
Conceptos Básicos de Inferencia - Intervalos de confianza · Proceso inductivo que permite inferir...
45
Conceptos Básicos de Inferencia Intervalos de confianza Álvaro José Flórez 1 Escuela de Estadística Facultad de Ingenierías Febrero - Junio 2012
Transcript of Conceptos Básicos de Inferencia - Intervalos de confianza · Proceso inductivo que permite inferir...

Conceptos Básicos de InferenciaIntervalos de confianza
Álvaro José Flórez
1Escuela de EstadísticaFacultad de Ingenierías
Febrero - Junio 2012

Inferencia EstadísticaCuando obtenemos una muestra, conocemos las respuestas de cadauno de sus individuos. No obstante, en general, no tenemos suficientecon la información de la muestra. Queremos inferir a partir de losdatos de la muestra algunas conclusiones sobre la población que estarepresenta (Moore, 2005).
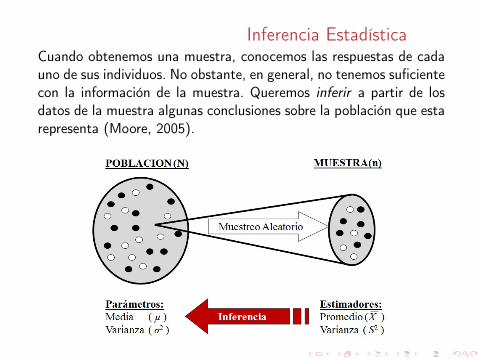
Inferencia EstadísticaCuando obtenemos una muestra, conocemos las respuestas de cadauno de sus individuos. No obstante, en general, no tenemos suficientecon la información de la muestra. Queremos inferir a partir de losdatos de la muestra algunas conclusiones sobre la población que estarepresenta (Moore, 2005).

Inferencia Estadística
Definición:Proceso inductivo que permite inferir acerca de una característicade la población proposiciones, usando información obtenida de unsubconjunto o una muestra de la población.
Ejemplo:Una empresa productora está interesada en conocer el gasto promediosemanal en alimentos de las familias de estrato socioeconómico bajo, conel fin de diseñar una estrategia de mercado para promover la demanda enel mercado.
En la ciudad hay una gran cantidad de familias de este perfil, y resulta casiimposible saber el gasto de cada una de estas familias. Por lo cual, se hacenecesario el uso de una muestra representativa para lograr el objetivo deestimar el parámetro poblacional (gasto promedio semanal de una familiade estrato socioeconómico bajo)

Inferencia Estadística
Definición:Proceso inductivo que permite inferir acerca de una característicade la población proposiciones, usando información obtenida de unsubconjunto o una muestra de la población.
Ejemplo:Una empresa productora está interesada en conocer el gasto promediosemanal en alimentos de las familias de estrato socioeconómico bajo, conel fin de diseñar una estrategia de mercado para promover la demanda enel mercado.
En la ciudad hay una gran cantidad de familias de este perfil, y resulta casiimposible saber el gasto de cada una de estas familias. Por lo cual, se hacenecesario el uso de una muestra representativa para lograr el objetivo deestimar el parámetro poblacional (gasto promedio semanal de una familiade estrato socioeconómico bajo)

Población
Se llama población objetivo al conjunto de elementos de interés enun estudio, sobre los cuales se desea información y hacia los cualesse extenderán las conclusiones. Esta población puede ser concreta(estar delimitada e identificada, en el sentido de saber quiénes cuálesson sus miembros) o puede ser hipotética.
• En un estudio de mercados se puede estar interesado en lasfamilias de estrato socieconómico bajo.
• En un estudio social se puede estar interesado en las personasque están desempleadas en la ciudad.
• En un estudio de calidad se puede estar interesado en loselementos producidos por una maquina.

Población
Se llama población objetivo al conjunto de elementos de interés enun estudio, sobre los cuales se desea información y hacia los cualesse extenderán las conclusiones. Esta población puede ser concreta(estar delimitada e identificada, en el sentido de saber quiénes cuálesson sus miembros) o puede ser hipotética.
• En un estudio de mercados se puede estar interesado en lasfamilias de estrato socieconómico bajo.
• En un estudio social se puede estar interesado en las personasque están desempleadas en la ciudad.
• En un estudio de calidad se puede estar interesado en loselementos producidos por una maquina.

Población
Se llama población objetivo al conjunto de elementos de interés enun estudio, sobre los cuales se desea información y hacia los cualesse extenderán las conclusiones. Esta población puede ser concreta(estar delimitada e identificada, en el sentido de saber quiénes cuálesson sus miembros) o puede ser hipotética.
• En un estudio de mercados se puede estar interesado en lasfamilias de estrato socieconómico bajo.
• En un estudio social se puede estar interesado en las personasque están desempleadas en la ciudad.
• En un estudio de calidad se puede estar interesado en loselementos producidos por una maquina.

Muestra Aleatoria
Una muestra es un subconjunto representativo de elementos obteni-dos de la población de interés.
¿Qué hace a una muestra representativa de la población?

Muestra Aleatoria
Una muestra es un subconjunto representativo de elementos obteni-dos de la población de interés.
¿Qué hace a una muestra representativa de la población?
La muestra debe conservar la estructura de las características y las rela-ciones que se quieren observar, que los alejamientos se deban solamente ala acción del azar (aleatoriedad)
el mecanismo de selección debe ser tal que se conozca la probabilidadque tiene cada unidad de la población de ser incluida en la muestra
Si una muestra no es aleatoria se puede estar tentado a elegir una muestraseleccionando los miembros más convenientes de la población, lo que puedellevar a una falsa idea sobre el valor del parámetro o una inadecuada tomade decisiones (Sesgo, sobre-estimación o sub-estimación del parámetro)

Muestra Aleatoria
Una muestra es un subconjunto representativo de elementos obteni-dos de la población de interés.
¿Qué hace a una muestra representativa de la población?
El tamaño también influye en la representatividad de la muestra, aunqueeste no está relacionado directamente con el tamaño de la población
El grado de homogeneidad, es decir la variabilidad de la característica deinterés, toma un papel importante en la definición del tamaño de muestra.El criterio que define si una muestra de un tamaño determinado, puedeconsiderarse como representativa, tiene relación también con el nivel deprecisión requerido.

Algunas otras definiciones
Variable:Característica de interés medible sobre cada elemento de la población.
Parámetro:Valor numérico constante que resume la característica de interés de todapoblación (µ, σ2)
Estadístico:Valor numérico que resume la característica de interés en unamuestra(X̄, S2)
En general, una estadística es una función de los datos de la muestra. Encaso de que se usen para hacerse idea (estimar) de los parámetros de unapoblación estos reciben el nombre de Estimadores

Estimación Puntual de un parámetro
Ejemplo:Para estimar el gasto promedio semanal en alimentos de familias deestratos bajos, se tomó una muestra aleatoria de tamaño 10 y losresultados (en miles de pesos) fueron: 70, 45, 50, 48, 40, 55, 66, 44,65. Por lo cual el promedio muestral (x̄ = $53,666) es un estimadorde la media teórica (µ)
Si:• El valor calculado de x̄ dificilmente nos da el valor exacto de µ• El valor de x̄ cambia cuando se toma otra muestra aleatoria
¿ Podemos estar seguros de que x̄ me proporcionaestimaciones confiables de la media poblacional ?

Estimación Puntual de un parámetro
Ejemplo:Para estimar el gasto promedio semanal en alimentos de familias deestratos bajos, se tomó una muestra aleatoria de tamaño 10 y losresultados (en miles de pesos) fueron: 70, 45, 50, 48, 40, 55, 66, 44,65. Por lo cual el promedio muestral (x̄ = $53,666) es un estimadorde la media teórica (µ)
Si:• El valor calculado de x̄ dificilmente nos da el valor exacto de µ• El valor de x̄ cambia cuando se toma otra muestra aleatoria
¿ Podemos estar seguros de que x̄ me proporcionaestimaciones confiables de la media poblacional ?
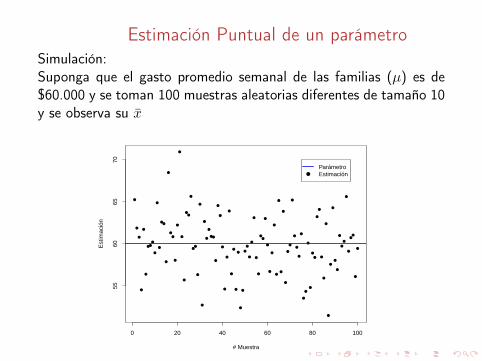
Estimación Puntual de un parámetroSimulación:Suponga que el gasto promedio semanal de las familias (µ) es de$60.000 y se toman 100 muestras aleatorias diferentes de tamaño 10y se observa su x̄
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
0 20 40 60 80 100
5560
6570
# Muestra
Est
imac
ión
●
ParámetroEstimación
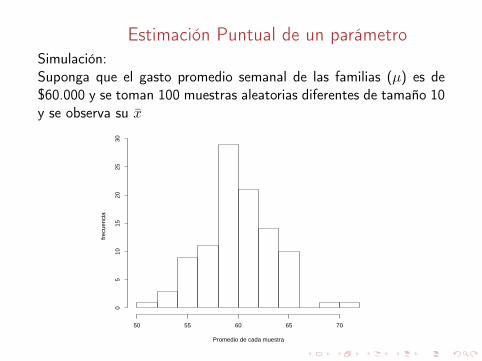
Estimación Puntual de un parámetroSimulación:Suponga que el gasto promedio semanal de las familias (µ) es de$60.000 y se toman 100 muestras aleatorias diferentes de tamaño 10y se observa su x̄
Promedio de cada muestra
frec
uenc
ia
50 55 60 65 70
05
1015
2025
30

Propiedades de un estimador
Puesto que cualquier estadístico puede ser usada para la estimaciónde un parámetro, es necesario que verificar que el estimador cumplacon unas propiedades para que pueda ser catalogado como un buenestimador. Algunas de estas son:
X Insesgamiento.X Eficiencia.X Consistencia.
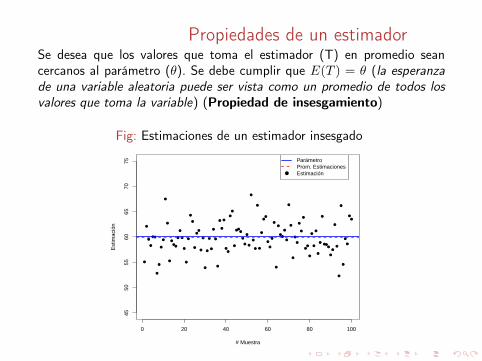
Propiedades de un estimadorSe desea que los valores que toma el estimador (T) en promedio seancercanos al parámetro (θ). Se debe cumplir que E(T ) = θ (la esperanzade una variable aleatoria puede ser vista como un promedio de todos losvalores que toma la variable) (Propiedad de insesgamiento)
Fig: Estimaciones de un estimador insesgado
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
0 20 40 60 80 100
4550
5560
6570
75
# Muestra
Est
imac
ión
●
ParámetroProm. EstimacionesEstimación
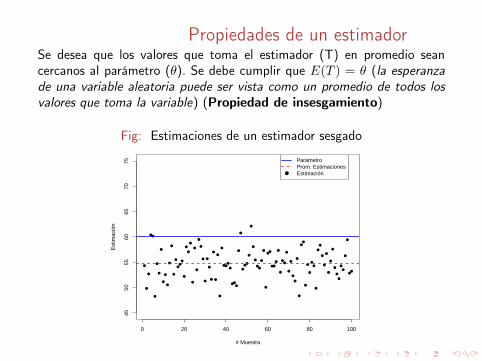
Propiedades de un estimadorSe desea que los valores que toma el estimador (T) en promedio seancercanos al parámetro (θ). Se debe cumplir que E(T ) = θ (la esperanzade una variable aleatoria puede ser vista como un promedio de todos losvalores que toma la variable) (Propiedad de insesgamiento)
Fig: Estimaciones de un estimador sesgado
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
0 20 40 60 80 100
4550
5560
6570
75
# Muestra
Est
imac
ión
●
ParámetroProm. EstimacionesEstimación
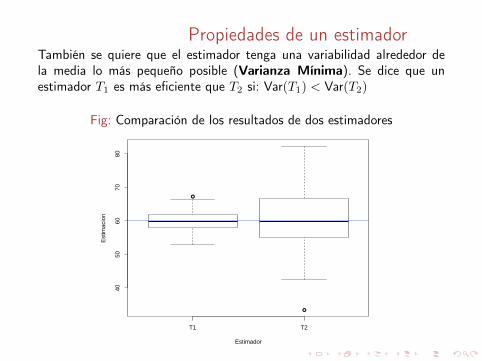
Propiedades de un estimadorTambién se quiere que el estimador tenga una variabilidad alrededor dela media lo más pequeño posible (Varianza Mínima). Se dice que unestimador T1 es más eficiente que T2 si: Var(T1) < Var(T2)
Fig: Comparación de los resultados de dos estimadores
●
●
T1 T2
4050
6070
80
Estimador
Est
imac
ion
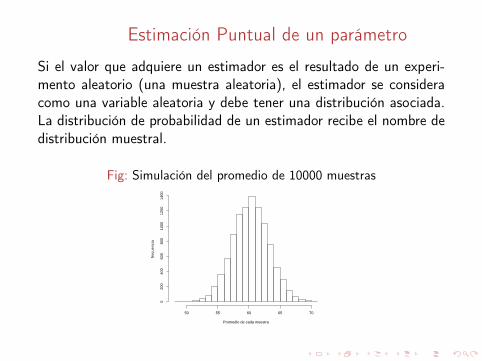
Estimación Puntual de un parámetro
Si el valor que adquiere un estimador es el resultado de un experi-mento aleatorio (una muestra aleatoria), el estimador se consideracomo una variable aleatoria y debe tener una distribución asociada.La distribución de probabilidad de un estimador recibe el nombre dedistribución muestral.
Fig: Simulación del promedio de 10000 muestras
Promedio de cada muestra
frec
uenc
ia
50 55 60 65 70
020
040
060
080
010
0012
0014
00

Distribución de la media muestral
Suponga que se toma una muestra aleatoria de tamaño n de unapoblación normal con media µ y varianza σ2 (conocida). Cada ob-servación xi, i = 1, . . . , n de la muestra tiene entonces la mismadistribución normal que la población que está siendo muestrada. Deaquí que:
X̄ =x1 + x2 + . . .+ xn
n
Tiene una distribución aproximadamente normal con media igual aµ y una varianza de σ2/n
X̄ ∼ Normal(µ,σ2
n
)

EjemploUna fabrica embotelladora de jugos emplea una maquina para enva-sarlo, la cual llena las botellas automáticamente con 16 onzas. Sinembargo, la cantidad de líquido que se vierte en cada botella puedediferir. El fabricante garantiza que la cantidad de líquido que se vierteen cada botella se aproxima a una distribución normal con media 16onzas y una desviación estándar de 1 onza.
¿Cuál es la probabilidad de que una botella sea llenada con menosde 15.5 onzas?
Si luego de tomar una muestra aleatoria de 10 botellas se encuentraque el promedio es inferior a 15.5 onzas ¿Usted dudaría de lo que el
fabricante le está afirmando?¿Y si la muestra es de 30 botellas?
¿Que puedo hacer si la distribución de los datos no es normal?

EjemploUna fabrica embotelladora de jugos emplea una maquina para enva-sarlo, la cual llena las botellas automáticamente con 16 onzas. Sinembargo, la cantidad de líquido que se vierte en cada botella puedediferir. El fabricante garantiza que la cantidad de líquido que se vierteen cada botella se aproxima a una distribución normal con media 16onzas y una desviación estándar de 1 onza.
¿Cuál es la probabilidad de que una botella sea llenada con menosde 15.5 onzas?
Si luego de tomar una muestra aleatoria de 10 botellas se encuentraque el promedio es inferior a 15.5 onzas ¿Usted dudaría de lo que el
fabricante le está afirmando?
¿Y si la muestra es de 30 botellas?
¿Que puedo hacer si la distribución de los datos no es normal?

EjemploUna fabrica embotelladora de jugos emplea una maquina para enva-sarlo, la cual llena las botellas automáticamente con 16 onzas. Sinembargo, la cantidad de líquido que se vierte en cada botella puedediferir. El fabricante garantiza que la cantidad de líquido que se vierteen cada botella se aproxima a una distribución normal con media 16onzas y una desviación estándar de 1 onza.
¿Cuál es la probabilidad de que una botella sea llenada con menosde 15.5 onzas?
Si luego de tomar una muestra aleatoria de 10 botellas se encuentraque el promedio es inferior a 15.5 onzas ¿Usted dudaría de lo que el
fabricante le está afirmando?¿Y si la muestra es de 30 botellas?
¿Que puedo hacer si la distribución de los datos no es normal?

EjemploUna fabrica embotelladora de jugos emplea una maquina para enva-sarlo, la cual llena las botellas automáticamente con 16 onzas. Sinembargo, la cantidad de líquido que se vierte en cada botella puedediferir. El fabricante garantiza que la cantidad de líquido que se vierteen cada botella se aproxima a una distribución normal con media 16onzas y una desviación estándar de 1 onza.
¿Cuál es la probabilidad de que una botella sea llenada con menosde 15.5 onzas?
Si luego de tomar una muestra aleatoria de 10 botellas se encuentraque el promedio es inferior a 15.5 onzas ¿Usted dudaría de lo que el
fabricante le está afirmando?¿Y si la muestra es de 30 botellas?
¿Que puedo hacer si la distribución de los datos no es normal?

Teorema Central del Límite
La suma de un gran numero de variables aleatorias independientestiende a seguir de manera asintótica una distribución normal,siempre que determinadas condiciones queden satisfechas
Importancia:La normalidad es fundamental en los procedimientos inferencialescomo son las estimaciones por intervalos de confianza, pruebas dehipótesis, pronósticos, entre otros procedimientos.
Uso de la normal como distribución de los errores aleatorios de me-dición. El error de medición esta compuesto de muchos errores pe-queños no observables que pueden considerarse aditivos

Teorema Central del Límite
La suma de un gran numero de variables aleatorias independientestiende a seguir de manera asintótica una distribución normal,siempre que determinadas condiciones queden satisfechas
Importancia:La normalidad es fundamental en los procedimientos inferencialescomo son las estimaciones por intervalos de confianza, pruebas dehipótesis, pronósticos, entre otros procedimientos.
Uso de la normal como distribución de los errores aleatorios de me-dición. El error de medición esta compuesto de muchos errores pe-queños no observables que pueden considerarse aditivos

Teorema Central del Límite
Sea X1, X2, Xn una sucesión de variables aleatorias independientese igualmente distribuidas con media µ y varianza σ2 <∞. Sea:
X̄ =
n∑j=1
Xj
n
Entonces, la sucesión de variables X̄1, X̄2, . . . converge en distribu-ción a una variable aleatoria con una distribución normal (cuando nes suficientemente grande) . Esto es,
X̄nd→ Normal
(µ,σ2
n
)

Ejemplo
Cierto fabricante de bombillos asegura que su producto tiene unavida media de 800 horas con una desviación estándar de 150 horas.Un distribuidor esta dispuesto a representar su producto si al efectuaruna prueba con 40 focos la duración media es superior a 750 horas.
Que probabilidad tiene el fabricante de cerrar el negocio si:
• Realmente la producción de bombillos tiene los parámetrosdeclarados.
• La verdadera duración media es de 700 horas con la mismadesviación estándar.
• La verdadera desviación estándar es de 300 horas (media igual,800).
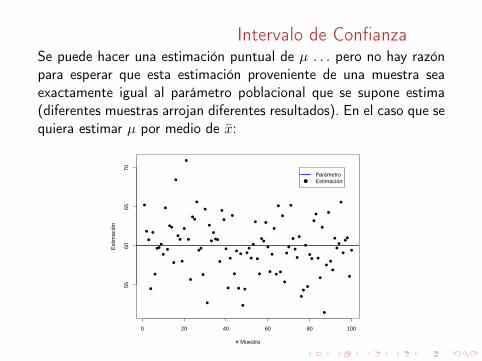
Intervalo de ConfianzaSe puede hacer una estimación puntual de µ . . . pero no hay razónpara esperar que esta estimación proveniente de una muestra seaexactamente igual al parámetro poblacional que se supone estima(diferentes muestras arrojan diferentes resultados). En el caso que sequiera estimar µ por medio de x̄:
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
0 20 40 60 80 100
5560
6570
# Muestra
Est
imac
ión
●
ParámetroEstimación

Intervalo de Confianza
Una estimación por intervalos para un parámetro poblacional es lla-mada un intervalo de confianza. No podemos estar seguros que elintervalo contiene al verdadero valor del parámetro poblacional des-conocido. Sin embargo, el intervalo de confianza es construido deforma que se tenga una alta confianza (probabilidad) de que el in-tervalo contenga el parámetro poblacional (?).
Definición: Dada una muestra aleatoria X1, . . . , Xn con función dedensidad f(xi, θ), un intervalo de confianza de (1−α)×100 % paraun parámetro θ es un intervalo aleatorio (T1, T2) con Pr(T1 < θ <T2) = 1− α.
Para la estimación de µ el intervalo de confianza estará determinadocomo:
x̄± Error de estimación

Intervalo de Confianza
Una estimación por intervalos para un parámetro poblacional es lla-mada un intervalo de confianza. No podemos estar seguros que elintervalo contiene al verdadero valor del parámetro poblacional des-conocido. Sin embargo, el intervalo de confianza es construido deforma que se tenga una alta confianza (probabilidad) de que el in-tervalo contenga el parámetro poblacional (?).
Definición: Dada una muestra aleatoria X1, . . . , Xn con función dedensidad f(xi, θ), un intervalo de confianza de (1−α)×100 % paraun parámetro θ es un intervalo aleatorio (T1, T2) con Pr(T1 < θ <T2) = 1− α.
Para la estimación de µ el intervalo de confianza estará determinadocomo:
x̄± Error de estimación

Intervalo de Confianza para µ
Si se tiene una muestra aleatoria x1, . . . , xn proveniente de una distribuciónnormal con media µ desconocida y σ2 conocida (o de cualquier distribuciónde probabilidad con un n suficientemente grande). Entonces, x̄ se distribuyenormalmente con media µ y varianza σ2/n. Además se tiene que:
Z =x̄− µσ/√n∼ Normal(0, 1)
Un intervalo de confianza para µ es un intervalo de la forma LI ≤ µ ≤ LS,donde LS y LI son calculados a partir de la muestra (Variables aleato-rias). Estos valores se determinan de tal forma que se cumpla la siguientecondición:
P (LI ≤ µ ≤ LS) = 1− α
Donde 0 ≤ α ≤ 1. Lo que indica que hay una probabilidad de 1 − α deque para la muestra seleccionada el intervalo de confianza contenga a µ

Intervalo de Confianza para µ
Si se tiene una muestra aleatoria x1, . . . , xn proveniente de una distribuciónnormal con media µ desconocida y σ2 conocida (o de cualquier distribuciónde probabilidad con un n suficientemente grande). Entonces, x̄ se distribuyenormalmente con media µ y varianza σ2/n. Además se tiene que:
Z =x̄− µσ/√n∼ Normal(0, 1)
Un intervalo de confianza para µ es un intervalo de la forma LI ≤ µ ≤ LS,donde LS y LI son calculados a partir de la muestra (Variables aleato-rias). Estos valores se determinan de tal forma que se cumpla la siguientecondición:
P (LI ≤ µ ≤ LS) = 1− α
Donde 0 ≤ α ≤ 1. Lo que indica que hay una probabilidad de 1 − α deque para la muestra seleccionada el intervalo de confianza contenga a µ
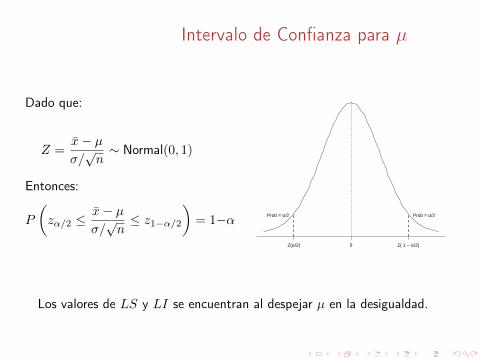
Intervalo de Confianza para µ
Dado que:
Z =x̄− µσ/√n∼ Normal(0, 1)
Entonces:
P
(zα/2 ≤
x̄− µσ/√n≤ z1−α/2
)= 1−α
0Z(α/2) Z( 1 − α/2)
Prob = α/2Prob = α/2
Los valores de LS y LI se encuentran al despejar µ en la desigualdad.

Intervalo de Confianza para µ
Si x̄ es la media muestral de una muestra aleatoria de tamaño nproveniente de una población normal (o de cualquier distribución sin es suficientemente grande) con varianza σ2 conocida, entonces elintervalo del (1− α)× 100 % para µ está dado por:
x̄+ zα/2σ√n≤ µ ≤ x̄+ z1−α/2
σ√n
• Se tiene probabilidad (1− α) de seleccionar una muestra aleatoriaque produzca un intervalo que contenga µ.
• A mayor nivel confianza mayor seguridad de que el intervalo dadocontiene a µ.

Intervalo de Confianza para µ
Si x̄ es la media muestral de una muestra aleatoria de tamaño nproveniente de una población normal (o de cualquier distribución sin es suficientemente grande) con varianza σ2 conocida, entonces elintervalo del (1− α)× 100 % para µ está dado por:
x̄+ zα/2σ√n≤ µ ≤ x̄+ z1−α/2
σ√n
• Se tiene probabilidad (1− α) de seleccionar una muestra aleatoriaque produzca un intervalo que contenga µ.
• A mayor nivel confianza mayor seguridad de que el intervalo dadocontiene a µ.

Ejemplo
Un fabricante produce pistones para motores de vehículos. Por es-pecificaciones del fabricante se sabe el diámetro de los pistones estánormalmente distribuido con σ = 0,01mm. Para realizar un controlde calidad sobre el producto se decide observar una muestra alea-toria de 15 pistones y se encontró que el promedio del diámetro de76,03mm.
• Construir un intervalo del 99% de confianza para la media deldiámetro de los pistones.
• Construir un intervalo del 95% de confianza para la media deldiámetro de los pistones.

Ejemplo
Un fabricante produce pistones para motores de vehículos. Por es-pecificaciones del fabricante se sabe el diámetro de los pistones estánormalmente distribuido con σ = 0,01mm. Para realizar un controlde calidad sobre el producto se decide observar una muestra alea-toria de 15 pistones y se encontró que el promedio del diámetro de76,03mm.
Para el caso del 99% el intervalo queda de la siguiente forma:
(76.02335; 76.03665 )
Lo que nos indica que con un 99% de confianza se puede concluirque el diámetro medio de los pistones está entre 76.02335mm y76.03665mm
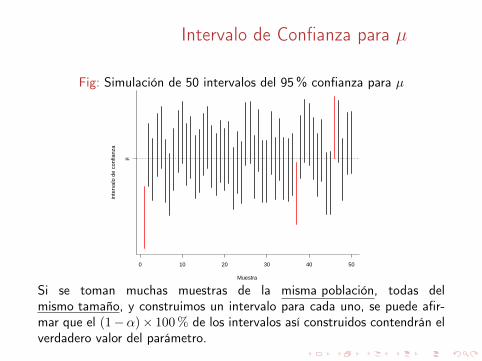
Intervalo de Confianza para µ
Fig: Simulación de 50 intervalos del 95% confianza para µ
Muestra
inte
rval
o de
con
fianz
a
0 10 20 30 40 50
µ
Si se toman muchas muestras de la misma población, todas delmismo tamaño, y construimos un intervalo para cada uno, se puede afir-mar que el (1−α)× 100 % de los intervalos así construidos contendrán elverdadero valor del parámetro.

Comportamiento de los intervalos deconfianza
Para estimar µ:
x̄± z1−α/2σ√n
Estimación ± Error de estimación
Es deseable tener un nivel de confianza alto y un error de estimaciónpequeño. El último se hace pequeño cuando:
• El nivel de confianza (1− α) se hace pequeño.• La variabilidad entre los elementos de la población es pequeña.(σ es pequeño).
• Se incrementa el tamaño de muestra.

Comportamiento de los intervalos deconfianza
Para estimar µ:
x̄± z1−α/2σ√n
Estimación ± Error de estimación
Este procedimiento es correcto sólo en circunstancias concretas:
• Los datos deben proceder de una muestra aleatoria.• La población de los datos debe ser normal.• Si la población no es normal, el tamaño de la muestra debe sergrande (teorema central del límite).
• Se tiene que tener conocimiento de la desviación estándar.

Ejemplo
Una compañía constructora resuelve estudiar la resistencia a la com-presión de una mezcla de concreto, con el objetivo de hacer controlde calidad. Para ello se tomaron 18 cilindros de prueba de acuerdocon las normas establecidas. Se encontró en la muestra que luegode 28 días de curado que x̄ = 280kg/cm2 y según la compañía ladesviación estándar del proceso es de 20 kg/cm2.
Construir un intervalo de confianza del 90% y del 96% para elvalor real de la resistencia a la compresión de la mezcla de concreto.

Bibliografía
Canavos, G. (1988). Probabilidad y Estadística: Aplicaciones y mé-todos. Mc Graw Hill, México, vol. 1 edition.
Devore, J. L. (2008). Probabilidad y estadística para ingeniería yciencias. Thomson Paraninfo, México, vol. 7 edition.
Gutierrez, A. and Zhang, H. (2010). Teoría Estadística: Aplicacionesy Métodos. Universidad Santo Tomás, Bogotá,Colombia, vol. 1edition.
Mayorga, J. H. (2004). Inferencia Estadística. Universidad Nacionalde Colombia, Bogotá,Colombia, vol. 1 edition.
Moore, D. S. (2005). Estadística aplicada básica. Antoni BoschEditor, Barcelona, España, vol. 2 edition.


















