Estructura Molecular
90
Ácido desoxirribonucleico «ADN» redirige aquí. Para otras acepciones, véase ADN (desambiguación) . «DNA» redirige aquí. Para otras acepciones, véase DNA (desambiguación) . Situación del ADN dentro de una célula eucariota .
description
todo loq ue queres saber del adn en algo muy simple y sencilla
Transcript of Estructura Molecular

Ácido desoxirribonucleico«ADN» redirige aquí. Para otras acepciones, véase ADN (desambiguación).
«DNA» redirige aquí. Para otras acepciones, véase DNA (desambiguación).
Situación del ADN dentro de una célula eucariota.
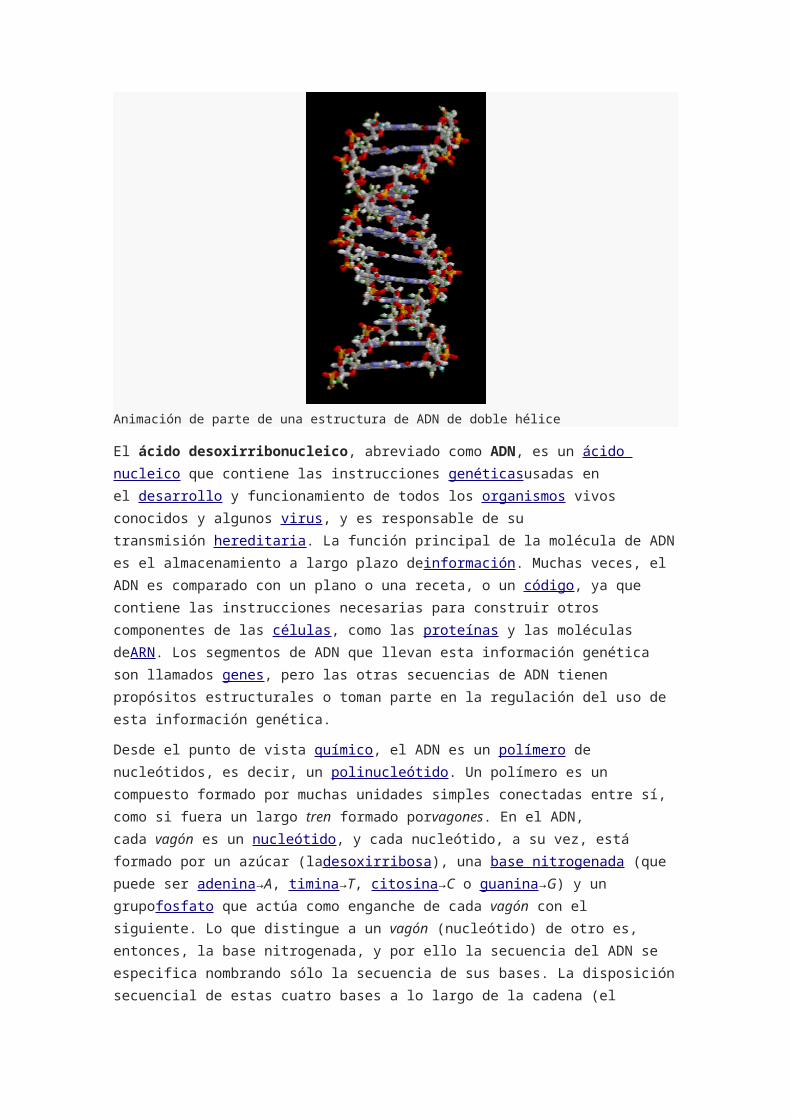
Animación de parte de una estructura de ADN de doble hélice
El ácido desoxirribonucleico, abreviado como ADN, es un ácido nucleico que contiene
las instrucciones genéticasusadas en el desarrollo y funcionamiento de todos
los organismos vivos conocidos y algunos virus, y es responsable de su
transmisión hereditaria. La función principal de la molécula de ADN es el almacenamiento
a largo plazo deinformación. Muchas veces, el ADN es comparado con un plano o una
receta, o un código, ya que contiene las instrucciones necesarias para construir otros
componentes de las células, como las proteínas y las moléculas deARN. Los segmentos
de ADN que llevan esta información genética son llamados genes, pero las otras
secuencias de ADN tienen propósitos estructurales o toman parte en la regulación del uso
de esta información genética.
Desde el punto de vista químico, el ADN es un polímero de nucleótidos, es decir,
un polinucleótido. Un polímero es un compuesto formado por muchas unidades simples
conectadas entre sí, como si fuera un largo tren formado porvagones. En el ADN,
cada vagón es un nucleótido, y cada nucleótido, a su vez, está formado por un azúcar
(ladesoxirribosa), una base nitrogenada (que puede
ser adenina→A, timina→T, citosina→C o guanina→G) y un grupofosfato que actúa como
enganche de cada vagón con el siguiente. Lo que distingue a un vagón (nucleótido) de otro
es, entonces, la base nitrogenada, y por ello la secuencia del ADN se especifica
nombrando sólo la secuencia de sus bases. La disposición secuencial de estas cuatro
bases a lo largo de la cadena (el ordenamiento de los cuatro tipos de vagones a lo largo de
todo el tren) es la que codifica la información genética: por ejemplo, una secuencia de ADN
puede ser ATGCTAGATCGC... En los organismos vivos, el ADN se presenta como una
doble cadena de nucleótidos, en la que las dos hebras están unidas entre sí por unas
conexiones denominadas puentes de hidrógeno.1

Para que la información que contiene el ADN pueda ser utilizada por la maquinaria celular,
debe copiarse en primer lugar en unos trenes de nucleótidos, más cortos y con unas
unidades diferentes, llamados ARN. Las moléculas de ARN se copian exactamente del
ADN mediante un proceso denominado transcripción. Una vez procesadas en elnúcleo
celular, las moléculas de ARN pueden salir al citoplasma para su utilización posterior. La
información contenida en el ARN se interpreta usando el código genético, que especifica la
secuencia de los aminoácidos de las proteínas, según una correspondencia de un triplete
de nucleótidos (codón) para cada aminoácido. Esto es, la información genética
(esencialmente: qué proteínas se van a producir en cada momento del ciclo de vida de una
célula) se halla codificada en las secuencias de nucleótidos del ADN y debe traducirse
para poder funcionar. Tal traducción se realiza usando el código genético a modo de
diccionario. El diccionario "secuencia de nucleótido-secuencia de aminoácidos" permite el
ensamblado de largas cadenas de aminoácidos (las proteínas) en el citoplasma de la
célula. Por ejemplo, en el caso de la secuencia de ADN indicada antes
(ATGCTAGATCGC...), la ARN polimerasa utilizaría como molde la cadena complementaria
de dicha secuencia de ADN (que sería TAC-GAT-CTA-GCG-...) para transcribir una
molécula de ARNm que se leería AUG-CUA-GAU-CGC-...; el ARNm resultante, utilizando
el código genético, se traduciría como la secuencia de aminoácidos metionina-leucina-
ácido aspártico-arginina-...
Las secuencias de ADN que constituyen la unidad fundamental, física y funcional de la
herencia se denominan genes. Cada gen contiene una parte que se transcribe a ARN y
otra que se encarga de definir cuándo y dónde deben expresarse. La información
contenida en los genes (genética) se emplea para generar ARN y proteínas, que son los
componentes básicos de las células, los "ladrillos" que se utilizan para la construcción de
los orgánulos u organelos celulares, entre otras funciones.
Dentro de las células, el ADN está organizado en estructuras llamadas cromosomas que,
durante el ciclo celular, se duplican antes de que la célula se divida. Los organismos
eucariotas (por ejemplo, animales, plantas, y hongos) almacenan la mayor parte de su
ADN dentro del núcleo celular y una mínima parte en elementos
celulares llamados mitocondrias, y en los plastos y los centros organizadores
de microtúbulos ocentríolos, en caso de tenerlos; los organismos
procariotas (bacterias y arqueas) lo almacenan en el citoplasma de la célula, y, por último,
losvirus ADN lo hacen en el interior de la cápside de naturaleza proteica. Existen multitud
de proteínas, como por ejemplo las histonas y los factores de transcripción, que se unen al
ADN dotándolo de una estructura tridimensional determinada y regulando su expresión.
Los factores de transcripción reconocen secuencias reguladoras del ADN y especifican la
pauta de transcripción de los genes. El material genético completo de una dotación
cromosómica se denomina genoma y, con pequeñas variaciones, es característico de
cada especie.
Índice

[ocultar]
1 Historia de la genética
2 Propiedades físicas y químicas
o 2.1 Componentes
o 2.2 Apareamiento de bases
2.2.1 Otros tipos de pares de bases
o 2.3 Estructura
2.3.1 Estructuras en doble hélice
2.3.2 Estructuras en cuádruplex
o 2.4 Hendiduras mayor y menor
o 2.5 Sentido y antisentido
o 2.6 Superenrollamiento
3 Modificaciones químicas
o 3.1 Modificaciones de bases del ADN
o 3.2 Daño del ADN
4 Funciones biológicas
o 4.1 Genes y genoma
4.1.1 El ADN codificante
4.1.2 El ADN no codificante
o 4.2 Transcripción y traducción
o 4.3 Replicación del ADN
4.3.1 Hipótesis sobre la duplicación del ADN
5 Interacciones ADN-proteína
o 5.1 Proteínas que unen ADN
5.1.1 Interacciones inespecíficas
5.1.2 Interacciones específicas
o 5.2 Enzimas que modifican el ADN
5.2.1 Nucleasas y ligasas
5.2.2 Topoisomerasas y helicasas
5.2.3 Polimerasas
6 Recombinación genética
7 Evolución del metabolismo de ADN
8 Técnicas comunes
o 8.1 Tecnología del ADN recombinante
o 8.2 Secuenciación
o 8.3 Reacción en cadena de la polimerasa (PCR)
o 8.4 Southern blot
o 8.5 Chips de ADN

9 Aplicaciones
o 9.1 Ingeniería genética
o 9.2 Medicina forense
o 9.3 Bioinformática
o 9.4 Nanotecnología de ADN
o 9.5 Historia, antropología y paleontología
10 Véase también
11 Referencias
o 11.1 Notas
o 11.2 Bibliografía
12 Enlaces externos
Historia de la genética[editar]
Artículo principal: Historia de la genética
Friedrich Miescher, biólogo y médico suizo (1844-1895).
El ADN lo aisló por primera vez, durante el invierno de 1869, el médico suizo Friedrich
Miescher mientras trabajaba en la Universidad de Tubinga. Miescher realizaba
experimentos acerca de la composición química del pus de
vendas quirúrgicas desechadas cuando notó un precipitado de una sustancia desconocida
que caracterizó químicamente más tarde.2 3 Lo llamó nucleína, debido a que lo había
extraído a partir de núcleos celulares.4 Se necesitaron casi 70 años de investigación para
poder identificar los componentes y la estructura de los ácidos nucleicos.
En 1919 Phoebus Levene identificó que un nucleótido está formado por una base
nitrogenada, un azúcar y un fosfato.5 Levene sugirió que el ADN generaba una estructura
con forma de solenoide (muelle) con unidades de nucleótidos unidos a través de los
grupos fosfato. En 1930 Levene y su maestro Albrecht Kossel probaron que la nucleína de
Miescher es un ácido desoxirribonucleico (ADN) formado por cuatro bases nitrogenadas
(citosina (C), timina (T), adenina (A) y guanina (G)), el azúcar desoxirribosa y un grupo
fosfato, y que, en suestructura básica, el nucleótido está compuesto por un azúcar unido a
la base y al fosfato.6 Sin embargo, Levene pensaba que la cadena era corta y que las
bases se repetían en un orden fijo. En 1937 William Astbury produjo el primer patrón
de difracción de rayos X que mostraba que el ADN tenía una estructura regular.7
Maclyn McCarty con Francis Crick y James D Watson.
La función biológica del ADN comenzó a dilucidarse en 1928, con una serie básica de
experimentos de la genética moderna realizados por Frederick Griffith, quien estaba
trabajando con cepas "lisas" (S) o "rugosas" (R) de la bacteria Pneumococcus (causante
de la neumonía), según la presencia (S) o no (R) de una cápsula azucarada, que es la que
confiere virulencia (véase también experimento de Griffith). La inyección de neumococos S
vivos en ratones produce la muerte de éstos, y Griffith observó que, si inyectaba ratones
con neumococos R vivos o con neumococos S muertos por calor, los ratones no morían.
Sin embargo, si inyectaba a la vez neumococos R vivos y neumococos S muertos, los
ratones morían, y en su sangre se podían aislar neumococos S vivos. Como las bacterias
muertas no pudieron haberse multiplicado dentro del ratón, Griffith razonó que debía
producirse algún tipo de cambio o transformación de un tipo bacteriano a otro por medio de
una transferencia de alguna sustancia activa, que denominó principio transformante. Esta
sustancia proporcionaba la capacidad a los neumococos R de producir una cápsula
azucarada y transformarse así en virulentas. En los siguientes 15 años, estos
experimentos iniciales se replicaron mezclando distintos tipos de cepas bacterianas
muertas por el calor con otras vivas, tanto en ratones (in vivo) como en tubos de ensayo
(in vitro).8 La búsqueda del «factor transformante» que era capaz de hacer virulentas a
cepas que inicialmente no lo eran continuó hasta 1944, año en el cual Oswald Avery, Colin
MacLeod y Maclyn McCarty realizaron un experimento hoy clásico. Estos investigadores

extrajeron la fracción activa (el factor transformante) y, mediante análisis químicos,
enzimáticos y serológicos, observaron que no contenía proteínas, ni lípidos no ligados, ni
polisacáridos activos, sino que estaba constituido principalmente por "una forma viscosa
de ácido desoxirribonucleico altamente polimerizado", es decir, ADN. El ADN extraído de
las cepas bacterianas S muertas por el calor lo mezclaron "in vitro" con cepas R vivas: el
resultado fue que se formaron colonias bacterianas S, por lo que se concluyó
inequívocamente que el factor o principio transformante era el ADN.9
A pesar de que la identificación del ADN como principio transformante aún tardó varios
años en ser universalmente aceptada, este descubrimiento fue decisivo en el conocimiento
de la base molecular de la herencia, y constituye el nacimiento de la genética molecular.
Finalmente, el papel exclusivo del ADN en la heredabilidad fue confirmado
en 1952 mediante los experimentos de Alfred Hershey y Martha Chase, en los cuales
comprobaron que el fago T2 transmitía su información genética en su ADN, pero no en su
proteína10 (véase también experimento de Hershey y Chase).
En cuanto a la caracterización química de la molécula, Chargaff realizó en 1940 algunos
experimentos que le sirvieron para establecer las proporciones de las bases nitrogenadas
en el ADN. Descubrió que las proporciones de purinas eran idénticas a las de pirimidinas,
la "equimolecularidad" de las bases ([A]=[T], [G]=[C]) y el hecho de que la cantidad de G+C
en una determinada molécula de ADN no siempre es igual a la cantidad de A+T y puede
variar desde el 36 hasta el 70 por ciento del contenido total.6 Con toda esta información y
junto con los datos de difracción de rayos X proporcionados por Rosalind Franklin, James
Watson y Francis Crick propusieron en 1953 el modelo de la doble hélice de ADN para
representar la estructura tridimensional del polímero.11 En una serie de cinco artículos en el
mismo número de Nature se publicó la evidencia experimental que apoyaba el modelo de
Watson y Crick.12 De éstos, el artículo de Franklin y Raymond Gosling fue la primera
publicación con datos de difracción de rayos X que apoyaba el modelo de Watson y
Crick,13 14 y en ese mismo número de Nature también aparecía un artículo sobre la
estructura del ADN de Maurice Wilkins y sus colaboradores.15
Watson, Crick y Wilkins recibieron conjuntamente, en 1962, después de la muerte de
Rosalind Franklin, el Premio Nobel en Fisiología o Medicina.16 Sin embargo, el debate
continúa sobre quién debería recibir crédito por el descubrimiento.17
Propiedades físicas y químicas[editar]

Estructura química del ADN: dos cadenas de nucleótidos conectadas mediante puentes de
hidrógeno, que aparecen como líneas punteadas.
El ADN es un largo polímero formado por unidades repetitivas, los nucleótidos.18 19 Una
doble cadena de ADN mide de 22 a 26 angstroms (2,2 a 2,6 nanómetros) de ancho, y una
unidad (un nucleótido) mide 3,3 Å (0,33 nm) de largo.20 Aunque cada unidad individual que
se repite es muy pequeña, los polímeros de ADN pueden ser moléculasenormes que
contienen millones de nucleótidos. Por ejemplo, el cromosoma humano más largo,
el cromosoma número 1, tiene aproximadamente 220 millones de pares de bases.21
En los organismos vivos, el ADN no suele existir como una molécula individual, sino como
una pareja de moléculas estrechamente asociadas. Las dos cadenas de ADN se enroscan
sobre sí mismas formando una especie de escalera de caracol, denominada doble hélice.
El modelo de estructura en doble hélice fue propuesto en 1953 porJames
Watson y Francis Crick (el artículo «Molecular Structure of Nucleic Acids: A Structure for
Deoxyribose Nucleic Acid» fue publicado el 25 de abril de 1953 en Nature), después de
obtener una imagen de la estructura de doble hélice gracias a la refracción por rayos X
hecha por Rosalind Franklin.22 El éxito de este modelo radicaba en su consistencia con las
propiedades físicas y químicas del ADN. El estudio mostraba además que
la complementariedad de bases podía ser relevante en su replicación, y también la
importancia de la secuencia de bases como portadora de información genética.23 24 25 Cada
unidad que se repite, el nucleótido, contiene un segmento de la estructura de soporte
(azúcar + fosfato), que mantiene la cadena unida, y una base, que interacciona con la otra
cadena de ADN en la hélice. En general, una base ligada a un azúcar se
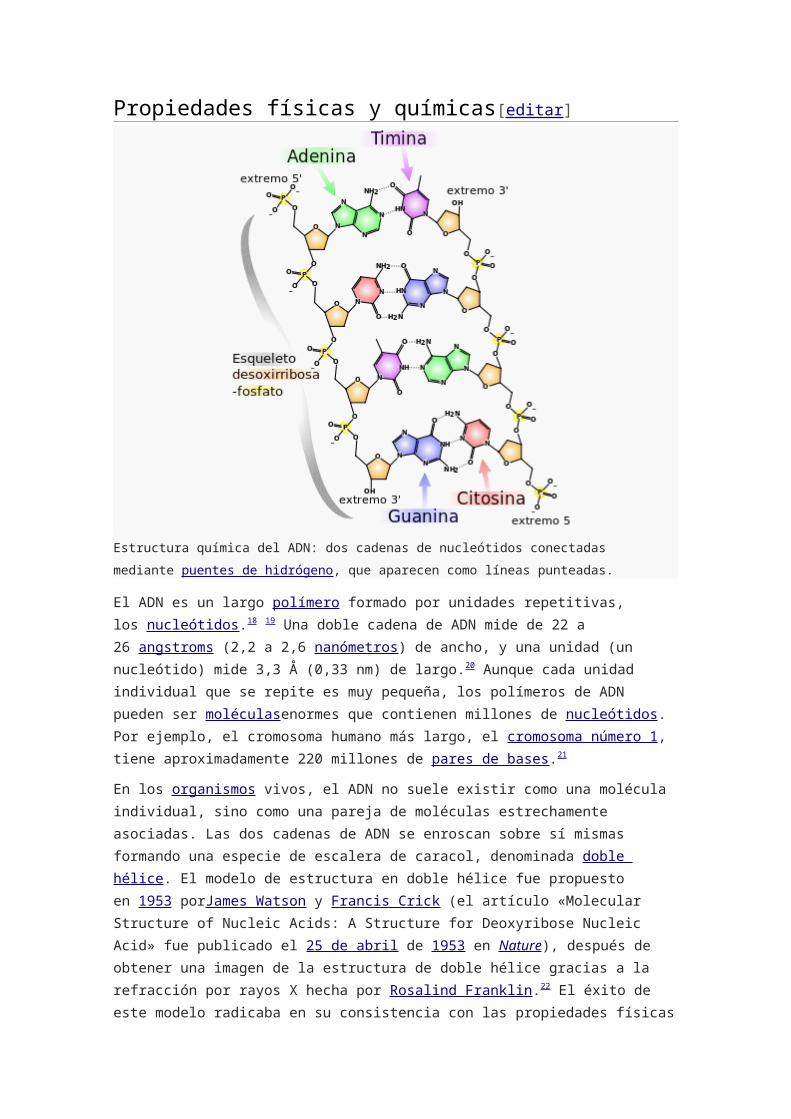
denomina nucleósido y una base ligada a un azúcar y a uno o más grupos fosfatos recibe
el nombre de nucleótido.
Cuando muchos nucleótidos se encuentran unidos, como ocurre en el ADN, el polímero
resultante se denominapolinucleótido.26
Componentes[editar]
Estructura de soporte: La estructura de soporte de una hebra de ADN está formada por
unidades alternas de grupos fosfato y azúcar (desoxirribosa).27 El azúcar en el ADN es una
pentosa, concretamente, la desoxirribosa.
Ácido fosfórico :
Enlace fosfodiéster. El grupo fosfato(PO43-) une el carbono 5' del azúcar de unnucleósido con
el carbono 3' del siguiente.
Su fórmula química es H3PO4. Cada nucleótido puede contener uno
(monofosfato: AMP), dos (difosfato: ADP) o tres (trifosfato:ATP) grupos de ácido
fosfórico, aunque como monómeros constituyentes de los ácidos nucleicos sólo
aparecen en forma de nucleósidos monofosfato.
Desoxirribosa :
Es un monosacárido de 5 átomos de carbono (una pentosa) derivado de la ribosa,
que forma parte de la estructura de nucleótidos del ADN. Su fórmula es C5H10O4.
Una de las principales diferencias entre el ADN y el ARN es el azúcar, pues en el

ARN la 2-desoxirribosa del ADN es reemplazada por una pentosa alternativa,
la ribosa.25
Las moléculas de azúcar se unen entre sí a través de grupos fosfato, que
forman enlaces fosfodiéster entre los átomos de carbono tercero (3′, «tres prima»)
y quinto (5′, «cinco prima») de dos anillos adyacentes de azúcar. La formación
de enlacesasimétricos implica que cada hebra de ADN tiene una dirección. En
una doble hélice, la dirección de los nucleótidos en una hebra (3′ → 5′) es opuesta
a la dirección en la otra hebra (5′ → 3′). Esta organización de las hebras de ADN
se denomina antiparalela; son cadenas paralelas, pero con direcciones opuestas.
De la misma manera, los extremos asimétricos de las hebras de ADN se
denominan extremo 5′ («cinco prima») y extremo 3′ («tres prima»),
respectivamente.
Bases nitrogenadas :
Las cuatro bases nitrogenadas mayoritarias que se encuentran en el ADN son
la adenina (A), la citosina (C), la guanina (G) y latimina (T). Cada una de estas
cuatro bases está unida al armazón de azúcar-fosfato a través del azúcar para
formar el nucleótido completo (base-azúcar-fosfato). Las bases son compuestos
heterocíclicos y aromáticos con dos o más átomos denitrógeno, y, dentro de las
bases mayoritarias, se clasifican en dos grupos: las bases
púricas o purinas (adenina y guanina), derivadas de la purina y formadas por dos
anillos unidos entre sí, y las bases pirimidínicas o bases
pirimídicas o pirimidinas(citosina y timina), derivadas de la pirimidina y con un solo
anillo.25 En los ácidos nucleicos existe una quinta base pirimidínica,
denominada uracilo (U), que normalmente ocupa el lugar de la timina en el ARN y
difiere de ésta en que carece de un grupo metilo en su anillo. El uracilo no se
encuentra habitualmente en el ADN, sólo aparece raramente como un producto
residual de la degradación de la citosina por procesos de desaminación oxidativa.
Timina: 2, 4-dioxo, 5-metilpirimidina.
Timina :
En el código genético se representa con la letra T. Es un derivado pirimidínico con
un grupo oxo en las posiciones 2 y 4, y un grupo metil en la posición 5. Forma
el nucleósido timidina (siempre desoxitimidina, ya que sólo aparece en el ADN) y
el nucleótido timidilato o timidina monofosfato (dTMP). En el ADN, la timina

siempre se empareja con la adenina de la cadena complementaria mediante
2 puentes de hidrógeno, T=A. Su fórmula química es C5H6N2O2 y su nomenclatura
2, 4-dioxo, 5-metilpirimidina.
Citosina: 2-oxo, 4-aminopirimidina.
Citosina :
En el código genético se representa con la letra C. Es un derivado pirimidínico, con
un grupo amino en posición 4 y un grupo oxo en posición 2. Forma
el nucleósido citidina (desoxicitidina en el ADN) y el nucleótido citidilato o
(desoxi)citidina monofosfato (dCMP en el ADN, CMP en el ARN). La citosina
siempre se empareja en el ADN con la guanina de la cadena complementaria
mediante un triple enlace, C≡G. Su fórmula química es C4H5N3O y su nomenclatura
2-oxo, 4 aminopirimidina. Su masa molecular es de 111,10 unidades de masa
atómica. La citosina se descubrió en 1894, al aislarla del tejido del timo de carnero.
Adenina: 6-aminopurina.
Adenina :
En el código genético se representa con la letra A. Es un derivado de la purina con
un grupo amino en la posición 6. Forma el nucleósido adenosina (desoxiadenosina
en el ADN) y el nucleótido adenilato o (desoxi)adenosina monofosfato (dAMP,
AMP). En el ADN siempre se empareja con la timina de la cadena complementaria
mediante 2 puentes de hidrógeno, A=T. Su fórmula química es C5H5N5 y su
nomenclatura 6-aminopurina. La adenina, junto con la timina, fue descubierta en
1885 por el médico alemán Albrecht Kossel.

Guanina: 6-oxo, 2-aminopurina.
Guanina :
En el código genético se representa con la letra G. Es un derivado púrico con un
grupo oxo en la posición 6 y un grupo amino en la posición 2. Forma el nucleósido
(desoxi)guanosina y el nucleótido guanilato o (desoxi)guanosina monofosfato
(dGMP, GMP). La guanina siempre se empareja en el ADN con la citosina de la
cadena complementaria mediante tres enlaces de hidrógeno, G≡C. Su fórmula
química es C5H5N5O y su nomenclatura 6-oxo, 2-aminopurina.
También existen otras bases nitrogenadas (las
llamadas bases nitrogenadas minoritarias), derivadas
de forma natural o sintética de alguna otra base
mayoritaria. Lo son por ejemplo la hipoxantina,
relativamente abundante en el tRNA, o la cafeína, ambas
derivadas de la adenina; otras, como el aciclovir,
derivadas de la guanina, son análogos sintéticos usados
en terapia antiviral; otras, como una de las derivadas del
uracilo, son antitumorales.
Las bases nitrogenadas tienen una serie de
características que les confieren unas propiedades
determinadas. Una característica importante es su
carácter aromático, consecuencia de la presencia en el
anillo de dobles enlaces en posición conjugada. Ello les
confiere la capacidad de absorber luz en la
zona ultravioleta del espectro en torno a los 260 nm, lo
cual puede aprovecharse para determinar el coeficiente
de extinción del ADN y hallar la concentración existente
de los ácidos nucleicos. Otra de sus características es
que presentan tautomería o isomería de grupos
funcionales, debido a que un átomo de hidrógeno unido a
otro átomo puede migrar a una posición vecina; en las
bases nitrogenadas se dan dos tipos de tautomerías:
tautomería lactama-lactima, donde el hidrógeno migra del
nitrógeno al oxígeno del grupo oxo (forma lactama) y
viceversa (forma lactima), y tautomería imina-

amina primaria, donde el hidrógeno puede estar formando
el grupo amina (forma amina primaria) o migrar al
nitrógeno adyacente (forma imina). La adenina sólo
puede presentar tautomería amina-imina, la timina y el
uracilo muestran tautomería doble lactama-lactima, y la
guanina y citosina pueden presentar ambas. Por otro
lado, y aunque se trate de moléculas apolares, las bases
nitrogenadas presentan suficiente carácter polar como
para establecer puentes de hidrógeno, ya que tienen
átomos muy electronegativos (nitrógeno y oxígeno) que
presentan carga parcial negativa, y átomos de hidrógeno
con carga parcial positiva, de manera que se forman
dipolos que permiten que se formen estos enlaces
débiles.
Se estima que el genoma humano haploide tiene
alrededor de 3000 millones de pares de bases. Para
indicar el tamaño de las moléculas de ADN se indica el
número de pares de bases, y como derivados hay dos
unidades de medida muy utilizadas, la kilobase (kb), que
equivale a 1000 pares de bases, y la megabase (Mb), que
equivale a un millón de pares de bases.
Apareamiento de bases[editar]
Véase también: Par de bases
Un par de bases C≡G con trespuentes de hidrógeno.
Un par A=T con dos puentes de hidrógeno. Los puentes de
hidrógeno se muestran como líneas discontinuas.
La dóble hélice de ADN se mantiene estable mediante la
formación de puentes de hidrógeno entre las bases

asociadas a cada una de las dos hebras. Para la
formación de un enlace de hidrógeno una de las bases
debe presentar un "donador" de hidrógenos con un átomo
de hidrógeno con carga parcial positiva (-NH2 o -NH) y la
otra base debe presentar un grupo "aceptor" de
hidrógenos con un átomo
cargado electronegativamente (C=O o N). Los puentes de
hidrógeno son uniones más débiles que los
típicos enlaces químicoscovalentes, como los que
conectan los átomos en cada hebra de ADN, pero más
fuertes que interacciones hidrófobas individuales,enlaces
de Van der Waals, etc. Como los puentes de hidrógeno
no son enlaces covalentes, pueden romperse y formarse
de nuevo de forma relativamente sencilla. Por esta razón,
las dos hebras de la doble hélice pueden separarse como
una cremallera, bien por fuerza mecánica o por
alta temperatura.28 La doble hélice se estabiliza además
por el efecto hidrofóbico y el apilamiento, que no se ven
influidos por la secuencia de bases del ADN.29
Cada tipo de base en una hebra forma un enlace
únicamente con un tipo de base en la otra hebra, lo que
se denominacomplementariedad de las bases. Así, las
purinas forman enlaces con las pirimidinas, de forma que
A se enlaza sólo con T, y C sólo con G. La organización
de dos nucleótidos apareados a lo largo de la doble hélice
se denomina apareamiento de bases. Este
emparejamiento corresponde a la observación ya
realizada por Erwin Chargaff (1905-2002),30 que mostró
que la cantidad de adenina era muy similar a la cantidad
de timina, y que la cantidad de citosina era igual a la
cantidad de guanina en el ADN. Como resultado de esta
complementariedad, toda la información contenida en la
secuencia de doble hebra de la hélice de ADN está
duplicada en cada hebra, lo cual es fundamental durante
el proceso de replicación del ADN. En efecto, esta
interacción reversible y específica entre pares de bases
complementarias es crítica para todas las funciones del
ADN en los organismos vivos.18
Como se ha indicado anteriormente, los dos tipos de
pares de bases forman un número diferente de enlaces

de hidrógeno: A=T forman dos puentes de hidrógeno, y
C≡G forman tres puentes de hidrógeno (ver imágenes). El
par de bases GC es por tanto más fuerte que el par de
bases AT. Como consecuencia, tanto el porcentaje de
pares de bases GC como la longitud total de la doble
hélice de ADN determinan la fuerza de la asociación entre
las dos hebras de ADN. Las dobles hélices largas de ADN
con alto contenido en GC tienen hebras que interaccionan
más fuertemente que las dobles hélices cortas con alto
contenido en AT.31 Por esta razón, las zonas de la doble
hélice de ADN que necesitan separarse fácilmente
tienden a tener un alto contenido en AT, como por
ejemplo la secuencia TATAAT de la caja de Pribnow de
algunos promotores.32 En el laboratorio, la fuerza de esta
interacción puede medirse buscando la temperatura
requerida para romper los puentes de hidrógeno,
la temperatura de fusión (también denominado valor Tm,
del inglés melting temperature). Cuando todas las pares
de bases en una doble hélice se funden, las hebras se
separan en solución en dos hebras completamente
independientes. Estas moléculas de ADN de hebra simple
no tienen una única forma común, sino que algunas
conformaciones son más estables que otras.33
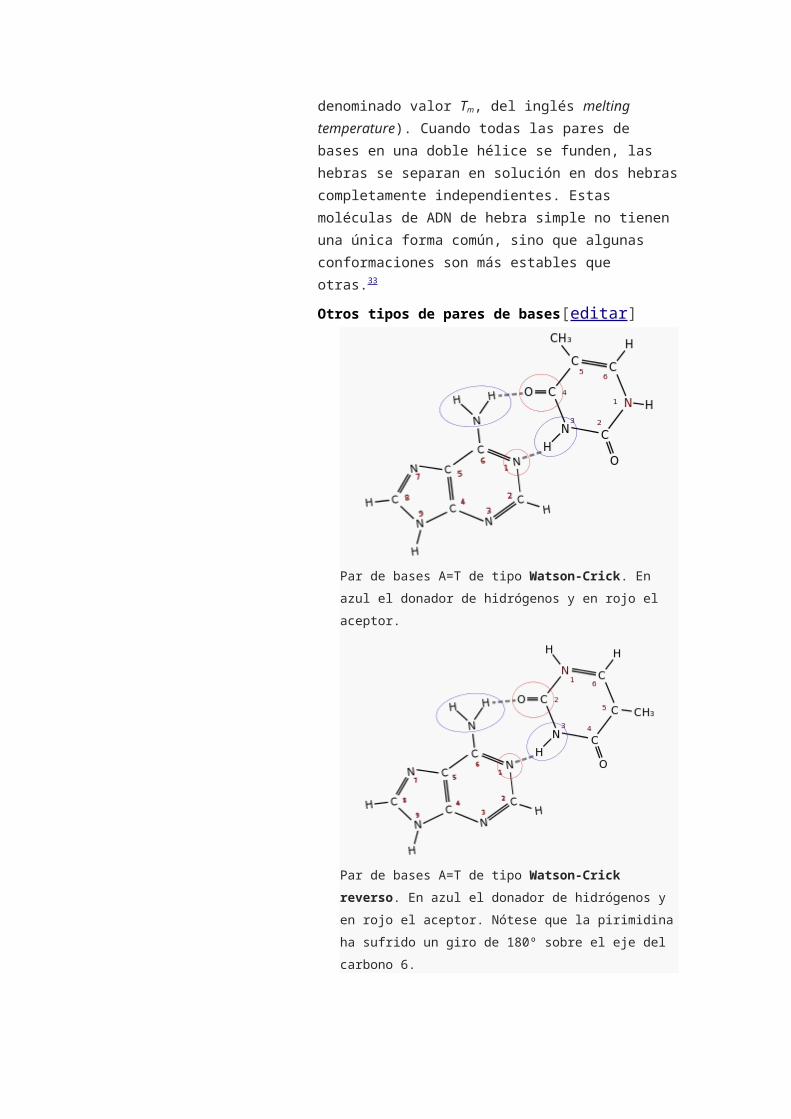
Otros tipos de pares de bases[editar]
Par de bases A=T de tipo Watson-Crick. En azul el
donador de hidrógenos y en rojo el aceptor.

Par de bases A=T de tipo Watson-Crick reverso. En azul
el donador de hidrógenos y en rojo el aceptor. Nótese que
la pirimidina ha sufrido un giro de 180º sobre el eje del
carbono 6.
Existen diferentes tipos de pares de bases que se pueden
formar según el modo como se forman los puentes de
hidrógeno. Los que se observan en la doble hélice de
ADN son los llamados pares de bases Watson-Crick, pero
también existen otros posibles pares de bases, como los
denominados Hoogsteen y Wobble u oscilante, que
pueden aparecer en circunstancias particulares. Además,
para cada tipo existe a su vez el mismo par reverso, es
decir, el que se da si se gira la base pirimidínica 180º
sobre su eje.
Watson-Crick (pares de bases de la doble hélice): los
grupos de la base púrica que intervienen en el enlace
de hidrógeno son los que corresponden a las
posiciones 1 y 6 (N aceptor y -NH2 donador si la
purina es una A) y los grupos de la base pirimidínica,
los que se encuentran en las posiciones 3 y 4 (-NH
donador y C=O aceptor si la pirimidina es una T). En
el par de bases Watson-Crick reverso participarían
los grupos de las posiciones 2 y 3 de la base
pirimidínica (ver imágenes).
Hoogsteen : en este caso cambian los grupos de la
base púrica, que ofrece una cara diferente
(posiciones 6 y 7) y que forman enlaces con los
grupos de las pirimidinas de las posiciones 3 y 4
(como en Watson-Crick). También puede haber

Hoogsteen reversos. Con este tipo de enlace pueden
unirse A=U (Hoogsteen y Hoogsteen reverso) y A=C
(Hoogsteen reverso).
Wobble u oscilante: este tipo de enlace permite que
se unan guanina y citosina con un doble enlace
(G=T). La base púrica (G) forma enlace con los
grupos de las posiciones 1 y 6 (como en Watson-
Crick) y la pirimidina (T) con los grupos de las
posiciones 2 y 3. Este tipo de enlace no funcionaría
con A=C, ya que quedarían enfrentados los 2
aceptores y los 2 donadores, y sólo se podría dar en
el caso inverso. Encontramos pares de bases de tipo
oscilante en el ARN, durante el apareamiento
de codón y anticodón. Con este tipo de enlace
pueden unirse G=U (oscilante y oscilante reverso) y
A=C (oscilante reverso).
En total, en su forma tautomérica mayoritaria, existen 28
posibles pares de bases nitrogenadas: 10 posibles pares
de bases purina-pirimidina (2 pares Watson-Crick y 2
Watson Crick reverso, 1 par Hoogsteen y 2 pares
Hoogsteen reverso, 1 par oscilante y 2 pares oscilante
reverso), 7 pares homo purina-purina (A=A, G=G), 4
pares A=G y 7 pares pirimidina-pirimidina. Esto sin contar
con los pares de bases que pueden formarse si también
tenemos en cuenta las otras formas tautoméricas
minoritarias de las bases nitrogenadas; éstos, además,
pueden ser responsables de mutaciones puntuales por
sustitución de tipo transición.
Estructura[editar]
El ADN es una molécula bicatenaria, es decir, está
formada por dos cadenas dispuestas de forma
antiparalela y con las bases nitrogenadas enfrentadas. En
su estructura tridimensional, se distinguen distintos
niveles:34 35
1. Estructura primaria:
Secuencia de nucleótidos encadenados. Es
en estas cadenas donde se encuentra la
información genética, y dado que el
esqueleto es el mismo para todos, la
diferencia de la información radica en la
distinta secuencia de bases nitrogenadas.
Esta secuencia presenta un código, que
determina una información u otra, según el
orden de las bases.
2. Estructura secundaria:
Es una estructura en doble hélice. Permite
explicar el almacenamiento de la información
genética y el mecanismo de duplicación del
ADN. Fue postulada por Watson y Crick,
basándose en la difracción de rayos X que
habían realizado Franklin y Wilkins, y en la
equivalencia de bases de Chargaff, según la
cual la suma de adeninas más guaninas es
igual a la suma de timinas más citosinas.
Es una cadena doble, dextrógira o levógira,
según el tipo de ADN. Ambas cadenas son
complementarias, pues la adenina y la
guanina de una cadena se unen,
respectivamente, a la timina y la citosina de
la otra. Ambas cadenas son antiparalelas,
pues el extremo 3´ de una se enfrenta al
extremo 5´ de la homóloga.
Existen tres modelos de ADN. El ADN de tipo
B es el más abundante y es el que tiene la
estructura descrita por Watson y Crick.
3. Estructura terciaria:
Se refiere a cómo se almacena el ADN en un
espacio reducido, para formar
los cromosomas. Varía según se trate de
organismos procariotas o eucariotas:
2. En procariotas el ADN se pliega como
una súper-hélice, generalmente en forma
circular y asociada a una pequeña
cantidad de proteínas. Lo mismo ocurre
enorgánulos celulares como
las mitocondrias y en los cloroplastos.
3. En eucariotas, dado que la cantidad de
ADN de cada cromosoma es muy
grande, el empaquetamiento ha de ser

más complejo y compacto; para ello se
necesita la presencia de proteínas, como
las histonas y otras proteínas de
naturaleza no histónica (en
los espermatozoides estas proteínas son
las protaminas).34
4. Estructura cuaternaria:
La cromatina presente en el núcleo tiene un grosor de 300 Å, pues la fibra de
cromatina de 100 Å se enrolla formando una fibra de cromatina de 300 Å. El
enrollamiento de los nucleosomas recibe el nombre de solenoide. Dichos
solenoides se enrollan formando la cromatina del núcleo interfásico de la célula
eucariota. Cuando la célula entra en división, el ADN se compacta más,
formando así los cromosomas.
Estructuras en doble hélice[editar]
De izquierda a derecha, las estructuras de ADN A, B y
Z.
El ADN existe en muchas conformaciones.27 Sin
embargo, en organismos vivos sólo se han observado
las conformaciones ADN-A, ADN-B y ADN-Z. La
conformación que adopta el ADN depende de su
secuencia, la cantidad y dirección
de superenrollamiento que presenta, la presencia
de modificaciones químicas en las bases y las
condiciones de la solución, tales como la
concentración de iones de metales ypoliaminas.36 De
las tres conformaciones, la forma "B" es la más
común en las condiciones existentes en las
células.37 Las dos dobles hélices alternativas del ADN
difieren en su geometría y dimensiones.
La forma "A" es una espiral que gira hacia la derecha,
más amplia que la "B", con una hendidura menor
superficial y más amplia, y una hendidura mayor más
estrecha y profunda. La forma "A" ocurre en

condiciones no fisiológicas en formas deshidratadas
de ADN, mientras que en la célula puede producirse
en apareamientos híbridos de hebras ADN-ARN,
además de en complejos enzima-ADN.38 39
Los segmentos de ADN en los que las bases han sido
modificadas por metilación pueden sufrir cambios
conformacionales mayores y adoptar la forma "Z". En
este caso, las hebras giran alrededor del eje de la
hélice en una espiral que gira a mano izquierda, lo
opuesto a la forma "B" más frecuente.40 Estas
estructuras poco frecuentes pueden ser reconocidas
por proteínas específicas que se unen a ADN-Z y
posiblemente estén implicadas en la regulación de
la transcripción.41
Estructuras en cuádruplex[editar]
Estructura de un ADN en cuádruplex formada por
repeticiones en los telómeros. La conformación de la
estructura de soporte del ADN difiere significativamente de
la típica estructura en hélice.42
En los extremos de los cromosomas lineales existen
regiones especializadas de ADN
denominadas telómeros. La función principal de estas
regiones es permitir a la célula replicar los extremos
cromosómicos utilizando la enzima telomerasa,
puesto que las enzimas que replican el resto del ADN
no pueden copiar los extremos 3' de los
cromosomas.43 Estas terminaciones cromosómicas
especializadas también protegen los extremos del

ADN, y evitan que los sistemas dereparación del
ADN en la célula los procesen como ADN dañado
que debe ser corregido.44 En las células humanas, los
telómeros son largas zonas de ADN de hebra sencilla
que contienen algunos miles de repeticiones de una
única secuencia TTAGGG.45
Estas secuencias ricas en guanina pueden estabilizar
los extremos cromosómicos mediante la formación de
estructuras de juegos apilados de unidades de cuatro
bases, en lugar de los pares de bases encontrados
normalmente en otras estructuras de ADN. En este
caso, cuatro bases guanina forman unidades con
superficie plana que se apilan una sobre otra, para
formar una estructura cuádruple-G estable.46 Estas
estructuras se estabilizan formando puentes de
hidrógeno entre los extremos de las bases y
la quelatación de un metal iónico en el centro de cada
unidad de cuatro bases.47 También se pueden formar
otras estructuras, con el juego central de cuatro
bases procedente, o bien de una hebra sencilla
plegada alrededor de las bases, o bien de varias
hebras paralelas diferentes, de forma que cada una
contribuye con una base a la estructura central.
Además de estas estructuras apiladas,
los telómeros también forman largas estructuras en
lazo, denominadas lazos teloméricos o lazos-T (T-
loops en inglés). En este caso, las hebras simples de
ADN se enroscan sobre sí mismas en un amplio
círculo estabilizado por proteínas que se unen a
telómeros.48 En el extremo del lazo T, el ADN
telomérico de hebra sencilla se sujeta a una región de
ADN de doble hebra porque la hebra de ADN
telomérico altera la doble hélice y se aparea a una de
las dos hebras. Esta estructura de triple hebra se
denomina lazo de desplazamiento o lazo D (D-loop).46
Hendiduras mayor y menor[editar]

Animación de la estructura de una sección de ADN. Las
bases se encuentran horizontalmente entre las dos
hebras en espiral. Versión ampliada 49
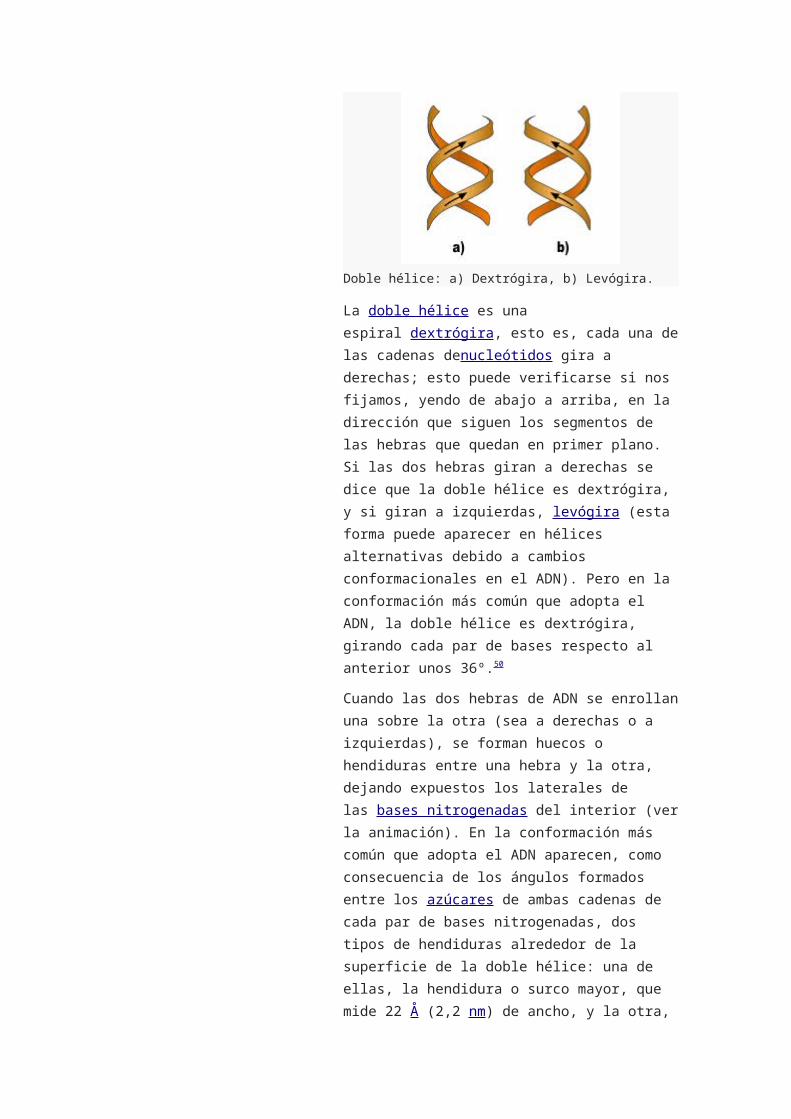
Doble hélice: a) Dextrógira, b) Levógira.
La doble hélice es una espiral dextrógira, esto es,
cada una de las cadenas denucleótidos gira a
derechas; esto puede verificarse si nos fijamos,
yendo de abajo a arriba, en la dirección que siguen
los segmentos de las hebras que quedan en primer
plano. Si las dos hebras giran a derechas se dice que
la doble hélice es dextrógira, y si giran a

izquierdas, levógira (esta forma puede aparecer en
hélices alternativas debido a cambios
conformacionales en el ADN). Pero en la
conformación más común que adopta el ADN, la
doble hélice es dextrógira, girando cada par de bases
respecto al anterior unos 36º.50
Cuando las dos hebras de ADN se enrollan una sobre
la otra (sea a derechas o a izquierdas), se forman
huecos o hendiduras entre una hebra y la otra,
dejando expuestos los laterales de las bases
nitrogenadas del interior (ver la animación). En la
conformación más común que adopta el ADN
aparecen, como consecuencia de los ángulos
formados entre los azúcares de ambas cadenas de
cada par de bases nitrogenadas, dos tipos de
hendiduras alrededor de la superficie de la doble
hélice: una de ellas, la hendidura o surco mayor, que
mide 22 Å (2,2 nm) de ancho, y la otra, la hendidura o
surco menor, que mide 12 Å (1,2 nm) de
ancho.51 Cada vuelta de hélice, que es cuando ésta
ha realizado un giro de 360º o lo que es lo mismo, de
principio de hendidura mayor a final de hendidura
menor, medirá por tanto 34 Å, y en cada una de esas
vueltas hay unos 10,5pb.
Hendiduras mayor y menor de la doble hélice.
La anchura de la hendidura mayor implica que los
extremos de las bases son más accesibles en ésta,
de forma que la cantidad de grupos químicos
expuestos también es mayor lo cual facilita la
diferenciación entre los pares de bases A-T, T-A, C-
G, G-C. Como consecuencia de ello, también se verá
facilitado el reconocimiento de secuencias de ADN
por parte de diferentes proteínas sin la necesidad de

abrir la doble hélice. Así, proteínas como los factores
de transcripción que pueden unirse a secuencias
específicas, frecuentemente contactan con los
laterales de las bases expuestos en la hendidura
mayor.52 Por el contrario, los grupos químicos que
quedan expuestos en la hendidura menor son
similares, de forma que el reconocimiento de los
pares de bases es más difícil; por ello se dice que la
hendidura mayor contiene más información que la
hendidura menor.50
Sentido y antisentido[editar]
Artículo principal: Antisentido
Una secuencia de ADN se denomina "sentido" (en
inglés, sense) si su secuencia es la misma que la
secuencia de un ARN mensajero que se traduce en
una proteína. La secuencia de la hebra de ADN
complementaria se
denomina "antisentido" (antisense). En ambas hebras
de ADN de la doble hélice pueden existir tanto
secuencias sentido, que codifican ARNm,
como antisentido, que no lo codifican. Es decir, las
secuencias que codifican ARNm no están todas
presentes en una sola de las hebras, sino repartidas
entre las dos hebras. Tanto en procariotas como
en eucariotas se producen ARN con
secuencias antisentido, pero la función de esos ARN
no está completamente clara.53 Se ha propuesto que
los ARN antisentido están implicados en la regulación
de la expresión génica mediante apareamiento ARN-
ARN: los ARN antisentido se aparearían con los
ARNm complementarios, bloqueando de esta forma
su traducción.54
En unas pocas secuencias de ADN en procariotas y
eucariotas (este hecho es más frecuente
en plásmidos y virus), la distinción entre
hebras sentido y antisentido es más difusa, debido a
que presentan genes superpuestos.55 En estos casos,
algunas secuencias de ADN tienen una función doble,
codificando una proteína cuando se lee a lo largo de
una hebra, y una segunda proteína cuando se lee en

la dirección contraria a lo largo de la otra hebra.
En bacterias, esta superposición puede estar
involucrada en la regulación de la transcripción del
gen,56 mientras que en virus los genes superpuestos
aumentan la cantidad de información que puede
codificarse en sus diminutos genomas.57
Superenrollamiento[editar]
Estructura de moléculas de ADN lineales con los
extremos fijos y superenrolladas. Por claridad, se ha
omitido la estructura en hélice del ADN.
El ADN puede retorcerse como una cuerda en un
proceso que se denomina superenrollamiento del
ADN(«supercoiling», en inglés). Cuando el ADN está
en un estado "relajado", una hebra normalmente gira
alrededor del eje de la doble hélice una vez cada 10,4
pares de bases, pero si el ADN está retorcido las
hebras pueden estar unidas más estrechamente o
más relajadamente.58 Si el ADN está retorcido en la
dirección de la hélice, se dice que el
superenrollamiento es positivo, y las bases se
mantienen juntas de forma más estrecha. Si el ADN
se retuerce en la dirección opuesta, el
superenrollamiento se llama negativo, y las bases se
alejan. En la naturaleza, la mayor parte del ADN tiene
un ligero superenrollamiento negativo que es
producido
por enzimas denominadas topoisomerasas.59 Estas
enzimas también son necesarias para liberar las
fuerzas de torsión introducidas en las hebras de ADN
durante procesos como la transcripción y
lareplicación.60

Modificaciones químicas[editar]
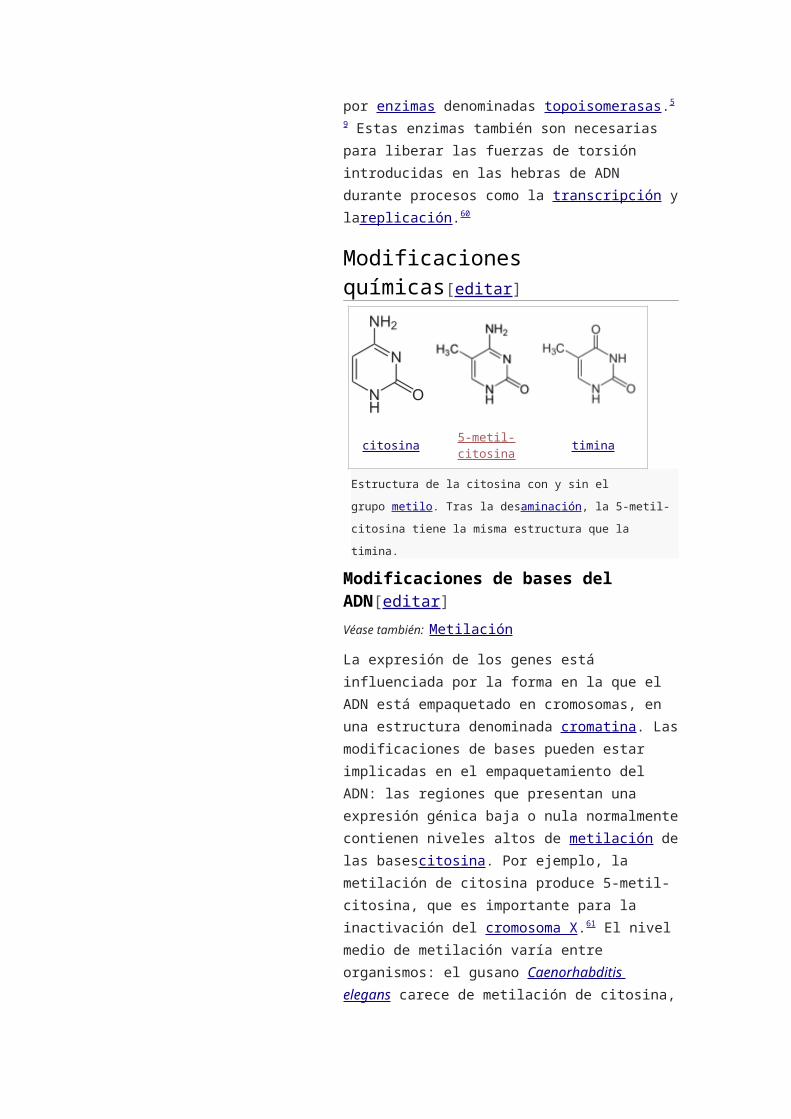
citosina 5-metil-citosina timina
Estructura de la citosina con y sin el grupo metilo. Tras la
desaminación, la 5-metil-citosina tiene la misma estructura que la
timina.
Modificaciones de bases del ADN[editar]
Véase también: Metilación
La expresión de los genes está influenciada por la
forma en la que el ADN está empaquetado en
cromosomas, en una estructura
denominada cromatina. Las modificaciones de bases
pueden estar implicadas en el empaquetamiento del
ADN: las regiones que presentan una expresión
génica baja o nula normalmente contienen niveles
altos de metilación de las basescitosina. Por ejemplo,
la metilación de citosina produce 5-metil-citosina, que
es importante para la inactivación del cromosoma
X.61 El nivel medio de metilación varía entre
organismos: el gusano Caenorhabditis
elegans carece de metilación de citosina, mientras
que los vertebrados presentan un nivel alto - hasta
1% de su ADN contiene 5-metil-citosina.62 A pesar de
la importancia de la 5-metil-citosina, ésta puede
desaminarse para generar una base timina. Las
citosinas metiladas son por tanto particularmente
sensibles a mutaciones.63 Otras modificaciones de
bases incluyen la metilación de adenina en bacteriasy
la glicosilación de uracilo para producir la "base-J"
en kinetoplastos.64 65
Daño del ADN[editar]
Véase también: Mutación
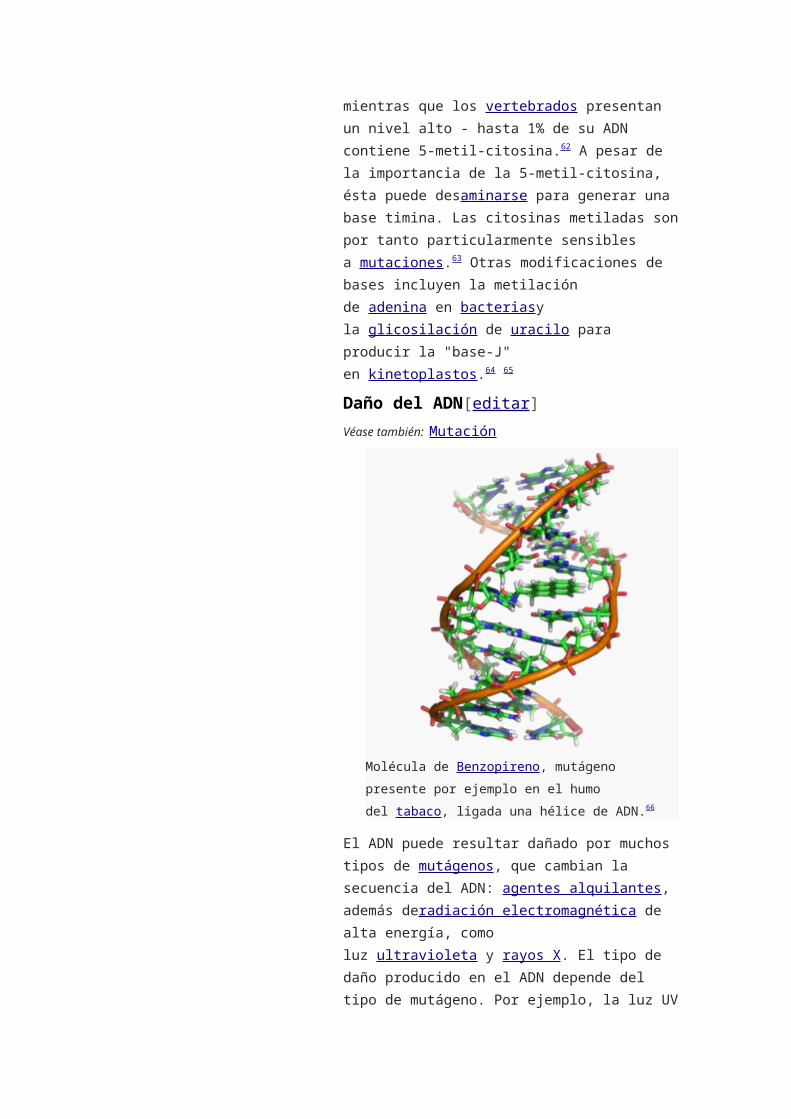
Molécula de Benzopireno, mutágeno presente por
ejemplo en el humo del tabaco, ligada una hélice de
ADN.66
El ADN puede resultar dañado por muchos tipos
de mutágenos, que cambian la secuencia del
ADN: agentes alquilantes, además deradiación
electromagnética de alta energía, como
luz ultravioleta y rayos X. El tipo de daño producido
en el ADN depende del tipo de mutágeno. Por
ejemplo, la luz UV puede dañar al ADN produciendo
dímeros de timina, que se forman por ligamiento
cruzado entre basespirimidínicas.67 Por otro lado,
oxidantes tales como radicales libres o el peróxido de
hidrógeno producen múltiples daños, incluyendo
modificaciones de bases, sobre todo guanina, y
roturas de doble hebra (double-strand breaks).68 En
una célula humana cualquiera, alrededor de 500
bases sufren daño oxidativo cada día.69 70 De estas
lesiones oxidativas, las más peligrosas son las
roturas de doble hebra, ya que son difíciles de reparar
y pueden producir mutaciones
puntuales, inserciones y deleciones de la secuencia
de ADN, así como translocaciones cromosómicas.71
Muchos mutágenos se posicionan entre dos pares de
bases adyacentes, por lo que se denominan agentes
intercalantes. La mayoría de los agentes intercalantes
son moléculas aromáticas y planas, como el bromuro

de etidio, la daunomicina, la doxorubicina y
la talidomida. Para que un agente intercalante pueda
integrarse entre dos pares de bases, éstas deben
separarse, distorsionando las hebras de ADN y
abriendo la doble hélice. Esto inhibe la transcripción y
la replicación del ADN, causando toxicidad y
mutaciones. Por ello, los agentes intercalantes del
ADN son a menudo carcinógenos: el benzopireno,
las acridinas, la aflatoxina y el bromuro de etidio son
ejemplos bien conocidos.72 73 74 Sin embargo, debido
a su capacidad para inhibir la replicación y la
transcripción del ADN, estas toxinas también se
utilizan en quimioterapia para inhibir el rápido
crecimiento de las células cancerosas.75
El daño en el ADN inicia una respuesta que activa
diferentes mecanismos de reparación que reconocen
lesiones específicas en el ADN, que son reparadas
en el momento para recuperar la secuencia original
del ADN. Asimismo, el daño en el ADN provoca una
parada en elciclo celular, que conlleva la alteración de
numerosos procesos fisiológicos, que a su vez
implica síntesis, transporte y degradación de
proteínas (véase también Checkpoint de daños en el
ADN). Alternativamente, si el daño genómico es
demasiado grande para que pueda ser reparado, los
mecanismos de control inducirán la activación de una
serie de rutas celulares que culminarán en la muerte
celular.
Funciones biológicas[editar]
Las funciones biológicas del ADN incluyen el
almacenamiento de información (genes y genoma), la
codificación de proteínas (transcripción y traducción)
y su autoduplicación (replicación del ADN) para
asegurar la transmisión de la información a las
células hijas durante la división celular.
Genes y genoma[editar]
Véanse también: Núcleo
celular, Cromatina, Cromosoma y Genoma.

El ADN se puede considerar como un almacén cuyo
contenido es la información (mensaje) necesaria para
construir y sostener el organismo en el que reside, la
cual se transmite de generación en generación. El
conjunto de información que cumple esta función en
un organismo dado se denomina genoma, y el ADN
que lo constituye, ADN genómico.
El ADN genómico (que se organiza en moléculas
de cromatina que a su vez se ensamblan
en cromosomas) se encuentra en el núcleo celular de
los eucariotas, además de pequeñas cantidades en
las mitocondrias y cloroplastos. En procariotas, el
ADN se encuentra en un cuerpo de forma irregular
denominado nucleoide.76
El ADN codificante[editar]
ARN polimerasa T7 (azul) produciendo un ARNm (verde) a
partir de un molde de ADN (naranja).77
Véase también: Gen
La información genética de un genoma está
contenida en los genes, y al conjunto de toda la
información que corresponde a un organismo se le
denomina su genotipo. Un gen es una unidad
de herencia y es una región de ADN que influye en
una característica particular de un organismo (como
el color de los ojos, por ejemplo). Los genes
contienen un "marco de lectura abierto" (open
reading frame) que puede transcribirse, además
de secuencias reguladoras, tales
como promotores yenhancers, que controlan la
transcripción del marco de lectura abierto.

Desde este punto de vista, las obreras de este
mecanismo son las proteínas. Estas pueden
ser estructurales, como las proteínas de
los músculos, cartílagos, pelo, etc., o funcionales,
como la hemoglobina o las innumerables enzimas del
organismo. La función principal de la herencia es la
especificación de las proteínas, siendo el ADN una
especie de plano oreceta para producirlas. La mayor
parte de las veces la modificación del ADN provocará
una disfunción proteica que dará lugar a la aparición
de alguna enfermedad. Pero en determinadas
ocasiones, las modificaciones podrán provocar
cambios beneficiosos que darán lugar a individuos
mejor adaptados a su entorno.
Las aproximadamente treinta mil proteínas diferentes
en el cuerpo humano están constituidas por
veinte aminoácidos diferentes, y una molécula de
ADN debe especificar la secuencia en que se unen
dichos aminoácidos.
En el proceso de elaborar una proteína, el ADN de un
gen se lee y se transcribe a ARN. Este ARN sirve
como mensajero entre el ADN y la maquinaria que
elaborará las proteínas y por eso recibe el nombre
de ARN mensajero o ARNm. El ARN mensajero sirve
de molde a la maquinaria que elabora las proteínas,
para que ensamble los aminoácidos en el orden
preciso para armar la proteína.
El dogma central de la biología molecular establecía
que el flujo de actividad y de información era: ADN
→ ARN → proteína. No obstante, en la actualidad ha
quedado demostrado que este "dogma" debe ser
ampliado, pues se han encontrado otros flujos de
información: en algunos organismos (virus de ARN) la
información fluye de ARN a ADN; este proceso se
conoce como "transcripción inversa o reversa",
también llamada "retrotranscripción". Además, se
sabe que existen secuencias de ADN que se
transcriben a ARN y son funcionales como tales, sin
llegar a traducirse nunca a proteína: son los ARN no
codificantes, como es el caso de los ARN
interferentes.34 35
El ADN no codificante[editar]
El ADN del genoma de un organismo puede dividirse
conceptualmente en dos: el que codifica las proteínas
(los genes) y el que no codifica. En muchas especies,
sólo una pequeña fracción del genoma codifica
proteínas. Por ejemplo, sólo alrededor del 1,5% del
genoma humano consiste en exones que codifican
proteínas (20.000 a 25.000 genes), mientras que más
del 90% consiste en ADN no codificante.78
El ADN no codificante (también denominado ADN
basura o junk DNA) corresponde a secuencias del
genoma que no generan una proteína (procedentes
de transposiciones, duplicaciones, translocaciones y
recombinaciones de virus, etc.), incluyendo
los intrones. Hasta hace poco tiempo se pensaba que
el ADN no codificante no tenía utilidad alguna, pero
estudios recientes indican que eso es inexacto. Entre
otras funciones, se postula que el llamado "ADN
basura" regula la expresión diferencial de los
genes.79 Por ejemplo, algunas secuencias tienen
afinidad hacia proteínas especiales que tienen la
capacidad de unirse al ADN (como
los homeodominios, los complejos receptores de
hormonas esteroides, etc.), con un papel importante
en el control de los mecanismos de trascripción y
replicación. Estas secuencias se llaman
frecuentemente "secuencias reguladoras", y los
investigadores suponen que sólo se ha identificado
una pequeña fracción de las que realmente existen.
La presencia de tanto ADN no codificante en
genomas eucarióticos y las diferencias en tamaño del
genoma entre especies representan un misterio que
es conocido como el "enigma del valor de C".80 Los
elementos repetitivos también son elementos
funcionales. Si no se considerasen así, se excluiría
más del 50% de los nucleótidos totales, ya que
constituyen elementos de repetición. Recientemente,
un grupo de investigadores de la Universidad de
Yale ha descubierto una secuencia de ADN no
codificante que sería la responsable de que los seres
humanos hayan desarrollado la capacidad de agarrar
y/o manipular objetos o herramientas.81
Por otro lado, algunas secuencias de ADN
desempeñan un papel estructural en los
cromosomas: los telómeros y centrómeros contienen
pocos o ningún gen codificante de proteínas, pero
son importantes para estabilizar la estructura de los
cromosomas. Algunos genes no codifican proteínas,
pero sí se transcriben en ARN: ARN ribosómico, ARN
de transferencia y ARN de interferencia (ARNi, que
son ARN que bloquean la expresión de genes
específicos). La estructura de intrones y exones de
algunos genes (como los
de inmunoglobulinas y protocadherinas) son
importantes por permitir los cortes y empalmes
alternativos del pre-ARN mensajero que hacen
posible la síntesis de diferentes proteínas a partir de
un mismo gen (sin esta capacidad no existiría el
sistema inmune, por ejemplo). Algunas secuencias de
ADN no codificante representan pseudogenes que
tienen valor evolutivo, ya que permiten la creación de
nuevos genes con nuevas funciones.35 Otros ADN no
codificantes proceden de la duplicación de pequeñas
regiones del ADN; esto tiene mucha utilidad, ya que
el rastreo de estas secuencias repetitivas permite
estudios de filogenia.
Transcripción y traducción[editar]
Artículos principales: Transcripción
(genética) y Traducción (genética).
En un gen, la secuencia de nucleótidos a lo largo de
una hebra de ADN se transcribe a un ARN
mensajero (ARNm) y esta secuencia a su vez
se traduce a una proteína que un organismo es capaz
de sintetizar o "expresar" en uno o varios momentos
de su vida, usando la información de dicha secuencia.
La relación entre la secuencia de nucleótidos y la
secuencia de aminoácidos de la proteína viene
determinada por el código genético, que se utiliza

durante el proceso de traducción o síntesis de
proteínas. La unidad codificadora del código genético
es un grupo de tres nucleótidos (triplete),
representado por las tres letras iniciales de las bases
nitrogenadas (por ej., ACT, CAG, TTT). Los tripletes
del ADN se transcriben en sus bases
complementarias en el ARN mensajero, y en este
caso los tripletes se denominancodones (para el
ejemplo anterior, UGA, GUC, AAA). En el ribosoma
cada codón del ARN mensajero interacciona con una
molécula de ARN de transferencia (ARNt o tRNA) que
contenga el triplete complementario, denominado
anticodón. Cada ARNt porta el aminoácido
correspondiente al codón de acuerdo con el código
genético, de modo que el ribosoma va uniendo los
aminoácidos para formar una nueva proteína de
acuerdo con las "instrucciones" de la secuencia del
ARNm. Existen 64 codones posibles, por lo cual
corresponde más de uno para cada aminoácido (por
esta duplicidad de codones se dice que el código
genético es un código degenerado: no es unívoco);
algunos codones indican la terminación de la síntesis,
el fin de la secuencia codificante; estos codones de
terminación o codones de parada son UAA, UGA y
UAG (en inglés, nonsense codons ostop codons).34
Replicación del ADN[editar]
Esquema representativo de la replicación del ADN.
Artículo principal: Replicación de ADN
La replicación del ADN es el proceso por el cual se
obtienen copias o réplicas idénticas de una molécula
de ADN. La replicación es fundamental para la
transferencia de la información genética de una
generación a la siguiente y, por ende, es la base de
la herencia. El mecanismo consiste esencialmente en
la separación de las dos hebras de la doble hélice, las
cuales sirven de molde para la posterior síntesis de
cadenas complementarias a cada una de ellas, que
llevará por nombre ARNm. El resultado final son dos
moléculas idénticas a la original. Este tipo de
replicación se denomina semiconservativa debido a
que cada una de las dos moléculas resultantes de la
duplicación presenta una cadena procedente de la
molécula "madre" y otra recién sintetizada.
Hipótesis sobre la duplicación del ADN[editar]
En un principio, se propusieron tres hipótesis:
Semiconservativa: Según el experimento de
Meselson-Stahl, cada hebra sirve de molde para
que se forme una hebra nueva, mediante la
complentariedad de bases, quedando al final dos
dobles hélices formadas por una hebra antigua
(molde) y una nueva hebra (copia).
Conservativa: Tras la duplicación quedarían las
dos hebras antiguas juntas y, por otro lado, las
dos hebras nuevas formando una doble hélice.
Dispersiva: Según esta hipótesis, las hebras
resultantes estarían formadas por fragmentos en
doble hélice ADN antiguo y ADN recién
sintetizado.
Interacciones ADN-proteína[editar]
Todas las funciones del ADN dependen de sus
interacciones con proteínas. Estas interacciones
pueden ser inespecíficas, o bien la proteína puede
unirse de forma específica a una única secuencia de
ADN. También pueden unirse enzimas, entre las
cuales son particularmente importantes las
polimerasas, que copian las secuencia de bases del
ADN durante la transcripción y la replicación.
Proteínas que unen ADN[editar]

Interacciones inespecíficas[editar]
Interacción de ADN con histonas (en blanco, arriba).
Los aminoácidos básicos de estas proteínas (abajo a la
izquierda, en azul) se unen a los grupos ácidos de los
fosfatos del ADN (abajo a la derecha, en rojo).
Las proteínas estructurales que se unen al ADN son
ejemplos bien conocidos de interacciones
inespecíficas ADN-proteínas. En los cromosomas, el
ADN se encuentra formando complejos con proteínas
estructurales. Estas proteínas organizan el ADN en
una estructura compacta denominada cromatina.
En eucariotas esta estructura implica la unión del
ADN a un complejo formado por pequeñas proteínas
básicas denominadas histonas, mientras que
en procariotas están involucradas una gran variedad
de proteínas.82 83 Las histonas forman un complejo de
forma cilíndrica denominado nucleosoma, en torno al
cual se enrollan casi dos vueltas de ADN de doble
hélice. Estas interacciones inespecíficas quedan
determinadas por la existencia de residuos básicos
en las histonas, que forman enlaces iónicos con el
esqueleto de azúcar-fosfato del ADN y, por tanto, son
en gran parte independientes de la secuencia de
bases.84 Estos aminoácidos básicos experimentan
modificaciones químicas
de metilación, fosforilación yacetilación,85 que alteran
la fuerza de la interacción entre el ADN y las histonas,
haciendo al ADN más o menos accesible a
losfactores de transcripción y por tanto modificando la
tasa de transcripción.86
Otras proteínas que se unen a ADN de manera
inespecífica en la cromatina incluyen las proteínas

del grupo de alta movilidad(HMG, High Mobility
Group) que se unen a ADN plegado o
distorsionado.87 Estas proteínas son importantes
durante el plegamiento de los nucleosomas,
organizándolos en estructuras más complejas para
constituir los cromosomas88 durante el proceso
decondensación cromosómica. Se ha propuesto que
en este proceso también intervendrían otras
proteínas, formando una especie de "andamio" sobre
el cual se organiza la cromatina; los principales
componentes de esta estructura serían la
enzima topoisomerasaII α (topoIIalpha) y
la condensina 13S.89 Sin embargo, el papel
estructural de la topoIIalpha en la organización de los
cromosomas aún es discutido, ya que otros grupos
argumentan que esta enzima se intercambia
rápidamente tanto en los brazos cromosómicos como
en los cinetocoros durante la mitosis.90
Interacciones específicas[editar]
Un grupo bien definido de proteínas que unen ADN
es el conformado por las proteínas que se unen
específicamente a ADN monocatenario o ADN de
hebra sencilla (ssDNA). En humanos, la proteína A
de replicación es la mejor conocida de su familia y
actúa en procesos en los que la doble hélice se
separa, como la replicación del ADN,
larecombinación o la reparación del ADN.91 Estas
proteínas parecen estabilizar el ADN monocatenario,
protegiéndolo para evitar que forme estructuras de
tallo-lazo (stem-loop) o que sea degradado
por nucleasas.

El factor de transcripción represor del fago
lambda unido a su ADN diana mediante un motivo
hélice-giro-hélice (helix-turn-helix).92
Sin embargo, otras proteínas han evolucionado para
unirse específicamente a secuencias particulares de
ADN. La especificidad de la interacción de las
proteínas con el ADN procede de los múltiples
contactos con las bases de ADN, lo que les permite
"leer" la secuencia del ADN. La mayoría de esas
interacciones con las bases ocurre en la hendidura
mayor, donde las bases son más accesibles.93
Las proteínas específicas estudiadas con mayor
detalle son las encargadas de regular la transcripción,
denominadas por ello factores de transcripción.
Cada factor de transcripción se une a una secuencia
concreta de ADN y activa o inhibe la transcripción de
los genes que presentan estas secuencias próximas
a sus promotores. Los factores de transcripción
pueden efectuar esto de dos formas:
En primer lugar, pueden unirse a la polimerasa de
ARN responsable de la transcripción, bien
directamente o a través de otras proteínas
mediadoras. De esta forma. se estabiliza la unión
entre la ARN polimerasa y el promotor, lo que
permite el inicio de la transcripción.94
En segundo lugar, los factores de transcripción
pueden unirse a enzimas que modifican las

histonas del promotor, lo que altera la
accesibilidad del molde de ADN a la ARN
polimerasa.95
Como los ADN diana pueden encontrarse por todo
el genoma del organismo, los cambios en la actividad
de un tipo de factor de transcripción pueden afectar a
miles de genes.96 En consecuencia, estas proteínas
son frecuentemente las dianas de los procesos
de transducción de señales que controlan las
respuestas a cambios ambientales o diferenciación y
desarrollo celular.
La enzima de restricción EcoRV (verde) formando un
complejo con su ADN diana.97
Enzimas que modifican el ADN[editar]
Nucleasas y ligasas[editar]
Las nucleasas son enzimas que cortan las hebras de
ADN mediante la catálisis de la hidrólisis de
los enlaces fosfodiéster. Las nucleasas que
hidrolizan nucleótidos a partir de los extremos de las
hebras de ADN se denominanexonucleasas, mientras
que las endonucleasas cortan en el interior de las
hebras. Las nucleasas que se utilizan con mayor
frecuencia en biología molecular son las enzimas de
restricción, endonucleasas que cortan el ADN por
determinadas secuencias específicas. Por ejemplo, la
enzima EcoRV, que se muestra a la izquierda,
reconoce la secuencia de 6 bases 5′-GAT|ATC-3′, y
hace un corte en ambas hebras en la línea vertical
indicada, generando dos moléculas de ADN con los
extremos romos. Otras enzimas de restricción
generan sin embargo extremos cohesivos, ya que
cortan de forma diferente las dos hebras de ADN. En

la naturaleza, estas enzimas protegen a
las bacterias contra las infecciones de fagos, al digerir
el ADN de dicho fago cuando entra a través de la
pared bacteriana, actuando como un mecanismo de
defensa.98 En biotecnología, estas nucleasas
específicas de la secuencias de ADN se utilizan
en ingeniería genética para clonar fragmentos de
ADN y en la técnica de huella genética.
Las enzimas denominadas ADN ligasas pueden
reunir hebras de ADN cortadas o rotas.99 Las ligasas
son particularmente importantes en la replicación de
la hebra que sufre replicación discontinua en el ADN,
ya que unen los fragmentos cortos de ADN
generados en la horquilla de replicación para formar
una copia completa del molde de ADN. También se
utilizan en la reparación del ADN y en procesos
de recombinación genética.99
Topoisomerasas y helicasas[editar]
Las topoisomerasas son enzimas que poseen a la
vez actividad nucleasa y ligasa. Estas proteínas
varían la cantidad de ADN superenrollado. Algunas
de estas enzimas funcionan cortando la hélice de
ADN y permitiendo que una sección rote, de manera
que reducen el grado de superenrollamiento. Una vez
hecho esto, la enzima vuelve a unir los fragmentos de
ADN.59 Otros tipos de enzimas son capaces de cortar
una hélice de ADN y luego pasar la segunda hebra de
ADN a través de la rotura, antes de reunir las
hélices.100 Las topoisomerasas son necesarias para
muchos procesos en los que interviene el ADN, como
la replicación del ADN y la transcripción.60
Las helicasas son unas proteínas que pertenecen al
grupo de los motores moleculares. Utilizan energía
química almacenada en los nucleósidos trifosfatos,
fundamentalmenteATP, para romper puentes de
hidrógeno entre bases y separar la doble hélice de
ADN en hebras simples.101 Estas enzimas son
esenciales para la mayoría de los procesos en los
que las enzimas necesitan acceder a las bases del
ADN.

Polimerasas[editar]
Las polimerasas son enzimas que sintetizan cadenas
de nucleótidos a partir de nucleósidos trifosfatos. La
secuencia de sus productos son copias de cadenas
de polinucleótidos existentes, que se
denominan moldes. Estas enzimas funcionan
añadiendo nucleótidos al grupo hidroxilo en 3' del
nucleótido previo en una hebra de ADN. En
consecuencia, todas las polimerasas funcionan en
dirección 5′ --> 3′.102 En los sitios activos de estas
enzimas, el nucleósido trifosfato que se incorpora
aparea su base con la correspondiente en el molde:
esto permite que la polimerasa sintentice de forma
precisa la hebra complementaria al molde.
Las polimerasas se clasifican de acuerdo al tipo de
molde que utilizan:
En la replicación del ADN, una ADN polimerasa
dependiente de ADN realiza una copia de ADN
a partir de una secuencia de ADN. La precisión
es vital en este proceso, por lo que muchas de
estas polimerasas tienen una actividad de
verificación de la lectura (proofreading). Mediante
esta actividad, la polimerasa reconoce errores
ocasionales en la reacción de síntesis, debido a
la falta de apareamiente entre el nucleótido
erróneo y el molde, lo que genera un
desacoplamiento (mismatch). Si se detecta un
desacoplamiento, se activa una
actividad exonucleasa en dirección 3′ --> 5′ y la
base incorrecta se elimina.103 En la mayoría de
los organismos las ADN polimerasas funcionan
en un gran complejo denominado replisoma, que
contiene múltiples unidades accesorias,
como helicasas.104
Las ADN polimerasas dependientes de
ARN son una clase especializada de polimerasas
que copian la secuencia de una hebra de ARN en
ADN. Incluyen la transcriptasa inversa, que es
una enzima viral implicada en la infección de

células por retrovirus, y la telomerasa, que es
necesaria para la replicación de los
telómeros.105 43 La telomerasa es una polimerasa
inusual, porque contiene su propio molde de ARN
como parte de su estructura.44
La transcripción se lleva a cabo por una ARN
polimerasa dependiente de ADN que copia la
secuencia de una de las hebras de ADN en ARN.
Para empezar a transcribir un gen, la ARN
polimerasa se une a una secuencia del ADN
denominada promotor, y separa las hebras del
ADN. Entonces copia la secuencia del gen en un
transcrito de ARN mensajero hasta que alcanza
una región de ADN denomimada terminador,
donde se detiene y se separa del ADN. Como
ocurre con las ADN polimerasas dependientes de
ADN en humanos, la ARN polimerasa II (la
enzima que transcribe la mayoría de los genes
del genoma humano) funciona como un gran
complejo multiproteico que contiene múltiples
subunidades reguladoras y accesorias.106
Recombinación genética[editar]
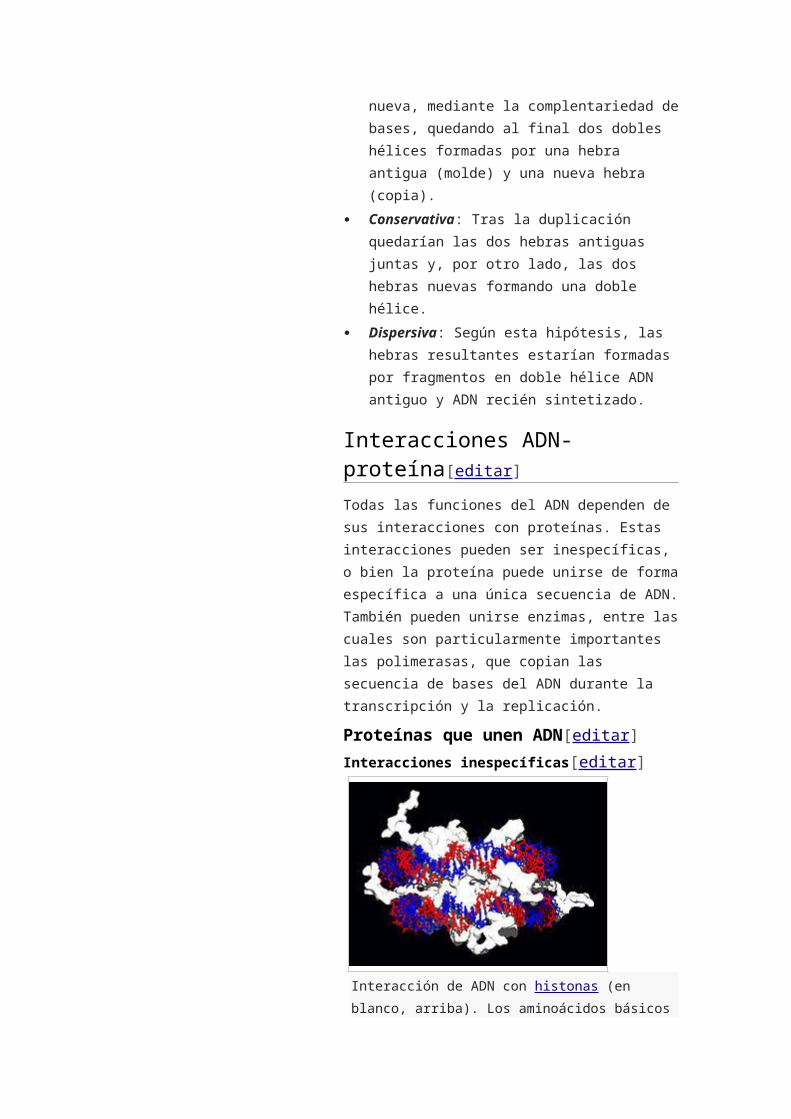
Estructura de un intermedio en unión de Holliday en
la recombinación genética. Las cuatro hebras de ADN
separadas están coloreadas en rojo, azul, verde y
amarillo.107
Artículo principal: Recombinación genética
La recombinación implica la rotura y reunión de dos
cromosomas homólogos (M y F) para producir dos
cromosomas nuevos reorganizados (C1 y C2).
Una hélice de ADN normalmente no interacciona con
otros segmentos de ADN, y en las células humanas
los diferentes cromosomas incluso ocupan áreas
separadas en el núcleo celular denominadas
“territorios cromosómicos”.108 La separación física de
los diferentes cromosomas es importante para que el
ADN mantenga su capacidad de funcionar como un
almacén estable de información. Uno de los pocos
momentos en los que los cromosomas interaccionan
es durante el sobrecruzamiento
cromosómico (chromosomal crossover), durante el
cual se recombinan. El sobrecruzamiento
cromosómico ocurre cuando dos hélices de ADN se
rompen, se intercambian y se unen de nuevo.

La recombinación permite a los cromosomas
intercambiar información genética y produce nuevas
combinaciones de genes, lo que aumenta la eficiencia
de la selección natural y puede ser importante en la
evolución rápida de nuevas proteínas.109 Durante la
profase I de lameiosis, una vez que los cromosomas
homólogos están perfectamente apareados formando
estructuras llamadas bivalentes, se produce el
fenómeno de sobrecruzamiento o
entrecruzamiento (crossing-over), en el cual las
cromátidas homólogas no hermanas (procedentes del
padre y de la madre) intercambian material genético.
La recombinación genética resultante hace aumentar
en gran medida la variación genética entre la
descendencia de progenitores que se reproducen por
vía sexual. La recombinación genética también puede
estar implicada en la reparación del ADN, en
particular en la respuesta celular a las roturas de
doble hebra (double-strand breaks).110
La forma más frecuente de sobrecruzamiento
cromosómico es la recombinación homóloga, en la
que los dos cromosomas implicados comparten
secuencias muy similares. La recombinación no-
homóloga puede ser dañina para las células, ya que
puede producir translocaciones cromosómicas y
anomalías genéticas. La reacción de recombinación
está catalizada por enzimas conocidas
como recombinasas, tales como RAD51.111 El primer
paso en el proceso de recombinación es una rotura
de doble hebra, causada bien por una
endonucleasa o por daño en el
ADN.112 Posteriormente, una serie de pasos
catalizados en parte por la recombinasa, conducen a
la unión de las dos hélices formando al menos
una unión de Holliday, en la que un segmento de una
hebra simple es anillado con la hebra complementaria
en la otra hélice. La unión de Holliday es una
estructura de unión tetrahédrica que puede moverse
a lo largo del par de cromosomas, intercambiando
una hebra por otra. La reacción de recombinación se

detiene por el corte de la unión y la reunión de los
segmentos de ADN liberados.113
Evolución del metabolismo de ADN[editar]
Véase también: Hipótesis del mundo de ARN
El ADN contiene la información genética que permite
a la mayoría de los organismos vivientes funcionar,
crecer y reproducirse. Sin embargo, no está claro
durante cuánto tiempo ha ejercido esta función en los
~3000 millones de años de la historia de la vida, ya
que se ha propuesto que las formas de vida más
tempranas podrían haber utilizadoARN como material
genético.114 115 El ARN podría haber funcionado como
la parte central de un metabolismo primigenio, ya que
puede transmitir información genética y
simultáneamente actuar como catalizador formando
parte de las ribozimas.116 Este antiguo Mundo de
ARN donde los ácidos nucleicos funcionarían como
catalizadores y como almacenes de información
genética podría haber influido en
la evolución del código genético actual, basado en
cuatro nucleótidos. Esto se debería a que el número
de bases únicas en un organismo es un compromiso
entre un número pequeño de bases (lo que
aumentaría la precisión de la replicación) y un
número grande de bases (que a su vez aumentaría la
eficiencia catalítica de las ribozimas).117
Desafortunadamente, no se cuenta con evidencia
directa de los sistemas genéticos ancestrales porque
la recuperación del ADN a partir de la mayor parte de
los fósiles es imposible. Esto se debe a que el ADN
es capaz de sobrevivir en el medio ambiente durante
menos de un millón de años, y luego empieza a
degradarse lentamente en fragmentos de menor
tamaño en solución.118 Algunas investigaciones
pretenden que se ha obtenido ADN más antiguo, por
ejemplo un informe sobre el aislamiento de una
bacteria viable a partir de un cristal salino de 250

millones de años de antigüedad,119 pero estos datos
son controvertidos.120 121
Sin embargo, pueden utilizarse herramientas de
evolución molecular para inferir los genomas de
organismos ancestrales a partir de organismos
contemporáneos.122 123 En muchos casos, estas
inferencias son suficientemente fiables, de manera
que una biomolécula codificada en un genoma
ancestral puede resucitarse en el laboratorio para ser
estudiada hoy.124 125 Una vez que la biomolécula
ancestral se ha resucitado, sus propiedades pueden
ofrecer inferencias sobre ambientes y estilos de vida
primigenios. Este proceso se relaciona con el campo
emergente de la paleogenética experimental.126
A pesar de todo, el proceso de trabajo hacia
atrás desde el presente tiene limitaciones inherentes,
razón por la cual otros investigadores tratan de
elucidar el mecanismo evolutivo trabajando desde el
origen de la Tierra en adelante. Dada suficiente
información sobre la química en el cosmos, la manera
en la que las sustancias cósmicas podrían haberse
depositado en la Tierra, y las transformaciones que
podrían haber tenido lugar en la superficie terrestre
primigenia, tal vez podríamos ser capaces de
aprender sobre los orígenes para desarrollar modelos
de evolución ulterior de la información
genética127 (véase también el artículo sobre el origen
de la vida).
Técnicas comunes[editar]
El conocimiento de la estructura del ADN ha permitido
el desarrollo de multitud de herramientas tecnológicas
que explotan sus propiedades fisicoquímicas para
analizar su implicación en problemas concretos: por
ejemplo, desde análisis filogeńeticos para detectar
similitudes entre diferentes taxones, a la
caracterización de la variabilidad individual de un
paciente en su respuesta a un determinado fármaco,
pasando por un enfoque global, a nivel genómico, de

cualquier característica específica en un grupo de
individuos de interés. 128
Podemos clasificar las metodologías de análisis del
ADN en aquellas que buscan su multiplicación, ya in
vivo, como la reacción en cadena de la
polimerasa (PCR), ya in vitro, como la clonación, y
aquellas que explotan las propiedades específicas de
elementos concretos, o de genomas adecuadamente
clonados. Es el caso de la secuenciación de ADN y
de la hibridación con sondas específicas ("southern
blot" y chips de ADN).
Tecnología del ADN recombinante[editar]
Artículo principal: ADN recombinante
La tecnología del ADN recombinante, piedra angular
de la ingeniería genética, permite propagar grandes
cantidades de un fragmento de ADN de interés, el
cual se dice que ha sido clonado. Para ello, debe
introducirse dicho fragmento en otro elemento de
ADN, generalmente un plásmido, que posee en su
secuencia los elementos necesarios para que la
maquinaria celular de un hospedador,
normalmente Escherichia coli, lo replique. De este
modo, una vez transformada la cepa bacteriana, el
fragmento de ADN clonado se reproduce cada vez
que aquella se divide.129
Para clonar la secuencia de ADN de interés, se
emplean enzimas como herramientas de corte y
empalme del fragmento y del vector (el plásmido).
Dichas enzimas corresponden a dos grupos: en
primer lugar, las enzimas de restricción, que poseen
la capacidad de reconocer y cortar secuencias
específicas; en segundo lugar, la ADN ligasa, que
establece un enlace covalente entre extremos de
ADN compatibles128 (ver sección Nucleasas y
ligasas).
Secuenciación[editar]
Artículo principal: Secuenciación de ADN
La secuenciación del ADN consiste en dilucidar el
orden de los nucleótidos de un polímero de ADN de

cualquier longitud, si bien suele dirigirse hacia la
determinación degenomas completos, debido a que
las técnicas actuales permiten realizar esta
secuenciación a gran velocidad, lo cual ha sido de
gran importancia para proyectos de secuenciación a
gran escala como el Proyecto Genoma Humano.
Otros proyectos relacionados, en ocasiones fruto de
la colaboración de científicos a escala mundial, han
establecido la secuencia completa del ADN de
muchos genomas de animales, plantas y microorgani
smos.
El método de secuenciación de Sanger ha sido el
más empleado durante el siglo XX. Se basa en la
síntesis de ADN en presencia
de didesoxinucleósidos, compuestos que, a diferencia
de los desoxinucleósidos normales (dNTPs), carecen
de un grupo hidroxilo en su extremo 3'. Aunque los
didesoxinucleótidos trifosfatados (ddNTPs) pueden
incorporarse a la cadena en síntesis, la carencia de
un extremo 3'-OH imposibilita la generación de un
nuevo enlace fosfodiéster con el nucleósido siguiente;
por tanto, provocan la terminación de la síntesis. Por
esta razón, el método de secuenciación también se
denomina «de terminación de cadena». La reacción
se realiza usualmente preparando un tubo con el
ADN molde, la polimerasa, un cebador, dNTPs
convencionales y una pequeña cantidad de ddNTPs
marcados fluorescentemente en su base nitrogenada.
De este modo, el ddTTP puede ir marcado en azul, el
ddATP en rojo, etc. Durante la polimerización, se van
truncando las cadenas crecientes, al azar, en
distintas posiciones. Por tanto, se produce una serie
de productos de distinto tamaño, coincidiendo la
posición de la terminación debido a la incorporación
del ddNTP correspondiente. Una vez terminada la
reacción, es posible correr la mezcla en
una electroforesis capilar (que resuelve todos los
fragmentos según su longitud) en la cual se lee la
fluorescencia para cada posición del polímero. En
nuestro ejemplo, la lectura azul-rojo-azul-azul se
traduciría como TATT.130 131

Reacción en cadena de la polimerasa (PCR)[editar]
Artículo principal: Reacción en cadena de la polimerasa
La reacción en cadena de la polimerasa,
habitualmente conocida como PCR por sus siglas en
inglés, es una técnica de biología molecular descrita
en 1986 por Kary Mullis,132cuyo objetivo es obtener un
gran número de copias de un fragmento
de ADN dado, partiendo de una escasa cantidad de
aquél. Para ello, se emplea una ADN
polimerasatermoestable que, en presencia de una
mezcla de los cuatro desoxinucleótidos, un tampón
de la fuerza iónica adecuada y los cationes precisos
para la actividad de la enzima, dos oligonucleótidos
(denominados cebadores) complementarios a parte
de la secuencia (situados a distancia suficiente y en
sentido antiparalelo) y bajo unas condiciones de
temperatura adecuadas, moduladas por un aparato
denominado termociclador,
genera exponencialmente nuevos fragmentos de
ADN semejantes al original y acotados por los dos
cebadores.129
La PCR puede efectuarse como una técnica de punto
final, esto es, como una herramienta de generación
del ADN deseado, o como un método continuo, en el
que se evalúe dicha polimerización a tiempo real.
Esta última variante es común en la PCR
cuantitativa.128
Southern blot[editar]
Artículo principal: Southern blot
El método de «hibridación Southern» o «Southern
blot» (el nombre original en el idioma inglés) permite
la detección de una secuencia de ADN en una
muestra compleja o no del ácido nucleico. Para ello,
combina una separación
mediante masa y carga (efectuada mediante
una electroforesis en gel) con una hibridación con una
sonda de ácido nucleico marcada de algún modo (ya
sea con radiactividad o con un compuesto químico)
que, tras varias reacciones, dé lugar a la aparición de

una señal de color o fluorescencia. Dicha hibridación
se realiza tras la transferencia del ADN separado
mediante la electroforesis a una membrana de filtro.
Una técnica semejante, pero en la cual no se produce
la mencionada separación electroforética se
denomina dot blot.
El método recibe su nombre en honor a su inventor,
el biólogo inglés Edwin Southern.133 Por analogía al
método Southern, se han desarrollado técnicas
semejantes que permiten la detección de secuencias
dadas de ARN (método Northern, que emplea sondas
de ARN o ADN marcadas)134 o de proteínas
específicas (técnica Western, basada en el uso
de anticuerpos).135
Chips de ADN[editar]
Artículo principal: Chip de ADN
Microarray con 37.500 oligonucleótidos específicos.
Arriba a la izquierda se puede apreciar una región
ampliada del chip.
Los chips de ADN son colecciones
de oligonucleótidos de ADN complementario
dispuestos en hileras fijadas sobre un soporte,
frecuentemente de cristal. Se utilizan para el estudio
de mutaciones de genes conocidos o para monitorizar
la expresión génica de una preparación de ARN.
Aplicaciones[editar]
Ingeniería genética[editar]
Véanse también: Ingeniería genética y Biología
molecular.
La investigación sobre el ADN tiene un impacto
significativo, especialmente en el ámbito de
la medicina, pero también en agricultura y ganadería

(donde los objetivos son los mismos que con las
técnicas tradicionales que el hombre lleva utilizando
desde hace milenios - la domesticación, la selección y
los cruces dirigidos - para obtener variedades de
animales y plantas más productivos). La moderna
biología y bioquímica hacen uso intensivo de
la tecnología del ADN recombinante, introduciendo
genes de interés en organismos, con el objetivo de
expresar una proteína recombinante concreta, que
puede ser:
aislada para su uso posterior: por ejemplo, se
pueden transformar microorganismos para
convertirlos en auténticas fábricas que producen
grandes cantidades de sustancias útiles,
como insulina o vacunas, que posteriormente se
aíslan y se utilizan terapéuticamente.136 137 138
necesaria para reemplazar la expresión de un
gen endógeno dañado que ha dado lugar a una
patología, lo que permitiría el restablecimiento de
la actividad de la proteína perdida y
eventualmente la recuperación del estado
fisiológico normal, no patológico. Este es el
objetivo de la terapia génica, uno de los campos
en los que se está trabajando activamente en
medicina, analizando ventajas e inconvenientes
de diferentes sistemas de administración del gen
(virales y no virales) y los mecanismos de
selección del punto de integración de los
elementos genéticos (distintos para los virus y los
transposones) en el genoma diana.139 En este
caso, antes de plantearse la posibilidad de
realizar una terapia génica en una determinada
patología, es fundamental comprender el impacto
del gen de interés en el desarrollo de dicha
patología, para lo cual es necesario el desarrollo
de un modelo animal, eliminando o modificando
dicho gen en un animal de laboratorio, mediante
la técnica ‘’knockout’’.140 Sólo en el caso de que
los resultados en el modelo animal sean
satisfactorios se procedería a analizar la
posibilidad de restablecer el gen dañado
mediante terapia génica.
utilizada para enriquecer un alimento: por
ejemplo, la composición de la leche (una
importante fuente de proteínas para el consumo
humano y animal) puede modificarse mediante
transgénesis, añadiendo genes exógenos y
desactivando genes endógenos para mejorar su
valor nutricional, reducir infecciones en las
glándulas mamarias, proporcionar a los
consumidores proteínas antipatógenas y preparar
proteínas recombinantes para su uso
farmacéutico.141 142
útil para mejorar la resistencia del organismo
transformado: por ejemplo en plantas se pueden
introducir genes que confieren resistencia a
patógenos (virus, insectos, hongos…), así como
a agentes estresantes abióticos (salinidad,
sequedad, metales pesados…).143 144 145
Medicina forense[editar]
Véase también: Huella genética
Los médicos forenses pueden utilizar el ADN
presente en la sangre, el semen, la piel, la saliva o
el pelo en la escena de un crimen para identificar al
responsable. Esta técnica se denomina huella
genética, o también "perfil de ADN". Al realizar la
huella genética, se compara la longitud de secciones
altamente variables de ADN repetitivo, como
losmicrosatélites, entre personas diferentes. Este
método es frecuentemente muy fiable para identificar
a un criminal.146 Sin embargo, la identificación puede
complicarse si la escena está contaminada con ADN
de personas diferentes.147 La técnica de la huella
genética fue desarrollada en 1984 por el genetista
británico Sir Alec Jeffreys,148 y fue utilizada por
primera vez en medicina forense para condenar
a Colin Pitchfork por los asesinatos de Narborough en
1983 y de Enderby en 1986.149 Se puede requerir a
las personas acusadas de ciertos tipos de crímenes

que proporcionen una muestra de ADN para
introducirlos en una base de datos. Esto ha facilitado
la labor de los investigadores en la resolución de
casos antiguos, donde sólo se obtuvo una muestra de
ADN de la escena del crimen, en algunos casos
permitiendo exonerar a un convicto. La huella
genética también puede utilizarse para identificar
víctimas de accidentes en masa,150 o para realizar
pruebas de consanguinidad.151
Bioinformática[editar]
Véase también: Bioinformática
La bioinformática implica la manipulación, búsqueda
y extracción de información de los datos de la
secuencia del ADN. El desarrollo de las técnicas para
almacenar y buscar secuencias de ADN ha generado
avances en el desarrollo de software de los
ordenadores, para muchas aplicaciones,
especialmente algoritmos de búsqueda de
frases,aprendizaje automático y teorías de bases de
datos.152 La búsqueda de frases o algoritmos de
coincidencias, que buscan la ocurrencia de una
secuencia de letras dentro de una secuencia de letras
mayor, se desarrolló para buscar secuencias
específicas de nucleótidos.153 En otras aplicaciones
como editores de textos, incluso algoritmos simples
pueden funcionar, pero las secuencias de ADN
pueden generar que estos algoritmos presenten un
comportamiento de casi-el-peor-caso, debido al bajo
número de caracteres. El problema relacionado
del alineamiento de secuencias persigue identificar
secuencias homólogas y
localizar mutaciones específicas que las diferencian.
Estas técnicas, fundamentalmente el alineamiento
múltiple de secuencias, se utilizan al estudiar las
relaciones filogenéticas y la función de las
proteínas.154 Las colecciones de datos que
representan secuencias de ADN del tamaño de un
genoma, tales como las producidas por el Proyecto
Genoma Humano, son difíciles de usar sin
anotaciones, que marcan la localización de los genes

y los elementos reguladores en cada cromosoma. Las
regiones de ADN que tienen patrones asociados con
genes que codifican proteínas – o ARN – pueden
identificarse por algoritmos de localización de genes,
lo que permite a los investigadores predecir la
presencia de productos génicos específicos en un
organismo incluso antes de que haya sido aislado
experimentalmente.155
Nanotecnología de ADN[editar]
La estructura de ADN de la izquierda (mostrada de
forma esquemática) se auto-ensambla en la estructura
visualizada pormicroscopía de fuerza atómica a la
derecha. La nanotecnología de ADN es el campo que
busca diseñar estructuras a nanoescala utilizando las
propiedades de reconocimiento molecular de las
moléculas de ADN. Imagen de Strong,
2004. Plantilla:Doi-inline
Véase también: Nanotecnología
La nanotecnología de ADN utiliza las propiedades
únicas de reconocimiento molecular del ADN y otros
ácidos nucleicos para crear complejos ramificados
auto-ensamblados con propiedades útiles. En este
caso, el ADN se utiliza como un material estructural,
más que como un portador de información
biológica.156 Esto ha conducido a la creación de
láminas periódicas de dos dimensiones (ambas
basadas en azulejos, así como usando el método
de ADN origami157 ), además de estructuras en tres
dimensiones con forma depoliedros.

Historia, antropología y paleontología[editar]
Véanse también: Filogenia y Genealogía molecular.
A lo largo del tiempo, el ADN almacena mutaciones
que se heredan y, por tanto, contiene información
histórica, de manera que comparando secuencias de
ADN, los genetistas pueden inferir la historia evolutiva
de los organismos, su filogenia.158 La investigación
filogenética es una herramienta fundamental
en biología evolutiva. Si se comparan las secuencias
de ADN dentro de una especie, los genetistas de
poblacionespueden conocer la historia de
poblaciones particulares. Esto se puede utilizar en
una amplia variedad de estudios,
desde ecología hasta antropología, como ilustra el
análisis de ADN llevado a cabo para identificar las
Diez Tribus Perdidas de Israel.159 160 Por otro lado, el
ADN también se utiliza para estudiar relaciones
familiares recientes.
Igualmente en paleontología (en la paleogenética) el
ADN en algunos casos también se puede utilizar para
estudiar a especies extintas (ADN fósil).
Véase también[editar]
ARN
Cromatina
Cromosoma
Genoma
Genoma humano
Glosario de términos relacionados con el genoma
Genes MEIS
Cerberus
Desoxirribonucleótido
Genes HOX y genes PARAHOX
Genética
Medicina genómica
Prueba de ADN
Elementos funcionales del ADN
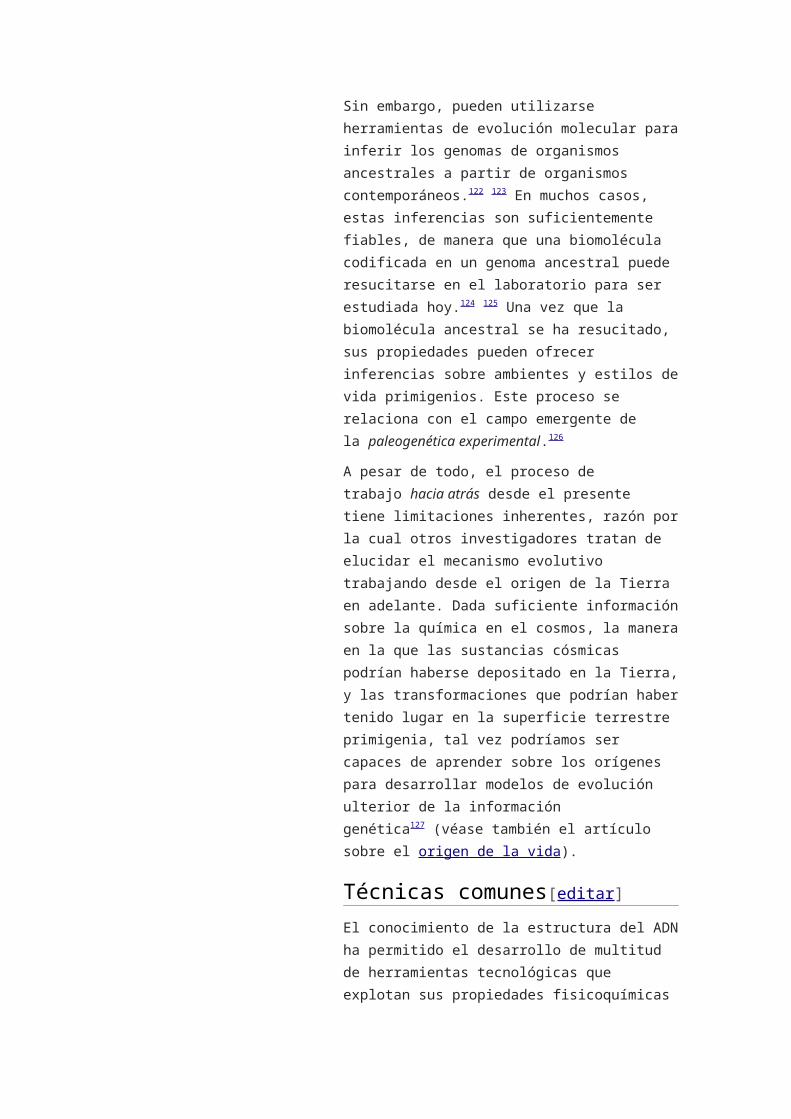
Referencias[editar]
Notas[editar]
1. Volver arriba↑ Sergio Ferrer. El verdadero sentido
de la vida Journal of Feelsynapsis (JoF). ISSN:
2254-3651. 2011 (1): 119-127
2. Volver arriba↑ Dahm R (2005). «Friedrich
Miescher and the discovery of DNA». Dev
Biol 278 (2): 274–
88. doi:10.1016/j.ydbio.2004.11.028. PMID 15680349.
3. Volver
arriba↑ http://www.terradaily.com/reports/Building_
Life_On_Earth_999.html Dato del descubrimiento
del ADN en terradaily.com
4. Volver arriba↑ Dahm R (2008). «Discovering DNA:
Friedrich Miescher and the early years of nucleic
acid research». Hum Genet 122 (2): 565–
581. PMID 17901982.
5. Volver arriba↑ Levene P, (1919). «The structure of
yeast nucleic acid». J Biol Chem 40 (2): 415–24.
6. ↑ Saltar a:a b Dhanda, J.S.; Shyam S. Chauhan
(22-Feb-2008). «Structural Levels of Nucleic Acids
and Sequencing.». En All India Institute of Medical
Sciences. Molecular Biology.(Department of
Biochemistry edición). New Delhi – 110
029. (Revisado el 7 de octubre de 2008).
7. Volver arriba↑ Astbury W, (1947). «Nucleic
acid». Symp. SOC. Exp. Bbl 1 (66).
8. Volver arriba↑ Lorenz MG, Wackernagel W
(1994). «Bacterial gene transfer by natural genetic
transformation in the environment». Microbiol.
Rev. 58 (3): 563–602. PMID 7968924.
9. Volver arriba↑ Avery O, MacLeod C, McCarty M
(1944). «Studies on the chemical nature of the
substance inducing transformation of
pneumococcal types. Inductions of transformation
by a desoxyribonucleic acid fraction isolated from
pneumococcus type III». J Exp Med 79(2): 137–
158.

10. Volver arriba↑ Hershey A, Chase M
(1952). «Independent functions of viral protein and
nucleic acid in growth of bacteriophage». J Gen
Physiol 36 (1): 39–56. PMID 12981234.
11. Volver arriba↑ Watson J.D. and Crick F.H.C.
(1953). «A Structure for Deoxyribose Nucleic
Acid».Nature 171: 737–
738. doi:10.1038/171737a0. PMID 13054692. Consultado
el 13 feb 2007.
12. Volver arriba↑ Nature Archives Double Helix of
DNA: 50 Years
13. Volver arriba↑ Franklin, R. E. (1953). «Molecular
Configuration in Sodium Thymonucleate. Franklin
R. and Gosling R.G.». Nature 171: 740–
741. doi:10.1038/171740a0. PMID 13054694.
14. Volver arriba↑ Original X-ray diffraction image
15. Volver arriba↑ Wilkins M.H.F., A.R. Stokes A.R. &
Wilson, H.R. (1953). «Molecular Structure of
Deoxypentose Nucleic Acids». Nature 171: 738–
740. doi:10.1038/171738a0.PMID 13054693.
16. Volver arriba↑ The Nobel Prize in Physiology or
Medicine 1962 Nobelprize.org (Revisado el 22 de
diciembre de 06).
17. Volver arriba↑ Brenda Maddox (23 de enero de
2003). «The double helix and the 'wronged
heroine'». Nature 421: 407–
408. doi:10.1038/nature01399. PMID 12540909.
18. ↑ Saltar a:a b Alberts, Bruce; Alexander Johnson,
Julian Lewis, Martin Raff, Keith Roberts, and Peter
Walters (2002). Molecular Biology of the Cell;
Fourth Edition. New York and London: Garland
Science. ISBN 0-8153-3218-1.
19. Volver arriba↑ Butler, John M. (2001) Forensic
DNA Typing "Elsevier". pp. 14–15. ISBN 978-0-12-
147951-0.
20. Volver arriba↑ Mandelkern M, Elias J, Eden D,
Crothers D (1981). «The dimensions of DNA in
solution».J Mol Biol 152 (1): 153–61. PMID 7338906.
21. Volver arriba↑ Gregory S, et al. (2006). «The DNA
sequence and biological annotation of human

chromosome 1». Nature 441 (7091): 315–
21. PMID 16710414.
22. Volver arriba↑ Watson JD; Crick FHC. A structure
for Deoxyribose Nucleic
Acid. Nature 171(4356):737-738.. (April,
1953) Texto Completo
23. Volver arriba↑ Watson J, Crick F
(1953). «Molecular structure of nucleic acids; a
structure for deoxyribose nucleic
acid». Nature 171 (4356): 737–8. PMID 13054692.
24. Volver arriba↑ Andrew Bates (2005). «DNA
structure». DNA topology. Oxford University
Press. ISBN 0-19-850655-4.
25. ↑ Saltar a:a b c Berg J., Tymoczko J. and Stryer L.
(2002) Biochemistry. W. H. Freeman and
Company ISBN 0-7167-4955-6
26. Volver arriba↑ Abbreviations and Symbols for
Nucleic Acids, Polynucleotides and their
ConstituentsIUPAC-IUB Commission on
Biochemical Nomenclature (CBN), consultado el 3
ene 2006
27. ↑ Saltar a:a b Ghosh A, Bansal M (2003). «A
glossary of DNA structures from A to Z». Acta
Crystallogr D Biol Crystallogr 59 (Pt 4): 620–
6. PMID 12657780.
28. Volver arriba↑ Clausen-Schaumann H, Rief M,
Tolksdorf C, Gaub H (2000). «Mechanical stability
of single DNA molecules». Biophys J 78 (4):
1997–2007. PMID 10733978.
29. Volver arriba↑ Ponnuswamy P, Gromiha M (1994).
«On the conformational stability of oligonucleotide
duplexes and tRNA molecules». J Theor
Biol 169 (4): 419–32. PMID 7526075.
30. Volver arriba↑ Erwin Chargaff Papers
31. Volver arriba↑ Chalikian T, Völker J, Plum G,
Breslauer K (1999). «A more unified picture for the
thermodynamics of nucleic acid duplex melting: a
characterization by calorimetric and volumetric
techniques». Proc Natl Acad Sci U S A 96 (14):
7853–8. PMID 10393911.

32. Volver arriba↑ deHaseth P, Helmann J (1995).
«Open complex formation by Escherichia coli RNA
polymerase: the mechanism of polymerase-
induced strand separation of double helical
DNA». Mol Microbiol 16 (5): 817–24. PMID 7476180.
33. Volver arriba↑ Isaksson J, Acharya S, Barman J,
Cheruku P, Chattopadhyaya J (2004). «Single-
stranded adenine-rich DNA and RNA retain
structural characteristics of their respective
double-stranded conformations and show
directional differences in stacking
pattern». Biochemistry43 (51): 15996–
6010. PMID 15609994.
34. ↑ Saltar a:a b c d Hib, J. & De Robertis, E. D. P.
1998. Fundamentos de biología celular y
molecular. El Ateneo, 3.ª edición, 416
páginas. ISBN 950-02-0372-3. ISBN 978-950-02-
0372-2
35. ↑ Saltar a:a b c De Robertis, E.D.P. 1998. Biología
celular y molecular. El Ateneo, 617 páginas.ISBN
950-02-0364-2. ISBN 978-950-02-0364-7
36. Volver arriba↑ Basu H, Feuerstein B, Zarling D,
Shafer R, Marton L (1988). «Recognition of Z-RNA
and Z-DNA determinants by polyamines in
solution: experimental and theoretical studies». J
Biomol Struct Dyn 6 (2): 299–309. PMID 2482766.
37. Volver arriba↑ Leslie AG, Arnott S,
Chandrasekaran R, Ratliff RL (1980).
«Polymorphism of DNA double helices». J. Mol.
Biol. 143 (1): 49–72. PMID 7441761.
38. Volver arriba↑ Wahl M, Sundaralingam M (1997).
«Crystal structures of A-DNA
duplexes». Biopolymers44 (1): 45–
63. PMID 9097733.
39. Volver arriba↑ Lu XJ, Shakked Z, Olson WK
(2000). «A-form conformational motifs in ligand-
bound DNA structures». J. Mol. Biol. 300 (4): 819–
40. PMID 10891271.
40. Volver arriba↑ Rothenburg S, Koch-Nolte F, Haag
F. «DNA methylation and Z-DNA formation as
mediators of quantitative differences in the

expression of alleles». Immunol Rev 184: 286–
98. PMID 12086319.
41. Volver arriba↑ Oh D, Kim Y, Rich A (2002). «Z-
DNA-binding proteins can act as potent effectors
of gene expression in vivo». Proc. Natl. Acad. Sci.
U.S.A. 99 (26): 16666–71. PMID 12486233.
42. Volver arriba↑ Created from NDB UD0017
43. ↑ Saltar a:a b Greider C, Blackburn E (1985).
«Identification of a specific telomere terminal
transferase activity in Tetrahymena
extracts». Cell 43 (2 Pt 1): 405–13. PMID 3907856.
44. ↑ Saltar a:a b Nugent C, Lundblad V (1998). «The
telomerase reverse transcriptase: components and
regulation». Genes Dev 12 (8): 1073–
85. PMID 9553037.
45. Volver arriba↑ Wright W, Tesmer V, Huffman K,
Levene S, Shay J (1997). «Normal human
chromosomes have long G-rich telomeric
overhangs at one end». Genes Dev 11 (21):
2801–9. PMID 9353250.
46. ↑ Saltar a:a b Burge S, Parkinson G, Hazel P, Todd
A, Neidle S (2006). «Quadruplex DNA: sequence,
topology and structure». Nucleic Acids
Res 34 (19): 5402–15.PMID 17012276.
47. Volver arriba↑ Parkinson G, Lee M, Neidle S
(2002). «Crystal structure of parallel quadruplexes
from human telomeric DNA». Nature 417 (6891):
876–80. PMID 12050675.
48. Volver arriba↑ Griffith J, Comeau L, Rosenfield S,
Stansel R, Bianchi A, Moss H, de Lange T (1999).
«Mammalian telomeres end in a large duplex
loop». Cell 97 (4): 503–14. PMID 10338214.
49. Volver arriba↑ Created from PDB 1D65
50. ↑ Saltar a:a b Watson, J. D.; Baker, T. A.; Bell, S.
P.; Gann, A.; Levine, M. et Losick, R (2006). «6.
Las estructuras del DNA y el RNA». Biología
Molecular del Gen (5ª Ed.) (Madrid: Médica
Panamericana). ISBN 84-7903-505-6.
51. Volver arriba↑ Wing R, Drew H, Takano T, Broka
C, Tanaka S, Itakura K, Dickerson R (1980).
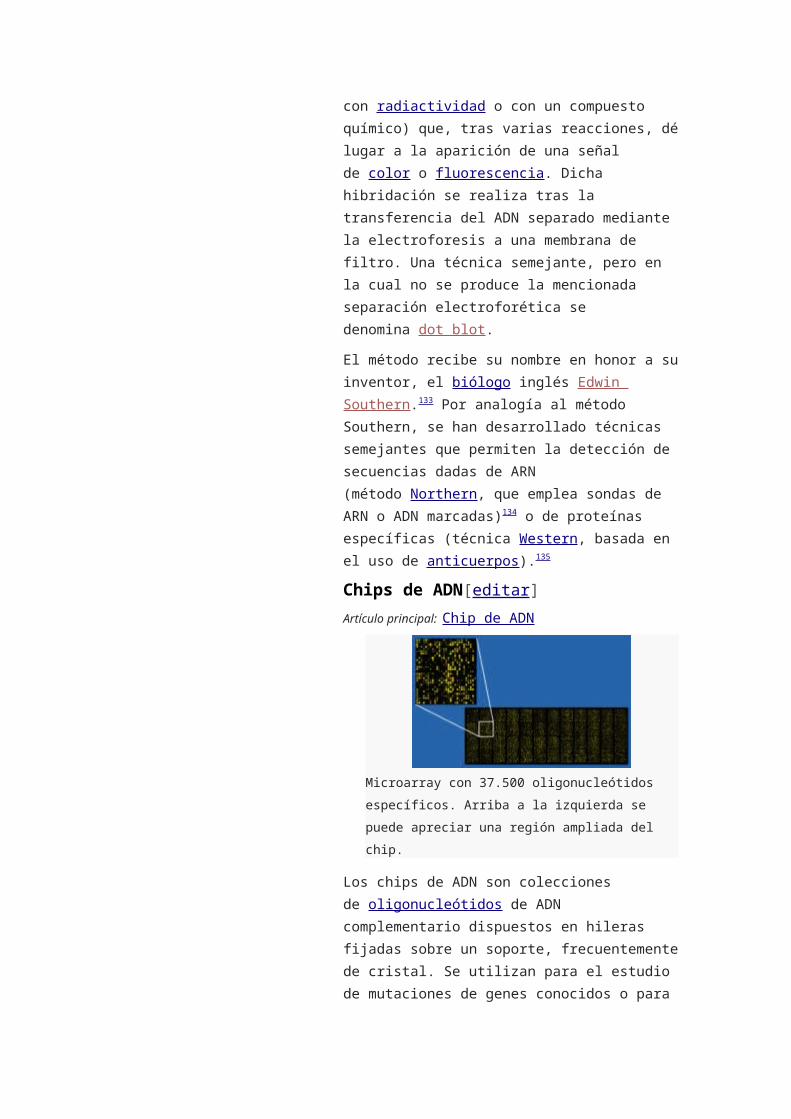
«Crystal structure analysis of a complete turn of B-
DNA». Nature 287 (5784): 755–8.PMID 7432492.
52. Volver arriba↑ Pabo C, Sauer R (1984). «Protein-
DNA recognition». Annu Rev Biochem 53: 293–
321.PMID 6236744.
53. Volver arriba↑ Hüttenhofer A, Schattner P, Polacek
N (2005). «Non-coding RNAs: hope or
hype?».Trends Genet 21 (5): 289–
97. PMID 15851066.
54. Volver arriba↑ Munroe S (2004). «Diversity of
antisense regulation in eukaryotes: multiple
mechanisms, emerging patterns». J Cell
Biochem 93 (4): 664–71. PMID 15389973.
55. Volver arriba↑ Makalowska I, Lin C, Makalowski W
(2005). «Overlapping genes in vertebrate
genomes».Comput Biol Chem 29 (1): 1–
12. PMID 15680581.
56. Volver arriba↑ Johnson Z, Chisholm S (2004).
«Properties of overlapping genes are conserved
across microbial genomes». Genome Res 14 (11):
2268–72. PMID 15520290.
57. Volver arriba↑ Lamb R, Horvath C (1991).
«Diversity of coding strategies in influenza
viruses». Trends Genet 7 (8): 261–6. PMID 1771674.
58. Volver arriba↑ Benham C, Mielke S (2005). «DNA
mechanics». Annu Rev Biomed Eng 7: 21–
53.PMID 16004565.
59. ↑ Saltar a:a b Champoux J (2001). «DNA
topoisomerases: structure, function, and
mechanism».Annu Rev Biochem 70: 369–
413. PMID 11395412.
60. ↑ Saltar a:a b Wang J (2002). «Cellular roles of
DNA topoisomerases: a molecular
perspective». Nat Rev Mol Cell Biol 3 (6): 430–
40. PMID 12042765.
61. Volver arriba↑ Klose R, Bird A (2006). «Genomic
DNA methylation: the mark and its
mediators». Trends Biochem Sci 31 (2): 89–
97. doi:10.1016/j.tibs.2005.12.008. PMID 16403636.
62. Volver arriba↑ Bird A (2002). «DNA methylation
patterns and epigenetic memory». Genes
Dev 16 (1): 6–
21. doi:10.1101/gad.947102. PMID 11782440.
63. Volver arriba↑ Walsh C, Xu G (2006). «Cytosine
methylation and DNA repair». Curr Top Microbiol
Immunol 301: 283–315. doi:10.1007/3-540-31390-
7_11. PMID 16570853.
64. Volver arriba↑ Ratel D, Ravanat J, Berger F, Wion
D (2006). «N6-methyladenine: the other
methylated base of DNA». Bioessays 28 (3): 309–
15. doi:10.1002/bies.20342. PMID 16479578.
65. Volver arriba↑ Gommers-Ampt J, Van Leeuwen F,
de Beer A, Vliegenthart J, Dizdaroglu M, Kowalak
J, Crain P, Borst P (1993). «beta-D-glucosyl-
hydroxymethyluracil: a novel modified base
present in the DNA of the parasitic protozoan T.
brucei». Cell 75 (6): 1129–36.doi:10.1016/0092-
8674(93)90322-H. PMID 8261512.
66. Volver arriba↑ Creado a partir de: PDB 1JDG
67. Volver arriba↑ Douki T, Reynaud-Angelin A, Cadet
J, Sage E (2003). «Bipyrimidine photoproducts
rather than oxidative lesions are the main type of
DNA damage involved in the genotoxic effect of
solar UVA radiation». Biochemistry 42 (30): 9221–
6. doi:10.1021/bi034593c.PMID 12885257.,
68. Volver arriba↑ Cadet J, Delatour T, Douki T,
Gasparutto D, Pouget J, Ravanat J, Sauvaigo S
(1999). «Hydroxyl radicals and DNA base
damage». Mutat Res 424 (1–2): 9–
21. PMID 10064846.
69. Volver arriba↑ Shigenaga M, Gimeno C, Ames B
(1989). «Urinary 8-hydroxy-2′-deoxyguanosine as
a biological marker of in vivo oxidative DNA
damage». Proc Natl Acad Sci U S A 86 (24):
9697–701. doi:10.1073/pnas.86.24.9697. PMID 2602371.
70. Volver arriba↑ Cathcart R, Schwiers E, Saul R,
Ames B (1984). «Thymine glycol and thymidine
glycol in human and rat urine: a possible assay for
oxidative DNA damage». Proc Natl Acad Sci U S

A 81 (18): 5633–
7. doi:10.1073/pnas.81.18.5633. PMID 6592579.
71. Volver arriba↑ Valerie K, Povirk L (2003).
«Regulation and mechanisms of mammalian
double-strand break repair». Oncogene 22 (37):
5792–812. doi:10.1038/sj.onc.1206679. PMID 12947387.
72. Volver arriba↑ Ferguson L, Denny W (1991). «The
genetic toxicology of acridines». Mutat
Res 258 (2): 123–60. PMID 1881402.
73. Volver arriba↑ Jeffrey A (1985). «DNA modification
by chemical carcinogens». Pharmacol Ther 28 (2):
237–72. doi:10.1016/0163-7258(85)90013-0. PMID 3936066.
74. Volver arriba↑ Stephens T, Bunde C, Fillmore B
(2000). «Mechanism of action in thalidomide
teratogenesis». Biochem Pharmacol 59 (12):
1489–99. doi:10.1016/S0006-2952(99)00388-3.PMID 107996
45.
75. Volver arriba↑ Braña M, Cacho M, Gradillas A, de
Pascual-Teresa B, Ramos A (2001). «Intercalators
as anticancer drugs». Curr Pharm Des 7 (17):
1745–80. doi:10.2174/1381612013397113.PMID 11562309.
76. Volver arriba↑ Thanbichler M, Wang S, Shapiro L
(2005). «The bacterial nucleoid: a highly organized
and dynamic structure». J Cell Biochem 96 (3):
506–21. doi:10.1002/jcb.20519.PMID 15988757.
77. Volver arriba↑ Creado a partir de: PDB 1MSW
78. Volver arriba↑ Wolfsberg T, McEntyre J, Schuler G
(2001). «Guide to the draft human
genome». Nature409 (6822): 824–
6. doi:10.1038/35057000. PMID 11236998.
79. Volver arriba↑ The ENCODE Project Consortium
(2007). «Identification and analysis of functional
elements in 1% of the human genome by the
ENCODE pilot project». Nature 447 (7146): 799–
816. doi:10.1038/nature05874.
80. Volver arriba↑ Gregory T (2005). «The C-value
enigma in plants and animals: a review of parallels
and an appeal for partnership». Ann Bot
(Lond) 95 (1): 133–
46. doi:10.1093/aob/mci009.PMID 15596463.

81. Volver arriba↑ Yale University. Yale Researchers
Find “Junk DNA” May Have Triggered Key
Evolutionary Changes in Human Thumb and Foot.
82. Volver arriba↑ Sandman K, Pereira S, Reeve J
(1998). «Diversity of prokaryotic chromosomal
proteins and the origin of the nucleosome». Cell
Mol Life Sci 54 (12): 1350–
64.doi:10.1007/s000180050259. PMID 9893710.
83. Volver arriba↑ Dame RT (2005). «The role of
nucleoid-associated proteins in the organization
and compaction of bacterial chromatin». Mol.
Microbiol. 56 (4): 858–70. doi:10.1111/j.1365-
2958.2005.04598.x. PMID 15853876.
84. Volver arriba↑ Luger K, Mäder A, Richmond R,
Sargent D, Richmond T (1997). «Crystal structure
of the nucleosome core particle at 2.8 A
resolution». Nature 389 (6648): 251–
60.doi:10.1038/38444. PMID 9305837.
85. Volver arriba↑ Jenuwein T, Allis C (2001).
«Translating the histone
code». Science 293 (5532): 1074–
80. doi:10.1126/science.1063127. PMID 11498575.
86. Volver arriba↑ Ito T. «Nucleosome assembly and
remodelling». Curr Top Microbiol Immunol 274: 1–
22.PMID 12596902.
87. Volver arriba↑ Thomas J (2001). «HMG1 and 2:
architectural DNA-binding proteins». Biochem Soc
Trans 29 (Pt 4): 395–
401. doi:10.1042/BST0290395. PMID 11497996.
88. Volver arriba↑ Grosschedl R, Giese K, Pagel J
(1994). «HMG domain proteins: architectural
elements in the assembly of nucleoprotein
structures». Trends Genet 10 (3): 94–
100. doi:10.1016/0168-9525(94)90232-1. PMID 8178371.
89. Volver arriba↑ Maeshima K, Laemmli UK. (2003).
«A Two-Step Scaffolding Model for Mitotic
Chromosome Assembly». Developmental
Cell 4. 467-480. [1]
90. Volver arriba↑ Tavormina PA, Côme MG, Hudson
JR, Mo YY, Beck WT, Gorbsky GJ. (2002). «Rapid
exchange of mammalian topoisomerase II alpha at
kinetochores and chromosome arms in mitosis». J
Cell Biol. 158 (1). 23-9. [2]
91. Volver arriba↑ Iftode C, Daniely Y, Borowiec J
(1999). «Replication protein A (RPA): the
eukaryotic SSB». Crit Rev Biochem Mol
Biol 34 (3): 141–
80. doi:10.1080/10409239991209255.PMID 10473346.
92. Volver arriba↑ Creado a partir de PDB 1LMB
93. Volver arriba↑ Pabo C, Sauer R (1984). «Protein-
DNA recognition». Annu Rev Biochem 53: 293–
321.doi:10.1146/annurev.bi.53.070184.001453. PMID 623674
4.
94. Volver arriba↑ Myers L, Kornberg R (2000).
«Mediator of transcriptional regulation». Annu Rev
Biochem69: 729–
49. doi:10.1146/annurev.biochem.69.1.729. PMID 10966474.
95. Volver arriba↑ Spiegelman B, Heinrich R (2004).
«Biological control through regulated
transcriptional coactivators». Cell 119 (2): 157–
67. doi:10.1016/j.cell.2004.09.037. PMID 15479634.
96. Volver arriba↑ Li Z, Van Calcar S, Qu C, Cavenee
W, Zhang M, Ren B (2003). «A global
transcriptional regulatory role for c-Myc in Burkitt's
lymphoma cells». Proc Natl Acad Sci U S
A 100 (14): 8164–
9. doi:10.1073/pnas.1332764100. PMID 12808131.
97. Volver arriba↑ Creado a partir de PDB 1RVA
98. Volver arriba↑ Bickle T, Krüger D (1993). «Biology
of DNA restriction». Microbiol Rev 57 (2): 434–
50.PMID 8336674.
99. ↑ Saltar a:a b Doherty A, Suh S (2000). «Structural
and mechanistic conservation in DNA
ligases.». Nucleic Acids Res 28 (21): 4051–
8. doi:10.1093/nar/28.21.4051.PMID 11058099.
100.Volver arriba↑ Schoeffler A, Berger J (2005).
«Recent advances in understanding structure-
function relationships in the type II topoisomerase
mechanism». Biochem Soc Trans 33 (Pt 6): 1465–
70. doi:10.1042/BST20051465. PMID 16246147.
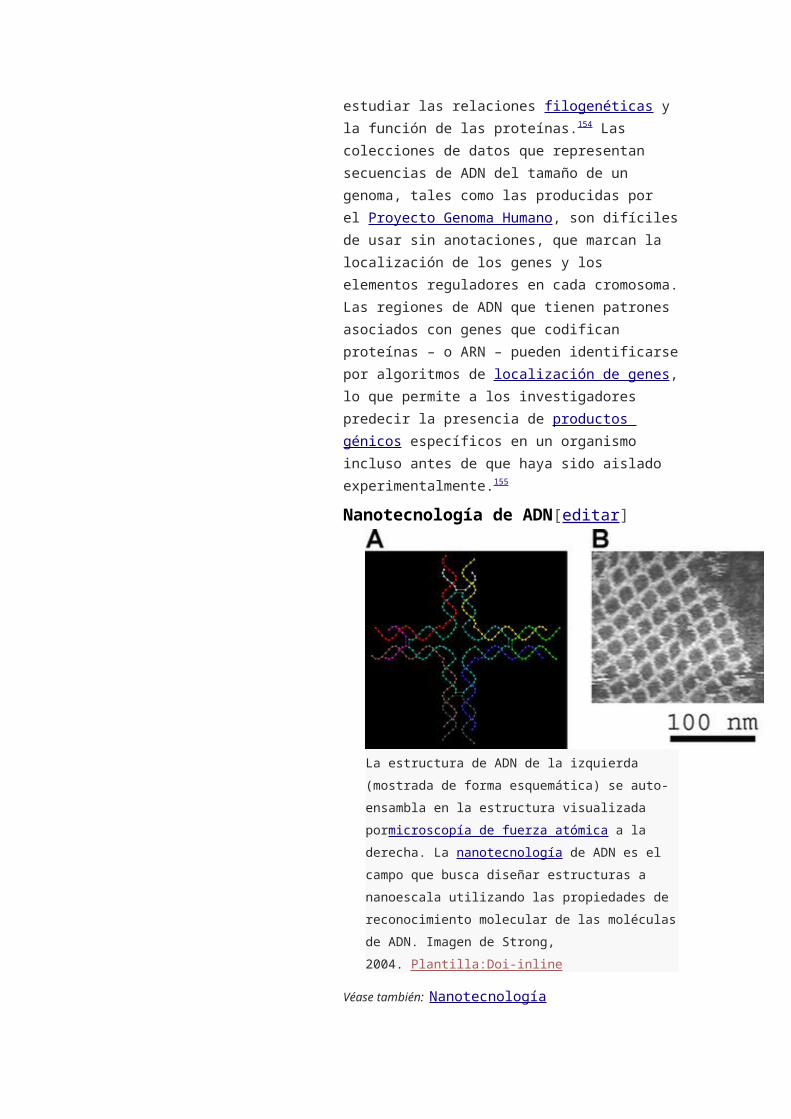
101.Volver arriba↑ Tuteja N, Tuteja R (2004).
«Unraveling DNA helicases. Motif, structure,
mechanism and function». Eur J
Biochem 271 (10): 1849–63. doi:10.1111/j.1432-
1033.2004.04094.x.PMID 15128295.
102.Volver arriba↑ Joyce C, Steitz T
(1995). «Polymerase structures and function:
variations on a theme?». J Bacteriol 177 (22):
6321–9. PMID 7592405.
103.Volver arriba↑ Hubscher U, Maga G, Spadari S
(2002). «Eukaryotic DNA polymerases». Annu
Rev Biochem 71: 133–
63. doi:10.1146/annurev.biochem.71.090501.150041. PMID 12
045093.
104.Volver arriba↑ Johnson A, O'Donnell M (2005).
«Cellular DNA replicases: components and
dynamics at the replication fork». Annu Rev
Biochem 74: 283–
315.doi:10.1146/annurev.biochem.73.011303.073859. PMID 1
5952889.
105.Volver arriba↑ Tarrago-Litvak L, Andréola M,
Nevinsky G, Sarih-Cottin L, Litvak S (1994). «The
reverse transcriptase of HIV-1: from enzymology
to therapeutic intervention». FASEB J 8 (8): 497–
503. PMID 7514143.
106.Volver arriba↑ Martinez E (2002). «Multi-protein
complexes in eukaryotic gene transcription». Plant
Mol Biol 50 (6): 925–
47. doi:10.1023/A:1021258713850. PMID 12516863.
107.Volver arriba↑ Creado a partir de PDB 1M6G
108.Volver arriba↑ Cremer T, Cremer C (2001).
«Chromosome territories, nuclear architecture and
gene regulation in mammalian cells». Nat Rev
Genet 2 (4): 292–
301. doi:10.1038/35066075.PMID 11283701.
109.Volver arriba↑ Pál C, Papp B, Lercher M (2006).
«An integrated view of protein evolution». Nat Rev
Genet 7 (5): 337–
48. doi:10.1038/nrg1838. PMID 16619049.
110.Volver arriba↑ O'Driscoll M, Jeggo P (2006). «The
role of double-strand break repair - insights from
human genetics». Nat Rev Genet 7 (1): 45–
54. doi:10.1038/nrg1746. PMID 16369571.
111.Volver arriba↑ Vispé S, Defais M (1997).
«Mammalian Rad51 protein: a RecA homologue
with pleiotropic functions». Biochimie 79 (9-10):
587–92. doi:10.1016/S0300-9084(97)82007-X.PMID 946669
6.
112.Volver arriba↑ Neale MJ, Keeney S (2006).
«Clarifying the mechanics of DNA strand
exchange in meiotic
recombination». Nature 442 (7099): 153–
8. doi:10.1038/nature04885.PMID 16838012.
113.Volver arriba↑ Dickman M, Ingleston S,
Sedelnikova S, Rafferty J, Lloyd R, Grasby J,
Hornby D (2002). «The RuvABC
resolvasome». Eur J Biochem 269 (22): 5492–
501. doi:10.1046/j.1432-1033.2002.03250.x. PMID 12423347.
114.Volver arriba↑ Joyce G (2002). «The antiquity of
RNA-based evolution». Nature 418 (6894): 214–
21.doi:10.1038/418214a. PMID 12110897.
115.Volver arriba↑ Orgel L. «Prebiotic chemistry and
the origin of the RNA world». Crit Rev Biochem
Mol Biol 39 (2): 99–
123. doi:10.1080/10409230490460765. PMID 15217990.
116.Volver arriba↑ Davenport R (2001). «Ribozymes.
Making copies in the RNA
world». Science 292 (5520):
1278. doi:10.1126/science.292.5520.1278a. PMID 11360970.
117.Volver arriba↑ Szathmáry E (1992). «What is the
optimum size for the genetic alphabet?». Proc Natl
Acad Sci U S A 89 (7): 2614–
8. doi:10.1073/pnas.89.7.2614. PMID 1372984.
118.Volver arriba↑ Lindahl T (1993). «Instability and
decay of the primary structure of
DNA». Nature 362(6422): 709–
15. doi:10.1038/362709a0. PMID 8469282.
119.Volver arriba↑ Vreeland R, Rosenzweig W,
Powers D (2000). «Isolation of a 250 million-year-
old halotolerant bacterium from a primary salt
crystal». Nature 407 (6806): 897–
900.doi:10.1038/35038060. PMID 11057666.

120.Volver arriba↑ Hebsgaard M, Phillips M, Willerslev
E (2005). «Geologically ancient DNA: fact or
artefact?». Trends Microbiol 13 (5): 212–
20. doi:10.1016/j.tim.2005.03.010. PMID 15866038.
121.Volver arriba↑ Nickle D, Learn G, Rain M, Mullins
J, Mittler J (2002). «Curiously modern DNA for a
"250 million-year-old" bacterium». J Mol
Evol 54 (1): 134–7. doi:10.1007/s00239-001-0025-
x.PMID 11734907.
122.Volver arriba↑ Birnbaum D, Coulier F, Pébusque
MJ, Pontarotti P. (2000). «"Paleogenomics":
looking in the past to the future». J Exp
Zool. 288 ((1):). 21-2. [3]
123.Volver arriba↑ Blanchette M, Green ED, Miller W,
Haussler D. (2004). «Reconstructing large regions
of an ancestral mammalian genome in
silico». Genome Res. 14 ((12):). 2412-23. Erratum
in: Genome Res. 2005 Mar;15(3):451.[4]
124.Volver arriba↑ Gaucher EA, Thomson JM, Burgan
MF, Benner SA. (2003). «Inferring the
palaeoenvironment of ancient bacteria on the
basis of resurrected
protein». Nature 425((6955):). 285-8. [5]
125.Volver arriba↑ Thornton JW. (2004).
«Resurrecting ancient genes: experimental
analysis of extinct molecules». Nat Rev
Genet. 5 ((5):). 366-75. [6]
126.Volver arriba↑ Benner SA, Caraco MD, Thomson
JM, Gaucher EA. (2002). «Planetary biology--
paleontological, geological, and molecular
histories of life». Science 296 ((5569):). 864-8.[7]
127.Volver arriba↑ Brenner SA, Carrigan MA, Ricardo
A, Frye F. (2006). «Setting the stage: the history,
chemistry and geobiology behind RNA». The RNA
World, 3rd Ed. Cold Spring Harbor Laboratory
Press. ISBN 0-87969-739-3.[8]
128.↑ Saltar a:a b c Griffiths, J .F. A. et
al. (2002). Genética. McGraw-Hill
Interamericana. ISBN 84-486-0368-0.
129.↑ Saltar a:a b Watson, J, D.; Baker, T. A.; Bell, S.
P.; Gann, A.; Levine, M. et Losick, R

(2004).Molecular Biology of the Gene (Fifth edition
edición). San Francisco: Benjamin Cummings.ISBN
0-321-22368-3.
130.Volver arriba↑ Sanger F, Coulson AR. A rapid
method for determining sequences in DNA by
primed synthesis with DNA polymerase. J Mol
Biol. 1975 Mayo 25;94(3):441–448
131.Volver arriba↑ Sanger F, Nicklen s, y Coulson
AR, DNA sequencing with chain-terminating
inhibitors, Proc Natl Acad Sci U S A. 1977
Diciembre; 74(12): 5463–5467
132.Volver arriba↑ Bartlett & Stirling (2003)—A Short
History of the Polymerase Chain Reaction. In:
Methods Mol Biol. 226:3-6
133.Volver arriba↑ Southern, E.M. (1975): "Detection
of specific sequences among DNA fragments
separated by gel electrophoresis", J Mol Biol.,
98:503-517. PMID 1195397
134.Volver arriba↑ Alwine JC, Kemp DJ, Stark GR
(1977). «Method for detection of specific RNAs in
agarose gels by transfer to diazobenzyloxymethyl-
paper and hybridization with DNA probes». Proc.
Natl. Acad. Sci. U.S.A. 74 (12): 5350–
4. doi:10.1073/pnas.74.12.5350.PMID 414220.
135.Volver arriba↑ W. Neal Burnette (abril de
1981). «'Western blotting': electrophoretic transfer
of proteins from sodium dodecyl sulfate —
polyacrylamide gels to unmodified nitrocellulose
and radiographic detection with antibody and
radioiodinated protein A». Analytical
Biochemistry (United States: Academic
Press) 112 (2): 195–203. doi:10.1016/0003-
2697(81)90281-5. ISSN 0003-2697. PMID 6266278.
Consultado el 3 de abril de 2008.
136.Volver arriba↑ Miller WL. (1979). «Use of
recombinant DNA technology for the production of
polypeptides». Adv Exp Med Biol. 118: 153–74. [9]
137.Volver arriba↑ Leader B, Baca QJ, Golan DE.
(2008). «Protein therapeutics: a summary and
pharmacological classification». Nat Rev Drug
Discov. 7 ((1)). 21-39. [10]

138.Volver arriba↑ Dingermann T. (2008).
«Recombinant therapeutic proteins: production
platforms and challenges». Biotechnol
J. 3 ((1)). 90-7. [11]
139.Volver arriba↑ Voigt K, Izsvák Z, Ivics Z. (2008).
«Targeted gene insertion for molecular
medicine». J Mol Med. Jul 8. (Epub ahead of
print). [12]
140.Volver arriba↑ Houdebine L (2007). «Transgenic
animal models in biomedical research». Methods
Mol Biol 360: 163–202. PMID 17172731. [13]
141.Volver arriba↑ Soler E, Thépot D, Rival-Gervier S,
Jolivet G, Houdebine LM. (2006 publicación =
Reprod Nutr Dev.). Preparation of recombinant
proteins in milk to improve human and animal
health 46 ((5)). 579-88. [14]
142.Volver arriba↑ Chávez A, Muñoz de Chávez M.
(2003). «Nutrigenomics in public health nutrition:
short-term perspectives». Eur J Clin
Nutr. 57 (Suppl 1). S97-100. [15]
143.Volver arriba↑ Vasil IK. (2007). «Molecular genetic
improvement of cereals: transgenic wheat
(Triticum aestivum L.)». Plant Cell
Rep. 26 ((8)). 1133-54. [16]
144.Volver arriba↑ Daniell H, Dhingra A (2002).
«Multigene engineering: dawn of an exciting new
era in biotechnology». Curr Opin Biotechnol 13 (2):
136–41. doi:10.1016/S0958-1669(02)00297-5.PMID 1195056
5.
145.Volver arriba↑ Job D (2002). «Plant biotechnology
in agriculture». Biochimie 84 (11): 1105–
10.doi:10.1016/S0300-9084(02)00013-5. PMID 12595138.
146.Volver arriba↑ Collins A, Morton N
(1994). «Likelihood ratios for DNA
identification». Proc Natl Acad Sci USA 91 (13):
6007–11. doi:10.1073/pnas.91.13.6007. PMID 8016106.
147.Volver arriba↑ Weir B, Triggs C, Starling L, Stowell
L, Walsh K, Buckleton J (1997). «Interpreting DNA
mixtures». J Forensic Sci 42 (2): 213–
22. PMID 9068179.

148.Volver arriba↑ Jeffreys A, Wilson V, Thein S
(1985). «Individual-specific 'fingerprints' of human
DNA».Nature 316 (6023): 76–
9. doi:10.1038/316076a0. PMID 2989708.
149.Volver arriba↑ Colin Pitchfork — first murder
conviction on DNA evidence also clears the prime
suspect Forensic Science Service Accessed 23
Dec 2006
150.Volver arriba↑ «DNA Identification in Mass Fatality
Incidents». National Institute of Justice.
septiembre de 2006.
151.Volver arriba↑ Bhattacharya, Shaoni. "Killer
convicted thanks to relative's
DNA". newscientist.com (20 abril 2004).
Consultado 22 dic 2006
152.Volver arriba↑ Baldi, Pierre. Brunak, Soren
(2001). Bioinformatics: The Machine Learning
Approach. MIT Press. ISBN 978-0-262-02506-5.
153.Volver arriba↑ Gusfield, Dan. Algorithms on
Strings, Trees, and Sequences: Computer
Science and Computational Biology. Cambridge
University Press, 15 January 1997. ISBN 978-0-
521-58519-4.
154.Volver arriba↑ Sjölander K (2004). «Phylogenomic
inference of protein molecular function: advances
and challenges». Bioinformatics 20 (2): 170–
9. doi:10.1093/bioinformatics/bth021.PMID 14734307.
155.Volver arriba↑ Mount, DM (2004). Bioinformatics:
Sequence and Genome Analysis (2 edición). Cold
Spring Harbor, NY: Cold Spring Harbor Laboratory
Press. ISBN 0879697121.
156.Volver arriba↑ Yin P, Hariadi RF, Sahu S, Choi
HMT, Park SH, LaBean T, Reif JH. (2008).
«Programming DNA Tube
Circumferences». Science 321 ((5890))
.doi:10.1126/science.1157312. 824 - 826. [17]
157.Volver arriba↑ Modelos de ADN en papiroflexia
realizados en el Sanger Center (UK) [18]
158.Volver arriba↑ Wray G (2002). «Dating branches
on the tree of life using DNA». Genome Biol 3 (1):

REVIEWS0001. doi:10.1046/j.1525-142X.1999.99010.x. P
MID 11806830.
159.Volver arriba↑ Lost Tribes of Israel, NOVA, PBS
airdate: 22 February 2000. Transcript available
fromPBS.org, (último acceso el 4 marzo de 2006)
160.Volver arriba↑ Kleiman, Yaakov. "The
Cohanim/DNA Connection: The fascinating story
of how DNA studies confirm an ancient biblical
tradition". aish.com (13 enero 2000). Consultado
el 4 de marzo de 2006.
Bibliografía[editar]
Clayton, Julie. (Ed.). 50 Years of DNA, Palgrave
MacMillan Press, 2003. ISBN 978-1-4039-1479-8.
Judson, Horace Freeland. The Eighth Day of
Creation: Makers of the Revolution in Biology,
Cold Spring Harbor Laboratory Press, 1996. ISBN
978-0-87969-478-4.
Olby, Robert . The Path to The Double Helix:
Discovery of DNA, first published in October 1974
by MacMillan, with foreword by Francis
Crick; ISBN 978-0-486-68117-7; the definitive
DNA textbook, revised in 1994, with a 9 page
postscript.
Ridley, Matt . Francis Crick: Discoverer of the
Genetic Code (Eminent Lives) HarperCollins
Publishers; 192 pp, ISBN 978-0-06-082333-
7 2006.
Rose, Steven . The Chemistry of Life,
Penguin, ISBN 978-0-14-027273-4.
Watson, James D. and Francis H.C. Crick. A
structure for Deoxyribose Nucleic
Acid (PDF). Nature 171, 737–738 p. 25 de
abril de 1953.
Watson, James D. DNA: The Secret of Life ISBN
978-0-375-41546-3.
Watson, James D. The Double Helix: A Personal
Account of the Discovery of the Structure of DNA
(Norton Critical Editions). ISBN 978-0-393-95075-
5.

Watson, James D. "Avoid boring people and other
lessons from a life in science" (2007) New York:
Random House. ISBN 978-0-375-41284-4.
Calladine, Chris R.; Drew, Horace R.; Luisi, Ben
F. and Travers, Andrew A. Understanding DNA,
Elsevier Academic Press, 2003. ISBN 978-0-12-
155089-9
Enlaces externos[editar]
Wikimedia Commons alberga contenido
multimedia sobre Ácido desoxirribonucleico.
Wikiquote alberga frases célebres de o
sobre Ácido desoxirribonucleico.
Wikcionario tiene definiciones y otra
información sobre ácido desoxirribonucleico.
Wikcionario tiene definiciones y otra
información sobre ADN cromosómico.
Wikcionario tiene definiciones y otra
información sobre ADN recombinante.
Wikcionario tiene definiciones y otra
información sobre ADN nuclear.
Wikcionario tiene definiciones y otra
información sobre ADN mitocondrial.
Wikcionario tiene definiciones y otra
información sobre ADN ribosomal.
Modelo en 3 dimensiones de la estructura del
ADN. Interactivo. Requiere Java.
Experimento para extraer ADN
«Descifrar la vida»: Gráfico interactivo
La Replicación de ADN: características, proteínas
que participan y proceso
Animación en 3D de la Replicación de ADN
Proceso de extracción de ADN
Uso del ADN en medicina forense
Creación del primer genoma artificial
Construye una molécula de ADN
El método de secuenciación de Sanger

El misterioso elfo de Leewenhoek: el recorrido
desde el microscopio hasta el ADN en el Museu
Virtual Interactivo de la Genética y el ADN