
Guía de solución de problemas de los servidores HPE ProLiant …h20628. · 2019-01-17 · No se...
522
Guía de solución de problemas de los servidores HPE ProLiant Gen9 Volumen II: Mensajes de error Resumen Esta guía ofrece una lista de mensajes de error relacionados con los servidores HPE ProLiant, Integrated Lights-Out, dispositivos de almacenamiento Smart Array, Onboard Administrator, Virtual Connect, ROM y Configuration Replication Utility (Utilidad de replicación de la configuración). Esta guía está dirigida a la persona encargada de la instalación, administración y solución de problemas de los servidores o blades de servidor. Hewlett Packard Enterprise le considera una persona cualificada para la reparación de equipos informáticos y preparada para reconocer los riesgos de los productos con niveles de energía peligrosos.
Transcript of Guía de solución de problemas de los servidores HPE ProLiant …h20628. · 2019-01-17 · No se...

Guía de solución de problemas de los servidores HPE ProLiant Gen9Volumen II: Mensajes de errorResumenEsta guía ofrece una lista de mensajes de error relacionados con los servidores HPE ProLiant, Integrated Lights-Out, dispositivos de almacenamiento Smart Array, Onboard Administrator, Virtual Connect, ROM y Configuration Replication Utility (Utilidad de replicación de la configuración). Esta guía está dirigida a la persona encargada de la instalación, administración y solución de problemas de los servidores o blades de servidor. Hewlett Packard Enterprise le considera una persona cualificada para la reparación de equipos informáticos y preparada para reconocer los riesgos de los productos con niveles de energía peligrosos.

© Copyright 2012, 2016 Hewlett Packard Enterprise Development LP
La información contenida en el presente documento está sujeta a cambios sin previo aviso. Las únicas garantías de los productos y servicios de Hewlett Packard Enterprise están establecidas en las declaraciones expresas de garantía que acompañan a dichos productos y servicios. No se podrá utilizar nada de lo que se incluye en este documento como parte de una garantía adicional. Hewlett Packard Enterprise no se hace responsable de los errores u omisiones de carácter técnico o editorial que puedan figurar en este documento.
Java es una marca registrada de Oracle y/o sus filiales.
Linux® es una marca registrada de Linus Torvalds en los Estados Unidos y en otros países.
Microsoft®, Windows® y Windows Server® son marcas comerciales o registradas de Microsoft Corporation en los Estados Unidos y en otros países.
SD y microSD son marcas comerciales o marca registradas de SD-3C en Estados Unidos, otros países o en ambos.
UNIX® es una marca comercial registrada de The Open Group.
Referencia: 795673-074
Julio de 2016
Edición: 5

Tabla de contenido
1 Introducción ...................................................................................................................................................... 1Información general .............................................................................................................................. 1Recursos de solución de problemas .................................................................................................... 1
2 Errores de los servidores HPE ProLiant ........................................................................................................... 2Mensajes de error de diagnóstico de arrays ........................................................................................ 2
Mensajes de error de HPE Smart Storage Administrator Diagnostics Utility ....................... 2Array status: The array has failed ....................................................................... 2Array status: The array currently has a drive erase operation queued, running, stopped or completed on a logical or physical drive ............................. 2Array Status: The array has a spare drive assigned which is smaller than the smallest data drive in the array ..................................................................... 2Cache module: The batteries were hot-removed ................................................ 3Cache module: The cache for this controller is temporarily disabled since a snapshot is in progress ....................................................................................... 3Cache module: The cache is disabled because a capacitor has failed to charge to an acceptable level ............................................................................. 3Cache module: The cache is disabled because a flash memory or capacitor hardware failure has been detected .................................................................... 3Cache module: The cache is disabled because the backup operation to flash memory failed ............................................................................................. 4Cache module: The cache is disabled because the batteries are low on the redundant controller ............................................................................................ 4Cache module: The cache is disabled because the batteries are low ................ 4Cache module: The cache is disabled because the charge on the flash-memory capacitor is too low ................................................................................ 5Cache module: The cache is disabled because the restore operation from flash memory failed ............................................................................................. 5Cache module: The cache is disabled because there are no capacitors attached to the cache module ............................................................................. 5Cache module: This controller has been set up to be a part of a redundant pair of controllers ................................................................................................. 5Cache module: This controller's firmware is not backward compatible with the cache module revision .................................................................................. 6Controller State: A logical drive is configured with a newer version of the Array Configuration tools than is currently running ............................................. 6Controller State: The array controller contains a volume that was created with a different version of controller firmware ...................................................... 6
ESES iii

Controller State: The array controller contains more logical drives than are supported in the current configuration ................................................................. 7Controller State: The array controller contains one or more logical drives with a RAID level that is not supported in the current configuration .................... 7Controller State: The array controller contains redundant connections to one or more physical drives that are not supported in the current configuration ........................................................................................................ 8Controller State: The array controller has a configuration that requires more physical drives than are currently supported ....................................................... 8Controller State: The array controller has an unknown disabled configuration status message ............................................................................. 9Controller State: The array controller has an unsupported configuration ............ 9Controller State: The array controller is connected to an expander card or an external enclosure ........................................................................................ 10Controller State: The array controller is operating without a memory board and contains more logical drives than are supported in the current configuration ...................................................................................................... 10Controller State: The array controller is operating without a memory board and has a bad volume position ......................................................................... 10Controller State: The array controller is operating without a memory board and has an invalid physical drive connection .................................................... 11Controller State: The array controller is operating without a memory board ..... 11Controller State: The controller cannot be configured. CACHE STATUS PROBLEM DETECTED .................................................................................... 11Controller State: The HBA does not have an access ID ................................... 11Drive Offline due to Erase Operation: The logical drive is offline from having an erase in progress .............................................................................. 12Drive Offline due to Erase Operation: The physical drive is currently queued for erase ............................................................................................... 12Drive Offline due to Erase Operation: The physical drive is offline and currently being erased ....................................................................................... 12Drive Offline due to Erase Operation: The physical drive is offline and the erase process has been failed .......................................................................... 13Drive Offline due to Erase Operation: The physical drive is offline and the erase process has completed ........................................................................... 13Drive Offline due to Erase Operation: The physical drive is offline from having an erase in progress .............................................................................. 13Failed Array Controller: code:<lockup Code> : Restart the server and run a diagnostic report ................................................................................................ 13Logical drive state: A logical drive is configured with a newer version of Storage/Config Mod than is currently running ................................................... 14Logical drive state: Background parity initialization is currently queued ........... 14Logical drive state: The current array controller is performing capacity expansion .......................................................................................................... 14
iv ESES

Logical drive state: The logical drive is disabled from a SCSI ID conflict .......... 15Logical drive state: The logical drive is not configured ...................................... 15Logical drive state: The logical drive is not yet available .................................. 15Logical drive state: The logical drive is offline from being ejected .................... 15Logical drive state: The logical drive is queued for erase ................................. 16Logical drive state: The logical drive is queued for expansion .......................... 16Logical drive state: The logical drive is queued for rebuilding ........................... 16Logical drive state: This logical drive has a high physical drive count .............. 16NVRAM Error: Board ID could not be read ....................................................... 17NVRAM Error: Bootstrap NVRAM image failed checksum test ........................ 17NVRAM Error: Bootstrap NVRAM image failed checksum test ........................ 17Physical Drive State: Predictive failure. This physical drive is predicted to fail soon ............................................................................................................. 17Physical Drive State: SATA drives are not supported for configuration and should be disconnected from this controller ...................................................... 18Physical Drive State: Single-ported drives are not supported for configuration and should be disconnected from this controller ......................... 18Physical Drive State: The data on the physical drive is being rebuilt ................ 18Physical Drive State: This drive contains unsupported configuration data ....... 19Physical Drive State: This drive is not supported for configuration by this version of controller firmware ............................................................................ 19Physical Drive State: This drive is not supported for configuration ................... 19Physical Drive State: This drive is smaller in size than the drive it is replacing ............................................................................................................ 20Physical Drive State: This drive is unrecognizable ........................................... 20Physical Drive State: This physical drive is part of a logical drive that is not supported by the current configuration .............................................................. 20Redundancy State: This controller has been setup to be part of a redundant pair of controllers ............................................................................. 21Redundancy State: This controller has been setup to be part of a redundant pair of controllers ............................................................................. 21Redundant Path Failure: Multi-domain path failure ........................................... 21Redundant Path Failure: The logical drive is degraded due to the loss of a redundant path .................................................................................................. 22Redundant Path Failure: The physical drive is degraded due to the loss of a redundant path ............................................................................................... 22Redundant Path Failure: Warning: Redundant I/O modules of this storage box ....................................................................................................... 22Smart SSD State: SSD has less than 2% of usage remaining before wearout ............................................................................................................. 22Smart SSD State: SSD has less than 2% of usage remaining before wearout ............................................................................................................. 23
ESES v

Smart SSD State: SSD has less than 5% of usage remaining before wearout ............................................................................................................. 23Smart SSD State: SSD has less than 5% of usage remaining before wearout ............................................................................................................. 23Smart SSD State: SSD has less than an estimated 56 days before it reaches the maximum usage limit for writes (wearout) ..................................... 23Smart SSD State: SSD has reached the maximum rated usage limit for writes (wearout) and should be replaced immediately ...................................... 24Smart SSD State: The SmartSSD Wear Gauge log is full ................................ 24Storage Enclosure: One or more fans have failed ............................................ 24Storage Enclosure: The enclosure is reporting a critical temperature status condition ............................................................................................................ 24Storage Enclosure: Warning: One or more redundant power supplies in this enclosure has failed or is not plugged in correctly ............................................ 25Storage Enclosure: Warning: The enclosure is reporting a high temperature status ................................................................................................................. 25
Mensajes de error de la POST ........................................................................................................... 26Introducción a los mensajes de error de la POST ............................................................. 26Serie 100 ........................................................................................................................... 26
101-Option ROM Error ...................................................................................... 26102-System board error .................................................................................... 26104-ASR Timer Failure ..................................................................................... 27162-System options error .................................................................................. 27163-Time and date not set ................................................................................ 27
Serie 200 ........................................................................................................................... 28207-DIMM configuration errors ......................................................................... 28208-Memory speed error ................................................................................... 28209-DIMM Configuration Error .......................................................................... 29210-Processor X: Quick Path Interconnect (QPI) Link Degradation ................. 29212-CPU failed .................................................................................................. 29213-CPU installation error ................................................................................. 30217-Processor cannot cache all installed memory ............................................ 30222-DIMM Configuration Error – The DIMM configuration is incorrect ............. 31223-Memory Error – A memory error occurred ................................................. 31224-Power fault detected – FlexLOM X ............................................................ 31225-Power fault detected – Mezzanine X .......................................................... 32226-Power fault detected – Embedded storage controller ................................ 32227-Processor mismatch – Core count must match between processors ........ 32228-DIMM Configuration Error - Processor X, Channel Y ................................ 33229-DIMM Configuration Error – Processor X, DIMM Y .................................... 33230-DIMM Configuration Error – Processor X, Channel Y ................................ 33231-DIMM Configuration Error – No memory is available ................................. 33
vi ESES

232-Memory initialization error – Processor A, DIMM B failed .......................... 34233-Trusted Execution Technology (TXT) Failure ............................................ 34234-DIMM Initialization Error – Memory cannot be initialized ........................... 35235-DIMM Configuration Error – Only 2 DIMMs can be installed on a channel with UDIMMs ....................................................................................... 35236-DIMM Configuration Error – Ultra-Low Voltage DIMMs installed ............... 35238-DIMM Configuration Error – Processor X, DIMM Y .................................... 36239-DIMM Configuration Error – Mismatched DIMM types ............................... 36240-Unsupported Expansion Riser Board Detected ......................................... 36241-Expansion Riser Board Detected in Incorrect Slot ..................................... 37242-Unsupported Processor Configuration Detected ....................................... 37243-Unsupported Option Card configuration .................................................... 38244-IMPORTANT: PCIe Slot X only supports 8 functions for a SR-IOV capable Expansion Card ................................................................................... 38245-Processor Power-on Issue ......................................................................... 38246-IMPORTANT: The system has exceeded the amount of available Option ROM space ............................................................................................ 39247-Memory Initialization Error ......................................................................... 39248-Unsupported Option Card configuration .................................................... 40249-Unsupported Option Card configuration .................................................... 40250-Unsupported Processor Configuration Detected ....................................... 40251-IMPORTANT: Switches SW1 and SW3 are ON ........................................ 41252-Unsupported Processor Configuration Detected ....................................... 41253-IMPORTANT: The PCI-e Device installed in Slot X has no corresponding processor installed and will not function .................................... 41254-IMPORTANT: A FlexCompute license is installed that cannot be utilized by installed processor(s) ....................................................................... 42255-An attempt to increase the frequency or core count of a FlexCompute capable processor without installing the appropriate license has been detected ............................................................................................................ 42256-IMPORTANT: A PCI-e Riser Card is installed that requires 2 processors to function .................................................................................... 42257-Memory Initialization Error ......................................................................... 43258-Unsupported Processor Configuration Detected ....................................... 43259-Unsupported Processor Configuration Detected ....................................... 43260-Configuration Error ..................................................................................... 44261-Server Platform Services Firmware requires update ................................. 44262-Redundant ROM Error ............................................................................... 44263-Redundant ROM Error ............................................................................... 45264-Fatal System ROM Error ............................................................................ 45265-Fatal System ROM Error ............................................................................ 45266-Non-Volatile Memory Corruption Detected ................................................ 46
ESES vii

267-IMPORTANT: Default configuration settings have been restored ............. 46268-iLO FW Not Responding ............................................................................ 46269-IMPORTANT: Default configuration settings have been restored ............. 47270-iLO FW Communication Issue ................................................................... 47271-Processor X, DIMM Y could not be authenticated ..................................... 47273-Unsupported Option Card Configuration .................................................... 48274-Unsupported DIMM Configuration Detected .............................................. 48275-Unsupported Processor Detected .............................................................. 49276-Option Card Configuration Error ................................................................ 49277-Secure Boot Authentication Failure ........................................................... 49278-Secure Boot Authentication Failure ........................................................... 49279-Cable Error ................................................................................................. 50280-Cable Error ................................................................................................. 50281-IMPORTANT: SW12 is ON indicating physical presence .......................... 50282-Invalid Server Serial Number and Product ID ............................................ 51283-Memory Address/Command Parity Error Detected .................................... 51284-DIMM Failure – Memory Board X, DIMM Y ................................................ 51284-DIMM Failure – Processor X, DIMM Y ....................................................... 52285-DIMM Failure ............................................................................................. 52285-DIMM Failure ............................................................................................. 52286-IMPORTANT: The removal of a storage device has been detected .......... 52287-IMPORTANT: The removal of a network device has been detected ......... 53288-IMPORTANT: A new storage device has been detected ........................... 53289-IMPORTANT: A new network or storage device has been detected ......... 53290-IMPORTANT: The Boot Mode for the system has been changed ............. 53291-IMPORTANT: The Standard Boot Order (IPL) has been detected as corrupted ........................................................................................................... 54292-Invalid HP Software RAID Configuration ................................................... 54293-A critical error occurred resulting in a reboot of the system ....................... 54294-Memory Board X Training Failure .............................................................. 55295-DIMM Failure – Memory Board X, DIMM Y ................................................ 55295-DIMM Failure – Processor X, DIMM Y ....................................................... 55296-DIMM Configuration Error – Processor X, DIMM Y .................................... 55297-IMPORTANT: The iLO Security switch is set to the ON position ............... 56298-IMPORTANT: The Boot Mode has been changed to Legacy Boot Mode for this boot only ...................................................................................... 56299-IMPORTANT: The Boot Mode has been changed to UEFI Boot Mode for this boot only ................................................................................................ 56
Serie 300 ........................................................................................................................... 57300-IMPORTANT: Unable to log an entry to the Integrated Management Log (IML) ........................................................................................................... 57
viii ESES

301-Keyboard Error ........................................................................................... 57301-Keyboard Error or Test Fixture Installed .................................................... 58304-Keyboard or System Unit Error .................................................................. 58303-Keyboard controller error ........................................................................... 59305-Redundant ROM Error ............................................................................... 59306-Redundant ROM Error ............................................................................... 60307-Fan Failure Detected ................................................................................. 60308-Required Fan NOT Installed ...................................................................... 60309-Insufficient Fan Solution ............................................................................. 61310-IMPORTANT: Fan Solution Not Redundant .............................................. 61311-HP Smart Storage Battery Configuration Error .......................................... 61312-HP Smart Storage Battery X Failure .......................................................... 62313-HP Smart Storage Battery X Failure .......................................................... 62314-A critical error occurred prior to this system boot ....................................... 63315-An uncorrectable memory error was detected prior to this system boot .... 63316-Chassis Firmware Error ............................................................................. 63317-Chassis Firmware Error ............................................................................. 63318-Trusted Platform Module (TPM) Self-Test Error ........................................ 64319-An unexpected shutdown was detected prior to this boot .......................... 64320-IMPORTANT: Enclosure Power Event detected ........................................ 64321-HP Dual microSD Device Unsupported Configuration ............................... 65322-HP Dual microSD Device Unsupported Configuration ............................... 65323-HP Dual microSD Device Error .................................................................. 65324-HP Dual microSD Device Error .................................................................. 66325-HP Dual microSD Device Error .................................................................. 66326-HP Dual microSD Device Error .................................................................. 66327-AMP Configuration Error ............................................................................ 67328-Power Management Controller Firmware Error ......................................... 67329-Power Management Controller FW Error ................................................... 67330-Unsupported Processor Configuration Detected ....................................... 68331-Memory Board Configuration Error ............................................................ 68332-Memory Board Configuration Error ............................................................ 68333-HP RESTful API Error ................................................................................ 68334-HP RESTful API Error ................................................................................ 69335-HP RESTful API Error ................................................................................ 69336-HP RESTful API Error ................................................................................ 69337-HP RESTful API Error ................................................................................ 70338-HP RESTful API Error ................................................................................ 70340-NVDIMM Error – Backup Error ................................................................... 70341-NVDIMM Error – Restore Error .................................................................. 71342-NVDIMM Error – Uncorrectable Memory Error .......................................... 71
ESES ix

343-NVDIMM Error – Backup Power Error ....................................................... 71344-NVDIMM Error – NVDIMM Controller Error ............................................... 72345-NVDIMM Error – Erase Error ..................................................................... 72346-NVDIMM Error – Arming Error ................................................................... 73347-NVDIMM Population Error ......................................................................... 73348-NVDIMM Population Error ......................................................................... 74349-NVDIMM Population Error ......................................................................... 74350-NVDIMM Population Error ......................................................................... 75351-IMPORTANT: HP Smart Storage Battery is not charged sufficiently ......... 75352-IMPORTANT: HPE Smart Storage Battery is not charged sufficiently ...... 75353-IMPORTANT: Possible Password Corruption ............................................ 75354-LRDIMM Memory Configuration Issue ....................................................... 76355-Processor X, DIMM Y ................................................................................ 76356-NVDIMM Error – Sanitization Error ............................................................ 76357-IMPORTANT: Processor X, DIMM Y ......................................................... 77358-IMPORTANT: Processor X, DIMM Y ......................................................... 77359-NVDIMM Population Error ......................................................................... 77360-IMPORTANT: The System Programmable Logic Device revision in this system does not meet minimum requirements for operation with NVDIMMs ... 78361-IMPORTANT: The Processor RAPL wattage value is configured to an invalid value ...................................................................................................... 78362-IMPORTANT: The DRAM RAPL wattage value is configured to an invalid value ...................................................................................................... 78363-Memory Initialization Error ......................................................................... 79364-NVDIMM Controller Error ........................................................................... 79365-Backplane Configuration Error ................................................................... 80366-Backplane Configuration Error ................................................................... 80371-NVDIMM Error – Processor X, DIMM Y ..................................................... 80372-NVDIMM Error – Processor X, DIMM Y ..................................................... 81373-NVDIMM Error ........................................................................................... 81374-NVDIMM Error ........................................................................................... 81375-NVDIMM Error – Processor X, DIMM Y ..................................................... 82376-NVDIMM Error – Processor X, DIMM Y ..................................................... 82377-NVDIMM Error – Processor X, DIMM Y ..................................................... 83378-NVDIMM Error – Processor X, DIMM Y ..................................................... 83379-NVDIMM Error – Processor X, DIMM Y ..................................................... 84380-NVDIMM Error – Processor X, DIMM Y ..................................................... 84381-NVDIMM Error – Processor X, DIMM Y ..................................................... 85382-NVDIMM Error – Processor X, DIMM Y ..................................................... 85383-NVDIMM Error ........................................................................................... 86384-NVDIMM Error – Processor X, DIMM Y ..................................................... 86
x ESES

385-NVDIMM Error – Processor X, DIMM Y ..................................................... 86386-NVDIMM Error – Processor X, DIMM Y ..................................................... 87387-NVDIMM Error – Processor X, DIMM Y ..................................................... 87388-Memory Failure – Uncorrectable Memory Error ......................................... 87389-Unexpected Shutdown and Restart ........................................................... 88390-On Package High-Bandwidth Memory Failure ........................................... 88
Serie 400 ........................................................................................................................... 8840X-Parallel Port X Address Assignment Conflict ............................................. 88404-Parallel Port Address Conflict Detected ..................................................... 89
Serie 500 ........................................................................................................................... 89501-PCI card needs to be in alternate slot ........................................................ 89
Serie 1500 ......................................................................................................................... 901500-iLO 4 configuration is temporarily unavailable ......................................... 901501-iLO 4 Security Override Switch is set ....................................................... 901502-iLO 4 is disabled ...................................................................................... 901503-iLO 4 ROM-based Setup Utility is disabled .............................................. 91
Serie 1600 ......................................................................................................................... 911609-Battery Failure message .......................................................................... 911610-Temperature violation detected ............................................................... 911611-CPU Zone Fan Assembly Failure Detected ............................................. 921611-CPU Zone Fan Assembly Failure Detected ............................................. 921611-Fan failure detected ................................................................................. 921611-Fan X Failure Detected (Fan Zone CPU) ................................................. 921611-Fan X Failure Detected (Fan Zone I/O) ................................................... 931611-Fan X Not Present (Fan Zone CPU) ........................................................ 931611-Fan X Not Present (Fan Zone I/O) ........................................................... 931611-Power Supply Zone Fan Assembly Failure Detected .............................. 931611-Power Supply Zone Fan Assembly Failure Detected .............................. 941611-Primary Fan Failure (Fan Zone System) .................................................. 941611-Redundant Fan Failure (Fan Zone System) ............................................ 941612-Primary Power Supply Failure ................................................................. 941613-Low System Battery warning ................................................................... 951614-Redundant Fan Failure ............................................................................ 951616-Power Supply Configuration Failure ........................................................ 951623-Power Supply Failure ............................................................................... 961624-Power Supply Unplugged ........................................................................ 961625-Unsupported Power Supply Configuration ............................................... 961626-Unsupported Power Supply Configuration ............................................... 971627-Power Supply Configuration Insufficient .................................................. 971628-IMPORTANT: The system contains multiple types of power supplies ..... 97
Serie 1700 ......................................................................................................................... 98
ESES xi

1700-Slot # Drive Array – Please replace battery ............................................. 981701-Slot # Drive Array – Please install battery ................................................ 981702-SCSI Cable Error Detected ...................................................................... 981703-Slot X Drive Array controller - Memory Self-Test Error ............................ 991704-Slot X System Halted ............................................................................... 991705-Slot X Drive Array .................................................................................... 991706-The Extended BIOS Data Area in Server Memory has been Overwritten ...................................................................................................... 1001707-Slot X Drive Array Controller .................................................................. 1001707-Slot X Drive Array Controller .................................................................. 1001709-One or more attached hard drives could not be authenticated .............. 1011710-Slot X Drive Array – Non-Array Controller Drives Detected ................... 1011711-Slot # Drive Array – Stripe size too large ............................................... 1021712-Slot X Drive Array – RAID 5 volume(s) present ..................................... 1021713-Slot X Array Controller – Redundant ROM Reprogramming Failure ...... 1021714-Slot X Array Controller – Redundant ROM Checksum Error ................. 1031715-Slot # Drive Array Controller – Memory Error(s) Occurred .................... 1031716-Slot # Drive Array – Unrecoverable Media Errors Detected on Drives .. 1041717-Slot X Drive Array – Disk Drive(s) Reporting OVERHEATED Condition ......................................................................................................... 1041718-Slot X Drive Array – Device discovery found more devices attached .... 104Se ha producido el evento de fallo de la controladora 1719-A ....................... 1051720-Slot X Drive Array – S.M.A.R.T. Hard Drive(s) Detect imminent failure . 1051721-Slot # Drive Array – Drive Parameter Tracking Predicts Imminent Failure ............................................................................................................. 1061723-Slot X Drive Array – Improving signal integrity ....................................... 1061724-Slot # Drive Array – Physical Drive Position Change(s) Detected ......... 1061726-Slot X Drive Array – Cache Memory Size or Battery Presence Has Changed .......................................................................................................... 1071727-Slot X Drive Array – New (or Previously Failed) Logical Drive(s) Attachment Detected ....................................................................................... 1071728-Slot # Drive Array – Abnormal Shut-Down Detected ............................. 1071729-Slot # Drive Array – Disk Performance Optimization Scan in Progress . 1081730-Fixed Disk 0 Does Not Support DMA Mode ........................................... 1081731-Fixed Disk 1 Does Not Support DMA Mode ........................................... 1081732-Slot # Drive Array – Cache Module Battery Pack Missing ..................... 1091733-Slot # Drive Array – Storage Enclosure Firmware Upgrade Problem Detected .......................................................................................................... 1091734-Slot # Drive Array – Disk Drive(s) Responding to Incorrect SCSI ID ..... 1091735-Slot # Drive Array – Unsupported Redundant Cabling Configuration Detected .......................................................................................................... 1101736-Trusted Platform Module Error ............................................................... 110
xii ESES

1737-Slot X Drive Array – Redundant Cabling Configuration has excess Device Paths ................................................................................................... 1111738-Slot # Drive Array – Storage Enclosure Redundant Cabling Problem Detected .......................................................................................................... 1111739-Slot # Drive Array – Redundant Cabling is not as recommended .......... 1121740-Fixed Disk 0 failed set Block Mode ........................................................ 1121741-Fixed Disk 1 failed set Block Mode ........................................................ 1121742-Slot X Drive Array - Previously Ejected Drive(s) Detected ..................... 1121743-Slot # Drive Array – Logical Drive Erase Operation in Progress ............ 1131743-Slot # Drive Array – Logical Drive Erase Operation(s) are Queued ....... 1131744-Slot X Drive Array – Drive Erase Operation In Progress ........................ 1141745-Slot X Drive Array - Drive Erase Operation Completed ......................... 1141746-Slot X Drive Array – Unsupported Storage Connection Detected .......... 1141747-Slot # Drive Array – Unsupported Array Configuration Detected ........... 1151748-Slot # Drive Array – Unsupported Cache Module Battery Attached ....... 1161749-Slot X Drive Array – Cache Module Flash Memory being erased .......... 1161750-Fixed Disk 0 failed ID command ............................................................ 1171751-Fixed Disk 1 failed ID command ............................................................ 1171752-Slot X Drive Array – Controller not supported in this server model ........ 1171753-Slot X Drive Array – Array Controller Maximum Operating Temperature Exceeded ................................................................................... 1171754-Slot X Drive Array – One or more RAID levels are configured ............... 1181762-Slot X Drive Array – Controller Firmware Upgrade Needed ................... 1181763-Slot X Drive Array – Cache module is detached .................................... 1181764-Slot X Drive Array – Capacity Expansion Process is Temporarily Disabled .......................................................................................................... 1191766-Slot X Drive Array requires System ROM Upgrade ............................... 1191768-Slot X Drive Array – Resuming logical drive expansion process ........... 1201769-Slot X Drive Array – Drive(s) Disabled ................................................... 1201770-Slot X Drive Array – Disk Drive Firmware Update Recommended ........ 1211774-Slot X Drive Array – Obsolete data found in Cache Module .................. 1211775-Slot X Drive Array – Storage Enclosure Cabling Problem Detected ...... 1221776-Slot X Drive Array – Shared SAS Port Connection Conflict Detected .... 1221777-Slot X Drive Array – Storage Enclosure Problem Detected ................... 1221778-Slot X Drive Array resuming Automatic Data Recovery (Rebuild) process ............................................................................................................ 1241779-Slot X Drive Array – Replacement drive(s) detected .............................. 1251779-Slot X Drive Array – Logical drive(s) previously failed ........................... 1251783-Slot X Drive Array Controller Failure ...................................................... 1261784-Slot X Drive Array – Logical Drive Failure .............................................. 1271784-Slot X Drive Array – Drive Failure .......................................................... 1271785-Slot XX Not Configured .......................................................................... 128
ESES xiii

1786-Slot X Drive Array Recovery Needed ..................................................... 1281787-Slot X Drive Array Operating in Interim Recovery (Degraded) Mode .... 1291788-Slot X Drive Array Reports Incorrect Drive Replacement ...................... 1301789-Slot X Drive Array Disk Drive(s) Not Responding .................................. 1311792-Slot X Drive Array – Valid Data Found in Write-Back Cache ................. 1321793-Slot X Drive Array – Data in Cache has been lost ................................. 1321794-Slot X Drive Array – Cache Module Battery is Charging ........................ 1321795-Slot X Drive Array – Cache Module Configuration Error ........................ 1331796-Slot X Drive Array – Flash Backed Write Cache module is not responding ...................................................................................................... 1331797-Slot X Drive Array – Write-Back Cache Backup Previously Failed ........ 1331797-Slot X Drive Array – Write-Back Cache Read Error Occurred ............... 1341797-Slot X Drive Array – Write-Back Cache Restore Previously Failed ........ 1341798-Slot X Drive Array – Cache Module Self-Test Error Occurred ............... 1351799-Slot X Drive Array – Drive(s) Disabled due to Cache Data Loss ........... 1351799-Slot X Drive Array – Drive(s) Disabled due to Write-Back Cache Data Loss ........................................................................................................ 135179A-Slot X Drive Array – Flash Backed Write Cache has been disabled ..... 136
Serie 1800 ....................................................................................................................... 1361802-Slot # Drive Array – Dual domain configured or detected ...................... 1361803-Slot X Drive Array – Cache Module is not installed ................................ 1361804-Slot X Drive Array – Cache Module critical error .................................... 1371806-Slot X Drive Array – Cache Module flash memory is not installed ......... 1371807-Slot X Drive Array – Cache Module incompatible with this controller .... 1371808-Slot X Drive Array – Cache Module critical error .................................... 1381809-Slot X Encryption Failure ....................................................................... 1381810-Slot X Encryption Failure ....................................................................... 1381811-Slot X Encryption Failure ....................................................................... 1391812-Slot X Encryption Failure ....................................................................... 1391813-Slot X Drive Array – Cache Module critical error .................................... 1391814-Slot X Encryption Failure ....................................................................... 1391815-Slot X Encryption Failure ....................................................................... 1401816-Slot X Encryption Failure ....................................................................... 1401817-Slot X Encryption Failure ....................................................................... 1401818-Slot X Encryption Failure ....................................................................... 1411819-Slot X Encryption Failure ....................................................................... 1411820-Slot X Encryption Failure ....................................................................... 141182-Slot X Encryption Failure ......................................................................... 1421822-Slot X Encryption Failure ....................................................................... 1421823-Slot X Encryption Failure ....................................................................... 1421824-Slot X One or more storage cables has failed ....................................... 143
xiv ESES

1825-Slot X Encryption Failure ....................................................................... 1431826-Slot X Encryption Failure ....................................................................... 1431827-Slot X Drive Array – Please install cache module battery pack ............. 1441828-Slot X Drive Array – Cache Module Battery Pack is not installed .......... 1441829-Slot # Drive Array – Please replace cache module battery pack ........... 1441830-Slot X Drive Array – Incorrect cache module power source detected .... 1451831-Slot X Drive Array – Data in Write-Back SmartCache has been lost ..... 1451832-Slot X One or more physical drives are not exposed ............................. 1451833-Slot X Drive Array – Unsupported Array Configuration Detected ........... 146
Mensajes de error del registro de gestión integrado ........................................................................ 146Introducción a los mensajes de error del registro de gestión integrado .......................... 146Automatic operating system shutdown initiated due to fan failure ................................... 146Automatic Operating System Shutdown Initiated Due to Overheat Condition... .............. 146Operating System failure: Cause [NT] ............................................................................. 146Corrected Memory Error Threshold exceeded (Processor X, Memory Module Y) .......... 147Uncorrectable PCI Express Error (Slot X, Bus Y, Device Z, Function W, Error status <valor hexadecimal>) ...................................................................................................... 147Uncorrectable Machine Check Exception (Board X, Processor Y, APIC ID <valor hexadecimal>, Bank <valor hexadecimal> Status <valor hexadecimal>) ....................... 147System Fan Failure (Fan X, Location) ............................................................................. 147System Fans Not Redundant ........................................................................................... 147System Overheating (Zone X, Location) .......................................................................... 147System Power Supplies Not Redundant .......................................................................... 147System Power Supply Failure (Power Supply X) ............................................................. 148Uncorrectable Memory Error (Slot X, Memory Module Y)... ............................................ 148
3 HPE ProLiant Gen9, códigos de fallos de alimentación ............................................................................... 149Códigos de fallos de alimentación de los indicadores LED del panel frontal ................................... 149
4 Errores de HPE Smart Array ......................................................................................................................... 150Indicadores LED de tiempo de ejecución de la controladora ........................................................... 150
Indicadores LED de la controladora P440ar .................................................................... 150Indicadores LED de la controladora P440 ....................................................................... 151Indicadores LED de la controladora P441 ....................................................................... 152Indicadores LED de la controladora P840 ....................................................................... 153
Indicadores LED del módulo de memoria caché .............................................................................. 154Mensajes del registro de eventos de Windows para Smart Array .................................................... 156
Identificadores de mensajes 24578-24599 ...................................................................... 156Identificadores de mensajes 24600-24624 ...................................................................... 166Identificadores de mensajes 24625-24649 ...................................................................... 172Identificadores de mensajes 24650-24674 ...................................................................... 175
ESES xv

Identificadores de mensajes 24675-24699 ...................................................................... 179Identificadores de mensajes 24700-24724 ...................................................................... 184Identificadores de mensajes 24725-24749 ...................................................................... 193Identificadores de mensajes 24750-24774 ...................................................................... 198Identificadores de mensajes 24775-24799 ...................................................................... 204Identificadores de mensajes 24800-24808 ...................................................................... 211
Errores del controlador de Windows para Smart Array .................................................................... 213
5 Errores de HPE Onboard Administrator ........................................................................................................ 214Mensajes de error de Onboard Administrator .................................................................................. 214Errores de Onboard Administrator ................................................................................................... 214Errores de captura de pantalla de Insight Display ............................................................................ 236Mensajes de SysLog ........................................................................................................................ 237
Mensajes del registro de Alertmail ................................................................................... 237Mensajes del registro de inicio y de autenticación .......................................................... 237Mensajes del registro de CGI .......................................................................................... 238Mensajes del registro de la CLI ....................................................................................... 238Mensajes del registro del compartimento de interconexión ............................................. 238Mensajes del registro de DHCP ...................................................................................... 239Mensajes del registro del enlace del chasis .................................................................... 240Mensajes del registro de la configuración no volátil ........................................................ 242Mensajes del registro de actualización del firmware ....................................................... 243Mensajes del registro de almacenamiento, configuración y certificados de la actualización .................................................................................................................... 244Mensajes del registro de configuración de red DNS ....................................................... 246Mensajes del registro de LCD ......................................................................................... 247Mensajes del registro relacionados con operaciones ...................................................... 248Mensajes del registro de Linux ........................................................................................ 257Mensajes del registro de gestión ..................................................................................... 257Mensajes del registro internos de OA .............................................................................. 265Mensajes del registro de LDAP ....................................................................................... 266Mensajes del registro de redundancia ............................................................................. 267Mensajes del registro de SSO ......................................................................................... 268Mensajes del registro de dos factores ............................................................................. 269Mensajes del registro de FIPS ......................................................................................... 269Mensajes del registro de VLAN ....................................................................................... 270
Capturas SNMP de Onboard Administrator ..................................................................................... 270Notificaciones de eventos del chasis ............................................................................................... 271Notificaciones de eventos de la línea de comandos ........................................................................ 272
xvi ESES

6 Errores de HPE Virtual Connect ................................................................................................................... 274Información general sobre SNMP .................................................................................................... 274
Capturas SNMP ............................................................................................................... 275Capturas de la MIB de módulo VC .................................................................. 279Capturas MIB de dominio de VC ..................................................................... 280Capturas de cambio de estado gestionado del dominio de VC ...................... 280Capturas de punto de comprobación del dominio de VC ................................ 285vcDomainStackingLinkRedundancyStatusChange ......................................... 285vcTestTrap ...................................................................................................... 285
Eventos de SysLog de Virtual Connect Manager ............................................................................. 285Eventos de los dominios (1000-1999) ............................................................................. 286
1003 - VCM-OA communication down ............................................................ 2861022 - Domain state FAILED .......................................................................... 2871023 - Domain state PROFILE_FAILED ......................................................... 2881026 - Domain state NO_COMM .................................................................... 288
Eventos de los chasis (2000-2999) ................................................................................. 2882003 - Enclosure import failed ........................................................................ 2882011 - Enclosure state NO_COMM ................................................................. 2892013 - Enclosure state failed ........................................................................... 2892016 - Enclosure Find failed ........................................................................... 290
Eventos de los módulos Ethernet (3000-3999) ............................................................... 2913009 - Enet Module OA CPU Fault Event ....................................................... 2913012 - Enet Module State FAILED .................................................................. 2913014 - Enet Module state INCOMPATIBLE .................................................... 2923019 - Enet Module state MISSING ................................................................ 2933023 - Enet Module state NO_COMM ............................................................ 2933031 - Enet Module IP is 0.0.0.0 ..................................................................... 2943101 - Port is disabled as network loop is detected ........................................ 2943102 - Port was disabled because a pause flood was detected ..................... 294
Eventos de los módulos FC (4000-4999) ........................................................................ 2944009 - FC Module OA CPU Fault Event ......................................................... 2944012 - FC Module State Failed ....................................................................... 2954014 - FC Module State Incompatible ............................................................. 2954019 - FC Module State is NO_COMM ........................................................... 295
Eventos de los servidores (5000-5999) ........................................................................... 2965009 - Server OA fault event ........................................................................... 2965012 - Server state FAILED ............................................................................ 2965014 - Server state INCOMPATIBLE .............................................................. 2965019 - Server state is NO_COMM .................................................................. 2965022 - Missing information for one or more blades of a multi-blade server .... 297
ESES xvii

5050 - The BIOS for the following devices is not compatible with Virtual Connect ........................................................................................................... 2975055 - The server BIOS needs to be updated to at least the version dated ... 2975056 - Unable to release power hold on the server. Unassign and re-assign profile .............................................................................................................. 297
Eventos de los perfiles (6000-6999) ................................................................................ 2986012 - Profile state FAILED ............................................................................ 2986020 - Profile has the same network on two Flex-10 NICs on the same physical port .................................................................................................... 2986021 - Profile has PXE enabled on a non-primary Flex-10 NIC ...................... 2986022 - Profile has iSCSI boot enabled on an unsupported Flex-10 NIC ......... 2986023 - Profile is assigned to a multi-blade server that has data missing ........ 2996030 - Profile could not be assigned to powered up server ............................ 299
Eventos de la red Ethernet (7000-7999) .......................................................................... 2997012 - Enet Network state FAILED ................................................................. 2997014 - Enet Network state DISABLED ............................................................ 300
Eventos de la estructura FC (8000-8999) ........................................................................ 3008012 - FC Fabric state FAILED ....................................................................... 300
Eventos de módulos desconocidos (9000-9999) ............................................................. 3009012 - Unknown Module state FAILED ........................................................... 3009014 - Unknown Module state INCOMPATIBLE ............................................. 3019019 - Unknown Module state NO_COMM ..................................................... 301
Eventos de conjuntos de enlaces ascendentes Ethernet (17000-17999) ....................... 30117012 - Enet uplinkset state FAILED .............................................................. 30117014 - Enet uplinkset state is DISABLED ..................................................... 302
7 Errores de CONREP ..................................................................................................................................... 303Uso de CONREP .............................................................................................................................. 303Códigos de retorno de CONREP ..................................................................................................... 303Salida de pantalla de CONREP ....................................................................................................... 304
8 Errores de HPE iLO ...................................................................................................................................... 306Indicadores LED de la POST de iLO ................................................................................................ 306Entradas del registro de eventos ...................................................................................................... 307Mensajes de RIBCL ......................................................................................................................... 317
9 HPE Insight Management Agents for Servers para Windows ...................................................................... 327Mensajes del registro de eventos asociados a capturas SNMP ...................................................... 327Formato del registro de eventos de Windows NT® ......................................................................... 327Descripciones de los agentes .......................................................................................................... 328Agentes base ................................................................................................................................... 328
xviii ESES

Identificadores de eventos 1105-1808 ............................................................................. 328Identificadores de eventos 2048-2359 ............................................................................. 338Identificadores de eventos 3072-3876 ............................................................................. 342Identificadores de eventos 4352-4626 ............................................................................. 347
Agentes de almacenamiento ............................................................................................................ 351Identificadores de eventos 256-774 ................................................................................. 351Identificadores de eventos 1061-1098 ............................................................................. 356Identificadores de eventos 1101-1199 ............................................................................. 363Identificadores de eventos 1200-1294 ............................................................................. 395Identificadores de eventos 1343-4613 ............................................................................. 415
Agentes de servidor ......................................................................................................................... 421Identificadores de eventos 256-1024 ............................................................................... 421Identificadores de eventos 1025-1092 ............................................................................. 425Identificadores de eventos 1103-1183 ............................................................................. 435Identificadores de eventos 1539-3352 ............................................................................. 475Identificadores de eventos 5632-5684 ............................................................................. 478
Agentes NIC ..................................................................................................................................... 480Identificadores de eventos 256-299 ................................................................................. 480Identificadores de eventos 300-1293 ............................................................................... 485
10 Asistencia y otros recursos ......................................................................................................................... 493Acceso al soporte de Hewlett Packard Enterprise ........................................................................... 493
Información que se debe recopilar .................................................................................. 493Acceso a las actualizaciones ........................................................................................................... 493Páginas web ..................................................................................................................................... 494Soporte remoto ................................................................................................................................. 494
11 Siglas y abreviaturas ................................................................................................................................... 495
12 Comentarios sobre la documentación ........................................................................................................ 499
Índice ................................................................................................................................................................ 500
ESES xix

1 Introducción
Información generalEsta guía forma parte de un conjunto de dos volúmenes. La Guía de solución de problemas de HPE ProLiant Gen9, Volumen I: Solución de problemas, proporciona procedimientos para resolver problemas comunes. Esta Guía de solución de problemas de HPE ProLiant Gen9, Volumen II: Mensajes de error ofrece una lista de los mensajes de error e información para interpretar y resolver los mensajes de error en servidores ProLiant y blades de servidor. Utilice estos mensajes para resolver problemas y optimizar el funcionamiento de su equipo Hewlett Packard Enterprise.
Recursos de solución de problemasEn la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas encontrará procedimientos para resolver problemas comunes e instrucciones completas para el aislamiento y la identificación de fallos, la solución de problemas y el mantenimiento del software en los blades de servidor y servidores ProLiant.
Para acceder a los recursos de solución de problemas, consulte la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
ESES Información general 1

2 Errores de los servidores HPE ProLiant
Mensajes de error de diagnóstico de arraysMensajes de error de HPE Smart Storage Administrator Diagnostics Utility
Esta sección contiene una lista completa, ordenada alfabéticamente, de todos los mensajes de error que presenta HPE Smart Storage Administrator Diagnostics Utility en el informe de diagnóstico de arrays.
Array status: The array has failedSíntoma
Array status: The array has failed.
Causa
Se ha producido un fallo en una unidad física o lógica del array.
Acción
Compruebe si hay errores en las unidades físicas o lógicas del array y solucione los problemas. Para obtener más información, consulte la sección "Problemas de la unidad física" y "Problemas de la unidad lógica" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
Array status: The array currently has a drive erase operation queued, running, stopped or completed on a logical or physical drive
Síntoma
Array status: The array currently has a drive erase operation queued, running, stopped or completed on a logical or physical drive.
Causa
Se pone en cola, se ejecuta, se detiene o se completa una operación de borrado de la unidad.
Acción
No es necesario hacer nada.
Array Status: The array has a spare drive assigned which is smaller than the smallest data drive in the array
Síntoma
Array Status: The array has a spare drive assigned which is smaller than the smallest data drive in the array. Some operations in the array will not be available.
Causa
La unidad de repuesto no es lo suficientemente grande.
Acción
2 Capítulo 2 Errores de los servidores HPE ProLiant ESES

Sustituya la unidad de repuesto por otra unidad que tenga como mínimo el tamaño de la unidad de datos más pequeña del array. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
Cache module: The batteries were hot-removedSíntoma
Cache module: The batteries were hot-removed.
Causa
Se quitaron las baterías del módulo de memoria caché.
Acción
Instale las baterías. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
Cache module: The cache for this controller is temporarily disabled since a snapshot is in progress
Síntoma
Cache module: The cache for this controller is temporarily disabled since a snapshot is in progress. The controller requires a reboot to enable the cache. Until the reboot occurs, cache module operations such as Expansion, Extension, and Migration are disabled.
Causa
Se está realizando una copia de seguridad.
Acción
Reinicie la controladora para activar la memoria caché. Las operaciones del módulo de memoria caché, como la expansión, extensión y migración, estarán desactivadas hasta que se complete el reinicio.
Cache module: The cache is disabled because a capacitor has failed to charge to an acceptable level
Síntoma
Cache module: The cache is disabled because a cache module battery has failed to charge to an acceptable level.
Causa
No se cargará la batería del módulo de memoria caché.
Acción
Sustituya la batería del módulo de memoria caché. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
Cache module: The cache is disabled because a flash memory or capacitor hardware failure has been detected
Síntoma
ESES Mensajes de error de diagnóstico de arrays 3

Cache module: The cache is disabled because a flash memory or capacitor hardware failure has been detected.
Causa
Se ha detectado un error en uno de los siguientes elementos:
● Memoria flash
● Hardware del condensador
Acción
Póngase en contacto con el soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
Cache module: The cache is disabled because the backup operation to flash memory failedSíntoma
Cache module: The cache is disabled because the backup operation to flash memory failed.
Causa
No se completó la operación de copia de seguridad.
Acción
1. Vuelva a colocar el módulo de memoria caché en la controladora.
2. Si el problema continúa, póngase en contacto el servicio de soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
Cache module: The cache is disabled because the batteries are low on the redundant controller
Síntoma
Cache module: The cache is disabled because the batteries are low on the redundant controller.
Causa
Las baterías no están cargadas.
Acción
Si las baterías no se han recargado después de 36 horas, sustitúyalas. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
Cache module: The cache is disabled because the batteries are lowSíntoma
Cache module: The cache is disabled because the batteries are low.
Causa
Las baterías no están cargadas.
Acción
4 Capítulo 2 Errores de los servidores HPE ProLiant ESES

Si las baterías no se han recargado después de 36 horas, sustitúyalas. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
Cache module: The cache is disabled because the charge on the flash-memory capacitor is too low
Síntoma
Cache module: The cache is disabled because the charge on the flash-memory capacitor is too low.
Causa
● La batería no está cargada.
● Se ha producido un fallo en la batería.
Acción
Sustituya la batería si esta no se recarga después de 10 minutos. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
Cache module: The cache is disabled because the restore operation from flash memory failed
Síntoma
Cache module: The cache is disabled because the restore operation from flash memory failed.
Causa
No se completó la operación de restauración.
Acción
Vuelva a colocar el módulo de memoria caché en la controladora. Si el problema continúa, póngase en contacto el servicio de soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
Cache module: The cache is disabled because there are no capacitors attached to the cache module
Síntoma
Cache module: The cache is disabled because there are no capacitors attached to the cache module.
Causa
No hay condensadores instalados.
Acción
Instale un condensador. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
Cache module: This controller has been set up to be a part of a redundant pair of controllersSíntoma
ESES Mensajes de error de diagnóstico de arrays 5

Cache module: This controller has been set up to be a part of a redundant pair of controllers but the cache module cache sizes are different on the two controllers. Make certain that both controllers are using cache modules with the same amount of cache memory installed.
Causa
Los módulos de memoria caché instalados no son de la misma capacidad.
Acción
Ajuste la memoria instalada en los módulos de memoria caché para que los tamaños sean iguales.
Cache module: This controller's firmware is not backward compatible with the cache module revision
Síntoma
Cache module: This controller's firmware is not backward compatible with the cache module revision.
Causa
El firmware de la controladora no es compatible con el módulo de memoria caché.
Acción
1. Actualice la controladora con el firmware más reciente. Para obtener más información, consulte la sección "Actualización del sistema" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
2. Si el problema continúa, póngase en contacto el servicio de soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
Controller State: A logical drive is configured with a newer version of the Array Configuration tools than is currently running
Síntoma
Controller State: A logical drive is configured with a newer version of the Array Configuration tools than is currently running. Please obtain a newer version of the Array Configuration tools to configure or diagnose this controller.
Causa
Se ha configurado una unidad lógica con una versión más reciente de las herramientas configuración del array que se están ejecutando actualmente.
Acción
Instale la versión más reciente de la HPE SSA. Para obtener más información, consulte la sección "Actualización del sistema" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
Controller State: The array controller contains a volume that was created with a different version of controller firmware
Síntoma
Controller State: The array controller contains a volume that was created with a different version of controller firmware and is not backward-compatible with the current version of firmware. You may
6 Capítulo 2 Errores de los servidores HPE ProLiant ESES

reconfigure the controller, but the existing configuration and data will be overwritten and potentially lost.
Causa
El volumen se creó con una versión del firmware de la controladora que no es compatible con la versión actual.
Acción
1. Actualice la controladora con el firmware más reciente. Para obtener más información, consulte la sección "Actualización del sistema" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
2. Si el problema continúa, vuelva a colocar los arrays configurados en la controladora original.
Controller State: The array controller contains more logical drives than are supported in the current configuration
Síntoma
Controller State: The array controller contains more logical drives than are supported in the current configuration. Any configuration command (e.g. logical drive creation, array expansion, etc.) or modification to the controller will result in the loss of all existing data on the disabled volume(s).
Causa
La controladora del array contiene más unidades lógicas que las compatibles en la configuración actual.
Acción
1. Identifique las unidades que contienen los volúmenes lógicos perdidos.
2. Realice una de las siguientes operaciones:
● Coloque las unidades en otra controladora en la que puedan volver a crearse los volúmenes lógicos.
● Si una unidad contiene un volumen lógico válido que está en uso y un volumen lógico perdido, no mueva dicha unidad a otra controladora.
Controller State: The array controller contains one or more logical drives with a RAID level that is not supported in the current configuration
Síntoma
Controller State: The array controller contains one or more logical drives with a RAID level that is not supported in the current configuration. Any configuration command (e.g. logical drive creation, array expansion, etc.) or modification to the controller will result in the loss of all existing data on the disabled volume(s).
Causa
La controladora del array contiene una o más unidades lógicas con nivel RAID que no son compatibles en la configuración actual.
Acción
Realice una de las siguientes operaciones:
ESES Mensajes de error de diagnóstico de arrays 7

● Si este mensaje aparece después de mover un array de unidades configurado desde otra controladora, realice el siguiente procedimiento:
◦ Actualice el firmware de esta controladora.
◦ Asegúrese de que el módulo de la memoria caché esté instalado. Instale el módulo de memoria caché si no está instalado.
◦ Si el problema continúa, apague el servidor y vuelva a colocar las unidades en la controladora original.
● Si aparece este mensaje sin haber movido ninguna unidad, realice lo siguiente:
◦ Asegúrese de que el módulo de la memoria caché esté funcionando. Sustituya el módulo de la memoria caché, si fuese necesario.
◦ Si el problema continúa, póngase en contacto el servicio de soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493).
Controller State: The array controller contains redundant connections to one or more physical drives that are not supported in the current configuration
Síntoma
Controller State: The array controller contains redundant connections to one or more physical drives that are not supported in the current configuration. Please remove the redundant connection(s) or, if your controller supports it, install the appropriate license key to enable the dual domain feature.
Causa
La controladora de array contiene conexiones redundantes no compatibles.
Acción
Realice una de las siguientes operaciones:
● Quite las conexiones redundantes.
● Instale una clave de licencia para activar la función de dominio doble.
Controller State: The array controller has a configuration that requires more physical drives than are currently supported
Síntoma
Controller State: The array controller has a configuration that requires more physical drives than are currently supported. You may reconfigure the controller, but the existing configuration and data will be overwritten and potentially lost.
Causa
La configuración requiere más unidades que son compatibles actualmente.
Acción
Realice una de las siguientes operaciones:
● Si este mensaje aparece después de mover un array de unidades configurado desde otra controladora, realice el siguiente procedimiento:
8 Capítulo 2 Errores de los servidores HPE ProLiant ESES

◦ Actualice el firmware de esta controladora.
◦ Asegúrese de que el módulo de la memoria caché esté instalado. Instale el módulo de memoria caché si no está instalado.
◦ Si el problema continúa, apague el servidor y vuelva a colocar las unidades en la controladora original.
● Si aparece este mensaje sin haber movido ninguna unidad, realice lo siguiente:
◦ Asegúrese de que el módulo de la memoria caché esté funcionando. Sustituya el módulo de la memoria caché, si fuese necesario.
◦ Si el problema continúa, póngase en contacto el servicio de soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493).
Controller State: The array controller has an unknown disabled configuration status messageSíntoma
Controller State: The array controller has an unknown disabled configuration status message. Any configuration command (e.g. logical drive creation, array expansion, etc.) or modification to the controller will result in the loss of all existing data on the disabled volume(s).
Causa
La controladora del array tiene un mensaje de estado de configuración desactivado.
Acción
Póngase en contacto con el soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
Controller State: The array controller has an unsupported configurationSíntoma
Controller State: The array controller has an unsupported configuration. You may reconfigure the controller, but the existing configuration and data will be overwritten and potentially lost.
Causa
La controladora del array tiene una configuración no compatible.
Acción
Realice una de las siguientes operaciones:
● Si este mensaje aparece después de mover un array de unidades configurado desde otra controladora, realice el siguiente procedimiento:
◦ Actualice el firmware de esta controladora.
◦ Asegúrese de que el módulo de la memoria caché esté instalado. Instale el módulo de memoria caché si no está instalado.
◦ Si el problema continúa, apague el servidor y vuelva a colocar las unidades en la controladora original.
● Si aparece este mensaje sin haber movido ninguna unidad, realice lo siguiente:
ESES Mensajes de error de diagnóstico de arrays 9

◦ Asegúrese de que el módulo de la memoria caché esté funcionando. Sustituya el módulo de la memoria caché, si fuese necesario.
◦ Si el problema continúa, póngase en contacto el servicio de soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493).
Controller State: The array controller is connected to an expander card or an external enclosure
Síntoma
Controller State: The array controller is connected to an expander card or an external enclosure and is operating without a memory board. If there are physical drives attached to the expander card or external enclosure, and those drives contain any logical drives, then making any configuration change will lead to potential data loss on those logical drives.
Causa
El módulo de memoria caché no está instalado.
Acción
Instale un módulo de memoria caché. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
Controller State: The array controller is operating without a memory board and contains more logical drives than are supported in the current configuration
Síntoma
Controller State: The array controller is operating without a memory board and contains more logical drives than are supported in the current configuration. Any configuration command (e.g. logical drive creation, array expansion, etc.) or modification to the controller will result in the loss of all existing data on the disabled volume(s).
Causa
El módulo de memoria caché no está instalado.
Acción
Instale un módulo de memoria caché. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
Controller State: The array controller is operating without a memory board and has a bad volume position
Síntoma
Controller State: The array controller is operating without a memory board and has a bad volume position. Any configuration command (e.g. logical drive creation, array expansion, etc.) or modification to the controller will result in the loss of all existing data on the disabled volume(s).
Causa
El módulo de memoria caché no está instalado.
Acción
Instale un módulo de memoria caché. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
10 Capítulo 2 Errores de los servidores HPE ProLiant ESES

Controller State: The array controller is operating without a memory board and has an invalid physical drive connection
Síntoma
Controller State: The array controller is operating without a memory board and has an invalid physical drive connection. Any configuration command (e.g. logical drive creation, array expansion, etc.) or modification to the controller will result in the loss of all existing data on the disabled volume(s).
Causa
El módulo de memoria caché no está instalado.
Acción
Instale un módulo de memoria caché. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
Controller State: The array controller is operating without a memory boardSíntoma
Controller State: The array controller is operating without a memory board (RAID) and contains one or more logical drives with a RAID level that is not supported in the current configuration. Any configuration command (e.g. logical drive creation, array expansion, etc.) or modification to the controller will result in the loss of all existing data on the disabled volume(s).
Causa
El módulo de memoria caché no está instalado.
Acción
Instale un módulo de memoria caché. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
Controller State: The controller cannot be configured. CACHE STATUS PROBLEM DETECTED
Síntoma
Controller State: The controller cannot be configured. CACHE STATUS PROBLEM DETECTED: The cache on this controller has a problem. To prevent data loss, configuration changes to this controller are not allowed. Please replace the cache to be able to continue to configure this controller.
Causa
Se ha producido un fallo en el módulo de la memoria caché.
Acción
Sustituya el módulo de memoria caché. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
Controller State: The HBA does not have an access IDSíntoma
Controller State: The HBA does not have an access ID. External SCSI array controllers that support SSP require HBAs to have an access ID.
Causa
ESES Mensajes de error de diagnóstico de arrays 11

El HBA no tiene un ID de acceso.
Acción
1. Actualice el HBA. Para obtener más información, consulte la sección "Actualización del sistema" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
2. Si el problema continúa, póngase en contacto el servicio de soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
Drive Offline due to Erase Operation: The logical drive is offline from having an erase in progress
Síntoma
Drive Offline due to Erase Operation: The logical drive is offline from having an erase in progress.
Causa
Una operación de borrado está en curso.
Acción
No es necesario hacer nada. La unidad lógica estará temporalmente fuera de línea. No se puede realizar la migración o expansión de la unidad lógica mientras hay una operación de borrado en proceso.
Drive Offline due to Erase Operation: The physical drive is currently queued for eraseSíntoma
Drive Offline due to Erase Operation: The physical drive is currently queued for erase.
Causa
Una operación de borrado está en curso.
Acción
No es necesario hacer nada. La unidad lógica que contiene esta unidad física no se puede migrar o ampliar mientras haya una operación de borrado en proceso.
Drive Offline due to Erase Operation: The physical drive is offline and currently being erasedSíntoma
Drive Offline due to Erase Operation: The physical drive is offline and currently being erased.
Causa
Una operación de borrado está en curso.
Acción
No es necesario hacer nada. La unidad lógica que contiene esta unidad física no se puede migrar o ampliar mientras haya una operación de borrado en proceso.
12 Capítulo 2 Errores de los servidores HPE ProLiant ESES

Drive Offline due to Erase Operation: The physical drive is offline and the erase process has been failed
Síntoma
Drive Offline due to Erase Operation: The physical drive is offline and the erase process has been failed. The drive may now be brought online through the re-enable erased drive command in SSA.
Causa
El proceso de borrado ha fallado.
Acción
Reactive la unidad física con HPE SSA. Para obtener más información, consulte la Guía de usuario de HPE Smart Storage Administrator en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage-docs).
Drive Offline due to Erase Operation: The physical drive is offline and the erase process has completed
Síntoma
Drive Offline due to Erase Operation: The physical drive is offline and the erase process has completed. The drive may now be brought online through the re-enable erased drive command in SSA.
Causa
El proceso de borrado se ha completado.
Acción
Reactive la unidad física con HPE SSA. Para obtener más información, consulte la Guía de usuario de HPE Smart Storage Administrator en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage-docs).
Drive Offline due to Erase Operation: The physical drive is offline from having an erase in progress
Síntoma
Drive Offline due to Erase Operation: The physical drive is offline from having an erase in progress.
Causa
Una operación de borrado está en curso.
Acción
No es necesario hacer nada. La unidad lógica que contiene esta unidad física no se puede migrar o ampliar mientras haya una operación de borrado en proceso.
Failed Array Controller: code:<lockup Code> : Restart the server and run a diagnostic reportSíntoma
Failed Array Controller: code:<lockup Code>: Restart the server and run a diagnostic report. Install the latest version of controller firmware. If the condition persists, the controller may need to be replaced or require service.
Causa
ESES Mensajes de error de diagnóstico de arrays 13

● La controladora no tiene el firmware más reciente.
● Hay otro problema con la controladora, tal como aparece en el informe de diagnóstico.
● Se ha producido un fallo en la controladora.
Acción
1. Reinicie el servidor.
2. Ejecute el informe de diagnóstico y realice la acción adecuada como se indica.
3. Si el problema continúa, sustituya la controladora.
4. Si el problema continúa, póngase en contacto el servicio de soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
Logical drive state: A logical drive is configured with a newer version of Storage/Config Mod than is currently running
Síntoma
Logical drive state: A logical drive is configured with a newer version of Storage/Config Mod than is currently running.
Causa
Se instala una versión anterior de HPE SSA.
Acción
Instale la versión más reciente de la HPE SSA. Para obtener más información, consulte la sección "Actualización del sistema" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
Logical drive state: Background parity initialization is currently queuedSíntoma
Logical drive state: Background parity initialization is currently queued or in progress on this logical drive. If background parity initialization is queued, it will start when I/O is performed on the drive. When background parity initialization completes, the performance of the logical drive will improve.
Causa
La inicialización de paridad de fondo está actualmente en la cola o está en curso.
Acción
No es necesario hacer nada.
Logical drive state: The current array controller is performing capacity expansionSíntoma
Logical drive state: The current array controller is performing capacity expansion, extension, or migration on this logical drive.
Causa
La migración, la extensión o la expansión de la capacidad está en curso.
14 Capítulo 2 Errores de los servidores HPE ProLiant ESES

Acción
No es necesario hacer nada. No es posible llevar a cabo más configuración hasta que el proceso termine.
Logical drive state: The logical drive is disabled from a SCSI ID conflictSíntoma
Logical drive state: The logical drive is disabled from a SCSI ID conflict.
Causa
Se ha producido un conflicto con un id. de SCSI existente.
Acción
Compruebe todos los componentes SCSI para asegurarse de que todos tienen un ID SCSI único.
Logical drive state: The logical drive is not configuredSíntoma
Logical drive state: The logical drive is not configured.
Causa
No se ha configurado una unidad lógica.
Acción
Actualice el sistema con HPE SSA. Para obtener más información, consulte la Guía de usuario de HPE Smart Storage Administrator en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage-docs).
Logical drive state: The logical drive is not yet availableSíntoma
Logical drive state: The logical drive is not yet available.
Causa
Hay una operación en curso de expansión, reducción o traslado en este array.
Acción
No es necesario hacer nada. Esta unidad lógica permanecerá en este estado hasta que todas las operaciones de expansión, reducción o traslado de este array hayan terminado. Se rechazarán todas las peticiones de E/S enviadas a la unidad lógica en este estado.
Logical drive state: The logical drive is offline from being ejectedSíntoma
Logical drive state: The logical drive is offline from being ejected.
Causa
La unidad se ha eliminado.
Acción
Reinstale las unidades físicas extraídas.
ESES Mensajes de error de diagnóstico de arrays 15

Logical drive state: The logical drive is queued for eraseSíntoma
Logical drive state: The logical drive is queued for erase.
Causa
Se ha puesto en cola una unidad lógica para la operación de borrado.
Acción
No es necesario hacer nada. No se puede realizar la migración o expansión de la unidad lógica mientras hay una operación de borrado en proceso.
Logical drive state: The logical drive is queued for expansionSíntoma
Logical drive state: The logical drive is queued for expansion.
Causa
Se ha puesto en cola una unidad lógica para la operación de expansión.
Acción
No es necesario hacer nada.
Logical drive state: The logical drive is queued for rebuildingSíntoma
Logical drive state: The logical drive is queued for rebuilding.
Causa
Se ha puesto en cola una unidad lógica para la operación de reconstrucción.
Acción
No es necesario hacer nada. Durante el proceso de reconstrucción, es posible que se produzcan operaciones normales; sin embargo, el rendimiento no será óptimo.
Logical drive state: This logical drive has a high physical drive countSíntoma
Logical drive state: This logical drive has a high physical drive count as well as a high stripe size value such that a controller lock up could occur. It is recommended that the stripe size be migrated to a lower value.
Causa
Una unidad lógica tiene un número de unidad física alto y un valor de tamaño de stripe alto que puede causar un bloqueo de la controladora.
Acción
Migre el tamaño de stripe a un valor inferior con HPE SSA. Para obtener más información, consulte la Guía de usuario de HPE Smart Storage Administrator en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage/docs).
16 Capítulo 2 Errores de los servidores HPE ProLiant ESES

NVRAM Error: Board ID could not be readSíntoma
NVRAM Error: Board ID could not be read (Read-Only Table failed checksum test). Unrecoverable error.
Causa
Se ha producido un error irrecuperable.
Acción
Póngase en contacto con el soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
NVRAM Error: Bootstrap NVRAM image failed checksum testSíntoma
NVRAM Error: Bootstrap NVRAM image failed checksum test, but a backup image was found and successfully restored. A system restart is needed.
Causa
Se ha producido un error en la prueba de la suma de comprobación de la imagen de NVRAM Bootstrap.
Acción
Reinicie el servidor.
NVRAM Error: Bootstrap NVRAM image failed checksum testSíntoma
NVRAM Error: Bootstrap NVRAM image failed checksum test and could not be restored. This error may or may not be recoverable. A firmware update might be able to correct the error.
Causa
Se ha producido un error en la prueba de la suma de comprobación de la imagen de NVRAM Bootstrap.
Acción
1. Actualice el firmware de la controladora. Para obtener más información, consulte la sección "Actualización del sistema" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
2. Si no se completa la actualización, póngase en contacto el servicio de soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
Physical Drive State: Predictive failure. This physical drive is predicted to fail soonSíntoma
Physical Drive State: Predictive failure. This physical drive is predicted to fail soon.
ESES Mensajes de error de diagnóstico de arrays 17

Causa
La unidad puede fallar pronto.
Acción
Realice una de las siguientes operaciones:
● Si esta unidad forma parte de una configuración sin tolerancia a fallos, haga lo siguiente:
a. Haga una copia de seguridad de todos los datos de la unidad.
b. Sustituya la unidad.
c. Restaure todos los datos en la nueva unidad.
● Si esta unidad forma parte de una configuración sin tolerancia a fallos:
a. Ponga todas las unidades del array en línea.
b. Sustituya la unidad.
Physical Drive State: SATA drives are not supported for configuration and should be disconnected from this controller
Síntoma
Physical Drive State: SATA drives are not supported for configuration and should be disconnected from this controller.
Causa
Las unidades no son compatibles con la controladora.
Acción
Sustituya la unidad física por una unidad admitida por la controladora. Para ubicar una opción compatible, consulte las QuickSpecs (Especificaciones rápidas) del producto en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/qs).
Physical Drive State: Single-ported drives are not supported for configuration and should be disconnected from this controller
Síntoma
Physical Drive State: Single-ported drives are not supported for configuration and should be disconnected from this controller.
Causa
Las unidades no son compatibles con la controladora.
Acción
Sustituya la unidad física por una unidad admitida por la controladora. Para ubicar una opción compatible, consulte las QuickSpecs (Especificaciones rápidas) del producto en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/qs).
Physical Drive State: The data on the physical drive is being rebuiltSíntoma
Physical Drive State: The data on the physical drive is being rebuilt.
18 Capítulo 2 Errores de los servidores HPE ProLiant ESES

Causa
The data on the physical drive is being rebuilt.
Acción
No es necesario hacer nada. Durante el proceso de reconstrucción, es posible que se produzcan operaciones normales; sin embargo, el rendimiento no será óptimo.
Physical Drive State: This drive contains unsupported configuration dataSíntoma
Physical Drive State: This drive contains unsupported configuration data. It cannot be used for configuration and should be disconnected from this controller.
Causa
La unidad no es compatible.
Acción
Sustituya la unidad física por una unidad admitida por la controladora. Para ubicar una opción compatible, consulte las QuickSpecs (Especificaciones rápidas) del producto en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/qs).
Physical Drive State: This drive is not supported for configuration by this version of controller firmware
Síntoma
Physical Drive State: This drive is not supported for configuration by this version of controller firmware.
Causa
La versión del firmware de la controladora no admite la unidad.
Acción
Sustituya la unidad física por una unidad admitida por la controladora. Para ubicar una opción compatible, consulte las QuickSpecs (Especificaciones rápidas) del producto en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/qs).
Physical Drive State: This drive is not supported for configurationSíntoma
Physical Drive State: This drive is not supported for configuration and should be disconnected from this controller.
Causa
La unidad no es compatible.
Acción
Sustituya la unidad física por una unidad admitida por la controladora. Para ubicar una opción compatible, consulte las QuickSpecs (Especificaciones rápidas) del producto en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/qs).
ESES Mensajes de error de diagnóstico de arrays 19

Physical Drive State: This drive is smaller in size than the drive it is replacingSíntoma
Physical Drive State: This drive is smaller in size than the drive it is replacing. It is not supported for configuration and should be disconnected from this controller.
Causa
La unidad es más pequeña que la unidad que se está sustituyendo.
Acción
Sustituya la unidad física por una unidad más grande admitida por la controladora. Para ubicar una opción compatible, consulte las QuickSpecs (Especificaciones rápidas) del producto en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/qs).
Physical Drive State: This drive is unrecognizableSíntoma
Physical Drive State: This drive is unrecognizable. It is not supported for configuration and should be disconnected from this controller.
Causa
La unidad no es compatible.
Acción
Sustituya la unidad física por una unidad admitida por la controladora. Para ubicar una opción compatible, consulte las QuickSpecs (Especificaciones rápidas) del producto en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/qs).
Physical Drive State: This physical drive is part of a logical drive that is not supported by the current configuration
Síntoma
Physical Drive State: This physical drive is part of a logical drive that is not supported by the current configuration. Any configuration command (e.g. logical drive creation, array expansion, etc.) or modification to the controller will result in the loss of all existing data on the disabled logical drive(s).
Causa
La unidad no es compatible con la configuración actual.
Acción
Realice una de las siguientes operaciones:
● Si este mensaje aparece después de mover un array de unidades configurado desde otra controladora, realice el siguiente procedimiento:
◦ Actualice el firmware de esta controladora.
◦ Asegúrese de que el módulo de la memoria caché esté instalado. Instale el módulo de memoria caché si no está instalado.
◦ Si el problema continúa, apague el servidor y vuelva a colocar las unidades en la controladora original.
● Si aparece este mensaje sin haber movido ninguna unidad, realice lo siguiente:
20 Capítulo 2 Errores de los servidores HPE ProLiant ESES

◦ Asegúrese de que el módulo de la memoria caché esté funcionando. Sustituya el módulo de la memoria caché, si fuese necesario.
◦ Si el problema continúa, póngase en contacto el servicio de soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493).
Redundancy State: This controller has been setup to be part of a redundant pair of controllers
Síntoma
Redundancy State: This controller has been setup to be part of a redundant pair of controllers but redundancy is temporarily disabled. Redundancy is temporarily disabled because capacity expansion, extension, or migration is in progress. Redundancy will be enabled when this process is complete.
Causa
La redundancia está desactivada porque la migración, extensión y expansión de la capacidad está en curso.
Acción
No es necesario hacer nada.
Redundancy State: This controller has been setup to be part of a redundant pair of controllers
Síntoma
Redundancy State: This controller has been setup to be part of a redundant pair of controllers but redundancy is disabled. Redundancy is disabled for an unknown reason.
Causa
Redundancy is disabled for an unknown reason.
Acción
Póngase en contacto con el servicio de soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
Redundant Path Failure: Multi-domain path failureSíntoma
Redundant Path Failure: Multi-domain path failure.
Causa
● Hay un cable que no está instalado correctamente.
● Hay un cable dañado o ha fallado.
● El módulo de E/S de la caja de almacenamiento no se ha instalado correctamente.
● Se ha producido un fallo en el módulo de E/S de la caja de almacenamiento.
Acción
Compruebe el módulo de E/S del dispositivo de almacenamiento y los cables para restablecer las rutas redundantes.
ESES Mensajes de error de diagnóstico de arrays 21

Redundant Path Failure: The logical drive is degraded due to the loss of a redundant pathSíntoma
Redundant Path Failure: The logical drive is degraded due to the loss of a redundant path.
Causa
● Hay un cable que no está instalado correctamente.
● Hay un cable dañado o ha fallado.
● El módulo de E/S de la caja de almacenamiento no se ha instalado correctamente.
● Se ha producido un fallo en el módulo de E/S de la caja de almacenamiento.
Acción
Compruebe el módulo de E/S de la caja de almacenamiento y los cables para restablecer las rutas redundantes a la unidad lógica.
Redundant Path Failure: The physical drive is degraded due to the loss of a redundant pathSíntoma
Redundant Path Failure: The physical drive is degraded due to the loss of a redundant path.
Causa
● Hay un cable que no está instalado correctamente.
● El módulo de E/S de la caja de almacenamiento no se ha instalado correctamente.
● Se ha producido un fallo en el módulo de E/S de la caja de almacenamiento.
Acción
Compruebe el módulo de E/S de la caja de almacenamiento y los cables para restablecer las rutas redundantes a la unidad física.
Redundant Path Failure: Warning: Redundant I/O modules of this storage boxSíntoma
Redundant Path Failure: Warning: Redundant I/O modules of this storage box are not cabled in a recommended configuration.
Causa
Los cables están instalados incorrectamente.
Acción
Conecte correctamente los cables al sistema de almacenamiento. Para obtener más información, consulte la guía de usuario del producto en la página web de Hewlett Packard Enterprise.
Smart SSD State: SSD has less than 2% of usage remaining before wearoutSíntoma
Smart SSD State: SSD has less than 2% of usage remaining before wearout.
Causa
La unidad SSD alcanzará pronto el límite de desgaste.
22 Capítulo 2 Errores de los servidores HPE ProLiant ESES

Acción
Supervise la unidad frecuentemente y sustitúyala antes de que se desgaste.
Smart SSD State: SSD has less than 2% of usage remaining before wearoutSíntoma
Smart SSD State: SSD has less than 2% of usage remaining before wearout. It has less than an estimated 56 days before it reaches the maximum usage limit and should be replaced as soon as possible.
Causa
La unidad SSD alcanzará pronto el límite de desgaste.
Acción
Sustituya cuanto antes la unidad SSD.
Smart SSD State: SSD has less than 5% of usage remaining before wearoutSíntoma
Smart SSD State: SSD has less than 5% of usage remaining before wearout.
Causa
La unidad SSD alcanzará pronto el límite de desgaste.
Acción
Supervise la unidad frecuentemente y sustitúyala antes de que se desgaste.
Smart SSD State: SSD has less than 5% of usage remaining before wearoutSíntoma
Smart SSD State: SSD has less than 5% of usage remaining before wearout. It has less than an estimated 56 days before it reaches the maximum usage limit and should be replaced as soon as possible.
Causa
La unidad SSD alcanzará pronto el límite de uso máximo.
Acción
Sustituya cuanto antes la unidad SSD.
Smart SSD State: SSD has less than an estimated 56 days before it reaches the maximum usage limit for writes (wearout)
Síntoma
Smart SSD State: SSD has less than an estimated 56 days before it reaches the maximum usage limit for writes (wearout) and should be replaced as soon as possible.
Causa
La unidad alcanzará pronto el límite máximo de desgaste.
Acción
ESES Mensajes de error de diagnóstico de arrays 23

Sustituya cuanto antes la unidad SSD.
Smart SSD State: SSD has reached the maximum rated usage limit for writes (wearout) and should be replaced immediately
Síntoma
Smart SSD State: SSD has reached the maximum rated usage limit for writes (wearout) and should be replaced immediately.
Causa
La unidad SSD ha alcanzado el límite de desgaste.
Acción
Sustituya la unidad SSD inmediatamente.
Smart SSD State: The SmartSSD Wear Gauge log is fullSíntoma
Smart SSD State: The SmartSSD Wear Gauge log is full. Wear Gauge parameters are not available.
Causa
The SmartSSD Wear Gauge log is full.
Acción
No se puede supervisar el desgaste de la unidad SSD. Si es necesario supervisar el desgaste, sustituya la unidad.
Storage Enclosure: One or more fans have failedSíntoma
Storage Enclosure: One or more fans have failed.
Causa
Se ha producido un error en uno o más ventiladores.
Acción
Sustituya el ventilador. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
Storage Enclosure: The enclosure is reporting a critical temperature status conditionSíntoma
Storage Enclosure: The enclosure is reporting a critical temperature status condition. Apague el chasis inmediatamente.
Causa
● Un ventilador necesario no gira o falta.
● Se ha producido un error en uno o más ventiladores.
● El flujo de aire de los ventiladores está obstruido.
24 Capítulo 2 Errores de los servidores HPE ProLiant ESES

Acción
1. Apague el chasis inmediatamente.
2. Asegúrese de que todos los ventiladores están conectados y funcionan.
3. Sustituya los ventiladores averiados.
4. Para un mejorar la ventilación, elimine cualquier acumulación de polvo de los ventiladores u otras áreas.
5. Si el problema continúa, póngase en contacto el servicio de soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
Storage Enclosure: Warning: One or more redundant power supplies in this enclosure has failed or is not plugged in correctly
Síntoma
Storage Enclosure: Warning: One or more redundant power supplies in this enclosure has failed or is not plugged in correctly.
Causa
● La fuente de alimentación no está colocada correctamente.
● El cable de alimentación no está conectado correctamente.
● Se ha producido un fallo en la fuente de alimentación.
Acción
1. Vuelva a colocar la fuente de alimentación.
2. Asegúrese de que el cable de alimentación está conectado correctamente.
3. Si el problema continúa, sustituya la fuente de alimentación.
Storage Enclosure: Warning: The enclosure is reporting a high temperature statusSíntoma
Storage Enclosure: Warning: The enclosure is reporting a high temperature status.
Causa
● Un ventilador necesario no gira o falta.
● Se ha producido un error en uno o más ventiladores.
● El flujo de aire de los ventiladores está obstruido.
Acción
1. Asegúrese de que todos los ventiladores están conectados y funcionan.
2. Sustituya los ventiladores averiados.
3. Para un mejorar la ventilación, elimine cualquier acumulación de polvo de los ventiladores u otras áreas.
4. Si el problema continúa, póngase en contacto el servicio de soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
ESES Mensajes de error de diagnóstico de arrays 25

Mensajes de error de la POSTIntroducción a los mensajes de error de la POST
Los mensajes y códigos de error descritos en esta sección incluyen todos los mensajes generados por los servidores ProLiant. Algunos mensajes son únicamente informativos y no indican ningún error. Un servidor solo genera los códigos que son aplicables a su configuración y opciones.
¡ADVERTENCIA! Para evitar posibles problemas, lea SIEMPRE la información de las advertencias y precauciones que aparecen en la documentación del producto antes de extraer, sustituir, volver a ajustar o modificar componentes del sistema.
NOTA: En esta guía se proporciona información relativa a varios servidores. Es posible que parte de la información no se aplique al servidor concreto donde se encuentra el problema. Consulte la documentación específica del servidor para obtener información sobre los procedimientos, las opciones de hardware, las herramientas de software y los sistemas operativos admitidos por el servidor.
Serie 100101-Option ROM Error
Síntoma
101-Option ROM Error. An option ROM for a PCIe device is invalid. Action: Update the option ROM/firmware for the PCIe device (may be an Option Card or an embedded device).
Causa
Una ROM opcional para un dispositivo PCIe no es válida.
Acción
Actualice el firmware o la ROM opcional para el dispositivo integrado o la tarjeta opcional. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
102-System board errorSíntoma
102-System board error.
Causa
Existe un problema con la placa del sistema.
Acción
PRECAUCIÓN: Únicamente los técnicos autorizados y formados por Hewlett Packard Enterprise deberían extraer la placa del sistema. Si cree que es necesario sustituir la placa del sistema, póngase en contacto con el servicio de soporte técnico de Hewlett Packard Enterprise antes de continuar. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
Póngase en contacto con el soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
26 Capítulo 2 Errores de los servidores HPE ProLiant ESES

104-ASR Timer FailureSíntoma
104-ASR Timer Failure.
Causa
Existe un problema con la placa del sistema.
PRECAUCIÓN: Únicamente los técnicos autorizados y formados por Hewlett Packard Enterprise deberían extraer la placa del sistema. Si cree que es necesario sustituir la placa del sistema, póngase en contacto con el servicio de soporte técnico de Hewlett Packard Enterprise antes de continuar. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
Acción
Póngase en contacto con el soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
162-System options errorSíntoma
162-System options not set.
Causa
● La configuración es incorrecta.
● Ha cambiado la configuración del sistema tras el último arranque (por ejemplo, la adición de una unidad de disco duro).
● Se ha producido una pérdida de alimentación eléctrica en el reloj en tiempo real (el reloj en tiempo real pierde potencia si la batería integrada no funciona correctamente).
Acción
1. Pulse la tecla F1 para especificar las utilidades del sistema de HPE UEFI.
2. Ejecute la utilidad de configuración del servidor para cambiar la configuración.
Para obtener más información, consulte la sección "Utilidades del sistema HPE UEFI" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
3. Si el problema continúa, sustituya la batería integrada.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
163-Time and date not setSíntoma
163-Time and date not set.
Causa
ESES Mensajes de error de la POST 27

La hora o la fecha en la memoria de configuración no es válida.
Acción
Ejecute la utilidad de configuración del servidor y corrija la fecha u hora.
Para obtener más información, consulte la sección "Utilidades del sistema HPE UEFI" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
Serie 200207-DIMM configuration errors
Síntoma
207-DIMM configuration errors.
Causa
Se ha producido un error de configuración de DIMM de protección de memoria avanzada.
Acción
Instale los DIMM en una configuración compatible. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
208-Memory speed errorSíntoma
208-Memory speed error.
Causa
● La placa de memoria no está instalada correctamente.
● La placa de memoria ha fallado.
● Existe un problema con la placa del sistema.
Acción
1. Vuelva a colocar la tarjeta de memoria.
2. Si el problema continúa, sustituya la tarjeta de memoria.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
PRECAUCIÓN: Únicamente los técnicos autorizados y formados por Hewlett Packard Enterprise deberían extraer la placa del sistema. Si cree que es necesario sustituir la placa del sistema, póngase en contacto con el servicio de soporte técnico de Hewlett Packard Enterprise antes de continuar. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
3. Si el problema continúa, póngase en contacto el servicio de soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
28 Capítulo 2 Errores de los servidores HPE ProLiant ESES

209-DIMM Configuration ErrorSíntoma
209-DIMM Configuration Error - Installed DIMM configuration does NOT support configured AMP Mode. System will operate in Advanced ECC Mode. Action: Ensure DIMM configuration meets requirements for configured AMP mode.
Causa
La configuración DIMM no coincide con el modo AMP configurado.
Acción
Instale los DIMM en una configuración compatible. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
210-Processor X: Quick Path Interconnect (QPI) Link DegradationSíntoma
210-Processor X: Quick Path Interconnect (QPI) Link Degradation. A QPI link on this processor is operating in a degraded performance state.
Causa
● El procesador no se ha colocado correctamente.
● El zócalo del procesador está contaminado.
● Se ha producido un error en el procesador.
Acción
PRECAUCIÓN: Antes de extraer o sustituir los procesadores, asegúrese de seguir las directrices de solución de problemas del procesador en "Realización de procedimientos de procesador en el proceso de solución de problemas" de la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I, Solución de problemas. Si no se siguen las directrices recomendadas, es posible que se produzcan daños en la placa del sistema y que sea necesario sustituirla.
1. Asegúrese de que el procesador esté correctamente instalado y colocado.
Para obtener más información, consulte la sección "Problemas del procesador" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
2. Si el problema continúa, asegúrese de que el zócalo del procesador no esté contaminado.
3. Si el problema continúa, sustituya el procesador.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
212-CPU failedSíntoma
212-CPU failed.
ESES Mensajes de error de la POST 29

Causa
Se ha producido un error en el procesador.
Acción
1. Ejecute Insight Diagnostics para identificar los componentes.
PRECAUCIÓN: Antes de extraer o sustituir los procesadores, asegúrese de seguir las directrices de solución de problemas del procesador en "Realización de procedimientos de procesador en el proceso de solución de problemas" de la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I, Solución de problemas. Si no se siguen las directrices recomendadas, es posible que se produzcan daños en la placa del sistema y que sea necesario sustituirla.
2. Sustituya el procesador.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
213-CPU installation errorSíntoma
213-CPU installation error.
Causa
El procesador no se ha colocado correctamente.
Acción
PRECAUCIÓN: Antes de extraer o sustituir los procesadores, asegúrese de seguir las directrices de solución de problemas del procesador en "Realización de procedimientos de procesador en el proceso de solución de problemas" de la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I, Solución de problemas. Si no se siguen las directrices recomendadas, es posible que se produzcan daños en la placa del sistema y que sea necesario sustituirla.
Asegúrese de que el procesador esté correctamente instalado y colocado. Para obtener más información, consulte la sección "Problemas del procesador" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
217-Processor cannot cache all installed memorySíntoma
217-Processor cannot cache all installed memory
Causa
La cantidad de memoria instalada en el servidor supera la cantidad máxima compatible.
Acción
Extraiga la memoria adicional que supera la cantidad máxima compatible. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
30 Capítulo 2 Errores de los servidores HPE ProLiant ESES

222-DIMM Configuration Error – The DIMM configuration is incorrectSíntoma
222-DIMM Configuration Error – The DIMM configuration is incorrect and prevents the system from initializing memory. System video output may have additional information regarding failure. The system is halted.
Causa
La memoria no está instalada correctamente.
Acción
Instale los DIMM en una configuración compatible. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
223-Memory Error – A memory error occurredSíntoma
223-Memory Error. A memory error occurred which prevents the system from initializing memory. System video output may have additional information regarding failure. The system is halted.
Causa
Se ha producido un error de memoria.
Acción
Compruebe la salida de vídeo o el registro de gestión integrado para obtener información adicional. Para obtener más información, consulte la sección "Registro de gestión integrado" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
224-Power fault detected – FlexLOM XSíntoma
224-Power fault detected – FlexLOM X. Action: Unplug the server (or remove the server if a blade or SL-server) and re-seat the indicated FlexLOM.
Causa
FlexibleLOM no está completamente asentado en el conector.
Acción
1. Apague el servidor.
2. Realice una de las siguientes operaciones:
● Para el servidor que no es blade o no es de la serie SL, desconecte el servidor.
● Para los servidores blade o de la serie SL, desconecte el servidor.
3. Localice y vuelva a colocar el FlexibleLOM indicado.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
ESES Mensajes de error de la POST 31

225-Power fault detected – Mezzanine XSíntoma
225-Power fault detected – Mezzanine X. Action: re-seat the indicated mezzanine card.
Causa
La opción de tarjeta intermedia no está completamente asentada en el conector.
Acción
Localice y vuelva a colocar la opción de tarjeta intermedia indicada. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
226-Power fault detected – Embedded storage controllerSíntoma
226-Power fault detected – Embedded storage controller.
Causa
La controladora de almacenamiento no está completamente asentada.
Acción
Realice una de las siguientes operaciones:
● Si la controladora de almacenamiento está integrada en la placa del sistema, póngase en contacto con el servicio de soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493).
● Si la controladora de almacenamiento está en una tarjeta extraíble, localice y vuelva a colocar la opción de controladora de almacenamiento indicada.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
227-Processor mismatch – Core count must match between processorsSíntoma
227-Processor mismatch. Core count must match between processors.
Causa
Hay instalados dos procesadores que tienen números de núcleos diferentes.
Acción
PRECAUCIÓN: Antes de extraer o sustituir los procesadores, asegúrese de seguir las directrices de solución de problemas del procesador en "Realización de procedimientos de procesador en el proceso de solución de problemas" de la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I, Solución de problemas. Si no se siguen las directrices recomendadas, es posible que se produzcan daños en la placa del sistema y que sea necesario sustituirla.
Extraiga los procesadores e instálelos con el mismo número de núcleos. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
32 Capítulo 2 Errores de los servidores HPE ProLiant ESES

228-DIMM Configuration Error - Processor X, Channel YSíntoma
228-DIMM Configuration Error – Processor X, Channel Y
– Memory channel not populated in correct order. See User Guide.
– System Halted!
Causa
El banco de memoria no se completa en el orden correcto.
Acción
Complete el banco de memoria en el orden correcto. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
229-DIMM Configuration Error – Processor X, DIMM YSíntoma
229-DIMM Configuration Error – Processor X, DIMM Y
– Unsupported DIMM.
– System Halted!
Causa
Se ha detectado un tipo de DIMM desconocido.
Acción
Instale el tipo de DIMM correcto. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
230-DIMM Configuration Error – Processor X, Channel YSíntoma
230-DIMM Configuration Error – Processor X, Channel Y
– Only 2 DIMMs can be installed on a channel containing Quad-Rank DIMM(s).
– System Halted!
Causa
Hay demasiados módulos DIMM instalados en un canal que contiene módulos DIMM de cuatro rangos.
Acción
Instale los DIMM en una configuración compatible. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
231-DIMM Configuration Error – No memory is availableSíntoma
ESES Mensajes de error de la POST 33

231-DIMM Configuration Error – No memory is available. If DIMMs are installed, verify that the corresponding processor is installed.
– System Halted!
Causa
● No hay ningún módulo DIMM instalado en el servidor.
● No hay ningún módulo DIMM instalado para el que exista un procesador correspondiente.
Acción
Realice una de las siguientes operaciones:
● Instale los DIMM en una configuración compatible.
● Compruebe que el procesador correspondiente esté presente para los módulos DIMM instalados.
Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
232-Memory initialization error – Processor A, DIMM B failedSíntoma
232-Memory initialization error – Processor A, DIMM B failed.
Causa
Los módulos DIMM instalados no pasaron la prueba de memoria.
Acción
Sustituya el módulo DIMMs. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
233-Trusted Execution Technology (TXT) FailureSíntoma
233-Trusted Execution Technology (TXT) Failure – Secrets in Memory detected and BIOS may be compromised.
– System Halted
Causa
TXT detectó que la ROM cambiaba después de un arranque anterior y no pudo borrar los secretos de memoria después de un apagado inesperado.
Acción
1. Quite la alimentación del servidor.
2. Extraiga la pila del sistema.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
34 Capítulo 2 Errores de los servidores HPE ProLiant ESES

3. Espere al menos de 1 minuto antes de volver a instalar la batería del sistema y volver a conectar la alimentación del servidor.
4. Encienda el servidor y reanude las operaciones normales.
234-DIMM Initialization Error – Memory cannot be initializedSíntoma
234-DIMM Initialization Error – Memory cannot be initialized. Action: Re-seat DIMMs. Si el problema persiste, vuelva a colocar los procesadores. Si esto no resuelve el problema, póngase en contacto con el servicio de soporte de HP. System halted.
Causa
● Los módulos DIMM no se colocaron correctamente.
● Los procesadores no se colocaron correctamente.
Acción
1. Vuelva a colocar el módulo DIMMs.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
PRECAUCIÓN: Antes de extraer o sustituir los procesadores, asegúrese de seguir las directrices de solución de problemas del procesador en "Realización de procedimientos de procesador en el proceso de solución de problemas" de la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I, Solución de problemas. Si no se siguen las directrices recomendadas, es posible que se produzcan daños en la placa del sistema y que sea necesario sustituirla.
2. Si el problema continúa, vuelva a colocar los procesadores.
3. Si el problema continúa, póngase en contacto el servicio de soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
235-DIMM Configuration Error – Only 2 DIMMs can be installed on a channel with UDIMMsSíntoma
235-DIMM Configuration Error – Only 2 DIMMs can be installed on a channel with UDIMMs.
– System Halted!
Causa
Un canal con módulos UDIMM tiene más de dos módulos DIMM instalados.
Acción
Instale los DIMM en una configuración compatible. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
236-DIMM Configuration Error – Ultra-Low Voltage DIMMs installedSíntoma
ESES Mensajes de error de la POST 35

236-DIMM Configuration Error – Ultra-Low Voltage (1.25V) DIMMs installed on Processor X. These DIMMs are not supported. Action: Remove Ultra-Low Voltage DIMMs.
Causa
No se admiten módulos DIMM de tensión ultrabaja (1,25 V).
Acción
1. Extraiga todos los módulos DIMM de voltaje ultrabajo del servidor.
2. Instale el tipo de DIMM correcto.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
238-DIMM Configuration Error – Processor X, DIMM YSíntoma
238-DIMM Configuration Error – Processor X, DIMM Y – Quad Rank DIMMs must be installed in the first socket of any memory channel in which they are populated.
– System Halted!
Causa
Hay módulos DIMM de cuatro rangos instalados en el canal de memoria después de los módulos DIMM SR o DR.
Acción
Instale los módulos DIMM de cuatro rangos en la primera ranura de cualquier canal de memoria. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
239-DIMM Configuration Error – Mismatched DIMM typesSíntoma
239-DIMM Configuration Error – X and Y are installed in the system. The system cannot have both types of DIMMs installed.
– System Halted!
Causa
Existe un error en la configuración de la memoria DIMM con módulos DIMM que no coinciden. En este mensaje, X e Y pueden ser RDIMM, UDIMM o LRDIMM. No se admite la combinación de tipos de DIMM.
Acción
Compruebe que todos los módulos DIMM son del mismo tipo. Para obtener más información sobre los módulos DIMM admitidos en el servidor, consulte las QuickSpecs (Especificaciones rápidas) del producto en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/qs).
240-Unsupported Expansion Riser Board DetectedSíntoma
36 Capítulo 2 Errores de los servidores HPE ProLiant ESES

240-Unsupported Expansion Riser Board Detected – One or more of the installed expansion riser boards is not supported by this server. Action: Replace the installed riser board with one supported by this server.
– System Halted!
Causa
La placa elevadora de expansión instalada no es compatible con este servidor.
Acción
1. Para ubicar una opción compatible, consulte las QuickSpecs (Especificaciones rápidas) del producto en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/qs).
2. Sustituya la placa elevadora por una opción compatible.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
241-Expansion Riser Board Detected in Incorrect SlotSíntoma
241-Expansion Riser Board Detected in Incorrect Slot – An expansion riser board is installed in a riser slot in which it is not supported. Action: Please move the expansion riser board to a slot in which it is supported. Refer to server documentation for any requirements regarding the installation of expansion riser boards.
– System Halted!
Causa
La placa elevadora de expansión está instalada en una ranura no compatible.
Acción
Mueva la placa elevadora a una ranura que sea compatible. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
242-Unsupported Processor Configuration DetectedSíntoma
242-Unsupported Processor Configuration Detected - System does not support booting with three processors installed. Action: Install an additional processor or remove one processor.
– System Halted!
Causa
El sistema no es compatible con el arranque con tres procesadores.
Acción
PRECAUCIÓN: Antes de extraer o sustituir los procesadores, asegúrese de seguir las directrices de solución de problemas del procesador en "Realización de procedimientos de procesador en el proceso de solución de problemas" de la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I, Solución de problemas. Si no se siguen las directrices recomendadas, es posible que se produzcan daños en la placa del sistema y que sea necesario sustituirla.
ESES Mensajes de error de la POST 37

Realice una de las siguientes operaciones:
● Instale un procesador adicional.
Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
● Extraiga uno de los procesadores.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
243-Unsupported Option Card configurationSíntoma
243-Unsupported Option Card configuration. The option card installed in Slot X is not supported in that slot with the current server configuration. Action: Move the Option Card to a different slot.
Causa
La tarjeta opcional está instalada en una configuración no admitida.
Acción
1. Extraiga la tarjeta opcional de la ranura indicada.
2. Instale la tarjeta opcional en una ranura compatible.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
244-IMPORTANT: PCIe Slot X only supports 8 functions for a SR-IOV capable Expansion Card
Síntoma
244-IMPORTANT: PCIe Slot X only supports 8 functions for an SR-IOV capable Expansion Card. Action: HP recommends moving this Expansion Card to another available slot to avoid possible SR-IOV limitations.
Causa
La ranura PCIe actual solo admite ocho funciones para una tarjeta de expansión con capacidad SR-IOV.
Acción
Mueva la tarjeta de expansión a otra ranura para evitar limitaciones de SR-IOV. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
245-Processor Power-on IssueSíntoma
245-Processor Power-on Issue: Processor X did not power up. Action: Confirm installed processors are the same model. Si es así, apague y encienda. Si no se soluciona, vuelva a colocar los procesadores o intercámbielos. Si el problema continúa, póngase en contacto con el servicio de soporte de HP.
38 Capítulo 2 Errores de los servidores HPE ProLiant ESES

Causa
● Hay instalados procesadores que tienen números de modelo diferentes.
● El procesador no se ha colocado correctamente.
Acción
1. Asegúrese de que los procesadores instalados en el servidor tengan el mismo número de modelo. Sustituya los procesadores que no tengan el mismo número de modelo.
2. Si el problema continúa, reinicie el servidor.
3. Si el problema continúa, vuelva a colocar los procesadores.
4. Si el problema continúa, póngase en contacto el servicio de soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
Para realizar los procedimientos de extracción y sustitución, consulte a la guía de mantenimiento y servicio del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
246-IMPORTANT: The system has exceeded the amount of available Option ROM spaceSíntoma
246-IMPORTANT: The system has exceeded the amount of available Option ROM space. The Option ROM for one or more devices cannot be executed. Action: Disable unneeded Option ROMs (such as PXE).
Causa
Se ha superado el espacio disponible para la ROM opcional.
Acción
Deshabilite las ROM opcionales innecesarias (como PXE). Para obtener más información, consulte la sección "Utilidades del sistema HPE UEFI" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
247-Memory Initialization ErrorSíntoma
247-Memory Initialization Error – Ultra-Low Voltage (1.25V) and Standard Voltage (1.5V) DIMMs are mixed in the same system. No common voltage available. Action: Remove 1.25V or 1.5V DIMMs as mixing is not supported.
Causa
Se han instalado en el servidor módulos DIMM de voltaje ultrabajo y de voltaje estándar.
Acción
1. Extraiga los módulos DIMM de 1,25 o de 1,5 V.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
2. Instale los DIMM en una configuración compatible.
ESES Mensajes de error de la POST 39

Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
248-Unsupported Option Card configurationSíntoma
248-Unsupported Option Card configuration. The option card installed in Slot X is only supported in Slot Y. Action: Move the option card from Slot X to Slot Y.
Causa
No se admite la tarjeta opcional en la ranura X.
Acción
Extraiga la tarjeta de opciones de la ranura X y muévala a la ranura Y. Para obtener más información, consulte la guía de mantenimiento y servicio del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
249-Unsupported Option Card configurationSíntoma
249-Unsupported Option Card configuration. The option card installed in Slot X is not supported unless Slot Y is unpopulated. Action: Move the Option Card in Slot X to a different slot or remove the card in Slot Y.
Causa
La tarjeta opcional está instalada en una configuración no admitida.
Acción
Realice una de las siguientes operaciones:
● Extraiga la tarjeta opcional en la ranura X y trasládela a otra ranura.
● Extraiga la tarjeta de la ranura Y.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
250-Unsupported Processor Configuration DetectedSíntoma
250-Unsupported Processor Configuration Detected. The installed processors are only supported in single processor configurations. Action: Remove Processor 2.
Causa
Dos procesadores se instalan en un servidor configurado para un procesador único.
Acción
Retire el procesador 2. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
40 Capítulo 2 Errores de los servidores HPE ProLiant ESES

251-IMPORTANT: Switches SW1 and SW3 are ONSíntoma
251-IMPORTANT: Switches SW1 and SW3 are ON. This is only used to recover iLO functionality. Action: Power down the server and put these switches in the OFF position (SW1 in the ON position disables iLO Security).
Causa
SW1 en la posición ON desactiva la seguridad de iLO.
Acción
1. Apague el servidor.
2. Coloque los interruptores SW1 y SW3 en la posición OFF.
Para localizar el banco de conmutadores de mantenimiento del sistema, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
252-Unsupported Processor Configuration DetectedSíntoma
252-Unsupported Processor Configuration Detected. The installed processors do not all have the same FlexCompute capabilities. Action: Ensure all installed processors have the same level of FlexCompute support.
Causa
Procesadores con diversos niveles de compatibilidad con FlexCompute están instalados en el servidor.
Acción
Compruebe que todos los procesadores instalados tengan el mismo nivel de compatibilidad con FlexCompute. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
253-IMPORTANT: The PCI-e Device installed in Slot X has no corresponding processor installed and will not function
Síntoma
253-IMPORTANT: The PCI-e Device installed in Slot X has no corresponding processor installed and will not function. Action: Move the PCI-e Device to another slot or install Processor Y.
Causa
Un dispositivo PCIe está instalado en una ranura no compatible.
Acción
Realice una de las siguientes operaciones:
1. Extraiga el dispositivo PCIe e instálelo en otra ranura compatible.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
2. Instale el procesador Y.
ESES Mensajes de error de la POST 41

Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
254-IMPORTANT: A FlexCompute license is installed that cannot be utilized by installed processor(s)
Síntoma
254-IMPORTANT: A FlexCompute license is installed that cannot be utilized by installed processor(s).
Causa
El procesador no puede utilizar la licencia FlexCompute instalada.
Acción
Realice una de las siguientes operaciones:
● Instale un procesador que admita la licencia instalada.
● Instale una licencia compatible con los procesadores instalados.
Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
255-An attempt to increase the frequency or core count of a FlexCompute capable processor without installing the appropriate license has been detected
Síntoma
255-An attempt to increase the frequency or core count of a FlexCompute capable processor without installing the appropriate license has been detected. The processor's frequency has been reduced to the minimum supported.
Causa
La licencia actual no admite el aumento de la frecuencia del procesador o el número de núcleos.
Acción
Realice una de las siguientes operaciones:
● Cambie el número de núcleos o la frecuencia del procesador para que coincida con el soporte de la licencia actual.
● Instale una licencia con mayor frecuencia o soporte de número de núcleos.
256-IMPORTANT: A PCI-e Riser Card is installed that requires 2 processors to functionSíntoma
256-IMPORTANT: A PCI-e Riser Card is installed that requires 2 processors to function. Slots on this riser are unusable with the current configuration. Action: Install a second processor to use this riser.
Causa
La tarjeta elevadora instalada solo es compatible cuando hay dos procesadores instalados.
Acción
Instale un segundo procesador compatible. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
42 Capítulo 2 Errores de los servidores HPE ProLiant ESES

257-Memory Initialization ErrorSíntoma
257-Memory Initialization Error - Memory on Processor X failed to initialize. The operating system may not have access to all installed memory. Action: Replace the failed processor.
Causa
Se ha producido un error en el procesador.
Acción
PRECAUCIÓN: Antes de extraer o sustituir los procesadores, asegúrese de seguir las directrices de solución de problemas del procesador en "Realización de procedimientos de procesador en el proceso de solución de problemas" de la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I, Solución de problemas. Si no se siguen las directrices recomendadas, es posible que se produzcan daños en la placa del sistema y que sea necesario sustituirla.
Sustituya el procesador. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
258-Unsupported Processor Configuration DetectedSíntoma
258-Unsupported Processor Configuration Detected. This system supports either 2 processor or 4 processor configurations and is currently configured with <1 or 3> processor(s). Acción: Instale 2 o 4 procesadores.
Causa
Hay instalado un número incorrecto de procesadores.
Acción
PRECAUCIÓN: Antes de extraer o sustituir los procesadores, asegúrese de seguir las directrices de solución de problemas del procesador en "Realización de procedimientos de procesador en el proceso de solución de problemas" de la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I, Solución de problemas. Si no se siguen las directrices recomendadas, es posible que se produzcan daños en la placa del sistema y que sea necesario sustituirla.
Realice una de las siguientes operaciones:
● Instale un procesador adicional.
Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
● Extraiga uno de los procesadores.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
259-Unsupported Processor Configuration DetectedSíntoma
ESES Mensajes de error de la POST 43

259-Unsupported Processor Configuration Detected. All installed processors do not have the same model number. Action: Only install processors with the same model number.
Causa
Hay instalados procesadores que tienen números de modelo diferentes.
Acción
Sustituya los procesadores que no tengan el mismo número de modelo. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
260-Configuration ErrorSíntoma
260-Configuration Error – Online Spare (OLS) Mode and Combined Channel (CC) Mode are both Enabled. This is not supported. CC Mode will be disabled so OLS can be enabled. Action: Disable OLS mode if CC Mode is desired.
Causa
Los modos de canal combinado y de reparación en línea están activados.
Acción
Desactive el modo de canal combinado o de reparación en línea. Para obtener más información, consulte la Guía de usuario de las utilidades del sistema HPE UEFI para servidores HPE ProLiant Gen9 en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/UEFI/docs).
261-Server Platform Services Firmware requires updateSíntoma
261-Server Platform Services Firmware requires update. Action: Please run the Server Platform Services Firmware Flash Component to update this firmware.
Causa
Hay disponible una actualización de firmware.
Acción
Actualice el firmware. Para obtener más información, consulte la sección "Actualización del sistema" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
262-Redundant ROM ErrorSíntoma
262-Redundant ROM Error: The Backup System ROM is invalid. The system is operating on the Primary System ROM. Action: No action required, but flashing the System ROM will restore System ROM Redundancy.
Causa
La ROM del sistema de respaldo está dañada o no es válida.
Acción
44 Capítulo 2 Errores de los servidores HPE ProLiant ESES

Actualice la ROM del sistema para restaurar la redundancia. Para obtener más información, consulte la sección "Actualización del sistema" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
263-Redundant ROM ErrorSíntoma
263-Redundant ROM Error: The Primary System ROM is invalid. The system is operating on the Backup System ROM. Action: Flash the System ROM to the desired revision to restore System ROM Redundancy.
Causa
La ROM primaria del sistema está dañada o no es válida.
Acción
Actualice la ROM del sistema para restaurar la redundancia. Para obtener más información, consulte la sección "Actualización del sistema" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
264-Fatal System ROM ErrorSíntoma
264-Fatal System ROM Error: The System ROM is not programmed properly. Action: Replace the System ROM part.
– System halted
Causa
La ROM del sistema no está correctamente programada.
Acción
Sustituya la pieza de la ROM física.
265-Fatal System ROM ErrorSíntoma
265-Fatal System ROM Error: The programming of the System ROM cannot be verified. Action: Reset iLO and cold boot the system.
Causa
No se puede comprobar la programación de la ROM del sistema.
Acción
1. Reinicie iLO.
Para obtener más información, consulte la guía de usuario de iLO la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/ilo-docs).
2. Reinicie el servidor.
ESES Mensajes de error de la POST 45

266-Non-Volatile Memory Corruption DetectedSíntoma
266-Non-Volatile Memory Corruption Detected. Configuration settings restored to defaults. If enabled, Secure Boot security settings may be lost. Action: Restore configuration settings. Contact support if issue persists.
Causa
Se ha interrumpido un blade de servidor HPE ProLiant c-Class mientras se escribía en NVRAM debido a:
● Una eliminación repentina de energía
● Pulsación del botón de encendido
● Pulsación del botón de encendido virtual de iLO
Acción
1. Restablezca los valores de configuración que difieren de la configuración predeterminada.
2. Si el problema continúa, póngase en contacto el servicio de soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
267-IMPORTANT: Default configuration settings have been restoredSíntoma
267- IMPORTANT: Default configuration settings have been restored at the request of the user. Action: Restore any desired configuration settings which differ from defaults.
Causa
Se ha restablecido la configuración a la predeterminada.
Acción
Restablezca los valores de configuración que difieren de la configuración predeterminada.
268-iLO FW Not RespondingSíntoma
268- iLO FW Not Responding – Unable to communicate with iLO FW. Certain management functionality is not available.
Causa
El sistema no puede comunicarse con el firmware de iLO.
Acción
46 Capítulo 2 Errores de los servidores HPE ProLiant ESES

1. Quite la alimentación del servidor:
2. Si el problema continúa, actualice el firmware de iLO.
Para obtener más información, consulte la guía de usuario de iLO la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/ilo-docs).
3. Si el problema continúa, póngase en contacto el servicio de soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
269-IMPORTANT: Default configuration settings have been restoredSíntoma
269-IMPORTANT: Default configuration settings have been restored per user request. If Secure Boot was enabled, related security settings may have been lost. Action: Restore any desired configuration settings.
Causa
Se ha restablecido la configuración a la predeterminada.
Acción
Restablezca los valores de configuración que difieren de la configuración predeterminada.
270-iLO FW Communication IssueSíntoma
270-iLO FW Communication Issue – Unable to communicate with iLO FW. Certain management functionality is not available. Action: Remove power. Si el problema sigue sin resolverse, actualice el firmware de iLO. Si esto no resuelve el problema, llame servicio de soporte de HP.
Causa
El sistema no puede comunicarse con el firmware de iLO.
Acción
1. Quite la alimentación del servidor:
2. Si el problema continúa, actualice el firmware de iLO.
Para obtener más información, consulte la guía de usuario de iLO la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/ilo-docs).
3. Si el problema continúa, póngase en contacto el servicio de soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
271-Processor X, DIMM Y could not be authenticatedSíntoma
271-Processor X, DIMM Y could not be authenticated as genuine HP SmartMemory. Enhanced and extended HP SmartMemory features will not be active. (Las características de HP SmartMemory mejoradas y extendidas no estarán activas.)
Causa
Hay instalados módulos DIMM no compatibles.
ESES Mensajes de error de la POST 47

Acción
1. Extraiga todos los módulos DIMM.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
2. Instale los DIMM en una configuración compatible.
Para obtener una lista de las opciones admitidas, consulte las QuickSpecs (Especificaciones rápidas) del producto en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/qs).
273-Unsupported Option Card ConfigurationSíntoma
273-Unsupported Option Card Configuration. The option card installed in Slot Y is not supported in Slot 3 or Slot 4. Action: Move the option card to a different slot.
– System Halted!
Causa
La tarjeta opcional está instalada en una configuración no admitida.
Acción
Extraiga la tarjeta opcional y trasládela a otra ranura. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
274-Unsupported DIMM Configuration DetectedSíntoma
274-Unsupported DIMM Configuration Detected. LRDIMMs are not supported with Xeon E5-2600 v2 processors with this System ROM revision. Action: Remove LRDIMMs or update to a System ROM w/ support (if available).
Causa
La ROM del sistema actual no es compatible con la configuración del módulo DIMM.
Acción
Realice una de las siguientes operaciones:
● Extraiga los módulos LRDIMM del servidor.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
● Actualice una ROM del sistema con el soporte técnico, si está disponible.
Para obtener más información, consulte la sección "Actualización del sistema" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
48 Capítulo 2 Errores de los servidores HPE ProLiant ESES

275-Unsupported Processor DetectedSíntoma
275-Unsupported Processor Detected - Processor stepping not supported.
– System halted!
Causa
La versión actual de la ROM del sistema no admite la revisión del procesador.
Acción
Si está disponible, actualice la ROM del sistema a una versión compatible con la revisión del procesador a través de la interfaz de actualización de firmware fuera de banda de iLO. Para obtener más información, consulte la guía de usuario de iLO la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/ilo-docs).
276-Option Card Configuration ErrorSíntoma
276-Option Card Configuration Error. One or more option cards are requesting more memory mapped I/O than is available. Action: Remove one or more option cards to allow the system to boot.
– System halted!
Causa
Una o varias tarjetas opcionales están solicitando más memoria de E/S asignada de la que está disponible.
Acción
Quite una o varias tarjetas opcionales para permitir que el sistema arranque. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
277-Secure Boot Authentication FailureSíntoma
277-Secure Boot Authentication Failure. One or more UEFI drivers or applications failed authentication and was not executed.
Causa
La versión de firmware del sistema actual no admite el arranque seguro.
Acción
Confirme que el sistema tiene firmware o software compatible con el arranque seguro y que no se ha visto comprometido. Para obtener más información, consulte la sección "Configuración de arranque seguro" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
278-Secure Boot Authentication FailureSíntoma
ESES Mensajes de error de la POST 49

278- Secure Boot Authentication Failure. One or more UEFI drivers or applications was not authorized due to revoked certificate(s) and was not executed. Action: Update the SW/FW to a revision with a valid certificate.
Causa
La revisión de software o firmware actual no tiene un certificado válido.
Acción
Actualice el software o el firmware a una revisión con un certificado válido. Para obtener más información, consulte la sección "Actualización del sistema" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
279-Cable ErrorSíntoma
279-Cable Error - An internal cable routed to the LED Board is not plugged in or plugged in incorrectly. Action: Plug in the internal cable correctly.
Causa
La placa de la placa de indicadores LED no está instalada correctamente.
Acción
Instale y coloque correctamente el cable interno de la placa de indicadores LED. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
280-Cable ErrorSíntoma
280-Cable Error - An internal cable routed to the SUV connector is not plugged in or plugged in correctly. Action: Plug in the internal cable correctly.
Causa
El cable interno no está conectado correctamente.
Acción
Conecte y coloque el cable interno correctamente. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
281-IMPORTANT: SW12 is ON indicating physical presenceSíntoma
281-IMPORTANT: SW12 is ON indicating physical presence. This switch should only be ON to override certain security protections. Action: Power down the server and put SW12 OFF if physical presence is not required.
Causa
El conmutador SW12 está establecido en ON.
Acción
50 Capítulo 2 Errores de los servidores HPE ProLiant ESES

Si no se necesita la presencia física, apague el servidor y establezca el conmutador SW12 en la posición OFF. Para localizar el banco de conmutadores de mantenimiento del sistema, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
282-Invalid Server Serial Number and Product IDSíntoma
282-Invalid Server Serial Number and Product ID. The Serial Number and/or Product ID have been corrupted or lost. Action: Enter the correct values for these fields in Platform Configuration (RBSU).
Causa
El número de serie, el ID del producto o ambos no son válidos, están dañados o se han perdido.
Acción
Introduzca los valores correctos para estos campos en BIOS/Platform Configuration (RBSU) (Configuración del BIOS/plataforma [RBSU]). Para obtener más información, consulte la sección "Reintroducción del ID de producto y el número de serie del servidor" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
283-Memory Address/Command Parity Error DetectedSíntoma
283-Memory Address/Command Parity Error Detected – Processor X, Channel Y. Action: Reseat the DIMMs. Si el problema continúa, póngase en contacto con el servicio de soporte de HP.
Causa
Los módulos DIMM no están instalados correctamente.
Acción
1. Vuelva a colocar el módulo DIMMs.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
2. Si el problema continúa, póngase en contacto el servicio de soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
284-DIMM Failure – Memory Board X, DIMM YSíntoma
284-DIMM Failure – Uncorrectable Memory Error – Memory Board X, DIMM Y. Action: Replace Failed DIMM.
Causa
Se ha producido un fallo en el módulo DIMM.
Acción
ESES Mensajes de error de la POST 51

Sustituya el módulo DIMM. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
284-DIMM Failure – Processor X, DIMM YSíntoma
284-DIMM Failure – Uncorrectable Memory Error – Processor X, DIMM Y. Action: Replace Failed DIMM.
Causa
Se ha producido un fallo en el módulo DIMM.
Acción
Sustituya el módulo DIMM. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
285-DIMM FailureSíntoma
285-DIMM Failure – Uncorrectable Memory Error – Memory Board X, DIMM Y or Processor X, DIMM Z (exact DIMM could not be determined). Action: Attempt to isolate which DIMM is failed and replace it.
Causa
Se ha producido un fallo en el módulo DIMM.
Acción
Intente aislar el módulo DIMM que está produciendo el error y sustitúyalo. Para obtener más información, consulte la sección "Problemas generales de la memoria" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
285-DIMM FailureSíntoma
285-DIMM Failure – Uncorrectable Memory Error – Processor X, DIMM Y or Processor X, DIMM Z (exact DIMM could not be determined). Action: Attempt to isolate which DIMM is failed and replace it.
Causa
Se ha producido un fallo en el módulo DIMM.
Acción
Intente aislar el módulo DIMM que está produciendo el error y sustitúyalo. Para obtener más información, consulte la sección "Problemas generales de la memoria" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
286-IMPORTANT: The removal of a storage device has been detectedSíntoma
52 Capítulo 2 Errores de los servidores HPE ProLiant ESES

286-IMPORTANT: The removal of a storage device has been detected. The device has been removed from the Boot Controller Order. Action: No action required.
Causa
El dispositivo de almacenamiento se retiró del servidor.
Acción
No es necesario hacer nada.
287-IMPORTANT: The removal of a network device has been detectedSíntoma
287-IMPORTANT: The removal of a network device has been detected. The device has been removed from the Standard Boot Order (IPL). Action: No action required.
Causa
Se ha eliminado un dispositivo de red.
Acción
No es necesario hacer nada.
288-IMPORTANT: A new storage device has been detectedSíntoma
288-IMPORTANT: A new storage device has been detected and has been added to the end of the Boot Controller Order. Action: No action required.
Causa
Se ha conectado un nuevo dispositivo de almacenamiento al servidor.
Acción
No es necesario hacer nada.
289-IMPORTANT: A new network or storage device has been detectedSíntoma
289-IMPORTANT: A new network or storage device has been detected. This device will not be shown in the Legacy BIOS Boot Order options in RBSU until the system has booted once. Action: No action required.
Causa
Se ha conectado un nuevo dispositivo de almacenamiento o de red al servidor.
Acción
No es necesario hacer nada.
290-IMPORTANT: The Boot Mode for the system has been changedSíntoma
290-IMPORTANT: The Boot Mode for the system has been changed to Legacy Boot Mode. The Legacy BIOS Boot Order options are not configurable until the system has booted once. Action: No action required.
ESES Mensajes de error de la POST 53

Causa
Se ha cambiado el servidor para iniciar en modo de arranque heredado.
Acción
No es necesario hacer nada.
291-IMPORTANT: The Standard Boot Order (IPL) has been detected as corruptedSíntoma
291-IMPORTANT: The Standard Boot Order (IPL) has been detected as corrupted and has been restored to default values. Action: No action required.
Causa
El orden de arranque estándar (IPL) está dañado.
Acción
No es necesario hacer nada. Configure el orden de arranque estándar (IPL) en la RBSU si desea realizar modificaciones.
292-Invalid HP Software RAID ConfigurationSíntoma
292-Invalid HP Software RAID Configuration. HP B140i SW RAID Mode is NOT supported when the Boot Mode is configured for Legacy BIOS Mode.
Causa
El servidor está configurado para el modo BIOS heredado.
Acción
Configure el modo UEFI como modo de arranque si está utilizando SW RAID. Para obtener más información, consulte la guía de usuario de iLO la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/ilo-docs).
293-A critical error occurred resulting in a reboot of the systemSíntoma
293-A critical error occurred resulting in a reboot of the system. The source of the error could not be identified. Action: Check hardware and software for issues. Contact HP service if the issue persists.
Causa
Existe un problema de hardware o software.
Acción
1. Compruebe si hay problemas en el hardware y el software.
Para obtener más información, consulte la sección "Gráfico de flujo de problemas de la POST" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
2. Si el problema continúa, póngase en contacto el servicio de soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
54 Capítulo 2 Errores de los servidores HPE ProLiant ESES

294-Memory Board X Training FailureSíntoma
294-Memory Board X Training Failure. DIMMs on this Memory Board are not available to the operating system. Action: Reseat the Memory Board. Si el problema continúa, póngase en contacto con el servicio de soporte de HP.
Causa
La placa de memoria no está instalada correctamente.
Acción
1. Vuelva a colocar la tarjeta de memoria.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
2. Si el problema continúa, póngase en contacto el servicio de soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
295-DIMM Failure – Memory Board X, DIMM YSíntoma
295-DIMM Failure – Uncorrectable Memory Error – Memory Board X, DIMM Y. This memory will not be available to the operating system. Action: Replace the failed DIMM to restore the full amount of memory.
Causa
Se ha producido un fallo en el módulo DIMM.
Acción
Sustituya el módulo DIMM para restablecer la cantidad total de memoria. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
295-DIMM Failure – Processor X, DIMM YSíntoma
295-DIMM Failure – Uncorrectable Memory Error – Processor X, DIMM Y. This memory will not be available to the operating system. Action: Replace the failed DIMM to restore the full amount of memory.
Causa
Se ha producido un fallo en el módulo DIMM.
Acción
Sustituya el módulo DIMM para restablecer la cantidad total de memoria. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
296-DIMM Configuration Error – Processor X, DIMM YSíntoma
ESES Mensajes de error de la POST 55

296-DIMM Configuration Error – Processor X, DIMM Y – Non-production DIMM detected. Action: Remove non-production DIMM.
– System halted!
Causa
Se ha instalado un módulo DIMM que no es de producción.
Acción
1. Extraiga el módulo DIMM que no es de producción.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
2. Instale un módulo DIMM compatible.
Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs). Para ubicar una opción compatible, consulte las QuickSpecs (Especificaciones rápidas) del producto en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/qs).
297-IMPORTANT: The iLO Security switch is set to the ON positionSíntoma
297-IMPORTANT: The iLO Security switch is set to the ON position. Platform security is DISABLED.
Causa
El conmutador de seguridad de iLO está establecido en ON.
Acción
Coloque este conmutador en la posición OFF para el funcionamiento normal. Para localizar el banco de conmutadores de mantenimiento del sistema, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
298-IMPORTANT: The Boot Mode has been changed to Legacy Boot Mode for this boot onlySíntoma
298-IMPORTANT: The Boot Mode has been changed to Legacy Boot Mode for this boot only. On the next reboot, the Boot Mode will return to UEFI Boot Mode. Action: No action required.
Causa
Temporalmente, el servidor está configurado para iniciarse en modo de arranque heredado.
Acción
No es necesario hacer nada.
299-IMPORTANT: The Boot Mode has been changed to UEFI Boot Mode for this boot onlySíntoma
299-IMPORTANT: The Boot Mode has been changed to UEFI Boot Mode for this boot only. On the next reboot, the Boot Mode will return to Legacy Boot Mode. Action: No action required.
Causa
56 Capítulo 2 Errores de los servidores HPE ProLiant ESES

Temporalmente, el servidor está configurado para iniciarse en modo de arranque UEFI.
Acción
No es necesario hacer nada.
Serie 300300-IMPORTANT: Unable to log an entry to the Integrated Management Log (IML)
Síntoma
300-IMPORTANT: Unable to log an entry to the Integrated Management Log (IML). Action: Remove power. Si el problema sigue sin resolverse, actualice el firmware de iLO. Si esto no resuelve el problema, llame servicio de soporte de HP.
Causa
El firmware de iLO no es la versión más reciente.
Acción
1. Apague y desconecte toda la alimentación del servidor.
Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
2. Si el problema continúa, actualice el firmware de iLO.
Para obtener más información, consulte la guía de usuario de iLO la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/ilo-docs).
3. Si el problema continúa, póngase en contacto el servicio de soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
301-Keyboard ErrorSíntoma
301-Keyboard Error
Causa
● El teclado no está conectado correctamente.
● Las teclas están pulsadas o bloqueadas.
● Se ha producido un error en el teclado.
Acción
1. Asegúrese de que el teclado esté funcionando.
Para obtener más información, consulte la sección "Problemas de ratón y teclado" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
2. Si el problema continúa, sustituya el teclado.
ESES Mensajes de error de la POST 57

301-Keyboard Error or Test Fixture InstalledSíntoma
301-Keyboard Error or Test Fixture Installed.
Causa
● El teclado no está conectado correctamente.
● Las teclas están pulsadas o bloqueadas.
● Se ha producido un error en el teclado.
Acción
1. Asegúrese de que el teclado esté funcionando.
Para obtener más información, consulte la sección "Problemas de ratón y teclado" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
2. Si el problema continúa, sustituya el teclado.
304-Keyboard or System Unit ErrorSíntoma
304-Keyboard or System Unit Error.
Causa
● El teclado no está conectado correctamente.
● Se ha producido un error en el teclado.
● El ratón no está conectado correctamente.
● Se ha producido un fallo en el ratón.
● Existe un problema con la placa del sistema.
Acción
1. Compruebe que el teclado y el ratón estén conectados.
Para obtener más información, consulte la sección "Problemas de ratón y teclado" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
PRECAUCIÓN: Únicamente los técnicos autorizados y formados por Hewlett Packard Enterprise deberían extraer la placa del sistema. Si cree que es necesario sustituir la placa del sistema, póngase en contacto con el servicio de soporte técnico de Hewlett Packard Enterprise antes de continuar. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
2. Ejecute Insight Diagnostics y sustituya los componentes que presentan fallos siguiendo las indicaciones.
58 Capítulo 2 Errores de los servidores HPE ProLiant ESES

Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
303-Keyboard controller errorSíntoma
303-Keyboard controller error.
Causa
● El teclado no está conectado correctamente.
● Se ha producido un error en el teclado.
● El ratón no está conectado correctamente.
● Se ha producido un fallo en el ratón.
● Existe un problema con la placa del sistema.
Acción
1. Compruebe que el teclado y el ratón estén conectados.
Para obtener más información, consulte la sección "Problemas de ratón y teclado" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
PRECAUCIÓN: Únicamente los técnicos autorizados y formados por Hewlett Packard Enterprise deberían extraer la placa del sistema. Si cree que es necesario sustituir la placa del sistema, póngase en contacto con el servicio de soporte técnico de Hewlett Packard Enterprise antes de continuar. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
2. Ejecute Insight Diagnostics y sustituya los componentes que presentan fallos siguiendo las indicaciones.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
305-Redundant ROM ErrorSíntoma
305-Redundant ROM Error: Both the Primary and Backup System ROMs are invalid. Action: Flash the Primary and Backup System ROMs to the desired revisions. Si el servidor no arranca, lleve a cabo la actualización de la memoria flash a través de iLO.
Causa
Las ROM del sistema principal y de reserva no son válidas o están dañadas.
Acción
1. Actualice la memoria flash de la copia principal y de la copia de seguridad de la ROM del sistema a las versiones adecuadas.
ESES Mensajes de error de la POST 59

Para obtener más información, consulte la sección "Actualización del sistema" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
2. Si el servidor no arranca, lleve a cabo la actualización de la memoria flash a través de iLO.
Para obtener más información, consulte la guía de usuario de iLO la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/ilo-docs).
306-Redundant ROM ErrorSíntoma
306-Redundant ROM Error: iLO FW did not set the Primary System ROM. The error has been corrected. iLO FW may have an issue. Action: Remove power. Si el problema sigue sin resolverse, actualice el firmware de iLO. Si esto no resuelve el problema, llame servicio de soporte de HP.
Causa
Un error evitó la configuración de la ROM del sistema principal.
Acción
1. Apague y desconecte toda la alimentación del servidor.
Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
2. Si el problema continúa, actualice el firmware de iLO.
Para obtener más información, consulte la guía de usuario de iLO la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/ilo-docs).
3. Si el problema continúa, póngase en contacto el servicio de soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
307-Fan Failure DetectedSíntoma
307-Fan Failure Detected – Fan X Failed.
Causa
Se ha producido un fallo en el ventilador.
Acción
Extraiga y vuelva a colocar el ventilador indicado. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
308-Required Fan NOT InstalledSíntoma
308-Required Fan NOT Installed – Fan X Missing.
Causa
Falta el ventilador necesario.
60 Capítulo 2 Errores de los servidores HPE ProLiant ESES

Acción
Instale el ventilador indicado. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
309-Insufficient Fan SolutionSíntoma
309-Insufficient Fan Solution. The system does not have the minimum required number of operating fans.
Algunas instancias de este mensaje irá seguidas de "System Halted" (Sistema detenido) cuando el sistema se detenga durante la POST.
Causa
El número de ventiladores instalados en el servidor no cumple con los requisitos mínimos.
Acción
Instale los ventiladores que se necesitan como mínimo para evitar posibles daños en los componentes del sistema. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
310-IMPORTANT: Fan Solution Not RedundantSíntoma
310- IMPORTANT: Fan Solution Not Redundant. The system does not have the minimum required operating fans for redundancy.
Causa
El número de ventiladores instalados en el servidor no cumple con los requisitos mínimos de redundancia.
Acción
Instale ventiladores adicionales si la redundancia es necesaria. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
311-HP Smart Storage Battery Configuration ErrorSíntoma
311-HP Smart Storage Battery Configuration Error – The system has exceeded the installed battery capacity.
Causa
La capacidad de la batería no es suficiente para admitir la configuración actual del servidor.
Acción
Realice una de las siguientes operaciones:
● Instale una batería de mayor capacidad.
Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
● Retire los dispositivos con respaldo de batería.
ESES Mensajes de error de la POST 61

Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
312-HP Smart Storage Battery X FailureSíntoma
312-HP Smart Storage Battery X Failure – Communication with the battery failed and its output may not be enabled. Action: Verify battery is properly installed. Refer to user guide. Contact HP support if condition persists.
Causa
● La batería de HPE Smart Storage no está instalada correctamente.
● La batería de HPE Smart Storage está deteriorada o ha fallado.
Acción
1. Compruebe que la batería se ha instalado correctamente.
Para obtener más información, consulte la sección "Gráfico de flujos de problemas de la batería de HPE Smart Storage" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
2. Si el problema continúa, póngase en contacto el servicio de soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
313-HP Smart Storage Battery X FailureSíntoma
313-HP Smart Storage Battery X Failure – Battery Shutdown Event Code: XXXX. Action: Remove power. Si el problema sigue sin resolverse, actualice el firmware de iLO. Si esto no resuelve el problema, llame servicio de soporte de HP.
Causa
● La batería de HPE Smart Storage podría perder la carga cuando se deja almacenada durante largos períodos.
● La batería de HPE Smart Storage está deteriorada o ha fallado.
● El firmware de iLO no es la versión más reciente.
Acción
1. Apague y desconecte toda la alimentación del servidor.
Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
2. Si el problema continúa, actualice el firmware de iLO.
Para obtener más información, consulte la guía de usuario de iLO la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/ilo-docs).
3. Si el problema continúa, póngase en contacto el servicio de soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
62 Capítulo 2 Errores de los servidores HPE ProLiant ESES

314-A critical error occurred prior to this system bootSíntoma
314-A critical error occurred prior to this system boot.
Causa
Se ha producido un error crítico.
Acción
Compruebe el registro de gestión integrado para obtener información adicional. Para obtener más información, consulte la sección "Registro de gestión integrado" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
315-An uncorrectable memory error was detected prior to this system bootSíntoma
315-An uncorrectable memory error was detected prior to this system boot.
Causa
Se ha producido un error de memoria incorregible.
Acción
Compruebe el registro de gestión integrado para obtener información adicional. Para obtener más información, consulte la sección "Registro de gestión integrado" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
316-Chassis Firmware ErrorSíntoma
316-Chassis Firmware Error – The Chassis Firmware is in Recovery Mode. Action: Update the Chassis Firmware.
Causa
El firmware del chasis tiene que actualizarse.
Acción
Actualice el firmware del chasis. Para obtener más información, consulte la sección "Actualización del sistema" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
317-Chassis Firmware ErrorSíntoma
317-Chassis Firmware Error – Unable to communicate with the Chassis Firmware. Action: Reset iLO FW. If issue persists reset Chassis FW (remove AC to chassis). If issue persists attempt to update the Chassis FW.
Causa
Hay un problema de comunicación dentro de iLO o el firmware del chasis.
ESES Mensajes de error de la POST 63

Acción
1. Restablezca el firmware de iLO.
Para obtener más información, consulte la guía de usuario de iLO la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/ilo-docs).
2. Si el problema continúa, quite la alimentación del chasis.
3. Si el problema continúa, actualice el firmware del chasis.
Para obtener más información, consulte la sección "Actualización del sistema" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
318-Trusted Platform Module (TPM) Self-Test ErrorSíntoma
318-Trusted Platform Module (TPM) Self-Test Error.
Causa
● El TPM no está disponible en el servidor.
● Se ha producido un fallo en el TPM.
Acción
1. Reinicie el servidor.
2. Si el problema continúa, póngase en contacto el servicio de soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
319-An unexpected shutdown was detected prior to this bootSíntoma
319-An unexpected shutdown was detected prior to this boot.
Causa
El servidor se apagó de forma inesperada.
Acción
No es necesario hacer nada.
320-IMPORTANT: Enclosure Power Event detectedSíntoma
320-IMPORTANT: Enclosure Power Event detected. Boot delayed until condition resolved.
Causa
Se ha producido un evento de alimentación dentro del receptáculo.
Acción
Compruebe el estado del receptáculo y resuelva los problemas indicados. Para obtener más información, consulte lo siguiente:
64 Capítulo 2 Errores de los servidores HPE ProLiant ESES

● "Uso de Onboard Administrator para la solución de problemas remota de blades de servidor" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/proliantgen9/docs).
● HPE BladeSystem c-Class Enclosure Troubleshooting Guide (Guía de solución de problemas del chasis HPE BladeSystem c-Class) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/bladesystem/docs).
321-HP Dual microSD Device Unsupported ConfigurationSíntoma
321-HP Dual microSD Device Unsupported Configuration – A microSD card is not installed in Slot X.
Causa
● Falta una tarjeta microSD.
● El dispositivo microSD ha fallado.
Acción
1. Instale la tarjeta microSD que se proporcionó con el dispositivo.
2. Si el problema continúa, sustituya el dispositivo HPE Dual microSD.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
322-HP Dual microSD Device Unsupported ConfigurationSíntoma
322-HP Dual microSD Device Unsupported Configuration – No microSD cards are installed.
Causa
● Falta una tarjeta microSD.
● El dispositivo microSD ha fallado.
Acción
1. Instale las tarjetas microSD que se proporcionaron con el dispositivo.
2. Si el problema continúa, sustituya el dispositivo HPE Dual microSD.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
323-HP Dual microSD Device ErrorSíntoma
323-HP Dual microSD Device Error – The microSD card in Slot X has failed.
Causa
El dispositivo microSD ha fallado.
Acción
ESES Mensajes de error de la POST 65

1. Sustituya el dispositivo HPE Dual microSD.
2. Instale la tarjeta microSD correcta del dispositivo original en el nuevo dispositivo para conservar los datos.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
324-HP Dual microSD Device ErrorSíntoma
324-HP Dual microSD Device Error – Both microSD cards have failed.
Causa
El dispositivo microSD ha fallado.
Acción
Sustituya el dispositivo HPE Dual microSD. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
325-HP Dual microSD Device ErrorSíntoma
325-HP Dual microSD Device Error – microSD cards have conflicting metadata. Configuration required.
Causa
La tarjeta microSD no está configurada correctamente.
Acción
Entre en las utilidades del sistema y configure la tarjeta microSD principal mediante las opciones de System Configuration (Configuración del sistema). Para obtener más información, consulte la sección "Utilidades del sistema HPE UEFI" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
326-HP Dual microSD Device ErrorSíntoma
326-HP Dual microSD Device Error – The microSD card in Slot X has failed. A microSD card is not installed in Slot Y.
Causa
El dispositivo microSD ha fallado.
Acción
Sustituya el dispositivo HPE Dual microSD. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
66 Capítulo 2 Errores de los servidores HPE ProLiant ESES

327-AMP Configuration ErrorSíntoma
327-AMP Configuration Error – An installed processor does NOT support the configured AMP Mode. System will operate in Advanced ECC Mode.
Causa
El procesador instalado no es compatible con el modo AMP actual.
Acción
1. Para ubicar una opción compatible, consulte las QuickSpecs (Especificaciones rápidas) del producto en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/qs).
2. Instale un procesador que admita el modo AMP configurado.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
328-Power Management Controller Firmware ErrorSíntoma
328-Power Management Controller Firmware Error – The firmware is in Recovery Mode. Action: Update the Power Management Controller Firmware.
Causa
El firmware de la controladora de gestión de alimentación tiene que actualizarse.
Acción
Actualice el firmware de la controladora de gestión de alimentación. Para obtener más información, consulte la sección "Actualización del sistema" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
329-Power Management Controller FW ErrorSíntoma
329-Power Management Controller FW Error – Unable to communicate with the FW. Action: Reset iLO FW. Si el problema continúa, reinicie el firmware de la controladora de Power Management (retire CA). Si el problema continúa, intente actualizar el firmware.
Causa
Hay un problema de comunicación dentro de iLO o el firmware de la controladora de gestión de alimentación.
Acción
1. Restablezca el firmware de iLO.
Para obtener más información, consulte la guía de usuario de iLO la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/ilo-docs).
2. Si el problema continúa, reinicie el firmware de la controladora de gestión de alimentación quitando la alimentación de CA.
3. Si el problema continúa, actualice el firmware de la controladora de gestión de alimentación.
ESES Mensajes de error de la POST 67

Para obtener más información, consulte la sección "Actualización del sistema" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
330-Unsupported Processor Configuration DetectedSíntoma
330–Unsupported Processor Configuration Detected – Processors are installed in the incorrect order.
Causa
Los procesadores no están instalados en el orden correcto.
Acción
Instale los procesadores secuencialmente a partir del procesador 1. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
331-Memory Board Configuration ErrorSíntoma
331-Memory Board Configuration Error – The system contains multiple types of memory boards. Mixing types is NOT supported.
– System Halted
Causa
Hay instalado más de un tipo de tarjeta de memoria.
Acción
Instale solo un tipo de tarjeta de memoria. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
332-Memory Board Configuration ErrorSíntoma
332-Memory Board Configuration Error – One or more installed memory boards is of a type NOT supported by the installed processor.
– System Halted
Causa
Hay instalada una tarjeta de memoria no compatible.
Acción
Extraiga las tarjetas de memoria no compatibles con el procesador instalado. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
333-HP RESTful API ErrorSíntoma
68 Capítulo 2 Errores de los servidores HPE ProLiant ESES

333-HP RESTful API Error – Unable to communicate with iLO FW. BIOS configuration resources may not be up-to-date.
Causa
Se agotó el tiempo de espera de la transferencia de archivos hacia o desde el iLO, lo que provoca un error durante la comunicación.
Acción
1. Restablezca el firmware de iLO.
Para obtener más información, consulte la guía de usuario de iLO la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/ilo-docs).
2. Reinicie el servidor.
3. Si el problema continúa, quite la alimentación de CA al servidor.
334-HP RESTful API ErrorSíntoma
334-HP RESTful API Error – RESTful API GET request failed (HTTP Status Code = NNN). BIOS configuration resources were not consumed.
Causa
La API de iLO RESTful devolvió un estado de error HTTP (distinto de 200-Success, 204-No Content, 304-Not Modified, or 401-Unauthorized) como una respuesta a una solicitud GET desde el BIOS.
Acción
Restaure los valores predeterminados de fabricación en la RBSU. Para obtener más información, consulte la sección "Utilidades del sistema HPE UEFI" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
335-HP RESTful API ErrorSíntoma
335-HP RESTful API Error – RESTful API PUT request failed (HTTP Status Code = NNN). BIOS configuration resources may not be up-to-date.
Causa
La API de iLO RESTful devolvió un estado de error HTTP (distinto de 200-Success, 412-Precondition Failed, or 401-Unauthorized) como una respuesta a una solicitud PUT desde el BIOS.
Acción
1. Reinicie la placa RESTful API.
2. Si el problema continúa, restablezca la API de iLO.
Para obtener más información, consulte Gestión de servidores Hewlett Packard Enterprise con la API de RESTful en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/restfulinterface/docs).
336-HP RESTful API ErrorSíntoma
ESES Mensajes de error de la POST 69

336-HP RESTful API Error – One or more configuration settings could not be applied.
Causa
El cambio de configuración del BIOS se consumió a través de la API de RESTful y uno o varios de los cambios solicitados provocó un error. Por ejemplo, al intentar establecer un atributo en un valor no válido o no compatible.
Acción
Para obtener más información, consulte la propiedad SettingsResult en la API de RESTful. Para obtener más información, consulte Gestión de servidores Hewlett Packard Enterprise con la API de RESTful en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/restfulinterface/docs).
337-HP RESTful API ErrorSíntoma
337-HP RESTful API Error – Unable to communicate with iLO FW due to datacenter configuration lock being enabled. BIOS configuration resources may not be up-to-date.
Causa
ILO API de RESTful devuelve un estado de HTTP Error de 401 no autorizado para cualquier BIOS GET o PUT solicitud. Esto sucede cuando la configuración de seguridad de iLO evita la comunicación del BIOS con iLO.
Acción
Deshabilite el bloqueo de la configuración del centro de datos.
338-HP RESTful API ErrorSíntoma
338-HP RESTful API Error – Unable to communicate with iLO FW. BIOS configuration resources may not be up-to-date.
Causa
La API de RESTful de iLO devolvió un estado de error HTTP distinto de 200-OK or 201-Created para una solicitud de la POST de BIOS para registrar o actualizar el proveedor de REST del BIOS.
Acción
Restaure los valores predeterminados de fabricación en la RBSU. Para obtener más información, consulte la sección "Utilidades del sistema HPE UEFI" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
340-NVDIMM Error – Backup ErrorSíntoma
Persistent data backup failed and data is not available. Action: Replace NVDIMM if error persists.
Causa
La última operación de copia de seguridad, la copia de datos desde la memoria flash NVDIMM-N DRAM a NVDIMM-N, no se completó correctamente después de una pérdida de alimentación o un restablecimiento del servidor.
70 Capítulo 2 Errores de los servidores HPE ProLiant ESES

Acción
1. Desinfecte el NVDIMM.
Para obtener más información, consulte la HPE 8GB NVDIMM User Guide (Guía de usuario de HPE 8GB NVDIMM) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/NVDIMM-docs).
2. Si el error continúa, sustituya el NVDIMM.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
341-NVDIMM Error – Restore ErrorSíntoma
341-NVDIMM Error – Restore Error - Processor X, DIMM Y. Persistent data restore failed and data is not available.
Causa
● La operación de restauración, la copia de datos de la memoria flash de NVDIMM-N a NVDIMM-N DRAM no se completó correctamente.
● NVDIMM ha fallado.
Acción
Sustituya el módulo NVDIMM. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
342-NVDIMM Error – Uncorrectable Memory ErrorSíntoma
342-NVDIMM Error – Uncorrectable Memory Error - Processor X, DIMM Y. This NVDIMM will not be available to the operating system. Action: Replace the NVDIMM.
Causa
Los datos de copia de seguridad de NVDIMM contienen errores de memoria incorregibles.
Acción
1. Desinfecte el NVDIMM.
Para obtener más información, consulte la HPE 8GB NVDIMM User Guide (Guía de usuario de HPE 8GB NVDIMM) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/NVDIMM-docs).
2. Si el error continúa, sustituya el NVDIMM.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
343-NVDIMM Error – Backup Power ErrorSíntoma
ESES Mensajes de error de la POST 71

343-NVDIMM Error – Backup Power Error – Processor X, DIMM Y. Backup power is not available and a future backup is not possible.
Causa
● La batería de Smart Storage no se recarga completamente en un servidor con una directiva de alimentación de copia de seguridad NVDIMM-N de arranque continuo sin la alimentación de respaldo.
● La batería de Smart Storage está desconectada, ha perdido la carga o ha fallado.
● NVDIMM ha fallado.
Acción
1. Asegúrese de que la batería de Smart Storage esté instalada y en funcionamiento.
Para obtener más información, consulte la sección "Gráfico de flujos de problemas de la batería de HPE Smart Storage" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
2. Vuelva a colocar el módulo NVDIMM.
3. Vuelva a colocar todos los módulos NVDIMM y DIMM.
4. Si el error continúa, sustituya el NVDIMM.
Para realizar los procedimientos de extracción y sustitución, consulte a la guía de mantenimiento y servicio del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
344-NVDIMM Error – NVDIMM Controller ErrorSíntoma
344-NVDIMM Error – NVDIMM Controller Error - Processor X, DIMM Y. An error was found with the NVDIMM controller. The OS will not use the NVDIMM. Action: Update the NVDIMM FW. If issue persists, replace the NVDIMM.
Causa
● Se ha interrumpido una actualización del firmware de la controladora del módulo NVDIMM.
● La controladora del módulo NVDIMM ha fallado.
Acción
Si el error continúa, sustituya el NVDIMM. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
345-NVDIMM Error – Erase ErrorSíntoma
345-NVDIMM Error – Erase Error - Processor X, DIMM Y. NVDIMM could not be erased and future backups are not possible. Action: Save NVDIMM contents to other media to preserve data and then replace the NVDIMM.
Causa
72 Capítulo 2 Errores de los servidores HPE ProLiant ESES

La última operación de borrado falló y el módulo NVDIMM contiene solo la copia de los datos restaurados. Si el servidor se ha restablecido o apagado, la copia de seguridad no se completará y se perderán los datos.
Acción
PRECAUCIÓN: El contenido del módulo NVDIMM debe guardarse en otro origen multimedia de inmediato. Si el servidor se ha restablecido o apagado antes de conservar los datos, estos se perderán.
1. Guarde el contenido del módulo NVDIMM en otro medio para conservar los datos.
2. Sustituya el módulo NVDIMM.
3. Desinfecte el nuevo módulo NVDIMM.
4. Copie los datos conservados en el nuevo módulo NVDIMM.
Para obtener más información, consulte la HPE 8GB NVDIMM User Guide (Guía de usuario de HPE 8GB NVDIMM) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/NVDIMM-docs).
346-NVDIMM Error – Arming ErrorSíntoma
346-NVDIMM Error – Arming Error - Processor X, DIMM Y. NVDIMM could not be armed and future backups are not possible. Action: Save NVDIMM contents to other media to preserve data and then replace the NVDIMM.
Causa
La operación de restauración se realizó correctamente, pero el módulo NVDIMM no se pudo armar para la copia de seguridad debido a un fallo de la controladora del módulo NVDIMM. Como consecuencia, se informa que el módulo NVDIMM es de solo lectura para el sistema operativo.
Acción
1. Guarde el contenido del módulo NVDIMM en otro medio para conservar los datos.
2. Sustituya el módulo NVDIMM.
3. Desinfecte el nuevo módulo NVDIMM.
4. Copie los datos conservados en el nuevo módulo NVDIMM.
Para obtener más información, consulte la HPE 8GB NVDIMM User Guide (Guía de usuario de HPE 8GB NVDIMM) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/NVDIMM-docs).
347-NVDIMM Population ErrorSíntoma
347-NVDIMM Population Error – X NVDIMMs are present in the system. Only Y NVDIMMs are supported. Action: Install a maximum of Y NVDIMMs in the system.
– System Halted!
● X = Number of NVDIMMs currently installed.
● Y= Maximum number of NVDIMMs supported.
ESES Mensajes de error de la POST 73

Causa
Se ha instalado un número no compatible de módulos NVDIMM en el servidor.
Acción
Reduzca el número de módulos NVDIMM en el servidor a Y o inferior. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
348-NVDIMM Population ErrorSíntoma
348-NVDIMM Population Error – NVDIMMs are not supported in Processor X, DIMM Y. Action: Remove the NVDIMM from Processor X, DIMM Y.
– System Halted!
Causa
● El servidor no admite módulos NVDIMM.
● El servidor no admite módulos NVDIMM instalados en la ranura del módulo DIMM indicada.
Acción
Extraiga el módulo NVDIMM del procesador X, ranura Y. Para obtener más información, consulte la guía de mantenimiento y servicio del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
Para obtener más información sobre tipos de memoria admitidos en el servidor, consulte las QuickSpecs (Especificaciones rápidas) del producto en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/qs).
349-NVDIMM Population ErrorSíntoma
349-NVDIMM Population Error – NVDIMMs and LRDIMMs are installed in this system. NVDIMMs are only supported with RDIMMs on this system. Action: Remove all LRDIMMs from the system.
– System Halted!
Causa
El servidor contiene una combinación no compatible de tipos de módulos DIMM.
Acción
Realice una de las siguientes operaciones:
● Quite todos los módulos LRDIMM del servidor.
● Quite todos los módulos NVDIMM del servidor.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
Para obtener más información sobre tipos de memoria admitidos en el servidor, consulte las QuickSpecs (Especificaciones rápidas) del producto en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/qs).
74 Capítulo 2 Errores de los servidores HPE ProLiant ESES

350-NVDIMM Population ErrorSíntoma
350-NVDIMM Population Error – Processor X, DIMM Y. NVDIMMs and RDIMMs are in the incorrect order on Channel Z. NVDIMMs on the channel should be closest to the CPU. Action: Install DIMMs in correct order.
– System Halted!
Causa
Los módulos NVDIMM y RDIMM no se instalan en el orden correcto.
Acción
Siga las directrices de completado para la instalación de los módulos DIMM y NVDIMM en un servidor. Para obtener más información, consulte la HPE 8GB NVDIMM User Guide (Guía de usuario de HPE 8GB NVDIMM) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/NVDIMM-docs).
351-IMPORTANT: HP Smart Storage Battery is not charged sufficientlySíntoma
351-IMPORTANT: HPE Smart Storage Battery is not charged sufficiently to support the NVDIMMs installed in the system.
Causa
El sistema está configurado para esperar a que la batería se cargue, pero el sistema no tiene suficiente para gestionar todos los módulos NVDIMM.
Acción
● Espere a que la batería cargue lo suficiente de manera que el servidor siga arrancando.
● También puede pulsar la tecla ESC para dejar de esperar a que la batería cargue.
352-IMPORTANT: HPE Smart Storage Battery is not charged sufficientlySíntoma
352-IMPORTANT: HPE Smart Storage Battery is not charged sufficiently to support the NVDIMMs installed in the system. Action: System configured to not wait for battery to charge. NVDIMMs not armed to support backup.
Causa
● El sistema no está configurado para esperar a que HPE Smart Storage Battery cargue.
● Ha pulsado la tecla ESC para dejar de esperar a que la batería cargue.
Acción
Espere a que la batería cargue lo suficiente de manera que el servidor siga arrancando.
353-IMPORTANT: Possible Password Corruption
Síntoma
ESES Mensajes de error de la POST 75

353-IMPORTANT: Possible Password Corruption. The PW authentication algorithm detected an issue which has been corrected. Action: If a PW was not previously configured, remove the PW using the Password Disable Switch.
Causa
Se ha perdido o dañado una contraseña.
Acción
Establezca el conmutador de desactivación de contraseña (S5) en la posición ON para quitar la contraseña. Para localizar el banco de conmutadores de mantenimiento del sistema, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
354-LRDIMM Memory Configuration IssueSíntoma
354-LRDIMM Memory Configuration Issue – The current BIOS requires all memory channels to be populated with the same number of LRDIMMs. Action: Populate all channels with the same number of LRDIMMs.
Causa
Se ha instalado un número incorrecto de módulos LRDIMM en un canal de memoria.
Acción
Instale el mismo número de módulos LRDIMM en todos los canales de memoria. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
355-Processor X, DIMM YSíntoma
355-Processor X, DIMM Y – This NVDIMM-N was selected for Sanitizing/Erasing. All data saved in the NVDIMM has been erased. Action: No action required.
Causa
El módulo NVDIMM se seleccionó para la desinfección y se reinició el servidor.
Acción
No es necesario hacer nada. El servidor se reinicia según la desinfección/borrado en la configuración de la directiva de próximo reinicio.
Para obtener más información, consulte la HPE 8GB NVDIMM User Guide (Guía de usuario de HPE 8GB NVDIMM) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/NVDIMM-docs).
356-NVDIMM Error – Sanitization ErrorSíntoma
356-NVDIMM Error – Sanitization Error - Processor X, DIMM Y – This NVDIMM-N was selected for Sanitizing/Erasing but this process was not successful. Action: Retry Sanitization. Replace NVDIMM if issue persists.
Causa
76 Capítulo 2 Errores de los servidores HPE ProLiant ESES

NVDIMM ha fallado.
Acción
1. Intente desinfectar el módulo NVDIMM.
Para obtener más información, consulte la HPE 8GB NVDIMM User Guide (Guía de usuario de HPE 8GB NVDIMM) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/NVDIMM-docs).
2. Si el error continúa, sustituya el NVDIMM.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
357-IMPORTANT: Processor X, DIMM YSíntoma
357-IMPORTANT: Processor X, DIMM Y – This NVDIMM is NOT an HPE SmartMemory NVDIMM. Only HPE SmartMemory NVDIMMs are supported. NVDIMM will be used as a standard DIMM. Action: Use HPE NVDIMM for persistency.
Causa
Se ha instalado un módulo NVDIMM no compatible. El sistema operativo reconocerá el módulo NVDIMM no compatible solo como módulo DIMM estándar.
Acción
Sustituya el módulo NVDIMM no compatible con el módulo NVDIMM de HPE SmartMemory. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
358-IMPORTANT: Processor X, DIMM YSíntoma
358-IMPORTANT: Processor X, DIMM Y – The installed NVDIMM has a Supercap attached. This is not supported. Action: Remove the Supercap from Processor X, DIMM Y.
– System Halted!
Causa
Un paquete de condensadores no compatible se conecta a un módulo NVDIMM instalado. En los servidores HPE Proliant, se proporciona potencia a los módulos NVDIMM mediante la batería de HPE Smart Storage.
Acción
Extraiga el paquete de condensadores no compatible del módulo NVDIMM en el procesador X, ranura Y.
359-NVDIMM Population ErrorSíntoma
359-NVDIMM Population Error – Processor 1 must have at least one RDIMM installed when NVDIMMs are present in the system. Action:Install an RDIMM on Processor 1.
– System Halted!
ESES Mensajes de error de la POST 77

Causa
Al menos un módulo DIMM estándar no está instalado en el procesador 1 como requieren las directrices de completado.
Acción
Instale un módulo DIMM normal en el procesador 1. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
Cuando se instalan módulos NVDIMM de HPE 8 GB en un servidor, todos los módulos DIMM normales en el servidor deben ser RDIMM. Para obtener más información, consulte la HPE 8GB NVDIMM User Guide (Guía de usuario de HPE 8GB NVDIMM) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/NVDIMM-docs).
360-IMPORTANT: The System Programmable Logic Device revision in this system does not meet minimum requirements for operation with NVDIMMs
Síntoma
360-IMPORTANT: The System Programmable Logic Device revision in this system does not meet minimum requirements for operation with NVDIMMs. All NVDIMM functionality has been disabled. Action: Remove all NVDIMMs from the system.
Causa
Los módulos NVDIMM no son compatibles en este servidor.
Acción
Quite todos los módulos NVDIMM del servidor. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
Para obtener más información sobre tipos de memoria admitidos en el servidor, consulte las QuickSpecs (Especificaciones rápidas) del producto en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/qs).
361-IMPORTANT: The Processor RAPL wattage value is configured to an invalid valueSíntoma
361-IMPORTANT: The Processor RAPL wattage value is configured to an invalid value. The closest available valid value will be used. Action: Configure the DRAM RAPL wattage to the desired valid value.
Causa
El valor de vataje de RAPL del procesador es incorrecto o no es válido.
Acción
Establezca el vataje de RAPL del procesador en el valor adecuado.
362-IMPORTANT: The DRAM RAPL wattage value is configured to an invalid valueSíntoma
362-IMPORTANT: The DRAM RAPL wattage value is configured to an invalid value. The closest available valid value will be used. Action: Configure the DRAM RAPL wattage to the desired valid value.
78 Capítulo 2 Errores de los servidores HPE ProLiant ESES

Causa
The DRAM RAPL wattage value is incorrect or invalid.
Acción
Establezca el vataje de RAPL de DRAM en el valor adecuado.
363-Memory Initialization ErrorSíntoma
363-Memory Initialization Error – Processor X, DIMM Y failed initialization. Action: Reseat the processor and DIMM. Call Service if issue persists.
– System Halted!
Causa
El procesador o módulo DIMM están instalados incorrectamente.
Acción
PRECAUCIÓN: Antes de extraer o sustituir los procesadores, asegúrese de seguir las directrices de solución de problemas del procesador en "Realización de procedimientos de procesador en el proceso de solución de problemas" de la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I, Solución de problemas. Si no se siguen las directrices recomendadas, es posible que se produzcan daños en la placa del sistema y que sea necesario sustituirla.
1. Vuelva a colocar el procesador.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
2. Vuelva a colocar el módulo DIMM.
3. Si el problema continúa, póngase en contacto el servicio de soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
364-NVDIMM Controller ErrorSíntoma
364-NVDIMM Error – NVDIMM Controller Error - Processor X, DIMM Y. The NVDIMM controller firmware has been corrupted. The OS will not use the NVDIMM. Action: Re-program the firmware to restore NVDIMM functionality.
Causa
Es posible que el firmware de la controladora NVDIMM esté dañado.
Acción
Actualice el firmware. Para obtener más información, consulte la sección "Actualizaciones de firmware" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
ESES Mensajes de error de la POST 79

365-Backplane Configuration ErrorSíntoma
365-Backplane Configuration Error – A storage controller is installed in the incorrect drive backplane. The controller will not be usable. Action: Install the storage controller in drive backplane X.
Causa
Una controladora de almacenamiento está instalada incorrectamente.
Acción
Instale la controladora de almacenamiento en la matriz de conectores de unidades X. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
366-Backplane Configuration ErrorSíntoma
366-Backplane Configuration Error – Unsupported drive backplane configuration detected. Action: Install the drive backplanes in a supported configuration.
Causa
La matriz de conectores de unidades está instalada en una configuración no admitida.
Acción
Instale la matriz de conectores de unidades en una configuración compatible. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
371-NVDIMM Error – Processor X, DIMM YSíntoma
371-NVDIMM Error – Processor X, DIMM Y. New NVDIMM detected and has been disabled. Action:Sanitize all NVDIMMs on Processor X to enable the NVDIMM.
Causa
El módulo NVDIMM es nuevo para este servidor y el servidor tiene la intercalación de memoria del módulo NVDIMM-N activado.
Acción
Realice una de las siguientes operaciones:
● Extraiga el NVDIMM-N.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
● Desinfecte todos los módulos NVDIMM en el procesador X para comenzar a usar el módulo NVDIMM en este servidor.
Para obtener más información, consulte la HPE 8GB NVDIMM User Guide (Guía de usuario de HPE 8GB NVDIMM) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/NVDIMM-docs).
80 Capítulo 2 Errores de los servidores HPE ProLiant ESES

372-NVDIMM Error – Processor X, DIMM YSíntoma
372-NVDIMM Error – Processor X, DIMM Y. New NVDIMM detected and has been disabled. Action: Sanitize the NVDIMM to enable the NVDIMM.
Causa
El módulo NVDIMM es nuevo para este servidor y el servidor tiene la intercalación de memoria del módulo NVDIMM-N desactivado.
Acción
Realice una de las siguientes operaciones:
● Extraiga el NVDIMM-N.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
● Desinfecte el módulo NVDIMM para empezar a utilizarlo en este servidor.
Para obtener más información, consulte la HPE 8GB NVDIMM User Guide (Guía de usuario de HPE 8GB NVDIMM) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/NVDIMM-docs).
373-NVDIMM ErrorSíntoma
373-NVDIMM Error – NVDIMM(s) have been removed from Processor X. All NVDIMMs on Processor X have been disabled. Action: Re-install missing NVDIMM or sanitize all NVDIMMs on Processor X.
Causa
Se quitaron uno o más módulos NVDIMM de este servidor y el servidor tiene la intercalación de memoria del módulo NVDIMM-N habilitada.
Acción
Realice una de las siguientes operaciones:
● Reinstale los módulos NVDIMM que faltan.
Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
● Desinfecte todos los módulos NVDIMM en el procesador X para comenzar a usar el conjunto de intercalación más pequeño.
Para obtener más información, consulte la HPE 8GB NVDIMM User Guide (Guía de usuario de HPE 8GB NVDIMM) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/NVDIMM-docs).
374-NVDIMM ErrorSíntoma
374-NVDIMM Error – Processor X, DIMM Y received a memory initialization or uncorrectable error. All NVDIMMs on Processor X are disabled. Action: Sanitize all NVDIMMs on Processor X. If problem persists, replace the NVDIMM.
ESES Mensajes de error de la POST 81

Causa
El servidor tiene la intercalación de memoria del módulo NVDIMM-N habilitada y se ha producido alguna de las siguientes situaciones:
● El módulo NVDIMM ha experimentado un error incorregible y provocó que el servidor se reiniciara.
● El servidor no pudo inicializar el módulo NVDIMM durante la POST.
Acción
1. Vuelva a colocar los módulos NVDIMM y DIMM en el servidor.
2. Desinfecte todos los módulos NVDIMM en el procesador X.
3. Si el error continúa, sustituya el NVDIMM.
Para obtener más información, consulte la HPE 8GB NVDIMM User Guide (Guía de usuario de HPE 8GB NVDIMM) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/NVDIMM-docs). Para realizar los procedimientos de extracción y sustitución, consulte a la guía de mantenimiento y servicio del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
375-NVDIMM Error – Processor X, DIMM YSíntoma
375-NVDIMM Error – Processor X, DIMM Y. NVDIMM has received a memory initialization or uncorrectable error. NVDIMM has been disabled. Action: Sanitize the NVDIMM. If problem persists, replace the NVDIMM.
Causa
El servidor tiene la intercalación de memoria del módulo NVDIMM-N deshabilitada y se ha producido alguna de las siguientes situaciones:
● El módulo NVDIMM ha experimentado un error incorregible y provocó que el servidor se reiniciara.
● El servidor no pudo inicializar el módulo NVDIMM durante la POST.
Acción
1. Vuelva a colocar los módulos NVDIMM y DIMM en el servidor.
2. Desinfecte el NVDIMM.
3. Si el error continúa, sustituya el NVDIMM.
Para obtener más información, consulte la HPE 8GB NVDIMM User Guide (Guía de usuario de HPE 8GB NVDIMM) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/NVDIMM-docs). Para realizar los procedimientos de extracción y sustitución, consulte a la guía de mantenimiento y servicio del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
376-NVDIMM Error – Processor X, DIMM YSíntoma
76-NVDIMM Error – Processor X, DIMM Y. NVDIMM set for interleaving disabled but system configured for interleaving enabled. All NVDIMMs on Processor X are disabled. Action: Sanitize all NVDIMMs on Processor X.
82 Capítulo 2 Errores de los servidores HPE ProLiant ESES

Causa
El módulo NVDIMM se utilizaba anteriormente en un servidor con la intercalación de memoria del módulo NVDIMM-N desactivada, pero este servidor se configuró para tener la intercalación de memoria del módulo NVDIMM-N habilitada.
Acción
Realice una de las siguientes operaciones:
● Desactive la intercalación de memoria del módulo NVDIMM-N y reinicie el servidor. Los datos del módulo NVDIMM estarán disponibles después del reinicio.
● Desinfecte todos los módulos NVDIMM en el procesador X. Los datos del módulo NVDIMM no estarán disponibles después de la desinfección.
Para obtener más información, consulte la HPE 8GB NVDIMM User Guide (Guía de usuario de HPE 8GB NVDIMM) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/NVDIMM-docs).
377-NVDIMM Error – Processor X, DIMM YSíntoma
377-NVDIMM Error – Processor X, DIMM Y. NVDIMM set for interleaving enabled but system configured for interleaving disabled. NVDIMM has been disabled. Action: Sanitize the NVDIMM.
Causa
El módulo NVDIMM se utilizaba anteriormente en un servidor con la intercalación de memoria del módulo NVDIMM-N deshabilitada, pero el servidor se ha configurado ahora para tener la intercalación de memoria del módulo NVDIMM-N habilitada.
Acción
Realice una de las siguientes operaciones:
● Habilite la intercalación de memoria del módulo NVDIMM-N y reinicie el servidor.
Si los demás módulos NVDIMM en el conjunto de intercalación siguen estando instalados, los datos del módulo NVDIMM estarán disponibles después del reinicio.
Si falta alguno de los otros módulos NVDIMM en el conjunto de intercalación, puede producirse un mensaje de error distinto.
● Desinfecte el NVDIMM. Los datos del módulo NVDIMM no estarán disponibles después de la desinfección.
Para obtener más información, consulte la HPE 8GB NVDIMM User Guide (Guía de usuario de HPE 8GB NVDIMM) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/NVDIMM-docs).
378-NVDIMM Error – Processor X, DIMM YSíntoma
378-NVDIMM Error – Processor X, DIMM Y. NVDIMM is configured for a different processor type. All NVDIMMs on Processor X are disabled. Action: Sanitize all NVDIMMs on Processor X.
Causa
El servidor no coincide con el servidor original, en donde se usó el módulo NVDIMM y la intercalación de memoria del módulo NVIDMM está habilitada.
ESES Mensajes de error de la POST 83

Acción
1. Guarde el contenido del módulo NVDIMM en otro medio para conservar los datos.
2. Quite el procesador y sustitúyalo por el tipo de procesador instalado anteriormente.
3. Restaure los datos al módulo NVDIMM.
4. Si el error continúa, desinfecte el módulo NVDIMM. Los datos del módulo NVDIMM no estarán disponibles después de la desinfección.
Para obtener más información, consulte la HPE 8GB NVDIMM User Guide (Guía de usuario de HPE 8GB NVDIMM) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/NVDIMM-docs). Para realizar los procedimientos de extracción y sustitución, consulte a la guía de mantenimiento y servicio del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
379-NVDIMM Error – Processor X, DIMM YSíntoma
379-NVDIMM Error – Processor X, DIMM Y. NVDIMM is configured for a different processor type. NVDIMM has been disabled. Action: Sanitize the NVDIMM.
Causa
El servidor no coincide con el servidor original, en donde se usó el módulo NVDIMM y la intercalación de memoria del módulo NVIDMM está deshabilitada.
Acción
1. Copie los datos del módulo NVDIMM a un dispositivo de almacenamiento u otro módulo NVDIMM.
2. Quite el procesador y sustitúyalo por el tipo de procesador instalado anteriormente.
3. Restaure los datos al módulo NVDIMM.
4. Si el error continúa, desinfecte el módulo NVDIMM. Los datos del módulo NVDIMM no estarán disponibles después de la desinfección.
Para obtener más información, consulte la HPE 8GB NVDIMM User Guide (Guía de usuario de HPE 8GB NVDIMM) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/NVDIMM-docs). Para realizar los procedimientos de extracción y sustitución, consulte a la guía de mantenimiento y servicio del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
380-NVDIMM Error – Processor X, DIMM YSíntoma
380-NVDIMM Error – Processor X, DIMM Y. NVDIMM location changed. All NVDIMMs on Processor X are disabled. Action: Install NVDIMM in Processor A, DIMM B or sanitize all NVDIMMs on Processor X.
Causa
El módulo NVDIMM se ha trasladado o instalado en la ubicación errónea, y la intercalación de la memoria del módulo NVDIMM-N está habilitada.
Acción
Realice una de las siguientes operaciones:
84 Capítulo 2 Errores de los servidores HPE ProLiant ESES

● Instale el módulo NVDIMM en el procesador A, DIMM B para conservar los datos.
● Desinfecte todos los módulos NVDIMM en el procesador X. Los datos del módulo NVDIMM no estarán disponibles después de la desinfección.
Para obtener más información, consulte la HPE 8GB NVDIMM User Guide (Guía de usuario de HPE 8GB NVDIMM) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/NVDIMM-docs).
381-NVDIMM Error – Processor X, DIMM YSíntoma
381-NVDIMM Error – Processor X, DIMM Y. NVDIMM location changed. NVDIMM has been disabled. Action: Install NVDIMM in Processor A, DIMM B or sanitize the NVDIMM.
Causa
El módulo NVDIMM se ha trasladado o instalado en la ubicación errónea, y la intercalación de la memoria del módulo NVDIMM-N está deshabilitada.
Acción
Realice una de las siguientes operaciones:
● Instale el módulo NVDIMM en el procesador A, DIMM B para conservar los datos.
● Desinfecte el NVDIMM. Los datos del módulo NVDIMM no estarán disponibles después de la desinfección.
Para obtener más información, consulte la HPE 8GB NVDIMM User Guide (Guía de usuario de HPE 8GB NVDIMM) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/NVDIMM-docs).
382-NVDIMM Error – Processor X, DIMM YSíntoma
382-NVDIMM Error – Processor X, DIMM Y is NOT configured for Cluster On Die (CoD) but system is configured for CoD. All NVDIMMs on Proc X are disabled. Action: Disable CoD or Sanitize all NVDIMMs on Proc X.
Causa
El módulo NVDIMM se ha utilizado previamente en un servidor que tenía una configuración de búsqueda de QPI de Cluster on Die. El servidor actual tiene un valor diferente de la configuración de búsqueda de QPI.
Acción
Realice una de las siguientes operaciones:
● Cambie la configuración de la configuración de búsqueda de QPI a búsqueda temprana o doméstica.
● Desinfecte todos los módulos NVDIMM en el procesador X.
Para obtener más información, consulte la HPE 8GB NVDIMM User Guide (Guía de usuario de HPE 8GB NVDIMM) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/NVDIMM-docs).
ESES Mensajes de error de la POST 85

383-NVDIMM ErrorSíntoma
383-NVDIMM Error – Proc X, DIMM Y is configured for Cluster On Die (CoD) but system is NOT configured for CoD. All NVDIMMs on Proc X are disabled. Action: Enable CoD or Sanitize all NVDIMMs on Proc X.
Causa
El módulo NVDIMM se utilizó previamente en un servidor que no tenía una configuración de búsqueda de QPI de Cluster on Die. El servidor actual tiene un valor diferente de la configuración de búsqueda de QPI.
Acción
Realice una de las siguientes operaciones:
● Cambie la configuración de la búsqueda de QPI a Cluster on Die.
● Desinfecte todos los módulos NVDIMM en el procesador X.
Para obtener más información, consulte la HPE 8GB NVDIMM User Guide (Guía de usuario de HPE 8GB NVDIMM) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/NVDIMM-docs).
384-NVDIMM Error – Processor X, DIMM YSíntoma
NVDIMM Error – Processor X, DIMM Y. NVDIMM set for Channel Interleaving disabled but system configured for enabled. All NVDIMMs on Processor X are disabled. Action: Sanitize all NVDIMMs on Proc X.
Causa
El módulo NVDIMM se instaló previamente en un servidor que tenía la intercalación de canales deshabilitada. El servidor actual tiene la intercalación de canales habilitada.
Acción
Realice una de las siguientes operaciones:
● Active la intercalación de canales en las utilidades del sistema.
● Desinfecte todos los módulos NVDIMM en el procesador X.
Para obtener más información, consulte la HPE 8GB NVDIMM User Guide (Guía de usuario de HPE 8GB NVDIMM) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/NVDIMM-docs).
385-NVDIMM Error – Processor X, DIMM YSíntoma
385-NVDIMM Error – Processor X, DIMM Y. NVDIMM set for Channel Interleaving enabled but system configured for disabled. All NVDIMMs on Processor X are disabled. Action: Sanitize all NVDIMMs on Proc X.
Causa
El módulo NVDIMM se ha instalado anteriormente en un servidor que tenía la intercalación de canales habilitada. El servidor actual tiene la intercalación de canales deshabilitada.
86 Capítulo 2 Errores de los servidores HPE ProLiant ESES

Acción
Realice una de las siguientes operaciones:
● Desactivar la intercalación de canales en las utilidades del sistema.
● Desinfecte todos los módulos NVDIMM en el procesador X.
Para obtener más información, consulte la HPE 8GB NVDIMM User Guide (Guía de usuario de HPE 8GB NVDIMM) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/NVDIMM-docs).
386-NVDIMM Error – Processor X, DIMM YSíntoma
386-NVDIMM Error – Processor X, DIMM Y. NVDIMM Metadata is corrupted. All NVDIMMs on Processor X are disabled. Action: Sanitize all NVDIMMs on Processor X.
Causa
Los datos de los metadatos del módulo NVDIMM que define cómo se usa el módulo NVDIMM en el servidor están dañados y el servidor tiene la intercalación de memoria del módulo NVDIMM-N habilitada.
Acción
Desinfecte todos los módulos NVDIMM en el procesador X. Para obtener más información, consulte la HPE 8GB NVDIMM User Guide (Guía de usuario de HPE 8GB NVDIMM) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/NVDIMM-docs).
387-NVDIMM Error – Processor X, DIMM YSíntoma
387-NVDIMM Error – Processor X, DIMM Y. NVDIMM Metadata is corrupted. NVDIMM is disabled. Action: Sanitize the NVDIMM.
Causa
Los datos de los metadatos del módulo NVDIMM que define cómo se usa el módulo NVDIMM en el servidor están dañados y el servidor tiene la intercalación de memoria del módulo NVDIMM-N deshabilitada.
Acción
Desinfecte el NVDIMM. Para obtener más información, consulte la HPE 8GB NVDIMM User Guide (Guía de usuario de HPE 8GB NVDIMM) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/NVDIMM-docs).
388-Memory Failure – Uncorrectable Memory ErrorSíntoma
388-Memory Failure – Uncorrectable Memory Error – The failed memory module could not be determined. Action: Inspect the IML for another event that may indicate what memory module has failed.
Causa
Se ha producido un error imposible de corregir en un módulo DIMM o NVDIMM.
Acción
ESES Mensajes de error de la POST 87

Revise el registro de Insight Management para obtener información sobre el motivo por que fallaron los módulos DIMM o NVDIMM. Para obtener más información, consulte la sección "Registro de gestión integrado" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
389-Unexpected Shutdown and RestartSíntoma
389-Unexpected Shutdown and Restart – An undetermined error type resulted in a reboot of the server. Action: If issue persists, contact HPE service.
Causa
El servidor se apagó de forma inesperada.
Acción
Si el problema continúa, póngase en contacto el servicio de soporte técnico de Hewlett Packard Enterprise. Para obtener más información, consulte "Acceso al soporte técnico de Hewlett Packard Enterprise (Acceso al soporte de Hewlett Packard Enterprise en la página 493)".
390-On Package High-Bandwidth Memory FailureSíntoma
390-On Package High-Bandwidth Memory Failure – Uncorrectable Memory Error – Processor X. Action: Replace processor.
Causa
Se ha producido un error en el procesador.
Acción
PRECAUCIÓN: Antes de extraer o sustituir los procesadores, asegúrese de seguir las directrices de solución de problemas del procesador en "Realización de procedimientos de procesador en el proceso de solución de problemas" de la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I, Solución de problemas. Si no se siguen las directrices recomendadas, es posible que se produzcan daños en la placa del sistema y que sea necesario sustituirla.
Sustituya el procesador. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
Serie 40040X-Parallel Port X Address Assignment Conflict
Síntoma
40X-Parallel Port X Address Assignment Conflict.
Causa
Tanto el puerto externo como el interno están asignados al puerto paralelo X.
Acción
88 Capítulo 2 Errores de los servidores HPE ProLiant ESES

Ejecute la utilidad de configuración del servidor y corrija la configuración. Para obtener más información, consulte la sección "Utilidades del sistema HPE UEFI" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
404-Parallel Port Address Conflict DetectedSíntoma
404-Parallel Port Address Conflict Detected. A hardware conflict in your system is keeping some system components from working correctly. If you have recently added new hardware remove it to see if it is the cause of the conflict. Alternatively, use Computer Setup or your operating system to insure that no conflicts exist.
Causa
Un conflicto de hardware en el sistema evita que el puerto paralelo funcione correctamente.
Acción
1. Si recientemente ha añadido hardware nuevo, elimínelo para comprobar si dicho hardware es la causa del conflicto.
Para obtener más información, consulte la sección "Problemas de nuevo hardware" Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
2. Ejecute la utilidad de configuración del servidor para reasignar recursos al puerto paralelo y resolver manualmente el conflicto de recursos.
Para obtener más información, consulte la sección "Utilidades del sistema HPE UEFI" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
3. Ejecute Insight Diagnostics y sustituya los componentes que presentan fallos siguiendo las indicaciones.
Para realizar los procedimientos de extracción y sustitución, consulte a la guía de mantenimiento y servicio del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
Serie 500501-PCI card needs to be in alternate slot
Síntoma
501-PCI card needs to be in alternate slot.
Causa
Hay una tarjeta PCI instalada en una ranura incorrecta.
Acción
Mueva la tarjeta PCI a la ranura correcta. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
ESES Mensajes de error de la POST 89

Serie 15001500-iLO 4 configuration is temporarily unavailable
Síntoma
1500-iLO 4 configuration is temporarily unavailable.
Causa
iLO está ocupado o no responde al software que se ejecuta en el sistema.
Acción
1. Reinicie el procesador iLO.
2. Actualice el firmware de iLO.
3. Restablezca la NVRAM de iLO.
Para obtener más información, consulte la guía de usuario de iLO la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/ilo-docs).
1501-iLO 4 Security Override Switch is setSíntoma
1501-iLO 4 Security Override Switch is set. iLO 4 security is DISABLED!
Causa
El conmutador de anulación de seguridad de iLO está establecido en la posición ON.
Acción
Configure el conmutador de anulación de seguridad de iLO en la posición OFF. Para localizar el banco de conmutadores de mantenimiento del sistema, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1502-iLO 4 is disabledSíntoma
1502-iLO 4 is disabled. Use the Security Override Switch and iLO 4 F8 ROM-Based Setup Utility to enable iLO functionality.
Causa
El conmutador de anulación de seguridad de iLO está establecido en la posición ON.
Acción
1. Configure el conmutador de anulación de seguridad de iLO en la posición OFF.
Para localizar el banco de conmutadores de mantenimiento del sistema, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
2. Utilice la RBSU de iLO para activar y restablecer iLO.
Para obtener más información, consulte la guía de usuario de iLO la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/ilo-docs).
90 Capítulo 2 Errores de los servidores HPE ProLiant ESES

1503-iLO 4 ROM-based Setup Utility is disabledSíntoma
1503-iLO 4 ROM-based Setup Utility is disabled.
Causa
La RBSU o iLO está desactivada y el conmutador de anulación de la seguridad de iLO está en la posición OFF.
Acción
Realice una de las siguientes operaciones:
● Active RBSU a través de RIBCL.
● Configure el conmutador de anulación de seguridad en la posición ON y active iLO.
Para localizar el banco de conmutadores de mantenimiento del sistema, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs). Para obtener más información, consulte la guía de usuario de iLO la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/ilo-docs).
Serie 16001609-Battery Failure message
Síntoma
1609-Battery Failure message. This is detected by checking the RTC Lost Power bit in CMOS (Byte 0Dh - Bit 7).
Causa
La batería del sistema de reloj de tiempo real ha perdido potencia.
Acción
Sustituya la batería del sistema. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1610-Temperature violation detectedSíntoma
1610-Temperature violation detected. Waiting 5 Minutes for System to Cool. Press Esc key to resume booting without waiting for the system to cool. WARNING: Pressing Esc is NOT recommended as the system may shutdown unexpectedly. (ADVERTENCIA: No es recomendable pulsar ESC ya que el sistema podría cerrarse de manera inesperada).
Causa
La temperatura medida por uno de los sensores de temperatura del sistema ha superado los niveles aceptables. En muchos casos, esto se debe a que la temperatura del aire ambiente que entra supera los niveles aceptables.
Acción
Asegúrese de seguir todos los requisitos ambientales, espacio, ventilación y temperatura para el servidor. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
ESES Mensajes de error de la POST 91

1611-CPU Zone Fan Assembly Failure DetectedSíntoma
1611-CPU Zone Fan Assembly Failure Detected. Either the Assembly is not installed or multiple fans have failed in the CPU zone.
Causa
No se encuentran los ventiladores necesarios o no están girando.
Acción
Asegúrese de que todos los ventiladores necesarios estén instalados correctamente y que estén girando. Para obtener más información, consulte la sección "Problemas del ventilador" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
1611-CPU Zone Fan Assembly Failure DetectedSíntoma
1611-CPU Zone Fan Assembly Failure Detected. Single fan failure. Assembly will provide adequate cooling.
Causa
Un ventilador redundante no gira o falta.
Acción
Sustituya el ventilador para proporcionar redundancia, si procede. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1611-Fan failure detectedSíntoma
1611-Fan failure detected.
Causa
Un ventilador necesario no gira o falta.
Acción
Asegúrese de que todos los ventiladores necesarios estén instalados correctamente y que estén girando. Para obtener más información, consulte la sección "Problemas del ventilador" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
1611-Fan X Failure Detected (Fan Zone CPU)Síntoma
1611-Fan X Failure Detected (Fan Zone CPU).
Causa
Un ventilador necesario no gira o falta.
Acción
92 Capítulo 2 Errores de los servidores HPE ProLiant ESES

Asegúrese de que todos los ventiladores necesarios estén instalados correctamente y que estén girando. Para obtener más información, consulte la sección "Problemas del ventilador" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
1611-Fan X Failure Detected (Fan Zone I/O)Síntoma
1611-Fan X Failure Detected (Fan Zone I/O).
Causa
Un ventilador necesario no gira o falta.
Acción
Asegúrese de que todos los ventiladores necesarios estén instalados correctamente y que estén girando. Para obtener más información, consulte la sección "Problemas del ventilador" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
1611-Fan X Not Present (Fan Zone CPU)Síntoma
1611-Fan X Not Present (Fan Zone CPU).
Causa
Un ventilador necesario no gira o falta.
Acción
Asegúrese de que todos los ventiladores necesarios estén instalados correctamente y que estén girando. Para obtener más información, consulte la sección "Problemas del ventilador" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
1611-Fan X Not Present (Fan Zone I/O)Síntoma
1611-Fan X Not Present (Fan Zone I/O).
Causa
Un ventilador necesario no gira o falta.
Acción
Asegúrese de que todos los ventiladores necesarios estén instalados correctamente y que estén girando. Para obtener más información, consulte la sección "Problemas del ventilador" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
1611-Power Supply Zone Fan Assembly Failure DetectedSíntoma
1611-Power Supply Zone Fan Assembly Failure Detected. Either the Assembly is not installed or multiple fans have failed.
ESES Mensajes de error de la POST 93

Causa
Un ventilador necesario no gira o falta.
Acción
Asegúrese de que todos los ventiladores necesarios estén instalados correctamente y que estén girando. Para obtener más información, consulte la sección "Problemas del ventilador" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
1611-Power Supply Zone Fan Assembly Failure DetectedSíntoma
1611-Power Supply Zone Fan Assembly Failure Detected. Single fan failure. Assembly will provide adequate cooling.
Causa
Un ventilador necesario no gira o falta.
Acción
Sustituya el ventilador para proporcionar redundancia, si procede. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1611-Primary Fan Failure (Fan Zone System)Síntoma
1611-Primary Fan Failure (Fan Zone System).
Causa
Un ventilador necesario no gira o falta.
Acción
Replace the fan. (El subsistema de ventiladores tiene el estado Failed. Sustituya el ventilador.) Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1611-Redundant Fan Failure (Fan Zone System)Síntoma
1611-Redundant Fan Failure (Fan Zone System).
Causa
Un ventilador redundante no gira o falta.
Acción
Replace the fan. (El subsistema de ventiladores tiene el estado Failed. Sustituya el ventilador.) Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1612-Primary Power Supply FailureSíntoma
94 Capítulo 2 Errores de los servidores HPE ProLiant ESES

1612-Primary power supply failure.
Causa
Se ha producido un fallo en la fuente de alimentación.
Acción
Sustituya la fuente de alimentación. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1613-Low System Battery warningSíntoma
1613-Low System Battery warning.
Causa
La pila del sistema del reloj de tiempo real tiene poca carga.
Acción
Sustituya la batería del sistema. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1614-Redundant Fan FailureSíntoma
1614-Redundant Fan Failure.
Causa
Un ventilador redundante no gira o falta.
Acción
Asegúrese de que todos los ventiladores necesarios estén instalados correctamente y que estén girando. Para obtener más información, consulte la sección "Problemas del ventilador" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
1616-Power Supply Configuration FailureSíntoma
1616-Power Supply Configuration Failure
– A working power supply must be installed in Bay 1 for proper cooling.
– System Halted!
Causa
● Falta la fuente de alimentación.
● Se ha producido un fallo en la fuente de alimentación.
Acción
Realice una de las siguientes operaciones:
ESES Mensajes de error de la POST 95

● Instale la fuente de alimentación.
● Sustituya la fuente de alimentación.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1623-Power Supply FailureSíntoma
1623-Power Supply Failure – Power Supply X is failed. Action: Replace the power supply.
Causa
Se ha producido un fallo en la fuente de alimentación.
Acción
Sustituya la fuente de alimentación. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1624-Power Supply UnpluggedSíntoma
1624- Power Supply Unplugged – Power Supply X is unplugged. Action: Ensure the Power Supply is plugged in.
Causa
● Falta la fuente de alimentación.
● Se ha producido un fallo en la fuente de alimentación.
Acción
Realice una de las siguientes operaciones:
● Instale la fuente de alimentación.
● Sustituya la fuente de alimentación.
Para obtener más información, consulte la sección "Problemas de la fuente de alimentación" Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
1625-Unsupported Power Supply ConfigurationSíntoma
1625-Unsupported Power Supply Configuration – Unsupported Power Supply Mismatch. Action: Ensure the Power Supply configuration is valid.
Causa
El servidor no admite la configuración actual de la fuente de alimentación.
Acción
96 Capítulo 2 Errores de los servidores HPE ProLiant ESES

Instale fuentes de alimentación en una configuración admitida. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1626-Unsupported Power Supply ConfigurationSíntoma
1626-Unsupported Power Supply Configuration – Unsupported Power Supply detected. Action: Replace the unsupported Power Supply.
Causa
Se ha instalado una fuente de alimentación no compatible en el servidor.
Acción
1. Extraiga la fuente de alimentación.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
2. Instale una fuente de alimentación compatible.
Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
Para ubicar una opción compatible, consulte las QuickSpecs (Especificaciones rápidas) del producto en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/qs).
1627-Power Supply Configuration InsufficientSíntoma
1627-Power Supply Configuration Insufficient. Instale una o varias fuentes de alimentación para satisfacer los requisitos de alimentación, o pulse la tecla F9 para entrar en las utilidades del sistema para anular los requisitos si Power Advisor indica que esto es posible.
Causa
La fuente de alimentación actual no es suficiente para utilizar el servidor.
Acción
Para obtener más información, consulte la sección "Configuración de la fuente de alimentación insuficiente" Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
1628-IMPORTANT: The system contains multiple types of power suppliesSíntoma
1628-IMPORTANT: The system contains multiple types of power supplies. Certain features are not supported and power redundancy may be limited.
Causa
Hay más de un tipo de fuente de alimentación instalada en el servidor.
Acción
ESES Mensajes de error de la POST 97

No es necesario hacer nada. Este mensaje puede desactivarse en la RBSU. Para obtener más información sobre la RBSU, consulte la Guía de usuario de HPE ROM-Based Setup Utility en la biblioteca de información de RBSU (http://www.hpe.com/info/rbsu/docs).
Serie 17001700-Slot # Drive Array – Please replace battery
Síntoma
1700-Slot # Drive Array – Please replace battery. Caching will be enabled once the battery has been replaced and charged.
Causa
La batería de HPE Smart Storage está deteriorada o ha fallado.
Acción
1. Sustituya la batería de HPE Smart Storage.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
2. Cargue la batería de HPE Smart Storage.
1701-Slot # Drive Array – Please install batterySíntoma
1701-Slot # Drive Array – Please install battery. Caching will be enabled once the battery is installed and charged.
Causa
La batería de HPE Smart Storage no se ha instalado.
Acción
Instale y cargue la batería de HPE Smart Storage. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1702-SCSI Cable Error DetectedSíntoma
1702-SCSI Cable Error Detected.
Causa
● Hay pasadores doblados en los conectores de cable.
● Hay un cable que no está instalado correctamente.
● Se ha producido un fallo en el cable.
Acción
98 Capítulo 2 Errores de los servidores HPE ProLiant ESES

1. Examine los conectores de cable para ver si hay pasadores doblados.
2. Asegúrese de que todas las conexiones de cable sean seguras.
Para obtener más información, consulte la sección "Resolución de conexiones sueltas" Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
3. Si el problema continúa, sustituya los cables.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1703-Slot X Drive Array controller - Memory Self-Test ErrorSíntoma
1703-Slot X Drive Array controller - Memory Self-Test Error. Access to all storage has been disabled. Action: Replace Flash Backed Write Cache module. Si el error continúa, sustituya la controladora.
Causa
● La controladora o el módulo de memoria caché están experimentando un fallo.
● La controladora o el módulo de memoria caché han fallado.
Acción
1. Sustituya el módulo de memoria caché.
2. Si el problema continúa, sustituya la controladora.
Para realizar los procedimientos de extracción y sustitución, consulte a la guía de mantenimiento y servicio del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1704-Slot X System HaltedSíntoma
1704-Slot X System Halted. Unsupported Virtual Mode Disk Operation. Action: Install proper DOS driver.
Causa
El sistema operativo que se está ejecutando actualmente no admite el servicio virtual.
Acción
Instale a una controladora que admite el servicio virtual. Para obtener más información, consulte la sección "Actualización del sistema" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
1705-Slot X Drive ArraySíntoma
1705-Slot # Drive Array – Please replace Cache Module Super-Cap. Caching will be enabled once Super-Cap has been replaced and charged.
ESES Mensajes de error de la POST 99

Causa
La batería de HPE Smart Storage está deteriorada o ha fallado.
Acción
1. Sustituya la batería de HPE Smart Storage.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
2. Cargue la batería de HPE Smart Storage.
1706-The Extended BIOS Data Area in Server Memory has been OverwrittenSíntoma
1706-The Extended BIOS Data Area in Server Memory has been Overwritten. Smart Array Interrupt 13h BIOS Cannot Continue.
– System Halted
Causa
Una aplicación ha sobrescrito la memoria reservada por la controladora Smart Array.
Acción
Si esto sucede al cargar una aplicación concreta, verifique si existe una versión actualizada de la aplicación. Para obtener más información, consulte la sección "Problemas de software" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
1707-Slot X Drive Array ControllerSíntoma
1707-Slot X Drive Array Controller - Bootstrap NVRAM checksum invalid. Action: Re-flash Smart Array controller. Si el error continúa, sustituya la controladora.
Causa
La NVRAM Bootstrap de la controladora Smart Array específica está dañada o es inválida.
Acción
1. Vuelva a actualizar la controladora Smart Array.
2. Si el problema continúa, sustituya la controladora.
Para obtener más información, consulte la sección "Problemas generales de la controladora" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
Para realizar los procedimientos de extracción y sustitución, consulte a la guía de mantenimiento y servicio del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1707-Slot X Drive Array ControllerSíntoma
100 Capítulo 2 Errores de los servidores HPE ProLiant ESES

1708-Slot X Drive Array Controller - Bootstrap NVRAM restored from backup. System restart required.
Causa
La controladora Smart Array específica Bootstrap NVRAM se ha recuperado de una de las siguientes formas:
● Se detectó que estaba dañada, y se restauró la copia de seguridad.
● Se actualizó automáticamente porque estaba disponible una versión más reciente.
Acción
1. Reinicie el servidor.
2. Si el problema continúa, actualice el firmware de la controladora.
Para obtener más información, consulte la sección "Actualizaciones de firmware" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
1709-One or more attached hard drives could not be authenticatedSíntoma
1709-One or more attached hard drives could not be authenticated as a genuine HP hard drive. Smart Array will not control the LEDs to these drives. Please run ACU or ADU to learn which drives could not be validated as genuine.
Causa
Una o más unidades físicas no se han podido validar como originales.
Acción
Para determinar las unidades que no se han podido validar como originales, ejecute la HPE SSA. Para obtener más información, consulte la Guía de usuario de HPE Smart Storage Administrator en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage-docs).
1710-Slot X Drive Array – Non-Array Controller Drives DetectedSíntoma
1710-Slot X Drive Array – Non-Array Controller Drives Detected Warning: possible data loss may occur. Physical drive(s) detected which had been previously attached to a non-array controller. Any non-array data on these drives will be lost unless they are removed. To save data, turn off system power immediately and remove the drives.
Causa
Se han conectado una o varias unidades físicas en una controladora que no es de array.
Acción
1. Apague el servidor.
2. Extraiga la unidad.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
ESES Mensajes de error de la POST 101

1711-Slot # Drive Array – Stripe size too largeSíntoma
1711-Slot # Drive Array – Stripe size too large for RAID 5/6 logical drive(s). This configuration is not recommended due to transfer buffer usage. Consider migrating to lower stripe size via Array Configuration Utility.
Causa
El tamaño de stripe es demasiado grande para las unidades lógicas RAID 5 o 6.
Acción
Realice la migración de RAID a un tamaño de stripe menor utilizando HPE SSA. Para obtener más información, consulte la Guía de usuario de HPE Smart Storage Administrator en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage-docs).
1712-Slot X Drive Array – RAID 5 volume(s) presentSíntoma
1712-Slot X Drive Array – RAID 5 volume(s) present with 56 drives or more, but cache size <= 32MB. This configuration is not recommended. Consider configuring volume(s) to RAID 0 or 1, reducing the number of drives, or upgrading the Array Accelerator module.
Causa
El tamaño de la memoria caché es menor que el recomendado para la configuración actual.
Acción
Realice una de las siguientes operaciones:
● Migre las unidades lógicas a RAID 0 o 1.
● Reduzca el número de unidades en el array.
● Actualice el módulo de la memoria caché con un tamaño mayor.
Para obtener más información, consulte la Guía de usuario de HPE Smart Storage Administrator en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage-docs).
1713-Slot X Array Controller – Redundant ROM Reprogramming FailureSíntoma
1713-Slot X Array Controller – Redundant ROM Reprogramming Failure. Replace the controller if this error persists after restarting system.
Causa
La grabación de la memoria flash de la ROM falla. La controladora detecta un fallo de suma de comprobación, pero no puede reprogramar la ROM de copia de seguridad.
Acción
1. Actualice la controladora a la última versión del firmware.
Para obtener más información, consulte la sección "Actualizaciones de firmware" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas
102 Capítulo 2 Errores de los servidores HPE ProLiant ESES

en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
2. Si el problema continúa, sustituya la controladora.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1714-Slot X Array Controller – Redundant ROM Checksum ErrorSíntoma
1714-Slot X Array Controller – Redundant ROM Checksum Error. Backup ROM has automatically been activated; check firmware version.
Causa
El funcionamiento de la memoria flash de la controladora se interrumpe por un ciclo de encendido y apagado o la grabación de la memoria flash de la ROM presenta fallos. La controladora detecta un error de suma de comprobación ROM y cambia automáticamente a la imagen ROM de copia de seguridad.
Acción
Si la imagen de ROM de copia de seguridad se encuentra en una versión inferior que la imagen que se ejecuta originalmente, actualice la controladora a la versión más reciente del firmware. Para obtener más información, consulte la sección "Actualizaciones de firmware" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
1715-Slot # Drive Array Controller – Memory Error(s) OccurredSíntoma
1715-Slot # Drive Array Controller – Memory Error(s) Occurred. Warning: Corrected Memory Error(s) were detected during controller memory self-test. Upgrade to the latest firmware. If the problem persists, replace the Cache Module or controller.
Causa
● El firmware de la controladora está obsoleto.
● Se ha producido un fallo en el módulo de la memoria caché.
● Se ha producido un fallo en la controladora.
Acción
1. Actualice el firmware.
Para obtener más información, consulte la sección "Actualizaciones de firmware" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
2. Si el problema continúa, sustituya el módulo de la memoria caché.
3. Si el problema continúa, sustituya la controladora.
ESES Mensajes de error de la POST 103

Para realizar los procedimientos de extracción y sustitución, consulte a la guía de mantenimiento y servicio del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1716-Slot # Drive Array – Unrecoverable Media Errors Detected on DrivesSíntoma
1716-Slot # Drive Array – Unrecoverable Media Errors Detected on Drives during previous Rebuild or Background Surface Analysis (ARM) scan. Errors will be fixed automatically when the sector(s) are overwritten. Backup and Restore recommended.
Causa
Se detecta un error de dispositivo en una unidad y no se puede corregir debido a una tolerancia a fallos deteriorada o a un error de dispositivo en la misma ubicación en otra unidad del mismo array. Se enviará un error de lectura que no se puede recuperar al sistema operativo cuando se lea la dirección de este bloque.
Acción
Realice una copia de seguridad y restaure los datos de la unidad. Las operaciones secuenciales de escritura de los bloques afectados deberían resolver los errores del dispositivo.
1717-Slot X Drive Array – Disk Drive(s) Reporting OVERHEATED ConditionSíntoma
1717-Slot X Drive Array – Disk Drive(s) Reporting OVERHEATED Condition: Port X Box Y Bay(s) Z.
Causa
Las unidades enumeradas en este mensaje se encuentran actualmente en un estado de sobrecalentamiento.
Acción
1. Compruebe los ventiladores y asegúrese de que el aire fluye por la unidad.
Para obtener más información, consulte la sección "Problemas del ventilador" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
2. Instale el panel de acceso, si lo ha extraído.
Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1718-Slot X Drive Array – Device discovery found more devices attachedSíntoma
1718-Slot X Drive Array – Device discovery found more devices attached to this controller than firmware currently supports. Some devices are ignored.
Causa
El firmware no admite el número de dispositivos conectados actualmente a la controladora.
Acción
Realice una de las siguientes operaciones:
104 Capítulo 2 Errores de los servidores HPE ProLiant ESES

● Si las notas de la versión indican que se han añadido dispositivos adicionales, actualice a la versión más reciente de firmware de la controladora.
Para obtener más información, consulte la sección "Actualizaciones de firmware" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
● Quite algunos de los dispositivos conectados a la controladora.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
Se ha producido el evento de fallo de la controladora 1719-ASíntoma
1719–A controller failure event occurred prior to this power-up. (Previous lock up code = 0x####)
Causa
Se ha producido un fallo en la controladora antes del encendido del servidor.
Acción
1. Actualice la controladora a la última versión del firmware.
Para obtener más información, consulte la sección "Actualizaciones de firmware" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
2. Si el problema continúa, sustituya la controladora.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1720-Slot X Drive Array – S.M.A.R.T. Hard Drive(s) Detect imminent failureSíntoma
1720-Slot X Drive Array – S.M.A.R.T. Hard Drive(s) Detect imminent failure: Port X Box Y Bay(s) Z. Do not replace drive unless all other drives in the array are online! Back up data before replacing drive(s) if using RAID 0.
Causa
Se ha detectado una previsión de fallo SMART del disco duro. Es posible que la unidad deba sustituirse en el futuro.
Acción
● Si esta unidad forma parte de una configuración sin tolerancia a fallos, realice una copia de seguridad de todos los datos antes de sustituir la unidad y, posteriormente, restaure todos los datos.
ESES Mensajes de error de la POST 105

Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
● Si la unidad forma parte de una configuración con tolerancia a fallos, no sustituya dicha unidad a menos que las demás unidades del array se encuentren en línea.
1721-Slot # Drive Array – Drive Parameter Tracking Predicts Imminent FailureSíntoma
1721-Slot # Drive Array – Drive Parameter Tracking Predicts Imminent Failure. The following drives should be replaced when conditions permit:
Port # Box # Bay(s) #
Causa
Se detectó la condición de fallo predictivo de la unidad.
Acción
Sustituya las unidades cuando las condiciones lo permitan. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1723-Slot X Drive Array – Improving signal integritySíntoma
1723-Slot X Drive Array – To improve signal integrity, internal SCSI connector should be removed if external drives are attached to the same SCSI port.
Causa
Existe un problema de cableado.
Acción
1. Apague el servidor.
2. Retire o sustituya la placa de expansión de conectores y los cables externos conectados a la placa de la controladora Smart Array. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1724-Slot # Drive Array – Physical Drive Position Change(s) DetectedSíntoma
1724-Slot # Drive Array – Physical Drive Position Change(s) Detected. Logical drive configuration has automatically been updated.
(Sometimes followed by:)
Inactive spare drive assignments have been lost due to invalid movement.
Causa
La configuración de la unidad lógica se ha actualizado automáticamente tras los cambios de posición de la unidad física.
Acción
106 Capítulo 2 Errores de los servidores HPE ProLiant ESES

Reasigne las unidades de repuesto con HPE SSA. Esta acción solo es necesaria si hay asignaciones de unidades de repuesto inactivas.
Para obtener más información, consulte la Guía de usuario de HPE Smart Storage Administrator en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage-docs).
1726-Slot X Drive Array – Cache Memory Size or Battery Presence Has ChangedSíntoma
1726-Slot X Drive Array – Cache Memory Size or Battery Presence Has Changed. Cache Module configuration has automatically been updated.
Causa
La configuración del módulo de memoria caché se ha actualizado automáticamente ya que se ha sustituido el módulo de memoria caché (o la controladora) por otro que contiene un tamaño de memoria caché diferente. Es posible que este mensaje también aparezca después de la extracción o instalación del paquete de baterías de la memoria caché.
Acción
Para cambiar el porcentaje de asignación de lectura/escritura predeterminado de la memoria caché, ejecute HPE SSA. Para obtener más información, consulte la Guía de usuario de HPE Smart Storage Administrator en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage-docs).
1727-Slot X Drive Array – New (or Previously Failed) Logical Drive(s) Attachment DetectedSíntoma
1727-Slot X Drive Array - New (or Previously Failed) Logical Drive(s) Attachment Detected.
(Sometimes followed by:)
● Auto-configuration failed: Too many logical drives
● Auto-configuration failed: RAID 5/6 Drive Array migrated
Causa
La controladora ha detectado un array adicional de unidades que estaba conectado cuando la alimentación se desconectó. La información de configuración de unidades lógicas se ha actualizado para añadir las unidades lógicas nuevas. El número máximo de unidades lógicas admitido es 64. No se pueden añadir unidades lógicas adicionales a la configuración.
Acción
Confirme la configuración de unidades lógicas mediante HPE SSA. Para obtener más información, consulte la Guía de usuario de HPE Smart Storage Administrator en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage-docs).
1728-Slot # Drive Array – Abnormal Shut-Down DetectedSíntoma
1728-Slot # Drive Array – Abnormal Shut-Down Detected with Write Cache Enabled.
Causa
ESES Mensajes de error de la POST 107

La batería de HPE Smart Storage no estaba instalada o no estaba conectada correctamente, pero la memoria caché estaba activada. Los datos que pudieran estar en la memoria del módulo de memoria caché se han perdido debido a la pérdida de alimentación de la controladora.
Acción
Restaure los datos a partir de una copia de seguridad. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1729-Slot # Drive Array – Disk Performance Optimization Scan in ProgressSíntoma
1729-Slot # Drive Array – Disk Performance Optimization Scan in Progress. RAID 5/6 performance may be higher after completion.
(Sometimes followed by:)
Automatic RAID 6 parity data reinitialization in progress after migration from another controller model – multiple drive failure is not tolerated until this background initialization process completes.
Causa
Si recibe el mensaje especificado después de (en ocasiones seguido por:), significa que se está realizando la reinicialización automática de los datos de paridad de RAID 6 tras la migración desde otro modelo de controladora.
Acción
No es necesario hacer nada.
1730-Fixed Disk 0 Does Not Support DMA ModeSíntoma
1730-Fixed Disk 0 does not support DMA Mode.
Causa
Se ha detectado un error de unidad fijo.
Acción
Ejecute la utilidad de configuración del servidor y corrija la configuración. Para obtener más información, consulte la sección "Utilidades del sistema HPE UEFI" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
1731-Fixed Disk 1 Does Not Support DMA ModeSíntoma
1731-Fixed Disk 1 does not support DMA Mode.
Causa
Se ha detectado un error de unidad fijo.
Acción
Ejecute la utilidad de configuración del servidor y corrija la configuración. Para obtener más información, consulte la sección "Utilidades del sistema HPE UEFI" en la Guía de solución de
108 Capítulo 2 Errores de los servidores HPE ProLiant ESES

problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
1732-Slot # Drive Array – Cache Module Battery Pack MissingSíntoma
1732-Slot # Drive Array – Cache Module Battery Pack Missing. Posted-Write Cache is disabled until additional battery packs are installed.
Causa
● El paquete de baterías no se ha instalado.
● El paquete de baterías está deteriorado o ha fallado.
Acción
Asegúrese de que la batería esté conectada y en funcionamiento. Para obtener más información, consulte la sección "Gráfico de flujos de problemas de la batería de HPE Smart Storage" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
1733-Slot # Drive Array – Storage Enclosure Firmware Upgrade Problem DetectedSíntoma
1733-Slot # Drive Array – Storage Enclosure Firmware Upgrade Problem Detected. Port # Box #
(seguido por uno de los mensajes siguientes:)
● Enclosure firmware upgrade needed - run Flash Components. (Puerto X caja x: Es necesaria una actualización del firmware del chasis: ejecute los componentes Flash.)
● Unable to read firmware version of one or more components.
Causa
● Hay instalada una versión del firmware del chasis incorrecta.
● Es necesaria la actualización del firmware del chasis.
● Se ha producido un error en el componente del chasis.
Acción
1. Actualice el firmware del chasis y el firmware de la controladora.
Para obtener más información, consulte la sección "Actualizaciones de firmware" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
2. Si el problema continúa, sustituya los componentes afectados del chasis.
1734-Slot # Drive Array – Disk Drive(s) Responding to Incorrect SCSI IDSíntoma
1734-Slot # Drive Array – Disk Drive(s) Responding to Incorrect SCSI ID. Back up data, Replace faulty drive, Reconfigure array, and Restore.
Causa
ESES Mensajes de error de la POST 109

Se ha producido un fallo en la unidad.
Acción
1. Realice una copia de seguridad de los datos contenidos en la unidad de disco duro.
Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
2. sustituya la unidad.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
3. Reconfigure el array.
Para obtener más información, consulte la Guía de usuario de HPE Smart Storage Administrator en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage-docs).
4. Restaure los datos en una nueva unidad de disco duro.
1735-Slot # Drive Array – Unsupported Redundant Cabling Configuration DetectedSíntoma
1735-Slot # Drive Array – Unsupported Redundant Cabling Configuration Detected. Multiple paths to the same enclosure/drives are not supported by this Smart Array firmware version. Access to all drives has been disabled until redundant SAS cable(s) are detached, or firmware is updated to a version that supports dual-domain.
Causa
La versión del firmware de Smart Array no es compatible con la configuración de cableado redundante.
Acción
Realice una de las siguientes operaciones:
● Desconecte los cables de SAS redundantes.
● Actualice el firmware.
Para obtener más información, consulte la sección "Actualizaciones de firmware" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
1736-Trusted Platform Module ErrorSíntoma
1736-HP Trusted Platform Module Error.
Causa
Se ha instalado un TPM, pero la ROM del sistema no puede establecer la comunicación con TPM.
Acción
Solicite una nueva placa del sistema y la placa del TPM a un servicio técnico autorizado (Acceso al soporte de Hewlett Packard Enterprise en la página 493). Para obtener más información, consulte la sección "Problemas del módulo de la plataforma de confianza de HP" en la Guía de solución de
110 Capítulo 2 Errores de los servidores HPE ProLiant ESES

problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
1737-Slot X Drive Array – Redundant Cabling Configuration has excess Device PathsSíntoma
1737-Slot X Drive Array – Redundant Cabling Configuration has excess Device Paths. Redundant I/O paths to some of the devices attached to the controller are exceeding per device limit by firmware. These excess paths are ignored.
Causa
La configuración de cableado redundante crea más rutas de E/S de las que el firmware permite.
Acción
Realice una de las siguientes operaciones:
● Compruebe la configuración de cableado redundante.
Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
● Actualice el firmware.
Para obtener más información, consulte la sección "Actualizaciones de firmware" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
1738-Slot # Drive Array – Storage Enclosure Redundant Cabling Problem DetectedSíntoma
1738-Slot # Drive Array – Storage Enclosure Redundant Cabling Problem Detected. Check storage box I/O module and cable to restore redundant paths to the following disk drive(s):
Port # Box # Bay(s) #
Select “F1” to persist with this message on reboots until failed paths are restored
Select “F2” to disable this message on reboots – no further POST message for recurring path failure with logical drive(s) corresponding to these disk drives
Causa
Se ha producido un problema con el cableado redundante del chasis de almacenamiento. Se ha encontrado una ruta única a la unidades que previamente se conectaron de un modo redundante.
Acción
Compruebe el módulo de E/S de la caja de almacenamiento y el cable para restablecer las rutas redundantes a las unidades; a continuación, realice una de las siguientes acciones:
● Si los cables/rutas no se han eliminado a propósito, pulse la tecla F1 para mostrar este mensaje al reiniciar hasta que se resuelva el problema. Estas unidades deben estar accesibles a través de la ruta restante.
● Si las rutas redundantes se han eliminado a propósito, pulse la tecla F2 para desactivar este mensaje en todos los reinicios posteriores.
ESES Mensajes de error de la POST 111

1739-Slot # Drive Array – Redundant Cabling is not as recommendedSíntoma
1739-Slot # Drive Array – Redundant Cabling is not as recommended (followed by one or more of the following:)
● Storage box has multiple paths from same controller port
● I/O modules are not cabled for good fault tolerance
● Redundant I/O paths exist due to direct loopback of controller ports
● Redundant I/O module supported and unsupported storage boxes are cabled together
● Refer to product user guide
Causa
Configuración incorrecta de cableado redundante.
Acción
Para obtener más información sobre cómo cablear el dispositivo de un modo compatible para un soporte de ruta redundante de dominio doble, consulte la guía de usuario del producto.
1740-Fixed Disk 0 failed set Block ModeSíntoma
1740-Fixed Disk 0 failed set Block Mode.
Causa
Se ha detectado un error de unidad fijo.
Acción
Ejecute la utilidad de configuración del servidor y corrija la configuración. Para obtener más información, consulte la sección "Utilidades del sistema HPE UEFI" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
1741-Fixed Disk 1 failed set Block ModeSíntoma
1741-Fixed Disk 1 failed set Block Mode.
Causa
Se ha detectado un error de unidad fijo.
Acción
Ejecute la utilidad de configuración del servidor y corrija la configuración. Para obtener más información, consulte la sección "Utilidades del sistema HPE UEFI" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
1742-Slot X Drive Array - Previously Ejected Drive(s) DetectedSíntoma
112 Capítulo 2 Errores de los servidores HPE ProLiant ESES

1742- Slot X Drive Array - Previously Ejected Drive(s) Detected. The logical drive(s) will remain unavailable until re-enabled by the Array Configuration Utility. Port x Box y Bay(s) z. (Las unidades lógicas dejarán de estar disponibles hasta que Array Configuration Utility las active de nuevo. Puerto x Caja y Compartimentos z.)
Causa
El sistema detecta que las unidades continúan presentes durante el POST y que el usuario solicitó su eliminación anteriormente a partir de la información de configuración de la controladora.
Acción
Realice una de las siguientes operaciones:
● Si las unidades se van a eliminar posteriormente, para continuar ignorando las unidades físicas, pulse la tecla F1.
● Para cancelar la solicitud de eliminación y añadir estas unidades físicas y lógicas de nuevo a la controladora, pulse la tecla F2.
● Para volver a activar las unidades, utilice HPE SSA.
Para obtener más información, consulte la Guía de usuario de HPE Smart Storage Administrator en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage/docs).
1743-Slot # Drive Array – Logical Drive Erase Operation in ProgressSíntoma
1743-Slot # Drive Array – Logical Drive Erase Operation in Progress. Logical drives being erased are temporarily offline.
Causa
Las unidades son inaccesibles temporalmente durante una operación de borrado, o cuando se ponen en cola para el borrado.
Acción
Realice una de las siguientes operaciones:
● Espere a que el proceso de borrado finalice antes de utilizar la unidad lógica.
● Cancele el proceso de borrado utilizando HPE SSA.
Para obtener más información, consulte la Guía de usuario de HPE Smart Storage Administrator en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage/docs).
1743-Slot # Drive Array – Logical Drive Erase Operation(s) are QueuedSíntoma
1743-Slot # Drive Array – Logical Drive Erase Operation(s) are Queued. Logical drives will temporarily go offline while being erased.
Causa
Las unidades son inaccesibles temporalmente durante una operación de borrado, o cuando se ponen en cola para el borrado.
Acción
Realice una de las siguientes operaciones:
ESES Mensajes de error de la POST 113

● Espere a que el proceso de borrado finalice antes de utilizar la unidad lógica.
● Cancele el proceso de borrado utilizando HPE SSA.
Para obtener más información, consulte la Guía de usuario de HPE Smart Storage Administrator en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage/docs).
1744-Slot X Drive Array – Drive Erase Operation In ProgressSíntoma
1744-Slot X Drive Array – Drive Erase Operation In Progress (or Queued). The following disk drive(s) will be blank upon completion: (followed by a list of drives).
Causa
El usuario ha iniciado previamente una operación de borrado de la unidad. Esta operación se encuentra en curso o se ha programado para todas las unidades de la lista.
Acción
No es necesario hacer nada.
1745-Slot X Drive Array - Drive Erase Operation CompletedSíntoma
1745- Slot X Drive Array - Drive Erase Operation Completed. The following disk drive(s) have been erased and will remain offline until hot-replaced or re-enabled by the Array Configuration Utility:
(Followed by a list of drives)
Causa
La operación de borrado de la unidad se ha llevado a cabo con éxito y las unidades se conservan en un estado fuera de línea para asegurar que las unidades permanecen vacías hasta que el usuario vuelva a activarlas.
Acción
Sustituya cada unidad de la lista o actívelas de nuevo mediante uno de los siguientes métodos:
● Use HPE SSA.
Para obtener más información, consulte la Guía de usuario de HPE Smart Storage Administrator en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage/docs).
● Lleve a cabo la extracción de conexión en caliente y la reinstalación (solo discos duros de conexión en caliente).
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1746-Slot X Drive Array – Unsupported Storage Connection DetectedSíntoma
1746-Slot X Drive Array – Unsupported Storage Connection Detected. SAS connection via expander is not supported on this controller model. Access to all storage has been disabled until the expander and connections beyond it are detached or controller is upgraded.
Causa
114 Capítulo 2 Errores de los servidores HPE ProLiant ESES

La versión del firmware o la controladora no es compatible con el chasis de la unidad conectada.
Acción
Realice una de las siguientes operaciones:
● Actualiza la controladora.
● Actualice el firmware.
Para obtener más información, consulte la sección "Actualizaciones de firmware" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
● Desconecte las conexiones de almacenamiento basadas en el expansor.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1747-Slot # Drive Array – Unsupported Array Configuration DetectedSíntoma
1747-Slot # Drive Array – Unsupported Array Configuration Detected (followed by one of the following:)
● More logical drive(s) configured than what this controller model can support when the memory module is detached
● One or more logical drive(s) are configured in positions that this controller does not support when the memory module is detached.
● One or more logical drive(s) are configured for RAID fault tolerance level(s) that are not supported when the memory module is detached.
● Configuration information indicates one or more hard drive(s) are located in drive bays that are inaccessible when the memory module is detached.
● Capacity Expansion operation(s) are pending but cannot continue because the Cache Module has been detached.
● ALL logical drive(s) have been disabled. To avoid data loss, upgrade controller or move the drives back to the original controller. Run Array Configuration Utility to discard the current array and create new configuration (* Se han desactivado todas las unidades lógicas. Para evitar la pérdida de datos, actualice la controladora o vuelva a conectar las unidades a la controladora original. Ejecute Array Configuration Utility para descartar el array actual y crear una nueva configuración)
● Access to the following disk drives(s) has been disabled:
Select “F1” to continue disabling these drives until a new array configuration is created on them. To avoid data loss, move these drives back to the original controller. (Seleccione “F1” para continuar desactivando estas unidades hasta que se cree una nueva configuración de array en ellas. Para evitar que se pierdan datos, vuelva a colocar las unidades en la controladora original.)
Select “F2” to reset configuration in these disk drives now. (Seleccione “F2” para restablecer la configuración en estas unidades de disco ahora.)
Causa
ESES Mensajes de error de la POST 115

● Se ha extraído el módulo de memoria caché o este está defectuoso.
● Las unidades se han movido a una controladora que no tiene un módulo de memoria caché conectado.
Acción
1. Conecte un módulo de memoria caché a esta controladora o mueva las unidades de nuevo a la controladora original. Si las operaciones de expansión de la capacidad están pendientes, asegúrese de que el módulo de memoria caché está conectado.
2. Si se han desactivado todas las unidades lógicas, actualice la controladora o vuelva a colocar las unidades en la controladora original para evitar la pérdida de datos.
3. Ejecute HPE SSA para descartar el array actual y crear una nueva configuración.
Para obtener más información, consulte la Guía de usuario de HPE Smart Storage Administrator en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage/docs).
4. Si se ha desactivado el acceso a determinadas unidades, realice una de las siguientes acciones:
● Pulse la tecla F1 para que las unidades continúen desactivadas hasta que se cree una nueva configuración de array. Para evitar que se pierdan datos, vuelva a colocar las unidades en la controladora original.
● Pulse la tecla F2 para restablecer la configuración de las unidades.
1748-Slot # Drive Array – Unsupported Cache Module Battery AttachedSíntoma
1748-Slot # Drive Array – Unsupported Cache Module Battery Attached. Please install battery pack(s) with the correct part number.
Causa
La batería de HPE Smart Storage actual no es compatible con este módulo de memoria caché.
Acción
1. Utilice el número de referencia para comprobar que el componente es compatible.
Para obtener una lista de las opciones admitidas, consulte las QuickSpecs (Especificaciones rápidas) del producto en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/qs).
2. Instale una batería de HPE Smart Storage compatible.
Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1749-Slot X Drive Array – Cache Module Flash Memory being erasedSíntoma
1749-Slot X Drive Array – Cache Module Flash Memory being erased. Caching will be re-enabled when flash memory erase has completed.
Causa
Se está borrando la memoria flash del módulo de memoria caché.
Acción
116 Capítulo 2 Errores de los servidores HPE ProLiant ESES

No es necesario hacer nada.
1750-Fixed Disk 0 failed ID commandSíntoma
1750-Fixed Disk 0 failed ID command.
Causa
Se ha detectado un error de unidad fijo.
Acción
Ejecute la utilidad de configuración del servidor y corrija la configuración. Para obtener más información, consulte la sección "Utilidades del sistema HPE UEFI" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
1751-Fixed Disk 1 failed ID commandSíntoma
1751-Fixed Disk 1 failed ID command.
Causa
Se ha detectado un error de unidad fijo.
Acción
Ejecute la utilidad de configuración del servidor y corrija la configuración. Para obtener más información, consulte la sección "Utilidades del sistema HPE UEFI" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
1752-Slot X Drive Array – Controller not supported in this server modelSíntoma
1752-Slot X Drive Array – Controller not supported in this server model.
Causa
Se ha instalado una controladora no compatible.
Acción
Sustituya la controladora de Smart Array por un modelo compatible. Para obtener una lista de las opciones admitidas, consulte las QuickSpecs (Especificaciones rápidas) del producto en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/qs).
1753-Slot X Drive Array – Array Controller Maximum Operating Temperature ExceededSíntoma
1753-Slot X Drive Array – Array Controller Maximum Operating Temperature Exceeded During Previous Power Up.
Causa
La controladora está sobrecalentada.
ESES Mensajes de error de la POST 117

Acción
Asegúrese de que la controladora cuenta con la refrigeración del sistema adecuada y de que tiene un flujo de aire suficiente. Para obtener más información sobre los requisitos de flujo de aire y espacio óptimos, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1754-Slot X Drive Array – One or more RAID levels are configuredSíntoma
1754-Slot X Drive Array – One or more RAID levels are configured but are not supported due to controller model or an inactive/missing license key. Please re-attach drives to original controller or enter license key.
Causa
● El modelo de la controladora no es compatible con la configuración de las unidades.
● La clave de licencia está inactiva o falta.
Acción
Realice una de las siguientes operaciones:
● Vuelva a colocar las unidades en la controladora original.
● Escriba una clave de licencia válida.
1762-Slot X Drive Array – Controller Firmware Upgrade NeededSíntoma
1762-Slot X Drive Array – Controller Firmware Upgrade Needed (Unsupported Cache Module Attached). Caching is disabled. (Los datos de la memoria caché se han perdido. La memoria caché está desactivada.)
Causa
El firmware de la controladora actual no es compatible con el tipo de módulo de memoria caché conectado.
Acción
1. Actualice el firmware.
Para obtener más información, consulte la sección "Actualizaciones de firmware" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
2. Si el problema continúa, sustituya el módulo de la memoria caché.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs). Para ubicar una opción compatible, consulte las QuickSpecs (Especificaciones rápidas) del producto en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/qs).
1763-Slot X Drive Array – Cache module is detachedSíntoma
1763-Slot X Drive Array – Cache module is detached; please reattach.
118 Capítulo 2 Errores de los servidores HPE ProLiant ESES

Causa
El módulo de la memoria caché suelto, ausente o defectuoso.
Acción
Asegúrese de que el módulo de la memoria caché esté instalado correctamente y en funcionamiento. Para obtener más información, consulte la sección "Gráfico de flujo de problemas del módulo de la memoria caché" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
1764-Slot X Drive Array – Capacity Expansion Process is Temporarily DisabledSíntoma
1764-Slot X Drive Array – Capacity Expansion Process is Temporarily Disabled (followed by one of the following:)
● Expansion will resume when Cache Module has been reattached.
● Expansion will resume when Cache Module has been replaced.
● Expansion will resume when Cache Module RAM allocation is successful.
● Expansion will resume when Cache Module battery/capacitor reaches full charge.
● Expansion will resume when Automatic Data Recovery has been Completed.
● Expansion will resume when Cache Module battery/capacitor is connected.
Causa
● El módulo de la memoria caché se ha desconectado.
● El módulo de la memoria caché se ha sustituido.
● La ubicación de la memoria RAM del módulo de la memoria caché no era correcta.
● La batería de HPE Smart Storage no está cargada al completo.
● La recuperación automática de datos no se ha completado aún.
● La batería de HPE Smart Storage está desconectada.
Acción
Siga las instrucciones que se muestran en pantalla para reanudar el proceso de expansión de la capacidad.
1766-Slot X Drive Array requires System ROM UpgradeSíntoma
1766-Slot X Drive Array requires System ROM Upgrade.
Causa
La versión de la ROM del sistema no es la más actualizada.
Acción
Ejecute la utilidad FWUPDATE. Para obtener más información, consulte la sección "Utilidad FWUPDATE" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I:
ESES Mensajes de error de la POST 119

Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
1768-Slot X Drive Array – Resuming logical drive expansion processSíntoma
1768-Slot X Drive Array – Resuming logical drive expansion process.
Causa
● Se ha perdido la alimentación mientras se llevaba a cabo la operación de expansión lógica.
● Se ha producido un restablecimiento de la controladora o un ciclo de apagado y encendido mientras se realizaba la expansión del array.
Acción
No es necesario hacer nada.
1769-Slot X Drive Array – Drive(s) DisabledSíntoma
1769- Slot X Drive Array – Drive(s) Disabled due to Failure During Expansion
(Posiblemente seguido por uno de los siguientes mensajes adicionales):
● Cache Module Removed or Failed; Expansion Progress Data Lost. (El módulo de memoria caché se ha extraído o ha fallado; los datos de progreso de la expansión se han perdido.)
● Expansion Progress Data Could Not Be Read From Cache Module. (Los datos de progreso de la expansión no se han podido leer desde el módulo de memoria caché.)
● Expansion Aborted due to Unrecoverable Drive Errors. (La expansión se ha cancelado debido a errores de la unidad imposibles de recuperar.)
● Expansion Aborted due to Cache Module Errors. (La expansión se ha cancelado debido a errores en el módulo de memoria caché.)
Select "F1" to continue with logical drives disabled (Seleccione "F1" para continuar con las unidades lógicas desactivadas)
Select "F2" to accept data loss and to re-enable logical drives (Seleccione "F2" para aceptar la pérdida de datos y reactivar las unidades lógicas)
Causa
Se han perdido datos mientras se ampliaba el array; por lo tanto, las unidades se han desactivado temporalmente. Se ha producido un fallo en la expansión de la capacidad debido a:
● Se ha producido un fallo en el módulo de memoria caché o en el disco duro o este se ha extraído; los datos de progreso de la expansión se han perdido.
● Los datos de progreso de la expansión no se han podido leer desde el módulo de memoria caché.
● La expansión se ha cancelado debido a errores de la unidad imposibles de recuperar.
● La expansión se ha cancelado debido a errores en el módulo de memoria caché.
Acción
Realice una de las siguientes operaciones:
120 Capítulo 2 Errores de los servidores HPE ProLiant ESES

● Pulse la tecla F1 para continuar con las unidades lógicas desactivadas.
● Pulse la tecla F2 para aceptar la pérdida de datos y reactivar las unidades lógicas. Si es necesario, restaure los datos desde la copia de seguridad.
Acciones adicionales para errores específicos
● Cache Module Removed or Failed; Expansion Progress Data Lost. (El módulo de memoria caché se ha extraído o ha fallado; los datos de progreso de la expansión se han perdido.) Compruebe que el módulo de memoria caché está colocado correctamente. Sustitúyalo si es necesario.
● Expansion Progress Data Could Not Be Read From Cache Module. (Los datos de progreso de la expansión no se han podido leer desde el módulo de memoria caché.) Compruebe que el módulo de memoria caché está colocado correctamente. Sustitúyalo si es necesario.
● Expansion Aborted due to Unrecoverable Drive Errors. (La expansión se ha cancelado debido a errores de la unidad imposibles de recuperar.) Utilice HPE SSA para comprobar los discos que han fallado y sustituya los que sea necesario.
● Expansion Aborted due to Cache Module Errors. (La expansión se ha cancelado debido a errores en el módulo de memoria caché.) Compruebe que el módulo de memoria caché está colocado correctamente. Sustitúyalo si es necesario.
Si es necesario, restaure los datos desde la copia de seguridad.
1770-Slot X Drive Array – Disk Drive Firmware Update RecommendedSíntoma
1770-Slot X Drive Array – Disk Drive Firmware Update Recommended. Please upgrade firmware on the following drive model(s) using ROM Flash Components: Model XYZ (minimum version = ####)
Causa
Es necesaria la actualización del firmware de la unidad.
Acción
Actualice todas las unidades a la última versión del firmware. Para obtener más información, consulte la sección "Actualizaciones de firmware" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
1774-Slot X Drive Array – Obsolete data found in Cache ModuleSíntoma
1774-Slot X Drive Array – Obsolete data found in Cache Module. Data Found in Cache Module was Older Than Data Found on Drives. Obsolete Data has been Discarded.
Causa
Se han utilizado las unidades en otra controladora y se han conectado de nuevo a la controladora original mientras los datos estaban en la memoria caché de la controladora original. Los datos encontrados en el módulo de memoria caché son anteriores a los datos encontrados en las unidades y se han descartado automáticamente.
Acción
No es necesario hacer nada.
ESES Mensajes de error de la POST 121

1775-Slot X Drive Array – Storage Enclosure Cabling Problem DetectedSíntoma
1775-Slot X Drive Array – Storage Enclosure Cabling Problem Detected: SAS Port Y: OUT port of this box is attached to OUT port of previous box. Turn system and storage box power OFF and check cables. Drives in this box and connections beyond it will not be available until the cables are attached correctly.
Causa
Los cables no están conectados correctamente.
Acción
1. Apague el servidor.
2. Apague el chasis de almacenamiento
3. Corrija el cableado del chasis de almacenamiento.
Para obtener más información, consulte la documentación del chasis de almacenamiento.
1776-Slot X Drive Array – Shared SAS Port Connection Conflict DetectedSíntoma
1776-Slot X Drive Array – Shared SAS Port Connection Conflict Detected - Ports 1I, 1E: Storage connections detected on both shared internal and external ports. Controller selects internal port until connection is removed from one of the ports.
Causa
Los cables no están conectados correctamente.
Acción
Quite las conexiones de almacenamiento interno y externo de los puertos en que estén conectadas. Para obtener información acerca de la configuración de cableado, consulte la documentación de la controladora.
1777-Slot X Drive Array – Storage Enclosure Problem DetectedSíntoma
1777-Slot X Drive Array – Storage Enclosure Problem Detected
(followed by one or more of the following):
● Cooling Fan Malfunction Detected
● Overheated Condition Detected
● Side-Panel must be Closed to Prevent Overheating
● Redundant Power Supply Malfunction Detected
● Unsupported ROM Type Installed on Backplane
● Enclosure Processor Not Detected or Responding – Turn system and storage enclosure power OFF and turn them back ON to retry. If this error persists, upgrade the enclosure firmware or replace the I/O module.
● Link Errors Detected by Expander
122 Capítulo 2 Errores de los servidores HPE ProLiant ESES

● Incorrect Bay Information Received from Enclosure
● Installed drives not detected, only I/O module 2 present
Causa
Se ha superado el umbral del entorno en el chasis de la unidad.
Acción
Cooling Fan Malfunction Detected (Puerto SCSI Y: se ha detectado una avería en el ventilador de refrigeración)
1. Compruebe el funcionamiento del ventilador de refrigeración colocando una mano sobre el ventilador.
2. Vuelva a colocar el ventilador.
3. Cierre el panel lateral.
4. Si el problema continúa, sustituya el ventilador.
Overheated Condition Detected (Puerto SCSI Y: se ha detectado una condición de sobrecalentamiento)
1. Compruebe si existen obstrucciones.
2. Compruebe todas las conexiones internas.
3. Compruebe el funcionamiento del ventilador de refrigeración colocando una mano sobre el ventilador.
4. Vuelva a colocar el ventilador.
5. Cierre el panel lateral.
6. Si el problema continúa, sustituya el ventilador.
Side-Panel must be Closed to Prevent Overheating (Puerto SCSI Y: es necesario que el panel lateral esté cerrado para evitar el sobrecalentamiento)
1. Compruebe si existen obstrucciones.
2. Compruebe todas las conexiones internas.
3. Cierre el panel lateral.
Redundant Power Supply Malfunction Detected (Puerto SCSI Y: se ha detectado una avería en la fuente de alimentación redundante)
1. Compruebe los indicadores LED. Si el indicador LED de alimentación del sistema de almacenamiento ProLiant se muestra en ámbar en lugar de en verde, indica un fallo redundante en la fuente de alimentación.
2. Vuelva a colocar la fuente de alimentación.
3. Si el problema continúa, sustituya la fuente de alimentación.
Unsupported ROM Type Installed on Backplane
1. Vuelva a colocar la controladora.
2. Vuelva a colocar el módulo de memoria caché.
ESES Mensajes de error de la POST 123

3. Actualice el firmware de la controladora.
4. Si el problema continúa:
a. Sustituya la controladora.
b. Actualice el firmware.
Enclosure Processor Not Detected or Responding
1. Apague el chasis de almacenamiento y el sistema.
2. Encienda el chasis de almacenamiento y el sistema.
3. Si el problema continúa, realice uno de los siguientes procedimientos:
● Actualice el firmware del chasis.
● Sustituya el módulo de E/S.
Link Errors Detected by Expander
1. Vuelva a colocar los módulos de E/S.
2. Vuelva a colocar los cables del módulo de E/S.
3. Sustituya los cables si están dañados.
4. Si el problema continúa, sustituya los módulos de E/S.
Incorrect Bay Information Received from Enclosure
1. Vuelva a colocar los módulos de E/S.
2. Vuelva a colocar los cables del módulo de E/S.
3. Sustituya los cables si están dañados.
4. Si el problema continúa, sustituya los módulos de E/S.
Installed drives not detected, only I/O module 2 present
1. Vuelva a colocar los módulos de E/S.
2. Vuelva a colocar los cables del módulo de E/S.
3. Sustituya los cables si están dañados.
4. Si el problema continúa, sustituya el módulo de E/S 1.
1778-Slot X Drive Array resuming Automatic Data Recovery (Rebuild) processSíntoma
1778-Slot X Drive Array resuming Automatic Data Recovery (Rebuild) process.
Causa
Se ha producido un restablecimiento de la controladora o ciclo de alimentación mientras la recuperación de datos automática se encontraba en curso.
Acción
No es necesario hacer nada.
124 Capítulo 2 Errores de los servidores HPE ProLiant ESES

1779-Slot X Drive Array – Replacement drive(s) detectedSíntoma
1779-Slot X Drive Array – Replacement drive(s) detected OR previously failed drive(s) now appear to be operational: Port X Box Y Bay(s) Z
Restore data from backup if replacement drives have been installed. (Restaure los datos a partir de la copia de seguridad si se han instalado unidades de sustitución.)
Causa
● Se han producido fallos en más unidades (o estas se han sustituido) de las que permite el nivel de tolerancia de fallos. No es posible reconstruir el array. Si no se han sustituido las unidades, este mensaje indica un fallo intermitente en la unidad.
● El sistema no se ha encendido o apagado correctamente.
Acción
1. Resuelva los problemas que provocaron que se desactivara la unidad.
2. Si se sustituye la unidad, restaure los datos desde la copia de seguridad.
Asegúrese de que el sistema siempre se enciende y apaga correctamente:
● Cuando encienda el sistema, los sistemas de almacenamiento externos deben encenderse antes (o al mismo tiempo) que el servidor.
● Cuando apague el sistema, es necesario apagar el servidor antes de apagar cualquier sistema de almacenamiento externo.
1779-Slot X Drive Array – Logical drive(s) previously failedSíntoma
1779-Slot X Drive Array – Logical drive(s) previously failed.
Select "F1" to continue with logical drives disabled (Seleccione "F1" para continuar con las unidades lógicas desactivadas)
Select "F2" to accept data loss and to re-enable logical drives (Seleccione "F2" para aceptar la pérdida de datos y reactivar las unidades lógicas)
(seguido por uno de los mensajes siguientes:)
● Logical drive(s) disabled due to possible data loss.
● Logical drive(s) reenabled.
Restore data from backup if replacement drives have been installed. (Restaure los datos a partir de la copia de seguridad si se han instalado unidades de sustitución.)
Causa
● La controladora tiene conectadas algunas unidades que han fallado anteriormente.
● El sistema no se ha encendido o apagado correctamente.
Acción
1. Realice una de las siguientes operaciones:
ESES Mensajes de error de la POST 125

● Pulse la tecla F1 para continuar con las unidades lógicas desactivadas.
● Pulse la tecla F2 para aceptar la pérdida de datos y reactivar las unidades lógicas.
2. Resuelva los problemas que provocaron que se desactivara la unidad.
3. Si se sustituye la unidad, restaure los datos desde la copia de seguridad.
Asegúrese de que el sistema siempre se enciende y apaga correctamente:
● Cuando encienda el sistema, los sistemas de almacenamiento externos deben encenderse antes (o al mismo tiempo) que el servidor.
● Cuando apague el sistema, es necesario apagar el servidor antes de apagar cualquier sistema de almacenamiento externo.
1783-Slot X Drive Array Controller FailureSíntoma
1783-Slot X Drive Array Controller Failure
(seguido por uno de los mensajes siguientes:)
● [Board ID not programmed (replace ROMs or replace controller)]
● [I2C read error]
● [Image checksum error]
● [Inconsistent volume count2
● [Inconsistent volume count (B)]
● [Unexpected hardware revision – hardware rework needed]
● [Unsupported Flash ROM type installed]
● [iLO communication mechanism self-test error]
● [PROGRAM BUG! Insufficient padding bytes (cmd=##h)] (* [¡ERROR EN EL PROGRAMA! Número insuficiente de bytes de relleno (cmd=##h)])
● [Incorrect EEPROM type]
● [Init failure (cmd=##h, err=##h)]
● [Command failure (cmd=##h, err=##h)]
● [Self-test failure (ErrCode=####h)]
● [I2C NVRAM reconfiguration failure]
● [PCI bridge missing]
● [PCI bridge disabled; check System ROM version]
● [PDPI not found]
● [PDPI disabled; check System ROM version]
● [Board ID not programmed]
Causa
126 Capítulo 2 Errores de los servidores HPE ProLiant ESES

● El módulo de memoria caché no está instalado correctamente.
● La controladora no se ha instalado correctamente.
● El firmware de la controladora está obsoleto.
● Se ha producido un fallo en la controladora.
Acción
1. Vuelva a colocar el módulo de memoria caché.
2. Coloque de nuevo la controladora en la ranura PCI.
3. Actualice la controladora a la última versión del firmware.
Para obtener más información, consulte la sección "Actualizaciones de firmware" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
4. Si el problema continúa, sustituya la controladora.
Para realizar los procedimientos de extracción y sustitución, consulte a la guía de mantenimiento y servicio del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1784-Slot X Drive Array – Logical Drive FailureSíntoma
1784-Slot X Drive Array – Logical Drive Failure
Causa
● Se ha producido un fallo o no se ha instalado una unidad correctamente.
● Hay un cable que no está instalado correctamente.
Acción
1. Asegúrese de que todos los cables están conectados de forma adecuada y segura.
Para obtener más información, consulte la sección "Resolución de conexiones sueltas" Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
2. Asegúrese de que todas las unidades se han colocado correctamente.
3. Utilice HPE SSA para determinar cuál es la unidad defectuosa. A continuación, sustituya la unidad o los cables defectuosos.
Para obtener más información, consulte la Guía de usuario de HPE Smart Storage Administrator en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage/docs). Para realizar los procedimientos de extracción y sustitución, consulte a la guía de mantenimiento y servicio del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1784-Slot X Drive Array – Drive FailureSíntoma
1784-Slot X Drive Array – Drive Failure. The following disk drive(s) should be replaced:
ESES Mensajes de error de la POST 127

Port X Box Y Bay(s) Z (...Es necesario sustituir las unidades de disco siguientes: Puerto X Caja Y Compartimentos Z)
Causa
● Hay un cable que no está instalado correctamente.
● Se ha producido un fallo o no se ha instalado una unidad correctamente.
Acción
1. Asegúrese de que todos los cables están conectados de forma adecuada y segura.
Para obtener más información, consulte la sección "Resolución de conexiones sueltas" Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
2. Asegúrese de que todas las unidades se han colocado correctamente.
3. Utilice HPE SSA para determinar cuál es la unidad defectuosa. A continuación, sustituya la unidad o los cables defectuosos.
Para obtener más información, consulte la Guía de usuario de HPE Smart Storage Administrator en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage/docs). Para realizar los procedimientos de extracción y sustitución, consulte a la guía de mantenimiento y servicio del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1785-Slot XX Not ConfiguredSíntoma
1785-Slot XX Not Configured. SAS cable configuration is invalid. Action: See User’s Guide for supported cabling guidelines.
Causa
Las conexiones entre las unidades o las controladoras faltan o son incorrectas.
Acción
Compruebe las conexiones entre las unidades, las matrices de conectores y la controladora. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1786-Slot X Drive Array Recovery NeededSíntoma
1786-Slot X Drive Array Recovery Needed. The following drive(s) need Automatic Data Recovery (Rebuild): Port x Box y Bay(s) z
Select F1 to continue with recovery of data to drive. (Seleccione F1 para continuar con la recuperación de datos de la unidad.) Select F2 to continue without recovery of data to drive. (Seleccione F2 para continuar sin recuperar los datos de la unidad.)
Causa
Todavía no se ha reconstruido una unidad de sustitución o con fallos.
Acción
128 Capítulo 2 Errores de los servidores HPE ProLiant ESES

1. Realice una de las siguientes operaciones:
● Pulse la tecla F1 para continuar con la recuperación de datos de la unidad. Los datos se restaurarán automáticamente a la unidad cuando se sustituya una unidad que presente fallos o a la unidad original si funciona de nuevo sin errores.
● Pulse la tecla F2 para continuar sin la recuperación de datos de la unidad. La unidad que presenta fallos no se reconstruirá y el sistema continuará en funcionamiento en un estado Failed de modo provisional de recuperación de datos.
2. Sustituya la unidad que presenta el fallo y pulse la tecla F1 para reconstruir el array. Si la reconstrucción de la unidad no tiene éxito o si se cancela porque el sistema se ha reiniciado antes de finalizar la reconstrucción de la unidad, se muestra otra versión del mensaje de error 1786 POST.
1787-Slot X Drive Array Operating in Interim Recovery (Degraded) ModeSíntoma
1787-Slot X Drive Array Operating in Interim Recovery (Degraded) Mode.
(Followed by one or more of the following:)
● The following disk drive(s) are failed and should be replaced
● The following disk drive(s) are insufficient size and should be replaced
● The following disk drive(s) are mismatched type and should be replaced
● The following disk drive(s) are unsupported type and should be replaced
● The following disk drive(s) are offline due to the erase process
(Additionally followed by one of the following if a spare drive is activated:)
● On-Line Spare Drive is being Activated
● On-Line Spare Drive Active
● On-Line Spare Drive Failed
Causa
● Se ha producido un fallo en la unidad.
● Las unidades no tienen el tamaño suficiente.
● Las unidades son de distintos tipos.
● Las unidades no son compatibles.
● Las unidades están desconectadas.
● Hay un cable que no está instalado correctamente.
● Se ha producido un fallo en el cable.
Después de reiniciar el sistema, este mensaje indica que la unidad es defectuosa y que puede que la unidad lógica no tenga tolerancia a fallos, y que falle si falla otra unidad física.
Acción
1. Asegúrese de que todos los cables están conectados de forma adecuada y segura.
Para obtener más información, consulte la sección "Resolución de conexiones sueltas" Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas
ESES Mensajes de error de la POST 129

en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
2. Asegúrese de que todas las unidades se han colocado correctamente.
3. Utilice HPE SSA para determinar cuál es la unidad defectuosa. A continuación, sustituya la unidad o los cables defectuosos. En función del nivel de tolerancia a fallos, es posible que se pierdan todos los datos si falla otra unidad.
Para obtener más información, consulte la Guía de usuario de HPE Smart Storage Administrator en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage/docs). Para realizar los procedimientos de extracción y sustitución, consulte a la guía de mantenimiento y servicio del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1788-Slot X Drive Array Reports Incorrect Drive ReplacementSíntoma
1788-Slot X Drive Array Reports Incorrect Drive Replacement. The following drive(s) should have been replaced: Port x Box y Bay(s) z
The following drive(s) were incorrectly replaced: Port x Box y Bay(s) z (Se sustituyeron incorrectamente las unidades de disco siguientes: Puerto x Caja y Compartimentos z)
Select "F1" to continue – drive array will remain disabled. (Seleccione "F1" para continuar: el array de unidades permanecerá desactivado.)
Select "F2" to reset configuration – all data will be lost. (Seleccione "F2" para restablecer la configuración: se perderán todos los datos.)
Causa
● Las unidades de sustitución se han instalado en los compartimentos de unidad incorrectos.
● Se ha producido una conexión incorrecta del cable de alimentación a la unidad, ruido en el cable de datos o un cable SAS defectuoso.
Acción
● Si las unidades de sustitución están instaladas en los compartimentos incorrectos, instale de nuevo las unidades correctamente, tal como se indica y, a continuación, realice una de las acciones siguientes:
◦ Pulse la tecla F1 para reiniciar el servidor con el array de unidad desactivado.
◦ Pulse la tecla F2 para utilizar las unidades tal y como se han configurado y perder todos los datos que contienen.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
● Si se ha producido una conexión del cable de alimentación incorrecta:
a. Repare la conexión y, a continuación, pulse la tecla F2.
b. Si el problema continúa, ejecute HPE SSA.
130 Capítulo 2 Errores de los servidores HPE ProLiant ESES

Para obtener más información, consulte la Guía de usuario de HPE Smart Storage Administrator en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage/docs).
● Compruebe que el cable esté instalado correctamente.
Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1789-Slot X Drive Array Disk Drive(s) Not RespondingSíntoma
1789-Slot X Drive Array Disk Drive(s) Not Responding. Check cables or replace the following drive(s): Port x Box y Bay(s) z.
Select "F1" to continue – drive array will remain disabled. (Seleccione "F1" para continuar: el array de unidades permanecerá desactivado).
Select "F2" to fail drive(s) that are not responding - Interim Recovery Mode will be enabled if configured for fault tolerance. (Seleccione "F2" para marcar como erróneas las unidades que no respondan: el modo provisional de recuperación se activará si está configurado para la tolerancia a fallos.)
Causa
● Se ha producido un fallo o no se ha instalado una unidad correctamente.
● Hay un cable que no está instalado correctamente.
● Se ha producido un fallo en el cable.
● El sistema no se ha encendido o apagado correctamente.
Acción
1. Apague el sistema.
2. Compruebe que todos los cables están correctamente conectados.
3. Asegúrese de que todas las unidades se han colocado correctamente.
4. Apague y encienda todos los chasis externos mientras el sistema esté apagado.
5. Encienda el servidor para ver si el problema continúa.
6. Si se ha configurado para una operación de tolerancia de fallos y el nivel de RAID puede admitir fallos de todas las unidades indicadas:
a. Pulse la tecla F2 para desactivar las unidades que no responden
b. Sustituya las unidades.
7. Pulse la tecla F1 para iniciar el sistema con todas las unidades lógicas de la controladora desactivadas.
Asegúrese de que el sistema siempre se enciende y apaga correctamente:
● Cuando encienda el sistema, los sistemas de almacenamiento externos deben encenderse antes (o al mismo tiempo) que el servidor.
● Cuando apague el sistema, es necesario apagar el servidor antes de apagar cualquier sistema de almacenamiento externo.
ESES Mensajes de error de la POST 131

1792-Slot X Drive Array – Valid Data Found in Write-Back CacheSíntoma
1792-Slot X Drive Array – Valid Data Found in Write-Back Cache. Data will automatically be written to drive array.
Causa
La alimentación se ha interrumpido mientras había datos en la memoria caché de escritura no simultánea. La alimentación se ha restablecido al cabo de unos días y los datos de la memoria caché de escritura no simultánea se han vaciado al array de unidades.
Acción
No es necesario hacer nada. No se ha perdido ningún dato. Para evitar que queden datos en la memoria caché de escritura no simultánea, cierre el sistema de un modo ordenado.
1793-Slot X Drive Array – Data in Cache has been lostSíntoma
1793-Slot X Drive Array – Data in Cache has been lost.
(seguido por uno de los mensajes siguientes:)
● Cache Module Battery Depleted
● Cache Module Battery Disconnected
● Cache Data Backup Failed
● Cache Backup Data Restore Failed
Causa
● La alimentación se ha interrumpido mientras había datos en la memoria caché.
● La batería de HPE Smart Storage está deteriorada o ha fallado.
Acción
1. Compruebe la integridad de los datos almacenados en la unidad. La alimentación no se ha restablecido en un periodo de tiempo suficiente para guardar los datos.
2. Para evitar que queden datos en la memoria caché, cierre el sistema de un modo ordenado.
3. Si los datos están dañados, restaure datos de copia de seguridad anteriores.
1794-Slot X Drive Array – Cache Module Battery is ChargingSíntoma
1794–Slot X Drive Array – Cache Module Battery is Charging. Caching will be enabled once the battery has been charged. No es necesario hacer nada.
Causa
La batería del módulo de la memoria caché se está cargando.
Acción
No es necesario hacer nada.
132 Capítulo 2 Errores de los servidores HPE ProLiant ESES

1795-Slot X Drive Array – Cache Module Configuration ErrorSíntoma
1795-Slot X Drive Array – Cache Module Configuration Error. Data does not correspond to this drive array. Caching is temporarily disabled.
Causa
● La alimentación se ha interrumpido mientras había datos en la memoria caché.
● Los datos almacenados en la memoria caché no se corresponden con el array de la unidad.
Acción
Realice una de las siguientes operaciones:
● Haga que la memoria caché coincida con el array de la unidad correcto.
● Ejecute HPE SSA para borrar los datos en la memoria caché.
Para obtener más información, consulte la Guía de usuario de HPE Smart Storage Administrator en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage/docs).
1796-Slot X Drive Array – Flash Backed Write Cache module is not respondingSíntoma
1796-Slot X Drive Array - Flash Backed Write Cache module is not responding. Action: Turn off power and reseat the Flash Backed Write Cache Module. If error persists, replace module.
Causa
● Falta el módulo de la memoria caché.
● Se ha producido un fallo en el módulo de la memoria caché.
En función del modelo de controladora de array, es posible que la memoria caché esté desactivada o que la controladora no se pueda utilizar hasta que se solucione el problema.
Acción
1. Vuelva a colocar el módulo de memoria caché.
2. Si el problema continúa, sustituya el módulo de la memoria caché.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1797-Slot X Drive Array – Write-Back Cache Backup Previously FailedSíntoma
1797-Slot X Drive Array - Flash Backed Write Cache module read or backup error occurred. Action: Replace Flash Backed Write Cache module.
Causa
ESES Mensajes de error de la POST 133

● La batería de HPE Smart Storage no se ha cargado lo suficiente como para proporcionar alimentación de reserva para el módulo de memoria caché.
● Los datos no se pudieron copiar en la memoria caché de escritura no simultánea.
● Los metadatos almacenados en la memoria caché de escritura no simultánea no se pudieron leer ni escribir.
Acción
1. Utilice iLO para comprobar la carga de la batería de HPE Smart Storage. Compruebe que la carga de la batería es suficiente permitir el almacenamiento en memoria caché.
2. Compruebe que el módulo de memoria caché está colocado correctamente.
3. Vuelva a colocar el módulo de memoria caché.
4. Sustituya el módulo de memoria caché.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1797-Slot X Drive Array – Write-Back Cache Read Error OccurredSíntoma
1797-Slot X Drive Array – Write-Back Cache Read Error Occurred. Data in Cache has been lost. Caching is disabled. (Los datos de la memoria caché se han perdido. La memoria caché está desactivada.)
Causa
Se ha detectado un error de paridad de hardware mientras se leían los datos de la memoria de escrituras enviadas.
Acción
Sustituya el módulo de memoria caché. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1797-Slot X Drive Array – Write-Back Cache Restore Previously FailedSíntoma
1797-Slot X Drive Array – Write-Back Cache Restore Previously Failed. Caching is disabled. (Los datos de la memoria caché se han perdido. La memoria caché está desactivada.)
Causa
● Se ha producido un problema con la lectura de la memoria caché de escritura no simultánea.
● Se ha producido un error al escribir en la memoria DDR.
● A failure occurred with reading or writing to the metadata stored in the Write-Back Cache.
Acción
1. Utilice iLO para comprobar la carga de la batería de HPE Smart Storage. Compruebe que la carga de la batería es suficiente permitir el almacenamiento en memoria caché.
2. Compruebe que el módulo de memoria caché está colocado correctamente.
134 Capítulo 2 Errores de los servidores HPE ProLiant ESES

3. Vuelva a colocar el módulo de memoria caché.
4. Sustituya el módulo de memoria caché.
5. Si los datos están dañados, restaure datos de copia de seguridad anteriores.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1798-Slot X Drive Array – Cache Module Self-Test Error OccurredSíntoma
1798-Slot X Drive Array - Flash Backed Write Cache Self-Test Error Occurred. Action: Replace Flash Backed Write Cache module.
Causa
Se ha producido un fallo en la autocomprobación del módulo de memoria caché. En función del modelo de controladora de array, es posible que la memoria caché esté desactivada o que la controladora no se pueda utilizar hasta que se solucione el problema.
Acción
Sustituya el módulo de memoria caché. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1799-Slot X Drive Array – Drive(s) Disabled due to Cache Data LossSíntoma
1799-Slot # Drive Array - Drive(s) Disabled due to Cache Data Loss.
Select “F1” to continue with logical drives disabled.
Select “F2” to accept data loss and to re-enable logical drives. (Seleccione “F2” para aceptar la pérdida de datos y reactivar las unidades lógicas.)
Causa
Al menos una unidad lógica ha fallado debido a la pérdida de datos de la memoria de escrituras enviadas.
Acción
Realice una de las siguientes operaciones:
● Pulse la tecla F1 para continuar con las unidades lógicas desactivadas.
● Pulse la tecla F2 para aceptar la pérdida de datos y reactivar las unidades lógicas.
Tras pulsar la tecla F2 compruebe la integridad del sistema de archivos y restaure los datos perdidos desde la copia de seguridad.
1799-Slot X Drive Array – Drive(s) Disabled due to Write-Back Cache Data LossSíntoma
1799-Slot X Drive Array – Drive(s) Disabled due to Write-Back Cache Data Loss.
Select “F1” to continue with logical drives disabled.
ESES Mensajes de error de la POST 135

Select “F2” to accept data loss and to re-enable logical drives. (Seleccione “F2” para aceptar la pérdida de datos y reactivar las unidades lógicas.)
Causa
Al menos una unidad lógica ha fallado debido a la pérdida de datos de la memoria de escrituras enviadas.
Acción
Realice una de las siguientes operaciones:
● Pulse la tecla F1 para continuar con las unidades lógicas desactivadas.
● Pulse la tecla F2 para aceptar la pérdida de datos y reactivar las unidades lógicas.
Tras pulsar la tecla F2 compruebe la integridad del sistema de archivos y restaure los datos perdidos desde la copia de seguridad.
179A-Slot X Drive Array – Flash Backed Write Cache has been disabledSíntoma
179A-Slot X Drive Array - Flash Backed Write Cache has been disabled due to operation error. Action: Replace Flash Backed Write Cache module.
Causa
Se ha producido un fallo en el módulo de la memoria caché.
Acción
Sustituya el módulo de memoria caché. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
Serie 18001802-Slot # Drive Array – Dual domain configured or detected
Síntoma
1802-Slot # Drive Array – Dual domain configured or detected but is not supported due to a missing or expired license key. Action: Enter HP Smart Array Advanced Pack License Key.
Causa
Falta una clave de licencia o ha caducado.
Acción
Escriba una clave de licencia de HPE Smart Array Advanced Pack nueva o válida.
1803-Slot X Drive Array – Cache Module is not installedSíntoma
1803-Slot X Drive Array – Cache Module is not installed. IMPORTANT: Unsupported Configuration: Controller performance and supported configurations are limited. (IMPORTANTE: Configuración no admitida; se han limitado el rendimiento y las configuraciones admitidas por la controladora.) Action: Install the Cache Module to remove these limitations.
Causa
136 Capítulo 2 Errores de los servidores HPE ProLiant ESES

El módulo de la memoria caché no está instalado.
Acción
Instale el módulo de la memoria caché para quitar las limitaciones. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1804-Slot X Drive Array – Cache Module critical errorSíntoma
1804-Slot X Drive Array – Cache Module critical error. Action: Replace Cache Module (Controller is disabled until this problem is resolved).
Causa
Se ha producido un fallo en el módulo de la memoria caché.
Acción
Sustituya el módulo de memoria caché. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1806-Slot X Drive Array – Cache Module flash memory is not installedSíntoma
1806-Slot # Drive Array – Cache Module flash memory is not installed. IMPORTANT: Unsupported Configuration: Cache Module functionality is limited. (IMPORTANTE: Configuración no admitida; las funciones del módulo de memoria caché están limitadas.) Action: Install the flash memory to remove these limitations.
Causa
La memoria flash del módulo de memoria caché no está instalada.
Acción
Instale la memoria flash. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1807-Slot X Drive Array – Cache Module incompatible with this controllerSíntoma
1807-Slot X Drive Array – Cache Module incompatible with this controller. IMPORTANT: Access to all storage has been disabled. (IMPORTANTE: Se ha desactivado el acceso a todos los dispositivos de almacenamiento.) Action: Replace the Cache Module to re-enable all storage.
Causa
El módulo de memoria caché es incompatible con la controladora.
Acción
1. Para ubicar una opción compatible, consulte las QuickSpecs (Especificaciones rápidas) del producto en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/qs).
2. Sustituya el módulo de memoria caché por una opción compatible.
ESES Mensajes de error de la POST 137

Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1808-Slot X Drive Array – Cache Module critical errorSíntoma
1808-Slot X Drive Array – Cache Module critical error. IMPORTANT: Access to all storage has been disabled. (IMPORTANTE: Se ha desactivado el acceso a todos los dispositivos de almacenamiento.) Action: Replace the Cache Module to re-enable all storage.
Causa
Se ha producido un fallo en el módulo de la memoria caché.
Acción
Sustituya el módulo de memoria caché. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1809-Slot X Encryption FailureSíntoma
1809-Slot X Encryption Failure-Communication issue prevents drive keys from being retrieved. Encrypted logical drives are offline. System may not boot. Action: See iLO Key Manager Page to troubleshoot.
Causa
Hay un problema de comunicación.
Acción
Reinicie el servidor para restablecer la controladora. Para obtener más información, consulte la HPE Secure Encryption Installation and User Guide (Guía de usuario e instalación de HPE Secure Encryption) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage-docs).
1810-Slot X Encryption FailureSíntoma
1810-Slot X Encryption Failure-Master Key is incorrect or not retrieved from Remote Key Manager. Encrypted logical drives may be offline. System may not boot. Action: Correct problem on the Key Manager.
Causa
La clave maestra es incorrecta o no se ha obtenido desde el gestor de claves remoto.
Acción
Utilice HPE Enterprise Secure Key Manager para corregir el problema. Para obtener más información, consulte la HPE Secure Encryption Installation and User Guide (Guía de usuario e instalación de HPE Secure Encryption) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage-docs).
138 Capítulo 2 Errores de los servidores HPE ProLiant ESES

1811-Slot X Encryption FailureSíntoma
1811-Slot X Encryption Failure-Drive Keys not retrieved from the Remote Key Manager. Dependent encrypted logical drives are offline. System may not boot. Action: Correct the problem on the Key Manager.
Causa
Las claves de la unidad no se pudieron recuperar del gestor de claves remoto.
Acción
Utilice HPE Enterprise Secure Key Manager para corregir el problema. Para obtener más información, consulte la HPE Secure Encryption Installation and User Guide (Guía de usuario e instalación de HPE Secure Encryption) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage-docs).
1812-Slot X Encryption FailureSíntoma
1812-Slot X Encryption Failure-Invalid Drive Keys on Remote Key Manager. Encrypted logical drives may be offline. System may not boot. Action: Restore correct version of the Drive Key(s) on the Key Manager.
Causa
Se establecieron claves de unidad incorrectas o no válidas en el gestor de claves remoto.
Acción
Restaure la versión correcta de las claves de unidad en el gestor de claves remoto. Para obtener más información, consulte la HPE Secure Encryption Installation and User Guide (Guía de usuario e instalación de HPE Secure Encryption) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage-docs).
1813-Slot X Drive Array – Cache Module critical errorSíntoma
1813-Slot X Drive Array – Cache Module critical error. The Cache Module charging circuit is not functional. IMPORTANT: Caching has been disabled. Action: Replace Cache Module.
Causa
Se ha producido un fallo en el módulo de la memoria caché.
Acción
Sustituya el módulo de memoria caché. Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1814-Slot X Encryption FailureSíntoma
1814-Slot X Encryption Failure-Communication issue prevents keys from being retrieved. Dependent encrypted logical drives are offline. System may not boot. Action: Reset controller by rebooting server.
ESES Mensajes de error de la POST 139

Causa
Hay un problema de comunicación.
Acción
Reinicie el servidor para restablecer la controladora. Para obtener más información, consulte la HPE Secure Encryption Installation and User Guide (Guía de usuario e instalación de HPE Secure Encryption) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage-docs).
1815-Slot X Encryption FailureSíntoma
1815-Slot X Encryption Failure – All encrypted logical drives are offline due to failure to enter proper Controller Password. Action: Reboot the server and enter the proper password.
Causa
Se ha introducido una contraseña de la controladora incorrecta.
Acción
Realice una de las siguientes operaciones:
● Reinicie el servidor y, a continuación, introduzca la contraseña de la controladora correcta.
Para obtener más información, consulte la HPE Secure Encryption Installation and User Guide (Guía de usuario e instalación de HPE Secure Encryption) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage-docs).
● Use HPE SSA para desbloquear la controladora.
Para obtener más información, consulte la Guía de usuario de HPE Smart Storage Administrator en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage/docs).
1816-Slot X Encryption FailureSíntoma
1816- Slot X Encryption Failure- Encrypted logical drives are present but encryption is not yet enabled. Encrypted logical drives are offline. Action: Use HP Smart Storage Administrator to enable encryption.
Causa
El cifrado de la controladora no está activado.
Acción
Utilice HPE SSA para activar el cifrado. Para obtener más información, consulte la Guía de usuario de HPE Smart Storage Administrator en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage/docs).
1817-Slot X Encryption FailureSíntoma
1817-Slot X Encryption Failure-Encryption is enabled for the controller but the Master Key name is not set. Action: Use HP Smart Storage Administrator to set Master Key name for the controller and reboot.
140 Capítulo 2 Errores de los servidores HPE ProLiant ESES

Causa
No se ha establecido el nombre de la clave maestra de la controladora.
Acción
1. Establezca el nombre de la clave maestra de la controladora en el gestor de cifrado.
Para obtener más información, consulte la HPE Secure Encryption Installation and User Guide (Guía de usuario e instalación de HPE Secure Encryption) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage-docs).
2. Reinicie el servidor.
1818-Slot X Encryption FailureSíntoma
1818-Slot X Encryption Failure-Key Management Mode mismatch between controller and drives. Las unidades cifradas afectadas están fuera de línea. Action: Use HP Smart Storage Administrator to match key management modes.
Causa
Hay una discrepancia entre los modos de gestión de claves.
Acción
Utilice el gestor de cifrado para que los modos de gestión de claves coincidan. Para obtener más información, consulte la HPE Secure Encryption Installation and User Guide (Guía de usuario e instalación de HPE Secure Encryption) en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage-docs).
1819-Slot X Encryption FailureSíntoma
1819-Slot X Encryption Failure-Unsupported System ROM detected. Encrypted logical drives may be offline. System may not boot. Action: Update the System ROM to a version supporting encryption.
Causa
El servidor está ejecutando una ROM del sistema no compatible.
Acción
Actualice la ROM del sistema a una versión compatible con el cifrado. Para obtener más información, consulte la sección "Actualización del sistema" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
1820-Slot X Encryption FailureSíntoma
1820-Slot X Encryption Failure-Encrypted logical drives are offline. La característica de cifrado no está disponible en esta controladora. Action: Move drives to a controller with encryption or delete the logical drives.
Causa
Las unidades están conectadas a una controlador que no es compatible con el cifrado.
ESES Mensajes de error de la POST 141

Acción
Realice una de las siguientes operaciones:
● Traslade las unidades a una controladora con cifrado.
● Elimine las unidades lógicas.
182-Slot X Encryption FailureSíntoma
1821–Slot X Encryption Failure – FW version for this controller does not support HP Secure Encryption. Encrypted logical drives are offline. System may not boot. Action: Upgrade the FW on this controller.
Causa
El firmware instalado no es compatible con HPE Secure Encryption.
Acción
Actualice el firmware de esta controladora. Para obtener más información, consulte la sección "Actualizaciones de firmware" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
1822-Slot X Encryption FailureSíntoma
1822-Slot X Encryption Failure – Imported encrypted logical drives are offline. Matching Local Master Key required. System may not boot. Action: Use HP Smart Storage Administrator to enter Local Master Key.
Causa
Las unidades lógicas cifradas están desconectadas debido a que falta la clave maestra local.
Acción
Use HPE SSA para especificar la clave maestra local. Para obtener más información, consulte la Guía de usuario de HPE Smart Storage Administrator en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage/docs).
1823-Slot X Encryption FailureSíntoma
1823-Slot X Encryption Failure-Unsupported iLO FW detected. Encrypted logical drives may be offline. System may not boot. Action: Update iLO FW to a version supporting encryption.
Causa
La versión actual del firmware de iLO no es compatible con el cifrado.
Acción
Actualice el firmware de iLO a una versión compatible con el cifrado. Para obtener más información, consulte la sección "Actualizaciones de firmware" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
142 Capítulo 2 Errores de los servidores HPE ProLiant ESES

1824-Slot X One or more storage cables has failedSíntoma
1824-Slot X One or more storage cables have failed preventing discovery of attached storage. Action: Turn OFF power and re-attach the failed cables (run SSA to determine failed cables). Replace the cables if errors persist.
Causa
● Hay un cable que no está instalado correctamente.
● Se ha producido un fallo en el cable.
Acción
1. Use HPE SSA para determinar qué cables tienen que volver a conectarse.
Para obtener más información, consulte la Guía de usuario de HPE Smart Storage Administrator en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage/docs).
2. Apague el servidor.
3. Vuelva a conectar los cables.
4. Si el problema continúa, sustituya los cables.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1825-Slot X Encryption FailureSíntoma
1825-Slot X Encryption Failure-Non-volatile storage corrupted: Critical Security Parameters erased per policy. Encrypted drives offline. Action: Use HP Smart Storage Administrator to reestablish CSPs.
Causa
El almacenamiento no volátil está dañado.
Acción
Use HPE SSA para reestablecer los parámetros de seguridad críticos. Para obtener más información, consulte la Guía de usuario de HPE Smart Storage Administrator en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage/docs).
1826-Slot X Encryption FailureSíntoma
1826-Slot X Encryption Failure-Encryption engine hardware failure. Encrypted logical drives offline. Las unidades lógicas cifradas están fuera de línea hasta que se corrija el problema. Action: Replace the controller to bring encrypted drives online.
Causa
Se ha producido un fallo en la controladora.
Acción
1. Sustituya la controladora.
ESES Mensajes de error de la POST 143

Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
2. Actualice el firmware.
Para obtener más información, consulte la sección "Actualizaciones de firmware" en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I: Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting).
3. Configure el cifrado de la controladora para proporcionar las unidades cifradas en línea.
1827-Slot X Drive Array – Please install cache module battery packSíntoma
1827-Slot X Drive Array – Please install cache module battery pack. Caching will be enabled once Battery Pack is installed and charged.
Causa
La batería de HPE Smart Storage no está instalada o no está conectada correctamente.
Acción
Realice una de las siguientes operaciones:
● Asegúrese de que la batería de HPE Smart Storage esté instalada y conectada correctamente.
● Instale y cargue la batería de HPE Smart Storage.
Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1828-Slot X Drive Array – Cache Module Battery Pack is not installedSíntoma
1828-Slot X Drive Array – Cache Module Battery Pack is not installed. IMPORTANT: Unsupported Configuration: Cache Module functionality is limited. (IMPORTANTE: Configuración no admitida; las funciones del módulo de memoria caché están limitadas.) Action: Install the Battery Pack to remove these limitations.
Causa
La batería de HPE Smart Storage no está instalada.
Acción
Instale y cargue la batería de HPE Smart Storage. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1829-Slot # Drive Array – Please replace cache module battery packSíntoma
1829-Slot # Drive Array – Please replace cache module battery pack. Caching will be enabled once the Battery Pack has been replaced and charged.
Causa
144 Capítulo 2 Errores de los servidores HPE ProLiant ESES

La batería de HPE Smart Storage no funciona o no está cargada.
Acción
1. Sustituya la batería de HPE Smart Storage.
Para obtener más información, consulte la guía de servicio y mantenimiento del servidor que se encuentra en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
2. Cargue la batería de HPE Smart Storage.
1830-Slot X Drive Array – Incorrect cache module power source detectedSíntoma
1830-Slot X Drive Array – Incorrect cache module power source detected. Caching will be enabled when Cache Module Battery Pack is installed and charged. Action: Remove the Super-cap. Instale un paquete de baterías.
Causa
Se instaló un paquete del condensador de FBWC.
Acción
1. Extraiga el paquete de condensadores eléctricos FBWC.
2. Instale una batería de HPE Smart Storage. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
1831-Slot X Drive Array – Data in Write-Back SmartCache has been lostSíntoma
1831-Slot X Drive Array – Data in Write-Back Smart Cache has been lost. Action: Restore data from backup.
Causa
La alimentación se ha interrumpido mientras había datos en la memoria caché.
Acción
Restaure los datos a partir de una copia de seguridad.
1832-Slot X One or more physical drives are not exposedSíntoma
1832-Slot X One or more physical drives are not exposed to the host due to presence of logical unit metadata. Action: Run HPE SSA to manage these drives.
Causa
Las unidades contienen metadatos de unidades lógicas.
Acción
Utilice HPE SSA para administrar las unidades. Para obtener más información, consulte la Guía de usuario de HPE Smart Storage Administrator en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/smartstorage/docs).
ESES Mensajes de error de la POST 145

1833-Slot X Drive Array – Unsupported Array Configuration DetectedSíntoma
1833-Slot X Drive Array – Unsupported Array Configuration Detected. One or more logical drive(s) are configured for RAID fault tolerance level(s) that are not supported.
Causa
Hay un array configurado con un nivel de tolerancia a fallos RAID no compatible.
Acción
Corrija la configuración del array. Para obtener más información, consulte la guía de usuario del servidor en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
Mensajes de error del registro de gestión integradoIntroducción a los mensajes de error del registro de gestión integrado
El registro de gestión integrado (IML) es un registro de eventos históricos que han tenido lugar en el servidor. Los eventos los generan la ROM del sistema y los servicios como el controlador de estado de iLO. Esta sección contiene los mensajes de error que se guardan en el IML, que se puede visualizar desde distintas herramientas. Es posible que los mensajes de error de esta sección no estén escritos exactamente igual a como se muestran en el servidor. Para obtener más información sobre el IML, consulte la Guía de usuario de HPE iLO 4 en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/ilo/docs).
¡ADVERTENCIA! Para evitar posibles problemas, lea SIEMPRE la información de las advertencias y precauciones que aparecen en la documentación del producto antes de extraer, sustituir, volver a ajustar o modificar componentes del sistema.
NOTA: En esta guía se proporciona información relativa a varios servidores. Es posible que parte de la información no se aplique al servidor concreto donde se encuentra el problema. Consulte la documentación específica del servidor para obtener información sobre los procedimientos, las opciones de hardware, las herramientas de software y los sistemas operativos admitidos por el servidor.
Automatic operating system shutdown initiated due to fan failureTipo de evento: Fallo del ventilador
Acción: Sustituya el ventilador.
Automatic Operating System Shutdown Initiated Due to Overheat Condition......Fatal Exception (Number X, Cause)
Tipo de evento: Condición de sobrecalentamiento
Acción: Compruebe los ventiladores. Asegúrese también de que el servidor está ventilado correctamente y de que la temperatura de la habitación se encuentra dentro del rango necesario.
Operating System failure: Cause [NT]...Kernel Panic: Cause [UNIX]
Abnormal Program Termination: Cause [NetWare]
146 Capítulo 2 Errores de los servidores HPE ProLiant ESES

Tipo de evento: Bloqueo del sistema
Acción: Consulte la documentación del sistema operativo.
Corrected Memory Error Threshold exceeded (Processor X, Memory Module Y)...Corrected Memory Error Threshold Exceeded (System Memory)
Corrected Memory Error Threshold Exceeded (Memory Module Unknown)
Tipo de evento: Se ha superado el umbral de errores corregibles
Acción: Continúe con el funcionamiento normal y sustituya el módulo de memoria durante el siguiente mantenimiento programado para asegurar un funcionamiento fiable.
Uncorrectable PCI Express Error (Slot X, Bus Y, Device Z, Function W, Error status <valor hexadecimal>)
Tipo de evento: Error del bus de expansión
Acción: Sustituya la tarjeta PCI.
Uncorrectable Machine Check Exception (Board X, Processor Y, APIC ID <valor hexadecimal>, Bank <valor hexadecimal> Status <valor hexadecimal>)
Tipo de evento: Error imposible de corregir
Acción:
PRECAUCIÓN: Antes de extraer o sustituir los procesadores, asegúrese de seguir las directrices de la solución de problemas del procesador en la Guía de solución de problemas de los servidores HPE ProLiant Gen9, Volumen I, Solución de problemas en la página web de Hewlett Packard Enterprise (http://www.hpe.com/info/Gen9-troubleshooting). Si no se siguen las directrices recomendadas, es posible que se produzcan daños en la placa del sistema y que sea necesario sustituirla.
Sustituya el procesador.
System Fan Failure (Fan X, Location)Tipo de evento: Fallo del ventilador
Acción: Sustituya el ventilador.
System Fans Not RedundantTipo de evento: Ventiladores no redundantes
Acción: Añada un ventilador o sustituya el averiado.
System Overheating (Zone X, Location)Tipo de evento: Condición de sobrecalentamiento
Acción: Compruebe los ventiladores.
System Power Supplies Not RedundantTipo de evento: Fuente de alimentación no redundante
ESES Mensajes de error del registro de gestión integrado 147

Acción: Añada una fuente de alimentación o sustituya la averiada.
System Power Supply Failure (Power Supply X)Tipo de evento: Fallo de la fuente de alimentación
Acción: Sustituya la fuente de alimentación.
Uncorrectable Memory Error (Slot X, Memory Module Y)......Uncorrectable Memory Error (System Memory)
Uncorrectable Memory Error (Memory Module Unknown)
Tipo de evento: Error imposible de corregir
Acción: Sustituya el módulo de memoria. Si el problema continúa, sustituya la tarjeta de memoria.
148 Capítulo 2 Errores de los servidores HPE ProLiant ESES

3 HPE ProLiant Gen9, códigos de fallos de alimentación
Códigos de fallos de alimentación de los indicadores LED del panel frontal
Cuando ocurre un fallo de alimentación, los siguientes indicadores LED del panel frontal parpadean de manera simultánea:
● Indicador LED de alimentación del sistema
● Indicador LED de estado
● Indicador LED de NIC
● Indicador LED UID
Para obtener más información sobre la ubicación de los indicadores LED en el servidor, consulte la guía de usuario del servidor en la Biblioteca de información de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/docs).
El número de parpadeos de cada secuencia se corresponde con el subsistema afectado por el fallo de alimentación. En la tabla siguiente se proporciona una lista de códigos de fallos de alimentación y los subsistemas afectados. No se producen todos los errores de alimentación en todos los servidores.
Subsistema Comportamiento de los indicadores LED del panel frontal
Placa del sistema 1 parpadeo
Procesador 2 parpadeos
Memoria 3 parpadeos
Ranuras PCIe para placas elevadoras 4 parpadeos
FlexibleLOM 5 parpadeos
Controladora HBA Smart SAS/controladora Smart Array flexible de HPE extraíbles
6 parpadeos
Ranuras PCIe de la placa del sistema 7 parpadeos
Matriz de conectores de alimentación o matriz de conectores de almacenamiento
8 parpadeos
Fuente de alimentación 9 parpadeos
ESES Códigos de fallos de alimentación de los indicadores LED del panel frontal 149

4 Errores de HPE Smart Array
Indicadores LED de tiempo de ejecución de la controladoraPara determinar el estado de la controladora, consulte la sección correspondiende de la controladora.
Indicadores LED de la controladora P440arInmediatamente después de encender el servidor, los indicadores LED de tiempo de ejecución de la controladora se iluminan brevemente de acuerdo con un patrón predeterminado como parte de la secuencia de la POST. En el resto del tiempo durante el funcionamiento del servidor, el patrón de iluminación de los indicadores LED de tiempo de ejecución indica el estado de la controladora.
Elemento Color Nombre Interpretación
1 Verde Latencia Cuando la controladora funciona correctamente, este indicador LED parpadea a 1 Hz. Durante el arranque, este indicador permanece encendido un máximo de 2 segundos.
2 Ámbar Fallo Cuando ocurre un error, este indicador LED está encendido. Durante el arranque, este indicador permanece encendido un máximo de 2 segundos.
3 Verde Cifrado Encendido = todos los volúmenes conectados están cifrados.
150 Capítulo 4 Errores de HPE Smart Array ESES

Elemento Color Nombre Interpretación
Apagado = todos los volúmenes conectados son de texto sin cifrar.
Intermitente = hay volúmenes cifrados y sin cifrar.
4 Ámbar Depuración Encendido = la controladora se está restableciendo.
Apagado = la controladora está inactiva o en ejecución.
Parpadeando a 5 Hz = la controladora y la memoria caché están realizando una copia de seguridad.
Indicadores LED de la controladora P440Inmediatamente después de encender el servidor, los indicadores LED de tiempo de ejecución de la controladora se iluminan brevemente de acuerdo con un patrón predeterminado como parte de la secuencia de la POST. En el resto del tiempo durante el funcionamiento del servidor, el patrón de iluminación de los indicadores LED de tiempo de ejecución indica el estado de la controladora.
Elemento Color Nombre Interpretación
1 Verde Latencia Cuando la controladora funciona correctamente, este indicador LED parpadea a 1 Hz. Durante el arranque, este indicador permanece encendido un máximo de 2 segundos.
2 Ámbar Fallo Cuando ocurre un error, este indicador LED está
ESES Indicadores LED de tiempo de ejecución de la controladora 151

Elemento Color Nombre Interpretación
encendido. Durante el arranque, este indicador permanece encendido un máximo de 2 segundos.
3 Verde Cifrado Encendido = todos los volúmenes conectados están cifrados.
Apagado = todos los volúmenes conectados son de texto sin cifrar.
Intermitente = hay volúmenes cifrados y sin cifrar.
Indicadores LED de la controladora P441Inmediatamente después de encender el servidor, los indicadores LED de tiempo de ejecución de la controladora se iluminan brevemente de acuerdo con un patrón predeterminado como parte de la secuencia de la POST. En el resto del tiempo durante el funcionamiento del servidor, el patrón de iluminación de los indicadores LED de tiempo de ejecución indica el estado de la controladora.
Elemento Color Nombre Interpretación
1 Verde Latencia Cuando la controladora funciona correctamente, este indicador LED parpadea a 1 Hz. Durante el arranque, este indicador permanece encendido un máximo de 2 segundos.
2 Ámbar Fallo Cuando ocurre un error, este indicador LED está encendido. Durante el arranque, este indicador
152 Capítulo 4 Errores de HPE Smart Array ESES

Elemento Color Nombre Interpretación
permanece encendido un máximo de 2 segundos.
3 Verde Cifrado Encendido = todos los volúmenes conectados están cifrados.
Apagado = todos los volúmenes conectados son de texto sin cifrar.
Intermitente = hay volúmenes cifrados y sin cifrar.
4 Verde Reservado Reservado para uso futuro
Indicadores LED de la controladora P840Inmediatamente después de encender el servidor, los indicadores LED de tiempo de ejecución de la controladora se iluminan brevemente de acuerdo con un patrón predeterminado como parte de la secuencia de la POST. En el resto del tiempo durante el funcionamiento del servidor, el patrón de iluminación de los indicadores LED de tiempo de ejecución indica el estado de la controladora.
Elemento Color Nombre Interpretación
1 Verde Latencia Cuando la controladora funciona correctamente, este indicador LED parpadea a 1 Hz. Durante el arranque, este indicador permanece encendido un máximo de 2 segundos.
2 Ámbar Fallo Cuando ocurre un error, este indicador LED está encendido. Durante el arranque, este indicador
ESES Indicadores LED de tiempo de ejecución de la controladora 153

Elemento Color Nombre Interpretación
permanece encendido un máximo de 2 segundos.
3 Verde Cifrado Encendido = todos los volúmenes conectados están cifrados.
Apagado = todos los volúmenes conectados son de texto sin cifrar.
Intermitente = hay volúmenes cifrados y sin cifrar.
Indicadores LED del módulo de memoria cachéIndicadores LED del módulo de memoria caché P440ar
Indicadores LED del módulo de memoria caché (para controladoras Smart Array verticales)
El módulo de memoria caché incluye tres LED de un único color (uno ámbar y dos verdes). Dichos LED también se han incluido en la parte posterior del módulo de memoria caché para facilitar la visualización del estado.
154 Capítulo 4 Errores de HPE Smart Array ESES

1 - Ámbar 2 - Verde 3 - Verde Interpretación
Apagado Apagado Apagado El módulo de memoria caché no está encendido.
Apagado Intermitente una vez cada 2 segundos
Intermitente una vez cada 2 segundos
El microcontrolador de la memoria caché se ejecuta desde su gestor de arranque y recibe el código flash nuevo de la controladora de host.
Apagado Intermitente 1 vez por segundo
Intermitente 1 vez por segundo
El módulo de memoria caché se está encendiendo y la batería se está cargando.
Apagado Apagado Intermitente 1 vez por segundo
El módulo de memoria caché está inactivo y la batería se está cargando.
Apagado Apagado Encendido El módulo de memoria caché está inactivo y la batería está cargada.
Apagado Encendido Encendido El módulo de memoria caché está inactivo, la batería está cargada y la memoria caché contiene datos que todavía no se han escrito en las unidades.
Apagado Intermitente 1 vez por segundo
Apagado Se está realizando una copia de seguridad del contenido de la memoria DDR en el módulo caché.
Apagado Encendido Apagado La copia de seguridad actual ha finalizado sin errores.
Intermitente 1 vez por segundo
Intermitente 1 vez por segundo
Apagado La copia de seguridad actual ha fallado y los datos se han perdido.
Intermitente 1 vez por segundo
Intermitente 1 vez por segundo
Encendido Se ha producido un error de alimentación durante el arranque actual o anterior. Los datos pueden estar dañados.
Intermitente 1 vez por segundo
Encendido Apagado Se ha superado la temperatura.
Intermitente 2 veces por segundo
Intermitente 2 veces por segundo
Apagado La batería no está conectada a la placa del sistema.
Intermitente 2 veces por segundo
Intermitente 2 veces por segundo
Encendido La batería se ha cargado durante 10 minutos, pero no ha alcanzado la autonomía suficiente para realizar una copia de seguridad completa.
Encendido Encendido Apagado La copia de seguridad actual ha finalizado, pero se han producido fluctuaciones en la
ESES Indicadores LED del módulo de memoria caché 155

1 - Ámbar 2 - Verde 3 - Verde Interpretación
alimentación durante la copia de seguridad.
Encendido Encendido Encendido El microcontrolador del módulo de memoria caché presenta fallos.
Mensajes del registro de eventos de Windows para Smart ArrayIdentificadores de mensajes 24578-24599
ID del mensaje: 24578
Nivel de gravedad: Informativo
Mensaje del registro: The Smart Array SAS/SATA event notification service version %1ID del mensaje: 24579
Nivel de gravedad: Informativo
Mensaje del registro: An event queue overflow has occurred for the array controller <controller name / slot information>. At least one event has been lost. This controller will only queue up to 100 events.ID del mensaje: 24580
Nivel de gravedad: Error
Mensaje del registro: The Smart Array SAS/SATA Event Notification Service needs to be upgraded and cannot process events at this time. The service is being stopped and processing of Smart Array controller events to the Windows system event log, ProLiant Integrated Management Log (IML) and Integrity System Event Log (SEL) will not occur until the software is updated.To upgrade your software, please visit http://www.hpe.com/support/driversID del mensaje: 24581
Nivel de gravedad: Informativo
Mensaje del registro: The Smart Array SAS/SATA event notification service <status message>.Valores de <mensaje de estado>:
● “has encountered an error and has stopped” (ha encontrado un error y se ha detenido)
● “has stopped due to a message file error” (se ha detenido debido a un error en el archivo de mensajes)
● “was not able to update the service control manager with updated status” (no ha podido actualizar el estado en Service Control Manager)
156 Capítulo 4 Errores de HPE Smart Array ESES

● “cannot open a registry parameter key” (no puede abrir una clave de parámetros de registro)
● “cannot start due to system event logging being disabled” (no se puede iniciar porque se está desactivando el registro de eventos del sistema)
ID del mensaje: 24582
Nivel de gravedad: Informativo
Mensaje del registro: A <drive type> physical drive located in bay <bay number> was <inserted / removed>. The drive can be found in box <box number> which is attached to port <port number> of array controller <controller name / slot information>.ID del mensaje: 24583
Nivel de gravedad: Informativo
Mensaje del registro: Array controller <controller name / slot information> has detected more than one cable with active drives attached.ID del mensaje: 24584
Nivel de gravedad: Advertencia
Mensaje del registro: Too many runtime ECC errors have been received from the array controller <controller name / slot information>. The controller has restarted without utilizing its DIMM.ID del mensaje: 24585
Nivel de gravedad: Advertencia
Mensaje del registro: The <drive type> physical drive located in bay <bay number> is offline but operational. This drive can be found in box <box number> which is connected to port <port number> of the array controller <controller name / slot information>. The offline reason received from the Smart Array firmware is: <firmware error code>.Valores de <código de error del firmware>:
● TOO_SMALL_IN_LOAD_CONFIG - Replacement drive is too small for configured volume(s).
● ERROR_ERASING_RIS - Could not write to reserved configuration sectors after multiple retries.
● ERROR_SAVING_RIS - Could not write to reserved configuration sectors after multiple retries.
● FAIL_DRIVE_COMMAND - “Fail Drive” command received from host.● MARK_BAD_FAILED - Unable to create media defect after multiple retries.● MARK_BAD_FAILED_IN_FINISH_REMAP - Unable to create media defect after
multiple retries.● TIMEOUT - Too many SCSI command timeouts.● AUTOSENSE_FAILED - Drive is failing commands but is not returning SCSI
sense data after multiple retries.
ESES Mensajes del registro de eventos de Windows para Smart Array 157

● MEDIUM_ERROR_1 - Caused by a particular set of SCSI sense codes that indicate the drive is in bad shape and its data may be corrupt.
● MEDIUM_ERROR_2 - Caused by a particular set of SCSI sense codes that indicate the drive is in bad shape; retries did not help.
● NOT_READY_BAD_SENSE - Drive is returning unrecognized Not Ready sense codes.
● NOT_READY - Drive is not ready and will not spin up.● HARDWARE_ERROR - Drive is returning a Hardware Error sense key;
controller unable to get drive back online.● ABORTED_COMMAND - Drive is returning an Aborted Command sense key;
controller unable to get drive back online.● WRITE_PROTECTED - Drive is returning a sense key indicating it is
write protected.● SPIN_UP_FAILURE_IN_RECOVER - “Start Unit” command failed during error
recovery● REBUILD_WRITE_ERROR - Drive failed write command after multiple
retries during rebuild.● TOO_SMALL_IN_HOT_PLUG - Replacement drive is too small for configured
volume(s).● BUS_RESET_RECOVERY_ABORTED - Unable to communicate with drive after
multiple bus resets and retries; may be due to this drive or another drive that is corrupting the parallel SCSI bus.
● REMOVED_IN_HOT_PLUG - Drive has been hot-removed.● INIT_REQUEST_SENSE_FAILED - “Request Sense” command failed during
device discovery/initialization.● INIT_START_UNIT_FAILED - “Start Unit” command failed during device
discovery/initialization.● INQUIRY_FAILED - “Inquiry” command failed after multiple retries.● NON_DISK_DEVICE - Attached device is not a hard disk per its
inquiry data.● READ_CAPACITY_FAILED - “Read Capacity” command failed after multiple
retries.● INVALID_BLOCK_SIZE - Drive indicates it is not formatted for 512 bytes
per sector.● HOT_PLUG_REQUEST_SENSE_FAILED - “Request Sense” command failed after
drive hot-added.● HOT_PLUG_START_UNIT_FAILED - “Start Unit” command failed after drive
hot-added)● WRITE_ERROR_AFTER_REMAP - After reassigning a media error reported
during a write command, the write command failed with another media error.
158 Capítulo 4 Errores de HPE Smart Array ESES

● INIT_RESET_RECOVERY_ABORTED - Unable to communicate with drive during initialization after multiple bus resets and retries; may be due to this drive or another drive that is corrupting the parallel SCSI bus.
● DEFERRED_WRITE_ERROR - Drive with write cache enabled reported that it could not complete a write command that it previously indicated was successful [lost data].
● MISSING_IN_SAVE_RIS - Could not write to reserved configuration sectors after multiple retries.
● WRONG_REPLACE - A hot-plug tape drive was plugged in as a replacement into a drive bay that a hard disk was removed from.
● GDP_VPD_INQUIRY_FAILED - Could not read drive serial number after multiple retries.
● GDP_MODE_SENSE_FAILED - Could not read certain mode pages after multiple retries.
● DRIVE_NOT_IN_48BIT_MODE - SATA drive is not supported in 48-bit LBA mode.
● DRIVE_TYPE_MIX_IN_HOT_PLUG - Attempt to hot-add a SATA drive as a replacement in a SAS-only volume, or vice versa.
● DRIVE_TYPE_MIX_IN_LOAD_CFG - attempt to use a SATA drive as a replacement in a SAS-only volume, or vice versa.
● PROTOCOL_ADAPTER_FAILED - Protocol layer reports that the protocol hardware has failed; may be a controller failure.
● FAULTY_ID_BAY_EMPTY - Drive responds to SCSI ID, but the corresponding bay is empty.
● FAULTY_ID_BAY_OCCUPIED - Bay is occupied by a drive that does not respond to the corresponding SCSI ID.
● FAULTY_ID_INVALID_BAY - Drive responds to an ID that doesn’t have a valid corresponding bay.
● WRITE_RETRIES_FAILED - Unable to complete a write operation after several retries.
● QUEUE_FULL_ON_ZERO - Drive indicates that its queue is full when we have no requests outstanding to the drive.
● SMART_ERROR_REPORTED - Drive has reported a predictive-failure error when controller is configured to automatically fail [instead of reporting imminent failure of] drives that report this error.
● PHY_RESET_FAILED - Phy reset request failed.● FR_CHKBLK_FAILED_WRITE - Drive failed write command while checking for
media errors.● FR_ATI_TEST_FAILED_WRITE - Drive failed write command while checking
for errors.● OFFLINE_ERASE - Drive is offline due to a Secure Erase operation.● OFFLINE_TOO_SMALL - Drive is offline because it’s a replacement drive
that is too small.
ESES Mensajes del registro de eventos de Windows para Smart Array 159

● OFFLINE_DRIVE_TYPE_MIX - Drive is offline because it is not the correct type for this array [SATA vs SAS].
● OFFLINE_ERASE_COMPLETE - Drive is offline because a Secure Erase operation has completed on it but it hasn’t been replaced yet.
ID del mensaje: 24586
Nivel de gravedad: Informativo
Mensaje del registro: The <drive type> physical drive located in bay <bay number> is now online. This drive can be found in box <box number> which is connected to port <port number> of the array controller <controller name / slot information>.ID del mensaje: 24587
Nivel de gravedad: Advertencia
Mensaje del registro: The <drive type> physical drive located in bay <bay number> is in a SMART trip state that indicates the drive has reached 0 percent usage left. Indicates that the drive has a SMART wear error and is approaching the maximum usage limit for writes (wear out). The drive should be replaced as soon as possible. This drive can be found in box <box number> which is connected to port <port number> of the array controller <controller name / slot information>.ID del mensaje: 24588
Nivel de gravedad: Advertencia
Mensaje del registro: Sensor number <sensor number> has reported that the internal temperature has exceeded the preset limit. This sensor is located in box <box number> which is connected to port <port number> of array controller <controller name / slot information>. The array controller may attempt to shut down power to the attached box and/or spin down the installed disk drive(s).ID del mensaje: 24589
Nivel de gravedad: Advertencia
Mensaje del registro: Sensor number <sensor number> has reported that the internal temperature is nearing the preset temperature limit. This sensor is located in box <box number> which is connected to port <port number> of array controller <controller name / slot information>. The array controller may enact precautionary measures to prevent data loss should the temperature reach the operating limit.ID del mensaje: 24590
Nivel de gravedad: Informativo
Mensaje del registro: Sensor number <sensor number> has reported that a previously existing temperature condition has been corrected. This sensor is located in box <box number> which is connected to port <port number> of array controller <controller name / slot information>. All of the temperature sensors in the attached box are now reporting acceptable temperature levels.ID del mensaje: 24591
160 Capítulo 4 Errores de HPE Smart Array ESES

Nivel de gravedad: Advertencia
Mensaje del registro: Redundant power supply number <power supply number> has reported a fault. This power supply is located in box <box number> which is connected to port <port number> of array controller <controller name / slot information>.ID del mensaje: 24592
Nivel de gravedad: Informativo
Mensaje del registro: Redundant power supply number <power supply number> is no longer sensed as being in a failed state. Some possible reasons that would cause this state change to occur include:1. The previously failed power supply has returned to an operational state.2. The previously failed power supply was removed from the chassis.The power supply state change occurred in box <box number> which is connected to port <port number> of array controller <controller name / slot information>.ID del mensaje: 24593
Nivel de gravedad: Informativo
Mensaje del registro: Array controller <controller name / slot information> has reported that more physical devices were detected than the controller is currently capable of supporting. Some physical drives will not be accessible.ID del mensaje: 24594
Nivel de gravedad: Advertencia
Mensaje del registro: Redundant path number <path number> for the <drive type> physical drive located in bay <bay number> has either failed or been removed. The drive can be found in box <box number> which is attached to port <port number> of array controller <controller name / slot information>.ID del mensaje: 24595
Nivel de gravedad: Error
Mensaje del registro: A drive failure notification has been received for the <drive type> physical drive located in bay <bay number>. This drive can be found in box <box number> which is connected to port <port number> of the array controller <controller name / slot information>. The failure reason received from the Smart Array firmware is: <firmware error code>.Valores de <código de error del firmware>:
● TOO_SMALL_IN_LOAD_CONFIG - Replacement drive is too small for configured volume(s).
● ERROR_ERASING_RIS - Could not write to reserved configuration sectors after multiple retries.
● ERROR_SAVING_RIS - Could not write to reserved configuration sectors after multiple retries.
ESES Mensajes del registro de eventos de Windows para Smart Array 161

● FAIL_DRIVE_COMMAND - “Fail Drive” command received from host.● MARK_BAD_FAILED - Unable to create media defect after multiple retries.● MARK_BAD_FAILED_IN_FINISH_REMAP - Unable to create media defect after
multiple retries.● TIMEOUT - Too many SCSI command timeouts.● AUTOSENSE_FAILED - Drive is failing commands but is not returning SCSI
sense data after multiple retries.● MEDIUM_ERROR_1 - Caused by a particular set of SCSI sense codes that
indicate the drive is in bad shape and its data may be corrupt.● MEDIUM_ERROR_2 - Caused by a particular set of SCSI sense codes that
indicate the drive is in bad shape; retries did not help.● NOT_READY_BAD_SENSE - Drive is returning unrecognized Not Ready sense
codes.● NOT_READY - Drive is not ready and will not spin up.● HARDWARE_ERROR - Drive is returning a Hardware Error sense key;
controller unable to get drive back online.● ABORTED_COMMAND - Drive is returning an Aborted Command sense key;
controller unable to get drive back online.● WRITE_PROTECTED - Drive is returning a sense key indicating it is
write protected.● SPIN_UP_FAILURE_IN_RECOVER - “Start Unit” command failed during error
recovery● REBUILD_WRITE_ERROR - Drive failed write command after multiple
retries during rebuild.● TOO_SMALL_IN_HOT_PLUG - Replacement drive is too small for configured
volume(s).● BUS_RESET_RECOVERY_ABORTED - Unable to communicate with drive after
multiple bus resets and retries; may be due to this drive or another drive that is corrupting the parallel SCSI bus.
● REMOVED_IN_HOT_PLUG - Drive has been hot-removed.● INIT_REQUEST_SENSE_FAILED - “Request Sense” command failed during
device discovery/initialization.● INIT_START_UNIT_FAILED - “Start Unit” command failed during device
discovery/initialization.● INQUIRY_FAILED - “Inquiry” command failed after multiple retries.● NON_DISK_DEVICE - Attached device is not a hard disk per its
inquiry data.● READ_CAPACITY_FAILED - “Read Capacity” command failed after multiple
retries.● INVALID_BLOCK_SIZE - Drive indicates it is not formatted for 512 bytes
per sector.
162 Capítulo 4 Errores de HPE Smart Array ESES

● HOT_PLUG_REQUEST_SENSE_FAILED - “Request Sense” command failed after drive hot-added.
● HOT_PLUG_START_UNIT_FAILED - “Start Unit” command failed after drive hot-added)
● WRITE_ERROR_AFTER_REMAP - After reassigning a media error reported during a write command, the write command failed with another media error.
● INIT_RESET_RECOVERY_ABORTED - Unable to communicate with drive during initialization after multiple bus resets and retries; may be due to this drive or another drive that is corrupting the parallel SCSI bus.
● DEFERRED_WRITE_ERROR - Drive with write cache enabled reported that it could not complete a write command that it previously indicated was successful [lost data].
● MISSING_IN_SAVE_RIS - Could not write to reserved configuration sectors after multiple retries.
● WRONG_REPLACE - A hot-plug tape drive was plugged in as a replacement into a drive bay that a hard disk was removed from.
● GDP_VPD_INQUIRY_FAILED - Could not read drive serial number after multiple retries.
● GDP_MODE_SENSE_FAILED - Could not read certain mode pages after multiple retries.
● DRIVE_NOT_IN_48BIT_MODE - SATA drive is not supported in 48-bit LBA mode.
● DRIVE_TYPE_MIX_IN_HOT_PLUG - Attempt to hot-add a SATA drive as a replacement in a SAS-only volume, or vice versa.
● DRIVE_TYPE_MIX_IN_LOAD_CFG - attempt to use a SATA drive as a replacement in a SAS-only volume, or vice versa.
● PROTOCOL_ADAPTER_FAILED - Protocol layer reports that the protocol hardware has failed; may be a controller failure.
● FAULTY_ID_BAY_EMPTY - Drive responds to SCSI ID, but the corresponding bay is empty.
● FAULTY_ID_BAY_OCCUPIED - Bay is occupied by a drive that does not respond to the corresponding SCSI ID.
● FAULTY_ID_INVALID_BAY - Drive responds to an ID that doesn’t have a valid corresponding bay.
● WRITE_RETRIES_FAILED - Unable to complete a write operation after several retries.
● QUEUE_FULL_ON_ZERO - Drive indicates that its queue is full when we have no requests outstanding to the drive.
● SMART_ERROR_REPORTED - Drive has reported a predictive-failure error when controller is configured to automatically fail [instead of reporting imminent failure of] drives that report this error.
● PHY_RESET_FAILED - Phy reset request failed.
ESES Mensajes del registro de eventos de Windows para Smart Array 163

● FR_CHKBLK_FAILED_WRITE - Drive failed write command while checking for media errors.
● FR_ATI_TEST_FAILED_WRITE - Drive failed write command while checking for errors.
● OFFLINE_ERASE - Drive is offline due to a Secure Erase operation.● OFFLINE_TOO_SMALL - Drive is offline because it’s a replacement drive
that is too small.● OFFLINE_DRIVE_TYPE_MIX - Drive is offline because it is not the
correct type for this array [SATA vs SAS].● OFFLINE_ERASE_COMPLETE - Drive is offline because a Secure Erase
operation has completed on it but it hasn’t been replaced yet.ID del mensaje: 24596
Nivel de gravedad: Error
Mensaje del registro: The <drive type> physical drive located in bay <bay number> is in a SMART predictive failure state. This drive can be found in box <box number> which is connected to port <port number> of the array controller <controller name / slot information>.ID del mensaje: 24597
Nivel de gravedad: Advertencia
Mensaje del registro: The <drive type> physical hard drive located in bay <bay number> is not supported <not supported reason>. This drive can be found in box <box number> which is connected to port <port number> of the array controller <controller name / slot information>.Valores de <motivo por el que no es compatible>:
● “because it is a singled ported drive” (porque se trata de una unidad de disco aislada y portada)
● “because it is a SATA drive” (porque se trata de una unidad de disco SATA)
● “because it is smaller than the drive it is replacing” (porque es más pequeña que la unidad que está reemplazando)
● “because it is of an unrecognized type” (porque es de un tipo no reconocido)
● “because it contains an unsupported RIS configuration” (porque contiene una configuración RIS no compatible)
ID del mensaje: 24598
Nivel de gravedad: Informativo
Mensaje del registro: Logical drive <logical drive number> of array controller <controller name / slot information> has encountered a status change from:Status: <previous status>toStatus: <current status>
164 Capítulo 4 Errores de HPE Smart Array ESES

Valores de <estado anterior> y <estado actual>:
● “OK” (CORRECTA)
● “FAILED” (FALLO)
● “NOT CONFIGURED” (SIN CONFIGURAR)● “INTERIM RECOVERY MODE” (MODO PROVISIONAL DE RECUPERACIÓN)● “READY FOR RECOVERY” (PREPARADA PARA LA RECUPERACIÓN)● “RECOVERING” (RECUPERÁNDOSE)● “WRONG PHYSICAL DRIVE REPLACED” (SE HA SUSTITUIDO LA UNIDAD FÍSICA
INCORRECTA)● “PHYSICAL DRIVE NOT PROPERLY CONNECTED” (UNIDAD FÍSICA NO CONECTADA
CORRECTAMENTE)● “HARDWARE IS OVERHEATING” (EL HARDWARE SE ESTÁ SOBRECALENTANDO)● “HARDWARE HAS OVERHEATED” (EL HARDWARE SE HA SOBRECALENTADO)● “EXPANDING” (EXPANDIENDO)● “NOT YET AVAILABLE” (AÚN NO DISPONIBLE)● “QUEUED FOR EXPANSION” (EN COLA PARA EXPANSIÓN)● “DISABLED DUE TO SCSI ID CONFLICT” (DESACTIVADA DEBIDO A UN CONFLICTO
DE ID DE SCSI)● “EJECTED” (EXPULSADA)● “ERASING” (BORRÁNDOSE)● “UNKNOWN” (DESCONOCIDO)ID del mensaje: 24599
Nivel de gravedad: Advertencia
Mensaje del registro: Logical drive <logical drive number> of array controller <controller name / slot information> has encountered a status change from:Status: <previous status>toStatus: <current status>Valores de <estado anterior> y <estado actual>:
● “OK” (CORRECTA)● “FAILED” (FALLO)● “NOT CONFIGURED” (SIN CONFIGURAR)● “INTERIM RECOVERY MODE” (MODO PROVISIONAL DE RECUPERACIÓN)● “READY FOR RECOVERY” (PREPARADA PARA LA RECUPERACIÓN)● “RECOVERING” (RECUPERÁNDOSE)
ESES Mensajes del registro de eventos de Windows para Smart Array 165

● “WRONG PHYSICAL DRIVE REPLACED” (SE HA SUSTITUIDO LA UNIDAD FÍSICA INCORRECTA)
● “PHYSICAL DRIVE NOT PROPERLY CONNECTED” (UNIDAD FÍSICA NO CONECTADA CORRECTAMENTE)
● “HARDWARE IS OVERHEATING” (EL HARDWARE SE ESTÁ SOBRECALENTANDO)● “HARDWARE HAS OVERHEATED” (EL HARDWARE SE HA SOBRECALENTADO)● “EXPANDING” (EXPANDIENDO)● “NOT YET AVAILABLE” (AÚN NO DISPONIBLE)● “QUEUED FOR EXPANSION” (EN COLA PARA EXPANSIÓN)● “DISABLED DUE TO SCSI ID CONFLICT” (DESACTIVADA DEBIDO A UN CONFLICTO
DE ID DE SCSI)● “EJECTED” (EXPULSADA)● “ERASING” (BORRÁNDOSE)● “UNKNOWN” (DESCONOCIDO)
Identificadores de mensajes 24600-24624ID del mensaje: 24600
Nivel de gravedad: Error
Mensaje del registro: Logical drive <logical drive number> of array controller <controller name / slot information> has encountered a status change from:Status: <previous status>toStatus: <current status>Valores de <estado anterior> y <estado actual>:
● “OK” (CORRECTA)● “FAILED” (FALLO)● “NOT CONFIGURED” (SIN CONFIGURAR)● “INTERIM RECOVERY MODE” (MODO PROVISIONAL DE RECUPERACIÓN)● “READY FOR RECOVERY” (PREPARADA PARA LA RECUPERACIÓN)● “RECOVERING” (RECUPERÁNDOSE)● “WRONG PHYSICAL DRIVE REPLACED” (SE HA SUSTITUIDO LA UNIDAD FÍSICA
INCORRECTA)● “PHYSICAL DRIVE NOT PROPERLY CONNECTED” (UNIDAD FÍSICA NO CONECTADA
CORRECTAMENTE)● “HARDWARE IS OVERHEATING” (EL HARDWARE SE ESTÁ SOBRECALENTANDO)● “HARDWARE HAS OVERHEATED” (EL HARDWARE SE HA SOBRECALENTADO)● “EXPANDING” (EXPANDIENDO)
166 Capítulo 4 Errores de HPE Smart Array ESES

● “NOT YET AVAILABLE” (AÚN NO DISPONIBLE)● “QUEUED FOR EXPANSION” (EN COLA PARA EXPANSIÓN)● “DISABLED DUE TO SCSI ID CONFLICT” (DESACTIVADA DEBIDO A UN CONFLICTO
DE ID DE SCSI)● “EJECTED” (EXPULSADA)● “ERASING” (BORRÁNDOSE)● “UNKNOWN” (DESCONOCIDO)ID del mensaje: 24601
Nivel de gravedad: Informativo
Mensaje del registro: Logical drive <logical drive number> configured on array controller <controller name / slot information> is in a failed state but has had one or more drive replacements and is now ready to change to a status of "OK". However, this status change will not occur until the logical drive is re-enabled. Please re-enable the logical drive either via the Array Configuration Utility or by rebooting the system.ID del mensaje: 24602
Nivel de gravedad: Advertencia
Mensaje del registro: The recovery of logical drive <logical driver number> configured on array controller <controller name / slot information> was aborted while rebuilding due to an unrecoverable read error. Physical drive number <physical drive number> was the replacement drive being rebuilt before the read error occurred, while physical drive number <physical drive number> is the error drive which reported the read error.ID del mensaje: 24603
Nivel de gravedad: Advertencia
Mensaje del registro: Due to an unrecoverable read error, the recovery of logical drive %3 configured on array controller <controller name / slot information> was aborted while rebuilding a physical drive.The physical drive which was being rebuilt is located in bay <bay number> of box <box number> which is connected to port <port number> of array controller <controller name / slot information>.The physical drive that reported the read error is located in bay <bay number> of box <box number> which is connected to port <port number> of array controller <controller name / slot information>.ID del mensaje: 24604
Nivel de gravedad: Advertencia
Mensaje del registro: The recovery of logical drive <logical drive number> configured on array controller <controller name / slot information> was aborted while rebuilding due to an unrecoverable write error. Physical drive number <physical drive number> was the replacement drive being rebuilt before the write error occurred, while physical drive number <physical drive number> is the error drive which reported the write error. (La recuperación de la unidad lógica <número de unidad lógica>
ESES Mensajes del registro de eventos de Windows para Smart Array 167

configurada en la controladora de array <nombre de controladora/ información sobre la ranura> se ha cancelado durante la reconstrucción debido a un error de escritura imposible de recuperar. La unidad física número <número de unidad física> era la unidad de sustitución que se estaba reconstruyendo antes de que se produjera el error de escritura, mientras que la unidad física número <número de unidad física> es la unidad que informó del error de escritura.)ID del mensaje: 24605
Nivel de gravedad: Advertencia
Mensaje del registro: Due to an unrecoverable write error, the recovery of logical drive <logical drive number> configured on array controller <controller name / slot information> was aborted while rebuilding a physical drive.The physical drive which was being rebuilt is located in bay <bay number> of box <box number> which is connected to port <port number> of array controller <controller name / slot information>.The physical drive that reported the write error is located in bay <bay number> of box <box number> which is connected to port <port number> of array controller <controller name / slot information>.ID del mensaje: 24606
Nivel de gravedad: Error
Mensaje del registro: Logical drive <logical drive number> configured on array controller <controller name / slot information> returned a fatal error during a read/write request from/to the volume.Logical block address <lba number>, block count <bc number> and command <command number> were taken from the failed logical I/O request.Array controller <controller name / slot information> is also reporting that the last physical drive to report a fatal error condition (associated with this logical request), is located on bus <bus number> and ID <ID number>.ID del mensaje: 24607
Nivel de gravedad: Advertencia
Mensaje del registro: The event information received from array controller <controller name / slot information> was of an unknown or unrecognized class.An excerpt of the controller message is as follows: <message from firmware>.ID del mensaje: 24608
Nivel de gravedad: Informativo
Mensaje del registro: Array controller <controller name / slot information> has reported that storage box number <box number> was added to port <port number>. This connection is through I/O module number <module number> on the storage box.ID del mensaje: 24609
168 Capítulo 4 Errores de HPE Smart Array ESES

Nivel de gravedad: Error
Mensaje del registro: Array controller <controller name / slot information> has reported that storage box number <box number> was removed from port <port number>. This connection was through I/O module number <module number> on the storage box. This event can occur when either a sole I/O module or data cable is removed.ID del mensaje: 24610
Nivel de gravedad: Advertencia
Mensaje del registro: Array controller <controller name / slot information> has reported that either redundant I/O module number <module number> in box <box number> was removed or the cable to this module was removed. The cable and I/O module were connected to port <port number> of the array controller.ID del mensaje: 24611
Nivel de gravedad: Informativo
Mensaje del registro: Array controller <controller name / slot information> has reported that either redundant I/O module number <module number> in box <box number> was added or the cable to this module was connected. The cable and I/O module are connected to port <port number> of the array controller.ID del mensaje: 24612
Nivel de gravedad: Informativo
Mensaje del registro: Array controller <controller name / slot information> has reported that box <box number> connected to port <port number> is now marked as repaired (re-added after a previous failure).ID del mensaje: 24613
Nivel de gravedad: Informativo
Mensaje del registro: Array controller <controller name / slot information> has reported that either redundant I/O module number <module number> in box <box number> was repaired or its path was repaired. Box <box number> is connected to port <port number> of the array controller.ID del mensaje: 24614
Nivel de gravedad: Informativo
Mensaje del registro: Array controller <controller name / slot information> has reported that the external array controller attached to port <port number> has been disconnected or powered down.ID del mensaje: 24615
Nivel de gravedad: Informativo
Mensaje del registro: Array controller <controller name / slot information> has reported that an external array controller was attached to port <port number> or was previously attached and was powered on.ID del mensaje: 24616
ESES Mensajes del registro de eventos de Windows para Smart Array 169

Nivel de gravedad: Advertencia
Mensaje del registro: Array controller <controller name / slot information> is reporting that an unsupported configuration has occurred with the redundant cabling that is attached between port <port number> and box <box number>. <firmware information>. Please check the cabling and ensure that a supported configuration is being used.Valores de <información del firmware>:
● “The Smart Array firmware is reporting that no additional details are available” (El firmware de Smart Array informa de que no se dispone de detalles adicionales)
● “The Smart Array firmware is reporting that the redundant cabling configuration on the controller has a mix of storage boxes with and without redundant I/O modules” (El firmware de Smart Array informa de que la configuración del cableado redundante en la controladora tiene una combinación de cajas de almacenamiento con y sin módulos de E/S redundantes)
● “The Smart Array firmware is reporting that a redundant I/O paths exist due to direct loopback of the controller ports” (El firmware de Smart Array informa de que existen rutas de E/S redundantes debido al bucle directo de los puertos de la controladora)
● “The Smart Array firmware is reporting that the redundant I/O modules of this box are not cabled for good fault tolerance” (El firmware de Smart Array informa de que los módulos de E/S redundantes de esta caja no están cableados para una buena tolerancia a fallos)
● “The Smart Array firmware is reporting that the redundant I/O modules of this box have multiple paths to the controller” (El firmware de Smart Array informa de que los módulos de E/S redundantes de esta caja tienen varias rutas de acceso a la controladora)
ID del mensaje: 24617
Nivel de gravedad: Advertencia
Mensaje del registro: Array controller <controller name / slot information> is reporting that an unsupported configuration has occurred with the redundant cabling that is attached to port <port number>. <firmware information>. Please check the cabling and ensure that a supported configuration is being used.Valores de <información del firmware>:
● “The Smart Array firmware is reporting that no additional details are available” (El firmware de Smart Array informa de que no se dispone de detalles adicionales)
● “The Smart Array firmware is reporting that the redundant cabling configuration on the controller has a mix of storage boxes with and without redundant I/O modules” (El firmware de Smart Array informa de que la configuración del cableado redundante en la controladora tiene una combinación de cajas de almacenamiento con y sin módulos de E/S redundantes)
170 Capítulo 4 Errores de HPE Smart Array ESES

● “The Smart Array firmware is reporting that a redundant I/O paths exist due to direct loopback of the controller ports” (El firmware de Smart Array informa de que existen rutas de E/S redundantes debido al bucle directo de los puertos de la controladora)
● “The Smart Array firmware is reporting that the redundant I/O modules of this box are not cabled for good fault tolerance” (El firmware de Smart Array informa de que los módulos de E/S redundantes de esta caja no están cableados para una buena tolerancia a fallos)
● “The Smart Array firmware is reporting that the redundant I/O modules of this box have multiple paths to the controller” (El firmware de Smart Array informa de que los módulos de E/S redundantes de esta caja tienen varias rutas de acceso a la controladora)
ID del mensaje: 24618
Nivel de gravedad: Advertencia
Mensaje del registro: Array controller <controller name / slot information> is reporting that an unsupported configuration has occurred with the redundant cabling that is attached to port <port number>. Please check the cabling and ensure that a supported configuration is being used.ID del mensaje: 24619
Nivel de gravedad: Informativo
Mensaje del registro: Fan number <fan number> in box <box number> was <inserted / removed>. Box <box number> is attached to port <port number> of array controller <controller name / slot information>.ID del mensaje: 24620
Nivel de gravedad: Informativo
Mensaje del registro: Fan number <fan number> located on fan module <fan module number> in box <box number> was <inserted / removed>. Box <box number> is attached to port <port number> of array controller <controller name / slot information>.ID del mensaje: 24621
Nivel de gravedad: Error
Mensaje del registro: Fan number <fan number> is reporting a failure. This fan is located in box number <box number> which is connected to port <port number> of array controller <controller name / slot information>. The controller may attempt to shut down the power to the storage device and/or spin down the installed disk drive(s).ID del mensaje: 24622
Nivel de gravedad: Error
Mensaje del registro: Fan number <fan number> located on fan module <fan module number> is reporting a failure. This fan is located in box number <box number> which is connected to port <port number> of array controller <controller name / slot information>. The controller may attempt to shut down the power to the storage device and/or spin down the installed disk drive(s).
ESES Mensajes del registro de eventos de Windows para Smart Array 171

ID del mensaje: 24623
Nivel de gravedad: Informativo
Mensaje del registro: Fan number <fan number> is reporting a degraded condition. This fan is located in box number <box number> which is connected to port <port number> of array controller <controller name / slot information>.ID del mensaje: 24624
Nivel de gravedad: Informativo
Mensaje del registro: Fan number <fan number> located on fan module <fan module number> is reporting a degraded condition. This fan is located in box number <box number> which is connected to port <port number> of array controller <controller name / slot information>.
Identificadores de mensajes 24625-24649ID del mensaje: 24625
Nivel de gravedad: Informativo
Mensaje del registro: Fan number <fan number> is reporting that it is now operational. This fan is located in box number <box number> which is connected to port <port number> of array controller <controller name / slot information>.ID del mensaje: 24626
Nivel de gravedad: Informativo
Mensaje del registro: Fan number <fan number> located on fan module <fan module number> is reporting that it is now operational. This fan is located in box number <box number> which is connected to port <port number> of array controller <controller name / slot information>.ID del mensaje: 24627
Nivel de gravedad: Informativo
Mensaje del registro: Array controller <controller name / slot information> is reporting excessive correctable PCI-e errors. Please check this controller to ensure it is functioning properly.ID del mensaje: 24628
Nivel de gravedad: Informativo
Mensaje del registro: Fan module <fan module number> in box <box number> was <inserted / removed>. Box <box number> is attached to port <port number> of array controller <controller name / slot information>.ID del mensaje: 24629
Nivel de gravedad: Error
Mensaje del registro: Fan module <fan module number> in box number <box number> is reporting a failure. Box number <box number> is connected to port <port number> of array controller <controller name / slot information>. The controller may attempt to shut down the power to the storage device and/or spin down the installed disk drive(s).
172 Capítulo 4 Errores de HPE Smart Array ESES

ID del mensaje: 24630
Nivel de gravedad: Informativo
Mensaje del registro: A tape drive connected to port <port number> of array controller <controller name / slot information> has been <inserted / removed>.ID del mensaje: 24631
Nivel de gravedad: Informativo
Mensaje del registro: Fan module <fan module number> in box number <box number> is reporting a degraded condition. Box number <box number> is connected to port <port number> of array controller <controller name / slot information>.ID del mensaje: 24632
Nivel de gravedad: Informativo
Mensaje del registro: Array controller <controller name / slot information> has reported that its cache has been disabled.ID del mensaje: 24633
Nivel de gravedad: Informativo
Mensaje del registro: Array controller <controller name / slot information> has reported that its cache has been enabled.ID del mensaje: 24634
Nivel de gravedad: Informativo
Mensaje del registro: Array controller <controller name / slot information> has reported that its cache batteries are missing.ID del mensaje: 24635
Nivel de gravedad: Advertencia
Mensaje del registro: Array controller <controller name / slot information> has reported that its cache batteries have failed.ID del mensaje: 24636
Nivel de gravedad: Informativo
Mensaje del registro: Fan module <fan module number> is reporting that it is now operational. This fan module is located in box number <box number> which is connected to port <port number> of array controller <controller name / slot information>. (El módulo de ventilador <número de módulo de ventilador> informa de que ya está operativo. Este módulo de ventilador se encuentra en la caja número <número de caja> que está conectada al puerto <número de puerto> de la controladora de array <nombre de controladora/información sobre la ranura>.)ID del mensaje: 24637
Nivel de gravedad: Informativo
Mensaje del registro: A previously failed storage enclosure processor (SEP) is now responding and operational. This SEP is located in box <box number>
ESES Mensajes del registro de eventos de Windows para Smart Array 173

which is connected to port <port number> of array controller <controller name / slot information>.ID del mensaje: 24638
Nivel de gravedad: Error
Mensaje del registro: A storage enclosure processor (SEP) has failed. This SEP is located in box <box number> which is connected to port <port number> of array controller <controller name / slot information>.ID del mensaje: 24639
Nivel de gravedad: Error
Mensaje del registro: All of the storage enclosure processors (SEPs) in box <box number> have failed and there is currently no environmental management and monitoring available for this storage box. Box <box number> is connected to port <port number> of array controller <controller name / slot information>.ID del mensaje: 24640
Nivel de gravedad: Informativo
Mensaje del registro: The Smart Array controller <controller name / slot information> is now redundant.ID del mensaje: 24641
Nivel de gravedad: Advertencia
Mensaje del registro: The Smart Array controller <controller name / slot information> is reporting that no redundant array controller is installed.ID del mensaje: 24642
Nivel de gravedad: Error
Mensaje del registro: The Smart Array controller <controller name / slot information> is not redundant because it is a different model than its partner controller.ID del mensaje: 24643
Nivel de gravedad: Advertencia
Mensaje del registro: The Smart Array controller <controller name / slot information> is not redundant because an inter-controller link could not be established with the partner controller.ID del mensaje: 24644
Nivel de gravedad: Error
Mensaje del registro: The Smart Array controller <controller name / slot information> is not redundant because it is of a different firmware revision than its partner controller.ID del mensaje: 24645
Nivel de gravedad: Error
174 Capítulo 4 Errores de HPE Smart Array ESES

Mensaje del registro: The Smart Array controller <controller name / slot information> is not redundant because it is using a different cache size than its partner controller.ID del mensaje: 24646
Nivel de gravedad: Error
Mensaje del registro: The Smart Array controller <controller name / slot information> is not redundant because its partner controller has reported a cache failure.ID del mensaje: 24647
Nivel de gravedad: Error
Mensaje del registro: The Smart Array controller <controller name / slot information> is no longer redundant because this controller and its partner controller can no longer see all the physical drives.ID del mensaje: 24648
Nivel de gravedad: Error
Mensaje del registro: The Smart Array controller <controller name / slot information> is no longer redundant because one or more drives has been determined not to be able to support redundant controller operations.ID del mensaje: 24649
Nivel de gravedad: Advertencia
Mensaje del registro: The Smart Array controller <controller name / slot information> is no longer redundant because an expand operation is in progress. The controller will become redundant once again once the expand operation has completed.
Identificadores de mensajes 24650-24674ID del mensaje: 24650
Nivel de gravedad: Informativo
Mensaje del registro: SnapShot ID <ID number> of logical drive <logical drive number> on <external specification> array controller <controller name / slot information> has been created.Valores de <especificación externa>:
● “the external controller attached to” (la controladora externa conectada a)
● “”
ID del mensaje: 24651
Nivel de gravedad: Error
Mensaje del registro: SnapShot ID <ID number> of logical drive <logical drive number> on <external specification> array controller <controller name / slot information> failed and has been deleted.Valores de <especificación externa>:
ESES Mensajes del registro de eventos de Windows para Smart Array 175

● “the external controller attached to” (la controladora externa conectada a)
● “”
ID del mensaje: 24652
Nivel de gravedad: Informativo
Mensaje del registro:SnapShot ID <ID number> of logical drive <logical drive number> on <external specification> array controller <controller name / slot information> has been restored.Valores de <especificación externa>:
● “the external controller attached to” (la controladora externa conectada a)
● “”
ID del mensaje: 24653
Nivel de gravedad: Informativo
Mensaje del registro: SnapShot ID <ID number> of logical drive <logical drive number> on <external specification> array controller <controller name / slot information> has been detached.Valores de <especificación externa>:
● “the external controller attached to” (la controladora externa conectada a)
● “”
ID del mensaje: 24654
Nivel de gravedad: Informativo
Mensaje del registro: SnapShot ID <ID number> of logical drive <logical drive number> on <external specification> array controller <controller name / slot information> has been deleted.Valores de <especificación externa>:
● “the external controller attached to” (la controladora externa conectada a)
● “”
ID del mensaje: 24655
Nivel de gravedad: Error
Mensaje del registro: Restore operation of SnapShot ID <ID number> of logical drive <logical drive number> on <external specification> array controller <controller name / slot information> failed due to possible data corruption.Valores de <especificación externa>:
● “the external controller attached to” (la controladora externa conectada a)
● “”
176 Capítulo 4 Errores de HPE Smart Array ESES

ID del mensaje: 24656
Nivel de gravedad: Advertencia
Mensaje del registro: SnapShot ID <ID number> of logical drive <logical drive number> on <external specification> array controller <controller name / slot information> has been disabled.Valores de <especificación externa>:
● “the external controller attached to” (la controladora externa conectada a)
● “”
ID del mensaje: 24657
Nivel de gravedad: Informativo
Mensaje del registro: Performing a recovery for a restore operation on SnapShot ID <ID number> for logical drive <logical drive number> on <external specification> array controller <controller name / slot information>.Valores de <especificación externa>:
● “the external controller attached to” (la controladora externa conectada a)
● “”
ID del mensaje: 24658
Nivel de gravedad: Informativo
Mensaje del registro: Restore operation started on Snapshot ID <ID number> of logical drive <logical drive number> on <external specification> array controller <controller name / slot information>.Valores de <especificación externa>:
● “the external controller attached to” (la controladora externa conectada a)
● “”
ID del mensaje: 24659
Nivel de gravedad: Informativo
Mensaje del registro: Port <port number> of controller <controller name / slot information> is reporting <PHY status> for PHY number <phy number>.ID del mensaje: 24660
Nivel de gravedad: Informativo
Mensaje del registro: Smart Array controller <controller name / slot information> has reported that its partner controller has been <added to / removed from> the SAS fabric.ID del mensaje: 24661
Nivel de gravedad: Informativo
ESES Mensajes del registro de eventos de Windows para Smart Array 177

Mensaje del registro: Surface analysis parity/consistency initialization forced complete for logical drive <logical drive number> on Smart Array controller <controller name / slot information>.ID del mensaje: 24662
Nivel de gravedad: Informativo
Mensaje del registro: Smart Array controller <controller name / slot information> has reported that <number of passes> surface analysis passes have completed for logical drive <logical drive number>.ID del mensaje: 24668
Nivel de gravedad: Informativo
Mensaje del registro: SnapShot resource volume of logical drive <logical drive number> on <external specification> array controller <controller name / slot information> is okay.Valores de <especificación externa>:
● “the external controller attached to” (la controladora externa conectada a)
● “”
ID del mensaje: 24669
Nivel de gravedad: Advertencia
Mensaje del registro: Snapshot resource volume of logical drive <logical drive number> on <external specification> array controller <controller name / slot information> is approaching its limit.Valores de <especificación externa>:
● “the external controller attached to” (la controladora externa conectada a)
● “”
ID del mensaje: 24670
Nivel de gravedad: Error
Mensaje del registro: Snapshot resource volume of logical drive <logical drive number> on <external specification> array controller <controller name / slot information> has failed.Valores de <especificación externa>:
● “the external controller attached to” (la controladora externa conectada a)
● “”
ID del mensaje: 24671
Nivel de gravedad: Informativo
Mensaje del registro: Snapshot resource volume of logical drive <logical drive number> on <external specification> array controller <controller name / slot information> has been deleted.
178 Capítulo 4 Errores de HPE Smart Array ESES

Valores de <especificación externa>:
● “the external controller attached to” (la controladora externa conectada a)
● “”
ID del mensaje: 24672
Nivel de gravedad: Error
Mensaje del registro: Snapshot resource volume of logical drive <logical drive number> on <external specification> array controller <controller name / slot information> has reached its limit.Valores de <especificación externa>:
● “the external controller attached to” (la controladora externa conectada a)
● “”
ID del mensaje: 24673
Nivel de gravedad: Informativo
Mensaje del registro: Power supply number <power supply number> was <inserted / removed>. This power supply is located in the storage chassis with serial number <serial number> which is attached to port <port number> of array controller <controller name / slot information>.ID del mensaje: 24674
Nivel de gravedad: Advertencia
Mensaje del registro: Array controller <controller name / slot information> is reporting inconsistent data that was previously consistent.<additional data> The inconsistent data may be caused by a power loss during write activity or by a drive returning corrupt data. The inconsistent data is between block address <block address 1> and block address <block address 2> of logical drive <logical drive number>.Valores de <datos adicionales>:
● “The parity data does not match the data drives.” (Los datos de paridad no coinciden con las unidades de datos.)
● “”
Identificadores de mensajes 24675-24699ID del mensaje: 24675
Nivel de gravedad: Advertencia
Mensaje del registro: Data that was previously consistent is now being reported as inconsistent.<additional data> The inconsistent data may be caused by a power loss during write activity or by a drive returning corrupt data. The inconsistent data is between block address <block address 1> and block address <block address 2> of logical drive <logical drive number>. The inconsistent physical drive can be found in bay <bay number> of box
ESES Mensajes del registro de eventos de Windows para Smart Array 179

<box number> connected to port <port number> of array controller <controller name / slot information>.Valores de <datos adicionales>:
● “The parity data does not match the data drives.” (Los datos de paridad no coinciden con las unidades de datos.)
● “”
ID del mensaje: 24676
Nivel de gravedad: Informativo
Mensaje del registro: Surface analysis has repaired an inconsistent stripe on logical drive <logical drive number>. This repair was conducted by overwriting the statistically incorrect stripe on the physical drive found in bay <bay number> of box <box number> connected to port <port number> of array controller <controller name / slot information>.ID del mensaje: 24677
Nivel de gravedad: Informativo
Mensaje del registro: Surface analysis has repaired an inconsistent stripe on logical drive <logical drive number> connected to array controller <controller name / slot information>. This repair was conducted by updating the parity data to match the data drive contents.ID del mensaje: 24678
Nivel de gravedad: Advertencia
Mensaje del registro: The license key <license key> on array controller <controller name / slot information> is nearing its expiration date. The license key will expire in <number of days> day(s).ID del mensaje: 24679
Nivel de gravedad: Error
Mensaje del registro: The license key <license key> on array controller <controller name / slot information> has expired.ID del mensaje: 24680
Nivel de gravedad: Informativo
Mensaje del registro: The firmware image for Smart Array controller <controller name / slot information> has changed.The firmware was flashed from:Revision: <old revision number>toRevision: <new revision number>ID del mensaje: 24681
Nivel de gravedad: Advertencia
Mensaje del registro: Device bus fault occurred on storage box <box number>, port <port number> of array controller <controller name / slot
180 Capítulo 4 Errores de HPE Smart Array ESES

information>. This may result in a downshift in transfer rate for one or more hard drives on the bus.ID del mensaje: 24682
Nivel de gravedad: Informativo
Mensaje del registro: An error log update has occurred for the physical drive with BMIC device index <device index number> of array controller <controller name / slot information>.ID del mensaje: 24683
Nivel de gravedad: Advertencia
Mensaje del registro: Array controller <controller name / slot information> has reported an uncorrectable read error during rebuild operations for logical drive <logical drive number>. The uncorrectable media defects are between logical block address <block address 1> and logical block address <block address 2>. The host will be unable to read some blocks between this address range until the blocks are overwritten. The logical drive rebuild is continuing so that the volume can regain fault tolerance. Capacity expansion operations must be avoided while the affected blocks are unreadable.ID del mensaje: 24684
Nivel de gravedad: Informativo
Mensaje del registro: The consistency initialization pass has completed for logical drive <logical drive number> of array controller <controller name / slot information>.ID del mensaje: 24685
Nivel de gravedad: Advertencia
Mensaje del registro: Array controller <controller name / slot information> has reported an uncorrectable read error during surface analysis operations for logical drive <logical drive number>. A media error was encountered that is not correctable due to media errors on other physical drive(s) belonging to this logical volume. The uncorrectable media defects are between logical block address <block address 1> and logical block address <block address 2>. The host will be unable to read some blocks between this address range until the blocks are overwritten. Capacity expansion operations must be avoided while the blocks are unreadable.ID del mensaje: 24686
Nivel de gravedad: Informativo
Mensaje del registro: Array controller <controller name / slot information> has reported that the surface analysis uncorrectable read error condition for logical drive <logical drive number> has ended. The previously reported media defects have been overwritten. Capacity expansion operations may now be conducted.ID del mensaje: 24687
Nivel de gravedad: Informativo
ESES Mensajes del registro de eventos de Windows para Smart Array 181

Mensaje del registro: A firmware update is needed for the physical drive with product ID <ID number> connected to array controller <controller name / slot information>. The recommended minimum firmware revision should be <revision number>.ID del mensaje: 24688
Nivel de gravedad: Informativo
Mensaje del registro: Power supply number <power supply number> was <inserted / removed>. This power supply is located in box <box number> which is attached to port <port number> of array controller <controller name / slot information>.ID del mensaje: 24690
Nivel de gravedad: Advertencia
Mensaje del registro: A SAS link PHY error has been detected. The PHY error threshold has been exceeded for PHY number <PHY number> located on expander number <expander number>. This expander can be found in box <box number> which is attached to port <port number> of array controller <controller name / slot information>. (Se ha detectado un error de PHY en un enlace SAS. El umbral de errores de PHY se ha sobrepasado en la PHY número <número de PHY> situada en la tarjeta de expansión número <número de tarjeta de expansión>. Esta tarjeta de expansión se encuentra en la caja <número de caja> que está conectada al puerto <número de puerto> de la controladora de array <nombre de controladora/información sobre la ranura>.)ID del mensaje: 24691
Nivel de gravedad: Advertencia
Mensaje del registro: A SAS link error has been detected between port <port number> of array controller <controller name / slot information> and I/O module number <module number> located in box number <box number>. Please check this data path and the associated hardware.ID del mensaje: 24692
Nivel de gravedad: Advertencia
Mensaje del registro: A SAS link error has been detected between port <port number> of array controller <controller name / slot information> and <attached device><attached device index>. Please check this data path and the associated hardware.Valores de <dispositivo conectado>:
● “an expander” (una tarjeta de expansión)● “another controller” (otra controladora)● “a hard drive in bay“ (un disco duro en el compartimento)● “an unknown internal device” (un dispositivo interno desconocido)ID del mensaje: 24693
Nivel de gravedad: Advertencia
182 Capítulo 4 Errores de HPE Smart Array ESES

Mensaje del registro: A SAS link error has been detected from the onboard expander of array controller <controller name / slot information>. Please check this controller to ensure it is functioning properly.ID del mensaje: 24694
Nivel de gravedad: Advertencia
Mensaje del registro: A SAS link error has been detected between a Smart Array controller's onboard expander and an externally attached storage box. The error was detected between port <port number> of array controller <controller name / slot information> and I/O module number <module number> located in box number <box number>. Please check this data path and the associated hardware.ID del mensaje: 24695
Nivel de gravedad: Advertencia
Mensaje del registro: A SAS link error has been detected between the onboard expander (port <port number>) of array controller <controller name / slot information> and <attached device><attached device index>. Please check this data path and the associated hardware.ID del mensaje: 24696
Nivel de gravedad: Advertencia
Mensaje del registro: A SAS link error has been detected between I/O module <module number 1> of box <box number 1> and I/O module <module number 2> of box <box number 2>. These boxes are connected to port <port number> of array controller <controller name / slot information>. Please check this data path and the associated hardware.ID del mensaje: 24697
Nivel de gravedad: Advertencia
Mensaje del registro: A SAS link error has been detected in bay <bay number> of box <box number> which is connected to port <port number> of array controller <controller name / slot information>. Please check this data path and the associated hardware.ID del mensaje: 24698
Nivel de gravedad: Advertencia
Mensaje del registro: A SAS link error has been detected between array controller <controller name / slot information> and the switch expander connected to port <port number> of this controller. Please check this data path and the associated hardware.ID del mensaje: 24699
Nivel de gravedad: Advertencia
Mensaje del registro: A SAS link error has been detected between a switch expander and I/O module <module number> of box <box number>. This hardware is connected to port <port number> of controller <controller name / slot information>. Please check this data path and the associated hardware.
ESES Mensajes del registro de eventos de Windows para Smart Array 183

Identificadores de mensajes 24700-24724ID del mensaje: 24700
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that a <drive type> physical hard drive in bay <bay number> was <inserted / removed>.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24701
Nivel de gravedad: Error
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that fan number <fan number> has failed. The external Smart Array controller may attempt to shut down power and/or spin down the installed disk drive(s).The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24702
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that fan number <fan number> is reporting a degraded condition.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24703
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that fan number <fan number> is now operational.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24704
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> is indicating that sensor number <sensor number> has reported that the internal temperature has exceeded the preset temperature limit. The external Smart Array controller may attempt to shut down power to and/or spin down the installed disk drive(s).The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24705
184 Capítulo 4 Errores de HPE Smart Array ESES

Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> is indicating that sensor number <sensor number> has reported that the internal temperature is nearing the preset temperature limit. The external Smart Array controller may enact precautionary measures to prevent data loss should the temperature reach the operating limit.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24706
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> is indicating that sensor number <sensor number> has reported that a previously existing temperature condition has been corrected. All of the temperature sensors in the attached box are now reporting acceptable temperature levels.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24707
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that redundant power supply number <power supply number> has reported a fault.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24708
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that redundant power supply number <power supply number> is no longer sensed as being in a failed state. Some possible reasons that would cause this state change to occur include:1. The previously failed power supply has returned to an operational state.2. The previously failed power supply was removed from the chassis.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24709
Nivel de gravedad: Error
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> is reporting a drive failure notification for the <drive type> physical hard drive located in bay <bay
ESES Mensajes del registro de eventos de Windows para Smart Array 185

number>. The failure reason received from the Smart Array firmware is: <firmware error code>.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.Valores de <código de error del firmware>:
● TOO_SMALL_IN_LOAD_CONFIG - Replacement drive is too small for configured volume(s).
● ERROR_ERASING_RIS - Could not write to reserved configuration sectors after multiple retries.
● ERROR_SAVING_RIS - Could not write to reserved configuration sectors after multiple retries.
● FAIL_DRIVE_COMMAND - “Fail Drive” command received from host.● MARK_BAD_FAILED - Unable to create media defect after multiple retries.● MARK_BAD_FAILED_IN_FINISH_REMAP - Unable to create media defect after
multiple retries.● TIMEOUT - Too many SCSI command timeouts.● AUTOSENSE_FAILED - Drive is failing commands but is not returning SCSI
sense data after multiple retries.● MEDIUM_ERROR_1 - Caused by a particular set of SCSI sense codes that
indicate the drive is in bad shape and its data may be corrupt.● MEDIUM_ERROR_2 - Caused by a particular set of SCSI sense codes that
indicate the drive is in bad shape; retries did not help.● NOT_READY_BAD_SENSE - Drive is returning unrecognized Not Ready sense
codes.● NOT_READY - Drive is not ready and will not spin up.● HARDWARE_ERROR - Drive is returning a Hardware Error sense key;
controller unable to get drive back online.● ABORTED_COMMAND - Drive is returning an Aborted Command sense key;
controller unable to get drive back online.● WRITE_PROTECTED - Drive is returning a sense key indicating it is
write protected.● SPIN_UP_FAILURE_IN_RECOVER - “Start Unit” command failed during error
recovery● REBUILD_WRITE_ERROR - Drive failed write command after multiple
retries during rebuild.● TOO_SMALL_IN_HOT_PLUG - Replacement drive is too small for configured
volume(s).● BUS_RESET_RECOVERY_ABORTED - Unable to communicate with drive after
multiple bus resets and retries; may be due to this drive or another drive that is corrupting the parallel SCSI bus.
● REMOVED_IN_HOT_PLUG - Drive has been hot-removed.
186 Capítulo 4 Errores de HPE Smart Array ESES

● INIT_REQUEST_SENSE_FAILED - “Request Sense” command failed during device discovery/initialization.
● INIT_START_UNIT_FAILED - “Start Unit” command failed during device discovery/initialization.
● INQUIRY_FAILED - “Inquiry” command failed after multiple retries.● NON_DISK_DEVICE - Attached device is not a hard disk per its
inquiry data.● READ_CAPACITY_FAILED - “Read Capacity” command failed after multiple
retries.● INVALID_BLOCK_SIZE - Drive indicates it is not formatted for 512 bytes
per sector.● HOT_PLUG_REQUEST_SENSE_FAILED - “Request Sense” command failed after
drive hot-added.● HOT_PLUG_START_UNIT_FAILED - “Start Unit” command failed after drive
hot-added)● WRITE_ERROR_AFTER_REMAP - After reassigning a media error reported
during a write command, the write command failed with another media error.
● INIT_RESET_RECOVERY_ABORTED - Unable to communicate with drive during initialization after multiple bus resets and retries; may be due to this drive or another drive that is corrupting the parallel SCSI bus.
● DEFERRED_WRITE_ERROR - Drive with write cache enabled reported that it could not complete a write command that it previously indicated was successful [lost data].
● MISSING_IN_SAVE_RIS - Could not write to reserved configuration sectors after multiple retries.
● WRONG_REPLACE - A hot-plug tape drive was plugged in as a replacement into a drive bay that a hard disk was removed from.
● GDP_VPD_INQUIRY_FAILED - Could not read drive serial number after multiple retries.
● GDP_MODE_SENSE_FAILED - Could not read certain mode pages after multiple retries.
● DRIVE_NOT_IN_48BIT_MODE - SATA drive is not supported in 48-bit LBA mode.
● DRIVE_TYPE_MIX_IN_HOT_PLUG - Attempt to hot-add a SATA drive as a replacement in a SAS-only volume, or vice versa.
● DRIVE_TYPE_MIX_IN_LOAD_CFG - attempt to use a SATA drive as a replacement in a SAS-only volume, or vice versa.
● PROTOCOL_ADAPTER_FAILED - Protocol layer reports that the protocol hardware has failed; may be a controller failure.
● FAULTY_ID_BAY_EMPTY - Drive responds to SCSI ID, but the corresponding bay is empty.
ESES Mensajes del registro de eventos de Windows para Smart Array 187

● FAULTY_ID_BAY_OCCUPIED - Bay is occupied by a drive that does not respond to the corresponding SCSI ID.
● FAULTY_ID_INVALID_BAY - Drive responds to an ID that doesn’t have a valid corresponding bay.
● WRITE_RETRIES_FAILED - Unable to complete a write operation after several retries.
● QUEUE_FULL_ON_ZERO - Drive indicates that its queue is full when we have no requests outstanding to the drive.
● SMART_ERROR_REPORTED - Drive has reported a predictive-failure error when controller is configured to automatically fail [instead of reporting imminent failure of] drives that report this error.
● PHY_RESET_FAILED - Phy reset request failed.● FR_CHKBLK_FAILED_WRITE - Drive failed write command while checking for
media errors.● FR_ATI_TEST_FAILED_WRITE - Drive failed write command while checking
for errors.● OFFLINE_ERASE - Drive is offline due to a Secure Erase operation.● OFFLINE_TOO_SMALL - Drive is offline because it’s a replacement drive
that is too small.● OFFLINE_DRIVE_TYPE_MIX - Drive is offline because it is not the
correct type for this array [SATA vs SAS].● OFFLINE_ERASE_COMPLETE - Drive is offline because a Secure Erase
operation has completed on it but it hasn’t been replaced yet.ID del mensaje: 24710
Nivel de gravedad: Informativo
Mensaje del registro:
The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that logical drive <logical drive number> has encountered a status change from:Status: <previous status>toStatus: <current status>The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.Valores de <estado anterior> y <estado actual>:
● “OK” (CORRECTA)● “FAILED” (FALLO)● “NOT CONFIGURED” (SIN CONFIGURAR)● “INTERIM RECOVERY MODE” (MODO PROVISIONAL DE RECUPERACIÓN)● “READY FOR RECOVERY” (PREPARADA PARA LA RECUPERACIÓN)
188 Capítulo 4 Errores de HPE Smart Array ESES

● “RECOVERING” (RECUPERÁNDOSE)● “WRONG PHYSICAL DRIVE REPLACED” (SE HA SUSTITUIDO LA UNIDAD FÍSICA
INCORRECTA)● “PHYSICAL DRIVE NOT PROPERLY CONNECTED” (UNIDAD FÍSICA NO CONECTADA
CORRECTAMENTE)● “HARDWARE IS OVERHEATING” (EL HARDWARE SE ESTÁ SOBRECALENTANDO)● “HARDWARE HAS OVERHEATED” (EL HARDWARE SE HA SOBRECALENTADO)● “EXPANDING” (EXPANDIENDO)● “NOT YET AVAILABLE” (AÚN NO DISPONIBLE)● “QUEUED FOR EXPANSION” (EN COLA PARA EXPANSIÓN)● “DISABLED DUE TO SCSI ID CONFLICT” (DESACTIVADA DEBIDO A UN CONFLICTO
DE ID DE SCSI)● “EJECTED” (EXPULSADA)● “ERASING” (BORRÁNDOSE)● “UNKNOWN” (DESCONOCIDO)ID del mensaje: 24711
Nivel de gravedad: Advertencia
Mensaje del registro:
The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that logical drive <logical drive number> has encountered a status change from:Status: <current status>toStatus: <previous status>The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.Valores de <estado anterior> y <estado actual>:
● “OK” (CORRECTA)● “FAILED” (FALLO)● “NOT CONFIGURED” (SIN CONFIGURAR)● “INTERIM RECOVERY MODE” (MODO PROVISIONAL DE RECUPERACIÓN)● “READY FOR RECOVERY” (PREPARADA PARA LA RECUPERACIÓN)● “RECOVERING” (RECUPERÁNDOSE)● “WRONG PHYSICAL DRIVE REPLACED” (SE HA SUSTITUIDO LA UNIDAD FÍSICA
INCORRECTA)● “PHYSICAL DRIVE NOT PROPERLY CONNECTED” (UNIDAD FÍSICA NO CONECTADA
CORRECTAMENTE)● “HARDWARE IS OVERHEATING” (EL HARDWARE SE ESTÁ SOBRECALENTANDO)
ESES Mensajes del registro de eventos de Windows para Smart Array 189

● “HARDWARE HAS OVERHEATED” (EL HARDWARE SE HA SOBRECALENTADO)● “EXPANDING” (EXPANDIENDO)● “NOT YET AVAILABLE” (AÚN NO DISPONIBLE)● “QUEUED FOR EXPANSION” (EN COLA PARA EXPANSIÓN)● “DISABLED DUE TO SCSI ID CONFLICT” (DESACTIVADA DEBIDO A UN CONFLICTO
DE ID DE SCSI)● “EJECTED” (EXPULSADA)● “ERASING” (BORRÁNDOSE)● “UNKNOWN” (DESCONOCIDO)ID del mensaje: 24712
Nivel de gravedad: Error
Mensaje del registro:
The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that logical drive <logical drive number> has encountered a status change from:Status: <current status>toStatus: <previous status>The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.Valores de <estado anterior> y <estado actual>:
● “OK” (CORRECTA)● “FAILED” (FALLO)● “NOT CONFIGURED” (SIN CONFIGURAR)● “INTERIM RECOVERY MODE” (MODO PROVISIONAL DE RECUPERACIÓN)● “READY FOR RECOVERY” (PREPARADA PARA LA RECUPERACIÓN)● “RECOVERING” (RECUPERÁNDOSE)● “WRONG PHYSICAL DRIVE REPLACED” (SE HA SUSTITUIDO LA UNIDAD FÍSICA
INCORRECTA)● “PHYSICAL DRIVE NOT PROPERLY CONNECTED” (UNIDAD FÍSICA NO CONECTADA
CORRECTAMENTE)● “HARDWARE IS OVERHEATING” (EL HARDWARE SE ESTÁ SOBRECALENTANDO)● “HARDWARE HAS OVERHEATED” (EL HARDWARE SE HA SOBRECALENTADO)● “EXPANDING” (EXPANDIENDO)● “NOT YET AVAILABLE” (AÚN NO DISPONIBLE)● “QUEUED FOR EXPANSION” (EN COLA PARA EXPANSIÓN)
190 Capítulo 4 Errores de HPE Smart Array ESES

● “DISABLED DUE TO SCSI ID CONFLICT” (DESACTIVADA DEBIDO A UN CONFLICTO DE ID DE SCSI)
● “EJECTED” (EXPULSADA)● “ERASING” (BORRÁNDOSE)● “UNKNOWN” (DESCONOCIDO)ID del mensaje: 24713
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that logical drive <logical drive number> is in a failed state but has had one or more drive replacements and is now ready to change to a status of "OK". However, this status change will not occur until the logical drive is re-enabled. Please re-enable the logical drive either via the Array Configuration Utility or by power cycling the MSA chassis.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24714
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that the recovery of logical drive <logical drive number> was aborted while rebuilding due to an unrecoverable read error. Physical drive number <physical drive number 1> was the replacement drive being rebuilt before the read error occurred, while physical drive number <physical drive number 2> is the error drive which reported the read error.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24715
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that due to an unrecoverable read error, the recovery of logical drive <logical drive number> was aborted while rebuilding a physical drive. The physical drive which was being rebuilt is located in bay <bay number 1> of the MSA chassis. The physical drive that reported the read error is located in bay <bay number 2> of the MSA chassis.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24716
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that the recovery of logical drive <logical drive number> was aborted while rebuilding due to an unrecoverable write error. Physical drive number <physical drive
ESES Mensajes del registro de eventos de Windows para Smart Array 191

number 1> was the replacement drive being rebuilt before the write error occurred, while physical drive number <physical drive number 2> is the error drive which reported the write error.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24717
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that due to an unrecoverable write error, the recovery of logical drive <logical drive number> was aborted while rebuilding a physical drive. The physical drive which was being rebuilt is located in bay <bay number 1> of the MSA chassis. The physical drive that reported the write error is located in bay <bay number 2> of the MSA chassis.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24718
Nivel de gravedad: Error
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that logical drive <logical drive number> returned a fatal error during a read/write request from/to the volume.Logical block address <lba number>, block count <block count> and command <command number> were taken from the failed logical I/O request.The external Smart Array controller is also reporting that the last physical drive to report a fatal error condition(associated with this specific logical request), is located on bus <bus number> and ID <ID number>.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24719
Nivel de gravedad: Advertencia
Mensaje del registro: The event information received from the external Smart Array controller located in the MSA chassis labeled as <chassis label> was of an unknown or unrecognized class.An excerpt of the controller message is as follows: <firmware message>.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24720
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that its cache has been disabled.
192 Capítulo 4 Errores de HPE Smart Array ESES

The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24721
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that its cache has been enabled.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24722
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that its cache batteries are missing.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24723
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that its cache batteries have failed.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24724
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that an error log update has occurred for the physical drive with BMIC device index <device index>.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.
Identificadores de mensajes 24725-24749ID del mensaje: 24725
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that the consistency initialization pass has completed for logical drive <logical drive number>.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24726
ESES Mensajes del registro de eventos de Windows para Smart Array 193

Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported an uncorrectable read error during surface analysis operations for logical drive <logical drive number>. A media error was encountered that is not correctable due to media errors on other physical drive(s) belonging to this logical volume. The uncorrectable media defects are between logical block address <lba number 1> and logical block address <lba number 2>. The host will be unable to read some blocks between this address range until the blocks are overwritten. Capacity expansion operations must be avoided while the blocks are unreadable.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24727
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that the surface analysis uncorrectable read error condition for logical drive <logical drive number> has ended. The previously reported media defects have been overwritten. Capacity expansion operations may now be conducted.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24728
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that a firmware update is needed for the physical drive with product ID <ID number>. The recommended minimum firmware revision should be <firmware revision number>.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24729
Nivel de gravedad: Informativo
Mensaje del registro: The MSA chassis labeled as <chassis label> has reported that external redundant controller <slot number> has been <inserted / removed>. (El chasis MSA <etiqueta del chasis> informa de que se ha <introducido/extraído> la controladora redundante externa <número de ranura>.)The external Smart Array controller reporting this operation is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24730
Nivel de gravedad: Informativo
194 Capítulo 4 Errores de HPE Smart Array ESES

Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that power supply number <power supply number> was <inserted / removed>.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24731
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that fan number <fan number> was <inserted / removed>.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24732
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that a SAS link PHY error has been detected. The PHY error threshold has been exceeded for PHY number <PHY number> located on expander number <expander number>.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24733
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controllers located in the MSA chassis labeled as <chassis label> are now redundant.The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24734
Nivel de gravedad: Error
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> is reporting that no redundant array controller is installed.The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24735
Nivel de gravedad: Error
Mensaje del registro: The external Smart Array controllers located in the MSA chassis labeled as <chassis label> are not redundant because they are different models.The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24736
ESES Mensajes del registro de eventos de Windows para Smart Array 195

Nivel de gravedad: Error
Mensaje del registro: The external Smart Array controllers located in the MSA chassis labeled as <chassis label> are not redundant because an inter-controller link could not be established.The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24737
Nivel de gravedad: Error
Mensaje del registro: The external Smart Array controllers located in the MSA chassis labeled as <chassis label> are not redundant because the array controllers are reporting different firmware revisions.The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24738
Nivel de gravedad: Error
Mensaje del registro: The external Smart Array controllers located in the MSA chassis labeled as <chassis label> are not redundant because the array controllers are reporting different cache sizes.The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24739
Nivel de gravedad: Error
Mensaje del registro: An external Smart Array controller located in the MSA chassis labeled as <chassis label> is reporting that it is not redundant because the other external controller is reporting a cache failure.The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24740
Nivel de gravedad: Error
Mensaje del registro: The external Smart Array controllers located in the MSA chassis labeled as <chassis label> are no longer redundant because both array controllers cannot see all the physical drives.The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24741
Nivel de gravedad: Error
Mensaje del registro: The external Smart Array controllers located in the MSA chassis labeled as <chassis label> are no longer redundant because one or more drives has been determined not to be able to support redundant controller operations.
196 Capítulo 4 Errores de HPE Smart Array ESES

The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24742
Nivel de gravedad: Error
Mensaje del registro: The external Smart Array controllers located in the MSA chassis labeled as <chassis label> are no longer redundant because an expand operation is in progress. The controllers will become redundant once again once the expand operation has completed.The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24743
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that a SAS link error has been detected between port <port number> of the external controller and I/O module number <module number> of box number <box number>. Please check this data path and the associated hardware.The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24744
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that a SAS link error has been detected between port <port number> and <attached device><attached device index>. Please check this data path and the associated hardware.The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24745
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that a SAS link error has been detected from its onboard expander. Please check this controller to ensure it is functioning properly.The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24746
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that a SAS link error has been detected between its onboard expander and an externally connected storage box. This error has been detected between port <port number> of the external controller and I/O module number <module number> located in
ESES Mensajes del registro de eventos de Windows para Smart Array 197

box number <box number>. Please check this data path and the associated hardware.The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24747
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that a SAS link error has been detected between its onboard expander (port <port number>) and <attached device><attached device index>. Please check this data path and the associated hardware.The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24748
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that a SAS link error has been detected between I/O module <module number 1> of box <box number 1> and I/O module <module number 2> of box <box number 2>. These boxes are connected to port <port number> of the external array controller. Please check this data path and the associated hardware.The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24749
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that a SAS link error has been detected in bay <bay number> of box <box number> which is connected to port <port number> of the external array controller. Please check this data path and the associated hardware.The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.
Identificadores de mensajes 24750-24774ID del mensaje: 24750
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that a SAS link error has been detected between port <port number> and the switch expander connected to this port. Please check this data path and the associated hardware.The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24751
198 Capítulo 4 Errores de HPE Smart Array ESES

Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that a SAS link error has been detected between a switch expander and I/O module <module number> of box <box number>. This hardware is connected to port <port number> of the external array controller. Please check this data path and the associated hardware.The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24752
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that storage box number <box number> was added to port <port number>. This connection is through I/O module number <module number> on the storage box.The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24753
Nivel de gravedad: Error
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that storage box number <box number> was removed from port <port number>. This connection was through I/O module number <module number> on the storage box. This event can occur when either a sole I/O module or data cable is removed.The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24754
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis number> has reported that either redundant I/O module number <module number> in box <box number> was removed or the cable to this module was removed. The cable and I/O module were connected to port <port number> of the external controller.The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24755
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis number> has reported that either redundant I/O module number <module number> in box <box number> was added or the cable to this module was connected. The cable and I/O module are connected to port <port number> of the external controller.The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.
ESES Mensajes del registro de eventos de Windows para Smart Array 199

ID del mensaje: 24756
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis number> has reported that box <box number> connected to port <port number> is now marked as repaired (re-added after a previous failure).The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24757
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis number> has reported that either redundant I/O module number <module number> in box <box number> was repaired or its path was repaired. Box <box number> is connected to port <port number> of the external array controller.The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24758
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that redundant path number <path number> for the <drive type> physical drive located in bay <bay number> has either failed or been removed.The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24759
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis number> has reported that an unsupported configuration has occurred with the redundant cabling that is attached between port <port number> and box <box number>. <firmware information>. Please check the cabling and ensure that a supported configuration is being used.The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24760
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that an unsupported configuration has occurred with the redundant cabling that is attached to port <port number>. <firmware information>. Please check the cabling and ensure that a supported configuration is being used.
200 Capítulo 4 Errores de HPE Smart Array ESES

The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24761
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that an unsupported configuration has occurred with the redundant cabling that is attached to port <port number>. Please check the cabling and ensure that a supported configuration is being used.The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24762
Nivel de gravedad: Informativo
Mensaje del registro:
External Smart Array controller number <controller number> located in the MSA chassis labeled as <chassis label> is reporting the following flash operation: "<firmware message>."The firmware was flashed from:Revision: <old revision number>toRevision: <new revision number>The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24763
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported an uncorrectable read error during rebuild operations for logical drive <logical drive number>. The uncorrectable media defects are between logical block address <lba number 1> and logical block address <lba number 2>. The host will be unable to read some blocks between this address range until the blocks are overwritten. The logical drive rebuild is continuing so that the volume can regain fault tolerance. Capacity expansion operations must be avoided while the affected blocks are unreadable.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24764
Nivel de gravedad: Advertencia
Mesaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> is reporting that the <drive type> physical hard drive located in bay <bay number> is not supported <not supported reason>.
ESES Mensajes del registro de eventos de Windows para Smart Array 201

The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.Valores de <motivo por el que no es compatible>:
● “because it is a singled ported drive” (porque se trata de una unidad de disco aislada y portada)
● “because it is a SATA drive” (porque se trata de una unidad de disco SATA)
● “because it is smaller than the drive it is replacing” (porque es más pequeña que la unidad que está reemplazando)
● “because it is of an unrecognized type” (porque es de un tipo no reconocido)
● “because it contains an unsupported RIS configuration” (porque contiene una configuración RIS no compatible)
ID del mensaje: 24765
Nivel de gravedad: Informativo
Mensaje del registro: The MSA chassis labeled as <chassis label> has reported that battery pack number <battery pack number> located on controller number <controller number> has been <inserted / removed>.The external Smart Array controller reporting this operation is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24766
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> is reporting that the <drive type> physical hard drive located in bay <bay number> is in a SMART predictive failure state.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24767
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that more physical devices were detected than the controller is currently capable of supporting. Some physical drives will not be accessible.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24768
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that the storage enclosure attached to port <port number> with chassis serial number
202 Capítulo 4 Errores de HPE Smart Array ESES

<serial number> has had power supply number <power supply number> <inserted / removed>.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24769
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that fan number <fan number> located on fan module <fan module number> was <inserted / removed>.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24770
Nivel de gravedad: Error
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that fan number <fan number> located on fan module <fan module number> has failed. The external Smart Array controller may attempt to shut down power and/or spin down the installed disk drive(s).The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24771
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that fan number <fan number> located on fan module <fan module number> is reporting a degraded condition.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24772
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that fan number <fan number> located on fan module <fan module number> is now operational.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24773
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis number> has reported that a tape drive has been <inserted / removed>.
ESES Mensajes del registro de eventos de Windows para Smart Array 203

The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24774
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> is reporting <link up / down> for PHY number <PHY number>. This PHY link status change has occurred on port <port number> of the external array controller.The external Smart Array controller reporting this event is attached to the host side Smart Array controller <controller name / slot information>.
Identificadores de mensajes 24775-24799ID del mensaje: 24775
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> is reporting that the <drive type> physical hard drive located in bay <bay number> is offline. The offline reason received from the Smart Array firmware is: <firmware error code>.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.Valores de <código de error del firmware>:
● TOO_SMALL_IN_LOAD_CONFIG - Replacement drive is too small for configured volume(s).
● ERROR_ERASING_RIS - Could not write to reserved configuration sectors after multiple retries.
● ERROR_SAVING_RIS - Could not write to reserved configuration sectors after multiple retries.
● FAIL_DRIVE_COMMAND - “Fail Drive” command received from host.● MARK_BAD_FAILED - Unable to create media defect after multiple retries.● MARK_BAD_FAILED_IN_FINISH_REMAP - Unable to create media defect after
multiple retries.● TIMEOUT - Too many SCSI command timeouts.● AUTOSENSE_FAILED - Drive is failing commands but is not returning SCSI
sense data after multiple retries.● MEDIUM_ERROR_1 - Caused by a particular set of SCSI sense codes that
indicate the drive is in bad shape and its data may be corrupt.● MEDIUM_ERROR_2 - Caused by a particular set of SCSI sense codes that
indicate the drive is in bad shape; retries did not help.● NOT_READY_BAD_SENSE - Drive is returning unrecognized Not Ready sense
codes.● NOT_READY - Drive is not ready and will not spin up.
204 Capítulo 4 Errores de HPE Smart Array ESES

● HARDWARE_ERROR - Drive is returning a Hardware Error sense key; controller unable to get drive back online.
● ABORTED_COMMAND - Drive is returning an Aborted Command sense key; controller unable to get drive back online.
● WRITE_PROTECTED - Drive is returning a sense key indicating it is write protected.
● SPIN_UP_FAILURE_IN_RECOVER - “Start Unit” command failed during error recovery
● REBUILD_WRITE_ERROR - Drive failed write command after multiple retries during rebuild.
● TOO_SMALL_IN_HOT_PLUG - Replacement drive is too small for configured volume(s).
● BUS_RESET_RECOVERY_ABORTED - Unable to communicate with drive after multiple bus resets and retries; may be due to this drive or another drive that is corrupting the parallel SCSI bus.
● REMOVED_IN_HOT_PLUG - Drive has been hot-removed.● INIT_REQUEST_SENSE_FAILED - “Request Sense” command failed during
device discovery/initialization.● INIT_START_UNIT_FAILED - “Start Unit” command failed during device
discovery/initialization.● INQUIRY_FAILED - “Inquiry” command failed after multiple retries.● NON_DISK_DEVICE - Attached device is not a hard disk per its
inquiry data.● READ_CAPACITY_FAILED - “Read Capacity” command failed after multiple
retries.● INVALID_BLOCK_SIZE - Drive indicates it is not formatted for 512 bytes
per sector.● HOT_PLUG_REQUEST_SENSE_FAILED - “Request Sense” command failed after
drive hot-added.● HOT_PLUG_START_UNIT_FAILED - “Start Unit” command failed after drive
hot-added)● WRITE_ERROR_AFTER_REMAP - After reassigning a media error reported
during a write command, the write command failed with another media error.
● INIT_RESET_RECOVERY_ABORTED - Unable to communicate with drive during initialization after multiple bus resets and retries; may be due to this drive or another drive that is corrupting the parallel SCSI bus.
● DEFERRED_WRITE_ERROR - Drive with write cache enabled reported that it could not complete a write command that it previously indicated was successful [lost data].
● MISSING_IN_SAVE_RIS - Could not write to reserved configuration sectors after multiple retries.
ESES Mensajes del registro de eventos de Windows para Smart Array 205

● WRONG_REPLACE - A hot-plug tape drive was plugged in as a replacement into a drive bay that a hard disk was removed from.
● GDP_VPD_INQUIRY_FAILED - Could not read drive serial number after multiple retries.
● GDP_MODE_SENSE_FAILED - Could not read certain mode pages after multiple retries.
● DRIVE_NOT_IN_48BIT_MODE - SATA drive is not supported in 48-bit LBA mode.
● DRIVE_TYPE_MIX_IN_HOT_PLUG - Attempt to hot-add a SATA drive as a replacement in a SAS-only volume, or vice versa.
● DRIVE_TYPE_MIX_IN_LOAD_CFG - attempt to use a SATA drive as a replacement in a SAS-only volume, or vice versa.
● PROTOCOL_ADAPTER_FAILED - Protocol layer reports that the protocol hardware has failed; may be a controller failure.
● FAULTY_ID_BAY_EMPTY - Drive responds to SCSI ID, but the corresponding bay is empty.
● FAULTY_ID_BAY_OCCUPIED - Bay is occupied by a drive that does not respond to the corresponding SCSI ID.
● FAULTY_ID_INVALID_BAY - Drive responds to an ID that doesn’t have a valid corresponding bay.
● WRITE_RETRIES_FAILED - Unable to complete a write operation after several retries.
● QUEUE_FULL_ON_ZERO - Drive indicates that its queue is full when we have no requests outstanding to the drive.
● SMART_ERROR_REPORTED - Drive has reported a predictive-failure error when controller is configured to automatically fail [instead of reporting imminent failure of] drives that report this error.
● PHY_RESET_FAILED - Phy reset request failed.● FR_CHKBLK_FAILED_WRITE - Drive failed write command while checking for
media errors.● FR_ATI_TEST_FAILED_WRITE - Drive failed write command while checking
for errors.● OFFLINE_ERASE - Drive is offline due to a Secure Erase operation.● OFFLINE_TOO_SMALL - Drive is offline because it’s a replacement drive
that is too small.● OFFLINE_DRIVE_TYPE_MIX - Drive is offline because it is not the
correct type for this array [SATA vs SAS].● OFFLINE_ERASE_COMPLETE - Drive is offline because a Secure Erase
operation has completed on it but it hasn’t been replaced yet.ID del mensaje: 24776
Nivel de gravedad: Informativo
206 Capítulo 4 Errores de HPE Smart Array ESES

Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> is reporting that the <drive type> physical hard drive located in bay <bay number> is now online.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24777
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> is reporting inconsistent data that was previously consistent.<additional information> The inconsistent data may be caused by a power loss during write activity or by a drive returning corrupt data. The inconsistent data is between block address <lba number 1> and block address <lba number 2> of logical drive <logical drive number>.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.Valores de <información adicional>:
● “The parity data does not match the data drives.” (Los datos de paridad no coinciden con las unidades de datos.)
● “”
ID del mensaje: 24778
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> is reporting that surface analysis has repaired an inconsistent stripe on logical drive <logical drive number> by overwriting the statistically incorrect stripe on the physical drive found in bay <bay number>.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24779
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> is reporting that surface analysis has repaired an inconsistent stripe on logical drive <logical drive number> by updating the parity data to match the data drive contents.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24780
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> is reporting inconsistent data that was previously consistent.<additional information>The inconsistent data may be caused by a power loss during write activity or by a drive
ESES Mensajes del registro de eventos de Windows para Smart Array 207

returning corrupt data. The inconsistent data is between block address <lba number 1> and block address <lba number 2> of logical drive <logical drive number>. The physical drive containing the inconsistent data can be found in bay <bay number> of the MSA chassis.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.Valores de <información adicional>:
● “The parity data does not match the data drives.” (Los datos de paridad no coinciden con las unidades de datos.)
● “”
ID del mensaje: 24781
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that fan module <module number> was <inserted / removed>.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24782
Nivel de gravedad: Error
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that fan module <fan module number> has failed. The external Smart Array controller may attempt to shut down power and/or spin down the installed disk drive(s).The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24783
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that fan module <fan module number> is reporting a degraded condition.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24784
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that fan module <fan module number> is now operational.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24785
Nivel de gravedad: Informativo
208 Capítulo 4 Errores de HPE Smart Array ESES

Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that a previously failed storage enclosure processor (SEP) is now responding and operational.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24786
Nivel de gravedad: Error
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that a storage enclosure processor (SEP) has failed.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24787
Nivel de gravedad: Error
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that all storage enclosure processors (SEPs) have failed and there is currently no environmental management and monitoring available for this storage enclosure.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24788
Nivel de gravedad: Informativo
Mensaje del registro: Surface analysis parity/consistency initialization forced complete for logical drive <logical drive number> on external Smart Array array controller located in the MSA chassis labeled as <chassis label>.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24789
Nivel de gravedad: Informativo
Mensaje del registro: External Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that <number of passes> surface analysis passes have completed for logical drive <logical drive number>.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24790
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis number> is reporting that the <drive type> physical drive located in bay <bay number> is in a SMART trip state that indicates the drive has reached 0 percent usage left. Indicates that the drive has a S.M.A.R.T wear error and is approaching the maximum usage
ESES Mensajes del registro de eventos de Windows para Smart Array 209

limit for writes (wear out). The drive should be replaced as soon as possible.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24791
Nivel de gravedad: Error
Mensaje del registro: Array controller <controller name / slot information> has reported that its internal temperature has exceeded the preset limit of <temperature limit>°C. The current temperature is <current temperature>°C as reported by sensor number <sensor number>. The controller may attempt to shut down power and/or spin down installed disk drives.ID del mensaje: 24792
Nivel de gravedad: Advertencia
Mensaje del registro: Array controller <controller name / slot information> has reported that its internal temperature is nearing the preset temperature limit of <temperature limit>°C. The current temperature is <current temperature>°C as reported by sensor number <sensor number>. The array controller may enact precautionary measures to prevent data loss should the temperature reach the operating limit.ID del mensaje: 24793
Nivel de gravedad: Informativo
Mensaje del registro: Array controller <controller name / slot information> has reported that a previously existing temperature condition on the controller from sensor <sensor number> has been corrected. All of the temperature sensors are now reporting acceptable temperature levels.ID del mensaje: 24794
Nivel de gravedad: Error
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis number> is indicating that sensor number <sensor number> has reported that the internal temperature of <internal temperature>°C has exceeded the preset temperature limit of <temperature limit>°C. The external Smart Array controller may attempt to shut down power to and/or spin down installed disk drives.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24795
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> is indicating that its internal temperature is nearing the preset temperature limit of <temperature limit>°C. The current temperature is <current temperature>°C as reported by sensor number <sensor number>. The external Smart Array controller may enact precautionary measures to prevent data loss should the temperature reach the operating limit.
210 Capítulo 4 Errores de HPE Smart Array ESES

The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24796
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> is indicating that a previously existing temperature condition on the controller from sensor <sensor number> has been corrected. All of the temperature sensors are now reporting acceptable temperature levels.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24797
Nivel de gravedad: Informativo
Mensaje del registro: The <drive type> physical drive located in bay <bay number> has passed a pre-defined usage threshold. It currently has <days or percent> <days of / percentage> usage remaining. Indicates that the drive is approaching the maximum usage limit for writes (wear out). This drive can be found in box <box number> which is connected to port <port number> of the array controller <controller name / slot information>.ID del mensaje: 24798
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> is reporting that the <drive type> physical drive located in bay <bay number> has passed a pre-defined usage threshold.It currently has <days or percent> <days of / percentage> usage remaining. Indicates that the drive is approaching the maximum usage limit for writes (wear out).The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24799
Nivel de gravedad: Advertencia
Mensaje del registro: The <drive type> physical drive located in bay <bay number> could not be authenticated as a genuine HPE hard drive. This drive's status LEDs will not be controlled. This drive can be found in box <box number> which is connected to port <port number> of the array controller <controller name / slot information>.
Identificadores de mensajes 24800-24808ID del mensaje: 24800
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> is reporting that the%3physical drive
ESES Mensajes del registro de eventos de Windows para Smart Array 211

located in bay <bay number> could not be authenticated as a genuine HPE hard drive. This drive's status LEDs will not be controlled.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24801
Nivel de gravedad: Informativo
Mensaje del registro: Array controller <controller name / slot information> has reported that its cache is missing. This is an unsupported configuration.ID del mensaje: 24802
Nivel de gravedad: Informativo
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> is reporting that its cache is missing. This is an unsupported configuration.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24803
Nivel de gravedad: Advertencia
Mensaje del registro: Array controller <controller name / slot information> has reported that it previously locked up with code <lockup code>.ID del mensaje: 24804
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that it previously locked up with code <lockup code>.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24805
Nivel de gravedad: Advertencia
Mensaje del registro: Array controller <controller name / slot information> has reported that Supercap is enabled but the cache module flash memory is missing. This is an unsupported configuration.ID del mensaje: 24806
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that Supercap is enabled but the cache module flash memory is missing. This is an unsupported configuration.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.ID del mensaje: 24807
212 Capítulo 4 Errores de HPE Smart Array ESES

Nivel de gravedad: Advertencia
Mensaje del registro: Array controller <controller name / slot information> has reported that the cache module flash memory is installed but Supercap is disabled. This is an unsupported configuration.ID del mensaje: 24808
Nivel de gravedad: Advertencia
Mensaje del registro: The external Smart Array controller located in the MSA chassis labeled as <chassis label> has reported that the cache module flash memory is installed but Supercap is disabled. This is an unsupported configuration.The external Smart Array controller is attached to the host side Smart Array controller <controller name / slot information>.
Errores del controlador de Windows para Smart ArrayID del mensaje: 5001
Nivel de gravedad: Error
Mensaje del registro: The controller in slot %3 (bus %4, device %5, function %6) heartbeat has not changed in %2 seconds.ID del mensaje: 5002
Nivel de gravedad: Error
Mensaje del registro: The driver has taken the failed controller in slot %2 (bus %3, device %4, function %5) offline.ID del mensaje: 5003
Nivel de gravedad: Error
Mensaje del registro: The controller (bus %2, device %3, function %4) has failed. Invalid driver configuration buffer.ID del mensaje: 5004
Nivel de gravedad: Error
Mensaje del registro: The controller (bus %2, device %3, function %4) has failed. Critical memory allocation failure.ID del mensaje: 5005
Nivel de gravedad: Error
Mensaje del registro: The controller (bus %2, device %3, function %4) failed to post. (La controladora [bus %2, dispositivo %3, función %4] no pudo publicar.)ID del mensaje: 5006
Nivel de gravedad: Error
Mensaje del registro: The controller (bus %2, device %3, function %4) failed with lockup code=0x%5 LED status=0x%6.
ESES Errores del controlador de Windows para Smart Array 213

5 Errores de HPE Onboard Administrator
Mensajes de error de Onboard Administrator● Errores de respuesta Soap: estos son los errores generales generados por el servicio gSoap
para los errores de validación, fallos en los dispositivos, etc. Estos errores se organizan en dos categorías:
◦ Errores de solicitud del usuario
◦ Errores de Onboard Administrator
● Errores de interfaz Soap: estos errores señalan problemas internos con el servicio gSoap
● Errores de aplicación CGI: estos errores los generan los distintos procesos de CGI. Cada uno emite su propio conjunto de errores:
◦ Errores de carga de archivos
◦ Errores de captura de pantalla de Insight Display
Errores de Onboard Administrator1 The submitted user already exists. (El usuario enviado ya existe.)
2 The submitted user name is not valid. (El nombre de usuario enviado no es válido.)
3 The maximum number of users already exists. (Ya existe el número máximo de usuarios.)
5 The requested user does not exist. (El usuario solicitado no existe.)
6 The submitted group already exists. (El grupo enviado ya existe.)
7 Invalid privilege level. (Nivel de privilegio no válido.)
8 Insufficient privileges for the requested operation. (No hay privilegios suficientes para la operación solicitada.)
10 The submitted user was already enabled. (El usuario enviado ya ha sido activado.)
11 The submitted user was already disabled. (El usuario enviado ya ha sido desactivado.)
12 The submitted user already has administrator rights. (El usuario enviado ya posee derechos de administrador.)
13 The submitted user is not an administrator. (El usuario enviado no es un administrador.)
14 An error occurred while creating a group entry. (Error al crear una entrada de grupo.)
16 Unable to perform the operation. Retry the operation or restart OA. (System Error 16) (No es posible realizar la operación. Vuelva a intentar la operación o reinicie OA. [Error del sistema 16])
17 Unable to perform the operation. Retry the operation or restart OA. (System Error 17) (No es posible realizar la operación. Vuelva a intentar la operación o reinicie OA. [Error del sistema 17])
18 Unable to perform the operation. Retry the operation or restart OA. (System Error 18) (No es posible realizar la operación. Vuelva a intentar la operación o reinicie OA. [Error del sistema 18])
214 Capítulo 5 Errores de HPE Onboard Administrator ESES

19 The submitted bay is already assigned. (El compartimento enviado ya ha sido asignado.)
20 The submitted bay is not assigned. (El compartimento enviado no ha sido asignado.)
22 The submitted value is already in use. (El valor enviado ya está en uso.)
23 The first character in the submitted value is not valid. (El primer carácter del valor enviado no es válido.)
24 The submitted value contains an invalid character. (El valor enviado contiene un carácter no válido.)
25 The submitted value is too short. (El valor enviado es demasiado corto.)
26 The submitted value is too long. (El valor enviado es demasiado largo.)
27 The submitted trap receiver already exists. (El receptor de captura enviado ya existe.)
28 The maximum number of trap receivers already exists. (Ya existe el número máximo de receptores de captura.)
29 The maximum number of IP managers already exists. (Ya existe el número máximo de administradores IP.)
30 The IP Manager already exists. (El administrador IP ya existe.)
31 The submitted bay number is out of range. (El número de compartimento enviado está fuera del intervalo.)
32 The submitted IP address is not valid. (La dirección IP enviada no es válida.)
33 The submitted value is null. (El valor enviado es nulo.)
34 An error occurred while generating an event. (Error al generar un evento.)
35 An error occurred opening the enclosure system log. (Error al abrir el registro del sistema del chasis.)
36 The submitted date and/or time value was not formatted correctly. (El valor de fecha y/o hora enviado no tiene el formato correcto.)
37 An error occurred while opening the Onboard Administrator's system log. (Error al abrir el registro del sistema del Onboard Administrator.)
38 The NMI Dump failed for the submitted blade. (Error en el volcado NMI para el blade enviado.)
39 Setting the UID for the submitted blade failed. (Error en la configuración de UID para el blade enviado.)
40 Setting the environment variable for the submitted blade failed. (Error en la configuración de la variable de entorno para el blade enviado.)
41 Setting the boot order for the submitted blade failed. (Error en el orden de arranque para el blade enviado.)
42 Setting the power control for the submitted blade failed. (Error en la configuración del control de alimentación para el blade enviado.)
43 Setting the max power for the submitted blade failed. (Error en la configuración de la alimentación máxima para el blade enviado.)
44 Shutting down the submitted blade failed. (Error al cerrar el blade enviado.)
45 Clearing the submitted blade failed. (Error al eliminar el blade enviado.)
ESES Errores de Onboard Administrator 215

46 Getting blade information for the submitted blade failed. (Error al obtener información sobre el blade para el blade enviado.)
47 Getting blade status for the submitted blade failed. (Error al obtener el estado del blade para el blade enviado.)
48 Getting sensor information for the submitted sensor failed. (Error al obtener información sobre el sensor para el sensor enviado.)
49 Setting the submitted rack name failed. (Error al configurar el nombre del bastidor enviado.)
50 Getting power supply information for the submitted power supply failed. (Error al obtener información sobre la fuente de alimentación para la fuente de alimentación enviada.)
51 Getting power supply status for the submitted power supply failed. (Error al obtener el estado de la fuente de alimentación para la fuente de alimentación enviada.)
52 Getting power supply measurements for the submitted power supply failed. (Error al obtener las mediciones de la fuente de alimentación para la fuente de alimentación enviada.)
53 Setting the Onboard Administrator's UID state failed. (Error al configurar el estado de UID del Onboard Administrator.)
54 Getting the Onboard Administrator's status failed. (Error al obtener el estado del Onboard Administrator.)
55 Getting the Onboard Administrator's information failed. (Error al obtener la información del Onboard Administrator.)
56 Getting fan information for the submitted fan failed. (Error al obtener la información sobre el ventilador para el ventilador enviado.)
57 Rebooting the enclosure failed. (Error al reiniciar el chasis.)
58 Shutting down the enclosure failed. (Error al cerrar el chasis.)
59 Getting the enclosure information failed. (Error al obtener información sobre el chasis.)
60 Getting the enclosure names failed. (Error al obtener los nombres del chasis.)
61 Getting the enclosure status failed. (Error al obtener el estado del chasis.)
62 Setting the enclosure name failed. (Error al obtener el nombre del chasis.)
63 Setting the enclosure asset tag failed. (Error al obtener la etiqueta de inventario del chasis.)
64 Setting the enclosure time zone failed. (Error al configurar la zona horaria del chasis.)
65 Setting the enclosure UID failed. (Error al configurar el UID del chasis.)
66 Setting the UID for the submitted interconnect failed. (Error en la configuración del UID para la interconexión enviada.)
67 Resetting the submitted interconnect failed. (Error al reajustar la interconexión enviada.)
68 Getting interconnect information for the submitted interconnect failed. (Error al obtener la información de interconexión para la interconexión enviada.)
69 Getting interconnect status for the submitted interconnect failed. (Error al obtener el estado de interconexión para la interconexión enviada.)
70 An error occurred while accessing the connected user for the requested blade. (Error al acceder el usuario conectado para el blade solicitado.)
216 Capítulo 5 Errores de HPE Onboard Administrator ESES

71 An error occurred while reading the lockfile for the submitted blade. (Error al leer el archivo de bloqueo para el blade enviado.)
72 The submitted e-mail address is not valid. (La dirección de correo electrónico enviada no es válida.)
73 Libem is not able to talk to iLO. (Libem no puede comunicarse con iLO.)
74 Downloading the submitted file failed. (Error al descargar el archivo enviado.)
75 The certificate could not be verified. (No se pudo verificar el certificado.)
76 Could not save the authorization keys. (No fue posible guardar las claves de autorización.)
77 The SSH key size is not correct. (El tamaño de la clave SSH no es correcto.)
78 Could not ping the requested url. (No se pudo hacer ping a la url solicitada.)
79 Could not generate the CSR. (No se pudo generar una solicitud de firma de certificado (CSR, Certificate Signing Request).)
80 Could not generate the SSO (No se pudo generar una firma única (SSO, Single Sign-On).)
81 Could not read the fingerprint. (No se pudo leer la huella digital.)
82 Could not get SSH key. (No se pudo obtener la clave SSH.)
83 The field is already enabled. (El campo ya está activado.)
84 The field is already disabled. (El campo ya está desactivado.)
85 The system is already in DHCP mode. (El sistema ya está en modo DHCP.)
86 The system is currently in static IP mode. (El sistema actualmente está en modo de IP estático.)
87 Could not clear the system log. (No se pudo borrar el registro del sistema.)
88 Could not restore the factory settings. (No se pudo restaurar la configuración de fábrica.)
89 Could not read the configuration file. (No se pudo leer el archivo de configuración.)
90 Could not write to the configuration file. (No se pudo escribir el archivo de configuración.)
92 The submitted URL is not valid. (La dirección URL enviada no es válida.)
93 Could not update the firmware with the submitted image file. (No se pudo actualizar el firmware con al archivo de imagen enviado.)
94 Unable to acquire the rack topology. (No es posible adquirir la topología del bastidor.)
95 Invalid domain. (Dominio no válido.)
97 Connecting to the blade's iLO failed. (Error al conectar con el iLO del blade.)
98 Sending the RIBCL command to the requested blade failed. (Error al enviar el comando RIBCL al blade solicitado.)
99 Could not find the requested element in the RIBCL response. (No se pudo encontrar el elemento solicitado en la respuesta RIBCL.)
100 Could not find the requested attribute in the RIBCL response. (No se pudo encontrar el atributo solicitado en la respuesta RIBCL.)
101 Could not find the starting boundary in the RIBCL response. (No se pudo encontrar el límite inicial en la respuesta RIBCL.)
ESES Errores de Onboard Administrator 217

102 Could not find the ending boundary in the RIBCL response. (No se pudo encontrar el límite final en la respuesta RIBCL.)
103 Could not determine the IP address of the management processor for the requested blade. (No se pudo determinar la dirección IP del procesador de gestión para el blade solicitado.)
104 Could not locate a Primary NTP server. (No se pudo ubicar un servidor NTP primario.)
105 You must set at least one (1) trusted host before enabling trusted hosts. (Debe establecer al menos un (1) host de confianza antes de activar los hosts de confianza.)
107 Could not create the RIBCL request. (No se pudo crear la solicitud RIBCL.)
108 This error message should be taken from the soap errorText (varies). (Este mensaje de error debe tomarse del errorText de Soap (varía).)
118 The management processor auto-login feature is not supported. (La característica de inicio de sesión automático del procesador de gestión no es compatible.)
119 The maximum number of EBIPA DNS servers has already been reached. (Ya se ha alcanzado el número máximo de servidores DNS de EBIPA.)
120 The starting IP address and Net Mask must be set before enabling EBIPA. (Debe ajustar la dirección IP inicial y la Máscara de red antes de activar EBIPA.)
121 The LDAP group does not exist. (El grupo LDAP no existe.)
122 The LDAP group already exists. (El grupo LDAP ya existe.)
123 The maximum number of LDAP groups has already been reached. (Ya se ha alcanzado el número máximo de grupos LDAP.)
125 Error getting Insight Display information. (Error al obtener la información de Insight Display.)
126 Error getting Insight Display status. (Error al obtener el estado de Insight Display.)
127 Error reading the certificate (Error al leer el certificado.)
128 Error setting the time zone. (Error al ajustar la zona horaria.)
129 Error installing the certificate. (Error al instalar el certificado.)
130 Exceeded the maximum number of SSO certificates. (Excede el número máximo de certificados SSO.)
131 The X509 Certificate is not formatted correctly. (El certificado X509 no tiene el formato correcto.)
132 HP SIM station already in trusted list. (La estación HP SIM ya se encuentra en la lista de confianza.)
133 HP SIM station name not found. (No se ha encontrado el nombre de la estación HP SIM.)
134 HP SIM SSO API received a bad parameter. (La API SSO de HP SIM recibió un parámetro dañado.)
135 The maximum number of SIM XE stations already configured. (Ya se ha configurado el número máximo de estaciones XE de SIM.)
136 The maximum number of EBIPA interconnects DNS servers has been reached. (Se ha alcanzado el número máximo de servidores DNS de interconexiones EBIPA.)
137 The session could not be created. (No se pudo crear la sesión.)
138 The session could not be deleted. (No se pudo eliminar la sesión.)
218 Capítulo 5 Errores de HPE Onboard Administrator ESES

139 Not a valid request while running in standby mode. (No es una solicitud válida mientras se ejecuta en modo de espera.)
140 Not a valid request while transitioning to active mode. (No es una solicitud válida mientras se cambia a modo activo.)
141 Not a valid request while running in active mode. (No es una solicitud válida mientras se ejecuta en modo activo.)
142 The maximum number of LDAP certificates already exist. (Ya existe el número máximo de certificados LDAP.)
143 Could not remove LDAP certificate. (No se pudo eliminar el certificado LDAP.)
144 You must configure the directory server and at least one search context before enabling LDAP. (Debe configurar el servidor del directorio y al menos un contexto de búsqueda antes de activar el LDAP.)
145 Could not set the LDAP group description. (No se pudo ajustar la descripción del grupo LDAP.)
146 An error occurred while communicating with the other Onboard Administrator. (Error en la comunicación con el otro Onboard Administrator.)
147 Unable to perform the operation. Retry the operation or restart OA. (System Error 147) (No es posible realizar la operación. Vuelva a intentar la operación o reinicie OA. [Error del sistema 147])
148 The other Onboard Administrator is not present. (El otro Onboard Administrator no está presente.)
149 No redundant Onboard Administrator found. Cannot failover. (No se encontró un Onboard Administrator redundante. No se puede realizar la conmutación por error.)
150 The user could not be authenticated. (No se pudo autenticar el usuario.)
151 Invalid parameter for setting blade one time boot. (Parámetro no válido para ajustar el arranque de una sola vez del blade.)
152 Invalid parameter for setting the blade boot priority. (Parámetro no válido para ajustar la prioridad de arranque del blade.)
153 A blade boot device can only be listed once. (Solo se puede enumerar una vez el dispositivo de arranque del blade.)
154 NTP Poll time must be between 60 and 86400 seconds. (El tiempo de la consulta NTP debe ser entre 60 y 86400 segundos.)
155 Could not create new file. (No se pudo crear un archivo nuevo.)
156 Could not write the file to the disk. (No se pudo escribir el archivo en el disco.)
157 The submitted image is too big. (La imagen enviada es demasiado grande.)
158 The submitted image is not a BMP image. (La imagen enviada no es una imagen BMP.)
159 The submitted image does not have the appropriate dimensions. (La imagen enviada no posee las dimensiones apropiadas.)
160 Non-standard BMP images are not supported. (No se admiten imágenes BMP estándar.)
161 The specified item was not found. (No se encontró el elemento especificado.)
162 The protocol specified in the URL is not supported. (No se admite el protocolo especificado en la URL.)
163 The upload to the specified URL failed. (Error al cargar la URL especificada.)
ESES Errores de Onboard Administrator 219

164 The Onboard Administrator did not fail over. (El Onboard Administrator no realizó la conmutación por error.)
165 The blade is in a powered off state. (El blade se encuentra en estado apagado.)
167 The IP manager does not exist. (El administrador de IP no existe.)
168 There is no SSH key installed. (No hay una clave SSH instalada.)
169 There was a problem running the configuration script. (Sucedió un problema al ejecutar la secuencia de comandos de configuración.)
170 Missing credentials. (Faltan las credenciales.)
171 Caught the SIGSEGV signal. (Se interceptó la señal SIGSEGV.)
173 No trap receivers were specified. (No se han especificado receptores de captura.)
174 There are no SSH keys installed. (No hay claves SSH instaladas.)
175 There was an error attempting to clear the SSH keys. (Error al intentar borrar las claves SSH.)
176 The IP address is already listed. (La dirección IP ya está en la lista.)
177 There was an error getting the SSO trust mode. (Error al obtener el modo de confianza de la SSO.)
178 The submitted SSO trust mode is invalid. (El modo de confianza de la SSO enviado no es válido.)
179 The certificate cannot be removed because it does not exist. (No se puede eliminar el certificado porque no existe.)
180 The interconnect tray is not present. (La bandeja de interconexión no está presente.)
181 The blade is not present. (El blade no está presente.)
182 Users cannot remove or disable themselves. (Los usuarios no se pueden eliminar o desactivar a sí mismos.)
183 Invalid time zone. (Zona horaria no válida.)
184 Error setting CLP strings. (Error al establecer las cadenas de CLP.)
185 Error getting CLP status. (Error al obtener el estado de CLP.)
186 Error setting ISMIC info block. (Error al establecer el bloque de información de ISMIC.)
187 Error reading ISMIC info block. (Error al leer el bloque de información de ISMIC.)
188 Error clearing blade signature. (Error al eliminar la firma del blade.)
189 Error setting blade signature. (Error al establecer la firma del blade.)
190 Request is valid only for server blades. (La solicitud solo es válida para los blades de servidor.)
191 Request is valid only for ProLiant server blades. (La solicitud solo es válida para los blades de servidor ProLiant.)
192 The string entered is not a valid netmask. (La cadena introducida no es una máscara de red válida.)
193 The string entered is not a valid gateway. (La cadena introducida no es una puerta de enlace válida.)
220 Capítulo 5 Errores de HPE Onboard Administrator ESES

194 The string entered for DNS server 1 is not valid. (La cadena introducida para el servidor DNS 1 no es válida.)
195 The string entered for DNS server 2 is not valid. (La cadena introducida para el servidor DNS 2 no es válida.)
196 Error trying to remove a nonexistent SSO name. (Error al intentar eliminar un nombre de SSO inexistente.)
197 Error trying to add an SSO name. (Error al intentar añadir un nombre de SSO.)
198 Invalid SNMP trap community. (Comunidad de captura SNMP no válida.)
201 Could not open the event pipe for reading. (No se ha podido abrir la canalización del evento para su lectura.)
202 Did not read the proper size for events. (No se han leído los eventos en el tamaño apropiado.)
203 Event length mismatch. (Desajuste de la longitud del evento.)
204 The event listener was terminated. (Ha finalizado la escucha del evento.)
211 Error obtaining blade power reduction status. (Error al obtener el estado de reducción de alimentación del blade.)
212 Update the other OA firmware to enable this feature. (Actualice el otro firmware de OA para habilitar esta característica.)
213 Dates before 14 June 2006 are not valid. (Las fechas anteriores al 14 de junio de 2006 no son válidas.)
214 The certificate exceeds the maximum valid size. (El certificado supera el tamaño válido máximo.)
215 E-Fuse cannot be reset. (No se puede restablecer el fusible electrónico.)
216 Firmware update in progress. Login is disabled. (Actualización de firmware en curso. El inicio de sesión está desactivado.)
217 An error occurred while setting the enclosure PDU type. (Error al establecer el tipo de PDU del chasis.)
218 An error occurred while setting the enclosure part number. (Error al establecer la referencia del chasis.)
219 An error occurred while setting the enclosure serial number. (Error al establecer el número de serie del chasis.)
220 Cannot set time when NTP is enabled. (No se puede ajustar la hora si NTP está activado.)
221 Request is valid only for Itanium/BCS/IPF blades. (La solicitud es válida solo para los servidores Itanium/BCS/IPF.)
222 The Active and Standby Onboard Administrator are not the same hardware build. (Los Onboard Administrator activo y en espera no tienen la misma estructura de hardware.)
223 The firmware installed on an Onboard Administrator module is incompatible with FirmwareSync. (El firmware instalado en un módulo Onboard Administrator no es compatible con FirmwareSync.)
224 Failed to create firmware image. (Error al crear una imagen de firmware.)
225 The Active and Standby Onboard Administrator have the same firmware version installed. (Los Onboard Administrator activo y en espera tienen la misma versión de firmware instalada.)
226 Upgrade an Onboard Administrator to firmware 2.10 or later to enable this feature. (Actualice un Onboard Administrator al firmware 2.10 o posterior para habilitar esta característica.)
ESES Errores de Onboard Administrator 221

227 The requested user cannot be removed from iLO because it is the only remaining administrator account. (El usuario solicitado no se puede eliminar de iLO porque es la única cuenta de administrador restante.)
228 The requested user cannot be added to iLO because iLO local accounts have been disabled. (El usuario solicitado no se puede añadir a iLO porque se han desactivado las cuentas locales de iLO.)
229 The requested user cannot be added to iLO because the maximum number of local accounts already exists. (El usuario solicitado no se puede añadir a iLO porque ya existe el número máximo de cuentas locales.)
230 One or more of the specified SNMP traps were not already configured on the Onboard Administrator and cannot be removed. (Una o varias de las capturas SNMP especificadas no se habían configurado todavía en el Onboard Administrator y no se pueden eliminar.)
231 Reset Factory Defaults in progress. Login disabled. (Restablecimiento de los valores predeterminados de fábrica en curso. Inicio de sesión desactivado.)
232 The requested operation is not available on c3000 enclosures. (La operación solicitada no está disponible en los chasis c3000.)
233 This feature requires the iLO Select Pack License or iLO Advanced Pack License on the server blade when LDAP is enabled on the Onboard Administrator. (Esta característica requiere la licencia para iLO Select Pack o iLO Advanced Pack en el blade de servidor cuando LDAP está activado en el Onboard Administrator.)
234 Invalid characters detected. (Se han detectado caracteres no válidos.)
235 HP Onboard Administrator is initializing. (HP Onboard Administrator se está inicializando.) Login disabled. (HP Onboard Administrator se está inicializando. Inicio de sesión desactivado.)
236 Cannot retrieve Onboard Administrator media device array. (No se puede recuperar el array del dispositivo de soportes de Onboard Administrator.)
237 The requested device is not ready. (El dispositivo solicitado no está preparado.)
238 Power off or remove the partner blade. (Desconecte o extraiga el blade asociado.)
239 The current firmware does not support this operation. (El firmware actual no es compatible con esta operación.)
240 Serial number update requires newer firmware version. (La actualización del número de serie requiere una versión de firmware más reciente.)
241 The requested device is not present or no firmware upgrade is required. (El dispositivo solicitado no está presente o no se requiere una actualización de firmware.)
242 The operation cannot be performed on the requested device. (La operación no se puede realizar en el dispositivo solicitado.)
243 iLO license information cannot be retrieved because iLO XML Reply is disabled. (La información de licencia de iLO no se puede recuperar porque iLO XML Reply está desactivado.)
244 SSH is disabled on this blade. (SSH está desactivado en este blade.)
245 Disconnect the virtual media applet. (Desconecte el subprograma Virtual Media.)
246 Invalid SNMP Write Community string. (Cadena SNMP Write Community [Comunidad de escritura SNMP] no válida.)
247 Invalid SNMP Read Community string. (Cadena SNMP Read Community [Comunidad de lectura SNMP] no válida.)
222 Capítulo 5 Errores de HPE Onboard Administrator ESES

248 Invalid port number. The LDAP server SSL port can be any number between 1 and 65535. (Número de puerto no válido. El puerto SSL del servidor LDAP puede tener cualquier número comprendido entre 1 y 65535.)
249 Feb 29 was specified but the year is not a leap year. (Se ha especificado 29 de febrero, pero el año no corresponde a un año bisiesto.)
250 The CA certificate is invalid. (El certificado de CA no es válido.)
251 Exceeded the maximum number of CA certificates. (Se ha superado el número máximo de certificados SSO.)
252 No CA certificates are imported. (No se han importado certificados CA.)
253 This CA certificate is already imported. (Este certificado de CA ya se ha importado.)
254 A certificate is already mapped to this user. (Ya se ha asignado un certificado a este usuario.)
255 An undocumented error has occurred. Please update your firmware to the latest firmware version if necessary. Contact Hewlett Packard Enterprise if the problem persists. (Se ha producido un problema no documentado. Actualice el firmware a la última versión si fuese necesario. Póngase en contacto con Hewlett Packard Enterprise si el problema continúa.)
256 This certificate is already mapped to another user. (Este certificado ya se ha asignado a otro usuario.)
257 The user certificate could not be verified. (No se pudo verificar el certificado de usuario.)
258 This operation is not permitted when two-factor authentication is enabled. (Esta operación no está permitida si la autenticación basada en dos factores está activada.)
260 This operation cannot be performed when AlertMail is disabled. (Esta operación no se puede realizar si SNMP está desactivado.)
261 This operation cannot be performed when the AlertMail settings are not configured. (Esta operación no se puede realizar si los ajustes de AlertMail no están configurados.)
262 This operation cannot be performed when SNMP is disabled. (Esta operación no se puede realizar si SNMP está desactivado.)
263 A certificate must be mapped to Administrator or LDAP must be enabled with a configured groups with administrator privilege to enable two-factor authentication. (Se debe asignar un certificado al administrador o habilitar LDAP con un grupo configurado con privilegios de administrador para activar la autenticación basada en dos factores.)
265 A certificate is not mapped to this user account. (No se ha asignado un certificado a esta cuenta de usuario.)
266 Two-factor authentication is in effect. (La autenticación basada en dos factores está vigente.)
267 Two-factor authentication configuration was not changed. (No se ha cambiado la configuración de la autenticación basada en dos factores.)
268 An iLO image is already staged. (Ya se ha almacenado provisionalmente una imagen de iLO.)
269 The file was not a proper iLO image for the blade. (El archivo no era una imagen de iLO adecuada para el blade.)
270 The crc32 supplied does not match the provided file. (El crc32 suministrado no coincide con el archivo proporcionado.)
271 Cannot delete the last CA with two-factor authentication enabled. (No se puede eliminar el último CA con la autenticación basada en dos factores activada.)
ESES Errores de Onboard Administrator 223

272 The Onboard Administrator cannot communicate with iLO. (El Onboard Administrator no se puede comunicar con iLO.)
273 An EBIPA configuration error occurred. (Se produjo un error de configuración de EBIPA.)
274 Link Loss Failover intervals must be between 30 and 86400 seconds. (Los intervalos de conmutación por error de pérdida de enlace deben estar comprendidos entre 30 y 86400 segundos.)
275 Network speed must be either 10Mbit or 100Mbit. (La velocidad de red debe ser bien 10 MB o 100 MB.)
276 Network duplex setting must be HALF or FULL. (La configuración de dúplex de red debe ser HALF o FULL.)
277 The password does not conform to password rules. (La contraseña no se ajusta a las reglas de contraseña.)
278 Invalid minimum password value (Valor de contraseña mínimo no válido.)
279 A firmware image is already staged. (Ya se ha almacenado provisionalmente una imagen de firmware.)
280 The provided file was not a proper image. (El archivo proporcionado no era una imagen adecuada.)
281 Bad image CRC checksum (Suma de comprobación de CRC de imagen no válida.)
282 Remote system logging must be enabled to perform this operation. (Se debe habilitar el registro del sistema remoto para realizar esta operación.)
283 Invalid remote port. The port must be a number between 1 and 65535. (Puerto remoto no válido. El puerto debe ser un número entre 1 y 65535.)
284 The remote syslog server address must be configured before enabling remote system logging. (Se debe configurar la dirección del servidor de registro del sistema remoto antes de activar el registro del sistema remoto.)
285 Invalid remote server address. (Dirección del servidor remoto no válida.)
286 This setting is already enabled. (Este ajuste ya está activado.)
287 This setting is already disabled. (Este ajuste ya está desactivado.)
288 Enclosure IP mode was not enabled because the active Onboard Administrator does not have a static IPv4 address. (No se había activado el modo IP del chasis porque el Onboard Administrator activo no tiene una dirección IPv4 estática.)
289 This feature is not available for this Onboard Administrator. (Esta característica no está disponible para este Onboard Administrator.)
290 Request to enable DHCP addressing on the active Onboard Administrator is denied because Enclosure IP Mode is enabled. (La solicitud para activar el direccionamiento DHCP en el Onboard Administrator activo se ha rechazado porque el Modo IP del chasis está activado.)
291 The value provided is not proper base64. (El valor facilitado no es un valor base64.)
292 The firmware image provided is an older version than the current firmware. Onboard Administrator settings cannot be preserved. (La imagen de firmware proporcionada es una versión anterior al firmware actual. La configuración de Onboard Administrator no se puede conservar.)
293 The file provided is not a valid Onboard Administrator firmware image. (El archivo proporcionado no es una imagen de firmware de Onboard Administrator válida.)
224 Capítulo 5 Errores de HPE Onboard Administrator ESES

294 There are no USB keys connected to the enclosure. (No hay ninguna llave USB conectada al chasis.)
295 No valid firmware images found on USB key. (No se han encontrado imágenes de firmware válidas en la llave USB.)
296 No configuration scripts found on USB key. (No se han encontrado secuencias de comandos de configuración en la llave USB.)
297 I/O error on USB key. (Error de E/S en la llave USB.)
298 Badly formatted USB file URL. (URL de archivo USB con formato no válido.)
299 Permission problems when accessing USB media. (Problemas de permiso al acceder al soporte USB.)
300 Error uploading to USB media. (Error al cargar el soporte USB.)
301 An invalid number of GUIDs was passed to the Onboard Administrator. (Se ha pasado un número no válido de GUID al Onboard Administrator.)
302 URL flash image for microcode download not available. (No está disponible la URL de la imagen de la flash para la descarga de microcódigo.)
303 Invalid session timeout. (Tiempo de espera de sesión no válido.)
304 Invalid watts value. (Valor de vatios no válido.)
305 Failed to store change for power cap. (Error al almacenar los cambios para la limitación de alimentación.)
306 Enclosure Dynamic Power Cap feature is not allowed. (La característica de limitación de alimentación dinámica del chasis no está permitida.)
307 Wrong number of bays specified for enclosure while setting capping bays to exclude. (Número incorrecto de compartimentos especificados para el chasis al establecer los compartimentos de limitación a excluir.)
308 The number of bays opted out exceeds the maximum allowed. (El número de compartimentos descartados supera el máximo permitido.)
309 Enclosure Dynamic Power Cap feature is not allowed. (La característica de limitación de alimentación dinámica del chasis no está permitida.)
310 Enclosure Dynamic Power Cap is set. (Se ha establecido la limitación de alimentación dinámica del chasis.)
311 Enclosure Dynamic Power Cap is not set. Cannot confirm that device tray meets minimum firmware version required. (No se ha establecido la limitación de alimentación dinámica del chasis. No se puede confirmar que la bandeja del dispositivo cumpla con la versión de firmware mínima requerida.)
312 Enclosure Dynamic Power Cap not set. Device tray fails to meet the minimum required firmware version. (No se ha establecido la limitación de alimentación dinámica del chasis. La bandeja del dispositivo no cumple con la versión de firmware mínima requerida.)
313 The requested cap is outside the allowable range of Enclosure Dynamic Power Cap values. (La limitación solicitada está fuera del intervalo permitido de valores de limitación de alimentación dinámica del chasis.)
314 Server Power Reduction cannot currently be enabled. Enclosure Dynamic Power Cap is not allowed. (La reducción de la alimentación del servidor no se puede activar actualmente. No se permite la limitación de alimentación dinámica del chasis.)
ESES Errores de Onboard Administrator 225

315 No valid ISO images found on USB key. (No se han encontrado imágenes de ISO válidas en la llave USB.)
316 Bay privileges cannot be revoked for Administrators with OA permission. (No se pueden revocar los privilegios del compartimento para los administradores con permiso OA.)
317 Invalid DNS hostname. (Nombre de host DNS no válido.)
318 Factory defaults cannot be restored because the enclosure is in VC mode. (No se pueden restablecer los valores predeterminados de fábrica porque el chasis está en modo VC.)
319 The string entered is not a valid IPv6 address. (La cadena introducida no es una dirección Ipv6 válida.)
320 IPv6 static address already exists. (La dirección estática IPv6 ya existe.)
321 IPv6 static address not found. (No se ha encontrado una dirección estática IPv6.)
322 Unable to add. (No es posible añadir.)
323 Invalid SMTP server. (Servidor NTP no válido.)
324 Invalid SNMP Trap receiver. (Receptor de captura SNMP no válido.)
325 Invalid NTP server. (Servidor NTP no válido.)
326 Invalid EBIPA configuration. Multiple subnets were detected. (Configuración de EBIPA no válida. Se han detectado múltiples subredes.)
327 Specified VLAN ID does not exist. (El identificador de VLAN especificado no existe.)
328 Cannot delete the default VLAN ID. (No se puede eliminar el identificador de VLAN predeterminada.)
329 Maximum VLAN entries reached. (Se ha alcanzado el número de entradas de VLAN máximo.)
330 Duplicated VLAN ID. (Identificador de VLAN duplicado.)
331 Specified VLAN ID is invalid. (El identificador de VLAN especificado no es válido.)
332 Operation partially successful. (Operación parcialmente correcta.)
333 Duplicated VLAN name. (Nombre de VLAN duplicado.)
334 A pending command already exists. (Ya existe un comando pendiente.)
337 The remote syslog server address cannot be cleared while remote logging is enabled. (La dirección del servidor de registro del sistema remoto no se puede borrar mientras el registro remoto esté activado.)
338 Invalid search context number. (Número de contexto de búsqueda no válido.)
339 Not on the same VLAN ID domain. (No se encuentra en el mismo dominio del identificador de VLAN.)
340 This command is not valid for auxiliary blades. (Este comando no es válido para blades auxiliares.)
341 No LDAP groups currently exist. (Actualmente no existen grupos LDAP.)
342 The requested Derated Circuit Capacity is outside the allowable range of values for this enclosure. (La capacidad reducida del circuito solicitada se encuentra fuera del intervalo de valores para este chasis.)
226 Capítulo 5 Errores de HPE Onboard Administrator ESES

343 The requested Rated Circuit Capacity is outside the allowable range of values for this enclosure. (La capacidad reducida del circuito solicitada se encuentra fuera del intervalo de valores permitidos para este chasis.)
344 The requested cap is greater than the requested Derated Circuit Capacity. (La limitación solicitada es superior a la capacidad reducida del circuito solicitada.)
345 The requested Derated Circuit Capacity is greater than the requested Rated Circuit Capacity. (La capacidad reducida del circuito solicitada es superior a la capacidad nominal del circuito solicitada.)
346 The requested set of bays to exclude cause the cap to be outside the allowable range. (El conjunto de compartimentos solicitado para excluir provoca que la limitación quede fuera del intervalo permitido.)
347 The requested set of bays to exclude cause the Derated Circuit Capacity to be outside the allowable range. (El conjunto de compartimentos solicitado para excluir provoca que la capacidad reducida del circuito quede fuera del intervalo permitido.)
348 The requested set of bays to exclude cause the Rated Circuit Capacity to be outside the allowable range. (El conjunto de compartimentos solicitado para excluir provoca que la capacidad nominal del circuito quede fuera del intervalo permitido.)
353 IPv6 is currently disabled. Cannot download certificate from the specified address. (IPv6 está actualmente desactivado. No es posible descargar el certificado de la dirección especificada.)
354 The date cannot be set to a date in the past. (La fecha no se puede establecer en una fecha pasada.)
356 The setting cannot be cleared while LDAP is enabled. (El parámetro no se puede eliminar mientras LDAP esté activado.)
357 URB reporting using HTTP(S) cannot be enabled until an HTTP(S) endpoint has been configured. (Los informes URB que utilizan HTTP(S) no se pueden activar hasta que se haya configurado un extremo HTTP(S)).
358 URB reporting using SMTP cannot be enabled until an SMTP server and mailbox have been configured. (Los informes URB que utilizan SMTP no se pueden activar hasta que se haya configurado un servidor SMTP y un buzón de correo electrónico.)
359 URB reporting using SMTP and HTTP(S) cannot be enabled until HTTP(S) and SMTP settings have been configured. (Los informes URB que utilizan SMTP y HTTP(S) no se pueden activar hasta que se hayan configurado los parámetros HTTP(S) y SMTP.)
360 Warning: Not all VC-Enet modules are on the same VLAN ID. (Advertencia: no todos los módulos VC-Enet están en el mismo ID de VLAN.)
361 File doesn't exist. (El archivo no existe.)
362 This operation cannot be performed when AlertMail is enabled. (Esta operación no se puede realizar si AlertMail está activado.)
363 Setting SolutionsId failed. (Ha fallado la configuración de SolutionsId.)
364 SolutionsId must be an 8-byte hex string, between 0000000000000000 and FFFFFFFFFFFFFFFF. (SolutionsId debe ser una cadena hexadecimal de 8 bytes, comprendida entre 0000000000000000 y FFFFFFFFFFFFFFFF.)
365 Failed Remote Support registration. (Ha fallado el registro de Remote Support.)
366 Failed Remote Support un-registration. (Ha fallado la anulación del registro de Remote Support.)
ESES Errores de Onboard Administrator 227

367 Failed Remote Support restore registration. (Ha fallado el registro de la restauración de Remote Support.)
368 Failed to send Remote Support message (Hint: Check the Remote Support proxy and endpoint URL. Use SET REMOTE_SUPPORT PROXY to configure and re-try.) (Ha fallado el envío del mensaje de Remote Support [Sugerencia: compruebe el proxy de Remote Support y la dirección URL del extremo. Utilice SET REMOTE_SUPPORT PROXY para realizar la configuración y volver a intentarlo.])
369 Failed to set Remote Support interval. Valid interval is 0 to 60 (days). (Ha fallado la definición del intervalo de Remote Support. El intervalo válido está comprendido entre 0 y 60 días.)
370 You must configure the directory server and SSL port before testing LDAP. (Debe configurar el servidor de directorios y el puerto SSL antes de probar LDAP.)
371 The string contains an invalid character. (La cadena enviada contiene un carácter no válido.)
372 This operation cannot be performed when Remote Support is disabled. (Esta operación no se puede realizar si Remote Support está desactivado.)
373 Cannot set Maintenance Mode Timeout. Value should be between 5 minutes and 2 weeks. (No se puede establecer el tiempo de espera del modo de mantenimiento. El valor debe estar comprendido entre 5 minutos y 2 semanas.)
374 Insert eRs error here. (Introduzca el error eRs aquí.)
375 The string entered is not a valid LDAP server. A LDAP server must be a IP address or DNS name. (La cadena introducida no es un servidor LDAP válido. Un servidor LDAP debe ser una dirección IP o un nombre DNS.)
376 Unable to perform the operation. Retry the operation or restart OA. (System Error 376) (No es posible realizar la operación. Vuelva a intentar la operación o reinicie OA. [Error del sistema 376])
377 The HP Passport credentials provided are invalid. (Las credenciales de HP Passport proporcionadas no son válidas.)
378 This system is already registered. (Este sistema ya está registrado.)
379 Please disable Remote Support before performing this action. (Desactive Remote Support antes de realizar esta acción.)
380 Transaction UUID is mismatched. (El UUID de transacción no coincide.)
381 Unable to download ilo flash image from the url provided. Supported protocols are http, https, tftp and ftp. (No es posible descargar la imagen de la flash de ilo de la dirección url proporcionada. Los protocolos admitidos son http, https, tftp y ftp.)
382 The Onboard Administrator is still initializing. Please try your request again later. (El Onboard Administrator todavía se está inicializando. Intente de nuevo la solicitud más tarde.)
383 Failed to send Remote Support message. Please make sure DNS is enabled and verify Insight Remote Support host and port information. (Ha fallado el envío del mensaje de Remote Support. Asegúrese de que el DNS está activado y revise la información del host y el puerto de Insight Remote Support.)
384 Failed to resolve Insight Remote Support hosting server. (Error al resolver el servidor de hosting de Insight Remote Support.) Please verify DNS settings and Insight Remote Support host and port information. (Ha fallado la resolución del servidor de hosting de HP Insight Remote Support. Compruebe la configuración de DNS y la información del host y el puerto de Insight Remote Support.)
228 Capítulo 5 Errores de HPE Onboard Administrator ESES

385 Transmission to the Insight Remote Support receiver was unsuccessful. (La transmisión al receptor de Insight Remote Support no era correcta). Please check connectivity between the OA and the Insight Remote Support receiver. (La transmisión al receptor de HP Insight Remote Support no se realizó correctamente. Compruebe la conectividad entre el OA y el receptor de Insight Remote Support.)
389 This action cannot be performed in FIPS MODE ON/DEBUG. (Esta acción no se puede realizar en el modo ON/DEBUG de FIPS.)
391 No Variable Name-Value pairs are provided for substitution. (No se ha proporcionado ningún par Nombre de variable-Valor para la sustitución.)
392 Attempted to substitute more than 25 variables. (Se han intentado sustituir más de 25 variables.)
395 Trying to substitute the same variable twice. (Se ha intentado sustituir dos veces la misma variable.)
396 String_list searchFlag out of range. (El searchFlag de la lista de cadenas está fuera del intervalo.)
397 No variable names are passed in for searching. (No se han pasado nombres de variables para la búsqueda.)
398 No variable values are passed in for searching. (No se han pasado valores de variables para la búsqueda.)
401 Enclosure Firmware Management is currently disabled. (Enclosure Firmware Management está desactivado actualmente.)
402 The Enclosure Firmware Management ISO URL is not set. (No se ha establecido la URL de ISO de gestión de Enclosure Firmware Management.)
403 The operation cannot be performed while Enclosure Firmware Management is running. (La operación no se puede realizar mientras se esté ejecutando Enclosure Firmware Management.)
404 Unable to mount ISO or validate version information.
Check URL and validate ISO is available from URL entered. (No es posible montar la ISO o validar la información de versión. Compruebe la dirección URL y asegúrese de que la ISO está disponible en la dirección URL introducida.)
405 Unable to open firmware log. (No es posible abrir el registro del firmware.)
406 The blade's firmware has not been discovered. (El firmware del blade no se ha detectado.)
407 An error occurred while reading the firmware log. (Error al leer el registro del firmware del chasis.)
408 Enclosure Firmware Management is not supported by this device type. (Enclosure Firmware Management no es compatible con este tipo de dispositivo.)
409 Firmware ISO image is in use, changing url is not allowed. (La imagen ISO del firmware está en uso, no se permite el cambio de la dirección URL.)
410 Blade must be powered off before starting Enclosure Firmware Management. (Se debe apagar el blade antes de iniciar Enclosure Firmware Management.)
411 Unable to change passwords for any LDAP or SIM users. (No es posible cambiar contraseñas para los usuarios de HPSIM o de LDAP.)
412 Enclosure Firmware Management is not available. To use this feature, it needs to be unlocked. (Enclosure Firmware Management no está disponible. Para utilizar esta característica, debe estar desbloqueado.)
ESES Errores de Onboard Administrator 229

413 Enclosure Firmware Management is not supported on the Active OA hardware present. (Enclosure Firmware Management no es compatible con el hardware del OA activo actual.)
414 Could not persist firmware management log. (No se pudo conservar el registro de gestión del firmware.)
415 When in FIPS MODE ON/DEBUG, the password length must be between 8 and 40 characters. (En el modo ON/DEBUG de FIPS, la longitud de la contraseña debe encontrarse entre 8 y 40 caracteres.)
416 When in FIPS MODE ON/DEBUG, strict passwords must be enabled. (En el modo ON/DEBUG de FIPS, se deben activar las contraseñas estrictas.)
417 Certificate hash algorithm is not supported. See OA syslog for more information. (El algoritmo de hash del certificado no se admite. Consulte el registro del sistema de OA para obtener más información.)
418 Downgrade is not allowed in FIPS Mode ON/DEBUG. Please set FIPS mode to OFF and retry the operation. (El cambio a una versión anterior no está permitido en el modo ON/DEBUG de FIPS. Establezca el modo FIPS en OFF y vuelva a intentar la operación.)
419 Could not persist firmware management log. (No se pudo conservar el registro de gestión del firmware.)
427 E-Keying busy. (El proceso de generación de claves electrónicas está ocupado.)
428 Error getting CLP strings (Error al obtener las cadenas de CLP.)
431 Enclosure Firmware Management is not ready, please try again in a few minutes. (Enclosure Firmware Management no está preparado, vuelva a intentarlo en unos minutos.)
434 PIN Protection cannot be disabled in FIPS Mode. (La protección mediante PIN no se puede desactivar en el modo FIPS.)
435 Cannot restore the factory defaults while in FIPS mode. (No se pueden restaurar los valores predeterminados de fábrica en el modo FIPS.)
437 Bad EBIPAv6 device. (Dispositivo EBIPAv6 incorrecto.)
438 An EBIPAv6 configuration error occurred. Extended information is available as a bitcode reason code. (Se produjo un error de configuración de EBIPAv6. Hay disponible información extendida en forma de código de motivo de código de bits.)
439 Invalid hash algorithm. The hash algorithm must be one of: SHA1, SHA-224, SHA-256, SHA-384, or SHA-512. (Algoritmo de hash no válido. El algoritmo de hash debe ser uno de los siguientes: SHA1, SHA-224, SHA-256, SHA-384 o SHA-512.)
440 You must set a new pin code before unlocking the LCD buttons. (Debe establecer un nuevo código pin antes de desbloquear los botones LCD.)
441 The requested operation cannot be completed during a firmware update. (La operación solicitada no se puede completar durante una actualización del firmware.)
442 This enclosure is incapable of performing a reset on a non-redundant Onboard Administrator. (Este chasis no puede realizar un reinicio en un Onboard Administrator no redundante.)
444 Power cap configuration locked due to active group management. (Se ha bloqueado la configuración del límite de alimentación debido a la gestión de grupos activos.)
REMOTE SUPPORT TIER2
230 Capítulo 5 Errores de HPE Onboard Administrator ESES

445 Remote Support receiver temporarily unavailable. (El receptor de Remote Support no está disponible temporalmente.) Please retry later. (El receptor de HP Remote Support no está disponible de forma temporal. Vuelva a intentarlo más tarde.)
446 Unregistration request was not processed successfully by the Remote Support receiver (El receptor de Remote Support no procesó correctamente la solicitud de cancelación de registro.) Remote Support has been disabled locally. No service events or data collections will be sent until this device has been re-registered. (El receptor de HP Remote Support no procesó correctamente la solicitud de anulación de registro. Se ha desactivado Remote Support localmente. No se enviarán eventos de servicio ni recopilaciones de datos hasta que se haya vuelto a registrar este dispositivo.)
447 Authentication error. Please unregister and re-register device. (Error de autenticación. Anule el registro del dispositivo y vuelva a registrarlo.)
448 Missing device identifiers. Please unregister and re-register device. (Faltan identificadores del dispositivo. Anule el registro del dispositivo y vuelva a registrarlo.)
449 Corrupt device identifiers. Please unregister and re-register device. (Identificadores del dispositivo dañados. Anule el registro del dispositivo y vuelva a registrarlo.)
450 Insufficient device identifier information. Please unregister and re-register device. (La información del identificador del dispositivo es insuficiente. Anule el registro del dispositivo y vuelva a registrarlo.)
451 Invalid device identifier information. Please unregister and re-register device. (La información del identificador del dispositivo no es válida. Anule el registro del dispositivo y vuelva a registrarlo.)
452 Stale device identifiers. Please unregister and re-register device. (Identificadores del dispositivo retenidos. Anule el registro del dispositivo y vuelva a registrarlo.)
453 Missing GDID. Please unregister and re-register device. (Falta el GDID. Anule el registro del dispositivo y vuelva a registrarlo.)
454 Corrupt GDID. Please unregister and re-register device. (El GDID está dañado. Anule el registro del dispositivo y vuelva a registrarlo.)
455 Missing registration token. Please unregister and re-register device. (Falta la señal de registro. Anule el registro del dispositivo y vuelva a registrarlo.)
456 Corrupt registration token. Please unregister and re-register device. (Señal de registro dañada. Anule el registro del dispositivo y vuelva a registrarlo.)
457 Expired registration token. Please unregister and re-register device. (La señal de registro ha caducado. Anule el registro del dispositivo y vuelva a registrarlo.)
458 Invalid HP Passport credentials. Please verify and enter valid HP Passport account credentials. (Credenciales de HP Passport no válidas. Compruébelas e introduzca credenciales de cuenta de HP Passport válidas.)
459 Device is already registered. Please delete the device from Insight Remote Support user interface and retry registration. (El dispositivo ya está registrado. Elimine el dispositivo de la interfaz de usuario de Insight Remote Support y vuelva a intentar registrarlo)
460 Unknown device. Please unregister and re-register device. (Dispositivo desconocido. Anule el registro del dispositivo y vuelva a registrarlo.)
461 Insufficient registration data. Please retry registration. (Datos de registro insuficientes. Vuelva a intentar el registro.)
462 Missing SOAP header. Please retry your last step. If error persists and device is currently registered, unregister and re-register device. (Falta el encabezado SOAP. Vuelva a intentar el último paso. Si el error continúa y el dispositivo ya está registrado, anule el registro del mismo y vuelva a registrarlo.)
ESES Errores de Onboard Administrator 231

463 Missing GUID. Please retry your last step. If error persists and device is currently registered, unregister and re-register device. (Falta el GUID. Vuelva a intentar el último paso. Si el error continúa y el dispositivo ya está registrado, anule el registro del mismo y vuelva a registrarlo.)
464 Corrupt GUID. Please retry your last step. If error persists and device is currently registered, unregister and re-register device. (GUID dañado. Vuelva a intentar el último paso. Si el error continúa y el dispositivo ya está registrado, anule el registro del mismo y vuelva a registrarlo.)
465 Missing data package. Please retry your last step. If error persists and device is currently registered, unregister and re-register device. (Falta un paquete de datos. Vuelva a intentar el último paso. Si el error continúa y el dispositivo ya está registrado, anule el registro del mismo y vuelva a registrarlo.)
466 Data Package validation failed. Please retry your last step. If error persists and device is currently registered, unregister and re-register device. (Error en la validación del paquete de datos. Vuelva intentar el último paso. Si el error continúa y el dispositivo ya está registrado, anule el registro del mismo y vuelva a registrarlo.)
467 HP Passport password must be changed or reset. Please attempt to register again after correcting the HP Passport account issue. (Se debe cambiar o restablecer la contraseña de HP Passport. Intente registrarse de nuevo después de corregir el problema con la cuenta de HP Passport.)
468 Expired HP Passport credentials. Please attempt to register again after correcting the HP Passport account issue. (Credenciales de HP Passport caducadas. Intente registrarse de nuevo después de corregir el problema con la cuenta de HP Passport.)
469 HP Passport account locked out. Please attempt to register again after correcting the HP Passport account issue. (Cuenta de HP Passport bloqueada. Intente registrarse de nuevo después de corregir el problema con la cuenta de HP Passport.)
470 GDID and device identifiers do not match. If error persists and device is not currently registered, unregister and re-register device. (El GDID y los identificadores del dispositivo no coinciden. Si el error continúa y el dispositivo no está registrado, anule el registro del mismo y vuelva a registrarlo.)
471 Device is not registered. Remote Support registration has been disabled locally on this device. No service events or data collections will be sent until this device has been re-registered. (El dispositivo no está registrado. Se ha desactivado el registro de Remote Support localmente en este dispositivo. No se enviarán eventos de servicio ni recopilaciones de datos hasta que se haya vuelto a registrar este dispositivo.)
472 Deleted device. This device has been previously deleted from the Insight Remote Support user interface. Please unregister and re-register device. (Dispositivo eliminado. Este dispositivo se ha eliminado previamente de la interfaz de usuario de Insight Remote Support. Anule el registro del dispositivo y vuelva a registrarlo.)
473 Unhandled Error. (Error no controlado.)
474 Failed to connect to Insight Remote Support direct connect web service. (Error al conectar con el servicio web de conexión directa de Insight Remote Support.) Please verify DNS settings, proxy settings and connectivity. (Error al conectar con el servicio web de HP Insight Remote Support con Direct Connect. Compruebe la configuración de DNS, la configuración del proxy y la conectividad.)
475 Dynamic DNS is not enabled. (DNS dinámico no está activado.)
476 Invalid SNMP Engine ID. The Engine ID must start with '0x' followed by an even number of up to 64 hexadecimal digits. (ID de motor SNMP no válido. El ID de motor debe comenzar por "ox" seguido de un número par compuesto por un máximo de 64 dígitos hexadecimales.)
477 Invalid Authentication Protocol. (Protocolo de autenticación no válido.)
232 Capítulo 5 Errores de HPE Onboard Administrator ESES

478 Invalid Authentication Password, must contain 8 to 40 printable characters. (Contraseña de autenticación no válida, debe contener entre 8 y 40 caracteres imprimibles.)
479 Invalid Privacy Protocol. (Protocolo de privacidad no válido.)
480 Invalid Privacy Password, must contain 8 to 40 printable characters. (Contraseña de privacidad no válida, debe contener entre 8 y 40 caracteres imprimibles.)
481 Duplicate user, a SNMP user by this name and engine id already exists. (Usuario duplicado, ya existe un usuario SNMP con este nombre e ID de motor.)
482 Invalid minimal security setting. (Configuración de seguridad mínima no válida.)
483 Invalid security setting. (Configuración de seguridad no válida.)
484 Selected algorithm cannot be used while FIPS mode is enabled. (El algoritmo seleccionado no se puede utilizar mientras esté activado el modo FIPS.)
485 A user with read-write access cannot be created while FIPS mode is enabled. (No se puede crear un usuario con acceso de lectura/escritura mientras esté activado el modo FIPS.)
486 You cannot use a remote engine id with a trap. (No puede utilizar un ID de motor remoto con una captura.)
487 You cannot use the local engine id with an inform. (No puede utilizar el ID de motor local con un InForm.)
489 Error adding the language pack. (Error al agregar el paquete de idioma.)
490 Error removing the language pack. (Error al eliminar el paquete de idioma.)
491 The file provided is not a valid Onboard Administrator language pack image. (El archivo proporcionado no es una imagen de paquete de idioma de Onboard Administrator válida.)
492 Cannot remove the English language pack. (No se puede eliminar el paquete de idioma inglés.)
493 The language support pack is not installed. (El paquete de soporte de idioma no está instalado.)
494 The submitted file is not a valid SSH key. (El archivo enviado no es una clave SSH válida.)
499 The firmware image provided doesn't meet the VC Minimum Firmware Version requirement. Check the OA Syslog for more details. (La imagen del firmware proporcionada no cumple el requisito de versión de firmware mínima de VC. Compruebe el registro del sistema de OA para obtener más información.)
500 The action did not complete successfully. (La acción no se completó correctamente.)
502 Invalid response. No connection or network busy. (Respuesta no válida. No hay conexión o la red está ocupada.)
503 Web server busy or in service. (El servidor web está ocupado o en servicio.)
510 Remote Support services are provided by other solution. (Los servicios de Remote Support los proporciona otra solución.)
511 DHCP-Supplied Domain Name cannot be disabled when the user-supplied domain name is not set. (El nombre de dominio proporcionado por DHCP no se puede desactivar si no se ha establecido el nombre de dominio proporcionado por el usuario.)
512 The text must contain at least one visible character. (El texto debe contener al menos un carácter visible.)
514 User ID is a required field. Please retry registration. (El ID de usuario es un campo obligatorio. Vuelva a intentar el registro.)
ESES Errores de Onboard Administrator 233

515 The user must have an active authenticated session. Please retry registration. (El usuario debe tener una sesión autenticada activa. Vuelva a intentar el registro.)
516 HP Passport system failure occurred. A problem has been detected in the HP Passport system. Please retry later. (Se ha producido un fallo del sistema de HP Passport. Se ha detectado un problema en el sistema de HP Passport. Vuelva intentarlo más tarde.)
517 The session token is invalid due to any of the following reasons: failed decoding, token is null or empty, userId is empty or session start value is not a number. Please retry registration. (El token de sesión no es válido por alguna de las razones siguientes: se ha producido un error en la descodificación, el token es nulo o está vacío, el ID de usuario está vacío o el valor de inicio de la sesión no es un número. Vuelva a intentar el registro.)
518 Password is required. Please retry registration. (Se requiere contraseña. Vuelva a intentar el registro.)
519 HP Passport user ID is invalid. Please retry registration with a valid user ID. (El ID de usuario de HP Passport no es válido. Vuelva a intentar el registro con un ID de usuario válido.)
520 HP Passport account is locked out due to excessive login authentication failures. Please reset your password and retry registration. (La cuenta de HP Passport está bloqueada debido a un número excesivo de errores de autenticación de inicio de sesión. Restablezca la contraseña y vuelva a intentar el registro.)
521 User has reached half the maximum allowed HP Passport login authentication failures. Please verify your username and password are correct and retry registration. (El usuario ha alcanzado la mitad del número máximo de errores de autenticación de inicio de sesión permitidos de HP Passport. Compruebe que el nombre de usuario y la contraseña son correctos y vuelva a intentar el registro.)
522 HP Passport password has expired. Please update your password and retry registration. (La contraseña de HP Passport ha caducado. Actualice la contraseña y vuelva a intentar el registro.)
523 User has at least one of the HP Passport required on-line identity elements missing. Please update your HP Passport profile and retry registration. (Falta al menos uno de los elementos de identidad en línea del usuario requeridos por HP Passport. Actualice la contraseña y vuelva a intentar el registro.)
524 HP Passport Security Q and A is not compliant; the user must enter a new security Q and A upon login. Please update your HP Passport security Q and A and retry registration. (La pregunta y la respuesta de seguridad de HP Passport no son compatibles; el usuario debe introducir unas nuevas al iniciar sesión. Actualice la pregunta y la respuesta de seguridad de HP Passport y vuelva a intentar el registro.)
525 HP Passport password entered is incorrect. Please retry registration using the correct password. (La contraseña de HP Passport introducida no es correcta. Vuelva a intentar el registro utilizando la contraseña correcta.)
526 HP Passport user has been added to a group. Please reset your password and retry registration. (El usuario de HP Passport se ha añadido a un grupo. Restablezca la contraseña y vuelva a intentar el registro.)
527 User must enter an HP Passport security Q and A and change password. Please update your security Q and A, update your password, and retry registration. (El usuario debe introducir una pregunta y una respuesta de seguridad de HP Passport y cambiar la contraseña. Actualice la pregunta y la respuesta de seguridad, actualice la contraseña y vuelva a intentar el registro.)
528 Protocol error occurred while communicating with the Insight Remote Support receiver. (Se produjo un error de protocolo en las comunicaciones con el receptor de Insight Remote Support.)
234 Capítulo 5 Errores de HPE Onboard Administrator ESES

529 Failed to resolve proxy. Please verify DNS settings, proxy settings and connectivity. (Error al resolver el proxy. Compruebe la configuración de DNS, la configuración del proxy y la conectividad.)
530 Failed to connect to Insight Remote Support hosting server. (Error al conectar con el servidor de hosting de Insight Remote Support.) Please verify Insight Remote Support host and port information. (Error al conectarse con el servidor de hosting de HP Insight Remote Support. Compruebe la información de host y de puertos de Insight Remote Support.)
531 Failed to connect to the Insight Remote Support direct connect web service. (Error al conectar con el servicio web de conexión directa de Insight Remote Support.) Please verify DNS settings, proxy settings and connectivity. (Error al conectar con el servicio web de HP Insight Remote Support con Direct Connect. Compruebe la configuración de DNS, la configuración del proxy y la conectividad.)
532 Remote Support receiver protocol error (Error del protocolo del receptor de Remote Support.)
533 The setting cannot be cleared when user domain name is enabled. (El valor no se puede borrar si el nombre de dominio del usuario está activado.)
534 The operation cannot be performed while Enclosure Firmware Management is enabled. (La operación no se puede realizar mientras esté activado Enclosure Firmware Management.)
535 Invalid SNMP Engine ID string. The Engine ID string must contain 1 to 27 printable characters. (Cadena de ID de motor SNMP no válida. La cadena de ID de motor debe contener entre 1 y 27 caracteres imprimibles.)
536 The password is too short. (La contraseña es demasiado corta.)
537 The password is too long. (La contraseña es demasiado larga.)
538 Error installing the certificate. (Error al instalar el certificado.)
539 Enclosure IP mode requires the active Onboard Administrator to have a static IPv4 address or a static IPv6 address. If IPv6 is not enabled, only the static IPv4 address can be used. (El modo IP del chasis requiere que el Onboard Administrator activo tenga una dirección IPv4 o IPv6 estática. Si IPv6 no está activado, solo se puede utilizar la dirección IPv4.)
540 Configure a static IPv6 address for your active OA or disable Enclosure IP Mode before enabling DHCP for IPv4. (Configure una dirección IPv6 estática para el OA activo o desactive el modo IP del chasis antes de activar DHCP para IPv4.)
541 Configure a static IPv4 address for your active OA or disable Enclosure IP Mode before disabling IPv6. (Configure una dirección IPv4 estática para el OA activo o desactive el modo IP del chasis antes de desactivar IPv6.)
542 The submitted URL is invalid for uploading. (La dirección URL enviada no es válida para la carga.)
543 This version of Onboard Administrator firmware does not support boot options for servers configured in UEFI Boot mode. (Esta versión del firmware de Onboard Administrator no es compatible con las opciones de arranque de los servidores configurados en el modo de arranque UEFI.)
561 Transmission from the Insight Remote Support receiver was unsuccessful. (La transmisión del receptor de Insight Remote Support fue incorrecta.)
562 Transmission from the Insight Remote Support receiver was unsuccessful. (La transmisión del receptor de Insight Remote Support fue incorrecta.) Please check connectivity between OA and the Insight Remote Support receiver. (La transmisión desde el receptor de HP Insight Remote Support no se realizó correctamente. Compruebe la conectividad entre el OA y el receptor de Insight Remote Support.)
ESES Errores de Onboard Administrator 235

563 The key strength for the provided key is invalid for this configuration. (La seguridad de la clave proporcionada no es válida para esta configuración.)
564 This command is not supported by the interconnect. (Este comando no es compatible con la interconexión.)
565 The string entered is a link-local address and cannot be used for assignment. (La cadena introducida es una dirección local de enlace y no se puede utilizar para la asignación.)
566 Invalid IPv6 static route gateway. Route gateway must not be empty and must not contain prefix length. (Puerta de enlace de la ruta IPv6 estática no válida. La puerta de enlace de la ruta no debe estar vacía y no debe contener la longitud del prefijo.)
567 IPv6 static route destination already exists. (El destino de la ruta IPv6 estática ya existe.)
568 Unable to add IPv6 route. The maximum number of IPV6 static routes already exist. (No es posible agregar la ruta IPv6. Ya existe el número máximo de rutas IPv6 estáticas.)
569 IPv6 static route not found (No se ha encontrado una ruta estática IPv6.)
570 Invalid IPv6 static route destination. The route destination must be a valid IPv6 address. (Destino de ruta IPv6 estática no válido. El destino de la ruta debe ser una dirección IPv6 válida.)
571 All items cannot be disabled. (No es posible desactivar todos los elementos.)
572 This action requires the OA to be in FIPS Mode ON/DEBUG. (Esta acción necesita que el OA esté en el modo ON/DEBUG de FIPS.)
573 Must set MINRATE option if using timeout range. (Debe configurar la opción MINRATE si utiliza el intervalo de tiempo de espera.)
574 Minimum data rate must be larger than 0. (La velocidad de datos mínima debe ser mayor que 0.)
575 Maximum timeout must be larger than minimum timeout. (El tiempo de espera máximo debe ser mayor que el tiempo de espera mínimo.)
576 Timeout must be larger than 0. (El tiempo de espera debe ser mayor que 0.)
577 HTTP Read Timeout is already set to the requested value. (El tiempo de espera de lectura de HTTP ya está establecido en el valor solicitado.)
Errores de captura de pantalla de Insight Display1 Missing credentials. (Faltan las credenciales.)
2 The getLCDImage CGI process has caught the SIGSEGV signal. (El proceso de CGI getLCDImage ha interceptado la señal SIGSEGV.)
3 Could not acquire access to the image in a reasonable amount of time. (No se pudo adquirir acceso a la imagen en una cantidad razonable de tiempo.)
4 Cannot open semaphores. (No se pueden abrir los semáforos.)
5 Produce SEMV does not work. (Produce SEMV no funciona.)
6 Consume SEMV does not work. (Consume SEMV no funciona.)
7 Cannot lock the image file. (No se puede bloquear el archivo de imagen.)
8 Cannot open the image file. (No se puede abrir el archivo de imagen.)
9 Cannot seek in the image file. (No se puede encontrar el archivo de imagen.)
10 Unable to resume session. (No es posible reanudar la sesión.)
236 Capítulo 5 Errores de HPE Onboard Administrator ESES

11 Insufficient privileges. (Privilegios insuficientes.)
Mensajes de SysLogEstos mensajes se envían al registro del sistema del Onboard Administrator y se pueden consultar mediante las distintas interfaces de este.
Los tipos de mensajes del registro del sistema se definen de la manera siguiente:
● LOG_EMERG: el sistema no se puede utilizar
● LOG_ALERT: se deben tomar medidas inmediatamente
● LOG_CRIT: condiciones críticas
● LOG_ERR: condiciones de error
● LOG_WARNING: condiciones de advertencia
● LOG_NOTICE: condición normal pero significativa
● LOG_INFO: informativo
Mensajes del registro de AlertmailTipo de registro: LOG_ERR, Tipo de fallo: SW
Alertmail: Calculated invalid enclosure count for topology eventAlertmail: Failed to get initial enclosure statusAlertmail: Failed to read cooling infoAlertmail: Failed to read enclosure infoAlertmail: Failed to read enclosure namesAlertmail: Failed to read enclosure statusAlertmail: Failed to read event from mgmt subsystemAlertmail: Failed to read LCD statusAlertmail: Failed to read powersupply measurementsAlertmail: Failed to read rack topology informationAlertmail: Failed to read status of fan [value]Alertmail: Failed to read status of Interconnect [value]Alertmail: Failed to read status of powersupply [value]Alertmail: Failed to read topology after eventAlertmail: Failed to register with mgmtAlertmail: Failed to send AlertMail to [value]Alertmail: Failed to start reboot notifier thread
Mensajes del registro de inicio y de autenticaciónTipo de registro: LOG_WARNING, Tipo de fallo: SW
ESES Mensajes de SysLog 237

sulogin: cannot open [value]sulogin: No password fileTipo de registro: LOG_WARNING, Tipo de fallo: Info
OA: An error occurred updating the password fileOA: can't change pwd for `[value]'OA: Failed login attempt with user [username]OA: incorrect password for `[username]'OA: Onboard Administrator is rebootingOA: password locked for `[value]'OA: [value:username] logged out of the Onboard AdministratorTipo de registro: LOG_CRIT, Tipo de fallo: Info
OA: daemon is exiting because of SIGTERM system will reset.Tipo de registro: LOG_ERR, Tipo de fallo: Info
OA: can't setuid(0)OA: unable to determine TTY name got [value]Tipo de registro: LOG_INFO, Tipo de fallo: Info
OA: Password for `[username]' changed by systemOA: Password for `[value]' changed by user `[username]'OA: root login [value]sulogin: Normal startupsulogin: System Maintenance Mode
Mensajes del registro de CGITipo de registro: LOG_ERR, Tipo de fallo: SW
cdrom.iso: There was a problem reading from /dev/cdrom, however we cannot back out now.
Mensajes del registro de la CLITipo de registro: LOG_WARNING, Tipo de fallo: Info
OA: [value] logged out of the Onboard AdministratorTipo de registro: LOG_INFO, Tipo de fallo: Info
OA: ProLiant iLO firmware update attempted by user [value]
Mensajes del registro del compartimento de interconexiónTipo de registro: LOG_WARNING, Tipo de fallo: Info
OA: [value] was connected to interconnect bay #[value]OA: [value] was disconnected from interconnect bay #[value]
238 Capítulo 5 Errores de HPE Onboard Administrator ESES

Mensajes del registro de DHCPTipo de registro: LOG_WARNING, Tipo de fallo: SW
OA: dhcpStart: retrying MAC address request (returned [value:MAC-Address]DHCP Monitor: Arping thread did not get created properly: [value]DHCP Monitor: Thread [value] did not get created properly: [value]DHCP Monitor: Monitor thread for dhcpv4 did not get created properly: [value]Tipo de registro: LOG_ERR, Tipo de fallo: SW
OA: arpCheck: recvfrom: [value]OA: arpCheck: sendto: [value]OA: arpInform: sendto: [value]OA: arpRelease: sendto: [value]OA: classIDsetup: uname: [value]OA: DHCP_NAK server response receivedOA: DHCP_NAK server response received: [value]OA: dhcpConfig: fopen: [value]OA: dhcpConfig: ioctl SIOCSIFADDR: [value]OA: dhcpConfig: ioctl SIOCSIFBRDADDR: [value]OA: dhcpConfig: ioctl SIOCSIFNETMASK: [value]OA: dhcpConfig: open/write/close: [value]OA: dhcpDecline: sendto: [value]OA: dhcpInform: no IP address givenOA: dhcpRelease: sendto: [value]OA: dhcpStart: bind: [value]OA: dhcpStart: fcntl: [value]OA: dhcpStart: interface [value] is not Ethernet or 802.2 Token RingOA: dhcpStart: ioctl SIOCGIFFLAGS: [value]OA: dhcpStart: ioctl SIOCGIFHWADDR: [value]OA: dhcpStart: ioctl SIOCSIFFLAGS: [value]OA: dhcpStart: setsockopt: [value]OA: dhcpStart: socket: [value]OA: dhcpStop: ioctl SIOCSIFFLAGS: [value]OA: error executing [value] [value] [value]: [value]OA: mkdir([value]",0): [value]"OA: recvfrom: [value]
ESES Mensajes de SysLog 239

OA: sendto: [value]OA: Timed out waiting for a valid DHCP server response. Will keep trying in the backgroundOA: writePidFile: fopen: [value]DHCP Monitor: Could not start DHCPD for IPv4. Error: [value]DHCP Monitor: Could not start DHCPD for IPv6. Error: [value]DHCP Monitor: Could not stop dhcpd for [value]DHCP Monitor: DHCPD is not running. Restarting OA.Tipo de registro: LOG_NOTICE, Tipo de fallo: SW
OA: Got IP lease: address = [address]Tipo de registro: LOG_INFO, Tipo de fallo: SW
OA: infinite IP address lease time. Exiting
Mensajes del registro del enlace del chasisTipo de registro: LOG_WARNING, Tipo de fallo: SW
OA: Enclosure Link Daemon could not register for events.Tipo de registro: LOG_CRIT, Tipo de fallo: SW
Enclosure-Link: Could not acquire bottom enclosure's UUID. Cannot set RUID.Enclosure-Link: Failed to read topologyEnclosure-Link: Got unexpected error from socket: [value]Enclosure-Link: RUID recovered: [value]Log type: LOG_ERR, Failure type: SW
Enclosure-Link: [value] enclosure(s) seen on Enclosure Link. Only [value:Max_Enclosures] enclosure(s) supported. Please remove [value] enclosure(s)Enclosure-Link: Corrupted topology on eth2Enclosure-Link: Corrupted topology on eth3Enclosure-Link: Failed to create socketEnclosure-Link: Failed to detect Enclosure topologyEnclosure-Link: Failed to disable lower chainEnclosure-Link: Failed to disable upper chainEnclosure-Link: Failed to enable lower chainEnclosure-Link: Failed to enable upper chainEnclosure-Link: Failed to generate EVENT for initial topology detectionEnclosure-Link: Failed to generate EVENT for topology changeEnclosure-Link: Failed to get local address. Will keep retrying
240 Capítulo 5 Errores de HPE Onboard Administrator ESES

Enclosure-Link: Failed to log into enclosure [value:IpAddress]Enclosure-Link: Failed to probe newly attached/detached deviceEnclosure-Link: Failed to read events from chainEnclosure-Link: Failed to register with enclosure [value:IpAddress]Enclosure-Link: Failed to retrieve enclosure addresses from lower elink chainEnclosure-Link: Failed to retrieve enclosure addresses from upper elink chainEnclosure-Link: Failed to send ICMP packet to hostEnclosure-Link: Failed to update hosts fileEnclosure-Link: Failed to write updated topology mapEnclosure-Link: Found 2 GuestPCs on Enclosure Link. This setup is not supported.Enclosure-Link: Ignoring invalid Enclosure Link addressEnclosure-Link: Seeing heavy traffic on Enclosure Link chain. This may affect topology.Enclosure-Link: This can also occur if the enclosures have been connected in a loop which is an unsupported configuration. Please make sure the top and bottom enclosures are not connected to each other.Tipo de registro: LOG_INFO, Tipo de fallo: Info
Enclosure-Link: Calling getEventEnclosure-Link: Device attached on lower interfaceEnclosure-Link: Device attached on upper interfaceEnclosure-Link: Device attached/detached but no topology changes detectedEnclosure-Link: Device detached on lower interfaceEnclosure-Link: Device detached on upper interfaceEnclosure-Link: Doing elink topology scan nowEnclosure-Link: Found new elink topology. Notifying subsystemsEnclosure-Link: Found new Topology: [value] enclosure added to chain ([value] total)Enclosure-Link: Found new Topology: [value] enclosure removed from chain ([value] total)Enclosure-Link: Found new Topology: New enclosure connected ([value] total)Enclosure-Link: Got new TOPOLOGY event on enclosure [value:IpAddress]Enclosure-Link: Initial topology scan completed successfullyEnclosure-Link: Service started
ESES Mensajes de SysLog 241

Mensajes del registro de la configuración no volátilTipo de registro: LOG_WARNING, Tipo de fallo: SW
CLI: Error accessing User Configuration Files (Error al acceder a los archivos de configuración del usuario)Tipo de registro: LOG_ERR, Tipo de fallo: SW
envtools: Block [value] failed encodingenvtools: Error in default gatewayenvtools: Error in DNS1 addressenvtools: Error in DNS2 addressenvtools: Error in ipaddressenvtools: Error in ipAllow1 addressenvtools: Error in ipAllow2 addressenvtools: Error in ipAllow3 addressenvtools: Error in ipAllow4 addressenvtools: Error in ipAllow5 addressenvtools: Error in ipv6Dns1 addressenvtools: Error in ipv6Dns2 addressenvtools: Error in ipv6StaticAddress1 addressenvtools: Error in ipv6StaticAddress2 addressenvtools: Error in ipv6StaticAddress3 addressenvtools: Error in netmaskenvtools: Error: Administrator account was disabled and will be re-enabled upon restart.envtools: Error: Administrator account was missing, and will be re-created upon restart. LPR required.envtools: NVRAM write failed: [value]DHCP Monitor: Error opening dhcpv6.conf for writing.Tipo de registro: LOG_NOTICE, Tipo de fallo: SW
envtools: NVRAM block [value] failed checkenvtools: NVRAM format could not be preserved.envtools: NVRAM is unformatted or corrupted.envtools: Warning: EBIPA has been disabled on device and interconnect bays. Please check configuration after downgrade.Tipo de registro: LOG_NOTICE, Tipo de fallo: Info
envtools: Downgrading NVRAM version from 24 to 23.envtools: Downgrading NVRAM version from 25 to 24.
242 Capítulo 5 Errores de HPE Onboard Administrator ESES

envtools: Downgrading NVRAM version from 26 to 25.envtools: Downgrading NVRAM version from 27 to 26.envtools: Factory Settings Restored.envtools: NVRAM downgraded from [value] to [value].envtools: NVRAM downgraded to version [value]envtools: Updating NVRAM version to 19.envtools: Updating NVRAM version to 20.envtools: Updating NVRAM version to 21.envtools: Updating NVRAM version to 22.envtools: Updating NVRAM version to 23.envtools: Updating NVRAM version to 24.envtools: Updating NVRAM version to 25.envtools: Updating NVRAM version to 26.envtools: Updating NVRAM version to 27.envtools: Updating NVRAM version to 28.envtools: Updating NVRAM version to 29.
Mensajes del registro de actualización del firmwareTipo de registro: LOG_ALERT, Tipo de fallo: SW
FWSync: OA firmware sync flash failed and system is in an unstable state. Do not reboot! Try to flash again with a new image.OA_Flash: Flash failed and system is in an unstable state. Do not reboot!Try to flash again with a new image.Tipo de registro: LOG_ERR, Tipo de fallo: SW
FWSync: Error opening OA firmware sync image.FWSync: Error opening OA firmware sync image.FWSync: Invalid flash image.FWSync: OA firmware sync image is corrupted.FWSync: OA firmware sync image is older than current firmware.FWSync: Only one flash instance can run at a time.FWSync: Only one instance of OA firmware sync can run at a time.OA_Flash: Downloading flash image failed.OA_Flash: Error opening [value] for input.OA_Flash: Firmware image is corrupted or not a valid image. Please verify the url and try again.OA_Flash: Firmware version [value:version] is not supported on this hardware.
ESES Mensajes de SysLog 243

OA_Flash: Found core file. Reboot after flash suppressed to allow developer to debug.OA_Flash: Invalid flash image.OA_Flash: Invalid flash image.OA_Flash: Only one flash instance can run at a time.OA_Flash: Out of memory while decoding flash image.OA_Flash: The firmware image provided is older than the current firmware and OA settings cannot be preserved. The force downgrade option must be used. Please re-try with the force option to flash and go back to factory defaults.Tipo de registro: LOG_NOTICE, Tipo de fallo: Info
FWSync: New firmware image flashed.FWSync: OA firmware sync to [value:version] completeOA_Flash: Firmware image flashed from [value:version] to [value:version]Tipo de registro: LOG_INFO, Tipo de fallo: Info
OA_Flash: Image verified successfully and applies to this system using the parameters supplied. Test Mode specified, skipping the actual flash process Firmware version [value:version] ExitCode=0
Mensajes del registro de almacenamiento, configuración y certificados de la actualización
Tipo de registro: LOG_ERR, Tipo de fallo: SW
CERTS: .ssh has wrong directory permissionsCERTS: [value] has wrong file permissionsCERTS: [value] has wrong permissions. Please reset to factory defaultsCERTS: authorized_keys2 has wrong file permissionsCERTS: dsaparam has wrong file permissionsCERTS: Failed to compute MD5CERTS: Failed to open flashCERTS: Failed to open input fileCERTS: Fail to open the file to be flashedCERTS: Failed to open output fileCERTS: Failed to read data from flashCERTS: Failed to read system filesCERTS: Failed to update system with new dataCERTS: Failed to write data to flashCERTS: server.crt has wrong file permissionsCERTS: server.key has wrong file permissions
244 Capítulo 5 Errores de HPE Onboard Administrator ESES

CERTS: ssh_host_dsa_key has wrong file permissionsCERTS: Tar file [value] is too big for flash [value]CERTS: Wrong file permissions detected. Please reset to factory defaultsCERTS: Removing installed keys and certificates as part of setting factory defaultsCERTS: Failed to create dataCERTS: Failed to locate dataCERTS: Capacity exceeded by [value] bytesCERTS: Failed to stage dataCONFIG: [value] has wrong file permissionsCONFIG: [value] has wrong permissions. Please reset to factory defaultsCONFIG: Failed to compute MD5CONFIG: Failed to open flashCONFIG: Failed to open input fileCONFIG: Fail to open the file to be flashedCONFIG: Failed to open output fileCONFIG: Failed to read data from flashCONFIG: Failed to read system filesCONFIG: Failed to update system with new dataCONFIG: Failed to write data to flashCONFIG: Tar file [value] is too big for flash [value]CONFIG: Wrong file permissions detected. Please reset to factory defaultsCONFIG: Failed to create dataCONFIG: Failed to locate dataCONFIG: Capacity exceeded by [value] bytesCONFIG: Failed to stage dataCONFIG: Reverting back to factory default configurationSTORAGE: Failed to open output fileSTORAGE: Failed to open flash deviceSTORAGE: Failed to open flashSTORAGE: Failed to create dataSTORAGE: Failed to locate dataSTORAGE: Capacity exceeded by [value] bytesSTORAGE: Failed to stage dataSTORAGE: Failed to write file to flash
ESES Mensajes de SysLog 245

STORAGE: Failed to read file from storage partitionSTORAGE: Failed to read complete file from storage partitionSTORAGE: Failed to read file header from storage partition
Mensajes del registro de configuración de red DNSTipo de registro: LOG_NOTICE, Tipo de fallo: SW
netreg: Can't open netconf filenetreg: Can't read netconf filenetreg: Couldn't fork a new processnetreg: Couldn't start main ddns threadnetreg: DDNS: Failed to add OA hostname to DDNS server. Server is not authoritative for the DNS zonenetreg: DDNS: Not implementednetreg: DDNS: Not in zonenetreg: DDNS: Server failurenetreg: DDNS: Unable to create socketnetreg: DDNS: Update refused by DNS servernetreg: Error starting DDNS threadnetreg: Error starting NetBIOS threadnetreg: NETBIOS: Refreshed WINS registrationTipo de registro: LOG_NOTICE, Tipo de fallo: Info
netreg: DDNS: Registered with Dynamic DNSnetreg: DDNS: Update successfulnetreg: NETBIOS: Registered with WINSOA: WARNING: The [value:label] ‘[value:hostname]’ is not pingableOA: The [value:label] '[value:hostname]' is pingable again.OA: WARNING: There is no DNS record for [value:label] '[value:hostname]'OA: WARNING: DNS resolution has failed. This will impair OA operation significantly.OA: WARNING: The DNS resolution for is slow, one or more DNS servers may be down. This will impair OA operation.OA: The DNS resolution is working again.OA: WARNING: DNS resolution has failed. This will impair OA operation significantly.OA: WARNING: The DNS resolution is slow, one or more DNS servers may be down. This will impair OA operation.OA: The DNS resolution is working again.
246 Capítulo 5 Errores de HPE Onboard Administrator ESES

OA: Restarted the System Logger.Tipo de registro: LOG_CRIT, Tipo de fallo: SW
OA: Onboard Administrator %d domain name change failed.Tipo de registro: LOG_ALERT, Tipo de fallo: SW
OA: Cannot start Network Monitoring.
Mensajes del registro de LCDTipo de registro: LOG_ERR, Tipo de fallo: SW
OA: Blade [value:bladeNumber]: KVM access denied.OA: Consume SEMV post failed errno [value]OA: Error creating fifo SAVEPNG_FIFO ". No screenshot thread available"OA: Error opening fifo SAVEPNG_FIFO ". No screenshot thread available"OA: KVM Bay [value:bladeNumber] - All HTTP sessions to ILO are full. Wait a few seconds and try again.OA: KVM Bay [value:bladeNumber] - Connection to blade failed.OA: KVM Bay [value:bladeNumber] - Connecting to blade failed because the blade is powered off.OA: KVM Bay [value:bladeNumber] - Could not connect. Error([value]).OA: KVM Bay [value:bladeNumber] - Could not connect. If error persists reboot the OA.OA: KVM Bay [value:bladeNumber] - Could not create thread.OA: KVM Bay [value:bladeNumber] - Disconnected from blade. Bad getmoreOA: KVM Bay [value:bladeNumber] - Disconnected from blade. Bad next state detected.OA: KVM Bay [value:bladeNumber] - Disconnected from blade. Bad state transition detected.OA: KVM Bay [value:bladeNumber] - Disconnected from blade. Exit state detected.OA: KVM Socket connect error [value] ([value]) to ILO addr [value:Address]:[value:port]OA: KVM Socket creation error [value] ([value]) to ILO addr[value:Address]OA: Mutex SEMV post failed errno [value]OA: Mutex SEMV wait failed errno [value]OA: Screenshot Thread exiting....OA: KVM Bay [value:bladeNumber] - Could not determine fips modeOA: KVM Bay [value:bladeNumber] - Configure ILO to enforce AES Encryption in FIPS mode.OA: KVM - Could determine OA fips mode
ESES Mensajes de SysLog 247

OA: KVM Bay [value:bladeNumber] - ILO2 is not supported in FIPS MODE.Tipo de registro: LOG_ERR, Tipo de fallo: Info
OA: KVM ([value:address]) Change ILO setting to enable 'acquire remote console' failed.OA: KVM Bay [value:bladeNumber] - Acquired console. Connected to blade.OA: KVM Bay [value:bladeNumber] - Connecting to blade failed because the blade is powered off.OA: KVM Bay [value:bladeNumber] - Connecting to blade.OA: KVM Bay [value:bladeNumber] - Console in use by another client.OA: KVM Bay [value:bladeNumber] - Console is in use by another client and could not be acquired.OA: KVM Bay [value:bladeNumber] - Console session acquired by [value:OA user / username] at [value:address]OA: KVM Bay [value:bladeNumber] - Disconnected from blade due to app exit.OA: KVM Bay [value:bladeNumber] - Disconnected from blade.OA: KVM Bay [value:bladeNumber] - Must wait 5 minutes before attempting to acquire the console.OA: KVM Bay [value:bladeNumber] - Session acquired by different user.OA: KVM Blade [value:bladeNumber] console session closed due to ILO firmware upgrade
Mensajes del registro relacionados con operacionesTipo de registro: LOG_EMERG, Tipo de fallo: SW
OA: Internal System Firmware Error. Rebooting.Tipo de registro: LOG_WARNING, Tipo de fallo: SW
FWSync: OA firmware sync failed to create firmware image from the Active Onboard AdministratorFWSync: OA firmware sync failed to create firmware image from the Standby Onboard AdministratorFWSync: OA firmware sync of the Active Onboard Administrator failedFWSync: OA firmware sync of the Standby Onboard Administrator failedOA: Active Onboard Administrator will not be flashedOA: Consider resetting the Standby and/or Active Onboard Administrators and retryingOA: Failed flashing Standby Onboard AdministratorOA: Failed to copy firmware image to the Standby Onboard AdministratorOA: Failed to register for events on the Standby Onboard Administrator(error=0x[value])OA: Failed to send URB message to configured endpoint. Check URB settings.
248 Capítulo 5 Errores de HPE Onboard Administrator ESES

OA: Firmware image corrupt. Please verify the image and retryOA: Please inspect the system log on the Standby Onboard Administrator for further detailsOA: The Active and Standby Onboard Administrators may not be communicating reliablyOA: The Onboard Administrator in bay %d has been reset via e-fuse by user [value].OA: LDAP Server Timed Out.Tipo de registro: LOG_WARNING, Tipo de fallo: Info
FWSync: OA firmware sync initiated by user [value:username]FWSync: Other (STANDBY) OA will be upgraded to firmware [value:versionNumber]FWSync: This (ACTIVE) OA will be upgraded to firmware [value:versionNumber]OA: Flashing Active Onboard Administrator. Initiated by user [value:username]OA: Flashing Standby Onboard Administrator. Initiated by user [value:username]Tipo de registro: LOG_CRIT, Tipo de fallo: SW
OA: Enclosure Name change failed.OA: Failed NVRAM commit of Enclosure Dynamic Power Cap bay opt out list by [value:username].OA: Failed to reset the Onboard Administrator.OA: Rack Name change failedTipo de registro: LOG_CRIT, Tipo de fallo: Info
Log cleared by [value:username].OA: CA certificate (issuer = [value:issuer-CN]) installed by user [value:username].OA: CA certificate (issuer = [value:issuer-CN]) removed by user [value:username].OA: Certificate for user [value:username] installed by user [value:username].OA: Certificate for user [value:username] removed by user [value:username]. All web sessions (if any) were ended.OA: Certificate owner field set to ([SAN/SUBJECT]) on Onboard Administrator by user [value:username].OA: Certificate Revocation check [enabled/disabled] on Onboard Administrator by user [value:username].OA: Downloaded SIM certificate by user [value:username]
ESES Mensajes de SysLog 249

OA: Enclosure Dynamic Power Cap bay opt out list set to [value] by [value:username].OA: Enclosure Dynamic Power Cap set to: [value], derated circuit [value], rated circuit [value] by [value:username].OA: Enclosure Dynamic Power Cap set to: OFF by [value:username].OA: Enclosure part number changed from '[value]' to '[value]' by [value:username].OA: Enclosure PDU type changed from '[value]' to '[value]' by [value:username].OA: Forced takeover requested by user [value:username].OA: SSO certificate [value:subject-CN] added by user [value:username].OA: SSO certificate [value] removed by user [value:username].OA: LDAP Directory Server certificate(MD5=[value]) installed by user [value:username].OA: LDAP Directory Server certificate(MD5=[value]) removed by user [value:username].OA: Onboard Administrator [value:bayNumber] name change failed.OA: Resetting the Onboard Administrator because two-factor authentication configuration has changed.OA: Self signed certificate generated and installed by user [value:username].OA: Time changed by [value:username].OA: Time zone changed by [value:username].OA: Time zone changed from [value] to [value]OA: Time zone changed to [value]OA: Two Factor Authentication [enabled/disabled] on Onboard Administrator by user [value:username].Tipo de registro: LOG_NOTICE, Tipo de fallo: SW
FWSync: Sync failed because the Active and Standby OAs do not have the same hardware version.OA: unable to run [value:mount]OA: Warning: Unable to ping the remote oa_syslog server [value:Address]Tipo de registro: LOG_NOTICE, Tipo de fallo: Info
FWSync: OA firmware sync to [value:versionNumber] completeOA: [value:protocol] was [enabled/disabled] by user [value:username]OA: Alertmail domain changed to [value:mailDomain] by user [value:username]OA: Alertmail recipient changed to [value] by user [value:username]
250 Capítulo 5 Errores de HPE Onboard Administrator ESES

OA: Alertmail server changed to [value:mailServer] by user [value:username]OA: Default VLAN ID for enclosure changed to [value]OA: DHCPv6 was [enabled/disabled] by user [value:username].OA: EBIPA Interconnect DNS [value:bladeNumber] [value] [value] by user [value:username]OA: EBIPA Interconnect Domain [value] [value] by user [value:username]OA: EBIPA Interconnect domain for bay [value:bladeNumber] set to [value] by user [value:username]OA: EBIPA Interconnect first DNS IP for bay [value:bladeNumber] set to [value] by user [value:username]OA: EBIPA Interconnect first NTP IP for bay [value:bladeNumber] set to [value] by user [value:username]OA: EBIPA Interconnect gateway for bay [value:bladeNumber] set to [value] by user [value:username]OA: EBIPA Interconnect IP Address [value] [value] for bay #[value:bladeNumber] by user [value:username]OA: EBIPA Interconnect IP Gateway [value] [value] by user [value:username]OA: EBIPA Interconnect IP Net Mask [value] [value] by user [value:username]OA: EBIPA Interconnect netmask for bay [value:bladeNumber] set to [value] by user [value:username]OA: EBIPA Interconnect NTP [value:bladeNumber] [value] [value] by user [value:username]OA: EBIPA Interconnect second DNS IP for bay [value:bladeNumber] set to [value] by user [value:username]OA: EBIPA Interconnect second NTP IP for bay [value:bladeNumber] set to [value] by user [value:username]OA: EBIPA Interconnect third DNS IP for bay [value:bladeNumber] set to [value] by user [value:username]OA: EBIPA Server DNS [value:bladeNumber] [value] [value] by user [value:username]OA: EBIPA Server Domain [value] [value] by user [value:username]OA: EBIPA Server domain for bay [value:bladeNumber] set to [value] by user [value:username]OA: EBIPA Server first DNS IP for bay [value:bladeNumber] set to [value] by user [value:username]OA: EBIPA Server gateway for bay [value:bladeNumber] set to [value] by user [value:username]OA: EBIPA Server IP Address [value] [value] for bay #[value:bladeNumber] by user [value:username]
ESES Mensajes de SysLog 251

OA: EBIPA Server IP Gateway [value] [value] by user [value:username]OA: EBIPA Server IP Net Mask [value] [value] by user [value:username]OA: EBIPA Server netmask for bay [value:bladeNumber] set to [value] by user [value:username]OA: EBIPA Server NTP [value:bladeNumber] [value] [value] by user [value:username]OA: EBIPA Server second DNS IP for bay [value:bladeNumber] set to [value] by user [value:username]OA: EBIPA Server third DNS IP for bay [value:bladeNumber] set to [value] by user [value:username]OA: EBIPA was [disabled/enabled] for device bay #[value:bladeNumber] by user [value:username]OA: EBIPA was [disabled/enabled] for interconnect bay #[value:bladeNumber] by user [value:username]OA: EBIPAv6 Server IP Address for bay [value:bayNumber] set to [value] by user [value:username].OA: EBIPAv6 was [value] for bay [value:bayNumber] by user [value:username].OA: EBIPAv6 Server domain for bay [value:bayNumber] set to [value] by user [value:username].OA: EBIPAv6 Server first DNS IP for bay [value:bayNumber] set to [value] by user [value:username].OA: EBIPAv6 Server second DNS IP for bay [value:bayNumber] set to [value] by user [value:username].OA: EBIPAv6 Server third DNS IP for bay [value:bayNumber] set to [value] by user [value:username].OA: EBIPAv6 Interconnect IP Address for bay [value:bayNumber] set to [value] by user [value:username].OA: EBIPAv6 was [value] for Interconnect bay [value:bayNumber] by user [value:username].OA: EBIPAv6 Inteconnect domain for bay [value:bayNumber] set to [value] by user [value:username].OA: EBIPAv6 Interconnect first DNS IP for bay [value:bayNumber] set to [value] by user [value:username].OA: EBIPAv6 Interconnect second DNS IP for bay [value:bayNumber] set to [value] by user [value:username].OA: EBIPAv6 Interconnect third DNS IP for bay [value:bayNumber] set to [value] by user [value:username].OA: Enclosure Name was changed to [value:Enclosure Name] by user [value:username]OA: ENCRYPTION changed to [value:mode] by user [value:username].
252 Capítulo 5 Errores de HPE Onboard Administrator ESES

OA: Error: iLO Select license is not in place for this Single Sign-on attempt by the LDAP authenticated userOA: Factory defaults restored by [value]OA: Firmware management interconnect bays to include have been changedOA: Firmware management iso URL set to [value:URL]OA: Firmware management Onboard Administrator bays to include have been changedOA: Firmware management policy set to auto discoverOA: Firmware management policy set to auto updateOA: Firmware management policy set to manualOA: Firmware management scheduled update disabledOA: Firmware management scheduled update time set to [value:date] [value:time]OA: Firmware management server bays to include have been changedOA: Firmware management was [enabled/disabled] by user [value:username].OA: Could not factory reset firmware management log: [value:error] (Code: [value:number])OA: Group [value:groupname] was added.OA: Group [value:groupname] was deleted.OA: Group [value:username] description was set to [value:description].OA: SIM Trust Mode changed to [value] by user [value:username].OA: IPv6 address [value:address] added by user [value:username].OA: IPv6 address [value:address] removed by user [value:username].OA: IPv6 protocol was disabled by user [value:username].OA: IPv6 protocol was enabled by user [value:username].OA: IPv6 Router Advertisement was [enabled/disabled] by user [value:username].OA: User[value:username] successfully removed the [value:name] language pack.OA: User [value:username] successfully installed language pack [value:name].OA: Unable to download language pack from the url provided. Supported protocols are http, https, tftp and ftp.OA: LDAP authentication was [Disabled/Enabled] by user [value:username].OA: LDAP group "[value:groupName]" was added by user [value:username].OA: LDAP group "[value]" was deleted by user [value:username].OA: LDAP group [value:groupName]'s description changed to [value] by user [value:username].
ESES Mensajes de SysLog 253

OA: LDAP group [value] privilege level was changed from [value:Administrator/Operator/User/Anonymous] to [value:Administrator/Operator/User/Anonymous] by user [value:username].OA: LDAP NT name mapping was [Disabled/Enabled] by user [value:username].OA: LDAP search context [value:number] was changed to [value] by user [value:username].OA: LDAP search context [value:number] was cleared by user [value:username].OA: LDAP server address was changed from [value:ipaddress] to [value:ipaddress] by user [value:username].OA: LDAP server SSL port was changed to [value:port] by user [value:username].OA: Link Loss Failover interval set to [value] seconds by user [value:username].OA: Local user authentication was [Disabled/Enabled] by user [value:username].OA: Name of Onboard Administrator [value:bayNumber] was changed to [value:username].OA: Network Interface link forced to [value:speed]Mbps - Full Duplex by user [value:username].OA: Network Interface link forced to [value:speed]Mbps - Half Duplex by user [value:username].OA: Network Interface link set to Auto negotiation by user [value:username].OA: New SSH key installed by user [value:username]OA: Nothing needs to be reverted as VLAN setting has not changedOA: Polling Interval of NTP set to [value] seconds by user [value:username].OA: PowerDelay has been initiated for the selected devices.OA: PowerDelay has completed for the selected devices.OA: PowerDelay interconnect settings have been changed by user [value:username].OA: PowerDelay server settings have been changed by user [value:username].OA: Primary NTP server was set to [value:ntp] by user [value:username].OA: Protocol http was [enabled/disabled] by user [value:username]OA: Protocol SSH was [enabled/disabled] by user [value:username]OA: Protocol Telnet was [enabled/disabled] by user [value:username]OA: Protocol XML was [enabled/disabled] by user [value:username]OA: Rack Name was changed to [value] by user [value:username]OA: Remote syslog test message.
254 Capítulo 5 Errores de HPE Onboard Administrator ESES

OA: Remote system log address set to [value:Address]OA: Remote system log port set to [value:port]OA: Remote system logging enabled to server [value:Address], port [value:port]OA: Remote system logging was disabled.OA: Saving VLAN IPCONFIG changesOA: Secondary NTP server was set to [value:ntp] by user [value:username].OA: Secure Shell authorized key file added by [value]OA: Secure Shell authorized key file cleared by [value]OA: SNMP Contact set to [value] by user [value:username].OA: SNMP Location set to [value] by user [value:username].OA: SNMP ReadOnly community string set to [value] by user [value:username].OA: SNMP ReadWrite community string set to [value] by user [value:username].OA: Static TCP/IP settings was modified by user [value:username].OA: TCP/IP settings was set to DHCP - DynamicDNS by user [value:username].OA: TCP/IP settings was set to DHCP by user [value:username].OA: Tcp timeout set to [value:number] minutes.OA: Trap Receiver [value:address] was added by user [value:username].OA: Trap Receiver [value:address] was also added as alternative for IPv6 host.OA: Trap Receiver [value:address] was deleted by user [value:username].OA: Trusted Host [value:address] was added by user [value:username].OA: Trusted Host [value:address] was deleted by user [value:username].OA: Undoing VLAN IPCONFIG changes. IP mode is set to DHCP for OA #[value:number]OA: Undoing VLAN IPCONFIG changes. IP mode is set to STATIC for OA #[value:number]OA: USB enable changed to [value]. Rebooting...OA: User [value:username] privilege level was changed from [value:Administrator/Operator/User/Anonymous] to [value:Administrator/Operator/User/Anonymous] by user [value:username]. All web and CLI sessions (if any) were ended.OA: User [value:username] was added by user [value:username].OA: User [value:username] was assigned to group [value:groupname].OA: User [value:username] was deleted by user [value:username].
ESES Mensajes de SysLog 255

OA: User [value:username] was disabled by user [value:username]. All web and CLI sessions (if any) were ended.OA: User [value:username] was enabled by user [value:username].OA: User [value:username] was removed from group [value:groupname].OA: User [value:username]'s contact was set removed by user [value:username].OA: User [value:username]'s contact was set to [value] by user [value:username].OA: User [value:username]'s full name was removed by user [value:username].OA: User [value:username]'s full name was set to [value:fullname] by user [value:username].OA: VLAN IPCONFIG set to DHCP IP mode and VLAN ID [value] for OA #[value:number]OA: VLAN IPCONFIG set to STATIC IP mode and VLAN ID [VALUE] for OA #[value:number]OA: VLAN setting has been restored to factory defaultsOA: VLAN setting has been reverted back to saved FLASH config dataOA: VLAN will be reverted to saved config data in [value] secsOA: Removing VLAN [value:name] ID [value:number].OA: Removing unnamed VLAN ID [value:number].OA: Adding VLAN [value:name] ID [value:number].OA: Adding unnamed VLAN ID [value:number].OA: Changing VLAN ID [value:number] name to [value:name]OA: Deleting VLAN ID [value:name].OA: Waiting DHCPv4 server response.Tipo de registro: LOG_INFO, Tipo de fallo: SW
OA: ERROR: Event [value] with location [value] sentTipo de registro: LOG_INFO, Tipo de fallo: Info
OA: Blade #[value:bladeNumber] boot order settings changed by user [value:username].OA: Blade #[value:bladeNumber] boot order settings changed by user [value:username]. First Boot Device: [value]. Boot Agent: [value].OA: Blade [value:bladeNumber] DVD connection changed by user [value:username] to '[value:URL]'.OA: Cold Boot virtual command enacted on blade[value:bladeNumber] by user [value:username].OA: Interconnect module [value:number] has been reset by user [value:username].
256 Capítulo 5 Errores de HPE Onboard Administrator ESES

OA: Momentary Press virtual command enacted on blade [value:bladeNumber] by user [value:username].OA: Onboard Administrator in bay [value:bayNumber] was restarted by user [value:username].OA: Power limit was set to [value] by user [value:username]OA: Power savings mode was set to [ON/OFF] by user [value:username]OA: Power subsystem redundancy mode was set to [value] by user [value:username]OA: Press and Hold virtual command enacted on blade [value:bladeNumber] by user [value:username].OA: Reboot virtual command enacted on blade [value:bladeNumber] by user [value:username].OA: Session on interconnect [value:bayNumber] cleared by [value]OA: Standby Onboard Administrator flashed successfullyOA: Virtual power command enacted on interconnect [value:number] by user [value:username]OA: Warning: Not all VC-Enet modules are on the same VLAN IDTipo de registro: LOG_ERR, Tipo de fallo: Info
OA: Not possible to get the actual VC Mode of the enclosure.
Mensajes del registro de LinuxTipo de registro: LOG_NOTICE, Tipo de fallo: Info
OA: Authentication failure for user [username] from [remote host] requesting [value]OA: Authentication failure for user [username] from Enclosure Link requesting [value]OA: Authentication failure for user [username] on [value].OA: Authentication failure for user [username] on the OA KVM.OA: Authentication failure for user [username] on the OA serial console.OA: Authentication failure for user [username] requesting [value]
Mensajes del registro de gestiónTipo de registro: LOG_EMERG, Tipo de fallo: SW
OA: Internal System Firmware Error, Rebooting.Tipo de registro: LOG_WARNING, Tipo de fallo: HW
OA: A port mismatch was found with server blade bay [value:bladeNumber] and interconnect bay [value:slotNumber]OA: Temperature of I/O module in slot [value:slotNumber] is at alert levelTipo de registro: LOG_WARNING, Tipo de fallo: SW
ESES Mensajes de SysLog 257

OA: iLO in bay [value] has not responded to the previous [value:count] capping requests from the Enclosure Dynamic Power Cap.Tipo de registro: LOG_CRIT, Tipo de fallo: HW
OA Tray firmware upgrade failed.OA: Blade in bay [value:bladeNumber] contains an unsupported #[value] mezz card.OA: Enclosure Status changed from [N/A/Unknown/OK/Degraded/Failed] to [N/A/Unknown/OK/Degraded/Failed].OA: Failed to initialize key components. Please call support immediately.OA: Fan [value] firmware upgrade failed.OA: Interconnect [value:slotNumber] firmware upgrade failed.OA: Interconnect [value] firmware upgrade failed.OA: LCD fails to respond to keystrokes.OA: LCD firmware upgrade failed.OA: LCD not functioning properly, pausing operation for 10 seconds.OA: LCD Status is: FailedOA: mgmt: GPIO initialization failed.OA: mgmt: i2c initialization failed.OA: Mismatching I/O was detected on Blade [value:bladeNumber], interconnect [value].OA: Mismatching I/O was detected on Blade [value:bladeNumber], Mezzanine Card [value], Port [value].OA: Mismatching I/O was detected on Interconnect [value], Port [value].OA: Temperature of I/O module in slot [value:slotNumber] is critical - module shut downOA: Unsupported Device in bay #[value:bladeNumber].OA: Unsupported IO Module in bay #[value:slotNumber].OA: Unsupported IO Module location in bay #[value:slotNumber].Tipo de registro: LOG_CRIT, Tipo de fallo: SW
OA: Blade [value:bladeNumber] management processor firmware upgrade failed.OA: Error reading Fru Board Info for the LCD.OA: Error reading Fru information for the LCD.OA: Error reading Fru Internal Use Area for the LCD.OA: mgmt: Failed to acquire enclosure semaphore.Tipo de registro: LOG_CRIT, Tipo de fallo: Info
OA: Mismatching I/O condition resolved, Blade [value:bladeNumber], interconnect [value] was removed.
258 Capítulo 5 Errores de HPE Onboard Administrator ESES

OA: Mismatching I/O was removed on Blade [value:bladeNumber], Mezzanine Card [value], Port [value].OA: Mismatching I/O was removed on Interconnect [value], Port [value].Tipo de registro: LOG_NOTICE, Tipo de fallo: HW
OA: AC Subsystem Overload - FAILED. Redundant Power: [value]W DC, Present Power [value]W AC.OA: Blade [value:bladeNumber] Ambient Temperature Cable fault...state is CRITICAL.OA: Blade [value:bladeNumber] Ambient Temperature Cable fault...state is DEGRADED.OA: Blade [value:bladeNumber] Ambient Temperature caution...state is CRITICAL.OA: Blade [value:bladeNumber] Ambient Temperature caution...state is DEGRADED.OA: Blade [value:bladeNumber] Ambient Temperature Sensor fault...state is CRITICAL.OA: Blade [value:bladeNumber] Ambient Temperature Sensor fault...state is DEGRADED.OA: Blade [value:bladeNumber] cannot partner with its neighbor.OA: Blade [value:bladeNumber] Disk Tray is Open...state is CRITICAL.OA: Blade [value:bladeNumber] Disk Tray is Open...state is DEGRADED.OA: Blade [value:bladeNumber] FRU memory fault...state is CRITICAL.OA: Blade [value:bladeNumber] FRU memory fault...state is DEGRADED.OA: Blade [value:bladeNumber] has integrated blade cross connection, Mezzanine card [value] is superfluous.OA: Blade [value:bladeNumber] Internal Temperature caution...state is CRITICAL.OA: Blade [value:bladeNumber] Internal Temperature caution...state is DEGRADED.OA: Blade [value:bladeNumber] Internal Temperature Sensor fault...state is CRITICAL.OA: Blade [value:bladeNumber] Internal Temperature Sensor fault...state is DEGRADED.OA: Blade [value:bladeNumber] is not properly cooled.OA: Blade [value:bladeNumber] is not supported.OA: Blade [value:bladeNumber] is reporting degraded health status.OA: Blade [value:bladeNumber] is reporting failed health status.OA: Blade [value:bladeNumber] Main Logic Board fault...state is CRITICAL.OA: Blade [value:bladeNumber] Main Logic Board fault...state is DEGRADED.
ESES Mensajes de SysLog 259

OA: Blade [value:bladeNumber] needs a partner device.OA: Blade [value:bladeNumber] over temperature...state is CRITICAL.OA: Blade [value:bladeNumber] over temperature...state is DEGRADED.OA: Blade [value:bladeNumber] PCI device missing...state is CRITICAL.OA: Blade [value:bladeNumber] PCI device missing...state is CRITICAL.OA: Blade [value:bladeNumber] PCI device missing...state is DEGRADED.OA: Blade [value:bladeNumber] PCI device missing...state is DEGRADED.OA: Blade [value:bladeNumber] Power Control fault...state is CRITICAL.OA: Blade [value:bladeNumber] Power Control fault...state is DEGRADED.OA: Blade [value:bladeNumber] properly partners with its neighbor.OA: Blade [value:bladeNumber] reported an unusually high power allocation value. Please see customer advisory c01668472. Its invalid power value of [value]W has been capped at [value]W.OA: Blade [value:bladeNumber] requested too little power.OA: Blade [value:bladeNumber] Storage Condition fault...state is CRITICAL.OA: Blade [value:bladeNumber] Storage Condition fault...state is DEGRADED.OA: Blade [value:bladeNumber] thermal state is CRITICAL.OA: Blade [value:bladeNumber] thermal state is DEGRADED.OA: Blade in bay #[value:bladeNumber] status changed from [OK/Degraded/Failed] to [OK/Degraded/Failed]OA: Blade in bay #[value:bladeNumber] status changed to [OK/Degraded/Failed]OA: Blade removed from bay [value:bladeNumber]OA: Blade removed from bay [value:bladeNumber]OA: DC Subsystem Overload - FAILED. Redundant Power: [value]W DC, Present Power [value]W AC.OA: Ekeying: Partner device of blade [value:bladeNumber] was removed, no more mezzanine card required on blade [value:bladeNumber].OA: Fan Removed: Bay #[value:fanNumber]OA: Fan Status Changed: Bay #[value:fanNumber] From: [degraded/failed/ok] To: [degraded/failed/ok]OA: Fan Subsystem Status Changed: From: [degraded/failed/ok] To: [degraded/failed/ok]OA: Hewlett Packard Enterprise strongly recommends replacing power supply #[value] at the customer's earliest possible convenience pursuant to Customer Advisory c01519680.OA: Internal communication problem detected.OA: Internal communications restored.
260 Capítulo 5 Errores de HPE Onboard Administrator ESES

OA: Internal health status of interconnect in bay [value:slotNumber] changed to DegradedOA: Internal health status of interconnect in bay [value:slotNumber] changed to FailedOA: Internal health status of interconnect in bay [value:slotNumber] changed to UnknownOA: Management Processor on Blade [value:bladeNumber] appears unresponsive.OA: Mixing different fan models is not supported. The fan in bay #[value:fanNumber] must be replaced with the proper part number.OA: Mixing different power supply models is not supported. The power supply in bay #[value] must be replaced with the proper part number.OA: Power Supplies Connected To Both AC and DC Input Lines: Unsupported Configuration.OA: Power Supplies Not Connected To Identical Capacity Input Lines.OA: PS Removed: Bay #[value]OA: PS Status Changed: Bay #[value] From: [unknown/ok/degraded/failed] To: [unknown/ok/degraded/failed]OA: PS Status Changed: Bay #[value] From: [unknown/ok/degraded/failed] To: [unknown/ok/degraded/failed] - due to communication issues. Reinserting Power Supplies may correct the issue.OA: PS Subsystem N + 1 Redundancy - FAILED.OA: PS Subsystem N + 1 Redundancy - REPAIRED.OA: PS Subsystem N + N Redundancy - FAILED.OA: PS Subsystem Overload - FAILED.OA: PS Subsystem Overload – REPAIRED.OA: PS Subsystem Power Limit - FAILED.OA: PS Subsystem Power Limit – REPAIRED.OA: Redundant Onboard Administrator was removedOA: Required fan is missing from fan bay [value]OA: The fan in bay #[value:fanNumber] is not supported in this enclosure. Please replace this fan with the proper part number.OA: The power management controller firmware on blade [value:bladeNumber] must be upgraded. Please see customer advisory c01668472.OA: TRAY microcode update failedTipo de registro: LOG_NOTICE, Tipo de fallo: SW
OA: Blade [value:bladeNumber] and its partner device need be powered up in a different order.
ESES Mensajes de SysLog 261

OA: Blade [value:bladeNumber] cannot be managed as part of the Enclosure Dynamic Power Cap. The blade's iLO firmware version is [value:version] and version [value:version] is required.OA: Blade [value:bladeNumber] cannot be powered on at this time due to location rules.OA: Blade [value:bladeNumber] has been allocated a default power value of [value]W because iLO appears unresponsive.OA: Blade [value:bladeNumber] is missing a Scalable Blade Link.OA: Blade [value:bladeNumber] is not configured for Virtual Connect Manager.OA: Blade [value:bladeNumber] requires a proper mezzanine card to partner.OA: Blade [value:bladeNumber] requires partner in bay [value:bladeNumber] to be powered on first.OA: Blade [value:bladeNumber]: SMBIOS data carries more than [value] CPU records which cannot be processed with this OA firmware version.OA: Blade [value:bladeNumber]: SMBIOS data carries more than [value] DIMM records which cannot be processed with this OA firmware version.OA: Blade [value:bladeNumber]: SMBIOS data carries more than [value] NIC records which cannot be processed with this OA firmware version.OA: Blade [value:bladeNumber]: SMBIOS data requires [value] DIMM records. [value] are supported by this OA firmware version.OA: Enclosure Dynamic Power Cap: Device tray firmware doesn't meet minimum required version.OA: Enclosure Dynamic Power Cap: Server Power Reduction is not enabled; enclosure cap is not guaranteed if power redundancy is lost.OA: Fan Inserted: Bay #[value:fanNumber]OA: iLO in bay [value:bladeNumber] appears responsive to the Enclosure Dynamic Power Cap again.OA: iLO in bay [value:bladeNumber] is not responding to capping requests from the Enclosure Dynamic Power Cap. Reset the iLO.OA: Server Power Reduction - DeactivatedOA: Tray Update: Can't get TRAY PS microcode versionOA: Warning: Integrated device on bus 0x[value] at address 0x[value] has not respondedTipo de registro: LOG_NOTICE, Tipo de fallo: Info
OA: AC Subsystem Overloaded - REPAIREDOA: Blade [value:bladeNumber] Ambient Temperature Cable state is OK.OA: Blade [value:bladeNumber] Ambient Temperature Sensor state is OK.OA: Blade [value:bladeNumber] Ambient Temperature state is OK.OA: Blade [value:bladeNumber] cannot be managed as part of the Enclosure Dynamic Power Cap. The blade is not a supported model.
262 Capítulo 5 Errores de HPE Onboard Administrator ESES

OA: Blade [value:bladeNumber] cannot be managed as part of the Enclosure Dynamic Power Cap. The blade reports that it is not capable of dynamic power capping.OA: Blade [value:bladeNumber] cannot be managed as part of the Enclosure Dynamic Power Cap. The blade does not have the required iLO license.OA: Blade [value:bladeNumber] complies with location rules now.OA: Blade [value:bladeNumber] Disk Tray is Open state is OK.OA: Blade [value:bladeNumber] firmware management completed.OA: Blade [value:bladeNumber] firmware management started.OA: Blade [value:bladeNumber] found a partner device.OA: Blade [value:bladeNumber] FRU memory state is OK.OA: Blade [value:bladeNumber] has been allocated [value] watts but iLO is reporting the blade is powered off.OA: Blade [value:bladeNumber] has been denied power but iLO is reporting the blade is powered on.OA: Blade [value:bladeNumber] Internal Temperature Sensor state is OK.OA: Blade [value:bladeNumber] Internal Temperature state is OK.OA: Blade [value:bladeNumber] is now configured for Virtual Connect Manager.OA: Blade [value:bladeNumber] is properly cooled.OA: Blade [value:bladeNumber] is reporting nominal health status.OA: Blade [value:bladeNumber] Main Logic Board state is OK.OA: Blade [value:bladeNumber] over temperature state is OK.OA: Blade [value:bladeNumber] PCI device state is OK.OA: Blade [value:bladeNumber] PCI device state is OK.OA: Blade [value:bladeNumber] Power Control state is OK.OA: Blade [value:bladeNumber] Storage Condition state is OK.OA: Blade [value:bladeNumber] thermal state is OK.OA: Blade inserted in bay [value:bladeNumber]OA: DC Subsystem Overloaded - REPAIREDOA: Enclosure ID setting has been restored to factory defaultsOA: Fan Inserted: Bay #[value:fanNumber]OA: Internal health status of interconnect in bay [value:slotNumber] changed to OKOA: IO module in slot [value:slotNumber] temperature is normalOA: Management Process on Blade [value:bladeNumber] appears responsive again.
ESES Mensajes de SysLog 263

OA: Midplane replacement detected. Serial number changed from [value] to [value].OA: Mixing 400Hz PSs with other PSs is not supportedOA: Power Limit Set To: [value]OA: Power Limit Set To: Not SetOA: Power Subsystem Redundancy Mode Set To: [N+N/N+1/N+0/]OA: Power Supplies Connected To Both AC and DC Input Lines: REPAIREDOA: PS Inserted: Bay #[value]OA: PS Subsystem N + 1 Redundancy - REPAIREDOA: PS Subsystem N + 1 Redundancy Power Limit - REPAIREDOA: PS Subsystem N + N Redundancy - REPAIREDOA: PS Subsystem N + N Redundancy Power Limit - REPAIREDOA: PS Subsystem Overloaded - REPAIREDOA: PS Subsystem Power Limit - REPAIREDOA: Redundant Onboard Administrator was insertedOA: Server Power Reduction - ActivatedOA: Server Power Reduction Mode - DisabledOA: Server Power Reduction Mode - EnabledOA: Server Power Reduction Mode - EnabledOA: TRAY microcode updated from UNKNOWN version to version [value:version]OA: TRAY microcode updated from version [value:version] to version [value:version]Tipo de registro: LOG_INFO, Tipo de fallo: HW
OA: Interconnect removed from bay [value:slotNumber]Tipo de registro: LOG_INFO, Tipo de fallo: SW
OA: A USB Key was inserted into the Onboard Administrator.OA: A USB Key was removed from the Onboard Administrator.OA: A CD-ROM Drive was inserted into the Onboard Administrator.OA: Media was removed from CD-ROM Drive.OA: CD-ROM Drive has no media.OA: Media in CD-ROM Drive detected. Volume Label: [value] (Se ha detectado un soporte en la unidad de CD-ROM. Etiqueta de volumen: [valor])OA: Blade [value:bladeNumber]: Mezz card internal data problem for [value].OA: Failed to mount [CD/DVD/USB Key]: [value:errorCode]OA: Failed to mount [CD/DVD/USB Key][value]: unsupported filesystem.
264 Capítulo 5 Errores de HPE Onboard Administrator ESES

OA: Interconnect inserted in bay [value:slotNumber]OA: VC module in interconnect bay [value:slotNumber] has firmware revision [value:version] but minimum firmware revision [value:version] is requiredTipo de registro: LOG_INFO, Tipo de fallo: Info
OA Tray firmware upgrade initiated.OA Tray firmware upgrade succeeded.OA: Blade [value:bladeNumber] management processor firmware upgrade initiated.OA: Blade [value:bladeNumber] management processor firmware upgrade succeeded.OA: Fan [value] firmware upgrade initiated.OA: Fan [value] firmware upgrade succeeded.OA: Interconnect [value:slotNumber] firmware upgrade initiated.OA: Interconnect [value:slotNumber] firmware upgrade succeeded.OA: Interconnect [value] firmware upgrade initiated.OA: Interconnect [value] firmware upgrade succeeded.OA: Interconnect module in bay [value:slotNumber] was powered offOA: Interconnect module in bay [value:slotNumber] was powered onOA: LCD firmware upgrade initiated.OA: LCD firmware upgrade succeeded.OA: Server Blade in bay [value:bladeNumber] has been powered downOA: Server blade in bay [value:bladeNumber] has been powered on
Mensajes del registro internos de OATipo de registro: LOG_WARNING, Tipo de fallo: Info
OA: Internal switch reset required. Rebooting...Tipo de registro: LOG_CRIT, Tipo de fallo: SW
OA: daemon is exiting because of SIGTERM, system will reset.Tipo de registro: LOG_ERR, Tipo de fallo: SW
OA: [value] is not a regular file!OA: Archive file failed to read.OA: Archive Header for File [value] failed to write.OA: Bad Archive Header.OA: Cannot archive file [value] due to lack of space ([value] vs. [value] bytes)OA: Cannot archive file with filepath > [value]: [value]
ESES Mensajes de SysLog 265

OA: Cannot open [value]OA: Cannot open file [value]OA: Cannot stat file [value]OA: Can't open watchdog device errno [value].OA: Could not read file count.);OA: Could not write file count ([value]).OA: File [value] could not set permissions [value]OA: File [value] could not set user [value] group [value]OA: File [value] failed to open.OA: File [value] failed to read.OA: File [value] failed to writeOA: File [value] failed to write into archive.OA: flar [x|c]);OA: Flash Archiver could not obtain root privileges (errno [value])OA: Invalid file descriptor [value].OA: malloc failure ([value] bytes)OA: Management process failure.OA: NULL object passed.OA: Object read failed errno [value]OA: Object read failed size [value]OA: Object write failed errno [value]OA: Object write failed size [value]Tipo de registro: LOG_NOTICE, Tipo de fallo: SW
OA: Internal communication problem detected.OA: Internal communications restored.Tipo de registro: LOG_NOTICE, Tipo de fallo: Info
OA: Internal communications restored.Tipo de registro: LOG_INFO, Tipo de fallo: SW
OA: Can't read main mgmt process id.
Mensajes del registro de LDAPTipo de registro: LOG_ALERT, Tipo de fallo: SW
LDAP: pam_get_item returned error to ldap-read-passwordTipo de registro: LOG_WARNING, Tipo de fallo: Info
OA: LDAP [value:username] logged into the Onboard Administrator
266 Capítulo 5 Errores de HPE Onboard Administrator ESES

OA: LDAP [value:username] logged into the Onboard Administrator from [value:remoteHost]OA: LDAP [value:username] logged into the Onboard Administrator from Enclosure LinkOA: LDAP [value:username] logged into the Onboard Administrator on [value]OA: LDAP [value:username] logged into the Onboard Administrator on the OA KVM.OA: LDAP [value:username] logged into the Onboard Administrator on the OA serial console.Tipo de registro: LOG_CRIT, Tipo de fallo: SW
LDAP: auth could not identify password for [value:username]LDAP: error manipulating passwordTipo de registro: LOG_ERR, Tipo de fallo: SW
LDAP: bad username [value:username]LDAP: couldn't obtain coversation function [value]Tipo de registro: LOG_NOTICE, Tipo de fallo: SW
LDAP: authentication failure; [value] for [value] service, not a member of any configured groupLDAP: could not recover authentication token
Mensajes del registro de redundanciaTipo de registro: LOG_WARNING, Tipo de fallo: SW
Redundancy: Active Onboard Administrator has lost link connectivity on the external NIC for [value] seconds. Forcing take overRedundancy: Failed to read event from mgmt subsystemRedundancy: Onboard Administrator is switching to Active modeRedundancy: Onboard Administrator is switching to Standby mode. This OA will now rebootTipo de registro: LOG_CRIT, Tipo de fallo: HW
Redundancy: Onboard Administrator redundancy failed to initialize properly. Try rebooting the Onboard Administrator by reseating the OA module in its bay. If the problem persists, please contact Hewlett Packard Enterprise support.Tipo de registro: LOG_CRIT, Tipo de fallo: SW
Redundancy: Caught Signal SIGSEGVRedundancy: redund: Failed to startup threadsTipo de registro: LOG_ERR, Tipo de fallo: HW
Redundancy: Failed automatic Onboard Administrator failover as a result of network link loss on the Active OA board
ESES Mensajes de SysLog 267

Tipo de registro: LOG_ERR, Tipo de fallo: SW
Redundancy: Couldn't get random seedRedundancy: Error communicating via ethernet with the other Onboard Administrator (heartbeat).Redundancy: Error communicating via ethernet with the other Onboard Administrator (timeout).Redundancy: Error communicating with the other Onboard Administrator.Redundancy: Failed to get enclosure networkRedundancy: Failed to read OA bay numberRedundancy: Failed to read OA statusRedundancy: Other ([Standby/Active]) OA firmware: v[value:version] - This OA ([Standby/Active]) firmware: v[value:version]Redundancy: Please upgrade to the latest firmware using [this/the other] Onboard Administrator which is the activeRedundancy: WARNING: The other OA ([Standby/Active]) is running a different firmware. OA Redundancy will be degradedTipo de registro: LOG_NOTICE, Tipo de fallo: SW
Redundancy: Assuming active Onboard Administrator network settings.Redundancy: Enclosure IP mode was [disabled/enabled]Tipo de registro: LOG_INFO, Tipo de fallo: SW
Redundancy: Enclosure IP mode configurations have been reset.Redundancy: Onboard Administrator has now completed the Standby to Active transitionRedundancy: Onboard Administrator redundancy restored.Redundancy: Service started ([ACTIVE/STANDBY])
Mensajes del registro de SSOTipo de registro: LOG_WARNING, Tipo de fallo: Info
OA: SSO [value] logged into the Onboard AdministratorOA: SSO [value] logged into the Onboard Administrator from [value:remoteAddress]Tipo de registro: LOG_NOTICE, Tipo de fallo: Info
OA: Authentication failure for user SSO [value]OA: Authentication failure for user SSO [value] from [value:remoteAddress]OA: SSO Trust Mode changed to [value] by user [value:username]. (El usuario [valor: nombredeusuario] ha cambiado el modo de confianza de HPSIM a [valor].)
268 Capítulo 5 Errores de HPE Onboard Administrator ESES

Mensajes del registro de dos factoresTipo de registro: LOG_WARNING, Tipo de fallo: SW
OA: Two Factor: Two-Factor authentication failed for user at [value]: local user certificate status check failed.Tipo de registro: LOG_WARNING, Tipo de fallo: Info
OA: Two Factor: [value:username] logged into the Onboard Administrator from [value] using Two-FactorOA: Two Factor: [value:username] logged into the Onboard Administrator from Enclosure Link using Two-FactorOA: Two Factor: Unable to create session for user [value:username]: the maximum number of sesssions has been reached.Tipo de registro: LOG_CRIT, Tipo de fallo: SW
OA: Two Factor: Two-Factor authentication failed for user at [value]: the certificate provided could not be authenticated.Tipo de registro: LOG_ERR, Tipo de fallo: SW
Two Factor: Error allocating memory.Two Factor: Error creating place holder for CRLTwo Factor: Error creating temp store for CRLTwo Factor: Error downloading CRL from [value:URL]Two Factor: Error mapping CRL files.Two Factor: Error starting CRL service.Two Factor: Insufficient privileges.Two Factor: Internal error.Two Factor: Invalid/corrupt CRL file at [value:URL]Two Factor: Messaging system error.
Mensajes del registro de FIPSTipo de registro: LOG_INFO, Tipo de fallo: SW
FIPS: Onboard Administrator is operating in FIPS Mode Debug.FIPS: Onboard Administrator is operating in FIPS Mode On.FIPS: Too many Known Answer Test (KAT) failures: left FIPS modeFIPS: "Last reboot was due to a Known Answer Test (KAT) failure.Tipo de registro: LOG_ERR, Tipo de fallo: SW
OA: Error restoring factory default settings. Restoring FIPS mode...OA: Failed to restore FIPS mode for standby Onboard Administrator.OA: Could not restore FIPS mode (error code: [value]).OA: Could not restore the password for user [value].
ESES Mensajes de SysLog 269

OA: Could not restore the strict passwords setting.OA: Could not restore the minimum password length.OA: Could not restore the password for user [value].
Mensajes del registro de VLANTipo de registro: LOG_NOTICE, Tipo de fallo: Info
OA: May need to reboot the interconnects to pick up new IP address or wait until DHCP lease expiresOA: VLAN ID for interconnect bay [value] changed to [value]. May need to reboot the interconnect to pick up new IP address or wait until DHCP lease expiresOA: VLAN ID for OA changed from [value] to [value]OA: VLAN ID for server bay [value] changed to [value]OA: VLAN is disabledOA: VLAN is enabled. OA VLAN ID = [value]Tipo de registro: LOG_INFO, Tipo de fallo: Info
OA: VLAN revert is canceled
Capturas SNMP de Onboard AdministratorOnboard Administrator admite las siguientes capturas SNMP.
ID de captura Nombre de la captura Descripción
22001 cpqRackNameChanged El nombre del bastidor ha cambiado
22002 cpqRackEnclosureNameChanged El nombre del chasis ha cambiado
22003 cpqRackEnclosureRemoved Se ha detectado la eliminación de un chasis vinculado
22004 cpqRackEnclosureInserted Se ha detectado la inserción de un chasis vinculado
22008 cpqRackEnclosureFanFailed Se ha producido un fallo en el ventilador del chasis
22009 cpqRackEnclosureFanDegraded El ventilador del chasis tiene el estado Degraded
22010 cpqRackEnclosureFanOk La temperatura del ventilador es correcta
22011 cpqRackEnclosureFanRemoved El ventilador del chasis se ha retirado
22012 cpqRackEnclosureFanInserted El ventilador del chasis se ha introducido
22013 cpqRackPowerSupplyFailed Se ha producido un fallo en la fuente de alimentación del chasis
22014 cpqRackPowerSupplyDegraded La fuente de alimentación del chasis tiene el estado Degraded
270 Capítulo 5 Errores de HPE Onboard Administrator ESES

ID de captura Nombre de la captura Descripción
22015 cpqRackPowerSupplyOk La fuente de alimentación del chasis funciona correctamente
22016 cpqRackPowerSupplyRemoved La fuente de alimentación del chasis se ha retirado
22017 cpqRackPowerSupplyInserted La fuente de alimentación del chasis se ha introducido
22018 cpqRackPowerSubsystemNotRedundant El subsistema de alimentación del chasis no es redundante
22019 cpqRackPowerSubsystemLineVoltageProblem
Problema de tensión en la línea del subsistema de alimentación del chasis
22020 cpqRackPowerSubsystemOverloadCondition Sobrecarga del subsistema de alimentación del chasis
22028 cpqRackServerBladeRemoved Blade extraído (sustituido por 22050 en OA v1.30)
22029 cpqRackServerBladeInserted Blade introducido (sustituido por 22051 en OA v1.30)
22037 cpqRackEnclosureManagerDegraded Onboard Administrator en estado Degraded
22038 cpqRackEnclosureManagerOk Onboard Administrator funciona correctamente
22039 cpqRackEnclosureManagerRemoved Onboard Administrator se ha extraído
22040 cpqRackEnclosureManagerInserted Onboard Administrator se ha introducido
22041 cpqRackManagerPrimaryRole Onboard Administrator está activo
22042 cpqRackServerBladeEKeyingFailed Error de configuración de clave electrónica de blade
22044 cpqRackNetConnectorRemoved Interconexión extraída
22045 cpqRackNetConnectorInserted Interconexión introducida
22046 cpqRackNetConnectorFailed Error de interconexión
22047 cpqRackNetConnectorDegraded Interconexión en estado Degraded
22048 cpqRackNetConnectorOk Interconexión correcta
22049 cpqRackServerBladeToLowPower El blade ha solicitado un nivel de potencia demasiado bajo
22050 cpqRackServerBladeRemoved2 Blade extraído2
22051 cpqRackServerBladeInserted2 Blade introducido2
Notificaciones de eventos del chasisLos eventos que se producen en el chasis aparecen en mensajes de pantalla cuando la opción de show events está activada. Si un usuario se ve afectado directamente por un evento, el mensaje se mostrará independientemente de si la opción show events se encuentra activada.
Los mensajes de eventos incluyen el dispositivo afectado, el nombre del dispositivo, y la fecha y la hora del evento. Entre algunos ejemplos de mensajes de evento se incluyen:
ESES Notificaciones de eventos del chasis 271

● The enclosure is in a degraded state (El chasis se encuentra en estado Degraded).
● Blade X has experienced a failure (Se ha producido un fallo en el blade X).
● The temperature on Blade X has exceeded the failed threshold (La temperatura del blade X ha sobrepasado el límite de fallos).
● Fan X has experienced a failure (Se ha producido un fallo en el ventilador X).
● The power supplies are no longer redundant (Las fuentes de alimentación han dejado de ser redundantes).
● Power supply X is in a degraded state (La fuente de alimentación X se encuentra en estado Degraded).
● The enclosure temperature has exceeded the degraded threshold (La temperatura del chasis ha sobrepasado el límite de degradación).
Notificaciones de eventos de la línea de comandosCuando se activa la opción SET DISPLAY EVENTS, la interfaz de terminal muestra mensajes de error, de advertencia y de estado, según el comportamiento del chasis y sus componentes.
La sintaxis de estos mensajes es la siguiente:
● <error>: descripción del error
● <warning>: descripción de la advertencia
● <status>: descripción del estado
En la tabla siguiente se enumeran las causas de los eventos de error, advertencia o estado que se muestran.
Evento Causa
Bay Event (Evento de compartimento) Se ha asignado un compartimento a un grupo o se anulado la asignación de un compartimento a un grupo.
Blade Inserted (Blade introducido) Se ha introducido un blade en el chasis.
Blade Thermal Status Changed (Cambio del estado térmico del blade)
Ha cambiado el estado térmico del blade.
Blade Removed (Blade extraído) Se ha extraído un blade del chasis.
Blade Port Map Info (Información de asignación de puertos del blade)
Se ha actualizado la información de asignación de puertos de un blade.
Enclosure Status Change (Cambio de estado del chasis) Se ha producido un fallo en el estado debido a un cambio en el estado de uno o varios componentes de hardware o en las lecturas del servidor.
Enclosure Name Change (Cambio de nombre del chasis) Se ha cambiado el nombre del chasis.
Fan Status Change (Cambio en el estado del ventilador) Ha cambiado el estado de un ventilador.
Fan Inserted (Ventilador introducido) Se ha introducido un ventilador.
Fan Removed (Ventilador extraído) Se ha extraído un ventilador.
Interconnect Inserted (Interconexión introducida) Se ha introducido un módulo de interconexión en el chasis.
Interconnect Thermal Status Changed (Cambio del estado térmico de interconexión)
Ha cambiado el estado térmico de un módulo de interconexión.
272 Capítulo 5 Errores de HPE Onboard Administrator ESES

Evento Causa
Interconnect Removed (Interconexión extraída) Se ha extraído un módulo de interconexión del chasis.
Interconnect Power Reset (Restablecimiento de alimentación de la interconexión)
Se ha restablecido la alimentación de un módulo de interconexión.
Interconnect Port Map Info (Información de asignación de puertos de interconexión)
Se ha actualizado la información de asignación de puertos de un módulo de interconexión.
LDAP Group Removed (Grupo LDAP quitado) Se ha quitado un grupo LDAP del Onboard Administrator. Si ha iniciado sesión en el Onboard Administrator dentro de este grupo LDAP, se ha desconectado.
OA System Log Cleared (Registro del sistema del OA borrado)
Se ha borrado el registro del sistema del Onboard Administrator.
OA Name Changed (Cambio de nombre del OA) Se ha cambiado el nombre DNS del Onboard Administrator.
OA Inserted (OA introducido) Se ha introducido un Onboard Administrator en el chasis.
OA Removed (OA quitado) Se ha quitado el Onboard Administrator redundante del chasis.
OA Takeover (Relevo de OA) Los Onboard Administrators activo y redundante están intercambiando sus funciones. El Onboard Administrator activo se reinicia en modo de espera y el Onboard Administrator redundante cambia a modo activo.
Power Supply Status Change (Cambio en el estado de la fuente de alimentación)
Ha cambiado el estado de una fuente de alimentación.
Power Supply Inserted (Fuente de alimentación introducida) Se ha introducido una fuente de alimentación.
Power Supply Removed (Fuente de alimentación extraída) Se ha extraído una fuente de alimentación.
Power Supply Redundancy Change (Cambio en la redundancia de la fuente de alimentación)
Las fuentes de alimentación son ahora redundantes o han dejado de serlo.
Power Supply Overload (Sobrecarga de la fuente de alimentación)
Se está solicitando a las fuentes de alimentación que permitan la entrada de una corriente superior a su capacidad.
Restart Event (Evento de reinicio) El Onboard Administrator está a punto de iniciarse.
Rack Name Change (Cambio de nombre de bastidor) Ha cambiado el nombre de bastidor almacenado en el chasis.
Rack Topology (Topología del bastidor) Se han conectado o desconectado los chasis del enlace de chasis.
Thermal Status Change (Cambio en el estado térmico) Un sensor térmico ha cambiado de estado.
User Removed (Usuario quitado) Se ha quitado un usuario del Onboard Administrator. Si ha iniciado sesión como este usuario, se ha desconectado del Onboard Administrator.
User Disabled (Usuario desactivado) Se ha desactivado un usuario. Si ha iniciado sesión como este usuario, se ha desconectado del Onboard Administrator.
User Rights (Derechos de usuario) Ha cambiado el nivel de privilegio de un usuario en el Onboard Administrator. Si ha iniciado sesión como este usuario, se ha desconectado del Onboard Administrator. Puede volver a iniciar sesión con su nuevo nivel de privilegio.
ESES Notificaciones de eventos de la línea de comandos 273

6 Errores de HPE Virtual Connect
Información general sobre SNMPSNMP es el protocolo usado por los sistemas de gestión de red para supervisar los dispositivos que están conectados a la red cuando las condiciones requieren atención administrativa. SNMP consiste en un conjunto de estándares de gestión de red, incluido un protocolo de nivel de aplicación, un esquema de base de datos y un conjunto de objetos de datos. El software del agente SNMP se encuentra en el módulo y proporciona acceso a la información de gestión. La información de gestión se estructura como una base de datos jerárquica conocida como MIB. Cada elemento de MIB se identifica mediante un identificador exclusivo denominado ID de objeto.
Cada módulo VC tiene un agente SNMP independiente que soporta un conjunto de MIB. El soporte de MIB para cada módulo depende tanto del tipo de módulo (VC-Enet o VC-FC) como de la función del módulo en el dominio de VC. Virtual Connect es compatible con SNMPv1, SNMPv2 y SNMPv3.
La versión más reciente de las MIB específicas de VC puede descargarse desde la página web de Hewlett Packard Enterprise (http://www.hpe.com/support/hpsim/mibkit).
Se aplican las siguientes restricciones y limitaciones:
● De forma predeterminada, los agentes SNMPv1 y SNMPv2 están activos en los módulos VC-Enet y VC-FC que tienen una cadena de comunidad de lectura cuyo valor es "public". La característica de acceso SNMP no se aplica a SNMPv3.
● Debe tener privilegios de rol de dominio para configurar las capacidades de SNMP. El tipo de privilegio necesario depende del elemento que se está configurando.
● La GUI y la CLI de VCM no admiten la configuración de los parámetros de captura del umbral (nivel máximo, nivel mínimo y período medio).
● Para las conexiones Flex-10, las capturas de umbral reflejan el estado de todo el puerto físico. Estas capturas no se generan para FlexNIC individuales. Para obtener más información sobre las conexiones Flex-10, consulte "Información general sobre Flex-10" en la Guía de usuario de HPE Virtual Connect para c-Class BladeSystem.
● Al actualizar desde una versión de VC anterior a la 3.00, si las capturas SNMP de Fibre Channel se definieron con el tipo DNS de la dirección de destino de captura, la configuración de SNMP no se aplica a los módulos VC-FC una vez finalizada la actualización. Para resolver este problema, utilice la GUI o la CLI para modificar cualquier destino de captura SNMP de FC que tenga un nombre DNS para el destino de captura, y cambie el nombre DNS por una dirección IPv4.
● Las versiones 3.00 y posteriores de VC limitan a cinco el número de capturas PortStatus de FC que puede configurar a través de la CLI. Las versiones anteriores no aplicaban esta restricción. Si tiene más de cinco capturas PortStatus de FC configuradas en una versión anterior del firmware de VC y actualiza a VC 3.00 o a una versión posterior, las capturas se mantendrán. Del mismo modo, si restaura en VC 3.00 o una versión posterior una configuración de una versión anterior del firmware de VC que contiene más de cinco capturas PortStatus de FC configuradas, tendrá un número de capturas PortStatus de FC configuradas superior al permitido. Tenga cuidado de no superar el número máximo de capturas PortStatus de FC configuradas en estos escenarios.
274 Capítulo 6 Errores de HPE Virtual Connect ESES
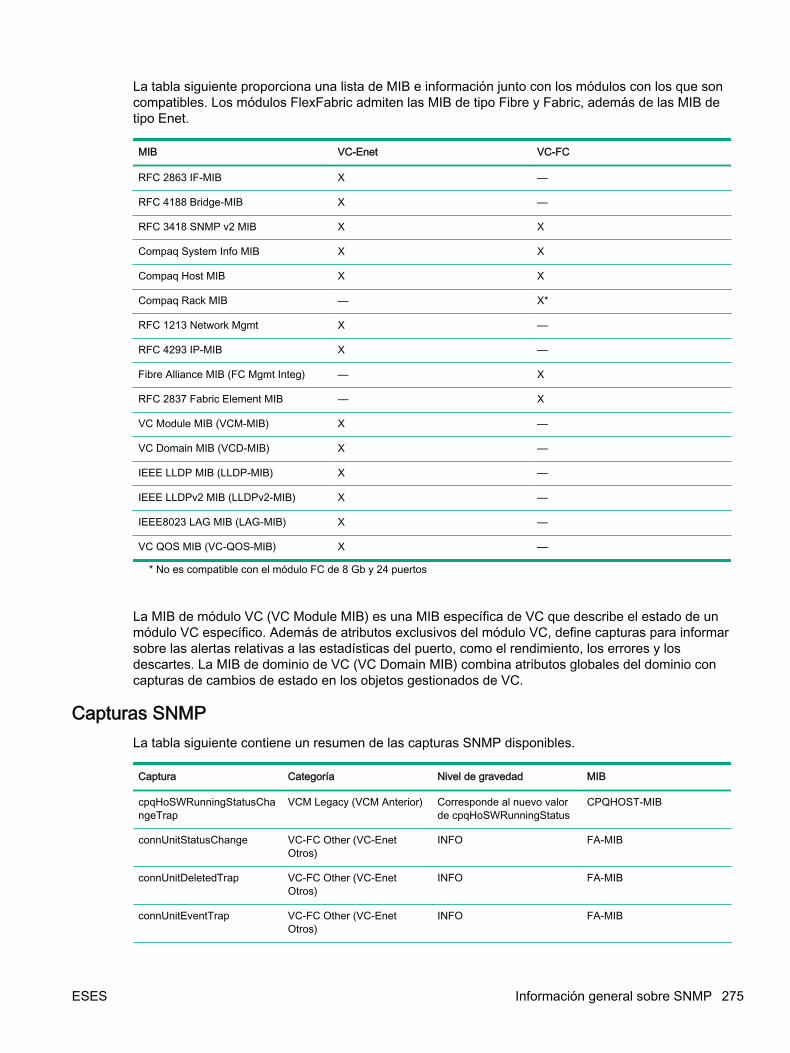
La tabla siguiente proporciona una lista de MIB e información junto con los módulos con los que son compatibles. Los módulos FlexFabric admiten las MIB de tipo Fibre y Fabric, además de las MIB de tipo Enet.
MIB VC-Enet VC-FC
RFC 2863 IF-MIB X —
RFC 4188 Bridge-MIB X —
RFC 3418 SNMP v2 MIB X X
Compaq System Info MIB X X
Compaq Host MIB X X
Compaq Rack MIB — X*
RFC 1213 Network Mgmt X —
RFC 4293 IP-MIB X —
Fibre Alliance MIB (FC Mgmt Integ) — X
RFC 2837 Fabric Element MIB — X
VC Module MIB (VCM-MIB) X —
VC Domain MIB (VCD-MIB) X —
IEEE LLDP MIB (LLDP-MIB) X —
IEEE LLDPv2 MIB (LLDPv2-MIB) X —
IEEE8023 LAG MIB (LAG-MIB) X —
VC QOS MIB (VC-QOS-MIB) X —
* No es compatible con el módulo FC de 8 Gb y 24 puertos
La MIB de módulo VC (VC Module MIB) es una MIB específica de VC que describe el estado de un módulo VC específico. Además de atributos exclusivos del módulo VC, define capturas para informar sobre las alertas relativas a las estadísticas del puerto, como el rendimiento, los errores y los descartes. La MIB de dominio de VC (VC Domain MIB) combina atributos globales del dominio con capturas de cambios de estado en los objetos gestionados de VC.
Capturas SNMPLa tabla siguiente contiene un resumen de las capturas SNMP disponibles.
Captura Categoría Nivel de gravedad MIB
cpqHoSWRunningStatusChangeTrap
VCM Legacy (VCM Anterior) Corresponde al nuevo valor de cpqHoSWRunningStatus
CPQHOST-MIB
connUnitStatusChange VC-FC Other (VC-Enet Otros)
INFO FA-MIB
connUnitDeletedTrap VC-FC Other (VC-Enet Otros)
INFO FA-MIB
connUnitEventTrap VC-FC Other (VC-Enet Otros)
INFO FA-MIB
ESES Información general sobre SNMP 275

Captura Categoría Nivel de gravedad MIB
connUnitSensorStatusChange
VC-FC Other (VC-Enet Otros)
CRITICAL FA-MIB
connUnitPortStatusChange VC-FC Port Status (Estado del puerto HBA)
Consulte la tabla siguiente FA-MIB
authenticationFailure¹ VC-FC Other (VC-Enet Otros)
CRITICAL SNMPv2-MIB
coldStart VC-FC Other (VC-Enet Otros)
CRITICAL SNMPv2-MIB
cpqHoSWRunningStatusChange
VC-FC Other (VC-Enet Otros)
INFO CPQHOST-MIB
authenticationFailure VC-Enet Other (VC-Enet Otros)
CRITICAL SNMPv2-MIB
Cambio de estado de dominio (obsoleto)
— — —
vcDomainManagedStateChanged
VCM Domain Status (Estado del dominio de VCM)
Corresponde al nombre del nuevo estado
VCD-MIB
StackingLinkRedundant status change (Cambio de estado de StackingLinkRedundant)
VCM Domain Status (Estado del dominio de VCM)
Corresponde al nombre del nuevo estado
VCD-MIB
Module role change (Cambio en la función del módulo)
VCM Domain Status (Estado del dominio de VCM)
INFO VCM-MIB
Stale checkpoint (Punto de control obsoleto)
VCM Domain Status (Estado del dominio de VCM)
WARNING VCD-MIB
Valid checkpoint (Punto de control válido)
VCM Domain Status (Estado del dominio de VCM)
NORMAL VCD-MIB
Enclosure status change (Cambio de estado del chasis) (obsoleto)
— — —
vcEnclosureManagedStateChanged3
VCM Domain Status (Estado del dominio de VCM)
Corresponde al nombre del nuevo estado
VCD-MIB
Network status change (Cambio de estado de red) (obsoleto)
— — —
vcEnetNetworkManagedStatusChanged3
VCM Network Status (Estado de la red de VCM)
Corresponde al nombre del nuevo estado
VCD-MIB
Fabric status change (Cambio de estado de estructura) (obsoleto)
— — —
vcFcFabricManagedStatusChanged3
VCM Fabric Status (Estado de la estructura de VCM)
Corresponde al nombre del nuevo estado
VCD-MIB
VC module status change (Cambio de estado del módulo VC) (obsoleto)
— — —
vcModuleManagedStatusChanged3
VC-Enet Module Status or VC-FC Module Status
Corresponde al nombre del nuevo estado
VCD-MIB
276 Capítulo 6 Errores de HPE Virtual Connect ESES

Captura Categoría Nivel de gravedad MIB
(Estado del módulo VC-Enet o Estado del módulo VC-FC)
Profile status change (Cambio de estado del perfil) (obsoleto)
— — —
vcProfileManagedStatusChanged3
VCM Profile Status (Estado del perfil de VCM)
Corresponde al nombre del nuevo estado
VCD-MIB
Physical server change (Cambio en el servidor físico) (obsoleto)
— — —
vcPhysicalServerManagedStatusChanged3
VCM Server Status (Estado del servidor de VCM)
Corresponde al nombre del nuevo estado
VCD-MIB
vcTesttrap VCM Domain Status (Estado del dominio de VCM)
INFO VCD-MIB
Enet IF-MIB LinkDown VC-Enet Port Status (Estado del puerto HBA)
INFO IF-MIB
Enet IF-MIB LInkUp VC-Enet Port Status (Estado del puerto HBA)
NORMAL IF-MIB
Input utilization above high-water mark2 (Utilización de la entrada encima de la marca de agua superior)
VC-Enet Port Threshold (Umbral del puerto VC-Enet)
WARNING VCM-MIB
Input utilization below low-water mark2 (Utilización de la entrada debajo de la marca de agua inferior)
VC-Enet Port Threshold (Umbral del puerto VC-Enet)
NORMAL VCM-MIB
Output utilization above high-water mark2 (Utilización de la salida encima de la marca de agua superior)
VC-Enet Port Threshold (Umbral del puerto VC-Enet)
WARNING VCM-MIB
Output utilization below low-water mark2 (Utilización de la salida debajo de la marca de agua inferior)
VC-Enet Port Threshold (Umbral del puerto VC-Enet)
NORMAL VCM-MIB
Input errors above high-water mark2 (Errores de entrada encima de la marca de agua superior)
VC-Enet Port Threshold (Umbral del puerto VC-Enet)
WARNING VCM-MIB
Input errors below low-water mark2 (Errores de entrada debajo de la marca de agua inferior)
VC-Enet Port Threshold (Umbral del puerto VC-Enet)
NORMAL VCM-MIB
Output errors above high-water mark2 (Errores de salida encima de la marca de agua superior)
VC-Enet Port Threshold (Umbral del puerto VC-Enet)
WARNING VCM-MIB
Output errors below low-water mark2 (Errores de
VC-Enet Port Threshold (Umbral del puerto VC-Enet)
NORMAL VCM-MIB
ESES Información general sobre SNMP 277

Captura Categoría Nivel de gravedad MIB
salida debajo de la marca de agua inferior)
vcModPortBpduLoopDetected
VC-Enet Port Status (Estado del puerto HBA)
CRITICAL VCM-MIB
vcModPortBpduLoopCleared VC-Enet Port Status (Estado del puerto HBA)
INFO VCM-MIB
vcModPortProtectionConditionDetected
VC-Enet Port Status (Estado del puerto HBA)
CRITICAL VCM-MIB
vcModPortProtectionConditionCleared
VC-Enet Port Status (Estado del puerto HBA)
INFO VCM-MIB
1 Solo es compatible con el módulo VC FC de 8 Gb y 24 puertos2 La MIB de módulo VC tiene la capacidad de enviar capturas cuando se alcanzan ciertos umbrales de utilización del ancho de banda y el rendimiento. Los contadores se muestrean cada 30 segundos; en esta versión no se pueden configurar ni el valor del intervalo de muestreo ni los valores de los umbrales. Los umbrales están definidos de la forma siguiente:— Nivel máximo de utilización del puerto: 95 %— Nivel mínimo de utilización del puerto: 75 %— Nivel máximo de errores: 5 %— Nivel mínimo de errores: 1 %Para obtener más información, consulte el campo de descripción en el código fuente de cada una de las MIB.3 Para obtener más información, consulte "Capturas cambiadas de estado gestionado de dominio de VC (Capturas de cambio de estado gestionado del dominio de VC en la página 280)".
NOTA: Durante una conmutación por error del OA u otras interrupciones de la red de gestión, es posible que las capturas de SNMP de VC no lleguen a la estación de gestión.
El módulo VC-FC genera capturas connUnitPortStatusChange basándose en los cambios realizados en el elemento connUnitPortStatus de la FA-MIB. La tabla siguiente muestra la asignación de niveles de gravedad de la captura connUnitPortStatusChange a las definiciones de nivel de gravedad de las capturas de la MIB de dominio de VC.
Valor de connUnitPortStatus Nivel de gravedad
unknown INFO
unused INFO
ready NORMAL
warning WARNING
failure CRITICAL
nonparticipating INFO
initializing INFO
bypass INFO
ols MAJOR
other INFO
278 Capítulo 6 Errores de HPE Virtual Connect ESES

Capturas de la MIB de módulo VCLa tabla siguiente muestra las capturas de la MIB de módulo VC.
Nombre de la captura Datos de la captura Descripción
vcModRoleChange moduleRole La función de VCM del módulo ha cambiado.
vcModInputUtilizationUp port identification (identificación de puerto)
La utilización de la línea de entrada de un puerto ha superado el nivel máximo durante más de 30 segundos. port es el índice del puerto afectado en ifTable.
vcModInputUtilizationDown port identification (identificación de puerto)
La utilización de la línea de entrada de un puerto ha caído por debajo del nivel mínimo durante más de 30 segundos. port es el índice del puerto afectado en ifTable.
vcModOutputUtilizationUp port identification (identificación de puerto)
La utilización de la línea de salida de un puerto ha superado el nivel máximo durante más de 30 segundos. port es el índice del puerto afectado en ifTable.
vcModOutputUtilizationDown port identification (identificación de puerto)
La utilización de la línea de salida de un puerto ha caído por debajo del nivel mínimo durante más de 30 segundos. port es el índice del puerto afectado en ifTable.
vcModInputErrorsUp port identification (identificación de puerto)
ifInErrors
El número de errores de entrada de un puerto ha superado el nivel máximo durante un período superior al período medio de errores. port es el índice del puerto afectado en ifTable.
vcModInputErrorsDown port identification (identificación de puerto)
ifInErrors
El número de errores de entrada de un puerto ha caído por debajo del nivel mínimo durante un período superior al período medio de errores. port es el índice del puerto afectado en ifTable.
vcModOutputErrorsUp port identification (identificación de puerto)
ifOutErrors
El número de errores de salida de un puerto ha superado el nivel máximo durante un período superior al período medio de umbral. port es el índice del puerto afectado en ifTable.
vcModOutputErrorsDown port identification (identificación de puerto)
ifOutErrors
El número de errores de salida de un puerto ha caído por debajo del nivel mínimo durante más de 30 segundos. port es el índice del puerto afectado en ifTable.
vcModPortBpduLoopDetected port identification (identificación de puerto)
estado del bucle
Se ha detectado una condición de bucle de red en este puerto. Si la condición de bucle se detecta en un puerto Flex-10, los datos de captura indican el puerto físico asociado al puerto Flex-10.
Si varios puertos Flex-10 de un puerto físico detectan una condición de bucle,
ESES Información general sobre SNMP 279

Nombre de la captura Datos de la captura Descripción
se envía una captura independiente para cada condición de bucle.
vcModPortBpduLoopCleared port identification (identificación de puerto)
estado del bucle
Se ha borrado una condición de bucle de red en este puerto. Los datos de la captura indican el puerto físico asociado a un puerto Flex-10.
Para los puertos Flex-10, esta captura solo se envía después de que se hayan borrado de una condición de bucle todos los puertos Flex-10 de un puerto físico.
vcModPortProtectionConditionDetected Port index to the ifTable (ifIndex) (Índice de puerto a ifTable) (ifIndex)
Port index to the vcModulePortTable (Índice de puerto a vcModulePortTable)
Port protection status (Estado de protección de puerto)
Se ha detectado una condición de protección de puerto en este puerto. Si el nuevo estado de protección de puerto es un valor distinto a OK, el puerto puede estar desactivado para proteger el módulo VC frente a una mayor degradación del servicio. Se requiere la intervención del administrador para recuperar el puerto de esta condición.
vcModPortProtectionConditionCleared Port index to the ifTable (ifIndex) (Índice de puerto a ifTable) (ifIndex)
Port index to the vcModulePortTable (Índice de puerto a vcModulePortTable)
Port protection status (Estado de protección de puerto)
El puerto se ha recuperado de la condición de protección de puerto a estado operativo normal.
vcSwitchMemParityErrorEvent Error counter vcSwitchMemParityErrorCount
El hardware del conmutador ha detectado un error de paridad. El error de paridad se corrige automáticamente.
Capturas MIB de dominio de VCLa MIB vc-domain-mib.mib de Virtual Connect proporciona visibilidad de varios componentes de un dominio de Virtual Connect.
Capturas de cambio de estado gestionado del dominio de VCEsta sección describe los OID *ManagedStatus, *Cause, *RootCause y *ReasonCode encontrados en cada captura *ManagedStatusChanged de la MIB del dominio de VC.
Las enumeraciones ManagedStatus (vcDomainManagedStatus, vcEnclosureManagedStatus, etc.) de todos los objetos cambiados de estado gestionado (vcDomainManagedStatusChanged, cEnclosureManagedStatusChanged, etc.) se describen en la siguiente tabla.
Estado gestionado Descripción
unknown Indica que la condición del componente no se pudo determinar.
normal Indica que el componente es completamente funcional.
warning Indica que un umbral de componente se ha alcanzado o que una condición de error es inminente.
280 Capítulo 6 Errores de HPE Virtual Connect ESES

Estado gestionado Descripción
minor Indica que existe una condición de error con un impacto sobre el componente escaso o nulo.
major Indica que existe una condición de error que afecta considerablemente al componente.
critical Indica que existe una condición de error a causa de la cual el componente no seguirá proporcionando el servicio.
disabled Indica que el componente está desactivado y sin funcionamiento.
info Indica que existe una condición que no afecta a los servicios, como la inicialización de componentes y el inicio/cierre de sesión del sistema.
● La cadena Cause (Causa) indica por qué un objeto ha pasado al estado gestionado actual desde la perspectiva de objetos específica. Un fallo de red es un ejemplo de cadena Cause.
● La cadena RootCause (Causa principal) indica la causa raíz de que un objeto cambie de estado gestionado. La RootCause de un fallo de red podría indicar que todos los puertos de enlace ascendente de la red han fallado.
● La cadena ReasonCode (Código de motivo) proporciona un motivo específico de objeto para la transición de estado gestionado. Los códigos de motivo son únicos entre los objetos, ya que permiten realizar acciones más específicas mediante programación desde estaciones de gestión de SNMP.
vcDomainManagedStatusChanged
● A continuación, se muestra un ejemplo de una cadena Cause de dominio:
2 of 7 profiles contain unmapped connections in the domain● A continuación, se muestra un ejemplo de una cadena RootCause de dominio:
Modules not redundantly connected, failure of module enc0:iobay1 or enc0:iobay2 or enc1:iobay2 will isolate some modules; Port enc0:iobay5:d3:v1 loop detected and automatically disabled
Las cadenas ReasonCode de estado gestionado de dominio se proporcionan en la siguiente tabla.
Código de motivo de dominio Descripción
vcDomainOk Todos los chasis y perfiles son normales en el dominio.
vcDomainAbnormalEnclosuresAndProfiles Uno o varios chasis y perfiles no son normales en el dominio.
vcDomainSomeEnclosuresAbnormal Al menos un chasis no tiene el estado OK (Correcto) o Degraded (Degradado).
vcDomainUnmappedProfileConnections El perfil contiene conexiones que no están asignadas a un puerto de servidor.
vcDomainStackingFailed Se ha producido un fallo en todos los enlaces de apilamiento entre uno o varios módulos.
vcDomainStackingNotRedundant Se ha producido un fallo en algunos enlaces de apilamiento entre uno o varios módulos, pero sigue habiendo conectividad entre los módulos.
ESES Información general sobre SNMP 281

Código de motivo de dominio Descripción
vcDomainSomeProfilesAbnormal Uno o varios perfiles del dominio no son normales.
vcDomainUnknown La condición del dominio no se puede determinar.
vcDomainOverProvisioned Más de 16 módulos VC están en el dominio.
vcEnclosureManagedStatusChanged
● A continuación, se muestra un ejemplo de una cadena Cause de chasis:
2 of 6 Ethernet modules are abnormal in enclosure enc0● A continuación, se muestra un ejemplo de una cadena RootCause de chasis:
Module in bay enc0:iobay3 has been removedLas cadenas ReasonCode de estado gestionado de chasis se proporcionan en la siguiente tabla.
Código de motivo de chasis Descripción
vcEnclosureOk El chasis está normal.
vcEnclosureAllEnetModulesFailed Ningún módulo de Ethernet está normal, correcto o degradado.
vcEnclosureSomeEnetModulesAbnormal Uno o varios módulos de Ethernet no están normales.
vcEnclosureSomeModulesOrServersIncompatible El chasis contiene módulos incompatibles, o faltan módulos configurados.
vcEnclosureSomeFcModulesAbnormal Uno o varios módulos FC no están normales.
vcEnclosureSomeServersAbnormal Al menos un servidor tiene estado no conocido y ningún servidor está correcto, o al menos un servidor está degradado.
vcEnclosureUnknown La condición del chasis no se puede determinar, o se desconoce el estado de los servidores o módulos.
vcModuleManagedStatusChanged
● A continuación, se muestra un ejemplo de una cadena Cause de módulo:
Port enc0:iobay5:d3:v1 loop detected and automatically disabled● A continuación, se muestra un ejemplo de una cadena RootCause de módulo:
Port enc0:iobay5:d3:v1 loop detected and automatically disabledLas cadenas ReasonCode de estado gestionado de módulo se proporcionan en la siguiente tabla.
Código de motivo de módulo Descripción
vcEnetmoduleOk El módulo Ethernet funciona normalmente.
vcEnetmoduleEnclosureDown El módulo no puede comunicarse con el chasis/OA.
vcEnetmoduleModuleMissing Se ha extraído un módulo configurado.
282 Capítulo 6 Errores de HPE Virtual Connect ESES

Código de motivo de módulo Descripción
vcEnetmodulePortprotect Se ha detectado una condición en el puerto que ha causado que se active la protección del puerto.
vcEnetmoduleIncompatible El módulo no es compatible; por ejemplo, un módulo Enet configurado se ha sustituido por un módulo FC.
vcEnetmoduleHwDegraded El módulo se encuentra degradado por el OA.
vcEnetmoduleUnknown La condición del módulo se desconoce.
vcFcmoduleOk El módulo FC funciona normalmente.
vcFcmoduleEnclosureDown El módulo FC no puede comunicarse con el chasis/OA.
vcFcmoduleModuleMissing Se ha extraído un módulo configurado.
vcFcmoduleHwDegraded El módulo tiene una condición de hardware degradado.
vcFcmoduleIncompatible El módulo no es compatible; por ejemplo, un módulo FC configurado se ha sustituido por un módulo Enet.
vcFcmoduleUnknown La condición del módulo se desconoce.
vcPhysicalServerManagedStatusChanged
● A continuación, se muestra un ejemplo de una cadena Cause de servidor físico:
Server enc0:dev1 unable to communicate with enclosure enc0● A continuación, se muestra un ejemplo de una cadena RootCause de servidor físico:
Server enc0:dev2 profile pendingLas cadenas ReasonCode de estado gestionado de servidor físico se proporcionan en la siguiente tabla.
Código de motivo de servidor físico Descripción
vcPhysicalServerOk El servidor funciona normalmente.
vcPhysicalServerEnclosureDown El servidor no puede comunicarse con el chasis/OA.
vcPhysicalServerFailed El servidor tiene una condición de fallo.
vcPhysicalServerDegraded El servidor se encuentra en condición de degradado.
vcPhysicalServerUnknown La condición del servidor se desconoce.
vcFcFabricManagedStatusChanged
● A continuación, se muestra un ejemplo de una cadena Cause de estructura FC:
1 of 2 uplink ports are abnormal on BackupSAN fabric● A continuación, se muestra un ejemplo de una cadena RootCause de estructura FC:
1 of 2 uplink ports are abnormal on BackupSAN fabricLas cadenas ReasonCode de estado gestionado de estructura FC se proporcionan en la siguiente tabla.
ESES Información general sobre SNMP 283

Código de motivo de estructura FC Descripción
vcFabricOk La estructura funciona normalmente.
vcFabricNoPortsConfigured La estructura no tiene ningún puerto de enlace ascendente configurado.
vcFabricSomePortsAbnormal Algunos puertos de enlace ascendente no tienen una condición normal.
vcFabricAllPortsAbnormal Ningún puerto de enlace ascendente de la estructura tiene una condición normal.
vcFabricWwnMismatch Se ha detectado una condición de falta de correspondencia de WWN.
vcFabricUnknown La condición de la estructura se desconoce.
vcEnetNetworkManagedStatusChanged
● A continuación, se muestra un ejemplo de una cadena Cause de red Ethernet:
Network BLUE has failed● A continuación, se muestra un ejemplo de una cadena RootCause de red Ethernet:
Port enc0:iobay5:X3 is unlinked; Port enc0:iobay5:X4 is incompatibleLas cadenas ReasonCode de estado gestionado de red Ethernet se proporcionan en la siguiente tabla.
Código de motivo de red Ethernet Descripción
vcNetworkOk La red funciona normalmente.
vcNetworkUnknown La condición de la red se desconoce.
vcNetworkDisabled La red está desactivada.
vcNetworkAbnormal La condición de la red no es normal.
vcNetworkFailed La red tiene una condición de fallo.
vcNetworkDegraded La red se encuentra en condición degradada.
vcNetworkNoPortsAssignedToPrivateNetwork No se ha asignado ningún puerto a la red privada.
vcProfileManagedStatusChanged
● A continuación, se muestra un ejemplo de una cadena Cause de perfil:
3 TCServer profile connections for server in bay enc0:devbay3 are not mapped
● A continuación, se muestra un ejemplo de una cadena RootCause de perfil:
The TelecomServer profile is assigned to an abnormal server in bay enc0:devbay1
Las cadenas ReasonCode de estado gestionado de perfil se proporcionan en la siguiente tabla.
284 Capítulo 6 Errores de HPE Virtual Connect ESES

Código de motivo de perfil Descripción
vcProfileOk El perfil está normal.
vcProfileServerAbnormal El servidor al que está asignado el perfil no está normal.
vcProfileAllConnectionsFailed Se ha producido un fallo en todas las conexiones del perfil.
vcProfileSomeConnectionsUnmapped Una o varias conexiones del perfil no están asignadas a un puerto físico.
vcProfileAllConnectionsAbnormal Ninguna conexión del perfil está normal.
vcProfileSomeConnectionsAbnormal Algunas conexiones del perfil no están normales.
Capturas de punto de comprobación del dominio de VCLa captura del punto de comprobación del dominio indica que se han guardado cambios de configuración en la memoria no volátil y que se han copiado (como punto de comprobación) en el módulo adyacente horizontalmente.
vcCheckpointTimeout
El estado válido del punto de comprobación ha permanecido falso durante más de cinco minutos.
vcCheckpointCompleted
Se ha completado una operación de punto de comprobación tras una captura de tiempo de espera de punto de comprobación. El estado válido del punto de comprobación es verdadero de nuevo. Esta captura no se envía cada vez que se completa un punto de comprobación, sino solo cuando se completa un punto de comprobación después de que se envíe una captura vcCheckpointTimeout.
vcDomainStackingLinkRedundancyStatusChangeEl estado de redundancia de la conexión de enlace de apilamiento ha cambiado. El OID vcDomainStackingLinkRedundant que se encuentra en esta captura indica si todos los módulos VC-Enet permanecerán conectados entre sí con la pérdida de un enlace.
vcTestTrapLa captura de prueba de dominio de VC se recibe cuando el administrador envía una captura de prueba mediante la GUI o la CLI de VC. La captura de prueba se envía a todos los destinos de captura configurados.
Eventos de SysLog de Virtual Connect ManagerLos eventos generados en el registro del sistema (SysLog) se agrupan en las siguientes áreas gestionadas por Virtual Connect Manager:
● Dominio (1000–1999)
● Chasis (2000–2999)
● Módulos de interconexión Ethernet (3000–3999)
● Módulos de interconexión FC (4000–4999)
● Servidores (5000–5999)
● Perfiles (6000-6999)
ESES Eventos de SysLog de Virtual Connect Manager 285

● Red Ethernet (7000–7999)
● Estructura FC (8000–8999)
● Módulo desconocido (9000-9999)
Los eventos se caracterizan por el nivel de gravedad, que refleja el estado funcional del componente. El nivel de gravedad le dará una idea sobre el tipo de atención que se debe prestar para realizar una acción si se produce del evento. A continuación se muestra una lista de las categorías:
● SEVERITY_INFO
Un evento de tipo info es una condición de bajo nivel para equipos que están fuera de servicio, inicios y fines de sesión en el sistema, y otra información que no afecta al servicio. El color estándar con que se muestran los eventos de este tipo es el negro.
● SEVERITY_WARNING
Una alerta de tipo warning indica que se ha alcanzado un umbral o es inminente una condición de error. El color estándar con que se muestran los eventos de este tipo es el azul.
● SEVERITY_MINOR
Una alerta de tipo minor es una condición de error que no tiene ningún impacto en el servicio. El color estándar con que se muestran los eventos de este tipo es el amarillo.
● SEVERITY_MAJOR
Una alerta de este tipo afecta gravemente al servicio y requiere una acción inmediata. Esta alerta indica una interrupción del servicio o una reducción considerable de la capacidad. El color estándar con que se muestran los eventos de este tipo es el rojo.
● SEVERITY_CRITICAL
Una alerta de este tipo afecta gravemente al servicio y requiere una acción inmediata. Esta alerta indica una interrupción del servicio o una reducción considerable de la capacidad. El color estándar con que se muestran los eventos de este tipo es el rojo.
Eventos de los dominios (1000-1999)1003 - VCM-OA communication down
Nivel de gravedad: CRITICAL
Descripción: La comunicación entre la aplicación de gestión de VC y el Onboard Administrator activo se ha interrumpido.
Causas posibles:
● Se ha producido un error durante la ejecución de una llamada SOAP desde la aplicación de gestión de VC al Onboard Administrator. Las causas conocidas específicas son:
◦ Reinicio de OA (incluida la actualización del firmware)
◦ Desconexión de red
◦ OA ya no está en el modo VC
◦ OA sustituido
◦ Red de gestión sobrecargada con tráfico de datos
◦ Errores de OA
286 Capítulo 6 Errores de HPE Virtual Connect ESES

◦ Fallos de hardware
◦ Servidor DHCP de depuración
● La aplicación de gestión de VC ha detectado que la versión de firmware de OA es anterior a la mínima aceptable.
Acción: Haga lo siguiente si el fallo de comunicaciones es persistente:
● Actualice el firmware de OA si es necesario.
● Proporcione las credenciales de OA apropiadas (IP/usuario/contraseña) si lo pide VC.
● Compruebe que OA y VC tienen asignadas direcciones IP y que estas no están en conflicto con otras direcciones IP asignadas en la red.
● Compruebe que la red de gestión no está siendo utilizada para un tráfico de datos sustancial.
● Compruebe que la topología de la red de gestión es correcta.
● Compruebe la conectividad de extremo a extremo.
● Asegúrese de que la versión de OA es apropiada.
● Exporte un paquete de soporte desde VC para que Hewlett Packard Enterprise pueda analizarlo.
● Capture la salida del comando show all de OA para que Hewlett Packard Enterprise pueda analizarla.
1022 - Domain state FAILEDNivel de gravedad: CRITICAL
Descripción: El dominio de VC ha sufrido una avería que no permite a VC comunicarse con ningún chasis o dispositivo. Si bien esta avería no afecta al tráfico actual de la red, no es posible realizar la configuración ni la supervisión del dominio.
Causa: No hay ningún chasis en el estado OK o DEGRADED debido a fallos físicos en el chasis o a la falta de comunicación de VC entre OA y los chasis.
Acción: No intente realizar ningún cambio de configuración en el dominio de Virtual Connect. Si el error continúa o se repite frecuentemente, se debe investigar la causa. Acciones correctivas recomendadas:
● Proporcione las credenciales de OA apropiadas (IP/usuario/contraseña) si lo pide VC.
● Compruebe que OA y VC tienen asignadas direcciones IP y que estas no están en conflicto con otras direcciones IP asignadas en la red.
● Compruebe que la red de gestión de OA no está siendo utilizada para un tráfico de datos sustancial.
● Compruebe que la topología de la red de gestión es correcta.
● Compruebe la conectividad de extremo a extremo (por ejemplo, mediante el comando ping).
● Asegúrese de que el OA tiene la versión de firmware apropiada y actualícela si fuera necesario.
● Si fallan todas las soluciones alternativas:
ESES Eventos de SysLog de Virtual Connect Manager 287

a. Exporte un paquete de soporte desde VC para que Hewlett Packard Enterprise pueda analizarlo.
b. Capture la salida del comando show all de OA para que Hewlett Packard Enterprise pueda analizarla.
c. Póngase en contacto con el servicio de soporte al cliente de Hewlett Packard Enterprise y tenga a mano la información recopilada anteriormente.
1023 - Domain state PROFILE_FAILEDNivel de gravedad: MAJOR
Descripción: Este evento se produce cuando hay al menos un perfil cuyo estado no es OK.
Causa posible: Un perfil ha cambiado de un estado OK a un estado distinto de OK.
Acción: Compruebe el estado de todos los perfiles y busque aquellos cuyo estado no sea OK. Solucione el problema que motiva el estado de cada uno de esos perfiles.
1026 - Domain state NO_COMMNivel de gravedad: CRITICAL
Descripción: Esta condición indica que los enlaces de apilamiento de los módulos Ethernet no están totalmente conectados, lo que provoca que los módulos afectados estén aislados.
Causa posible: Los enlaces de apilamiento no están totalmente conectados. Esta condición hace que algunos módulos Ethernet estén aislados, lo que provoca problemas críticos con la configuración de red y la movilidad de los perfiles de servidor o el acceso a los servidores.
Acción: Conecte los cables de los enlaces de apilamiento correctamente.
Eventos de los chasis (2000-2999)2003 - Enclosure import failed
Nivel de gravedad: CRITICAL
Descripción: Ha fallado la importación o la recuperación de un chasis. Las importaciones se producen cuando un usuario solicita añadir un chasis al dominio. Las recuperaciones pueden producirse por los siguientes motivos:
● Reajuste de VCM
● Conmutación por error de VCM
● Restauración de la configuración
● Actualización del firmware
● Solicitud de reautenticación de usuario
● Reconexión de un chasis que estaba previamente en un estado NO-COMM
Causas posibles:
● El nombre de usuario, la contraseña o la dirección IP del OA principal no son válidos. Esto incluiría el hecho de no tener los permisos suficientes. Se necesita tener privilegios de administrador con acceso total de tipo IOBAY y Device Bay.
● La versión de firmware del OA principal del chasis no es >= 3.11.
288 Capítulo 6 Errores de HPE Virtual Connect ESES

Acción: No intente realizar ningún cambio de configuración en el dominio de Virtual Connect. Acciones correctivas recomendadas:
● Proporcione credenciales de OA válidas (IP/usuario/contraseña) si lo pide VC.
● Asegúrese de que el usuario tiene privilegios de acceso para los compartimentos de interconexión.
● Compruebe que OA y VC tienen asignadas direcciones IP y que estas no están en conflicto con otras direcciones IP asignadas en la red.
● Compruebe que la red de gestión de OA no está siendo utilizada para un tráfico de datos sustancial.
● Compruebe que la topología de la red de gestión es correcta.
● Compruebe la conectividad de extremo a extremo (por ejemplo, mediante el comando ping).
● Asegúrese de que el OA tiene la versión de firmware apropiada y actualícela si fuera necesario.
● Si fallan todas las soluciones alternativas:
a. Exporte un paquete de soporte desde VC para que Hewlett Packard Enterprise pueda analizarlo.
b. Capture la salida del comando show all de OA para que Hewlett Packard Enterprise pueda analizarla.
c. Póngase en contacto con el servicio de soporte al cliente de Hewlett Packard Enterprise y tenga a mano la información recopilada anteriormente.
2011 - Enclosure state NO_COMMNivel de gravedad: CRITICAL
Descripción: La aplicación de gestión de VC es incapaz de comunicarse con un chasis.
Causa posible: La aplicación de gestión de VC ha determinado que el número de serie del chasis no coincide con la configuración almacenada. Este evento puede producirse cuando un OA se ha trasladado de un chasis a otro, o cuando se ha sustituido la matriz de conectores del chasis.
Acción:
● Si el OA se ha trasladado a otro chasis, proporcione a VC las credenciales de OA (IP/usuario/contraseña) del OA del chasis que VC debe importar.
● Si se ha sustituido la matriz de conectores del chasis, siga el procedimiento de sustitución de la matriz de conectores.
2013 - Enclosure state failedNivel de gravedad: CRITICAL
Descripción: El chasis no está operativo debido a fallos en el hardware de todos los módulos Ethernet o de todos los servidores. VC no puede configurar ni supervisar este chasis.
Causas posibles:
ESES Eventos de SysLog de Virtual Connect Manager 289

● Ningún módulo Ethernet tiene el estado OK ni DEGRADED. Todos los módulos Ethernet están sufriendo de algún tipo de fallo de hardware que les impide aceptar la configuración y transferir el tráfico de red.
● Ningún servidor tiene el estado OK ni DEGRADED. Todos los servidores están sufriendo de algún tipo de fallo de hardware que les impide aceptar la configuración y transferir el tráfico de red.
Acción: No intente realizar ningún cambio de configuración en el dominio de Virtual Connect. Acciones correctivas recomendadas:
● Compruebe todos los módulos Ethernet que no tienen el estado OK ni Degraded. Sustitúyalos si es necesario.
● Compruebe todos los servidores que no tienen el estado OK ni Degraded. Sustitúyalos si es necesario.
● Si el problema no se corrige sustituyendo el hardware:
a. Exporte un paquete de soporte desde VC para que Hewlett Packard Enterprise pueda analizarlo.
b. Capture la salida del comando show all de OA para que Hewlett Packard Enterprise pueda analizarla.
c. Póngase en contacto con el servicio de soporte al cliente de Hewlett Packard Enterprise y tenga a mano la información recopilada anteriormente.
2016 - Enclosure Find failedNivel de gravedad: MAJOR
Descripción: Ha fallado una operación de adición, importación o recuperación de un chasis al intentar realizar una conexión o reconexión con el chasis. Las operaciones de búsqueda se producen cuando el usuario realiza una solicitud para añadir un chasis al dominio. Las reconexiones pueden deberse a las siguientes situaciones:
● Reajuste de VCM
● Conmutación por error de VCM
● Restauración de la configuración
● Actualización del firmware
● Solicitud de reautenticación de usuario
● Reconexión de un chasis que estaba previamente en un estado NO-COMM
Causas posibles:
● El nombre de usuario, la contraseña o la dirección IP del OA principal no son válidos.
● La versión de firmware del OA principal del chasis no es >= 3.11.
● Durante la operación de conexión o reconexión, falla una llamada al OA. Esto podría ser debido a que falla una parte del hardware del OA/chasis o a que el OA no se ha recuperado lo suficiente después de un fallo anterior.
● Las comunicaciones con el OA no están disponibles debido a problemas de red.
Acción: No intente realizar ningún cambio de configuración en el dominio de Virtual Connect. Acciones correctivas recomendadas:
290 Capítulo 6 Errores de HPE Virtual Connect ESES

● Proporcione credenciales de OA válidas (IP/usuario/contraseña) si lo pide VC.
● Asegúrese de que el usuario tiene privilegios de acceso para los compartimentos de interconexión.
● Compruebe que OA y VC tienen asignadas direcciones IP y que estas no están en conflicto con otras direcciones IP asignadas en la red.
● Compruebe que la red de gestión de OA no está siendo utilizada para un tráfico de datos sustancial.
● Compruebe que la topología de la red de gestión es correcta.
● Compruebe la conectividad de extremo a extremo (por ejemplo, mediante el comando ping).
● Asegúrese de que el OA tiene la versión de firmware apropiada y actualícela si fuera necesario.
● Si fallan todas las soluciones alternativas:
a. Exporte un paquete de soporte desde VC para que Hewlett Packard Enterprise pueda analizarlo.
b. Capture la salida del comando show all de OA para que Hewlett Packard Enterprise pueda analizarla.
c. Póngase en contacto con el servicio de soporte al cliente de Hewlett Packard Enterprise y tenga a mano la información recopilada anteriormente.
Eventos de los módulos Ethernet (3000-3999)3009 - Enet Module OA CPU Fault Event
Nivel de gravedad: MAJOR
Descripción: El Onboard Administrator ha informado a la aplicación de gestión de VC de que el módulo indicado ha detectado un fallo de hardware.
Causas posibles:
● Se ha detectado un fallo en el hardware de un componente.
● Fallo transitorio de hardware o de firmware.
Acción: Apague y encienda el módulo para borrar los fallos transitorios. Si la situación continúa o se repite con frecuencia, sustituya el módulo.
3012 - Enet Module State FAILEDNivel de gravedad: CRITICAL
Descripción: El módulo no está operativo debido a un fallo en el hardware o en el sistema operativo. VC no puede configurar ni supervisar este módulo. Este error afectará al tráfico de red.
Causa: El OA informa de que el módulo tiene el estado Failed. Esto es debido a un fallo en el hardware o en el sistema operativo. El fallo del sistema operativo puede deberse a un error grave del núcleo, a que se ha agotado la memoria, a una sobrecarga de la CPU o a un fallo en el arranque del sistema operativo.
Acción: No intente realizar ningún cambio de configuración en el dominio de Virtual Connect. Acciones correctivas recomendadas:
● Extraiga físicamente y vuelva a instalar el módulo Ethernet que falla.
ESES Eventos de SysLog de Virtual Connect Manager 291

Si el módulo sigue en el estado Failed, sustitúyalo.
● Si el problema no se corrige sustituyendo el hardware:
a. Exporte un paquete de soporte desde VC para que Hewlett Packard Enterprise pueda analizarlo.
b. Capture la salida del comando show all de OA para que Hewlett Packard Enterprise pueda analizarla.
c. Póngase en contacto con el servicio de soporte al cliente de Hewlett Packard Enterprise y tenga a mano la información recopilada anteriormente.
3014 - Enet Module state INCOMPATIBLENivel de gravedad: MAJOR
Descripción: Un módulo que existe en un chasis no es compatible con la configuración del dominio de VC.
Causa posible 1: Un módulo instalado recientemente no es compatible con un módulo adyacente.
Acción: Instale un módulo que sea compatible con el módulo adyacente.
Tenga en cuenta las directrices siguientes cuando instale módulos de interconexión en compartimentos adyacentes horizontalmente:
● Solo es posible situar módulos VC similares en compartimentos adyacentes horizontalmente.
● Si se instala un módulo VC-Enet en un compartimento de interconexión, el único módulo que puede instalarse en el compartimento adyacente horizontalmente es otro módulo VC-Enet del mismo tipo.
● Los módulos Virtual Connect Flex-10 Ethernet de 10 Gb pueden instalarse en cualquier compartimento. Sin embargo, únicamente se puede instalar otro módulo Flex-10 Ethernet de 10 Gb en un compartimento adyacente.
● Los módulos VC-Enet de 1/10 Gb y los módulos Ethernet de 1/10 Gb-F pueden instalarse en cualquier compartimento. Sin embargo, únicamente puede instalarse otro módulo VC-Enet de 1/10 Gb o un módulo Ethernet de 1/10 Gb-F en un compartimento adyacente.
● Los módulos VC FC de 8 Gb y 20 puertos pueden instalarse en cualquier compartimento. Sin embargo, únicamente se puede instalar otro módulo VC FC de 8 Gb y 20 puertos en un compartimento adyacente.
● Los módulos Virtual Connect Fibre Channel de 8 Gb y 24 puertos pueden instalarse en cualquier compartimento. Sin embargo, únicamente se puede instalar otro módulo Fibre Channel de 8 Gb y 24 puertos en un compartimento adyacente.
● No mezcle módulos Virtual Connect FC de 8 Gb y 24 puertos con módulos Virtual Connect FC de 4 u 8 Gb y 20 puertos en los compartimentos de interconexión adyacentes horizontalmente conectados con la misma tarjeta intermedia de blade de servidor.
● Para los chasis c3000, los módulos VC-FC no se admiten en el compartimento de interconexión 2.
Causa posible 2: Un módulo instalado recientemente no es del mismo tipo que el módulo configurado previamente que estaba en el compartimiento de interconexión.
Acción:
292 Capítulo 6 Errores de HPE Virtual Connect ESES

● Instale un módulo del mismo tipo que el que se había configurado previamente.
● Antes de extraer el módulo anterior, modifique el dominio para que el módulo que se ha quitado deje de usarse en la configuración del dominio (perfiles, redes y estructuras). Cuando se extraiga el módulo, no debería existir en la configuración del dominio y podrá sustituirse por uno de otro tipo.
Causa posible 3: La versión del firmware de un módulo no es compatible con la versión actual del dominio de VC.
Acción: Actualice el firmware del módulo a una versión que sea compatible con el dominio. (Una versión compatible con el firmware que se ejecuta en el módulo principal).
3019 - Enet Module state MISSINGNivel de gravedad: CRITICAL
Descripción: Un módulo que está configurado en el dominio se ha extraído físicamente del chasis.
Causa posible: Un módulo estaba configurado como “en uso” por el dominio, por una red, por un conjunto de enlaces ascendentes o por un perfil y se ha extraído físicamente de un chasis. Los módulos que están configurados y están siendo utilizados por el dominio no pueden eliminarse del dominio (debido a las dependencias en el dominio) y deben sustituirse por módulos del mismo tipo.
Acción: Cuando extraiga módulos, asegúrese de sustituirlos por otros del mismo tipo. Si no piensa sustituir el módulo, debe modificar el dominio antes de extraerlo físicamente y eliminar las dependencias del módulo para poder retirarlo del dominio sin problemas. Si piensa sustituir el módulo por uno de otro tipo, antes de instalar el nuevo módulo debe eliminar las dependencias del módulo antiguo para poder retirarlo del dominio sin problemas.
3023 - Enet Module state NO_COMMNivel de gravedad: MAJOR
Descripción: La aplicación de gestión de VC ha detectado un problema en las comunicaciones con el módulo VC-Enet.
Causas posibles:
● La configuración de las direcciones IP o la topología de la red impide la comunicación entre el módulo VC-Enet principal y el módulo VC-Enet identificado.
● Se ha producido un error inesperado durante el envío de una actualización de configuración al módulo o al solicitar información sobre su estado al módulo. Este error puede deberse a una interrupción o a que se ha agotado el tiempo de espera de las comunicaciones TCP/IP, o bien a un fallo provocado por el software.
● El módulo VC-Enet principal es incapaz de intercambiar paquetes de red con el módulo indicado. Esto puede deberse a que el Onboard Administrator ha configurado de forma incorrecta el conmutador interno que conecta los módulos de E/S.
Acción:
● Compruebe que la configuración de red (dirección IP, topología, etc.) es correcta. Si el módulo se encuentra en un chasis remoto (no está en el mismo chasis que el módulo VC-Enet principal), restablezca o reinicie el Onboard Administrator activo del chasis remoto.
● Compruebe en el OA que el Direccionamiento IP de los compartimentos de los chasis (EBIPA) no está activado o que está proporcionando la información correcta a cada módulo.
ESES Eventos de SysLog de Virtual Connect Manager 293

3031 - Enet Module IP is 0.0.0.0Nivel de gravedad: MAJOR
Descripción: El OA informa de que un módulo Ethernet no tiene una dirección IP. El módulo se marcará como NO-COMM.
Causas posibles:
● El servidor DHCP externo no proporcionó al módulo una dirección IP.
● Existe un problema de red con el servidor DHCP.
● Existe un problema de hardware o software con un módulo de E/S o un Onboard Administrator.
Acción:
● Compruebe que el OA está configurado para proporcionar una dirección IP específica.
● Compruebe que existe un servidor DHCP externo en la red de gestión.
3101 - Port is disabled as network loop is detectedNivel de gravedad: MAJOR
Descripción: Se ha detectado un bucle de red en un puerto Ethernet; por ello, se ha desactivado para evitar la degradación del servicio.
Causa posible 1: Se ha asignado a la misma red más de un puerto de enlace ascendente activo o grupo de agregación de enlaces (LAG) ascendentes desde un conjunto de enlaces ascendentes desde el dominio de Virtual Connect al entorno de conmutación Ethernet externo, lo que provoca un bucle de red.
Causa posible 2: La configuración incorrecta de los enlaces apilados en la configuración de varios módulos VC-Enet está provocando un bucle de red.
Acción: Se requieren medidas administrativas para volver a configurar el puerto donde se está produciendo el bucle de red.
3102 - Port was disabled because a pause flood was detectedNivel de gravedad: MAJOR
Descripción: Se ha detectado un desbordamiento de pausa en un puerto Ethernet; por ello, se ha desactivado para evitar la degradación del servicio.
Causa posible: El servidor tiene una NIC defectuosa. Si se detectan demasiadas tramas de pausa en un puerto, el puerto se desactiva con este estado.
Acciones:
● Actualice el firmware de la NIC.
● Active los puertos desactivados en la CLI de Virtual Connect mediante el comando reset port-protect o a través de la GUI de Virtual Connect.
● Sustituya la NIC.
Eventos de los módulos FC (4000-4999)4009 - FC Module OA CPU Fault Event
Nivel de gravedad: MAJOR
294 Capítulo 6 Errores de HPE Virtual Connect ESES

Descripción: El Onboard Administrator ha informado a la aplicación de gestión de VC de que el módulo indicado ha detectado un fallo de hardware.
Causas posibles:
● Se ha detectado un fallo en el hardware de un componente.
● Se ha producido un fallo transitorio de hardware o de firmware.
Acción: Apague y encienda el módulo para borrar los fallos transitorios. Si la situación continúa o se repite con frecuencia, sustituya el módulo.
4012 - FC Module State FailedNivel de gravedad: CRITICAL
Descripción: El módulo no está operativo debido a un fallo en el hardware o en el firmware. VC no puede configurar ni supervisar este módulo. Este error afectará al tráfico Fibre Channel.
Causa posible: El OA informa de que el módulo tiene el estado Failed. Esto es debido a un fallo en el hardware o en el firmware. El fallo del firmware puede deberse a un error grave del núcleo, a que se ha agotado la memoria, a una sobrecarga de la CPU o a un fallo en el arranque.
Acción: Apague y encienda el módulo para borrar los fallos de hardware transitorios. Si la situación continúa, será necesario generar un volcado de soporte y analizarlo para determinar posibles fallos de firmware.
4014 - FC Module State IncompatibleNivel de gravedad: MAJOR
Descripción: El módulo Fibre Channel de este compartimento de interconexión es incompatible con el dominio de VCM.
Causas posibles:
● El módulo está ejecutando un firmware que no está actualizado. Podría estar ejecutando una versión anterior o posterior a la que espera Virtual Connect Manager.
● El módulo no es compatible con un módulo que se ejecuta en un compartimiento adyacente en modo de doble densidad o de densidad normal.
● El módulo no es compatible con otro módulo del mismo grupo de compartimentos para el modo de varios chasis o el modo de doble densidad.
Acción: Sustituya el módulo por uno de un tipo compatible con el grupo compartimientos del dominio de VC. En el caso de una revisión de firmware incorrecta, actualice el módulo a la revisión de firmware correcta.
4019 - FC Module State is NO_COMMNivel de gravedad: MAJOR
Descripción: Virtual Connect Manager no se puede comunicar con el módulo FC.
Causas posibles:
● El módulo VC-FC se está reiniciando después de un error grave de firmware y no responde a los comandos de VCM.
● El módulo VC-FC no responde a los comandos ISMIC debido a un defecto de firmware.
ESES Eventos de SysLog de Virtual Connect Manager 295

● El módulo VC-FC no es capaz de iniciar el cliente DHCP debido a un defecto de firmware, por lo que no responde a los comandos procedentes de VCM para proporcionar la configuración del conmutador, incluyendo el número de revisión de firmware.
● El módulo VC-FC no obtiene nunca una dirección IP mediante DHCP y, por lo tanto, no responde a los comandos de VCM.
● El módulo VC-FC nunca envía un evento COMM_OK de OA después de reiniciar el firmware debido a que el firmware tiene un defecto o a un problema de hardware.
Acción: Asegúrese de que el servidor DHCP está funcionando y asigna correctamente las direcciones. En el caso de un error transitorio, apague y encienda el módulo para ver si se restablece la comunicación. Es necesario analizar un volcado de soporte del módulo VC-FC para determinar la causa básica del problema. Es posible que tenga que sustituir el módulo.
Eventos de los servidores (5000-5999)5009 - Server OA fault event
Nivel de gravedad: MAJOR
Descripción: Virtual Connect Manager ha recibido un evento de fallo en el blade desde el OA.
Causa posible: El hardware del servidor ha fallado.
Acciones:
● Compruebe el funcionamiento de las comunicaciones entre VC y el Onboard Administrator del servidor afectado.
● Compruebe que el servidor se encuentra en buen estado.
5012 - Server state FAILEDNivel de gravedad: CRITICAL
Descripción: El estado del servidor es FAILED.
Causa posible: Se ha producido un error cuando VC estaba intentando aplicar un perfil a un servidor.
Acción: Compruebe el funcionamiento de las comunicaciones entre VC y el Onboard Administrator del servidor afectado. Compruebe que el estado del servidor es correcto (ni "Failed" ni "Faulted").
5014 - Server state INCOMPATIBLENivel de gravedad: MAJOR
Descripción: La aplicación de gestión de VC ha determinado que la versión del BIOS del servidor no es compatible con las capacidades mínimas necesarias para Virtual Connect.
Causa posible: El servidor tiene una versión antigua del BIOS.
Acción: Actualice el BIOS del servidor a la última versión.
5019 - Server state is NO_COMMNivel de gravedad: MAJOR
Descripción: Virtual Connect Manager no se puede comunicar con el servidor.
Causa posible: El servidor no está respondiendo a los comandos de Virtual Connect Manager debido a un problema de iLO/BIOS o del hardware.
296 Capítulo 6 Errores de HPE Virtual Connect ESES

Acciones:
● Asegúrese de que no hay ningún problema de alimentación en el chasis.
● Compruebe que se han instalado las versiones apropiadas del BIOS y de ILO.
● Compruebe las comunicaciones entre el OA y VC.
● Extraiga e instale el blade de servidor.
● Sustituya el servidor.
5022 - Missing information for one or more blades of a multi-blade serverNivel de gravedad: MAJOR
Descripción: Falta información sobre uno o varios blades de un servidor de varios blades.
Causa posible: La inicialización del servidor de varios blades no finalizó correctamente.
Acciones:
● Apague y encienda el servidor para comprobar si la inicialización del servidor se realiza correctamente.
● Extraiga e instale el blade de servidor.
● Sustituya el servidor de varios blades.
5050 - The BIOS for the following devices is not compatible with Virtual ConnectNivel de gravedad: MAJOR
Descripción: El BIOS de los adaptadores de servidor no es compatible con Virtual Connect.
Causa posible: El BIOS de los adaptadores de servidor tiene una versión de firmware no compatible.
Acción: Actualice el BIOS de los adaptadores de servidor.
5055 - The server BIOS needs to be updated to at least the version datedNivel de gravedad: MAJOR
Descripción: La aplicación de gestión de VC ha determinado que la versión del BIOS del servidor no es compatible con las capacidades mínimas necesarias para Virtual Connect.
Causa posible: El servidor tiene una versión antigua del BIOS.
Acción: Actualice el BIOS del servidor a la última versión.
5056 - Unable to release power hold on the server. Unassign and re-assign profileNivel de gravedad: CRITICAL
Descripción: Virtual Connect Manager ha determinado que no fue posible liberar la retención de la alimentación del servidor.
Causa posible: Se produjo un error cuando Virtual Connect Manager estaba intentando aplicar un perfil al servidor.
Acción: Cancele la asignación y vuelva a asignar el perfil al servidor.
ESES Eventos de SysLog de Virtual Connect Manager 297

Eventos de los perfiles (6000-6999)6012 - Profile state FAILED
Nivel de gravedad: CRITICAL
Descripción: Ha fallado la asignación del perfil.
Causa posible: Se han producido daños en la EV del servidor.
Acción: Reinicie físicamente el servidor o ejecute el comando reset server <número de servidor> en la CLI de OA. A continuación, vuelva a aplicar el perfil. Si el problema continúa, borre la configuración del BIOS del servidor y, a continuación, vuelva a aplicar el perfil.
6020 - Profile has the same network on two Flex-10 NICs on the same physical portNivel de gravedad: CRITICAL
Descripción: Esto ocurre siempre que se aplica un perfil a un servidor con tarjetas de red Flex-10 y la misma red Ethernet se encuentra en más de una conexión Ethernet que está asignada a una función física Flex-10 en el mismo puerto físico. Se desactivarán todas las funciones físicas posteriores a la primera que tengan la red duplicada, y no pasará ningún tráfico por la conexión.
Causa posible: Se ha aplicado un perfil a un servidor y esa asignación da como resultado redes Ethernet duplicadas en el mismo puerto físico Flex-10.
Acción: Elimine la red duplicada de una o varias de las conexiones Ethernet. El editor de perfiles de la GUI indica cuáles son las conexiones que están duplicadas.
6021 - Profile has PXE enabled on a non-primary Flex-10 NICNivel de gravedad: MAJOR
Descripción: Se ha activado PXE en una conexión Ethernet de un perfil asignado a una función física no principal de una NIC Flex-10. La implementación actual de Flex-10 únicamente permite el arranque PXE en la primera función física de un puerto NIC Flex-10.
Causa posible: Se ha activado PXE en una conexión Ethernet que está asignada a la segunda, tercera o cuarta función física de una NIC Flex-10.
Acción: Utilice la interfaz gráfica de usuario para editar el perfil y desactivar PXE en las conexiones que indican que no son compatibles con PXE.
6022 - Profile has iSCSI boot enabled on an unsupported Flex-10 NICNivel de gravedad: MAJOR
Descripción: Existe un perfil de arranque desde iSCSI activado en una NIC Flex-10 no compatible.
Causa posible: Un administrador ha configurado incorrectamente los parámetros de arranque del perfil.
Acciones:
● Corrija los parámetros especificados del perfil para activar el arranque desde iSCSI en una NIC compatible.
● Quite la configuración de iSCSI del perfil.
● Introduzca una tarjeta NIC compatible para configurar el arranque desde iSCSI.
298 Capítulo 6 Errores de HPE Virtual Connect ESES

6023 - Profile is assigned to a multi-blade server that has data missingNivel de gravedad: MAJOR
Descripción: VCM no dispone de información acerca de todos los compartimentos de un servidor de varios blades. La GUI debe mostrar el estado apropiado.
Causa posible: Todos los blades del servidor no pudieron completar la inicialización correctamente; por lo tanto, algunos blades del servidor de varios blades todavía no se han detectado.
Acciones:
● Compruebe el estado de los compartimientos y busque un indicio del problema.
● Extraiga e instale el servidor en los compartimentos que presentan un error.
● Vuelva a arrancar el servidor y compruebe si se detecta.
● Extraiga físicamente el servidor y sustitúyalo.
● Analice los registros de Onboard Administrator por si puede obtener más detalles con respecto al fallo.
6030 - Profile could not be assigned to powered up serverNivel de gravedad: MAJOR
Descripción: Se ha cambiado o asignado un perfil, y alguna configuración requiere que el servidor se apague para hacer el cambio. Por ejemplo, si se cambia el número de conexiones Ethernet de un perfil que está asignado a un servidor con tarjetas Flex-10, es necesario apagar el servidor.
Causas posibles:
● Una acción del usuario da como resultado un perfil que requiere que se apague el servidor para realizar el cambio, para asignar el perfil inicialmente o para eliminarlo.
● VCM detecta y reinicia un servidor encendido cuyo compartimento tiene asignado un perfil que necesita hacer un cambio en el servidor para el que es preciso apagarlo.
Acción: Apague el servidor y vuelva a intentar hacer el cambio.
Eventos de la red Ethernet (7000-7999)7012 - Enet Network state FAILED
Nivel de gravedad: CRITICAL
Descripción: La red Ethernet de VC ha perdido todas las conexiones de los enlaces ascendentes debido a la falta de puertos configurados o a que todos los puertos configurados están en un estado incorrecto, o a que se ha instalado un transceptor defectuoso o incompatible.
Causas posibles:
● Todos los puertos de enlace ascendente asociados a la red están sin enlazar.
● El usuario ha desactivado todos los puertos de enlace ascendente asociados a una red no compartida.
● El usuario ha desactivado todos los puertos de enlace ascendente de un conjunto de enlaces ascendentes compartidos asociado a una red compartida.
Acción:
ESES Eventos de SysLog de Virtual Connect Manager 299

● Conecte los puertos de enlace ascendente.
● Active los puertos de enlace ascendente asociados a una red no compartida.
● Active los puertos de enlace ascendente de un conjunto de enlaces ascendentes compartidos asociado a una red compartida.
7014 - Enet Network state DISABLEDNivel de gravedad: MAJOR
Descripción: Se ha desactivado una red administrativamente.
Causa posible: Un usuario ha desactivado una red a través de la interfaz de usuario.
Acción: Active la red a través de la interfaz de usuario.
Eventos de la estructura FC (8000-8999)8012 - FC Fabric state FAILED
Nivel de gravedad: CRITICAL
Descripción: La estructura de VC ha perdido todas las conexiones de los enlaces ascendentes debido a la falta de puertos configurados o a que todos los puertos configurados están en un estado incorrecto.
Causas posibles:
● La estructura de VC no tiene puertos configurados. El usuario ha eliminado todos los puertos de enlace ascendente de la estructura.
● Todos los puertos de las estructuras de VC tienen uno de los siguientes estados:
◦ FAILED (error de hardware), UNAVAILABLE (no se ha iniciado sesión), DISABLED (puerto desactivado), UNKNOWN (módulo FC en NO-COMM).
◦ No hay ningún enlace ascendente con el estado DEGRADED u OK.
Acción: Configure los puertos de enlace ascendente.
Eventos de módulos desconocidos (9000-9999)9012 - Unknown Module state FAILED
Nivel de gravedad: CRITICAL
Descripción: Se ha marcado un módulo desconocido con un estado FAILED. Este estado lo suele indicar el OA después de una operación de inserción de conexión en caliente del módulo o cuando VCM se está iniciando. Esta condición generalmente es muy grave.
Causa posible: Un fallo de hardware o firmware dañado.
Acción:
● Instale un módulo del mismo tipo en el compartimento que está marcado como MISSING.
● Introduzca modificaciones en el dominio para eliminar las dependencias del módulo que falta. Una vez eliminadas las dependencias, la indicación del módulo que falta debería desaparecer al restablecer VCM.
300 Capítulo 6 Errores de HPE Virtual Connect ESES

9014 - Unknown Module state INCOMPATIBLENivel de gravedad: MAJOR
Descripción: Un módulo desconocido es incompatible con la configuración actual del dominio.
Causas posibles:
● Un módulo desconocido es adyacente a un módulo que no es desconocido (un módulo VC).
● No se admite un módulo desconocido en el compartimento donde se encuentra físicamente. Por ejemplo, en compartimentos principales o en espera, o en un compartimiento de un grupo de compartimentos FC.
Acción:
● Extraiga el módulo desconocido o el módulo adyacente al mismo.
● Extraiga el módulo desconocido del compartimento de interconexión.
● Intente volver a colocar o reiniciar el módulo para ver si se puede recuperar.
● Extraiga físicamente el módulo y sustitúyalo.
● Analice los registros de Onboard Administrator por si puede obtener más detalles con respecto al fallo.
9019 - Unknown Module state NO_COMMNivel de gravedad: MAJOR
Descripción: VCM no puede comunicarse correctamente con el módulo.
Causa posible 1: El módulo está apagado.
Acción: Vuelva a encender el módulo a través de la interfaz de OA.
Causa posible 2: No es posible comunicar con el módulo a través de las interfaces de gestión.
Acción: Vuelva a colocar, reinicie o sustituya el módulo por otro del mismo tipo.
Causa posible 3: Si un módulo se ha restablecido recientemente, podría permanecer en este estado durante cierto tiempo hasta que VCM pueda comunicarse correctamente con él. En este caso, normalmente el estado desaparece pasados unos pocos minutos.
Acción: Espere hasta 5 minutos para ver si el módulo se recupera de este estado.
Causa posible 4: Se restableció el módulo, pero nunca se recuperó de este estado porque VCM no recibió una notificación de evento del OA. Esto puede deberse a un problema con el firmware de OA, o a un problema con el módulo.
Acción: Vuelva a colocar, reinicie o sustituya el módulo por otro del mismo tipo.
Eventos de conjuntos de enlaces ascendentes Ethernet (17000-17999)17012 - Enet uplinkset state FAILED
Nivel de gravedad: CRITICAL
Descripción: La red Ethernet de VC ha perdido toda la conectividad de los enlaces ascendentes del conjunto de enlaces ascendentes debido a la falta de puertos configurados, a que todos los puertos configurados están en un estado incorrecto o a que se ha instalado un transceptor defectuoso o incompatible.
ESES Eventos de SysLog de Virtual Connect Manager 301

Causa posible: Todos los puertos de enlace ascendente del conjunto de enlaces ascendentes compartidos asociado a la red están sin enlazar o todos los puertos de enlace ascendente de un conjunto de enlaces ascendentes compartidos asociado a una red compartida se han desactivado.
Acciones:
● Conecte los puertos de enlace ascendente.
● Active los puertos de enlace ascendente de un conjunto de enlaces ascendentes compartidos asociado a una red compartida.
17014 - Enet uplinkset state is DISABLEDNivel de gravedad: MAJOR
Descripción: Todos los puertos del conjunto de puertos de enlace ascendente Ethernet se han desactivado administrativamente.
Causa posible: Puede que se haya configurado como Disabled el SpeedType de los puertos del conjunto de puertos de enlace ascendente.
Acción: Compruebe el parámetro SpeedType de los puertos del conjunto de puertos de enlace ascendente y seleccione la negociación automática o cualquier otro valor apropiado.
302 Capítulo 6 Errores de HPE Virtual Connect ESES

7 Errores de CONREP
Uso de CONREPLa utilidad CONREP genera un archivo XML de configuración del sistema que se utiliza para duplicar la configuración de hardware de un servidor ProLiant en otro. La utilidad CONREP utiliza el archivo XML de configuración de hardware para identificar y configurar el sistema; de forma predeterminada, el archivo se denomina conrep.xml. Puede cambiar el nombre predeterminado mediante la opción -x. El archivo de configuración real del sistema se captura como un archivo de datos XML. El nombre predeterminado es conrep.dat.
PRECAUCIÓN: La modificación incorrecta de los archivos de datos de CONREP puede provocar la pérdida de datos importantes. Solo los usuarios experimentados en el kit de herramientas deben intentar modificar los archivos de datos. Debido al riesgo de una posible pérdida de datos, debe tomar todas las precauciones necesarias para garantizar que los sistemas más importantes permanecen en funcionamiento si se produce un error.
La utilidad CONREP lee el estado de los valores de entorno del sistema para determinar la configuración del servidor y escribe los resultados en un archivo que se puede editar. La utilidad CONREP utiliza los datos del archivo generado para configurar el hardware del servidor de destino.
La utilidad CONREP utiliza un archivo de definición XML para determinar qué tipo de información debe recuperar y restaurar en el servidor. Puede modificar este archivo para actualizar características nuevas o restringir características al capturar configuraciones. El archivo conrep.xml predeterminado contiene opciones de configuración de hardware comunes para la mayoría de los servidores ProLiant de las series 300, 500 y 700. Algunas plataformas requieren configuraciones especiales contenidas en otros archivos XML. Estos archivos están incluidos en el Scripting Toolkit y se encuentran en la página web de Hewlett Packard Enterprise (http://www.hpe.com/support), en la página de soporte de cada plataforma. Puede emplearlos con la opción -x para configurar sistemas que no son compatibles con el archivo de configuración de hardware predeterminado.
Muchos de los campos del archivo conrep.xml contienen texto de ayuda que permite configurarlos. Esta información también se añade al archivo conrep.dat. Las características de hardware que no son compatibles con la versión de la ROM o con las plataformas existentes aparecen en el archivo conrep.dat.
NOTA: El formato de archivo de la versión para DOS de CONREP y el de la versión actual de CONREP no son compatibles.
Códigos de retorno de CONREPSistema operativo Linux
Valor Significado
0 El comando se ha completado correctamente.
1 El archivo de datos de definición de hardware (conrep.xml) está dañado o no se encuentra.
2 El archivo de datos de configuración del sistema (conrep.xml) está dañado o no se encuentra.
ESES Uso de CONREP 303

Valor Significado
4 Se ha establecido la contraseña del administrador del sistema. No se puede cambiar la configuración a menos que se borre esta contraseña.
5 El archivo XML de definición de hardware (conrep.xml) está dañado o no es adecuado para la plataforma actual.
Sistema operativo Microsoft Windows
Valor Significado
0 El comando se ha completado correctamente.
1 El archivo de datos de definición de hardware (conrep.xml) está dañado o no se encuentra.
2 El archivo de datos de configuración del sistema (conrep.xml) está dañado o no se encuentra.
3 El controlador de estado es necesario para esta operación, pero no está cargado.
4 Se ha establecido la contraseña del administrador del sistema. No se puede cambiar la configuración a menos que se borre esta contraseña.
5 El archivo XML de definición de hardware (conrep.xml) está dañado o no es adecuado para la plataforma actual.
Salida de pantalla de CONREPUna salida de pantalla típica generada por CONREP es similar a la siguiente:
conrep 3.00 - Scripting Toolkit Configuration Replication ProgramCopyright (c) 2007-2009 Hewlett Packard Enterprise Development LPSystem Type: ProLiant DL360 G4ROM Date: 08/16/2005ROM Family: P52XML System Configuration: conrep.xmlHardware Configuration: demo.datFile contains global platform restrictionsGlobal Restriction: [minimumconrepversion] OKPlatform check:[ProLiant DL3] match[ProLiant DL5] no matchSaving configuration data to demo.dat.
304 Capítulo 7 Errores de CONREP ESES

CONREP Return code: 0
ESES Salida de pantalla de CONREP 305

8 Errores de HPE iLO
Indicadores LED de la POST de iLODurante el arranque inicial de iLO, los indicadores LED de la POST parpadean para mostrar el progreso de dicho proceso. Una vez finalizado el proceso de arranque, el LED HB parpadea a intervalos de un segundo. Los indicadores LED (del 1 al 6) se encenderán tras el arranque del sistema para indicar que se ha producido un error de hardware. Si se detecta un error de hardware, reinicie el sistema iLO. Para conocer la ubicación de los indicadores LED, consulte la documentación del servidor.
Un fallo de tiempo de ejecución de iLO se indica mediante HB, que permanece en estado On (Encendido) u Off (Apagado) constantemente. Un error en tiempo de ejecución de iLO también se puede indicar mediante un patrón de parpadeo repetido en los ocho LED. Si se produce un error en tiempo de ejecución, reinicie iLO.
A continuación se muestra la asignación de los indicadores LED.
HB 7 6 5 4 3 2 1
Indicador LEDCódigo de POST (actividad completada) Descripción Fallo indicado
Ninguno 00 Configura las selecciones de chip
—
2 02 - Funcionamiento normal Limpieza realizada —
HB y 2 82 Inicio del kernel Fallo de inicio del subsistema, si este estado se prolonga durante un largo periodo de tiempo (aproximadamente 60 segundos).
5, 4, 3, 2 y 1 parpadeando 0F Error principal - recuperación El programa de carga principal está dañado; el kernel está ejecutando una recuperación de la memoria flash.
HB, 7 y 6 fijos
5, 4, 3, 2 y 1 parpadeando
E0 Error del kernel Error de búsqueda y carga de un kernel
HB — Parpadea mientras el procesador de iLO ejecuta código de firmware. No cambia el valor de los siete indicadores LED inferiores.
—
306 Capítulo 8 Errores de HPE iLO ESES

Entradas del registro de eventosPantalla del registro de eventos Explicación del registro de eventos
Access options IPMI/DCMI modified by: [user name] (Opciones de acceso de IPMI/DCMI modificadas por: [nombre de usuario])
El usuario indicado ha modificado las opciones para acceder a iLO a través de IPMI/DCMI.
Active Health System cleared by: [user name] (Active Health System borrado por: [nombre de usuario])
El usuario indicado ha borrado Active Health System.
Active Health System disabled by: [user name] (Active Health System desactivado por: [nombre de usuario])
El usuario indicado ha desactivado Active Health System.
Active Health System enabled by: [user name] (Active Health System activado por: [nombre de usuario])
El usuario indicado ha activado Active Health System.
Active Health System logging hardware disabled (Registro de Active Health System desactivado por hardware)
Active Health System se ha desactivado en el hardware.
Active Health System logging hardware enabled (Registro de Active Health System activado por hardware)
Active Health System se ha activado en el hardware.
Added group [group name] by: [user name] (Grupo [nombre de grupo] añadido por: [nombre de usuario])
El usuario indicado ha añadido el grupo de directorios indicado.
AlertMail modified by: [user name] (AlertMail modificado por: [nombre de usuario])
El usuario indicado ha modificado la configuración de AlertMail.
AlertMail sent to: [user name] (AlertMail enviado a: [nombre de usuario])
Se ha enviado un AlertMail al usuario indicado.
APO: iLO attempting to power-on the system (APO: iLO ha intentado encender el sistema)
iLO ha intentado encender el sistema de acuerdo con la configuración de Auto Power On (encendido automático).
APO: Last power state restored (APO: Último estado de alimentación restaurado)
Auto Power On (encendido automático) estaba configurado para restaurar el último estado de encendido al restablecerse la alimentación del sistema.
APO: Restored power state to standby (APO: Restaurado el estado de encendido al modo en espera)
El encendido del sistema se ha restaurado en el estado de espera, de acuerdo con la configuración de Auto Power On (encendido automático).
APO: Settings modified by: [user name] (APO: Configuración modificada por: [nombre de usuario])
El usuario indicado ha modificado la configuración de Auto Power On (encendido automático).
APO: System configured to always remain off after power was restored (APO: Sistema configurado para permanecer siempre apagado al restablecerse la alimentación)
Auto Power On (encendido automático) estaba configurado para permanecer apagado al restablecerse la alimentación del sistema.
Asset tag changed by: [user name] (Etiqueta de inventario cambiada por: [nombre de usuario])
El usuario indicado ha modificado la etiqueta de inventario del servidor.
Attempting to install language pack [name] (Intentando instalar el paquete de idioma [nombre])
iLO ha intentado instalar el paquete de idioma indicado.
BMC IPMI iLO: [event message] (BMC IPMI iLO: [mensaje del evento])
Eventos IPMI de BMC
BMC IPMI Watchdog Timer Timeout: [details] (Tiempo de espera del temporizador de protección de IPMI de BMC: [detalles])
Se ha agotado el tiempo de espera del temporizador de protección de IPMI de BMC con los detalles indicados.
Brown-out: recovery (Caída de tensión: Recuperación) El sistema se ha recuperado de una caída de tensión.
ESES Entradas del registro de eventos 307

Pantalla del registro de eventos Explicación del registro de eventos
Brown-out: System configured to always remain off after power was restored (Caída de tensión: Sistema configurado para permanecer siempre apagado al restablecerse la alimentación)
La recuperación del sistema tras una caída de tensión no se ha producido debido a que el sistema estaba configurado para permanecer apagado al restablecerse la alimentación.
Browser login failure from: [IP address and DNS name] (Fallo de inicio de sesión con el explorador desde: [dirección IP y nombre DNS])
Ha fallado un intento de inicio de sesión en la interfaz de usuario web de iLO. La solicitud de inicio de sesión procedía de la dirección IP y el nombre DNS indicados.
Browser login: [user name] - [IP address and DNS name] (Inicio de sesión con el explorador: [nombre de usuario] - [dirección IP y nombre DNS])
El usuario indicado ha iniciado sesión en iLO a través de la interfaz de usuario web desde la dirección IP y el nombre DNS indicados.
Browser logout: [user name] - [IP address and DNS name] (Fin de sesión con el explorador: [nombre de usuario] - [dirección IP y nombre DNS])
El usuario indicado ha finalizado la sesión en iLO a través de la interfaz de usuario web desde la dirección IP y el nombre DNS indicados.
Certificate Warning: Subject [certificate subject] does not match server name [server name] (Advertencia de certificado: El sujeto [sujeto de certificado] no coincide con el nombre del servidor [nombre de servidor])
La conexión entre iLO y el servidor indicado no era segura debido a que el nombre del servidor no coincidía con el certificado SSL del servidor.
Default language settings modified by: [user name] (Configuración del idioma predeterminado modificada por: [nombre de usuario])
El usuario indicado ha modificado la configuración del idioma predeterminado.
Deleted group [group name] by: [user name] (Grupo [nombre de grupo] eliminado por: [nombre de usuario])
El usuario indicado ha eliminado el grupo de directorios indicado.
Deleted user: [user name] (Usuario eliminado: [nombre de usuario])
Se ha eliminado la cuenta de usuario indicada.
Directory settings modified by: [user name] (Configuración de directorio modificada por: [nombre de usuario])
El usuario indicado ha modificado la configuración de directorio.
Duplicate IP address [IP address] detected on network. (Dirección IP [dirección IP] duplicada detectada en la red.)
Se ha detectado la duplicación de la dirección IP indicada.
Dynamic Power Cap disabled by : [user name] (Limitación de alimentación dinámica desactivada por: [nombre de usuario])
El usuario indicado ha desactivado la limitación de alimentación dinámica del servidor.
Dynamic Power Cap set to [value] by : [user name] (Limitación de alimentación dinámica establecida en [valor] por: [nombre de usuario])
El usuario indicado ha establecido la limitación de alimentación dinámica del servidor en el valor indicado.
Embedded Flash/SD-CARD: [status details] (Memoria flash/tarjeta SD integrada: [detalles de estado])
Estado de la memoria flash/tarjeta SD integrada.
Enforce AES/3DES encryption disabled: [user name] (Imposición del cifrado AES/3DES desactivada: [nombre de usuario])
El usuario indicado ha desactivado la imposición del cifrado AES/3DES.
Enforce AES/3DES encryption enabled: [user name] (Imposición del cifrado AES/3DES activada: [nombre de usuario])
El usuario indicado ha activado la imposición del cifrado AES/3DES.
eRS - [status] (eRS - [estado]) Estado del subsistema Embedded Remote Support.
Event log cleared (Registro de eventos borrado) Se ha borrado el registro de eventos de iLO.
Event log cleared by: [user name] (Registro de eventos borrado por: [nombre de usuario])
El usuario indicado ha borrado el registro de eventos de iLO.
308 Capítulo 8 Errores de HPE iLO ESES

Pantalla del registro de eventos Explicación del registro de eventos
Excessive network delay while communicating with virtual [virtual media device] (Retraso de la red excesivo mientras se comunicaba con [dispositivo Virtual Media] virtual)
La conexión de Virtual Media ha agotado el tiempo de espera debido a un retraso de red excesivo mientras se comunicaba con el dispositivo Virtual Media indicado.
FIPS Mode Enabled (Modo FIPS activado) El modo compatible con FIPS se ha activado.
FIPS Mode was disabled and iLO was reset because of multiple Known Answer Test failures. (El modo FIPS se ha desactivado e iLO se ha reiniciado debido a varios fallos de prueba de respuesta conocida.)
Se ha desactivado el modo FIPS y se ha restablecido la configuración predeterminada de fábrica de iLO porque se han producido varios fallos de prueba de respuesta conocida de FIPS.
Firmware reset by [source] for network modifications. (Firmware restablecido por [origen] debido a modificaciones realizadas en la red.)
El origen indicado ha reiniciado iLO debido a modificaciones realizadas en la red.
Firmware reset to use new hardware (Firmware reiniciado para utilizar hardware nuevo)
iLO se ha reiniciado para utilizar hardware nuevo.
Firmware upgrade complete (Actualización del firmware finalizada)
La actualización del firmware ha finalizado.
Firmware upgrade started from: [IP address and DNS name] (Actualización del firmware iniciada desde: [dirección IP y nombre DNS])
Se ha iniciado la actualización del firmware desde la dirección IP y el nombre DNS indicados.
Firmware upgrade via CLI failed (Fallo de la actualización del firmware a través de la CLI)
Ha fallado un intento de actualizar el firmware a través de la CLI.
Firmware upgrade via online flash component failed (Ha fallado la actualización del firmware mediante el componente de flash en línea)
Ha fallado un intento de actualizar el firmware con el componente de flash en línea.
Firmware upgrade via web page failed (Ha fallado la actualización del firmware a través de la página web)
La actualización del firmware no se ha completado correctamente. Asegúrese de que el archivo de la imagen del firmware es correcto.
Firmware upgrade via XML failed (Ha fallado la actualización del firmware a través de XML)
Ha fallado la actualización del firmware a través de una secuencia de comandos RIBCL. Asegúrese de que el archivo de la imagen del firmware es correcto.
Firmware upgraded to version [version] (Firmware actualizado a la versión [versión])
El firmware se ha actualizado correctamente a la versión indicada.
Group Power Cap for [group] disabled by: [user name] (Limitación de alimentación del grupo [grupo] desactivada por: [nombre de usuario])
El usuario indicado ha desactivado la limitación de alimentación del grupo de iLO Federation indicado.
Group Power Cap for [group] set to [value] by: [user name] (Limitación de alimentación del grupo [grupo] establecida en [valor] por: [nombre de usuario])
El usuario indicado ha establecido la limitación de alimentación del grupo de iLO Federation indicado en el valor indicado.
Host server reset by: [user name] (Servidor host restablecido por: [nombre de usuario])
El usuario indicado ha restablecido (ha reiniciado en caliente) el servidor.
Hotkey modified by: [user name] (Tecla de acceso directo modificada por: [nombre de usuario])
El usuario indicado ha modificado la configuración de las teclas de acceso directo.
iLO clock has been synchronized with [IP address] (El reloj de iLO se ha sincronizado con [dirección IP])
El reloj de iLO se ha sincronizado con el servidor NTP de la dirección IP indicada.
iLO clock has been synchronized with the Onboard Administrator (El reloj de iLO se ha sincronizado con el Onboard Administrator)
El reloj de iLO se ha sincronizado con el BladeSystem Onboard Administrator.
ESES Entradas del registro de eventos 309

Pantalla del registro de eventos Explicación del registro de eventos
iLO Federation Group [group] added by: [user name] (Grupo de iLO Federation [grupo] añadido por: [nombre de usuario])
El usuario indicado ha añadido a este iLO el grupo de iLO Federation indicado.
iLO Federation Group [group] deleted by: [user name] (Grupo de iLO Federation [grupo] eliminado por: [nombre de usuario])
El usuario indicado ha eliminado de iLO el grupo de iLO Federation indicado.
iLO Federation Group [group] modified by: [user name] (Grupo de iLO Federation [grupo] modificado por: [nombre de usuario])
El usuario indicado ha modificado el grupo de iLO Federation indicado.
iLO Federation Management login failure from: [IP address and DNS name] (Fallo de inicio de sesión en iLO Federation Management desde: [dirección IP y nombre DNS])
Ha fallado un intento de inicio de sesión en iLO Federación Management.
iLO Federation Management login: [user name] - [IP address and DNS name] (Inicio de sesión en iLO Federation Management: [nombre de usuario] - [dirección IP y nombre DNS])
Se ha iniciado sesión en iLO Federation Management con el nombre de usuario indicado desde la dirección IP y el nombre DNS indicados.
iLO Federation Management logout: [user name] - [IP address and DNS name] (Fin de sesión en iLO Federation Management: [nombre de usuario] - [dirección IP y nombre DNS])
Se ha finalizado la sesión en iLO Federation Management con el nombre de usuario indicado desde la dirección IP y el nombre DNS indicados.
iLO Management Processor reset (Procesador de gestión de iLO reiniciado)
Se ha reiniciado iLO.
iLO Management Processor reset (Procesador de gestión de iLO reiniciado)
El firmware ha reiniciado iLO, normalmente para aplicar la configuración.
iLO Management Processor reset to factory defaults (Procesador de gestión de iLO restablecido a los valores predeterminados de fábrica)
Se ha restablecido la configuración predeterminada de fábrica de iLO. Se han restablecido todas las configuraciones a sus valores predeterminados de fábrica.
iLO memory error detected at [address] (Error de memoria de iLO detectado en [dirección])
iLO ha detectado un error de memoria corregible en la dirección indicada.
iLO Network Configuration modified by [user name] (Configuración de red de iLO modificada por [nombre de usuario])
El usuario indicado ha modificado la configuración de red de iLO.
iLO network link down (Enlace de red de iLO inactivo) iLO no está conectado a la red.
iLO network link up at [link speed] (Enlace de red de iLO activo a [velocidad de enlace])
Se ha establecido la conexión de red de iLO a la velocidad indicada
iLO RBSU exited (Se ha cerrado la RBSU de iLO) Ha finalizado la sesión de la RBSU de iLO. El usuario ha finalizado la sesión y la RBSU de iLO se ha cerrado.
iLO RBSU login failure (Fallo de inicio de sesión en la RBSU de iLO)
Ha fallado un intento de inicio de sesión en iLO a través de la RBSU de iLO.
iLO RBSU login: [user name] (Inicio de sesión en la RBSU de iLO: [nombre de usuario])
El usuario indicado ha iniciado sesión en iLO a través de la RBSU de iLO.
iLO reset by user diagnostics (iLO reiniciado por diagnóstico de usuario)
El usuario ha reiniciado iLO para realizar diagnósticos. Esto normalmente se inicia desde la página Diagnostic (Diagnóstico) de la interfaz de usuario de web iLO.
iLO reset for Firmware upgrade (iLO reiniciado para actualización del firmware)
iLO se ha reiniciado para aplicar actualizaciones de firmware.
310 Capítulo 8 Errores de HPE iLO ESES

Pantalla del registro de eventos Explicación del registro de eventos
iLO Self Test Error: [error code] (Error de autocomprobación de iLO: [código de error])
iLO no ha pasado una prueba interna. La causa probable es el fallo de un componente crítico. Se recomienda que no se siga utilizando iLO en este servidor.
iLO SNMP settings modified by: [user name] (Configuración de SNMP de iLO modificada por: [nombre de usuario])
Los servidores SNMP han modificado SNMP.
iLO time update failed. Unable to contact NTP server (Ha fallado la actualización de tiempo de iLO. No es posible ponerse en contacto con el servidor NTP.)
iLO no ha podido sincronizar la hora con el servidor NTP debido a que no se puede acceder al servidor.
iLO updated the host Date and Time. (iLO ha actualizado la fecha y la hora del host.)
iLO ha actualizado el reloj integrado del servidor.
iLO was hard reset by a local user or device (Un dispositivo o un usuario local ha realizado un reinicio forzado de iLO)
Un dispositivo o un usuario local ha realizado un reinicio forzado de iLO
iLO was reset because a FIPS Known Answer Test failed (iLO se ha reiniciado porque ha fallado una prueba de respuesta conocida de FIPS)
iLO se ha reiniciado porque ha fallado una prueba de respuesta conocida de FIPS.
iLO was reset for network link auto-detection (iLO se ha reiniciado para la detección automática del enlace de red)
iLO se ha reiniciado para la detección automática del enlace de red.
iLO was soft reset by a local user, device or enclosure (Un chasis, dispositivo o usuario local ha realizado un reinicio en caliente de iLO)
Un chasis, dispositivo o usuario local ha realizado un reinicio en caliente de iLO
Integrated Remote Console Trust Settings disabled by: [user name] (Opción de confianza de la consola remota integrada desactivada por: [nombre de usuario])
El usuario indicado ha desactivado la opción de confianza de la IRC. Se necesitaría un certificado SSL de confianza para iniciar la IRC.
Integrated Remote Console Trust Settings Enabled by: [user name] (Opción de confianza de la consola remota integrada activada por: [nombre de usuario])
El usuario indicado ha activado la opción de confianza de la IRC. Se necesitaría un certificado SSL de confianza para iniciar la IRC.
IPMI/RMCP login by [user name] - [IP address and DNS name] (Inicio de sesión con IPMI/RMCP de [nombre de usuario] - [dirección IP y nombre DNS])
El usuario indicado ha iniciado sesión en iLO a través de IPMI/RMCP desde la dirección IP y el nombre DNS indicados.
IPMI/RMCP login failure from: [IP address and DNS name] (Fallo de inicio de sesión con IPMI/RMCP desde: [dirección IP y nombre DNS])
Ha fallado un intento de inicio de sesión en iLO a través de IPMI/RMCP desde la dirección IP y el nombre DNS indicados.
IPMI/RMCP logout: [user name] - [IP address and DNS name] (Fin de sesión con IPMI/RMCP: [nombre de usuario] - [dirección IP y nombre DNS])
El usuario indicado ha finalizado la sesión en iLO a través de IPMI/RMCP desde la dirección IP y el nombre DNS indicados.
Key manager configuration modified by: [user name] (Configuración del gestor de claves modificada por: [nombre de usuario])
El usuario indicado ha modificado la configuración del gestor de claves.
Key manager redundancy modified by: [user name] (Redundancia del gestor de claves modificada por: [nombre de usuario])
El usuario indicado ha modificado la configuración de redundancia del gestor de claves.
Language pack added (Paquete de idioma añadido) Se ha instalado el paquete de idioma.
Language pack removed (Paquete de idioma eliminado) Se ha eliminado el paquete de idioma.
Language pack upgrade failed (Fallo al actualizar el paquete de idioma)
Se ha producido un error mientras iLO intentaba actualizar el paquete de idioma.
ESES Entradas del registro de eventos 311

Pantalla del registro de eventos Explicación del registro de eventos
License activation error by: [user name] (Error de activación de licencia por: [nombre de usuario])
No se ha podido instalar la clave de activación de licencia. Es posible que la clave de activación no sea válida o que no sea compatible.
License added by: [user name] (Licencia añadida por: [nombre de usuario])
El usuario indicado ha instalado una clave de activación de licencia.
License expired (Licencia caducada) La licencia ha caducado y las funciones con licencia se han desactivado.
Login security banner disabled by: [user name] (Anuncio de seguridad de inicio de sesión desactivado por: [nombre de usuario])
El usuario indicado ha desactivado el anuncio de seguridad de inicio de sesión.
Login security banner enabled by: [user name] (Anuncio de seguridad de inicio de sesión activado por: [nombre de usuario])
El usuario indicado ha activado el anuncio de seguridad de inicio de sesión.
Modified group [group name] by: [user name] (Grupo [nombre de grupo] modificado por: [nombre de usuario])
El usuario indicado ha modificado el grupo de directorios indicados.
Modified user: [user name] (Usuario modificado: [nombre de usuario])
Se ha modificado la cuenta de usuario indicada.
Multicast configuration modified by: [user name] (Configuración de multidifusión modificada por: [nombre de usuario])
El usuario indicado ha modificado la configuración de multidifusión indicada.
New user: [user name] (Usuario nuevo: [nombre de usuario]) Se ha añadido una cuenta de usuario con el nombre de usuario indicado.
No valid SNMP trap destinations. FQDN lookup failed (No hay destinos de captura SNMP válidos. Ha fallado la consulta del nombre FQDN.)
No hay destinos de captura SNMP válidos. iLO no ha podido buscar los FQDN especificados.
On-board clock set; was [mm/dd/yyyy ##:##:##] (Reloj integrado establecido; era [mm/dd/aaaa ##:##:##])
El reloj integrado del servidor se ha establecido o modificado.
Persistent mouse and keyboard DISABLED by: [user name] (Ratón y teclado persistentes DESACTIVADOS por: [nombre de usuario])
El usuario indicado ha desactivado el ratón y el teclado persistentes.
Persistent mouse and keyboard ENABLED by: [user name] (Ratón y teclado persistentes ACTIVADOS por: [nombre de usuario])
El usuario indicado ha activado la configuración de ratón y teclado persistentes.
Power consumption exceeded user-defined threshold, SNMP warning issued (El consumo de energía ha superado el umbral definido por el usuario. Se ha enviado una advertencia de SNMP.)
El consumo de energía del servidor ha superado un umbral definido por el usuario y se ha enviado una advertencia de SNMP.
Power on request received by: [source] (Solicitud de encendido recibida por: [origen])
iLO ha recibido una solicitud de encendido desde el origen indicado. El origen pueden ser los botones de encendido, wake-on-LAN, recuperación de alimentación automática.
Power Regulator setting changed by: [user name] (Configuración de Power Regulator modificada por: [nombre de usuario])
El usuario indicado ha modificado la configuración de Power Regulator.
Power-Off signal sent to host server by: [user name] (Señal de apagado enviada al servidor host por: [nombre de usuario])
El usuario indicado ha enviado la solicitud para apagar el servidor.
312 Capítulo 8 Errores de HPE iLO ESES

Pantalla del registro de eventos Explicación del registro de eventos
Power-On signal sent to host server by: [user name] (Señal de encendido enviada al servidor host por: [nombre de usuario])
El usuario indicado ha enviado la solicitud para encender el servidor.
Recoverable iLO Error, code [error code] (Error de iLO recuperable, código [código de error])
Se ha producido un error no crítico en iLO e iLO se ha reiniciado automáticamente. Si el problema sigue sin resolverse, llame al servicio de soporte.
Remote console computer lock Disabled by: [user name] (Bloqueo del equipo de la consola remota desactivado por: [nombre de usuario])
Se ha desactivado la configuración de bloqueo automático de la consola remota. El bloqueo de la consola del servidor debe efectuarse manualmente.
Remote console computer lock Enabled by: [user name] (Bloqueo del equipo de la consola remota activado por: [nombre de usuario])
Se ha activado la configuración de bloqueo automático de la consola remota. La consola del servidor se bloqueará automáticamente cuando finalice la sesión de la consola remota.
Remote console login failure from: [IP address and DNS name] (Fallo de inicio de sesión en la consola remota desde: [dirección IP y nombre DNS])
Ha fallado un intento de inicio de sesión para utilizar la consola remota de iLO. La solicitud se realizó desde la dirección IP y el nombre DNS indicados.
Remote console session shared by: [IP address and DNS name] (Sesión de la consola remota compartida por: [dirección IP y nombre DNS])
Se ha establecido una sesión de la consola remota compartida para la dirección IP y el nombre DNS indicados.
Remote console started by: [user name] - [IP address and DNS name] (Consola remota iniciada por: [nombre de usuario] - [dirección IP y nombre DNS])
El usuario indicado ha iniciado la sesión de la consola remota desde la dirección IP y el nombre DNS indicados.
Remote console started by: [user name] - [IP address and DNS name] (Consola remota cerrada por: [nombre de usuario] - [dirección IP y nombre DNS])
El usuario indicado ha cerrado la sesión de la consola remota desde la dirección IP y el nombre DNS indicados.
Remote Syslog modified by: [user name] (Registro del sistema remoto modificado por: [nombre de usuario])
El usuario indicado ha modificado la configuración del registro del sistema remoto.
Rest API Info: Rest API Provider Added [provider index] (Información de la API de REST: Proveedor de la API de REST añadido [índice de proveedor])
Se ha añadido un proveedor de la API de REST en el índice indicado.
Rest API Warning: Rest API memory cleared [reason] (Advertencia de la API de REST: Memoria de la API de REST borrada [motivo])
La memoria de la API de REST se ha borrado por el motivo indicado.
Rest API Warning: Rest API Provider Removed [reason] (Advertencia de la API de REST: Proveedor de la API de REST eliminado [motivo])
Un proveedor de la API de REST se ha eliminado por el motivo indicado.
RIBCL AHS count cleared by: [user name] (Contador de AHS de RIBCL borrado por: [nombre de usuario])
El usuario indicado ha borrado el contador de AHS de RIBCL.
ROM Swap: System ROM has been swapped to backup ROM by: [user name] (Intercambio de ROM: ROM del sistema intercambiada a la ROM de copia de seguridad por: [nombre de usuario])
El usuario indicado ha intercambiado la ROM del sistema por la ROM de copia de seguridad.
Scriptable virtual media ejected by: [user name] (Virtual Media en secuencia de comandos expulsado por: [nombre de usuario])
El usuario indicado ha expulsado el Virtual Media en secuencia de comandos.
Scriptable Virtual Media HTTP error [error code] (Error HTTP de Virtual Media en secuencia de comandos [código de error])
iLO ha recibido un error HTTP con el código de error indicado desde el servidor de hosting de Virtual Media en secuencia de comandos.
ESES Entradas del registro de eventos 313

Pantalla del registro de eventos Explicación del registro de eventos
Scriptable virtual media inserted by: [user name] (Virtual Media en secuencia de comandos insertado por: [nombre de usuario])
El usuario indicado ha insertado el Virtual Media en secuencia de comandos.
Scripted Virtual Media could not establish a connection to [URL] (Virtual Media en secuencia de comandos no ha podido establecer una conexión con [URL])
iLO no ha podido establecer una conexión con la dirección URL indicada para utilizarla como dispositivo de Virtual Media en secuencia de comandos.
Security jumper override detected. Security disabled! (Puente de anulación de la seguridad detectado. Seguridad desactivada.)
El puente de anulación de la seguridad se ha colocado en la placa del sistema (no recomendado). La seguridad se ha desactivado (anulado).
Security jumper setting normal (Configuración normal del puente de seguridad)
El puente de anulación de la seguridad no está colocado en la placa del sistema (recomendado). La configuración de seguridad funciona con normalidad.
Serial CLI login failure (Fallo de inicio de sesión de la CLI serie)
Ha fallado un intento de inicio de sesión en iLO a través de la CLI serie.
Serial CLI login: [user name] (Inicio de sesión de la CLI serie: [nombre de usuario])
El usuario indicado ha iniciado sesión en iLO a través de la CLI serie.
Serial CLI logout: [user name] (Fin de sesión de la CLI serie: [nombre de usuario])
El usuario indicado ha finalizado la sesión en iLO a través de la CLI serie.
Serial CLI session started (Sesión de la CLI serie iniciada) Se ha iniciado una sesión de la CLI serie.
Serial CLI session stopped (Sesión de la CLI serie detenida) Se ha detenido una sesión de la CLI serie.
Server cumulative power on time cleared by [user name] - [IP address and DNS name] (Tiempo de encendido acumulativo del servidor borrado por [nombre de usuario] - [dirección IP y nombre DNS])
El usuario indicado ha borrado el tiempo de encendido acumulativo del servidor desde la dirección IP y el nombre DNS indicados.
Server FQDN changed by: [user name] (Nombre FQDN del servidor modificado por: [nombre de usuario])
El usuario indicado ha modificado el nombre de dominio completo del servidor.
Server Name changed by: [user name] (Nombre del servidor modificado por: [nombre de usuario])
El usuario indicado ha modificado el nombre del servidor.
Server power loss caused by: [cause]. Attempt to restore server power in [duration]. (Pérdida de alimentación del servidor provocada por: [causa]. Intentar restablecer la alimentación del servidor en [tiempo].)
La alimentación del servidor se ha perdido por la causa indicada. iLO intentará restablecer la alimentación del servidor cuando pase el tiempo indicado.
Server power removed (Alimentación del servidor eliminada) Se ha apagada la alimentación del servidor.
Server power restored (Alimentación del servidor restablecida)
Se ha encendido la alimentación del servidor.
Server reset (Servidor restablecido) El servidor se ha restablecido (reiniciado en caliente).
Shared remote console session has disconnected: [IP address and DNS name] (Sesión de consola remota compartida desconectada: [dirección IP y nombre DNS])
La sesión de la consola remota compartida se ha desconectado desde la dirección IP y el nombre DNS indicados.
SMH FQDN changed by: [user name] (FQDN de SMH modificado por: [nombre de usuario])
El usuario indicado ha modificado el nombre de dominio completo de System Management Homepage.
SNMP Alert on Breach of Power Threshold modified by: [user name] (Alerta SNMP cuando se sobrepasa el umbral de alimentación modificada por: [nombre de usuario])
El usuario indicado ha modificado la alerta SNMP que se envía cuando se sobrepasa el umbral de alimentación.
314 Capítulo 8 Errores de HPE iLO ESES

Pantalla del registro de eventos Explicación del registro de eventos
SNTP server settings modified by: [user name] (Configuración del servidor SNTP modificada por: [nombre de usuario])
El usuario indicado ha modificado los servidores NTP.
SSH key for [user 1] added by: [user 2] (Clave SSH de [usuario 1] añadida por: [usuario 2])
El usuario 2 ha añadido la clave SSH del usuario 1.
SSH key for [user 1] removed by: [user 2] (Clave SSH de [usuario 1] eliminada por: [usuario 2])
El usuario 2 ha eliminado La clave SSH del usuario 1.
SSH login failure from: [IP address and DNS name] (Fallo de inicio de sesión SSH desde: [dirección IP y nombre DNS])
Ha fallado un intento de inicio de sesión en iLO a través de SSH desde la dirección IP y el nombre DNS indicados.
SSH login: [user name] - [IP address and DNS name] (Inicio de sesión con SSH: [nombre de usuario] - [dirección IP y nombre DNS])
El usuario indicado ha iniciado sesión en iLO a través de SSH desde la dirección IP y el nombre DNS indicados.
SSH logout: [user name] - [IP address and DNS name] (Fin de sesión con SSH: [nombre de usuario] - [dirección IP y nombre DNS])
El usuario indicado ha finalizado la sesión en iLO a través de SSH desde la dirección IP y el nombre DNS indicados.
SSL Certificate installed by : [user name] (Certificado SSL instalado por: [nombre de usuario])
El usuario indicado ha instalado un certificado SSL en iLO.
SSO [role] role privileges set by user: [user name] (Privilegios del rol [rol] de SSO establecidos por el usuario: [nombre de usuario])
El usuario indicado ha establecido el rol de SSO (administrador, operador, usuario...) en el rol indicado.
SSO login attempt from [IP address] via [SSO server] as [SSO role] by user: [user name] (Intento de inicio de sesión de SSO desde [dirección IP] a través de [servidor SSO] como [rol SSO] por el usuario: [nombre de usuario])
El usuario indicado ha intentado iniciar una sesión en iLO a través de SSO desde la dirección IP y el servidor SSO indicados.
SSO rejected (SSO rechazado) Se ha rechazado un intento de inicio de sesión en iLO utilizando SSO.
SSO rejected: Certificate mismatch (SSO rechazado: Discrepancia de certificado)
Se ha rechazado un intento de inicio de sesión en iLO utilizando SSO porque el certificado SSO no era de confianza.
SSO rejected: not enabled (SSO rechazado: No activado) Se ha rechazado un intento de inicio de sesión en iLO utilizando SSO porque SSO no estaba activado.
SSO rejected: Unknown host (SSO rechazado: Host desconocido)
Se ha rechazado un intento de inicio de sesión en iLO utilizando SSO porque el nombre de host no era de confianza.
SSO server [index] removed by user: [user name] (Servidor SSO [índice] eliminado por el usuario: [nombre de usuario])
El usuario indicado ha eliminado el servidor de SSO que tiene el índice indicado.
SSO server [server name] added by user: [user name] (Servidor SSO [nombre de servidor] añadido por el usuario: [nombre de usuario])
El usuario indicado ha añadido el nombre de servidor SSO indicado.
SSO server [server name] removed by user: [user name] (Servidor SSO [nombre de servidor] eliminado por el usuario: [nombre de usuario])
El usuario indicado ha eliminado el nombre de servidor SSO indicado.
SSO Trust Mode set to [mode] by user: [user name] (Modo de confianza de SSO establecido en [modo] por el usuario: [nombre de usuario])
El usuario indicado ha establecido el modo de confianza de SSO en el modo indicado.
Stale host ROM detected. Please use System ROM [mm/dd/yyyy] or later. (ROM de host obsoleta detectada. Utilice la ROM del sistema [mm/dd/aaaa] o posterior.)
El BIOS del sistema no cumple los requisitos mínimos de este firmware de iLO. Utilice una versión del BIOS del
ESES Entradas del registro de eventos 315

Pantalla del registro de eventos Explicación del registro de eventos
sistema que coincida con la fecha indicada o una más reciente.
System Boot Mode modified by: [user name] (Modo de arranque del sistema modificado por: [nombre de usuario])
El usuario indicado ha modificado la configuración del modo de arranque del servidor.
System Boot Order modified by: [user name] (Orden de arranque del sistema modificado por: [nombre de usuario])
El usuario indicado ha modificado el orden de los dispositivos de arranque del servidor.
System One-Time Boot modified by: [user name] (Arranque de un solo uso del sistema modificado por: [nombre de usuario])
El usuario indicado ha modificado la selección de arranque de un solo uso del sistema.
System power was cycled for update to take effect (Se ha realizado un ciclo de apagado y encendido del sistema para que surta efecto la actualización)
Se ha realizado un ciclo de apagado y encendido del sistema para que surta efecto la actualización.
System Programmable Logic Device update complete. Mandatory system A/C power cycle is required for update to take effect. (Actualización del dispositivo lógico programable del sistema finalizada. Es necesario un ciclo de apagado y encendido de CA para que la actualización surta efecto.)
El dispositivo lógico programable del sistema se ha actualizado correctamente. Realice un ciclo de apagado y encendido de CA en el sistema para que la actualización surta efecto.
System Programmable Logic Device update failed (Fallo de la actualización del dispositivo lógico programable del sistema)
Ha fallado un intento de actualizar el dispositivo lógico programable del sistema.
System Programmable Logic Device update starting (Iniciando la actualización del dispositivo lógico programable del sistema)
Se ha iniciado la actualización del dispositivo lógico programable del sistema.
Textcons session started by: [user name] - [IP address and DNS name] (Sesión de Textcons iniciada por: [nombre de usuario] - [dirección IP y nombre DNS])
El usuario indicado ha iniciado una sesión de la consola remota basada en texto (TEXTCONS) desde la dirección IP y el nombre DNS indicados.
Textcons session stopped by: [user name] - [IP address and DNS name] (Sesión de Textcons finalizada por: [nombre de usuario] - [dirección IP y nombre DNS])
El usuario indicado ha finalizado una sesión de la consola remota basada en texto (TEXTCONS) desde la dirección IP y el nombre DNS indicados.
Unable to export key from key manager (No se ha podido exportar la clave desde el gestor de claves)
iLO no ha podido exportar una clave desde el gestor de claves.
Unable to import key into key manager (No se ha podido importar una clave en el gestor de claves)
iLO no ha podido importar una clave en el gestor de claves.
Update of Power Management Controller failed (Fallo al actualizar el controlador de gestión de la alimentación)
Ha fallado un intento de actualizar el controlador de gestión de la alimentación.
Update of Power Management Controller from version [version number] starting. (Iniciando la actualización del controlador de gestión de la alimentación desde la versión [número de versión].)
Se ha iniciado la actualización del controlador de gestión de la alimentación. Se indica la versión actual.
Update of Power Management Controller to version [version number] complete (Actualización del controlador de gestión de la alimentación a la versión [número de versión] finalizada)
El controlador de gestión de la alimentación se ha actualizado correctamente a la versión indicada.
User [user 1] added by [user 2] (User [usuario 1] añadido por [usuario 2])
Se ha añadido una cuenta de usuario.
User [user 1] deleted by [user 2] (Usuario [usuario 1] eliminado por [usuario 2])
Se ha eliminado una cuenta de usuario.
316 Capítulo 8 Errores de HPE iLO ESES

Pantalla del registro de eventos Explicación del registro de eventos
User [user 1] modified by [user 2] (Usuario [usuario 1] modificado por [usuario 2])
Se ha modificado una cuenta de usuario.
Utility data center lock disabled by: [user name] (Bloqueo del centro de datos de utilidad desactivado por: [nombre de usuario])
El usuario indicado ha desactivado el bloqueo del centro de datos de utilidad.
Utility data center lock enabled by: [user name] (Bloqueo del centro de datos de utilidad activado por: [nombre de usuario])
El usuario indicado ha activado el bloqueo del centro de datos de utilidad.
Virtual media connected by: [user name] (Virtual Media conectado por: [nombre de usuario])
El usuario indicado ha conectado un dispositivo Virtual Media.
Virtual media disconnected by: [user name] (Virtual Media desconectado por: [nombre de usuario])
El usuario indicado ha desconectado un dispositivo Virtual Media.
Virtual NMI selected by: [user name] (NMI virtual seleccionada por: [nombre de usuario])
El usuario indicado ha generado la interrupción no enmascarable virtual.
Virtual Serial Port started by: [user name] - [IP address and DNS name] (Puerto serie virtual iniciado por: [nombre de usuario] - [dirección IP y nombre DNS])
El usuario indicado ha iniciado el puerto serie virtual desde la dirección IP y el nombre DNS indicados.
Virtual Serial Port stopped by: [user name] - [IP address and DNS name] (Puerto serie virtual detenido por: [nombre de usuario] - [dirección IP y nombre DNS])
El usuario indicado ha detenido el puerto serie virtual desde la dirección IP y el nombre DNS indicados.
XML login failure from: [IP address and DNS name]. (Fallo de inicio de sesión XML desde: [dirección IP y nombre DNS].)
Ha fallado un intento de inicio de sesión en iLO a través de la interfaz RIBCL desde la dirección IP y el nombre DNS indicados.
XML login: [user name] - [IP address and DNS name]. (Inicio de sesión XML: [nombre de usuario] - [dirección IP y nombre DNS].)
El usuario indicado ha iniciado sesión en iLO a través de la interfaz RIBCL desde la dirección IP y el nombre DNS indicados.
XML logout: [user name] - [IP address and DNS name]. (Fin de sesión XML: [nombre de usuario] - [dirección IP y nombre DNS].)
El usuario indicado ha finalizado la sesión en iLO a través de la interfaz RIBCL desde la dirección IP y el nombre DNS indicados.
Mensajes de RIBCLEn la tabla siguiente se enumeran los mensajes de error que aparecen cuando se utiliza el lenguaje de secuencias de comandos XML de RIBCL.
Número de estado Mensaje de error
0x0000 No error. (Sin errores.)
0x0001 Syntax error. (Error de sintaxis.)
0x0002 This user is not logged in. (Este usuario no ha iniciado sesión.)
0x0003 Login name is too long. (El nombre de inicio de sesión es demasiado largo.)
0x0004 Password is too short. (La contraseña es demasiado corta.)
0x0005 Password is too long. (La contraseña es demasiado larga.)
ESES Mensajes de RIBCL 317

Número de estado Mensaje de error
0x0006 User table is full. No room for new user. (La tabla de usuarios está llena. No hay espacio para un nuevo usuario.)
0x0007 Cannot add user. The login/ user name already exists. (No se puede añadir el usuario. El nombre de inicio de sesión o de usuario ya existe.)
0x0008 Cannot modify user. The login/ user name already exists. (No se puede modificar el usuario. El nombre de inicio de sesión o de usuario ya existe.)
0x0009 Cannot delete user information for currently logged user. (No se puede eliminar la información del usuario que ha iniciado la sesión actual.)
0x000A User login name was not found. (No se encontró un nombre de inicio de sesión de usuario.)
0x000B User information is open for read-only access. Write access is required for this operation. (La información del usuario tiene acceso de solo lectura. Se requiere acceso de escritura para realizar esta operación.)
0x000C Server information is open for read-only access. Write access is required for this operation. (La información del servidor tiene acceso de solo lectura. Se requiere acceso de escritura para realizar esta operación.)
0x000D iLO information is open for read-only access. Write access is required for this operation. (La información de iLO tiene acceso de solo lectura. Se requiere acceso de escritura para realizar esta operación.)
0x000E Rack information is open for read-only access. Write access is required for this operation. (La información del bastidor tiene acceso de solo lectura. Se requiere acceso de escritura para realizar esta operación.)
0x000F Directory information is open for read-only access. Write access is required for this operation. (La información del directorio tiene acceso de solo lectura. Se requiere acceso de escritura para realizar esta operación.)
0x0010 Internal error. Unknown RIB action. (Error interno. Acción RIB desconocida.)
0x0011 Internal error. Unknown SERVER action. (Error interno. Acción SERVER desconocida.)
0x0012 Virtual Power Button feature is not supported or not enabled on this server. (La característica Virtual Power Button [Botón de encendido virtual] no es compatible o no está activada en este servidor.)
0x0013 Virtual Power Button cable is attached (El cable de botón de alimentación virtual está conectado)
0x0014 Virtual Power Button cable is either not attached or not supported. (El cable de Virtual Power Button [Botón de encendido virtual] no está conectado o no es compatible.)
0x0015 The IP address specified is not valid. (La dirección IP especificada no es válida.)
318 Capítulo 8 Errores de HPE iLO ESES

Número de estado Mensaje de error
0x0016 The firmware image file is not valid. (El archivo de la imagen del firmware no es válido.)
0x0017 A valid firmware image has not been loaded. (No se cargó una imagen del firmware válida.)
0x0018 The flash process could not be started. (No se pudo iniciar el proceso de memoria flash.)
0x0019 The Remote Insight Board Firmware is being updated. The board will be reset after the operation. (El firmware de la placa Remote Insight se está actualizando. La placa se restablecerá después de la operación.)
0x001A The Remote Insight Board is being reset. (La placa Remote Insight se está restableciendo.)
0x001B The server is being reset. (El servidor se está restableciendo)
0x001C The Integrated Lights-Out Event Log is being cleared. (El registro de eventos de Integrated Lights-Out se está borrando.)
0x001D No image present in the Virtual Floppy drive. (No hay ninguna imagen en la unidad de disquete virtual.)
0x001E An invalid virtual floppy option has been given. (Se especificó una opción de disquete virtual no válida.)
0x001F Failed to allocate virtual floppy image space. (No se pudo asignar espacio para la imagen de disquete virtual.)
0x0020 The Virtual Floppy image is invalid. (La imagen de Virtual Floppy [disquete virtual] no es válida.)
0x0021 The key parameter specified is not valid. (El parámetro de tecla especificado no es válido.)
0x0022 The SESSION TIMEOUT value specified is greater the maximum value allowed, 120. (El valor de SESSION TIMEOUT especificado es mayor que 120, que es el máximo permitido.)
0x0023 User does NOT have correct privilege for action. ADMIN_PRIV required. (El usuario no tiene el privilegio correcto para realizar esta acción. Se requiere ADMIN_PRIV.)
0x0024 User does NOT have correct privilege for action. RESET_SERVER_PRIV required. (El usuario no tiene el privilegio correcto para realizar esta acción. Se requiere RESET_SERVER_PRIV.)
0x0025 User does NOT have correct privilege for action. UPDATE_ILO_PRIV required. (El usuario NO tiene el privilegio correcto para realizar esta acción. Se requiere UPDATE_ILO_PRIV.)
0x0026 User does NOT have correct privilege for action. CONFIG_ILO_PRIV required. (El usuario no tiene el privilegio correcto para realizar esta acción. Se requiere CONFIG_ILO_PRIV.)
0x0027 User does NOT have correct privilege for action. CLEAR_LOGS_PRIV required. (El usuario NO tiene el privilegio correcto para realizar esta acción. Se requiere CLEAR_LOGS_PRIV.)
ESES Mensajes de RIBCL 319

Número de estado Mensaje de error
0x0028 User does NOT have correct privilege for action. CONFIG_RACK_PRIV required. (El usuario NO tiene el privilegio correcto para realizar esta acción. Se requiere CONFIG_RACK_PRIV.)
0x0029 User does NOT have correct privilege for action. VIRTUAL_MEDIA_PRIV required. (El usuario no tiene el privilegio correcto para realizar esta acción. Se requiere VIRTUAL_MEDIA_PRIV.)
0x002A Server is not a rack server; Rack commands do not apply. (El servidor no es un servidor de bastidor; no se aplican los comandos de bastidor.)
0x002B Minimum password length value exceeded. (Se ha superado el valor mínimo de longitud de la contraseña.)
0x002C Unable to allocate memory for parser. (No es posible asignar memoria para el analizador.)
0x002D Unable to allocate memory from memory pool. (No es posible asignar memoria desde el pool de memoria.)
0x002E License key error. (Error de clave de licencia.)
0x002F License is already active. (La licencia ya está activa.)
0x0030 Login is currently being delayed. (El inicio de sesión se está retrasando.)
0x0031 A firmware update is already in progress. (Hay una actualización del firmware en curso.)
0x0032 LENGTH does not match post-translated length of VALUE. (LENGTH no coincide con la longitud de VALUE una vez traducido.)
0x0033 Problem manipulating EV. (Problema al manipular EV.)
0x0034 Cannot disable both LDAP and user account. (No se puede desactivar LDAP y la cuenta de usuario.)
0x0035 An invalid Virtual Media option has been given. (Se especificó una opción de Virtual Media no válida.)
0x0036 Unable to parse Virtual Media URL. (No es posible analizar la dirección URL de Virtual Media.)
0x0037 Virtual Media URL is not accessible. (No se puede acceder a la dirección URL de Virtual Media.)
0x0038 Virtual Media already connected via applet. (Virtual Media ya está conectado a través del subprograma.)
0x0039 No image present in the Virtual Media drive. (No hay ninguna imagen en la unidad de Virtual Media.)
0x003A Virtual Media already connected via script. Must EJECT/DISCONNECT before inserting new media (Virtual Media ya está conectado a través de la secuencia de comandos. Se debe expulsar o desconectar antes de introducir nuevos soportes.)
0x003B Unrecognized keyboard model. (Modelo de teclado no reconocido.)
0x003C Feature not supported. (Característica no compatible.)
0x003D IP Range is invalid. (Intervalo de IP no válido.)
320 Capítulo 8 Errores de HPE iLO ESES

Número de estado Mensaje de error
0x003E Error writing configuration. (Error al escribir la configuración.)
0x003F Domain Name is too long. (El nombre del dominio es demasiado largo.)
0x0040 Error reading certificate. (Error al leer el certificado.)
0x0041 Invalid certificate common name. (Nombre común de certificado no válido.)
0x0042 Certificate signature does not match private key. (La firma del certificado no coincide con la clave privada.)
0x0043 This feature requires an installed license key. (Esta característica requiere que se haya instalado una clave de licencia.)
0x0044 This setting can not be changed while virtual media is connected. (Este valor no puede cambiarse mientras Virtual Media está conectado.)
0x0045 This setting can not be changed while remote console is connected. (Este valor no puede cambiarse mientras la consola remota está conectada.)
0x0046 This setting can not be changed while Two-Factor authentication is enabled. (Este valor no puede cambiarse mientras la autenticación basada en dos factores está activada.)
0x0047 This setting can not be changed while Shared Network port is enabled. (Este valor no puede cambiarse mientras el puerto de red compartido se encuentra activo.)
0x0048 The Virtual Media image is invalid. (La imagen de Virtual Media no es válida.)
0x0049 This setting can not be enabled unless a trusted CA certificate has been imported. (Este valor no puede activarse salvo que se haya importado un certificado de CA de confianza.)
0x004A The value specified is invalid. (El valor especificado no es válido.)
0x004B No data available. (No hay datos disponibles.)
0x004C Power management is disabled. (La gestión de energía está desactivada.)
0x004D Feature not supported. (Característica no compatible.)
0x004E Unable to import the SIM certificate from the specified source. (No es posible importar el certificado de SIM desde el origen especificado.)
0x004F Insufficient room to add a SIM Server record. (Espacio insuficiente para añadir un registro de servidor SIM.)
0x0050 Single Sign-On information is open for read-only access. Write access is required for this operation. (La información de inicio de sesión único tiene acceso de solo lectura. Se requiere acceso de escritura para realizar esta operación.)
ESES Mensajes de RIBCL 321

Número de estado Mensaje de error
0x0051 The COMPUTER_LOCK value must be "custom" to use the tag COMPUTER_LOCK_KEY. (El valor de COMPUTER_LOCK debe ser "custom" para poder usar la etiqueta COMPUTER_LOCK_KEY.)
0x0052 Invalid COMPUTER_LOCK option; value must be "windows", "custom", "disabled", or "". (Opción COMPUTER_LOCK no válida; el valor debe ser "windows", "custom", "disabled", o "".)
0x0053 COMPUTER_LOCK_KEY tag is missing; programmable key sequence did not change. (Falta la etiqueta COMPUTER_LOCK_KEY; la secuencia de teclas programables no ha cambiado.)
0x0054 Command without TOGGLE="Yes" attribute is ignored when host power is off. (El comando sin el atributo TOGGLE="Yes" se ignora cuando el host está apagado.)
0x0055 Duplicate record exists. (Hay un registro duplicado.)
0x0056 Premature operation refused. (La operación prematura se ha rechazado.)
0x0057 SSH key was not found. (No se ha hallado la clave SSH.)
0x0058 There is no user name or the user name appended to SSH key does not exist (No existe ningún nombre de usuario o el nombre de usuario anexado a la clave SSH no existe).
0x0059 SSH key is too large for storage space (La clave SSH es demasiado grande para el espacio de almacenamiento).
0x005A No available slot for additional SSH key. (No hay ninguna ranura disponible para la clave SSH adicional.)
0x005B A Trusted Platform Module (TPM) has been detected in this system. TPM_ENABLED needs to be set to "Yes" in order to perform firmware update. (Se ha detectado un módulo de plataforma de confianza [TPM] en este sistema. TPM_ENABLED debe tener el valor "Yes" para poder llevar a cabo la actualización del firmware.)
0x005C Firmware image is not available or not valid. (El archivo de la imagen del firmware no está disponible o no es válido.)
0x005D Firmware flash failed. (La actualización del firmware ha fallado.)
0x005E Open flash part failed. (Fallo en la parte Open flash.)
0x005F Login failed. (El inicio de sesión ha fallado.)
0x0060 RIBCL parser is busy. Retry later. (El analizador de RIBCL está ocupado. Vuelva a intentarlo más tarde.)
0x0061 RIBCL parser is not active. No output is being generated. (El analizador de RIBCL no está activo. No se está generando ninguna salida.)
0x0062 VLAN configuration is available on Shared Network Port(SNP) only. Either modify this script to enable SNP or do it manually. (La configuración de VLAN solo está disponible en el puerto de red compartido [SNP]. Modifique esta secuencia de comandos para activar el SNP o hágalo manualmente.)
0x0063 Changing link configuration is NOT allowed for Shared Network Port(SNP). Avoid options: SPEED_AUTOSELECT, NIC_SPEED and/or
322 Capítulo 8 Errores de HPE iLO ESES

Número de estado Mensaje de error
FULL_DUPLEX. (No está permitido cambiar la configuración de los enlaces en el puerto de red compartido [SNP]. Evite estas opciones: SPEED_AUTOSELECT, NIC_SPEED y/o FULL_DUPLEX.)
0x0064 Chosen Interface is not set to be enabled, thus no change in configuration. ENABLE_NIC needs to be set to "Yes" to proceed. (La interfaz elegida no está activa, por lo que no hay ningún cambio en la configuración. Para continuar, ENABLE_NIC debe tener el valor "Yes".)
0x0065 Invalid VLAN ID. Valid Range is: 1 to 4094, both inclusive. (ID de VLAN no válido. El intervalo válido es del 1 al 4094, ambos inclusive)
0x0066 Power capping is handled by Onboard Administrator. (La limitación de la alimentación está a cargo de Onboard Administrator.)
0x0067 Power capping information is not available. (La información de la limitación de la alimentación no está disponible.)
0x0068 Duplicate of existing SSH key (Duplicación de la clave SSH existente).
0x0069 Invalid SSH key data (Datos de clave SSH no válidos).
0x006A User data error, please retry. (Error en los datos del usuario; vuelva a intentarlo.)
0x006B iLO has been automatically configured for Flex-10 mode therefore NIC configuration is not allowed. (iLO se ha configurado automáticamente para el modo Flex-10; por lo tanto, no está permitida la configuración de la NIC.)
0x006C This command cannot be run from this account. (Este comando no se puede ejecutar desde esta cuenta.)
0x006D The iLO is not configured for this command. (iLO no está configurado para este comando.)
0x006E iLO may not be disabled on this server. (iLO no puede desactivarse en este servidor.)
0x006F Keytab Error, Keytab not properly encoded. (Error en la tabla de claves; la tabla de claves no está codificada correctamente.)
0x0070 Could not set the Default Language. (No se pudo establecer el idioma predeterminado.)
0x0071 Could not get the Default Language. (No se pudo obtener el idioma predeterminado.)
0x0072 Single sign on server index could not be found. (No se pudo encontrar el inicio de sesión único en el índice del servidor.)
0x0073 Could not get the current timezone. (No se pudo obtener la zona horaria actual.)
0x0074 Could not find the timezone selected. (No se pudo encontrar la zona horaria seleccionada.)
0x0082 eRS - Only one connect model can be selected. (eRS: solo se puede seleccionar un modelo de conexión.)
ESES Mensajes de RIBCL 323

Número de estado Mensaje de error
0x0083 eRS - Missing required parameter for direct connect model setup. (eRS: falta un parámetro obligatorio para la configuración directa de modelos de conexión.)
0x0084 eRS - Missing required parameter for IRS connect model setup. (eRS: falta un parámetro obligatorio para la configuración IRS de modelos de conexión.)
0x0085 eRS - No connect model specified. (eRS: no se ha especificado ningún modelo de conexión.)
0x0086 There are missing parameters in the xml script. (Faltan parámetros en la secuencia de comandos XML.)
0x0087 Either SNMP Pass-through OR Embedded Health must be enabled. (Es necesario activar la transferencia SNMP O BIEN el estado integrado.)
Una de estas etiquetas, AGENTLESS_MANAGEMENT_ENABLE,or SNMP_PASSTHROUGH_STATUS debe tener el valor “yes”, y la otra debe tener el valor “no”.
0x0088 The iLO subsystem is currently generating a Certificate Signing Request(CSR), run script after 10 minutes or more to receive the CSR. (El subsistema iLO está generando una solicitud de firma de certificado [CSR]; ejecute la secuencia de comandos después de 10 minutos o más para recibir la CSR.)
0x0089 Power capping information is not available at this time, try again later. (La información de la limitación de la alimentación no está disponible en este momento; inténtelo más tarde.)
0x008A Failed to import the certificate. (No se pudo importar el certificado.)
0x008B Unknown error. (Error desconocido.)
0x008C Problem reading the EV. (Problema al leer la EV.)
0x008D There is no EV by the name given. (No hay ninguna EV con el nombre indicado.)
0x008E User does NOT have correct privilege for action. REMOTE_CONS_PRIV required. (El usuario no tiene el privilegio correcto para realizar esta acción. Se requiere REMOTE_CONS_PRIV.)
0x008F Error reading configuration (Error al leer la configuración)
0x0090 Unable to clear the SSH key. (No es posible borrar la clave SSH.)
0x0091 The system is configured incorrectly for this feature. (El sistema no está configurado correctamente para esta característica.)
0x0092 An invalid data error occurred, a single system reboot may clear this error. (Se produjo un error de datos no válidos; es posible que un reinicio del sistema elimine este error.)
0x0093 An internal comm error occurred. (Se produjo un error de comunicaciones interno.)
324 Capítulo 8 Errores de HPE iLO ESES

Número de estado Mensaje de error
0x0094 An internal communication error occurred. (Se produjo un error de comunicaciones interno.)
0x0095 A timeout occurred, please try again. (Se ha superado el tiempo de espera, inténtelo de nuevo.)
0x0096 Busy, please retry. (Ocupado, vuelva a intentarlo.)
0x0097 A single system reboot is required. (Es necesario reiniciar el sistema.)
0x0098 Power capping is not available at this time, try a single system reboot. (La limitación de la alimentación no está disponible en este momento; intente reiniciar el sistema.)
0x99 Power capping has been disabled in the ROM by the user. (El usuario ha desactivado la limitación de la alimentación en la ROM.)
0XA0 Incorrect URL. (Dirección URL incorrecta.)
0XA1 Failed to connect to the URL. (Error al conectar con la dirección URL.)
0XA3 Failed to update the hot key. (Error al actualizar la tecla de acceso directo.)
0XA4 Invalid number of keystrokes. (Número no válido de combinaciones de teclas.)
0XA5 Unable to get the hot keys. (No es posible obtener las teclas de acceso directo.)
0XA6 Demo license previously installed. (Licencia de demostración ya instalada.)
0XA7 Some parameters are defined that are not to be specified together. (Se han definido algunos parámetros que no se pueden especificar juntos.)
0XA8 The AHS Log can not be cleared when AHS logging is disabled. (El contenido del registro de AHS no se puede borrar si se ha desactivado el registro de AHS.)
0XA9 Error updating the group. (Error al actualizar el grupo.)
0XAA The Group SID is not valid. (El SID del grupo no es válido.)
0XAB Error adding group. (Error al agregar el grupo.)
0XAC Error setting group privilege. (Error al establecer el privilegio del grupo.)
0XAD Error while reading or writing SNMP data. (Error al leer o escribir los datos de SNMP.)
0XAF Error uninstalling the language. (Error al desinstalar el idioma.)
0XB0 This feature requires an advanced license key. (Esta característica requiere que se haya instalado una clave de licencia avanzada.)
0XB1 There was an error on reading the data. (Se ha producido un error al leer los datos.)
ESES Mensajes de RIBCL 325

Número de estado Mensaje de error
0XB2 There was an error on setting the data. (Se ha producido un error al establecer los datos.)
0XB3 Invalid port. (Puerto no válido.)
0XB4 Port assignments must be unique. (Las asignaciones de puertos deben ser exclusivas.)
326 Capítulo 8 Errores de HPE iLO ESES

9 HPE Insight Management Agents for Servers para Windows
Mensajes del registro de eventos asociados a capturas SNMP
Esta sección contiene una lista de los mensajes del registro de eventos de Microsoft Windows Server asociados a capturas SNMP generadas por HPE Insight Management Agents for Servers for Windows. Cada entrada de evento tiene el correspondiente número de captura SNMP que utilizan los agentes.
La información adicional sobre los eventos en esta sección incluye:
● Gravedad del evento
● Mensaje del evento
● Origen del mensaje del evento
● Síntoma del evento
● Datos complementarios de la captura SNMP
Formato del registro de eventos de Windows NT®Las páginas siguientes contienen eventos de HPE Insight Management que se introducen en el registro de eventos de Microsoft Windows NT en el momento de producirse.
Los valores son de 32 bits, dispuestos de la siguiente manera:
3 3 2 2 2 2 2 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 1 0 9 8 7 6 5 4 3 2 1 0 9 8 7 6 5 4 3 2 1 0 9 8 7 6 5 4 3 2 1 0 +----+---+—--+--------------------+--------------------------------------------+ |Sev | C|R | Facility | Code | +----+--+-—-—+--------------------+------------------------------------------+Donde:
● Grav: el código de nivel de gravedad
● 00: correcto
● 01: informativo
● 10: advertencia
● 11: error
● C: el indicador del código de cliente
ESES Mensajes del registro de eventos asociados a capturas SNMP 327

● R: bit reservado
● Instalación: el código de instalación (siempre “CPQ”)
● Código (código de estado de la instalación): el número de evento. El byte superior hace referencia al agente de HPE Insight Management Agent que sirvió el evento; el byte inferior es el número de evento real
Descripciones de los agentes● Foundation/Host Agent (Agente base/host): cpqhsmsg
● Sever Agent (Agente de servidor): cpqsvmsg
● Storage Agent (Agente de almacenamiento): cpqstmsg
● NIC Agent (Agente NIC): cpqnimsg
Agentes baseIdentificadores de eventos 1105-1808
ID de evento de NT: 1105 (Hex)0x44350451 (cpqhsmsg.dll)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: %1
Captura SNMP: cpqHo2GenericTrap - 11003 en CPQHOST.MIB
Síntoma: Captura genérica.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqHoGenericData
Descripción complementaria de la captura SNMP: “[cpqHoGenericData]”
ID de evento de NT: 1106 (Hex)0x44350452 (cpqhsmsg.dll)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: %1
Captura SNMP: cpqHo2AppErrorTrap - 11004 en CPQHOST.MIB
Síntoma: Una aplicación ha generado una excepción. La información sobre el error se encuentra en la variable cpqHoSwPerfAppErrorDesc.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqHoSwPerfAppErrorDesc
Descripción complementaria de la captura SNMP: “[cpqHoSwPerfAppErrorDesc]”
ID de evento de NT: 1162 (Hex)0x8435048a (cpqhsmsg.dll)
328 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Rising Threshold Passed. (Se ha sobrepasado el umbral superior.)
Captura SNMP: cpqMeRisingAlarmExtended - 10005 en CPQTHRSH.MIB
Síntoma: Se ha sobrepasado el umbral superior. Una entrada de alarma ha sobrepasado el umbral superior. Las instancias de los objetos incluidos en la lista de variables son las de la entrada de alarma que generó esta captura.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqMeAlarmVariable
● cpqMeAlarmSampleType
● cpqMeAlarmValue
● cpqMeAlarmRisingThreshold
● cpqMeAlarmOwner
● cpqMeAlarmSeverity
● cpqMeAlarmExtendedDescription
Descripción complementaria de la captura SNMP: “[cpqMeAlarmOwner]: Variable [cpqMeAlarmVariable] has value [cpqMeAlarmValue] >= [cpqMeAlarmRisingThreshold].” ([cpqMeAlarmOwner]: la variable [cpqMeAlarmVariable] tiene el valor [cpqMeAlarmValue] >= [cpqMeAlarmRisingThreshold].)
ID de evento de NT: 1163 (Hex)0x8435048b (cpqhsmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Falling Threshold Passed. (Se ha sobrepasado el umbral inferior.)
Captura SNMP: cpqMeFallingAlarmExtended - 10006 en CPQTHRSH.MIB
Síntoma: Se ha sobrepasado el umbral inferior. Una entrada de alarma ha sobrepasado su umbral inferior. Las instancias de los objetos incluidos en la lista de variables son las de la entrada de alarma que generó esta captura.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqMeAlarmVariable
● cpqMeAlarmSampleType
● cpqMeAlarmValue
● cpqMeAlarmFallingThreshold
● cpqMeAlarmOwner
● cpqMeAlarmSeverity
● cpqMeAlarmExtendedDescription
ESES Agentes base 329

Descripción complementaria de la captura SNMP: “[cpqMeAlarmOwner]: Variable [cpqMeAlarmVariable] has value [cpqMeAlarmValue] <= [cpqMeAlarmFallingThreshold].” ([cpqMeAlarmOwner]: la variable [cpqMeAlarmVariable] tiene el valor [cpqMeAlarmValue] <= [cpqMeAlarmFallingThreshold].)
ID de evento de NT: 1164 (Hex)0x8435048c (cpqhsmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Critical Rising Threshold Passed. (Se ha sobrepasado el umbral superior crítico.)
Captura SNMP: cpqMeCriticalRisingAlarmExtended - 10007 en CPQTHRSH.MIB
Síntoma: Se ha sobrepasado el umbral superior crítico. Una entrada de alarma ha sobrepasado el umbral superior crítico. Las instancias de los objetos incluidos en la lista de variables son las de la entrada de alarma que generó esta captura.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqMeAlarmVariable
● cpqMeAlarmSampleType
● cpqMeAlarmValue
● cpqMeAlarmRisingThreshold
● cpqMeAlarmOwner
● cpqMeAlarmSeverity
● cpqMeAlarmExtendedDescription
Descripción complementaria de la captura SNMP: “[cpqMeAlarmOwner]: Variable [cpqMeAlarmVariable] has value [cpqMeAlarmValue] >= [cpqMeAlarmRisingThreshold].” ([cpqMeAlarmOwner]: la variable [cpqMeAlarmVariable] tiene el valor [cpqMeAlarmValue] >= [cpqMeAlarmRisingThreshold].)
ID de evento de NT: 1165 (Hex)0x8435048d (cpqhsmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Critical Falling Threshold Passed. (Se ha sobrepasado el umbral inferior crítico.)
Captura SNMP: cpqMeCriticalFallingAlarmExtended - 10008 en CPQTHRSH.MIB
Síntoma: Se ha sobrepasado el umbral inferior crítico. Una entrada de alarma ha sobrepasado el umbral inferior crítico. Las instancias de los objetos incluidos en la lista de variables son las de la entrada de alarma que generó esta captura.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqMeAlarmVariable
● cpqMeAlarmSampleType
330 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

● cpqMeAlarmValue
● cpqMeAlarmFallingThreshold
● cpqMeAlarmOwner
● cpqMeAlarmSeverity
● cpqMeAlarmExtendedDescription
Descripción complementaria de la captura SNMP: “[cpqMeAlarmOwner]: Variable [cpqMeAlarmVariable] has value [cpqMeAlarmValue] <= [cpqMeAlarmFallingThreshold].” ([cpqMeAlarmOwner]: la variable [cpqMeAlarmVariable] tiene el valor [cpqMeAlarmValue] <= [cpqMeAlarmFallingThreshold].)
ID de evento de NT: 1166 (Hex)0x8435048e (cpqhsmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: %1
Captura SNMP: cpqHoProcessEventTrap - 11011 en CPQHOST.MIB
Síntoma: Un proceso supervisado ha iniciado o finalizado su ejecución.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqHoSwRunningTrapDesc
Descripción complementaria de la captura SNMP: “[cpqHoSwRunningTrapDesc]”
ID de evento de NT: 1167 (Hex)0x8435048f (cpqhsmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The cluster resource %4 has become degraded. (El estado del recurso de clúster %4 ha cambiado a Degraded.)
Captura SNMP: cpqClusterResourceDegraded - 15005 en CPQCLUS.MIB
Síntoma: Esta captura se envía cada vez que el estado de un recurso de clúster cambia a Degraded.
Acción del usuario: Anote el nombre del recurso de clúster y, a continuación, compruebe el recurso para averiguar la causa del estado Degraded.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqClusterResourceName
Descripción complementaria de la captura SNMP: “Cluster resource [cpqClusterResourceName] has become degraded.” (El estado del recurso de clúster [cpqClusterResourceName] ha cambiado a Degraded.)
ID de evento de NT: 1168 (Hex)0xc4350490 (cpqhsmsg.dll)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: The cluster resource %4 has failed. (El recurso de clúster %4 ha fallado.)
ESES Agentes base 331

Captura SNMP: cpqClusterResourceFailed - 15006 en CPQCLUS.MIB
Síntoma: Esta captura se envía cada vez que se produce un fallo en el estado de un recurso de clúster.
Acción del usuario: Anote el nombre del recurso de clúster y, a continuación, compruebe el recurso para averiguar la causa del fallo.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqClusterResourceName
Descripción complementaria de la captura SNMP: “Cluster resource [cpqClusterResourceName] has failed.” (El recurso de clúster [cpqClusterResourceName] ha fallado.)
ID de evento de NT: 1169 (Hex)0x84350491 (cpqhsmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The cluster network %4 has become degraded. (El estado de la red de clúster %4 ha cambiado a Degraded.)
Captura SNMP: cpqClusterNetworkDegraded - 15007 en CPQCLUS.MIB
Síntoma: Esta captura se envía cada vez que el estado de una red de clúster cambia a Degraded.
Acción del usuario: Anote el nombre de la red de clúster y, a continuación, compruebe la red para averiguar la causa del estado Degraded.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqClusterNetworkName
Descripción complementaria de la captura SNMP: “Cluster network [cpqClusterNetworkName] has become degraded.” (El estado de la red de clúster [cpqClusterNetworkName] ha cambiado a Degraded.)
ID de evento de NT: 1170 (Hex)0xc4350492 (cpqhsmsg.dll)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: The cluster network %4 has failed. (La red de clúster %4 ha fallado.)
Captura SNMP: cpqClusterNetworkFailed - 15008 en CPQCLUS.MIB
Síntoma: Esta captura se envía cada vez que se produce un fallo en el estado de una red de clúster.
Acción del usuario: Anote el nombre de la red de clúster y, a continuación, compruebe la red para averiguar la causa del fallo.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqClusterNetworkName
332 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Descripción complementaria de la captura SNMP: “Cluster network [cpqClusterNetworkName] has failed.” (La red de clúster [cpqClusterNetworkName] ha fallado.)
ID de evento de NT:1171 (Hex)0x84350493 (cpqhsmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The cluster service on %4 has become degraded. (El estado del servicio de clúster de %4 ha cambiado a Degraded.)
Captura SNMP: cpqClusterNodeDegraded - 15003 en CPQCLUS.MIB
Síntoma: Esta captura se envía cada vez que el estado de un nodo del clúster cambia a Degraded.
Acción del usuario: Anote el nombre del nodo del clúster y, a continuación, compruebe el nodo para averiguar la causa del estado Degraded.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqClusterNodeName
Descripción complementaria de la captura SNMP: “Cluster service on [cpqClusterNodeName] has become degraded.” (El estado del servicio de clúster de [cpqClusterNodeName] ha cambiado a Degraded.)
ID de evento de NT: 1172 (Hex)0xc4350494 (cpqhsmsg.dll)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: The cluster service on %4 has failed. (El servicio de clúster de %4 ha fallado.)
Captura SNMP: cpqClusterNodeFailed - 15004 en CPQCLUS.MIB
Síntoma: Esta captura se envía cada vez que se produce un fallo en el estado de un nodo del clúster.
Acción del usuario: Anote el nombre del nodo del clúster y, a continuación, compruebe el nodo para averiguar la causa del fallo.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqClusterNodeName
Descripción complementaria de la captura SNMP: “Cluster service on [cpqClusterNodeName] has failed.” (El servicio de clúster de [cpqClusterNodeName] ha fallado.)
ID de evento de NT: 1173 (Hex)0x84350495 (cpqhsmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Processor Performance Instance, '%4' is degraded with Processor Time of %5 percent. (El estado de la instancia de rendimiento Processor '%4' es Degraded, con un tiempo de procesador del %5 por ciento.)
Captura SNMP: cpqOsCpuTimeDegraded - 19001 en CPQWINOS.MIB
Síntoma: La propiedad de rendimiento Processor Time tiene el estado Degraded.
ESES Agentes base 333

Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqOsCpuIndex
● cpqOsCpuInstance
● cpqOsCpuTimePercent
Descripción complementaria de la captura SNMP: “The Processor performance Instance, [cpqOsCpuInstance] is degraded with Processor Time of [cpqOsCpuTimePercent] percent.” (El estado de la instancia de rendimiento Processor [cpqOsCpuInstance] es Degraded, con un tiempo de procesador del [cpqOsCpuTimePercent] por ciento.)
ID de evento de NT: 1174 (Hex)0xc4350496 (cpqhsmsg.dll)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: The Processor Performance Instance, '%4' is failed with Processor Time of %5 percent. (El estado de la instancia de rendimiento Processor '%4' es Failed, con un tiempo de procesador del %5 por ciento.)
Captura SNMP: cpqOsCpuTimeFailed - 19002 en CPQWINOS.MIB
Síntoma: La propiedad de rendimiento Processor Time tiene el estado Critical.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqOsCpuIndex
● cpqOsCpuInstance
● cpqOsCpuTimePercent
Descripción complementaria de la captura SNMP: “The Processor performance Instance, [cpqOsCpuInstance] is critical with Processor Time of [cpqOsCpuTimePercent] percent.” (El estado de la instancia de rendimiento Processor [cpqOsCpuInstance] es Critical, con un tiempo de procesador del [cpqOsCpuTimePercent] por ciento.)
ID de evento de NT: 1175 (Hex)0x84350497 (cpqhsmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Cache Performance Instance, '%4' is degraded with Cache Copy Read Hits of %5 percent. (El estado de la instancia de rendimiento Cache '%4' es Degraded, con un porcentaje de aciertos de lecturas de copia en la memoria caché del %5 por ciento.)
Captura SNMP: cpqOsCacheCopyReadHitsDegraded - 19003 en CPQWINOS.MIB
Síntoma: La propiedad de rendimiento Cache CopyReadHits tiene el estado Degraded.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqOsCacheIndex
334 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

● cpqOsCacheInstance
● cpqOsCacheCopyReadHitsPercent
Descripción complementaria de la captura SNMP: “The Cache performance property is degraded with Copy Read Hits of [cpqOsCacheCopyReadHitsPercent] percent.” (El estado de la propiedad de rendimiento Cache es Degraded, con un porcentaje de aciertos de lecturas de copia del [cpqOsCacheCopyReadHitsPercent] por ciento.)
ID de evento de NT: 1176 (Hex)0xc4350498 (cpqhsmsg.dll)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: The Cache Performance Instance, '%4' is failed with Cache Copy Read Hits of %5 percent. (El estado de la instancia de rendimiento Cache '%4' es Failed, con un porcentaje de aciertos de lecturas de copia en la memoria caché del %5 por ciento.)
Captura SNMP: cpqOsCacheCopyReadHitsFailed - 19004 en CPQWINOS.MIB
Síntoma: La propiedad de rendimiento Cache Copy Read Hits tiene el estado Critical.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqOsCacheIndex
● cpqOsCacheInstance
● cpqOsCacheCopyReadHitsPercent
Descripción complementaria de la captura SNMP: “The Cache performance property is critical with Copy Read Hits of [cpqOsCacheCopyReadHitsPercent] percent.” (El estado de la propiedad de rendimiento Cache es Critical, con un porcentaje de aciertos de lecturas de copia del [cpqOsCacheCopyReadHitsPercent] por ciento.)
ID de evento de NT: 1177 (Hex)0x84350499 (cpqhsmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The PagingFile Performance Instance, '%4' is degraded with PagingFile Usage of %5 percent. (El estado de la instancia de rendimiento PagingFile '%4' es Degraded, con un uso del archivo de paginación del %5 por ciento.)
Captura SNMP: cpqOsPageFileUsageDegraded - 19005 en CPQWINOS.MIB
Síntoma: La propiedad de rendimiento PagingFile Usage tiene el estado Degraded.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqOsPagingFileIndex
● cpqOsPagingFileInstance
● cpqOsPageFileUsagePercent
Descripción complementaria de la captura SNMP: “The PagingFile performance instance, [cpqOsPagingFileInstance] is degraded with PagingFile Usage of [cpqOsPageFileUsagePercent]
ESES Agentes base 335

percent.” (El estado de la instancia de rendimiento PagingFile [cpqOsPagingFileInstance] es Degraded, con un uso del archivo de paginación del [cpqOsPageFileUsagePercent] por ciento.)
ID de evento de NT: 1178 (Hex)0xc435049a (cpqhsmsg.dll)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: The PagingFile Performance Instance, '%4' is failed with PagingFile Usage of %5 percent. (El estado de la instancia de rendimiento PagingFile '%4' es Failed, con un uso del archivo de paginación del %5 por ciento.)
Captura SNMP: cpqOsPageFileUsageFailed - 19006 en CPQWINOS.MIB
Síntoma: La propiedad de rendimiento PagingFile Usage tiene el estado Critical.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqOsPagingFileIndex
● cpqOsPagingFileInstance
● cpqOsPageFileUsagePercent
Descripción complementaria de la captura SNMP: “The PagingFile performance instance, [cpqOsPagingFileInstance] is critical with PagingFile Usage of [cpqOsPageFileUsagePercent] percent.” (El estado de la instancia de rendimiento PagingFile [cpqOsPagingFileInstance] es Critical, con un uso del archivo de paginación del [cpqOsPageFileUsagePercent] por ciento.)
ID de evento de NT: 1179 (Hex)0x8435049b (cpqhsmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Logical Disk Performance Instance, '%4' is degraded with Disk Busy Time of %5 percent. (El estado de la instancia de rendimiento Logical Disk '%4' es Degraded, con un tiempo de actividad de disco del %5 por ciento.)
Captura SNMP: cpqOsLogicalDiskBusyTimeDegraded - 19007 en CPQWINOS.MIB
Síntoma: La propiedad de rendimiento LogicalDisk BusyTime tiene el estado Degraded.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqOsLogicalDiskIndex
● cpqOsLogicalDiskInstance
● cpqOsLogicalDiskBusyTimePercent
Descripción complementaria de la captura SNMP: “The LogicalDisk performance instance, [cpqOsLogicalDiskInstance] is degraded with DiskBusyTime of [cpqOsLogicalDiskBusyTimePercent] percent.” (El estado de la instancia de rendimiento LogicalDisk [cpqOsLogicalDiskInstance] es Degraded, con un DiskBusyTime del [cpqOsLogicalDiskBusyTimePercent] por ciento.)
ID de evento de NT: 1180 (Hex)0xc435049c (cpqhsmsg.dll)
Nivel de gravedad del registro: Error (3)
336 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Mensaje del registro: The Logical Disk Performance Instance, '%4' is failed with Disk Busy Time of %5 percent. (El estado de la instancia de rendimiento Logical Disk '%4' es Failed, con un tiempo de actividad de disco del %5 por ciento.)
Captura SNMP: cpqOsLogicalDiskBusyTimeFailed - 19008 en CPQWINOS.MIB
Síntoma: La propiedad de rendimiento LogicalDisk BusyTime tiene el estado Critical.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqOsLogicalDiskIndex
● cpqOsLogicalDiskInstance
● cpqOsLogicalDiskBusyTimePercent
Descripción complementaria de la captura SNMP: “The LogicalDisk performance instance, [cpqOsLogicalDiskInstance] is critical with DiskBusyTime of [cpqOsLogicalDiskBusyTimePercent] percent.” (El estado de la instancia de rendimiento LogicalDisk [cpqOsLogicalDiskInstance] es Critical, con un DiskBusyTime del [cpqOsLogicalDiskBusyTimePercent] por ciento.)
ID de evento de NT: 1181 (Hex)0xc435049d (cpqhsmsg.dll)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: '%4'
Captura SNMP: cpqHoCriticalSoftwareUpdateTrap - 11014 en CPQHOST.MIB
Síntoma: Esta captura se envía para informar al usuario de la existencia de una actualización importante del software.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqHoCriticalSoftwareUpdateData
Descripción complementaria de la captura SNMP: “[cpqHoCriticalSoftwareUpdateData]”
Identificador del evento cpqhsmsg.dll - 1792 (Hex)0x84350700 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The agent is unable to generate traps due to an error during initialization. (El agente no puede generar capturas debido a un error durante la inicialización.)
Identificador del evento: cpqhsmsg.dll - 1795 (Hex)0x84350703 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The agent is older than other components. The agent is older than the other components of the Management Agents. Reinstall all of the Management Agents to correct this error. (El agente es anterior a otros componentes. El agente es anterior a los demás componentes de Management Agents. Vuelva a instalar todos los agentes de Management Agents para corregir este error.)
Identificador del evento: cpqhsmsg.dll - 1796 (Hex)0x84350704 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
ESES Agentes base 337

Mensaje del registro: The %1 Agent is older than other components. The %1 Agent is older than the other components of the Management Agents. Reinstall all of the Management Agents to correct this error. (%1 Agent es anterior a otros componentes. %1 Agent es anterior a los demás componentes de Management Agents. Vuelva a instalar todos los agentes de Management Agents para corregir este error.)
Identificador del evento: cpqhsmsg.dll - 1800 (Hex)0x84350708 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to read security configuration information. SNMP sets have been disabled. (No es posible leer la información de configuración de la seguridad. Se han desactivado los conjuntos SNMP.)
Identificador del evento: cpqhsmsg.dll - 1803 (Hex)0xc435070b (evento de servicio)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: Unable to load a required library. This error can be caused by a corrupt or missing file. Reinstalling the Management Agents or running the Emergency Repair procedure may correct this error. (No es posible cargar una biblioteca obligatoria. Este error puede deberse a un archivo dañado o ausente. Volver a instalar Management Agents o ejecutar el procedimiento de reparaciones de emergencia puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 1806 (Hex)0x8435070e (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Foundation SNMP Agent service is not running. The agent has determined that the Foundation Agents service is not running. Stop the SNMP service and restart the Foundation Agents service. If the error persists, reinstalling the Management Agents may correct this error. (El servicio Management Agent no se está ejecutando. SNMP Management Agent ha determinado que el servicio Management Agent no se está ejecutando. Detenga el servicio SNMP y reinicie el servicio Management Agents. Si el error continúa, es posible que se corrija volviendo a instalar Management Agents.)
Identificador del evento: cpqhsmsg.dll - 1808 (Hex)0x44350710 (evento de servicio)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: The agent could not deliver trap %1. The agent was unable to use Asynchronous Management to deliver a trap. This can be caused by a failure in the Remote Access Service or by a missing or invalid configuration. Use the Management Agents control panel to verify the Asynchronous Management configuration settings. Use the Network control panel to verify the Remote Access configuration. If this error persists, reinstalling the Management Agents or the Remote Access Service may correct this error. For more information, see the Management Agents Asynchronous Management documentation. (El agente no pudo entregar la captura %1. El agente no pudo utilizar Asynchronous Management [Gestión asíncrona] para entregar una captura. Esto puede deberse a un fallo en el servicio de acceso remoto [Remote Access Service] o a una configuración no válida o ausente. Utilice el panel de control de Management Agents para comprobar los parámetros de configuración de Asynchronous Management. Utilice el panel de control de la red para comprobar la configuración del acceso remoto. Si el error continúa, es posible que se corrija volviendo a instalar Management Agents o el servicio de acceso remoto. Para obtener más información, consulte los temas sobre los agentes de gestión en la documentación de Asynchronous Management.)
Identificadores de eventos 2048-2359Identificador del evento: cpqhsmsg.dll - 2048 (Hex)0x84350800 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
338 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Mensaje del registro: Unable to allocate memory. This indicates a low memory condition. Rebooting the system will correct this error. (No es posible asignar memoria. Esto indica un problema de memoria insuficiente. Reinicie el sistema para corregir este error.)
Identificador del evento: cpqhsmsg.dll - 2049 (Hex)0x84350801 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to read from the registry. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No es posible leer el registro. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 2050 (Hex)0x84350802 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not create the registry sub-key: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo crear la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 2051 (Hex)0x84350803 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to read from the registry. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No es posible leer el registro. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 2052 (Hex)0x84350804 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to read “%1” from the registry. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No es posible leer “%1” en el registro. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 2053 (Hex)0x84350805 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to read “%1” from the registry. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No es posible leer “%1” en el registro. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 2056 (Hex)0x84350808 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to create thread. This error can be caused by a low memory condition. Rebooting the server may correct this error. (No es posible crear el subproceso. Este error puede deberse a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 2098 (Hex)0x84350832 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to acquire file system information. This error can be caused by an unformatted partition or by a partition that has been recently modified. Formatting the partition or
ESES Agentes base 339

rebooting the server may correct this error. (No es posible obtener la información del sistema de archivos. Este error puede deberse a una partición sin formatear o a una partición modificada recientemente. Formatear la partición o reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 2099 (Hex)0x84350833 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to acquire file system information for %1. This error can be caused by a low memory condition. Rebooting the server may correct this error. (No es posible obtener la información del sistema de archivos para %1. Este error puede deberse a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 2100 (Hex)0x84350834 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to acquire the current process list. This error can be caused by a low memory condition. Rebooting the server may correct this error. (No es posible obtener la lista de procesos actuales. Este error puede deberse a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 2101 (Hex)0x84350835 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to acquire the CPU performance data. This error can be caused by a low memory condition. Rebooting the server may correct this error. (No es posible obtener los datos de rendimiento de la CPU. Este error puede deberse a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 2304 (Hex)0x84350900 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Threshold Agent could not allocate memory. The data contains the error code. (Threshold Agent no pudo asignar memoria. Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 2305 (Hex)0x84350901 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Threshold Agent could not open the base of the registry. The data contains the error code. (Threshold Agent no pudo abrir la base del registro. Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 2306 (Hex)0x84350902 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: “%1”. The data contains the error code. (Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 2307 (Hex)0x84350903 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: “%1”. The data contains the error code. (Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 2308 (Hex)0x84350904 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
340 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Mensaje del registro: The Threshold Agent could not read the registry value “%1”. The data contains the error code. (Threshold Agent no pudo leer el valor del registro “%1”. Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 2309 (Hex)0x84350905 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Threshold Agent found an incorrect type for registry value “%1”. The data contains the type found. (Threshold Agent encontró un tipo incorrecto para el valor del registro “%1”. Los datos contienen el tipo encontrado.)
Identificador del evento: cpqhsmsg.dll - 2310 (Hex)0x84350906 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Threshold Agent could not create a necessary event. The data contains the error code. (Threshold Agent no pudo crear un evento necesario. Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 2311 (Hex)0x84350907 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Threshold Agent could not set an event. The data contains the error code. (Threshold Agent no pudo configurar un evento. Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 2312 (Hex)0x84350908 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Threshold Agent could not create its main thread of execution. The data contains the error code. (Threshold Agent no pudo crear su subproceso principal de ejecución. Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 2313 (Hex)0x84350909 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Threshold Agent main thread did not terminate properly. The data contains the error code. (El subproceso principal de Threshold Agent no finalizó correctamente. Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 2314 (Hex)0x8435090a (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Threshold Agent got an unexpected error code while waiting for an event. The data contains the error code. (Threshold Agent obtuvo un código de error inesperado mientras esperaba que se produjese un evento. Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 2315 (Hex)0x8435090b (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Threshold Agent did not respond to a request. The data contains the error code. (Threshold Agent no respondió a una solicitud. Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 2316 (Hex)0x8435090c (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Threshold Agent received an unknown action code from the service. The data contains the action code. (Threshold Agent recibió un código de acción desconocido del servicio. Los datos contienen el código de acción.)
ESES Agentes base 341

Identificador del evento: cpqhsmsg.dll - 2317 (Hex)0x8435090d (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Threshold Agent could not get the system type. The data contains the error code. (Threshold Agent no pudo obtener el tipo del sistema. Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 2354 (Hex)0x84350932 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Threshold Agent could not create an SNMP session. The data contains the error code. (Threshold Agent no pudo crear una sesión SNMP. Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 2355 (Hex)0x84350933 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Threshold Agent SNMP request failed. The data contains the error code. Action: 1) Be sure that the SNMP service is configured to allow SNMP requests from “localhost”. 2) Be sure that there is an adequate amount of free memory. (Error en la solicitud SNMP de Threshold Agent. Los datos contienen el código del error. Acción: (1) Asegúrese de que el servicio SNMP está configurado para que permita solicitudes SNMP de “localhost”. (2) Asegúrese de que hay suficiente memoria disponible.)
Identificador del evento: cpqhsmsg.dll - 2356 (Hex)0x84350934 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: “%1”. The data contains the error code. (Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 2357 (Hex)0x84350935 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Threshold Agent could not set the variable because it is unsupported. The data contains the error code. (Threshold Agent no pudo configurar la variable debido a que esta no es compatible. Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 2358 (Hex)0x84350936 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Threshold Agent could not set the variable because the value is invalid or out of range. The data contains the error code. (Threshold Agent no pudo configurar la variable debido a que el valor no es válido o está fuera del intervalo. Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 2359 (Hex)0x84350937 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Threshold Agent is not loaded. Sets are not available. The data contains the error code. (Threshold Agent no está cargado. Los conjuntos no están disponibles. Los datos contienen el código del error.)
Identificadores de eventos 3072-3876Identificador del evento: cpqhsmsg.dll - 3072 (Hex)0x84350c00 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
342 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Mensaje del registro: Could not read from the registry sub-key. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo leer la subclave del registro. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 3073 (Hex)0x84350c01 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not create the registry sub-key: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo crear la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 3074 (Hex)0x84350c02 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not create the registry sub-key: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo crear la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 3075 (Hex)0x84350c03 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to read “%1” from the registry. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No es posible leer “%1” en el registro. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 3076 (Hex)0x84350c04 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to read “%1” from the registry. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No es posible leer “%1” en el registro. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 3084 (Hex)0xc4350c0c (evento de servicio)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: Unable to read configuration (%1) from the registry. This error can be caused by a corrupt registry, a low memory condition, or incomplete configuration. Reconfigure the Management Agents using the control panel. Rebooting the server may also correct this error. (No es posible leer la configuración [%1] del registro. Este error puede deberse a un registro dañado, a un problema de memoria insuficiente o a una configuración incompleta. Vuelva a configurar Management Agents utilizando el panel de control. Reiniciar el servidor también puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 3085 (Hex)0x84350c0d (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to write (%1) to the registry. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No es posible escribir [%1] en el registro. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 3086 (Hex)0x84350c0e (evento de servicio)
ESES Agentes base 343

Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to load a required library. This error can be caused by a corrupt or missing file. Reinstalling the Management Agents or running the Emergency Repair procedure may correct this error. (No es posible cargar una biblioteca obligatoria. Este error puede deberse a un archivo dañado o ausente. Volver a instalar Management Agents o ejecutar el procedimiento de reparaciones de emergencia puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 3090 (Hex)0x84350c12 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to allocate memory. This indicates a low memory condition. Rebooting the system will correct this error. (No es posible asignar memoria. Esto indica un problema de memoria insuficiente. Reinicie el sistema para corregir este error.)
Identificador del evento: cpqhsmsg.dll - 3840 (Hex)0x84350f00 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to allocate memory. This indicates a low memory condition. Rebooting the system will correct this error. (No es posible asignar memoria. Esto indica un problema de memoria insuficiente. Reinicie el sistema para corregir este error.)
Identificador del evento: cpqhsmsg.dll - 3841 (Hex)0x84350f01 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not read from the registry sub-key. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo leer la subclave del registro. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 3842 (Hex)0x84350f02 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not write the registry sub-key: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo escribir la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 3843 (Hex)0x84350f03 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not read the registry sub-key: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo leer la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 3844 (Hex)0x84350f04 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not write the registry sub-key: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo escribir la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 3845 (Hex)0x84350f05 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
344 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Mensaje del registro: Could not write the registry sub-key: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo escribir la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 3855 (Hex)0x84350f0f (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not open a cluster enumeration object. The Cluster service may not be running. Try to restart the Cluster service. (No se pudo abrir un objeto de enumeración de clúster. Es posible que el servicio de clúster no se esté ejecutando. Intente reiniciar el servicio de clúster.)
Identificador del evento: cpqhsmsg.dll - 3856 (Hex)0x84350f10 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not enumerate all of the nodes in the cluster. The data contains the error code. (No se pudieron enumerar todos los nodos del clúster. Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 3857 (Hex)0x84350f11 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not get the cluster's status. The Cluster service may not be running. Try to restart the Cluster service. (No se pudo obtener el estado del clúster. Es posible que el servicio de clúster no se esté ejecutando. Intente reiniciar el servicio de clúster.)
Identificador del evento: cpqhsmsg.dll - 3858 (Hex)0x84350f12 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not open the enumerated resource. The Cluster service may not be running. Try to restart the Cluster service. (No se pudo abrir el recurso enumerado. Es posible que el servicio de clúster no se esté ejecutando. Intente reiniciar el servicio de clúster.)
Identificador del evento: cpqhsmsg.dll - 3859 (Hex)0x84350f13 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not enumerate the cluster's resources. The Cluster service may not be running. Try to restart the Cluster service. (No se pudieron enumerar los recursos del clúster. Es posible que el servicio de clúster no se esté ejecutando. Intente reiniciar el servicio de clúster.)
Identificador del evento: cpqhsmsg.dll - 3860 (Hex)0x44350f14 (evento de servicio)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: Resource status is online. (El estado del recurso es Online.)
Identificador del evento: cpqhsmsg.dll - 3861 (Hex)0x44350f15 (evento de servicio)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: Resource status is offline. The resource has failed or was taken offline by a cluster administrator. (El estado del recurso es Offline. Se ha producido un fallo en el recurso o el administrador del clúster le ha asignado el estado Offline.)
Identificador del evento: cpqhsmsg.dll - 3862 (Hex)0x44350f16 (evento de servicio)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: Could not get the resource status. The Cluster service may not be running. Try to restart the Cluster service. (No se pudo obtener el estado del recurso. Es posible que el servicio de clúster no se esté ejecutando. Intente reiniciar el servicio de clúster.)
ESES Agentes base 345

Identificador del evento: cpqhsmsg.dll - 3863 (Hex)0x44350f17 (evento de servicio)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: Resource status is inherited. (El estado del recurso es heredado.)
Identificador del evento: cpqhsmsg.dll - 3864 (Hex)0x44350f18 (evento de servicio)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: Resource status is initializing. The Cluster service is starting. (El recurso se está inicializando. El servicio de clúster se está iniciando.)
Identificador del evento: cpqhsmsg.dll - 3865 (Hex)0x44350f19 (evento de servicio)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: Resource status is pending. The Cluster service is starting or the resource is being put back online or being taken offline. (El estado del recurso es Pending. El servicio de clúster se está iniciando, o el recurso se está poniendo en estado Online u Offline.)
Identificador del evento: cpqhsmsg.dll - 3866 (Hex)0x44350f1a (evento de servicio)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: Resource status is online pending. The resource is being put back online. (El estado del recurso es Online Pending. El recurso se está poniendo de nuevo en estado Online.)
Identificador del evento: cpqhsmsg.dll - 3867 (Hex)0x44350f1b (evento de servicio)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: Resource status is offline pending. The resource is being taken offline. (El estado del recurso es Offline Pending. El recurso se está poniendo en estado Offline.)
Identificador del evento: cpqhsmsg.dll - 3868 (Hex)0x84350f1c (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Cluster information is unavailable. The Cluster service may not be running. Try to restart the Cluster service. (La información del clúster no está disponible. Es posible que el servicio de clúster no se esté ejecutando. Intente reiniciar el servicio de clúster.)
Identificador del evento: cpqhsmsg.dll - 3869 (Hex)0x84350f1d (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Cluster service is not running. The Cluster service has failed or has not started yet. Try to restart the cluster service. (El servicio de clúster no se está ejecutando. Se ha producido un fallo en el servicio de clúster o todavía no se ha iniciado. Intente reiniciar el servicio de clúster.)
Identificador del evento: cpqhsmsg.dll - 3870 (Hex)0x84350f1e (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Agent could not open the Cluster service. The Cluster service may have been stopped. Try to restart the cluster service. (El agente no pudo abrir el servicio de clúster. Es posible que el servicio de clúster se haya detenido. Intente reiniciar el servicio de clúster.)
Identificador del evento: cpqhsmsg.dll - 3871 (Hex)0x84350f1f (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
346 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Mensaje del registro: The Agent could not open the Cluster service registry key. (El agente no pudo abrir la clave del registro del servicio de clúster.)
Identificador del evento: cpqhsmsg.dll - 3872 (Hex)0x84350f20 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The specified storage class is not supported by the Agent. The Agent only supports the disk resource class. (El agente no admite la clase de almacenamiento especificada. El agente solo admite la clase de recurso de disco.)
Identificador del evento: cpqhsmsg.dll - 3873 (Hex)0x84350f21 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The fibre controller resided at the storage box is off-line. The Agent only supports the disk resource class. (La controladora de fibra ubicada en la caja de almacenamiento está Offline. El agente solo admite la clase de recurso de disco.)
Identificador del evento: cpqhsmsg.dll - 3874 (Hex)0x84350f22 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not read the registry sub-key: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo leer la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 3875 (Hex)0x84350f23 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not open enumerated network. The Cluster service may not be running. Try to restart the Cluster service. (No se pudo abrir la red enumerada. Es posible que el servicio de clúster no se esté ejecutando. Intente reiniciar el servicio de clúster.)
Identificador del evento: cpqhsmsg.dll - 3876 (Hex)0x84350f24 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not enumerate the cluster's networks. The Cluster service may not be running. Try to restart the Cluster service. (No se pudieron enumerar las redes del clúster. Es posible que el servicio de clúster no se esté ejecutando. Intente reiniciar el servicio de clúster.)
Identificadores de eventos 4352-4626Identificador del evento: cpqhsmsg.dll - 4352 (Hex)0x84351100 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The External Status MIB Agent could not allocate memory. The data contains the error code. (External Status MIB Agent no pudo asignar memoria. Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 4353 (Hex)0x84351101 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The External Status MIB Agent could not open the base of the registry. The data contains the error code. (External Status MIB Agent no pudo abrir la base del registro. Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 4354 (Hex)0x84351102 (evento de servicio)
ESES Agentes base 347

Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: “%1”. The data contains the error code. (Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 4355 (Hex)0x84351103 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: “%1”. The data contains the error code. (Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 4356 (Hex)0x84351104 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The External Status MIB Agent could not read the registry value “%1”. The data contains the error code. (External Status MIB Agent no pudo leer el valor del registro “%1”. Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 4357 (Hex)0x84351105 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The External Status MIB Agent found an incorrect type for registry value “%1”. The data contains the type found. (External Status MIB Agent encontró un tipo incorrecto para el valor del registro “%1”. Los datos contienen el tipo encontrado.)
Identificador del evento: cpqhsmsg.dll - 4358 (Hex)0x84351106 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The External Status MIB Agent could not create a necessary event. The data contains the error code. (External Status MIB Agent no pudo crear un evento necesario. Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 4359 (Hex)0x84351107 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The External Status MIB Agent could not set an event. The data contains the error code. (External Status MIB Agent no pudo configurar un evento. Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 4360 (Hex)0x84351108 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The External Status MIB Agent could not create its main thread of execution. The data contains the error code. (External Status MIB Agent no pudo crear su subproceso principal de ejecución. Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 4361 (Hex)0x84351109 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The External Status MIB Agent main thread did not terminate properly. The data contains the error code. (El subproceso principal de External Status MIB Agent no finalizó correctamente. Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 4362 (Hex)0x8435110a (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
348 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Mensaje del registro: The External Status MIB Agent got an unexpected error code while waiting for an event. The data contains the error code. (External Status MIB Agent obtuvo un código de error inesperado mientras esperaba que se produjese un evento. Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 4363 (Hex)0x8435110b (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The External Status MIB Agent did not respond to a request. The data contains the error code. (External Status MIB Agent no respondió a una solicitud. Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 4364 (Hex)0x8435110c (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The External Status MIB Agent received an unknown action code from the service. The data contains the action code. (External Status MIB Agent recibió un código de acción desconocido del servicio. Los datos contienen el código de acción.)
Identificador del evento: cpqhsmsg.dll - 4365 (Hex)0x8435110d (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The External Status MIB Agent could not get the system type. The data contains the error code. (External Status MIB Agent no pudo obtener el tipo del sistema. Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 4402 (Hex)0x84351132 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The External Status MIB Agent could not create an SNMP session. The data contains the error code. (External Status MIB Agent no pudo crear una sesión SNMP. Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 4403 (Hex)0x84351133 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The External Status MIB Agent SNMP request failed. The data contains the error code. (Error en la solicitud SNMP de External Status MIB Agent. Los datos contienen el código del error.)
Acción: Realice los pasos siguientes:
1. Asegúrese de que el servicio SNMP está configurado para que permita solicitudes SNMP de “localhost”.
2. Asegúrese de que hay suficiente memoria disponible.
Identificador del evento: cpqhsmsg.dll - 4405 (Hex)0x84351135 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The External Status MIB Agent could not set the variable because it is unsupported. The data contains the error code. (External Status MIB Agent no pudo configurar la variable debido a que esta no es compatible. Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 4406 (Hex)0x84351136 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
ESES Agentes base 349

Mensaje del registro: The External Status MIB Agent could not set the variable because the value is invalid or out of range. The data contains the error code. (External Status MIB Agent no pudo configurar la variable debido a que el valor no es válido o está fuera del intervalo. Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 4407 (Hex)0x84351137 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The External Status MIB Agent is not loaded. Sets are not available. The data contains the error code. (External Status MIB Agent no está cargado. Los conjuntos no están disponibles. Los datos contienen el código del error.)
Identificador del evento: cpqhsmsg.dll - 4608 (Hex)0x84351200 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to allocate memory. This indicates a low memory condition. Rebooting the system will correct this error. (No es posible asignar memoria. Esto indica un problema de memoria insuficiente. Reinicie el sistema para corregir este error.)
Identificador del evento: cpqhsmsg.dll - 4609 (Hex)0x84351201 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not read from the registry sub-key. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo leer la subclave del registro. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 4610 (Hex)0x84351202 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not write the registry sub-key: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo escribir la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 4611 (Hex)0x84351203 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not read the registry sub-key: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo leer la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 4612 (Hex)0x84351204 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not read from the registry sub-key: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo leer la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 4613 (Hex)0x84351205 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not read from the registry sub-key: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo
350 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

leer la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqhsmsg.dll - 4623 (Hex)0x8435120f (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Agent could not access WMI. The WMI support may have not been started or installed. Restart or Install WMI service and restart the agents. (El agente no pudo acceder a WMI. Es posible que no se haya iniciado o instalado la compatibilidad con WMI. Reinicie o instale el servicio WMI y vuelva a iniciar los agentes.)
Identificador del evento: cpqhsmsg.dll - 4624 (Hex)0x84351210 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Agent requires WMI service to be running. If NT 4.0 installed the latest version of WMI from Microsoft®, WMI service may need to be started. (El agente requiere el servicio WMI para su ejecución. Si NT 4.0 instaló la versión más reciente de WMI de Microsoft®, es posible que sea necesario reiniciar el servicio WMI.)
Identificador del evento: cpqhsmsg.dll - 4625 (Hex)0x84351211 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Agent failed to initialize WMI. WMI service may not have started or may still be in the starting state. (El agente no pudo inicializar WMI. Es posible que el servicio WMI no se haya iniciado o que se encuentre todavía en el estado de inicio.)
Identificador del evento: cpqhsmsg.dll - 4626 (Hex)0x84351212 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Agent failed to process the MOF file to get the data from WMI. Problem with WMI service or MOF file or wrong file paths used. (El agente no pudo procesar el archivo MOF para obtener los datos de WMI. Se ha producido un problema con el servicio WMI, el archivo MOF o con el uso de rutas de archivo erróneas.)
Agentes de almacenamientoIdentificadores de eventos 256-774
Identificador del evento: cpqstmsg.dll - 256 (Hex)0x84350100 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Storage Agents service detected an error. The insertion string is: %1. The data contains the error code. (El servicio Storage Agents detectó un error. La cadena de inserción es: %1. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 257 (Hex)0x84350101 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Storage Agents service could not allocate memory. The data contains the error code. (El servicio Storage Agents no pudo asignar memoria. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 258 (Hex)0x84350102 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
ESES Agentes de almacenamiento 351

Mensaje del registro: The Storage Agents service could not register with the Service Control Manager. The data contains the error code. (El servicio Storage Agents no se pudo registrar en Service Control Manager. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 259 (Hex)0x84350103 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Storage Agents service could not set the service status with the Service Control Manager. The data contains the error code. (El servicio Storage Agents no pudo configurar el estado del servicio en Service Control Manager. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 260 (Hex)0x84350104 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Storage Agents service could not create an event object. The data contains the error code. (El servicio Storage Agents no pudo crear un objeto de evento. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 261 (Hex)0x84350105 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Storage Agents service could not open registry key “%1”. The data contains the error code. (El servicio Storage Agents no pudo abrir la clave del registro “%1”. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 262 (Hex)0x84350106 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Storage Agents service could not start any agents successfully. (El servicio Storage Agents no pudo iniciar correctamente ningún agente.)
Identificador del evento: cpqstmsg.dll - 263 (Hex)0x84350107 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Storage Agents service could not read the registry value “%1”. The data contains the error code. (El servicio Storage Agents no pudo leer el valor del registro “%1”. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 264 (Hex)0x84350108 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Storage Agents service could not load the module “%1”. The data contains the error code. (El servicio Storage Agents no pudo cargar el módulo “%1”. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 265 (Hex)0x84350109 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Storage Agents service could get the control function for module “%1”. The data contains the error code. (El servicio Storage Agents pudo obtener la función de control para el módulo “%1”. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 267 (Hex)0x8435010b (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
352 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Mensaje del registro: The Storage Agents service could not start agent “%1”. The data contains the error code. (El servicio Storage Agents no pudo iniciar el agente “%1”. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 268 (Hex)0x8435010c (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Storage Agents service detected an invalid state for agent “%1”. The data contains the state. (El servicio Storage Agents detectó un estado no válido para el agente “%1”. Los datos contienen el estado.)
Identificador del evento: cpqstmsg.dll - 269 (Hex)0x8435010d (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Storage Agents service could not stop agent “%1”. The data contains the error code. (El servicio Storage Agents no pudo detener el agente “%1”. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 270 (Hex)0x8435010e (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Storage Agents service could not terminate agent “%1”. The data contains the error code. (El servicio Storage Agents no pudo finalizar el agente “%1”. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 271 (Hex)0x8435010f (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Storage Agents service could not unload the module “%1”. The data contains the error code. (El servicio Storage Agents no pudo descargar el módulo “%1”. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 272 (Hex)0x84350110 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Storage Agents service could not create the registry key “%1”. The data contains the error code. (El servicio Storage Agents no pudo crear la clave del registro “%1”. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 273 (Hex)0x84350111 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Storage Agents service could not write the registry value “%1”. The data contains the error code. (El servicio Storage Agents no pudo escribir el valor del registro “%1”. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 399 (Hex)0xc435018f (evento de servicio)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: The Storage Agents service encountered a fatal error. The service is terminating. The data contains the error code. (El servicio Storage Agents encontró un error muy grave. El servicio está finalizando. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 400 (Hex)0x44350190 (evento de servicio)
Nivel de gravedad del registro: Información (1)
ESES Agentes de almacenamiento 353

Mensaje del registro: The Storage Agents service version %1 has started. (Se ha iniciado la versión %1 del servicio Storage Agents.)
Identificador del evento: cpqstmsg.dll - 401 (Hex)0x44350191 (evento de servicio)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: %1
Identificador del evento: cpqstmsg.dll - 512 (Hex)0x84350200 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to allocate memory. This indicates a low memory condition. Rebooting the system will correct this error. (No es posible asignar memoria. Esto indica un problema de memoria insuficiente. Reinicie el sistema para corregir este error.)
Identificador del evento: cpqstmsg.dll - 513 (Hex)0x84350201 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not read from the registry subkey. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo leer la subclave del registro. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqstmsg.dll - 514 (Hex)0x84350202 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not write the registry subkey: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo escribir la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqstmsg.dll - 515 (Hex)0x84350203 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not read the registry subkey: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo leer la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqstmsg.dll - 516 (Hex)0x84350204 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not read the registry subkey: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo leer la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqstmsg.dll - 517 (Hex)0x84350205 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not read the registry subkey: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo leer la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqstmsg.dll - 526 (Hex)0x8435020e (evento de servicio)
354 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unsupported storage system. The ProLiant storage system %1 is not supported by this version of the Storage Agents. Upgrade the agents to the latest version. (Sistema de almacenamiento no compatible. El sistema de almacenamiento ProLiant %1 no es compatible con esta versión de Storage Agents. Actualice los agentes a la versión más reciente.)
Identificador del evento: cpqstmsg.dll - 527 (Hex)0x8435020f (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Drive Array Agent storage system table is full. (La tabla del sistema de almacenamiento de Drive Array Agent está llena.)
Identificador del evento: cpqstmsg.dll - 574 (Hex)0x8435023e (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Drive Array Agent failed to get capacity on SCSI drive because SCSI pass through IOCTL failed. (Drive Array Agent no pudo obtener la capacidad de la unidad SCSI debido a que se ha producido un fallo en la transferencia SCSI a través de IOCTL.)
Identificador del evento: cpqstmsg.dll - 768 (Hex)0x84350300 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Remote Alerter Agent detected an invalid data type within an alert definition. (Remote Alerter Agent detectó un tipo de datos no válido dentro de una definición de alerta.)
Identificador del evento: cpqstmsg.dll - 769 (Hex)0x84350301 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Remote Alerter Agent detected an error while attempting to log an alert remotely. The data contains the error code. (Remote Alerter Agent detectó un error al intentar registrar una alerta de forma remota. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 771 (Hex)0x84350303 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Remote Alerter Agent was unable to log an event in the event log of the system named %1. The data contains the error code. (Remote Alerter Agent no pudo registrar un evento en el registro de eventos del sistema %1. Los datos contienen el código de error.)
Identificador del evento: cpqstmsg.dll - 772 (Hex)0xc4350304 (evento de servicio)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: The Remote Alerter Agent detected a null handle on initialization. The data contains the error code. (Remote Alerter Agent detectó un identificador nulo durante la inicialización. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 773 (Hex)0xc4350305 (evento de servicio)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: The Remote Alerter Agent received an error on WaitForMultipleObjects call. The data contains the error code. (Remote Alerter Agent recibió un error en la llamada a WaitForMultipleObjects. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 774 (Hex)0xc4350306 (evento de servicio)
Nivel de gravedad del registro: Error (3)
ESES Agentes de almacenamiento 355

Mensaje del registro: The Remote Alerter Agent received an error on ResetEvent call. The data contains the error code. (Remote Alerter Agent recibió un error en la llamada a ResetEvent. Los datos contienen el código del error.)
Identificadores de eventos 1061-1098ID de evento de NT: 1061 (Hex)0xc4350425 (cpqstmsg.dll)
Nivel de gravedad del registro: Error (3)
Título del evento: Drive Array Physical Drive Threshold Exceeded. (Se ha sobrepasado el umbral de unidades físicas del array de unidades.)
Mensaje del registro: The physical drive in slot %4, port %5, bay %6 with serial number “%7”, has exceeded a drive threshold. (La unidad física de la ranura %4, puerto %5, compartimento %6, con el número de serie “%7”, ha sobrepasado un umbral de unidades.)
Captura SNMP: cpqDa5PhyDrvThreshPassedTrap - 3030 en CPQIDA.MIB
Síntoma: Se ha sobrepasado el umbral de unidades físicas. Esta captura indica que el agente ha detectado que se ha sobrepasado un umbral de fábrica asociado con uno de los objetos de unidad física de un array de unidades.
Acción del usuario: Sustituya la unidad física.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqDaPhyDrvCntlrIndex
● cpqDaPhyDrvBusNumber
● cpqDaPhyDrvBay
● cpqDaPhyDrvModel
● cpqDaPhyDrvFWRev
● cpqDaPhyDrvSerialNum
Descripción complementaria de la captura SNMP: “Factory threshold passed for a physical drive.” (Se ha sobrepasado el umbral de fábrica para una unidad física.)
ID de evento de NT: 1062 (Hex)0xc4350426 (cpqstmsg.dll)
Nivel de gravedad del registro: Error (3)
Título del evento: Drive Array Logical Drive Status Change. (El estado de la unidad lógica del array de unidades ha cambiado.)
Mensaje del registro: Logical drive number %5 on the array controller in slot %4 has a new status of %2. (El estado de la unidad lógica número %5 de la controladora de array de la ranura %4 ha cambiado a %2.)
Captura SNMP: cpqDa3LogDrvStatusChange - 3008 en CPQIDA.MIB
Síntoma: El estado de la unidad lógica ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de la unidad lógica de un array de unidades. La variable cpqDaLogDrvStatus indica el estado actual de la unidad lógica.
Datos complementarios de la captura SNMP:
356 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

● sysName
● cpqHoTrapFlags
● cpqDaLogDrvStatus
Descripción complementaria de la captura SNMP: “Status is now [cpqDaLogDrvStatus].” (Ahora, el estado es [cpqDaLogDrvStatus].)
ID de evento de NT: 1063 (Hex)0xc4350427 (cpqstmsg.dll)
Nivel de gravedad del registro: Error (3)
Título del evento: Drive Array Spare Drive Status Change. (El estado de la unidad de repuesto del array de unidades ha cambiado.)
Mensaje del registro: The spare drive in slot %4, port %5, bay %6 has a new status of %2. (El estado de la unidad de repuesto de la ranura %4, puerto %5, compartimento %6, ha cambiado a %2.)
Captura SNMP: cpqDa4SpareStatusChange - 3017 en CPQIDA.MIB
Síntoma: El estado de la unidad de repuesto del array de unidades ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de la unidad de repuesto de un array de unidades. La variable cpqDaSpareStatus indica el estado actual de la unidad de repuesto.
Acción del usuario: Si el estado de la unidad de repuesto es Failed, sustitúyala.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqDaSpareStatus
● cpqDaSpareCntlrIndex
● cpqDaSpareBusNumber
● cpqDaSpareBay
Descripción complementaria de la captura SNMP: “Spare Status is now [cpqDaSpareStatus].” (Ahora, el estado de la unidad de repuesto es [cpqDaSpareStatus].)
ID de evento de NT: 1064 (Hex)0xc4350428 (cpqstmsg.dll)
Nivel de gravedad del registro: Error (3)
Título del evento: Drive Array Physical Drive Status Change. (El estado de la unidad física del array de unidades ha cambiado.)
Mensaje del registro: The physical drive in slot %4, port %5, bay %6 with serial number “%7”, has a new status of %2. (El estado de la unidad física de la ranura %4, puerto %5, compartimento %6, con el número de serie “%7”, ha cambiado a %2.)
Captura SNMP: cpqDa5PhyDrvStatusChange - 3029 en CPQIDA.MIB
Síntoma: El estado de la unidad física ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de la unidad física de un array de unidades. La variable cpaDaPhyDrvStatus indica el estado actual de la unidad física.
Acción del usuario: Si el estado de la unidad física es failed(3) o predictiveFailure(4), sustitúyala.
Datos complementarios de la captura SNMP:
ESES Agentes de almacenamiento 357

● sysName
● cpqHoTrapFlags
● cpqDaPhyDrvStatus
● cpqDaPhyDrvCntlrIndex
● cpqDaPhyDrvBusNumber
● cpqDaPhyDrvBay
● cpqDaPhyDrvModel
● cpqDaPhyDrvFWRev
● cpqDaPhyDrvSerialNum
● cpqDaPhyDrvFailureCode
Descripción complementaria de la captura SNMP: “Physical Drive Status is now [cpqDaPhyDrvStatus].” (Ahora, el estado de la unidad física es [cpqDaPhyDrvStatus].)
ID de evento de NT: 1065 (Hex)0xc4350429 (cpqstmsg.dll)
Nivel de gravedad del registro: Error (3)
Título del evento: Drive Array Accelerator Status Change. (El estado del acelerador de array de unidades ha cambiado.)
Mensaje del registro: The array accelerator board attached to the array controller in slot %4 has a new status of %2. (El estado de la placa del acelerador de array conectada a la controladora de array de la ranura %4 ha cambiado a %2.)
Captura SNMP: cpqDa5AccelStatusChange - 3025 en CPQIDA.MIB
Síntoma: El estado de la placa del acelerador ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de una placa de la memoria caché del acelerador de array. La variable cpqDaAccelStatus representa el estado actual.
Acción del usuario: Si el estado de la placa del acelerador es permDisabled(5), es posible que necesite sustituirla.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqDaCntlrSlot
● cpqDaCntlrModel
● cpqDaAccelSerialNumber
● cpqDaAccelTotalMemory
● cpqDaAccelStatus
● cpqDaAccelErrCode
Descripción complementaria de la captura SNMP: “Status is now [cpqDaAccelStatus].” (Ahora, el estado es [cpqDaAccelStatus].)
ID de evento de NT: 1066 (Hex)0xc435042a (cpqstmsg.dll)
Nivel de gravedad del registro: Error (3)
358 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Título del evento: Drive Array Accelerator Bad Data. (Datos incorrectos en el acelerador de array de unidades.)
Mensaje del registro: The array accelerator board attached to the array controller in slot %4 is reporting that it contains bad cached data. (La placa del acelerador de array conectada a la controladora de array de la ranura %4 informa de que contiene datos incorrectos en la memoria caché.)
Captura SNMP: cpqDa5AccelBadDataTrap - 3026 en CPQIDA.MIB
Síntoma: Datos incorrectos en la placa del acelerador. Esta captura indica que el agente ha detectado una placa de memoria caché del acelerador de array que ha perdido la alimentación por batería. Si se estaban almacenando datos en la memoria caché del acelerador en el momento en el que se interrumpió el suministro de alimentación al servidor, dichos datos se han perdido.
Acción del usuario: Compruebe que no se ha perdido ningún dato.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqDaCntlrSlot
● cpqDaCntlrModel
● cpqDaAccelSerialNumber
● cpqDaAccelTotalMemory
Descripción complementaria de la captura SNMP: “Accelerator lost battery power. Data Loss possible.” (El acelerador ha perdido la alimentación por batería. Es posible que se hayan perdido datos.)
ID de evento de NT: 1067 (Hex)0xc435042b (cpqstmsg.dll)
Nivel de gravedad del registro: Error (3)
Título del evento: Drive Array Accelerator Battery Failed. (La batería del acelerador de array de unidades ha fallado.)
Mensaje del registro: The array accelerator board attached to the array controller in slot %4 is reporting a battery failure. (La placa del acelerador de array conectada a la controladora de array de la ranura %4 informa de un fallo en la batería.)
Captura SNMP: cpqDa5AccelBatteryFailed - 3027 en CPQIDA.MIB
Síntoma: La batería de la placa del acelerador ha fallado. Esta captura indica que el agente ha detectado un fallo en la batería asociado con la placa de memoria caché del acelerador de array.
Acción del usuario: Sustituya la placa de memoria caché del acelerador.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqDaCntlrSlot
● cpqDaCntlrModel
ESES Agentes de almacenamiento 359

● cpqDaAccelSerialNumber
● cpqDaAccelTotalMemory
Descripción complementaria de la captura SNMP: “Battery status is failed.” (El estado de la batería es Failed.)
ID de evento de NT: 1068 (Hex)0xc435042c (cpqstmsg.dll)
Nivel de gravedad del registro: Error (3)
Título del evento: SCSI Controller Status Change. (El estado de la controladora SCSI ha cambiado.)
Mensaje del registro: The SCSI controller in slot %4, SCSI bus %5 has a new status of %2. (El estado de la controladora SCSI de la ranura %4, bus SCSI %5, ha cambiado a %2.)
Captura SNMP: cpqScsi3CntlrStatusChange - 5005 en CPQSCSI.MIB
Síntoma: El estado de la controladora SCSI ha cambiado. Insight Agent ha detectado un cambio en el estado de una controladora SCSI. La variable cpqScsiCntlrStatus indica el estado actual de la controladora.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqScsiCntlrStatus
Descripción complementaria de la captura SNMP: “Status is now [cpqScsiCntlrStatus].” (Ahora, el estado es [cpqScsiCntlrStatus].)
ID de evento de NT: 1069 (Hex)0xc435042d (cpqstmsg.dll)
Nivel de gravedad del registro: Error (3)
Título del evento: SCSI Logical Drive Status Change. (El estado de la unidad lógica SCSI ha cambiado.)
Mensaje del registro: The SCSI logical drive with SCSI target %6 connected to SCSI bus %5 of the controller in slot %4, SCSI has a new status of %2. (El estado de la unidad lógica SCSI con destino SCSI %6 conectado al bus SCSI %5 de la controladora de la ranura %4 ha cambiado a %2.)
Captura SNMP: cpqScsi3LogDrvStatusChange - 5021 en CPQSCSI.MIB
Síntoma: El estado de la unidad lógica ha cambiado. Storage Agent ha detectado un cambio en el estado de una unidad lógica SCSI. La variable cpqScsiLogDrvStatus indica el estado actual de la unidad lógica.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqScsiLogDrvStatus
● cpqScsiLogDrvCntlrIndex
● cpqScsiLogDrvBusIndex
● cpqScsiLogDrvIndex
● cpqScsiLogDrvOsName
360 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Descripción complementaria de la captura SNMP: “Status is now [cpqScsiLogDrvStatus].” (Ahora, el estado es [cpqScsiLogDrvStatus].)
ID de evento de NT: 1070 (Hex)0xc435042e (cpqstmsg.dll)
Nivel de gravedad del registro: Error (3)
Título del evento: SCSI Physical Drive Status Change. (El estado de la unidad física SCSI ha cambiado.)
Mensaje del registro: The SCSI physical drive with SCSI target %6 connected to SCSI bus %5 of the controller in slot %4 has a new status of %2. (El estado de la unidad física SCSI con destino SCSI %6 conectado al bus SCSI %5 de la controladora de la ranura %4 ha cambiado a %2.)
Captura SNMP: cpqScsi5PhyDrvStatusChange - 5020 en CPQSCSI.MIB
Síntoma: El estado de la unidad física ha cambiado. Storage Agent ha detectado un cambio en el estado de una unidad física SCSI. La variable pqScsiPhyDrvStatus indica el estado actual de la unidad física.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqScsiPhyDrvStatus
● cpqScsiPhyDrvCntlrIndex
● cpqScsiPhyDrvBusIndex
● cpqScsiPhyDrvIndex
● cpqScsiPhyDrvVendor
● cpqScsiPhyDrvModel
● cpqScsiPhyDrvFWRev
● cpqScsiPhyDrvSerialNum
● cpqScsiPhyDrvOsName
Descripción complementaria de la captura SNMP: “Status is now [cpqScsiPhyDrvStatus].” (Ahora, el estado es [cpqScsiPhyDrvStatus].)
ID de evento de NT: 1075 (Hex)0x84350433 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Storage System Fan Status Change. (El estado del ventilador del sistema de almacenamiento ha cambiado.)
Mensaje del registro: The %6 %7 storage system connected to SCSI bus %5 of the controller in slot %4 has a new status of %2. (El estado del %7 del %6 del sistema de almacenamiento conectado al bus SCSI %5 de la controladora de la ranura %4 ha cambiado a %2.)
Captura SNMP: cpqSs3FanStatusChange - 8008 en CPQSTSYS.MIB
Síntoma: El estado del ventilador del sistema de almacenamiento ha cambiado. El agente ha detectado un cambio en el estado del ventilador de un sistema de almacenamiento. La variable cpqSsBoxFanStatus indica el estado actual del ventilador.
ESES Agentes de almacenamiento 361

Acción del usuario: Si el estado del ventilador es Degraded o Failed, sustituya los ventiladores defectuosos.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSsBoxFanStatus
Descripción complementaria de la captura SNMP: “Storage System fan status changed to [cpqSsBoxFanStatus].” (El estado del ventilador del sistema de almacenamiento ha cambiado a [cpqSsBoxFanStatus].)
ID de evento de NT: 1076 (Hex)0xc4350434 (cpqstmsg.dll)
Nivel de gravedad del registro: Error (3)
Título del evento: Storage System Temperature Failure. (Fallo en la temperatura del sistema de almacenamiento.)
Mensaje del registro: The %6 %7 storage system connected to SCSI bus %5 of the controller in slot %4 has a failed temperature status. Shut down the storage system as soon as possible. (El estado de la temperatura del %7 del %6 del sistema de almacenamiento conectado al bus SCSI %5 de la controladora de la ranura %4 es Failed. Apague el sistema de almacenamiento tan pronto como sea posible.)
Captura SNMP: cpqSs3TempFailed - 8009 en CPQSTSYS.MIB
Síntoma: Fallo en la temperatura del sistema de almacenamiento. El agente ha detectado que la temperatura tiene el estado Failed. El sistema de almacenamiento está apagado.
Acción del usuario: Apague el sistema de almacenamiento tan pronto como sea posible. Asegúrese de que el entorno del sistema de almacenamiento tiene una refrigeración apropiada y de que no hay componentes sobrecalentados.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSsBoxTempStatus
Descripción complementaria de la captura SNMP: “Storage System will be shut down.” (El sistema de almacenamiento se apagará.)
ID de evento de NT: 1077 (Hex)0x84350435 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Storage System Temperature Degraded. (La temperatura del sistema de almacenamiento tiene el estado Degraded.)
Mensaje del registro: The %6 %7 storage system connected to SCSI bus %5 of the controller in slot %4 system has a temperature outside the normal operating range. (El estado del %7 del %6 del sistema de almacenamiento conectado al bus SCSI %5 de la controladora de la ranura %4 tiene una temperatura que se encuentra fuera del intervalo de funcionamiento normal.)
Captura SNMP: cpqSs3TempDegraded - 8010 en CPQSTSYS.MIB
362 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Síntoma: La temperatura del sistema de almacenamiento tiene el estado Degraded. El agente ha detectado que la temperatura tiene el estado Degraded. La temperatura del sistema de almacenamiento está fuera del intervalo de funcionamiento normal.
Acción del usuario: Apague el sistema de almacenamiento tan pronto como sea posible. Asegúrese de que el entorno del sistema de almacenamiento tiene una refrigeración apropiada y de que no hay componentes sobrecalentados.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSsBoxTempStatus
Descripción complementaria de la captura SNMP: “Temp is outside of normal range.” (La temperatura está fuera del intervalo normal.)
ID de evento de NT: 1078 (Hex)0x44350436 (cpqstmsg.dll)
Nivel de gravedad del registro: Información (1)
Título del evento: Storage System Temperature OK. (Temperatura del sistema de almacenamiento correcta.)
Mensaje del registro: The temperature in the %6 %7 storage system connected to SCSI bus %5 of the controller in slot %4 has returned to the normal operating range. (La temperatura del %7 del %6 del sistema de almacenamiento conectado al bus SCSI %5 de la controladora de la ranura %4 vuelve a estar dentro del intervalo de funcionamiento normal.)
Captura SNMP: cpqSs3TempOk - 8011 en CPQSTSYS.MIB
Síntoma: La temperatura del sistema de almacenamiento es correcta. La temperatura tiene el estado OK (Correcto). La temperatura del sistema de almacenamiento vuelve a estar dentro del intervalo de funcionamiento normal. El administrador puede volver a activarla.
Acción del usuario: Ninguna.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSsBoxTempStatus
Descripción complementaria de la captura SNMP: “Storage System temperature ok.” (Temperatura del sistema de almacenamiento correcta.)
Identificador del evento: cpqstmsg.dll - 1098 (Hex)0x4435044a (evento de servicio)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: Drive Array Physical Drive Monitoring is not enabled. The physical drive in slot %4, port %5, bay %6 with serial number “%7”, does not have drive threshold monitoring enabled. (La supervisión de la unidad física del array de unidades no está activada. La unidad física de la ranura %4, puerto %5, compartimento %6, con el número de serie “%7”, no tiene activada la supervisión del umbral de unidades.)
Identificadores de eventos 1101-1199ID de evento de NT: 1101 (Hex)0x8435044d (cpqstmsg.dll)
ESES Agentes de almacenamiento 363

Nivel de gravedad del registro: Advertencia (2)
Título del evento: Storage System Side Panel Removed. (Se ha quitado el panel lateral del sistema de almacenamiento.)
Mensaje del registro: The side panel has been removed on the %6 %7 storage system connected to SCSI bus %5 of the controller in slot %4. (Se ha quitado el panel lateral en el %7 del %6 del sistema de almacenamiento conectado al bus SCSI %5 de la controladora de la ranura %4.)
Captura SNMP: cpqSs3SidePanelRemoved - 8013 en CPQSTSYS.MIB
Síntoma: Se ha quitado el panel lateral del sistema de almacenamiento. El panel lateral tiene el estado Removed. El panel lateral del sistema de almacenamiento no está instalado correctamente. Esta situación puede dar como resultado una refrigeración incorrecta de las unidades del sistema de almacenamiento debido a los cambios en el flujo de aire ocasionados por la ausencia del panel lateral.
Acción del usuario: Vuelva a colocar el panel lateral del sistema de almacenamiento.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSsBoxSidePanelStatus
Descripción complementaria de la captura SNMP: “Side panel is removed from unit.” (Se ha quitado el panel lateral de la unidad.)
ID de evento de NT: 1102 (Hex)0x4435044e (cpqstmsg.dll)
Nivel de gravedad del registro: Información (1)
Título del evento: Storage System Side Panel In Place. (El panel lateral del sistema de almacenamiento tiene el estado In Place.)
Mensaje del registro: The side panel has been replaced on the %6 %7 storage system connected to SCSI bus %5 of the controller in slot %4. (Se ha vuelto a colocar el panel lateral en el %7 del %6 del sistema de almacenamiento conectado al bus SCSI %5 de la controladora de la ranura %4.)
Captura SNMP: cpqSs3SidePanelInPlace - 8012 en CPQSTSYS.MIB
Síntoma: El panel lateral del sistema de almacenamiento está colocado en su sitio. El panel lateral tiene el estado In place. El panel lateral del sistema de almacenamiento vuelve a estar correctamente instalado.
Acción del usuario: Ninguna.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSsBoxSidePanelStatus
Descripción complementaria de la captura SNMP: “Side panel is re-installed on unit.” (El panel lateral se ha vuelto a instalar en la unidad.)
ID de evento de NT: 1104 (Hex)0x84350450 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
364 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Título del evento: Storage System Fault Tolerant Power Supply Degraded. (La fuente de alimentación con tolerancia a fallos del sistema de almacenamiento tiene el estado Degraded.)
Mensaje del registro: The fault tolerant power supply in the %6 %7 storage system connected to SCSI bus %5 of the controller in slot %4 has a degraded status. Restore power or replace any failed power supply. (La fuente de alimentación con tolerancia a fallos del %7 del %6 del sistema de almacenamiento conectado al bus SCSI %5 de la controladora de la ranura %4 tiene el estado Degraded. Restaure la alimentación o sustituya las fuentes de alimentación defectuosas.)
Captura SNMP: cpqSs4PwrSupplyDegraded - 8015 en CPQSTSYS.MIB
Síntoma: La fuente de alimentación del sistema de almacenamiento tiene el estado Degraded.
Acción del usuario: Restaure la alimentación o sustituya las fuentes de alimentación del sistema de almacenamiento defectuosas.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSsBoxFltTolPwrSupplyStatus
Descripción complementaria de la captura SNMP: “A storage system power supply unit has become degraded.” (El estado de una fuente de alimentación del sistema de almacenamiento ha cambiado a Degraded.)
ID de evento de NT: 1107 (Hex)0xc4350453 (cpqstmsg.dll)
Nivel de gravedad del registro: Error (3)
Título del evento: SCSI Tape Drive Status Change. (El estado de la unidad de cinta SCSI ha cambiado.)
Mensaje del registro: The tape drive with SCSI target %6 connected to SCSI bus %5 of the controller in slot %4 has a new status of %2. (El estado de la unidad de cinta con destino SCSI %6 conectada al bus SCSI %5 de la controladora de la ranura %4 ha cambiado a %2.)
Captura SNMP: cpqTape4PhyDrvStatusChange - 5016 en CPQSCSI.MIB
Síntoma: El estado de la unidad de cinta ha cambiado. Storage Agent ha detectado un cambio en el estado de una unidad de cinta. La variable pqTapePhyDrvStatus indica el estado actual de la unidad física.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqTapePhyDrvCntlrIndex
● cpqTapePhyDrvBusIndex
● cpqTapePhyDrvScsiIdIndex
● cpqTapePhyDrvStatus
Descripción complementaria de la captura SNMP: “Status is now [cpqTapePhyDrvStatus].” (Ahora, el estado es [cpqTapePhyDrvStatus].)
ID de evento de NT: 1119 (Hex)0x8435045f (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
ESES Agentes de almacenamiento 365

Título del evento: SCSI Tape Drive Head Needs Cleaning. (El cabezal de la unidad de cinta SCSI necesita limpieza.)
Mensaje del registro: The tape drive with SCSI target %6 connected to SCSI bus %5 of the controller in slot %4 needs to have a cleaning tape inserted and run. (Se debe introducir y reproducir una cinta de limpieza en la unidad de cinta con destino SCSI %6 conectada al bus SCSI %5 de la controladora de la ranura %4.)
Captura SNMP: cpqTape3PhyDrvCleaningRequired - 5008 en CPQSCSI.MIB
Síntoma: Captura que indica que es necesario limpiar la unidad de cinta. Insight Agent ha detectado que es necesario introducir y reproducir una cinta de limpieza en una unidad de cinta. Esto hará que los cabezales de la unidad de cinta se limpien.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqTapePhyDrvCondition
Descripción complementaria de la captura SNMP: “Status is now [cpqTapePhyDrvCondition].” (Ahora, el estado es [cpqTapePhyDrvCondition].)
ID de evento de NT: 1120 (Hex)0x84350460 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: SCSI Tape Drive Cleaning Tape Needs Replacing. (Es necesario sustituir la cinta de limpieza de la unidad de cinta SCSI.)
Mensaje del registro: The tape drive with SCSI target %6 connected to SCSI bus %5 of the controller in slot %4 needs the cleaning tape replaced. (Es necesario sustituir la cinta de limpieza de la unidad de cinta con destino SCSI %6 conectada al bus SCSI %5 de la controladora de la ranura %4.)
Captura SNMP: cpqTape3PhyDrvCleanTapeReplace - 5009 en CPQSCSI.MIB
Síntoma: Es necesario sustituir la cinta de limpieza de la unidad de cinta. Insight Agent ha detectado que una unidad de cinta de autocargador tiene una cinta de limpieza que se ha utilizado por completo, por lo que debe sustituirse por una nueva.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqTapePhyDrvCondition
Descripción complementaria de la captura SNMP: “Status is now [cpqTapePhyDrvCondition].” (Ahora, el estado es [cpqTapePhyDrvCondition].)
ID de evento de NT: 1121 (Hex)0x84350461 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: IDE Drive Status Degraded. (La unidad IDE tiene el estado Degraded.)
Mensaje del registro: The IDE drive %4 has a degraded status and should be scheduled for replacement. (La unidad IDE %4 tiene el estado Degraded y debería sustituirse.)
Captura SNMP: cpqIdeDriveDegraded - 14001 en CPQIDE.MIB
Síntoma: Una unidad IDE tiene el estado Degraded.
366 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Acción del usuario: Se debe sustituir la unidad. Para obtener información detallada sobre la sustitución de un componente, consulte la Guía de mantenimiento y servicio correspondiente.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqIdeIdentIndex
Descripción complementaria de la captura SNMP: “IDE drive [cpqIdeIdentIndex] has become degraded.” (El estado de la unidad IDE [cpqIdeIdentIndex] ha cambiado a Degraded.)
ID de evento de NT: 1122 (Hex)0x44350462 (cpqstmsg.dll)
Nivel de gravedad del registro: Información (1)
Título del evento: IDE Drive Status OK. (La unidad IDE tiene el estado OK.)
Mensaje del registro: The IDE drive %4 has returned to a normal operating condition. (La unidad IDE %4 ha vuelto a las condiciones de funcionamiento normal.)
Captura SNMP: cpqIdeDriveOk - 14002 en CPQIDE.MIB
Síntoma: Una unidad IDE tiene el estado OK.
Acción del usuario: Ninguna.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqIdeIdentIndex
Descripción complementaria de la captura SNMP: “IDE drive [cpqIdeIdentIndex] has returned to normal operating condition.” (La unidad IDE [cpqIdeIdentIndex] ha vuelto a las condiciones de funcionamiento normal.)
ID de evento de NT: 1145 (Hex)0xc4350479 (cpqstmsg.dll)
Nivel de gravedad del registro: Error (3)
Título del evento: External Array Logical Drive Status Change. (El estado de la unidad lógica de array externo ha cambiado.)
Mensaje del registro: Logical drive number %5 on array “%4” has a new status of %6. (El estado de la unidad lógica número %5 del array “%4” ha cambiado a %6.)
Captura SNMP: cpqExtArrayLogDrvStatusChange - 16022 en CPQFCA.MIB
Síntoma: El estado de la unidad lógica de array externo ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de una unidad lógica de array externo. La variable cpqFcaLogDrvStatus indica el estado actual de la unidad lógica.
Acción del usuario: Si el estado de la unidad lógica es Failed, examine el array y localice las unidades defectuosas que es necesario sustituir.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
ESES Agentes de almacenamiento 367

● cpqSsChassisName
● cpqSsChassisTime
● cpqFcaLogDrvBoxIndex
● cpqFcaLogDrvIndex
● cpqFcaLogDrvStatus
● cpqFcaLogDrvOsName
● cpqFcaLogDrvFaultTol
● cpqFcaLogDrvSize
Descripción complementaria de la captura SNMP: “Status is now [cpqFcaLogDrvStatus].” (Ahora, el estado es [cpqFcaLogDrvStatus].)
ID de evento de NT: 1146 (Hex)0xc435047a (cpqstmsg.dll)
Nivel de gravedad del registro: Error (3)
Título del evento: External Array Physical Drive Status Change. (El estado de la unidad física de array externo ha cambiado.)
Mensaje del registro: The physical drive in port %5, bay %6 on array “%4” has a new status of %7. (El estado de la unidad física del puerto %5, compartimento %6, del array “%4”, ha cambiado a %7.)
Captura SNMP: cpqFca2PhyDrvStatusChange - 16016 en CPQFCA.MIB
Síntoma: El estado de la unidad física de array externo ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de una unidad física. La variable cpaFcaPhyDrvStatus indica el estado actual de la unidad física.
Acción del usuario: Si el estado de la unidad física es threshExceeded(4), predictiveFailure(5) o failed(6), sustitúyala.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSsChassisName
● cpqSsChassisTime
● cpqFcaPhyDrvBusNumber
● cpqFcaPhyDrvBay
● cpqFcaPhyDrvStatus
● cpqFcaPhyDrvModel
● cpqFcaPhyDrvSerialNum
● cpqFcaPhyDrvFWRev
● cpqFcaPhyDrvFailureCode
Descripción complementaria de la captura SNMP: “Status is now [cpqFcaPhyDrvStatus] for a physical drive on bus [cpqFcaPhyDrvBusNumber], bay [cpqFcaPhyDrvBay].” (Ahora, el estado de la unidad física en el bus [cpqFcaPhyDrvBusNumber], compartimento [cpqFcaPhyDrvBay] es [cpqFcaPhyDrvStatus].)
368 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

ID de evento de NT: 1147 (Hex)0xc435047b (cpqstmsg.dll)
Nivel de gravedad del registro: Error (3)
Título del evento: External Array Spare Drive Status Change. (El estado de la unidad de repuesto del array externo ha cambiado.)
Mensaje del registro: The spare drive in port %5, bay %6 on array “%4” has a new status of %7. (El estado de la unidad de repuesto del puerto %5, compartimento %6, del array “%4”, ha cambiado a %7.)
Captura SNMP: cpqFcaSpareStatusChange - 16002 en CPQFCA.MIB
Síntoma: El estado de la unidad de repuesto del array externo ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de una unidad de repuesto de array de canal externo. La variable cpqFcaSpareStatus indica el estado actual de la unidad de repuesto. La variable cpqFcaSpareBusNumber indica el número de bus SCSI asociado con esta unidad.
Acción del usuario: Si el estado de la unidad de repuesto es Failed, sustitúyala.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSsChassisName
● cpqSsChassisTime
● cpqFcaSpareBusNumber
● cpqFcaSpareBay
● cpqFcaSpareStatus
Descripción complementaria de la captura SNMP: “Spare Status is now [cpqFcaSpareStatus] on bus [cpqFcaSpareBusNumber].” (Ahora, el estado del bus [cpqFcaSpareBusNumber] es [cpqFcaSpareStatus].)
ID de evento de NT: 1148 (Hex)0xc435047c (cpqstmsg.dll)
Nivel de gravedad del registro: Error (3)
Título del evento: External Array Accelerator Status Change. (El estado del acelerador de array externo ha cambiado.)
Mensaje del registro: The array accelerator board attached to the external controller in I/O slot %5 of array “%4” has a new status of %6. (El estado de la placa del acelerador de array conectada a la controladora externa de la ranura de E/S %5 del array “%4” ha cambiado a %6.)
Captura SNMP: cpqFca2AccelStatusChange - 16017 en CPQFCA.MIB
Síntoma: El estado de la placa del acelerador de array externo ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de una placa de memoria caché del acelerador de array. La variable cpqFcaAccelStatus representa el estado actual.
Acción del usuario: Si el estado de la placa del acelerador es permDisabled(5), es posible que necesite sustituirla.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
ESES Agentes de almacenamiento 369

● cpqSsChassisName
● cpqSsChassisTime
● cpqFcaAccelBoxIoSlot
● cpqFcaAccelStatus
● cpqFcaCntlrModel
● cpqFcaAccelSerialNumber
● cpqFcaAccelTotalMemory
● cpqFcaAccelErrCode
Descripción complementaria de la captura SNMP: “Status is now [cpqFcaAccelStatus].” (Ahora, el estado es [cpqFcaAccelStatus].)
ID de evento de NT: 1149 (Hex)0xc435047d (cpqstmsg.dll)
Nivel de gravedad del registro: Error (3)
Título del evento: External Array Accelerator Bad Data. (Datos incorrectos en el acelerador de array externo.)
Mensaje del registro: The array accelerator board attached to the external controller in I/O slot %5 of array “%4” is reporting that it contains bad cached data. (La placa del acelerador de array conectada a la controladora externa de la ranura de E/S %5 del array “%4” informa de que contiene datos incorrectos en la memoria caché.)
Captura SNMP: cpqFca2AccelBadDataTrap - 16018 en CPQFCA.MIB
Síntoma: Datos incorrectos en la placa del acelerador de array externo. Esta captura indica que el agente ha detectado una placa de memoria caché del acelerador de array que ha perdido la alimentación por batería. Si se estaban almacenando datos en la memoria del acelerador en el momento en el que se interrumpió el suministro de alimentación al sistema, dichos datos se han perdido.
Acción del usuario: Compruebe que no se ha perdido ningún dato.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSsChassisName
● cpqSsChassisTime
● cpqFcaAccelBoxIoSlot
● cpqFcaCntlrModel
● cpqFcaAccelSerialNumber
● cpqFcaAccelTotalMemory
Descripción complementaria de la captura SNMP: “Accelerator lost battery power. Data Loss possible.” (El acelerador ha perdido la alimentación por batería. Es posible que se hayan perdido datos.)
ID de evento de NT: 1150 (Hex)0xc435047e (cpqstmsg.dll)
Nivel de gravedad del registro: Error (3)
370 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Título del evento: External Array Accelerator Battery Failed. (Fallo en la batería del acelerador de array externo.)
Mensaje del registro: The array accelerator board attached to the external controller in I/O slot %5 of array “%4” is reporting a battery failure. (La placa del acelerador de array conectada a la controladora externa de la ranura de E/S %5 del array “%4” informa de que hay un fallo en la batería.)
Captura SNMP: cpqFca2AccelBatteryFailed - 16019 en CPQFCA.MIB
Síntoma: Error en la batería de la placa del acelerador de array externo. Esta captura indica que el agente ha detectado un fallo en la batería asociado con la placa de memoria caché del acelerador de array.
Acción del usuario: Sustituya la placa de memoria caché del acelerador.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSsChassisName
● cpqSsChassisTime
● cpqFcaAccelBoxIoSlot
● cpqFcaCntlrModel
● cpqFcaAccelSerialNumber
● cpqFcaAccelTotalMemory
Descripción complementaria de la captura SNMP: “Battery status is failed.” (El estado de la batería es Failed.)
ID de evento de NT: 1151 (Hex)0xc435047f (cpqstmsg.dll)
Nivel de gravedad del registro: Error (3)
Título del evento: External Array Controller Status Change. (El estado de la controladora de array externa ha cambiado.)
Mensaje del registro: The external controller in I/O slot %5 of array “%4” has a new status of %6. (El estado de la controladora externa de la ranura de E/S %5 del array “%4” ha cambiado a %6.)
Captura SNMP: cpqFca2CntlrStatusChange - 16020 en CPQFCA.MIB
Síntoma: El estado de la controladora de array externa ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de una controladora de array externa. La variable cpqFcaCntlrStatus indica el estado actual de la controladora.
Acción del usuario: Si el estado de la controladora es offline(4), se ha perdido el acceso a la caja de almacenamiento. Compruebe si hay algún problema en la caja de almacenamiento y en las conexiones Fibre Channel.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSsChassisName
● cpqSsChassisTime
ESES Agentes de almacenamiento 371

● cpqFcaCntlrBoxIoSlot
● cpqFcaCntlrStatus
● cpqFcaCntlrModel
● cpqFcaCntlrSerialNumber
● cpqFcaAccelTotalMemory
Descripción complementaria de la captura SNMP: “Status is now [cpqFcaCntlrStatus].” (Ahora, el estado es [cpqFcaCntlrStatus].)
ID de evento de NT: 1152 (Hex)0x84350480 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Storage System Fan Module Status Change. (El estado del módulo de ventilador del sistema de almacenamiento ha cambiado.)
Mensaje del registro: Storage system “%4” fan module at location %5 has a new status of %6. (El estado del módulo de ventilador del sistema de almacenamiento “%4” situado en %5 ha cambiado a %6.)
Captura SNMP: cpqSsEx2FanStatusChange - 8020 en CPQSTSYS.MIB
Síntoma: El estado del ventilador del sistema de almacenamiento ha cambiado. El agente ha detectado un cambio en el estado del módulo de ventilador de un sistema de almacenamiento. La variable cpqSsFanModuleStatus indica el estado actual del ventilador.
Acción del usuario: Si el estado del ventilador es Degraded o Failed, sustituya los ventiladores defectuosos.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSsChassisName
● cpqSsChassisTime
● cpqSsFanModuleLocation
● cpqSsFanModuleStatus
● cpqSsFanModuleSerialNumber
● cpqSsFanModuleBoardRevision
Descripción complementaria de la captura SNMP: “Storage system fan status changed to [cpqSsFanModuleStatus].” (El estado del ventilador del sistema de almacenamiento ha cambiado a [cpqSsFanModuleStatus].)
ID de evento de NT: 1153 (Hex)0x84350481 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Storage System Power Supply Status Change. (El estado de la fuente de alimentación del sistema de almacenamiento ha cambiado.)
Mensaje del registro: Storage system “%4” power supply in bay %5 has a new status of %6. (El estado de la fuente de alimentación del sistema de almacenamiento “%4” del compartimento %5 ha cambiado a %6.)
372 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Captura SNMP: cpqSsEx2PowerSupplyStatusChange - 8021 en CPQSTSYS.MIB
Síntoma: El estado de la fuente de alimentación del sistema de almacenamiento ha cambiado. El agente ha detectado un cambio en el estado de la fuente de alimentación de un sistema de almacenamiento. La variable cpqSsPowerSupplyStatus indica el estado actual.
Acción del usuario: Si el estado de la fuente de alimentación es Failed, restaure la energía o sustituya la fuente de alimentación.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSsChassisName
● cpqSsChassisTime
● cpqSsPowerSupplyBay
● cpqSsPowerSupplyStatus
● cpqSsPowerSupplySerialNumber
● cpqSsPowerSupplyBoardRevision
● cpqSsPowerSupplyFirmwareRevision
Descripción complementaria de la captura SNMP: “Storage system power supply status changed to [cpqSsPowerSupplyStatus].” (El estado de la fuente de alimentación del sistema de almacenamiento ha cambiado a [cpqSsPowerSupplyStatus].)
ID de evento de NT: 1154 (Hex)0x84350482 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Storage System Power Supply UPS Status Change. (El estado del UPS de la fuente de alimentación del sistema de almacenamiento ha cambiado.)
Mensaje del registro: The UPS attached to storage system “%4” power supply bay %5 has a new status of %7. (El estado del UPS conectado con la fuente de alimentación del sistema de almacenamiento “%4” compartimento %5 ha cambiado a %7.)
Captura SNMP: cpqSsExPowerSupplyUpsStatusChange - 8018 en CPQSTSYS.MIB
Síntoma: El estado del UPS de la fuente de alimentación del sistema de almacenamiento ha cambiado. El agente ha detectado un cambio en el estado de un UPS conectado a la fuente de alimentación de un sistema de almacenamiento. La variable cpqSsPowerSupplyUpsStatus indica el estado actual.
Acción del usuario: Si el estado del UPS es powerFailed(4) o batteryLow(5), restaure la energía al UPS.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSsChassisName
● cpqSsChassisTime
ESES Agentes de almacenamiento 373

● cpqSsPowerSupplyBay
● cpqSsPowerSupplyUpsStatus
Descripción complementaria de la captura SNMP: “Storage system power supply UPS status changed to [cpqSsPowerSupplyUpsStatus].” (El estado del UPS de la fuente de alimentación del sistema de almacenamiento ha cambiado a [cpqSsPowerSupplyUpsStatus].)
ID de evento de NT: 1155 (Hex)0x84350483 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Storage System Temperature Sensor Status Change. (El estado del sensor de temperatura del sistema de almacenamiento ha cambiado.)
Mensaje del registro: Storage system “%4” temperature sensor at location %5 has a new status of %6 and a current temperature value of %7 celsius. (El estado del sensor de temperatura del sistema de almacenamiento “%4” situado en %5 ha cambiado a %6 y tiene una temperatura actual de %7 grados celsius.)
Captura SNMP: cpqSsExTempSensorStatusChange - 8019 en CPQSTSYS.MIB
Síntoma: El estado del sensor de temperatura del sistema de almacenamiento ha cambiado. El agente ha detectado un cambio en el estado de un sensor de temperatura del sistema de almacenamiento. La variable cpqSsTempSensorStatus indica el estado actual.
Acción del usuario: Si el estado de la temperatura es Degraded o Failed, apague el sistema de almacenamiento tan pronto como sea posible. Asegúrese de que el entorno del sistema de almacenamiento tiene una refrigeración apropiada y de que no hay componentes sobrecalentados.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSsChassisName
● cpqSsChassisTime
● cpqSsTempSensorLocation
● cpqSsTempSensorStatus
● cpqSsTempSensorCurrentValue
Descripción complementaria de la captura SNMP: “Storage system temperature sensor status changed to [cpqSsTempSensorStatus].” (El estado del sensor de temperatura del sistema de almacenamiento ha cambiado a [cpqSsTempSensorStatus].)
ID de evento de NT: 1156 (Hex)0x84350484 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: SCSI Tape Library Failed. (Fallo en la biblioteca de cintas SCSI.)
Mensaje del registro: The SCSI tape library with SCSI target %6 connected to SCSI bus %5 of the controller in slot %4 has encountered an error. (La biblioteca de cintas SCSI con destino SCSI %6 conectada al bus SCSI %5 de la controladora de la ranura %4 ha encontrado un error.)
Captura SNMP: cpqTape3LibraryFailed - 5010 en CPQSCSI.MIB
Síntoma: Error en la biblioteca de cintas. Insight Agent ha detectado que una unidad de autocargador ha encontrado un error.
374 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqTapeLibrarySerialNumber
Descripción complementaria de la captura SNMP: “Tape library [cpqTapeLibrarySerialNumber] is not operational.” (La biblioteca de cintas [cpqTapeLibrarySerialNumber] no está operativa.)
ID de evento de NT: 1157 (Hex)0x84350485 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: SCSI Tape Library OK. (La biblioteca de cintas SCSI tiene el estado OK.)
Mensaje del registro: The SCSI tape library with SCSI target %6 connected to SCSI bus %5 of the controller in slot %4 has recovered from errors. (La biblioteca de cintas SCSI con destino SCSI %6 conectada al bus SCSI %5 de la controladora de la ranura %4 se ha recuperado de los errores.)
Captura SNMP: cpqTape3LibraryOkay - 5011 en CPQSCSI.MIB
Síntoma: La biblioteca de cintas tiene el estado OK. Insight Agent ha detectado que una unidad de autocargador se ha recuperado de los errores.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqTapeLibrarySerialNumber
Descripción complementaria de la captura SNMP: “Tape Library [cpqTapeLibrarySerialNumber] Recovered.” (Se ha recuperado la biblioteca de cintas [cpqTapeLibrarySerialNumber].)
ID de evento de NT: 1158 (Hex)0x84350486 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: SCSI Tape Library Degraded. (La biblioteca de cintas SCSI tiene el estado Degraded.)
Mensaje del registro: The SCSI tape library with SCSI target %6 connected to SCSI bus %5 of the controller in slot %4 is in a degraded condition. (La biblioteca de cintas SCSI con destino SCSI %6 conectada al bus SCSI %5 de la controladora de la ranura %4 tiene el estado Degraded.)
Captura SNMP: cpqTape3LibraryDegraded - 5012 en CPQSCSI.MIB
Síntoma: La biblioteca de cintas tiene el estado Degraded. Insight Agent ha detectado que una unidad de autocargador tiene el estado Degraded.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqTapeLibrarySerialNumber
Descripción complementaria de la captura SNMP: “Tape library [cpqTapeLibrarySerialNumber] is in a degraded condition.” (La biblioteca de cintas [cpqTapeLibrarySerialNumber] tiene el estado Degraded.)
ID de evento de NT: 1159 (Hex)0x84350487 (cpqstmsg.dll)
ESES Agentes de almacenamiento 375

Nivel de gravedad del registro: Advertencia (2)
Título del evento: SCSI Tape Library Door Open. (La puerta de la biblioteca de cintas SCSI está abierta.)
Mensaje del registro: The SCSI tape library with SCSI target %6 connected to SCSI bus %5 of the controller in slot %4 has a door open, so the unit is not operational. (La biblioteca de cintas SCSI con destino SCSI %6 conectada al bus SCSI %5 de la controladora de la ranura %4 tiene una puerta abierta, por lo que la unidad no está operativa.)
Captura SNMP: cpqTape3LibraryDoorOpen - 5013 en CPQSCSI.MIB
Síntoma: La puerta de la biblioteca de cintas está abierta. Insight Agent ha detectado que la puerta de un autocargador está abierta, por lo que la unidad no está operativa.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqTapeLibrarySerialNumber
Descripción complementaria de la captura SNMP: “Tape library [cpqTapeLibrarySerialNumber] door opened.” (La puerta de la biblioteca de cintas [cpqTapeLibrarySerialNumber] está abierta.)
ID de evento de NT: 1160 (Hex)0x84350488 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: SCSI Tape Library Door Closed. (La puerta de la biblioteca de cintas SCSI está cerrada.)
Mensaje del registro: The SCSI tape library with SCSI target %6 connected to SCSI bus %5 of the controller in slot %4 has a closed door and is now operational. (La biblioteca de cintas SCSI con destino SCSI %6 conectada al bus SCSI %5 de la controladora de la ranura %4 tiene la puerta cerrada y ahora ya está operativa.)
Captura SNMP: cpqTape3LibraryDoorClosed - 5014 en CPQSCSI.MIB
Síntoma: La puerta de la biblioteca de cintas está cerrada. Insight Agent ha detectado que la puerta de un autocargador está cerrada.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqTapeLibrarySerialNumber
Descripción complementaria de la captura SNMP: “Tape library [cpqTapeLibrarySerialNumber] door closed.” (La puerta de la biblioteca de cintas [cpqTapeLibrarySerialNumber] está cerrada.)
ID de evento de NT: 1161 (Hex)0xc4350489 (cpqstmsg.dll)
Nivel de gravedad del registro: Error (3)
Título del evento: SCSI CD Library Status Change. (El estado de la biblioteca de CD SCSI ha cambiado.)
Mensaje del registro: The CD Library with SCSI target %6 connected to SCSI bus %5 of the controller in slot %4 has a new status of %2. (El estado de la biblioteca de CD con destino SCSI %6 conectada al bus SCSI %5 de la controladora de la ranura %4 ha cambiado a %2.)
376 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Captura SNMP: cpqScsiCdLibraryStatusChange - 5015 en CPQSCSI.MIB
Síntoma: El estado de la biblioteca de CD ha cambiado. Insight Agent ha detectado un cambio en el estado de un dispositivo de la biblioteca de CD. La variable cpqScsiCdLibraryStatus indica el estado actual de la biblioteca de CD.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqCdLibraryCntlrIndex
● cpqCdLibraryBusIndex
● cpqCdLibraryScsiIdIndex
● cpqCdLibraryStatus
Descripción complementaria de la captura SNMP: “Status is now [cpqCdLibraryStatus].” (Ahora, el estado es [cpqCdLibraryStatus].)
ID de evento de NT: 1164 (Hex)0x8435048c (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Drive Array Controller Status Change. (El estado de la controladora de array de unidades ha cambiado.)
Mensaje del registro: The Drive Array Controller in slot %4 has a new status of %5. (El estado de la controladora de array de unidades de la ranura %4 ha cambiado a %5.)
Captura SNMP: cpqDa5CntlrStatusChange - 3028 en CPQIDA.MIB
Síntoma: El estado de la controladora ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de una controladora de array de unidades. La variable cpqDaCntlrBoardStatus indica el estado actual de la controladora.
Acción del usuario: Si el estado de la placa es generalFailure(3), es posible que necesite sustituir la controladora. Si el estado de la placa es cableProblem(4), compruebe las conexiones de cables entre la controladora y el sistema de almacenamiento.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqDaCntlrSlot
● cpqDaCntlrBoardStatus
● cpqDaCntlrModel
● cpqDaCntlrSerialNumber
● cpqDaCntlrFWRev
● cpqDaAccelTotalMemory
Descripción complementaria de la captura SNMP: “Status is now [cpqDaCntlrBoardStatus].” (Ahora, el estado es [cpqDaCntlrBoardStatus].)
ID de evento de NT: 1165 (Hex)0x8435048d (cpqstmsg.dll)
ESES Agentes de almacenamiento 377

Nivel de gravedad del registro: Advertencia (2)
Título del evento: Drive Array Controller Active. (Controladora de array de unidades activa.)
Mensaje del registro: The Drive Array Controller in slot %4 has become the active controller. (La controladora de array de unidades de la ranura %4 se ha convertido en la controladora activa.)
Captura SNMP: cpqDaCntlrActive - 3016 en CPQIDA.MIB
Síntoma: La controladora está activa. Esta captura indica que el agente ha detectado que una controladora de array de reserva de un par en modo dúplex ha cambiado a la función activa. La variable cpqDaCntlrSlot indica la ranura de la controladora activa, y cpqDaCntlrPartnerSlot indica la ranura de reserva.
Acción del usuario: Compruebe si hay algún problema en la controladora asociada. Si este es el resultado de un cambio iniciado por el usuario, no es necesario hacer nada.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqDaCntlrSlot
● cpqDaCntlrPartnerSlot
Descripción complementaria de la captura SNMP: “Controller in slot [cpqDaCntlrSlot] is now active.” (Ahora, la controladora de la ranura [cpqDaCntlrSlot] está activa.)
ID de evento de NT: 1173 (Hex)0x84350495 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Fibre Channel Tape Controller Status Change. (El estado de la controladora de cinta Fibre Channel ha cambiado.)
Mensaje del registro: Fibre Channel tape controller with world wide name “%4” has a new status of %5. (El estado de la controladora de cinta Fibre Channel con el nombre World Wide “%4” ha cambiado a %5.)
Captura SNMP: cpqFcTapeCntlrStatusChange - 16008 en CPQFCA.MIB
Síntoma: El estado de la controladora de cinta Fibre Channel ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de una controladora de cinta Fibre Channel. La variable cpqFcTapeCntlrStatus indica el estado actual de la controladora de cinta. La variable cpqFcTapeCntlrWWN indica el nombre World Wide único de la controladora de cinta asociado con esta controladora.
Acción del usuario: Si el estado de la controladora de cinta es Offline, se ha perdido el acceso a la biblioteca de cintas y a las cintas. Compruebe si hay algún problema en la biblioteca de cintas y en las conexiones Fibre Channel.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqFcTapeCntlrWWN
● cpqFcTapeCntlrStatus
378 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Descripción complementaria de la captura SNMP: “Status is now [cpqFcTapeCntlrStatus] for tape controller [cpqFcTapeCntlrWWN].” (Ahora, el estado de la controladora de cinta [cpqFcTapeCntlrWWN] es [cpqFcTapeCntlrStatus].)
ID de evento de NT: 1174 (Hex)0x84350496 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Fibre Channel Tape Library Status Change. (El estado de la biblioteca de cintas Fibre Channel ha cambiado.)
Mensaje del registro: The Fibre Channel tape library on tape controller with world wide name “%4”, SCSI bus %5, SCSI target %6, has a new status of %7. (El estado de la biblioteca de cintas Fibre Channel de la controladora de cinta con el nombre World Wide “%4”, bus SCSI %5, destino SCSI %6, ha cambiado a %7.)
Captura SNMP: cpqFcTapeLibraryStatusChange - 16009 en CPQFCA.MIB
Síntoma: El estado de la biblioteca de cintas Fibre Channel ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de una biblioteca de cintas Fiber Channel. La variable cpqFcTapeLibraryStatus indica el estado actual de la biblioteca de cintas. La variable cpqFcTapeLibraryScsiTarget indica el ID de SCSI de la biblioteca de cintas.
Acción del usuario: Si el estado de la biblioteca de cintas es Failed u Offline, compruebe el panel frontal y todas las conexiones Fibre Channel.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqFcTapeCntlrWWN
● cpqFcTapeLibraryScsiBus
● cpqFcTapeLibraryScsiTarget
● cpqFcTapeLibraryScsiLun
● cpqFcTapeLibraryStatus
Descripción complementaria de la captura SNMP: “Status is now [cpqFcTapeLibraryStatus] for the tape library.” (Ahora, el estado de la biblioteca de cintas es [cpqFcTapeLibraryStatus].)
ID de evento de NT: 1175 (Hex)0x84350497 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Fibre Channel Tape Library Door Status Change. (El estado de la puerta de la biblioteca de cintas Fibre Channel ha cambiado.)
Mensaje del registro: The Fibre Channel tape library on tape controller with world wide name “%4”, SCSI bus %5, SCSI target %6, has a new door status of %7. (El estado de la biblioteca de cintas Fibre Channel de la controladora de cinta con el nombre World Wide “%4”, bus SCSI %5, destino SCSI %6, ha cambiado a %7.)
Captura SNMP: cpqFcTapeLibraryDoorStatusChange - 16010 en CPQFCA.MIB
Síntoma: El estado de la puerta de la biblioteca de cintas Fibre Channel ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de la puerta de una biblioteca de cintas Fiber Channel. La variable cpqFcTapeLibraryDoorStatus indica el estado actual de la puerta de la biblioteca de cintas. La variable cpqFcTapeLibraryScsiTarget indica el ID de SCSI de la biblioteca de cintas.
ESES Agentes de almacenamiento 379

Acción del usuario: Si la puerta de la biblioteca de cintas está abierta, ciérrela.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqFcTapeCntlrWWN
● cpqFcTapeLibraryScsiBus
● cpqFcTapeLibraryScsiTarget
● cpqFcTapeLibraryScsiLun
● cpqFcTapeLibraryDoorStatus
Descripción complementaria de la captura SNMP: “The door is [cpqFcTapeLibraryDoorStatus] for tape library.” (El estado de la puerta de la biblioteca de cintas es [cpqFcTapeLibraryDoorStatus].)
ID de evento de NT: 1176 (Hex)0x84350498 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Fibre Channel Tape Drive Status Change. (El estado de la unidad de cinta Fibre Channel ha cambiado.)
Mensaje del registro: The Fibre Channel tape drive on tape controller with world wide name “%4”, SCSI bus %5, SCSI target %6, has a new status of %7. (El estado de la unidad de cinta Fibre Channel de la controladora de cinta con nombre World Wide “%4”, bus SCSI %5, destino SCSI %6, ha cambiado a %7.)
Captura SNMP: cpqFcTapeDriveStatusChange - 16011 en CPQFCA.MIB
Síntoma: El estado de la unidad de cinta Fibre Channel ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de una unidad de cinta Fiber Channel. La variable cpqFcTapeDriveStatus indica el estado actual de la cinta. La variable cpqFcTapeDriveScsiTarget indica el ID de SCSI de la unidad de cinta.
Acción del usuario: Si el estado de la cinta es Failed u Offline, compruebe la cinta y todas las conexiones Fibre Channel.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqFcTapeCntlrWWN
● cpqFcTapeDriveScsiBus
● cpqFcTapeDriveScsiTarget
● cpqFcTapeDriveScsiLun
● cpqFcTapeDriveStatus
Descripción complementaria de la captura SNMP: “Status is now [cpqFcTapeDriveStatus] for a tape drive.” (Ahora, el estado de la unidad de cinta es [cpqFcTapeDriveStatus].)
ID de evento de NT: 1177 (Hex)0x84350499 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
380 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Título del evento: Fibre Channel Tape Drive Cleaning Required. (Es necesario limpiar la unidad de cinta Fibre Channel.)
Mensaje del registro: The Fibre Channel tape drive on tape controller with world wide name “%4”, SCSI bus %5, SCSI target %6, requires cleaning. (Es necesario limpiar la unidad de cinta Fibre Channel de la controladora de cinta con nombre World Wide “%4”, bus SCSI %5, destino SCSI %6.)
Captura SNMP: cpqFcTapeDriveCleaningRequired - 16012 en CPQFCA.MIB
Síntoma: Captura que indica que es necesario limpiar la unidad de cinta Fibre Channel. El agente ha detectado que es necesario introducir y reproducir una cinta de limpieza en una unidad de cinta. Esto hará que los cabezales de la unidad de cinta se limpien.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqFcTapeCntlrWWN
● cpqFcTapeDriveScsiBus
● cpqFcTapeDriveScsiTarget
● cpqFcTapeDriveScsiLun
Descripción complementaria de la captura SNMP: “Cleaning is needed for tape drive.” (Es necesario limpiar la unidad de cinta.)
ID de evento de NT: 1178 (Hex)0x8435049a (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Fibre Channel Tape Drive Replace Cleaning Tape. (Es necesario sustituir la cinta de limpieza de la unidad de cinta Fibre Channel.)
Mensaje del registro: The cleaning tape in the Fibre Channel tape drive on tape controller with world wide name “%4”, SCSI bus %5, SCSI target %6, needs to be replaced. (Es necesario sustituir la cinta de limpieza de la unidad de cinta Fibre Channel de la controladora de cinta con nombre World Wide “%4”, bus SCSI %5, destino SCSI %6.)
Captura SNMP: cpqFcTapeDriveCleanTapeReplace - 16013 en CPQFCA.MIB
Síntoma: Es necesario sustituir la cinta de limpieza de la unidad de cinta Fibre Channel. El agente ha detectado que una unidad de cinta de autocargador tiene una cinta de limpieza que se ha utilizado por completo, por lo que debe sustituirse por una nueva.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqFcTapeCntlrWWN
● cpqFcTapeDriveScsiBus
● cpqFcTapeDriveScsiTarget
● cpqFcTapeDriveScsiLun
Descripción complementaria de la captura SNMP: “Cleaning tape needs replacing.” (Es necesario sustituir la cinta de limpieza.)
ESES Agentes de almacenamiento 381

ID de evento de NT: 1179 (Hex)0x8435049b (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: External Array Controller Active. (Controladora de array externa activa.)
Mensaje del registro: The external controller in I/O slot %5 of array “%4” has become the active controller. (La controladora externa de la ranura de E/S %5 del array “%4” se ha convertido en la controladora activa.)
Captura SNMP: cpqFcaCntlrActive - 16014 en CPQFCA.MIB
Síntoma: Controladora de array externa activa. Esta captura indica que Storage Agent ha detectado que una controladora de array de reserva de un par en modo dúplex ha cambiado a la función activa. La variable cpqFcaCntlrBoxIoSlot indica el índice de la controladora activa nueva.
Acción del usuario: Compruebe si hay algún problema en la controladora asociada. Si este es el resultado de un cambio iniciado por el usuario, no es necesario hacer nada.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSsChassisName
● cpqSsChassisTime
● cpqFcaCntlrBoxIoSlot
Descripción complementaria de la captura SNMP: “Controller in I/O slot [cpqFcaCntlrBoxIoSlot] is now active on chassis [cpqSsChassisName].” (La controladora de la ranura de E/S [cpqFcaCntlrBoxIoSlot] ahora está activa en el chasis [cpqSsChassisName].)
ID de evento de NT: 1180 (Hex)0x8435049c (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Drive Array Tape Library Status Change. (El estado de la biblioteca de cintas del array de unidades ha cambiado.)
Mensaje del registro: The tape library in slot %4, SCSI bus %5, SCSI target %6 has a new status of %7 (El estado de la biblioteca de cintas de la ranura %4, bus SCSI %5, destino SCSI %6 ha cambiado a %7)
Captura SNMP: cpqDa2TapeLibraryStatusChange - 3031 en CPQIDA.MIB
Síntoma: El estado de la biblioteca de cintas ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de una biblioteca de cintas. La variable cpqDaTapeLibraryStatus indica el estado actual de la biblioteca de cintas. La variable cpqDaTapeLibraryScsiTarget indica el ID de SCSI de la biblioteca de cintas.
Acción del usuario: Si el estado de la biblioteca de cintas es Failed, compruebe el panel frontal de la misma.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqDaTapeLibraryCntlrIndex
● cpqDaTapeLibraryScsiBus
382 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

● cpqDaTapeLibraryScsiTarget
● cpqDaTapeLibraryScsiLun
● cpqDaTapeLibraryModel
● cpqDaTapeLibraryFWRev
● cpqDaTapeLibrarySerialNumber
● cpqDaTapeLibraryStatus
Descripción complementaria de la captura SNMP: “Status is now [cpqDaTapeLibraryStatus] for the tape library.” (Ahora, el estado de la biblioteca de cintas es [cpqDaTapeLibraryStatus].)
ID de evento de NT: 1181 (Hex)0x8435049d (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Drive Array Tape Library Door Status Change. (El estado de la puerta de la biblioteca de cintas del array de unidades ha cambiado.)
Mensaje del registro: The tape library in slot %4, SCSI bus %5, SCSI target %6 has a new door status of %7. (El estado de la puerta de la biblioteca de cintas de la ranura %4, bus SCSI %5, destino SCSI %6 ha cambiado a %7.)
Captura SNMP: cpqDaTapeLibraryDoorStatusChange - 3021 en CPQIDA.MIB
Síntoma: El estado de la puerta de la biblioteca de cintas ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de la puerta de una biblioteca de cintas. La variable cpqDaTapeLibraryDoorStatus indica el estado actual de la puerta de la biblioteca de cintas. La variable cpqDaTapeLibraryScsiTarget indica el ID de SCSI de la biblioteca de cintas.
Acción del usuario: Si la puerta de la biblioteca de cintas está abierta, ciérrela.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqDaTapeLibraryCntlrIndex
● cpqDaTapeLibraryScsiBus
● cpqDaTapeLibraryScsiTarget
● cpqDaTapeLibraryScsiLun
● cpqDaTapeLibraryDoorStatus
Descripción complementaria de la captura SNMP: “The door is [cpqDaTapeLibraryDoorStatus] for tape library.” (El estado de la puerta de la biblioteca de cintas es [cpqDaTapeLibraryDoorStatus].)
ID de evento de NT: 1182 (Hex)0x8435049e (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Drive Array Tape Drive Status Change. (El estado de la unidad de cinta del array de unidades ha cambiado.)
Mensaje del registro: The tape drive in slot %4, SCSI bus %5, SCSI target %6 has a new status of %7. (El estado de la unidad de cinta de la ranura %4, bus SCSI %5, destino SCSI %6 ha cambiado a %7.)
Captura SNMP: cpqDa2TapeDriveStatusChange - 3032 en CPQIDA.MIB
ESES Agentes de almacenamiento 383

Síntoma: El estado de la unidad de cinta ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de una unidad de cinta. La variable cpqDaTapeDrvStatus indica el estado actual de la cinta. La variable cpqDaTapeDrvScsiIdIndex indica el ID de SCSI de la unidad de cinta.
Acción del usuario: Si el estado de la cinta es Failed, compruebe la cinta y todas las conexiones SCSI.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqDaTapeDrvCntlrIndex
● cpqDaTapeDrvBusIndex
● cpqDaTapeDrvScsiIdIndex
● cpqDaTapeDrvLunIndex
● cpqDaTapeDrvName
● cpqDaTapeDrvFwRev
● cpqDaTapeDrvSerialNumber
● cpqDaTapeDrvStatus
Descripción complementaria de la captura SNMP: “Status is now [cpqDaTapeDrvStatus] for a tape drive.” (Ahora, el estado de la unidad de cinta es [cpqDaTapeDrvStatus].)
ID de evento de NT: 1183 (Hex)0x8435049f (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Drive Array Tape Drive Cleaning Required. (Es necesario limpiar la unidad de cinta del array de unidades.)
Mensaje del registro: The tape drive in slot %4, SCSI bus %5, SCSI target %6 requires cleaning. (Es necesario limpiar la unidad de cinta de la ranura %4, bus SCSI %5, destino SCSI %6.)
Captura SNMP: cpqDaTapeDriveCleaningRequired - 3023 en CPQIDA.MIB
Síntoma: Captura que indica que es necesario limpiar la unidad de cinta. El agente ha detectado que es necesario introducir y reproducir una cinta de limpieza en una unidad de cinta. Esto hará que los cabezales de la unidad de cinta se limpien.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqDaTapeDrvCntlrIndex
● cpqDaTapeDrvBusIndex
● cpqDaTapeDrvScsiIdIndex
● cpqDaTapeDrvLunIndex
Descripción complementaria de la captura SNMP: “Cleaning is needed for the tape drive.” (Es necesario limpiar la unidad de cinta.)
384 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

ID de evento de NT: 1184 (Hex)0x843504a0 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Drive Array Tape Drive Replace Cleaning Tape. (Es necesario sustituir la cinta de limpieza de la unidad de cinta del array de unidades.)
Mensaje del registro: The cleaning tape in the tape drive in slot %4, SCSI bus %5, SCSI target %6 needs to be replaced. (Es necesario sustituir la cinta de limpieza de la unidad de cinta de la ranura %4, bus SCSI %5, destino SCSI %6.)
Captura SNMP: cpqDaTapeDriveCleanTapeReplace - 3024 en CPQIDA.MIB
Síntoma: Es necesario sustituir la cinta de limpieza de la unidad de cinta. El agente ha detectado que una unidad de cinta de autocargador tiene una cinta de limpieza que se ha utilizado por completo, por lo que debe sustituirse por una nueva.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqDaTapeDrvCntlrIndex
● cpqDaTapeDrvBusIndex
● cpqDaTapeDrvScsiIdIndex
● cpqDaTapeDrvLunIndex
Descripción complementaria de la captura SNMP: “Cleaning tape needs replacing.” (Es necesario sustituir la cinta de limpieza.)
ID de evento de NT: 1185 (Hex)0x843504a1 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Fibre Channel Controller Status Change. (El estado de la controladora Fibre Channel ha cambiado.)
Mensaje del registro: The Fibre Channel Controller in slot %4 has a new status of %5. (El estado de la controladora Fibre Channel de la ranura %4 ha cambiado a %5.)
Captura SNMP: cpqFca2HostCntlrStatusChange - 16021 en CPQFCA.MIB
Síntoma: El estado de la controladora de host Fibre Channel ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de una controladora de host Fibre Channel. La variable cpqFcaHostCntlrStatus indica el estado actual de la controladora.
Acción del usuario: Si el estado de la controladora es Failed, sustitúyala.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqFcaHostCntlrSlot
● cpqFcaHostCntlrStatus
● cpqFcaHostCntlrModel
● cpqFcaHostCntlrWorldWideName
ESES Agentes de almacenamiento 385

Descripción complementaria de la captura SNMP: “Host controller in slot [cpqFcaHostCntlrSlot] has a new status of [cpqFcaHostCntlrStatus].” (El estado de la controladora de host de la ranura [cpqFcaHostCntlrSlot] ha cambiado a [cpqFcaHostCntlrStatus].)
ID de evento de NT: 1186 (Hex)0x843504a2 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: IDE ATA Disk Status Change. (El estado del disco IDE ATA ha cambiado.)
Mensaje del registro: The ATA disk drive with model %6 and serial number %7 has a new status of %2. (El estado de la unidad de disco ATA, modelo %6 y número de serie %7 ha cambiado a %2.)
Captura SNMP: cpqIdeAtaDiskStatusChange - 14004 en CPQIDE.MIB
Síntoma: El estado del disco ATA ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de una unidad de disco ATA. La variable cpqIdeAtaDiskStatus indica el estado actual de la unidad de disco.
Acción del usuario: Si el estado de la unidad física es smartError(3), failed(4) o ssdWearOut(5), sustitúyala.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqIdeAtaDiskControllerIndex
● cpqIdeAtaDiskIndex
● cpqIdeAtaDiskModel
● cpqIdeAtaDiskFwRev
● cpqIdeAtaDiskSerialNumber
● cpqIdeAtaDiskStatus
● cpqIdeAtaDiskChannel
● cpqIdeAtaDiskNumber
Descripción complementaria de la captura SNMP: “Status is now [cpqIdeAtaDiskStatus] for the ATA disk.” (Ahora, el estado del disco ATA es [cpqIdeAtaDiskStatus].)
ID de evento de NT: 1187 (Hex)0x843504a3 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: ATA RAID Logical Drive Status Change. (El estado de la unidad lógica ATA RAID ha cambiado.)
Mensaje del registro: ATA RAID logical drive number %6 on the “%5” in slot %4 has a new status of %2. (El estado de la unidad lógica ATA RAID número %6 situada en el “%5” de la ranura %4 ha cambiado a %2.)
Captura SNMP: cpqIdeLogicalDriveStatusChange - 14005 en CPQIDE.MIB
Síntoma: El estado de la unidad lógica IDE ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de una unidad lógica IDE. La variable cpqIdeLogicalDriveStatus indica el estado actual de la unidad lógica.
386 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Acción del usuario: Si el estado de la unidad lógica es failed(5), examine el array y localice las unidades defectuosas que es necesario sustituir.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqIdeControllerModel
● cpqIdeControllerSlot
● cpqIdeLogicalDriveControllerIndex
● cpqIdeLogicalDriveIndex
● cpqIdeLogicalDriveStatus
Descripción complementaria de la captura SNMP: “Status is now [cpqIdeLogicalDriveStatus] for the IDE logical drive.” (Ahora, el estado de la unidad lógica IDE es [cpqIdeLogicalDriveStatus].)
ID de evento de NT: 1188 (Hex)0x843504a4 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Storage System Fan Status Change. (El estado del ventilador del sistema de almacenamiento ha cambiado.)
Mensaje del registro: An enclosure attached to port %5 of storage system “%4” has a new fan status of %7. The enclosure model is “%6”. (El estado del ventilador del chasis conectado al puerto %5 del sistema de almacenamiento “%4” ha cambiado a %7. El modelo del chasis es “%6”.)
Captura SNMP: cpqSsExBackplaneFanStatusChange - 8022 en CPQSTSYS.MIB
Síntoma: El estado del ventilador del sistema de almacenamiento ha cambiado. El agente ha detectado un cambio en el estado del ventilador de un sistema de almacenamiento. La variable cpqSsBackplaneFanStatus indica el estado actual del ventilador.
Acción del usuario: Si el estado del ventilador es Degraded o Failed, sustituya los ventiladores defectuosos.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSsChassisName
● cpqSsChassisTime
● cpqSsBackplaneIndex
● cpqSsBackplaneVendor
● cpqSsBackplaneModel
● cpqSsBackplaneSerialNumber
● cpqSsBackplaneFanStatus
Descripción complementaria de la captura SNMP: “Storage system fan status changed to [cpqSsBackplaneFanStatus].” (El estado del ventilador del sistema de almacenamiento ha cambiado a [cpqSsBackplaneFanStatus].)
ESES Agentes de almacenamiento 387

ID de evento de NT: 1189 (Hex)0x843504a5 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Storage System Temperature Status Change. (El estado de la temperatura del sistema de almacenamiento ha cambiado.)
Mensaje del registro: An enclosure attached to port %5 of storage system “%4” has a new temperature status of %7. The enclosure model is “%6”. (El estado de la temperatura del chasis conectado al puerto %5 del sistema de almacenamiento “%4” ha cambiado a %7. El modelo del chasis es “%6”.)
Captura SNMP: cpqSsExBackplaneTempStatusChange - 8023 en CPQSTSYS.MIB
Síntoma: El estado de la temperatura del sistema de almacenamiento ha cambiado. El agente ha detectado un cambio en el estado de la temperatura de un sistema de almacenamiento. La variable cpqSsBackplaneTempStatus indica el estado actual.
Acción del usuario: Si el estado de la temperatura es Degraded o Failed, apague el sistema de almacenamiento tan pronto como sea posible. Asegúrese de que el entorno del sistema de almacenamiento tiene una refrigeración apropiada y de que no hay componentes sobrecalentados.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSsChassisName
● cpqSsChassisTime
● cpqSsBackplaneIndex
● cpqSsBackplaneVendor
● cpqSsBackplaneModel
● cpqSsBackplaneSerialNumber
● cpqSsBackplaneTempStatus
Descripción complementaria de la captura SNMP: “Storage system temperature status changed to [cpqSsBackplaneTempStatus].” (El estado de la temperatura del sistema de almacenamiento ha cambiado a [cpqSsBackplaneTempStatus].)
ID de evento de NT: 1190 (Hex)0x843504a6 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Storage System Power Supply Status Change. (El estado de la fuente de alimentación del sistema de almacenamiento ha cambiado.)
Mensaje del registro: An enclosure attached to port %5 of storage system “%4” has a new power supply status of %7. The enclosure model is “%6”. (El estado de la fuente de alimentación del chasis conectado al puerto %5 del sistema de almacenamiento “%4” ha cambiado a %7. El modelo del chasis es “%6”.)
Captura SNMP: cpqSsExBackplanePowerSupplyStatusChange - 8024 en CPQSTSYS.MIB
Síntoma: El estado de la fuente de alimentación del sistema de almacenamiento ha cambiado. El agente ha detectado un cambio en el estado de la fuente de alimentación de un sistema de almacenamiento. La variable cpqSsBackplaneFtpsStatus indica el estado actual.
388 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Acción del usuario: Si la fuente de alimentación tiene el estado Degraded, restaure la energía o sustituya la fuente de alimentación averiada.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSsChassisName
● cpqSsChassisTime
● cpqSsBackplaneIndex
● cpqSsBackplaneVendor
● cpqSsBackplaneModel
● cpqSsBackplaneSerialNumber
● cpqSsBackplaneFtpsStatus
Descripción complementaria de la captura SNMP: “Storage system power supply status changed to [cpqSsBackplaneFtpsStatus].” (El estado de la fuente de alimentación del sistema de almacenamiento ha cambiado a [cpqSsBackplaneFtpsStatus].)
ID de evento de NT: 1191 (Hex)0x843504a7 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: SCSI Tape Library Status Change. (El estado de la biblioteca de cintas SCSI ha cambiado.)
Mensaje del registro: The tape library with SCSI target %6 connected to SCSI bus %5 of the controller in slot %4 has a new status of %7. (El estado de la biblioteca de cintas con destino SCSI %6 conectada al bus SCSI %5 de la controladora de la ranura %4 ha cambiado a %7.)
Captura SNMP: cpqTapeLibraryStatusChange - 5018 en CPQSCSI.MIB
Síntoma: El estado de la biblioteca de cintas ha cambiado. Storage Agent ha detectado un cambio en el estado de una biblioteca de cintas. La variable cpqTapeLibraryState indica el estado actual de la biblioteca de cintas.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqTapeLibraryCntlrIndex
● cpqTapeLibraryBusIndex
● cpqTapeLibraryScsiIdIndex
● cpqTapeLibraryLunIndex
● cpqTapeLibraryName
● cpqTapeLibraryFwRev
● cpqTapeLibrarySerialNumber
● cpqTapeLibraryState
ESES Agentes de almacenamiento 389

Descripción complementaria de la captura SNMP: “Status is now [cpqTapeLibraryState].” (Ahora, el estado es [cpqTapeLibraryState].)
ID de evento de NT: 1192 (Hex)0x843504a8 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: SCSI Tape Drive Status Change. (El estado de la unidad de cinta SCSI ha cambiado.)
Mensaje del registro: The tape drive with SCSI target %6 connected to SCSI bus %5 of the controller in slot %4 has a new status of %2. (El estado de la unidad de cinta con destino SCSI %6 conectada al bus SCSI %5 de la controladora de la ranura %4 ha cambiado a %2.)
Captura SNMP: cpqTape5PhyDrvStatusChange - 5019 en CPQSCSI.MIB
Síntoma: El estado de la unidad de cinta ha cambiado. Storage Agent ha detectado un cambio en el estado de una unidad de cinta. La variable pqTapePhyDrvStatus indica el estado actual de la unidad física.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqTapePhyDrvCntlrIndex
● cpqTapePhyDrvBusIndex
● cpqTapePhyDrvScsiIdIndex
● cpqTapePhyDrvLunIndex
● cpqTapePhyDrvName
● cpqTapePhyDrvFwRev
● cpqTapePhyDrvSerialNumber
● cpqTapePhyDrvStatus
Descripción complementaria de la captura SNMP: “Status is now [cpqTapePhyDrvStatus].” (Ahora, el estado es [cpqTapePhyDrvStatus].)
ID de evento de NT: 1193 (Hex)0x843504a9 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: External Tape Drive Status Change. (El estado de la unidad de cinta externa ha cambiado.)
Mensaje del registro: The tape drive at location “%4”, has a new status of %7. (El estado de la unidad de cinta situada en “%4” ha cambiado a %7.)
Captura SNMP: cpqExtTapeDriveStatusChange - 16023 en CPQFCA.MIB
Síntoma: El estado de la unidad de cinta externa ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de una unidad de cinta externa. La variable cpqFcTapeDriveStatus indica el estado actual de la cinta.
Acción del usuario: Si el estado de la cinta es Failed u Offline, compruebe la cinta y todas las conexiones.
Datos complementarios de la captura SNMP:
390 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

● sysName
● cpqHoTrapFlags
● cpqFcTapeDriveCntlrIndex
● cpqFcTapeDriveScsiBus
● cpqFcTapeDriveScsiTarget
● cpqFcTapeDriveScsiLun
● cpqFcTapeDriveModel
● cpqFcTapeDriveFWRev
● cpqFcTapeDriveSerialNumber
● cpqFcTapeDriveLocation
● cpqFcTapeDriveStatus
Descripción complementaria de la captura SNMP: “Status is now [cpqFcTapeDriveStatus] for a tape drive.” (Ahora, el estado de la unidad de cinta es [cpqFcTapeDriveStatus].)
ID de evento de NT: 1194 (Hex)0x843504aa (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: External Tape Drive Cleaning Required. (Es necesario limpiar la unidad de cinta externa.)
Mensaje del registro: The tape drive at location “%4” requires cleaning. (Es necesario limpiar la unidad de cinta situada en “%4”.)
Captura SNMP: cpqExtTapeDriveCleaningRequired - 16024 en CPQFCA.MIB
Síntoma: Captura que indica que es necesario limpiar la unidad de cinta externa. El agente ha detectado que es necesario introducir y reproducir una cinta de limpieza en una unidad de cinta. Esto hará que los cabezales de la unidad de cinta se limpien.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqFcTapeDriveCntlrIndex
● cpqFcTapeDriveScsiBus
● cpqFcTapeDriveScsiTarget
● cpqFcTapeDriveScsiLun
● cpqFcTapeDriveModel
● cpqFcTapeDriveFWRev
● cpqFcTapeDriveSerialNumber
● cpqFcTapeDriveLocation
Descripción complementaria de la captura SNMP: “Cleaning is needed for tape drive.” (Es necesario limpiar la unidad de cinta.)
ID de evento de NT: 1195 (Hex)0x843504ab (cpqstmsg.dll)
ESES Agentes de almacenamiento 391

Nivel de gravedad del registro: Advertencia (2)
Título del evento: External Tape Drive Replace Cleaning Tape. (Es necesario sustituir la cinta de limpieza de la unidad de cinta externa.)
Mensaje del registro: The cleaning tape in the tape drive at location “%4” needs to be replaced. (Es necesario sustituir la cinta de limpieza de la unidad de cinta situada en “%4”.)
Captura SNMP: cpqExtTapeDriveCleanTapeReplace - 16025 en CPQFCA.MIB
Síntoma: Es necesario sustituir la cinta de limpieza de la unidad de cinta externa. El agente ha detectado que una unidad de cinta de autocargador tiene una cinta de limpieza que se ha utilizado por completo, por lo que debe sustituirse por una nueva.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqFcTapeDriveCntlrIndex
● cpqFcTapeDriveScsiBus
● cpqFcTapeDriveScsiTarget
● cpqFcTapeDriveScsiLun
● cpqFcTapeDriveModel
● cpqFcTapeDriveFWRev
● cpqFcTapeDriveSerialNumber
● cpqFcTapeDriveLocation
Descripción complementaria de la captura SNMP: “Cleaning tape needs replacing.” (Es necesario sustituir la cinta de limpieza.)
ID de evento de NT: 1196 (Hex)0x843504ac (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Storage System Recovery Server Option Status Change. (El estado de la opción de servidor de recuperación [RSO] del sistema de almacenamiento ha cambiado.)
Mensaje del registro: Storage system “%4” has a new RSO status of %5. (El estado de la RSO del sistema de almacenamiento situado en “%4” ha cambiado a %5.)
Captura SNMP: cpqSsExRecoveryServerStatusChange - 8025 en CPQSTSYS.MIB
Síntoma: El estado de la opción de servidor de recuperación [RSO] del sistema de almacenamiento ha cambiado. El agente ha detectado un cambio en el estado de la opción de servidor de recuperación de un sistema de almacenamiento. La variable cpqSsChassisRsoStatus indica el estado actual.
Acción del usuario: Si el estado de la RSO es noSecondary(6) o linkDown(7), asegúrese de que el servidor secundario está operativo y de que todos los cables están conectados correctamente. Si el estado de la RSO es secondaryRunningAuto(8) o secondaryRunningUser(9), examine el servidor principal y localice los componentes que presentan fallos.
Datos complementarios de la captura SNMP:
392 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

● sysName
● cpqHoTrapFlags
● cpqSsChassisName
● cpqSsChassisTime
● cpqSsChassisRsoStatus
● cpqSsChassisIndex
Descripción complementaria de la captura SNMP: “Storage system recovery server option status changed to [cpqSsChassisRsoStatus].” (El estado de la opción de servidor de recuperación del sistema de almacenamiento ha cambiado a [cpqSsChassisRsoStatus].)
ID de evento de NT: 1197 (Hex)0x843504ad (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: External Tape Library Status Change. (El estado de la biblioteca de cintas externa ha cambiado.)
Mensaje del registro: The tape library at location “%4”, has a new status of %7. (El estado de la biblioteca de cintas situada en “%4” ha cambiado a %7.)
Captura SNMP: cpqExtTapeLibraryStatusChange - 16026 en CPQFCA.MIB
Síntoma: El estado de la biblioteca de cintas externa ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de una biblioteca de cintas externa. La variable cpqFcTapeLibraryStatus indica el estado actual de la biblioteca de cintas.
Acción del usuario: Si el estado de la biblioteca de cintas es Failed u Offline, compruebe el panel frontal de la biblioteca y todas las conexiones.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqFcTapeLibraryCntlrIndex
● cpqFcTapeLibraryScsiBus
● cpqFcTapeLibraryScsiTarget
● cpqFcTapeLibraryScsiLun
● cpqFcTapeLibraryModel
● cpqFcTapeLibraryFWRev
● cpqFcTapeLibrarySerialNumber
● cpqFcTapeLibraryLocation
● cpqFcTapeLibraryStatus
Descripción complementaria de la captura SNMP: “Status is now [cpqFcTapeLibraryStatus] for the tape library.” (Ahora, el estado de la biblioteca de cintas es [cpqFcTapeLibraryStatus].)
ID de evento de NT: 1198 (Hex)0x843504ae (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
ESES Agentes de almacenamiento 393

Título del evento: External Tape Library Door Status Change. (El estado de la puerta de la biblioteca de cintas externa ha cambiado.)
Mensaje del registro: The tape library at location “%4”, has a new door status of %7. (El estado de la puerta de la biblioteca de cintas situada en “%4” ha cambiado a %7.)
Captura SNMP: cpqExtTapeLibraryDoorStatusChange - 16027 en CPQFCA.MIB
Síntoma: El estado de la puerta de la biblioteca de cintas externa ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de la puerta de una biblioteca de cintas externa. La variable cpqFcTapeLibraryDoorStatus indica el estado actual de la puerta de la biblioteca de cintas.
Acción del usuario: Si la puerta de la biblioteca de cintas está abierta, ciérrela.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqFcTapeLibraryCntlrIndex
● cpqFcTapeLibraryScsiBus
● cpqFcTapeLibraryScsiTarget
● cpqFcTapeLibraryScsiLun
● cpqFcTapeLibraryModel
● cpqFcTapeLibraryFWRev
● cpqFcTapeLibrarySerialNumber
● cpqFcTapeLibraryLocation
● cpqFcTapeLibraryDoorStatus
Descripción complementaria de la captura SNMP: “The door is [cpqFcTapeLibraryDoorStatus] for tape library.” (El estado de la puerta de la biblioteca de cintas es [cpqFcTapeLibraryDoorStatus].)
ID de evento de NT: 1199 (Hex)0x843504af (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Drive Array Controller Status Change. (El estado de la controladora de array de unidades ha cambiado.)
Mensaje del registro: The Drive Array Controller in %7 has a new status of %5. (El estado de la controladora de array de unidades de la ranura %7 ha cambiado a %5.)
Captura SNMP: cpqDa6CntlrStatusChange - 3033 en CPQIDA.MIB
Síntoma: El estado de la controladora ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de una controladora de array de unidades. La variable cpqDaCntlrBoardStatus indica el estado actual de la controladora.
Acción del usuario: Si el estado de la placa es generalFailure(3), es posible que necesite sustituir la controladora. Si el estado de la placa es cableProblem(4), compruebe las conexiones de cables entre la controladora y el sistema de almacenamiento.
Datos complementarios de la captura SNMP:
394 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

● sysName
● cpqHoTrapFlags
● cpqDaCntlrHwLocation
● cpqDaCntlrIndex
● cpqDaCntlrBoardStatus
● cpqDaCntlrModel
● cpqDaCntlrSerialNumber
● cpqDaCntlrFWRev
● cpqDaAccelTotalMemory
Descripción complementaria de la captura SNMP: “Status is now [cpqDaCntlrBoardStatus].” (Ahora, el estado es [cpqDaCntlrBoardStatus].)
Identificadores de eventos 1200-1294ID de evento de NT: 1200 (Hex)0x843504b0 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Drive Array Logical Drive Status Change. (El estado de la unidad lógica del array de unidades ha cambiado.)
Mensaje del registro: Logical drive number %5 on the array controller in %4 has a new status of %2. (El estado de la unidad lógica número %5 situada en la controladora de array de %4 ha cambiado a %2.)
Captura SNMP: cpqDa6LogDrvStatusChange - 3034 en CPQIDA.MIB
Síntoma: El estado de la unidad lógica ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de la unidad lógica de un array de unidades. La variable cpqDaLogDrvStatus indica el estado actual de la unidad lógica.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqDaCntlrHwLocation
● cpqDaLogDrvCntlrIndex
● cpqDaLogDrvIndex
● cpqDaLogDrvStatus
Descripción complementaria de la captura SNMP: “Status is now [cpqDaLogDrvStatus].” (Ahora, el estado es [cpqDaLogDrvStatus].)
ID de evento de NT: 1201 (Hex)0x843504b1 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Drive Array Spare Drive Status Change. (El estado de la unidad de repuesto del array de unidades ha cambiado.)
ESES Agentes de almacenamiento 395

Mensaje del registro: The spare drive in %4, port %5, bay %6 has a new status of %2. (El estado de la unidad de repuesto de %4, puerto %5, compartimento %6 ha cambiado a %2.)
Captura SNMP: cpqDa6SpareStatusChange - 3035 en CPQIDA.MIB
Síntoma: El estado de la unidad de repuesto del array de unidades ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de la unidad de repuesto de un array de unidades. La variable cpqDaSpareStatus indica el estado actual de la unidad de repuesto.
Acción del usuario: Si el estado de la unidad de repuesto es Failed, sustitúyala.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqDaCntlrHwLocation
● cpqDaSpareCntlrIndex
● cpqDaSparePhyDrvIndex
● cpqDaSpareStatus
● cpqDaSpareBusNumber
● cpqDaSpareBay
Descripción complementaria de la captura SNMP: “Spare Status is now [cpqDaSpareStatus].” (Ahora, el estado de la unidad de repuesto es [cpqDaSpareStatus].)
ID de evento de NT: 1202 (Hex)0x843504b2 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Drive Array Physical Drive Status Change. (El estado de la unidad física del array de unidades ha cambiado.)
Mensaje del registro: The physical drive in %4, port %5, bay %6 with serial number “%7”, has a new status of %2. (El estado de la unidad física de %4, puerto %5, compartimento %6, con el número de serie “%7”, ha cambiado a %2.)
Captura SNMP: cpqDa6PhyDrvStatusChange - 3036 en CPQIDA.MIB
Síntoma: El estado de la unidad física ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de la unidad física de un array de unidades. La variable cpaDaPhyDrvStatus indica el estado actual de la unidad física.
Acción del usuario: Si el estado de la unidad física es failed(3) o predictiveFailure(4), sustitúyala.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqDaCntlrHwLocation
● cpqDaPhyDrvIndex
● cpqDaPhyDrvBusNumber
● cpqDaPhyDrvBay
● cpqDaPhyDrvModel
396 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

● cpqDaPhyDrvFWRev
● cpqDaPhyDrvSerialNum
● cpqDaPhyDrvFailureCode
● cpqDaPhyDrvStatus
Descripción complementaria de la captura SNMP: “Physical Drive Status is now [cpqDaPhyDrvStatus].” (Ahora, el estado de la unidad física es [cpqDaPhyDrvStatus].)
ID de evento de NT: 1203 (Hex)0x843504b3 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Drive Array Physical Drive Threshold Exceeded. (Se ha sobrepasado el umbral de unidades físicas del array de unidades.)
Mensaje del registro: The physical drive in %4, port %5, bay %6 with serial number “%7”, has exceeded a drive threshold. (La unidad física de %4, puerto %5, compartimento 6%, con el número de serie “%7”, ha superado un umbral de unidades.)
Captura SNMP: cpqDa6PhyDrvThreshPassedTrap - 3037 en CPQIDA.MIB
Síntoma: Se ha sobrepasado el umbral de unidades físicas. Esta captura indica que el agente ha detectado que se ha superado un umbral de fábrica asociado con uno de los objetos de unidad física de un array de unidades.
Acción del usuario: Sustituya la unidad física.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqDaCntlrHwLocation
● cpqDaPhyDrvCntlrIndex
● cpqDaPhyDrvIndex
● cpqDaPhyDrvBusNumber
● cpqDaPhyDrvBay
● cpqDaPhyDrvModel
● cpqDaPhyDrvFWRev
● cpqDaPhyDrvSerialNum
Descripción complementaria de la captura SNMP: “Factory threshold passed for a physical drive.” (Se ha sobrepasado el umbral de fábrica para una unidad física.)
ID de evento de NT: 1204 (Hex)0x843504b4 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Drive Array Accelerator Status Change. (El estado del acelerador de array de unidades ha cambiado.)
Mensaje del registro: The array accelerator board attached to the array controller in %4 has a new status of %2. (El estado de la placa del acelerador de array conectada a la controladora de array de %4 ha cambiado a %2.)
ESES Agentes de almacenamiento 397

Captura SNMP: cpqDa6AccelStatusChange - 3038 en CPQIDA.MIB
Síntoma: El estado de la placa del acelerador ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de una placa de la memoria caché del acelerador de array. La variable cpqDaAccelStatus representa el estado actual.
Acción del usuario: Si el estado de la placa del acelerador es permDisabled(5), es posible que necesite sustituirla.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqDaCntlrHwLocation
● cpqDaCntlrModel
● cpqDaAccelCntlrIndex
● cpqDaAccelSerialNumber
● cpqDaAccelTotalMemory
● cpqDaAccelStatus
● cpqDaAccelErrCode
Descripción complementaria de la captura SNMP: “Status is now [cpqDaAccelStatus].” (Ahora, el estado es [cpqDaAccelStatus].)
ID de evento de NT: 1205 (Hex)0x843504b5 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Drive Array Accelerator Bad Data. (Datos incorrectos en el acelerador de array de unidades.)
Mensaje del registro: The array accelerator board attached to the array controller in %4 is reporting that it contains bad cached data. (La placa del acelerador de array conectada a la controladora de array de %4 informa de que contiene datos incorrectos en la memoria caché.)
Captura SNMP: cpqDa6AccelBadDataTrap - 3039 en CPQIDA.MIB
Síntoma: Datos incorrectos en la placa del acelerador. Esta captura indica que el agente ha detectado una placa de memoria caché del acelerador de array que ha perdido la alimentación por batería. Si se estaban almacenando datos en la memoria caché del acelerador en el momento en el que se interrumpió el suministro de alimentación al servidor, dichos datos se han perdido.
Acción del usuario: Compruebe que no se ha perdido ningún dato.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqDaCntlrHwLocation
● cpqDaCntlrModel
● cpqDaAccelCntlrIndex
398 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

● cpqDaAccelSerialNumber
● cpqDaAccelTotalMemory
Descripción complementaria de la captura SNMP: “Accelerator lost battery power. Data Loss possible.” (El acelerador ha perdido la alimentación por batería. Es posible que se hayan perdido datos.)
ID de evento de NT: 1206 (Hex)0x843504b6 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Drive Array Accelerator Battery Failed. (La batería del acelerador de array de unidades ha fallado.)
Mensaje del registro: The array accelerator board attached to the array controller in %4 is reporting a battery failure. (La placa del acelerador de array conectada a la controladora de array de %4 informa de un fallo en la batería.)
Captura SNMP: cpqDa6AccelBatteryFailed - 3040 en CPQIDA.MIB
Síntoma: La batería de la placa del acelerador ha fallado. Esta captura indica que el agente ha detectado un fallo en la batería asociado con la placa de memoria caché del acelerador de array.
Acción del usuario: Sustituya la placa de memoria caché del acelerador.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqDaPhyDrvCntlrIndex
● cpqDaCntlrHwLocation
● cpqDaCntlrModel
● cpqDaAccelCntlrIndex
● cpqDaAccelSerialNumber
● cpqDaAccelTotalMemory
Descripción complementaria de la captura SNMP: “Battery status is failed.” (El estado de la batería es Failed.)
ID de evento de NT: 1207 (Hex)0x843504b7 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Drive Array Tape Library Status Change. (El estado de la biblioteca de cintas del array de unidades ha cambiado.)
Mensaje del registro: The tape library in %4, SCSI bus %5, SCSI target %6 has a new status of %7. (El estado de la biblioteca de cintas de %4, bus SCSI %5, destino SCSI %6 ha cambiado a %7.)
Captura SNMP: cpqDa6TapeLibraryStatusChange - 3041 en CPQIDA.MIB
Síntoma: El estado de la biblioteca de cintas ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de una biblioteca de cintas. La variable cpqDaTapeLibraryStatus indica el estado actual de la biblioteca de cintas. La variable cpqDaTapeLibraryScsiTarget indica el ID de SCSI de la biblioteca de cintas.
ESES Agentes de almacenamiento 399

Acción del usuario: Si el estado de la biblioteca de cintas es Failed, compruebe el panel frontal de la misma.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqDaCntlrHwLocation
● cpqDaTapeLibraryCntlrIndex
● cpqDaTapeLibraryScsiBus
● cpqDaTapeLibraryScsiTarget
● cpqDaTapeLibraryScsiLun
● cpqDaTapeLibraryModel
● cpqDaTapeLibraryFWRev
● cpqDaTapeLibrarySerialNumber
● cpqDaTapeLibraryStatus
Descripción complementaria de la captura SNMP: “Status is now [cpqDaTapeLibraryStatus] for the tape library.” (Ahora, el estado de la biblioteca de cintas es [cpqDaTapeLibraryStatus].)
ID de evento de NT: 1208 (Hex)0x843504b8 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Drive Array Tape Library Door Status Change. (El estado de la puerta de la biblioteca de cintas del array de unidades ha cambiado.)
Mensaje del registro: The tape library in %4, SCSI bus %5, SCSI target %6 has a new door status of %7. (El estado de la puerta de la biblioteca de cintas de %4, bus SCSI %5, destino SCSI %6 ha cambiado a %7.)
Captura SNMP: cpqDa6TapeLibraryDoorStatusChange - 3042 en CPQIDA.MIB
Síntoma: El estado de la puerta de la biblioteca de cintas ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de la puerta de una biblioteca de cintas. La variable cpqDaTapeLibraryDoorStatus indica el estado actual de la puerta de la biblioteca de cintas. La variable cpqDaTapeLibraryScsiTarget indica el ID de SCSI de la biblioteca de cintas.
Acción del usuario: Si la puerta de la biblioteca de cintas está abierta, ciérrela.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqDaCntlrHwLocation
● cpqDaTapeLibraryCntlrIndex
● cpqDaTapeLibraryScsiBus
● cpqDaTapeLibraryScsiTarget
● cpqDaTapeLibraryScsiLun
● cpqDaTapeLibraryModel
400 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

● cpqDaTapeLibraryFWRev
● cpqDaTapeLibrarySerialNumber
● cpqDaTapeLibraryDoorStatus
Descripción complementaria de la captura SNMP: “The door is [cpqDaTapeLibraryDoorStatus] for tape library.” (El estado de la puerta de la biblioteca de cintas es [cpqDaTapeLibraryDoorStatus].)
ID de evento de NT: 1209 (Hex)0x843504b9 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Drive Array Tape Drive Status Change. (El estado de la unidad de cinta del array de unidades ha cambiado.)
Mensaje del registro: The tape drive in %4, SCSI bus %5, SCSI target %6 has a new status of %7. (El estado de la unidad de cinta de %4, bus SCSI %5, destino SCSI %6 ha cambiado a %7.)
Captura SNMP: cpqDa6TapeDriveStatusChange - 3043 en CPQIDA.MIB
Síntoma: El estado de la unidad de cinta ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de una unidad de cinta. La variable cpqDaTapeDrvStatus indica el estado actual de la cinta. La variable cpqDaTapeDrvScsiIdIndex indica el ID de SCSI de la unidad de cinta.
Acción del usuario: Si el estado de la cinta es Failed, compruebe la cinta y todas las conexiones SCSI.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqDaCntlrHwLocation
● cpqDaTapeDrvCntlrIndex
● cpqDaTapeDrvBusIndex
● cpqDaTapeDrvScsiIdIndex
● cpqDaTapeDrvLunIndex
● cpqDaTapeDrvName
● cpqDaTapeDrvFwRev
● cpqDaTapeDrvSerialNumber
● cpqDaTapeDrvStatus
Descripción complementaria de la captura SNMP: “Status is now [cpqDaTapeDrvStatus] for a tape drive.” (Ahora, el estado de la unidad de cinta es [cpqDaTapeDrvStatus].)
ID de evento de NT: 1210 (Hex)0x843504ba (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Drive Array Tape Drive Cleaning Required. (Es necesario limpiar la unidad de cinta del array de unidades.)
Mensaje del registro: The tape drive in %4, SCSI bus %5, SCSI target %6 requires cleaning. (Es necesario limpiar la unidad de cinta de %4, bus SCSI %5, destino SCSI %6.)
ESES Agentes de almacenamiento 401

Captura SNMP: cpqDa6TapeDriveCleaningRequired - 3044 en CPQIDA.MIB
Síntoma: Captura que indica que es necesario limpiar la unidad de cinta. El agente ha detectado que es necesario introducir y reproducir una cinta de limpieza en una unidad de cinta. Esto hará que los cabezales de la unidad de cinta se limpien.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqDaCntlrHwLocation
● cpqDaTapeDrvCntlrIndex
● cpqDaTapeDrvBusIndex
● cpqDaTapeDrvScsiIdIndex
● cpqDaTapeDrvLunIndex
● cpqDaTapeDrvName
● cpqDaTapeDrvFwRev
● cpqDaTapeDrvSerialNumber
Descripción complementaria de la captura SNMP: “Cleaning is needed for the tape drive.” (Es necesario limpiar la unidad de cinta.)
ID de evento de NT: 1211 (Hex)0x843504bb (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Drive Array Tape Drive Replace Cleaning Tape. (Es necesario sustituir la cinta de limpieza de la unidad de cinta del array de unidades.)
Mensaje del registro: The cleaning tape in the tape drive in %4, SCSI bus %5, SCSI target %6 needs to be replaced. (Es necesario sustituir la cinta de limpieza de la unidad de cinta de %4, bus SCSI %5, destino SCSI %6.)
Captura SNMP: cpqDa6TapeDriveCleanTapeReplace - 3045 en CPQIDA.MIB
Síntoma: Es necesario sustituir la cinta de limpieza de la unidad de cinta. El agente ha detectado que una unidad de cinta de autocargador tiene una cinta de limpieza que se ha utilizado por completo, por lo que debe sustituirse por una nueva.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqDaCntlrHwLocation
● cpqDaTapeDrvCntlrIndex
● cpqDaTapeDrvBusIndex
● cpqDaTapeDrvScsiIdIndex
● cpqDaTapeDrvLunIndex
● cpqDaTapeDrvName
402 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

● cpqDaTapeDrvFwRev
● cpqDaTapeDrvSerialNumber
Descripción complementaria de la captura SNMP: “Cleaning tape needs replacing.” (Es necesario sustituir la cinta de limpieza.)
ID de evento de NT: 1212 (Hex)0x843504bc (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Storage System Fan Status Change. (El estado del ventilador del sistema de almacenamiento ha cambiado.)
Mensaje del registro: The %6 %7 storage system connected to SCSI bus %5 of the controller in %4 has a new status of %2. (El estado del %7 del %6 del sistema de almacenamiento conectado al bus SCSI %5 de la controladora de %4 ha cambiado a %2.)
Captura SNMP: cpqSs5FanStatusChange - 8026 en CPQSTSYS.MIB
Síntoma: El estado del ventilador del sistema de almacenamiento ha cambiado. El agente ha detectado un cambio en el estado del ventilador de un sistema de almacenamiento. La variable cpqSsBoxFanStatus indica el estado actual del ventilador.
Acción del usuario: Si el estado del ventilador es Degraded o Failed, sustituya los ventiladores defectuosos.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSsBoxCntlrHwLocation
● cpqSsBoxCntlrIndex
● cpqSsBoxBusIndex
● cpqSsBoxVendor
● cpqSsBoxModel
● cpqSsBoxSerialNumber
● cpqSsBoxFanStatus
Descripción complementaria de la captura SNMP: “Storage System fan status changed to [cpqSsBoxFanStatus].” (El estado del ventilador del sistema de almacenamiento ha cambiado a [cpqSsBoxFanStatus].)
ID de evento de NT: 1213 (Hex)0x843504bd (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Storage System Temperature Status Change. (El estado de la temperatura del sistema de almacenamiento ha cambiado.)
Mensaje del registro: The %6 %7 storage system connected to SCSI bus %5 of the controller in %4 has a new temperature status of %2. (El estado de la temperatura del %7 del %6 del sistema de almacenamiento conectado al bus SCSI %5 de la controladora de %4 ha cambiado a %2.)
Captura SNMP: cpqSs5TempStatusChange - 8027 en CPQSTSYS.MIB
ESES Agentes de almacenamiento 403

Síntoma: El estado de la temperatura del sistema de almacenamiento ha cambiado. El agente ha detectado un cambio en el estado de la temperatura de un sistema de almacenamiento. La variable cpqSsBoxTempStatus indica el estado actual de la temperatura.
Acción del usuario: Si el estado de la temperatura es Degraded o Failed, apague el sistema de almacenamiento tan pronto como sea posible. Asegúrese de que el entorno del sistema de almacenamiento tiene una refrigeración apropiada y de que no hay componentes sobrecalentados.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSsBoxCntlrHwLocation
● cpqSsBoxCntlrIndex
● cpqSsBoxBusIndex
● cpqSsBoxVendor
● cpqSsBoxModel
● cpqSsBoxSerialNumber
● cpqSsBoxTempStatus
Descripción complementaria de la captura SNMP: “Storage System temperature status changed to [cpqSsBoxTempStatus].” (El estado de la temperatura del sistema de almacenamiento ha cambiado a [cpqSsBoxTempStatus].)
ID de evento de NT: 1214 (Hex)0x843504be (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Storage System Fault Tolerant Power Supply Status Change. (El estado de la fuente de alimentación con tolerancia a fallos del sistema de almacenamiento ha cambiado.)
Mensaje del registro: The fault tolerant power supply in the %6 %7 storage system connected to SCSI bus %5 of the controller in %4 has a new status of %2. (El estado de la fuente de alimentación con tolerancia a fallos del %7 del %6 del sistema de almacenamiento conectado al bus SCSI %5 de la controladora %4 ha cambiado a %2.)
Captura SNMP: cpqSs5PwrSupplyStatusChange - 8028 en CPQSTSYS.MIB
Síntoma: El estado de la fuente de alimentación con tolerancia a fallos del sistema de almacenamiento ha cambiado. El agente ha detectado un cambio en el estado de la fuente de alimentación de un sistema de almacenamiento. La variable cpqSsBoxFltTolPwrSupplyStatus indica el estado actual de la fuente de alimentación.
Acción del usuario: Si la fuente de alimentación tiene el estado Degraded, restaure la energía o sustituya la fuente de alimentación averiada.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSsBoxCntlrHwLocation
● cpqSsBoxCntlrIndex
● cpqSsBoxBusIndex
404 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

● cpqSsBoxVendor
● cpqSsBoxModel
● cpqSsBoxSerialNumber
● cpqSsBoxFltTolPwrSupplyStatus
Descripción complementaria de la captura SNMP: “Storage system power supply status changed to [cpqSsBoxFltTolPwrSupplyStatus].” (El estado de la fuente de alimentación del sistema de almacenamiento ha cambiado a [cpqSsBoxFltTolPwrSupplyStatus].)
ID de evento de NT: 1215 (Hex)0x843504bf (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Fibre Channel Controller Status Change. (El estado de la controladora Fibre Channel ha cambiado.)
Mensaje del registro: The Fibre Channel Controller in %4 has a new status of %5. (El estado de la controladora Fibre Channel de %4 ha cambiado a %5.)
Captura SNMP: cpqFca3HostCntlrStatusChange - 16028 en CPQFCA.MIB
Síntoma: El estado de la controladora de host Fibre Channel ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de una controladora de host Fibre Channel. La variable cpqFcaHostCntlrStatus indica el estado actual de la controladora.
Acción del usuario: Si el estado de la controladora es Failed, sustitúyala.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqFcaHostCntlrHwLocation
● cpqFcaHostCntlrIndex
● cpqFcaHostCntlrStatus
● cpqFcaHostCntlrModel
● cpqFcaHostCntlrSerialNumber
● cpqFcaHostCntlrWorldWideName
● cpqFcaHostCntlrWorldWidePortName
Descripción complementaria de la captura SNMP: “Host controller has a new status of [cpqFcaHostCntlrStatus].” (El estado de la controladora de host ha cambiado a [cpqFcaHostCntlrStatus].)
ID de evento de NT: 1216 (Hex)0x843504c0 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Drive Array Physical Drive Status Change. (El estado de la unidad física del array de unidades ha cambiado.)
Mensaje del registro: The physical drive in %4, %5 with serial number “%7”, has a new status of %2. (La unidad física de %4, %5, con el número de serie “%7”, ha cambiado a %2.)
Captura SNMP: cpqDa7PhyDrvStatusChange - 3046 en CPQIDA.MIB
ESES Agentes de almacenamiento 405

Síntoma: El estado de la unidad física ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de la unidad física de un array de unidades. La variable cpqDaPhyDrvStatus indica el estado actual de la unidad física.
Acción del usuario: Si el estado de la unidad física es failed(3), predictiveFailure(4), ssdWearOut(8) o notAuthenticated(9), sustitúyala.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqDaCntlrHwLocation
● cpqDaPhyDrvCntlrIndex
● cpqDaPhyDrvIndex
● cpqDaPhyDrvLocationString
● cpqDaPhyDrvType
● cpqDaPhyDrvModel
● cpqDaPhyDrvFWRev
● cpqDaPhyDrvSerialNum
● cpqDaPhyDrvFailureCode
● cpqDaPhyDrvStatus
● cpqDaPhyDrvBusNumber
Descripción complementaria de la captura SNMP: “Physical Drive Status is now [cpqDaPhyDrvStatus].” (Ahora, el estado de la unidad física es [cpqDaPhyDrvStatus].)
ID de evento de NT: 1217 (Hex)0x843504c1 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Drive Array Spare Drive Status Change. (El estado de la unidad de repuesto del array de unidades ha cambiado.)
Mensaje del registro: The spare drive in %4, %5 has a new status of %2. (El estado de la unidad de repuesto de %4, %5, ha cambiado a %2.)
Captura SNMP: cpqDa7SpareStatusChange - 3047 en CPQIDA.MIB
Síntoma: El estado de la unidad de repuesto del array de unidades ha cambiado. Esta captura indica que el agente ha detectado un cambio en el estado de la unidad de repuesto de un array de unidades. La variable cpqDaSpareStatus indica el estado actual de la unidad de repuesto.
Acción del usuario: Si el estado de la unidad de repuesto es Failed, sustitúyala.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqDaCntlrHwLocation
● cpqDaSpareCntlrIndex
● cpqDaSparePhyDrvIndex
406 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

● cpqDaSpareStatus
● cpqDaSpareLocationString
● cpqDaSpareDrvBusNumber
Descripción complementaria de la captura SNMP: “Spare Status is now [cpqDaSpareStatus].” (Ahora, el estado de la unidad de repuesto es [cpqDaSpareStatus].)
ID de evento de NT: 1218 (Hex)0x843504c2 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Storage System Fan Status Change. (El estado del ventilador del sistema de almacenamiento ha cambiado.)
Mensaje del registro: The %6 %7 storage system connected to %5 of the controller in %4 has a new status of %2. (El estado del %7 del %6 del sistema de almacenamiento conectado al %5 de la controladora de %4 ha cambiado a %2.)
Captura SNMP: cpqSs6FanStatusChange - 8029 en CPQSTSYS.MIB
Síntoma: El estado del ventilador del sistema de almacenamiento ha cambiado. El agente ha detectado un cambio en el estado del ventilador de un sistema de almacenamiento. La variable cpqSsBoxFanStatus indica el estado actual del ventilador.
Acción del usuario: Si el estado del ventilador es Degraded o Failed, sustituya los ventiladores defectuosos.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSsBoxCntlrHwLocation
● cpqSsBoxCntlrIndex
● cpqSsBoxBusIndex
● cpqSsBoxVendor
● cpqSsBoxModel
● cpqSsBoxSerialNumber
● cpqSsBoxFanStatus
● cpqSsBoxLocationString
Descripción complementaria de la captura SNMP: “Storage System fan status changed to [cpqSsBoxFanStatus].” (El estado del ventilador del sistema de almacenamiento ha cambiado a [cpqSsBoxFanStatus].)
ID de evento de NT: 1219 (Hex)0x843504c3 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Storage System Temperature Status Change. (El estado de la temperatura del sistema de almacenamiento ha cambiado.)
Mensaje del registro: The %6 %7 storage system connected to %5 of the controller in %4 has a new temperature status of %2. (El estado de la temperatura del %7 del %6 del sistema de almacenamiento conectado al %5 de la controladora de %4 ha cambiado a %2.)
ESES Agentes de almacenamiento 407

Captura SNMP: cpqSs6TempStatusChange - 8030 en CPQSTSYS.MIB
Síntoma: El estado de la temperatura del sistema de almacenamiento ha cambiado. El agente ha detectado un cambio en el estado de la temperatura de un sistema de almacenamiento. La variable cpqSsBoxTempStatus indica el estado actual de la temperatura.
Acción del usuario: Si el estado de la temperatura es Degraded o Failed, apague el sistema de almacenamiento tan pronto como sea posible. Asegúrese de que el entorno del sistema de almacenamiento tiene una refrigeración apropiada y de que no hay componentes sobrecalentados.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSsBoxCntlrHwLocation
● cpqSsBoxCntlrIndex
● cpqSsBoxBusIndex
● cpqSsBoxVendor
● cpqSsBoxModel
● cpqSsBoxSerialNumber
● cpqSsBoxTempStatus
● cpqSsBoxLocationString
Descripción complementaria de la captura SNMP: “Storage System temperature status changed to [cpqSsBoxTempStatus].” (El estado de la temperatura del sistema de almacenamiento ha cambiado a [cpqSsBoxTempStatus].)
ID de evento de NT: 1220 (Hex)0x843504c4 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Storage System Fault Tolerant Power Supply Status Change. (El estado de la fuente de alimentación con tolerancia a fallos del sistema de almacenamiento ha cambiado.)
Mensaje del registro: The fault tolerant power supply in the %6 %7 storage system connected to %5 of the controller in %4 has a new status of %2. (El estado de la fuente de alimentación con tolerancia a fallos del %7 del %6 del sistema de almacenamiento conectado al %5 de la controladora de %4 ha cambiado a %2.)
Captura SNMP: cpqSs6PwrSupplyStatusChange - 8031 en CPQSTSYS.MIB
Síntoma: El estado de la fuente de alimentación con tolerancia a fallos del sistema de almacenamiento ha cambiado. El agente ha detectado un cambio en el estado de la fuente de alimentación de un sistema de almacenamiento. La variable cpqSsBoxFltTolPwrSupplyStatus indica el estado actual de la fuente de alimentación.
Acción del usuario: Si la fuente de alimentación tiene el estado Degraded, restaure la energía o sustituya la fuente de alimentación averiada.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSsBoxCntlrHwLocation
408 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

● cpqSsBoxCntlrIndex
● cpqSsBoxBusIndex
● cpqSsBoxVendor
● cpqSsBoxModel
● cpqSsBoxSerialNumber
● cpqSsBoxFltTolPwrSupplyStatus
● cpqSsBoxLocationString
Descripción complementaria de la captura SNMP: “Storage system power supply status changed to [cpqSsBoxFltTolPwrSupplyStatus].” (El estado de la fuente de alimentación del sistema de almacenamiento ha cambiado a [cpqSsBoxFltTolPwrSupplyStatus].)
ID de evento de NT: 1221 (Hex)0x843504c5 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: SAS/SATA Physical Drive Status Change. (El estado de la unidad física SAS/SATA ha cambiado.)
Mensaje del registro: The physical drive in %4, %5 with serial number “%6”, has a new status of %7. (La unidad física de %4, %5, con el número de serie “%6”, ha cambiado a %7.)
Captura SNMP: cpqSasPhyDrvStatusChange - 5022 en CPQSCSI.MIB
Síntoma: El estado de la unidad física ha cambiado. Storage Agent ha detectado un cambio en el estado de una unidad física SAS o SATA. La variable pqSasPhyDrvStatus indica el estado actual de la unidad física.
Acción del usuario: Si el estado de la unidad física es predictiveFailure(3), failed(5), ssdWearOut(10) o notAuthenticated(12), sustitúyala.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSasHbaHwLocation
● cpqSasPhyDrvLocationString
● cpqSasPhyDrvHbaIndex
● cpqSasPhyDrvIndex
● cpqSasPhyDrvStatus
● cpqSasPhyDrvType
● cpqSasPhyDrvModel
● cpqSasPhyDrvFWRev
● cpqSasPhyDrvSerialNumber
● cpqSasPhyDrvSasAddress
Descripción complementaria de la captura SNMP: “Status is now [cpqSasPhyDrvStatus].” (Ahora, el estado es [cpqSasPhyDrvStatus].)
ID de evento de NT: 1222 (Hex)0x843504c6 (cpqstmsg.dll)
ESES Agentes de almacenamiento 409

Nivel de gravedad del registro: Advertencia (2)
Título del evento: SAS/SATA Logical Drive Status Change. (El estado de la unidad lógica SAS/SATA ha cambiado.)
Mensaje del registro: Logical drive number %5 on the HBA in %4 has a new status of %6. (El estado de la unidad lógica número %5 situada en el HBA de %4 ha cambiado a %6.)
Captura SNMP: cpqSasLogDrvStatusChange - 5023 en CPQSCSI.MIB
Síntoma: El estado de la unidad lógica ha cambiado. Storage Agent ha detectado un cambio en el estado de una unidad lógica SAS o SATA. La variable cpqSasLogDrvStatus indica el estado actual de la unidad lógica.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSasHbaHwLocation
● cpqSasLogDrvHbaIndex
● cpqSasLogDrvIndex
● cpqSasLogDrvStatus
● cpqSasLogDrvOsName
Descripción complementaria de la captura SNMP: “Status is now [cpqSasLogDrvStatus].” (Ahora, el estado es [cpqSasLogDrvStatus].)
ID de evento de NT: 1223 (Hex)0x843504c7 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: SAS Tape Drive Status Change. (El estado de la unidad de cinta SAS ha cambiado.)
Mensaje del registro: The tape drive in %4, %5 with serial number "%6", has a new status of %7. (Tape Drive status values: 1=other, 2=ok, 3=offline) (El estado de la unidad de cinta de %4, %5, con el número de serie “%6”, ha cambiado a %7. Valores de estado de la unidad de cinta: 1=other, 2=ok, 3=fuera de línea)
Captura SNMP: cpqSas2TapeDrvStatusChange - 5025 en CPQSCSI.MIB
Síntoma: Storage Agent ha detectado un cambio en el estado de una unidad de cinta SAS. La variable cpqSasTapeDrvStatus indica el estado actual de la unidad de cinta.
Datos complementarios de la captura SNMP
● sysName
● cpqHoTrapFlags
● cpqSasHbaHwLocation
● cpqSasTapeDrvLocationString
● cpqSasTapeDrvHbaIndex
● cpqSasTapeDrvIndex
● cpqSasTapeDrvName
410 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

● cpqSasTapeDrvFWRev
● cpqSasTapeDrvSerialNumber
● cpqSasTapeDrvSasAddress
● cpqSasTapeDrvStatus
Descripción complementaria de la captura SNMP: “Status is now %d.”(Ahora, el estado es %d.)
ID de evento de NT: 1224 (Hex)0x843504c8 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Partner Controller Status Change. (El estado de la controladora asociada ha cambiado.)
Mensaje del registro: The Drive Array Controller in %4 has a Drive Array Partner Controller with serial number %5. This Partner Controller has a new status of %2. (Partner Controller status values: 1=other, 2=ok, 3=generalFailure) (La controladora de array de unidades de %4 tiene una controladora asociada de array de unidades con el número de serie %5. El estado de esta controladora asociada ha cambiado a %2. Valores del estado de la controladora asociada: 1=other, 2=ok, 3=generalFailure)
Captura SNMP: cpqDaCntlrPartnerStatusChange - 3048 en CPQIDA.MIB
Síntoma: El agente ha detectado un cambio en el estado de una controladora asociada de array de unidades. La variable cpqDaCntlrPartnerBoardStatus indica el estado actual de la controladora asociada. La variable cpqDaCntlrSerialNumber indica el número de serie de la controladora y la variable cpqDaCntlrPartnerSerialNumber indica el número de serie de la controladora asociada.
Acción del usuario: Compruebe si hay algún problema en la controladora asociada. La pérdida de la comunicación con la controladora asociada es consecuencia de una acción iniciada por el usuario y no precisa de ninguna acción correctiva.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqDaCntlrHwLocation
● cpqDaCntlrIndex
● cpqDaCntlrModel
● cpqDaCntlrSerialNumber
● cpqDaCntlrPartnerSerialNumber
● cpqDaCntlrPartnerBoardStatus
Descripción complementaria de la captura SNMP: “Partner controller status is now %d.” (Ahora, el estado de la controladora asociada es %d.)
ID de evento de NT: 1225 (Hex)0x843504c9 (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Storage System Connection Status Change. (El estado de la conexión del sistema de almacenamiento ha cambiado.)
Mensaje del registro: The %7 storage system connected to %5 of the controller in %4 has a new connection status of %6. (Connection status values: 1=other, 2=notSupported, 3=connected,
ESES Agentes de almacenamiento 411

4=notConnected) (El estado de conexión del sistema de almacenamiento %7 conectado a %5 de la controladora de %4 ha cambiado a %6. Valores del estado de la conexión: 1=other, 2=notSupported, 3=connected, 4=notConnected)
Captura SNMP: cpqSsConnectionStatusChange - 8032 en CPQSTSYS.MIB
Síntoma: El agente ha detectado un cambio en el estado de la conexión de un sistema de almacenamiento. La variable cpqSSboxConnectionStatus indica el estado actual de la conexión.
Acción del usuario: Si el estado de la conexión es desconectado, tome medidas para restaurar la conexión entre el HBA y el sistema de almacenamiento.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSsBoxCntlrHwLocation
● cpqSsBoxCntlrIndex
● cpqSsBoxBusIndex
● cpqSsBoxVendor
● cpqSsBoxModel
● cpqSsBoxSerialNumber
● cpqSsBoxConnectionStatus
● cpqSsBoxLocationString
● cpqSsBoxTargetSasAddress
● cpqSsBoxLocalManageIpAddress
Descripción complementaria de la captura SNMP: “Storage system connection status changed to %d.” (El estado de la conexión del sistema de almacenamiento ha cambiado a %d.)
ID de evento de NT: 1226 (Hex)0x843504ca (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: SAS/SATA Physical Drive SSD Wear Status Change. (El estado de desgaste de la unidad física SSD SAS/SATA ha cambiado.)
Mensaje del registro: The physical drive in %4, %5 with serial number "%6", has a new solid state wear status of %7. (Drive status values: 1=other, 2=ok, 3=fiftySixDayThreshold, 4=fivePercentThreshold, 5=twoPercentThreshold, 6=ssdWearOut) (El estado de desgaste de estado sólido de la unidad física de %4, %5, con el número de serie "%6", ha cambiado a %7. Valores del estado de la unidad: 1=other, 2=ok, 3=fiftySixDayThreshold, 4=fivePercentThreshold, 5=twoPercentThreshold, 6=ssdWearOut)
Captura SNMP: cpqSasPhyDrvSSDWearStatusChange - 5026 en CPQSCSI.MIB
Síntoma: El agente ha detectado un cambio en el estado de desgaste de la unidad física SSD SAS o SATA. La variable cpqSasPhyDrvSSDWearStatus indica el estado de desgaste actual de la unidad física SSD.
Acción del usuario: Si el estado de desgaste de la unidad SSD es ssdWearOut(6), sustitúyala.
Datos complementarios de la captura SNMP:
412 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

● sysName
● cpqHoTrapFlags
● cpqSasHbaHwLocation
● cpqSasPhyDrvLocationString
● cpqSasPhyDrvHbaIndex
● cpqSasPhyDrvIndex
● cpqSasPhyDrvType
● cpqSasPhyDrvModel
● cpqSasPhyDrvFWRev
● cpqSasPhyDrvSerialNumber
● cpqSasPhyDrvSasAddress
Descripción complementaria de la captura SNMP: “Solid State Disk Wear Status is now %d.” (Ahora, el estado de desgaste de la unidad SSD es %d.)
ID de evento de NT: 1227 (Hex)0x843504cb (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Drive Array Physical Drive SSD Wear Status Change. (El estado de desgaste de la unidad física SSD del array de unidades ha cambiado.)
Mensaje del registro: The physical drive in %4, %5 with serial number "%6", has a new solid state wear status of %7. (Drive status values: 1=other, 2=ok, 3=fiftySixDayThreshold, 4=fivePercentThreshold, 5=twoPercentThreshold, 6=ssdWearOut) (El estado de desgaste de estado sólido de la unidad física de %4, %5, con el número de serie "%6", ha cambiado a %7. Valores del estado de la unidad: 1=other, 2=ok, 3=fiftySixDayThreshold, 4=fivePercentThreshold, 5=twoPercentThreshold, 6=ssdWearOut)
Captura SNMP: cpqDaPhyDrvSSDWearStatusChange- 3049 en CPQIDA.MIB
Síntoma: Esta captura indica que el agente ha detectado un cambio en el estado de desgaste de una unidad física SSD de un array de unidades. La variable cpqDaPhyDrvSSDWearStatus indica el estado de desgaste actual de la unidad física SSD.
Acción del usuario: Si el estado de desgaste de la unidad SSD es ssdWearOut(6), sustitúyala.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqDaCntlrHwLocation
● cpqDaPhyDrvCntlrIndex
● cpqDaPhyDrvIndex
● cpqDaPhyDrvLocationString
● cpqDaPhyDrvType
● cpqDaPhyDrvModel
● cpqDaPhyDrvFWRev
ESES Agentes de almacenamiento 413

● cpqDaPhyDrvSerialNum
● cpqDaPhyDrvSSDWearStatus
● cpqSasPhyDrvSSDWearStatus
Descripción complementaria de la captura SNMP: “Solid State Disk Wear Status is now %d.” (Ahora, el estado de desgaste de la unidad SSD es %d.)
ID de evento de NT: 1228 (Hex)0x843504cc (cpqstmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: IDE Disk SSD Wear Status Change. (El estado de desgaste de la unidad SSD de disco IDE ha cambiado.)
Mensaje del registro: The ATA disk drive with model %6 and serial number %7 has a new solid state wear status of %2. (SSD wear status values: 1=other, 2=ok, 3=fiftySixDayThreshold, 4=fivePercentThreshold, 5=twoPercentThreshold, 6=ssdWearOut) (El estado de desgaste de estado sólido de la unidad de disco ATA modelo %6 y número de serie %7 ha cambiado a %2. Valores del estado de desgaste de SSD: 1=other, 2=ok, 3=fiftySixDayThreshold, 4=fivePercentThreshold, 5=twoPercentThreshold, 6=ssdWearOut)
Captura SNMP: cpqIdeAtaDiskSSDWearStatusChange - 14006 en CPQIDE.MIB
Síntoma: Esta captura indica que el agente ha detectado un cambio en el estado de desgaste de una unidad física SSD SATA. La variable cpqIdeAtaDiskSSDWearStatus indica el estado de desgaste actual de la unidad física SSD.
Acción del usuario: Si el estado de desgaste de la unidad SSD es ssdWearOut(6), sustitúyala.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqIdeAtaDiskControllerIndex
● cpqIdeAtaDiskIndex
● cpqIdeAtaDiskModel
● cpqIdeAtaDiskFwRev
● cpqIdeAtaDiskSerialNumber
● cpqIdeAtaDiskSSDWearStatus
● cpqIdeAtaDiskChannel
● cpqIdeAtaDiskNumber
Descripción complementaria de la captura SNMP: “Solid State Disk Wear Status is now %d.” (Ahora, el estado de desgaste de la unidad SSD es %d.)
Identificador del evento: cpqstmsg.dll - 1280 (Hex)0x84350500 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to allocate memory. This indicates a low memory condition. Rebooting the system will correct this error. (No es posible asignar memoria. Esto indica un problema de memoria insuficiente. Reiniciar el sistema puede corregir este error.)
Identificador del evento: cpqstmsg.dll - 1281 (Hex)0x84350501 (evento de servicio)
414 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not read from the registry subkey. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo leer la subclave del registro. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqstmsg.dll - 1282 (Hex)0x84350502 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not write the registry subkey: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo escribir la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqstmsg.dll - 1283 (Hex)0x84350503 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not read the registry subkey: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo leer la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqstmsg.dll - 1284 (Hex)0x84350504 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not write the registry subkey: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo escribir la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqstmsg.dll - 1285 (Hex)0x84350505 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not write the registry subkey: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo escribir la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqstmsg.dll - 1294 (Hex)0x8435050e (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unsupported storage system. The ProLiant storage system %1 is unsupported by this version of the Storage Agents. Upgrade the agents to the latest version. (Sistema de almacenamiento no compatible. El sistema de almacenamiento ProLiant %1 no es compatible con esta versión de Storage Agents. Actualice los agentes a la versión más reciente.)
Identificadores de eventos 1343-4613Identificador del evento: cpqstmsg.dll - 1343 (Hex) 0x8435053f (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Duplicate SCSI port found in slot %1. The current system ROM may not support this SCSI controller. You may need to update your system ROM. (Se ha hallado un puerto SCSI duplicado en la ranura %1. Es posible que la ROM del sistema actual no sea compatible con esta controladora SCSI. Es posible que tenga que actualizar la ROM del sistema.)
ESES Agentes de almacenamiento 415

Identificador del evento: cpqstmsg.dll - 1344 (Hex) 0x84350540 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: A version mismatch has been detected with the SCSI device monitor driver (CPQSDM.SYS). The current driver version is %1.
Cause: You may not have rebooted after a Storage Agents upgrade. Always reboot the system after installing agents. (Se han detectado versiones diferentes del controlador de supervisión de dispositivos SCSI [CPQSDM.SYS]. La versión actual del controlador es %1. Causa: es posible que no haya reiniciado después de actualizar Storage Agents. Siempre que instale agentes, reinicie el sistema.)
Identificador del evento: cpqstmsg.dll – 1346 (Hex) 0x84350540 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The SCSI controller on port %1 has been omitted. The SCSI Agent could not get the slot data for the controller. (Se ha omitido la controladora SCSI del puerto %1. El agente de SCSI no pudo obtener los datos de la ranura para la controladora.)
Identificador del evento: cpqstmsg.dll - 1792 (Hex) 0x84350700 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The SNMP Agent is unable to generate traps due to an error during initialization. (SNMP Agent no puede generar capturas debido a un error durante la inicialización.)
Causa: El servicio SNMP puede no estar ejecutándose. Volver a instalar los agentes puede corregir este error.
Identificador del evento: cpqstmsg.dll - 1795 (Hex) 0x84350703 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The SNMP Agent is older than other components. The SNMP Agent is older than the other components of the Storage Agents. Reinstall the entire Storage Agents package to correct this error. (SNMP Agent es anterior a otros componentes. SNMP Agent es anterior a los demás componentes de Storage Agents. Vuelva a instalar el paquete Storage Agents completo para corregir este error.)
Identificador del evento: cpqstmsg.dll - 1796 (Hex) 0x84350704 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The %1 Agent is older than other components. The %1 Agent is older than the other components of the Storage Agents. Reinstall the entire Storage Agents package to correct this error. (%1 Agent es anterior a otros componentes. %1 Agent es anterior a los demás componentes de Storage Agents. Vuelva a instalar el paquete Storage Agents completo para corregir este error.)
Identificador del evento: cpqstmsg.dll - 1800 (Hex) 0x84350708 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to read security configuration information. SNMP sets have been disabled. (No es posible leer la información de configuración de la seguridad. Se han desactivado los conjuntos SNMP.)
Causa: Esto puede deberse a que falta una configuración o es incorrecta, o a la existencia de un registro dañado. Volver a instalar Storage Agents puede solucionar este problema.
Identificador del evento: cpqstmsg.dll - 1803 (Hex) 0xc435070b (evento de servicio)
Nivel de gravedad del registro: Error (3)
416 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Mensaje del registro: Unable to load a required library. This error can be caused by a corrupt or missing file. Reinstalling the Storage Agents or running the Emergency Repair procedure may correct this error. (No es posible cargar una biblioteca obligatoria. Este error puede deberse a un archivo dañado o ausente. Volver a instalar Storage Agents o ejecutar el procedimiento de reparaciones de emergencia puede corregir este error.)
Identificador del evento: cpqstmsg.dll - 1804 (Hex) 0x8435070c (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Storage SNMP Agent was unable to forward an SNMP trap to the Remote Insight Board trap due to processing error. The data contains the error code. (Storage SNMP Agent no pudo reenviar una captura SNMP a la captura de la placa Remote Insight debido a un error de procesamiento. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 1806 (Hex) 0x8435070e (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Storage Agent service is not running. The SNMP Agent has determined that the Storage Agent service is not running. Stop the SNMP service and restart the Storage Agents service. If the error persists, reinstalling the Storage Agents may correct this error. (El servicio Storage Agent no se está ejecutando. SNMP Agent ha determinado que el servicio Storage Agent no se está ejecutando. Detenga el servicio SNMP y reinicie el servicio Storage Agents. Si el error continúa, es posible que se corrija volviendo a instalar Storage Agents.)
Identificador del evento: cpqstmsg.dll - 1807 (Hex) 0x4435070f (evento de servicio)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: The Storage SNMP Agent has determined the Storage Agents service is running. (Storage SNMP Agent ha determinado que el servicio Storage Agents se está ejecutando.)
Identificador del evento: cpqstmsg.dll - 1808 (Hex) 0x44350710 (evento de servicio)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: The agent could not deliver trap %1. The agent was unable to use Asynchronous Management to deliver a trap. This can be caused by a failure in the Remote Access Service or by a missing or invalid configuration. Use the HPE Insight Management Agents control panel to verify the Asynchronous Management configuration settings. Use the Network control panel to verify the Remote Access configuration. If this error persists, reinstalling the Storage Agents or the Remote Access Service may correct this error. For more information, see the Insight Asynchronous Management documentation. (El agente no pudo entregar la captura %1. El agente no pudo utilizar Asynchronous Management [Gestión asíncrona] para entregar una captura. Esto puede deberse a un fallo en el servicio de acceso remoto [Remote Access Service] o a una configuración no válida o ausente. Utilice el panel de control de HP Insight Management Agents para comprobar los parámetros de configuración de Asynchronous Management. Utilice el panel de control de la red para comprobar la configuración del acceso remoto. Si el error continúa, es posible que se corrija volviendo a instalar Storage Agents o el servicio de acceso remoto. Para obtener más información, consulte la documentación de Insight Asynchronous Management.)
Identificador del evento: cpqstmsg.dll - 3584 (Hex) 0x84350e00 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The IDE Agent could not allocate memory. The data contains the error code. (IDE Agent no pudo asignar memoria. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 3585 (Hex) 0x84350e01 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
ESES Agentes de almacenamiento 417

Mensaje del registro: The IDE Agent could not open the base of the registry. The data contains the error code. (IDE Agent no pudo abrir la base del registro. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 3586 (Hex) 0x84350e02 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: “%1”. The data contains the error code. (Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 3587 (Hex) 0x84350e03 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: “%1”. The data contains the error code. (Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 3588 (Hex) 0x84350e04 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The IDE Agent could not read the registry value “%1”. The data contains the error code. (IDE Agent no pudo leer el valor del registro “%1”. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 3589 (Hex) 0x84350e05 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The IDE Agent found an incorrect type for registry value “%1”. The data contains the type found. (IDE Agent encontró un tipo incorrecto para el valor del registro “%1”. Los datos contienen el tipo encontrado.)
Identificador del evento: cpqstmsg.dll - 3590 (Hex) 0x84350e06 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The IDE Agent could not create an event. The data contains the error code. (IDE Agent no pudo crear un evento. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 3591 (Hex)0x84350e07 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The IDE Agent could not open an event. The data contains the error code. (IDE Agent no pudo abrir un evento. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 3592 (Hex) 0x84350e08 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The IDE Agent could not set an event. The data contains the error code. (IDE Agent no pudo configurar un evento. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 3593 (Hex) 0x84350e09 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The IDE Agent could not create a mutex. The data contains the error code. (IDE Agent no pudo crear un mutex. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 3594 (Hex) 0x84350e0a (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
418 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Mensaje del registro: The IDE Agent could not open a mutex. The data contains the error code. (IDE Agent no pudo abrir un mutex. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 3595 (Hex) 0x84350e0b (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The IDE Agent could not create its main thread of execution. The data contains the error code. (IDE Agent no pudo crear su subproceso principal de ejecución. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 3596 (Hex) 0x84350e0c (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The IDE Agent main thread did not terminate properly. The data contains the error code. (El subproceso principal de IDE Agent no finalizó correctamente. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 3597 (Hex) 0x84350e0d (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The IDE Agent got an unexpected error code while waiting for an event. The data contains the error code. (IDE Agent obtuvo un código de error inesperado mientras esperaba que se produjese un evento. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 3598 (Hex) 0x84350e0e (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The IDE Agent got an unexpected error code while waiting for multiple events. The data contains the error code. (IDE Agent obtuvo un código de error inesperado mientras esperaba que se produjesen varios eventos. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 3599 (Hex) 0x84350e0f (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The IDE Agent did not respond to a request. The data contains the error code. (IDE Agent no respondió a una solicitud. Los datos contienen el código del error.)
Identificador del evento: cpqstmsg.dll - 3600 (Hex) 0x84350e10 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The IDE Agent received an unknown action code from the service. The data contains the action code. (IDE Agent recibió un código de acción desconocido del servicio. Los datos contienen el código de acción.)
Identificador del evento: cpqstmsg.dll - 4097 (Hex) 0x84351001 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not read from the registry subkey. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo leer la subclave del registro. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqstmsg.dll - 4098 (Hex) 0x84351002 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not write the registry subkey: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo escribir
ESES Agentes de almacenamiento 419

la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqstmsg.dll - 4099 (Hex) 0x84351003 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not read the registry subkey: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo leer la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqstmsg.dll - 4100 (Hex) 0x84351004 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not read the registry subkey: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo leer la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqstmsg.dll - 4101 (Hex) 0x84351005 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not read the registry subkey: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo leer la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqstmsg.dll - 4609 (Hex) 0x84351201 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not read the registry subkey. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo leer la subclave del registro. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqstmsg.dll - 4610 (Hex) 0x84351202 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not write the registry subkey: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo escribir la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqstmsg.dll - 4611 (Hex) 0x84351203 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not read the registry subkey: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo leer la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqstmsg.dll - 4612 (Hex) 0x84351204 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not read the registry subkey: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo leer la
420 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqstmsg.dll - 4613 (Hex) 0x84351205 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not read the registry subkey: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo leer la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Agentes de servidorIdentificadores de eventos 256-1024
Identificador del evento: cpqsvmsg.dll - 256 (Hex)0x84350100 (Service Event)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Server Agents service detected an error. The insertion string is: %1. The data contains the error code. (El servicio Server Agents detectó un error. La cadena de inserción es: %1. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 257 (Hex)0x84350101 (Service Event)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Server Agents service could not allocate memory. The data contains the error code. (El servicio Server Agents no pudo asignar memoria. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 258 (Hex)0x84350102 (Service Event)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Server Agents service could not register with the Service Control Manager. The data contains the error code. (El servicio Server Agents no se pudo registrar en Service Control Manager. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 259 (Hex)0x84350103 (Service Event)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Server Agents service could not set the service status with the Service Control Manager. The data contains the error code. (El servicio Server Agents no pudo configurar el estado del servicio en Service Control Manager. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 260 (Hex)0x84350104 (Service Event)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Server Agents service could not create an event object. The data contains the error code. (El servicio Server Agents no pudo crear un objeto de evento. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 261 (Hex)0x84350105 (Service Event)
Nivel de gravedad del registro: Advertencia (2)
ESES Agentes de servidor 421

Mensaje del registro: The Server Agents service could not open registry key “%1”. The data contains the error code. (El servicio Server Agents no pudo abrir la clave del registro “%1”. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 262 (Hex)0x84350106 (Service Event)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Server Agents service could not start any agents successfully. (El servicio Server Agents no pudo iniciar correctamente ningún agente.)
Identificador del evento: cpqsvmsg.dll - 263 (Hex)0x84350107 (Service Event)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Server Agents service could not read the registry value “%1”. The data contains the error code. (El servicio Server Agents no pudo leer el valor del registro “%1”. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 264 (Hex)0x84350108 (Service Event)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Server Agents service could not load the module “%1”. The data contains the error code. (El servicio Server Agents no pudo cargar el módulo “%1”. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 265 (Hex)0x84350109 (Service Event)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Server Agents service could not get the control function for module “%1”. The data contains the error code. (El servicio Server Agents no pudo obtener la función de control para el módulo “%1”. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 266 (Hex)0x8435010a (Service Event)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Server Agents service could not initialize agent “%1”. The data contains the error code. (El servicio Server Agents no pudo inicializar el agente “%1”. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 267 (Hex)0x8435010b (Service Event)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Server Agents service could not start agent “%1”. The data contains the error code. (El servicio Server Agents no pudo iniciar el agente “%1”. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 268 (Hex)0x8435010c (Service Event)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Server Agents service detected an invalid state for agent “%1”. The data contains the state. (El servicio Server Agents detectó un estado no válido para el agente “%1”. Los datos contienen el estado.)
Identificador del evento: cpqsvmsg.dll - 269 (Hex)0x8435010d (Service Event)
Nivel de gravedad del registro: Advertencia (2)
422 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Mensaje del registro: The Server Agents service could not stop agent “%1”. The data contains the error code. (El servicio Server Agents no pudo detener el agente “%1”. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 270 (Hex)0x8435010e (Service Event)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Server Agents service could not terminate agent “%1”. The data contains the error code. (El servicio Server Agents no pudo finalizar el agente “%1”. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 271 (Hex)0x8435010f (Service Event)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Server Agents service could not unload the module “%1”. The data contains the error code. (El servicio Server Agents no pudo descargar el módulo “%1”. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 272 (Hex)0x84350110 (Service Event)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Server Agents service could not create the registry key “%1”. The data contains the error code. (El servicio Server Agents no pudo crear la clave del registro “%1”. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 273 (Hex)0x84350111 (Service Event)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Server Agents service could not write the registry value “%1”. The data contains the error code. (El servicio Server Agents no pudo escribir el valor del registro “%1”. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 399 (Hex)0xc435018f (Service Event)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: The Server Agents service encountered a fatal error. The service is terminating. The data contains the error code. (El servicio Server Agents encontró un error muy grave. El servicio está finalizando. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 400 (Hex)0x44350190 (Service Event)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: The Server Agents service version %1 has started. (El servicio Server Agents versión %1 se ha iniciado.)
Identificador del evento: cpqsvmsg.dll - 401 (Hex)0x44350191 (Service Event)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: %1
Identificador del evento: cpqsvmsg.dll - 768 (Hex)0x84350300 (Service Event)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Remote Alerter Agent detected an invalid data type within an alert definition. (Remote Alerter Agent detectó un tipo de datos no válido dentro de una definición de alerta.)
ESES Agentes de servidor 423

Identificador del evento: cpqsvmsg.dll - 769 (Hex)0x84350301 (Service Event)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Remote Alerter Agent detected an error while attempting to log an alert remotely. The data contains the error code. (Remote Alerter Agent detectó un error al intentar registrar una alerta de forma remota. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 770 (Hex)0x84350302 (Service Event)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Remote Alerter Agent detected an error while attempting to retrieve data from key = %1 in the registry. The data contains the error code. (Remote Alerter Agent detectó un error al intentar recuperar los datos de la clave %1 del registro. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 771 (Hex)0x84350303 (Service Event)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Remote Alerter Agent was unable to log an event in the event log of the system named %1. The data contains the error code. (Remote Alerter Agent no pudo registrar un evento en el registro de eventos del sistema %1. Los datos contienen el código de error.)
Identificador del evento: cpqsvmsg.dll - 772 (Hex)0xc4350304 (Service Event)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: The Remote Alerter Agent detected a null handle on initialization. The data contains the error code. (Remote Alerter Agent detectó un identificador nulo durante la inicialización. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 773 (Hex)0xc4350305 (Service Event)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: The Remote Alerter Agent received an error on WaitForMultipleObjects call. The data contains the error code. (Remote Alerter Agent recibió un error en la llamada a WaitForMultipleObjects. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 774 (Hex)0xc4350306 (Service Event)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: The Remote Alerter Agent received an error on ResetEvent call. The data contains the error code. (Remote Alerter Agent recibió un error en la llamada a ResetEvent. Los datos contienen el código del error.)
ID de evento de NT: 1024 (Hex)0xc4350400 (cpqsvmsg.dll)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: A cache accelerator parity error indicates a cache module needs to be replaced. (Un error de paridad del acelerador de la memoria caché indica que es necesario sustituir un módulo de memoria caché.)
Captura SNMP: cpqHe3CacheAccelParityError - 6046 en CPQHLTH.MIB
Síntoma: Un error de paridad del acelerador de la memoria caché indica que es necesario sustituir un módulo de memoria caché. La información sobre el error se encuentra en la variable cpqHeEventLogErrorDesc.
Datos complementarios de la captura SNMP:
424 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

● sysName
● cpqHoTrapFlags
Descripción complementaria de la captura SNMP: “Cache Accelerator errors may require a replacement module.” (Es posible que sea necesario sustituir el módulo para corregir los errores del acelerador de la memoria caché.)
Identificadores de eventos 1025-1092ID de evento de NT: 1025 (Hex)0x84350401 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Advanced Memory Protection subsystem has detected a memory fault. The Online Spare Memory has been activated. Schedule server down time to replace the memory. (El subsistema de protección de memoria avanzada ha detectado un fallo de memoria. Se ha activado la memoria auxiliar en línea. Programe un tiempo de inactividad en el servidor para sustituir la memoria.)
Captura SNMP: cpqHeResilientMemOnlineSpareEngaged - 6047 en CPQHLTH.MIB
Síntoma: Se ha activado la memoria auxiliar en línea del subsistema de protección de memoria avanzada. El subsistema Advanced Memory Protection (Protección de memoria avanzada) ha detectado un error en la memoria. Se ha activado la memoria auxiliar en línea.
Acción del usuario: Programe un tiempo de inactividad en el servidor para sustituir la memoria defectuosa.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
Descripción complementaria de la captura SNMP: “The Advanced Memory Protection subsystem has engaged the online spare memory.” (El subsistema de protección de memoria avanzada ha activado la memoria auxiliar en línea.)
ID de evento de NT: 1026 (Hex)0x84350402 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Advanced Memory Protection sub-system has detected a memory fault. The Mirrored Memory has been activated. Schedule server down time to replace the memory. (El subsistema de protección de memoria avanzada ha detectado un fallo de memoria. Se ha activado la réplica de memoria. Programe un tiempo de inactividad en el servidor para sustituir la memoria.)
Captura SNMP: cpqHeResilientMemMirroredMemoryEngaged - 6051 en CPQHLTH.MIB
Síntoma: Se ha activado la réplica de memoria del subsistema de protección de memoria avanzada. El subsistema Advanced Memory Protection (Protección de memoria avanzada) ha detectado un error en la memoria. Se ha activado la réplica de memoria.
Acción del usuario: Sustituya la memoria defectuosa.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
ESES Agentes de servidor 425

Descripción complementaria de la captura SNMP: “The Advanced Memory Protection subsystem has engaged the online spare memory.” (El subsistema de protección de memoria avanzada ha activado la memoria auxiliar en línea.)
ID de evento de NT: 1027 (Hex)0x84350403 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Advanced Memory Protection sub-system has detected a memory fault. Advanced ECC has been activated. Schedule server down time to replace the memory. (El subsistema de protección de memoria avanzada ha detectado un fallo de memoria. Se ha activado la memoria ECC avanzada. Programe un tiempo de inactividad en el servidor para sustituir la memoria.)
Captura SNMP: cpqHeResilientAdvancedECCMemoryEngaged - 6052 en CPQHLTH.MIB
Síntoma: Se ha activado la memoria ECC avanzada del subsistema de protección de memoria avanzada. El subsistema Advanced Memory Protection (Protección de memoria avanzada) ha detectado un error en la memoria. Se ha activado la memoria ECC avanzada.
Acción del usuario: Sustituya la memoria defectuosa.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
Descripción complementaria de la captura SNMP: “The Advanced Memory Protection subsystem has engaged the advanced ECC memory.” (El subsistema de protección de memoria avanzada ha activado la memoria ECC avanzada.)
ID de evento de NT: 1028 (Hex)0x84350404 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Advanced Memory Protection sub-system has detected a memory fault. The XOR recovery engine has been activated. Schedule server down time to replace the memory. (El subsistema de protección de memoria avanzada ha detectado un fallo de memoria. Se ha activado el motor de recuperación XOR. Programe un tiempo de inactividad en el servidor para sustituir la memoria.)
Captura SNMP: cpqHeResilientMemXorMemoryEngaged - 6053 en CPQHLTH.MIB
Síntoma: Se ha activado la memoria del motor XOR del subsistema de protección de memoria avanzada. El subsistema Advanced Memory Protection (Protección de memoria avanzada) ha detectado un error en la memoria. Se ha activado el motor XOR.
Acción del usuario: Sustituya la memoria defectuosa.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
Descripción complementaria de la captura SNMP: “The Advanced Memory Protection subsystem has engaged the XOR memory.” (El subsistema de protección de memoria avanzada ha activado la memoria XOR.)
ID de evento de NT: 1029 (Hex)0x44350405 (cpqsvmsg.dll)
Nivel de gravedad del registro: Información (1)
426 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Mensaje del registro: The Fault Tolerant Power Supply Sub-system has returned to a redundant state. (El subsistema de fuentes de alimentación con tolerancia a fallos ha recuperado el estado redundante.)
Captura SNMP: cpqHe3FltTolPowerRedundancyRestored - 6054 en CPQHLTH.MIB
Síntoma: Las fuentes de alimentación con tolerancia a fallos han vuelto a un estado redundante para el chasis especificado.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqHeFltTolPowerSupplyChassis
Descripción complementaria de la captura SNMP: “The Power Supplies are now redundant on Chassis [cpqHeFltTolPowerSupplyChassis].” (Las fuentes de alimentación ahora son redundantes en el chasis [cpqHeFltTolPowerSupplyChassis].)
ID de evento de NT: 1030 (Hex) 0x44350406 (cpqsvmsg.dll)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: The Fan Sub-system has returned to a redundant state. (El subsistema de ventiladores ha recuperado el estado redundante.)
Captura SNMP: cpqHe3FltTolFanRedundancyRestored - 6055 en CPQHLTH.MIB
Síntoma: Los ventiladores con tolerancia a fallos han vuelto a un estado redundante para el chasis especificado.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqHeFltTolFanChassis
Descripción complementaria de la captura SNMP: “The Fans are now redundant on Chassis [cpqHeFltTolFanChassis].” (Los ventiladores ahora son redundantes en el chasis [cpqHeFltTolFanChassis].)
ID de evento de NT: 1035 (Hex) 0x8435040BL (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Corrected/uncorrected memory errors detected. The errors have been corrected, but the memory module should be replaced. Value 0 for CPU means memory is not Processor based. (Se han detectado errores de memoria corregidos/no corregidos. Los errores se han corregido, pero se debe sustituir el módulo de memoria. El valor 0 para la CPU significa que la memoria no está basada en el procesador.)
Captura SNMP: cpqHe5CorrMemReplaceMemModule - 6064 en CPQHLTH.MIB
Síntoma: Se han detectado errores de memoria corregidos. Los errores se han corregido, pero se debe sustituir el módulo de memoria. El valor 0 para la CPU significa que la memoria no está basada en el procesador.
Datos complementarios de la captura SNMP:
ESES Agentes de servidor 427

● sysName
● cpqHoTrapFlags
● cpqHeResMem2BoardNum
● cpqHeResMem2CpuNum
● cpqHeResMem2RiserNum
● cpqHeResMem2ModuleNum
● cpqHeResMem2ModulePartNo
● cpqHeResMem2ModuleSize
● cpqSiServerSystemId
Descripción complementaria de la captura SNMP: “Correctable memory errors require a replacement of the memory module in slot [cpqHeResMem2BoardNum], socket [cpqHeResMem2ModuleNum], Cpu [cpqHeResMem2CpuNum] Riser [cpqHeResMem2RiserNum].” Correctable/uncorrectable memory errors require a replacement of the memory module in slot [cpqHeResMem2BoardNum], cpu [cpqHeResMem2CpuNum], riser [cpqHeResMem2RiserNum], socket [cpqHeResMem2ModuleNum]. (La existencia de errores de memoria que se pueden corregir hace necesaria la sustitución del módulo de memoria de la ranura [cpqHeResMem2BoardNum], zócalo [cpqHeResMem2ModuleNum], CPU [cpqHeResMem2CpuNum], placa elevadora [cpqHeResMem2RiserNum]. La existencia de errores de memoria que se pueden corregir/imposibles de corregir hace necesaria la sustitución del módulo de memoria de la ranura [cpqHeResMem2BoardNum], CPU [cpqHeResMem2CpuNum], placa elevadora [cpqHeResMem2RiserNum], zócalo [cpqHeResMem2ModuleNum].)
ID de evento de NT: 1036 (Hex) 0x4435040CL (cpqsvmsg.dll)
Nivel de gravedad del registro: Informativo (1)
Mensaje del registro: A memory board or cartridge has been removed from the system. Please reinsert the memory board or cartridge. (Se ha extraído del sistema una tarjeta o un cartucho de memoria. Vuelva a introducir la tarjeta o el cartucho de memoria.)
Captura SNMP: cpqHe5ResMemBoardRemoved - 6065 en CPQHLTH.MIB
Síntoma: Se ha extraído una tarjeta, un cartucho o una placa elevadora de memoria. Se ha extraído del sistema una tarjeta, un cartucho o una placa elevadora del subsistema de protección de memoria avanzada. El valor 0 para la CPU significa que la memoria no está basada en el procesador.
Acción del usuario: Asegúrese de que se ha instalado correctamente la memoria de la tarjeta, el cartucho o la placa elevadora y, a continuación, vuelva a instalar la tarjeta, el cartucho o la placa elevadora.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqHeResMem2BoardSlotNum
● cpqHeResMem2BoardCpuNum
● cpqHeResMem2BoardRiserNum
Descripción complementaria de la captura SNMP “Memory Board or Cartridge Removed from Slot [cpqHeResMem2BoardSlotNum], Cpu [cpqHeResMem2BoardCpuNum], Riser [cpqHeResMem2BoardRiserNum].” (Se ha extraído una tarjeta o un cartucho de memoria de la
428 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

ranura [cpqHeResMem2BoardSlotNum], CPU [cpqHeResMem2BoardCpuNum], placa elevadora [cpqHeResMem2BoardRiserNum].)
ID de evento de NT: 1037 (Hex) 0x4435040DL (cpqsvmsg.dll)
Nivel de gravedad del registro: Informativo (1)
Mensaje del registro: System Information Agent: Health: A memory board or cartridge has been inserted into the system. (Se ha introducido en el sistema una tarjeta o un cartucho de memoria.)
Captura SNMP: cpqHe5ResMemBoardInserted - 6066 en CPQHLTH.MIB
Síntoma: Se ha introducido una tarjeta, un cartucho o una placa elevadora de memoria. Se ha instalado una tarjeta, un cartucho o una placa elevadora del subsistema de protección de memoria avanzada. El valor 0 para la CPU significa que la memoria no está basada en el procesador.
Acción del usuario: Ninguna.
Datos de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqHeResMem2BoardSlotNum
● cpqHeResMem2BoardCpuNum
● cpqHeResMem2BoardRiserNum
Descripción complementaria de la captura SNMP: “Memory Board or Cartridge Inserted into Slot [cpqHeResMem2BoardSlotNum], Cpu[cpqHeResMem2BoardCpuNum], Riser[cpqHeResMem2BoardRiserNum].” (Se ha introducido una tarjeta o un cartucho de memoria en la ranura [cpqHeResMem2BoardSlotNum], CPU [cpqHeResMem2BoardCpuNum], placa elevadora [cpqHeResMem2BoardRiserNum].)
ID de evento de NT: 1038 (Hex) 0xC435040EL (cpqsvmsg.dll)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: A memory board or cartridge bus error has been detected in the memory subsystem. (Se ha detectado un error en el bus de tarjeta o cartucho de memoria del subsistema de memoria.)
Captura SNMP: cpqHe5ResMemBoardBusError- 6067 en CPQHLTH.MIB
Síntoma: Se ha detectado un error en el bus de tarjeta, cartucho o placa elevadora de memoria. Se ha detectado un error en el bus de tarjeta, cartucho o placa elevadora del subsistema de protección de memoria avanzada. El valor 0 para la CPU significa que la memoria no está basada en el procesador.
Acción del usuario: Sustituya la tarjeta, el cartucho o la placa elevadora indicada.
Datos de la captura SNMP:
● sysName,
● cpqHoTrapFlags
● cpqHeResMem2BoardSlotNum
● cpqHeResMem2BoardCpuNum
● cpqHeResMem2BoardRiserNum
ESES Agentes de servidor 429

Descripción complementaria de la captura SNMP: “Memory Board or Cartridge Inserted into Slot [cpqHeResMem2BoardSlotNum], Cpu[cpqHeResMem2BoardCpuNum], Riser[cpqHeResMem2BoardRiserNum].” (Se ha introducido una tarjeta o un cartucho de memoria en la ranura [cpqHeResMem2BoardSlotNum], CPU [cpqHeResMem2BoardCpuNum], placa elevadora [cpqHeResMem2BoardRiserNum].)
ID de evento de NT: 1039 (Hex) 0x8435040FL (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (3)
Mensaje del registro: The Advanced Memory Protection sub-system has detected a memory fault. The LockStep recovery engine has been activated. For instruction on replacing the faulty memory, see the server documentation. (El subsistema de protección de memoria avanzada ha detectado un fallo de memoria. Se ha activado el motor de recuperación LockStep. Si desea instrucciones para sustituir la memoria defectuosa, consulte la documentación del servidor.)
Captura SNMP: cpqHeResilientMemLockStepMemoryEngaged - 6068 en CPQHLTH.MIB
Síntoma: Se ha activado la memoria del motor LockStep del subsistema de protección de memoria avanzada. El subsistema Advanced Memory Protection (Protección de memoria avanzada) ha detectado un error en la memoria. Se ha activado el motor LockStep.
Acción del usuario: Sustituya la memoria defectuosa.
Datos complementarios de la captura SNMP:
● sysName,
● cpqHoTrapFlags
Descripción complementaria de la captura SNMP: “The Advanced Memory Protection subsystem has engaged the LockStep memory.” (El subsistema de protección de memoria avanzada ha activado la memoria LockStep.)
ID de evento de NT: 1040 (Hex) 0xC43504A0L (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (3)
Mensaje del registro: The fault tolerant power supply AC power loss for the specified chassis and bay location. (Pérdida de alimentación de CA en la fuente de alimentación con tolerancia a fallos para el chasis y el compartimento especificados.)
Captura SNMP: cpqHeResilientMemLockStepMemoryEngaged - 6069 en CPQHLTH.MIB
Síntoma: Pérdida de alimentación de CA en la fuente de alimentación con tolerancia a fallos para el chasis y el compartimento especificados.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqHeFltTolPowerSupplyChassis
● cpqHeFltTolPowerSupplyBay
● cpqHeFltTolPowerSupplyStatus
● cpqHeFltTolPowerSupplyModel
● cpqHeFltTolPowerSupplySerialNumber
● cpqHeFltTolPowerSupplyAutoRev
430 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

● cpqHeFltTolPowerSupplyFirmwareRev
● cpqHeFltTolPowerSupplySparePartNum
● cpqSiServerSystemId
Descripción complementaria de la captura SNMP: “The Power Supply AC power loss in [sysName], Bay [cpqHeFltTolPowerSupplyBay], Status [cpqHeFltTolPowerSupplyStatus], Model [cpqHeFltTolPowerSupplyModel], Serial Num [cpqHeFltTolPowerSupplySerialNumber], Firmware [cpqHeFltTolPowerSupplyFirmwareRev].” (Pérdida de alimentación de CA en la fuente de alimentación [sysName], compartimento [cpqHeFltTolPowerSupplyBay], estado [cpqHeFltTolPowerSupplyStatus], modelo [cpqHeFltTolPowerSupplyModel], número de serie [cpqHeFltTolPowerSupplySerialNumber], firmware [cpqHeFltTolPowerSupplyFirmwareRev].)
ID de evento de NT: 1072 (Hex)0x84350430 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The frequency of memory errors is high enough such that tracking of correctable memory errors has been temporarily disabled. (La frecuencia de los errores de memoria es tan alta que se ha desactivado temporalmente el seguimiento de errores de memoria que se pueden corregir.)
Captura SNMP: cpqHe3CorrectableMemoryLogDisabled - 6016 en CPQHLTH.MIB
Síntoma: Se ha desactivado el seguimiento de errores de memoria que se pueden corregir. La frecuencia de los errores es tan alta que se ha desactivado temporalmente la lógica de seguimiento de errores. La variable cpqHeCorrMemLogStatus indica el estado actual del seguimiento.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqHeCorrMemLogStatus
Descripción complementaria de la captura SNMP: “Too many memory errors - tracking now disabled.” (Demasiados errores de memoria; el seguimiento se ha desactivado.)
ID de evento de NT: 1082 (Hex)0xc435043a (cpqsvmsg.dll)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: A Thermal Temperature Condition has been set to failed. The system will be shut down due to this thermal condition. (Una condición de temperatura tiene el estado Failed. El sistema se apagará debido a esta condición de temperatura.)
Captura SNMP: cpqHe3ThermalTempFailed - 6017 en CPQHLTH.MIB
Síntoma: La temperatura tiene el estado Failed. El sistema se ha apagado debido a esta condición de temperatura.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
Descripción complementaria de la captura SNMP: “System will be shut down due to this thermal condition.” (El sistema se apagará debido a esta condición de temperatura.)
ID de evento de NT: 1083 (Hex)0x8435043b (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
ESES Agentes de servidor 431

Mensaje del registro: The Thermal Temperature Condition has been set to degraded. The system may be shut down due to this thermal condition depending on the state of the thermal degraded action value '%4'. (La condición de temperatura tiene el estado Degraded. El sistema podría apagarse debido a esta condición de temperatura dependiendo del estado del valor de la acción de temperatura degradada '%4'.)
Captura SNMP: cpqHe3ThermalTempDegraded - 6018 en CPQHLTH.MIB
Síntoma: La temperatura tiene el estado Degraded. La temperatura del servidor está fuera del intervalo de funcionamiento normal. El servidor se apagará si la variable cpqHeThermalDegradedAction tiene el valor shutdown (3).
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqHeThermalDegradedAction
Descripción complementaria de la captura SNMP: “Temperature out of range. Shutdown may occur.” (Temperatura fuera del intervalo. El sistema puede apagarse.)
ID de evento de NT: 1084 (Hex)0x4435043c (cpqsvmsg.dll)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: The Thermal Temperature Condition has been set to OK. The server's temperature has returned to its normal operating range. (La condición de temperatura tiene el estado OK. La temperatura del servidor vuelve a estar dentro del intervalo de funcionamiento normal.)
Captura SNMP: cpqHe3ThermalTempOk - 6019 en CPQHLTH.MIB
Síntoma: La temperatura tiene el estado OK. La temperatura del servidor vuelve a estar dentro del intervalo de funcionamiento normal.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
Descripción complementaria de la captura SNMP: “Temperature has returned to normal range.” (La temperatura vuelve a estar dentro del intervalo normal.)
ID de evento de NT: 1085 (Hex)0xc435043d (cpqsvmsg.dll)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: A System Fan Condition has been set to failed. The system may be shut down due to this thermal condition. (Una condición de ventilador del sistema tiene el estado Failed. El sistema podría apagarse debido a esta condición de temperatura.)
Captura SNMP: cpqHe3ThermalSystemFanFailed - 6020 en CPQHLTH.MIB
Síntoma: El ventilador del sistema tiene el estado Failed. Un ventilador del sistema necesario no funciona con normalidad. El sistema se apagará si la variable cpqHeThermalDegradedAction tiene el valor shutdown (3).
Datos complementarios de la captura SNMP:
432 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

● sysName
● cpqHoTrapFlags
● cpqHeThermalDegradedAction
Descripción complementaria de la captura SNMP: “Required fan not operating normally. Shutdown may occur.” (Un ventilador necesario no funciona con normalidad. El sistema puede apagarse.)
ID de evento de NT: 1086 (Hex)0x8435043e (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: A System Fan Condition has been set to degraded. If the system fan is part of a redundancy group, the system will not be shut down. If the system fan is not part of a redundancy group, the system may be shut down depending on the state of the thermal degraded action value '%4'. (Una condición de ventilador del sistema tiene el estado Degraded. Si el ventilador del sistema forma parte de un grupo de redundancia, el sistema no se apagará. Si el ventilador del sistema no forma parte de un grupo de redundancia, el sistema podría apagarse dependiendo del estado del valor de la acción de temperatura degradada '%4'.)
Captura SNMP: cpqHe3ThermalSystemFanDegraded - 6021 en CPQHLTH.MIB
Síntoma: El ventilador del sistema tiene el estado Degraded. Un ventilador del sistema opcional no funciona con normalidad.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
Descripción complementaria de la captura SNMP: “An optional fan is not operating normally.” (Un ventilador opcional no funciona con normalidad.)
ID de evento de NT: 1087 (Hex)0x4435043f (cpqsvmsg.dll)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: A System Fan Condition has been set to OK. The server's system fan has resumed normal operation. (Una condición de ventilador del sistema tiene el estado OK. El ventilador del sistema del servidor vuelve a funcionar con normalidad.)
Captura SNMP: cpqHe3ThermalSystemFanOk - 6022 en CPQHLTH.MIB
Síntoma: El ventilador del sistema tiene el estado OK. Cualquier ventilador del sistema que antes no era operativo ha vuelto a funcionar con normalidad.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
Descripción complementaria de la captura SNMP: “System fan has returned to normal operation.” (El ventilador del sistema vuelve a funcionar con normalidad.)
ID de evento de NT: 1088 (Hex)0xc4350440 (cpqsvmsg.dll)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: A Processor Fan Condition has been set to failed. The system will be shut down due to this condition. (Una condición de ventilador del procesador tiene el estado Failed. El sistema se apagará debido a esta condición.)
ESES Agentes de servidor 433

Captura SNMP: cpqHe3ThermalCpuFanFailed - 6023 en CPQHLTH.MIB
Síntoma: El ventilador de la CPU tiene el estado Failed. Un ventilador del procesador no funciona con normalidad. El servidor está apagado.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
Descripción complementaria de la captura SNMP: “CPU fan has failed. Server will be shutdown.” (El ventilador de la CPU ha fallado. El servidor se apagará.)
ID de evento de NT: 1089 (Hex)0x44350441 (cpqsvmsg.dll)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: A Processor Fan Condition has been set to OK. The server's processor fan has resumed normal operation. (Una condición de ventilador del procesador tiene el estado OK. El ventilador del procesador del servidor vuelve a funcionar con normalidad.)
Captura SNMP: cpqHe3ThermalCpuFanOk - 6024 en CPQHLTH.MIB
Síntoma: El ventilador de la CPU tiene el estado OK. Cualquier ventilador del procesador que antes no era operativo ha vuelto a funcionar con normalidad.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
Descripción complementaria de la captura SNMP: “CPU fan is now OK.” (Ahora, el ventilador de la CPU tiene el estado OK.)
ID de evento de NT: 1090 (Hex)0x44350442 (cpqsvmsg.dll)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: The server is operational again. The server has previously been shut down by the Automatic Server Recovery (ASR) feature and has just become operational again. (El servidor vuelve a estar operativo. La característica ASR [Recuperación automática del servidor] había apagado el servidor, pero este ha vuelto a estar operativo.)
Captura SNMP: cpqHe3AsrConfirmation - 6025 en CPQHLTH.MIB
Síntoma: El servidor vuelve a estar operativo. La característica ASR (Recuperación automática del servidor) había apagado el servidor, pero este ha vuelto a estar operativo.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
Descripción complementaria de la captura SNMP: “Server is operational again after ASR shutdown.” (El servidor vuelve a estar operativo tras haberlo apagado la característica ASR.)
ID de evento de NT: 1091 (Hex)0x44350443 (cpqsvmsg.dll)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: The server is operational again. The server has previously been shut down due to a thermal anomaly and has just become operational again. (El servidor vuelve a estar operativo. El
434 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

servidor se había apagado debido a una anomalía en la temperatura, pero ha vuelto a estar operativo.)
Captura SNMP: cpqHe3ThermalConfirmation - 6026 en CPQHLTH.MIB
Síntoma: El servidor vuelve a estar operativo. El servidor se había apagado debido a una anomalía en la temperatura, pero ha vuelto a estar operativo.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
Descripción complementaria de la captura SNMP: “Server is operational again after thermal shutdown.” (El servidor vuelve a estar operativo tras haberse apagado debido a una anomalía en la temperatura.)
ID de evento de NT: 1092 (Hex)0x84350444 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Post Errors were detected. One or more Power-On-Self-Test errors were detected during server startup. (Se han detectado errores de la POST. Durante el inicio del servidor, se detectaron uno o varios errores en la POST.)
Captura SNMP: cpqHe3PostError - 6027 en CPQHLTH.MIB
Síntoma: Se han producido uno o varios errores en la POST. Se han producido errores en la POST (Powern-On Self-Test) durante el proceso de reinicio del servidor.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
Descripción complementaria de la captura SNMP: “Errors occurred during server restart.” (Se han producido errores durante el reinicio del servidor.)
Identificadores de eventos 1103-1183ID de evento de NT: 1103 (Hex)0x8435044f (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Fault Tolerant Power Sub-system has been set to Degraded. Check power connections and replace the power supply as needed. (El subsistema de fuentes de alimentación con tolerancia a fallos tiene el estado Degraded. Compruebe las conexiones de alimentación y sustituya la fuente de alimentación si fuera necesario.)
Captura SNMP: cpqHe3FltTolPwrSupplyDegraded - 6028 en CPQHLTH.MIB
Síntoma: El subsistema de fuentes de alimentación con tolerancia a fallos tiene el estado Degraded.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
Descripción complementaria de la captura SNMP: “The server power supply status has become degraded.” (El estado de la fuente de alimentación del servidor ha cambiado a Degraded.)
ID de evento de NT: 1108 (Hex)0x84350454 (cpqsvmsg.dll)
ESES Agentes de servidor 435

Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Remote Insight Board has detected unauthorized login attempts. More than '%4' login attempts detected. (La placa Remote Insight ha detectado intentos no autorizados de inicio de sesión. Se han detectado más de '%4' intentos de inicio de sesión.)
Captura SNMP: cpqSm2UnauthorizedLoginAttempts - 9003 en CPQSM2.MIB
Síntoma: Intentos no autorizados de inicio de sesión en Remote Insight/Integrated Lights-Out. El firmware de Remote Insight/Integrated Lights-Out ha detectado intentos no autorizados de inicio de sesión.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSm2CntlrBadLoginAttemptsThresh
Descripción complementaria de la captura SNMP: “More than [cpqSm2CntlrBadLoginAttemptsThresh] unauthorized login attempts detected.” (Se han detectado más de [cpqSm2CntlrBadLoginAttemptsThresh] intentos no autorizados de inicio de sesión.)
ID de evento de NT: 1109 (Hex)0xc4350455 (cpqsvmsg.dll)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: The Remote Insight Board has detected a battery failure. (La placa Remote Insight ha detectado un fallo en la batería.)
Captura SNMP: cpqSm2BatteryFailed - 9004 en CPQSM2.MIB
Síntoma: La batería de Remote Insight ha fallado. La batería de Remote Insight ha fallado y es necesario sustituirla.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
Descripción complementaria de la captura SNMP: “Remote Insight battery failed.” (La batería de Remote Insight ha fallado.)
ID de evento de NT: 1110 (Hex)0xc4350456 (cpqsvmsg.dll)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: The Remote Insight Board has detected self test error '%4'. (La placa Remote Insight ha detectado el error de autocomprobación '%4'.)
Captura SNMP: cpqSm2SelfTestError - 9005 en CPQSM2.MIB
Síntoma: Error de autocomprobación de Remote Insight/Integrated Lights-Out. El firmware de Remote Insight/Integrated Lights-Out ha detectado un error de autocomprobación de Remote Insight.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSm2CntlrSelfTestErrors
436 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Descripción complementaria de la captura SNMP: “Remote Insight/Integrated Lights-Out self test error [cpqSm2CntlrSelfTestErrors].” (Error de autocomprobación de Remote Insight/Integrated Lights-Out [cpqSm2CntlrSelfTestErrors].)
ID de evento de NT: 1111 (Hex)0xc4350457 (cpqsvmsg.dll)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: The Remote Insight Board has detected a controller interface error. (La placa Remote Insight ha detectado un error en la interfaz de la controladora.)
Captura SNMP: cpqSm2InterfaceError - 9006 en CPQSM2.MIB
Síntoma: Error en la interfaz de Remote Insight/Integrated Lights-Out. El sistema operativo del host ha detectado un error en la interfaz de Remote Insight/Integrated Lights-Out. El firmware no responde.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
Descripción complementaria de la captura SNMP: “Server [sysName], Remote Insight/Integrated Lights-Out interface error.” (Servidor [sysName], error en la interfaz de Remote Insight/Integrated Lights-Out.)
ID de evento de NT: 1112 (Hex)0x84350458 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Remote Insight Board has detected that the battery is disconnected. (La placa Remote Insight ha detectado que la batería está desconectada.)
Captura SNMP: cpqSm2BatteryDisconnected - 9007 en CPQSM2.MIB
Síntoma: La batería de Remote Insight está desconectada. El cable de la batería de Remote Insight se ha desconectado.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
Descripción complementaria de la captura SNMP: “Remote Insight battery disconnected.” (La batería de Remote Insight está desconectada.)
ID de evento de NT: 1113 (Hex)0x84350459 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Remote Insight Board has detected that the keyboard cable is disconnected. (La placa Remote Insight ha detectado que el cable del teclado está desconectado.)
Captura SNMP: cpqSm2KeyboardCableDisconnected - 9008 en CPQSM2.MIB
Síntoma: El cable del teclado está desconectado. El cable del teclado de Remote Insight se ha desconectado.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
ESES Agentes de servidor 437

Descripción complementaria de la captura SNMP: “Remote Insight keyboard cable disconnected.” (El cable del teclado de Remote Insight se ha desconectado.)
ID de evento de NT: 1114 (Hex)0x8435045a (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: A processor has crossed the threshold of allowable corrected errors. The processor should be replaced. (Un procesador ha sobrepasado el umbral de errores corregidos permitidos. El procesador debe sustituirse.)
Captura SNMP: cpqSeCpuThresholdPassed - 1005 en CPQSTDEQ.MIB
Síntoma: Esta captura se envía cuando se sobrepasa un umbral de errores internos en un procesador determinado, provocando que este cambie su estado a Degraded. Esta captura se envía cuando cpqSeCpuThreshPassed pasa de false a true.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSeCpuSlot
● cpqSeCpuSocketNumber
● cpqSeCpuSpeed
● cpqSeCpuExtSpeed
● cpqSeCpuCacheSize
Descripción complementaria de la captura SNMP: “CPU internal corrected errors have passed a set threshold.” (Los errores internos corregidos de la CPU han sobrepasado un umbral establecido.)
Captura SNMP: cpqSeCpuStatusChange - 1006 en CPQSTDEQ.MIB
Síntoma: Esta captura se envía cuando cambia el estado de la CPU. La CPU se puede poner en el estado Stop y quitarse del conjunto activo del sistema operativo o volver a ponerse en el estado Running para que forme parte de dicho conjunto.
Acción del usuario: Ninguna.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSeCpuUnitIndex
● cpqSeCpuSlot
● cpqSeCpuName
● cpqSeCpuSpeed
● cpqSeCpuStep
● cpqSeCpuStatus
● cpqSeCpuExtSpeed
● cpqSeCpuSocketNumber
● cpqSeCpuHwLocation
438 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Descripción complementaria de la captura SNMP: “Processor in Slot [cpqSeCpuSlot] status change to [cpqSeCpuStatus].” (El estado del procesador de la ranura [cpqSeCpuSlot] ha cambiado a [cpqSeCpuStatus].)
Captura SNMP: cpqSeCpuPowerPodstatusChange - 1007 en CPQSTDEQ.MIB
Síntoma: Esta captura se envía si cambia el estado del Pod de la alimentación de la CPU.
Acción del usuario: Ninguna.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSeCpuUnitIndex
● cpqSeCpuSlot
● cpqSeCpuName
● cpqSeCpuSpeed
● cpqSeCpuStep
● cpqSeCpuPowerpodStatus
● cpqSeCpuExtSpeed
● cpqSeCpuSocketNumber
● cpqSeCpuHwLocation
Descripción complementaria de la captura SNMP: “Processor in Slot [cpqSeCpuSlot] Power supply status is [cpqSeCpuPowerpodStatus].” (El estado de la fuente de alimentación del procesador de la ranura [cpqSeCpuSlot] es [cpqSeCpuPowerpodStatus].)
ID de evento de NT: 1115 (Hex)0x8435045b (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: A computer cover has been removed since last system start up. Be sure the system cover is installed properly. This situation may result in improper cooling of the system due to air flow changes caused by the missing cover. (Se ha retirado una cubierta del equipo después de arrancar el sistema por última vez. Asegúrese de que la cubierta del sistema está instalada correctamente. Esta situación puede dar como resultado una incorrecta refrigeración del sistema debido a los cambios en el flujo de aire ocasionados por la ausencia de la cubierta.)
Captura SNMP: cpqSiHoodRemoved - 2001 en CPQSINFO.MIB
Síntoma: Se ha quitado el panel de acceso. El panel de acceso tiene el estado Removed. El panel de acceso no está instalado correctamente. Esta situación puede dar como resultado una incorrecta refrigeración del sistema debido a los cambios en el flujo de aire ocasionados por la ausencia del panel de acceso.
Acción del usuario: Vuelva a colocar el panel de acceso y asegúrese de que se ha instalado correctamente. Compruebe que el sistema funciona correctamente.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
ESES Agentes de servidor 439

Descripción complementaria de la captura SNMP: “Hood is removed from unit.” (La cubierta se ha retirado de la unidad.)
ID de evento de NT: 1116 (Hex)0x8435045c (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Remote Insight Board has detected that the mouse cable is disconnected. (La placa Remote Insight ha detectado que el cable del ratón está desconectado.)
Captura SNMP: cpqSm2MouseCableDisconnected - 9009 en CPQSM2.MIB
Síntoma: El cable del ratón está desconectado. El cable del ratón de Remote Insight se ha desconectado.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
Descripción complementaria de la captura SNMP: “Remote Insight mouse cable disconnected.” (El cable del ratón de Remote Insight se ha desconectado.)
ID de evento de NT: 1117 (Hex)0x8435045d (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Remote Insight Board has detected that the external power cable is disconnected. (La placa Remote Insight ha detectado que el cable de alimentación externa está desconectado.)
Captura SNMP: cpqSm2ExternalPowerCableDisconnected - 9010 en CPQSM2.MIB
Síntoma: El cable de alimentación externa está desconectado. El cable de alimentación externa de Remote Insight se ha desconectado.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
Descripción complementaria de la captura SNMP: “Remote Insight external power cable disconnected.” (El cable de alimentación externa de Remote Insight se ha desconectado.)
ID de evento de NT: 1118 (Hex)0x4435045e (cpqsvmsg.dll)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: The Fault Tolerant Power Supply Sub-system has been returned to the OK state. (El subsistema de fuentes de alimentación con tolerancia a fallos ha recuperado el estado OK.)
Captura SNMP: cpqHe4FltTolPowerSupplyOk - 6048 en CPQHLTH.MIB
Síntoma: La fuente de alimentación con tolerancia a fallos ha recuperado el estado OK para el chasis y el compartimento especificados.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqHeFltTolPowerSupplyChassis
440 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

● cpqHeFltTolPowerSupplyBay
● cpqHeFltTolPowerSupplyStatus
● cpqHeFltTolPowerSupplyModel
● cpqHeFltTolPowerSupplySerialNumber
● cpqHeFltTolPowerSupplyAutoRev
● cpqHeFltTolPowerSupplyFirmwareRev
● cpqHeFltTolPowerSupplySparePartNum
● cpqSiServerSystemId
Descripción complementaria de la captura SNMP: “The Power Supply is OK on Chassis [cpqHeFltTolPowerSupplyChassis], Bay [cpqHeFltTolPowerSupplyBay], Status [cpqHeFltTolPowerSupplyStatus], Model [cpqHeFltTolPowerSupplyModel], Serial Num [cpqHeFltTolPowerSupplySerialNumber], Firmware [cpqHeFltTolPowerSupplyFirmwareRev].” (La fuente de alimentación tiene el estado OK en el chasis [cpqHeFltTolPowerSupplyChassis], compartimento [cpqHeFltTolPowerSupplyBay], estado [cpqHeFltTolPowerSupplyStatus], modelo [cpqHeFltTolPowerSupplyModel], número de serie [cpqHeFltTolPowerSupplySerialNumber], firmware [cpqHeFltTolPowerSupplyFirmwareRev].)
ID de evento de NT: 1123 (Hex)0x84350463 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Post Errors were detected. One or more Power-On-Self-Test errors were detected during server startup. (Se han detectado errores de la POST. Durante el inicio del servidor, se detectaron uno o varios errores en la POST.)
Captura SNMP: cpqHe3PostError - 6027 en CPQHLTH.MIB
Síntoma: Se han producido uno o varios errores en la POST. Se han producido errores en la POST (Powern-On Self-Test) durante el proceso de reinicio del servidor.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
Descripción complementaria de la captura SNMP: “Errors occurred during server restart.” (Se han producido errores durante el reinicio del servidor.)
ID de evento de NT: 1124 (Hex)0x84350464 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Fault Tolerant Power Supply Sub-system is in a degraded state. Restore power or replace the failed power supply. (El subsistema de fuentes de alimentación con tolerancia a fallos tiene el estado Degraded. Restaure la alimentación o sustituya la fuente de alimentación defectuosa.)
Captura SNMP: cpqHe4FltTolPowerSupplyDegraded - 6049 en CPQHLTH.MIB
Síntoma: La fuente de alimentación con tolerancia a fallos tiene el estado Degraded para el chasis y el compartimento especificados.
Datos complementarios de la captura SNMP:
ESES Agentes de servidor 441

● sysName
● cpqHoTrapFlags
● cpqHeFltTolPowerSupplyChassis
● cpqHeFltTolPowerSupplyBay
● cpqHeFltTolPowerSupplyStatus
● cpqHeFltTolPowerSupplyModel
● cpqHeFltTolPowerSupplySerialNumber
● cpqHeFltTolPowerSupplyAutoRev
● cpqHeFltTolPowerSupplyFirmwareRev
● cpqHeFltTolPowerSupplySparePartNum
● cpqSiServerSystemId
Descripción complementaria de la captura SNMP: “The Power Supply is Degraded on Chassis [cpqHeFltTolPowerSupplyChassis], Bay [cpqHeFltTolPowerSupplyBay], Status [cpqHeFltTolPowerSupplyStatus], Model [cpqHeFltTolPowerSupplyModel], Serial Num [cpqHeFltTolPowerSupplySerialNumber], Firmware [cpqHeFltTolPowerSupplyFirmwareRev].” (La fuente de alimentación tiene el estado Degraded en el chasis [cpqHeFltTolPowerSupplyChassis], compartimento [cpqHeFltTolPowerSupplyBay], estado [cpqHeFltTolPowerSupplyStatus], modelo [cpqHeFltTolPowerSupplyModel], número de serie [cpqHeFltTolPowerSupplySerialNumber], firmware [cpqHeFltTolPowerSupplyFirmwareRev].)
ID de evento de NT: 1125 (Hex)0xc4350465 (cpqsvmsg.dll)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: The Fault Tolerant Power Supply Sub-system is in a failed state. Restore power or replace the failed power supply. (El subsistema de fuentes de alimentación con tolerancia a fallos tiene el estado Failed. Restaure la alimentación o sustituya la fuente de alimentación defectuosa.)
Captura SNMP: cpqHe4FltTolPowerSupplyFailed - 6050 en CPQHLTH.MIB
Síntoma: La fuente de alimentación con tolerancia a fallos tiene el estado Failed para el chasis y el compartimento especificados.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqHeFltTolPowerSupplyChassis
● cpqHeFltTolPowerSupplyBay
● cpqHeFltTolPowerSupplyStatus
● cpqHeFltTolPowerSupplyModel
● cpqHeFltTolPowerSupplySerialNumber
● cpqHeFltTolPowerSupplyAutoRev
● cpqHeFltTolPowerSupplyFirmwareRev
442 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

● cpqHeFltTolPowerSupplySparePartNum
● cpqSiServerSystemId
Descripción complementaria de la captura SNMP: “The Power Supply is Failed on Chassis [cpqHeFltTolPowerSupplyChassis], Bay [cpqHeFltTolPowerSupplyBay], Status [cpqHeFltTolPowerSupplyStatus], Model [cpqHeFltTolPowerSupplyModel], Serial Num [cpqHeFltTolPowerSupplySerialNumber], Firmware [cpqHeFltTolPowerSupplyFirmwareRev].” (La fuente de alimentación tiene el estado Failed en el chasis [cpqHeFltTolPowerSupplyChassis], compartimento [cpqHeFltTolPowerSupplyBay], estado [cpqHeFltTolPowerSupplyStatus], modelo [cpqHeFltTolPowerSupplyModel], número de serie [cpqHeFltTolPowerSupplySerialNumber], firmware [cpqHeFltTolPowerSupplyFirmwareRev].)
ID de evento de NT: 1126 (Hex)0x84350466 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Fault Tolerant Power Supply Sub-system has lost redundancy. Restore power or replace any failed or missing power supplies. (El subsistema de fuentes de alimentación con tolerancia a fallos ha perdido la redundancia. Restaure la alimentación o sustituya las fuentes de alimentación defectuosas o ausentes.)
Captura SNMP: cpqHe3FltTolPowerRedundancyLost - 6032 en CPQHLTH.MIB
Síntoma: Las fuentes de alimentación con tolerancia a fallos han perdido la redundancia para el chasis especificado.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqHeFltTolPowerSupplyChassis
Descripción complementaria de la captura SNMP: “The Power Supplies are no longer redundant on Chassis [cpqHeFltTolPowerSupplyChassis].” (Las fuentes de alimentación ya no son redundantes en el chasis [cpqHeFltTolPowerSupplyChassis].)
ID de evento de NT: 1127 (Hex)0x44350467 (cpqsvmsg.dll)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: Fault Tolerant Power Supply Inserted. A hot-plug fault tolerant power supply has been inserted into the system. (Se ha introducido la fuente de alimentación con tolerancia a fallos. Se ha introducido en el sistema una fuente de alimentación de conexión en caliente con tolerancia a fallos.)
Captura SNMP: cpqHe3FltTolPowerSupplyInserted - 6033 en CPQHLTH.MIB
Síntoma: Se ha introducido una fuente de alimentación con tolerancia a fallos en el chasis y el compartimento especificados.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqHeFltTolPowerSupplyChassis
● cpqHeFltTolPowerSupplyBay
ESES Agentes de servidor 443

Descripción complementaria de la captura SNMP: “The Power Supply Inserted on Chassis [cpqHeFltTolPowerSupplyChassis], Bay [cpqHeFltTolPowerSupplyBay].” (Se ha introducido la fuente de alimentación en el chasis [cpqHeFltTolPowerSupplyChassis], compartimento [cpqHeFltTolPowerSupplyBay].)
ID de evento de NT: 1128 (Hex)0x84350468 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Fault Tolerant Power Supply Removed. A hot-plug fault tolerant power supply has been removed from the system. (Se ha extraído la fuente de alimentación con tolerancia a fallos. Se ha extraído del sistema una fuente de alimentación de conexión en caliente con tolerancia a fallos.)
Captura SNMP: cpqHe3FltTolPowerSupplyRemoved - 6034 en CPQHLTH.MIB
Síntoma: Se ha extraído una fuente de alimentación con tolerancia a fallos del chasis y el compartimento especificados.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqHeFltTolPowerSupplyChassis
● cpqHeFltTolPowerSupplyBay
Descripción complementaria de la captura SNMP: “The Power Supply Removed on Chassis [cpqHeFltTolPowerSupplyChassis], Bay [cpqHeFltTolPowerSupplyBay].” (Se ha extraído la fuente de alimentación del chasis [cpqHeFltTolPowerSupplyChassis], compartimento [cpqHeFltTolPowerSupplyBay].)
ID de evento de NT: 1129 (Hex)0x84350469 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Fan Sub-system is in a degraded state. Replace the fan. (El subsistema de ventiladores tiene el estado Degraded. Sustituya el ventilador.)
Captura SNMP: cpqHe3FltTolFanDegraded - 6035 en CPQHLTH.MIB
Síntoma: El ventilador con tolerancia a fallos tiene el estado Degraded para el chasis y la ubicación especificados.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqHeFltTolFanChassis
● cpqHeFltTolFanIndex
Descripción complementaria de la captura SNMP: “The Fan Degraded on Chassis [cpqHeFltTolFanChassis], Fan [cpqHeFltTolFanIndex].” (El ventilador tiene el estado Degraded para el chasis [cpqHeFltTolFanChassis], ventilador [cpqHeFltTolFanIndex].)
ID de evento de NT: 1130 (Hex)0xc435046a (cpqsvmsg.dll)
Nivel de gravedad del registro: Error (3)
444 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Mensaje del registro: The Fan Sub-system is in a failed state. Replace the fan. (El subsistema de ventiladores tiene el estado Failed. Sustituya el ventilador.)
Captura SNMP: cpqHe3FltTolFanFailed - 6036 en CPQHLTH.MIB
Síntoma: El ventilador con tolerancia a fallos tiene el estado Failed para el chasis y la ubicación especificados.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqHeFltTolFanChassis
● cpqHeFltTolFanIndex
Descripción complementaria de la captura SNMP: “The Fan Failed on Chassis [cpqHeFltTolFanChassis], Fan [cpqHeFltTolFanIndex].” (El ventilador tiene el estado Failed en el chasis [cpqHeFltTolFanChassis], ventilador [cpqHeFltTolFanIndex].)
ID de evento de NT: 1131 (Hex)0x8435046b (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Fan Sub-system has lost redundancy. Replace any failed or missing fans. (El subsistema de ventiladores ha perdido la redundancia. Sustituya los ventiladores defectuosos o ausentes.)
Captura SNMP: cpqHe3FltTolFanRedundancyLost - 6037 en CPQHLTH.MIB
Síntoma: Los ventiladores con tolerancia a fallos han perdido la redundancia para el chasis especificado.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqHeFltTolFanChassis
Descripción complementaria de la captura SNMP: “The Fans are no longer redundant on Chassis [cpqHeFltTolFanChassis].” (Los ventiladores ya no son redundantes en el chasis [cpqHeFltTolFanChassis].)
ID de evento de NT: 1132 (Hex)0x4435046c (cpqsvmsg.dll)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: Fan Inserted. A hot-plug fan has been inserted into the system. (Ventilador introducido. Se ha introducido en el sistema un ventilador de conexión en caliente.)
Captura SNMP: cpqHe3FltTolFanInserted - 6038 en CPQHLTH.MIB
Síntoma: Se ha introducido un ventilador con tolerancia a fallos en el chasis y la ubicación especificados.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
ESES Agentes de servidor 445

● cpqHeFltTolFanChassis
● cpqHeFltTolFanIndex
Descripción complementaria de la captura SNMP: “The Fan Inserted on Chassis [cpqHeFltTolFanChassis], Fan [cpqHeFltTolFanIndex].” (Se ha introducido el ventilador en el chasis [cpqHeFltTolFanChassis], ventilador [cpqHeFltTolFanIndex].)
ID de evento de NT: 1133 (Hex)0x8435046d (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Fan Removed. A hot-plug fan has been removed from the system. (Ventilador extraído. Se ha extraído del sistema un ventilador de conexión en caliente.)
Captura SNMP: cpqHe3FltTolFanRemoved - 6039 en CPQHLTH.MIB
Síntoma: Se ha extraído un ventilador con tolerancia a fallos del chasis y la ubicación especificados.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqHeFltTolFanChassis
● cpqHeFltTolFanIndex
Descripción complementaria de la captura SNMP: “The Fan Removed on Chassis [cpqHeFltTolFanChassis], Fan [cpqHeFltTolFanIndex].” (Se ha extraído el ventilador del chasis [cpqHeFltTolFanChassis], ventilador [cpqHeFltTolFanIndex].)
ID de evento de NT: 1134 (Hex)0xc435046e (cpqsvmsg.dll)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: A Temperature Sensor Condition has been set to failed. The system will be shut down due to this overheat condition. (Una condición de sensor de temperatura tiene el estado Failed. El sistema se apagará debido a esta condición de sobrecalentamiento.)
Captura SNMP: cpqHe3TemperatureFailed - 6040 en CPQHLTH.MIB
Síntoma: La temperatura tiene el estado Failed en el chasis y la ubicación especificados. El sistema se ha apagado debido a esta condición.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqHeTemperatureChassis
● cpqHeTemperatureLocale
Descripción complementaria de la captura SNMP: “Temperature Exceeded on Chassis [cpqHeTemperatureChassis], Location [cpqHeTemperatureLocale].” (Se ha superado la temperatura máxima en el chasis [cpqHeTemperatureChassis], ubicación [cpqHeTemperatureLocale].)
ID de evento de NT: 1135 (Hex)0x8435046f (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: A Temperature Sensor Condition has been set to degraded. The system may or may not shut down depending on the state of the thermal degraded action value '%6'. (Una condición
446 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

de sensor de temperatura tiene el estado Degraded. El sistema podría apagarse dependiendo del estado del valor de la acción de temperatura degradada '%6'.)
Captura SNMP: cpqHe3TemperatureDegraded - 6041 en CPQHLTH.MIB
Síntoma: La temperatura tiene el estado Degraded en el chasis y la ubicación especificados.
La temperatura del servidor está fuera del intervalo de funcionamiento normal. El servidor se apagará si la variable cpqHeThermalDegradedAction tiene el valor shutdown (3).
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqHeThermalDegradedAction
● cpqHeTemperatureChassis
● cpqHeTemperatureLocale
Descripción complementaria de la captura SNMP: “Temperature out of range on Chassis [cpqHeTemperatureChassis], Location [cpqHeTemperatureLocale]. Shutdown may occur.” (Temperatura fuera del intervalo en el chasis [cpqHeTemperatureChassis], ubicación [cpqHeTemperatureLocale]. El sistema puede apagarse.)
ID de evento de NT: 1136 (Hex)0x44350470 (cpqsvmsg.dll)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: A Temperature Sensor Condition has been set to OK. The system's temperature has returned to the normal operating range. (Una condición de sensor de temperatura tiene el estado OK. La temperatura del sistema vuelve a estar dentro del intervalo de funcionamiento normal.)
Captura SNMP: cpqHe3TemperatureOk - 6042 en CPQHLTH.MIB
Síntoma: La temperatura tiene el estado OK en el chasis y la ubicación especificados. La temperatura del servidor vuelve a estar dentro del intervalo de funcionamiento normal.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqHeTemperatureChassis
● cpqHeTemperatureLocale
Descripción complementaria de la captura SNMP: “Temperature Normal on Chassis [cpqHeTemperatureChassis], Location [cpqHeTemperatureLocale].” (Temperatura normal en el chasis [cpqHeTemperatureChassis], ubicación [cpqHeTemperatureLocale].)
ID de evento de NT: 1137 (Hex)0x84350471 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The DC-DC power converter is in a degraded state. Replace the power converter. (El convertidor de alimentación CC-CC tiene el estado Degraded. Sustitúyalo.)
Captura SNMP: cpqHe3PowerConverterDegraded - 6043 en CPQHLTH.MIB
ESES Agentes de servidor 447

Síntoma: El convertidor de alimentación CC-CC tiene el estado Degraded para el chasis, la ranura y el zócalo especificados.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqHePwrConvChassis
● cpqHePwrConvSlot
● cpqHePwrConvSocket
Descripción complementaria de la captura SNMP: “The Power Converter Degraded on Chassis [cpqHePwrConvChassis], Slot [cpqHePwrConvSlot], Socket [cpqHePwrConvSocket].” (El convertidor de alimentación tiene el estado Degraded en el chasis [cpqHePwrConvChassis], ranura [cpqHePwrConvSlot], zócalo [cpqHePwrConvSocket].)
ID de evento de NT: 1138 (Hex)0xc4350472 (cpqsvmsg.dll)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: The DC-DC power converter is in a failed state. Replace the power converter. (El convertidor de alimentación CC-CC tiene el estado Failed. Sustitúyalo.)
Captura SNMP: cpqHe3PowerConverterFailed - 6044 en CPQHLTH.MIB
Síntoma: El convertidor de alimentación CC-CC tiene el estado Failed para el chasis, la ranura y el zócalo especificados.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqHePwrConvChassis
● cpqHePwrConvSlot
● cpqHePwrConvSocket
Descripción complementaria de la captura SNMP: “The Power Converter Failed on Chassis [cpqHePwrConvChassis], Slot [cpqHePwrConvSlot], Socket [cpqHePwrConvSocket].” (El convertidor de alimentación tiene el estado Failed en el chasis [cpqHePwrConvChassis], ranura [cpqHePwrConvSlot], zócalo [cpqHePwrConvSocket].)
ID de evento de NT: 1139 (Hex)0x84350473 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The DC-DC power converter is in a failed state. The DC-DC Power Converter sub-system has lost redundancy. Replace any failed or degraded power converters. (El subsistema del convertidor de alimentación CC-CC ha perdido la redundancia. Sustituya los convertidores de alimentación en estado Failed o Degraded.)
Captura SNMP: cpqHe3PowerConverterRedundancyLost - 6045 en CPQHLTH.MIB
Síntoma: Los convertidores de alimentación CC-CC han perdido la redundancia para el chasis especificado.
Datos complementarios de la captura SNMP:
448 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

● sysName
● cpqHoTrapFlags
● cpqHePwrConvChassis
Descripción complementaria de la captura SNMP: “The Power Converters are no longer redundant on Chassis [cpqHePwrConvChassis].” (Los convertidores de alimentación ya no son redundantes en el chasis [cpqHePwrConvChassis].)
ID de evento de NT: 1140 (Hex)0x84350474 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Hot Plug PCI Board Removed. A hot plug PCI adapter has been removed from the system. (Se ha extraído la placa PCI de conexión en caliente. Se ha extraído del sistema un adaptador PCI de conexión en caliente.)
Captura SNMP: cpqSiHotPlugSlotBoardRemoved - 2008 en CPQSINFO.MIB
Síntoma: Se ha extraído una placa para ranuras de conexión en caliente. Se ha extraído una placa para ranuras de conexión en caliente del chasis y la ranura especificados.
Acción del usuario: Ninguna.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSiHotPlugSlotChassis
● cpqSiHotPlugSlotIndex
Descripción complementaria de la captura SNMP: “Hot Plug Slot Board Removed from Chassis [cpqSiHotPlugSlotChassis], Slot [cpqSiHotPlugSlotIndex].” (Se ha extraído una placa para ranuras de conexión en caliente del chasis [cpqSiHotPlugSlotChassis], ranura [cpqSiHotPlugSlotIndex].)
ID de evento de NT: 1141 (Hex)0x44350475 (cpqsvmsg.dll)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: Hot Plug PCI Board Inserted. A hot plug PCI adapter has been inserted into the system. (Se ha introducido un adaptador PCI de conexión en caliente. Se ha introducido en el sistema un adaptador PCI de conexión en caliente.)
Captura SNMP: cpqSiHotPlugSlotBoardInserted - 2009 en CPQSINFO.MIB
Síntoma: Se ha introducido una placa para ranuras de conexión en caliente. Se ha introducido una placa para ranuras de conexión en caliente en el chasis y la ranura especificados.
Acción del usuario: Ninguna.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSiHotPlugSlotChassis
● cpqSiHotPlugSlotIndex
ESES Agentes de servidor 449

Descripción complementaria de la captura SNMP: “Hot Plug Slot Board Inserted into Chassis [cpqSiHotPlugSlotChassis], Slot [cpqSiHotPlugSlotIndex].” (Se ha introducido una placa para ranuras de conexión en caliente en el chasis [cpqSiHotPlugSlotChassis], ranura [cpqSiHotPlugSlotIndex].)
ID de evento de NT: 1142 (Hex)0xc4350476 (cpqsvmsg.dll)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: Hot Plug PCI Board Failed. A hot plug PCI adapter has failed to power up. Insure the board and all cables are installed correctly. (Se ha producido un fallo en la placa PCI de conexión en caliente. Ha fallado el encendido de un adaptador PCI de conexión en caliente. Asegúrese de que la placa y todos los cables están instalados correctamente.)
Captura SNMP: cpqSiHotPlugSlotPowerUpFailed - 2010 en CPQSINFO.MIB
Síntoma: Ha fallado el encendido de una placa para ranuras de conexión en caliente. Ha fallado el encendido de una placa para ranuras de conexión en caliente en el chasis y la ranura especificados.
Acción del usuario: Asegúrese de que la placa y los cables están instalados correctamente, y de que el tipo y la revisión de la placa son idénticos a los de la placa sustituida.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSiHotPlugSlotChassis
● cpqSiHotPlugSlotIndex
● cpqSiHotPlugSlotErrorStatus
Descripción complementaria de la captura SNMP: “Hot Plug Slot Board Failed in Chassis [cpqSiHotPlugSlotChassis], Slot [cpqSiHotPlugSlotIndex], Error [cpqSiHotPlugSlotErrorStatus].” (Se ha producido un fallo en la placa para ranuras de conexión en caliente del chasis [cpqSiHotPlugSlotChassis], ranura [cpqSiHotPlugSlotIndex], error [cpqSiHotPlugSlotErrorStatus].)
ID de evento de NT: 1143 (Hex)0x44350477 (cpqsvmsg.dll)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: Rack Name Changed. (Cambio de nombre del bastidor.)
Captura SNMP: cpqRackNameChanged - 22001 en CPQRACK.MIB
Síntoma: El nombre del bastidor ha cambiado. Esta captura indica que un agente o utilidad ha cambiado el nombre del bastidor. Los blades de servidor de cada uno de los chasis pertenecientes al bastidor se actualizan para reflejar el nuevo nombre del bastidor. El cambio de nombre tardará varios minutos en propagarse a todo el bastidor.
Acción del usuario: Ninguna.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
450 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

● cpqRackSerialNum
● cpqRackTrapSequenceNum
Descripción complementaria de la captura SNMP: “The rack name has changed to [cpqRackName].” (El nombre del bastidor ha cambiado a [cpqRackName].)
ID de evento de NT: 1144 (Hex)0x44350478 (cpqsvmsg.dll)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: Rack Enclosure Name Changed. (Cambio de nombre del chasis del bastidor.)
Captura SNMP: cpqRackEnclosureNameChanged - 22002 en CPQRACK.MIB
Síntoma: El nombre del chasis ha cambiado. Esta captura indica que un agente o utilidad ha cambiado el nombre de un chasis perteneciente al bastidor. Cada uno de los componentes del bastidor se actualiza para reflejar el nuevo nombre del chasis. El cambio de nombre tardará varios minutos en propagarse a todo el chasis.
Acción del usuario: Ninguna.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackCommonEnclosureName
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureModel
● cpqRackCommonEnclosureSparePartNumber
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “The enclosure name has changed to [cpqRackCommonEnclosureName] in rack [cpqRackName].” (El nombre del chasis ha cambiado a [cpqRackCommonEnclosureName] en el bastidor [cpqRackName].)
ID de evento de NT: 1145 (Hex)0x44350479 (cpqsvmsg.dll)
Nivel de gravedad del registro: Información (1)
Título del evento: Enclosure Removed (Se ha extraído el chasis)
Mensaje del registro: This trap indicates that an enclosure has been removed from the rack. (Esta captura indica que se ha extraído un chasis del bastidor.)
Captura SNMP: cpqRackEnclosureRemoved - 22003 en CPQRACK.MIB
Síntoma: Se ha extraído el chasis. Esta captura indica que se ha extraído un chasis del bastidor.
Acción del usuario: Ninguna.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
ESES Agentes de servidor 451

● cpqRackName
● cpqRackUid
● cpqRackCommonEnclosureName
● cpqRackCommonEnclosureModel
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureSparePartNumber
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “The enclosure [cpqRackCommonEnclosureName] has been removed from rack [cpqRackName].” (El chasis [cpqRackCommonEnclosureName] se ha extraído del bastidor [cpqRackName].)
ID de evento de NT: 1146 (Hex)0x4435047a (cpqsvmsg.dll)
Nivel de gravedad del registro: Información (1)
Título del evento: Enclosure Inserted (Se ha introducido el chasis)
Mensaje del registro: This trap indicates that an enclosure has been inserted into the rack. (Esta captura indica que se ha introducido un chasis en el bastidor.)
Captura SNMP: cpqRackEnclosureInserted - 22004 en CPQRACK.MIB
Síntoma: Se ha introducido el chasis. Esta captura indica que se ha introducido un chasis en el bastidor.
Acción del usuario: Ninguna.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackCommonEnclosureName
● cpqRackCommonEnclosureModel
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureSparePartNumber
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “The enclosure [cpqRackCommonEnclosureName] has been inserted into rack [cpqRackName].” (Se ha introducido el chasis [cpqRackCommonEnclosureName] en el bastidor [cpqRackName].)
ID de evento de NT: 1147 (Hex)0xc435047b (cpqsvmsg.dll)
Nivel de gravedad del registro: Error (3)
Título del evento: Rack Enclosure Overheated (Chasis del bastidor sobrecalentado)
Mensaje del registro: This trap indicates that an enclosure temperature sensor has been tripped indicating an overheat condition. (Esta captura indica que se ha disparado un sensor de temperatura del chasis, lo que sugiere una condición de sobrecalentamiento.)
452 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Captura SNMP: cpqRackEnclosureTempFailed - 22005 en CPQRACK.MIB
Síntoma: La temperatura del chasis tiene el estado Failed. Esta captura indica que se ha disparado un sensor de temperatura del chasis, lo que sugiere una condición de sobrecalentamiento
Acción del usuario: Apague cuanto antes el chasis y el bastidor. Asegúrese de que todos los ventiladores funcionan correctamente y de que no se ha bloqueado el flujo de aire en el bastidor.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackCommonEnclosureName
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureTempLocation
● cpqRackCommonEnclosureSparePartNumber
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “The enclosure [cpqRackCommonEnclosureName] temperature sensor in rack [cpqRackName] has been set to failed.” (El sensor de temperatura del chasis [cpqRackCommonEnclosureName] del bastidor [cpqRackName] tiene el estado Failed.)
ID de evento de NT: 1148 (Hex)0x8435047c (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Rack Enclosure Overheating (El chasis del bastidor se está sobrecalentando)
Mensaje del registro: This trap indicates that an enclosure temperature sensor has been tripped indicating a possible overheat condition. (Esta captura indica que se ha disparado un sensor de temperatura del chasis, lo que sugiere una posible condición de sobrecalentamiento.)
Captura SNMP: cpqRackEnclosureTempDegraded - 22006 en CPQRACK.MIB
Síntoma: La temperatura del chasis tiene el estado Degraded. Esta captura indica que se ha disparado un sensor de temperatura del chasis, lo que sugiere una posible condición de sobrecalentamiento.
Acción del usuario: Apague cuanto antes el chasis y el bastidor. Asegúrese de que todos los ventiladores funcionan correctamente y de que no se ha bloqueado el flujo de aire en el bastidor.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackCommonEnclosureName
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureTempLocation
ESES Agentes de servidor 453

● cpqRackCommonEnclosureSparePartNumber
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “The enclosure [cpqRackCommonEnclosureName] temperature sensor in rack [cpqRackName] has been set to degraded.” (El sensor de temperatura del chasis [cpqRackCommonEnclosureName] del bastidor [cpqRackName] tiene el estado Degraded.)
ID de evento de NT: 1149 (Hex)0x4435047d (cpqsvmsg.dll)
Nivel de gravedad del registro: Información (1)
Título del evento: Rack Enclosure Temperature Normal (Temperatura normal del chasis del bastidor)
Mensaje del registro: This trap indicates that an enclosure temperature sensor has returned to normal. (Esta captura indica que un sensor de temperatura del chasis ha vuelto a registrar valores normales.)
Captura SNMP: cpqRackEnclosureTempOk - 22007 en CPQRACK.MIB
Síntoma: La temperatura del chasis tiene el estado OK. Esta captura indica que un sensor de temperatura del chasis ha vuelto a registrar valores normales.
Acción del usuario: Ninguna.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackCommonEnclosureName
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureTempLocation
● cpqRackCommonEnclosureSparePartNumber
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “The enclosure [cpqRackCommonEnclosureName] temperature sensor in rack [cpqRackName] has been set to ok.” (El sensor de temperatura del chasis [cpqRackCommonEnclosureName] del bastidor [cpqRackName] tiene el estado OK.)
ID de evento de NT: 1150 (Hex)0xc435047e (cpqsvmsg.dll)
Nivel de gravedad del registro: Error (3)
Título del evento: Rack Enclosure Fan Failed (Se ha producido un fallo en el ventilador del chasis del bastidor)
Mensaje del registro: This trap indicates that an enclosure fan has failed and less than the minimum number of fans in the redundant fan group are operating. This may result in overheating of the enclosure. (Esta captura indica que un ventilador del chasis ha fallado y que hay un número inferior al mínimo de ventiladores operativos en el grupo de ventiladores redundantes. Esto puede ocasionar un sobrecalentamiento del chasis.)
Captura SNMP: cpqRackEnclosureFanFailed - 22008 en CPQRACK.MIB
454 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Síntoma: El estado de los ventiladores del chasis es Failed. Esta captura indica que un ventilador del chasis ha fallado y que no hay ningún otro ventilador operativo en el grupo de ventiladores redundantes. Esto puede ocasionar un sobrecalentamiento del chasis.
Acción del usuario: Sustituya cuanto antes el ventilador.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackCommonEnclosureName
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureFanLocation
● cpqRackCommonEnclosureFanSparePartNumber
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “The enclosure [cpqRackCommonEnclosureName] fan in rack [cpqRackName] has been set to failed.” (El ventilador del chasis [cpqRackCommonEnclosureName] del bastidor [cpqRackName] tiene el estado Failed.)
ID de evento de NT: 1151 (Hex)0x8435047f (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Rack Enclosure Fan Degraded (El ventilador del chasis del bastidor tiene el estado Degraded)
Mensaje del registro: This trap indicates that an enclosure fan has failed but other fans in the redundant fan group are still operating. This may result in overheating of the enclosure. (Esta captura indica que un ventilador del chasis ha fallado, pero que hay otros ventiladores todavía operativos en el grupo de ventiladores redundantes. Esto puede ocasionar un sobrecalentamiento del chasis.)
Captura SNMP: cpqRackEnclosureFanDegraded - 22009 en CPQRACK.MIB
Síntoma: El ventilador del chasis tiene el estado Degraded. Esta captura indica que un ventilador del chasis ha fallado, pero que hay otros ventiladores todavía operativos en el grupo de ventiladores redundantes. Esto puede ocasionar un sobrecalentamiento del chasis.
Acción del usuario: Sustituya cuanto antes el ventilador.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackCommonEnclosureName
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureFanLocation
ESES Agentes de servidor 455

● cpqRackCommonEnclosureFanSparePartNumber
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “The enclosure [cpqRackCommonEnclosureName] fan in rack [cpqRackName] has been set to degraded.” (El ventilador del chasis [cpqRackCommonEnclosureName] del bastidor [cpqRackName] tiene el estado Degraded.)
ID de evento de NT: 1152 (Hex)0x44350480 (cpqsvmsg.dll)
Nivel de gravedad del registro: Información (1)
Título del evento: Rack Enclosure Fan OK (El ventilador del chasis del bastidor tiene el estado OK)
Mensaje del registro: This trap indicates that an enclosure fan has returned to normal operation. (Esta captura indica que un ventilador del chasis vuelve a funcionar con normalidad.)
Captura SNMP: cpqRackEnclosureFanOk - 22010 en CPQRACK.MIB
Síntoma: El ventilador del chasis tiene el estado OK. Esta captura indica que un ventilador del chasis vuelve a funcionar con normalidad.
Acción del usuario: Ninguna.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackCommonEnclosureName
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureFanLocation
● cpqRackCommonEnclosureFanSparePartNumber
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “The enclosure [cpqRackCommonEnclosureName] fan in rack [cpqRackName] has been set to ok.” (El ventilador del chasis [cpqRackCommonEnclosureName] del bastidor [cpqRackName] tiene el estado OK.)
ID de evento de NT: 1153 (Hex)0x84350481 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Rack Enclosure Fan Removed (Se ha extraído el ventilador del chasis del bastidor)
Mensaje del registro: The enclosure fan has been removed. (El ventilador del chasis se ha extraído.)
Captura SNMP: cpqRackEnclosureFanRemoved - 22011 en CPQRACK.MIB
Síntoma: Se ha extraído el ventilador del chasis.
Acción del usuario: Ninguna.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
456 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

● cpqRackName
● cpqRackUid
● cpqRackCommonEnclosureName
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureFanLocation
● cpqRackCommonEnclosureFanSparePartNumber
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “The enclosure [cpqRackCommonEnclosureName] fan in rack [cpqRackName] has been removed.” (Se ha extraído el ventilador del chasis [cpqRackCommonEnclosureName] del bastidor [cpqRackName].)
ID de evento de NT: 1154 (Hex)0x44350482 (cpqsvmsg.dll)
Nivel de gravedad del registro: Información (1)
Título del evento: Rack Enclosure Fan Inserted (Se ha introducido el ventilador del chasis del bastidor)
Mensaje del registro: The enclosure fan has been inserted. (El ventilador del chasis se ha introducido.)
Captura SNMP: cpqRackEnclosureFanInserted - 22012 en CPQRACK.MIB
Síntoma: Se ha introducido el ventilador del chasis.
Acción del usuario: Ninguna.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackCommonEnclosureName
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureFanLocation
● cpqRackCommonEnclosureFanSparePartNumber
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “The enclosure [cpqRackCommonEnclosureName] fan in rack [cpqRackName] has been inserted.” (Se ha introducido el ventilador del chasis [cpqRackCommonEnclosureName] del bastidor [cpqRackName].)
ID de evento de NT: 1155 (Hex)0xc4350483 (cpqsvmsg.dll)
Nivel de gravedad del registro: Error (3)
Título del evento: Rack Power Supply Failed (Se ha producido un fallo en la fuente de alimentación del bastidor)
Mensaje del registro: This trap indicates that a power supply has failed. (Esta captura indica que una fuente de alimentación ha fallado.)
ESES Agentes de servidor 457

Captura SNMP: cpqRackPowerSupplyFailed - 22013 en CPQRACK.MIB
Síntoma: La fuente de alimentación tiene el estado Failed. Esta captura indica que una fuente de alimentación ha fallado.
Acción del usuario: Sustituya cuanto antes la fuente de alimentación.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackPowerSupplyEnclosureName
● cpqRackPowerSupplySerialNum
● cpqRackPowerSupplyPosition
● cpqRackPowerSupplyFWRev
● cpqRackPowerSupplySparePartNumber
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “The power supply [cpqRackPowerSupplyPosition] in enclosure [cpqRackPowerSupplyEnclosureName] in rack [cpqRackName] has been set to failed.” (La fuente de alimentación [cpqRackPowerSupplyPosition] del chasis [cpqRackPowerSupplyEnclosureName] del bastidor [cpqRackName] tiene el estado Failed.)
ID de evento de NT: 1156 (Hex)0x84350484 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Rack Power Supply Degraded (La fuente de alimentación del bastidor tiene el estado Degraded)
Mensaje del registro: This trap indicates that a power supply has degraded. (Esta captura indica que una fuente de alimentación tiene el estado Degraded.)
Captura SNMP: cpqRackPowerSupplyDegraded - 22014 en CPQRACK.MIB
Síntoma: La fuente de alimentación tiene el estado Degraded. Esta captura indica que una fuente de alimentación tiene el estado Degraded.
Acción del usuario: Sustituya cuanto antes la fuente de alimentación.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackPowerSupplyEnclosureName
● cpqRackPowerSupplySerialNum
458 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

● cpqRackPowerSupplyPosition
● cpqRackPowerSupplyFWRev
● cpqRackPowerSupplySparePartNumber
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “The power supply [cpqRackPowerSupplyPosition] in enclosure [cpqRackPowerSupplyEnclosureName] in rack [cpqRackName] has been set to degraded.” (La fuente de alimentación [cpqRackPowerSupplyPosition] del chasis [cpqRackPowerSupplyEnclosureName] del bastidor [cpqRackName] tiene el estado Degraded.)
ID de evento de NT: 1157 (Hex)0x44350485 (cpqsvmsg.dll)
Nivel de gravedad del registro: Información (1)
Título del evento: Rack Power Supply OK (La fuente de alimentación del bastidor tiene el estado OK)
Mensaje del registro: This trap indicates that a power supply has returned to normal operation. (Esta captura indica que una fuente de alimentación vuelve a funcionar con normalidad.)
Captura SNMP: cpqRackPowerSupplyOk - 22015 en CPQRACK.MIB
Síntoma: La fuente de alimentación tiene el estado OK. Esta captura indica que una fuente de alimentación vuelve a funcionar con normalidad.
Acción del usuario: Ninguna.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackPowerSupplyEnclosureName
● cpqRackPowerSupplySerialNum
● cpqRackPowerSupplyPosition
● cpqRackPowerSupplyFWRev
● cpqRackPowerSupplySparePartNumber
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “The power supply [cpqRackPowerSupplyPosition] in enclosure [cpqRackPowerSupplyEnclosureName] in rack [cpqRackName] has been set to ok.” (La fuente de alimentación [cpqRackPowerSupplyPosition] del chasis [cpqRackPowerSupplyEnclosureName] del bastidor [cpqRackName] tiene el estado OK.)
ID de evento de NT: 1158 (Hex)0x84350486 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Rack Power Supply Removed (Se ha extraído la fuente de alimentación del bastidor)
ESES Agentes de servidor 459

Mensaje del registro: The power supply has been removed. (Se ha extraído la fuente de alimentación.)
Captura SNMP: cpqRackPowerSupplyRemoved - 22016 en CPQRACK.MIB
Síntoma: Se ha extraído la fuente de alimentación.
Acción del usuario: Ninguna.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackPowerSupplyEnclosureName
● cpqRackPowerSupplySerialNum
● cpqRackPowerSupplyPosition
● cpqRackPowerSupplyFWRev
● cpqRackPowerSupplySparePartNumber
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “The power supply [cpqRackPowerSupplyPosition] in enclosure [cpqRackPowerSupplyEnclosureName] in rack [cpqRackName] has been removed.” (Se ha extraído la fuente de alimentación [cpqRackPowerSupplyPosition] del chasis [cpqRackPowerSupplyEnclosureName] del bastidor [cpqRackName].)
ID de evento de NT: 1159 (Hex)0x44350487 (cpqsvmsg.dll)
Nivel de gravedad del registro: Información (1)
Título del evento: Rack Power Supply Inserted (Se ha introducido la fuente de alimentación en el bastidor)
Mensaje del registro: The power supply has been inserted. (Se ha introducido la fuente de alimentación.)
Captura SNMP: cpqRackPowerSupplyInserted - 22017 en CPQRACK.MIB
Síntoma: Se ha introducido la fuente de alimentación.
Acción del usuario: Ninguna.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackPowerSupplyEnclosureName
● cpqRackPowerSupplySerialNum
460 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

● cpqRackPowerSupplyPosition
● cpqRackPowerSupplyFWRev
● cpqRackPowerSupplySparePartNumber
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “The power supply [cpqRackPowerSupplyPosition] in enclosure [cpqRackPowerSupplyEnclosureName] in rack [cpqRackName] has been inserted.” (Se ha introducido la fuente de alimentación [cpqRackPowerSupplyPosition] del chasis [cpqRackPowerSupplyEnclosureName] del bastidor [cpqRackName].)
ID de evento de NT: 1160 (Hex)0x84350488 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Rack Power Subsystem Not Redundant (El subsistema de alimentación del bastidor no es redundante)
Mensaje del registro: The rack power subsystem is no longer in a redundant state. (El subsistema de alimentación del bastidor ya no está en un estado redundante.)
Captura SNMP: cpqRackPowerSubsystemNotRedundant - 22018 en CPQRACK.MIB
Síntoma: El subsistema de alimentación del bastidor ya no está en un estado redundante.
Acción del usuario: Sustituya cuanto antes las fuentes de alimentación defectuosas para que el sistema vuelva a tener un estado redundante.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackPowerEnclosureName
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “The power subsystem in enclosure [cpqRackPowerEnclosureName] in rack [cpqRackName] is no longer redundant.” (El subsistema de alimentación del chasis [cpqRackPowerEnclosureName] del bastidor [cpqRackName] ya no es redundante.)
ID de evento de NT: 1161 (Hex)0x84350489 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Rack Power Subsystem Input Voltage Problem (Problema de voltaje de entrada en el subsistema de alimentación del bastidor)
Mensaje del registro: The rack power supply detected an input line voltage problem. (La fuente de alimentación del bastidor detectó un problema de voltaje en la línea de entrada.)
Captura SNMP: cpqRackPowerSubsystemLineVoltageProblem - 22019 en CPQRACK.MIB
ESES Agentes de servidor 461

Síntoma: La fuente de alimentación del bastidor detectó un problema de voltaje en la línea de entrada.
Acción del usuario: Compruebe la entrada de alimentación para la fuente de alimentación o sustituya cuanto antes las fuentes de alimentación defectuosas.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackPowerSupplyEnclosureName
● cpqRackPowerSupplyPosition
● cpqRackPowerSupplyFWRev
● cpqRackPowerSupplyInputLineStatus
● cpqRackPowerSupplySparePartNumber
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “The rack power supply detected an input line voltage problem in power supply [cpqRackPowerSupplyPosition], enclosure [cpqRackPowerSupplyEnclosureName], rack [cpqRackName].” (La fuente de alimentación del bastidor detectó un problema de voltaje en la línea de entrada de la fuente de alimentación [cpqRackPowerSupplyPosition], chasis [cpqRackPowerSupplyEnclosureName], bastidor [cpqRackName].)
ID de evento de NT: 1162 (Hex)0x8435048a (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Rack Power Subsystem Overload (Sobrecarga del subsistema de alimentación del bastidor)
Mensaje del registro: The rack power subsystem overload condition. (El subsistema de alimentación del bastidor está sobrecargado.)
Captura SNMP: cpqRackPowerSubsystemOverloadCondition - 22020 en CPQRACK.MIB
Síntoma: El subsistema de alimentación del bastidor está sobrecargado.
Acción del usuario: Sustituya cuanto antes las fuentes de alimentación defectuosas para que el sistema vuelva a tener un estado redundante.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackPowerEnclosureName
462 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

● cpqRackCommonEnclosureSparePartNumber
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “The power subsystem in enclosure [cpqRackPowerEnclosureName] in rack [cpqRackName] is in an overload condition.” (El subsistema de alimentación del chasis [cpqRackPowerEnclosureName] del bastidor [cpqRackName] se encuentra en un estado de sobrecarga.)
ID de evento de NT: 1163 (Hex)0xc435048b (cpqsvmsg.dll)
Nivel de gravedad del registro: Error (3)
Título del evento: Server Power Shedding Shutdown (Se ha apagado el servidor por fallo de alimentación)
Mensaje del registro: Server shutdown due to power shedding. (Se ha apagado el servidor debido a un fallo de alimentación.)
Captura SNMP: cpqRackPowerShedAutoShutdown - 22021 en CPQRACK.MIB
Síntoma: Se ha apagado el servidor debido a un fallo de alimentación. El blade de servidor se apagó debido a un fallo de alimentación.
Acción del usuario: Compruebe las conexiones de alimentación o agregue fuentes de alimentación.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackServerBladeEnclosureName
● cpqRackServerBladePosition
● cpqRackServerBladeSparePartNumber
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “The server shutdown due to lack of power blade [cpqRackServerBladePosition], in enclosure [cpqRackServerBladeEnclosureName], in rack [cpqRackName].” (El servidor se apagó debido a un fallo de alimentación del blade [cpqRackServerBladePosition] del chasis [cpqRackServerBladeEnclosureName] del bastidor [cpqRackName].)
ID de evento de NT: 1164 (Hex)0xc435048c (cpqsvmsg.dll)
Nivel de gravedad del registro: Error (3)
Título del evento: Server Power On Prevented (Se ha impedido el encendido del servidor)
Mensaje del registro: Server power on prevented to preserve redundancy. (Se ha impedido el encendido del servidor para preservar la redundancia.)
Captura SNMP: cpqRackServerPowerOnFailedNotRedundant - 22022 en CPQRACK.MIB
ESES Agentes de servidor 463

Síntoma: Se ha impedido el encendido del servidor para preservar la redundancia. No hay suficiente potencia para encender el blade de servidor y mantener la redundancia en los demás blades del chasis.
Acción del usuario: Compruebe las conexiones de alimentación o agregue fuentes de alimentación.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackServerBladeEnclosureName
● cpqRackServerBladePosition
● cpqRackServerBladeSparePartNumber
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “Server power on prevented to preserve redundancy in blade [cpqRackServerBladePosition], in enclosure [cpqRackServerBladeEnclosureName], in rack [cpqRackName].” (Se ha impedido el encendido del servidor para preservar la redundancia en el blade [cpqRackServerBladePosition] del chasis [cpqRackServerBladeEnclosureName] del bastidor [cpqRackName].)
ID de evento de NT: 1165 (Hex)0xc435048d (cpqsvmsg.dll)
Nivel de gravedad del registro: Error (3)
Título del evento: Not Enough Power To Power On (No hay suficiente potencia para el encendido)
Mensaje del registro: Inadequate power to power on. (Potencia inadecuada para el encendido.)
Captura SNMP: cpqRackServerPowerOnFailedNotEnoughPower - 22023 en CPQRACK.MIB
Síntoma: Potencia inadecuada para el encendido. No hay suficiente potencia para encender el blade de servidor.
Acción del usuario: Compruebe las conexiones de alimentación o agregue fuentes de alimentación.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackServerBladeEnclosureName
● cpqRackServerBladePosition
● cpqRackServerBladeSparePartNumber
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureTrapSequenceNum
464 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Descripción complementaria de la captura SNMP: “Inadequate power to power on blade [cpqRackServerBladePosition], in enclosure [cpqRackServerBladeEnclosureName], in rack [cpqRackName].” (Potencia inadecuada para encender el blade [cpqRackServerBladePosition] del chasis [cpqRackServerBladeEnclosureName] del bastidor [cpqRackName].)
ID de evento de NT: 1166 (Hex)0xc435048e (cpqsvmsg.dll)
Nivel de gravedad del registro: Error (3)
Título del evento: Inadequate Power To Power On. (Potencia inadecuada para el encendido.)
Mensaje del registro: There is not enough power to power on the server blade. The server enclosure micro-controller was not found. (No hay suficiente potencia para encender el blade de servidor. No se encontró el microcontrolador del chasis de servidores.)
Captura SNMP: cpqRackServerPowerOnFailedEnclosureNotFound - 22024 en CPQRACK.MIB
Síntoma: Potencia inadecuada para el encendido. No hay suficiente potencia para encender el blade de servidor. No se encontró el microcontrolador del chasis de servidores.
Acción del usuario: Compruebe las conexiones del chasis del servidor o agregue fuentes de alimentación.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackServerBladeEnclosureName
● cpqRackServerBladePosition
● cpqRackServerBladeSparePartNumber
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “Inadequate power to power on blade [cpqRackServerBladePosition], in enclosure [cpqRackServerBladeEnclosureName], in rack [cpqRackName].” (Potencia inadecuada para encender el blade [cpqRackServerBladePosition] del chasis [cpqRackServerBladeEnclosureName] del bastidor [cpqRackName].)
ID de evento de NT: 1167 (Hex)0xc435048f (cpqsvmsg.dll)
Nivel de gravedad del registro: Error (3)
Título del evento: Inadequate Power To Power On. (Potencia inadecuada para el encendido.)
Mensaje del registro: There is not enough power to power on the server blade. The power enclosure micro-controller was not found. (No hay suficiente potencia para encender el blade de servidor. No se encontró el microcontrolador del chasis de alimentación.)
Captura SNMP: cpqRackServerPowerOnFailedPowerChassisNotFound - 22025 en CPQRACK.MIB
Síntoma: Potencia inadecuada para el encendido. No hay suficiente potencia para encender el blade de servidor. No se encontró el microcontrolador del chasis de alimentación.
Acción del usuario: Compruebe las conexiones del chasis de alimentación o agregue fuentes de alimentación.
ESES Agentes de servidor 465

Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackServerBladeEnclosureName
● cpqRackServerBladePosition
● cpqRackServerBladeSparePartNumber
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “Inadequate power to power on blade [cpqRackServerBladePosition], in enclosure [cpqRackServerBladeEnclosureName], in rack [cpqRackName].” (Potencia inadecuada para encender el blade [cpqRackServerBladePosition] del chasis [cpqRackServerBladeEnclosureName] del bastidor [cpqRackName].)
ID de evento de NT: 1168 (Hex)0x84350490 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Server Power On Via Manual Override (Encendido del servidor mediante anulación manual)
Mensaje del registro: Server power on via manual override. (Encendido del servidor mediante anulación manual.)
Captura SNMP: cpqRackServerPowerOnManualOverride - 22026 en CPQRACK.MIB
Síntoma: Encendido del servidor mediante anulación manual. El blade de servidor se encendió mediante una anulación manual.
Acción del usuario: Ninguna.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackServerBladeEnclosureName
● cpqRackServerBladePosition
● cpqRackServerBladeSparePartNumber
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “Server power on via manual override on blade [cpqRackServerBladePosition], in enclosure [cpqRackServerBladeEnclosureName], in rack [cpqRackName].” (El servidor se encendió mediante anulación manual en el blade
466 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

[cpqRackServerBladePosition] del chasis [cpqRackServerBladeEnclosureName] del bastidor [cpqRackName].)
ID de evento de NT: 1169 (Hex)0x84350491 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Fuse or Breaker Tripped (Se ha disparado el fusible o disyuntor)
Mensaje del registro: The fuse has been tripped. (El fusible se ha disparado.)
Captura SNMP: cpqRackFuseOpen - 22027 en CPQRACK.MIB
Síntoma: Fusible abierto. El fusible se ha disparado.
Acción del usuario: Compruebe el chasis y las conexiones de alimentación del blade y restablezca el fusible.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackCommonEnclosureName
● cpqRackCommonEnclosureFuseLocation
● cpqRackCommonEnclosureSparePartNumber
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “Fuse open fuse [cpqRackCommonEnclosureFuseLocation], in enclosure [cpqRackCommonEnclosureName], in rack [cpqRackName].” (Se ha disparado el fusible [cpqRackCommonEnclosureFuseLocation] del chasis [cpqRackCommonEnclosureName] del bastidor [cpqRackName].)
ID de evento de NT: 1170 (Hex)0x84350492 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Server Blade Removed (Se ha extraído el blade de servidor)
Mensaje del registro: The server blade has been removed from the enclosure. (El blade de servidor se ha extraído del chasis.)
Captura SNMP: cpqRackServerBladeRemoved - 22028 en CPQRACK.MIB
Síntoma: Se ha extraído el blade de servidor. El blade de servidor se ha extraído del chasis.
Acción del usuario: Ninguna.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
ESES Agentes de servidor 467

● cpqRackServerBladeEnclosureName
● cpqRackServerBladeName
● cpqRackServerBladePosition
● cpqRackServerBladeSparePartNumber
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “Server blade [cpqRackServerBladeName] removed from position [cpqRackServerBladePosition], in enclosure [cpqRackServerBladeEnclosureName], in rack [cpqRackName].” (El blade de servidor [cpqRackServerBladeName] se ha extraído de la posición [cpqRackServerBladePosition] del chasis [cpqRackServerBladeEnclosureName] del bastidor [cpqRackName].)
ID de evento de NT: 1171 (Hex)0x44350493 (cpqsvmsg.dll)
Nivel de gravedad del registro: Información (1)
Título del evento: Server Blade Inserted (Se ha introducido el blade de servidor)
Mensaje del registro: The server blade has been inserted from the enclosure. (El blade de servidor se ha introducido en el chasis.)
Captura SNMP: cpqRackServerBladeInserted - 22029 en CPQRACK.MIB
Síntoma: Se ha introducido el blade de servidor. El blade de servidor se ha introducido en el chasis.
Acción del usuario: Ninguna.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackServerBladeEnclosureName
● cpqRackServerBladeName
● cpqRackServerBladePosition
● cpqRackServerBladeSparePartNumber
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “Server blade [cpqRackServerBladeName] inserted into position [cpqRackServerBladePosition], in enclosure [cpqRackServerBladeEnclosureName], in rack [cpqRackName].” (El blade de servidor [cpqRackServerBladeName] se ha introducido en la posición [cpqRackServerBladePosition] del chasis [cpqRackServerBladeEnclosureName] del bastidor [cpqRackName].)
ID de evento de NT: 1172 (Hex)0x84350494 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
468 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Título del evento: Rack Power Subsystem Not Load Balanced (Carga no equilibrada en el subsistema de alimentación del bastidor)
Mensaje del registro: The power subsystem is out of balance for this power enclosure. (La carga del subsistema de alimentación no está equilibrada para este chasis de alimentación.)
Captura SNMP: cpqRackPowerChassisNotLoadBalanced - 22030 en CPQRACK.MIB
Síntoma: Carga no equilibrada en el subsistema de alimentación. La carga del subsistema de alimentación no está equilibrada para este chasis de alimentación.
Acción del usuario: Compruebe el chasis de alimentación y las fuentes de alimentación. Sustituya las fuentes de alimentación en estado Failed o Degraded. Agregue fuentes de alimentación adicionales si es necesario.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackCommonEnclosureName
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureSparePartNumber
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “Power subsystem not load balanced in enclosure [cpqRackCommonEnclosureName], in rack [cpqRackName].” (La carga del subsistema de alimentación no está equilibrada en el chasis [cpqRackCommonEnclosureName] del bastidor [cpqRackName].)
ID de evento de NT: 1173 (Hex)0x84350495 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Power Subsystem DC Power Problem (Problema de alimentación de CC en el subsistema de alimentación)
Mensaje del registro: There is a power subsystem DC power problem for this enclosure. (Existe un problema de alimentación de CC en el subsistema de alimentación de este chasis de alimentación.)
Captura SNMP: cpqRackPowerChassisDcPowerProblem - 22031 en CPQRACK.MIB
Síntoma: Problema de alimentación de CC en el subsistema de alimentación. Existe un problema de alimentación de CC en el subsistema de alimentación de este chasis de alimentación.
Acción del usuario: Compruebe el chasis de alimentación y las fuentes de alimentación. Sustituya las fuentes de alimentación en estado Failed o Degraded.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
ESES Agentes de servidor 469

● cpqRackCommonEnclosureName
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureSparePartNumber
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “Power subsystem DC power problem in enclosure [cpqRackCommonEnclosureName], in rack [cpqRackName].” (Problema de alimentación de CC en el subsistema de alimentación del chasis [cpqRackCommonEnclosureName] del bastidor [cpqRackName].)
ID de evento de NT: 1174 (Hex)0x84350496 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Power Subsystem Facility AC Power Problem (Problema de alimentación de CA en el subsistema de alimentación)
Mensaje del registro: The AC facility input power has been exceeded for this power enclosure. (Se ha superado la alimentación de CA de entrada para este chasis de alimentación.)
Captura SNMP: cpqRackPowerChassisAcFacilityPowerExceeded - 22032 en CPQRACK.MIB
Síntoma: Se ha superado la alimentación de CA de entrada del subsistema de alimentación para este chasis de alimentación.
Acción del usuario: Compruebe el chasis de alimentación y las fuentes de alimentación. Sustituya las fuentes de alimentación en estado Failed o Degraded.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackCommonEnclosureName
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureSparePartNumber
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “Power subsystem AC facility input power exceeded in enclosure [cpqRackCommonEnclosureName], in rack [cpqRackName].” (Se ha superado la alimentación de CA de entrada del subsistema de alimentación del chasis [cpqRackCommonEnclosureName] del bastidor [cpqRackName].)
ID de evento de NT: 1175 (Hex)0x84350497 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Power Subsystem Unknown Power Consumption (Consumo de energía desconocido del subsistema de alimentación)
Mensaje del registro: There is an unknown power consumer drawing power. (Existe un dispositivo desconocido que está consumiendo energía.)
Captura SNMP: cpqRackPowerUnknownPowerConsumption - 22033 en CPQRACK.MIB
470 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Síntoma: Consumo de energía desconocido. Existe un dispositivo desconocido que está consumiendo energía.
Acción del usuario: Compruebe el chasis de alimentación y las fuentes de alimentación. Sustituya las fuentes de alimentación en estado Failed o Degraded.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “Unknown power consumption in rack [cpqRackName].” (Consumo de energía desconocido en el bastidor [cpqRackName].)
ID de evento de NT: 1176 (Hex)0x84350498 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Power Subsystem Load Balancing Wire Missing (Falta el cable de equilibrio de la carga del subsistema de alimentación)
Mensaje del registro: The power subsystem load balancing wire missing. (Falta el cable de equilibrio de la carga del subsistema de alimentación.)
Captura SNMP: cpqRackPowerChassisLoadBalancingWireMissing - 22034 en CPQRACK.MIB
Síntoma: Falta el cable de equilibrio de la carga del subsistema de alimentación. El cable de equilibrio de la carga del subsistema de alimentación no está instalado.
Acción del usuario: Conecte el cable de equilibrio de la carga.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackCommonEnclosureName
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureSparePartNumber
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “Power subsystem load balancing wire missing for enclosure [cpqRackCommonEnclosureName], in rack [cpqRackName].” (Falta el cable de equilibrio de la carga del subsistema de alimentación para el chasis [cpqRackCommonEnclosureName] del bastidor [cpqRackName].)
ID de evento de NT: 1177 (Hex)0x84350499 (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
ESES Agentes de servidor 471

Título del evento: Power Subsystem Too Many Power Enclosures (Hay demasiados chasis de alimentación en el subsistema de alimentación)
Mensaje del registro: The maximum number of power enclosures has been exceeded. (Se ha superado el número máximo de chasis de alimentación.)
Captura SNMP: cpqRackPowerChassisTooManyPowerChassis - 22035 en CPQRACK.MIB
Síntoma: El subsistema de alimentación tiene demasiados chasis de alimentación. Se ha superado el número máximo de chasis de alimentación.
Acción del usuario: Extraiga los chasis de alimentación adicionales.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackCommonEnclosureName
● cpqRackCommonEnclosureSerialNum
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “Power subsystem has too may power enclosures [cpqRackCommonEnclosureName], in rack [cpqRackName].” (El subsistema de alimentación tiene demasiados chasis de alimentación [cpqRackCommonEnclosureName] en el bastidor [cpqRackName].)
ID de evento de NT: 1178 (Hex)0x8435049a (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Título del evento: Power Subsystem Configuration Error (Error de configuración del subsistema de alimentación)
Mensaje del registro: The power subsystem has been improperly configured. (El subsistema de alimentación no se ha configurado correctamente.)
Captura SNMP: cpqRackPowerChassisConfigError - 22036 en CPQRACK.MIB
Síntoma: El subsistema de alimentación no se ha configurado correctamente. La configuración del subsistema de alimentación no es correcta.
Acción del usuario: Compruebe el cableado del chasis de alimentación.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqRackName
● cpqRackUid
● cpqRackCommonEnclosureName
● cpqRackCommonEnclosureSerialNum
472 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

● cpqRackCommonEnclosureSparePartNumber
● cpqRackCommonEnclosureTrapSequenceNum
Descripción complementaria de la captura SNMP: “Power subsystem has been improperly configured in enclosure [cpqRackCommonEnclosureName], in rack [cpqRackName].” (El subsistema de alimentación no se ha configurado correctamente en el chasis [cpqRackCommonEnclosureName] del bastidor [cpqRackName].)
ID de evento de NT: 1179 (Hex) 0x8435049B (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Management Processor is in reset state. The data contains the error code. (El procesador de gestión se está restableciendo. Los datos contienen el código del error.)
Captura SNMP: cpqHeManagementProcInReset - 6061 en CPQHLTH.MIB
Síntoma: El procesador de gestión se está restableciendo. El procesador de gestión se está restableciendo debido a una actualización de firmware o a algún otro evento.
Acción del usuario: Ninguna
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
Descripción complementaria de la captura SNMP: “The Management processor is in the process of being reset.” (El procesador de gestión se está restableciendo.)
ID de evento de NT: 1180 (Hex) 0x0435049c (cpqsvmsg.dll)
Nivel de gravedad del registro: Informativo (1)
Mensaje del registro: The Management Processor has successfully reset and is now available again. The data contains the error code. (El procesador de gestión se ha restablecido correctamente y está disponible de nuevo. Los datos contienen el código del error.)
Captura SNMP: cpqHeManagementProcReady - 6062 en CPQHLTH.MIB
Síntoma: El procesador de gestión está listo. El procesador de gestión se ha restablecido correctamente y está disponible de nuevo.
Acción del usuario: Ninguna
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
Descripción complementaria de la captura SNMP: “The Management processor is ready after a successfull reset” (El procesador de gestión está listo después de restablecerse correctamente)
ID de evento de NT: 1181 (Hex) 0x8435049D (cpqsvmsg.dll)
Nivel de gravedad del registro: Advertencia (3)
Mensaje del registro: The Management Processor has not reset successfully and is not operational. The data contains the error code. (El procesador de gestión no se ha restablecido correctamente y no está operativo. Los datos contienen el código del error.)
Captura SNMP: cpqHeManagementProcFailedReset - 6063 en CPQHLTH.MIB
ESES Agentes de servidor 473

Síntoma: El procesador de gestión no ha podido restablecerse. El procesador de gestión no se restableció correctamente y no está operativo.
Acción del usuario: Restablezca de nuevo el procesador de gestión o vuelva a actualizar el firmware de este.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
Descripción complementaria de la captura SNMP: “The Management processor failed reset.” (El procesador de gestión no ha podido restablecerse.)
ID de evento de NT: 1182 (Hex)0x4435049EL
Nivel de gravedad del registro: Informativo
Mensaje del registro: USB storage device '%5' attached. The data contains the error code. (Dispositivo de almacenamiento USB '%5' conectado. Los datos contienen el código del error.)
Captura SNMP: 1008 en CPQSTDEQ.MIB
Síntoma: La llave USB se ha conectado al servidor.
Acción del usuario: No es necesario hacer nada.
Datos complementarios de la captura SNMP:
● sysName,
● cpqHoTrapFlags
● cpqSeUSBDeviceType
● cpqSeUSBDeviceName
Descripción complementaria de la captura SNMP: “This trap is sent when a USB storage device has been attached.” (Esta captura se envía cuando se conecta un dispositivo de almacenamiento USB.)
Nombre simbólico: CPQ_STD_USB_DEV_ATTACHED
ID de evento de NT: 1183 (Hex)0x4435049FL
Nivel de gravedad del registro: Informativo
Mensaje del registro: USB storage device '%5' removed. The data contains the error code. (Dispositivo de almacenamiento USB '%5' extraído. Los datos contienen el código del error.)
Captura SNMP: 1009 en CPQSTDEQ.MIB
Síntoma: La llave USB se ha extraído del servidor.
Acción del usuario: No es necesario hacer nada.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqSeUSBDeviceType
● cpqSeUSBDeviceName
474 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Descripción complementaria de la captura SNMP: “This trap is sent when a attached USB storage device is removed.” (Esta captura se envía cuando se extrae un dispositivo de almacenamiento USB conectado.)
Nombre simbólico: CPQ_STD_USB_DEV_REMOVED
Identificadores de eventos 1539-3352Identificador del evento: cpqsvmsg.dll - 1539 (Hex)0xc4350603 (Service Event)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: Unable to write to the registry. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No es posible escribir en el registro. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqsvmsg.dll - 1540 (Hex)0xc4350604 (Service Event)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: Unable to read from the registry. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No es posible leer el registro. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqsvmsg.dll - 1543 (Hex)0xc4350607 (Service Event)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: Unable to load a required driver. This error can be caused by a corrupt or missing file. Reinstalling the Server Agents, the software support drivers, or running the Emergency Repair procedure may correct this error. (No es posible cargar un controlador obligatorio. Este error puede deberse a un archivo dañado o ausente. Volver a instalar Server Agents, los controladores del soporte del software o ejecutar el procedimiento de reparaciones de emergencia puede corregir este error.)
Identificador del evento: cpqsvmsg.dll - 1544 (Hex)0x84350608 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to read from the registry. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No es posible leer el registro. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqsvmsg.dll - 1574 (Hex)0xc4350626 (evento de servicio)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: Could not write the registry sub-key: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo escribir la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqsvmsg.dll - 1792 (Hex)0x84350700 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Server SNMP Agent is unable to generate traps due to an error during initialization. (Server SNMP Agent no puede generar capturas debido a un error durante la inicialización.)
ESES Agentes de servidor 475

Identificador del evento: cpqsvmsg.dll - 1795 (Hex)0x84350703 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The SNMP Agent is older than other components. The SNMP Agent is older than the other components of the Server Agents. Reinstall the entire Server Agents package to correct this error. (SNMP Agent es anterior a otros componentes. SNMP Agent es anterior a los demás componentes de Server Agents. Vuelva a instalar el paquete Server Agents completo para corregir este error.)
Identificador del evento: cpqsvmsg.dll - 1796 (Hex)0x84350704 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The %1 Agent is older than other components. The %1 Agent is older than the other components of the Server Agents. Reinstall the entire Server Agents package to correct this error. (%1 Agent es anterior a otros componentes. %1 Agent es anterior a los demás componentes de Server Agents. Vuelva a instalar el paquete Server Agents completo para corregir este error.)
Identificador del evento: cpqsvmsg.dll - 1800 (Hex)0x84350708 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to read security configuration information. SNMP sets have been disabled. (No es posible leer la información de configuración de la seguridad. Se han desactivado los conjuntos SNMP.)
Identificador del evento: cpqsvmsg.dll - 1803 (Hex)0xc435070b (evento de servicio)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: Unable to load a required library. This error can be caused by a corrupt or missing file. Reinstalling the Server Agents or running the Emergency Repair procedure may correct this error. (No es posible cargar una biblioteca obligatoria. Este error puede deberse a un archivo dañado o ausente. Volver a instalar Server Agents o ejecutar el procedimiento de reparaciones de emergencia puede corregir este error.)
Identificador del evento: cpqsvmsg.dll - 1806 (Hex)0x8435070e (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Server Agent service is not running. The Server SNMP Agent has determined that the Server Agent service is not running. Stop the SNMP service and restart the Server Agents service. If the error persists, reinstalling the Server Agents may correct this error. (El servicio Server Agent no se está ejecutando. Server SNMP Agent ha determinado que el servicio Server Agent no se está ejecutando. Detenga el servicio SNMP y reinicie el servicio Server Agents. Si el error continúa, es posible que se corrija volviendo a instalar el servicio Server Agents.)
Identificador del evento: cpqsvmsg.dll - 1808 (Hex)0x44350710 (evento de servicio)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: The agent could not deliver trap %1. The agent was unable to use Asynchronous Management to deliver a trap. This can be caused by a failure in the Remote Access Service or by a missing or invalid configuration. Use the Management Agent control panel to verify the Asynchronous Management configuration settings. Use the Network control panel to verify the Remote Access configuration. If this error persists, reinstalling the Server Agents or the Remote Access Service may correct this error. For more information, see the Asynchronous Management documentation. (El agente no pudo entregar la captura %1. El agente no pudo utilizar Asynchronous Management [Gestión asíncrona] para entregar una captura. Esto puede deberse a un fallo en el servicio de acceso remoto [Remote Access Service] o a una configuración no válida o ausente. Utilice el panel de control de Management Agent para comprobar los parámetros de configuración de
476 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Asynchronous Management. Utilice el panel de control de la red para comprobar la configuración del acceso remoto. Si el error continúa, es posible que se corrija volviendo a instalar Server Agents o el servicio de acceso remoto. Para obtener más información, consulte la documentación de Asynchronous Management.)
Identificador del evento: cpqsvmsg.dll - 3328 (Hex)0x84350d00 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to allocate memory. This indicates a low memory condition. Rebooting the system may correct this error. (No es posible asignar memoria. Esto indica un problema de memoria insuficiente. Reiniciar el sistema puede corregir este error.)
Identificador del evento: cpqsvmsg.dll - 3329 (Hex)0x84350d01 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not read from the registry sub-key. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo leer la subclave del registro. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqsvmsg.dll - 3330 (Hex)0x84350d02 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not write the registry sub-key: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo escribir la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqsvmsg.dll - 3331 (Hex)0x84350d03 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not read the registry sub-key: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo leer la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqsvmsg.dll - 3332 (Hex)0x84350d04 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not read the registry sub-key: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo leer la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqsvmsg.dll - 3333 (Hex)0x84350d05 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not read the registry sub-key: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo leer la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqsvmsg.dll - 3342 (Hex)0x84350d0e (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
ESES Agentes de servidor 477

Mensaje del registro: The Remote Insight Agent got an unexpected error code while waiting for multiple events. The data contains the error code. (Remote Insight Agent obtuvo un código de error inesperado mientras esperaba que se produjesen varios eventos. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 3345 (Hex)0x84350d11 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Remote Insight Board device driver not present. The Remote Insight Agent requires the Remote Insight Board device driver (CPQSM2.SYS) to be installed. Install the driver from the latest Software Support for Windows. If you do not have a Remote Insight Board in this system, disable the Remote Insight Agent via the Management Agents Control Panel. (El controlador de dispositivo de la placa Remote Insight no está presente. Remote Insight Agent requiere la instalación del controlador de dispositivo de la placa Remote Insight [CPQSM2.SYS]. Instale el controlador del soporte del software más reciente para Windows. Si no dispone de una placa Remote Insight en este sistema, desactive Remote Insight Agent a través del panel de control de Management Agents.)
Identificador del evento: cpqsvmsg.dll - 3351 (Hex)0x84350d17 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The shared memory interface has been reset. (La interfaz de memoria compartida se ha restablecido.)
Identificador del evento: cpqsvmsg.dll - 3352 (Hex)0xc4350d18 (evento de servicio)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: The Remote Insight board has been reset. (La placa Remote Insight se ha restablecido.)
Identificadores de eventos 5632-5684Identificador del evento: cpqsvmsg.dll - 5632 (Hex)0x84351600 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Rack And Enclosure MIB Agent could not allocate memory. The data contains the error code. (Rack And Enclosure MIB Agent no pudo asignar memoria. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 5633 (Hex)0x84351601 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Rack And Enclosure MIB Agent could not open the base of the registry. The data contains the error code. (Rack And Enclosure MIB Agent no pudo abrir la base del registro. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 5634 (Hex)0x84351602 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: “%1”. The data contains the error code. (Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 5635 (Hex)0x84351603 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: “%1”. The data contains the error code. (Los datos contienen el código del error.)
478 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Identificador del evento: cpqsvmsg.dll - 5636 (Hex)0x84351604 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Rack And Enclosure MIB Agent could not read the registry value “%1”. The data contains the error code. (Rack And Enclosure MIB Agent no pudo leer el valor del registro “%1”. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 5637 (Hex)0x84351605 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Rack And Enclosure MIB Agent found an incorrect type for registry value “%1”. The data contains the type found. (Rack And Enclosure MIB Agent encontró un tipo incorrecto para el valor del registro “%1”. Los datos contienen el tipo encontrado.)
Identificador del evento: cpqsvmsg.dll - 5638 (Hex)0x84351606 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Rack And Enclosure MIB Agent could not create a necessary event. The data contains the error code. (Rack And Enclosure MIB Agent no pudo crear un evento necesario. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 5639 (Hex)0x84351607 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Rack And Enclosure MIB Agent could not set an event. The data contains the error code. (Rack And Enclosure MIB Agent no pudo configurar un evento. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 5640 (Hex)0x84351608 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Rack And Enclosure MIB Agent could not create its main thread of execution. The data contains the error code. (Rack And Enclosure MIB Agent no pudo crear su subproceso principal de ejecución. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 5641 (Hex)0x84351609 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Rack And Enclosure MIB Agent main thread did not terminate properly. The data contains the error code. (El subproceso principal de Rack And Enclosure MIB Agent no finalizó correctamente. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 5642 (Hex)0x8435160a (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Rack And Enclosure MIB Agent got an unexpected error code while waiting for an event. The data contains the error code. (Rack And Enclosure MIB Agent obtuvo un código de error inesperado mientras esperaba que se produjese un evento. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 5643 (Hex)0x8435160b (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Rack And Enclosure MIB Agent did not respond to a request. The data contains the error code. (Rack And Enclosure MIB Agent no respondió a una solicitud. Los datos contienen el código del error.)
ESES Agentes de servidor 479

Identificador del evento: cpqsvmsg.dll - 5644 (Hex)0x8435160c (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Rack And Enclosure MIB Agent received an unknown action code from the service. The data contains the action code. (Rack And Enclosure MIB Agent recibió un código de acción desconocido del servicio. Los datos contienen el código de acción.)
Identificador del evento: cpqsvmsg.dll - 5645 (Hex)0x8435160d (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Rack And Enclosure MIB Agent could not get the system type. The data contains the error code. (Rack And Enclosure MIB Agent no pudo obtener el tipo del sistema. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 5682 (Hex)0x84351632 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Rack And Enclosure MIB Agent could not set the variable because it is unsupported. The data contains the error code. (Rack And Enclosure MIB Agent no pudo configurar la variable debido a que esta no es compatible. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 5683 (Hex)0x84351633 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Rack And Enclosure MIB Agent could not set the variable because the value is invalid or out of range. The data contains the error code. (Rack And Enclosure MIB Agent no pudo configurar la variable debido a que el valor no es válido o está fuera del intervalo. Los datos contienen el código del error.)
Identificador del evento: cpqsvmsg.dll - 5684 (Hex)0x84351634 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Rack And Enclosure MIB Agent is not loaded. Sets are not available. The data contains the error code. (Rack And Enclosure MIB Agent no se ha cargado. Los conjuntos no están disponibles. Los datos contienen el código del error.)
Agentes NICIdentificadores de eventos 256-299
Identificador del evento: cpqnimsg.dll - 256 (Hex)0x84350100 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The NIC Management Agent detected an error. The insertion string is: %1. The data contain the error code. (NIC Management Agent detectó un error. La cadena de inserción es: %1. Los datos contienen el código de error.)
Identificador del evento: cpqnimsg.dll - 257 (Hex)0x84350101 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to allocate memory. This indicates a low memory condition. Rebooting the system will correct this error. (No es posible asignar memoria. Esto indica un problema de memoria insuficiente. Reinicie el sistema para corregir este error.)
Identificador del evento: cpqnimsg.dll - 258 (Hex)0x84350102 (evento de servicio)
480 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The NIC Management Agent could not register with the Service Control Manager. The data contain the error code. (NIC Management Agent no se pudo registrar en Service Control Manager. Los datos contienen el código de error.)
Identificador del evento: cpqnimsg.dll - 259 (Hex)0x84350103 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The NIC Management Agent could not set the service status with the Service Control Manager. The data contain the error code. (NIC Management Agent no pudo configurar el estado del servicio en Service Control Manager. Los datos contienen el código de error.)
Identificador del evento: cpqnimsg.dll - 260 (Hex)0x84350104 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The NIC Management Agent could not start the Service Control Dispatcher. The data contain the error code. (NIC Management Agent no pudo iniciar el Service Control Dispatcher. Los datos contienen el código de error.)
Identificador del evento: cpqnimsg.dll - 261 (Hex)0x84350105 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to read from the registry. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No es posible leer el registro. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqnimsg.dll - 262 (Hex)0x84350106 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not create the registry key: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo crear la subclave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqnimsg.dll - 263 (Hex)0x84350107 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not delete the registry key: “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No se pudo eliminar la clave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqnimsg.dll - 264 (Hex)0x84350108 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to open the registry key “%1”. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No es posible abrir la clave del registro: “%1”. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqnimsg.dll - 265 (Hex)0x84350109 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to read “%1” from the registry. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No es posible leer
ESES Agentes NIC 481

“%1” en el registro. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqnimsg.dll - 266 (Hex)0x8435010a (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to read “%1” from the registry. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No es posible leer “%1” en el registro. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqnimsg.dll - 267 (Hex)0x8435010b (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to write “%1” to the registry. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No es posible escribir “%1” en el registro. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqnimsg.dll - 268 (Hex)0x8435010c (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to enumerate “%1” from the registry. This error can be caused by a corrupt registry or a low memory condition. Rebooting the server may correct this error. (No es posible enumerar “%1” del registro. Este error puede deberse a un registro dañado o a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqnimsg.dll - 269 (Hex)0xc435010d (evento de servicio)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: The NIC Management Agent encountered a fatal error. The service is terminating. The data contain the error code. (NIC Management Agent encontró un error muy grave. El servicio está terminando. Los datos contienen el código de error.)
Identificador del evento: cpqnimsg.dll - 270 (Hex)0x8435010e (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to create thread. This error can be caused by a low memory condition. Rebooting the server may correct this error. (No es posible crear el subproceso. Este error puede deberse a un problema de memoria insuficiente. Reiniciar el servidor puede corregir este error.)
Identificador del evento: cpqnimsg.dll - 271 (Hex)0x8435010f (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Could not open the driver for device “%1”. This error can be caused by an improperly installed adapter. Removing and reinstalling the device may correct the problem. The data contain the error code. (No se pudo abrir el controlador para el dispositivo “%1”. Este error puede deberse a un adaptador que no se ha instalado correctamente. Extraer y volver a instalar el dispositivo puede solucionar el problema. Los datos contienen el código de error.)
Identificador del evento: cpqnimsg.dll - 272 (Hex)0x84350110 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Failure in driver %1. This error can be caused by an outdated driver version. Installing a later version of the driver may correct the problem. The data contain the error code. (Se ha producido un fallo en el controlador %1. Este error puede deberse a una versión del controlador
482 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

no actualizada. Instalar una versión posterior del controlador puede solucionar el problema. Los datos contienen el código de error.)
Identificador del evento: cpqnimsg.dll - 273 (Hex)0x84350111 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: There were no physical adapters in team: “%1.” This error can be caused by improperly installed drivers. Remove all device instances associated with the team and re-install the drivers and team. (No había adaptadores físicos en el equipo: Este error puede deberse a que los controladores no se han instalado correctamente. Elimine todas las instancias de dispositivo asociadas con el equipo y vuelva a instalar los controladores y el equipo.)
Identificador del evento: cpqnimsg.dll - 274 (Hex)0x84350112 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The NIC Management Agent cannot generate Traps due to a communication problem with the NIC SNMP extension agent. (NIC Management Agent no puede generar capturas debido a un problema de comunicación con el agente de la extensión SNMP de NIC.)
Identificador del evento: cpqnimsg.dll - 275 (Hex)0x44350113 (evento de servicio)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: Communication with the NIC SNMP extension agent has been restored. TRAPS can now be sent. (Se ha restablecido la comunicación con el agente de la extensión SNMP de NIC. Ahora ya se pueden enviar capturas.)
Identificador del evento: cpqnimsg.dll - 276 (Hex)0x84350114 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The NIC Management Agent cannot communicate with the Token Ring Protocol driver (CNMPROT.SYS). (NIC Management Agent no se puede comunicar con el controlador del protocolo Token Ring [CNMPROT.SYS].)
Identificador del evento: cpqnimsg.dll - 277 (Hex)0x44350115 (evento de servicio)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: The NIC Management Agent version %1 has started. (Se ha iniciado NIC Management Agent versión %1.)
Identificador del evento: cpqnimsg.dll - 279 (Hex)0x84350117 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The NIC Management Agent could not set an event. The data contain the error code. (NIC Management Agent no pudo configurar un evento. Los datos contienen el código de error.)
Identificador del evento: cpqnimsg.dll - 280 (Hex)0x84350118 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The NIC Management Agent service could not start any agents successfully. (El servicio NIC Management Agent no pudo iniciar correctamente ningún agente.)
Identificador del evento: cpqnimsg.dll - 281 (Hex)0x84350119 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
ESES Agentes NIC 483

Mensaje del registro: The NIC Management Agent main thread did not terminate properly. The data contain the error code. (El subproceso principal de NIC Management Agent no finalizó correctamente. Los datos contienen el código de error.)
Identificador del evento: cpqnimsg.dll - 283 (Hex)0x8435011b (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The NIC Management Agent did not respond to a request. The data contain the error code. (NIC Management Agent no respondió a una solicitud. Los datos contienen el código de error.)
Identificador del evento: cpqnimsg.dll - 285 (Hex)0x8435011d (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The NIC Management Agent could not get the system type. The data contain the error code. (NIC Management Agent no pudo obtener el tipo del sistema. Los datos contienen el código de error.)
Identificador del evento: cpqnimsg.dll - 287 (Hex)0x8435011f (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The NIC Agent service could not load the module “%1”. The data contain the error code. (El servicio NIC Agent no pudo cargar el módulo “%1”. Los datos contienen el código de error.)
Identificador del evento: cpqnimsg.dll - 288 (Hex)0x84350120 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The NIC Agent service could get the control function for module “%1”. The data contain the error code. (El servicio NIC Agent pudo obtener la función de control para el módulo “%1”. Los datos contienen el código de error.)
Identificador del evento: cpqnimsg.dll - 290 (Hex)0x84350122 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The NIC Agent service could not start agent “%1”. The data contain the error code. (El servicio NIC Agent no pudo iniciar el agente “%1”. Los datos contienen el código de error.)
Identificador del evento: cpqnimsg.dll - 291 (Hex)0x84350123 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The NIC Agent service detected an invalid state for agent *”%1”. The data contain the state. (El servicio NIC Agent detectó un estado no válido para el agente *”%1”. Los datos contienen el estado.)
Identificador del evento: cpqnimsg.dll - 292 (Hex)0x84350124 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The NIC Agent service could not stop agent “%1”. The data contain the error code. (El servicio NIC Agent no pudo detener el agente “%1”. Los datos contienen el código de error.)
Identificador del evento: cpqnimsg.dll - 293 (Hex)0x84350125 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
484 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Mensaje del registro: The NIC Agent service could not terminate agent “%1”. The data contain the error code. (El servicio NIC Agent no pudo finalizar el agente “%1”. Los datos contienen el código de error.)
Identificador del evento: cpqnimsg.dll - 294 (Hex)0x84350126 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The NIC Agent service could not unload the module “%1”. The data contain the error code. (El servicio NIC Agent no pudo descargar el módulo “%1”. Los datos contienen el código de error.)
Identificador del evento: cpqnimsg.dll - 296 (Hex)0xc4350128 (evento de servicio)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: A driver for a NIC failed to open. This error can be caused by an improperly installed adapter. Removing and reinstalling all adapters may correct the problem. The NIC Agent service will not respond to any management requests. (Error al abrir un controlador para una NIC. Este error puede deberse a un adaptador que no se ha instalado correctamente. Extraer y volver a instalar todos los adaptadores puede solucionar el problema. El servicio NIC Agent no responderá a ninguna solicitud de gestión.)
Identificador del evento: cpqnimsg.dll - 297 (Hex)0x84350129 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: An attempt to log an event to the IML failed. The IML log may be full. Clearing the IML log may correct this problem. (Error al intentar registrar un evento en el IML. Es posible que el IML esté lleno. Borrar el registro IML puede solucionar este problema.)
Identificador del evento: cpqnimsg.dll - 298 (Hex)0xc435012a (evento de servicio)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: A fatal error occurred during Virus Throttle WMI event processing. Virus Throttle related traps will not be sent. (Se ha producido un error muy grave durante el procesamiento de eventos WMI Virus Throttle. Las capturas relacionadas con Virus Throttle no se enviarán.)
Causa: Es probable que el servicio WMI no se esté ejecutando. Iniciar el servicio WMI o el NIC Agent puede solucionar este problema.
Identificador del evento: cpqnimsg.dll - 299 (Hex)0x8435012b (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: An attempt to query WMI for Virus Throttle event failed. The event data gives the error number. (Error al intentar realizar una consulta WMI para el evento Virus Throttle. Los datos del evento contienen el número de error.)
Identificadores de eventos 300-1293Identificador del evento: cpqnimsg.dll - 300 (Hex)0x8435012c (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The WBEM query was cancelled by WMI. The query was issued again. (WMI canceló la consulta WBEM. La consulta se volvió a enviar.)
Causa: Es probable que el servicio WMI se haya reiniciado.
Identificador del evento: cpqnimsg.dll - 1024 (Hex)0x84350400 (evento de servicio)
ESES Agentes NIC 485

Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The SNMP Insight Agent is unable to generate traps due to an error during initialization. (SNMP Insight Agent no puede generar capturas debido a un error durante la inicialización.)
Causa: Asegúrese de que el servicio SNMP se está ejecutando. Volver a instalar los agentes puede corregir este error.
Identificador del evento: cpqnimsg.dll - 1025 (Hex)0x84350401 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The NIC SNMP Management Agent's trap thread has encountered an error while waiting for event notification from event log. (El subproceso de captura de NIC SNMP Management Agent ha encontrado un error mientras esperaba la notificación de eventos del registro de eventos.)
Identificador del evento: cpqnimsg.dll - 1027 (Hex)0x84350403 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The SNMP Agent is older than other components. The SNMP Agent is older than the other components of the Insight Agents. Reinstall the entire Insight Agents package to correct this error. (SNMP Agent es anterior a los demás componentes de Insight Agents. Vuelva a instalar el paquete Insight Agents completo para solucionar este error.)
Identificador del evento: cpqnimsg.dll - 1028 (Hex)0x84350404 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The %1 Agent is older than other components. The %1 Agent is older than the other components of the Insight Agents. Reinstall the entire Insight Agents package to correct this error. (%1 Agent es anterior a otros componentes. %1 Agent es anterior a los demás componentes de Insight Agents. Vuelva a instalar el paquete Insight Agents completo para solucionar este error.)
Identificador del evento: cpqnimsg.dll - 1029 (Hex)0x84350405 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The NIC SNMP Management Agent has failed to refresh data associated with key %1. Check to make sure management service is up and running. This may cause data received from Compaq SNMP agent to be old or invalid. (NIC SNMP Management Agent ha fallado al actualizar los datos asociados con la clave %1. Asegúrese de que el servicio de gestión está en funcionamiento. Como consecuencia, es posible que los datos recibidos del agente SNMP de Compaq estén sin actualizar o no sean válidos.)
Identificador del evento: cpqnimsg.dll - 1030 (Hex)0xc4350406 (evento de servicio)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: The NIC SNMP Management Agent was unable to process a SNMP request because the Insight Agents Service is not up and running. (NIC SNMP Management Agent no pudo procesar una solicitud SNMP debido a que el servicio Insight Agents no está en funcionamiento.)
Identificador del evento: cpqnimsg.dll - 1031 (Hex)0x44350407 (evento de servicio)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: The NIC SNMP Management Agent has continued refreshing data for the key associated with %1. (NIC SNMP Management Agent ha continuado actualizando los datos para la clave asociada con %1.)
486 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Identificador del evento: cpqnimsg.dll - 1032 (Hex)0x84350408 (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: Unable to read security configuration information. SNMP sets have been disabled. (No es posible leer la información de configuración de la seguridad. Se han desactivado los conjuntos SNMP.)
Causa: Esto puede deberse a que falta una configuración o es incorrecta, o a la existencia de un registro dañado. Volver a instalar Insight Agents puede solucionar este problema.
Identificador del evento: cpqnimsg.dll - 1033 (Hex)0x44350409 (evento de servicio)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: The SNMP Insight Agent will allow SNMP sets. (SNMP Insight Agent permitirá los conjuntos SNMP.)
Identificador del evento: cpqnimsg.dll - 1034 (Hex)0x4435040a (evento de servicio)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: The SNMP Insight Agent will not allow SNMP sets. (SNMP Insight Agent no permitirá los conjuntos SNMP.)
Identificador del evento: cpqnimsg.dll - 1035 (Hex)0xc435040b (evento de servicio)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: Unable to load a required library. This error can be caused by a corrupt or missing file. Reinstalling the Insight Agents or running the Emergency Repair procedure may correct this error. (No es posible cargar una biblioteca obligatoria. Este error puede deberse a un archivo dañado o ausente. Volver a instalar Insight Agents o ejecutar el procedimiento de reparaciones de emergencia puede corregir este error.)
Identificador del evento: cpqnimsg.dll - 1036 (Hex)0x8435040c (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The NIC SNMP Management Agent was unable to forward an SNMP trap to the Compaq Remote Insight Board trap due to processing error. The data contains the error code. (NIC SNMP Management Agent no pudo reenviar una captura SNMP a la captura de la placa Remote Insight de Compaq debido a un error de procesamiento. Los datos contienen el código del error.)
Identificador del evento: cpqnimsg.dll - 1037 (Hex)0x8435040d (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The NIC SNMP Management Agent was unable to get last modification time for key %1. (NIC SNMP Management Agent no pudo obtener la hora de la última modificación de la clave %1.)
Identificador del evento: cpqnimsg.dll - 1038 (Hex)0x8435040e (evento de servicio)
Nivel de gravedad del registro: Advertencia (2)
Mensaje del registro: The Management Agent service is not running. The SNMP Management Agent has determined that the Management Agent service is not running. Stop the SNMP service and restart the Management Agents service. If the error persists, reinstalling the Management Agents may correct this error. (El servicio Management Agent no se está ejecutando. SNMP Management Agent ha determinado que el servicio Management Agent no se está ejecutando. Detenga el servicio SNMP y reinicie el servicio Management Agents. Si el error continúa, es posible que se corrija volviendo a instalar Management Agents.)
ESES Agentes NIC 487

Identificador del evento: cpqnimsg.dll - 1039 (Hex)0x4435040f (evento de servicio)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: The NIC SNMP Management Agent has determined the Insight Agent Management service is running. (NIC SNMP Management Agent ha determinado que el servicio Insight Agent Management se está ejecutando.)
Identificador del evento: cpqnimsg.dll - 1040 (Hex)0x44350410 (evento de servicio)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: The agent could not deliver trap %1. The agent was unable to use Asynchronous Management to deliver a trap. This can be caused by a failure in the Remote Access Service or by a missing or invalid configuration. Use the Insight Agent control panel to verify the Asynchronous Management configuration settings. Use the Network control panel to verify the Remote Access configuration. If this error persists, reinstalling the Insight Agents or the Remote Access Service may correct this error. For more information, see the Insight Asynchronous Management documentation. (El agente no pudo entregar la captura %1. El agente no pudo utilizar Asynchronous Management [Gestión asíncrona] para entregar una captura. Esto puede deberse a un fallo en el servicio de acceso remoto [Remote Access Service] o a una configuración no válida o ausente. Utilice el panel de control de Insight Agent para comprobar los parámetros de configuración de Asynchronous Management. Utilice el panel de control de la red para comprobar la configuración del acceso remoto. Si el error continúa, es posible que se corrija volviendo a instalar Insight Agents o el servicio de acceso remoto. Para obtener más información, consulte la documentación de Insight Asynchronous Management.)
ID de evento de NT: 1282 (Hex)0x44350502 (cpqnimsg.dll)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: Redundancy has been increased by the NIC in slot %1, port %2. Number of functional NICs in the team: %3. (La NIC de la ranura %1, puerto %2 ha aumentado la redundancia. Número de NIC funcionales en el equipo: %3.)
Captura SNMP: cpqNicRedundancyIncreased - 18003 en CPQNIC.MIB
Síntoma: Esta captura se envía cada vez que vuelve al estado OK un adaptador físico de un grupo de adaptadores lógicos conectados que antes había fallado. Esta captura no se envía si se restaura la conectividad de un grupo de adaptadores lógicos desde un estado Failed. En su lugar, se envía la captura cpqNicConnectivityRestored. Esto puede deberse a la sustitución de un cable defectuoso o a la conexión de un cable que estaba desconectado.
Acción del usuario: No es necesario hacer nada.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqNicIfPhysAdapterSlot
● cpqNicIfPhysAdapterPort
● cpqNicIfLogMapAdapterOKCount
Descripción complementaria de la captura SNMP: “Redundancy increased by adapter in slot [cpqNicIfPhysAdapterSlot], port [cpqNicIfPhysAdapterPort].” (El adaptador de la ranura [cpqNicIfPhysAdapterSlot], puerto [cpqNicIfPhysAdapterPort] incrementó la redundancia.)
ID de evento de NT: 1283 (Hex)0xc4350503 (cpqnimsg.dll)
488 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Nivel de gravedad del registro: Error (3)
Mensaje del registro: Redundancy has been reduced by the NIC in slot %1, port %2. Number of functional NICs in the team: %3. (La NIC de la ranura %1, puerto %2 ha reducido la redundancia. Número de NIC funcionales en el equipo: %3.)
Captura SNMP: cpqNicRedundancyReduced - 18004 en CPQNIC.MIB
Síntoma: Esta captura se envía cada vez que un adaptador físico de un grupo de adaptadores lógicos cambia al estado Failed, pero al menos un adaptador físico permanece en el estado OK. Esto puede deberse a una pérdida de enlace provocada por la extracción de un cable del adaptador, del concentrador o del conmutador. Este problema también pueden ocasionarlo fallos en el adaptador interno, el concentrador o el conmutador.
Acción del usuario: Compruebe los cables que van al adaptador y al concentrador o al conmutador. Si no hay ningún problema con los cables, es posible que necesite sustituir el adaptador, el concentrador o el conmutador.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqNicIfPhysAdapterSlot
● cpqNicIfPhysAdapterPort
● cpqNicIfLogMapAdapterOKCount
Descripción complementaria de la captura SNMP: “Redundancy decreased by adapter in slot [cpqNicIfPhysAdapterSlot], port [cpqNicIfPhysAdapterPort].” (El adaptador de la ranura [cpqNicIfPhysAdapterSlot], puerto [cpqNicIfPhysAdapterPort] disminuyó la redundancia.)
ID de evento de NT: 1290 (Hex)0x4435050A (cpqnimsg.dll)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: Connectivity has been restored for the NIC in slot %1, port %2. (Se ha restaurado la conectividad para la NIC de la ranura %1, puerto %2.)
Captura SNMP: cpqNic3ConnectivityRestored - 18011 en CPQNIC.MIB
Síntoma: Esta captura se envía cada vez que se restaura la conectividad en un adaptador lógico. Esto ocurre cuando el adaptador físico de una configuración de adaptador único vuelve al estado OK o al menos un adaptador físico de un grupo de adaptadores lógicos vuelve al estado OK. Esto puede deberse a la sustitución de un cable defectuoso o a que se ha vuelto a conectar un cable que estaba desconectado.
Acción del usuario: No es necesario hacer nada.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqNicIfPhysAdapterSlot
● cpqNicIfPhysAdapterPort
● cpqSiServerSystemId
● cpqNicIfPhysAdapterStatus
ESES Agentes NIC 489

● cpqSePciSlotBoardName
● cpqNicIfPhysAdapterPartNumber
● ipAdEntAddr
● cpqNicIfLogMapIPV6Address
Descripción complementaria de la captura SNMP: “Connectivity is restored for adapter in slot [cpqNicIfPhysAdapterSlot], port [cpqNicIfPhysAdapterPort].” (Se ha restaurado la conectividad para el adaptador de la ranura [cpqNicIfPhysAdapterSlot], puerto [cpqNicIfPhysAdapterPort].)
ID de evento de NT: 1291 (Hex)0xc435050B (cpqnimsg.dll)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: Connectivity has been lost for the NIC in slot %1, port %2. (Se ha perdido la conectividad para la NIC de la ranura %1, puerto %2.)
Captura SNMP: cpqNic3ConnectivityLost - 18012 en CPQNIC.MIB
Síntoma: Esta captura se envía cada vez que un adaptador lógico cambia al estado Failed. Esto ocurre cuando falla el adaptador de una configuración de adaptador único, o cuando falla el último adaptador de una configuración redundante. Esto puede deberse a una pérdida de enlace provocada por la extracción de un cable del adaptador, del concentrador o del conmutador. Este problema también pueden ocasionarlo fallos en el adaptador interno, el concentrador o el conmutador.
Acción del usuario: Compruebe los cables que van al adaptador y al concentrador o al conmutador. Si no hay ningún problema con los cables, es posible que necesite sustituir el adaptador, el concentrador o el conmutador.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqNicIfPhysAdapterSlot
● cpqNicIfPhysAdapterPort
● cpqSiServerSystemId
● cpqNicIfPhysAdapterStatus
● cpqSePciSlotBoardName
● cpqNicIfPhysAdapterPartNumber
● ipAdEntAddr
● cpqNicIfLogMapIPV6Address
Descripción complementaria de la captura SNMP: “Connectivity lost for adapter in slot [cpqNicIfPhysAdapterSlot], port [cpqNicIfPhysAdapterPort].” (Se ha perdido la conectividad para el adaptador de la ranura [cpqNicIfPhysAdapterSlot], puerto [cpqNicIfPhysAdapterPort].)
ID de evento de NT: 1292 (Hex)0x4435050C (cpqnimsg.dll)
Nivel de gravedad del registro: Información (1)
Mensaje del registro: Redundancy has been increased by the NIC in slot %1, port %2. Number of functional NICs in the team: %3. (La NIC de la ranura %1, puerto %2 ha aumentado la redundancia. Número de NIC funcionales en el equipo: %3.)
490 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

Captura SNMP: cpqNic3RedundancyIncreased - 18013 en CPQNIC.MIB
Síntoma: Esta captura se envía cada vez que vuelve al estado OK un adaptador físico de un grupo de adaptadores lógicos conectados que antes había fallado. Esta captura no se envía si se restaura la conectividad de un grupo de adaptadores lógicos desde un estado Failed. En su lugar, se envía la captura cpqNicConnectivityRestored. Esto puede deberse a la sustitución de un cable defectuoso o a la conexión de un cable que estaba desconectado.
Acción del usuario: No es necesario hacer nada.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqNicIfPhysAdapterSlot
● cpqNicIfPhysAdapterPort
● cpqSiServerSystemId
● cpqNicIfPhysAdapterStatus
● cpqSePciSlotBoardName
● cpqNicIfPhysAdapterPartNumber
● ipAdEntAddr
● cpqNicIfLogMapIPV6Address
● cpqNicIfLogMapAdapterOKCount
Descripción complementaria de la captura SNMP: “Redundancy increased by adapter in slot [cpqNicIfPhysAdapterSlot], port [cpqNicIfPhysAdapterPort].” (El adaptador de la ranura [cpqNicIfPhysAdapterSlot], puerto [cpqNicIfPhysAdapterPort] incrementó la redundancia.)
ID de evento de NT: 1293 (Hex)0xc435050D (cpqnimsg.dll)
Nivel de gravedad del registro: Error (3)
Mensaje del registro: Redundancy has been reduced by the NIC in slot %1, port %2. Number of functional NICs in the team: %3. (La NIC de la ranura %1, puerto %2 ha reducido la redundancia. Número de NIC funcionales en el equipo: %3.)
Captura SNMP: cpqNic3RedundancyReduced - 18014 en CPQNIC.MIB
Síntoma: Esta captura se envía cada vez que un adaptador físico de un grupo de adaptadores lógicos cambia al estado Failed, pero al menos un adaptador físico permanece en el estado OK. Esto puede deberse a una pérdida de enlace provocada por la extracción de un cable del adaptador, del concentrador o del conmutador. Este problema también pueden ocasionarlo fallos en el adaptador interno, el concentrador o el conmutador.
Acción del usuario: Compruebe los cables que van al adaptador y al concentrador o al conmutador. Si no hay ningún problema con los cables, es posible que necesite sustituir el adaptador, el concentrador o el conmutador.
Datos complementarios de la captura SNMP:
● sysName
● cpqHoTrapFlags
● cpqNicIfPhysAdapterSlot
ESES Agentes NIC 491

● cpqNicIfPhysAdapterPort
● cpqSiServerSystemId
● cpqNicIfPhysAdapterStatus
● cpqSePciSlotBoardName
● cpqNicIfPhysAdapterPartNumber
● ipAdEntAddr
● cpqNicIfLogMapIPV6Address
● cpqNicIfLogMapAdapterOKCount
Descripción complementaria de la captura SNMP: “Redundancy decreased by adapter in slot [cpqNicIfPhysAdapterSlot], port [cpqNicIfPhysAdapterPort].” (El adaptador de la ranura [cpqNicIfPhysAdapterSlot], puerto [cpqNicIfPhysAdapterPort] disminuyó la redundancia.)
492 Capítulo 9 HPE Insight Management Agents for Servers para Windows ESES

10 Asistencia y otros recursos
Acceso al soporte de Hewlett Packard Enterprise● Para obtener soporte en tiempo real, vaya a la página web de contacto con Hewlett Packard
Enterprise en todo el mundo (http://www.hpe.com/assistance).
● Para acceder a la documentación y los servicios de soporte técnico, vaya a la página web del centro de soporte de Hewlett Packard Enterprise (http://www.hpe.com/support/hpesc).
Información que se debe recopilar● Número de registro de soporte técnico (si corresponde)
● Nombre, modelo o versión y número de serie del producto
● Nombre y versión del sistema operativo
● Versión de firmware
● Mensajes de error
● Informes y registros específicos del producto
● Productos o componentes adicionales
● Productos o componentes de otros fabricantes
Acceso a las actualizaciones● Algunos productos de software proporcionan un mecanismo para acceder a las actualizaciones
de software a través de la interfaz del producto. Revise la documentación del producto para identificar el método recomendado de actualización del software.
● Para descargar actualizaciones del producto, vaya a cualquiera de las páginas web siguientes:
◦ Página Get connected with updates (Conéctese con las actualizaciones) del centro de soporte de Hewlett Packard Enterprise (http://www.hpe.com/support/e-updates)
◦ Página web de Software Depot (Almacén de software) (http://www.hpe.com/support/softwaredepot)
● Para ver y actualizar sus concesiones, así como para vincular sus contratos y garantías con su perfil, vaya a la página More Information on Access to Support Materials (Más información sobre cómo acceder a los materiales de soporte) del centro de soporte de Hewlett Packard Enterprise (http://www.hpe.com/support/AccessToSupportMaterials).
NOTA: El acceso a algunas actualizaciones podría requerir la concesión de producto cuando se accede a través del centro de soporte de Hewlett Packard Enterprise. Debe disponer de una cuenta de HP Passport configurada con las concesiones correspondientes.
ESES Acceso al soporte de Hewlett Packard Enterprise 493

Páginas web● Biblioteca de información de Hewlett Packard Enterprise (http://www.hpe.com/info/enterprise/
docs)
● Centro de soporte de Hewlett Packard Enterprise (http://www.hpe.com/support/hpesc)
● Contacto con Hewlett Packard Enterprise en todo el mundo (http://www.hpe.com/assistance)
● Servicio de suscripción/alertas de soporte (http://www.hpe.com/support/e-updates)
● Software Depot (Almacén de software) (http://www.hpe.com/support/softwaredepot)
● Reparaciones del propio cliente (http://www.hpe.com/support/selfrepair)
● Insight Remote Support (http://www.hpe.com/info/insightremotesupport/docs)
● Soluciones Serviceguard para HP-UX (http://www.hpe.com/info/hpux-serviceguard-docs)
● Matriz de compatibilidad de dispositivos de almacenamiento de Single Point of Connectivity Knowledge (SPOCK) (http://www.hpe.com/storage/spock)
● Documentos técnicos e informes analíticos de almacenamiento (http://www.hpe.com/storage/whitepapers)
Soporte remotoEl soporte remoto está disponible con los dispositivos compatibles como parte de su garantía o de un contrato de soporte. Proporciona diagnóstico inteligente de eventos y envío automático y seguro de notificaciones de eventos de hardware a Hewlett Packard Enterprise, que iniciará un proceso de solución rápido y preciso basándose en el nivel de servicio de su producto. Hewlett Packard Enterprise le recomienda que registre su dispositivo en el soporte remoto.
Para obtener más información y detalles de los dispositivos compatibles, vaya a la página web de Insight Remote Support (http://www.hpe.com/info/insightremotesupport/docs).
494 Capítulo 10 Asistencia y otros recursos ESES

11 Siglas y abreviaturas
ADG
Advanced Data Guarding (Protección avanzada de datos) (también conocido como RAID 6)
ADU
Array Diagnostics Utility (Utilidad de diagnóstico de array)
AHS
Active Health System (Sistema de estado activo)
ASR
Automatic Server Recovery (Recuperación automática del servidor)
CA
Certificate authority (Entidad emisora de certificados)
CGI
Common Gateway Interface (Interfaz común de gateway)
CLP
Command Line Protocol (Protocolo de línea de comandos)
CONREP
Configuration Replication Utility (Utilidad de replicación de la configuración)
DDNS
Dynamic Domain Name System (Sistema de nombres de dominio dinámico)
DHCP
Dynamic Host Configuration Protocol (Protocolo de configuración dinámica de host)
DMA
Direct Memory Access (Acceso directo a memoria)
DNS
Domain Name System (Sistema de nombres de dominio)
EBIPA
Enclosure Bay IP Addressing (Direccionamiento IP de los compartimentos de los chasis)
EEPROM
Electrical Erasable Programmable Read Only Memory (Memoria de solo lectura programable y borrable eléctricamente)
EV
Environment Variable (Variable de entorno)
ESES 495

FBDIMM
Fully buffered DIMM (DIMM completamente almacenado en la memoria intermedia)
FBWC
Flash-Backed Write Cache (Memoria caché de escritura respaldada por flash)
HB
Latencia
HBA
Host Bus Adapter (Adaptador de bus de host)
HPE SSA
HPE Smart Storage Administrator
HPERCU
HPE ROM Configuration Utility (Utilidad de configuración de la ROM de HPE)
iLO
Integrated Lights-Out
IML
Integrated Management Log (Registro de gestión integrado)
IRC
Integrated Remote Console (Consola remota integrada)
JRC
Java Remote Console (Consola remota de Java)
LDAP
Lightweight Directory Access Protocol (Protocolo ligero de acceso a directorios)
LOM
Lights-Out Management (Gestión de Lights-Out)
MMC
Microsoft Management Console (Consola de gestión de Microsoft)
NMI
Nonmaskable Interrupt (Interrupción no enmascarable)
NTP
Network Time Protocol (Protocolo de tiempo de la red)
NVDIMM
Non-Volatile Dual In-line Memory Module (Módulo de memoria en línea doble no volátil)
NVDIMM-N
Memoria en línea doble no volátil con interfaz dirigible de bytes a DRAM
NVRAM
496 Capítulo 11 Siglas y abreviaturas ESES

Nonvolatile Memory (Memoria no volátil)
OA
Onboard Administrator
POST
Autocomprobación al arrancar (Power-On Self-Test)
PPM
Processor Power Module (módulo de alimentación del procesador)
QPI
QuickPath Interconnect
RBSU
ROM-Based Setup Utility (Utilidad de configuración basada en ROM)
RDIMM
Registered Dual In-line Memory Module (Módulo de memoria en línea doble registrada)
RIBCL
Remote Insight Board Command Language (Lenguaje de comandos de la placa Remote Insight)
RIS
Reserve Information Sector (Sector de información de reserva)
SAS
Serial Attached SCSI (SCSI con conexión serie)
SATA
Serial ATA (ATA con conexión serie)
SIM
Systems Insight Manager
SLES
SUSE Linux Enterprise Server
SMART
Self-Monitoring Analysis and Reporting Technology (Tecnología de supervisión automática, análisis y generación de informes)
SR-IOV
Single root I/O Virtualization (Virtualización de E/S de raíz única)
SSD
Solid-State Drive (unidad de estado sólido)
SSH
Secure Shell (Shell de seguridad)
SSL
ESES 497

Secure Sockets Layer (Capa de sockets seguros)
SSO
Single sign-on (Inicio de sesión único)
SSP
Selective Storage Presentation (Presentación de almacenamiento selectivo)
UDIMM
Unregistered Dual In-line Memory Module (Módulo de memoria en línea doble no registrada)
UEFI
Unified Extensible Firmware Interface (Interfaz de firmware extensible unificada)
UID
Unit Identification (Identificación de unidades)
VC
Virtual Connect
VRM
Voltage regulator module (Módulo regulador de tensión)
WINS
Windows® Internet Naming Service (Servicio de denominación Internet de Windows®)
498 Capítulo 11 Siglas y abreviaturas ESES

12 Comentarios sobre la documentación
Hewlett Packard Enterprise se compromete a proporcionar documentación que se adapte a sus necesidades. Para ayudarnos a mejorar la documentación, envíenos cualquier error, sugerencia o comentario a Comentarios sobre la documentación (mailto:[email protected]). Cuando envíe sus comentarios, incluya el título del documento, el número de referencia, la edición y la fecha de publicación, que se encuentran en la portada del documento. Para el contenido de ayuda en línea, incluya el nombre y la versión del producto, la edición y la fecha de publicación de la ayuda, que se encuentran en la página de avisos legales.
ESES 499

Índice
Símbolos/números1003 - VCM-OA communication
down 2861022 - Domain state FAILED
2871023 - Domain state
PROFILE_FAILED 2881026 - Domain state NO_COMM
28817012 - Enet UplinkSet state
FAILED 30117014 - Enet uplinkset state is
DISABLED 3022003 - Enclosure import failed
2882011 - Enclosure state
NO_COMM 2892013 - Enclosure state failed
2892016 - Enclosure Find failed 2903009 - Enet Module OA CPU Fault
Event 2913012 - Enet Module State
FAILED 2913014 - Enet Module state
INCOMPATIBLE 2923019 - Enet Module state
MISSING 2933023 - Enet Module state
NO_COMM 2933031 - Enet Module IP is 0.0.0.0
2943101 - Port is disabled as network
loop is detected 2943102 - Port was disabled because
a pause flood was detected294
4009 - FC Module OA CPU Fault Event 294
4012 - FC Module State Failed295
4014 - FC Module State Incompatible 295
4019 - FC Module State is NO_COMM 295
5009 - Server OA fault event296
5012 - Server state FAILED 2965014 - Server state
INCOMPATIBLE 2965019 - Server state is
NO_COMM 2965022 - Missing information for one
or more blades of a multi-blade server 297
5050 - The BIOS for the following devices is not compatible with Virtual Connect 297
5055 - The server BIOS needs to be updated to at least the version dated 297
5056 - Unable to release power hold on the server. Unassign and re-assign profile 297
6012 - Profile state FAILED 2986020 - Profile has the same
network on two Flex-10 NICs on the same physical port 298
6021 - Profile has PXE enabled on a non-primary Flex-10 NIC 298
6022 - Profile has iSCSI boot enabled on an unsupported Flex-10 NIC 298
6023 - Profile is assigned to a multi-blade server that has data missing 299
6030 - Profile could not be assigned to powered up server299
7012 - Enet Network state FAILED 299
7014 - Enet Network state DISABLED 300
8012 - FC Fabric state FAILED300
9012 - Unknown Module state FAILED 300
9014 - Unknown Module state INCOMPATIBLE 301
9019 - Unknown Module state NO_COMM 301
AADU, mensajes de error
Mensajes de error de diagnóstico de arrays 2
Mensajes de error de HPE Smart Storage Administrator Diagnostics Utility 2
agentes base, errores 328alimentación, fuentes
System Power Supplies Not Redundant 147
System Power Supply Failure (Power Supply X) 148
Ccapturas de la MIB de módulo
VC 279Capturas de la MIB de módulo
VC 279capturas SNMP
Capturas SNMP 275Capturas SNMP de Onboard
Administrator 270Capturas SNMP
Capturas SNMP 275Capturas SNMP de Onboard
Administrator 270códigos de fallos de alimentación
Códigos de fallos de alimentación de los indicadores LED del panel frontal 149
HPE ProLiant Gen9, códigos de fallos de alimentación149
códigos de fallos de alimentación de los indicadores LED del panel frontal 149
códigos de retorno, CONREP303
CONREP, códigos de retorno303
500 Índice ESES

CONREP, salida de pantalla 304CONREP (Utilidad de replicación
de la configuración) 303controladora, indicadores LED
Indicadores LED de la controladora P440 151
Indicadores LED de la controladora P440ar 150
Indicadores LED de la controladora P441 152
Indicadores LED de la controladora P840 153
Indicadores LED de tiempo de ejecución de la controladora 150
controladoras de array 13
Ddescripciones de los agentes
328descripción general de SNMP
274Descripción general de SNMP
274diagnóstico de arrays, mensajes
de errorMensajes de error de
diagnóstico de arrays 2Mensajes de error de HPE
Smart Storage Administrator Diagnostics Utility 2
Eerror de bus PCI 147error en el ventilador del sistema
147errores de CONREP 303Errores de CONREP 303errores del controlador de
Windows, Smart Array 213errores de los agentes de
almacenamiento 351errores de los agentes de
servidor 421errores de los agentes NIC 480errores de Onboard Administrator
Mensajes de error de Onboard Administrator 214
Errores de Onboard AdministratorCapturas SNMP de Onboard
Administrator 270error interno de procesador
imposible de corregir 147evento de pantalla azul 146eventos de conjuntos de enlaces
ascendentes Ethernet, Virtual Connect 301
eventos de la estructura FC, Virtual Connect 300
eventos de la red Ethernet, Virtual Connect 299
eventos de los chasis, Virtual Connect 288
eventos de los dominios, Virtual Connect 286
eventos de los módulos Ethernet, Virtual Connect 291
eventos de los módulos FC, Virtual Connect 294
eventos de los perfiles, Virtual Connect 298
eventos de los servidores, Virtual Connect 296
eventos de módulos desconocidos, Virtual Connect300
eventos de SysLog de Virtual Connect Manager 285
Eventos de SysLog de Virtual Connect Manager 285
Ffallo en la fuente de alimentación
del sistema 148fuentes de alimentación del
sistema no redundantes 147
HHPE ProLiant Gen9, códigos de
fallos de alimentaciónCódigos de fallos de
alimentación de los indicadores LED del panel frontal 149
HPE ProLiant Gen9, códigos de fallos de alimentación149
Iidentificadores de eventos,
agentes base 328identificadores de eventos,
agentes de almacenamiento351
identificadores de eventos, agentes de servidor 421
identificadores de eventos, agentes NIC 480
identificadores de eventos 1025-1092, agentes de servidor 425
identificadores de eventos 1061-1098, agentes de almacenamiento 356
identificadores de eventos 1101-1199, agentes de almacenamiento 363
identificadores de eventos 1103-1183, agentes de servidor 435
identificadores de eventos 1105-1808, agentes base 328
identificadores de eventos 1200-1294, agentes de almacenamiento 395
identificadores de eventos 1343-4613, agentes de almacenamiento 415
identificadores de eventos 1539-3352, agentes de servidor 475
identificadores de eventos 2048-2359, agentes base 338
identificadores de eventos 256-1024, agentes de servidor421
identificadores de eventos 256-299, agentes de NIC 480
identificadores de eventos 256-774, agentes de almacenamiento 351
identificadores de eventos 300-1293, agentes de NIC 485
identificadores de eventos 3072-3876, agentes base 342
identificadores de eventos 4352-4626, agentes base 347
ESES Índice 501

identificadores de eventos 5632-5684, agentes de servidor 478
identificadores de mensajes 24578-24599, Smart Array 156
identificadores de mensajes 24600-24624, Smart Array 166
identificadores de mensajes 24625-24649, Smart Array 172
identificadores de mensajes 24650-24674, Smart Array 175
identificadores de mensajes 24675-24699, Smart Array 179
identificadores de mensajes 24700-24724, Smart Array 184
identificadores de mensajes 24725-24749, Smart Array 193
identificadores de mensajes 24750-24774, Smart Array 198
identificadores de mensajes 24775-24799, Smart Array 204
identificadores de mensajes 24800-24824, Smart Array 211
iLO, errores 306IML (Registro de gestión
integrado) 146indicadores de estado,
controladora 150indicadores LED de fallos de
alimentaciónCódigos de fallos de
alimentación de los indicadores LED del panel frontal 149
HPE ProLiant Gen9, códigos de fallos de alimentación149
indicadores LED de la POST306
indicadores LED del módulo de memoria caché 154
indicadores LED de tiempo de ejecución de la controladora
Indicadores LED de la controladora P440ar 150
Indicadores LED de la controladora P840 153
Indicadores LED de tiempo de ejecución de la controladora 150
Insight Diagnostics 146
Llínea de comandos, mensajes de
eventos 272lista de eventos, mensajes de
error 146
Mmemoria 147memoria, error 148
208-Memory speed error 28Uncorrectable Memory Error
(Slot X, Memory Module Y)... 148
mensajes de error, información general 1
mensajes de error, lista de eventosIntroducción a los mensajes de
error del registro de gestión integrado 146
Mensajes de error del registro de gestión integrado 146
mensajes de error, POSTIntroducción a los mensajes de
error de la POST 26Mensajes de error de la
POST 26mensajes de error, RIBCL 317mensajes del registro de
actualización del firmware 243mensajes del registro de
alertmail 237mensajes del registro de CGI
238Mensajes del registro de CGI
238Mensajes del registro de CLI 238mensajes del registro de
configuración y certificados de la actualización 244
mensajes del registro de DHCP239
Mensajes del registro de DHCP239
mensajes del registro de DNS246
Mensajes del registro de DNS246
mensajes del registro de dos factores 269
mensajes del registro de FIPS269
Mensajes del registro de FIPS269
mensajes del registro de gestión257
mensajes del registro de inicio y de autenticación 237
mensajes del registro de la CLI238
mensajes del registro de la configuración no volátil 242
mensajes del registro de LCD247
Mensajes del registro de LCD247
mensajes del registro del compartimento de interconexión 238
mensajes del registro de LDAP266
Mensajes del registro de LDAP266
mensajes del registro del enlace del chasis 240
Mensajes del registro de Linux257
mensajes del registro del sistema (SysLog), Onboard Administrator 237
mensajes del registro de redundancia 267
mensajes del registro de SSO268
Mensajes del registro de SSO268
mensajes del registro de VLAN270
Mensajes del registro de VLAN270
mensajes del registro internos de Onboard Administrator 265
mensajes del registro relacionados con operaciones 248
módulo de memoria caché, indicadores LED 154
502 Índice ESES

Nnotificaciones de eventos,
definición 271
Ppanel frontal, indicadores LED
149POST, mensajes de error de la
serie 100 26POST, mensajes de error de la
serie 1500 90POST, mensajes de error de la
serie 1600 91POST, mensajes de error de la
serie 1700 98POST, mensajes de error de la
serie 1800 136POST, mensajes de error de la
serie 200 28POST, mensajes de error de la
serie 300 57POST, mensajes de error de la
serie 400 88problemas del sistema operativo
Automatic operating system shutdown initiated due to fan failure 146
Automatic Operating System Shutdown Initiated Due to Overheat Condition... 146
Rregistro de eventos, entradas
307registro de eventos, mensajes
327registro de eventos de Windows
Formato del registro de eventos de Windows NT® 327
Mensajes del registro de eventos de Windows para Smart Array 156
registro de gestión integrado (IML) 146
RIBCL, mensajes de error 317ROM, error 26
Ssalida de pantalla, CONREP 304serie 1500, mensajes de error
90
serie 1600, mensajes de error91
serie 1700, mensajes de error98
serie 1800, mensajes de error136
serie 200, mensajes de error 28serie 300, mensajes de error 57serie 400, mensajes de error 88sintaxis de la línea de comandos
303sistema, sobrecalentamiento
147SNMP, entradas del registro de
eventos 307sobrecalentamiento 147
Ttemporizador ASR, fallo 27tiempo de ejecución, indicadores
LED 150
UUtilidad de replicación de la
configuración (CONREP) 303
Vventilador del sistema
System Fan Failure (Fan X, Location) 147
System Fans Not Redundant147
ventiladores 146ventiladores del sistema no
redundantes 147
WWindows, identificadores de
eventos y capturas SNMP 327
ESES Índice 503


















