Apuntes del Curso SOR (Tema 6 a 8) · • CentOS! • Fedora!! ... 6.4.ComparticióndeRecursos.$...
40
Tema 6: Gestión de los Sistemas Operativos de Red A partir de este tema, nos abocaremos a utilizar el Sistema Operativo de Red basado en Linux, por lo que se recomienda instalar cualquiera de los siguientes S.O.R.: • Ubuntu • OpenSuse • CentOS • Fedora 6.1. Creación de Cuentas de Usuarios. Dentro de Linux, podemos administrar a los usuarios por dos métodos: • Grafico y • Línea de comandos Actualmente la solución mas utilizada es la gráfica, para esto, debemos irnos al menú de Sistema Administración Usuarios y Grupos, tal como lo muestra la siguiente imagen.
Transcript of Apuntes del Curso SOR (Tema 6 a 8) · • CentOS! • Fedora!! ... 6.4.ComparticióndeRecursos.$...

Tema 6: Gestión de los Sistemas Operativos de Red
A partir de este tema, nos abocaremos a utilizar el Sistema Operativo de Red basado
en Linux, por lo que se recomienda instalar cualquiera de los siguientes S.O.R.:
• Ubuntu
• OpenSuse
• CentOS
• Fedora
6.1. Creación de Cuentas de Usuarios.
Dentro de Linux, podemos administrar a los usuarios por dos métodos:
• Grafico y
• Línea de comandos
Actualmente la solución mas utilizada es la gráfica, para esto, debemos irnos al menú
de Sistema à Administración à Usuarios y Grupos, tal como lo muestra la siguiente
imagen.

!
Una vez estando en el gestor gráfico de usuarios, para agregar un usuario debemos
dar click en + Añadir Usuario, esto abrirá el Editor de Cuentas de Usuario. Los
requisitos mínimos para crear un usuario son el Nombre de usuario y la contraseña
(generada automáticamente o escrita por el administrador). Para el nombre de
usuario, no se permite la utilización de espacios en blanco ni caracteres ASCII.

!

!
Para agregar un usuario desde la línea de comandos, deben hacerlo desde super
usuario, más el comando de useradd.
Los parámetros básicos para agregar un usuario son:
-‐d directorio home
-‐s registrar el nombre del usuario en el shell

!
Actividad: Crear un usuario en Linux en modo gráfico, e investigar como crear
un usuario en modo línea de comandos.
En línea de comandos, deberán crear un usuario y un grupos de usuarios.
Deberán crear en una tabla el listado de los parámetros que se utilizan en
useradd y la descripción de para que sirve cada uno de ellos, para esto deben
usar el comando man useradd para identificar los parámetros que se utilizan
en la línea de comandos.
Preguntas de estudio:
1.-‐ ¿Se puede crear un usuario cuando nos conectamos remotamente al
equipo?
2.-‐ ¿Cuáles son los tipos de usuario que maneja Linux?
3.-‐ ¿Cuáles son los tipos de usuario que maneja Windows?
4.-‐ ¿Con que parámetro desde la lista de comandos se pueden ver los usuarios
registrados?
5.-‐ ¿Cómo podemos eliminar un usuario?

!
Resumen, pasos para crear un usuario en línea de comandos:
Creamos el usuario: $ sudo useradd nombre_usuario
Creamos contraseña: $ sudo passwd nombre_usuario
Resumen de comandos de usuario utilizados
Comando Función
useradd nombre_usuario Agrega un usuario
passwd Cambiar la contraseña del usuario actual
passwd nombre usuario Cambia la contraseña de un usuario, en
modo sudo
cat /etc/passwd Saber usuarios en el equipo
cat /etc/group Saber grupos de usuarios del equipo
finger nombre_usuario Conocer más información del usuario
(nota, deben instalar este comando)
userdel nombre_usuario Elimina a un usuario
usermod nombre_usuario Modifica a un usuario
usermod –p contraseña
nombre_usuario
Modifica la contraseña de un usuario
chfn Modifica los datos del usuario
chsh Modifica la Shell de acceso del usuario
Grupos de usuarios
Comando Función

!
groupadd nombre_grupo Agrega un grupo
gpasswd Cambiar el password del grupo
cat /etc/group Saber grupos de usuarios del equipo
groupdel nombre_grupo Elimina un grupo de usuarios
groupmod nombre_grupo Modifica a un grupo
groups Muestra los grupos a los que pertenece
un usuario
usermod –g nombre_grupo
nombre_usuario
Agrega un usuario a un grupo
6.2. Habilitación de Servicios.
Instalación de un servidor WEB
En este caso instalaremos Apache2 web server, el cual es uno de los servidores web
más utilizados y estables que existen.
Para su instalación se puede hacer de dos formas:
la primera es descargarlo desde la línea de comandos mediante el comando:
$ apt-‐get install apache2
La segunda opción es entrado en la página web de apache
(http://httpd.apache.org ) y descargar la versión mas reciente en este caso la
versión 2.4.3, para su instalación ir a la línea de comandos y ejecutar el
siguiente código:
-‐ Se descomprime el paquete descargado
$ gzip -‐d httpd-‐2_1_NN.tar.gz

!
$ tar xvf httpd-‐2_1_NN.tar
-‐ Se ejecuta el script configure
$./configure -‐-‐prefix=PREFIX
-‐ Compilamos el programa
$ make
-‐ Instalamos el programa
$ make install
-‐ Personalizamos el programa, para esto se recomienda consultar
http://httpd.apache.org/docs/2.4/ que es la guía mas reciente de
apache
$ vi PREFIX/conf/httpd.conf
-‐ Ahora iniciamos el servidor
$ PREFIX/bin/apachectl start
-‐ Comprobamos que la instalación funciona
En el explorador de internet del servidor escribimos
http://localhost/
-‐ Para detener el servidor
$ PREFIX/bin/apachectl stop
6.3. Filtrado y Manejo de Procesos.
Un proceso es un programa en ejecución dentro del S.O., pero ¿como se filtran y
manejan?
Para esto, es necesario saber que un proceso se compone de tres partes en linux, estas
son:
-‐ Segmento de texto: código de programa
-‐ Segmento de datos: variables globales y estáticas
-‐ Pila: Lo crea el kernel y su tamaño es gestionado dinámicamente por el. Es una
secuencia de bloques lógicos o stack frames. Un stack frame se introduce o
extrae en función de si se llama o se vuelve de la llamada a una función.

!
Los procesos pueden ejecutarse en dos modos:
-‐ usuario y
-‐ kernel.
Cada modo maneja su propia pila:
-‐ Stack del kernel: contiene las llamadas a sistema (funciones que se ejecutan en
modo kernel)
-‐ Stack del usuario: contiene las funciones que se ejecutan en modo usuario
Ahora bien, procedemos a ver el listado de procesos en Linux mediante el comando:
ps –A o ps –e
Para mas información sobre el comando “ps”, les recomiendo entrar al manual
mediante el comando “man ps”
Para matar o eliminar un proceso, lo que debemos hacer primero es identificar cual es
el ID del proceso que queremos matar:
ps -‐e
kill numero_proceso

!
6.4. Compartición de Recursos.
Para compartir recursos en Linux, se requiere como prerrequisito tener habilitado
nuestro servidor samba, este servidor nos va a permitir que usuarios de otros
sistemas operativos, especialmente Windows, puedan acceder a nuestras carpetas y
archivos.

!"

!!
6.5. Gateway a Internet
El Gateway a Internet, o puerta de enlace a Internet, también se conoce como la salida
por default, la cual es necesaria para enviar un paquete al exterior de nuestra red
local.
Si la parte correspondiente a la red de la dirección de destino de el paquete es
diferente de la red del host de origen, el paquete es canalizado al exterior de la red.
Para esto es que se utiliza la puerta de enlace.
Esto es, supongamos que tenemos un host con la dirección 192.168.1.10, con puerta
de enlace 192.168.1.1, y le quiere enviar un paquete al nodo 200.35.35.1, como la

!"
dirección no concuerda con el rango correspondiente a la subred, el router canaliza el
paquete por la puerta de enlace para enviar el paquete al exterior.
El Gateway es una interfaz que tienen los routers en la cual se conectan a la red local.
La interfaz de Gateway tiene una interfaz de red que corresponde con la dirección de
red de los hosts, por lo que el host debe ser configurado para reconocer esa dirección
de Gateway.
¿Cual es la principal característica de un Gateway a Internet?
Su principal característica es que va a conectar a nuestra red local hacia el Internet
¿Cómo sabemos cual es nuestra puerta de enlace?
En caso de que debamos configurar manualmente el direccionamiento IP, solamente
como administradores de la red sabremos la IP que debemos ingresar, aunque por
default siempre se sugiere que se ponga la primer dirección IP de nuestra subred
como puerta de enlace. Por ejemplo si tenemos la IP 192.168.1.10, nuestra puerta de
enlace por default sería 192.168.1.1

!"
6.6. Proxy
Práctica 7
Primera Parte
• Crear el usuario: Laboratorio • Asignarle la contraseña: LabSor503 • Crear el usuario: Laboratorio2 • Asignarle la contraseña: Lab2sor • Crear el grupo: SOR • Asignar contraseña a grupo: LabSor503 • Vincular los usuarios creado con el grupo: SOR • Crear una carpeta compartida llamada: Practica 7 • Asignarle a la carpeta para usarla con el grupo SOR • Crear un archivo de texto y guardarlo en la carpeta de Practica 7 • Ahora remotamente caerle a la carpeta de Practica 7 y abrir el archivo de
texto.
Segunda Parte
Desde la línea de comandos de Linux:
• Eliminar el archivo de texto creado anteriormente • Eliminar la carpeta de Practica 7 • Eliminar el grupo SOR • Eliminar al usuario Laboratorio2
Tercera Parte
Identificar:
• Dirección IP del equipo local y remoto • Mascara de subred del equipo local y remoto • La dirección de Gateway del equipo local y remoto • Conectarse a la red de la UV e identificar cual es la dirección de Gateway que
se les asignó

!"
¿Qué es un servicio de Proxy?
Un servicio de Proxy, es la técnica utilizada para almacenar páginas de Internet para
utilizarlas posteriormente, a esta técnica, también se le conoce como almacenamiento
en caché.
¿Para que se utiliza un Proxy?
Se utiliza para mejorar el desempeño de las páginas web más solicitadas, de tal forma
que cuando un cliente solicita una página como www.google.com, www.cnn.com,
entre muchas otras, el servidor Proxy lo que hace es almacenarla en el servidor, para
que cuando otro cliente la solicite la descargue del servidor local, en vez de solicitar la
información del servidor remoto en el que se encuentra alojada la página web.
¿Cómo se utiliza el Proxy?
Para utilizar el almacenamiento en caché, un navegador puede configurarse para que
todas las solicitudes de páginas se le hagan a un proxy en lugar de al servidor real de
la página. Si el proxy tiene la página, la regresa de inmediato. De lo contrario, la
obtiene del servidor, la agrega al caché para uso posterior y la envía al cliente que la
solicitó.
¿Quién debe realizar el almacenamiento en caché?
Las PC’s con frecuencia ejecutan un servicio Proxy con la finalidad de que puedan
buscar con rapidez las páginas web previamente consultadas, esto lo hacen mediante
el explorador web local, el cual, almacena en memoria caché las páginas consultadas
por el cliente.
También en una LAN de una compañía, el proxy con frecuencia es una máquina
compartida por todas las máquinas de la LAN, por lo que si un usuario busca cierta
página y luego otro usuario de la misma LAN desea la misma página, ésta se puede
obtener del caché del proxy.

!"
Adicionalmente muchos ISPs también ejecutan proxies, a fin de que todos sus clientes
puedan tener un acceso más rápido.
Con frecuencia, todos estos cachés funcionan al mismo tiempo, por lo que las
solicitudes primero van al proxy local. Si éste falla, consulta al proxy de la LAN. Si éste
también falla, prueba el proxy del ISP. Este último debe tener éxito, ya sea desde su
caché, un caché de nivel superior o desde el servidor mismo.
¿Por cuánto tiempo deben almacenarse en caché las páginas?
Determinar el tiempo que deben permanecer las páginas en caché es un poco difícil.
Algunas páginas no deberían almacenarse en caché. Por ejemplo, una página que
contiene los precios de las 50 acciones más activas ya que estas cambian cada
segundo. Si se almacenara en caché, un usuario que obtuviera una copia del caché
obtendría datos obsoletos. Por lo tanto, el almacenamiento en caché de una página
podría variar con el tiempo.
El elemento clave para determinar cuándo expulsar una página del caché es qué tanta
obsolescencia están dispuestos a aceptar los usuarios (debido a que las páginas en
caché se almacenan en el disco, la cantidad de espacio consumido por lo general no es
un problema).
Si un proxy elimina páginas con rapidez, raramente regresará una página obsoleta
pero tampoco será muy efectivo (es decir, tendrá una tasa baja de coincidencias). En
cambio, si se mantienen las páginas por mucho tiempo, se corre el riesgo de que las
páginas sean obsoletas al momento de consultarlas.
Hay dos métodos para tratar este problema.
• El primero utiliza una heurística para adivinar cuánto tiempo se mantendrá
cada página. Una común es basar el tiempo de almacenamiento en el
encabezado Last-‐Modified. Si una página se modificó hace una hora, se

!"
mantendrá en caché por una hora. Si se modificó hace un año, obviamente es
una página muy estable.
• El segundo método, tiene como característica que es más costoso y que utiliza
el RFC 2616 por lo que elimina la posibilidad de tener páginas obsoletas. Todo
esto es porque utiliza el encabezado de solicitud If-‐Modified-‐Since, que puede
ser enviado por un proxy a un servidor. Especifica la página que el proxy desea
y la fecha en que ésta fue modificada por última vez, si la página no se ha
modificado el servidor regresa un mensaje corto Not Modified, el cual indica al
proxy que utilice la página en caché. Si ésta ha sido modificada, se regresa la
nueva página.
Instalación de un servidor Proxy
Para nuestro caso, instalaremos el programa llamado “Squid”, el cual es un capturador
de proxy para la web soportando http, HTTPS, FTP, entre otros protocolos. Reduce el
ancho de banda e implementa tiempos de respuesta al capturar y reutilizar
frecuentemente paginas web solicitadas. Corre en múltiples S.O. incluyendo Windows,
MacOS y Linux.
Una buena referencia sobre como administrar este programa pueden consultar:
http://tuxjm.net/docs/Manual_de_Instalacion_de_Servidor_Proxy_Web_con_Ubuntu_S
erver_y_Squid/html-‐multiples/
¿Cómo instalarlo?
Utilizando el comando apt-‐get, descargamos el programa.
• apt-‐get install squid3 squidclient squid-‐cgi
Opcionalmente para poder configurarlo, se requiere descargar los archivos fuente,
para esto seguir la siguiente sentencia:
• apt-‐get build-‐dep squid3
• mkdir /usr/src/squid
• # cd /usr/src/squid

!"
• # apt-‐get source squid3
El paquete squid3 instala el ejecutable de squid en /usr/sbin/squid3, normalmente
usará solamente squid3 en la línea de comandos para controlar el proceso squid. Los
módulos o plugins de Squid son instalados en el directorio /usr/lib/squid3.
Al instalar squid se creó un usuario y un grupo llamado proxy, es con los privilegios de
este usuario con el que se ejecutará el proceso del proxy squid, por lo tanto dicho
usuario y grupo deben tener privilegios sobre los archivos de configuración, logs y
cache para que el proxy funcione apropiadamente.
Validamos la existencia del usuario y grupo:
• # grep proxy /etc/{passwd,group}
Validamos que los permisos del archivo de configuración principal de squid son para
root:
• ls –l /etc/squid3/squid.conf
Verificamos que los permisos de usuario y grupo proxy sean quienes tienen acceso a
squid:
• ls –ld /var/spool/squid3
!"
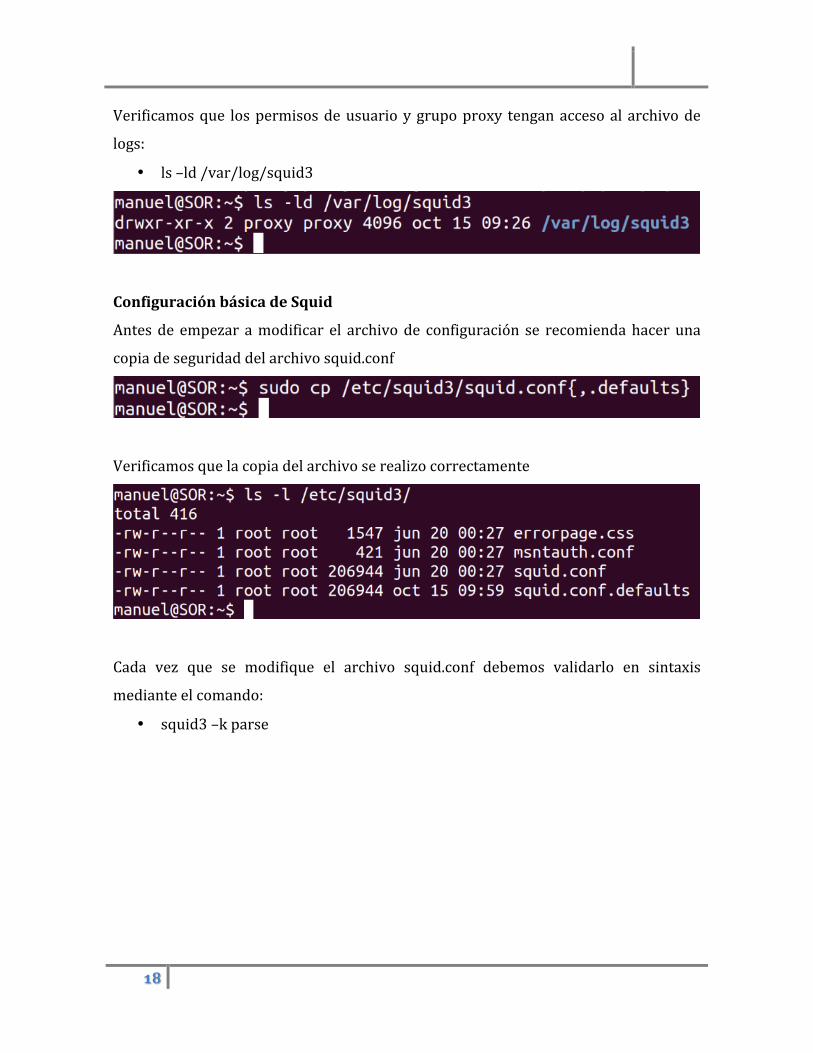
Verificamos que los permisos de usuario y grupo proxy tengan acceso al archivo de
logs:
• ls –ld /var/log/squid3
Configuración básica de Squid
Antes de empezar a modificar el archivo de configuración se recomienda hacer una
copia de seguridad del archivo squid.conf
Verificamos que la copia del archivo se realizo correctamente
Cada vez que se modifique el archivo squid.conf debemos validarlo en sintaxis
mediante el comando:
• squid3 –k parse

!"
Para editar el archivo squid.conf, utilizamos el comando
• vi /etc/squid3/squid.conf
Para detener el proceso Squid3 se utiliza el comando:
• /etc/init.d/squid3 stop
Para eliminar elementos de la memoria cache:
• rm -‐rf /var/spool/squid3/*

!"
Si se eliminaron los elementos del cache hay que montar el directorio cache
nuevamente
• mount /var/spool/squid3
Para arrancar el proceso Squid3:
• start squid3

!"
6.7. Base de datos.
Un servidor de base de datos es aquel provee servicios de almacenamiento de
información a otros programas u otras computadoras. Para esto utiliza la arquitectura
cliente – servidor, en donde un cliente puede ser un usuario u otro servidor. Algunos
de los principales servidores de base de datos se encuentran:
• Oracle
• Sybase
• Mysql
• Postgresql
• SQLServer
En este caso veremos Mysql, por contar con una versión gratuita que nos permitirá
administrarla desde Windows o Linux.
Práctica 8
• Deben instalar el servidor Proxy Squid • Una vez instalado, deben verificar que la instalación se realizo
correctamente • Crear una copia de seguridad del archivo squid.conf • Editar el archivo squid.conf, e identificar lo siguiente:
o Puerto utilizado para http. o En donde se configuran los servidores DNS. o En donde se modifica el tamaño de la memoria cache y cual es el
tamaño de la memoria por default. o Cual es el directorio utilizado para almacenar los objetos cache en el
servidor o Cual es el tamaño que tiene esta carpeta para almacenar los objetos
cache y cuantos subdirectorios tiene asignados. • Modificar el tamaño del cache a 150 MB y mostrar como lo hicieron

!!
6.8. Autenticación
Todo sistema computacional que se llama o dice ser “Seguro”, debe requerir que todos
los usuarios se autentiquen al momento de iniciar sesión. Después de todo, si el S.O. no
esta seguro de quien es el usuario que esta ingresado, tampoco puede saber a que
archivos y otros recursos puede acceder.
¿Porque es importante que todos los usuarios cuenten con contraseña en las
PC’s?
La importancia radica en que con un usuario que no tenga contraseña o su contraseña
sea light (nos referimos a light cuando una contraseña es muy fácil de adivinar y no es
compleja), es muy factible que un intruso pueda acceder al S.O. y por lo tanto puede
llegar a tomar control de los archivos, procesos y recursos del equipo.
Es por ello que las personas que desea ocasionar problemas en un sistema en
particular (conocidos coloquialmente como Hackers) primero tienen que iniciar
sesión en ese sistema, y para esto, primero tienen que pasar por el procedimiento de
autenticación propio que el S.O. utilice.
Para evitar que este tipo de personas accedan al S.O. se recomienda establecer
mecanismos de autenticación a los equipos, con la finalidad de hacerlos más
“seguros”, o por lo menos dificultar el acceso a los Hackers, para ello se utilizan
principalmente los siguientes métodos:
• Autenticación por contraseña
• Autenticación por objeto físico
• Autenticación biométrica

!"
Autenticación por contraseña
Es la técnica más utilizada, en la cual se le requiere al usuario que escriba un nombre
de inicio de sesión y una contraseña, su comprensión e implementación es fácil de
implementar, ya que la mayoría de los S.O. cuentan con esta función de seguridad.
Para su funcionamiento, al momento de introducir el nombre de inicio de sesión, este
se busca en la lista de usuario para verificar que sea un usuario registrado, si el
usuario se encuentra en la lista, se solicita la contraseña, la cual se compara con la
contraseña registrada para ese usuario, en caso de coincidir, se da el inicio de sesión,
en caso contrario se rechaza.
Lo que se recomienda siempre para dar una mayor seguridad al sistema es que las
contraseñas no sean débiles o light, esto es fáciles de adivinar, ya que los hackers la
pueden usar como puerta de entrada al equipo, por lo que la contraseña debe ser
fuerte.
A que nos referimos con que una contraseña debe ser fuerte, esto quiere decir que la
clave de acceso debe soportar un ataque de los hackers por fuerza bruta, para esto, la
contraseña debe ser larga, con mayúsculas, minúsculas, números, caracteres
especiales y preferentemente caracteres al azar.
Autenticación mediante un objeto físico
Este método de autenticación consiste en tener un objeto que sirva para
proporcionarnos acceso, un ejemplo de estos son las tarjetas de crédito, las cuales
cuando las insertamos al cajero automático, nos inicia la sesión, sin embargo, aun así
se requiere de una contraseña, en caso de que esta tarjeta se pierda y otra persona la
pueda utilizar.
Autenticación biométrica

!"
Permiten el inicio de sesión basándose en características personales inalterables
como es el uso de la huella digital o el iris ocular, aunque en la actualidad tienen altas
tasas de error y requieren hardware adicional para escaneo de rasgos corporales.
6.9. Respaldo de datos.
La pérdida de un sistema de archivos es a menudo un desastre aún mayor que la
destrucción de un computadora. Si la computadora se destruye debido a un incendio,
tormenta eléctrica, derrame de algún liquido entre otras causas, es molesto y costará
dinero, pero en general, son objetos físicos que se pueden reemplazar fácilmente.
Pero que sucede si lo que llegamos a perder es la información, si esto ocurre
normalmente es algo irreparable ya que si se intenta recuperar la información, es
complicado restaurarla por completo, para empezar porque tomaría mucho tiempo y
la información recuperada, no es muy confiable ya que puede tener daños, por lo que
se debe analizar archivo por archivo de que no estén corruptos.
Por lo que, aunque el sistema de archivos no cuente con protección contra la
destrucción física del equipo, se pueden aplicar técnicas de respaldo de datos que
permitan tener a cierta fecha y hora una copia de la información que tenemos
almacenada, logrando con esto minimizar un daño por una destrucción del equipo.
Ahora bien, las dos principales causas por las que se requiere tener un respaldo de la
información es:
1. Perdida de la información por algún desastre y
2. Perdida de la información por error humano
Para el primer caso, lo que normalmente se hace es crear respaldos de la información
en medios externos que no estén en contacto con la computadora, estos medios
pueden ser cintas magnéticas, discos duros externos, discos duros en red, sistemas de
archivos remotos y por servidores de respaldo en la nube.

!"
En cambio para el segundo caso, además de poder recurrir a los métodos de respaldo
mencionados en la primer causa de perdida de información, se puede recurrir a lo que
en los sistemas operativos llamamos como papelera de reciclaje, en donde el S.O.
guarda una copia del archivo borrado, por lo que si este se elimino accidentalmente,
se puede recuperar de esta papelera.
¿Cómo se recomienda hacer los respaldos?
Lo principal para hacer un respaldo es que estos no se hagan dentro del mismo equipo
al que se esta respaldando la información, ya que si se destruye el equipo, el respaldo
y la información se perderán.
Además es recomendable que los respaldos se realicen en espejo, esto es, que se tenga
una copia de seguridad en un medio externo y aparte se cuente con una segunda copia
en un medio externo a la empresa y si es posible en otra ciudad.
¿Cada cuanto tiempo se deben hacer los respaldos?
El tiempo con el que se deben hacer los respaldos depende de la cantidad de
información que se maneja y con la importancia que esta tiene, por ejemplo, para un
banco, la información se respalda cada minuto, con la finalidad de tener la
información más actualizada en caso de un desastre, en cambio, otro tipo de
empresas, normalmente respaldan la información una vez al día al culminar la jornada
laboral.
Realización de respaldos de información personal
En el caso de los usuarios de equipos de computo, podemos realizar respaldos de
información periódicamente con la finalidad de no perder nuestra información, en el
sistema operativo se cuentan con estas funciones.

!"
En el caso de Microsoft Windows, se cuenta con “copias de seguridad”, la cual nos hace
una imagen del disco duro y la puede guardar en un medio externo, en otro equipo en
la red o en la misma computadora.
Para Mac OSX, existe la opción de “time machine”, la cual, realiza copias de seguridad
automáticas, en segundo plano de tal forma que el usuario no se percata de que se
están realizando, este sistema, permite guardar las copias de seguridad en medios
externos, en la nube o bien en la misma computadora en una partición protegida.
Por último, en el caso de Linux, existe la opción de “Respaldo”, la cual, permite realizar
copias de seguridad automáticas, en segundo plano de tal forma que el usuario no se
percata de que se están realizando, este sistema, permite guardar las copias de
seguridad en medios externos, en la nube o bien en la misma computadora en una
partición protegida.

!"
En la pestaña de vista general podemos activar que las copias se hagan de forma
automática o bien podemos elegir si realizarlas manualmente. Además tiene la opción
para restaurar una copia de seguridad.
En la pestaña de “almacenamiento”, nos pregunta en donde queremos que se guarde
la copia de seguridad.

!"
En la pestaña de “Carpetas”, nos permite elegir que información es la que queremos
respaldar.
En la pestaña de “Planificación” nos permite elegir la periodicidad con la cual se van a
realizar las copias de respaldo.

!"

!"
Tema 7. Afinación del rendimiento.
7.1. Introducción.
La afinación del rendimiento no es mas que la optimización del Sistema Operativo de
Red, de los servidores y de las redes. Este término se refiere a como eficientarlos de
acuerdo a los requerimientos de los usuarios.
Esto es por ejemplo, cuando abrimos un documento de Word, si esta almacenado en
nuestra propia PC se abrirá relativamente rápido, pero en caso de que el archivo se
encuentre almacenado en otra computadora o en un servidor de datos, la apertura del
documento se puede tornar un poco más lento.
Que es lo que debemos hacer aquí en la afinación del rendimiento, lograr que la
apertura de este documento almacenado en un servidor de datos se abra tan rápido
como si estuviera almacenado en el equipo local.
Los problemas de rendimiento son de los problemas mas difíciles de rastrear y
solucionar, por ejemplo si un usuario no puede acceder a la red, ya sabemos cuales
pueden ser las posibles causas, un cable de red roto, que no funcionen correctamente
la tarjeta de red o el Switch, o que el ISP tiene problemas de conectividad. Pero este
caso es relativamente fácil de solucionar porque ya se sabe que hacer.
Sin embargo, cuando tratamos problemas de afinación del rendimiento es un enredo
componerlos. Algunos problemas de rendimiento a los que se enfrentan los
administradores son:
• Son difíciles de cuantificar: por ejemplo que tanto es exactamente mas lento
el servidor con respecto al rendimiento de hace una semana, un mes, o más
tiempo, algunas veces se siente lento pero como se puede definir exactamente
que tan lento es realmente.

!"
• Usualmente se desarrollan gradualmente: algunas veces el rendimiento se
vuelve lento de repente y drásticamente. Pero en el caso de las redes este
rendimiento es mas paulatino que para el usuario casi no lo percibe hasta que
se torna notorio.
• A menudo no son reportados: Cuando el rendimiento comienza a bajar
normalmente no se reporta, hasta que comienza a ser un problema esta baja
para el usuario, ya que el usuario asume que mientras puedan acceder que el
problema puede ser temporal o que es cosa de su imaginación.
• Muchos de los problemas son intermitentes: Algunas veces los usuarios nos
avisan de un problema pero cuando revisamos el problema aparentemente no
existe. Es por ello que se deben registrar estos reportes e ir viendo si más
usuarios los reportan para ir identificando patrones que puedan ser los que
originen estos problemas.
• No es exactamente una ciencia: Algunas veces el mejorar el rendimiento
puede ser en base a conjeturas, por ejemplo se puede asumir que segmentar la
red, agregar mas memoria RAM, restaurando el sistema, ampliando el disco
duro, etc… puede servir para optimizar el rendimiento.
• La solución suele ser difícil de vender: cuando la falla es debido a un
componente los usuarios no preguntan tanto y acceden más fácil a comprar o
cambiar un dispositivo que sirva para mejorar el rendimiento, sin embargo
cuando lo que se requiere hacer es un rediseño es más complicado que acepten
que el problema es de administración del sistema.
7.2. Cuellos de botella.

!"
Este termino no difiere mucho de su forma física y es utilizada para expresar que el
sistema es tan rápido como el componente más lento se lo permite.
Por ejemplo podemos tener un servidor muy potente y muy eficiente, pero si
mandamos a imprimir un documento en una impresora lenta, veremos que tarda
mucho tiempo en tener el documento impreso, aquí el cuello de botella es la
impresora, en donde la solución no es el comprar un componente que haga más
eficiente al servidor, ya que este ya esta en un punto óptimo, aquí lo que se debe hacer
es cambiar la impresora por una más rápida.
7.3. Desempeño del servidor.
Algunos de los cuellos de botella (bottlenecks) más comunes del hardware en un
servidor son:
• Procesador: Como regla general un servidor debe tener un procesador
poderoso, hay que evitar tener procesadores diseñados para uso domestico.
• Memoria: En el caso de los servidores siempre entre más memoria se pueda
tener instalada siempre es mejor.
• Disco: Debe contar con discos duros basados en el estándar SCSI, y no en IDE.
• Tarjeta de red: Hay que equipar a los servidores con buenas tarjetas de red y
no con tarjetas domesticas, recordando que no es lo mismo atender a múltiples
usuarios que ser solo un cliente. Se puede instalar mas de una tarjeta de red
para lograr atender todas las peticiones.

!!
En cuanto a la configuración del servidor, lo que se puede hacer para optimizarlo es lo
siguiente:
• Optimización de la memoria virtual: Esta característica es importante ya que
sirve de apoyo a la memoria RAM, el tamaño de esta memoria puede ser hasta
1.5 veces del tamaño de la RAM, por ejemplo si tenemos 1GB, podemos tener
una memoria virtual por 1.5 GB.
• Sectores del disco duro: Continuamente se debe revisar los sectores del disco
duro, para esto se debe utilizar el desfragmentador del disco para optimizar el
almacenamiento de la información.
• Protocolos de red: Se debe estar seguro de tener los protocolos configurados
correctamente y de sólo tener configurados aquellos que se utilizan los que no
hay que eliminarlos.
• Espacio libre en el D.D. del Servidor: Cuando el espacio libre en el D.D. es poco,
su funcionamiento decrece dramáticamente, ya que colapsa, para esto, se debe
contar con un espacio suficiente libre para tener un buffer saludable.
Otro detalle que debemos tener en cuenta es que los servidores comúnmente son
sobrepasados por su capacidad al contar con muchas obligaciones, a que nos
referimos con esto, que cuentan con muchos servicios dados de alta (DHCP, DNS,
Proxy, Datos, Impresión, Base de Datos, etc…).
Aunque un S.O.R. permita tener dados de alta múltiples servicios, esto no quiere decir
que se tengan que dar de alta todos en un solo servidor, por lo que se debe analizar la
carga de trabajo de los servicios y separarlos en múltiples servidores.
Como nota, no es recomendable establecer fondos de pantalla ni protectores de
pantalla en los servidores, ya que estos consumen muchos recursos, por lo que en la
parte gráfica entre más austero este el servidor rendirá mejor.
7.4. Desempeño de la red.

!"
El desempeño de la red incluye la infraestructura de la red, la cual consiste en todos
los cables, hubs, switchs, routers y cualquier otro componente de la red que se
encuentre entre los clientes y los servidores:
• HUB: poco utilizados pero más económicos que un switch, se recomienda
cambiarlos paulatinamente hasta que sólo se cuenten con switchs.
• Segmentación de los paquetes: Mantener el numero de computadores en un
numero razonable de segmentos, se recomienda tener un máximo de 20
equipos por segmento de subred.
• Velocidad de la red: si se cuenta con una red antigua, se pueden tener
dispositivos que funcionen a 10 Mbps, lo cual si se conectan en conjunto con
dispositivos nuevos tendremos un cuello de botella, ya que los nuevos manejan
velocidades de 100Mbps y 1Gbps, por lo que se recomienda actualizar
dispositivos.
• La velocidad del troncal (backbone): se debe analizar la velocidad que tenemos
y en un momento incrementar su velocidad.
Existen dos técnicas para optimizar el desempeño de la red, la primera es pensando
un poco y adivinar que es lo que puede mejorar el rendimiento, se prueba y vemos
que paso, si la red trabaja más rápido, la optimización fue correcta (técnica más
utilizada).
La segunda técnica consiste en hacer las pruebas de una forma mas organizada
siguiendo los siguientes pasos:
1. Establecer un método objetivo de prueba que mida el desempeño de varios
aspectos de la red: este método es llamado como benchmark, y como resultado
se tiene una línea base.
2. Cambiar una de las variables de la configuración y volver a probar: por
ejemplo, suponer que se incrementa el tamaño del cache, y reiniciar el servidor
y ver que pasa.
3. Repetir el paso 2 para cada variable que se desee probar.

!"
Práctica 9: Afinación del rendimiento del servidor
• Investigar y responder las siguientes preguntas: o Optimización sobre monitoreo de recursos o ¿Qué nos muestra el monitoreo de recursos en tiempo real? o ¿Existe un archivo Log que almacene un histórico de lo que ha pasado
en el sistema? o ¿El monitoreo se puede programar para realizarse periódicamente?
• Realizar un archivo de respaldo en Linux de la carpeta personal
o Guardar el archivo en una memoria externa con el nombre Respaldo_Fecha
o Establecer seguridad al archivo o Planificar que las copias de seguridad se realicen periódicamente una
vez a la semana • Identificación de posibles cuellos de botella en sus equipos
o Elaborar una tabla con las siguientes características del equipo § Características del procesador § Tamaño de memoria Ram § Tamaño memoria virtual § Versión del S.O. § Tarjeta de Red § Tamaño de D.D. § Tarjeta de video
o Elaborar una tabla en la que identifiquen los posibles cuellos de botella, a través del administrador de tareas y otras herramientas administrativas del S.O.
§ Número de procesos ejecutándose § Tamaño de la memoria utilizada § Comportamiento del procesador § Actividad del D.D. § Uso del D.D. § Ultima desfragmentación § Comportamiento de la red

!"
Tema 8. Planeación de la capacidad.
Para poder planear la capacidad de nuestros S.O.R. requerimos conocer cuales son los
recursos de procesamiento, conectividad y las capacidades de administración que
requerimos, por ejemplo un servidor de base de datos no requiere lo mismo que un
servidor de DHCP, al igual que un servidor de directorios, no requiere lo mismo que
un servidor de FTP.
Es por ello que debemos saber que servidor queremos dar de alta para poder estimar
que recursos requerimos para que nuestro servidor sea optimo, esto es que no tenga
recursos de menos ni que este sobrado, si no que este hecho a la medida de lo que se
requiere con las capacidades de escalabilidad que permitan tenga una vida útil
prolongada.
8.1. Recursos de procesamiento.
En cuanto a los recursos de procesamiento debemos de tomar en cuenta que servidor
vamos a dar de alta y analizar que requisitos de hardware va a requerir el servidor.
Para esto, se debe investigar cuales son los requisitos mínimos y óptimos para el
funcionamiento de los servidores a instalar. La siguiente tabla nos puede servir para
poder saber cuales son los requisitos de hardware que requerimos.
Hardware Requisitos Mínimos Requisitos Óptimos
Procesador
Memoria Física
Disco Duro
Tarjeta de Video
Tarjeta Red

!"
Tarjeta Madre
Enfriador
Rack
Monitor
Software Requisitos Mínimos Requisitos Óptimos
Plataforma
Memoria Virtual
Sistema Operativo
Protocolos requeridos
Software adicional
Sistema de Archivos
Al llenar estas tablas para cada servidor que requerimos levantar nos puede servir
para tomar la decisión de que se requiere en cuanto al hardware y software del
servidor para que funcione lo más óptimo de acuerdo a nuestros requisitos.
8.2. Recursos de conectividad
Para los recursos de conectividad debemos respondernos antes que nada a la
siguiente pregunta:
¿Es para uso local, externo o ambos?
A que nos referimos con uso “local”, a que es utilizado el servidor únicamente en una
LAN, esto es un usuario del exterior (WAN o Internet) no puede acceder a los
servicios. En cambio cuando decimos que un servidor es de uso “externo”, nos
referimos a que solamente usuarios de una WAN o Internet pueden ver la información

!"
del servidor, restringiendo el acceso a los usuarios de la LAN. Por último cuando se
refiere que el servicio se puede acceder a “ambos”, nos referimos a que todos los
posibles clientes se pueden conectar al servidor, ya sean de una LAN, WAN o Internet.
El saber a que tipo de cliente va a estar orientado el servidor es muy importante, ya
que es la base para saber que recursos utilizaremos para realizar la conectividad, ya
sea conectividad interna o externa.
Recordando los conocimientos de Redes: ¿Cuáles son los principales dispositivos de
Red?
• HUB
• Switch
• Router
• Access Point
• Tarjeta de Red
• Bridge
• Cableado
De los dispositivos uno de los más principales es el cableado, ya que de su elección
depende el ancho de banda que tendremos en nuestra LAN, para determinar el ancho
de banda que requerimos ¿que se necesita?
• Número de clientes locales
• Conocer que servicios vamos a ofrecer a nuestros clientes
• Preguntarnos si utilizamos voz sobre IP
• Preguntarnos si utilizamos video conferencias
Una vez que vimos estos elementos, los cuales son los principales, hacemos una
estimación de cuanto ancho de banda requiere cada servicio y se planean posibles
escenarios en donde se manejen principalmente tres, el mejor de los casos, el peor de
los casos y un escenario promedio.

!"
En el escenario del mejor de los casos, se analiza un ambiente en el cual casi nadie
hace consultas, la red se utiliza al mínimo, y esta sobrado el ancho de banda. En el
peor de los casos, la red se satura, no es suficiente y los servicios se caen por no poder
responder todas las peticiones de los clientes. En el caso del escenario promedio se
calcula tener los servicios utilizados entre un 50% y 60% en donde todo funciona muy
bien, teniendo un margen para evitar que se sature la red.
Práctica 10: Planeación de la capacidad
• Investigar lo siguiente: o Cuales son los requisitos mínimos y óptimos para Hardware y
Software para los siguientes servidores: § Base de Datos § WEB § FTP § TELNET § DHCP § DNS § Archivos § Impresión
• Elaborar una tabla en la que pongan para cada uno de los siguientes dispositivos de red sus principales características (velocidad de transmisión, numero de puertos máximo y mínimo, seguridad, distancia máxima de transmisión y capa a la que pertenecen):
o HUB o Switch o Router o Access Point o Bridge o Tarjeta de Red o Firewall o Cable UTP Cat 5 o Cable UTP Cat 5e o Cable UTP Cat 6 o Cable UTP Cat 6ª o Fibra Óptica monomodo o Fibra Óptica multimodo