicológico para conseguir el propósito que se busca: Informar y Persuadir. Por tanto, hay que tener en cuenta lo que puede llegar a expresar o transmitir, un color, una forma, un tamaño, una imagen o una disposición determinada de los elementos que debemos incluir..., ya que ello determinará nuestra comunicación. En ambos casos, se consigue por medio de la atracción, motivación o interés
2.1.2 DIAGRAMA DE FLUJO DE DATOS
Un diagrama de flujo de datos (DFD sus siglas en español e inglés) es una representación gráfica del flujo de datos a través de un sistema de información. Un diagrama de flujo de datos también se puede utilizar para la visualización de procesamiento de datos (diseño estructurado). Es una práctica común para un diseñador dibujar un contexto a nivel de DFD que primero muestra la interacción entre el sistema y las entidades externas. Este contexto a nivel de DFD se "explotó"
Los diagramas de flujo de datos fueron inventados por Larry Constantine, el desarrollador original del diseño estructurado, basado en el modelo de computación de Martin y Estrin: "flujo gráfico de datos" . Los diagramas de flujo de datos (DFD) son una de las tres perspectivas esenciales de Análisis de Sistemas Estructurados y Diseño por Método SSADM. El patrocinador de un proyecto y los usuarios finales tendrán que ser informados y consultados en todas las etapas de una evolución del sistema. Con un diagrama de flujo de datos, los usuarios van a poder visualizar la forma en que el sistema funcione, lo que el sistema va a lograr, y cómo el sistema se pondrá en práctica. El antiguo sistema de diagramas de flujo de datos puede ser elaborado y se comparó con el nuevo sistema de diagramas de flujo para establecer diferencias y mejoras a aplicar para desarrollar un sistema más eficiente. Los diagramas de flujo de datos pueden ser usados para proporcionar al usuario final una idea física de cómo resultarán los datos a última instancia, y cómo tienen un efecto sobre la estructura de todo el sistema. La manera en que cualquier sistema es desarrollado, puede determinarse a través de un diagrama de flujo de datos. modelo de datos.
niveles, los cuales son:
Nivel 0: Diagrama de contexto. Nivel 1: Diagrama de nivel superior.
40

Nivel 2: Diagrama de detalle o expansión.
Características de los niveles
En el diagrama de contexto se caracterizan todas las interacciones que realiza un
sistema con su entorno (entidades externas), estas pueden ser otros sistemas,
sectores internos a la organización, o factores externos a la misma. Se dibuja un
sólo proceso que representa al sistema en cuestión y se escribe su nombre en
dicha burbuja como un sustantivo común más adjetivos. De él solamente parten
los flujos de datos que denotan las interrelaciones entre el sistema y sus agentes
externos, no admitiéndose otros procesos ni almacenamientos en el dibujo.
Resulta de gran utilidad para los niveles posteriores de análisis como herramienta
de balanceo. Y es conocido como el Diagrama de Flujo de Datos DFD de Nivel "0"
Diagrama de Nivel Superior: Nivel 1
En el diagrama de nivel superior se plasman todos los procesos que describen al
proceso principal. En este nivel los procesos no suelen interrelacionarse
directamente, sino que entre ellos debe existir algún almacenamiento o entidad
externa que los una. Esta regla de construcción sirve como ayuda al analista para
contemplar que en un nivel tan elevado de abstracción (DFD Nivel 1) es altamente
probable que la información que se maneja requiera ser almacenada en el sistema
aunque no esté especificado por un Requisito funcional, siendo en realidad.
Diagrama de Detalle o Expansión: Nivel 2
En un diagrama de nivel 2 o mayor, comienzan a explotarse las excepciones a los
caminos principales de la información dado que aumenta progresivamente el nivel
de detalle. De aquí en adelante se permiten los flujos entre procesos. El DFD
(Diagrama De Flujo De Datos) nivel 2 puede considerarse el máximo para ser
validado en forma conjunta con el usuario dado que en los niveles posteriores el
alto grado de complejidad del diagrama puede resultar de muy difícil lectura para
41

personas ajenas al equipo de sistemas. También se recomienda el diagrama de
nivel superior.
2.1.3 APLICACIONES PARA SISTEMAS DE TIEMPO REAL
Los Sistemas Operativos de tiempo real son la plataforma para establecer un sistema de tiempo real ya que en los SOTR no tiene importancia el usuario, sino los procesos.Algunos ejemplos de Sistemas Operativos de tiempo real son:a. VxWorks,b. Solaris,c. Lyns OSd. Spectra
Por lo regular Sistema Operativo de tiempo real suele tener la misma arquitectura que un Sistema Operativo convencional, pero su diferencia radica en que proporciona mayor prioridad a los elementos de control y procesamiento que son utilizados para ejecutar los procesos o tareas.a. El SOTR debe ser multitarea y permisibleb. Un SOTR debe poder asignar prioridades a las tareasc. El SOTR debe proporcionar medios de comunicación y sincronización entre
tareasd. Un SOTR debe poder evitar el problema de inversión de prioridadese. El comportamiento temporal del SOTR debe ser conocido
Clasificación de los sistemas de tiempo real
Los sistemas de tiempo real pueden ser de dos tipos, esto es en función de su
severidad en el tratamiento de los errores que puedan presentarse:
Sistemas de tiempo real blandos o Soft real-time systems: estos pueden tolerar un exceso en el tiempo de respuesta, con una penalización por el incumplimiento del plazo. Estos sistemas garantizan que las tareas críticas se ejecutan en tiempo.
42

Aquí los datos son almacenados en memorias no volátiles, no utilizan técnicas de memoria virtual ni tiempo compartido, estas técnicas no pueden ser implementadas en hardware.
Sistemas de tiempo real duros o Hard real-time systems: aquí la respuesta fuera de término no tiene valor alguno, y produce la falla del sistema. Estos sistemas tienen menos utilidades que los implementados por hard.
2.2 DIAGRAMAS DE ITERACIÓN DE OBJETOS
Diagramas de interacción
Los diagramas de interacción ilustran cómo interaccionan unos objetos con otros,
intercambiando mensajes.
Los diagramas de interacción son importantes es aconsejable crearlos en
colaboración con otros programadores. Elaborarlos implica asignar
responsabilidades a los objetos: ésta no es una tarea fácil considerar patrones de
diseño puede ser útil.
Estos son modelos que describen como los grupos de objetos que colaboran en
algunos ambientes. Por lo general, un diagrama de interacción captura el
comportamiento de un único caso de uso. Hay dos tipos de diagramas de
interacción: diagramas de secuencia y diagramas de colaboración.
Diagramas del UML
El UML está compuesto por diversos elementos gráficos que se combinan para
conformar diagramas. Debido a que el UML es un lenguaje, cuenta con reglas
para combinar tales elementos.
La finalidad de los diagramas es presentar diversas perspectivas de un sistema, a
las cuales se les conoce como modelo. Recordemos que un modelo es una
representación simplificada de la realidad; el modelo UML describe lo que
supuestamente hará un sistema, pero no dice cómo implementar dicho sistema.
43

Diagramas más comunes del UML
Diagrama de Clases
Los diagramas de clases describen la estructura estática de un sistema.
Las cosas que existen y que nos rodean se agrupan naturalmente en categorías.
Una clase es una categoría o grupo de cosas que tienen atributos (propiedades) y
acciones similares.
Un rectángulo es el símbolo que representa a la clase, y se divide en tres áreas.
Un diagrama de clases está formado por varios rectángulos de este tipo
conectados por líneas que representan las asociaciones o maneras en que las
clases se relacionan entre sí.
Clase Abstracta
Las clases se representan con rectángulos divididos en tres
áreas: la superior contiene el nombre de la clase, la central
contiene los atributos y la inferior las acciones.
Asociaciones
Las asociaciones son las que representan a las relaciones estáticas entre las
clases. El nombre de la asociación va por sobre o por debajo de la línea que la
representa. Una flecha rellena indica la dirección de la relación. Los roles se
44
Nombre de Clase
atributo: Tipo /
atributo Derivado
operación( )
ubican cerca del final de una asociación. Los roles representan la manera en que
dos clases se ven entre ellas. No es común el colocar ambos nombres, el de la
asociación y el de los roles a la vez. Cuando una asociación es calificada, el
símbolo correspondiente se coloca al final de la asociación, contra la clase que
hace de calificador.
Multiplicidad
Las notaciones utilizadas para señalar la multiplicidad se colocan cerca del final de
una asociación. Estos símbolos indican el número de instancias de una clase
vinculadas a una de las instancias de la otra clase. Por ejemplo, una empresa
puede tener uno o más empleados, pero cada empleado trabaja para una sola
empresa solamente.
Asociación Tripartita
45
Uno o muchos 1...*
Cero o muchos 0...*
Muchos *
Cero o uno 0...1
No más de uno 1
1...*
1
Empleado
Empresa
Clase A
Clase B Clase A
Asociación Tripartita

Composición y Agregación
Composición es un tipo especial de agregación que denota una fuerte posesión de
la Clase “Todo”, a la Clase “Parte”. Se grafica con un rombo diamante relleno
contra la clase que representa el todo.
La agregación es una relación en la que la Clase “Todo” juega un rol más
importante que la Clase "Parte", pero las dos clases no son dependientes una de
otra. Se grafica con un rombo diamante vacío contra la Clase “Todo”.
Generalización
Generalización es otro nombre para herencia. Se refiere a una relación entre dos
clases en donde una Clase “Específica” es una versión especializada de la otra, o
Clase “General”. Por ejemplo, Honda es un tipo de auto, por lo que la Clase
“Honda” va a tener una relación de generalización con la Clase “Auto”
46
Clase A
Parte Parte
Todo Todo
Específica Clase
General Clase

Diagrama de Objetos
Los Diagramas de Objetos están vinculados con los Diagramas de Clases. Un
objeto es una instancia de una clase, por lo que un diagrama de objetos puede ser
visto como una instancia de un diagrama de clases. Los diagramas de objetos
describen la estructura estática de un sistema en un momento particular y son
usados para probar la precisión de los diagramas de clases.
Nombre de los objetos
Cada objeto es representado como un rectángulo, que contiene el nombre del
objeto y su clase subrayadas y separadas por dos puntos.
Nombre Objeto: Clase
Atributos
Como con las clases, los atributos se listan en un área inferior. Sin embargo, los
atributos de los objetos deben tener un valor asignado
.
Diagrama de Casos de Uso
47
Nombre Objeto : Clase
Atributo tipo = ´Valor´
Atributo tipo = ´Valor´
Atributo tipo = ´Valor´
Atributo tipo = ´Valor´

Un caso de uso es una descripción de las acciones de un sistema desde el punto
de vista del usuario. Es una herramienta valiosa dado que es una técnica de
aciertos y errores para obtener los requerimientos del sistema, justamente desde
el punto de vista del usuario.
Los diagramas de caso de uso modelan la funcionalidad del sistema usando
actores y casos de uso. Los casos de uso son servicios o funciones
provistas por el sistema para sus usuarios.
Sistema
El rectángulo representa los límites del sistema que contiene los casos de uso.
Los actores se ubican fuera de los límites del sistema.
Casos de Uso
Se representan con óvalos. La etiqueta en el óvalo indica la función del sistema.
Actores
Los actores son los usuarios de un sistema.
48
Imprimir

Relaciones
Las relaciones entre un actor y un caso de uso, se dibujan con una línea simple.
Para relaciones entre casos de uso, se utilizan flechas etiquetadas "incluir" o
"extender." Una relación "incluir" indica que un caso de uso es necesitado por otro
para poder cumplir una tarea. Una relación "extender" indica opciones alternativas
para un cierto caso de uso.
Diagrama de Estados
En cualquier momento, un objeto se encuentra en un estado particular, la luz está
encendida o apagada, el auto en movimiento o detenido, la persona leyendo o
cantando, etc. El diagrama de estados UML captura esa pequeña realidad.
Estado
El estado representa situaciones durante la vida de un objeto. Se representa con
un rectángulo que tiene sus esquinas redondeadas.
49
<<Extender>>
<<
Caso de uso Caso de uso
Caso de uso

Transición
Una flecha representa el pasaje entre diferentes estados de un objeto. Se etiqueta
con el evento que lo provoca y con la acción resultante.
Evento / acción
Estado Inicial
Estado Final
Ejemplo de Diagrama de Estado
Diagrama de Secuencias
Los diagramas de clases y los de objetos representan información estática. No
obstante, en un sistema funcional, los objetos interactúan entre sí, y tales
interacciones suceden con el tiempo. El diagrama de secuencias UML muestra la
mecánica de la interacción con base en tiempos.
Rol de la Clase
50
Estado
Desacelera
Desciende
Eleva
Acelera

El rol de la clase describe la manera en que un objeto se va a comportar en el
contexto. No se listan los atributos del objeto.
Activación
Los cuadros de activación representan el tiempo que un objeto necesita para
completar una tarea.
Mensajes
Los mensajes son flechas que representan comunicaciones entre objetos. Las
medias flechas representan mensajes asincrónicos. Los mensajes asincrónicos
Son enviados desde un objeto que no va a esperar una respuesta del receptor
para continuar con sus tareas.
Líneas de Vida
51

Las líneas de vida son verticales y en línea de puntos, ellas indican la presencia
del objeto durante el tiempo.
Destrucción de Objetos
Los objetos pueden ser eliminados tempranamente usando una flecha etiquetada
"<<destruir>>" que apunta a una X.
Loops
Una repetición o loop en un diagrama de secuencias, es representado como un
rectángulo. La condición para abandonar el loop se coloca en la parte inferior entre
corchetes [ ].
52
jj
Líneas de Vida
Destruir <<

Diagrama de Actividades
Un diagrama de actividades ilustra la naturaleza dinámica de un sistema mediante
el modelado del flujo ocurrente de actividad en actividad. Una actividad representa
una operación en alguna clase del sistema y que resulta en un cambio en el
estado del sistema. Típicamente, los diagramas de actividad son utilizados para
modelar el flujo de trabajo interno de una operación.
Estados de Acción
Los estados de acción representan las acciones no interrumpidas de los
objetos.
Flujo de la Acción
Los flujos de acción, representados con flechas, ilustran las relaciones entre
los estados de acción.
Flujo de Objetos
El flujo de objetos se refiere a la creación y modificación de objetos por parte
de actividades. Una flecha de flujo de objeto, desde una acción a un objeto,
significa que la acción está creando o influyendo sobre dicho objeto. Una
flecha de flujo de objeto, desde un objeto a una acción, indica que el estado
de acción utiliza dicho objeto.
53
llir] Condición para sa[
jj
Actividad
Actividad
Actividad
Nombre Objeto : Clase
Actividad

Estado Inicial
Estado inicial de un estado de acción.
Final State
Estado final de un estado de acción.
Ramificación
Un rombo representa una decisión con camino.
54
Condición 1] [Actividad
Actividad
Actividad

Sincronización
Una barra de sincronización ayuda a ilustrar la ocurrencia de transiciones
paralelas, así quedan representadas las acciones concurrentes.
Marcos de Responsabilidad
Los marcos de responsabilidad agrupan a las actividades relacionadas en una
misma columna.
.
55
Actividad
Actividad Actividad
Actividad
Marco 2 Marco 1
Objeto: Clase
Actividad
Actividad

Diagrama de Colaboraciones
El diagrama de colaboraciones describe las interacciones entre los objetos en
términos de mensajes secuenciados. Los diagramas de colaboración representan
una combinación de información tomada de los diagramas de clases, de
secuencias y de casos de uso, describiendo el comportamiento, tanto de la
estructura estática, como de la estructura dinámica de un sistema.
Rol de la Clase
El rol de la clase describe cómo se comporta un objeto. Los atributos del objeto no
se listan.
Rol de las Asociaciones
Los roles de asociación describen cómo se va a comportar una asociación en una
situación particular. Se usan líneas simple etiquetadas con un estereotipo*.
Mensajes
Contrariamente a los diagramas de secuencias, los diagramas de colaboración no
tienen una manera explícita para denotar el tiempo, por lo que entonces numeran
a los mensajes en orden de ejecución. La numeración puede anidarse; por
ejemplo, para mensajes anidados al mensaje número 1: 1.1, 1.2, 1.3, etc. La
condición para un mensaje se suele colocar entre corchetes. Para indicar un loop
se usa * después de la numeración.
56

Diagrama de Componentes
Un diagrama de componentes describe la organización de los componentes físicos
de un sistema.
Componente
Un componente es un bloque de construcción física del sistema.
Interface
Una interface describe a un grupo de operaciones usada o creada por
componentes.
Dependencias
Las dependencias entre componentes se grafican usando flechas de puntos.
Diagrama de Distribución
57
Componente
Dependencia Componente
Componente
Componente

El diagrama de distribución UML muestra la arquitectura física de un sistema
informático. Puede representar a los equipos y a los dispositivos, y también
mostrar sus interconexiones y el software que se encontrará en cada máquina.
Nodo
Un nodo es un recurso físico capaz de ejecutar componentes de código. .
(Procesador)
Asociación
La asociación se refiere a la conexión física entre los nodos, como por ejemplo
Ethernet.
Componentes y Nodos
Adaptación del UML
Ahora que ha comprendido los diagramas del UML y su estructura, ya casi es hora
de ponerlo a funcionar. El UML es una herramienta maravillosa, pero no la utilizará
de manera aislada. El UML tiene la intención de impulsar el desarrollo de software,
por ello, es necesario aprender los procesos y metodologías de desarrollo como
un vehículo para comprender el uso del UML en un contexto.
El método antiguo Esta idea demasiado simplificada del proceso de desarrollo
podrá darle una idea de que las etapas deberán sucederse en lapsos claramente
definidos, una después de otra. De hecho, las metodologías de desarrollo iniciales
se estructuraban de esa manera.
58
Nombre “Procesador”
Nodo Nodo
Componente 2
Componente 1
Nodo

2.3 MODELO DE CLASES
2.3.1 CLASES
Es la unidad básica que encapsula toda la información de un Objeto (un objeto es
una instancia de una clase). A través de ella podemos modelar el entorno en
estudio (una Casa, un Auto, una Cuenta Corriente, etc.).
En UML, una clase es representada por un rectángulo que posee tres divisiones:
En donde:
Superior: Contiene el nombre de la Clase
Intermedio: Contiene los atributos (o variables de instancia) que
caracterizan a la Clase (pueden ser private, protected o public).
Inferior: Contiene los métodos u operaciones, los cuales son la forma como
interactúa el objeto con su entorno (dependiendo de la visibilidad: private,
protected o public).
Ejemplo:
Una Cuenta Corriente que posee como característica:
Balance
Puede realizar las operaciones de:
Depositar
Girar
y Balance
59

2.3.1.2 PROPIEDAD
Casos Particulares:
Clase Abstracta:
Una clase abstracta se denota con el nombre de la clase y de los métodos con
letra "itálica". Esto indica que la clase definida no puede ser instanciada pues
posee métodos abstractos (aún no han sido definidos, es decir, sin
implementación). La única forma de utilizarla es definiendo subclases, que
implementan los métodos abstractos definidos.
Clase parametrizada:
Una clase parametrizada se denota con un subcuadro en el extremo superior de la
clase, en donde se especifican los parámetros que deben ser pasados a la clase
para que esta pueda ser instanciada. El ejemplo más típico es el caso de un
Diccionario en donde una llave o palabra tiene asociado un significado, pero en
este caso las llaves y elementos pueden ser genéricos. La genericidad puede
venir dada de un Template (como en el caso de C++) o bien de alguna estructura
predefinida (especialización a través de clases).
60

2.3.3 INTERACCIÓN
Relaciones entre Clases:
Ahora ya definido el concepto de Clase, es necesario explicar como se pueden
interrelacionar dos o más clases (cada uno con características y objetivos
diferentes).
Antes es necesario explicar el concepto de cardinalidad de relaciones: En UML, la
cardinalidad de las relaciones indica el grado y nivel de dependencia, se anotan en
cada extremo de la relación y éstas pueden ser:
uno o muchos: 1..* (1..n)
0 o muchos: 0..* (0..n)
número fijo: m (m denota el número).
i. Herencia (Especialización/Generalización):
Indica que una subclase hereda los métodos y atributos especificados por una
Super Clase, por ende la Subclase además de poseer sus propios métodos y
atributos, poseerá las características y atributos visibles de la Super Clase (public
y protected), ejemplo:
En la figura se especifica que Auto y Camión heredan de Vehículo, es decir, Auto
posee las Características de Vehículo (Precio, VelMax, etc.) además posee algo
61

particular que es Descapotable, en cambio Camión también hereda las
características de Vehículo (Precio, VelMax, etc.) pero posee como particularidad
propia Acoplado, Tara y Carga.
Cabe destacar que fuera de este entorno, lo único "visible" es el método
Caracteristicas aplicable a instancias de Vehículo, Auto y Camión, pues tiene
definición pública, en cambio atributos como Descapotable no son visibles por ser
privados.
Agregación:
Para modelar objetos complejos, n bastan los tipos de datos básicos que proveen
los lenguajes: enteros, reales y secuencias de caracteres. Cuando se requiere
componer objetos que son instancias de clases definidas por el desarrollador de la
aplicación, tenemos dos posibilidades:
Por Valor: Es un tipo de relación estática, en donde el tiempo de vida del objeto
incluido esta condicionado por el tiempo de vida del que lo incluye. Este tipo de
relación es comúnmente llamada Composición (el Objeto base se construye a
partir del objeto incluido, es decir, es "parte/todo").
Por Referencia: Es un tipo de relación dinámica, en donde el tiempo de vida del
objeto incluido es independiente del que lo incluye. Este tipo de relación es
comúnmente llamada Agregación (el objeto base utiliza al incluido para su
funcionamiento).
Un Ejemplo es el siguiente:
En donde se destaca que:
62
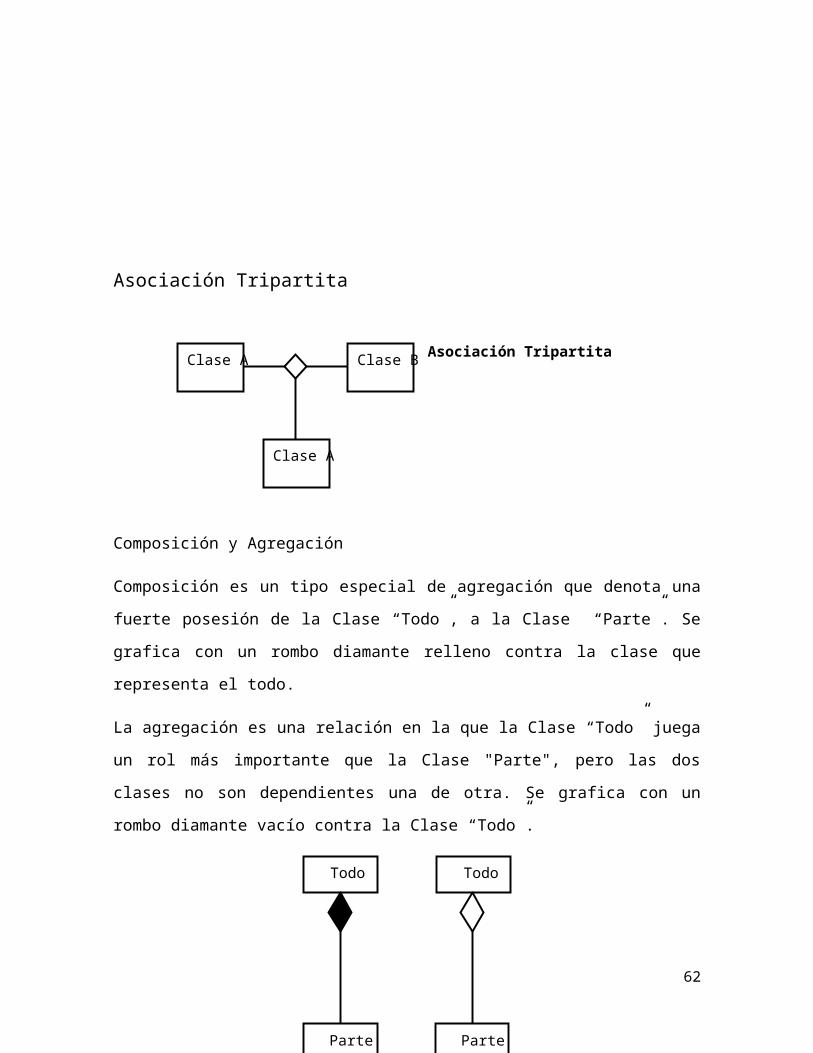
Un Almacén posee Clientes y Cuentas (los rombos van en el objeto que posee las
referencias).
Cuando se destruye el Objeto Almacén también son destruidos los objetos Cuenta
asociados, en cambio no son afectados los objetos Cliente asociados.
La composición (por Valor) se destaca por un rombo relleno.
La agregación (por Referencia) se destaca por un rombo transparente.
La flecha en este tipo de relación indica la navegabilidad del objeto referenciado.
Cuando no existe este tipo de particularidad la flecha se elimina.
Asociación:
La relación entre clases conocida como Asociación, permite asociar objetos que
colaboran entre sí. Cabe destacar que no es una relación fuerte, es decir, el
tiempo de vida de un objeto no depende del otro.
Ejemplo:
Un cliente puede tener asociadas muchas Órdenes de Compra, en cambio una
orden de compra solo puede tener asociado un cliente.
Dependencia o Instanciación (uso):
Representa un tipo de relación muy particular, en la que una clase es instanciada
(su instanciación es dependiente de otro objeto/clase). Se denota por una flecha
punteada.
2.3.2 CARACTERÍSTICAS
Herencia.
La herencia define la relación entre clases es un, donde una subclase hereda de
una o más superclases.
63

La herencia implica una jerarquía de generalización/especialización, en la que una
subclase especializa el comportamiento y/o la estructura, más general, de sus
superclases.
Herencia simple.
La herencia simple se da cuando, en una jerarquía de clases, las subclases
solamente pueden heredar de una superclase.
Herencia múltiple.
A diferencia de la herencia simple, en la herencia múltiple las subclases pueden
heredar de más de una superclase.
Polimorfismo.
La palabra polimorfismo tiene como origen las palabras griegas poli (muchos) y
moros (formas) y se utiliza para indicar que un nombre puede denotar instancias
(objetos) de clases diferentes que están relacionadas por alguna superclase
común.
El polimorfismo puede considerarse como la característica más potente de los
lenguajes orientados a objetos, después de su capacidad para soportar la
abstracción.
Existe polimorfismo cuando interactúan las características de herencia y enlace
dinámico.
Enlace estático y enlace dinámico
El enlace estático (denominado también enlace temprano) consiste en la
asignación estática de tipos a todas las variables y expresiones, en tiempo de
compilación.
El enlace dinámico (denominado también enlace tardío) consiste en asignar, en
tiempo de ejecución, los tipos a las variables y expresiones.
2.3.1.3 ESTRUCTURAS JERÁRQUICAS
Según el Diccionario of OT la jerarquía es “cualquier clasificación u ordenación de
abstracciones en una estructura de árbol. Algunos tipos de Jerarquía son:
64

Jerarquía de agregación, jerarquía de clases, jerarquía de herencia, jerarquía de
partición, jerarquía de especialización, jerarquía de tipo. Éste concepto es
sumamente importante ya que con ello conocemos la importancia de dividir los
problemas en una jerarquía de ideas.
Como se muestra en el ejemplo cada figura tiene su nivel de jerarquía a
continuación se explicará más detalladamente cada nivel. La clase es la que
contiene las características comunes a dichas figuras concretas por tanto, no tiene
forma ni tiene área. Esto lo expresamos declarando como una clase abstracta,
declarando la función miembro área abstract.
LAS CLASES ABSTRACTAS
Solamente se pueden usar como clases base para otras clases. No se pueden
crear objetos pertenecientes a una clase abstracta. Sin embargo, se pueden
declarar variables de dichas clases. La característica de hacer una Clase/Método
abstract reside en que no puede ser generada una instancia de la misma, este
comportamiento se demuestra en el método principal (main). Como se muestra en
las figuras cada clase tiene diferentes niveles, por decirlo así, de importancia de
ahí se desprenden los términos de Superclase y Subclases.
SUPERCLASE Y SUBCLASE
La clase “Padre” o Superclase se llama de ese modo debido a que de la misma se
desprenden otras clases llamadas “Subclases” las cuales heredarán sus atributos
y operaciones, una Superclase puede contener cualquier número de Subclases.
CIRCULO
La Clase Circulo es una de las Subclases de la Superclase Figura, ésta a su vez
puede convertirse en una Superclase si de ella se desprenden otras clases. La
misma posee su nivel de importancia y a su vez hereda los métodos y atributos
dela superclase.
65

En éste segundo ejemplo podemos ver que al contrario del anterior del anterior,
que de una subclase pueden desprenderse otras subclases lo que convierte a ésta
Subclase en una Superclase:
A es la superclase de B, C y D.
D es la superclase de E.
B, C y D son subclases de A.
E es una subclase de D. Una de las características que no se pueden apreciar en
éstas figuras es que cada Subclase obtiene “hereda”, características de su Clase
Padre de aquí proviene el término de herencia que detallaré a continuación.
HERENCIA
Es una propiedad esencial de la Programación Orientada a Objetos que consiste
en la creación de nuevas clases a partir de otras ya existentes éstas nuevas
clases obtienen propiedades de sus clases padres, las cuales propagan sus
atributos y operaciones a sus subclases. Las Subclases admiten la definición de
nuevos atributos, así como crear, modificar o inhabilitar propiedades.
La herencia ofrece una ventaja importante, ya que permite la reutilización del
código. Hay dos tipos de herencia las cuales son:
Herencia Simple y Herencia Múltiple
66
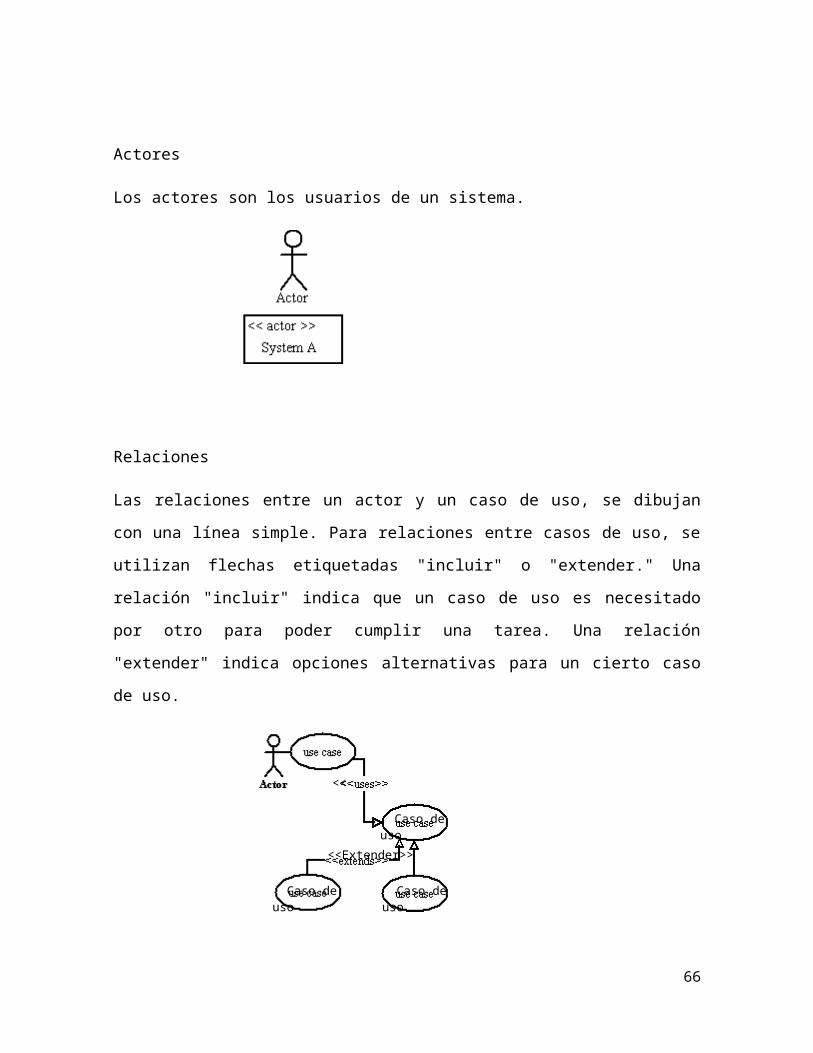
. La primera indica que se pueden definir nuevas clases solamente a partir de una
clase inicial mientras que la segunda indica que se pueden definir nuevas clases a
partir de dos o más clases iniciales. Java sólo permite herencia simple. En la
herencia los constructores no son heredados. El termino Herencia ha sido tomado
prestado de la Biología donde por ejemplo afirmamos que un niño tiene la cara de
su padre, que ha heredado ciertas facetas físicas o del comportamiento de sus
progenitores. Entre otras palabras son las diferentes características que
comparten unas clases con las otras.
2.3.4 Subsistemas
Objetos.
Los objetos, concretos y abstractos, están a nuestro alrededor, forman nuestro
entorno. Podemos distinguir cada objeto en base a sus características y
comportamientos.
Por ejemplo, en el aula observamos los objetos:
• alumno
• profesor
• mesa
• silla
• mesabanco
• pizarrón
Abstracción.
La abstracción es una de las principales herramientas con que combatimos la
complejidad.
67

Una abstracción denota las características esenciales de un objeto y proporciona
límites conceptuales definidos respecto a la perspectiva del observador.
En el modelo de objetos se persigue construir abstracciones que imiten
directamente el vocabulario de un determinado dominio de problema, por lo que el
problema central del diseño orientado a objetos es tomar la decisión acerca del
conjunto adecuado de abstracciones para ese dominio.
Comportamiento.
Los objetos no solamente poseen atributos, sino que también exhiben
comportamientos que manifiestan al interactuar con otros objetos en un esquema
cliente/servidor, donde un cliente es cualquier objeto que utiliza los recursos de
otro objeto denominado servidor.
Encapsulamiento.
El encapsulamiento es el proceso de almacenar en un mismo compartimento los
elementos de una abstracción que constituyen su estructura y su comportamiento;
sirve para separar la interfaz contractual de una abstracción y su implementación.
El encapsulamiento se consigue, a menudo, mediante la ocultación de
información. Generalmente, la estructura de un objeto está oculta, así como la
implementación de sus métodos.
Modularidad.
La modularidad es la descomposición de un sistema en un conjunto de módulos
cohesivos y débilmente acoplados.
La descomposición de un sistema en componentes individuales ayuda a manejar
la complejidad. Sin embargo, una descomposición desordenada puede producir un
efecto contrario que se puede contrarrestar reagrupando los componentes en
módulos o paquetes. Cada módulo debe contener componentes con
características afines, de tal manera que faciliten la producción de la arquitectura
física de un sistema.
68

2.4 DIAGRAMAS DE IMPLEMENTACIÓN
2.4.1 DEFINICIÓN
Los diagramas de implementación muestran las instancias existentes al ejecutarse
así como sus relaciones. También se representan los nodos que identifican
recursos físicos, típicamente un ordenador así como interfaces y objetos
(instancias de las clases).
2.4.2 OBJETIVO
• Muestran los aspectos de implementación del modelo
. Estructura del código fuente y objeto
. Estructura de la implementación en ejecución
2.4.3 TIPOS
Dos tipos de diagramas
2.4.3.1 DIAGRAMA DE COMPONENTES
Organización y dependencias entre los componentes software
Clases de implementación
Artifactos binarios, ejecutables, ficheros de scripts
2.4.3.2 DIAGRAMA DE EJECUCIÓN
Configuración de los elementos de proceso en tiempo de ejecución y los
componentes software, procesos y objetos que viven en ellos
Distribución de componentes
2.4.4 APLICACIONES
Visual Studio 2008
Los diagramas de implementación evalúan la implementación de un sistema de
aplicaciones en un centro de datos lógico concreto. Existen dos maneras de crear
diagramas de implementación. La primera es desde el Diseñador de aplicaciones,
sin definir con anterioridad un sistema explícito. Los Diseñadores de sistemas
69
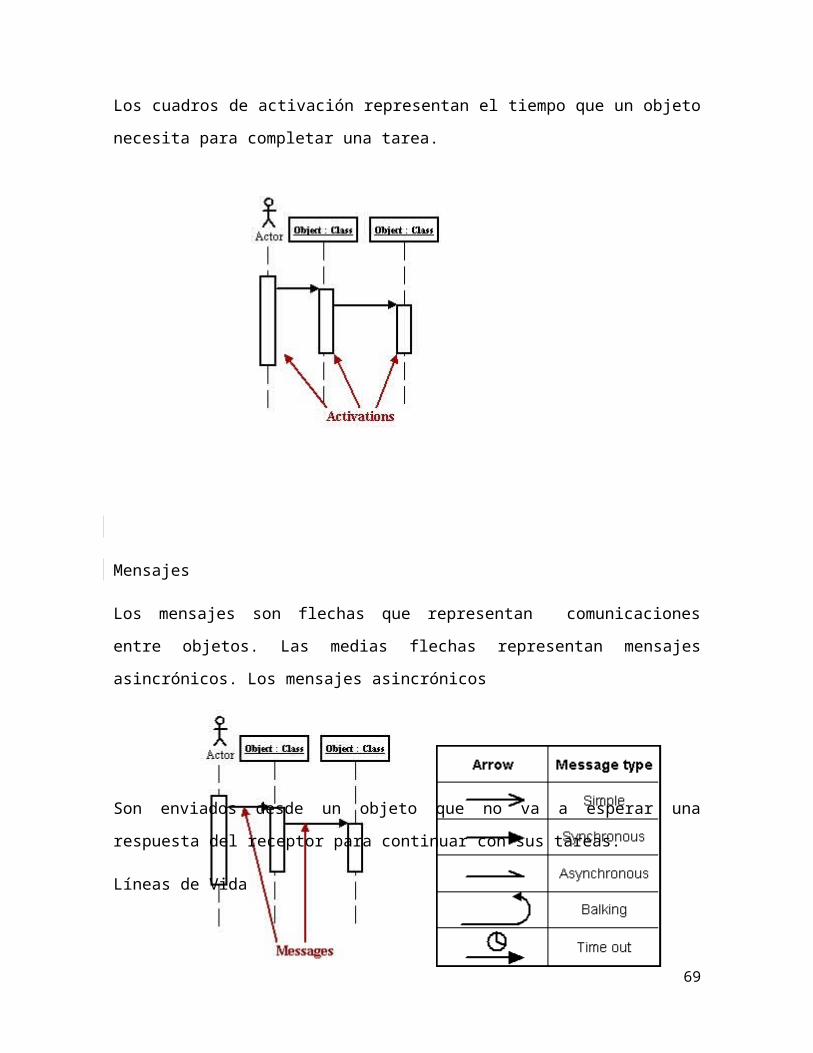
distribuidos crean un sistema predeterminado mediante las definiciones de
aplicación del diagrama de aplicaciones porque siempre se requiere que un
sistema describa una implementación del sistema. La segunda opción es crearlo
desde un sistema definido en el Diseñador de sistemas.
Para crear un diagrama de implementación desde el Diseñador de aplicaciones
1. En el Diseñador de aplicaciones, elija Definir implementación en el menú
Diagrama.
Aparecerá el cuadro de diálogo Definir implementación. Se rellena
automáticamente con el nombre de un diagrama de centros de datos lógicos, si
aparece uno en la solución.
2. Bajo Diagrama de centros de datos lógicos, elija un diagrama en la solución
o haga clic en Examinar para buscar un diagrama (archivo .ldd) fuera de la
solución.
3. Haga clic en Aceptar.
Se abre el diagrama de implementación en el Diseñador de implementación.
2.4.5 ADAPTACIONES DE UML
Existen dos tipos de metodologías: antiguas y recientes. Se entiende por
metodología a la estructura y naturaleza de los pasos en un esfuerzo de
desarrollo. Pero antes de iniciar a programar los desarrolladores deben tener
claridad sobre el problema.
Método antiguo
Las etapas deben suceder en lapsos definidos, una después de otra. Obsérvese el
método en cascada:
Este método reduce el impacto de la comprensión obtenida en el proyecto. Si el
proceso no puede retroceder y volver a ver los primeros estados, es posible que
las ideas desarrolladas no sean utilizadas.
Método reciente
70
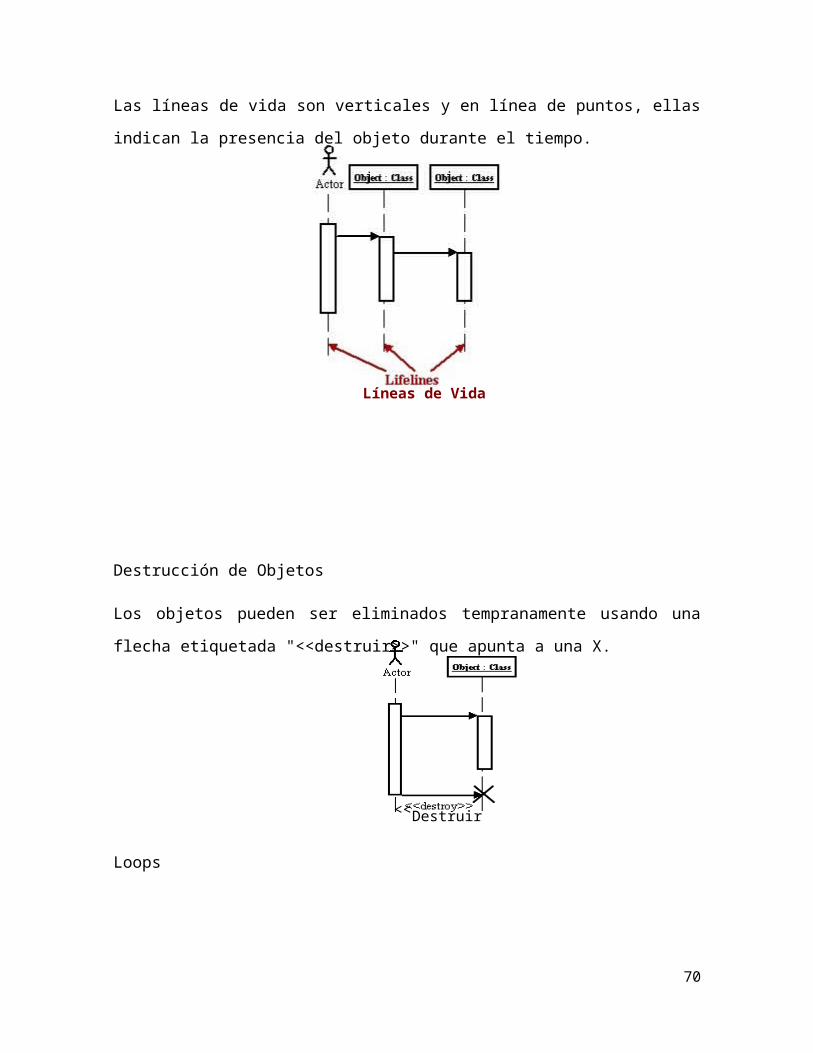
Tiende a la colaboración entre las fases de desarrollo esta moderna ingeniería de
programas, los analistas y diseñadores hacen revisiones para desarrollar un sólido
fundamento para los desarrolladores. Existe interacción entre todo el equipo de
trabajo.
La ventaja es que conforme crece la comprensión, el equipo incorpora nuevas
ideas y genera un sistema más confiable.
Lo que debe hacer un proceso de desarrollo
El equipo tiene que formarse de analistas para comunicarse con el cliente y
comprender el problema, diseñadores para generar una solución, programadores
para codificarla e ingenieros de sistemas para distribuirlas.
A su vez debe asegurar que sus fases no sean discontinuas.
GRAPPLE
Significa Guías para la Ingeniería de Aplicaciones Rápidas, tiene dentro de sí una
condensación de ideas de varias otras personas.
Consta de cinco segmentos en lugar de fases, cada segmento consta de diversas
acciones cada acción es responsabilidad de un jugador.
Los segmentos son: recopilación, análisis, diseño, desarrollo y distribución. Lo que
otorga un acrónimo RADDD.
Recopilación de necesidades
La función es comprender lo que desea el cliente.
Realice un análisis del dominio
El objetivo es comprender de la mejor manera posible el dominio del cliente. El
analista debe acomodarse al cliente.
Descubra las necesidades del sistema
El equipo realiza su primera sesión de JAD(Desarrollo de conjunto de
aplicaciones).En dónde se reúne a quienes toman las decisiones en la empresa
71

del cliente, a los usuarios potenciales y a los miembros de los equipos de
desarrollo.
Presentar los resultados al cliente
Cuando finaliza todas las acciones de Necesidades, el administrador de proyectos
presentará los resultados al cliente.
Análisis
En este segmento aumenta la comprensión por parte del equipo. Se necesita
trabajar sobre: la comprensión del uso del sistema, hacer realidad de los casos de
uso, depurar los diagramas de clases, analizar cambios de estado en los objetos,
definir la comunicación entre objetos, analizar la integración con diagramas de
colaboraciones.
Diseño
El equipo trabajará con los resultados del segmento de Análisis para diseñar la
solución, en este punto se harán revisiones pertinentes hasta que el diseño se
haya completado. Contiene las siguientes fases: desarrollo y depuración de
diagramas de componentes, desarrollo de diagramas de componentes, planeación
para la distribución, diseño y prototipos de la interfaz del usuario, pruebas de
diseño, iniciar la documentación.
Desarrollo
De este segmento se encargan los programadores, debe realizarse con rapidez y
sin problemas.
Fases: generación del código, verificación del código, generación de interfaces del
usuario y conexión con el código, prueba, consumación de la documentación.
Distribución
En este segmento se distribuye en el hardware adecuado y se integra con los
sistemas cooperativos.
72

Fases: planeación para copias de seguridad y recuperación, instalación del
sistema terminado en el hardware adecuado, verificación del sistema instalado,
celebración.
73

2.5 DISEÑO DE INTERFAZ DE USUARIO
El diseño de interfaz de usuario o ingeniería de la interfaz es el diseño
de computadoras, aplicaciones, máquinas, dispositivos de comunicación móvil,
aplicaciones de software, y sitios web enfocado en la experiencia de usuario y la
interacción.
Normalmente es una actividad multidisciplinar que involucra a varias ramas es
decir al diseño y el conocimiento como el diseño gráfico, industrial, web, de
software y la ergonomía; y está implicado en un amplio rango de proyectos, desde
sistemas para computadoras, vehículos hasta aviones comerciales.
Su objetivo es que las aplicaciones o los objetos sean más atractivos y además,
hacer que la interacción con el usuario sea lo más intuitiva posible, conocido como
el diseño centrado en el usuario. En este sentido las disciplinas del diseño
industrial y gráfico se encargan de que la actividad a desarrollar se comunique y
aprenda lo más rápidamente, a través de recursos como la gráfica, los
pictogramas, los estereotipos y la simbología, todo sin afectar el funcionamiento
técnico eficiente.
2.5.1 INTERACCION HOMBRE MAQUINA
Todavía no hay una definición concreta para el conjunto de conceptos que forman
el área de la interacción persona-computador. En términos generales, podríamos
decir que es la disciplina que estudia el intercambio de
información mediante software entre las personas y las computadoras. Esta se
encarga del diseño, evaluación e implementación de los aparatos tecnológicos
interactivos, estudiando el mayor número de casos que les pueda llegar a afectar.
El objetivo es que el intercambio sea más eficiente: minimizar errores, incrementar
la satisfacción, disminuir la frustración y, en definitiva, hacer más productivas las
tareas que rodean a las personas y los computadores.
Aunque la investigación en este campo es muy complicada, la recompensa una
vez conseguido el objetivo de búsqueda es muy gratificante. Es muy importante
diseñar sistemas que sean efectivos, eficientes, sencillos y amenos a la hora de
74
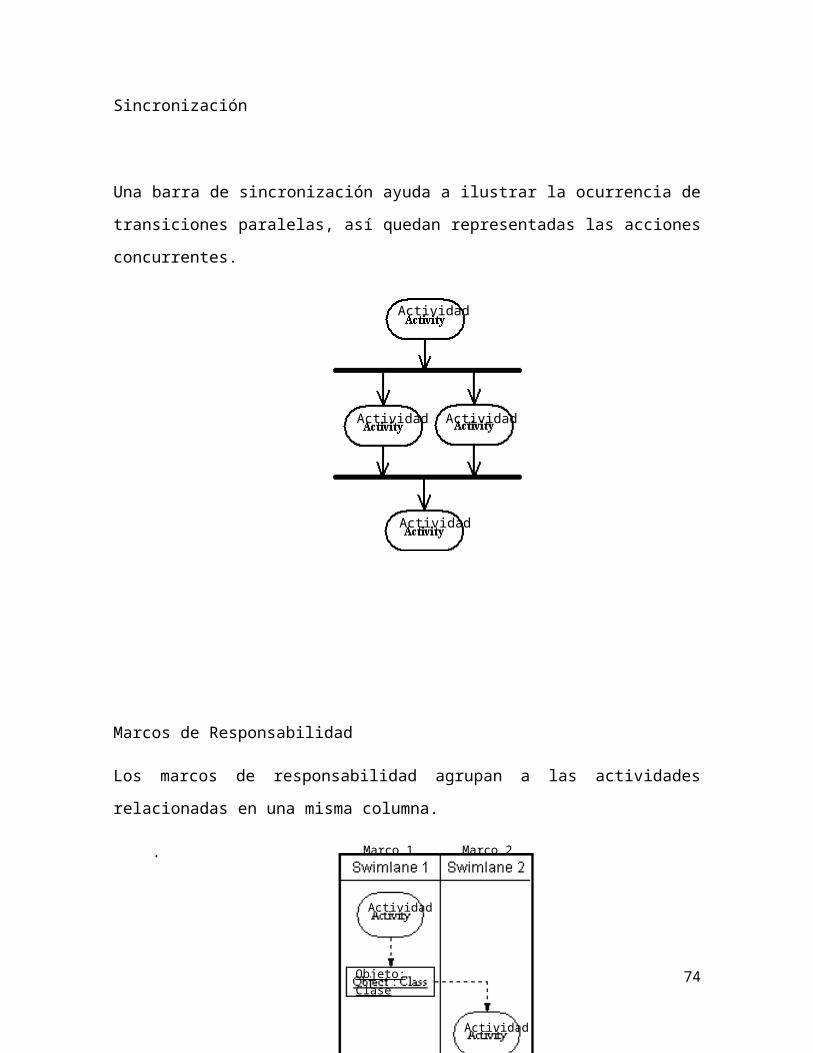
utilizarlos, dado que la sociedad disfrutará de estos avances. La dificultad viene
dada por una serie de restricciones y por el hecho de que en ocasiones se tienen
que hacer algunos sacrificios. La recompensa sería: la creación de librerías
digitales donde los estudiantes pueden encontrar manuscritos medievales virtuales
de hace centenares de años; los utensilios utilizados en el campo de la medicina,
como uno que permita a un equipo de cirujanos conceptualizar, alojar y
monitorizar una compleja operación neurológica; los mundos virtuales para el
entretenimiento y la interacción social, servicios del gobierno eficientes y
receptivos, que podrían ir desde renovar licencias en línea hasta el análisis de un
testigo parlamentario; o bien teléfonos inteligentes que saben donde están y
cuentan con la capacidad de entender ciertas frases en un idioma. Los
diseñadores crean una interacción con mundos virtuales integrándolos con el
mundo físico.
2.5.2 DISEÑO DE INTERFAZ HOMBRE MAQUINA
La sigla HMI es la abreviación en ingles de Interfaz Hombre Maquina. Los
sistemas HMI podemos pensarlos como una ventana de un proceso. Esta ventana
puede estar en dispositivos especiales como paneles de operador o en
computadora. Los sistemas HMI en computadoras se les conoce también como
software HMI o de monitoreo y control de supervisión. Las señales del proceso
son conocidas al HMI por medio de dispositivos como tarjetas de entrada / salida
en la computadoras, PLC’s (controladores lógicos programables), RTU (unidades
remotas I/O) o DRIVE´s (variadores de velocidad de motores). Todos estos
dispositivos deben tener una comunicación que entienda el HMI.
2.5.3 DIRECTRICES PARA EL DISEÑO DE INTERFACES
No forzar al usuario a leer grandes cantidades de texto, ya que la lectura
en un monitor de un computador es, aproximadamente, un 25% más
lenta que la lectura en papel.
Evitar los llamados iconos “under construction”, pues causan
expectación y pueden decepcionar al usuario si el resultado final no es
el esperado.
75

La información importante debe colocarse dentro de las dimensiones
típicas de la ventana del navegador, ya que los usuarios prefieren no
desplazarse sobre la ventana.
Los menús de navegación y las barras de cabecera de las páginas Web
deben ser consistentes y aparecer en todas las páginas que se le
muestrean al usuario.
La estética nunca debe sustituir a la funcionalidad.
2.5.4 ESTANDARES DE INTERFAZ
Muchas aplicaciones web obvian algunos de los principios de los que hablaremos,
y dichos principios no cambian aunque sea una aplicación web, todo lo contrario,
respetarlos puede llegar a ser aún más importante y necesario.
Las interfaces gráficas efectivas son visualmente comprensibles y permiten
errores por parte del usuario, dándole una sensación de control. Los usuarios ven
rápidamente el alcance de las opciones y comprenden como obtener sus metas y
realizar su trabajo.
Dichas interfaces ocultan al usuario el funcionamiento interno del sistema. El
trabajo se va guardando constantemente brindando una opción de deshacer en
todo momento cualquier acción que se haya hecho. Las aplicaciones y servicios
efectivos realizan el máximo trabajo requiriendo la mínima información del usuario.
Anticiparse.
Una buena aplicación intentará anticiparse a las necesidades y deseos de los
usuarios. No esperes que el usuario busque o recuerde información o
herramientas. Muestra al usuario toda la información y herramientas necesarias
para cada etapa en su trabajo.
Autonomía.
El ordenador, la interfaz y el entorno de la tarea pertenecen al usuario, pero no
podemos abandonarlo.
76

Ante una interface, al usuario hay que darle “cuerda” para que investigue y sienta
que tiene el control del sistema. No obstante, hay que tener en cuenta que los
adultos nos sentimos más cómodos en un entorno que no sea ni muy restrictivo, ni
demasiado grande, un entorno explorable pero no peligroso.
Mantén informado al usuario del estado del sistema.
No existe autonomía en ausencia de control; y el control no se puede tener sin
información suficiente. Comunicar el estado es fundamental para que el usuario
responda apropiadamente con la información disponible.
Ejemplo: los trabajadores sin información del estado del sistema, tienden a
mantenerse bajo presión durante cortos periodos de tiempo hasta que el trabajo
se termina. Un estrés y fatiga innecesarios por lo que cuando venga la siguiente
carga de trabajo, puede que los trabajadores no estén en las mejores condiciones
físicas y mentales.
Los usuarios no tienen que buscar la información de estado. De un vistazo
deberían ser capaces de hacerse una idea aproximada del estado del sistema. La
información de estado pude ser bastante sutil: el icono de la bandeja de entrada
puede mostrarse vacía, media llena o hasta los topes, por ejemplo. Sin embargo,
no es conveniente abusar: En Mac se utilizó durante años un icono de la papelera
que parecía que iba a estallar en cualquier momento, aunque sólo tuviese un
documento. Los usuarios adquirieron la costumbre de vaciar la papelera apenas
contuviese un documento, convirtieron un proceso de un paso en uno de dos
(primero llevamos el documento a la papelera, luego lo vaciamos). Esto tuvo el
efecto negativo de reducir una de las funciones básicas de la papelera: la
posibilidad de deshacer la acción.
77

2.6 DISEÑO DE LA BASE DE DATOS
Son muchas las consideraciones a tomar en cuenta al momento de hacer el
diseño de la base de datos, quizás las más fuertes sean:
La velocidad de acceso.
El tamaño de la información.
El tipo de la información.
Facilidad de acceso a la información.
Facilidad para extraer la información requerida.
El comportamiento del manejador de bases de datos con cada tipo de
información.
No obstante que pueden desarrollarse sistemas de procesamiento de archivo e
incluso manejadores de bases de datos basándose en la experiencia del equipo
de desarrollo de software logrando resultados altamente aceptables, siempre es
recomendable la utilización de determinados estándares de diseño que garantizan
el nivel de eficiencia más alto en lo que se refiere a almacenamiento y
recuperación de la información.
De igual manera se obtiene modelos que optimizan el aprovechamiento
secundario y la sencillez y flexibilidad en las consultas que pueden proporcionarse
al usuario.
El proceso de diseño de una base de datos se guía por algunos principios. El
primero de ellos es que se debe evitar la información duplicada o, lo que es lo
mismo, los datos redundantes, porque malgastan el espacio y aumentan la
probabilidad de que se produzcan errores e incoherencias. El segundo principio es
que es importante que la información sea correcta y completa. Si la base de datos
contiene información incorrecta, los informes que recogen información de la base
de datos contendrán también información incorrecta y, por tanto, las decisiones
que tome a partir de esos informes estarán mal fundamentadas.
78

2.6.1 OBJETIVOS
Un buen diseño de base de datos es, por tanto, aquél que:
Divide la información en tablas basadas en temas para reducir los datos
redundantes.
Proporciona a Access la información necesaria para reunir la información de las
tablas cuando así se precise.
Ayuda a garantizar la exactitud e integridad de la información.
Satisface las necesidades de procesamiento de los datos y de generación de
informes.
El proceso de diseño consta de los pasos siguientes:
Determinar la finalidad de la base de datos:
Esto le ayudará a estar preparado para los demás pasos.
Buscar y organizar la información necesaria:
Reúna todos los tipos de información que desee registrar en la base de datos,
como los nombres de productos o los números de pedidos.
Dividir la información en tablas:
Divida los elementos de información en entidades o temas principales, como
Productos o Pedidos. Cada tema pasará a ser una tabla.
Convertir los elementos de información en columnas:
Decida qué información desea almacenar en cada tabla. Cada elemento se
convertirá en un campo y se mostrará como una columna en la tabla. Por ejemplo,
79

una tabla Empleados podría incluir campos como Apellido y Fecha de
contratación.
Especificar claves principales:
Elija la clave principal de cada tabla. La clave principal es una columna que se
utiliza para identificar inequívocamente cada fila, como Id. de producto o Id. de
pedido.
Definir relaciones entre las tablas:
Examine cada tabla y decida cómo se relacionan los datos de una tabla con las
demás tablas. Agregue campos a las tablas o cree nuevas tablas para clarificar las
relaciones según sea necesario.
Ajustar el diseño:
Analice el diseño para detectar errores. Cree las tablas y agregue algunos
registros con datos de ejemplo. Compruebe si puede obtener los resultados
previstos de las tablas. Realice los ajustes necesarios en el diseño.
Aplicar las reglas de normalización:
Aplique reglas de normalización de los datos para comprobar si las tablas están
estructuradas correctamente. Realice los ajustes necesarios en las tablas.
2.6.2 ALMACEN DE DATOS
Los Almacenes de Datos son repositorios diseñador para facilitar la confección de
los informes y la realización de análisis; tal como ocurre con las bases de datos,
pueden ser completamente separados del sistema de información principal; lo cual
80

significa una ganancia enorme en el rendimiento de los sistemas cuando se
ejecuten las consultas.
El Procesamiento de Transacciones Online, usado normalmente por aplicaciones
orientadas a la transacción como pueda ser vtiger CRM, no han sido construidas
teniendo en cuenta la creación de bases de datos segregadas, y los potenciales
análisis que puedan realizarse se hacen sobre los mismos datos usados por la
aplicación, y tampoco han sido diseñadas para situaciones donde la cantidad de
datos a ser analizados es considerable.
Modelo de Datos usado en OLTP (OnlineTransaction Processing).
Los Almacenes de datos (Datawarehouses) usados en OLAP (Analytical
Processing) utilizan un modelo de datos denominado multidimensional.
81

La topología típica usada para construir un almacén de datos se denomina
"modelo en forma de estrella": La tabla central se llama "tabla de hechos" y
referencia un número de "dimensiones" (que son las tablas que están alrededor).
Usando este método es posible producir informes que incluyan información tal
como, por ejemplo, la cantidad de procesador producidos en el segundo
cuatrimestre del 2006. Por esta razón se construyen (hiper)cubos, y mediante este
modelo de datos desde diferentes dimensiones (potencialmente todas variables)
pueden ser enlazadas todas juntas.
Modelo en forma de estrella usado en OLAP
82

Cubo OLAP con Tiempo, Cliente y Producto como dimensiones.
Finalmente indicar que los almacenes de datos crean versiones de la información
con el objeto de conservar "información histórica" en un intento de dar coherencia
a los informes a lo largo del tiempo. Por ejemplo, si el nombre de una cuenta
(cliente) cambia, el sistema BI creará una nueva versión marcada con un nueva
marca de tiempo de forma que las entidades que existían antes del cambio sigan
estando relacionadas con la misma cuenta mientras que las nuevas entidades que
se vayan a crear a partir de ahora se relacionen con la nueva versión.
Para este proyecto vtiger CRM - BI hemos construido un almacén de datos capaz
de almacenar toda la información contenida dentro de un vtiger CRM en
producción. Todas las entidades del sistema son almacenadas como tablas de
dimensiones y versionadas según una serie de decisiones tomadas durante el
análisis realizado. Por ejemplo, la cuenta ha sido versionada cada vez que la
ciudad, país, provincia, código postal, dirección, miembro de, correo y el campo
"asignado a" sean modificados.
Hemos creado las siguientes tablas de hechos:
Ventas (que pueden ser estudiadas por Factura o Líneas de factura)
Incidencias post-venta (HelpDesk)
Campañas
Potentiales
Tarifas
En la tabla de hechos de Ventas hemos añadido cálculos específicos para obtener
información importante sobre beneficios y rentabilidades:
Cantidad: número de unidades en cada línea
Precio unitario: precio de cada unidad en la línea
83

Beneficio bruto por línea
Descuento en línea de venda por promociones. Aunque esto pueda ser
reflejado en vtiger CRM con las tarifas, no podemos saber si se ha aplicado
una tarifa en una línea determinada ya que vtiger CRM no guarda esta
información (siempre será cero).
Detalle de descuento por línea
Margen neto por línea
Coste interno de la línea para la empresa.
Beneficio total de la venta.
Impuestos aplicados.
Una vez creado el almacén de datos, necesitamos crear los procesos ETL
(Extract-Transform-Load) que periódicamente extraerán la información desde el
vtiger CRM en producción y cargarán con ella el Almacén de Datos, para ser
usado por las diversas herramientas de confección de informes (reporting) y
análisis disponibles. El procedimiento esencial se muestra en la imagen siguiente:
Como puede verse, el almacén de datos refleja la lógica del negocio y debe ser
construida para adaptarse perfectamente a esta lógica. Así pues, será necesario
realizar cuantas adaptaciones sean necesarias, al almacén y al resto de procesos,
para conseguir esto y por consiguiente el máximo beneficio y aprovechamiento de
la herramienta BI.
84

2.7 MÉTRICAS DEL DISEÑO
Como ya se ha visto por las distintas métricas estudiadas, la complejidad de un
programa crece con su tamaño: los programas largos son más difíciles de
escribir y comprender, contienen habitualmente más errores, y su depuración
resulta más compleja. Con objeto de reducir esta complejidad, los diseñadores de
software han hecho un uso progresivo de técnicas de modularización y diseño
estructurado. Entre las diversas ventajas de las técnicas de diseño se
pueden destacar las siguientes:
· Comprensibilidad: programadores y usuarios pueden comprender
fácilmente la lógica del programa.
· Manejabilidad: los gestores pueden asignar fácilmente personal y
recursos a los distintos módulos representados por tareas.
· Eficiencia: el esfuerzo de implementación puede reducirse.
· Reducción de errores: los planes de prueba se simplifican notablemente.
· Reducción del esfuerzo de mantenimiento: la división en módulos
favorece que las distintas funciones las lleven a cabo módulos
diferenciados.
Aunque estos beneficios también son discutidos y para ello se alega toda clase de
inconvenientes, en general se admite que el paso a la modularidad es un gran
salto adelante. Pero el problema que se plantea ahora se refiere a los módulos en
si: ¿Cuál es el tamaño idóneo, la complejidad máxima, la extensión adecuada de
un módulo?
Algunas de las métricas vistas hasta el momento tratan este problema. Así
algunos autores estiman que el tamaño de un módulo debe oscilar entre las 50-
200 líneas de código. Otros simplemente indican que un módulo debe completar
una función por sí solo. La complejidad límite de un módulo se fija en algunos
casos en un número de complejidad ciclomática igual a 10.
85

Otras discusiones se centran en la organización de los módulos en el
programa: estructuras en árbol, o lineales. Con objeto de obtener una valoración
de los módulos y una disposición que pueda emplearse como base para
comparaciones, surgen las métricas orientadas al diseño.
Muchas de estas métricas son generalizaciones de otras referidas a ámbitos más
restringidos (números de complejidad ciclomática, métricas de la ciencia del
software,...)
Uno de los estudios más completos relativos a la cuestión de valorar los módulos
software es el llevado a cabo por Troy y Zweben en el que se relaciona una serie
de métricas básicas con valores de calidad representados por la tasa de
modificaciones en pruebas.
En este estudio, un gran sistema fue dividido en módulos usando varias
convenciones de diseño. Cada módulo se codificó, probó y preparó para la
integración. Se registraron los cambios realizados en cada módulo. Cada
implementación de diseño se acompañó de un gráfico que representaba las
interconexiones entre los módulos. En total se obtuvieron veintiuna métricas
asociadas a cada gráfico.
Los principios que dirigen estas métricas son:
· Acoplamiento: Se mide como el número de interconexiones entre
módulos. El acoplamiento crece con el número de llamadas, o con la cantidad de
datos compartidos. Se supone que un diseño con un acoplamiento alto
puede contener más errores. Se cuantifica como el número de conexiones por
nodo del gráfico de diseño.
· Cohesión: Valora las relaciones entre los elementos de un módulo. En un
diseño cohesivo, las funciones están ubicadas en un solo módulo. Los diseños
con una cohesión baja contendrán más errores. Las medidas que valoren la
información compartida entre módulos cuantificarán la cohesión.
· Complejidad: Un diseño debe ser lo más simple posible. La complejidad
crece con el número de construcciones de control, y el número de módulos
86

de un programa. Un diseño complejo contendrá más errores. La complejidad se
evidencia en el número de elementos del gráfico de diseño.
· Modularidad: El grado de modularidad afecta a la calidad del diseño. Es
preferible un exceso a un defecto de modularidad, pues en este último caso
contendrá más errores. La cuantificación de la modularidad se obtiene
midiendo la cantidad de elementos del gráfico.
· Tamaño: Un diseño con grandes módulos, o gran profundidad en su gráfico
contendrá más errores. De hecho, complejidad y tamaño están muy relacionados y
las consecuencias de un exceso de cualquiera de los dos principios tienen los
mismos resultados.
Las conclusiones finales del estudio sugieren que a pesar de la correlación
encontrada entre los factores estudiados y los errores encontrados, sigue
habiendo una serie de factores no detectados que determinan a su vez la
calidad de un diseño. De todas formas es posible afirmar que las
interconexiones entre módulos, y la complejidad de los diseños aumentan
notablemente los errores, y disminuyen la calidad.
Otras métricas del software.
Además de las mencionadas, existen algunas otras métricas que valoran ciertos
aspectos del software.
Las métricas de reusabilidad tratan de medir el grado en que un elemento software
puede ser empleado por otros programas, en otras palabras, su independencia.
Debido a que es difícil valorar objetivamente esta independencia, la referencia
más común es la independencia del hardware expresada en número de cambios
en el código al adaptar un programa a una nueva plataforma. Esta medida puede
ampliarse al número de cambios realizados en el código por líneas al adaptarlo a
un nuevo sistema operativo, o a un nuevo sistema gráfico. Las métricas de
portabilidad valoran aspectos muy similares.
87

Las métricas de mantenibilidad se enuncian como función de los valores de
concisión, consistencia, instrumentación, modularidad, auto documentación y
simplicidad.
Las métricas de testeabilidad (o capacidad de probar el software) son
función de la auditabilidad (capacidad de someter el software a auditoría), la
complejidad de software (ciclomática, contando los GOTO y bucles, o según los
valores de la Ciencia del Software), instrumentación, modularidad,
autodocumentación y simplicidad.
Las de flexibilidad tienen como componentes a la complejidad, la concisión,
la consistencia, la expandibilidad, la generalidad, la autodocumentación, y la
simplicidad.
La interpretación que se da de los componentes de cada una de estas métricas
es, no obstante, discutible e imprecisa, sin un método definido para obtener
una valoración. También se carece de expresiones que determinen el peso que
cada componente tiene en la métrica.
2.7.1 FACTORES QUE AFECTAN
McCall y Cavano [John A. McDermid ‘91 definieron un juego de factores de calidad
como los primeros pasos hacia el desarrollo de métricas de la calidad del software.
Estos factores evalúan el software desde tres puntos de vista distintos:
(1) Operación del producto (utilizándolo),
(2) revisión del producto (cambiándolo) y
(3) transición del producto (modificándolo para que funcione en un entorno
diferente, por ejemplo: “portándolo”) Los autores describen la relación entre estos
factores de calidad (lo que llaman un ‘marco de trabajo’) y otros aspectos del
proceso de ingeniería del software:
En primer lugar el marco de trabajo proporciona al administrador identificar en el
proyecto lo que considera importante, como: facilidad de mantenimiento y
transportabilidad, atributos del software, además de su corrección y rendimiento
88

funcional teniendo un impacto significativo en el costo del ciclo de vida. En
segundo lugar, proporciona un medio de evaluar cuantitativamente el progreso en
el desarrollo de software teniendo relación con los objetivos de calidad
establecidos. En tercer lugar, proporciona más interacción del personal de calidad,
en el esfuerzo de desarrollo. Por último, el personal de calidad puede utilizar
indicaciones de calidad que se establecieron como “pobres” para ayudar a
identificar estándares “mejores” para verificar en el futuro. Es importante destacar
que casi todos los aspectos del cálculo han sufrido cambios radicales con el paso
de los años desde que McCall y Cavano hicieron su trabajo, teniendo gran
influencia, en 1978. Pero los atributos que proporcionan una indicación de la
calidad del software siguen siendo los mismos. Si una 63 organización de
software adopta un juego de factores de calidad como una “lista de comprobación”
para evaluar la calidad del software, es probable que el software construido hoy
siga exhibiendo la buena calidad dentro de las primeras décadas del siglo XXI.
Incluso, cuando las arquitecturas del cálculo sufran cambios radicales (como
seguramente ocurrirá), el software que exhibe alta calidad en operación, transición
y revisión continuará sirviendo a sus usuarios.
2.7.2 PRODUCTIVIDAD
En el terreno de las metodologías de desarrollo de software, se aprecia una
necesaria mejora en la puesta en práctica de dichas metodologías de desarrollo,
así como la flexibilización de éstas para potenciar la productividad de las mismas
sin renunciar a la calidad de los mismos.
Por esta razón se hace cada vez más necesario disponer de herramientas
efectivas para aumentar la productividad, no solo desde un punto de vista teórico
sino especialmente en la puesta en práctica de dichas metodologías, consiguiendo
que su despliegue impacte positivamente en el negocio de la empresa.
La mejora de la efectividad y la productividad en el desarrollo de software está
ligada a la utilización de buenas prácticas de Ingeniería de Software. En la
actualidad es indiscutible que el uso de una metodología apropiada es un factor
89

clave para el éxito de cualquier esfuerzo de ingeniería y también debería ser-lo en
la ingeniería del software. La ingeniería de software, por su relativa juventud como
disciplina y por la altísima variabilidad de los productos que gestiona, pocas
organizaciones que desarrollen software utilizan metodologías de forma
sistemática, aunque esta tendencia está cambiando día a día.
La Ingeniería de Procesos contribuye en esta línea, diseñando y construyendo
metodologías en función de las necesidades específicas de cada organización. De
este modo, de la misma forma que las metodologías deben responder a
multiplicidad de estándares, también deben adaptarse a las características
particulares de cada uno de los proyectos que se llevan a cabo en la organización.
La complejidad del proceso hace imprescindible que una gran parte de las
actividades del desarrollo de software se automatice.
Los modelos y las metodologías basadas en modelos son la herramienta para
abstraer de los detalles irrelevantes en un determinado contexto y poder razonar
sobre el sistema a construir. Los modelos están demostrando ser una herramienta
de productividad, acercando los modelos a los expertos del dominio de aplicación.
Este enfoque permite separar los modelos que describen la solución al problema
en términos de negocio, de los modelos que describen la implementación en
términos de la plataforma software. Esta arquitectura de solución separa los
aspectos del negocio de la tecnología de implementación facilitando que ambos
evolucionen independientemente uno de otro y posibilitando verdaderas factorías
de software estructuradas por dominio de aplicación y por tecnología de
implementación.
2.7.3 MEDIDAS RELACIONADAS
Aunque hay muchas medidas de la calidad de software, la corrección, facilidad de
mantenimiento, integridad y facilidad de uso suministran indicadores útiles para el
equipo del proyecto. Gilb [Len O. Ejiogo ‘90] sugiere definiciones y medidas para
cada uno de ellos, tales como:
Corrección: A un programa le corresponde operar correctamente o suministrará
90

poco valor a sus usuarios. La corrección es el grado en el que el software lleva a
cabo una función requerida. La medida más común de corrección son los defectos
por KLDC, en donde un defecto se define como una falla verificada de
conformidad con los requisitos. Facilidad de mantenimiento. El mantenimiento del
software cuenta con más esfuerzo que cualquier otra actividad de ingeniería del
software. La facilidad de mantenimiento es la habilidad con la que se puede
corregir un programa si se encuentra un error, se puede adaptar si su entorno
cambia o optimizar si el cliente desea un cambio de requisitos. No hay forma de
medir directamente la facilidad de 64mantenimiento; por consiguiente, se deben
utilizar medidas indirectas. Una métrica orientada al tiempo simple es el tiempo
medio de cambio (TMC), es decir, el tiempo que se tarda en analizar la petición de
cambio, en diseñar una modificación apropiada, en efectuar el cambio, en probarlo
y en distribuir el cambio a todos los usuarios. En promedio, los programas que son
más fáciles de mantener tendrán un TMC más bajo (para tipos equivalentes de
cambios) que los programas que son más difíciles de mantener. Hitachi ha
empleado una métrica orientada al costo (precio) para la
capacidad de mantenimiento, llamada “desperdicios”. El costo estará en corregir
defectos hallados después de haber distribuido el software a sus usuarios finales.
Cuando la proporción de desperdicios en el costo global del proyecto se simboliza
como una función del tiempo, es aquí donde el administrador logra determinar si la
facilidad de mantenimiento del software producido por una organización de
desarrollo está mejorando y asimismo se pueden emprender acciones a partir de
las conclusiones obtenidas de esa información. Integridad En esta época de
intrusos informáticos y de virus, la integridad del software ha llegado a tener
mucha importancia. Este atributo mide la habilidad de un sistema para soportar
ataques (tanto accidentales como intencionados) contra su seguridad. El ataque
se puede ejecutar en cualquiera de los tres componentes
del software, ya sea en los programas, datos o documentos. Para medir la
integridad, se tienen que definir dos atributos adicionales: amenaza y seguridad.
91

La amenaza es la probabilidad (que se logra evaluar o concluir de la evidencia
empírica) de que un ataque de un tipo establecido ocurra en un tiempo
establecido. La seguridad es la probabilidad (que se puede estimar o 65 deducir
de la evidencia empírica) de que se pueda repeler el ataque de un tipo
establecido, en donde la integridad del sistema se puede especificar como:
integridad = Ó[1- amenaza x (1- seguridad donde se suman la amenaza y la
seguridad para cada tipo de ataque.
Facilidad de uso. El calificativo “amigable con el usuario” se ha transformado
universalmente en disputas sobre productos de software. Si un programa no es
“amigable con el usuario”, prácticamente está próximo al fracaso, incluso aunque
las funciones que realice sean valiosas. La facilidad de uso es un intento de
cuantificar “lo amigable que pude ser con el usuario” y se consigue medir en
función de cuatro características:
(1) destreza intelectual y/o física solicitada para aprender el sistema;
(2) el tiempo requerido para alcanzar a ser moderadamente eficiente en el uso del
sistema;
(3) aumento neto en productividad (sobre el enfoque que el sistema reemplaza)
medida cuando alguien emplea el sistema moderadamente y eficientemente, y (4)
valoración subjetiva (a veces obtenida mediante un cuestionario) de la disposición
de los usuarios hacia el sistema.
Los cuatro factores anteriores son sólo un ejemplo de todos los que se han
propuesto como medidas de la calidad del software.
Medidas de fiabilidad y de disponibilidad. Los trabajos iniciales sobre fiabilidad
buscaron extrapolar las matemáticas de la teoría de fiabilidad del hardware a la
predicción de la fiabilidad del software. La mayoría de los modelos de fiabilidad
relativos al hardware van más orientados a los fallos debidos al desajuste, que a
los fallos debidos a defectos de diseño, ya que son más probables debido al
92

desgaste físico (p. ej.: el efecto de la temperatura, del deterioro, y los golpes) que
los fallos relativos al diseño. Desgraciadamente, para el software lo que ocurre es
lo contrario. De hecho, todos los fallos del software, se producen por problemas de
diseño o de implementación. Considerando un sistema basado en computadora,
una medida sencilla de la fiabilidad es el tiempo medio entre fallos (TMEF)
[Mayrhauser´91], donde:
TMEF = TMDF+TMDR (4.2)
(TMDF (tiempo medio de fallo) y TMDR (tiempo medio de reparación)).
Muchos investigadores argumentan que el TMDF es con mucho, una medida más
útil que los defectos/KLDC, simplemente porque el usuario final se enfrenta a los
fallos, no al número total de errores. Como cada error de un programa no tiene la
misma tasa de fallo, la cuenta total de errores no es una buena indicación de la
fiabilidad de un sistema. Por ejemplo, consideremos un programa que ha estado
funcionando durante 14 meses. Muchos de los errores del programa pueden pasar
desapercibidos durante décadas antes de que se 67 detecten. El TMEF de esos
errores puede ser de 50 e incluso de 100 años. Otros errores, aunque no se hayan
descubierto aún, pueden tener una tasa de fallo de 18 ó 24 meses, incluso aunque
se eliminen todos los errores de la primera categoría (los que tienen un gran
TMEF), el impacto sobre la fiabilidad del software será muy escaso.
Además de una medida de la fiabilidad debemos obtener una medida de la
disponibilidad. La disponibilidad (4.1.3.2) del software es la probabilidad de que un
programa funcione de acuerdo con los requisitos en un momento dado, y se define
como:
Disponibilidad = TMDF/(TMDF + TMDR) x 100 % (4.3)
La medida de fiabilidad TMEF es igualmente sensible al TMDF que al TMDR. La
medida de disponibilidad es algo más sensible al TMDR ya que es una medida
indirecta de la facilidad de mantenimiento del software.
93

2.7.3.1 TAMAÑO
El proceso a seguir para realizar desarrollo orientado a objetos es complejo,
debido a la complejidad que nos vamos a encontrar al intentar desarrollar
cualquier sistema software de tamaño medio-alto. El proceso está formado por
una serie de actividades y subactividades, cuya realización se va repitiendo en el
tiempo aplicado a distintos elementos.
En este apartado se va a presentar una visión general para poder tener una idea
del proceso a alto nivel, y más adelante se verán los pasos que componen cada
fase.
Las tres fases al nivel más alto son las siguientes:
· Planificación y Especificación de Requisitos: Planificación, definición de
requisitos, construcción de prototipos, etc. 26 IV.1 Proceso de Desarrollo
Desarrollo Orientado a Objetos con UML Xavier Ferré Grau, María Isabel Sánchez
Segura
· Construcción: La construcción del sistema. Las fases dentro de esta etapa son
las siguientes:
- Análisis: Se analiza el problema a resolver desde la perspectiva de los usuarios y
de las entidades externas que van a solicitar servicios al sistema.
- Diseño: El sistema se especifica en detalle, describiendo cómo va a funcionar
internamente para satisfacer lo especificado en el análisis.
- Implementación: Se lleva lo especificado en el diseño a un lenguaje de
programación.
- Pruebas: Se llevan a cabo una serie de pruebas para corroborar que el software
funciona correctamente y que satisface lo especificado en la etapa de Planificación
y
Especificación de Requisitos.
94

· Instalación: La puesta en marcha del sistema en el entorno previsto de uso.
De ellas, la fase de Construir es la que va a consumir la mayor parte del esfuerzo
y del tiempo en un proyecto de desarrollo. Para llevarla a cabo se va adoptar un
enfoque iterativo, tomando en cada iteración un subconjunto de los requisitos
(agrupados según casos de uso) y llevándolo a través del análisis y diseño hasta
la implementación y pruebas, tal y como se muestra en la
El sistema va creciendo incrementalmente en cada ciclo.
Con esta aproximación se consigue disminuir el grado de complejidad que se trata
en cada ciclo, y se tiene pronto en el proceso una parte del sistema funcionando
que se puede contrastar con el usuario/cliente.
2.7.3.2 FUNCION
Hewlett-Packard ha desarrollado un conjunto de factores de calidad de software al
que se le ha dado el acrónimo de FURPS:
- Funcionalidad. Se aprecia evaluando el conjunto de características y
capacidades del programa, la generalidad de las funciones entregadas y la
seguridad del sistema global.
- Usabilidad (facilidad de empleo o uso) Se valora considerando factores
humanos, la estética, consistencia y documentación general.
- Fiabilidad. Se evalúa midiendo la frecuencia y gravedad de los fallos, la exactitud
de las salidas (resultados), el tiempo medio entre fallos (TMEF), la capacidad de
recuperación de un fallo y la capacidad de predicción del programa.
- Rendimiento. Se mide por la velocidad de procesamiento, el tiempo de
respuesta, consumo de recursos, rendimiento efectivo total y eficacia. 75
- Capacidad de soporte. Combina la capacidad de ampliar el programa
(extensibilidad), adaptabilidad y servicios (los tres representan mantenimiento),
así como capacidad de hacer pruebas, compatibilidad, capacidad de
configuración, la facilidad de instalación de un sistema y la facilidad con que se
pueden localizar los problema
95

2.7.3.3 PUNTOS DE OBJETO
Para conocer Puntos función, No ajustados y factor de complejidad.
Es necesario detectar ciertos parámetros:
-Entradas externas: Se cuenta cada entrada de usuario que proporciona diferentes
datos orientados a la aplicación. Las entradas se deberían diferenciar de las
peticiones, las cuales se cuentan de forma separada.
-Salidas externas: Se cuenta cada salida que proporciona al usuario información
orientada a la aplicación. En este contexto la salida se refiere a informes,
pantallas, mensajes de error, etc. Los elementos de datos particulares dentro de
un informe no se cuentan de forma separada.
-Archivos lógicos. Se cuenta cada archivo maestro lógico (esto es, un grupo lógico
de datos que puede ser una parte de una gran base de datos o un archivo
independiente).
-Archivos externos de interface. Una petición se define como una entrada
interactiva que produce la generación de alguna respuesta del software inmediata
en forma de salida interactiva. Se cuenta cada petición por separado.
-Consultas externas. Se cuentan todas las interfaces legibles por la máquina (por
ejemplo: archivos de datos de cinta o disco) que se utilizan para transmitir
información a otro sistema.
2.7.4 METRICAS DE DISEÑO ARQUITECTONICO
El diseño de más alto nivel también es llamado: diseño general, arquitectónico o
conceptual. También es una actividad de modelaje.
El objetivo del diseñador: es producir un modelo o representación del software que
se continuara más adelante. El diseño del software es la primera de tres (3)
actividades técnicas:
1) Diseño
2) Codificación.
96

3) Prueba.
Diseño de Datos. Transforma el modelo del campo de información, creado durante
el análisis, en las estructuras de datos que se van a requerir para implementar el
software.
Diseño Arquitectónico: Define las relaciones entre los principales elementos
estructurales del programa.
Diseño Procedimental: Transforma los elementos estructurales en una descripción
procedimental del software. Se genera el código fuente y para integrar y validar el
software, se llevan a cabo las pruebas.
Alcance del Diseño del Software:
1) Diseño de la arquitectura del sistema: Este es el proceso durante el cual se
produce una especificación completa y verificada del hardware en general
2) Diseño detallado del software: Este ocurre cuando se producen
especificaciones verificadas de estructuras de datos.
La elección de un mecanismo de persistencia adecuado:1)El tipo de sistema de
base de datos a utilizar.
2) La forma en que la aplicación se comunicará con el mismo.
3) La distribución de la lógica: qué parte resolverá la aplicación y qué otra se
delegará a mecanismos propios del sistema elegido las bases de datos de objetos
(OODBMS). Como su nombre lo indica, la forma en la que éstas organizan y
almacenan la información se acerca bastante a la manera en que se trabaja con
objetos y referencias en las aplicaciones orientada a objeto las bases relacionales
(RDBMS) han demostrado poseer características: 1) Constituyen una
aproximación robusta y flexible para el manejo de los datos.
2) Se encuentran soportadas por una teoría capaz de, entre otras cosas, asegurar
la integridad de la información.
3) Están sustentadas por estándares
97

Ciertas cuestiones se delegan al motor:
1) Almacenamiento, organización y recuperación de información estructurada.
2) Concurrencia e integridad de datos.
3) Administración de los datos compartidos.
La arquitectura de software de un sistema de programa o computación es la
estructura de las estructuras del sistema, la cual comprende los componentes del
software, las propiedades de esos componentes visibles externamente, y las
relaciones entre ellos.
La arquitectura Mas bien, es la representación que capacita al ingeniero del
software para:
1-Analizar la efectividad del diseño para la consecución de los requisitos fijados.
2-Considerar las alternativas arquitectónicas en una etapa en la cual hacer
cambios en el diseño es relativamente fácil, y
3-Reducir los riesgos asociados a la construcción del software.
Porque es importante la arquitectura La arquitectura destaca decisiones
tempranas de diseño que tendrán un profundo impacto en todo el trabajo de
ingeniería del software que sigue
Sistemas basados en las arquitecturas de flujo de datos: Esta familia de estilos
enfatiza la reutilización y la modificabilidad. Es apropiada para sistemas que
implementan transformaciones de datos en pasos sucesivos. Históricamente él se
relaciona con las redes de proceso descriptas por Kahn hacia 1974 y con el
proceso secuenciales comunicantes (CSP) ideados por Tony Hoare cuatro años
más tarde.
Sistemas basados en arquitecturas de llamada y retorno (capas): Esta familia de
estilos enfatiza la modificabilidad y la escalabilidad. Son los estilos más
generalizados en sistemas en gran escala. Existen dos subestilos dentro de esta
categoría:
98

1-Arquitecturas de programa principal.
2-Arquitecturas de llamada de procedimiento remoto.
las concepciones formuladas por el patriarca Edsger Dijkstra en la década de
1960,
Sistemas basados en arquitectura heterogénea: Es la familia más fuertemente
referida en los últimos tiempos, se incluyen en este grupo formas compuestas o
indóciles a la clasificación en las categorías habituales. Es por cierto objetable y
poco elegante que existan clases residuales de este tipo en una taxonomía, pero
ninguna clasificación conocida ha podido resolver este dilema conceptual
1-Sistemas de control de procesos: los sistemas de control de procesos se
caracterizan no sólo por los tipos de componentes, sino por las relaciones que
mantienen entre ellos
2-Arquitecturas Basadas en Atributos: La arquitectura basada en atributos o ABAS
fue propuesta por Klein y Klazman. La intención de estos autores es asociar a la
definición del estilo arquitectónico un framework de razonamiento basado en
modelos de atributos específicos.
La arquitectura Cliente servidor el remitente de una solicitud es conocido
como cliente. Sus características son:
1-Es quien inicia solicitudes o peticiones, tienen por tanto un papel activo en la
comunicación
2-Espera y recibe las respuestas del servidor.
3-Por lo general, puede conectarse a varios servidores a la vez.
El diseño de un sistema de software se representa a través de dos fases:
1-El diseño lógico: un diseño lógico escriben las especificaciones detalladas del
nuevo sistema, esto es, describen sus características como son: las salidas,
entradas, archivos, bases de datos y procedimientos; todas de manera que cubran
los requerimientos del proyecto.
99

2-El diseño físico: El diseño físico, actividad que sigue al diseño lógico, produce
programas de software, archivos y un sistema en marcha, las especificaciones del
diseño indican a los programadores qué debe hacer el sistema.
Diseño físico deben delinearse las características de cada uno de los
componentes que se enumeran a continuación:
1-Diseño de hardware: debe especificarse todo el equipo de cómputo, lo que
incluye todo dispositivo de entrada, procedimientos y salidas con sus
características de rendimiento
2- Diseño de software: deben especificarse las características de todo el software
3-Diseño de base de datos: es necesario detallar el tipo estructura y funciones de
las base de datos, las relaciones de los elementos de datos establecidos en el
diseño lógico y físico
2.7.5 METRICAS DE NIVEL DE COMPONENTES
Las métricas de diseño a nivel de componentes se concentran en las
características internas de los componentes del software e incluyen medidas de la
cohesión, acoplamiento y complejidad del módulo. Estas tres medidas pueden 88
ayudar al desarrollador de software a juzgar la calidad de un diseño a nivel de
componentes. Las métricas presentadas son de “caja blanca” en el sentido de que
requieren conocimiento del trabajo interno del módulo en cuestión. Las métricas
de diseño en los componentes se pueden aplicar una vez que se ha desarrollado
un diseño procedimental. También se pueden retrasar hasta tener disponible el
código fuente.
2.7.6 METRICAS DE DISEÑO DE INTERFAZ
Aunque existe una significativa cantidad de literatura sobre el diseño de interfaces
hombre-máquina, se ha publicado relativamente poca información sobre métricas
que proporcionen una visión interna de la calidad y facilidad de empleo de la
interfaz.
100

Sears [Pressman ´98] sugiere la conveniencia de la representación (CR) como una
valiosa métrica de diseño para interfaces hombre-máquina. Una IGU
(Interfaz Gráfica de Usuario) típica usa entidades de representación, iconos
gráficos, texto, menús, ventanas y otras para ayudar al usuario a completar tareas.
Para realizar una tarea dada usando una IGU, el usuario debe moverse de una
entidad de representación a otra. Las posiciones absolutas y relativas de cada
entidad de representación, la frecuencia con que se utilizan y el “costo” de la
transición de una entidad de representación a la siguiente contribuirá a la
conveniencia de la interfaz. Para una representación específica (p. ej.: un diseño
de una IGU específica), se pueden asignar costos a cada secuencia de acciones
de acuerdo con la siguiente relación:
Costos = Ó[frecuencia de transición (ki) x costos de transición (ki)] (4.30)
donde k es la transición i específica de una entidad de representación a la
siguiente cuando se realiza una tarea específica. Esta suma se da con todas las
transiciones de una tarea en particular o conjunto de tareas requeridas para
conseguir alguna función de la aplicación. El costo puede estar caracterizado en
términos de tiempo, retraso del proceso o cualquier otro valor razonable, tal como
la distancia que debe moverse el ratón entre entidades de la representación.
La conveniencia de la representación se define como:
CR = 100 x [(costo de la representación óptima CR)/
(costo de la representación propuesta)] .
(4.31) 95 donde CR = para una representación óptima. Para calcular la
representación óptima de una IGU, la superficie de la interfaz (el área de la
pantalla) se divide en una cuadrícula. Cada cuadro de la cuadrícula representa
una posible posición de una entidad de la representación. Para una cuadrícula con
N posibles posiciones y K diferentes entidades de representación para colocar, el
101

número posible de distribuciones se representa de la siguiente manera [Pressman
‘98]:
Número posible de distribuciones = [N !/
(K! * (N - K)!] * K!
(4.32)
La CR se emplea para valorar diferentes distribuciones propuestas de IGU y la
sensibilidad de una representación en particular a los cambios en las
descripciones de tareas (por ejemplo, cambios en la secuencia y/o frecuencia de
transiciones) Es importante apuntar que la selección de un diseño de IGU puede
guiarse con métricas tales como CR, pero el árbitro final debería ser la respuesta
del usuario basada en prototipos de IGU.
102

3. IMPLEMENTACIÓN
3.1 ELABORACION DE UN PROGRAMA DE IMPLEMENTACIÓN
3.1.1 OBJETIVO
Una implementación es la realización de una aplicación, instalación o la ejecución
de un plan, idea, modelo científico, diseño, especificación, estándar, algoritmo o
política.
En ciencias de la computación, una implementación es la realización de una
especificación técnica o algoritmos como un programa, componente software, u
otro sistema de cómputo. Muchas implementaciones son dadas según a una
especificación o un estándar.
Por ejemplo, un navegador web respeta (o debe respetar) en su implementación,
las especificaciones recomendadas según el World Wide Web Consortium, y las
herramientas de desarrollo del software contienen implementaciones de lenguajes
de programación.
103

3.2 DESARROLLO DE SOFTWARE BASADO EN PROCESOS
ÁGILES
3.2.1 DEFINICIÓN DE PROCESOS ÁGILES
El desarrollo ágil de software son métodos de ingeniería del software basado en el
desarrollo iterativo e incremental, donde los requerimientos y soluciones
evolucionan mediante la colaboración de grupos autos organizados y
multidisciplinarios.
Existen muchos métodos de desarrollo ágil; la mayoría minimiza riesgos
desarrollando software en lapsos cortos. El software desarrollado en una unidad
de tiempo es llamado una iteración, la cual debe durar de una a cuatro semanas.
3.2.2 MODELOS DE PROCESOS ÁGILES
Lean software development
La metodología de desarrollo de software Lean es una translación de los
principios y prácticas de la manufactura esbelta hacia el dominio del
desarrollo de software. Adaptado del Sistema de producción Toyota,
apoyado por una sub-cultura pro-lean que está surgiendo desde la
comunidad ágil.
Programación extrema
La programación extrema o eXtreme Programming (XP) es una
metodología de desarrollo de la ingeniería de software formulada por Kent
Beck, autor del primer libro sobre la materia, Extreme Programming
Explained: Embrace Change (1999). Es el más destacado de los procesos
ágiles de desarrollo de software. Al igual que éstos, la programación
104

extrema se diferencia de las metodologías tradicionales principalmente en
que pone más énfasis en la adaptabilidad que en la previsibilidad.
Método de desarrollo de sistemas dinámicos
El método de desarrollo de sistemas dinámicos (en inglés Dynamic
Systems Development Method o DSDM) es un método que provee un
framework para el desarrollo ágil de software, apoyado por su continua
implicación del usuario en un desarrollo iterativo y creciente que sea
sensible a los requerimientos cambiantes, para desarrollar un sistema que
reuna las necesidades de la empresa en tiempo y presupuesto. Es uno de
un número de métodos de desarrollo ágil de software y forma parte de la
alianza ágil.
105

106
UNIDAD 3.
IMPLEMENTACIÓN

3.3 REUTILIZACIÓN DEL SOFTWARE
La reutilización de software es el proceso de implementar o actualizar sistemas de
software utilizando activos del mismo. Aunque al principio podría pensarse que un
activo de software es simplemente otro término para código fuente, éste no es el
caso. Los activos de software o componentes incluyen todos los productos
derivados del mismo, desde requerimientos y propuestas, especificaciones y
diseños a manuales y juegos de prueba. Cualquier cosa que sea producto de un
esfuerzo de desarrollo de software potencialmente puede ser reutilizada.
3.3.1 USOS DE REUTILIZACIÓN
Hay muchas metodologías para poner en práctica la reutilización de software.
Desde la reutilización de código ad hoc, a prácticas de reutilización repetible,
donde la reutilización es dentro de un proyecto o en múltiples proyectos.
Éstos pueden ser resumidos dentro de dos categorías generales:
Prácticas de reutilización con desarrollo
La reutilización de software es más comúnmente referida dentro del contexto de reutilización durante el desarrollo. Hay muchos enfoques hacia la reutilización de software durante el desarrollo.Tecnologías orientadas a objetos: Un concepto clave en las tecnologías de objetos es la idea de “objeto”. Los objetos caracterizan el dominio del problema, cada uno teniendo atributos y comportamientos específicos. Los objetos son manipulados con una colección de funciones y se comunican unas con otras utilizando un protocolo de mensajes, y están organizados dentro de clases y subclases.
Desarrollo con reutilización, reutilización oportunista.
En una organización de desarrollo que practica reutilización oportunista, ésta es ad hoc, cuando la oportunidad para reutilización se presenta por sí misma, es explotada. Por ejemplo, si una organización estuviera construyendo un sistema, y encuentra que durante el diseño o desarrollo, se podría ahorrar tiempo debido a que uno de sus subsistemas puede heredar las propiedades de otro, entonces esa organización está practicando reutilización oportunista.
Desarrollo con reutilización: reutilización sistemática.
107

La reutilización sistemática está “enfocada al dominio”. Se basa en un proceso repetible, y de manera primaria relacionada con la reutilización de los artefactos del ciclo de vida de más alto nivel, tales como: requerimientos, diseños y subsistemas. La idea detrás de la reutilización sistemática de software es que la reutilización no debería ser ad hoc, sino debería ser implementada dentro de la organización como parte del desarrollo de procesos.
Prácticas de reutilización sin desarrollo con reutilización del software.
Hay otras clases de reutilización en relación con el desarrollo de software. Uno de estos tipos es la reutilización del producto, la que se refiere a la reutilización de un sistema entero. Esencialmente, en vez de construir un sistema específico para un sólo cliente, se construye un sistema más general que puede ser utilizado por muchos clientes. El ejemplo más obvio de reutilización de producto son los sistemas operativos para PC de escritorio en el mundo, tales como los productos Windows de Microsoft.
3.3.2 PATRONES DE DISEÑO
Un patrón de diseño es básicamente una solución (un diseño) que surge de la
experimentación práctica con varios proyectos, y los equipos de desarrollo han
encontrado que se puede aplicar en diversos contextos. Cada patrón de diseño
describe a un conjunto de objetos y clases comunicadas. El conjunto se ajusta
para resolver un problema de diseño en un contexto específico.
Se dividen en tres categorías: 1) Patrones de creación que atañen al proceso de
creación de objetos, 2) Patrones de estructura que se orientan a la composición de
clases y objetos, y 3) Patrones de comportamiento que especifican la forma en
que las clases u objetos interactúan y distribuyen la responsabilidad.
3.3.3 BASADA EN GENERADORES
El conocimiento reutilizable se captura en un sistema generador de programas que
puede ser programado por expertos en el dominio utilizando un lenguaje orientado
a dominios o una herramienta CASE interactiva que soporte la generación de
sistemas. La descripción de la aplicación específica, de forma abstracta, qué
componentes reutilizables tienen que usarse y cómo tienen que ser combinados y
parametrizados. Utilizando esta información se puede generar un sistema software
operativo.
108

Generadores de analizadores para el procesamiento del lenguaje. La entrada del generador es una gramática que describe el lenguaje que va a ser analizado, y la salida es el analizador del lenguaje. Esta aproximación se incluye en sistemas tales como lex y yace para C y Java CC, un compilador de Java.
Generadores de código en herramientas CASE. La entrada de estos generadores es un diseño software y la salida es un programa que implementa el sistema diseñado. Pueden basarse en modelos UML y, dependiendo de la información en los modelos UML, generar un programa completo o componente, o bien un esqueleto de código. El desarrollador del software a continuación añade detalles para completar el código.
3.3.4 MARCOS DE TRABAJO
Un marco de trabajo (o marco de trabajo de aplicaciones) es un diseño de un
subsistema formado por una colección de clases concretas y abstractas y la
interfaz entre ellas (Wirí Brock y Johnson, 1990). Los detalles particulares del
subsistema de aplicación son implementados añadiendo componentes y
proporcionando implementaciones concretas de las clases abstractas en el marco
de trabajo. Los marcos de trabajo raramente son aplicados por sí mismos. Las
aplicaciones se construyen normalmente integrando varios marcos trabajo.
109
Marcos de trabajo de infraestructura de sistemas. Estos marcos de trabajo soportan desarrollo de infraestructuras de sistemas tales como comunicaciones, interfaces de usuario y compiladores (Schmidt, 1997).
Marcos de trabajo para la integración de middleware. Consisten en un conjunto de estándares y clases de objetos asociados que soportan la comunicación de componentes y el intercambio de información. Ejemplos de este tipo de marcos son COF BA, COM+ de Microsoft y Enterprise Java Beans. Estos marcos proporcionan soporte para modelos de componentes estandarizados.
Marcos de trabajo de aplicaciones empresariales. Se refieren a dominios de aplicaciones específicos tales como telecomunicaciones o sistemas financieros (Baumer al, 1997). Estos marcos de trabajo encapsulan el conocimiento del dominio de la aplicación y soportan el desarrollo de aplicaciones para los usuarios finales.
3.3.5 SISTEMAS DE APLICACIONES
La totalidad de un sistema de aplicaciones puede ser reutilizada incorporándolo
sin ningún cambio en otros sistemas, configurando la aplicación para diferentes
clientes o desarrollando familias de aplicaciones que tienen una arquitectura
común pero que son adaptadas a clientes particulares.
Reutilización de productos cots
La denominación producto COTS se aplica a un sistema software que puede utilizarse sin cambios por su comprador. Virtualmente todo el software de sobremesa y un gran número de productos servidores son software COTS. Debido a que este software se diseña para uso general, normalmente incluye muchas características y funciones para que sea
110

potencialmente reutilizable en diferentes aplicaciones y entornos. Si bien puede haber problemas con esta aproximación para la construcción de sistemas (Tracz, 2001), existe un número creciente de experiencias con éxito que demuestran su viabilidad (Baker, 2002; Balk y Kedia, 2000; Pfarr y Reis, 2002).
Líneas de productos software
Una de las aproximaciones más efectivas para la reutilización es la creación de líneas de productos software o familias de aplicaciones. Una línea de productos es un conjunto de aplicaciones con una arquitectura común específica de dichas aplicaciones.
Cada aplicación específica se especializa de alguna manera. El núcleo como de la familia de aplicaciones se reutiliza cada vez que se requiere una nueva aplicación. El nuevo desarrollo puede implicar una configuración específica de componentes, implementación de componentes adicionales y adaptación de algunos componentes para satisfacer las nuevas demandas.
3.4 DOCUMENTACIÓN
La documentación de sistema de información es el conjunto de información que
nos dice qué hacen los sistemas, como lo hacen y para quién lo hacen. La
documentación es un material que explica las características técnicas y la
operación de un sistema de información.
Hay varios tipos de documentación como:
La primera es la información acerca de programas, que explica la lógica de un
programa e incluye descripciones, diagramas de flujo, listados de programas y
otros documentos.
La segunda es referente a los usuarios que contienen de forma general
la naturaleza y capacidades del sistema.
Según la norma IEEE 830, debe contener los siguientes puntos:
I. Introducción (Se definen los fines y los objetivos del software)
A. Referencia del sistema
111

B. Descripción general
C. Restricciones del proyecto
II. Descripción de la información (Descripción detallada del problema, incluyendo
el HW y SW necesario)
A. Representación del flujo de la información.
1. Flujo de datos
2. Flujo de control
B. Representación del contenido de la información.
C. Descripción de la interfaz del sistema.
III. Descripción funcional (Descripción de cada función requerida, incluyendo
diagramas)
A. Partición funcional
B. Descripción funcional
1. Narrativa de procesamiento
2. Restricciones/Limitaciones.
3. Requisitos de rendimiento.
4. Restricciones de diseño
5. Diagramas de soporte
C. Descripción del control
1. Especificación del control
2. Restricciones de diseño.
IV. Descripción del comportamiento (comportamiento del SW ante sucesos
externos y controles internos)
A. Estados del sistema
112

B. Sucesos y acciones
V. Criterios de validación.
A. Límites de rendimiento
B. Clases de pruebas
C. Respuesta esperada del SW
D. Consideraciones especiales
VI. Bibliografía
VII. Apéndice.
3.4.1 OBJETIVO E IMPORTANCIA.
Dentro del ciclo de vida se encuentra la fase de implementación de un sistema, es
la fase más costosa y que consume más tiempo, se dice que es costosa porque
muchas personas, herramientas y recursos, están involucrados en el proceso y
consume mucho tiempo porque se completa todo el trabajo realizado previamente
durante el ciclo de vida.
En la fase de implementación se instala el nuevo sistema de información para que
empiece a trabajar y se capacita a sus usuarios para que puedan utilizarlo.
3.4.2 TIPOS
Método directo: Se abandona el sistema antiguo y se adopta inmediatamente el
nuevo. Esto puede ser sumamente riesgoso porque si algo marcha mal, es
imposible volver al sistema anterior, las correcciones deberán hacerse bajo la
marcha. Regularmente con un sistema nuevo suelen surgir problemas de pequeña
y gran escala. Si se trata de grandes sistemas, un problema puede significar una
catástrofe, perjudicando o retrasando el desempeño entero de la organización.
Método paralelo: Los sistemas de información antiguo y nuevo operan juntos
hasta que el nuevo demuestra ser confiable. Este método es de bajo riesgo. Si el
sistema nuevo falla, la organización puede mantener sus actividades con el
sistema antiguo. Pero puede representar un alto costo al requerir contar con
113

personal y equipo para laborar con los dos sistemas, por lo que este método se
reserva específicamente para casos en los que el costo de una falla sería
considerable.
Método piloto: Pone a prueba el nuevo sistema sólo en una parte de la
organización. Al comprobar su efectividad, se implementa en el resto de la
organización. El método es menos costoso que el paralelo, aunque más riesgoso.
Pero en este caso el riesgo es controlable al limitarse a ciertas áreas, sin afectar
toda la empresa.
Método en fases: La implementación del sistema se divide en partes o fases, que
se van realizando a lo largo de un periodo de tiempo, sucesivamente. Una vez
iniciada la primera fase, la segunda no se inicia hasta que la primera se ha
completado con éxito. Así se continúa hasta que se finaliza con la última fase. Es
costoso porque se hace más lenta la implementación, pero sin duda tiene el menor
riesgo.
114

115
UNIDAD 4.
VERIFIACIÓN
Y VALIDACIÓN

4. VERIFICACIÓN Y VALIDACIÓN
4.1 PRUEBAS
4.1.1 OBJETIVO
Las pruebas de software (en inglés software testing) son las investigaciones
empíricas y técnicas cuyo objetivo es proporcionar información objetiva e
independiente sobre la calidad del producto a la parte interesada o stakeholder. Es
una actividad más en el proceso de control de calidad.
Las pruebas son básicamente un conjunto de actividades dentro del desarrollo de
software. Dependiendo del tipo de pruebas, estas actividades podrán ser
implementadas en cualquier momento de dicho proceso de desarrollo
El objetivo de las pruebas es presentar información sobre la calidad del producto a
las personas responsables de este.
Teniendo esta afirmación en mente, la información que puede ser requerida es de
lo más variada. Esto hace que el proceso de testing sea completamente
dependiente del contexto1 en el que se desarrolla.
A pesar de lo que muchos promueven, no existen las "mejores prácticas" como tal.
Toda práctica puede ser ideal para una situación pero completamente inútil o
incluso perjudicial en otra.
Por esto, las actividades, técnicas, documentación, enfoques y demás elementos
que condicionarán las pruebas a realizar, deben ser seleccionados y utilizados de
la manera más eficiente según contexto del proyecto.
4.1.2 JUSTIFICACIÓN
Los principales objetivos que se buscan con la prueba de software suelen ser:
• Conocer el nivel de calidad de productos intermedios, para actuar a tiempo (v.gr.
rehacer un componente); esto facilita una administración realista del time to
market del producto en cuestión.
116

• No pagar por un producto de software sino hasta que alcance el nivel de calidad
pactado; esto eleva el nivel de certidumbre en el comprador de software, y
minimiza riesgos.
• Disminuir la penosa y costosa labor de soporte a usuarios insatisfechos,
consecuencia de liberar un producto inmaduro. Esto puede mejorar la imagen de
la organización desarrolladora (y la credibilidad en ella).
• Reducir costos de mantenimiento (la fase más costosa del desarrollo de
software), mediante el diagnóstico oportuno de los componentes del sistema (v.gr.
seguimiento a estándares, legibilidad del código, integración adecuada de los
componentes, rendimiento apropiado, nivel y calidad del reuso, calidad de la
documentación, etc.).
• Obtener información concreta acerca de fallas, que pueda usarse como apoyo en
la mejora de procesos, y en la de los desarrolladores (v.gr. capacitación en áreas
de oportunidad).
Entre más pronto se apliquen mecanismos de prueba en el proceso de desarrollo,
más fácilmente podrá evitarse que el proyecto se salga del tiempo y presupuesto
planeado, pues se podrán detectar más problemas originados en las fases
tempranas del proceso, que son los que mayor impacto tienen.
117

4.2 TIPOS DE PRUEBAS
Las pruebas de validación en la ingeniería de software son el proceso de revisión
que verifica que el sistema de software producido cumple con las especificaciones
y que logra su cometido. Es normalmente una parte del proceso de pruebas de
software de un proyecto, que también utiliza técnicas tales como evaluaciones,
inspecciones y tutoriales. La validación es el proceso de comprobar que lo que se
ha especificado es lo que el usuario realmente quería.
4.2.1 INTEGRACION
La prueba de integración es una técnica sistemática para construir la estructura
del programa mientras al mismo tiempo, se lleva a cabo pruebas para detectar
errores asociados con la interacción. El objetivo es tomar los módulos probados en
unidad y estructurar un programa que esté de acuerdo con el que dicta el diseño.
La integración puede ser descendente si se integran los módulos desde el control
o programa principal, o bien, ascendente, si la verificación del diseño empieza
desde los módulos más bajos y de allí al principal. La selección de una estrategia
de integración depende de las características depende de las características del
software y, a veces, del plan del proyecto, en algunos de los casos se puede
combinar ambas estrategias.
Pruebas de integración.
Errores.
comunicación a través de la interface.
efectos colaterales perniciosos.
acumulación notable de errores de cálculo.
acceso incoherente a estructuras de datos globales.
tiempos de respuesta.
4.2.1.1 DESCENDENTE
De arriba hacia abajo, avanzado.
primero en profundidad.
primero en anchura.
118

tomamos el módulo principal como driver.
Substituimos los módulos dependientes por stubs.
Estrategia descendente (cont).
Realizando pruebas específicas para el modulo
Repitiendo las realizadas previamente (pruebas regresivas)
Progresamos sustituyendo stubs por módulos reales.
4.2.1.2 ASCENDENTE
Agrupamos los módulos inferiores (según funcionabilidad p.e.)
Preparamos un driver para cada grupo y realizamos las pruebas.
Progresamos sustituyendo los driver por módulos reales.
Realizamos pruebas específicas y regresivas.
Descendente.
A favor:
Se prueban antes los módulos más importantes,
si primero en profundidad quedan probadas antes ramas completas.
En contra:
Elaboración stubs.
Ascendente.
En contra:
Gran incertidumbre hasta el final.
119

4.2.1.3 REGRESION
Regresión (informática): las pruebas de regresión son cualquier tipo de
pruebas de software que intentan descubrir las causas de nuevos errores
(bugs), carencias de funcionalidad, o divergencias funcionales con respecto al
comportamiento esperado del software, inducidos por cambios recientemente
realizados en partes de la aplicación que anteriormente al citado cambio no
eran propensas a este tipo de error.
4.2.2 VALIDACION
Las pruebas de validación en la ingeniería de software son el proceso de revisión
que verifica que el sistema de software producido cumple con las especificaciones
y que logra su cometido. Es normalmente una parte del proceso de pruebas de
software de un proyecto, que también utiliza técnicas tales como evaluaciones,
inspecciones y tutoriales. La validación es el proceso de comprobar que lo que se
ha especificado es lo que el usuario realmente quería.
Se trata de evaluar el sistema o parte de este durante o al final del desarrollo para
determinar si satisface los requisitos iniciales. La pregunta a realizarse es: ¿Es
esto lo que el cliente quiere?
Comprobar que se satisfacen los requisitos:
Se usan la mismas técnicas, pero con otro objetivo.
No hay programas de prueba, sino sólo el código final de la
aplicación.
Se prueba el programa completo.
Uno o varios casos de prueba por cada requisito o caso de
uso especificado.
Se prueba también rendimiento, capacidad, etc. (y no sólo
resultados correctos).
120

Pruebas alfa (desarrolladores) y beta (usuarios).
4.2.2.1 ALFA
Las pruebas de tipo alfa son la que se realizan con una muestra de datos reales.
A prueba alfa se lleva a cabo, por un cliente, en el mismo lugar de desarrollo. Se
usa el software de forma natural con el desarrollador como observador del
usuario y registrando los errores y problemas de uso. Las pruebas alfa se llevan a
cabo en un entorno controlado.
Alfa de prueba se hace antes de que el software se ponga a disposición
del público. Por lo general, los desarrolladores se realicen la prueba alfa utilizando
técnicas de pruebas de caja blanca. Caja posterior negro y técnicas de caja gris se
llevará a cabo después. La atención se centra en la simulación de los usuarios
reales mediante el uso de estas técnicas y la realización de tareas y operaciones
que un usuario típico podría llevar a cabo. Normalmente, las pruebas alfa en sí se
llevarán a cabo en un entorno de tipo de laboratorio y no en el lugar de trabajo
habitual. Una vez que estas técnicas se han cumplido satisfactoriamente, la
prueba alfa se considera completa.
4.2.2.2 BETA
La prueba beta es la que se lleva a cabo por los usuarios finales del
software en los lugares de trabajo de los clientes. A diferencia de la prueba
alfa, el desarrollador no está presente. Así, la prueba beta es una aplicación en
vivo del software en un entorno que no puede ser controlado por el desarrollador.
El cliente registra todos los problemas que encuentra durante la prueba beta e
informa a intervalos regulares al desarrollador.
Hay muchos ejemplos de programas en fase beta, uno de ellos es el Minecraft, un
juego que se encuentra en fase beta y que está en constante actualización y
correción de bugs (errores/fallos). Normalmente los programas en fase beta
suelen distribuirse gratuitamente, en este caso el Minecraft empezó igual pero
ahora para coger la fase beta tienes que comprar el juego, pero con la promesa de
que cuando salga la versión final tendrás el juego gratis y las actualizaciones
121

futuras también serán gratis. Además el juego te cuesta un 25% más barato que
cuando salga la versión final. En el caso del Minecraft los usuarios que prueban el
juego en fase beta reportan los fallos al desarrollador, y este va publicando en su
blog en los errores que está trabajando y en las mejoras que va a implementar.
A diferencia de las pruebas alfa, la gente fuera de la empresa se incluye
para realizar las pruebas. Como el objetivo es hacer una simple comprobación
antes del lanzamiento de productos, es posible que los defectos encontrados
durante esta etapa, por lo que la distribución del software se limita a una selección
de los usuarios de fuera de la empresa. Por lo general, las empresas
subcontratadas se utilizan como pruebas de su opinión es independiente y desde
una perspectiva diferente que la de los empleados de la compañía de desarrollo
de software. Los comentarios se pueden utilizar para corregir los defectos que se
perdieron, ayudar en la preparación de equipos de apoyo para temas que se
espera o en algunos casos incluso imponer cambios de última hora a la
funcionalidad.
4.2.3 SISTEMA
Verifica el sistema completo o su aplicación como tal. Se toma un punto de vista
del usuario final y los casos de uso de pruebas ejecutando acciones típicas de
usuario.
RUEBAS DE SOFTWARE: VERIFICACIÓN Y VALIDACIÓN (V y V)
Nuestros servicios de Verificación y Validación (Pruebas de Software) son la
respuesta a su necesidad de contar con aplicaciones confiables, reducir sus
costos de desarrollo y de mantenimiento y que, además, permitan mejorar la
calidad de sus procesos de desarrollo y optimizar recursos para efectos futuros.
Nuestra propuesta consiste en acompañar el Ciclo de Vida del Software “CVS”
con un Proceso Planeado de Verificación y Validación ejecutado porun Grupo
122

Independiente de Verificación y Validación “GIVV”, lo cual tiene las siguientes
ventajas:
Identificar defectos en etapas tempranas
Mejorar la calidad del producto
Mejorar la calidad del proceso
Importancia del Grupo Independiente de Verificación y Validación “GIVV”.
Ser un equipo independiente de los grupos de desarrollo nos permite realizar
nuestra tarea con absoluta objetividad. Esta independencia da como resultado la
eliminación de cualquier conflicto de interés provocado por tener otras actividades
como prioritarias (desarrollo en sí) o por el apego a los programas producidos.
Nuestros Testers están especialmente capacitados en técnicas de identificación
de defectos y realizan su trabajo de manera profesional, ética y con respeto hacia
las personas de desarrollo.
Asegurar la apropiada navegación dentro del sistema, ingreso de datos,
procesamiento y recuperación.
deben enfocarse en requisitos que puedan ser tomados directamente de
casos de uso y reglas y funciones de negocios
Ejecute cada caso de uso, flujo básico o función utilizando datos válidos e
inválidos
123

4.2.3.1. RECUPERACIÓN.
Verificar que los procesos de recuperación (manual o automatica) restauran
apropiadamente la Base de datos.
Estas pruebas aseguran que una aplicación o sistema se recupere de una
variedad de anomalías de hardware, software o red con perdidas de datos o fallas
de integridad.
Se deben utilizar las pruebas creadas para la Funcionalidad del sistema y
Procesos de Negocios para crear una serie de transacciones
4.2.3.2 SEGURIDAD
Nivel de seguridad de la aplicación: Verifica que un actor solo pueda acceder a las
funciones y datos que su usuario tiene permitido
Seguridad del sistema, incluyendo acceso a datos o Funciones de negocios e
incluyendo accesos remotos
Funciones / Seguridad de Datos: Identificar cada tipo de usuario y las funciones y
datos a los que se debe autorizar.
4.2.3.3. RESISTENCIA.
Estas pruebas se diseñan para enfrentar a los sistemas a situaciones anormales,
es decir ejecutar el sistema en forma que demande recursos en cantidad,
frecuencia o volúmenes anormales. Igualmente busca validar el correcto
funcionamiento del sistema bajo las condiciones de carga normales para la
operación para concluir sobre variables como: el tiempo de respuesta, carga de
procesamiento, trabajo por unidad de tiempo y utilización de recursos.
124

Stress:
Verificar que el sistema funciona apropiadamente y sin errores
Las pruebas de stress se proponen encontrar errores debidos a recursos
bajos o completitud de recursos
Use los scripts utilizados en las pruebas de desempeño
Carga:
Validar el tiempo de respuesta para las transacciones
miden tiempos de respuesta, índices de procesamiento de transacciones y
otros requisitos sensibles al tiempo
Modifique archivos de datos (para incrementar el número de transacciones)
o los scripts para incrementar el número de veces que ocurre cada
transacción
4.2.3.4 RENDIMIENTO
Son las pruebas que se realizan, desde una perspectiva, para determinar lo rápido
que realiza una tarea un sistema en condiciones particulares de trabajo. También
puede servir para validar y verificar otros atributos de la calidad del sistema, tales
como la escalabilidad, fiabilidad y uso de los recursos. Las pruebas de rendimiento
son un subconjunto de la ingeniería de pruebas, una práctica informática que se
esfuerza por mejorar el rendimiento, englobándose en el diseño y la arquitectura
de un sistema, antes incluso del esfuerzo inicial de la codificación.
125

4.3 MANTENIMIENTO
“Es el trabajo emprendido para cuidar y restaurar hasta un nivel económico, todos
y cada uno de los medio de producción existentes en una planta “.
Podemos definir el mantenimiento como el “conjunto de actividades que deben
realizarse a instalaciones y equipos con el fin de corregir o prevenir fallas,
buscando que estos continúen prestando el servicio para el cual fueron
diseñados”.
Como los equipos no se pueden mantener en buen funcionamiento por si solos, se
debe contar con un grupo de personas que se encarguen de ello, conformando
así el departamento de mantenimiento de nuestras empresas.
OBJETIVOS DEL MANTENIMIENTO INDUSTRIAL
En cualquier empresa, el mantenimiento debe cumplir con los dos objetivos
fundamentales: reducir costos de producción y garantizar la seguridad industrial.
Cuando se habla de reducir los costos de producción se deben tener en cuenta
los siguientes aspectos:
Optimizar la disponibilidad de equipos e instalaciones para la producción.
Se busca reducir los costos de las paradas de producción ocasionadas por
deficiencia en el mantenimiento de los equipos, mediante la aplicación de
una determinada cantidad de mantenimiento en los momentos más
apropiados.
Incrementar la vida útil de los equipos
Uno de los objetivos evidentes del mantenimiento es el de procurar la
utilización de los equipos durante toda su vida útil. La reducción de los
factores de desgastes, deterioros y roturas garantiza que los equipos
alcancen una mayor vida útil.
126

Maximizar el aprovechamiento de los recursos disponibles para la función
del mantenimiento.
Es aquí donde se debe analizar la convivencia o no de continuar prestando
el servicio de mantenimiento a una máquina que presenta problemas de
funcionamiento buscar su reemplazo.
La planificación del mantenimiento reduce los costos de operación y
reparación de los equipos industriales. Los programas para la lubricación,
limpieza y ajustes de los equipos permiten una reducción notable en el
consumo de energía y un aumento en la calidad de los productos
terminados. A mayor descuido en la conversación de los equipos, mayor
será la producción de baja calidad.
Para cumplir estos objetivos es necesario realizar algunas funciones
específicas a través del departamento de mantenimiento, tales como:
Administrar el personal de mantenimiento
Programar los trabajos de mantenimiento
Establecer los mecanismos para retirar de la producción aquellos equipos
que presenten altos costos de mantenimiento
Proveer al personal de mantenimiento de la herramienta adecuada para sus
funciones
Mantener actualizadas las listas de repuestos y lubricantes
Adiestrar al personal de mantenimiento sobre los principios y normas de
seguridad industrial.
Disponer adecuadamente de los desperdicios y del material recuperable
127

4.4.3 TIPOS DE MANTENIMIENTO
4.4.3.1 MANTENIMIENTO CORRECTIVO
Es aquel mantenimiento encaminado a corregir una falla que se presente en
determinado momento. Se puede afirmar que es el equipo quien determina
cuando se debe parar. Su función principal es poner en marcha el equipo lo más
rápido posible y al mínimo costo posibles.
Este mantenimiento es común encontrarlo en las empresas pequeñas y
medianas, presentando una serie de inconvenientes a saber:
Normalmente cuando se hace una reparación no se alcanzan a detectar
otras posibles fallas porque no se cuenta con el tiempo disponible.
Por lo general el repuesto no se encuentra disponible porque no se tiene un
registro del tipo y cantidad necesarios
Generalmente la calidad de la producción cae debido al desgaste
progresivo de los equipos
MANTENIMIENTO PERIODICO
Este mantenimiento se realiza después de un periodo de tiempo relativamente
largo (entre seis y doce meses).su objetivo general es realizar operaciones
mayores e los equipos .para implementar este tipo de mantenimiento se debe
contar con una excelente planeación y una coordinación con las diferentes áreas
de la empresa para lograr que las reparaciones se efectúen en el menor tiempo
posible.
MANTENIMIENTO PROGRAMADO
Este tipo de mantenimiento basa su aplicación en el supuesto de que todas las
piezas se desgastan en la misma forma y en el mismo periodo de tiempo, no
importa que se esté trabajando en condiciones diferentes
128

Para implementar el mantenimiento programado se hace un estudio de todos los
equipos de la empresa y se determina con la ayuda de datos estadísticos de los
repuestos y la información del fabricante, cuales piezas se deben cambiar en
determinados periodos de tiempo.
4.4.3.2 MANTENIMIENTO PREVENTIVO
Este tipo de mantenimiento tiene su importancia en que realiza inspecciones
periódicas sobre los equipos, teniendo en cuenta que todas las partes de un
mecanismo se desgastan en forma desigual y es necesario atenderlos para
garantizar su buen funcionamiento.
El mantenimiento previo se hace mediante un programa de actividades
(revisiones y lubricación), con el fin de anticipar a las posibles fallas en el equipo.
Tiene en cuenta cuales actividades se deben realizar sobre el equipo en marcha
o cuando este detenido.
4.4.3.2 MANTENIMIENTO PREDECTIVO
Este tipo de mantenimiento consiste en efectuar una serie de mediciones o
ensayos no destructivos con equipos sofisticados a todas aquellas partes de la
maquinaria susceptibles deterioro, pudiendo con ello aplicarse a la falla
castratofica. La mayoría de estas mediciones se efectúan con el equipo en
marcha y sin interrumpir la producción.
MANTENIMIENTO PROACTIVO
Selecciona aquellos lubricantes y procedimientos óptimos donde se logra
incrementar la producción, disminuyendo los costos directos de energía y
prolongando la vida útil de los equipos.
129

4.4 CARACTERÍSTICAS DEL MANTENIMIENTO
No es el mismo tipo de mantenimiento el del software que el de hardware, como
primera aproximación al mantenimiento del software lo definiremos como el
conjunto de medidas que hay que tomar para que el sistema siga trabajando
correctamente. Entre las características sobresalientes del mantenimiento del
software destacan:
- El software no envejece.
- El mantenimiento del software supone adaptar el paquete o sistema objeto del
mismo a nuevas situaciones como:
• Cambio de hardware.
• Cambio de software de base (S.O.).
- Todo sistema software conlleva mejoras o añadidos indefinidamente.
Al cerrar todo proyecto se debe considerar y preveer las normas del
mantenimiento del sistema (tanto en connotaciones hardware como software).
4.4.1 COSTOS
El coste del mantenimiento de un producto software a lo largo de su vida útil es
superior al doble de los costes de su desarrollo.
Por norma general, el porcentaje de recursos necesarios en el mantenimiento se
incrementa a medida que se genera más software. A esta situación se le conoce
como
Barrera de Mantenimiento.
Las causas a las que se debe este incremento de trabajo de mantenimiento son:
130

1) Gran cantidad de software antiguo (más de 10 años); aún siendo construidos
con las mejores técnicas de diseño y codificación del momento (rara vez), su
creación se produjo con restricciones de tamaño y espacio de almacenamiento y
con herramientas desfasadas tecnológicamente.
2) Los programas sufren migraciones continuas de plataformas o SSOO.
3) El software ha experimentado modificaciones, correcciones, mejoras y
adaptaciones a nuevas necesidades de los usuarios. Además, estos cambios se
realizaron sin técnicas de reingeniería o ingeniería inversa, dando como resultado
sistemas que funcionan con baja calidad (mal diseño de estructuras de datos,
mala codificación, lógica defectuosa y escasa documentación).
Como consecuencia de estos grandes costes, es que el coste relativo de reparar
un error aumenta considerablemente en las últimas fases del ciclo de vida del
software. Las razones por las que es menos costoso reparar defectos en las
primeras fases del ciclo de vida software son:
- Es más sencillo cambiar la documentación que modificar el código.
- Un cambio en las fases posteriores puede repercutir en cambiar toda la
documentación de las fases anteriores.
- Es más sencillo detectar un error en la fase en la que se ha introducido que
detectarlo y repararlo en fases posteriores. - Un defecto se puede ocultar en la
inexistencia o falta de actualización de los documentos de especificación o diseño.
Existen otra serie de costes intangibles del mantenimiento del software, que son:
- Oportunidades de desarrollo que se han de posponer o que se pierden debido a
los recursos dedicados a las tareas de mantenimiento.
- Insatisfacción del cliente cuando no se le satisface en un tiempo debido una
solicitud de reparación o modificación.
- Los cambios en el software durante el mantenimiento también introducen errores
ocultos.
131

- Perjuicios en otros proyectos de desarrollo cuando la plantilla tiene que dejarlos o
posponerlos debido a una solicitud de mantenimiento.
En conclusión, la productividad en LDC (líneas de código) por persona y mes
durante el proceso de mantenimiento puede llegar a ser 40 veces inferior con
respecto al proceso de desarrollo.
4.4.2 EFECTOS
En el mantenimiento del software existe el riesgo del llamado efecto bola de nieve;
que consiste en que los cambios introducidos por una petición de mantenimiento
conllevan efectos secundarios que implican futuras peticiones de mantenimiento.
Efectos secundarios sobre el código:
1.- Cambios en el diseño que suponen muchos cambios en el código.
2.- Eliminación o modificación de un subprograma.
3.- Eliminación o modificación de una etiqueta.
4.- Eliminación o modificación de un identificador.
5.- Cambios para mejorar el rendimiento.
6.- Modificación de la apertura/cierre de ficheros.
7.- Modificación de operaciones lógicas.
Efectos secundarios sobre los datos:
1.- Redefinición de constantes locales o globales.
2.- Modificación de los formatos de registros o archivos.
3.- Cambio en el tamaño de una matriz u otras estructuras similares.
4.- Modificación de la definición de variables globales.
5.- Reinicialización de indicadores de control o punteros.
6.- Cambios en los argumentos de los subprogramas. Es importante una correcta
documentación de los datos.
132

Efectos secundarios sobre la documentación:
1.- Modificar el formato de las entradas interactivas.
2.- Nuevos mensajes de error no documentados.
3.- Tablas o índices no actualizados.
4.- Texto no actualizado correctamente.
4.4.3 TIPOS
Existen 4 tipos de mantenimiento:
• Correctivo.
• Adaptativo.
• Perfectivo.
• Preventivo.
Mantenimiento correctivo:
Tiene por objetivo localizar y eliminar los posibles defectos de los programas.
Un defecto en un sistema es una característica del sistema con el potencial de
provocar un fallo. Un fallo se produce cuando el comportamiento de un sistema
difiere con respecto al comportamiento definido en la especificación.
Los fallos en un sistema software pueden ser:
- Procesamiento (salidas incorrectas de un programa).
- Rendimiento (tiempo de respuesta demasiado alto).
- Programación (inconsistencias en el diseño).
133

- Documentación (inconsistencias entre la funcionalidad de un programa y el
manual de usuario).
Mantenimiento adaptativo:
Consiste en la modificación de un programa debido a cambios en el entorno
(hardware o software) en el que se ejecuta. Desde cambios en el sistema
operativo, pasando por cambios en la arquitectura física del sistema informático,
hasta en el entorno de desarrollo del software. Este tipo de mantenimiento puede
ser desde un pequeño retoque hasta una reescritura de todo el código.
Los cambios en el entorno de desarrollo del software pueden ser:
- En el entorno de los datos (p.e. cambiar sistema de ficheros por BD relacional). - En el entorno de los procesos (p.e. migración a plataforma con procesos distribuidos).
Este mantenimiento es cada vez más frecuente debido a la tendencia actual de
Actualización de hardware y SSOO cada poco tiempo.
Mantenimiento perfectivo:
Conjunto de actividades para mejorar o añadir nuevas funcionalidades requeridas
por el usuario.
Se divide en dos:
- Mantenimiento de Ampliación: incorporación de nuevas Funcionalidades.
- Mantenimiento de Eficiencia: mejora de la eficiencia de ejecución.
Mantenimiento preventivo:
Modificación del software para mejorar las propiedades de dicho software
(calidad y mantenibilidad) sin alterar sus especificaciones funcionales. Incluir
sentencias que comprueben la validez de los datos de entrada, reestructuración
de los programas para aumentar su legibilidad o incluir nuevos comentarios. Este
tipo de mantenimiento utiliza las técnicas de ingeniería inversa y reingeniería.
134

4.4.3.1 MANTENIMIENTO CORRECTIVO
Consiste en la reparación de alguno de los componentes de la computadora,
puede ser una soldadura pequeña, el cambio total de una tarjeta (sonido, video,
SIMMS de memoria, entre otras), o el cambio total de algún dispositivo periférico
como el ratón, teclado, monitor, entre otros.
Resulta mucho más barato cambiar algún dispositivo que el tratar de repararlo
pues muchas veces nos vemos limitados de tiempo y con sobre carga de trabajo,
además de que se necesitan aparatos especiales para probar algunos
dispositivos.
Así mismo, para realizar el mantenimiento debe considerarse lo siguiente:
• En el ámbito operativo, la reconfiguración de la computadora y los principales
programas que utiliza.
• Revisión de los recursos del sistema, memoria, procesador y disco duro.
• Optimización de la velocidad de desempeño de la computadora.
• Revisión de la instalación eléctrica (sólo para especialistas).
• Un completo reporte del mantenimiento realizado a cada equipo.
• Observaciones que puedan mejorar el ambiente de funcionamiento.
Criterios que se deben considerar para el mantenimiento a la PC.
La periodicidad que se recomienda para darle mantenimiento a la PC es de una
vez por trimestre, esto quiere decir que como mínimo debe dársele cuatro veces al
año, pero eso dependerá de cada usuario, de la ubicación y uso de la
computadora.
135

4.4.3.2 MANTENIMIENTO PREVENTIVO/PERFECTIVO
El mantenimiento preventivo en general se ocupa en la determinación de
condiciones operativas, de durabilidad y de confiabilidad de un equipo en mención
este tipo de mantenimiento nos ayuda en reducir los tiempos que pueden
generarse por mantenimiento correctivo.
En lo referente al mantenimiento preventivo de un producto software, se diferencia
del resto de tipos de mantenimiento (especialmente del mantenimiento perfectivo)
en que, mientras que el resto (correctivo, evolutivo, perfectivo, adaptativo...) se
produce generalmente tras una petición de cambio por parte del cliente o del
usuario final, el preventivo se produce tras un estudio de posibilidades de mejora
en los diferentes módulos del sistema.
Aunque el mantenimiento preventivo es considerado valioso para las
organizaciones, existen una serie de fallas en la maquinaria o errores humanos a
la hora de realizar estos procesos de mantenimiento. El mantenimiento preventivo
planificado y la sustitución planificada son dos de las tres políticas disponibles
para los ingenieros de mantenimiento.
Algunos de los métodos más habituales para determinar que procesos de
mantenimiento preventivo deben llevarse a cabo son las recomendaciones de los
fabricantes, la legislación vigente, las recomendaciones de expertos y las acciones
llevadas a cabo sobre activos similares.
El primer objetivo del mantenimiento es evitar o mitigar las consecuencias de los
fallos del equipo, logrando prevenir las incidencias antes de que estas ocurran.
Las tareas de mantenimiento preventivo incluyen acciones como cambio de piezas
desgastadas, cambios de aceites y lubricantes, etc. El mantenimiento preventivo
debe evitar los fallos en el equipo antes de que estos ocurran.
136

4.4.3.2 MANTENIMIENTO ADAPTATIVO
En muchas ocasiones el concepto de mantenimiento adaptativo se utiliza de forma
incorrecta confundiéndose muy a menudo con el mantenimiento evolutivo, siendo
dos tipos de mantenimiento que persiguen objetivos distintos.
Lo mejor es recordar las definiciones que Métrica V.3, hace de cada uno de estos
mantenimientos:
- Mantenimiento evolutivo: “Incorporaciones, modificaciones y eliminaciones
necesarias en un producto software para cubrir la expansión o cambios en las
necesidades del usuario.”
- Mantenimiento adaptativo: “Modificaciones que afectan a los entornos en los que
el sistema opera, por ejemplo, cambios en la configuración del hardware, software
de base, gestores de bases de datos, comunicaciones, etc…”.
Con las definiciones por delante resulta bastante sencillo discernir un tipo de
mantenimiento de otro, ya que el primero está centrado en un cambio en las
necesidades del usuario o lo que es lo mismo, en una modificación de los
requisitos funcionales de la aplicación (por muy pequeños o grandes que sean) y
el segundo se basa en los cambios en cualquiera de los elementos que conforman
el entorno sobre el que funciona el programa, a los ejemplos que indica Métrica
V.3, yo añadiría los servidores de aplicaciones, servidores web e incluso las
interfaces con terceros sistemas, es decir, si una aplicación se comunica con otra
por servicios web y ésta modifica la interfaz el cambio a realizar en la aplicación es
de carácter adaptativo ya que el requisito funcional (que es comunicarse con ese
tercer sistema) no ha variado.
137












