
Portafolio de Evidencias de Estructura y Organizaciones Internacionales.

ING. SISTEMAS COMPUTACIONALES
Docente: Niels Henryk Aranda Cuevas
Alumna: Marleni Tuyub Che
Instituto Tecnológico Superior de Felipe Carrillo Puerto

Unidad 2recursividad

2.1 Definición
La recursividad es una técnica de programación importante, se utiliza para realizar una llamada a una función desde
la misma función
2.2 procedimiento recursivos
Los procedimientos recursivos o recurrentes se pueden clasificar en dos formas distintas:
- Recursividad directa o
- Recursividad indirecta
La recursividad directa se presenta cuando el método se manda llamar a sí mismo dentro de su propio cuerpo de
instrucciones.
public int Metodo(int n)
{
:
n = Metodo(n-1);
}
La recursividad indirecta se manifiesta cundo un método llama a otro y dentro del segundo se manda llamar al
primero. O cuando existe la llamada a métodos de forma encadenada y al terminar el último método llamado,
transfiere el control al anterior, hasta llegar al método que inicio la serie de llamadas.

public int Metodo1(int n)
{
:
n = Metodo2(n-1);
}
public int Metodo2(int n)
{
:
n = Metodo1(n-1);
}
Analizando el concepto de recursividad y su clasificación, puede indicar que es un
procedimiento infinito, que solo se detendrá en el momento que se agote la memoria,
generando un error de programación y la interrupción del mismo.
Pero esto no es así, ya que debe existir un elemento que indica el retorno de un
resultado concreto y no el retorno de la llamada al método recursivo o recurrente.
Funcionamiento del proceso
n Llamado a factorial
4 4*factorial(3)
3 3*factorial(2)
2 2*factorial(1)
1 1*factorial(0)
0 1

Imprimir de manera recursiva la serie de fibonnaci
Fibonnacci de manera recursiva
Fibonacci(0,1,21)=1
Fibonacci(1,1,21)=2
Fibonacci(1,2,21)=3
Fibonacci(2,3,21)=5
Fibonacci(3,5,21)=8
Fibonacci(5,8,21)=13
Fibonacci(8,13,21)=21
Realizar de manera recursiva la potencia de un número para n.
24 2*potencia(2*potencia(2*potencia(2*potencia(2,0))
Potencia(2,4)=2*potencia(2,3)=16
Potencia(2,3)=2*potencia(2,2)=8
Potencia(2,2)=2*potencia(2,1)=4
Potencia(2,1)=2*potencia(2,0)=2
Potencia(2,0)=1

conclusión
se llama a una función recursiva es llamar una función en si misma para resolver un problema. En realidad la
función sólo sabe cómo resolver el(los) caso(s) más sencillo(s), o lo que se conoce como base(s).Si a la función
se le llama con el caso base, la función sencillamente devuelve el resultado. Si a la función se le llama con un
problema más complicado, la función divide el problema en partes conceptuales, la parte que la función sabe
cómo resolver y la parte que la función o resolver.

Unidad 3
Estructura lineales

Operaciones asociadas con la pila
Crear la pila
Ver si la pila esta vacía
Insertar elementos en la pila
Eliminar un elemento de la pila
Vaciar la pila
Pilas
Una pila, es una estructura de datos en la que el último elemento en entrar es el primero en salir, por lo
que también se denominan estructuras LIFO (Last In, First Out) o también estructuras lineales con una
política UEPS (Ultimo en entrar, primero en salir).
En esta estructura sólo se tiene acceso a la cabeza o cima de la pila, también solo se pueden insertar
elementos en la pila cuando esta tiene espacio y solo se pueden extraer elementos de la pila cuando
tenga valores
Representacion grafica de la operación de una pila

Las operaciones básicas en una pila son push y pop
· - Push permite insertar un elemento a la pila
· - Pop extrae un elemento de la pila
La forma de implementar una pila es a través de:
· - Por medio de un arreglo unidimensional
· - A través de la clase Stack de la java.util.*
· - Con una lista de elementos.
Pilas a través de la clase Stack.
Stack (Pila) es una subclase de Vector que implementa una pila estándar; ultimo en
entrar, primero en salir.
Stack solo define el constructor por defecto, que crea una pila vacía. Stack incluye
todos los métodos definidos por vector y añade varios métodos propios:

Colas
Una cola, es una estructura de datos lineal que permite almacenar elementos por un extremo y extraerlos
por el otro. Por tal motivo, es una estructura FIFO
Al igual que en las pilas, se debe tener el control de la cola, tomando en cuenta de que si se quiere
extraer un elemento de la cola se debe asegurar de que no esté vacía, o si se quiere insertar un elemento
se debe asegurar de que la cola no esté llena, estas dos acciones se deben desarrollar al hacer
operaciones con una cola. Las operaciones que aplican a una cola son:
- Crear una cola.
- Revisar si la cola está vacía.
- Revisar si la cola está llena.
- Insertar un elemento en la cola.
- Extraer un elemento de la cola.
- Revisar cuál es el siguiente elemento en la cola.

Listas enlazadas
Una lista enlazada o estructura ligada, es una estructura lineal que almacena una colección de elementos generalmente
llamados nodos, en donde cada nodo puede almacenar datos y ligas a otros nodos. De esta manera los nodos pueden
localizarse en cualquier parte de la memoria, utilizando la referencia que lo relaciona con otro nodo dentro de la
estructura.
Las listas enlazadas son estructuras dinámicas que se utilizan para almacenar datos que están cambiando constante
mente. A diferencia de los vectores, las estructuras dinámicas se expanden y se contraen haciéndolas más flexibles a la
hora de añadir o eliminar información.
Las listas enlazadas permiten almacenar información en posiciones de memoria que no sean contiguas; para almacenar
la información contienen elementos llamados nodos. Estos nodos poseen dos campos uno para almacenar la información
o valor del elemento y otro para el enlace que determina la posición del siguiente elemento o nodo de la lista.
Lo más recomendable y flexible para la creación de un nodo es utilizar un objeto por cada nodo, para ello debe
comprender cuatro conceptos fundamentales que son:
- Clase auto-referenciada,
- Nodo,
- Campo de enlace y
- Enlace
Una clase auto-referenciada es una clase con al menos un campo cuyo tipo de referencia es el nombre de la misma
clase.
public clase Nodo
{
Object elemento;
Nodo siguiente;
//métodos
}

Las listas enlazadas se dividen en:
- Listas enlazadas simples (con una sola dirección) y
- Listas enlazadas dobles (con dos direcciones).
Simples
Una lista enlazada simple es una colección de nodos que tienen una sola dirección y que en conjunto forman una
estructura de datos lineal. Cada nodo es un objeto compuesto que guarda una referencia a un elemento (dato) y
una referencia a otro nodo (dirección).
La referencia que guarda un nodo a otro nodo se puede considerar un enlace o un puntero hacia el segundo
nodo y el salto que los relaciona recibe el nombre de salto de enlace o salto de puntero. El primer nodo de una
lista recibe el nombre de cabeza, cabecera o primero y el último es llamado final, cola o último (es el único nodo
con la referencia a otro objeto como nula).
Un nodo de una lista enlazada simple puede determinar quien se encuentra después de él pero no puede
determinar quien se encuentra antes, ya que solo cuenta con la dirección del nodo siguiente pero no del anterior.
cabezafinal

Dobles.Una lista enlazada doble es una colección de nodos que cuentan con dos direcciones en cada uno de sus nodos y
que en conjunto forman una estructura de datos lineal. Cada nodo es un objeto compuesto que guarda una
referencia a un elemento (dato), una referencia al nodo anterior (dirección predecesora) y una referencia al nodo
siguiente (dirección sucesora).
Un nodo de una lista enlazada doble puede determinar quien se encuentra después de él y quien se encuentra antes
de él, ya que cuenta con las direcciones de los nodos siguiente y anterior.
Operaciones
Inserción (Al final del la lista, al inicio de la lista y en cierta posición de la lista)
Recorrido (Por el inicio y por el final)
Eliminación (Del inicio de la lista, del final de la lista y de cierta posición de la lista).

CONCLUSIÓN
La lista enlazada nos permite almacenar datos de una forma organizada, pero, a diferencia de estos, esta
estructura es dinámica, en una lista enlazada , cada elemento apunta al siguiente excepto el ultimo que no
tiene sucesor y el valor del enlace es null suelen recibir también el nombre de nodos de la lista.

Unidad 4Estructuras no lineales
ARBOLES
Un árbol es una estructura de datos homogénea, dinámica y no lineal, en la que cada nodo (elemento)
puede tener varios nodos posteriores, pero solo puede tener un nodo anterior
Un árbol es dinámico porque su estructura puede cambiar durante la ejecución de un programa. Y no lineal, ya
que cada nodo del árbol puede contener varios nodos que dependan de él.
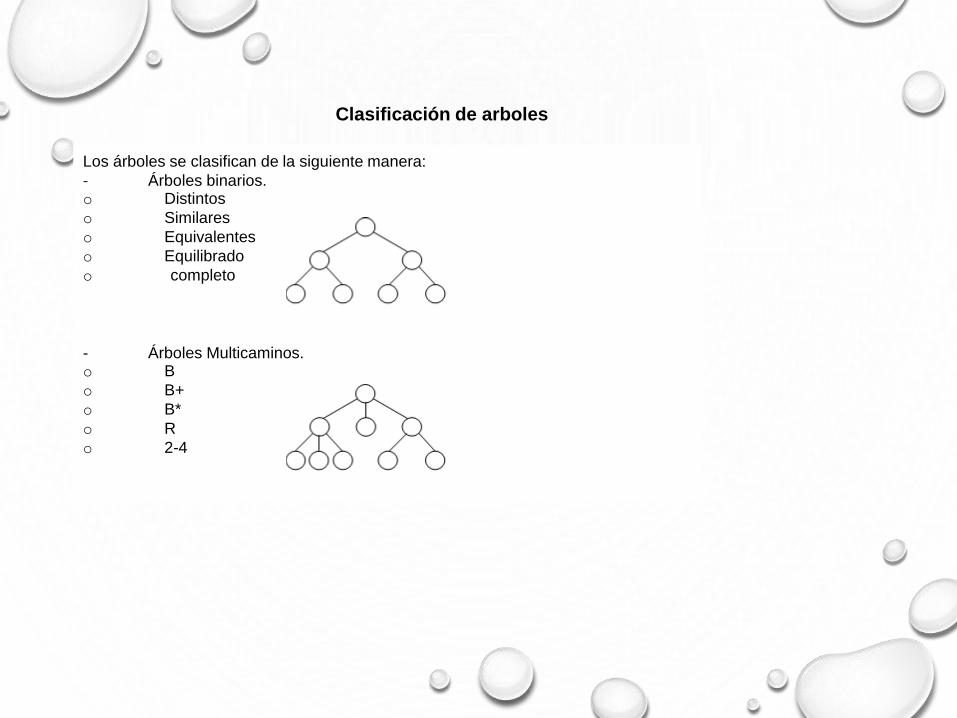
Los árboles se clasifican de la siguiente manera:
- Árboles binarios.o Distintos
o Similares
o Equivalentes
o Equilibrado
o completo
- Árboles Multicaminos.o B
o B+
o B*
o R
o 2-4
Clasificación de arboles

OPERACIONES BÁSICAS SOBRE ÁRBOLES BINARIOS.
las operaciones que se pueden aplicar a un árbol binario son las siguientes:
1-Creación de un árbol
public class nodob
{
object elemento;
nodob padre, izquierdo, derecho;
//métodos
}
2-inserción de un nodo árbol
permite agregar un nuevo nodo hoja al árbol, pero antes de agregarlo, debemos tomar en cuenta como se hace el acomodo u organización de los nodos dentro de la estructura del árbol. el primer nodo que entra en el árbol se le conoce como nodo raíz, del cual se desprendes los nodos intermedio y hojas.

3-Eliminación de un nodo.
la operación de eliminación de un nodo consiste en borrar el nodo del árbol binario de una forma definitiva, para este proceso la relación del nodo que se quiere eliminar con otros nodos debe desaparecer, pero que sucede con los nodos que dependen del nodo que se quiere eliminar. para esto analizaremos los tres casos de eliminación en un árbol binario:
4- recorrido del árbol.
Recorrer significa visitar cada uno de los nodos de un árbol exactamente una sola vez, este proceso puede interpretarse como poner todos los nodos en una línea o linealizar el árbol.existen tres formas de efectuar el recorrido y todas son de manera recursiva:a) recorrido en preorden· visitar la raíz· recorrer el subárbol izquierdo· recorrer el subárbol derechob) recorrido en inorden· recorrer el subárbol izquierdo· visitar la raíz· recorrer el subárbol derechoc) recorrido en postorden· recorrer el subárbol izquierdo· recorrer el subárbol derecho· visitar la raíz
Recorrido Preorden: 34,10,25,56,46,82Recorrido Inorden: 10,25,34,46,56,82Recorrido Postorden: 25,10,46,82,56,34

5- balanceo del árbol
Un árbol binario se encuentra balanceado si la diferencia en la altura de los dos subárboles de cualquier nodo en
el árbol es cero o uno
El árbol izquierdo se encuentra balanceado ya que la diferencia en la altura entre sus dos
subárboles (izquierdo y derecho) es 1. En cambo el árbol de la derecha no se encuentra balanceado ya que la
diferencia en la altura entre sus dos subárboles es 2.
APLICACIONESUn árbol es una estructura de datos útil cunado se trata de hacer modelos de procesos en donde se requiere tomar
decisiones en uno de dos sentidos en cada parte del proceso. Por ejemplo, supongamos que tenemos un arreglo
en donde queremos encontrar todos los duplicados. Esta situación es bastante útil en el manejo de las bases de
datos, para evitar un problema que se llama redundancia
• Si el elemento del arreglo es igual que la información del nodo raíz, entonces notificar duplicidad
• Si el elemento del arreglo es menor que la información del nodo raíz entonces se crea un hijo izquierdo
• Si el elemento del arreglo es mayor que la información del nodo raíz, entonces se crea un hijo derecho

arboles balanceados AVL
los arboles AVL fueron nombrados por sus desarrolladores Adel’ son-vel’skii y Landis probablemente la principal característica de los arboles AVL es su excelente tiempo de ejecución para las diferentes operaciones (búsquedas, altas y bajas).
Grafos
los grafos son un conjunto de puntos, de los cuales algún par de ellos esta conectado por unas líneas. Si estas líneas son flechas . Mientras que si son simples líneas estamos ante un grafo no dirigido se puede definir como un conjunto de vértices y un conjunto de aristas. Cada arista es un par (u,v) donde u y v pertenecen al conjunto de vértices
operaciones básicas de los grafos
operaciones básicas de los grafos
Insertar arista
Eliminar vértice
Eliminar arista

un árbol binario se define como un conjunto finito de elementos llamados nodos. los nodos de un árbol;
y que un árbol puede ser implementado fácilmente en una computadora. es bueno hacer énfasis en
esto ya que entre las cosas que podemos mencionar se encuentra la raíz, los nodos de un árbol y la
diferencia entre nodos sucesores y nodos terminales, como se muestran en el contenido del trabajo.

ordenamiento interno
ordenar significa reagrupar o reorganizar un conjunto de datos u objetos en una secuencia especifica, la cual puede ser de dos formas distintas:- ascendente (menor a mayor) o- descendente (mayor a menor).
la ordenación interna o de arreglos, recibe este nombre ya que los elementos o componentes del arreglo se encuentran en la memoria principal de la computadora.los métodos de ordenación interna a su vez se clasifican en:- métodos directos (n2) y- métodos logarítmicos (n * log n).
Métodos de ordenamiento

Burbuja
es el más simple y consiste en comparar dos elementos adyacentes para determinar si se realiza un intercambio entre los mismos, esto en caso de que el primero sea mayor que el segundo (forma ascendente) o el caso de que el primero sea menor que el segundo (forma descendente).el primer procedimiento del método de la burbuja es:
1-generar un ciclo que inicie desde uno hasta el número de elementos del arreglo.generar un segundo ciclo dentro del anterior que inicie desde cero hasta el número de elementos del arreglo menos dos.
2-dentro del segundo ciclo debe existir una comparación que determina el tipo de ordenamiento (ascendente o descendente) entre el primer elemento (posición generado por el segundo ciclo) y el segundo elemento (el que le sigue), si la respuesta a la condición es verdadera se realiza un intercambio entre los dos elementos.
3-para realizar el intercambio se genera un almacenamiento temporal, el cual guarda el dato del primer elemento, el segundo elemento toma el lugar del primero y en el lugar del segundo se coloca lo que contiene el almacenamiento temporal.

Quicksort
es una técnica basada en otra conocida con el nombre divide y vencerás, que permite ordenar una cantidad
de elementos en un tiempo proporcional a n2 en el peor de los casos o a n log n en el mejor de los casos. El
algoritmo original es recursivo, como la técnica en la que se basa.
La descripción del algoritmo para el método de ordenamiento quicksort es la siguiente:
1-Debe elegir uno de los elementos del arreglo al que llamaremos pivote.
2-Debe acomodar los elementos del arreglo a cada lado del pivote, de manera que del lado izquierdo
queden todos los menores al pivote y del lado derecho los mayores al pivote; considere que en este
momento, el pivote ocupa exactamente el lugar que le corresponderá en el arreglo ordenado.
3-Colocado el pivote en su lugar, el arreglo queda separado en dos subarreglos, uno formado por los
elementos del lado izquierdo del pivote, y otro por los elementos del lado derecho del pivote.
4-Repetir este proceso de forma recursiva para cada subarreglo mientras éstos contengan más de un
elemento. Una vez terminado este proceso todos los elementos estarán ordenados.

Shellsort
El método de ordenación Shellsort es una versión mejorada del método de ordenación por inserción directa, que
se utiliza cuando el número de elementos es grande. Este método recibe su nombre gracias a su creados
Donald L. Shell, también se conoce con el nombre inserción con incrementos decrecientes.
En el método de ordenación por inserción directa, cada elemento se compara con los elementos contiguos de su
izquierda de uno por uno, para lograr su ordenamiento; si por ejemplo, el elemento a comparar es el más
pequeño y se encuentra en la última posición del arreglo, hay que ejecutar muchas comparaciones antes de
colocar el elemento en su lugar de forma definitiva.
Radix
El método de ordenación radix es un algoritmo que ordena datos procesando sus elementos de forma individual,
según la posición que ocupan dentro del dato. Los datos numéricos los por dígitos y los datos alfabéticos por
letras.
El método radix se clasifica en dos tipos según el orden en el que procesan los datos:
- De derecha a izquierda y
- De izquierda a derecha.
Si aplicamos este método solo a enteros, el método se clasificaría de la siguiente manera:
- El digito menos significativo (LSD, Least Significat Digit) y
- El digito más significativo (MSD, More Significat Digit).
El radix LSD procesa los enteros iniciando por el digito menos significativo y moviéndose al digito más
significativo (de derecha a izquierda).
El radix MSD procesa los enteros iniciando por el digito más significativo y moviéndose al digito menos
significativo (de izquierda a derecha).

Ordenación externa
La ordenación externa o de archivos, recibe este nombre ya que los elementos se encuentran almacenados en un
archivo, el cual se almacena en un dispositivo de almacenamiento secundario o externo.
Los algoritmos de ordenación externa son necesarios cuando los datos que se quiere ordenar no cabe en la
memoria principal (RAM) de la computadora y por tal motivo se encuentran almacenados en un dispositivo
secundario externo (el disco duro, cinta, memoria USB, etc.). La mayoría de estos algoritmos utilizan la técnica de
divide y vencerás y la intercalación de archivos, para aplicar el ordenamiento.
Intercalación
Por intercalación de archivos se entiende la unión o fusión de dos o más archivos, previamente ordenados, en un
solo archivo, el cual debe quedar ordenado al hacer la intercalación.
La intercalación directa o mezcla directa es un algoritmo de ordenación externa, que permite organizar los elementos
de un archivo, de forma ascendente o descendente.
La idea centrar de este algoritmo consiste en realizar de forma sucesiva una partición y una fusión que produce
secuencias ordenadas de longitud cada vez mayor. En la primera pasada la partición es de longitud 1 y la fusión
produce secuencias ordenadas de longitud 2. En la segunda pasada la partición es de longitud 2 y la fusión produce
secuencias ordenadas de longitud 4. Este proceso se repite hasta que la longitud de la partición sea menor o igual al
número de elementos del archivo original.
.

Mezcla directa
Mezcla natural
La mezcla natural o mezcla equilibrada es un algoritmo de ordenación externa, que se encarga de organizar
los elementos de un archivo de forma ascendente o descendente.
La idea central de este algoritmo consiste en realizar particiones tomando secuencias ordenadas de máxima
longitud en lugar de secuencias ordenadas de tamaño fijo previamente determinadas, como la intercalación
directa. Posteriormente se realiza la fusión de esas secuencias ordenadas, alternándolas entre los dos
archivos auxiliares.
ConclusiónMétodos de ordenamiento podemos definir que nos permiten ordenar de manera mas rápida, el método
burbuja su función es ordenar los valores de menor a mayor y Quicksort es el método mas rápido para
ordenar algún valor utilizando pivotes

Métodos de búsqueda
Métodos de búsqueda.
permite recuperar datos previamente almacenados. El resultado de una búsqueda puede ser un éxito, si se encuentra la
información o un fracaso, si no la encuentra.
La búsqueda se puede aplicar sobre elementos previamente ordenados o sobre elementos desordenados, se trata de
encontrar una cantidad de elementos similares.
Los métodos de búsqueda se clasifican en:
- Búsqueda interna.
- Búsqueda externa.
Búsqueda interna.
La búsqueda interna es aquella en la que todos los elementos de la estructura estática (arreglo) o dinámica (lista ligada o
árbol) se encuentran almacenados en la memoria principal de la computadora.
Los métodos de búsqueda interna más importantes son:
- Secuencial o lineal.
- Binaria.
- Hash (transformación de claves)

Secuencial.
El método de búsqueda secuencial consiste en revisar la estructura de datos elemento por elemento hasta
encontrar el dato que estamos buscando, o hasta llegar al final de la estructura de datos.
Binaria.
El método de búsqueda binaria divide el total de los elementos en dos, comparando el elemento buscado con
el central, en caso de no ser iguales, se determina si el elemento buscado es menor o mayor al central, para
determinar si la búsqueda continua del lado izquierdo (menor) o derecho (mayor) del central, repitiendo el
mismo proceso de división y comparación, hasta encontrar el elemento buscado o que la división ya no sea
posible.
Ejemplo. Si tenemos una estructura ordenada 0, 1, 2, 3, 5, 5, 5, 7, 8, 9 y estamos buscando el número 5, el
resultado de la búsqueda nos mostraría la posicione
4 y el proceso terminaría ya que el elemento buscado no es diferente al que esta en la posición central.

Hash
El método de búsqueda hash o por transformación de clave aumenta la velocidad de búsqueda sin necesidad de
que los elementos estén previamente ordenados, comparándolo con los métodos anteriores. Además tiene la
ventaja de que el tiempo de búsqueda es independiente del número de elementos de la estructura que los
almacena.
Este método permite que el acceso a los datos sea por una llave que indica directamente la posición donde
están guardados los datos que se buscan. Prácticamente trabaja con una función que transforma la llave o dato
clave en una dirección (índice) dentro de la estructura y que en ocasiones puede generar una colisión, que se
define como una misma dirección para dos o más claves distintas.
Ejemplo. Si tenemos un total de 100 elementos y dos claves que sean 7259 y 9359, las direcciones generadas son las siguientes:
La función módulo o por divisióndirección = (clave % total elementos)
dirección = (7259%100) = 59dirección = (9359%100) = 59
dirección = (7259%97) = 81dirección = (9359%97) = 47

conclusión
Se ha dicho que el ordenamiento puede efectuarse moviendo los registros con las claves. El mover un registro
completo implica un costo, el cual se incrementa conforme sea mayor el tamaño del registro. Es por ello que es
deseable evitar al máximo el movimiento de los registros. La eficiencia de los algoritmos se mide por el número
de comparaciones e intercambios que tienen que hacer, es decir, se toma n como el número de elementos que
tiene el arreglo a ordenar

Análisis de algoritmo
Un algoritmo es una secuencia de pasos lógica para encontrar la solución de un problema.
Todo algoritmo debe contar con las siguientes características: preciso, definido y finito. Por Preciso, entenderemos que cada
paso del algoritmo tiene una relación con el anterior y el siguiente; un algoritmo es Definido, cuando se ejecuta más de una vez
con los mismos datos y el resultado es el mismo; y Finito, indica que el algoritmo cuenta con una serie de pasos definidos o que
tiene un fin.
Complejidad Tiempo de ejecución de un algoritmo
El tiempo de ejecución de un algoritmo, se refiere a la suma de los tiempos en los que el programa tarda en ejecutar una a una
todas sus instrucciones, tomando en cuanta que cada instrucción requiere una unidad de tiempo, dicho tiempo se puede calcularen función de n (el numero de datos), lo que se denomina T(n)
Asignación de un valor a una variable.
- Llamada a un método.
- Ejecución de una operación aritmética.
- Comparar dos números.
- Poner índices a un arreglo.
- Seguir una referencia de objeto.
- Retorno de un método.

public int Mayor()
{
int may=arr[0];
for(ind=0; ind<arr.length; ind++)
if(arr[ind]>may)
may=arr[ind];
return may;
}
Para este ejemplo se pueden encontrar dos formulas que determinen el tiempo de ejecución, la primera representa el
peor de los casos y la segunda el mejor de los casos.
Complejidad en espacio
La complejidad de espacio, se refiere a la memoria que utiliza un programa para su ejecución; es decir el espacio de
memoria que ocupan todas las variables propias del programa. Dicha memoria se divide en Memoria estática y Memoria
dinámica.
Tipo de dato
primitivo
Tamaño en bits Tamaño en
Bytes
byte
char
short
int
float
long
double
8
16
16
32
32
64
64
1
2
2
4
4
8
8

Conclusión
El análisis de algoritmos se trata si bien a veces conviene analizar igualmente el caso mejor y hacer alguna
estimación sobre un caso promedio. el lenguaje de programación, la habilidad del codificador, la máquina soporte, etc.
Para problemas pequeños es cierto que casi todos los algoritmos son "más o menos iguales", primando otros
aspectos como esfuerzo de codificación, legibilidad, etc. Los órdenes de complejidad sólo son importantes para
grandes problemas.








