
Base de Datos
178
Anl. Mauricio Arévalo M. - Pág. 1 - INDICE INDICE ____________________________________________________________1 INTRODUCCIÓN ____________________________________________________4 CAPITULO I: LAS BASES DE DATOS ___________________________________6 1.1. Historia ______________________________________________________6 1.2. Objetivos de los Sistemas de Gestión de Bases de Datos _______________7 1.3. Ventajas y Desventajas de los Sistemas de Bases de Datos _____________9 1.3.1. Ventajas _________________________________________________10 1.3.2. Desventajas ______________________________________________11 1.4. Generalidades y Características de las Bases de Datos________________11 1.4.1. Abstracción de Datos _______________________________________12 1.4.2. Modelos de Datos__________________________________________14 1.4.3. Integridad en la base de datos ________________________________16 1.4.4. Normalización de la base de datos_____________________________17 1.5. Los Sistemas de Gestión de Bases de Datos (SGBD) _________________19 1.5.1. Estructura del Sistema de Gestión de Base de Datos ____________21 1.6. Lenguaje de Definición de datos (DDL)_____________________________22 1.7. Lenguaje de Manipulación de Datos (DML) _________________________23 CAPITULO II: LENGUAJE ESTRUCTURADO DE CONSULTAS (SQL) ________24 2.1. Historia ______________________________________________________24 2.2. Características y Estructura ______________________________________25 2.2.1. Comandos _____________________________________________29 2.2.2. Cláusulas ________________________________________________29 2.2.3. Operadores lógicos ________________________________________30 2.2.4. Operadores de Comparación _________________________________30 2.2.5. Funciones de Agregado _____________________________________31 CAPITULO III: LICENCIAMIENTO DE SOFTWARE________________________32 3.1. Licencias de Software __________________________________________32 3.2. Software Libre ________________________________________________33 3.2.1. Tipos de Licencias de Software Libre___________________________34 3.3. Software Propietario____________________________________________36 3.3.1. Tipos de Licencias de Software Propietario ______________________37 CAPITULO IV: MY SQL______________________________________________39 4.1. Historia y Antecedentes _________________________________________39 4.2. Características y Funcionalidad del Servidor MySQL___________________40 4.3. Estructura del Servidor MySQL ___________________________________56
-
Upload
deltha-child -
Category
Documents
-
view
298 -
download
4
Transcript of Base de Datos

Anl. Mauricio Arévalo M.
- Pág. 1 -
INDICE
INDICE ____________________________________________________________1 INTRODUCCIÓN ____________________________________________________4 CAPITULO I: LAS BASES DE DATOS___________________________________6
1.1. Historia ______________________________________________________6 1.2. Objetivos de los Sistemas de Gestión de Bases de Datos _______________7 1.3. Ventajas y Desventajas de los Sistemas de Bases de Datos _____________9
1.3.1. Ventajas _________________________________________________10 1.3.2. Desventajas ______________________________________________11
1.4. Generalidades y Características de las Bases de Datos________________11 1.4.1. Abstracción de Datos _______________________________________12 1.4.2. Modelos de Datos__________________________________________14 1.4.3. Integridad en la base de datos ________________________________16 1.4.4. Normalización de la base de datos_____________________________17
1.5. Los Sistemas de Gestión de Bases de Datos (SGBD) _________________19 1.5.1. Estructura del Sistema de Gestión de Base de Datos ____________21
1.6. Lenguaje de Definición de datos (DDL)_____________________________22 1.7. Lenguaje de Manipulación de Datos (DML) _________________________23
CAPITULO II: LENGUAJE ESTRUCTURADO DE CONSULTAS (SQL) ________24
2.1. Historia ______________________________________________________24 2.2. Características y Estructura ______________________________________25
2.2.1. Comandos _____________________________________________29 2.2.2. Cláusulas ________________________________________________29 2.2.3. Operadores lógicos ________________________________________30 2.2.4. Operadores de Comparación _________________________________30 2.2.5. Funciones de Agregado _____________________________________31
CAPITULO III: LICENCIAMIENTO DE SOFTWARE________________________32
3.1. Licencias de Software __________________________________________32 3.2. Software Libre ________________________________________________33
3.2.1. Tipos de Licencias de Software Libre___________________________34 3.3. Software Propietario____________________________________________36
3.3.1. Tipos de Licencias de Software Propietario ______________________37 CAPITULO IV: MY SQL______________________________________________39
4.1. Historia y Antecedentes _________________________________________39 4.2. Características y Funcionalidad del Servidor MySQL___________________40 4.3. Estructura del Servidor MySQL ___________________________________56

Anl. Mauricio Arévalo M.
- Pág. 2 -
4.3.1. Tipos de Tablas _________________________________________58 4.3.2. Tipos de Datos de MySQL _________________________________60
4.4. Ventajas y Desventajas de MySQL ________________________________61 4.4.1. Ventajas _______________________________________________61 4.4.2. Desventajas ______________________________________________63
4.5. Gestión de Bases de Datos MySQL________________________________63 4.5.1. Cliente mysql _____________________________________________66 4.5.2. Mysqladmin ______________________________________________70 4.5.3. Myisampack ______________________________________________71 4.5.4. Mysqlcheck y Myisamchk ____________________________________72 4.5.5. Mysqlimport ______________________________________________73 4.5.6. Mysqldump y Mysqlhotcopy __________________________________73 4.5.7. Perror ___________________________________________________74 4.5.8. MySQL Administrator _______________________________________75 4.5.12. MySQL Front _____________________________________________79 4.5.13. PhpMyAdmin _____________________________________________81 4.5.14. MySQL Developer Studio ____________________________________83 4.5.15. DBDesigner ______________________________________________84
4.6. Instalación y Configuración de MySQL______________________________84 4.6.1. Instalación sobre Windows___________________________________85 4.6.2. Instalación sobre Linux______________________________________92
CAPITULO V: PostgreSQL___________________________________________95
5.1. Historia y Antecedentes _________________________________________95 5.2. Características y Funcionalidad de PostgreSQL ______________________97 5.3. Estructura del servidor PostgreSQL _______________________________110
5.3.1. Tipos de Tablas ________________________________________112 5.3.2. Tipos de Datos _________________________________________113
5.4. Ventajas y Desventajas de PostgreSQL____________________________114 5.4.1. Ventajas ______________________________________________114 5.4.2. Desventajas ___________________________________________116
5.5. Gestión de Bases de Datos PostgreSQL ___________________________117 5.5.1. psql____________________________________________________117 5.5.2. pg_dump y pg_dumpall ____________________________________120 5.5.3. pg_restore ______________________________________________122 5.5.4. createdb y dropdb_________________________________________123 5.5.5. Postmaster y pg_ctl _______________________________________124 5.5.6. PgAdmin________________________________________________125 5.5.7. PhpPgAdmin ____________________________________________127 5.5.8. EMS SQL Manager para PostgreSQL _________________________129
5.6. Instalación de PostgreSQL______________________________________131 5.6.1. Instalación sobre Windows__________________________________132 5.6.2. Instalación sobre Linux_____________________________________137
5.7. Configuración de PostgreSQL ___________________________________142 5.7.1. Archivo postgresql.conf ____________________________________143 5.7.2. Archivo pg_hba.conf_______________________________________144 5.7.3. Archivo pg_ident.conf______________________________________147 5.7.4. Finalización de la Configuración______________________________148

Anl. Mauricio Arévalo M.
- Pág. 3 -
CAPITULO VI: Otros Sistemas Gestores de Bases de Datos______________151 6.1. Oracle ___________________________________________________151 6.2. Microsoft SQL Server________________________________________153 6.3. SQL Lite__________________________________________________154 6.4. HSQLDB _________________________________________________155 6.5. Firebird___________________________________________________155 6.6. Informix __________________________________________________156 6.7. Comparaciones ____________________________________________157
CONCLUSIONES _________________________________________________160 RECOMENDACIONES _____________________________________________162 ANEXOS ________________________________________________________163 ANEXO A: MODOS DE MySQL ______________________________________163 ANEXO B: TIPOS DE DATOS EN POSTGRESQL________________________166 ANEXO C: ALTERNATIVAS PARA BUSINESS INTELLIGENCE (BI) _________167 ANEXO D: CONEXIONES PARA MySQL y PostgreSQL ___________________168 GLOSARIO ______________________________________________________ 172 BIBLIOGRAFIA___________________________________________________ 177

Anl. Mauricio Arévalo M.
- Pág. 4 -
INTRODUCCIÓN
Desde el punto de vista de que el bien más preciado para una empresa u organización
es su información, los medios mediante los cuales se guarda y se manipula la misma deben
ser en lo posible los más seguros y confiables para asegurar la integridad y veracidad de
dicha información. La importancia de la información en la mayoría de organizaciones, y por
tanto el valor de la base de datos, ha llevado al desarrollo de una gran cantidad de conceptos y
técnicas para la gestión eficiente de los datos.
El objetivo primordial de un Sistema de Gestión de Bases de Datos (SGBD o DBMS)
es proporcionar un entorno que sea a la vez conveniente y eficiente para manipular la
información o datos contenidos en las bases de datos. El mercado de sistemas manejadores de
bases de datos es bastante grande y ofrece diversas alternativas a la hora de elegir un software
en el cual confiar.
Para un profesional informático, el tomar una decisión con respecto a la herramienta
de gestión de bases de datos por cual inclinarse, cual es la óptima, cual nos ofrece mayores
garantías en un desarrollo de software específico y que detalles de implementación se
deberían tener en cuenta para asegurar el correcto desempeño de un sistema informático de
calidad, se convierte en una gran preocupación y responsabilidad en el diseño y desarrollo
de dicho sistema informático.
Entonces, es de vital importancia y prioridad el conocimiento de las características,
ventajas, desventajas, las herramientas de administración que dispone un determinado sistema
de gestión de bases de datos, además de las características de los sistemas informáticos que se
van a desarrollar y los requerimientos de los mismos; de modo que las características de estas
herramientas de gestión de bases de datos se ajusten a los requerimientos de nuestros sistemas
informáticos.

Anl. Mauricio Arévalo M.
- Pág. 5 -
En la presente monografía, inicialmente se analiza de una manera generalizada los
objetivos y naturaleza de los sistemas gestores de bases de datos; explicando su historia y
como se ha desarrollado el concepto de sistema de base de datos, qué es lo que hace un
sistema de gestión de bases de datos, sus componentes y características principales.
Se realiza luego un estudio general a cerca del lenguaje SQL (Lenguaje Estructurado
de Consultas), sus antecedentes, características, normas actuales, tipos de datos y sus
principales comandos de los que hacen uso los manejadores de las bases de datos que se dan a
conocer en la presente investigación. También son objeto de estudio los distintos tipos de
licenciamientos de software que existen y las licencias de software libre como GPL (Licencia
Pública General).
Se ponen en conocimiento las características, componentes y estructura, herramientas,
uso, ventajas y desventajas de dos de los manejadores de bases de datos con licenciamiento
libre más usados que actualmente existen en el medio y que se pueden ofrecer como bases de
datos para Sistemas Web o en sistemas empresariales con las respectivas versiones para
distintos sistemas operativos (Windows, MAC o Linux). Las bases de datos de software libre
que se analizan detalladamente en la presente monografía; por su uso popular entre su tipo y
sus muy buenas características técnicas son MySQL y PostgreSQL.
Además, para tener otros parámetros de evaluación a la hora de elegir el gestor de
bases de datos que mejor se acomode a nuestros requerimientos, en el último capítulo se dan
a conocer conceptos básicos sobre otros gestores de bases de datos de software libre como
Firebird, HSQLDB y SQLite y otros sistemas gestores de bases de datos que están bajo
licenciamiento propietario y comercial como Oracle, Informix y Microsoft SQL Server.
De esta manera, pretendo contribuir logrando que la presente investigación sirva como
un instrumento de información y orientación para estudiantes y profesionales vinculados
con el área de sistemas y desarrollo de software dando a conocer las características principales
de los dos productos de software libre más utilizados en el área de bases de datos a un costo
gratuito de licenciamiento, con libertad de modificación, con un potente desempeño y muy
buenas herramientas administrativas.

Anl. Mauricio Arévalo M.
- Pág. 6 -
CAPITULO I
LAS BASES DE DATOS
1.1. Historia
Antes de las bases de datos que hoy conocemos, se utilizaban ficheros secuenciales
como almacenes de datos. Estos daban un acceso muy rápido pero sólo de forma secuencial,
más tarde aparecieron los ficheros indexados, donde el acceso ya podía ser aleatorio; el
sistema de ficheros era el sistema más común de almacenamiento de datos.
Pero los programas y datos cada vez eran más complejos y grandes, por tal motivo se
requería de un almacenamiento que garantizara un cierto número de condiciones y que
permitiera operaciones complejas sin que se violaran estas restricciones. Además cada
usuario que accediera a los datos debía tener su trabajo protegido de las operaciones que
hicieran el resto de usuarios, respondiendo a estas necesidades, surgieron las bases de datos
jerárquicas, donde los datos se situaban siguiendo una jerarquía.
A mitad de los sesenta, se desarrolló el proyecto IDS (Integrated Data Store), de
General Electric. IDS era un nuevo tipo de sistema de bases de datos conocido como bases de
datos en red, y en parte se desarrolló para satisfacer la necesidad de representar relaciones
entre datos más complejas que las que se podían modelar con los sistemas jerárquicos. Los
sistemas jerárquico y de red constituyen la primera generación de los SGBD (Sistemas de
Gestión de Base de Datos).

Anl. Mauricio Arévalo M.
- Pág. 7 -
En 1970, en los laboratorios de investigación de IBM, se escribió un artículo
presentando el modelo de bases de datos relacionales. En este artículo, presentaba también
los inconvenientes de los sistemas previos (el jerárquico y el de red), y entonces se
comenzaron a desarrollar muchos sistemas relacionales, apareciendo los primeros a finales de
los setenta y principios de los ochenta. Esto condujo al desarrollo de un lenguaje de consultas
estructurado denominado SQL, que se ha convertido en el lenguaje estándar de los sistemas
relacionales.
El modelo de bases de datos relacionales se utiliza para describir la estructura de una
base de datos, las relaciones entre los datos, las restricciones, la semántica, etc., y es el que ha
marcado la línea de investigación por muchos años hasta la actualidad, existiendo cientos de
SGBDs relacionales. Los SGBDs relacionales constituyen la segunda generación de los
Sistemas de Gestión de Bases de Datos.
En 1976, se presentó el modelo entidad-relación; además, en los últimos años han
surgido dos nuevos modelos: el modelo de datos orientado a objetos y el modelo relacional
extendido. Sin embargo, a diferencia de los modelos que los preceden, la composición de
estos últimos modelos no está del todo clara. Esta evolución representa la tercera
generación de los sistemas gestores de bases de datos.
1.2. Objetivos de los Sistemas de Gestión de Bases de Datos
En el caso de los primeros sistemas típicos de procesamiento de archivos apoyados por
un sistema operativo convencional, los registros de diversas transacciones permanecían
almacenados en varios archivos y se escribían un número de diferentes programas de
aplicación para extraer, eliminar, actualizar y añadir registros a los archivos apropiados.
Estos tipos de sistemas tenían varias desventajas o problemas importantes entre los
cuales tenemos la redundancia e inconsistencia de datos, la dificultad para tener acceso a los
datos, el aislamiento de los mismos, las anomalías en los datos cuando se presentaban accesos
concurrentes y la seguridad e integridad de la información.

Anl. Mauricio Arévalo M.
- Pág. 8 -
Debido a estas dificultades, entre otras, se ha fomentado el desarrollo de los Sistemas
Gestores de Bases de Datos, los cuales proporcionan un interfaz eficiente entre aplicaciones y
el sistema operativo, consiguiendo, entre otras cosas, que el acceso a los datos se realice de
una forma más eficiente, más fácil de implementar y sobre todo, más segura.
El objetivo principal de un Sistema de Gestión de Bases de Datos es proporcionar un
entorno y las herramientas necesarias, convenientes y eficientes para manipular la
información o datos contenidos en las bases de datos, de una manera rápida, fácil y segura.
Los Sistemas de Gestión de Bases de Datos (SGBD) tratan de cumplir los siguientes
objetivos específicos:
• Abstracción de la información: Los SGBD ahorran a los usuarios detalles acerca del
almacenamiento y mantenimiento físico de los datos. Para lograr este objetivo, se
definen varios niveles de abstracción (físico, conceptual y de visión).
• Independencia: La independencia de los datos consiste en la capacidad de modificar
el esquema (físico o lógico) de una base de datos sin tener que realizar cambios en las
aplicaciones que se sirven de ella.
• Redundancia mínima: Un buen diseño de una base de datos logrará evitar la
aparición de información repetida o redundante. Lo ideal es lograr una redundancia
nula; no obstante, en algunos casos la complejidad de los cálculos hace necesaria la
aparición de ciertas redundancias.
• Consistencia: En aquellos casos en los que no se ha logrado una redundancia nula, es
necesario vigilar que aquella información que aparece repetida se actualice de forma
coherente, es decir, que todos los datos relacionados se actualicen de forma simultánea y
no aparezcan inconsistencias de dichos datos entre distintas tablas o archivos.
• Seguridad: La información almacenada en una base de datos llega a tener un gran
valor para cualquier organización. Los SGBD deben garantizar que esta información se
encuentre asegurada frente a usuarios malintencionados que intenten leer la información

Anl. Mauricio Arévalo M.
- Pág. 9 -
privilegiada y no autorizada a ellos o simplemente ante las distracciones de algún
usuario que puede estar autorizado, y por ello, los SGBD disponen de un sistema de
distintas clases de permisos a usuarios o grupos de usuarios.
• Integridad: Se trata de adoptar las medidas necesarias para garantizar la validez y
consistencia de los datos almacenados. Es decir, se trata de proteger los datos ante
fallos de hardware, datos introducidos por usuarios descuidados, o cualquier otra
circunstancia capaz de corromper la información almacenada.
• Respaldo y recuperación: Los SGBD deben proporcionar una forma eficiente de
realizar copias de seguridad de la información almacenada en ellos, y de restaurar a
partir de dichas copias los datos que se hayan podido perder o dañar.
• Control de la concurrencia: En la mayoría de entornos, lo más habitual es que sean
muchas las personas que acceden a una base de datos y es también frecuente que dichos
accesos se realicen de forma simultánea. Así pues, un SGBD debe ser capaz de
controlar este acceso concurrente a la información, que podría derivar en inconsistencias
en los datos.
• Tiempo de respuesta: Siempre se trata de minimizar el tiempo en que el SGBD tarda
en darnos la información solicitada y en almacenar o actualizar los cambios realizados
en los datos.
1.3. Ventajas y Desventajas de los Sistemas de Bases de Datos
Los sistemas de bases de datos presentan numerosas ventajas, y de la misma manera
traen ciertas desventajas o inconvenientes. A continuación menciono las más importantes:

Anl. Mauricio Arévalo M.
- Pág. 10 -
1.3.1. Ventajas
• Disponibilidad: Cuando se aplica la metodología de bases de datos, cada usuario ya no
es propietario de los datos, puesto que éstos se comparten entre el todo el conjunto de
aplicaciones, existiendo una mejor disponibilidad de los datos para todos los que tienen
necesidad de ellos.
• Facilidad de uso: Existen diferentes maneras de extraer la información almacenada en
una base de datos, por ejemplo, un programador lo puede realizar por medio de
instrucciones SQL, los usuarios lo pueden realizar por medio de las aplicaciones o
herramientas disponibles, obteniendo velocidad y precisión.
• Coherencia de los resultados: En todas las aplicaciones que hacen uso de las bases de
datos se utilizan los mismos datos, por lo que los resultados de todos ellos son
coherentes y perfectamente comparables.
• Confidencialidad y seguridad en el manejo de los datos: Toda la información puede
estar centralizada en un solo punto y debidamente clasificada pudiendo acceder a ella
con seguridad dependiendo del perfil con que se ingresa al sistema.
• Mantenimiento de estándares: Gracias a la integración es más fácil respetar los
estándares necesarios, tanto los establecidos a nivel de la empresa u organización como
los nacionales e internacionales.
• Aumento de la concurrencia: La mayoría de los SGBD gestionan el acceso
concurrente a la base de datos por parte de los usuarios y garantizan que no ocurran
problemas de inconsistencias en los datos.
• Mejora en las copias de seguridad y de recuperación ante fallos: Los SGBD nos dan
la posibilidad de hacer copias de seguridad o “Backups” de las bases de datos por si se
produce algún fallo o anomalía, utilizando estas copias de seguridad para restaurar los
datos.

Anl. Mauricio Arévalo M.
- Pág. 11 -
1.3.2. Desventajas
• Complejidad: Los SGBD son conjuntos de programas complejos con una gran
funcionalidad. Es preciso comprender muy bien esta funcionalidad para poder sacar un
buen provecho de ellos.
• Tamaño: Los SGBD son programas complejos y muy extensos que requieren una gran
cantidad de espacio en disco y de memoria para trabajar de forma eficiente.
• Coste económico del SGBD: El coste de un SGBD con licencia comercial, varía
dependiendo del entorno y de la funcionalidad que ofrece, lo cual se puede reducir con
el uso de Sistemas de Gestión de Bases de Datos con licenciamiento libre que ofrezcan
características similares. En algunas ocasiones, también es alto el coste de convertir y
migrar una aplicación con un nuevo sistema de gestión de bases de datos.
• Vulnerabilidad ante fallos: El hecho de que todo se centralice en el SGBD hace que el
sistema sea más vulnerable ante los fallos que puedan producirse, por lo que se debe
tener un proceso seguro para realizar copias de respaldo de la base de datos y un
correcto plan de contingencia, en caso de producirse cualquier fallo o anomalía.
1.4. Generalidades y Características de las Bases de Datos
Para diferenciar entre lo que es una Base de Datos y un Sistema de Gestión de Base de
Datos tenemos los siguientes conceptos:
Un Atributo o campo es cualquier elemento de información susceptible de tomar
valores; mientras que un Dominio comprende un rango de valores de donde toma sus datos
un atributo.
Una Base de Datos es una colección o depósito de datos integrados con redundancia
controlada y con una estructura que refleja las interrelaciones y restricciones existentes en el

Anl. Mauricio Arévalo M.
- Pág. 12 -
mundo real. Los procedimientos de actualización y recuperación de los datos deberían ser
capaces de conservar la integridad del conjunto de los mismos.
Un Sistema de Gestión de Bases de Datos (SGBD o DBMS), es el conjunto de
programas que se encargan de manejar la creación, administración, las seguridades y accesos
a las bases de datos que forman parte del SGBD. La principal función de un SGBD debe ser
la de proporcionar a los usuarios la capacidad de almacenar datos en la base de datos, acceder
a ellos y actualizarlos o modificarlos de forma correcta, sin violar las restricciones
establecidas.
Un SGBD se compone de un lenguaje de definición de datos (DDL) y de un lenguaje
de manipulación de datos (DML), en este último se incluye un lenguaje de consulta de datos.
La funcionalidad de las bases de datos ha ido aumentando de forma considerable, ya
que gran parte de la semántica de los datos que se encontraba dispersa en distintos programas
o aplicaciones se ha ido migrando hacia el servidor de datos. Surgen así las bases de datos
activas, deductivas, orientadas a objetos, multimedia, temporales, los almacenes de datos
(datawarehouse1) y la minería de datos (datamining2).
1.4.1. Abstracción de Datos
Un objetivo importante de una base de datos es proporcionar a los usuarios una visión
abstracta de los datos, es decir, la capacidad del sistema de esconder ciertos detalles de cómo
se almacenan y se mantienen los datos.
Así se han creado los niveles de abstracción indicados a continuación para simplificar la
interacción de los usuarios comunes o avanzados con el sistema:
1 Data Warehouse (DW) es un almacén o repositorio de datos categorizados, que concentra un gran volumen de información de interés para toda una organización. Genera aplicaciones que ayudan en la toma de decisiones. 2 Data mining o minería de datos a la solución de “Business Intelligence” (Inteligencia de Negocios) que consiste en un conjunto de técnicas avanzadas para la extracción de información predecible escondida en grandes bases de datos.

Anl. Mauricio Arévalo M.
- Pág. 13 -
• Nivel físico: Es la representación del nivel más bajo de abstracción, en éste se describe
en detalle la forma de como se almacenan los datos en los dispositivos de
almacenamiento (por ejemplo, mediante punteros o índices para el acceso aleatorio a los
datos).
• Nivel conceptual: Es el siguiente nivel más alto de abstracción, describe que datos son
almacenados realmente en la base de datos y las relaciones que existen entre los
mismos, aquí se describe la base de datos completa en términos de su estructura de
diseño. Este nivel lo utilizan los administradores de bases de datos, quienes deben
decidir qué información se va a guardar en la base de datos.
• Nivel de visión: Es el nivel más alto de abstracción, muestra solo lo que el usuario final
puede visualizar del sistema terminado ya que no necesita toda la información contenida
en la base de datos. Este nivel describe sólo una parte de la base de datos al usuario
acreditado para verla y se puede proporcionar muchas visiones en este nivel para la
misma base de datos.
La interrelación entre estos tres niveles de abstracción se ilustra en la siguiente figura:
Figura 1.1: Niveles de Abstracción de Datos

Anl. Mauricio Arévalo M.
- Pág. 14 -
1.4.2. Modelos de Datos
Un modelo no es más que una representación de la realidad que contiene las
características generales de algo que se va a realizar. En base de datos, esta representación se
la elabora de forma gráfica.
Un Modelo de Datos es una colección de herramientas conceptuales para describir los
datos, las relaciones que asocian a los mismos, su semántica y las restricciones para conservar
su consistencia. Los modelos de datos se pueden dividir en tres grupos:
• Modelos lógicos basados en objetos: Se usan para describir datos en los niveles
conceptual y de visión, es decir, con este modelo representamos los datos de tal forma
como nosotros los captamos en el mundo real, tienen una capacidad de estructuración
bastante flexible y permiten especificar restricciones de datos explícitamente. Existen
diferentes modelos de este tipo, como el modelo orientado a objetos, el modelo binario,
semántico, infológico; sin embargo el más utilizado por su sencillez y eficiencia es el
modelo Entidad-Relación, el cual representa a la realidad a través de una colección de
objetos básicos denominados entidades, y las relaciones entre estos objetos. Estas
relaciones cumplen con una restricción de la base de datos conocida como “cardinalidad
de asignación”, que nos representa el número de entidades a las que se puede asociar
otra entidad mediante un conjunto de relaciones; las mismas que pueden ser: uno a uno,
uno a muchos y muchos a muchos.
Figura 1.2: Modelo E-R (entidad Empleado relacionada con entidad Artículo con relación venta)
• Modelos lógicos basados en registros: Se utilizan para describir datos en los niveles
conceptual y físico. Estos modelos utilizan registros e instancias para representar la
realidad, así como las relaciones que existen entre estos registros. A diferencia de los

Anl. Mauricio Arévalo M.
- Pág. 15 -
modelos de datos basados en objetos, se usan para especificar la estructura lógica global
de la base de datos y para proporcionar una descripción a un nivel más alto de la
implementación. La base de datos está estructurada en registros agrupados de varios
tipos, y cada tipo de registros define un número fijo de campos o atributos. Los tres
modelos lógicos más importantes son:
� Modelo de red Este modelo representa los datos mediante colecciones de
registros y sus relaciones se representan por medio de ligas o enlaces, los cuales
pueden verse como punteros. Los registros se organizan en un conjunto de
gráficas arbitrarias, como se puede observar en la siguiente figura:
Figura 1.3: Modelo de red (con registros de dos entidades enlazadas arbitrariamente)
� Modelo jerárquico: Es similar al modelo de red en cuanto a que los datos y sus
relaciones se representan por medio de registros y sus enlaces o ligas. La
diferencia radica en que están organizados por conjuntos o colecciones de árboles
en lugar de gráficas arbitrarias como se muestra a continuación:
Figura 1.4: Modelo jerárquico (con registros de dos entidades enlazadas en estructura de árbol)
� Modelo Relacional: En este modelo se representan los datos y las relaciones entre
estos, a través de una colección de tablas en las cuales los renglones o tuplas
equivalen a los cada uno de los registros que contendrá la base de datos y las
columnas corresponden a las características (atributos) de cada registro.

Anl. Mauricio Arévalo M.
- Pág. 16 -
Figura 1.5: Modelo jerárquico (con registros de dos entidades enlazadas en estructura de árbol)
• Modelos físicos de datos: Se usan para describir a los datos en el nivel más bajo,
aunque existen muy pocos modelos de este tipo, básicamente capturan aspectos de la
implementación de los sistemas de base de datos.
1.4.3. Integridad en la base de datos
En un momento dado, los valores de los datos en una base de datos son una
representación de un fragmento de la realidad.
Las reglas de integridad son normas que ayudan a mantener la semántica y la
consistencia en los datos. Es decir, si tenemos una tabla con los atributos de personas y entre
ellos el peso o la edad, estos no pueden ser negativos porque en el mundo real esto no es
posible. Si añadimos una restricción de este tipo a una base de datos, estamos incluyéndole
una regla de integridad. Así, las bases de datos relacionales tienen reglas generales de
integridad que se clasifican en:
• Integridad específica: Donde depende de la semántica de los datos y su dominio para
que se cumpla este tipo de integridad. Por ejemplo, en un atributo o campo “edad”, para
que un valor sea válido o admitido debe ser mayor que 0 y menor que 100
(0≤edad≤100).

Anl. Mauricio Arévalo M.
- Pág. 17 -
• Integridad genérica: Donde depende del papel que juegue un atributo en el diseño de la
tabla, es decir, si forma parte de la llave primaria, única o foránea. Dentro de este tipo
de integridad, existe la integridad de entidades y la integridad referencial.
La integridad de las entidades verifica que ningún componente de la llave primaria de
una relación puede aceptar valores nulos ni valores que dupliquen la llave primaria en otro
registro de la entidad. Esta regla de integridad se aplica en procesos de inserción y
actualización de los datos.
La integridad referencial es una propiedad de las bases de datos relacionales y gracias
a ella se garantiza que una entidad siempre se relacione con otras entidades válidas, es decir,
que existan en la base de datos. La idea es que tengamos una concordancia entre los datos de
dos entidades mediante sus relaciones. Este proceso se aplica en procesos de inserción,
actualización y eliminación de los datos.
En el modelo de bases de datos relacionales, para representar las relaciones entre las
entidades (tablas), debemos saber que una Clave candidata o única es un atributo o conjunto
de atributos que identifican unívocamente a una tupla o registro, es decir, no hay dos tuplas
con dos claves candidatas iguales. En una relación puede haber más de una clave candidata,
por lo que una de las claves candidatas se debe adoptar como clave primaria.
Una clave primaria es un atributo o conjunto de atributos que los definimos como
atributo principal de entre las claves candidatas, de tal manera que se pueda identificar de
forma única a una entidad, mientras que una clave foránea es un atributo (también puede ser
compuesto) de una entidad cuyos valores deben de concordar con los de una llave primaria de
alguna otra entidad relacionada.
1.4.4. Normalización de la base de datos
La normalización de una base de datos puede considerarse como un proceso durante el
cual los esquemas de relación insatisfactorios se descomponen repartiendo sus atributos entre
esquemas de relación más pequeños que poseen las propiedades deseables.

Anl. Mauricio Arévalo M.
- Pág. 18 -
Un objetivo del proceso de normalización es garantizar que no ocurran las anomalías
en la actualización, ayudando también a la eliminación de información redundante en las
tuplas o registros. A continuación se presentan brevemente las tres primeras formas normales,
para ello seguiré el ejemplo con la siguiente Entidad “R”, que tiene los datos de la compra de
un cliente, la misma que se la irá pasando de una forma normal a otra:
R (Código_cliente, Nombre_cliente, Direccion_cliente, Número_factura, Fecha, Valor)
• Primera Forma Normal: Una relación se encuentra en primera forma normal cuando
no hay grupos repetidos entre sus atributos. Esta condición es una restricción inherente
al modelo relacional, y por tanto, el ejemplo dado está al menos en primera forma
normal (1FN).
• Segunda Forma Normal: Una relación se encuentra en segunda forma normal (2FN)
cuando está en 1FN y además todos los atributos que no forman parte de una clave
candidata dan información sobre la clave principal. El ejemplo en 2FN quedaría de la
siguiente forma:
R1 (Código_cliente, Nombre_ cliente, Direccion_ cliente)
R2 (Número_Factura, Código_ cliente, Fecha, Valor)
• Tercera Forma Normal: Una relación se encuentra en tercera forma normal (3FN)
cuando está en 2FN y además los atributos que no forman parte de una clave candidata
dan información sobre la clave principal completa y sólo sobre la clave principal. El
ejemplo anterior en 3FN quedaría así:
R1 (Código_cliente, Nombre_ cliente, Direccion_ cliente)
R2 (Numero_Factura, Codigo_cliente)
R3 (Numero_Factura, Fecha, Valor)

Anl. Mauricio Arévalo M.
- Pág. 19 -
1.5. Los Sistemas de Gestión de Bases de Datos (SGBD)
La base de datos es una colección de archivos interrelacionados almacenados en
conjunto sin redundancia y un Sistema de Gestión de Bases de Datos (SGBD o DBMS) se lo
describe como un conjunto de numerosas rutinas de software interrelacionadas, cada una de
las cuales es responsable de una determinada tarea. Las funciones principales de un Sistema
de Gestión de Bases de Datos son:
• Proporcionar a los usuarios la capacidad de almacenar datos en la base de datos, acceder
a ellos y actualizarlos. Esta es la función fundamental de un SGBD.
• Establecer y mantener las trayectorias de acceso a la base de datos de tal forma que los
datos puedan ser accedidos rápidamente.
• Registrar el uso de las base de datos, es decir mantener registros de accesos, usuarios,
tipos de transacciones realizadas en la base de datos.
• Interactuar con el manejador de archivos, lo cual se lo realiza mediante la traducción de
las distintas sentencias DML a comandos del sistema de archivos de bajo nivel; ya que
los datos se almacenan en el disco usando el sistema de archivos que normalmente es
proporcionado por un sistema operativo convencional. Así el Manejador de bases de
datos es el responsable del verdadero almacenamiento, recuperación y actualización de
los datos en la base de datos.
• Respaldar y recuperar información, ya que un SGBD debe contar con mecanismos o
rutinas adecuadas que permitan la recuperación fácilmente de los datos en caso de
ocurrir fallas en el sistema de base de datos.
• Tener control de concurrencia, que consiste en controlar la interacción de los usuarios
cuando actualizan la base de datos concurrentemente o al mismo tiempo, evitando
afectar la consistencia de los datos.

Anl. Mauricio Arévalo M.
- Pág. 20 -
• Mantener la seguridad, la cual consiste en contar con mecanismos que permitan el
control de la información de la base de datos, evitando que los datos se vean
perjudicados por cambios no autorizados o imprevistos por usuarios no autorizados;
algunos SGBD disponen de un sistema de permisos a usuarios y grupos de usuarios.
• Mantener la integridad de los datos, adoptando las medidas necesarias para garantizar la
validez y consistencia de los datos almacenados. Para ello, los datos que se almacenan
en la base de datos deben satisfacer ciertos tipos de restricciones de integridad.
• Un SGBD debe proporcionar un catálogo en el que se almacena información que
describe los datos de una base de datos (meta datos). A este catálogo se denomina
diccionario de datos.
• Un SGBD debería proporcionar un mecanismo que controle y garantice que todas las
transacciones3 se realicen si no existen errores, o que no se realice ninguna.
• Un SGBD debe ser capaz de integrarse con algún software (protocolos) de
comunicación. Muchos usuarios acceden a la base de datos desde terminales y ellos se
encuentran conectados a la máquina sobre la que funciona el SGBD mediante una red
local o de área extensa. En cualquiera de los casos, el SGBD recibe peticiones en forma
de mensajes y responde de modo similar.
Figura 1.6: Interacción del Usuario con la Base de datos a través del DBMS
3 Una Transacción es un conjunto de acciones tales como inserciones, eliminaciones y actualizaciones que cambian el contenido de una base de datos.

Anl. Mauricio Arévalo M.
- Pág. 21 -
1.5.1. Estructura del Sistema de Gestión de Base de Datos
Un sistema de base de datos se encuentra dividido en módulos, cada uno de los cuales
controla una parte de la responsabilidad total de sistema. En la mayoría de los casos, el
sistema operativo proporciona únicamente los servicios más básicos y el sistema de gestión de
bases de datos debe partir de estos servicios y controlar además el manejo correcto de los
datos. Así el diseño de un sistema de gestión de bases de datos incluye la interfaz entre el
sistema de base de datos y el sistema operativo.
Los componentes más importantes de un Sistema de Gestión de Bases de Datos o
SGBD, son:
• Gestor de archivos: Gestiona la asignación de espacio en la memoria del disco y de las
estructuras de datos usadas para representar información.
• Manejador de base de datos: Sirve de interfaz entre los datos y los programas de
aplicación.
• Procesador de consultas: Traduce las proposiciones en lenguajes de consulta a
instrucciones de bajo nivel comprensibles por el gestor de la base de Datos.
• Compilador de DDL: Convierte las proposiciones o sentencias DDL (Lenguaje de
Definición de Datos) en un conjunto de tablas que contienen metadatos4, estas se
almacenan en el diccionario de datos.
• Archivo de datos: En él se encuentran almacenados físicamente los datos de una base
de datos.
• Indices: Que permiten un rápido acceso a registros de datos que contienen valores
específicos.
4 Metadatos son “datos” o información acerca de la estructura de los datos que forman una tabla o entidad.

Anl. Mauricio Arévalo M.
- Pág. 22 -
En la figura 1.7 se representan los principales componentes de un SGBD y la relación
que existe entre ellos:
Figura 1.7: Estructura de un Sistema de Gestión de Bases de Datos
1.6. Lenguaje de Definición de datos (DDL)
Una vez finalizado el diseño de una base de datos y escogido un SGBD para su
implementación, el primer paso consiste en especificar el esquema conceptual y el esquema
interno o físico de la base de datos. Para ello, el administrador de la base de datos o los
diseñadores utilizan el lenguaje de definición de datos (DDL), el resultado de su

Anl. Mauricio Arévalo M.
- Pág. 23 -
compilación es un conjunto de tablas. Además el SGBD posee un compilador de DDL que
procesa las sentencias del lenguaje para identificar las descripciones de los distintos
elementos y almacenar su descripción en el diccionario de datos.
1.7. Lenguaje de Manipulación de Datos (DML)
“Una vez creados los esquemas de la base de datos, los usuarios necesitan un lenguaje
que les permita manipular los datos de la base de datos: realizar consultas, inserciones,
eliminaciones y modificaciones”5. Este lenguaje es el que se denomina lenguaje de manejo
o manipulación de datos (DML).
Existen dos tipos de lenguajes de manejo de datos: los procedurales y los no
procedurales; con un DML procedural el usuario especifica qué datos se necesitan y cómo
hay que obtenerlos. Las bases de datos jerárquicas y de red utilizan un DML procedural y sus
sentencias deben estar embebidas o contenidas en un lenguaje de alto nivel, ya que se
necesitan sus estructuras (bucles, condicionales, etc.) para obtener y procesar cada registro
individual. A este lenguaje de alto nivel se le denomina lenguaje anfitrión.
Un DML no procedural se puede utilizar de manera independiente para especificar
operaciones complejas sobre la base de datos de forma concisa. El usuario o programador
especifica qué datos quiere obtener sin decir cómo se debe acceder a ellos, siendo el SGBD
quien traduce las sentencias del DML en uno o varios procedimientos que manipulan los
conjuntos de registros necesarios, haciendo más fácil el trabajo del usuario.
A los DML no procedurales también se los denomina declarativos y las bases de datos
relacionales utilizan un DML no procedural, como SQL (Structured Query Language) o QBE
(Query By Example). La parte de los DML no procedurales que se dedica a la obtención o
recuperación de datos es la que se conoce como lenguaje de consultas de datos.
5 Tomado de http://es.tldp.org/Tutoriales/NOTAS-CURSO-BBDD/notas-curso-BD/node3.html

Anl. Mauricio Arévalo M.
- Pág. 24 -
CAPITULO II
LENGUAJE ESTRUCTURADO DE CONSULTAS (SQL)
2.1. Historia
El Lenguaje de Consultas Estructurado o SQL (Structured Query Languaje) empieza
en 1974, por parte de Donald Chamberlin y de otras personas que trabajaban en los
laboratorios de investigación de IBM, como un lenguaje para la especificación de las
características de bases de datos que adoptaban el modelo relacional. Inicialmente este
lenguaje se llamaba SEQUEL (Structured English Query Language) y se implementó en un
prototipo llamado SEQUEL-XRM entre 1974 y 1975.
Las experimentaciones con ese prototipo condujeron, entre 1976 y 1977 a una revisión
del lenguaje (SEQUEL/2), que a partir de ese momento cambió de nombre por motivos
legales, convirtiéndose en SQL. El prototipo del sistema de base de datos relacional, basado
en este lenguaje, se adoptó y se utilizó internamente en 1981 en la empresa IBM con su
producto DB2. Gracias al éxito de este sistema, otras compañías como Oracle y Sybase
empezaron a desarrollar sus productos relacionales basados en SQL en la década de los
ochenta.
En 1986, el ANSI (American National Standards Institute) adoptó SQL como estándar
para los lenguajes relacionales y en 1987 se transformó en estándar ISO (International

Anl. Mauricio Arévalo M.
- Pág. 25 -
Standarization Organization); esta versión del estándar tuvo el nombre de SQL/86. En los
años siguientes, este estándar ha sufrido diversas revisiones y mejoras que han conducido
primero a la versión SQL/89 y posteriormente, a la versión SQL/92 que es utilizado en
algunos SGBDs hasta la actualidad.
Hasta 1999 se siguió un proceso de revisión y mejora del lenguaje por parte de los
comités ANSI e ISO, que terminó en la definición de lo que en este momento se conoce como
SQL3. Sin embargo SQL3 está caracterizado como “SQL orientado a objetos” y es la base de
algunos sistemas de manejo de bases de datos orientadas a objetos (como ORACLE,
Informix’Universal Server, IBM’s DB Universal Database y Cloudscape, entre muchos
otros).
SQL es realmente un esfuerzo de colaboración internacional, que cumple las normas de
organismos de estandarización como ANSI e ISO. Desde el punto de vista práctico, el hecho
de tener un estándar definido por un lenguaje para bases de datos relacionales abre
potencialmente el camino a la intercomunicación y compatibilidad entre todos los productos
que se basan en él. Lamentablemente, muchos proveedores de sistemas de gestión de Bases
de Datos adoptan e implementan en la propia base de datos sólo el corazón del lenguaje SQL,
extendiéndolo de manera individual según la propia visión que cada proveedor tenga del
mundo de las bases de datos.
2.2. Características y Estructura
SQL es una herramienta para organizar, gestionar y recuperar datos almacenados en
una base de datos informática.
SQL engloba totalmente los lenguajes DDL (Lenguaje de Definición de Datos) y
DML (Lenguaje de Manipulación de Datos). Es un lenguaje de base de datos normalizado y
eficiente, utilizado por los diferentes gestores de bases de datos para realizar determinadas
operaciones sobre los datos o sobre la estructura de los mismos.

Anl. Mauricio Arévalo M.
- Pág. 26 -
SQL es un lenguaje de consulta de datos de cuarta generación. Lo que cabe destacar es
que mientras un lenguaje de tercera generación (3GL) como COBOL requiere cientos de
líneas de código, un lenguaje de cuarta generación o 4GL necesita diez o veinte líneas para
realizar la misma operación. Un 3GL es procedural, mientras que un 4GL es un lenguaje no
procedural ya que el usuario define qué se debe hacer y no cómo debe hacerse.
Los lenguajes normalizados de bases de datos SQL (Structured Query Lenguaje) y QBE
(Query by Example) son ejemplos de 4GL.
La versión SQL3 dada a conocer en 1999, se caracteriza porque fue desarrollado
principalmente para manejar objetos. Algunas de las características que están dentro de esta
categoría fueron definidas en el estándar SQL publicado en 1996, específicamente para
llamadas a funciones y procedimientos desde SQL.
Entre las características más importantes de SQL3 cabe destacar que tiene cuatro nuevos
tipos de datos; el primero de estos tipos es LARGE OBJECT (objeto grande) o LOB y las
variantes de este tipo son Character Large Object (CLOB) y Binary Large Object(BLOB).
Otro tipo de dato nuevo es el BOLEAN, que permite a SQL registrar valores lógicos de
falso o verdadero. Además se incorporan dos nuevos tipos compuestos: ARRAY y ROW.
El tipo ARRAY permite almacenar una colección de valores directamente en una
columna de una tabla, por ejemplo: Dias VARCHAR(10) ARRAY(7). El tipo ROW en SQL3
permite el almacenamiento estructurado de datos en columnas únicas de la base de datos,
por ejemplo:
CREATE TABLE empleado( emp_id INTEGER, nombre ROW( nombreVARCHAR(30), apellido VARCHAR(30)), direccion ROW(calle VARCHAR(50), ciudad VARCHAR(30), provincia CHAR(20)), salario REAL);
y para consultar el apellido de un empleado, se debería acceder así:
SELECT E.nombre.apellido FROM empleado E;

Anl. Mauricio Arévalo M.
- Pág. 27 -
Desde la primera versión del SQL estándar, las cadenas de caracteres están limitadas a
simples comparaciones (como =, > ó <>), luego se fueron sumando las capacidades de
comparación como el predicado LIKE y del predicado DISTINCT.
SQL reconoce la noción de base de datos activa. Esto es facilitado por los conocidos
triggers (disparadores). Un trigger tiene una funcionalidad que permite a los diseñadores de
bases de datos realizar operaciones seguras siempre que una aplicación realice determinadas
operaciones en tablas particulares.
Las nuevas facilidades de seguridad en SQL tienen un papel muy importante. Los
privilegios pueden ser otorgados según un rol y este a su vez puede otorgar privilegios
individuales para otros roles. Esta estructura anidada mejora el manejo de la seguridad en el
ambiente de una base de datos.
En su estructura, SQL posee 13 tipos de datos primarios y de varios sinónimos válidos
reconocidos por dichos tipos de datos. En la siguiente tabla se muestran los tipos de datos
primarios soportados por SQL:
Tabla 2.1: Tipos de datos SQL

Anl. Mauricio Arévalo M.
- Pág. 28 -
La siguiente tabla muestra los sinónimos de los tipos de datos definidos anteriormente:
Tabla 2.2: Sinónimos de tipos de datos SQL
El lenguaje SQL básicamente está compuesto por comandos, cláusulas, operadores y
funciones de agregado. Estos elementos se combinan en las instrucciones para crear,
actualizar y manipular la estructura e información almacenada en las bases de datos.

Anl. Mauricio Arévalo M.
- Pág. 29 -
2.2.1. Comandos
Existen dos tipos de comandos SQL:
• Los comandos DDL (Lenguaje de Definición de Datos) que permiten crear, modificar,
eliminar bases de datos, tablas, campos, índices, vistas y todos los objetos que contiene
una base de datos. Entre los comandos DDL tenemos:
Tabla 2.3: Comandos DDL
• Los comandos DML (Lenguaje de Manipulación de Datos) que permiten generar
consultas para ordenar, filtrar y extraer datos de la base de datos, así como insertar,
actualizar o eliminar información de la base de datos. Entre este tipo de comandos
tenemos:
Tabla 2.4: Comandos DML
2.2.2. Cláusulas
Son condiciones de modificación utilizadas para definir los datos, entre ellas tenemos:

Anl. Mauricio Arévalo M.
- Pág. 30 -
Tabla 2.5: Cláusulas SQL
2.2.3. Operadores lógicos
Tabla 2.6: Operadores Lógicos SQL
2.2.4. Operadores de Comparación
Tabla 2.7: Operadores de Comparación

Anl. Mauricio Arévalo M.
- Pág. 31 -
2.2.5. Funciones de Agregado
Las funciones de agregado se usan dentro de una cláusula SELECT en grupos de
registros para devolver un único valor que se aplica a todo un grupo de registros.
Tabla 2.8: Funciones de Agregado

Anl. Mauricio Arévalo M.
- Pág. 32 -
CAPITULO III
LICENCIAMIENTO DE SOFTWARE
3.1. Licencias de Software
El derecho de autor o propiedad intelectual es un conjunto de normas y principios que
regulan los derechos morales y patrimoniales que la ley concede a los autores por el solo
hecho de la creación de una obra. La ley protege los derechos de los autores sobre todas las
obras del ingenio de carácter creador, ya sean de índole literaria, científica o artística,
cualesquiera sea su género, forma de expresión, mérito o destino. Entre todas estas obras del
ingenio, se consideran también los programas de computación, así como su documentación
técnica y manuales de uso.
La licencia de software es una especie de contrato, en donde se especifican todas las
normas y cláusulas que rigen el uso de un determinado programa informático, principalmente
se estipulan los alcances de uso, instalación, reproducción y la copia de estos productos. En el
momento en que se decide descargar, instalar, copiar o utilizar un determinado software,
implica que se aceptan todas las condiciones que se estipulan en el licenciamiento de dicho
software.
Licenciar un Software es el procedimiento de conceder a otra persona o entidad el
derecho legal de usar un software con fines industriales, comerciales o personales de acuerdo

Anl. Mauricio Arévalo M.
- Pág. 33 -
a las cláusulas que detalla la licencia. Esta licencia se presenta como un documento
electrónico, en papel original o como un número de serie autorizado por el autor.
Se debe tener claro el concepto de que el software libre no quiere decir que no sea
comercial. El software comercial es software, libre o no, que es comercializado, es decir que
las compañías que lo producen cobran dinero por el producto, por su distribución o por su
soporte.
3.2. Software Libre
El Software Libre es un asunto de libertad, no de precio. Es conveniente no confundir el
software libre con el software gratuito, ya que este no cuesta nada pero no por esto se
convierte en software libre debido a que este tipo de software no es una cuestión de precio,
sino de libertad otorgada a los usuarios del software.
Para tener una mejor claridad de este concepto se debe pensar en libre, como en
libertad de expresión y no en algo que solamente es gratis, se refiere a la libertad de los
usuarios para ejecutar, copiar, distribuir, estudiar, cambiar y mejorar el software. En otras
palabras, se refiere a cuatro libertades principales que se les otorga a los usuarios de este tipo
de software:
• Libertad de usar o ejecutar el programa, con cualquier propósito.
• Libertad de estudiar cómo funciona el programa, y adaptarlo a las necesidades
propias, por lo que el acceso al código fuente es una condición previa para dar esta
libertad.
• Libertad de distribuir copias, con lo que se puede ayudar a otros usuarios interesados.
• Libertad de mejorar el programa original y hacer públicas las mejoras a los demás, de
modo que todos se beneficien.
El Software libre, no significa realmente que no es comercial; un programa libre puede
estar disponible para uso comercial, desarrollo comercial y distribución comercial.

Anl. Mauricio Arévalo M.
- Pág. 34 -
Los términos de Software Libre (Free Software) y recientemente de Software de fuentes
abiertas (Open Source Software), se refieren al modelo de desarrollo y de distribución del
software desarrollado cooperativamente. En vez de que el código del sistema o de cada uno
de los programas sea un secreto celosamente guardado por la empresa que lo produce, éste es
puesto a disposición del público, para que lo puedan modificar, mejorar o corregir.
Entre algunas de las más importantes aplicaciones producidas por los equipos de
desarrollo de Software Libre están:
• El sistema operativo Linux y sus diferentes versiones
• El servidor de Web Apache
• Los manejadores de bases de datos objeto-relacional como PostgreSQL y MySQL
• El navegador Mozilla
• Servidores de correo como Sendmail y Squirrel Mail
• Programas de cliente de correo electrónico como Sylpheed, GnuPG, Aspell
• El servidor de nombres de Dominio Bind
• El servidor proxy Squid
• Las suites de aplicaciones de escritorio OpenOffice, StarOffice, Abiword
• Software matemático y científico como Scilabs, Maxima, Yacas, Sistema R
• Software de dibujo y diseño como QCad, Gimp, Dia
• El Entorno de Desarrollo Integrado (IDE) “Eclipse” y el proyecto “Mono” con varias
herramientas de desarrollo para aplicaciones.
• Editores de texto de propósito general como Vim y Emacs
• Herramientas para diseño y desarrollo Web como PHP y Perl
3.2.1. Tipos de Licencias de Software Libre
Debemos conocer que ciertos conceptos como que el Freeware es software que el
usuario final puede bajar totalmente gratis de Internet; y la diferencia con el Open Source es
que el autor siempre es dueño de los derechos, o sea que el usuario no puede realizar algo que

Anl. Mauricio Arévalo M.
- Pág. 35 -
no esté expresamente autorizado por el autor del programa, como modificarlo o venderlo y no
se obliga a la distribución del código fuente.
El Shareware o software de evaluación es software que se distribuye gratis y que el
usuario puede utilizar durante algún tiempo; pero se requiere que después de un tiempo de
prueba el usuario pague por el software para continuar usando el programa. Un ejemplo de
este tipo de software son los compresores WinRar y WinZip.
Entre los tipos de licenciamiento para Open Source o software libre más conocidos
tenemos los siguientes:
• GNU GPL (General Public License): La licencia GPL se aplica al software de la FSF
(Free Software Foundation) y el proyecto GNU otorga al usuario la libertad de
compartir el software y realizar cambios en él. Dicho de otra forma, el usuario tiene
derecho a usar el programa, modificarlo y distribuir las versiones modificadas pero no
tiene permiso de realizar restricciones propias con respecto a la utilización de ese
programa modificado.
Además, esta licencia expresamente excluye el concepto de la Garantía, así como la
exclusión de la responsabilidad para el autor por las versiones modificadas,
permitiendo la copia y distribución de la obra siempre y cuando se acompañe con el
código fuente original o modificado.
• GNU LGPL (Lesser GPL): Es una variación de la licencia GPL que está destinada a
ser utilizada básicamente para las librerías. La licencia LGPL permite que obras libres
sean unidas a obras no-libres o privativas.
• GNU FDL (Free Documentation): Consiste en el equivalente de la licencia GPL pero
destinada a obras escritas y literarias, tales como manuales, libros así como otros
documentos relacionados con el producto de software.
• Perl Artistic License (PAL): Destinada fundamentalmente para programas. Permite el
uso y distribución de la obra original sin restricciones, siempre y cuando se incluya la

Anl. Mauricio Arévalo M.
- Pág. 36 -
licencia original con sus debidas excepciones. Este tipo de licencia permite el cobro de
cantidades razonables debiéndose incluir las instrucciones o manuales, el código fuente
y además se permite que la obra libre sea agregada y utilizada conjuntamente con una
obra privativa.
• BSD License: BSD (Berkeley Software Distribution) es una licencia de uso, copia,
modificación y distribución “corta”; permite que la obra sea modificada y cerrada
individualmente por un particular. Está diseñada para salvaguardar la responsabilidad
del autor, no la libertad de la obra. No obliga a la entrega del código fuente ni a la
redistribución del mismo y el usuario tiene libertad ilimitada con respecto al software,
ya que puede decidir incluso si redistribuirlo como software no libre.
3.3. Software Propietario
Por lo general cuando una empresa productora de software distribuye un producto de
este tipo, solamente entrega al comprador una copia del programa ejecutable, junto con la
autorización de ejecutar dicho programa en un número determinado de computadoras.
En el contrato que suscriben ambas partes, comúnmente denominado “licencia” del
producto, queda expresado claramente que lo que el cliente adquiere es simplemente la
facultad de utilizar dicho programa en una determinada cantidad de computadoras
(dependiendo del monto que haya abonado). El software sigue siendo propiedad de la
empresa productora del mismo y el usuario no está facultado a realizar ningún cambio.
La corrección de errores, actualizaciones o agregado de nuevas funciones en un
programa solamente puede hacerse si se dispone del código fuente. Es claro que, al ser la
empresa proveedora de software propietario la única que dispone de dicho código, solamente
ésta puede atender a los requerimientos de un cliente insatisfecho con el producto del cual ha
adquirido una licencia de uso. Esto pone al usuario en una clara situación de dependencia del
proveedor produciéndose un monopolio con dicho proveedor.

Anl. Mauricio Arévalo M.
- Pág. 37 -
3.3.1. Tipos de Licencias de Software Propietario
El software propietario está protegido bajo los derechos de autor. Al comprar una
licencia original de un producto de software, se está adquiriendo el derecho a utilizar ese
producto de acuerdo a las reglas establecidas por su autor y por tratarse de un contrato, es
necesario que el dueño de este software provea su consentimiento para que el mismo sea
utilizado por un tercero.
El contrato de licencia es la única vía legal por la cual el titular otorga este
consentimiento y dicha licencia se documenta en el Acuerdo de Licencia del Usuario Final
(EULA). Cada instalación de software requiere una licencia que la respalde.
Existen distintos tipos de contratos de licencias para legalizar el software propietario, sin
embargo, pueden identificarse 3 grandes grupos de licenciamiento:
• Habitualmente, el software original se presenta en cajas vistosas impresas en alta
calidad, y dentro de ellas pueden encontrarse, entre otras cosas, la licencia de uso del
software, los manuales de los productos y disquetes o CDs identificados con etiquetas
preimpresas que indican el nombre del productor del software, su versión y su lenguaje.
• Otra forma muy común de licenciamiento, es a través de la preinstalación del software
en el disco duro al momento de adquirir la PC. Este tipo de licenciamiento se conoce
como OEM (Original Equipment Manufacturing o Manufactura de Equipos Originales)
y generalmente se instala con equipos nuevos.
• Las empresas productoras poseen planes de licenciamiento para grandes usuarios que no
necesariamente incluyen la entrega física de paquetes de software, sino sólo la licencia
de uso de varias copias. Por lo general se las denomina licencias por volumen y este
tipo de licenciamiento es una manera sencilla de comprar licencias de productos de
software a un precio con un descuento según el volumen adquirido.
A continuación se describen los tipos más conocidos de licenciamiento de software
propietario:

Anl. Mauricio Arévalo M.
- Pág. 38 -
LICENCIA CARACTERISTICAS
Producto Empaquetado (caja) Para pequeñas empresas que necesitan 1 o 2 licencias o para usuarios domésticos.
Producto Preensamblado (OEM) Para cualquier usuario que adquiere el software preinstalado en una PC nueva.
OPEN LICENSE Para empresas que quieran beneficiarse de un descuento por volumen a partir de 5 licencias. Tiene derechos de uso perpetuos.
SELECT LICENSE Para empresas con más de 250 PCs. Ofrece descuentos por volumen para cada grupo de productos separadamente. Tiene derechos de uso perpetuos.
ENTERPRISE AGREEMENT (EA) Para empresas con más de 250 PCs que desean estandarizar toda su organización con dicho software. Los precios por volumen están basados en pagos anuales. Tiene una duración de 3 años y derechos de uso perpetuos.
Tabla 3.1: Tipos de Licencias de Software propietario

Anl. Mauricio Arévalo M.
- Pág. 39 -
CAPITULO IV
MY SQL
4.1. Historia y Antecedentes
MySQL es un sistema de gestión de bases de datos relacionales, creado por la empresa
sueca MySQL AB y licenciado bajo GPL (Licencia Pública General). Su diseño le permite
soportar una gran carga de forma rápida y muy eficiente.
MySQL surgió por la necesidad que vieron sus creadores de tener un gestor de bases
de datos rápido y sencillo, ya que los SGBDs en general no eran lo bastante flexibles ni
veloces para lo que necesitaban, por lo que tuvieron que desarrollar nuevas funciones. De
todo esto surgió una nueva interfaz SQL (con código más portable) desarrollada en lenguaje C
y con apariencia similar a los nombres y funciones de muchos de sus programas.
Su principal objetivo de diseño fue la velocidad, por ello en sus primeras versiones se
suprimieron algunas características de otros SGBDs (Sistemas de Gestion de Base de Datos),
como el control de transacciones y las subconsultas. Consume pocos recursos y se distribuye
bajo licencia GPL.

Anl. Mauricio Arévalo M.
- Pág. 40 -
Según sus autores en un fragmento del manual MySQL, comentan que “no se sabe con
certeza de donde proviene el nombre pero las librerías han llevado el prefijo 'my' durante los
diez últimos años, además de que la hija de uno de los desarrolladores, Monty Widenius, se
llama My”6. El nombre de la mascota o delfín de MySQL es "Sakila", que fue elegido por los
fundadores de MySQL AB.
Su primera versión publicada bajo licencia GPL fue la 3.22 por el año de 1997, luego
han surgido las que hoy en día son versiones estables y que se pueden descargar desde su sitio
web (www.mysql.com) como la 3.23, 4.0 y 4.1, la 5.0 publicada en el año 2005 y la 5.1
publicada el 2006. Se está desarrollando actualmente la versión 5.2 para publicarse en a
finales del 2006 o inicios del 2007. La versión en la que se hicieron las respectivas pruebas y
los ejemplos que se muestran en la presente monografía es la “5.0.24” para el sistema
operativo Microsoft Windows XP.
Aunque MySQL es software libre y gratuito, MySQL AB distribuye las respectivas
versiones comerciales de MySQL, que se diferencian de las versiones libres en el soporte
técnico y las actualizaciones que se ofrecen.
Este gestor de bases de datos es probablemente el gestor más usado en el mundo del
software libre, debido sobretodo a su gran rapidez y desempeño, su fácil instalación y
configuración además de la facilidad de uso mediante herramientas que permiten su operación
a través de diversos lenguajes de programación.
4.2. Características y Funcionalidad del Servidor MySQL
MySQL es actualmente el servidor de base de datos más popular para los desarrollos
web. Es muy rápido y sólido, siendo muchos los administradores que lo instalan, y sin
embargo pocos los que conocen todo su potencial y características que lo hacen ser una
excelente alternativa como un servidor de bases de datos por su desempeño rápido, estable,
óptimo, confiable y seguro.
6 Tomado de MySQL Manual (www.netpecos.org/docs/mysql_postgres/b164.html#MYSQL)

Anl. Mauricio Arévalo M.
- Pág. 41 -
En base a lo recopilado de la documentación de sus desarrolladores7, a continuación
resalto las que considero las principales características de MySQL clasificadas según su
funcionalidad:
- Interioridades y portabilidad
• MySQL está escrito en C y C++.
• Trabaja bajo diferentes plataformas: AIX 4x 5x, Digital Unix 4x, FreeBSD 2x 3x 4x,
HP-UX 10.20 11x, Linux 2x, Mac OS, NetBSD, Novell NetWare 6.0, OpenBSD 2.5,
OS/2, SCO OpenServer, SCO UnixWare 7.1.x, SGI Irix 6.x, Solaris 2.5, SunOS 4.x,
Tru64 Unix y Windows 9x, Me, NT, 2000, XP, 2003.
• Dispone de APIs (Interfaz de Programación para Aplicaciones) para C, C++, Eiffel,
Java, Perl, PHP, Pitón, etc.
• Tiene velocidad cuando se manipula datos con el tipo de tabla “Myisam”; también es
rápido manejando el uso de joins y procesos de optimización.
• Brinda un sistema de almacenamiento transaccional con tablas tipo InnoDB y no
transaccional con tablas tipo MyISAM.
- Sentencias y funciones
• Tiene soporte completo para operadores y funciones en las cláusulas de consultas de
los estándares SQL como SELECT y WHERE. También soporta las cláusulas
GROUP BY y ORDER BY así como las funciones de agrupación (COUNT(),
COUNT(DISTINCT ...), AVG(), STD(), SUM(), MAX(), MIN()).
• Tiene soporte para LEFT OUTER JOIN y RIGHT OUTER JOIN cumpliendo con los
estándares de sintaxis SQL.
• Soporte para alias en tablas y columnas como lo requiere el estándar SQL.
• DELETE, INSERT, REPLACE, y UPDATE devuelven siempre el número de filas
que han cambiado.
7 Más información sobre las características técnicas en el manual de referencia de MySQL: http://dev.mysql.com/doc/refman/5.0/es/

Anl. Mauricio Arévalo M.
- Pág. 42 -
• Se puede mezclar tablas de distintas bases de datos en la misma consulta (a partir de la
versión MySQL 3.22).
• Desde la versión 4.0 de My SQL se permite realizar la UNION de consultas mediante
la cláusula UNION.
- Seguridad
• MySQL posee un sistema de privilegios y contraseñas que es flexible y seguro ya que
todo el tráfico de contraseñas está encriptado cuando se conecta con un servidor.
- Escalabilidad y límites
• Se usa MySQL Server con grandes bases de datos que contienen hasta 50 millones de
registros y 60.000 tablas que trabajan de manera estable. Se permiten hasta 64 índices
por tabla (32 antes de la versión MySQL 4.1.2). Cada índice o clave puede consistir
desde 1 hasta 16 columnas.
- Conectividad
• Los clientes se pueden conectar con el servidor MySQL usando sockets TCP/IP en
cualquier plataforma.
• La interfaz para el conector ODBC (MyODBC) proporciona a MySQL el soporte para
programas clientes que usen conexiones ODBC (Open Database Connectivity) y se lo
puede descargar desde el sitio web de MySQL (http://dev.mysql.com/downloads). Los
clientes pueden ejecutarse en Windows, Unix o Linux; el código fuente de MyODBC
está disponible y todas las funciones del estándar ODBC 3.51 están soportadas.
- Localización
• El servidor puede proporcionar mensajes de error a los clientes en distintos idomas.

Anl. Mauricio Arévalo M.
- Pág. 43 -
• Tiene soporte completo para distintos conjuntos de caracteres, incluyendo latin1 (ISO-
8859-1), german, big5, ujis, etc. El soporte para Unicode también está disponible.
• Todas las comparaciones para columnas normales de cadenas de caracteres son “case-
insensitive”, es decir no distinguen mayúsculas y minúsculas.
- Clientes y herramientas
• MySQL Server viene con las aplicaciones mysqlcheck y myisamchk que realizan
operaciones como chequear, optimizar, y reparar tablas de tipo InnoDB y de tipo
MyISAM respectivamente.
• Incluye las aplicaciones mysqlhotcopy y el mysqldump para crear copias de seguridad
de la base de datos.
• Mysqladmin es una aplicación cliente para realizar operaciones administrativas, se usa
para comprobar la configuración y el estado actual del servidor; también para crear y
borrar bases de datos, entre otras finalidades.
• Existen herramientas en modo consola como el Cliente MySQL o de entorno gráfico
con Interfaz Gráfica de Usuario (GUI) como MySQL Front, MySQL Administrador,
MyODBC, phpMyAdmin; las mismas que nos son muy útiles facilitándonos la
administración del servidor MySQL y sus bases de datos con un entorno gráfico para
comodidad del usuario. Así también se pone en conocimiento buenas herramientas de
modelado de bases de datos MySQL como DeZings y DBDesigner. MySQL Query
Browser es una herramienta para crear, ejecutar y optimizar consultas; también existe
una herramienta llamada MySQL Migration Toolkit para migrar bases de datos de
otros sistemas manejadores de Bases de Datos hacia MySQL.
Además de las características mencionadas anteriormente, vale la pena realizar a
continuación un análisis de ciertas características que considero importantes y destacadas;
muchas de estas características8 se han venido incoorporado en las últimas versiones de
MySQL, algunas de ellas se muestran en la tabla4.1:
8 Se puede revisar más información en http://dev.mysql.com/doc/refman/5.0/es/roadmap.html

Anl. Mauricio Arévalo M.
- Pág. 44 -
Característica Serie (Versión) MySQL desde que se incluye
Cláusula Union 4.0
Subconsultas 4.1
Procedimientos Almacenados 5.0
Triggers o Disparadores 5.0 y 5.1
Claves foráneas para tablas MyISAM 5.2 (ya está implementado para tablas InnoDB)
Tabla 4.1: Historia de las características de MySQL
- Servidor Incrustrado
La biblioteca del Servidor incrustado “libmysqld” permite que MySQL Server pueda
trabajar con una gran cantidad de dominios de aplicaciones. Usando esta biblioteca, los
desarrolladores pueden añadir MySQL Server en varias aplicaciones y dispositivos
electrónicos, donde el usuario final no tiene conocimiento que hay una base de datos
incrustrada.
La biblioteca incrustada MySSQL usa la misma interfaz que la biblioteca cliente
normal, por lo que es conveniente y fácil de usar.
- Disparadores o Triggers
Otra de las características que presenta MySQL es la del soporte básico para
disparadores (triggers). Un disparador es un objeto programado de una base de datos que se
asocia a una tabla y se activa cuando ocurre un evento en particular para dicha tabla.
Algunos usos para los disparadores son verificar valores a ser insertados o llevar a
cabo cálculos sobre valores involucrados en una actualización. Un disparador se asocia con
una tabla y se define para que se active automáticamente al ocurrir una sentencia INSERT,
DELETE, o UPDATE sobre dicha tabla; además la activación puede ocurrir antes o después
de la sentencia. Para crear o eliminar un disparador se emplean las sentencias CREATE
TRIGGER y DROP TRIGGER. La sintaxis para crear un disparador es la siguiente:

Anl. Mauricio Arévalo M.
- Pág. 45 -
CREATE TRIGGER nombre_disp momento_disp evento_disp ON nombre_tabla FOR EACH ROW sentencia_disp
Por ejemplo, las siguientes sentencias crean una tabla y un disparador para sentencias
INSERT dentro de la tabla. El disparador suma en una variable “sum” los valores insertados
en una de las columnas de la tabla. Para utilizar el disparador, se debe establecer el valor de
la variable acumuladora a cero, ejecutar una sentencia INSERT, y luego obtener el valor que
presenta la variable:
mysql> CREATE TABLE prueba_suma (sum_num INT, monto DECIMAL(10,2)); mysql> CREATE TRIGGER ins_sum BEFORE INSERT ON prueba_suma -> FOR EACH ROW SET @sum = @sum + NEW.monto; mysql> SET @sum = 0; mysql>INSERT INTO account VALUES(137,14.98),(141,1937.50),(97,-100.00); mysql> SELECT @sum AS 'Total monto Insertado'; +-----------------------+ | Total monto Insertado | +-----------------------+ | 1852.48 | +-----------------------+
No se pueden tener dos disparadores para una misma tabla que sean activados por el
mismo evento. Por ejemplo, no se pueden definir dos BEFORE INSERT o dos AFTER
UPDATE en una misma tabla; sin embargo esta no es una gran limitación, porque es posible
definir un disparador que ejecute múltiples sentencias empleando el constructor de sentencias
compuestas BEGIN...END luego de FOR EACH ROW.
Dentro del bloque BEGIN, también pueden utilizarse otras sintaxis permitidas en
rutinas almacenadas, tales como condicionales y bucles. Cuando se crea un disparador que
ejecuta sentencias múltiples, se hace necesario redefinir el delimitador de sentencias
(con el comando delimiter) si el disparador se ingresa a través del programa mysql, de forma
que se pueda utilizar el caracter ';' dentro de la definición del disparador. Ejemplo:
mysql> delimiter // mysql> CREATE TRIGGER upd_check BEFORE UPDATE ON prueba_suma -> FOR EACH ROW -> BEGIN -> IF NEW.monto < 0 THEN -> SET NEW.monto = 0; -> ELSEIF NEW.monto > 100 THEN -> SET NEW.monto = 100;

Anl. Mauricio Arévalo M.
- Pág. 46 -
-> END IF; -> END;// mysql> delimiter ;
Las palabras claves OLD y NEW permiten acceder a columnas en los registros
afectados por un disparador. En un disparador para INSERT, solamente puede utilizarse
NEW.nom_col ya que no hay una versión anterior del registro, mientras que en un disparador
para DELETE sólo puede emplearse OLD.nom_col, porque no hay un nuevo registro. En un
disparador para UPDATE se puede emplear OLD.nom_col para referirse a las columnas de un
registro antes de que sea actualizado, y NEW.nom_col para referirse a las columnas del
registro luego de actualizarlo.
Se puede crear un trigger que ejecute varias operaciones al activarse un evento
(INSERT, DELETE Y UPDATE) que actúe sobre una tabla. En el ejemplo creado a
continuación se han creado 4 tablas y se crea un trigger que se dispare cuando ocurra un
evento INSERT en la tabla “test1” y que ejecuta 3 operaciones en las otras tablas:
CREATE TABLE test1(a1 INT); CREATE TABLE test2(a2 INT); CREATE TABLE test3(a3 INT NOT NULL AUTO_INCREMENT PRIMARY KEY); CREATE TABLE test4(a4 INT NOT NULL AUTO_INCREMENT PRIMARY KEY, b4 INT DEFAULT 0); DELIMITER // CREATE TRIGGER testref BEFORE INSERT ON test1 FOR EACH ROW BEGIN INSERT INTO test2 SET a2 = NEW.a1; DELETE FROM test3 WHERE a3 = NEW.a1; UPDATE test4 SET b4 = b4 + 1 WHERE a4 = NEW.a1; END // DELIMITER;
- MySQL Cluster
Una característica que incorporan las últimas versiones de MySQL es el MySQL
Cluster, una versión de alta disponibilidad y alta redundancia de MySQL adaptada para el
entorno de computación distribuida. Se usa el motor de almacenamiento NDB Cluster para
permitir la ejecución e interacción de varios servidores MySQL en un cluster. Este motor de
almacenamiento está disponible en las distribuciones de MySQL 5.0, en los paquetes
compatibles con las distribuciones Linux más modernas.

Anl. Mauricio Arévalo M.
- Pág. 47 -
Figura 4.1: Estructura del MySQL Clulster
MySQL Cluster integra el servidor MySQL estándar con un motor de almacenamiento
clusterizado en memoria llamado NDB (genera tablas de tipo NDB). Como se muestra en la
figura 4.1, un MySQL Cluster consiste en un conjunto de máquinas; cada una ejecuta un
número de procesos incluyendo varios servidores MySQL, nodos de datos para NDB Cluster,
servidores de administración, y programas especializados de acceso a datos.
Todos estos programas funcionan juntos para formar un MySQL Cluster. Cuando se
almacenan los datos en el motor NDB Cluster, las tablas se almacenan en los nodos de datos,

Anl. Mauricio Arévalo M.
- Pág. 48 -
utilizando así la tecnología de replicación síncrona. Tales tablas son directamente accesibles
desde todos los otros servidores MySQL en el cluster.
Al llevar MySQL Cluster al mundo “Open Source”, MySQL propociona tratamiento de
datos clusterizados con alta disponibilidad, rendimiento y escalabilidad.
- Replicación
Las características de MySQL 5.X soportan replicación asíncrona unidireccional en la
que un servidor actúa como el maestro y uno o más actúan como esclavos, que es lo que se
diferencia con la replicación síncrona, la misma que se usa en MySQL Cluster.
Se utilizan “logs” que sirven como registros de actualizaciones para enviarlos a todos
los servidores esclavos. Cuando un escalvo se conecta al maestro, informa al mismo de la
posición hasta la que el esclavo ha leído los logs en la última actualización satisfactoria; el
esclavo recibe cualquier actualización que hayan tenido los registros desde entonces, se
bloquea y espera para que el maestro le envíe nuevas actualizaciones.
Se debe tener en cuenta que cuando se usa esta replicación, todas las actualizaciones de
las tablas que se replican deben realizarse en el servidor maestro. La replicación
unidireccional tiene beneficios para mejorar la robustez y administración del sistema.
- Subconsultas
Una subconsulta es un comando de consulta SELECT anidado dentro de otro comando;
se permiten desde la versión 4.1. MySQL 5.0 soporta todas las formas de subconsultas y
operaciones que requiere el estándar SQL, así como algunas características específicas de
MySQL. A continuación se muestra un ejemplo de subconsulta:
SELECT * FROM t1 WHERE columna1 = (SELECT columna1 FROM t2);
En este ejemplo, la sentencia “SELECT * FROM t1..”. es la consulta externa (o
comando externo), y “SELECT column1 FROM t2” es la subconsulta. Una subconsulta está

Anl. Mauricio Arévalo M.
- Pág. 49 -
anidada dentro de la consulta exterior, y de hecho, es posible anidar subconsultas dentro de
otras subconsultas hasta una profundidad considerable.
Una subconsulta puede retornar un valor único (escalar), un registro, una columna o una
tabla; estas se llaman consultas de escalar, columna, registro y tabla.
Hay pocas restricciones sobre los tipos de comandos en que pueden usarse las
subconsultas. Una subconsulta puede contener cualquiera de las palabras claves o cláusulas
que puede contener una sentencia SELECT ordinaria: DISTINCT, GROUP BY, ORDER BY,
LIMIT, JOINS, restringir registros con WHERE, sentencias UNION, comentarios, funciones,
etc.
Una restricción es que el comando exterior de una subconsulta debe ser: SELECT,
INSERT, UPDATE, DELETE, SET. Otra restricción es que actualmente no se puede
modificar una tabla y seleccionar de la misma tabla los valores en la subconsulta.
Las subconsultas también se presentan en la cláusula FROM de un comando SELECT,
con la siguente sintaxis:
SELECT... FROM (subconsulta) [AS] nombre ...
La cláusula “[AS] nombre” es obligatoria, ya que cada tabla en la cláusula FROM debe
tener un nombre. Los nombres de columnas usados dentro de la subconsulta se reconocen en
la consulta exterior como si la subconsulta se tratara de cualquier tabla en la cláusula FROM.
- Procedimientos y Funciones almacenadas
MySQL ofrece soporte para procedimientos y funciones almacenadas, que son rutinas
que los procesa el servidor MySQL, en los que se puede insertar código para ejecutar bucles o
condiciones que incluyen sentencias SQL para que se ejecuten mediante llamadas (CALL)
cuando se las necesite. Los procedimientos almacenados y las funciones se crean con los
comandos CREATE PROCEDURE y CREATE FUNCTION.
CREATE PROCEDURE sp_name ([parametros[,...]]) [caracteristicas ...] cuerpo_rutina

Anl. Mauricio Arévalo M.
- Pág. 50 -
CREATE FUNCTION sp_name ([parametros[,...]]) RETURNS tipo [caracteristicas ...] cuerpo_rutina
Donde:
parametros: [ IN | OUT | INOUT ] param_nombre tipo
tipo: Es cualquier tipo de dato válido de MySQL
caracteristicas: LANGUAGE SQL | { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA } | COMMENT 'string'
cuerpo_rutina: Son procedimientos almacenados o comandos SQL válidos
Un procedimiento sólo puede pasar valores usando variables de salida (OUT). Una
función puede llamarse desde dentro de un comando como cualquier otra función (invocando
el nombre de la función) y puede retornar un valor escalar o único.
Desde MySQL 5.0.1, los procedimientos almacenados se asocian con una base de datos
y se pueden calificar los nombres de rutinas con el nombre de la base de datos; por ejemplo,
para invocar procedimientos almacenados p o funciones f que se asocian con la base de datos
“prueba”, se los puede invocar con CALL prueba.p() o prueba.f(). Cuando se borra una base
de datos, todos los procedimientos almacenados asociados con ella también se borrarán.
- Modos SQL
A partir de la versión 5.0.2 de MySQL, están disponibles los “modos SQL” que son
opciones que nos permiten proporcionar un mayor control sobre cómo aceptar valores.
Los modos definen qué sintaxis SQL debe soportar MySQL y que clase de chequeos de
validación de datos debe realizar. Esto hace más fácil de usar MySQL en distintos entornos y
usar MySQL junto con otros servidores de bases de datos.

Anl. Mauricio Arévalo M.
- Pág. 51 -
MySQL nos permite trabajar con tablas transaccionales, que permiten realizar un control
de transacciones, manteniendo y asegurando de esta manera la integridad de los datos pero
MySQL también nos da la opción de trabajar con tablas no transaccionales que no permiten
realizar un control transaccional.
Es por ello que las restricciones son algo distintas en MySQL respecto a otras bases de
datos. Debemos tratar el caso en el que se insertan o actualizan muchos registros en una tabla
no transaccional en la que los cambios no pueden deshacerse cuando ocurre un error. La
filosofía básica es que MySQL Server trata de producir un error para cualquier cosa que
detecte mientras chequea un comando que va a ejecutarse, y las opciones que MySQL nos
ofrece cuando ocurre un error en una transacción son parar el comando en medio de la
ejecución o recuperarse lo mejor posible del problema y continuar. Por defecto, en tablas no
transaccionales como MyISAM, el servidor utiliza esta última opción.
Esto significa, que el servidor puede cambiar algunos valores ilegales por el valor legal
más próximo. En este modo, cuando se inserta un valor incorrecto en una columna, MySQL
cambia el valor al “mejor valor posible” para la columna en lugar de producir un error. Los
modos SQL u opciones con las que MySQL nos permite realizar estas operaciones son
STRICT_TRANS_TABLES y STRICT_ALL_TABLES.
Para tablas no transaccionales como MyISAM, si un valor incorrecto se encuentra en el
primer registro a insertar o actualizar, el comando se aborta y la tabla continúa igual. Si el
comando inserta o modifica varios registros y el valor incorrecto aparece en el segundo o
posteriores registros, el resultado depende de cúal es el modo estricto que esté habilitado:
� Para STRICT_ALL_TABLES, MySQL devuelve un error e ignora el resto de los
registros. Sin embargo, en este caso los primeros registros se insertan o actualizan y esto
significa que puede producirse una actualización parcial, que puede ser no deseada.
� Para STRICT_TRANS_TABLES, MySQL convierte los valores inválidos en el valor
válido más próximo para la columna e inserta el nuevo valor. En este caso MySQL genera
una advertencia en lugar de un error y continúa procesando el comando.
Usando estas opciones, se puede configurar MySQL Server para actuar en un modo más
“tradicional” como otros servidores de bases de datos que rechazan datos incorrectos. Los

Anl. Mauricio Arévalo M.
- Pág. 52 -
modos SQL se pueden configurar cuando inicia la aplicación cliente mysql cambiando la
variable sql_mode como se muestra a continuación:
--sql-mode="modo_SQL"
El valor puede dejarse en blanco (--sql-mode="") si se desea resetearlo. En MySQL 5.0,
también se puede cambiar el modo SQL tras el tiempo de arranque cambiando la variable
sql_mode usando el comando
SET [SESSION|GLOBAL] sql_mode="modo_SQL"
Asignar la variable GLOBAL afecta a las operaciones de todos los clientes que se
conecten a partir de entonces; en cambio, asignar la variable SESSION afecta sólo al cliente
actual. Cualquier cliente puede cambiar el valor de la variable sql_mode en su sesión en
cualquier momento.
- Utilización de variables de usuario
Se pueden emplear variables de usuario de MySQL con el símbolo de ‘@’ para retener
resultados sin necesidad de almacenarlos en variables del lado del cliente. Por ejemplo, para
encontrar los artículos con el precio más alto y el más bajo de una tabla “compras” se puede
hacer lo siguiente:
mysql> SELECT @min_precio:=MIN(precio),@max_precio:=MAX(precio) FROM compras; mysql> SELECT * FROM compras WHERE precio=@min_precio OR precio=@max_precio; +---------+-------+ | articulo| precio| +---------+-------+ | 0003 | 1.25 | | 0004 | 19.95 | +---------+-------+
- Control de Transacciones en tablas “InnoDB”
MySQL permite el control transaccional en las operaciones SQL que afecten a las tablas
de tipo InnoDB para brindar mayor seguridad e integridad en los datos. De forma

Anl. Mauricio Arévalo M.
- Pág. 53 -
predeterminada, cada cliente que se conecta al servidor MySQL comienza con el modo de
“autocommit” habilitado, lo cual automáticamente confirma (commit) o almacena la
actualización en disco de cada sentencia SQL ejecutada en el instante de su ejecución.
Para utilizar transacciones de múltiples sentencias se puede deshabilitar el modo
autocommit con la sentencia SQL “SET AUTOCOMMIT = 0” y emplear COMMIT y
ROLLBACK para confirmar o cancelar una transacción.
Tras deshabilitar el modo autocommit poniendo la variable AUTOCOMMIT a cero, se
debe usar COMMIT para almacenar los cambios en disco o ROLLBACK si se quiere ignorar
los cambios hechos desde el comienzo de la transacción. Si se quiere deshabilitar el modo
autocommit sólo para una serie única de comandos, se usa el comando START
TRANSACTION o sus alias BEGIN o BEGIN WORK como se muestra a continuación:
START TRANSACTION; SELECT @A:=SUM(salary) FROM table1 WHERE type=1; UPDATE table2 SET summary=@A WHERE type=1; COMMIT;
Con START TRANSACTION, autocommit permanece deshabilitado hasta el final de la
transacción donde esté COMMIT o ROLLBACK; entonces el modo autocommit vuelve a su
estado previo. El siguiente ejemplo muestra dos transacciones, la primera se confirma con
BEGIN y COMMIT mientras la segunda se cancela con el comando ROLLBACK:
mysql> CREATE TABLE CLIENTE (A INT, B CHAR (20)) -> ENGINE=InnoDB; Query OK, 0 rows affected (0.00 sec) mysql> BEGIN; Query OK, 0 rows affected (0.00 sec) mysql> INSERT INTO CLIENTE VALUES (10, 'Pedro'); Query OK, 1 row affected (0.00 sec) mysql> COMMIT; Query OK, 0 rows affected (0.00 sec) mysql> SET AUTOCOMMIT=0; Query OK, 0 rows affected (0.00 sec) mysql> INSERT INTO CLIENTE VALUES (15, 'Juan'); Query OK, 1 row affected (0.00 sec) mysql> ROLLBACK; Query OK, 0 rows affected (0.00 sec) mysql> SELECT * FROM CLIENTE;

Anl. Mauricio Arévalo M.
- Pág. 54 -
+------+--------+ | A | B | +------+--------+ | 10 | Pedro | +------+--------+ 1 row in set (0.00 sec)
Desde MySQL 5.0, las tablas de tipo InnoDB soportan los comandos SQL para el
control de transacciones SAVEPOINT y ROLLBACK TO SAVEPOINT; su sintaxis es:
SAVEPOINT identificador ROLLBACK TO SAVEPOINT identificador
El comando SAVEPOINT crea un punto dentro de una transacción con un nombre
(identificador). El comando ROLLBACK TO SAVEPOINT deshace una transacción hasta el
punto nombrado. Todos los puntos de la transacción actual se borran si se ejecuta un
comando COMMIT o un ROLLBACK que no nombre ningún punto.
Suponiendo que, como en el ejemplo dado anteriormente, se está trabajando por defecto
con el motor de base de datos que crea por defecto tablas de tipo MyISAM, se debe
especificar la opción ENGINE = InnoDB o TYPE = InnoDB en la sentencia SQL de creación
de tabla para crearla como tipo InnoDB como se muestra a continuación:
CREATE TABLE CLIENTE (a INT, b CHAR (20)) ENGINE=InnoDB; CREATE TABLE CLIENTE (a INT, b CHAR (20)) TYPE=InnoDB;
- Pasar tablas MyISAM a InnoDB
Si se desea que todas las tablas que no sean de sistema se creen como tablas InnoDB,
simplemente debe agregarse la línea default-table-type=innodb a la sección [mysqld] del
fichero my.cnf9 o my.ini.
Cabe mencionar que no se deben convertir las tablas del sistema en la base de datos
Mysql (por ejemplo, user o host) al tipo InnoDB ya que las tablas del sistema siempre son del
tipo MyISAM.
9 Este archivo de configuración de MySQL se encuentra ubicado en C:\Archivos de programa\MySQL\MySQL Server 5.0 en Microsoft Windows o en el directorio

Anl. Mauricio Arévalo M.
- Pág. 55 -
Para cambiar una tabla al motor InnoDB se puede alterar el motor de almacenamiento en
la tabla o, hacer las inserciones directamente en la nueva tabla InnoDB con las mismas
definiciones que se tienen en las columnas de la tabla de tipo MyISAM. Es decir, podríamos
utilizar la sentencia ALTER TABLE... ENGINE=INNODB para alterar el motor de
almacenamiento, o crear una nueva tabla InnoDB vacía con idénticas definiciones e insertar
las filas con la sentencia INSERT, como se muestra a continuación:
INSERT INTO nuevatabla SELECT * FROM viejatabla WHERE clave > valor1 AND clave <= valor2;
- Conversiones de Tipos de Datos
Las funciones CAST() y CONVERT() pueden ser usadas para tomar un valor de un tipo
y producir un valor de otro tipo. Sin embargo, el tipo de dato internamente no cambia en la
estructura de la tabla. Su sintaxis es la siguiente:
CAST(expr AS tipo) CONVERT(expr,tipo) ó CONVERT(expr USING transcoding_name)
Donde “tipo” es el nuevo tipo de dato asignado al valor de “expr”. La función
CONVERT() junto con la palabra USING es usado para convertir datos entre distintos
conjuntos de caracteres, así se muestran los siguientes ejemplos:
SELECT CONVERT('abc' USING utf8);
SELECT (CONVERT(coltipo1 USING latin1))as coltipo2 FROM tabla1;
- El Diccionario de Datos (INFORMATION_SCHEMA )
La base de datos de información INFORMATION_SCHEMA está disponible en MySQL
5.0.2 y versiones posteriores, proporciona un acceso a los metadatos de la base de datos. Los
Metadatos son datos acerca de los datos, tales como el nombre de la base de datos o tabla, el
tipo de datos de una columna, o los permisos de acceso. Otros términos que a veces se usan
para esta información son diccionario de datos o catálogo del sistema.

Anl. Mauricio Arévalo M.
- Pág. 56 -
INFORMATION_SCHEMA es la base de datos de información, que almacena
información acerca de todas las otras bases de datos que mantiene el servidor MySQL .
Dentro de INFORMATION_SCHEMA hay varias tablas de sólo lectura, que realidad
son vistas, no tablas, así que no se puede ver ningún fichero asociado con ellas. Cada usuario
de MySQL tiene derecho a acceder a estas tablas, pero sólo a los registros que corresponden
a los objetos a los que tiene permiso de acceso.
En el siguiente ejemplo, el comando pide una lista de todas las tablas en la base de datos
“db5”, en orden alfabético inverso y mostrando tres informaciones: el nombre de la tabla, su
tipo y su motor.
mysql> SELECT table_name, table_type, engine -> FROM information_schema.tables -> WHERE table_schema = 'db5' -> ORDER BY table_name DESC; +------------+------------+--------+ | table_name | table_type | engine | +------------+------------+--------+ | v56 | VIEW | NULL | | v3 | VIEW | NULL | | v2 | VIEW | NULL | | v | VIEW | NULL | | tables | BASE TABLE | MyISAM | | t7 | BASE TABLE | MyISAM | | t3 | BASE TABLE | MyISAM | | t2 | BASE TABLE | MyISAM | | t | BASE TABLE | MyISAM | | pk | BASE TABLE | InnoDB | | loop | BASE TABLE | MyISAM | | kurs | BASE TABLE | MyISAM | | k | BASE TABLE | MyISAM | | into | BASE TABLE | MyISAM | | goto | BASE TABLE | MyISAM | | fk2 | BASE TABLE | InnoDB | | fk | BASE TABLE | InnoDB | +------------+------------+--------+ 17 rows in set (0.01 sec)
4.3. Estructura del Servidor MySQL
En el caso de MySQL, el servidor es el que realiza todas las operaciones sobre las
bases de datos, en realidad se comporta como un interfaz entre las bases de datos y nuestras

Anl. Mauricio Arévalo M.
- Pág. 57 -
aplicaciones. Las aplicaciones se comunicarán con el servidor mediante programas (clientes)
para leer o actualizar la base de datos:
El diseño de MySQL Server es multicapa, con módulos independientes, lo cual hace que
su desempeño sea óptimo, rápido, confiable y seguro. Algunos de los últimos módulos
creados para MySQL se listan a continuación con una indicación del nivel de pruebas o testeo
en el que se encuentran:
• Replicación (Estable): Hay grandes grupos de servidores usando replicación en
producción, con muy buenos resultados. Se sigue trabajando para mejorar las
características de replicación en MySQL 5.x.
• Tablas InnoDB (Estable): El motor de almacenamiento transaccional InnoDB es
estable y usado en grandes sistemas de producción con alta carga de trabajo.
• MyODBC 3.51 (Estable): MyODBC 3.51 usa ODBC (Open DataBase Connectivity)
3.51 y es usado ampliamente para la realizar las conexiones a bases de datos.
MySQL utiliza los comandos, cláusulas, tipos de datos, operadores y funciones que
cumplen con los estándares ANSI e ISO de SQL/92; aunque como la mayoría de gestores de
bases de datos posee algunos comandos, cláusulas y funciones “extendidas”, es decir,
implementadas por los propios desarrolladores de MySQL.
Figura 4.2: Estructura del Servidor MySQL

Anl. Mauricio Arévalo M.
- Pág. 58 -
4.3.1. Tipos de Tablas
El servidor MySQL cuenta con una variedad de tipos de tablas para el almacenamiento
de la información, dependiendo de las necesidades y cantidades de información que una
aplicación puede tener, se elige el tipo de tabla con la que más se acople. En una sola base de
datos es posible tener diferentes tipos de tablas y existe la posibilidad de variar el tipo de
tabla después de ser creada. La estructura de la tabla que se crea, es guardada en un
archivo con el nombre de la tabla y extensión .FRM mientras que el archivo de índices en
MySQL tiene la extensión .MYI.
Actualmente en MySQL existen 16 tipos de tablas; a continuación se mencionan las más
representativas:
• MYISAM: Es el tipo de tabla no transaccional por defecto en MySQL desde la versión
3.23. y hasta la versión 4; es optimizada para sistemas operativos de 64 bits. En este
tipo de tabla los datos se almacenan en un formato independiente, con lo que se pueden
copiar tablas de una máquina a otra de distinta plataforma. Tiene la posibilidad de
indexar los campos BLOB y TEXT. Su mayor característica es la velocidad y toda la
información a cerca de una tabla de este tipo, queda almacenada en un archivo con la
extensión .MYD.
• INNODB: Es el tipo de tabla transaccional por defecto desde de la versión 4 en
adelante. Este tipo de tabla maneja transacciones seguras mediante comandos como
begin trans, commit, rollback. Son menos rápidas y ocupan más memoria que las tablas
Myisam, pero a cambio ofrecen mayor seguridad frente a fallos durante una transacción
en la base de datos y soportan completamente restricciones de claves primarias, únicas y
foráneas. La información de esta tabla queda almacenada en un archivo con la
extensión .IDB.
• MEMORY: La estructura de estas tablas son almacenadas en disco en un archivo con
extensión .FRM usando por defecto indexación tipo “hash”. Estas tablas pueden ser
muy rápidas y muy utilizadas como tablas temporales. Sin embargo, cuando el servidor
Mysql Server es reiniciado, toda la información de las tablas se pierde quedando

Anl. Mauricio Arévalo M.
- Pág. 59 -
solamente la estructura. Este tipo de tablas no soportan las columnas de tipo blob o
Text.
• MERGE: También conocida como MRG_ISAM, más que un tipo de tabla es la
posibilidad de dividir tablas MYISAM de gran tamaño (solo es útil si son
verdaderamente de gran tamaño) y hacer consultas sobre todas ellas con mayor rapidez.
Las tablas deben ser de tipo MyIsam e idénticas en su estructura, luego se crea la tabla
tipo MERGE haciendo relación a las tablas creadas; esta tabla queda almacenada en un
archivo con la extensión .MRG.
• NDBCLUSTER: Este tipo de tabla se utiliza para el manejo de MySql Cluster en
Mysql Server. Se implementa con pruebas desde la versión MySQL 5.0.
• CSV: Este tipo de tabla fue adicionada desde la versión de MySQL 4.1.4 y almacena la
información en un archivo de texto separado por comas. Cuando se crea una tabla de
tipo Csv, se crean dos archivos, uno con extensión .FRM donde almacena la estructura
de la tabla y otro .CSV donde reposa la información.
• ARCHIVE: Este tipo de tabla fue adicionada a partir de la versión 4.1.3 y es usada
para almacenar información sin ningún tipo de indexación. Cuando se crea una tabla
de este tipo, MySQL crea un archivo con la extensión .FRM donde se almacena la
estructura de la tabla y otros archivos con la extensión .ARZ, .ARM y .ARN. Este
tipo de tabla soporta únicamente los comandos insert y select.
En las últimas versiones, el servidor MySQL con las tablas de tipo MyISAM puede
almacenar hasta 65 terabytes mientas que con tablas tipo Innodb la capacidad máxima de
almacenamiento es de 64 terabytes. Cuando se trabaja con altos volúmenes de información
es importante tener presente el límite en tamaño para un archivo que soporta el sistema
operativo. Por lo tanto, el tamaño efectivo máximo para las bases de datos en MySQL
usualmente los determinan los límites de tamaño de ficheros del sistema operativo y no los
límites internos de MySQL.

Anl. Mauricio Arévalo M.
- Pág. 60 -
En la siguiente tabla se muestra el límite máximo de tamaño que soporta un archivo
para algunos sistemas operativos:
Sistema operativo Limitaciones en el tamaño del archivo Linux 2.4 (Con sistema de archivo ext3 ) 4TB Solaris 9/10 16TB NetWare w/NSS 8TB Win32 w/ FAT/FAT32 2GB/4GB Win32 w/ NTFS 2TB (con posibilidad de crecer) MacOS X w/ HFS+ 2TB
Tabla 4.2: Límites de archivos en el sistema operativo
Se puede chequear el tamaño máximo de una tabla desde el Cliente MySQL con el
comando SHOW TABLE STATUS o con la herramienta myisamchk -dv nombre_tabla.
Los nombres de bases de datos, tablas, índices, columnas y alias son conocidos como
identificadores; los identificadores de bases de datos, tablas y columnas no pueden terminar
con espacios en blanco. La tabla siguiente describe la longitud máxima y los caracteres
permitidos para cada tipo de identificador en MySQL:
Identificador Longitud máxima (bytes) Caracteres permitidos
Base de datos 64
Cualquier carácter permitido en un nombre de directorio, excepto “/” “\” “.”
Tabla 64 Cualquier carácter permitido para un nombre de fichero, excepto “/” “\” “.”
Columna 64 Todos los caracteres Índice 64 Todos los caracteres Alias 255 Todos los caracteres
Tabla 4.3: Límites de archivos en el sistema operativo
4.3.2. Tipos de Datos de MySQL
En MySQL existen varios tipos de datos disponibles, cumpliendo con el estándar
SQL/92. A continuación enumero los tipos de datos agrupándolos por categorías: de
caracteres, enteros, de coma flotante, de fecha y hora, de bloques, enumerados y conjuntos.

Anl. Mauricio Arévalo M.
- Pág. 61 -
• Tipos de datos de cadenas de caracteres: CHAR, CHAR(), VARCHAR().
• Tipos de datos enteros: TINYINT, BIT, BOOL o BOOLEAN, SMALLINT,
MEDIUMINT, INT o INTEGER, BIGINT.
• Tipos de datos de coma flotante: FLOAT, FLOAT(), DOUBLE o REAL,
DECIMAL, NUMERIC o FIXED.
• Tipos de datos para hora y fecha: DATE, DATETIME, TIMESTAMP, TIME,
YEAR.
• Tipos de datos para datos sin tipo o grandes bloques de datos: TINYBLOB o
TINYTEXT, BLOB o TEXT, MEDIUMBLOB o MEDIUMTEXT, LONGBLOB o
LONGTEXT.
• Tipos enumerados y conjuntos: ENUM y SET
4.4. Ventajas y Desventajas de MySQL
4.4.1. Ventajas
• MySQL es Open Source: Significa que es posible para cualquiera usar y modificar el
software. Cualquiera puede bajar el software MySQL desde internet y usarlo sin pagar
nada en la versión gratuita y si se desea, se puede estudiar el código fuente y cambiarlo
para adaptarlo a nuestras necesidades específicas. El software MySQL usa la licencia
GPL (General Public License).
• El servidor de bases de datos relacionales MySQL es muy rápido, fiable y fácil de usar,
ya que en cooperación con los usuarios desarrolladores de Open Source a nivel mundial,
MySQL Server se desarrolló originalmente para manejar grandes bases de datos mucho

Anl. Mauricio Arévalo M.
- Pág. 62 -
más rápido que las soluciones de gestores de bases de datos existentes y ha sido usado
con éxito en entornos de producción de alto rendimiento durante varios años.
• MySQL Server trabaja en entornos cliente/servidor o incrustados; el software de bases
de datos MySQL es un sistema cliente/sevidor que consiste en un servidor SQL que
trabaja con diferentes programas y bibliotecas cliente, herramientas administrativas y
diversas interfaces de programación para aplicaciones (APIs). También se proporciona
el MySQL Server como biblioteca incrustada, que se puede incluir en una aplicación
para obtener un producto más pequeño, rápido y fácil de administrar.
• Una gran cantidad de software de contribuciones está disponible para MySQL, y por
esta razón se pueden usar muchas herramientas disponibles en modo consola y en
entorno gráfico para la administración completa del servidor My SQL.
• MySQL posee un buen control de acceso de usuarios y seguridad en los datos.
• Integración perfecta con el lenguaje PHP (Preprocesador de Hipertexto).
• Soporte completo para cláusulas, funciones, tipos de datos y comandos estándar y
extendidos del estándar SQL.
• Soporte para control de transacciones en tablas transaccionales (tipo InnoDB), y soporte
para procedimientos almacenados, subconsultas y disparadores (Triggers) en las últimas
versiones de MySQL (5.x).
• Gran portabilidad entre distintos sistemas o plataformas.
• Se permite la replicación de bases de datos trabajando con servidores MySQL maestros
y esclavos. También se permite trabajar con el entorno “MySQL Clúster” para dar alta
disponibilidad y rendimiento al sistema.
• Uso de MyODBC, que proporciona a MySQL soporte para programas clientes que usen
conexiones ODBC (Open Database Connectivity).
• Soporta múltiples modos asignados para comportarse como otros gestores de bases de
datos, definiendo la validación o no de los valores erróneos o incorrectos y la forma en
que se ingresan los datos.

Anl. Mauricio Arévalo M.
- Pág. 63 -
4.4.2. Desventajas
• Actualmente, el soporte para disparadores es básico, por lo tanto hay ciertas limitaciones
en lo que puede hacerse con ellos.
• Cuando MySQL maneja la Integridad referencial, con tablas NO transaccionales de tipo
MyISAM, aunque admite la declaración de claves ajenas o foráneas en la creación
tablas, internamente no las trata de forma diferente al resto de campos.
• Los privilegios para una tabla no se eliminan automáticamente cuando se borra una
tabla. Debe usarse explícitamente un comando REVOKE para quitar los privilegios de
una tabla.
• La función de conversión CAST() no soporta la conversión a REAL o BIGINT.
Los desarrolladores comentan en la documentación de MySQL que estas carencias no
les resultaban un problema, ya que era lo que en principio ellos necesitaban. Sin embargo se
las optimizará con la colaboración de los propios usuarios y desarrolladores a nivel mundial,
gracias a que es Software Libre.
4.5. Gestión de Bases de Datos MySQL
Existen muchas formas de establecer una comunicación con el servidor de MySQL; en
algunos casos, se usan librerías y APIs (Interfaz de Programación para Aplicaciones). En
PHP, por ejemplo, este API está integrado con el lenguaje, en C/C++ se trata de librerías de
enlace dinámico, en el proyecto “Mono” para el desarrollo de aplicaciones en la plataforma
.Net se usa el namespace “ByteFX.Data.MySql”, que es un proveedor de ADO.NET y en otros
lenguajes se puede utilizar el conector My ODBC (Open Database Connectivity) para realizar
conexiones con el servidor de MySQL desde cualquier cliente que soporte ODBC.
Así también existen herramientas o aplicaciones que nos son muy útiles facilitándonos
la administración del servidor MySQL y sus bases de datos con un entorno de consola como
el Cliente mysql y el mysqladmin que es una aplicación que nos sirve para realizar

Anl. Mauricio Arévalo M.
- Pág. 64 -
operaciones administrativas, o con herramientas de entorno gráfico como el MySQL Front y
MySQL Administrador.
Incluso existe una aplicación potente y amigable para administrar las bases de datos
MySQL mediante una interfaz Web llamada phpMyAdmin. Existe la aplicación MySQL
Query Browser que es una herramienta creada por MySQL AB para crear, ejecutar y
optimizar consultas en un entorno gráfico y sencillo de manejar para el usuario.
Se dispone también de herramientas de modelado de bases de datos MySQL como
DeZings o DBDesigner y aplicaciones como el MySQL Migration Toolkit para migrar bases
de datos de otros sistemas manejadores de Bases de Datos (DBMS) como Oracle, SQL Server
o Access a MySQL.
Además MySQL Server viene con aplicaciones cliente de consola para realizar
operaciones como chequear, optimizar, y reparar tablas como mysqlcheck o myisamchk para
efectuar estas operaciones en tablas de tipo “MyISAM”. Incluye también el programa para
importar datos mysqlimport y las aplicaciones para copias de seguridad de las bases de datos
mysqlhotcopy y el mysqldump.
Los programas clientes MySQL tienen varias opciones, pero todos ellos proporcionan
una opción --help que puede utilizarse para obtener una descripción completa de las distintas
opciones del programa. Por ejemplo, mysql --help.
Los programas clientes MySQL pueden leer opciones de inicio desde ficheros de
opciones (también llamados a veces ficheros de configuración).
Los siguientes programas clientes soportan ficheros de opciones: myisamchk,
myisampack, mysql, mysqladmin, mysqlcheck, mysqldump, mysqld, mysqlhotcopy,
mysqlimport, y mysqlshow. Los programas MySQL clientes leen las opciones de inicio en los
siguientes ficheros:

Anl. Mauricio Arévalo M.
- Pág. 65 -
Fichero Contenido
WINDIR\my.ini Opciones globales
C:\my.cnf Opciones globales
INSTALLDIR\my.ini Opciones globales
Tabla 4.4: Ubicación de los ficheros de configuración en Windows
WINDIR representa la ubicación del directorio Windows, INSTALLDIR representa el
directorio de instalación de MySQL (generalmente es C:\Archivos de
Programa\MySQL\MySQL 5.0 Server).
En Unix o Linux, los programas MySQL leen sus opciones de inicio en los siguientes
ficheros:
Fichero Contenido
/etc/my.cnf Opciones globales
$MYSQL_HOME/my.cnf Opciones específicas del servidor
Tabla 4.5: Ubicación de los ficheros de configuración en Linux
MYSQL_HOME es una variable de entorno que contiene la ruta al directorio donde
reside el fichero my.cnf específico del servidor. Generalmente esta ruta es
/usr/local/mysql/data para una instalación binaria o /var/lib/mysql para una instalación de
código fuente.
MySQL busca ficheros de opciones exactamente en el orden descrito en las tablas
anteriores y lee cualquiera que exista. Si se desea utilizar un fichero de opciones que no
existe, se lo debe crear con un editor de texto plano; y de existir múltiples ficheros de
opciones, las opciones leídas en último lugar prevalecen sobre las anteriores.
Con toda esta amplia gama de utilidades o herramientas de administración para el gestor
de bases de datos MySQL, realmente creo que está a la par con otros grandes sistemas
manejadores de bases de datos de licencia libre y propietaria, y puede ser usado e incorporado

Anl. Mauricio Arévalo M.
- Pág. 66 -
sin problemas a la mayoría de sistemas o aplicaciones que utilicen un motor de bases de datos
relacional independientemente de su arquitectura y plataforma en la que estén implementadas
a un bajo costo y con un alto rendimiento.
A continuación se citan las características más destacadas de las herramientas y
utilidades “clientes” que nos permiten administrar el servidor MySQL y gestionar sus bases
de datos en modo consola o de línea de comandos:
4.5.1. Cliente mysql
El cliente mysql es una poderosa herramienta interactiva en modo de consola que nos
permite realizar una conexión y administrar un servidor MySQL ejecutando sentencias SQL
para interactuar con las bases de datos, visualizando los resultados de las operaciones
solicitadas.
Se interactúa con el servidor MySQL de forma directa mediante el cliente mysql, el
mismo que se ejecuta en una consola (una ventana DOS en Windows, o un Shell en otros
sistemas como Linux).
Figura 4.3: Cliente MySQL
Para entrar en la consola (Cliente) de MySQL se requieren ciertos parámetros, y la
forma general de iniciar una sesión MySQL es:

Anl. Mauricio Arévalo M.
- Pág. 67 -
mysql -h host -u usuario –p
Los parámetros "-h" y "-u" indican que los parámetros a continuación son,
respectivamente, el nombre del host y el de usuario. El parámetro "-p" indica que se debe
solicitar una clave de acceso.
En versiones de MySQL anteriores a la 4.1.9 es posible abrir un cliente de forma
anónima sin especificar una contraseña, pero esto no es muy seguro y de hecho, las últimas
versiones de MySQL no lo permiten. Durante la instalación de MySQL se nos pide que
elijamos una clave de acceso para el superusuario 'root', el cual tiene todos los permisos o
privilegios y deberemos usar esa clave para iniciar por primera vez una sesión con el cliente
mysql como se muestra a continuación:
mysql -h localhost -u root -p
Enter password: ******* Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 76 to server version: 5.0.11-beta-nt Type 'help;' or '\h' for help. Type '\c' to clear the buffer. mysql>
Un comando interpretado por el Cliente mysql normalmente consiste de cualquier
sentencia SQL (de definición o manipulación de datos) seguida por un punto y coma.
Cuando se emite un comando, el cliente lo manda al servidor para que lo procese y nos
muestra los resultados regresando luego al prompt indicando que está listo para recibir más
consultas u operaciones SQL.
El cliente mysql muestra al final de una operación cuántas filas fueron regresadas o
afectadas y cuanto tiempo tardó en ejecutarse la operación que ejecutamos; lo cual nos da una
idea de la eficiencia del servidor. Las palabras claves y los comandos de MySQL pueden ser
escritos usando tanto mayúsculas como minúsculas (case-insensitive).
El cliente mysql representa los resultados de una consulta como una tabla (filas y
columnas). La primera fila contiene las etiquetas (alias o nombres) para las columnas. Las
filas siguientes muestran los resultados de la consulta como se muestra en el siguiente
ejemplo:

Anl. Mauricio Arévalo M.
- Pág. 68 -
mysql> SELECT * FROM compras; CONSULTA SQL +---------+-------+ | articulo| precio| COLUMNAS DE LA CONSULTA +---------+-------+ | 0003 | 1.25 | | 0004 | 19.95 | | 0005 | 20.95 | RESULTADOS (DATOS) | 0006 | 30.95 | | 0007 | 40.95 | | 0008 | 50.95 | +---------+-------+ 6 rows in set (0.01 sec) NUMERO DE FILAS RETORNADAS Y TIEMPO
QUE TARDÓ LA CONSULTA (EN SEGUNDOS)
Es posible escribir más de una sentencia por línea, siempre y cuando estén separadas por
punto y coma, por ejemplo:
mysql> SELECT VERSION(); SELECT NOW();
+----------------+ | VERSION() | +----------------+ | 5.0.11-beta-nt | +----------------+ 1 row in set (0.01 sec) +---------------------+ | NOW() | +---------------------+ | 2006-08-25 14:26:04 | +---------------------+ 1 row in set (0.01 sec)
Los comandos que requieran de varias líneas no son un problema. El cliente mysql
determinará en dónde finaliza la sentencia cuando encuentre el punto y coma, no cuando
encuentre el fin de línea. Ejemplo:
mysql> SELECT -> USER(),
-> CURRENT_DATE;
+-------------------+--------------+ | USER() | CURRENT_DATE | +-------------------+--------------+ | mauricio@localhost| 2006-08-25 | +-------------------+--------------+ 1 row in set (0.00 sec)
Para ver la lista de opciones proporcionadas por el cliente mysql, lo invocamos con la
opción -- help (mysql –-help). Para comenzar a utilizar e interactuar con el servidor MySQL
mediante el programa cliente mysql, tenemos varios commandos, sentencias, funciónes u

Anl. Mauricio Arévalo M.
- Pág. 69 -
operadores que cumplen con los estándares ANSI e ISO de SQL/92. Para obtener una ayuda
detallada sobre el manejo y las opciones de cada uno de ellos se puede acceder al manual de
referencia en español de MySQL (http://dev.mysql.com/doc/refman/5.0/es/index.html) o
escribiendo en el programa cliente la palabra “help” o “?” seguida por el nombre del comando
a cerca del cual queremos obtener ayuda, como se muestra en el siguiente ejemplo:
mysql>? create database;
Entre los comandos SQL tenemos por ejemplo CREATE DATABASE, que sirve para
crear una nueva base de datos como se muestra a continuación:
mysql> CREATE DATABASE prueba; Query OK, 1 row affected (0.01 sec)
Mediante el comando USE se selecciona la base de datos que se utilizará por defecto en las operaciones que realicemos:
mysql> USE prueba; Database changed
Para salir de una sesión del cliente mysql se usa el comando "QUIT", "EXIT", o
presionando CONTROL+D:
Figura 4.4: Salir del cliente MySQL

Anl. Mauricio Arévalo M.
- Pág. 70 -
4.5.2. Mysqladmin
Este es un programa cliente en modo de consola que realiza tareas administrativas, tales
como crear y borrar bases de datos, recargar las tablas de permisos, volcar tablas a disco y
reabrir ficheros de log. Mysqladmin también puede utilizarse para consultar la versión,
información de procesos, e información de estado del servidor. La siguiente sintaxis se utiliza
para invocar a mysqladmin:
> mysqladmin comando [opciones_de_comando]
Mysqladmin soporta los siguientes comandos:
- Create nombre_base_de_datos: Crea una nueva base de datos.
- Debug: Le dice al servidor que escriba información de depuración en el log de error.
- Drop nombre_base_de_datos: Borra la base de datos y todas sus tablas.
- Extended-status: Muestra las variables de estado del servidor y sus valores.
- Flush-logs: Vuelca todos los logs.
- Flush-privileges: Recarga las tablas de permisos (lo mismo que reload).
- Flush-status: Limpia las variables de estado.
- Flush-tables: Vuelca todas las tablas.
- Ping: Comprueba si el servidor está vivo; el estado retornado por mysqladmin es 0 si el servidor está en ejecución, 1 si no lo está. En MySQL 5.0, el estado es 0 incluso en caso de un error tal como Access denied, ya que esto significa que el servidor está en ejecución pero no ha admitido la conexión.
- Reload: Recarga las tablas de permisos.
- Refresh: Vuelca todas las tablas; cierra y abre los ficheros de logs.
- Shutdown: Detiene o apaga el servidor.
- Start-slave: Comienza la replicación en un servidor esclavo.
- Status: Muestra un mensaje de estado corto del servidor.
- Stop-slave: Detiene la replicación en un servidor esclavo.

Anl. Mauricio Arévalo M.
- Pág. 71 -
- Variables: Muestra las variables de sistema del servidor y sus valores.
- Version: Muestra información de la versión del servidor.
Todos los comandos pueden abreviarse a un prefijo único. Por ejemplo:
> mysqladmin proc stat +----+------+-----------+----+---------+------+------+------------------+ | Id | User | Host | db | Command | Time | State| Info | +----+------+-----------+----+---------+------+------+------------------+ | 51 | root | localhost | | Query | 0 | | show processlist | +----+------+-----------+----+---------+------+------+------------------+ Uptime: 1473624 Threads: 1 Questions: 39487 Slow queries: 0 Opens: 541 Flush tables: 1 Open tables: 19 Queries per second avg: 0.0268 Memory in use: 92M Max memory used: 410M
El apagado del servidor puede ejecutarse con la sentencia mysqladmin shutdown, pero
también son posibles otros métodos de encendido y apagado específicos de cada sistema
operativo. Por ejemplo en un servidor ejecutándose como servicio en Windows se apaga
cuando el administrador de servicios se lo indica.
Los pasos del proceso de apagado del servidor son:
1. Comienza el proceso de apagado
2. El servidor deja de aceptar nuevas conexiones
3. El servidor acaba con su tarea actual
4. Se apagan o cierran los motores de almacenamiento
5. El servidor se cierra
4.5.3. Myisampack
Esta es una utilidad que comprime tablas MyISAM para producir tablas más pequeñas
de sólo lectura. Myisampack funciona comprimiendo cada columna de la tabla
separadamente; normalmente, myisampack comprime el fichero de datos en un 40 a 70 por
ciento.

Anl. Mauricio Arévalo M.
- Pág. 72 -
Cuando la tabla se utiliza posteriormente, el servidor lee en la memoria la información
que se necesita para descomprimir las columnas. Esto da un rendimiento mucho mejor al
acceder a registros individuales, ya que sólo se tiene que descomprimir un registro.
Tras su compresión, la tabla será de sólo lectura. A continuación se muestra como se
invoca a myisampack:
> myisampack [opciones] nombre_fichero(.MYI)
Cada nombre de fichero debe ser el nombre de un fichero índice (.MYI). Si no se
encuentra en el directorio de la base de datos, debe especificar la ruta al fichero. Se permite
omitir la extensión .MYI .
4.5.4. Mysqlcheck y Myisamchk
Son programas clientes de mantenimiento de tablas que verifican, reparan, analizan y
optimizan las tablas del servidor MySQL.
Mysqlcheck es similar a myisamchk, pero funciona de forma distinta. La principal
diferencia operacional es que mysqlcheck debe usarse cuando el servidor mysqld está en
ejecución, mientras que myisamchk debe usarse cuando no lo está. El beneficio de usar
mysqlcheck es que no se tiene que parar el servidor para comprobar o reparar las tablas.
Mysqlcheck usa los comandos SQL CHECK TABLE, REPAIR TABLE, ANALYZE
TABLE, y OPTIMIZE TABLE de forma conveniente para los usuarios. Determina los
comandos a usar en función de la operación que se quiera realizar, luego envía los comandos
al servidor para ejecutarlos. Existen tres modos generales de invocar mysqlcheck:
> mysqlcheck [opciones] nombre_de_base_de_datos [tablas] > mysqlcheck [opciones] --databases DB1 [DB2 DB3...] > mysqlcheck [opciones] --all-databases
Si no se nombra ninguna tabla o se usa las opciones --databases o --all-databases, se
comprueban todas las bases de datos.

Anl. Mauricio Arévalo M.
- Pág. 73 -
4.5.5. Mysqlimport
Es un programa cliente que proporciona una interfaz de línea de comandos para
importar ficheros de texto en sus respectivas tablas usando el comando LOAD DATA INFILE;
mysqlimport se lo invoca como se muestra a continuación:
> mysqlimport [opciones] nombre_de_base_de_datos fichero_de_texto1 [fichero_de_texto2 ...]
Del nombre de cada fichero de texto especificado en la línea de comandos, mysqlimport
elimina cualquier extensión, y utliza el resultado para determinar el nombre de la tabla a la
que importar el contenido del fichero; por lo que el nombre del fichero y el de la tabla deben
ser los mismos. Por ejemplo, los ficheros con nombres “paciente.txt”, “paciente.text” y
“paciente” se importarían todos a la tabla llamada paciente.
El siguiente es un ejemplo de una sesión que demuestra el uso de mysqlimport,
suponiendo que exista una tabla imptest en la base de datos test, y un fichero de texto
“imptest.txt” que contenga dos registros para los campos id y nombre respectivamente:
> mysqlimport test imptest.txt test.imptest: Records: 2 Deleted: 0 Skipped: 0 Warnings: 0 > SELECT * FROM imptest +------+---------------+ | id | nombre | +------+---------------+ | 100 | Max Sydow | | 101 | Count Dracula | +------+---------------+
4.5.6. Mysqldump y Mysqlhotcopy
El cliente mysqldump puede utilizarse para volcar una base de datos o colección de
bases de datos en un fichero como comandos SQL o como ficheros separados por tabuladores
para copia de seguridad o para transferir datos a otro servidor SQL (no necesariamente un
servidor MySQL). EL volcado contiene comandos SQL para crear la tabla y/o rellenarla y
existen tres formas de invocar a mysqldump:

Anl. Mauricio Arévalo M.
- Pág. 74 -
> mysqldump [opciones] nombre_de_base_de_datos [tablas] > mysqldump [opciones] --databases DB1 [DB2 DB3...] > mysqldump [opciones] --all-databases
Si no se nombra ninguna tabla o se utiliza la opción --databases o --all-databases, se
vuelcan todas las bases de datos enteras.
Mysqlhotcopy es un script Perl que usa los comandos LOCK TABLES, para bloquear
las tablas a copiar y cp o scp para realizar una copia de seguridad rápida de la base de datos
mientras el servidor se encuentra en ejecución. Es la forma más rápida de hacer una copia de
seguridad de la base de datos o de tablas, pero sólo puede ejecutarse en la misma máquina
donde está el directorio de base de datos y sólo realiza copias de seguridad de tablas de tipo
MyISAM; además funciona solamente en Unix/Linux y NetWare. Este programa se invoca
como se indica a continuación:
shell> mysqlhotcopy nombre_de_base_de_datos [/ruta_nuevo_directorio]
4.5.7. Perror
Es una utilidad que muestra el significado de los errores de sistema de MySQL. Para la
mayoría de errores de sistema, MySQL muestra, además del mensaje de texto interno, el
código de error de sistema en uno de los siguientes estilos:
message ... (errno: #) message ... (Errcode: #)
Puede aclararse qué significa cada código de error utilizando la utilidad perror de la
siguiente manera:
shell> perror [opciones] código_de_error ...
Ejemplo con los codigos de error 13 y 64:
> perror 13 64 Error code 13: Permission denied Error code 64: Machine is not on the network

Anl. Mauricio Arévalo M.
- Pág. 75 -
Hay que tener en cuenta que el significado de los mensajes de error del sistema pueden
ser dependientes del sistema operativo. Un código de error puede significar cosas distintas en
diferentes sistemas operativos.
Los programas clientes vistos hasta ahora, generalmente se instalan junto con el servidor
MySQL en el directorio de instalación de MySQL/bin. El servidor junto con los programas
clientes se los puede descargar del sitio web de MySQL AB para descargas
(http://www.dev.mysql.com/downloads), donde también se proporcionan diversas
herramientas distribuidas por MySQL AB, como el sistema MySQL Cluster, o los conectores
MyODBC, o distintas APIs para trabanjar con lenguajes como .NET o C++, etc. También se
ofrecen algunos programas con interfaces gráficas de usuario (GUI) para administrar e
interactuar con el servidor MySQL.
Además existen varias herramientas y utilitarios con entorno gráfico desarrolladas por
distintos colaboradores a nivel mundial, que no son distribuidas por MySQL AB, sin embargo
también son muy funcionales y prácticas para gestionar las bases de datos MySQL.
A continuación se citan algunas de estas herramientas:
4.5.8. MySQL Administrator
Esta herramienta es desarrollada y distribuida por MySAL AB y se usa para administrar
servidores MySQL, bases de datos, tablas y usuarios.
MySQL Administrator es un programa para llevar a cabo operaciones administrativas,
como configurar el servidor de MySQL, supervisando su estado y desempeño, se puede
iniciarlo y detenerlo, administrar los usuarios y las conexiones, llevar a cabo los backups o
respaldos y las recuperaciones de las bases de datos y varias otras tareas administrativas,
además permite gestionar las tablas, sus campos, las vistas y procedimientos almacenados.
Todas estas tareas, se las puede realizar mediante programas clientes en modo de consola o
línea de comandos, sin embargo, MySQL Administrator nos facilita mucho la administración

Anl. Mauricio Arévalo M.
- Pág. 76 -
del servidor MySQL ya que gracias a su Interfaz Gráfica de Usuario (GUI) se tiene una
manera fácil e intuitiva de realizar las operaciones administrativas.
Figura 4.5: Conexión para MySQL Administrador
Figura 4.6: Ventana de Administración de MySQL Administrador
Permite la administración correcta del servidor, asegurando su desempeño, fiabilidad, y
seguridad; además despliega indicadores gráficos que muestran el desempeño del servidor,
facilitando su administración. Este software en su última versión (1.2) se lo puede descargar

Anl. Mauricio Arévalo M.
- Pág. 77 -
desde el sitio web de MySQL AB (http://dev.mysql.com/downloads/mysq/gui-tools/5.0.html)
en el paquete “MySQL GUI Tools Bundle for 5.0.” y está disponible para varias plataformas
incluyendo Windows, Linux, MacOS entre otras y se ha diseñado para trabajar con los
servidores de MySQL desde la version 4.0 y posteriores. Al iniciar esta aplicación, se nos
pide que especifiquemos los parámetros de conexión:
4.5.10. MySQL Query Browser
MySQL Query Browser es una herramienta gráfica proporcionada por MySQL AB para
crear, ejecutar, y optimizar consultas de las bases de datos MySQL en un ambiente gráfico,
donde MySQL Administrator está diseñado para administrar el servidor MySQL.
MySQL Query Browser esta diseñado para ayudar a consultar y analizar los datos
almacenados en una base de datos MySQL de una manera fácil, rápida e intuitiva.
Aunque todas las conslutas ejecutadas en el MySQL Query Browser pudieran ser
también ejecutadas en la utilidad cliente de línea de comando mysql, MySQL Query Browser
permite de una manera más intuitiva y grafica la consulta y la edición de datos.
La tarea realizada mas común con el MySQL Query Browser es ejecutar una o varias
consultas y analizar o comparar sus resultados. La manera más directa de crear consultas es
escribirlas directamente sobre el área de consultas, o por medio de las herramientas gráficas
generar las consultas deseadas. Conforme se va escribiendo en el área de resultados, las
porciones de sintaxis de SQL(SELECT, FROM, WHERE, etc) se van resaltando en azul.
Este software en su última versión (1.2) también se lo puede descargar desde el sitio
web de MySQL AB (http://dev.mysql.com/downloads/mysq/gui-tools/5.0.html) en el paquete
“MySQL GUI Tools Bundle for 5.0.” con versiones para varias plataformas incluyendo
Windows, Linux, MacOS entre otras y se ha diseñado para trabajar con los servidores de
MySQL desde la version 4.0 y posteriores.

Anl. Mauricio Arévalo M.
- Pág. 78 -
Figura 4.7: Ventana de MySQL Query Browser
4.5.11. MySQL Migration Toolkit:
Esta herramienta la proporciona MySQL AB y sirve de ayuda en la migración de
esquemas y datos desde otros sistemas de gestión de bases de datos realcionales hacia
MySQL, con un entorno gráfico y facilitando su utilización. Se encuentra en pruebas alfa y
todavía continúan haciendose esfuerzos para mejorarla, ya que contiene algunos errores por lo
que siempre se necesita realizar una copia de respaldo de las bases de datos antes de usar este
software.
MySQL Migration Toolkit soporta una variedad de sistemas gestores de bases de datos,
incluyendo Oracle, Microsoft SQL Server y Microsoft Access
La versión actual de este software es la 1.1 y se lo descarga desde el sitio web de
MySQL AB (http://dev.mysql.com/downloads/mysq/gui-tools/5.0.html) en el paquete

Anl. Mauricio Arévalo M.
- Pág. 79 -
“MySQL GUI Tools Bundle for 5.0.” con versiones para diversas plataformas; está diseñado
para trabajar con los servidores de MySQL desde la version 5.0 y posteriores.
La migración de los datos desde otros sistemas de gestión de bases de datos (SGBD) se
la realiza de una manera sencilla e intuitiva; MySQL Migration Toolkit usa un proceso o plan
de migración de datos por pasos hasta completar exitosamente la migración de los objetos
seleccionados de la base de datos.
Figura 4.8: Ventana de Migración de MySQL Migration Toolkit
4.5.12. MySQL Front
MySQL-Front es una poderosa herrmienta en entorno gráfico que nos permite manejar o
administrar bases de datos MySQL. A diferencia de otros sistemas, no esta programado en
PHP y HTML, por lo que el tiempo de respuesta es mucho más rápido y eficaz. Fue creada
por un grupo de desarrolladores llamado Star-Tools GMBH, en coordinación con la empresa
MySQL AB.
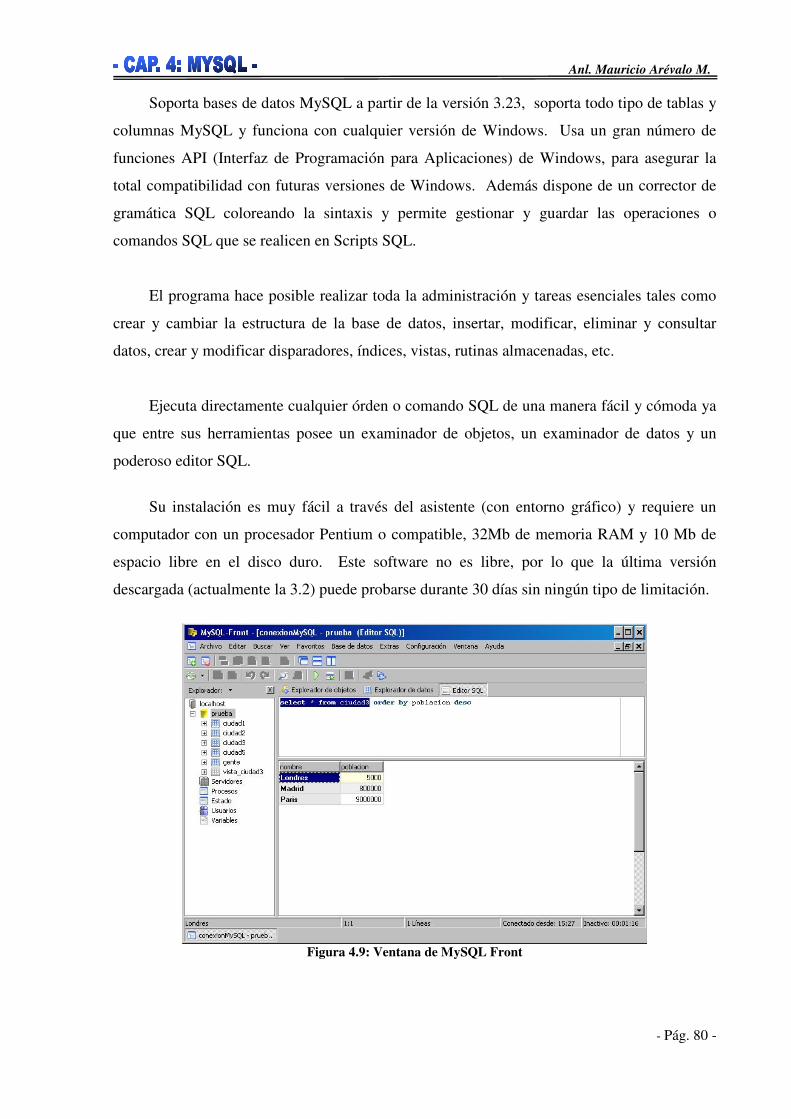
Anl. Mauricio Arévalo M.
- Pág. 80 -
Soporta bases de datos MySQL a partir de la versión 3.23, soporta todo tipo de tablas y
columnas MySQL y funciona con cualquier versión de Windows. Usa un gran número de
funciones API (Interfaz de Programación para Aplicaciones) de Windows, para asegurar la
total compatibilidad con futuras versiones de Windows. Además dispone de un corrector de
gramática SQL coloreando la sintaxis y permite gestionar y guardar las operaciones o
comandos SQL que se realicen en Scripts SQL.
El programa hace posible realizar toda la administración y tareas esenciales tales como
crear y cambiar la estructura de la base de datos, insertar, modificar, eliminar y consultar
datos, crear y modificar disparadores, índices, vistas, rutinas almacenadas, etc.
Ejecuta directamente cualquier órden o comando SQL de una manera fácil y cómoda ya
que entre sus herramientas posee un examinador de objetos, un examinador de datos y un
poderoso editor SQL.
Su instalación es muy fácil a través del asistente (con entorno gráfico) y requiere un
computador con un procesador Pentium o compatible, 32Mb de memoria RAM y 10 Mb de
espacio libre en el disco duro. Este software no es libre, por lo que la última versión
descargada (actualmente la 3.2) puede probarse durante 30 días sin ningún tipo de limitación.
Figura 4.9: Ventana de MySQL Front

Anl. Mauricio Arévalo M.
- Pág. 81 -
Aunque desafortunadamente este producto ya no se produce más y está descontinuado
por desacuerdos entre la comunidad que desarrolla MySQL Front y la empresa que distribuye
MySQL (MySQL AB); sin embargo todavía se lo puede descargar desde algunos sitios web
como “http://www.gamarod.com.ar/ recursos/downloads/programas-downloads.asp?cat=13”
y considero que este producto es una de las mejores herramientas con entorno gráfico para
administrar o gestionar de una manera rápida y eficiente las bases de datos MySQL.
4.5.13. PhpMyAdmin
Para administrar una base de datos MySQL, existe también una interfaz Web bastante
potente e intuitiva llamada PhpMyAdmin. Se la puede descargar desde el sitio web
“http://www.phpmyadmin.net/home_page/index.php” y su última versión estable es la 2.8.2.4;
su licencia es de tipo GPL.
En las palabras de los desarrolladores: “PhpMyAdmin es una herramienta escrita en
PHP con la intención de manejar la administración de MySQL a través de páginas Web,
utilizando la Internet. Actualmente puede crear y eliminar Bases de Datos, crear, eliminar y
alterar tablas, borrar, editar y añadir campos, ejecutar cualquier sentencia SQL, administrar
claves en campos, administrar privilegios y usuarios, exportar datos en varios formatos y está
disponible en 47 idiomas”10.
Esta herramienta está desarrollada sobre el lenguaje PHP (Hypertext Preprocessor"),
que es un lenguaje interpretado de alto nivel embebido en páginas HTML y ejecutado en el
servidor. Su versión 4 es la más reciente; es un lenguaje de script incrustado dentro de codigo
HTML. La mayor parte de su sintaxis ha sido tomada de C, Java y Perl con algunas
características especificas de si mismo. La meta del lenguaje es permitir rápidamente a los
desarrolladores la generación dinámica de páginas web.
Luego de descargar el programa, para que funcione, debemos tener configurado el
soporte php e instalado el servidor MySQL. Procederemos luego a descomprimir el fichero
descargado en nuestro servidor Web (puede ser Apache, Personal Web Server 3 y 4 o
10 Tomado de http://www.phpmyadmin.net/home_page/
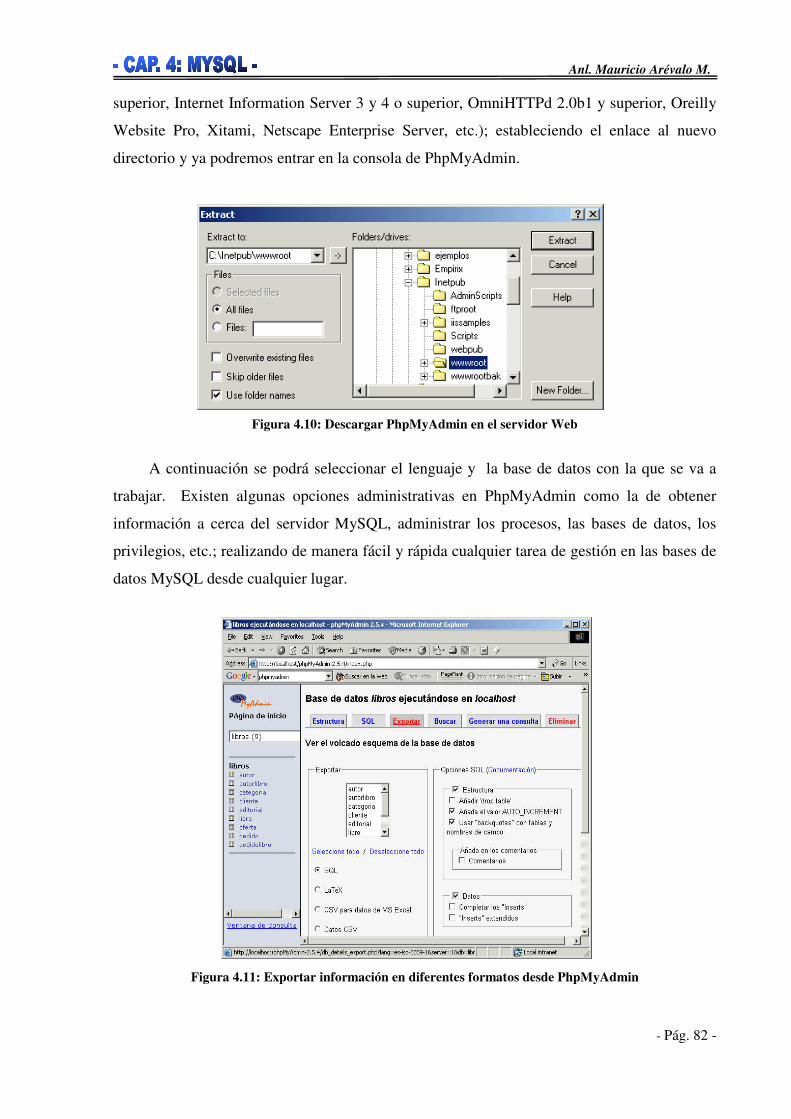
Anl. Mauricio Arévalo M.
- Pág. 82 -
superior, Internet Information Server 3 y 4 o superior, OmniHTTPd 2.0b1 y superior, Oreilly
Website Pro, Xitami, Netscape Enterprise Server, etc.); estableciendo el enlace al nuevo
directorio y ya podremos entrar en la consola de PhpMyAdmin.
Figura 4.10: Descargar PhpMyAdmin en el servidor Web
A continuación se podrá seleccionar el lenguaje y la base de datos con la que se va a
trabajar. Existen algunas opciones administrativas en PhpMyAdmin como la de obtener
información a cerca del servidor MySQL, administrar los procesos, las bases de datos, los
privilegios, etc.; realizando de manera fácil y rápida cualquier tarea de gestión en las bases de
datos MySQL desde cualquier lugar.
Figura 4.11: Exportar información en diferentes formatos desde PhpMyAdmin

Anl. Mauricio Arévalo M.
- Pág. 83 -
4.5.14. MySQL Developer Studio
MySQL Developer Studio es otra poderosa herramienta gráfica, creada y distribuida por
la empresa “CoreLab” y utilizada para diseñar y simplificar el proceso de desarrollo de bases
de datos MySQL. Ofrece una manera sencilla de administrar y realizar el mantenimiento de
las bases de datos MySQL, nos permite diseñar complejas sentencias SQL, consultas y
manipulación de los datos de diferentes maneras.
Ofrece soporte para bases de datos MySQL a partir de la versión 3.23, soporta todo tipo
de tablas y columnas MySQL y funciona con cualquier versión de Windows. Tiene licencia
de tipo propietara, pero una versión de prueba de 30 días se puede descargar desde su sitio
web para descargas (http://crlab.com/download.html) en su última versión 1.51.
Figura 4.12: Administración de bases de datos con MySQL Developer Studio

Anl. Mauricio Arévalo M.
- Pág. 84 -
4.5.15. DBDesigner
Existen herramientas de modelado de datos para MySQL como DeZign y DBDesigner.
DBDesigner es un Sistema de diseño de bases de datos optimizado para bases de datos
MySQL y es creado y distribuido por el grupo Fabforce. Esta herramienta es software libre,
bajo la licencia GPL e integra el diseño, modelado, creación y mantenimiento de bases de
datos en un solo ambiente gráfico y sencillo de utilizar.
Este software está diseñado para Microsoft Windows 2K/XP y Linux y su última
versión es la 4.0. Se lo puede descargar desde el sitio web “http://www.fabforce.net/
downloads.php”.
Figura 4.13: DB Designer para el Diseño de Bases de Datos
4.6. Instalación y Configuración de MySQL
Existen varias versiones de MySQL para instalarse sobre plataformas diferentes como
Linux, Windows, MacOS, entre otras.

Anl. Mauricio Arévalo M.
- Pág. 85 -
Siempre es posible conseguir la versión estable y recomendada o alguna versión
anterior, o también la versión que actualmente esté en fase de desarrollo, que está destinada a
personas que quieran colaborar en el desarrollo buscando errores o probando las últimas
versiones.
Después de haber decidido qué versión de MySQL instalar, se debe elegir entre una
distribución binaria o una de código fuente. Probablemente la elección más frecuente sea la
distribución binaria, si existe una para la plataforma en cuestión. Hay distribuciones binarias
disponibles en formato nativo para muchas plataformas, como los ficheros RPM para Linux,
paquetes de instalación DMG para Mac OS X, y ficheros comprimidos Zip y tar para
Windows.
Consultando la página de descargas del servidor MySQL
(http://dev.mysql.com/downloads/) se puede obtener información acerca de la versión más
actualizada para cada sistema operativo y ejecutar su descarga.
A continuación muestro una breve guía que espero sirva como ayuda para la instalación
y configuración del servidor MySQL sobre los sistemas operativos Microsoft Windows y el
sistema Linux (software libre). Estas instalaciones las he realizado sobre una máquina con un
procesador Intel Centrino de 1.7GHz, 1Gb de memoria RAM, 40Gb de espacio en Disco
Duro y con la instalación previa de los sistemas operativos Microsoft Windows XP Service
Pack 2 y Linux Fedora Core 5.
4.6.1. Instalación sobre Windows
Para ejecutar MySQL para Windows, se requiere lo siguiente:
• Una máquina con un mínimo de 64 Mb de memoria RAM, un procesador que Intel
Pentium (o compatible) que soporte sistemas operativos de 32 bits a una velocidad
considerable.

Anl. Mauricio Arévalo M.
- Pág. 86 -
• Un sistema operativo Windows de 32 bits, tal como 9x, Me, NT, 2000, XP, o Windows
Server 2003. Se recomienda fuertemente el uso de un sistema operativo Windows
basado en NT (NT, 2000, XP, 2003) puesto que éstos permiten ejecutar el servidor
MySQL como un servicio.
• Soporte para protocolo TCP/IP.
• Una herramienta capaz de leer ficheros .zip, para descomprimir el fichero de
distribución.
• Suficiente espacio en disco duro para descomprimir, instalar, y crear las bases de datos
de acuerdo a los requisitos de espacio en disco que se considere va a manejar el
servidor MySQL. Generalmente se recomienda un mínimo de 280 megabytes libres.
• Si se planea conectarse al servidor MySQL a través de ODBC (Open Database
Connectivity), se deberá descargar desde el mismo sitio el driver-Connector/ODBC
para MySQL “MyODBC”.
• Si se necesitan tablas con un tamaño superior a 4GB, debe instalarse MySQL en un
sistema de ficheros NTFS.
Al momento de desarrollar la presente monografía, la última versión estable de MySQL
sobre Microsoft Windows para producción es la 5.0, con la que realice las pruebas y
ejercicios; mientras que está en pruebas beta la versión 5.1 y en desarrollo la versión 5.2. El
fichero comprimido descargado tiene la extensión .zip y contiene un fichero de instalación
“setup.exe”, el mismo que instalará MySQL Server mediente un asistente con interfaz gráfica,
facilitando todo el proceso de instalación.
Después de descargar este fichero, se descomprime y se ejecuta el fichero "setup.exe";
el proceso de instalación está mejorado con respecto a versiones anteriores, y bastará con
seguir las indicaciones del asistente de instalación en cada pantalla, escogiendo el tipo de
instalación (típica, completa o personalizada); tendremos que aceptar las condiciones del
contrato y elegir la carpeta de instalación donde se van a copiar los archivos de MySQL;

Anl. Mauricio Arévalo M.
- Pág. 87 -
además, si se desea, se nos permite registrarnos con nuestro correo electrónico en el sitio de
MySQL AB (www.mysql.com) para obtener asistencia e información a cerca de sus últimos
productos.
Figura 4.14: Instalación de MySQL Server
Luego de instalar el servidor MySQL, podemos configurar algunas de sus opciones
mediante el Asistente de Configuración de instancias de MySQL Server, ubicado en la
carpeta o directorio en la que se instaló MySQL Server junto con algunas otras utilidades
clientes vistas en este capítulo.
Para configurar una instancia de MySQL mediante este asistente se siguen los siguientes
pasos:
1. Hacemos clic en siguiente en la pantalla de bienvenida del asistente.

Anl. Mauricio Arévalo M.
- Pág. 88 -
Fig 4.15: Pantalla de Bienvenida
2. Escogemos una configuración detallada o Standard, donde en esta última, el servidor se
configura con las opciones más usuales; sin embargo he escogido la detallada para mostrar
cada configuración en el servidor:
Fig 4.16: Escoger el tipo de configuración
3. Escogemos el tipo de servidor que queremos configurar; entre las opciones existentes está
el Servidor de desarrollo (Developer Machine), que ocupa poca memoria y permite la
ejecución de cualquier otra aplicación; también tenemos la opción de Máquina Servidor
(Server Machine), que permite la ejecución de otras aplicaciones de servidor y tiene un
consumo medio de memoria y finalmente el Servidor Dedicado MySQL (Dedicated MySQL
Server Machina), en el cual la máquina se dedicará exclusivamente a ejecutar el Servidor
MySQL, asignando la mayor cantidad de memoria al mismo.

Anl. Mauricio Arévalo M.
- Pág. 89 -
Fig 4.17: Escoger el tipo de Servidor
4. Escogemos el uso para las bases de datos que administraremos mediante el servidor
MySQL. Aquí tenemos la opción “Multifuncional”, para propósitos generales en la cual
podemos crear tablas de tipo InnoDB por defecto o también tablas de tipo MyISAM;
también tenemos la opción “Transaccional” que nos permite trabajar solamente con tablas
transaccionales de tipo InnoDB como motor principal. Finalmente tenemos la opción “No-
transaccional”, donde solamente se activa el motor de bases de datos no transaccionales
(MyISAM).
Fig 4.18: Escoger el tipo de Uso para las Bases de Datos
5. Escogemos la ruta o ubicación donde se guardarán las configuraciones para el motor de
tablas de tipo “InnoDB”.

Anl. Mauricio Arévalo M.
- Pág. 90 -
Fig 4.19: Ruta para guardar configuración del motor InnoDB
6. Escogemos el número aproximado de las conexiones concurrentes al servidor. Tenemos la
opción “Decision Support (DSS)”, que nos permite tener aproximadamente 20 conexiones
concurrentes, la opción “Online Transaction Processing (OLTP)” la cual nos permite tener
sobre las 500 conexiones al servidor o la opción “Manual”, para configurar manualmente las
conexiones concurrentes al servidor.
Fig 4.20: Escoger el número de conexiones concurrentes
7. A continuación podemos habilitar las conexiones TCP/IP (Transmission Control
Protocol/Internet Protocol) para permitir que el servidor MySQL interactúe a través de una
red TCP especificando el número de puerto (por defecto es el 3306).

Anl. Mauricio Arévalo M.
- Pág. 91 -
Fig 4.21: Habilitar conexiones TCP/IP
8. A continuación se escoge el conjunto de caracteres por defecto en el que se almacenarán
los datos en la base de datos.
Fig 4.22: Escoger el conjunto de caracteres por defecto
9. A continuación se escoge si el servidor MySQL es instalado como un servicio de
Windows.
Fig 4.23: Configuraciones para Windows

Anl. Mauricio Arévalo M.
- Pág. 92 -
10. A continuación se puede cambiar la contraseña del superusuario root para administrar las
bases de datos MySQL.
Fig 4.24: Configuraciones de seguridad
11. Se procede a ejecutar las configuraciones señaladas y se finaliza el asistente de
configuración de instancias del servidor MySQL.
4.6.2. Instalación sobre Linux
La manera recomendada de instalar MySQL en una distribución de Linux es utilizando
paquetes RPM (RedHat Package Manager).
En la mayoría de los casos, sólo será necesario instalar los paquetes MySQL-server y
MySQL-client para conseguir una instalación básica de MySQL en funcionamiento. Si se
deseara ejecutar un servidor MySQL-Max, el cual posee capacidades adicionales, se debería
instalar también el RPM MySQL-Max. No obstante, ello debería hacerse solamente después
de instalar el RPM de MySQL-server.
Muchas distribuciones Linux incluyen MySQL, en el caso de la versión de Fedora Core
5, la versión de MySQL que viene instalada es la 5.0.18. En caso de no tener instalado
MySQL, tenemos los siguientes paquetes RPM en la página de descargas de MySQL11:
11 Las descargas para MySQL están disponibles en http://dev.mysql.com/downloads/

Anl. Mauricio Arévalo M.
- Pág. 93 -
• MySQL-server-VERSION.i386.rpm: Es el servidor MySQL; será necesario a menos
que solamente se desee conectar a un servidor MySQL ejecutado en otro ordenador por
medio de programas clientes.
• MySQL-Max-VERSION.i386.rpm: El servidor MySQL-Max; este servidor tiene
capacidades adicionales que no posee el provisto en el RPM MySQL-server.
Igualmente, debe instalarse primero el RPM MySQL-server, ya que MySQL-Max
depende de él.
• MySQL-client-VERSION.i386.rpm Los programas clientes MySQL estándar. Es
recomendable que se instale siempre este paquete.
• MySQL-shared-VERSION.i386.rpm: Este paquete contiene las bibliotecas
compartidas (libmysqlclient) que ciertos lenguajes y aplicaciones necesitan para enlazar
dinámicamente y usar MySQL.
• MySQL-embedded-VERSION.i386.rpm: Instala la biblioteca del servidor MySQL
incrustado (desde MySQL 4.0).
• MySQL-VERSION.src.rpm: Contiene el código fuente de todos los paquetes
anteriores. Puede usarse para regenerar los RPMs bajo otras arquitecturas.
Para ver todos los ficheros contenidos en un paquete RPM (por ejemplo, un RPM
MySQL-server), se debe ejecutar la siguiente sentencia:
shell> rpm -qpl MySQL-server-VERSION.i386.rpm
Para llevar a cabo una instalación estándar mínima, debe ejecutarse:
shell> rpm -i MySQL-server-VERSION.i386.rpm shell> rpm -i MySQL-client-VERSION.i386.rpm

Anl. Mauricio Arévalo M.
- Pág. 94 -
El servidor RPM ubica los datos bajo el directorio “/var/lib/mysql”. También crea una
cuenta de acceso para el usuario mysql (si no existía anteriormente) a fin de ejecutar el
servidor MySQL, y crea las correspondientes entradas en /etc/init.d/ para iniciar el servidor
automáticamente al arrancar el sistema. Todas las principales distribuciones de Linux de la
actualidad soportan la nueva disposición de directorios que utiliza /etc/init.d, porque es un
requisito para cumplir con el LSB (Linux Standard Base, Base Estándar para Linux).
Si entre los ficheros RPM instalados se encuentra MySQL-server, el servidor mysqld
debería estar ejecutándose luego de la instalación, y se debería estar en condiciones de
comenzar a utilizar MySQL.
Las cuentas que se hallan en las tablas de permisos de MySQL, en principio no están
protegidas con contraseñas. Después de iniciar el servidor se deben establecer contraseñas
para esas cuentas siguiendo con los principios de seguridad para los usuarios que tiene
MySQL.

Anl. Mauricio Arévalo M.
- Pág. 95 -
CAPITULO V
POSTGRESQL
5.1. Historia y Antecedentes
El Sistema Gestor de Bases de Datos Relacionales conocida como PostgreSQL es un
proyecto de software libre distribuido bajo licencia BSD (Berkeley Software Distribution) y
creado con el aporte de varios colaboradores y auspiciantes a nivel mundial bajo los
estándares de ANSI-SQL 92/99. Su sitio web es http://www.postgresql.org y con más de una
década de desarrollo, PostgreSQL se ha convertido en la base de datos de software libre más
avanzada disponible en el momento, ofreciendo las características propias de los más potentes
motores de bases de datos comerciales como Oracle o SQLServer.
PostgreSQL es el último resultado de una larga evolución comenzada con el proyecto de
bases de datos relacionales Ingres en la Universidad de Berkeley. Luego se inició el proyecto
Post-Ingres para resolver los problemas con el modelo de base de datos relacional que se
habían presentado.
El proyecto resultante llamado Postgres completó el soporte de tipos de datos y la base
de datos comprendía también las relaciones entre tablas o clases.

Anl. Mauricio Arévalo M.
- Pág. 96 -
La implementación del DBMS (Sistema Manejador de Bases de Datos) Postgres
comenzó a desarrollarse en 1986 con la coordinación del profesor Michael Stonebraker, y fue
patrocinado por algunas fundaciones estatales y militares de investigación.
Los conceptos iniciales para el sistema fueron presentados con la definición del modelo
de datos inicial junto con la lógica y arquitectura del gestor de almacenamiento; desde
entonces, Postgres ha pasado por varias versiones. El primer sistema de pruebas fue
operacional en el año 1987 y la Versión 1 fue lanzada a unos pocos usuarios en Junio de 1989;
después de revisar el sistema de reglas de la primera versión, éste fue rediseñado y la Versión
2 se lanzó en Junio de 1990. La Versión 3 apareció en 1991 y añadió una implementación
para múltiples gestores de almacenamiento, un ejecutor de consultas mejorado junto con un
mejor sistema de reglas. En su mayor parte, las siguientes versiones hasta el lanzamiento de
Postgres95 se centraron en los temas de portabilidad y fiabilidad.
El mantenimiento del código y las tareas de soporte ocupaban demasiado tiempo que
debía dedicarse a la investigación, así que el proyecto terminó oficialmente con el
lanzamiento de la Versión 4.2.
En 1994, Andrew Yu y Jolly Chen añadieron un intérprete de lenguage SQL (Lenguaje
Estructurado de Consultas) a Postgres y el proyecto se denominó Postgres95, el mismo que
fue lanzado a continuación en la Web para que encontrara su sitio en el mundo de los gestores
de bases de datos como un descendiente de dominio público y código abierto del código
original Postgres de Berkeley. El código de Postgres95 fue optimizado y reducido en tamaño
en un 25% respecto a sus predecesores; muchos cambios internos mejoraron el rendimiento y
la facilidad de mantenimiento. Postgres95 en su versión v1.0 se ejecutaba en un 30 a 50%
más rápido que Postgres v4.2 y además de su corrección de errores, el lenguage de consultas
Postquel fue reemplazado con SQL (implementado en el servidor). También se incluyó un
nuevo programa (psql) para realizar consultas SQL interactivas.
En 1996 nace el proyecto PostgreSQL, siendo una nueva versión de Postgres95,
tratando de reflejar la relación entre el Postgres original y las versiones más recientes con
capacidades de SQL. Los números de versión parten de la 6.0, volviendo a la secuencia
seguida originalmente por el proyecto Postgres de Berkeley.

Anl. Mauricio Arévalo M.
- Pág. 97 -
El énfasis durante el desarrollo de Postgres95 estaba orientado a identificar, entender y
mejorar los problemas existentes en el código del servidor. Con PostgreSQL, además de estas
mejoras se puso énfasis para aumentar las características y capacidades del servidor de bases
de datos utilizando los estándares SQL92/SQL99.
PostgreSQL se distribuye bajo la licencia BSD12. La licencia BSD al contrario que la
GPL permite el uso del código fuente en software no libre.
El autor, bajo este tipo de licencia, mantiene la protección de copyright únicamente para
la renuncia de garantía y para requerir la adecuada atribución de la autoría en los trabajos
derivados, pero permite la libre redistribución y modificación, por lo que pienso que esta
licencia asegura un verdadero “software libre”, en el sentido que el usuario tiene libertad
ilimitada con respecto al software, y que puede decidir incluso si redistribuirlo como software
no libre.
Actualmente la última versión de PostgreSQL disponible para descargar desde su sitio
web (http://www.postgresql.org/download/) es la 8.1, liberada el 8 de noviembre del 2005.
5.2. Características y Funcionalidad de PostgreSQL
PostgreSQL está considerado como la base de datos de código abierto y con orientación
a objetos más avanzada del mundo porque proporciona un gran número de características que
normalmente sólo se encontraban en las bases de datos comerciales tales como DB2, Oracle o
SQLServer. A continuación presento a mi parecer las más importantes características de este
sistema manejador de bases de datos por la cuales es considerado uno de los más potentes
gestores de bases de datos en el mundo del software libre:
• Posee un completo soporte para control de transacciones (mediante los comandos
BEGIN WORK, COMMIT WORK o END WORK, ROLLBACK WORK o ABORT)
12 licencia BSD (Berkeley Software Distribution), pertenece al grupo de licencias de software Libre pero tiene menos restricciones en comparación con otras como la GPL estando muy cercana al dominio público.

Anl. Mauricio Arévalo M.
- Pág. 98 -
asegurando la integridad y consistencia de los datos. Un bloque de transacciones
comienza con una sentencia BEGIN WORK y si la transacción fue válida se cierra con
COMMIT WORK o END WORK. Si la transacción falla, se cierra con ABORT o
ROLLBACK WORK.
• Implementación de los estándares SQL92/SQL99 con sus operadores, funciones,
cláusulas y comandos (DDL y DML), junto con comandos extendidos de PostgreSQL.
• Soporte completo de ACID (Atomicity Consistency Isolation Durability):
o Es posible definir operaciones Atómicas, es decir, formadas por comandos que se
ejecutan todos o ninguno de ellos.
o Consistencia, que garantiza que la base de datos nunca se quede en un estado
intermedio de una transacción (con parte de los comandos ejecutados y otra parte
que no).
o Aislamiento, que mantiene separadas las transacciones de usuarios distintos hasta
que éstas han terminado, es decir controlando la concurrencia de usuarios.
o Durabilidad, garantizando que el servidor de bases de datos guarde en un registro
o log de transacciones las actualizaciones realizadas y pendientes de forma tal que
pueda recuperarse de una terminación brusca como un corte de energía en la
máquina.
• Soporta procedimientos almacenados, que como se comentó en el capítulo anterior, son
rutinas (procesos o funciones) de código ejecutable que se almacenan compiladas en el
servidor. Entre otras cosas, permiten optimizar y acelerar las aplicaciones y evitan
transferencias innecesarias a través de la red. Los procedimientos almacenados se
pueden escribir usando el lenguaje procedural propio de programación de PostgreSQL
denominado PL/pgSQL.

Anl. Mauricio Arévalo M.
- Pág. 99 -
• Posee soporte completo para subconsultas, que son consultas anidadas dentro de otro
comando como SELECT, INSERT, UPDATE, DELETE ó FROM.
• Soporta los Triggers o disparadores, que son procedimientos almacenados que se lanzan
automáticamente bajo determinadas circunstancias como cuando ocurren
actualizaciones, inserciones o eliminaciones de registros en una tabla (mediante
comandos UPDATE, INSERT o DELETE). Permiten establecer reglas de integridad y
consistencia a nivel del servidor de base de datos.
• Posee soporte para vistas, que son un conjunto de registros, resultados de una consulta
que se comportan como una tabla física para facilitar su manejo.
• PostgreSQL tiene soporte para todos los tipos de JOINS o uniones entre tablas,
cumpliendo con los estándares de sintaxis SQL.
• Puede operar sobre distintas plataformas, incluyendo Linux, UNIX, AIX, BSD, HP-UX,
Mac OS X, Solaris y Windows.
• Tiene una buena seguridad gracias a la correcta gestión de usuarios, grupos de usuarios
y contraseñas, así como también los permisos asignados a cada uno de ellos mediante
sentencias SQL como CREATE USER, CREATE GROUP, DROP USER, DROP
GROUP, ALTER USER, ALTER GROUP, GRANT y REVOKE.

Anl. Mauricio Arévalo M.
- Pág. 100 -
• PostgreSQL ofrece soporte completo para la integridad referencial mediante la
definición de claves únicas, primarias y foráneas. Esta característica es utilizada para
garantizar la validez de los datos de la base de datos.
• La flexibilidad del API (Interfaz de Programación para Aplicaciones) de PostgreSQL ha
permitido a los proveedores proporcionar soporte al desarrollo fácilmente para el
servidor PostgreSQL. Entre estas interfaces están Python, Perl, PHP, ODBC,
Java/JDBC, C/C++, etc.
• Posee MVCC (Control de Concurrencia Multi-Versión), que es la tecnología que
PostgreSQL usa para mantener la concurrencia de usuarios y evitar bloqueos
innecesarios de la base de datos. Cuando hay un usuario escribiendo en la base de datos
y otro leyendo sus datos, el MVCC evita que el usuario escritor bloquee al usuario
lector.
• PostgreSQL permite extenderse por parte de los usuarios, por ejemplo se pueden crear
nuevos tipos de datos, funciones, operadores o lenguajes procedurales. Por estas
razones y gracias a su tipo de licencia BSD, PostgreSQL puede usarse, modificarse y
distribuirse libremente para cualquier propósito, pudiendo ser privado, comercial o
académico.
• Para la conectividad del servidor Postgree, se implementa un ODBC (Open Database
Connectivity) llamado psqlODBC, que es un API de interfaz entre clientes y servidores
de bases de datos PostgreeSQL, siendo su última versión la 8.0.2. y se lo puede
descargar gratuita y libremente desde la dirección
“ftp://ftp10.us.postgresql.org/pub/postgresql/odbc/versions/” en versiones para Linux o
Windows. Además también está disponible en la página web de descargas de
PostgreSQL (http://www.postgresql.org/download/) el proveedor de acceso a datos

Anl. Mauricio Arévalo M.
- Pág. 101 -
Npgsql que es utilizado en aplicaciones que usan la plataforma .Net (como el proyecto
Mono) como un “Assembly”13 para acceder y manipular bases de datos PostgreSQL,
como se muestra en el siguiente ejemplo hecho en lenguaje C#:
using System; using System.Data; using Npgsql; public static class UsoNpgsql { public static void Main(String[] args) { NpgsqlConnection conn = new NpgsqlConnection("Server=127.0.0.1;Port=5432;User Id=mauricio; Password=secret;Database=prueba;"); conn.Open(); NpgsqlCommand command = new NpgsqlCommand("insert into table1 values(1, 1)", conn); Int32 filasafectadas; try { filasafectadas = command.ExecuteNonQuery(); } Console.WriteLine("Fueron añadidas {0} líneas en la tabla1", filasafectadas); try { conn.Close(); } } }
• Tiene soporte completo para distintos conjuntos de caracteres como latin1 (ISO-8859-
1), german, big5, ujis, etc.
• Soporta backups o respaldos en caliente (mientras trabaja el servidor PostgreSQL) y
recuperación completa de las bases de datos.
• Soporta Replicación con servidores PostgreSQL funcionando como maestros y otros
como esclavos. Todas las transacciones se las realiza primero en el servidor maestro
13 Assemblies son empaquetamientos físicos de las bibliotecas de clase, generalmente son archivos “.dll”

Anl. Mauricio Arévalo M.
- Pág. 102 -
para que se puedan actualizar en los esclavos. La replicación es un proceso asíncrono
en PostgreSQL, y se la realiza gracias a un archivo llamado binary Log que contiene la
información de las modificaciones y actualizaciones entre un nodo maestro y uno o
múltiples esclavos; la replicación con servidores PostgreSQL es un proceso
independiente del servidor y la aplicación que PostgreSQL utiliza para la replicación de
sus bases de datos se llama “Slony-I”.
• Incluye herencia entre tablas, por lo que a este gestor de bases de datos se le incluye
entre los gestores objeto-relacionales.
Para explicar la herencia de tablas con un ejemplo, crearé dos clases (tablas). La clase
capitales contiene las capitales de las provincias, las cuales son también ciudades.
Naturalmente, la clase capitales debería heredar de la clase ciudades sus atributos
(campos); esta herencia se la realiza en PostgreSQL mediante la cláusula “INHERITS”
en la sentencia CREATE TABLE como se muestra a continuación:
CREATE TABLE ciudades ( nombre text, poblacion float, altitud int );
CREATE TABLE capitales ( cod_provincia char(2) ) INHERITS (ciudades);
En este caso, una instancia de capitales hereda todos los atributos (nombre, población y
altitud) de su padre, ciudades. En PostgreSQL, una clase puede heredar de ninguna o
varias otras clases y una consulta puede hacer referencia a todas las instancias de una
clase y sus descendientes.
Por ejemplo, para consultar los nombres de todas las ciudades, incluida la capital que se
almacena en la tabla “capitales” (Quito), y que estén situadas a una altitud de 500 metros
o más, la consulta es:
SELECT c.nombre FROM ciudades* c WHERE c.altitud > 500;

Anl. Mauricio Arévalo M.
- Pág. 103 -
+----------+ |nombre | +----------+ |Quito | +----------+ |Cuenca | +----------+ |Riobamba | +----------+
Donde el asterisco “*” después de la tabla “ciudades” indica que la consulta debe
realizarse sobre la clase o tabla ciudades y sobre todas las clases que estén por debajo de
ella en la jerarquía de la herencia. Algunos comandos SQL como select, update, delete
o alter brindan soporte a esta notación.
• Soporta distintos tipos de datos según los estándares SQL92/SQL99; y además del
soporte para los tipos base, también soporta datos de tipo fecha, monetarios, elementos
gráficos, cadenas de bits, etc. También permite la creación de tipos de datos propios.
Entre los novedosos tipos de datos (o atributos) de PostgreSQL, existen los vectores
multidimensionales de longitud fija o variable. Para ilustrar su uso, crearé primero una
tabla con vectores:
CREATE TABLE SAL_EMP (nombre text, pago int4[], tareas text[][] );
La consulta anterior creará una tabla llamada SAL_EMP, la cual representa el salario
trimestral de un empleado y un vector bidimensional del tipo text (tareas), que
representa la tarea semanal del empleado. Ahora realizo algunos INSERTS y cuando se
agregan valores a un vector, se deben encerrar los valores entre llaves y separarlos
mediante comillas ('{“valor1”, “valor2”}'), como se muestra a continuación:
INSERT INTO SAL_EMP VALUES ('Luis', '{10000, 10000, 10000, 10000}', '{{"pintar", "ensamblar"}, {}}');
INSERT INTO SAL_EMP VALUES ('Carolina', '{20000, 25000, 25000, 25000}',

Anl. Mauricio Arévalo M.
- Pág. 104 -
'{{"vender", "cobrar"}, {"vender"}}');
Se puede acceder a cualquier porción de un vector, o subvectores, como se muestra a
continuación:
SELECT SAL_EMP.tareas[1:2][1:1] FROM SAL_EMP WHERE SAL_EMP.nombre = 'Luis'; +-----------------------+ |tareas | +-----------------------+ |{{"ensamblar"},{""}} | +-----------------------+
También existe el tipo de dato “SERIAL”, que es un tipo de dato especial de
PostgreSQL usado para autoincrementar valores; se usa típicamente para crear
identificadores únicos con autoincremento en las tablas. Este tipo de dato es equivalente
a especificar una secuencia (CREATE SEQUENCE) o a especificar la cláusula
“AUTO_INCREMENT” en MySQL. Su implementación es la siguiente:
CREATE TABLE nombre_tabla (nombre_col SERIAL);
Esta sentencia es equivalente a ejecutar las siguientes sentencias en PostgreSQL:
CREATE SEQUENCE nombre_sequencia;
CREATE TABLE nombre_tabla
(nombre_col INT4 DEFAULT nextval('nombre_sequencia');
CREATE UNIQUE INDEX nombre_índice on nombre_tabla (nombre_col);
La secuencia implícita en el tipo “SERIAL” no se borra cuando borramos o eliminamos
la tabla (mediante DROP TABLE) sino que permanece entre los objetos de la base de
datos hasta que se la elimine (mediante el comando DROP SEQUENCE).
• PosgreSQL tiene un catálogo del sistema (diccionario de datos) que contiene
información o metadatos a cerca de todos los objetos contenidos en las bases de datos
PostgreSQL. Este diccionario, se encuentra en las tablas pertenecientes al sistema que

Anl. Mauricio Arévalo M.
- Pág. 105 -
llevan el prefijo “pg_” como pg_database, pg_version, pgclass, pg_user, etc. Estas
tablas nos proporcionan información referente a las bases de datos, usuarios, tablas,
procedimientos, índices, tipos de datos, entre otros. Se encuentran en el directorio
“\Data” dentro del directorio en el que se instala PostgreSQL.
• El sistema de reglas que tiene PostgreSQL consiste en modificar las consultas de
acuerdo a reglas almacenadas como parte de la base de datos. Dichas consultas
modificadas son pasadas hacia el ejecutor de consultas; esto es una diferencia respecto a
otros DBMS que simplemente implementan los sistemas de reglas como procedimientos
y triggers o disparadores almacenados. Este sistema en PostgreSQL puede ser empleado
en el manejo de vistas con reglas para la especificación y actualizaciones de vistas. Una
regla se crea con el comando CREATE RULE.
La implementación del sistema de reglas posee una técnica llamada reescritura de la
consulta, la misma que procesa una consulta u operación de usuario y si existe una regla
que deba ser aplicada a dicha operación, la reescribe de tal forma que la consulta u
operación cumpla también con la regla.
Para una mejor ilustración, mostraré a continuación como implementar vistas utilizando
reglas; así tenemos la siguiente regla llamada “view rule” que actúa cuando se
seleccionan (select) registros de una vista (test_view):
create rule view_rule as on select to test_view do instead
select pro.nombre, par.nombre from proveedor pro, compra com, partes par where pro.cod = com.procod and par.pno = com.pno;
Esta regla se disparará cada vez que se detecte un comando SELECT en la vista
test_view. En lugar de seleccionar las tuplas de test_view, realmente se ejecutará la
instrucción SELECT dada en la parte de la acción de la regla, es decir si tenemos la
siguiente consulta de usuario sobre la vista view_rule:

Anl. Mauricio Arévalo M.
- Pág. 106 -
select nombre from test_view where nombre <> 'Smith';
Entonces para PostgreSQL, la consulta a la vista “test_view” realmente tomará primero
la consulta dada por la parte de acción de la regla “view_rule”, la adapta según el
número y orden de los atributos (campos) dados en la consulta del usuario y añade la
restricción dada en la cláusula WHERE de la consulta del usuario a las restricciones de
la parte de la acción de la regla. Es decir, la consulta anterior (select) original, será
reescrita de la siguiente forma:
select pro.nombre from proveedor pro, compra com, partes par where pro.cod = com.procod and par.pno = com.pno and pro.nombre <> 'Smith';
Pero también se pueden definir reglas que actúan cuando se ejecutan comandos como
INSERT, UPDATE o DELETE sobre una vista. A continuación muestro como ejemplo
el funcionamiento de varias reglas definidas para una vista “test_table_v” y que
funcionan actuando sobre una tabla “test_table” cuando se insertan, modifican o
suprimen registros en la vista:
CREATE TABLE test_table ( field1 char(1) NOT NULL, field2 SERIAL, field3 INTEGER DEFAULT 1, field4 VARCHAR(24) DEFAULT '(def val)', CONSTRAINT testdb_pkey PRIMARY KEY (field2)); CREATE VIEW test_table_v AS SELECT field1, field3, field4 FROM test_table; CREATE RULE test_table_rd AS ON DELETE TO test_table_v DO INSTEAD DELETE FROM test_table WHERE field1 = old.field1; CREATE RULE test_table_ri AS ON INSERT TO test_table_v DO INSTEAD INSERT INTO test_table (field1, field3, field4) VALUES (new.field1, new.field3, new.field4); CREATE RULE test_table_ru AS ON UPDATE TO test_table_v DO INSTEAD UPDATE test_table SET field1 = new.field1, field3=new.field3, field4=new.field4 WHERE field1 = old.field1; INSERT INTO test_table VALUES ('A'); INSERT INTO test_table_v VALUES ('B');

Anl. Mauricio Arévalo M.
- Pág. 107 -
-- Resultado -- =# SELECT * FROM test_table; field1 | field2 | field3 | field4 --------+--------+--------+----------------- A | 1 | 1 | (def val) B | 2 | | (2 rows)
• PostgreSQL soporta algunos lenguajes procedurales14. Estos lenguajes ejecutan o
procesan diversas operaciones directamente en el servidor y una de las principales
ventajas de ejecutar programación en el servidor de base de datos es que las consultas y
el resultado no tienen que ser transportadas entre el cliente y el servidor, ya que los
datos residen en el propio servidor.
Entre los lenguajes procedurales disponibles para PostgreSQL que se distribuyen con el
paquete estándar son los siguientes:
o PL/pgSQL - SQL Procedural Language
o PL/Tcl - Tcl Procedural Language
o PL/Perl - Perl Procedural Language
o PL/Python - Python Procedural Language
Donde el más destacado porque es desarrollado por los propios creadores y
colaboradores de PostgreSQL es PL/pgSQL, el mismo que permite ejecutar comandos
SQL mediante un lenguaje de sentencias imperativas y uso de funciones, dando mucho
más control automático que las sentencias SQL básicas.
Este lenguaje desarrollado en C, se ejecuta desde el propio cliente de PostgreSQL
(pgsql) y las metas del diseño como lenguaje procedural son:
o que pueda ser utilizado para crear funciones y disparadores (triggers)
o que pueda añadir estructuras de control al lenguaje SQL
o que sea capaz de realizar cómputos complejos
o que herede todas las definiciones de usuario como tipos, funciones y operadores.
14 Son lenguajes de programación utilizados en manejadores de Bases de Datos para programar operaciones como procedimientos, funciones, triggers, etc. con sentencias SQL y sentencias de control propias del lenguaje.

Anl. Mauricio Arévalo M.
- Pág. 108 -
o que sea confiable para correr dentro del DBMS
o de fácil empleo
Como un verdadero lenguaje de programación, PL/pgSQL dispone de estructuras de
control repetitivas y condicionales, además de darnos la posibilidad de creación de
funciones que pueden ser llamadas en sentencias SQL normales o ejecutadas en eventos
de tipo disparador (trigger). Las funciones escritas en PL/pgSQL aceptan argumentos o
parámetros y pueden devolver valores de tipo básico o de tipo complejo (por ejemplo,
registros, vectores, conjuntos o incluso tablas).
El lenguaje PL/pgSQL no es sensible a las mayúsculas y minúsculas y es un lenguaje
orientado a bloques. Un bloque se define con la siguiente estructura:
[<<etiqueta>>]
[DECLARE declaraciones] BEGIN Sentencias END;
Puede haber cualquier número de subbloques en la sección de la sentencia de un bloque,
las variables declaradas en la sección de declaraciones (DECLARE) se inicializan a su
valor por defecto cada vez que se inicia el bloque, no cada vez que se realiza la llamada
a la función.
Existen dos tipos de comentarios en PL/pgSQL. Un par de guiones '--' comienza un
comentario que se extiende hasta el fin de la línea mientras que los caracteres '/*'
comienzan un bloque de comentarios que se extiende hasta que se encuentre otra vez el
caracter '*/'.
Un ejemplo de una función escrita con PL/pgSQL que contiene subbloques es la
siguiente:
CREATE FUNCTION estafunc() RETURNS INTEGER AS ' DECLARE
cantidad INTEGER := 30; BEGIN
RAISE NOTICE ''Cantidad contiene aquí %'',cantidad; -- Cantidad contiene aquí 30 cantidad := 50; --

Anl. Mauricio Arévalo M.
- Pág. 109 -
-- Creamos un sub-bloque -- DECLARE
cantidad INTEGER := 80; BEGIN
RAISE NOTICE ''Cantidad contiene aquí %'',cantidad; -- Cantidad contiene aquí 80 END;
RAISE NOTICE ''Cantidad contiene aquí %'',cantidad; -- Cantidad contiene aquí 50 RETURN cantidad;
END;
' LANGUAGE 'plpgsql';
Nótese que al final de la función se define el lenguaje procedural que utilicemos
mediante la cláusula “LANGUAGE”. Todas las variables y constantes (CONSTANT)
usadas en un bloque o en sub-bloques deben declararse en la sección “DECLARE” del
bloque. Las variables en PL/pgSQL pueden ser de cualquier tipo de datos de SQL,
como INTEGER, VARCHAR y CHAR y su valor por omisión es NULL.
El siguiente procedimiento desencadenado asegura con la ayuda de un trigger o
disparador, que cada vez que se inserte o se actualice una fila en una tabla (emp_tabla),
se ejecute una función indicada (emp_funcion):
CREATE TRIGGER emp_trig BEFORE INSERT OR UPDATE ON emp_tabla FOR EACH ROW EXECUTE PROCEDURE emp_funcion();
A continuación muestro un ejemplo de una función (llamada) creada con PL/pgSQL que
actualiza dos tablas (llamadas y contactos) de un sistema de control de llamadas a
clientes, cuando estos no están interesados en la oferta que se les realiza:
CREATE OR REPLACE FUNCTION llamada(integer) RETURNS integer AS ' DECLARE
_millamada ALIAS FOR $1; _micontacto integer; BEGIN
-- buscar el contacto relacionado: SELECT contacto_id INTO _micontacto FROM llamadas WHERE id=_millamada; -- actualizar atendida en llamadas UPDATE llamadas SET atendida = true WHERE id = _millamada; -- actualizar bandera en contactos UPDATE contactos SET no_interesado = true WHERE id = _micontacto;

Anl. Mauricio Arévalo M.
- Pág. 110 -
RETURN _micontacto; END; ' LANGUAGE 'plpgsql';
• Existen herramientas libres y gratuitas con interfaces gráficas e intuitivas y fáciles de
utilizar para la administración completa de bases de datos PostgreSQL como son
PhpPgAdmin o el PgAdmin que son auspiciados por los mismos creadores del sistema
PostgreSQL. También existen algunas herramientas comerciales entre las que destaco
por su funcionalidad a PostgreSQL Manager.
Así también hay una variedad de herramientas para la administración de bases de datos
PostgreSQL en modo consola, fabricadas por los mismos creadores de PostgreSQL
(http://www.postgresql.org) como son por ejemplo el terminal de cliente interactivo de
postgreSQL psql, o las aplicaciones para realizar copias de seguridad y restauración de
base de datos pg_dump y pg_restore, o herramientas cliente para crear y eliminar bases
de datos como cretedb, dropdb entre otras que son incluidas en la descarga completa del
servidor PostgreSQL.
Estas, entre otras son algunas de las características que han hecho posible que
PostgreSQL se convierta en una poderosa y solvente herramienta de gestión de bases de datos
relacionales con ciertas características de orientación a objetos. Para hacerse una idea del
prestigio y la solvencia de este sistema de bases de datos, basta decir que la empresa Afilias
que gestiona los dominios .info y la parte técnica de los .org utiliza la versión estándar de
PostgreSQL para almacenar todos los dominios .info y .org registrados a nivel mundial.
5.3. Estructura del servidor PostgreSQL
Postgres usa un modelo de arquitectura cliente/servidor conocido como “proceso por
usuario”. Hay un proceso maestro que se ramifica para proporcionar conexiones adicionales
para cada cliente que se intente conectar a PostgreSQL.

Anl. Mauricio Arévalo M.
- Pág. 111 -
Una sesión PostgreSQL consiste en los siguientes procesos cooperativos (programas):
• Un proceso demonio supervisor (postmaster)
• La aplicación sobre la que trabaja el usuario (frontend)
• Uno o más servidores de bases de datos en segundo plano (servidor PostgreSQL).
Un único proceso postmaster controla una colección de bases de datos almacenadas en
un host; las aplicaciones de frontend o clientes que quieren acceder a una determinada base de
datos hacen llamadas y envían peticiones de usuario a través de la red al proceso postmaster,
el cual en respuesta inicia un proceso en el servidor y conecta el proceso de frontend al nuevo
servidor. A partir de este punto, el proceso cliente (frontend) y el servidor (backend) se
comunican sin la intervención del postmaster, aunque este proceso siempre se está ejecutando,
esperando peticiones de otros clientes (procesos frontend).
Figura 5.1: Estructura del Servidor PostgreSQL
En esta arquitectura el proceso postmaster y el proceso backend siempre se ejecutan en
la misma máquina (el servidor de base de datos), mientras que la aplicación frontend o cliente
se puede ejecutar desde cualquier equipo.
Existen en producción sistemas funcionando perfectamente con PostgreSQL que
manejan una capacidad de almacenamiento que fácilmente excede los 4 terabytes, algunos
límites en el espacio de disco que maneja PostgreSQL se describen a continuación:

Anl. Mauricio Arévalo M.
- Pág. 112 -
Límite Valor
Máximo tamaño de Base de Datos Ilimitado
Máximo tamaño de tabla 32 TB
Máximo tamaño de registro 1.6 TB
Máximo tamaño de campo 1 GB
Máximos registros por tabla Ilimitado
Máximas columnas por tabla 250 - 1600 dependiendo del tipo de columna
Máximos índices por tabla Ilimitado
Tabla 5.1: Límites de espacio en disco que maneja PostgreSQL
5.3.1. Tipos de Tablas
En Linux, PostgreSQL almacena las bases de datos en el directorio
“/var/lib/pgsql/data/base” y a partir de ahí un directorio para cada base. En Windows
PostgreSQL almacena los archivos de las bases de datos en el directorio “C:\Archivos de
Programa\PostgreSQL\8.1\data\Base”.
Cada tabla es considerada un archivo, así como los índices. Los nombres de las tablas
pertenecientes al sistema llevan el prefijo “pg_”. Por ejemplo, el archivo PG_VERSION
(presente en cada base de datos) contiene la versión mayor con la que fue creada la base y al
cambiar de versión de PostgreSQL es importante respaldar este archivo.
A continuación se muestra el contenido de las tablas que PostgreSQL utiliza como
catálogos para mantener el sistema. Cada base de datos que se crea, tiene estas mismas tablas,
salvo la primera (pg_database) que es única para todas las bases de datos:
Nombre tabla Descripción (que almacena)
pg_database Bases de datos
pg_class Clases o tablas
pg_attribute Atributos o campos de la clase o tabla
pg_index Índices secundarios

Anl. Mauricio Arévalo M.
- Pág. 113 -
Nombre tabla Descripción (que almacena)
pg_proc Procedimientos
pg_type Tipos de datos (del sistema y definidos por el usuario)
pg_user Usuarios de PostgreSQL
pg_operator Operadores (del sistema y definidos por el usuario)
Tabla 5.2: Contenido de las tablas que se usan como catálogos del sistema
Por ejemplo, para saber que bases de datos hay en el sistema se ejecuta la consulta:
SELECT * FROM pg_database;
Para saber que tablas tengo en la base de datos actual:
SELECT * FROM pg_class;
Si sólo queremos saber cuantos registros tiene una tabla, consultamos:
SELECT relname,reltuples FROM pg_class WHERE relname=’mitabla’;
5.3.2. Tipos de Datos
Como todos los manejadores de bases de datos, PostgreSQL implementa los tipos de
datos definidos para los estándares SQL/92 y SQL3 (SQL/99) y aumenta algunos otros.
Algunos de estos tipos de datos se muestran en las tablas que están a continuación:
Tipo en Postgres Correspondiente en SQL3 Descripción
Bool boolean valor lógico o booleano (true/false)
Char(n) character(n) cadena de carácteres de tamaño fijo
Date date fecha (sin hora)
Float8 real, double precision número de punto flotante de doble precisión
int2 smallint entero de dos bytes con signo
int4 int, integer entero de cuatro bytes con signo

Anl. Mauricio Arévalo M.
- Pág. 114 -
Tipo en Postgres Correspondiente en SQL3 Descripción
money decimal(9,2) cantidad monetaria
Time time hora en horas, minutos, segundos y centésimas
timespan interval intervalo de tiempo
timestamp timestamp with time zone fecha y hora con zonificación
varchar(n) character varying(n) cadena de caracteres de tamaño variable
Tabla 5.3: Tipos de datos del Estándar SQL3 en PostgreSQL
Tipos de datos extendidos en PostgreSQL
Tipo Descripción
Box caja rectangular en el plano
Cidr dirección de red o de host en IP versión 4
circle círculo en el plano
Inet dirección de red o de host en IP versión 4
int8 entero de ocho bytes con signo
Line línea infinita en el plano
Lseg segmento de línea en el plano
Path trayectoria geométrica, abierta o cerrada, en el plano
point punto geométrico en el plano
polygon trayectoria geométrica cerrada en el plano
serial identificador numérico único con autoincremento
Tabla 5.4: Tipos de datos Extendidos en PostgreSQL
5.4. Ventajas y Desventajas de PostgreSQL
5.4.1. Ventajas
• PostgreSQL es un sistema de gestión de bases de datos relacionales Open Source (de
código abierto), gratuito y que al tener licencia de tipo BSD, nos permite manejar

Anl. Mauricio Arévalo M.
- Pág. 115 -
libremente el código fuente del gestor de bases de datos PostgreSQL, mejorando u
optimizando su código. Incluso se permite redistribuirlo como producto comercial y
combinarlo con herramientas de licencia propietaria.
• Al sustituir los bloqueos de tabla por el control de concurrencia MVCC (Control de
Concurrencia Multi-Versión), se permite a los accesos de sólo lectura continuar leyendo
datos consistentes durante la actualización de registros, permitiendo también copias de
seguridad en caliente (mediante la aplicación pg_dump) mientras la base de datos
permanece disponible para consultas.
• Se han implementado importantes características al motor de datos, incluyendo
subconsultas, valores por defecto, restricciones a valores en los campos (constraints),
disparadores (triggers), etc.
• Se ha incluido un sistema de reglas consistente en modificar las consultas de acuerdo a
reglas almacenadas como parte de la base de datos.
• Posee manejo y control de transacciones para asegurar la consistencia de los datos.
• Soporta los tipos de datos, cláusulas, funciones y comandos de tipo estándar
SQL92/SQL99 y extendidos propios de PostgreSQL. Los tipos de datos internos han
sido mejorados incluyendo nuevos tipos.
• Para una fácil conectividad al servidor PostgreSQL, se implementa un ODBC (Open
Database Connectivity) llamado psqlODBC, que es un API de interfaz entre clientes y
servidores de bases de datos PostgreeSQL. Además se tiene el proveedor de acceso a
datos Npgsql que es utilizado en aplicaciones que usan la plataforma .Net para acceder y
manipular bases de datos PostgreSQL.
• PostgreSQL puede operar sobre distintas plataformas incluyendo Linux, Unix, MacOS
X, Solaris y últimamente Windows.
• Soporta replicación de bases de datos asíncrona, realizando primero las transacciones en
un “servidor maestro” para que se puedan actualizar en los “servidores esclavos” dando
alta disponibilidad al sistema.

Anl. Mauricio Arévalo M.
- Pág. 116 -
• Se han añadido características adicionales que cumplen el estándar SQL92, incluyendo
claves primarias y foráneas para asegurar reglas de integridad referencial,
identificadores entrecomillados, conversión de tipos de datos, etc.
• Posee un buen sistema de seguridad mediante la gestión de usuarios, grupos de usuarios,
permisos y contraseñas.
• Posee una gran capacidad de almacenamiento.
• Posee ciertas características de orientación a objetos, como la herencia entre tablas.
• Tiene una arquitectura Cliente – Servidor.
• Tiene algunas herramientas o aplicaciones para gestionar o administrar el servidor y sus
bases de datos con interfaces gráficas e intuitivas o en modo de línea de comandos.
• La velocidad del motor de bases de datos ha sido incrementada aproximadamente en un
20 a 40%, y su tiempo de arranque ha bajado al 80% desde que la versión 6.0 fue
lanzada.
• Tiene una buena escalabilidad ya que es capaz de ajustarse al número de CPUs y a la
cantidad de memoria que posee el sistema de forma óptima, soportando una mayor
cantidad de peticiones simultáneas a la base de datos de manera correcta; se dice que
“PostgreSQL ha llegado a soportar el doble de carga de lo que soporta MySQL”15.
5.4.2. Desventajas
• Consume más recursos que MySQL, por lo que se necesitan mayores características de
hardware para ejecutarlo.
• Aproximadamente es 2 veces más lento que MySQL (aunque en la práctica no se nota
esta diferencia).
15 Fragmento tomado de “http://www.netpecos.org/docs/mysql_postgres/index.html”

Anl. Mauricio Arévalo M.
- Pág. 117 -
• PostGreSQL es un magnífico gestor de bases de datos, capaz de competir con muchos
gestores comerciales, aunque el primer encuentro con este gestor es un poco “duro”, ya
que la sintaxis de algunos de sus comandos o sentencias no es nada intuitiva, sin
embargo existe una amplia documentación en su sitio web (http://www.postgresql.org) o
en la ayuda de PostgreSQL (aplicación psql y documentación de PostgreSQL).
5.5. Gestión de Bases de Datos PostgreSQL
Para la administración de un servidor de bases de datos PostgreSQL existen
herramientas libres y gratuitas con interfaces gráficas e intuitivas para la administración
completa de bases de datos PostgreSQL, entre estas herramientas están PhpPgAdmin o el
PgAdmin y herramientas comerciales como PostgreSQL Manager. También hay una
variedad de herramientas para la administración de bases de datos PostgreSQL en modo
consola, como el terminal de cliente interactivo de postgreSQL “psql”, o las aplicaciones
pg_dump y pg_restore para realizar copias de seguridad y restauración de bases de datos, o
las herramientas para crear y eliminar bases de datos como cretedb, dropdb, y otras más
generalmente ubicadas en el directorio “\bin” dentro del directorio donde se instaló
PostgreSQL. A continuación describo sus principales características:
5.5.1. psql
Asumiendo que PostgreSQL ya ha sido instalado e iniciado exitosamente, la
herramienta principal para trabajar en modo línea de comandos con PostgreSQL es “psql”.
Con psql tenemos una herramienta completa para poder manipular las bases de datos
PostgreSQL mediante comandos DML (Lenguaje de Manipulación de datos) y DDL
(Lenguaje de definición de datos). Psql viene incorporado en la instalación del paquete
PostgreSQL para Windows o Linux que se descarga desde el sitio web
“http://www.postgresql.org/download/” y con el mismo tipo de licencia que el paquete
PostgreSQL, es decir BSD (Berkeley Software Distribution). Este programa cuenta con ayuda

Anl. Mauricio Arévalo M.
- Pág. 118 -
en línea, por medio de la instrucción “\?” o “\h” para examinar la sintaxis de los comandos
SQL y se instala en el directorio “\bin” dentro del directorio de instalación de PosgreSQL.
Esta aplicación se la inicia en la línea de comandos del sistema operativo, escribiendo su
nombre (psql) con la siguiente sintaxis:
psql [opciones] [nombre_base_datos]
Como podemos ver, psql acepta opciones en la línea de comandos al momento de
invocar a la aplicación, entre las que están:
OPCION SIGNIFICADO -c Consulta Ejecuta una consulta. -d base_datos Especifica la base de datos. -e Hace “eco” de la consulta enviada al servidor. -E Hace “eco” de todas las consultas enviadas al servidor. -f nombre_arch Usa un archivo como fuente de consultas SQL. -F separador Coloca el separador de campos (por defecto es '|'). -h host Especifica el host del servidor. -l Lista las bases de datos disponibles. -o nombre_arch Guarda los resultados en el archivo especificado. -p puerto Especifica el número de puerto para habilitar la comunicación
entre procesos clientes (frontend) y servidores (backend o postmaster).
-q Ejecuta las consultas sin mostrar mensajes. -t No muestra cabeceras ni contadores de filas. -u Pregunta por un nombre de usuario y una contraseña para la
autentificación en el sistema. Tabla 5.5: Cliente psql
Entre las opciones más útiles a mi parecer, están “-h servidor” (conexión al host
servidor) y “-d base_datos” (especificar la base de datos), en cuyo caso también podemos
indicarle la opción -u para que nos solicite el usuario y la contraseña, como se muestra a
continuación:
psql -h servidor -d base_datos -u Username: fml Password:
Otra opción muy útil es “-l” para listar todas las bases existentes, por ejemplo:
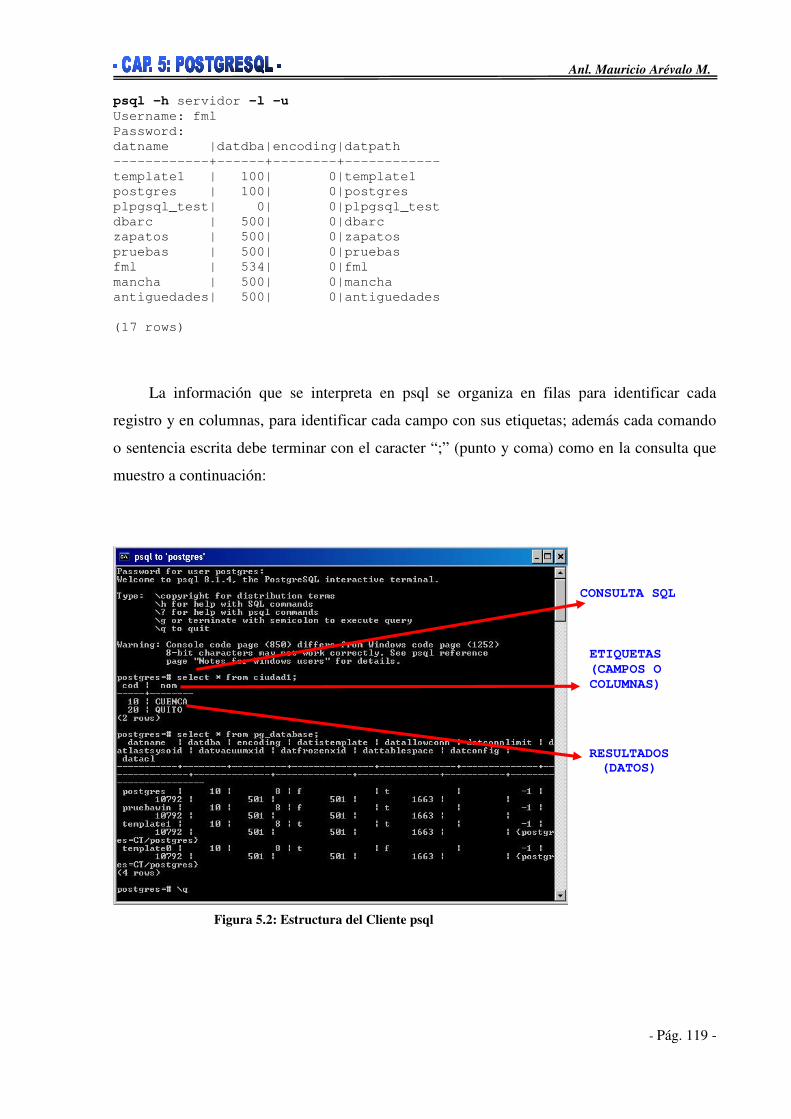
Anl. Mauricio Arévalo M.
- Pág. 119 -
psql -h servidor -l -u Username: fml Password: datname |datdba|encoding|datpath ------------+------+--------+------------ template1 | 100| 0|template1 postgres | 100| 0|postgres plpgsql_test| 0| 0|plpgsql_test dbarc | 500| 0|dbarc zapatos | 500| 0|zapatos pruebas | 500| 0|pruebas fml | 534| 0|fml mancha | 500| 0|mancha antiguedades| 500| 0|antiguedades (17 rows)
La información que se interpreta en psql se organiza en filas para identificar cada
registro y en columnas, para identificar cada campo con sus etiquetas; además cada comando
o sentencia escrita debe terminar con el caracter “;” (punto y coma) como en la consulta que
muestro a continuación:
Figura 5.2: Estructura del Cliente psql
ETIQUETAS
(CAMPOS O
COLUMNAS)
CONSULTA SQL
RESULTADOS (DATOS)

Anl. Mauricio Arévalo M.
- Pág. 120 -
Para salir de psql utilizamos la opción “\q”. Cabe mencionar que psql utiliza una
biblioteca llamada “readline”, por la cual cuenta con edición en la línea de comandos.
5.5.2. pg_dump y pg_dumpall
Las herramientas clientes pg_dump y pg_dumpall nos ayudan tanto para respaldar las
tablas o bases de datos o para migrarlas de un sistema a otro en un formato transportable.
Estas utilidades vienen incluidas en el paquete de instalación PostgreSQL para Windows o
Linux y tienen el mismo tipo de licencia que el paquete PostgreSQL, es decir BSD (Berkeley
Software Distribution). Se instalan en el directorio “\bin” dentro del directorio de instalación
de PosgreSQL.
La utilidad pg_dump apareció en la versión “release 0.02” de Postgres95, pero se
mejoró desde la versión de PostgreSQL “release 7.1”.
En algunos casos al actualizar la versión de PostgreSQL será necesario primero
respaldar las tablas con estas herramientas para posteriormente volverlas a cargar; pg_dump
se emplea para respaldar una base de datos o una tabla en particular, mientras que pg_dumpall
respalda todas las bases de datos del sistema. Su sintaxis es la siguiente:
pg_dump [opciones.] [nombre_base_datos]
A continuación muestro algunas de sus opciones más útiles:
-a: Respalda solo los datos en un archivo de texto plano, no las definiciones (esquema).
-f formato: Selecciona el formato de salida para el archivo; este formato puede ser:
p: Es el formato predeterminado; el archivo se genera en un archivo plano de texto de
tipo “SQL script”.
t: La salida se genera en un archivo “.tar”; este formato puede ser modificado en la
entrada del programa que recupera respaldos pg_restore. Usando este formato de
archivo se permite excluir objetos de la base de datos en el momento en que se restaura.

Anl. Mauricio Arévalo M.
- Pág. 121 -
c: El archivo de salida se genera en un formato modificable para la entrada en el
programa pg_restore. Este es el formato más flexible para reordenar la carga de datos
con las definiciones de los objetos (esquema). Este formato se comprime por defecto.
-s: Solamente respalda el esquema de la base de datos (definiciones de objetos), no los datos.
-t tabla: Respalda los datos y el esquema de la tabla especificada.
La forma más general de emplear pg_dump para respaldar sólo una tabla, es la
siguiente:
pg_dump -t mitabla mibase > mibase.mitabla.dump
Con lo cual en el archivo “mibase.mitabla.dump” tenemos un archivo con los datos y el
esquema de la tabla ‘mitabla’ para poder recuperar toda la información de la misma.
Al respaldar una tabla de esta manera, lo primero que hace pg_dump es tratar de
identificar al usuario creador de la tabla, luego crea la tabla, fija los permisos existentes, copia
los datos y finalmente crea el índice si es que la tabla tiene un índice asociado.
Es mejor comprimir los archivos para ocupar el mínimo espacio posible. Por ejemplo,
podemos hacerlo así:
pg_dump -t mitabla mibase | gzip -9c > mibase.mitabla.dump.gz pg_dump -t mitabla mibase | bzip2 -c > mibase.mitabla.dump.bz
Ambos programas de compresión (gzip y bzip2) pueden ser consultados con el sistema
man (de manual) en Linux. Para recuperar la información en la base de datos, podemos
emplear la siguiente instrucción en la línea de comandos:
gunzip -c mibase.mitabla.dump.gz bunzip2 -c mibase.mitabla.dump.bz

Anl. Mauricio Arévalo M.
- Pág. 122 -
5.5.3. pg_restore
Esta herramienta restaura o recupera una base de datos PostgreSQL desde un archivo
creado con la herramienta pg_dump. Pg_restore apareció por primera vez en la versión 7.1 de
PostgreSQL. Al igual que las anteriores, esta utilidad se instala en el directorio “\bin” dentro
del directorio de instalación de PosgreSQL y tiene el mismo tipo de licencia (BSD) que el
paquete PostgreSQL.
Esta utilidad restaura una base de datos de PostgreSQL desde un archivo especificado,
este archivo guarda los comandos SQL necesarios para reconstruir la base de datos al estado
en el cual fue guardada o respaldada y su sintaxis es:
pg_restore [opciones] [nombre_archivo_a_restaurar]
Algunas opciones que tiene pg_restore son las siguientes:
-a: Recupera solamente los datos, no el esquema o definición de objetos.
-d nombre_db: Se conecta a la base de datos especificada y recupera directamente los datos
en la misma.
-e: Termina la operación si ocurre un error mientras se envían los comandos SQL para
restaurar la base de datos. Por defecto, si se encuentra un error en la operación, continúa la
recuperación y al final se muestra un contador y una descripción de los errores ocurridos.
-f formato: Especifica el formato del archivo, esta opción no es necesaria ya que pg_restore
determina el formato de manera automática. El formato del archivo puede ser uno de los
siguientes:
t: El archivo es un archivo “.tar”. Usando este formato de archivo se permite excluir
objetos de la base de datos en el momento en que se restaura.
c: El formato de archivo se puede modificar en pg_restore. Este es el formato más
flexible para reordenar la carga de datos con las definiciones de los objetos (esquema).
Este formato se comprime por defecto.

Anl. Mauricio Arévalo M.
- Pág. 123 -
-s: Solamente recupera el esquema de la base de datos (definiciones de objetos), no los datos.
-t tabla: Recupera la definición y/o los datos de la tabla especificada.
A continuación muestro un ejemplo respaldando una base de datos llamada mydb con
pg_dump y luego la restauro con pg_restore en una nueva base de datos llamada newdb:
pg_dump -ft mydb > db.tar pg_restore -d newdb db.tar
5.5.4. createdb y dropdb
Una de las primeras operaciones para probar la conexión y correcta instalación del
servidor de bases de datos PostgreSQL es crear una base de datos. Para crear una base de
datos se puede utilizar la aplicación createdb y para eliminarla del servidor se utiliza dropdb.
Estas aplicaciones se instalan en el directorio “\bin” dentro del directorio de instalación de
PosgreSQL y su sintaxis es la siguiente:
createdb nombre_base_datos dropdb nombre_base_datos
Un ejemplo de como crear una base de datos (mydb) mediante la aplicación createdb se
muestra a continuación:
createdb mydb
Createdb es una aplicación alternativa al comando SQL “CREATE DATABASE” y
luego de ejecutarse esta aplicación se muestra la respuesta “CREATE DATABASE”.
Si se recibe un mensaje similar a “createdb: command not found” puede ser porque
PostgreSQL no fue instalado apropiadamente o porque no se encuentra la ruta de la aplicación
en el directorio “\bin” del directorio de instalación de PostgreSQL, entonces se debe probar
escribiendo la ruta completa en donde se encuentra la aplicación y ejecutarla.

Anl. Mauricio Arévalo M.
- Pág. 124 -
En Linux por ejemplo, la aplicación createdb se encuentra en “/usr/bin/createdb”
mientras que en Windows se encuentra en “C:\Archivos de
programa\PostgreSQL\8.1\bin\createdb”.
Otra respuesta de error al ejecutar createdb puede ser la siguiente:
psql: could not connect to server: Connection refused Is the server running on host "nombre_server" and accepting TCP/IP connections on port 5432?
En cuyo caso deberemos revisar los archivos de configuración de PostgreSQL
(pg_hba.conf, pg_ident.conf y postgresql.conf) ubicados en el directorio “/Data” donde se
instaló el servidor PostgreSQL o debemos reinstalar el servidor PostgreSQL porque no se
puede establecer una conexión al servidor.
Para eliminar una base de datos físicamente del servidor se utiliza la aplicación dropdb,
la misma que es una aplicación alternativa al comando SQL “DROP DATABASE”.
Al eliminar una base de datos se eliminan también todos los objetos que contiene la base
de datos, además se debe tener cuidado porque no se puede recuperar una base de datos una
vez que esta se elimine.
5.5.5. Postmaster y pg_ctl
Luego de instalar PostgreSQL y antes de acceder a cualquier base de datos se debe
arrancar el servidor PostgreSQL. Esta operación se la puede realizar mediante el programa
llamado postmaster, indicándole al mismo donde se encuentra el directorio “\Data” de
PostgreSQL mediante la opción -D. Este programa se encuentra en el directorio “bin” donde
se instaló PostgreSQL (/usr/bin/postmaster) y la manera más común de arrancar el servidor
mediante la aplicación postmaster es:
postmaster -D /var/lib/pgsql/data

Anl. Mauricio Arévalo M.
- Pág. 125 -
Pg_ctl es una aplicación incluida también en el directorio “bin” donde se instala
PostgreSQL, y se proporciona para simplificar algunas tareas como iniciar y detener al
servidor PostgreSQL. Por ejemplo:
pg_ctl start -l logfile
Esta operación arranca el servidor y coloca las transacciones en el archivo especificado
(logfile). La opción de -D le indica al servidor PostgreSQL donde se encuentra el directorio
“\Data” que es donde normalmente se guardan las bases de datos.
5.5.6. PgAdmin
PgAdmin es una aplicación con interfaz gráfica comprensible para el diseño y
administración total de bases de datos PostgreSQL; esta aplicación está diseñada para
ejecutarse en sistemas operativos como GNU/Linux y Windows 2000, XP o 2003. PgAdmin
versión 3 se ejecuta desde la versión de la base de datos PostgreSQL 7.3 y superiores. Para
versiones anteriores de la base de datos, se debe usar la versión de PgAdmin2.
Figura 5.3: Ventana de PgAdmin

Anl. Mauricio Arévalo M.
- Pág. 126 -
PgAdmin se distribuye libremente bajo licencia de tipo GNU separadamente de
PostgreSQL y se puede descargar su última versión (PgAdmin3-1.4.3) desde el sitio web
“http://www.pgadmin.org/download/” en las versiones para Linux o Windows.
En la versión del servidor PostgreSQL 8.1.4 para Windows, que fue la que descargue en
el momento que realicé la presente monografía, se instala junto con el servidor de bases de
datos la herramienta PgAdmin III en su versión 1.4.2 lanzada en marzo del 2006.
La versión de PgAdmin III contiene las siguientes características:
• Esquema de navegación de todos los objetos de PostgreSQL.
• Diálogos de creación y propiedades de objetos (usuarios, tablas, bases de datos,
disparadores, etc.).
• Herramienta de edición/visualización de tablas.
• Habilidad para navegar y conectarse a múltiples servidores a la vez.
• Interfaz de usuario intuitiva y traducida a más de 20 idiomas.
• La ventana principal muestra la estructura de la base de datos y todos los detalles de los
objetos contenidos en la misma.
• Se puede controlar o administrar los usuarios de las bases de datos, manejando los
privilegios, usuarios, grupos y contraseñas.
• Permite llevar un control sobre el estado del servidor de bases de datos, permitiendo
iniciarlo o detenerlo.
• Posee una herramienta avanzada para consultas, permitiendo ejecutar cualquier
sentencia SQL.
• Permite exportar datos en distintos formatos a partir de una consulta SQL generada.
• Permite ver y editar los datos de una consulta a una tabla o vista.
• Tiene una herramienta de Mantenimiento que ejecuta tareas como reconstruir las
estadísticas de las bases de datos y tablas, limpiar o eliminar los datos sin usar y
reorganizar los índices.
• Permite sacar copias o respaldos de las bases de datos y restaurarlas haciendo uso de las
herramientas pg_dump y pg_restore de PostgreSQL.
• La ventana del “estado del servidor” muestra los usuarios actualmente conectados, los
bloqueos y características del servidor seleccionado.

Anl. Mauricio Arévalo M.
- Pág. 127 -
5.5.7. PhpPgAdmin
PhpPgAdmin es una herramienta con una interfaz Web bastante potente que nos permite
administrar los servidores de bases de datos PostgreSQL, esta aplicación está escrita en PHP
con la intención de manejar la administración de PostgreSQL a través de páginas Web,
utilizando Internet y fue basado en otro producto visto anteriormente llamado phpMyAdmin,
que provee las mismas funcionalidades a los usuarios del servidor de base de datos MySQL.
PhpPgAdmin es un cliente web que ofrece una manera conveniente de crear objetos
como bases de datos, tablas, usuarios, funciones, vistas, disparadores, etc., alterarlos o
consultar sus datos usando el estándar SQL.
Esta aplicación se la puede descargar desde el sitio web
“http://phppgadmin.sourceforge.net/?page=download” y su última versión estable es la 4.0.1
publicada en noviembre del 2005. Es una herramienta de código abierto (Open Source) con
licencia de tipo GPL siendo creada y distribuida por la empresa SourceForge.
Entre sus principales características tenemos:
• PhpPgAdmin puede administrar múltiples servidores PostgreSQL.
• Soporta las versiones de PostgreSQL 7.0.x, 7.1.x, 7.2.x, 7.3.x, 7.4.x, 8.0.x y 8.1.x
• Permite la fácil administración de usuarios y grupos, bases de datos, tablas, índices,
triggers o disparadores, reglas, privilegios, vistas, secuencias, funciones, etc.
• Permite una fácil manipulación de los datos, con un buscador de tablas, vistas y
reportes.
• Permite la ejecución de la mayoría de comandos SQL de manipulación (DML) y
definición de datos (DDL).
• Puede exportar e importar los datos en una variedad de formatos: SQL, XML, XHTML
o CSV.
• Tiene una fácil instalación y configuración.
Para que funcione, debemos tener configurado PHP (Lenguaje Preprocesador de
Hipertexto) e instalado el servidor PostgreSQL. Procederemos luego a descomprimir el

Anl. Mauricio Arévalo M.
- Pág. 128 -
fichero descargado en nuestro servidor Web (puede ser puede ser Apache, Personal Web
Server, Internet Information Server) y ya podremos entrar en la consola de PhppgAdmin.
PhpPgAdmin funciona con versiones de PHP 4.1 o superiores, pero se recomienda 4.3 porque
ofrece más funcionalidad
Luego seleccionamos el lenguaje y la base de datos con la que se va a trabajar; existen
algunas opciones administrativas en PhppgAdmin como administrar las bases de datos, los
privilegios, exportar e importar información de un modo sencillo y remoto, entre otras;
realizando de manera fácil, rápida e intuitiva la mayoría de tareas de gestión de las bases de
datos PostgreSQL desde cualquier lugar vía Internet.
Una prueba de esta aplicación se la puede encontrar accediendo a la página
http://phppgadmin.kattare.com/phppgadmin4/, la misma que usa Phppgadmin para probar la
administración remota de bases de datos PostgreSQL, se escoge la base de datos para
administrarla y se digita el usuario ‘phppgadmin’ y la contraseña ‘webdb’.
Figura 5.4: Ventana de PhpPgAdmin

Anl. Mauricio Arévalo M.
- Pág. 129 -
5.5.8. EMS SQL Manager para PostgreSQL
SQL Manager es una herramienta de alto desempeño para administrar un servidor de
bases de datos PostgreSQL, trabaja con cualquier versión de la base de datos a partir de la 8.0
y soporta todas las características de PostgreSQL. SQL Manager dispone de una interfaz
gráfica de usuario que nos permite administrar las bases de datos de una manera eficiente,
segura y rápida. Entre sus principales características técnicas están las siguientes:
• Soporte completo desde la versión 8.1 de PostgreSQL.
• Interfaz gráfica de usuario (GUI).
• Manejo y administración rápida de la base de datos.
• Manejo de todos los objetos PostgreSQL.
• Posee herramientas avanzadas para la manipulación de datos.
• Posee un efectivo administrador de seguridad.
• Tiene excelentes herramientas visuales y de texto para generar consultas.
• Capacidad de exportar e importar datos.
• Posee una poderosa herramienta visual para diseñar las bases de datos.
• Fácil uso de tareas de mantenimiento de bases de datos mediante asistentes.
Esta herramienta es comercial pero se puede descargar la versión de prueba desde su
sitio web “http://www.sqlmanager.net/”. SQL Manager para PostgreSQL es una herramienta
con licencia propietaria y los derechos de autor le pertenecen a la empresa EMS, que se
dedica a brindar soluciones para poder trabajar de mejor manera con distintos manejadores de
bases de datos, que en este caso son herramientas diseñadas para trabajar con PostgreSQL.
En la misma página Web de SQL Manager se pueden descargar las siguientes
herramientas con interfaz gráfica, que son muy útiles para una administración completa de la
base de datos:
• Data Export para PostgreSQL: herramienta para exportar datos.
• Data Import para PostgreSQL: herramienta para importar datos.
• Data Pump para PostgreSQL : herramienta para generar respaldos o copias.
• DB Comparer for PostgreSQL: herramienta para comparar bases de datos y
encontrar diferencias en su estructura.

Anl. Mauricio Arévalo M.
- Pág. 130 -
• DB Extract for PostgreSQL: Es una utilidad para generar respaldos de bases de
datos en archivos “scripts” SQL.
• SQL Query for PostgreSQL: herramienta para generar consultas complejas.
La versión Enterprise, que viene con EMS SQL Manager y todos los productos de la
lista anterior cuesta 475 dólares mientras la versión Estándar, que viene con SQL Manager
pero con menos aplicaciones adicionales, tiene un costo de 420 dólares. Si solamente se
desea la aplicación EMS SQL Manager tiene un costo de 275 dólares.
Figura 5.5: Ventana de EMS SQL Manager
Esta herramienta solamente está disponible en su versión SQL Manager 2005 para
Microsoft Windows.

Anl. Mauricio Arévalo M.
- Pág. 131 -
5.6. Instalación de PostgreSQL
Existen versiones de PostgreSQL para instalarse sobre plataformas diferentes como
Linux, Solaris o Windows
Actualmente la última versión de PostgreSQL disponible para descargar desde su sitio
web (http://www.postgresql.org/download/) es la 8.1, liberada el 8 de noviembre del 2005 en
versiones para Linux o Windows.
Después de haber decidido la versión de PostgreSQL a instalar, se debe elegir entre una
distribución binaria o una de código fuente (source). Existen distribuciones binarias de la
versión 8.1 de PostgreSQL disponibles para descargar en ficheros RPM para Linux y ficheros
comprimidos Zip para Windows.
Figura 5.6: Página Web de descargas de PostgreSQL
La instalación de PostgreSQL para Windows y Linux la he realizado sobre una máquina
con un procesador Intel Movile de 1.7GHz, 1Gb de memoria RAM y 40Gb de espacio en
Disco Duro, aunque los requerimientos de hardware para instalar PostgreSQL 8.1 son una
máquina con un mínimo de 32 Mb de memoria RAM, un procesador Intel Celeron (o

Anl. Mauricio Arévalo M.
- Pág. 132 -
superior) que soporte sistemas operativos de 32 bits a una velocidad considerable y un disco
duro, que su tamaño esté calculado según el espacio que ocupen las bases de datos que tenga
el sistema, pero para la instalación de PostgreSQL se necesitan aproximadamente unos 60Mb
de espacio libre.
Para la instalación de PostgreSQL en los dos sistemas operativos (Windows y Linux),
instalé previamente los sistemas operativos Microsoft Windows XP Service Pack 2 como
sistema operativo de la máquina y la distribución de Linux Fedora Core 5, utilizando la
aplicación VMware WorkStation versión 5.0.0 para que Linux Fedora funcione en una
“máquina virtual” y pueda interactuar mediante una red virtual entre las dos máquinas (Linux
y Windows) administrando desde Windows una base de datos PostgreSQL instalada en
Linux.
En la versión de PostgreSQL 8.1 para Windows viene incluida la aplicación PgAdmin
junto con el servidor de bases de datos PostgreSQL para una administración gráfica, sencilla y
completa de las bases de datos PostgreSQL, incluyéndose también en la instalación los
controladores para acceso a datos psqlODBC y Npgsql; mientras que en el sistema operativo
Linux Fedora Core 5 viene incluida solamente una instalación del servidor PostgreSQL 8.1,
que hay que seleccionarla en el momento de la instalación de Fedora Core 5 y si se requieren
otras aplicaciones de administración con interfaz gráfica como PgAdmin o PhpPgAdmin, hay
que descargarlas desde sus sitios web e instalarlas por separado. Luego de realizar la
instalación de PostgreSQL en Windows y Linux, presento la configuración del servidor para
que pueda ser administrado desde Windows.
5.6.1. Instalación sobre Windows
Para instalar el servidor PostgreSQL sobre Windows se necesita un sistema operativo
Windows de 32 bits, tal como 9x, Me, NT, 2000, XP, o Windows Server 2003. Aunque se
recomienda el uso de un sistema operativo Windows basado en NT (NT, 2000, XP, 2003).
Además es necesaria una herramienta capaz de leer ficheros .zip, para descomprimir el fichero
de distribución.

Anl. Mauricio Arévalo M.
- Pág. 133 -
Al momento de desarrollar la presente monografía, la última versión estable de
PostgreSQL para Microsoft Windows es la 8.1, con la que realice las pruebas; el fichero
comprimido descargado desde el sitio web (http://www.postgresql.org/download/) se llama
postgresql-8.1.4-1.zip, luego se lo descomprime mediante la aplicación “WinZip” o una
herramienta compatible y entre los cuatro archivos que contiene, se ejecuta el fichero de
instalación “postgresql-8.1.msi”, el mismo que instalará el servidor de bases de datos
PostgreSQL, la herramienta de administración gráfica PgAdmin, el controlador de ODBC
(Open Database Connectivity) llamado psqlODBC y el proveedor de acceso a datos para .Net
llamado NpgSQL mediante un asistente con interfaz gráfica, facilitando de esta manera el
proceso de instalación.
Figura 5.7: Ficheros de la descarga de PostgreSQL para Windows
Los pasos que se siguen con el asistente para la instalación de PostgreSQL son:
• Primero seleccionamos el idioma de la instalación:
Figura 5.8: Idioma de la instalación

Anl. Mauricio Arévalo M.
- Pág. 134 -
• Luego aceptamos los términos que tiene la licencia de software libre de tipo BSD
(Berkeley Software Distribution) bajo la que se distribuye PostgreSQL:
Figura 5.9: Notas sobre la licencia de PostgreSQL
• A continuación elegimos las aplicaciones que vamos a instalar (el servidor PostgreSQL,
las interfaces psql y PgAdmin y los controladores psqlODBC y Npgsql):
Figura 5.10: Aplicaciones de PostgreSQL
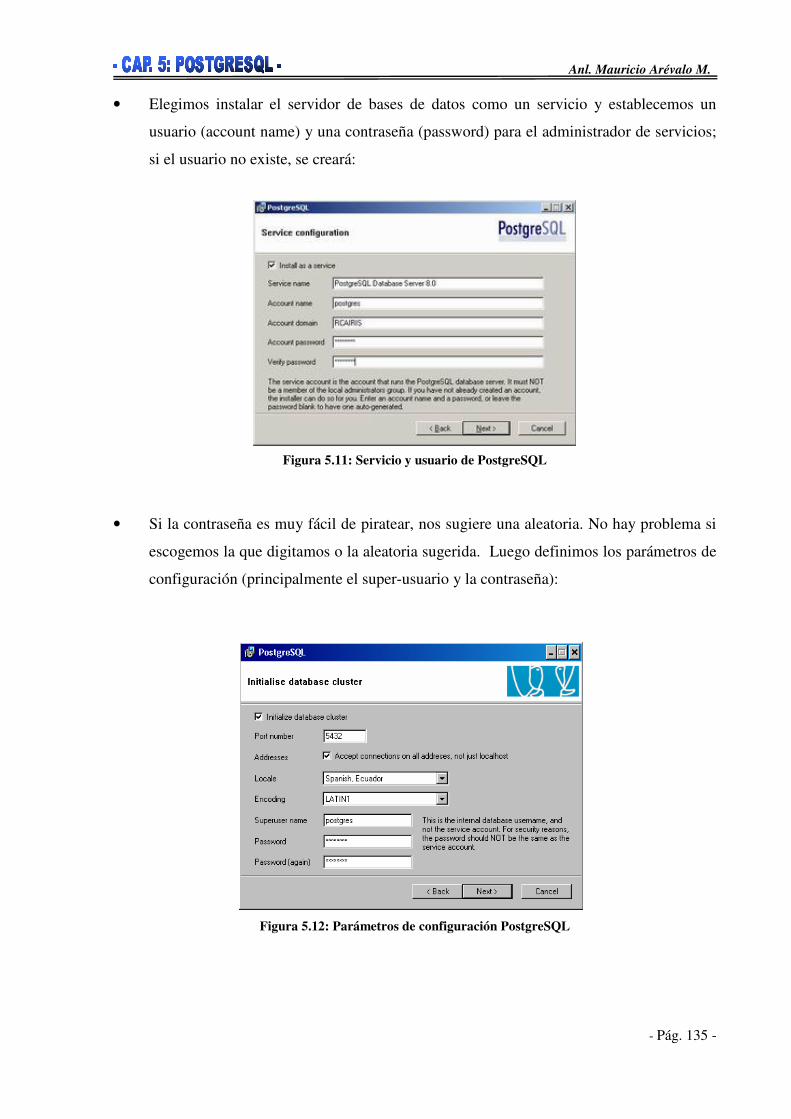
Anl. Mauricio Arévalo M.
- Pág. 135 -
• Elegimos instalar el servidor de bases de datos como un servicio y establecemos un
usuario (account name) y una contraseña (password) para el administrador de servicios;
si el usuario no existe, se creará:
Figura 5.11: Servicio y usuario de PostgreSQL
• Si la contraseña es muy fácil de piratear, nos sugiere una aleatoria. No hay problema si
escogemos la que digitamos o la aleatoria sugerida. Luego definimos los parámetros de
configuración (principalmente el super-usuario y la contraseña):
Figura 5.12: Parámetros de configuración PostgreSQL

Anl. Mauricio Arévalo M.
- Pág. 136 -
• Elegimos el lenguaje usado como lenguaje procedural o de Script (PL/pgsql) para
programar los procedimientos almacenados en PostgreSQL:
Figura 5.13: Elegir el lenguaje
• Seleccionamos los módulos opcionales de contribuciones, en este caso dejé los módulos
que vienen seleccionados por defecto en PostgreSQL:
Figura 5.14: Módulos Adicionales
• El asistente estará listo para instalar el servidor PostgreSQL con las configuraciones
indicadas, y al finalizar la instalación debemos verificar los programas instalados en el
menú “Inicio-Programas-PostgreSQL 8.1”, para finalmente reiniciar el equipo.

Anl. Mauricio Arévalo M.
- Pág. 137 -
Figura 5.15: Finalización de la Instalación
5.6.2. Instalación sobre Linux
Para instalar PostgreSQL sobre el sistema operativo Linux utilicé la distribución del
sistema Linux Fedora Core 5 y lo instalé como una máquina virtual con la aplicación VMware
Workstation 5.0.0 ejecutándose sobre Windows para realizar pruebas con bases de datos
PostgreSQL instaladas sobre la máquina con el sistema Linux Fedora Core 5; de esta manera
puedo administrar las bases de datos PostgreSQL que se encuentran en el equipo con Linux,
mediante la herramienta PgAdmin desde Windows a través de una red virtual creada por la
aplicación VmWare Workstation.
El Proyecto Fedora (Distribución Linux bajo licencia GPL) es un sistema operativo de
software libre, resultado de una fusión entre Red Hat Linux y el antiguo Proyecto Fedora
Extras, produciéndose el denominado sistema Fedora Core y está patrocinado oficialmente
por la empresa Red Hat, aunque es de libre distribución.

Anl. Mauricio Arévalo M.
- Pág. 138 -
Escogí esta distribución de Linux por su facilidad de instalación y configuración, siendo
su última versión estable la Core 5, publicada el 20 de marzo del 2006, y se lo puede
descargar desde sitios web como “www.fedoraproject.org” o “www.fedora.redhat.com”.
En Linux Fedora Core 5 viene ya integrado el servidor PostgreSQL versión 8.1 por lo
que solamente es necesario que se lo escoja como un paquete más en el momento de la
instalación del sistema operativo, como se muestra en la siguiente figura:
Figura 5.16: Instalación del Servidor PostgreSQL cuando se instala Fedora Core 5
Figura 5.17: Añadir el usuario y contraseña para el usuario “postgres”

Anl. Mauricio Arévalo M.
- Pág. 139 -
Luego de instalar el paquete de Postgresql junto con el sistema operativo, ingresé al
sistema como superusuario ‘root’, añadí el usuario “postgres” al sistema mediante las
cláusulas “adduser” y “passwd” para establecer su contraseña en la línea de comandos.
Este usuario es habilitado en el sistema operativo y como superusuario del servidor
PostgreSQL cuando se escoge instalar el paquete PostgreSQL en la instalación de Fedora.
A continuación para probar en el mismo equipo que el servidor PostgreSQL esté
funcionando correctamente, cerré la sesión e ingresé nuevamente al sistema con el usuario
creado (postgres) que es el superusuario de PostgreSQL.
Ingresé al Terminal de línea de comandos y creé una base de datos mediante la
aplicación “createdb” que se incluye con PostgreSQL; luego se pueden crear, modificar o
eliminar objetos de esa base de datos mediante sentencias SQL usando la aplicación “psql”,
que como se explicó anteriormente es el Terminal interactivo de PostgreSQL para su
administración.
Figura 5.18: Crear una base de datos y una tabla para probar el servidor PostgreSQL
Sin embargo, para distribuciones de Linux que no tengan instalado el paquete de
PostgreSQL, existen descargas binarias del servidor PostgreSQL y sus paquetes adicionales

Anl. Mauricio Arévalo M.
- Pág. 140 -
para algunas distribuciones de Linux en paquetes RPM (RedHat Package Manager) en el sitio
web http://www.postgresql.org/download/. Escogemos el paquete o paquetes de instalación
que pertenezcan a nuestra distribución de Linux, con la versión más reciente y los
descargamos.
Existen varios paquetes RPMs en cada distribución de PostgreSQL para Linux, pero si
queremos instalar el servidor PostgreSQL, instalaremos los paquetes “postgre-libs”,
“postgresql” y “postgresql-server”, identificados con la versión de PostgreSQL que
queramos instalar. Estos paquetes contienen respectivamente las librerías compartidas de
PostgreSQL, los programas clientes para administrar las bases de datos y el servidor
PostgreSQL. Para instalar solamente un cliente de PostgreSQL, se instalarán los paquetes
“postgre-libs” y “postgresql”.
Antes de instalar en el sistema dichos paquetes, creamos al usuario “postgres”, que será
el encargado de manejar la base de datos con las sentencias:
useradd postgres passwd postgres
Instalamos los paquetes del servidor PostgreSQL para llevar a cabo la instalación básica
del paquete que contiene al servidor PostgreSQL. Para instalarlos se debe ejecutar el
comando rpm con las opciones y el orden indicados desde la línea de comandos como se
muestra a continuación:
(rpm -ivh paquete_nombre_version.rpm)
rpm -ivh postgresql-server-8.1.4-3PGDG.i686.rpm
rpm -ivh postgresql-libs-8.1.4-3PGDG.i686.rpm
rpm -ivh postgresql-8.1.4-3PGDG.i686.rpm
Cabe señalar que el comando de instalación rpm16
tiene las opciones –ivh para instalar
los paquetes, -Uvh para actualizar los paquetes y para desinstalar un paquete RPM se utiliza la
opción –e, pero antes se debe detener el servicio de PostgreSQL.
16 Más opciones sobre el instalador rpm las podemos encontrar digitando el comando rpm – -help.

Anl. Mauricio Arévalo M.
- Pág. 141 -
También se debe saber que en la mayoría de distribuciones de Linux, los archivos de
PostgreSQL se guardan en las ubicaciones mostradas en la siguiente tabla17:
Tabla 5.6: Ubicaciones de los archivos de PostgreSQL en Linux
Luego de la instalación de los paquetes RPMs inicializaremos el directorio en el que se
guardarán los datos mediante las herramientas initdb o mediante el demonio postmaster,
indicando con la opción –D donde se encuentra el directorio “/Data” de PostgreSQL, como se
indica a continuación:
/usr/bin/initdb -D /var/lib/pgsql/data /usr/bin/postmaster -D /var/lib/pgsql/data
Iniciaremos a continuación el servicio de PostgreSQL mediante el comando:
service postgresql start
Luego se puede probar el funcionamiento del servidor PostgreSQL creando,
modificando o eliminando bases de datos y sus objetos usando la aplicación “psql” o
instalando aplicaciones con interfaz gráfica de usuario como PgAdmin o PhpPgAdmin.
17 Tabla tomada de la documentación del manual de instalación de PostgreSQL en Fedora (http://pgfoundry.org/docman/?group_id=1000048)
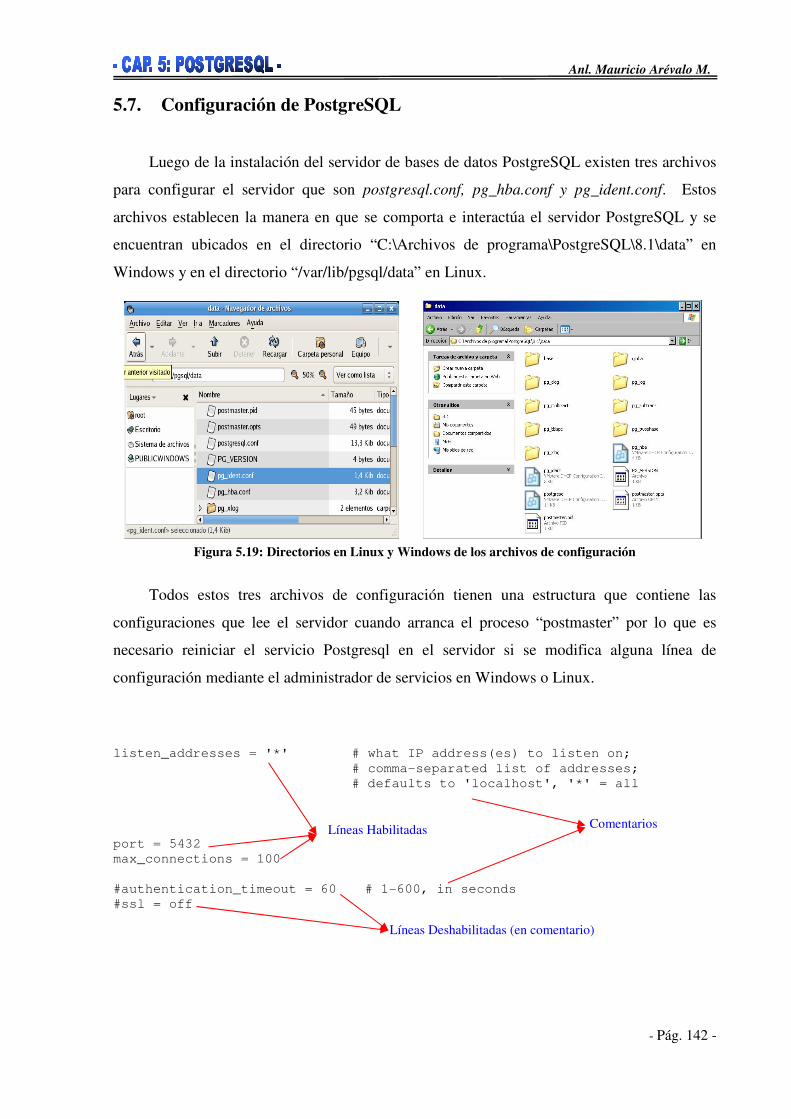
Anl. Mauricio Arévalo M.
- Pág. 142 -
5.7. Configuración de PostgreSQL
Luego de la instalación del servidor de bases de datos PostgreSQL existen tres archivos
para configurar el servidor que son postgresql.conf, pg_hba.conf y pg_ident.conf. Estos
archivos establecen la manera en que se comporta e interactúa el servidor PostgreSQL y se
encuentran ubicados en el directorio “C:\Archivos de programa\PostgreSQL\8.1\data” en
Windows y en el directorio “/var/lib/pgsql/data” en Linux.
Figura 5.19: Directorios en Linux y Windows de los archivos de configuración
Todos estos tres archivos de configuración tienen una estructura que contiene las
configuraciones que lee el servidor cuando arranca el proceso “postmaster” por lo que es
necesario reiniciar el servicio Postgresql en el servidor si se modifica alguna línea de
configuración mediante el administrador de servicios en Windows o Linux.
listen_addresses = '*' # what IP address(es) to listen on; # comma-separated list of addresses; # defaults to 'localhost', '*' = all port = 5432 max_connections = 100 #authentication_timeout = 60 # 1-600, in seconds #ssl = off
Comentarios Líneas Habilitadas
Líneas Deshabilitadas (en comentario)

Anl. Mauricio Arévalo M.
- Pág. 143 -
Los comentarios en estos archivos son precedidos por el caracter ‘#’, y también están en
comentarios de manera predeterminada algunas líneas que forman parte de la configuración
de PostgreSQL. Si quitamos el caracter ‘#’ dichas líneas quedarán habilitadas. A
continuación muestro como se presenta la estructura de estos archivos:
Luego de configurar estos archivos, es necesario reiniciar el servicio de “postgresql” en
Linux y en Windows para que los cambios tomen efecto y poder así realizar una conexión
administrando el servidor PostgreSQL en modo de consola de texto con la aplicación psql o
en modo gráfico con las aplicaciones PgAdmin o PhpPgAdmin. Además se puede acceder y
modificar los datos mediante aplicaciones clientes escritas en diversos lenguajes de
programación que utilicen el controlador ODBC psqlODBC o el proveedor de acceso a datos
Npgsql.
En la máquina con el sistema operativo Linux Fedora Core 5, ingresé al sistema con el
usuario ‘root’ para alterar estos archivos y luego reiniciar el servicio postresql, mientras que
en la máquina con Windows no los modifiqué puesto que solamente usé el servidor de bases
de datos PostgreSQL en Linux administrándolo con la herramienta PgAdmin desde Windows.
5.7.1. Archivo postgresql.conf
Este archivo configura aspectos generales del servidor PostgreSQL como la ubicación
de los archivos de configuración y del directorio “\Data”, las direcciones IP de los host y el
puerto por el cual las escucha (5432 es el predeterminado), el número máximo de conexiones,
el manejo de memoria, la seguridad y autentificación, etc.
Como se puede ver en la figura 5.20 solamente se chequea que el servidor escuche
cualquier dirección IP mediante la línea listen_addresses=‘*’. Se puede establecer también
en esta línea el parámetro ‘localhost’ si queremos solamente conexiones en el equipo local y
no de otros equipos o podemos escribir las direcciones IP de los equipos con los cuales
queremos que se comunique el servidor PostgreSQL separadas por una coma (,).

Anl. Mauricio Arévalo M.
- Pág. 144 -
Figura 5.20: Configuración en Linux del archivo postgresql.conf
También verifiqué el número de puerto por el cual escucha las peticiones el servidor
PostgreSQL (port = 5432)18 y el número máximo de conexiones concurrentes que en este
caso manejará el servidor (max_connections=100).
5.7.2. Archivo pg_hba.conf
HBA significa “Host-Based Authentication” o Autentificación basada en Host, y
mediante este archivo, PostgreSQL controla los host o equipos que tienen permiso de
conectarse al servidor, la manera o modo en que se autentifican19 los clientes, los nombres de
usuarios de las bases de datos PostgreSQL que pueden conectarse y las bases de datos que
pueden ser accedidas. Este archivo contiene registros que tienen uno de los siguientes
formatos:
18 El puerto 5432 debe estar habilitado en el Firewall de Windows, en el del antivirus y en el de Linux; o se debe deshabilitar el Firewall del sistema operativo y de cualquier antivirus. Además este puerto se lo debe habilitar en las propiedades del protocolo TCP/IP (Filtrado TCP/IP) o se debe permitir el acceso a todos los puertos TCP. 19 La autentificación es el proceso por el que el servidor de bases de datos establece la identidad del cliente mediante un usuario y una contraseña, y por ende determina si a la aplicación del cliente (o el usuario que ejecuta la aplicación del cliente) se le permite conectarse al servidor PostgreSQL.

Anl. Mauricio Arévalo M.
- Pág. 145 -
# local DATABASE USER METHOD [OPTION] # host DATABASE USER CIDR-ADDRESS METHOD [OPTION] # hostssl DATABASE USER CIDR-ADDRESS METHOD [OPTION] # hostnossl DATABASE USER CIDR-ADDRESS METHOD [OPTION]
En donde el primer campo indica el tipo de conexión: “local” es una conexión al equipo
local, “host” es una conexión con o sin encriptación SSL mediante el socket TCP/IP;
“hostssl” es una conexión encriptada SSL mediante el socket TCP/IP mientras que
“hostnossl” es una conexión TCP/IP que no está encriptada.
El campo DATABASE indica la base de datos, que puede ser “all” para especificar
todas, podemos también especificar la base o bases de datos que pueden ser accedidas
separándolas con una coma (,). También se puede poner “sameuser” para especificar que se
de acceso a todas las bases de datos a las que el usuario identificado tenga acceso.
En el campo USER se especifica el usuario, pudiendo ser “all”, para especificar que
todos los usuarios de las bases de datos tienen acceso al servidor, o podemos poner el nombre
de un usuario o de varios usuarios separados por una coma. También se puede poner el
nombre de un grupo de usuarios precedido por el signo (+).
El campo CIDR-ADDRESS especifica las direcciones de los equipos o el conjunto de
equipos (red) que se comunicarán con el servidor. Este campo se estructura por la dirección
IP del equipo y la máscara de red a la que pertenece, que se representa con un entero (entre 0
y 32 para IPv4 o 128 para IPv6) y especifica el número de bits significativos en la máscara de
red. A continuación muestro algunos ejemplos:
127.0.0.1/32: Es la dirección del “localhost” que se la puede representar también en columnas separadas como 127.0.0.1 255.255.255.255 que completan los cuatro octetos especificados (8*4=32 bits).
192.168.32.0/24: Es una dirección de Red utilizando IPv4 (con 24 bits
significativos). 192.168.0.1/32: Es una dirección de Host utilizando IPv4 (con 32 bits
significativos). ::1/128: Es la dirección de “localhost” utilizando IPv6. ::ffff:192.168.0.0/120: Es una dirección de red utilizando IPv6.

Anl. Mauricio Arévalo M.
- Pág. 146 -
El campo METHOD puede ser "trust", "reject", "md5", "crypt", "password", "krb5",
"ident", o "pam". Este campo especifica el modo de autentificación del usuario
Si se pone “trust” en dicho campo, se permite la conexión incondicionalmente, con este
método se permite a cualquiera que se conecte al servidor PostgreSQL identificarse con un
usuario de PostgreSQL, sin la necesidad de una contraseña.
Si se utiliza el método “reject” se deshecha la conexión incondicionalmente, se usa para
excluir ciertos host o redes que intenten conectarse al servidor PostgreSQL.
Cuando se utiliza el método “md5” se le exige al usuario que proporcione una
contraseña encriptada MD520 para la autentificación. Esta opción en versiones anteriores a la
7.2 de PostgreSQL se la conoce como “crypt”.
Con la opción “password” se requiere que el usuario proporcione una contraseña sin
encriptación para su autentificación.
Mediante la opción “krb5” se utiliza el protocolo Kerberos21 versión 5 para autentificar
el usuario. Este método se puede utilizar sólo para conexiones con TCP/IP.
Mediante el método “ident” se especifica el nombre del usuario del sistema operativo en
la máquina cliente, y se verifica si dicho usuario se identifica con el nombre del usuario de la
base de datos a la que se quiere acceder mediante una consulta al archivo pg_ident.conf.
Sin embargo, en el archivo pg_hba.conf en la máquina que tengo instalado Linux
Fedora Core 5, solamente ingresé el tipo “host” y di un acceso a todas las bases de datos y a
todos los usuarios cuyos equipos pertenezcan a la dirección de red 192.168.32.0, que es en la
que están configurados el equipo servidor de PostgreSQL con Linux Fedora (con la dirección
IP 192.168.32.100) y el equipo de Windows (con la dirección IP192.168.32.1 asignada
dinámicamente mediante la aplicación Vmware Workstation).
20 MD5 (acrónimo de Message-Digest Algorithm, o Algoritmo de Resumen de Mensaje) es un algoritmo de reducción criptográfico de 128 bits ampliamente usado para realizar autentificación de usuarios. 21 Kerberos es un protocolo de autentificación (cliente/servidor) estándar, seguro y conveniente utilizado sobre una red pública (por ejemplo Internet).

Anl. Mauricio Arévalo M.
- Pág. 147 -
Además seleccioné el método “md5” para la autentificación de los usuarios que quieran
acceder a las bases de datos del servidor PostgreSQL desde cualquier equipo que pertenezca a
esa red, como se muestra en la siguiente figura:
Figura 5.21: Configuración en Linux del archivo pg_hba.conf
5.7.3. Archivo pg_ident.conf
Este archivo configura la autentificación de los usuarios si es que en el archivo
pg_hba.conf se tiene un registro cuyo método de autentificación sea de tipo “ident”.
En el archivo pg_ident.conf se verifica si el usuario o usuarios que se identifican en el
archivo pg_hba.conf con el método “ident” tienen una correspondencia entre el nombre de
usuario del sistema operativo y el nombre del usuario de la base de datos a la que se quiere
acceder.
Los registros en este archivo están estructurados de la siguiente manera:
# MAPNAME IDENT-USERNAME PG-USERNAME
Donde en el campo MAPNAME se coloca el “nombre” de la identidad con la que en el
archivo pg_hba.conf se identifica al usuario, en el campo IDENT-USERNAME se coloca el

Anl. Mauricio Arévalo M.
- Pág. 148 -
nombre del usuario que se tiene en el sistema operativo y en el campo PG-USERNAME se
pone el nombre del usuario de PostgreSQL correspondiente.
Por ejemplo, si en el archivo pg_hba.conf se tiene la línea:
# TYPE DATABASE USER CIDR-ADDRESS METHOD host all all 192.168.0.0/16 ident omicron
Se indica que cualquier usuario con identidad “omicron” perteneciente a la red con
dirección IP 192.168.0.0 y que en el archivo pg_ident tenga un registro identificado en el
campo MAPNAME con “omicron” pueda acceder a las bases de datos correspondientes. En
el archivo pg_ident se tendría la siguiente línea:
# MAPNAME IDENT-USERNAME PG-USERNAME omicron usuarioso mauricio
En esta línea se especifica que en la entrada “omicron” se debe validar un usuario cuyo
nombre en el sistema operativo es “usuarioso” pero que su correspondencia como usuario de
PostgreSQL es “mauricio”.
5.7.4. Finalización de la Configuración
Al finalizar la configuración de estos archivos, se deben guardar los cambios y reiniciar
el servicio “postgresql” desde el administrador de servicios de Linux Fedora Core 5 como se
muestra en la figura 5.22 o también se lo puede reiniciar desde la línea de comandos
(Terminal) en Fedora mediante la sentencia service postgresql restart.
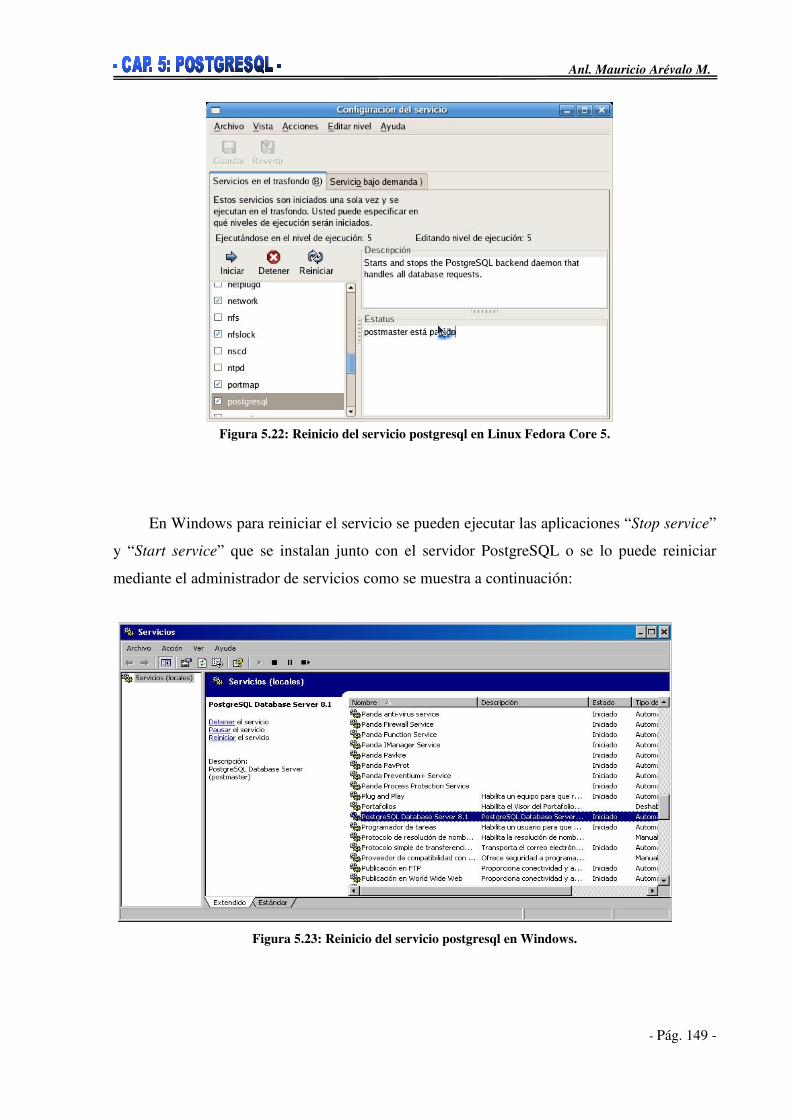
Anl. Mauricio Arévalo M.
- Pág. 149 -
Figura 5.22: Reinicio del servicio postgresql en Linux Fedora Core 5.
En Windows para reiniciar el servicio se pueden ejecutar las aplicaciones “Stop service”
y “Start service” que se instalan junto con el servidor PostgreSQL o se lo puede reiniciar
mediante el administrador de servicios como se muestra a continuación:
Figura 5.23: Reinicio del servicio postgresql en Windows.

Anl. Mauricio Arévalo M.
- Pág. 150 -
Finalmente pude probar la conexión a las bases de datos PostgreSQL instalado en la
máquina con Linux Fedora Core 5 desde la máquina que tiene el sistema operativo Windows
XP mediante la aplicación PgAdmin (Inicio-Programas-PostgreSQL 8.1-PgAdmin III),
digitando la dirección IP del servidor (en Linux) o su nombre, el puerto, la base de datos por
defecto (Maintenance DB), el usuario y la contraseña. Luego se podrán crear y administrar
bases de datos del servidor PostgreSQL y todos los objetos que contienen las mismas.
Figura 5.24: Conexión al servidor PostgreSQL desde Windows.

Anl. Mauricio Arévalo M.
- Pág. 151 -
CAPITULO VI
OTROS SISTEMAS GESTORES DE BASES DE DATOS
En este capítulo presento brevemente algunos Sistemas Gestores de Bases de Datos
Relacionales (RDBMS) con licencia libre y propietaria, junto con tablas comparativas en
donde se describen sus principales características, a fin de poder tener parámetros de
comparación con las bases de datos que son objeto de este estudio como MySQL y
PostgreSQL.
6.1. Oracle
Este sistema surgió a final de los años 70 y principio de los años 80. George Koch fue
su impulsador junto con un grupo de 25 desarrolladores; al principio se conoció a este sistema
como “Relational Software” para luego tomar el nombre de Oracle, que es desarrollado y
distribuido comercialmente bajo licencia propietaria por la empresa Oracle Corporation. Su
sitio web es “www.oracle.com” y es uno de los mayores y más usados Sistemas Manejadores
de Bases de Datos Relacionales (RDBMS) en el mundo.
Oracle es un Manejador de bases de datos relacionales que hace uso de los recursos del
sistema informático en la mayoría de arquitecturas de hardware, para garantizar su
aprovechamiento al máximo en ambientes cargados de información; Oracle corre en
computadoras personasles (PC), microcomputadoras, mainframes, soporta unos 17 idiomas y

Anl. Mauricio Arévalo M.
- Pág. 152 -
dispone de versiones para la mayoría de sistemas operativos, entre los más importantes están
Microsoft Windows, Linux, Unix, MacOS.
Ofrece además del Gestor de bases de datos, una suite de productos con una gran
variedad de herramientas propias de desarrollo, como SQL plus, Oracle Forms, Oracle
Reports, Oracle Designer, Oracle Discovered, Oracle JDeveloper, entre otras.
Podemos programar funciones y triggers (disparadores) en el lenguaje procedural de
Oracle PL/SQL, que es un dialecto del SQL combinado con programación procedural.
Soporta bases de datos de todos los tamaños y un verdadero ambiente cliente servidor, además
dispone de los tipos de datos definidos en los estándares ANSI/ISO SQL92, soporta también
el manejo de transacciones, subconsultas, replicación de bases de datos, integridad referencial,
respaldos y restauración, etc.
La versión 10g de Oracle vio la luz en febrero del 2004, primero en su versión para
UNIX y posteriormente en sus versiones para Linux y Windows. La novedad más llamativa
de esta versión es la capacidad de estos servidores de funcionar según la tecnología “Grid
Computing” (para distribuir la base de datos entre varios servidores).
El precio de las licencias de Oracle 10g son algo caras, el precio se eleva a los $4995
por procesador y $149 por usuario para la edición “Standard Edition One”, y $40000 por
procesador y $800 por usuario para la versión “Enterprise Edition”.
Además para aprovechar toda la potencia que ofrece Oracle se necesita de un potente
equipo y no lo recomiendo para entornos monousuarios, sino para entornos empresariales.
Se comenta que “Oracle ha anunciado que ofrecerá de manera gratuita una versión de su
motor de base de datos. Se denominará Oracle 10g Express Edition, la cual tendrá como
restricciones la limitación a instalaciones en máquinas monoprocesador gestionando hasta
1Gb. de memoria y 4Gb. de disco para el almacenamiento”22. Esta acción acompaña a la
realizada anteriormente por Oracle al adquirir InnoDB (recordemos que el soporte para este
tipo de motor de Bases de datos está también incluido dentro de MySQL).
22 Nota tomada de http://techdir.com/articles/20051028/209223_F.shtml

Anl. Mauricio Arévalo M.
- Pág. 153 -
6.2. Microsoft SQL Server
Es un sistema de gestión de bases de datos relacionales (SGBD) creado y distribuido por
la empresa Microsoft bajo licencia propietaria, se basa en el lenguaje SQL, y es capaz de
poner a disposición de muchos usuarios grandes cantidades de datos de manera simultánea
(multiusuario). Su sitio web es www.microsoft.com/latam/sql/.
SQL Server permite trabajar en modo cliente-servidor o monousuario. Además permite
administrar la información de otros servidores de datos SQL Server.
Soporta el manejo de transacciones, subconsultas, posee una gran estabilidad, seguridad
y escalabilidad, soporta procedimientos almacenados, replicación de bases de datos, respaldos
y restauración e incluye también un potente entorno gráfico de administración que permite el
uso de comandos DDL y DML con administración gráfica llamado “Enterprise Manager”
además de un “Analizador de consultas”, para escribir cualquier comando SQL mediante un
editor de texto.
El cluster tolerante a fallos de SQL Server proporciona redundancia de hardware
mediante una configuración en la que los recursos de misión crítica se transfieren
automáticamente de la máquina que ha generado el error a un servidor configurado de igual
modo.
Para el desarrollo de aplicaciones distribuidas (tres o más capas), Microsoft SQL Server
incluye interfaces de acceso para la mayoría de las plataformas de desarrollo, incluyendo
.NET.
Microsoft SQL Server no es multiplataforma, ya que sólo está disponible en Sistemas
Operativos de Microsoft (Windows) y está orientado solamente para sus entornos de
desarrollo.
La última versión de SQL Server es la 2005 (conocida como Yukon) y cuesta
aproximadamente $3899 en la versión Workgroup, $5999 para la versión “Standard Edition”
y $24999 en la versión “Enterprise Edition”.

Anl. Mauricio Arévalo M.
- Pág. 154 -
Existe también la version “Express Edition” de SQL Server 2005, siendo una versión
libre, gratuita, de fácil uso y ligera. SQL Server Express Edition incluye características como
SQL Server 2005 Reporting Services, una plataforma servidor para crear informes
tradicionales o interactivos y una herramienta de administración gráfica, SQL Server 2005
Management Studio Express, para la fácil administración de las bases de datos en un entorno
gráfico, gestiona hasta 1Gb de memoria RAM y 4Gb de espacio de disco duro.
6.3. SQL Lite
SQLite es una librería escrita en C que implementa un motor de base de datos SQL
empotrable23, su última versión es la 3.3.7 y está disponible para sistemas operativos como
Windows, Linux, Unix, BSD y MacOS bajo libre distribución y licencia de dominio público
GPL. El sitio web oficial de SQLite es “www.sqlite.org/index.html”.
Sus desarrolladores destacan entre sus principales características la encapsulación
completa en un único archivo por cada base de datos, su soporte transaccional, su rapidez, su
escaso tamaño y su completa portabilidad en distintas plataformas. Soporta las características
(tipos de datos, funciones, etc) del estándar SQL/92 y su máximo tamaño para
almacenamiento es aproximadamente de 2 Terabytes.
El motor de PHP 5 incluye soporte interno para SQLite y existen APIs para dar el
soporte para distintos lenguajes, como C y Python e incluso un proyecto de un conector
ODBC para SQLite24.
SQLite cuenta con una utilidad llamada sqlite que nos permitirá ejecutar comandos SQL
(DML y DDL) en modo de texto para administrar una base de datos SQLite y sus objetos.
Además es muy sencillo utilizar este programa con un script SQL, ya que basta ejecutar sqlite
junto con el nombre de la base de datos a la que queramos acceder y el archivo SQL que
contiene las sentencias SQL que queramos ejecutar.
23 Bases de datos empotradas o embebidas son aquellas que no inician un servicio en una máquina, sino que están en forma de librerías pudiéndose enlazar directamente a nuestro código fuente. 24 El controlador ODBC para SQLite se descarga desde el sitio “http://www.ch-werner.de/sqliteodbc”

Anl. Mauricio Arévalo M.
- Pág. 155 -
SQLite ejecuta las operaciones más rápido que MySQL o Postgresql, pero no olvidemos
que estos últimos se tratan de motores de bases de datos para propósitos distintos (Servidores
de Bases de datos). SQLite no permite múltiples usuarios accediendo en modo escritura a la
base de datos, ya que el mecanismo de bloqueo que utiliza es muy primitivo: bloquea toda la
base de datos, además no soporta replicación de bases de datos, manejo de transacciones,
integridad referencial ni características avanzadas (cluster). Así, esta librería está
especialmente recomendada cuando queramos una gran rapidez en las consultas y nos baste
que sólo un único usuario pueda realizar modificaciones. Por ejemplo es ideal como base de
datos para guardar configuraciones, logs, o sencillamente como base de datos monousuario.
6.4. HSQLDB
Es otro motor de bases de datos relacionales empotrable desarrollado en Java, es un
proyecto de software libre bajo licencia de tipo BSD (Berkeley Software Distribution);
soporta los estándares SQL/92 y SQL/99, es rápida y se la puede descargar desde su sitio web
www.hsqldb.org, siendo su última versión estable es la 1.8.0.7 (liberada en septiembre del
2006).
No soporta características avanzadas como replicación, acceso multiusuario, pero
soporta operaciones con comandos SQL de manipulación y definición de datos (DDL y
DML), permite el manejo de transacciones, integridad referencial y soporta varias plataformas
como Linux, Unix, Windows, MacOS.
El grupo de desarrollo se formó en el año 2001 y HSQLDB es utilizado como el motor
de bases de datos del proyecto OpenOffice.org 2.0 (software libre de ofimática).
6.5. Firebird
Firebird es un sistema de administración de base de datos (o RDBMS) de código abierto
bajo Licencia Pública basado en la versión 6 de Interbase, cuyo código fue liberado por la

Anl. Mauricio Arévalo M.
- Pág. 156 -
empresa Borland en el año 2000. Su código fue reescrito de C a C++ por la Fundación
FirebirdSQL, siendo su última versión la 1.5.3. Su sitio web es www.firebirdsql.org.
Es multiplataforma, y actualmente puede ejecutarse en los sistemas operativos: Linux,
HP-UX, FreeBSD, Mac OS, Solaris y Microsoft Windows. Es liviano, con requerimientos de
hardware bajos.
Posee una arquitectura Cliente/Servidor sobre el protocolo TCP/IP, pero también
permite la arquitectura embebida o incrustrada para aplicaciones monousuario, ofrece un
soporte de transacciones, subconsultas e integridad referencial, tiene una buena seguridad
basada en usuarios y roles. Tiene pleno soporte del estándar SQL-92, tanto de sintaxis como
de tipos de datos y permite la escritura de disparadores (triggers) y procedimientos
almacenados.
Existen controladores ODBC, OLEDB y JDBC para Firebird y se permite además un
mantenimiento con la realización de copias de seguridad y restauraciones periódicas de las
bases de datos. Una restricción que tiene es que no puede ejecutarse en máquinas con varios
procesadores.
6.6. Informix
Informix es un Sistema de Gestión de Bases de datos Relacionales (RDBMS) conocido
actualmente como una categoría de programas de IBM, y es distribuido comercialmente bajo
licencia propietaria por dicha empresa dentro de la familia de "Administración de
Información" (Information Management). En el año 2001 IBM compró a la empresa Informix
Inc. por aproximadamente 1.000 millones de dólares con lo que el mercado de las bases de
datos comerciales en UNIX quedó entre IBM y Oracle. Su página principal es
www.ibm.com/software/data/informix/.
Este gestor de base de datos, ahora llamado "Informix Dynamic Server" (IDS) incluye
un RDBMS basado en SQL y juegos de herramientas para la administración o gestión de las
bases de datos.

Anl. Mauricio Arévalo M.
- Pág. 157 -
Puede ser usado en plataformas como Windows 2000, 2003 Server, XP, Linux, UNIX,
AIX, HP-UX, IRIX, Solaris y TRU64. Su última versión es la 10.0.
Gestiona múltiples bases de datos remotas en una única y centralizada consola donde se
muestran gráficamente tanto las bases de datos, como los objetos que contienen (tablas,
índices, procedimientos, etc.). Ofrece herramientas para crear menús, formularios de entrada
de datos y generadores de reportes.
Tiene una arquitectura cliente/servidor, la capacidad de replicación de bases de datos,
dispone de los tipos de datos y sintaxis definidos en los estándares ANSI/ISO SQL92, ocupa
menos memoria y recursos que Oracle aunque mantiene sus características que lo consolidan
como un gran gestor de bases de datos como son la gestión del acceso de múltiples usuarios,
soporte para el manejo de transacciones, subconsultas, manejo de integridad referencial (con
claves principales y foráneas), soporte para procedimientos almacenados, disparadores,
respaldos, restauración, etc.
Informix además se especializa en el soporte para Datawarehouse (almacenes de datos)
y Datamining (minería de datos).
6.7. Comparaciones
A continuación presento comparaciones hechas en tablas25 en donde se dan a conocer
los creadores, la fecha de la primera versión, la última versión estable, el tipo de licencia de
software y algunas características importantes que tienen los sistemas de gestión de bases de
datos que se han visto en este capítulo incluyendo MySQL y PostgreSQL. Entre estas
características están los sistemas operativos soportados por cada gestor de bases de datos, el
soporte para algunas características técnicas (ACID, Integridad referencial, transacciones,
Unicote) y el soporte para objetos (disparadores, funciones, procedimientos, rutinas externas):
25 Tablas comparativas tomadas de “es.wikipedia.org/wiki/Comparación_de_sistemas”
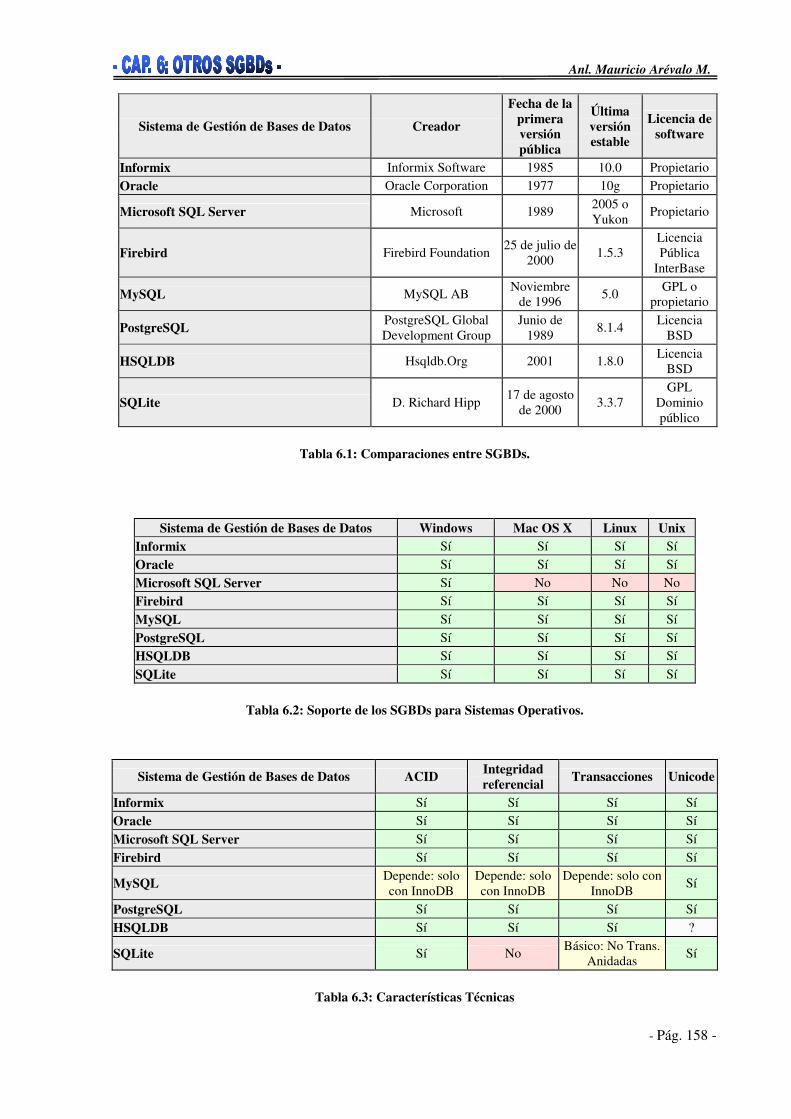
Anl. Mauricio Arévalo M.
- Pág. 158 -
Sistema de Gestión de Bases de Datos Creador
Fecha de la primera versión pública
Última versión estable
Licencia de software
Informix Informix Software 1985 10.0 Propietario
Oracle Oracle Corporation 1977 10g Propietario
Microsoft SQL Server Microsoft 1989 2005 o Yukon
Propietario
Firebird Firebird Foundation 25 de julio de
2000 1.5.3
Licencia Pública
InterBase
MySQL MySQL AB Noviembre
de 1996 5.0
GPL o propietario
PostgreSQL PostgreSQL Global Development Group
Junio de 1989
8.1.4 Licencia
BSD
HSQLDB Hsqldb.Org 2001 1.8.0 Licencia
BSD
SQLite D. Richard Hipp 17 de agosto
de 2000 3.3.7
GPL Dominio público
Tabla 6.1: Comparaciones entre SGBDs.
Sistema de Gestión de Bases de Datos Windows Mac OS X Linux Unix Informix Sí Sí Sí Sí
Oracle Sí Sí Sí Sí
Microsoft SQL Server Sí No No No
Firebird Sí Sí Sí Sí
MySQL Sí Sí Sí Sí
PostgreSQL Sí Sí Sí Sí
HSQLDB Sí Sí Sí Sí
SQLite Sí Sí Sí Sí
Tabla 6.2: Soporte de los SGBDs para Sistemas Operativos.
Sistema de Gestión de Bases de Datos ACID Integridad referencial
Transacciones Unicode
Informix Sí Sí Sí Sí
Oracle Sí Sí Sí Sí
Microsoft SQL Server Sí Sí Sí Sí
Firebird Sí Sí Sí Sí
MySQL Depende: solo con InnoDB
Depende: solo con InnoDB
Depende: solo con InnoDB
Sí
PostgreSQL Sí Sí Sí Sí
HSQLDB Sí Sí Sí ?
SQLite Sí No Básico: No Trans.
Anidadas Sí
Tabla 6.3: Características Técnicas

Anl. Mauricio Arévalo M.
- Pág. 159 -
Sistema de Gestión de Bases de Datos Trigger Función Procedimiento Rutina externa Informix Sí Sí Sí Sí
Oracle Sí Sí Sí Sí
Microsoft SQL Server Sí Sí Sí Sí
Firebird Sí Sí Sí Sí
MySQL Sí desde 5.0 Sí desde 5.0 Sí desde 5.0 Sí desde 5.0
PostgreSQL Sí Sí Sí Sí
HSQLDB Sí Sí Sí Sí
SQLite Sí No No Sí
Tabla 6.4: Objetos soportados por algunos SGBDs
Además de estas comparaciones, cabe señalar que existe un trabajo derivado de
PostgreSQL llamado BizGres (http://www.bizgres.org/). El Proyecto Bizgres busca hacer de
PostgreSQL la Base de Datos Open Source más robusta para Business Intelligence26 y Data
Warehousing. Para este propósito dispone de herramientas como JasperReports SDK,
Bizgres Loader, KTLSDK, entre otras.
Microsoft SQL Server por ejemplo también ofrece soluciones parecidas incluidas con el
manejador de bases de datos como son “Analysis Services” para analizar grandes cantidades
de datos y “Reporting Services” para generar informes que extraigan el contenido de una gran
variedad de orígenes de datos.
Ahora también, Pentaho y MySQL presentan una solución para proporcionar soluciones
OLAP (Online Analytical Processing) totalmente en entorno Open Source, con la base de
Pentaho Mondrian y de MySQL 5.
Esta solución informática27 va dirigida a todos aquellos que esten interesados en
aplicaciones “Business Intelligence” como Reporting, análisis, OLAP y Data Warehousing;
todo esto bajo Open Source.
26 Business Intelligence o “Inteligencia de Negocios” es una técnica que brinda soluciones de inteligencia de negocios y permiten al nivel gerencial minimizar el tiempo requerido para recolectar toda la información relevante de negocios, automatizar la asimilación de la información en inteligencia personalizada y proporcionar las herramientas para hacer comparaciones y tomar decisiones inteligentes. 27 Más información sobre dicha solución en “http://www.mysql.com/news-and-events/web-seminars/mysql-olap-pentaho-mondrian.php”

Anl. Mauricio Arévalo M.
- Pág. 160 -
CONCLUSIONES
En el momento de la evaluación de un proyecto no debemos cerrar nuestro criterio y
creer que la utilización de todo un conjunto de herramientas con licenciamiento propietario o
con licenciamiento libre es la que debe utilizarse en el desarrollo de dicho proyecto, sino que
para desarrollar un proyecto informático es necesario hacer una valoración de riesgos donde
se evalúa la posibilidad de utilizar un producto o herramienta propietaria por la que hay que
pagar una licencia o utilizar un producto de software libre, analizando en cada caso las
ventajas, inconvenientes y el desempeño de dicha herramienta siempre y cuando cumpla con
los requerimientos o necesidades de la aplicación o proyecto a desarrollar, donde muchas
veces se necesita de una arquitectura mixta o híbrida, es decir, utilizar una mezcla de
productos de software licenciado y otros de software libre.
Para ello se seleccionan los productos claves de software propietario y de open software
que más se adaptan a las necesidades de la organización y al proyecto informático.
Con la salida al mercado de múltiples entornos de desarrollo, es necesario conocer las
características, ventajas y desventajas de cada herramienta que se ofrece, por lo que en este
trabajo puse en conocimiento principalmente las características y ventajas de dos de los más
importantes sistemas gestores de bases de datos de software libre (MySQL y PostgreSQL).
MySQL es desarrollada y mantenida por la empresa MySQL AB mientras que el grupo
“PostgreSQL Global Development Group” es el que desarrolla y mantiene PostgreSQL.
Estos dos sistemas de gestión de bases de datos relacionales (RDBMS) se caracterizan
por su distribución como software libre y su intención de igualar las características técnicas de
otros potentes sistemas bajo licencia propietaria como Oracle, Informix o Microsoft SQL
Server.
Entre las principales características que llevan a estos dos gestores de bases de datos a
ser muy utilizados dentro de lo que es el software libre están que ambos utilizan el lenguaje

Anl. Mauricio Arévalo M.
- Pág. 161 -
SQL (Lenguaje estructurado de Consultas) con comandos DML y DDL, cláusulas, tipos de
datos, operadores, funciones y la sintaxis que cumplen con los estándares ANSI e ISO de
SQL/92 y PostgreSQL también utiliza el estándar SQL/99 (con orientación a objetos).
Además utilizan algunos comandos propios (extendidos) de cada manejador, soportan
una arquitectura cliente/servidor, soportan el manejo de transacciones, subconsultas, joins,
disparadores, manejo de acceso concurrente a la base de datos (no la bloquean), brindan
mantenimiento mediante el respaldo y restauración de las bases de datos, soportan
procedimientos y funciones almacenadas, soportan la integridad referencial en los datos,
gestionan de manera segura el acceso de los usuarios a la base de datos, ambos mantienen un
diccionario de datos y tienen características avanzadas como la replicación de bases de datos
o la tecnología de Clúster en MySQL. En PostgreSQL los procedimientos almacenados se
pueden escribir usando el lenguaje procedural propio denominado PL/pgSQL.
MySQL y PostgreSQL se acoplan fácilmente a diversas plataformas de desarrollo de
software gracias a que disponen de algunas herramientas como conectores ODBC y
proveedores de acceso a datos con tecnología ADO.Net y además varias APIs que se acoplan
a lenguajes como PHP, Perl, Python, Java, etc. Además se proveen muy buenas herramientas
de software libre o propietario para la gestión de bases de datos en modo de consola de
comandos de texto o mediante herramientas con una Interfaz Gráfica de Usuario (GUI)
trabajando bajo Linux o en Windows. Estas herramientas permiten administrar uno o varios
servidores de bases de datos en un entorno distribuido, actuando sobre distintas plataformas.
MySQL debe su popularidad a su gran desempeño y a las facilidades de desarrollo de
aplicaciones Web bajo la arquitectura que ha sido llamada: LAMP
(Linux+Apache+MySQL+Perl o PHP o Python).
Existe un trabajo derivado de PostgreSQL llamado BizGres que busca hacer de
PostgreSQL la Base de Datos Open Source más robusta para Business Intelligence. También,
Pentaho y MySQL, presentan una solución para proporcionar soluciones OLAP (Online
Analytical Processing) totalmente en entorno Open Source.

Anl. Mauricio Arévalo M.
- Pág. 162 -
RECOMENDACIONES
En mi opinión, debido a las potentes características que tienen ambos gestores de bases
de datos de software libre vistos, se pueden utilizar como una real alternativa a gestores de
bases de datos de software propietario como Oracle o SQL Server, aunque si se va a
desarrollar aplicaciones en ambientes Web recomiendo MySQL por su rapidez y
funcionalidad, mientras que si se piensa desarrollar aplicaciones con un entorno empresarial,
recomiendo PostgreSQL por su seguridad y potencia.
Finalmente, puedo decir que este trabajo me servirá de mucho en mi formación
profesional gracias a las investigaciones realizadas sobre los gestores de bases de datos que se
han detallado en la presente monografía, ya que aprendí sus características técnicas, sus
ventajas y debilidades, sus herramientas de administración y realicé una comparación con
otros sistemas gestores de bases de datos obteniendo de esta manera criterios acertados de
evaluación en el momento de decidir por el sistema de gestión de bases de datos a utilizar en
determinadas aplicaciones informáticas; por tales razones recomiendo que en la Unidad
Académica se sigan impulsando estos temas investigativos, ya que los estudiantes siempre
ganamos nuevos y útiles conocimientos.

Anl. Mauricio Arévalo M.
- Pág. 163 -
ANEXOS
ANEXO A: MODOS DE MySQL
Los “modos” que soporta MySQL Server son los siguientes:
• ALLOW_INVALID_DATES: No hace un chequeo total de las fechas en modo
estricto. Chequea sólo que los meses se encuentran en el rango de 1 a 12 y que los días
estén en el rango de 1 a 31. Este modo se aplica a columnas DATE y DATETIME.
• ANSI_QUOTES: Con ANSI_QUOTES activado, puede usar comillas dobles (“…”)
para delimitar una cadena de caracteres, ya que se interpreta como un identificador o
comilla(‘…’).
• NO_FIELD_OPTIONS: No muestra opciones específicas para columnas de MySQL
en la salida de SHOW CREATE TABLE.
• NO_KEY_OPTIONS: No muestra opciones específicas para índices de MySQL en la
salida de SHOW CREATE TABLE.
• NO_TABLE_OPTIONS: No muestra opciones específicas para tablas (tales como
ENGINE) en la salida de SHOW CREATE TABLE.
• ERROR_FOR_DIVISION_BY_ZERO: Produce un error en modo estricto (de otra
forma una advertencia) cuando encuentra una división por cero (o la división en módulo
MOD(X,0)) durante un INSERT o UPDATE, o en cualquier expresión como en

Anl. Mauricio Arévalo M.
- Pág. 164 -
WHERE que implique datos de tablas y una divisón para cero. Si este modo no se da,
MySQL retorna NULL para una división para cero.
• NO_AUTO_VALUE_ON_ZERO: Este modo afecta el tratamiento de las columnas
AUTO_INCREMENT. Normalmente, se genera el siguiente número de secuencia para
la columna insertando NULL o 0 en ella, pero este modo suprime este comportamiento
para 0 de forma que solamente NULL genere el siguiente número de secuencia.
• NO_ZERO_DATE: No permite '0000-00-00' como fecha válida. Se puede insertar
las fechas 0 con la opción IGNORE en el comando INSERT. Cuando MySQL no está
en modo estricto, la fecha se acepta pero se genera una advertencia.
• ONLY_FULL_GROUP_BY: No permite consultas que en la parte del GROUP BY
se refieran a una columna que no se seleccione.
• PIPES_AS_CONCAT: Trata a “||” como un concatenador de columnas de caracteres
(lo mismo que CONCAT()) en lugar de un sinónimo de OR.
• REAL_AS_FLOAT: Trata al tipo de dato REAL como un sinónimo de FLOAT en
lugar de sinónimo de DOUBLE.
• STRICT_ALL_TABLES: Activa el modo estricto para todos los motores de
almacenamiento. Rechaza los datos inválidos.
• STRICT_TRANS_TABLES: Habilita el modo estricto para motores de
almacenamiento transaccionales, y para los no transaccionales, devuelve el “mejor valor
posible” en caso de existir errores.
Los modos especiales listados en la siguiente tabla, se proporcionan como abreviaciones
de combinaciones de algunos de los modos explicados anteriormente y todos están
disponibles desde la versión MySQL 5.0.2.

Anl. Mauricio Arévalo M.
- Pág. 165 -
MODO MySQL EQUIVALENCIA
DB2 PIPES_AS_CONCAT, ANSI_QUOTES
MSSQL, ORACLE ó POSTGRESQL PIPES_AS_CONCAT, ANSI_QUOTES, NO_KEY_OPTIONS, NO_TABLE_OPTIONS, NO_FIELD_OPTIONS.
TRADITIONAL STRICT_TRANS_TABLES, STRICT_ALL_TABLES, NO_ZERO_DATE, ERROR_FOR_DIVISION_BY_ZERO.
Tabla A1: Equivalencia de Modos MySQL

Anl. Mauricio Arévalo M.
- Pág. 166 -
ANEXO B: TIPOS DE DATOS EN POSTGRESQL
Tabla B1: Tipos de datos en PostgreSQL
Tipo Descripción
abstime fecha y hora absoluta de rango limitado (Unix system time)
bool booleano 'true' o 'false'
Box rectángulo geométrico '(izquierda abajo, derecha arriba)'
bpchar caracteres rellenos con espacios, longitud especificada al momento de creación
bytea arreglo de bytes de longitud variable
char un sólo carácter
circle círculo geométrico '(centro, radio)'
date fecha ANSI SQL 'aaaa-mm-dd'
datetime fecha y hora 'aaaa-mm-dd hh:mm:ss'
float4 número real de precisión simple de 4 bytes
float8 número real de precisión doble de 8 bytes
inet dirección de red
Int2 número entero de dos bytes, de -32k a 32k
Int4 número entero de 4 bytes, -2B to 2B
Int8 número entero de 8 bytes, 90#9018 dígitos
line línea geométrica '(pt1, pt2)'
lseg segmento de línea geométrica '(pt1, pt2)'
macaddr dirección MAC
money unidad monetaria '$d,ddd.cc'
numeric número de precisión múltiple
Point punto geométrico '(x, y)'
polygon polígono geométrico '(pt1, ...)'
Text cadena de caracteres nativa de longitud variable
Time hora ANSI SQL 'hh:mm:ss'
timestamp fecha y hora en formato ISO de rango limitado
varchar cadena de caracteres sin espacios al final, longitud especificada al momento de creación

Anl. Mauricio Arévalo M.
- Pág. 167 -
ANEXO C: ALTERNATIVAS PARA
BUSINESS INTELLIGENCE (BI)
A continuación doy a conocer brevemente algunas herramientas de BI (Business
Intelligence) que existen a nivel propietario y cual puede ser su alternativa en el mundo Open
Source, en la cual se incluyen las bases de datos MySQL y PostgreSQL. Además, la idea
(independientemente de que muchos productos se usen para varias soluciones), es que cada
solucion se pueda clasificar (OLAP, reporting, data mining, etc).
Tabla C1: Alternativas Open Source para BI

Anl. Mauricio Arévalo M.
- Pág. 168 -
ANEXO D: CONEXIONES PARA
MySQL y PostgreSQL
A continuación muestro algunas conexiones para MySQL utilizando algunos
proveedores de datos:
• ODBC:
ODBC 2.50 Base de datos local:
"Driver={mySQL}; Server=localhost; Option=16834; Database=MiBaseDeDatos;"
ODBC 2.50 Base de datos remota:
"Driver={mySQL}; Server=NombreDelServidor; Port=3306; Option=131072; Stmt=;
Database=MiBaseDeDatos; Uid=MiNombreDeUsuario; Pwd=MiPassword;"
ODBC 3.51 Base de datos local:
"DRIVER={MySQL ODBC 3.51 Driver}; SERVER=localhost;
DATABASE=MiBaseDeDatos; USER=MiNombreDeUsuario;
PASSWORD=MiPassword; OPTION=3;"
ODBC 3.51 Base de datos remota:
"DRIVER={MySQL ODBC 3.51 Driver}; SERVER=NombreDelServidor;
PORT=3306; DATABASE=MiBaseDeDatos; USER=MiNombreDeUsuario;
PASSWORD=MiPassword; OPTION=3;"

Anl. Mauricio Arévalo M.
- Pág. 169 -
Creación de una conexión ODBC en C#:
Using System;
Using System.Data;
Using System.Data.Odbc;
string cadenaconexion=
"DRIVER ={MySQL ODBC 3.51 Driver}; " +
"Server=NombreDelServidor; " +
"Database=MiBaseDeDatos; " +
"User =NombreDeUsuario; " +
"Password=MiPassword;" +
"Option=3;"
IDBConnection dbcon;
dbcon= new OdbcConnection (cadenaconexion);
dbcon.Open();
• Estándar para OLE DB, OleDbConnection (.NET)
"Provider=MySQLProv; Data Source=MiBaseDeDatos; User Id=MiNombreDeUsuario;
Password=MiPassword;"
• Estándar para Connector/Net 1.0 (.NET):
"Server=NombreDelServidor; Database=MiBaseDeDatos; Uid=MiNombreDeUsuario;
Pwd=MiPassword;"
Especificando puerto: (Recuerdese que el puerto predeterminado es el 3306)
"Server=NombreDelServidor; Port=1234; Database=MiBaseDeDatos;
Uid=MiNombreDeUsuario; Pwd=MiPassword;"
Creación de una conexión MySqlClient en C#:

Anl. Mauricio Arévalo M.
- Pág. 170 -
using MySql.Data.MySqlClient;
MySqlConnection objMySqlConn = new MySqlConnection();
objMySqlConn.ConnectionString = "Server=NombreDelServidor;
Database=MiBaseDeDatos; Uid=MiNombreDeUsuario; Pwd=MiPassword;";
objMySqlConn.Open();
Creación de una conexión MySqlClient en VB .NET:
Imports MySql.Data.MySqlClient
Dim objMySqlConn As MySqlConnection = New MySqlConnection()
objMySqlConn.ConnectionString = "Server=NombreDelServidor;
Database=MiBaseDeDatos; Uid=MiNombreDeUsuario; Pwd=MiPassword;"
objMySqlConn.Open()
• ByteFX.Data.MySQLClient (Proveedor de ADO.NET en el proyecto Mono):
"Server=NombreDelServidor; Database=MiBaseDeDatos; User ID=NombreDeUsuario;
Password=MiPassword;"
Creación de una conexión ByteFX.Data.MySqlClient en C#:
Using System;
Using System.Data;
Using System.Data.MySQLClient;
string cadenaconexion=
"Server=NombreDelServidor; " +
"Database=MiBaseDeDatos; " +
"User ID=NombreDeUsuario; " +
"Password=MiPassword;"
IDBConnection dbcon;
dbcon= new.MySqlConnection (cadenaconexion)
dbcon.Open();

Anl. Mauricio Arévalo M.
- Pág. 171 -
A continuación muestro algunas conexiones para PostgreSQL:
• Core Labs PostgreSQLDirect (Proveedor ADO.NET) Estándar:
"User ID=root; Password=pwd; Host=localhost; Port=5432; Database=testdb;
Pooling=true; Min Pool Size=0; Max Pool Size=100; Connection Lifetime=0"
• Npgsql (Proveedor de ADO.NET para PostgreSQL):
"Server= NombreDelServidor; Port=Puerto; User Id=Nombre_Usuario;
Password=Contraseña; Database=Nombre_BaseDeDatos;"
Ejemplo de una conexión con Npgsql en C#:
using System; using System.Data; using Npgsql; public static class UsoNpgsql { public static void Main(String[] args) { NpgsqlConnection conn = new NpgsqlConnection("Server=127.0.0.1;Port=5432;User Id=mauricio; Password=secret;Database=prueba;"); conn.Open(); NpgsqlCommand command = new NpgsqlCommand("insert into table1 values(1,1)" , conn); Int32 filasafectadas; try { filasafectadas = command.ExecuteNonQuery(); } Console.WriteLine("Fueron añadidas {0} líneas en la tabla1", filasafectadas); try { conn.Close(); } } }

Anl. Mauricio Arévalo M.
- Pág. 172 -
GLOSARIO
Administrador de base de datos (DBA): Es la persona o equipo de personas profesionales
responsables del control y manejo del sistema de base de datos, generalmente tiene(n)
experiencia en DBMS, diseño de bases de datos, Sistemas operativos, comunicación de datos,
hardware y programación.
Base de Datos Distribuida: Una Base de Datos Distribuida es, una base de datos construida
sobre una red computacional y no por el contrario en una máquina aislada. La información
que constituye la base de datos esta almacenada en diferentes sitios en la red, y las
aplicaciones que se ejecutan acceden a los datos en distintos sitios. Una Base de Datos
Distribuida entonces es una colección de datos que pertenecen lógicamente a un sólo sistema,
pero se encuentran físicamente esparcidos en varios "sitios" de la red.
Business Intelligence: Son soluciones informáticas de “inteligencia de negocios” que se
implementan para ayudar a las organizaciones a entender los patrones de compra de los
clientes, identificar las oportunidades de venta y el incremento en las ganancias y mejorar en
sí la toma de decisiones. Las soluciones de inteligencia de negocios permiten al nivel
gerencial minimizar el tiempo requerido para recolectar toda la información relevante de
negocios, automatizar la asimilación de la información en inteligencia personalizada y
proporcionar las herramientas para hacer comparaciones y tomar decisiones inteligentes.
Colaciones (collation): Una colación es un conjunto de reglas para comparar caracteres
dentro de un conjunto de caracteres. Por ejemplo, para el conjunto de caracteres latin1
existen las colaciones latin1_spanish_ci, latin1_swedish_ci, latin1_german1_ci, entre otras.
Conjunto de caracteres (character set): Un conjunto de caracteres es un conjunto de
símbolos y codificaciones.

Anl. Mauricio Arévalo M.
- Pág. 173 -
Data mining: Básicamente se conoce como Data mining o minería de datos a la solución de
“Business Intelligence” o Inteligencia de Negocios que consiste en el conjunto de técnicas
avanzadas para la extracción de información predecible escondida en grandes bases de datos
con el fin de conseguir los objetivos de negocio. Es una combinación de tecnologías y
técnicas que permiten la extracción de información de grandes bases de datos, para convertirla
en conocimiento que será utilizado para tomar decisiones empresariales.
Data Warehouse (DW): es un almacén o repositorio de datos categorizados, que concentra
un gran volumen de información de interés para toda una organización, la cual se distribuye
por medio de diversas herramientas de consulta y de creación de informes orientadas a la
toma de decisiones. Nos ayuda a la recopilación, unificación, limpieza y filtro de datos,
también facilita la implantación de un sistema Data Mining.
DBI/DBD: DBI son las siglas en inglés de Database independent interface for Perl. El
concepto de funcionamiento es que mientras DBI es una interfase independiente del soporte
de un manejador de base de datos en particular, los DBD Database Drivers le dan la
funcionalidad para cada manejador o subsistema.
Esquema: Es la descripción lógica de la base de datos, es decir el diseño global de la base de
datos. Proporciona los nombres de las entidades y sus atributos especificando las relaciones
que existen entre ellos. El esquema no cambia o cambia en escasas ocasiones; los que varían
son los datos; es decir su instancia.
Funciones y procedimientos almacenados Se refieren a las rutinas internas escritas en SQL
o lenguajes procedurales como PL/SQL. Rutina externa se refiere a la escritura en los
lenguajes anfitriones como C, Java, Cobol, etc.
Instancia: Es el estado que presenta una base de datos en un tiempo determinado.
Entendámosla como una fotografía que se toma de la base de datos en un tiempo t, después de
que transcurre el tiempo t la base de datos ya no será la misma.
IPv4: Es la versión 4 del Protocolo IP (Internet Protocol). Esta fue la primera versión del
protocolo que se implementó extensamente, y forma la base de Internet. IPv4 usa direcciones

Anl. Mauricio Arévalo M.
- Pág. 174 -
de 32 bits, limitándola a 232 = 4.294.967.296 direcciones únicas, muchas de las cuales están
dedicadas a redes locales (LANs). Ejemplo: 192.168.32.100.
IPv6: Es la versión 6 del Protocolo de Internet (Internet Protocol), un estándar del nivel de
red encargado de dirigir y encaminar los paquetes a través de una red. Las direcciones IPv6,
de 128 bits de longitud, se escriben como ocho grupos de cuatro dígitos hexadecimales. Por
ejemplo, 2001:0db8:85a3:08d3:1319:8a2e:0370:7334 es una dirección IPv6 válida.
Lenguajes procedurales: Son lenguajes de programación utilizados en manejadores de Bases
de Datos que se ejecutan directamente en el servidor para programar operaciones como
procedimientos, funciones, triggers, etc. con sentencias SQL y sentencias de control propias
del lenguaje.
Multiproceso: Las computadoras que tienen mas de un CPU son llamadas multiproceso. Un
sistema operativo multiproceso coordina las operaciones de la computadoras
multiprocesadoras. Ya que cada CPU en una computadora de multiproceso puede estar
ejecutando una instrucción, el otro procesador queda liberado para procesar otras
instrucciones simultáneamente.
Named pipes: Una tubería o canalización con nombre es un fichero que actúa como una
tubería. Se pone algo en el fichero y sale por el otro lado; por ello se llama FIFO, o ``First-In-
First-Out'', «lo primero que entra es lo primero que sale», debido a que lo primero que se
introduce en la tubería es lo primero que sale por el otro lado, en el caso de peticiones al
servidor de bases de datos que utilice esta tecnología, la usa para transmitir los datos hacia
otro punto de la red. Si se escribe a una tubería con nombre, el proceso que escribe a la
tubería no termina hasta que la información que se escribe se lea desde el otro lado de la
tubería.
OLAP y OLETP: OLAP significa ‘On-Line Analytical Processing’, que se contrapone con el
término OLTP ‘On-Line Transactional Processing’. Término más habitual, que se define en
los sistemas de bases de datos relacionales usados ampliamente en el mundo empresarial.
En estos últimos sistemas lo importante es el registro de los datos, y en OLAP, lo importante
es el análisis de los mismos.

Anl. Mauricio Arévalo M.
- Pág. 175 -
PERL: (Practical Extraction and Report Language), es un lenguaje de programación utilizado
en el WWW a través de un CGI, principalmente para realizar consultas a bases de datos. Perl
es un lenguaje para manipular textos, archivos y procesos de una forma fácil y legible. Perl
nació y se ha difundido bajo el sistema operativo UNIX, aunque existe para otras plataformas.
PHP: PHP (acrónimo recursivo de "PHP: Hypertext Preprocessor"), originado inicialmente
del nombre PHP Tools, o Personal Home Page Tools, es un lenguaje de programación
interpretado, es decir, se ejecuta en el servidor. Aunque fue concebido en el tercer trimestre
de 1994 por Rasmus Lerdorf no fue hasta el día 8 de Junio de 1995 que fue lanzada la versión
1.0. Se utiliza entre otras cosas para la programación de páginas web activas, y se destaca por
su capacidad de mezclarse con el código HTML y motores de bases de datos como MySQL.
Propiedad Intelectual: Conjunto de normas y principios que regulan los derechos morales y
patrimoniales que la ley concede a los autores (los derechos de autor), por el solo hecho de la
creación de una obra en el ámbito literario, artístico o científico, tanto publicada o que todavía
no se haya publicado. Puede definirse como la especie de propiedad que se tiene sobre las
obras de la inteligencia
Puertos: Un puerto, no es nada más que un numero de 16 bits y que se utiliza para que un
determinado programa se comunique con la pila TCP. Es decir, un programa se hace "dueño"
de un puerto, y es capaz de enviar y recibir datos por él. Los puertos de números bajos:
inferiores al 1024, están reservados para el TCP-IP y normalmente tienen nombre propio: el
21 es el FTP, el 23 el telnet, el 80 es el servidor web... etc). Los puertos superiores quedan
libres pudiendo utilizarles cualquier aplicación y para cualquier uso.
Python: Es un lenguaje de programación interpretado e interactivo, capaz de ejecutarse en
una gran cantidad de plataformas. Fue creado por Guido van Rossum en 1990 y está
completamente orientado a objetos; la última versión estable del lenguaje es actualmente la
2.5 (Septiembre de 2006).
Secure Sockets Layer (SSL) y Transport Layer Security (TLS): Seguridad de la Capa de
Transporte (en el modelo de referencia OSI). Son protocolos criptográficos que proporcionan
comunicaciones seguras en Internet.

Anl. Mauricio Arévalo M.
- Pág. 176 -
Socket: Es un objeto de software utilizado por un cliente para conectarse a un servidor; un
socket no es nada más que un canal de comunicaciones entre dos host TCP. Por tanto, un
socket queda totalmente definido por 4 números: la dirección IP, el puerto de la máquina
origen, la dirección IP y el puerto de la máquina destino.
Tcl: (“Tool Command Language” o lenguaje de herramientas de comando), es un lenguaje de
script creado por John Ousterhout, ha sido concebido para su fácil aprendizaje, siendo a la vez
muy potente. Se usa principalmente para el desarrollo rápido de prototipos, aplicaciones
"script", interfaces gráficas y pruebas. La combinación de Tcl con Tk (del inglés Tool Kit) es
conocida como Tcl/Tk, y se utiliza para la creación de interfaces gráficas.
Unicode: Unicode es una norma de codificación de caracteres. Su objetivo es asignar a cada
posible carácter de cada posible lenguaje un número y nombre único, a diferencia de la mayor
parte de los juegos ISO como el ISO-8859-1, que sólo definen los necesarios para un idioma o
zona geográfica.

Anl. Mauricio Arévalo M.
- Pág. 177 -
BIBLIOGRAFIA
http://es.tldp.org/Tutoriales/NOTAS-CURSO-BBDD/notas-curso-BD/node3.html
http://es.tldp.org/Tutoriales/NOTAS-CURSO-BBDD/notas-curso-BD/node1.html
http://es.tldp.org/Tutoriales/NOTAS-CURSO-BBDD/notas-curso-BD/node1.html
http://es.wikipedia.org
http://www.monografias.com/trabajos11/basda/basda.shtml
http://www.monografias.com/trabajos29/comparacion-sistemas/comparacion-sistemas.shtml
http://es.wikipedia.org/wiki/Comparacion_de_sistemas_administradores_de_bases_de_datos_
relacionales
http://www.arsys.es/
http://www.acis.org.co
http://www.gnu.org/philosophy/why-free.es.html
http://manifiesto.cofradia.org/index.html
http://www.itlp.edu.mx/publica/tutoriales/basedat1/tema1_3.htm
http://todobi.blogspot.com
http://www.mysql.com
http://www.phpmyadmin.net/home_page/index.php
http://www.fabforce.net
http://www.datanamic.com
http://www.sqlmanager.net
http://dev.mysql.com/doc/refman/5.0/es/
www.netpecos.org/docs/mysql_postgres/b164.html#MYSQL
http://www.postgresql.org
http://es.tldp.org/Postgresql-es/web/navegable/todopostgresql/postgres.html

Anl. Mauricio Arévalo M.
- Pág. 178 -
http://personales.ya.com/reque/apuntes/memoria/index.html
http://www.pgadmin.org
http://phppgadmin.sourceforge.net
http://www.planetalinux.com.ar/
Celma, M; Casamayor, J. C; Mota, L. "Bases de datos relacionales", Pearson, Prentice Hall, Edición 2003.
Consultas al Ing. Alí Méndez
Consultas al Ing. Luis Loján
Consultas al Ing. Lauro Ulloa














