
compresion tds 2007 -...
29
! "# $ %& ’ ( "$& ( ) "& *+ ,,- ./ ) *- 0 "-& # 10 +0 # 2 $ # 2 3 %4 12 3 %4 10 *+ - , 5 6 6 ,0 ,- 2- 7,- 8 - 5 8 - $ , 6 ,- 7 8 $ - $ 2 ,- , - 8 - - , 4 , 4 ’ 8 8 8 0 -
Transcript of compresion tds 2007 -...

Compresión de Imágenes Digitales• Una imagen puede que valga más que mil palabras, pero ocupa mucho más.
• Libro de unas 200 páginas: 1Mbyte.
• Imagen color (800 x 600) : 2 Mbytes.
• Enciclopedia britanica: 500 Mbytes (texto), 25 Gbytes (escaneada).
• 1 hora de TV color alta definifición: 20-30 Gbytes.
• Transmisión de voz (analógica) necesita un ancho de banda de unos 8 Khz.
• Voz digital: 8000 muestras/segundo x 8 bits/muestra = 64 Kbits/sec = 64 Khz.
• Lo mismo ocurre con TV analógica frente a digital.
• Se ve claramente que a pesar de las ventajas de manejar datos digitales es preciso hacer un esfuerzo para reducir la información necesaria para su almacenamiento/transmisión.
Tipos de compresión de Datos• Clasificación de los métodos de compresión de datos:
• Sin pérdidas: invertibles, recuperación exacta.
aplicada a ficheros ordenador, ejecutables, etc.
aprovechan la redundancia de la información.
• Con pérdidas: no invertibles exactamente, recuperación aproximada.
aprovechan las limitaciones/tolerancia del observador, eliminando información poco significativa.
se usan principalmente en audio, imágenes, video.
• La compresión de un método se suele medir con la relación de compresión, un factor 4:1 indica que el resultado final ocupa 4 veces menos que el original
• En métodos con pérdidas también hemos de considerar la calidad de los datos una vez descomprimidos, esto es, el error introducido en la compresión.

Compresión sin pérdidas• Típicos métodos:
• Codificación de tiradas de píxeles consecutivas (Run Length Coding)
• Codificación de entropía (Huffman)
• Codificación aritmética (ARC)
• Compresores de diccionario (LZ77, LZ78, LZW)
• Los conocidos winzip, arj, arc , winrar, etc. usan estas técnicas.
• Desgraciadamente por si solos no consiguen grandes ganancias en imágenes (no suelen llegar a un factor de 2:1, salvo en imágenes muy especiales, p.e. fax).
• Si que se usan como un segundo paso en la compresión de imágenes (tras haber descartado lo que no nos importa perder, el resto si queremos conservarlo exactamente)
Códigos de Huffman
• Partimos de un alfabeto con L símbolos (p.e. niveles de gris) a codificar.
• En principio usaríamos log2(L) bits para cada codificar cada símbolo.
• Se trata ahora de estudiar la frecuencia relativa de aparición de cada símbolo:
p[k] = número de apariciones símbolo k / número total de símbolos
Esto es lo que en imágenes se denomina histograma.
• Aprovecharemos la distinta frecuencia de aparición de los símbolos.
• Se basa en asignar códigos de longitud variable:
• Códigos cortos para símbolos más probables.
• Códigos largos para símbolos poco probables.

Entropía de un mensaje/imagen
• Al límite ideal de un codificador de Huffman se denomina entropía mensaje
)log( 2 kk
k ppS ∑ −=p[k] es la probabilidad del símbolo k.
-log2(p[k]) es el número de bits dedicados a k
• Si p[k] tiende a 1 (muy probable), número de bits (-log2(p[k])) tiende a 0
• Si p[k] tiende a 0 (muy poco probable) el número de bits dedicados crece.
• S marca el límite de compresión usando la información del histograma.
• Lo ideal es tener histogramas muy concentrados y picudos.
• Huffman no puede sacar provecho de un histograma plano, de ahí la poca ganancia resultante al aplicarlo a imágenes
Código Huffman a partir del histograma
Objetivos: • Debe asignar menos bits a los símbolos más probables.
• No debe ser ambiguo en la reconstrucción.
Proceso:
1. Listar símbolos con su probabilidad.
2. Unir los dos símbolos menos probables en un árbol binario.
3. Eliminarlos de la lista, creando uno nuevo sumando sus probabilidades.
4. Repetir 2 y 3 hasta juntar todos los símbolos.
5. Al final tendremos un árbol binario que une todos los símbolos.
6. Asignar bit 0 y 1 a cada bifurcación (p.e 0 a la derecha, 1 a la izquierda)
7. Recorriendo el árbol leemos el código de cada signo.

Ejemplo de código Huffman
F 0.02
E 0.24E 0.24E 0.24E 0.24
DCFBE 0.50DCFB 0.26D 0.17D 0.17D 0.17
CFB 0.09CF 0.05C 0.03
B 0.04B 0.04
ADCFBE 1.0A 0.50A 0.50A 0.50A 0.50A 0.50
Árbol binario resultante: 0 1
A DCFBE
0 1
DCFB E
0 1
D CFB
0 1
CF B
0 1
C F
Códigos de Huffman
A 0 (1 bit)
B 1011 (4 bit)
C 10100 (5 bit)
D 100 (3 bit)
E 11 (2 bit)
F 10101 (5 bit)
Resultados de Huffman
• El resultado es un código de prefijo único (no hay ambigüedad)
• Bits por símbolo sin compresión:
log2(6) = 2.58 3 bits/símbolo.
• Entropía (ideal):
bits/símbolo.
• Compresión alcanzada por Huffman:
• Factor de compresión: R = 3 / 1.9 = 1.6
88.1log2 =−= ∑ kk
k ppS
9.1503.0404.0150.0)/( =+×+×+×=∑ Lsímbolobitspk
k

Inconvenientes código Huffman
• Depende de conocer la estadística de los datos.
• Dicha estadística puede cambiar con el tiempo.
• Solución: Métodos adaptativos.Actualizar estadística según se comprimen los datos.Más costoso computacionalmente (rehacer árbol, códigos).
• Otro problema: Huffman sólo alcanza el ideal si pkp
−= 2
• Cuando hay muchos niveles esto no es un problema.
• Con pocos niveles existen casos muy desfavorables.
• Típica situación: compresión de imágenes binarias (tipo fax)
Compresión de Imágenes Binarias.• Para una imagen binaria precisamos 1 bit/pixel sin compresión.
• FAX: asumamos 95% de blancos, 5% de negros.
• Entropía ideal: S = 0.28 bits/pixel, pero Huffman no puede usar menos de 1 bit/pixel, luego no ganamos nada.
• Una posibilidad es usar Run Lenght Encoding (RLC): basada en codificar repeticiones de símbolos: 100B 3N 10B.
• Otra posibilidad es usar codificación aritmética (ARC):
• Similar a Huffman en que usa información del histograma.
• Alcanza siempre el ideal de la entropía.
• Al contrario de Huffman no codifica el mensaje símbolo a símbolo (evitando así tener que dedicar un número entero de bits a cada símbolo), sino considerándolo como un todo.
• Todo mensaje se comprime como un número real entre 0 y 1.

Métodos de diccionario
• Basados en los trabajos de Lempel-Ziv (1977-78).
• Muy usados en compresión de texto, programas, ejecutables.
• Son la base de los programas de compresión más populares.
METODO:
• Los patrones repetidos en la entrada se almacenan en un diccionario.
• Cuando vuelven a salir se manda un índice al diccionario.
• El diccionario lo van creando/gestionando emisor y receptor de manera síncrona.
Codificación sin pérdidas en imágenes
• Los métodos anteriores no funcionan bien aplicados directamente a imágenes.
• Una “buena” imagen tiene un histograma bastante plano, por lo que los métodos de entropía (Huffman, ARC) obtendrán pocas ganancias.
• Igualmente, es difícil la repetición “exacta” de los valores de una imagen, por lo que los métodos de RLC o diccionario tampoco funcionan bien.
• Es importante conocerlos ya que se usan como una segunda etapa:
ImagenOriginal
Compresor Con pérdidas
Información A conservar
Compresor sin pérdidas
Imagencomprimida
• 1er paso: decidir que información se puede descartar.
•2do paso: comprimir la información esencial de forma integra.

Compresión de Imágenes Digitales con Pérdidas.
• En compresión sin pérdidas el “ratio” de compresión es el principal criterio.
• En compresión con pérdidas debemos considerar la calidad de la imagen
• Criterios posibles para juzgar la calidad de la imagen descomprimida:
• Matemáticos: Error medio cometido. Fácil de evaluar.
• Subjetivos : Calidad que aprecia el observador humano.
Más interesante , pero más costoso de evaluar.
• Muchas veces no coinciden ambos criterios.
• Las curvas calidad/ratio de compresión de dos compresores distintos pueden cortarse, indicando que dependiendo del rango será preferible uno u otro.
Codificación Predictiva• Elimina redundancia entre píxeles vecinos.
• Codifica únicamente la información adicional necesaria.
• Se predice el valor siguiente a partir de los ya conocidos:
p[n] = P(f[n-1], f[n-2], ...)
y se halla el error de predicción:
e[n] = f[n] – p[n]
• Es dicho error el que se guarda/transmite.
• Si la predicción es buena, e[n] andará siempre cerca del cero: histograma de e[n] estará muy concentrado y podremos aprovechar mejor los métodos de compresión sin pérdidas.
• Caso más sencillo: p[n] = f[n-1] e[n] = f[n] – p[n] = f[n] –f[n-1]

Ventajas de la codificación predictiva• Si la predicción es buena, e[n] andará siempre cerca del cero: histograma de e[n] estará muy concentrado y podremos codificarlo mejor que el original.
• Con pérdidas: aprovechando su menor rango dinámico podemos cuantificar dicho error con menos bits.
• Sin pérdidas: la entropía de e[n] será menor que la del original f[n] al estar sus valores más concentrados.
• La codificación del error de predicción puede ser con o sin pérdidas:
Codificación por transformadas
• Dividimos la imagen en bloques de un tamaño determinado: 8x8, 16x16, etc
• Aplicamos una transformación (T) invertible sobre cada bloque.
T
• ¿Qué transformación usar? Una en la que la energía esté más concentrada en los nuevos coeficientes.
• Similar a lo que vimos con la transformada de Fourier.
• En el siguiente paso despreciaremos (o codificaremos con menos bits) los coeficientes de baja energía.

Ventajas de las transformadas en el dominio de frecuencias
• Una elección típica son las transformadas en las que los nuevos coeficientes representan el contenido en la señal de ciertas frecuencias.
• No son dependientes de los datos a tratar y, aunque no son óptimas, logran una alta correlación de los coeficientes
• Explicación: en el mundo real predominan con mucho las bajas frecuencias.
• Los sistemas visuales y auditivos usan representaciones similares, por lo que es fácil traducir nuestro conocimiento de dichos sistemas en decisiones sobre qué coeficientes deben recibir más atención (más bits en la cuantificación) o cuales pueden despreciarse.
• Existen algoritmos rápidos, con implementaciones eficaces (FFT o similares).
• Las transformadas en frecuencias se usan en imágenes (JPEG, JPEG2000), video (MPEG) o audio (MP3).
Cuantificación de los nuevos coeficientes
T Q 1−Q 1−T
• Tras la transformación debemos cuantificar los nuevos coeficientes.
• Es en ese paso donde: • Introducimos errores.
• Comprimimos nuestros datos.
Bloque original
Bloque reconstruido
Bloque transformado (sin pérdidas)
Cuantificación: pérdidas.

El estándar JPEG de compresión de imágenes.
• Definido a principios de los 90 (joint Photographic Expert Group)
• La especificación JPEG consta de:
1. Esquema sin pérdidas basado en técnicas predictivas (poco usado).
2. Esquema con pérdidas basada en la Transformada Coseno Discreta (DCT)
• Nos centraremos en la implementación con pérdidas:
Imagen DCT Cuantificación
• El nuevo estándar JPEG2000 también usa una transformación en frecuencias (wavelets en vez de la transformada coseno discreta).
Transformada Coseno Discreta
• Muy similar a la transformada de Fourier pero sin usar complejos.
• Usa cosenos como elementos de la base en vez de exponenciales complejas
Unidimensional:
Bidimensional:
0≈k Nk ≈
• Es casi óptima decorrelando la energía de los distintos coeficientes.
• Separable: puede implementarse en dos pasadas unidimensionales.
• Relacionada con la TF, puede aprovechar el algoritmo rápido de FFT.
• Al igual que con la transformada de Fourier , las bajas frecuencias se dan en y las altas en
))21(cos(][1][ += ∑ nk
Nnf
NkD
n
π
))21(cos())
21(cos(],[1],[ ++= ∑∑ ml
Nnk
Nmnf
NlkD
mn
ππ

Aplicación de la DCT a Imágenes
DCT
DCT
Se observa la concentración de energía en bajas frecuencias 0, ≈lk
kn
m
n
m
k
l
l
Aplicación de la DCT por bloques
...
172152162163167136155152
179167148140147140152144
175179155140140147144144
DCT
0-6412-2-80
-2-1-7-14-319
-71-488-18-24
151818-111810-3
8-3-3-8-1514-5-8
-1-203-186-2-24-10
71411-11-926-3421
19-14-923-9º15-181120
• DCT[0,0] es una medida de la media (DC) del bloque original.
• Arriba/izquierda (k,l pequeños): bajas frecuencias, coeficientes altos.
• Abajo/derecha (k,l altos): altas frecuencias, poca energía, coeficientes bajos
• En JPEG se aplica la DCT a bloques de 8x8, 16x16 o 8x16 de la imagen original.

Cuantificación de coeficientes de la DCT
• Se divide los coeficientes del bloque 8x8 de la DCT por una matriz Q de cuantificación y se redondea al entero más próximo. Es esta parte la que implica pérdidas.
• En la descompresión se multiplica por la misma matriz Q, de forma que se recupera (casi) la matriz DCT del bloque inicial
• Mayores valores de Q implican mayores errores en reconstrucción:
182921204521RecCódigoQDCT
• Se definen diferentes matrices de Q según el factor de calidaddeseado: matrices Q con valores más pequeños dan más calidad.
• Dentro de un nivel de calidad, los valores de la matriz Q seránpequeños para las bajas frecuencias (poca error) y más grandes (más error) para las altas frecuencias.
Ejemplos de matrices de cuantificación 4x4
2015119
151197
11975
9753
30211715
21171411
1714108
151185
Factor calidad mas alto Factor de calidad mas bajo
• Con un factor de calidad más bajo se cometen más errores.
• Para un mismo factor de calidad se codifican peor las frecuencias altas.
• Valores de Q más altos generan más ceros y números pequeños, lo que se aprovecha en la siguiente fase: compresión sin pérdidas usando códigos de Huffman o similares.

Compresión sin pérdidas de los coeficientes de DCT
...DC
• Pasar del bloque 2D de la DCT cuantificada a una secuencia 1D.
• Secuencia en zigzag:
•Los únicos valores altos el primer coeficiente DCT[0][0], denominado componente DC y asociado a la media de cada bloque.
• La componente DC se resta al valor de la componente DC del bloque anterior (codificación predictiva) y se codifica la diferencia (Huffman)
• En el resto de los coeficientes (AC) tendremos muchos valores cerca del cero y tiras de ceros en altas frecuencias:
• Se codifican con un código de Huffman modificado, que incluye unos símbolos reservados para codificar varios ceros seguidos (RLE).
Ejemplo de aplicación (DCT) 82 74 74 72 81 75 81 80
128 130 138 139 138 152 168 170140 137 145 149 149 141 113 99126 129 122 120 128 134 143 166111 98 99 112 130 139 150 164117 136 150 155 155 169 150 118147 155 151 143 122 90 80 81140 141 140 130 112 91 103 119
Bloque 8x8 de la imagen
1002.62 3.65 -9.16 -6.64 3.12 -0.97 0.41 1.86-38.70 -57.97 12.28 16.74 -1.67 2.30 3.93 1.92-83.90 63.67 1.53 -18.00 3.28 3.66 -4.97 5.19-52.20 -36.12 -10.04 13.93 -9.88 3.91 -1.74 0.53-86.13 -40.17 48.90 -6.80 16.88 -5.92 -1.18 4.90-61.80 64.84 -12.60 -2.14 3.04 -8.45 -1.64 0.36-17.34 14.06 -36.22 17.33 -10.70 2.87 3.47 -1.06-53.95 32.37 -8.90 8.72 14.69 -0.63 1.06 2.99
DCT 2D del bloque 8x8

Aplicación de la matriz de calidad (Q) 8 x 8
5 7 9 11 13 15 17 197 9 11 13 15 17 19 229 11 13 15 17 19 22 25
11 13 15 17 19 22 25 2913 15 17 19 22 25 29 3315 17 19 22 25 29 33 3817 19 22 25 29 33 38 4419 22 25 29 33 38 44 50
Q =
200.52 0.52 -1.02 -0.60 0.24 -0.06 0.02 0.10-5.53 -6.44 1.12 1.29 -0.11 0.14 0.21 0.09-9.32 5.79 0.12 -1.20 0.19 0.19 -0.23 0.21-4.75 -2.78 -0.67 0.82 -0.52 0.18 -0.07 0.02-6.63 -2.68 2.88 -0.36 0.77 -0.24 -0.04 0.15-4.12 3.81 -0.66 -0.10 0.12 -0.29 -0.05 0.01-1.02 0.74 -1.65 0.69 -0.37 0.09 0.09 -0.02-2.84 1.47 -0.36 0.30 0.45 -0.02 0.02 0.06
DCT/Q =
Introducción de pérdidas
201 1 -1 -1 0 0 0 0-6 -6 1 1 0 0 0 0-9 6 0 -1 0 0 0 0-5 -3 -1 1 -1 0 0 0-7 -3 3 0 1 0 0 0-4 4 -1 0 0 0 0 0-1 1 -2 1 0 0 0 0-3 1 0 0 0 0 0 0
Round(DCT/Q ) =
• Hasta ahora no ha habido pérdidas. Si multiplicásemos la matrizdividida de nuevo por Q y aplicásemos la DCT inversa volveríamosa obtener el bloque 8x8 de la imagen original sin modificar.
• Las pérdidas se introducen al redondear DCT/Q al entero más próximo:
• Se observa la aparición de valores pequeños (buenos para un Huffman) y muchos ceros (buenos para un RLE).

Pasar a un vector unidimensional• Pasar del bloque 2D de la DCT cuantificada a una secuencia 1D.
• la componente DC (201) se resta de la DC del bloque anterior.
• Los coeficientes AC se cofifican con Huffman + RLE.
201 1 -1 -1 0 0 0 0-6 -6 1 1 0 0 0 0-9 6 0 -1 0 0 0 0-5 -3 -1 1 -1 0 0 0-7 -3 3 0 1 0 0 0-4 4 -1 0 0 0 0 0-1 1 -2 1 0 0 0 0-3 1 0 0 0 0 0 0
0 ...010-3-7-561-1-1-6-9-61201
-1 ...000000134-1-4-3-1-10
0 ...0000010-21-31-10-10
0 EOB000000000000010
Descompresor (recuperar la DCT)
1005 7 -9 -11 0 0 0 0-42 -54 11 13 0 0 0 0-81 66 0 -15 0 0 0 0-55 -39 -15 1 -19 0 0 0-91 -45 51 0 22 0 0 0-60 68 -19 0 0 0 0 0-17 19 -44 25 0 0 0 0-57 22 0 0 0 0 0 0
Recuperación de la DCT = Q x Round(DCT_org/Q ) =
• Los coeficientes del vector se mandan sin perdidas (Huffman/RLE)
• El decompresor los volverá a multiplicar por Q recuperando una aproximación a la DCT.
• Se observa la desaparición efectiva de los coeficientes que corresponden a frecuencias bajas.

Descompresor (recuperar el bloque 8x8) • Invirtiendo la DCT aproximada tendremos el bloque 8x8
79 76 73 74 79 81 78 74127 137 143 138 137 148 164 174139 142 147 152 149 134 114 101134 123 121 128 130 129 143 162103 98 97 105 120 138 157 170119 137 151 157 167 169 145 112142 158 162 141 113 96 87 81147 139 136 132 113 94 100 122
82 74 74 72 81 75 81 80128 130 138 139 138 152 168 170140 137 145 149 149 141 113 99126 129 122 120 128 134 143 166111 98 99 112 130 139 150 164117 136 150 155 155 169 150 118147 155 151 143 122 90 80 81140 141 140 130 112 91 103 119
Bloque 8x8 recuperado
Bloque 8x8 original
Compresión de imágenes en color
• Las imágenes en color se componen de 3 bytes por pixel, resultando en lo que se denominan tres bandas (RGB) de color.
• No interesa codificar cada banda por separado. Hacemos un cambio de coordenadas en el espacio de color, pasando de los tres canales RGB a luminancia (similar a versión blanco /negro de imagen) + 2 componentes cromáticos.
• JPEG no especifica la transformación de color. El standardrecomienda el sistema YCbCr:
R 1.000 1.371 0.000 Y -175.5
G = 1.000 -0.698 -0.336 Cr + 136.2
B 1.000 0.000 1.732 Cb -221.7

Tratamiento de las bandas Y Cb Cr
• La luminancia Y es la más importante (corresponde a una versión en blanco y negro de la original) y se codifica integramente.
• Las dos bandas de crominancia (Cb y Cr) se suelen submuestrearen un factor 2 en cada dimensión.
• Imagen original en color: 3 bandas de tamaño N x M:
3 x (N x M) píxeles.
• Antes de aplicar JPEG la información se reduce a
(N x M) + ( N x M) / 4 + (N x M) / 4 = (N x M) x 3/2 píxeles
• Reducción a la mitad previo a la aplicación de la DCT, cuantificación, etc.
Ejemplos de JPEG con poca degradación (Q alto)
Q = 50, R = 9
Q = 25, R = 11Q = 50, R = 7
Q = 25, R = 16Original (256 x256)
Original (256 x256)

Ejemplos de JPEG degradación visible (bajo Q)
Q = 5, R = 55 Q = 2, R = 100Q = 10 , R = 30
Q = 10 , R = 22 Q = 5, R = 42 Q = 2, R = 96
Compresión multiescala: pirámide laplaciana.
• Como introducción a los métodos basados en wavelets revisaremos el proceso conocido como pirámide laplaciana:
1. Hacer un filtrado pasobajo (promedio) de la imagen.
2. Restarlo de la imagen original.
3. Guardar el pasoalto así obtenido (detalle).
4. Reducir el pasobajo en un factor 2 (no habrá problemas de aliasing)
5. Repetir los pasos 1 a 4 para un cierto número de escalas.
• La codificación de la imagen consiste en:
1. Los sucesivos pasoaltos.
2. El último pasobajo reducido (de tamaño muy pequeño).
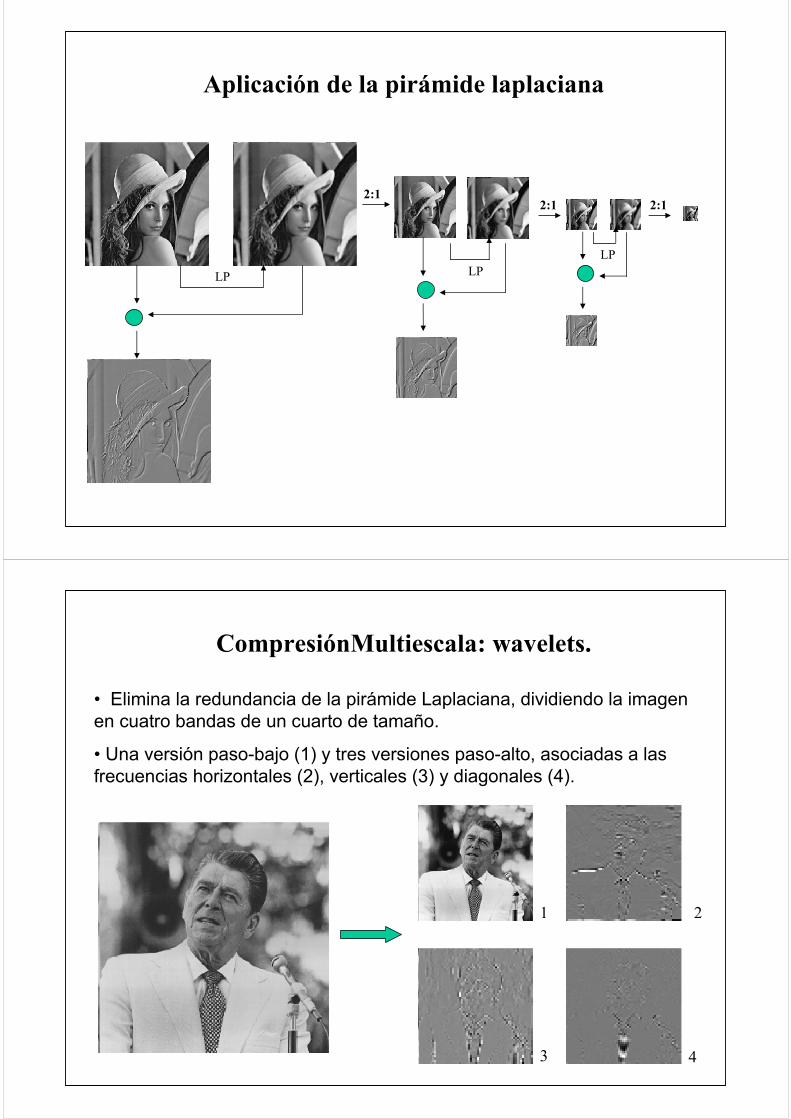
Aplicación de la pirámide laplaciana
-
LP-
LP
2:12:1
-LP
2:1
CompresiónMultiescala: wavelets.
• Elimina la redundancia de la pirámide Laplaciana, dividiendo la imagen en cuatro bandas de un cuarto de tamaño.
• Una versión paso-bajo (1) y tres versiones paso-alto, asociadas a las frecuencias horizontales (2), verticales (3) y diagonales (4).
1 2
43

Compresión multiescala: wavelets
• El proceso se aplica de nuevo a la versión paso-bajo de la imagen.
• Si lo repetimos varias veces tenemos un esquema MULTIESCALA.
• Contamos con una versión de la imagen de baja resolución más sucesivos niveles de detalle a distintas resoluciones.
• Muy apropiado para mostrar una imagen (mapa, foto) a escalas progresivamente mayores:
• Se presenta inicialmente la versión reducida. Tarda poco en cargarse.
• Si se aumenta la escala se amplia la imagen y se le añaden más niveles de detalle. La información que ya tenemos sigue siendo útil, sólo hay que cargar el nuevo detalle, “añadiéndolo” a lo que ya tenemos.
Aplicación de un esquema de wavelets.
I
HL
DV
H
DV
HL
DV
HL
DV
H
DV
H
DV

•Ventajas de la compresión basada en wavelets
• Elimina el efecto de bloques de JPEG a altos ratios de compresión.
• Muy adecuado para transmisión progresiva, zoom en imagen, etc.
• Se puede especificar un ratio de compresión determinado.
• Implementaciones de compresión wavelet:
• Adoptado por el FBI para su base de datos de huellas dactilares.
• Es la base de formatos como ECW (ErMapper) y MRSid(LizardTech), usados en el almacenamiento de grandes imágenes satélite, ortofotos, etc.
• El nuevo estándar JPEG2000 está también basado en una transformación wavelet: no ha llegado a desplazar a JPEG porque sus ventajas solo son claras a altas compresiones (además de ciertos problemas de licencias).
Wavelet más simple: transformada de Haar
• Un esquema wavelet define una forma de extraer un pasobajo y un pasoaltode una señal/imagen a partir de los cuales puede recuperarse el original.
• La wavelet más sencilla: transformada de Haar.
• Dada una señal 1D discreta x[n] se define:
• Paso bajo: Paso alto:
• De cada par de muestras del original obtenemos una muestra pasobajo(promedio de las dos) y otra pasoalto (diferencia de las dos).
• La recuperación a partir del pasobajo y el pasoalto es inmediata:
])[][(]2[ kxkxkx hplp += ])[][(]12[ kxkxkx hplp −=+
2])12[]2[(][ ++
=kxkxkxlp 2
])12[]2[(][ +−=
kxkxkxhp

Compresión basada en Wavelets.
• Si algo tan sencillo como Haar funciona ¿qué misterio tienen las wavelets?
• El problema es que cualquier esquema wavelet asegura la recuperación exacta de la señal original si NO se modifican el paso-bajo y paso-alto.
• Esto no sirve mucho para compresión ya que la transformación wavelet por si sola no “gana espacio”. La compresión se consigue no guardando toda la información.
• Por lo tanto lo importante de un esquema wavelet es como se recupere la imagen original cuando partamos de una versión incompleta de las distintas bandas.
• En particular la transformada de Haar es especialmente mala desde este punto de vista.
• Existe un gran trabajo actual para desarrollar filtros wavelet que aseguren buenas reconstrucciones a partir de bandas incompletas.
Una vez aplicada la wavelet ¿qué hacemos?
• La wavelet no es más que una transformación invertible, pero no comprime nada, terminamos con el mismo número de coeficientes wavelet que píxeles.
• La compresión aparece al transmitir/guardar parcialmente dichos datos.
• Se ordenan las bandas por su interes: típicamente las bandas de baja frecuencia se mandan antes.
• los coeficientes se van transmitiendo progresivamente, empezando por sus dígitos más significativos.
• Se aprovechan redundancias entre escalas. Se observa que generalmente cuando hay valores altos en una escala, también aparecen valores altos en las escalas inferiores. Y al contrario, zonas sin “actividad” en una cierta escala presagian coeficientes pequeños en la misma zona espacial a otras escalas.

Trasmisión progresiva en transformadas wavelet
Imaginemos tres coeficientes (1.234, 1.567, 1,987) obtenidos en la transformación wavelet correspondientes a tres bandas distintas.
Suponemos que las tres bandas están ordenadas por su importancia. La primera podría ser la versión pasobajo final, las otras niveles adicionales de detalle. Los coeficientes se reordenan de esta forma:
7891.
7651.
4321.
y se transmitirían recorriendo las sucesivas columnas.
De esta forma, para cuando transmitiéramos el primer dígito del 1.567 ya tendríamos tres dígitos del primer coeficiente. El primer dígito del tercer coeficiente aparecería cuando ya tuviéramos completo el primer coeficiente y gran parte del segundo.
MPEG (Moving-Image Photographic Expert Group)
• Comparte muchas similitudes con JPEG de imágenes estáticas.
• Fija aspectos que JPEG deja libres (para mayor rapidez):
Requiere el uso de sistema de color Y Cb Cr.Cb y Cr se muestrean a la mitad de resolución de Y.Requiere Huffman, no permite aritmético.Tablas de Huffman están prefijadas.
• No codifica los frames por separado. Usa codificación predictiva, codificando diferencias con otros frames vecinos.
• Incorpora codificación de audio/datos integrandolos en un único flujo de datos, con los adecuados mecanismos de sincronización.

Tipos de Frames en MPEG
1. Intra-coded (I): frame codificado independientemente de otros. Muy similar a una imagen comprimida en JPEG.
2. Predictive-coded (P): su compresión se basa en un frame anterior, ya sea I u otro P.
3. Bidirectional predictive-coded (B): se apoya tanto en frames anteriores como posteriores.
4. DC-coded (D): versión reducida de un frame, solo con información de los componentes DC (submuestreo 64:1 o mayor). Muy baja calidad, usada para ``cámara rápida'' o ``búsqueda rápida'' en Modo Edición.
Grupo de Imágenes (GoP) en MPEG
• Conjunto de imágenes (1 o más) inicializado por un frame tipo I.
• Contiene un número variable de P y B frames.
• Un GoP es autocontenido de cara al decodificador.
I B1 B2 B3 B4 B5 B6P1 P2
Frame # 0 1 2 3 4 5 6 7 8

Característiscas de un GoP
El standard deja casi todo al libre albedrío del codificador:
1. Cuando iniciar un grupo con un nuevo I frame: usualmente dictado por un cambio de escena (cuando no podemos sacar ventaja de frames anteriores).
2. Número de frames dentro del grupo: secuencias largas comprimen mejor, pero dificultan acceso aleatorio (para acceder a un frameindividual es preciso procesar otros frames).
3. Relación entre el numero de P y B frames: B frames suelen conseguir mejores compresiones, pero la estimación de sus parámetros se complica (al depender de dos imágenes).
Orden de los frames en el stream de datos
• Si se almacenasen los frames en el orden 0,1,2,3,4,5,6,7,8 en el que se van a mostrar tendríamos que leer la información de los frames 1, 2, 3, 4, y 5 (P) antes de poder decodificar frame 1 (que se apoya en el B5) y mostrarlo en pantalla.
• La información de los frames se almacena en el stream en el orden necesario para la decodificación, no para el display.
• En el ejemplo anterior almacenaríamos:
I, P_1, B_1, B_2, B_3, B_4, P_2, B_5, B_6
y siempre dispondríamos de la información necesaria para completar los frames que van llegando.
• Un decodificador debe disponer de memoria para al menos tres frames: uno pasado, uno presente y uno futuro.

Codificación de un GoP
• Cada GoP se segmenta en codificaciones separadas para cada frame que lo compone (en el orden antes indicado). C
• Cada imagen lleva una cabecera con información sobre el timing, tipo de frame, seguida de varias slices.
• Cada slice empieza con información de su posición en la imagen, información sobre la cuantificación usada y va seguido de 1 o más macrobloques.
• Un macrobloque lleva información de un bloque de 16 x 16 pixeles.
• La información se organiza en 6 bloques de datos: 4 bloques 8x8 para codificar la luminancia y 2 bloques 8x8 para codificar las dos bandas de crominancia (reducidas en un factor 2 en cada eje).
Codificación de un frame de tipo I
• Un frame I se codifica de forma autocontenida sin ninguna referencia a otros frames.
• Esencialmente es una codificación JPEG del frame en cuestión.
• El JPEG usado es una versión limitada de lo que se permite en imágenes, para facilitar su implementación.
• La imagen se divide en macrobloques de 16x16 píxeles y se pasa al espacio de color de Y Cr Cb (obligatorio). Las crominancias se submuestrean en un factor 2 dando lugar a 2 bloques de 8x8, que junto con los 4 bloques de luminancia forman el macrobloque.
• Los 6 bloques 8x8 de datos se codifican usando DCT, matrices Q de cuantificación y una tabla predefinida de códigos Huffman (no es preciso incluirlas en los datos, lo que consigue una mayor)

Codificación de un frame de tipo P
• Un frame P (predictive) se apoya parcialmente en framesanteriores, bien sean del tipo I o en otros P previos.
• Cada macrobloque es independientes, no todos tienen que apoyarse en el frame anterior.
• Algunos macrobloques se codifican de forma autocontenida(zonas de la imagen que entran nuevas y donde no se encuentran semejanzas a frames anteriores).
• Los macrobloques que si se apoyan en el frame anterior llevan un flag especial e información de un vector de movimiento.
• El vector de movimiento indica la posición del macrobloque del frame anterior en el que nos apoyamos.
• Un vector (-20, 4) indica que nos apoyamos en un macrobloque20 pixeles a la izda y 4 más abajo de nuestra posición actual.
Determinación del vector de Movimiento • Cuando estamos codificando un macrobloque de un frame P se trata de hallar el macrobloque del frame de apoyo que más se parezca al actual.
• En la práctica el rango permitido para el vector de movimiento (bits dedicados a codificarlo) y los bordes de la imagen limitan el rango de búsqueda.
• A pesar de todo, el espacio de búsqueda es de unos 10 millones de posibles candidatos.
• El standard MPEG deja todo en manos del codificador:
Zona de búsquedaTipo de búsqueda.Criterio de semejanza.

Codificación predictiva entre macrobloques
• Si no se encuentra un buen ajuste en la zona de búsqueda el macrobloque se codifica de forma autocontenida.
• Una vez determinado el vector de movimiento, el macrobloquedel frame de apoyo para el que se ha encontrado el mejor ajuste se resta del macrobloque actual.
• Las diferencias entre ambos macrobloques y no el macrobloqueoriginal es lo que pasa al proceso de formar los 6 bloques de datos, aplicar la DCT, cuantificar, etc.
• Si hay un buen ajuste entre macrobloques es posible que las diferencias sean nulas (por lo menos tras la cuantificación) y basta un símbolo especial de EOB para codificar el bloque completo.
Codificación de un frame de tipo B
En principio similar a los P-frames, pero mucho más complicado.
Un macrobloque de un frame B puede codificarse en base a :
1. el mismo, de forma autocontenida.2. un macrobloque de un P-frame o I-frame anterior.3. un macrobloque de un P-frame posterior.4. una media del macrobloque de un frame anterior y otro posterior.
Podemos tener 1(forward o backward) o 2 vectores de movimiento.
Aumenta la complejidad del codificador. Una búsqueda exhaustiva tendría ahora del orden de 10^7 x 10^7 candidatos.
Una establecido los macrobloques de apoyo el proceso es idéntico los P frames: se resta el macrobloque (o combinación) de apoyo del macrobloque actual y se procesan las diferencias.

Complejidad de un sistema MPEG
El Decompresor relativamente sencillo con pocas decisiones: decodificar los coeficientes, ir leyendo vectores de movimiento,recuperar los macrobloques de apoyo y regenerar cada macrobloque.
Implementar un compresor es una tarea muy compleja:
• Un sistema compresor en tiempo real debe restringir severamente sus capacidades:
Espacio de búsqueda de vectores de movimiento muy reducido.Secuencia predefinida de I,P y B frames, en vez de optimizar
su distribución.
• Un compresor off-line puede analizar una secuencia larga de frames (varias pasadas, etc) y decidir donde empezar y terminar los GoP, y donde usar P o B frames.


















