
INSTITUTO POLITÉCNICO NACIONAL - 148.204.210.201148.204.210.201/tesis/1436974736225PDF.pdf ·...
83
INSTITUTO POLITÉCNICO NACIONAL UNIDAD PROFESIONAL INTERDISCIPLINARIA DE INGENIERÍA Y CIENCIAS SOCIALES Y ADMINISTRATIVAS SECCIÓN DE ESTUDIOS DE POSGRADO E INVESTIGACIÓN PROPUESTA DE METODOLOGÍA DE DESARROLLO DE MODELOS DE SIMULACIÓN DE EVENTO DISCRETO EN ARENA PARA ANÁLISIS FARMACOECONÓMICO TESIS QUE PARA OBTENER EL GRADO DE: MAESTRO EN INGENIERÍA INDUSTRIAL PRESENTA: NORMAN RICARDO NAVARRETE FIGUEROA DIRECTOR DR. FAUSTINO RICARDO GARCÍA SOSA MÉXICO, D.F. 2015
Transcript of INSTITUTO POLITÉCNICO NACIONAL - 148.204.210.201148.204.210.201/tesis/1436974736225PDF.pdf ·...

INSTITUTO POLITÉCNICO NACIONAL
UNIDAD PROFESIONAL INTERDISCIPLINARIA DE
INGENIERÍA Y CIENCIAS SOCIALES Y ADMINISTRATIVAS
SECCIÓN DE ESTUDIOS DE POSGRADO E INVESTIGACIÓN
PROPUESTA DE METODOLOGÍA DE DESARROLLO DE
MODELOS DE SIMULACIÓN DE EVENTO DISCRETO EN
ARENA PARA ANÁLISIS FARMACOECONÓMICO
TESIS
QUE PARA OBTENER EL GRADO DE:
MAESTRO EN INGENIERÍA INDUSTRIAL
PRESENTA:
NORMAN RICARDO NAVARRETE FIGUEROA
DIRECTOR
DR. FAUSTINO RICARDO GARCÍA SOSA
MÉXICO, D.F. 2015



Agradecimientos
A Dios, por acompañarme a lo largo de este camino y permitirme llegar hasta
aquí. Gracias porque nunca he caminado solo y porque todos esos caminos,
que a veces no he entendido, me han llevado hasta aquí
A mi Madre con todo mi cariño, orgullo y admiración por acompañarme
durante toda esta etapa. Por ser siempre un ejemplo de perseverancia, de
cariño, de fortaleza, de humildad. Por enseñarme que todo es posible y que a
pesar de caer, siempre te puedes levantar, aprender y ver hacia adelante.
A mi abuelita (QEPD) por su ejemplo de vida y porque sin su apoyo nada de
esto habría pasado.
A mi primo Miguel por estar, por escuchar, por entenderme, por hacerme ver
las cosas de otra manera. Siempre con toda mi admiración y cariño.
A mi tío Pepe, por acompañarme y compartir conmigo con todo mi cariño.
A mis amigos, Bob y Obe, porque siempre sus consejos y apoyo me han
ayudado para ver la luz en los momentos más oscuros, a ver las cosas de otra
manera y a no tener miedo de intentar nuevos retos.
Al profesor Faustino por todo su apoyo en la realización de este trabajo.
A todos los profesores que han contribuido a mi formación, tanto académica
como personal.
A todas las personas que me han acompañado durante esta etapa y que me han
enseñado a ver otro punto de vista, que me han ayudado a crecer, a
entenderme, a descubrirme y a ver otras formas de hacer las cosas. Sin su
apoyo no estaría aquí.
Esto es sólo el inicio de una nueva etapa.

Resumen
Hoy en día, el sector salud requiere de una gran cantidad de recursos, tanto
económicos, como humanos y materiales para atender diversos padecimientos,
por ejemplo, la diabetes, que es la principal causa de muerte en México y que
actualmente es padecida por más de 8 millones de personas a nivel nacional,
cifra que crece año con año. Tratar estas enfermedades representa un alto
costo para el sistema de salud mexicano ya que generalmente vienen asociadas
con una series de complicaciones que afectan la calidad de vida de los
pacientes, al mismo tiempo que generan costos adicionales tanto directos
como indirectos.
Para el sector salud es fundamental tener un estimado de las necesidades para
tratar los distintos padecimientos de la población en los años siguientes para
asegurarse de tener tanto el presupuesto como los recursos materiales para
atender a todos los pacientes.
Mediante este trabajo, se desea desarrollar una propuesta de metodología que
utilice la simulación de evento discreto como base para realizar análisis
farmacoeconómicos de diversas enfermedades a nivel nacional.
Finalmente, se presentará un caso práctico en el cual se desarrollará un
modelo de simulación de evento discreto en el software Arena® para calcular
el costo del tratamiento de la diabetes tipo II en México, se ha elegido esta
enfermedad como un buen caso de estudio ya que se presenta con una serie de
complicaciones asociadas, además de que su evolución depende directamente
del tipo de tratamiento que siga, lo cual tiene un impacto directo en los
recursos monetarios necesarios para tratarla.

Abstract
Nowadays, a large amount of money, human and material resources are
required to look after people’s health and treat illnesses such as diabetes, for
example, which is suffered by more than 8 million people in Mexico and is the
first cause of death in our country. Dealing with these illnesses represents a
large cost to the health sector because they are usually related to some other
complications that affect people’s quality of life and that generate additional
direct and indirect costs.
For the health sector is vital to have an estimate of the needs of the population
over the next years in order to make sure that they will have the resources
needed to treat all of the patients.
The objective of this document is to propose a methodology that uses discrete
event simulation to develop pharmacoeconomic analyses of diverse illnesses
that are present in Mexico.
Finally, it is intended to develop a simulation model in Arena® to calculate
the costs derived from treating type II diabetes in Mexico, this illness has been
chosen because it is known to have to some collateral effects that increase its
treatment costs depending on the treatment followed by the patients, making it
a good study case.

Índice
Capítulo 1 ................................................................................................................................................... 9
1.1 Antecedentes ................................................................................................................................. 1
1.2 El Impacto de la Diabetes .......................................................................................................... 2
1.3 Problemática .................................................................................................................................. 3
1.4 Objetivos ......................................................................................................................................... 4
1.5 Hipótesis de Investigación ......................................................................................................... 4
1.6 Metodología de Investigación .................................................................................................. 4
Capítulo 2 ................................................................................................................................................... 6
2.1 La Simulación como herramienta de toma de decisiones ................................................ 6
2.2 Generación de números aleatorios .......................................................................................... 8
2.3 Estimación de parámetros para datos de entrada a modelos de simulación ............. 10
2.4 Uso de distribuciones de probabilidad para los datos de entrada en un modelo de
simulación .......................................................................................................................................... 15
2.5 Simulación de evento discreto............................................................................................... 16
2.5.1 Procesos de Markov en Simulación de Evento Discreto. .......................................... 17
2.6 Simulación de evento continuo ............................................................................................. 19
2.7 Otras consideraciones teóricas del uso de modelos de simulación ............................. 19
2.8 Uso de modelos de pronóstico y financieros para estimación de resultados de
modelos de simulación ................................................................................................................... 20
Capítulo 3 ................................................................................................................................................ 21
3.1 Métodos alternativos para la realización de análisis farmacoeconómicos ............... 21
3.2 Utilización de Simulación de Evento Discreto Para Análisis Farmacoeconómico 23
3.3 Ventajas del Uso de Simulación de Evento Discreto para Análisis
Farmacoeconómico .......................................................................................................................... 25
3.4 Desventajas del Uso de Simulación de Evento Continuo para Análisis
Farmacoeconómico .......................................................................................................................... 27
3.5 Construcción de Modelos Válidos de Simulación ........................................................... 27
Capítulo 4 ................................................................................................................................................ 33
4.1 Introducción al Análisis Farmacoeconómico .................................................................... 33
4.2 La Calidad de Vida y Preferencia de los Pacientes ......................................................... 34
4.3 Desarrollo de un Modelo de Análisis Farmacoeconómico ........................................... 35
1

Capítulo 5 ................................................................................................................................................ 37
5.1 Características generales del modelo de simulación. ..................................................... 37
5.2 El origen de los datos ............................................................................................................... 38
5.3 Escenarios de Simulación ....................................................................................................... 40
5.4 Entidades por Simular en el Modelo. .................................................................................. 41
5.4.1 Estimación de Características Físicas de Pacientes ..................................................... 42
5.4.2 Aparición de Complicaciones en Pacientes Diabéticos.............................................. 45
5.5 Las variables del modelo. ....................................................................................................... 49
5.6 Costos ........................................................................................................................................... 50
5.7 Complicaciones en el desarrollo del modelo .................................................................... 51
Capítulo 6 ................................................................................................................................................ 52
6.1 Características Físicas de los Pacientes .............................................................................. 52
6.2 Complicaciones ......................................................................................................................... 56
6.3 Costos de Tratamiento de Diabetes ..................................................................................... 60
CONCLUSIONES ................................................................................................................................ 67
ANEXO I ................................................................................................................................................. 70
REFERENCIAS .................................................................................................................................... 71
Referencias bibliográficas ............................................................................................................. 71
Referencias electrónicas ................................................................................................................. 72

Índice de Figuras
Figura 3.1 Proceso de Validación de un Modelo de Simulación……………………...…..29
Figura 5. 1 Vista general del modelo de simulación ……………………………...………38
Figura 5.2 Cadena de Markov para Complicaciones ……………………………...……...48
Figura 6.1 Talla de los Pacientes ……………………………….……...............................54
Figura 6.2 Edad de los Pacientes……………………….……………................................54
Figura 6.3 Índice de Masa Corporal…………………….…………………………………55
Figura 6.4 Sexo de los Pacientes…………………………..………………………………56
Figura 6.5 Costo de Tratamiento Individual Acumulado …………………………………62
Figura 6.6 Variación % en Costo vs. Escenario Base ……………………………………63
Figura 6.7 Variación % en Costo vs. Escenario Base Total …………….…...……..……66
Índice de Tablas
Tabla 5.1 Características Físicas de los Pacientes………………………………………....42
Tabla 6.1 Características Físicas de los Pacientes………………………………………....52
Tabla 6.2 Parámetros de Entrada y Calculados para Talla de una Distribución Triangular.53
Tabla 6.3 Parámetros de Entrada y Calculados para Edad IMC de una Distribución Beta.53
Tabla 6.4 Incidencia de Complicaciones Cardiovasculares……..…………………………57
Tabla 6.5 Reducción en QALY’s por Complicaciones Cardiovasculares.…...……………57
Tabla 6.6 Incidencia de Complicaciones Renales….………………………………………58
Tabla 6.7 Reducción en QALY’s por Complicaciones Renales……………...……………58
Tabla 6.8 Incidencia de Complicaciones en Ojos…………………………….……………58
Tabla 6.9 Reducción en QALY’s por Complicaciones en Ojos……………...……………59
Tabla 6.10 Incidencia de Complicaciones por Úlceras……………………….……………59
Tabla 6.11 Reducción en QALY’s por Complicaciones por Úlceras………...……………59
Tabla 6.12 Incidencia de Complicaciones por Neuropatías……………………..…………60
Tabla 6.13 Reducción en QALY’s por Complicaciones por Úlceras……………...………60
Tabla 6.14 Costo de Tratamiento Individual Acumulado………………………….………61
Tabla 6.15 Costo Total Estimado de Tratamiento de Diabetes…………………….………65

1
Capítulo 1
El Impacto Económico del Cuidado de la Salud en México y el Mundo
1.1 Antecedentes
A nivel mundial, se estima que anualmente se dedica el 7.1% del Producto Interno Bruto
para la atención del sector salud, tanto público como privado (Banco Mundial 2012). De
acuerdo con datos del Banco Mundial (Banco Mundial 2012), se estima que este porcentaje
ha aumentado en un 25% en los últimos 20 años. El crecimiento de la población mundial, el
estilo de vida sedentario, la aparición de nuevas enfermedades, los problemas alimenticios
o el aumento en la esperanza de vida son sólo algunas de las razones por las cuales ha sido
necesaria una mayor asignación de recursos al cuidado de la salud.
Tan sólo en México, se estima que en 2012 se dedicaron más de 72 mil millones de dólares
al cuidado de la salud, equivalentes al 6.1% del PIB del mismo año (Banco Mundial 2012).
Una gran parte de estos recursos se destinó para la atención de enfermedades como la
diabetes, que actualmente es la primera causa de muerte en nuestro país (Ensanut, 2011),
afecciones cardíacas, problemas gastrointestinales, enfermedades respiratorias,
desnutrición, entre muchas otras. Se estima que muchos de estos padecimientos tendrán una
mayor incidencia en los siguientes años (Shaw et al. 2011), incrementándose así los
recursos necesarios para atender estos padecimientos en el largo plazo. Esto genera la
necesidad de entender cuál será el impacto que estos cambios tendrán en el sector salud
mexicano, no sólo en lo que a costos se refiere sino en la asignación de recursos médicos
para así poder atender de forma adecuada a los pacientes que lo requieran.
Los principales padecimientos registrados en la población mexicana son enfermedades que
requieren de una gran atención, no sólo de recursos económicos, sino de personal, equipo
médico y tiempo. Padecimientos como la diabetes no sólo están relacionados con un alto
nivel de glucosa en la sangre sino que conllevan una serie de efectos secundarios que
requieren de constante atención médica, de una gran asignación de recursos, de

2
medicamentos y de acciones preventivas para evitar que el daño generado por esta
enfermedad aumente, disminuyendo así la calidad de vida de los pacientes.
De acuerdo con datos de la Secretaría de Salud, en 2010, cerca de 90 millones de
mexicanos estaban afiliados a alguna institución de salud pública. Siendo el IMSS la
institución con más afiliados (45 millones de derechohabientes), seguido por el Seguro
Popular (33 millones de afiliados) y finalmente el ISSSTE (11 millones de asegurados)
(Secretaría de Salud 2010). Y se estima que sólo en el IMSS, el número de
derechohabientes crece a una tasa cercana al 5% anual (IMSS 2011).
Lo anterior genera la necesidad de contar con una herramienta con una perspectiva a
mediano y largo plazo que sirva como auxiliar en la toma de decisiones de política pública
de salud a través de la cual se pueda estimar los recursos que serán necesarios para brindar
una atención adecuada a los derechohabientes de las instituciones de salud pública
principalmente.
1.2 El Impacto de la Diabetes
Se estima que a nivel mundial, cerca del 5% de la población padece algún tipo de diabetes
(Organización Mundial de la Salud 2012). De acuerdo con datos del Sistema Nacional de
Información en Salud, en México, esta enfermedad se ha convertido en la primera causa de
muerte (Ensanut 2009). En 2009 más del 14% de los decesos registrados se adjudican a la
diabetes o a complicaciones derivadas de la presencia de esta enfermedad. De acuerdo con
Shaw, en 2011 había más de 7 millones de casos de diabetes registrados en México y cada
año se diagnostican cerca de 250,000 nuevos casos (Shaw et al. 2009), convirtiéndose así
en el principal problema de salud de nuestro país.
De acuerdo con la Asociación Americana de Diabetes, esta enfermedad se caracteriza por la
presencia de un alto nivel de azúcar en la sangre como resultado de una deficiencia del
cuerpo para producir y/o utilizar insulina. La insulina es una hormona cuya función es
convertir la glucosa en energía para el cuerpo (American Diabetes Association 2011).
Existen varios tipos de diabetes, pero los más comunes son el tipo I, caracterizado por la
inhabilidad del cuerpo para producir insulina, y el tipo II, caracterizado porque la
producción de insulina no es suficiente o es ignorada por las células del cuerpo. Se estima
que más del 90% de los casos de diabetes son del tipo II.

3
La diabetes es una enfermedad que tiene ciertas características que la hacen especial, ya
que junto con ella se presenta una serie de complicaciones asociadas a un descontrol en el
nivel de glucosa en la sangre, entre las que se encuentran problemas renales, fallas
cardíacas, pie diabético o deficiencias en la visión (American Diabetes Association 2011).
La presencia de estos efectos secundarios merma la calidad de vida del paciente que padece
esta enfermedad, por lo que se debe monitorear de cerca su progreso por un especialista.
El tratamiento de enfermedades como la diabetes genera un gran costo para el sector salud,
se estima que durante 2010, se gastaron más de 800 millones de dólares en México
únicamente en su tratamiento y el de las complicaciones asociadas (Arredondo 2010). El
45% de los costos registrados corresponde únicamente a los costos directos del tratamiento
de la diabetes y sus complicaciones, mientras que el resto se asocia a costos indirectos tales
como el ausentismo laboral, discapacidad permanente o muerte prematura (Arredondo
2010).
La diabetes es tratada por diversas instituciones en nuestro país, tanto privadas como
públicas, entre estas últimas se encuentran los ya mencionados ISSSTE, Seguro Popular e
IMSS, tan sólo en esta institución, se estima que se gastaron más de 210 millones de
dólares en el tratamiento de esta enfermedad en 2009. (Villarreal 2009).
1.3 Problemática
Como se ha mencionado en los apartados anteriores, el tema del cuidado de la salud ha
cobrado una mayor importancia en los últimos años, especialmente porque cada vez es
necesaria una mayor asignación de recursos debido a que el número de pacientes con algún
padecimiento que requiere un tratamiento a largo plazo ha aumentado en los últimos años.
Para tratar enfermedades como la diabetes es necesario invertir una gran cantidad de dinero
para contar con los medicamentos necesarios para su tratamiento, doctores disponibles,
equipos de análisis, estudios clínicos, entre otros.
Adicionalmente, es necesario tener un estimado del impacto de los nuevos casos de
determinada enfermedad que se presentarán cada año para así hacer una asignación
adecuada de recursos que pueda cubrir la demanda que se tendrá de servicios de salud en un
futuro.
Lo anterior genera la necesidad de contar con una herramienta auxiliar en la toma de
decisiones en materia de política pública de salud. Una herramienta que permita calcular de

4
forma eficiente los recursos médicos que será necesario asignar para el tratamiento de cada
enfermedad y que al mismo tiempo provea un estimado confiable de cuál sería el costo de
tratamiento por persona, por enfermedad, por unidad médica, por período, etc. Finalmente,
mediante esta herramienta debería ser posible analizar diferentes escenarios en el
tratamiento de enfermedades y medir su impacto sin la necesidad de realizar estudios
clínicos que podrían requerir de mucho tiempo y recursos.
1.4 Objetivos
Mediante este trabajo de investigación se pretende desarrollar una metodología que sirva
como base para la generación de modelos de simulación a través de los cuales se pueda
replicar el comportamiento de enfermedades como la diabetes en todas sus aristas. Se
pretende estudiar todas las características que precisa un modelo de este tipo, tanto teóricas
como prácticas. Así mismo, se busca hacer una comparación entre distintos tipos de
simulación que existen en la actualidad y se buscará cuál es el tipo de modelo que es más
conveniente utilizar.
Finalmente, con el conocimiento investigado se desarrollará un modelo de simulación a
través del cual se replicará el comportamiento de la diabetes y su atención en una
institución médica como el Instituto Mexicano del Seguro Social y con base en esto
desarrollar un análisis de los costos generados por la atención de esta enfermedad y su
impacto sobre la calidad de vida de los pacientes.
1.5 Hipótesis de Investigación
La hipótesis que se presenta en este trabajo de investigación establece la posibilidad de
desarrollar una estrategia metodológica que permita el uso y desarrollo de modelos de
simulación para su uso en el sector salud como una herramienta auxiliar en la toma de
decisiones de política de salud que permita, de forma precisa, replicar enfermedades que se
atienden en las instituciones de salud pública de México y con ello realizar fácilmente
análisis que permitan medir el impacto de estas enfermedades, tanto en costos como en
calidad de vida de los pacientes, para así tomar las medidas correspondientes para
garantizar una correcta atención en estas instituciones.
1.6 Metodología de Investigación
Este trabajo se desarrollará en dos etapas distintas:

5
La primera comprende de una investigación sobre el uso de modelos de simulación.
En primer lugar se analizarán sus características teóricas, es decir, qué es lo que
debe tener todo modelo de simulación que se desarrolle en el sector salud, además
de todas las implicaciones teóricas tanto para generar el modelo como para analizar
los resultados.
En esta etapa también se analizarán distintos tipos de simulación, principalmente la
de evento discreto y la de evento continuo y se definirá cuál de ellos es mejor para
modelar enfermedades y su atención en clínicas.
Finalmente, se explicará la forma en la que se aplican los modelos de simulación al
sector salud y las consideraciones que se deben tener.
La segunda etapa, la cual es práctica, comprende el desarrollo de un modelo de
simulación que represente el tratamiento de la diabetes en alguna institución de
salud pública en México. A través de diversos estudios clínicos se ha obtenido
información sobre la forma en que se trata la diabetes en estas instituciones y con
base en información recolectada por López (López et al. 2007) acerca del
comportamiento de la enfermedad, la presencia de complicaciones, su tratamiento y
costos se desarrollará un análisis farmacoeconómico a través del cual se medirá el
impacto potencial, en costos y calidad de vida de los pacientes, de tratar o no esta
enfermedad sobre el sistema de salud mexicano.

6
Capítulo 2
Elementos Teóricos de la Simulación
2.1 La Simulación como herramienta de toma de decisiones
La simulación es el proceso de creación y experimentación de un sistema físico con un
modelo matemático computarizado (Chung 2003).
La simulación es una herramienta de análisis de comportamiento de un sistema, siendo este
definido como una colección de componentes que interactúan entre sí y que reciben y
proporcionan información a lo largo del tiempo (Law 2007). La base de un sistema es un
modelo, que no es otra cosa que una representación de la parte de la realidad que se desea
estudiar. Para que un modelo sirva como una efectiva herramienta de análisis y toma de
decisiones es necesario que represente de forma precisa la parte del sistema que se requiere
estudiar.
Lo anterior se logra mediante una adecuada inclusión de variables, tanto aleatorias como
deterministas, una correcta definición de las reglas que rijan el comportamiento del sistema
a lo largo del tiempo, las herramientas adecuadas para el análisis de los resultados
obtenidos y una óptima herramienta de desarrollo de modelos de simulación.
A lo largo del tiempo, la simulación se ha convertido en una herramienta cada vez más
usada en diversos ámbitos que van desde la salud hasta la manufactura pasando por áreas
como la comunicación o la teoría de colas (Law 2007). Aunado a esto, debido al avance
que ha habido en la computación, los paquetes de simulación con los que se cuenta hoy en
día son más poderosos, lo cual ha permitido que la simulación se convierta también en una
poderosa herramienta de análisis. Anteriormente, si se quería desarrollar un modelo de
simulación se requerían grandes conocimientos de programación, además de que, dadas las
restricciones computacionales, no era posible incluir un gran número de variables ni reglas
de cambio para modelar sistemas, sin embargo, con el avance en los paquetes
computacionales para simulación, cada vez es posible la inclusión de un mayor número de

7
variables, reglas de cambio, escenarios y características de los modelos que permiten
realizar mejores análisis y que los resultados obtenidos se puedan aplicar de forma
eficiente.
El uso de la simulación como herramienta de análisis y de toma de decisiones presenta
grandes ventajas, siendo una de las principales que cuando se desea estudiar un sistema, no
es necesario tener un modelo físicamente, cosa que sería bastante costosa, sino que
mediante herramientas computacionales es posible reproducirlo con gran precisión (Caro
2005). Adicional a esto, cuando se tiene un modelo a computadora es fácil realizar cambios
en caso de que sea necesario, incluir otras variables o estudiar distintos escenarios
cambiando alguna característica, por ejemplo, cuando se modela la atención de clientes en
un banco, se puede diseñar un modelo en el que haya únicamente un cajero, otro en el que
haya dos y así sucesivamente, según sean las necesidades del analista. Lo anterior posiciona
a la simulación como una herramienta flexible (Caro 2005) y que permite explorar un gran
número de posibilidades sin las dificultades que conllevaría realizarlas en la vida real.
Otra ventaja encontrada en el uso de la simulación es la posibilidad de obtener resultados
de algún experimento en un tiempo relativamente corto (Caro 2005). Esto representa un
gran cambio ya que al realizar un experimento, en lugar de esperar años a tener resultados,
estos se podrían obtener un tiempo considerablemente menor. Adicional a esto, mediante la
simulación se pueden hacer varias réplicas de un mismo experimento con el fin de obtener
significancia estadística y que los resultados obtenidos se consideren válidos para su uso
(Mood et al. 1975. Esto se estudiará en apartados posteriores.
Finalmente, mediante la simulación se puede obtener una ayuda visual sobre el estado de
un sistema mediante la animación, de esta forma se puede observar cómo opera el sistema
simulado a lo largo del tiempo.
A pesar de que el uso de la simulación como herramienta de análisis presenta un gran
número de ventajas también hay ciertas consideraciones que se deben de tomar en cuenta
antes de comenzar a utilizarla. Estas desventajas no están directamente relacionadas con el
desarrollo del modelo sino con lo que se espera del mismo (Chung 2003). La primera es
que si los datos de entrada no son lo suficientemente confiables, el resultado que se obtenga
tampoco lo será, no importando qué tan bien se haya desarrollado el modelo. Esto recalca la
importancia de utilizar datos válidos de entrada como se verá en secciones posteriores.

8
Otra desventaja encontrada en el uso de simulación, está relacionada con el analista ya que
si el modelo realizado es demasiado elaborado, se puede complicar la interpretación de los
resultados. Cuando esto sucede, es recomendable formular supuestos que simplifiquen el
problema pero sin afectar aquellos críticos para el modelo, ya que si se alteran, podrían
modificar por completo la esencia del modelo y de lo que se espera del mismo (Chung
2003).
Finalmente, si los resultados de la simulación no se saben interpretar, entonces no es
posible utilizar la simulación como una herramienta confiable de toma de decisiones.
Al utilizar modelos de simulación, es importante mencionar que los resultados que se
obtienen del modelo están directamente relacionados con los datos de entrada que se
proporcionen para el mismo, independientemente del modelo realizado.
Antes de continuar con la descripción de los diversos tipos de simulación que existen y que
se pueden aplicar para el análisis farmacoeconómico, hay ciertas consideraciones teóricas
que se deben tener para entender correctamente el funcionamiento de la simulación y que
serán importantes para desarrollar un modelo de calidad así como para la correcta
interpretación de la información obtenida. Estas consideraciones se estudiarán en los
siguientes apartados.
2.2 Generación de números aleatorios
Dada la naturaleza de la simulación, la cual contiene elementos aleatorios, es necesario
estudiar la generación de variables aleatorias (Law 2007), ya que los resultados obtenidos
de un modelo, así como la asignación de atributos, generación de variables aleatorias, entre
otras características están fuertemente relacionados con la forma en la que se maneja la
aleatoriedad. De ahí la necesidad de entender el papel preponderante de los números
aleatorios en la simulación.
La primera parte que se explicará será la generación de números aleatorios, la cual parte de
una distribución uniforme en el intervalo [0,1], denotada por U(0,1), todos los números
generados a partir de esta distribución se conocen como números aleatorios. A pesar de que
esta es la distribución continua más sencilla, es de gran importancia poder generar números
aleatorios independientes a partir de la misma (Law 2007). Mediante la transformación de
los números aleatorios generados a partir de la distribución U(0,1), es posible obtener

9
valores numéricos para otras distribuciones de probabilidad tales como la normal, la beta o
la gamma.
Desde hace tiempo es sabida la importancia de contar con números aleatorios para la
realización de experimentos estadísticos. Los primeros métodos que se desarrollaron para
su generación eran bastante simples, comprendían desde lanzamiento de dados hasta la
obtención de números contenidos en urnas, entre otros. No fue sino hasta la década de 1930
en la que los estadísticos empezaron a enfocarse en la generación de números aleatorios.
Para 1938 Kendall y Babington-Smith desarrollaron un disco giratorio que podía generar
hasta 100,000 números aleatorios. Posteriormente, se usaron algunos dispositivos
electrónicos para su generación como un aparato desarrollado que enviaba señales
eléctricas a través de tubos al vacío para generar números al azar (Law 2007).
Conforme la computación y la simulación adquirieron más importancia, se puso más
atención a la forma en la que se generaban los números aleatorios ya que la forma en que se
hacía anteriormente ya no era suficiente para los modelos que se querían desarrollar.
Durante la década de 1940 y 1950 se comenzaron a desarrollar métodos numéricos o
aritméticos para la generación de números aleatorios que son la base de los generadores de
números aleatorios que usan hoy en día los programas de computación para simulación. Es
posible encontrar diversos generadores de números aleatorios y sus descripciones en (Law,
2007), en este apartado únicamente, se hará énfasis en la importancia de contar con un
generador de números aleatorios sólido y sus características para desarrollar un análisis
farmacoeconómico adecuado.
Las características con las que debe de contar un generador de números aleatorios son las
siguientes:
Los números aleatorios generados deben tener una distribución uniforme en el
intervalo [0,1] y no deben mostrar correlación entre ellos, ya que de ser así, los
resultados obtenidos son inválidos (Law 2007).
Desde un punto de vista práctico, un generador de números aleatorios debe poder
generarlos de forma fácil y sin necesidad de grandes recursos de memoria
computacional para su almacenamiento.
Debe ser posible reproducir una cadena de números aleatorios exactamente, esto por
dos razones: la primera es que esto puede facilitar el proceso de verificación de un

10
modelo computacional. La segunda razón es que puede ser necesario utilizar los
mismos números aleatorios para simular distintos sistemas o escenarios para
obtener comparaciones más precisas (Law 2007).
El generador utilizado debería producir una cantidad suficiente de números
aleatorios para ser utilizados en el modelo.
Finalmente, es deseable que el generador pueda producir la misma secuencia de
números aleatorios, partiendo de la misma raíz, para todas las computadoras y
compiladores, esto con el fin de poder replicar un experimento en diversas
computadoras y que los mismos datos de entrada arrojen los mismos resultados para
así validar el modelo, sin embargo, para obtener validez estadística es necesario
replicar el experimento generando distintos números aleatorios.
2.3 Estimación de parámetros para datos de entrada a modelos de simulación
Como se ha explicado en apartados anteriores, es necesario contar con información válida
para incluir en el modelo para que los resultados que se obtengan sean estadísticamente
confiables, sin embargo, hay ocasiones en las que la naturaleza de los datos no permite
asignarles una función que describa su comportamiento aleatorio a lo largo del tiempo, a
raíz de lo cual surge el problema de la estimación de parámetros de funciones de
probabilidad, lo cual se puede hacer de diversas maneras, la primera de ellas y la que se
utilizará en este trabajo, es el método de momentos.
La estimación mediante el método de momentos surge cuando se tiene únicamente
información estadística sobre una muestra de la población, pero se busca obtener
información poblacional con base en esta información presente.
Para entender a detalle el método de estimación por el método de momentos, es necesario
dar de algunas definiciones que de paso serán de utilidad para entender las consideraciones
teóricas de la simulación.
Definición (Variable Aleatoria)
Se dice que X es una variable aleatoria si 𝑋:Ω → ℝ, es decir, una función cuyo dominio es
el espacio muestral de un experimento aleatorio y cuyo contradominio es la recta real.
Una variable aleatoria puede ser de dos tipos:
Discreta: cuando está asociada a espacios muestrales numerables, por ejemplo,
procesos de conteo.

11
Continua: cuando está asociada a espacios muestrales no numerables como podría
ser una medición.
Definición (Función de Distribución de Probabilidad)
Al conjunto de probabilidades asociadas a la variable aleatoria X se le llama Distribución
de Probabilidad o Distribución de la variable aleatoria X.
Definición (Función de Densidad de Probabilidad)
Si X es una variable aleatoria continua, se dice que la función 𝑓𝑋(∙), 𝑓𝑋: ℝ → [0,∞) es la
función de densidad de probabilidad de X si:
1. 𝑓𝑋(𝑥) ≥ 0 ∀𝑥 ∈ ℝ
2. ∫ 𝑓𝑋(𝑥)𝑑𝑥∞
−∞= 1
Esta función se define de forma análoga para las variables aleatorias discretas
Definición (Muestra Aleatoria)
Una muestra aleatoria es un conjunto de variables aleatorias 𝑋1, 𝑋2, … , 𝑋𝑛
independientes e idénticamente distribuidas, es decir,𝑃(𝑋𝑖 ∩ 𝑋𝑗) = 𝑃(𝑋𝑖) ∙ 𝑃(𝑋𝑗)
𝑃(𝑋𝑖|𝑋𝑗) = 𝑃(𝑋𝑖), 𝑠𝑖 𝑃(𝑋𝑗) > 0
𝑃(𝑋𝑗|𝑋𝑖) = 𝑃(𝑋𝑗), 𝑠𝑖 𝑃(𝑋𝑖) > 0
𝐹(𝑋𝑖) = 𝐹(𝑋𝑗), donde F(x) es la función de distribución de probabilidad de las
variables aleatorias.
El problema de la estimación de parámetros se define como sigue: se cuenta con una
muestra aleatoria de una determinada población y se desea estudiar alguna de sus
características 𝑋, cuya función de densidad de probabilidad es 𝑓𝑋(∙; 𝜃) = 𝑓(∙; 𝜃) donde la
forma de la función de densidad es conocida pero el valor del parámetro 𝜃 no lo es. Para
encontrar este parámetro o alguna función del mismo 𝜏(𝜃) se cuenta con los valores
𝑥1, 𝑥2, … , 𝑥𝑛 de una muestra aleatoria 𝑋1, 𝑋2, … , 𝑋𝑛 con una función de densidad 𝑓(∙; 𝜃).
Encontrar el estimador de un parámetro 𝜃 se puede hacer de dos formas distintas: la
primera es la estimación puntual, que consiste en representar el valor de 𝜃 o 𝜏(𝜃) por medio
de una estadística 𝑡(𝑋1, 𝑋2, … , 𝑋𝑛), a la que se le conoce como estimador puntual. La otra
forma de estimación es por medio de intervalos, consistente en obtener un rango en el cual

12
se encuentre el valor de 𝜃 o 𝜏(𝜃) con cierta confiabilidad (Mood, et al. 1974) En este
trabajo este método no será estudiado a fondo, sin embargo puede ser revisado a detalle en
(Mood, et al. 1974).
La estimación puntual tiene dos problemas principales: el primero de ellos es que el
encontrar una estadística que sirva de estimador puede resultar complicado y el segundo es
de todos los posibles estimadores, encontrar el mejor. Para esto se ha definido una serie de
características deseables que debe tener un estimador, las cuales se mencionan a
continuación:
Siempre se busca un estimador que sea lo más cercano posible al valor real que se
quiere estimar, por ello se busca que sus medidas de tendencia central como la
media sean lo más cercanamente posible al valor poblacional con una varianza
mínima. Una de las formas de medir esto es por medio del error cuadrático medio
(ECM), definido como Εθ[[𝑇 − 𝜏(𝜃)]2] donde T es el valor del estimador. Este
valor puede ser interpretado como una medida de la dispersión de los valores de T
con respecto a los de 𝜏(𝜃), tal como si se estuviera midiendo la variación de una
variable aleatoria con respecto a su media. Si se tuviera que elegir entre dos
estimadores bajo el criterio del ECM, se elegiría a aquél que tuviera un menor ECM
(Wackerly et al. 2002).
Encontrar un estimador con el menor ECM puede ser muy complicado debido al
gran número de estimadores posibles que pueden existir, es por ello que se define
otra medida conocida como insesgamiento. Se dice que un estimador es insesgado si
Εθ[𝑇] = Εθ[𝑡(𝑋1, 𝑋2, … , 𝑋𝑛)] = 𝜏(𝜃) ∀𝜃 ∈ Θ, donde Θ es el espacio de soluciones
para el estimador de 𝜏(𝜃). Es decir, un estimador es insesgado si su media es igual
al valor que se desea estimar.
Una forma de relacionar el ECM y el sesgo de un estimador es por medio de la
expresión 𝐸𝐶𝑀𝑡(𝜃) = 𝑉𝑎𝑟[𝑇] + {𝜏(𝜃) − 𝐸𝜃[𝑇]}2 donde la parte entre corchetes
del segundo término corresponde al sesgo del estimador, este valor puede ser
cualquier número real.
Las dos propiedades anteriores están definidas para tamaños de muestra finitos; sin
embargo, es necesario ver qué sucede para tamaños de muestra que van

13
aumentando. Si se considera una sucesión de estimadores {𝑇𝑛}, donde n indica el
tamaño de muestra usado para calcular el estimador, una propiedad deseable sería
que el valor del estimador calculado se aproximara cada vez más al valor real
conforme aumentara el tamaño de la muestra. Se dice que una sucesión de
estimadores es consistente en error cuadrático medio si lim𝑛→∞ 𝐸𝜃[[𝑇𝑛 − 𝜏(𝜃)]2] =
0 ∀ 𝜃 ∈ Θ, es decir, que el sesgo y la varianza de 𝑇𝑛 se aproximan a cero al crecer
el tamaño de la muestra.
Hay otra noción de consistencia que vale la pena mencionar que es la consistencia
débil. Si se tiene una sucesión de estimadores {𝑇𝑛}, igual que el punto anterior, se
dice que ésta es débilmente consistente si ∀ 𝜖 > 0 se cumple que lim𝑛→∞ 𝑃𝜃[|𝑇𝑛 −
𝜏(𝜃)| < 𝜖] = 1 ∀ 𝜃 ∈ Θ . Es importante mencionar que si un estimador es
consistente en ECM, entonces es débilmente consistente, pero no necesariamente al
revés. Una demostración de esto se puede encontrar en (Mood et al. 1974).
Finalmente, se desea que el estimador obtenido sea el que tenga menor varianza,
una cota inferior para la varianza de un estimador T está dada por la cota de Cramer
y Rao, definida como:
𝑣𝑎𝑟𝜃[𝑇] ≥ [𝜏′(𝜃)]
2
𝑛Ε𝜃[[𝜕
𝜕𝜃log𝑓(𝑋;𝜃)]
2] (2.1)
Un estimador que cumple con la cota inferior de Cramer y Rao se dice que es
eficiente, es decir, que tiene el menor ECM de entre todos los estimadores posibles
y cuya varianza es la menor posible (la cota inferior de Cramer y Rao).
Dada la naturaleza de los datos con que generalmente se cuenta al realizar modelos de
simulación para realizar análisis farmacoeconómico (Arnold 2010), una de las formas más
recomendadas, debido a su facilidad de aplicación, para obtener estimadores estadísticos es
el método de momentos, que se describe a continuación.
El método de momentos es uno de los más antiguos para obtener estimadores puntuales.
Para implementarlo es necesario recordar lo que significa el k-ésimo momento poblacional
de una variable aleatoria con respecto al origen:
𝜇𝑘′ = 𝐸(𝑌𝑘)
mientras que el k-ésimo momento muestral correspondiente es el promedio:
(2.2)
(2.3)

14
𝑚𝑘′ =
1
𝑛∑ 𝑌𝑖
𝑘𝑛𝑖=1
La idea detrás del método de momentos es que a través de los momentos muestrales es
posible obtener buenas estimaciones de los momentos poblacionales (Wackerly, et. al.
2002). Es decir, 𝑚𝑘′ debería ser un buen estimador de 𝜇𝑘
′ para 𝑘 = 1, 2, … . De esta forma
dado que los momentos poblacionales 𝜇1′ , 𝜇2
′ , … , 𝜇𝑘′ son funciones de los parámetros
poblacionales es posible igualar los momentos muestrales y poblacionales correspondientes
y con base en esto obtener el estimador para el parámetro 𝜃 que se busca.
Por ejemplo, si se desea encontrar estimadores para los parámetros 𝜃1 y 𝜃2 . Si estos
parámetros pueden ser expresados en términos de los primeros dos momentos como
𝜃1 = 𝑓1(𝜇1′ , 𝜇2
′ ) (2.4)
𝜃2 = 𝑓2(𝜇1′ , 𝜇2
′ )
Entonces los estimadores por método de momentos son:
𝜃1̂ = 𝑓1(𝜇1′,̂ 𝜇2 ′̂) (2.5)
𝜃2̂ = 𝑓2(𝜇1′,̂ 𝜇2 ′̂)
Este método se define formalmente de la siguiente forma:
Definición (Método de momentos)
Se eligen los estimadores por el método de momentos a los valores de los parámetros que
sean soluciones de la ecuación 𝜇𝑘′ = 𝑚𝑘
′ , para 𝑘 = 1,2, … , 𝑡, donde t es el número de
parámetros por estimar.
El método de momentos es probabilísticamente consistente, sin embargo, antes de probarlo
es necesario recurrir a la ley débil de los grandes números.
Teorema (Ley Débil de los Grandes Números)
Sea 𝑋1, 𝑋2, … una sucesión de variables aleatorias independientes e idénticamente
distribuidas, cada una con un valor esperado finito 𝐸[𝑋𝑖] = 𝜇. Entonces para cualquier
𝜖 > 0,
𝑃 {|𝑋1 +⋯+ 𝑋𝑛
𝑛− 𝜇| ≥ 𝜖} → 0, 𝑐𝑢𝑎𝑛𝑑𝑜 𝑛 → ∞
Una demostración de este teorema se puede encontrar en (Ross, 2010).
La ley débil de los grandes números implica que los momentos muestrales convergen en
probabilidad a los momentos poblacionales. Es por eso que el método de momentos es
consistente.

15
Es importante mencionar que los estimadores por método de momentos no son únicos. A
pesar de que se usaron los momentos con respecto al origen, es posible utilizar los
momentos centrales como base para estimar y la técnica seguiría siendo catalogada como
método de momentos. Otra forma sería no tomar los primeros k-ésimos momentos sino
otros.
A pesar de ser un método de fácil implementación y consistente, el método de momentos
tiene algunas desventajas, entre las que se encuentran que el estimador no siempre es
función de estadísticos suficientes, es decir, que la función proporcione suficiente
información sobre el valor desconocido 𝜃 tanto como lo haría la muestra (Mood et al.
1975). Esto ocasiona que los estimadores obtenidos por este método no sean eficientes, es
decir, que haya otro estimador con una varianza más cercana a la cota de Cramer y Rao.
A pesar de que este método tiene un gran número de desventajas conocidas, se escoge
como forma de estimación de parámetros cuando la única información muestral con la que
se cuenta es la media y varianza o desviación estándar de alguna variable como es el caso
de información obtenida de varios estudios médicos (Arnold 2010). Cuando se cuenta con
este tipo de información, este es el mejor método para obtener estimadores de valores
poblacionales (Mood et al. 1975).
Como se ha mencionado, existen otras formas de obtener estimadores poblacionales con
base en datos muestrales que también se podrían utilizar en un análisis farmacoeconómico,
entre estos métodos se encuentra el método de máxima verosimilitud, el cual es el que tiene
la varianza más cercana a la cota de Cramer y Rao y, el de mínima distancia, entre otros.
Dada la forma en la que se puede presentar la información para estudios de análisis
farmacoeconómico, que generalmente proviene de estudios clínicos, se describe
únicamente el método de momentos ya que es el recomendable de utilizar por las razones
antes explicadas. Una descripción del uso de otros métodos de estimación de parámetros se
puede encontrar en (Mood et al. 1975).
2.4 Uso de distribuciones de probabilidad para los datos de entrada en un modelo de
simulación
Para llevar a cabo una simulación con base en datos de entrada aleatorios es necesario
especificar cuál será la distribución de probabilidad a seguir. Estas distribuciones pueden
ser las ya conocidas tales como la beta, la gamma o la normal, o alguna empírica que se

16
adapte a los datos o el sistema a modelar. Sin embargo, es necesario cuidar a detalle si los
datos a modelar son discretos o continuos para elegir la distribución apropiada.
El problema de la estimación de parámetros para las distribuciones elegidas para la
simulación ya se ha explicado en la sección anterior.
2.5 Simulación de evento discreto
Existen diversos tipos de simulación, entre las principales se encuentra la de evento discreto
(DES por sus siglas en inglés), la misma que será descrita en esta sección y la de evento
continuo que será descrita posteriormente.
Un sistema por simular puede ser de dos tipos dependiendo del tipo de variables de estado
que contenga. El primero de ellos el de evento discreto, que se caracteriza porque la
variables de estado cambian en un conjunto numerable de veces en momentos previamente
definidos. El otro tipo es un sistema continuo que se caracteriza porque las variables de
estado cambian un conjunto no numerable de veces respecto al tiempo. En general, es
difícil encontrar un sistema que sea completamente discreto o continuo, ya que la mayoría
de ellos son mixtos. Sin embargo, con el fin de modelarlos adecuadamente, se utiliza el tipo
de simulación acorde al tipo de variables de estado predominantes (Law 2007).
La simulación de evento discreto (DES), es aquella en la que el estado del modelo cambia
únicamente en un conjunto numerable de puntos en el tiempo que pueden ocurrir de manera
aleatoria. En ocasiones, más de un cambio de estado tiene que ser realizado al mismo
tiempo, es por ello que se necesitan ciertas reglas de asignación de prioridad de eventos
dependiendo de su naturaleza.
En un modelo de simulación de evento discreto se tienen entidades que son las unidades de
flujo dentro del modelo. Estas entidades generan cambios en el estado del sistema,
conocidos como eventos, y a su vez responden a ellos. Las entidades pueden ser de dos
tipos: internas y externas, siendo las primeras las generadas y determinadas por el
modelador y las segundas son creadas y manipuladas por el software que se utiliza, estas
son entidades aleatorias que pueden, por ejemplo, usarse para modelar fallas en algún
recurso. Un recurso es un elemento del sistema que provee de servicio a las entidades del
modelo, como podría ser un cajero en una cola del banco. El comportamiento de lo anterior
está determinado por elementos que pueden ser: variables de control y decisión, contadores,
entre otros.

17
Dada la naturaleza dinámica de la simulación de evento discreto, es necesario contar con
una variable general que lleve control del tiempo en cada corrida. A esta se le conoce como
reloj de la simulación y es fundamental ya que es un determinante en la ocurrencia de un
cambio de estado en el sistema.
El reloj de la simulación puede definirse de dos formas: la primera de ellas consiste en
incrementos fijos de tiempo, después de cada uno de ellos se verifica cuáles fueron los
cambios en el sistema y se actualiza. En la segunda forma el incremento de tiempo se hace
cada vez que un determinado evento sucede. La anterior es la forma más usada, tanto por
paquetes de cómputo como por modelos de simulación programados en algún lenguaje
general (Law 2007).
En cada réplica, el reloj es inicializado en cero y con base en una lista que determina el
tiempo de ocurrencia de cada evento avanza hasta la ocurrencia del primer evento, en este
punto se actualizan tanto el sistema como la lista de eventos futuros. Seguido se adelanta el
reloj hasta el siguiente evento y se realizan las actualizaciones ya mencionadas. Esto ocurre
de un evento a otro hasta que se cumple la condición de paro. Los intervalos de tiempo no
necesariamente son uniformes. Con esta forma de llevar el tiempo no se consideran los
tiempos ociosos del sistema, como podría suceder con la otra forma de llevar el tiempo.
2.5.1 Procesos de Markov en Simulación de Evento Discreto.
Los sistemas de evento discreto describen estructuras que cambian estocásticamente con
base en una sucesión que indica el tiempo al que estos cambios deben ocurrir. Entre estos
cambios también se tiene variables de estado que cambian de forma determinista.
Los sistemas de evento discreto están cercanamente relacionados con la clase de los
procesos semi-Markovianos generalizados (GSMP por sus siglas en inglés), que no es otra
cosa que la generalización de un proceso de Markov, de espacio de estados discreto en
tiempo continuo), así como de un proceso semi-Markoviano (Asmussen & Glynn 2007).
Para poder definir un GSMP es necesario definir un conjunto S de estados así como el
conjunto E de eventos que pueden provocar cambios de estado, los eventos activos en
𝑠 ∈ 𝑆 se denotan por 𝐸(𝑠) ⊆ 𝐸.
El reloj de la simulación, ya mencionado, juega un papel importante en el cambio de estado
de un GSMP. Cuando un evento 𝑒 ∈ 𝐸 es programado se define un determinado reloj,
mientras el sistema está en un estado 𝑠 ∈ 𝑆 el reloj correspondiente a 𝑒 disminuye a una

18
tasa determinista 𝑟𝑠,𝑒 dada. Una vez que el reloj alcanza el cero, el evento e*
correspondiente a ese determinado reloj sucede y ocurre una transición aleatoria del estado
s al s’ con una probabilidad 𝑝(𝑠′; 𝑠, 𝑒 ∗). Una vez que se ha cambiado al nuevo estado, se
reprograman los eventos por ocurrir. Si se denota por 𝑁(𝑠′; 𝑠, 𝑒∗)al conjunto de eventos por
ocurrir que se reprograman, entonces una lectura del reloj de simulación para 𝑒′ ∈
𝑁(𝑠′; 𝑠, 𝑒∗) se define independientemente de la distribución de probabilidad para el cambio
de estado 𝐹(∙; 𝑠′, 𝑒′, 𝑠, 𝑒∗). Por otro lado, los demás relojes activos en s’, denotados por
𝑂(𝑠′; 𝑠, 𝑒∗) ≝ 𝐸(𝑠′) \𝑁(𝑠′; 𝑠, 𝑒∗) siguen corriendo hacia abajo en el estado s’ (Asmussen
& Glynn 2007).
Si S(t) es el estado del sistema al tiempo t, entonces {𝑆(𝑡)}𝑡≥0 es un GSMP. Si todas las
distribuciones𝐹(∙; 𝑠′, 𝑒′, 𝑠, 𝑒∗) son exponenciales, entonces {𝑆(𝑡)} es un proceso de Markov
en tiempo continuo. Si 𝐸(𝑠) tiene un solo elemento para cada 𝑠 ∈ 𝑆, entonces {𝑆(𝑡)} es un
proceso semi-Markoviano.
Debido al gran número de relojes activos en un GSMP, sus medidas de desempeño son
muy difíciles de resolver analíticamente, sin embargo, la simulación se vuelve una
herramienta que fácilmente lidia con este problema. Dado que 𝐸(𝑠) puede ser muy grande,
en ocasiones es necesario utilizar herramientas tales como las estructuras de datos con el fin
de determinar los tiempos de cambio de estado más fácilmente.
A pesar de lo difícil que es resolver un GSMP es importante mencionar que se puede
considerar y resolver como un proceso de Markov. En particular, si se añade el vector de
estado C(t) de los relojes activos en S(t), se tiene un proceso de Markov {(𝑆(𝑡), 𝑪(𝑡))}𝑡≥0
.
Dado que la dinámica de este proceso durante los períodos entre transiciones de estado son
deterministas, es posible utilizar el tiempo de la n-ésima transición de estado 𝑇𝑛 para
estudiar el sistema, de forma que el proceso queda de la siguiente
forma{(𝑆(𝑇𝑛), 𝑪(𝑇𝑛))}𝑛∈ℕ.
El hecho de poder ver un GSMP como un proceso de Markov es muy importante desde el
punto de vista de la simulación ya que esto implica que cualquier metodología desarrollada
para un proceso de Markov en un espacio general de estados aplica para simulaciones de
evento discreto. (Asmussen & Glynn 2007)

19
2.6 Simulación de evento continuo
La simulación de evento continuo, como su nombre lo explica, se encarga de modelar
sistemas en los cuales las variables de estado cambian respecto al tiempo en instantes no
numerables. Tradicionalmente, este tipo de simulación (continua) incluye el uso de
ecuaciones diferenciales, las cuales explican la tasa de cambio de las variables a lo largo del
tiempo. Si estas ecuaciones son simples, se pueden resolver de forma analítica para obtener
los valores de los estados del sistema en el tiempo, sin embargo, existen muchas ecuaciones
diferenciales que no se pueden resolver de forma analítica, lo cual hace necesario echar
mano de métodos numéricos para resolverlas y obtener su valor en el tiempo. Uno de estos
métodos es el de Runge-Kutta (Law 2007).
Algunas de las herramientas computacionales para simulación que existen hoy en día
cuentan con módulos para hacer modelos de simulación de evento continuo.
Como se mencionó en secciones anteriores, existen sistemas que no son completamente
discretos o completamente continuos, estos sistemas se conocen como mixtos, estos
sistemas cuentan con 3 tipos de interacciones que pueden ocurrir entre las variables
continuas y discretas:
Un evento discreto puede generar un cambio discreto en el valor de una variable de
estado continuo.
Un evento discreto pueda causar que la relación que rige una variable de estado
continuo cambie en un momento determinado.
Una variable de estado continuo que alcance determinado umbral puede ocasionar
que ocurra un evento discreto.
2.7 Otras consideraciones teóricas del uso de modelos de simulación
Una vez que todo lo anterior ha sido definido es posible empezar a diseñar el modelo de
estudio. Para ello se puede contar con varios escenarios por analizar, que representen al
mismo modelo pero bajo un cambio en alguna de las variables; por ejemplo, un banco con
dos y tres cajeros. Cada escenario puede ser simulado en una o más réplicas, una réplica es
una simulación del mismo modelo pero con un conjunto distinto de número aleatorios.
Cada réplica consiste en una fase de inicio, la corrida en sí y la generación de un reporte
con los resultados (Law 2007).

20
En ocasiones también se desea estudiar el estado estable de un sistema, es decir, cuando
teóricamente ha ocurrido un tiempo infinito en el sistema y se desea estudiar el
comportamiento de determinadas variables, sin embargo, en este estudio no se llevará a
cabo dadas las características del modelo a desarrollar. Es posible encontrar mayor
información sobre el análisis de estado estable en (Law 2007).
2.8 Uso de modelos de pronóstico y financieros para estimación de resultados de
modelos de simulación
De acuerdo a lo explicado en apartados anteriores, la simulación es una herramienta que
sirve para analizar sistemas en el tiempo. Los resultados obtenidos se pueden utilizar para
hacer pronósticos sobre alguna variable en especial. Para el caso del análisis
farmacoeconómico, puede servir de base para estimar los costos que se pueden generar del
tratamiento de alguna enfermedad en particular.
Existen diversas técnicas de pronóstico que se pueden utilizar dependiendo de los datos que
se estén analizando, entre estas técnicas se encuentran:
Series de tiempo
Promedios móviles, entre otras
Estas técnicas no son motivo de estudio en este documento de trabajo, sin embargo, es
posible encontrar una descripción y uso de cada una de ellas en (Gujarati & Porter 2010).
Dado que uno de los resultados que arrojan los modelos de simulación desarrollados para
análisis farmacoeconómicos es el costo del tratamiento de diversas enfermedades, ya sea a
corto, mediano o largo plazo, puede ser necesario utilizar algunas herramientas y conceptos
financieros con el fin de obtener resultados más apegados a la realidad, tales como tasas de
interés, inflación y valor presente neto, se puede encontrar una descripción de estas
herramientas en (Ross, et al. 2008).

21
Capítulo 3
Aplicación Práctica de la Simulación al Análisis Farmacoeconómico
3.1 Métodos alternativos para la realización de análisis farmacoeconómicos
Para realizar un análisis farmacoeconómico adecuado de cualquier enfermedad es necesario
el desarrollo de un modelo en el que se incluya la mayor cantidad posible de variables que
describan la enfermedad incluyendo la evolución de la misma, los pacientes a estudiar, el
tipo de tratamientos que se siguen, los recursos asignados al tratamiento, entre otras. Esto
con el fin de desarrollar una herramienta de análisis que arroje datos que sean confiables a
la hora de analizarlos y que sirva de forma apropiada para la toma de decisiones.
Como se ha explicó en el capítulo anterior, la simulación es una herramienta que se ha
vuelto más potente con el paso del tiempo, esto debido principalmente a la evolución de la
computación tanto en capacidad de procesamiento como en herramientas para la
simulación.
Anteriormente, este tipo de análisis se desarrollaban utilizando dos técnicas principalmente:
árboles de decisión y cadenas de Markov con espacio de estados discreto (Barton et al.
2004).
La primera de estas técnicas tiene la estructura más simple y familiar. Todos los posibles
estados en los que se puede encontrar un paciente, así como la probabilidad de cada estado
se muestran en un árbol de decisión. Esta técnica tiene la ventaja de que se puede utilizar
siempre y cuando no se considere un gran intervalo de tiempo en el modelo y si la tasa de
mortalidad de los pacientes no difiere dependiendo de las distintos tratamientos analizados
(Barton et al. 2004).
En principio, cualquier modelo en el que se asuma que los estados y pacientes que se
analizan son independientes se pueden representar a través de un árbol de decisión, sin
embargo, esta técnica tiene la limitante que después de considerar muchas ramas en el
árbol, este se vuelve cada vez más grande y difícil de analizar.

22
Adicionalmente, de acuerdo con (Caro 2005), esta técnica presenta muchas limitantes,
especialmente al lidiar con problemas de carácter médico, entre estas se encuentra el hecho
de tener un modelo en el que las ramas del árbol de decisión son mutuamente excluyente, lo
cual en diversos estados médicos no siempre es cierto, además de que el tiempo no se
considera de forma explícita dentro del modelo, lo cual limita considerablemente la validez
de los datos arrojados por el análisis realizado.
Debido a las complicaciones generadas al utilizar árboles de decisión, se comenzaron
utilizar modelos de Markov, estos modelos tienen la ventaja de que fácilmente pueden
representar eventos recurrentes, sin embargo, no permiten la interacción entre individuos
(Barton et al. 2004), lo cual puede ser una limitante, por ejemplo, cuando se estudian
enfermedades contagiosas como la influenza.
En los modelos de Markov, el comportamiento de una determinada enfermedad se
representa en “estados de salud” mutuamente excluyentes, así como las probabilidades de
transición entre ellos a través del tiempo (Caro 2005). A pesar de que mediante esta técnica
se considera el tiempo de una forma más explícita y es más fácil de analizar, conserva
mucha de la rigidez estructural de los árboles de decisión, lo cual limita considerablemente
la capacidad de análisis y el nivel de detalle que se puede lograr mediante esta herramienta.
La transición de árboles de decisiones a cadenas de Markov con espacio de estados discreto
ha sido complicada, incluso, todavía hay algunos de estos modelos cuya base son árboles
de decisión (Caro 2005).
El tener que modelar cada aspecto de una enfermedad al realizar un análisis
farmacoeconómico como un “estado” en una cadena de Markov ocasiona que muchas de
las variables que por su naturaleza son continuas se vuelvan discretas, por ejemplo, en el
caso de la diabetes, al replicar el comportamiento del nivel de azúcar en la sangre, el
intervalo en el que varía este nivel se divide en distintos grupos. Si cada cambio de estado
cuenta con variables asociadas al nivel de azúcar en la sangre, el problema de estudio se
vuelve más grande ya que también hay que incluir los cambios asociados en las variables
derivado del nuevo estado en el que se encuentra el sistema (Caro 2005).
Otra restricción que se presenta al utilizar cadenas de Markov es el hecho de que cada
paciente puede encontrarse únicamente en un estado a la vez, lo que genera la necesidad de
representar todas las combinaciones de variables posibles para poder realizar un análisis

23
extensivo de una enfermedad. Este problema se puede resolver mediante dos alternativas: la
primera es simplificar el modelo de forma que no se consideren algunas variables,
generando así que el nivel de realismo alcanzado en el modelo desarrollado disminuya. La
otra forma sería considerando todas la variables, así como sus posibles combinaciones, lo
cual, si se está estudiando algún padecimiento complicado, derivaría en un modelo
complejo, tanto de realizar como de analizar.
Finalmente, mediante modelos de Markov es complicado establecer la jerarquía de los
eventos por suceder, por ejemplo, cuando al modelar una enfermedad se requiere que un
paciente vaya primero a realizarse pruebas de laboratorio y después a la consulta con el
médico para platicar de los mismos. Al modelar estos eventos, se combinan en un estado
compuesto en el que el orden de los eventos se pierde o se manejan en ciclos separados
(Caro 2005). Se han desarrollado soluciones a este tipo de conflictos en los programas de
cómputo, sin embargo, no son lo suficientemente potentes para describir enfermedades
complejas como el VIH o la diabetes, además de que las transiciones entre estados son muy
restrictivas.
3.2 Utilización de Simulación de Evento Discreto Para Análisis Farmacoeconómico
Existen diversos tipos de simulación, entre los que se encuentra la de evento discreto (DES
por sus siglas en inglés) y se presenta como una alternativa al uso de árboles de decisión y
modelos de Markov con estado de eventos discreto (Barton et al. 2004).
El uso de la simulación como herramienta de análisis farmacoeconómico permite incluir
una mayor cantidad de variables, entidades, así como representar el comportamiento de las
mismas a lo largo del tiempo, permitiendo así que el modelo que se desarrolla sea más
apegado a la realidad que si se utilizara alguna otra técnica de modelaje como las ya
mencionadas.
Uno de los componentes principales en un modelo de DES son las entidades que se van a
simular, para el caso del análisis farmacoeconómico la mayoría de las veces las entidades
son los pacientes que padecen la enfermedad en estudio, sin embargo, se puede dar el caso
en que las entidades del modelo sean de otro tipo, por ejemplo unidades médicas o doctores
que atiendan determinado padecimiento, esto depende del enfoque que se le desee dar al
estudio en curso. A diferencia de un modelo de Markov, donde el enfoque es

24
principalmente en los resultados generales del modelo o en los estados, en un modelo de
DES, el paciente es un elemento explícito de estudio (Caro 2005).
Cada una de las entidades dentro de un modelo de simulación posee diversos atributos que
determinan la forma en la que se comportan durante la simulación, estos atributos tienen
ciertos valores iniciales y se van modificando con el tiempo dependiendo de las reglas
establecidas a la hora del diseño del modelo, por ejemplo, cuando se estudia una persona
con diabetes, uno de los atributos con los que cuenta es el peso que tenía al momento en
que se le diagnosticó la enfermedad, sin embargo, esta variable se modifica en el tiempo
dependiendo del tipo de tratamiento que siga el paciente, las complicaciones que se
presenten o los hábitos alimenticios que tenga. Es importante recalcar que se deben estudiar
y definir claramente las reglas de cambio e implicaciones en los atributos de los pacientes
de forma que los resultados que se obtengan sean válidos y se puedan interpretar de forma
adecuada.
Es importante recalcar que a cada uno de estos cambios se le puede asignar un valor
monetario que sirva como indicador en el análisis farmacoeconómico.
Al usar la simulación de evento discreto como herramienta de análisis, se deben de incluir
las reglas de cambio de estado de los pacientes, dependiendo de alguna variable global, por
ejemplo, en el caso particular de la diabetes, el nivel de glucosa puede funcionar como el
principal indicador de la salud de un determinado paciente, dependiendo de este nivel será
el tratamiento que reciba, las complicaciones que se puedan presentar debido al
padecimiento de esta enfermedad, el tipo de tratamiento que deba seguir o incluso la tasa de
mortalidad. Como se ha mencionado, de todos estos cambios es necesario llevar registro
con el fin de determinar cuáles son los costos generados al tratar determinada enfermedad.
Mediante un análisis farmacoeconómico también es posible estudiar la asignación de
recursos no monetarios, por ejemplo, con cuántas camas es necesario disponer para una
epidemia que se pueda presentar en un determinado momento, o cuántos médicos
especialistas deben estar de base para atender a pacientes con algún tipo de cáncer.
Mediante el uso de la simulación de evento discreto también es posible hacer un estudio de
diversos escenarios, por ejemplo, cuando se trata algún tipo de cáncer y se desea evaluar el
impacto en costo debido a la efectividad de diversos tratamientos es posible diseñar un
modelo en varias versiones, donde el cambio sea el tipo de tratamiento que recibe un

25
paciente, esto conociendo la efectividad y las implicaciones de cada uno de ellos. La
simulación se presenta como una herramienta de comparación entre escenarios distintos.
3.3 Ventajas del Uso de Simulación de Evento Discreto para Análisis
Farmacoeconómico
Utilizar un modelo de DES para análisis farmacoeconómico de enfermedades complejas
presenta un gran número de ventajas contra los otros dos métodos ya mencionados, entre
las que se encuentran:
Es una técnica menos restrictiva y más flexible que los árboles de decisión y las
cadenas de Markov con espacio de estados discreto, ya que permite introducir un
gran número de variables así como las reglas de eventos que producen un cambio en
las mismas a lo largo del tiempo, generando así un modelo más apegado a la
realidad (Caro 2005).
Es posible utilizar distribuciones de probabilidad de diferentes formas, dependiendo
de los datos de entrada con que se cuente. Además de que por medio de la
realización de varias réplicas se pueden obtener resultados estadísticamente
significativos.
Es un modelo de fácil implementación ya que no hay necesidad de forzar la
evolución de la enfermedad en estados mutuamente excluyentes ni forzarla a
cambiar en determinados intervalos de tiempo. Además de que puede reducir el
tiempo necesario para obtener conclusiones en lugar de realizar estudios médicos
que podrían tomar más tiempo y requerir de una mayor asignación de recursos
(Caro 2005).
Es un modelo claro ya que todos los componentes y entidades forman parte
explícita del modelo, contrario a lo que ocurriría en los otros dos métodos en los que
las características de los pacientes no son una parte definitiva del modelo, además
de que se lleva un control exacto del tiempo.
Es posible variar la estructura del modelo y con ello analizar varios escenarios, cosa
que no sería posible con árboles de decisión y modelos de Markov (Caro 2005).
Se obtienen estimadores estadísticos globales y diferenciados de los costos con base
en los recursos consumidos, el escenario simulado y el tratamiento seguido. Esto no

26
es fácil de obtener mediante los otros dos métodos en los que es necesario
desarrollar estimados de costos para cada rama o estado del modelo (Caro 2005).
Se pueden utilizar las técnicas estadísticas estudiadas para analizar las salidas de los
experimentos por simulación (Law 2007)
El tiempo se considera de forma explícita dentro de la simulación de evento
discreto, siendo así posible modelar el comportamiento de variables y entidades a lo
largo de la simulación.
Además de estas ventajas propias de la simulación de evento discreto, existen otras que
se obtienen al usar esta técnica como herramienta de análisis farmacoeconómico. Entre
estas se encuentran:
La simulación se presenta como una alternativa para evaluar la evolución de
enfermedades a lo largo del tiempo de una forma completa ya que considera todas
las variables incluidas y su evolución, además de que lo hace en un tiempo
razonable y a un costo relativamente menor (Caro 2005).
La simulación permite replicar con gran fidelidad el comportamiento de un sistema
de salud, con esto es posible medir su impacto, tanto en uso de recursos, como en
costos. La simulación permite además analizar diferentes escenarios y las
implicaciones de los mismos, siendo así una potente herramienta en la toma de
decisiones.
Al simular lo que sucede en un sistema de salud al tratar una determinada
enfermedad se adquiere una perspectiva más realista de las implicaciones de esta
enfermedad tal como las complicaciones suscitadas o las dosis de medicinas
necesarias para su tratamiento, influyendo en las acciones por tomar tales como la
prevención o respuestas más rápidas ante ciertos eventos.
A pesar de que no se cuente con información completa sobre el funcionamiento del
sistema, mediante la simulación es posible hacer estimaciones confiables sobre el
desempeño del mismo (Caro 2005, Law, 2007).
Estas bondades mencionadas, hacen que la simulación de evento discreto sea una
herramienta confiable y de gran utilidad, y por ella será utilizada, como se verá en los
siguientes capítulos.

27
3.4 Desventajas del Uso de Simulación de Evento Continuo para Análisis
Farmacoeconómico
Como se explicó, la simulación de evento discreto ofrece grandes ventajas como
herramienta de análisis farmacoeconómico, sin embargo, en el segundo capítulo de este
documento se ha introducido otro tipo de simulación que es el de evento continuo, lo cual
genera la pregunta de si es posible utilizar este tipo de simulación para realizar este tipo de
estudio.
El definir las reglas de cambio de estado en un modelo continuo puede resultar más
complejo ya que incluye el uso de ecuaciones diferenciales, algunas de las cuales podrían
no tener una solución explícita lo cual genera la necesidad de utilizar herramientas como
los métodos numéricos para resolverlas (Law 2007, Soares et al. 2012). Esto es posible de
hacer mediante los programas actuales de simulación, sin embargo, usar la simulación de
evento continuo complica el desarrollo del modelo.
Por lo anterior, se sugiere el uso de modelos de simulación de evento discreto, ya que son
más fáciles de implementar y analizar, sin embargo, es necesario tener en cuenta que
muchas veces al volver variables continuas a discretas se pueden presentar sesgos en la
información utilizada (Soares et al. 2012), y que deben ser corregidos mediante alguna
técnica.
3.5 Construcción de Modelos Válidos de Simulación
Uno de los problemas más frecuentes al desarrollar modelos de simulación es el determinar
si estos son una representación adecuada del sistema que se está estudiando (Law 2007), es
decir, si el modelo es válido, si está desarrollado de acuerdo a los objetivos planteados
inicialmente o si está realizado eficientemente.
En esta sección se hará un recuento de cuáles son las mejores prácticas para desarrollar un
modelo de simulación que sea válido, eficiente y que sirva como una adecuada herramienta
de toma de decisiones en el aspecto farmacoeconómico.
La validación de un modelo es el proceso mediante el cual se determina si un modelo de
simulación es una representación aproximada del sistema para un objetivo particular de
estudio (Law 2007). A continuación se presentan algunas consideraciones sobre la
validación de modelos de acuerdo con (Law 2007):

28
Si un modelo es válido, entonces se puede utilizar como herramienta de toma de
decisiones acerca de sistemas similares que se podrían desarrollar, si estos fueran
factibles y rentables.
La complejidad de la validación de un modelo depende de la complejidad del
sistema que se esté evaluando y de si existe alguna versión del mismo.
Un modelo de simulación de un sistema complejo no puede ser más que una
aproximación al sistema real, sin importar cuánto esfuerzo se le ponga. En ningún
caso existe un modelo que se apegue completamente a la realidad. No porque se le
invierta más tiempo o dinero al desarrollo de un modelo, implicará que este será
más válido, sin embargo, el modelo que sea más válido no necesariamente será el
más rentable.
Un modelo de simulación siempre se debe de desarrollar para un conjunto
específico de objetivos y sólo para esos. De hecho, un modelo que sea válido para
un propósito determinado puede no serlo para otros.
Las métricas de desempeño utilizadas para validar un modelo deben incluir aquellas
que se usarán en la realidad para evaluar el diseño de un sistema.
La validación de un modelo no se debe hacer hasta el final del desarrollo del
modelo y sólo si queda tiempo y dinero, no hacerlo puede llevar a conclusiones
erróneas.
Cada vez que se intente utilizar un modelo para un fin distinto al que inicialmente
fue concebido, se debe de reexaminar la validez del mismo.
Un modelo debe contar con credibilidad por parte de las personas que lo han
supervisado, sin embargo, el que un modelo sea creíble no implica que sea válido y
viceversa.
Un modelo debe ser verificado, es decir, se debe validar que los supuestos que se
están utilizando para su desarrollo se hayan efectivamente traducido en el modelo
que se ha desarrollado.
Un diagrama esquemático de cómo debe ser la validación de un modelo se presenta en la
figura 3.1.

29
Fuente: Law, 2007
Adicionalmente, los datos de salida arrojados por el modelo deben ser validados
estadísticamente contra valores esperados o medidas reales de desempeño si es que se
cuenta con ellos.
Existen diversas técnicas que se pueden utilizar para verificar y desarrollar eficientemente
un modelo computacional de simulación (Law 2007), entre estas se encuentran las
siguientes:
Al programar un modelo de simulación, se recomienda hacerlo en módulos o
subprogramas, esto con el fin de hacer la programación más limpia y encontrar
errores más fácilmente.
Se recomienda que más de una persona revise el modelo, especialmente si es uno
grande con muchas variables.
Para verificar el modelo, se puede correr la simulación bajo distintas
configuraciones de los parámetros de entrada y verificar si los datos de salida tienen
sentido.
Una de las técnicas más poderosas que se pueden usar para verificar un modelo de
simulación de evento discreto es el conocido como de “rastro”. Mediante esta
técnica es estado de un sistema simulado se muestra justo después de que ocurre un
evento, estos datos se validan para verificar si son los que se tenían contemplados.
El modelo se debería correr bajo supuestos simplificados para el cual sus
características sean conocidas o se puedan calcular fácilmente.
Utilizar la herramienta de animación puede dar una idea sobre el comportamiento
del sistema.
Puede ser de gran utilidad calcular la media y desviación estándar muestral para
cada dato de entrada al modelo y compararlo con la media y desviación poblacional.
Figura 3.1 Proceso de Validación de un Modelo de Simulación
Validación Verificación Validación Credibilidad

30
Esto ayuda a identificar si los datos se están generando de acuerdo con las
distribuciones de probabilidad elegidas.
Es recomendable utilizar alguno de los paquetes de simulación comerciales
existentes, esto con el fin de reducir la cantidad de programación requerida, así
como los errores en la programación. Sin embargo, es necesario tener cuidado con
aquellos programas de reciente lanzamiento ya que pueden contener errores que no
hayan sido detectados todavía.
Al desarrollar un modelo de simulación, es necesario definir el nivel de detalle al que se
quiere llegar, para ello es necesario definir qué variables o datos son los que forzosamente
deben estar en el modelo y cuáles de ellos se pueden ignorar sin que esto afecte la validez
del modelo generado. De acuerdo con (Law 2007), estas son algunas consideraciones a
tener en cuenta para determinar el nivel de detalle requerido para desarrollar un modelo de
simulación:
Es necesario determinar cuidadosamente cuáles son los aspectos específicos a
analizar mediante el modelo de simulación, para no incluir detalles irrelevantes y
que podrían afectar el tiempo de ejecución o la interpretación de resultados
arrojados por el modelo.
Se requiere definir claramente cuáles son las entidades, escenarios y variables que
se han de ocupar a lo largo de la simulación.
La entidad que se mueve a través de un modelo de simulación no siempre tiene que
ser la misma que se mueve dentro del sistema que se está replicando. Además, no
siempre es necesario modelar a detalle cada componente del sistema. Es un error
común incluir un gran nivel de detalle en modelos, ya que muchas veces no agrega
valor al estudio.
Es recomendable utilizar expertos en la materia y análisis de sensibilidad para
determinar el nivel de detalle requerido.
El nivel de detalle de un modelo tiene que ser consistente con la información
disponible para el estudio.
En ocasiones, los recursos asignados al proyecto suelen ser una limitante al nivel de
detalle que se debe utilizar.

31
Cuando un modelo tiene un gran número de aspectos para estudiar, se puede
comenzar con un modelo reducido en el que se incluyan sólo los factores más
relevantes y partir de este para llegar a un mayor detalle.
Existen algunas técnicas que se pueden utilizar para incrementar la validez y credibilidad
de un modelo de acuerdo con (Law 2007). Entre estas se encuentran:
Es necesario recolectar información de calidad sobre el sistema a estudiar, como se
mencionó anteriormente, los resultados que se obtienen de un modelo dependen
directamente de los datos de entrada que se incluyan al modelo. Algunas formas de
obtener información confiable para el modelo es platicando con gente que sepa a
fondo cómo funciona a detalle el sistema a estudiar, observando el comportamiento
del mismo, esto se puede hacer con base en datos históricos, sin embargo, antes de
incluirlos en el modelo, se deben de analizar para asegurarse de entenderlos de lleno
o para encontrar datos atípicos o sesgados. También se recomienda revisar la teoría
disponible sobre el sistema a estudiar, estudios similares realizados anteriormente y
hacer caso de la experiencia de quien está desarrollando el modelo.
Para el desarrollo de modelos de simulación es recomendable interactuar de forma
constante con la persona encargada del proyecto, esto con el fin de asegurarse que
se entiende de forma correcta el requerimiento, además de que garantiza que su
conocimiento se utilice en el desarrollo del modelo y aumenta así la credibilidad del
mismo.
Es importante llevar una bitácora sobre el desarrollo del modelo esto con el fin de
identificar los diversos pasos que se han seguido en su desarrollo.
Validar los componentes del modelo mediante el uso de técnicas cuantitativas, estas
pueden incluir verificar si los datos se comportan de acuerdo a alguna distribución
de probabilidad establecida inicialmente, llevar a cabo análisis de sensibilidad de los
datos, diseño de experimentos u otras técnicas según sea requerido.
Se recomienda también validar el resultado general del modelo de simulación. Esto
se puede hacer mediante comparación con un sistema que ya exista, en caso de que
se tenga, contra otro modelo o contra la opinión de algún experto.

32
Finalmente, se puede echar mano de la animación para verificar cómo se comporta
el sistema a lo largo del tiempo que dure la simulación. Esto también aumenta la
credibilidad del sistema.
Mediante estas recomendaciones es más factible realizar un modelo que cuente con los
elementos necesarios para realizar un análisis farmacoeconómico adecuado y que arroje
resultados que sean útiles para tomar decisiones adecuadas en materia de política pública de
salud.

33
Capítulo 4
La Problemática del Análisis Farmacoeconómico
4.1 Introducción al Análisis Farmacoeconómico
Como se ha mencionado en los capítulos anteriores, mediante este trabajo se pretende
desarrollar una metodología que sirva para realizar análisis farmacoeconómicos a través de
modelos de simulación, por ello es necesario entender qué es un análisis de este tipo, qué
factores comprende y cómo se desarrolla.
Hoy en día, la industria médica enfrenta una gran cantidad de enigmas ya que el desarrollo
de nuevas terapias de tratamiento de enfermedades parece no tener límite, sin embargo, los
recursos necesarios para desarrollarlas sí. Por ello es necesario elegir aquellas terapias que
tengan un mayor beneficio a un menor costo. La tendencia actual está cambiando a favor de
buscar aquellos tratamientos que tengan un mayor impacto en mejorar la calidad de vida de
los pacientes, sin embargo, el tema de los costos sigue ocupando un lugar preponderante en
la elección de tipos de terapia a seguir (McGhan 2010).
La farmacoeconomía es el estudio que evalúa el comportamiento o el bienestar de
individuos, empresas y mercados relacionados con el uso de productos farmacéuticos,
servicios y programas (McGhan 2010). En enfoque principal que se estudia es en los costos
y las consecuencias de su uso, sin embargo, también se estudian los factores clínicos,
económicos y humanitarios de las intervenciones del cuidado de la salud en la prevención,
diagnóstico, tratamiento y administración de las enfermedades.
La farmacoeconomía es una colección de técnicas descriptivas y analíticas para evaluar las
intervenciones farmacéuticas, abarcando a los pacientes individuales como un todo dentro
de un sistema de salud. Sus técnicas incluyen la minimización de costos, modelos de costo-
efectividad, costo-utilidad, costo-beneficio, costo de tratamiento de enfermedades, costo de
consecuencias de enfermedades y cualquier otra técnica analítica que pueda proporcionar
información valiosa para la asignación de recursos escasos. La farmaeconomía también se

34
conoce como economía de la salud, especialmente cuando incluye comparaciones con
terapias no farmacéuticas o estrategias preventivas tales como intervenciones quirúrgicas o
la utilización de equipo médico preventivo (McGhan 2010).
Las herramientas utilizadas por el análisis farmacoeconómico son de vital importancia para
analizar el valor potencial que puede tener tanto para los pacientes como para un sistema de
salud. Estos métodos sustituyen el enfoque tradicional de asignación de valor en el que se
consultaba a los pacientes cuánto estarían dispuestos a pagar por un determinado
tratamiento, sino que arroja un enfoque más apegado a la realidad.
El enfoque del análisis farmacoeconómico ha ido cobrando mayor importancia y ha tenido
mayor aceptación con el paso del tiempo debido a la visión integral que proporciona sobre
una enfermedad, se puede evaluar tanto las implicaciones de una enfermedad, como las
complicaciones derivadas de su presencia, haciendo así que sea una técnica cada vez más
utilizada tanto por los consumidores, agencias del gobierno o farmacéuticas.
Conforme ha pasado el tiempo, ha crecido la importancia de analizar todos los aspectos de
la salud ya que se busca encontrar un equilibrio entre recursos y dinero limitados y el
obtener un resultado óptimo, por ejemplo, hoy en día es necesario desarrollar análisis de
costo-efectividad para desarrollar un nuevo proyecto farmacéutico. Los métodos usados por
la farmacoeconomía ayudan a documentar los costos y beneficios de terapias médicas y
servicios farmacéuticos, así como a establecer prioridades para la adecuada asignación de
recursos.
4.2 La Calidad de Vida y Preferencia de los Pacientes
Dos componentes importantes dentro del análisis farmacoeconómico y que son indicadores
del efecto que determinada terapia puede tener en la vida de un paciente son los resultados
obtenidos por un paciente al seguir determinado tratamiento y la calidad de vida que posee.
A pesar de que se reconoce que existen complicaciones físicas, mentales y sociales por el
padecimiento de determinada enfermedad, no es fácil definir una forma eficiente de medir
su efecto. Además de que no se puede incluir fácilmente en un estudio de costo-efectividad.
Por ello, se propone la inclusión de una variable que mida la calidad de vida de las personas
a lo largo del tiempo, esta variable se relaciona directamente con el tipo de padecimiento
que tiene una persona, el tipo de tratamiento que sigue, así como las consecuencias
derivadas de la enfermedad (McGhan 2010).

35
La variable que se ha elegido, y que es una de las principales utilizadas en el análisis
farmacoeconómico, es la de los años ajustados de calidad de vida (QALY por sus siglas en
inglés: quality-adjusted life year) y es una medida de cómo mejora la vida de los pacientes
que combina la mortalidad y la calidad de vida obtenida como resultado de un tratamiento
medido como el número de años ganados, ajustados por la calidad de vida.
Hay diversos enfoques que se pueden tomar para medir la calidad de vida, dependiendo del
tipo de estudio que se lleve a cabo, por ejemplo:
Resultados reportados por los pacientes, por ejemplo, los síntomas.
Resultados reportados por quien cuida a los pacientes.
Resultados arrojados por los médicos.
Resultados sicológicos.
Es posible apreciar que el indicador de los QALY’s puede ser subjetivo en diversos
aspectos, sin embargo, este indicador es uno de los más ocupados en el análisis
farmacoeconómico (Soares et al. 2012).
4.3 Desarrollo de un Modelo de Análisis Farmacoeconómico
Como se explicó, el problema del análisis farmacoeconómico trata de cuantificar todas las
implicaciones del padecimiento de una determinada enfermedad, para poder definir
correctamente este problema y generar un modelo adecuado para cuantificarlo es necesario:
Definir la población por estudiar, además de la definición de las características
relevantes que se van a estudiar, tales como factores de riesgo o demográficos.
Comprender todas las características relevantes de la enfermedad a estudiar tales
como la duración de la misma, cambios en su comportamiento, población que la
padece, efectos secundarios, tratamientos y por supuestos costos.
Definir cuáles son los recursos disponibles para el tratamiento de la enfermedad,
tanto en monetario, como en personal, hospitales y otros recursos disponibles.
Definir cuál es el tipo de tratamiento que se ha de estudiar, así como cuáles son las
implicaciones que tiene sobre el comportamiento de la enfermedad en estudio.
Definir, si es el caso, los escenarios que se han de comparar, por ejemplo si se desea
medir la eficacia de un tratamiento nuevo contra uno existente en el tratamiento de
la diabetes.

36
Definir el flujo de las entidades dentro del modelo a lo largo del tiempo que dura la
simulación.
Considerar los eventos que ocurren en la simulación tal como las visitas al médico y
las pruebas de laboratorio, así como las implicaciones tanto económicas como de
salud que tengan.
Definir las medidas de desempeño de la simulación, estas pueden ser los costos,
principalmente, u otras tales como la mejora en la calidad de vida o la efectividad de
medicamentos.
Definir el tiempo de duración de la simulación, así como el número de réplicas del
modelo que se correrán.
Definir cuáles serán las técnicas de análisis que se han de ocupar para analizar los
resultados.
Definir claramente los alcances del estudio que se llevará a cabo.
Una vez que se ha definido toda la teoría necesaria para el desarrollo de un modelo
necesario, se procederá a desarrollar un modelo de simulación para realizar un análisis
farmacoeconómico, se estudiará el caso particular de la diabetes como se muestra en el
siguiente capítulo.

37
Capítulo 5
Diseño y Desarrollo de Modelo de Simulación de Evento Discreto en
Arena para Estudio de Diabetes
Una vez que se han sentado las bases para el desarrollo de un estudio farmacoeconómico
mediante modelos de simulación de evento discreto, se procederá a desarrollar un ejemplo
de su aplicación.
Se desarrollará un análisis del costo del tratamiento de la diabetes, en particular de Tipo II,
ya que es la que presenta la mayor incidencia tanto en México como en el mundo, además
de ser la principal causa de muerte en nuestro país (American Diabetes Association 2011 &
Ensanut 2009).
Esta enfermedad es compleja ya que se presenta con un gran número de complicaciones
cuya aparición está condicionada al tipo de tratamiento que se siga, el tiempo que tenga un
paciente con la enfermedad, factores demográficos, entre otros, lo que la hace un buen
ejemplo para desarrollar un análisis farmacoeconómico. Sin embargo, dada la misma
naturaleza compleja de la enfermedad, se harán algunas simplificaciones en el modelo, las
cuales serán detalladas en su momento, verificando que el modelo siga siendo válido como
se estudió en el capítulo 4.
El modelo se ha desarrollado con base en información obtenida a través de diversos
estudios clínicos desarrollados por (López et al. 2007) en los cuales se ha analizado la
presencia de diabetes y sus complicaciones en un grupo de pacientes latinoamericanos a lo
largo del tiempo. También se ha contado con información proporcionada por una compañía
farmacéutica en lo referente a los costos de los medicamentos y tratamientos de la
enfermedad, cómo se trata la enfermedad en el IMSS e información adicional que será
detallada posteriormente.
5.1 Características generales del modelo de simulación.
Este modelo se ha desarrollado utilizando el software Arena®, en su versión estudiantil. El
funcionamiento del modelo, a grandes rasgos, se presenta a continuación:

38
Se generan pacientes aleatoriamente, a cada uno de ellos se le asignan
características físicas con base en la información obtenida de los estudios clínicos
antes mencionados.
Se replica a cada paciente para simularlo en cada uno de los dos escenarios
diseñados. El primero será aquel en el que el paciente no sigue ningún tipo de
tratamiento de la enfermedad y el segundo será lo opuesto. El primer escenario es el
que sirve como base de comparación tanto de costos como de aparición de
complicaciones.
Para cada uno de los escenarios se definen las reglas que modelan la aparición de
complicaciones dependiendo del tiempo que tenga el paciente con diabetes y de si
sigue algún tratamiento o no.
Se define un número estadísticamente significativo para el total de pacientes que se
han de simular. Así como el número de réplicas que se harán del modelo, esto con el
fin de obtener estimadores estadísticamente significativos.
Se hace una recopilación de los costos y del número de complicaciones presentadas
a lo largo de la simulación y se hace una comparación entre los escenarios.
La figura 5.1 se presenta una vista general de un modelo en forma de diagrama de flujo.
Fuente: Desarrollo Propio
5.2 El origen de los datos
Como se ha mencionó, gran parte de la información sobre la evolución de la diabetes tipo II
en pacientes se ha obtenido a través de estudios clínicos.
Primer paciente paciente
Asignación de atributos
Replicar paciente
Escenario 4
Escenario 3
Escenario 2
Escenario 1
Último Paciente
Crear nuevo paciente
Estadísticas y resultados
Fin
S
N
Figura 5.1 Vista general del modelo de simulación

39
Uno de los estudios que se han analizado es el publicado en el artículo “Control of type 2
diabetes mellitus among general practitioners in private practice in nine countries of Latin
America” de López G., Tambascia M., y otros, quienes, mediante una investigación
epidemiológica se han dedicado a obtener datos tanto de características físicas de personas
diabéticas como de los tratamientos seguidos, principales indicadores sobre la presencia de
esta enfermedad, complicaciones y evolución de la misma.
La información presentada en el artículo se ha obtenido mediante la realización de
encuestas realizadas a pacientes de un grupo de médicos en nueve países distintos en
América Latina con una cierta experiencia en el tratamiento de la diabetes tipo II y con un
mínimo número de pacientes tratados al mes.
A los pacientes escogidos aleatoriamente por cada médico para ser parte del estudio, se les
ha pedido que a la fecha del estudio llevaran un determinado tratamiento para la diabetes,
se les realizaron los cuestionarios en los que se solicitaba una gran cantidad de información,
entre la que se encontraba datos demográficos, edad de diagnóstico de la diabetes, tiempo
que tenían con la enfermedad, número de complicaciones relacionadas que se habían
presentado desde su diagnóstico, así como el nivel promedio de azúcar en la sangre para los
últimos tres meses.
Con base en esto se ha obtenido información estadística, validada mediante análisis de
datos y modelos de regresión múltiple, sobre el comportamiento de esta enfermedad. Esta
información ha servido de base para conocer las características de los pacientes que
padecen de diabetes, así como para conocer la evolución del nivel de glucosa y cómo se
relaciona esto con la aparición de las complicaciones relacionadas con la enfermedad.
Dado que los datos que se obtuvieron para hacer este estudio hacen referencia a una
muestra de la población de pacientes diabéticos y en este trabajo se busca un modelo que
explique de la mejor manera posible al total de esta población se ha realizado una
estimación de los parámetros poblacionales mediante el método de momentos, el mismo
que se ha explicado anteriormente, y el ajuste de distribuciones de probabilidad, se ha
escogido este método porque para ciertas características por analizar únicamente se cuenta
con momentos muestrales como son la media o la desviación estándar, lo que justifican el
uso del método de momentos.

40
Es menester mencionar que dada la naturaleza de los datos usados y debido a la
complejidad de modelar, no ha sido posible obtener correlaciones entre las diversas
complicaciones, es decir, si la existencia de alguna complicación está relacionada con
alguna anterior, por esta razón se ha decidido considerar a las complicaciones como
independientes entre sí, sin embargo, en estudios posteriores, si se tiene esta información,
es posible incluirla para desarrollar un modelo más acertado.
En los estudios clínicos consultados se han incluido las características físicas de los
pacientes y que de cierto modo determinan cómo se comporta la enfermedad a lo largo del
tiempo, estas características incluyen estatura, índice de masa corporal, edad al momento de
diagnóstico. Además, se incluyen factores de riesgo tales como si el paciente es fumador,
padece de obesidad, presión alta, entre otras.
Para cada una de estas características es posible obtener parámetros poblacionales con base
en el método de momentos, se ha hecho este ejercicio, sin embargo no se ha incluido de
forma específica en el modelo ya que no se cuenta con información sobre cómo estas
características físicas determinan la evolución de la diabetes. Se ha hecho el ejercicio con el
método de momentos con el fin de mostrar que, para un modelo en el cual se cuente con
toda la información, el método de momentos es una herramienta válida de estimación de
parámetros poblaciones partiendo de información obtenida mediante estudios clínicos, así
como la forma de utilizarlo.
De igual forma, de los estudios clínicos antes mencionados se ha obtenido la probabilidad
de padecer cierta complicación dependiendo del tiempo que lleve el paciente de padecer
diabetes.
Finalmente, la información sobre el costo de los medicamentos, tipos de tratamiento,
pruebas de laboratorio y periodicidad han sido proporcionados por la compañía
farmacéutica antes mencionada, la misma que tiene presencia en México y que trabaja con
el Instituto Mexicano del Seguro Social.
5.3 Escenarios de Simulación
Una de las ventajas de utilizar la simulación como herramienta para modelar es el hecho de
que se puede simular a una misma entidad en distintos escenarios de forma fácil.
En este modelo se simulan dos escenarios distintos:

41
El primer escenario considera que los pacientes no siguen ningún tipo de
tratamiento, sin embargo, cuando presentan alguna complicación acuden al médico
para tratarla. Se probará que en este escenario el costo de tratamiento será mayor,
así como que habrá una mayor incidencia de complicaciones.
El segundo escenario es aquel en el que el paciente sigue un tratamiento estricto
para la diabetes. Este tratamiento incluye la ingesta de diversos medicamentos,
visitas al médico, realización de pruebas de laboratorio y la medición del nivel de
glucosa 3 veces al día, de forma que si se detecta algún nivel de glucosa fuera de los
parámetros normales sea posible actuar de forma inmediata. Se consideran 3 veces
ya que se relaciona directamente con el número de alimentos que se toman al día y
es la frecuencia común para un paciente que se cuida bien (The Permanente Medical
Group 2011).
Un estricto control de la enfermedad augura un menor costo en el tratamiento y un
mejor nivel de vida para los pacientes como se probará más adelante.
5.4 Entidades por Simular en el Modelo.
Las entidades que se simulan en el modelo son personas que ya han sido diagnosticadas con
diabetes y no se supone que haya nuevos casos que se agreguen al modelo durante la
simulación ya que lo que se busca analizar son los costos del tratamiento de la enfermedad
dependiendo del tiempo que un paciente tenga de padecerla. Inicialmente, se ha definido
que se simularán 1,000 pacientes en 100 réplicas, lo que significa que se simularán 100,000
pacientes en total.
A cada paciente, al inicio de la simulación, se le asignan dos tipos de variables:
QALY’s, que, como ya se ha mencionado, es un indicador de cómo disminuye el
nivel de vida de los pacientes conforme avanza la diabetes y se presentan diversas
complicaciones. Para fines de este modelo, se considera que la disminución en
QALY’s se debe únicamente debido a la presencia de complicaciones en un
paciente, el hecho de que un paciente haya sufrido una complicación implicará que
en el futuro esta complicación seguirá afectando su calidad de vida, aunque no
necesariamente en el mismo nivel que en el momento en que se presentó la
complicación, por ejemplo, si en el año 5, el paciente padece de un infarto, en los
años posteriores su calidad de vida se puede ver disminuida por alguna secuela del

42
evento o por alguna imposibilidad para realizar determinada actividad. Esto se ha
desarrollado así con el fin de hacer lo más realista posible la modelación de la
enfermedad.
La afectación en la calidad de vida debido a la diabetes se comparará en cada uno de
los escenarios a simular.
El segundo atributo asignado a cada paciente está relacionado con la presencia de
complicaciones. Como se verá más adelante, las complicaciones se agruparán en 5
categorías. El valor del atributo de complicaciones se modifica una vez que se
presenta alguna complicación, esto con el fin de tener registro del mismo y así
asignar los costos de forma adecuada.
5.4.1 Estimación de Características Físicas de Pacientes
En el modelo de simulación a desarrollar no se incluye de forma explícita las características
físicas de los pacientes ya que no se cuenta con la información necesaria para saber cómo
éstas influyen sobre la evolución de la diabetes, sin embargo, como parte de este
documento se explicará cómo se puede hacer un ajuste de parámetros mediante el método
de momentos ya que es algo que en una investigación posterior se podrá incluir.
Las características físicas, así como la distribución de probabilidad que se ha utilizado para
cada una se muestran en la tabla 5.1.
Datos físicos Datos de estudio clínico Distribución de
probabilidad ajustada
Talla (metros) Valor mínimo, media y varianza Triangular
Edad al momento del
diagnóstico
Media y varianza Beta ajustada
Sexo Porcentaje de hombres/mujeres Bernoulli
Índice de Masa Corporal Media, varianza Beta ajustada
Fuente: López et al., Desarrollo Propio
Como se puede apreciar en la tabla anterior, hay 3 tipos de distribución que se han utilizado
y para las cuales es necesario estimar los parámetros: Bernoulli, Triangular y Beta
Tabla 5.1 Características físicas de los pacientes
diabéticos

43
(5.1)
(5.2)
(5.3)
(5.4)
(5.5)
Ajustada. La estimación de parámetros para el primer caso no tiene mayor complicación,
sin embargo, para las distribuciones Beta Ajustada y Triangular se requiere un
procedimiento como se explica a continuación:
Distribución Triangular
Dadas las características de la distribución triangular, se ha utilizado para modelar la talla
de pacientes, estas características indican que la distribución triangular se puede utilizar en
descripciones subjetivas para poblaciones sobre las cuales se tiene una cantidad limitada de
información (Ross 2010), como es el caso de la información que se ha obtenido de los
estudios clínicos ya mencionados.
Como es sabido, una variable aleatoria X, con distribución Triangular (X~Tria(a,b,c)),
cuenta con los siguientes parámetros:
Valor mínimo (a)
Valor máximo (b)
Moda (c)
Y tiene la siguiente función de distribución de probablidad:
{
2(𝑥−𝑎)
(𝑏−𝑎)(𝑐−𝑎) 𝑠𝑖 𝑎 ≤ 𝑥 ≤ 𝑐
2(𝑏−𝑥)
(𝑏−𝑎)(𝑏−𝑐) 𝑠𝑖 𝑐 < 𝑥 ≤ 𝑏
0 𝑒. 𝑜. 𝑐
Con media y varianza, respectivamente:
𝐸[𝑋] = 𝑎+𝑏+𝑐
3
𝑉𝑎𝑟[𝑋] = 𝑎2 + 𝑏2 + 𝑐2 − 𝑎𝑏 − 𝑎𝑐 − 𝑏𝑐
18
Como se menciona en la tabla 5.1, los datos con los que se cuenta para la distribución
triangular son: el valor mínimo (a), la media (�̅�) y la varianza (𝜎2) y lo que se busca es
estimar los valores de la moda (c) y el máximo (b). Esto se puede llevar a cabo de la
siguiente forma:
1. Realizar los siguientes cambios de variable, partiendo de las ecuaciones 5.2 y 5.3:
𝐴 = 1

44
(5.10)
(5.11)
(5.12)
(5.6)
(5.7)
(5.9)
(5.8)
𝐵 = −(3�̅� − 𝑎)
𝐶 =(3�̅� − 𝑎)2 − 18𝜎2 − 𝑎(�̅� − 𝑎) + 𝑎2
3
2. Recordando la ecuación general para resolver ecuaciones de segundo grado:
𝑥1,2 =−𝐵 ± √𝐵2 − 4𝐴𝐶
2𝐴
3. Sustituyendo en la ecuación 5.7 los cambios de variable mencionado en el inciso 1
se obtiene el valor máximo de la distribución, así como la moda:
𝑏 =−𝐵+√𝐵2−4𝐴𝐶
2𝐴
𝑐 =−𝐵−√𝐵2−4𝐴𝐶
2𝐴
Distribución Beta
La distribución beta ajustada se ha utilizado para modelar el IMC y la edad al momento del
diagnóstico, los datos iniciales con los que se cuenta para esta distribución son la media y la
varianza muestrales observadas en los estudios clínicos.
Se dice que una variable aleatoria X tiene una distribución Beta, con parámetros 𝛼, 𝛽
(𝑋~𝐵𝑒𝑡𝑎(𝛼, 𝛽), si tiene una distribución de probabilidad:
𝑓(𝑥) =𝑥(𝛼−1)(1−𝑥)(𝛽−1)
Β(𝛼,𝛽)
Donde Β(𝛼, 𝛽) es la función Beta, más detalle sobre la misma se puede encontrar en (Ross,
2010). Esta distribución de probabilidad tiene una media y una varianza, respectivamente
de:
𝐸[𝑋] = 𝛼
𝛼 + 𝛽
𝑉𝑎𝑟[𝑋] = 𝛼𝛽
(𝛼+𝛽)2(𝛼+𝛽+1)
En este caso particular, se quiere estimar los valores 𝛼, 𝛽 partiendo de las ecuaciones 5.11 y
5.12. Esto se hace de la siguiente forma:

45
(5.13)
(5.14)
(5.15)
1. De la ecuación 5.12 se puede obtener:
𝛼 + 𝛽 =�̅�(1 − �̅�)
𝜎2− 1
2. De la ecuación 5.11 y 5.13 se sabe que:
𝛼 = �̅�(𝛼 + 𝛽)
3. Dado que todos los valores que conforman la ecuación 5.14 son conocidos se
puede obtener el valor de 𝛼
4. Finalmente, de la ecuación 5.13, se puede despejar el valor de 𝛽
Como se ha mencionado al inicio de este apartado, se está utilizando una distribución beta
de rango ajustada para ser coherente con los valores del IMC como la talla de los pacientes.
Esto se ha hecho mediante una transformación lineal de una distribución beta de la
siguiente forma:
𝑋1 = 𝑀𝑖𝑛 + (𝑀𝑎𝑥 −𝑀𝑖𝑛)𝑋
Donde:
Min: es el valor mínimo asignado para el intervalo de la variable 𝑋1
Max: es el valor máximo definido para el intervalo de la variable 𝑋1
X: 𝑋~𝐵𝑒𝑡𝑎(𝛼, 𝛽), con parámetros estimados como se ha explicado anteriormente
De esta forma se obtienen los valores de los parámetros de las distribuciones beta y
triangular para los datos físicos de los pacientes a simular.
5.4.2 Aparición de Complicaciones en Pacientes Diabéticos
Dada la naturaleza de la diabetes, esta se presenta junto con un gran número de
complicaciones que afectan la calidad de vida del paciente y que al mismo tiempo
incrementan los costos del tratamiento, estas enfermedades se relacionan directamente con
el nivel de glucosa en la sangre (el cual varía dependiendo del control que se tenga de la
enfermedad), así como de los años que se tenga de padecer diabetes. Existe un gran
número de complicaciones que se presentan como efectos secundarios, sin embargo, para
fines de este estudio se considerarán las más comunes de acuerdo con (Nutricia Advanced

46
Medical Nutrition 2014). Estas se pueden clasificar en 5 grandes grupos que componen las
siguientes complicaciones (López et al. 2007):
Problemas cardiovasculares: insuficiencia cardíaca, infarto al miocardio, falla
congestiva del corazón y angina de pecho
Problemas renales: microalbuminuria, complicaciones renales en general y
proteinuria
Problemas de visión: retinopatía, cataratas o pérdida de la visión
Úlceras y amputaciones
Neuropatías
El valor de la probabilidad de padecer una complicación por cada grupo antes mencionado
se compone de un valor promedio de incidencia de las complicaciones que componen cada
grupo. Se ha considerado este valor ya que algunas de estas complicaciones pueden estar
relacionadas entre sí, sin embargo, no se cuenta con la información sobre la correlación
entre las distintas complicaciones
Para modelar de forma apropiada la aparición de complicaciones y con base en la
información de (López et al. 2007) se definen intervalos de tiempo de padecimiento de
diabetes como sigue:
Etapa 1: De 0 a 2 años
Etapa 2: De 3 a 5 años
Etapa 3: De 6 a 9 años
Etapa 4: De 10 a 14 años
Etapa 5: De 15 años en adelante
Como es de suponer, conforme pasa el tiempo, la probabilidad de padecer alguna
complicación cambia, generalmente aumenta ya que el organismo se ve cada vez más
afectado por la presencia de la enfermedad.
Una vez que se han definido estas etapas, es necesario calcular la probabilidad de padecer
alguna complicación dependiendo de: (i) el tiempo que se tenga de padecer diabetes y (ii) el
tipo de tratamiento que se siga. Esto se ha hecho de la siguiente forma y con base en 3
grupos de información:

47
(5.16)
Se contó con la incidencia (en porcentaje) de cada tipo de las complicaciones antes
mencionadas en un estudio clínico al final de un período de prueba (López et al.
2007).
La presencia de complicaciones, dependiendo del tiempo que se tenga de padecer
diabetes.
Un factor de incidencia de complicaciones dependiendo del tipo de tratamiento
seguido por los pacientes, relacionado con la frecuencia de medición de azúcar en la
sangre.
Es importante mencionar que de acuerdo con los datos de (López et al., 2007), se cuenta
con la probabilidad de que un paciente padezca alguna complicación por cada una de las
etapas antes mencionadas. Dado que el modelo realizado está pensado para que los cambios
de evento discreto sean anuales, por lo anterior se ha tenido que hacer un ajuste para que la
probabilidad de padecer alguna complicación por cada etapa se vuelva anual, esto se ha
hecho bajo el siguiente supuesto:
𝑃[𝐶𝑜𝑚𝑝𝑙𝑖𝑐𝑎𝑐𝑖ó𝑛 𝐴ñ𝑜 𝑍] =𝑋
𝑌
Donde:
X es la probabilidad de padecer cierta complicación en determinada etapa
Y es el número de años que comprende cada etapa
∑𝑋
𝑌
𝑌𝑖=1 = 𝑋
Mezclando los datos anteriores se obtuvo una matriz de probabilidad de padecer alguna
complicación dependiendo del tiempo de padecer diabetes, así como del escenario que se
esté simulando. Esta será mostrada específicamente en la sección de resultados.
La aparición de cada una de las complicaciones se ha modelado como una cadena de
Markov en la que se tienen dos estados, cuando el paciente padece alguna complicación y
cuando no. Esta se puede describir como se muestra en la figura 5.2

48
Fuente: Desarrollo Propio
Donde:
P(0,0) es la probabilidad de no padecer una complicación en el momento t y
permanecer sin ella en el tiempo t+1. No olvidar que el modelo que se está
desarrollando es de evento discreto, por lo que la anterior nomenclatura se puede
utilizar.
P(0,1) es la probabilidad de pasar de no tener una complicación en el tiempo t y
pasar a tenerla en el tiempo t+1
P(0,0) + P(0,1) = 1
P(1,1) es el estado absobente en el que un paciente tiene una complicación para lo
que resta de la simulación. Es un estado absorbente ya que una vez que un paciente
padece una complicación esta no se termina y sigue generando costos.
Cada complicación es independiente de otra, es decir, la presencia de una no implica la otra
ni viceversa, esto debido a que no se cuenta con información sobre la correlación de estas
variables, así como la complejidad de modelarlas de forma simultánea, esto no es
necesariamente cierto en la vida real y en un estudio más completo del tema se puede
incluir.
Dado que el padecimiento de alguna complicación relacionada con la diabetes afecta de
forma negativa la calidad de vida, se ha diseñado una forma de medir el impacto de estas
sobre los pacientes mediante un indicador llamado QALY, el cual, disminuye dependiendo
No Padece Complicacio n
S
N
Figura 5.2 Cadena de Markov para Complicaciones
Padece Complicacio n
P(0,0) = x
P(0,1) = 1-x
P(1,1) =1

49
del tipo de complicación que se padezca de acuerdo a la siguiente regla implementada en el
modelo:
Problemas cardiovasculares: 1 punto
Problemas renales: 2 puntos
Problemas de visión: 2 puntos
Úlceras y amputaciones: 2 puntos
Neuropatías: 1 punto
Finalmente, se debe de mencionar que en este modelo, no se considera de forma explícita la
mortalidad de cada paciente, es decir, se asume que permanece vivo durante todo el
horizonte de simulación. Esto con el fin de determinar cuál sería el costo del tratamiento a
largo plazo. El horizonte de largo plazo considerado es de 25 años ya que de acuerdo con
Centers for Disease Control and Prevention, es la duración de la mayoría de las personas
con diabetes.
5.5 Las variables del modelo.
El principal indicador de la presencia de la diabetes en un paciente es un nivel anormal de
azúcar en la sangre. Para determinar este nivel, se han desarrollado diversas pruebas de
laboratorio tales como la de la hemoglobina glicosilada, también conocida como A1C, la
cual es una proteína presente en la sangre y que se mide como un porcentaje dentro de la
misma. Al estudiar el nivel de A1C es posible obtener el nivel promedio de azúcar en la
sangre para los últimos tres meses (American Diabetes Association).
Como es de suponerse, si un paciente tiene un nivel fuera del rango normal de azúcar en la
sangre es más probable que la enfermedad se presente con alguna complicación.
Dado que el principal motivo del análisis desarrollado en este documento es el del costo
generado por el tratamiento de la diabetes, este será la principal variable que se utilizará en
el modelo y que servirá como punto de comparación entre los escenarios propuestos.
Los costos generados están dados por el tipo de tratamiento seguido por los pacientes, así
como de las complicaciones que padezcan a lo largo del tiempo, por lo que la principal
variable que se ha de medir a lo largo de la simulación son los costos generados por el
tratamiento de la diabetes.

50
Para cada complicación está asignado un costo de tratamiento para la institución tratante.
Esto se explicará a detalle en secciones posteriores.
Como se habrá notado, no se está incluyendo de forma explícita el nivel de azúcar en la
sangre que, como se ha ya mencionado, es el principal indicador de la presencia de
diabetes, sin embargo, el hecho de que se considere una probabilidad de padecer una
complicación dependiendo del tipo de tratamiento y el tiempo que se tenga de padecer
diabetes asume de forma implícita el impacto del nivel de azúcar en la sangre. En estudios
posteriores, es posible incluir de forma explícita el nivel de A1C y utilizarlo para
determinar el comportamiento de la diabetes a lo largo del tiempo, sin embargo, para este
estudio se utilizará la metodología antes mencionada.
5.6 Costos
Dado que el objetivo primario de este modelo es analizar los costos directos del tratamiento
de la diabetes es necesario definir cuáles son los factores que generan costo dentro del
modelo de acuerdo a cada escenario.
En el primer escenario que se considera, es decir, aquél en el que los pacientes no siguen un
tratamiento estricto de la enfermedad, los costos que se consideran son:
Costo del tratamiento cada vez que se presenta una complicación. Este costo es más
alto que en el escenario en el que un paciente sigue un tratamiento ya que debido a
la falta del mismo, la complicación se puede agravar haciendo así más difícil su
tratamiento y por ende más costoso.
Costo de seguimiento de la complicación: a pesar de que no se siga un tratamiento
seguido, es necesario que cada complicación tenga un seguimiento. Este costo se
considera como un porcentaje sobre el costo de tratar la enfermedad sin que se siga
un tratamiento.
En el segundo escenario los costos que se generan son:
Pruebas de laboratorio y visitas al médico: se consideran diversas pruebas de
laboratorio y consultas con especialistas con distinta periodicidad al año.
Medicamentos: para tratar tanto la diabetes directamente como padecimientos
asociados tales como la presión alta o niveles altos de colesterol.
Insulina: para controlar los niveles de glucosa.
Tiras medidoras de glucosa.

51
Costo asociado a la aparición de complicaciones y seguimiento posterior de las
mismas, considerado como un porcentaje del costo del tratamiento.
El costo de cada uno de estos factores se ha considerado con base en información
proporcionada por el IMSS, la compañía farmacéutica antes mencionada y algunas otras
instituciones públicas de salud, algunos datos son para años pasados, sin embargo, se han
ajustado para tener su costo a valor presente (octubre de 2014) tomando en cuenta la
inflación anualizada. El costo futuro de estos factores se ha supuesto igual para todos los
años, para obtener un valor en términos nominales a valor presente y así tener un parámetro
de referencia común para todos los escenarios.
Dado que la información proporcionada es confidencial, no es posible mostrar
explícitamente las cantidades consideradas para el modelo.
Al final de la simulación se hacen comparativos entre el costo total en cada uno de los
escenarios analizados.
5.7 Complicaciones en el desarrollo del modelo
Uno de los principales problemas a los que fue necesario enfrentarse fue la falta de
información provista para modelar las características físicas de los pacientes, por ello fue
necesario echar mano del método de momentos para estimar los parámetros poblacionales,
así como decidir qué distribución es la que mejor ajusta los datos a modelar.
De igual forma, uno de los retos más grandes durante el desarrollo de este modelo fue la
búsqueda de una forma de mantener el modelo lo más simple posible, sin eliminar variables
fundamentales y que pudieran arrojar resultados incorrectos o afectar la validez del modelo,
esto aunado al hecho de utilizar una versión estudiantil de Arena®, la cual tiene ciertas
limitaciones de módulos y variables.
De nuevo, es importante mencionar, que los resultados que se obtienen del modelo,
dependen de los datos de entrada, un modelo puede estar muy bien desarrollado, sin
embargo, si los datos que se utilizan no son consistentes, tampoco lo será el resultado y
carecerá de validez como herramienta de toma de decisiones.

52
Capítulo 6
Resultados Arrojados por el Modelo de Simulación
En el capítulo anterior, se ha detallado cómo se ha armado el modelo de simulación, en este
capítulo se procederá a mostrar los resultados obtenidos del mismo, respecto a las
características físicas de los pacientes, así como los costos generados por cada
complicación, el efecto en la calidad de vida, el comparativo entre escenarios para medir el
efecto de seguir un tratamiento estricto sobre los costos y la calidad de vida de los
pacientes. Finalmente, se hará una extrapolación en la que se mostrará cuál es el efecto en
costos de la diabetes a nivel nacional sobre el sector salud y cómo el hecho de incluir un
tratamiento que incluya un mejor control del nivel de glucosa y por ende de la enfermedad
reduce de forma considerable los costos derivados del tratamiento de la diabetes
6.1 Características Físicas de los Pacientes
Como se mencionó en la sección 5.4.1 se han simulado las características físicas de los
pacientes, estas se muestran de nuevo en la Tabla 6.1.
Datos físicos Datos de estudio clínico Distribución de
probabilidad ajustada
Talla (metros) Valor mínimo, media y varianza Triangular
Edad al momento del
diagnóstico
Media y varianza Beta ajustada
Sexo Porcentaje de hombres/mujeres Bernoulli
Índice de Masa Corporal Media, varianza Beta ajustada
Fuente: López et al., Propia
Tabla 6.1 Características físicas de los pacientes
diabéticos

53
En el capítulo anterior la sección anterior, se explicó la forma de estimar los parámetros
poblacionales de las características físicas de los pacientes mediante el método de
momentos. En las tabla 6.1 y 6.2 se muestran cuáles son los parámetros tanto de entrada
como los calculados para las distribuciones Beta ajustada, Triangular y que se utilizaron
para simular pacientes.
Fuente: Desarrollo Propio
Fuente: Desarrollo Propio
Para el género de los pacientes, se contaba con el porcentaje de personas de sexo masculino
dentro del estudio clínico (46.4%), este dato se introdujo al modelo para simular esta
característica de los pacientes.
Una vez que se ajustaron los datos anteriores, se simularon 100,000 pacientes con estas
características aleatorias en Arena®, los resultados obtenidos se analizaron mediante la
herramienta de Output Analyzer del mismo software. En las figuras 6.1 a 6.4 se muestran
los histogramas con los resultados que se obtuvieron para cada grupo de datos, de estos se
puede observar la forma que tienen, la cual es congruente con el tipo de distribución de
probabilidad que se ha elegido, así como los parámetros de la misma.
Característica Mínimo Media
Desviación
Estándar Moda Máximo
Talla 1.50 1.66 0.08 1.59 1.88
Datos de Entrada Datos de Salida
Tabla 6.2 Parámetros de Entrada y Calculados para Talla de una Distribución Triangular
Tabla 6.3 Parámetros de Entrada y Calculados para Edad e IMC de una Distribución Beta
BetaPadiabéticos
Característica Mínimo Máximo Media
Desviación
Estándar a b
Edad 40.0 70.0 52.40 10.90 0.35 0.49
IMC 18.5 45.0 29.30 5.30 1.78 3.04
Datos de Entrada Datos de Salida

54
Fuente: López et al., Desarrollo Propio
De la figura 6.1 se observa que la talla de los pacientes es congruente con los datos de
entrada de una distribución triangular con moda 1.59 metros y un valor mínimo de 1.50
metros.
Fuente: López et al, Desarrollo Propio
Figura 6.2 Edad de los Pacientes
Figura 6.1 Talla de los Pacientes

55
De la figura 6.2 se puede apreciar que la edad simulada de los pacientes es congruente con
los parámetros de entrada, la edad mínima de los pacientes se ubica entre 40 y 70 años y
sigue una distribución beta ajustada. Se puede apreciar de esta figura que, los datos están
cargados a las orillas de la distribución.
Fuente: López et al, Desarrollo Propio
De la figura 6.3 se observa que el índice de masa corporal simulado es congruente con una
distribución beta ajustada a un intervalo de 18.5 a 45 𝑚
𝑘𝑔2
Finalmente, la figura 6.4 muestra la distribución Bernoulli que representa el sexo de los
pacientes, de aquí se puede apreciar que, similar a como se había incluido en los datos de
entrada, el 46.02% de los pacientes son hombres
Con lo anterior, se puede afirmar que los resultados que se han obtenido de la simulación
de las características de los pacientes son congruentes con los datos de entrada que se han
seleccionado con el modelo. De aquí también se confirma una de las ventajas de utilizar la
simulación de evento discreto como una herramienta para modelar características de
pacientes partiendo de una base conocida y sin una necesidad específica de desarrollar un
estudio clínico ya que, como se ha explicó anteriormente, el método de momentos, además
de ser fácil de usar, arroja estimadores poblacionales congruentes y al mismo tiempo, al
combinarlo con la simulación de evento discreto, se obtienen resultados de forma fácil. En
Figura 6.3 Índice de Masa Corporal de los Pacientes

56
caso de que se quisiera obtener datos para otro tipo de muestra, lo único que se debe de
hacer es cambiar los parámetros en el modelo desarrollado y simular de nuevo, apoyando
así el avance de estudios de análisis farmacoeconómicos y en el desarrollo de políticas
públicas de salud.
Fuente: López et al., Desarrollo Propio
6.2 Complicaciones
Como se mencionó en el capítulo anterior, las complicaciones se han agrupado en 5
distintas, para cada una de ellas se hará un análisis sobre la incidencia de cada una, así
como la afectación en la calidad de vida. En los resultados que se mostrarán a continuación,
el escenario base es aquel en el que el paciente no sigue ningún tipo de tratamiento,
mientras que el escenario comparativo es aquel en el que el paciente se encuentra bajo
constante supervisión médica y tratamiento.
La probabilidad de que aparezca una complicación dependiendo del escenario simulado, así
como del tiempo que tenga un paciente de padecer diabetes se muestra en el Anexo 1.Como
se explicó, el horizonte de simulación fue de 25 años, en los que se simularon 1,000
pacientes en 100 réplicas para un total de 100,000 pacientes simulados.
Complicaciones Cardiovasculares
En la tabla 6.4 se presenta la incidencia de complicaciones cardiovasculares por cada 1,000
pacientes, se puede apreciar una reducción en el número de complicaciones en cada etapa,
lo que genera que al final de la simulación se tenga una reducción en el número de
problemas cardiovasculares cercana al 2%.
Figura 6.4 Sexo de los Pacientes

57
Fuente: Desarrollo Propio
Con respecto a la calidad de vida de los pacientes, en la tabla 6.5 se aprecia una
disminución en la pérdida de calidad de vida del 2.4%.
Fuente: Desarrollo Propio
A simple vista estas reducciones pueden parecer pequeñas, sin embargo, cuando estos
resultados se extrapolan, el impacto en costos a nivel macro es considerable como se podrá
apreciar en secciones posteriores.
Complicaciones Renales
Una de las complicaciones más severas relacionadas con la diabetes son las renales, por lo
cual se ha decidido analizarlas para medir el efecto del tratamiento de la diabetes sobre este
tipo de complicaciones. Como se aprecia en la tabla 6.6, la reducción en la aparición de
complicaciones renales ha sido de hasta 20% en los primeros años en que se padece la
enfermedad y cercana al 17% en general, lo cual aumenta también la calidad de vida de los
pacientes como se puede apreciar en la tabla 6.7, donde se aprecia una disminución en la
pérdida de calidad de vida cercana al 18%.
Tabla 6.4 Incidencia de Complicaciones Cardiovasculares
diabéticos Complicaciones (por cada 1,000
Pacientes) Escenario Base Escenario Comparativo Variación (%)
0 -2 años 69.07 67.61 (2.1%)
3 -5 años 78.09 76.81 (1.6%)
6 -9 años 24.14 23.76 (1.6%)
10 - 14 años 17.86 17.43 (2.4%)
15 - 25 años 22.08 21.09 (4.5%)
Total 211.24 206.7 (2.1%)
Tabla 6.5 Reducción en QALY’s por Complicaciones Cardiovasculares
Disminución en QALY Anual Escenario Base Escenario Comparativo Variación (%)
Puntos por Paciente 0.170 0.166 (1.9%)

58
Fuente: Desarrollo Propio
Fuente: Desarrollo Propio
Se puede apreciar que, con respecto a las complicaciones cardiovasculares, el efecto
positivo de seguir un tratamiento es mayor en las complicaciones renales, lo que genera
menores costos.
Complicaciones en Ojos
Con respecto a las complicaciones en los ojos, se aprecia de la tabla 6.5 una disminución en
la incidencia de cerca de 16%, alcanzando un pico en la reducción en la tercera etapa de
cerca de 18%. En la tabla 6.8 se aprecia una considerable reducción en la pérdida de calidad
de vida.
Fuente: Desarrollo Propio
Tabla 6.6 Incidencia de Complicaciones Renales
Complicaciones (por cada 1,000
Pacientes) Escenario Base Escenario Comparativo Variación (%)
0 -2 años 69.88 55.72 (20.3%)
3 -5 años 57.51 46.35 (19.4%)
6 -9 años 97.62 82.31 (15.7%)
10 - 14 años 27.19 23.24 (14.5%)
15 - 25 años 96.09 82.81 (13.8%)
Total 348.29 290.43 (16.6%)
Tabla 6.7 Reducción en QALY’s por Complicaciones Renales
Disminución en QALY Anual Escenario Base Escenario Comparativo Variación (%)
Anual por Paciente 0.230 0.190 (17.7%)
Tabla 6.8 Incidencia de Complicaciones en Ojos
Complicaciones (por cada 1,000
Pacientes) Escenario Base Escenario Comparativo Variación (%)
0 -2 años 21.66 18.5 (14.6%)
3 -5 años 25.05 21.28 (15.0%)
6 -9 años 27.69 22.85 (17.5%)
10 - 14 años 53.84 44.94 (16.5%)
15 - 25 años 50.11 42.7 (14.8%)
Total 178.35 150.27 (15.7%)
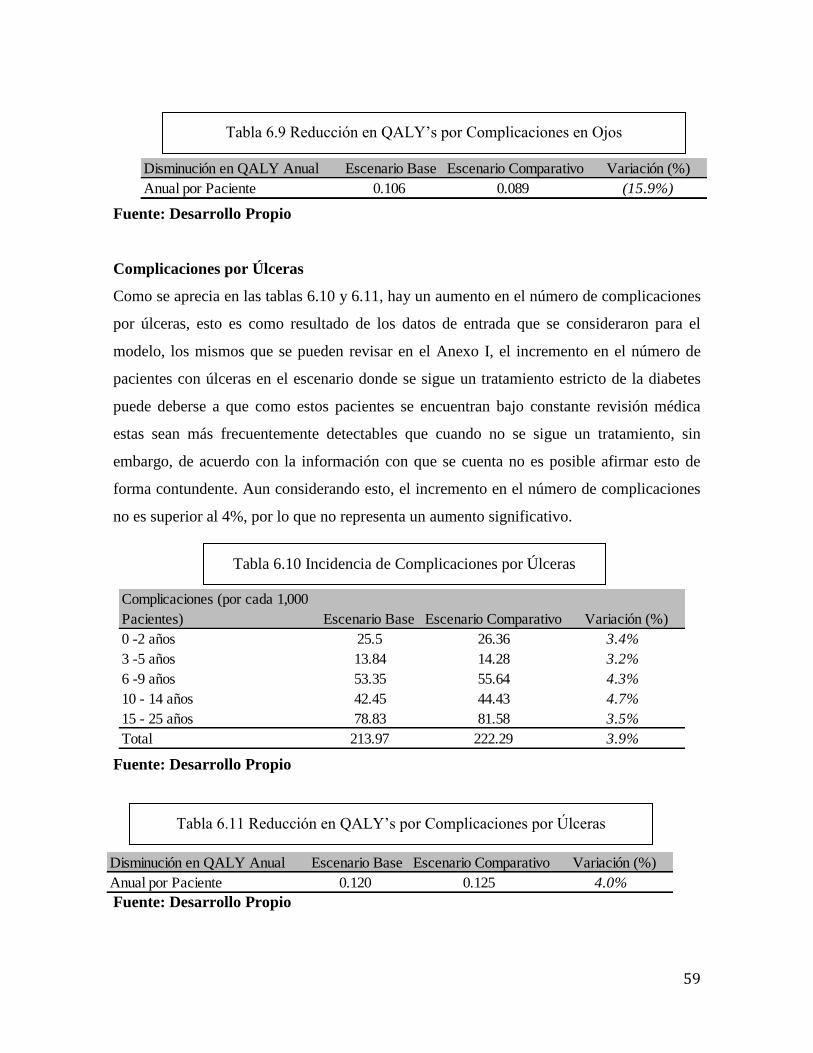
59
Fuente: Desarrollo Propio
Complicaciones por Úlceras
Como se aprecia en las tablas 6.10 y 6.11, hay un aumento en el número de complicaciones
por úlceras, esto es como resultado de los datos de entrada que se consideraron para el
modelo, los mismos que se pueden revisar en el Anexo I, el incremento en el número de
pacientes con úlceras en el escenario donde se sigue un tratamiento estricto de la diabetes
puede deberse a que como estos pacientes se encuentran bajo constante revisión médica
estas sean más frecuentemente detectables que cuando no se sigue un tratamiento, sin
embargo, de acuerdo con la información con que se cuenta no es posible afirmar esto de
forma contundente. Aun considerando esto, el incremento en el número de complicaciones
no es superior al 4%, por lo que no representa un aumento significativo.
Fuente: Desarrollo Propio
Fuente: Desarrollo Propio
Tabla 6.9 Reducción en QALY’s por Complicaciones en Ojos
Disminución en QALY Anual Escenario Base Escenario Comparativo Variación (%)
Anual por Paciente 0.106 0.089 (15.9%)
Tabla 6.11 Reducción en QALY’s por Complicaciones por Úlceras
Disminución en QALY Anual Escenario Base Escenario Comparativo Variación (%)
Anual por Paciente 0.120 0.125 4.0%
Tabla 6.10 Incidencia de Complicaciones por Úlceras
Complicaciones (por cada 1,000
Pacientes) Escenario Base Escenario Comparativo Variación (%)
0 -2 años 25.5 26.36 3.4%
3 -5 años 13.84 14.28 3.2%
6 -9 años 53.35 55.64 4.3%
10 - 14 años 42.45 44.43 4.7%
15 - 25 años 78.83 81.58 3.5%
Total 213.97 222.29 3.9%

60
Complicaciones por Neuropatías
Finalmente, el último grupo de complicaciones considerado son las neuropatías, como se
aprecia en las tablas 6.12 y 6.13 hay una reducción en la aparición de este tipo de
complicaciones cercana al 8%. Esto tiene un efecto positivo sobre la calidad de vida de los
pacientes que se ve reflejado en una disminución en la reducción de la calidad de vida
cercana al 9% por año.
Fuente: Desarrollo Propio
Fuente: Desarrollo Propio
6.3 Costos de Tratamiento de Diabetes
Como se ha mencionado a lo largo de este documento, uno de los objetivos principales es
medir el impacto en costos del tratamiento de diabetes y compararlo contra un escenario en
el que no se sigue tratamiento alguno. En esta sección se mostrarán los costos acumulados
del tratamiento de este padecimiento a lo largo del tiempo.
Como se ha mencionado, se ha acordado con el proveedor de esta información que no se
mostrarían los costos del tratamiento, sin embargo, estos incluyen el costo ponderado del
tratamiento de las complicaciones mencionadas para cada grupo, el costo del tratamiento,
de las revisiones periódicas, medicamentos, tiras reactivas, medidores de glucosa, entre
otros.
Tabla 6.12 Incidencia de Complicaciones por Neuropatías
Complicaciones (por cada 1,000
Pacientes) Escenario Base Escenario Comparativo Variación (%)
0 -2 años 134.72 120.74 (10.4%)
3 -5 años 58.69 53.32 (9.1%)
6 -9 años 91.87 85.15 (7.3%)
10 - 14 años 58.06 54.6 (6.0%)
15 - 25 años 74.27 70.01 (5.7%)
Total 417.61 383.82 (8.1%)
Tabla 6.13 Reducción en QALY’s por Complicaciones por Úlceras
Disminución en QALY Anual Escenario Base Escenario Comparativo Variación (%)
Anual por Paciente 0.303 0.276 (8.7%)

61
Los resultados del costo acumulado de tratamiento de cada paciente diabético se muestran
en la tabla 6.14 y en la Figura 6.5
Fuente: Desarrollo Propio
Tabla 6.14 Costo de Tratamiento Individual Acumulado
Año Escenario Base
Escenario
Comparativo
Variación vs.
Escenario Base
(%)
1 70,644 75,525 6.9%
2 141,288 148,277 4.9%
3 191,501 206,797 8.0%
4 241,714 262,544 8.6%
5 291,927 307,198 5.2%
6 354,597 356,066 0.4%
7 417,267 404,934 (3.0%)
8 479,938 453,802 (5.4%)
9 542,608 502,670 (7.4%)
10 586,633 551,318 (6.0%)
11 640,135 599,965 (6.3%)
12 693,637 648,613 (6.5%)
13 747,139 697,261 (6.7%)
14 800,641 745,909 (6.8%)
15 859,670 798,544 (7.1%)
16 918,698 851,180 (7.3%)
17 977,727 903,816 (7.6%)
18 1,036,756 956,452 (7.7%)
19 1,095,785 1,009,087 (7.9%)
20 1,154,814 1,061,723 (8.1%)
21 1,213,842 1,114,359 (8.2%)
22 1,272,871 1,166,995 (8.3%)
23 1,331,900 1,219,631 (8.4%)
24 1,390,929 1,272,266 (8.5%)
25 1,449,957 1,324,902 (8.6%)

62
Fuente: Desarrollo Propio
Como se puede apreciar en las figuras anteriores, en los primeros años, el costo de
tratamiento es mayor en el escenario en el que se sigue un tratamiento, esto a primera vista
puede llamar la atención, sin embargo, esto sucede porque en los primeros años se tiene
que incurrir en costos para tratar la enfermedad de forma adecuada, por ejemplo, se tienen
que realizar pruebas de laboratorio, comprar los medidores de glucosa, las tiras reactivas,
consultas con médicos, entre otros costos generados. Conforme pasa el tiempo, estos costos
permanecen, aunque a menor nivel y poco a poco los ahorros en que se incurre opacan
estos altos costos.
En la Figura 6.6 se presenta la variación porcentual en costo acumulado del escenario
comparativo contra el escenario base, en esta figura se aprecia de nuevo lo antes
mencionado.
Figura 6.5 Costo de Tratamiento Individual Acumulado

63
Fuente: Desarrollo Propio
Para entender la magnitud del costo del tratamiento de la diabetes y del ahorro en que se
puede incurrir por seguir un tratamiento contra la diabetes únicamente en México, se ha
realizado el siguiente ejercicio:
De acuerdo con (Shaw et al. 2009), cada año se detectan 254,000 nuevos casos de
diabetes. Con base en información de Ensanut (Ensaut 2011) y los datos antes
mencionados, para finales de 2014 habría aproximadamente 7.85 millones de
personas con diabetes tipo II en nuestro país.
Con base en información de Ensanut, se obtuvo una distribución de probabilidad
discreta de que una persona falleciera por causas relacionadas con la diabetes de
acuerdo con el tiempo que tuviera de padecer diabetes. La información de la que se
obtuvo esta distribución indica el número de fallecimientos por diabetes
dependiendo de la edad de los pacientes. Para este modelo, se ha considerado que la
edad de diagnóstico de la diabetes son 52 años, entonces, con la información antes
mencionada se cuenta el número de pacientes que fallecen en años posteriores hasta
los 76 años (que abarca los 25 años que dura la simulación). Del total de pacientes
que fallecen, se cuenta el número de pacientes que mueren cada año y con esto se
arma la distribución de probabilidad discreta antes mencionada.
El número de pacientes que hay en cada año se calcula de la siguiente forma:
Figura 6.6 Variación % en Costo vs. Escenario Base

64
(6.1)
(6.2)
(6.3)
𝑥 = 𝑁ú𝑚𝑒𝑟𝑜 𝑑𝑒 𝑛𝑢𝑒𝑣𝑜𝑠 𝑝𝑎𝑐𝑖𝑒𝑛𝑡𝑒𝑠
𝑃𝑎𝑐𝑖𝑒𝑛𝑡𝑒𝑠𝑎ñ𝑜1 = 𝑥(1 − 𝑝1)
𝑃𝑎𝑐𝑖𝑒𝑛𝑡𝑒𝑠𝑎ñ𝑜𝑘 = 𝑥(1 − ∑ 𝑝𝑖𝑘𝑖=1 )
Donde 𝑝𝑖 es la probabilidad de que un paciente fallezca por causas relacionadas con
la diabetes en el año i.
Usando los dos puntos anteriores como base, se calculó para cada uno de los 25
años del horizonte de simulación la cantidad de pacientes con diabetes a nivel
nacional, así como los costos de tratamiento, dependiendo del tiempo de padecer la
enfermedad.
Una vez que se juntaron estos datos, se obtuvieron los costos acumulados de
tratamiento a nivel nacional, en términos nominales, estos están reflejados en la
tabla 6.15 y en la figura 6.7.
Lo anterior implica un ahorro de 782,671 millones de pesos en un plazo de 25 años.
Para tener una idea de cuánto representa esta cantidad para el sistema de salud
mexicano se puede hacer el siguiente cálculo: para 2013 el valor nominal del PIB en
México fue de 16,101,884 millones de pesos. Por lo que la cifra anterior representa
un 4.86% del total del PIB de México para 2013.
Es importante recordar que estos costos representan únicamente un ahorro derivado del
tratamiento de la diabetes, sin embargo, no se consideran ahorros que podrían derivar de
acciones preventivas tales como pláticas informativas, alentar a la gente a seguir una dieta
balanceada, llevar un estilo de vida sano, entre otros. Considerando estos elementos, el
ahorro podría ser considerablemente más alto.
De los dos apartados anteriores, se aprecia que seguir un tratamiento adecuado para la
diabetes implica un menor número de complicaciones, lo que deriva en menores costos de
tratamiento para el sistema de salud en general.

65
Fuente: Desarrollo Propio
Tabla 6.15 Costo Total Estimado de Tratamiento de Diabetes
Año Base Comparativo Variación (%)
1 554,272,593,662 592,570,971,087 6.9%
2 1,116,072,100,610 1,171,838,349,750 5.0%
3 1,530,112,109,642 1,650,260,898,607 7.9%
4 1,947,691,270,177 2,112,385,180,650 8.5%
5 2,368,254,350,575 2,498,119,407,319 5.5%
6 2,877,325,927,284 2,914,641,255,953 1.3%
7 3,387,945,067,158 3,332,369,839,954 (1.6%)
8 3,899,652,274,525 3,750,946,860,749 (3.8%)
9 4,410,367,292,081 4,168,750,206,798 (5.5%)
10 4,805,804,702,326 4,584,214,016,555 (4.6%)
11 5,254,504,317,541 4,997,169,394,892 (4.9%)
12 5,699,767,444,896 5,407,000,079,867 (5.1%)
13 6,141,098,936,686 5,813,255,848,810 (5.3%)
14 6,578,392,735,897 6,215,840,267,318 (5.5%)
15 7,038,047,985,844 6,633,758,571,709 (5.7%)
16 7,492,113,930,489 7,046,692,909,725 (5.9%)
17 7,939,974,350,848 7,454,093,800,793 (6.1%)
18 8,381,698,962,171 7,856,023,409,785 (6.3%)
19 8,817,006,586,650 8,252,231,011,314 (6.4%)
20 9,245,553,310,401 8,642,409,938,425 (6.5%)
21 9,666,374,273,484 9,025,699,828,475 (6.6%)
22 10,079,540,862,769 9,402,164,336,914 (6.7%)
23 10,484,919,028,305 9,771,683,931,813 (6.8%)
24 10,882,980,406,739 10,134,679,170,122 (6.9%)
25 11,274,613,752,385 10,491,942,551,333 (6.9%)

66
Fuente: Desarrollo Propio
Figura 6.7 Variación % en Costo vs. Escenario Base Total

67
CONCLUSIONES
Al inicio de este documento se planteó el objetivo de este documento: desarrollar una
propuesta de metodología que sirva para desarrollar modelos de simulación de evento
discreto para realizar un análisis farmacoeconómico que sirva como una herramienta
auxiliar y de optimización en la toma de decisiones de política pública en materia de salud.
Para complementar este objetivo, y a forma de ilustrarlo, se ha desarrollado un modelo de
análisis farmacoeconómico aplicado al caso particular de la diabetes, en el cual se ha
partido de un conjunto de datos sobre el comportamiento de la enfermedad y la incidencia
de complicaciones asociadas a la misma dependiendo del tratamiento seguido y se ha
realizado un análisis de costos del tratamiento de la misma tratando de replicar, en medida
de lo posible y dadas las limitaciones de software e información, su comportamiento a lo
largo del tiempo.
Se ha buscado escribir este documento en una forma clara a fin de que aquellos que no
cuentan con una gran experiencia en temas de modelado y estadística lo encuentren fácil de
leer y así aportar al sector médico en el tema de análisis farmacoeconómico, el cual, como
se ha mencionado anteriormente, ha ido cobrando cada vez más importancia, la misma que
seguirá creciendo debido a que cada vez se requiere una mayor cantidad de recursos, los
cuales son escasos, por los pacientes con necesidad de servicios relacionados con el sector
salud. Por lo anterior, es recomendable y quizá necesario contar con una herramienta que
ayude a realizar este tipo de análisis de forma eficiente, a bajo costo, en poco tiempo y que
al mismo tiempo sea confiable. En este sentido, la simulación funciona como una
herramienta de análisis para toma de decisiones que puede ser de gran ayuda en la toma de
determinaciones de política pública de salud.
Un ejemplo de cómo se puede aplicar lo que se ha mencionado anteriormente, se puede ver
claramente en el ejemplo que se ha desarrollado en los capítulos anteriores, en los cuales se
ha demostrado que, mediante un adecuado tratamiento de la diabetes, se podrían ahorrar
hasta 800,000 millones de pesos en 25 años, equivalentes a cerca del 5% del valor del PIB
de México en 2013. Sin embargo, como se ha mencionado, este modelo contempla
únicamente algunas de las variables principales de esta enfermedad, por ejemplo, se
considera que los pacientes que se simulan en el modelo ya padecen la enfermedad, sin

68
embargo, si se consideraran elementos tales como la prevención de la enfermedad por
medio de invitaciones a la población a adoptar un estilo de vida saludable en el cual se
incluya una alimentación adecuada, realizar alguna actividad física o visitar frecuentemente
al médico podrían generar que el ahorro en que se incurriera fuera aun mayor.
Si se considerara lo anterior, como se vio en los resultados del modelo, es posible que a
principios de la simulación, los costos se elevaran, esto debido a la necesidad de realizar la
inversión inicial para el desarrollo de una campaña de prevención, sin embargo, tiempo
después, los ahorros en los que se incurriría por no tratar complicaciones relacionadas con
la diabetes serían mayores que la inversión requerida, generando así un valor positivo para
este tipo de proyectos.
El modelo que se ha desarrollado tiene algunas limitaciones, derivadas principalmente de la
falta de información, ya que sólo se contaba con información de población en general y se
ha buscado adaptarla para la población mexicana, y de la herramienta de modelado que se
ha utilizado, se contaba únicamente con la versión estudiantil de Arena ®. Sin embargo, el
modelo que se ha desarrollado no pretende ser exhaustivo sino dar una guía general de
cómo se puede utilizar la simulación como una herramienta para medir los costos de tratar
enfermedades como la diabetes, cómo utilizar la información con la que se cuenta y qué
otros tipos de análisis, como el de la calidad de vida, se pueden desarrollar. Sin embargo,
esta herramienta ofrece muchas más bondades, ya que se pueden incluir datos como la
correlación que hay entre diversas complicaciones, tratamientos relacionados con las
características demográficas de los pacientes, hacer un análisis de utilización de recursos
médicos o alguna otra característica de la enfermedad.
Así mismo, es importante mencionar que esta herramienta se puede utilizar no sólo para
analizar el comportamiento de la diabetes, la misma que se ha escogido porque se presenta
con un gran número de complicaciones asociadas y tiene otras características que hacen de
su modelado algo completo, sino que se pueden incluir enfermedades virales, contagiosas,
epidémicas, entre otras. Sólo es necesario conocer sus características y seguir las reglas
para modelarla de forma adecuada para así obtener datos estadísticamente válidos y que se
puedan aplicar con confianza. Se debe recordar que cada modelo es único dependiendo de
lo que se quiera analizar, por lo que se debe adaptar de acuerdo al fin buscado y los
resultados se deben analizar de esta misma forma. Es muy importante decir que los

69
resultados arrojados por un modelo dependen completamente de los datos de entrada al
mismo, por lo cual el trabajo previo hecho para recolectar los datos debe estar bien hecho,
ya que en caso de no ser así, se podría tener un modelo muy bien hecho, sin embargo, los
resultados podrían no ser confiables ni reflejar fidedignamente lo que se busca representar.

70
Escenario Base
Probabilidad Anual P[X <= 2 años] P[X 3-5 Años] P[X 6-9 Años] P[X 10-14 Años] P[X >= 14 Años]
Cardiovascular 7.02% 8.58% 2.82% 2.25% 2.73%
Renal 7.13% 6.24% 11.59% 3.57% 13.67%
Ojos 2.19% 2.56% 2.79% 5.88% 6.10%
Úlcera/Amputación 2.58% 1.48% 5.54% 4.80% 9.60%
Neuropatía 14.02% 6.92% 11.65% 8.38% 12.02%
Promedio 6.59% 5.16% 6.88% 4.97% 8.82%
Escenario Comparativo
Probabilidad Anual P[X <= 2 años] P[X 3-5 Años] P[X 6-9 Años] P[X 10-14 Años] P[X >= 14 Años]
Cardiovascular 6.85% 8.37% 2.75% 2.20% 2.66%
Renal 5.72% 5.00% 9.29% 2.86% 10.96%
Ojos 1.83% 2.14% 2.33% 4.91% 5.10%
Úlcera/Amputación 2.69% 1.54% 5.76% 4.99% 9.98%
Neuropatía 12.59% 6.21% 10.47% 7.52% 10.79%
Promedio 5.93% 4.65% 6.12% 4.50% 7.90%
ANEXO I
Probabilidad de padecer cada complicación dependiendo del escenario y del tiempo que
tenga un paciente de padecer diabetes

71
REFERENCIAS
Referencias bibliográficas
Arredondo. A. (2009), “Impacto Económico de la Diabetes en México: Implicaciones
Para el Sistema de Salud, los Pacientes y la Sociedad”, Reunión Regional Sur-Sureste
de la Sociedad Mexicana de Salud Pública, Junio 2009, Sociedad Mexicana de Salud
Pública, Mérida.
Asmussen, S. y Glynn P. (2007), “Stochastic Simulation”, Springer.
Banks Jerry (1999), “Discrete Event Simulation”, Proceedings of the 1999 Winter
Simulation Conference. Diciembre 1999, Winter Simulation Conferences, Atlanta.
Barton P, Stirling B, Robinson S, “Modelling in the Economic Valuation of Health
Care: selecting the appropriate approach”, Journal of Health Services Res. Policy, Vol.
9, No.2, pp 110-118.
Caro, J. (2005), “Pharmacoeconomic Analyses Using Discrete Event Simulation”,
Pharmacoeconomic.Vol 23. No. 4, pp. 323-332.
Chen J, Alemao E, Yin D, Cook J.(2008), “Development of a Diabetes Treatment
Simulation Model: With Application to Assessing Alternative Treatment Intensification
Strategies on Survival and Diabetes Related Complications”, Diabetes, Obesity and
Metabolism. No. 10, pp. 33-42
Chung, C (2003), “Simulation Modeling Handbook”, CRC Press.
Gujarati D, Porter D, (2010), “Econometría”, 5/e, Mc. Graw Hill
Kelton David, Sadowski Randall, Swets Nancy (2010), “Simulation with Arena”, Mc
Graw Hill.
Law, A. (2007), “Simulation Modeling & Analysis”, 4/e, McGraw Hill.
Lopez, G., Tambascia, M., Rosas, J., Etchegoyen, F., Ortega, J. y Artemenko S. (2007),
“Control of Type 2 Diabetes Mellitus Among General Practicioners in Private Practice
in Nine Countries of Latin America”, Panam Salud Pública,Vol 22, No. 1, pp 12-20.
McGhan (2010), “Introduction to Pharmacoeconomics”, Pharmacoeconomics,
fromTheory to Practice”
Mood, A, Graybill, F. y Boes, D. (1975), “Introduction to the Theory of Statistics”,3/e,
McGraw Hill International Editions.

72
Palacios, A. (2008), “Modelado y Simulación de un Sistema de Liquidación de
Valores” , México, ITAM
Rice, J. (1988), “Mathematical Statistics and Data Analysis”, Wadsworth & Brooks.
Rubinstein, R. y Melamed, B (1998), “Modern Simulation and Modeling”, John Wiley
& Sons Inc.
Ross, S.(2010), “A First Course in Probability”, 8/e Prentice Hall.
Schriber, T. y Brunner, D. (1997), “Inside Discrete Event Simulation Software: How it
Works and Why it Matters”, Proceedings of the 1997 Winter Simulation Conference,
Diciembre 1997, Winter Simulation Conferences, Atlanta.
Soares Marta, Canto e Castro L., “Continuous Time Simulation and Discretized Models
for Cost-Effectiveness Analysis” Pharmacoeconomics, 2012.
Shaw J. E., Sicree, R.A., Zimmet, P.Z. (2009), “Diabetes Atlas, Global estimates of the
prevalence of diabetes for 2010 and 2030”, Diabetes Research and Clinical Practice,
No. 87. Pp. 4-14.
Villarreal, E., Salinas, A., Medina, A., Garza, M., Núñez, G., Chuy, E., “The Cost of
Diabetes Mellitus and Its Impact on Health Spending in Mexico”, Archives of Medical
Research, No. 31, pp. 511-514.
Wackerly, D. Mendenhall y W. Scheaffer, R (2002), “Estadística Matemática con
Aplicaciones”, 6/e, Thomson.
Referencias electrónicas
American Diabetes Association (2011) Diabetes Basics, American Diabetes
Association, http://www.diabetes.org/diabetes-
basics/?utm_source=WWW&utm_medium=GlobalNavDB&utm_campaign=CON ,
[Consulta 22 de febrero 2013].
Banco Mundial (2013), Gasto en Salud, total (% del PIB),
http://datos.bancomundial.org/indicador/SH.XPD.TOTL.ZS/countries?display=default
[Consulta 28 de marzo 2013]
Centers for Disease Control and Prevention, Distribution of duration of diabetes
Among Adults Aged 18-79 Years, United States 2011,

73
http://www.cdc.gov/diabetes/statistics/duration/fig1.htm, [Consulta 29 de Noviembre
2014]
CNN Expansión (2010), PIB nominal, en 13.1 billones de pesos,
http://www.cnnexpansion.com/economia/2011/02/25/pib-nominal-mexico-inegi-oficial-
expansi [Consulta 28 de noviembre 2013]
CNN Expansión (2011), Cada paciente con diabetes le cuesta 708 dólares al año a
México, http://mexico.cnn.com/salud/2011/06/13/cada-paciente-con-diabetes-le-cuesta-
708-dolares-al-ano-a-mexico [Consulta 1 de Diciembre 2013]
Encuesta Nacional de Salud y Nutrición 2011, http://ensanut.insp.mx/ [Consulta 1 de
Mayo de 2013]
Index Mundi (2012), México Producto Interno Bruto (PIB),
http://www.indexmundi.com/es/mexico/producto_interno_bruto_(pib).html [Consulta 1
de Mayo 2013]
Instituto Nacional de Salud Pública, http://www.insp.mx/ [Consulta 22 de noviembre
2013]
México Evalua (2013), 10 Puntos para Entender el Gasto en Salud en México: En el
marco de la cobertura universal, http://www.mexicoevalua.org/wp-
content/uploads/2013/02/MEX_EVA-INHOUS-GASTO_SALUD-LOW.pdf [Consulta
1 de Diciembre 2013]
Nutritia Advanced Medical Nutrition,
http://www.nutriciaclinico.es/pacientes_enfermedades/diabetes_complicaciones.asp
[Consulta 21 de Septiembre 2014]
Organización Mundial de la Salud (2012), Diabetes,
http://www.who.int/mediacentre/factsheets/fs312/es/ [Consulta 1 de Diciembre 2013]
Sistema Nacional de Información en Salud http://www.sinais.salud.gob.mx [Consulta
27 de Enero de 2014]
The Permanente Medical Group
http://www.permanente.net/homepage/kaiser/pdf/7432.pdf [Consulta 23 de Noviembre
de 2013]

74


















