
ARTÍCULO - RDU UNAM » Revista Digital Universitaria · comerciales de Apache Hadoop para su...
15
ARTÍCULO Dirección General de Cómputo y de Tecnologías de Información y Comunicación - UNAM Departamento de Acervos Digitales INFRAESTRUCTURA PARA BIG DATA (http://www.revista.unam.mex/vol.17/num11/art77) Javier Salazar Argonza (Facultad de ingeniería, UNAM) 1 de noviembre de 2016 | Vol. 17 | Núm. 11 | ISSN 1607 - 6079
Transcript of ARTÍCULO - RDU UNAM » Revista Digital Universitaria · comerciales de Apache Hadoop para su...

ARTIacuteCULO
Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten - UNAM Departamento de Acervos Digitales
INFRAESTRUCTURA PARA BIG DATA
(httpwwwrevistaunammexvol17num11art77)
Javier Salazar Argonza(Facultad de ingenieriacutea UNAM)
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
2
INFRAESTRUCTURA PARA BIG DATA
Resumen
Se realiza un acercamiento a la infraestructura ne-cesaria para implementar una plataforma de Big Data en una institucioacuten Se explican los principales elementos de hardware y software que integran una solucioacuten arquitectoacutenica de Big Data Se habla sobre las principales diferencias entre las distribuciones comerciales de Apache Hadoop para su adopcioacuten y uso Se dan sugerencias generales para la adquisi-cioacuten de los componentes
Palabras clave Big Data infraestructura TIC marco de trabajo analiacutetica hadoop cluacutesteres sis-temas distribuidos arquitectura de hardware
Infrastructure for Big Data
Abstract
It explores the infrastructure needed to implement a Big Data platform in an institution The main elements of hardware and software for integrating an architecture solution for Big Data are explored It also explains the main differences between the commercial dis-tributions of Apache Hadoop for its adoption and use General suggestions are given for the acquisition of its components
Keywords Big Data Infrastructure TIC work frame analytics Hadoop Clusters Distrib-uted system Hardware architecture
[] la infraestructura
requeriraacute no solo de una inversioacuten importante sino
tambieacuten de una serie de nuevas habilidades y
conocimientos []
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
3
INFRAESTRUCTURA PARA BIG DATA
Introduccioacuten
El teacutermino Big Data se empleoacute por primera vez en 1997 en un artiacuteculo de los investiga-dores de la NASA Michael Cox y David Ellsworth y se define como ldquoLa gestioacuten y anaacutelisis de enormes voluacutemenes de datos que no pueden ser tratados de manera convencional ya que eacutestos superan los liacutemites y capacidades de las herramientas de software comuacuten-mente utilizadas para su captura gestioacuten y procesamientordquo De hecho involucra el uso de infraestructuras tecnologiacuteas y servicios especiales que han sido creados para dar so-lucioacuten especifica al procesamiento de estos enormes conjuntos de datos provenientes de muacuteltiples fuentes tales como archivos redes sensores microacutefonos caacutemaras escaacuteneres imaacutegenes videos entre otros El objetivo de Big Data al igual que los sistemas analiacuteticos convencionales es convertir los datos en informacioacuten uacutetil que facilite la toma de decisiones Esto inclusive en tiempo real para brindar maacutes oportunidades de negocio El poder de eacuteste sistema radica en que permite descubrir nueva informacioacuten sobre las cadenas de valor de las instituciones o empresas para abordar problemas antes irresolubles Algunas empresas estaacuten utilizando Big Data para entender el perfil las necesida-des y el sentir de sus clientes respecto a los productos yo servicios que ofrecen Esto les permite adecuar la forma en que interactuacutean con sus clientes y como prestan sus servi-cios No obstante las predicciones son aplicables a todas las ramas del quehacer humano
La evolucioacuten de la tecnologiacutea y los menores costos de almacenamiento han he-cho posible que las aplicaciones de Big Data esteacuten aumentando Sin embargo definir la infraestructura para un proyecto no es una tarea sencilla recordemos que una platafor-ma tecnoloacutegica para esta actividad debe facilitar muy raacutepidamente la recopilacioacuten el almacenamiento y el anaacutelisis de grandes voluacutemenes de datos los cuales ademaacutes pueden estar en diferentes formatos oacute inclusive generaacutendose en tiempo real y que a diferencia de los ldquosistemas tradicionalesrdquo -por razones de eficiencia- la forma de tratar y analizar la informacioacuten debe ser trasladada directamente a los datos sin precargarlos en memoria
[1] Un sistema distribuido se define como una colec-cioacuten de computadoras separadas fiacutesicamente y conectadas entre siacute por una red de comuni-caciones cada maacutequina posee sus componentes de hardware y software que el programador percibe como un solo sistema En los sistemas distribuidos si un com-ponente del sistema se descompone otro com-ponente es capaz de re-emplazarlo (Tolerancia a fallos) El tamantildeo de un sistema distribuido puede ser muy variado ya sean decenas (red de aacuterea local) centenas (red de aacuterea metropoli-tana) o miles y millones de hosts (Internet) esto se denomina escalabi-lidad FuentehttpseswikipediaorgwikiComputaciC3B3n_distribuida
[2] El teacutermino cluacutester (del ingleacutes cluster ldquogrupordquo o ldquoraiacutezrdquo) se aplica a los conjuntos o conglome-rados de computadoras unidas entre siacute normal-mente por una red de alta velocidad y que se comportan como si fuesen una uacutenica com-putadora Los cluacutesteres son usualmente em-pleados para mejorar el rendimiento yo la disponibilidad por enci-ma de la que es provista por un solo computa-dor Un cluacutester brinda los siguientes servicios Alto rendimiento alta disponibilidad balan-ceo de carga y escala-bilidad Fuentehttpse s w i k i p e d i a o r g wik iC lC 3BA ster_(informC3A1tica)
Figura 1 Ejemplo de Sistema Distribui-doCluacutester de Datos Piso de servidores del Google Data Cen-ter Lenoir NC USA Fuente httpswwwyoutub ecomwatchv=avP5d16wEp0ampfeature=youtube
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
4
Razoacuten por la que deben considerarse sistemas distribuidos o basados en cluacutesteres2 tanto para el procesamiento como el almacenamiento de la informacioacuten (Ver fig 1) En lo referente al software requerido para administrar los recursos de una pla-taforma de Big Data debido a que estamos hablando de trabajar con arreglos de com-putadoras (servidores) y cluacutesteres de almacenamiento -que deben operarse en conjunto como un solo sistemandash resulta evidente que se requiere de un entorno de trabajo ldquoFra-meworkrdquo3 capaz de administrar distribuir controlar y procesar raacutepidamente los datos dentro de los arreglos de sistemas computacionales y de almacenamiento Hoy en diacutea el principal framework utilizado para Big Data es Hadoop4 cuyo desa-rrollo pertenece a The Apache Software Foundation misma que otorga el permiso para utilizar sus programas sin costo El proyecto original de Apache Hadoop incluye los siguientes moacutedulos funcionales
bull Hadoop Distributed File System (HDFStrade) Sistema distribuido y crea-do para trabajar con archivos de gran tamantildeo escrito en Java con un muy alto desempentildeo Veacutease httpwwwhappymindse s a p a c h e - h a d o o p - i n t r o d u c c i o n - a - h d f s s t h a s h 2M 4 r I y x S d p b s
bull HadoopMapReduce Sistema para escribir aplicaciones de procesamiento en paralelo para grandes cantidades de datos en sistemas de procesamiento distribuido o cluacuteste-res Veacutease httpwwwtutorialspointcomeshadoophadoop_mapreducehtm
bull Hadoop YARN (Yet Another Resource Negotiator) Plataforma de trabajo que permite la programacioacuten de las tareas y la gestioacuten de los recursos de cluacuteste-res (Es baacutesicamente una nueva generacioacuten del software de MapReduce MRv2 para la administracioacuten de cluacutesteres) Veacutease httpsearchdatacentertechtargetcomesdefinicionApache-Hadoop-YARN-Yet-Another-Resource-Negotiator
bull h t t p s u n p o c o d e j av a wo r d p r e s s c o m 201 307 2 5q u e - e s - y a r n
bull HadoopCommon Utileriacuteas necesarias para soportar al resto de los moacutedu-los de Hadoop Estas proporcionan acceso a los sistemas de archivos so-portados De hecho contiene los archivos en Java (ldquojarrdquo) y los scripts ne-cesarios para hacerlo correr Veacutease httpseswikipediaorgwikiHadoop
Otros proyectos de la Fundacioacuten de Software Apache relacionados con Hadoop son los siguientes
bull Ambaritrade Herramienta con una interfaz web que permi-te la administracioacuten aprovisionamiento y monitoreo de cluacutes-teres bajo Apache Hadoop Veacutease httpsunpocodejava
bull Avrotrade Sistema de serializacioacuten de datos Serializa los datos en un formato binario compacto por medio del formato JSON que facilita la comunicacioacuten entre los nodos de Hadoop Avro permite almacenar datos y acceder a ellos faacutecilmente desde varios
[3] Framework (Entorno de trabajo) En el desa-rrollo de software un framework o infraes-tructura digital es una estructura conceptual y tecnoloacutegica con moacutedu-los concretos de soft-ware que puede servir de base para la organi-zacioacuten y desarrollo de software Tiacutepicamente puede incluir soporte de programas bibliotecas y un lenguaje interpre-tado entre otras herra-mientas para asiacute ayudar a desarrollar y unir los diferentes componen-tes de un proyecto
[4] Apache Hadoop Es un framework de software que soporta aplicacio-nes distribuidas bajo una licencia libre Per-mite a las aplicaciones trabajar con miles de nodos y petabytes de datos (En teacuterminos maacutes simples es un marco para el manejo de gran-des conjuntos de datos en un entorno de com-putacioacuten distribuida)
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
5
lenguajes de programacioacuten Estaacute disentildeado para minimizar el espacio que nuestros datos ocuparaacuten en disco Veacutease httpwwwdatasaltes201106avro-hadoop
bull Cassandratrade Base de Datos NO SQL distribuida y basada en un mo-delo de almacenamiento de Clave-Valor escrita en Java Veacutea-se httpswwwadictosaltrabajocomtutorialescassandra
bull Chukwatrade Sistema de recoleccioacuten de datos para la gestioacuten de grandes sistemas dis-tribuidos Permite recolectar logs (bitaacutecoras) de grandes sistemas para su control anaacutelisis y visualizacioacuten Veacutease httpsunpocodejavawordpresscom20120717hadoop-chuwka-procesamiento-de-logs-de-grandes-sistemas-en-hadoop
bull HBasetrade Base de datos distribuida y escalable para el almacenamien-to de tablas muy grandes de informacioacuten de miles de millones de fi-las por millones de columnas que se encuentran alojadas en siste-mas distribuidos o cluacutesteres de almacenamiento Veacutease httpwwwfranciscojavierpulidocom201309bigdata-hadoop-iv-hbase_17html
bull Hivetrade Apache Hive es un sistema de almacenamiento de datos ldquoData Ware-houserdquo de coacutedigo abierto para la consulta y el anaacutelisis de grandes conjun-tos de datos que se encuentran en los archivos de Hadoop Este baacutesicamente realiza tres funciones La consulta sumarizacioacuten y anaacutelisis de los datos Veacutea-se httpsearchdatamanagementtechtargetcomdefinitionApache-Hive
bull Mahouttrade Es una libreriacutea escalable para mineriacutea de datos y aprendizaje automati-zado (aprendizaje de maacutequinas) escrita en Java y optimizada para funcionar sobre Hadoop HDFS y MapReduce Dispone de un gran nuacutemero de algoritmos imple-mentados para trabajar con teacutecnicas de filtrado colaborativo (Collaborative fil-tering) Agrupacioacuten (Clustering) y Clasificacioacuten (Classification) Veacutease httpsun-pocodejavawordpresscom20121029mahout-machine-learning-en-hadoop
bull Pigtrade Apache Pig es una plataforma para el anaacutelisis de grandes conjuntos de datos Consta de un lenguaje de alto nivel para la expresioacuten de programas junto con la infraes-tructura necesaria para la evaluacioacuten de los programas Veacutease httpspigapacheorg y httpwwwibmcomdeveloperworksssadatalibrarybigdata-apachepig
bull Sparktrade Es un motor para el procesamiento de datos a gran escala Permite escribir raacutepidamente aplicaciones en los lenguajes de programacioacuten Java Scala Pyton y R Ejecuta los programas en la memoria hasta 100 veces maacutes raacutepido que Hadoop Ma-pReduce o 10 veces maacutes raacutepido en el disco Adicionalmente puede combinar co-mandos de SQL flujo de datos (streaming) y anaacutelisis complejos Veacutease httpsparkapacheorg y httpsgeekytheorycomapache-spark-que-es-y-como-funciona
bull Teztrade Tez es un nuevo marco de ejecucioacuten distribuido para Hadoop Esta he-rramienta convierte el modelo de MapReduce en una plataforma maacutes potente
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
6
que es uacutetil para una gran cantidad de casos de uso en donde el procesamiento de las consultas requiere de un rendimiento casi en tiempo real Veacutease httpwwwinfoqcomarticlesapache-tez-saha-murthy y httptezapacheorg
bull ZooKeepertrade Es un servicio centralizado para mantener la informacioacuten de confi-guracioacuten denominacioacuten sincronizacioacuten distribuida y de servicios de grupo que requieren las aplicaciones distribuidas Veacutease httpzookeeperapacheorg y httpsunpocodejavawordpresscom20101119zookeeper-se-ha-convertido-en-un-proyecto-apache-top
Para mayor informacioacuten sobre el Apache Hadoop sus proyectos relacionados e incluso descargar el software puede acceder al siguiente sitio web httphadoopapacheorgy httpinlabfibupceduesblogque-herramientas-necesitas-para-iniciarte-en-big-data
Distribuciones comerciales de Hadoop
Aunque Hadoop es un framework libre y por ende no tiene costo en la praacutectica existen varias distribuciones comerciales de Hadoop que permiten implementar un medio am-biente de trabajo maacutes robusto para Big Data Estas distribuciones ofrecen diferentes me-joras en la funcionalidad rendimiento facilidad de configuracioacuten gestioacuten e integracioacuten con otras plataformas externas producto de antildeos de investigacioacuten de las empresas que los distribuyen Incluyen ademaacutes herramientas adicionales soporte teacutecnico diferentes niveles de servicios y mantenimiento Como sentildeala David Loshin en su artiacuteculo Explorando distribuciones Hadoop para gestionar big data
El mercado incluye tres proveedores independientes que se especializan en Hadoop Cloudera Inc Hortonworks Inc y MapR Technologies Inc Otras empresas que ofrecen distribuciones o capacidades de Hadoop incluyen Pi-votal Software Inc IBM Amazon Web Services y Microsoft5
Debemos prestar mucha atencioacuten entre las diferencias y las distribuciones de Hadoop ya que pueden requerir de una gran inversioacuten para su funcionamiento (princi-palmente por contratos de licenciamiento muy caros) aportar un pobre desempentildeo o limitaciones en los resultados esperados ofrecer poco soporte tecnoloacutegico o inclusive requerir de hardware propietario para su instrumentacioacuten Appliances Entre los principales aspectos que deberemos revisar se tiene
bull Las mejoras o beneficios que aportan a la solucioacuten Recordemos que las variantes en los frameworks facilitan abordar los problemas de analiacuteti-ca con diferentes enfoques adiciones yo mejoras y por ende resultados
bull Facilidades de monitoreo y administracioacuten para Hadoop
[5] David Loshin Exploran-do distribuciones Ha-doop para gestionar big data en linea httpsear-chdatacentertechtargetcomescronicaExploran-do-distribuciones-Hadoop-para-gestionar-big-data
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
7
bull Los componentes especiacuteficos o propietarios de las distribuciones
bull Su compatibilidad con otras plataformas
bull El hardware requerido
bull Las facilidades de recuperacioacuten en caso de desastre
bull Modelo de servicio y soporte ofertado
bull Consultoriacutea
bull Su costo
iquestCuaacuteles son estas distribuciones liacutederes en el mercado en teacuterminos generales que es lo que ofrece cada una de ellas La tabla que se presenta a continuacioacuten lo resume
Distribucioacuten Comercial de Hadoop
Ambiente operativo
Ofrece
Amazone Web Servicves AWS
UnixLinux bull ElasticMapReduce (EMR) Servicio web que facilita el procesamiento raacutepido y renta-ble de grandes cantidades de datos EMR es Hadoop en la nube Aprovecha Amazon EC2 para coacutemputo y Amazon S3 para alma-cenamiento Veacutease httpsawsamazoncomeselasticmapreduce
bull Amazon Kinesis para el procesamiento de datos de streaming en tiempo real
bull Integracioacuten con el data warehouse Amazon Redshift y otras fuentes de datos autosca-ling que modificaraacute el tamantildeo de los cluacuteste-res en base a poliacuteticas soporte para bases de datos NoSQL adicionales sobre Hadoop y maacutes integracioacuten de inteligencia de nego-cios con proveedores externos
Cloudera UnixLinux bull Cloudera Manager Herramienta de moni-toreo y administracioacuten para Hadoop
bull Impala Motor SQL para Hadoopmuy raacutepi-do con una arquitectura de procesamiento paralelo masivo (MassivelyParallelProces-sing - MPP)
Tabla 1 Principales distri-buciones comerciales de Ha-doop Fuente httpcioperupefotoreportaje15543ha-doop-como-se-encuentran-las-distribuciones-lideres
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
8
Hortonworks UnixLinux bull Apache Ambari (Proporciona una consola de administracioacuten de cluacutesteres Hadoop)
bull Aliansas con Microsoft Teradata SAP Red Hat y otras empresas
IBM UnixLinux bull BigInsightsfor Apache Hadoop (Coacutedigo de Apache Hadoop integrado con activos de IBM para la analiacutetica avanzada SPSS administracioacuten de cargas de trabajo para computacioacuten de alto desempentildeo he-rramientas de inteligencia de negocio y herramientas de administracioacuten y modela-miento de datos)
MapRTechnoligies UnixLinux bull Soporte para Network File System (NFS) correr coacutedigo arbitrario en el cluacutester
bull Hbase mejorado (Base de datos para Hadoop)
bull Caracteriacutesticas de alta disponibilidad y recuperacioacuten en caso de desastre
Pivotal UnixLinux bull HAWQ (Motor de consulta SQL paralelo de Pivotal)
bull Familia de appliances que integran su Ha-doop EDW (Enterprise Data Warehouse) y capas de administracioacuten de datos
bull Sus innovaciones se enfocaraacuten en mejorar su motor HAWQ SQL y la integracioacuten con otros productos de Pivotal
bull Tecnologiacutea Greenplum Database de EMCbull Expertis de EMC y VMware
Teradata UnixLinux bull Hadoop como appliancebull SQL-H (Motor SQL para realizar consultas
en Hadoop)bull Herramientas de administracioacuten propieta-
rias de Teradatabull Aster6 (Software para realizar analiacutetica con
Hadoop)bull Appliances de alto desempentildeo
[6] Aster es un software ba-sado en el procesamien-to masivo en paralelo para el anaacutelisis y manejo de datos desarrolla-do por Teradata Corp ht tpsenwikipediaorgwikiAster_Data_Systems
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
9
Intel UnixLinux bull Tecnologiacutea de sus Chips Xeon optimizados para Hadoop
bull Capacidades de desempentildeo y seguridad mejoradas por hardware para Hadoop
bull Lustre7 bull Optimizacioacuten nativa de tareas y analiacutetica
graacutefica
Microsoft Windows Azure HDInsight Service
Windows bull Polybase8 Permite que los clientes de SQL ejecuten consultas que incluyan datos almacenados en Hadoop
bull Esfuerzos en el desarrollo de la siguiente generacioacuten de Hive y de otros proyectos de la comunidad de coacutedigo abierto de Hadoop
bull Herramientas de desarrollo y colaboracioacuten para los clientes de Microsoft
La arquitectura del hardware para Big Data
En teacuterminos arquitectoacutenicos las soluciones de hardware para Big Data disponibles en el mercado pareceriacutean maacutes complejas de lo que en realidad son tienen muchas cosas en comuacuten todas utilizan
bull Nodos computacionales
bull Almacenamiento
bull Frameworks y aplicaciones programadas en Java (Ejemplo Hadoop Hbase Spark etc)
bull Redes de alta velocidad de tecnologiacutea gigabit o superior
bull Sistemas de soporte vital para (alimentacioacuten de energiacutea eleacutectrica y el control de temperatura y humedad)
Podemos apreciar diferencias significativas como
bull Un nuacutemero diferente de nodos y de configuraciones entre eacutestos que producen rendimientos diferentes en la ejecucioacuten de los procesos
bull Tecnologiacuteas de almacenamiento diferentes que influyen de manera determinante en el tiempo de acceso a la informacioacuten y por ende en la obtencioacuten de resultados
[7] Lustre es un sistema de archivos distribuido Open Source normal-mente utilizado en clus-ters a gran escala El nombre es una mezcla de Linux y clusters El proyecto intenta pro-porcionar un sistema de archivos para clusters de decenas de miles de nodos con petabytes de capacidad de almace-namiento sin compro-meter la velocidad o la seguridad y estaacute dispo-nible bajo la GNU GPLht tpseswikipediaorgwikiLustre_(siste-ma_de_archivos)
[8] Polybase es una tecno-logiacutea de Microsoft que permite a los usuarios de SQL Server PDW eje-cutar consultas sobre los datos almacena-dos en Hadoop Veacutease httpfrancescsanchez-biwebnodeesnewsuso-de-hadoop-en-sql-server-con-pdw-y-poly-base-
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
10
bull Redes de datos de diferentes velocidades que influyen en el desempentildeo global de la solucioacuten
El anaacutelisis de las cargas de tra-bajo seraacute un factor determinante para lograr el mejor equilibrio en-tre rendimiento y ahorro del hard-ware por ejemplo
a)Nodos computacionales
Los nodos computacionales son servidores para rack con una configuracioacuten preestablecida de acuerdo a su funcioacuten Muacuteltiples nodos conforman un cluacutester eso siacute en ninguacuten momento se reco-miendan servidores de tipo Blade debido a que eacutestos comparten componentes en un chasis que los puede limitar en su desempe-ntildeo capacidad de crecimiento y posibilidades de conectividad La cantidad de nuacutecleos y de memo-ria RAM disponible en cada uno de ellos asiacute como su velocidad de interconexioacuten a la red influiraacute de manera determinante en el rendi-miento global del cluacutester
Los cluacutester basados en el Siste-ma de Archivos de Hadoop ldquoHDFSrdquo baacutesicamente utilizaraacute dos tipos de nodos diferentes de acuerdo a la funcioacuten que desempentildearaacuten
bull Nodo de Nombres (Rastrea-dor de trabajos Namenode Jo-bTracker) Responsable de la topologiacutea de todos los demaacutes nodos y de gestionar el espa-cio de nombres Solo hay uno por cluacutester El Nodo de nom-
bres se encarga de distribuir los archivos en los nodos de datos que rea-
Figura 2 Ejemplo de un cluacutester para Big Data ba-sado en Hadoop Fuente httpwwwnextplatformcom20150703building-a-better-hadoop-cluster
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
11
lizaraacuten el procesamiento de los datos Veacutease httpwwwhappymindse s a p a c h e - h a d o o p - i n t r o d u c c i o n - a - h d f s s t h a s h 1 A 9 o n P I j d p u f
bull Nodo de Datos (Rastreador de tareas Datanode TaskTracker) Acceden a los da-tos Almacenan los bloques de informacioacuten y los recuperan bajo demanda
Velocidad de procesamiento
En teacuterminos generales los caacutelculos requeridos para los procesos de Big Data comuacutenmen-te estaraacuten maacutes limitados por la velocidad de respuesta de las operaciones de entrada y salida a disco y de la red que por la velocidad del procesador Eso no significa que los pro-cesadores que deban emplearse en la solucioacuten requieran ser de bajo costo o pobre ren-dimiento Sino maacutes bien que eacutestos cuenten con la mayor cantidad de nuacutecleos operando a la mayor frecuencia posible para poder manejar maacutes tareas en paralelo de forma aacutegil En este sentido tambieacuten se tiene que cuidar el consumo de energiacutea y la disipacioacuten de calor asociado a la frecuencia y altos voltajes de operacioacuten de los microprocesadores que sin duda tendraacuten impactos negativos en el medio ambiente y el costo de operacioacuten de la plataforma completa
Memoria RAM
La memoria RAM necesaria para un cluacutester de Big Data normalmente deberaacute ser calcu-lada tomando en consideracioacuten varios aspectos Entre los maacutes importantes destacan
bull La cantidad de nodos de datos que contenga el cluacutester
bull El nuacutemero maacuteximo de tareas que ejecutaraacute cada nodo de datos de forma simul-taacutenea
bull La memoria necesaria para los demonios que se ejecutan en los nodos de datos de tareas y del sistema operativo
bull El nuacutemero de bloques almacenados en el sistema de archivos distribuidos
bull Las necesidades especiacuteficas del software a utilizar en la plataforma
Los detalles sobre su tecnologiacutea por supuesto que tambieacuten influiraacuten en el des-empentildeo y configuracioacuten de la solucioacuten
b) Almacenamiento
En cuanto a las caracteriacutesticas teacutecnicas del almacenamiento necesario para una plata-forma de Big Data recordemos que eacutestas deberaacuten ajustarse a los requerimientos del Framework y las aplicaciones que seraacuten utilizadas Desde esta oacuteptica nos encontraremos
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
12
que los sistemas de archivos paralelos como el HDFS (Hadoop Distributed File System) estaacuten disentildeados para expandirse en muacuteltiples nodos y manejar grandes voluacutemenes de datos y que por ende generan reacuteplicas para garantizar la tolerancia a fallos Ademaacutes tendraacuten acceso a todos los discos de forma independiente razoacuten por la cual no se sue-len utilizar RAID9 o LVM10 para agrupar los discos (ni por tolerancia a fallos ni por rendi-miento) Por otra parte las soluciones de almacenamiento deben ofrecer una tecnologiacutea robusta y confiable que soporte tanto datos estructurados como no estructurados con seguridad coherencia y credibilidad Asimismo deben
bull Disponer de una gran capacidad para almacenar datos (De acuerdo a los requeri-mientos del proyecto)
bull Deben poder escalar de forma modular faacutecilmente desde unos cuantos terabytes hasta muacuteltiples petabytes de informacioacuten
bull Contar con un muy alto rendimiento en IOPS (Operaciones de entrada y salida por segundo) Adecuado en tiempo real
bull Soportar y controlar todo tipo de datos
bull Contar con una tecnologiacutea que asegure una gran proteccioacuten para los datos
Recordemos tambieacuten que el tema del respaldo de la informacioacuten se volveraacute criacutetico cuan-do hablamos de terabytes o petabytes de informacioacuten Esto si no contamos con una infraestructura suficientemente robusta que asegure la preservacioacuten de la informacioacuten al paso del tiempo11
c) Redes de datos
En teacuterminos generales el software para Big Data hace un uso muy intensivo de la red Esto debido a que todos los nodos intercambian grandes voluacutemenes de datos tanto en un esquema normal de operacioacuten como en el caso de fallo de alguacuten nodo La razoacuten de este aumento de traacutefico en la red causado por la falla en alguacuten nodo del cluacutester se debe principalmente a que Hadoop obliga al resto de los nodos a que se pongan a replicar los datos para mantener la integridad de la informacioacuten Por estos mo-tivos es recomendable utilizar switches preferentemente de alta velocidad y dedicados para el uso exclusivo del cluacutester Dada la naturaleza del Big Data se requiere que la red a utilizar cuente con las siguientes caracteriacutesticas funcionales
bull Gran velocidad
bull Alta disponibilidad
bull Redundancia
[9] En informaacutetica el acroacute-nimo RAID (del ingleacutes Redundant Array of Inexpensive Disks o maacutes comuacuten a diacutea de hoy Redundant Array of Independent Disks) tra-ducido como laquoconjunto redundante de discos Independientesraquo hace referencia a un sistema de almacenamiento de datos en tiempo real que utiliza muacuteltiples unida-des de almacenamiento de datos (discos duros o SSD) entre los que se distribuyen o replican los datos Dependiendo de su configuracioacuten (a la que suele llamarse laquonivelraquo) los beneficios de un RAID respecto a un uacutenico disco son uno o varios de los siguientes mayor integridad ma-yor tolerancia a fallos mayor throughput (ren-dimiento) y mayor capa-cidad Fuente httpseswikipediaorgwikiRAID
[10] Logical Volume Mana-gement (LVM) en espa-ntildeol ldquoadministrador de voluacutemenes loacutegicosrdquo es una opcioacuten de gestioacuten de discos que todas las principales distribu-ciones de GNULinux presentan Ya sea que necesite para configurar grupos de almacena-miento o simplemente se necesite para crear dinaacutemicamente las par-ticiones LVM Veacutease httpsparbaedloword-presscom20120105que-es-lvm-como-se-administra-y-utiliza
[11] Veacutease httpwwwcom-puterweeklycomfea-tureBig-data-storage-choices
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
13
bull Resistencia a fallas
bull Alta capacidad de resolver situaciones de congestionamiento en la red
bull Consistencia
bull Faacutecil de escalabilidad
bull Altamente administrable
bull Resilencia (Capacidad de continuar funcionando dentro de paraacutemetros acepta-bles ante distintos tipos de problemas)
Resulta claro que a mayor velocidad el costo de la red se incrementaraacute Por tal motivo se puede iniciar con velocidades de conectividad a 1 Gbit y jugar con opciones de agre-gacioacuten de puertos para mejorar el desempentildeo12 No obstante el mejor desempentildeo se lograraacute con la tecnologiacutea de 10 Gbit o superior Por otra parte a mayor nuacutemero de nodos en el cluacutester la velocidad de la red seraacute un factor clave para su buen desempentildeo13 Como podremos darnos cuenta recomendar una configuracioacuten de hardware ideal para un proyecto de Big Data no es una tarea sencilla Algunos pasos para comenzar a definirla son
bull Identificar las preguntas que deberaacute responder la plataforma de Big Data
bull La urgencia de respuesta
bull Identificar las fuentes de informacioacuten de donde se deberaacute extraer la informacioacuten a procesar Incluso pueden ser a partir de programas de TV en tiempo real o el flujo de mensajes proveniente de redes sociales
bull Cuantificar la cantidad de informacioacuten con que se deberaacute trabajar
Con esta informacioacuten los especialistas en soluciones de Big Data podraacuten ayu-darle con facilidad No olvide que la infraestructura requeriraacute no solo de una inversioacuten importante sino tambieacuten de una serie de nuevas habilidades y conocimientos en el per-sonal para desarrollar las aplicaciones No obstante brindaraacute oportunidades reales de valor de negocio en nuestras empresas o instituciones [12] Consiste en el uso de va-
rios puertos de red o en-laces para incrementar la velocidad de comuni-cacioacuten Veacutease httpseswikipediaorgwikiAgregaciC3B3n_de_enlaces
[8] Veacutease httpsearchdata-centertechtargetcomescronicaSeis-conside-raciones-para-redes-de-big-data
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
14
Bibliografiacutea
[1] ALFOCEA J Detenido por amenazas a su alcalde en Redes Sociales Delitos informaacuteticos 2015 Revista legal [en liacutenea] Fecha de actualizacioacuten 22 septiembre 2015 [Consulta 6 de octubre de 2016] Disponible en httpwwwdelitosinformaticoscom092015delitosamenazas-2-delitosdetenido-amenazar-alcalde-redes-sociales
[2]CACHEIRO Javier Requisitos Hardware Big Data Fundacioacuten Puacuteblica Galega Centro Tecnoloacutexico de Supercomputacioacuten de Galicia CESGA [en Liacutenea] Fecha de actualizacioacuten 16 de Marzo de 2015 [Consultado 25 de Mayo de 2016] Disponible en httpswwwcesgaesesbibliotecadownloadAssetid775
[3] Enauro engineering services BIG DATA [En Liacutenea] [Consultado 14 de Noviembre de 2016] Disponible en httpwwwenaurocom20160610big-data
[4] HURTADO Gork Big Data y Hadoop Cloudera vs Hortonworks Mondragon Unibertsitatea Investigacioacuten en TICs [en Liacutenea] [Consultado 3 Mayo de 2016] Disponible en httpmukommondragoneduictbig-data-y-hadoop-cloudera-vs-hortonworks
[5] JCASANELLA Introduccioacuten a Hadoop y su ecosistema Ticout Outsourcing Center Tutoriales de Yellowfin y BI [En Liacutenea] Fecha de actualizacioacuten 01 de Abril de 2013 [Consultado 19 Mayo de 2016] Disponible en httpwwwticoutcomblog20130402introduccion-a-hadoop-y-su-ecosistema
[6] LOSHIN David Explorando distribuciones Hadoop para gestionar big data TechTarget SA de CV Guiacutea Escencial [En Liacutenea] Enero de 2016 [Consultado 14 Abril de 2016] Disponible es httpsearchdatacentertechtargetcomescronicaExplorando-distribuciones-Hadoop-para-gestionar-big-data
[7] LURIE Marty Big data de coacutedigo abierto para el impaciente Parte 1 Tutorial Hadoop Hello World con Java Pig Hive Flume Fuse Oozie y Sqoop con Informix DB2 y MySQL IBM IBM deveoperWorks [en liacutenea] 20 de Marzo de 2013 [Consultado 14 Abril de 2016] Disponible en httpswwwibmcomdeveloperworksssadatalibrarytecharticledm-1209hadoopbigdata
[8] MATTHEW Mayo Top Big Data Processing Frameworks KdnuggetsTM KDnuggets News [en Liacutenea] Marzo de 2016 [Consultado 14 Abril de 2016] Disponible en httpwwwkdnuggetscom201603top-big-data-processing-frameworkshtml
[9] OacuteDELL Kevin How-to Select the Right Hardware for Your New Hadoop Cluster Cloudera Inc Cloudera Engineering Blog [en Liacutenea] 28 de Agosto de 2013 [Consultado 28 Mayo de 2016] Disponible en httpsblogclouderacomblog201308how-to-select-the-right-hardware-for-your-new-hadoop-cluster
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
15
[10] STEVE Dertien Defining the Infrastructure for Big Data Analytics PTC Inc El Divan Digital [en Liacutenea] 22 de Mayo de 2015 [Consultado 11Abril de 2016] Disponible en httpblogsptccom20150522defining-the-infrastructure-for-big-data-analytics
[11] The apache software foundation Hadoop Web site the Apache Software Foundation Apache Hadoop Project [en Liacutenea] 13 de Febrero de 2016 [Consultado 17 Mayo de 2016] Disponible en httphadoopapacheorg
[12] TIRADOS Marible iquestEs Hadoop el fin del almacenamiento de datos tradicional Big Data Hispano [en Liacutenea] 10 de febrero de 2014 [Consultado 07 Mayo de 2016] Disponible en httpwwwbigdatahispanoorgnoticiases-hadoop-el-fin-del-almacenamiento-de-datos
[13] SAacuteNCHEZ Joseacute Manuel iquestQUEacute ES BIG DATA T2O AdMedia Services SL 2015 [en Liacutenea] 02 de julio de 2016 [Consultado 14 Noviembre de 2016] Disponible en httpwwwt2omediacomideasactualidadque-es-big-data-2 en maricultura Meacutexico Secretariacutea de Medio Ambiente Recursos Naturales y Pesca 1997 192-207pp

ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
2
INFRAESTRUCTURA PARA BIG DATA
Resumen
Se realiza un acercamiento a la infraestructura ne-cesaria para implementar una plataforma de Big Data en una institucioacuten Se explican los principales elementos de hardware y software que integran una solucioacuten arquitectoacutenica de Big Data Se habla sobre las principales diferencias entre las distribuciones comerciales de Apache Hadoop para su adopcioacuten y uso Se dan sugerencias generales para la adquisi-cioacuten de los componentes
Palabras clave Big Data infraestructura TIC marco de trabajo analiacutetica hadoop cluacutesteres sis-temas distribuidos arquitectura de hardware
Infrastructure for Big Data
Abstract
It explores the infrastructure needed to implement a Big Data platform in an institution The main elements of hardware and software for integrating an architecture solution for Big Data are explored It also explains the main differences between the commercial dis-tributions of Apache Hadoop for its adoption and use General suggestions are given for the acquisition of its components
Keywords Big Data Infrastructure TIC work frame analytics Hadoop Clusters Distrib-uted system Hardware architecture
[] la infraestructura
requeriraacute no solo de una inversioacuten importante sino
tambieacuten de una serie de nuevas habilidades y
conocimientos []
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
3
INFRAESTRUCTURA PARA BIG DATA
Introduccioacuten
El teacutermino Big Data se empleoacute por primera vez en 1997 en un artiacuteculo de los investiga-dores de la NASA Michael Cox y David Ellsworth y se define como ldquoLa gestioacuten y anaacutelisis de enormes voluacutemenes de datos que no pueden ser tratados de manera convencional ya que eacutestos superan los liacutemites y capacidades de las herramientas de software comuacuten-mente utilizadas para su captura gestioacuten y procesamientordquo De hecho involucra el uso de infraestructuras tecnologiacuteas y servicios especiales que han sido creados para dar so-lucioacuten especifica al procesamiento de estos enormes conjuntos de datos provenientes de muacuteltiples fuentes tales como archivos redes sensores microacutefonos caacutemaras escaacuteneres imaacutegenes videos entre otros El objetivo de Big Data al igual que los sistemas analiacuteticos convencionales es convertir los datos en informacioacuten uacutetil que facilite la toma de decisiones Esto inclusive en tiempo real para brindar maacutes oportunidades de negocio El poder de eacuteste sistema radica en que permite descubrir nueva informacioacuten sobre las cadenas de valor de las instituciones o empresas para abordar problemas antes irresolubles Algunas empresas estaacuten utilizando Big Data para entender el perfil las necesida-des y el sentir de sus clientes respecto a los productos yo servicios que ofrecen Esto les permite adecuar la forma en que interactuacutean con sus clientes y como prestan sus servi-cios No obstante las predicciones son aplicables a todas las ramas del quehacer humano
La evolucioacuten de la tecnologiacutea y los menores costos de almacenamiento han he-cho posible que las aplicaciones de Big Data esteacuten aumentando Sin embargo definir la infraestructura para un proyecto no es una tarea sencilla recordemos que una platafor-ma tecnoloacutegica para esta actividad debe facilitar muy raacutepidamente la recopilacioacuten el almacenamiento y el anaacutelisis de grandes voluacutemenes de datos los cuales ademaacutes pueden estar en diferentes formatos oacute inclusive generaacutendose en tiempo real y que a diferencia de los ldquosistemas tradicionalesrdquo -por razones de eficiencia- la forma de tratar y analizar la informacioacuten debe ser trasladada directamente a los datos sin precargarlos en memoria
[1] Un sistema distribuido se define como una colec-cioacuten de computadoras separadas fiacutesicamente y conectadas entre siacute por una red de comuni-caciones cada maacutequina posee sus componentes de hardware y software que el programador percibe como un solo sistema En los sistemas distribuidos si un com-ponente del sistema se descompone otro com-ponente es capaz de re-emplazarlo (Tolerancia a fallos) El tamantildeo de un sistema distribuido puede ser muy variado ya sean decenas (red de aacuterea local) centenas (red de aacuterea metropoli-tana) o miles y millones de hosts (Internet) esto se denomina escalabi-lidad FuentehttpseswikipediaorgwikiComputaciC3B3n_distribuida
[2] El teacutermino cluacutester (del ingleacutes cluster ldquogrupordquo o ldquoraiacutezrdquo) se aplica a los conjuntos o conglome-rados de computadoras unidas entre siacute normal-mente por una red de alta velocidad y que se comportan como si fuesen una uacutenica com-putadora Los cluacutesteres son usualmente em-pleados para mejorar el rendimiento yo la disponibilidad por enci-ma de la que es provista por un solo computa-dor Un cluacutester brinda los siguientes servicios Alto rendimiento alta disponibilidad balan-ceo de carga y escala-bilidad Fuentehttpse s w i k i p e d i a o r g wik iC lC 3BA ster_(informC3A1tica)
Figura 1 Ejemplo de Sistema Distribui-doCluacutester de Datos Piso de servidores del Google Data Cen-ter Lenoir NC USA Fuente httpswwwyoutub ecomwatchv=avP5d16wEp0ampfeature=youtube
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
4
Razoacuten por la que deben considerarse sistemas distribuidos o basados en cluacutesteres2 tanto para el procesamiento como el almacenamiento de la informacioacuten (Ver fig 1) En lo referente al software requerido para administrar los recursos de una pla-taforma de Big Data debido a que estamos hablando de trabajar con arreglos de com-putadoras (servidores) y cluacutesteres de almacenamiento -que deben operarse en conjunto como un solo sistemandash resulta evidente que se requiere de un entorno de trabajo ldquoFra-meworkrdquo3 capaz de administrar distribuir controlar y procesar raacutepidamente los datos dentro de los arreglos de sistemas computacionales y de almacenamiento Hoy en diacutea el principal framework utilizado para Big Data es Hadoop4 cuyo desa-rrollo pertenece a The Apache Software Foundation misma que otorga el permiso para utilizar sus programas sin costo El proyecto original de Apache Hadoop incluye los siguientes moacutedulos funcionales
bull Hadoop Distributed File System (HDFStrade) Sistema distribuido y crea-do para trabajar con archivos de gran tamantildeo escrito en Java con un muy alto desempentildeo Veacutease httpwwwhappymindse s a p a c h e - h a d o o p - i n t r o d u c c i o n - a - h d f s s t h a s h 2M 4 r I y x S d p b s
bull HadoopMapReduce Sistema para escribir aplicaciones de procesamiento en paralelo para grandes cantidades de datos en sistemas de procesamiento distribuido o cluacuteste-res Veacutease httpwwwtutorialspointcomeshadoophadoop_mapreducehtm
bull Hadoop YARN (Yet Another Resource Negotiator) Plataforma de trabajo que permite la programacioacuten de las tareas y la gestioacuten de los recursos de cluacuteste-res (Es baacutesicamente una nueva generacioacuten del software de MapReduce MRv2 para la administracioacuten de cluacutesteres) Veacutease httpsearchdatacentertechtargetcomesdefinicionApache-Hadoop-YARN-Yet-Another-Resource-Negotiator
bull h t t p s u n p o c o d e j av a wo r d p r e s s c o m 201 307 2 5q u e - e s - y a r n
bull HadoopCommon Utileriacuteas necesarias para soportar al resto de los moacutedu-los de Hadoop Estas proporcionan acceso a los sistemas de archivos so-portados De hecho contiene los archivos en Java (ldquojarrdquo) y los scripts ne-cesarios para hacerlo correr Veacutease httpseswikipediaorgwikiHadoop
Otros proyectos de la Fundacioacuten de Software Apache relacionados con Hadoop son los siguientes
bull Ambaritrade Herramienta con una interfaz web que permi-te la administracioacuten aprovisionamiento y monitoreo de cluacutes-teres bajo Apache Hadoop Veacutease httpsunpocodejava
bull Avrotrade Sistema de serializacioacuten de datos Serializa los datos en un formato binario compacto por medio del formato JSON que facilita la comunicacioacuten entre los nodos de Hadoop Avro permite almacenar datos y acceder a ellos faacutecilmente desde varios
[3] Framework (Entorno de trabajo) En el desa-rrollo de software un framework o infraes-tructura digital es una estructura conceptual y tecnoloacutegica con moacutedu-los concretos de soft-ware que puede servir de base para la organi-zacioacuten y desarrollo de software Tiacutepicamente puede incluir soporte de programas bibliotecas y un lenguaje interpre-tado entre otras herra-mientas para asiacute ayudar a desarrollar y unir los diferentes componen-tes de un proyecto
[4] Apache Hadoop Es un framework de software que soporta aplicacio-nes distribuidas bajo una licencia libre Per-mite a las aplicaciones trabajar con miles de nodos y petabytes de datos (En teacuterminos maacutes simples es un marco para el manejo de gran-des conjuntos de datos en un entorno de com-putacioacuten distribuida)
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
5
lenguajes de programacioacuten Estaacute disentildeado para minimizar el espacio que nuestros datos ocuparaacuten en disco Veacutease httpwwwdatasaltes201106avro-hadoop
bull Cassandratrade Base de Datos NO SQL distribuida y basada en un mo-delo de almacenamiento de Clave-Valor escrita en Java Veacutea-se httpswwwadictosaltrabajocomtutorialescassandra
bull Chukwatrade Sistema de recoleccioacuten de datos para la gestioacuten de grandes sistemas dis-tribuidos Permite recolectar logs (bitaacutecoras) de grandes sistemas para su control anaacutelisis y visualizacioacuten Veacutease httpsunpocodejavawordpresscom20120717hadoop-chuwka-procesamiento-de-logs-de-grandes-sistemas-en-hadoop
bull HBasetrade Base de datos distribuida y escalable para el almacenamien-to de tablas muy grandes de informacioacuten de miles de millones de fi-las por millones de columnas que se encuentran alojadas en siste-mas distribuidos o cluacutesteres de almacenamiento Veacutease httpwwwfranciscojavierpulidocom201309bigdata-hadoop-iv-hbase_17html
bull Hivetrade Apache Hive es un sistema de almacenamiento de datos ldquoData Ware-houserdquo de coacutedigo abierto para la consulta y el anaacutelisis de grandes conjun-tos de datos que se encuentran en los archivos de Hadoop Este baacutesicamente realiza tres funciones La consulta sumarizacioacuten y anaacutelisis de los datos Veacutea-se httpsearchdatamanagementtechtargetcomdefinitionApache-Hive
bull Mahouttrade Es una libreriacutea escalable para mineriacutea de datos y aprendizaje automati-zado (aprendizaje de maacutequinas) escrita en Java y optimizada para funcionar sobre Hadoop HDFS y MapReduce Dispone de un gran nuacutemero de algoritmos imple-mentados para trabajar con teacutecnicas de filtrado colaborativo (Collaborative fil-tering) Agrupacioacuten (Clustering) y Clasificacioacuten (Classification) Veacutease httpsun-pocodejavawordpresscom20121029mahout-machine-learning-en-hadoop
bull Pigtrade Apache Pig es una plataforma para el anaacutelisis de grandes conjuntos de datos Consta de un lenguaje de alto nivel para la expresioacuten de programas junto con la infraes-tructura necesaria para la evaluacioacuten de los programas Veacutease httpspigapacheorg y httpwwwibmcomdeveloperworksssadatalibrarybigdata-apachepig
bull Sparktrade Es un motor para el procesamiento de datos a gran escala Permite escribir raacutepidamente aplicaciones en los lenguajes de programacioacuten Java Scala Pyton y R Ejecuta los programas en la memoria hasta 100 veces maacutes raacutepido que Hadoop Ma-pReduce o 10 veces maacutes raacutepido en el disco Adicionalmente puede combinar co-mandos de SQL flujo de datos (streaming) y anaacutelisis complejos Veacutease httpsparkapacheorg y httpsgeekytheorycomapache-spark-que-es-y-como-funciona
bull Teztrade Tez es un nuevo marco de ejecucioacuten distribuido para Hadoop Esta he-rramienta convierte el modelo de MapReduce en una plataforma maacutes potente
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
6
que es uacutetil para una gran cantidad de casos de uso en donde el procesamiento de las consultas requiere de un rendimiento casi en tiempo real Veacutease httpwwwinfoqcomarticlesapache-tez-saha-murthy y httptezapacheorg
bull ZooKeepertrade Es un servicio centralizado para mantener la informacioacuten de confi-guracioacuten denominacioacuten sincronizacioacuten distribuida y de servicios de grupo que requieren las aplicaciones distribuidas Veacutease httpzookeeperapacheorg y httpsunpocodejavawordpresscom20101119zookeeper-se-ha-convertido-en-un-proyecto-apache-top
Para mayor informacioacuten sobre el Apache Hadoop sus proyectos relacionados e incluso descargar el software puede acceder al siguiente sitio web httphadoopapacheorgy httpinlabfibupceduesblogque-herramientas-necesitas-para-iniciarte-en-big-data
Distribuciones comerciales de Hadoop
Aunque Hadoop es un framework libre y por ende no tiene costo en la praacutectica existen varias distribuciones comerciales de Hadoop que permiten implementar un medio am-biente de trabajo maacutes robusto para Big Data Estas distribuciones ofrecen diferentes me-joras en la funcionalidad rendimiento facilidad de configuracioacuten gestioacuten e integracioacuten con otras plataformas externas producto de antildeos de investigacioacuten de las empresas que los distribuyen Incluyen ademaacutes herramientas adicionales soporte teacutecnico diferentes niveles de servicios y mantenimiento Como sentildeala David Loshin en su artiacuteculo Explorando distribuciones Hadoop para gestionar big data
El mercado incluye tres proveedores independientes que se especializan en Hadoop Cloudera Inc Hortonworks Inc y MapR Technologies Inc Otras empresas que ofrecen distribuciones o capacidades de Hadoop incluyen Pi-votal Software Inc IBM Amazon Web Services y Microsoft5
Debemos prestar mucha atencioacuten entre las diferencias y las distribuciones de Hadoop ya que pueden requerir de una gran inversioacuten para su funcionamiento (princi-palmente por contratos de licenciamiento muy caros) aportar un pobre desempentildeo o limitaciones en los resultados esperados ofrecer poco soporte tecnoloacutegico o inclusive requerir de hardware propietario para su instrumentacioacuten Appliances Entre los principales aspectos que deberemos revisar se tiene
bull Las mejoras o beneficios que aportan a la solucioacuten Recordemos que las variantes en los frameworks facilitan abordar los problemas de analiacuteti-ca con diferentes enfoques adiciones yo mejoras y por ende resultados
bull Facilidades de monitoreo y administracioacuten para Hadoop
[5] David Loshin Exploran-do distribuciones Ha-doop para gestionar big data en linea httpsear-chdatacentertechtargetcomescronicaExploran-do-distribuciones-Hadoop-para-gestionar-big-data
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
7
bull Los componentes especiacuteficos o propietarios de las distribuciones
bull Su compatibilidad con otras plataformas
bull El hardware requerido
bull Las facilidades de recuperacioacuten en caso de desastre
bull Modelo de servicio y soporte ofertado
bull Consultoriacutea
bull Su costo
iquestCuaacuteles son estas distribuciones liacutederes en el mercado en teacuterminos generales que es lo que ofrece cada una de ellas La tabla que se presenta a continuacioacuten lo resume
Distribucioacuten Comercial de Hadoop
Ambiente operativo
Ofrece
Amazone Web Servicves AWS
UnixLinux bull ElasticMapReduce (EMR) Servicio web que facilita el procesamiento raacutepido y renta-ble de grandes cantidades de datos EMR es Hadoop en la nube Aprovecha Amazon EC2 para coacutemputo y Amazon S3 para alma-cenamiento Veacutease httpsawsamazoncomeselasticmapreduce
bull Amazon Kinesis para el procesamiento de datos de streaming en tiempo real
bull Integracioacuten con el data warehouse Amazon Redshift y otras fuentes de datos autosca-ling que modificaraacute el tamantildeo de los cluacuteste-res en base a poliacuteticas soporte para bases de datos NoSQL adicionales sobre Hadoop y maacutes integracioacuten de inteligencia de nego-cios con proveedores externos
Cloudera UnixLinux bull Cloudera Manager Herramienta de moni-toreo y administracioacuten para Hadoop
bull Impala Motor SQL para Hadoopmuy raacutepi-do con una arquitectura de procesamiento paralelo masivo (MassivelyParallelProces-sing - MPP)
Tabla 1 Principales distri-buciones comerciales de Ha-doop Fuente httpcioperupefotoreportaje15543ha-doop-como-se-encuentran-las-distribuciones-lideres
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
8
Hortonworks UnixLinux bull Apache Ambari (Proporciona una consola de administracioacuten de cluacutesteres Hadoop)
bull Aliansas con Microsoft Teradata SAP Red Hat y otras empresas
IBM UnixLinux bull BigInsightsfor Apache Hadoop (Coacutedigo de Apache Hadoop integrado con activos de IBM para la analiacutetica avanzada SPSS administracioacuten de cargas de trabajo para computacioacuten de alto desempentildeo he-rramientas de inteligencia de negocio y herramientas de administracioacuten y modela-miento de datos)
MapRTechnoligies UnixLinux bull Soporte para Network File System (NFS) correr coacutedigo arbitrario en el cluacutester
bull Hbase mejorado (Base de datos para Hadoop)
bull Caracteriacutesticas de alta disponibilidad y recuperacioacuten en caso de desastre
Pivotal UnixLinux bull HAWQ (Motor de consulta SQL paralelo de Pivotal)
bull Familia de appliances que integran su Ha-doop EDW (Enterprise Data Warehouse) y capas de administracioacuten de datos
bull Sus innovaciones se enfocaraacuten en mejorar su motor HAWQ SQL y la integracioacuten con otros productos de Pivotal
bull Tecnologiacutea Greenplum Database de EMCbull Expertis de EMC y VMware
Teradata UnixLinux bull Hadoop como appliancebull SQL-H (Motor SQL para realizar consultas
en Hadoop)bull Herramientas de administracioacuten propieta-
rias de Teradatabull Aster6 (Software para realizar analiacutetica con
Hadoop)bull Appliances de alto desempentildeo
[6] Aster es un software ba-sado en el procesamien-to masivo en paralelo para el anaacutelisis y manejo de datos desarrolla-do por Teradata Corp ht tpsenwikipediaorgwikiAster_Data_Systems
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
9
Intel UnixLinux bull Tecnologiacutea de sus Chips Xeon optimizados para Hadoop
bull Capacidades de desempentildeo y seguridad mejoradas por hardware para Hadoop
bull Lustre7 bull Optimizacioacuten nativa de tareas y analiacutetica
graacutefica
Microsoft Windows Azure HDInsight Service
Windows bull Polybase8 Permite que los clientes de SQL ejecuten consultas que incluyan datos almacenados en Hadoop
bull Esfuerzos en el desarrollo de la siguiente generacioacuten de Hive y de otros proyectos de la comunidad de coacutedigo abierto de Hadoop
bull Herramientas de desarrollo y colaboracioacuten para los clientes de Microsoft
La arquitectura del hardware para Big Data
En teacuterminos arquitectoacutenicos las soluciones de hardware para Big Data disponibles en el mercado pareceriacutean maacutes complejas de lo que en realidad son tienen muchas cosas en comuacuten todas utilizan
bull Nodos computacionales
bull Almacenamiento
bull Frameworks y aplicaciones programadas en Java (Ejemplo Hadoop Hbase Spark etc)
bull Redes de alta velocidad de tecnologiacutea gigabit o superior
bull Sistemas de soporte vital para (alimentacioacuten de energiacutea eleacutectrica y el control de temperatura y humedad)
Podemos apreciar diferencias significativas como
bull Un nuacutemero diferente de nodos y de configuraciones entre eacutestos que producen rendimientos diferentes en la ejecucioacuten de los procesos
bull Tecnologiacuteas de almacenamiento diferentes que influyen de manera determinante en el tiempo de acceso a la informacioacuten y por ende en la obtencioacuten de resultados
[7] Lustre es un sistema de archivos distribuido Open Source normal-mente utilizado en clus-ters a gran escala El nombre es una mezcla de Linux y clusters El proyecto intenta pro-porcionar un sistema de archivos para clusters de decenas de miles de nodos con petabytes de capacidad de almace-namiento sin compro-meter la velocidad o la seguridad y estaacute dispo-nible bajo la GNU GPLht tpseswikipediaorgwikiLustre_(siste-ma_de_archivos)
[8] Polybase es una tecno-logiacutea de Microsoft que permite a los usuarios de SQL Server PDW eje-cutar consultas sobre los datos almacena-dos en Hadoop Veacutease httpfrancescsanchez-biwebnodeesnewsuso-de-hadoop-en-sql-server-con-pdw-y-poly-base-
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
10
bull Redes de datos de diferentes velocidades que influyen en el desempentildeo global de la solucioacuten
El anaacutelisis de las cargas de tra-bajo seraacute un factor determinante para lograr el mejor equilibrio en-tre rendimiento y ahorro del hard-ware por ejemplo
a)Nodos computacionales
Los nodos computacionales son servidores para rack con una configuracioacuten preestablecida de acuerdo a su funcioacuten Muacuteltiples nodos conforman un cluacutester eso siacute en ninguacuten momento se reco-miendan servidores de tipo Blade debido a que eacutestos comparten componentes en un chasis que los puede limitar en su desempe-ntildeo capacidad de crecimiento y posibilidades de conectividad La cantidad de nuacutecleos y de memo-ria RAM disponible en cada uno de ellos asiacute como su velocidad de interconexioacuten a la red influiraacute de manera determinante en el rendi-miento global del cluacutester
Los cluacutester basados en el Siste-ma de Archivos de Hadoop ldquoHDFSrdquo baacutesicamente utilizaraacute dos tipos de nodos diferentes de acuerdo a la funcioacuten que desempentildearaacuten
bull Nodo de Nombres (Rastrea-dor de trabajos Namenode Jo-bTracker) Responsable de la topologiacutea de todos los demaacutes nodos y de gestionar el espa-cio de nombres Solo hay uno por cluacutester El Nodo de nom-
bres se encarga de distribuir los archivos en los nodos de datos que rea-
Figura 2 Ejemplo de un cluacutester para Big Data ba-sado en Hadoop Fuente httpwwwnextplatformcom20150703building-a-better-hadoop-cluster
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
11
lizaraacuten el procesamiento de los datos Veacutease httpwwwhappymindse s a p a c h e - h a d o o p - i n t r o d u c c i o n - a - h d f s s t h a s h 1 A 9 o n P I j d p u f
bull Nodo de Datos (Rastreador de tareas Datanode TaskTracker) Acceden a los da-tos Almacenan los bloques de informacioacuten y los recuperan bajo demanda
Velocidad de procesamiento
En teacuterminos generales los caacutelculos requeridos para los procesos de Big Data comuacutenmen-te estaraacuten maacutes limitados por la velocidad de respuesta de las operaciones de entrada y salida a disco y de la red que por la velocidad del procesador Eso no significa que los pro-cesadores que deban emplearse en la solucioacuten requieran ser de bajo costo o pobre ren-dimiento Sino maacutes bien que eacutestos cuenten con la mayor cantidad de nuacutecleos operando a la mayor frecuencia posible para poder manejar maacutes tareas en paralelo de forma aacutegil En este sentido tambieacuten se tiene que cuidar el consumo de energiacutea y la disipacioacuten de calor asociado a la frecuencia y altos voltajes de operacioacuten de los microprocesadores que sin duda tendraacuten impactos negativos en el medio ambiente y el costo de operacioacuten de la plataforma completa
Memoria RAM
La memoria RAM necesaria para un cluacutester de Big Data normalmente deberaacute ser calcu-lada tomando en consideracioacuten varios aspectos Entre los maacutes importantes destacan
bull La cantidad de nodos de datos que contenga el cluacutester
bull El nuacutemero maacuteximo de tareas que ejecutaraacute cada nodo de datos de forma simul-taacutenea
bull La memoria necesaria para los demonios que se ejecutan en los nodos de datos de tareas y del sistema operativo
bull El nuacutemero de bloques almacenados en el sistema de archivos distribuidos
bull Las necesidades especiacuteficas del software a utilizar en la plataforma
Los detalles sobre su tecnologiacutea por supuesto que tambieacuten influiraacuten en el des-empentildeo y configuracioacuten de la solucioacuten
b) Almacenamiento
En cuanto a las caracteriacutesticas teacutecnicas del almacenamiento necesario para una plata-forma de Big Data recordemos que eacutestas deberaacuten ajustarse a los requerimientos del Framework y las aplicaciones que seraacuten utilizadas Desde esta oacuteptica nos encontraremos
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
12
que los sistemas de archivos paralelos como el HDFS (Hadoop Distributed File System) estaacuten disentildeados para expandirse en muacuteltiples nodos y manejar grandes voluacutemenes de datos y que por ende generan reacuteplicas para garantizar la tolerancia a fallos Ademaacutes tendraacuten acceso a todos los discos de forma independiente razoacuten por la cual no se sue-len utilizar RAID9 o LVM10 para agrupar los discos (ni por tolerancia a fallos ni por rendi-miento) Por otra parte las soluciones de almacenamiento deben ofrecer una tecnologiacutea robusta y confiable que soporte tanto datos estructurados como no estructurados con seguridad coherencia y credibilidad Asimismo deben
bull Disponer de una gran capacidad para almacenar datos (De acuerdo a los requeri-mientos del proyecto)
bull Deben poder escalar de forma modular faacutecilmente desde unos cuantos terabytes hasta muacuteltiples petabytes de informacioacuten
bull Contar con un muy alto rendimiento en IOPS (Operaciones de entrada y salida por segundo) Adecuado en tiempo real
bull Soportar y controlar todo tipo de datos
bull Contar con una tecnologiacutea que asegure una gran proteccioacuten para los datos
Recordemos tambieacuten que el tema del respaldo de la informacioacuten se volveraacute criacutetico cuan-do hablamos de terabytes o petabytes de informacioacuten Esto si no contamos con una infraestructura suficientemente robusta que asegure la preservacioacuten de la informacioacuten al paso del tiempo11
c) Redes de datos
En teacuterminos generales el software para Big Data hace un uso muy intensivo de la red Esto debido a que todos los nodos intercambian grandes voluacutemenes de datos tanto en un esquema normal de operacioacuten como en el caso de fallo de alguacuten nodo La razoacuten de este aumento de traacutefico en la red causado por la falla en alguacuten nodo del cluacutester se debe principalmente a que Hadoop obliga al resto de los nodos a que se pongan a replicar los datos para mantener la integridad de la informacioacuten Por estos mo-tivos es recomendable utilizar switches preferentemente de alta velocidad y dedicados para el uso exclusivo del cluacutester Dada la naturaleza del Big Data se requiere que la red a utilizar cuente con las siguientes caracteriacutesticas funcionales
bull Gran velocidad
bull Alta disponibilidad
bull Redundancia
[9] En informaacutetica el acroacute-nimo RAID (del ingleacutes Redundant Array of Inexpensive Disks o maacutes comuacuten a diacutea de hoy Redundant Array of Independent Disks) tra-ducido como laquoconjunto redundante de discos Independientesraquo hace referencia a un sistema de almacenamiento de datos en tiempo real que utiliza muacuteltiples unida-des de almacenamiento de datos (discos duros o SSD) entre los que se distribuyen o replican los datos Dependiendo de su configuracioacuten (a la que suele llamarse laquonivelraquo) los beneficios de un RAID respecto a un uacutenico disco son uno o varios de los siguientes mayor integridad ma-yor tolerancia a fallos mayor throughput (ren-dimiento) y mayor capa-cidad Fuente httpseswikipediaorgwikiRAID
[10] Logical Volume Mana-gement (LVM) en espa-ntildeol ldquoadministrador de voluacutemenes loacutegicosrdquo es una opcioacuten de gestioacuten de discos que todas las principales distribu-ciones de GNULinux presentan Ya sea que necesite para configurar grupos de almacena-miento o simplemente se necesite para crear dinaacutemicamente las par-ticiones LVM Veacutease httpsparbaedloword-presscom20120105que-es-lvm-como-se-administra-y-utiliza
[11] Veacutease httpwwwcom-puterweeklycomfea-tureBig-data-storage-choices
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
13
bull Resistencia a fallas
bull Alta capacidad de resolver situaciones de congestionamiento en la red
bull Consistencia
bull Faacutecil de escalabilidad
bull Altamente administrable
bull Resilencia (Capacidad de continuar funcionando dentro de paraacutemetros acepta-bles ante distintos tipos de problemas)
Resulta claro que a mayor velocidad el costo de la red se incrementaraacute Por tal motivo se puede iniciar con velocidades de conectividad a 1 Gbit y jugar con opciones de agre-gacioacuten de puertos para mejorar el desempentildeo12 No obstante el mejor desempentildeo se lograraacute con la tecnologiacutea de 10 Gbit o superior Por otra parte a mayor nuacutemero de nodos en el cluacutester la velocidad de la red seraacute un factor clave para su buen desempentildeo13 Como podremos darnos cuenta recomendar una configuracioacuten de hardware ideal para un proyecto de Big Data no es una tarea sencilla Algunos pasos para comenzar a definirla son
bull Identificar las preguntas que deberaacute responder la plataforma de Big Data
bull La urgencia de respuesta
bull Identificar las fuentes de informacioacuten de donde se deberaacute extraer la informacioacuten a procesar Incluso pueden ser a partir de programas de TV en tiempo real o el flujo de mensajes proveniente de redes sociales
bull Cuantificar la cantidad de informacioacuten con que se deberaacute trabajar
Con esta informacioacuten los especialistas en soluciones de Big Data podraacuten ayu-darle con facilidad No olvide que la infraestructura requeriraacute no solo de una inversioacuten importante sino tambieacuten de una serie de nuevas habilidades y conocimientos en el per-sonal para desarrollar las aplicaciones No obstante brindaraacute oportunidades reales de valor de negocio en nuestras empresas o instituciones [12] Consiste en el uso de va-
rios puertos de red o en-laces para incrementar la velocidad de comuni-cacioacuten Veacutease httpseswikipediaorgwikiAgregaciC3B3n_de_enlaces
[8] Veacutease httpsearchdata-centertechtargetcomescronicaSeis-conside-raciones-para-redes-de-big-data
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
14
Bibliografiacutea
[1] ALFOCEA J Detenido por amenazas a su alcalde en Redes Sociales Delitos informaacuteticos 2015 Revista legal [en liacutenea] Fecha de actualizacioacuten 22 septiembre 2015 [Consulta 6 de octubre de 2016] Disponible en httpwwwdelitosinformaticoscom092015delitosamenazas-2-delitosdetenido-amenazar-alcalde-redes-sociales
[2]CACHEIRO Javier Requisitos Hardware Big Data Fundacioacuten Puacuteblica Galega Centro Tecnoloacutexico de Supercomputacioacuten de Galicia CESGA [en Liacutenea] Fecha de actualizacioacuten 16 de Marzo de 2015 [Consultado 25 de Mayo de 2016] Disponible en httpswwwcesgaesesbibliotecadownloadAssetid775
[3] Enauro engineering services BIG DATA [En Liacutenea] [Consultado 14 de Noviembre de 2016] Disponible en httpwwwenaurocom20160610big-data
[4] HURTADO Gork Big Data y Hadoop Cloudera vs Hortonworks Mondragon Unibertsitatea Investigacioacuten en TICs [en Liacutenea] [Consultado 3 Mayo de 2016] Disponible en httpmukommondragoneduictbig-data-y-hadoop-cloudera-vs-hortonworks
[5] JCASANELLA Introduccioacuten a Hadoop y su ecosistema Ticout Outsourcing Center Tutoriales de Yellowfin y BI [En Liacutenea] Fecha de actualizacioacuten 01 de Abril de 2013 [Consultado 19 Mayo de 2016] Disponible en httpwwwticoutcomblog20130402introduccion-a-hadoop-y-su-ecosistema
[6] LOSHIN David Explorando distribuciones Hadoop para gestionar big data TechTarget SA de CV Guiacutea Escencial [En Liacutenea] Enero de 2016 [Consultado 14 Abril de 2016] Disponible es httpsearchdatacentertechtargetcomescronicaExplorando-distribuciones-Hadoop-para-gestionar-big-data
[7] LURIE Marty Big data de coacutedigo abierto para el impaciente Parte 1 Tutorial Hadoop Hello World con Java Pig Hive Flume Fuse Oozie y Sqoop con Informix DB2 y MySQL IBM IBM deveoperWorks [en liacutenea] 20 de Marzo de 2013 [Consultado 14 Abril de 2016] Disponible en httpswwwibmcomdeveloperworksssadatalibrarytecharticledm-1209hadoopbigdata
[8] MATTHEW Mayo Top Big Data Processing Frameworks KdnuggetsTM KDnuggets News [en Liacutenea] Marzo de 2016 [Consultado 14 Abril de 2016] Disponible en httpwwwkdnuggetscom201603top-big-data-processing-frameworkshtml
[9] OacuteDELL Kevin How-to Select the Right Hardware for Your New Hadoop Cluster Cloudera Inc Cloudera Engineering Blog [en Liacutenea] 28 de Agosto de 2013 [Consultado 28 Mayo de 2016] Disponible en httpsblogclouderacomblog201308how-to-select-the-right-hardware-for-your-new-hadoop-cluster
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
15
[10] STEVE Dertien Defining the Infrastructure for Big Data Analytics PTC Inc El Divan Digital [en Liacutenea] 22 de Mayo de 2015 [Consultado 11Abril de 2016] Disponible en httpblogsptccom20150522defining-the-infrastructure-for-big-data-analytics
[11] The apache software foundation Hadoop Web site the Apache Software Foundation Apache Hadoop Project [en Liacutenea] 13 de Febrero de 2016 [Consultado 17 Mayo de 2016] Disponible en httphadoopapacheorg
[12] TIRADOS Marible iquestEs Hadoop el fin del almacenamiento de datos tradicional Big Data Hispano [en Liacutenea] 10 de febrero de 2014 [Consultado 07 Mayo de 2016] Disponible en httpwwwbigdatahispanoorgnoticiases-hadoop-el-fin-del-almacenamiento-de-datos
[13] SAacuteNCHEZ Joseacute Manuel iquestQUEacute ES BIG DATA T2O AdMedia Services SL 2015 [en Liacutenea] 02 de julio de 2016 [Consultado 14 Noviembre de 2016] Disponible en httpwwwt2omediacomideasactualidadque-es-big-data-2 en maricultura Meacutexico Secretariacutea de Medio Ambiente Recursos Naturales y Pesca 1997 192-207pp

ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
3
INFRAESTRUCTURA PARA BIG DATA
Introduccioacuten
El teacutermino Big Data se empleoacute por primera vez en 1997 en un artiacuteculo de los investiga-dores de la NASA Michael Cox y David Ellsworth y se define como ldquoLa gestioacuten y anaacutelisis de enormes voluacutemenes de datos que no pueden ser tratados de manera convencional ya que eacutestos superan los liacutemites y capacidades de las herramientas de software comuacuten-mente utilizadas para su captura gestioacuten y procesamientordquo De hecho involucra el uso de infraestructuras tecnologiacuteas y servicios especiales que han sido creados para dar so-lucioacuten especifica al procesamiento de estos enormes conjuntos de datos provenientes de muacuteltiples fuentes tales como archivos redes sensores microacutefonos caacutemaras escaacuteneres imaacutegenes videos entre otros El objetivo de Big Data al igual que los sistemas analiacuteticos convencionales es convertir los datos en informacioacuten uacutetil que facilite la toma de decisiones Esto inclusive en tiempo real para brindar maacutes oportunidades de negocio El poder de eacuteste sistema radica en que permite descubrir nueva informacioacuten sobre las cadenas de valor de las instituciones o empresas para abordar problemas antes irresolubles Algunas empresas estaacuten utilizando Big Data para entender el perfil las necesida-des y el sentir de sus clientes respecto a los productos yo servicios que ofrecen Esto les permite adecuar la forma en que interactuacutean con sus clientes y como prestan sus servi-cios No obstante las predicciones son aplicables a todas las ramas del quehacer humano
La evolucioacuten de la tecnologiacutea y los menores costos de almacenamiento han he-cho posible que las aplicaciones de Big Data esteacuten aumentando Sin embargo definir la infraestructura para un proyecto no es una tarea sencilla recordemos que una platafor-ma tecnoloacutegica para esta actividad debe facilitar muy raacutepidamente la recopilacioacuten el almacenamiento y el anaacutelisis de grandes voluacutemenes de datos los cuales ademaacutes pueden estar en diferentes formatos oacute inclusive generaacutendose en tiempo real y que a diferencia de los ldquosistemas tradicionalesrdquo -por razones de eficiencia- la forma de tratar y analizar la informacioacuten debe ser trasladada directamente a los datos sin precargarlos en memoria
[1] Un sistema distribuido se define como una colec-cioacuten de computadoras separadas fiacutesicamente y conectadas entre siacute por una red de comuni-caciones cada maacutequina posee sus componentes de hardware y software que el programador percibe como un solo sistema En los sistemas distribuidos si un com-ponente del sistema se descompone otro com-ponente es capaz de re-emplazarlo (Tolerancia a fallos) El tamantildeo de un sistema distribuido puede ser muy variado ya sean decenas (red de aacuterea local) centenas (red de aacuterea metropoli-tana) o miles y millones de hosts (Internet) esto se denomina escalabi-lidad FuentehttpseswikipediaorgwikiComputaciC3B3n_distribuida
[2] El teacutermino cluacutester (del ingleacutes cluster ldquogrupordquo o ldquoraiacutezrdquo) se aplica a los conjuntos o conglome-rados de computadoras unidas entre siacute normal-mente por una red de alta velocidad y que se comportan como si fuesen una uacutenica com-putadora Los cluacutesteres son usualmente em-pleados para mejorar el rendimiento yo la disponibilidad por enci-ma de la que es provista por un solo computa-dor Un cluacutester brinda los siguientes servicios Alto rendimiento alta disponibilidad balan-ceo de carga y escala-bilidad Fuentehttpse s w i k i p e d i a o r g wik iC lC 3BA ster_(informC3A1tica)
Figura 1 Ejemplo de Sistema Distribui-doCluacutester de Datos Piso de servidores del Google Data Cen-ter Lenoir NC USA Fuente httpswwwyoutub ecomwatchv=avP5d16wEp0ampfeature=youtube
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
4
Razoacuten por la que deben considerarse sistemas distribuidos o basados en cluacutesteres2 tanto para el procesamiento como el almacenamiento de la informacioacuten (Ver fig 1) En lo referente al software requerido para administrar los recursos de una pla-taforma de Big Data debido a que estamos hablando de trabajar con arreglos de com-putadoras (servidores) y cluacutesteres de almacenamiento -que deben operarse en conjunto como un solo sistemandash resulta evidente que se requiere de un entorno de trabajo ldquoFra-meworkrdquo3 capaz de administrar distribuir controlar y procesar raacutepidamente los datos dentro de los arreglos de sistemas computacionales y de almacenamiento Hoy en diacutea el principal framework utilizado para Big Data es Hadoop4 cuyo desa-rrollo pertenece a The Apache Software Foundation misma que otorga el permiso para utilizar sus programas sin costo El proyecto original de Apache Hadoop incluye los siguientes moacutedulos funcionales
bull Hadoop Distributed File System (HDFStrade) Sistema distribuido y crea-do para trabajar con archivos de gran tamantildeo escrito en Java con un muy alto desempentildeo Veacutease httpwwwhappymindse s a p a c h e - h a d o o p - i n t r o d u c c i o n - a - h d f s s t h a s h 2M 4 r I y x S d p b s
bull HadoopMapReduce Sistema para escribir aplicaciones de procesamiento en paralelo para grandes cantidades de datos en sistemas de procesamiento distribuido o cluacuteste-res Veacutease httpwwwtutorialspointcomeshadoophadoop_mapreducehtm
bull Hadoop YARN (Yet Another Resource Negotiator) Plataforma de trabajo que permite la programacioacuten de las tareas y la gestioacuten de los recursos de cluacuteste-res (Es baacutesicamente una nueva generacioacuten del software de MapReduce MRv2 para la administracioacuten de cluacutesteres) Veacutease httpsearchdatacentertechtargetcomesdefinicionApache-Hadoop-YARN-Yet-Another-Resource-Negotiator
bull h t t p s u n p o c o d e j av a wo r d p r e s s c o m 201 307 2 5q u e - e s - y a r n
bull HadoopCommon Utileriacuteas necesarias para soportar al resto de los moacutedu-los de Hadoop Estas proporcionan acceso a los sistemas de archivos so-portados De hecho contiene los archivos en Java (ldquojarrdquo) y los scripts ne-cesarios para hacerlo correr Veacutease httpseswikipediaorgwikiHadoop
Otros proyectos de la Fundacioacuten de Software Apache relacionados con Hadoop son los siguientes
bull Ambaritrade Herramienta con una interfaz web que permi-te la administracioacuten aprovisionamiento y monitoreo de cluacutes-teres bajo Apache Hadoop Veacutease httpsunpocodejava
bull Avrotrade Sistema de serializacioacuten de datos Serializa los datos en un formato binario compacto por medio del formato JSON que facilita la comunicacioacuten entre los nodos de Hadoop Avro permite almacenar datos y acceder a ellos faacutecilmente desde varios
[3] Framework (Entorno de trabajo) En el desa-rrollo de software un framework o infraes-tructura digital es una estructura conceptual y tecnoloacutegica con moacutedu-los concretos de soft-ware que puede servir de base para la organi-zacioacuten y desarrollo de software Tiacutepicamente puede incluir soporte de programas bibliotecas y un lenguaje interpre-tado entre otras herra-mientas para asiacute ayudar a desarrollar y unir los diferentes componen-tes de un proyecto
[4] Apache Hadoop Es un framework de software que soporta aplicacio-nes distribuidas bajo una licencia libre Per-mite a las aplicaciones trabajar con miles de nodos y petabytes de datos (En teacuterminos maacutes simples es un marco para el manejo de gran-des conjuntos de datos en un entorno de com-putacioacuten distribuida)
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
5
lenguajes de programacioacuten Estaacute disentildeado para minimizar el espacio que nuestros datos ocuparaacuten en disco Veacutease httpwwwdatasaltes201106avro-hadoop
bull Cassandratrade Base de Datos NO SQL distribuida y basada en un mo-delo de almacenamiento de Clave-Valor escrita en Java Veacutea-se httpswwwadictosaltrabajocomtutorialescassandra
bull Chukwatrade Sistema de recoleccioacuten de datos para la gestioacuten de grandes sistemas dis-tribuidos Permite recolectar logs (bitaacutecoras) de grandes sistemas para su control anaacutelisis y visualizacioacuten Veacutease httpsunpocodejavawordpresscom20120717hadoop-chuwka-procesamiento-de-logs-de-grandes-sistemas-en-hadoop
bull HBasetrade Base de datos distribuida y escalable para el almacenamien-to de tablas muy grandes de informacioacuten de miles de millones de fi-las por millones de columnas que se encuentran alojadas en siste-mas distribuidos o cluacutesteres de almacenamiento Veacutease httpwwwfranciscojavierpulidocom201309bigdata-hadoop-iv-hbase_17html
bull Hivetrade Apache Hive es un sistema de almacenamiento de datos ldquoData Ware-houserdquo de coacutedigo abierto para la consulta y el anaacutelisis de grandes conjun-tos de datos que se encuentran en los archivos de Hadoop Este baacutesicamente realiza tres funciones La consulta sumarizacioacuten y anaacutelisis de los datos Veacutea-se httpsearchdatamanagementtechtargetcomdefinitionApache-Hive
bull Mahouttrade Es una libreriacutea escalable para mineriacutea de datos y aprendizaje automati-zado (aprendizaje de maacutequinas) escrita en Java y optimizada para funcionar sobre Hadoop HDFS y MapReduce Dispone de un gran nuacutemero de algoritmos imple-mentados para trabajar con teacutecnicas de filtrado colaborativo (Collaborative fil-tering) Agrupacioacuten (Clustering) y Clasificacioacuten (Classification) Veacutease httpsun-pocodejavawordpresscom20121029mahout-machine-learning-en-hadoop
bull Pigtrade Apache Pig es una plataforma para el anaacutelisis de grandes conjuntos de datos Consta de un lenguaje de alto nivel para la expresioacuten de programas junto con la infraes-tructura necesaria para la evaluacioacuten de los programas Veacutease httpspigapacheorg y httpwwwibmcomdeveloperworksssadatalibrarybigdata-apachepig
bull Sparktrade Es un motor para el procesamiento de datos a gran escala Permite escribir raacutepidamente aplicaciones en los lenguajes de programacioacuten Java Scala Pyton y R Ejecuta los programas en la memoria hasta 100 veces maacutes raacutepido que Hadoop Ma-pReduce o 10 veces maacutes raacutepido en el disco Adicionalmente puede combinar co-mandos de SQL flujo de datos (streaming) y anaacutelisis complejos Veacutease httpsparkapacheorg y httpsgeekytheorycomapache-spark-que-es-y-como-funciona
bull Teztrade Tez es un nuevo marco de ejecucioacuten distribuido para Hadoop Esta he-rramienta convierte el modelo de MapReduce en una plataforma maacutes potente
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
6
que es uacutetil para una gran cantidad de casos de uso en donde el procesamiento de las consultas requiere de un rendimiento casi en tiempo real Veacutease httpwwwinfoqcomarticlesapache-tez-saha-murthy y httptezapacheorg
bull ZooKeepertrade Es un servicio centralizado para mantener la informacioacuten de confi-guracioacuten denominacioacuten sincronizacioacuten distribuida y de servicios de grupo que requieren las aplicaciones distribuidas Veacutease httpzookeeperapacheorg y httpsunpocodejavawordpresscom20101119zookeeper-se-ha-convertido-en-un-proyecto-apache-top
Para mayor informacioacuten sobre el Apache Hadoop sus proyectos relacionados e incluso descargar el software puede acceder al siguiente sitio web httphadoopapacheorgy httpinlabfibupceduesblogque-herramientas-necesitas-para-iniciarte-en-big-data
Distribuciones comerciales de Hadoop
Aunque Hadoop es un framework libre y por ende no tiene costo en la praacutectica existen varias distribuciones comerciales de Hadoop que permiten implementar un medio am-biente de trabajo maacutes robusto para Big Data Estas distribuciones ofrecen diferentes me-joras en la funcionalidad rendimiento facilidad de configuracioacuten gestioacuten e integracioacuten con otras plataformas externas producto de antildeos de investigacioacuten de las empresas que los distribuyen Incluyen ademaacutes herramientas adicionales soporte teacutecnico diferentes niveles de servicios y mantenimiento Como sentildeala David Loshin en su artiacuteculo Explorando distribuciones Hadoop para gestionar big data
El mercado incluye tres proveedores independientes que se especializan en Hadoop Cloudera Inc Hortonworks Inc y MapR Technologies Inc Otras empresas que ofrecen distribuciones o capacidades de Hadoop incluyen Pi-votal Software Inc IBM Amazon Web Services y Microsoft5
Debemos prestar mucha atencioacuten entre las diferencias y las distribuciones de Hadoop ya que pueden requerir de una gran inversioacuten para su funcionamiento (princi-palmente por contratos de licenciamiento muy caros) aportar un pobre desempentildeo o limitaciones en los resultados esperados ofrecer poco soporte tecnoloacutegico o inclusive requerir de hardware propietario para su instrumentacioacuten Appliances Entre los principales aspectos que deberemos revisar se tiene
bull Las mejoras o beneficios que aportan a la solucioacuten Recordemos que las variantes en los frameworks facilitan abordar los problemas de analiacuteti-ca con diferentes enfoques adiciones yo mejoras y por ende resultados
bull Facilidades de monitoreo y administracioacuten para Hadoop
[5] David Loshin Exploran-do distribuciones Ha-doop para gestionar big data en linea httpsear-chdatacentertechtargetcomescronicaExploran-do-distribuciones-Hadoop-para-gestionar-big-data
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
7
bull Los componentes especiacuteficos o propietarios de las distribuciones
bull Su compatibilidad con otras plataformas
bull El hardware requerido
bull Las facilidades de recuperacioacuten en caso de desastre
bull Modelo de servicio y soporte ofertado
bull Consultoriacutea
bull Su costo
iquestCuaacuteles son estas distribuciones liacutederes en el mercado en teacuterminos generales que es lo que ofrece cada una de ellas La tabla que se presenta a continuacioacuten lo resume
Distribucioacuten Comercial de Hadoop
Ambiente operativo
Ofrece
Amazone Web Servicves AWS
UnixLinux bull ElasticMapReduce (EMR) Servicio web que facilita el procesamiento raacutepido y renta-ble de grandes cantidades de datos EMR es Hadoop en la nube Aprovecha Amazon EC2 para coacutemputo y Amazon S3 para alma-cenamiento Veacutease httpsawsamazoncomeselasticmapreduce
bull Amazon Kinesis para el procesamiento de datos de streaming en tiempo real
bull Integracioacuten con el data warehouse Amazon Redshift y otras fuentes de datos autosca-ling que modificaraacute el tamantildeo de los cluacuteste-res en base a poliacuteticas soporte para bases de datos NoSQL adicionales sobre Hadoop y maacutes integracioacuten de inteligencia de nego-cios con proveedores externos
Cloudera UnixLinux bull Cloudera Manager Herramienta de moni-toreo y administracioacuten para Hadoop
bull Impala Motor SQL para Hadoopmuy raacutepi-do con una arquitectura de procesamiento paralelo masivo (MassivelyParallelProces-sing - MPP)
Tabla 1 Principales distri-buciones comerciales de Ha-doop Fuente httpcioperupefotoreportaje15543ha-doop-como-se-encuentran-las-distribuciones-lideres
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
8
Hortonworks UnixLinux bull Apache Ambari (Proporciona una consola de administracioacuten de cluacutesteres Hadoop)
bull Aliansas con Microsoft Teradata SAP Red Hat y otras empresas
IBM UnixLinux bull BigInsightsfor Apache Hadoop (Coacutedigo de Apache Hadoop integrado con activos de IBM para la analiacutetica avanzada SPSS administracioacuten de cargas de trabajo para computacioacuten de alto desempentildeo he-rramientas de inteligencia de negocio y herramientas de administracioacuten y modela-miento de datos)
MapRTechnoligies UnixLinux bull Soporte para Network File System (NFS) correr coacutedigo arbitrario en el cluacutester
bull Hbase mejorado (Base de datos para Hadoop)
bull Caracteriacutesticas de alta disponibilidad y recuperacioacuten en caso de desastre
Pivotal UnixLinux bull HAWQ (Motor de consulta SQL paralelo de Pivotal)
bull Familia de appliances que integran su Ha-doop EDW (Enterprise Data Warehouse) y capas de administracioacuten de datos
bull Sus innovaciones se enfocaraacuten en mejorar su motor HAWQ SQL y la integracioacuten con otros productos de Pivotal
bull Tecnologiacutea Greenplum Database de EMCbull Expertis de EMC y VMware
Teradata UnixLinux bull Hadoop como appliancebull SQL-H (Motor SQL para realizar consultas
en Hadoop)bull Herramientas de administracioacuten propieta-
rias de Teradatabull Aster6 (Software para realizar analiacutetica con
Hadoop)bull Appliances de alto desempentildeo
[6] Aster es un software ba-sado en el procesamien-to masivo en paralelo para el anaacutelisis y manejo de datos desarrolla-do por Teradata Corp ht tpsenwikipediaorgwikiAster_Data_Systems
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
9
Intel UnixLinux bull Tecnologiacutea de sus Chips Xeon optimizados para Hadoop
bull Capacidades de desempentildeo y seguridad mejoradas por hardware para Hadoop
bull Lustre7 bull Optimizacioacuten nativa de tareas y analiacutetica
graacutefica
Microsoft Windows Azure HDInsight Service
Windows bull Polybase8 Permite que los clientes de SQL ejecuten consultas que incluyan datos almacenados en Hadoop
bull Esfuerzos en el desarrollo de la siguiente generacioacuten de Hive y de otros proyectos de la comunidad de coacutedigo abierto de Hadoop
bull Herramientas de desarrollo y colaboracioacuten para los clientes de Microsoft
La arquitectura del hardware para Big Data
En teacuterminos arquitectoacutenicos las soluciones de hardware para Big Data disponibles en el mercado pareceriacutean maacutes complejas de lo que en realidad son tienen muchas cosas en comuacuten todas utilizan
bull Nodos computacionales
bull Almacenamiento
bull Frameworks y aplicaciones programadas en Java (Ejemplo Hadoop Hbase Spark etc)
bull Redes de alta velocidad de tecnologiacutea gigabit o superior
bull Sistemas de soporte vital para (alimentacioacuten de energiacutea eleacutectrica y el control de temperatura y humedad)
Podemos apreciar diferencias significativas como
bull Un nuacutemero diferente de nodos y de configuraciones entre eacutestos que producen rendimientos diferentes en la ejecucioacuten de los procesos
bull Tecnologiacuteas de almacenamiento diferentes que influyen de manera determinante en el tiempo de acceso a la informacioacuten y por ende en la obtencioacuten de resultados
[7] Lustre es un sistema de archivos distribuido Open Source normal-mente utilizado en clus-ters a gran escala El nombre es una mezcla de Linux y clusters El proyecto intenta pro-porcionar un sistema de archivos para clusters de decenas de miles de nodos con petabytes de capacidad de almace-namiento sin compro-meter la velocidad o la seguridad y estaacute dispo-nible bajo la GNU GPLht tpseswikipediaorgwikiLustre_(siste-ma_de_archivos)
[8] Polybase es una tecno-logiacutea de Microsoft que permite a los usuarios de SQL Server PDW eje-cutar consultas sobre los datos almacena-dos en Hadoop Veacutease httpfrancescsanchez-biwebnodeesnewsuso-de-hadoop-en-sql-server-con-pdw-y-poly-base-
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
10
bull Redes de datos de diferentes velocidades que influyen en el desempentildeo global de la solucioacuten
El anaacutelisis de las cargas de tra-bajo seraacute un factor determinante para lograr el mejor equilibrio en-tre rendimiento y ahorro del hard-ware por ejemplo
a)Nodos computacionales
Los nodos computacionales son servidores para rack con una configuracioacuten preestablecida de acuerdo a su funcioacuten Muacuteltiples nodos conforman un cluacutester eso siacute en ninguacuten momento se reco-miendan servidores de tipo Blade debido a que eacutestos comparten componentes en un chasis que los puede limitar en su desempe-ntildeo capacidad de crecimiento y posibilidades de conectividad La cantidad de nuacutecleos y de memo-ria RAM disponible en cada uno de ellos asiacute como su velocidad de interconexioacuten a la red influiraacute de manera determinante en el rendi-miento global del cluacutester
Los cluacutester basados en el Siste-ma de Archivos de Hadoop ldquoHDFSrdquo baacutesicamente utilizaraacute dos tipos de nodos diferentes de acuerdo a la funcioacuten que desempentildearaacuten
bull Nodo de Nombres (Rastrea-dor de trabajos Namenode Jo-bTracker) Responsable de la topologiacutea de todos los demaacutes nodos y de gestionar el espa-cio de nombres Solo hay uno por cluacutester El Nodo de nom-
bres se encarga de distribuir los archivos en los nodos de datos que rea-
Figura 2 Ejemplo de un cluacutester para Big Data ba-sado en Hadoop Fuente httpwwwnextplatformcom20150703building-a-better-hadoop-cluster
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
11
lizaraacuten el procesamiento de los datos Veacutease httpwwwhappymindse s a p a c h e - h a d o o p - i n t r o d u c c i o n - a - h d f s s t h a s h 1 A 9 o n P I j d p u f
bull Nodo de Datos (Rastreador de tareas Datanode TaskTracker) Acceden a los da-tos Almacenan los bloques de informacioacuten y los recuperan bajo demanda
Velocidad de procesamiento
En teacuterminos generales los caacutelculos requeridos para los procesos de Big Data comuacutenmen-te estaraacuten maacutes limitados por la velocidad de respuesta de las operaciones de entrada y salida a disco y de la red que por la velocidad del procesador Eso no significa que los pro-cesadores que deban emplearse en la solucioacuten requieran ser de bajo costo o pobre ren-dimiento Sino maacutes bien que eacutestos cuenten con la mayor cantidad de nuacutecleos operando a la mayor frecuencia posible para poder manejar maacutes tareas en paralelo de forma aacutegil En este sentido tambieacuten se tiene que cuidar el consumo de energiacutea y la disipacioacuten de calor asociado a la frecuencia y altos voltajes de operacioacuten de los microprocesadores que sin duda tendraacuten impactos negativos en el medio ambiente y el costo de operacioacuten de la plataforma completa
Memoria RAM
La memoria RAM necesaria para un cluacutester de Big Data normalmente deberaacute ser calcu-lada tomando en consideracioacuten varios aspectos Entre los maacutes importantes destacan
bull La cantidad de nodos de datos que contenga el cluacutester
bull El nuacutemero maacuteximo de tareas que ejecutaraacute cada nodo de datos de forma simul-taacutenea
bull La memoria necesaria para los demonios que se ejecutan en los nodos de datos de tareas y del sistema operativo
bull El nuacutemero de bloques almacenados en el sistema de archivos distribuidos
bull Las necesidades especiacuteficas del software a utilizar en la plataforma
Los detalles sobre su tecnologiacutea por supuesto que tambieacuten influiraacuten en el des-empentildeo y configuracioacuten de la solucioacuten
b) Almacenamiento
En cuanto a las caracteriacutesticas teacutecnicas del almacenamiento necesario para una plata-forma de Big Data recordemos que eacutestas deberaacuten ajustarse a los requerimientos del Framework y las aplicaciones que seraacuten utilizadas Desde esta oacuteptica nos encontraremos
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
12
que los sistemas de archivos paralelos como el HDFS (Hadoop Distributed File System) estaacuten disentildeados para expandirse en muacuteltiples nodos y manejar grandes voluacutemenes de datos y que por ende generan reacuteplicas para garantizar la tolerancia a fallos Ademaacutes tendraacuten acceso a todos los discos de forma independiente razoacuten por la cual no se sue-len utilizar RAID9 o LVM10 para agrupar los discos (ni por tolerancia a fallos ni por rendi-miento) Por otra parte las soluciones de almacenamiento deben ofrecer una tecnologiacutea robusta y confiable que soporte tanto datos estructurados como no estructurados con seguridad coherencia y credibilidad Asimismo deben
bull Disponer de una gran capacidad para almacenar datos (De acuerdo a los requeri-mientos del proyecto)
bull Deben poder escalar de forma modular faacutecilmente desde unos cuantos terabytes hasta muacuteltiples petabytes de informacioacuten
bull Contar con un muy alto rendimiento en IOPS (Operaciones de entrada y salida por segundo) Adecuado en tiempo real
bull Soportar y controlar todo tipo de datos
bull Contar con una tecnologiacutea que asegure una gran proteccioacuten para los datos
Recordemos tambieacuten que el tema del respaldo de la informacioacuten se volveraacute criacutetico cuan-do hablamos de terabytes o petabytes de informacioacuten Esto si no contamos con una infraestructura suficientemente robusta que asegure la preservacioacuten de la informacioacuten al paso del tiempo11
c) Redes de datos
En teacuterminos generales el software para Big Data hace un uso muy intensivo de la red Esto debido a que todos los nodos intercambian grandes voluacutemenes de datos tanto en un esquema normal de operacioacuten como en el caso de fallo de alguacuten nodo La razoacuten de este aumento de traacutefico en la red causado por la falla en alguacuten nodo del cluacutester se debe principalmente a que Hadoop obliga al resto de los nodos a que se pongan a replicar los datos para mantener la integridad de la informacioacuten Por estos mo-tivos es recomendable utilizar switches preferentemente de alta velocidad y dedicados para el uso exclusivo del cluacutester Dada la naturaleza del Big Data se requiere que la red a utilizar cuente con las siguientes caracteriacutesticas funcionales
bull Gran velocidad
bull Alta disponibilidad
bull Redundancia
[9] En informaacutetica el acroacute-nimo RAID (del ingleacutes Redundant Array of Inexpensive Disks o maacutes comuacuten a diacutea de hoy Redundant Array of Independent Disks) tra-ducido como laquoconjunto redundante de discos Independientesraquo hace referencia a un sistema de almacenamiento de datos en tiempo real que utiliza muacuteltiples unida-des de almacenamiento de datos (discos duros o SSD) entre los que se distribuyen o replican los datos Dependiendo de su configuracioacuten (a la que suele llamarse laquonivelraquo) los beneficios de un RAID respecto a un uacutenico disco son uno o varios de los siguientes mayor integridad ma-yor tolerancia a fallos mayor throughput (ren-dimiento) y mayor capa-cidad Fuente httpseswikipediaorgwikiRAID
[10] Logical Volume Mana-gement (LVM) en espa-ntildeol ldquoadministrador de voluacutemenes loacutegicosrdquo es una opcioacuten de gestioacuten de discos que todas las principales distribu-ciones de GNULinux presentan Ya sea que necesite para configurar grupos de almacena-miento o simplemente se necesite para crear dinaacutemicamente las par-ticiones LVM Veacutease httpsparbaedloword-presscom20120105que-es-lvm-como-se-administra-y-utiliza
[11] Veacutease httpwwwcom-puterweeklycomfea-tureBig-data-storage-choices
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
13
bull Resistencia a fallas
bull Alta capacidad de resolver situaciones de congestionamiento en la red
bull Consistencia
bull Faacutecil de escalabilidad
bull Altamente administrable
bull Resilencia (Capacidad de continuar funcionando dentro de paraacutemetros acepta-bles ante distintos tipos de problemas)
Resulta claro que a mayor velocidad el costo de la red se incrementaraacute Por tal motivo se puede iniciar con velocidades de conectividad a 1 Gbit y jugar con opciones de agre-gacioacuten de puertos para mejorar el desempentildeo12 No obstante el mejor desempentildeo se lograraacute con la tecnologiacutea de 10 Gbit o superior Por otra parte a mayor nuacutemero de nodos en el cluacutester la velocidad de la red seraacute un factor clave para su buen desempentildeo13 Como podremos darnos cuenta recomendar una configuracioacuten de hardware ideal para un proyecto de Big Data no es una tarea sencilla Algunos pasos para comenzar a definirla son
bull Identificar las preguntas que deberaacute responder la plataforma de Big Data
bull La urgencia de respuesta
bull Identificar las fuentes de informacioacuten de donde se deberaacute extraer la informacioacuten a procesar Incluso pueden ser a partir de programas de TV en tiempo real o el flujo de mensajes proveniente de redes sociales
bull Cuantificar la cantidad de informacioacuten con que se deberaacute trabajar
Con esta informacioacuten los especialistas en soluciones de Big Data podraacuten ayu-darle con facilidad No olvide que la infraestructura requeriraacute no solo de una inversioacuten importante sino tambieacuten de una serie de nuevas habilidades y conocimientos en el per-sonal para desarrollar las aplicaciones No obstante brindaraacute oportunidades reales de valor de negocio en nuestras empresas o instituciones [12] Consiste en el uso de va-
rios puertos de red o en-laces para incrementar la velocidad de comuni-cacioacuten Veacutease httpseswikipediaorgwikiAgregaciC3B3n_de_enlaces
[8] Veacutease httpsearchdata-centertechtargetcomescronicaSeis-conside-raciones-para-redes-de-big-data
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
14
Bibliografiacutea
[1] ALFOCEA J Detenido por amenazas a su alcalde en Redes Sociales Delitos informaacuteticos 2015 Revista legal [en liacutenea] Fecha de actualizacioacuten 22 septiembre 2015 [Consulta 6 de octubre de 2016] Disponible en httpwwwdelitosinformaticoscom092015delitosamenazas-2-delitosdetenido-amenazar-alcalde-redes-sociales
[2]CACHEIRO Javier Requisitos Hardware Big Data Fundacioacuten Puacuteblica Galega Centro Tecnoloacutexico de Supercomputacioacuten de Galicia CESGA [en Liacutenea] Fecha de actualizacioacuten 16 de Marzo de 2015 [Consultado 25 de Mayo de 2016] Disponible en httpswwwcesgaesesbibliotecadownloadAssetid775
[3] Enauro engineering services BIG DATA [En Liacutenea] [Consultado 14 de Noviembre de 2016] Disponible en httpwwwenaurocom20160610big-data
[4] HURTADO Gork Big Data y Hadoop Cloudera vs Hortonworks Mondragon Unibertsitatea Investigacioacuten en TICs [en Liacutenea] [Consultado 3 Mayo de 2016] Disponible en httpmukommondragoneduictbig-data-y-hadoop-cloudera-vs-hortonworks
[5] JCASANELLA Introduccioacuten a Hadoop y su ecosistema Ticout Outsourcing Center Tutoriales de Yellowfin y BI [En Liacutenea] Fecha de actualizacioacuten 01 de Abril de 2013 [Consultado 19 Mayo de 2016] Disponible en httpwwwticoutcomblog20130402introduccion-a-hadoop-y-su-ecosistema
[6] LOSHIN David Explorando distribuciones Hadoop para gestionar big data TechTarget SA de CV Guiacutea Escencial [En Liacutenea] Enero de 2016 [Consultado 14 Abril de 2016] Disponible es httpsearchdatacentertechtargetcomescronicaExplorando-distribuciones-Hadoop-para-gestionar-big-data
[7] LURIE Marty Big data de coacutedigo abierto para el impaciente Parte 1 Tutorial Hadoop Hello World con Java Pig Hive Flume Fuse Oozie y Sqoop con Informix DB2 y MySQL IBM IBM deveoperWorks [en liacutenea] 20 de Marzo de 2013 [Consultado 14 Abril de 2016] Disponible en httpswwwibmcomdeveloperworksssadatalibrarytecharticledm-1209hadoopbigdata
[8] MATTHEW Mayo Top Big Data Processing Frameworks KdnuggetsTM KDnuggets News [en Liacutenea] Marzo de 2016 [Consultado 14 Abril de 2016] Disponible en httpwwwkdnuggetscom201603top-big-data-processing-frameworkshtml
[9] OacuteDELL Kevin How-to Select the Right Hardware for Your New Hadoop Cluster Cloudera Inc Cloudera Engineering Blog [en Liacutenea] 28 de Agosto de 2013 [Consultado 28 Mayo de 2016] Disponible en httpsblogclouderacomblog201308how-to-select-the-right-hardware-for-your-new-hadoop-cluster
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
15
[10] STEVE Dertien Defining the Infrastructure for Big Data Analytics PTC Inc El Divan Digital [en Liacutenea] 22 de Mayo de 2015 [Consultado 11Abril de 2016] Disponible en httpblogsptccom20150522defining-the-infrastructure-for-big-data-analytics
[11] The apache software foundation Hadoop Web site the Apache Software Foundation Apache Hadoop Project [en Liacutenea] 13 de Febrero de 2016 [Consultado 17 Mayo de 2016] Disponible en httphadoopapacheorg
[12] TIRADOS Marible iquestEs Hadoop el fin del almacenamiento de datos tradicional Big Data Hispano [en Liacutenea] 10 de febrero de 2014 [Consultado 07 Mayo de 2016] Disponible en httpwwwbigdatahispanoorgnoticiases-hadoop-el-fin-del-almacenamiento-de-datos
[13] SAacuteNCHEZ Joseacute Manuel iquestQUEacute ES BIG DATA T2O AdMedia Services SL 2015 [en Liacutenea] 02 de julio de 2016 [Consultado 14 Noviembre de 2016] Disponible en httpwwwt2omediacomideasactualidadque-es-big-data-2 en maricultura Meacutexico Secretariacutea de Medio Ambiente Recursos Naturales y Pesca 1997 192-207pp

ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
4
Razoacuten por la que deben considerarse sistemas distribuidos o basados en cluacutesteres2 tanto para el procesamiento como el almacenamiento de la informacioacuten (Ver fig 1) En lo referente al software requerido para administrar los recursos de una pla-taforma de Big Data debido a que estamos hablando de trabajar con arreglos de com-putadoras (servidores) y cluacutesteres de almacenamiento -que deben operarse en conjunto como un solo sistemandash resulta evidente que se requiere de un entorno de trabajo ldquoFra-meworkrdquo3 capaz de administrar distribuir controlar y procesar raacutepidamente los datos dentro de los arreglos de sistemas computacionales y de almacenamiento Hoy en diacutea el principal framework utilizado para Big Data es Hadoop4 cuyo desa-rrollo pertenece a The Apache Software Foundation misma que otorga el permiso para utilizar sus programas sin costo El proyecto original de Apache Hadoop incluye los siguientes moacutedulos funcionales
bull Hadoop Distributed File System (HDFStrade) Sistema distribuido y crea-do para trabajar con archivos de gran tamantildeo escrito en Java con un muy alto desempentildeo Veacutease httpwwwhappymindse s a p a c h e - h a d o o p - i n t r o d u c c i o n - a - h d f s s t h a s h 2M 4 r I y x S d p b s
bull HadoopMapReduce Sistema para escribir aplicaciones de procesamiento en paralelo para grandes cantidades de datos en sistemas de procesamiento distribuido o cluacuteste-res Veacutease httpwwwtutorialspointcomeshadoophadoop_mapreducehtm
bull Hadoop YARN (Yet Another Resource Negotiator) Plataforma de trabajo que permite la programacioacuten de las tareas y la gestioacuten de los recursos de cluacuteste-res (Es baacutesicamente una nueva generacioacuten del software de MapReduce MRv2 para la administracioacuten de cluacutesteres) Veacutease httpsearchdatacentertechtargetcomesdefinicionApache-Hadoop-YARN-Yet-Another-Resource-Negotiator
bull h t t p s u n p o c o d e j av a wo r d p r e s s c o m 201 307 2 5q u e - e s - y a r n
bull HadoopCommon Utileriacuteas necesarias para soportar al resto de los moacutedu-los de Hadoop Estas proporcionan acceso a los sistemas de archivos so-portados De hecho contiene los archivos en Java (ldquojarrdquo) y los scripts ne-cesarios para hacerlo correr Veacutease httpseswikipediaorgwikiHadoop
Otros proyectos de la Fundacioacuten de Software Apache relacionados con Hadoop son los siguientes
bull Ambaritrade Herramienta con una interfaz web que permi-te la administracioacuten aprovisionamiento y monitoreo de cluacutes-teres bajo Apache Hadoop Veacutease httpsunpocodejava
bull Avrotrade Sistema de serializacioacuten de datos Serializa los datos en un formato binario compacto por medio del formato JSON que facilita la comunicacioacuten entre los nodos de Hadoop Avro permite almacenar datos y acceder a ellos faacutecilmente desde varios
[3] Framework (Entorno de trabajo) En el desa-rrollo de software un framework o infraes-tructura digital es una estructura conceptual y tecnoloacutegica con moacutedu-los concretos de soft-ware que puede servir de base para la organi-zacioacuten y desarrollo de software Tiacutepicamente puede incluir soporte de programas bibliotecas y un lenguaje interpre-tado entre otras herra-mientas para asiacute ayudar a desarrollar y unir los diferentes componen-tes de un proyecto
[4] Apache Hadoop Es un framework de software que soporta aplicacio-nes distribuidas bajo una licencia libre Per-mite a las aplicaciones trabajar con miles de nodos y petabytes de datos (En teacuterminos maacutes simples es un marco para el manejo de gran-des conjuntos de datos en un entorno de com-putacioacuten distribuida)
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
5
lenguajes de programacioacuten Estaacute disentildeado para minimizar el espacio que nuestros datos ocuparaacuten en disco Veacutease httpwwwdatasaltes201106avro-hadoop
bull Cassandratrade Base de Datos NO SQL distribuida y basada en un mo-delo de almacenamiento de Clave-Valor escrita en Java Veacutea-se httpswwwadictosaltrabajocomtutorialescassandra
bull Chukwatrade Sistema de recoleccioacuten de datos para la gestioacuten de grandes sistemas dis-tribuidos Permite recolectar logs (bitaacutecoras) de grandes sistemas para su control anaacutelisis y visualizacioacuten Veacutease httpsunpocodejavawordpresscom20120717hadoop-chuwka-procesamiento-de-logs-de-grandes-sistemas-en-hadoop
bull HBasetrade Base de datos distribuida y escalable para el almacenamien-to de tablas muy grandes de informacioacuten de miles de millones de fi-las por millones de columnas que se encuentran alojadas en siste-mas distribuidos o cluacutesteres de almacenamiento Veacutease httpwwwfranciscojavierpulidocom201309bigdata-hadoop-iv-hbase_17html
bull Hivetrade Apache Hive es un sistema de almacenamiento de datos ldquoData Ware-houserdquo de coacutedigo abierto para la consulta y el anaacutelisis de grandes conjun-tos de datos que se encuentran en los archivos de Hadoop Este baacutesicamente realiza tres funciones La consulta sumarizacioacuten y anaacutelisis de los datos Veacutea-se httpsearchdatamanagementtechtargetcomdefinitionApache-Hive
bull Mahouttrade Es una libreriacutea escalable para mineriacutea de datos y aprendizaje automati-zado (aprendizaje de maacutequinas) escrita en Java y optimizada para funcionar sobre Hadoop HDFS y MapReduce Dispone de un gran nuacutemero de algoritmos imple-mentados para trabajar con teacutecnicas de filtrado colaborativo (Collaborative fil-tering) Agrupacioacuten (Clustering) y Clasificacioacuten (Classification) Veacutease httpsun-pocodejavawordpresscom20121029mahout-machine-learning-en-hadoop
bull Pigtrade Apache Pig es una plataforma para el anaacutelisis de grandes conjuntos de datos Consta de un lenguaje de alto nivel para la expresioacuten de programas junto con la infraes-tructura necesaria para la evaluacioacuten de los programas Veacutease httpspigapacheorg y httpwwwibmcomdeveloperworksssadatalibrarybigdata-apachepig
bull Sparktrade Es un motor para el procesamiento de datos a gran escala Permite escribir raacutepidamente aplicaciones en los lenguajes de programacioacuten Java Scala Pyton y R Ejecuta los programas en la memoria hasta 100 veces maacutes raacutepido que Hadoop Ma-pReduce o 10 veces maacutes raacutepido en el disco Adicionalmente puede combinar co-mandos de SQL flujo de datos (streaming) y anaacutelisis complejos Veacutease httpsparkapacheorg y httpsgeekytheorycomapache-spark-que-es-y-como-funciona
bull Teztrade Tez es un nuevo marco de ejecucioacuten distribuido para Hadoop Esta he-rramienta convierte el modelo de MapReduce en una plataforma maacutes potente
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
6
que es uacutetil para una gran cantidad de casos de uso en donde el procesamiento de las consultas requiere de un rendimiento casi en tiempo real Veacutease httpwwwinfoqcomarticlesapache-tez-saha-murthy y httptezapacheorg
bull ZooKeepertrade Es un servicio centralizado para mantener la informacioacuten de confi-guracioacuten denominacioacuten sincronizacioacuten distribuida y de servicios de grupo que requieren las aplicaciones distribuidas Veacutease httpzookeeperapacheorg y httpsunpocodejavawordpresscom20101119zookeeper-se-ha-convertido-en-un-proyecto-apache-top
Para mayor informacioacuten sobre el Apache Hadoop sus proyectos relacionados e incluso descargar el software puede acceder al siguiente sitio web httphadoopapacheorgy httpinlabfibupceduesblogque-herramientas-necesitas-para-iniciarte-en-big-data
Distribuciones comerciales de Hadoop
Aunque Hadoop es un framework libre y por ende no tiene costo en la praacutectica existen varias distribuciones comerciales de Hadoop que permiten implementar un medio am-biente de trabajo maacutes robusto para Big Data Estas distribuciones ofrecen diferentes me-joras en la funcionalidad rendimiento facilidad de configuracioacuten gestioacuten e integracioacuten con otras plataformas externas producto de antildeos de investigacioacuten de las empresas que los distribuyen Incluyen ademaacutes herramientas adicionales soporte teacutecnico diferentes niveles de servicios y mantenimiento Como sentildeala David Loshin en su artiacuteculo Explorando distribuciones Hadoop para gestionar big data
El mercado incluye tres proveedores independientes que se especializan en Hadoop Cloudera Inc Hortonworks Inc y MapR Technologies Inc Otras empresas que ofrecen distribuciones o capacidades de Hadoop incluyen Pi-votal Software Inc IBM Amazon Web Services y Microsoft5
Debemos prestar mucha atencioacuten entre las diferencias y las distribuciones de Hadoop ya que pueden requerir de una gran inversioacuten para su funcionamiento (princi-palmente por contratos de licenciamiento muy caros) aportar un pobre desempentildeo o limitaciones en los resultados esperados ofrecer poco soporte tecnoloacutegico o inclusive requerir de hardware propietario para su instrumentacioacuten Appliances Entre los principales aspectos que deberemos revisar se tiene
bull Las mejoras o beneficios que aportan a la solucioacuten Recordemos que las variantes en los frameworks facilitan abordar los problemas de analiacuteti-ca con diferentes enfoques adiciones yo mejoras y por ende resultados
bull Facilidades de monitoreo y administracioacuten para Hadoop
[5] David Loshin Exploran-do distribuciones Ha-doop para gestionar big data en linea httpsear-chdatacentertechtargetcomescronicaExploran-do-distribuciones-Hadoop-para-gestionar-big-data
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
7
bull Los componentes especiacuteficos o propietarios de las distribuciones
bull Su compatibilidad con otras plataformas
bull El hardware requerido
bull Las facilidades de recuperacioacuten en caso de desastre
bull Modelo de servicio y soporte ofertado
bull Consultoriacutea
bull Su costo
iquestCuaacuteles son estas distribuciones liacutederes en el mercado en teacuterminos generales que es lo que ofrece cada una de ellas La tabla que se presenta a continuacioacuten lo resume
Distribucioacuten Comercial de Hadoop
Ambiente operativo
Ofrece
Amazone Web Servicves AWS
UnixLinux bull ElasticMapReduce (EMR) Servicio web que facilita el procesamiento raacutepido y renta-ble de grandes cantidades de datos EMR es Hadoop en la nube Aprovecha Amazon EC2 para coacutemputo y Amazon S3 para alma-cenamiento Veacutease httpsawsamazoncomeselasticmapreduce
bull Amazon Kinesis para el procesamiento de datos de streaming en tiempo real
bull Integracioacuten con el data warehouse Amazon Redshift y otras fuentes de datos autosca-ling que modificaraacute el tamantildeo de los cluacuteste-res en base a poliacuteticas soporte para bases de datos NoSQL adicionales sobre Hadoop y maacutes integracioacuten de inteligencia de nego-cios con proveedores externos
Cloudera UnixLinux bull Cloudera Manager Herramienta de moni-toreo y administracioacuten para Hadoop
bull Impala Motor SQL para Hadoopmuy raacutepi-do con una arquitectura de procesamiento paralelo masivo (MassivelyParallelProces-sing - MPP)
Tabla 1 Principales distri-buciones comerciales de Ha-doop Fuente httpcioperupefotoreportaje15543ha-doop-como-se-encuentran-las-distribuciones-lideres
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
8
Hortonworks UnixLinux bull Apache Ambari (Proporciona una consola de administracioacuten de cluacutesteres Hadoop)
bull Aliansas con Microsoft Teradata SAP Red Hat y otras empresas
IBM UnixLinux bull BigInsightsfor Apache Hadoop (Coacutedigo de Apache Hadoop integrado con activos de IBM para la analiacutetica avanzada SPSS administracioacuten de cargas de trabajo para computacioacuten de alto desempentildeo he-rramientas de inteligencia de negocio y herramientas de administracioacuten y modela-miento de datos)
MapRTechnoligies UnixLinux bull Soporte para Network File System (NFS) correr coacutedigo arbitrario en el cluacutester
bull Hbase mejorado (Base de datos para Hadoop)
bull Caracteriacutesticas de alta disponibilidad y recuperacioacuten en caso de desastre
Pivotal UnixLinux bull HAWQ (Motor de consulta SQL paralelo de Pivotal)
bull Familia de appliances que integran su Ha-doop EDW (Enterprise Data Warehouse) y capas de administracioacuten de datos
bull Sus innovaciones se enfocaraacuten en mejorar su motor HAWQ SQL y la integracioacuten con otros productos de Pivotal
bull Tecnologiacutea Greenplum Database de EMCbull Expertis de EMC y VMware
Teradata UnixLinux bull Hadoop como appliancebull SQL-H (Motor SQL para realizar consultas
en Hadoop)bull Herramientas de administracioacuten propieta-
rias de Teradatabull Aster6 (Software para realizar analiacutetica con
Hadoop)bull Appliances de alto desempentildeo
[6] Aster es un software ba-sado en el procesamien-to masivo en paralelo para el anaacutelisis y manejo de datos desarrolla-do por Teradata Corp ht tpsenwikipediaorgwikiAster_Data_Systems
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
9
Intel UnixLinux bull Tecnologiacutea de sus Chips Xeon optimizados para Hadoop
bull Capacidades de desempentildeo y seguridad mejoradas por hardware para Hadoop
bull Lustre7 bull Optimizacioacuten nativa de tareas y analiacutetica
graacutefica
Microsoft Windows Azure HDInsight Service
Windows bull Polybase8 Permite que los clientes de SQL ejecuten consultas que incluyan datos almacenados en Hadoop
bull Esfuerzos en el desarrollo de la siguiente generacioacuten de Hive y de otros proyectos de la comunidad de coacutedigo abierto de Hadoop
bull Herramientas de desarrollo y colaboracioacuten para los clientes de Microsoft
La arquitectura del hardware para Big Data
En teacuterminos arquitectoacutenicos las soluciones de hardware para Big Data disponibles en el mercado pareceriacutean maacutes complejas de lo que en realidad son tienen muchas cosas en comuacuten todas utilizan
bull Nodos computacionales
bull Almacenamiento
bull Frameworks y aplicaciones programadas en Java (Ejemplo Hadoop Hbase Spark etc)
bull Redes de alta velocidad de tecnologiacutea gigabit o superior
bull Sistemas de soporte vital para (alimentacioacuten de energiacutea eleacutectrica y el control de temperatura y humedad)
Podemos apreciar diferencias significativas como
bull Un nuacutemero diferente de nodos y de configuraciones entre eacutestos que producen rendimientos diferentes en la ejecucioacuten de los procesos
bull Tecnologiacuteas de almacenamiento diferentes que influyen de manera determinante en el tiempo de acceso a la informacioacuten y por ende en la obtencioacuten de resultados
[7] Lustre es un sistema de archivos distribuido Open Source normal-mente utilizado en clus-ters a gran escala El nombre es una mezcla de Linux y clusters El proyecto intenta pro-porcionar un sistema de archivos para clusters de decenas de miles de nodos con petabytes de capacidad de almace-namiento sin compro-meter la velocidad o la seguridad y estaacute dispo-nible bajo la GNU GPLht tpseswikipediaorgwikiLustre_(siste-ma_de_archivos)
[8] Polybase es una tecno-logiacutea de Microsoft que permite a los usuarios de SQL Server PDW eje-cutar consultas sobre los datos almacena-dos en Hadoop Veacutease httpfrancescsanchez-biwebnodeesnewsuso-de-hadoop-en-sql-server-con-pdw-y-poly-base-
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
10
bull Redes de datos de diferentes velocidades que influyen en el desempentildeo global de la solucioacuten
El anaacutelisis de las cargas de tra-bajo seraacute un factor determinante para lograr el mejor equilibrio en-tre rendimiento y ahorro del hard-ware por ejemplo
a)Nodos computacionales
Los nodos computacionales son servidores para rack con una configuracioacuten preestablecida de acuerdo a su funcioacuten Muacuteltiples nodos conforman un cluacutester eso siacute en ninguacuten momento se reco-miendan servidores de tipo Blade debido a que eacutestos comparten componentes en un chasis que los puede limitar en su desempe-ntildeo capacidad de crecimiento y posibilidades de conectividad La cantidad de nuacutecleos y de memo-ria RAM disponible en cada uno de ellos asiacute como su velocidad de interconexioacuten a la red influiraacute de manera determinante en el rendi-miento global del cluacutester
Los cluacutester basados en el Siste-ma de Archivos de Hadoop ldquoHDFSrdquo baacutesicamente utilizaraacute dos tipos de nodos diferentes de acuerdo a la funcioacuten que desempentildearaacuten
bull Nodo de Nombres (Rastrea-dor de trabajos Namenode Jo-bTracker) Responsable de la topologiacutea de todos los demaacutes nodos y de gestionar el espa-cio de nombres Solo hay uno por cluacutester El Nodo de nom-
bres se encarga de distribuir los archivos en los nodos de datos que rea-
Figura 2 Ejemplo de un cluacutester para Big Data ba-sado en Hadoop Fuente httpwwwnextplatformcom20150703building-a-better-hadoop-cluster
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
11
lizaraacuten el procesamiento de los datos Veacutease httpwwwhappymindse s a p a c h e - h a d o o p - i n t r o d u c c i o n - a - h d f s s t h a s h 1 A 9 o n P I j d p u f
bull Nodo de Datos (Rastreador de tareas Datanode TaskTracker) Acceden a los da-tos Almacenan los bloques de informacioacuten y los recuperan bajo demanda
Velocidad de procesamiento
En teacuterminos generales los caacutelculos requeridos para los procesos de Big Data comuacutenmen-te estaraacuten maacutes limitados por la velocidad de respuesta de las operaciones de entrada y salida a disco y de la red que por la velocidad del procesador Eso no significa que los pro-cesadores que deban emplearse en la solucioacuten requieran ser de bajo costo o pobre ren-dimiento Sino maacutes bien que eacutestos cuenten con la mayor cantidad de nuacutecleos operando a la mayor frecuencia posible para poder manejar maacutes tareas en paralelo de forma aacutegil En este sentido tambieacuten se tiene que cuidar el consumo de energiacutea y la disipacioacuten de calor asociado a la frecuencia y altos voltajes de operacioacuten de los microprocesadores que sin duda tendraacuten impactos negativos en el medio ambiente y el costo de operacioacuten de la plataforma completa
Memoria RAM
La memoria RAM necesaria para un cluacutester de Big Data normalmente deberaacute ser calcu-lada tomando en consideracioacuten varios aspectos Entre los maacutes importantes destacan
bull La cantidad de nodos de datos que contenga el cluacutester
bull El nuacutemero maacuteximo de tareas que ejecutaraacute cada nodo de datos de forma simul-taacutenea
bull La memoria necesaria para los demonios que se ejecutan en los nodos de datos de tareas y del sistema operativo
bull El nuacutemero de bloques almacenados en el sistema de archivos distribuidos
bull Las necesidades especiacuteficas del software a utilizar en la plataforma
Los detalles sobre su tecnologiacutea por supuesto que tambieacuten influiraacuten en el des-empentildeo y configuracioacuten de la solucioacuten
b) Almacenamiento
En cuanto a las caracteriacutesticas teacutecnicas del almacenamiento necesario para una plata-forma de Big Data recordemos que eacutestas deberaacuten ajustarse a los requerimientos del Framework y las aplicaciones que seraacuten utilizadas Desde esta oacuteptica nos encontraremos
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
12
que los sistemas de archivos paralelos como el HDFS (Hadoop Distributed File System) estaacuten disentildeados para expandirse en muacuteltiples nodos y manejar grandes voluacutemenes de datos y que por ende generan reacuteplicas para garantizar la tolerancia a fallos Ademaacutes tendraacuten acceso a todos los discos de forma independiente razoacuten por la cual no se sue-len utilizar RAID9 o LVM10 para agrupar los discos (ni por tolerancia a fallos ni por rendi-miento) Por otra parte las soluciones de almacenamiento deben ofrecer una tecnologiacutea robusta y confiable que soporte tanto datos estructurados como no estructurados con seguridad coherencia y credibilidad Asimismo deben
bull Disponer de una gran capacidad para almacenar datos (De acuerdo a los requeri-mientos del proyecto)
bull Deben poder escalar de forma modular faacutecilmente desde unos cuantos terabytes hasta muacuteltiples petabytes de informacioacuten
bull Contar con un muy alto rendimiento en IOPS (Operaciones de entrada y salida por segundo) Adecuado en tiempo real
bull Soportar y controlar todo tipo de datos
bull Contar con una tecnologiacutea que asegure una gran proteccioacuten para los datos
Recordemos tambieacuten que el tema del respaldo de la informacioacuten se volveraacute criacutetico cuan-do hablamos de terabytes o petabytes de informacioacuten Esto si no contamos con una infraestructura suficientemente robusta que asegure la preservacioacuten de la informacioacuten al paso del tiempo11
c) Redes de datos
En teacuterminos generales el software para Big Data hace un uso muy intensivo de la red Esto debido a que todos los nodos intercambian grandes voluacutemenes de datos tanto en un esquema normal de operacioacuten como en el caso de fallo de alguacuten nodo La razoacuten de este aumento de traacutefico en la red causado por la falla en alguacuten nodo del cluacutester se debe principalmente a que Hadoop obliga al resto de los nodos a que se pongan a replicar los datos para mantener la integridad de la informacioacuten Por estos mo-tivos es recomendable utilizar switches preferentemente de alta velocidad y dedicados para el uso exclusivo del cluacutester Dada la naturaleza del Big Data se requiere que la red a utilizar cuente con las siguientes caracteriacutesticas funcionales
bull Gran velocidad
bull Alta disponibilidad
bull Redundancia
[9] En informaacutetica el acroacute-nimo RAID (del ingleacutes Redundant Array of Inexpensive Disks o maacutes comuacuten a diacutea de hoy Redundant Array of Independent Disks) tra-ducido como laquoconjunto redundante de discos Independientesraquo hace referencia a un sistema de almacenamiento de datos en tiempo real que utiliza muacuteltiples unida-des de almacenamiento de datos (discos duros o SSD) entre los que se distribuyen o replican los datos Dependiendo de su configuracioacuten (a la que suele llamarse laquonivelraquo) los beneficios de un RAID respecto a un uacutenico disco son uno o varios de los siguientes mayor integridad ma-yor tolerancia a fallos mayor throughput (ren-dimiento) y mayor capa-cidad Fuente httpseswikipediaorgwikiRAID
[10] Logical Volume Mana-gement (LVM) en espa-ntildeol ldquoadministrador de voluacutemenes loacutegicosrdquo es una opcioacuten de gestioacuten de discos que todas las principales distribu-ciones de GNULinux presentan Ya sea que necesite para configurar grupos de almacena-miento o simplemente se necesite para crear dinaacutemicamente las par-ticiones LVM Veacutease httpsparbaedloword-presscom20120105que-es-lvm-como-se-administra-y-utiliza
[11] Veacutease httpwwwcom-puterweeklycomfea-tureBig-data-storage-choices
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
13
bull Resistencia a fallas
bull Alta capacidad de resolver situaciones de congestionamiento en la red
bull Consistencia
bull Faacutecil de escalabilidad
bull Altamente administrable
bull Resilencia (Capacidad de continuar funcionando dentro de paraacutemetros acepta-bles ante distintos tipos de problemas)
Resulta claro que a mayor velocidad el costo de la red se incrementaraacute Por tal motivo se puede iniciar con velocidades de conectividad a 1 Gbit y jugar con opciones de agre-gacioacuten de puertos para mejorar el desempentildeo12 No obstante el mejor desempentildeo se lograraacute con la tecnologiacutea de 10 Gbit o superior Por otra parte a mayor nuacutemero de nodos en el cluacutester la velocidad de la red seraacute un factor clave para su buen desempentildeo13 Como podremos darnos cuenta recomendar una configuracioacuten de hardware ideal para un proyecto de Big Data no es una tarea sencilla Algunos pasos para comenzar a definirla son
bull Identificar las preguntas que deberaacute responder la plataforma de Big Data
bull La urgencia de respuesta
bull Identificar las fuentes de informacioacuten de donde se deberaacute extraer la informacioacuten a procesar Incluso pueden ser a partir de programas de TV en tiempo real o el flujo de mensajes proveniente de redes sociales
bull Cuantificar la cantidad de informacioacuten con que se deberaacute trabajar
Con esta informacioacuten los especialistas en soluciones de Big Data podraacuten ayu-darle con facilidad No olvide que la infraestructura requeriraacute no solo de una inversioacuten importante sino tambieacuten de una serie de nuevas habilidades y conocimientos en el per-sonal para desarrollar las aplicaciones No obstante brindaraacute oportunidades reales de valor de negocio en nuestras empresas o instituciones [12] Consiste en el uso de va-
rios puertos de red o en-laces para incrementar la velocidad de comuni-cacioacuten Veacutease httpseswikipediaorgwikiAgregaciC3B3n_de_enlaces
[8] Veacutease httpsearchdata-centertechtargetcomescronicaSeis-conside-raciones-para-redes-de-big-data
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
14
Bibliografiacutea
[1] ALFOCEA J Detenido por amenazas a su alcalde en Redes Sociales Delitos informaacuteticos 2015 Revista legal [en liacutenea] Fecha de actualizacioacuten 22 septiembre 2015 [Consulta 6 de octubre de 2016] Disponible en httpwwwdelitosinformaticoscom092015delitosamenazas-2-delitosdetenido-amenazar-alcalde-redes-sociales
[2]CACHEIRO Javier Requisitos Hardware Big Data Fundacioacuten Puacuteblica Galega Centro Tecnoloacutexico de Supercomputacioacuten de Galicia CESGA [en Liacutenea] Fecha de actualizacioacuten 16 de Marzo de 2015 [Consultado 25 de Mayo de 2016] Disponible en httpswwwcesgaesesbibliotecadownloadAssetid775
[3] Enauro engineering services BIG DATA [En Liacutenea] [Consultado 14 de Noviembre de 2016] Disponible en httpwwwenaurocom20160610big-data
[4] HURTADO Gork Big Data y Hadoop Cloudera vs Hortonworks Mondragon Unibertsitatea Investigacioacuten en TICs [en Liacutenea] [Consultado 3 Mayo de 2016] Disponible en httpmukommondragoneduictbig-data-y-hadoop-cloudera-vs-hortonworks
[5] JCASANELLA Introduccioacuten a Hadoop y su ecosistema Ticout Outsourcing Center Tutoriales de Yellowfin y BI [En Liacutenea] Fecha de actualizacioacuten 01 de Abril de 2013 [Consultado 19 Mayo de 2016] Disponible en httpwwwticoutcomblog20130402introduccion-a-hadoop-y-su-ecosistema
[6] LOSHIN David Explorando distribuciones Hadoop para gestionar big data TechTarget SA de CV Guiacutea Escencial [En Liacutenea] Enero de 2016 [Consultado 14 Abril de 2016] Disponible es httpsearchdatacentertechtargetcomescronicaExplorando-distribuciones-Hadoop-para-gestionar-big-data
[7] LURIE Marty Big data de coacutedigo abierto para el impaciente Parte 1 Tutorial Hadoop Hello World con Java Pig Hive Flume Fuse Oozie y Sqoop con Informix DB2 y MySQL IBM IBM deveoperWorks [en liacutenea] 20 de Marzo de 2013 [Consultado 14 Abril de 2016] Disponible en httpswwwibmcomdeveloperworksssadatalibrarytecharticledm-1209hadoopbigdata
[8] MATTHEW Mayo Top Big Data Processing Frameworks KdnuggetsTM KDnuggets News [en Liacutenea] Marzo de 2016 [Consultado 14 Abril de 2016] Disponible en httpwwwkdnuggetscom201603top-big-data-processing-frameworkshtml
[9] OacuteDELL Kevin How-to Select the Right Hardware for Your New Hadoop Cluster Cloudera Inc Cloudera Engineering Blog [en Liacutenea] 28 de Agosto de 2013 [Consultado 28 Mayo de 2016] Disponible en httpsblogclouderacomblog201308how-to-select-the-right-hardware-for-your-new-hadoop-cluster
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
15
[10] STEVE Dertien Defining the Infrastructure for Big Data Analytics PTC Inc El Divan Digital [en Liacutenea] 22 de Mayo de 2015 [Consultado 11Abril de 2016] Disponible en httpblogsptccom20150522defining-the-infrastructure-for-big-data-analytics
[11] The apache software foundation Hadoop Web site the Apache Software Foundation Apache Hadoop Project [en Liacutenea] 13 de Febrero de 2016 [Consultado 17 Mayo de 2016] Disponible en httphadoopapacheorg
[12] TIRADOS Marible iquestEs Hadoop el fin del almacenamiento de datos tradicional Big Data Hispano [en Liacutenea] 10 de febrero de 2014 [Consultado 07 Mayo de 2016] Disponible en httpwwwbigdatahispanoorgnoticiases-hadoop-el-fin-del-almacenamiento-de-datos
[13] SAacuteNCHEZ Joseacute Manuel iquestQUEacute ES BIG DATA T2O AdMedia Services SL 2015 [en Liacutenea] 02 de julio de 2016 [Consultado 14 Noviembre de 2016] Disponible en httpwwwt2omediacomideasactualidadque-es-big-data-2 en maricultura Meacutexico Secretariacutea de Medio Ambiente Recursos Naturales y Pesca 1997 192-207pp

ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
5
lenguajes de programacioacuten Estaacute disentildeado para minimizar el espacio que nuestros datos ocuparaacuten en disco Veacutease httpwwwdatasaltes201106avro-hadoop
bull Cassandratrade Base de Datos NO SQL distribuida y basada en un mo-delo de almacenamiento de Clave-Valor escrita en Java Veacutea-se httpswwwadictosaltrabajocomtutorialescassandra
bull Chukwatrade Sistema de recoleccioacuten de datos para la gestioacuten de grandes sistemas dis-tribuidos Permite recolectar logs (bitaacutecoras) de grandes sistemas para su control anaacutelisis y visualizacioacuten Veacutease httpsunpocodejavawordpresscom20120717hadoop-chuwka-procesamiento-de-logs-de-grandes-sistemas-en-hadoop
bull HBasetrade Base de datos distribuida y escalable para el almacenamien-to de tablas muy grandes de informacioacuten de miles de millones de fi-las por millones de columnas que se encuentran alojadas en siste-mas distribuidos o cluacutesteres de almacenamiento Veacutease httpwwwfranciscojavierpulidocom201309bigdata-hadoop-iv-hbase_17html
bull Hivetrade Apache Hive es un sistema de almacenamiento de datos ldquoData Ware-houserdquo de coacutedigo abierto para la consulta y el anaacutelisis de grandes conjun-tos de datos que se encuentran en los archivos de Hadoop Este baacutesicamente realiza tres funciones La consulta sumarizacioacuten y anaacutelisis de los datos Veacutea-se httpsearchdatamanagementtechtargetcomdefinitionApache-Hive
bull Mahouttrade Es una libreriacutea escalable para mineriacutea de datos y aprendizaje automati-zado (aprendizaje de maacutequinas) escrita en Java y optimizada para funcionar sobre Hadoop HDFS y MapReduce Dispone de un gran nuacutemero de algoritmos imple-mentados para trabajar con teacutecnicas de filtrado colaborativo (Collaborative fil-tering) Agrupacioacuten (Clustering) y Clasificacioacuten (Classification) Veacutease httpsun-pocodejavawordpresscom20121029mahout-machine-learning-en-hadoop
bull Pigtrade Apache Pig es una plataforma para el anaacutelisis de grandes conjuntos de datos Consta de un lenguaje de alto nivel para la expresioacuten de programas junto con la infraes-tructura necesaria para la evaluacioacuten de los programas Veacutease httpspigapacheorg y httpwwwibmcomdeveloperworksssadatalibrarybigdata-apachepig
bull Sparktrade Es un motor para el procesamiento de datos a gran escala Permite escribir raacutepidamente aplicaciones en los lenguajes de programacioacuten Java Scala Pyton y R Ejecuta los programas en la memoria hasta 100 veces maacutes raacutepido que Hadoop Ma-pReduce o 10 veces maacutes raacutepido en el disco Adicionalmente puede combinar co-mandos de SQL flujo de datos (streaming) y anaacutelisis complejos Veacutease httpsparkapacheorg y httpsgeekytheorycomapache-spark-que-es-y-como-funciona
bull Teztrade Tez es un nuevo marco de ejecucioacuten distribuido para Hadoop Esta he-rramienta convierte el modelo de MapReduce en una plataforma maacutes potente
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
6
que es uacutetil para una gran cantidad de casos de uso en donde el procesamiento de las consultas requiere de un rendimiento casi en tiempo real Veacutease httpwwwinfoqcomarticlesapache-tez-saha-murthy y httptezapacheorg
bull ZooKeepertrade Es un servicio centralizado para mantener la informacioacuten de confi-guracioacuten denominacioacuten sincronizacioacuten distribuida y de servicios de grupo que requieren las aplicaciones distribuidas Veacutease httpzookeeperapacheorg y httpsunpocodejavawordpresscom20101119zookeeper-se-ha-convertido-en-un-proyecto-apache-top
Para mayor informacioacuten sobre el Apache Hadoop sus proyectos relacionados e incluso descargar el software puede acceder al siguiente sitio web httphadoopapacheorgy httpinlabfibupceduesblogque-herramientas-necesitas-para-iniciarte-en-big-data
Distribuciones comerciales de Hadoop
Aunque Hadoop es un framework libre y por ende no tiene costo en la praacutectica existen varias distribuciones comerciales de Hadoop que permiten implementar un medio am-biente de trabajo maacutes robusto para Big Data Estas distribuciones ofrecen diferentes me-joras en la funcionalidad rendimiento facilidad de configuracioacuten gestioacuten e integracioacuten con otras plataformas externas producto de antildeos de investigacioacuten de las empresas que los distribuyen Incluyen ademaacutes herramientas adicionales soporte teacutecnico diferentes niveles de servicios y mantenimiento Como sentildeala David Loshin en su artiacuteculo Explorando distribuciones Hadoop para gestionar big data
El mercado incluye tres proveedores independientes que se especializan en Hadoop Cloudera Inc Hortonworks Inc y MapR Technologies Inc Otras empresas que ofrecen distribuciones o capacidades de Hadoop incluyen Pi-votal Software Inc IBM Amazon Web Services y Microsoft5
Debemos prestar mucha atencioacuten entre las diferencias y las distribuciones de Hadoop ya que pueden requerir de una gran inversioacuten para su funcionamiento (princi-palmente por contratos de licenciamiento muy caros) aportar un pobre desempentildeo o limitaciones en los resultados esperados ofrecer poco soporte tecnoloacutegico o inclusive requerir de hardware propietario para su instrumentacioacuten Appliances Entre los principales aspectos que deberemos revisar se tiene
bull Las mejoras o beneficios que aportan a la solucioacuten Recordemos que las variantes en los frameworks facilitan abordar los problemas de analiacuteti-ca con diferentes enfoques adiciones yo mejoras y por ende resultados
bull Facilidades de monitoreo y administracioacuten para Hadoop
[5] David Loshin Exploran-do distribuciones Ha-doop para gestionar big data en linea httpsear-chdatacentertechtargetcomescronicaExploran-do-distribuciones-Hadoop-para-gestionar-big-data
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
7
bull Los componentes especiacuteficos o propietarios de las distribuciones
bull Su compatibilidad con otras plataformas
bull El hardware requerido
bull Las facilidades de recuperacioacuten en caso de desastre
bull Modelo de servicio y soporte ofertado
bull Consultoriacutea
bull Su costo
iquestCuaacuteles son estas distribuciones liacutederes en el mercado en teacuterminos generales que es lo que ofrece cada una de ellas La tabla que se presenta a continuacioacuten lo resume
Distribucioacuten Comercial de Hadoop
Ambiente operativo
Ofrece
Amazone Web Servicves AWS
UnixLinux bull ElasticMapReduce (EMR) Servicio web que facilita el procesamiento raacutepido y renta-ble de grandes cantidades de datos EMR es Hadoop en la nube Aprovecha Amazon EC2 para coacutemputo y Amazon S3 para alma-cenamiento Veacutease httpsawsamazoncomeselasticmapreduce
bull Amazon Kinesis para el procesamiento de datos de streaming en tiempo real
bull Integracioacuten con el data warehouse Amazon Redshift y otras fuentes de datos autosca-ling que modificaraacute el tamantildeo de los cluacuteste-res en base a poliacuteticas soporte para bases de datos NoSQL adicionales sobre Hadoop y maacutes integracioacuten de inteligencia de nego-cios con proveedores externos
Cloudera UnixLinux bull Cloudera Manager Herramienta de moni-toreo y administracioacuten para Hadoop
bull Impala Motor SQL para Hadoopmuy raacutepi-do con una arquitectura de procesamiento paralelo masivo (MassivelyParallelProces-sing - MPP)
Tabla 1 Principales distri-buciones comerciales de Ha-doop Fuente httpcioperupefotoreportaje15543ha-doop-como-se-encuentran-las-distribuciones-lideres
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
8
Hortonworks UnixLinux bull Apache Ambari (Proporciona una consola de administracioacuten de cluacutesteres Hadoop)
bull Aliansas con Microsoft Teradata SAP Red Hat y otras empresas
IBM UnixLinux bull BigInsightsfor Apache Hadoop (Coacutedigo de Apache Hadoop integrado con activos de IBM para la analiacutetica avanzada SPSS administracioacuten de cargas de trabajo para computacioacuten de alto desempentildeo he-rramientas de inteligencia de negocio y herramientas de administracioacuten y modela-miento de datos)
MapRTechnoligies UnixLinux bull Soporte para Network File System (NFS) correr coacutedigo arbitrario en el cluacutester
bull Hbase mejorado (Base de datos para Hadoop)
bull Caracteriacutesticas de alta disponibilidad y recuperacioacuten en caso de desastre
Pivotal UnixLinux bull HAWQ (Motor de consulta SQL paralelo de Pivotal)
bull Familia de appliances que integran su Ha-doop EDW (Enterprise Data Warehouse) y capas de administracioacuten de datos
bull Sus innovaciones se enfocaraacuten en mejorar su motor HAWQ SQL y la integracioacuten con otros productos de Pivotal
bull Tecnologiacutea Greenplum Database de EMCbull Expertis de EMC y VMware
Teradata UnixLinux bull Hadoop como appliancebull SQL-H (Motor SQL para realizar consultas
en Hadoop)bull Herramientas de administracioacuten propieta-
rias de Teradatabull Aster6 (Software para realizar analiacutetica con
Hadoop)bull Appliances de alto desempentildeo
[6] Aster es un software ba-sado en el procesamien-to masivo en paralelo para el anaacutelisis y manejo de datos desarrolla-do por Teradata Corp ht tpsenwikipediaorgwikiAster_Data_Systems
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
9
Intel UnixLinux bull Tecnologiacutea de sus Chips Xeon optimizados para Hadoop
bull Capacidades de desempentildeo y seguridad mejoradas por hardware para Hadoop
bull Lustre7 bull Optimizacioacuten nativa de tareas y analiacutetica
graacutefica
Microsoft Windows Azure HDInsight Service
Windows bull Polybase8 Permite que los clientes de SQL ejecuten consultas que incluyan datos almacenados en Hadoop
bull Esfuerzos en el desarrollo de la siguiente generacioacuten de Hive y de otros proyectos de la comunidad de coacutedigo abierto de Hadoop
bull Herramientas de desarrollo y colaboracioacuten para los clientes de Microsoft
La arquitectura del hardware para Big Data
En teacuterminos arquitectoacutenicos las soluciones de hardware para Big Data disponibles en el mercado pareceriacutean maacutes complejas de lo que en realidad son tienen muchas cosas en comuacuten todas utilizan
bull Nodos computacionales
bull Almacenamiento
bull Frameworks y aplicaciones programadas en Java (Ejemplo Hadoop Hbase Spark etc)
bull Redes de alta velocidad de tecnologiacutea gigabit o superior
bull Sistemas de soporte vital para (alimentacioacuten de energiacutea eleacutectrica y el control de temperatura y humedad)
Podemos apreciar diferencias significativas como
bull Un nuacutemero diferente de nodos y de configuraciones entre eacutestos que producen rendimientos diferentes en la ejecucioacuten de los procesos
bull Tecnologiacuteas de almacenamiento diferentes que influyen de manera determinante en el tiempo de acceso a la informacioacuten y por ende en la obtencioacuten de resultados
[7] Lustre es un sistema de archivos distribuido Open Source normal-mente utilizado en clus-ters a gran escala El nombre es una mezcla de Linux y clusters El proyecto intenta pro-porcionar un sistema de archivos para clusters de decenas de miles de nodos con petabytes de capacidad de almace-namiento sin compro-meter la velocidad o la seguridad y estaacute dispo-nible bajo la GNU GPLht tpseswikipediaorgwikiLustre_(siste-ma_de_archivos)
[8] Polybase es una tecno-logiacutea de Microsoft que permite a los usuarios de SQL Server PDW eje-cutar consultas sobre los datos almacena-dos en Hadoop Veacutease httpfrancescsanchez-biwebnodeesnewsuso-de-hadoop-en-sql-server-con-pdw-y-poly-base-
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
10
bull Redes de datos de diferentes velocidades que influyen en el desempentildeo global de la solucioacuten
El anaacutelisis de las cargas de tra-bajo seraacute un factor determinante para lograr el mejor equilibrio en-tre rendimiento y ahorro del hard-ware por ejemplo
a)Nodos computacionales
Los nodos computacionales son servidores para rack con una configuracioacuten preestablecida de acuerdo a su funcioacuten Muacuteltiples nodos conforman un cluacutester eso siacute en ninguacuten momento se reco-miendan servidores de tipo Blade debido a que eacutestos comparten componentes en un chasis que los puede limitar en su desempe-ntildeo capacidad de crecimiento y posibilidades de conectividad La cantidad de nuacutecleos y de memo-ria RAM disponible en cada uno de ellos asiacute como su velocidad de interconexioacuten a la red influiraacute de manera determinante en el rendi-miento global del cluacutester
Los cluacutester basados en el Siste-ma de Archivos de Hadoop ldquoHDFSrdquo baacutesicamente utilizaraacute dos tipos de nodos diferentes de acuerdo a la funcioacuten que desempentildearaacuten
bull Nodo de Nombres (Rastrea-dor de trabajos Namenode Jo-bTracker) Responsable de la topologiacutea de todos los demaacutes nodos y de gestionar el espa-cio de nombres Solo hay uno por cluacutester El Nodo de nom-
bres se encarga de distribuir los archivos en los nodos de datos que rea-
Figura 2 Ejemplo de un cluacutester para Big Data ba-sado en Hadoop Fuente httpwwwnextplatformcom20150703building-a-better-hadoop-cluster
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
11
lizaraacuten el procesamiento de los datos Veacutease httpwwwhappymindse s a p a c h e - h a d o o p - i n t r o d u c c i o n - a - h d f s s t h a s h 1 A 9 o n P I j d p u f
bull Nodo de Datos (Rastreador de tareas Datanode TaskTracker) Acceden a los da-tos Almacenan los bloques de informacioacuten y los recuperan bajo demanda
Velocidad de procesamiento
En teacuterminos generales los caacutelculos requeridos para los procesos de Big Data comuacutenmen-te estaraacuten maacutes limitados por la velocidad de respuesta de las operaciones de entrada y salida a disco y de la red que por la velocidad del procesador Eso no significa que los pro-cesadores que deban emplearse en la solucioacuten requieran ser de bajo costo o pobre ren-dimiento Sino maacutes bien que eacutestos cuenten con la mayor cantidad de nuacutecleos operando a la mayor frecuencia posible para poder manejar maacutes tareas en paralelo de forma aacutegil En este sentido tambieacuten se tiene que cuidar el consumo de energiacutea y la disipacioacuten de calor asociado a la frecuencia y altos voltajes de operacioacuten de los microprocesadores que sin duda tendraacuten impactos negativos en el medio ambiente y el costo de operacioacuten de la plataforma completa
Memoria RAM
La memoria RAM necesaria para un cluacutester de Big Data normalmente deberaacute ser calcu-lada tomando en consideracioacuten varios aspectos Entre los maacutes importantes destacan
bull La cantidad de nodos de datos que contenga el cluacutester
bull El nuacutemero maacuteximo de tareas que ejecutaraacute cada nodo de datos de forma simul-taacutenea
bull La memoria necesaria para los demonios que se ejecutan en los nodos de datos de tareas y del sistema operativo
bull El nuacutemero de bloques almacenados en el sistema de archivos distribuidos
bull Las necesidades especiacuteficas del software a utilizar en la plataforma
Los detalles sobre su tecnologiacutea por supuesto que tambieacuten influiraacuten en el des-empentildeo y configuracioacuten de la solucioacuten
b) Almacenamiento
En cuanto a las caracteriacutesticas teacutecnicas del almacenamiento necesario para una plata-forma de Big Data recordemos que eacutestas deberaacuten ajustarse a los requerimientos del Framework y las aplicaciones que seraacuten utilizadas Desde esta oacuteptica nos encontraremos
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
12
que los sistemas de archivos paralelos como el HDFS (Hadoop Distributed File System) estaacuten disentildeados para expandirse en muacuteltiples nodos y manejar grandes voluacutemenes de datos y que por ende generan reacuteplicas para garantizar la tolerancia a fallos Ademaacutes tendraacuten acceso a todos los discos de forma independiente razoacuten por la cual no se sue-len utilizar RAID9 o LVM10 para agrupar los discos (ni por tolerancia a fallos ni por rendi-miento) Por otra parte las soluciones de almacenamiento deben ofrecer una tecnologiacutea robusta y confiable que soporte tanto datos estructurados como no estructurados con seguridad coherencia y credibilidad Asimismo deben
bull Disponer de una gran capacidad para almacenar datos (De acuerdo a los requeri-mientos del proyecto)
bull Deben poder escalar de forma modular faacutecilmente desde unos cuantos terabytes hasta muacuteltiples petabytes de informacioacuten
bull Contar con un muy alto rendimiento en IOPS (Operaciones de entrada y salida por segundo) Adecuado en tiempo real
bull Soportar y controlar todo tipo de datos
bull Contar con una tecnologiacutea que asegure una gran proteccioacuten para los datos
Recordemos tambieacuten que el tema del respaldo de la informacioacuten se volveraacute criacutetico cuan-do hablamos de terabytes o petabytes de informacioacuten Esto si no contamos con una infraestructura suficientemente robusta que asegure la preservacioacuten de la informacioacuten al paso del tiempo11
c) Redes de datos
En teacuterminos generales el software para Big Data hace un uso muy intensivo de la red Esto debido a que todos los nodos intercambian grandes voluacutemenes de datos tanto en un esquema normal de operacioacuten como en el caso de fallo de alguacuten nodo La razoacuten de este aumento de traacutefico en la red causado por la falla en alguacuten nodo del cluacutester se debe principalmente a que Hadoop obliga al resto de los nodos a que se pongan a replicar los datos para mantener la integridad de la informacioacuten Por estos mo-tivos es recomendable utilizar switches preferentemente de alta velocidad y dedicados para el uso exclusivo del cluacutester Dada la naturaleza del Big Data se requiere que la red a utilizar cuente con las siguientes caracteriacutesticas funcionales
bull Gran velocidad
bull Alta disponibilidad
bull Redundancia
[9] En informaacutetica el acroacute-nimo RAID (del ingleacutes Redundant Array of Inexpensive Disks o maacutes comuacuten a diacutea de hoy Redundant Array of Independent Disks) tra-ducido como laquoconjunto redundante de discos Independientesraquo hace referencia a un sistema de almacenamiento de datos en tiempo real que utiliza muacuteltiples unida-des de almacenamiento de datos (discos duros o SSD) entre los que se distribuyen o replican los datos Dependiendo de su configuracioacuten (a la que suele llamarse laquonivelraquo) los beneficios de un RAID respecto a un uacutenico disco son uno o varios de los siguientes mayor integridad ma-yor tolerancia a fallos mayor throughput (ren-dimiento) y mayor capa-cidad Fuente httpseswikipediaorgwikiRAID
[10] Logical Volume Mana-gement (LVM) en espa-ntildeol ldquoadministrador de voluacutemenes loacutegicosrdquo es una opcioacuten de gestioacuten de discos que todas las principales distribu-ciones de GNULinux presentan Ya sea que necesite para configurar grupos de almacena-miento o simplemente se necesite para crear dinaacutemicamente las par-ticiones LVM Veacutease httpsparbaedloword-presscom20120105que-es-lvm-como-se-administra-y-utiliza
[11] Veacutease httpwwwcom-puterweeklycomfea-tureBig-data-storage-choices
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
13
bull Resistencia a fallas
bull Alta capacidad de resolver situaciones de congestionamiento en la red
bull Consistencia
bull Faacutecil de escalabilidad
bull Altamente administrable
bull Resilencia (Capacidad de continuar funcionando dentro de paraacutemetros acepta-bles ante distintos tipos de problemas)
Resulta claro que a mayor velocidad el costo de la red se incrementaraacute Por tal motivo se puede iniciar con velocidades de conectividad a 1 Gbit y jugar con opciones de agre-gacioacuten de puertos para mejorar el desempentildeo12 No obstante el mejor desempentildeo se lograraacute con la tecnologiacutea de 10 Gbit o superior Por otra parte a mayor nuacutemero de nodos en el cluacutester la velocidad de la red seraacute un factor clave para su buen desempentildeo13 Como podremos darnos cuenta recomendar una configuracioacuten de hardware ideal para un proyecto de Big Data no es una tarea sencilla Algunos pasos para comenzar a definirla son
bull Identificar las preguntas que deberaacute responder la plataforma de Big Data
bull La urgencia de respuesta
bull Identificar las fuentes de informacioacuten de donde se deberaacute extraer la informacioacuten a procesar Incluso pueden ser a partir de programas de TV en tiempo real o el flujo de mensajes proveniente de redes sociales
bull Cuantificar la cantidad de informacioacuten con que se deberaacute trabajar
Con esta informacioacuten los especialistas en soluciones de Big Data podraacuten ayu-darle con facilidad No olvide que la infraestructura requeriraacute no solo de una inversioacuten importante sino tambieacuten de una serie de nuevas habilidades y conocimientos en el per-sonal para desarrollar las aplicaciones No obstante brindaraacute oportunidades reales de valor de negocio en nuestras empresas o instituciones [12] Consiste en el uso de va-
rios puertos de red o en-laces para incrementar la velocidad de comuni-cacioacuten Veacutease httpseswikipediaorgwikiAgregaciC3B3n_de_enlaces
[8] Veacutease httpsearchdata-centertechtargetcomescronicaSeis-conside-raciones-para-redes-de-big-data
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
14
Bibliografiacutea
[1] ALFOCEA J Detenido por amenazas a su alcalde en Redes Sociales Delitos informaacuteticos 2015 Revista legal [en liacutenea] Fecha de actualizacioacuten 22 septiembre 2015 [Consulta 6 de octubre de 2016] Disponible en httpwwwdelitosinformaticoscom092015delitosamenazas-2-delitosdetenido-amenazar-alcalde-redes-sociales
[2]CACHEIRO Javier Requisitos Hardware Big Data Fundacioacuten Puacuteblica Galega Centro Tecnoloacutexico de Supercomputacioacuten de Galicia CESGA [en Liacutenea] Fecha de actualizacioacuten 16 de Marzo de 2015 [Consultado 25 de Mayo de 2016] Disponible en httpswwwcesgaesesbibliotecadownloadAssetid775
[3] Enauro engineering services BIG DATA [En Liacutenea] [Consultado 14 de Noviembre de 2016] Disponible en httpwwwenaurocom20160610big-data
[4] HURTADO Gork Big Data y Hadoop Cloudera vs Hortonworks Mondragon Unibertsitatea Investigacioacuten en TICs [en Liacutenea] [Consultado 3 Mayo de 2016] Disponible en httpmukommondragoneduictbig-data-y-hadoop-cloudera-vs-hortonworks
[5] JCASANELLA Introduccioacuten a Hadoop y su ecosistema Ticout Outsourcing Center Tutoriales de Yellowfin y BI [En Liacutenea] Fecha de actualizacioacuten 01 de Abril de 2013 [Consultado 19 Mayo de 2016] Disponible en httpwwwticoutcomblog20130402introduccion-a-hadoop-y-su-ecosistema
[6] LOSHIN David Explorando distribuciones Hadoop para gestionar big data TechTarget SA de CV Guiacutea Escencial [En Liacutenea] Enero de 2016 [Consultado 14 Abril de 2016] Disponible es httpsearchdatacentertechtargetcomescronicaExplorando-distribuciones-Hadoop-para-gestionar-big-data
[7] LURIE Marty Big data de coacutedigo abierto para el impaciente Parte 1 Tutorial Hadoop Hello World con Java Pig Hive Flume Fuse Oozie y Sqoop con Informix DB2 y MySQL IBM IBM deveoperWorks [en liacutenea] 20 de Marzo de 2013 [Consultado 14 Abril de 2016] Disponible en httpswwwibmcomdeveloperworksssadatalibrarytecharticledm-1209hadoopbigdata
[8] MATTHEW Mayo Top Big Data Processing Frameworks KdnuggetsTM KDnuggets News [en Liacutenea] Marzo de 2016 [Consultado 14 Abril de 2016] Disponible en httpwwwkdnuggetscom201603top-big-data-processing-frameworkshtml
[9] OacuteDELL Kevin How-to Select the Right Hardware for Your New Hadoop Cluster Cloudera Inc Cloudera Engineering Blog [en Liacutenea] 28 de Agosto de 2013 [Consultado 28 Mayo de 2016] Disponible en httpsblogclouderacomblog201308how-to-select-the-right-hardware-for-your-new-hadoop-cluster
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
15
[10] STEVE Dertien Defining the Infrastructure for Big Data Analytics PTC Inc El Divan Digital [en Liacutenea] 22 de Mayo de 2015 [Consultado 11Abril de 2016] Disponible en httpblogsptccom20150522defining-the-infrastructure-for-big-data-analytics
[11] The apache software foundation Hadoop Web site the Apache Software Foundation Apache Hadoop Project [en Liacutenea] 13 de Febrero de 2016 [Consultado 17 Mayo de 2016] Disponible en httphadoopapacheorg
[12] TIRADOS Marible iquestEs Hadoop el fin del almacenamiento de datos tradicional Big Data Hispano [en Liacutenea] 10 de febrero de 2014 [Consultado 07 Mayo de 2016] Disponible en httpwwwbigdatahispanoorgnoticiases-hadoop-el-fin-del-almacenamiento-de-datos
[13] SAacuteNCHEZ Joseacute Manuel iquestQUEacute ES BIG DATA T2O AdMedia Services SL 2015 [en Liacutenea] 02 de julio de 2016 [Consultado 14 Noviembre de 2016] Disponible en httpwwwt2omediacomideasactualidadque-es-big-data-2 en maricultura Meacutexico Secretariacutea de Medio Ambiente Recursos Naturales y Pesca 1997 192-207pp

ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
6
que es uacutetil para una gran cantidad de casos de uso en donde el procesamiento de las consultas requiere de un rendimiento casi en tiempo real Veacutease httpwwwinfoqcomarticlesapache-tez-saha-murthy y httptezapacheorg
bull ZooKeepertrade Es un servicio centralizado para mantener la informacioacuten de confi-guracioacuten denominacioacuten sincronizacioacuten distribuida y de servicios de grupo que requieren las aplicaciones distribuidas Veacutease httpzookeeperapacheorg y httpsunpocodejavawordpresscom20101119zookeeper-se-ha-convertido-en-un-proyecto-apache-top
Para mayor informacioacuten sobre el Apache Hadoop sus proyectos relacionados e incluso descargar el software puede acceder al siguiente sitio web httphadoopapacheorgy httpinlabfibupceduesblogque-herramientas-necesitas-para-iniciarte-en-big-data
Distribuciones comerciales de Hadoop
Aunque Hadoop es un framework libre y por ende no tiene costo en la praacutectica existen varias distribuciones comerciales de Hadoop que permiten implementar un medio am-biente de trabajo maacutes robusto para Big Data Estas distribuciones ofrecen diferentes me-joras en la funcionalidad rendimiento facilidad de configuracioacuten gestioacuten e integracioacuten con otras plataformas externas producto de antildeos de investigacioacuten de las empresas que los distribuyen Incluyen ademaacutes herramientas adicionales soporte teacutecnico diferentes niveles de servicios y mantenimiento Como sentildeala David Loshin en su artiacuteculo Explorando distribuciones Hadoop para gestionar big data
El mercado incluye tres proveedores independientes que se especializan en Hadoop Cloudera Inc Hortonworks Inc y MapR Technologies Inc Otras empresas que ofrecen distribuciones o capacidades de Hadoop incluyen Pi-votal Software Inc IBM Amazon Web Services y Microsoft5
Debemos prestar mucha atencioacuten entre las diferencias y las distribuciones de Hadoop ya que pueden requerir de una gran inversioacuten para su funcionamiento (princi-palmente por contratos de licenciamiento muy caros) aportar un pobre desempentildeo o limitaciones en los resultados esperados ofrecer poco soporte tecnoloacutegico o inclusive requerir de hardware propietario para su instrumentacioacuten Appliances Entre los principales aspectos que deberemos revisar se tiene
bull Las mejoras o beneficios que aportan a la solucioacuten Recordemos que las variantes en los frameworks facilitan abordar los problemas de analiacuteti-ca con diferentes enfoques adiciones yo mejoras y por ende resultados
bull Facilidades de monitoreo y administracioacuten para Hadoop
[5] David Loshin Exploran-do distribuciones Ha-doop para gestionar big data en linea httpsear-chdatacentertechtargetcomescronicaExploran-do-distribuciones-Hadoop-para-gestionar-big-data
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
7
bull Los componentes especiacuteficos o propietarios de las distribuciones
bull Su compatibilidad con otras plataformas
bull El hardware requerido
bull Las facilidades de recuperacioacuten en caso de desastre
bull Modelo de servicio y soporte ofertado
bull Consultoriacutea
bull Su costo
iquestCuaacuteles son estas distribuciones liacutederes en el mercado en teacuterminos generales que es lo que ofrece cada una de ellas La tabla que se presenta a continuacioacuten lo resume
Distribucioacuten Comercial de Hadoop
Ambiente operativo
Ofrece
Amazone Web Servicves AWS
UnixLinux bull ElasticMapReduce (EMR) Servicio web que facilita el procesamiento raacutepido y renta-ble de grandes cantidades de datos EMR es Hadoop en la nube Aprovecha Amazon EC2 para coacutemputo y Amazon S3 para alma-cenamiento Veacutease httpsawsamazoncomeselasticmapreduce
bull Amazon Kinesis para el procesamiento de datos de streaming en tiempo real
bull Integracioacuten con el data warehouse Amazon Redshift y otras fuentes de datos autosca-ling que modificaraacute el tamantildeo de los cluacuteste-res en base a poliacuteticas soporte para bases de datos NoSQL adicionales sobre Hadoop y maacutes integracioacuten de inteligencia de nego-cios con proveedores externos
Cloudera UnixLinux bull Cloudera Manager Herramienta de moni-toreo y administracioacuten para Hadoop
bull Impala Motor SQL para Hadoopmuy raacutepi-do con una arquitectura de procesamiento paralelo masivo (MassivelyParallelProces-sing - MPP)
Tabla 1 Principales distri-buciones comerciales de Ha-doop Fuente httpcioperupefotoreportaje15543ha-doop-como-se-encuentran-las-distribuciones-lideres
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
8
Hortonworks UnixLinux bull Apache Ambari (Proporciona una consola de administracioacuten de cluacutesteres Hadoop)
bull Aliansas con Microsoft Teradata SAP Red Hat y otras empresas
IBM UnixLinux bull BigInsightsfor Apache Hadoop (Coacutedigo de Apache Hadoop integrado con activos de IBM para la analiacutetica avanzada SPSS administracioacuten de cargas de trabajo para computacioacuten de alto desempentildeo he-rramientas de inteligencia de negocio y herramientas de administracioacuten y modela-miento de datos)
MapRTechnoligies UnixLinux bull Soporte para Network File System (NFS) correr coacutedigo arbitrario en el cluacutester
bull Hbase mejorado (Base de datos para Hadoop)
bull Caracteriacutesticas de alta disponibilidad y recuperacioacuten en caso de desastre
Pivotal UnixLinux bull HAWQ (Motor de consulta SQL paralelo de Pivotal)
bull Familia de appliances que integran su Ha-doop EDW (Enterprise Data Warehouse) y capas de administracioacuten de datos
bull Sus innovaciones se enfocaraacuten en mejorar su motor HAWQ SQL y la integracioacuten con otros productos de Pivotal
bull Tecnologiacutea Greenplum Database de EMCbull Expertis de EMC y VMware
Teradata UnixLinux bull Hadoop como appliancebull SQL-H (Motor SQL para realizar consultas
en Hadoop)bull Herramientas de administracioacuten propieta-
rias de Teradatabull Aster6 (Software para realizar analiacutetica con
Hadoop)bull Appliances de alto desempentildeo
[6] Aster es un software ba-sado en el procesamien-to masivo en paralelo para el anaacutelisis y manejo de datos desarrolla-do por Teradata Corp ht tpsenwikipediaorgwikiAster_Data_Systems
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
9
Intel UnixLinux bull Tecnologiacutea de sus Chips Xeon optimizados para Hadoop
bull Capacidades de desempentildeo y seguridad mejoradas por hardware para Hadoop
bull Lustre7 bull Optimizacioacuten nativa de tareas y analiacutetica
graacutefica
Microsoft Windows Azure HDInsight Service
Windows bull Polybase8 Permite que los clientes de SQL ejecuten consultas que incluyan datos almacenados en Hadoop
bull Esfuerzos en el desarrollo de la siguiente generacioacuten de Hive y de otros proyectos de la comunidad de coacutedigo abierto de Hadoop
bull Herramientas de desarrollo y colaboracioacuten para los clientes de Microsoft
La arquitectura del hardware para Big Data
En teacuterminos arquitectoacutenicos las soluciones de hardware para Big Data disponibles en el mercado pareceriacutean maacutes complejas de lo que en realidad son tienen muchas cosas en comuacuten todas utilizan
bull Nodos computacionales
bull Almacenamiento
bull Frameworks y aplicaciones programadas en Java (Ejemplo Hadoop Hbase Spark etc)
bull Redes de alta velocidad de tecnologiacutea gigabit o superior
bull Sistemas de soporte vital para (alimentacioacuten de energiacutea eleacutectrica y el control de temperatura y humedad)
Podemos apreciar diferencias significativas como
bull Un nuacutemero diferente de nodos y de configuraciones entre eacutestos que producen rendimientos diferentes en la ejecucioacuten de los procesos
bull Tecnologiacuteas de almacenamiento diferentes que influyen de manera determinante en el tiempo de acceso a la informacioacuten y por ende en la obtencioacuten de resultados
[7] Lustre es un sistema de archivos distribuido Open Source normal-mente utilizado en clus-ters a gran escala El nombre es una mezcla de Linux y clusters El proyecto intenta pro-porcionar un sistema de archivos para clusters de decenas de miles de nodos con petabytes de capacidad de almace-namiento sin compro-meter la velocidad o la seguridad y estaacute dispo-nible bajo la GNU GPLht tpseswikipediaorgwikiLustre_(siste-ma_de_archivos)
[8] Polybase es una tecno-logiacutea de Microsoft que permite a los usuarios de SQL Server PDW eje-cutar consultas sobre los datos almacena-dos en Hadoop Veacutease httpfrancescsanchez-biwebnodeesnewsuso-de-hadoop-en-sql-server-con-pdw-y-poly-base-
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
10
bull Redes de datos de diferentes velocidades que influyen en el desempentildeo global de la solucioacuten
El anaacutelisis de las cargas de tra-bajo seraacute un factor determinante para lograr el mejor equilibrio en-tre rendimiento y ahorro del hard-ware por ejemplo
a)Nodos computacionales
Los nodos computacionales son servidores para rack con una configuracioacuten preestablecida de acuerdo a su funcioacuten Muacuteltiples nodos conforman un cluacutester eso siacute en ninguacuten momento se reco-miendan servidores de tipo Blade debido a que eacutestos comparten componentes en un chasis que los puede limitar en su desempe-ntildeo capacidad de crecimiento y posibilidades de conectividad La cantidad de nuacutecleos y de memo-ria RAM disponible en cada uno de ellos asiacute como su velocidad de interconexioacuten a la red influiraacute de manera determinante en el rendi-miento global del cluacutester
Los cluacutester basados en el Siste-ma de Archivos de Hadoop ldquoHDFSrdquo baacutesicamente utilizaraacute dos tipos de nodos diferentes de acuerdo a la funcioacuten que desempentildearaacuten
bull Nodo de Nombres (Rastrea-dor de trabajos Namenode Jo-bTracker) Responsable de la topologiacutea de todos los demaacutes nodos y de gestionar el espa-cio de nombres Solo hay uno por cluacutester El Nodo de nom-
bres se encarga de distribuir los archivos en los nodos de datos que rea-
Figura 2 Ejemplo de un cluacutester para Big Data ba-sado en Hadoop Fuente httpwwwnextplatformcom20150703building-a-better-hadoop-cluster
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
11
lizaraacuten el procesamiento de los datos Veacutease httpwwwhappymindse s a p a c h e - h a d o o p - i n t r o d u c c i o n - a - h d f s s t h a s h 1 A 9 o n P I j d p u f
bull Nodo de Datos (Rastreador de tareas Datanode TaskTracker) Acceden a los da-tos Almacenan los bloques de informacioacuten y los recuperan bajo demanda
Velocidad de procesamiento
En teacuterminos generales los caacutelculos requeridos para los procesos de Big Data comuacutenmen-te estaraacuten maacutes limitados por la velocidad de respuesta de las operaciones de entrada y salida a disco y de la red que por la velocidad del procesador Eso no significa que los pro-cesadores que deban emplearse en la solucioacuten requieran ser de bajo costo o pobre ren-dimiento Sino maacutes bien que eacutestos cuenten con la mayor cantidad de nuacutecleos operando a la mayor frecuencia posible para poder manejar maacutes tareas en paralelo de forma aacutegil En este sentido tambieacuten se tiene que cuidar el consumo de energiacutea y la disipacioacuten de calor asociado a la frecuencia y altos voltajes de operacioacuten de los microprocesadores que sin duda tendraacuten impactos negativos en el medio ambiente y el costo de operacioacuten de la plataforma completa
Memoria RAM
La memoria RAM necesaria para un cluacutester de Big Data normalmente deberaacute ser calcu-lada tomando en consideracioacuten varios aspectos Entre los maacutes importantes destacan
bull La cantidad de nodos de datos que contenga el cluacutester
bull El nuacutemero maacuteximo de tareas que ejecutaraacute cada nodo de datos de forma simul-taacutenea
bull La memoria necesaria para los demonios que se ejecutan en los nodos de datos de tareas y del sistema operativo
bull El nuacutemero de bloques almacenados en el sistema de archivos distribuidos
bull Las necesidades especiacuteficas del software a utilizar en la plataforma
Los detalles sobre su tecnologiacutea por supuesto que tambieacuten influiraacuten en el des-empentildeo y configuracioacuten de la solucioacuten
b) Almacenamiento
En cuanto a las caracteriacutesticas teacutecnicas del almacenamiento necesario para una plata-forma de Big Data recordemos que eacutestas deberaacuten ajustarse a los requerimientos del Framework y las aplicaciones que seraacuten utilizadas Desde esta oacuteptica nos encontraremos
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
12
que los sistemas de archivos paralelos como el HDFS (Hadoop Distributed File System) estaacuten disentildeados para expandirse en muacuteltiples nodos y manejar grandes voluacutemenes de datos y que por ende generan reacuteplicas para garantizar la tolerancia a fallos Ademaacutes tendraacuten acceso a todos los discos de forma independiente razoacuten por la cual no se sue-len utilizar RAID9 o LVM10 para agrupar los discos (ni por tolerancia a fallos ni por rendi-miento) Por otra parte las soluciones de almacenamiento deben ofrecer una tecnologiacutea robusta y confiable que soporte tanto datos estructurados como no estructurados con seguridad coherencia y credibilidad Asimismo deben
bull Disponer de una gran capacidad para almacenar datos (De acuerdo a los requeri-mientos del proyecto)
bull Deben poder escalar de forma modular faacutecilmente desde unos cuantos terabytes hasta muacuteltiples petabytes de informacioacuten
bull Contar con un muy alto rendimiento en IOPS (Operaciones de entrada y salida por segundo) Adecuado en tiempo real
bull Soportar y controlar todo tipo de datos
bull Contar con una tecnologiacutea que asegure una gran proteccioacuten para los datos
Recordemos tambieacuten que el tema del respaldo de la informacioacuten se volveraacute criacutetico cuan-do hablamos de terabytes o petabytes de informacioacuten Esto si no contamos con una infraestructura suficientemente robusta que asegure la preservacioacuten de la informacioacuten al paso del tiempo11
c) Redes de datos
En teacuterminos generales el software para Big Data hace un uso muy intensivo de la red Esto debido a que todos los nodos intercambian grandes voluacutemenes de datos tanto en un esquema normal de operacioacuten como en el caso de fallo de alguacuten nodo La razoacuten de este aumento de traacutefico en la red causado por la falla en alguacuten nodo del cluacutester se debe principalmente a que Hadoop obliga al resto de los nodos a que se pongan a replicar los datos para mantener la integridad de la informacioacuten Por estos mo-tivos es recomendable utilizar switches preferentemente de alta velocidad y dedicados para el uso exclusivo del cluacutester Dada la naturaleza del Big Data se requiere que la red a utilizar cuente con las siguientes caracteriacutesticas funcionales
bull Gran velocidad
bull Alta disponibilidad
bull Redundancia
[9] En informaacutetica el acroacute-nimo RAID (del ingleacutes Redundant Array of Inexpensive Disks o maacutes comuacuten a diacutea de hoy Redundant Array of Independent Disks) tra-ducido como laquoconjunto redundante de discos Independientesraquo hace referencia a un sistema de almacenamiento de datos en tiempo real que utiliza muacuteltiples unida-des de almacenamiento de datos (discos duros o SSD) entre los que se distribuyen o replican los datos Dependiendo de su configuracioacuten (a la que suele llamarse laquonivelraquo) los beneficios de un RAID respecto a un uacutenico disco son uno o varios de los siguientes mayor integridad ma-yor tolerancia a fallos mayor throughput (ren-dimiento) y mayor capa-cidad Fuente httpseswikipediaorgwikiRAID
[10] Logical Volume Mana-gement (LVM) en espa-ntildeol ldquoadministrador de voluacutemenes loacutegicosrdquo es una opcioacuten de gestioacuten de discos que todas las principales distribu-ciones de GNULinux presentan Ya sea que necesite para configurar grupos de almacena-miento o simplemente se necesite para crear dinaacutemicamente las par-ticiones LVM Veacutease httpsparbaedloword-presscom20120105que-es-lvm-como-se-administra-y-utiliza
[11] Veacutease httpwwwcom-puterweeklycomfea-tureBig-data-storage-choices
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
13
bull Resistencia a fallas
bull Alta capacidad de resolver situaciones de congestionamiento en la red
bull Consistencia
bull Faacutecil de escalabilidad
bull Altamente administrable
bull Resilencia (Capacidad de continuar funcionando dentro de paraacutemetros acepta-bles ante distintos tipos de problemas)
Resulta claro que a mayor velocidad el costo de la red se incrementaraacute Por tal motivo se puede iniciar con velocidades de conectividad a 1 Gbit y jugar con opciones de agre-gacioacuten de puertos para mejorar el desempentildeo12 No obstante el mejor desempentildeo se lograraacute con la tecnologiacutea de 10 Gbit o superior Por otra parte a mayor nuacutemero de nodos en el cluacutester la velocidad de la red seraacute un factor clave para su buen desempentildeo13 Como podremos darnos cuenta recomendar una configuracioacuten de hardware ideal para un proyecto de Big Data no es una tarea sencilla Algunos pasos para comenzar a definirla son
bull Identificar las preguntas que deberaacute responder la plataforma de Big Data
bull La urgencia de respuesta
bull Identificar las fuentes de informacioacuten de donde se deberaacute extraer la informacioacuten a procesar Incluso pueden ser a partir de programas de TV en tiempo real o el flujo de mensajes proveniente de redes sociales
bull Cuantificar la cantidad de informacioacuten con que se deberaacute trabajar
Con esta informacioacuten los especialistas en soluciones de Big Data podraacuten ayu-darle con facilidad No olvide que la infraestructura requeriraacute no solo de una inversioacuten importante sino tambieacuten de una serie de nuevas habilidades y conocimientos en el per-sonal para desarrollar las aplicaciones No obstante brindaraacute oportunidades reales de valor de negocio en nuestras empresas o instituciones [12] Consiste en el uso de va-
rios puertos de red o en-laces para incrementar la velocidad de comuni-cacioacuten Veacutease httpseswikipediaorgwikiAgregaciC3B3n_de_enlaces
[8] Veacutease httpsearchdata-centertechtargetcomescronicaSeis-conside-raciones-para-redes-de-big-data
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
14
Bibliografiacutea
[1] ALFOCEA J Detenido por amenazas a su alcalde en Redes Sociales Delitos informaacuteticos 2015 Revista legal [en liacutenea] Fecha de actualizacioacuten 22 septiembre 2015 [Consulta 6 de octubre de 2016] Disponible en httpwwwdelitosinformaticoscom092015delitosamenazas-2-delitosdetenido-amenazar-alcalde-redes-sociales
[2]CACHEIRO Javier Requisitos Hardware Big Data Fundacioacuten Puacuteblica Galega Centro Tecnoloacutexico de Supercomputacioacuten de Galicia CESGA [en Liacutenea] Fecha de actualizacioacuten 16 de Marzo de 2015 [Consultado 25 de Mayo de 2016] Disponible en httpswwwcesgaesesbibliotecadownloadAssetid775
[3] Enauro engineering services BIG DATA [En Liacutenea] [Consultado 14 de Noviembre de 2016] Disponible en httpwwwenaurocom20160610big-data
[4] HURTADO Gork Big Data y Hadoop Cloudera vs Hortonworks Mondragon Unibertsitatea Investigacioacuten en TICs [en Liacutenea] [Consultado 3 Mayo de 2016] Disponible en httpmukommondragoneduictbig-data-y-hadoop-cloudera-vs-hortonworks
[5] JCASANELLA Introduccioacuten a Hadoop y su ecosistema Ticout Outsourcing Center Tutoriales de Yellowfin y BI [En Liacutenea] Fecha de actualizacioacuten 01 de Abril de 2013 [Consultado 19 Mayo de 2016] Disponible en httpwwwticoutcomblog20130402introduccion-a-hadoop-y-su-ecosistema
[6] LOSHIN David Explorando distribuciones Hadoop para gestionar big data TechTarget SA de CV Guiacutea Escencial [En Liacutenea] Enero de 2016 [Consultado 14 Abril de 2016] Disponible es httpsearchdatacentertechtargetcomescronicaExplorando-distribuciones-Hadoop-para-gestionar-big-data
[7] LURIE Marty Big data de coacutedigo abierto para el impaciente Parte 1 Tutorial Hadoop Hello World con Java Pig Hive Flume Fuse Oozie y Sqoop con Informix DB2 y MySQL IBM IBM deveoperWorks [en liacutenea] 20 de Marzo de 2013 [Consultado 14 Abril de 2016] Disponible en httpswwwibmcomdeveloperworksssadatalibrarytecharticledm-1209hadoopbigdata
[8] MATTHEW Mayo Top Big Data Processing Frameworks KdnuggetsTM KDnuggets News [en Liacutenea] Marzo de 2016 [Consultado 14 Abril de 2016] Disponible en httpwwwkdnuggetscom201603top-big-data-processing-frameworkshtml
[9] OacuteDELL Kevin How-to Select the Right Hardware for Your New Hadoop Cluster Cloudera Inc Cloudera Engineering Blog [en Liacutenea] 28 de Agosto de 2013 [Consultado 28 Mayo de 2016] Disponible en httpsblogclouderacomblog201308how-to-select-the-right-hardware-for-your-new-hadoop-cluster
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
15
[10] STEVE Dertien Defining the Infrastructure for Big Data Analytics PTC Inc El Divan Digital [en Liacutenea] 22 de Mayo de 2015 [Consultado 11Abril de 2016] Disponible en httpblogsptccom20150522defining-the-infrastructure-for-big-data-analytics
[11] The apache software foundation Hadoop Web site the Apache Software Foundation Apache Hadoop Project [en Liacutenea] 13 de Febrero de 2016 [Consultado 17 Mayo de 2016] Disponible en httphadoopapacheorg
[12] TIRADOS Marible iquestEs Hadoop el fin del almacenamiento de datos tradicional Big Data Hispano [en Liacutenea] 10 de febrero de 2014 [Consultado 07 Mayo de 2016] Disponible en httpwwwbigdatahispanoorgnoticiases-hadoop-el-fin-del-almacenamiento-de-datos
[13] SAacuteNCHEZ Joseacute Manuel iquestQUEacute ES BIG DATA T2O AdMedia Services SL 2015 [en Liacutenea] 02 de julio de 2016 [Consultado 14 Noviembre de 2016] Disponible en httpwwwt2omediacomideasactualidadque-es-big-data-2 en maricultura Meacutexico Secretariacutea de Medio Ambiente Recursos Naturales y Pesca 1997 192-207pp

ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
7
bull Los componentes especiacuteficos o propietarios de las distribuciones
bull Su compatibilidad con otras plataformas
bull El hardware requerido
bull Las facilidades de recuperacioacuten en caso de desastre
bull Modelo de servicio y soporte ofertado
bull Consultoriacutea
bull Su costo
iquestCuaacuteles son estas distribuciones liacutederes en el mercado en teacuterminos generales que es lo que ofrece cada una de ellas La tabla que se presenta a continuacioacuten lo resume
Distribucioacuten Comercial de Hadoop
Ambiente operativo
Ofrece
Amazone Web Servicves AWS
UnixLinux bull ElasticMapReduce (EMR) Servicio web que facilita el procesamiento raacutepido y renta-ble de grandes cantidades de datos EMR es Hadoop en la nube Aprovecha Amazon EC2 para coacutemputo y Amazon S3 para alma-cenamiento Veacutease httpsawsamazoncomeselasticmapreduce
bull Amazon Kinesis para el procesamiento de datos de streaming en tiempo real
bull Integracioacuten con el data warehouse Amazon Redshift y otras fuentes de datos autosca-ling que modificaraacute el tamantildeo de los cluacuteste-res en base a poliacuteticas soporte para bases de datos NoSQL adicionales sobre Hadoop y maacutes integracioacuten de inteligencia de nego-cios con proveedores externos
Cloudera UnixLinux bull Cloudera Manager Herramienta de moni-toreo y administracioacuten para Hadoop
bull Impala Motor SQL para Hadoopmuy raacutepi-do con una arquitectura de procesamiento paralelo masivo (MassivelyParallelProces-sing - MPP)
Tabla 1 Principales distri-buciones comerciales de Ha-doop Fuente httpcioperupefotoreportaje15543ha-doop-como-se-encuentran-las-distribuciones-lideres
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
8
Hortonworks UnixLinux bull Apache Ambari (Proporciona una consola de administracioacuten de cluacutesteres Hadoop)
bull Aliansas con Microsoft Teradata SAP Red Hat y otras empresas
IBM UnixLinux bull BigInsightsfor Apache Hadoop (Coacutedigo de Apache Hadoop integrado con activos de IBM para la analiacutetica avanzada SPSS administracioacuten de cargas de trabajo para computacioacuten de alto desempentildeo he-rramientas de inteligencia de negocio y herramientas de administracioacuten y modela-miento de datos)
MapRTechnoligies UnixLinux bull Soporte para Network File System (NFS) correr coacutedigo arbitrario en el cluacutester
bull Hbase mejorado (Base de datos para Hadoop)
bull Caracteriacutesticas de alta disponibilidad y recuperacioacuten en caso de desastre
Pivotal UnixLinux bull HAWQ (Motor de consulta SQL paralelo de Pivotal)
bull Familia de appliances que integran su Ha-doop EDW (Enterprise Data Warehouse) y capas de administracioacuten de datos
bull Sus innovaciones se enfocaraacuten en mejorar su motor HAWQ SQL y la integracioacuten con otros productos de Pivotal
bull Tecnologiacutea Greenplum Database de EMCbull Expertis de EMC y VMware
Teradata UnixLinux bull Hadoop como appliancebull SQL-H (Motor SQL para realizar consultas
en Hadoop)bull Herramientas de administracioacuten propieta-
rias de Teradatabull Aster6 (Software para realizar analiacutetica con
Hadoop)bull Appliances de alto desempentildeo
[6] Aster es un software ba-sado en el procesamien-to masivo en paralelo para el anaacutelisis y manejo de datos desarrolla-do por Teradata Corp ht tpsenwikipediaorgwikiAster_Data_Systems
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
9
Intel UnixLinux bull Tecnologiacutea de sus Chips Xeon optimizados para Hadoop
bull Capacidades de desempentildeo y seguridad mejoradas por hardware para Hadoop
bull Lustre7 bull Optimizacioacuten nativa de tareas y analiacutetica
graacutefica
Microsoft Windows Azure HDInsight Service
Windows bull Polybase8 Permite que los clientes de SQL ejecuten consultas que incluyan datos almacenados en Hadoop
bull Esfuerzos en el desarrollo de la siguiente generacioacuten de Hive y de otros proyectos de la comunidad de coacutedigo abierto de Hadoop
bull Herramientas de desarrollo y colaboracioacuten para los clientes de Microsoft
La arquitectura del hardware para Big Data
En teacuterminos arquitectoacutenicos las soluciones de hardware para Big Data disponibles en el mercado pareceriacutean maacutes complejas de lo que en realidad son tienen muchas cosas en comuacuten todas utilizan
bull Nodos computacionales
bull Almacenamiento
bull Frameworks y aplicaciones programadas en Java (Ejemplo Hadoop Hbase Spark etc)
bull Redes de alta velocidad de tecnologiacutea gigabit o superior
bull Sistemas de soporte vital para (alimentacioacuten de energiacutea eleacutectrica y el control de temperatura y humedad)
Podemos apreciar diferencias significativas como
bull Un nuacutemero diferente de nodos y de configuraciones entre eacutestos que producen rendimientos diferentes en la ejecucioacuten de los procesos
bull Tecnologiacuteas de almacenamiento diferentes que influyen de manera determinante en el tiempo de acceso a la informacioacuten y por ende en la obtencioacuten de resultados
[7] Lustre es un sistema de archivos distribuido Open Source normal-mente utilizado en clus-ters a gran escala El nombre es una mezcla de Linux y clusters El proyecto intenta pro-porcionar un sistema de archivos para clusters de decenas de miles de nodos con petabytes de capacidad de almace-namiento sin compro-meter la velocidad o la seguridad y estaacute dispo-nible bajo la GNU GPLht tpseswikipediaorgwikiLustre_(siste-ma_de_archivos)
[8] Polybase es una tecno-logiacutea de Microsoft que permite a los usuarios de SQL Server PDW eje-cutar consultas sobre los datos almacena-dos en Hadoop Veacutease httpfrancescsanchez-biwebnodeesnewsuso-de-hadoop-en-sql-server-con-pdw-y-poly-base-
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
10
bull Redes de datos de diferentes velocidades que influyen en el desempentildeo global de la solucioacuten
El anaacutelisis de las cargas de tra-bajo seraacute un factor determinante para lograr el mejor equilibrio en-tre rendimiento y ahorro del hard-ware por ejemplo
a)Nodos computacionales
Los nodos computacionales son servidores para rack con una configuracioacuten preestablecida de acuerdo a su funcioacuten Muacuteltiples nodos conforman un cluacutester eso siacute en ninguacuten momento se reco-miendan servidores de tipo Blade debido a que eacutestos comparten componentes en un chasis que los puede limitar en su desempe-ntildeo capacidad de crecimiento y posibilidades de conectividad La cantidad de nuacutecleos y de memo-ria RAM disponible en cada uno de ellos asiacute como su velocidad de interconexioacuten a la red influiraacute de manera determinante en el rendi-miento global del cluacutester
Los cluacutester basados en el Siste-ma de Archivos de Hadoop ldquoHDFSrdquo baacutesicamente utilizaraacute dos tipos de nodos diferentes de acuerdo a la funcioacuten que desempentildearaacuten
bull Nodo de Nombres (Rastrea-dor de trabajos Namenode Jo-bTracker) Responsable de la topologiacutea de todos los demaacutes nodos y de gestionar el espa-cio de nombres Solo hay uno por cluacutester El Nodo de nom-
bres se encarga de distribuir los archivos en los nodos de datos que rea-
Figura 2 Ejemplo de un cluacutester para Big Data ba-sado en Hadoop Fuente httpwwwnextplatformcom20150703building-a-better-hadoop-cluster
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
11
lizaraacuten el procesamiento de los datos Veacutease httpwwwhappymindse s a p a c h e - h a d o o p - i n t r o d u c c i o n - a - h d f s s t h a s h 1 A 9 o n P I j d p u f
bull Nodo de Datos (Rastreador de tareas Datanode TaskTracker) Acceden a los da-tos Almacenan los bloques de informacioacuten y los recuperan bajo demanda
Velocidad de procesamiento
En teacuterminos generales los caacutelculos requeridos para los procesos de Big Data comuacutenmen-te estaraacuten maacutes limitados por la velocidad de respuesta de las operaciones de entrada y salida a disco y de la red que por la velocidad del procesador Eso no significa que los pro-cesadores que deban emplearse en la solucioacuten requieran ser de bajo costo o pobre ren-dimiento Sino maacutes bien que eacutestos cuenten con la mayor cantidad de nuacutecleos operando a la mayor frecuencia posible para poder manejar maacutes tareas en paralelo de forma aacutegil En este sentido tambieacuten se tiene que cuidar el consumo de energiacutea y la disipacioacuten de calor asociado a la frecuencia y altos voltajes de operacioacuten de los microprocesadores que sin duda tendraacuten impactos negativos en el medio ambiente y el costo de operacioacuten de la plataforma completa
Memoria RAM
La memoria RAM necesaria para un cluacutester de Big Data normalmente deberaacute ser calcu-lada tomando en consideracioacuten varios aspectos Entre los maacutes importantes destacan
bull La cantidad de nodos de datos que contenga el cluacutester
bull El nuacutemero maacuteximo de tareas que ejecutaraacute cada nodo de datos de forma simul-taacutenea
bull La memoria necesaria para los demonios que se ejecutan en los nodos de datos de tareas y del sistema operativo
bull El nuacutemero de bloques almacenados en el sistema de archivos distribuidos
bull Las necesidades especiacuteficas del software a utilizar en la plataforma
Los detalles sobre su tecnologiacutea por supuesto que tambieacuten influiraacuten en el des-empentildeo y configuracioacuten de la solucioacuten
b) Almacenamiento
En cuanto a las caracteriacutesticas teacutecnicas del almacenamiento necesario para una plata-forma de Big Data recordemos que eacutestas deberaacuten ajustarse a los requerimientos del Framework y las aplicaciones que seraacuten utilizadas Desde esta oacuteptica nos encontraremos
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
12
que los sistemas de archivos paralelos como el HDFS (Hadoop Distributed File System) estaacuten disentildeados para expandirse en muacuteltiples nodos y manejar grandes voluacutemenes de datos y que por ende generan reacuteplicas para garantizar la tolerancia a fallos Ademaacutes tendraacuten acceso a todos los discos de forma independiente razoacuten por la cual no se sue-len utilizar RAID9 o LVM10 para agrupar los discos (ni por tolerancia a fallos ni por rendi-miento) Por otra parte las soluciones de almacenamiento deben ofrecer una tecnologiacutea robusta y confiable que soporte tanto datos estructurados como no estructurados con seguridad coherencia y credibilidad Asimismo deben
bull Disponer de una gran capacidad para almacenar datos (De acuerdo a los requeri-mientos del proyecto)
bull Deben poder escalar de forma modular faacutecilmente desde unos cuantos terabytes hasta muacuteltiples petabytes de informacioacuten
bull Contar con un muy alto rendimiento en IOPS (Operaciones de entrada y salida por segundo) Adecuado en tiempo real
bull Soportar y controlar todo tipo de datos
bull Contar con una tecnologiacutea que asegure una gran proteccioacuten para los datos
Recordemos tambieacuten que el tema del respaldo de la informacioacuten se volveraacute criacutetico cuan-do hablamos de terabytes o petabytes de informacioacuten Esto si no contamos con una infraestructura suficientemente robusta que asegure la preservacioacuten de la informacioacuten al paso del tiempo11
c) Redes de datos
En teacuterminos generales el software para Big Data hace un uso muy intensivo de la red Esto debido a que todos los nodos intercambian grandes voluacutemenes de datos tanto en un esquema normal de operacioacuten como en el caso de fallo de alguacuten nodo La razoacuten de este aumento de traacutefico en la red causado por la falla en alguacuten nodo del cluacutester se debe principalmente a que Hadoop obliga al resto de los nodos a que se pongan a replicar los datos para mantener la integridad de la informacioacuten Por estos mo-tivos es recomendable utilizar switches preferentemente de alta velocidad y dedicados para el uso exclusivo del cluacutester Dada la naturaleza del Big Data se requiere que la red a utilizar cuente con las siguientes caracteriacutesticas funcionales
bull Gran velocidad
bull Alta disponibilidad
bull Redundancia
[9] En informaacutetica el acroacute-nimo RAID (del ingleacutes Redundant Array of Inexpensive Disks o maacutes comuacuten a diacutea de hoy Redundant Array of Independent Disks) tra-ducido como laquoconjunto redundante de discos Independientesraquo hace referencia a un sistema de almacenamiento de datos en tiempo real que utiliza muacuteltiples unida-des de almacenamiento de datos (discos duros o SSD) entre los que se distribuyen o replican los datos Dependiendo de su configuracioacuten (a la que suele llamarse laquonivelraquo) los beneficios de un RAID respecto a un uacutenico disco son uno o varios de los siguientes mayor integridad ma-yor tolerancia a fallos mayor throughput (ren-dimiento) y mayor capa-cidad Fuente httpseswikipediaorgwikiRAID
[10] Logical Volume Mana-gement (LVM) en espa-ntildeol ldquoadministrador de voluacutemenes loacutegicosrdquo es una opcioacuten de gestioacuten de discos que todas las principales distribu-ciones de GNULinux presentan Ya sea que necesite para configurar grupos de almacena-miento o simplemente se necesite para crear dinaacutemicamente las par-ticiones LVM Veacutease httpsparbaedloword-presscom20120105que-es-lvm-como-se-administra-y-utiliza
[11] Veacutease httpwwwcom-puterweeklycomfea-tureBig-data-storage-choices
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
13
bull Resistencia a fallas
bull Alta capacidad de resolver situaciones de congestionamiento en la red
bull Consistencia
bull Faacutecil de escalabilidad
bull Altamente administrable
bull Resilencia (Capacidad de continuar funcionando dentro de paraacutemetros acepta-bles ante distintos tipos de problemas)
Resulta claro que a mayor velocidad el costo de la red se incrementaraacute Por tal motivo se puede iniciar con velocidades de conectividad a 1 Gbit y jugar con opciones de agre-gacioacuten de puertos para mejorar el desempentildeo12 No obstante el mejor desempentildeo se lograraacute con la tecnologiacutea de 10 Gbit o superior Por otra parte a mayor nuacutemero de nodos en el cluacutester la velocidad de la red seraacute un factor clave para su buen desempentildeo13 Como podremos darnos cuenta recomendar una configuracioacuten de hardware ideal para un proyecto de Big Data no es una tarea sencilla Algunos pasos para comenzar a definirla son
bull Identificar las preguntas que deberaacute responder la plataforma de Big Data
bull La urgencia de respuesta
bull Identificar las fuentes de informacioacuten de donde se deberaacute extraer la informacioacuten a procesar Incluso pueden ser a partir de programas de TV en tiempo real o el flujo de mensajes proveniente de redes sociales
bull Cuantificar la cantidad de informacioacuten con que se deberaacute trabajar
Con esta informacioacuten los especialistas en soluciones de Big Data podraacuten ayu-darle con facilidad No olvide que la infraestructura requeriraacute no solo de una inversioacuten importante sino tambieacuten de una serie de nuevas habilidades y conocimientos en el per-sonal para desarrollar las aplicaciones No obstante brindaraacute oportunidades reales de valor de negocio en nuestras empresas o instituciones [12] Consiste en el uso de va-
rios puertos de red o en-laces para incrementar la velocidad de comuni-cacioacuten Veacutease httpseswikipediaorgwikiAgregaciC3B3n_de_enlaces
[8] Veacutease httpsearchdata-centertechtargetcomescronicaSeis-conside-raciones-para-redes-de-big-data
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
14
Bibliografiacutea
[1] ALFOCEA J Detenido por amenazas a su alcalde en Redes Sociales Delitos informaacuteticos 2015 Revista legal [en liacutenea] Fecha de actualizacioacuten 22 septiembre 2015 [Consulta 6 de octubre de 2016] Disponible en httpwwwdelitosinformaticoscom092015delitosamenazas-2-delitosdetenido-amenazar-alcalde-redes-sociales
[2]CACHEIRO Javier Requisitos Hardware Big Data Fundacioacuten Puacuteblica Galega Centro Tecnoloacutexico de Supercomputacioacuten de Galicia CESGA [en Liacutenea] Fecha de actualizacioacuten 16 de Marzo de 2015 [Consultado 25 de Mayo de 2016] Disponible en httpswwwcesgaesesbibliotecadownloadAssetid775
[3] Enauro engineering services BIG DATA [En Liacutenea] [Consultado 14 de Noviembre de 2016] Disponible en httpwwwenaurocom20160610big-data
[4] HURTADO Gork Big Data y Hadoop Cloudera vs Hortonworks Mondragon Unibertsitatea Investigacioacuten en TICs [en Liacutenea] [Consultado 3 Mayo de 2016] Disponible en httpmukommondragoneduictbig-data-y-hadoop-cloudera-vs-hortonworks
[5] JCASANELLA Introduccioacuten a Hadoop y su ecosistema Ticout Outsourcing Center Tutoriales de Yellowfin y BI [En Liacutenea] Fecha de actualizacioacuten 01 de Abril de 2013 [Consultado 19 Mayo de 2016] Disponible en httpwwwticoutcomblog20130402introduccion-a-hadoop-y-su-ecosistema
[6] LOSHIN David Explorando distribuciones Hadoop para gestionar big data TechTarget SA de CV Guiacutea Escencial [En Liacutenea] Enero de 2016 [Consultado 14 Abril de 2016] Disponible es httpsearchdatacentertechtargetcomescronicaExplorando-distribuciones-Hadoop-para-gestionar-big-data
[7] LURIE Marty Big data de coacutedigo abierto para el impaciente Parte 1 Tutorial Hadoop Hello World con Java Pig Hive Flume Fuse Oozie y Sqoop con Informix DB2 y MySQL IBM IBM deveoperWorks [en liacutenea] 20 de Marzo de 2013 [Consultado 14 Abril de 2016] Disponible en httpswwwibmcomdeveloperworksssadatalibrarytecharticledm-1209hadoopbigdata
[8] MATTHEW Mayo Top Big Data Processing Frameworks KdnuggetsTM KDnuggets News [en Liacutenea] Marzo de 2016 [Consultado 14 Abril de 2016] Disponible en httpwwwkdnuggetscom201603top-big-data-processing-frameworkshtml
[9] OacuteDELL Kevin How-to Select the Right Hardware for Your New Hadoop Cluster Cloudera Inc Cloudera Engineering Blog [en Liacutenea] 28 de Agosto de 2013 [Consultado 28 Mayo de 2016] Disponible en httpsblogclouderacomblog201308how-to-select-the-right-hardware-for-your-new-hadoop-cluster
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
15
[10] STEVE Dertien Defining the Infrastructure for Big Data Analytics PTC Inc El Divan Digital [en Liacutenea] 22 de Mayo de 2015 [Consultado 11Abril de 2016] Disponible en httpblogsptccom20150522defining-the-infrastructure-for-big-data-analytics
[11] The apache software foundation Hadoop Web site the Apache Software Foundation Apache Hadoop Project [en Liacutenea] 13 de Febrero de 2016 [Consultado 17 Mayo de 2016] Disponible en httphadoopapacheorg
[12] TIRADOS Marible iquestEs Hadoop el fin del almacenamiento de datos tradicional Big Data Hispano [en Liacutenea] 10 de febrero de 2014 [Consultado 07 Mayo de 2016] Disponible en httpwwwbigdatahispanoorgnoticiases-hadoop-el-fin-del-almacenamiento-de-datos
[13] SAacuteNCHEZ Joseacute Manuel iquestQUEacute ES BIG DATA T2O AdMedia Services SL 2015 [en Liacutenea] 02 de julio de 2016 [Consultado 14 Noviembre de 2016] Disponible en httpwwwt2omediacomideasactualidadque-es-big-data-2 en maricultura Meacutexico Secretariacutea de Medio Ambiente Recursos Naturales y Pesca 1997 192-207pp
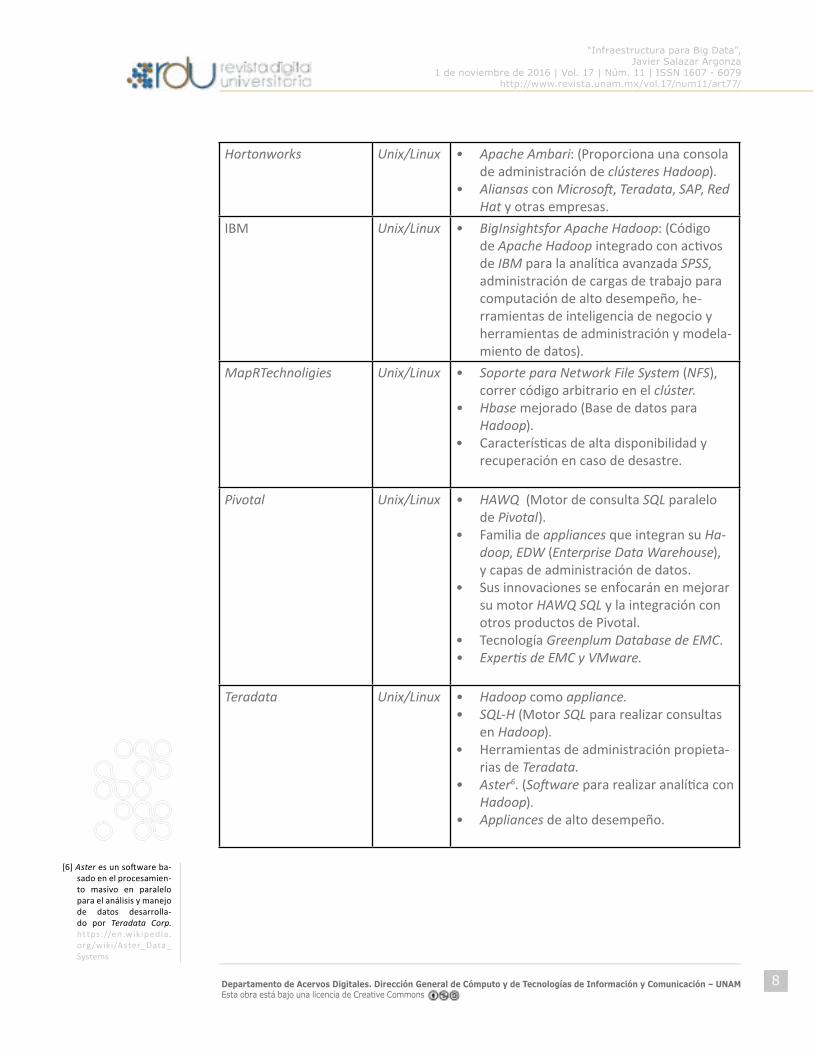
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
8
Hortonworks UnixLinux bull Apache Ambari (Proporciona una consola de administracioacuten de cluacutesteres Hadoop)
bull Aliansas con Microsoft Teradata SAP Red Hat y otras empresas
IBM UnixLinux bull BigInsightsfor Apache Hadoop (Coacutedigo de Apache Hadoop integrado con activos de IBM para la analiacutetica avanzada SPSS administracioacuten de cargas de trabajo para computacioacuten de alto desempentildeo he-rramientas de inteligencia de negocio y herramientas de administracioacuten y modela-miento de datos)
MapRTechnoligies UnixLinux bull Soporte para Network File System (NFS) correr coacutedigo arbitrario en el cluacutester
bull Hbase mejorado (Base de datos para Hadoop)
bull Caracteriacutesticas de alta disponibilidad y recuperacioacuten en caso de desastre
Pivotal UnixLinux bull HAWQ (Motor de consulta SQL paralelo de Pivotal)
bull Familia de appliances que integran su Ha-doop EDW (Enterprise Data Warehouse) y capas de administracioacuten de datos
bull Sus innovaciones se enfocaraacuten en mejorar su motor HAWQ SQL y la integracioacuten con otros productos de Pivotal
bull Tecnologiacutea Greenplum Database de EMCbull Expertis de EMC y VMware
Teradata UnixLinux bull Hadoop como appliancebull SQL-H (Motor SQL para realizar consultas
en Hadoop)bull Herramientas de administracioacuten propieta-
rias de Teradatabull Aster6 (Software para realizar analiacutetica con
Hadoop)bull Appliances de alto desempentildeo
[6] Aster es un software ba-sado en el procesamien-to masivo en paralelo para el anaacutelisis y manejo de datos desarrolla-do por Teradata Corp ht tpsenwikipediaorgwikiAster_Data_Systems
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
9
Intel UnixLinux bull Tecnologiacutea de sus Chips Xeon optimizados para Hadoop
bull Capacidades de desempentildeo y seguridad mejoradas por hardware para Hadoop
bull Lustre7 bull Optimizacioacuten nativa de tareas y analiacutetica
graacutefica
Microsoft Windows Azure HDInsight Service
Windows bull Polybase8 Permite que los clientes de SQL ejecuten consultas que incluyan datos almacenados en Hadoop
bull Esfuerzos en el desarrollo de la siguiente generacioacuten de Hive y de otros proyectos de la comunidad de coacutedigo abierto de Hadoop
bull Herramientas de desarrollo y colaboracioacuten para los clientes de Microsoft
La arquitectura del hardware para Big Data
En teacuterminos arquitectoacutenicos las soluciones de hardware para Big Data disponibles en el mercado pareceriacutean maacutes complejas de lo que en realidad son tienen muchas cosas en comuacuten todas utilizan
bull Nodos computacionales
bull Almacenamiento
bull Frameworks y aplicaciones programadas en Java (Ejemplo Hadoop Hbase Spark etc)
bull Redes de alta velocidad de tecnologiacutea gigabit o superior
bull Sistemas de soporte vital para (alimentacioacuten de energiacutea eleacutectrica y el control de temperatura y humedad)
Podemos apreciar diferencias significativas como
bull Un nuacutemero diferente de nodos y de configuraciones entre eacutestos que producen rendimientos diferentes en la ejecucioacuten de los procesos
bull Tecnologiacuteas de almacenamiento diferentes que influyen de manera determinante en el tiempo de acceso a la informacioacuten y por ende en la obtencioacuten de resultados
[7] Lustre es un sistema de archivos distribuido Open Source normal-mente utilizado en clus-ters a gran escala El nombre es una mezcla de Linux y clusters El proyecto intenta pro-porcionar un sistema de archivos para clusters de decenas de miles de nodos con petabytes de capacidad de almace-namiento sin compro-meter la velocidad o la seguridad y estaacute dispo-nible bajo la GNU GPLht tpseswikipediaorgwikiLustre_(siste-ma_de_archivos)
[8] Polybase es una tecno-logiacutea de Microsoft que permite a los usuarios de SQL Server PDW eje-cutar consultas sobre los datos almacena-dos en Hadoop Veacutease httpfrancescsanchez-biwebnodeesnewsuso-de-hadoop-en-sql-server-con-pdw-y-poly-base-
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
10
bull Redes de datos de diferentes velocidades que influyen en el desempentildeo global de la solucioacuten
El anaacutelisis de las cargas de tra-bajo seraacute un factor determinante para lograr el mejor equilibrio en-tre rendimiento y ahorro del hard-ware por ejemplo
a)Nodos computacionales
Los nodos computacionales son servidores para rack con una configuracioacuten preestablecida de acuerdo a su funcioacuten Muacuteltiples nodos conforman un cluacutester eso siacute en ninguacuten momento se reco-miendan servidores de tipo Blade debido a que eacutestos comparten componentes en un chasis que los puede limitar en su desempe-ntildeo capacidad de crecimiento y posibilidades de conectividad La cantidad de nuacutecleos y de memo-ria RAM disponible en cada uno de ellos asiacute como su velocidad de interconexioacuten a la red influiraacute de manera determinante en el rendi-miento global del cluacutester
Los cluacutester basados en el Siste-ma de Archivos de Hadoop ldquoHDFSrdquo baacutesicamente utilizaraacute dos tipos de nodos diferentes de acuerdo a la funcioacuten que desempentildearaacuten
bull Nodo de Nombres (Rastrea-dor de trabajos Namenode Jo-bTracker) Responsable de la topologiacutea de todos los demaacutes nodos y de gestionar el espa-cio de nombres Solo hay uno por cluacutester El Nodo de nom-
bres se encarga de distribuir los archivos en los nodos de datos que rea-
Figura 2 Ejemplo de un cluacutester para Big Data ba-sado en Hadoop Fuente httpwwwnextplatformcom20150703building-a-better-hadoop-cluster
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
11
lizaraacuten el procesamiento de los datos Veacutease httpwwwhappymindse s a p a c h e - h a d o o p - i n t r o d u c c i o n - a - h d f s s t h a s h 1 A 9 o n P I j d p u f
bull Nodo de Datos (Rastreador de tareas Datanode TaskTracker) Acceden a los da-tos Almacenan los bloques de informacioacuten y los recuperan bajo demanda
Velocidad de procesamiento
En teacuterminos generales los caacutelculos requeridos para los procesos de Big Data comuacutenmen-te estaraacuten maacutes limitados por la velocidad de respuesta de las operaciones de entrada y salida a disco y de la red que por la velocidad del procesador Eso no significa que los pro-cesadores que deban emplearse en la solucioacuten requieran ser de bajo costo o pobre ren-dimiento Sino maacutes bien que eacutestos cuenten con la mayor cantidad de nuacutecleos operando a la mayor frecuencia posible para poder manejar maacutes tareas en paralelo de forma aacutegil En este sentido tambieacuten se tiene que cuidar el consumo de energiacutea y la disipacioacuten de calor asociado a la frecuencia y altos voltajes de operacioacuten de los microprocesadores que sin duda tendraacuten impactos negativos en el medio ambiente y el costo de operacioacuten de la plataforma completa
Memoria RAM
La memoria RAM necesaria para un cluacutester de Big Data normalmente deberaacute ser calcu-lada tomando en consideracioacuten varios aspectos Entre los maacutes importantes destacan
bull La cantidad de nodos de datos que contenga el cluacutester
bull El nuacutemero maacuteximo de tareas que ejecutaraacute cada nodo de datos de forma simul-taacutenea
bull La memoria necesaria para los demonios que se ejecutan en los nodos de datos de tareas y del sistema operativo
bull El nuacutemero de bloques almacenados en el sistema de archivos distribuidos
bull Las necesidades especiacuteficas del software a utilizar en la plataforma
Los detalles sobre su tecnologiacutea por supuesto que tambieacuten influiraacuten en el des-empentildeo y configuracioacuten de la solucioacuten
b) Almacenamiento
En cuanto a las caracteriacutesticas teacutecnicas del almacenamiento necesario para una plata-forma de Big Data recordemos que eacutestas deberaacuten ajustarse a los requerimientos del Framework y las aplicaciones que seraacuten utilizadas Desde esta oacuteptica nos encontraremos
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
12
que los sistemas de archivos paralelos como el HDFS (Hadoop Distributed File System) estaacuten disentildeados para expandirse en muacuteltiples nodos y manejar grandes voluacutemenes de datos y que por ende generan reacuteplicas para garantizar la tolerancia a fallos Ademaacutes tendraacuten acceso a todos los discos de forma independiente razoacuten por la cual no se sue-len utilizar RAID9 o LVM10 para agrupar los discos (ni por tolerancia a fallos ni por rendi-miento) Por otra parte las soluciones de almacenamiento deben ofrecer una tecnologiacutea robusta y confiable que soporte tanto datos estructurados como no estructurados con seguridad coherencia y credibilidad Asimismo deben
bull Disponer de una gran capacidad para almacenar datos (De acuerdo a los requeri-mientos del proyecto)
bull Deben poder escalar de forma modular faacutecilmente desde unos cuantos terabytes hasta muacuteltiples petabytes de informacioacuten
bull Contar con un muy alto rendimiento en IOPS (Operaciones de entrada y salida por segundo) Adecuado en tiempo real
bull Soportar y controlar todo tipo de datos
bull Contar con una tecnologiacutea que asegure una gran proteccioacuten para los datos
Recordemos tambieacuten que el tema del respaldo de la informacioacuten se volveraacute criacutetico cuan-do hablamos de terabytes o petabytes de informacioacuten Esto si no contamos con una infraestructura suficientemente robusta que asegure la preservacioacuten de la informacioacuten al paso del tiempo11
c) Redes de datos
En teacuterminos generales el software para Big Data hace un uso muy intensivo de la red Esto debido a que todos los nodos intercambian grandes voluacutemenes de datos tanto en un esquema normal de operacioacuten como en el caso de fallo de alguacuten nodo La razoacuten de este aumento de traacutefico en la red causado por la falla en alguacuten nodo del cluacutester se debe principalmente a que Hadoop obliga al resto de los nodos a que se pongan a replicar los datos para mantener la integridad de la informacioacuten Por estos mo-tivos es recomendable utilizar switches preferentemente de alta velocidad y dedicados para el uso exclusivo del cluacutester Dada la naturaleza del Big Data se requiere que la red a utilizar cuente con las siguientes caracteriacutesticas funcionales
bull Gran velocidad
bull Alta disponibilidad
bull Redundancia
[9] En informaacutetica el acroacute-nimo RAID (del ingleacutes Redundant Array of Inexpensive Disks o maacutes comuacuten a diacutea de hoy Redundant Array of Independent Disks) tra-ducido como laquoconjunto redundante de discos Independientesraquo hace referencia a un sistema de almacenamiento de datos en tiempo real que utiliza muacuteltiples unida-des de almacenamiento de datos (discos duros o SSD) entre los que se distribuyen o replican los datos Dependiendo de su configuracioacuten (a la que suele llamarse laquonivelraquo) los beneficios de un RAID respecto a un uacutenico disco son uno o varios de los siguientes mayor integridad ma-yor tolerancia a fallos mayor throughput (ren-dimiento) y mayor capa-cidad Fuente httpseswikipediaorgwikiRAID
[10] Logical Volume Mana-gement (LVM) en espa-ntildeol ldquoadministrador de voluacutemenes loacutegicosrdquo es una opcioacuten de gestioacuten de discos que todas las principales distribu-ciones de GNULinux presentan Ya sea que necesite para configurar grupos de almacena-miento o simplemente se necesite para crear dinaacutemicamente las par-ticiones LVM Veacutease httpsparbaedloword-presscom20120105que-es-lvm-como-se-administra-y-utiliza
[11] Veacutease httpwwwcom-puterweeklycomfea-tureBig-data-storage-choices
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
13
bull Resistencia a fallas
bull Alta capacidad de resolver situaciones de congestionamiento en la red
bull Consistencia
bull Faacutecil de escalabilidad
bull Altamente administrable
bull Resilencia (Capacidad de continuar funcionando dentro de paraacutemetros acepta-bles ante distintos tipos de problemas)
Resulta claro que a mayor velocidad el costo de la red se incrementaraacute Por tal motivo se puede iniciar con velocidades de conectividad a 1 Gbit y jugar con opciones de agre-gacioacuten de puertos para mejorar el desempentildeo12 No obstante el mejor desempentildeo se lograraacute con la tecnologiacutea de 10 Gbit o superior Por otra parte a mayor nuacutemero de nodos en el cluacutester la velocidad de la red seraacute un factor clave para su buen desempentildeo13 Como podremos darnos cuenta recomendar una configuracioacuten de hardware ideal para un proyecto de Big Data no es una tarea sencilla Algunos pasos para comenzar a definirla son
bull Identificar las preguntas que deberaacute responder la plataforma de Big Data
bull La urgencia de respuesta
bull Identificar las fuentes de informacioacuten de donde se deberaacute extraer la informacioacuten a procesar Incluso pueden ser a partir de programas de TV en tiempo real o el flujo de mensajes proveniente de redes sociales
bull Cuantificar la cantidad de informacioacuten con que se deberaacute trabajar
Con esta informacioacuten los especialistas en soluciones de Big Data podraacuten ayu-darle con facilidad No olvide que la infraestructura requeriraacute no solo de una inversioacuten importante sino tambieacuten de una serie de nuevas habilidades y conocimientos en el per-sonal para desarrollar las aplicaciones No obstante brindaraacute oportunidades reales de valor de negocio en nuestras empresas o instituciones [12] Consiste en el uso de va-
rios puertos de red o en-laces para incrementar la velocidad de comuni-cacioacuten Veacutease httpseswikipediaorgwikiAgregaciC3B3n_de_enlaces
[8] Veacutease httpsearchdata-centertechtargetcomescronicaSeis-conside-raciones-para-redes-de-big-data
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
14
Bibliografiacutea
[1] ALFOCEA J Detenido por amenazas a su alcalde en Redes Sociales Delitos informaacuteticos 2015 Revista legal [en liacutenea] Fecha de actualizacioacuten 22 septiembre 2015 [Consulta 6 de octubre de 2016] Disponible en httpwwwdelitosinformaticoscom092015delitosamenazas-2-delitosdetenido-amenazar-alcalde-redes-sociales
[2]CACHEIRO Javier Requisitos Hardware Big Data Fundacioacuten Puacuteblica Galega Centro Tecnoloacutexico de Supercomputacioacuten de Galicia CESGA [en Liacutenea] Fecha de actualizacioacuten 16 de Marzo de 2015 [Consultado 25 de Mayo de 2016] Disponible en httpswwwcesgaesesbibliotecadownloadAssetid775
[3] Enauro engineering services BIG DATA [En Liacutenea] [Consultado 14 de Noviembre de 2016] Disponible en httpwwwenaurocom20160610big-data
[4] HURTADO Gork Big Data y Hadoop Cloudera vs Hortonworks Mondragon Unibertsitatea Investigacioacuten en TICs [en Liacutenea] [Consultado 3 Mayo de 2016] Disponible en httpmukommondragoneduictbig-data-y-hadoop-cloudera-vs-hortonworks
[5] JCASANELLA Introduccioacuten a Hadoop y su ecosistema Ticout Outsourcing Center Tutoriales de Yellowfin y BI [En Liacutenea] Fecha de actualizacioacuten 01 de Abril de 2013 [Consultado 19 Mayo de 2016] Disponible en httpwwwticoutcomblog20130402introduccion-a-hadoop-y-su-ecosistema
[6] LOSHIN David Explorando distribuciones Hadoop para gestionar big data TechTarget SA de CV Guiacutea Escencial [En Liacutenea] Enero de 2016 [Consultado 14 Abril de 2016] Disponible es httpsearchdatacentertechtargetcomescronicaExplorando-distribuciones-Hadoop-para-gestionar-big-data
[7] LURIE Marty Big data de coacutedigo abierto para el impaciente Parte 1 Tutorial Hadoop Hello World con Java Pig Hive Flume Fuse Oozie y Sqoop con Informix DB2 y MySQL IBM IBM deveoperWorks [en liacutenea] 20 de Marzo de 2013 [Consultado 14 Abril de 2016] Disponible en httpswwwibmcomdeveloperworksssadatalibrarytecharticledm-1209hadoopbigdata
[8] MATTHEW Mayo Top Big Data Processing Frameworks KdnuggetsTM KDnuggets News [en Liacutenea] Marzo de 2016 [Consultado 14 Abril de 2016] Disponible en httpwwwkdnuggetscom201603top-big-data-processing-frameworkshtml
[9] OacuteDELL Kevin How-to Select the Right Hardware for Your New Hadoop Cluster Cloudera Inc Cloudera Engineering Blog [en Liacutenea] 28 de Agosto de 2013 [Consultado 28 Mayo de 2016] Disponible en httpsblogclouderacomblog201308how-to-select-the-right-hardware-for-your-new-hadoop-cluster
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
15
[10] STEVE Dertien Defining the Infrastructure for Big Data Analytics PTC Inc El Divan Digital [en Liacutenea] 22 de Mayo de 2015 [Consultado 11Abril de 2016] Disponible en httpblogsptccom20150522defining-the-infrastructure-for-big-data-analytics
[11] The apache software foundation Hadoop Web site the Apache Software Foundation Apache Hadoop Project [en Liacutenea] 13 de Febrero de 2016 [Consultado 17 Mayo de 2016] Disponible en httphadoopapacheorg
[12] TIRADOS Marible iquestEs Hadoop el fin del almacenamiento de datos tradicional Big Data Hispano [en Liacutenea] 10 de febrero de 2014 [Consultado 07 Mayo de 2016] Disponible en httpwwwbigdatahispanoorgnoticiases-hadoop-el-fin-del-almacenamiento-de-datos
[13] SAacuteNCHEZ Joseacute Manuel iquestQUEacute ES BIG DATA T2O AdMedia Services SL 2015 [en Liacutenea] 02 de julio de 2016 [Consultado 14 Noviembre de 2016] Disponible en httpwwwt2omediacomideasactualidadque-es-big-data-2 en maricultura Meacutexico Secretariacutea de Medio Ambiente Recursos Naturales y Pesca 1997 192-207pp
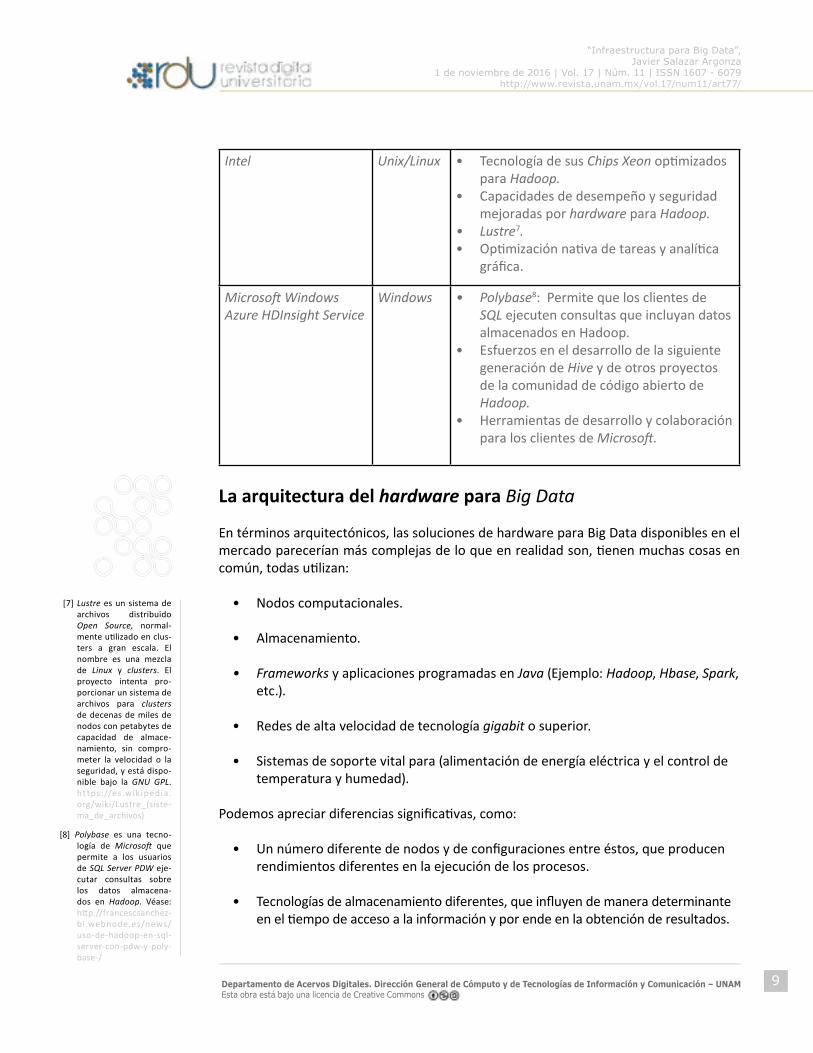
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
9
Intel UnixLinux bull Tecnologiacutea de sus Chips Xeon optimizados para Hadoop
bull Capacidades de desempentildeo y seguridad mejoradas por hardware para Hadoop
bull Lustre7 bull Optimizacioacuten nativa de tareas y analiacutetica
graacutefica
Microsoft Windows Azure HDInsight Service
Windows bull Polybase8 Permite que los clientes de SQL ejecuten consultas que incluyan datos almacenados en Hadoop
bull Esfuerzos en el desarrollo de la siguiente generacioacuten de Hive y de otros proyectos de la comunidad de coacutedigo abierto de Hadoop
bull Herramientas de desarrollo y colaboracioacuten para los clientes de Microsoft
La arquitectura del hardware para Big Data
En teacuterminos arquitectoacutenicos las soluciones de hardware para Big Data disponibles en el mercado pareceriacutean maacutes complejas de lo que en realidad son tienen muchas cosas en comuacuten todas utilizan
bull Nodos computacionales
bull Almacenamiento
bull Frameworks y aplicaciones programadas en Java (Ejemplo Hadoop Hbase Spark etc)
bull Redes de alta velocidad de tecnologiacutea gigabit o superior
bull Sistemas de soporte vital para (alimentacioacuten de energiacutea eleacutectrica y el control de temperatura y humedad)
Podemos apreciar diferencias significativas como
bull Un nuacutemero diferente de nodos y de configuraciones entre eacutestos que producen rendimientos diferentes en la ejecucioacuten de los procesos
bull Tecnologiacuteas de almacenamiento diferentes que influyen de manera determinante en el tiempo de acceso a la informacioacuten y por ende en la obtencioacuten de resultados
[7] Lustre es un sistema de archivos distribuido Open Source normal-mente utilizado en clus-ters a gran escala El nombre es una mezcla de Linux y clusters El proyecto intenta pro-porcionar un sistema de archivos para clusters de decenas de miles de nodos con petabytes de capacidad de almace-namiento sin compro-meter la velocidad o la seguridad y estaacute dispo-nible bajo la GNU GPLht tpseswikipediaorgwikiLustre_(siste-ma_de_archivos)
[8] Polybase es una tecno-logiacutea de Microsoft que permite a los usuarios de SQL Server PDW eje-cutar consultas sobre los datos almacena-dos en Hadoop Veacutease httpfrancescsanchez-biwebnodeesnewsuso-de-hadoop-en-sql-server-con-pdw-y-poly-base-
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
10
bull Redes de datos de diferentes velocidades que influyen en el desempentildeo global de la solucioacuten
El anaacutelisis de las cargas de tra-bajo seraacute un factor determinante para lograr el mejor equilibrio en-tre rendimiento y ahorro del hard-ware por ejemplo
a)Nodos computacionales
Los nodos computacionales son servidores para rack con una configuracioacuten preestablecida de acuerdo a su funcioacuten Muacuteltiples nodos conforman un cluacutester eso siacute en ninguacuten momento se reco-miendan servidores de tipo Blade debido a que eacutestos comparten componentes en un chasis que los puede limitar en su desempe-ntildeo capacidad de crecimiento y posibilidades de conectividad La cantidad de nuacutecleos y de memo-ria RAM disponible en cada uno de ellos asiacute como su velocidad de interconexioacuten a la red influiraacute de manera determinante en el rendi-miento global del cluacutester
Los cluacutester basados en el Siste-ma de Archivos de Hadoop ldquoHDFSrdquo baacutesicamente utilizaraacute dos tipos de nodos diferentes de acuerdo a la funcioacuten que desempentildearaacuten
bull Nodo de Nombres (Rastrea-dor de trabajos Namenode Jo-bTracker) Responsable de la topologiacutea de todos los demaacutes nodos y de gestionar el espa-cio de nombres Solo hay uno por cluacutester El Nodo de nom-
bres se encarga de distribuir los archivos en los nodos de datos que rea-
Figura 2 Ejemplo de un cluacutester para Big Data ba-sado en Hadoop Fuente httpwwwnextplatformcom20150703building-a-better-hadoop-cluster
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
11
lizaraacuten el procesamiento de los datos Veacutease httpwwwhappymindse s a p a c h e - h a d o o p - i n t r o d u c c i o n - a - h d f s s t h a s h 1 A 9 o n P I j d p u f
bull Nodo de Datos (Rastreador de tareas Datanode TaskTracker) Acceden a los da-tos Almacenan los bloques de informacioacuten y los recuperan bajo demanda
Velocidad de procesamiento
En teacuterminos generales los caacutelculos requeridos para los procesos de Big Data comuacutenmen-te estaraacuten maacutes limitados por la velocidad de respuesta de las operaciones de entrada y salida a disco y de la red que por la velocidad del procesador Eso no significa que los pro-cesadores que deban emplearse en la solucioacuten requieran ser de bajo costo o pobre ren-dimiento Sino maacutes bien que eacutestos cuenten con la mayor cantidad de nuacutecleos operando a la mayor frecuencia posible para poder manejar maacutes tareas en paralelo de forma aacutegil En este sentido tambieacuten se tiene que cuidar el consumo de energiacutea y la disipacioacuten de calor asociado a la frecuencia y altos voltajes de operacioacuten de los microprocesadores que sin duda tendraacuten impactos negativos en el medio ambiente y el costo de operacioacuten de la plataforma completa
Memoria RAM
La memoria RAM necesaria para un cluacutester de Big Data normalmente deberaacute ser calcu-lada tomando en consideracioacuten varios aspectos Entre los maacutes importantes destacan
bull La cantidad de nodos de datos que contenga el cluacutester
bull El nuacutemero maacuteximo de tareas que ejecutaraacute cada nodo de datos de forma simul-taacutenea
bull La memoria necesaria para los demonios que se ejecutan en los nodos de datos de tareas y del sistema operativo
bull El nuacutemero de bloques almacenados en el sistema de archivos distribuidos
bull Las necesidades especiacuteficas del software a utilizar en la plataforma
Los detalles sobre su tecnologiacutea por supuesto que tambieacuten influiraacuten en el des-empentildeo y configuracioacuten de la solucioacuten
b) Almacenamiento
En cuanto a las caracteriacutesticas teacutecnicas del almacenamiento necesario para una plata-forma de Big Data recordemos que eacutestas deberaacuten ajustarse a los requerimientos del Framework y las aplicaciones que seraacuten utilizadas Desde esta oacuteptica nos encontraremos
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
12
que los sistemas de archivos paralelos como el HDFS (Hadoop Distributed File System) estaacuten disentildeados para expandirse en muacuteltiples nodos y manejar grandes voluacutemenes de datos y que por ende generan reacuteplicas para garantizar la tolerancia a fallos Ademaacutes tendraacuten acceso a todos los discos de forma independiente razoacuten por la cual no se sue-len utilizar RAID9 o LVM10 para agrupar los discos (ni por tolerancia a fallos ni por rendi-miento) Por otra parte las soluciones de almacenamiento deben ofrecer una tecnologiacutea robusta y confiable que soporte tanto datos estructurados como no estructurados con seguridad coherencia y credibilidad Asimismo deben
bull Disponer de una gran capacidad para almacenar datos (De acuerdo a los requeri-mientos del proyecto)
bull Deben poder escalar de forma modular faacutecilmente desde unos cuantos terabytes hasta muacuteltiples petabytes de informacioacuten
bull Contar con un muy alto rendimiento en IOPS (Operaciones de entrada y salida por segundo) Adecuado en tiempo real
bull Soportar y controlar todo tipo de datos
bull Contar con una tecnologiacutea que asegure una gran proteccioacuten para los datos
Recordemos tambieacuten que el tema del respaldo de la informacioacuten se volveraacute criacutetico cuan-do hablamos de terabytes o petabytes de informacioacuten Esto si no contamos con una infraestructura suficientemente robusta que asegure la preservacioacuten de la informacioacuten al paso del tiempo11
c) Redes de datos
En teacuterminos generales el software para Big Data hace un uso muy intensivo de la red Esto debido a que todos los nodos intercambian grandes voluacutemenes de datos tanto en un esquema normal de operacioacuten como en el caso de fallo de alguacuten nodo La razoacuten de este aumento de traacutefico en la red causado por la falla en alguacuten nodo del cluacutester se debe principalmente a que Hadoop obliga al resto de los nodos a que se pongan a replicar los datos para mantener la integridad de la informacioacuten Por estos mo-tivos es recomendable utilizar switches preferentemente de alta velocidad y dedicados para el uso exclusivo del cluacutester Dada la naturaleza del Big Data se requiere que la red a utilizar cuente con las siguientes caracteriacutesticas funcionales
bull Gran velocidad
bull Alta disponibilidad
bull Redundancia
[9] En informaacutetica el acroacute-nimo RAID (del ingleacutes Redundant Array of Inexpensive Disks o maacutes comuacuten a diacutea de hoy Redundant Array of Independent Disks) tra-ducido como laquoconjunto redundante de discos Independientesraquo hace referencia a un sistema de almacenamiento de datos en tiempo real que utiliza muacuteltiples unida-des de almacenamiento de datos (discos duros o SSD) entre los que se distribuyen o replican los datos Dependiendo de su configuracioacuten (a la que suele llamarse laquonivelraquo) los beneficios de un RAID respecto a un uacutenico disco son uno o varios de los siguientes mayor integridad ma-yor tolerancia a fallos mayor throughput (ren-dimiento) y mayor capa-cidad Fuente httpseswikipediaorgwikiRAID
[10] Logical Volume Mana-gement (LVM) en espa-ntildeol ldquoadministrador de voluacutemenes loacutegicosrdquo es una opcioacuten de gestioacuten de discos que todas las principales distribu-ciones de GNULinux presentan Ya sea que necesite para configurar grupos de almacena-miento o simplemente se necesite para crear dinaacutemicamente las par-ticiones LVM Veacutease httpsparbaedloword-presscom20120105que-es-lvm-como-se-administra-y-utiliza
[11] Veacutease httpwwwcom-puterweeklycomfea-tureBig-data-storage-choices
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
13
bull Resistencia a fallas
bull Alta capacidad de resolver situaciones de congestionamiento en la red
bull Consistencia
bull Faacutecil de escalabilidad
bull Altamente administrable
bull Resilencia (Capacidad de continuar funcionando dentro de paraacutemetros acepta-bles ante distintos tipos de problemas)
Resulta claro que a mayor velocidad el costo de la red se incrementaraacute Por tal motivo se puede iniciar con velocidades de conectividad a 1 Gbit y jugar con opciones de agre-gacioacuten de puertos para mejorar el desempentildeo12 No obstante el mejor desempentildeo se lograraacute con la tecnologiacutea de 10 Gbit o superior Por otra parte a mayor nuacutemero de nodos en el cluacutester la velocidad de la red seraacute un factor clave para su buen desempentildeo13 Como podremos darnos cuenta recomendar una configuracioacuten de hardware ideal para un proyecto de Big Data no es una tarea sencilla Algunos pasos para comenzar a definirla son
bull Identificar las preguntas que deberaacute responder la plataforma de Big Data
bull La urgencia de respuesta
bull Identificar las fuentes de informacioacuten de donde se deberaacute extraer la informacioacuten a procesar Incluso pueden ser a partir de programas de TV en tiempo real o el flujo de mensajes proveniente de redes sociales
bull Cuantificar la cantidad de informacioacuten con que se deberaacute trabajar
Con esta informacioacuten los especialistas en soluciones de Big Data podraacuten ayu-darle con facilidad No olvide que la infraestructura requeriraacute no solo de una inversioacuten importante sino tambieacuten de una serie de nuevas habilidades y conocimientos en el per-sonal para desarrollar las aplicaciones No obstante brindaraacute oportunidades reales de valor de negocio en nuestras empresas o instituciones [12] Consiste en el uso de va-
rios puertos de red o en-laces para incrementar la velocidad de comuni-cacioacuten Veacutease httpseswikipediaorgwikiAgregaciC3B3n_de_enlaces
[8] Veacutease httpsearchdata-centertechtargetcomescronicaSeis-conside-raciones-para-redes-de-big-data
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
14
Bibliografiacutea
[1] ALFOCEA J Detenido por amenazas a su alcalde en Redes Sociales Delitos informaacuteticos 2015 Revista legal [en liacutenea] Fecha de actualizacioacuten 22 septiembre 2015 [Consulta 6 de octubre de 2016] Disponible en httpwwwdelitosinformaticoscom092015delitosamenazas-2-delitosdetenido-amenazar-alcalde-redes-sociales
[2]CACHEIRO Javier Requisitos Hardware Big Data Fundacioacuten Puacuteblica Galega Centro Tecnoloacutexico de Supercomputacioacuten de Galicia CESGA [en Liacutenea] Fecha de actualizacioacuten 16 de Marzo de 2015 [Consultado 25 de Mayo de 2016] Disponible en httpswwwcesgaesesbibliotecadownloadAssetid775
[3] Enauro engineering services BIG DATA [En Liacutenea] [Consultado 14 de Noviembre de 2016] Disponible en httpwwwenaurocom20160610big-data
[4] HURTADO Gork Big Data y Hadoop Cloudera vs Hortonworks Mondragon Unibertsitatea Investigacioacuten en TICs [en Liacutenea] [Consultado 3 Mayo de 2016] Disponible en httpmukommondragoneduictbig-data-y-hadoop-cloudera-vs-hortonworks
[5] JCASANELLA Introduccioacuten a Hadoop y su ecosistema Ticout Outsourcing Center Tutoriales de Yellowfin y BI [En Liacutenea] Fecha de actualizacioacuten 01 de Abril de 2013 [Consultado 19 Mayo de 2016] Disponible en httpwwwticoutcomblog20130402introduccion-a-hadoop-y-su-ecosistema
[6] LOSHIN David Explorando distribuciones Hadoop para gestionar big data TechTarget SA de CV Guiacutea Escencial [En Liacutenea] Enero de 2016 [Consultado 14 Abril de 2016] Disponible es httpsearchdatacentertechtargetcomescronicaExplorando-distribuciones-Hadoop-para-gestionar-big-data
[7] LURIE Marty Big data de coacutedigo abierto para el impaciente Parte 1 Tutorial Hadoop Hello World con Java Pig Hive Flume Fuse Oozie y Sqoop con Informix DB2 y MySQL IBM IBM deveoperWorks [en liacutenea] 20 de Marzo de 2013 [Consultado 14 Abril de 2016] Disponible en httpswwwibmcomdeveloperworksssadatalibrarytecharticledm-1209hadoopbigdata
[8] MATTHEW Mayo Top Big Data Processing Frameworks KdnuggetsTM KDnuggets News [en Liacutenea] Marzo de 2016 [Consultado 14 Abril de 2016] Disponible en httpwwwkdnuggetscom201603top-big-data-processing-frameworkshtml
[9] OacuteDELL Kevin How-to Select the Right Hardware for Your New Hadoop Cluster Cloudera Inc Cloudera Engineering Blog [en Liacutenea] 28 de Agosto de 2013 [Consultado 28 Mayo de 2016] Disponible en httpsblogclouderacomblog201308how-to-select-the-right-hardware-for-your-new-hadoop-cluster
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
15
[10] STEVE Dertien Defining the Infrastructure for Big Data Analytics PTC Inc El Divan Digital [en Liacutenea] 22 de Mayo de 2015 [Consultado 11Abril de 2016] Disponible en httpblogsptccom20150522defining-the-infrastructure-for-big-data-analytics
[11] The apache software foundation Hadoop Web site the Apache Software Foundation Apache Hadoop Project [en Liacutenea] 13 de Febrero de 2016 [Consultado 17 Mayo de 2016] Disponible en httphadoopapacheorg
[12] TIRADOS Marible iquestEs Hadoop el fin del almacenamiento de datos tradicional Big Data Hispano [en Liacutenea] 10 de febrero de 2014 [Consultado 07 Mayo de 2016] Disponible en httpwwwbigdatahispanoorgnoticiases-hadoop-el-fin-del-almacenamiento-de-datos
[13] SAacuteNCHEZ Joseacute Manuel iquestQUEacute ES BIG DATA T2O AdMedia Services SL 2015 [en Liacutenea] 02 de julio de 2016 [Consultado 14 Noviembre de 2016] Disponible en httpwwwt2omediacomideasactualidadque-es-big-data-2 en maricultura Meacutexico Secretariacutea de Medio Ambiente Recursos Naturales y Pesca 1997 192-207pp

ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
10
bull Redes de datos de diferentes velocidades que influyen en el desempentildeo global de la solucioacuten
El anaacutelisis de las cargas de tra-bajo seraacute un factor determinante para lograr el mejor equilibrio en-tre rendimiento y ahorro del hard-ware por ejemplo
a)Nodos computacionales
Los nodos computacionales son servidores para rack con una configuracioacuten preestablecida de acuerdo a su funcioacuten Muacuteltiples nodos conforman un cluacutester eso siacute en ninguacuten momento se reco-miendan servidores de tipo Blade debido a que eacutestos comparten componentes en un chasis que los puede limitar en su desempe-ntildeo capacidad de crecimiento y posibilidades de conectividad La cantidad de nuacutecleos y de memo-ria RAM disponible en cada uno de ellos asiacute como su velocidad de interconexioacuten a la red influiraacute de manera determinante en el rendi-miento global del cluacutester
Los cluacutester basados en el Siste-ma de Archivos de Hadoop ldquoHDFSrdquo baacutesicamente utilizaraacute dos tipos de nodos diferentes de acuerdo a la funcioacuten que desempentildearaacuten
bull Nodo de Nombres (Rastrea-dor de trabajos Namenode Jo-bTracker) Responsable de la topologiacutea de todos los demaacutes nodos y de gestionar el espa-cio de nombres Solo hay uno por cluacutester El Nodo de nom-
bres se encarga de distribuir los archivos en los nodos de datos que rea-
Figura 2 Ejemplo de un cluacutester para Big Data ba-sado en Hadoop Fuente httpwwwnextplatformcom20150703building-a-better-hadoop-cluster
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
11
lizaraacuten el procesamiento de los datos Veacutease httpwwwhappymindse s a p a c h e - h a d o o p - i n t r o d u c c i o n - a - h d f s s t h a s h 1 A 9 o n P I j d p u f
bull Nodo de Datos (Rastreador de tareas Datanode TaskTracker) Acceden a los da-tos Almacenan los bloques de informacioacuten y los recuperan bajo demanda
Velocidad de procesamiento
En teacuterminos generales los caacutelculos requeridos para los procesos de Big Data comuacutenmen-te estaraacuten maacutes limitados por la velocidad de respuesta de las operaciones de entrada y salida a disco y de la red que por la velocidad del procesador Eso no significa que los pro-cesadores que deban emplearse en la solucioacuten requieran ser de bajo costo o pobre ren-dimiento Sino maacutes bien que eacutestos cuenten con la mayor cantidad de nuacutecleos operando a la mayor frecuencia posible para poder manejar maacutes tareas en paralelo de forma aacutegil En este sentido tambieacuten se tiene que cuidar el consumo de energiacutea y la disipacioacuten de calor asociado a la frecuencia y altos voltajes de operacioacuten de los microprocesadores que sin duda tendraacuten impactos negativos en el medio ambiente y el costo de operacioacuten de la plataforma completa
Memoria RAM
La memoria RAM necesaria para un cluacutester de Big Data normalmente deberaacute ser calcu-lada tomando en consideracioacuten varios aspectos Entre los maacutes importantes destacan
bull La cantidad de nodos de datos que contenga el cluacutester
bull El nuacutemero maacuteximo de tareas que ejecutaraacute cada nodo de datos de forma simul-taacutenea
bull La memoria necesaria para los demonios que se ejecutan en los nodos de datos de tareas y del sistema operativo
bull El nuacutemero de bloques almacenados en el sistema de archivos distribuidos
bull Las necesidades especiacuteficas del software a utilizar en la plataforma
Los detalles sobre su tecnologiacutea por supuesto que tambieacuten influiraacuten en el des-empentildeo y configuracioacuten de la solucioacuten
b) Almacenamiento
En cuanto a las caracteriacutesticas teacutecnicas del almacenamiento necesario para una plata-forma de Big Data recordemos que eacutestas deberaacuten ajustarse a los requerimientos del Framework y las aplicaciones que seraacuten utilizadas Desde esta oacuteptica nos encontraremos
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
12
que los sistemas de archivos paralelos como el HDFS (Hadoop Distributed File System) estaacuten disentildeados para expandirse en muacuteltiples nodos y manejar grandes voluacutemenes de datos y que por ende generan reacuteplicas para garantizar la tolerancia a fallos Ademaacutes tendraacuten acceso a todos los discos de forma independiente razoacuten por la cual no se sue-len utilizar RAID9 o LVM10 para agrupar los discos (ni por tolerancia a fallos ni por rendi-miento) Por otra parte las soluciones de almacenamiento deben ofrecer una tecnologiacutea robusta y confiable que soporte tanto datos estructurados como no estructurados con seguridad coherencia y credibilidad Asimismo deben
bull Disponer de una gran capacidad para almacenar datos (De acuerdo a los requeri-mientos del proyecto)
bull Deben poder escalar de forma modular faacutecilmente desde unos cuantos terabytes hasta muacuteltiples petabytes de informacioacuten
bull Contar con un muy alto rendimiento en IOPS (Operaciones de entrada y salida por segundo) Adecuado en tiempo real
bull Soportar y controlar todo tipo de datos
bull Contar con una tecnologiacutea que asegure una gran proteccioacuten para los datos
Recordemos tambieacuten que el tema del respaldo de la informacioacuten se volveraacute criacutetico cuan-do hablamos de terabytes o petabytes de informacioacuten Esto si no contamos con una infraestructura suficientemente robusta que asegure la preservacioacuten de la informacioacuten al paso del tiempo11
c) Redes de datos
En teacuterminos generales el software para Big Data hace un uso muy intensivo de la red Esto debido a que todos los nodos intercambian grandes voluacutemenes de datos tanto en un esquema normal de operacioacuten como en el caso de fallo de alguacuten nodo La razoacuten de este aumento de traacutefico en la red causado por la falla en alguacuten nodo del cluacutester se debe principalmente a que Hadoop obliga al resto de los nodos a que se pongan a replicar los datos para mantener la integridad de la informacioacuten Por estos mo-tivos es recomendable utilizar switches preferentemente de alta velocidad y dedicados para el uso exclusivo del cluacutester Dada la naturaleza del Big Data se requiere que la red a utilizar cuente con las siguientes caracteriacutesticas funcionales
bull Gran velocidad
bull Alta disponibilidad
bull Redundancia
[9] En informaacutetica el acroacute-nimo RAID (del ingleacutes Redundant Array of Inexpensive Disks o maacutes comuacuten a diacutea de hoy Redundant Array of Independent Disks) tra-ducido como laquoconjunto redundante de discos Independientesraquo hace referencia a un sistema de almacenamiento de datos en tiempo real que utiliza muacuteltiples unida-des de almacenamiento de datos (discos duros o SSD) entre los que se distribuyen o replican los datos Dependiendo de su configuracioacuten (a la que suele llamarse laquonivelraquo) los beneficios de un RAID respecto a un uacutenico disco son uno o varios de los siguientes mayor integridad ma-yor tolerancia a fallos mayor throughput (ren-dimiento) y mayor capa-cidad Fuente httpseswikipediaorgwikiRAID
[10] Logical Volume Mana-gement (LVM) en espa-ntildeol ldquoadministrador de voluacutemenes loacutegicosrdquo es una opcioacuten de gestioacuten de discos que todas las principales distribu-ciones de GNULinux presentan Ya sea que necesite para configurar grupos de almacena-miento o simplemente se necesite para crear dinaacutemicamente las par-ticiones LVM Veacutease httpsparbaedloword-presscom20120105que-es-lvm-como-se-administra-y-utiliza
[11] Veacutease httpwwwcom-puterweeklycomfea-tureBig-data-storage-choices
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
13
bull Resistencia a fallas
bull Alta capacidad de resolver situaciones de congestionamiento en la red
bull Consistencia
bull Faacutecil de escalabilidad
bull Altamente administrable
bull Resilencia (Capacidad de continuar funcionando dentro de paraacutemetros acepta-bles ante distintos tipos de problemas)
Resulta claro que a mayor velocidad el costo de la red se incrementaraacute Por tal motivo se puede iniciar con velocidades de conectividad a 1 Gbit y jugar con opciones de agre-gacioacuten de puertos para mejorar el desempentildeo12 No obstante el mejor desempentildeo se lograraacute con la tecnologiacutea de 10 Gbit o superior Por otra parte a mayor nuacutemero de nodos en el cluacutester la velocidad de la red seraacute un factor clave para su buen desempentildeo13 Como podremos darnos cuenta recomendar una configuracioacuten de hardware ideal para un proyecto de Big Data no es una tarea sencilla Algunos pasos para comenzar a definirla son
bull Identificar las preguntas que deberaacute responder la plataforma de Big Data
bull La urgencia de respuesta
bull Identificar las fuentes de informacioacuten de donde se deberaacute extraer la informacioacuten a procesar Incluso pueden ser a partir de programas de TV en tiempo real o el flujo de mensajes proveniente de redes sociales
bull Cuantificar la cantidad de informacioacuten con que se deberaacute trabajar
Con esta informacioacuten los especialistas en soluciones de Big Data podraacuten ayu-darle con facilidad No olvide que la infraestructura requeriraacute no solo de una inversioacuten importante sino tambieacuten de una serie de nuevas habilidades y conocimientos en el per-sonal para desarrollar las aplicaciones No obstante brindaraacute oportunidades reales de valor de negocio en nuestras empresas o instituciones [12] Consiste en el uso de va-
rios puertos de red o en-laces para incrementar la velocidad de comuni-cacioacuten Veacutease httpseswikipediaorgwikiAgregaciC3B3n_de_enlaces
[8] Veacutease httpsearchdata-centertechtargetcomescronicaSeis-conside-raciones-para-redes-de-big-data
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
14
Bibliografiacutea
[1] ALFOCEA J Detenido por amenazas a su alcalde en Redes Sociales Delitos informaacuteticos 2015 Revista legal [en liacutenea] Fecha de actualizacioacuten 22 septiembre 2015 [Consulta 6 de octubre de 2016] Disponible en httpwwwdelitosinformaticoscom092015delitosamenazas-2-delitosdetenido-amenazar-alcalde-redes-sociales
[2]CACHEIRO Javier Requisitos Hardware Big Data Fundacioacuten Puacuteblica Galega Centro Tecnoloacutexico de Supercomputacioacuten de Galicia CESGA [en Liacutenea] Fecha de actualizacioacuten 16 de Marzo de 2015 [Consultado 25 de Mayo de 2016] Disponible en httpswwwcesgaesesbibliotecadownloadAssetid775
[3] Enauro engineering services BIG DATA [En Liacutenea] [Consultado 14 de Noviembre de 2016] Disponible en httpwwwenaurocom20160610big-data
[4] HURTADO Gork Big Data y Hadoop Cloudera vs Hortonworks Mondragon Unibertsitatea Investigacioacuten en TICs [en Liacutenea] [Consultado 3 Mayo de 2016] Disponible en httpmukommondragoneduictbig-data-y-hadoop-cloudera-vs-hortonworks
[5] JCASANELLA Introduccioacuten a Hadoop y su ecosistema Ticout Outsourcing Center Tutoriales de Yellowfin y BI [En Liacutenea] Fecha de actualizacioacuten 01 de Abril de 2013 [Consultado 19 Mayo de 2016] Disponible en httpwwwticoutcomblog20130402introduccion-a-hadoop-y-su-ecosistema
[6] LOSHIN David Explorando distribuciones Hadoop para gestionar big data TechTarget SA de CV Guiacutea Escencial [En Liacutenea] Enero de 2016 [Consultado 14 Abril de 2016] Disponible es httpsearchdatacentertechtargetcomescronicaExplorando-distribuciones-Hadoop-para-gestionar-big-data
[7] LURIE Marty Big data de coacutedigo abierto para el impaciente Parte 1 Tutorial Hadoop Hello World con Java Pig Hive Flume Fuse Oozie y Sqoop con Informix DB2 y MySQL IBM IBM deveoperWorks [en liacutenea] 20 de Marzo de 2013 [Consultado 14 Abril de 2016] Disponible en httpswwwibmcomdeveloperworksssadatalibrarytecharticledm-1209hadoopbigdata
[8] MATTHEW Mayo Top Big Data Processing Frameworks KdnuggetsTM KDnuggets News [en Liacutenea] Marzo de 2016 [Consultado 14 Abril de 2016] Disponible en httpwwwkdnuggetscom201603top-big-data-processing-frameworkshtml
[9] OacuteDELL Kevin How-to Select the Right Hardware for Your New Hadoop Cluster Cloudera Inc Cloudera Engineering Blog [en Liacutenea] 28 de Agosto de 2013 [Consultado 28 Mayo de 2016] Disponible en httpsblogclouderacomblog201308how-to-select-the-right-hardware-for-your-new-hadoop-cluster
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
15
[10] STEVE Dertien Defining the Infrastructure for Big Data Analytics PTC Inc El Divan Digital [en Liacutenea] 22 de Mayo de 2015 [Consultado 11Abril de 2016] Disponible en httpblogsptccom20150522defining-the-infrastructure-for-big-data-analytics
[11] The apache software foundation Hadoop Web site the Apache Software Foundation Apache Hadoop Project [en Liacutenea] 13 de Febrero de 2016 [Consultado 17 Mayo de 2016] Disponible en httphadoopapacheorg
[12] TIRADOS Marible iquestEs Hadoop el fin del almacenamiento de datos tradicional Big Data Hispano [en Liacutenea] 10 de febrero de 2014 [Consultado 07 Mayo de 2016] Disponible en httpwwwbigdatahispanoorgnoticiases-hadoop-el-fin-del-almacenamiento-de-datos
[13] SAacuteNCHEZ Joseacute Manuel iquestQUEacute ES BIG DATA T2O AdMedia Services SL 2015 [en Liacutenea] 02 de julio de 2016 [Consultado 14 Noviembre de 2016] Disponible en httpwwwt2omediacomideasactualidadque-es-big-data-2 en maricultura Meacutexico Secretariacutea de Medio Ambiente Recursos Naturales y Pesca 1997 192-207pp

ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
11
lizaraacuten el procesamiento de los datos Veacutease httpwwwhappymindse s a p a c h e - h a d o o p - i n t r o d u c c i o n - a - h d f s s t h a s h 1 A 9 o n P I j d p u f
bull Nodo de Datos (Rastreador de tareas Datanode TaskTracker) Acceden a los da-tos Almacenan los bloques de informacioacuten y los recuperan bajo demanda
Velocidad de procesamiento
En teacuterminos generales los caacutelculos requeridos para los procesos de Big Data comuacutenmen-te estaraacuten maacutes limitados por la velocidad de respuesta de las operaciones de entrada y salida a disco y de la red que por la velocidad del procesador Eso no significa que los pro-cesadores que deban emplearse en la solucioacuten requieran ser de bajo costo o pobre ren-dimiento Sino maacutes bien que eacutestos cuenten con la mayor cantidad de nuacutecleos operando a la mayor frecuencia posible para poder manejar maacutes tareas en paralelo de forma aacutegil En este sentido tambieacuten se tiene que cuidar el consumo de energiacutea y la disipacioacuten de calor asociado a la frecuencia y altos voltajes de operacioacuten de los microprocesadores que sin duda tendraacuten impactos negativos en el medio ambiente y el costo de operacioacuten de la plataforma completa
Memoria RAM
La memoria RAM necesaria para un cluacutester de Big Data normalmente deberaacute ser calcu-lada tomando en consideracioacuten varios aspectos Entre los maacutes importantes destacan
bull La cantidad de nodos de datos que contenga el cluacutester
bull El nuacutemero maacuteximo de tareas que ejecutaraacute cada nodo de datos de forma simul-taacutenea
bull La memoria necesaria para los demonios que se ejecutan en los nodos de datos de tareas y del sistema operativo
bull El nuacutemero de bloques almacenados en el sistema de archivos distribuidos
bull Las necesidades especiacuteficas del software a utilizar en la plataforma
Los detalles sobre su tecnologiacutea por supuesto que tambieacuten influiraacuten en el des-empentildeo y configuracioacuten de la solucioacuten
b) Almacenamiento
En cuanto a las caracteriacutesticas teacutecnicas del almacenamiento necesario para una plata-forma de Big Data recordemos que eacutestas deberaacuten ajustarse a los requerimientos del Framework y las aplicaciones que seraacuten utilizadas Desde esta oacuteptica nos encontraremos
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
12
que los sistemas de archivos paralelos como el HDFS (Hadoop Distributed File System) estaacuten disentildeados para expandirse en muacuteltiples nodos y manejar grandes voluacutemenes de datos y que por ende generan reacuteplicas para garantizar la tolerancia a fallos Ademaacutes tendraacuten acceso a todos los discos de forma independiente razoacuten por la cual no se sue-len utilizar RAID9 o LVM10 para agrupar los discos (ni por tolerancia a fallos ni por rendi-miento) Por otra parte las soluciones de almacenamiento deben ofrecer una tecnologiacutea robusta y confiable que soporte tanto datos estructurados como no estructurados con seguridad coherencia y credibilidad Asimismo deben
bull Disponer de una gran capacidad para almacenar datos (De acuerdo a los requeri-mientos del proyecto)
bull Deben poder escalar de forma modular faacutecilmente desde unos cuantos terabytes hasta muacuteltiples petabytes de informacioacuten
bull Contar con un muy alto rendimiento en IOPS (Operaciones de entrada y salida por segundo) Adecuado en tiempo real
bull Soportar y controlar todo tipo de datos
bull Contar con una tecnologiacutea que asegure una gran proteccioacuten para los datos
Recordemos tambieacuten que el tema del respaldo de la informacioacuten se volveraacute criacutetico cuan-do hablamos de terabytes o petabytes de informacioacuten Esto si no contamos con una infraestructura suficientemente robusta que asegure la preservacioacuten de la informacioacuten al paso del tiempo11
c) Redes de datos
En teacuterminos generales el software para Big Data hace un uso muy intensivo de la red Esto debido a que todos los nodos intercambian grandes voluacutemenes de datos tanto en un esquema normal de operacioacuten como en el caso de fallo de alguacuten nodo La razoacuten de este aumento de traacutefico en la red causado por la falla en alguacuten nodo del cluacutester se debe principalmente a que Hadoop obliga al resto de los nodos a que se pongan a replicar los datos para mantener la integridad de la informacioacuten Por estos mo-tivos es recomendable utilizar switches preferentemente de alta velocidad y dedicados para el uso exclusivo del cluacutester Dada la naturaleza del Big Data se requiere que la red a utilizar cuente con las siguientes caracteriacutesticas funcionales
bull Gran velocidad
bull Alta disponibilidad
bull Redundancia
[9] En informaacutetica el acroacute-nimo RAID (del ingleacutes Redundant Array of Inexpensive Disks o maacutes comuacuten a diacutea de hoy Redundant Array of Independent Disks) tra-ducido como laquoconjunto redundante de discos Independientesraquo hace referencia a un sistema de almacenamiento de datos en tiempo real que utiliza muacuteltiples unida-des de almacenamiento de datos (discos duros o SSD) entre los que se distribuyen o replican los datos Dependiendo de su configuracioacuten (a la que suele llamarse laquonivelraquo) los beneficios de un RAID respecto a un uacutenico disco son uno o varios de los siguientes mayor integridad ma-yor tolerancia a fallos mayor throughput (ren-dimiento) y mayor capa-cidad Fuente httpseswikipediaorgwikiRAID
[10] Logical Volume Mana-gement (LVM) en espa-ntildeol ldquoadministrador de voluacutemenes loacutegicosrdquo es una opcioacuten de gestioacuten de discos que todas las principales distribu-ciones de GNULinux presentan Ya sea que necesite para configurar grupos de almacena-miento o simplemente se necesite para crear dinaacutemicamente las par-ticiones LVM Veacutease httpsparbaedloword-presscom20120105que-es-lvm-como-se-administra-y-utiliza
[11] Veacutease httpwwwcom-puterweeklycomfea-tureBig-data-storage-choices
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
13
bull Resistencia a fallas
bull Alta capacidad de resolver situaciones de congestionamiento en la red
bull Consistencia
bull Faacutecil de escalabilidad
bull Altamente administrable
bull Resilencia (Capacidad de continuar funcionando dentro de paraacutemetros acepta-bles ante distintos tipos de problemas)
Resulta claro que a mayor velocidad el costo de la red se incrementaraacute Por tal motivo se puede iniciar con velocidades de conectividad a 1 Gbit y jugar con opciones de agre-gacioacuten de puertos para mejorar el desempentildeo12 No obstante el mejor desempentildeo se lograraacute con la tecnologiacutea de 10 Gbit o superior Por otra parte a mayor nuacutemero de nodos en el cluacutester la velocidad de la red seraacute un factor clave para su buen desempentildeo13 Como podremos darnos cuenta recomendar una configuracioacuten de hardware ideal para un proyecto de Big Data no es una tarea sencilla Algunos pasos para comenzar a definirla son
bull Identificar las preguntas que deberaacute responder la plataforma de Big Data
bull La urgencia de respuesta
bull Identificar las fuentes de informacioacuten de donde se deberaacute extraer la informacioacuten a procesar Incluso pueden ser a partir de programas de TV en tiempo real o el flujo de mensajes proveniente de redes sociales
bull Cuantificar la cantidad de informacioacuten con que se deberaacute trabajar
Con esta informacioacuten los especialistas en soluciones de Big Data podraacuten ayu-darle con facilidad No olvide que la infraestructura requeriraacute no solo de una inversioacuten importante sino tambieacuten de una serie de nuevas habilidades y conocimientos en el per-sonal para desarrollar las aplicaciones No obstante brindaraacute oportunidades reales de valor de negocio en nuestras empresas o instituciones [12] Consiste en el uso de va-
rios puertos de red o en-laces para incrementar la velocidad de comuni-cacioacuten Veacutease httpseswikipediaorgwikiAgregaciC3B3n_de_enlaces
[8] Veacutease httpsearchdata-centertechtargetcomescronicaSeis-conside-raciones-para-redes-de-big-data
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
14
Bibliografiacutea
[1] ALFOCEA J Detenido por amenazas a su alcalde en Redes Sociales Delitos informaacuteticos 2015 Revista legal [en liacutenea] Fecha de actualizacioacuten 22 septiembre 2015 [Consulta 6 de octubre de 2016] Disponible en httpwwwdelitosinformaticoscom092015delitosamenazas-2-delitosdetenido-amenazar-alcalde-redes-sociales
[2]CACHEIRO Javier Requisitos Hardware Big Data Fundacioacuten Puacuteblica Galega Centro Tecnoloacutexico de Supercomputacioacuten de Galicia CESGA [en Liacutenea] Fecha de actualizacioacuten 16 de Marzo de 2015 [Consultado 25 de Mayo de 2016] Disponible en httpswwwcesgaesesbibliotecadownloadAssetid775
[3] Enauro engineering services BIG DATA [En Liacutenea] [Consultado 14 de Noviembre de 2016] Disponible en httpwwwenaurocom20160610big-data
[4] HURTADO Gork Big Data y Hadoop Cloudera vs Hortonworks Mondragon Unibertsitatea Investigacioacuten en TICs [en Liacutenea] [Consultado 3 Mayo de 2016] Disponible en httpmukommondragoneduictbig-data-y-hadoop-cloudera-vs-hortonworks
[5] JCASANELLA Introduccioacuten a Hadoop y su ecosistema Ticout Outsourcing Center Tutoriales de Yellowfin y BI [En Liacutenea] Fecha de actualizacioacuten 01 de Abril de 2013 [Consultado 19 Mayo de 2016] Disponible en httpwwwticoutcomblog20130402introduccion-a-hadoop-y-su-ecosistema
[6] LOSHIN David Explorando distribuciones Hadoop para gestionar big data TechTarget SA de CV Guiacutea Escencial [En Liacutenea] Enero de 2016 [Consultado 14 Abril de 2016] Disponible es httpsearchdatacentertechtargetcomescronicaExplorando-distribuciones-Hadoop-para-gestionar-big-data
[7] LURIE Marty Big data de coacutedigo abierto para el impaciente Parte 1 Tutorial Hadoop Hello World con Java Pig Hive Flume Fuse Oozie y Sqoop con Informix DB2 y MySQL IBM IBM deveoperWorks [en liacutenea] 20 de Marzo de 2013 [Consultado 14 Abril de 2016] Disponible en httpswwwibmcomdeveloperworksssadatalibrarytecharticledm-1209hadoopbigdata
[8] MATTHEW Mayo Top Big Data Processing Frameworks KdnuggetsTM KDnuggets News [en Liacutenea] Marzo de 2016 [Consultado 14 Abril de 2016] Disponible en httpwwwkdnuggetscom201603top-big-data-processing-frameworkshtml
[9] OacuteDELL Kevin How-to Select the Right Hardware for Your New Hadoop Cluster Cloudera Inc Cloudera Engineering Blog [en Liacutenea] 28 de Agosto de 2013 [Consultado 28 Mayo de 2016] Disponible en httpsblogclouderacomblog201308how-to-select-the-right-hardware-for-your-new-hadoop-cluster
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
15
[10] STEVE Dertien Defining the Infrastructure for Big Data Analytics PTC Inc El Divan Digital [en Liacutenea] 22 de Mayo de 2015 [Consultado 11Abril de 2016] Disponible en httpblogsptccom20150522defining-the-infrastructure-for-big-data-analytics
[11] The apache software foundation Hadoop Web site the Apache Software Foundation Apache Hadoop Project [en Liacutenea] 13 de Febrero de 2016 [Consultado 17 Mayo de 2016] Disponible en httphadoopapacheorg
[12] TIRADOS Marible iquestEs Hadoop el fin del almacenamiento de datos tradicional Big Data Hispano [en Liacutenea] 10 de febrero de 2014 [Consultado 07 Mayo de 2016] Disponible en httpwwwbigdatahispanoorgnoticiases-hadoop-el-fin-del-almacenamiento-de-datos
[13] SAacuteNCHEZ Joseacute Manuel iquestQUEacute ES BIG DATA T2O AdMedia Services SL 2015 [en Liacutenea] 02 de julio de 2016 [Consultado 14 Noviembre de 2016] Disponible en httpwwwt2omediacomideasactualidadque-es-big-data-2 en maricultura Meacutexico Secretariacutea de Medio Ambiente Recursos Naturales y Pesca 1997 192-207pp

ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
12
que los sistemas de archivos paralelos como el HDFS (Hadoop Distributed File System) estaacuten disentildeados para expandirse en muacuteltiples nodos y manejar grandes voluacutemenes de datos y que por ende generan reacuteplicas para garantizar la tolerancia a fallos Ademaacutes tendraacuten acceso a todos los discos de forma independiente razoacuten por la cual no se sue-len utilizar RAID9 o LVM10 para agrupar los discos (ni por tolerancia a fallos ni por rendi-miento) Por otra parte las soluciones de almacenamiento deben ofrecer una tecnologiacutea robusta y confiable que soporte tanto datos estructurados como no estructurados con seguridad coherencia y credibilidad Asimismo deben
bull Disponer de una gran capacidad para almacenar datos (De acuerdo a los requeri-mientos del proyecto)
bull Deben poder escalar de forma modular faacutecilmente desde unos cuantos terabytes hasta muacuteltiples petabytes de informacioacuten
bull Contar con un muy alto rendimiento en IOPS (Operaciones de entrada y salida por segundo) Adecuado en tiempo real
bull Soportar y controlar todo tipo de datos
bull Contar con una tecnologiacutea que asegure una gran proteccioacuten para los datos
Recordemos tambieacuten que el tema del respaldo de la informacioacuten se volveraacute criacutetico cuan-do hablamos de terabytes o petabytes de informacioacuten Esto si no contamos con una infraestructura suficientemente robusta que asegure la preservacioacuten de la informacioacuten al paso del tiempo11
c) Redes de datos
En teacuterminos generales el software para Big Data hace un uso muy intensivo de la red Esto debido a que todos los nodos intercambian grandes voluacutemenes de datos tanto en un esquema normal de operacioacuten como en el caso de fallo de alguacuten nodo La razoacuten de este aumento de traacutefico en la red causado por la falla en alguacuten nodo del cluacutester se debe principalmente a que Hadoop obliga al resto de los nodos a que se pongan a replicar los datos para mantener la integridad de la informacioacuten Por estos mo-tivos es recomendable utilizar switches preferentemente de alta velocidad y dedicados para el uso exclusivo del cluacutester Dada la naturaleza del Big Data se requiere que la red a utilizar cuente con las siguientes caracteriacutesticas funcionales
bull Gran velocidad
bull Alta disponibilidad
bull Redundancia
[9] En informaacutetica el acroacute-nimo RAID (del ingleacutes Redundant Array of Inexpensive Disks o maacutes comuacuten a diacutea de hoy Redundant Array of Independent Disks) tra-ducido como laquoconjunto redundante de discos Independientesraquo hace referencia a un sistema de almacenamiento de datos en tiempo real que utiliza muacuteltiples unida-des de almacenamiento de datos (discos duros o SSD) entre los que se distribuyen o replican los datos Dependiendo de su configuracioacuten (a la que suele llamarse laquonivelraquo) los beneficios de un RAID respecto a un uacutenico disco son uno o varios de los siguientes mayor integridad ma-yor tolerancia a fallos mayor throughput (ren-dimiento) y mayor capa-cidad Fuente httpseswikipediaorgwikiRAID
[10] Logical Volume Mana-gement (LVM) en espa-ntildeol ldquoadministrador de voluacutemenes loacutegicosrdquo es una opcioacuten de gestioacuten de discos que todas las principales distribu-ciones de GNULinux presentan Ya sea que necesite para configurar grupos de almacena-miento o simplemente se necesite para crear dinaacutemicamente las par-ticiones LVM Veacutease httpsparbaedloword-presscom20120105que-es-lvm-como-se-administra-y-utiliza
[11] Veacutease httpwwwcom-puterweeklycomfea-tureBig-data-storage-choices
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
13
bull Resistencia a fallas
bull Alta capacidad de resolver situaciones de congestionamiento en la red
bull Consistencia
bull Faacutecil de escalabilidad
bull Altamente administrable
bull Resilencia (Capacidad de continuar funcionando dentro de paraacutemetros acepta-bles ante distintos tipos de problemas)
Resulta claro que a mayor velocidad el costo de la red se incrementaraacute Por tal motivo se puede iniciar con velocidades de conectividad a 1 Gbit y jugar con opciones de agre-gacioacuten de puertos para mejorar el desempentildeo12 No obstante el mejor desempentildeo se lograraacute con la tecnologiacutea de 10 Gbit o superior Por otra parte a mayor nuacutemero de nodos en el cluacutester la velocidad de la red seraacute un factor clave para su buen desempentildeo13 Como podremos darnos cuenta recomendar una configuracioacuten de hardware ideal para un proyecto de Big Data no es una tarea sencilla Algunos pasos para comenzar a definirla son
bull Identificar las preguntas que deberaacute responder la plataforma de Big Data
bull La urgencia de respuesta
bull Identificar las fuentes de informacioacuten de donde se deberaacute extraer la informacioacuten a procesar Incluso pueden ser a partir de programas de TV en tiempo real o el flujo de mensajes proveniente de redes sociales
bull Cuantificar la cantidad de informacioacuten con que se deberaacute trabajar
Con esta informacioacuten los especialistas en soluciones de Big Data podraacuten ayu-darle con facilidad No olvide que la infraestructura requeriraacute no solo de una inversioacuten importante sino tambieacuten de una serie de nuevas habilidades y conocimientos en el per-sonal para desarrollar las aplicaciones No obstante brindaraacute oportunidades reales de valor de negocio en nuestras empresas o instituciones [12] Consiste en el uso de va-
rios puertos de red o en-laces para incrementar la velocidad de comuni-cacioacuten Veacutease httpseswikipediaorgwikiAgregaciC3B3n_de_enlaces
[8] Veacutease httpsearchdata-centertechtargetcomescronicaSeis-conside-raciones-para-redes-de-big-data
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
14
Bibliografiacutea
[1] ALFOCEA J Detenido por amenazas a su alcalde en Redes Sociales Delitos informaacuteticos 2015 Revista legal [en liacutenea] Fecha de actualizacioacuten 22 septiembre 2015 [Consulta 6 de octubre de 2016] Disponible en httpwwwdelitosinformaticoscom092015delitosamenazas-2-delitosdetenido-amenazar-alcalde-redes-sociales
[2]CACHEIRO Javier Requisitos Hardware Big Data Fundacioacuten Puacuteblica Galega Centro Tecnoloacutexico de Supercomputacioacuten de Galicia CESGA [en Liacutenea] Fecha de actualizacioacuten 16 de Marzo de 2015 [Consultado 25 de Mayo de 2016] Disponible en httpswwwcesgaesesbibliotecadownloadAssetid775
[3] Enauro engineering services BIG DATA [En Liacutenea] [Consultado 14 de Noviembre de 2016] Disponible en httpwwwenaurocom20160610big-data
[4] HURTADO Gork Big Data y Hadoop Cloudera vs Hortonworks Mondragon Unibertsitatea Investigacioacuten en TICs [en Liacutenea] [Consultado 3 Mayo de 2016] Disponible en httpmukommondragoneduictbig-data-y-hadoop-cloudera-vs-hortonworks
[5] JCASANELLA Introduccioacuten a Hadoop y su ecosistema Ticout Outsourcing Center Tutoriales de Yellowfin y BI [En Liacutenea] Fecha de actualizacioacuten 01 de Abril de 2013 [Consultado 19 Mayo de 2016] Disponible en httpwwwticoutcomblog20130402introduccion-a-hadoop-y-su-ecosistema
[6] LOSHIN David Explorando distribuciones Hadoop para gestionar big data TechTarget SA de CV Guiacutea Escencial [En Liacutenea] Enero de 2016 [Consultado 14 Abril de 2016] Disponible es httpsearchdatacentertechtargetcomescronicaExplorando-distribuciones-Hadoop-para-gestionar-big-data
[7] LURIE Marty Big data de coacutedigo abierto para el impaciente Parte 1 Tutorial Hadoop Hello World con Java Pig Hive Flume Fuse Oozie y Sqoop con Informix DB2 y MySQL IBM IBM deveoperWorks [en liacutenea] 20 de Marzo de 2013 [Consultado 14 Abril de 2016] Disponible en httpswwwibmcomdeveloperworksssadatalibrarytecharticledm-1209hadoopbigdata
[8] MATTHEW Mayo Top Big Data Processing Frameworks KdnuggetsTM KDnuggets News [en Liacutenea] Marzo de 2016 [Consultado 14 Abril de 2016] Disponible en httpwwwkdnuggetscom201603top-big-data-processing-frameworkshtml
[9] OacuteDELL Kevin How-to Select the Right Hardware for Your New Hadoop Cluster Cloudera Inc Cloudera Engineering Blog [en Liacutenea] 28 de Agosto de 2013 [Consultado 28 Mayo de 2016] Disponible en httpsblogclouderacomblog201308how-to-select-the-right-hardware-for-your-new-hadoop-cluster
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
15
[10] STEVE Dertien Defining the Infrastructure for Big Data Analytics PTC Inc El Divan Digital [en Liacutenea] 22 de Mayo de 2015 [Consultado 11Abril de 2016] Disponible en httpblogsptccom20150522defining-the-infrastructure-for-big-data-analytics
[11] The apache software foundation Hadoop Web site the Apache Software Foundation Apache Hadoop Project [en Liacutenea] 13 de Febrero de 2016 [Consultado 17 Mayo de 2016] Disponible en httphadoopapacheorg
[12] TIRADOS Marible iquestEs Hadoop el fin del almacenamiento de datos tradicional Big Data Hispano [en Liacutenea] 10 de febrero de 2014 [Consultado 07 Mayo de 2016] Disponible en httpwwwbigdatahispanoorgnoticiases-hadoop-el-fin-del-almacenamiento-de-datos
[13] SAacuteNCHEZ Joseacute Manuel iquestQUEacute ES BIG DATA T2O AdMedia Services SL 2015 [en Liacutenea] 02 de julio de 2016 [Consultado 14 Noviembre de 2016] Disponible en httpwwwt2omediacomideasactualidadque-es-big-data-2 en maricultura Meacutexico Secretariacutea de Medio Ambiente Recursos Naturales y Pesca 1997 192-207pp

ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
13
bull Resistencia a fallas
bull Alta capacidad de resolver situaciones de congestionamiento en la red
bull Consistencia
bull Faacutecil de escalabilidad
bull Altamente administrable
bull Resilencia (Capacidad de continuar funcionando dentro de paraacutemetros acepta-bles ante distintos tipos de problemas)
Resulta claro que a mayor velocidad el costo de la red se incrementaraacute Por tal motivo se puede iniciar con velocidades de conectividad a 1 Gbit y jugar con opciones de agre-gacioacuten de puertos para mejorar el desempentildeo12 No obstante el mejor desempentildeo se lograraacute con la tecnologiacutea de 10 Gbit o superior Por otra parte a mayor nuacutemero de nodos en el cluacutester la velocidad de la red seraacute un factor clave para su buen desempentildeo13 Como podremos darnos cuenta recomendar una configuracioacuten de hardware ideal para un proyecto de Big Data no es una tarea sencilla Algunos pasos para comenzar a definirla son
bull Identificar las preguntas que deberaacute responder la plataforma de Big Data
bull La urgencia de respuesta
bull Identificar las fuentes de informacioacuten de donde se deberaacute extraer la informacioacuten a procesar Incluso pueden ser a partir de programas de TV en tiempo real o el flujo de mensajes proveniente de redes sociales
bull Cuantificar la cantidad de informacioacuten con que se deberaacute trabajar
Con esta informacioacuten los especialistas en soluciones de Big Data podraacuten ayu-darle con facilidad No olvide que la infraestructura requeriraacute no solo de una inversioacuten importante sino tambieacuten de una serie de nuevas habilidades y conocimientos en el per-sonal para desarrollar las aplicaciones No obstante brindaraacute oportunidades reales de valor de negocio en nuestras empresas o instituciones [12] Consiste en el uso de va-
rios puertos de red o en-laces para incrementar la velocidad de comuni-cacioacuten Veacutease httpseswikipediaorgwikiAgregaciC3B3n_de_enlaces
[8] Veacutease httpsearchdata-centertechtargetcomescronicaSeis-conside-raciones-para-redes-de-big-data
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
14
Bibliografiacutea
[1] ALFOCEA J Detenido por amenazas a su alcalde en Redes Sociales Delitos informaacuteticos 2015 Revista legal [en liacutenea] Fecha de actualizacioacuten 22 septiembre 2015 [Consulta 6 de octubre de 2016] Disponible en httpwwwdelitosinformaticoscom092015delitosamenazas-2-delitosdetenido-amenazar-alcalde-redes-sociales
[2]CACHEIRO Javier Requisitos Hardware Big Data Fundacioacuten Puacuteblica Galega Centro Tecnoloacutexico de Supercomputacioacuten de Galicia CESGA [en Liacutenea] Fecha de actualizacioacuten 16 de Marzo de 2015 [Consultado 25 de Mayo de 2016] Disponible en httpswwwcesgaesesbibliotecadownloadAssetid775
[3] Enauro engineering services BIG DATA [En Liacutenea] [Consultado 14 de Noviembre de 2016] Disponible en httpwwwenaurocom20160610big-data
[4] HURTADO Gork Big Data y Hadoop Cloudera vs Hortonworks Mondragon Unibertsitatea Investigacioacuten en TICs [en Liacutenea] [Consultado 3 Mayo de 2016] Disponible en httpmukommondragoneduictbig-data-y-hadoop-cloudera-vs-hortonworks
[5] JCASANELLA Introduccioacuten a Hadoop y su ecosistema Ticout Outsourcing Center Tutoriales de Yellowfin y BI [En Liacutenea] Fecha de actualizacioacuten 01 de Abril de 2013 [Consultado 19 Mayo de 2016] Disponible en httpwwwticoutcomblog20130402introduccion-a-hadoop-y-su-ecosistema
[6] LOSHIN David Explorando distribuciones Hadoop para gestionar big data TechTarget SA de CV Guiacutea Escencial [En Liacutenea] Enero de 2016 [Consultado 14 Abril de 2016] Disponible es httpsearchdatacentertechtargetcomescronicaExplorando-distribuciones-Hadoop-para-gestionar-big-data
[7] LURIE Marty Big data de coacutedigo abierto para el impaciente Parte 1 Tutorial Hadoop Hello World con Java Pig Hive Flume Fuse Oozie y Sqoop con Informix DB2 y MySQL IBM IBM deveoperWorks [en liacutenea] 20 de Marzo de 2013 [Consultado 14 Abril de 2016] Disponible en httpswwwibmcomdeveloperworksssadatalibrarytecharticledm-1209hadoopbigdata
[8] MATTHEW Mayo Top Big Data Processing Frameworks KdnuggetsTM KDnuggets News [en Liacutenea] Marzo de 2016 [Consultado 14 Abril de 2016] Disponible en httpwwwkdnuggetscom201603top-big-data-processing-frameworkshtml
[9] OacuteDELL Kevin How-to Select the Right Hardware for Your New Hadoop Cluster Cloudera Inc Cloudera Engineering Blog [en Liacutenea] 28 de Agosto de 2013 [Consultado 28 Mayo de 2016] Disponible en httpsblogclouderacomblog201308how-to-select-the-right-hardware-for-your-new-hadoop-cluster
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
15
[10] STEVE Dertien Defining the Infrastructure for Big Data Analytics PTC Inc El Divan Digital [en Liacutenea] 22 de Mayo de 2015 [Consultado 11Abril de 2016] Disponible en httpblogsptccom20150522defining-the-infrastructure-for-big-data-analytics
[11] The apache software foundation Hadoop Web site the Apache Software Foundation Apache Hadoop Project [en Liacutenea] 13 de Febrero de 2016 [Consultado 17 Mayo de 2016] Disponible en httphadoopapacheorg
[12] TIRADOS Marible iquestEs Hadoop el fin del almacenamiento de datos tradicional Big Data Hispano [en Liacutenea] 10 de febrero de 2014 [Consultado 07 Mayo de 2016] Disponible en httpwwwbigdatahispanoorgnoticiases-hadoop-el-fin-del-almacenamiento-de-datos
[13] SAacuteNCHEZ Joseacute Manuel iquestQUEacute ES BIG DATA T2O AdMedia Services SL 2015 [en Liacutenea] 02 de julio de 2016 [Consultado 14 Noviembre de 2016] Disponible en httpwwwt2omediacomideasactualidadque-es-big-data-2 en maricultura Meacutexico Secretariacutea de Medio Ambiente Recursos Naturales y Pesca 1997 192-207pp

ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
14
Bibliografiacutea
[1] ALFOCEA J Detenido por amenazas a su alcalde en Redes Sociales Delitos informaacuteticos 2015 Revista legal [en liacutenea] Fecha de actualizacioacuten 22 septiembre 2015 [Consulta 6 de octubre de 2016] Disponible en httpwwwdelitosinformaticoscom092015delitosamenazas-2-delitosdetenido-amenazar-alcalde-redes-sociales
[2]CACHEIRO Javier Requisitos Hardware Big Data Fundacioacuten Puacuteblica Galega Centro Tecnoloacutexico de Supercomputacioacuten de Galicia CESGA [en Liacutenea] Fecha de actualizacioacuten 16 de Marzo de 2015 [Consultado 25 de Mayo de 2016] Disponible en httpswwwcesgaesesbibliotecadownloadAssetid775
[3] Enauro engineering services BIG DATA [En Liacutenea] [Consultado 14 de Noviembre de 2016] Disponible en httpwwwenaurocom20160610big-data
[4] HURTADO Gork Big Data y Hadoop Cloudera vs Hortonworks Mondragon Unibertsitatea Investigacioacuten en TICs [en Liacutenea] [Consultado 3 Mayo de 2016] Disponible en httpmukommondragoneduictbig-data-y-hadoop-cloudera-vs-hortonworks
[5] JCASANELLA Introduccioacuten a Hadoop y su ecosistema Ticout Outsourcing Center Tutoriales de Yellowfin y BI [En Liacutenea] Fecha de actualizacioacuten 01 de Abril de 2013 [Consultado 19 Mayo de 2016] Disponible en httpwwwticoutcomblog20130402introduccion-a-hadoop-y-su-ecosistema
[6] LOSHIN David Explorando distribuciones Hadoop para gestionar big data TechTarget SA de CV Guiacutea Escencial [En Liacutenea] Enero de 2016 [Consultado 14 Abril de 2016] Disponible es httpsearchdatacentertechtargetcomescronicaExplorando-distribuciones-Hadoop-para-gestionar-big-data
[7] LURIE Marty Big data de coacutedigo abierto para el impaciente Parte 1 Tutorial Hadoop Hello World con Java Pig Hive Flume Fuse Oozie y Sqoop con Informix DB2 y MySQL IBM IBM deveoperWorks [en liacutenea] 20 de Marzo de 2013 [Consultado 14 Abril de 2016] Disponible en httpswwwibmcomdeveloperworksssadatalibrarytecharticledm-1209hadoopbigdata
[8] MATTHEW Mayo Top Big Data Processing Frameworks KdnuggetsTM KDnuggets News [en Liacutenea] Marzo de 2016 [Consultado 14 Abril de 2016] Disponible en httpwwwkdnuggetscom201603top-big-data-processing-frameworkshtml
[9] OacuteDELL Kevin How-to Select the Right Hardware for Your New Hadoop Cluster Cloudera Inc Cloudera Engineering Blog [en Liacutenea] 28 de Agosto de 2013 [Consultado 28 Mayo de 2016] Disponible en httpsblogclouderacomblog201308how-to-select-the-right-hardware-for-your-new-hadoop-cluster
ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
15
[10] STEVE Dertien Defining the Infrastructure for Big Data Analytics PTC Inc El Divan Digital [en Liacutenea] 22 de Mayo de 2015 [Consultado 11Abril de 2016] Disponible en httpblogsptccom20150522defining-the-infrastructure-for-big-data-analytics
[11] The apache software foundation Hadoop Web site the Apache Software Foundation Apache Hadoop Project [en Liacutenea] 13 de Febrero de 2016 [Consultado 17 Mayo de 2016] Disponible en httphadoopapacheorg
[12] TIRADOS Marible iquestEs Hadoop el fin del almacenamiento de datos tradicional Big Data Hispano [en Liacutenea] 10 de febrero de 2014 [Consultado 07 Mayo de 2016] Disponible en httpwwwbigdatahispanoorgnoticiases-hadoop-el-fin-del-almacenamiento-de-datos
[13] SAacuteNCHEZ Joseacute Manuel iquestQUEacute ES BIG DATA T2O AdMedia Services SL 2015 [en Liacutenea] 02 de julio de 2016 [Consultado 14 Noviembre de 2016] Disponible en httpwwwt2omediacomideasactualidadque-es-big-data-2 en maricultura Meacutexico Secretariacutea de Medio Ambiente Recursos Naturales y Pesca 1997 192-207pp

ldquoInfraestructura para Big Datardquo Javier Salazar Argonza
1 de noviembre de 2016 | Vol 17 | Nuacutem 11 | ISSN 1607 - 6079 httpwwwrevistaunammxvol17num11art77
Departamento de Acervos Digitales Direccioacuten General de Coacutemputo y de Tecnologiacuteas de Informacioacuten y Comunicacioacuten ndash UNAM Esta obra estaacute bajo una licencia de Creative Commons
15
[10] STEVE Dertien Defining the Infrastructure for Big Data Analytics PTC Inc El Divan Digital [en Liacutenea] 22 de Mayo de 2015 [Consultado 11Abril de 2016] Disponible en httpblogsptccom20150522defining-the-infrastructure-for-big-data-analytics
[11] The apache software foundation Hadoop Web site the Apache Software Foundation Apache Hadoop Project [en Liacutenea] 13 de Febrero de 2016 [Consultado 17 Mayo de 2016] Disponible en httphadoopapacheorg
[12] TIRADOS Marible iquestEs Hadoop el fin del almacenamiento de datos tradicional Big Data Hispano [en Liacutenea] 10 de febrero de 2014 [Consultado 07 Mayo de 2016] Disponible en httpwwwbigdatahispanoorgnoticiases-hadoop-el-fin-del-almacenamiento-de-datos
[13] SAacuteNCHEZ Joseacute Manuel iquestQUEacute ES BIG DATA T2O AdMedia Services SL 2015 [en Liacutenea] 02 de julio de 2016 [Consultado 14 Noviembre de 2016] Disponible en httpwwwt2omediacomideasactualidadque-es-big-data-2 en maricultura Meacutexico Secretariacutea de Medio Ambiente Recursos Naturales y Pesca 1997 192-207pp


















