
Herramienta para construir bases de conocimiento a partir ... · Internet y leer los ficheros RDF...
155
PROYECTO FIN DE CARRERA Herramienta para construir bases de conocimiento a partir de información en la web JORGE GIL PEÑA Madrid, Septiembre 2010 UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI) INGENIERO INFORMÁTICO
Transcript of Herramienta para construir bases de conocimiento a partir ... · Internet y leer los ficheros RDF...

PROYECTO FIN DE CARRERA
Herramienta para
construir bases de conocimiento
a partir de información en la web
JORGE GIL PEÑA
Madrid, Septiembre 2010
UNIVERSIDAD PONTIFICIA COMILLAS
ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
INGENIERO INFORMÁTICO

Jorge Gil Peña
Dr. David Contreras Bárcena
Dr. Miguel Ángel Sanz

PROYECTO FIN DE CARRERA
Herramienta para
construir bases de conocimiento
a partir de información en la web
AUTOR: Gil Peña, Jorge
DIRECTOR: Dr. Miguel Ángel Sanz Bobi
MADRID, Septiembre 2010
UNIVERSIDAD PONTIFICIA COMILLAS
ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
INGENIERO INFORMÁTICO

HERRAMIENTA PARA CONSTRUIR BASES DE
CONOCIMIENTO A PARTIR DE INFORMACIÓN EN LA
WEB
RESUMEN DEL PROYECTO
En una época en la que los contenidos de Internet tienen cada día un
nivel de disponibilidad mayor y uno de los principales problemas del
internauta empieza a ser cómo decidir entre unos y otros. La
recomendación de contenidos personalizados es, cada vez más, un
fenómeno de importancia crucial: una necesidad cada vez más
apremiante para los usuarios que quieren acceder a los contenidos que
suscitan un verdadero interés para ellos de manera rápida.
Con el objetivo de satisfacer esta necesidad de recomendación de
contenidos, nace el servicio desarrollado por este Proyecto Fin de
Carrera, el servicio web llamado “my Web”, que será accesible a través
de Internet y que pretende ofrecer al usuario una selección de contenidos
acordes a sus intereses y gustos. El nombre de este servicio hace alusión
a la pretensión de ser un portal de personalización de contenidos de
Internet.
El objetivo del proyecto será pues el de crear una web personal en la
cual, a partir de un test inicial que todo usuario deberá completar,
aparezcan una serie de recomendaciones en lo que a posibles intereses
musicales, de cine y literatura se refiere. Para poder ofertarles contenidos
acordes a sus gustos, será condición sine quanon darse de alta y rellenar
un test personal, con la finalidad de recabar información del usuario. En
"myWeb", el usuario podrá ver las recomendaciones hechas por el
sistema, acceder a fotos, links o videos de YouTube, así como modificar
sus enlaces favoritos y realizar búsquedas asociadas a su perfil.
El desarrollo de este proyecto supone un gran alivio de tiempo para los
usuarios de Internet, ya que filtra los contenidos más interesantes para

cada usuario. Pero es que, además del ahorro de tiempo, este servicio
puede suponer adicionalmente una herramienta de ocio, posibilitando el
acceso del internauta a contenidos de la web de manera personalizada.
El proceso hacia el desarrollo de “my Web” implica todo un compromiso
por la investigación y la innovación, así como una apuesta por las nuevas
tecnologías de la web 3.0., la web semántica y, sobretodo, por la
aplicación de la inteligencia artificial y sus tecnologías a las páginas web
que se usan a diario.
Este servicio web se ha realizado como aplicación web programada en
Java. Este programa, emplea técnicas de Inteligencia Artificial tales
como la adquisición automática de conocimiento, la representación de
conocimiento por medio de las ontologías y el incremento de éstas
mediante un algoritmo de incremento del conocimiento. Se trata de un
sistema basado en conocimiento que tiene un claro enfoque hacia las
nuevas tecnologías semánticas.
La aplicación comienza leyendo una ontología completa basada en la
Wikipedia y una vez el usuario completa la encuesta, esta es enviada al
servidor. A partir de los intereses del usuario se accede a webs 3.0 como
DbPedia y MusicBrainz, con el fin de recabar información semántica
asociada a dichos intereses. Esta información servirá para que la
ontología continúe incrementándose.
Para la recomendación de contenidos se ha implementado un algoritmo
que se encargará de controlar el crecimiento de la ontología y asignara un
peso a los recursos más interesantes. Este algoritmo parte de la base
teórica de que nuestros intereses están relacionados a nuestra forma de
ser, por lo que nuestros intereses están conectados en distintos dominios.
Esto hace que el algoritmo busque relaciones entre nuestros intereses.
Asigna pesos, a los recursos asociados al usuario, y a los datos
relacionados con estos. En función del número y del tipo de conexiones
entre estos se considerará un recurso como más interesante.
Para tratar con las ontologías se emplea una herramienta también
desarrollada en Java, conocida como Jena, que facilitara dicha tarea.
Permitiendo la unión, la lectura y la modificación de ontologías y de sus

entidades y relaciones. Además esta biblioteca se usara para conectarse a
Internet y leer los ficheros RDF mediante un motor de consulta
SPARQL.
La implementación de la aplicación a servicio web ha sido llevada cabo
en paralelo. Se han desarrollado con una arquitectura de tres niveles,
siguiendo el esquema MVC. Del interfaz gráfico ha sido desarrollado en
JSP , empleando JSTL para recibir objetos Java. El código Java, que se
encarga de ejecutar la lógica del programa y los Servlets que se encargan
de generar páginas web de forma dinámica. Y se dispone de una base de
datos en MySQL que se encarga de la administración de datos, dándole
permeabilidad a la ontología.
Los objetivos han sido cumplidos al desarrollar una herramienta
completa con la que se ha podido cerrar el ciclo completo, construyendo
bases de conocimiento a partir de información en la web, disponiendo
además de un algoritmo de recomendación de contenidos y de una
aplicación web para mostrar los resultados.
El aprendizaje que se ha llevado a cabo en la realización e investigación
para este proyecto de “my Web” ha sido voluminoso y variado desde
técnicos a conceptuales. Este proyecto va a significar, de cara al futuro,
el comienzo de una nueva etapa en la que este servicio de
personalización de contenidos pueda seguir desarrollándose de forma
muy prometedora.

TOOL FOR BUILDING FOUNDATIONS OF
KNOWLEDGE IN INFORMATION FROM THE WEB
ABSTRACT
At a time that Internet content every day has a greater level of
availability and one of the main problems of the Internet begins to be
how to decide between them. The personalized content recommendation
is, increasingly, a critical phenomenon: an increasingly urgent need for
users who want to access to genuine and interesting content quickly.
In order to satisfy this need for content recommendation, was born on
service developed by this thesis, the web service called "my Web", which
is accessible through the Internet and aims to offer users a consistent
selection of content their interests and tastes. The name of this service
refers to the claim of being a portal of Internet content personalization.
The aim of the project is therefore to create a personal website in which,
after an initial test that all users must complete and appear a number of
recommendations as to any interest in music, film and literature are
concerned. To be able to offer content tailored to their tastes, be a
condition sine quanon register and fill out a personal test, in order to
collect user information. In "myWeb", the user can view the
recommendations made by the system, accessing photos, links or videos
to YouTube and edit your favorite links and search associated with your
profile.
The development of this project is a great relief from time to Internet
users, since most interesting content filters for each user. But is that, in
addition to saving time, this service may involve additional entertainment
tool, enabling internet access to web content in a personalized way.
The process towards the development of "my Web" implies considerable
commitment to research and innovation and a commitment to new web
3.0 technologies., Semantic web and, above all, by the application of
artificial intelligence and their technologies to web pages that are used

daily.
This web service has been done as a Web application programmed in
Java. This program uses Artificial Intelligence techniques such as the
automatic acquisition of knowledge, knowledge representation through
ontologies and increasing them by an algorithm for knowledge
enhancement. It is a knowledge based system that has a clear focus on
semantic technologies.
The application begins reading a complete ontology based on Wikipedia
and once the user completes the survey, this is sent to the server. From a
user's interests can be accessed as web 3.0 DBpedia and MusicBrainz in
order to obtain semantic information associated with those interests. This
information will help the ontology continue to rise.
For content recommendation has been implemented an algorithm that
will control the growth of ontology and assign a weight to the most
interesting resources. This algorithm theory assumes that our interests are
linked to our way of being, so that our interests are connected in different
domains. This makes the algorithm look for relations between our
interests. Weights assigned to the resources associated with the user, and
data related to these. Depending on the number and type of connections
between these are considered a resource as more interesting.
To deal with ontologies also used a tool developed in Java, known as
Jena, to facilitate this task. Allowing the union, reading and modification
of ontologies and its entities and relationships. In addition this library
will be used to connect to the Internet and read RDF files using a
SPARQL query engine.
Implementing the Web service application has been carried out in
parallel. Have developed a three-tier architecture following the MVC
pattern. The graphic interface has been developed in JSP, JSTL to receive
objects using Java. Java code, which is responsible for implementing the
program logic and Servlets which are responsible for geerating web
pages dynamically. And you have a MySQL database that handles data
management, giving patency to the ontology.
Targets have been met to develop a comprehensive tool with which he

was unable to close the whole period, building knowledge bases from
information in the web, besides providing a recommendation algorithm
and content of a web application to display results.
The learning that has taken place for the practice and research for this
project "my Web" has been voluminous and varied from technical to
conceptual. This project will mean, for the future, the beginning of a new
era in which this content personalization service can continue to develop
very promising.
.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
9
MEMORIA
PROYECTO FIN DE CARRERA
Herramienta para
construir bases de conocimiento
a partir de información en la web

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
10
I N D I CE
1.1.1.1. Introducción _________________________________________________ 12
1.1. Justificación _______________________________________________ 13
1.2. Motivación del proyecto ________________________________ 14
2.2.2.2. Objetivos. _____________________________________________________ 16
3.3.3.3. Revisión de técnicas y tecnologías ______________________ 18
3.1. Conceptos y definiciones básicas ______________________ 18
3.1.1. Web2.0. ________________________________________________________ 19
3.1.2. Web3.0. ___________________________________________________________ 21
3.1.3. Técnicas de Inteligencia Artificial _______________________________ 26
3.2. Arquitectura ______________________________________________ 29
3.2.1. Introducción ___________________________________________________ 29
3.2.2. Arquitectura Cliente Servidor ________________________________ 30
3.2.3 Arquitectura de tres niveles __________________________________ 33
3.3. Descripción funcionamiento de Tecnologías
empleadas 36
3.3.1 Java _____________________________________________________________ 37
3.3.2 Funcionamiento de Jena _____________________________________ 39
3.3.3 Servidor web __________________________________________________ 56
3.3.4. Páginas dinámicas ________________________________________________ 57
3.3.5 Sistema Gestor de base de datos _____________________________ 64
4.4.4.4. Análisis de la aplicación ___________________________________ 66
4.1. Introducción ______________________________________________ 66
4.2. Análisis de alternativas _________________________________ 66
5.5.5.5. Diseño y desarrollo de la aplicación myWeb __________ 73
5.1. Introducción ______________________________________________ 73
5.2. Diseño ______________________________________________________ 73
5.2.1. Modelo de Casos de Uso ______________________________________ 74
5.2.1. Modelo de Dominio ___________________________________________ 80

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
11
5.3. Tareas desarrolladas en el proyecto __________________ 86
5.3.1. Estudio psicológico de conexiones musicales _______________ 87
5.3.2. Diseño de myWeb _____________________________________________ 88
5.3.3. Diseño entradas al programa ________________________________ 93
5.3.4. Utilización de la herramienta JENA __________________________ 95
5.3.5. Realización del algoritmo con Java. ________________________ 100
5.3.6.Crear y preparación del proyecto web ________________________ 108
6. Desarrollo de la aplicación myWeb ____________________ 113
6.1. Modulo Java _________________________________________________ 113
6.1.1. Introducción ____________________________________________________ 113
6.1.2. Parte Jena _______________________________________________________ 115
6.1.3.Parte Algoritmo _________________________________________________ 117
6.2. Módulo Servlets ____________________________________________ 125
6.3. Módulo JSP __________________________________________________ 129
6.4. Modulo base de datos _____________________________________ 133
7. Caso ejemplo ___________________________________________________ 136
8 Especificaciones Tecnológicas ______________________________ 140
8.1. Proyecto en desarrollo ____________________________________ 140
8.2. Proyecto en explotación __________________________________ 142
9. Presupuesto ___________________________________________________ 145
10. Planificación _________________________________________________ 147
11. Conclusiones _________________________________________________ 148
12. Tabla de ilustraciones _____________________________________ 151
13. Bibliografía __________________________________________________ 153

Jorge Gil Peña
Herramienta para construir bases de conocimiento a partir de información en la web
través de información disponible en
poder ofertar
gustos se realiza una
en el servicio
contenidos recomendados
trata de un servicio web
acceder a través de internet.
El nombre de este servicio
pretende realizar
interés del usuario
En este punto de acceso a él
recomendaciones
videos de YouTube
ver los más
perfil.
E
Jorge Gil Peña Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
1.1.1.1. Introducción
ste proyecto está orientado a adquirir los
gustos de la música, películas, libros,
intereses y forma de ser de los usuar
información disponible en la web semántica.
poder ofertar de forma ontológica contenidos acordes a sus
se realiza una encuesta al comienzo, al darse de alta
en el servicio, y un algoritmo se encarga de buscar
recomendados más acordes con el perfil
trata de un servicio web llamado myWeb, al cual se puede
acceder a través de internet.
Ilustración 3.1.1
El nombre de este servicio viene dado porque
realizar una selección de contenidos acordes a
del usuario siendo su punto de acceso a Internet.
este punto de acceso a él puede
recomendaciones, acceder a fotos, links interesantes o
YouTube, pero también modificar sus favoritos,
votados, y realizar búsquedas asociadas a
E
Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
12
Introducción
orientado a adquirir los
gustos de la música, películas, libros,
forma de ser de los usuarios a
la web semántica. Para
contenidos acordes a sus
al darse de alta
se encarga de buscar los
más acordes con el perfil. Se
, al cual se puede
viene dado porque
ción de contenidos acordes al
u punto de acceso a Internet.
ver sus
otos, links interesantes o
us favoritos,
asociadas a su

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
13
El camino para el desarrollo ha sido toda una
apuesta por la investigación y la innovación. Una apuesta
por las nuevas tecnologías de la web 3.0., la web semántica
y una apuesta, sobretodo, por aplicar técnicas de
inteligencia artificial y a las páginas web que se usan a
diario.
1.1. Justificación
Este proyecto viene motivado por intentar proponer
una Internet sencilla y entretenida para la gente con ganas
de conocer cosas nuevas y de sacarle el mejor partido a esta
gran fuente de conocimientos. Este enfoque está
plenamente justificado porque no existe una página web
unificada, estandarizada y completa, que aporte contenidos
de la web o simplemente conceptos que puedan entretener,
interesar, divertir o simplemente llamar la atención en
función de nuestro perfil.
Considerándose que esto podría ser muy útil en el
mundo de Internet, el proyecto se ha orientado hacia una
interfaz web, con objeto de hacerlo mucho más accesible
para todo el mundo y de una manera mucho más dinámica.
Además trata de evitar los temidos tiempos de descargas y
posibles desconfianzas en la descarga del programa desde
Internet. Pero aun así es muy importante tener en cuenta
que esta página web cuenta con un gran proyecto Java en

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
14
el backend (servidor), y que será el encargado de llevar la
lógica de negocio.
1.2. Motivación del
proyecto
Como suele suceder las justificaciones y las
motivaciones suelen ir de la mano, y en este proyecto no ha
sido una excepción. La principal motivación del proyecto es
proponer una manera de entretenimiento y de ofrecer
contenidos interesantes adaptados al perfil de cada usuario
concreto usando técnicas elaboradas y automatizadas de
tratamiento del conocimiento.
Sin embargo ha habido otras motivaciones técnicas
importantes como el hecho de trabajar con conceptos de
Inteligencia Artificial. Para tratar de mejorar lo que ofrecen
los programas actuales, y de simular inteligencia humana
para lograr los propósitos de búsqueda de información
interésate. Por ejemplo en este caso se ha trabajado con
técnicas de incremento del conocimiento, en los que
partiendo de conceptos básicamente descritos por el
usuario acerca de su perfil extrayendo de la web más
conocimientos interesantes basados en los originales,
dando resultados interesantes.
A nivel técnico una de las mayores motivaciones y
complicaciones ha sido el hecho de trabajar con tecnologías
en vías de continuo desarrollo. Éstas están abriendo

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
15
muchas puertas a desarrolladores y usuarios, como pueden
ser la web 3.0. o la web semántica, motores de
procesamiento como Lucene o de búsqueda como SPARQL,
tecnologías como los RDF , o los OWL y conceptos como
ontología y clasificación de perfiles. Todos estos conceptos
serán debidamente comentados más adelante.
También ha sido muy ilusionante el hecho de montar
un servidor desde cero, este concepto hasta ahora
prácticamente abstracto para los estudiantes de informática
y en cambio tan importante. Pudiendo ofrecer a unos
clientes una conexión con un servidor para acceder desde
cualquier lugar del mundo en apenas unas centésimas de
segundo a una base de datos, a unos contenidos, a un
programa trabajando en local.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
16
2.2.2.2. Objetivos.
l motivo del proyecto es desarrollar una
herramienta para construir bases de conocimiento
a partir de información en la web. El proyecto ha
de desarrollar una herramienta en JAVA capaz de elaborar
de forma automática los contenidos de una base de
conocimientos.
Para ello, por un lado, usará conjuntos de ejemplos de los
que se extraerán conceptos básicos y sus relaciones, por
otro lado se generará de forma automática una ontología
sobre el dominio de conocimiento a través de búsquedas
inteligentes en documentos web. Finalmente la información
se mostrará en una página web que será un sistema de
recomendación de contenidos de la web, según el perfil del
usuario.
El proyecto hará elaboración automática de una
ontología y su correspondiente base de conocimientos
creada a partir de ejemplos y contenidos informativos
asociados a los mismos en la web 2.0.
Para alcanzar el objetivo del proyecto se han de
conseguir los siguientes objetivos parciales que a su vez son
objeto de las tareas de que consta el proyecto:
E

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
17
• Desarrollar una herramienta de búsqueda en la
web 2.0 sobre términos introducidos bien por un
usuario, bien recibidos de otra aplicación. El
resultado de esta búsqueda será un listado de
contenidos que posteriormente hay que procesar.
Los contenidos serán casos ejemplo que hay que
procesar posteriormente.
• Desarrollar un algoritmo que clasifique y filtre
jerárquicamente los conceptos y términos más
relevantes obtenidos en los contenidos de la
búsqueda inicial.
• Desarrollar una aplicación que organice en una
jerarquía los conceptos y términos obtenidos.
• Adaptación de la ontología al perfil del usuario.
• Desarrollo de una aplicación capaz de hacer crecer
los términos de la ontología de manera automática.
• Elaboración de una base de conocimientos
asociada a la ontología. Integración en un sistema
experto.
• Integración de aplicaciones en un entorno
multiagente capaz de realizar una búsqueda
guiada por el conocimiento extraído y el perfil del
usuario reflejado en la ontología.
• Desarrollo de un servicio web y puesta a punto en
un servidor web particular.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
18
3.3.3.3. Revisión de técnicas y
tecnologías
sta parte de la memoria es la encargada de
introducir al lector en las tecnologías que se van a
emplear durante el desarrollo de esta memoria. De
manera que cuando se expliquen cómo usarlas se pueda
dar por conocidos un conocimiento básico de estas.
El capitulo está dividido en tres sub apartados, que
son conceptos y definiciones básicos, arquitectura y por
último descripción del funcionamiento de tecnologías
empleadas. Los dos primeros apartados se refieren más a
conceptos y técnicas, mientras que el tercero en cambio se
centra en las tecnologías, es decir en cómo son las
herramientas empleadas que implementan estas técnicas o
conceptos.
3.1. Conceptos y definiciones
básicas
Los conceptos básicos que se van a explicar aquí, son
conceptos que seguramente se tenga una vaga idea de ellos
o por lo menos se hayan oído alguna vez, pero no se tenga
E

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
19
muy claro a que se refieren con exactitud. Así que se
comenzara explicando que es y a que se refiere la web
2.0,la web semántica, la inteligencia artificial y alguna de
sus técnicas que se emplearan en este proyecto.
3.1.1. Web2.0.
(1)El término Web 2.0 se estableció como tal entorno
al año 2004, aunque hoy en día se sigue dudando de que
estas webs sean cualitativamente diferentes de las
tecnologías web anteriores. Sin embargo sí que es cierto que
estas webs están asociadas con un fenómeno social, basado
en la interacción que se logra a partir de diferentes
aplicaciones web, que facilitan el compartir información.
Además de la interoperabilidad y el diseño centrado en el
usuario (D.C.U.). Algunos ejemplos de la Web 2.0 serian las
comunidades web en torno a una temática, las wikis, blogs,
los servicios web, las aplicaciones Web, los servicios de
alojamiento de videos, mashups (aplicación web hibrida) y
folksonomías.
El concepto original del contexto, llamado Web 1.0 se
basaba en páginas estáticas programadas en HTML (Hyper
Text Mark Language) que no eran actualizadas
frecuentemente. El éxito de las .com dependía de webs más
dinámicas, a veces llamadas Web 1.5, donde los CMS
(Content Management System en inglés, abreviado CMS)
Sistema de gestión de contenidos servían páginas HTML
dinámicas creadas al vuelo desde una actualizada base de
datos. En ambos sentidos, el conseguir hits (visitas) y la

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
20
estética visual eran considerados como factores
importantes.
Los teóricos de la aproximación a la Web 2.0 creen
que el uso de la web está orientado a la interacción y redes
sociales, que pueden servir contenidos y explotar los efectos
de las redes, creando o no webs interactivas y visuales. Es
decir, los sitios Web 2.0 actúan más como puntos de
encuentro, o webs dependientes de usuarios, que como
webs tradicionales.
Resumiendo se puede decir que un sitio Web 2.0
permite a sus usuarios interactuar con otros usuarios o
cambiar contenidos del sitio web, esto en contraste a sitios
web no-interactivos donde los usuarios se limitan a la
visualización pasiva de información que se les proporciona,
por lo que este tipo de web aumentan y su información
crece de manera descentralizada. Sin que la
responsabilidad de todos los contenidos recaiga sobre un
administrador.
En la ilustración 3.1, se resaltan algunos de los
ejemplos más representativos que la Web 2.0 representa.
Ilustración 3.1.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
21
3.1.2. Web3.0.
(2)La tecnología de la Web 3.0, se basa originalmente
en programas inteligentes que utilizan datos semánticos; se
han ido implementado y usando a pequeña escala en
compañías para conseguir una manipulación de datos más
eficiente. Se considera la realización y extensión del
concepto de la “Web semántica”, apoyándose en la
Inteligencia artificial. Las investigaciones académicas están
dirigidas a desarrollar programas que puedan razonar,
basados en descripciones lógicas y agentes inteligentes.
Dichas aplicaciones, pueden llevar a cabo
razonamientos lógicos utilizando reglas que expresan
relaciones lógicas entre conceptos y datos en la red. La
"Data Web" es el primer paso hacia la completa “Web
Semántica”. En la fase “Data Web”, el objetivo es
principalmente, hacer que los datos estructurados sean
accesibles utilizando un formato de texto conocido como
RDF, que se explicara más detenidamente a continuación.
El escenario de la "Web Semántica" ampliará su alcance en
tanto que los datos estructurados e incluso, lo que
tradicionalmente se ha denominado contenido semi-
estructurado (como páginas web, documentos, etc.), esté
disponible en los formatos semánticos de RDF y OWL.
Muy importante para este proceso de evolución es el
proceso de estandarización que desde el consorcio de la
World Wide Web, se intenta liderar, ya que los formatos en

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
22
que se publica la información en Internet son dispares,
como XML, RDF, OWL y otros micro formatos. No obstante
la apuesta del grupo de la World Wide Web con la creación y
estandarización de la tecnología SPARQL, y su reciente
crecimiento permite un lenguaje estandarizado de acceso a
estos datos. Así el desarrollo de las APIs para la búsqueda
a través de bases de datos en la red también está siendo
muy bien recibido.
Es curioso que se intentaba desde el nacimiento de
Internet incluir información semántica en todas las webs, la
World Wide Web, pero debido a la rápida expansión de
Internet, no se pudo realizar su implementación, ya que las
prisas por tener una web iban contra esta idea. Sin
embargo con el paso de los años y el crecimiento de la web,
se ha hecho necesario volver a pensar en la web semántica
con el fin de poner un poco de control y mejor manejo de la
información. La Web semántica, como se ha comentado se
basa en la idea de añadir metadatos semánticos y
ontológicos a la World Wide Web para que los programas y
sus empresas puedan compartir información estandarizada.
Ilustración 3.2.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
23
Esas informaciones adicionales —que describen el
contenido, el significado y la relación de los datos— se
deben proporcionar de manera formal, para que así sea
posible evaluarlas automáticamente por máquinas de
procesamiento. El objetivo es mejorar Internet ampliando la
interoperabilidad entre los sistemas informáticos usando
"agentes inteligentes".
Se puede ver en la Ilustración 3.3 la conexión entre
las distintas web semánticas a fecha de Julio del 2009. En
este gráfico se puede observar como las distintas webs
trabajan de la mano para ofrecer contenidos de distintos
dominios de manera actualizada.
Ilustración 3.3

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
24
El lenguaje HTML es válido para adecuar el aspecto
visual de un documento e incluir objetos multimedia en el
texto (imágenes, esquemas de diálogo, etc.). Pero ofrece
pocas posibilidades para categorizar los elementos que
configuran el texto más allá de las típicas funciones
estructurales. Para ello la web semántica dispone de
tecnologías de descripción de contenidos, como RDF y OWL,
además de XML, el lenguaje de marcas diseñado para
describir los datos.
-RDF: es un modelo de datos para los recursos y las
relaciones que se puedan establecer entre ellos. Aporta una
semántica básica para ese modelo de datos que puede
representarse mediante XML.
-RDF Schema: es un vocabulario para describir las
propiedades y las clases de los recursos RDF, con una
semántica para establecer jerarquías de generalización
entre dichas propiedades y clases.
-OWL: añade más vocabulario para describir
propiedades y clases: tales como relaciones entre clases
(p.ej. disyunción), cardinalidad (por ejemplo "únicamente
uno"), igualdad, tipologías de propiedades más complejas,
caracterización de propiedades (por ejemplo simetría) o
clases enumeradas.
Estas tecnologías se combinan para aportar
descripciones explícitas de los recursos de la Web (ya sean
estos catálogos, formularios, mapas u otro tipo de objeto
documental). Esas etiquetas permiten que los gestores de
contenidos o los lenguajes de consulta interpreten los

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
25
documentos y realicen procesos inteligentes de captura y
tratamiento de información. SPARQL es el lenguaje de
consulta más empleado.
-SPARQL: es un acrónimo recursivo del inglés
SPARQL Protocol y RDF Query Language. Se trata de un
lenguaje estandarizado para la consulta de grafos RDF.
Únicamente incorpora funciones para la recuperación
sentencias RDF. Es necesario distinguir entre el lenguaje de
consulta y el motor para el almacenamiento y recuperación
de los datos. Por este motivo, existen múltiples
implementaciones de SPARQL, generalmente ligados a
entornos de desarrollo y plataforma tecnológicas.
El desarrollo y difusión masivos de la web semántica
tiene algunas dificultades que no se han podido superar
todavía, una de ellas es tecnológica y la otra está
relacionada con la falta de interés de los propietarios de las
páginas web.
Ilustración 3.4.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
26
La Ilustración 3.4 en la que se observa un gráfico
sencillo e intuitivo puede ayudar a resumir lo citado hasta
ahora. En el primer nivel la web 1.0 donde la máquina hace
de servidor de páginas web estática, en la Web 2.0 los
usuarios tienen iteración entre ellos y con las páginas web,
de manera que estas se rellenan de contenidos
dinámicamente. En la web 3.0 son directamente las
máquinas las que leen estas páginas y en muchos casos
son estas máquinas las que directamente generan otras
páginas.
3.1.3. Técnicas de
Inteligencia Artificial
Con objeto de extraer conocimiento de forma
automática, su posterior representación y su incremento se
van a usar técnicas de Inteligencia Artificial en este
proyecto. Con objeto de tener claros algunos conceptos se
va a proceder a su definición.
-Incremento del conocimiento: Consiste en
desarrollar técnicas que permitan a las computadoras
aprender. De forma más concreta, se trata de crear
programas capaces de generalizar comportamientos. Es, por
lo tanto, un proceso de inducción del conocimiento. En este
caso consistiría básicamente en primer lugar en usar
palabras clave del resultado de una búsqueda para lanzar
otras búsquedas y completar la información de manera
automática, y así sucesivamente.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
27
Agentes inteligentes: Son programas que buscan
información como los trataría una persona. Gozan de
propiedades muy características como la autonomía en la
toma de decisiones, en la relación con otros agentes para
cooperar aun fin común.
-Ontologías: En el área de la inteligencia artificial, la
resolución de problemas puede ser simplificada con la
elección apropiada de una representación del conocimiento.
La ontología se utiliza para la clasificación en bibliotecas y
para procesar conceptos en un sistema de información.
El término ontología en informática hace referencia a
la formulación de un exhaustivo y riguroso esquema
conceptual dentro de uno o varios dominios dados; con la
finalidad de facilitar la comunicación y el intercambio de
información entre diferentes sistemas y entidades (esta es la
diferencia con la ontología filosófica, que solo tiene un
punto de referencia).
En algunas aplicaciones, se combinan varios
esquemas en una estructura de facto completa de datos,
que contiene todas las entidades relevantes y sus relaciones
dentro del dominio. Los programas informáticos pueden
utilizar así este punto de vista de la ontología para una
variedad de propósitos, incluyendo el razonamiento

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
28
inductivo, la clasificación, y una variedad de técnicas de
resolución de problemas.
El desarrollo de una ontología facilitará que el
conocimiento sea incremental, pero para esto se necesitan
usar nuevos conceptos y tecnologías, como el concepto de
ontología. Concepto históricamente reconocido y empleado
desde los griegos hasta nuestros ordenadores más
modernos. Aristóteles ya pensó en la necesidad de crear
una ontología en su época, y la definió como enciclopedia de
las palabras. Y este concepto permite unir las palabras y el
conocimiento, que va encontrando por la web anexándolo a
la ontología, así la ontología va creciendo con todo la
información recogida por las webs con información
semántica.
-Tripletas de conocimiento: Es un modelo de
metadatos basado en el concepto de sentencias de la forma
“sujeto-predicado-objeto”, denominadas tripletas RDF. Este
modelo ofrece una adecuación mayor para la representación
del conocimiento que el modelo relacional de las bases de
datos tradicionales. Se pueden almacenar de diversas
formas, aunque la serialización (marshalling) más habitual
se basa en la utilización de archivos XML.
-Modelo ontológico: Es una representación de la
realidad ontológica de un sistema. En este modelo, basado
en la lógica descriptiva, se definen los conceptos, términos y

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
29
secuencias, así como la relación que existe entre los
distintos términos. La creación de terminología se llevará a
cabo directamente en un sistema basado en un modelo. Es
utilizado para el manejo y representación de ontologías.
Ilustración 3.5.
3.2. Arquitectura
3.2.1. Introducción
a manera de acceder a la información inicial
relativa al usuario era partiendo de las
canciones en local del usuario y obtener sus
artistas favoritos para que sirviese de manera automática
para obtener un perfil de intereses. Como se ha comentado,
poco a poco esta idea fue disolviéndose debido a
complejidad a la hora de procesar datos locales en un
servidor, esto hizo que se planteasen alternativas como que
el usuario rellenase información relativa a su personalidad
y gustos en un cuestionario inicial. Esto condicionó la
arquitectura del proyecto.
L

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
30
Para la arquitectura de esta aplicación se va a usar el
Modelo Vista Controlador (MVC) es un estilo que separa los
datos de una aplicación, la interfaz de usuario, y la lógica
de control en tres componentes distintos. El patrón MVC se
ve frecuentemente en aplicaciones web, donde la vista es la
página HTML y el código provee de datos dinámicos a la
página.
El modelo es el Sistema de Gestión de Base de Datos
y la Lógica de negocio, y el controlador es el responsable de
recibir los eventos de entrada desde la vista. Será revisado a
continuación de manera rápida y útil las diferencias entre
las arquitecturas más básicas. Se va a proceder a explicar
la arquitectura de dos niveles, existente antes del MVC, de
manera que sea más fácil la comprensión de la arquitectura
de tres niveles.
3.2.2. Arquitectura Cliente
Servidor
Esta arquitectura consiste básicamente en que un
programa, el cliente, realiza peticiones a otro programa, el
servidor que les da respuesta. Esto resulta muy ventajoso
en un sistema operativo multiusuario distribuido a través
de una red de computadoras.
En esta arquitectura la capacidad de proceso está
repartida entre los clientes y los servidores, aunque son
más importantes las ventajas de tipo organizativo debidas a
la centralización de la gestión de la información y la

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
31
separación de responsabilidades, lo que facilita y clarifica el
diseño del sistema. La separación entre cliente y servidor es
una separación de tipo lógico, donde el servidor no se
ejecuta necesariamente sobre una sola máquina ni es
necesariamente un sólo programa.
La arquitectura cliente-servidor sustituye a la
arquitectura monolítica en la que no hay distribución, tanto
a nivel físico como a nivel lógico.
Ventajas de la arquitectura cliente-servidor
a.) Centralización del control: los accesos, recursos y
la integridad de los datos son controlados por el servidor de
forma que un programa cliente defectuoso o no autorizado
no pueda dañar el sistema.
b.) Escalabilidad: se puede aumentar la capacidad de
clientes y servidores por separado.
Desventajas de esta arquitectura
a.) La congestión del tráfico: cuando una gran
cantidad de clientes envían peticiones al mismo servidor al
mismo tiempo.
b.) Robustez: Cliente/Servidor no tiene la buena
robustez como red del P2P. Cuando el servidor está caído,
las peticiones de los clientes no pueden ser satisfechas al

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
32
estar todos los datos centralizados como puede
comprobarse en la imagen siguiente hay un único servidor:
Ilustración 3.6
El servidor de cliente es la arquitectura de red que
separa al cliente (a menudo un uso que utiliza un interfaz
utilizador gráfico) de un servidor. Cada caso del software del
cliente puede enviar peticiones a un servidor a través de la
red como se puede observar en el gráfico Ilustración 3.6 .
Los tipos específicos de servidores incluyen los servidores
Web, los servidores del uso, los servidores de archivo, los
servidores terminales, y los servidores del correo. Mientras
que sus propósitos varían algo, la arquitectura básica sigue
siendo igual.
Aunque esta idea se aplica en una variedad de
maneras, en muchas diversas clases de usos, el ejemplo
más fácil de visualizar es el uso actual de las páginas Web
en Internet. Por ejemplo, si se está leyendo una página Web,

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
33
la computadora y Web browser serían considerados un
cliente, y las computadoras, las bases de datos, y los usos
que componen la página Web serían considerados el
servidor.
3.2.3 Arquitectura de tres
niveles
Una vez introducida la arquitectura Cliente/Servidor,
hay que añadir una parte de almacenamiento y gestión de
datos a este modelo y llevarlo al caso que nos atañe, el
modelo Web, En la mayoría de los casos, el navegador suele
ser un mero presentador de información (modelo de cliente
delgado), y no lleva a cabo ningún procesamiento
relacionado con la lógica de negocio.
No obstante, con la utilización de applets, código de
JavaScript y DHTML la mayoría de los sistemas se sitúa en
un punto intermedio entre un modelo de cliente delgado y
un modelo de cliente grueso (donde el cliente realiza el
procesamiento de la información y el servidor solo es
responsable de la administración de datos). Por este motivo
el desarrollo de la capa de cliente se ha concentrado en un
simple visualizador con apenas alguna validación de datos.
Con lo que se ha conseguido un proceso de cliente ligero y
sencillo.
El procesamiento realizado en el cliente está
relacionado con aspectos de la interfaz (como ocultar o
mostrar secciones de la página en función de determinados

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
34
eventos) y nunca con la lógica de negocio. En todos los
sistemas de este tipo y ortogonalmente a cada una de las
capas de despliegue comentadas, se puede dividir la
aplicación en tres áreas o niveles:
-Nivel de presentación: Es el encargado de generar
la interfaz de usuario en función de las acciones llevadas a
cabo por el mismo. (Páginas JSP)
-Nivel de negocio: Contiene toda la lógica que
modela los procesos de negocio y es donde se realiza todo el
procesamiento necesario para atender a las peticiones del
usuario. (Programa JAVA)
-Nivel de administración de datos: Encargado de
hacer persistente toda la información, además suministra y
almacena información para el nivel de negocio. (MySQL)
Los dos primeros y una parte del tercero (el código
encargado de las actualizaciones y consultas) suelen estar
en el servidor mientras que la parte restante del tercer nivel
se sitúa en la base de datos, que aunque es posible que la
base de datos resida en el servidor, se separe en otra capa
lógica.
En la figura Ilustración 3.7 puede verse una
representación aproximada de un sistema en el que la base
de datos se encuentra fuera del servidor:

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
35
Ilustración 3.7.
Respecto al nivel de negocio no hay ninguna “receta”
para asegurar un buen diseño. La aplicación de patrones de
diseño conocidos y el respeto a los principios de
encapsulación de información y distribución de
responsabilidad (que cada objeto haga solo aquello que le
ha sido asignado) es la mejor manera de conseguir un
diseño apropiado.
Un principio que suele resultar de bastante utilidad
es agrupar en servicios las operaciones de negocio
relacionadas. Por ejemplo, en una aplicación de comercio
virtual, se podría tener un servicio para la gestión de
usuarios, otro para la tramitación de pedidos, etc. De esta
manera, si se aplica la estrategia vista anteriormente, los
comandos invocarán uno o más métodos de estos servicios,
que serían los que accederían a los objetos que constituyen
el modelo.
Por último se comentará brevemente el nivel de
administración de datos. Este último nivel es proporcionado
por el framework de persistencia utilizado junto con la base
de datos propiamente dicha. Cada uno tiene unas
características y funcionalidad concretas que obligarán a

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
36
adaptar el diseño de manera apropiada. Solo apuntar que
normalmente, en una aplicación Web una petición http
equivale a una transacción. Es decir, si mientras se sirve la
petición ocurre un error todo lo hecho a raíz de la petición
debe deshacerse.
Por tanto, en función del modelo de persistencia,
habrá que actuar de manera que los cambios en la base de
datos no se hagan definitivos hasta que la petición se haya
completado. La mejor forma de gestionar esto es en el
Servlet controlador, pues al ser el que finaliza la petición
enviando la respuesta al cliente, es el mejor lugar para
asegurar de que todo ha ido bien y hacer definitivos los
cambios en la base de datos.
Con esto se completa el breve análisis de la
arquitectura de los sistemas Web modernos, donde se han
comentado ideas básicas para un diseño lo más correcto
posible de los mismos sobre todo en el nivel o capa de
presentación, que es con el que más se ha trabajado en este
proyecto.
3.3. Descripción funcionamiento de
Tecnologías empleadas
Antes de proceder a explicar cómo se ha realizado
esta implementación, se va a realizar una introducción a las
tecnologías empleadas en el proyecto.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
37
Se comienza con una breve introducción al entorno de
desarrollo Java. Dando por conocidos unos mínimos
básicos de este.
3.3.1 Java
Java es un lenguaje de programación con el que se
puede realizar cualquier tipo de programa. En la actualidad
es un lenguaje muy extendido y cada vez cobra más
importancia tanto en el ámbito de Internet como en la
informática en general. Está desarrollado por la compañía
Sun Microsystems con gran dedicación y siempre enfocado a
cubrir las necesidades tecnológicas más punteras. (5)
Una de las principales características por las que
Java se ha hecho muy famoso es que es un lenguaje
independiente de la plataforma. Eso quiere decir que si se
hace un programa en Java, esté podrá funcionar en
cualquier ordenador del mercado. Es una ventaja
significativa para los desarrolladores de software, pues
antes tenían que hacer un programa para cada sistema
operativo, por ejemplo Windows, Linux, Apple, etc. Esto lo
consigue porque se ha creado una Máquina de Java para
cada sistema que hace de puente entre el sistema operativo
y el programa de Java y posibilita que éste último se
entienda perfectamente.
La independencia de plataforma es una de las razones
por las que Java es interesante para Internet, ya que
muchas personas deben tener acceso con ordenadores
distintos. Pero no se queda ahí, Java está desarrollándose

Jorge Gil Peña
Herramienta para construir bases de conocimiento a partir de información en la web
incluso para distintos tipos de dispositivos además del
ordenador como
para cualquier
Arquitectura
El programa Java será el que implemente toda la
lógica de negocio y procese y almacene el algoritmo de
recomendación de contenidos. Usará el
y sus librerías para los accesos a ficheros en la web con el
formato XML
los cuales la información está asociada a un concepto. Se
trata de información semántica con herencia, y donde la
gran parte de los conceptos están definidos. Para ello hay
que localizar los puntos de información fiables, que se
actualicen fácilmente
Para ello se está trabajando principalmente con
DbPedia (proyecto para la extracción de datos de
para proponer una versión
(proyecto que mantiene servidores con acceso a info
estructurada en relación con la música) y
Jorge Gil Peña Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
incluso para distintos tipos de dispositivos además del
ordenador como teléfonos móviles, agendas y en general
para cualquier dispositivo de información.
Ilustración 3.8
Arquitectura Java
El programa Java será el que implemente toda la
lógica de negocio y procese y almacene el algoritmo de
recomendación de contenidos. Usará el framework
y sus librerías para los accesos a ficheros en la web con el
XML, bien RDF, OWL, N3, o formatos similares, en
los cuales la información está asociada a un concepto. Se
trata de información semántica con herencia, y donde la
gran parte de los conceptos están definidos. Para ello hay
que localizar los puntos de información fiables, que se
actualicen fácilmente y que sean accesibles.
ra ello se está trabajando principalmente con
(proyecto para la extracción de datos de
para proponer una versión Web semántica
(proyecto que mantiene servidores con acceso a info
estructurada en relación con la música) y MusicBrainz
Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
38
incluso para distintos tipos de dispositivos además del
móviles, agendas y en general
El programa Java será el que implemente toda la
lógica de negocio y procese y almacene el algoritmo de
framework de Jena
y sus librerías para los accesos a ficheros en la web con el
, o formatos similares, en
los cuales la información está asociada a un concepto. Se
trata de información semántica con herencia, y donde la
gran parte de los conceptos están definidos. Para ello hay
que localizar los puntos de información fiables, que se
ra ello se está trabajando principalmente con
(proyecto para la extracción de datos de Wikipedia
Web semántica), DbTune
(proyecto que mantiene servidores con acceso a información
MusicBrainz

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
39
(proyecto de la fundación estadounidense sin ánimo de
lucro MetaBrainz, que pretende crear una base de datos
musical de contenido abierto). Pero hay muchos otros
interesantes como se puede observar en el gráfico:
La base de datos esta almacenada y gestionada por
MySql que es un sistema de gestión de bases de datos
relacional, multihilo y multiusuario. Será accedida desde el
código Java gracias al conector especifico (driver o conector
de la JVM para MySql).
3.3.2 Funcionamiento de
Jena
Jena es una librería para Java que se encarga de la
gestión de contenidos de la web semántica. Esta librería se
encarga de conectarse a la web, y leer los ficheros de RDF
que se encuentran en Internet. La información leída con
SPARQL, se puede almacenar en memoria o en disco duro.
Igualmente la información leída se almacena o bien en un
modelo, o en una lista, o en un ResultSet (estructura de
Java) para poder leerlos y tratarlos. En un modelo la
información se almacena en tripletas (o Statements), Esto
permite ir incorporando el conocimiento a un modelo
general de conocimiento, uniendo modelos, incluso los
generados por otras personas o ya establecidos. (4)
Esta herramienta, es muy cómoda a la hora de tratar
con esta información, poder manejarla y filtrarla. Además

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
40
de ser la más completa para usarla con Java, como se ha
analizado anteriormente en el momento en que se
seleccionó.
Jena es un framework Java para la creación de
aplicaciones de la Web Semántica. Proporciona de un
entorno de programación para RDF , RDFS and OWL ,
SPARQL. Proporciona un entorno de programación para
RDF , RDFS y OWL , SPARQL e incluye un motor de
inferencia basado en regla.
Jena es de código abierto y desarrollado a partir del
trabajo con los laboratorios de HP Web Semántica Programa
.
Ilustración 3.9
El Marco de Jena incluye:
• Un API RDF de
• Lectura y escritura de RDF en RDF / XML, N3 y N-
Triples
• Una API de OWL
• En la memoria de almacenamiento y persistente

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
41
• Motor de consulta SPARQL
(5)Funcionamiento de RDF: El Resource Description
Framework (RDF) es un estándar (técnicamente una
recomendación del W3C) para describir los recursos. ¿Qué
es un recurso? Se puede pensar que es algo que se puede
identificar. Usted es un recurso, como es su página de
inicio, este documento, el número uno y la gran ballena
blanca en Moby Dick.
La forma de representar un nodo es con diagramas de
arco para sus propiedades. Un vcard suele ser usado como
la clase que engloba propiedades (prefijo de espacio) y que
une dos recursos. Tómese como ejemplo las personas.
Podría ser así en RDF como se observa en la Ilustración
3.10, donde ser ve como el recurso, John Smith, se muestra
dentro de una elipse y se identifica por un Uniform Resource
Identifier (URI), en este caso "http://.../JohnSmith".
Ilustración 3.10

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
42
Los recursos tienen propiedades. En estos ejemplos
se está interesado en el tipo de propiedades que podrían
aparecer en tarjeta de visita de John Smith. La figura de la
Ilustración 3.10 muestra sólo una propiedad, el nombre
completo de John Smith. Una propiedad es representada
por un arco, etiquetado junto a esta el nombre de la
propiedad. El nombre de una propiedad también es una
URI. (14)
La parte que precede al ':' se llama un prefijo de
espacio y representa un espacio de nombres. La parte que
sigue al ':' se llama un nombre local y representa un
nombre en ese espacio de nombres. Las propiedades son
por lo general referenciadas a un prefijo de espacio
(namespace). En sentido estricto, sin embargo, las
propiedades se identifican mediante una URI completa.
El nsprefix: nombre_local forma es un atajo para el
URI del espacio de nombres concatenados con el
nombre_local. No hay requisito de que la URI de una
propiedad se deba resolver mediante un navegador. Cada
propiedad tiene un valor. En este caso el valor es un literal.
Los literales se muestran en rectángulos.
Jena es una API Java que se puede utilizar para crear
y manipular gráficos RDF. Jena tiene clases de objetos para
representar gráficos, recursos, propiedades y literales. Las
interfaces que representan los recursos, propiedades y
literales son llamados de recursos y literal, respectivamente.
En Jena, una gráfica de una ontología o una parte de ella se

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
43
llama un modelo y está representado por la interfaz de
Model.
El código para crear este gráfico, o modelo, es simple.
Primero se definen las variables, y luego con el método
createDefaultModel (), se genera un modelo vacio. Con la
función createResource genera un recurso incluyéndolo en
la ontología actual, lo mismo seria para generar una
propiedad con la función addProperty.
/ / Algunas definiciones estática personURI String = "http://somewhere/JohnSmith"; estática FullName String = "John Smith"; / Crea un vacío Modelo Modelo = modelo ModelFactory.createDefaultModel (); / / Crear el recurso Recursos JohnSmith = model.createResource (personURI); / / Añade la propiedad johnSmith.addProperty (VCARD.FN, nombre completo);
Es muy importante tener en cuenta antes de
continuar que hay distintas maneras de representar este
conocimiento y esto es debido a la complejidad en poner a
todo el mundo de acuerdo a la hora de serializar. (6)
a) RDF / XML: es una sintaxis, definida por el W3C,
para expresar un grafo RDF como un documento XML. Es
uno de las serializaciones más empleadas.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
44
<rdf:RDF> <rdf:Description rdf:about="http://dbpedia.org/resource/Mana_%28musical_group%29"> <dbpprop:redirect rdf:resource="http://dbpedia.org/resource/Man%C3%A1"/> </rdf:Description> − <rdf:Description rdf:about="http://dbpedia.org/resource/Falta_Amor"> <dbpedia-owl:artist rdf:resource="http://dbpedia.org/resource/Man%C3%A1"/> </rdf:Description>
b) Notation3, N3: es una serialización no XML. Se
basa en la descripción de los recursos de un modelos de
Marco. Diseñado para que los humanos puedan leerlo. N3
es mucho más compacto y fácil de leer que la notación
XML/RDF. Ejemplo:
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:dc="http://purl.org/dc/elements/1.1/"> <rdf:Description rdf:about="http://en.wikipedia.org/wiki/Tony_Benn"> <dc:title>Tony Benn</dc:title> <dc:publisher>Wikipedia</dc:publisher> </rdf:Description> </rdf:RDF>
c) N-Triples: es una línea basada en texto sin formato
para la codificación de un grafo RDF. Fue diseñado para ser
un subconjunto fijo de N3 y por lo tanto las herramientas

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
45
como cwm N3, n-triples2kif.pl y Euler se puede utilizar para
leer y procesar la misma. cwm puede dar salida a este
formato cuando se invoca como "cwm-ntriples". Ejemplo:
<http://www.w3.org/2001/sw/RDFCore/ntriples/> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> ↵ <http://xmlns.com/foaf/0.1/Document> . <http://www.w3.org/2001/sw/RDFCore/ntriples/> <http://purl.org/dc/terms/title> "N-Triples" . <http://www.w3.org/2001/sw/RDFCore/ntriples/> <http://xmlns.com/foaf/0.1/maker> _:art . <http://www.w3.org/2001/sw/RDFCore/ntriples/> <http://xmlns.com/foaf/0.1/maker> _:dave .
d) Turtle/RDF: es un formato de serialización de RDF
(Resource Description Framework) gráficos. Un subconjunto
del formato mínimo de N-Triples. A diferencia de N3
completo, la sintaxis Turtle no va más allá del modelo
gráfico de RDF. El Protocolo SPARQL y RDF Query Language
utiliza un subconjunto N3 similar a el sistema Turtle para
pintar los patrones de su gráfica, pero el uso de llaves N3 es
una sintaxis para delimitar subgrafos. Es uno de los
formatos complejos de leer por un humano. Ejemplo:
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> . @prefix dc: <http://purl.org/dc/elements/1.1/> . @prefix ex: <http://example.org/stuff/1.0/> . <http://www.w3.org/TR/rdf-syntax-grammar> dc:title "RDF/XML Syntax Specification (Revised)" ; ex:editor [ ex:fullname "Dave Beckett"; ex:homePage <http://purl.org/net/dajobe/> ] .

Jorge Gil Peña
Herramienta para construir bases de conocimiento a partir de información en la web
Como se puede confirmar a pesar de las variantes que
existen con respecto a la notación más específica y más
rápida a la hora de procesarse, hay una idea clara en torno
a todas las posibles notaciones, y esa es que cada
básico de conocimiento se r
también conocida como
Aquí puede verse un ejemplo en la
ve como Perú tiene la propiedad capital y se conecta con el
recurso Lima. Por lo tanto
Exactamente lo m
propiedad IS FROM (es de) Perú.
Funcionamiento de OWL
inglés Ontology Web Language
para publicar y compartir datos usan
web 3.0. OWL
marcado construido sobre
Jorge Gil Peña Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
Como se puede confirmar a pesar de las variantes que
existen con respecto a la notación más específica y más
rápida a la hora de procesarse, hay una idea clara en torno
a todas las posibles notaciones, y esa es que cada
de conocimiento se representa con una tripleta,
también conocida como statement en Jena.
Aquí puede verse un ejemplo en la Ilustración
ve como Perú tiene la propiedad capital y se conecta con el
recurso Lima. Por lo tanto se lee "Perú capital Lima".
Exactamente lo mismo ocurre con el Machu Pichu, y la
propiedad IS FROM (es de) Perú.
Funcionamiento de OWL: OWL es el acrónimo
Ontology Web Language, un lenguaje de marcado
para publicar y compartir datos usando ontologías
OWL tiene como objetivo facilitar un modelo de
marcado construido sobre RDF y codificado en XML
Ilustración 3.11
Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
46
Como se puede confirmar a pesar de las variantes que
existen con respecto a la notación más específica y más
rápida a la hora de procesarse, hay una idea clara en torno
a todas las posibles notaciones, y esa es que cada elemento
epresenta con una tripleta,
Ilustración 3.11. Se
ve como Perú tiene la propiedad capital y se conecta con el
se lee "Perú capital Lima".
ismo ocurre con el Machu Pichu, y la
acrónimo del
lenguaje de marcado
ontologías en la
tiene como objetivo facilitar un modelo de
XML.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
47
Tiene como antecedente DAML+OIL, en los cuales se
inspiraron los creadores de OWL para crear el lenguaje.
Junto al entorno RDF y otros componentes, estas
herramientas hacen posible el proyecto de web semántica.
OWL ayuda de manera sencilla a interpretar a una
máquina el contenido Web, con el apoyo de XML, RDF y RDF
Schema (RDF-S). Proporciona un vocabulario adicional junto
con una semántica formal. OWL tiene tres sublenguajes en
función de su nivel de expresividad: OWL Lite, OWL DL y
OWL Full. (4)
Se presenta como alternativa al RDF Schema (RDF-S),
como . lenguaje primitivo de ontologías y proporciona los
elementos básicos para la descripción completa de
vocabularios no solo de los recursos. Diferencia importante.
Ejemplo de dominio las cámaras de fotos, en el que se
puede observar primero las etiquetas establecidas para que
el ordenador reconozca que se trata de una ontología con
formato RDFS. Usa las propiedades de namespace OWL
como se puede observar todas las clases definidas
pertenecen a la ontología de OWL.
<?xml version="1.0" encoding="UTF-8"?> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#" xmlns:owl="http://www.w3.org/2002/07/owl#" xmlns="http://www.xfront.com/owl/ontologies/camera/#" xmlns:camera="http://www.xfront.com/owl/ontologies/camera/#" xml:base="http://www.xfront.com/owl/ontologies/camera/">

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
48
<owl:Ontology rdf:about=""> <rdfs:comment> Camera OWL Ontology Author: Roger L. Costello </rdfs:comment> </owl:Ontology> <owl:Class rdf:ID="Money"> <rdfs:subClassOf rdf:resource="http://www.w3.org/2002/07/owl#Thing"/> </owl:Class> <owl:DatatypeProperty rdf:ID="currency"> <rdfs:domain rdf:resource="#Money"/> <rdfs:range rdf:resource="http://www.w3.org/2001/XMLSchema#string"/> </owl:DatatypeProperty> <owl:Class rdf:ID="Range"> <rdfs:subClassOf rdf:resource="http://www.w3.org/2002/07/owl#Thing"/> </owl:Class> <owl:DatatypeProperty rdf:ID="min"> <rdfs:domain rdf:resource="#Range"/> <rdfs:range rdf:resource="http://www.w3.org/2001/XMLSchema#float"/> </owl:DatatypeProperty> <owl:DatatypeProperty rdf:ID="max"> <rdfs:domain rdf:resource="#Range"/> <rdfs:range rdf:resource="http://www.w3.org/2001/XMLSchema#float"/> </owl:DatatypeProperty>
Funcionamiento de SPARQL: SPARQL es un
lenguaje de consulta y un protocolo de acceso a RDF
diseñado por el W3C.
Como un lenguaje de consulta, SPARQL es "orientado
a datos" en el que sólo se consulta la información contenida
en los modelos, no hay inferencia en el lenguaje de consulta

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
49
en sí. SPARQL no hace otra cosa que tomar la descripción
de lo que la aplicación desea, realiza una consulta y
devuelve esa información, en forma de un conjunto de
enlaces o un gráfico de RDF.
Al igual que sucede con SQL, es necesario distinguir
entre el lenguaje de consulta y el motor para el
almacenamiento y recuperación de los datos. Por este
motivo, existen múltiples implementaciones de esta
tecnología, generalmente ligados a entornos de desarrollo y
plataforma tecnológicas. Un ejemplo de consulta SPARQL
sería, donde de una ontología que se encuentra en la
dirección http://wwww.owl-ontologies.com/unnamed.owl,
se seleccionan las empresas que venden madera.
PREFIX po: <http://wwww.owl-ontologies.com/unnamed.owl> select empresa where { ?empresa po:vende po:madera . }
Como se ha podido observar todas estas tecnologías
tratan con URIs, a las que se accede a recoger información.
Estas son webs semánticas ya que si no, no lee nada la
aplicación. A continuación se va a proceder a la explicación
e introducción a las web semánticas mas empleadas con el
framework de Jena en esta aplicación.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
50
Funcionamiento DbPedia:
es una web orientada hacia las nuevas tecnologías, es
un proyecto de las universidades más innovadoras de
Alemania y la compañía OpenLink Software. El proyecto
DbPedia trata de la extracción automática de datos de
Wikipedia para proponer una versión semántica de está.
Surgió ante la necesidad de ofrecer los contenidos cada vez
mayores, auto crecientes y precisos de la wiki. Se trata de
un proyecto bastante complejo e interesante. (7)
En la base de datos se describen 3.380.000
entidades, entre ellas al menos 312.000 personas, 413.000
lugares, 94.000 álbumes de música y 49.000 películas y
contiene 1.460.000 enlaces a imágenes, 5.543.000 enlaces
a páginas externas, 4.878.000 enlaces a datasets externos y
415.000 categorías Wikipedia.
Se ha seleccionado DbPedia como fuente más fiable y
completa para el desarrollo de este programa, ya que ofrece,
gracias a su apoyo en Wikipedia, una fuente muy amplia y
completa de datos, y un acceso a estos de manera
estandarizada y rápida.
Es interesante que su fuente de acceso información
sea de un dominio tan amplio, como el de la Wikipedia. Ya
que la wiki es una de las web 2.0. de mayor éxito en todo
Internet. Su información pese a su manera de adquirir
conocimiento es completos, e interesante, ya que en ella se
apoya gran parte de nuestra sociedad y el resto del mundo,
y la gran mayoría confía o se apoya para ampliar su
conocimiento o simplemente para saciar su curiosidad. (3)
Jorge Gil Peña
Herramienta para construir bases de conocimiento a partir de información en la web
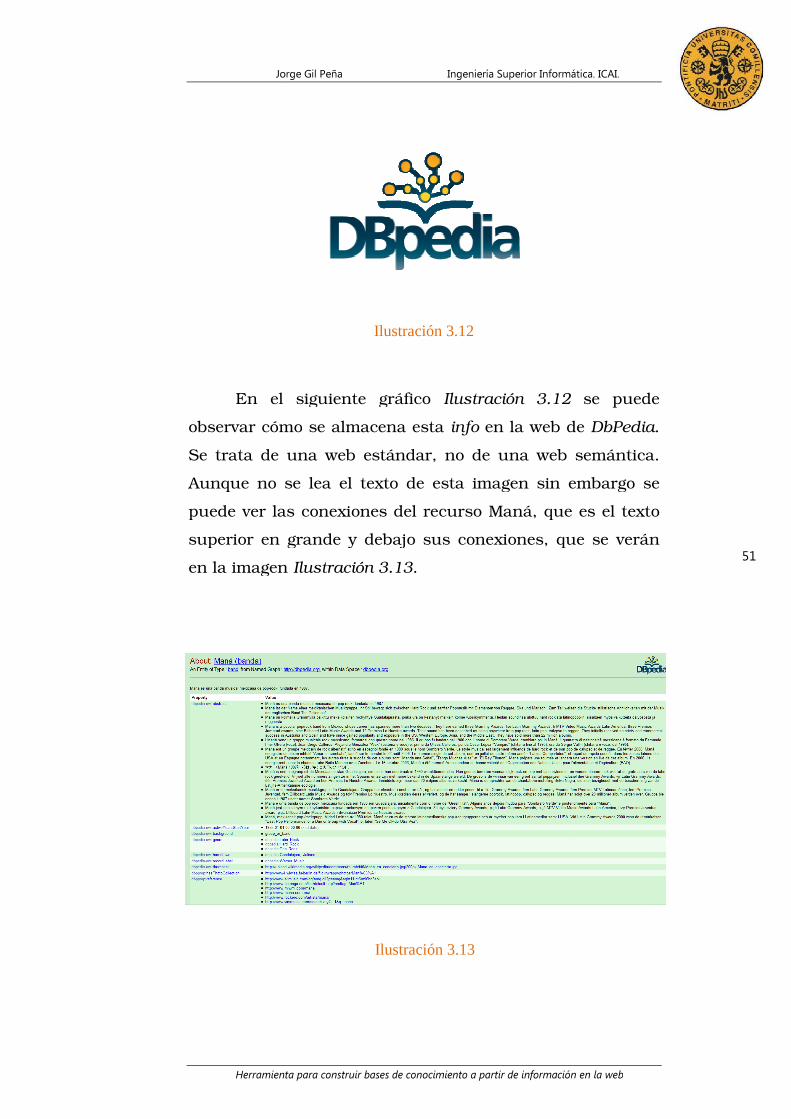
En el siguiente gráfico
observar cómo
Se trata de una web estándar, no de una web semántica.
Aunque no se lea el texto de esta imagen s
puede ver las
superior en grande y debajo sus conexiones, que se
en la imagen
Ilustración 0.1 Ilustración 0.2 Ilustración 0.3
Jorge Gil Peña Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
Ilustración 3.12
En el siguiente gráfico Ilustración 3.12
cómo se almacena esta info en la web de
Se trata de una web estándar, no de una web semántica.
Aunque no se lea el texto de esta imagen sin embargo se
puede ver las conexiones del recurso Maná, que es el texto
superior en grande y debajo sus conexiones, que se
en la imagen Ilustración 3.13.
Ilustración 3.13
Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
51
se puede
en la web de DbPedia.
Se trata de una web estándar, no de una web semántica.
in embargo se
, que es el texto
superior en grande y debajo sus conexiones, que se verán

Jorge Gil Peña
Herramienta para construir bases de conocimiento a partir de información en la web
A la izquierda del
como: el abstract
empezaron o el
derecha cuando es un link se trata de otro recurso (del que
se podría repetir el mismo proceso) y si no de un objeto que
nos aporta una información de esta relación.
ver como continúan las relacione
Jorge Gil Peña Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
A la izquierda del gráfico 3.14 quedan las propiedades
abstract de la banda Maná, el género, el año que
empezaron o el lugar de nacimiento. Lo que queda más a la
derecha cuando es un link se trata de otro recurso (del que
se podría repetir el mismo proceso) y si no de un objeto que
nos aporta una información de esta relación. Aquí se puede
ver como continúan las relaciones de Maná:
Ilustración 3.14
Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
52
quedan las propiedades
de la banda Maná, el género, el año que
lugar de nacimiento. Lo que queda más a la
derecha cuando es un link se trata de otro recurso (del que
se podría repetir el mismo proceso) y si no de un objeto que
Aquí se puede

Jorge Gil Peña
Herramienta para construir bases de conocimiento a partir de información en la web
No obstante este mismo fichero si se intenta leer de la
manera RDF/Turtle
nada. Y es que estos formatos están pensados para que los
lea otra máquina, no los humanos.
Funcionamiento de YAGO
Es una ontología ligera y extensible con alta
cobertura y calidad incorporada en la base de
conocimientos de
durante este proyecto como fuente de conocimiento.
se basa en la
actualmente más de 1 millón
statements. Esto incluye la jerarquía así como las relaciones
no taxonómicas entre las entidades. Los datos han sido
extraídos de forma automática de
WordNet, utilizando una combinación cuidadosamente
diseñada basada en reglas y métodos de heurística
descritos en este documento.
El conocimiento resultante
más allá de
Jorge Gil Peña Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
No obstante este mismo fichero si se intenta leer de la
RDF/Turtle, en la Ilustración 3.15, no se entiende
nada. Y es que estos formatos están pensados para que los
lea otra máquina, no los humanos.
Funcionamiento de YAGO
Es una ontología ligera y extensible con alta
cobertura y calidad incorporada en la base de
conocimientos de DbPedia, así que ha sido empleada
durante este proyecto como fuente de conocimiento.
se basa en las entidades y las relaciones y contiene
actualmente más de 1 millón entidades y 5 millones de
. Esto incluye la jerarquía así como las relaciones
no taxonómicas entre las entidades. Los datos han sido
extraídos de forma automática de Wikipedia y unificado con
, utilizando una combinación cuidadosamente
diseñada basada en reglas y métodos de heurística
descritos en este documento. (9)
El conocimiento resultante es un paso importante
más allá de WordNet: agregando el conocimiento acerca de
Ilustración 3.15
Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
53
No obstante este mismo fichero si se intenta leer de la
, no se entiende
nada. Y es que estos formatos están pensados para que los
Es una ontología ligera y extensible con alta
cobertura y calidad incorporada en la base de
, así que ha sido empleada
durante este proyecto como fuente de conocimiento. YAGO
s entidades y las relaciones y contiene
entidades y 5 millones de
. Esto incluye la jerarquía así como las relaciones
no taxonómicas entre las entidades. Los datos han sido
unificado con
, utilizando una combinación cuidadosamente
diseñada basada en reglas y métodos de heurística
es un paso importante
: agregando el conocimiento acerca de

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
54
los individuos como personas, organizaciones, productos,
etc con sus relaciones semánticas - y en cantidad,
aumentando el número de hechos por más de un orden de
magnitud. YAGO se basa en un modelo limpio, que es
extensible y compatible con RDFS. Es una parte de
conocimiento semántico dentro del proyecto DbPedia muy
importante.
Funcionamiento de MusicBrainz
Es una web social de la web 2.0. en la que se
almacena la información relativa a gran parte de los artistas
medianamente conocidos. Esta web es empleada en la
aplicación para confirmar la existencia de los artistas
introducidos por el usuario. (10)
MusicBrainz almacena información sobre artistas, sus
grabaciones, y la relación entre ellos. Los registros sobre las
grabaciones contienen, al menos, el título del álbum, los
nombres de las pistas, y la longitud de cada una de ellas.
La información es mantenida de acuerdo a una guía de
estilo común. Adicionalmente, las grabaciones almacenadas
pueden incorporar información sobre la fecha y país de
lanzamiento, el ID del CD, una huella acústica de cada
pista y un campo de texto libre o de anotaciones. A día 2 de
julio de 2007 MusicBrainz tenía información sobre 315.366
artistas, 494.248 álbumes, y 5,8 millones de pistas.
En esta web la gente va rellenando información de
sobre los artistas de manera altruista. Esta web contiene

Jorge Gil Peña
Herramienta para construir bases de conocimiento a partir de información en la web
una oferta de programas que rellenan las etiquetas de las
canciones mediante ID3, y sus libre
información se encargan de
formato semántico de manera que
para comprobar su base de datos de artistas.
Los usuarios finales pueden utilizar
comunican con
audio. Desde la propia página
pueden crear y mantener la
los discos de forma que, muy al estilo de la
de datos va mejorando de forma colaborativa.
Muy interesante
innovación
MusicBrainz
recursivo que significa: TRM Reconoce Música) para la
búsqueda de coincidencias mediante el uso de una
digital acústica; un código único generado que permite
identificar cada una de las pistas.
atrajo muchos usuarios y permitió que la base de datos
creciera de forma muy rápida
Jorge Gil Peña Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
una oferta de programas que rellenan las etiquetas de las
mediante ID3, y sus librerías. Además esta
información se encargan de presentar la información
formato semántico de manera que se puede acceder a él,
para comprobar su base de datos de artistas.
Los usuarios finales pueden utilizar programas
comunican con MusicBrainz para etiquetar su ficheros de
. Desde la propia página los usuarios registrados
pueden crear y mantener la información disponible sobre
los discos de forma que, muy al estilo de la web 2.0
de datos va mejorando de forma colaborativa.
Muy interesante a tener en cuenta en este proyecto l
que propusieron inicialmente, y es que
utilizó el algoritmo TRM (un acrónimo
recursivo que significa: TRM Reconoce Música) para la
búsqueda de coincidencias mediante el uso de una
acústica; un código único generado que permite
identificar cada una de las pistas.[4] Esta característica,
chos usuarios y permitió que la base de datos
creciera de forma muy rápida.
Ilustración 3.16
Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
55
una oferta de programas que rellenan las etiquetas de las
rías. Además esta
r la información con
acceder a él,
programas que se
para etiquetar su ficheros de
los usuarios registrados
información disponible sobre
web 2.0, la base
este proyecto la
y es que
utilizó el algoritmo TRM (un acrónimo
recursivo que significa: TRM Reconoce Música) para la
búsqueda de coincidencias mediante el uso de una huella
acústica; un código único generado que permite
Esta característica,
chos usuarios y permitió que la base de datos

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
56
3.3.3 Servidor web
En las arquitecturas explicadas con anterioridad se
ha definido que un servidor es un ordenador al que se
conecta un cliente. Pero ahora la descripción tecnológica se
centrara en la parte Software de un servidor. Un servidor
web es un programa que está diseñado para transferir
hipertextos, páginas web o páginas HTML (HyperText
Markup Language): textos complejos con enlaces, figuras,
formularios, botones y objetos incrustados como
animaciones o reproductores de música. El programa
implementa el protocolo HTTP (HyperText Transfer Protocol)
que pertenece a la capa de aplicación del modelo OSI. El
término también se emplea para referirse al ordenador que
ejecuta el programa.
Estructura de un documento HTML: En un
documento HTML se puede incluir texto, imagen, sonido y
referencias a otros documentos. Para diferenciar las
directivas de HTML (instrucciones) del texto normal, dichas
directivas se encuentran encerradas entre los signos < y >.
Determinadas directivas tienen un inicio y un final. La
directiva final se acompaña del símbolo /. La estructura
básica de un documento HTML tendría las siguientes
directivas:
<HTML> inicio del documento
<HEAD> inicio de la cabecera
<TITLE> inicio del título

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
57
Titulo de la pagina
</TITLE> final del título
</HEAD> final de la cabecera
<BODY> inicio del cuerpo de la página
Texto, gráficos y demás componentes de la página
</BODY> final del cuerpo de la página
</HTML> final del documento
El título de la página será el texto que identificará a la
página, la hoja en sí la se escribirá entre las directivas
<BODY> y </BODY>. Muchas de las directivas de HTML
pueden incluir parámetros. Estos parámetros añaden
opciones especiales a la directiva.
3.3.4. Páginas dinámicas
Las páginas dinámicas son páginas HTML generadas
a partir de lenguajes de programación (scripts) que son
ejecutados en el propio servidor web. A diferencia de otros
scripts, como el JavaScript, que se ejecutan en el propio
navegador del usuario, los 'Server Side' scripts generan un
código HTML desde el propio servidor web.
Este código HTML puede ser modificado -por ejemplo-
en función de una petición realizada por el usuario en una
Base de Datos. Dependiendo de los resultados de la
consulta en la Base de Datos, se generará un código HTML
u otro, mostrando diferentes contenidos.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
58
En la actualidad la mayoría de las páginas Web se
desarrollan mediante la utilización de HTML. Este lenguaje
no es de programación si no, más bien se trata de un
lenguaje descriptivo que tiene como objeto dar formato al
texto y las imágenes que pretenden visualizar en el
navegador.
A partir de este leguaje se puede de introducir
enlaces, seleccionar el tamaño de las fuentes o intercambiar
imágenes, todo esto de una manera prefijada y en ningún
caso inteligente. En efecto, HTML no permite realizar un
simple cálculo matemático o crear una página de la nada de
una base de datos. A decir verdad HTML, aunque muy útil
a pequeña escala, resulta muy limitado a la hora de
concebir grandes sitios o portales.
Es esta deficiencia de HTML la que ha hecho
necesario el empleo de otros lenguajes accesorios mucho
más versátiles y de un aprendizaje relativamente más
complicado, ya que son capaces de responder de manera
inteligente a las demandas del navegador y que permiten
automatización de determinadas tareas tediosas e
irremediables como pueden ser actualizaciones, el
tratamiento de pedidos de una tienda virtual… Estos
leguajes capaces de recrear a partir de ciertos “scripts” un
sinfín de páginas automatizadas son los protagonistas de
este concepto de páginas dinámicas.
Las páginas dinámicas proporcionan beneficios en
muchos aspectos, como por ejemplo en el acceso a datos, ya
que permiten interactuar con la información y mostrarla al
usuario o bien para actualizar su contenido.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
59
Son muchas las aplicaciones de este concepto en los
sistemas de información actuales, por ejemplo, una
empresa que vende sus artículos por Internet debe disponer
de páginas en las que se visualicen los datos de sus
productos, disponibilidad, precio, color, etc. Y almacenar
los pedidos de sus clientes.
Al tratarse de información en continua actualización,
es necesaria la presencia de una base de datos y su
consulta y actualización inmediata, ya que si no podría
crear un gran caos. Las páginas dinámicas pueden ayudar
a gestionar más fácilmente los contenidos de nuestro sitio
Web y también, a interactuar con bases de datos.
Dichas páginas, también proporcionan ayuda en la
administración y captación de personal para actualizar las
páginas Web. Al tener una base de datos, la actualización
de la base de datos requiere de muy poco tiempo ya que la
manipulación de código HTML es mínima. Mediante un
gestor de base de datos se pueden actualizar múltiples
páginas y si se necesita modificar una mayor cantidad de
contenido se puede realizar desde la página del
administrador de la base de datos.
Para poder implantar páginas Web dinámicas, se
requiere poseer distintos elementos. A la hora de trabajar
con páginas Web dinámicas en conjunto con Bases de
Datos, hay que conocer el funcionamiento de los
componentes del sistema. Las tecnologías web con las que
se ha trabajado en el desarrollo de este proyecto para la
implantación de páginas web dinámicas se indican a
continuación:

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
60
JSP: es un acrónimo de Java Server Pages, que en
castellano vendría a decir algo como Páginas de Servidor
Java. Es, pues, una tecnología orientada a crear páginas
web con programación en Java.
Con JSP se pueden crear aplicaciones web que se
ejecuten en variados servidores web, de múltiples
plataformas, ya que Java es en esencia un lenguaje
multiplataforma. Las páginas JSP están compuestas de
código HTML/XML mezclado con etiquetas especiales para
programar scripts de servidor en sintaxis Java. Por tanto,
las JSP se pueden escribir con un editor HTML/XML
habitual.
El motor de las páginas JSP está basado en los
Servlets de Java -programas en Java destinados a
ejecutarse en el servidor-, aunque el número de
desarrolladores que pueden afrontar la programación de
JSP es mucho mayor, dado que resulta mucho más sencillo
aprender que los Servlets. En JSP se crean páginas de
manera parecida a como se crean en ASP o PHP -otras dos
tecnologías de servidor-.
Se generan archivos con extensión .JSP que incluyen,
dentro de la estructura de etiquetas HTML, las sentencias
Java a ejecutar en el servidor. Antes de que sean
funcionales los archivos, el motor JSP lleva a cabo una fase
de traducción de esa página en un Servlet, implementado
en un archivo class (Byte codes de Java). Esta fase de
traducción se lleva a cabo habitualmente cuando se recibe

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
61
la primera solicitud de la página .JSP, aunque existe la
opción de precompilar en código para evitar ese tiempo de
espera la primera vez que un cliente solicita la página.
Las JSP's permiten la utilización de código Java
mediante scripts. Además, es posible utilizar algunas
acciones JSP predefinidas mediante etiquetas. Estas
etiquetas pueden ser enriquecidas mediante la utilización
de Bibliotecas de Etiquetas (TagLibs o Tag Libraries)
externas e incluso personalizadas. Como ha sido el caso al
emplear la librería JSTL, y la de EL con el JSF
implementado.
JSTL y JSF: La librería JSTL es un componente
dentro de la especificación del Java 2 Enterprise Edition
(J2EE) y es controlada por Sun MicroSystems. JSTL no es
más que un conjunto de librerías de etiquetas simples y
estándares que encapsulan la funcionalidad principal que
es usada comúnmente para escribir páginas JSP. Las
etiquetas JSTL están organizadas en 4 librerías:
• core: Comprende las funciones script básicas como
loops, condicionales, y entrada/salida.
• xml: Comprende el procesamiento de xml
• fmt: Comprende la internacionalización y formato
de valores como de moneda y fechas.
• sql: Comprende el acceso a base de datos.
• Los Servlets, son objetos que corren dentro del
contexto de un contenedor de Servlets en este
caso Tomcat y extienden su funcionalidad de

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
62
manera que conectan el código Java con los
servicios web.
(11)
Servlets: es un objeto que se ejecuta en un servidor o
contenedor JEE, especialmente diseñado para ofrecer
contenido dinámico desde un servidor web, generalmente
HTML. Otras opciones que permiten generar contenido
dinámico son los lenguajes ASP, PHP, JSP (un caso especial
de Servlet), Ruby y Python. Forman parte de JEE (Java
Enterprise Edition), que es una ampliación de JSE (Java
Standard Edition).
Un Servlets implementa la interfaz
javax.servlet.Servlet o hereda alguna de las clases más
convenientes para un protocolo específico (ej:
javax.servlet.HttpServlet). Al implementar esta interfaz el
servlet es capaz de interpretar los objetos de tipo
HttpServletRequest y HttpServletResponse quienes
contienen la información de la página que invocó al Servlet.
JavaScript: La diferencia de esta tecnología con el
HTML o el JSP estriba en que en el JavaScript el servidor
proporciona el código de las aplicaciones al cliente y éste,
mediante el navegador las ejecuta en local. Es necesario,
por tanto, que el cliente disponga de un navegador con
capacidad para ejecutar aplicaciones (también llamadas
scripts). Comúnmente, los navegadores permiten ejecutar
aplicaciones escritas en lenguaje JavaScript y java, aunque
pueden añadirse más lenguajes mediante el uso de Plugins.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
63
JavaScript es un lenguaje de programación utilizado
para crear pequeños programas encargados de realizar
acciones dentro del ámbito de una página Web. Con
JavaScript se pueden crear efectos especiales en las páginas
y definir interactividades con el usuario. El navegador del
cliente es el encargado de interpretar las instrucciones Java
Script y ejecutarlas para realizar estos efectos e
interactividades, de modo que el mayor recurso, y tal vez el
único, con que cuenta este lenguaje es el propio navegador
en el que se ejecuta.
JavaScript es el siguiente paso, después del HTML,
que puede dar un programador de la Web que decida
mejorar sus páginas y la potencia de sus proyectos. Es un
lenguaje de programación bastante sencillo y pensado para
hacer las cosas con rapidez, a veces con ligereza. Incluso
las personas que no tengan una experiencia previa en la
programación podrán aprender este lenguaje con facilidad y
utilizarlo en toda su potencia con sólo un poco de práctica.
Entre las acciones típicas que se pueden realizar en
JavaScript hay dos vertientes. Por un lado los efectos
especiales sobre páginas Web, para crear contenidos
dinámicos y elementos de la página que tengan movimiento,
cambien de color o cualquier otro dinamismo. Por el otro,
nos permite ejecutar instrucciones como respuesta a las
acciones del usuario, con lo que se pueden crear páginas
interactivas con programas como calculadoras, agendas, o
tablas de cálculo.
JavaScript es un lenguaje con muchas
posibilidades, permite la programación de pequeños scripts,

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
64
pero también de programas más grandes, orientados a
objetos, con funciones, estructuras de datos complejas, etc.
Toda esta potencia de JavaScript se pone a disposición del
programador, que se convierte en el verdadero dueño y
controlador de cada cosa que ocurre en la página.
Ilustración 3.17
3.3.5 Sistema Gestor de
base de datos
Los sistemas de gestión de base de datos son un tipo
de software muy específico, dedicado a servir de interfaz
entre la base de datos, el usuario y las aplicaciones que la
utilizan. En este caso se ha empleado MySQL, como opción
más rentable y fiable para la gestión de base de datos.
MySQL: es un sistema de gestión de base de datos
relacional, multihilo y multiusuario, de código libre. De
hecho MySQL es la base de datos open source más popular
y, posiblemente, mejor del mundo. Su continuo desarrollo y
su creciente popularidad está haciendo de MySQL un

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
65
competidor cada vez más directo de gigantes en la materia
de las bases de datos como Oracle. (12)
Ilustración 3.18
Es un sistema de administración de bases de datos
(Database Management System, DBMS) para bases de datos
relacionales. Así, no es más que una aplicación que permite
gestionar archivos llamados de bases de datos. Su
popularidad como aplicación web está muy ligada a PHP,
que a menudo aparece en combinación con MySQL. En
aplicaciones web ofrece un entorno de intensiva lectura de
datos, lo que hace a MySQL ideal para este tipo de
aplicaciones

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
66
4.4.4.4. Análisis de la aplicación
4.1. Introducción
sta parte de la memoria se encarga de
comentar el análisis realizado para llevar a
cabo la aplicación. Como se ha comentado
anteriormente esta fase fue corta ya que había una
necesidad de elegir rápido las tecnología con el fin de
empezar a probarlas y ponerse en sintonía con el desarrollo
que ellas implicaban. Además algunas características eran
requisitos del sistema.
4.2. Análisis de alternativas
Desde el comienzo de este proyecto se ha tenido muy
en cuenta el reto tecnológico que conlleva. Así que se sabía
que para el desarrollo de este software era muy importante
la fase de aprendizaje de las tecnologías empleadas.
Como ya se ha comentado anteriormente ha sido una
de las mayores motivaciones, ya que estas tecnologías al
encontrarse en continuo desarrollo no se encontraban del
todo bien documentadas y se tenían muchas dudas en
torno a ellas. Esta circunstancia ha hecho que una de las
etapas más importantes de este proyecto haya sido el
E

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
67
conocimiento y aprendizaje de estas tecnologías, y no solo
de ellas si no de los conceptos que implementan, como los
que se han introducido ya de web 2.0., web 3.0. u ontología.
La curva de aprendizaje ha sido algo larga, pero ha
permitido ir asentando esos conocimientos que se han
nombrado.
Este temor y respeto hizo acelerar la fase de análisis
deseando pasar rápidamente al aprendizaje de las
cuestiones en materia. Tras un pequeño análisis, que no se
quiso alargar mucho, se llego a una serie de propuestas de
desarrollo.
Entorno de trabajo
La mejor solución que se concluyó fue basar todo el
desarrollo en la plataforma Java. Este lenguaje de
programación ofrecía la independencia de la plataforma en
la que fuese a ser desarrollo, su amplio reconocimiento y
su gratuicidad ya que es una fuente abierta. Una vez
tomada esta decisión. Se seleccionó como entorno de
programación Eclipse, que es uno de los programas más
usados junto con NetBeans para el desarrollo de programas
en Java, sin embargo se seleccionó Eclipse por su amplitud
del numero de plugins, que facilitaban el trabajo.
Una vez decidido el entorno de trabajo había que
seleccionar qué herramienta emplear para recoger la
información de la web y del conjunto de ejemplos, para
obtener conocimiento, y por otro que ayudara a generar de
forma automática una ontología sobre el dominio de

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
68
conocimiento a través de búsquedas inteligentes que se
realizarían en documentos web.
Herramientas ontológicas
Existían varias opciones para el manejo de la
ontología y su recogida de datos de la web semántica. La
opciones más interesantes analizadas fueron:
• Jena (http://jena.sourceforge.net/es,) la
herramienta más ampliamente utilizada en el
momento, y depende en gran medida de las
normas de la comunidad (OWL, SPARQL, etc.)
Orientada al marco de desarrollo para la Web
Semántica.
• KOAN (http://kaon.semanticweb.org/), tal vez
puede ser utilizado de una forma más reducida de
la moda, pero se aparta de las normas con un
lenguaje propietario y extensiones.
• Sesame (http://www.openrdf.org/), comparable a
Jena a menos que se esté interesado en comparar
la eficacia a gran escala de recuperación, o si se
necesita apoyo OWL.
• JRDF (jrdf.sourceforge.net), supuestamente
mezcla varios de los marcos de RDF, menos
potente y en vías de desarrollo.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
69
• Protégé (protege.stanford.edu), para el entorno de
desarrollo de ontologías pero no tan orientada a la
Web Semántica.
Tras este análisis finalmente se decidió por Jena que
parecía la más robusta, estable y completa de las
herramientas vistas.
Definición del proceso principal
Inicialmente el código estaba pensado como una
aplicación capaz de recibir la información de manera
automática sin que el usuario tuviese que escribirla a
mano, dando una mayor comodidad al usuario y dotando al
programa de mayores automatismos. Se estuvo probando
inicialmente la manera en que el usuario introdujese la ruta
de sus canciones favoritas en su disco duro y la aplicación
recorriese esta ruta en busca de todos sus mp3, y fuese
leyendo sus artistas y canciones.
Esto se realizaba con la librería de ID3 para Java. La
verdad es que el funcionamiento era muy aceptable y las
ventajas de no tener que hacer al usuario introducir sus
datos a mano parecía bastante ventajoso.
Sin embargo según se fue desarrollando el proyecto
se cayó en la cuenta de que ante una necesidad imperiosa
de que el programa funcionase con internet, era mejor que
se tratase de un programa web. Tras varias pruebas del

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
70
sistema para incorporar este código en un cliente web con
los ya caídos en desuso applets, fue dejado de lado. Los
problemas que generaba el entrar en un ordenador en local,
y las desconfianzas que generaría al futuro usuario eran
desventajas insalvables.
Tras estos devaneos con los applets se comenzó a
considerar muy interesante el desarrollo de una encuesta o
test de favoritos, de manera que el usuario pudiese definir
sus intereses de manera rápida y segura, además de
disponer la aplicación de una fuente de conocimiento del
usuario más completa que tratándose de música
simplemente.
Análisis de web semánticas
Luego hubo que decidir de qué webs se iba tomar la
información semántica que rellenaría la ontología. A pesar
de haber una gran oferta, ésta era no obstante, bastante
dispersa y poco estandarizada (pese al esfuerzo de muchos).
Tras diversos estudios de varias, la más completa y
accesible resultó ser DbPedia. Una web en la que el
contenido de la Wikipedia, era pasado a formato semántico
empleando la tecnología RDF.
También se emplea actualmente MusicBrainz, con un
dominio más reducido, que es el de la música y los artistas
que se usa para confirmar el nombre de los artistas
introducidos por los usuarios.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
71
Se emplea también contenidos en YAGO, que es una
librería almacenada por DbPedia pero clasifica los
conceptos de la Wikipedia usando el conocimiento
distribuido por WordNet. Freebase es otro proyecto, no
lúdico pero similar al de DbPedia, con el cual se estuvo
trabajando en este proyecto también, pero presentaba un
problema a la hora de mostrar el titulo de sus conceptos y
direcciones.
Por consiguiente los proyectos que ofrecen contenidos
semánticos y que se emplean en este proyecto son:
• DbPedia
• MusicBrainz
• YAGO
Las otras web de la "nube semántica", como
Jammeddo, BBC Net,... han sido tenidas en cuenta pero
debido a distintas circunstancias no se ha llevado a cabo
una implementación concreta para el acceso a su
información semántica.
Tecnologías de desarrollo
El resto de las decisiones con respecto a la tecnología
web han estado muy condicionadas a la decisión de
emplear la tecnología Java. Por lo que el análisis resultó
bastante sencillo, ya que eran las soluciones propuestas por
Java para ese tipo de situaciones prácticamente la única

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
72
solución. Estas casi por estándar seria el empleo de los
Servlets, los JSP, las librerías JSTL,...
Siguiendo con la coherencia de todo el proyecto se
buscó tanto soluciones gratuitas como completas y
establecidas en el mercado, tal como MySql para Sistema
Gestor de Base de Datos y Tomcat como servidor web.
Todas estas tecnologías serán explicadas con mayor
detenimiento más adelante.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
73
5.5.5.5. Diseño y desarrollo de la
aplicación myWeb
5.1. Introducción
ntes de contar como se realizo la
implementación es importante conocer el
diseño de este servicio web. Además se
aprovechar este capítulo para recalcar como se definieron y
diseñaron otros aspectos de este proyecto y en que tareas se
dividieron. Sin mayor dilatación se va a proceder a explicar
el diseño de este complejo servicio.
5.2. Diseño
Para el proceso de diseño del sistema se han
empleado los diagramas de comportamiento ya que
enfatizan en lo que debe suceder en el sistema modelado. Y
en función de lo que debe hacer la aplicación se desarrolla
la estructura y la iteración de datos. Para visualizar,
especificar, construir y documentar este sistema se ha
empleado el Modelo de Casos de Uso.
A

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
74
5.2.1. Modelo de
Casos de Uso
Diagrama de Casos de Uso
Se usa el caso de uso como técnica para la captura de
requisitos potenciales de un nuevo sistema. Cada caso de
uso proporciona uno o más escenarios que indican cómo
debería interactuar el sistema con el usuario o con otro
sistema para conseguir un objetivo específico. Se usa un
lenguaje más cercano al usuario final de manera que sea
más fácilmente comprensible.
Un usuario puede en principio darse de alta o hacer el
Login accediendo a sus recomendaciones. Si se está dando
de alta rellena un cuestionario, y busca sus
recomendaciones. El usuario podrá cambiar sus favoritos, y
buscar más recursos. También podrá seleccionar un
recurso si le parece interesante
En este proyecto tan solo interactúa con un actor,
que es el usuario, que es el que genera todos los
escenarios posibles. Como se h podido comprobar en l
ilustración el usuario comienza o bien dándose de alta o
bien registrándose.

Jorge Gil Peña
Herramienta para construir bases de conocimiento a partir de información en la web
A partir de ahí tiene las distintas opciones, que
serán, además de los anteriores, los casos de uso del
sistema:
• Ver recomendaciones
• Buscar recurso
• Seleccionar recurso
• Cambiar favoritos
• Salir
Jorge Gil Peña Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
A partir de ahí tiene las distintas opciones, que
demás de los anteriores, los casos de uso del
Ver recomendaciones
Buscar recurso
Seleccionar recurso
Cambiar favoritos
Salir
Ilustración 5.1
Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
75
A partir de ahí tiene las distintas opciones, que
demás de los anteriores, los casos de uso del

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
76
Descripción de Casos de Uso
a.) Login
Nombre: Login
Objetivo: El objetivo del Login es que el usuario pueda volver a la
aplicación una vez se haya registrado. Permitiéndole volver a ver sus
recomendaciones.
Actor: Usuario
Precondiciones:
-El usuario debe estar dado de alto en la base de datos.
-El alumno debe autenticarse
Trigger:
-Desde la web, el botón Login
Escenario primario:
1. El usuario introduce contraseña y usuario
2. El usuario pulsa Login
3. El usuario ve sus recomendaciones
Extensiones:
Descripción de datos:
b.) darseAlta
Nombre: Darse de alta
Objetivo: Cuando el usuario va a darse de alta, registrándose por
primera vez, tiene que almacenar el sistema su información y registrarle.
Actor: Usuario
Precondiciones:
-El usuario debe acceder a la web.
Trigger:
-Desde la web, el botón de darse de alta

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
77
Escenario primario:
1. El usuario pulsa darse de alta
2. EL usuario introduce contraseña y usuario
3. El usuario rellena la encuesta con sus favoritos
4. El usuario pulsa recomendar
5. El usuario ve sus recomendaciones
Extensiones:
Descripción de datos:
c.) verRecomendaciones
Nombre: verRecomendaciones
Objetivo: cuando el usuario quiere ver sus recomendaciones tiene
que tener la opción tras registrarse de volver a ver sus recomendaciones.
Actor: Usuario
Precondiciones:
-El usuario debe estar dado de alto en la base de datos.
-El alumno debe autenticarse
Trigger:
-Desde la web, el botón Login o darse de alta
Escenario primario:
1. El usuario ve sus recomendaciones
2. El usuario selecciona alguna recomendación
3. El usuario va a cambiar sus favoritos
4. El usuario realiza una búsqueda
Extensiones:
Descripción de datos:

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
78
d.) buscarRecurso
Nombre: buscar un nuevo recurso
Objetivo: cuando el usuario quiere añadir en sus recomendaciones
una nueva búsqueda tiene que poder añadir nuevas búsquedas tras
registrase, con el fin de que siga creciendo su ontología.
Actor: Usuario
Precondiciones:
-El usuario debe estar dado de alta en la base de datos.
-El alumno debe autenticarse
Trigger:
-Desde la web en el botón buscar
Escenario primario:
1. El usuario ve sus recomendaciones
2. El usuario selecciona buscar alguna nueva recomendación
Extensiones:
Descripción de datos:
e.) seleccionarRecurso
Nombre: buscar un nuevo recurso
Objetivo: cuando el usuario le interesa una recomendación y
accede a ella, y la aplicación debe tener en cuenta que al usuario le
interesa.
Actor: Usuario
Precondiciones:
-El usuario debe estar viendo las recomendaciones
Trigger:

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
79
-Desde la web en el botón del recurso
Escenario primario:
1. El usuario ve sus recomendaciones
2. El usuario selecciona una recomendación
Extensiones:
Descripción de datos:
f.) salir
Nombre: salir del programa/página
Objetivo: cuando el usuario quiere salir del programa se tiene que
realizar una desconexión del usuario, eliminando las variables de sesión.
Actor: Usuario
Precondiciones:
-El alumno debe estar autenticado
Trigger:
-Desde la web en el botón salir o cerrando la ventana
Escenario primario:
1. El usuario sale
2. Se almacenan la información del usuario y sus cambios
Extensiones:
Descripción de datos:

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
80
5.2.1. Modelo de Dominio
En el modelo de dominio según la profundidad de este
se emplean dos diagramas, el diagrama de paquetes y el de
clases. En el diagrama de paquetes se muestra cómo se
organiza la estructura del software de la aplicación.
Muestra cómo un sistema está dividido en agrupaciones
lógicas mostrando las dependencias entre esas
agrupaciones.
Ilustración 5.2
Se puede observar el siguiente diagrama para
representar la estructura de algunos elementos con
herencia en esta aplicación dentro de los paquetes
representados con anterioridad.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
81
Ilustración 5.3
Para representar un poco más a bajo nivel se emplea
el diagrama de clases, que muestra la lógica del sistema en
su iteración con el usuario., pero no deja de ser un
diagrama de estructura.
Se puede observar que clases llaman a cuales, como
se conectan entre ellas. No se trata de un diagrama
completo pero si de uno bastante aproximado. Se pueden
observar las flechas que están sueltas que son las llamadas
por las que el usuario puede acceder a la aplicación,
concretamente Login (cuando ya está dado de alta) y Darse
de alta. Estas dos clases se trata de clases que heredan de
HTTP Servlet, que significa que son Servlets, por eso se ha
representado como clases simples.

Jorge Gil Peña
Herramienta para construir bases de conocimiento a partir de información en la web
Aquí en la figura 5.3. vemos
de clases de la aplicación
Diagramas de Interacción
diagramas de
fijan en la iteración de las clases,
de control y de datos entre los elementos del sistema
modelado
Jorge Gil Peña Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
Aquí en la figura 5.3. vemos como queda el diagrama
de clases de la aplicación:
Ilustración 5.4
Diagramas de Interacción son un subtipo de
diagramas del lenguaje UML. Estos como dice su nombre se
fijan en la iteración de las clases, enfatizando sobre el flujo
de control y de datos entre los elementos del sistema
Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
82
el diagrama
son un subtipo de
l lenguaje UML. Estos como dice su nombre se
sobre el flujo
de control y de datos entre los elementos del sistema

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
83
Diagrama de flujo
A continuación se muestran una serie de diagramas
de flujo, para representar el funcionamiento de la lógica de
las clases Java, se centra en el algoritmo, que ha sido el
proceso más complejo de desarrollar.
Jenate es la clase principal. Desde la que se ejecuta el
código del algoritmo y controla la lógica de recomendación
de contenidos. Su función main es la que recibe los Strings
introducidos por el usuario y acaba generando un objeto
Map de claves-valor. en el que se encuentran los recursos
ya filtrados que resultaran interesantes. Luego una vez
conocidos estos se procede a clasificarlos según el tipo de
recurso y a enviarlos en forma de array o almacenarlos,
según el caso de uso.
En la primera imagen, que es la Ilustración 8.1., se ve
cómo funciona la aplicación a la hora de buscar un recurso
y como los llega a listar. Jenate le solicita a DbPedia que le
de la url del recurso pedido por el usuario y un vez la tiene
va a su búsqueda en la web, obteniendo sus objetos hijo de
la consulta realizada en DAO_Sparql. Está devuelve un
modelo de los objetos hijo y se recorre y trata con
listResources, para poder incorporarla a la ontología del
usuario.

Jorge Gil Peña
Herramienta para construir bases de conocimiento a partir de información en la web
En el
envío a la base de datos,
representa y
sale la flecha y que pertenece a la clase destino, que será la
encargada de ejecutarla. No se
recibidos ni los devueltos
legibilidad.
Ilustración 5.
Jorge Gil Peña Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
En el diagrama se ve como realiza desde
a la base de datos, MySQL..Y en los arcos se
representa y transcribe la función que se llama desde la que
sale la flecha y que pertenece a la clase destino, que será la
gada de ejecutarla. No se transcriben los tipos
recibidos ni los devueltos para obtener una mejor
Ilustración 5.5 Ilustración 5.6
Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
84
se ve como realiza desde Jenate el
Y en los arcos se
la función que se llama desde la que
sale la flecha y que pertenece a la clase destino, que será la
transcriben los tipos
para obtener una mejor
.6

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
85
Diseño de la base de datos:
Se ha empleado un diseño de base datos sencillo
como se puede observar en el esquema Ilustración. El
diseño de la base de datos c está formado por tres tablas:
• user
• user_resources
• resource
Como se puede observar en la Ilustración 5.7. las tres
tablas están conectadas entre si, ya que un usuario tiene
unos recursos y estos recursos a su vez tienen unas
propiedades.
Ilustración5.7

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
86
Como se puede observar en user se almacena el
nombre tras verificar que no exista con anterioridad, la
dirección de coreo electrónico sin verificación y se solicita
de manera opcional así que es campo no clave y la
password. La de resource almacena la info básica de un
recurso para poder mostrarlo sin tener que acceder a
Internet.
La de user-resource guarda la información básica
para poder almacenar y relacionar al usuario con sus
recomendaciones, de manera que no se generen campos
repetidos. De ahí que se usen los campos clave de user y
resource y el valor de esta conexión.
Como se ha comentado anteriormente es un diseño
muy sencillo, pero eficiente. Permite recuperar la info de la
ontología de manera rápida. En casi de que el usuario
quiera añadir más favoritos, a la hora de leer de la base de
datos se combina con la ontología con la base de datos y se
tiene la ontología con los pesos de nuevo. y sin embargo si
solo se quieren ver los recursos se recupera muy
sencillamente leyendo de la base de datos los recursos
asociados al usuario.
5.3. Tareas desarrolladas en el
proyecto
La formulación del proyecto ha sido el proceso más
complejo. No tanto la implementación en sí, la cual se verá
en el próximo capítulo con ejemplos de programación. Este

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
87
capítulo se centra en las tareas desarrolladas para definir el
proyecto que han sido los siguientes:
• Estudio psicológico conexiones musicales con
forma de ser
• Diseño de myWeb
• Análisis de posibles entradas al programa
• Utilización de la herramienta JENA.
• Realización del algoritmo con Java.
• Convertir el proyecto en web
• Preparación del entorno web
5.3.1. Estudio psicológico de
conexiones musicales
Se ha llevado a cabo una búsqueda e investigación a
través de la web, para intentar conocer las relaciones entre
los gustos musicales y la forma de ser de la persona de
manera que se pueda establecer unas relaciones entre la
música que escuchan y su forma de ser. Era una de las
ideas principales de este programa, poco a poco, ha ido
perdiendo fuerza, según se ha ido desarrollando el test. Sin
embargo no deja de ser un factor más, sobre el que se ha
estado investigando y sobre el que recae cierto peso en el
algoritmo desarrollado.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
88
Hay muchos estudios que confirman la estrecha
relación entre la música que escucha el usuario y como se
relaciona con la gente que le rodea. Estos estudios llegan a
decir que se puede saber sus intereses y es que la música
que uno escucha dice mucho de sí mismo. (15)
Sobre todo ha sido muy útil un estudio de la
universidad de Cambridge titulado "You are what you listen
to" (13). Los investigadores encontraron que esto existía en
el 77% de los casos, y que la gente acordó firmes posiciones
respecto de los tipos de personas que les gusta la música
clásica, rock y rap. Los perfiles de cada género fueron
consistentes y están fuertemente diferenciados entre sí, lo
que sugiere que los estereotipos están a la vez clara y
firmemente en manos de muchos temas.
Los aficionados al jazz, por ejemplo, eran vistos como
gente amable y emocionalmente estable, con un sentido
limitado de la responsabilidad. Los fans del Rap eran vistos
de una manera más hostil, pero también más enérgicos y
atléticos. La música clásica estaba vinculada a personas
blancas, de clase alta y el rap a la gente negra o mezclado,
de orígenes de clase baja. Los seis estilos se consideraron
asociables con la gente de clase media.
5.3.2. Diseño de myWeb
El diseño de myWeb ha sido realizado utilizando el
programa Adobe DreamWeaver para su desarrollo e
implementación. Usa la tecnología de CSS para separar la

Jorge Gil Peña
Herramienta para construir bases de conocimiento a partir de información en la web
parte gráfica de la
este caso. Sin embargo se realizó
luego se pasó
tratándose de una página web
El diseño del logotipo es el
se ve tanto un
logotipo lleva la M y la W, jugando con las dos primeras
palabras del servicio. Se ha empleado el n
de un servicio dinámico y de entretenimiento como color
que trasmite viveza y
El diseño de
Y ha ido variando y evolucionando con el tiempo. Se
dispone de un
parecido a la Ilustración 5.
variaciones con el desarrollo de la aplicación.
En esta imagen se
usuario, y puede ver su
películas, libros,...
Existe una idea reflejada en este mapa web, todavía no
Jorge Gil Peña Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
parte gráfica de la parte de estructura definida en el JSP, en
ste caso. Sin embargo se realizó originalmente en HTML y
ó a JSP con el fin de poder usar ese diseño pero
de una página web dinámica.
El diseño del logotipo es el de la Ilustración 5.
nto un símbolo como el nombre del servicio. El
logotipo lleva la M y la W, jugando con las dos primeras
palabras del servicio. Se ha empleado el naranja al tratarse
de un servicio dinámico y de entretenimiento como color
que trasmite viveza y alegría.
Ilustración 5.8
El diseño de la web ha sido un proceso muy evolutivo.
Y ha ido variando y evolucionando con el tiempo. Se
dispone de un mapa web del sitio, que quedaría algo
la Ilustración 5.9. aunque ha sufirdo algunas
variaciones con el desarrollo de la aplicación.
esta imagen se ve como a la web se accede por el
usuario, y puede ver sus recursos recomendados:
, libros,...y llegar a ver los recursos seleccionados.
una idea reflejada en este mapa web, todavía no
Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
89
parte de estructura definida en el JSP, en
originalmente en HTML y
con el fin de poder usar ese diseño pero
de la Ilustración 5.8, en el
como el nombre del servicio. El
logotipo lleva la M y la W, jugando con las dos primeras
ranja al tratarse
de un servicio dinámico y de entretenimiento como color
a web ha sido un proceso muy evolutivo.
Y ha ido variando y evolucionando con el tiempo. Se
que quedaría algo
aunque ha sufirdo algunas
ve como a la web se accede por el
: música,
a ver los recursos seleccionados.
una idea reflejada en este mapa web, todavía no

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
90
implementada, y es el acceso desde el inicio a los recursos
mejor valorados y más recomendados a todos los usuarios,
que se podrían ver desde la página principal sin darse de
alta, pulsando en los links a música, libros, sitios,
películas, ...
Como herramienta de comunicación y discusión del
diseño se han empleado los wireframe. El de la página
principal seria tal como se puede observar en la Ilustración
5.10 muy sencillo. Se trata de una página en la que se
puede dar de alta o acceder a nuestra cuenta en la esquina
derecha. Y en la parte inferior los distintos módulos a los
que se pueden acceder y el logo en la parte superior.
Ilustración 5..9

Jorge Gil Peña
Herramienta para construir bases de conocimiento a partir de información en la web
El diseño
queda como se puede observar en l
Con un fondo gris oscuro y
una capa na
recurso.
Jorge Gil Peña Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
Ilustración 5.10
El diseño de la página principal de recomendaciones,
queda como se puede observar en la figura Ilustración 5.
Con un fondo gris oscuro y los recursos se diferencian en
aranja sobre una capa gris según el tipo de
Ilustración 5.11
Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
91
de recomendaciones,
figura Ilustración 5.11.
los recursos se diferencian en
ranja sobre una capa gris según el tipo de

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
92
El diseño de la pagina de recomendación en la que el
usuario accede para ver más información de un recurso que
le llame la atención, de un recurso concreto, quedaría como
muestra la imagen Ilustración 5.12, con la foto del recurso a
la izquierda, el abstract en el centro y un infobox a la
derecha.
Ilustración 5.12

Jorge Gil Peña
Herramienta para construir bases de conocimiento a partir de información en la web
Inicialmente
de manera automática sin que el usuari
escribirla a mano
de manera que el usuario pudiese definir sus intereses de
manera completa
ilustración 5.
Jorge Gil Peña Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
5.3.3. Diseño entradas al
Inicialmente se pensó que se recibiese la información
de manera automática sin que el usuario tuviese que
escribirla a mano. Finalmente se desarrolló una encue
de manera que el usuario pudiese definir sus intereses de
completa y segura. Esto se muestra en la
ilustración 5.13.
Ilustración 5.13
Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
93
Diseño entradas al
programa
recibiese la información
o tuviese que
una encuesta,
de manera que el usuario pudiese definir sus intereses de
Esto se muestra en la

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
94
Se puede observar en la imagen Ilustración 5.6 como
se solicita información relativa al usuario para poder
clasificar sus intereses. Se diferencian cuatro apartados en
los que en cada uno de ellos se solicitan 4 recursos
(ejemplos) Los cuatro apartados son:
• Grupos de música
• Ciudades/países
• Artista/actor/personalidad
• Películas/Libros
Aparte se le solicita al usuario su email, usuario y
contraseña. y se le propone rellenar un cuestionario para
completar más su perfil.
A la hora de introducir datos a la aplicación se
diferencia entre dos posibilidades: o bien introducir grupos
de música (o cantantes) o el resto . Los artistas o bandas se
corrobora su existencia, tipo y su nombre correcto
conectándome a MusicBrainz, usando sus librerías con
webServices (abandonaron un desarrollo inicial para la
consulta RDF debido a sobrecarga).
El resto de igual manera se plantea en un futuro usar
otras webs que de igual manera gracias a su concepción de
web 2.0 se auto rellenan y actualizan y comparten a
formato semántico. Pero por ahora se comprueba en
DbPedia directamente si el String que introduce el usuario

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
95
tiene un recurso del tipo buscado, consultándose recursos
que pueden considerarse películas, ciudades, actores o
directores que se buscan directamente en DbPedia.
A mayor variedad de información introducida se
obtienen recomendaciones más variadas. Se tuvo que poner
más tipos de recursos de manera que la información
recogida de la web no estuviese tan orientadas a la música.
5.3.4. Utilización de la herramienta
JENA
Para la ejecución de esta aplicación, desde el
momento en que se reciben los intereses del usuario, la
herramienta Jena es vital para realizar el proceso de esta
aplicación. Más específicamente se ha usado para:
• Consultas en la web semántica
• Representar y almacenar el conocimiento.
• Tratar la ontología, recorrerla, modificar recursos .
Al comenzar el programa busca en más de un sitio
con contenido semántico las palabras clave del usuario
(rellenadas en su test), a través de una consulta SPARQL se
recibe el modelo asociado a un recurso. También se carga

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
96
una ontología de un fichero .owl descargado en local. Se
trata de la ontología que se ha ido creando mientras se
desarrollaba el proyecto DbPedia y que va por la versión
3.2. Se puede observar un trozo de esta ontología básica
que va desde conceptos musicales, pasando por empresas y
sus relaciones con los deportes, a la cocina y sus utensilios.
Un trozo de esta ontológica escrita en forma de
tripletas seria:
Sujeto es AmericanFootballLeague El predicado o propiedad es subClassOf El object es http://dbpedia.org/ontology/SportsLeague El Sujeto es AmericanFootballLeague El predicado o propiedad es comment El object es A group of sports teams that compete against each other in american football.@en El Sujeto es AmericanFootballLeague El predicado o propiedad es label El object es american football league@en El Sujeto es AmericanFootballLeague El predicado o propiedad es type El object es http://www.w3.org/2002/07/owl#Class El Sujeto es schoolCode El predicado o propiedad es range El object es http://www.w3.org/2001/XMLSchema#string El Sujeto es schoolCode El predicado o propiedad es domain El object es http://dbpedia.org/ontology/School El Sujeto es schoolCode El predicado o propiedad es label El object es school code@en El Sujeto es schoolCode El predicado o propiedad es type El object es http://www.w3.org/2002/07/owl#DatatypeProperty El Sujeto es maximumBoatBeam

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
97
El predicado o propiedad es range El object es http://dbpedia.org/datatype/metre El Sujeto es maximumBoatBeam El predicado o propiedad es domain El object es http://dbpedia.org/ontology/Canal El Sujeto es maximumBoatBeam El predicado o propiedad es label El object es maximum boat beam (m)@en El Sujeto es maximumBoatBeam El predicado o propiedad es type El object es http://www.w3.org/2002/07/owl#DatatypeProperty El Sujeto es numberOfBronzeMedalsWon El predicado o propiedad es range El object es http://www.w3.org/2001/XMLSchema#integer El Sujeto es numberOfBronzeMedalsWon El predicado o propiedad es domain El object es http://dbpedia.org/ontology/OlympicResult
En la Ilustración 5.7. se puede ver un ejemplo de una
parte de la ontología de DbPedia con respecto a la música
más concretamente respecto a un sonido o acorde y su
relación con el tiempo y las notas. Se trata de la figura
Ilustración 5.7, en la que se ve como de acorde (chord) salen
una serie d recursos con los que esta relacionados. Por
ejemplo se observa que un acorde tiene su origen en una
nota.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
98
Ilustración 5.14
Aunque en este proyecto no se ha usado se provee de
la opción de pintar la ontología, gracias a la clase
RDFGraph, de manera muy sencilla.
Se va a continuar con el resto de usos dados a la
herramienta Jena, y es que el resultado de las búsquedas
servirá para lanzar otras búsquedas y para recorrer la
ontología generada es necesario Jena. Esa información se
procesa en un algoritmo que mientras recorre la ontología
busca nuevos términos sobre los que lanzar la búsqueda
filtrando los resultados y recorriendo en un principio los
recursos que cuelgan del padre y asignándoles una nueva
propiedad que sirva al algoritmo para saber que ese recurso
ha resultado interesante, o modificando ésta si es que el
algoritmo informa que tiene que cambiar su valor.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
99
El proceso de adquisición de conocimiento se puede
hacer durante tantas veces se desee, de manera que se
adquieran los hijos del raíz y así sucesivamente. A mayor
profundidad se desvirtúa el caso ejemplo del usuario. Así
que se ha buscado un equilibrio entre profundidad y
obtener variedad y cantidad de resultados suficientes.
Actualmente se accede a los recursos hijos y los hijos de
estos, por cada acceso inferior se le da menos peso. Pero
estos factores están puestos como variables constantes de
la clase Algorithym, de manera que son fácilmente
modificables. Y van evolucionando con el desarrollo y
pruebas del proyecto.
Una vez la adquisición de conocimiento se haya hecho
varias veces, para cada búsqueda, lo que hará la aplicación
es construir un diccionario de términos básicos alrededor
de los términos originales del usuario cuando accedió por
primera vez, construyendo así una ontología general gracias
a la función proporcionada por Jena que es union(model), y
que pertenece a la clase Model. Así que un modelo se une a
otro modelo.
Una vez generado se accederá a esta ontología
simplemente para completarlo y consultarlo. Para este
complejo proceso conforme la ontología va creciendo con las
palabras introducidas, se aplicaran filtros o complementos
de términos por parte del algritmo. De manera que las
búsquedas estén guiadas o orientadas por el programa.
Creciendo de manera controlada en cierto modo la
ontología. Estos filtros serán explicados en la base teórica
del algoritmo.

Jorge Gil Peña
Herramienta para construir bases de conocimiento a partir de información en la web
Introducción
Es la parte más abstracta y creativa de todo este
proceso pero tamb
la parte donde el desarrollador tiene mayor libertad para
tomar decisiones
pueden tomar decisiones en tor
• Profundidad de la adquisición de conocimiento
• Valor inicial asignado
• Valor a los hijos en función del padre
• Valor a los recursos hijos de los dominios que
interesan al usuario
• Namespaces
• Filtrados de información
• Operación
pesos
• Conexiones o propiedades importantes
• Quien tiene un peso o quien no
• Valor a asignar a un recurso que el usuario accede
y a sus hijos
Este algoritmo
este proyecto,
Jorge Gil Peña Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
5.3.5. Realización del algoritmo con
Introducción
Es la parte más abstracta y creativa de todo este
proceso pero también una de las más costosas, dado que es
e donde el desarrollador tiene mayor libertad para
decisiones en torno a cómo realizarlo. Por ejemplo se
pueden tomar decisiones en torno a una serie de factores
rofundidad de la adquisición de conocimiento
alor inicial asignado
alor a los hijos en función del padre
Valor a los recursos hijos de los dominios que
interesan al usuario
amespaces a emplear
Filtrados de información
Operación a llevar a cabo con valores de distintos
pesos
Conexiones o propiedades importantes
Quien tiene un peso o quien no
Valor a asignar a un recurso que el usuario accede
y a sus hijos
algoritmo es uno de los valores añadidos
este proyecto, dado que ya existen programas que recorren
Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
100
Realización del algoritmo con
Java.
Es la parte más abstracta y creativa de todo este
dado que es
e donde el desarrollador tiene mayor libertad para
realizarlo. Por ejemplo se
no a una serie de factores:
rofundidad de la adquisición de conocimiento
Valor a los recursos hijos de los dominios que
a llevar a cabo con valores de distintos
Valor a asignar a un recurso que el usuario accede
es uno de los valores añadidos en
que recorren

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
101
la web semántica y manejan ontologías. Sin embargo la
diferencia de éste estriba en la manera en que se realiza el
crecimiento ontológico ya que se emplea el algoritmo para
filtrar los resultados y orientar el crecimiento de la
ontología. Para ello se ha introducido un concepto nuevo en
el manejo de ontologías, que es la asignación de un peso a
cada uno los recursos.
Base tecnológica
Para la asignación de pesos a los recursos no existe, o
no se ha encontrado, ninguna herramienta, ni en Jena ni
en otra, además de ninguna ontología con una propiedad
estandarizada que permita asignarles un peso a los
recursos.
Para ello se ha desarrollado una propiedad value, la
cual se ha incluido en la ontología generada por la
aplicación, que se desarrolla con los recursos interesantes.
Para ello ha sido necesario a la hora de leer las tripletas con
un valor, convertirlo a texto para poder introducirlo en la
ontología como si el valor fuese un String y al leerlo
transformarlo a int antes de poder manejar ese valor.
El algoritmo ha sido desarrollado a base de pruebas
con el fin de que el incremento de conocimientos sea lo más
aproximado posible a los resultados esperados. Dichos
resultados son:
• Un número mínimo de recursos
• Variedad de tipos de recursos

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
102
• Suficientes recomendaciones
• Resultados coherentes con lo introducido por el
usuario
• No se repitan siempre los mismos resultados
Base teórica
Se ha partido de la base teórica de que las cosas que
gustan o interesan a los usuarios tienen relaciones entre
ellos aunque sean en dominios distintos. Un ejemplo de
esto es si te gusta mucho la música mejicana es posible que
te guste la literatura mejicana o simplemente que te
interese saber quiénes eran los Zapatistas. Un ejemplo más
sencillo podría ser: si te gusta una película es probable te
guste su banda sonora, por lo que se le asignara un valor
de interés a todo lo asociado a lo que el usuario haya
indicado que le interese.
Se usa un sistema de pesos, de manera, que estas
relaciones comentadas no sean más que un punto a favor
de los Zapatistas o de la banda sonora de Titanic. Este
proceso de recomendación no es tan sencillo y por eso
tendrán que aparecer otras conexiones con estos recursos,
de manera que aparezcan como los recursos más
interesantes para el usuario.
Esta base teórica ha hecho que el filtrado a la hora de
leer información asociada a un recurso (al hacer la consulta
SPARQL inicial) sea mínima.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
103
El filtrado real se hace después, una vez se han leído
todos los datos asociados al recurso original. Estos filtros se
clasifican de dos formas :
• Filtros crecimiento de la ontología:
• Filtrado de resultados
a) Filtros crecimiento dela ontología:
Para saber si un recurso es válido para incorporarlo a
la ontología. Estos filtros previenen que la ontología se
desarrolle:
• En torno a conceptos de vocabulario si no en torno
a recursos
• En namespaces distintos a los conocidos.
• En trono propiedades
• Con recursos que no estén correctamente descritos
b)Filtrado de resultados:
A la hora de analizar si un resultado obtenido es apto
para considerarlo como "interesante" para el usuario y
mostrárselo. Estos filtros evitan mostrar contenidos :
• Pertenecientes a un vocabulario (palabras o
conceptos), a no ser que interese
• El mismo recurso introducido por el usuario

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
104
• Pertenecientes a webs sin estandarizar la
presentación de datos
Resumen funcionamiento
A la hora de introducir datos se diferencia entre dos
posibilidades: bien introducir grupos o cantantes, de los
que se corrobora su existencia, tipo y su correcto nombre
conectándose a MusicBrainz o bien si no búsqueda de
recursos (cualquier cosa que se pudiese buscar en
Wikipedia, artistas, libros, películas,..) que se busca
directamente con una consulta SPARQL sobre la nube de
"Linked Data" de la web 3.0. de DbPedia.
Una vez se localiza ese path de cada recurso, se
genera un modelo inicial, partiendo de la ontología principal
de DbPedia, sobre la que se apoyarán todos los contenidos
generados, será la ontología asociada al usuario.
Una vez se ha generado este modelo y cada recurso
buscado se genera un modelo con su contenido, y entonces
se integran, usando la librería Jena. Teniendo con cada
recurso un modelo mayor, y así sucesivamente. Para saber
qué recursos de los encontrados nuevos puede resultar más
interesante al nuevo usuario se genera, por cada recurso,
una propiedad value y un peso.
El proceso de generación de la propiedad value se
realiza generando una tripleta más por cada recurso nuevo
encontrado como se ha comentado antes.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
105
Para recoger los recursos con propiedad value una vez
finalizado el algoritmo se pasara a un Map(Collection),
almacenando la URI del recurso y su valor. Éste al finalizar
será almacenado en la base de datos con el fin de poder
recuperarlo la próxima vez que se conecte el usuario.
Tras la generación del usuario y conocidos sus
intereses, al volver a logear e interesarse (cliquear para
obtener mas info) por un recurso la puntuación de este
incrementara, y por consiguiente sus recursos hijos,
produciéndose un incremento del conocimiento guiado por
el algoritmo. Además se pretende establecer un campo de
búsqueda, en el cual al buscar nuevos intereses dándoles
un peso nuevo de manera que el modelo del usuario
aumente y pueda ofrecer más contenidos asociados a su
perfil ya a su nueva búsqueda.
Los resultados obtenidos se aproximan bastante a lo
esperado, sin embargo ha sido complicado el filtrado de
contenidos. Debido a la cantidad de propiedades existentes
que impiden clasificar de manera automática. Además
aunque la DbPedia esté conectada con otras webs
semánticas y esto resulte altamente interesante, al no estar
estandarizadas las propiedades ni la serializacion de los
datos no se ha podido llevar a cabo el proceso de
adquisición de datos de esas webs semánticas.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
106
Desarrollo de la propiedad value
Los pesos son la clave de este proceso de
reforzamiento del conocimiento y es con lo que se puede
jugar dando mayor importancia a unos factores o a otros.
Básicamente se toma un valor inicial para los hijos de
los recursos principales del usuario y se suman estos
valores en caso de que coincidan. Al repetirse el proceso con
los hijos, los siguientes tendrán un valor igual al valor del
padre dividido entre 2 más un valor fijo. Existe un valor
mínimo también.
Como se puede ver en el siguiente código se
establecen estáticamente estos valores para poder ir
cambiándolos de manera cómoda ya que están repartidos a
lo largo del algoritmo. Como se comenta el primero es el
número mínimo de recursos de cada tipo. La segunda
constante hace referencia al valor inicial de los hijos. Y la
tercera es el valor límite para darle fiabilidad a un resultado
y mostrarlo como recomendación.
private static int numRes =6; //Number of reesources private static int valueStart =2; //Start value for the algorithym private static int limit=5; //Number limit for showing the results
Como se ha comentado repetidamente es un proceso
repetitivo y a base de pruebas se va depurando para
aproximarse a los resultados esperados o deseados. Existe

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
107
un método con el que se establece con que profundidad se
realiza este proceso, este es developModel.
//Get more profundity data Integer value=(Integer)Integer.parseInt(obj.toString()); modelNew=DbPedia.getRelatedModelFull(path); int valueForResources=1; (value>1){ valueForResources=value/2; }
En este método se ha encontrado con algún problema
tecnológico ya que mientras se recorre la ontología para ir
añadiendo nuevos se ha de comprobar si el recurso ya
existe y en caso afirmativo sumar los valores de su peso,
eliminando la sentencia anterior, usando el nuevo peso
para calcular el peso de los nuevos hijos y demás sumarle a
la ontología la nueva ontología asociada al recurso del que
se quiere desarrollar.
Este proceso ha sido complicado llevarlo a cabo ya
que salía una excepción en Java de concurrent modification
y que avis de que mientras se recorre un iterator se está
intentando modificar, produciendo un error. Finalmente se
ha optado por rellenar un arraylist con lasa tripletas a
eliminar y eliminarlas al finalizar el recorrido y antes de
unir todas las ontologías.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
108
Evolución de algoritmo
El algoritmo es lo que hace que este proyecto tenga o
no un valor añadido, de ahí que se haya dedicado este
subapartado a una explicación un poco profunda del
funcionamiento de este. Hay que recalcar que lo bueno de
disponer de un algoritmo es que tiene la ventaja de que
siempre se podrán introducir más factores que afecten a
éste y siga evolucionando.
El algoritmo se encuentra en constante desarrollo y
mejora, través de pruebas, filtrados e incorporaciones.
Incluyendo reglas de conocimiento, o combinándolo con un
algoritmo de aprendizaje automático.
Posteriormente el algoritmo se podrá complicar más
generando un algoritmo en el que según el usuario y el
perfil en el que establezca los dominios que le interesan se
le dará más o menos peso a todos los hijos y subhijos de un
dominio. Así si un recurso aparece como interesante por
varios sitios, tiene mayor peso, y por consiguiente mayor
probabilidad de aparecer entre los recomendados.
5.3.6.Crear y preparación del
proyecto web
Una de las tareas principales realizadas para crear un
proyecto web ha sido cambiar las entradas y salidas del
código inicial del programa para que pudiesen ser

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
109
desarrolladas en modo web. Esto permitía un mayor
alcance al proyecto y una mayor proyección hacia el
exterior. Aprovechando que Internet es un gran modo de
exponerse a todo el mundo, sin necesidad de conocimientos
informáticos, ni de Inteligencia Artificial o de las ontologías.
Para llevar a cabo este proceso ha sido necesario
implementar todos los Servlets y las páginas web en JSP, y
las tecnologías correspondientes a JSP que se especificaran
en el siguiente capítulo. En este caso se ha usado Tomcat.
y Eclipse ha facilitado mucho la tarea de conversión del
proyecto ya que rellena los xml correspondientes, donde se
describen las relaciones entre los Servlets, los JSP y las
clases Java, además de incluir las librerías necesarias e
incluso generar la estructura de ficheros y paquetes de un
proyecto web y en caso de necesidad genera el paquete web,
el WAR.
Al tratarse de un proyecto web la aplicación pasó a
tener una estructura de carpetas configurada en forma de
árbol de directorios. Como se puede ver en la siguiente
imagen Ilustración 5.8 con la carpeta Web Content como raíz
del proyecto web y que contiene tanto las páginas Web,
como dos directorios que son necesarios para definir la
configuración de la aplicación. Estos directorios son:
META-INF: Contiene el fichero context.xml.
WEB-INF: Contiene los ficheros de configuración
como:

Jorge Gil Peña
Herramienta para construir bases de conocimiento a partir de información en la web
• config.xml
configuración que atañen a las clases java de
respaldo de las páginas Web. Aquí se inicializan
variables, se enlaza código Java con páginas Web,
se indica
etc.
• web.xml:
generales de la aplicación, tales como cuales son
las páginas de inicio y error, qué recursos
adicionales usa la aplicación,
etc.
Jorge Gil Peña Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
config.xml, que contiene instrucciones de
configuración que atañen a las clases java de
respaldo de las páginas Web. Aquí se inicializan
variables, se enlaza código Java con páginas Web,
se indica cómo se salta de una página Web a otra,
etc.
web.xml: Recoge parámetros de configuración
generales de la aplicación, tales como cuales son
las páginas de inicio y error, qué recursos
adicionales usa la aplicación, temas de seguridad,
etc.
Ilustración 5.15
Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
110
ontiene instrucciones de
configuración que atañen a las clases java de
respaldo de las páginas Web. Aquí se inicializan
variables, se enlaza código Java con páginas Web,
se salta de una página Web a otra,
Recoge parámetros de configuración
generales de la aplicación, tales como cuales son
las páginas de inicio y error, qué recursos
temas de seguridad,

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
111
Los ficheros JSP sin embargo se quedan fuera de
estos directorios y cuelgan directamente de WebContent. Un
nivel por arriba están las carpetas:
Source Packages: Contiene nuestro código Java. Que
envía los .class ala carpeta classes de WEB-INF.
Libraries: Las librerías que necesita nuestro
programa.
Hay que diferenciar en ese proceso el hecho de crear
un proyecto web en un entorno de trabajo o desarrollo como
puede ser Eclipse, y en el proceso de llevar el proyecto Web
a explotación.
Para poner el servidor en explotación, hay que
preparar el entorno web con el correspondiente servicio
escuchando peticiones y llamando a la JVM para ejecutar el
código en Java.
Primero, para poder acceder al ordenador desde el
exterior ha sido necesario un análisis de conocimiento de la
red. Tras concluir que se disponía de un punto de acceso
con IP pública dinámica. Este punto de acceso es un
Router y genera en el interior una red privada de la que
será el Gateway a Internet. Para la instalación y puesta a
punto del servidor web, ha sido necesario dar de alta en
DynDNS, para redireccionar la web a este Router con IP
dinámica. Se desactivo el servicio DHCP y se estableció
para el servidor una IP fija. Lo que ha permitido usar reglas

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
112
de NAT para redireccionar los paquetes. Abriendo los
puertos correspondientes.
Posteriormente, en el servidor se ha contado un
ordenador Windows 7, con un servidor web y un contenedor
de Servlets Tomcat 6 que redirigirá las peticiones al
servidor. El servidor web será el encargado de dirigir al
Servlet concreto para que se ejecute enviándolo a la
máquina virtual de Java. En este servidor se encontrará el
código de la aplicación Java y los JSP con JavaScript .
Al cliente se le enviarán los response del HTML tras
rellenar los JSP, y los objetos EL para rellenar la info
recogida del servidor, se enviarán el HTML y el CSS para
que el software cliente pinte el interfaz visual.
Los objetivos han sido cumplidos con creces con
respecto a este desarrollo, ya que se ha conseguido llevar a
cabo el desarrollo del servidor web sin grandes
contratiempos. Quizás podría mejorarse el tiempo de
respuesta, pero un tiempo de respuesta corto no estaba
planteado como objetivo del proyecto.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
113
6. Desarrollo de la aplicación
myWeb
a implementación de este proyecto como es
lógico ha quedado muy condicionada por la
estructura general de esté. Y por lo tanto de las
tecnologías empleadas.
En este proyecto se dividen claramente cuatro
módulos lógicos de programación según la manera en la
que se ha trabajado con ellos. Por el tipo de desarrollo hay
claramente cuatro módulos:
• Modulo Java
• Módulo Servlets
• Módulo JSP
• Modulo base de datos
6.1. Modulo Java
6.1.1. Introducción
El modulo Java es el módulo de la lógica de negocio,
el modulo principal, en el que se desarrolla el programa. Se
L

Jorge Gil Peña
Herramienta para construir bases de conocimiento a partir de información en la web
va a dividir esta parte del código en dos: una donde se
explica la implementación de
correspondiente a Jena
desarrolla el algoritmo. Aunque estas
directo.
El código realizado en Java se encuentra en la carpeta
de Java Resources
Como se puede observar la Ilustración 6.1 e
encuentra a su vez clasificado en paquetes
ellos las DAO, el dominio que se refiere a los propios del
sistema, el de
interactúan con
encargados de interactuar con
Jorge Gil Peña Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
a dividir esta parte del código en dos: una donde se
explica la implementación de la parte del código
correspondiente a Jena y otra donde se explica
desarrolla el algoritmo. Aunque estas están en contacto
código realizado en Java se encuentra en la carpeta
Resources, normalmente conocido como
Como se puede observar la Ilustración 6.1 e
encuentra a su vez clasificado en paquetes. A recalcar de
ellos las DAO, el dominio que se refiere a los propios del
, el de Jena donde se encuentran las clases que
interactúan con Jena y los de MusicBrainz
encargados de interactuar con MusicBrainz.
Ilustración 6.1
Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
114
a dividir esta parte del código en dos: una donde se
la parte del código
y otra donde se explica cómo se
n contacto
código realizado en Java se encuentra en la carpeta
, normalmente conocido como "src".
Como se puede observar la Ilustración 6.1 este se
recalcar de
ellos las DAO, el dominio que se refiere a los propios del
las clases que
usicBrainz son los

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
115
6.1.2. Parte Jena
En la parte del código Jena se realiza la obtención de
la primera ontología sobre la que se va a trabajar que es un
archivo .OWL, una ontología completa descargada de
DbPedia y que se lee con las funciones de Jena creadas
para ello.
La lectura de la OWL genérica que servirá de base
para la ontología del usuario y que se encuentra en una
carpeta local se realiza creando primero un modelo vacio
con createDefaultModel, luego se genera un InputStream con
la dirección del fichero y finalmente se lee de ella con la
función de model read(). Como se ve en el siguiente código.
Lectura de un fichero OWL
String inputFileName="C://Users//JORGE//Desktop//Proyecto//dbpedia_3.5.1.owl"; Model model = ModelFactory.createDefaultModel(); // use the FileManager to find the input file InputStream in = FileManager.get().open( inputFileName ); if (in == null) {throw new IllegalArgumentException( "File: " + inputFileName + " not found"); } // read the RDF/XML file model.read(in, null);

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
116
Tras generar la URL del recurso que el usuario ha
dicho que le gustaba o le interesaba se lee su contenido
llamando a la función getRelatedModelFull() de DbPedia,
que devuelve un modelo nuevo.
Llamada a getRelatedModelFull
Model modelNew=DbPedia.getRelatedModelFull(path);
Se lee su contenido tras la consulta en SPARQL y se
genera la ontología asociada al recurso leído con la función
ResultSetFormatter:toModel(), que devuelve un modelo.
Función getRelatedModelFull
String serviceEndpoint="http://dbpedia.org/sparql"; if (pathResource.startsWith("<")&& pathResource.endsWith(">")){ pathResource.replace("<", ""); pathResource.replace(">", ""); } String qsInfoDbpedia = "SELECT DISTINCT * WHERE {{<"+pathResource+"> ?property ?resource} UNION{?resource ?property <"+pathResource+">}}"; ResultSet rs=DAO_Sparql.selectQuery(pathResource,serviceEndpoint,qsInfoDbpedia); // System.out.print("RS tiene "+rs.getRowNumber()); Model mo= ResultSetFormatter.toModel(rs);
Se procede luego a la unión. La unión de la ontología
recibida con la ontología general del usuario, de manera

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
117
que va creciendo con cada nuevo recurso, o en caso de que
ya exista le sumará el nuevo peso al peso anterior del
recurso.
Función DbPedia.union()
model=DAO_Model.modelUnion(model,modelNew); int tamaño2=(int) model.size()-tamaño1; System.out.println("\nHa devuelto "+info+"resources modificados de "+name + " añade al model "+modelNew.size()+"="+tamaño2+"\n\n");
6.1.3.Parte Algoritmo
La parte del código Java que se encarga de controlar
las clases encargadas del algoritmo de recomendación de
contenidos se encuentra en Jenate, las funciones
principales que se explicarán a continuación son:
• main(listInterestedResources, listInterestedArtists)
• fillModel(pathResource, model)
• convertMapToArray(mapUrlResources,
urlsResources, urlsPlaces, urlsPersons)

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
118
Map<Integer,Collection<DbPediaResource>>main(L
ist<String>listInterestedResources,List<Artist>listIntere
stedArtists)
En la función main es en la que se ejecuta toda la
lógica de recomendación de contenidos. Recibe de los
Servlets correspondientes un array de artistas y de recursos
con el que comenzar a buscar y ejecutar la lógica de la
búsqueda y recomendación de contenidos.
A continuación se puede ver cómo va llamando a las
distintas clases y recolectando datos para acabar
devolviendo el Map de datos asociados al usuario con
formato Integer,Collection<DbPediaResource>.
Función main
while (i<listInterestedResources.size()) { System.out.println(listInterestedResources.get(i).toString()); pathResource=getDbPediaPathResource(listInterestedResources.get(i)); model=fillModel(pathResource,model); i+=1; } System.out.println("El modelo tiene "+model.size()+" tuplas"); //get list of ARTIST i=0; while (i<listInterestedArtists.size()) { System.out.println(listInterestedArtists.get(i).getName().toString()); pathResource=getDbPediaPathArtist(listInterestedArtists.get(i)); model=fillModel(pathResource,model); i+=1; } System.out.println("El modelo tiene "+model.size()+" tuplas despues de los artist"); //Where the model is desarrolleted and oriented by me

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
119
Model model2=Algorithym.developModel(model,listInterestedResources,listInterestedArtists); System.out.println("El modelo tiene "+model2.size()+" tuplas despues develop"); //Where I search the most valuables resources Map<Integer, Collection<DbPediaResource>> mapUrlResources=Algorithym.getMostValuableResources(model2);
Model fillModel(String pathResource,Model model)
La función fillModel se encarga de rellenar el modelo
nuevo de la propiedad value asignándole el valor correcto,
de ahí que reciba también el model, para comprobar su
valor anterior en caso de que exista. En el se realiza un
filtrdo como se ha comentado en la explicación del
algoritmo de manera que la ontología no crezca de manera
descontrolada.
A continuación se puede ver un ejemplo de cómo
funcionan los filtros que tras el filtrado con el if, son
eliminadas las tripletas correspondientes en caso de que
sea necesario.
Función fillModel
for (String pathNotValid : new String[]{ "http://dbpedia.org/ontology/Band", "http://www.w3.org", "http://dbpedia.org/ontology/Organisation"}) { if (path.startsWith(pathNotValid)) { if (!statementsEliminar.contains(st)) { statementsEliminar.add(st);

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
120
Model convertMapToArray(mapUrlResources,
urlsResources, urlsPlaces, urlsPersons)
Y convertMapToArray se encarga como dice su
nombre de convertir el Map en los arrays clasificados como
se ha mostrado en el filtrado del capítulo anterior, tras un
nueva consulta a DbPedia, para enviárselo al JSP.
La clase Algorithym es la que básicamente se encarga
de todos los aspectos relacionados con el algoritmo, en ella
las funciones principales son las siguientes:
• int fillPropertyValue(Model modelRelatedTerms,
String pathResource, Model model,int z)
• Map<Integer,Collection<DbPediaResource>>
getMostValuableResources(Model model) {
• developModel(Model model,List<String>
listInterestedResources,List<Artist>
listInterestedArtists)
Se asigna dentro de la ontología un valor a cada
recurso que podría resultar interesante, diferenciándose de
si es la primera vez que se accede a dicho recurso o no.
int fillPropertyValue(Model modelRelatedTerms,
String pathResource, Model model,int z)
Como se puede leer en su nombre en inglés esta
función es la encargada de dentro de una ontología y según

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
121
distintos pesos rellanar la ontología con los atributos o
propiedades value. Se ve al final que genera en:
modelRelatedTerms.add(r1, fillPropertyValue:
modelRelatedTerms .createProperty("vvalue"),
String.valueOf(value2)); Generando la tripleta r1-
>property:value->value2.
Función fillProperrtValue
Property pvalue =modelRelatedTerms.getProperty("vvalue"); (model.contains(r1, pvalue)){ Statement st=model.getProperty(r1, pvalue); RDFNode object=st.getObject(); int valor=Integer.parseInt(object.toString()); //System.out.println("Entro en fillProp y modifico "+object.toString()+ "de valor"+valor); valor+=2*z; model.remove(st); String s=new String(); modelRelatedTerms.add(r1, modelRelatedTerms.createProperty("vvalue"), String.valueOf(valor)); System.out.print(r1.getLocalName()+ " valor="+valor+","); }else{ int value2=1*z; System.out.print(r1.getLocalName()+ " valor="+value2+","); modelRelatedTerms.add(r1, modelRelatedTerms.createProperty("vvalue"),String.valueOf(value2));
Se establece un peso distinto, en función del peso del
recurso del que provenga el recurso, para cada nuevo
recurso. Obsérvese valueForResources=value/2.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
122
Función fillProperrtValue
Model modelNew=DbPedia.getRelatedModelFull(path); int tamaño1=(int) model.size(); int valueForResources=1; if(value>1){ valueForResources=value/2; } int info=fillPropertyValue(modelNew,path,model,valueForResources); model=DAO_Model.modelUnion(model,modelNew); int tamaño2=(int) model.size()-tamaño1;
getMostValuableResources(Model model) {
Luego se lee la ontología entera del usuario en busca
de los recursos con un valor mayor, usando el método
getMostValuableResources que devuelve una serie de arrays
con recursos según el tipo. Se recogen los recursos más
valorados del Map del usuario.
Función getMostValuableResources
Set <Integer> s=mapUrlResources.keySet(); Iterator it =s.iterator(); //Get the bigger value of the keys int mayor=0; while(it.hasNext()){ int valor =(Integer) it.next(); if (valor>mayor){ mayor=valor; } }
Hay que tener en cuenta, que una vez cogidos los
recursos de mayor valor para poder mostrarlos y enviarlos
en un array al JSP, se necesita recoger info para saber de

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
123
qué tipo de recurso se trata, para recoger su foto y su
nombre o label.
Se diferencia entre si los recursos recibidos son
artistas u otro tipo de recursos, para luego continuar
filtrándolos. Se puede comprobar cómo se filtran los
resultados confirmando si el type de recurso acaba con la
palabra Band, o si contiene la palabra "artist", teniendo en
cuenta que tipo es un array ya que no están
estandarizadas las propiedades.
Función getMostValuableResources
Iterator <String>it=dpr.getType().iterator(); Boolean artist=false; while(it.hasNext() && !artist){ if(type.endsWith("sMusicGroups") || type.endsWith("Band") || type.contains("Artist") || type.contains("Singers")){ artist=true; } } if(artist && urlsArtists.size()<15){ urlsArtists.add(dpr); System.out.println("Es un artista+tamaño="+urlsArtists.size()+"\n"); }else if(!artist && urlsResources.size()<15){ urlsResources.add(dpr); System.out.println("Es un resource+tamaño="+urlsResources.size()+"\n"); }
También se filtran los recursos del Map para
establecer de qué tipo de recurso se trata. Se realiza
comprobando las propiedades o recursos asociados a un

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
124
recurso recogidos con una consulta SPARQL sobre el
recurso padre recogiendo los hijos con la propiedad
rdf:type. Pero al no estar estandarizado como se puede
observar se comprueban si los tipos contienen palabras o si
pertenecen a un namespace. Este proceso va refinándose a
base de pruebas. Y aprovecha el filtrado para clasificar los
resultdos.
Función getMostValuableResources
while(it.hasNext() && !artist){ String type=it.next(); if(type.endsWith("sMusicGroups") || type.endsWith("Band") || type.contains("Artist") || type.contains("Singers")){ artist=true; System.out.println("Es un artista+tamaño="+ urlsArtists.size()+"\n"); }else{ if (type.endsWith("Person")){ person=true; System.out.println("Es una persona+tamaño="+urlsPersons.size()+"\n"); } else{ if( type.contains("Place") || type.equals("Settlement")){ place=true; System.out.println("Es un sitio+tamaño="+urlsPlaces.size()+"\n"); }else{

Jorge Gil Peña
Herramienta para construir bases de conocimiento a partir de información en la web
Se van fil
que si por ejemplo tienen la propiedad
interesante para el usuario. Luego habrá que ver si es
suficientemente interesante para este. Eso dependerá de su
valor como se verá a continuación en el d
algoritmo.
En este proyecto ha sido necesario implementar
bastantes Servlets
bastantes funcio
van a ver un par de ejemplos.
Ilustración 6.2 la lista de
Jorge Gil Peña Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
Se van filtrando los contenidos del modelo de manera
que si por ejemplo tienen la propiedad value, entonces es
interesante para el usuario. Luego habrá que ver si es
suficientemente interesante para este. Eso dependerá de su
valor como se verá a continuación en el desarrollo del
6.2. Módulo
En este proyecto ha sido necesario implementar
Servlets al tratarse de un servicio web con
bastantes funcionalidades, aunque todas muy simples.
a ver un par de ejemplos. Como se puede ver
Ilustración 6.2 la lista de Servlets es muy sencilla.
Ilustración 6.2
Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
125
trando los contenidos del modelo de manera
, entonces es
interesante para el usuario. Luego habrá que ver si es
suficientemente interesante para este. Eso dependerá de su
esarrollo del
Módulo Servlets
En este proyecto ha sido necesario implementar
al tratarse de un servicio web con
simples. Se
Como se puede ver en la
es muy sencilla.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
126
La lista de Servlets contiene básicamente los mismos
que los casos de uso analizados al comienzo de la memoria
en el capítulo 5, en el apartado 5.2.1. Se van a presentar
sólo los más importantes o significativos, que son:
• New User
• Login
• MoreInfo
• SeeRecomendations
El NewUser es un Servlet de creación de contenidos
de usuarios. En él se ve como llaman al código Java,
creando primero un usuario y avisando si el usuario ya
existe.
Servlet NewUser
if (!login.equalsIgnoreCase("") && !pass.equalsIgnoreCase("")) { usuario = ServicioUsuarios.getInstancia().generaUsuario(login,pass,email); }else{ System.out.print("Usuario ya existe"); }
Y luego generando array de contenidos o recursos
interesantes para el usuario nada más recibirlos de la
encuesta con el fin de poder pasárselo al código Java. Se

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
127
puede ver como se añaden a un array, en este caso los
artistas.
Servlet NewUser
if(!grupo1.equals("")){ listResourcesArtist.add(grupo1);} if(!grupo2.equals("")){ listResourcesArtist.add(grupo2);} if(!grupo3.equals("")){ listResourcesArtist.add(grupo3);} if(!grupo4.equals("")){
Finalmente se ve como envía un Servlet la respuesta a
un JSP:
Servlet Login
request.setAttribute("urls", urls); RequestDispatcher rd = null; try{ rd=request.getRequestDispatcher("recomendaciones.jsp"); rd.forward(request,response);
El Servlet Login sirve para acceder al menú de
usuario. seeResources para al conectarse a la web una vez
dado un usuario de alta que desde el menú de usuario el
usuario pueda ver los recursos almacenados para él.
El Servlet MoreInfo es el único que no estaba en los
caso de uso con ese nombre, sino como seleccionarRecurso
y es que este se encarga de mostrar más información de un

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
128
recurso que el usuario cliquee y por lo tanto significa que le
interesa un recurso, dándole más valor a su peso y a los
hijos. Es muy interesante este Servlet ya que recibe
directamente la llamada desde el JSP con una llamada al
Servlet generada de manera dinámica, que luego se
mostrará en el JSP.
Entonces se conecta a la URL recibida busca
información asociada al recurso y la muestra en el JSP,
ficha_recurso.jsp.
Servlet MoreInfo
pathResource=(String) request.getParameter("pathResource"); DbPediaResource dp=DbPedia.getMoreInfo(pathResource);
En el siguiente recuadro está dispuesto el fichero xml
de configuración del servidor web:
Web.xml
<servlet-name>Login</servlet-name> <servlet-class>servlets.Login</servlet-class> </servlet> <servlet> <servlet-name>newUser</servlet-name> <servlet-class>servlets.newUser</servlet-class> </servlet> <servlet> <servlet-name> moreInfo</servlet-name> <servlet-class>servlets.moreInfo</servlet-class> </servlet> <servlet-mapping> <servlet-name>Login</servlet-name>

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
129
<url-pattern>/Login</url-pattern> </servlet-mapping> <servlet-mapping> <servlet-name>newUser</servlet-name> <url-pattern>/newUser</url-pattern> </servlet-mapping> <servlet-mapping> <servlet-name>moreInfo</servlet-name> <url-pattern>/moreInfo</url-pattern> </servlet-mapping>
6.3. Módulo JSP
El módulo JSP es el que se encuentra dentro de la
carpeta WEB-CONTENT del proyecto web. En esta carpeta
se encuentran todos los JSP, que son los encargados de la
lógica del diseño implementada. Con la librería JSTL se
puede invocar a los ficheros Java que se han enviado vía
request a la JSP o que se encuentran a la session, un
ejemplo seria: ${DbPediaResource.image}, y esto se hace de
la forma objeto.atributo, y directamente imprime por
pantalla el toString() del objeto que recibe por un get del
atributo.
La carpeta de ficheros JSP se encuentra como se ha
comentado anteriormente en WEB-CONTENT, y queda como
se ve en la Ilustración 6.3.

Jorge Gil Peña
Herramienta para construir bases de conocimiento a partir de información en la web
En el ej
añade una librería
que es añadida en el
<%@page import="java.sql.Time" %> <%@ taglib prefix="c" uri="http://java.sun.com/jstl/core_rt" %>
Aquí se puede ver como se emplea la librería JSTL,
para realizar el
dentro del HTML. Este es el bucle con el que
las recomendaciones, tantos bucles de estos como tipos de
Jorge Gil Peña Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
Ilustración 6.3
En el ejemplo siguiente se puede observar
librería a un JSP, en este caso la core
que es añadida en el index.jsp es:
<%@page import="java.sql.Time" %>
<%@ taglib prefix="c" uri="http://java.sun.com/jstl/core_rt" %>
Aquí se puede ver como se emplea la librería JSTL,
para realizar el for each, pudiendo realizar un poco de lógica
dentro del HTML. Este es el bucle con el que se muestran
las recomendaciones, tantos bucles de estos como tipos de
Ingeniería Superior Informática. ICAI.
erramienta para construir bases de conocimiento a partir de información en la web
130
e puede observar cómo se
core de JSTL,
index.jsp
<%@ taglib prefix="c" uri="http://java.sun.com/jstl/core_rt" %>
Aquí se puede ver como se emplea la librería JSTL,
poco de lógica
se muestran
las recomendaciones, tantos bucles de estos como tipos de

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
131
recursos reciba. Es curioso, como se ha comentado antes,
la llamada al Servlet moreInfo, que envía por get la URL del
recurso que está siendo generado dinámicamente siempre y
cuando se pulse porque está dentro de un link.
recomendaciones.jsp
<c:forEach items="${urls}" var="DbPediaResource"> <div class="recomendacion"> a href="moreInfo?pathResource=<c:out value="${DbPediaResource.uri}"/>" title="${DbPediaResource.name}"> <img src="${DbPediaResource.image}" align="left" width="50" height="75" alt="Cartel de ${DbPediaResource.name}" /> <h3>${DbPediaResource.name}</h3></a> <a href="${DbPediaResource.uri}" title="${DbPediaResource.name}"> ${DbPediaResource.uri}<br> </p> </a>
Los fichero JSP también pueden construir páginas
web normales, solo que las ejecutará con el contenedor de
Servlets también con su consiguiente pérdida de tiempo.
ejemplo.jsp
<div id="cabecera"> <a id="logo" href="newUser" title="Página de inicio de My Web"> <h1>My Web</h1> <img src="img/logo.png" /></a> <div class="clear"> </div> <ul id="barra_navegacion"> <li > <a id="libros" href="#"> <span> Libros </span> </a> </li> <li > <a id="peliculas" href="#"> <span> Peliculas </span> </a> </li> <li > <a id="series" href="#"> <span> Series </span> </a> </li>

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
132
Aquí se puede ver como el JSP hace el envió de
formulario a la clase del Login con el método action, desde
la página principal en la que el usuario se conecta.
index.jsp
<div id="contenido"> <h1>Acceso a tus recomendaciones- myWeb</h1> <form action="Login" method="POST"> Login: <input type="text" name="login" value="" /> Password: <input type="password" name="pass" value="" /> <input type="submit" value="Entrar" /> </form><br><br>
También se han empleado código JavaScript de
manera que no se sobrecargue el servidor y ganando tiempo
para el usuario ya que valida el formulario antes de
enviarlo:
encuesta.jsp
function MM_validateForm() { if (document.getElementById){ var i,p,q,nm,test,num,min,max,errors='',args=MM_validateForm.arguments; for (i=0; i<(args.length-2); i+=3) { test=args[i+2]; val=document.getElementById(args[i]); if (val) { nm=val.name; if ((val=val.value)!="") { if (test.indexOf('isEmail')!=-1) { p=val.indexOf('@'); if (p<1 || p==(val.length-1)) errors+='- '+nm+' must contain an e-mail address.\n'; } else if (test!='R') { num = parseFloat(val); if (isNaN(val)) errors+='- '+nm+' must contain a number.\n'; if (test.indexOf('inRange') != -1) { p=test.indexOf(':'); min=test.substring(8,p); max=test.substring(p+1);

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
133
if (num<min || max<num) errors+='- '+nm+' must contain a number between '+min+' and '+max+'.\n'; } } } else if (test.charAt(0) == 'R') errors += '- '+nm+' is required.\n'; } } if (errors) alert('The following error(s) occurred:\n'+errors); document.MM_returnValue = (errors == ''); } }
6.4. Modulo base
de datos
El modulo de base de datos implementado con MySql,
está compuesto por tres tablas básicas como se ha visto en
el diseño de base de datos. La de usuario o user donde se
almacena la info relativa al usuario al darse de alta. La de
resources, donde se almacenan los recursos con la
información básica para poder acceder a ellos de manera
rápida. Almacenando los nombres de estos, su imagen, su
URL y sus tipos. Y por último la conexión entre los recursos
y los usuarios, con su valor relativo.
El lenguaje empleado ha sido el de DTD, para definir
las tablas. Para crear la tabla user se utilizó la siguiente
sentencia:
Creación de tabla user
CREATE TABLE USER (name varchar (100), email varchar(150), pass varchar (50));
Aparte para conectar la base de datos con el código
Java, se ha usado el conector dado por MySQL y se ha

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
134
generado un fichero DAO_MySQL, para acceder de manera
segura e independiente a la base de datos. Así se genera
una conexión por usuario y se ejecuta las sentencias
Aquí hay un ejemplo de escritura cundo se
almacenan los datos del usuario recién dado de alta.
DAO_MySQL.java
public static void storeResource(String resource, String urlResource, String image,String type) throws SQLException { Statement st = conexion.createStatement(); st.executeUpdate("INSERT INTO resources(name,url,image,type) VALUES ('"+resource+"','"+urlResource+"','"+image+"','"+type+"')"); st.executeUpdate("INSERT INTO properties (name,url,value) VALUES ('"+resource+"','"+urlProperty+"','"+value+"')"); /st.executeUpdate("INSERT INTO user_resources (nameUser,nameResources,value) VALUES ('"+user+"','"+resource+"','"+value+"')"); }
Aquí se muestra un ejemplo de lectura del fichero
usando la clase DAO de acceso al servidor de MySQL, en
este se lee de la clase resources para poder pintar en la
página recomendaciones de manera rápida sin tener que
acceder a Internet a coger la foto y el tipo de recurso.
DAO_MySQL.java
public static boolean readResource(String urlResource) throws SQLException { Statement st = conexion.createStatement(); st.executeUpdate("SELECT (name,url,relation,resource) FROM resources WHERE url='"+urlResource+"')"); // TODO Auto-generated method stub ResultSet rs=st.getResultSet(); return rs.next();

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
135
Con esta demostración de los accesos a base de datos
se finalizan los ejemplos de implementación. La verdad es
que no ha habido grandes problemas con el desarrollo de
estas tecnologías, en todo caso los Servlets y los JSP que
han sido un poco más novedosos. Sin embargo, los Servlets
una vez se tiene uno funcionando el resto son iguales, en
cambio el tratar con los JSP y sobre todo con la librería de
JSTL y El sí que ha sido más costoso en algún momento,
pero han resultado muy útiles e interesantes.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
136
7. Caso ejemplo
Se va a proceder a ejecutar un ejemplo con el fin de
ver los resultados obtenidos en un caso ejemplo. No se
aseguran los mismos resultados en todo momento ya que el
programa está expuesto a cambios constantes.
Acceso a la web
Ilustración 7.1

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
137
Acceso a encuesta
En la Ilustración 7.2. se puede observar el tipo de
encuesta que se realiza preguntando por los gustos del
usuario e intereses. Entre ellos por sus peliculas, libros,
actores y artistas favoritos.
Ilustración 7.2
Tras la imagen Ilustración 7.2. al enviar el formulario
se comienza a procesar el algoritmo, que lleva un intervalo
de tiempo largo al tratarse de la primera vez que se accede.
Es importante recalcar que la rapidez de ejecución
dependerá de la conexión de la que se dispong, tanto el
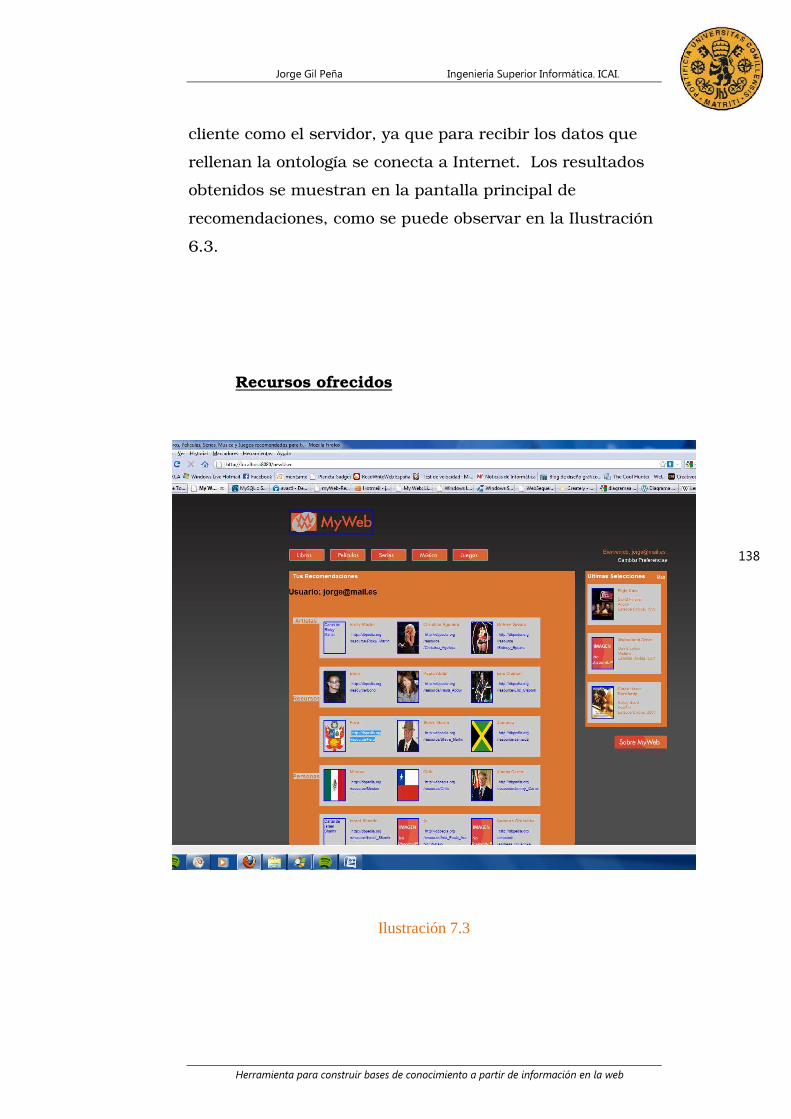
Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
138
cliente como el servidor, ya que para recibir los datos que
rellenan la ontología se conecta a Internet. Los resultados
obtenidos se muestran en la pantalla principal de
recomendaciones, como se puede observar en la Ilustración
6.3.
Recursos ofrecidos
Ilustración 7.3

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
139
Posteriormente se accede a un recurso para coger
más información y el usuario marcaria ese recurso como
me interesa. Al resultar Paula Abdul desconocida se accede
a ella. Quedando los resultados como en la Ilustración 5.4.
Seleccionar Recurso
Ilustración 7.4
Accediendo desde la página principal con el usuario
generado [email protected], accedo a su menú principal. Y
desde ahí se puede acceder al resto de opciones de la
aplicación.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
140
8 Especificaciones
Tecnológicas
8.1. Proyecto en
desarrollo
Tomcat
ontenedor de Servlets desarrollado bajo el
proyecto Jakarta en la Apache Software
Foundation. Tomcat puede funcionar como
servidor web por sí mismo. Implementa las especificaciones
de los Servlets y de JavaServer Pages (JSP) de Sun
Microsystems. Dado que Tomcat fue escrito en Java,
funciona en cualquier sistema operativo que disponga de la
máquina virtual Java.
Eclipse Helios
Este IDE de Java ha sido descargar de la web de
Eclipse, la última versión. En este caso se trataba de la
versión de Eclipse Helios, y se descargó la que ponía
"Eclipse IDE for Java developers". Con un peso de unos
200MB, y la versión de 64 bits, correspondientemente con
la arquitectura del ordenador usado.
Tras su posterior descarga es necesaria su extracción
del zip y su posterior instalación. Al crear el proyecto, se
crea un proyecto en la pestaña de web, Dynamic web
Project, ya que se va a generar contenido dinámico. Al ir a
C

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
141
ejecutar se indica que se tiene que seleccionar tanto un
servidor web, como una JDK para compilar, con su
correspondiente JVM(Java Virtual Machine).
Tomcatv6
Al seleccionar un servidor web para probar el
proyecto por defecto viene el IBM WebSphere v 6.0. sin
embargo al no tratarse del servidor que se va a usar para la
producción del proyecto se decidió ir a la pestaña de apache
en busca de mi querido Apache Tomcat 6.0..El problema es
que ya no se encuentra, y se indica donde está instalado
para descargarlo. Se buscó en la web y se descargó de
tomcat.apache.org, la binary distribution de la versión 6.0.
de este reconocido servidor web.
Tras descomprimirlo no es necesario instalarlo, se
indica su ruta al eclipse y al ir a ejecutar el proyecto avisa
de que no arranca correctamente. Se intenta levantar por
comandos y entonces un error mucho más claro aparece. Ni
la JAVA_HOME ni la JRE_HOME están definidas. Se
procede a la búsqueda de dónde se crean estas variables, ya
que las variables globales del SO según la versión del
Windows se hace de una forma o de otra. Sin embargo
normalmente esta en propiedades del sistema en opciones
avanzadas, en la parte inferior que pone variables de
entorno. Ahí se pasa a definirlas.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
142
JRE
Al ir a ejecutar el proyecto aparece un aviso de que la
JRE que se va a usar es la jre_1.6.0_03, que es la última
versión disponible, o por lo menos la ultima que viene
instalada por defecto en esta JDK, por consiguiente en esta
versión del compilador Eclipse.
Subversion
Durante el desarrollo del proyecto se ha ido subiendo
el código en un host de SVN, donde se almacena aparte la
documentación que se va cogiendo y una wiki en la que se
apuntaba alguna cosa. La web del servicio de SVN web es
http://www.xp-dev.com/, el nombre de mi proyecto es
dentro JenaSourceControl, proyecto jena2. Para ir
actualizando el contenido se ha usado un plugin de Eclipse,
el conocido subversión, que con un solo clic solicitando el
usuario y contraseña, permite actualizar las distintas
versiones del código. (17)
8.2. Proyecto en
explotación
Tomcat v6 Servidor Web
Una vez conectados los Servlets correctamente con
el código de mi algoritmo se instala una versión de este

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
143
contenedor de Servlets de manera que pueda correr como
servicio Windows o demonio, y este a la escucha tras
arrancarse el ordenador. Todas las peticiones entrantes se
encarga el Tomcat v6 de responderlas. Se puede comprobar
que si se a accede a generar un usuario, luego te deja logear
con ese nombre de usuario y acceder a su menú,
mostrándose sus contenidos.
Establecido el servidor Tomcat 6.0, corriendo con el
contexto del programa a la escucha de las peticiones.
Recibe las peticiones del router, gracias a que el router envía
los paquetes recibidos del exterior al puerto 80, los re
direcciona, a la IP publica de mi servidor web.
DynDNS
Ahora la web está colgada en:
http://myweb.endofinternet.net/. Se puede acceder desde
cualquier lugar, gracias a que el router esta dado de alta en
DynDNS. Es un servidor de nombres que se encarga de
publicar y recibir las IPs de los puertos dinámicos. Se ha
planteado en un futuro la compra de un dominio más
sencillo. (18)
JVM
La Java Virtual Machine que usa el apache es el que
se encarga de convertir el código bytecode, tanto los .jar
como los .class, en código maquina. Una Máquina virtual
Java (en inglés Java Virtual Machine, JVM) es un máquina

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
144
virtual de proceso nativo, es decir, ejecutable en una
plataforma específica, capaz de interpretar y ejecutar
instrucciones expresadas en un código binario especial (el
Java bytecode), el cual es generado por el compilador del
lenguaje Java.
El código binario de Java no es un lenguaje de alto
nivel, sino un verdadero código máquina de bajo nivel,
viable incluso como lenguaje de entrada para un
microprocesador físico. La JVM es una de las piezas
fundamentales de la plataforma Java.
Red con router 3com
Se trata de una red con un punto de acceso con IP
pública dinámica, y en el interior una red privada con IP
fija, sin usar DHCP. Lo que ha permitido usar reglas de
NAT, que re direccionan los paquetes de TCP que llegan al
router por el puerto 80, son redireccionados a una IP
privada fija. Además en e router se han abierto una serie de
puertos para poder acceder desde el exterior.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
145
9. Presupuesto
e ha realizado una estimación de presupuesto
de implantación de la aplicación.
Se ha estimado la realización del proyecto en un total
de 4.800 euros.
SRecursos Humanos
Horas €/Hora Total
Análisis Aplicación 100 10 1.000 €
Desarrollo Aplicación 120 10 1.200 €
Análisis Base de Datos 60 10 600 €
Desarrollo Base de Datos 40 10 400 €
Subtotal 300 3.200 €
Recursos Técnicos
Hardware
Horas €/Hora Total
Servidor P-IV,
12028Mb RAM, 550 HDD 700 €
Subtotal 700 €
Software
Horas €/Hora Total
Ms Windows 7Home Edition 150 €
My SQL Server 5 SE Edition 0 €
Java 0 €
Subtotal 2.700 €
PRESUPUESTO TOTAL 4.800 €

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
146
Hay que tener muy en cuenta que el proyecto se ha
realizado íntegramente usando SW libre, menos el Sistema
Operativo, que se selecciono finalmente Windows, por los
problemas encontrados en los SO de SW libre, tales como
Linux. Recuérdese que estos datos son aproximados ya que
este estudio es irreal, no es más que una aproximación, ya
que nadie ha cobrado por estos servicios ni por el hardware.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
147
10. Planificación
a planificación de este proyecto como se ha
comentado anteriormente ha venido marcado
por los hitos del proyecto, y ha venido muy
marcada por la necesidad de programar constante, para
desenvolverse en los nuevos entornos tecnológicos
encontrados, como se puede observar en la Ilustración 9.1.
Ha sido uno de los procesos más complejos de este
desarrollo ya que el proyecto ha sido realizado
compaginándose con otras actividades. Se ha procurado
tener una planificación sensiblemente flexible, por lo que la
planificación ha sido utilizada para recordar los hitos para
la entrega del proyecto de fin de carrera.
También ha tenido una labor muy importante de
organización, de priorización de objetivos y de organización.
A continuación se muestra un esquema de la planificación:.
6.6.6.6.
L
Ilustración 10.1

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
148
11. Conclusiones
l proyecto se ha desarrollado en un entorno
de trabajo complicado ya que ha sido un año
muy intenso con muchas variables y con
mucho aprendizaje constante, ya que ha sido compaginado
con una beca en Telefónica I+D. Se considera que ha
servido para desarrollar intelectualmente una serie de ideas
y conceptos que apenas se conocían y que han resultado
ser altamente interesantes.
Con los resultados obtenidos y la investigación
llevada a cabo se puede afirmar que hay proyectos muy
interesantes e innovadores, abarcando diferentes campos
de actuación, que los procesos de desarrollo tecnológico son
inacabables, y que el verdadero desafío está en saber
buscarlos, elegirlos y priorizarlos. Es sorprendente
constatar la cantidad de gente que, al calor del software
libre, comparte su trabajo y trabaja por vocación, sin los
cuales el proyecto no hubiera sido posible.
En este sentido, el proyecto de “myWeb" ha servido
para llevar a cabo un aprendizaje muy completo tanto a
nivel tecnológico, como a nivel conceptual. En muchos
momentos los retos de comprensión e interiorización
conceptuales han sido más complicados que las propias
tecnologías en sí mismas. Ha habido un periodo no
esperado, de interiorización de conceptos: como el de la web
semántica, el de algunas técnicas de inteligencia artificial o
los propios servicios web.
E

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
149
Debido a la curva de aprendizaje tan alta ha sido
complicado en algunos momentos separar algunas ideas de
otras y visualizarlas como tareas independientes. Ha sido
por ejemplo costoso asimilar que se podía llegar a conseguir
al obtener ontologías. Otro reto ha sido definir
completamente desde cero un servicio como el finalmente
generado, aunado grandes esfuerzos para dotar a todos los
desarrollos de un hilo común.
Todos estos desarrollos hubiesen sido más sencillos
con una fase de análisis mayor, pero al no disponer de
conocimientos tecnológicos suficientes no se llevo a cabo
correctamente, malinterpretándose algunos conceptos
inicialmente. Esto ocurrió por ejemplo al intentar acceder a
información en un disco duro local a través de un servicio
web, fruto de la inexperiencia y desconocimiento,
retrasando el desarrollo final.
Sin embargo los objetivos han sido satisfechos en su
práctica totalidad, con la elaboración automática de una
ontología y su correspondiente base de conocimientos
asociada a la web semántica, disponiendo además de un
algoritmo de recomendación de contenidos y de una
aplicación web para mostrar los resultados.
Tras esta entrega es más que probable que el proyecto
siga creciendo de manera que su ontología siga
desarrollándose con el algoritmo y sus recomendaciones
sean cada vez más precisas y completas. Se pretende seguir
desarrollando “my Web” con el fin de conseguir un interfaz
más amigable y dinámica, así como un sistema de caché,

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
150
para realizar las peticiones de forma asíncrona a los
diferentes servicios, anticipándose a posibles peticiones del
usuario para mejorar su usabilidad. Se prevé añadir un
algoritmo de aprendizaje automático, echado en falta, que
enriquezca el conocimiento adquirido y que permita que el
incremento de conocimiento sea controlado
estadísticamente a través de un conjunto de ejemplos.
Así mismo se va a seguir incorporando mejoras al
algoritmo clasificando mejor los contenidos y también se
ampliará el número de web semánticas de las que se extrae
información con el objetivo de incrementar el conocimiento,
mejorando la fiabilidad del sistema.
El estado de avance del proyecto “my Web” alcanzado
con este trabajo tendrá, pues, una estupenda oportunidad
de ser desarrollado y potenciado en futuras fechas. Y la
satisfacción profesional que suscita en su autor este
desarrollo inicial corre paralela con una confianza plena en
que su futura evolución podrá responder a todas las
promesas y expectativas que el presente proyecto permite
augurar.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
151
12. Tabla de ilustraciones
Ilustración 1.1 ........................................................ 11
Ilustración 3.1 ........................................................ 40
Ilustración 3.2 ........................................................ 21
Ilustración 3.3 ........................................................ 22
Ilustración 3.4 ........................................................ 24
Ilustración 3.5 ........................................................ 28
Ilustración 3.6 ........................................................ 31
Ilustración 3.7 ........................................................ 34
Ilustración 3.8 ........................................................ 36
Ilustración 3.9 ........................................................ 37
Ilustración 3.10 ...................................................... 40
Ilustración 3.11 ...................................................... 45
Ilustración 3.12 ...................................................... 50
Ilustración 3.13 ...................................................... 50
Ilustración 3.14 ...................................................... 51
Ilustración 3.15 ...................................................... 81
Ilustración 3.16 ...................................................... 60
Ilustración 3.17 ...................................................... 63
Ilustración 3.18 ...................................................... 64
Ilustración 5.1 ........................................................ 74
Ilustración 5.2 ........................................................ 75
Ilustración 5.3 ........................................................ 77
Ilustración 5.4 ........................................................ 80
Ilustración 5.5 ........................................................ 91

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
152
Ilustración 5.6 ........................................................ 83
Ilustración 5.7 ........................................................ 84
Ilustración 5.8 ........................................................ 85
Ilustración 5.9 ........................................................ 85
Ilustración 5.10 ...................................................... 88
Ilustración 5.11 ...................................................... 90
Ilustración 5.12 ...................................................... 91
Ilustración 5.13 ...................................................... 94
Ilustración 7.1 ...................................................... 135
Ilustración 7.2 ...................................................... 136
Ilustración 7.3 ...................................................... 137
Ilustración 7.4 ...................................................... 145
Ilustración 10.1 .................................................... 146

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
153
13. Bibliografía
[1]. -
http://www.maestrosdelweb.com/editorial/web2/.
[2]. -
http://www.maestrosdelweb.com/editorial/web2/.
[3]. -
http://www.maestrosdelweb.com/editorial/web2/.
[4]. -
http://www.maestrosdelweb.com/editorial/web2/.
[5]. - http://web30websemantica.comuf.com/.
[6]. - jena.sourceforge.net/.
[7]. - http://jena.sourceforge.net/tutorial/RDF_API/.
[8]. - http://es.wikipedia.org.
[9]. - http://www.wiwiss.fu-
berlin.de/en/institute/pwo/bizer/research/publications/Bi
zer-etal-DBpedia-CrystallizationPoint-JWS-Preprint.pdf.
[10]. - http://www4.wiwiss.fu-
berlin.de/bizer/pub/DBpedia-WWW2007-draft-slides.pdf.
[11]. - http://www2007.org/papers/paper391.pdf.
[12]. -
http://musicbrainz.org/doc/FrequentlyAskedQuestions.
[13]. -
http://java.ciberaula.com/articulo/introduccion_jstl/.
[14]. - www.superhosting.cl/.../administrar-y-
actualizar-una-base-de-datos-mysql-desde-access.html.

Jorge Gil Peña Ingeniería Superior Informática. ICAI.
Herramienta para construir bases de conocimiento a partir de información en la web
154
[15]. -
http://www.admin.cam.ac.uk/news/dp/2009082101.
[16]. -
http://www.ibm.com/developerworks/xml/library/j-jena/.
[17]. - subclipse.tigris.org.
[18]. - https://www.dyndns.com/ .
[19]. - http://www.antronio.com/topic/1000995-
estilo-musical-favorito-tiene-relacion-con-tu-nivel-de-
inteligencia/.


















