Apuntes de Linux Ubuntu
220
Í N D I C E 1. Historia. ..................................................................................................................................................... 5 2. Instalación de Ubuntu Linux. ................................................................................................................. 6 2.1. Iniciando Linux. .................................................................................................................................. 7 2.2. Habilitar la cuenta de usuario root. ..................................................................................................... 8 2.2.1 Usuarios sudoers. .......................................................................................................................... 9 2.3. Instalando y actualizando software. .................................................................................................. 11 2.3.1 Desde la línea de comandos. ....................................................................................................... 12 2.3.2 Orígenes del software. ................................................................................................................ 13 2.4. Gestor de arranque GRUB. ............................................................................................................... 15 2.5. Recuperación del sistema. ................................................................................................................. 18 2.5.1 Desde el menú de inicio de GRUB. ............................................................................................ 18 2.5.2 Restaurar el menú de GRUB al iniciar el sistema. ...................................................................... 21 2.5.3 Recuperar GRUB desde un CD live. .......................................................................................... 22 2.5.4 Recuperar GRUB con el paquete Super Grub Disk. ................................................................... 23 2.5.5 Acelerar el inicio del sistema. ..................................................................................................... 27 2.5.6 Sistema de tolerancia a fallos RAID 5. ....................................................................................... 28 2.6. Protocolo TCP/IP. ............................................................................................................................. 36 2.6.1 Protocolo IPv4 (Internet Protocol). ............................................................................................. 38 2.6.2 Protocolo IPv6 (Internet Protocol version 6). ............................................................................. 40 2.6.3 Protocolo TCP (Transmission Control Protocol). ....................................................................... 41 2.6.4 Administración de las tarjetas de red desde la línea de comandos. ............................................ 42 2.6.5 Nombre de host. .......................................................................................................................... 46 2.6.6 Servidores DNS. ......................................................................................................................... 47 2.7. Redes inalámbricas. .......................................................................................................................... 48 2.8. Administración de Bluetooth. ........................................................................................................... 52 2.9. Servidor DHCP. ................................................................................................................................ 54 2.9.1 Ejemplo de archivo /etc/dhcpd.conf. .......................................................................................... 57 3. El Kernel. ................................................................................................................................................ 58 4. Sistemas de archivos. ............................................................................................................................. 60 5. Administración de los sistemas de archivos. ........................................................................................ 64 5.1. Archivo /etc/fstab. ............................................................................................................................. 66 5.2. Creación de sistemas de archivos. .................................................................................................... 70 5.2.1 Crear particiones. ........................................................................................................................ 70 5.2.2 Formatear particiones. ................................................................................................................. 74 5.3. Particiones y archivos de intercambio. ............................................................................................. 76 6. Administración de sistemas de archivos remotos. .............................................................................. 78 6.1. Sistema de archivos NFS. ................................................................................................................. 78 6.2. Administración de samba. ................................................................................................................. 82 6.2.1 Introducción. ............................................................................................................................... 82 6.2.2 Instalación y configuración. ........................................................................................................ 82 6.2.3 Autenticación de usuarios. .......................................................................................................... 85 6.2.4 Agrupación de servidores. .......................................................................................................... 86 7. Proceso de inicialización del sistema. ................................................................................................... 87 8. Administración de servicios. ................................................................................................................. 90 9. El shell. .................................................................................................................................................... 91 9.1. Escritura de órdenes. ......................................................................................................................... 91 9.2. Redireccionamiento. ......................................................................................................................... 92 9.3. Historia de órdenes. .......................................................................................................................... 93 9.4. Tipos de shell. ................................................................................................................................... 94 9.5. Archivos de configuración del shell. ................................................................................................ 95 9.6. Terminales virtuales. ......................................................................................................................... 98 10. Comandos de Unix/Linux. ................................................................................................................... 99 10.1. Archivos especiales. ........................................................................................................................ 99 10.2. Nombres de archivos. .................................................................................................................... 100 10.3. Comandos para la gestión de directorios y archivos. .................................................................... 101 10.3.1 Comando cat. .......................................................................................................................... 101 10.3.2 Comando cd. ........................................................................................................................... 101 1
Transcript of Apuntes de Linux Ubuntu

Í N D I C E1. Historia. ..................................................................................................................................................... 5 2. Instalación de Ubuntu Linux. ................................................................................................................. 6
2.1. Iniciando Linux. .................................................................................................................................. 7 2.2. Habilitar la cuenta de usuario root. ..................................................................................................... 8
2.2.1 Usuarios sudoers. .......................................................................................................................... 9 2.3. Instalando y actualizando software. .................................................................................................. 11
2.3.1 Desde la línea de comandos. ....................................................................................................... 12 2.3.2 Orígenes del software. ................................................................................................................ 13
2.4. Gestor de arranque GRUB. ............................................................................................................... 15 2.5. Recuperación del sistema. ................................................................................................................. 18
2.5.1 Desde el menú de inicio de GRUB. ............................................................................................ 18 2.5.2 Restaurar el menú de GRUB al iniciar el sistema. ...................................................................... 21 2.5.3 Recuperar GRUB desde un CD live. .......................................................................................... 22 2.5.4 Recuperar GRUB con el paquete Super Grub Disk. ................................................................... 23 2.5.5 Acelerar el inicio del sistema. ..................................................................................................... 27 2.5.6 Sistema de tolerancia a fallos RAID 5. ....................................................................................... 28
2.6. Protocolo TCP/IP. ............................................................................................................................. 36 2.6.1 Protocolo IPv4 (Internet Protocol). ............................................................................................. 38 2.6.2 Protocolo IPv6 (Internet Protocol version 6). ............................................................................. 40 2.6.3 Protocolo TCP (Transmission Control Protocol). ....................................................................... 41 2.6.4 Administración de las tarjetas de red desde la línea de comandos. ............................................ 42 2.6.5 Nombre de host. .......................................................................................................................... 46 2.6.6 Servidores DNS. ......................................................................................................................... 47
2.7. Redes inalámbricas. .......................................................................................................................... 48 2.8. Administración de Bluetooth. ........................................................................................................... 52 2.9. Servidor DHCP. ................................................................................................................................ 54
2.9.1 Ejemplo de archivo /etc/dhcpd.conf. .......................................................................................... 57 3. El Kernel. ................................................................................................................................................ 58 4. Sistemas de archivos. ............................................................................................................................. 60 5. Administración de los sistemas de archivos. ........................................................................................ 64
5.1. Archivo /etc/fstab. ............................................................................................................................. 66 5.2. Creación de sistemas de archivos. .................................................................................................... 70
5.2.1 Crear particiones. ........................................................................................................................ 70 5.2.2 Formatear particiones. ................................................................................................................. 74
5.3. Particiones y archivos de intercambio. ............................................................................................. 76 6. Administración de sistemas de archivos remotos. .............................................................................. 78
6.1. Sistema de archivos NFS. ................................................................................................................. 78 6.2. Administración de samba. ................................................................................................................. 82
6.2.1 Introducción. ............................................................................................................................... 82 6.2.2 Instalación y configuración. ........................................................................................................ 82 6.2.3 Autenticación de usuarios. .......................................................................................................... 85 6.2.4 Agrupación de servidores. .......................................................................................................... 86
7. Proceso de inicialización del sistema. ................................................................................................... 87 8. Administración de servicios. ................................................................................................................. 90 9. El shell. .................................................................................................................................................... 91
9.1. Escritura de órdenes. ......................................................................................................................... 91 9.2. Redireccionamiento. ......................................................................................................................... 92 9.3. Historia de órdenes. .......................................................................................................................... 93 9.4. Tipos de shell. ................................................................................................................................... 94 9.5. Archivos de configuración del shell. ................................................................................................ 95 9.6. Terminales virtuales. ......................................................................................................................... 98
10. Comandos de Unix/Linux. ................................................................................................................... 99 10.1. Archivos especiales. ........................................................................................................................ 99 10.2. Nombres de archivos. .................................................................................................................... 100 10.3. Comandos para la gestión de directorios y archivos. .................................................................... 101
10.3.1 Comando cat. .......................................................................................................................... 101 10.3.2 Comando cd. ........................................................................................................................... 101
1

10.3.3 Comando cp. ........................................................................................................................... 101 10.3.4 Comando df. ............................................................................................................................ 101 10.3.5 Comando du. ........................................................................................................................... 102 10.3.6 Comando file. .......................................................................................................................... 102 10.3.7 Comando find. ......................................................................................................................... 103 10.3.8 Comando less. ......................................................................................................................... 105 10.3.9 Comando ln. ............................................................................................................................ 107 10.3.10 Comando ls. .......................................................................................................................... 107 10.3.11 Comando lshw. ..................................................................................................................... 109 10.3.12 Comando mkdir. ................................................................................................................... 109 10.3.13 Comando more. ..................................................................................................................... 109 10.3.14 Comando mv. ........................................................................................................................ 111 10.3.15 Comando nl. .......................................................................................................................... 111 10.3.16 Comando od. ......................................................................................................................... 111 10.3.17 Comando pwd. ...................................................................................................................... 112 10.3.18 Comando rm. ......................................................................................................................... 112 10.3.19 Comando rmdir. .................................................................................................................... 113
10.4. Comandos para operar con ficheros de texto. ............................................................................... 114 10.4.1 Comando cat. .......................................................................................................................... 114 10.4.2 Comando cut. .......................................................................................................................... 114 10.4.3 Comando grep. ........................................................................................................................ 114 10.4.4 Comando paste. ....................................................................................................................... 115 10.4.5 Comando pr. ............................................................................................................................ 115 10.4.6 Comando sort. ......................................................................................................................... 116 10.4.7 Comando tail. .......................................................................................................................... 117 10.4.8 Comando tee. .......................................................................................................................... 118 10.4.9 Comando touch. ...................................................................................................................... 118 10.4.10 Comando wc. ........................................................................................................................ 118
10.5. Otros comandos Unix/Linux. ........................................................................................................ 119 10.5.1 Comando clear. ....................................................................................................................... 119 10.5.2 Comando date. ........................................................................................................................ 119 10.5.3 Comando finger. ..................................................................................................................... 121 10.5.4 Comando id. ............................................................................................................................ 121 10.5.5 Comando logname. ................................................................................................................. 122 10.5.6 Comando sleep. ....................................................................................................................... 122 10.5.7 Comando stty. ......................................................................................................................... 122 10.5.8 Comando tty. ........................................................................................................................... 123 10.5.9 Comando uname. .................................................................................................................... 123 10.5.10 Comando hostname. .............................................................................................................. 124
11. El editor de textos vi. ......................................................................................................................... 125 11.1. Introducción. ................................................................................................................................. 125 11.2. Entrada al editor vi. ....................................................................................................................... 126 11.3. Salida del editor vi. ....................................................................................................................... 127 11.4. Órdenes de desplazamiento del cursor. ......................................................................................... 128 11.5. Órdenes para modificar texto. ....................................................................................................... 131 11.6. Órdenes de edición avanzada. ....................................................................................................... 133
11.6.1 Órdenes de borrado. ................................................................................................................ 133 11.6.2 Órdenes de copia. .................................................................................................................... 135 11.6.3 Órdenes de cambio de caracteres. ........................................................................................... 137
11.7. Órdenes para buscar y sustituir caracteres. ................................................................................... 139 11.8. Edición de múltiples archivos. ...................................................................................................... 141 11.9. Buffers del editor vi. ..................................................................................................................... 142
11.9.1 Buffers numéricos. .................................................................................................................. 142 11.9.2 Buffers alfabéticos. ................................................................................................................. 143
11.10. Ejecución de órdenes del shell. ................................................................................................... 144 11.11. Configuración del editor vi. ........................................................................................................ 145 11.12. Abreviaturas. ............................................................................................................................... 148 11.13. Macros. ........................................................................................................................................ 149 11.14. Archivo de configuración del editor vi. ...................................................................................... 150
12. Administración de cuentas de usuario. ............................................................................................ 151
2

12.1. Creación de cuentas de usuario. .................................................................................................... 151 12.2. Eliminación de cuentas de usuario. ............................................................................................... 154 12.3. Modificación de cuentas de usuario. ............................................................................................. 155 12.4. Otras consideraciones sobre las cuentas de usuario. ..................................................................... 156
13. Administración de contraseñas de usuario. ..................................................................................... 157 14. Administración de cuentas de grupos de usuarios. ......................................................................... 159
14.1. Creación de cuentas de grupo. ...................................................................................................... 159 14.2. Eliminación de cuentas de grupo. ................................................................................................. 160 14.3. Modificación de cuentas de grupo. ............................................................................................... 161
15. Administración de permisos. ............................................................................................................. 162 15.1. Cambio de permisos. ..................................................................................................................... 163 15.2. Cambio de propietario. .................................................................................................................. 166 15.3. Máscara de permisos. Orden umask. ............................................................................................ 167 15.4. Otras consideraciones. .................................................................................................................. 168
16. Administración de impresoras. ......................................................................................................... 169 16.1. Impresora local. ............................................................................................................................. 169 16.2. Impresora TCP/IP. ........................................................................................................................ 170 16.3. Impresora SAMBA. ...................................................................................................................... 171
16.3.1 Conexión desde Windows a una impresora en un servidor SAMBA. .................................... 171 16.3.2 Conexión desde Linux a una impresora en un servidor Windows. ......................................... 171 16.3.3 Conexión desde Linux a una impresora en un servidor SAMBA. .......................................... 171
16.4. Impresora remota utilizando CUPS. ............................................................................................. 172 16.5. Instalación de una impresora PDF. ............................................................................................... 173 16.6. Comandos para realizar las tareas de impresión. .......................................................................... 174
16.6.1 Comando lpr. ........................................................................................................................... 174 16.6.2 Comando lpq. .......................................................................................................................... 176 16.6.3 Comando lprm. ....................................................................................................................... 177 16.6.4 Comando lpc. .......................................................................................................................... 178
17. Administración de procesos. ............................................................................................................. 180 17.1. Multiusuario y multitarea. ............................................................................................................. 180 17.2. Planificación de los procesos a ejecutar. ....................................................................................... 182
17.2.1 Demonio cron y atd. ................................................................................................................ 182 17.2.2 Comando at. ............................................................................................................................ 183 17.2.3 Comando batch. ...................................................................................................................... 185 17.2.4 Comando crontab. ................................................................................................................... 186 17.2.5 Comando nohup. ..................................................................................................................... 188
17.3. Supervisión de usuarios conectados. ............................................................................................. 189 17.4. Supervisión del estado de los procesos. ........................................................................................ 191 17.5. Finalización de los procesos. ........................................................................................................ 195
17.5.1 Captura de señales. .................................................................................................................. 197 17.6. Prioridad de los procesos. ............................................................................................................. 198
17.6.1 Comando nice. ........................................................................................................................ 198 17.6.2 Comando renice. ..................................................................................................................... 198
18. Guiones shell. ...................................................................................................................................... 199 18.1. Introducción. ................................................................................................................................. 199 18.2. Variables. ...................................................................................................................................... 200
18.2.1 Definición de variables. .......................................................................................................... 201 18.2.2 Asignación de valores. ............................................................................................................ 202 18.2.3 Gestión de parámetros. ............................................................................................................ 204 18.2.4 Visualización del contenido de las variables. ......................................................................... 205
18.3. Expresiones. .................................................................................................................................. 206 18.4. Evaluación de condiciones. ........................................................................................................... 207
18.4.1 Datos numéricos. ..................................................................................................................... 207 18.4.2 Cadenas. .................................................................................................................................. 208 18.4.3 Archivos. ................................................................................................................................. 209 18.4.4 Operadores. ............................................................................................................................. 210 18.4.5 Otras consideraciones. ............................................................................................................ 211
18.5. Rupturas de control. ...................................................................................................................... 212 18.5.1 Instrucción if. .......................................................................................................................... 212 18.5.2 Instrucción case. ...................................................................................................................... 213
3

18.6. Bucles. ........................................................................................................................................... 214 18.6.1 while. ....................................................................................................................................... 215 18.6.2 until. ........................................................................................................................................ 216 18.6.3 for. ........................................................................................................................................... 217
18.7. Funciones. ..................................................................................................................................... 218 18.8. Ejecución de los guiones shell. ..................................................................................................... 219
4

1. Historia.
En el año 1.970, Ken Thompson escribió la primera versión de Unix en ensamblador, que fue reescrita en un 95% en C por Dennis Ritchie, en 1.973. La compañía Western Electric lo comercializó en 1.975.
Las cuatro grandes potencias en Unix son:
AT&T.
Desarrolló, en 1.983, el estándar de Unix System V, que, en las sucesivas versiones que han ido apareciendo, ha ido desarrollando Unix en cuanto a su tamaño, herramientas y utilidades.
Berkeley (Universidad de California).
Añadió numerosas características y realizó grandes cambios en Unix, que han servido para que sus versiones sean la más avanzadas técnicamente en algunos aspectos.
Sun Microsystems.
Desarrolla estaciones que trabajan en Unix. Son responsables de la primera estación de trabajo sin discos y del sistema de ficheros NFS.
Microsoft Corporation.
Desarrolla el sistema operativo Xenix, versión de Unix para ordenadores personales.
Linus Torvald inicia un proyecto para hacer del sistema operativo Minix, que era una versión de Unix ampliamente extendida entre estudiantes de todo el mundo, una versión de Unix para PC, destinada a los usuarios de Minix. Este proyecto fue conocido a través de Internet y se sumaron multitud de expertos, comenzando a desarrollarse Linux. La versión 0.11 de Linux se lanzó en 1.991. Actualmente sigue desarrollándose por programadores, que incorporan aplicaciones y características estándar de Unix.
El sistema operativo Linux dispone de la Licencia General Pública GNU. GNU quiere decir que el software tiene copyright, pero sus autores han dado su autorización para que se distribuya de acuerdo a determinadas condiciones. Estas condiciones se refieren a la obligatoriedad de suministrar códigos fuente y de no incluir copyright a ninguna parte del software de Linux. De esta forma, los usuarios no pueden utilizar en sus programas códigos fuente protegidos por copyright sin permitir, previamente, el acceso público a sus códigos fuente. Un programador puede exigir el pago de una cuota por utilizar su programa, pero en dicha cuota se incluirá el acceso a los códigos fuente del programa que está siendo utilizado.
5

2. Instalación de Ubuntu Linux.
Existen numerosas versiones del sistema operativo Linux. En este apartado se va a describir la instalación de Ubuntu Linux.
Antes de instalar cualquier sistema operativo, es necesario realizar un estudio sobre los distintos sistemas que van a convivir en el mismo equipo. Es fundamental que este estudio se realice de forma concienzuda, para realizar las particiones necesarias donde se ubicarán los distintos sistemas operativos. El tamaño de cada partición dependerá de los programas que se vayan a instalar en cada una de ellas y de los datos que soportarán cada uno de los programas.
Actualmente, la mayor parte de dispositivos y periféricos son admitidos por Linux, por lo que no tendremos problemas con ellos durante la instalación.
La instalación se iniciará automáticamente cuando encendamos el ordenador con el disco de instalación insertado en la unidad de DVD, accediendo a una ventana desde la que podremos iniciar el equipo desde el Cd-Rom, para probar Linux sin necesidad de instalarlo, o lanzar el proceso de instalación.
Si iniciamos el equipo desde el Cd Live se pueden realizar tareas de administración y recuperación de cualquier sistema Linux, ya que podemos acceder al disco duro y a los archivos que contienen las carpetas, siempre que montemos adecuadamente las particiones. Para realizar tareas de administración tenemos que ejecutar todas las órdenes precediéndolas del comando sudo, porque no se ha iniciado sesión con el usuario root, que se encuentra deshabilitado. Para habilitarlo, ver el punto 2.2 Habilitar la cuenta de usuario root.
También es posible particionar el disco o reducir el tamaño de las particiones ya realizadas, siempre que dispongan de espacio libre.
Al lanzar la instalación tenemos que seleccionar la zona horaria, el idioma con el que se va a configurar el sistema operativo, configurar el teclado para comprobar que el idioma seleccionado es el apropiado para escribir todos los caracteres de nuestro país, particionar el disco duro, importar cuentas de usuario de los sistemas operativos de Microsoft, si tenemos alguna partición en el equipo con uno de estos sistemas instalados, escribir nuestro nombre, el nombre del usuario que va a iniciar sesión, su contraseña y el nombre del equipo. Este nombre de usuario es muy importante porque es el único usuario con el que podremos iniciar sesión una vez finalizada la instalación, ya que el usuario root está deshabilitado y no podremos iniciar sesión con él. Seguidamente, el sistema se instalará, debiendo reiniciar el equipo para poder trabajar.
6

2.1. INICIANDO LINUX.
Una vez reiniciado el sistema después de la instalación tenemos que escribir el nombre de usuario que introducimos durante la instalación y su contraseña, accediendo al escritorio de GNOME. Desde el Escritorio de Ubuntu, además de las tareas que se pueden realizar desde los accesos directos (navegador web, correo electrónico, configuración de la tarjeta de red, etc. ), tenemos tres menús desde los que se pueden realizar todas las tareas del sistema operativo: el menú Aplicaciones, el menú Lugares y el menú Sistema.
Al igual que en el resto de sistemas operativos con interfaz gráfica, se pueden crear accesos directos, añadir opciones en la barra de tareas, etc.
7

2.2. HABILITAR LA CUENTA DE USUARIO ROOT.
Cuando se instala Ubuntu, la única cuenta de usuario con la que se puede iniciar sesión es la que creamos durante el proceso de instalación. Esta cuenta está limitada para realizar tareas administrativas, por lo que hay que ejecutar la orden sudo cada vez que queramos ejecutar una orden para administrar el sistema. La cuenta root está creada pero no está activa porque no tiene contraseña.
Para habilitar la cuenta de usuario root, hay que abrir un terminal (ejecutar la opción Terminal del menú Accesorios, que se encuentra en el menú Aplicaciones) y ejecutar la orden sudo passwd root. El sistema nos pide la contraseña del usuario que creamos durante el proceso de instalación y la contraseña que se va a asignar al usuario root.
Una vez iniciada la sesión con el usuario root conviene activar las tareas que puede realizar. Para ello, hay que ejecutar la herramienta Usuarios y grupos del menú Administración, que se encuentra en el menú Sistema, seleccionar el usuario root y pulsar el botón Propiedades, accediendo a una ventana en la que debemos abrir la ficha Privilegios del usuario y activar las casillas correspondientes.
8

2.2.1 Usuarios sudoers.
Cuando se instala el sistema, sólo el usuario creado durante la instalación puede realizar tareas administrativas, siempre que se ejecute la orden sudo. Si no queremos ejecutar la orden sudo contínuamente, se puede ejecutar sudo su una sóla vez, en cada sesión, y, a partir de ese momento, realizar las tareas administrativas.
Si queremos utilizar el usuario root, hay que habilitarlo de la forma descrita en el punto anterior.
Por cuestiones de seguridad, no es conveniente iniciar una sesión con el usuario root para trabajar normalmente. Es más seguro iniciar una sesión con cualquier otro usuario y ejecutar la orden sudo o sudo su cuando se quieran realizar tareas administrativas.
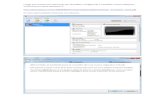
Cuando se crean nuevos usuarios, estos no pueden realizar tareas administrativas con la orden sudo, debido a que sólo los usuarios incluidos en el grupo admin pueden ejecutar la orden sudo para administrar el sistema. Esta configuración se realiza en el archivo /etc/sudoers, cuyo contenido se muestra a continuación:
# /etc/sudoers # # This file MUST be edited with the 'visudo' command as root. # # See the man page for details on how to write a sudoers file. # Host alias specification
# User alias specification
# Cmnd alias specification
# Defaults
Defaults !lecture,tty_tickets,!fqdn
# User privilege specification root ALL=(ALL) ALL
# Members of the admin group may gain root privileges %admin ALL=(ALL) ALL
La última línea de este archivo es la que indica que todos los usuarios miembros del grupo admin pueden realizar tareas administrativas con la orden sudo.
Si consultamos el archivo /etc/group, que es el archivo que contiene los grupos creados, y sus miembros, creados en el sistema, veremos una línea parecida a la siguiente:
admin:x:117:coralio,root
Esta línea indica que los usuarios coralio y root son los únicos usuarios miembros del grupo admin y, por lo tanto, sólo estos usuarios pueden realizar tareas administrativas con la orden sudo.
Para incluir un usuario en el grupo admin, se puede ejecutar la orden adduser usuario admin, donde usuario es la cuenta que se quiere agregar al grupo admin. Las siguientes líneas muestran la salida de esta orden:
root@servidor2dai:~# adduser usuario admin
Añadiendo usuario 'usuario' al grupo 'admin' ...
Terminado.
9

Si visualizamos el contenido del archivo /etc/group, veremos la siguiente línea:admin:x:117:coralio,root,usuario
En esta línea observamos que el usuario con nombre usuario se ha añadido al grupo admin y, por lo tanto, podrá realizar tareas administrativas con la orden sudo.
10

2.3. INSTALANDO Y ACTUALIZANDO SOFTWARE.
Todo el software que se va a instalar o actualizar se encuentra disponible en repositorios, que son archivos de software. Por lo tanto, cada vez que vamos a realizar estas operaciones, nos conectaremos con un repositorio desde el que descargaremos los paquetes requeridos.
Para actualizar o instalar software, Ubuntu nos ofrece dos gestores. El primero está ubicado en el menú Aplicaciones, opción Centro de software de Ubuntu. Se accede a una ventana desde la que se pueden realizar las tareas de instalación, actualización y desinstalación de software.
El segundo gestor de instalaciones y actualizaciones se denomina Synaptic y se lanza desde la opción Gestor de paquetes Synaptic del menú Administración, que se encuentra en el menú Sistema. Se accede a una ventana desde la que se puede instalar, actualizar y desinstalar software. También se pueden administrar los repositorios que se van a utilizar para la búsqueda de los paquetes a instalar. Esta tarea se realiza desde la opción Repositorios del menú Configuración.
Para instalar nuevos paquetes hay que seleccionarlos, abrir el menú emergente, elegir la opción Marcar para instalar y pulsar el botón Aplicar.
Para desinstalar un paquete instalado hay que seleccionarlo, abrir el menú emergente, elegir la opción Marcar para eliminar o Marcar para eliminar completamente y pulsar el botón Aplicar.
El botón Buscar se utiliza para escribir el nombre del software que se desea instalar y que el gestor de paquetes localizará.
Cuando se instala un nuevo paquete el gestor busca otras aplicaciones que necesitan ser instaladas (dependencias) para que el nuevo software funcione correctamente, aunque no siempre instala todas las dependencias necesarias. Para asegurarnos que siempre se instale todo el software necesario, hay que abrir el menú Configuración y ejecutar la opción Preferencias y, en la ventana que se muestra, activar la casilla Considerar los paquetes recomendados como si fuesen dependencias.
Para actualizar paquetes ya instalados hay que seleccionarlos en la ventana de Synaptic, abrir el menú contextual y ejecutar la opción Marcar para actualizar. Seguidamente, hay que pulsar el botón Aplicar para actualizar el software seleccionado. Mediante este procedimiento, también se puede reinstalar un paquete instalado previamente.
Cuando se instala Ubuntu por primera vez hay que actualizar el sistema para instalar actualizaciones del software instalado y parches de seguridad del sistema. Estas actualizaciones se detectan automáticamente y el sistema nos avisa para proceder con la descarga e instalación.
En esta primera actualización el kernel se actualizará, debiendo reiniciar el sistema para que los cambios tengan efecto.
Cuando se actualiza el kernel el sistema conserva una opción de arranque del equipo con la antigua versión del kernel,para que se pueda utilizar como medida de seguridad por si el nuevo kernel no funciona correctamente, alguna aplicación ha dejado de funcionar, etc. El nuevo menú de inicio del equipo se muestra en la ventana de la Figura 2.3.1.
Figura 2.3.1
Una vez que se ha comprobado que la actualización del kernel funciona correctamente, se puede eliminar la opción del menú de inicio que apunta al anterior kernel (ver el punto 2.4 Gestor de arranque GRUB).
11

2.3.1 Desde la línea de comandos.
Para instalar, actualizar y eliminar software desde la línea de comandos, se utiliza la orden apt-get.
Algunas de las opciones más usuales son las siguientes:
update.
Se utiliza para actualizar las últimas versiones de todos los paquetes disponibles.Conviene ejecutarla antes de instalar para que se actualicen los repositorios locales.
upgrade.
Se utiliza para actualizar los paquetes instalados.
install paquete.
Descarga e instala el paquete especificado. Si se añade el carácter – antes de install,el paquete se desinstala.
remove paquete.
Desinstala el paquete especificado. Si se escribe el carácter + delante de remove,el paquete se instala.
autoremove.
12

Con esta opción se eliminan todos los paquetes que se no se han borrado cuando se ha eliminado el software del que dependían, limpiando así el sistema de la “basura” que permanece cuando se desinstalan paquetes instalados.
-d paquete.
Sólo descarga el paquete especificado; no lo instala.
-f.
Intenta reparar las dependencias rotas. Si se utiliza conjuntamente con install,intentará reparar las dependencias del paquete especificado.
Para más información, ejecutar la orden man apt-get.
En algunas ocasiones, necesitamos instalar o borrar paquetes con la extensión .deb, que han sido desarrollados por Debian GNU/Linux. Estos paquetes se instalan con la orden dpkg -i paquete.deb y se eliminan con la orden dpkg -r paquete.deb.
Algunos paquetes que nos descargamos desde Internet, tienen la extensión .tar.gz, .tar.bz2, .tar o .tgz, que indica que son archivos comprimidos. Para descomprimirlos, hay que ejecutar la orden tar -xfvz paquete.extensión. A continuación, hay que acceder a la carpeta en la que se ha descomprimido el paquete y lanzar el programa de instalación (normalmente INSTALL), aunque hay algunos paquetes que, una vez descomprimidos, ya están listos para ejecutarse. En la carpeta donde se ha descomprimido el paquete, se suele incluir un archivo README con instrucciones sobre la instalación. Hay algunos de estos paquetes que necesitan ser compilados para poder instalarse. Los programas necesarios para compilar los paquetes se pueden instalar todos de una vez instalando el paquete build-essential.
2.3.2 Orígenes del software.
Con los métodos de instalación y actualización del software descritos anteriormente, podemos gestionar las aplicaciones soportadas oficialmente por Ubuntu. Estas aplicaciones se encuentran en repositorios, que son archivos de software.
Los repositorios de Ubuntu no son demasiado grandes, por lo que hay que activar otros repositorios para tener acceso a las miles de aplicaciones disponibles para Linux.
Los repositorios externos más importantes son Universe y Multiverse. Estos repositorios tienen que estar activados para poder acceder a ellos durante las tareas de instalación y actualización del software.
Para activarlos desde el entorno gráfico, hay que ejecutar la opción Orígenes del software, que se encuentra en el menú Administración del menú Sistema. Se muestra la ventana de la Figura 2.3.2.1.
Figura 2.3.2.1
En esta ventana, hay que activar las casillas correspondientes a los repositorios que queramos acceder para instalar y actualizar el software.
Para activar los repositorios de Universe y Multiverse desde la línea de comandos, hay que editar el archivo /etc/apt/sources.list y quitar los comentarios de las líneas que incluyen las direcciones de internet de estos repositorios. Estas líneas son:
deb http://es.archive.ubuntu.com/ubuntu/ feisty universe
13

deb-src http://es.archive.ubuntu.com/ubuntu/ feisty universe
deb http://es.archive.ubuntu.com/ubuntu/ feisty multiverse
deb-src http://es.archive.ubuntu.com/ubuntu/ feisty multiverse
deb http://security.ubuntu.com/ubuntu feisty-security main restricted
deb-src http://security.ubuntu.com/ubuntu feisty-security main restricted
deb http://security.ubuntu.com/ubuntu feisty-security universe
deb-src http://security.ubuntu.com/ubuntu feisty-security universe
deb http://security.ubuntu.com/ubuntu feisty-security multiverse
deb-src http://security.ubuntu.com/ubuntu feisty-security multiverse
Una vez realizadas estas operaciones, hay que ejecutar la orden apt-get update para tener accesibles las últimas versiones de todo el software disponible.
Si instalamos software que no ha sido desarrollado por Ubuntu y queremos que se actualice automáticamente, hay que incluir las líneas necesarias en el archivo /etc/apt/sources.list. En la página web del software descargado encontraremos la línea que hay que incluir en este archivo.
Por ejemplo, para incluir el repositorio de Linux Max accederemos a la página http://max.educa.madrid.org/max40/, en la que podemos ver la dirección del repositorio. Por lo tanto, hay que incluir, en el archivo /etc/apt/sources.list la siguiente línea:
deb http://max.educa.madrid.org/max40 max main
Para actualizar los repositorios locales hay que ejecutar la orden apt-get update. El sistema informa de un error porque no se ha instalado la clave pública de Linux Max para acceder a su repositorio. Esta clave pública se instala con la orden apt-get install max-keyring. Si ahora volvemos a ejecutar la orden apt-get update no se genera ningún error. Desde este momento tenemos disponible todo el repositorio de la distribución Max de Linux.
14

2.4. GESTOR DE ARRANQUE GRUB.
GRUB es la abreviatura de GRand Unified Bootloader. GRUB es el programa que se ejecuta para iniciar el sistema, permitiendo seleccionar el sistema operativo con el que el equipo se va a iniciar. La versión actual de GRUB es grub2. La ventana del gestor de arranque de GRUB es la que se muestra en la Figura 2.4.1.
Figura 2.4.1
En esta ventana, aparece una opción por cada uno de los distintos sistemas operativos existentes en el equipo. La configuración de GRUB consiste en especificar el sistema operativo por defecto que se iniciará en el equipo y el tiempo que GRUB esperará la selección de otros sistemas operativos antes de que se inicie el que se ha indicado por defecto. Además, hay que seleccionar la partición de cada sistema operativo e introducir un nombre para cada uno de ellos. Este nombre es el que se muestra en la ventana de la Figura 2.4.1.
La configuración de GRUB se encuentra en el archivo /boot/grub/grub.cfg. El contenido de este archivo podría ser el siguiente:
## DO NOT EDIT THIS FILE## It is automatically generated by /usr/sbin/grub-mkconfig using templates# from /etc/grub.d and settings from /etc/default/grub#
### BEGIN /etc/grub.d/00_header ###if [ -s $prefix/grubenv ]; then load_envfiset default="0"if [ ${prev_saved_entry} ]; then set saved_entry=${prev_saved_entry} save_env saved_entry set prev_saved_entry= save_env prev_saved_entry set boot_once=truefi
function savedefault { if [ -z ${boot_once} ]; then saved_entry=${chosen} save_env saved_entry fi}
function recordfail { set recordfail=1 if [ -n ${have_grubenv} ]; then if [ -z ${boot_once} ]; then save_env recordfail; fi; fi}insmod ext2set root='(hd0,2)'search --no-floppy --fs-uuid --set 74ea5808-3c13-4008-90e6-973de3e29f12if loadfont /usr/share/grub/unicode.pf2 ; then
15

set gfxmode=640x480 insmod gfxterm insmod vbe if terminal_output gfxterm ; then true ; else # For backward compatibility with versions of terminal.mod that don't # understand terminal_output terminal gfxterm fifiinsmod ext2set root='(hd0,2)'search --no-floppy --fs-uuid --set 74ea5808-3c13-4008-90e6-973de3e29f12set locale_dir=($root)/boot/grub/localeset lang=esinsmod gettextif [ ${recordfail} = 1 ]; then set timeout=-1else set timeout=10fi### END /etc/grub.d/00_header ###
### BEGIN /etc/grub.d/05_debian_theme ###set menu_color_normal=white/blackset menu_color_highlight=black/light-gray### END /etc/grub.d/05_debian_theme ###
### BEGIN /etc/grub.d/10_linux ###menuentry 'Ubuntu, con Linux 2.6.32-21-generic' --class ubuntu --class gnu-linux --class gnu --class os {
recordfailinsmod ext2set root='(hd0,2)'search --no-floppy --fs-uuid --set 74ea5808-3c13-4008-90e6-973de3e29f12linux /boot/vmlinuz-2.6.32-21-generic root=UUID=74ea5808-3c13-4008-90e6-
973de3e29f12 ro quiet splashinitrd /boot/initrd.img-2.6.32-21-generic
}menuentry 'Ubuntu, con Linux 2.6.32-21-generic (modo recuperación)' --class ubuntu --class gnu-linux --class gnu --class os {
recordfailinsmod ext2set root='(hd0,2)'search --no-floppy --fs-uuid --set 74ea5808-3c13-4008-90e6-973de3e29f12echo 'Cargando Linux 2.6.32-21-generic ...'linux /boot/vmlinuz-2.6.32-21-generic root=UUID=74ea5808-3c13-4008-90e6-
973de3e29f12 ro single echo 'Cargando el disco RAM inicial...'initrd /boot/initrd.img-2.6.32-21-generic
}### END /etc/grub.d/10_linux ###
### BEGIN /etc/grub.d/20_memtest86+ ###menuentry "Memory test (memtest86+)" {
insmod ext2set root='(hd0,2)'search --no-floppy --fs-uuid --set 74ea5808-3c13-4008-90e6-973de3e29f12linux16 /boot/memtest86+.bin
}menuentry "Memory test (memtest86+, serial console 115200)" {
16

insmod ext2set root='(hd0,2)'search --no-floppy --fs-uuid --set 74ea5808-3c13-4008-90e6-973de3e29f12linux16 /boot/memtest86+.bin console=ttyS0,115200n8
}### END /etc/grub.d/20_memtest86+ ###
### BEGIN /etc/grub.d/30_os-prober ###menuentry "Microsoft Windows XP Professional (on /dev/sda1)" {
insmod ntfsset root='(hd0,1)'search --no-floppy --fs-uuid --set 3a1007a3100764ebdrivemap -s (hd0) ${root}chainloader +1
}### END /etc/grub.d/30_os-prober ###
### BEGIN /etc/grub.d/40_custom #### This file provides an easy way to add custom menu entries. Simply type the# menu entries you want to add after this comment. Be careful not to change# the 'exec tail' line above.### END /etc/grub.d/40_custom ###
La información activa (son las líneas que no están comentadas) de este archivo es la siguiente:
La línea set default indica la partición que se iniciará por defecto si, transcurrido el tiempo especificado en timeout, el usuario no selecciona otra partición. El valor 0 se refiere a la primera etiqueta menuentry que aparece en el archivo /boot/grub/grub.cfg, el valor 1 se refiere a la segunda etiqueta menuentry que aparece en el archivo /boot/grub/grub.cfg, y así sucesivamente.
La línea set timeout indica los segundos que el sistema esperará para iniciar el sistema operativo por defecto. De forma predeterminada, el menú GRUB no se muestra al iniciar el sistema, arrancando en la opción definida en la línea set default (normalmente, set default=”0”). Para que este menú se visualice hay que asignar un valor a timeout al final del archivo, para que sea esta última asignación la que prevalezca sobre las que se realizan en el resto del archivo. Por ejemplo, se puede incluir la línea set timeout=60 para que el menú se muestre, durante 60 segundos, al iniciar el equipo.
Las líneas que se encuentran a continuación de la línea ### BEGIN /etc/grub.d/10_linux
###, indican el disco duro y la partición donde se encuentran cada uno de los sistemas operativos que se pueden iniciar en el sistema.
Los parámetros quiet splash se utilizan para que durante el inicio del sistema se visualice un entorno gráfico. Si quitamos estos argumentos el inicio del sistema se visualiza en modo texto.
El archivo /boot/grub/grub.cfg se puede instalar ejecutando la orden grub-install /dev/sda. El dispositivo /dev/sda indica el disco duro en el que queremos instalarlo. Esta orden realiza una compilación del archivo y, si no hay errores, lo instala en el Master Boot Record (MBR) del disco duro indicado.
El archivo /boot/grub/grub.cfg se puede crear o modificar ejecutando la orden update-grub2. Esta orden busca las versiones del kernel ubicadas en el directorio /boot y crea una entrada en el archivo /boot/grub/grub.cfg para cada una de estas versiones.
En realidad, GRUB es un entorno desde el que se pueden realizar varias operaciones, introduciendo comandos propios del entorno. Para iniciar este entorno hay que pulsar la tecla c en la ventana de la Figura 2.4.1 o, una vez iniciado el sistema, ejecutar la orden grub. Se muestra el prompt grub>, desde el que se pueden escribir las órdenes de GRUB. Desde este
17

entorno se sale escribiendo reboot, si hemos accedido al entorno desde el menú de inicio del sistema, o escribiendo quit, si hemos accedido al entorno una vez iniciado el sistema.
Desde la ventana de la Figura 2.4.1 también se pueden editar líneas del archivo /boot/grub/grub.cfg para modificar sus valores e iniciar el sistema con los nuevos valores introducidos. Para ello, hay que pulsar la tecla e en la ventana de la Figura 2.4.1.
2.5. RECUPERACIÓN DEL SISTEMA.
A continuación, veremos algunas formas de intentar recuperar el sistema.
2.5.1 Desde el menú de inicio de GRUB.
Si no se puede iniciar el sistema porque GRUB no se carga, debemos seguir los pasos indicados en los puntos 2.5.2 Restaurar el menú de GRUB al iniciar el sistema, 2.5.3 Recuperar Grub desde un CD live y 2.5.4 Recuperar GRUB con el paquete Super Grub Disk.
Cuando se carga GRUB correctamente, se muestra la ventana de la Figura 2.5.1.1.
Figura 2.5.1.1
18

En la parte inferior de esta ventana, se indica que se pueden teclear las teclas e (para editar las órdenes de inicio de la línea seleccionada) o c (para acceder al entorno de GRUB). Desde este entorno se pueden introducir órdenes para intentar reparar el sistema (ver el punto 2.5.3 Recuperar GRUB desde un CD live).
Si se utiliza un menú gráfico, no se pueden teclear estas órdenes. Para poder acceder a este menú, hay que pulsar la tecla Esc en el menú gráfico.
Si pulsamos la tecla e con la opción Ubuntu, kernel 2.6.20-16-generic seleccionada, se muestra la ventana de la Figura 2.5.1.2.
Figura 2.5.1.2En esta ventana, se muestran las líneas que el gestor de arranque ejecuta para iniciar el sistema. Desde esta ventana, podemos editar la línea seleccionada, acceder al entorno de GRUB, añadir una nueva línea, borrar la línea seleccionada, iniciar el sistema o regresar al menú de GRUB (ventana de la Figura 2.5.1.1).
Si, en la ventana de la Figura 2.5.1.1, ejecutamos la opción Ubuntu, kernel 2.6.20-16-generic (recovery mode), el sistema chequea algunos componentes e intenta levantar algunos servicios. Si todo es correcto, se muestra la ventana de la Figura 2.5.1.3.
Figura 2.5.1.3
En esta ventana, podemos pulsar las teclas Control-D para continuar con el inicio del sistema o introducir la contraseña del usuario root para iniciar una sesión en modo texto y poder introducir órdenes del sistema operativo para reparar la partición.
Si, en la ventana de la Figura 2.5.1.1, ejecutamos la opción Ubuntu, memtest86+, el sistema realiza un chequeo de la memoria, según se muestra en la ventana de la Figura 2.5.1.4.
19

Figura 2.5.1.4
Si, en esta ventana, pulsamos la tecla c, se muestra la ventana de la Figura 2.5.1.5.
Figura 2.5.1.5
Desde esta ventana, se pueden realizar distintos chequeos de la memoria (esta operación tarda bastante tiempo en completarse) y visualizar resultados de los test realizados.
Si tenemos instalado un menú gráfico para presentar GRUB al iniciar el sistema, hay que pulsar la tecla Esc para acceder a la ventana de la Figura 2.5.1.1.
20

2.5.2 Restaurar el menú de GRUB al iniciar el sistema.
En algunas ocasiones, el menú de GRUB no se puede cargar, el equipo no se puede iniciar y el sistema entra automáticamente en el entorno de GRUB, presentando el prompt grub>. Para cargar el menú de GRUB desde este entorno, hay que ejecutar la orden configfile /boot/grub/menu.lst.
21

2.5.3 Recuperar GRUB desde un CD live.
Cuando el gestor de arranque GRUB no funciona correctamente, es posible repararlo iniciando el sistema desde el CD live de instalación. Para ello, una vez en el Escritorio, hay que abrir un Terminal y seguir los siguientes pasos:
1. Crear un directorio para montar la partición de sistema del disco duro, ejecutando la orden sudo mkdir /media/disk-2.
2. Consultar el dispositivo asociado a la partición del disco duro donde está instalado Ubuntu, ejecutando la orden sudo fdisk -l.
3. Montar la partición en el directorio creado en el punto 1. Para ello, hay que ejecutar la orden sudo mount /dev/sda1 /media/disk-2 (/dev/sda1 es el dispositivo que nos ha devuelto la orden sudo fdisk -l ejecutada en el punto 2.)
4. Editar el archivo menu.lst para comprobar que es correcto y modificarlo si procede. Para ello, hay que ejecutar la orden sudo gedit /media/disk-2/boot/grub/menu.lst.
5. Instalar GRUB, ejecutando la orden sudo grub-install --root-directory=/media/disk-2 /dev/sda (/media/disk-2 es el punto donde se ha montado la partición de Ubuntu y /dev/sda es el disco duro en el que se va a instalar GRUB).
Otra forma de recuperar GRUB desde un CD live es, una vez iniciado el sistema, entrar en el entorno de GRUB, buscar la partición donde está instalado Ubuntu, posicionarnos en esta partición e instalar GRUB. El resultado de estas operaciones se indican a continuación (para entrar en el entorno de GRUB hay que ejecutar la orden sudo grub):
grub>find /boot/grub/stage1(hd0,2)
grub>root (hd0,2)
grub>setup (hd0)Checking if "/boot/grub/stage1" exists... yesChecking if "/boot/grub/stage2" exists... yesChecking if "/boot/grub/e2fs_stage1_5" exists... yes
22

Running "embed /boot/grub/e2fs_stage1_5 (hd0)"... 17 sectors are embedded.succeededRunning "install /boot/grub/stage1 (hd0) (hd0)1+17 p (hd0,2)/boot/grub/stage2/boot/grub/menu.lst"... succeededDone.
grub>
La orden find /boot/grub/stage1 (hd0,2), busca la partición en la que está instalado Ubuntu y devuelve (hd0,2). La línea root (hd0,2) se posiciona en la partición de Ubuntu (observar que en esta orden se incluye la partición que ha devuelto la orden find /boot/grub/stage1). La línea setup (hd0) instala GRUB en el disco duro desde el que se inicia el equipo.
2.5.4 Recuperar GRUB con el paquete Super Grub Disk.
Existe una aplicación, llamada Super Grub Disk, que se utiliza para arrancar el sistema desde cualquier partición de sistema instalada en nuestro equipo. La página oficial de Super Grub Disk es: http://geocities.com/supergrubdisk/ . Desde esta página, siguiendo los enlaces incluidos, nos podemos descargar el software necesario para iniciar el sistema desde un puerto usb, desde un disquete o desde un cd o dvd.
Una vez descargado el software y preparado el soporte desde el que se va a iniciar el equipo, hay que arrancar el odenador, accediendo a la ventana principal de Super Grub Disk y, desde esta, a la ventana de la Figura 2.5.4.1.
Figura 2.5.4.1
Si, desde esta ventana, pulsamos la tecla -> (flecha derecha) con una de las dos primeras opciones seleccionadas, se muestra la ventana de la Figura 2.5.4.2.
23

Figura 2.5.4.2En esta ventana, seleccionamos el idioma deseado y se visualiza información de Super Grub Disk. Una vez leída la información, se muestra la ventana de la Figura 2.5.4.3.
Figura 2.5.4.3
En esta ventana, si pulsamos la tecla -> con la opción Gnu/Linux seleccionada, accedemos a la ventana de la Figura 2.5.4.4.
24

Figura 2.5.4.4
En esta ventana, podemos intentar la reparación del arranque de Linux (pulsando la opción Arregla Arranque de Gnu/Linux (GRUB)) y reiniciar el equipo si la reparación ha sido exitosa, o iniciar la partición de Linux (pulsando las opciones Arranque Gnu/Linux o Arranque Gnu/Linux Directamente). Si pulsamos la opción Gnu/Linux (Avanzado), se muestra la ventana de la Figura 2.5.4.5.
Figura 2.5.4.5
Desde esta ventana, se pueden intentar varias opciones de reparación y arranque del sistema.
Si, en la ventana de la Figura 2.5.4.3, seleccionamos la opción Windows, accedemos a una ventana desde la que podemos intentar reparar e iniciar el sistema desde Windows, de forma similar a la detallada para Gnu/Linux.
Si, en la ventana de la Figura 2.5.4.3, seleccionamos la opción Arranque & Herramientas, se muestra la ventana de la Figura 2.5.4.6.
25

Figura 2.5.4.6
Desde esta ventana, se pueden realizar varias operaciones para intentar arrancar el equipo.
Si, en la ventana de la Figura 2.5.4.3, seleccionamos la opción Avanzado, se muestra la ventana de la Figura 2.5.4.7.
Figura 2.5.4.7
En esta ventana, se pueden restaurar los gestores de arranque de Linux (GRUB y LILO) y de Windows. La opción Arranque especial nos permite intercambiar discos duros, de tal forma que el disco 1 pase a ser el disco 2 y viceversa. La opción Configuración permite cambiar opciones como el color, teclado, etc. La opción Miscelanea permite arrancar Linux desde GRUB.
Si, en la ventana de la Figura 2.5.4.1, seleccionamos la opción GRUB => MBR & !LINUX! (1) AUTO, GRUB se instala en el MBR y se carga el menú de GRUB para iniciar el sistema.
26

Si, en la ventana de la Figura 2.5.4.1, seleccionamos la opción GRUB => MBR & !LINUX! (>=2) MANUAL, accederemos a unas ventanas en las que deberemos seleccionar la partición donde se encuentra GRUB y, posteriormente, GRUB se instalará en el MBR y se cargará el menú de GRUB para iniciar el sistema.
Si, en la ventana de la Figura 2.5.4.1, seleccionamos las opciones !LINUX! (1) AUTO o !LINUX! (>=2) MANUAL, el sistema se iniciará desde Linux, pero GRUB no se instalará en el MBR.
Si, en la ventana de la Figura 2.5.4.1, seleccionamos la opción !WIN!, el sistema se iniciará desde la partición donde está instalado Windows.
Si, en la ventana de la Figura 2.5.4.1, seleccionamos la opción WIN -> MBR & !WIN!, el sistema se iniciará desde la partición donde está instalado Windows y el arranque de Windows se instalará en el MBR.
2.5.5 Acelerar el inicio del sistema.
Ubuntu utiliza el proceso readahead para que el inicio del sistema sea más rápido. La función de este proceso es cargar en la memoria caché del disco todos los archivos que serán necesarios para iniciar el sistema. La lista de estos archivos se encuentra en el fichero /etc/readahead/boot.
Un problema que se puede encontrar este proceso es que en la lista de archivos de /etc/readahead/boot existan entradas de elementos que ya no existan en nuestro sistema. En este caso, readahead no continúa leyendo el archivo, por lo que el resto de ficheros no se cargarían en la memoria caché y el sistema se iniciaría más lentamente.
Para solucionar este problema, Cuando se muestre el menú de GRUB, hay que pulsar la tecla e con la opción de nuestra partición de arranque seleccionada, pasando al estado de edición de las órdenes de inicio de esta partición. Seguidamente, hay que seleccionar la línea kernel /boot/vmlinuz-..., pulsar la tecla e para editar esta línea, añadir, al final de la línea, el parámetro profile, pulsar la tecla Intro y pulsar la tecla b para iniciar el sistema.
Con estas acciones, el archivo /etc/readahead/boot se actualizará con los elementos que realmente existen en el sistema. La siguiente vez que iniciemos el sistema, no se ejecutará el parámetro profile, ya que este parámetro sólo se habrá activado para el arranque en el que se ha incluido.
27

2.5.6 Sistema de tolerancia a fallos RAID 5.
Es el sistema de tolerancia a fallos más popular. Consiste en la creación de conjuntos de bandas con paridad. En esta técnica se necesitan, como mínimo, tres discos duros, de los cuales uno de ellos se utiliza para guardar la información de paridad.
Supongamos que tenemos tres discos duros y queremos grabar la información 110 011. Esta información se grabará en dos discos (110 en el primero y 011 en el segundo) y en el tercer disco se guardará la información de paridad. Si utilizamos la paridad par (el número de 1 de cada dígito entre los tres discos ha de ser par), en el tercer disco se grabaría 101. Si un disco se deteriora, su información se reconstruye calculando la paridad con el resto de los discos.
Este sistema aumenta el rendimiento del ordenador en la lectura de la información y permite la recuperación total de la información contenida en un disco defectuoso. Por el contrario, las operaciones de escritura se ralentizan al tener que crear la información de paridad asociada a cada fichero. Además, cuando un disco se deteriora, la reconstrucción de su contenido mediante la información de paridad del resto de discos es una operación muy lenta.
Cuando un disco se deteriora, el sistema baja su rendimiento considerablemente debido a los cálculos que tiene que realizar para reconstruir su información, por lo que es conveniente volver a la situación original lo antes posible. Una vez que el disco se ha reparado o se ha comprado uno nuevo, hay que incluir una parte del mismo en el conjunto de bandas con paridad creado.
Es posible reemplazar un disco duro sin apagar el ordenador gracias a la técnica de intercambio con tensión (hot-plug).
Para implementar este sistema de tolerancia a fallos en Linux, hay que instalar el paquete mdadm, actualizando previamente los repositorios.
28

Para crear el sistema de tolerancia a fallos RAID 5 y probar que todo funciona correctamente cuando un disco se estropea y después de repararlo y reconstruir el raid, hay que seguir los siguientes pasos:
1. Los siguientes ejercicios los vamos a realizar con VirtualBox. La primera acción a realizar es convertir el disco duro instalado en el ordenador en disco SATA e iniciar el sistema para comprobar que el disco está ubicado en el dispositivo lógico /dev/sda. Apagar el sistema.
2. Añadir tres discos duros nuevos, del mismo tamaño, para crear el RAID 5. Estos discos los convertiremos a discos SATA.
3. Crear una partición, en cada uno de los discos duros nuevos, que ocupe todo el disco.
La salida de la orden fdisk para crear la partición en el disco duro /dev/sdb se muestra en las siguientes líneas (la ejecución para los otros dos discos duros sería de igual forma, cambiando la orden fdisk /dev/sdb por fdisk /dev/sdc y fdisk /dev/sdd):
root@plantilla-desktop:~# fdisk /dev/sdb
El número de cilindros para este disco está establecido en 1044.No hay nada malo en ello, pero es mayor que 1024, y en algunos casos podría causar problemas con:1) software que funciona en el inicio (p.ej. versiones antiguas de LILO)2) software de arranque o particionamiento de otros sistemas operativos (p.ej. FDISK de DOS, FDISK de OS/2)
Orden (m para obtener ayuda): nAcción de la ordene Partición extendida p Partición primaria (1-4)pNúmero de partición (1-4): 1Primer cilindro (1-1044, valor predeterminado 1): Se está utilizando el valor predeterminado 1Último cilindro o +tamaño o +tamañoM o +tamañoK (1-1044, valor predeterminado 1044): Se está utilizando el valor predeterminado 1044
Orden (m para obtener ayuda): wq¡Se ha modificado la tabla de particiones!
Llamando a ioctl() para volver a leer la tabla de particiones.
ATENCIÓN: La relectura de la tabla de particiones falló con el error 16: Dispositivo ó recurso ocupado.El núcleo todavía usa la tabla antigua.La nueva tabla se usará en el próximo reinicio.Se están sincronizando los discos.
4. Crear el RAID 5 con la orden mdadm.
root@plantilla-desktop:~# mdadm --create /dev/md0 --level=5 --raid-devices=3 /dev/sdb1 /dev/sdc1 /dev/sdd1
mdadm: array /dev/md0 started.
El proceso de construcción del raid 5 comienza. Si ejecutamos la orden mdadm --detail /dev/md0, podemos ver el estado del RAID 5. La salida de esta orden es la siguiente:
root@plantilla-desktop:~# mdadm --detail /dev/md0
29

/dev/md0: Version : 00.90.03 Creation Time : Mon Feb 11 12:06:57 2008 Raid Level : raid5 Array Size : 16771584 (15.99 GiB 17.17 GB) Device Size : 8385792 (8.00 GiB 8.59 GB) Raid Devices : 3 Total Devices : 3 Preferred Minor : 0 Persistence : Superblock is persistent
Update Time : Mon Feb 11 12:06:57 2008 State : clean, degraded, recovering Active Devices : 2 Working Devices : 3 Failed Devices : 0 Spare Devices : 1
Layout : left-symmetric Chunk Size : 64K
Rebuild Status : 22% complete
UUID : 06907195:9dfd3ffc:9dc65f4a:e13fd1ee (local to host plantilla-desktop) Events : 0.1
Number Major Minor RaidDevice State 0 8 17 0 active sync /dev/sdb1
1 8 33 1 active sync /dev/sdc1 3 8 49 2 spare rebuilding /dev/sdd1
Se puede consultar el estado de construcción del RAID 5 ejecutando la siguiente orden: cat /proc/mdstat. La salida de esta orden durante la construcción del RAID 5, ejecutada varias veces, es la siguiente:
root@plantilla-desktop:~# cat /proc/mdstat Personalities : [raid6] [raid5] [raid4] md0 : active raid5 sdd1[3] sdc1[1] sdb1[0] 16771584 blocks level 5, 64k chunk, algorithm 2 [3/2] [UU_] [=====>...............] recovery = 25.8% (2170920/8385792) finish=5.2min
speed=19855K/sec
unused devices: <none> root@plantilla-desktop:~# cat /proc/mdstat Personalities : [raid6] [raid5] [raid4] md0 : active raid5 sdd1[3] sdc1[1] sdb1[0] 16771584 blocks level 5, 64k chunk, algorithm 2 [3/2] [UU_] [========>............] recovery = 44.3% (3716464/8385792) finish=4.0min
speed=19154K/sec
unused devices: <none> root@plantilla-desktop:~# cat /proc/mdstat Personalities : [raid6] [raid5] [raid4] md0 : active raid5 sdd1[3] sdc1[1] sdb1[0] 16771584 blocks level 5, 64k chunk, algorithm 2 [3/2] [UU_] [===============>.....] recovery = 75.9% (6369044/8385792) finish=1.7min speed=19724K/sec
unused devices: <none>
30

Cuando ejecutemos la orden cat /proc/mdstat y el RAID 5 esté construido, la salida del comando será la siguiente:
root@plantilla-desktop:~# cat /proc/mdstat Personalities : [raid6] [raid5] [raid4] md0 : active raid5 sdd1[2] sdc1[1] sdb1[0] 16771584 blocks level 5, 64k chunk, algorithm 2 [3/3] [UUU]
unused devices: <none>
5. Modificar el archivo /etc/mdadm/mdadm.conf, añadiendo las siguientes líneas:
DEVICE /dev/sdb1 /dev/sdc1 /dev/sdd1ARRAY /dev/md0 devices=/dev/sdb1,/dev/sdc1,/dev/sdd1
En estas líneas se indica que los dispositivos /dev/sdb1 /dev/sdc1 /dev/sdd1 se van a utilizar para formar parte de sistemas RAID y, además, que estos mismos dispositivos forman el sistema RAID creado en el dispositivo /dev/md0, que es el que acabamos de crear.
6. Formatear el dispositivo RAID 5 con la orden mkfs.ext3 /dev/md0. La salida de esta orden es la siguiente:
root@plantilla-desktop:~# mkfs.ext3 /dev/md0 mke2fs 1.40-WIP (14-Nov-2006) Etiqueta del sistema de ficheros= Tipo de SO: Linux Tamaño del bloque=4096 (bitácora=2) Tamaño del fragmento=4096 (bitácora=2) 2097152 nodos i, 4192896 bloques 209644 bloques (5.00%) reservados para el súper usuario Primer bloque de datos=0 Maximum filesystem blocks=0 128 bloque de grupos 32768 bloques por grupo, 32768 fragmentos por grupo 16384 nodos i por grupo Respaldo del súper bloque guardado en los bloques: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000
Mientras se escribían las tablas de nodos i: terminado Creando el fichero de transacciones (32768 bloques): hecho Escribiendo superbloques y la información contable del sistema de ficheros: hecho
Este sistema de ficheros se revisará automáticamente cada 34 meses o 180 dias, lo que suceda primero. Utilice tune2fs -c o -i para cambiarlo.
7. Reiniciar el equipo. Observar que el sistema reconoce y configura el RAID 5 creado anteriormente. Se puede visualizar el archivo /var/log/dmesg, una vez iniciado el equipo, para consultar el proceso que el sistema realiza durante el arranque para activar el dispositivo RAID 5. Las líneas que realizan esta acción son las siguientes:
[ 4873.889765] md: bind<sdc1> [ 4873.892837] md: bind<sdd1> [ 4873.893813] md: bind<sdb1> [ 4874.491567] raid5: device sdb1 operational as raid disk 0 [ 4874.492535] raid5: device sdd1 operational as raid disk 2 [ 4874.492669] raid5: device sdc1 operational as raid disk 1 [ 4874.496813] raid5: allocated 3163kB for md0 [ 4874.496970] raid5: raid level 5 set md0 active with 3 out of 3 devices, algorithm 2
31

[ 4874.499757] RAID5 conf printout: [ 4874.500425] --- rd:3 wd:3 [ 4874.500572] disk 0, o:1, dev:sdb1 [ 4874.500694] disk 1, o:1, dev:sdc1 [ 4874.500800] disk 2, o:1, dev:sdd1
8. De esta forma, el sistema RAID 5 está activado pero no es accesible, ya que todavía no se ha realizado la operación de montaje. Para realizar esta operación, hay que proceder de la siguiente forma:
8.1.Crear un directorio, que será el punto de montaje.
8.2.Montar el dispositivo /dev/md0 en el directorio creado en el punto anterior.
8.3.Visualizar el contenido del directorio.
8.4.Crear un archivo en este directorio.
8.5.Visualizar el contenido del directorio.
8.6.Visualizar el contenido del archivo.
8.7.Desmontar el dispositivo /dev/md0.
Estas acciones se muestran a continuación:
root@plantilla-desktop:~# mkdir /raid5 root@plantilla-desktop:~# mount /dev/md0 /raid5 root@plantilla-desktop:~# ls /raid5 lost+found root@plantilla-desktop:~# cat >/raid5/prueba Esto es una prueba de raid5 root@plantilla-desktop:~# ls /raid5 lost+found prueba root@plantilla-desktop:~# cat /raid5/prueba Esto es una prueba de raid5 root@plantilla-desktop:~# umount /dev/md0
9. Para realizar el montaje del dispositivo RAID 5 automáticamente al iniciar el sistema, hay que modificar el archivo /etc/fstab, incluyendo la siguiente línea:
/dev/md0 /raid5 ext3 defaults 0 0
El contenido del archivo /etc/fstab quedaría de la siguiente forma:
# /etc/fstab: static file system information. # # <file system> <mount point> <type> <options> <dump> <pass> proc /proc proc defaults 0 0 # /dev/sda1 UUID=7ee856c0-add5-4acb-aa1f-f576190d326b / ext3 defaults,errors=remount-ro 0 1 # /dev/sda2 UUID=94d845d9-76b6-4ba4-83f2-86f1dca664ee none swap sw 0 0 /dev/hdc /media/cdrom0 udf,iso9660 user,noauto 0 0 /dev/fd0 /media/floppy0 auto rw,user,noauto 0 0 # # Montar el sistema de tolerancia a fallos RAID 5 # /dev/md0 /raid5 ext3 defaults 0 0
32

10. Reiniciar el sistema y comprobar que el dispositivo RAID 5 se ha montado automáticamente. Para ello, hay que ejecutar la orden ls /raid5. La salida de esta orden es la siguiente:
root@plantilla-desktop:~# ls /raid5 lost+found prueba
11.Apagar el equipo y quitar el disco duro 3.
12.Encender el equipo.
Puede ocurrir que el sistema sea capaz de iniciar el dispositivo RAID 5 o que el dispositivo no se inicie. En el primer caso, si consultamos el contenido del archivo /var/log/dmesg, se habrán incluido las siguientes líneas:
[ 33.315072] raid5: device sdb1 operational as raid disk 0 [ 33.315229] raid5: device sdc1 operational as raid disk 1 [ 33.321803] raid5: allocated 3163kB for md0 [ 33.321963] raid5: raid level 5 set md0 active with 2 out of 3 devices, algorithm 2 [ 33.322987] RAID5 conf printout: [ 33.323116] --- rd:3 wd:2 [ 33.323255] disk 0, o:1, dev:sdb1 [ 33.323374] disk 1, o:1, dev:sdc1
En estas líneas, vemos que el RAID 5 se ha iniciado sólo con dos discos.
Si el sistema no ha podido iniciar el dispositivo RAID 5, se iniciará manualmente. Para ello, hay que ejecutar la orden mdadm --assemble --scan. A continuación, se muestra la salida de esta orden.
root@plantilla-desktop:~# mdadm --assemble --scanmdadm: /dev/md0 has been started with 2 drivers (out of 3).
Seguidamente, hay que montar el dispositivo /dev/md0 en /raid5.
13. Visualizar el contenido del dispositivo RAID 5 con la orden ls /raid5. La salida de esta orden es la siguiente:
root@plantilla-desktop:~# ls /raid5 lost+found prueba
De esta forma, vemos que el RAID 5 está montado correctamente.
14. Ejecutar la orden mdadm --detail /dev/md0. La salida es la siguiente:
root@plantilla-desktop:~# mdadm --detail /dev/md0 /dev/md0: Version : 00.90.03 Creation Time : Mon Feb 11 12:06:57 2008 Raid Level : raid5 Array Size : 16771584 (15.99 GiB 17.17 GB) Device Size : 8385792 (8.00 GiB 8.59 GB) Raid Devices : 3 Total Devices : 2 Preferred Minor : 0 Persistence : Superblock is persistent
Update Time : Mon Feb 11 14:00:53 2008 State : clean, degraded Active Devices : 2
33

Working Devices : 2 Failed Devices : 0 Spare Devices : 0
Layout : left-symmetric Chunk Size : 64K
UUID : 06907195:9dfd3ffc:9dc65f4a:e13fd1ee (local to host plantilla-desktop) Events : 0.16
Number Major Minor RaidDevice State 0 8 17 0 active sync /dev/sdb1 1 8 33 1 active sync /dev/sdc1 2 0 0 2 removed
Como vemos en la salida de esta orden, el sistema RAID 5 se ha montado y está funcionando sólo con dos discos.
15. Ejecutar la orden cat /proc/mdstat. La salida es la siguiente:
root@plantilla-desktop:~# cat /proc/mdstat Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10] md0 : active raid5 sdb1[0] sdc1[1] 6771584 blocks level 5, 64k chunk, algorithm 2 [3/2] [UU_]
unused devices: <none>
Como vemos en la salida de esta orden, el sistema RAID 5 se ha montado y está funcionando sólo con dos discos.
16. Modificar el contenido del archivo /raid5/prueba y visualizar su nuevo contenido. La salida es la siguiente:
root@plantilla-desktop:~# cat >>/raid5/prueba Prueba de raid5 con un disco menos root@plantilla-desktop:~# cat /raid5/prueba Esto es una prueba de raid5 Prueba de raid5 con un disco menos
17. Apagar el equipo y añadir un nuevo disco duro para reconstruir el RAID 5 (recordar que este disco hay que convertirlo a SATA). En este caso, vamos a añadir el disco que quitamos anteriormente, simulando con ello que este disco ha sido reparado. Si añadimos un nuevo disco, seguiremos en el punto 21.
18. Encender el ordenador. El sistema realizará la regeneración del dispositivo RAID 5. Si ejecutamos varias veces la orden cat /proc/mdstat podremos ver el proceso de regeneración. A continuación, se muestra la salida de esta orden.
root@plantilla-desktop:~# mdadm --manage /dev/md0 --re-add /dev/sdd1 mdadm: added /dev/sdd1 root@plantilla-desktop:~# cat /proc/mdstat Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10] md0 : active raid5 sdd1[3] sdb1[0] sdc1[1] 16771584 blocks level 5, 64k chunk, algorithm 2 [3/2] [UU_] [==>..................] recovery = 10.5% (881352/8385792) finish=7.0min
speed=17694K/sec
unused devices: <none> root@plantilla-desktop:~# cat /proc/mdstat Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
34

md0 : active raid5 sdd1[3] sdb1[0] sdc1[1] 16771584 blocks level 5, 64k chunk, algorithm 2 [3/2] [UU_] [==============>......] recovery = 74.8% (6275808/8385792) finish=2.5min speed=13554K/sec
unused devices: <none>
root@plantilla-desktop:~# cat /proc/mdstat Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10] md0 : active raid5 sdd1[2] sdb1[0] sdc1[1] 16771584 blocks level 5, 64k chunk, algorithm 2 [3/3] [UUU]
unused devices: <none>
19. Consultar el contenido del directorio /raid5 y del archivo /raid5/prueba para comprobar que todo funciona correctamente.
20. Reiniciar el equipo y consultar el contenido del directorio /raid5 y del archivo /raid5/prueba para comprobar que todo funciona correctamente.
21. Si hemos añadido un disco duro distinto (recordad que hay que convertirlo a disco SATA), debemos realizar las siguientes acciones:
21.1.Crear una partición en el nuevo disco duro. 21.2.Activar el dispositivo raid5 ejecutando la orden mdadm --assemble --scan. 21.3.Añadir el nuevo disco duro al dispositivo raid 5, ejecutando la siguiente orden:
mdadm --manage /dev/md0 --re-add /dev/sdd1
Esta orden genera la siguiente salida:
mdadm: added /dev/sdd1
21.4.El sistema raid 5 comienza a reconstruirse. Podemos ejecutar las órdenes para ver la reconstrucción en curso.
21.5.Al finalizar el proceso de reconstrucción, el sistema raid 5 se habrá montado automáticamente. Podemos comprobarlo visualizando el contenido del directorio /raid5 y del archivo /raid5/prueba.
35

2.6. PROTOCOLO TCP/IP.
El Departamento de Defensa de EEUU, preocupado por el corte de la comunicación en una guerra, crea un sistema de información basado en la unión de todos sus puntos de comunicación por varios destinos distintos. De esta forma, si se corta un punto el resto siguen comunicados por otros. Para unir los distintos puntos utilizan la red telefónica y así nace ARPANET (Advanced Research Project Agency Network) en 1970.
En 1974 nace el protocolo TCP/IP y en 1980 el Departamento de Defensa de EEUU decide desclasificar este protocolo como secreto militar. Unix incluye gratuitamente el código TCP/IP para su uso en universidades, lo cual lleva al crecimiento vertiginoso de la hoy conocida como red mundial o red de redes.
TCP/IP no es propiedad de ninguna empresa ni organismo. Todas las particularidades y evoluciones se describen en documentos públicos denominados RFC (Request for Comments) y numerados por orden de aparición. Estas características y posibilidades están convirtiendo a TCP/IP en un protocolo universal.
El protocolo TCP/IP se compone de dos protocolos:
o Protocolo TCP (Transmission Control Protocol).
Es el que asegura que los datos son transmitidos correctamente. Está orientado a la transmisión y controla si la información llega en orden (si no llega ordenada, la ordena), si hay errores, etc.
o Protocolo IP (Internet Protocol).
Permite que las aplicaciones se ejecuten independientemente del hardware que se esté utilizando, tanto a nivel local como en la red. Proporciona un sistema de entrega de paquetes no fiable.
36

Todo esto implica que, mediante el protocolo TCP/IP, se pueden conectar ordenadores de diferentes tipos, con distinto hardware y con distintos sistemas operativos, tanto en redes de área local como en redes con equipos conectados a larga distancia.
El funcionamiento del protocolo TCP/IP se realiza según el estándar OSI (Open System Interface), que consiste en la transmisión de datos por niveles. Para poder controlar la transmisión, cada nivel incorpora al nivel siguiente su propia cabecera. Cuando la información llega a su destino, la comunicación entre niveles se realiza de forma inversa, quitando las cabeceras recibidas y comprobando que la transmisión es correcta.
Los siete niveles o capas del modelo OSI son los siguientes:
• Capa física.
Define el modo de transmisión y de propagación de las señales. Se inicia en la tarjeta de red y se propaga a través de cables y demás soportes.
Las señales pueden ser eléctricas, electromagnéticas u ópticas.
• Capa de enlace.
En este nivel los datos digitales se traducen en señales a las que se añaden elementos para formar tramas o paquetes.
Algunos elementos que se añaden son las direcciones físicas del emisor y del destinatario, que hacen referencia a las tarjetas de red.
• Capa de red.
En este nivel se realiza un proceso que se denomina enrutamiento, consistente en la elección del mejor itinerario para transmitir el paquete en caso de que exista más de una ruta.
La elección se calcula en base a distintos parámetros, como pueden ser el número de redes que se va a atravesar, la duración del transporte, el coste de la comunicación, la saturación de la línea, etc.
• Capa de transporte.
Se encarga de comprobar la transmisión correcta de los paquetes entre los emisores y los receptores.
En este nivel se encuentra el protocolo TCP.
• Capa de sesión.
Esta capa gestiona la recuperación de la comunicación en caso de incidentes.
• Capa de presentación.
Se encarga de resolver los problemas asociados con la representación de la información entre los diferentes nodos: juegos de caracteres, caracteres de control, compresión de datos, etc. En este nivel actúa el lenguaje HTML.
• Capa de aplicación.
37

Este nivel constituye la interfaz de comunicación con el usuario. La interfaz puede actuar como un software específico (navegadores, gestores de correo electrónico, etc.) o como comandos del sistema operativo (ftp, telnet, etc.).
A continuación, veamos en detalle los protocolos que componen TCP/IP.
2.6.1 Protocolo IPv4 (Internet Protocol).
El protocolo IP proporciona un sistema de entrega de paquetes no fiable. Gestiona direcciones lógicas que se denominan direcciones IP. Actúa en la capa de red.
Una dirección IP es una dirección lógica de 32 bits, que sirve para identificar cada nodo (equipo) en la red, por lo que cada adaptador de la red dispondrá de su propia dirección IP, que será distinta para cada uno de los nodos.
Las direcciones IP se representan por cuatro bytes, que se escriben separados por un punto (notación decimal puntuada). Cada uno de estos bytes está representado por 8 bits, por lo que su rango de valores oscilará entre 0 y 255.
Las direcciones IP constan de dos campos: un identificador de red (netid), que identifica la red a la que está conectada la estación, y un identificador de host (hostid), que identifica cada host dentro de la red.
En terminología TCP/IP, una red es un grupo de hosts que pueden comunicarse entre sí sin utilizar un encaminador. Todos los hosts TCP/IP que forman una misma red deben tener asignado el mismo identificador de red. Los hosts con distintos identificadores de red deben comunicarse mediante un encaminador.
Dependiendo del número de bits tomados para definir el identificador de red, existen distintas clases de redes, que vienen diferenciadas por el número de redes y de hosts disponibles. Estos valores se indican en la máscara de subred, de forma análoga a las direcciones IP, por lo que tienen 4 bytes y 32 bits. Si un byte tiene el valor 255, indica que dicho byte en la dirección IP se refiere al identificador de red y si tiene el valor 0 indica que dicho byte en la dirección IP se refiere al identificador de host.
Las clases de redes son las siguientes:
38

Clase A.
Contiene el valor 255.0.0.0. Esta máscara de subred indica que el primer byte de la dirección IP se destina al identificador de red. Este byte sólo puede contener un valor comprendido entre 1 y 126. Los restantes 3 bytes se destinan al identificador de host. Por lo tanto, en esta red se pueden definir 256 redes (1 byte = 8 bits = 2^8 = 256) y 16.777.216 estaciones (3 bytes = 24 bits = 2^24 = 16.777.216). En realidad, en redes de tipo A sólo se admiten 128 redes y no 256, porque sólo se utilizan los 7 primeros bits y no los 8. El primer bit contiene siempre el valor 0, que indica el tipo de red.
El rango de direcciones IP disponibles en este tipo de redes es desde 1.0.0.0 hasta 126.0.0.0.
Para utilizar direcciones IP de esta clase en una Intranet con salida a Internet se usan las direcciones IP que comiencen por 10, es decir, 10.0.0.0. Estas direcciones IP no existen en Internet.
Clase B.
Contiene el valor 255.255.0.0. Esta máscara de subred indica que los dos primeros bytes de la dirección IP se destinan al identificador de red. El primer byte sólo puede contener un valor comprendido entre 128 y 191. Los restantes 2 bytes se destinan al identificador de hosts. Por lo tanto, en esta red se pueden definir 65.536 redes (2 bytes = 16 bits = 2^16 = 65.536) y 65.536 estaciones (2 bytes = 16 bits = 2^16 = 65.536). En realidad, en redes de tipo B sólo se admiten 16.384 redes y no 65.536, porque sólo se utilizan los 14 primeros bits y no los 16. Los dos primeros bits contienen el valor 10, que indican el tipo de red.El rango de direcciones IP disponibles en este tipo de redes es desde 128.0.0.0 hasta 191.0.0.0.
Para utilizar direcciones IP de esta clase en una Intranet con salida a Internet se usan las direcciones IP que comiencen por 172.16, es decir, 172.16.0.0. Estas direcciones IP no existen en Internet.
Clase C.
Contiene el valor 255.255.255.0. Esta máscara de subred indica que los tres primeros bytes de la dirección IP se destinan al identificador de red. El primer byte sólo puede contener un valor comprendido entre 192 y 223. El byte restante se destina al identificador de hosts. Por lo tanto, en esta red se pueden definir 16.777.216 redes (3 bytes = 24 bits = 2^24 = 16.777.216) y 256 estaciones (1 byte = 8 bits = 2^8 = 256). En realidad, en redes de tipo C sólo se admiten 2.097.152 redes y no 16.777.216, porque sólo se utilizan los 21 primeros bites y no los 24. Los tres primeros bits contienen el valor 110, que identifican el tipo de red.
El rango de direcciones IP disponibles en este tipo de redes es desde 192.0.0.0 hasta 223.0.0.0.
Para utilizar direcciones IP de esta clase en una Intranet con salida a Internet se usan las direcciones IP que comiencen por 192.168, es decir, 192.168.0.0. Estas direcciones IP no existen en Internet.
Clase D.
Se reservan para mensajes de multidifusión o broadcast. En esta máscara de subred no hay porción de red ni porción de host. Se representa por un número entero que identifica un grupo de hosts.
Cuando un nodo de la red quiere enviar información a otro pero sólo conoce su dirección IP y no conoce su dirección MAC, el protocolo ARP envía un mensaje broadcast solicitando al
39

nodo destino su dirección física. Todos los nodos de la red reciben el mensaje pero sólo responde el que tiene la dirección IP conocida.
Este mensaje lleva como máscara de subred el valor 255 en la parte de la dirección IP que se refiere a los hosts.
Así, si una dirección IP tiene el valor 192.124.255.255 quiere decir que se está enviando un mensaje de multidifusión a todos los hosts de la red 192.124.0.0.
• Clase E.
Su uso es experimental. Los cinco primeros bits son 11110.
Actualmente, las direcciones de clase A están agotadas, las direcciones de clase B están disponibles sólo para grandes empresas y las direcciones de clase C son las únicas disponibles, aunque ya son muy escasas. Los proveedores disponen de bloques de direcciones IP para proporcionar a sus clientes. Para disponer de nuevas direcciones IP, se está trabajando sobre la versión 6 de IP, que se denomina IPNG (IP Next Generation).
Todos los equipos tienen una dirección IP local o look back, que es la 127.0.0.1. Esta dirección IP no se puede asignar a ningún puesto.
La combinación de una dirección IP y la máscara de red nos indica la red a la que está conectado un equipo. Por ejemplo, el puesto con dirección IP 192.168.1.110 y máscara de red 255.255.255.0 está conectado a la red 192.168.1.0; el puesto con dirección IP 192.168.1.111 y máscara de red 255.255.255.0 está conectado a la red 192.168.1.0; el puesto con dirección IP 192.168.2.210 y máscara de red 255.255.255.0 está conectado a la red 192.168.2.0; el puesto con dirección IP 192.168.2.211 y máscara de red 255.255.255.0 está conectado a la red 192.168.2.0; el puesto con dirección IP 192.168.3.110 y máscara de red 255.255.0.0 está conectado a la red 192.168.0.0; el puesto con dirección IP 192.168.3.111 y máscara de red 255.255.0.0 está conectado a la red 192.168.0.0; y así sucesivamente.
2.6.2 Protocolo IPv6 (Internet Protocol version 6).
Aunque el protocolo IPv4 permite direccionar 4.000 millones de dispositivos, muchas de las direcciones no se pueden utilizar debido a su distribución poco eficaz en un momento en el que no podía preveerse la explosión de Internet.
El protocolo IPv6 permite direccionar un gran número de dispositivos, ya que las direcciones se codifican en 16 bytes (128 bits) en lugar de los 4 (32 bits) de IPv4. Además, se ha previsto el uso de redes de alta velocidad y el transporte de datos multimedia.
Es necesario reescribir algunos protocolos, como ARP, RARP o ICMP, pero se ha compatibilizado el uso de las dos versiones. De esta forma, se utilizarán conjuntamente en las redes y los programas que funcionan con IPv6 serán compatibles con Ipv4.
40

2.6.3 Protocolo TCP (Transmission Control Protocol).
Es un protocolo de transporte que asegura un servicio fiable. Es el que asegura que los datos son transmitidos correctamente. Está orientado a la transmisión y controla si la información llega en orden (si no llega ordenada, la ordena), si hay errores, etc. Actúa en la capa de transporte.
El protocolo TCP se basa en las direcciones IP para realizar la transmisión y es el principal usuario del protocolo IP.
Al realizar el control de los datos, la transmisión es más lenta pero se libera a las aplicaciones que utilizan los servicios de TCP del control de la integridad de los datos.
41

2.6.4 Administración de las tarjetas de red desde la línea de comandos.
Para administrar las tarjetas de red desde la línea de comandos, se utiliza la orden ifconfig. La sintaxis de esta orden es la siguiente:
ifconfig [interfaz] [opciones]
Si se ejecuta la orden sin parámetros, se muestran todas las tarjetas de red instaladas en el equipo.
La interfaz hace referencia a la tarjeta de red instalada. Las tarjetas de red se nombran como eth0, eth1, ...
Algunas opciones son las siguientes:
up.
Activa la interfaz especificada, asignándole una dirección IP.
down.
Desactiva la interfaz especificada.
Dirección IP.
Asigna la dirección IP especificada.
netmask.
Asigna la máscara de red a la interfaz especificada.
42

Ejemplo: La orden ifconfig eth0 192.168.1.2 netmask 255.255.255.0 asigna la dirección IP 192.168.1.2 y la máscara de red 255.255.255.0 a la interfaz eth0.
Para saber si la tarjeta de red funciona correctamente, se utiliza la orden ping dirección IP. Si la tarjeta funciona correctamente, la orden ping devuelve una respuesta de la dirección IP especificada. En caso contrario, devuelve un error.
A continuación, se muestra un ejemplo de respuesta correcta al utilizar la orden ping.
root@alsico-laptop:~# ping 192.168.1.1
PING 192.168.1.1 (192.168.1.1) 56(84) bytes of data.
64 bytes from 192.168.1.1: icmp_seq=1 ttl=255 time=0.795 ms
64 bytes from 192.168.1.1: icmp_seq=2 ttl=255 time=0.532 ms
64 bytes from 192.168.1.1: icmp_seq=3 ttl=255 time=0.563 ms
--- 192.168.1.1 ping statistics ---
6 packets transmitted, 6 received, 0% packet loss, time 5019ms
rtt min/avg/max/mdev = 0.494/0.578/0.795/0.103 ms
El siguiente ejemplo es la respuesta de la orden ping cuando se produce un error.
root@alsico-laptop:~# ping 192.168.1.1
PING 192.168.1.1 (192.168.1.1) 56(84) bytes of data.
From 169.254.4.243 icmp_seq=2 Destination Host Unreachable
From 169.254.4.243 icmp_seq=3 Destination Host Unreachable
From 169.254.4.243 icmp_seq=4 Destination Host Unreachable
--- 192.168.1.1 ping statistics ---
8 packets transmitted, 0 received, +6 errors, 100% packet loss, time 7002ms
, pipe 3
Si queremos administrar el servicio que controla la interfaz de red, hay que ejecutar la orden /etc/init.d/networking {start,stop,restart,force-reload}. En algunas distribuciones de Linux, el servicio networking se llama network.
La orden route se utiliza para administrar la puerta de enlace que utiliza la interfaz de comunicaciones. La salida de la orden route podría ser la siguiente:
root@alsico-laptop:~# route
Kernel IP routing table
43

Destination Gateway Genmask Flags Metric Ref Use Iface
192.168.1.0 * 255.255.255.0 U 0 0 0 eth0
192.168.94.0 * 255.255.255.0 U 0 0 0 vmnet1
172.16.168.0 * 255.255.255.0 U 0 0 0 vmnet8
link-local * 255.255.0.0 U 0 0 0 wlan0
link-local * 255.255.0.0 U 1000 0 0 eth0
default 192.168.1.1 0.0.0.0 UG 0 0 0 eth0
default * 0.0.0.0 U 1000 0 0 wlan0
En las siguientes líneas, se va a asignar a la interfaz eth0 la dirección IP 172.26.1.100, la máscara de red 255.255.255.0 y la puerta de enlace 172.26.1.1.
root@alsico-laptop:~# ifconfig eth0 172.26.1.100 netmask 255.255.255.0
root@alsico-laptop:~# route add default gw 172.26.1.1 eth0
Con estas órdenes, tanto la dirección IP como la puerta de enlace sólo son asignadas temporalmente para la sesión actual. Cuando se reinicie el equipo, la dirección IP y la puerta de enlace serán las que tiene asignada de forma permanente (más adelante se explica el proceso a seguir para asignar estos parámetros de forma permanente).La salida de la orden route después de realizar las asignaciones anteriores sería la siguiente:
root@alsico-laptop:~# route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
172.26.1.0 * 255.255.255.0 U 0 0 0 eth0
192.168.94.0 * 255.255.255.0 U 0 0 0 vmnet1
172.16.168.0 * 255.255.255.0 U 0 0 0 vmnet8
link-local * 255.255.0.0 U 0 0 0 wlan0
default 172.26.1.1 0.0.0.0 UG 0 0 0 eth0
default * 0.0.0.0 U 1000 0 0 wlan0
Los archivos que administra el servicio networking son /etc/iftab, que contiene la dirección MAC de la tarjeta de red, y /etc/network/interfaces, que contiene una lista con las tarjetas de red instaladas en el equipo. El contenido de estos archivos podría ser el siguiente:
root@alsico-laptop:~# cat /etc/iftab
# This file assigns persistent names to network interfaces.
# See iftab(5) for syntax.
eth0 mac 00:02:3f:0b:87:19 arp 1
44

root@alsico-laptop:~# cat /etc/network/interfaces
auto lo iface lo inet loopback
auto eth1 iface eth1 inet dhcp
auto wlan0 iface wlan0 inet dhcp
El archivo /etc/network/interfaces es el que se utiliza para configurar la dirección IP de forma permanente. Como vemos en este archivo, la tarjeta de red eth1, se inicia al arrancar el sistema (auto eth1) y solicita la dirección IP de un servidor DHCP (iface eth1 inet dhcp). Lo mismo ocurre con la tarjeta inalámbrica (wlan0).
Para asignar una dirección IP fija, habría que añadir las siguientes líneas:
iface eth1 inet static address 192.168.100.2 netmask 255.255.255.0
Si, además, queremos asignar una puerta de enlace, habría que añadir la línea gateway 192.168.100.1.
También se puede asignar una nueva dirección IP a la misma tarjeta de red, añadiendo las siguientes líneas:
iface eth1:0 inet static address 192.168.100.3netmask 255.255.255.0
En este ejemplo, se ha añadido un nombre alias a la interfaz eth1, denominado eth1:0.
El archivo /etc/network/interfaces, después de realizar las acciones de los ejemplos anteriores, quedaría como sigue:
auto lo iface lo inet loopback
auto eth1iface eth1 inet static
address 192.168.100.2 netmask 255.255.255.0 gateway 192.168.100.1
auto eth1:0iface eth1:0 inet static
address 192.168.100.3 netmask 255.255.255.0
auto wlan0 iface wlan0 inet dhcp
Para activar los cambios realizados en el archivo /etc/network/interfaces, hay que ejecutar la orden ifup eth1, para la interfaz eth1, o ifup eth1:0, para la interfaz eth1:0.
Si ejecutamos la orden ifconfig después de activar esta configuración, la salida sería la siguiente:
45

root@plantilla-desktop:~# ifconfig eth1 Link encap:Ethernet HWaddr 00:0C:29:86:07:61 inet addr:192.168.100.2 Bcast:192.168.100.255 Mask:255.255.255.0 inet6 addr: fe80::20c:29ff:fe86:761/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:498 errors:0 dropped:0 overruns:0 frame:0 TX packets:712 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:501435 (489.6 KiB) TX bytes:74657 (72.9 KiB) Interrupt:18 Base address:0x1400
eth1:0 Link encap:Ethernet HWaddr 00:0C:29:86:07:61 inet addr:192.168.100.3 Bcast:192.168.100.255 Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 Interrupt:18 Base address:0x1400
lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 inet6 addr: ::1/128 Scope:Host UP LOOPBACK RUNNING MTU:16436 Metric:1 RX packets:2477 errors:0 dropped:0 overruns:0 frame:0 TX packets:2477 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:126178 (123.2 KiB) TX bytes:126178 (123.2 KiB)
2.6.5 Nombre de host.
Para cambiar el nombre del equipo, hay que modificar el archivo /etc/hostname.
El contenido de un archivo /etc/hostname podría ser el siguiente:
root@plantilla-desktop:~# cat /etc/hostname plantilla-desktop
En este archivo, se indica que el nombre del equipo es plantilla-desktop. Si queremos cambiar este nombre por el de prueba, el archivo /etc/hostname quedaría como sigue:
root@plantilla-desktop:~# cat /etc/hostname prueba
Si abrimos un terminal después de reiniciar el sistema, veremos el nuevo nombre del equipo en el shell:
root@prueba:~#
46

2.6.6 Servidores DNS.
Para asignar la dirección de los servidores DNS que se van a utilizar, hay que modificar el archivo /etc/resolv.conf. El contenido de este archivo es el siguiente:
root@alsico-laptop:~# cat /etc/resolv.conf
nameserver 80.58.61.250
nameserver 80.58.61.254
Si queremos añadir el servidor DNS con dirección IP 80.58.0.33, tendríamos que añadir la línea nameserver 80.58.0.33 en el archivo /etc/resolv.conf.
47

2.7. REDES INALÁMBRICAS.
Para utilizar la tarjeta de red inalámbrica, hay que descargar e instalar el paquete ndiswrapper, que usará los drivers de la tarjeta de red inalámbrica para los sistemas de Microsoft.
Para instalar la tarjeta de red inalámbrica, hay que seguir los siguientes pasos:
1. Descargar e instalar el paquete ndiswrapper.
Si esta acción la realizamos desde Synaptic, en la Figura 2.7.1 se muestran los paquetes necesarios para instalar este software.
Figura 2.7.1
48

Si la descarga e instalación la realizamos desde la línea de comandos, hay que ejecutar la orden apt-get install ndiswrapper-utils-1.9 (esta es la última versión de este paquete en el momento de la elaboración de estos apuntes).
2. Insertar el DVD con los drivers de Microsoft para la tarjeta inalámbrica. En la Figura 2.7.2, se muestran estos drivers para el sistema operativo Windows XP, que son los drivers que vamos a instalar.
Figura 2.7.2
En esta ventana, están seleccionados los archivos i2220ntx.sys y neti2220.inf, que son los que hay que copiar para la instalación de los drivers. Estos archivos los vamos a copiar en la carpeta drivers que crearemos en /opt.
3. Posicionarse en el directorio /opt/drivers y ejecutar la orden ndiswrapper -i neti2220.inf, para instalar los drivers de la tarjeta inalámbrica. Si visualizamos el contenido del directorio /etc/ndiswrapper, existirá un subdirectorio llamado neti2220, que contiene los drivers que acabamos de instalar. Si nuestra tarjeta de red inalámbrica se conecta al puerto usb, conectarla en este momento. En las siguientes líneas se muestra el resultado de la ejecución de estas órdenes:
root@alsico-laptop:~# cd /opt/drivers
root@alsico-laptop:/opt/drivers# ndiswrapper -i neti2220.inf
installing neti2220 ...
root@alsico-laptop:/opt/drivers# ls /etc/ndiswrapper/neti2220
17FE:2220:0305:1468.5.conf 17FE:2220.5.conf i2220ntx.sys neti2220.inf
4. Ejecutar la orden ndiswrapper -l para comprobar que el driver se ha instalado correctamente. La salida de esta orden es la siguiente:
root@alsico-laptop:/opt/drivers# ndiswrapper -l
neti2220 : driver installed
device (17FE:2220) present
49

5. Ejecutar la orden ndiswrapper -m. Esta orden crea el archivo ndiswrapper en el directorio /etc/modprobe.d, cuyo contenido es la línea alias wlan0 ndiswrapper, que indica que se va a utilizar el alias wlan0 para la tarjeta de red inalámbrica. La salida de la orden ndiswrapper -m es la siguiente:
root@alsico-laptop:/opt/drivers# ndiswrapper -m
adding "alias wlan0 ndiswrapper" to /etc/modprobe.d/ndiswrapper ...
6. Ejecutar la orden ifconfig wlan0 para activar la tarjeta de red inalámbrica. Si, después de ejecutar esta orden, hacemos clic sobre el icono de administración de las tarjetas de red, se visualizarán todas las redes inalámbricas a nuestro alcance. La ventana de la Figura 2.7.3 muestra un posible aspecto de esta acción.
Figura 2.7.3
7. Para conectarnos a una red inalámbrica, hay que seleccionarla en la ventana de la Figura 2.7.3. Si la red a la que nos queremos conectar está protegida, nos pedirá la contraseña de la red, según se muestra en la ventana de la Figura 2.7.4.
Figura 2.7.4
Observar, en esta ventana, que se ha seleccionado ASCII WEP de 64/128 bits comoSeguridad inalámbrica, que es el tipo de cifrado de contraseña utilizado habitualmente.
Cuando pulsemos el botón Entrar en la red en la ventana de la Figura 2.7.4, se muestrala ventana de la Figura 2.7.5, en la que debemos pulsar el botónDenegar para conectarnos con la red inalámbrica.
50

Figura 2.7.5
La contraseña para el anillo de claves se refiere a que el sistema mantiene unabase de datos cifrada con todas nuestras contraseñas y nos pedirá una contraseña paraacceder a este archivo. Esta contraseña sólo se pide la primera vez que se ejecuta una aplicación, pero cuando el sistema se apague o se reinicie, se volverá a pedir cuandola aplicación se vuelva a lanzar.
Una vez conectados a la red inalámbrica, se visualiza el icono de conexiónmostrado en la ventana de la Figura 2.7.6.
Figura 2.7.6
8. Ejecutar la orden iwconfig para ver la configuración de la tarjeta de red inalámbrica. También se puede ejecutar la orden iwlist wlan0 scan para ver las redes que tenemos a nuestro alcance.
9. Finalmente, para que la tarjeta de red se active al encender el ordenador, hay que editar el archivo /etc/modules y añadir la línea ndiswrapper.
Una vez finalizada la configuración de la tarjeta inalámbrica, se puede borrar el directorio /opt/drivers en el que copiamos los drivers de Microsoft para realizar la instalación.
51

2.8. ADMINISTRACIÓN DE BLUETOOTH.
Para poder enviar y recibir información a través de Bluetooth, hay que instalar el paquete bluez-utils. Una vez instalado podemos acceder a los archivos de configuración, ubicados en el directorio /etc/bluetooth.
Para escanear los dispositivos Bluetooth a nuestro alcance, hay que ejecutar la orden hcitool scan. En el siguiente ejemplo, esta orden devuelve la dirección MAC y el nombre de un teléfono móvil que tiene activada la conectividad Bluetooth.
root@alsico-laptop:~# hcitool scan
Scanning ...
00:18:C5:DE:87:C4 Dpto. Informática
Para enviar un archivo desde nuestro sistema al dispositivo Bluetooth, hay que seleccionarlo en el Navegador de archivos, abrir el menú emergente y ejecutar la opción Enviar a. Se muestra la ventana de la Figura 2.8.1.
52

Figura 2.8.1
En esta ventana, hay que desplegar la lista Enviar como y seleccionar Bluetooth (OBEX Push). El dispositivo detecta automáticamente el terminal Bluetooth a nuestro alcance, según se muestra en la ventana de la Figura 2.8.2.
Figura 2.8.2
En esta ventana, hay que pulsar el botón Enviar y, una vez aceptada la recepción del archivo en el dispositivo Bluetooth, el envío es completado, según se muestra en la ventana de la Figura 2.8.3.
Figura 2.8.3
Para visualizar el dispositivo Bluetooth activo en nuestro sistema, se pueden ejecutar las órdenes hcitool dev o hciconfig. A continuación, se muestran unos ejemplos de la ejecución de estos comandos.
root@alsico-laptop:~# hcitool dev
Devices:
hci0 00:80:5A:65:28:E9root@alsico-laptop:~# hciconfig
hci0: Type: USB
53

BD Address: 00:80:5A:65:28:E9 ACL MTU: 384:8 SCO MTU: 64:8
UP RUNNING PSCAN ISCAN
RX bytes:5263 acl:130 sco:0 events:179 errors:0
TX bytes:24742 acl:108 sco:0 commands:39 errors:0
2.9. SERVIDOR DHCP.
El protocolo DHCP (Dynamic Host Configuration Protocol) se encarga de asignar direcciones IP dinámicamente. El demonio que gestiona este servicio se llama dhcp3-server y se administra con el programa /etc/init.d/dhcp3-server.
Para instalar el servicio DHCP, hay que ejecutar la orden apt-get install dhcp3-server. Conviene recordar que el servidor que se configura como servidor DHCP debe tener la dirección IP fija. Si no tiene una dirección IP fija, cuando intenta iniciar el servicio después de la instalación, se produce un error.
Si, después de la instalación (una vez que el servidor tiene una dirección IP fija), se iniciar el servicio, se genera un error. Este error se puede consultar en el archivo /var/log/syslog, donde encontramos las líneas que se muestran a continuación.
Mar 27 20:14:32 plantilla-desktop dhcpd: No subnet declaration for eth1 (192.168.1.34). Mar 27 20:14:32 plantilla-desktop dhcpd: Please write a subnet declaration in your dhcpd.conf file for the Mar 27 20:14:32 plantilla-desktop dhcpd: network segment to which interface eth1 is attached. Mar 27 20:14:32 plantilla-desktop dhcpd: exiting.
Este error se produce porque no se ha definido la red y la máscara de red en la que el servidor DHCP servirá direcciones IP. Para ello, hay que modificar el archivo de configuración del servidor DHCP, que se denomina /etc/dhcp3/dhcpd.conf. Las líneas que hay que incluir en este archivo para que el servicio se pueda iniciar sin errores son las siguientes (suponemos que el servidor DHCP tiene la dirección IP 192.168.7.2 y la máscara de red 255.255.255.0):
subnet 192.168.7.0 netmask 255.255.255.0 { range 192.168.7.20 192.168.7.200;
}
La línea range 192.168.7.20 192.168.7.200; no es necesaria para iniciar el servicio DHCP sin errores, pero esta línea es la que define el ámbito de direcciones IP que se van a servir
54

automáticamente y, si se omitiera, el servicio funcionaría correctamente pero no se servirían direcciones IP.
Algunas opciones que se pueden configurar en el servidor DHCP, que deben incluirse en el archivo /etc/dhcp3/dhcpd.conf, son las siguientes:
o Definición del ámbito.
Para definir el ámbito de direcciones IP que el servidor DHCP asignará, se utiliza la directiva range, incluida en las directivas subnet y netmask. Por ejemplo, las líneas
subnet 192.168.7.0 netmask 255.255.255.0 {range 192.168.7.20 192.168.7.200;
}
definen un rango de direcciones IP desde la 192.168.7.20 hasta la 192.168.7.200, que se asignarán a las estaciones cliente que lo soliciten. Las direcciones IP que se sirvan pertenecen a la red 192.168.7.0, de clase C.
o Servir direcciones de routers.
Para servir a un cliente la dirección IP del router que se utilizará en la red junto con su dirección IP, se utiliza la directiva option routers, incluida en las directivas subnet y netmask. Por ejemplo, las líneas
subnet 192.168.7.0 netmask 255.255.255.0 {range 192.168.7.20 192.168.7.200;option routers 192.168.7.1;
}
además de definir el rango de direcciones IP que se asignarán automáticamente, especifica la dirección IP del router que se utilizará en la red y que servirá a la estación cliente junto con su dirección IP.
o Servir direcciones de servidores DNS.
Para servir automáticamente las direcciones IP de los servidores DNS que van a utilizar las estaciones cliente, se utiliza la directiva option domain-name-servers dirIP1[, dirIP2, ...];.
Por ejemplo, la línea option domain-name-servers 194.179.1.100, 193.144.238.1;, define las direcciones IP de los servidores DNS que se servirán a las estaciones cliente junto con su dirección IP.
Esta directiva siempre debe ubicarse antes de las líneas donde se definen la red, máscara de red, ámbito de direcciones IP y direcciones IP de los routers.
Desde los clientes, se pueden consultar las direcciones de los servidores DNS visualizando el contenido del archivo /etc/resolv.conf.
o Reserva de direcciones IP.
Para reservar determinadas direcciones IP para que se asignen siempre a la misma estación, hay que incluir la directiva fixed-address, que indica la dirección IP reservada, y la directiva hardware ethernet, que define la dirección MAC o dirección física de la estación para la que se va realizar la reserva. Estas directivas se incluyen en la directiva host, que define el nombre del host para el que se reserva la dirección IP.
Por ejemplo, las líneas
host linuxubuntu40 {
55

hardware ethernet 00:0C:29:DF:80:1B;fixed-address 192.168.7.40;
}
reservan la dirección IP 192.168.7.40 al host linuxubuntu40, que tiene la dirección MAC 00:0C:29:DF:80:1B.
Una vez que se ha configurado o modificado el archivo /etc/dhcp3/dhcpd.conf, hay que reiniciar el servicio dhcp3-server.
Los clientes pueden obtener una dirección IP del servidor DHCP con la orden dhclient eth1, donde eth1 es el nombre de la tarjeta de red a la que se va a asignar la dirección IP. En las siguientes líneas se muestra la ejecución de esta orden.
root@linuxubuntu40:~# dhclient Internet Systems Consortium DHCP Client V3.0.4 Copyright 2004-2006 Internet Systems Consortium. All rights reserved. For info, please visit http://www.isc.org/sw/dhcp/
Listening on LPF/eth1/00:0c:29:dd:ca:15 Sending on LPF/eth1/00:0c:29:dd:ca:15 Sending on Socket/fallback DHCPDISCOVER on eth1 to 255.255.255.255 port 67 interval 3 DHCPOFFER from 192.168.7.2 DHCPREQUEST on eth1 to 255.255.255.255 port 67 DHCPACK from 192.168.7.2 SIOCADDRT: Network is unreachable bound to 192.168.7.40 -- renewal in 256 seconds.
Se pueden consultar las direcciones IP concedidas por el servidor visualizando el archivo /var/log/syslog. En las siguientes líneas, se muestra la parte de este archivo correspondiente al registro de concesión de dos direcciones IP, la 192.168.7.40 y la 192.168.7.10.
Mar 27 21:40:45 plantilla-desktop dhcpd: DHCPDISCOVER from 00:0c:29:dd:ca:15 via eth1 Mar 27 21:40:45 plantilla-desktop dhcpd: DHCPOFFER on 192.168.7.40 to 00:0c:29:dd:ca:15 via eth1 Mar 27 21:40:45 plantilla-desktop dhcpd: Both dynamic and static leases present for 192.168.7.40. Mar 27 21:40:45 plantilla-desktop dhcpd: Either remove host declaration prueba or remove 192.168.7.40 Mar 27 21:40:45 plantilla-desktop dhcpd: from the dynamic address pool for 192.168.7.0 Mar 27 21:40:45 plantilla-desktop dhcpd: DHCPREQUEST for 192.168.7.40 from 00:0c:29:dd:ca:15 via eth1 Mar 27 21:40:45 plantilla-desktop dhcpd: DHCPACK on 192.168.7.40 to 00:0c:29:dd:ca:15 via eth1 Mar 27 21:41:52 plantilla-desktop dhcpd: DHCPREQUEST for 192.168.7.10 from 00:0c:29:24:d2:a7 via eth1 Mar 27 21:41:52 plantilla-desktop dhcpd: DHCPACK on 192.168.7.10 to 00:0c:29:24:d2:a7 via eth1
El archivo /var/lib/dhcp3/dhcpd.leases contiene la actividad del servidor DHCP, con información de las direcciones IP concedidas, los equipos a los que se les ha concedido, junto con su dirección MAC, y la duración de la concesión. En las siguientes líneas se muestra un ejemplo de este archivo.
root@plantilla-desktop:~# cat /var/lib/dhcp3/dhcpd.leases
# All times in this file are in UTC (GMT), not your local timezone. This is
# not a bug, so please don't ask about it. There is no portable way to
# store leases in the local timezone, so please don't request this as a
# feature. If this is inconvenient or confusing to you, we sincerely
# apologize. Seriously, though - don't ask.
56

# The format of this file is documented in the dhcpd.leases(5) manual page.
lease 192.168.100.100 {
starts 4 2008/04/10 10:47:22;
ends 4 2008/04/10 10:57:22;
hardware ethernet 00:0c:29:e7:5d:c3;
client-hostname "prueba";
}
2.9.1 Ejemplo de archivo /etc/dhcpd.conf.
## Archivo /etc/dhcp3/dhcpd.conf para configurar el servidor DHCP.## Cada vez que se modifique este archivo, hay que reiniciar el servicio dhcpd.## Algunas directivas para configurar el servicio DCHP son las siguientes:### Directiva para servir las direcciones IP de los DNS.#option domain-name-servers 194.179.1.100, 193.144.238.1;## Directiva para definir la red en la que va a servir direcciones IP el# servidor DHCP, el ámbito de direcciones IP que se van a servir y la# dirección IP del router que se servirá a los clientes junto con su# dirección IP.#subnet 192.168.7.0 netmask 255.255.255.0 {
range 192.168.7.20 192.168.7.200;option routers 192.168.7.1;
}## Directiva para reservar direcciones IP a determinadas estaciones.#host linuxubuntu40 {
hardware ethernet 00:0C:29:DF:80:1B;fixed-address 192.168.7.40;
}## Fin del archivo /etc/dhcpd.conf.#
57

3. El Kernel.
El kernel es la parte del sistema operativo que reside en memoria. Se encarga de programar los procesos, asignar el almacenamiento de la memoria y de los discos, supervisar la transferencia de datos entre la memoria y los periféricos y atender los requerimientos de los procesos.
El kernel comprende tres partes principales: la administración de procesos, la administración de los dispositivos y la administración de las operaciones para redes.
La administración de procesos consiste en asignar recursos, lanzar los procesos y atender las solicitudes de los procesos.
La administración de dispositivos controla la transferencia de datos entre la memoria principal y los dispositivos periféricos. Todos los periféricos conectados al ordenador contienen un módulo en la parte del kernel que administra los dispositivos. Cuando se añade un nuevo periférico, hay que añadir un módulo de programa en esta parte del kernel.
El kernel está escrito, casi en su totalidad, en lenguaje C. El resto se mantiene escrito en lenguajes ensambladores. En Linux se distribuyen los programas fuente del kernel, con lo que los propios usuarios pueden modificarlo y crearse su propio sistema operativo.
Un sistema Unix ejecuta instrucciones que forman parte de un proceso generado por un usuario e instrucciones propias del kernel. El reloj interno es la parte que se encarga de mantener la integridad del sistema. El reloj interrumpe periódicamente los procesos que se están ejecutando para evaluar sus prioridades y cambiar la ejecución de los distintos procesos según sus prioridades. Una interrupción es una señal de hardware que puede desviar la ejecución hacia una rutina especial de software. Cuando un programa de usuario necesita un servicio del sistema operativo, se genera una llamada al sistema que hace que se ejecute, desde el kernel, dicho servicio. En las operaciones de E/S, el resto de procesos pueden quedar en suspenso mientras se realiza la transferencia de datos, aunque, siempre que sea posible, se intentarán ejecutar procesos de otros usuarios.
58

El sistema Unix emplea el tiempo compartido para la ejecución de los procesos. Cuando el ordenador sólo tiene un procesador, el tiempo de ejecución se debe repartir entre los distintos procesos. En cada momento, sólo un proceso se estará ejecutando, permaneciendo el resto en espera. Los procesos que están en espera se dividen en dos grupos: los que están listos para ejecutarse y los que están bloqueados. Los procesos pueden estar bloqueados por varias causas, como, por ejemplo, porque estén realizando operaciones de E/S o porque necesiten datos de otros procesos. Para liberar memoria RAM y, por lo tanto, los procesos que están listos para ser ejecutados lo hagan más rápidamente, el sistema almacena los procesos bloqueados en disco en las áreas de swap o de intercambio.
Toda la información que necesita el kernel para ejecutar los procesos se almacena en la tabla de procesos y en la tabla de usuario o segmento de datos.
La tabla de procesos siempre se encuentra en memoria y contiene información sobre la posición del proceso (dirección de memoria o de disco), el tamaño del proceso y las señales recibidas. Cada proceso ocupa una entrada en la tabla de procesos.
La información secundaria de cada proceso se almacena en la tabla de usuario, conteniendo los números de identificación de usuario y de grupo para determinar los privilegios de acceso a los ficheros, los punteros a la tabla del sistema de ficheros de todos los ficheros utilizados por el proceso, un puntero al inodo del directorio activo y una lista de respuestas para las diferentes señales. Cada una de estas señales que pueden realizar los procesos está ubicada en una posición de la lista de señales y puede tener tres valores: 0, en cuyo caso la señal se ejecutará, 1, que indica que la señal se ignorará, y cualquier otro número, que apunta a la dirección de una rutina de manejo de señales. Por ejemplo, una señal puede ser sigkill (valor 9), que indica que el proceso finalizará su ejecución.
Existe una tabla de usuario para cada proceso activo y los programas del kernel sólo pueden acceder directamente a la tabla de usuario del proceso que se está ejecutando.
Cada sistema Unix permite un número determinado de entradas en la tabla de procesos, por lo que no es posible tener más procesos activos que el número de entradas en la tabla de procesos. La creación de un proceso comprende la inicialización de una posición en la tabla de procesos, la inicialización de la tabla de usuario y la carga de los datos y del texto del proceso. Cuando un proceso finaliza, la posición que ocupaba en la tabla de procesos se borra para que pueda ser utilizada por otros procesos.
59

4. Sistemas de archivos.
El sistema operativo Unix almacena toda la información en archivos, que son organizados en directorios y subdirectorios.
Unix utiliza una estructura jerárquica en forma de árbol para organizar los directorios. La estructura principal del árbol parte de un directorio principal que se denomina root (raíz) y se representa por el carácter “/”.
Un directorio se comporta a todos los efectos como un archivo, con la característica de que sus registros son de longitud fija.
El sistema de archivos actual en Linux es ext4 (fourth extended filesystem o «cuarto sistema de archivos extendido»), que es un sistema de archivos con registro por diario (en inglés Journaling), anunciado el 10 de octubre de 2006 por Andrew Morton, como una mejora compatible de ext3. El 25 de diciembre de 2008 se publicó el kernel Linux 2.6.28, que elimina ya la etiqueta de "experimental" de código de ext4.
Las principales características de ext4 son:
• El sistema de archivos ext4 es capaz de trabajar con volúmenes de hasta 1 Exabyte y ficheros de tamaño de hasta 16 Terabytes.
• El sistema de archivos ext4 permite la reserva de espacio en disco para un fichero. La anterior metodología consistía en rellenar el fichero en el disco con ceros en el momento de su creación. Esta técnica ya no es necesaria con ext4, ya que una nueva llamada del sistema "preallocate()" ha sido añadida al kernel Linux para uso de los sistemas de archivos que permitan esta función. El espacio reservado para estos ficheros quedará garantizado y con mucha probabilidad será contiguo. Esta función tiene útiles aplicaciones en streaming y bases de datos.
• Los extents han sido introducidos para reemplazar al tradicional esquema de bloques usado por los sistemas de archivos ext2/3. Un extent es un conjunto de bloques físicos contiguos, mejorando el rendimiento al trabajar con ficheros de gran tamaño y
60

reduciendo la fragmentación. Un extent simple en ext4 es capaz de mapear hasta 128Mb de espacio contiguo con un tamaño de bloque igual a 4Kb. Por ejemplo, en las anteriores versiones, para almacenar un fichero de 1Gb se utilizarían 256.000 bloques de 4Kb cada uno, que podrían estar contiguos o no. En este caso, el sistema debe realizar 256.000 comprobaciones de bloques para alojar el fichero. Con el sistema extents se utilizarían 8 (8 extents*128Mb=1024Mb) extents simples, consiguiendo sólo 8 comprobaciones para alojar el fichero. Además, con el método Allocate-on-flush explicado más abajo, es muy probable que los bloques extents sean contiguos.
• Ext4 hace uso de una técnica de mejora de rendimiento llamada Allocate-on-flush, también conocida como reserva de memoria retrasada. Consiste en retrasar la reserva de bloques de memoria hasta que la información esté a punto de ser escrita en el disco, a diferencia de otros sistemas de archivos, los cuales reservan los bloques necesarios antes de ese paso. Además, este sistema utiliza un asignador multibloque, en lugar de asignar un sólo bloque cada vez, que permite seleccionar varios bloques (extents) de una sóla vez. Esto optimiza el rendimiento y reduce la fragmentación al mejorar las decisiones de reserva de memoria basada en el tamaño real del fichero.
• El sistema Journaling se combina con la función checksum, Esta función consiste en sumar los bytes tratados y almacenar el resultado. Cuando se vuelven a utilizar estos mismos bytes, se vuelven a sumar y el resultado se compara con el valor almacenado. Si coinciden la información no se ha corrompido. Este proceso se realiza con cada fichero procesado por el sistema y es almacenado en el registro de diario para asegurar la integridad de la información.
• En ext4, los grupos de bloques no asignados y secciones de la tabla de inodos están marcados como tales. Esto permite a e2fsck saltárselos completamente en los chequeos y en gran medida reduce el tiempo requerido para chequear un sistema de archivos del tamaño para el que ext4 está preparado. Esta función está implementada desde la versión 2.6.24 del kernel Linux.
El contenido de los directorios no apunta directamente a los bloques de datos de los archivos o subdirectorios que dependen de él, sino a unas tablas, que se llaman inodos, separadas de la estructura. El contenido de los inodos es el que realmente apunta a los bloques físicos de los archivos dentro del disco.
Cada registro del directorio tiene una longitud fija de 256 bytes, que contienen un apuntador a la tabla de inodos y el resto de datos del archivo (nombre, tipo, permisos, fechas, etc.).
El sistema de archivos que contiene el directorio raíz es el principal. Cuando se carga el sistema operativo, la única parte accesible de la estructura es la contenida en el sistema de archivos principal. Para poder acceder a la información contenida en los restantes directorios, es necesario realizar una operación denominada montaje, que consiste en enlazar cada sistema de archivos con el resto de directorios de la estructura para que los usuarios puedan acceder a los mismos. La función de montaje la realiza el administrador del sistema y, normalmente, se automatiza para que se ejecute al arrancar el sistema. Todos los directorios que se encuentran en raíz son sistemas de archivos que se han montado durante el proceso de inicialización del sistema.
Normalmente, la mayor parte del sistema operativo reside en dos sistemas de archivos: el sistema de archivos raíz (/) y el sistema de archivos de usuario, montado bajo /usr.
Cuando un sistema de archivos se monta, entra a formar parte de la estructura de directorios del sistema de archivos sobre el que se ha montado. De esta forma, un árbol de directorios puede estar formado por directorios de distintas particiones, de distintos discos duros e, incluso, de otros ordenadores, formando todos un único sistema de archivos.
Algunos de los directorios o sistemas de archivos que se montan durante la inicialización del sistema son los siguientes:
61

Directorio bin.
Contiene programas ejecutables. La mayoría de las órdenes de Unix se encuentran en este directorio.
Directorio sbin.
Contiene programas ejecutables. En este directorio se encuentran archivos que se utilizan en la administración del sistema.
Directorio etc.
Contiene la mayor parte de los archivos de configuración del sistema, como el archivo de contraseñas (passwd), lista de archivos que se montan al iniciarse el sistema (fstab), etc.
Directorio dev.
Contiene archivos de dispositivos, que se utilizan para acceder a los distintos dispositivos hardware del sistema.
Algunos dispositivos de este directorio son los siguientes:
/dev/cdrom.
Se utiliza para referenciar la unidad de Cd-Rom.
/dev/console.
Se refiere a la consola del sistema.
/dev/fd.
Se utiliza para referenciar las unidades de disquete. La primera unidad de disquete es /dev/fd0 y la segunda /dev/fd1.
/dev/hd.
Es la interfaz de dispositivo para las unidades de disco duro. El dispositivo /dev/hda hace referencia al primer disco duro en su totalidad, el dispositivo /dev/hdb referencia al segundo disco duro en su totalidad, etc. El dispositivo /dev/hda1 se refiere a la primera partición del primer disco duro, el dispositivo /dev/hda2 se refiere a la segunda partición del primer disco duro, el dispositivo /dev/hdb1 se refiere a la primera partición del segundo disco duro, y así sucesivamente.
/dev/null.
Se utiliza para referenciar el dispositivo nulo.
/dev/tty.
Se refieren a las consolas virtuales del mismo sistema. Las consolas virtuales se utilizan para iniciar sesiones con distintos usuarios en un mismo equipo de forma simultánea. La primera consola virtual será /dev/tty0, la segunda /dev/tty1, y así sucesivamente.
/dev/ttyS.
Hacen referencia a los puertos serie. El puerto Com1 se corresponde con /dev/ttyS0, Com2 con /dev/ttyS1, y así sucesivamente. El ratón se referencia como /dev/mouse, que es un enlace simbólico con el dispositivo ttyS que le corresponde.
62

Directorio proc.
Se utiliza para leer información de los procesos desde la memoria.
Directorio home.
En este directorio se ubican los directorios de todos los usuarios. El directorio home de los usuarios se define durante la creación de los mismos y, por defecto, se le asigna el mismo nombre que el usuario, aunque se pueden cambiar tanto el nombre como la ubicación.
Directorio var.
Contiene archivos que se utilizan durante la ejecución de Unix. El tamaño de los archivos varía durante la sesión de trabajo.
Directorio usr.
Contiene archivos del sistema y los paquetes de software que se instalan.
Los subdirectorios más importantes de usr son los siguientes:
bin.
Se utiliza para el mantenimiento de programas ejecutables de Unix.
etc.
Contiene archivos de configuración del sistema.
include.
Contiene archivos include (archivos de cabecera que definen constantes y funciones) utilizados por el compilador C.
lib.
Contiene librerías utilizadas por los programas.
man.
Contiene las páginas del manual de consulta desde la línea de comandos.
src.
Contiene el código fuente de los archivos del sistema.
local.
Este directorio se utiliza para instalar el software que se va a utilizar en cada equipo de manera local.
63

5. Administración de los sistemas de archivos.
Como hemos dicho, los directorios de una partición, de diferentes particiones, de diferentes discos duros o de diferentes ordenadores, pueden formar un sistema de ficheros. Estos elementos se tienen que montar en un directorio existente, que se denomina punto de montaje.
Para montar un sistema de archivos se utiliza la orden mount. Su sintaxis es:
mount SistemaDeFicheros PuntoDeMontaje Argumentos
SistemaDeFicheros.
Es el nombre del directorio o dispositivo físico que se quiere montar.
PuntoDeMontaje.
Es el directorio donde se va a montar el sistema de ficheros.
Los argumentos son los siguientes:
-a.
Intenta montar el sistema de archivos especificado en /etc/fstab.
-f.
Realiza un montaje virtual del sistema de ficheros, pero el sistema de ficheros no se monta realmente.
-n.
El montaje se realiza sin escribir la operación de montaje en el archivo /etc/mtab.
-r.
64

El sistema de ficheros se monta en modo sólo lectura.
-t tipo.
Especifica el tipo de sistema de ficheros que se ha montado. Los tipos válidos son minix, ext, ext2, ext3, xiafs, msdos, hpfs, proc, nfs, umsdos, iso9660 y sysv.
-v.
Visualiza información detallada de la ejecución de la orden.
-w.
El sistema de archivos se monta en modo lectura y escritura.
-o opciones.
Aplica las opciones especificadas al sistema de ficheros que se está montando. Para la lista de opciones, consultar la página de la orden man para la orden mount.
Para visualizar los sistemas de archivos montados se utiliza la orden fdisk -l.
Los sistemas de ficheros montados tienen que desmontarse. La orden para desmontar un sistema de ficheros es umount. Su sintaxis es:
umount PuntoDeMontaje Argumentos
Ver la página de la orden man para la orden umount y consultar los argumentos de la sintaxis.
Los disquetes y los Cd-Rom se tienen que montar para poder utilizarse. Una vez que se ha montado un disquete o un Cd-Rom, para utilizar uno distinto, hay que desmontar el que está montado, insertar el nuevo disquete o Cd-Rom y volverlo a montar. Hay que tener en cuenta que lo que se monta es el diskete o Cd-Rom y no la unidad de disquetes o la unidad de Cd-Rom.
Para montar un disquete, se puede utilizar la siguiente orden: mount /dev/fd0 /media/floppy. A partir de este momento, todas las operaciones con el disquete se realizarán sobre el directorio /media/floppy.
Para montar un Cd-Rom, se puede utilizar la siguiente orden: mount /dev/scd0 /media/cdrom. A partir de este momento, todas las operaciones con el Cd-Rom se realizarán sobre el directorio /media/cdrom.
Cuando estamos trabajando en el entorno gráfico, las operaciones de montaje y desmontaje de los disquetes y Cd-Rom se realizan automáticamente. Por ejemplo, cuando se inserta un Cd se muestra el icono de la Figura 5.1.
Figura 5.1
65

Una vez que el Cd está montado, no se puede abrir la unidad de Cd-Rom. Para desmontar y, por lo tanto, sacar el Cd, hay que abrir el menú contextual del icono de la Figura 5.1 y ejecutar la opción Expulsar, según se muestra en la Figura 5.2.
Figura 5.25.1. ARCHIVO /ETC/FSTAB.
En el archivo /etc/fstab (file system table o tabla del sistema de archivos) se configuran determinados sistemas de ficheros para montarlos de forma abreviada. Este archivo contiene, entre otras, estas dos líneas (estas líneas pueden variar en distintos equipos):
/dev/scd0 /media/cdrom0 udf,iso9660 user,noauto 0 0
/dev/fd0 /media/floppy0 auto rw,user,noauto 0 0
Estas dos líneas quieren decir que, al montar los dispositivos, se pueden omitir los nombres /dev/fd0 y /dev/scd0. Por lo tanto, para montar el disquete se podría utilizar la orden mount /media/floppy0, y para montar el Cd-Rom se puede escribir la orden mount /media/cdrom0. En el caso de los disquetes, esta sintaxis no funciona si el disquete ha sido formateado en otro sistema operativo, debiendo utilizar la sintaxis completa con el argumento –t tipo. Por ejemplo, para montar un disquete formateado en un sistema operativo de Microsoft, hay que ejecutar la orden mount /dev/fd0 /media/floppy0 -t msdos.
El archivo /etc/fstab se utiliza para montar sistemas de archivos durante el proceso de arranque del sistema. Los valores de cada una de las líneas de este archivo son los siguientes (en el orden que aparecen en cada línea):
Especificador del sistema de archivos.
Indica el sistema de archivos que se va a montar. El valor none se utiliza para sistemas de archivos especiales, como archivos de intercambio, dejándolos activos y no visibles. En el archivo /etc/fstab de Ubuntu se incluye la línea proc /proc proc defaults 0 0, que se utiliza para el sistema de archivos virtual que señala el espacio de información de los procesos de memoria. No es un dispositivo real.
Punto de montaje.
Indica el punto de montaje para el sistema de archivos. Cuando se especifica none, el sistema de archivos no aparece en el árbol del sistema de archivos montado.
Tipo.
Especifica el tipo de sistema de archivos que se va a montar. Los tipos de sistemas de archivos son los siguientes:
ext.
Sistema de archivos local con nombres de archivos más largos e inodos más grandes. Se ha sustituido por el tipo ext2 y prácticamente no se utiliza.
ext2.
Igual que el sistema de archivos ext, pero con más características.
hpfs.
Sistema de archivos local para particiones del sistema de archivos de alto rendimiento de OS/2.
66

iso9660.
Sistema de archivos local para unidades de Cd-Rom.
minix.
Sistema de archivos local, que admite nombres de 14 a 30 caracteres.
msdos.
Sistema de archivos local para particiones Ms-Dos.
nfs.
Sistema de archivos para montar particiones desde sistemas remotos.
swap.
Partición de disco o archivo especial utilizado para intercambio.
sysv.
Sistema de archivos SystemV.
umsdos.
Sistema de archivos UMSDOS.
xiafs.
Sistema de archivos local.
ntfs-3g.
Sistema de archivos ntfs de Windows en modo lectura y escritura.
Opciones de montaje.
Se puede incluir una lista de opciones de montaje, separadas por comas, para el sistema de archivos.
Las opciones de montaje son las siguientes:
async.
Las operaciones de E/S realizadas sobre el sistema de ficheros se realizan de forma asíncrona.
atime.
Es la opción por defecto. Actualiza el tiempo de acceso a los inodos.
auto.
El montaje se realiza automáticamente, con las opciones del fichero /etc/fstab.
defaults.
67

Utiliza las opciones por defecto, que son: rw, suid, dev, exec, auto, nouser y async.
dev.
Interpreta el sistema de archivos como un dispositivo especial de bloques. exec.
Permite la ejecución de ficheros binarios.
force.
Fuerza el montaje del sistema de archivos aunque se generen errores durante laoperación de montaje.
noatime.
No actualiza el tiempo de acceso a los inodos.
noauto.
El montaje se realizará una vez que el sistema se haya iniciado.
nodev.
No interpreta el sistema de archivos como un dispositivo especial de bloques.
noexec.
No permite la ejecución de ficheros binarios.
nosuid.
No interpreta los bits de conjunto UID (identificador de usuario) y de conjunto GID (identificador de grupo) de los archivos.
nouser.
Es la opción por defecto. El sistema de ficheros no puede ser montado por usuarios normales.
remount.
Permite volver a montar un sistema de ficheros montado, sin necesidad de desmontarlo.
ro.
El sistema de ficheros sólo se puede leer.
rw.
El sistema de ficheros se puede leer y escribir.
suid.
Interpreta los bits de conjunto UID (identificador de usuario) y de conjunto GID (identificador de grupo) de los archivos.
68

sw.
El sistema de archivos es una partición de intercambio.
sync.
Las operaciones de E/S sobre el sistema de ficheros se realizan de forma síncrona. user.
El sistema de ficheros puede ser montado por usuarios normales.
Frecuencia de volcado.
Especifica la frecuencia de realización de copias de seguridad del sistema de archivos con la orden dump. Si este campo no existe, dump interpreta que no es necesario hacer copias de seguridad del sistema de archivos.
Número de secuencia.
Especifica el orden de comprobación de los sistemas de archivos por la orden fsck cuando el sistema se inicia. El sistema de archivos raíz debe tener el valor 1. El resto de sistemas tendrían el valor 2. Si no se especifica ningún valor o se indica el valor 0, la consistencia del sistema de archivos no se comprobará durante el arranque del equipo.
En el archivo /etc/fstab se pueden incluir líneas de comentarios, incluyendo el carácter # al principio de la línea.
Los sistemas de archivos incluidos en el fichero /etc/fstab, se montan y desmontan automáticamente cuando el sistema se inicia y se cierra, respectivamente.
69

5.2. CREACIÓN DE SISTEMAS DE ARCHIVOS.
Para crear un nuevo sistema de archivos, primero hay que crear una partición y, posteriormente, formatearla. Las particiones posibles que se pueden crear se encuentran en el directorio /dev, y se nombran como hd seguido de una letra (a,b,c, etc.), que indica el disco duro, y de un número (1,2,...), que indica el número de la partición dentro del disco duro. De esta forma, /dev/hda1 indica la primera partición del primer disco duro, /dev/hda2 indica la segunda partición del primer disco duro, /dev/hdb1 indica la primera partición del segundo disco duro, y así sucesivamente.
5.2.1 Crear particiones.
Para crear una partición, se utiliza la orden fdisk. Un disco puede tener cuatro particiones primarias o tres particiones primarias y una extendida, en la que podemos crear unidades lógicas. La sintaxis de fdisk es la siguiente:
fdisk Dispositivo
El parámetro Dispositivo indica el disco duro en el que se van a realizar las operaciones con fdisk (hda, hdb, sda, sdb, etc.)
Una vez ejecutado el comando fdisk, se muestra la línea Orden (m para obtener ayuda):, para introducir las órdenes necesarias para realizar las distintas acciones de fdisk. Las órdenes que se pueden introducir son las siguientes:
a.
Conmuta el indicador de arranque en una partición.
c.
Conmuta el indicador de compatibilidad DOS en una partición.
d.
Elimina una partición. En algunas versiones Unix/Linux, esta opción no borra las particiones. En estos casos, para borrar una partición hay que eliminarla con esta opción y crear una nueva con +0Kb de tamaño.
l.
Lista los tipos de partición, en hexadecimal, que fdisk reconoce.
m.
Muestra una lista con las órdenes que se pueden ejecutar en fdisk.
n.
Añade una nueva partición.
p.
Visualiza la tabla de particiones del disco.
70

q.
Sale de fdisk sin almacenar los cambios realizados.
t.
Cambia el tipo de sistema de archivos de una partición.
u.
Cambia las unidades de visualización y entrada. Con esta opción, el listado de las particiones que se obtiene con el comando p se mostrará en sectores o en cilindros.
v.
Comprueba la tabla de particiones.
w.
Sale de fdisk guardando los cambios realizados.
x.
Se utiliza para ejecutar funciones por usuarios expertos. Cuando se ejecuta el comando x, se muestra la línea Expert command (m for help):. Los comandos que se pueden ejecutar son los siguientes:
b.
Mueve la ubicación de comienzo de los datos en una partición.
c.
Cambia el número de cilindros.
d.
Imprime los datos sin formato de la tabla de particiones.
e.
Lista las particiones extendidas del disco.
h.
Cambia el número de cabezas del disco.
p.
Visualiza la tabla de particiones.
q.
Sale de fdisk sin almacenar los cambios realizados.
r.
71

Vuelve al menú principal, que es la línea Orden (m para obtener ayuda):.
s.
Cambia el número de sectores del disco.
w.
Sale de fdisk guardando los cambios realizados.
Si introducimos el comando p, se mostrará una información parecida a la siguiente:
Disk /dev/hda: 255 heads, 63 sectors, 523 cylindersUnits = cylinders of 16065 * 512 bytes
Device Boot Start End Blocks Id System/dev/hda1 * 1 261 2096451 7 HPFS/NTFS/dev/hda5 262 453 1542208+ 83 Linux/dev/hda6 454 466 104391 82 Linux swap
La primera línea de este listado, muestra el disco actual (/dev/hda), que tiene 255 cabezas, 63 sectores y 523 cilindros.
La segunda línea, nos informa de que las unidades de visualización están en cilindros de 16065 * 512 bytes (8.225.280 bytes) cada una. Al tener 523 cilindros con 8.225.280 bytes cada uno, se deduce que el disco puede contener 4.301.821.440 bytes (523 * 8.225.280), que son unos 4 Gb.
Las siguientes líneas, muestran cada una de las particiones, la partición que tiene activado el indicador de arranque (carácter * en la columna Boot), el cilindro de comienzo y de final de cada una de ellas, el tamaño en bytes y el tipo de sistema de archivos en número (columna Id) y en letra (columna System).
Para crear una partición, hay que introducir la opción n. Se muestra la siguiente información:
Acción de la ordene Partición extendidap Partición primaria (1-4)
Seguidamente, se muestra el siguiente mensaje:
Número de partición (1-4):
Hay que introducir el número de partición que vamos a asignar a la nueva partición, que ha de ser un número que todavía no se haya asignado a ninguna otra partición.
A continuación, se muestra el siguiente mensaje:
Primer cilindro (467-523, valor predeterminado 467):
Este mensaje indica el primer y último cilindro libre, debiendo introducir el número de cilindro donde va a comenzar la partición.
La siguiente línea que se visualiza es la siguiente:
Último cilindro o +tamaño o +tamañoM o +tamañoK (467-523, valor predeterminado 523):
En esta línea se define el tamaño de la partición. Si introducimos el cilindro final y en la línea Primer cilindro (467-523, valor predeterminado 467): hemos introducido el cilindro inicial, estaremos tomando todo el tamaño disponible para la nueva partición. Si se quiere definir el
72

tamaño en bytes, Mb o Kb, hay que introducir una valor como +número, +númeroM o +númeroK, respectivamente. Por ejemplo, si se introduce +100, el tamaño será de 100 bytes, si se introduce +100M, el tamaño será de 100 Mb y si se introduce +100K, el tamaño será de 100 Kb.
Las particiones creadas con Linux Ubuntu son del tipo 83, correspondiente al sistema de archivos Linux. Si queremos cambiar el sistema de archivos, hay que introducir el comando t, el número de partición que se desea cambiar y el tipo de sistema de archivos, que se lista con el comando l. Por ejemplo, si queremos que la partición creada sea de intercambio, hay que introducir el tipo 82.
Cuando salimos de fdisk almacenando los cambios realizados, hay que reiniciar el sistema para que las nuevas particiones se reconozcan.
Si ejecutamos la orden fdisk -l, se visualizan los sistemas de archivos montados en el equipo.
73

5.2.2 Formatear particiones.
Una vez que se ha creado la partición, es necesario crear el sistema de archivos que se va a utilizar en dicha partición. Para ello, hay que ejecutar el comando mkfs. La sintaxis es la siguiente:
mkfs [-v] [-t tipo] [fs –opciones] dispositivo [tamaño]
-v.
Cuando se ejecuta mkfs, se visualizan detalles de las operaciones que se están realizando.
-t tipo.
Indica el sistema de archivos que se va a construir. Los tipos válidos son minux, ext, ext2, ext3, xiafs, msdos, hpfs, proc, nfs, umsdos, iso9660 y sysv. Si se omite, mkfs genera un sistema de archivos de tipo ext2. Se puede indicar el formato ext3 escribiendo la orden mkfs.ext3.
Las particiones que van a ser utilizadas desde otros sistemas operativos, tienen que ser formateadas con los comandos proporcionados por Unix para crear los sistemas de archivos específicos. Por ejemplo, para crear una partición que va a ser utilizada desde los sistemas operativos de Microsoft, hay que utilizar el comando mkdosfs.
Ejemplo.
Vamos a crear una partición de tipo msdos para que se pueda ver desde los sistemas operativos de Microsoft. Los pasos a seguir son los siguientes:
Ejecutar el comando fdisk y crear una partición primaria o una unidad lógica en una partición extendida.
Sin salir de fdisk, convertir la partición creada anteriormente al tipo FAT16.
Reiniciar el equipo.
Formatear la partición, creando un sistema de archivos de tipo msdos. Para ello, hay que formatear la partición utilizando la orden mkdosfs dispositivo. En este momento, la nueva partición se verá desde los sistemas operativos de Microsoft (Ms-Dos, Windows 9x y Windows NT). Se puede realizar una prueba montando la nueva partición, creando un archivo con el Editor vi, reiniciar el equipo con un sistema operativo de Microsoft y acceder a la partición y al archivo que se han creado.
fs –opciones.
Especifica las opciones del sistema de archivos que se pasarán al programa que construye dicho sistema de archivos. Las opciones son las siguientes (estas opciones funcionan en la mayoría de los programas de construcción de sistemas de archivos, pero no en todos):
-c.
Comprueba el dispositivo, antes de construir el sistema de archivos, para verificar si existen bloques incorrectos.
74

-l NombreDeFichero.
Lee desde el fichero especificado una lista de los bloques incorrectos en el disco.
-v.
Visualiza detalles de las operaciones que realiza el constructor del sistema de archivos.
dispositivo.
Especifica el dispositivo en el que se ubica el sistema de archivos ( /dev/hda1, /dev/hda2, /dev/hb1, etc.).
tamaño.
Especifica el número de bloques que utilizará el sistema de archivos. Para un disquete de 1.44 Mb se introducirá el valor 1440. Para formatear un disquete hay que ejecutar la orden mkfs /dev/fd0 1440. Si el disquete lo vamos a utilizar desde los sistemas de Microsoft, para formatearlo hay que ejecutar el comando mkdosfs /dev/fd0, aunque es mejor formatear los disquetes desde un sistema de Microsoft y utilizarlo, exclusivamente, desde estos sistemas (ya sabemos que se pueden crear particiones que son vistas desde ambos sistemas).
Si queremos asignar una etiqueta a un sistema de archivos, hay que instalar el paquete e2fsprogs (en Linux Ubuntu 9.04 ya está instalado) y ejecutar la orden e2label. Por ejemplo, la orden e2label /dev/sda6 `Datos Linux` establece la etiqueta Datos Linux al sistema de archivos creado en la partición /dev/sda6 (observar que se han utilizado los acentos graves en el nombre de la etiqueta por contener un espacio en blanco).
75

5.3. PARTICIONES Y ARCHIVOS DE INTERCAMBIO.
Las particiones de intercambio se utilizan como memoria virtual. Linux puede utilizar, además de particiones de intercambio, archivos de intercambio, que son archivos de gran tamaño ubicados en un sistema de archivos normal y que se utilizan como área de intercambio. Es preferible utilizar una partición de intercambio, pues la información que se gestione en ella siempre estará almacenada consecutivamente, mientras que un archivo de intercambio puede que no esté creado en bloques continuos. Los archivos de intercambio son útiles cuando se quiere ampliar la zona de intercambio pero no hay espacio en el disco para realizar nuevas particiones.
Para crear una partición de intercambio se utiliza el comando fdisk, identificando la partición con el tipo 82. Para que la nueva partición la reconozca el sistema, hay que reiniciar el equipo. Seguidamente, hay que preparar la partición con el comando mkswap. La sintaxis es la siguiente:
mkswap [-c] dispositivo [tamaño]
-c.
Comprueba la existencia de bloques incorrectos.
dispositivo.
Especifica el dispositivo en el que se ubica la partición de intercambio (/dev/hda1, /dev/hda2, /dev/hb1, etc.).
tamaño.
Especifica el número de bloques que utilizará la partición de intercambio.
Una vez que se ha creado y preparado la partición de intercambio, hay que activarla para que pueda ser utilizada por el kernel de Linux. La orden para activar una partición de intercambio es swapon. La sintaxis es la siguiente:
swapon {dispositivo [opciones], -s}
dispositivo.
Indica el dispositivo donde está ubicada la partición de intercambio que se quiere activar.
-s.
Visualiza información de las particiones de intercambio activadas y de los archivos de intercambio activados.
Las opciones pueden ser:
-a.
Activa todas las particiones de intercambio incluidas en el fichero /etc/fstab. Cuando el sistema se inicia, ejecuta una orden swapon –a.
-h.
76

Muestra la sintaxis completa de la orden swapon.
-p prioridad.
Indica la prioridad de la partición de intercambio que se va a activar. Si se omite esta opción, la partición de intercambio se activa con la prioridad mínima (-1). Cuando existen varias particiones de intercambio con distinta prioridad, primero se utilizan las de prioridad mayor. Si tienen la misma prioridad, las páginas de intercambio se reparten entre ellas.
Las particiones de intercambio se pueden desactivar con el comando swapoff, debiendo indicar el dispositivo donde está ubicada la partición de intercambio que se quiere desactivar.
Para crear un archivo de intercambio se utiliza la orden dd (consultar la página de la orden man para ver la sintaxis completa de la orden dd). Una vez creado, hay que prepararlo y activarlo.
Ejemplo.
dd if=/dev/zero of=/swap bs=1024 count=10240
Crea un archivo de intercambio con el nombre /swap (of=/swap) de 10240 bloques (count=10240), que son unos 10 Mb, pues toma bloques de 1024 bytes (bs=1024).
mkswap /swap 10240
Prepara el archivo de intercambio /swap, de 10240 bloques.
swapon /swap
Activa el archivo de intercambio /swap.
swapoff /swap
Desactiva el archivo de intercambio /swap.
El archivo de intercambio se borra con la orden rm.
77

6. Administración de sistemas de archivos remotos.
6.1. SISTEMA DE ARCHIVOS NFS.
Los sistemas de archivos remotos o de red se utilizan para montar, en la estructura de directorios local, un sistema de archivos de un equipo remoto. El sistema de archivos remoto se denomina NFS (Network File System) y utiliza el protocolo TCP/IP.
Por defecto, Ubuntu no instala el paquete necesario para configurar los sistemas de archivos en red. Para instalarlos, hay que ejecutar la orden apt-get install nfs-kernel-server en un terminal, que, demás de algunas librerías, instala los paquetes nfs-common y portmap, necesarios para poder utilizar el sistema de archivos NFS. Una vez finalizada la instalación de NFS, el sistema activa los servicios necesarios.
Para definir un sistema de archivos remoto, hay que incluirlo en el archivo /etc/exports. En este archivo también se incluyen los equipos que van a poder acceder al sistema de archivos NFS, el punto de montaje del sistema de archivos remoto y las opciones de montaje. Las opciones de montaje pueden ser las siguientes:
all_squash.
Asigna los identificadores de usuario y de grupo a los usuarios anónimos. Esta opción es útil para los directorios públicos NFS exportados, que se utilizan en FTP o en grupos de noticias.
no_all_squash.
Realiza la acción contraria a all_squash. Es la opción por defecto.
anonuid.
Establece el identificador de usuario para una cuenta anónima. Esta opción es útil para clientes PC/NFS.
anongid.
Determina el identificador de grupo para una cuenta anónima. Esta opción es útil para clientes PC/NFS.
insecure.
Permite el acceso al sistema de archivos desde el equipo que se está exportando, sin pedir autentificación.
secure.
Se utiliza para pedir autentificación cuando se desea acceder al sistema de archivos desde el equipo que lo está exportando.
link_relative.
Los enlaces simbólicos absolutos se convierten en relativos. De esta forma, para acceder al sistema de archivos remoto, hay que escribir la ruta empezando por el carácter ‘/’, pues
78

el sistema añade, de forma automática, los carateres ‘../’ necesarios para acceder al directorio raíz de la estación exportadora del sistema de archivos remoto.
link_absolute.
Los enlaces simbólicos se mantienen. Esta es la opción por defecto.
map_daemon.
Utiliza el demonio lname/uid map para asignar nombres locales y remotos e identificadores numéricos en la estación que ha solicitado un acceso a un sistema de archivos remoto.
noaccess.
Excluye el acceso a los subdirectorios del sistema de archivos de red.
ro.
El sistema de archivos se monta sólo para lectura. Es la opción por defecto.
rw.
El sistema de archivos se monta para lectura y escritura. Para que los usuarios que montan el sistema de archivos remoto puedan realizar operaciones de escritura, deben tener asignado permiso de escritura, al grupo resto de usuarios, sobre el sistema de archivos remoto (ver el punto 15.1 Cambio de permisos).
root_squash.
Cuando el usuario root (UID 0) accede al sistema de archivos, la petición se reasigna a un equipo remoto (UID NOBODY-UID) que accede al sistema de archivos de red. En este caso, el usuario root accede como usuario anónimo, sólo con permisos de lectura.
no_root_squash.
Las peticiones de root para acceder al sistema de archivos no se reasignan a otro equipo. Es la opción por defecto. De esta forma, el usuario root podrá ejecutar todos los comandos de red y accederá con los permisos establecidos al sistema de archivos remoto.
squash_uids.
Se utiliza para definir una lista de identificadores de usuario de asignación anónima. Un ejemplo podría ser el siguiente: squash_uids=4-8,12,30-45.
squash_gids.
Define una lista de identificadores de grupo que van a utilizar asignaciones anónimas. Un ejemplo podría ser el siguiente: squash_gids=3-8,22,340-55.
sync.
Indica que hasta que las operaciones de escritura no hayan finalizado, no se responde4rán a nuevas peticiones para modificar el sistema de archivos remoto.
Un ejemplo para incluir un sistema de archivos a exportar en el archivo /etc/exports, podría ser el siguiente:
79

/remoto Serv101(rw,sync,no_root_squash)
En este ejemplo, se exporta el sistema de archivos /remoto de lectura y escritura para el equipo Serv101, de forma síncrona y asignando privilegios al usuario root del sistema cliente para que pueda realizar las operaciones de escritura sobre el sistema de archivos remoto.
Si se utiliza sólo la opción rw, omitiendo la opción no_root_squash, hay que asignar permiso de escritura al grupo del resto de usuarios sobre la carpeta /remoto y sobre cada uno de sus elementos para que se puedan realizar operaciones de escritura.
Cuando se realiza una modificación en el archivo /etc/exports, hay que reiniciar el servicio nfs-kernel-server para que tenga efecto.
El sistema de archivos que se va a exportar debe estar montado, localmente, en la estación desde la que se va a exportar.
Para que un sistema de archivos remoto sea accesible desde otros equipos, hay que iniciar los demonios portmap, nfs-kernel-server y nfs-common. Estos servicios se inician de forma manual con la orden /etc/init.d/portmap start, /etc/init.d/nfs-kernel-server start o /etc/init.d/nfs-common start, respectivamente, o de forma automática cada vez que el ordenador arranque, activándolos para el nivel de inicio del equipo (ver el punto 7. Proceso de inicialización del sistema.) .
Además, hay que configurar los equipos para que puedan comunicarse entre sí. Para ello, hay que incluir en el archivo /etc/hosts de la estación exportadora del sistema de archivos de red, la dirección I.P. y el host de cada una de las estaciones que van a acceder al sistema de archivos remoto. En cada una de las estaciones desde la que se va a acceder al sistema de archivos de red, hay que incluir la dirección I.P., el host y el dominio de la estación exportadora del sistema de archivos remoto. En el archivo /etc/hosts se incluye una línea por cada uno de los equipos que se quieran añadir. Un ejemplo de una línea en el archivo /etc/hosts podría ser el siguiente:
192.168.0.100 EstTrab00
Para que un equipo pueda acceder a un sistema de archivos remoto, debe montarlo en su estructura de directorios local. Para ello, hay que incluir una entrada en el archivo /etc/fstab si la operación de montaje se quiere hacer de forma automática o hay que ejecutar el comando mount para montar el sistema de archivos remoto desde la línea de comandos. Las opciones de montaje que más se utilizan son las siguientes:
hard.
Cuando el sistema remoto deja de responder, el equipo local intenta restablecer la conexión de forma continuada. Para poder interrumpir o matar el proceso de intentar restablecer la conexión, se debe especificar la opción de montaje intr. Cuando no se puede restablecer la conexión, en el siguiente intento se utiliza el doble del tiempo que el especificado en la opción de montaje timeo=tiempo; si tampoco lo consigue, en el siguiente intento se utiliza el doble del tiempo empleado la vez anterior, y así sucesivamente. La opción de montaje hard es el modo de montaje por defecto.
soft.
Cuando el sistema remoto deja de responder, el equipo local intenta restablecer la conexión durante un tiempo determinado, que es el definido en la opción timeo=tiempo. Cuando este tiempo ha transcurrido, se produce un mensaje de error y se detiene el intento de restablecer la conexión.
intr.
Permite interrumpir la conexión con un sistema de archivos de red cuando el servidor en el que está ubicado no responde.
80

rsize=bytes.
Define el tamaño del búffer utilizado en las operaciones de lectura. El valor por defecto son 1.024 bytes.
wsize=bytes.
Especifica el tamaño del búffer utilizado en las operaciones de escritura. El valor por defecto son 1.024 bytes.
timeo=tiempo.
Determina el tiempo, expresado en décimas de segundo, que una estación esperará a que responda el servidor donde está ubicado el sistema de archivos remoto. El valor por defecto es 7 (0,7 segundos).
Un ejemplo de montaje de un sistema de archivos remoto en una estación local desde el archivo /etc/fstab sería el siguiente:
Serv100:/remoto /remotoNfs nfs timeo=50
En este ejemplo, se monta el sistema de archivos remoto /remoto, que se encuentra en el equipo llamado Serv100. El equipo local monta el sistema remoto en el punto de montaje /remotoNfs. Este sistema de archivos es de tipo nfs (sistema de archivos de red) y se esperará 50 décimas de segundo (5 segundos) para que el equipo remoto responda a la petición de montaje.
Un ejemplo de montaje de un sistema de archivos remoto en una estación local desde la línea de comandos sería el siguiente:
mount Serv101:/remoto /remoto/Nfs
81

6.2. ADMINISTRACIÓN DE SAMBA.
6.2.1 Introducción.
Samba es un paquete que permite a los sistemas Unix/Linux integrarse en redes Windows. De esta forma, se pueden compartir recursos entre equipos que tengan instalados distintos sistemas operativos. Los sistemas Unix/Linux pueden ser accedidos desde el Entorno de red de Windows.
Samba incluye dos servicios, smbd y nmbd, que utilizan el protocolo NETBIOS de Windows para acceder a la red. El demonio smbd se encarga de ofrecer el servicio de acceso remoto a ficheros e impresoras y de autentificar a los usuarios y el servicio nmbd permite que los sistemas Unix/Linux se puedan incluir en las redes Windows y puedan utilizar los procesos de gestión de redes de este sistema operativo (inclusión en el grupo de trabajo, inclusión en las listas de ordenadores y recursos disponibles en la red, etc.).
Si no tenemos instalado Samba, en las redes Windows sólo se ven los equipos con este sistema instalado. Las ventanas de las Figuras 6.2.1.1 y 6.2.1.2 muestran la red de Windows desde el Entorno de red de Windows y de Linux, respectivamente.
Figura 6.2.1.1
Figura 6.2.1.2
6.2.2 Instalación y configuración.
Para instalar Samba, hay que ejecutar la orden apt-get install samba (es conveniente ejecutar previamente apt-get update).
Después de realizar esta instalación, el servidor Samba instalado se incluye en la red Windows y se puede visualizar en el Entorno de red de los dos sistemas operativos. Las ventanas de las Figuras 6.2.2.1 (Windows) y 6.2.2.2 (Linux) muestran el grupo de trabajo mshome, que es el grupo en el que se incluye el servidor Samba recién instalado.
Figura 6.2.2.1
Figura 6.2.2.2
Para poder acceder al servidor Samba y a sus recursos compartidos, hay que configurar el archivo /etc/samba/smb.conf. Este archivo tiene varias secciones para configurar distintos aspectos del servidor.
La sección [global] define aspectos que afectan al funcionamiento general del servidor (grupo de trabajo al que pertenece el servidor, tipo de autenticación de los usuarios, etc.).
La sección [recurso compartido] define un recurso al que se puede acceder a través de la red.
La sección [printers] define las impresoras accesibles utilizando Samba.
Con la configuración por defecto que se realiza con la instalación, el servidor Samba está visible pero no accesible. Para que se pueda acceder a él, hay que configurar el tipo de autenticación de usuarios. Si utilizamos la autenticación SHARE, cualquier usuario podrá
82

acceder al servidor. Para ello, hay que incluir la línea security = SHARE en el archivo de configuración de Samba.
Para compartir un recurso en el servidor Samba, hay que crear la carpeta a compartir e incluirla en el archivo de configuración /etc/samba/smb.conf. En el siguiente ejemplo, se crea un recurso compartido en /home/public, llamado public, y un archivo dentro de esta carpeta, llamado prueba.
# # Carpeta compartida # [public]
comment = carpeta de pruebapath = /home/public public = yes writable = yes
La orden public = yes hace este recurso visible a través de la red y la orden writable = yes permite modificar el contenido del recurso.
Las siguientes líneas muestran la creación de la carpeta /home/public y del archivo prueba.
root@plantilla:~# mkdir /home/publicroot@plantilla:~# cat >/home/public/prueba prueba de samba
Una vez modificado el archivo /etc/samba/smb.conf, hay que reiniciar el servicio samba. Las siguientes líneas muestran esta acción.
root@plantilla:~# /etc/init.d/samba restart • Stopping Samba daemons... [ OK ] • Starting Samba daemons... [ OK ]
Con esta configuración, el servidor y la carpeta compartida son accesibles a través de la red, según se muestra en las ventanas de las Figuras 6.2.2.3, 6.2.2.4 y 6.2.2.5, ejecutadas desde Windows.
Figura 6.2.2.3
Figura 6.2.2.4
Figura 6.2.2.5
Estas mismas acciones se pueden realizar desde los servidores de Linux.
Si abrimos el archivo prueba y modificamos su contenido, el sistema nos avisa de que esta operación no se puede realizar, ya que el archivo prueba no tiene los permisos necesarios para realizar esta acción. En las siguientes líneas se visualizan los permisos asignados al archivo prueba y la asignación del permiso de escritura para que se pueda modificar.
root@plantilla:~# ls -l /home/public total 4 -rw-r--r-- 1 root root 16 2008-02-23 23:30 prueba root@plantilla:~# chmod o+w /home/public/pruebaroot@plantilla:~# ls -l /home/public-rw-r--rw- 1 root root 16 2008-02-23 23:30 /home/public
83

Con estas acciones, el archivo se podrá modificar a través de la red.
Para ver los servidores que controla el protocolo Samba, hay que ejecutar la orden findsmb. La salida de esta orden es la siguiente:
root@plantilla:~# findsmb
*=DMB +=LMB IP ADDR NETBIOS NAME WORKGROUP/OS/VERSION --------------------------------------------------------------------- 192.168.1.35 PLANTILLA +[MSHOME] [Unix] [Samba 3.0.24] 192.168.1.36 W2000PROFE +[GRUPO_TRABAJO] [Windows 5.0] [Windows 2000 LAN Manager]
84

6.2.3 Autenticación de usuarios.
Con la configuración realizada anteriormente para autentificar a los usuarios (línea security = SHARE), cualquier usuario que se conecte al servidor Samba tendrá acceso al recurso compartido. Si queremos que sólo los usuarios con cuenta puedan acceder al servidor, debemos crear una cuenta de usuario en el servidor Unix/Linux, utilizando la orden adduser usuario, y esta misma cuenta en el servidor Samba, utilizando la orden smbpasswd -a usuario. Asimismo, el servidor Windows debe tener creada una cuenta de usuario con este mismo nombre. En todos los casos, las contraseñas también deben coincidir.
Además de la gestión de usuarios descrita anteriormente, hay que modificar el archivo /etc/samba/smb.conf y añadir la línea security = user, debiendo comentar la línea security = SHARE.
Para definir el acceso y las operaciones a realizar sobre el recurso compartido, hay que utilizar las siguientes órdenes:
● valid users.
En este parámetro se incluyen los únicos usuarios o grupos de usuarios que podránacceder al recurso. Los usuarios se incluyen escribiendo el nombre de cuenta de usuario y los grupos con el nombre de grupo precedido por el carácter @.
● read only.
En este parámetro se indica si el recurso será de sólo lectura (valor Yes) o de lectura yescritura (valor No).Se puede definir qué usuarios podrán leer y escribir y quéusuarios podrán sólo leer. Estas definiciones se realizan en los parámetros read list ywrite list descritos a continuación.
● read list.
En este parámetro se incluyen los usuarios o grupos de usuarios que sólo podránrealizar operaciones de lectura en el recurso compartido. Los usuarios se incluyen escribiendo el nombre de cuenta de usuario y los grupos con el nombre de grupoprecedido por el carácter @.
● write list.
En este parámetro se incluyen los usuarios o grupos de usuarios que podrán leer yescribir en el recurso compartido. Los usuarios se incluyen escribiendo el nombre de cuenta de usuario y los grupos con el nombre de grupo precedido por el carácter @.
La configuración del recurso compartido public creado anteriormente, quedaría como sigue:
## Carpeta compartida#[public]
comment = carpeta de pruebapath = /home/publicpublic = yeswritable = yesvalid users = ususambaread only = nowrite list = ususamba
Con esta configuración, sólo el usuario ususamba podrá acceder y escribir en el recurso compartido public.
85

6.2.4 Agrupación de servidores.
Con la configuración creada en los puntos anteriores, los servidores Windows y Samba están ubicados en grupos distintos, según se muestra en la ventana de la Figura 6.2.4.1.
Figura 6.2.4.1
Para que los servidores formen parte de la misma estructura, deben estar incluidos en el mismo grupo. Para ello, el servidor Windows debe pasar a formar parte del grupo Mshome o el servidor Samba debe ser incluido en el grupo Grupo_trabajo, modificando la línea workgroup = MSHOME por la línea workgroup = Grupo_trabajo en el archivo /etc/samba/smb.conf, debiendo reiniciar el servicio /etc/init.d/samba después de realizar esta acción.
En la ventana de la Figura 6.2.4.2 se muestra la inclusión del servidor Windows en el grupo MSHOME.
Figura 6.2.4.2
La ventana de la Figura 6.2.4.3, muestra los dos servidores incluidos en el grupo de trabajo MSHOME.
Figura 6.2.4.3
Si ejecutamos la orden findsmb, se muestra la siguiente información, con los dos servidores incluidos en el grupo MSHOME:
root@casa01:~# findsmb
*=DMB
+=LMB
IP ADDR NETBIOS NAME WORKGROUP/OS/VERSION
---------------------------------------------------------------------
86

192.168.1.35 PLANTILLA +[MSHOME] [Unix] [Samba 3.0.24]
192.168.1.36 W2000PROFE [MSHOME] [Windows 5.0] [Windows 2000 LAN Manager]
7. Proceso de inicialización del sistema.
La primera acción que realiza el sistema operativo Unix cuando se enciende el ordenador es verificar el correcto funcionamiento del hardware. Una vez realizada la comprobación, se carga en memoria el programa boot, que permite arrancar el kernel del sistema. El kernel del sistema ejecuta el proceso init, que se encarga de lanzar los procesos incluidos en el archivo /etc/inittab.
Las líneas del archivo /etc/inittab tienen la siguiente estructura:
etiqueta:estado:acción:proceso #comentarios.
La etiqueta es el identificador de la línea de tratamiento.
El estado corresponde a los niveles de ejecución en los que está permitido que se ejecuten determinados procesos. Hay seis niveles de ejecución de procesos:
0.
Es un nivel de ejecución especial, reservado para el cierre del sistema.
1.
Indica el nivel de ejecución en modo monousuario. Este es el nivel de ejecución en el que se inicia el sistema en el modo recuperación.
2.
Es el nivel de ejecución en modo multiusuario cuando no tenemos una red instalada. Si queremos acceder al entorno X-Windows, hay que ejecutar el comando startx. Para salir del entorno gráfico y volver al entorno multiusuario, hay que ejecutar la opción logout (cerrar sesión) desde le entorno gráfico.
3.
Se corresponde con el nivel de ejecución multiusuario en red. Si queremos acceder al entorno X-Windows, hay que ejecutar el comando startx. Para salir del entorno gráfico y volver al entorno multiusuario, hay que ejecutar la opción logout (cerrar sesión) desde le entorno gráfico.
87

5.
Es el nivel de ejecución para el entorno X-Windows. La instalación de Ubuntu configura este nivel por defecto para el inicio del sistema.
6.
Es el nivel que se ejecuta cuando el sistema se reinicia (comando reboot).
Una vez que el sistema se ha iniciado en uno de los niveles anteriores, es posible reiniciarlo en un modo distinto. Para ello, hay que ejecutar el comando init nivel, donde nivel es uno de los modos de inicialización comprendidos entre 0 y 6.
La línea del archivo /etc/inittab en la que se indica el nivel de inicio del sistema es la siguiente:
id:5:initdefault:
Si queremos iniciar el sistema en el nivel 3, habría que modificar la línea anterior de la siguiente forma:
id:3:initdefault:
La acción define la forma en la que se ejecutará el proceso. Puede tener los siguientes valores:
off.
Indica que el proceso está desactivado.
once.
El proceso se ejecuta sin espera.
wait.
El proceso permanece en espera hasta que finalice la ejecución del proceso asociado.
respawn.
El proceso se ejecuta de forma continuada. Es el modo en el que se ejecutan los terminales (impresoras, monitores, etc.).
boot.
El proceso se ejecuta en la inicialización del sistema sin esperar a que termine.
bootwait.
El proceso se ejecuta en la inicialización del sistema esperando a que termine.
initdefault.
Indica el estado en el que el sistema arrancará. Existen dos procesos que se inician con esta acción:
rc.
88

Llama a un nivel de ejecución nuevo y los procesos que se ejecutan dependen del estado del sistema.
getty.
Define las características del monitor en el archivo /etc/gettydefs e inicia la sesión de cada terminal con el login y su shell asociado.
sysinit.
El proceso asociado se ejecuta antes de que el sistema envíe información a la consola.
Una línea con esta estructura podría ser x:5:respawn:/etc/X11/prefdm –nodaemon.
Ubuntu ha cambiado este proceso de arranque, dejando de utilizar el archivo /etc/fstab. En su lugar utilizan el paquete upstart. Con este paquete, el sistema siempre se inicia con el nivel de ejecución 2, que varía con respecto al descrito anteriormente, incluyendo el modo multiusuario, la red y el entorno gráfico. Por lo tanto, este nivel 2 es como si el equipo se iniciara en el nivel 5. Si visualizamos el contenido del directorio /etc/rc2.d veremos que todos los servicios se levantan al iniciar el sistema. Debian también ha adoptado este proceso de arranque.
Los archivos de inicio del sistema se encuentran en el directorio /etc/event.d.
Para cambiar el nivel de inicio por defecto hay que modificar el nombre del archivo /etc/rc2.d/S30gdm, cambiando la letra S (primera letra del nombre del archivo) por la letra K. Esta acción no se puede realizar desde la línea de comandos porque el servicio gdm está en ejecución. Para realizar esta operación, Debian ha creado el paquete sysv-rc-conf. Después de instalarlo lo ejecutamos desde la línea de comandos (escribiendo el nombre del paquete sysv-rc-conf), mostrándose la ventana de la Figura 7.1.
Figura 7.1
En esta ventana hay que situarse sobre la X de gdm en la columna del nivel 2 y pulsar la barra espaciadora para desactivar el elemento. Seguidamente, hay que pulsar la tecla q para salir. De esta forma, la próxima vez que se inicie el sistema, arrancará en el modo texto. Para acceder a otro nivel de ejecución, hay que escribir la orden init N, donde N es el nivel de ejecución que se quiere iniciar. Para regresar al nivel 2 hay que escribir la orden init 2.
El directorio /etc/rcS.d contiene los servicios que se ejecutan nada más encender el ordenador, necesarios para continuar con el inicio del sistema.
89

8. Administración de servicios.
Los servicios que se inician en cada uno de los modos se encuentran en el directorio /etc/rc.d. En este directorio existen, entre otros, unos directorios llamados rc0.d, rc1.d, rc2.d, rc3.d, rc4.d, rc5.d y rc6.d, que se corresponden con cada uno de los 6 niveles de inicialización del sistema. En estos directorios se encuentran los servicios o demonios que se van a iniciar o parar cuando se arranque el sistema en cada uno de los niveles. Si el archivo empieza por la letra ‘K’, indica que el servicio se va a parar o no se va a iniciar. Si el archivo empieza por la letra ‘S’, indica que el servicio se va a iniciar. Por ejemplo, en el directorio rc0.d, que se corresponde con el cierre del sistema, todos los archivos empiezan por la letra ‘K’, excepto el archivo S00halt, que es el servicio responsable del cierre del sistema; el resto de servicios, al empezar por la letra ‘K’, serán detenidos cuando el sistema se cierre. Estos programas inician o detienen el demonio especificado, que se encuentra en el directorio /etc/init.d.
Para administrar los servicios desde la línea de comandos se utiliza la siguiente sintaxis:
servicio {start,stop,restart,reload,status}
donde servicio es el nombre del demonio que se desea administrar. Por ejemplo, para iniciar el servicio atd, se utiliza la orden /etc/init.d/atd start, para detener el servicio atd, se utiliza la orden /etc/rc.d/init.d/atd stop, para reiniciar el demonio lpd, se utiliza la orden /etc/rc.d/init.d/lpd restart, para ver el estado del servicio lpd, se utiliza la orden /etc/rc.d/init.d/lpd status, etc.
También se puede utilizar la orden service para administrar los servicios. En los ejemplos anterior, se utilizarían las órdenes service atd start, service atd stop, service lpd restart, service lpd status, etc. En Ubuntu, esta orden no está instalada.
90

9. El shell.
El shell es el encargado de recibir las órdenes de los usuarios y convertirlas a lenguaje máquina para que se puedan procesar. El shell compila las instrucciones de los usuarios y, si no tienen errores, las envía al kernel para realizar la operación solicitada. Si existen errores al teclear las órdenes, se produce un aviso para que el usuario vuelva a teclear la instrucción de forma correcta. Hay órdenes que envían estos avisos de error al correo electrónico.
El shell sirve, por tanto, para comunicarse con el sistema operativo y realizar todas las funciones que el sistema permita.
9.1. ESCRITURA DE ÓRDENES.
Las órdenes se pueden introducir en el shell una a una, pulsando la tecla Enter después de escribir cada orden. Otra forma de introducir órdenes en el shell son las siguientes:
orden1;orden2;orden3;... .
Las instrucciones se ejecutan de forma consecutiva, siguiendo el orden en el que se han introducido.
(orden1[;orden2;...]) &.
Las órdenes se ejecutan en el orden escrito y en segundo plano, liberando el terminal para realizar otras tareas. Si sólo se escribe una orden no es necesario utilizar los paréntesis. Los procesos que se ejecutan en segundo plano se denominan daemon.
orden1 && orden2.
Ejecuta la orden1 y, si la ejecución es correcta, ejecuta la orden2. Si la ejecución de la orden1 es incorrecta, la orden2 no se ejecuta.
orden1 || orden2.
La orden2 se ejecuta sólo si la orden1 genera un error.
Utilizando tuberías o conducciones.
Las órdenes se escriben en la misma línea y se separan por el carácter ‘|’. Cada orden escrita toma como entrada la salida de la orden anterior.
Ejemplo.
ls /etc | less
La salida de la orden ls /etc sobrepasa las 24 líneas de la pantalla. Para que el listado se realice de forma paginada, la salida de la orden ls /etc se recibe como entrada de la orden less, que toma el control del proceso y realiza la salida del listado del directorio /etc de forma paginada.
91

9.2. REDIRECCIONAMIENTO.
Normalmente, las órdenes utilizan como salida de sus resultados la salida estándar, que es el monitor. Esta salida se puede cambiar utilizando el redireccionamiento de salida a un archivo. Para ello, se utilizan los caracteres ‘>’ y ‘>>’. El símbolo ‘>’ sobreescribe el contenido del archivo si existe y crea el archivo si no existe. Con los caracteres ‘>>’ se crea el archivo si no existe y si existe se añade la nueva información a los datos que contiene el archivo.
Los mensajes de error que generan los comandos se pueden redireccionar a un archivo utilizando la sintaxis orden 2>archivo. Por ejemplo, si ejecutamos la orden cd prueba 2>errores y el directorio prueba no existe, el mensaje de error que genera la orden se envía al archivo errores. También se puede utilizar el redireccionamiento >>. Si se redirecciona al dispositivo /dev/null, el mensaje no se muestra y no se guarda en ningún archivo.
Por defecto, la mayoría de las órdenes toman su entrada desde el teclado. Esta entrada se puede modificar para que las órdenes tomen sus datos de entrada desde un archivo. Para ello, se utiliza el carácter ‘<’. Por ejemplo, la orden mail root <carta envía el contenido del archivo carta, por correo electrónico, al usuario root.
Si deseamos que una orden forme parte de otra orden, hay que pasarla como parámetro encerrada entre acentos graves o comilla inversa. Por ejemplo, la orden echo La fecha y hora del sistema es `date`, visualiza el mensaje La fecha y hora del sistema y, a continuación, ejecuta la orden date.
92

9.3. HISTORIA DE ÓRDENES.
El shell mantiene una historia de todas las órdenes que se han ejecutado. El comando history muestra una lista numerada de todas las órdenes que se han ejecutado. Para acceder a las órdenes anteriores o posteriores de la historia de órdenes se utilizan las flechas ↑↓. Una vez situados en una línea, se pueden utilizar las flechas →← para desplazarse por la línea y modificarla.
Si queremos desplazarnos al principio de la historia, hay que introducir Esc <; para desplazarse al final de la historia, hay que introducir Esc >.
Se puede introducir !número o !caracteres para ejecutar la orden que tiene el número indicado en la historia de órdenes o que comienza por los caracteres tecleados. También se puede incluir un patrón para que el shell ejecute la orden, incluida en la historia, que contenga el patrón especificado. Para ello, hay que utilizar el formato !?patrón?.
Si se introducen unos caracteres y se pulsan las teclas Esc Tab, el shell muestra la orden, incluida en la historia, que comience con los caracteres tecleados. Si hay más de una orden coincidente, se emite un pitido y, si se vuelve a teclear Esc Tab, se muestra una lista de órdenes, incluidas en la historia, que comienzan por los caracteres tecleados.
Se pueden editar varias líneas de la historia utilizando el comando fc rango, donde rango puede ser un intervalo de números de sucesos ( fc 2 10, editará los sucesos comprendidos entre el 2 y el 10) o un intervalo marcado por los caracteres especificados (fc cd vi editará las líneas comprendidas entre la primera que empiece por cd y la primera que empiece por vi). Todas las líneas editadas con la orden fc se ejecutan cuando salimos del editor.
El archivo .bash_history, que se encuentra en el directorio home de cada usuario, contiene todas las órdenes que el usuario ha ejecutado, sin incluir las ejecutadas en la sesión actual. Este archivo se actualiza cuando el usuario ejecuta logout. El nombre de este archivo se puede cambiar, asignando el nuevo nombre del histórico de órdenes mediante la variable HISTFILE. El nuevo archivo deberá ser creado.
Por defecto, se almacena una historia de 1000 órdenes, aunque este valor se puede cambiar con la variable HISTSIZE. Las variables HISTFILE e HISTSIZE se definen en el archivo .bash_profile.
Cuando se está escribiendo una orden, se puede pulsar la tecla Tab para escribir de forma automática el nombre completo de la orden. Por ejemplo, queremos escribir rmdir utilizando este método. Para ello, hay que escribir rmd y pulsar la tecla Tab. Como existen varias órdenes que empiezan por rmd, el sistema emite un pitido. Si pulsamos nuevamente la tecla Tab se muestra una lista de todas las órdenes que comienzan por rmd, que son rmdfile, rmdir y rmdtopvf. A continuación, escribimos el carácter i y pulsamos la tecla Tab. Se escribirá, automáticamente, rmdir.
El shell incorpora una función para visualizar nombres de archivos cuando se está escribiendo un comando. Para ello, hay que introducir los primeros caracteres de un archivo y, seguidamente, pulsar la tecla Esc seguida del carácter ‘?’. El shell mostrará, a continuación, todos los archivos que comiencen por los caracteres escritos y la línea del comando escrita antes de pulsar Esc ?, para que se complete el nombre del archivo.
Se puede utilizar el ratón para copiar y pegar texto. Para ello, hay que seleccionar el texto con el botón izquierdo del ratón y, posteriormente, posicionar el cursor en el lugar donde se quiere insertar el texto seleccionado y pulsar el botón derecho del ratón.
93

9.4. TIPOS DE SHELL.
Existen distintos tipos de shell, como pueden ser el shell de Bourne (sh), el shell de Korn (ksh), el shell C (csh), el shell visual (vsh), etc. Se puede cambiar de un shell a otro introduciendo la abreviatura de cada uno de ellos (sh, ksh, csh o vsh). Para volver al shell anterior hay que introducir la orden exit. El shell que utiliza Linux Ubuntu es el bash (shell Bourne Again), que es una versión avanzada del shell Bourne. Estos shell se encuentran en el directorio /bin.
El shell que se está utilizando se encuentra en la variable $SHELL. Se puede visualizar el shell que se está utilizando escribiendo la orden echo $SHELL.
El shell que utiliza cada usuario se encuentra en la línea que cada usuario tiene en el archivo /etc/passwd. Se puede cambiar el shell que utilizará un usuario modificando su línea en este archivo. También se puede indicar el shell que utilizará cada usuario cuando se crean con los comandos adduser o useradd.
94

9.5. ARCHIVOS DE CONFIGURACIÓN DEL SHELL.
La configuración del shell se realiza mediante una serie de variables a las que se asigna un determinado valor. Para mostrar estas variables y sus valores se utiliza la orden set. Estas variables toman su valor desde los archivos de configuración e inicialización de los usuarios (/etc/profile, /etc/bashrc, etc.), cuando estos inician una sesión. Estos archivos son comunes para todos los usuarios. En el directorio home de los usuarios se encuentra el archivo .bash_profile, que es un archivo oculto. Desde este archivo se pueden configurar nuevas variables del shell o modificar los valores que toman estas variables desde los archivos comunes de configuración. El shell gestiona una serie de variables de entorno, cuyo valor se puede modificar desde el archivo .bash_profile . Estas variables se muestran con la orden env. Para acceder al contenido de la variable, hay que escribir el carácter ‘$’ delante del nombre de la variable.
Algunas de estas variables de entorno son las siguientes:
Variable $.
Contiene el número de identificación del proceso (PID) en ejecución.
Variable !.
Contiene el número de identificación del proceso padre (PPID) en ejecución.
Variable CDPATH.
Contiene nombres de directorios. Cuando se utiliza el comando cd directorio, el shell busca el directorio especificado en las rutas existentes en esta variable. Los directorios asignados a la variable CDPATH deben estar separados por dos puntos (:).
Variable EXINIT.
Se utiliza para establecer opciones de configuración para el Editor vi. Por ejemplo, EXINIT=’set nu ai’, establece numeración de líneas y tabulación automáticas.
Variable HOME.
Contiene el directorio de trabajo del usuario, que es el directorio donde se encuentra el usuario cuando inicia una sesión. Cuando se ejecuta el comando cd sin especificar ninguna ruta, se cambia al directorio especificado en la variable HOME.
Variable IFS.
Contiene el carácter utilizado como separador interno de los campos. Normalmente será el espacio, el tabulador o el carácter de nueva línea. Este carácter también será utilizado para separar los distintos argumentos que se pasan a un comando o guión shell desde la línea de comandos.
Variable LOGNAME.
Contiene el nombre del usuario que ha iniciado una sesión.
Variable PATH.
Se utiliza para indicar al sistema los directorios donde tiene que buscar los archivos ejecutables. Estos directorios deben estar separados con dos puntos (:). La variable PATH toma valor en el archivo .bash_profile.
95

Ejemplo.
PATH=/bin:/usr/bin:/usr/sbin:.
Busca los archivos ejecutables en los directorios /bin, /usr/bin, /usr/sbin y directorio actual (.).
Si queremos añadir la búsqueda de los archivos ejecutables en el directorio /bin, que se encuentra en el directorio home del usuario, hay que modificar el archivo .bash_profile de la siguiente forma:
PATH=$PATH:$HOME/bin
En Linux se crea el directorio /usr/local/bin, que se utiliza para ubicar en él programas ejecutables que utilizarán los usuarios que se conecten localmente a una estación. Conviene, por tanto, añadir este directorio a la variable PATH.
Variable PS1.
Se utiliza para especificar el prompt o indicador que mostrará el shell para que se introduzcan las órdenes. El sistema utiliza una serie de códigos que se pueden utilizar para definir el prompt de usuario.
Estos códigos son los siguientes (deben ser escritos entre comillas dobles o simples):
\d.
Muestra la fecha del sistema.
\t.
Incluye la hora del sistema.
\u.
Visualiza el nombre de usuario.
\W.
Representa el directorio de trabajo o directorio home del usuario.
\!.
Muestra el número actual del histórico de órdenes.
Variable PS2.
Establece el prompt que se utilizará cuando una orden necesite ser escrita en varias líneas. El prompt secundario por defecto es ‘>’.
Variable SHELL.
Se utiliza para asignar el shell que usará el usuario.
Variable TERM.
Contiene el tipo de terminal que se utiliza. Algunos programas, como el editor vi, necesitan esta información para su correcto funcionamiento. Un terminal que está muy extendido
96

entre los fabricantes es el vt100, que es utilizado para compatibilizar los terminales desde el software.
Si desde el shell que estamos trabajando abrimos un subshell (por ejemplo, al ejecutar un programa shell o al ejecutar el comando su usuario), el contenido de las variables de entorno no se mantienen en el nuevo subshell. Para que los valores pasen de un shell a otro, hay que utilizar la instrucción export variable, siendo variable el nombre de la variable de entorno que se quiere mantener para el shell y el subshell. La exportación de variables de entorno entre distintos shell, sólo se realiza del shell al subshell, pero no del subshell al shell. La orden export se puede incluir en el archivo .bash_profile.
Se pueden utilizar nombres alias para definir las órdenes que nos interesen. Para ejecutar la orden se escribirá el nombe alias creado. Por ejemplo, la orden alias perm=’ls –l’, asigna el nombre perm al comando ls –l. Cada vez que se escriba perm se ejecutará la orden ls –l. Para mostrar los nombres alias que se están utilizando, hay que introducir la orden alias. Para eliminar un nombre alias, se utiliza la orden unalias nombre, donde nombre es un nombre alias definido previamente. Los nombres alias se pierden cuando el usuario cierra la sesión en la que han sido creados. Si se quieren mantener, hay que incluirlos en el archivo .bash_profile o .bashrc.
El archivo /etc/environment se utiliza para configurar variables de entorno que van a utilizar las aplicaciones (variable JAVA_HOME, utilizar el símbolo del euro, etc.).
El funcionamiento del shell se puede configurar mediante una serie de opciones que se pueden activar y desactivar, utilizando la orden set {-o,+o} opción. Para activar la opción se utiliza –o y para desactivarla +o. La activación o desactivación de estas opciones se pueden incluir en el archivo .bash_profile. Las opciones son las siguientes:
noclobber.
Se utiliza para activar o desactivar la sobreescritura de archivos mediante la redirección.
ignoreeof.
Cuando está activada no se puede utilizar Ctrl+d para cerrar una sesión de usuario. En este caso, si se pulsa Ctrl+d para abandonar la sesión, el shell muestra el mensaje Use “logout” to leave the shell.
Cuando los usuarios cambian de un shell a un subshell o ejecutan un programa shell, se ejecuta el archivo .bashrc, que es un archivo oculto que se encuentra en el directorio home de cada usuario. Este archivo se utiliza para definir nombres alias y opciones de funcionamiento que sólo queremos mantener cuando se ejecuta un subshell. Los usuarios, cuando inician una sesión, ejecutan el archivo /etc/bashrc, que contiene opciones de configuración comunes a todos los usuarios.
Existe también un archivo que se ejecuta cuando el usuario cierra su sesión. Este archivo está oculto en el directorio home de cada usuario y se llama .bash_logout.
Cuando los archivos .bash_profile, .bashrc y .bash_logout se modifican, los cambios no surten efecto hasta que se inicia una nueva sesión. Si se desea que los cambios surtan efecto en la sesión actual, hay que ejecutar el archivo correspondiente. Para ello, hay que escribir . archivo (observar que hay un espacio en blanco entre el punto y el nombre del archivo). De esta forma, para ejecutar el archivo .bash_profile, hay que escribir . .bash_profile, para ejecutar el archivo .bashrc, hay que escribir . .bashrc y para ejecutar el archivo .bash_logout, hay que escribir . .bash_logout.
97

9.6. TERMINALES VIRTUALES.
Cuando un usuario inicia una sesión, el shell se inicia en el terminal tty1. Sin salir de este shell, el usuario puede iniciar un terminal virtual pulsando las teclas Alt y alguna de las teclas F2, F3, F4, F5 o F6. A continuación, se pedirá el nombre de un usuario y su contraseña. En ese momento, en dicho terminal se estarán ejecutando dos shell. Para cambiar de un shell a otro, hay que pulsar las teclas Alt-Fnúmero.
Ejemplo.
Al inciar una sesión, el shell se encuentra en el terminal tty1, que se corresponde con las teclas Alt-F1.
Si pulsamos Alt-F3, el sistema nos pedirá un usuario y su contraseña. Cuando iniciemos la nueva sesión, el shell se encontrará en el terminal virtual tty3.
Para cambiar al shell de tty1 hay que pulsar Alt-F1. Para cambiar al shell de tty3 hay que pulsar Alt-F3.
98

10.Comandos de Unix/Linux.
10.1. ARCHIVOS ESPECIALES.
Son los que identifican los dispositivos físicos del ordenador, como son discos duros, cintas magnéticas, terminales, líneas de comunicaciones, etc. Todos los dispositivos son tratados como archivos y todos éstos archivos residen en el directorio /dev.
Las ventajas de tratar a las unidades de E/S como archivos son:
Los archivos y dispositivos son tratados de forma parecida.
La forma de pasar los nombres de los archivos y dispositivos a los programas es la misma.
Los archivos especiales están sujetos al mismo tipo de protección de acceso que los archivos y directorios ordinarios.
99

10.2. NOMBRES DE ARCHIVOS.
Las características de los nombres de archivos son las siguientes:
Pueden tener un máximo de 14 caracteres, aunque depende de las versiones de Unix.
Se diferencian las mayúsculas y las minúsculas.
Se pueden utilizar los siguientes caracters: a-z, A-Z, . y _)
No se pueden utilizar los siguientes caracteres: $, ^, [, ], /, *, (, ), <, >, ;, &, ¿, ?, \, #, @, |, {, }.
Para nombrar los archivos de forma abreviada y acceder a múltiples archivos y directorios en un solo comando, se utilizan los siguientes metacaracteres:
?.
Sustituye un solo carácter.
*.
Sustituye una serie de caracteres.
[rango].
Permite especificar un rango de caracteres.
Ejemplos.
Supongamos que tenemos los siguientes archivos: texto1, texto2, texto3, texto11, texto12, texto13, texto113, texto112 y texto113.
1. Para buscar los archivos texto1, texto2 y texto3, hay que utilizar texto?.
2. Para buscar los archivos texto11, texto12 y texto13, hay que utilizar texto??.
3. Para buscar los archivos texto111, texto112 y texto113, hay que utilizar texto???.
4. Para buscar todos los archivos texto, hay que utilizar texto*.
5. Si utilizamos texto??[23], buscaría text112 y texto113. Los caracteres entre corchetes indican que busque los archivos que contengan un 2 o un 3 en dicha posición.
6. Si utilizamos texto[1-2], buscaría texto1 y texto2. Los caracteres entre corchetes indican que busque los archivos cuyo rango de valores en dicho carácter sea el especificado.
7. Si utilizamos texto?[!1], buscaría texto12 y texto13. Los caracteres entre corchetes indican que no busque los archivos que contengan el carácter 1 en dicha posición.
100

10.3. COMANDOS PARA LA GESTIÓN DE DIRECTORIOS Y ARCHIVOS.
10.3.1 Comando cat.
Se utiliza para crear archivos desde el teclado y para visualizar el contenido de un archivo.
La sintaxis es:
cat [{>,>>}] archivo
Si se utiliza >, el archivo se crea y, si ya existe, se pierde la información que contiene.
Si se utiliza >>, el archivo se crea y, si ya existe, la nueva información se añade al contenido del archivo.
Cuando se ejecuta el comando, todos los caracteres que se introduzcan por teclado formarán parte del archivo, hasta que se teclee la combinación de teclas Ctrl-d (fin de fichero).
Si se utiliza cat archivo, visualiza en pantalla el contenido del archivo.
Ver el apartado Comandos para operar sobre ficheros de texto para otras aplicaciones del comando cat.
10.3.2 Comando cd.
Se utiliza para cambiar de directorio.
La sintaxis es:
cd [ruta]
Si se utiliza el comando cd sin indicar ninguna trayectoria, se cambia al directorio de trabajo o directorio home del usuario. Si se utiliza la sintaxis cd $HOME, también se cambia al directorio de trabajo o directorio home del usuario.
En los nombres de rutas, los niveles de la estructura arborescente deben ir separados por el carácter “/”.
Cuando queramos ascender de nivel, se pueden utilizar los caracteres “..”. De ésta forma, si queremos subir a dos niveles superiores del directorio donde nos encontramos, hay que escribir cd ../.. .
10.3.3 Comando cp.
Se utiliza para copiar archivos y directorios.
La sintaxis es:
cp archivo1 archivo2 [-r]
-r.
Se utiliza cuando archivo1 y archivo2 son dos directorios y se quieren copiar todos los subdirectorios con su contenido. Si el directorio especificado en archivo2 no existe, se crea.
10.3.4 Comando df.
101

Muestra el espacio libre en disco, el espacio ocupado y el tamaño de la partición donde estamos ubicados.
La sintaxis es:
df [opciones]
Las opciones son las siguientes:
-h.
Muestra la información en bytes.
-H.
Muestra la información en megas, gigas, etc.
-i.
Muestra información sobre los inodos del sistema de archivos.
-T.
Además del resto de información, muestra el tipo de sistema de ficheros.
10.3.5 Comando du.
Visualiza el espacio que ocupan los ficheros en el disco.
La sintaxis es:
du [opciones] [archivo]
En el argumento archivo podemos incluir el nombre de un fichero o de un directorio.
Las opciones pueden ser:
-a.
Muestra el tamaño de todos los archivos, incluidos los ocultos.
-b.
Muestra el tamaño total del archivo o del directorio en bytes.
-h.
Muestra el tamaño en bytes, kas, megas, etc.
10.3.6 Comando file.
Se utiliza para determinar el tipo de información que contiene un fichero. La información de un fichero puede ser binaria o texto. En algunas ocasiones, no es muy fiable el tipo de fichero que el comando file interpreta.
La sintaxis es:
file archivo
102

10.3.7 Comando find.
Se utiliza para buscar archivos en cualquier directorio de la estructura de directorios. La búsqueda puede ser condicional.La sintaxis es:
find [ruta1 [ruta2 ...]] [opciones]
Las rutas especifican los directorios donde se va a realizar la búsqueda. Si no se introduce ninguna ruta, la búsqueda se realiza en el directorio actual. Si se utiliza el carácter “/”, la búsqueda se realiza en todos los directorios.
Si se ejecuta el comando find sin argumentos, se visualizan todos los ficheros, incluidos los ficheros ocultos, del directorio actual.
Las opciones pueden ser:
-user usuario.
Busca los archivos del usuario indicado en el directorio especificado. Si en lugar de un nombre de usuario, se escribe $LOGNAME, se buscan todos los archivos del usuario que está conectado en ese momento.
-name fichero.
Se utiliza para indicar el nombre del fichero o directorio que se quiere buscar.
Ejemplo.
find / -name ‘*.o’
Busca todos los archivos cuyo nombre termine con la cadena ‘.o’.
-print.
Muestra la ruta completa del fichero especificado. Es la opción por defecto, por lo que, si se omite, también visualiza la ruta completa del archivo buscado.
-size n.
Busca los ficheros con un tamaño superior o inferior al indicado.
Ejemplos.
1. find / -size +20
Busca todos los ficheros con un tamaño superior a 20 bloques.
2. find / -size –10
Busca todos los ficheros con un tamaño inferior a 10 bloques.
-atime n.
Busca archivos a los que se ha accedido hace un número de días o que se han creado antes que el número de días especificado.
Ejemplos.
103

1. find / -atime –1
Busca todos los archivos a los que se ha accedido hace un día.
2. find / -atime +10
Busca todos los archivos que se han creado hace más de diez días.
-type x.
Busca los archivos del tipo especificado en x. x debe ser uno de los siguientes tipos: b (archivo especial de tipo bloque), c (archivo especial de tipo carácter), d (directorios), p (FIFO, archivos especiales) y f (archivos ordinarios).
Ejemplos.
1. find /usr –type d
Visualiza todos los directorios de /usr.
2. find /usr –type f
Muestra todos los archivos ordinarios de /usr.
-exec comando ‘{}’ ‘;’
Ejecuta el comando especificado si la búsqueda se realiza con éxito.
‘{}’ se refiere al archivo especificado.
‘;’ es obligatorio ponerlo.
Ejemplo.
find / -name pepe –exec rm ‘{}’ ‘;’
Borra el archivo pepe si lo encuentra.
-ok comando ‘{}’ ‘;’
Ejecuta el comando especificado si la búsqueda se realiza con éxito, pidiendo confirmación. Para contestar afirmativamente, hay que utilizar el carácter “s”.
Ejemplo.
find / -name pepe –ok ls ‘{}’ ‘;’
Si encuentra el archivo pepe, pregunta si lo visualiza, es decir, pregunta si ejecuta el comando ls.
Se pueden combinar varias opciones utilizando operadores lógicos. Los operadores lógicos que se pueden utilizar son los siguientes: -o (condición lógica Or) y -a (condición lógica And). Se pueden utilizar paréntesis para agrupar los operadores lógicos.
Ejemplo.
find / -name pepe –a –atime –1
Visualiza el archivo pepe si lo encuentra y se ha accedido a él hace un día.
104

10.3.8 Comando less.
Visualiza el contenido de uno o varios archivos de forma paginada (30 líneas por página).
La sintaxis es:
less [opciones] archivo1 [archivo2 ...]
Las opciones son las siguientes:
-número.
Indica el número de líneas que se visualizarán por página.
+número.
El archivo se visualiza a partir de la línea especificada en número. Si la línea especificada en número sobrepasa las líneas que contiene el archivo, no se muestra nada.
+/cadena.
El archivo se visualiza a partir de los caracteres especificados en cadena. Si la cadena no se encuentra, el archivo se muestra desde el principio, mostrándose el mensaje Pattern not found.
Cuando el archivo se está visualizando y la orden less está en espera, se pueden introducir órdenes para desplazarse por el archivo. Estas órdenes son las siguientes:
Órdenes de desplazamiento.
Teclas de flechas.
Desplaza el contenido del archivo en la dirección de la flecha que se teclea.
Barra espaciadora.
Se visualiza la página siguiente. Esta acción también se realiza con los comandos f y z o pulsando la tecla AvPág.
[número] Enter.
Avanzas las líneas especificadas en número. Si se omite número, avanza una línea. Esta acción también se realiza con los comandos [número] e, número f, número d y número z.
b.
Retrocede una página. Esta acción también se realiza con la orden w o pulsando la tecla RePág.
número b.
Retrocede las líneas especificadas en número. Esta acción también se realiza con los comandos [número] y, número w y número u.
d.
Avanza media página.
105

[número] g.
Visualiza el fichero desde la línea especificada en número, empezando desde el principio. Si no se especifica número, se visualiza desde la primera línea.
[número] G.
Visualiza el fichero hasta la línea especificada en número, empezando desde el final. Si no se especifica número, se visualiza hasta la última línea.
h.
Visualiza la ayuda.
Q/q.
Termina la ejecución de la orden less y de la ayuda de less (comando h).
u.
Retrocede media página.
Órdenes de búsqueda.
/cadena.
Busca los caracteres especificados en cadena. La búsqueda se realiza hacia delante. Las cadenas encontradas son marcadas.
?cadena.
Busca los caracteres especificados en cadena. La búsqueda se realiza hacia atrás. Las cadenas encontradas son marcadas.
n.
Continúa la búsqueda hacia delante. Las cadenas encontradas son marcadas.
N.
Continúa la búsqueda hacia atrás. Las cadenas encontradas son marcadas.
Esc u.
Finaliza la búsqueda. Las cadenas encontradas dejan de estar marcadas.
Órdenes para gestionar marcas.
m.
Cuando se ejecuta la orden m se muestra el mensaje mark: y, a continuación, hay que escribir una letra, que será la marca realizada en el lugar del fichero que estamos posicionados en ese momento. Puede haber varias marcas en un mismo fichero. Si la letra que se introduzca se ha utilizado para realizar otra marca, se anula la primera marca realizada.
‘.
106

Cuando se ejecuta la orden ‘ se muestra el mensaje goto mark: y, a continuación, se introduce la letra de la marca que se quiere visualizar. Si la letra que se introduzca no existe como marca, se muestra el mensaje Mark not set. Si cuando se muestra el mensaje goto mark: se introduce ‘, se muestra la siguiente marca. Esto se utiliza para movernos por las marcas realizadas en el fichero.
Órdenes para ficheros.
:e.
Cuando se ejecuta la orden :e, se muestra Examine: y, a continuación, hay que introducir el nombre de un fichero. Si el fichero existe se visualiza.
:n.
Visualiza el siguiente fichero introducido al ejecutar el comando less.
:p.
Visualiza el anterior fichero introducido al ejecutar el comando less.
v.
Ejecuta el editor vi, editando la pantalla que está visualizando el comando less.
:x.
Visualiza el primer fichero introducido al ejecutar el comando less.
=.
Visualiza el nombre del fichero que se está visualizando e información sobre el mismo.
![comando].
Ejecuta el comando especificado. Si no se indica ningún comando, se muestra el símbolo del Shell, pudiendo ejecutar cualquier comando. Para volver a less hay que ejecutar la orden exit o pulsar las teclas Ctrl-d.
10.3.9 Comando ln.
Crea una copia de un fichero, dejando los dos ficheros enlazados. Mediante este enlace, cuando se cambia el contenido de un fichero, el contenido del fichero enlazado se cambia automáticamente. Si dos ficheros están enlazados, cuando se utiliza la opción –i en el comando ls, el número de inodo de los dos ficheros debe ser el mismo.
La sintaxis es:
ln fichero1 fichero2
10.3.10 Comando ls.
Visualiza el contenido de un directorio.
La sintaxis es:
ls [opciones] [ruta]
Si se ejecuta el comando ls sin opciones y sin ruta, visualiza el contenido del directorio actual ordenado alfabéticamente.
107

En el parámetro ruta se puede especificar el nombre de una trayectoria hasta un directorio o archivo.
Algunas de las opciones más usuales son:
-a.
Visualiza el contenido del directorio con los archivos ocultos, que empiezan por el carácter “.”.
-F.
Añade el carácter “/” después del nombre de los directorios, el carácter “*” después de cada archivo ejecutable o el carácter “@” después de los enlaces simbólicos.
-i.
Muestra los nombres de archivos y directorios junto a sus direcciones en la tabla de inodos.
-l.
Visualiza el contenido del directorio en formato largo.
La información que muestra es la siguiente:
El primer carácter indica el tipo de archivo. Puede contener uno de los siguientes caracteres: d (directorio), b (archivo especial de tipo bloque), c (archivo especial de tipo carácter), p (archivo especial FIFO), l (enlace simbólico) y – (archivo ordinario).
Los siguientes tres caracteres indican los permisos del propietario.
Los permisos que se muestran pueden ser: r (lectura), w (escritura), x (ejecución). Siempre aparecen en éste orden: rwx. Si en lugar del correspondiente permiso, se muestra el carácter “-“, indica que dicho permiso está denegado. Por ejemplo, rw- indica que tiene los permisos de lectura y de escritura, pero no tiene el permiso de ejecución.
Los siguientes tres caracteres indican los permisos de los usuarios pertenecientes al grupo del propietario. Si un usuario pertenece a varios grupos, el grupo del propietario es el que está activo en el momento de crear el directorio o archivo.
Los siguientes tres caracteres indican los permisos del resto de usuarios.
Los siguientes caracteres muestran los enlaces, el propietario, el grupo al que pertenece el propietario, el tamaño en bytes, la fecha de creación o de la última modificación y el nombre. Si se combina con la opción –n se muestran los identificadores de usuario y grupo del propietario, en lugar de sus nombres.
-ld.
Muestra información sobre el directorio (la misma información que muestra con la opción l), pero no visualiza el contenido del directorio.
-p.
Añade una barra (/) a la derecha del nombre de los directorios.
108

-r.
Lista el contenido del directorio en orden alfabético inverso.
-R.
Visualiza el contenido de todos los subdirectorios.
-s.
Visualiza el tamaño físico de los ficheros en bloques de 512 bytes.
--color=opciones.
Se utiliza para visualizar los archivos y directorios en distintos colores. Las opciones pueden ser: never, auto y always.
10.3.11 Comando lshw.
Esta orden se utiliza para visualizar un listado de todo el hardware del equipo. La salida de la orden se realiza en el terminal, en modo texto. Si queremos visualizar el listado en modo gráfico hay que instalar el paquete lshw-gtk, con la orden apt-get install lshw-gtk, y ejecutar el comando lshw -X. En la ventana que se muestra hay que hacer doble clic sobre los elementos visualizados y se irán mostrando, en los paneles siguientes, los componentes hardware y sus características.
10.3.12 Comando mkdir.
Se utiliza para crear subdirectorios.
La sintaxis es:
mkdir directorio1 [directorio2 ...]
Se pueden crear varios directorios utilizando una sóla vez el comando.
10.3.13 Comando more.
Visualiza el contenido de uno o varios archivos de forma paginada (29 líneas por página).
La sintaxis es:
more [opciones] archivo1 [archivo2 ...]
Las opciones son las siguientes:
-número.
Indica el número de líneas que se visualizarán por página.
+número.
El archivo se visualiza a partir de la línea especificada en número. Si la línea especificada en número sobrepasa las líneas que contiene el archivo, no se muestra nada.
-d.
Muestra el mensaje [Press space to continue, ‘q’ to quit.].
109

+/cadena.
El archivo se visualiza a partir de los caracteres especificados en cadena. Si la cadena no se encuentra, el archivo se muestra desde el principio, mostrándose el mensaje Pattern not found.
Cuando el archivo se está visualizando y la orden more está en espera, se pueden introducir órdenes para desplazarse por el archivo.
Estas órdenes son las siguientes:
Barra espaciadora.
Se visualiza la página siguiente. Tecla Enter.
Visualiza la línea siguiente.
Carácter ‘.’.
Cuando se teclea el caácter ‘.’, se repite la última orden ejecutada.
/cadena.
Busca los caracteres especificados en cadena. Si la cadena no se encuentra se muestra el mensaje Pattern not found y se visualiza la línea siguiente. Una vez encontrada la cadena, hay que introducir la orden n para continuar la búsqueda.
!comando.
Ejecuta el comando especificado. También se puede utilizar :!comando.
:f.
Visualiza el nombre del fichero y el número de línea.
:n.
Visualiza el siguiente fichero introducido al ejecutar la orden more. Si se visualiza el último fichero y se introduce :n, termina la ejecución de more.
:p.
Visualiza el anterior fichero introducido al ejecutar la orden more.
=.
Visualiza el número de línea.
[número]b.
Retrocede tantas páginas como se indique en número. Si se omite número retrocede una página.
d.
Visualiza las siguientes 14 líneas.
[número]f.
110

Avanza tantas páginas como se indique en número. Si se omite número avanza una página.
h.
Visualiza las órdenes que se pueden ejecutar cuando el comando more está en espera.
Q/q.
Termina la ejecución de la orden more.
v.
Ejecuta el editor vi, editando la pantalla que está visualizando el comando more.
10.3.14 Comando mv.
Se utiliza para renombrar archivos y directorios y mover archivos entre directorios.
La sintaxis es:
mv [-f] archivo1 [archivo2] archivoDestino
La opción –f sobreescribe el archivo destino si existe, sin pedir confirmación.
10.3.15 Comando nl.
Se utiliza para visualizar el contenido de un archivo con sus líneas numeradas.
La sintaxis es:
nl [opciones] archivo1 [,archivo2,...]
Si se especifica más de un archivo, la numeración de las líneas continúa de un archivo a otro.
10.3.16 Comando od.
Visualiza el contenido de un fichero en distintos formatos.
La sintaxis es:
od fichero1 [, fichero2, ...] opciones
Se pueden incluir los nombres de varios ficheros. En este caso, se visualizan los ficheros de forma consecutiva, sin visualizar el principio y final de cada fichero.
Las opciones pueden ser:
-a.
Visualiza los datos del fichero en formato ASCII.
-c.
Visualiza los datos del fichero en formato carácter.
-d.
111

Visualiza los datos del fichero en formato decimal. Si se utiliza –ad, se visualiza una fila con los caracteres en ASCII y otra fila con su correspondiente código decimal.
-o.
Visualiza los datos del fichero en formato octal. Si se utiliza –ao, se visualiza una fila con los caracteres en ASCII y otra fila con su correspondiente código octal.
-x.
Visualiza los datos del fichero en formato hexadecimal. Si se utiliza –ax, se visualiza una fila con los caracteres en ASCII y otra fila con su correspondiente código hexadecimal.
Los caracteres especiales se visualizan de la siguiente forma:
Alimentador de hojas. \f.
Nueva línea. \n.
Nulo. \O.
Retorno de carro. \r.
Tabulador. \t.
Tecla de retroceso. \b.
El usuario root puede visualizar el contenido de las particiones. Para ello, se puede introducir el comando od –ac /dev/hda1. Si se quiere ver el contenido de una partición desde un determinado byte se puede introducir la orden od –ac +10678. Si se quiere ver el contenido de una partición desde un determinado bloque se puede introducir la orden od –ac +10b.
10.3.17 Comando pwd.
Visualiza el nombre completo de la ruta actual.
La sintaxis es:
pwd
10.3.18 Comando rm.
Se utiliza para borrar archivos (recordar que los directorios son archivos).
La sintaxis es:
rm archivo1 [archivo2 ...] [opciones]
Las opciones más usuales son las siguientes:
-r.
Borra todo el contenido del directorio especificado, incluidos los subdirectorios y el contenido de éstos.
-f.
Realiza el borrado sin pedir confirmación. Por defecto, pide confirmación antes de borrar.
112

10.3.19 Comando rmdir.
Se utiliza para borrar directorios. Los directorios deben estar vacíos.
La sintaxis es:
rmdir directorio1 [directorio2 ...] [-p]
-p.
Borra el directorio padre si se queda vacío.
Ejemplo.
rmdir prueba/prueba1 –pEl comando rmdir borra el directorio prueba1 y, si el directorio prueba (directorio padre de prueba1) se queda vacío, también lo borra. Si el directorio prueba no se queda vacío, no lo borra.
113

10.4. COMANDOS PARA OPERAR CON FICHEROS DE TEXTO.
10.4.1 Comando cat.
Se utiliza para concatenar ficheros. La sintaxis es:
cat archivo1 [ archivo2 …] {>,>>} archivo
Ver el apartado Comandos para la gestión de directorios y ficheros para otras aplicaciones del comando cat.
10.4.2 Comando cut.
Se utiliza para seleccionar una parte de un fichero. Se pueden seleccionar bytes, caracteres o campos.
La sintaxis es:
cut {-b número –c número –f número} archivo1 [archivo2 ...]
La salida de la selección se produce por el monitor.
-b número.
Indica el byte que se va a seleccionar.
-c número.
Indica el carácter que se va a seleccionar.
-f número.
Indica el campo que se va a seleccionar. Los campos deben estar separados por un carácter tabulador.
-d carácter.
Indica el carácter que se utiliza como separador de los campos del fichero.
10.4.3 Comando grep.
Se utiliza para buscar una cadena de caracteres en los archivos especificados. Cuando grep encuentra la cadena especificada, se visualiza la línea que contiene dicha cadena.
La sintaxis es:
grep [opciones] cadena [archivo1 [archivo2 ...]]
Si se utiliza grep cadena, sin opciones ni argumentos, la cadena se busca en los caracteres introducidos desde el teclado.
Si la cadena buscada contiene espacios en blanco o caracteres de control, hay que introducirla entre comillas.
114

Si se especifican varios archivos, cuando encuentra la cadena se lista el nombre del archivo delante de la línea que contiene la cadena.
Las opciones son las siguientes:
-c.
Visualiza el número de líneas que contienen la cadena especificada.
-i.
No distingue mayúsculas y minúsculas.
-l.
Muestra los nombres de los archivos que contienen la cadena especificada.
-n.
Visualiza el número de línea delante de la línea que contiene la cadena especificada.
-v.
Selecciona las líneas que no contienen la cadena especificada.
10.4.4 Comando paste.
Se utiliza para unir el contenido de varios ficheros.
La sintaxis es:
paste [-d carácter] archivo1 archivo2 [archivo3 ...]
Una utilización muy usual es en combinación con la orden cut.
La opción –d se utiliza para indicar el carácter separador de campos. Por defecto, se usa el carácter tabulador como separador de campos.
10.4.5 Comando pr.
Se utiliza para preparar un fichero de texto para ser impreso. Este comando introduce un encabezamiento en el listado del fichero, permite imprimir la información en columnas, numerar las líneas, reemplazar los espacios por tabuladores y viceversa, etc.
La sintaxis es:
pr [opciones] [archivo]
Si pr se ejecuta sin parámetros, se introduce información desde el teclado y el comando pr añade, por cada página, la cabecera por defecto y 5 líneas en blanco al final. La cabecera por defecto consta de 5 líneas, de las cuales sólo la tercera tiene información (fecha, hora y número de página). Cada página contiene 66 líneas.
Si se introduce un nombre de archivo, se visualiza el contenido del archivo con el formato descrito en el párrafo anterior. Se puede redireccionar la salida a otro archivo.
Las opciones más usuales son las siguientes:
+número.
115

El listado se realiza a partir de la página especificada en número.
-número.
El listado se realiza con las columnas indicadas en número.
-d.
Realiza un doble espacio entre las líneas.
-h nombre.
Sustituye el nombre del fichero que se visualiza en la cabecera del listado por el nombre especificado. Si el nombre especificado tiene más de dos palabras, debe ir entre comillas.
-l líneas.
Indica el número de líneas por página. Por defecto, se escriben 66 líneas en cada página. Si se introduce un número de líneas menor que 10, no se visualizan las líneas de la cabecera (5 líneas) y del final (5 líneas).
-n.
Númera las líneas del listado. Si el listado se realiza por columnas, se numeran todas las filas de todas las columnas.
-t.
Suprime las 10 líneas de cabecera y final de cada página.
-w número.
Indica el número de caracteres por línea que se visualizarán. Por defecto, se visualizan 72 caracteres por línea.
10.4.6 Comando sort.
Se utiliza para ordenar ficheros de texto.
La sintaxis es:
sort [opciones] [archivo1 [archivo2 …]]
Si se ejecuta sort sin parámetros, el sistema espera que se introduzcan caracteres desde el teclado, separando las líneas con Enter, hasta que se pulsa CtrlD, realizando entonces la ordenación, tomando el monitor como salida.
Las opciones pueden ser:
-b.
Ignora los espacios en blanco o tabuladores de principio de línea.
-d.
Se ignoran los caracteres de puntuación y de control en la ordenación. La ordenación se realiza por letras, números y blancos (espacios y tabuladores).
116

-f.
No se distingue entre mayúsculas y minúsculas.
-n.
Los números no se toman como cadenas, sino por su valor aritmético, teniendo en cuenta los caracteres de puntuación y los signos + y -.
-o fichero.
El resultado de la ordenación se almacena en el fichero especificado.
-r.
La ordenación se realiza de mayor a menor.
-t carácter.
Indica el carácter que se utiliza como separador de los campos del fichero.
La orden sort ordena los archivos línea a línea. Si un archivo contiene varios campos en una línea, es posible que queramos ordenar según un determinado campo. Los campos estarán separados por un espacio en blanco o por un tabulador. Para ordenar por el primer campo se utiliza +0, para ordenar por el segundo +1, y así sucesivamente.
10.4.7 Comando tail.
Se utiliza para visualizar el final de uno o varios archivos. Por defecto, se muestran las diez últimas líneas de cada archivo.
La sintaxis es:
tail [{+número,-número} [opciones]] [archivo1 [archivo2 ...]]
Si se introduce tail sin parámetros, se realiza la entrada de datos por teclado. Cuando finaliza la entrada de datos, tail muestra las diez últimas líneas introducidas.
Las opciones son las siguientes:
b.
El final del fichero se cuenta por bloques.
c.
El final del fichero se cuenta por caracteres.
l.
El final del fichero se cuenta por líneas.
Las opciones deben ir precedidas de uno de los siguientes caracteres:
+número.
Se visualiza desde el bloque, carácter o línea especificada en número, contando desde el principio del fichero. Si se omiten las opciones, por defecto se cuentan líneas.
-número.
117

Se visualiza desde el bloque, carácter o línea especificada en número, contando desde el final del fichero. Si se omiten las opciones, por defecto se cuentan líneas.
10.4.8 Comando tee.
Se utiliza en combinación con otros comandos. Visualiza la salida del comando en pantalla y la almacena en el/los fichero/s especificado/s. Los comandos se separan por el carácter “|”.
La sintaxis es:
tee [-a] [archivo1 [archivo2 ...]]
Si se utiliza la orden tee sin argumentos, sólo se utiliza la salida estándar (el monitor) como salida del comando.
-a.
Si el archivo especificado no existe, se crea. Si existe, la información generada por la orden tee se añade a la contenida en el archivo especificado.
10.4.9 Comando touch.
Se utiliza para crear archivos y modificar las fechas del último acceso y última modificación de los archivos.
La sintaxis es:
touch [opciones] archivo1 [archivo2 ...]
Si se omiten las opciones, se crea el archivo o archivos especificados. Los archivos se crean vacíos.
Las opciones son las siguientes:
-a.
Cambia la fecha y hora del último acceso por la fecha del sistema.
-c.
Si el archivo especificado no existe, no lo crea.
-m.
Cambia la fecha y hora de la última modificación por la fecha del sistema.
10.4.10 Comando wc.
Se utiliza para contar líneas, palabras y/o caracteres en los archivos especificados.
La sintaxis es:
wc [-l –w -c] archivo1 [archivo2 ...]
Si se utiliza wc sin opciones, se muestra, por este orden, el número de líneas, el número de palabras, el número de caracteres y el nombre del archivo. Si se introduce el nombre de varios archivos, la última línea muestra el total de líneas, palabras y caracteres de todos los archivos.
118

Las opciones –l –w –c muestra el número de líneas, palabras o caracteres, respectivamente. Si se combinan varias opciones, el carácter “-“ sólo se escribe una vez.
10.5. OTROS COMANDOS UNIX/LINUX.
10.5.1 Comando clear.
Borra el contenido de la pantalla.
La sintaxis es:
clear
10.5.2 Comando date.
Se utiliza para visualizar o modificar la fecha y hora del sistema. Sólo el usuario administrador puede modificar la fecha y hora del sistema.
Para modificar la fecha y hora del sistema, hay que utilizar la siguiente sintaxis:
date MMDDhhmmYY
La sintaxis para visualizar la fecha y hora es la siguiente:
date [opciones] [‘+formato’]
El argumento formato se utiliza para controlar la salida. Puede tomar los siguientes valores:
%a Visualiza el día de la semana en formato corto (mié, como miércoles).
%A Visualiza el día de la semana en formato largo (miércoles).
%b Visualiza el mes en formato corto (may, como mayo).
%B Visualiza el mes en formato largo (mayo).
%c Visualiza la fecha y hora con el formato día dd mes aaaa hh:mm:ss (mié 19 may 1999 18:45:40).
%d Visualiza el día del mes en números.
%D Visualiza la fecha con el formato mm/dd/aa.
%H Visualiza la hora con el formato de 0 a 23 horas. %k realiza la misma operación.
%I Visualiza la hora con el formato de 0 a 12 horas. %l realiza la misma operación.
%j Visualiza el día del año en números.
%m Visualiza el mes en números.
%M Visualiza los minutos.
%n Salta a la línea siguiente.
%r Visualiza la hora del sistema con un reloj de 12 horas.
119

%S Visualiza los segundos.
%t Inserta el carácter tabulador.
%T Visualiza la hora del sistema con un reloj de 24 horas.
%U Visualiza el número de semana del año, tomando el domingo como primer día de la semana y comenzando a contar desde 0.
%V Visualiza el número de semana del año, tomando el lunes como primer día de la semana y comenzando a contar desde 1.
% w Visualiza el día de la semana en número, tomando el domingo como primer día de la semana y comenzando a contar desde 0.
%W Visualiza el número de semana del año, tomando el lunes como primer día de la semana y comenzando a contar desde 0.
%x Visualiza la fecha con el formato dd/mm/aa.
%X Visualiza la hora con el formato hh:mm:ss, utilizando un reloj de 24 horas.
%y Visualiza los dos últimos dígitos del año.
%Y Visualiza el año con cuatro dígitos.
Ejemplos.
1. Visualizar la fecha y la hora del sistema sin utilizar ningún argumento.
date
2. Visualizar el día de la semana en formato largo.
date ‘+%A’
3. Visualizar la fecha del sistema con el formato dd/mm/aa.
date ‘+%x’
4. Visualizar la hora del sistema con el formato hh:mm:ss, utilizando el reloj de 24 horas.
date ‘+%X’
5. Visualizar la fecha y la hora del sistema con el siguiente formato:
diasemanaddmesaahh:mm:ss, donde diasemana y mes se representarán en letras y en formato largo.
date ‘+%A%d%B%y%X’
Observar que la fecha y la hora del sistema se visualizan sin espacios en blanco.
6. Repetir el ejercicio anterior dejando espacios en blanco.
date ‘+%A %d %B %y %X’
7. Repetir el ejercicio anterior utilizando el siguiente formato:
120

diasemana, dd de mes de aaaa hh:mm:ss
date ‘+%A, %d de %B de %Y %X’
8. Repetir el ejercicio anterior utilizando el siguiente formato:
Fecha: diasemana, dd de mes de aaaa Hora: hh:mm:ss
date ‘+Fecha: %A, %d de %B de %Y Hora: %X’
9. Repetir el ejercicio anterior utilizando el siguiente formato:
Fecha: diasemana, dd de mes de aaaa Hora: hh:mm:ss
date ‘+Fecha: %A, %d de %B de %Y %nHora: %X’
10.5.3 Comando finger.
Muestra información de los usuarios conectados al sistema. La información se muestra por columnas.
La sintaxis es la siguiente:
finger [opciones] [usuario1 [usuario2 ...]]
La opción más utilizada es –l, que muestra información adicional sobre los usuarios indicados.
10.5.4 Comando id.
Muestra el nombre de los usuarios y los grupos a los que pertenecen.
La sintaxis es:
id [opciones] [usuario]
Si se ejecuta el comando id sin opciones, muestra información sobre el usuario conectado al sistema.
Si se introduce el nombre de un usuario, muestra información sobre dicho usuario.
Las opciones pueden ser:
-g.
Visualiza el número del grupo principal al que pertenece el usuario.
-G.
Visualiza el número de todos los grupos a los que pertenece el usuario.
-u.
Visualiza el número de usuario.
-n.
Se utiliza en combinación con las opciones –g, -G y –u. Visualiza el nombre del usuario o de los grupos al que pertenece, dependiendo de la opción con la que se utilice.
121

Ejemplos.
1. Visualizar el grupo al que pertenece el usuario que está conectado al sistema.
id –g
2. Visualizar información sobre el usuario root.
id root
3. Visualizar los números de todos los grupos a los que pertenece el usuario root.
id –G root o también id –r –G root
4. Visualizar los nombres de todos los grupos a los que pertenece el usuario root.
id –n –G root
10.5.5 Comando logname.
Muestra el nombre de usuario con el que se ha accedido al sistema. El nombre del usuario se almacena en la variable $LOGNAME.
La sintaxis es:
logname
Ejemplo.
1. Mostrar el nombre del usuario conectado al sistema.
logname
10.5.6 Comando sleep.
Se utiliza para ejecutar los comandos indicados en el tiempo especificado.
La sintaxis es la siguiente:
sleep número[s,m,h,d]
El tiempo se puede expresar en segundos, minutos, horas y días. Por defecto, se toman segundos.
Una vez ejecutado el comando, hay que introducir los comandos que se ejecutarán en el tiempo indicado.
10.5.7 Comando stty.
Se utiliza para mostrar o modificar las teclas de control del terminal.
La sintaxis es la siguiente:
stty [-a] [campo valor]
122

Si se utiliza stty sin opciones, se muestra información sobre el terminal.
La opción –a muestra los campos utilizados para el control del terminal y sus valores.
Si se quiere modificar el valor de un campo, hay que escribir el campo que se desea cambiar y su nuevo valor.
Ejemplo.
El campo intr contiene las teclas que hay que utilizar para abortar un proceso que se está ejecutando en primer plano. Estas teclas son Ctrl-C. Si se desea cambiar estas teclas por la tecla k (kill), hay que introducir la orden siguiente:
stty intr k
10.5.8 Comando tty.
Visualiza el controlador de terminal asignado y su ruta de acceso.
La sintaxis es:
tty
10.5.9 Comando uname.
Visualiza información sobre el sistema.
La sintaxis es:
uname [opciones]
Si se utiliza el comando sin opciones, muestra el nombre del sistema operativo.
Las opciones pueden ser:
-m.
Visualiza el nombre de la CPU.
-n.
Visualiza el nombre del nodo (servidor y dominio).
-r.
Visualiza la versión Unix o Linux instalada.
-a.
Visualiza toda la información anterior.
Ejemplos.
1. Visualizar el nombre del sistema operativo.
uname
2. Visualizar el nombre de la CPU.
123

uname –m
3. Visualizar el nombre del nodo.
uname –n
4. Visualizar la versión del sistema operativo instalada.
uname –r
5. Visualizar toda la información del sistema.
uname –a
10.5.10 Comando hostname.
Visualiza el nombre del host del equipo desde el que se ejecuta la orden. El host de un equipo se muestra con la sintaxis equipo.dominio.
La sintaxis de este comando es la siguiente:
hostname [opciones]
Si se ejecuta el comando hostname sin opciones, se muestra el nombre del host del equipo. Para ver las opciones, consultar la página de la orden man para este comando.
Para cambiar el nombre del host hay que acceder al archivo /etc/sysconfig/network y asignar a la variable de entorno HOSTNAME el nuevo nombre del host. Además, hay que modificar el contenido del archivo /etc/hosts, escribiendo el nombre del host asignado a la variable HOSTNAME. En el archivo /etc/hosts también se puede asignar una nueva dirección IP al host.
124

11.El editor de textos vi.
11.1. INTRODUCCIÓN.
El Editor vi es un editor de textos a pantalla completa. La pantalla del editor vi consta de 23 líneas para texto y una línea de estado. Esta última se utiliza para mostrar mensajes de error y otra serie de informaciones e introducir determinadas órdenes.
El editor vi permite dos modos de operación:
Modo de orden.
Es el modo por defecto en el que se inicia vi. En este modo, las teclas que se pulsen no formarán parte del texto, sino que realizarán diferentes acciones (borrar líneas, buscar palabras, mover el cursor por la pantalla, etc.). Algunas órdenes comienzan con los caracteres ‘:’, ‘/’ y ‘?’. Estas órdenes se escriben en la línea de estado. Para cambiar al modo de entrada de texto hay que ejecutar una orden para introducir texto.
Modo de entrada de texto.
Es el modo destinado a escribir el contenido del fichero que se está editando. Para cambiar al modo de orden hay que pulsar la tecla Esc.
125

11.2. ENTRADA AL EDITOR VI.
Para ejecutar el editor vi hay que utilizar la siguiente sintaxis:
vi [opciones] [archivo]
Si no se especifica el nombre del archivo a editar, vi presenta la pantalla de inicio. Esta pantalla consta de 23 líneas que comienzan con el carácter ‘~’, información sobre vi en el centro de la pantalla y la información Empty Buffer en la línea de estado. Cuando se sale de vi hay que especificar un nombre de archivo.
Si se especifica un nombre de archivo puede ocurrir que el archivo no exista, en cuyo caso se muestra la pantalla de inicio, o que el archivo exista, en cuyo caso se muestran las primeras 23 líneas del archivo y, en la línea de estado, el nombre, número de líneas y número de caracteres del archivo.
Cuando entramos en vi estamos en modo de orden.
Las opciones son las siguientes:
+número.
El editor vi muestra el archivo con el cursor al principio de la línea especificada en número.
-c orden.
Se utiliza para ejecutar una orden del editor vi cuando se abre un archivo con dicho editor.
Ejemplo.
vi –c /caracteres carta
Abre el archivo carta y busca la cadena caracteres en dicho archivo. Si encuentra la cadena, el cursor se posiciona en ella, pudiendo continuar la búsqueda. Si la cadena no se encuentra, se muestra un mensaje de error y se visualiza la primera página del archivo.
-r.
Si, cuando estamos editando un archivo, el sistema sale del editor vi de forma incorrecta por cualquier circunstancia, los cambios realizados en el archivo no se graban. En este caso, podemos intentar recuperar los cambios que no se han podido almacenar introduciendo la orden vi –r archivo.
-R.
El archivo se abre en modo sólo lectura. Si se ejecuta alguna orden para insertar texto, se muestra el mensaje Warning: Changing a readonly file, permitiendo escribir el nuevo texto. Si se ejecuta una orden para grabar el contenido del archivo, se muestra el mensaje ‘readonly’ option is set (use ! to overide), permitiendo grabar el contenido del archivo si se ejecutan las órdenes :wq! o :w!.
126

11.3. SALIDA DEL EDITOR VI.
Para salir del editor, vi debe estar en el modo de orden. Si estamos en el modo de texto, para volver al modo de orden hay que pulsar la tecla Esc. A continuación, hay que escribir :wq para guardar y salir. Si queremos permanecer en el editor y guardar los cambios, hay que ejecutar la orden :w.
Si hemos entrado al editor sin escribir un nombre de archivo, hay que escribir :wq archivo si queremos grabar y salir o :w archivo si queremos grabar sin salir.
Podemos guardar los cambios realizados en otro archivo. Para ello, hay que ejecutar la orden :wq archivo1 o :w archivo1. Si archivo1 no existe, se crea. Si archivo1 existe, el editor vi muestra el mensaje File exists (use ! to override). En este caso, si queremos sobrescribir archivo1, hay que ejecutar las órdenes :wq! Archivo1 o :w! archivo1.
También se puede almacenar una parte del archivo que se está editando en otro archivo. Para ello, hay que ejecutar la orden :líneainicial,líneafinal wq archivo1 o :líneainicial,líneafinal w archivo1. Si archivo1 existe, hay que utilizar la misma sintaxis con el carácter ‘!’ después de las órdenes wq o w.
Si no se han realizado modificaciones, se puede salir de vi escribiendo :q. Si se han realizado modificaciones pero no se van a guardar, hay que escribir :q!.
Después de todas las órdenes anteriores hay que pulsar la tecla Enter.
Otra forma de salir de vi guardando las modificaciones es escribiendo ZZ. En este caso no hay que pulsar la tecla Enter. También se sale del editor vi, almacenando los cambios, ejecutando la orden :x.
127

11.4. ÓRDENES DE DESPLAZAMIENTO DEL CURSOR.
Tecla AvPág.
Avanza una página. Esta tecla se puede pulsar en el modo de orden y en el modo de entrada de texto.
Tecla RePág.
Retrocede una página. Esta tecla se puede pulsar en el modo de orden y en el modo de entrada de texto.
Ctrl-d.
Avanza media página.
Ctrl-g.
Muestra un mensaje con el nombre del archivo, si el archivo ha sido modificado, la línea donde se encuentra el cursor, el total de líneas, el porcentaje del archivo con respecto a la línea donde está posicionado el cursor y la columna donde se encuentra el cursor.
Ctrl-u.
Retrocede media página.
Tecla Enter.
Mueve el cursor al principio de la línea siguiente.
‘’.
Mueve el cursor a su posición anterior. De esta forma, pulsando repetidas veces esta orden, se pueden visualizar dos partes de un archivo, pues el cursor, cada vez que se teclee ‘’, se moverá a la posición donde se encontraba anteriormente.
+.
Mueve el cursor al principio de la línea siguiente.
-.
Mueve el cursor al principio de la línea anterior.
(.
Mueve el cursor a la frase anterior.
).
Mueve el cursor a la frase siguiente.
{.
Mueve el cursor al principio del párrafo anterior.
}.
128

Mueve el cursor al principio del párrafo siguiente. $.
Mueve el cursor al final de la línea. Esta acción se puede realizar con la tecla Fin, que se puede pulsar en el modo de orden y en el modo de entrada de texto.
0 (cero).
Mueve el cursor al principio de la línea. Esta acción se puede realizar con la tecla Inicio, que se puede pulsar en el modo de orden y en el modo de entrada de texto.
:número.
Posiciona el cursor en la línea indicada en número.
b.
Mueve el cursor al principio de la palabra anterior.
e.
Mueve el cursor al final de la palabra. Si el cursor está situado al final de una palabra y se ejecuta la orden e, el cursor se desplaza al final de la palabra siguiente.
gg.
Posiciona el cursor en el primer carácter de la primera línea del fichero.
[número]G.
Posiciona el cursor en la línea especificada en número. Si se omite número, el cursor se posiciona en el primer carácter de la última línea del fichero.
[número]h.
Mueve el cursor al carácter situado a la izquierda. Si se especifica número, el cursor se desplaza los caracteres indicados. Esta acción también se puede realizar pulsando [número]←,que se puede teclear en el modo de orden y en el modo de entrada de texto.
H.
Mueve el cursor al primer carácter de la primera línea de la pantalla.
[número]j.
Mueve el cursor una línea hacia abajo. Si se especifica número, el cursor se desplaza las líneas indicadas. Esta acción también se puede realizar pulsando [número]↓, que se puede teclear en el modo de orden y en el modo de entrada de texto.
k.
Mueve el cursor una línea hacia arriba. Si se especifica número, el cursor se desplaza las líneas indicadas. Esta acción también se puede realizar pulsando [número]↑, que se puede teclear en el modo de orden y en el modo de entrada de texto.
l.
129

Mueve el cursor al carácter situado a la derecha. Si se especifica número, el cursor se desplaza los caracteres indicados. Esta acción también se puede realizar pulsando [número]→, que se puede teclear en el modo de orden y en el modo de entrada de texto.
L.
Mueve el cursor al primer carácter de la última línea de la pantalla.
mletra.
Se utiliza para realizar marcas. Las marcas se nombran con una letra de la a a la z, por lo que se pueden establecer 26 marcas. Para desplazarse a una marca hay que escribir ‘ letra, donde letra es una marca que se ha realizado previamente.
M.
Mueve el cursor al primer carácter de la línea de la mitad de la pantalla. w.
Mueve el cursor al principio de la palabra siguiente.
z. .
La orden z seguida de un punto (.) mueve la línea donde está posicionado el cursor a la mitad de la pantalla.
z- .
La orden z seguida de un guión (-) mueve la línea donde se encuentra el cursor al final de la pantalla.
130

11.5. ÓRDENES PARA MODIFICAR TEXTO.
.(punto).
Repite la última orden ejecutada
a.
El texto que se escriba se inserta a continuación de la posición del cursor.
A.
El texto se inserta al final de la línea.
línea1[,línea2]colínea3.
La orden co se utiliza para copiar líneas. En esta sintaxis, línea1 y línea2 indican el rango de líneas que se quieren copiar (si se omite línea2 sólo se copiará una línea) y línea3 indica la línea a partir de la cual se va a copiar el texto. Si el texto se va a copiar al principio del archivo, asignaremos el valor 0 a línea3.
[número] dd.
Borra la línea donde se encuentra el cursor. Si escribimos un número y ejecutamos la orden dd, se borran las líneas especificadas en número, desde la posición del cursor hacia abajo. Las líneas borradas se pueden copiar utilizando las órdenes p o P.
i.
El texto que se escriba se inserta antes de la posición del cursor.
I.
El texto se inserta al principio de la línea.
J.
Une la línea donde se encuentra el cursor y la siguiente. Si el resultado de la unión supera la longitud de la línea, vi parte la línea en dos, aunque las dos líneas son la misma.
línea1[,línea2]mlínea3.
La orden m utilizada con esta sintaxis se utiliza para mover líneas. En esta sintaxis, línea1 y línea2 indican el rango de líneas que se quieren mover (si se omite línea2 sólo se moverá una línea) y línea3 indica la línea hasta la que se va a insertar el texto. Si el texto se va a insertar al principio del archivo, asignaremos el valor 0 a línea3.
o.
Inserta una línea en blanco debajo de la línea actual.
O.
Inserta una línea en blanco encima de la línea actual.
p.
131

Copia líneas o caracteres borrados con las órdenes [número]dd o [número]x o líneas copiadas con la orden yy. La copia la realiza en la línea anterior donde se encuentra el cursor si copia líneas o a continuación del carácter donde está posicionado el cursor si copia caracteres.
P.
Copia líneas o caracteres borrados con las órdenes dd o [número] x o líneas copiadas con la orden yy. La copia la realiza en la línea posterior donde se encuentra el cursor si copia líneas o antes del carácter donde está posicionado el cursor si copia caracteres.
r.
Cambia el carácter donde está situado el cursor por el que se escriba después de ejecutar la orden r. Una vez que el carácter se ha cambiado, se vuelve al modo de orden. Por lo tanto, esta orden se utiliza para cambiar o sobreescribir un solo carácter. Esta acción se puede realizar con la tecla Insert, que se puede pulsar en el modo de orden y en el modo de entrada de texto.
R.
Igual que la orden r, pero esta orden cambia varios caracteres, pues después de ejecutarla, el editor vi cambia al modo de entrada de texto y se cambian o sobreescriben todos los caracteres tecleados.
s.
Borra el carácter donde se encuentra el cursor y los siguientes caracteres que se tecleen se insertan a continuación.
u.
Restaura los cambios realizados en el texto. Si se pulsa la orden u repetidamente, se restauran las modificaciones realizadas en el texto hasta que suena un pitido, en cuyo caso se han finalizado todas las restauraciones que se pueden realizar.
U.
Restaura los cambios efectuados en el texto sobre una línea. Esta orden siempre actúa sobre la última línea que se ha modificado.
[número]x.
Borra el carácter en el que está situado el cursor. Después de borrar el carácter, vi permanece en modo de orden, por lo que se pueden seguir borrando caracteres introduciendo nuevamente la orden x. Si escribimos un número y, seguidamente, ejecutamos la orden x, se borran los caracteres, a partir de la posición del cursor, especificados en número. También se puede utilizar la tecla Supr para borrar caracteres, que se puede pulsar en el modo de orden y en el modo de entrada de texto. Los caracteres borrados se pueden copiar utilizando las órdenes p o P.
xp.
Cambia el orden de los caracteres donde está situado el cursor y el siguiente. Por ejemplo, si hemos escrito Liunx, posicionamos el cursor en el carácter u y ejecutamos la orden xp, cambiándose el orden de los caractes un, quedando escrita la palabra Linux.
[número]yy.
132

Copia la línea donde se encuentra el cursor en un buffer temporal (portapapeles). Si se especifica número, se copian las líneas indicadas. Estas líneas se pueden copiar en otra parte del archivo utilizando las órdenes p o P.
11.6. ÓRDENES DE EDICIÓN AVANZADA.
La edición avanzada nos va a permitir combinar las órdenes para modificar texto y cambiar el ámbito de actuación de algunas de estas órdenes, combinándolas con las órdenes de desplazamiento del cursor.
11.6.1 Órdenes de borrado.
d$.
Borra el texto desde la posición del cursor hasta el final de la línea.
d).
Borra la frase siguiente.
d(.
Borra la frase anterior.
d}.
Borra el párrafo siguiente.
d{.
Borra el párrafo anterior.
d/cadena/.
Borra todas las líneas comprendidas entre la línea donde se encuentra el cursor y la línea que contiene la cadena especificada.
d’marca.
Borra todas las líneas comprendidas entre la marca especificada y la línea donde se encuentra el cursor.
d0.
Borra el texto desde la posición del cursor hasta el principio de la línea.
:línea1,línea2d.
Borra las líneas comprendidas entre línea1 y línea2.
[número]db.
Borra la palabra anterior a la posición del cursor. Si se especifica número, se borran las palabras indicadas. Si en la línea donde se encuentra el cursor no hay número palabras, continúa borrando en la línea anterior.
[número]de.
Borra hasta el final de la palabra donde se encuentra el cursor. Si especificamos número, se borra desde la palabra donde se encuentra el cursor hasta número-1 palabras situadas
133

a continuación. Se borran número-1 palabras porque la palabra donde se encuentra el cursor está incluida en número. Si en la línea donde se encuentra el cursor no hay número palabras, continúa borrando en la línea siguiente.
dG.
Borra todas las líneas comprendidas entre la línea donde se encuentra el cursor y el final del archivo.
[número]dw.
Borra la palabra situada a continuación de la posición del cursor. Si especificamos número, se borran las palabras indicadas. Si en la línea donde se encuentra el cursor no hay número palabras, continúa borrando en la línea siguiente.
134

11.6.2 Órdenes de copia.
y$.
Copia el texto, en el buffer temporal, desde la posición del cursor hasta el final de la línea.
y).
Copia la frase siguiente.
y(.
Copia la frase anterior.
y}.
Copia el párrafo siguiente.
y{.
Copia el párrafo anterior.
y/cadena/.
Copia todas las líneas comprendidas entre la línea donde se encuentra el cursor y la línea que contiene la cadena especificada.
y’marca.
Copia todas las líneas comprendidas entre la marca especificada y la línea donde se encuentra el cursor.
y0.
Copia el texto, en el buffer temporal, desde la posición del cursor hasta el principio de la línea.
:línea1,línea2y.
Copia las líneas comprendidas entre línea1 y línea2.
[número]yb.
Copia, en el buffer temporal, la palabra anterior a la posición del cursor. Si se especifica número, se copian las palabras indicadas. Si en la línea donde se encuentra el cursor no hay número palabras, continúa copiando de la línea anterior.
[número]ye.
Copia, en el buffer temporal, hasta el final de la palabra donde se encuentra el cursor. Si especificamos número, se copia desde la palabra donde se encuentra el cursor hasta número-1 palabras situadas a continuación. Se copian número-1 palabras porque la palabra donde se encuentra el cursor está incluida en número. Si en la línea donde se encuentra el cursor no hay número palabras, continúa copiando de la línea siguiente.
yG.
135

Copia todas las líneas comprendidas entre la línea donde se encuentra el cursor y el final del archivo.
[número]yw.
Copia, en el buffer temporal, la palabra situada a continuación de la posición del cursor. Si especificamos número, se copian las palabras indicadas. Si en la línea donde se encuentra el cursor no hay número palabras, continúa copiando de la línea siguiente.
136

11.6.3 Órdenes de cambio de caracteres.
Todas las órdenes siguientes cambian del modo de orden al modo de entrada de texto. Para volver al modo de orden hay que pulsar la tecla Esc.
c$.
Borra el texto desde la posición del cursor hasta el final de la línea. Los caracteres que se tecleen sustituyen al texto borrado.
c).
Borra la frase siguiente. Los caracteres que se tecleen sustituyen al texto borrado.
c(.
Borra la frase anterior. Los caracteres que se tecleen sustituyen al texto borrado.
c}.
Borra el párrafo siguiente. Los caracteres que se tecleen sustituyen al texto borrado. c{.
Borra el párrafo anterior. Los caracteres que se tecleen sustituyen al texto borrado.
c/cadena/.
Borra todas las líneas comprendidas entre la línea donde se encuentra el cursor y la línea que contiene la cadena especificada. Los caracteres que se tecleen sustituyen al texto borrado.
c’marca.
Borra todas las líneas comprendidas entre la marca especificada y la línea donde se encuentra el cursor. Los caracteres que se tecleen sustituyen al texto borrado.
c0.
Borra el texto desde la posición del cursor hasta el principio de la línea. Los caracteres que se tecleen sustituyen al texto borrado.
:línea1,línea2c.
Borra las líneas comprendidas entre línea1 y línea2. A continuación se escriben las nuevas líneas y, para detener el estado de inserción, se pulsa la tecla Esc. En este momento se realiza la sustitución.
[número]cb.
Borra la palabra anterior a la posición del cursor. Si se especifica número, se borran las palabras indicadas. Si en la línea donde se encuentra el cursor no hay número palabras, continúa borrando en la línea anterior. Los caracteres que se tecleen sustituyen al texto borrado.
[número]cc.
137

Borra la línea donde se encuentra el cursor. Si se especifica número, se borran las líneas indicadas. Los caracteres que se tecleen sustituyen a la/s línea/s borrada/s.
[número]ce.
Borra hasta el final de la palabra donde se encuentra el cursor. Si especificamos número, se borra desde la palabra donde se encuentra el cursor hasta número-1 palabras situadas a continuación. Se borran número-1 palabras porque la palabra donde se encuentra el cursor está incluida en número. Si en la línea donde se encuentra el cursor no hay número palabras, continúa borrando en la línea siguiente. Los caracteres que se tecleen sustituyen al texto borrado.
cG.
Borra todas las líneas comprendidas entre la línea donde se encuentra el cursor y el final del archivo. Los caracteres que se tecleen sustituyen al texto borrado.
[número]cw.
Borra la palabra situada a continuación de la posición del cursor. Si especificamos número, se borran las palabras indicadas. Si en la línea donde se encuentra el cursor no hay número palabras, continúa borrando en la línea siguiente. Los caracteres que se tecleen sustituyen al texto borrado.
Estas órdenes de borrado y copiado se utilizan en combinación con las órdenes p y P, para pegar el texto copiado en el buffer temporal en una determinada posición del fichero. De esta forma, las órdenes p y P actúan de la siguiente manera:
[número]p.
Inserta el texto copiado en el buffer temporal a continuación del carácter donde se encuentra el cursor. Si se especifica número, el texto se inserta repetido el número de veces indicado.
[número]P.
Inserta el texto copiado en el buffer temporal antes del carácter donde se encuentra el cursor. Si se especifica número, el texto se inserta repetido el número de veces indicado.
138

11.7. ÓRDENES PARA BUSCAR Y SUSTITUIR CARACTERES.
/ caracteres.
Busca, desde la posición del cursor hacia delante, la cadena de caracteres especificada. Si los caracteres a buscar no se encuentran, se muestra el mensaje Pattern not found: caracteres.
? caracteres.
Busca, desde la posición del cursor hacia atrás, la cadena de caracteres especificada. Si los caracteres a buscar no se encuentran, se muestra el mensaje Pattern not found: caracteres.
n.
Continúa la búsqueda de los caracteres especificados en la orden ejecutada previamente (/,?). Si se ha ejecutado la orden /, la búsqueda continúa hacia delante. Cuando llega al final del fichero se muestra el mensaje search hit BOTTOM, continuing at TOP. Si se ha ejecutado la orden ?, la búsqueda continúa hacia atrás. Cuando llega al principio del fichero se muestra el mensaje search hit TOP, continuing at BOTTOM.
N.
Continúa la búsqueda de los caracteres especificados en la orden ejecutada previamente (/,?). Si se ha ejecutado la orden /, la búsqueda continúa hacia atrás. Cuando llega al principio del fichero se muestra el mensaje search hit TOP, continuing at. Si se ha ejecutado la orden ?, la búsqueda continúa hacia delante. Cuando llega al final del fichero se muestra el mensaje BOTTOM search hit BOTTOM, continuing at TOP.
Al introducir la cadena de caracteres a buscar, se pueden utilizar los siguientes caracteres:
^.
El carácter ^ indica que el texto se busque al principio de la línea. Para introducir el acento circunflejo (^) hay que pulsar la tecla ^ y, después, la barra espaciadora.
$.
El símbolo $ indica que el texto se busque al final de la línea.
%.
Se utiliza para buscar paréntesis, corchetes y llaves. Para realizar la búsqueda el cursor tiene que estar situado sobre un paréntesis, corchete o llave. Por ejemplo, si el cursor está situado sobre el paréntesis abierto ‘(‘ busca, hacia delante, el siguiente paréntesis cerrado ‘)’; si está situado sobre el paréntesis cerrado ‘)‘ busca, hacia atrás, el anterior paréntesis abierto ‘(’. De la misma forma funciona para buscar corchetes y las llaves.
\<.
Los caracteres \< indican que el texto se busca al principio de las palabras.
*.
Busca la palabra donde se encuentra situado el cursor. Para continuar la búsqueda se puede pulsar n para buscar hacia delante y N para buscar hacia atrás. Si se pulsa *
139

repetidas veces, la búsqueda se sigue realizando hacia delante. Cuando se pulsa * por primera vez, en la línea de estado se muestra /\<palabra\>, donde palabra es la cadena que se está buscando.
Otras órdenes para buscar caracteres son las siguientes:
fcarácter.
Busca el carácter especificado en la línea donde se encuentra el cursor. La búsqueda se realiza hacia delante. Si se pulsa el carácter “;” se continúa buscando hacia delante. Si se pulsa el carácter “,” se continúa buscando hacia atrás.
Fcarácter.
Busca el carácter especificado en la línea donde se encuentra el cursor. La búsqueda se realiza hacia atrás. Si se pulsa el carácter “;” se continúa buscando hacia atrás. Si se pulsa el carácter “,” se continúa buscando hacia delante.
El editor vi permite buscar una cadena de caracteres y sustituirlos por otra cadena. Para ello, hay que utilizar la siguiente sintaxis:
:línea1,línea2 s/cadena1/cadena2
línea1 y línea2 son las líneas entre las que se va a realizar la búsqueda y la sustitución.
cadena1 indica los caracteres que se van a buscar y cadena2 indica los caracteres que van a sustituir a los caracteres buscados.
Si a línea1 le asignamos el valor 1 y a línea2 le asignamos el valor $, la búsqueda y la sustitución se realizará en todo el archivo.
Ejemplos.
:4,20 s/Unix/Linux
Busca la cadena Unix entre las líneas 4 y 20 y, si la encuentra, la sustituye por la cadena Linux.
:1,$ s/Unix/Linux
Busca la cadena Unix en todo el archivo y, si la encuentra, la sustituye por la cadena Linux.
140

11.8. EDICIÓN DE MÚLTIPLES ARCHIVOS.
El editor vi permite editar varios archivos de forma simultánea. Para ello, hay que ejecutar una de las siguientes órdenes:
vi archivo1 archivo2 [archivo3 ...]
El editor vi muestra la primera página del primer archivo escrito en la orden. Si introducimos una orden para salirnos de un archivo sin haber editado los otros, se muestra un mensaje avisando de los archivos que quedan por editar. Si, aún así, deseamos salirnos, hay que ejecutar nuevamente la orden de salida del editor.
:e archivo.
Edita el archivo especificado sin salir del editor vi. Si el archivo actual se ha modificado y no se ha grabado, se muestra el mensaje No write since last change (use ! to override), debiendo grabar el contenido del fichero para editar el siguiente archivo. Si no se quieren grabar las modificaciones, hay que ejecutar la orden :e! archivo.
Para gestionar la edición de múltiples archivos se pueden ejecutar las siguientes órdenes:
:ar.
Muestra una lista de los archivos que se están editando. El archivo actual se visualiza entre corchetes.
:e#.
Se visualiza el archivo anterior de la lista de archivos editados. Si se vuelve a introducir la orden, se visualiza el archivo que se estaba mostrando cuando se introdujo la orden por primera vez.
:n.
Edita el siguiente archivo de la lista de archivos editados. Si el archivo actual se ha modificado y no se ha grabado, se muestra el mensaje No write since last change (use ! to override), debiendo grabar el contenido del fichero para editar el siguiente archivo. Si no se quieren grabar las modificaciones, hay que ejecutar la orden :n!.
Ejemplo.
Ejecutamos la orden vi prueba texto carta. Se visualiza el archivo prueba. Ejecutamos :n y se visualiza el archivo texto. Ejecutamos :n y se visualiza el archivo carta. Si ejecutamos :e#, se visualiza el archivo texto. Si volvemos a ejecutar :e# se visualiza el archivo carta. A partir de este momento, cada vez que ejecutemos :e# se visualizarán, de forma alternativa, los archivos texto y carta.
Existe una orden para mezclar el contenido de los archivos. Esta orden es la siguiente:
:r archivo.
El contenido del archivo especificado se añade a partir de la línea siguiente donde se encuentra el cursor.
141

11.9. BUFFERS DEL EDITOR VI.
El editor vi utiliza buffers temporales para guardar los caracteres y las líneas que se borran o copian. El contenido de estos buffers se puede insertar en la posición del archivo que se desee. Para ello, hay que acceder al buffer que contiene la información requerida.Existen dos tipos de buffers:
11.9.1 Buffers numéricos.
Los buffers numéricos que utiliza el editor vi son nueve y están numerados del 1 al 9. Cuando se borran o se copian líneas, vi utiliza estos buffers para almacenar la información borrada o copiada.
Cuando se borran líneas, los buffers numéricos funcionan de la siguiente forma: la primera información borrada se almacena en el buffer 1. La siguiente información que se borre también se almacena en el buffer 1, pasando el contenido del buffer 1 al buffer 2. La siguiente información que se borre también se almacena en el buffer 1, pasando el contenido del buffer 1 al buffer 2 y el del buffer 2 al buffer 3. Este es el funcionamiento de los buffers. Cuando todos los buffers están llenos y se borra nueva información, la información contenida en el buffer 9 se pierde.
En las operaciones de copiado de líneas, hay que indicar el buffer en el que se van a almacenar las líneas copiadas. Si el buffer especificado contenía información, se cambia por las líneas copiadas. Esta operación se realiza con la siguiente sintaxis:
“buffer[número]yy, donde buffer es el número de buffer donde se van a almacenar las líneas copiadas y número indica el número de líneas que se van a copiar. Si se omite número, se copia la línea donde se encuentra el cursor.
Para recuperar la información de los buffers hay que utilizar la siguiente sintaxis:
“númerop
“númeroP
donde número indica el buffer cuya información se quiere recuperar y p P son las órdenes para recuperar e insertar la información del buffer especificado.
Estas órdenes no se visualizan en la pantalla y no hay que pulsar la tecla Enter para su ejecución.
El contenido de los buffers numéricos se mantiene cuando se edita un nuevo fichero sin salir del editor vi. De esta forma se puede copiar texto de un fichero a otro. Cuando se sale del editor vi, el contenido de los buffers numéricos se borra.
142

11.9.2 Buffers alfabéticos.
Los buffers alfabéticos se utilizan para almacenar la información borrada o copiada. El editor vi utiliza 26 buffers alfabéticos, nombrados desde la letra a (minúscula) hasta la letra z (minúscula). Cuando se utilizan los buffers alfabéticos, hay que especificar el buffer donde se va a guardar la información borrada o copiada. La información contenida en cada buffer se mantiene hasta que dicho buffer no se vuelva a utilizar. Cuando se almacena información en un buffer alfabético en una operación de borrado, también se guarda en el buffer numérico 1.
La sintaxis para almacenar la información en los buffers alfabéticos es la siguiente:
“letraorden
donde letra indica el buffer alfabético donde se va a guardar la información y orden es el comando para borrar o copiar la información que se desea almacenar en el buffer.
Para recuperar la información de los buffers alfabéticos, hay que utilizar la siguiente sintaxis:
“letrap
“letraP
donde letra indica el buffer cuya información se quiere recuperar y p P son las órdenes para recuperar e insertar la información del buffer especificado.
El contenido de los buffers alfabéticos se mantiene cuando se edita un nuevo fichero sin salir del editor vi. De esta forma se puede copiar texto de un fichero a otro. Cuando se sale del editor vi, el contenido de los buffers alfabéticos se borra.
143

11.10.EJECUCIÓN DE ÓRDENES DEL SHELL.
Durante la edición de archivos con el editor vi se pueden ejecutar órdenes del Shell. Para ello, hay que utilizar la sintaxis :! orden. El sistema ejecuta la orden indicada y visualiza el mensaje Press RETURN or enter command to continue.
Se puede insertar el resultado de la orden ejecutada a continuación del carácter donde se encuentra el cursor. Para ello, hay que escribir :r ! orden.
También se pueden ejecutar comandos del shell desde un subshell. Esto significa que aparentemente se ha salido del editor vi para ejecutar comandos, pero, después de ejecutar los comandos necesarios, se puede regresar el editor vi y seguir la sesión que se había iniciado antes de salir al subshell. Esta acción se realiza ejecutando la orden :sh. A continuación, se muestra el prompt del shell y se pueden ejecutar comandos del shell. Para regresar al editor vi hay que introducir la orden exit desde el shell.
144

11.11.CONFIGURACIÓN DEL EDITOR VI.
El editor vi tiene una gran cantidad de opciones de configuración. Estas opciones se pueden ver utilizando la orden :set all.
Todas las opciones de configuración tienen un valor por defecto. Para personalizar el entorno de trabajo de vi, hay que modificar las opciones deseadas. Estas opciones se modifican con la orden set.
Las opciones de configuración pueden ser de tres tipos:
Booleanas.
Tienen el valor verdadero o falso, activada o desactivada, etc. Para activar una opción booleana se utiliza la sintaxis :set Opción. Para desactivar una opción booleana se utiliza la sintaxis set noOpción.
Numéricas.
Contienen valores numéricos. Cada opción tiene un rango de valores admitidos. Para asignar un valor a una opción numérica se utiliza la sintaxis :set Opción=número, donde número ha de estar comprendido en el rango de valores permitido para la opción.
Cadena.
Contienen valores de tipo cadena. Para asignar un valor a una opción de tipo cadena se utiliza la sintaxis :set Opción=cadena.
La orden set se puede utilizar, además, para mostrar las opciones que se han cambiado. En este caso se utiliza la sintaxis :set. También se puede visualizar el valor de una opción, utilizando la sintaxis :set Opción?.
Algunas opciones de configuración son las siguientes:
autoindent (ai).
Es la opción de autosangrado y es de tipo booleana. Si está activada, cada línea se alinea con la anterior. Para activar esta opción se utiliza :set ai y para desactivarla :set noai. El valor por defecto es activada. Se puede utilizar Ctrl-d para retroceder, en la misma línea, a los niveles de sangrado anteriores. Ctrl-d retrocede las columnas especificadas en la opción shiftwidth.
autowrite(aw).
Es una opción de tipo booleana. Para activarla hay que ejecutar :set aw y para desactivarla :set noaw. Por defecto, está activada. Cuando está activada, los cambios realizados en un archivo se guardan automáticamente al ejecutar un comando del shell o al ejecutar la orden :n para visualizar un nuevo archivo en una edición de múltiples archivos.
ignorecase (ic).
Es una opción de tipo booleana. Se utiliza para que vi no distinga mayúsculas y minúsculas en las operaciones de búsqueda. Para que no distinga mayúsculas y minúsculas se escribe :set ic. Para que sí distinga mayúsculas y minúsculas se utiliza :set noic, que es la opción por defecto.
145

list.
Muestra los tabuladores como ^I y los retornos de fin de línea con el carácter $. Para activar esta opción se utiliza :set list y para desactivarla :set nolist. El valor por defecto es desactivado.
magic.
Es una opción de tipo booleana. Se utiliza para indicar que algunos caracteres, como los corchetes, sean caracteres especiales. Para que estos caracteres sean tomados como especiales se escribe :set magic. Para que estos caracteres no sean tomados como especiales se escribe :set nomagic, que es la opción por defecto.
number (nu).
Es una opción de tipo booleana. Por defecto, vi no escribe los números de línea porque esta opción tiene el valor :set nonu. Para que se visualicen los números de línea, hay que ejecutar :set nu.
report.
Es una opción de tipo numérica. Se utiliza para que el editor vi muestre mensajes de las operaciones que se están realizando, cuando estas operaciones afecten a más líneas que las especificadas en esta opción. Por defecto, su valor es 5, lo cual quiere decir que si, por ejemplo, se copian seis líneas con la orden 6yy, el editor vi muestra el mensaje 6 lines yanqed. Para asignar un nuevo valor a esta opción se utiliza la sintaxis :set report=número.
scroll.
Es una opción de tipo numérica. Define el número de líneas que avanza o retrocede la pantalla cuando se pulsa Ctrl-d o Ctrl-u, respectivamente. El valor por defecto es 15. Para asignar un nuevo valor se utiliza la sintaxis :set scroll=número.
shiftwidth (sw).
Es una opción de tipo numérica. Indica el número de espacios o columnas que retrocede Ctrl-d cuando está activa la opción autoindent. El valor por defecto es 8.
showmatch(sm).
Es una opción booleana. Muestra la posición del paréntesis abierto “(“ cuando se escribe el paréntesis cerrado “)”. Por defecto, está desactivada.
showmode (smd).
Es una propiedad booleana. Se utiliza para mostrar mensajes de la operación que se está realizando. Por ejemplo, cuando se va a insertar texto, se visualiza el mensaje – INSERT – en la línea de estado. Para visualizar estos mensajes, hay que ejecutar :set showmode, que es la opción por defecto. Si no se quieren mostrar los mensajes, se utiliza :set noshowmode.
tabstop (ts).
Es una opción de tipo numérica. Se utiliza para fijar el número de espacios que se escribirán cuando se incluyan tabuladores en el archivo. El valor por defecto es 8.
warn.
146

Es una opción booleana. Muestra un mensaje de aviso cuando intentamos salir del editor vi sin guardar las modificaciones realizadas. Por defecto, está activada.
wrapmargin (wm).
Es una opción de tipo numérica. El número de caracteres que se pueden escribir en una línea es de 80. Cuando se escriben más de 80 caracteres en una línea sin pulsar la tecla Enter, el editor vi continúa escribiendo dicha línea en la línea siguiente, aunque las dos líneas serán la misma, lo cual puede ocasionar que la línea no se lea de forma correcta si el archivo se ha imprimido, sobre todo si el archivo contiene un programa. Para que esto no ocurra, se puede limitar el tamaño de la línea con la opción wrapmargin, que es una opción de tipo numérica. Esta opción indica el número de caracteres en el margen derecho de la línea. Por ejemplo, si se ejecuta :set wm=5, la línea tendrá un máximo de 75 caracteres. Cuando se está escribiendo la línea y se alcanza el tamaño indicado en esta opción, el editor vi inserta de forma automática un retorno (tecla Enter) y continúa escribiendo el resto de caracteres en la línea siguiente, formándose dos líneas diferentes. Si, al partir la línea, se está escribiendo una palabra, la palabra completa se escribe en la línea siguiente. El valor por defecto de esta opción es :set wm=0, que indica que las líneas no se partirán.
wrapscan.
Es una opción de tipo booleana. Se utiliza para activar o desactivar las búsquedas circulares en un archivo. Cuando la búsqueda circular está activada y la operación de búsqueda llega al principio o al final del fichero, según la dirección en la que se esté buscando, el editor vi continúa por el final o el principio del fichero, respectivamente. Para activar la búsqueda circular se utiliza :set wrapscan y para desactivarla :set nowrapscan. Por defecto, la operación de búsqueda circular está activada.
147

11.12.ABREVIATURAS.
Las abreviaturas se utilizan para facilitar la escritura de texto que se repite con cierta frecuencia.
Para definir una abreviatura se utiliza la sintaxis :ab abreviatura cadena, donde abreviatura es el nombre que se utilizará cada vez que se quierea escribir la cadena especificada. Cuando se quiera escribir la cadena que se ha asignado a la abreviatura, se escribirá la abreviatura definida y el editor vi la cambiará por la cadena. Si la abreviatura forma parte de una palabra, la sustitución no se realiza. Para que la sustitución se produzca, la abreviatura debe ir precedida y seguida de un espacio en blanco.
Ejemplo.
:ab op opción de tipo
Se ha definido la abreviatura op para la cadena opción de tipo. Cada vez que se escriba op (precedido y seguido de un espacio en blanco) se sustituye por opción de tipo. Si, por ejemplo, se escribe tope, la sustitución no se produce.
Para eliminar una abreviatura existente se utiliza la sintaxis :unab abreviatura.
Para mostrar una lista de abreviaturas creadas se utiliza la sintaxis :ab.
148

11.13.MACROS.
Las macros se utilizan para asignar una combinación de teclas a una única tecla, lo cual facilita la ejecución de las órdenes. Para ejecutar una macro hay que estar en modo orden y escribir los dos puntos seguido del nombre de la macro.
Para crear una macro se utiliza la sintaxis :map macro orden, donde macro es el nombre de la macro a la que se asigna la orden especificada. El editor vi deja sin utilizar muy pocas letras, por lo que las macros deberán tener más de una letra. También se pueden asignar las teclas de función para crear macros. Para ello, hay que utilizar la sintaxis :map #número orden, donde número es la tecla de función que se va a asignar a la orden. Se pueden asignar desde la tecla de función F1 hasta la F9.
Ejemplos.
:map del 5dd
Crea la macro del para borrar 5 líneas.
:map #1 yy
Crea la macro F1 para copiar una línea en el buffer temporal.
Para eliminar una macro se utiliza la sintaxis :unmap macro.
Para mostrar las macros creadas se utiliza la sintaxis :map.
149

11.14.ARCHIVO DE CONFIGURACIÓN DEL EDITOR VI.
Todas las opciones modificadas para personalizar la configuración del editor vi, incluidas las abreviaturas y las macros, permanecen durante la sesión en la que se definen. Cuando esta sesión finaliza, las opciones modificadas, macros y abreviaturas se pierden y, si se quieren utilizar en una nueva sesión, hay que volver a definirlas. Para evitar este problema, se utiliza el archivo de configuración del editor vi.
El archivo de configuración del editor vi es un archivo oculto que se ubicará en el directorio home del usuario. Su nombre es .exrc y contendrá las opciones personalizadas para utilizar el editor vi, así como las abreviaturas y macros que se deseen utilizar.
Todos los usuarios pueden tener un archivo de configuración distinto del resto, siempre que el archivo .exrc esté almacenado en el directorio home de cada uno de los usuarios. De lo contrario, cada usuario ejecutará el editor vi con las opciones de configuración por defecto y no dispondrá de abreviaturas ni de macros.También se puede incluir la variable EXINIT en el archivo .bash_profile para definir las opciones de configuración del Editor vi. Por ejemplo, EXINIT=’set nu ai’ establece numeración de líneas y tabulación automáticas.
150

12.Administración de cuentas de usuario.
12.1. CREACIÓN DE CUENTAS DE USUARIO.
Para que los usuarios puedan acceder al sistema, deben disponer de una cuenta de usuario y de una contraseña.
Cuando se crea un usuario nuevo, se añade una entrada en el archivo /etc/passwd. Cada entrada de este archivo se compone de los siguientes elementos: nombre del usuario, contraseña codificada o encriptada, número del usuario, número del grupo primario al que pertenece el usuario, información adicional del usuario, directorio home del usuario y shell utilizado por el usuario. Además, en el directorio home del usuario se copian los programas existentes en el directorio /etc/skel, necesarios para el funcionamiento del usuario que se acaba de crear.
Para crear una cuenta de usuario, se utiliza el comando adduser usuario. Con esta orden, el sistema comprueba la existencia del nuevo usuario. Si existe, se genera un mensaje de error, y si no existe, se crea con las opciones por defecto. Las opciones por defecto se encuentran en el archivo /etc/default/useradd. La sintaxis del comando adduser es la siguiente:
adduser [-u uid [-o]] [-g grupo1] [-G grupo2 [,grupo3,...]] [-d directorio] [-s shell] [-c comentario] [-m [-k directorio]] [-f número] [-e fecha] usuario
Las opciones son las siguientes:
-u uid.
Número de identificación del usuario. Por defecto, se asigna el siguiente número al último especificado. Al primer usuario que se crea, si no se indica nada, se le asigna el número 500.
-o.
Permite utilizar una cuenta de usuario existente.
-g grupo1.
Número de identificación o nombre del grupo principal al que va a pertenecer el usuario. Por defecto, crea un grupo con el mismo número de identificación y el mismo nombre que el usuario.
-G grupo2 [,grupo3,...].
Números de identificación o nombres de los grupos secundarios a los que pertenecerá el usuario.
-d directorio.
Indica el directorio home del usuario. Hay que especificar la ruta completa. Por defecto, el directorio home será /home/usuario.
-s shell.
Asigna el shell que utilizará el usuario. Los shell que se pueden utilizar se encuentran en el directorio /bin. Por defecto, utiliza el shell /bin/bash.
151

-c comentario.
Se utiliza para incluir un comentario sobre la cuenta de usuario.
-m.
Crea el directorio home del usuario. Esta opción está activa, es decir, por defecto, el directorio home del usuario se crea al ejecutar el comando adduser.
-k directorio.
El contenido del directorio especificado se copia en el directorio home del usuario. Por defecto, se copia la información del directorio /etc/skel.
-f número.
Indica el número de días que la cuenta puede estar inactiva antes de ser desactivada. Por defecto, esta opción tiene el valor -1. Si se ha asignado algún valor a esta opción y se quiere anular, hay que introducir el valor –1.
-e fecha.
Establece la fecha a partir de la cual la cuenta de usuario no se podrá utilizar. Por defecto, esta opción no tiene ningún valor. Cuando se introduce “” se anula el valor establecido con anterioridad.
Cuando se utiliza la orden adduser usuario sin opciones, se crea la cuenta de usuario con las opciones por defecto. Estas opciones se pueden visualizar y modificar con la siguiente sintaxis:
useradd –D [-g grupo] [-s shell] [-f número] [-e fecha]
Al modificar estas opciones, permanecen después de reiniciar el sistema y prevalecen sobre las opciones establecidas en el archivo /etc/default/useradd.
Las opciones de esta sintaxis son las siguientes:
-D.
Muestra las opciones por defecto que se asignan a las cuentas de usuario cuando se utiliza la sintaxis adduser usuario. Estas opciones son las incluidas en el archivo /etc/default/useradd.
-g group.
Establece el grupo por defecto que se asigna a las cuentas de usuario. Este grupo debe existir.
-s shell.
Asigna el shell por defecto que utilizarán los usuarios.
-f número.
Determina el número de días por defecto que las cuentas de usuario deben permanecer inactivas antes de ser desactivadas.
-e fecha.
152

Establece la fecha de expiración de las cuentas de usuario.
El archivo /etc/default/useradd está en desuso y se está sustituyendo por el archivo /etc/adduser.conf (este archivo es el que utiliza Ubuntu).
Se puede utilizar el comando useradd para crear cuentas de usuario. La sintaxis de este comando es la misma que la del comando adduser.
Cuando se crea una cuenta de usuario, además de añadir una entrada para ese usuario en el archivo /etc/passwd, se añade una entrada en los archivos /etc/shadow (archivo de contraseñas) y /etc/group (archivo de grupos).
Se puede añadir una cuenta de usuario a un grupo existente utilizando la siguiente sintaxis:
adduser usuario grupo
153

12.2. ELIMINACIÓN DE CUENTAS DE USUARIO.
Para eliminar una cuenta de usuario, hay que utilizar la siguiente sintaxis:
userdel [-r] usuario
Si no se utiliza la opción –r, se borran las entradas correspondientes a la cuenta de usuario en los archivos /etc/paswd y /etc/shadow. Si se incluye la opción –r, además de borrar las entradas de la cuenta de usuario en los archivos /etc/paswd y /etc/shadow, borra su directorio home. La entrada en el archivo /etc/group no se elimina, pues puede haber otras cuentas de usuario que pertenezcan al grupo principal del usuario.
Las cuentas de usuario se pueden eliminar manualmente, utilizando cualquiera de los métodos siguientes:
Editando el archivo /etc/passwd y borrando la entrada del usuario que se quiere eliminar. De esta forma, el usuario no podrá entrar en el sistema, pero su directorio home seguirá existiendo, por lo que el borrado del usuario será de forma temporal, pues, si se vuelve a crear dicho usuario, la información que poseía antes de ser eliminado todavía permanece.
Borrar la línea del archivo /etc/passwd para el usuario de la forma descrita en el punto anterior y eliminar el directorio home del usuario. Esta es la forma de eliminar al usuario de forma definitiva.
154

12.3. MODIFICACIÓN DE CUENTAS DE USUARIO.
Para modificar la configuración de las cuentas de usuario, se utiliza el comando usermod. La sintaxis es la siguiente:
usermod [-u uid [-o]] [-g grupo1] [-G grupo2 [,grupo3,...]] [-d directorio [-m]] [-s shell] [-c comentario] [-l nombre] [-f número] [-e fecha] usuario
Todas las opciones tienen el mismo significado que en el comando adduser. La opción –l nombre, se utiliza para cambiar el nombre de la cuenta de usuario. Si se cambia el nombre de la cuenta de usuario, las entradas del usuario antiguo en los archivos /etc/paswd y /etc/shadow se cambian por el nuevo usuario. Si se omiten el resto de opciones, el nuevo usuario tendrá la misma configuración que el usuario antiguo, incluido su directorio home y su contraseña.
Para modificar la configuración de los usuarios sin utilizar el comando usermod, hay que acceder al archivo /etc/passwd y cambiar la línea del usuario deseado, pudiendo modificar el identificador de usuario, el grupo al que pertenece, el directorio home y el shell que va a utilizar.
155

12.4. OTRAS CONSIDERACIONES SOBRE LAS CUENTAS DE USUARIO.
Cuando un usuario pertenece a varios grupos, puede cambiar de grupo activo utilizando el comando newgrp grupo. El grupo activo de un usuario es importante porque es el grupo del propietario al que se asignan permisos sobre un nuevo archivo o directorio. Para volver al grupo principal del usuario, que es el grupo activo cuando un usuario inicia una sesión, basta con ejecutar newgrp.
Cuando un usuario ha iniciado una sesión, puede iniciar una subsesión o subshell con otro usuario distinto. Para ello, hay que ejecutar el comando su usuario. El sistema pide la contraseña del nuevo usuario para iniciar el subshell. Para volver al shell o sesión inicial, hay que ejecutar el comando exit. Los permisos que el usuario tenía sobre los archivos de la sesión inicial se pierden y solo tendrá permisos sobre los archivos y directorios del nuevo subshell. También se puede iniciar un nuevo subshell ejecutando el comando su - usuario. En este caso, para volver a la sesión inicial, hay que ejecutar exit o logout.
156

13.Administración de contraseñas de usuario.
El archivo /etc/shadow contiene las contraseñas de todos los usuarios existentes. Cada una de las líneas de este archivo incluye la siguiente información:
Nombre del usuario.
Contraseña encriptada o codificada.
Si contiene el carácter ‘*’ indica que todavía no se ha asignado una contraseña al usuario y, por lo tanto, no se podrá utilizar la cuenta hasta que no se le asigne una contraseña.
Ultimo cambio de la contraseña.
Se expresa en número de días transcurridos desde el 1 de enero de 1.970 hasta la fecha en que se realizó el último cambio.
Número de días.
Indica el número de días, desde el último cambio, que han de transcurrir para que el usuario pueda cambiar la contraseña.
Número de días de validez de la contraseña.
Número de días en que el sistema avisará para cambiar la contraseña.
Número máximo de días inactivos permitidos para la cuenta de usuario.
La cuenta de usuario es eliminada si se sobrepasa esta cantidad de días sin utilizar.
Fecha desde la que no se podrá utilizar la cuenta de usuario.
Información adicional.
El comando passwd se utiliza para administrar las contraseñas de los usuarios. Los usuarios normales tienen limitadas las operaciones de administración de las contraseñas; sólo el usuario root puede realizar todas las tareas de administración de las contraseñas del resto de usuarios.
La sintaxis del comando passwd es la siguiente:
passwd [-k [usuario]] [-l usuario] [-u usuario] [-d usuario] [-S usuario] [usuario]
Si se utiliza passwd sin opciones, el usuario que ha ejecutado el comando deberá cambiar su contraseña.
Las opciones son las siguientes:
-k [usuario].
Permite cambiar la contraseña. La nueva contraseña se verificará para que no coincida con las contraseñas de otros usuarios o con palabras reservadas de Unix, que no contenga dos caracteres iguales, que no contenga ningún carácter de la contraseña antigua, etc. Si esta opción la ejecuta el usuario root, puede introducir un nombre de usuario.
-l usuario.
Esta opción sólo la puede utilizar el usuario root. Se utiliza para bloquear la cuenta de usuario indicada.
157

-u usuario.
Esta opción sólo la puede utilizar el usuario root. Se utiliza para desbloquear la cuenta de usuario especificada.
-S usuario.
Esta opción sólo la puede utilizar el usuario root. Visualiza información sobre la cuenta de usuario indicada.
usuario.
Esta opción sólo la puede utilizar el usuario root. Permite cambiar la contraseña del usuario especificado.
158

14.Administración de cuentas de grupos de usuarios.
Todos los usuarios van a pertenecer, como mínimo, a un grupo. Cuando se crea un usuario con el comando adduser, se crea automáticamente un grupo con el mismo nombre y el mismo identificador que el usuario.
Los grupos existentes se encuentran en el archivo /etc/group. Este archivo contiene una línea por cada uno de los grupos, con la siguiente información: nombre del grupo, identificador y miembros del grupo, separados por comas.
14.1. CREACIÓN DE CUENTAS DE GRUPO.
Para crear un nuevo grupo, hay que añadir una línea en el archivo /etc/group para dicho grupo o utilizar el comando groupadd. La sintaxis de este comando es la siguiente:
groupadd [-g gid] grupo
La opción –g gid se utiliza para especificar el número de identificación del nuevo grupo. Si se omite, el sistema asigna el siguiente número al último existente.
159

14.2. ELIMINACIÓN DE CUENTAS DE GRUPO.
Para eliminar un grupo existente, hay que borrar la entrada de dicho grupo en el archivo /etc/group o utilizar el comando groupdel. La sintaxis de este comando es la siguiente:
groupdel grupo
160

14.3. MODIFICACIÓN DE CUENTAS DE GRUPO.
Para modificar la configuración de los grupos existentes, hay que modificar su entrada en el archivo /etc/group o utilizar el comando groupmod. La sintaxis de este comando es la siguiente:
groupmod [-g gid [-o]] [-n nombre] grupo
La opción –o se utiliza para permitir utilizar un nombre de grupo existente. La opción –n nombre asigna un nuevo nombre al grupo.
161

15.Administración de permisos.
Para restringir el acceso del resto de usuarios a los archivos y directorios, hay que establecer un sistema de permisos. El sistema de permisos sólo se puede establecer por el usuario propietario. El propietario de un archivo o de un directorio es el usuario que lo crea.
El comando ls –l, visualiza el contenido del directorio en formato largo. La información que muestra es la siguiente:
El primer carácter indica el tipo de archivo. Puede contener uno de los siguientes caracteres: d (directorio), b (archivo especial de tipo bloque), c (archivo especial de tipo carácter), p (archivo especial FIFO), l (enlace simbólico) y – (archivo ordinario).
Los siguientes tres caracteres indican los permisos del propietario.
Los siguientes tres caracteres indican los permisos de los usuarios pertenecientes al grupo del propietario. Si un usuario pertenece a varios grupos, el grupo del propietario es el que está activo en el momento de crear el directorio o archivo.
Los siguientes tres caracteres indican los permisos del resto de usuarios.
Los siguientes caracteres muestran los enlaces, el propietario, el grupo al que pertenece el propietario, el tamaño en bytes, la fecha de creación o de la última modificación y el nombre. Si se combina con la opción –n, se muestran los identificadores de usuario y grupo del propietario, en lugar de sus nombres.
Los permisos que se muestran pueden ser: r (lectura), w (escritura), x (ejecución). Siempre aparecen en este orden: rwx. Si en lugar del correspondiente permiso se muestra el carácter -, indica que dicho permiso está denegado. Por ejemplo, rw- indica que tiene los permisos de lectura y de escritura, pero no tiene el permiso de ejecución.
Cuando un usuario crea un archivo, se asignan, por defecto, los siguientes permisos: rw- para el usuario propietario, r-- para el grupo del propietario y r-- para el resto de usuarios. Cuando un usuario crea un directorio, se asignan, por defecto, los siguientes permisos: rwx para el usuario propietario, r-x para el grupo del propietario y r-x para el resto de usuarios. Estos valores se obtienen de los valores por defecto del sistema (rw-rw-rw- para los archivos y rwxrwxrwx para los directorios) y de los valores por defecto del comando umask (ver este comando más adelante).
162

15.1. CAMBIO DE PERMISOS.
El usuario que crea un directorio o un fichero es el propietario del mismo. Sólo el usuario propietario del directorio o del fichero puede cambiar los permisos existentes.
Para cambiar los permisos sobre un directorio o sobre un fichero desde la línea de comandos, se utiliza el comando chmod. Su sintaxis es la siguiente:
chmod [usuario] operación permiso archivo1 [archivo2 ...]
En el parámetro usuario, se utilizan códigos para indicar el usuario sobre el que se van a cambiar los permisos. Estos códigos son los siguientes:
u.
Se refiere al usuario propietario.
g.
Indica el grupo del propietario.
o.
Se utiliza para referirse al resto de usuarios.
a.
Con este código se incluyen todos los usuarios (propietario, grupo del propietario y resto de usuarios). Esta es la opción por defecto, es decir, si se omite el parámetro usuario, los permisos se establecen a todos los usuarios (propietario, grupo del propietario y resto de usuarios).
El parámetro operación puede contener uno de los siguientes valores:
+.
El permiso especificado se añade a los ya existentes.
-.
El permiso indicado se elimina.
=.
El permiso especificado es asignado. El resto de permisos son eliminados.
El parámetro permiso se utiliza para especificar el permiso de acceso. Puede contener uno de los valores r (lectura), w (escritura), x (ejecución).
Se puede introducir más de un permiso. Por ejemplo, la orden chmod o+wx prueba añade los permisos de escritura y ejecución para el resto de usuarios sobre el archivo prueba.
También se pueden modificar los permisos de un archivo para distintos grupos de usuarios, utilizando una sóla vez el comando chmod. Por ejemplo, para añadir al archivo prueba el permiso de ejecución para el usuario propietario y los usuarios del grupo del propietario y asignar el permiso de ejecución al resto de usuarios, se introduce la orden chmod ug+x,o=x prueba.
163

El comando chmod admite otra sintaxis para cambiar los permisos a los archivos y directorios. Esta sintaxis es la siguiente:
chmod número1número2número3 archivo1 [archivo2 ...]
número1 se refiere a los permisos del propietario, número2 a los del grupo del propietario y número3 a los del resto de usuarios.
Los valores de estos números se representan en octal. Cada permiso tiene una representación octal: el permiso de lectura se representa por el número 4 octal, el permiso de escritura se representa por el número 2 octal y el permiso de ejecución se representa por el número 1 octal. Si se quieren eliminar los permisos, hay que escribir el número 0 octal.
Si estos valores en octal los pasamos a binario, obtenemos los siguientes números:
4 en octal es 100 en binario.
2 en octal es 010 en binario.
1 en octal es 001 en binario.
Realmente, Unix trabaja con la conversión del número octal en binario. El número en binario consta de tres dígitos, cada uno de los cuales se corresponde con un permiso dependiendo de su posición. De esta forma, el dígito de la izquierda se corresponde con el permiso de lectura, el dígito del medio se corresponde con el permiso de escritura y el dígito de la derecha se corresponde con el permiso de ejecución. El sistema asigna el permiso si tiene el valor 1 y lo elimina si tiene el valor 0. Por eso el número 4 en octal se refiere al permiso de lectura (100 → r--), 2 en octal se refiere al permiso de escritura (010 → -w-), 1 en octal se refiere al permiso de ejecución (001 → --x) y 0 en octal elimina todos los permisos (000 → ---).
Si queremos asignar varios permisos, hay que sumar las cifras en octal y el resultado será un número, que indicará la combinación de permisos asignada. La siguiente tabla muestra las combinaciones de permisos utilizando este método.
Octal Binario Permisos
0 000 Sin permiso (---)
1 001 Ejecución (--x)
2 010 Escritura (-w-)
3 (2+1) 011 Escritura y ejecución (-wx)
4 100 Lectura (r--)
5 (4+1) 101 Lectura y ejecución (r-x)
6 (4+2) 110 Lectura y escritura (rw-)
7 (4+2+1) 111 Lectura, escritura y ejecución (rwx)
Ejemplo.
Si establecemos los siguientes permisos sobre el archivo texto:
chmod 754 texto
estamos asignando permiso de lectura, escritura y ejecución al usuario propietario, de lectura y ejecución al grupo del propietario y de lectura al resto de usuarios.
164

Los permisos 754 en octal se convertirían de la siguiente forma:
Octal Binario Permisos
754 111101100 rwxr-xr--
165

15.2. CAMBIO DE PROPIETARIO.
Para cambiar el propietario de un archivo o de un directorio desde la línea de comandos, hay que ejecutar el comando chown (este comando sólo lo puede ejecutar el usuario root). La sintaxis de este comando es la siguiente:
chown usuario archivo1 [archivo2 ...]
El nombre de usuario especificado tiene que existir y, después de ejecutar el comando, pasará a ser el propietario de los archivos indicados.
166

15.3. MÁSCARA DE PERMISOS. ORDEN UMASK.
Cuando se crean los archivos o directorios, se asignan unos permisos por defecto. Estos permisos se pueden modificar con el comando umask, que utiliza el sistema octal, explicado anteriormente, para asignar los nuevos permisos por defecto.
La sintaxis de la orden umask es la siguiente:
umask [número1número2número3]
Si se ejecuta el comando umask sin argumentos, se muestra la máscara de permisos actual.
La máscara asignada en número1número2número3, indica que los permisos especificados se eliminan de los permisos por defecto que el sistema asigna a ficheros y directorios. Por defecto, el valor de umask es 022. Esto quiere decir que, sobre los permisos existentes, no se va a eliminar ningún permiso al propietario (valor 0 de umask), y se va a eliminar el permiso de escritura sobre el grupo del propietario (primer valor 2 de umask) y sobre el resto de usuarios (segundo valor 2 de umask).
Los permisos por defecto que el sistema asigna cuando se crea un fichero son rw-rw-rw- pero, como el valor de umask es 022, cuando se crea un fichero se asignan los permisos rw-r--r--.
Los permisos por defecto que el sistema asigna cuando se crea un directorio son rwxrwxrwx pero, como el valor de umask es 022, cuando se crea un directorio se asignan los permisos rwxr-xr-x.
167

15.4. OTRAS CONSIDERACIONES.
Cuando un usuario pertenece a varios grupos, puede cambiar de grupo activo utilizando el comando newgrp grupo, donde grupo indica el nombre de un grupo existente (no se puede introducir el identificador del grupo). El grupo activo de un usuario es importante porque es el grupo del propietario al que se asignan permisos sobre un nuevo archivo o directorio. Para volver al grupo principal del usuario, que es el grupo activo cuando un usuario inicia una sesión, basta con ejecutar newgrp.
168

16.Administración de impresoras.
La administración de las impresoras en Ubuntu, se realiza ejecutando la opción Sistema – Adminitración – Impresoras. En los siguiente puntos veremos algunas las impresoras que se pueden instalar en Linux.
16.1. IMPRESORA LOCAL.
Para instalar una impresora local, hay que ejecutar la opción Sistema – Administración – Impresoras. Al conectar la impresora, el sistema la detectará e instalará automáticamente, sin intervención del usuario. Si el sistema no la instala automáticamente, habrá que pulsar el botón Nuevo, seleccionar la impresora detectada, pulsar el botón Adelante y seguir las indicaciones del asistente de instalación.
Cuando se envía un trabajo a la impresora, el sistema gestiona un spool, donde almacena los archivos a imprimir en forma de cola. Esta cola se encuentra en el directorio /var/spool/cups. Cuando el archivo se está imprimiendo se crea un archivo temporal, que, una vez que el trabajo ha sido impreso, se elimina. Las siguientes líneas muestran el contenido del directorio /var/spool/cups con el trabajo número 96 imprimiéndose en ese momento (el archivo d00096-001 es el archivo temporal de este trabajo).
root@alsico-laptop:~# ls /var/spool/cups
c00041 c00048 c00055 c00062 c00069 c00076 c00083 c00090
c00042 c00049 c00056 c00063 c00070 c00077 c00084 c00091
c00043 c00050 c00057 c00064 c00071 c00078 c00085 c00092
c00044 c00051 c00058 c00065 c00072 c00079 c00086 c00093
c00045 c00052 c00059 c00066 c00073 c00080 c00087 c00096
c00046 c00053 c00060 c00067 c00074 c00081 c00088 d00096-001
c00047 c00054 c00061 c00068 c00075 c00082 c00089 tmp
Cuando el trabajo número 96 ha sido impreso, el archivo temporal se destruye. Las siguientes líneas muestran el contenido del directorio /var/spool/cups después de realizarse la impresión de este trabajo.
root@alsico-laptop:~# ls /var/spool/cups
c00041 c00047 c00053 c00059 c00065 c00071 c00077 c00083 c00089 tmp
c00042 c00048 c00054 c00060 c00066 c00072 c00078 c00084 c00090
c00043 c00049 c00055 c00061 c00067 c00073 c00079 c00085 c00091
c00044 c00050 c00056 c00062 c00068 c00074 c00080 c00086 c00092
c00045 c00051 c00057 c00063 c00069 c00075 c00081 c00087 c00093
c00046 c00052 c00058 c00064 c00070 c00076 c00082 c00088 c00096
La gestión y administración de las impresoras locales las realiza el paquete CUPS (Common UNIX Printing System). Para más detalles sobre este paquete, ver el punto 16.4 Impresora remota utilizando CUPS.
169

16.2. IMPRESORA TCP/IP.
Una impresora TCP/IP es la que está conectada directamente a la red, a través de su propia tarjeta de red. Para conectarse a este tipo de impresoras, hay que ejecutar la opción Sistema – Administración – Impresoras y, en la ventana que se muestra, pulsar el botón Nuevo, accediendo a una nueva ventana en la que hay que seleccionar la opción AppSocket/HP JetDirect y pulsar el botón Adelante.
Seguidamente, hay que introducir la dirección IP de la impresora de red, dejar el puerto 9100 y pulsar el botón Adelante, siguiendo las indicaciones del asistente de instalación para finalizar la instalación de la impresora de TCP/IP.
170

16.3. IMPRESORA SAMBA.
Para configurar una impresora que se pueda utilizar con Samba, hay que instalar este paquete (ver el punto 6.2 Administración de Samba). Una vez instalado el paquete, todas las impresoras instaladas en local y compartidas en los servidores de Windows de la red son accesibles desde Linux. De igual forma, todas las impresoras instaladas en local en los servidores Samba de Linux son accesibles desde cualquier equipo de la red, independientemente del sistema operativo que esté utilizando.
A continuación, veremos las distintas formas de instalar impresoras utilizando el software de Samba. En los tres casos que se van a exponer hay que autenticarse con un usuario que exista en el servidor que comparte la impresora y que se haya añadido al servidor SAMBA.
16.3.1 Conexión desde Windows a una impresora en un servidor SAMBA.
La conexión desde Windows con una impresora instalada en un servidor Linux con Samba instalado, se realiza desde el Mis sitios de red del servidor Windows. Accedemos al servidor Linux y abrimos el icono de la impresora que tiene instalada y que se visualiza como un recurso compartido por este servidor, debiendo seguir las indicaciones del asistente de instalación para finalizar la conexión a la impresora.
En ocasiones, al acceder a las propiedades de la impresora, se produce el error Acceso denegado, no se pudo establecer la conexión, aunque todo funciona de forma adecuada. Este error se muestra en la barra de título de la ventana Propiedades de la impresora o en el icono de la impresora de la ventana Impresoras.
16.3.2 Conexión desde Linux a una impresora en un servidor Windows.
Para realizar esta acción, hay que instalar una impresora local en el servidor Windows y compartirla. Desde el servidor Linux, hay que ejecutar la opción Sistema – Administración – Impresoras y, en la ventana que se muestra, pulsar el botón Nuevo, accediendo a una nueva ventana en la que hay que seleccionar la opción Windows Printer via SAMBA y pulsar el botón Adelante.
Seguidamente, hay que pulsar el botón Examinar y navegar hasta seleccionar la impresora del servidor de Windows y pulsar el botón Adelante, debiendo seguir las indicaciones del asistente de instalación para finalizar la conexión a la impresora.
16.3.3 Conexión desde Linux a una impresora en un servidor SAMBA.
Para realizar esta acción, hay que instalar una impresora local en el servidor SAMBA. Desde el equipo que se va a conectar a la impresora, hay que ejecutar la opción Sistema – Administración – Impresoras y, en la ventana que se muestra, pulsar el botón Nuevo, accediendo a una nueva ventana en la que hay que seleccionar la opción Windows Printer via SAMBA y pulsar el botón Adelante.
Seguidamente, hay que pulsar el botón Examinar y navegar hasta seleccionar la impresora del servidor SAMBA y pulsar el botón Adelante, debiendo seguir las indicaciones del asistente de instalación para finalizar la conexión a la impresora.
171

16.4. IMPRESORA REMOTA UTILIZANDO CUPS.
CUPS (Common UNIX Printing System) es un paquete desarrollado para administrar las impresoras instaladas en el sistema desde un navegador web. Con la configuración que se instala por defecto en Ubuntu, CUPS es el que gestiona la administración de las impresoras locales. En el punto 16.1 Impresora local, hemos visto que la cola de trabajos enviados a una impresora local está ubicada en el directorio /var/spool/cups, que se crea cuando se instala el paquete CUPS.
Cuando se realice alguna modificación en la configuración de CUPS, hay que reiniciar el servicio /etc/init.d/cups. El demonio que se reinicia es cupsd.
CUPS se configura desde el archivo /etc/cups/cupsd.conf, que se puede modificar desde la web de administración de este paquete, accediendo a la dirección http://localhost:631.
Para acceder de forma remota a la web de administración de CUPS, hay que escribir la dirección IP del servidor y modificar el archivo /etc/cups/cupsd.conf, añadiendo la línea Listen IP:631, donde IP es la dirección IP del servidor al que se quiere acceder. Por ejemplo, si este servidor tiene la dirección IP 192.168.1.33, hay que añadir la línea Listen 192.168.1.33:631 en el archivo /etc/cups/cupsd.conf y, para acceder al servidor desde otro equipo, escribir la dirección http://192.168.1.33:631 en el navegador.
Con la configuración anterior sólo se puede acceder de forma remota a la web de CUPS pero no se pueden realizar tareas administrativas. Para poder administrar CUPS hay que modificar el apartado <Location /Admin> del archivo /etc/cups/cupsd.conf, añadiendo la directiva Allow y la dirección IP o conjunto de direcciones IP desde las que se puede realizar la administración de CUPS. Por ejemplo, si incluimos la línea Allow 192.168.1.34, se podrán realizar tareas administrativas desde el equipo con la dirección IP 192.168.1.34; si incluimos la línea Allow 192.168.1.* se podrán realizar tareas administrativas desde los equipos cuyas direcciones IP comiencen por 192.168.1.
Si queremos acceder a la impresora CUPS desde un sistema Windows, hay que instalar una impresora de red y escribir la dirección http://192.168.1.33:631/printers/NombreDeImpresora.
Si queremos acceder a la impresora CUPS desde un sistema Linux, hay que ejecutar la opción Sistema – Administración – Impresoras y, en la ventana que se muestra, pulsar el botón Nuevo, accediendo a una nueva ventana en la que hay que seleccionar la opción Internet Printing Protocol (ipp) y pulsar el botón Adelante.
Seguidamente, hay que escribir la dirección IP y el puerto del servidor CUPS. En el apartado Cola hay que escribir printers/NombreDeImpresora o pulsar el botón Buscar cola y seleccionar la impresora deseada.
A continuación, hay que pulsar el botón Adelante y seguir las indicaciones del asistente de instalación para finalizar la conexión a la impresora.
172

16.5. INSTALACIÓN DE UNA IMPRESORA PDF.
Una impresora PDF es una configuración que consiste en instalar una impresora virtual que se utilizará para enviar los trabajos a imprimir en formato PDF. Estos trabajos no se imprimirán, sino que se guardarán en un directorio desde el que se pueden visualizar, con un visor de ficheros PDF, y, desde aquí, si nos interesa, enviarlos a la impresora real instalada en el sistema.
Para instalar una impresora PDF, hay que instalar el paquete cups-pdf.
Una vez instalado el paquete, se crea un archivo de configuración, denominado /etc/cups/cups-pdf.conf. En este archivo podemos ver que el sistema va a utilizar el directorio ${HOME}/PDF como salida para guardar los archivos en formato PDF que enviemos al realizar la acción de imprimir. Esta carpeta se creará, automáticamente, la primera vez que se utilice la impresora PDF.
Para instalar la impresora PDF hay que ejecutar la opción Sistema – Administración – Impresoras y, en la ventana que se muestra, pulsar el botón Nuevo, accediendo a una nueva ventana en la que hay que seleccionar la impresora PDF, pulsar el botón Adelante y seguir las indicaciones del asistente para finalizar la instalación.
173

16.6. COMANDOS PARA REALIZAR LAS TAREAS DE IMPRESIÓN.
El sistema operativo Unix/Linux nos proporciona una serie de comandos para gestionar las colas de impresión. Estos comandos son los que vamos a detallar a continuación (algunas opciones de estos comandos sólo funcionan para impresoras instaladas con el servicio LPD, que en estos apuntes no lo vamos a tratar).
16.6.1 Comando lpr.
Envía a la cola de impresión el trabajo especificado. Ls sintaxis es la siguiente:
lpr [opciones] [archivo1 [archivo2 ...]]
Si se introduce lpr sin parámetros, se envían al spool los caracteres que se escriben desde el teclado (entrada estándar).
Las opciones más utilizadas son las siguientes (estas opciones varían dependiendo de las versiones de Unix/Linux instaladas):
-#número.
Realiza las copias, indicadas en número, del trabajo especificado.
-[1234]font.
Indica la fuente que se utilizará en la impresión del trabajo.
-C cabecera.
Imprime una página que contendrá la cabecera especificada.
-h.
Elimina la página utilizada como cabecera.
-i [número]
La salida se realiza de forma tabulada. Si se incluye número, indica los espacios en blanco que utilizará como tabulador.
-J número.
Imprime una página que contendrá el número de trabajo especificado.
-Pimpresora.
Envía el archivo a la impresora especificada. Si no se especifica esta opción, el comando lpr envía los archivos a la impresora por defecto o a la impresora especificada en la variable de entorno PRINTER.
-T título.
Imprime una página que contendrá el título especificado.
-U usuario.
Imprime una página que contendrá el nombre de la cuenta de usuario especificada.
174

-w número.
Determina la anchura de la página de impresión.
175

16.6.2 Comando lpq.
Se utiliza para visualizar el contenido del directorio spool de la impresora. La información que visualiza es la siguiente: el estado del trabajo (active) o, si el trabajo está en espera, la posición que ocupa en la cola, el usuario que ha enviado el trabajo, el número de trabajo, los nombres de los ficheros que contiene el trabajo y el tamaño del trabajo en bytes.
La sintaxis es la siguiente:
lpq [opciones] [número] [usuario1 [usuario2 ...]]
Si se introduce el comando sin argumentos, se muestra el spool de la impresora por defecto.
Las opciones son las siguientes:
-l.
Visualiza el número de ficheros que contiene el trabajo.
-Pimpresora.
Visualiza el spool de la impresora especificada. Si no se especifica esta opción, el comando lpr visualiza los archivos de la impresora por defecto o de la impresora especificada en la variable de entorno PRINTER.
El argumento número, muestra información sobre el número del trabajo especificado.
Si se introducen nombres de cuentas de usuario, se muestra información de los trabajos asociados a dichas cuentas.
176

16.6.3 Comando lprm.
Se utiliza para borrar trabajos de la cola de impresión. Su sintaxis es la siguiente:
lprm [opciones] [número] [usuario1 [usuario2 ...]]
Si se introduce lprm sin parámetros, se borra el trabajo que se está imprimiendo en ese momento.
Las opciones son las siguientes:
-.
Borra todos los archivos de la cola de impresión.
-Pimpresora.
Borra el archivo que está siendo impreso en la impresora especificada. Si no se especifica esta opción, el comando lprm borra el archivo que se está imprimiendo en la impresora por defecto o en la impresora especificada en la variable de entorno PRINTER.
El argumento número, borra el trabajo con el número especificado.
Si se introducen nombres de cuentas de usuario, se borran los trabajos asociados a dichas cuentas.
177

16.6.4 Comando lpc.
Se utiliza para administrar las impresoras, es decir, activar o desactivar las impresoras, activar o desactivar las colas de impresión y cambiar el número de los trabajos a imprimir.
La sintaxis es la siguiente:
lpc [comandos] [argumentos]
Si se ejecuta el comando lpc sin introducir ningún nombre de comando, se muestra el prompt lpc>, permitiendo introducir comandos lpc de forma interactiva.
La mayoría de los comandos admiten como argumentos {all,impresora}. Si se indica all, el comando afectará a todas las impresoras del sistema. Si se especifica el nombre de una impresora, el comando actuará sobre la impresora indicada.
Los comandos que se pueden ejecutar con lpc son los siguientes:
abort {all,impresora}.
Desactiva la impresora especificada, interrumpiéndose la impresión del trabajo actual. Si se envían nuevos trabajos, se almacenan en la cola.
clean {all,impresora}.
Borra, de la impresora indicada, los ficheros temporales creados para imprimir los trabajos y los archivos que no se puedan imprimir.
disable {all,impresora}.
Desactiva la cola de la impresora especificada, aunque los trabajos pendientes de imprimir se envían a la impresora. Si se realizan nuevas tareas de impresión, se envían directamente a la impresora, sin pasar por el spool.
down {all,impresora}mensaje.
Desactiva la impresora indicada, enviando el mensaje especificado al archivo de control de la impresora (este mensaje es mostrado, por ejemplo, al ejecutar el comando lpq). El trabajo actual termina de imprimirse. Si se envían nuevos trabajos, se almacenan en la cola de impresión.
enable {all,impresora}.
Activa la impresora especificada.
exit.
Sale de lpc. Esta acción también se realiza con el comando quit.
help [comando].
Muestra información sobre los comandos que se pueden utilizar con lpc o sobre el comando especificado. También se puede utilizar la orden ? [comando].
restart {all,impresora}.
Reinicia una impresora que se ha detenido por un mal funcionemiento. También reinicia el demonio lpd.
178

start {all,impresora}.
Activa la impresora especificada.
status {all,impresora}.
Visualiza el estado de la impresora indicada y del demonio lpd.
stop {all,impresora}.
Detiene la impresora especificada, aunque los trabajos enviados a dicha cola siguen entrando. El trabajo actual termina de imprimirse.
topq impresora [número1 [número2 ...]] [usuario1 [usuario2 ...]]
Los números de trabajo especificados o los trabajos pertenecientes a los usuarios indicados, se sitúan al principio de la cola de impresión de la impresora especificada.
up {all,impresora}.
Activa la impresora indicada, su spool y el demonio lpd.
179

17.Administración de procesos.
17.1. MULTIUSUARIO Y MULTITAREA.
El sistema operativo Unix/Linux es multiusuario, pues permite trabajar a varios usuarios de forma simultánea. Estos usuarios, o incluso un sólo usuario, pueden ejecutar varios trabajos al mismo tiempo y el sistema debe ser capaz de compartir sus recursos (procesador, memoria, etc.) para que todos los trabajos se procesen de forma, aparentemente, simultánea.
Para procesar todas las tareas, el sistema gestiona una lista o cola de tareas, asignando un tiempo de proceso a cada una de las tareas que se encuentran en la cola. El sistema ejecuta una tarea durante un tiempo determinado y, a continuación, ejecuta la siguiente tarea de la cola para, seguidamente, procesar la siguiente y así sucesivamente. Cuando una tarea termina su ejecución, la elimina de la cola. En este proceso, los recursos del sistema son utilizados por las tareas que lo soliciten, repartiendo el tiempo de ejecución (time-sharing) entre dichas tareas.
En este reparto del tiempo de ejecución de los recursos del sistema, se ejecutan todas las tareas varias veces en un segundo y, cada vez que se ejecuta una tarea, se pueden procesar cientos o miles de instrucciones.
Las tareas que se ejecutan en el sistema no tienen todas la misma prioridad. Las tareas con mayor prioridad tendrán derecho a un mayor tiempo de ejecución de los recursos del sistema.
Existen varios tipos de tareas o procesos que el sistema puede ejecutar:
Interactivo.
Es un proceso que puede ser iniciado desde un shell y se puede ejecutar en primer o segundo plano.
Por lotes.
Es un conjunto de procesos que se ejecutarán cuando el sistema lo decida.
Daemon.
Son procesos que se activan al iniciar el sistema para ejecutar funciones del sistema operativo, como SAMBA o NFS.
Los procesos que se ejecutan en segundo plano, permiten al usuario introducir órdenes o iniciar nuevas tareas mientras se están ejecutando. Para iniciar un proceso en segundo plano, hay que escribir su nombre y, a continuación, el carácter ‘&’. El sistema nos devuelve el número de identificación del proceso (PID). Si se ejecuta el comando jobs se muestran todos los procesos ejecutándose en segundo plano.
Los procesos que se están ejecutando en segundo plano, pueden modificarse para que sigan ejecutándose en primer plano (foreground). Para ello, hay que ejecutar el comando fg PID.
Los procesos que se están ejecutando en primer plano, pueden modificarse para que sigan ejecutándose en segundo plano (background). Para ello, hay que ejecutar el comando bg PID.
El funcionamiento de los procesos es el siguiente: al ejecutarse un proceso, el proceso que lo genera, o proceso padre, efectúa una llamada fork o petición del sistema, que crea una imagen del proceso a ejecutarse, llamado proceso hijo. Estos dos procesos (padre e hijo) comparten los ficheros abiertos, pero tienen distintos números de identificación, PPID para el proceso padre y PID para el proceso hijo. Además de la llamada fork, se produce otra petición al sistema, la llamada exec, que modifica el estado del proceso que ha realizado la llamada (proceso padre) al nuevo proceso (proceso hijo) y le transfiere sus características o “herencia” (variables, parámetros, funciones, etc.). Junto a las llamadas fork y exec, en los procesos en
180

primer plano se ejecuta una orden wait, que hace que el proceso padre permanezca en espera hasta la terminación del proceso hijo.
Para ejecutar un programa, el shell (proceso padre) realiza una llamada fork y lanza un shell hijo, que ejecuta el programa con una petición exec, mientras el proceso padre, a consecuencia de la ejecución de una orden wait, se queda en espera hasta que el proceso hijo termina y muere. Por último, el shell del proceso padre muestra el prompt en el terminal para que se introduzca una nueva orden.
Si un proceso generado por un usuario (programa en C, shell script, etc.) se ejecuta utilizando la sintaxis . proceso, no se genera un proceso hijo. En este caso, si el shell script ejecuta una instrucción exit, se abandonará la sesión del usuario, de igual forma que si se hubiera ejecutado la orden logout. Si el proceso se ejecuta con la orden sh, se genera un proceso hijo y, al ejecutar una instrucción exit, el sistema permanece en la sesión de usuario, pues el proceso que termina su ejecución es el proceso hijo, permaneciendo en ejecución el proceso padre, que es el shell.
Unix/Linux nos proporciona una serie de órdenes para administrar todos los procesos que se están ejecutando en el sistema.
181

17.2. PLANIFICACIÓN DE LOS PROCESOS A EJECUTAR.
Unix/Linux nos permite la posibilidad de ejecutar los procesos en un determinado momento. De esta forma, podemos ejecutar determinadas tareas a ciertas horas en que el sistema esté más liberado o dejar al sistema la elección de ejecutar determinados procesos cuando encuentre tiempo para su ejecución. También es posible planificar la ejecución de determinados procesos sin necesidad de que el usuario que planificó dichos procesos esté conectado en el momento de ejecutarse.
A continuación, se pasa a detallar los comandos y demonios que nos permiten realizar estas tareas.
17.2.1 Demonio cron y atd.
Estos demonios se lanzan cuando el sistema se inicia. Su función es comprobar si hay procesos planificados, con las órdenes at, batch y crontab, pendientes de ser ejecutados. La comprobación de los procesos pendientes la realiza cada minuto y, aunque está activado continuamente, consume muy pocos recursos. Se ejecutan en segundo plano. Unix nombra a un proceso que se ejecuta en segundo plano como daemon.
182

17.2.2 Comando at.
Se utiliza para indicar la fecha y hora en la que se ejecutarán los procesos indicados. Estos procesos se ejecutan en segundo plano. También se puede ver la lista de procesos pendientes de ejecución y eliminar procesos para que no se ejecuten.
Para que este servicio esté disponible al iniciarse el sistema, hay que indicarlo en el directorio correspondiente al nivel de inicio del equipo, de la forma descrita en el punto 7.Proceso de inicialización del sistema.
La sintaxis del comando at es la siguiente:
at hora [fecha] [incremento]
Cuando se ejecuta el comando, se muestran, en la siguiente línea, los caracteres at>. En esta línea se escribe la orden que se desea ejecutar en el tiempo indicado y se pulsa la tecla Enter. Se vuelve a mostrar una nueva línea con los caracteres at> para escribir una nueva orden. Cuando finalice la introducción de las órdenes que se desean ejecutar en el tiempo indicado, hay que pulsar Ctrl+d. Se muestra el número de identificación del proceso (PID) asignado.
Las opciones son las siguientes:
hora.
Las horas se pueden indicar según un reloj de 24 horas, con el formato hh:mm. A continuación de la hora indicada se pueden incluir las siguientes opciones:
pm.
Se utiliza según un reloj de 12 horas para indicar la hora después del mediodía.
am.
Se utiliza según un reloj de 12 horas para indicar la hora antes del mediodía.
next.
La hora indicada se refiere al día siguiente.
En lugar de la hora se pueden incluir las siguientes opciones:
now.
Se refiere a la hora actual.
noon.
Indica las 12:00 horas de la mañana (mediodía).
midnight.
Se refiere a las 00:00 horas (medianoche).
La fecha admite una de las siguientes opciones:
Mes día [año].
El mes se indica con sus tres primeras letras (en inglés). Los doce meses del año, en inglés, son los siguientes: January, February, March, April, May, June, July, August,
183

September, October, November y December. El año, si se incluye, se escribe con cuatro dígitos.
Dia de la semana.
Se escribe en inglés. Los días de la semana en inglés son los siguientes: Monday, Tuesday, Wednesday, Thursday, Friday, Saturday y Sunday.
Otro día.
Se puede incluir Today (hoy) o Tomorrow (mañana).
Incremento.
El incremento indica el tiempo que debe transcurrir desde la fecha indicada para que el proceso se ejecute. Para determinar el incremento, hay que escribir el signo ‘+’, un número y una de las siguientes opciones: minutes (minutos), hours (horas), days (días), weeks (semanas), months (meses) o years (años).
Para visualizar la lista de procesos que están pendientes de ejecución se utiliza la sintaxis at –l o la orden atq. También se puede mostrar un determinado proceso. Para ello, hay que utilizar las órdenes atq PID o at – l PID. Estos procesos se encuentran en el directorio /var/spool/cron/atjobs.
Para eliminar un proceso de la lista de procesos pendientes de ejecutar se utiliza la sintaxis at –d PID o la orden atrm PID.
Cuando el proceso se ejecuta, la salida de las órdenes del proceso se envían al correo electrónico. Si se desea que la salida de las órdenes se produzca en el monitor, hay que añadir al final de cada orden la redirección al dispositivo deseado. Si se está ejecutando un entorno no gráfico, el monitor es el dispositivo /dev/tty1. Si se está trabajando en el entorno X-Windows, el monitor es el dispositivo /dev/pts/0.
Ejemplo.
Deseamos ejecutar el archivo programa1 dentro de una hora, utilizando el monitor como salida del archivo.
at now +1 hour
at> bash programa1 >/dev/tty1 #si estamos en un entorno no gráfico.at> bash programa1 >/dev/pts/0 # si estamos en X-Windows.at> Ctrl+d
Si utilizamos la sintaxis at –f fichero now +1 minute, se ejecuta el contenido del fichero especificado.
El administrador del sistema decidirá los usuarios que podrán ejecutar el comando at. Para ello dispone de los ficheros /etc/at.allow y /etc/at.deny. Los usuarios incluidos en el fichero /etc/at.allow podrán utilizar este comando. Los usuarios incluidos en el fichero /etc/at.deny no podrán ejecutarlo. Si el fichero /etc/at.allow no existe todos los usuarios podrán ejecutar el comando at, excepto los incluidos en el archivo /etc/at.deny. Si estos archivos no existen, sólo el usuario root podrá ejecutar at.
184

17.2.3 Comando batch.
Se utiliza para ejecutar procesos cuando el sistema se encuentre más liberado de trabajo. Estos procesos se ejecutan en segundo plano y se encuentran en el directorio /var/spool/cron/atjobs.
Cuando se ejecuta el comando batch se muestran, en la línea siguiente, los caracteres ‘at>’, debiendo introducir las órdenes de la forma descrita para la orden at. La salida de la orden batch se envía al monitor.
Si se utiliza la sintaxis batch –f fichero se ejecuta el contenido del fichero especificado. También se puede ejecutar el contenido de un archivo redirigiendo la entrada de dicho archivo al comando batch.
185

17.2.4 Comando crontab.
Este comando se utiliza para indicar al sistema la realización de uno o varios procesos en determinados momentos y de forma regular, como puede ser realizar copias de seguridad todos los días a las 10 de la noche.
Los procesos que se quieren ejecutar de esta forma se deben incluir en un archivo. En realidad, el comando crontab instala este archivo para que los procesos se ejecuten en el tiempo establecido.
El archivo donde se incluyen los procesos a ejecutar debe contener una línea por cada proceso. Cada línea constará de los siguientes datos, que se escriben separados por espacios o tabuladores:
Minuto.
Se refiere al minuto en que se ejecutará el proceso. Puede tener un valor comprendido entre 0 y 59. El carácter ‘*’ indica que el proceso se ejecutará todos los minutos. Si los minutos indicados son anteriores a los minutos de la hora actual, el proceso se ejecutará la hora siguiente.
Hora.
Especifica la hora en que el proceso se ejecutará. Tendrá un valor comprendido entre 0 y 23. El carácter ‘*’ indica que el proceso se ejecutará todas las horas. Si la hora indicada es anterior a la hora actual, el proceso se ejecutará el día siguiente.
Día del mes.
Determina el día del mes en que el proceso será ejecutado. Su valor oscilará entre 1 y 31. El carácter ‘*’ indica que el proceso se ejecutará todos los días.
Mes del año.
Establece el mes del año en que se ejecutará el proceso. Su valor está comprendido entre 1 y 12. El carácter ‘*’ indica que el proceso se ejecutará todos los meses.
Día de la semana.
Indica el día de la semana en que el proceso será ejecutado. Su valor oscilará entre 0 y 6, correspondiendo el 0 al Domingo. El carácter ‘*’ indica que el proceso se ejecutará todos los días de la semana.
Proceso.
Indica el proceso que se va a ejecutar.
Una vez creado el archivo que contiene los procesos que se van a ejecutar, hay que instalarlo. Para ello, se utiliza la orden crontab archivo. Después de ejecutar esta orden, se crea un archivo con el nombre del usuario en el directorio /var/spool/cron/crontabs. Si el archivo existe, se sobreescribe. Este archivo es el que ejecuta el daemon cron para lanzar los procesos indicados en él y se puede modificar con cualquier editor de textos.
Ejemplo.
La línea 10 20 * * * echo Prueba del comando crontab >/dev/tty1, visualiza en el monitor los caracteres Prueba del comando crontab a las 20:10 horas de todos los días, meses y años.
Se pueden incluir varios minutos, horas, meses, años y días de la semana.
186

Ejemplo.
La línea * 20,21,22 10 01,02 01,02,03 echo Prueba del comando crontab >/dev/tty1, visualiza en el monitor los caracteres Prueba del comando crontab a las 20 horas, 21 horas y 22 horas (20,21,22) de los lunes, martes y miércoles (01,02,03) y, además, los días 10 de los meses enero y febrero (10 01,02). En este ejemplo, el carácter ‘*’ en el campo reservado a los minutos no se refiere a todos los minutos de las horas indicadas.
El comando crontab admite tres opciones:
-e.
Edita el archivo crontab del usuario actual. Utiliza el editor incluido en la variable EDITOR del shell. Por defecto, utiliza el Editor nano.
-l.
Visualiza el contenido del archivo crontab del usuario actual.
-r.
Borra el archivo crontab del usuario actual.
También se puede utilizar la sintaxis crontab –u usuario fichero para generar un archivo crontab para el usuario especificado, que contendrá los procesos incluidos en el fichero indicado. El nombre del archivo crontab del directorio /var/spool/cron/crontabs será el mismo que el usuario introducido. Este fichero se puede editar, listar o borrar utilizando la sintaxis crontab –u usuario {-e,-l,-r}.
187

17.2.5 Comando nohup.
Cuando un proceso se está ejecutando en segundo plano y el usuario se desconecta, dicho proceso termina su ejecución. Si queremos que un proceso que se está ejecutando en segundo plano continúe aunque el usuario se desconecte o que los procesos planificados por un usuario se ejecuten aunque dicho usuario no esté conectado, hay que ejecutar el comando nohup.
La sintaxis es la siguiente:
nohup orden &
Si se utilizan las conducciones, hay que escribir una orden nohup por cada orden incluida en la tubería.
Cuando el comando que se va a ejecutar genera datos para ser visualizados, se envían al archivo nohup.out, a no ser que se redireccione a otro archivo. El archivo nohup.out se crea en el directorio de cada usuario. Si, durante la ejecución del comando, se producen errores, también se graban en este archivo.
188

17.3. SUPERVISIÓN DE USUARIOS CONECTADOS.
Cuando se trabaja en entorno multiusuario, como es el caso de Unix/Linux, es conveniente saber los usuarios que están conectados al sistema y el tiempo que están conectados. Para ello, se utiliza el comando who.
El comando who visualiza los usuarios conectados, la estación desde la que están conectados, la fecha y hora de conexión y la dirección IP de todas las estaciones, excepto desde la que está conectado el usuario root.
La sintaxis es la siguiente:
who [opciones]
Si utilizamos el comando sin opciones, nos muestra todos los usuarios conectados.
Las opciones pueden ser (tanto las opciones como la información que ofrecen pueden variar entre distintos sistemas):
-H.
Muestra una cabecera por cada columna. Dependiendo de las opciones utilizadas, las cabeceras que se muestran son las siguientes (estas cabeceras pueden variar entre distintos sistemas):
NAME.
Muestra el nombre de conexión del usuario.
LINE.
Lista el terminal que el usuario está utilizando.
LOGIN-TIME.
Indica el día y la hora de conexión.
IDLE.
Lista las horas y minutos que han transcurrido desde que el usuario realizó la última actividad. Si se muestra el carácter ‘.’, indica que la última actividad se ha realizado en el último minuto. Si se muestra la palabra old, indica que han transcurrido más de veinticuatro horas desde que el usuario realizó la última acción.
PID.
Lista el número de identificación del proceso de conexión al shell del usuario.
-i.
Muestra el tiempo, con el formato hh:mm, que llevan los usuarios sin realizar ninguna operación. Cuando visualiza el carácter “.”, indica que el usuario ha realizado alguna operación en el último minuto. Esta información se muestra, asimismo, con la opción –u.
-m.
El nombre del usuario está precedido del servidor y el dominio al que está conectado.
189

-q.
Muestra solo los nombres de los usuarios y el número de usuarios conectados.
-T.
Visualiza el estado de los terminales. Si muestra el carácter “-“, indica que el terminal no puede recibir mensajes. El carácter “+” indica que el terminal puede recibir mensajes. Esta información también se muestra con la opción –w.
am i.
Muestra nuestro nombre de usuario.
190

17.4. SUPERVISIÓN DEL ESTADO DE LOS PROCESOS.
En los sistemas multitarea, como es el caso de Unix/Linux, es conveniente conocer el estado de los procesos. Esta acción la realiza el comando ps, que nos permite visualizar los procesos que se están ejecutando, comprobar la terminación correcta o posibles problemas de los procesos, el tiempo que los procesos tardan en ejecutarse, los recursos que utilizan los procesos, la prioridad relativa de los procesos y el número de identificación de los procesos.
La sintaxis del comando ps es la siguiente:
ps [opciones]
Si se ejecuta ps sin opciones, se muestran los procesos en ejecución asociados al shell del usuario.
Dependiendo de las opciones utilizadas al ejecutar el comando ps, en el listado que aparece en pantalla se visualizarán diferentes cabeceras. Algunas de las cabeceras que se muestran son las siguientes:
ADDR.
Indica la dirección en memoria del proceso.
C.
Muestra la cantidad de recursos de CPU que el proceso ha utilizado recientemente. Cuando el sistema tiene que seleccionar el siguiente proceso a ejecutar, escoge, de forma preferente, un proceso con un valor bajo en la columna C.
CMD.
Lista el nombre del proceso.
F.
Contiene un indicador del proceso. Puede tener uno de los siguientes valores:
00.
Indica que el proceso se encuentra en la zona swap de intercambio.
01.
El proceso está en memoria.
02.
Indica que el proceso es un proceso del sistema.
04.
El proceso está bloqueado en memoria.
10.
El proceso está siendo cambiado de lugar.
191

20.
El proceso está controlado por otro proceso.
Estos valores pueden variar de un sistema a otro. También se pueden representar como la suma en octal de varios valores.
NI.
Contiene un valor numérico que se utilizará para calcular la prioridad del proceso cuando se modifica su prioridad con los comandos nice o renice.
PID.
Lista el número de identificación del proceso.
PPID.
Indica el número de identificación del proceso padre o superior.
PRI.
Muestra la prioridad del proceso. El valor que se muestra en esta columna es una combinación de las prioridades de tiempo compartido y tiempo real. Si se han utilizado los comandos nice y renice para modificar la prioridad de un proceso, el valor de esta columna es una combinación de las prioridades de tiempo compartido y tiempo real y del valor asignado al proceso en los comandos nice y renice.
S o STAT.
Muestra el estado en que se encuentra el proceso. Puede tener uno de los siguientes valores:
I.
Proceso intermedio.
O.
Proceso inexistente.
R.
Proceso en ejecución.
S.
Proceso durmiendo.
T.
Proceso parado.
W.
Proceso esperando.
192

Z.
Proceso terminado.
STIME.
Visualiza la hora de inicio del proceso.
SZ.
Indica el tamaño del proceso en bloques.
TIME.
Muestra el tiempo que el proceso ha estado o está activo.
TTY.
Indica el terminal donde se inicia el proceso.
WCHAN.
Muestra información de la función del kernel donde se encuentra almacenado el proceso.
Las opciones que se pueden utilizar son las siguientes:
-a.
Se muestran los procesos de todos los usuarios.
-c.
Muestra la prioridad de ejecución de los procesos.
-e.
Muestra los procesos de todos los usuarios y todos los terminales.
-f.
Se muestra la información de los procesos en forma de árbol, informando de los procesos y subprocesos. Un ejemplo de un listado de procesos con esta opción podría ser el siguiente:
UID PID PPID C STIME TTY TIME CMDroot 423 1 0 09:09 tty1 00:00:00 login – rootroot 431 423 0 09:09 tty1 00:00:00 -bashroot 503 431 10 10:11 tty1 00:00:00 ps –f
En este ejemplo vemos, entre otra información, que el proceso login – root tiene como proceso padre el inicio del sistema (PPID 1), que el proceso –bash tiene como proceso padre al proceso login – root (PPID 423) y que el proceso ps –f tiene como proceso padre al proceso –bash (PPID 431).
-l.
El listado de los procesos se realiza en formato largo, visualizándose nuevas cabeceras.
193

-p procesos.
Muestra los procesos especificados. Los procesos se indican con su PID.
-r.
Sólo se muestran los procesos en ejecución.
-tnúmero.
Se visualizan los procesos asociados a la estación ttynúmero.
-u [usuario].
Se muestra, entre otra información, el usuario asociado a cada proceso. También se puede incluir el nombre de un usuario para mostrar los procesos que está ejecutando dicho usuario.
-x.
Muestra todos los procesos, incluidos los que no están asociados a ningún terminal.
Ejemplos.
Si se quiere obtener un listado de todos los procesos en ejecución, hay que introducir el comando ps –uax.
Si se quieren listar los procesos de los terminales 1 (tty1) y 2 (tty2), hay que introducir la orden ps –t “1 2”.
En ocasiones, se muestran procesos marcados como defunct, que quiere decir que el proceso ha finalizado su ejecución pero su proceso padre todavía no se ha enterado. Este proceso se denomina proceso zombi. Si se muestran muchos procesos zombi, es posible que exista algún error en el sistema. Los procesos zombi desaparecen cuando el ordenador se apaga.
También es posible ejecutar un proceso y mostrar, después de haber sido ejecutado, el tiempo que ha empleado en su ejecución y el tiempo de uso de la CPU, entre otras informaciones. Para ello, se utiliza el comando time seguido del proceso que se quiere ejecutar.
194

17.5. FINALIZACIÓN DE LOS PROCESOS.
Cuando un proceso está causando problemas en el sistema, se puede suspender su ejecución utilizando las teclas Ctrl-c. Si el proceso se está ejecutando en segundo plano, no se puede suspender utilizando estas teclas. Para suspender procesos en segundo plano, hay que utilizar el comando kill.
La sintaxis de la orden kill es la siguiente:
kill [señal] PID
Se pueden suspender varios procesos, incluyendo sus números de identificación separados por espacios. Cuando se desea detener un proceso que ha lanzado nuevos procesos, hay que detenerlos todos, porque si se suspende sólo el proceso superior, los procesos que haya lanzado seguirán ejecutándose, pudiendo ocasionar problemas.
Si un terminal se encuentra bloqueado, se puede iniciar una sesión en un terminal virtual (pulsando las teclas Alt-Fnúmero) y, desde esta nueva sesión, suspender el shell bloqueado. Para ver el shell bloqueado, que normalmente se encontrará en tty1, hay que ejecutar el comando ps para mostrar su PID.
La orden kill envía una señal a los procesos que van a ser detenidos, que indica la forma en la que se detendrán. Las señales que se pueden enviar se pueden visualizar escribiendo la orden kill –l. Las señales que se envían a los procesos se pueden incluir en la orden kill, utilizando el número de señal. Si se omite la señal, el comando kill envía la señal 15 al proceso indicado. Si el proceso se sigue ejecutando, significa que se ha definido para ignorar la señal 15 enviada por el comando kill. La señal 9 indica que el proceso especificado se detendrá de forma incondicional, aunque haya sido definido para ignorar ciertas señales. El número de señal debe ir precedido de un guión. Si se quieren detener todos los procesos que se están ejecutando en segundo plano, hay que ejecutar la orden kill 0.
Algunas de las señales que generan los procesos o que pueden ser enviadas por el comando kill a los procesos son las siguientes:
1.
Esta señal se produce cuando se pierde la línea telefónica o cuando se desconecta el cable que une el terminal con el ordenador.
2.
Se genera cuando el usuario introduce las teclas de interrupción de un proceso. Estas teclas son Ctrl+c.
3.
Se genera cuando el usuario introduce las teclas de abandonar un proceso. Estas teclas son Ctrl+\. En este caso se crea un archivo core.
4.
El proceso ha ejecutado una instrucción ilegal.
9.
Terminación incondicional del proceso.
14.
Se ha producido una alarma de reloj.
195

15.
El proceso ha terminado desde el software que lo está ejecutando.
Los usuarios sólo pueden eliminar sus propios procesos, a excepción del usuario root, que puede eliminar cualquier proceso.
196

17.5.1 Captura de señales.
Las señales generadas por los procesos o enviadas a estos por el comando kill, pueden ser capturadas para que el proceso controle la acción que ha de realizar cuando reciban estas señales. Para ello, se utiliza la orden trap. Esta orden debe formar parte de la ejecución del proceso. Por ejemplo, si el proceso es un guión shell, la orden trap debe ser incluida en el propio guión shell.
La sintaxis de la orden trap es la siguiente:
trap [orden] señal
En el parámetro señal hay que incluir la señal o señales que se desean capturar.
En el parámetro orden se puede incluir:
Una orden o programa, que se ejecutará cuando se genere la señal o señales indicadas. Posteriormente, el proceso continuará su ejecución en la orden siguiente a la que se estaba ejecutando cuando recibió la señal. La orden o programa debe ir encerrado entre comillas.
Ejemplo.
En un guión shell se incluye la orden trap ‘echo Enviada señal 15’ 15.
Si se ejecuta la orden kill guiónshell (por defecto se envía la señal 15) se muestra el mensaje Enviada señal 15 y, posteriormente, el guión shell continúa su ejecución.
La cadena vacía (‘’). Indica que las señales incluidas son ignoradas, no realizándose ninguna acción y continuando la ejecución del proceso en la orden siguiente a la que se estaba ejecutando cuando recibió la señal.
Ejemplo.
En un guión shell se incluye la orden trap ‘’ 15.
Si se ejecuta la orden kill guiónshell (por defecto se envía la señal 15) el guión shell continúa su ejecución, ignorando la señal de terminación enviada desde el comando kill.
No inclusión del parámetro. Cuando este parámetro se omite, las señales incluidas dejan de ser interceptadas. Esta acción es útil cuando en un mismo proceso es necesario que algunas señales se capturen en un determinado momento y no se capturen en otra parte del proceso.
Ejemplo.
En un guión shell se incluye la orden trap 15. La señal 15 deja de ser capturada. De esta forma, si se ejecuta la orden kill guiónshell, el guión shell termina su ejecución.
La señal 9 (terminación incondicional) no se puede capturar.
197

17.6. PRIORIDAD DE LOS PROCESOS.
Cuando un proceso se ejecuta, el sistema le asigna una prioridad de ejecución. Esta prioridad se tendrá en cuenta a la hora de utilizar los recursos del sistema. Los procesos con mayor prioridad utilizan los recursos con mayor frecuencia que los procesos con menor prioridad. Los procesos hijo heredan la prioridad de los procesos padre.
La prioridad de los procesos se establece mediante valores numéricos. Cuanto menor sea el valor numérico de la prioridad de los procesos, mayor será su prioridad.
Para gestionar la prioridad de los procesos se utilizan dos comandos:
17.6.1 Comando nice.
Se utiliza para asignar prioridad a los procesos.
La sintaxis es la siguiente:
nice –número proceso
La opción –número determina la prioridad del proceso, cuyo rango de valores oscila entre –20 (máxima prioridad) y 19 (mínima prioridad). Para ejecutar un proceso con la prioridad más alta, hay que introducir nice --20 orden (observar que se escriben dos guiones delante del número 20).
17.6.2 Comando renice.
Se utiliza para modificar la prioridad de los procesos que están ejecutándose.
La sintaxis es la siguiente:
renice número {[[-p] PID],[[-g] IDgrupo],[[-u] IDusuario]}
La nueva prioridad del proceso se asigna en el parámetro número. Se puede cambiar la prioridad a un determinado proceso (parámetro PID), a todos los procesos de un grupo de usuarios (parámetro IDgrupo) o a todos los procesos de un usuario (parámetro IDusuario).
Los usuarios normales sólo podrán modificar la prioridad de sus procesos, no pudiendo asignarles una prioridad mayor.
El usuario root puede modificar, aumentando o disminuyendo, la prioridad de todos los procesos en ejecución.
198

18.Guiones shell.
18.1. INTRODUCCIÓN.
Un guión shell o shell script es un programa elaborado por el usuario que permite ejecutar cualquier orden de Unix. Además de los comandos Unix, se pueden ejecutar instrucciones propias de los lenguajes de programación, como son bucles, sentencias de control, instrucciones de E/S de datos, definición de variables, definición de funciones, etc. Podemos consultar un manual del lenguaje de programación en la dirección http://tldp.org/LDP/abs/html/index.html.
Para ejecutar un guión shell, hay que escribir . guiónshell o sh guiónshell. Si el usuario tiene permiso de ejecución sobre el guión shell, hay que introducir el nombre del guión para ejecutarlo, omitiendo la orden sh.
Para introducir comentarios en los guiones shell, deben estar precedidos del carácter ‘#’.
Es conveniente que cada usuario se cree un directorio, dentro de su directorio home, para guardar todos sus guiones shell. Este directorio se podría llamar bin y habría que incluirlo en la variable PATH para tener acceso directo a dicho directorio.
199

18.2. VARIABLES.
Los guiones shell utilizan dos tipos de variables:
Variables locales.
Son las que se definen en cada guión y sólo pueden ser utilizadas por el guión en el que han sido creadas. Si se quieren utilizar en otros programas, hay que exportarlas con la orden export. La lista de variables locales se muestra con la orden set.
Variables globales.
Son aquellas que se pueden utilizar en todos los guiones. Estas variables, para que estén disponibles en todos los programas, deben ser exportadas con la orden export. Si una variable local se redefine con la orden export, pasará a ser global. La lista de variables globales o de entorno se visualiza con la orden env. Un proceso hijo puede modificar una variable exportada por su proceso padre, pero cuando el proceso hijo finalice su ejecución, la variable exportada tendrá el mismo valor que antes de ser exportada al proceso hijo y modificada por éste.
Para más información sobre variables de entorno, consultar el punto 9. El shell.
200

18.2.1 Definición de variables.
Para definir una variable, hay que asignarle un valor. La forma de asignar un valor a una variable es escribiendo el nombre de la variable, el signo ‘=’ y el valor que se desea asignar. Por ejemplo, para asignar el valor 4 a la variable Numero, hay que escribir Numero=4 (observar que, a ambos lados del signo ‘=’, no se introducen espacios), para asignar la fecha del sistema a la variable Fecha, hay que escribir Fecha=`date`.
Se pueden definir variables de solo lectura. Para ello, se utiliza la sintaxis readonly variable. Si se ejecuta la instrucción readonly sin argumentos, se muestran todas la variables que se han definido de solo lectura.
Las variables se crean en memoria y permenecen accesibles durante la ejecución del shell script. Para borrar una variable de memoria se utiliza la sintaxis unset variable.
Para hacer referencia al nombre de la variable, hay que escribir el carácter ‘$’ delante del nombre de la variable. Por ejemplo, para visualizar el contenido de la variable Numero, hay que escribir echo $Numero.
201

18.2.2 Asignación de valores.
Cuando una variable está vacía, se puede asignar un valor de forma temporal a dicha variable para realizar una accción determinada. La variable puede mantener o no el valor que se le ha asignado de forma temporal. Para ello, se utiliza la sintaxis ${variable:opción cadena}. Las opciones pueden ser:
-.
La cadena especificada se asigna a la variable indicada. Después de la asignación, la variable sigue estando vacía.
Ejemplo.
ejemplo=echo $ejemploecho ${ejemplo:-Hola}echo $ ejemplo
Este ejemplo visualiza una línea en blanco con la instrucción echo $ejemplo, pues la variable ejemplo contiene la cadena vacía, visualiza la cadena Hola, que es el contenido de la variable ejemplo, asignado en la instrucción echo ${ejemplo:-Hola} porque la variable ejemplo está vacía, y, por último, visualiza, nuevamente, una línea en blanco con la instrucción echo $ejemplo, pues la variable ejemplo sigue conteniendo la cadena vacía.
=.
El valor de cadena se asigna a la variable indicada y, después de la asignación, la variable contendrá la cadena especificada.
Ejemplo.
ejemplo=echo $ejemploecho ${ejemplo:=Hola}echo $ ejemplo
Este ejemplo visualiza una línea en blanco con la instrucción echo $ejemplo, pues la variable ejemplo contiene la cadena vacía, visualiza la cadena Hola, que es el contenido de la variable ejemplo, asignado en la instrucción echo ${ejemplo:=Hola} porque la variable ejemplo está vacía, y, por último, visualiza, nuevamente, la cadena Hola con la instrucción echo $ejemplo, pues la variable ejemplo, al contener la cadena vacía, cambia su contenido por la cadena Hola.
+.
Si la variable no está vacía, se le asigna la cadena especificada. Después de la asignación, la variable contendrá el valor que tenía antes de la asignación.
Ejemplo.
ejemplo=Adiosecho $ejemploecho ${ejemplo:+Hola}echo $ ejemplo
Este ejemplo visualiza la cadena Adios con la instrucción echo $ejemplo, visualiza la cadena Hola, que es el contenido de la variable ejemplo, asignado en la instrucción echo ${ejemplo:+Hola} porque la variable ejemplo no está vacía, y, por último,
202

visualiza, nuevamente, la palabra Adios con la instrucción echo $ejemplo, pues la variable ejemplo, al no contener la cadena vacía, no cambia su contenido por la cadena Hola.
?.
Si la variable indicada no tiene valor, se visualiza la cadena especificada y el guión shell termina su ejecución.
Ejemplo.
ejemplo=echo $ejemploecho ${ejemplo:?Error}
Este ejemplo visualiza una línea en blanco con la instrucción echo $ejemplo, pues la variable ejemplo contiene la cadena vacía, y visualiza la cadena Error, que es el contenido de la variable ejemplo, asignado en la instrucción echo ${ejemplo:=Hola} porque la variable ejemplo está vacía, finalizando la ejecución del guión script.
También se puede utilizar la sintaxis ${variable}cadena para que la cadena especificada no forme parte del nombre de la variable indicada.
Las variables pueden tomar valor de los datos tecleados por el usuario. Para ello, se utiliza la orden read, seguida del nombre de la variable o variables donde se va a almacenar el dato introducido por el usuario. Si el usuario introduce caracteres especiales que utiliza el shell y no se quieren tener en cuenta, por ejemplo, al imprimir el contenido de la variable, hay que encerrar el nombre de la variable entre comillas.
Un guión shell puede tomar valores que se generan dentro del propio guión. Para ello, se utiliza el operador <<. La sintaxis es la siguiente: orden << fin, siendo fin una cadena de caracteres que se utilizará como final de los datos que se tomarán del propio guión shell.
Ejemplo.
mail usuario << FinMensajeEl sistema se cerrará dentro de cinco minutos.Por favor, guarde sus datos.
FinMensaje
203

18.2.3 Gestión de parámetros.
Al ejecutar un guión shell, se pueden pasar parámetros que podrán ser ejecutados desde el propio guión. Estos parámetros se escribirán a continuación del nombre del guión. Para acceder a estos parámetros desde el guión shell, se utilizan las variables $1 a $9. Por ejemplo, si se quieren pasar los nombres de los archivos carta1, carta2 y carta3 a un guión que se llama copiar, hay que escribir, en la línea de comandos, copiar carta1 carta2 carta3. Las variables $1, $2 y $3 contendrán los valores carta1, carta2 y carta3, respectivamente. Además de las variables $1 a $9, el shell genera las siguientes variables:
$0.
Contiene el nombre del guión shell que se está ejecutando.
$-.
Contiene los argumentos o indicadores que se utilizan, por ejemplo con la orden set, al ejecutar el guión shell.
$*.
En algunas versiones de Unix/Linux se utilizan las varables $. o $@. Contiene todos los parámetros introducidos en la línea de comandos.
$#.
Contiene el número de parámetros introducidos.
$?.
Contiene el código de retorno, que puede ser un código de error, de la orden ejecutada. Si la orden se ha ejecutado en segundo plano, esta variable no toma valor.
$$.
Contiene el PID.
$!.
Contiene el PPID.
Para acceder a los distintos parámetros introducidos desde la línea de comandos al ejecutar el guión shell, hay que utilizar la orden shift. Esta orden desplaza el valor de los parámetros una posición a la izquierda. Al ejecutar la orden shift, la variable $1 toma el valor de la variable $2, la variable $2 toma el valor de la variable $3, la variable $3 toma el valor de la variable $4, y así sucesivamente. La variable $0 siempre contendrá el mismo valor.
Puede haber más de 9 parámetros. Para referenciar los parámetros superiores a 9, hay que encerrarlos entre llaves. Por ejemplo, para acceder al contenido del parámetro 15, hay que escribir ${15}.
204

18.2.4 Visualización del contenido de las variables.
Para visualizar el contenido de las variables se utiliza la orden echo, también utilizada para visualizar constantes. La orden echo admite las siguientes opciones:
-n.
No realiza el salto de línea después de visualizar la información especificada.
-e.
Se utiliza para incluir uno de los siguiente caracteres (estos caracteres se incluyen entre comillas dobles o simples):
\a.
Emite un pitido.
\c.
No realiza el salto de línea después de visualizar la información especificada.
\f.
Realiza un salto de página.
\n.
Realiza un salto de línea.
\r.
Realiza un retorno de carro.
\t.
Incluye un tabulador horizontal.
\nnn.
Incluye el código ASCII especificado en nnn. El número nnn se indica en octal.
Ejemplo.
echo –n Introduzca un valorread variable # La entrada de la variable se pide a continuación de la cadena Introduzca un valorecho Ha introducido el valor $variable
Este ejemplo también se podría escribir de la siguiente forma:
echo -e Introduzca un valor ‘\c’read variable # La entrada de la variable se pide a continuación de la cadena Introduzca un valorecho Ha introducido el valor $variable
205

18.3. EXPRESIONES.
En un guión shell se pueden realizar las operaciones de sumar (+), restar (-), multiplicar (*), dividir (/) y calcular el resto de una división (%). El símbolo de la multiplicación debe ir precedido por el carácter ‘\’.
Para realizar estas operaciones se utiliza la instrucción expr. Por ejemplo, para sumar los números 2 y 3, hay que escribir expr 2 + 3 (observar que se introduce un espacio antes y después del signo +).
El resultado de la operación se puede almacenar en una variable. Para ello, hay que introducir la expresión entre acentos graves ‘`’. Por ejemplo, si queremos almacenar el resultado de la suma de los números 2 y 3 en la variable Suma, hay que escribir Suma=`expr 2 + 3`.
También se puede utilizar una variable como operando de la expresión. Por ejemplo, para almacenar en la variable Producto el producto de la variable Suma por 4, hay que escribir Producto =`$Suma \* 4`.
Una expresión puede contener varias expresiones. Por ejemplo, si queremos dividir la suma de las variables Var1 y Var2 entre el producto de las variables Var3 y Var4, hay que escribir expr `expr Var1 + Var2` / `expr Var3 \* Var4`. Si el resultado de la expresión anterior se quiere guardar en una variable, hay que utilizar los paréntesis para agrupar las expresiones.
Ejemplo.
Var1=50Var2=20Var3=5Var4=2Resultado=`expr \( $Var1 + $Var2 \) / \( $Var3 \* $Var4 \)`echo $Resultado # Imprime el valor 7
206

18.4. EVALUACIÓN DE CONDICIONES.
Cuando en un programa se necesitan tomar decisiones, es necesario realizar una evaluación de las condiciones que producirán la toma de decisiones. Para ello, se utiliza la orden test. Esta orden permite evaluar números, cadenas y archivos. Los números, cadenas y los nombres de los archivos que van a ser evaluados pueden estar almacenados en variables.
Dependiendo del tipo de dato que se vaya a evaluar, hay que utilizar distintas opciones para realizar la evaluación:
18.4.1 Datos numéricos.
Las opciones que se utilizan para realizar las evaluaciones son las siguientes:
-eq.
Igual.
-gt.
Mayor que.
-ge.
Mayor o igual que.
-le.
Menor o igual que.
-lt.
Menor que.
-ne.
Distinto.
207

18.4.2 Cadenas.
Las opciones que se utilizan para realizar las evaluaciones son las siguientes:
=.
Igual.
!=.
Distinto.
-n.
Cadena con datos o de longitud mayor que cero.
str.
Comprueba que la cadena no sea nula.
-z.
Cadena vacía o de longitud cero.
208

18.4.3 Archivos.
Las opciones que se utilizan para realizar las evaluaciones son las siguientes:
-a.
Archivo existente. En algunos sistemas esta opción no funciona, debiendo utilizar -e.
-b.
Archivo de dispositivo de bloques.
-c.
Archivo de dispositivo de caracteres.
-d.
Archivo de directorio.
-e.
Archivo existente.
-f.
Archivo normal.
-h.
Archivo de vínculo simbólico.
-r.
Archivo con permiso de lectura.
-s.
Archivo existente y con datos.
-w.
Archivo con permiso de escritura.
-x.
Archivo con permiso de ejecución.
209

18.4.4 Operadores.
Se pueden combinar varias evaluaciones de condiciones utilizando los operadores And, Or y Not. El operador And se represenrta con los caracteres –a o con los caracteres &&, el operador Or se representa con los caracteres –o o con los caracteres || y el operador Not se representa con el carácter ! (ver los ejemplos de las instrucciones while y until ).
210

18.4.5 Otras consideraciones.
La ejecución de los comandos también se puede evaluar mediante los códigos de salida que generan. Si el comando se ha ejecutado con éxito, genera el código de salida 0, en cuyo caso la evaluación de la ejecución del comando es verdadera. Si el comando no se ha ejecutado con éxito, genera un código de salida distinto de 0, en cuyo caso la evaluación de la ejecución del comando es falsa.
La orden test se puede sustituir encerrando la evaluación de la condición entre corchetes, debiendo dejar un espacio después del corchete [ y un espacio antes del corchete ].
211

18.5. RUPTURAS DE CONTROL.
Cuando no queremos que las instrucciones de un programa se ejecuten en secuencia, es necesario realizar rupturas de control para que se ejecuten unas instrucciones cuando se cumpla una condición y otras cuando se cumpla otra determinada condición. Para ello, se utilizan las estructuras de control if y case.
18.5.1 Instrucción if.
La sintaxis de la intrucción if es la siguiente:
if [ condición ]then
<instrucciones>else
<instrucciones>fi<instrucciones>
Esta estructura funciona de la siguiente forma: Se evalúa la condición. Si la condición evaluada es verdadera se ejecutan las instrucciones escritas a continuación de then y si es falsa se ejecutan las instrucciones que siguen a else. En ambos casos, después de ejecutar las instrucciones correspondientes, se ejecutan las instrucciones a continuación de fi.
Se pueden anidar varias instrucciones if. En este caso, por cada instrucción if anidada, existirá una instrucción fi.
Si después de la instrucción else se quiere ejecutar una nueva instrucción if, se puede utilizar la instrucción elif. En este caso, sólo es necesario una única instrucción fi. La sintaxis de esta estructura es la siguiente:
if [ condición ]then
<instrucciones>elif [ condición ] then
<instrucciones> elif [ condición ] then <instrucciones>fi<instrucciones>
212

18.5.2 Instrucción case.
Se utiliza para ejecutar unas determinadas instrucciones dependiendo del valor contenido en una expresión.
La sintaxis es la siguiente:
case expresión invalor 1) <instrucciones> <última instrucción;;>valor 2) <instrucciones> <última instrucción;;>valor n) <instrucciones> <última instrucción;;> *) <instrucciones>
<última instrucción;;>esac
El funcionamiento de esta estructura es el siguiente: la expresión (variable o cadena) se compara con cada uno de los valores indicados (valor1, valor2, valorn) y, si coincide con alguno de ellos, se ejecutan las instrucciones del valor coincidente (observar que la última instrucción acaba con los caracteres ‘;;’). El valor *) se utiliza para ejecutar las instrucciones que le siguen en el caso de que la expresión no coincida con ninguno de los valores especificados. Este valor es opcional. La orden esac indica el final de la estructura.
En los valores se pueden utilizar los metacaracteres *, ? y [ ] y varios valores separados por el carácter ‘|’, que equivale al operador Or.
Ejemplo.
clearecho –e ‘\t\t’ 1. Altasecho –e ‘\t\t’ 2. Bajasecho –e ‘\t\t’ 3. Modificacionesecho –e ‘\t\t’ 4. Consultasecho –e ‘\t\t’ 5 Listado totalecho –e ‘\t\t’ 6. Listado parcialecho –e ‘\t\t’ 7. Finecho –n –e ‘\t\t\t\t’ ‘Elija una opción: ‘read opcioncase $opcion in
1) echo Ha elegido la opción de Altas;;2) echo Ha elegido la opción de Bajas;;3) echo Ha elegido la opción de Modificaciones;;4) echo Ha elegido la opción de Consultas;;5|6) echo Ha elegido la opción de Listados;;7) echo Ha elegido la opción de Fin;;*) echo –e \a Error al teclear una opción;;
esac
213

18.6. BUCLES.
Los bucles se utilizan para ejecutar una serie de instrucciones de forma repetitiva. Para ello, se utiliza la estructura do <instrucciones> done.
Para indicar el número de veces que se repetirán las instrucciones incluidas dentro del bucle, se utilizan las sentencias while, until y for.
214

18.6.1 while.
Las instrucciones contenidas en el bucle se ejecutan mientras se cumpla la condición indicada en la instrucción while.
La sintaxis es la siguiente:
while condicióndo <instrucciones>done
Ejemplo1.
Opcion=0while test $Opcion –ne 7do clear echo –e ‘\t\t’ 1. Altas echo –e ‘\t\t’ 2. Bajas echo –e ‘\t\t’ 3. Modificaciones echo –e ‘\t\t’ 4. Consultas echo –e ‘\t\t’ 5 Listado total echo –e ‘\t\t’ 6. Listado parcial echo –e ‘\t\t’ 7. Fin echo –n –e ‘\t\t\t\t’ ‘Elija una opción: ‘ read Opcion
case $Opcion in1) echo –n Ha elegido la opción de Altas;;2) echo –n Ha elegido la opción de Bajas;;3) echo –n Ha elegido la opción de Modificaciones;;4) echo –n Ha elegido la opción de Consultas;;5|6) echo –n Ha elegido la opción de Listados;;7) echo –n Ha elegido la opción de Fin;;*) echo –n –e ‘\a’ Error al teclear una opción;;
esac echo –n . Pulse Enter; read Tecla
done
Ejemplo2.
Respuesta=’’while [ “$Respuesta” != “s” –a “$Respuesta” != “n” ]do read Respuestadone
Este ejemplo también se puede escribir de la siguiente forma:
Respuesta=’’while [ “$Respuesta” != “s” ] && [ “$Respuesta” != “n” ]do read Respuestadone
215

18.6.2 until.
Las instrucciones contenidas en el bucle se ejecutan hasta que se cumpla la condición indicada en la instrucción until.
La sintaxis es la siguiente:
until condicióndo <instrucciones>done
Ejemplo1.
Opcion=0until [ $Opcion –eq 7 ]do clear echo –e ‘\t\t’ 1. Altas echo –e ‘\t\t’ 2. Bajas echo –e ‘\t\t’ 3. Modificaciones echo –e ‘\t\t’ 4. Consultas echo –e ‘\t\t’ 5 Listado total echo –e ‘\t\t’ 6. Listado parcial echo –e ‘\t\t’ 7. Fin echo –n –e ‘\t\t\t\t’ ‘Elija una opción: ‘ read Opcion
case $Opcion in5) echo –n Ha elegido la opción de Altas;;6) echo –n Ha elegido la opción de Bajas;;7) echo –n Ha elegido la opción de Modificaciones;;8) echo –n Ha elegido la opción de Consultas;;5|6) echo –n Ha elegido la opción de Listados;;7) echo –n Ha elegido la opción de Fin;;*) echo –n –e ‘\a’ Error al teclear una opción;;
esac echo –n . Pulse Enter; read Tecla
done
Ejemplo2.
Respuesta=’’until [ “$Respuesta” = “s” –o “$Respuesta” = “n” ]do read Respuestadone
Este ejemplo también se puede escribir de la siguiente forma:
Respuesta=’’until [ “$Respuesta” = “s” ] || [ “$Respuesta” = “n” ]do read Respuestadone
216

18.6.3 for.
Las instrucciones comprendidas dentro del bucle se ejecutan para todos los valores que pueda tomar la variable especificada.
La sintaxis es la siguiente:
for variable [in lista] do
<instrucciones> done
Si no se especifica in lista, la variable utiliza como valores los parámetros introducidos al ejecutar el guión shell.
Ejemplo. Mostrar el contenido de los archivos carta, texto y documento.
for Archivo in carta texto documento do cat $Archivo|less done
217

18.7. FUNCIONES.
Las funciones se utilizan para incluir en ellas una serie de órdenes que se van a ejecutar varias veces en distintos lugares de un mismo guión shell o que se ejecutarán desde distintos guiones shell.
La sintaxis para definir una función es la siguiente:
NombreFunción (){<órdenes>}
Las órdenes se deben escribir entre llaves ‘{}’.
Las variables que se utilicen dentro de una función, no pueden llamarse de igual forma a las utilizadas en el guión shell desde el que se realiza la llamada a la función.
Para llamar a una función, se utiliza la siguiente sintaxis:
NombreFunción
Se pueden pasar parámetros a una función. La gestión de los parámetros dentro de una función se realiza de la misma forma que la descrita, anteriormente, en la gestión de parámetros, es decir, el primer parámetro se encuentra en la variable $1, el segundo en la variable $2, y así sucesivamente.
Las funciones se definen al principio del shell script. Si se definen en cualquier otro lugar, hay que ejecutar el guión shell con la sintaxis . GuiónShell; de lo contrario, cuando se llame a la función se producirá el error Command not found.
Es posible que la función devuelva valores, que serán tratados en el guión shell que ha llamado a la función. Para ello, se utiliza la siguiente sintaxis:
return valor
Para consultar los valores que se retornan de una función, se utiliza la variable $?.
Si no se retorna ningún valor, la función devuelve el código de salida del último comando ejecutado en la función.
218

18.8. EJECUCIÓN DE LOS GUIONES SHELL.
Para ejecutar un guión shell, hay que escribir su nombre seguido de la lista de parámetros, si el guión shell gestiona parámetros.
Otra forma de ejecutar los guiones shell es utilizando la siguiente sintaxis:
sh GuiónShell [parámetros] [set {-,+} opción1 set {-,+} opción2 ...]
Todas las opciones set deben ir precedidas de uno de los caracters ‘-‘ o ‘+’, que indican que la opción será activada, carácter ‘-‘, o desactivada, carácter ‘+’.
Las opciones que se pueden incluir en la orden set son las siguientes:
e.
Detiene la ejecución del shell script si al ejecutar alguno de sus comandos genera un código de salida distinto de cero.
n.
Lee las órdenes de un guión shell sin ejecutarlas.
u.
Las variables que no se han inicializado generan un error.
v.
Muestra la orden del shell script que se está ejecutando.
x.
Muestra el resultado de la ejecución de las órdenes.
Las opciones de la orden set, se pueden ejecutar al llamar al shell script o pueden ser incluidas dentro del mismo.
Cuando un guión shell se va a ejecutar desde un shell distinto al shell desde el que se creó, hay que incluir, como primera orden del guión shell, la orden “#/usr/bin/shell” (en algunos sistemas se utiliza la sintaxis “#!/usr/bin/shell”), siendo shell el nombre del shell desde el que se va a ejecutar (sh, csh, etc.).
Se puede generar un código de salida cuando un guión shell termine su ejecución. Para ello, se utiliza la orden exit número, donde número es el código de salida que el guión shell devuelve. Si no se utiliza la orden exit, el shell script devuelve el código de salida de la última orden que se ha ejecutado.
Los mensajes de error que generan los comandos, se pueden redireccionar a un archivo utilizando la sintaxis orden 2>archivo. Por ejemplo, si ejecutamos la orden cd prueba 2>errores y el directorio prueba no existe, el mensaje de error que genera la orden se envía al archivo errores. También se puede utilizar el redireccionamiento >>. Si se redirecciona al dispositivo /dev/null, el mensaje no se muestra y no se guarda en ningún archivo. Posteriormente, se puede preguntar por el valor de la variable $? para saber si se ha producido o no un error.
219

220