BIOESTADISTICA - vet.unicen.edu.ar · - Los médicos veterinarios para saber el grado de eficiencia...
69
[2015] BIOESTADISTICA Para Ciencias Veterinarias. UNCPBA Notas de clases. E.M. Rodriguez, R. E. Cepeda, J.A. Passucci
Transcript of BIOESTADISTICA - vet.unicen.edu.ar · - Los médicos veterinarios para saber el grado de eficiencia...

[2015]
BIOESTADISTICA Para Ciencias Veterinarias. UNCPBA
Notas de clases. E.M. Rodriguez, R. E. Cepeda, J.A. Passucci

BIOESTADISTICA 2015
Página 1
UNIDAD 1: ORGANIZACIÓN Y REPRESENTACION DE DATOS
Variables cualitativas y cuantitativas. Distribución de frecuencias. Tallos y hojas. Gráficos
INTRODUCCION
La estadística puede ser divertida, fácil y también útil. La utilizamos todos los días, para cuestiones de la vida cotidiana así como también en las diferentes ciencias para tomar decisiones. Por ejemplo,
• Para analizar la producción lechera de un establecimiento, el encargado registra y consulta la planilla diaria de litros por animal.
• En un mercado de valores los productores observan cómo se distribuyen los precios entre los distintos puestos para realizar la mejor compra/venta que combine calidad y precio.
La necesitan: - Los médicos veterinarios para saber el grado de eficiencia de un tratamiento - Los profesionales de la salud, para entender los resultados de las investigaciones médicas. - Los economistas, porque cálculos eficientes les permitirán llegar al fondo de la cuestión que
analizan. - Los docentes cuando se enfrentan al problema de evaluar el rendimiento de los alumnos. - Los sociólogos para diseñar y procesar sus encuestas. - Los responsables de la calidad en un proceso productivo, al detectar las piezas defectuosas y
controlar los factores que influyen en la producción de las mismas. - La industria farmacéutica para desarrollar nuevos medicamentos y establecer las dosis
terapéuticas. - Los ciudadanos, para sacar sus propias conclusiones sobre los resultados de las encuestas
políticas, los índices de precios y desocupación, y los resultados estadísticos que habitualmente se presentan en los medios masivos de comunicación (diarios, revistas, radio, televisión).
La estadística no tiene una definición formal, se trata de una ciencia que involucra métodos científicos relacionados con la recolección, presentación y análisis de datos, para la deducción de conclusiones y la toma de decisiones objetivas. Es el arte de la decisión en presencia de azar o incertidumbre.
Podemos utilizar la estadística de dos maneras generales: para describir los datos, mediante la organización, representación y cálculo de medidas de resumen; y para realizar inferencia a partir de la información recolectada. Así tenemos la Estadística descriptiva que se encarga de la presentación, ordenamiento y resumen de los datos y la Estadística inductiva o inferencial que permite generalizar información los datos provenientes de una muestra a un número más grande de individuos (población).
1.1. ALGUNAS DEFINICIONES.
La estadística tiene su propio vocabulario. Veremos algunos términos básicos, que volveremos a encontrar más adelante, además, seguiremos incorporando términos a lo largo de las notas.

BIOESTADISTICA 2015
Página 2
Población:
Una población es un conjunto de elementos (personas, animales, o individuos) acotados en un tiempo y en un espacio determinados, con alguna característica común observable o medible.
Si la población es finita, diremos que el tamaño poblacional es el número de elementos de la misma y lo denotaremos con N. Muestra:
Generalmente es imposible o impracticable examinar alguna característica en la población entera, por lo que se examina una parte de ella y en base a la información relevada en esa porción se hacen inferencias sobre toda la población. Una muestra es un subconjunto de elementos de la población en estudio con alguna característica común observable o medible.
El problema es cómo debe seleccionarse esa parte de la población, que proveerá la información acerca de la o de las características buscadas, de manera tal que puedan obtenerse conclusiones. Más adelante, nos enfocaremos a presentar algunas técnicas para la obtención de muestras de una población y las principales formas de resumir la información que éstas proveen, así como también a calcular un número óptimo de individuos que forman la muestra. Una parte importante al pensar en una situación de interés es definir la unidad de análisis con la que se va a trabajar y en la que se va a registrar la variable de interés.
Las Unidades muestrales o experimental (UE) son los objetos donde se registra la información de interés del estudio o sobre quien se mide el efecto del tratamiento. Muchas veces, las unidades muestrales son individuos, animales, otras veces las unidades están compuestas por muchos individuos: ciudades, lotes (de animales) etc.
También podemos definir la unidad observacional (UO), lo hacemos mediante un ejemplo: Cuando en un ensayo clínico veterinario, a varios perros se les aplican diferentes medicamentos, cada perro es una UE y si, por otra parte, a cada perro se la aplica una pomada sobre los pies, entonces cada pie es una UO. Cuando se aplica un tipo de alimento (tratamiento) a unos cerdos de un chiquero, esta sería la UE; sin embargo, las observaciones de aumento de peso se hacen a cada animal, por lo cual los animales son las UO. En algunos casos las UE y las UO son iguales pero en otros no.
Variables: Las observaciones o mediciones sobre los elementos de una población constituyen la materia prima con la cual se trabaja en Estadística. Para que dichas observaciones puedan ser tratadas estadísticamente deben estar expresadas, o poder ser re-expresadas, en términos numéricos. Aunque sea obvio, se destaca que la característica de interés a observar o medir en cada elemento de la población debe ser la misma, en tanto que se espera que no tomar el mismo valor en cada uno de los elementos que la conforman. Las variables son características que pueden cambiar de una unidad muestral a otra, como la edad de los animales, la población de cada ciudad, el porcentaje de animales enfermos de un establecimiento, la preferencia de un alimento balanceado para un animal, el tiempo de sobrevida de una enfermedad, la cantidad de larvas por muestra de agua, el ancho de la grupa, etc.
Desde el punto de vista de su naturaleza, se habla de variables CUALITATIVAS para referirse a aquellas cuyos elementos de variación tienen un carácter cualitativo, no susceptible de observación medible

BIOESTADISTICA 2015
Página 3
numéricamente y de variables CUANTITATIVAS como aquellas cuyas propiedades pueden presentarse en forma numérica.
De acuerdo con su naturaleza matemática, se diferencian las variables cuantitativas en DISCRETAS Y CONTINUAS, siendo las primeras aquellas que están definidas sobre recorridos finitos o infinitos numerables; no pueden tomar valores intermedios entre dos valores dados. Las continuas son aquellas definidas sobre recorridos infinitos no numerables; pueden tomar cualquier valor dentro de un recorrido o intervalo dado.
Para clasificar variables, se utilizan diferentes tipos de escalas, siendo las más comunes las NOMINALES, las ORDINALES, su uso depende básicamente de los objetivos del estudio y de la naturaleza de la variable.
La escala nominal consiste en clasificar objetos o fenómenos, según ciertas características, tipologías o nombres, dándoles una denominación o símbolo, sin que implique ninguna relación de orden, distancia o proporción entre los objetos o fenómeno. La medición se da a un nivel elemental cuando los números u otros símbolos se usan para la distinción y clasificación de objetos, persona o características. Cuando se utilizan números para representar las diferentes clases de una escala nominal, estos no poseen propiedades cuantitativas y sirven solamente para identificar las clases.
La escala ordinal, llamada también escala de orden jerárquico, establece posiciones relativas de los objetos o fenómenos en estudio, respecto a alguna característica de interés, sin que se reflejen distancias entre ellos.
A continuación resumimos los tipos de variables y presentamos ejemplos para cada situación.
Cuantitativas
Continuas
Litros de leche producidos por vaca por día
kilos de ganancia de peso de terneros
Tiempo que tarda en ocurrir un determinado evento
Discretas
Cantidad de huevos que pone una gallina ponedora por día.
Número de lechones por camada
Cualitativas
Nominales
Estado sanitario de un rodeo respecto a una enfermedad (sano o enfermo).
Pelajes de equinos
Razas de perros
Ordinales Altura: Alto- medio- bajo
Tamaño: Grande, mediano y chico

BIOESTADISTICA 2015
Página 4
1.2 ORGANIZACIÓN DE DATOS CUANTITATIVOS.
Al registrar los resultados de un estudio, se obtiene un número de observaciones que puede ser muy grande y su simple listado es de poca relevancia en el sentido interpretativo, es decir no nos dice nada del fenómeno que se está estudiando.
Cuando se registran datos ya sean de una muestra o de la población se deben presentar en forma resumida, elaborando tablas y gráficos apropiados. Así, de éstas se pueden extraer las principales características de los datos. En esta sesión mostramos cómo se pueden organizar y presentar conjuntos de datos cuantitativos en forma de tablas y gráficas apropiadas para su análisis.
1.2.1 TABLAS DE FRECUENCIAS.
Una tabla de distribución de frecuencias posee una columna que contiene los diferentes valores que toma la variable en estudio y otra columna que indica la frecuencia absoluta, que es el número de veces que el valor de la variable se repite en el conjunto de datos.
Generalmente en una tabla de distribución de frecuencias no sólo se muestran las frecuencias absolutas, sino que también se incluyen las frecuencias relativas y las frecuencias acumuladas. Cada una de estas columnas contiene información útil para describir la información que poseen los datos. Las tablas de frecuencias pueden considerarse para datos simples, o para datos agrupados por intervalos de clases, dependiendo de la cantidad de datos y de la repetición que tengan esos datos, vemos a continuación un ejemplo:
Ejemplo 1: Los siguientes datos corresponden a la cantidad de colmenas en producción que tuvo el Apiario H en el partido de Tandil, desde el año 1993 al 2000:
Año Total de colmenas
1993 28
1994 26
1995 30
1996 27
1997 28
1998 31
1999 29
2000 24
Tabla 1: datos de colmenas
Teniendo en cuenta la variable de interés, que es el número de colmenas productivas, la distribución de frecuencias simples consiste en observar los valores que toma la variable y cuantas veces se repite, esto es su frecuencia absoluta, la tabla completa sería entonces:
Cant. Colmenas Frecuencia
Frecuencia relativa
Frecuencia relativa%
Frecuencia acumulada creciente
Frecuencia acumulada creciente %
24 1 =1/8=0.125 12.5% 1 12.5
26 1 0.125 12.5 2 25
27 1 0.125 12.5 3 37.5
28 2 0.25 25 5 52.5

BIOESTADISTICA 2015
Página 5
29 1 0.125 12.5 6 65
30 1 0.125 12.5 7 77.5
31 1 0.125 12.5 8 100
Tabla 2: medidas de resumen para los datos de colmenas.
Vemos que podría ser más útil definir intervalos para agrupar la cantidad de colmenas, la utilización de intervalos se recomienda cuando la cantidad de datos es grande y hay poca repetición de los valores de la variable, un número de intervalos entre 5 y 10 suele ser una cantidad razonable aunque existen diferentes métodos para calcular la cantidad.
Mostramos a continuación cual sería una distribución por intervalos posible para estos datos, aunque recalcamos que no es lo más recomendable para este caso por tratarse de pocos datos.
Cant. Colmenas Frecuencia
Frecuencia relativa
Frecuencia relativa%
Frecuencia acumulada creciente
24-26 1 =1/8=0.125 12.5% 12.5%
26-28 2 0.25 25% 37.5%
28-30 3 0.375 37.5% 75%
30-32 2 0.25 25% 100%
Tabla 3: tabla de frecuencia por intervalos para datos de colmenas
Como mencionamos antes las otras columnas de la tabla tienen información muy útil, así por ejemplo, el 37.5% de la cuarta columna se interpreta como: el 37.5% de los años la cantidad de colmenas fue inferior a 30, así por ejemplo la última fila de la tercer columna indica que el 25% de los años hubo entre 30 y 32 colmenas.
1.2.2 EL DIAGRAMA DE TALLOS Y HOJAS.
Dado un conjunto de datos formado por n observaciones, las cuales tiene por lo menos dos dígitos, una forma rápida de obtener una representación visual del conjunto de datos es construir un diagrama de tallos y hojas. Este diagrama es usado cuando hay un número no muy pequeño de datos.
Los siguientes son los pasos para construir un diagrama de tallos y hojas. Los diagramas de tallos y hojas nos dan una idea de la localización de los datos y de la forma de la distribución. Esta técnica funciona bien para los conjuntos de datos que no tienen una dispersión muy grande. Mostramos el procedimiento a partir de un ejemplo,
Ejemplo 2: La siguiente tabla representa el porcentaje de proteína en un alimento balanceado para perros, tomado de 64 días consecutivos de producción de la fábrica.
33.1 35.3 34.2 33.6 33.6 33.1 37.6 33.6 35.1 36.2 35.2 36.8 37.1 33.6 32.8 36.8
34.5 34.7 33.4 32.5 35.4 34.6 37.3 34.1 34.7 36.8 35 37.9 34 32.9 32.1 34.3
35.6 35 34.7 34.1 34.6 35.9 34.6 34.7 33.6 35.1 34.9 36.4 34.1 33.5 34.5 32.7
36.3 35.4 34.6 35.1 33.8 34.7 35.5 35.7 32.6 33.6 33.8 34.2 34.6 34.7 35.8 37.8
Tabla 4: datos de porcentaje de proteína en alimento balanceado

BIOESTADISTICA 2015
Página 6
El diagrama de tallos y hojas para los anteriores datos aparece a continuación. Consideramos el Tallo como los enteros desde el 32 hasta el 37 y las repeticiones decimales son las hojas:
Tallo Hojas
6 32 156789
18 33 114566666688
(21) 34 011122355666667777779
25 35 00111234456789
11 36 234888
5 37 13689
Figura 1: representación en tallos y hojas
Con el método de tallos y hojas se muestran simultáneamente la tabla de distribución de frecuencia así como también el aspecto de su distribución.
Ejemplo 3: Un experimento consistió en contar el número de crías en 50 perras del criadero “Ciudad Mascota”. Los valores resultantes del conteo fueron los siguientes:
10 8 6 3 9 7 5 4 6 9 6 7 8 8 6 7 7 8 10 7 9 10 6 8 6 3 2 5 3 2 1 4 3 0 4 3 2 7 5 5 4 3 7 6 7 9 8 6 6 8
Tabla 5: datos de cantidad de crías
Los datos así presentados son de difícil comprensión, por lo que conviene resumirlos en una tabla:
X Cant cachorros
Frec. Absoluta Cant perras
Frec acum Frec. rel. Frec. rel acum-
0 1 1 0.02 0.02
1 1 2 0.02 0.04
2 3 5 0.06 0.1
3 6 11 0.12 0.22
4 4 15 0.08 0.3
5 4 19 0.08 0.38
6 9 28 0.18 0.56
7 8 36 0.16 0.72
8 7 43 0.14 0.86
9 4 47 0.08 0.94
10 3 50 0.06 1
Tabla 6: Distribución de frecuencias para el número de crías

BIOESTADISTICA 2015
Página 7
En esta tabla se puede ver que el número total de datos es 50, que las perras con menos de 3 crías y con más de 9 son poco frecuentes y que las perras con 6 u 8 crías son las más frecuentes. Solo el 10 % tiene menos de 3 crías.
1.3 REPRESENTACIÓN GRÁFICA DE DATOS CUANTITATIVOS.
1.3.1 GRAFICO DE BARRAS.
Cuando la variable es tratada como dato simple o de manera discreta, como en la tabla 2 y la 6 para los ejemplos de las colmenas y las crías respectivamente, el grafico que corresponde es el de barras, donde sobre el eje X se identifican los valores (discretos) de X y sobre el eje de coordenadas la frecuencia, que puede ser absoluta, relativa o porcentual, en todos los casos el grafico que se obtiene es equivalente, solo
cambia la escala, el primero va de 0 a n, mientras que en el segundo va de 0 a 1, y el ultimo de 0 a 100.
Figura 2
1.3.2 HISTOGRAMAS.
El histograma es una técnica gráfica utilizada para presentar gran cantidad de datos; se le atribuye a Karl Pearson en 1895. Como en el gráfico de barras, el histograma puede realizarse con las frecuencias absolutas o las frecuencias relativas y no cambia su interpretación. Para la construcción del histograma se requiere elaborar una tabla de distribución de frecuencias definiendo previamente los intervalos en los que si divide el rango de variación de la variable de interés.
El histograma (de frecuencias) en si es una sucesión de rectángulos construidos sobre un sistema de coordenadas de la siguiente manera:
1. Las bases de los rectángulos se localizan en el eje horizontal. La longitud de la base es igual al ancho del intervalo.
2. Las alturas de los rectángulos se registran sobre el eje vertical y corresponden a las frecuencias de los intervalos.
3. Las áreas de los rectángulos son proporcionales a las frecuencias de las clases.
0 1 2 3 4 5 6 7 8 9 10
cachorros
0.60
2.80
5.00
7.20
9.40
fa
24 26 27 28 29 30 31
Cant. Colmenas
0.00
0.33
0.67
1.00
1.33
1.67
2.00
2.33
2.67
3.00F
recu
en
cia

BIOESTADISTICA 2015
Página 8
Algunos términos:
Cada uno de los intervalos se llama intervalos de clase, el menor y mayor valor de cada intervalo se llaman límite inferior y superior respectivamente, el punto medio de cada clase se llama marca de clase, y es el valor que representa a todos los valores de esa clase y finalmente la diferencia entre los limites se llama amplitud de la clase, que se intenta que sea la misma a lo largo de los distintos intervalos. Entonces para los ejemplos anteriores los histogramas correspondientes se muestran a continuación:
Figura 3
cachorros LI LS
Clase MC FA FR
[0-2] 1 1.00 5 0.10
(2-4] 2 3.00 10 0.20
(4-6] 3 5.00 13 0.26
(6-8] 4 7.00 15 0.30
(8-10] 5 9.00 7 0.14 Tabla 7: Distribución de frecuencias por intervalos
1.3.3 POLÍGONO DE FRECUENCIAS.
Otro recurso gráfico para ilustrar el comportamiento de los datos es el polígono de frecuencias. Este se construye sobre el sistema de coordenadas cartesianas, al colocar sobre cada marca de clase un punto a una altura igual a la frecuencia asociada a esa clase; luego se unen dichos puntos por segmentos de recta. Para los casos anteriores mostramos los polígonos asociados.
23 25 27 28 30 32
Cant. Colmenas
0.00
0.10
0.20
0.30
0.39
fre
cu
en
cia
re
lativa
0 2 4 6 7 9 11
Cant cachorros
0.00
0.08
0.16
0.24
0.32
fre
cu
en
cia
re
lativa

BIOESTADISTICA 2015
Página 9
0 2 3 5 7 9 10 12
Cant cachorros
0.00
0.08
0.16
0.24
0.32
frecu
enci
a re
lativ
a
Figura 4
1.4 PRESENTACIÓN DE DATOS CUALITATIVOS.
Cuando se manejan variables cualitativas, las respuestas categóricas se pueden presentar en tablas de frecuencia o tablas resumen y luego en forma gráfica. En esta sección se presentan algunos gráficos de uso frecuente en la presentación de datos cualitativos.
1.4.1 TABLA DE FRECUENCIA O TABLA RESUMEN.
La construcción de una tabla de frecuencia para datos cualitativos requiere solo contar el número de elementos o individuos que caen dentro de cierta clase o categoría, es decir la frecuencia absoluta de la clase o la categoría.
Ejemplo 4: Según un informe de estudio de mercado realizado en Argentina en 2013, en los últimos años se vislumbra una clara recuperación de la actividad porcina: hoy se estiman a nivel país 3458995 cabezas (Área Porcinos. Dirección de Ovinos, Porcinos, Aves de Granja y Pequeños Rumiantes con datos de SENASA). En cuanto a la distribución del stock nacional por provincia, existe una marcada concentración en las de la Pampa Húmeda, donde Buenos Aires posee el 920084 cabezas (26.77 %), Córdoba 840346, (el 24.45 %) y Santa Fe 701835 (el 20.42 %). El resto del país tiene el 29 % del stock, destacándose por su importancia Salta, Chaco, Entre Ríos, Formosa, La Pampa, Santiago del Estero y San Luis. Para este ejemplo, la procedencia forma una variable cualitativa, nominal. Organizamos esta información primero en una tabla de frecuencias:
Pcia Fi Fr%
Bs.AS 920084 26.77
Cordoba 840346 24.45
Santa Fe 701835 20.42
Resto 996730 29
Total 3458995 100 Tabla 8
De esta forma tenemos organizada la información. ¿La tabla termina ahí?, ¿tendría sentido calcular las frecuencias acumuladas?
No, las frecuencias acumuladas responden a preguntas con desigualdades generadas a partir de los valores de X, que en este caso es la pcia. Sería muy útil además poder asociarle un gráfico.

BIOESTADISTICA 2015
Página 10
1.4.2. GRÁFICO PORCENTUAL O EN FORMA DE TORTA.
Se trata de un gráfico circular que provee un concepto visual de un todo, de modo que el 100% es igual a 360 grados. La torta se divide en sectores, cada uno de ellos corresponde a la categoría o clase de la variable representada. El tamaño de los sectores es proporcional al porcentaje de la categoría correspondiente. Para nuestro ejemplo:
Figura 5
Es muy importante que los valores figuren al lado de cada porción y no en el cuadro de referencias. Existen otro tipo de representaciones dentro del grupo de las tortas en las que las porciones aparecen separadas.
1.4.3. DIAGRAMA DE BARRAS.
Este gráfico consiste de una serie de barras horizontales o verticales asignadas a cada categoría de la variable cualitativa cuyas alturas son dadas por la frecuencia de la categoría. A continuación se dan algunas sugerencias para la elaboración de gráficas de barras.
1. Para respuestas categóricas cualitativas, las barras se deben diseñar en forma horizontal y para respuestas categóricas numéricas, en forma vertical.
2. Todas las barras deben ser del mismo ancho para no confundir al lector. 3. Se deben incluir las escalas y algunas indicaciones para que ayuden a la lectura de las gráficas. 4. Los ejes de las gráficas se deben identificar en forma clara.
Bs.AS Cordoba Santa Fe Resto
Pcia
0.00
12.50
25.00
37.50
50.00
Fr%
Figura 6

BIOESTADISTICA 2015
Página 11
1.4.4. GRAFICO DE BARRAS COMPARATIVAS.
Se utiliza para comparar series, donde la variable de interés es cualitativa o cuantitativa discreta, por ejemplo si en el caso del ejemplo 4, tuviésemos la misma información para el año anterior, podríamos hacer el siguiente grafico comparativo:
Pcia Año Fi
Bs.AS 2013 920084
Córdoba 2013 840346
Santa Fe 2013 701835
Resto 2013 996730
Bs.AS 2012 810000
Córdoba 2012 820350
Santa Fe 2012 780870
Resto 2012 975000
Tabla 7
Figura 8
Ejemplo 5: Supongamos que estamos interesados en analizar la cantidad de ovinos que han sufrido diarrea en los últimos 30 días (de cada 100), en tres campos vecinos, los datos son:
Campo 1 Campo 2 Campo 3
Sanos 20 27 32
Enfermos 80 73 68
Tabla 9: Distribución de frecuencias por campos
Figura 10
2012 2013
Bs.AS Cordoba Santa Fe Resto
Pcia
687090.25
768186.38
849282.50
930378.63
1011474.75
2012 2013
0
10
20
30
40
50
60
70
80
Campo 1 Campo 2 Campo 3
Sanos
Enfermos

BIOESTADISTICA 2015
Página 12
UNIDAD 2: MEDIDAS DE RESUMEN Media, mediana, moda, rango, desvío estándar, varianza y cuantiles
La mente humana puede captar la información que aportan diez números, cien es difícil y con mil, casi imposible. Por esa razón, es muy importante contar con pocos valores (medidas resumen), que de alguna manera puedan describir las características más sobresalientes del conjunto que se está analizando. Una medida resumen es un número. Se obtiene a partir de una muestra y, en cierta forma, la caracteriza. Es el valor de un estadístico (valor obtenido de la muestra, lo definiremos más adelante más formalmente). Por ejemplo, un porcentaje o una proporción son medidas resumen. Se utilizan con datos categóricos o con datos numéricos. Las medidas resumen permiten tener una idea rápida de como son los datos. Pero, un estadístico mal utilizado puede dar una idea equivocada respecto de las características generales que interesa mostrar. El cálculo de medidas resumen es el primer paso; se realiza cuando se recolectan los datos en un estudio para tener una idea de que está pasando. Posteriormente, los investigadores pondrán a prueba sus hipótesis respecto a algún valor poblacional (parámetro), estimaran características de la población y estudiaran posibles relaciones entre las variables. Cuando presentan sus conclusiones al público en general, las medidas resumen muestran los resultados en forma concisa y clara, volviendo a tener importancia. En principio, se pueden obtener muchísimas formas de resumir los valores de un conjunto de datos numéricos. Es importante que sean fáciles de interpretar. Cualquier conjunto de datos tiene dos propiedades importantes: un valor central y la dispersión alrededor de ese valor. Vemos esta idea en los siguientes histogramas hipotéticos
2.1 MEDIDAS DE POSICIÓN.
Como se observa en las Figuras 8A, 8B y 8C la distribución de los datos es similar pero difieren en la ubicación, en el eje X, respecto al origen.
Figura 8A Figura 8B Figura 8C
0
10
20
30
40
50
60
70
80
0
10
20
30
40
50
60
70
80

BIOESTADISTICA 2015
Página 13
En este caso lo que ocurre es que se desplazan los datos sobre el eje X.
Las medidas de tendencia central (MTC), son valores numéricos que describen o indican el centro de un conjunto de datos, nos interesan especialmente tres medidas: la MEDIA, la MEDIANA y la MODA o MODO. Promedio, media o media aritmética: El promedio de un conjunto de n observaciones es simplemente la suma de las observaciones dividida por el número total de observaciones, en el caso de una muestra, n.
n
i
i
n
xx
1
Si los datos organizados es una tabla de distribución de frecuencias, el promedio es la suma ponderada de los valores de x por su frecuencia dividida el total de datos, lo representamos con la siguiente expresión:
1 1 2 2 1
1 2 3
1
.....
.....
n
i i
n n i
n
ni
i
x fx f x f x f
Xf f f f
f
En el caso de que los datos estén agrupados en intervalos o clases, en el lugar de ix de la
expresión, se utiliza la marca de clase, recordemos que este valor es el representante de su
intervalo o clase. Mencionamos algunas de sus principales propiedades:
a) La media es única y fácil de calcular.
b) La suma algebraica de los desvíos respecto a la media es 0, es decir:
n
ii xx
1
0)(
c) También se cumple para cualquier valor A en R, que:
n
ii
n
ii Axxx
1
2
1
2 )()(
Es decir, la suma de las desviaciones -respecto a la media- elevadas al cuadrado siempre es menor que las desviaciones respecto de otro punto del conjunto de datos. A esta propiedad se la denomina “suma de cuadrados mínima”.
d) Es sensible a datos extremos, como el cálculo se basa en todos los individuos de la muestra, si alguno de ellos es o muy grande o muy chico, va a afectar al promedio.
e) Si a cada observación se le suma (o resta) un valor constante c, el promedio del nuevo conjunto de datos, será el promedio original sumado (o restado) la constante c. Podemos formalizar esta propiedad de la siguiente forma: Sea X una variable de interés que en una muestra adopta los valores x1, x2, x3, . . ., xn y sea c una constante, llamamos Y a la variable X+c, entonces:
cXn
yY
n
i
i 1
.
f) Sean X1 y X2 dos variables “aleatorias” y hacemos yi = x1i + x2i luego: 21 XXY , y
equivalentemente para la resta: si yi = x1i - x2i luego 21 XXY
g) Si xi = c para todo i, donde c es constante luego x = c.
h) Si a cada observación xi se la multiplica (o divide) por una constante c la media aritmética de la nueva variable será igual al promedio original multiplicado (o dividido) por la constante c, es decir:

BIOESTADISTICA 2015
Página 14
Xcn
xc
n
cx
n
yY
n
i
in
i
in
i
i 111
Calculamos la media para el ejemplo 3 de los cachorros:
X: Cant cachorros fi xifi Fi
0 1 0 1
1 1 1 2
2 3 6 5
3 6 18 11
4 4 16 15
5 4 20 19
6 9 54 28
7 8 56 36
8 7 56 45
9 4 36 49
10 3 30 52
n=50 Total =293
Tabla 11. Distribución de frecuencias cantidad de cachorros
El promedio es: 293/50=5.86. ¿Cómo se interpreta? Observemos que el promedio puede no coincidir con uno de los valores que adopta la variable. Moda o modo: El valor de variable que tenga la mayor frecuencia, es decir que más se repite (puede no existir y si existe puede no ser única), se define como la moda o modo de un conjunto de datos. Para el ejemplo la moda corresponde a X=6, es decir lo más frecuente en esta muestra es que un animal tenga 6 cachorros. Mediana: Es un valor tal que el número de observaciones menores ó iguales que él es igual al número de observaciones mayores ó iguales que él, es decir reparte a la distribución en el 50%. Es importante considerar los datos ordenados, por ejemplo de menor a mayor, se define a la mediana
como el valor de observación que ocupa el lugar2
1n, si n es impar y si n es par será la promedio de
los valores que ocupan el lugar 2
n y 1
2
n, es decir:
parnsi
XX
imparnsiX
Md
nn
n
2
122
2
1

BIOESTADISTICA 2015
Página 15
Podemos resumir los pasos para hallar la mediana: a) Ordenar los datos de menor a mayor (o viceversa).
b) Calcular el orden o la posición de la mediana: 2
1nMdº
c) Calcular el valor de la mediana: - Si n es impar el valor de la mediana se obtiene directamente. - Si n es par el valor de la Md será el promedio entre el valor anterior y posterior al valor calculado. Volviendo al ejemplo 3, tenemos 50 datos, cantidad par, al utilizar la tabla de distribución de frecuencias los datos ya están ordenados, tenemos que ubicar la posición de la mediana, en este caso, el lugar seria entre el 25 y 26, como es par, debemos promediar los valores de X de esas dos posiciones, es decir el promedio de dos valores 6, lo que resulta también en 6. Propiedades:
a) Solo utiliza los datos del centro de la distribución por lo que no se ve afectada por valores extremos
b) Es única y simple de calcular Existen otras medidas conocidas como media geométrica y media armónica de uso en situaciones específicas, que no utilizaremos en la materia. Veamos otro ejemplo: Supongamos que se realizan 55 observaciones de una variable "X", cantidad de cortes de carne con lesiones por cada media res, obteniendo los siguientes datos: 1 4 7 2 5 5 4 6 9 2 6 4 4 2 3 2 4 3 5 2 4 7 4 5 5 3 6 4 6 3 4 3 6 4 3 5 1 4 6 8 3 7 4 5 3 3 4 5 4 3 5 5 1 4 5
Primero organizamos la información en una tabla de distribución de frecuencias:
X Frecuencia
Frecuencia relativa
Frecuencia acumulada
Frec. rel. acumulada %
fi xi
1 3 0.055 3 5.45 3
2 5 0.091 8 14.55 10
3 10 0.182 18 32.73 30
4 15 0.273 33 60.00 60
5 11 0.200 44 80.00 55
6 6 0.109 50 90.91 36
7 3 0.055 53 96.36 21
8 1 0.018 54 98.18 8
9 1 0.018 55 100 9
Total 55 1.000 232
Tabla 12. Distribución de frecuencias cortes de carnes con lesiones

BIOESTADISTICA 2015
Página 16
Media: n
x
x
n
i
i 1 = 218.4
55
232
55
42442741
o según la tabla:
n
xf
x
n
i
ii
1 218.455
232
55
918173665114153102513
Mediana: los datos están ordenados en la tabla, entonces calculamos la posición de la mediana, en
este caso el lugar 28 ( º282
155
2
1nMdº
), en la tabla vemos que en esta posición X vale 4, es
decir: Md=4 1º 2º 3º 4º 5º 18º 19º 27º 28º 29º 33º 34º 53º 54º 55º
1 1 1 2 2 3 4 4 4 4 4 5 7 8 9
Moda: vemos que la cantidad que más se repite es 4, es decir la moda de este conjunto es: Mo=4
Existen otras medidas de centralización o promedios, que se utilizan en situaciones muy específicas, la media geométrica, cuando la variable en estudio tiene un comportamiento de crecimiento geométrico y la media armónica que es de utilidad cuando la variable adopta unidades en razón o relativas, como por ejemplo km/h, donde la media aritmética no es útil.
Media geométrica: n
n
i
in
n xxxxxMg
1
321
Para facilitar el cálculo la solución se obtiene utilizando logaritmo, entonces:
nxxxxn
Mg loglogloglog1
)log( 321
y luego se calcula el antilogaritmo:
nxxxx
nantiMgantiMg loglogloglog
1log)log(log 321 .
Si las observaciones están agrupadas en una tabla de frecuencia, la formula será:
n
n
i
f
in f
n
fff in xxxxxMg
1
321321
Media armónica: Se define como:
n
i ix
nMh
1
1

BIOESTADISTICA 2015
Página 17
2.2 MEDIDAS DE DISPERSIÓN.
Supongamos que observamos el tamaño de las camadas de 10 perras de la misma raza y edad de dos lugares, criadero A y B. En el caso del criadero A, fueron de 4, 4, 5, 6 y 6 mientras que en el criadero B fueron 5, 5, 5, 5 y 5. La cantidad promedio de cachorros fue en ambos sitios de 5, pero claramente la situación fue distinta. ¿Cómo los comparamos? ¿Cuál es la diferencia entre ellos? Las distribuciones son distintas, tienen la misma medida de centralización, pero los datos varían más en el primer caso que en el segundo, es decir sus distribuciones difieren en cuanto a su dispersión.
Una medida de dispersión es una medida de cuan alejados están los datos del centro de la distribución, ya sea que se tome como centro a la media o a la mediana de los datos. En las Figuras 9 se observan histogramas que probablemente tengan promedios similares o iguales, pero distinto agrupamiento respecto al valor central. La diferencia está en que estas tres distribuciones tienen diferente dispersión, vale decir se distribuyen de diferente forma. Figura 9ª
Figura 9 A y B
Existe una cantidad importante de medidas de dispersión, veremos a continuación las más sencillas y las de mayor uso. a) Rango (también llamada amplitud o recorrido): Es la diferencia entre el mayor valor y el menor
que alcanza la variable de interés en el conjunto de valores de la variable. Depende mucho de la presencia de valores extremos o atípicos, por lo que no es muy confiable. R=Xmax-Xmin
b) Desvío medio: La desviación media o desvío medio es la media aritmética o promedio de los valores absolutos de las desviaciones respecto a la media aritmética. Tiene las mismas dimensiones que las observaciones. La suma de valores absolutos es relativamente sencilla de calcular, pero esta simplicidad tiene un inconveniente, cuando mayor sea el valor de la desviación media, mayor es la dispersión de los datos. Sin embargo, no proporciona una relación matemática precisa entre su magnitud y la posición de un dato dentro de una distribución. La desviación media al tomar los valores absolutos mide una observación sin mostrar si la misma está por encima o por debajo de la media aritmética.
n
xx
MD
n
i
1..
0
5
10
15
20
25
30
35
40
45
50
1 3 5 7 9 11 13 15 17
0
5
10
15
20
25
30
35
40
45
50
1 3 5 7 9 11 13 15 17

BIOESTADISTICA 2015
Página 18
c) Varianza (s2): Una medida natural de la dispersión seria promediar los desvíos o diferencias entre cada observación y el promedio, pero esta cantidad se anula por la propiedad de la media, entonces se elevan al cuadrado estas cantidades y surge la varianza. Es el promedio de los cuadrados de las desviaciones respecto a la media:
Debido a que la varianza está elevada al cuadrado, las unidades de la misma serán también al cuadrado. Por ejemplo si la variable está expresada en kilos la varianza será en Kg2. Algunas de sus principales propiedades son:
- Es siempre positiva: Var (x)0 - Si los datos coinciden, es decir son constantes su varianza es nula (Si k es constante Var(k)=0) - Si los datos se trasladan por efecto de sumar o restar una constante, la varianza no cambia:
Var(k+x)=Var(x) - Si los datos se modifican por efecto de multiplicar o dividir por una constante, la varianza se ve
afectada por la constante elevada al cuadrado: Var(kx)=k2 Var(x) - Si X e Y son dos variables “aleatorias” cualesquiera:
Var(x+y)=Var(x) + Var(y) + 2cov(x,y)
Var(x-y)=Var(x) + Var(y) - 2cov(x,y),
donde Cov(X,Y) indica la covarianza entre X e Y, una medida de la relación lineal que hay entre ellas y
que se define como:
1),cov( 1
n
yyxx
yxi
n
i
i
.
d) Se llama desviación estándar o simplemente desvío, a la raíz cuadrada de la varianza. Es más útil
que la varianza ya que tiene las mismas unidades que los datos.
e) Coeficiente de variación: es el cociente entre la desviación estándar y la media. Se utiliza para evaluar la representatividad de la media en la muestra, y para comparar distintas muestras. Valores bajos indican muestras menos dispersas y una media más representativa, valores altos indican lo contrario.
También se acostumbra a multiplicar por 100 al CV y hablar entonces de un porcentaje de variación de los datos. Este coeficiente no posee unidades por ello es muy útil para comparar muestras o grupos. Para el ejemplo anterior, calculamos las medidas de dispersión, para ello completamos unas columnas más de la tabla, generando los desvíos al cuadrado:

BIOESTADISTICA 2015
Página 19
X f (x i- x ) (xi - x )2 fi . (xi - x )2
1 3 -3.218 10.356 31.067
2 5 -2.218 4.920 24.598
3 10 -1.218 1.484 14.835
4 15 -0.218 0.048 0.713
5 11 0.782 0.612 6.727
6 6 1.782 3.176 19.053
7 3 2.782 7.740 23.219
8 1 3.782 14.304 14.304
9 1 4.782 22.868 22.868
Total 55 157.382 Tabla 13
Claramente el rango de variación de la cantidad de cortes con lesiones es de 8, Rango= 9-1 = 8, por otra parte la varianza es:
914.254
382.157
155
868.221304.141920.45356.103
1
)(
ˆ)(var 1
2
22
n
xxf
Sx
n
i
ii
Y el desvío estándar de 707.1914.2 S . Es decir, en promedio la cantidad de cortes con lesiones
por cada media res se desvía de su promedio en 2.91, es decir aproximadamente 3 unidades.
2.3 OTRAS MEDIDAS DE POSICIÓN:
Los Cuantiles son medidas de posición que separan a los datos en partes iguales. Así, la mediana los
divide en dos partes iguales, los cuartiles en cuatro partes iguales, los deciles en 10 y los
percentiles en 100. Se calculan manera análoga a la mediana. Es decir, una vez ordenados los datos,
se calcula la posición, por ejemplo ¿en qué posición estará el dato que divide a la distribución en el
primer 25%? Este dato se conoce como cuartil uno (Q1) y obtiene observando el valor de x en la
posición n/4. De forma similar el 75% corresponde al Q3.
El Box –Plot es una herramienta grafica sumamente útil para describir la distribución de los datos, el
diagrama de caja refleja la forma de la distribución de frecuencias dando información acerca de su
simetría ó sesgo, sus cuartiles y detectando la presencia de valores extremos y/ó atípicos. El box plot
consiste en construir una caja cuyos límites son el Q1 y el Q3, luego se ubican en el la media y
mediana, y se considera las líneas extremas que unen la caja al mínimo y máximo (o a veces al P(5) y
P(95), para contener en la representación el 90% central de los datos)
El Box-Plot puede presentarse horizontal o verticalmente y su lectura es la siguiente:
Si la distancia entre el primer cuartil y la mediana es aproximadamente igual a la distancia entre el segundo cuartil y la mediana se concluye que la distribución de los datos es simétrica
Si la distancia entre el primer cuartil y la mediana es menor que la distancia entre la mediana y el segundo cuartil se dice que la distribución presenta un sesgo a izquierda.
Si la distancia entre el primer cuartil y la mediana es mayor que la distancia entre la mediana

BIOESTADISTICA 2015
Página 20
y el segundo cuartil se dice que la distribución presenta un sesgo a derecha.
Para el ejemplo de las lesiones, vemos que n/4=13.75, el Q1 es 3, y 3/4N=41.25, entonces el Q3 corresponde al 5. n Media D.E. Var CV Mín Máx Mediana Q1 Q3
55 4.22 1.71 2.91 40.47 1 9 4 3 5
El box plot es:
0
2
4
6
8
10
nro
le
sio
ne
s
Figura 10

BIOESTADISTICA 2015
Página 21
UNIDAD 3: MEDIDAS DE RESUMEN
PARA DATOS CUALITATIVOS
Tasas. Índices. Mortalidad, morbilidad, letalidad
En general la medición de un evento en una población, como puede ser medir la cantidad de enfermos; puede llevarse a cabo en términos absolutos, sin tener en cuenta la población, ó en términos relativos.
3.1 CIFRAS ABSOLUTAS Y RELATIVAS.
Supongamos la siguiente situación:
Año 1994 1998
No. de casos 6000 8000
¿Qué puede haber pasado?
a) La atención veterinaria y las medidas sanitarias aplicadas fueron insuficientes.
b) Mejoraron las medidas de detección de casos.
c) Hubo un aumento del número de animales en esa área.
Si relacionamos el número de casos con el total de la población existente en los dos años tendríamos:
Año 1994 1998
No. de casos 6000 8000
No. de animales 300000 500000
Un cálculo sencillo nos permitirá una mejor comparación:
deanimalesNro
decasosNro
.
.020.0
300000
6000 y 016.0
500000
8000
Para evitar los decimales se acostumbra a multiplicar el resultado por un múltiplo de 10 dependiendo de la situación (100, 1000, 10000, etc.). En el ejemplo multiplicando el resultado por 1000, tendríamos 20 casos por cada 1000 animales en 1994 y en 1998, 16 casos por cada 1000 animales (20‰ y16‰ respectivamente). Este cociente representa una medida relativa que indica claramente la magnitud de la diferencia.

BIOESTADISTICA 2015
Página 22
La siguiente tabla muestra el número de Bovinos positivos a tuberculosis según sexo en un establecimiento del partido de Tandil en 1996:
Sexo N° de positivos
Hembras 70
Machos 24
Total 94
Una PROPORCIÓN relaciona una parte de la población con el total al cual pertenece y se expresa en porciento, asi:
%5.7410094
70100
positivosdetotal
positivashembras
Que interpretamos como que de cada 100 animales positivos aproximadamente el 74.5% son hembras.
Una RAZÓN relaciona dos categorías distintas de la misma variable o las intensidades de dos fenómenos distintos en un mismo lugar
9.224
70
positivosmachos
positivashembras
Con este resultado podemos interpretar que, entre los positivos se encuentran, aproximadamente, 3 hembras por cada macho.
TASAS
Sabemos que el 74,5 % de los positivos son hembras y que hay 2.9 hembras positivas por cada macho enfermo. Tanto la proporción como la razón muestran en este caso, que serían más frecuentes las hembras positivas. Pero significa esto que, ¿las hembras corren más riesgo de enfermar de tuberculosis que los machos?
No, para determinar el riesgo que corren los machos y hembras y compararlos hay que relacionar los positivos con la cantidad de machos y hembras del establecimiento, es decir con la población expuesta al riesgo. Esta forma de relación se denomina tasa y surge de relacionar una parte de la población sobre el total, por lo tanto son cifras relativas.
En general podemos definir a las tasas como:
El número de veces que se presenta un hecho cualquiera, en la población de un área determinada, durante un período de tiempo también determinado.
. fa
Población correspondiente a esa área estimada a la mitad del período de tiempo.
Lo fundamental en la construcción de una tasa, es relacionar un hecho con la población expuesta al riesgo de que el hecho ocurra.

BIOESTADISTICA 2015
Página 23
Siguiendo con el ejemplo anterior y sabiendo que en el establecimiento había 450 hembras y 120 machos, la tasa para las hembras y machos serían:
%5.15100450
70100
hembrasdetotal
positivashembras
%20100120
24100
machosdetotal
positivosmachos
ÍNDICES: Un uso común es expresar diferencias positivas o negativas como porcentajes.
Bovinos en un partido
Año cantidad de animales
1990 391 524
1980 305 293
1970 300.297
¿Cuál fue el aumento porcentual de población bovina en 1990 con respecto a 1970? La población de 1970 representa el 100% (número índice), por lo tanto la diferencia con el año 1990 es:
300297 100%
391524 300297
391524%100 =130, 39 %
Es decir, la población bovina aumentó un 30,39 % en 1990 con relación a 1970.
Los índices no solo sirven para comparar una variable a través del tiempo (como en este caso), sino que también podrían comparar la misma variable pero en lugares diferentes en un mismo momento.
3.2 TASAS DE USO MÁS FRECUENTE.
Tasas para medir el riesgo de muerte: Se llaman tasas brutas o generales, aquellas en que el denominador incluye el total de los animales, por ejemplo: Tasa bruta de mortalidad general y la Tasa bruta de mortalidad por una causa determinada
La tasa de mortalidad se define como:
Número de animales muertos . fa
Población susceptible expuesta estimada a la mitad del período de tiempo, en un área determinada
Cuando se miden riesgos para subgrupos de población, las tasas se denominan específicas
Tasa de mortalidad especifica por edad
Tasa de mortalidad por una causa dada especifica por edad

BIOESTADISTICA 2015
Página 24
En estos casos tanto el numerador como el denominador, solo se tendrá en cuenta los individuos pertenecientes al subgrupo en cuestión.
El factor ampliatorio (fa) es un múltiplo de 10, que permite comprender mejor la magnitud de un fenómeno. Así veremos expresadas prevalencias como por ejemplo 1.3‰ en lugar de 0.13%, lo cual facilita la interpretación. Esto es usual cuando la prevalencia o la mortalidad son bajas. La letalidad siempre es expresada en porcentaje (fa=100).
Tasas para medir el riesgo de enfermar o morbilidad, hay varias formas de medir la morbilidad:
PREVALENCIA: Mide la magnitud del problema causado por una enfermedad en un momento dado
Número de animales enfermos . fa
Población susceptible expuesta estimada a la mitad del período de tiempo, en un área determinada
INCIDENCIA: Mide las magnitud del problema causado por una enfermedad a través de un período de tiempo, considerando solamente los casos que comenzaron durante ese periodo (casos nuevos):
Número de animales enfermos nuevos . fa
Población susceptible expuesta estimada a la mitad del período de tiempo, en un área determinada
Una tasa de incidencia particular es la tasa de ataque, que está dada cuando se presenta un elevado número de casos de una determinada enfermedad en un período corto de tiempo.
Tasa de letalidad: Relaciona las muertes por una causa determinada con los enfermos por esa misma causa.
Número de animales muertos . fa
Número de animales enfermos, en un área determinada

BIOESTADISTICA 2015
Página 25
UNIDAD 4: PROBABILIDADES Espacio muestral. Evento. Probabilidad.
4.1 ANTECEDENTES. La probabilidad estudia la incertidumbre de las variables de los modelos aleatorios para asignar una medida del grado de certeza de que tales variables tomen un cierto valor. La teoría de la probabilidad se empezó a estudiar en el siglo XVII cuando los matemáticos franceses Pascal y Fermat intercambió correspondencia sobre una controversia surgida de observaciones sobre juegos de azar; pues se trataba de asignar el grado de certeza con que ocurrían determinados resultados en un juego de dados. En el siglo XIX, Laplace demostró que el cálculo de probabilidades podía aplicarse a una gran variedad de problemas científicos y prácticos; sin embargo, fue hasta la tercera década del siglo XX cuando la teoría de probabilidad se desarrolló sobre bases matemáticas sólidas. Desde entonces, esta disciplina se ha aplicado a muchos campos del conocimiento, especialmente a la ingeniería, en donde frecuentemente se utiliza para tomar decisiones bajo incertidumbre, tanto en aspectos de diseño, como de gestión y control.
4.2 ESPACIO MUESTRAL Se dice que un fenómeno ó experimento es aleatorio si pueden asumirse válidas las siguientes hipótesis:
1. El experimento puede repetirse, y en las mismas condiciones cada vez 2. El conjunto de todos los resultados posibles del experimento es conocido 3. El resultado particular del experimento no puede predecirse (incerteza)
El conjunto de todos los resultados posibles del experimento o fenómeno se llama espacio muestral y a cada uno de esos resultados posibles se le llama punto o elemento. Un evento es una colección de puntos contenidos en el espacio muestral. Los espacios muestrales son discretos cuando sus puntos son contables o numerables, o continuos cuando sus puntos son incontables o innumerables. Los espacios muestrales discretos pueden ser finitos o infinitos; los continuos son siempre infinitos. Por extensión, los adjetivos continuo y discreto se aplican también a los modelos y a las variables. En un espacio muestral, dos eventos son mutuamente excluyentes si la ocurrencia de uno de ellos implica la imposibilidad de que ocurra el otro. Si la ocurrencia de dos o más eventos incluye a todo el espacio muestral, tales eventos son exhaustivos.
Ejemplo 6: a) supongamos que se considera el experimento de arrojar una moneda, existen dos
resultados posibles, que salga cara o seca, entonces el espacio muestral es .
b) Si el experimento consiste en arrojar dos monedas, todos los resultados posibles son las
combinaciones de C y S es decir:
a) Ahora si contamos el número de caras en el resultado del caso (a) y (b),
entonces y son los respectivos espacios muestrales.

BIOESTADISTICA 2015
Página 26
4.3 ELEMENTOS DE TEORÍA DE CONJUNTOS
Un conjunto es una colección bien definida de objetos, elementos, miembros o puntos, que se designa con alguna letra mayúscula. El contenido de los conjuntos se encierra entre llaves y se describe con la relación de sus elementos o con alguna propiedad que los caracteriza Si x es un elemento del conjunto A, se escribe: x ∈ A. Al número de elementos del conjunto A se le designa con n(A). Si cada elemento de A pertenece también al conjunto B, pero no todos los puntos de B pertenecen a A, se dice que A es subconjunto de B (A⊂ B) o que está contenido en B (B⊃ A). Dos conjuntos son iguales, A=B, si A⊆B y B⊆ A. Si dos conjuntos no tienen elementos comunes, se dice que los conjuntos son disjuntos. Un conjunto vacío (Φ) es el que no tiene elementos, por lo que corresponde al evento imposible; en cambio, el conjunto universal (Ω o S) contiene a todos los elementos posibles, por lo que corresponde al evento seguro. Las operaciones de conjuntos básicas son la unión y la intersección y el complemento, definidas:
Unión: A∪B = x: x ∈ A ó x ∈ B
Intersección: A∩B = x: x ∈ A y x ∈ B
Complemento: AC = x: x∈Ω , x ∉ A A la representación gráfica de las operaciones se les llama diagrama de Venn. En estos, el rectángulo representa al conjunto universal, las figuras cerradas en su interior representan a los conjuntos y lo sombreado a la operación. Así: Figura 11
C
4.4 DEFINICIONES
a) "Definición clásica de Probabilidades (Def. a priori)": "Si un experimento aleatorio puede producir n resultados mutuamente excluyentes, siendo todos igualmente probables y si f de estos resultados se consideran favorables, la probabilidad de que aparezca un resultado favorable es el número de casos favorables dividido el número de casos posibles".
P ( A ) f
n
nº de casos favorables
nº de casos posibles
Las limitaciones de esta teoría están dadas por la condición de "igualmente probable" y que requiere del conocimiento previo de la experiencia (a priori).

BIOESTADISTICA 2015
Página 27
¿Qué valores puede tomar P(A)? ¿Qué relación tiene con un porcentaje? Veamoslo con un ejemplo, supongamos que se arroja un dado y se observa el número que sale:
la probabilidad de obtener un 1 es: P ( x 1 )1
60 .16666i
la probabilidad de obtener un 5 o un 6 es: P ( x 5 o x = 6 )2
60 .33333i i
b) Teoría del límite de la frecuencia relativa (Definición a posteriori): "Si un experimento
aleatorio se realiza n veces con f éxitos, se supone que la frecuencia relativa, f
n, tiende a un
límite cuando n aumenta". Entonces la probabilidad de éxito será:
P ( A ) = Lim f
n = p
n
A
En este caso el límite no tiene el sentido estrictamente matemático, sino que intenta representar la propiedad de la regularidad y estabilidad estadística de la frecuencia relativa, dado que al aumentar n también aumenta proporcionalmente la cantidad de éxitos (fA). Para obtener el valor de la
probabilidad no es necesario calcular el límite, pero esta teoría permite estimar el verdadero valor de la probabilidad para un número de pruebas, n grande.
c) Teoría Axiomática de la Probabilidad (Kolmogov, 1937)
Esta definición enuncia 3 axiomas que debe cumplir una función de probabilidad. Sea el suceso A en un espacio muestral se cumple:
0 P(A) ) 1 para todo suceso A,
2 ) P( S ) = 1,
)P(A+...+)P(A+)P(A= )A...AP(A 3) k21k21
De estos axiomas surgen tres leyes o teoremas:
3.1 0 P ( ) 1 , los valores que puede tomar la probabilidad están entre 0 y 1 (No puede haber
menos de 0% fracasos ni más de 100 % de éxitos).
3.2 Ley de la suma: Si dos eventos A y B son mutuamente excluyentes la probabilidad de obtener el suceso A o B es igual a la suma de la probabilidad de A más la probabilidad de B, es decir,
(B) P + (A) P= B) (A PB)oP(A .
En cambio, si A y B no son mutuamente excluyentes:
B)P(A -(B) P + (A) P= B) (A PB)oP(A ,
donde P(A ∩ B) es la probabilidad conjunta, es decir la probabilidad de que ocurran ambos sucesos al mismo tiempo.
3.3 Ley de la multiplicación: Dos sucesos A y B pertenecientes a S son "estadísticamente independientes", si:
(B). P (A) P= B) (A P= B)y (A P

BIOESTADISTICA 2015
Página 28
A y B no son "estadísticamente independientes", si
)B
AA
B P( (B) P= )( P (A) P= B) (A P= B)y (A P
donde P(B/A) y P(A/B) son probabilidades condicionadas.
P(B/A), es la probabilidad de que ocurra el suceso B dado (condicionado a) que ocurrió previamente A.
4.5 VARIABLE ALEATORIA
Un experimento aleatorio es aquel que repetido en las "mismas condiciones" no produce siempre el mismo resultado. Por el contrario un experimento no aleatorio, se denomina determinístico.
Asociado al concepto de experimento aleatorio se encuentra el de variable aleatoria. Los experimentos aleatorios originan variables aleatorias.
Podemos definir a una variable aleatoria como una función que relaciona los eventos de un espacio muestral, asignando valores en la recta real. Esquemáticamente sería:
MMM 3
MHH
HMH 1
HHM
MMH
MHM 2
HMM
HHH 0
Veamos algunos ejemplos:
a) Del experimento de arrojar un dado, se puede definir una variable aleatoria X como: X = resultados posibles, los valores que adopta la variable aleatoria son: x
1=1; x2=2; x3=3; x
4=4; x
5=5
y x6=6.
b) Del experimento de registrar el número de partir de los animales de un establecimiento, la variable X puede tomar valores enteros a partir de 0, x1=0 ; x2=1 ;...; xi=40 ,…., etc.
Observación: La variable aleatoria puede tomar una cantidad finita o no de valores y estos valores pueden estar bien definidos, como por ejemplo la edad, o pueden variar en un intervalo real, como por ejemplo el peso.

BIOESTADISTICA 2015
Página 29
Mostramos a continuación como se llaman las funciones asociadas al cálculo de probabilidades:
Variable Función de probabilidad P(X≤x) o función acumulada
Cuantitativa Discreta P(x): función masa F(X)
Cuantitativa Continua f(x): función densidad de probabilidad
F(X): función distribución o acumulada
Estas funciones deben cumplir con los 3 axiomas, luego,
1) p( x ) = f ( x ) 0i i
2) 1n
1i)
if(x
n
ii
xp
1
)(
3) al cumplir con el tercer axioma podemos sumar las probabilidades y de esta manera se define la función F(x), Función de distribución de probabilidad o función de probabilidad acumulada como:
i
1j
jii )(x p= )x(X P= )(x F
donde la sumatoria se extiende para todo valor de Xxi.
Ejemplo 7: para el experimento de arrojar dos dados, se tiene que el espacio muestral es
S = (1,1), (1,2), (1,3), ..., (6,6) con 36 puntos muestrales.
Todos los sucesos elementales tienen la misma probabilidad de ocurrir, 1/36.
Se define la v.a. X: suma de las dos caras. Esta variable puede tomar los valores 2, 3, 4, ...., 12.
La tabla con la función masa de probabilidad y la función distribución acumulada, F(x) seran:
x Sucesos f(x) F(x)
2 (1,1) 1/36 =0.028 1/36
3 (1,2), (2,1) 2/36 =0.056 3/36
4 (1,3), (2,2), (3,1) 3/36 =0.083 6/36
5 (1,4), (2,3), (3,2), (4,1) 4/36 =0.111 10/36
6 (1,5), (2,4), (3,3), (4,2), (5,1) 5/36 =0.139 15/36
7 (1,6), (2,5), (3,4), (4,3), (5,2), (6,1) 6/36 =0.167 21/36
8 (2,6), (3,5), (4,4), (5,3), (6,2) 5/36 =0.139 26/36
9 (3,6), (4,5), (5,4), (6,3) 4/36 =0.111 30/36
10 (4,6), (5,5), (6,4) 3/36 =0.083 33/36
11 (5,6), (6,5) 2/36 =0.056 35/36
12 (6,6) 1/36 =0.028 36/36

BIOESTADISTICA 2015
Página 30
Y gráficamente,
0
0,02
0,04
0,06
0,08
0,1
0,12
0,14
0,16
0,18
2 3 4 5 6 7 8 9 10 11 12x
f(x)
Figura 12
Ejemplo 8: Dado el experimento de observar la presencia de cierta enfermedad en un Apiario, la siguiente tabla muestra la función masa para la variable X: número de colmenas enfermas.
X 0 1 2 3 4 5
p(x) 0,01 0,1 0,3 0,4 0,1 ?
Encontrar f(5). Construir F(x). Encontrar p(X2), p(X<2) y p(X>3).
Para que se cumpla las condiciones 1 y 2, es necesario que f(5)=0,09:
X 0 1 2 3 4 5
f(x) 0,01 0,1 0,3 0,4 0,1 0,09
F(x) 0,01 0,11 0,41 0,81 0,91 1
P(X2) = F(2) = 0,41.
P(X<2) = P(X1) = F(1)=0,11 o P(X<2) = P(X1) =f(0)+f(1)=0,01+0,1=0,11
P(X>3) = 1 - p(X3) = 1- F(3) = 1 - 0,81 = 0,19.
Del mismo modo se define la función para las variables continuas, que también cumplen con los 3 axiomas, luego
1) p( x ) = f ( x ) 0i i para todo x que pertenece al intervalo (-,+ )
2) 1dxf(x)
.
3) Si A = X: a X b entonces dx
b
a
f(x)= (A) P .

BIOESTADISTICA 2015
Página 31
4.6 PARÁMETROS DE UNA DISTRIBUCION.
Esperanza Matemática: Sea X una variable aleatoria con función de probabilidad p(X) o f (X). La esperanza matemática de X es:
E ( X ) = x p( x )i i
i=1
n
si X es discreta.
E (X) = x f(x )dxi i-
si X es continua.
La esperanza matemática de una v.a es “un promedio de los valores de la variable, donde cada valor está ponderado por su probabilidad de ocurrencia”.
¿Cuál es la interpretación de esta cantidad?
Para el ejemplo 2, calcular e interpretar la esperanza matemática (o media).
75.209,0.51,0.44,0.33,0.21,0.101,0.0)x(p.x)x(E0x
x
Varianza Matemática: Dos o más distribuciones pueden tener la misma medida de posición (medias) y sin embargo ser distintas. La varianza es una medida de cuán disímiles son los valores de la v.a. Esta cantidad hace referencia a la dispersión de la distribución.
Sea X una variable aleatoria con función de probabilidad p(X) o f (X). La varianza matemática de X, se define como:
22 )x(E)x(E)x(V ,
si X es discreta o continua, se simboliza con, 2x
22x )x(E , donde:
n
0x
22 )x(fx)x(E .
En nuestro problema, del ejemplo 2,
1875.1)75,2(09,0.251,0.164,0.93,0.41,0.101,0.0)x(E 22x
22x
Desvío Estándar: La varianza se expresa en función de los desvíos al cuadrado, luego el valor de la variable no está en la escala original, el desvío se define entonces como la raíz cuadrada de la varianza:
)X(V 2σσ .

BIOESTADISTICA 2015
Página 32
UNIDAD 5: MODELOS PROBABILISTICOS
Binomial. Poisson. Normal
5.1 MODELO BINOMIAL
Supongamos que se realizan n pruebas independientes cada una con dos resultados posibles, mutuamente excluyentes: éxito y fracaso y que la probabilidad de éxito p (y la de fracaso q=1-p) son constantes en cada prueba. Considerando X como la variable aleatoria cantidad de éxitos en las n pruebas, se dice que X tiene función de distribución binomial, luego la probabilidad de que X tome un valor k, k=1, 2, …., n, puede calcularse como:
nk1,qp)!kn(!k
!n)p1(p
k
n)kX(P knkknk
.
donde 12...)2()1(! nnnn
Observación: en un muestreo una variable binomial debe responder a pruebas con reposición, salvo que el tamaño de la población sea muy grande.
Los parámetros de este modelo son: E(X)=np, Var(X)=npq.
En resumen las características de un modelo binomial son:
hay solo dos resultados posibles: éxito y fracaso
p y q contantes en cada prueba.
el experimento puede repetirse (n pruebas )
los eventos son independientes.
Ejemplo 9: Dentro de las abejas en estado larval, la enfermedad más importante por su gravedad y rápido contagio, es la Loque Americana que es producida por una bacteria. La Loque Americana, es transmitida por las abejas adultas, el alimento, o sea, la miel, y también el néctar. Tal enfermedad puede llegar a matar a toda la colmena y es muy peligrosa desde el punto de vista de su alta contagiosidad. Se sabe que al inyectar un determinado antibiótico el 85% de las abejas sobrevive. En un apiario se aplica el antibiótico a 6 colmenas. Calcular:
a) la probabilidad de que al menos mueran 4 colmenas
b) la probabilidad de que mueran a lo sumo 2 colmenas
c) la esperanza de la v.a. “cantidad de colmenas muertas” (entre las 6 a las que se aplicó la droga).
d) Si el apicultor trata el total de sus colmenas (200), cuantas colmenas curadas esperaría tener.

BIOESTADISTICA 2015
Página 33
De los datos rescatamos que el número de pruebas es n=6, y definimos el éxito X= cantidad de colmenas que no sobreviven, por ello, p=0.15 (probabilidad de morir) yq=0.85 (probabilidad de sobrevivir), entonces:
a) X: cantidad de colmenas que no sobreviven
005881.0000011.000038.000549.015.085.015.05
685.015.0
4
6
)6()5()4()4(
6524
XPXPXPXP
b) )X(P)X(P)X(P)X(P 2102 =
9526.017618.03994.03771.085.015.02
685.015.0
1
685.015.0
0
6425160
c) E(X)=np=6. 0,15=0.90
d) E(X)=np=200. 0,85= 170
5.1 MODELO POISSON Otra de las distribuciones discretas de probabilidad que ocurren muy frecuentemente en la ciencia animal y vegetal, es la distribución Poisson.
La variable aleatoria Poisson representa el conteo del número de eventos que ocurren independiente y
aleatoriamente en el tiempo o en el espacio, a una tasa (o razón) constante, λ , en promedio. Una v.a.
X es Poisson con parámetro λ si,
casootroen
,....,,Xsi!k
e),kX(f
k
0
210λ
λ
λ
La media y varianza de esta distribución coinciden y son iguales a λ , el promedio de ocurrencia por unidad de análisis.
Por lo tanto las características del modelo Poisson son:
la variable aleatoria es conteo en una unidad de tiempo o espacio
la probabilidad de ocurrencia es baja
el número de experiencias es alto
Ejemplo 10: En una experiencia realizada en una plantación de girasol sometida a polinización un investigador estimó que el promedio de visitas fue de 15 abejas por hora y por capítulo, utilizando 2,5 colmenas por ha.
a) Calcular la probabilidad de que una planta reciba 40 abejas en 3 horas.
b) ¿Cuál es la probabilidad de que una planta no reciba ninguna visita en los primeros 30 minutos?

BIOESTADISTICA 2015
Página 34
Si en una hora una planta recibe 15 visitas en 3 horas recibe en promedio 45 visitas, luego 45 y la
P(X=40)= 04716.0!40
45 4540
e
. En 30 minutos 5,7 y la P(X=0)= 00055.0!0
5,7 5,70
e
.
5.3 DISTRIBUCIÓN NORMAL
Esta función también conocida como campana de Gauss, desempeña un papel central en la teoría y en la práctica de la estadística. Muchos fenómenos de la naturaleza se estudian a partir de la distribución normal. Variables continúas tales como peso, longitud, altura, temperatura etc. presentan gráficas de distribuciones de frecuencias que se pueden aproximar muy bien por esta función de densidad.
Una variable aleatoria se define como normalmente distribuida si su función densidad de probabilidad está dada por:
22
1
2
1)(
x
exf ,
donde los parámetros μ y σ , satisfacen, 0σμ , .
La representación gráfica de la función de densidad normal es una curva simétrica respecto de que μ
(la media o esperanza) y la mayor o menor amplitud de la campana viene dada por 2σ (la varianza).
Una variable aleatoria normal con los parámetros mencionados se simboliza con: X~N(μ , 2σ ).
La probabilidad de que X se halle entre a y b corresponde al área bajo la curva f(x) entre a y b. Este área se halla mediante el cálculo de una integral definida por a y b (esta integral no tiene una expresión analítica, por lo que el área se aproxima numéricamente).
Dado que existen infinitas distribuciones normales (tantas como combinaciones posibles de valores de los parámetros), se realiza una transformación para llevar todas estas distribuciones a una con forma
estándar, es decir con media 0 y varianza 1, esta transformación es: ZX
2σ
μ, entonces, Z~N(0,1).
Figura 12

BIOESTADISTICA 2015
Página 35
-5 0 5 10 15 20 25 30
N(0,1) N(20,1) N(20,4)
Figura 13
La ventaja de la transformación es que se han tabulado (Tabla de curva normal) las probabilidades para una v. a. N(0,1), luego es posible calcular cualquier probabilidad bajo distribución normal.
Propiedades de la distribución normal:
Tiene una única moda (o modo), que coincide con su media y su mediana.
La curva normal es asintótica al eje de abscisas. Por ello, cualquier valor en R es teóricamente posible. El área total bajo la curva es igual a 1.
Es simétrica con respecto a su media μ , por ello la probabilidad de observar un dato mayor
que la media es de un 0.5, y un 0.5 de observar un dato menor.
La distancia entre la línea trazada en la media y el punto de inflexión de la curva es igual a una desviación estándar (σ ). Cuanto mayor sea σ , más concentrada será la curva.
El área bajo la curva comprendida entre los valores situados aproximadamente a una desviación estándar de la media es igual a 0.68. Es decir, existe un 68% de posibilidad de
observar un valor comprendido en el intervalo ),( .
El área bajo la curva comprendida entre los valores situados aproximadamente a dos desviaciones estándar de la media es igual a 0.95. Es decir, existe un 95% de posibilidades de
observar un valor comprendido en el intervalo )2,2( .
El área bajo la curva comprendida entre los valores situados aproximadamente a tres desviaciones estándar de la media es igual a 0.99. Es decir, existe un 99% de posibilidades de
observar un valor comprendido en el intervalo )3,3( .
La forma de la campana de Gauss depende de los parámetros μ y σ . La media indica la
posición de la campana, de modo que para diferentes valores la gráfica es desplazada a lo largo del eje horizontal. Por otra parte, la desviación estándar determina la forma de la curva. Cuanto mayor sea el valor de σ , más se dispersarán los datos en torno a la media y la curva será más baja. Un valor pequeño de este parámetro indica, una gran probabilidad de obtener datos cercanos al valor medio de la distribución y la curva será más alta.

BIOESTADISTICA 2015
Página 36
Ejemplo 11: Suponga que se sabe que el peso promedio de 500 animales de un establecimiento es de 151 kg y que la varianza es de 225 Kg2, ¿Cuántos animales pesan menos de 125 kg?
X~(151;225),luego, 04182.0)733.1()15
151125()125(
ZP
XPXP
=21animales
5.4 DISTRIBUCIÓN T DE STUDENT.
La distribución de probabilidad de t se publicó por primera vez en 1908 en un artículo de W. S. Gosset. En esa época, Gosset era empleado de una cervecería irlandesa que desaprobaba la publicación de investigaciones de sus empleados. Para evadir esta prohibición, publicó su trabajo en secreto bajo el nombre de "Student". En consecuencia, la distribución t comúnmente se llama distribución t de Student, o simplemente distribución t.
En la siguiente gráfica se muestra como la distribución t extendida que la distribución normal Z.
Las características de la distribución t son:
1. Es una distribución continua. 2. Tiene forma de campana y es simétrica. 3. Es una familia de curvas. Todas tienen la misma media de cero, pero sus desviaciones estándar
difieren de acuerdo al tamaño de la muestra. 4. La distribución t es más baja y dispersa que la distribución normal. Cuando el tamaño de la muestra
se incrementa, la distribución t se aproxima a la normal.
5.5 DISTRIBUCIÓN JI- CUADRADO
En estadística, la distribución ji-cuadrado, también denominada ji-cuadrado de Pearson, es una
distribución de probabilidad continua con un parámetro n que representa los grados de libertad de la
variable aleatoria:
221 .... nZZX
donde Zi son variables de distribución normal, de media cero y varianza uno, es decir estandarizadas.
Esta distribución se expresa habitualmente 2
~ nX .

BIOESTADISTICA 2015
Página 37
Propiedades
1. Los valores de X2 son mayores o iguales que 0.
2. La forma de una distribución X2 depende del gl=n-1. En consecuencia, hay un número infinito de distribuciones X2.
3. El área bajo una curva ji-cuadrada y sobre el eje horizontal es 1.
4. Las distribuciones X2 no son simétricas. Tienen colas estrechas que se extienden a la derecha; esto es, están sesgadas a la derecha.
5. Cuando n>2, la media de una distribución X2 es n-1 y la varianza es 2(n-1).
6. El valor modal de una distribución X2se da en el valor (n-3).
La siguiente figura ilustra tres distribuciones X2. Note que el valor modal aparece en el valor (n-3) = (gl-
2).
La función de densidad de la distribución X2 esta dada por:
para x>0
La tabla que se utiliza muestra el área a la derecha del valor de abscisa, según sus gl.

BIOESTADISTICA 2015
Página 38
La distribución ji-cuadrado tiene muchas aplicaciones en inferencia estadística, por ejemplo en el test
ji-cuadrado y en la estimación de varianzas. También está involucrada en el problema de estimar la
media de una población normalmente distribuida y en el problema de estimar la pendiente de una
recta de regresión lineal.
5.6 Distribución F de Fisher - Snedecor
Esta distribución es usada en teoría de probabilidad y estadística, la distribución F es una distribución
de probabilidad continua. También se la conoce como distribución F de Snedecor o como distribución F
de Fisher-Snedecor. Una variable aleatoria de distribución F se construye como cociente de dos
variables de distribución Chi-cuadrada:
donde U1 y U2 tienen una distribución chi-cuadrado de d1 y d2 grados de libertad respectivamente, y
U1 y U2 son estadísticamente independientes.
La distribución F aparece frecuentemente como la distribución nula de una prueba estadística
especialmente en el análisis de varianza.

BIOESTADISTICA 2015
Página 39
UNIDAD 6: MUESTREO E INFERENCIA Muestra. Muestreo. Estimador. Estadístico. Tamaño de muestra. Intervalos de confianza
6.1 CONCEPTOS PARA LA SELECCIÓN DE UNA MUESTRA.
• Población diana: Aquella población de la que se desea obtener una información. En ocasiones parte de la misma es desconocida por lo que en ese caso no puede ser utilizada para seleccionar de ella la muestra.
• Población a estudiar: La población de la que realmente se obtendrá la información porque de esta es de la que se extrae la muestra. Corresponde a la parte de la población diana que es conocida.
• Unidad de muestreo: Elemento básico sobre el que desarrollaremos la investigación. Esta puede ser, dependiendo del objetivo del estudio, los animales, los rodeos, los productores, etc.
• Muestra: Grupo de unidades de muestreo, seleccionadas de la población a estudiar, sobre las que se realizará toda la investigación propuesta.
• Fracción de muestreo: Cociente entre el tamaño de la muestra y el tamaño de la población a estudiar, en caso de conocerse.
6.2 VENTAJAS Y DESVENTAJAS DEL MUESTREO.
Ventajas:
a) Se mejora la calidad de la información obtenida, debido a que al trabajar con menos personal, éste puede ser de mejor nivel.
b) Disminución del tiempo y costo de ejecución.
c) Por ser menos multitudinario permite mayor detalle de los datos.
× Desventajas:
a) No se conoce la población completa
b) Debe realizarlo un especialista en el tema.
MUESTREO EXPLORADOR Y MUESTREO PILOTO.
Si no se conoce nada de la población o del fenómeno a estudiar, debe hacerse previamente un muestreo que en estos casos se llama explorador o de prueba; si se conoce algo y quiere ajustarse detalles, puede también hacerse un muestreo previo, que se denomina piloto.

BIOESTADISTICA 2015
Página 40
ERRORES SISTEMÁTICOS Y PROPIOS DEL AZAR.
Errores sistemáticos o vicios ocultos: Normalmente el investigador desconoce la existencia de los mismos. En la medida que aumenta el tamaño de la muestra, aumenta dicho error. Ejemplo de este tipo de error es el tener mal calibrada una balanza. Cuantos más animales pesemos, más error estaremos cometiendo.
Errores propios del azar: son cometidos por el hecho de no trabajar con toda la población. En este caso a medida que aumenta el tamaño de la muestra, disminuye dicho error.
MARCO MUESTREAL.
Son las características y límites que deberá tener el muestreo, del que no debe apartarse el que lo realiza. Se deberá tener en cuenta el tipo de características a estudiar: si son atributos (enfermedad) o variables discretas (número de huevos puestos por gallina ponedora de un criadero) ó continuas (producción de litros de leche).
Debe considerarse si se va a trabajar directamente con los integrantes o si se utilizará un símbolo que los represente. Utilizar definiciones operativas: si se van a investigar tambos, establecer que se entiende por ellos. Deberá definirse el área geográfica donde se desarrollará el estudio.
MUESTRA REPRESENTATIVA.
Hacer representativa una muestra tomada de una población supone, por un lado, que posea un tamaño adecuado y por otro que el método de selección sea el correcto, de manera que todas las subpoblaciones posibles estén representadas de forma adecuada. Para realizar esto es imprescindible conocer previamente los conceptos que están implicados en la selección de una muestra.
DISEÑO DE LA MUESTRA
a) El tamaño de la muestra (n).
Hay cinco elementos a tener en cuenta para el cálculo del "n"
a1) Variación de la población: A mayor homogeneidad, menor muestra. Se mide con la varianza
(variable cuantitativa) ( 2 ) ó con la proporción (variable cualitativa) [p (1-p)].
a2) Precisión de la estimación ó Diferencia (D): Mide cuan precisa es la muestra.
A mayor precisión, mayor muestra ó lo que es lo mismo a menor diferencia mayor muestra. Se mide
como la diferencia entre P y p ó entre y x . Es decir (P-p) y (- x ).
a3) Nivel de confianza: El nivel de confianza representa la probabilidad de que la estimación sea verdadera y tiene relación directa con el tamaño de la muestra a través del coeficiente de confianza z. A mayor confianza, mayor muestra.
a4) Tamaño de la población: a mayor población mayor muestra. Este elemento no está incluído en la fórmula, debido a que en la mayoría de las veces se trabaja con poblaciones infinitas. Cuando se conoce el número de integrantes de la población existe otra fórmula para ajusta el tamaño de la muestra en función del tamaño de la población.

BIOESTADISTICA 2015
Página 41
a5) Recursos: esta variable influye directamente sobre los otros elementos a tener en cuenta para el cálculo de "n".
Luego las expresiones para el cálculo del tamaño muestra para variables cualitativas y cuantitativas, serán respectivamente:
2
2 1.
D
ppZn
ó 2
22.
D
Zn
Si el tamaño de la muestra obtenido con la fórmula precedente puede ser excesivo cuando esa muestra representa mas del 10% del tamaño total de la población, puede ser excesivo, sobre todo en poblaciones memores a 1000 unidades de muestreo. Cuando la población es finita y con menos de 1000 individuos y el muestreo es sin reposición, el tamaño de la muestra obtenido puede ajustarse por el tamaño de la población (N). En este caso el tamaño de la muestra ajustado será menor, con el consecuente ahorro de recursos. La corrección, que determina el tamaño final de la muestra que se
debe tomar es:
N
n
nn
1
' , siendo n el tamaño de la muestra y N el tamaño de la población.
b) El método de selección de los elementos.
Existen dos métodos diferentes de muestreo de las poblaciones de individuos atendiendo a la intervención o no del azar en la selección de las unidades de muestreo:
Probabilístico: Todos los individuos de la población a estudiar tienen la misma probabilidad de formar parte de la muestra, siendo el azar el que determina que individuos forman parte de la muestra y cuáles no. En este caso se utilizan sistemas de "lotería" o de "números aleatorios", tablas de números distribuidos en filas y columnas distribuidos al azar, para seleccionar cada unidad de muestreo. Atendiendo a las características de la población investigada y de los objetivos de la investigación existen diversos tipos de métodos probabilísticos:
- Simple: Es necesario tener identificados todos los individuos. Consiste en seleccionar uno a uno, mediante lotería o tablas de números aleatorios, los animales que entran a formar parte de la muestra. Es el método más sencillo y se utiliza cuando no existen factores que puedan hacer que la población se distribuya en subgrupos diferentes atendiendo a dicho factor.
- Sistemático: Se utiliza cuando no se conoce la identidad de los individuos. En ese caso se establece entre los mismos un orden (por ejemplo, orden de paso de los animales por una cinta de clasificación). Se seleccionan, mediante loterías o números aleatorios, un primer número, que corresponde a aquel del orden establecido que constituirá la primera muestra. Posteriormente se selecciona (con el mismo sistema) un segundo número que corresponderá al intervalo de muestreo. Para evitar errores debidos al azar, como número que representa el intervalo de muestreo puede utilizarse el valor obtenido de dividir el tamaño de la población por el tamaño de la muestra.
- Estratificado: En ocasiones, interesa analizar la población en función de la existencia de diferencias en un determinado carácter, por ejemplo el sexo. En ese caso, se divide la población total en subgrupos en función de ese carácter tomando de cada subgrupo una muestra por métodos simples o sistemáticos. El número de individuos a muestrear en cada grupo será proporcional al tamaño de ese

BIOESTADISTICA 2015
Página 42
grupo respecto al total de la población (si un sexo supone en la población el 75% de los animales, en la muestra ese sexo debe estar representado en un 75%).
- Conglomerados o cluster: En ocasiones encontramos la población dividida en grupos de los que conocemos el número que hay dentro de la población pero no se conoce el número de unidades de cada uno de esos grupos. En ese caso, se realiza un muestreo, simple o sistemático de los grupos, incluyendo en la muestra la totalidad de las unidades de cada grupo seleccionado (ejemplo: zonas geográficas).
- Multietápico: Consiste en un sistema mixto de los métodos anteriormente desarrollados. Se trata de realizar el muestreo a dos niveles: por ejemplo un primer nivel entre grupos y un segundo nivel entre unidades dentro de los grupos seleccionados.
No probabilístico: En este método no todos los individuos de la población tienen la misma probabilidad de formar parte de la muestra, siendo el investigador o el propio productor el que decide cuales forman parte de la muestra y cuáles no. En estos casos, se corre el riesgo de que la muestra no sea representativa de la población. En función de quien es el que decide los individuos que integran la muestra, los métodos no probabilísticos se denominan:
- Con voluntarios: El productor decide voluntariamente que animales o lotes de los mismos forman parte de la muestra y cuales no según a él le interese.
- De conveniencia: El investigador decide qué animales forman parte de la muestra, en función de que posean o no algún carácter que desea analizar.
c) La forma como se harán las estimaciones de los parámetros que se quieren conocer.
d) Determinación del tamaño muestral.
e) Métodos de selección de una muestra en una investigación epidemiológica.
6.8 INFERENCIA ESTADÍSTICA. ESTIMACIÓN PUNTUAL Y POR INTERVALOS.
Inferencia estadística es obtener conclusiones para la población a partir de la información que nos brinda una porción pequeña de ella, ya sea una muestra o realizando un experimento. Para que las conclusiones sean válidas es necesario aplicar una metodología que pueda reproducirse. Hemos hablado ya de algunas técnicas de muestreo que permiten recolectar información de la población y posteriormente veremos algunas condiciones mínimas necesarias para llevar a cabo un experimento. La inferencia estadística puede realizarse de dos formas: Mediante la Estimación o el Test de Hipótesis, a su vez la estimación puede ser: Estimación Puntual o por Intervalos de confianza
6.8.1 ESTIMACIÓN PUNTUAL.
Vamos a definir al estimador puntual como una función de una muestra aleatoria. Por ejemplo: sea x1, x2, . . .,xn una muestra aleatoria, una función sería:

BIOESTADISTICA 2015
Página 43
n
x
x
n
i
i 1
la cual es en sí, misma una variable aleatoria, y en este caso es un estimador puntual del parámetro . La calidad de la estimación obtenida depende de la adecuada elección del estimador puntual. Debido a que existe una gran variedad de estimadores posibles en cada situación particular es que necesitamos de criterios de selección. Para seleccionar un buen estimador entre un conjunto de posibles estimadores, los estadísticos propuestos son estudiados teniendo en cuenta ciertas propiedades.
Las propiedades de los buenos estimadores son:
a) Insesgadez: Un estimador ( ) es insesgado si, para cualquier tamaño muestral, su esperanza
es igual al parámetro (θ) que estima. Esto es, E( ) = θ , para todo valor de θ. El sesgo del
estimador es definido como: Sesgo ( )=E( - θ ). Esto se puede probar para la media muestral, de la siguiente manera: si se considera a la muestra de “n” observaciones como una colección de “n” variables aleatorias, todas idénticamente distribuidas con E(Xi ) = μi luego,
n
n
nn
XE
n
XE
n
X
ExE
n
i
n
i
n
i
i
n
i
i
1111)(
b) Consistencia: Un estimador es consistente si la probabilidad de que la diferencia entre el parámetro y su estimador (en valor absoluto) sea mayor que un valor ε, tienda a cero cuando “n” tiende a infinito.
Esto es si la P(| -θ|>ε) tiende a 0, para ε>0, cuando el tamaño de la muestra tiende a ∞.
c) Eficiencia: Un estimador insesgado, se dice que es eficiente si tiene la mínima varianza posible.
Los estimadores más usuales son:
Parámetro Estimador
Promedio (MTC) x
Variancia (MD) S
Proporción p
Correlación r
Regresión:
ordenada al origen
a
Pendiente b

BIOESTADISTICA 2015
Página 44
6.8.2 ESTIMACIÓN POR INTERVALO DE CONFIANZA.
Los estimadores puntuales son también variables aleatorias y, por lo tanto, es de esperar que diferentes muestras de una misma población, arrojen distintas estimaciones puntales para un mismo parámetro. Supongamos que se quiere determinar el peso promedio de un lote de novillos y para ello se seleccionan distintas muestras, cada una de tamaño 10, es lógico pensar que si cambian los individuos de una muestra a la otra, también cambiará el promedio resultante de cada muestra. Por lo tanto es deseable que la estimación puntual esté acompañada de alguna medida del posible error de esa estimación. Esto puede hacerse indicando el error estándar del estimador o dando un intervalo (límite inferior y superior) que incluya al verdadero valor del parámetro con un cierto nivel de confianza. El procedimiento que permite calcular los límites inferior y superior del intervalo se conoce como: Estimación por Intervalo, el intervalo obtenido: Intervalo de Confianza y (1- α)100 se el Nivel de Confianza. Los niveles de confianza más usados son 95%, 99% o 99,9%.
Simbólicamente:
P(LiθLs) = 1- α
donde:
Li: es el límite inferior del intervalo de confianza
Ls: es el límite superior del intervalo de confianza
1- α es nivel de confianza, generalmente expresado en porcentaje: (1-α)100
INTERVALO DE CONFIANZA PARA .
Para el cálculo del intervalo de confianza nos basaremos en distribuciones conocidas que nos permitirán encontrar fácilmente los límites (Li y Ls). Por ejemplo conociendo la distribución normal podemos encontrar z1 y z2 de modo que se cumpla la siguiente expresión:
P( z1 z z2 ) =0.95 [1]
En este caso z1 corresponde al valor de z que acumula un area bajo la curva normal (0,1) de α/2 y z2 corresponde al valor de z que acumula (1-α/2). Si α=0.05 luego se tiene:
Z(α/2)= -1.96 y Z(1-α/2)= 1.96.
Por otra parte también conocemos que Z= x
(que tiene distribución normal). Luego remplazando
en la expresión [1] y realizando pasajes de términos y los reemplazos correspondientes llegamos a la siguiente expresión:
1..
21
21 n
Zxn
ZxP
Para que esta expresión pueda ser utilizada debemos conocer la varianza σ2. Sin embargo cuando no se conoce la varianza poblacional σ2, la distribución en la cual nos basaremos será la distribución “t” de
Student, luego el cálculo del intervalo de confianza para tendrá la siguiente expresión:

BIOESTADISTICA 2015
Página 45
1..
21,
21, n
Stx
n
StxP
glgl
En este caso los grados de libertad sería gl= n-1
INTERVALO DE CONFIANZA PARA LA DIFERENCIAS DE MEDIAS (1-2).
Cuando se desea estimar la diferencia entre los promedios de dos poblaciones independientes, el
estimador puntual natural sería x 1- x 2, y también podríamos calcular el intervalo de confianza. Dependiendo de la situación, si conocemos las variancias poblacionales (σ2
1 y σ22) nos basaremos en la
distribución normal, mientras que si tenemos los estimadores (S21 y S2
2) utilizaremos la distribución “t” de Student. En este caso las expresiones para el cálculo son respectivamente las siguientes:
1..
2
2
2
1
2
1
2111
2
2
2
1
2
1
21 2121
nnZxx
nnZxxP
1..
2
2
2
1
2
1
21;211
2
2
2
1
2
1
21;2 21
2121
21
n
S
n
Stxx
n
S
n
StxxP
nnnn
INTERVALO DE CONFIANZA PARA σ2
En ocasiones es de interés estimar la variancia de la población, y en este caso basaremos la inferencia
en la distribución de Chi cuadrado (2), resultando la siguiente expresión:
1.1.1
2
),(
22
2
)1,(
2
22glgl
X
Sn
X
SnP
En este caso los grados de libertad sería gl= n-1.
INTERVALO DE CONFIANZA PARA UNA PROPORCIÓN
Cuando nuestros estudios involucran variables cualitativas dicotómicas, el estimador puntual sería una “proporción” (p), por ejemplo la proporción de enfermos (P) (prevalencia), en esta situación también podemos estimar su intervalo de confianza y la expresión sería la siguiente:

BIOESTADISTICA 2015
Página 46
1
)1(.
)1(.
21
21 n
ppZpP
n
ppZpP
6.9 ENSAYOS COMPARATIVOS.
Podemos diferenciar dos tipos de ensayos comparativos: Los “diseños experimentales” y los “estudios observacionales”.
Es necesario especificar el objetivo del experimento, para ello debemos:
Identificar los factores que influyen, cuales son variables y cuales hay que mantener constantes
Identificar las características a medir
Especificar el procedimiento de medición de las características
Determinar el número de repeticiones
Precisar los recursos y materiales
Además debemos preguntarnos:
¿Cuál es mi objetivo?
¿Qué es lo que quiero saber?
¿Por qué quiero saberlo?
Un “Experimento” es una investigación que establece un particular conjunto de circunstancias bajo un protocolo específico con motivo de observar y evaluar los resultados observados.
Podemos diferencias dos tipos de experimentos:
Experimento comparativo: Es el experimento típico en el campo de la biología, medicina veterinaria, agricultura, ingeniería. El objetivo comparativo implica establecer más de una circunstancia y las respuestas observadas resultan de las diferentes circunstancias y pueden ser comparadas unas con otras. La unidad básica de estudio se denomina “unidad experimental”.
Estudio observacional comparativo: cuando la experiencia no puede llevarse a cabo por razones éticas o prácticas. La unidad básica de estudio tiene el mismo rol que la unidad experimental y se la denomina “unidad observacional”.
La inferencia estadística es la primer diferencia entre un diseño experimental y un estudio observacional. En el diseño experimental es a menudo posible asignar relación causal entre la respuesta y el tratamiento. Los estudios observacionales son limitados para relacionar asociación entre la respuesta y las condiciones del tratamiento.
El tratamiento, es el conjunto de circunstancias creadas por el experimentador en respuesta a la hipótesis a investigar y ellos son el foco de la investigación. También existen los tratamientos control y placebo. Hay distintas circunstancias en las cuales un tratamiento control es útil y necesario. Este tratamiento revela las condiciones bajo las cuales se desarrolló la experiencia, esto también es denominado testigo. Por lo general el tratamiento control se refiere a la ausencia total de tratamiento, no obstante hay experiencias en las que el control puede representar una práctica estándar por lo cual el método experimental puede ser comparado, en estos casos el tratamiento control se denomina

BIOESTADISTICA 2015
Página 47
“placebo”. En el tratamiento placebo se realizan las mismas maniobras que en el tratamiento a comparar pero sin la droga o principio activo que queremos probar. El placebo puede revelar el efecto de la manipulación de las unidades experimentales en ausencia de algún tratamiento. En ocasiones son necesarios ambos tratamientos testigos, el control propiamente dicho y el placebo. A modo de ejemplo supongamos que queremos probar una nueva droga "H" para tratar alguna enfermedad, y dicha droga es inyectada a animales afectados por dicha enfermedad y posteriormente se evalúa el efecto. En esta experiencia podríamos tener animales a los que no se les realiza ningún tratamiento (Tratamiento Control), otros a los que se les inyecta solamente el excipiente (Tratamiento Placebo) y otro grupo a los cuales se le aplica el tratamiento de interés (excipiente + la droga “H”)
Unidad Experimental: Es la entidad física o sujeto expuesto al tratamiento. El tratamiento debe ser asignado en forma aleatoria en cada unidad experimental, esto contribuye a obtener “independencia” entre las respuestas por parte de las unidades experimentales. Cada unidad experimental constituye una simple réplica. Las repeticiones son necesarias para poder medir el error experimental y permiten una mejor estimación del o los efectos que queremos comparar. La aleatorización permite validar la inferencia. Provee la justificación para la inferencia estadística de los métodos de estimación y del test de hipótesis. La réplica por si sola no garantiza la validez de la estimación.
Tanto en los diseños experimentales como en los estudios observacionales, nos interesará obtener conclusiones válidas que podamos referir a toda la población, para ello tendremos que plantearnos objetivos claros y formularnos "preguntas" que trataremos de responder objetivamente y con rigor científico. Para tomar una decisión estadística, será necesario plantear hipótesis que podamos contrastar y poner a prueba mediante métodos estadísticos. Para poner a prueba una hipótesis debemos seguir una serie de pasos, que se detallan a continuación:
6.10 PRUEBA DE HIPÓTESIS.
1) Plantear las hipótesis
De acuerdo al objetivo propuesto se planteara una hipótesis nula (H0), en la cual siempre debe incluirse la igualdad y una hipótesis alternativa (H1) que expresa lo contrario de la nula. El conjunto de hipótesis (H0 y H1) generan pruebas bilaterales o unilaterales, En el siguiente esquema se representan los 3 conjuntos de hipótesis posibles:
Bilateral Unilateral derecha Unilateral izquierda
H0 : =0 H0 : 0 H0 : 0
H1 : 0 H1 : >0 H1 : <0
2) Elección del estadístico
En este paso elegiremos el estadístico más apropiado para probar nuestra hipótesis. La elección de la herramienta estadística dependerá del tipo de variable en estudio, de la cantidad de información y principalmente del parámetro que se desea evaluar y será necesario conocer la distribución del estimador. Las pruebas que conoceremos en este curso serán:

BIOESTADISTICA 2015
Página 48
Cuantitativas Una población Test “z” (Variancias conocida)
Test “t” (Variancias desconocida)
Dos poblaciones Test “z”; (Variancias conocidas)
Test “t” (Variancias desconocidas pero iguales)
Test “t” (Variancias desconocidas y distintas)
Datos pareados Test “t”
Categóricas Chi2 Prueba de la bondad de Ajuste
Prueba de la Independencia
Prueba de la Homogeneidad de proporciones
3) Determinar el nivel de confianza
Al tomar una decisión estadística se pueden cometer dos tipos de errores, de Tipo I y de Tipo II. El error
de tipo I se lo simboliza con la letra griega y representa la probabilidad de rechazar una hipótesis
nula que es verdadera. Por el contrario, la probabilidad de aceptar H0 cuando es verdadera es (1-) y
expresada en porcentaje se la denomina “nivel de confianza” y se simboliza como (1-)100. El error de tipo II se comete, cuando aceptamos una hipótesis nula que en realidad es falsa y cuya probabilidad se
simboliza con la letra griega .Por el contrario la probabilidad de no cometer error de tipo II sería (1-), y se la denomina “potencia” del test. La potencia del test es la capacidad de la prueba de rechazar una hipótesis nula que es falsa.
De este modo fijando el nivel de confianza determinamos el error que estamos dispuestos a cometer,
así si (1-)100 es igual a 95%, estaremos dispuestos a cometer un error = 0.05
4) Determinar la zona de rechazo
En función del nivel de confianza y la cantidad de información (grados de libertad) se determina el valor crítico, delimitando la zona de aceptación y de rechazo.
5) Cálculo del estadístico
En este paso se desarrolla el cálculo bajo hipótesis nula.
6) Conclusión
En este paso se toma una decisión. En este momento se deberá aceptar o no la hipótesis nula planteada anteriormente. Cuando la hipótesis nula es rechazada, se dice que, por ejemplo, las diferencias son estadísticamente significativas, o sea que no se debieron al azar. Por el contrario, si se

BIOESTADISTICA 2015
Página 49
acepta la hipótesis nula, se concluye que dichas diferencias no son estadísticamente significativas, o sea que se debieron al azar.
6.11 TEST DE HIPOTESIS PARA EL ANÁLISIS DE DATOS CATEGÓRICOS.
En algunas oportunidades es necesario determinar si existe asociación entre dos variables cualitativas (por ejemplo: presencia/ausencia de enfermedad y algún factor de riesgo para contraer la misma). En estos casos se debe recurrir al test de Chi2. Recordamos que los datos categóricos se clasifican de la siguiente manera:
Nominales: color, variedad, raza, etc.
Ordinales: tienen un orden natural: Chico, mediano y grande. Bueno, regular o malo
De intervalos: Variables numéricas agrupadas en intervalos de clase: por ejemplo la edad (15-20, 21-25 y26-30 años).
Ejemplo 12:
Tabla 14: Frecuencia de colmenas según el tratamiento y el tipo de diagnóstico Tipo de Diagnóstico
Tratamiento Curada No curada
A 78 20
Complicado B 101 11
C 68 46
A 40 5
Simple B 54 5
C 34 6
k
i i
iiHo
fe
fefoX
1
22 )(
Tablas de Contingencia (2 variables)
Síntomas Tratamiento A Tratamiento B Tratamiento C Total
Enfermas n11 n12 n13 n1
Sanas n21 n22 n23 n2
Total n1 n2 n3 n
Donde:
nij es la frecuencia observada en la fila i columna j
ni y nj: totales marginales (filas y columnas, respectivamente) y el total general (n).

BIOESTADISTICA 2015
Página 50
6.11.1 PRUEBA DE LA BONDAD DE AJUSTE.
En algunas oportunidades se quiere determinar si los resultados observados se ajustan a un marco teórico. En esos casos es que se requiere de la prueba de Bondad de Ajuste para el Chi2.
Ejemplo 13: Ante el cruzamiento de 2 genotipos de semillas, se observan las siguientes frecuencias para cada uno de los 4 resultados posibles:
Genotipo fo Fe
l a 950 900
l v 260 300
r a 270 300
r v 120 100
Total 1600 1600
Calculamos de las frecuencias esperadas:
900160016
9 3001600
16
3 1001600
16
1
1) Hipótesis
H0: la frecuencia observada responde a la proporción teórica 9:3:3:1
H1: la frecuencia observada no responde a la proporción teórica 9:3:3:1
2) Elección del estadístico
k
i i
iiHo
fe
fefoX
1
22 )(
Prueba de la bondad de Ajuste
3) Nivel de confianza
(1-)100=95 % =0.05
gl= k – 1 = 4 –1 = 3
4) Regla de decisión:
81.72
)3,95(.
2 XX Ho
5) Cálculo
11.15
100
100120
300
300270
300
300260
900
9009502222
2
Ho
6) Conclusión:
La evidencia estadística permite rechazar la hipótesis nula (P<0.05). Por lo tanto la frecuencia observada no se ajusta a la proporción 9:3:3:1.

BIOESTADISTICA 2015
Página 51
6.11.2 PRUEBA DE LA INDEPENDENCIA.
En ciertas situaciones es necesario determinar la existencia de asociación entre ciertos factores de riesgo para determinada enfermedad y la presencia de la misma. En general, estas son situaciones que se presentan a diario para quienes realizan Epidemiología, o sea que la información es obtenida a través de Estudios Observacionales. Ejemplo 14:
Fo Expuestos a traslado en camión
Enfermedad Si No Total
Si 40 10 50
No 35 35 70
Total 75 45 120
Cálculo de las frecuencias esperadas
Fe Expuestos a traslado en camión
Enfermedad Si No Total
Si 31 19 50
No 44 26 70
Total 75 45 120
1) Hipótesis:
H0: Hay independencia entre las variables H0:P(EnfExp)=P(Enf)P(Exp)
H1: No hay independencia entre las variables H1:P(EnfExp) P(Enf)P(Exp)
2) Estadístico: Test de Chi2: Prueba de la Independencia
k
i i
iiHo
fe
fefoX
1
22 )(
3) Nivel de confianza:
(1-) 100 95 % 0.05 gl= (2-1) . (2-1) = 1
4) Regla de decisión:
84.32)1,95(.
2 XX Ho

BIOESTADISTICA 2015
Página 52
5) Cálculo:
82.1126
2635...
31
314022
2
Ho (P-valor= 0.0008)
6) Conclusión: La evidencia estadística permite rechazar la hipótesis nula (P<0.05). Por lo tanto no hay independencia entre las variables, el trasladar animales en camión no es independiente de la presencia de la enfermedad.
6.11.3 PRUEBA DE HOMOGENEIDAD DE PROPORCIONES.
En otras circunstancias, es necesario probar la validez de una nueva droga o por ejemplo la validez de una vacuna, para lo cual se realiza un Estudio Experimental con dos grupos de animales, los tratados y los no tratados y se determina cuantos de cada grupo se curan y/o enferman. En estos casos se realiza un test de Chi2 para homogeneidad de proporciones.
Ejemplo 15:
Fo Curadas Sanas Total
ATB "A" 32 18 50
ATB "B" 28 22 50
Total 60 40 100
Cálculo de las frecuencias esperadas:
Fe Curadas No curadas Total
ATB "A" 30 20 50
ATB "B" 30 20 50
Total 60 40 100
1) Hipótesis
Ho: P(Curadas con ATB "A”) = P(Curadas con ATB "B")
H1 : P(Curadas con ATB "A") P(Curadas con ATB "B")
2) Estadístico: Test de Chi2: Prueba de la Homogeneidad de proporciones
k
i i
iiHo
fe
fefoX
1
22 )(
3) Nivel de confianza:
(1-) 100 95 % 0.05
4) Regla de decisión:
X XHo2
95 1
2 384 (. , ) .

BIOESTADISTICA 2015
Página 53
5) Cálculo: X2 = 0.6667 (P-valor= 0.4142)
6) Conclusión: La evidencia estadística no permite rechazar la hipótesis nula (P>0.05). Por lo tanto ambos ATB presentan igual porcentaje de éxito al tratamiento.

BIOESTADISTICA 2015
Página 54
UNIDAD 7: REGRESIÓN LINEAL Y CORRELACIÓN Correlación. Pendiente. Ordenada al origen. Residuo
Muchas veces en la práctica nos encontramos con situaciones en las que se requiere analizar la relación entre dos variables cuantitativas. Los dos objetivos fundamentales de este análisis serán, por un lado, determinar si dichas variables están asociadas y en qué sentido se da dicha asociación (es decir, si los valores de una de las variables tiende a aumentar –o disminuir- al aumentar los valores de la otra); y por otro, estudiar si los valores de una variable pueden ser utilizados para predecir el valor de la otra. La forma correcta de abordar el primer problema es recurriendo a coeficientes de correlación. Sin embargo, el estudio de la correlación es insuficiente para obtener una respuesta a la segunda cuestión: se limita a indicar la fuerza de la asociación mediante un único número, tratando las variables de modo simétrico, mientras que nosotros estaríamos interesados en modelar dicha relación y usar una de las variables para explicar la otra. Para tal propósito se recurrirá a la técnica de regresión. Aquí analizaremos el caso más sencillo en el que se considera únicamente la relación entre dos variables. Así mismo, nos limitaremos al caso en el que la relación que se pretende modelar es de tipo lineal. En cada uno de estos casos se pueden plantear varios interrogantes: ¿existe alguna relación entre las variables?, si se conoce el comportamiento de una de ellas, ¿se puede predecir el comportamiento de la otra?
El Análisis de Regresión Lineal es una técnica que tiene como objetivo describir como varía la esperanza de la variable dependiente E(Y), frente a cambios en X. Es decir, permite estudiar la relación funcional entre una variable respuesta Y (variable dependiente) y una variable regresora X (variable independiente o predictora). Identifica el modelo o función que liga a las variables, estima sus parámetros y eventualmente, prueba hipótesis sobre ellos. Por último, modelar por regresión también tiene como objetivo la predicción, es decir el uso del modelo para dar el valor esperado de Y cuando X toma un valor particular.
7.1 LA RECTA DE REGRESIÓN. Sea Y una variable aleatoria respuesta (o variable dependiente), que se supone relacionada con otra variable (no necesariamente aleatoria) que llamaremos explicativa, predictora o independiente y que se denotará por X. A partir de una muestra de n individuos para los que se dispone de los valores de ambas variables, (Xi,Yi),i = 1,...n, se puede visualizar gráficamente la relación existente entre ambas mediante un gráfico de dispersión, en el que los valores de la variable X se disponen en el eje horizontal y los de Y en el vertical. El problema que subyace a la metodología de la regresión lineal simple es el de encontrar una recta que ajuste a la nube de puntos del diagrama así dibujado, y que pueda ser utilizada para predecir los valores de Y a partir de los de X. Por ejemplo, las siguientes figuras muestran dos diagramas de dispersión, para variables que pueden considerarse relacionadas linealmente:
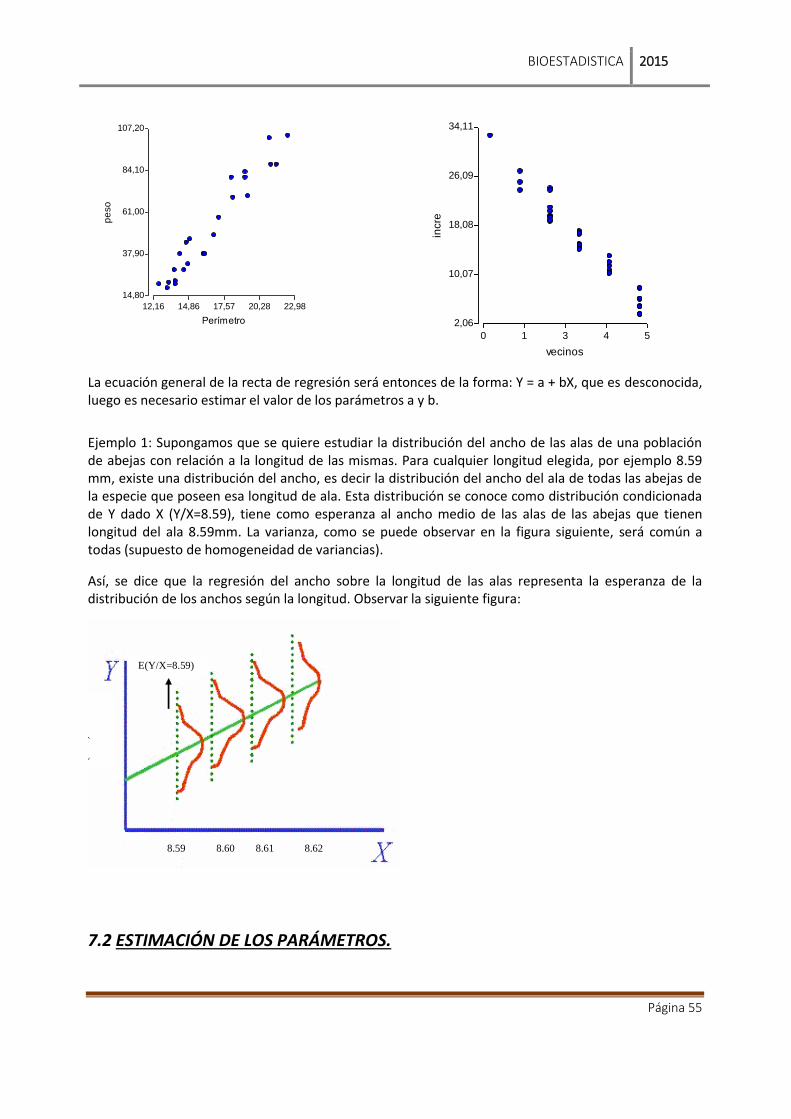
BIOESTADISTICA 2015
Página 55
12,16 14,86 17,57 20,28 22,98
Perímetro
14,80
37,90
61,00
84,10
107,20
pe
so
La ecuación general de la recta de regresión será entonces de la forma: Y = a + bX, que es desconocida, luego es necesario estimar el valor de los parámetros a y b.
Ejemplo 1: Supongamos que se quiere estudiar la distribución del ancho de las alas de una población de abejas con relación a la longitud de las mismas. Para cualquier longitud elegida, por ejemplo 8.59 mm, existe una distribución del ancho, es decir la distribución del ancho del ala de todas las abejas de la especie que poseen esa longitud de ala. Esta distribución se conoce como distribución condicionada de Y dado X (Y/X=8.59), tiene como esperanza al ancho medio de las alas de las abejas que tienen longitud del ala 8.59mm. La varianza, como se puede observar en la figura siguiente, será común a todas (supuesto de homogeneidad de variancias).
Así, se dice que la regresión del ancho sobre la longitud de las alas representa la esperanza de la distribución de los anchos según la longitud. Observar la siguiente figura:
8.59
8.59 8.60
f(Y
/X)
E(Y/X=8.59)
8.61 8.62
7.2 ESTIMACIÓN DE LOS PARÁMETROS.
0 1 3 4 5
vecinos
2,06
10,07
18,08
26,09
34,11
incre

BIOESTADISTICA 2015
Página 56
El problema radica en encontrar aquella recta que mejor ajuste a los datos. Es usual utilizar el método de mínimos cuadrados, que elige como recta de regresión a aquella que minimiza las distancias verticales de las observaciones a la recta. Más concretamente, se pretende encontrar a y b tales que:
n
1i
2i
n
1i
2i
1ii
2ii
b,ae)XbaY()YY(Min .
Donde ii XbaY es el valor predicho o ajustado por el modelo lineal y ei es el residuo definido
como iii YYe
Resolviendo este problema mediante un sencillo cálculo de derivación, se obtienen el estimador mínimo cuadrático de cada uno de los coeficientes de la recta de regresión:
XbYa,
n
X
X
n
YX
YX
)XX(
)YY)(XX(
b2
n
1iin
1i
2i
n
1ii
n
1iin
1iii
n
1i
2i
n
1iii
.
Como se puede suponer, la relación Y = a + bX no va a cumplirse exactamente, sino que existirá un error que representa la variación de Y para cada valor de la variable independiente. Las distancias verticales entre el valor observado y el valor dado por la recta para cada individuo (o
valor ajustado) reciben el nombre de residuos, y se suelen denotar por i . La expresión teórica del
modelo matemático será entonces:
n,...,1iεbXaY iii ,
en esta expresión i es el componente o variable aleatoria del modelo, lo que hace que la variable Y
sea aleatoria. Se deben realizar una serie de supuestos (ver figura ) sobre esta variable aleatoria:
1- La esperanza de la distribución de los errores es 0:
.n,...,1i,0)ε(E i
2- La varianza de la distribución de los errores es constante (homogeneidad de variancias u
homocedasticidad), .n,...,1i,σ)ε(Var 2i
3- La distribución de los errores es normal,
.n,...,1i),σ,0(N~ε 2i
4- Las observaciones Y i son independientes. Bajo las hipótesis de normalidad. Esta hipótesis en función de los errores sería “los i son independientes”.
La validación de estos supuestos puede hacerse mediante diferentes herramientas. Varias de ellas pueden inspeccionarse mediante gráficos.

BIOESTADISTICA 2015
Página 57
7.3 INTERPRETACIÓN DE LOS COEFICIENTES DE REGRESIÓN En la ecuación general de la recta de regresión, claramente b es la pendiente de la recta y a el valor de la variable dependiente Y para X = 0. En consecuencia, una vez estimados estos coeficientes, en la mayoría de las aplicaciones el valor de â no tendrá una interpretación directa, mientras que el valor
b servirá como un indicador del sentido de asociación entre ambas variables.
b >0: indica una relación directa entre las variables (a mayor valor de la variable explicativa, mayor valor de la variable dependiente),
b <0: indica una relación de tipo inverso,
b =0 : indica que no existe una relación lineal entre ambas variables. Ejemplo 2: en la siguiente tabla se muestran los datos de 69 pacientes de los que se conoce su edad y una medición de su tensión sistólica. Si estamos interesados en estudiar la variación en la tensión sistólica en función de la edad del individuo, deberemos considerar como variable respuesta la tensión y como variable predictora la edad.
Es decir que la ecuación de ajuste es la recta: Y=103.35 +0.98X. Ejemplo 16: Datos de presión según la edad
Nº Tensión Sistólica Edad Nº Tensión Sistólica Edad Nº Tensión Sistólica Edad
1 114 17 24 152 41 47 150 56
2 134 18 25 158 41 48 154 56
3 124 19 26 124 42 49 165 56
4 128 19 27 128 42 50 164 57
5 116 20 28 138 42 51 168 57
6 120 21 29 142 44 52 140 59
7 138 21 30 160 44 53 170 59
8 130 22 31 135 45 54 185 60
9 139 23 32 138 45 55 154 61
10 125 25 33 142 46 56 169 61
11 132 26 34 145 47 57 172 62
12 130 29 35 149 47 58 144 63
…. ………

BIOESTADISTICA 2015
Página 58
Diagrama de dispersión. Recta de regresión. Es interesante plantear la hipótesis de pendiente nula, es decir, b=0. El hecho de que el test no resulte significativo, indicará la ausencia de una relación clara de tipo lineal entre las variables, aunque pueda existir una asociación que no sea captada a través de una recta, por ejemplo una relación cuadrática. Para los datos del ejemplo, el resultado de ajustar un modelo de regresión lineal se muestra a continuación:
Variable Coeficiente (B) IC 95% (B) T P
Constante 103,35 (94,72; 111,99) 23,89 <0,001
Edad 0,98 (0,81; 1,16) 11,03 <0,001
Fuente de Variación Suma de Cuadrados g.l. Cuadrado Medio F P
Regresión en edad 14965,31 1 14,965,31 121,59 <0,001
Residual 8246,46 67 123,08
Total 23211,77 68
7.4 ANÁLISIS DE VARIANZA.
En este curso no entramos en el detalle de estas tablas conocidas como Análisis de la Varianza. Generalmente un análisis de regresión suele ser expresado por este tipo de tablas.
La bondad de un ajuste lineal, puede medirse en función de la proporción de variabilidad explicada por el modelo (coeficiente de correlación lineal de Pearson) que recibe el nombre de coeficiente de determinación, y que se pretende sea próximo a 1.

BIOESTADISTICA 2015
Página 59
En nuestro ejemplo el coeficiente de determinación es R2=0,645 y R=0.80 (se obtiene del cociente 14965.31/23211.77)
La columna "Suma de cuadrados" muestra una descomposición de la variación total de Y en las partes explicada y no explicada (residual) por la regresión.
Esto se deduce de la siguiente identidad en términos de sumas de cuadrados:
2n
1jjj
n
1j
2j
n
1j
2j )xbay()yy()yy(
O equivalentemente suele expresarse como: SSTO = SSR + SSE
A partir de esta descomposición es posible utilizar una medida de la calidad del ajuste o “capacidad predictiva” del modelo, el coeficiente de determinación, R2,
SSTO
SSR
)yy(
)yy(
)yy(
ε
1Rn
1j
2j
n
1j
2j
n
1j
2j
n
1j
2j
2
Ejemplo 17: Cada fila representa los valores observados sobre una unidad experimental, conformada por una parcela de 50 cm. por 50 cm. en la que se midió el Nitrógeno en el suelo y por planta calculado como promedio sobre todas las plantas de la parcela.
X: Nitrogeno en Suelo (ppm) Y: Nitrógeno en plantas (ppm)
0.42 0.13 0.45 0.15 0.50 0.16 0.55 0.17 0.68 0.18 0.69 0.18 0.70 0.19 0.73 0.2 0.80 0.2 0.9 0.21 0.92 0.22 0.94 0.23
El diagrama de dispersión para los datos se presenta en la siguiente figura:
Suma de cuadrados
Total Suma de cuadrados de la
Regresión
Suma de cuadrados
Residual

BIOESTADISTICA 2015
Página 60
Análisis de regresión lineal
Variable N R²
Nitrógeno plantas 12 0,95
Coeficientes de regresión y estadísticos asociados
Coeficientes Estimación E.E. LI(95%) LS(95%) T Valor p
const 0,08 0,01 0,06 0,09 9,35 <0,0001
Nitrog.Suelo 0,16 0,01 0,13 0,18 13,94 <0,0001
Tabla de análisis de la varianza
FV SC gl CM F Valor p
Modelo 0,01 1 0,01 194,32 <0,0001
Nitrogeno Suelo 0,01 1 0,01 194,32 <0,0001
Error 4,6E-04 10 4,6E-05
Total 0,01 11
Residuo Nitrógeno plantas Valores Ajustados
-0,01 0,14 0,00 0,15 0,01 0,15 0,01 0,16 0,00 0,18 -0,01 0,18 0,00 0,19 0,01 0,19 0,00 0,20
0,39 0,54 0,68 0,82 0,97
Nitrogeno Suelo
0,13
0,15
0,18
0,21
0,24
Nitró
ge
no
pla
nta
s

BIOESTADISTICA 2015
Página 61
-0,01 0,22 0,00 0,22 0,01 0,22
7.5 ANÁLISIS DE CORRELACIÓN LINEAL.
En el análisis de regresión la variable X es usualmente fija, mientras que la variable dependiente Y es aleatoria. Si X e Y son ambas variables aleatorias observables sobre una misma unidad o elemento de la población, podría ser de interés medir el grado en que estas variables covarian ya sea positiva o negativamente.
La simple observación de que dos variables parecen estar relacionadas, no revela mucho. Dos preguntas que pueden surgir al respecto, son:
¿Qué tan estrecha es la relación entre las variables? O ¿Cuál es el grado de asociación que existe entre ambas?
¿Es real la asociación observada o podría haber ocurrido solo por azar?
Para responder a la primer pregunta se necesita una medida del grado de asociación entre dos variables. Esta medida es el coeficiente de correlación, que se denota en general con la letra griega ρ
(rho). Para la segunda, se precisa una prueba de hipótesis sobre ρ .
El análisis de correlación clásico supone que los pares de variables aleatorias tienen una distribución normal bivariada. El coeficiente de correlación lineal entre dos variables aleatorias X e Y se define como:
)Y(Var)X(Var
)Y,X(Covρ ,
donde Cov(X,Y) es la covarianza entre X e Y que se define como )Y(E)X(E)XY(E)Y,X(Cov . La
versión muestral del coeficiente de correlación de denomina con r, y puede calcularse como:
n
Y
Yn
X
X
n
YX
YX
)YY()XX(
)YY)(XX(
r2
n
1iin
1i
2i
2n
1iin
1i
2i
n
1ii
n
1iin
1iii
n
1i
2i
n
1i
2i
n
1iii
.

BIOESTADISTICA 2015
Página 62
Características:
r es un número sin dimensiones que se encuentra entre -1 y 1.
si las variables son independientes r =0. La inversa no es necesariamente cierta. Si las variables son normales sí es cierto que si r=0, las variables son independientes.
si las variables estuvieran relacionadas linealmente r =1
Cuando X e Y no están correlacionadas, r=0.
Prueba de hipótesis sobre ρ : Si se satisface la suposición de distribución normal bivariada, y se tiene
una muestra aleatoria de n pares de valores (X,Y), es posible utilizar el coeficiente de correlación muestral r, para probar la hipótesis de independencia entre X e Y probando la hipótesis H0
: ρ =0.
Para probar esta hipótesis contra 0ρ:H1 , el estadístico utilizado es
2n
r1
rT
2
, que tiene una
distribución t de Student con n-2 grados de libertad, donde n es el número de pares (X,Y).
Ejemplo: Los datos de la siguiente tabla se refieren al contenido de proteína bruta (PB) y caseína (CA) en leche de 23 tambos de la cuenca lechera de la región central Argentina.
PB CA PB CA
2,74 1,87 3,25 2,33
3,19 2,26 2,95 2,04
2,96 2,07 3,08 2,16
2,91 2,09 3,14 2,16
3,23 2,28 3,22 2,22
3,04 2,04 3,14 2,22
3,08 2,18 3,15 2,24
3,23 2,3 3,2 2,22
3,11 2,17 2,95 2,07
3,11 2,15 3,19 2,25
3,1 2,16 3,12 2,23
2,99 2,16
0
0,5
1
1,5
2
2,5
2,7 2,8 2,9 3 3,1 3,2 3,3
PB
CA

BIOESTADISTICA 2015
Página 63
El coeficiente de correlación lineal muestral es de r=0.9327. ¿Es esta correlación significativa? Parar responder se realiza la prueba de hipótesis: H0
: ρ =0 versus 0ρ:H1 , fijando 05.0α . El valor de
prueba 85.11
223
9327.01
9327.0T
2
, mientras que los cuantiles 0.025 y 0.975 de una
t n-2 son de –2.079 y 2.079 respectivamente, lo que determina que debe rechazarse la hipótesis nula, se concluye entonces que la correlación lineal existente es estadísticamente significativa.

BIOESTADISTICA 2015
Página 64
UNIDAD 8: ANÁLISIS DE LA VARIANZA Hipótesis. Tratamientos. Comparación de medias
El análisis de la varianza ANOVA es probablemente la herramienta de inferencia estadística mas utilizada en las investigaciones científicas en el campo de las ciencias biológicas en general y en las agropecuarias en particular. El ANOVA es un método estadístico cuya finalidad es probar hipótesis referidas a los parámetros de posición de dos o más poblaciones en estudio. El análisis de la varianza puede entenderse como un método que permite comparar varias medias en diversas situaciones.
Unidad experimental: se llama unidad experimental o parcela experimental a la mínima porción del material experimental sobre el cual un tratamiento puede ser realizado.
Por ejemplo, en un ensayo comparativo de rendimientos de trigo donde se desea evaluar 3 variedades se puede disponer de 30 parcelas de 1 m2 cada una (unidades experimentales). Al final de la experiencia las plantas de cada parcela se cosecharan y en base a ello se realizara una medición del rendimiento en cada unidad.
Es importante conducir las experiencias de forma tal que las unidades experimentales generen información independiente. En nuestro caso para que la información de las parcelas (rendimiento) sea independiente se recurre a la aleatorización de las variedades en las parcelas.
Tratamiento: se denomina tratamiento al conjunto de acciones que se aplican a las unidades experimentales con el objeto de observar cómo responden estas. La forma de “aplicar” a la que se refiere esta definición es asignar aleatoriamente los tratamientos a las unidades experimentales.
En nuestro ejemplo los tratamientos consisten en las tres variedades de trigo en las parcelas experimentales y observar la respuesta rendimiento de la parcela. En este caso se dice que el factor tratamiento (variedad) tiene 3 niveles.
Las observaciones reales bajo cada tratamiento se asocian teóricamente a una distribución subyacente, así si hay a tratamientos en estudios hay a distribuciones a considerar.
Repetición: se llama repetición a cada realización de un tratamiento.
Si en el ejemplo se asignan 10 parcelas a cada cultivare, se tendrán 10 repeticiones para cada tratamiento.
En el siguiente gráfico se esquematizan tres distribuciones centradas en sus esperanzas:

BIOESTADISTICA 2015
Página 65
1 2 3
La media general es el centro de equilibrio de todas las distribuciones y se trata de un parámetro
fijo. El efecto del tratamiento i se presenta como un corrimiento respecto de la media general y en el
modelo conocido como ANOVA de efectos fijo, se asume constante
La hipótesis nula del anova postula la igualdad de las medias de todos los tratamientos. Si la hipótesis nula fuera cierta todas las distribuciones estarían centradas en la media general. Los valores de la variable aleatoria ij representan las diferencias entre las observaciones individuales y las esperanzas
de la distribución de la cual proviene la observación.
8.1 MODELOS DE ANÁLISIS DE LA VARIANZA.
El anova permite distinguir dos modelos para la hipótesis alternativa:
modelo I o de efectos fijos en el que la H1 supone que las k muestras son muestras de k poblaciones distintas y fijas.
Un valor individual se puede escribir en este modelo como:
ijiijY , con i=1, .., k y j=1, …, n,
Yij: es al j-ésima observación del i-ésimo tratamiento.
: es la media general de las observaciones
i : es el efecto del i-ésimo tratamiento
ij : es una variable aleatoria normal independientemente distribuida con esperanza 0 y varianza 2 para todo ij.
La hipótesis nula en este análisis es que todas las medias son iguales
que puede escribirse en términos del modelo como:

BIOESTADISTICA 2015
Página 66
Un ejemplo de modelo I de anova es el ejemplo 1, porque en él se asume que existen cinco poblaciones (sin tratamiento, con poca sal, sin sal, etc.) fijas, de las que se han extraído las muestras.
modelo II o de efectos aleatorios en el que se supone que las k muestras, se han seleccionado aleatoriamente de un conjunto de m>k poblaciones.
Un ejemplo de modelo II sería: un investigador está interesado en determinar el contenido, y sus variaciones, de grasas en las células hepáticas de cobayas; toma del animalario 5 cobayas al azar y les realiza, a cada una, 3 biopsias hepáticas.
La manera más sencilla de distinguir entre ambos modelos es pensar que, si se repitiera el estudio un tiempo después, en un modelo I las muestras serían iguales (no los individuos que las forman) es decir corresponderían a la misma situación, mientras que en un modelo II las muestras serían distintas.
Aunque las asunciones iniciales y los propósitos de ambos modelos son diferentes, los cálculos y las pruebas de significación son los mismos y sólo difieren en la interpretación y en algunas pruebas de hipótesis suplementarias.
8.2 ANÁLISIS DE VARIANZA DE EFECTOS FIJOS A UN FACTOR DE CLASIFICACIÓN.
El objetivo del ANOVA de efectos fijos es contrastar la hipótesis de que los efectos de los tratamientos son nulos versus que al menos uno no lo es. Es decir:
Si se toma una muestra aleatoria simple de cada uno de las k distribuciones con idéntica varianza, entonces las k varianzas muestrales estiman al mismo parámetro y el promedio ponderado de estas
varianzas es un buen estimador para 2 . Si además se piden igualdad de medias (hipótesis nula del
análisis) las k medias muestrales son estimaciones de la media poblacional y tienen varianza 2 /n.
bajo estas condiciones se puede obtener otra estimación para 2 . Por lo tanto bajo estas
consideraciones se tienen dos estimaciones independientes de la varianza poblacional. Si la hipótesis de igualad de medias no es cierta entonces la varianza estimada a partir de las medias incluirá una fuente de variación debida a la diferencia de los parámetros de posición de las distribuciones muestreadas Luego la comparación del promedio ponderado d elas varianzas muestrales con el estimador obtenido a partir de las varianzas de las medias muestrales es la clave del análisis.
Cuadrados medios dentro o del Error CME: promedio ponderado de las k varianzas estimadas en cada tratamiento:
)1(.....)1(
)1(.....)1(
1
2211
k
kk
nn
SnSnCME
CME es un estimador insesgado de 2 , es decir E(CME)=
2 .
Cuadrado medio entre o cuadrado medio de tratamiento: varianza ponderada de las medias muestrales
nSCMTXrat2
CMTrat es un estimador de la varianza si las esperanzas de lso tratamientos que se comparan son iguales.

BIOESTADISTICA 2015
Página 67
Considerando que el estadístico F compara varianzas, la prueba consiste en calcular el estadístico F
utilizando los estimadores de 2e y
2trat de la siguiente forma:
k
ii
ratNk nn
CME
CMTF
1)1)(1( ,
Los resultados de un anova se suelen representar en una tabla como la siguiente:
Fuente de variación G.L. SS MS F
Entre grupos: Tratamientos k-1 SSTrat SSTrat /(k-1) MSTrat /MSE
Dentro: Error (n-1)k SSE SSE /k(n-1)
Total Kn-1 SST
Ejemplo 17: Se quiere evaluar la eficacia de distintas dosis de un fármaco contra la hipertensión arterial, comparándola con la de una dieta sin sal. Para ello se seleccionan al azar 25 hipertensos y se distribuyen aleatoriamente en 5 grupos. Al primero de ellos no se le suministra ningún tratamiento (grupo Placebo o control), al segundo una dieta con un contenido pobre en sal, al tercero una dieta sin sal, al cuarto el fármaco a una dosis determinada y al quinto el mismo fármaco a otra dosis.
Las presiones arteriales sistólicas de los 25 sujetos al finalizar los tratamientos son:
Grupo
1 2 3 4 5
180 172 163 158 147
173 158 170 146 152
175 167 158 160 143
182 160 162 171 155
181 175 170 155 160
La tabla de anova es:
Fuente de variación GL SS MS F
Tratamiento 4 2010,64 502,66 11,24
Error 20 894,4 44,72
Total 24 2905,04
Como F0,05(4,20) =2,87 y 11,24>2,87 rechazamos la hipótesis nula y concluimos que los resultados de los tratamientos son diferentes.

BIOESTADISTICA 2015
Página 68
7.3 DISEÑOS EXPERIMENTALES
El procedimiento descompone la variabilidad total de las observaciones (suma de cuadrados total) en fuentes de variación (sumas de cuadrados) asociadas, cada una, al efecto de un factor experimental. Esta descomposición se basa en el modelo propuesto para las observaciones, el cual depende del Diseño del experimento.
A continuación se describen brevemente algunos diseños experimentales corrientemente utilizados.
Diseño Completamente Aleatorizado: Se utiliza cuando las unidades experimentales son homogéneas; es decir, cuando la variación entre las mismas es pequeña. Los tratamientos se asignan en forma aleatoria a las unidades experimentales. No se imponen restricciones a la aleatorización. Este diseño sólo está limitado por el número de unidades experimentales disponibles. El número de repeticiones puede variar de un tratamiento a otro.
Diseño en Bloques Completamente Aleatorizados: En muchas situaciones experimentales, se sabe que ciertas unidades experimentales se comportan en forma diferente aunque sean tratadas de modo similar. Las unidades pueden agruparse de manera tal que unidades similares pertenezcan al mismo grupo o bloque, ese agrupamiento se llama bloqueo. Los bloques de unidades experimentales homogéneas, permiten inferir que las diferencias observadas se deben a los tratamientos. Los tratamientos son asignados al azar dentro de un bloque y esta asignación se repite independientemente para cada bloque. Si cada bloque tiene tantas unidades experimentales como tratamientos y todos los tratamientos están presentes en cada bloque, siendo asignados al azar, el diseño se denomina Diseño en bloques completos al azar. La variación entre bloques no afecta las diferencias entre medias, ya que cada tratamiento aparece el mismo número de veces en cada bloque. Este diseño permite mayor precisión que el completamente aleatorizado, cuando su uso está justificado por la variabilidad entre bloques. Un supuesto subyacente en el análisis de un diseño en bloques es que los tratamientos no interactúan con la estructura de parcelas (bloques).
Diseño en Cuadrados Latinos: En muchas situaciones experimentales, las unidades experimentales pueden ser agrupadas de acuerdo a más de un factor de bloqueo. Un cuadrado latino es un caso particular donde intervienen dos factores de agrupamiento, llamados factor fila y factor columna, y cada tratamiento es aplicado una vez en cada fila y una vez en cada columna. El número total de unidades experimentales es igual al cuadrado del número de tratamientos. El supuesto de aditividad bloque-tratamiento se extiende a las filas y a las columnas; es decir, los tratamientos no interactúan con los factores que agrupan a las unidades experimentales (factor fila y factor columna).
Diseño en Parcelas Divididas: Este diseño se usa frecuentemente en experimentos con más de un factor de agrupamiento de unidades experimentales. Es un diseño útil cuando uno de los factores necesita parcelas o unidades experimentales grandes y los otros factores se pueden asignar a unidades más pequeñas (subunidades). Se llaman parcelas “principales" a las unidades completas o parcelas completas a las que se les aplican los niveles de un factor (por ejemplo, el factor A). Estas se dividen en subparcelas, o subunidades, a las cuales se aplican uno o más factores adicionales (por ejemplo, el factor B).
La aleatorización se realiza en dos etapas: primero se aleatorizan los niveles del factor correspondiente a las parcelas principales y luego se aleatorizan los niveles del factor correspondiente a las subparcelas. También, podrían existir, o no, factores que definan las estructuras de las parcelas. Es así como se podría tener un diseño en parcelas divididas con estructura de parcelas completamente aleatorizadas, o parcelas divididas con estructura de parcelas en bloques.