
Correlaciones y Análisis de Regresión - rinace.net. Correlaciones y... · Correlaciones y...
14
5 Correlaciones y Análisis de Regresión = ∑ =1
Transcript of Correlaciones y Análisis de Regresión - rinace.net. Correlaciones y... · Correlaciones y...

5
Correlaciones y Análisis de Regresión
𝑟𝑥𝑦 =∑ 𝑥𝑖𝑦𝑖𝑛𝑖=1
𝑛𝑠𝑥𝑦𝑥

5. Correlaciones y Análisis de Regresión
F.J. Murillo y C. Martínez-Garrido Página 66
5. Correlaciones y Análisis de Regresión
En el tema 1 estudiamos y estimamos el índice de correlación de Pearson con Excel. Si
recordáis, con este índice se estimaba la relación entre dos variables cuantitativas (de intervalo
o de razón). En este tema 5 profundizaremos en el conocimiento de este índice, así como
otros, y abordaremos una poderosa estrategia de análisis basada en la correlación: el Análisis
de Regresión.
5.1. Correlación Lineal Bivariada
El índice de correlación es una estimación del grado en el que dos variables varían
conjuntamente. Esta correlación (o relación) puede ser lineal, curvilínea, logística... En
investigación educativa, la gran mayoría de las correlaciones que se trabajan son lineales, por
lo que nos centraremos en estas. Si la correlación se da entre dos variables se denomina
correlación simple o bivariada.
Dentro de las correlaciones lineales bivariadas tenemos diferentes índices o coeficientes,
dependiendo del tipo de variables que tengamos. Los más habituales y que nos ofrece el SPSS
en el cuadro "Correlaciones bivariadas" son:
Coeficiente de correlación de Pearson
Rho de Spearman
Tau-b de Kendall
El Coeficiente de Correlación de Pearson es el más utilizado para estudiar el grado de relación
lineal entre dos variables cuantitativas (de intervalo o de razón) y se obtiene mediante la
siguiente fórmula:
𝑟𝑥𝑦 =∑ 𝑥𝑖𝑦𝑖𝑛𝑖=1
𝑛𝑠𝑥𝑦𝑥
Como vimos en el tema 1, este coeficiente toma valores entre -1 y 1, con dos informaciones: el
sentido (positivo si es una relación directa y negativo si es inversa) y la intensidad (de 0 no
relación o independencia a 1 relación máxima o perfecta).
FIGURA 5.1. GRÁFICOS DE DISPERSIÓN CON TRES CORRELACIONES DIFERENTES
Correlación alta e inversa Correlación alta y directa Correlación nula (independencia)
0,0
500,0
1000,0
1500,0
0,000 50,000 100,000

5. Correlaciones y Análisis de Regresión
F.J. Murillo y C. Martínez-Garrido Página 67
e.5.1. ¿Hay relación en las calificaciones en Lengua y en Matemáticas?,
e.5.2. ¿El Nivel Socio-económico de los estudiantes está relacionado con el Rendimiento en
Matemáticas?
En el tema 1 lo vimos para unos pocos datos y con Excel. El SPSS no sólo nos da una estimación
de ese índice, sino que nos dice si esa relación es estadísticamente significativa. Es decir si lo
encontrado para la muestra puede ser extrapolable a la población.
De esta forma, la hipótesis que está validando es:
Ho: ρxy=0
H1: ρxy≠0
Como se señaló en el tema 3, los estadísticos (referidos a la población) se denotan con una
letra griega, en este caso “ρ”, mientras que los parámetros (referidos a la muestra) lo hacen
con letras latinas (r).
Vamos con los ejercicios propuestos. Se trata, en definitiva, de estimar el coeficiente de
correlación de Pearson entre Rendimiento y Matemáticas y Rendimiento en Lengua y entre
Rendimiento en Matemáticas y Nivel Socio-económico de las familias. Y, a continuación, saber
si esa correlación es estadísticamente significativa.
Elije en los menús: Analizar -> Correlaciones -> Bivariadas
FIGURA 5.2. CUADRO DE DIÁLOGO CORRELACIONES BIVARIADAS

5. Correlaciones y Análisis de Regresión
F.J. Murillo y C. Martínez-Garrido Página 68
1. Selecciona las tres variables que vamos a estudiar (Rdto_Matemáticas,
Rdto_Lengua y N_SocEc) e introdúcelas en "Variables".
2. Acepta, las opciones por defecto son las que nos interesan.
Lo que en realidad le hemos pedido es que nos calcule las correlaciones variadas de "todas con
todas", es decir la matriz de correlaciones donde nos aparecen las dos pedidas y una tercera
más.
TABLA 5.1. RESULTADOS DE LAS CORRELACIONES BIVARIADAS
Rendimiento en
Matemáticas Rendimiento en
Lengua
Nivel socio-económico de la
familia
Rendimiento en Matemáticas Correlación de Pearson 1 ,680** ,329**
Sig. (bilateral) ,000 ,000
N 6598 6598 6598
Rendimiento en Lengua Correlación de Pearson ,680** 1 ,338**
Sig. (bilateral) ,000 ,000
N 6598 6598 6598
Nivel socio-económico de la familia
Correlación de Pearson ,329** ,338** 1
Sig. (bilateral) ,000 ,000
N 6598 6598 6598
**. La correlación es significativa al nivel 0,01 (bilateral).

5. Correlaciones y Análisis de Regresión
F.J. Murillo y C. Martínez-Garrido Página 69
Como resultado, nos aparece la llamada "matriz de correlaciones", es decir todas las
correlaciones posibles entre las tres variables (tabla 5.1). Como puede observarse es una
matriz simétrica con unos en la diagonal. La información que contiene cada celda es:
1. Correlación Pearson: El coeficiente de correlación entre las dos variables que
aparecen en el encabezamiento de fila y de columna.
2. Sig: El nivel crítico (la significación) que indica la probabilidad de aceptar la Hipótesis
nula, es decir que la correlación sea 0.
3. N: El número de estudiantes utilizado para hacer cada análisis.
Como ya es habitual, comparamos el nivel crítico con nuestro nivel de confianza (α). Así:
Si Sig > α: aceptamos la Hipótesis Nula, luego no hay relación entre ambas variables.
Si Sig < α: rechazamos, la Hipótesis Nula, luego aceptamos la Alterna. Ello implica que
la correlación es significativa (estadísticamente diferente de 0).
En este caso, las tres correlaciones son estadísticamente significativas.
Como hemos señalado, el índice de correlación de Pearson exige que las variables sean
cuantitativas, pero también que se distribuyan normalmente. Si no se cumplen alguna de las
dos condiciones, o las dos, tenemos dos alternativas:
Tau-b de Kendall. Estima la relación entre dos variables ordinales. Se interpreta igual que el índice de Pearson.
Rho de Sperman, es igual que el coeficiente de correlación de Pearson, pero tras transformar las puntuaciones originales en rangos.
En ambos casos, el procedimiento de cálculo, las tablas de resultado y su interpretación son
exactamente igual que en el caso del Coeficiente de Correlación de Pearson.
5.2. Correlación parcial
Con la Correlación parcial es posible analizar la correlación lineal entre dos variables
controlando el efecto de otra u otras extrañas. Los coeficientes de Correlación Parcial, por
tanto, estiman el grado de relación lineal entre dos variables tras quitar el efecto de una
tercera, cuarta o quinta variable.
e.5.3. ¿El Clima de aula influye en el Rendimiento en Matemáticas de los estudiantes?
e.5.4. Y si restamos el efecto del Nivel Socio-económico de las familias, ¿sigue influyendo?
El procedimiento es sencillo:
Analizar -> Correlaciones -> Parciales

5. Correlaciones y Análisis de Regresión
F.J. Murillo y C. Martínez-Garrido Página 70
Se seleccionan las variables a correlacionar en "Variables" (Rend_Matematicas y Clima_aula), y
la variable a controlar en "Controlado para" (N_SocEc). El resultado es aparentemente igual
que el de la Correlación Lineal Bivariada, pero ya está descartada la influencia de la variable
controlada.
En este caso, si estimamos la Correlación Bivariada entre Clima de aula y Rendimiento en
Matemáticas, encontramos que la correlación es de la correlación es de 0,140
(estadísticamente significativo); y controlando por Nivel Socioeconómico de 0,100 (también
estadísticamente significativo). Es decir, el clima de aula incide en el rendimiento, incluso
controlando el efecto de nivel socio-económico.
5.3. Análisis de Regresión Simple
El análisis de regresión es una técnica que estudia la relación entre variables cuantitativas. Su
uso más habitual es la predicción (aunque, como luego veremos, tiene más utilidades), de tal
forma que a través del análisis de regresión es posible predecir una o varias variables a partir
del conocimiento de otra u otras relacionadas. La variables predictoras (o explicativas) son las
independientes y las pronosticadas (o explicadas) son las dependientes.
La situación más sencilla se da cuando sólo hay una variable independiente y otra
dependiente: entonces se llama Análisis de Regresión Simple; si son varias independientes es
el Análisis de Regresión Múltiple. Y si, como vimos en el apartado anterior, la relación es lineal,
tenemos una Análisis de regresión lineal (simple o múltiple).
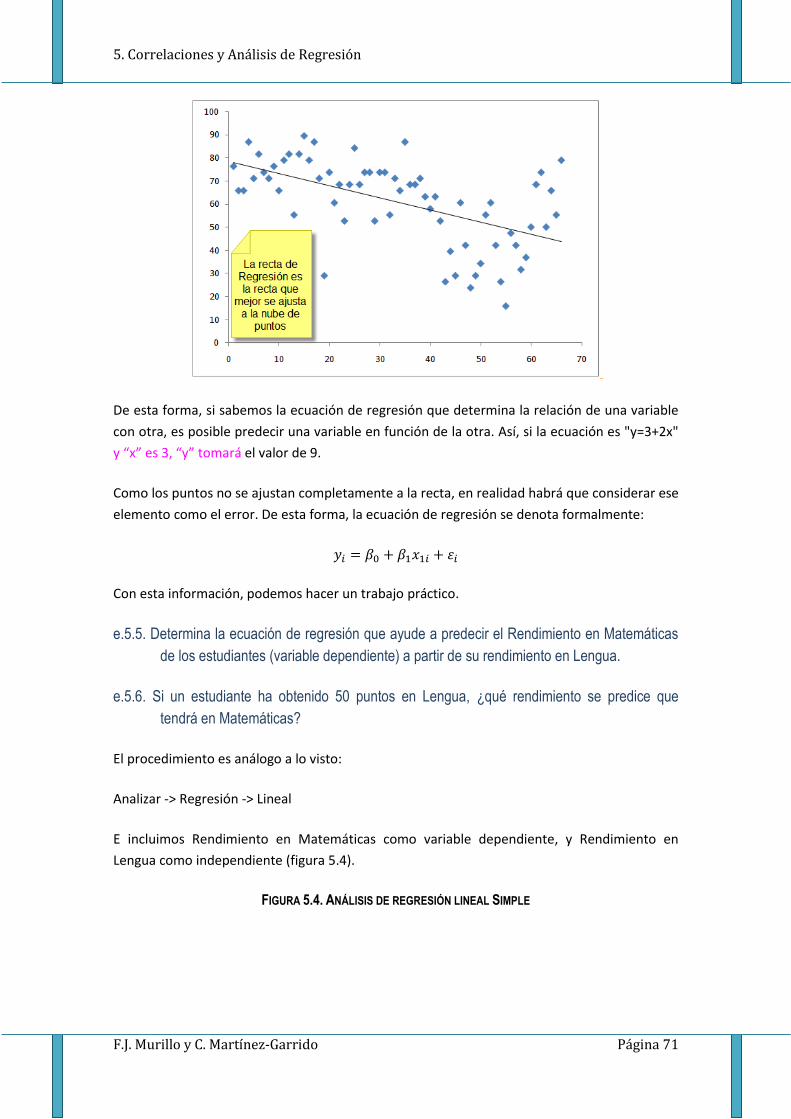
Veamos un poco la lógica del Análisis de Regresión. Si tenemos dos variables cuantitativas
sobre una misma muestra, podemos representarlas gráficamente mediante un gráfico de
dispersión (ver figura 5.3). Si, como vimos en el apartado 5.1, estas variables están
relacionadas, la nube de puntos que se genera tendrá una forma alargada. La recta que mejor
se ajusta a esos puntos, que minimiza las distancias, es la llamada Recta de regresión.
Dicha recta, como cualquier recta en el plano, puede escribirse algebraicamente como:
𝑦 = 𝑎 + 𝑏𝑥
en donde: y es la variable dependiente,
a es el punto de corte con el eje y (o intercepto),
b es la pendiente, y
x es la variable independiente
FIGURA 5.3. RECTA DE REGRESIÓN
5. Correlaciones y Análisis de Regresión
F.J. Murillo y C. Martínez-Garrido Página 71
De esta forma, si sabemos la ecuación de regresión que determina la relación de una variable
con otra, es posible predecir una variable en función de la otra. Así, si la ecuación es "y=3+2x"
y “x” es 3, “y” tomará el valor de 9.
Como los puntos no se ajustan completamente a la recta, en realidad habrá que considerar ese
elemento como el error. De esta forma, la ecuación de regresión se denota formalmente:
𝑦𝑖 = 𝛽0 + 𝛽1𝑥1𝑖 + 𝜀𝑖
Con esta información, podemos hacer un trabajo práctico.
e.5.5. Determina la ecuación de regresión que ayude a predecir el Rendimiento en Matemáticas
de los estudiantes (variable dependiente) a partir de su rendimiento en Lengua.
e.5.6. Si un estudiante ha obtenido 50 puntos en Lengua, ¿qué rendimiento se predice que
tendrá en Matemáticas?
El procedimiento es análogo a lo visto:
Analizar -> Regresión -> Lineal
E incluimos Rendimiento en Matemáticas como variable dependiente, y Rendimiento en
Lengua como independiente (figura 5.4).
FIGURA 5.4. ANÁLISIS DE REGRESIÓN LINEAL SIMPLE
5. Correlaciones y Análisis de Regresión
F.J. Murillo y C. Martínez-Garrido Página 72
Los resultados aportan la siguiente información (tabla 5.2).
TABLA 5.2. RESULTADOS DEL ANÁLISIS DE REGRESIÓN LINEAL SIMPLE
Variables introducidas/eliminadasb
Modelo Variables
introducidas Variables
eliminadas Método
1 Rendimiento en Lenguaa
. Introducir
a. Todas las variables solicitadas introducidas.
b. Variable dependiente: Rendimiento en Matemáticas
Resumen del modelo
Modelo R R cuadrado R cuadrado corregida
Error típ. de la estimación
1 ,680a ,462 ,462 13,376099
a. Variables predictoras: (Constante), Rendimiento en Lengua
ANOVAb
Modelo Suma de
cuadrados gl Media cuadrática F Sig.
1 Regresión 1013537,328 1 1013537,328 5664,751 ,000a
Residual 1180156,464 6596 178,920
Total 2193693,791 6597
a. Variables predictoras: (Constante), Rendimiento en Lengua
b. Variable dependiente: Rendimiento en Matemáticas
Coeficientesa

5. Correlaciones y Análisis de Regresión
F.J. Murillo y C. Martínez-Garrido Página 73
Modelo
Coeficientes no estandarizados Coeficientes tipificados
t Sig. B Error típ. Beta
1 (Constante) ,583 ,706 ,825 ,409
Rendimiento en Lengua ,769 ,010 ,680 75,265 ,000
a. Variable dependiente: Rendimiento en Matemáticas
Nos aparecen cuatro tablas:
1. La tabla Variables introducidas/eliminadas nos muestra las variables del modelo y el
método de incorporación de variables (que luego veremos)
2. La tabla Resumen del modelo aporta información de la bondad de ajuste, es decir, el
coeficiente de correlación múltiple y su cuadrado. En este caso como son sólo dos
variables es el coeficiente de correlación de Pearson que conocemos. La información
interesante es la R2, que es una estimación la proporción de varianza de la variable
dependiente explicada por la variable dependiente. Cuanta más alta sea esta cifra
mejor podremos predecir una variable en función de la otra. En nuestro caso 0,462; es
decir el 46,2% de las diferencias de las calificaciones en Matemáticas pueden ser
explicadas por les diferencias en Lengua.
3. La tabla ANOVA, nos aporta información sobre si existe o no relación significativa entre
la variable independiente y la dependiente. Como siempre, la información clave nos la
aporta el nivel crítico (Sig). Si es menor que nuestro α, concluimos que hay relación
significativa (diferente de 0) y por lo tanto que le ecuación de regresión tiene sentido.
4. La tabla Coeficientes nos aporta información sobre los coeficientes de la recta de
regresión. En dos formas:
Coeficientes no estandarizados, donde el coeficiente de la constante es el
intercepto o punto de corte y el coeficiente de la variable es la pendiente.
Coeficientes estandarizados, que son los obtenidos cuando la ecuación de
regresión se obtiene tras convertir las variables de origen en típicas. EN ese caso la
constante (o intercepto) es cero.
También se aporta información acerca de si los coeficientes de las variables hacen una
aportación significativa al modelo.
Es decir, con esta información, la ecuación de regresión solicitada es:
Ren_Mat = 0,583 + 0,769·Ren_Leng
De tal forma que un estudiante que obtenga 50 puntos en Lengua obtendrá 39,04 puntos en
Matemáticas.
Aunque hemos señalado que uno de los usos del Análisis de Regresión es la predicción, hay
más utilidades:

5. Correlaciones y Análisis de Regresión
F.J. Murillo y C. Martínez-Garrido Página 74
1. Descripción: Permite describir la relación entre la variable dependiente y la o las
variables predictoras.
2. Control: Posibilita controlar el comportamiento o variación de la variable de respuesta
de acuerdo a los valores que asumen las variables predictoras.
3. Identificación: Para determinar qué factores inciden en una variables dependiente de
forma conjunta.
e.5.5. Determina la ecuación de regresión que describa la relación entre Rendimiento en
Matemáticas de los estudiantes a partir del nivel Socio-económico de sus familias, ¿qué
porcentaje de varianza explica la variable dependiente?
Más adelante veremos los supuestos que exige el uso del análisis de regresión.
5.4. Análisis de Regresión Múltiple
Una sola variable independiente hace una pobre predicción de la variable independiente, por
lo que lo habitual es utilizar varias de ellas, es esta forma tenemos el Análisis de Regresión
Múltiple.
La esencia es la misma, la única diferencia es que la ecuación de regresión no es de una recta,
sino de un hiperplano en un espacio de múltiples dimensiones. Matemáticamente se expresa
así:
𝑦𝑖 = 𝛽0 + 𝛽1𝑥1𝑖 + 𝛽2𝑥2𝑖 + 𝛽3𝑥3𝑖 +⋯+ 𝛽𝑛𝑥𝑛𝑖 + 𝜀𝑖
Donde cada β es la pendiente de cada variable x.
Veámoslo con un ejemplo.
e.5.5. Estima la ecuación de regresión múltiple para Rendimiento en Matemáticas como variable
dependiente y Nivel socio-económico de las familias, Actitud hacia las Matemáticas y
Satisfacción con la escuela y Género como independientes.
Figura 5.5. Análisis de regresión lineal múltiple

5. Correlaciones y Análisis de Regresión
F.J. Murillo y C. Martínez-Garrido Página 75
Los resultados son análogos al análisis de regresión simple (tabla 5.3).
TABLA 5.3. RESULTADOS DEL ANÁLISIS DE REGRESIÓN LINEAL MÚLTIPLE
Modelo
Coeficientes no estandarizados Coeficientes tipificados
t Sig. B Error típ. Beta
1 (Constante) 50,555 ,658 76,795 ,000
Nivel socio-económico de la familia
5,623 ,205 ,308 27,405 ,000
Actitud hacia las matemáticas (en z)
3,809 ,210 ,209 18,161 ,000
Satisfacción del estudiante hacia el centro
1,796 ,211 ,098 8,524 ,000
Género del estudiante 1,140 ,412 ,031 2,769 ,006
a. Variable dependiente: Rendimiento en Matemáticas
La R2 o varianza explicada por el modelo es de 0,171, es decir estas tres variables explican el
17% de la variabilidad del Rendimiento en Matemáticas del estudiante.
La tabla Coeficientes indica, en primer término, que todos los coeficientes hacen una
aportación significativa (todos tiene un nivel crítico menor que nuestro α=0,05). También el
valor de esos coeficientes. Así, la ecuación de regresión pedida es:
Rend_Mat = 50,55 + 5,62·Niv_SEc + 3,8·Act_Mat + 1,79·Sac_Cen_Est + 1,14·Genero
Hemos incluido en el modelo la variable "Género" que obviamente no es cuantitativa sino
nominal dicotómica. Ello es posible, la única precaución es que tiene que estar codificada
como 0-1. De esta forma, toma el nombre de variable dummy y puede ser introducida en el
modelo.
5. Correlaciones y Análisis de Regresión
F.J. Murillo y C. Martínez-Garrido Página 76
Veamos cómo se interpreta esta ecuación de regresión. Con este ejemplo, los datos indican:
Un estudiante "medio" obtiene 50,55 puntos de rendimiento en Matemáticas (medio y
varón, como luego se verá),
por cada unidad de Nivel Socio-económico aumente o disminuya, aumentará o
disminuirá 5,62puntos su rendimiento (como está tipificada esa unidad es la deviación
típica),
por cada unidad de Actitud hacia las matemáticas aumente o disminuya, aumentará o
disminuirá 3,8 puntos su rendimiento,
por cada unidad de "Satisfacción hacia la escuela" aumente o disminuya, aumentará o
disminuirá 1,79puntos su rendimiento (como está tipificada esa unidad es la deviación
típica), y
si el estudiante es mujer (por que la variable está codificada 0 niño y 1 niña) su
puntuación aumentará 1,14 puntos.
Una precaución: si en un modelo de regresión algún coeficiente sale no significativo no es
suficiente dejarlo así, es preciso quitarlo del modelo y volver a estimar el nuevo modelo.
Métodos de selección de variables
El SPSS permite utilizar diferentes métodos para seleccionar qué variable independientes
incluir en el modelo de regresión y en qué orden. Por defecto, utiliza el método Introducir,
pero hay más (figura 5.6).
FIGURA 5.6. ANÁLISIS DE REGRESIÓN LINEAL MÚLTIPLE CON LAS DIFERENTES ALTERNATIVAS DE MÉTODOS DE
SELECCIÓN DE VARIABLES
Son los siguientes:

5. Correlaciones y Análisis de Regresión
F.J. Murillo y C. Martínez-Garrido Página 77
Introducir. Conforma la ecuación utilizando todas las variables independientes y en el
orden en que se le ha indicado. Es el método utilizado por defecto.
Pasos sucesivos. El SPSS selecciona qué variables formarán parte del modelo y en
qué orden. Así, selecciona en primer lugar la variable que más correlaciona con la
variable independiente y elabora el modelo 1. Con la varianza que queda por
explicar, selecciona la variable que más explica y la introduce en la ecuación
formando el modelo 2, y así sucesivamente hasta que ninguna variable hace una
aportación significativa. Es el procedimiento más cómodo y por ello el más popular.
Eliminar: Elimina en un solo paso todas las variables independientes y ofrece los
coeficientes que se obtendrían en el caso de que se utilizaran independientemente.
Atrás (eliminación hacia atrás). Por el mismo, se introducen todas las variables en la
ecuación y después se van excluyendo una tras otra. Aquella variable que tenga la
menor correlación parcial con la variable dependiente será la primera en ser
considerada para su exclusión. Si satisface el criterio de eliminación, será eliminada.
Tras haber excluido la primera variable, se pondrá a prueba aquella variable, de las
que queden en la ecuación, que presente una correlación parcial más pequeña. El
procedimiento termina cuando ya no quedan en la ecuación variables que satisfagan
el criterio de exclusión.
Adelante (selección hacia adelante). Las variables independientes son introducidas
secuencialmente en el modelo. La primera variable que se considerará para ser
introducida en la ecuación será aquélla que tenga mayor correlación, positiva o
negativa, con la variable dependiente. Dicha variable será introducida en la ecuación
sólo si satisface el criterio de entrada. Si ha entrado la primera variable, se
considerará como próxima candidata la variable independiente que no esté en la
ecuación y cuya correlación parcial sea la mayor. Cuando no queden variables que
satisfagan este criterio el procedimiento termina.
e.5.6. Estima la ecuación de regresión múltiple para Rendimiento en Matemáticas como variable
dependiente y Nivel socio-económico de las familias, Actitud hacia las Matemáticas y
Satisfacción con la escuela y Género como independientes, con el método Pasos
Sucesivos.
Supuestos del Análisis de Regresión Lineal
Esta técnica estadística, como todas, exige el cumplimiento de una serie de supuestos sin cuyo
cumplimiento los resultados pueden verse seriamente alterados. Aunque este texto no
pretende ser un libro de estadística, se señalarán por su importancia:
Linealidad. Si la relación entre las variables no es una línea (un hiperplano) el
resultado puede ser erróneo: puede señalar no relación cuando la hay. La forma de
estudiarlo es mediante un gráfico de dispersión.

5. Correlaciones y Análisis de Regresión
F.J. Murillo y C. Martínez-Garrido Página 78
Independencia: Los residuos1 (es decir, la diferencia entre el valor esperado y el
pronosticado) deben ser independientes entre sí. Es decir, los residuos son una
variable aleatoria. Se verifica mediante el estadístico Durbin-Watson (recuadro de
diálogo Regresión ->Lineal-> Estadísticos)
Normalidad. Los residuos de cada variable independiente se distribuyen como una
curva normal con media 0. Hay varios procedimientos, pero uno de ellos es estimar la
prueba de Kolmogorov-Smirnov (ya vista) para los residuos. Una comprobación visual
nos la ofrece este mismo menú: Regresión -> Lineal -> Gráficos.
Homocedasticidad. La varianza de los residuos de las variables independientes (o de
la combinación de ellos) es constante. Se obtiene representando los valores
pronosticados (ZPRED) y los residuos (ZRESID): si no hay ninguna pauta es que son
homocedásticos.
No-colinealidad. No existencia de una relación lineal entre ninguna ni las variables
independientes. Se estudia mediante la opción "Diagnóstico de colinealidad" en
Regresión -> Lineal -> Estadísticos.
5.6. Ejercicios
e.5.7. ¿Los alumnos más contentos con la escuela obtiene mejor rendimiento en Lengua? ¿Y si
contralamos el efecto del nivel socio-económico de las familias?
e.5.8. ¿Cuál es la variable que más varianza del rendimiento en Lengua de los estudiantes
explica? ¿Cuánto es?
e.5.9. Con las variables de la base de datos de trabajo, elabora el modelo de regresión lineal que
más varianza del rendimiento en Matemáticas de los estudiantes explique (sin incluir los
otros rendimientos).
e.5.10. Elabora el modelo "lógico" que explique la autoestima de los estudiantes con los datos
que se poseen.
e.5.11. Elabora el mejor modelo de regresión que explique Rendimiento en Ciencia Naturales
con tres variables independientes y verifica el cumplimiento de los supuestos.
1 Los residuos (o residuales) se pueden guardar mediante el cuadro de diálogo Regresión -> Lineal -> Guardar


















