
Integración de iptables y snort
86
INSTITUTO TECNOLOGICO Y DE ESTUDIOS SUPERIORES DE MONTERREY INTEGRACIÓN DE IPTABLES Y SNORT TESIS QUE PARA OPTAR EL GRADO DE MAESTRO EN CIENCIAS COMPUTACIONALES PRESENTA JORGE HERRERÍAS GUERRERO Asesor: Dr. ROBERTO GóMEZ CÁRDENAS Comité de tesis: Dr. Nora Erika Sánchez Velázquez Dr. Felipe Rolando Menchaca Atizapán de Zaragoza, Edo. Méx., Diciembre de 2003.
Transcript of Integración de iptables y snort

INSTITUTO TECNOLOGICO Y DE ESTUDIOS SUPERIORES DE MONTERREY
INTEGRACIÓN DE IPT ABLES Y SNORT
TESIS QUE PARA OPTAR EL GRADO DE MAESTRO EN CIENCIAS COMPUTACIONALES
PRESENTA
JORGE HERRERÍAS GUERRERO
Asesor: Dr. ROBERTO GóMEZ CÁRDENAS
Comité de tesis: Dr. Nora Erika Sánchez Velázquez Dr. Felipe Rolando Menchaca
Atizapán de Zaragoza, Edo. Méx., Diciembre de 2003.

2
CONTENIDO
INTRODUCCION ......................................................................................................................... 4
1 CORTAFUEGOS .................................................................................................................. 7 1.1 CONCEPTOS TEÓRICOS ............................................................................................. 8 1.2 CARACTERÍSTICAS DE DISEÑO .... : .......................................................................... 9 1.3 COMPONENTES DE UN CORTAFUEGOS .............................................................. 11
1.3.1 FILTRADO DE PAQUETES ................................................................................ 11 1.3.2 PROXY DE APLICACIÓN .................................................................................. 13 1.3.3 MONITOREO DE LA ACTIVIDAD ................................................................... 13
1.4 ARQUITECTURAS DE CORTAFUEGOS ................................................................. 14 1.4.1 CORTAFUEGOS DE FILTRADO DE PAQUETES ........................................... 14 1.4.2 DUAL-HOMED HOST ......................................................................................... 15 1.4.3 SCREENED HOST ............................................................................................... 15 1.4.4 SCREENED SUBNET (DMZ) ............................................................................. 17 1.4.5 OTRAS ARQUITECTURAS ................................................................................ 18
1.5 IPTABLES .................................................................................................................... 19 1.5.1 ¿POR QUÉ FILTRAR PAQUETES? ................................................................... 19 1.5.2 COMANDO IPTABLES ....................................................................................... 21
1.5.2.1 Tablas ................................................................................................................ 21 1.5.2.2 Estructura ........................................................................................................... 22 1.5.2.3 Comandos .......................................................................................................... 22 1.5.2.4 Parámetros ......................................................................................................... 24 1.5.2.5 Opciones de identificación de paquetes ............................................................. 25 1.5.2.6 Módulos con opciones de selección adicionales ............................................... 27 1.5.2.7 Opciones del objetivo ........................................................................................ 28 1.5.2.8 Opciones de listado ............................................................................................ 30
1.5.3 GUARDAR INFORMACIÓN DE IPT ABLES .................................................... 30 1.5.4 MEJORAS SOBRE IPCHAINS ............................................................................ 31
2 SISTEMAS DE DETECCIÓN DE INTRUSOS ............................................................... 33 2.1 CLASIFICACIÓN DE LOS IDS .................................................................................. 34 2.2 REQUISITOS DE UN IDS ........................................................................................... 36 2.3 IDS BASADOS EN MÁQUINA .................................................................................. 37

3
2.4 IDS BASADOS EN RED ...................................................................... ... .... ... ........... 39 2.5 DETECCIÓN DE ANOMALÍAS .............................................................................. .42 2.6 DETECCIÓN DE USOS INDEBIDOS .............. ...................... ....... ........... ....... ... ..... .44 2.7 SNORT ...................................................................................................................... 46
2.7.1 FORMAS DE USO ............................................................................................ 47 2.7.1.1 Modo sniffer ................................................................................................... 49 2.7.1.2 Modo Registro de paquetes ............................................................................. 50 2.7.1.3 Modo NIDS .................................................................................................... 51
2.7.2 REGLAS ............................................................................................................ 53
. 3 ™PLEMENTACION ..................................................................................................... 56
3.1 ARQillTECTURA ..................................................................................................... 57 3.2 MODELO DE DATOS IDMEF ................................................................................. 57
3.2.1 LA CLASE IDMEF-MESSAGE ......................................................................... 60 3.2.2 LA CLASE ALERT ........................................................................................... 60
3.2.2.1 La Clase ToolAlert ......................................................................................... 62 3.2.2.2 La Clase CorrelationAlert ............................................................................... 63 3.2.2.3 La Clase OverflowAlert .............................................. .................................... 64
3.2.3 LA CLASE HEARTBEAT ..................................... ....... ....... ......................... ..... 65 3.2.4 LAS CLASES PRINCIPALES ........................................................................... 66
3.2.4.1 La Clase Analyzer. ............................................. .............. .......................... ..... 66 3.2.4.2 La Clase Classification ................................................................................... 68 3.2.4.3 La Clase Source ....................................................................... .... ....... ............ 69 3.2.4.4 La Clase Target ......................................................................................... ...... 70 3.2.4.5 La Clase Assessment ............................................... ....................................... 71 3. 2. 4. 6 La Clase AdditionalData ........................................................ .... ... ....... ... ........ 72
3.3 IMPLEMENTACIÓNDELIDMEF: LIBIDMEF ....................................................... 72 3.4 PLUG-IN ................................................................................................................... 75 3. 5 ESTRATEGIA DE RESPUESTA .............................................................................. 78
CONCLUSIONES ................................................................................................................... 83
REFERENCIAS ....................................................................................................................... 85

4
INTRODUCCIÓN
La seguridad en las redes computacionales está llegando a ser cada vez más importante en la medida en que la gente pasa más tiempo conectada. Poner en riesgo la seguridad de las redes es, con frecuencia, mucho más fácil y común de lo que nos podríamos imaginar. ¿Puede un intruso leer o escribir archivos o ejecutar programas que podrían causar daño? ¿Puede borrar datos críticos? Este conjunto de acciones, entre muchas otras conforma lo que llamaremos riesgo, es decir la posibilidad de que un intruso pueda tener éxito en el intento de acceder a nuestro sistema.
Hay que tener en cuenta que ningún sistema de computadoras puede ser completamente seguro. Lo más que es posible hacerse es que le sea más dificil a alguien acceder al sistema sin permiso. De entre las varias herramientas que podemos encontrar para lograr lo anterior, podemos utilizar dos: los cortafuegos1 y los sistemas de detección de intrusos2
.
Los cortafuegos son un medio de controlar a qué información se le permite entrar y salir de la red local. Normalmente, la computadora donde se encuentra el cortafuegos está conectada a Internet y a la red local, y el único acceso desde la red local a Internet es a través del cortafuegos. De este modo, el cortafuegos puede controlar lo que pasa en una u otra dirección entre Internet y la red interna.
El núcleo del sistema operativo Linux contiene utilidades avanzadas para la filtración de paquetes, es decir, utilidades propias de un cortafuegos convencional. Las versiones de los núcleos anteriores al 2.4 tenían la posibilidad de manipular paquetes usando ipchains que a su vez usaba listas de reglas que se aplicaban a los paquetes en cada paso del proceso de filtrado. La presentación del núcleo 2.4 trajo consigo iptables, que es parecido a ipchains pero con mejoras en el funcionamiento y en el control disponible a la hora de filtrar paquetes.
Sin embargo, en muchos casos los controles de los cortafuegos no pueden protegemos ante un ataque. Por poner un ejemplo sencillo, pensemos en un cortafuegos donde hemos implementado
I Se usará cortafuegos como traducción dcjirewa/1. ~ En adelante nos referiremos a los Sistemas de Detección de Intrusos con sus siglas en inglés IDS.

5
una política que deje acceder al puerto 80 de nuestros servidores Web desde cualquier máquina de Internet~ ese cortafuegos sólo comprobará si el puerto destino de una trama es el que hemos decidido para el servicio HTIP, pero seguramente no tendrá en cuenta si ese tráfico representa un ataque o una violación de nuestra política de seguridad. Esto significa que no detendrá a un pirata que trate de acceder al archivo de contraseñas de una máquina aprovechando un error del servidor Web. A los sistemas utilizados para detectar las intrusiones o los intentos de intrusión se les denomina sistemas de detección de intrusos. Llamaremos intrusión a un conjunto de acciones que intentan poner en riesgo la integridad, la confidencialidad o la disponibilidad de un recurso.
Debemos esperar que en cualquier momento alguien consiga romper la seguridad de nuestro entorno informático, y por tanto hemos de ser capaces de detectar ese problema tan pronto como sea posible (incluso antes de que se produzca, cuando el potencial atacante se limite a probar suerte contra nuestras máquinas). Aunque nadie haya conseguido violar nuestras políticas de seguridad, es vital contar con un sistema de detección de intrusos, ya que éste se encargará de mostramos todos los intentos que una multitud de piratas hace para penetrar en nuestro entorno, lo que no nos dejará caer en ninguna falsa sensación de seguridad. Si somos conscientes de que a diario hay gente que trata de romper nuestros sistemas, no cometeremos el error de pensar que nuestras máquinas están seguras porque nadie sabe de su existencia o porque no son interesantes para un pirata.
Snort es un sistema de detección de intrusos con la licencia de software libre capaz de realizar análisis de tráfico en tiempo real y de registrar de paquetes en redes IP. Snort también puede realizar análisis de protocolos, búsqueda de contenidos y puede ser usado para detectar una gran variedad de ataques. Existen tres formas en las que Snort puede ser configurado: sniffer3, registro de paquetes y detector de intrusos en red. Este último es el más complejo y configurable, ya que habilita a la herramienta para el análisis de tráfico de red y, lo que es más importante, para el reconocimiento de cualquier intento de intrusión.
A pesar de todas las ventajas que las herramientas descritas anteriormente presentan, éstas no garantizan la seguridad del sistema contra distintos tipos de ataques, por lo que en un momento dado lo más valioso de la organización, la información, puede estar en riesgo. Es por esta razón, que este trabajo tiene por objetivo el diseño de un protocolo de comunicación entre ambas herramientas, lo que permitirá conformar un sistema de respuesta automática ante diversos tipos de ataques.
La comunicación entre ambas herramientas se llevará a cabo bajo el formato de intercambio de mensajes de detección de intrusiones (IDMEF) propuesto por el Grupo de Trabajo en Detección de Intrusiones (IDWG). Dicho modelo es una representación orientada a objetos de los datos de las alertas y se encuentra implementado en XML debido a la flexibilidad que provee, la que lo hace una buena elección para los fines requeridos: un documento que pueda variar de acuerdo a las condiciones presentadas, dependiendo de factores tales como el tipo de ataque, el tipo de herramienta usada y la fuente y objetivo del mismo entre otros.
'Programa que monitorca la información que circula por la red con el objetivo de capturar información ajena

6
Las alertas generadas con el formato IDMEF XML serán escuchadas en tiempo real por un agente, el cual usará la información proporcionada para reconfigurar el cortafuegos y, de esta manera, frenar el ataque o intento de intrusión.
El presente trabajo se encuentra organiz.ado de la siguiente forma: en el primer capítulo se introduce al lector a la teoría de cortafuegos y posteriormente profundizamos en el cortafuegos de Linux iptables; en el segundo capítulo hablamos acerca de los sistemas de detección de intrusos para dar paso a uno de los IDS más importantes, Snort, y por último, el tercer capítulo trata los asuntos relacionados con la implementación del protocolo de comunicación entre las herramientas referidas en los capítulos anteriores. Al final del documento se presentan las conclusiones y una propuesta para un trabajo futuro en la misma línea.

7
1 CORTAFUEGOS
Un cortafuegos es un sistema o grupo de sistemas que hace cumplir una política de control de acceso entre dos redes. De una forma más clara, podemos definir un cortafuegos como cualquier sistema (desde un simple ruteador4 hasta varias redes en serie) utilizado para separar, en cuanto a seguridad se refiere, una máquina o subred del resto, protegiéndola así de servicios y protocolos que desde el exterior puedan suponer una amenaz.a a la seguridad. El espacio protegido, denominado perímetro de seguridad, suele ser propiedad de la misma organización, y la protección se realiza contra una red externa, no confiable, llamada zona de riesgo.
A / B ( :~ ~
~ -
-i i -
A :&'.::
IN et l.AN - IN et lAN - ---( • ~
\ .. - ---~ • - -
/ ;.__ • e -....
• =~ IN et - - LAN
- - ---•
--Figura 1.1 (a) Aislamiento. (b) Conexión total. (c) Cortafuegos entre la zona de riesgo y el
perímetro de seguridad.
I Dispositivo de conexión y distribución de datos en una red encargado de dirigir el tráfico entre redes_

8
Evidentemente, la forma de aislamiento más efectiva para cualquier política de seguridad consiste en el aislamiento físico, es decir, no tener conectada la máquina o la subred a otros equipos o a Internet (figura 1.1 (a)). Sin embargo, en la mayoría de organiz.aciones, los usuarios necesitan compartir información con otras personas situadas en muchas ocasiones a miles de kilómetros de distancia, con lo que no es posible un aislamiento total. El punto opuesto consistiría en una conectividad completa con la red (figura 1.1 (b )), lo que desde el punto de vista de la seguridad es muy problemático: cualquiera, desde cualquier parte del mundo, puede potencialmente tener acceso a nuestros recursos. Un término medio entre ambas aproximaciones consiste en implementar cierta separación lógica mediante un cortafuegos (figura 1.1 (c)).
1.1 CONCEPTOS TEÓRICOS
Antes de hablar de cortafuegos es casi obligatorio dar una serie de definiciones de partes o características de funcionamiento del mismo; por máquina o hosr bastión se conoce a un sistema especialmente asegurado, pero en principio vulnerable a todo tipo de ataques por estar abierto a Internet, que tiene como función ser el punto de contacto de los usuarios de la red interna de una organización con otro tipo de redes. El host bastión filtra tráfico de entrada y salida, y también esconde la configuración de la red hacia fuera.
Por filtrado de paquetes entendemos la acción de denegar o permitir el flujo de tramas entre dos redes (por ejemplo la interna, protegida con el cortafuegos, y el resto de Internet) de acuerdo con unas normas predefinidas; aunque el filtro más elemental puede ser un simple ruteador, trabajando en el nivel de red del modelo de referencia OSI, esta actividad puede realizarse además en un puente o en una máquina individual. El filtrado también se conoce como screening, y a los dispositivos que lo implementan se les denomina chokes; el choke puede ser la máquina bastión o un elemento diferente.
Un proxy es un programa (trabajando en el nivel de aplicación de OSI) que permite o niega el acceso a una aplicación determinada entre dos redes. Los clientes proxy se comunican sólo con los servidores proxy, que autorizan las peticiones y las envían a los servidores reales o las deniegan y las devuelven a quien las solicitó.
Físicamente, en casi todos los cortafuegos existen al menos un choke y una máquina bastión, aunque también se considera cortafuegos a un simple ruteador filtrando paquetes, es decir, actuando como choke; desde el punto de vista lógico, en el cortafuegos suelen existir servidores proxy para las aplicaciones que han de atravesar el sistema, y que se sitúan habitualmente en el host bastión También se implementa en el choke un mecanismo de filtrado de paquetes, y en
" Cualquier computadora conectada a la red y que dispone de un número IP y un nombre definido. es decir. cualquier computadora que puede enviar o recibir información a otra computadorn.

9
alguno de los dos elementos se suele situar otro mecanismo para poder monitorear y detectar la actividad sospechosa.
Los cortafuegos son cada vez más necesarios en nuestras redes, pero todos los expertos recomiendan que no se usen en lugar de otras herramientas, sino junto a ellas; cualquier cortafuegos, desde el más simple al más avanzado, presenta dos gravísimos problemas de seguridad: por un lado, centraliz.an todas las medidas en un único sistema, de forma que si éste se ve puesto en alguna clase de riesgo y el resto de nuestra red no está lo suficientemente protegido el atacante consigue amenaz.ar a toda la subred simplemente poniendo en jaque a una máquina. El segundo problema relacionado con éste es la falsa sensación de seguridad que un cortafuegos proporciona: generalmente un administrador que no disponga de este elemento va a preocuparse de la integridad de todas y cada una de sus máquinas, pero en el momento en que instala el cortafuegos y lo configura asume que toda su red es segura, · por lo que se suele descuidar enormemente la seguridad de los equipos de la red interna. Esto, como acabamos de comentar, es un grave error ya que en el momento que un pirata acceda a nuestro cortafuegos automáticamente va a tener la posibilidad de controlar toda nuestra red.
Además, un cortafuegos evidentemente no protege contra ataques que no pasan por él: esto incluye todo tipo de ataques internos dentro del perímetro de seguridad,· pero también otros factores que a priori no deberían suponer un problema. El típico ejemplo de estos últimos son los usuarios que instalan sin permiso, sin conocimiento del administrador de la red, y muchas veces sin pensar en sus consecuencias, un simple módem6 en sus estaciones de trabajo; esto, tan habitual en muchas organizaciones, supone la violación y la ruptura total del perímetro de seguridad, ya que posibilita accesos a la red no controlados por el cortafuegos. Otro problema de sentido común es la reconfiguración de los sistemas al pasarlos de una zona a otra con diferente nivel de seguridad, por ejemplo al mover un equipo que se encuentra en el área protegida a la DMZ (zona desprotegida). Este acto, que en ocasiones no implica ni tan siquiera el movimiento fisico del equipo, sino simplemente conectarlo en una toma de red diferente, puede ocasionar graves problemas de seguridad en nuestra organización, por lo que cada vez que un cambio de este estilo se produzca no sólo es necesaria la reconfiguración del sistema, sino la revisión de todas las políticas de seguridad aplicadas a esa máquina.
1.2 CARACTERÍSTICAS DE DISEÑO
Existen tres decisiones básicas en el diseño o la configuración de un cortafuegos; la primera de ellas, la más importante, hace referencia a la política de seguridad de la organización propietaria del cortafuegos: evidentemente, la configuración y el nivel de seguridad potencial será distinto en una empresa que utilice un cortafuegos para bloquear todo el tráfico externo hacia el dominio de su propiedad (excepto, quizás, las consultas a su página Web) frente a otra donde sólo se intente evitar que los usuarios internos pierdan el tiempo en la red, bloqueando por ejemplo todos los
h Dispositivo de comunicaciones capaz de hacer \llla conexión a Internet a través de la red telefónica convencional.

10
servicios de salida al exterior excepto el correo electrónico. Sobre esta decisión influyen, aparte de motivos de seguridad, motivos administrativos de cada organismo.
La segunda decisión de diseño a tener en cuenta es el nivel de monitoreo, redundancia y control deseado en la organización; una vez definida la política a seguir, hay que definir cómo implementarla en el cortafuegos indicando básicamente qué se va a permitir y qué se va a denegar. Para esto existen dos aproximaciones generales: o bien se adopta una postura restrictiva ( denegamos todo lo que explícitamente no se permita) o bien una permisiva (permitimos todo excepto lo explícitamente negado); evidentemente es la primera la más recomendable de cara a la seguridad, pero no siempre es aplicable debido a factores no técnicos sino humanos ( esto es, los usuarios y sus protestas por no poder ejecutar tal o cual aplicación a través del cortafuegos).
Por último, la tercera decisión a la hora de instalar un sistema de cortafuegos es meramente económica: en función del valor estimado de lo que deseemos proteger, debemos gastar más o menos dinero, o no gastar nada. Un cortafuegos puede no entrañar gastos extras para la organización, o suponer un gran desembolso: seguramente un departamento o laboratorio con pocos equipos en su interior puede utilizar un computadora con Linux, Solaris o FreeBSD a modo de cortafuegos, sin invertir nada en él, pero esta aproximación evidentemente no funciona cuando el sistema a proteger es una red de tamaño considerable; en este caso se pueden utilizar sistemas propietarios, que suelen ser caros, o aprovechar los ruteadores de salida de la red, algo más barato pero que requiere más tiempo de configuración que los cortafuegos sobre el sistema operativo Unix en una computadora de los que hemos hablado antes. De cualquier forma, no es recomendable a la hora de evaluar el dinero a invertir en el cortafuegos fijarse sólo en el costo de su instalación y puesta a punto, sino también en el de su mantenimiento.
Estas decisiones, aunque concernientes al diseño, eran básicamente políticas; la primera decisión técnica a la que nos vamos a enfrentar a la hora de instalar un cortafuegos es elemental: ¿dónde lo situamos para que cumpla eficientemente su cometido? Evidentemente, si aprovechamos como cortafuegos un equipo ya existente en la red, por ejemplo un ruteador, no tenemos muchas posibilidades de elección: con toda seguridad hemos de dejarlo donde ya está; si por el contrario utilizamos una máquina Unix con un cortafuegos implementado en ella, tenemos varias posibilidades para situarla con respecto a la red externa y a la interna. Sin importar dónde situemos al sistema hemos de recordar siempre que los equipos que queden fuera del cortafuegos, en la zona de riesgo, serán igual de vulnerables que antes de instalar el cortafuegos; por eso es posible que si por obligación hemos tenido que instalar un cortafuegos en un punto que no protege completamente nuestra red, pensemos en añadir cortafuegos internos dentro de la misma, aumentando así la seguridad de las partes más importantes.
Una vez que hemos decidido dónde situar nuestro cortafuegos se debe elegir qué elemento o elementos fisicos utilizar como bastión; para tomar esta decisión existen dos principios básicos: mínima complejidad y máxima seguridad_. Cuanto más simple sea el host bastión, cuanto menos servicios ofrezca, más fácil será su mantenimiento y por tanto mayor su seguridad; mantener esta máquina especialmente asegurada es algo vital para que el cortafuegos funcione correctamente, ya que va a soportar por sí sola todos los ataques que se efectúen contra nuestra re_d al ser elemento más accesible de ésta. Si la seguridad de la máquina bastión se ve puesta en nesgo, la

11
amenaza se traslada inmediatamente a todos los equipos dentro del perímetro de seguridad. Suele ser una buena opción elegir como máquina bastión un servidor corriendo alguna de las versiones de Unix, ya que aparte de la seguridad del sistema operativo tenemos la ventaja de que la mayor parte de aplicaciones de cortafuegos han sido desarrolladas y comprobadas desde hace años sobre dicha plataforma.
Una vez que ya hemos decidido qué utilizar como cortafuegos y dónde situarlo; hemos de implementar sobre él los mecanismos necesarios para hacer cumplir nuestra política de seguridad. En todo cortafuegos existen tres componentes básicos para los que debemos implementar mecanismos: el filtrado de paquetes, el prory de aplicación y el monitorec> y detección de actividad sospechosa.
1.3 COMPONENTES DE UN CORTAFUEGOS
1.3.1 FILTRADO DE PAQUETES
Cualquier ruteador IP utiliza reglas de filtrado para reducir la carga de la red; por ejemplo, se descartan paquetes cuyo TfL ha llegado a cero, paquetes con un control de errores erróneos o simplemente tramas de broadcast7. Además de estas aplicaciones, el filtrado de paquetes se puede utilizar para implementar diferentes políticas de seguridad en una red; el objetivo principal de todas ellas suele ser evitar el acceso no autorizado entre dos redes, pero manteniendo intactos los accesos autorizados. Su funcionamiento es habitualmente muy simple: se analiza la cabecera de cada paquete, y en función de una serie de reglas establecidas de antemano la trama es bloqueada o se le permite seguir su camino; estas reglas suelen contemplar campos como el protocolo utilizado (TCP, UDP, ICMP ... ), las direcciones fuente y destino, y el puerto destino, lo cual ya nos dice que el cortafuegos ha de ser capaz de trabajar en los niveles de red (para discriminar en función de las direcciones origen y destino) y de transporte (para hacerlo en función de los puertos usados). Además de la información de cabecera de las tramas, algunas implementaciones de filtrado permiten especificar reglas basadas en la interfaz del ruteador por donde se ha de reenviar el paquete, y también en la interfaz por donde ha llegado hasta nosotros.
¿Cómo se especifican tales reglas? Generalmente se expresan como una simple tabla de condiciones y acciones que se consulta en orden hasta encontrar una regla que permita tomar una decisión sobre el bloqueo o el reenvío de la trama; adicionalmente, ciertas implementaciones permiten indicar si el bloqueo de un paquete se notificará a la máquina origen mediante un mensaje ICMP. Siempre hemos de tener presente el orden de análisis de las tablas para poder implementar la política de seguridad de una forma correcta; cuanto más complejas sean las reglas y su orden de análisis, más difícil será para el administrador comprenderlas.
- Paquete de datos enYiado a todos los nodos de una red

12
Por ejemplo, imaginemos una hipotética tabla de reglas de filtrado de la siguiente forma:
Origen Destino Tipo Puerto Acción
158.43.0.0 * * * Den y
* 195.53.22.0 * * Den y
158.42.0.0 * * * Allow
* 193.22.34.0 * * Den y
Si al cortafuegos donde está definida la política anterior llegara un paquete proveniente de una máquina de la red 158.43.0.0 se bloquearla su paso, sin importar el destino de la trama; de la misma forma, todo el tráfico hacia la red 195.53.22.0 también se detendría. Pero, ¿qué sucedería si llega un paquete de un sistema de la red 158.42.0.0 hacia 193.22.34.0? Una de las reglas nos indica que dejemos pasar todo el tráfico proveniente de 158.42.0.0, pero la siguiente nos dice que si el destino es 193.22.34.0 lo bloqueemos sin importar el origen. En este caso depende de nuestra implementación particular y el orden de análisis que siga: si se comprueban las reglas desde el principio, el paquete atravesaría el cortafuegos, ya que al analizar la tercera entrada se finalizarían las comprobaciones; si operamos al revés, el paquete se bloquearía porque leemos antes la última regla. Como podemos ver, ni siquiera en esta tabla sencilla las cosas son obvias, por lo que si extendemos el ejemplo a un cortafuegos real podemos hacemos una idea de hasta que punto hemos de ser cuidadosos con el orden de las entradas de nuestra tabla.
¿Qué sucedería si, con la tabla del ejemplo anterior, llega un paquete que no cumple ninguna de nuestras reglas? El sentido común nos dice que por seguridad se debería bloquear, pero esto no siempre sucede así; diferentes implementaciones ejecutan diferentes acciones en este caso. Algunas deniegan el paso por defecto y otras dejan pasar este tipo de tramas. De cualquier forma, para evitar problemas cuando uno de estos datagramas llega al cortafuegos, lo mejor es insertar siempre una regla por defecto al final de nuestra lista con la acción que deseemos realizar por defecto; si por ejemplo deseamos bloquear el resto del tráfico que llega al cortafuegos con la tabla anterior, y suponiendo que las entradas se analizan en el orden habitual, podríamos añadir a nuestra tabla la siguiente regla:
Origen Destino Tipo Puerto Acción
------------------------------ ----------------------------------------
* * * * Den y
La especificación incorrecta de estas reglas constituye uno de los problemas de seguridad habituales en los cortafuegos de filtrado de paquetes; no obstante, el mayor problema es que un sistema de filtrado de paquetes es incapaz de analizar (y por tanto verificar) datos situados por encima del nivel de red del modelo OSI. A esto se le añade el hecho de que si utilizamos un simple ruteador como filtro, las capacidades de re~ist~o de infor~~ción del mismo suelen ser bastante limitadas, por lo que en ocasiones es d1fic1l la detecc1on de un ataq~e; se puede considerar un mecanismo de prevención más que de detección. Para intentar solucionar estas Y

13
otras vulnerabilidades, es recomendable utilizar aplicaciones de software capaces de filtrar las conexiones a servicios, a las cuales se les denomina proxies de aplicación.
1.3.2 PROXY DE APLICACIÓN
Además del filtrado de paquetes, es habitual que los cortafuegos utilicen aplicaciones para reenviar o bloquear conexiones a servicios como .finger, telnet o FTP; a tales aplicaciones se les denomina servicios prory, mientras que a la máquina donde se ejecutan se le llama gateway.
Los servicios proxy poseen una serie de ventajas de cara a incrementar nuestra seguridad; en primer lugar, permiten únicamente la utilización de servicios para los que existe un proxy, por lo que si en nuestra organización el gateway contiene únicamente proxies para telnet, HTTP y FTP, el resto de servicios no estarán disponibles para nadie. Una segunda ventaja es que en el gateway es posible filtrar protocolos basándose en algo más que la cabecera de las tramas, lo que hace posible por ejemplo tener habilitado un servicio como FTP pero con órdenes restringidas (podríamos bloquear todos los comandos put para que nadie pueda subir ficheros a un servidor). Además, los gateways permiten un grado de ocultación de la estructura de la red protegida (por ejemplo, el gateway es el único sistema cuyo nombre está disponible hacia el exterior), facilita la autenticación y la auditoria del tráfico sospechoso antes de que alcance el host destino y, quizás más importante, simplifica enormemente las reglas de filtrado implementadas en el ruteador (que como hemos dicho antes pueden convertirse en la fuente de muchos problemas de seguridad): sólo hemos de permitir el tráfico hacia el gateway y bloquear el resto.
El principal inconveniente que encontramos a la hora de instalar un gateway es que cada servicio que deseemos ofrecer necesita su propio proxy; además se trata de un elemento que frecuentemente es más caro que un simple filtro de paquetes, y su rendimiento es mucho menor (por ejemplo, puede llegar a limitar el ancho de banda efectivo de la red). En el caso de protocolos cliente-servidor, como telnet, se añade la desventaja de que necesitamos dos pasos para conectar hacia la zona segura o hacia el resto de la red; incluso algunas implementaciones necesitan clientes modificados para funcionar correctamente.
1.3.3 MONITOREO DE LA ACTIVIDAD
Monitorear la actividad de nuestro cortafuegos es algo indispensable para la seguridad de todo el perímetro protegido; el monitoreo nos facilitará información sobre los intentos de ataqu~ q_u~ estemos sufriendo, así como la existencia de tramas que aunque no supongan un ataque a pnon s1
que son al menos sospechosas.
¿Qué información debemos registrar? Además de l~s regist~os ~stándar (los que i~cluyen estadísticas de tipos de paquetes recibidos, frecuencias, o dlfecc1ones fuente Y d~stmo) se recomienda auditar información de la conexión (origen y destino, nombre de usuano, hora Y

14
duración), intentos de uso de protocolos denegados, intentos de falsificación de dirección por parte de máquinas internas al perímetro de seguridad (paquetes que llegan desde la red externa con la dirección de un equipo interno) y tramas recibidas desde ruteadores desconocidos. Evidentemente, todos esos registros han de ser leídos con frecuencia, y el administrador de la red ha de tomar medidas si se detectan actividades sospechosas; si la cantidad de /ogs8 generada es considerable nos puede interesar el uso de herramientas que filtren dicha información.
Un excelente mecanismo para incrementar mucho nuestra seguridad puede ser la sustitución de servicios reales en el cortafuegos por programas trampa o honeypots. La idea es sencilla: se trata de pequeñas aplicaciones que simulan un determinado servicio, de forma que un posible atacante piense que dicho servicio está habilitado y prosiga su ataque, pero que realmente nos están enviando toda la información posible sobre el pirata. Este tipo de programas, una especie de troyano9
, suele tener una finalidad múltiple: aparte de detectar y notificar ataques, el atacante permanece entretenido intentando un ataque que cree factible, lo que por un lado nos beneficia directamente, esa persona no intenta otro ataque quizás más peligroso, y por otro nos permite entretener al pirata ante una posible traz.a de su conexión. Evidentemente, nos estamos arriesgando a que nuestro atacante descubra el mecanismo y lance ataques más peligrosos, este mecanismo nos permite descubrir posibles exploits10 utilizados por los piratas y observar a qué tipo de atacantes nos enfrentamos.
1.4 ARQUITECTURAS DE CORTAFUEGOS
1.4.1 CORTAFUEGOS DE FILTRADO DE PAQUETES
Un cortafuegos sencillo puede consistir en un dispositivo capaz de filtrar paquetes, un choke: se trata del modelo de cortafuegos más antiguo, basado simplemente en aprovechar la capacidad de algunos ruteadores, denominados screening routers, para hacer un enrutado selectivo, es decir, para bloquear o permitir el tránsito de paquetes mediante listas de control de acceso en función de ciertas características de las tramas, de forma que el ruteador actúe como gateway de toda la red. Generalmente estas características para determinar el filtrado son las direcciones origen y destino, el protocolo, los puertos origen y destino (en el caso de TCP y UDP), el tipo de mensaje (en el caso de ICMP) y los interfaces de entrada y salida de la trama en el ruteador.
En un cortafuegos de filtrado de paquetes los accesos desde la red interna al exterior que no están bloqueados son directos (no hay necesidad de utilizar proxies, como sucede en los cortafuegos basados en una máquina con dos tarjetas de red), por lo que esta arquitectura es la más simple de implementar (en muchos casos sobre hardware ya ubicado en la red) y la más utilizada en organizaciones que no precisan grandes niveles de seguridad. No obstante, elegir un cortafuegos
~ Archivo de texto que almacena genernlmente datos sobre procesos determinados. 9 Programa que contiene un código dañino dentro de d.11os aparentemente inofensivos. 1" Método concreto de utili,.ación de un bug que permite entrnr de forma ilegítima en un sistema infonnático.

15
tan sencillo puede no ser recomendable en ciertas situaciones o para organizaciones que requieren una mayor seguridad para su subred, ya que los simples cho/ces presentan más desventajas que beneficios para la red protegida. El principal problema es que no disponen de un sistema de monitoreo sofisticado, por lo que muchas veces el administrador no puede determinar si el ruteador está siendo atacado o si su seguridad ha sido puesta en riesgo. Además las reglas de filtrado pueden llegar a ser complejas de establecer, y por tanto es dificil comprobar su corrección: habitualmente sólo se comprueba a través de pruebas directas, con los problemas de seguridad que esto puede implicar.
Si a pesar de esto decidimos utilizar un ruteador como filtro de paquetes, como en cualquier cortafuegos es recomendable bloquear todos los servicios que no se utilicen desde el exterior (especialmente NIS, NFS, X-Window y TFfP), así como el acceso desde máquinas no confiables hacia nuestra subred. Además, es también importante para nuestra seguridad bloquear los paquetes con encaminamiento en origen activado.
1.4.2 DUAL-HOMED HOST
El segundo modelo de cortafuegos está formado por simples máquinas Unix equipadas con dos o más tarjetas de red y denominadas anfitriones de dos bases (dual-homed hosts) o multibase (multi-homed hosts), y en las que una de las tarjetas se suele conectar a la red interna a proteger y la otra a la red externa a la organización. En esta configuración el choke y el bastión coinciden en el mismo equipo: la máquina Unix.
El sistema ha de ejecutar al menos un servidor prory para cada uno de los servicios que deseemos pasar a través del cortafuegos, y también es necesario que el IP Forwarding esté deshabilitado en el equipo: aunque una máquina con dos tarjetas puede actuar como un ruteador, para aislar el tráfico entre la red interna y la externa es necesario que el choice no enrute paquetes entre ellas. Así, los sistemas externos verán al host a través de una de las tarjetas y los internos a través de la otra, pero entre las dos partes no puede existir ningún tipo de tráfico que no pase por el cortafuegos: todo el intercambio de datos entre las redes se ha de realizar bien a través de servidores prory situados en el host bastión o bien permitiendo a los usuarios conectar directamente al mismo. La segunda de estas aproximaciones es sin duda poco recomendable, ya que un usuario que consiga aumentar su nivel de privilegios en el sistema puede romper toda la protección del cortafuegos, además suele ser incómodo para los usuarios tener que acceder a una máquina que haga de puente entre ellos e Internet. De esta forma, la ubicación de proxies es lo más recomendable, pero puede ser problemático el configurar cierto tipo de servicios o protocolos que no se diseñaron teniendo en cuenta la existencia de un proxy entre los dos extremos de una conexión.

16
1.4.3 SCREENED HOST
Un paso más en términos de seguridad de los cortafuegos es la arquitectura screened host o choke-gate, que combina un ruteador con un host bastión. y donde el principal nivel de seguridad proviene del filtrado de paquetes ( es decir, el ruteador es la primera y más importante línea de defensa). En la máquina bastión. único sistema accesible desde el exterior, se ejecutan los proxies de las aplicaciones, mientras que el choice se encarga de filtrar los paquetes que se puedan considerar peligrosos para la seguridad de la red interna, permitiendo únicamente la comunicación con un reducido número de servicios.
Pero, ¿dónde situar el sistema bastión, en la red interna o en el exterior del ruteador? La mayoría de autores recomiendan situar el ruteador entre la red exterior y el host bastión, pero otros defienden justo lo contrario. En todo caso, aparte de por estos matices, asumiremos la primera opción por considerarla mayoritaria entre los expertos en seguridad informática; así, cuando una máquina de la red interna desea comunicarse con el exterior existen dos posibilidades:
• El choke permite la salida de algunos servicios a todas o a parte de las máquinas internas a través de un simple filtrado de paquetes.
• El choke prohíbe todo el tráfico entre máquinas de la red interna y el exterior, permitiendo sólo la salida de ciertos servicios que provienen de la máquina bastión y que han sido autorizados por la política de seguridad de la organización.
La primera aproximación entraña un mayor nivel de complejidad a la hora de configurar las listas de control de acceso del ruteador, mientras que si elegimos la segunda la dificultad está en configurar los servidores prory (recordemos que no todas las aplicaciones soportan bien estos mecanismos) en el host bastión. Desde el punto de vista de la seguridad es más recomendable la segunda opción. ya que la probabilidad de dejar escapar tráfico no deseado es menor. Por supuesto, en función de la política de seguridad que definamos en nuestro entorno, se pueden combinar ambas aproximaciones, por ejemplo permitiendo el tráfico entre las máquinas internas y el exterior de ciertos protocolos difíciles de encaminar a través de un prory o sencillamente que no entrañen mucho riesgo para nuestra seguridad y obligando para el resto de servicios a utilizar el host bastión.
La arquitectura screened host puede parecer a primera vista más peligrosa que la basada en una simple máquina con varias interfaces de red; en primer lugar, tenemos no uno sino dos sistemas accesibles desde el exterior, por lo que ambos han de ser configurados con las máximas medidas de seguridad. Además, la mayor complejidad de diseño hace más fácil la presencia de errores que puedan desembocar en una violación de la política implementada, mientras que con un host con cios tarjetas nos aseguramos de que únicamente aquellos servicios con un proxy configurado podrán generar tráfico entre la red externa y la interna (a no ser que por error activemos el IP Forwarding). Sin embargo, aunque estos problemas son reales, se resuelven tomando las precauciones necesarias a la hora de diseñar e implementar el cortafuegos y definiendo una política de seguridad correcta. De cualquier forma, en la práctica esta arquitectura de cortafuegos está cada vez más en desuso debido a que presenta dos puntos únicos de fallo, el choke y el bastión: si un atacante consigue controlar cualquiera de ellos. tiene acceso a toda la red protegida;
17
por tanto, es más popular, y recomendable, una arquitectura screened subnel, de la que vamos a hablar a continuación.
1.4.4 SCREENED SUBNET (DMZ)
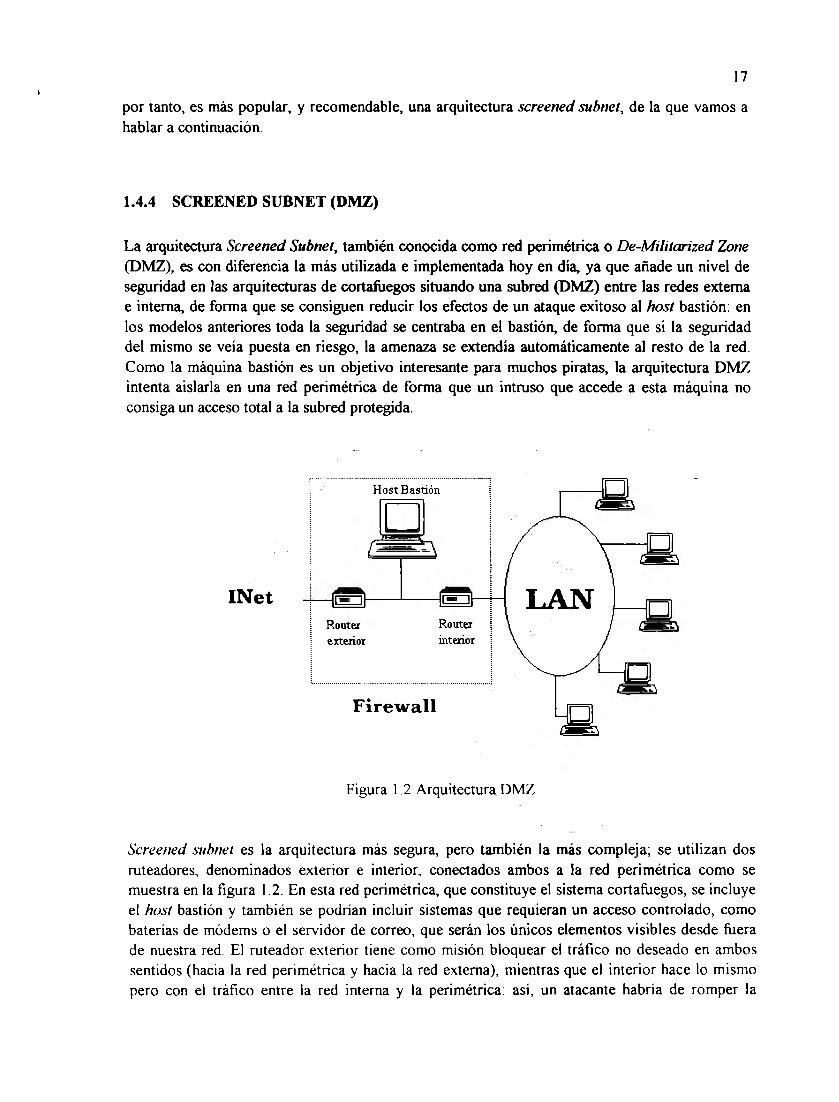
La arquitectura Screened Subnel, también conocida como red perimétrica o De-Militarized Zone (DMZ), es con diferencia la más utilizada e implementada hoy en día, ya que añade un nivel de seguridad en las arquitecturas de cortafuegos situando una subred (DMZ) entre las redes externa e interna, de forma que se consiguen reducir los efectos de un ataque exitoso al host bastión: en los modelos anteriores toda la seguridad se centraba en el bastión, de forma que si la seguridad del mismo se veía puesta en riesgo, la amenaza se extendía automáticamente al resto de la red. Como la máquina bastión es un objetivo interesante para muchos piratas, la arquitectura DMZ intenta aislarla en una red perimétrica de forma que un intruso que accede a esta máquina no consiga un acceso total a la subred protegida.
IN et
HostBastión
Route.r exterior
Firewall
Routcr interior
LAN
Figura 1.2 Arquitectura DMZ
Screened subnel es la arquitectura más segura, pero también la más compleja; se utilizan dos ruteadores, denominados exterior e interior, conectados ambos a la red perimétrica como se muestra en la figura 1.2. En esta red perimétrica, que constituye el sistema cortafuegos, se incluye el host bastión y también se podrían incluir sistemas que requieran un acceso controlado, como baterías de módems o el servidor de correo, que serán los únicos elementos visibles desde fuera de nuestra red. El ruteador exterior tiene como misión bloquear el tráfico no deseado en ambos sentidos (hacia la red perimétrica y hacia la red externa), mientras que el interior hace lo mismo pero con el tráfico entre la red interna y la perimétrica: así, un atacante habría de romper la

18
seguridad de ambos ruteadores para acceder a la red protegida; incluso es posible implementar una zona desmilitariz.ada con un único ruteador que posea tres o más interfaces de red, pero en este caso si se pone en riesgo este único elemento se rompe toda nuestra seguridad, frente al caso general en que hay que poner en riesgo a ambos, tanto el externo como el interno. También podemos, si necesitamos mayores niveles de seguridad, definir varias redes perimétricas en serie, situando los servicios que requieran de menor fiabilidad en las redes más externas: así, el atacante habrá de saltar por todas y cada una de ellas para acceder a nuestros equipos; evidentemente, si en cada red perimétrica se siguen las mismas reglas de filtrado, niveles adicionales no proporcionan mayor seguridad.
Esta arquitectura de cortafuegos elimina los puntos únicos de fallo presentes en las anteriores: antes de llegar al bastión (por definición, el sistema más vulnerable) un atacante ha de saltarse las medidas de seguridad impuestas por el ruteador externo. Si lo consigue, como hemos aislado la máquina bastión en una subred estamos reduciendo el impacto de un atacante que logre controlarlo, ya que antes de llegar a la red interna ha de poner en riesgo también al segundo ruteador; en este caso extremo, la arquitectura DMZ no es mejor que un screened host. Por supuesto, en cualquiera de los tres casos (riesgo en el ruteador externo, el host bastión o del ruteador interno) las actividades de un pirata pueden violar nuestra seguridad, pero de forma parcial: por ejemplo, simplemente accediendo al primer ruteador puede aislar toda nuestra organización del exterior, creando una negación de servicio importante, pero esto suele ser menos grave que si lograra acceso a la red protegida.
Aunque, como hemos dicho antes, la arquitectura DMZ es la que mayores niveles de seguridad puede proporcionar, no se trata de la panacea de los cortafuegos. Evidentemente existen problemas relacionados con este modelo: por ejemplo, se puede utilizar el cortafuegos para que los servicios fiables pasen directamente sin acceder al bastión, lo que puede dar lugar a un incumplimiento de la política de la organización. Un segundo problema, quizás más grave, es que la mayor parte de la seguridad reside en los ruteadores utiliz.ados, ya que como hemos dicho antes las reglas de filtrado pueden ser complicadas de configurar y comprobar, lo que puede dar lugar a errores que abran importantes brechas de seguridad en nuestro sistema.
1.4.5 OTRAS ARQUITECTURAS
Algo que puede incrementar en gran medida nuestra seguridad y al mismo tiempo facilitar la administración de los cortafuegos es utilizar un bastión diferente para cada protocolo o servicio en lugar de uno sólo; sin embargo, esta arquitectura presenta el grave inconveniente de la cantidad de máquinas necesarias para implementar el cortafuegos, lo que impide que muchas organizaciones la puedan adoptar. Una variante más barata consistiría en utilizar un único bastión pero servidores proxy diferentes para cada servicio ofrecido.
Cada día es más habitual en todo tipo de organizaciones dividir su red en diferentes subredes; esto es especialmente aplicable en empresas medianas, donde con frecuencia se han de conectar oficinas separadas geográficamente. En esta situación es recomendable incrementar los niveles de

19
seguridad de las zonas que presentan mayor riesgo insertando cortafuegos internos entre estas zonas y el resto de la red. Aparte de incrementar la seguridad, los cortafuegos internos son especialmente recomendables en zonas de la red desde la que no se permite la conexión con Internet debido a las políticas: como laboratorios de prácticas, donde una simple computadora con Linux que deniegue cualquier conexión con el exterior será suficiente para evitar que los usuarios se dediquen a conectar a páginas Web desde equipos no destinados a estos usos.
1.5 IPT ABLES
El núcleo de Linux contiene utilidades avanzadas para filtrado de paquetes, el proceso de controlar los paquetes de red cuando intentan entrar, moverse o salir del sistema. Los núcleos anteriores al 2.4 tenían la posibilidad de manipular paquetes usando ipchains que a su vez usaba listas de reglas que se aplicaban a los paquetes en cada paso del proceso de filtrado. La presentación del núcleo 2.4 trajo consigo iptables, que es parecido a ipchains pero con mejoras en el funcionamiento y en el control disponible a la hora de filtrar paquetes.
1.5.1 ¿POR QUÉ FILTRAR PAQUETES?
El tráfico se mueve a través de una red en paquetes, que son colecciones de datos en diferentes tamaños. Un archivo que se envía por red entre dos computadoras puede estar compuesto por diferentes paquetes, los cuales contendrán una parte pequeña de los datos del archivo. La computadora emisora toma el archivo y lo parte en diferentes paquetes para enviarlo por la red, usando las reglas del protocolo particular de red que se esté utilizando. La otra computadora recibe los paquetes y, usando el método especificado por el protocolo, los reensambla para volver a construir el archivo.
Cada paquete contiene información que le ayuda a navegar por la red y moverse hacia su destino. El paquete puede decirle a las computadoras a lo largo del camino, así como a la computadora destino, de dónde viene, a dónde va, qué tipo de paquete es, y otras muchas cosas más. La mayoría de los paquetes se diseñan para transportar datos, pero algunos protocolos pueden usar los paquetes de forma especial. El protocolo Transmission Control Protocol (TCP), por ejemplo, utiliza un paquete SYN, que no contiene datos, para iniciar la comunicación entre dos sistemas.
Hay 3 razones principales por las cuales queremos filtrar dichos paquetes:
• Control. Cuando se está usando Linux para conectar la máquina a otra red ( corno Internet) tienes la oportunidad de permitir ciertos tipos de tráfico y de desactivar otros. Por ejemplo, la cabecera de un paquete permite la dirección del destinatario del paquete, así se puede prevenir que los paquetes vayan a cierta parte de la red.

20
• Seguridad. Cuando una máquina con Linux es lo único Internet y una red interna, es recomendable y necesario restringir el acceso. Por ejemplo, se debe tener cuidado con los posible ataques provenientes de Internet como el conocido "Ping de la muerte".
• Vigilancia. Algunas veces una mala configuración de una máquina en una red local puede decidir devolver todos los paquetes al resto del mundo. Se deberla decirle al filtro que nos avise cuando ocurra algo anormal.
El núcleo de Linux contiene la caracteristica interna de filtrado de paquetes, que le permite aceptar algunos de ellos en el sistema mientras que intercepta y para a otros. El núcleo 2.4 contiene tres tablas de cadenas; aquí hablaremos de la tabla de filtros. La tabla de filtros contiene tres juegos de listas de reglas por defecto llamadas cadenas INPUT, OUTPUT y FORWARD; cada paquete que se envía o recibe desde la máquina está sujeto a una de estas listas de reglas. Cuando un paquete entra en el sistema a través de la interfaz de red, el núcleo decide si su destino es el sistema local (cadena INPUT) o cualquier otro destino (cadena FORDWARD) para determinar qué lista de reglas se va a utilizar con el mismo. De la misma forma, si un paquete tiene su origen en el sistema, el núcleo lo verificará con la cadena OUTPUT.
Cada paquete puede que sea verificado contra muchas, muchas reglas antes de llegar al final de una cadena. La estructura y propósito de estas reglas puede variar, pero normalmente buscan identificar un paquete que viene de o se dirige a una dirección IP en particular o un conjunto de direcciones que usen un determinado protocolo y servicio de red.
Independientemente de su destino, cuando un paquete cumple una regla en particular de una de las listas de reglas, se asignan a un objetivo (target) particular o una acción a aplicárseles. Si la regla especifica un objetivo ACCEPT para un paquete que la cumpla, el paquete se salta el resto de las verificaciones de la regla y se permite que continúe hacia su destino. Si una regla especifica un objetivo DROP, el paquete "se deja caer", significando esto que no se permite que el paquete acceda al sistema y no se envía ninguna respuesta de vuelta al servidor que envió el paquete. Si una regla especifica un objetivo REJECT, el paquete se deja caer, pero se envía un mensaje de error al emisor.
Cada cadena tiene una política ACCEPT, DROP o REJECT sobre el paquete o puede ser enviado al espacio de usuario con QUEUE. Si ninguna de las reglas de la cadena se aplica al paquete, entonces el paquete se trata de acuerdo a la política por defecto de las cadenas.
En resumen, el procedimiento de filtrado compara el paquete contra cada una de las reglas de la cadena a la que pertenece, cada una de ellas dice "si la cabecera de un paquete se parece a esto, entonces esto es lo que se debe hacer con ese paquete". Si una regla no corresponde con el paquete, entonces la siguiente regla de la cadena se examina. Finalmente, si no hay más reglas que consultar, el núcleo mirará la política para decidir qué se debe hacer. En un sistema con una buena política de seguridad, la política normalmente será hacer DROP del paquete.
1. Cuando un paquete llega por una de las interfaces, el núcleo mira el_destino de dicho paquete. si no está destinado a ese equipo el paquete es enrutado.

21
2. Si está destinado a ese equipo, el paquete pasa a la cadena de entrada. Si la pasa, cualquier proceso esperando el paquete lo recibirá.
3. De otro modo, si el núcleo no tiene activado el reenvío, o si no sabe cómo reenviar el paquete, éste será ignorado (DROP). Si el reenvío está activado y el paquete está destinado para otra interfaz de red, entonces el paquete irá a la cadena de reenvío {FORDWARD). Si es aceptado, se enviará fuera.
4. Finalmente, si un programa ejecutándose en el equipo puede enviar paquetes, éstos pasarán por la cadena de salida {OUTPUT) inmediatamente. Si dice aceptar, entonces el paquete saldrá a donde quiera que esté destinado.
El comando iptables le permite configurar estas listas de reglas, así como configurar nuevas cadenas y tablas para ser usadas en si situación particular.
1.5.2 COMANDO IPTABLES
Las reglas que permiten a los paquetes ser filtrados por el núcleo se ponen en ejecución ejecutando el comando iptables con una serie de opciones que identifican qué tipos de paquetes van a ser filtrados, el origen o destino de los mismos, y qué hacer con el paquete si cumple la regla. Las opciones usadas con una regla de iptables en particular deben estar agrupadas localmente, basándonos en el propósito y en las condiciones de la regla general del cortafuegos, para que una regla sea válida.
1.5.2.1 Tablas
Un aspecto muy potente de iptables es que se pueden utilizar múltiples tablas para decidir el destino de un paquete en particular, dependiendo del tipo de paquete que se esté monitoreando y de qué es lo que se va a hacer con el paquete. Gracias a la naturaleza extensible de iptables se pueden crear tablas especializadas que se almacenarán en el directorio para objetivos especiales: /etc/modules/<núcleo-version>/núcleo/net/ipv4/netfilter
lptables es capaz de ejecutar múltiples conjuntos de reglas ipchains en las cadenas definidas, en las que cada conjunto cumple un rol específico.
La tabla por defecto, llamada fil ter, contiene las cadenas estándar por defecto para INPUT, OUT PUT y FORWARD. Esto es parecido a las cadenas estándar que se utilizan con ipchains. Además, por defecto, iptab/es también incluye dos tablas adicionales que realizan tareas de filtrado específico de paquetes. La tabla na t se puede utilizar para modificar las direcciones de origen y destino grabadas en un paquete, y la tabla rnang le permite alterar los paquetes de forma especializada

22
Cada tabla contiene cadenas por defecto que realizan las tareas necesarias basándose en el objetivo de la tabla, pero se pueden configurar fácilmente nuevas cadenas en el resto de las tablas.
1.5.2.2 Estructura
De forma general la estructura del comando es la siguiente:
iptables [-t <table-name>] <command> <chain-name> <parameter-1> <option-1>
<parameter-n> <option-n>
La opción <table-name> permite al usuario seleccionar una tabla diferente de la tabla fil ter por defecto que se usa con el comando. La opción <command> es el centro del comando, dictando cuál es la acción específica a realizar, como pueda ser añadir o borrar una regla de una cadena particular, que es lo que se especifica en la opción <chain-name>. Tras <chain-name> se encuentran los pares de parámetros y opciones que realmente definen la forma en la que la regla funcionará y qué pasará cuando un paquete cumpla una regla.
Cuando miramos a la estructura de un comando iptables es importante recordar que la longitud y complejidad de un comando iptables puede cambiar en función de su propósito. Un comando simple para borrar una regla de una cadena puede ser muy corto mientras que un comando diseflado para filtrar paquetes de una subred particular usando un conjunto de parámetros específicos y opciones puede ser mucho más largo. Una forma de pensar en comandos iptab/es es reconocer que algunos parámetros y opciones que se pueden utilizar pueden crear la necesidad de utilizar otros parámetros y opciones para especificar algo de los requisitos de la anterior opción. Para construir una regla válida, esto deberá ser así para todos los parámetros y reglas que requieran satisfacer otro conjunto de opciones.
1.5.2.3 Comandos
Los comandos le dicen a iptables que realice una tarea específica y solamente un comando se permite por cada cadena de comandos iptab/es. Excepto el comando de ayuda, todos los comandos se escriben en mayúsculas.
Los comandos de iptables son:
• -A - Añade la regla iptahles al final de la cadena especificada. Este es el comando utilizado para simplemente añadir una regla cuando el orden de las reglas en la cadena no importa

23
• -e - Verifica una regla en particular antes de añadirla en la cadena especificada por el usuario. Este comando puede ser de ayuda para construir reglas iptables complejas pidiéndole que introduzca parámetros y opciones adicionales.
• - D - Borra una regla de una cadena en particular por número ( como el 5 para la quinta regla de una cadena). Es posible también introducir la regla entera e iptables borrará la regla en la cadena que corresponda.
• - E - Renombra una cadena definida por el usuario. Esto no afecta a la estructura de la tabla. Tan sólo le evita el problema de borrar la cadena. creándola bajo un nuevo nombre, y reconfigurando todas las reglas de dicha cadena.
• - F - Libera la cadena seleccionada, que borra cada regla de la cadena. Si no se especifica ninguna cadena, este comando libera cada regla de cada cadena-
• - h - Proporciona una lista de estructuras de comandos útiles, así como una resumen rápido de parámetros de comandos y opciones.
• - I - Inserta una regla en una cadena en un punto determinado. Asigne un número a la regla a insertar e iptables lo pondrá allí. Si no especifica ningún número, iptables posicionará su comando al principio de la lista de reglas.
• - L - Lista todas las reglas de la cadena especificada tras el comando. Para ver una lista de todas las cadenas en la tabla fil ter por defecto. La sintaxis siguiente deberá utilizarse para ver la lista de todas las reglas de una cadena específica en una tabla en particular: iptables -L <nombre-cadena> -t <nombre-tabla>.
• -N - Crea una nueva cadena con un nombre especificado por el usuario.
• - P - Configura la política por defecto para una cadena en particular de tal forma que cuando los paquetes atravieses la cadena completa sin cumplir ninguna regla. serán enviados a un objetivo en particular, como puedan ser ACCEPT o DROP.
• - R - Reemplaza una regla en una cadena en particular. Deberá utilizar un número de regla detrás del nombre de la cadena para reemplazar esta cadena. La primera regla de una cadena se refiere a la regla número 1.
• - X - Borra una cadena especificada por el usuario. No se permite borrar ninguna de las cadenas predefinidas para cualquier tabla.
• - z - Pone ceros en los contadores de byte y de paquete en todas las cadenas de una tabla en particular.

24
1.5.2.4 Parámetros
Una vez que se hayan especificado algunos comandos de iptab/es , incluyendo aquellos para crear, añadir, borrar, insertar o reemplaz.ar reglas de una cadena en particular, se necesitan parámetros para comenzar la construcción de la regla de filtrado de paquetes.
• -e Reestablece el valor de los contadores de una regla en particular. Este parámetro acepta las opciones PKTS y BYTES para especificar qué contador hay que resetear.
• -d Configura el nombre de la máquina destino, dirección IP o red de un paquete que cumplirá la regla. Cuando se especifique una red, puede utiliz.ar dos métodos diferentes para describir las máscaras de red, como 192.168.0.0/255.255.255.0ó192.168.0.0/24.
• - f Aplica esta regla sólo a los paquetes fragmentados. Usando la opción "!" después de este parámetro, sólo los paquetes no fragmentados se tendrán en cuenta.
• -i Configura las interfaces de entrada de red, como ethü o pppü, para ser usadas por una regla en particular. Con iptables, este parámetro opcional sólo debería de ser usado por las cadenas INPUT y FORWARD cuando se utilice junto con la tabla f i 1 ter y la cadena PREROUTING con las tablas nat y mangle.
Este parámetro proporciona varias opciones útiles que pueden ser usadas antes de especificar el nombre de una interfaz:
o ! - Dice a este parámetro que no concuerde, queriendo decir esto que las interfaces especificadas se excluirán de esta regla.
o + - Caracter comodín usado para hacer coincidir todas las interfaces que concuerden con una cadena en particular. Por ejemplo, el parámetro -i eth+
aplicará esta regla a todas las interfaces Ethernet de su sistema excluyendo cualquier otro tipo de interfaces, como pueda ser la pppO.
Si el parámetro - i se utiliza sin especificar ninguna interfaz, todas las interfaces estarán afectadas por la regla.
• -j Dice a iptab/es que salte a un objetivo en particular cuando un paquete cumple una regla en particular. Los objetivos válidos que se usarán tras la opción - j incluyen opciones estándar, ACCEPT, DROP, QUEDE y RETURN, así como opciones extendidas que están disponibles a través de módulos que se cargan por defectos con el paquete RPM de iptables de RedHat Linux, como LOG, MARK y REJECT, así como otras

25
En lugar de especificar la acción objetivo, puede también dirigir un paquete que cumpla la regla hacia una cadena definida por el usuario fuera de la cadena actual. Esto le permitirá aplicar otras reglas contra este paquete y filtrarlo mejor con respecto a otros criterios.
Si no especifica ningún objetivo, el paquete se mueve hacia atrás en la regla sin llevar a cabo ninguna acción. A pesar de todo, el _contador para esta regla se sigue incrementando en uno, a partir del momento en el que el paquete cumplió la regla especificada.
• -o Configura la interfaz de red de salida para una regla en particular y sólo puede ser usada con las cadenas OUTPUT y FORWARD en la tabla fil ter y la cadena POSTROUTING en las tablas nat y mangle. Estas opciones de los parámetros son los mismos que para los de la interfaz de red de entrada ( opción - i ).
• -p Configura el protocolo IP para la regla, que puede ser i cmp, t cp, udp o a 11 (todos los anteriores) para usar cualquier protocolo. Además, se pueden usar otros protocolos menos usados de los que aparecen en / etc/protocols. Si esta opción se omite al crear una regla, la opción al 1 es la que se selecciona por defecto.
• - s Configura el origen de un paquete en particular usando la misma sintaxis que en el parámetro de destino (opción -d).
1.5.2.5 Opciones de identificación de paquetes
Los diferentes protocolos de red proporcionan opciones especializadas de concordancia que pueden ser configurados de forma específica para identificar un paquete en particular usando dicho protocolo. Por supuesto el protocolo deberá ser especificado en un primer momento en el comando iptables, como con la opción siguiente para hacer que las opciones de dicho protocolo estén disponibles: -p tcp <nombre-protocolo>
Protocolo TCP
Estas opciones de identificación están disponibles en el protocolo TCP (-p tcp ):
• --dport Configura el puerto de destino para el paquete. Se puede utilizar un nombre de servicio de red (como www o smtp), un número de puerto o un rango de números de puertos para configurar esta opción. Para ver los nombres o alias de los servicios de red y los números de puertos que usan mire el archivo / etc/ services. Además es posible usar la opción --destination-port para especificar esta opción de identificación de paquete.
Para especificar un rango de números de puertos separe los dos números de puertos con dos puntos(:), como en -p tcp --dport 3000: 3200. El rango válido más grande es O: 65535.

26
También se puede usar el caracter de punto de exclamación ( ! ) como bandera tras la opción --dport para indicar a iptables que seleccione los paquetes que no usen ese servicio o puerto.
• --sport Configura el puerto de origen del paquete, usando las mismas opciones que -dport. También se puede usar --source-port para especificar esta opción.
• --syn Provoca que todos los paquetes designados de TCP, comúnmente llamados paquetes SYN, cumplan esta regla. Cualquier paquete que esté llevando un payload de datos no será tocado. Si se sitúa un punto de exclamación (!)como bandera tras la opción - - s yn se provoca que todos los paquetes no-SYN sean seleccionados.
• --tcp-f lags Permite que los paquetes TCP con conjuntos de bits específicos o banderas (tlags}, sean seleccionados para una regla. Esta opción de selección acepta dos parámetros, que son las banderas para los diferentes bits ordenados en una lista separada por comas. El primer parámetro es la máscara, que configura las banderas que serán examinados en el paquete. El segundo parámetro se refiere a las banderas que se deben configurar en el paquete para ser seleccionado. Las banderas posibles son ACK, FIN,
PSH, RST, SYN y URG. Adicionalmente, se pueden usar ALL y NONE para seleccionar todas las banderas o ninguno de ellos.
Por ejemplo, una regla iptables que contiene -p tcp --tcp-flags ACK, FIN, SYN
SYN tan sólo seleccionará los paquetes TCP que tengan la bandera SYN activo y las banderas ACK y FIN sin activar.
Como en otras _opciones, al usar el punto de exclamación ( ! ) tras - -t cp- flag s invierte el efecto de la opción, de tal forma que las banderas del parámetro no tendrán que estar presentes para poder ser seleccionados.
• --tcp-option Intenta seleccionar con opciones específicas de TCP que pueden estar activas en un paquete en particular. Esta opción se puede revertir con el punto de exclamación ( ! ).
Protocolo UDP
Estas opciones de selección están disponibles para el protocolo UDP (-p udp ):
• --dport Especifica el puerto destino del paquete UDP usando el nombre del servicio, el número del puerto, o un rango de puertos. La opción de selección de paquetes - -destination-port se puede utilizar en lugar de --dport.
• - - sport Especifica el puerto origen del paquete UDP usando el nombre del serv1c10 número de puerto, o rango de puertos. La opción --source-port puede ser usada en
lugar de --sport.

27
Protocolo ICMP
Los paquetes que usan el protocolo de control de mensajes de Internet (Internet Control Message Protocol, ICMP) pueden ser seleccionados usando la siguiente opción cuando se especifique -p
icmp:
• --icmp-type Selecciona el nombre o el número del tipo ICMP que concuerde con la regla. Se puede obtener una lista de nombres válidos ICMP tecleando el comando iptables -p icmp -h.
1.5.2.6 Módulos con opciones de selección adicionales
Las opciones de selección adicionales, que no son específicas de ningún protocolo en particular, están también disponibles a través de módulos que se cargan cuando el comando iptables los necesite. Para usar una de estas opciones es necesario cargar el módulo por su nombre incluyendo -m <nombre-modulo> en el comando iptables que crea la regla.
Un gran número de módulos, cada uno de ellos con sus diferentes opciones de selección de paquetes, están disponibles por defecto. También es posible crear módulos que proporcionen funcionalidades de selección adicionales para requisitos específicos.
El módulo 1 imi t permite poner un límite en el número de paquetes que podrán ser seleccionados por una regla en particular. Esto es especialmente conveniente cuando se usa la regla de logging ya que hace que el flujo de paquetes seleccionados no llene nuestros archivos log con mensajes repetitivos ni utilice demasiados recursos del sistema.
• - -1 imi t - Configura el número de coincidencias en un intervalo de tiempo, especificado con un número y un modificador de tiempo ordenados en el formato <número>/<tiempo>. Por ejemplo si se usa --limit 5/hour sólo se permitirá que una regla sea efectiva cinco veces a la hora.
Si no se utiliza ningún número ni modificador de tiempo, se asume el siguiente valor por defecto: 3/hour.
• - -1 imi t - bur s t - Configura un límite en el número de paquetes capaces de cumplir una regla en un determinado tiempo. Esta opción deberá ser usada junto con la opción - -1 imi t, y acepta un número para configurar el intervalo de tiempo.
Si no se especifica ningún número, tan sólo cinco paquetes serán capaces inicialmente de cumplir la regla.

28
El módulo state, que utiliza la opción --state, puede seleccionar un paquete con los siguientes estados de conexión particulares:
• ESTABLISHED El paquete seleccionado se asocia con otros paquetes en una conexión establecida.
• INVALID El paquete seleccionado no puede ser asociado a una conexión conocida.
• NEW El paquete seleccionado o bien está creando una nueva conexión o bien fonna parte de una conexión de dos caminos que antes no había sido vista.
• RELATED El paquete seleccionado está iniciando una nueva conexión en algún punto de la conexión existente.
Estos estados de conexión se pueden utilizar en combinación con otros separándolos mediante comas como en -m state --state INVALID, NEW.
Para seleccionar una dirección MAC 11 de un dispositivo Ethernet en particular utilice el módulo mac, que acepta --mac-source con una dirección MAC como opción. Para excluir una dirección MAC de una regla, ponga un punto de exclamación ( ! ) tras la opción --macsource.
1.5.2. 7 Opciones del objetivo
Una vez que un paquete cumple una regla en particular, la regla puede dirigir el paquete a un número de objetivos (destinos) diferentes que decidirán cuál será su destino y, posiblemente, las acciones adicionales que se tomarán, como el guardar un registro de lo que está ocurriendo. Adicionalmente, cada cadena tiene un objetivo por defecto que será el que se utilice si ninguna de las reglas disponibles en dicha cadena se puede aplicar a dicho paquete, o si ninguna de las reglas que se aplican al mismo especifica un objetivo concreto.
Existen pocos objetivos estándar disponibles para decidir qué ocurrirá con el paquete:
• <user-defined-chain> El nombre de una cadena que ya ha sido creada y definida con anterioridad junto con esta tabla con reglas que serán verificadas contra este paquete, además de cualquier otra regla en otras cadenas que se deban verificar contra este paquete. Este tipo de objetivo resulta útil para examinar un paquete antes de decidir qué ocurrirá con él o guardar información sobre el paquete.
• ACCEPT - Permite que el paquete se mueva hacia su destino (o hacia otra cadena, si no ha sido configurado ningún destino ha sido configurado para seguir a esta cadena).
11 Dirección de un dispositivo hardware conectado a un medio compartido.

29
• DROP - Deja caer el paquete. El sistema que envió el paquete no es informado del fallo. El paquete simplemente se borra de la regla que está verificando la cadena y se descarta.
• QUEUE - El paquete se pone en una cola para ser manejado en el espacio de usuario, donde un usuario o una aplicación, por ejemplo, podrá hacer algo con él.
• RETURN - Para la verificación del paquete contra las reglas de la cadena actual. Si el paquete con un destino RETURN cumple una regla de una cadena llamada desde otra cadena, el paquete es dewelto a la primera cadena para retomar la verificación de la regla allí donde se dejó. Si la regla RETURN se utiliza en una cadena predefinida, y el paquete no puede moverse hacia la cadena anterior, el objetivo por defecto de la cadena actual decide qué hará con él.
Además de estos objetivos estándar, se pueden usar otros más con extensiones llamadas módulos de objetivos (target modules}, que trabajan de forma similar a como los hacían los módulos de las opciones de selección.
Existen varios módulos extendidos de objetivos, la mayoría de los cuales tan sólo se aplicarán a tablas o situaciones específicas. Un par de estos módulos de los más populares e incluidos por defecto en RedHat Linux son:
• LOG Guarda un registro de todos los paquetes que cumplen esta regla. Como estos paquetes son monitoreados por el núcleo, el archivo / etc/ syslog. conf determina dónde se escribirán esas entradas en el archivo de registro (log). Por defecto, se sitúan en el archivo /var / log/messages.
Se pueden usar varias opciones tras el objetivo LOG para especificar la manera en la que tendrá lugar el registro:
o --log-level Configura un nivel de prioridad al evento de registro del sistema. Se puede encontrar una lista de los eventos del sistema en la página del manual de syslog. conf, y sus nombres se pueden usar como opciones tras la opción -log-level.
o -- log-ip-options Cualquier opción en la cabecera de un paquete IP se guarda en el registro.
o --log-prefix Pone una cadena de texto antes de la línea de registro cuando ésta sea escrita. Acepta hasta 29 caracteres tras la opción -- log-pre f ix. Esto puede ser útil para escribir filtros del registro del sistema para ser usados conjuntamente junto con el registro de paquetes.
o --log-tcp-options Cualquier opción en la cabecera de un paquete TCP se guarda en el registro

30
o --log-tcp-sequence Escribe le número de secuencia TCP del paquete en el registro del sistema.
• REJECT Envía un paquete de error de vuelta al sistema que envió el paquete, y lo deja caer (DROP). Este objetivo puede ser útil si queremos notificar al sistema que envió el paquete del problema.
El objetivo REJECT acepta una opción --reject-with <type> para proporcionar más detalles para ser enviados junto con el paquete de error. El mensaje portunreachable es el error <type> que se envía por defecto cuando no se utiliza junto con otra opción. Para obtener una lista completa de todas las opciones <type> que se pueden utilizar, vea la página del manual de iptables.
1.5.2.8 Opciones de listado
El comando de listado por defecto, iptables -L, proporciona una visión básica de la tabla de filtros por defecto de las cadenas de reglas actuales. Existen opciones adicionales que proporcionan más información y la ordenan de diferentes formas:
• -v Muestra la salida por pantalla, como el número de paquetes y bytes que cada cadena ha visto, el número de paquetes y bytes que cada regla ha encontrado y qué interfaces se aplican a una regla en particular.
• - x Expande los números en sus valores exactos. En un sistema ocupado, el número de paquetes y bytes vistos por una cadena en concreto o por una regla puede estar abreviado usando K (miles), M (millones), y G (billones) detrás del número. Esta opción fuerza a que se muestre el número completo.
• -n Muestra las direcciones IP y los números de puertos en formato numérico, en lugar de utilizar el nombre del servidor y la red tal y como se hace por defecto.
• --line-numbers Proporciona una lista de cada cadena junto con su orden numérico
en la cadena. Esta opción puede ser útil cuando esté intentando borrar una regla específica en una cadena, o localizar dónde insertar una regla en una cadena.
1.5.3 GUARDAR INFORMACIÓN DE IPTABLES
Las reglas creadas con el comando iptables se almacenan solamente en RAM 12_ Si tiene que reiniciar su sistema tras haber configurado varias reglas de iptah/es, éstas se perderán y tendrá
1: Memoria de acceso <1lca1orio en donde la compuladorn almacena elatos para rápido acceso.

31
que volver a teclearlas. Si quiere que determinadas reglas tengan efecto en cualquier momento que inicie su sistema, necesita guardarlas en el archivo/ etc/ sysconf ig / iptables.
Para hacer esto, ordene sus tablas, cadenas y reglas de la forma en que deben de estar la próxima vez que se inicie el sistema o se reinicie iptables. y teclee el comando / sbin/ service iptables save como usuario root. Esto hace que el script de inicio de iptables ejecute el programa/ sbin/ iptables-save y escriba la configuración actual de iptables en el archivo / etc/ sysconf ig/ iptables. Este archivo debería ser de sólo lectura para el usuario root, para que las reglas de filtrado de paquetes no sean visibles por el resto de los usuarios.
La próxima vez que se inicie el sistema, el script de inicio de iptables volverá a aplicar las reglas guardadas en / etc/ sysconf ig/ iptables usando el comando / sbin/ iptablesrestore.
Mientras que siempre es una buena idea el verificar cada nueva regla de iptables antes de que se escriba en el archivo /etc/sysconfig/iptables. es posible copiar las reglas de iptables en este archivo a partir de otra versión del sistema de este archivo. Esto permite distribuir rápidamente conjuntos de reglas iptables a diferentes máquinas de una sola vez. Simplemente es necesario reiniciar iptables para que las nuevas reglas tengan efecto.
1.5.4 MEJORAS SOBRE IPCHAINS
En un primer momento, ipchains e iptables parecen ser bastante similares. Al fin y al cabo ambos son métodos de filtrado de paquetes usando cadenas o reglas que operan con el núcleo de Linux para decidir no sólo qué paquetes se permite entrar o salir, sino también qué hacer con los paquetes que cumplen determinadas reglas, donde iptab/es ofrece un método mucho más extensible de filtrado de paquetes, proporcionando al administrador un nivel de control mucho más refinado sin tener que aumentar la complejidad del sistema entero.
Más concretamente, las diferencias significativas entre ipchains e iptables son las siguientes:
• Bajo iptables, cada paquete filtrado se procesa únicamente usando las reglas de una cadena, en lugar de hacerse con múltiples. En otras palabras, un paquete FORWARD que llega al sistema usando ipchains tendrá que pasar por las cadenas INPUT, FORWARD y OUTPUT para llegar a su destino. Con iptables, el paquete tan solo se envía a la cadena INPUT si su destino es el sistema local y tan solo los envía a la cadena OUTPUT si el sistema local es quien genera los paquetes. Por esta razón, deberá estar seguro de situar la regla destinada a interceptar un paquete en particular en la cadena adecuada que será la que vea el paquete.
La principal ventaja es que tendrá un control más refinado sobre la disposición de cada paquete. Si está intentando bloquear el acceso a un sitio Web en particular, ahora es posible bloquear los intentos de acceso desde clientes que están en máquinas que utilicen

32
nuestro servidor como gateway. Una regla OUTPUT que deniegue el acceso no prevendrá más el acceso a las máquinas que utilicen nuestro servidor como gateway.
• El objetivo DENY ha sido cambiado por DROP. En ipchains, los paquetes que cumplían una regla en una cadena podían ser redirigidos a un objetivo DENY, que dejaba caer el paquete en silencio. Este objetivo deberá cambiarse a DROP con iptables para obtener el mismo resultado.
• El orden es importante al poner opciones en una regla de una cadena Anteriormente, con ipchains, no era muy importante cómo se ordenaban las opciones de las reglas a la hora de escribirlas. El comando iptables es un poco más reticente sobre el lugar que ocupan las diferentes opciones. Por ejemplo, ahora se debe especificar el puerto origen y destino después del protocolo (ICMP, TCP o UDP) que se vaya a utilizar en una regla de una cadena.
• Cuando se especifican las interfaces de red a usar en una regla, se deberán utilizar sólo interfaces de entrada (opción -i) con cadenas INPUT o FORWARD y las de salida (opción -o) con cadenas FORWARD o OUTPUT. Esto es necesario debido al hecho de que las cadenas OUTPUT no se utilizan más con las interfaces de entrada y las cadenas INPUT no son vistas por los paquetes que se mueven hacia las interfaces de salida.

33
2 SISTEMAS DE DETECCIÓN DE INTRUSOS
A pesar de que un enfoque clásico de la seguridad de un sistema informático siempre define como principal defensa del mismo sus controles de acceso (desde una política implementada en un cortafuegos hasta listas de control de acceso en un ruteador o en el propio sistema de archivos de una máquina), esta visión es extremadamente simplista ya que no se tiene en cuenta que en muchos casos esos controles no pueden protegemos ante un ataque. Por ejemplo, pensemos en un cortafuegos donde hemos implementado una política que deje acceder al puerto 80 de nuestros servidores Web desde cualquier máquina de Internet; ese cortafuegos sólo comprobará si el puerto destino de una trama es el que hemos decidido para el servicio HTTP, pero seguramente no tendrá en cuenta si ese tráfico representa un ataque o una violación de nuestra política de seguridad. Esto significa que no detendrá a un pirata que trate de acceder al archivo de contraseñas de una máquina aprovechando un error del servidor Web. Desde un pirata informático externo a nuestra organización a un usuario autorizado que intenta obtener privilegios que no le corresponden en un sistema, nuestro entorno de trabajo no va a estar nunca a salvo de intrusiones.
Llamaremos intrusión a un conjunto de acciones que intentan poner en riesgo la integridad, la confidencialidad o la disponibilidad de un recurso; analizando esta definición, podemos damos cuenta de que una intrusión no tiene que consistir únicamente en un acceso no autorizado a una máquina sino que también puede ser un ataque de negación de servicio. A los sistemas utilizados para detectar las intrusiones o los intentos de intrusión se les denomina sistemas de detección de intrusos (lntrnsion Detection Systems, IDS). Cualquier mecanismo de seguridad con este propósito puede ser considerado un IDS pero generalmente sólo se aplica esta denominación a los sistemas automáticos.
Una de las primeras cosas que deberíamos planteamos a la hora de hablar de IDS es si realmente necesitamos uno de ellos en nuestro entorno de trabajo; a fin de cuentas, debemos tener ya un sistema de protección perimetral basado en cortafuegos, y por si nuestro cortafuegos fallara, cada sistema habría de estar configurado de una manera correcta. de forma que incluso sin un cortafuegos cualquier máquina pudiera seguirse considerando relativamente segura. La respuesta es. sin duda. sí; debemos esperar que en cualquier momento alguien consiga romper la seguridad

34
e:! nuestro entorno informático, y por tanto hemos de ser capaces de detectar ese problema tan Jnto como sea posible (incluso antes de que se produzca, cuando el potencial atacante se limite probar suerte contra nuestras máquinas). Aunque nadie haya conseguido violar nuestras
_¡Jolíticas de seguridad, es vital contar con un sistema de detección de intrusos, ya que éste se encargará de mostrarnos todos los intentos que una multitud de piratas hace para penetrar en nuestro entorno, lo que no nos dejará caer en ninguna falsa sensación de seguridad. Si somos conscientes de que a diario hay gente que trata de romper nuestros sistemas, no cometeremos el error de pensar que nuestras máquinas están seguras porque nadie sabe de su existencia o porque no son interesantes para un pirata.
Los sistemas de detección de intrusos no son precisamente nuevos: el primer trabajo sobre esta materia data de 1980. No obstante, este es uno de los campos más en auge desde hace ya unos años dentro de la seguridad informática. Y no es extraño, la capacidad para detectar y responder ante los intentos de ataque contra nuestros sistemas es realmente muy interesante. Durante estos veinte años, cientos de investigadores de todo el mundo han desarrollado, con mayor o menor éxito, sistemas de detección de todo tipo, desde simples procesadores de /ogs13 hasta complejos sistemas distribuidos, especialmente vigentes con el auge de las redes de computadores en los últimos años.
2.1 CLASIFICACIÓN DE LOS IDS
Generalmente existen dos grandes enfoques a la hora de clasificar a los sistemas de detección de intrusos: en función de qué sistemas vigilan y en función de cómo lo hacen.
La primera de estas aproximaciones se divide a su vez en dos grupos: los que analizan actividades de una única máquina en busca de posibles ataques y los que lo hacen de una subred aunque se ubiquen en uno sólo de los hosts de la misma. Cabe destacar de acuerdo a lo último, que un IDS que detecta actividades sospechosas en una red no tiene porqué (y de hecho en la mayor parte de casos no suele ser así) ubicarse en todas las máquinas de esa red.
1. IDS basados en red. Un IDS basado en red monitorea los paquetes que circulan por nuestra red en busca de elementos que denoten un ataque contra alguno de los sistemas ubicados en ella; el IDS puede situarse en cualquiera de los hosts o en un elemento que analice todo el tráfico ( como un HUB o un enrutador). Esté donde esté, monitoreará diversas máquinas y no una sola: esta es la principal diferencia con los sistemas de detección de intrusos basados en host.
2. IDS basados en máquina. Mientras que los sistemas de detección de intrusos basados en red operan bajo todo un dominio de colisión, los basados en máquina realizan su función protegiendo un único
1' Archi\"O de texto que almacena generalmente datos sobre procesos determinados.

35
sistema; el IDS es un proceso que despierta periódicamente buscando patrones que puedan denotar un intento de intrusión y alertando o tomando las medidas oportunas en caso de que uno de estos intentos sea detectado.
Éstos pueden ser divididos en tres subcategorias:
a. Verificadores de integridad del sistema (SIV). Un verificador de integridad no es más que un mecanismo encargado de monitorerar archivos de una máquina en busca de posibles modificaciones no autorizadas, por lo general puertas traseras14 dejadas por un intruso (por ejemplo, una entrada adicional en el archivo de contraseñas o un /bin/ login que permite el acceso ante cierto nombre de usuario no registrado).
b. Monitores de registros (LFM). Estos sistemas monitorean los archivos de /og generados por los programas de una máquina en busca de patrones que puedan indicar un ataque o una intrusión. Un ejemplo de monitor puede ser swatch, pero más habituales que él son los pequeños shellscripts que casi todos los administradores realizan para comprobar periódicamente sus archivos de /og en busca de entradas sospechosas.
c. Sistemas de decepción. Los sistemas de decepción o tarros de miel (honeypots), como Deception Too/kit (DTK), son mecanismos encargados de simular servicios con problemas de seguridad de forma que un pirata piense que realmente el problema se puede aprovechar para acceder a un sistema, cuando realmente se está aprovechando para registrar todas sus actividades. Se trata de un mecanismo útil en muchas ocasiones, por ejemplo, para conseguir entretener al atacante mientras se rastrea su conexión, pero que puede resultar peligroso: ¿qué sucede si el propio sistema de decepción tiene un error que desconocemos, y el atacante lo aprovecha para acceder realmente a nuestra máquina?
La segunda gran clasificación de los IDS se realiza en función de cómo actúan estos sistemas; actualmente existen dos grandes técnicas de detección de intrusos: las basadas en la detección de anomalías y las basadas en la detección de usos indebidos del sistema. La idea básica de los mismos es la siguiente:
1. Detección de anomalías. La base del funcionamiento de estos sistemas es suponer que una intrusión se puede ver como una anomalía de nuestro sistema, por lo que si fuéramos capaces de establecer un perfil del comportamiento habitual de los sistemas seríamos capaces de detectar las intrusiones por pura estadística: probablemente una intrusión sería una desviación excesiva de la media de nuestro perfil de comportamiento.
1 ~ Trozos de código de un programa que pcnniten entrar en un sistema informático e\'itando los métodos de autentificación usuales durante el procedimiento habitual de entrada.

36
2. Detección de usos indebidos. El funcionamiento de los IDS basados en la detección de usos indebidos presupone que podemos establecer patrones para los diferentes ataques conocidos y algunas de sus variaciones; mientras que la detección de anomalías conoce lo normal ( conocimiento positivo) y detecta lo que no lo es, este esquema se limita a conocer lo anormal para poderlo detectar ( conocimiento negativo).
Para ver más claramente la diferencia entre ambos esquemas, imaginemos un sistema de detección basado en monitorear las máquinas origen desde las que un usuario sospechoso conecta a nuestro sistema: si se tratara de un modelo basado en la detección de anomalías, seguramente mantendría una lista de las dos o tres direcciones más utilizadas por el usuario legítimo, alertando al responsable de seguridad en caso de que el usuario se conecte desde otro lugar; por el contrario, si se tratara de un modelo basado en la detección de usos indebidos, mantendría una lista mucho más amplia que la anterior, pero formada por las direcciones desde las sabemos con una alta probabilidad que ese usuario no se va a conectar, de forma que si detectara un acceso desde una de esas máquinas, entonces es cuando el sistema tomaría las acciones oportunas.
2.2 REQUISITOS DE UN IDS
Sin importar los sistemas que vigile o su forma de trabajar, cualquier sistema de detección de intrusos ha de cumplir algunas propiedades para poder desarrollar su trabajo correctamente. En primer lugar, y quizás como característica más importante, el IDS ha de ejecutarse continuamente sin nadie que esté obligado a supervisarlo, independientemente de que al detectar un problema se informe a un operador o se lance una respuesta automática, el funcionamiento habitual no debe implicar interacción con un humano. Los sistemas de detección son mecanismos automatizados que se instalan y configuran de forma que su trabajo habitual sea transparente a los operadores del entorno informático.
Otra propiedad, y también como una característica a tener siempre en cuenta, es el grado de aceptación del IDS. Al igual que sucedía con cualquier modelo de autenticación, los mecanismos de detección de intrusos han de ser aceptables para las personas que trabajan habitualmente en el entorno. Por ejemplo, no ha de introducir una sobrecarga considerable en el sistema (si un IDS hace demasiado lenta una máquina, simplemente no se utilizará) ni generar una cantidad elevada de falsos positivos (detección de intrusiones que realmente no lo son) o de /ogs, ya que entonces llegará un momento en que nadie se preocupe de comprobar las alertas emitidas por el detector.
Una tercera característica a evaluar a la hora de hablar de sistemas de detección de intrusos es la adaptabilidad del mismo a cambios en el entorno de trabajo. Ningún sistema informático puede considerarse estático: desde la aplicación más pequeña hasta el propio núcleo de Unix, pasando por supuesto por la forma de trabajar de los usuarios, todo cambia con una periodicidad más o menos elevada. Los mecanismos de detección de intrusos deben ser capaces de adaptarse rápidamente a dichos cambios.

37
Todo IDS debe además presentar cierta tolerancia a fallos o capacidad de respuesta ante situaciones inesperadas. Recordando el carácter altamente dinámico de un entorno informático, algunos de los cambios que se pueden producir en dicho entorno no son graduales sino bruscos y un IDS ha de ser capaz de responder siempre adecuadamente ante los mismos.
2.3 IDS BASADOS EN MÁQUINA
Como antes hemos comentado, un sistema de detección de intrusos basado en máquina (hostbased IDS) es un mecanismo que permite detectar ataques o intrusiones contra la máquina sobre la que se ejecuta.
Tradicionalmente, los modelos de detección basados en máquina han consistido por una parte en la utilización de herramientas automáticas de análisis de /ogs generados por diferentes aplicaciones o por el propio núcleo del sistema operativo, prestando siempre especial atención a los registros relativos a demonios de red, como un servidor Web, y por otro lado, de manera menos habitual, en el uso de verificadores de integridad de determinados archivos vitales para el sistema, como el de contraseñas. No obstante, desde hace unos años un tercer esquema de detección se está implementando con cierta fuerza: se trata de los sistemas de detección: honeypots o tarros de miel.
El análisis de /ogs generados por el sistema varía entre diferentes clones de Unix ya que cada uno de ellos guarda la información con un cierto formato y en determinados archivos, aunque todos son capaces de registrar casi los mismos datos que pueden ser indicativos de un ataque. La mayor parte de los sabores de Unix son capaces de registrar con una granularidad lo suficientemente fina casi todas las actividades que se llevan a cabo en el sistema, en especial aquellas que pueden suponer una vulnerabilidad en la seguridad. Sin embargo, el problema radica en que pocos administradores se preocupan de revisar con un mínimo de atención esos logs, por lo que muchos ataques contra la máquina, tanto externos como internos, y tanto fallidos como exitosos, pasan finalmente desapercibidos. Aquí es donde entran en juego las herramientas automáticas de análisis, como swatch o logcheck. A grandes rasgos, realizan la misma actividad que podría ejecutar un shellscript convenientemente planificado que incluyera entre sus líneas algunos grep de registros sospechosos en los archivos de log.
¿A qué entradas de estos archivos debemos estar atentos? Evidentemente, esto depende de cada sistema y de lo que sea normal en él, aunque suelen existir registros que en cualquier máquina denotan una actividad cuanto menos sospechosa. Esto incluye ejecuciones ciertos comandos como su, peticiones no habituales al servicio SMTP, conexiones a diferentes puertos rechazadas por TCP Wrappers, intentos de acceso remotos como superusuario, etc. Si en la propia máquina se tiene instalado un cortafuegos independiente del corporativo, o cualquier otro software de seguridad, también conviene estar atentos a los logs generados por los mismos. que

38
habitualmente se registran en los archivos normales de auditoria del sistema (~yslog, messages) y que suelen contener información que con una probabilidad elevada denotan un ataque real.
Por otra parte, la verificación de integridad de archivos se puede realizar a diferentes niveles, cada uno de los cuales ofrece un mayor o menor grado de seguridad. Por ejemplo, un administrador puede programar y planificar un sencillo shellscript para que se ejecute periódicamente y compruebe el propietario y el tamaño de ciertos archivos como /etc/passwd
o /etc/shadow. Evidentemente, este esquema es extremadamente débil, ya que si un usuario se limita a cambiar en el archivo correspondiente su VID de 100 a 000, este modelo no descubriría el ataque a pesar de su gravedad. Por tanto, parece obvio que se necesita un esquema de detección mucho más robusto, que compruebe aparte de la integridad de la información registrada en el inodo asociado a cada archivo (fecha de última modificación, propietario, grupo propietario) la integridad de la información contenida en dicho archivo. Esto se consigue muy fácilmente utilizando funciones resumen sobre cada uno de los archivos a monitorear, funciones capaces de generar un hash único para cada contenido de los archivos. De esta forma, cualquier modificación en su contenido generará un resumen diferente, que al ser comparado con el original dará la voz de alarma. Ésta es la forma de trabajar de Tripwire, el más conocido y utilizado de todos los verificadores de integridad disponibles para entornos Unix.
Sea cual sea nuestro modelo de verificación, en cualquiera de ellos debemos llevar a cabo inicialmente un paso común: generar una base de datos de referencia contra la que posteriormente compararemos la información de cada archivo. Por ejemplo, si nos limitamos a comprobar el tamaño de ciertos archivos debemos, nada más configurar el sistema, registrar todos los nombres y tamaños de los archivos que deseemos, para después comparar la información que periódicamente registraremos en nuestra máquina con la que hemos almacenado en dicha base de datos. Si existen diferencias, podemos encontramos ante un indicio de ataque. Lo mismo sucederá si registramos funciones resumen: debemos generar un hash inicial de cada archivo contra el que comparar después la información obtenida en la máquina. Independientemente de los contenidos que deseemos registrar en esa base de datos inicial, siempre hemos de tener presente una cosa: si un pirata consigue modificarla. de forma no autorizada, habrá burlado por completo a nuestro sistema de verificación. Así, es vital mantener su integridad; incluso es recomendable utilizar medios de sólo lectura, como un CD-ROM o disquetes, que habitualmente no estarán disponibles en el sistema y sólo se utilizarán cuando tengamos que comprobar la integridad de los archivos de la máquina.
Por último, aunque su utilización no esté tan extendida como la de los analizadores de logs o la de los verificadores de integridad, es necesario hablar, dentro de la categoría de los sistemas de detección de intrusos basados en máquina, de los sistemas de decepción o honeypots. Básicamente, estos tarros de miel son sistemas completos o parte de los mismos diseñados para recibir ciertos tipos de ataques; cuando sufren uno, los honeypots detectan la actividad hostil y aplican una estrategia de respuesta. Dicha estrategia puede consistir desde un simple correo electrónico al responsable de la seguridad de la máquina hasta un bloqueo automático de la dirección atacante. Incluso muchos de estos sistemas son capaces de simular vulnerabilidades conocidas de forma que el atacante piense que ha tenido éxito y prosiga con su actividad, mientras es monitoreado por el detector de intrusos.

39
El concepto teórico que está detrás de los tarros de miel es el denominado conocimiento negativo: proporcionar deliberadamente a un intruso información falsa, pero que él considerará real, de nuestros sistemas, con diferentes fines: desde poder monitorear durante más tiempo sus actividades hasta despistarlo. Evidentemente, para lograr engañar a un pirata medianamente experimentado la simulación de vulnerabilidades ha de ser muy real, dedicando a tal efecto incluso sistemas completos, pero con atacantes de nivel medio o bajo dicho engaño es muchísimo más sencillo: en muchos casos basta simular la existencia de un troyano como BackOrifice para que el pirata determine que realmente estamos infectados e intente utilizar ese camino en su ataque contra nuestro sistema.
Algunos sistemas de decepción no simulan vulnerabilidades, su objetivo no es engañar a un atacante durante mucho tiempo, sino que su "decepción" es bastante más elemental: se limitan a presentar un aspecto con el único objetivo recopilar información del atacante y del ataque en sí. Por ejemplo, un programa que se encargue de escuchar en el puerto 31337 de nuestro sistema, donde lo hace el troyano, y cada vez que alguien acceda a él, guardar la hora, la dirección origen, y los datos enviados por el atacante. En realidad, no es una simulación que pueda engañar ni al pirata más novato, pero hemos logrado el objetivo de cualquier sistema de detección de intrusos: registrar el ataque.
2.4 IDS BASADOS EN RED
Los sistemas de detección de intrusos basados en red (network-based IDS) son aquellos capaces de detectar ataques contra diferentes sistemas de una misma red aunque generalmente se ejecuten en uno sólo de los hosts de esa red. Para lograr su objetivo, al menos uno de las interfaces de red de esta máquina sensor trabaja en modo promiscuo, capturando y analizando todas las tramas que pasan por él en busca de patrones indicativos de un ataque.
¿Cuáles pueden ser estos patrones identificables de un ataque a los que estamos haciendo referencia? Casi cualquiera de los diferentes campos de una trama de red TCP/IP puede tener un valor que, con mayor o menor probabilidad, represente un ataque real. Los casos de ataque más habituales incluyen:
• Campos de fragmentación. Una cabecera IP contiene dieciséis bits reservados a información sobre el nivel de fragmentación del datagrama; de ellos, uno no se utiliza y trece indican el desplazamiento del fragmento que transportan. Los otros dos bits indican o bien que el paquete no ha de ser fragmentado por un ruteador intermedio (DF, Don 't Fragment) o bien que el paquete ha sido fragmentado y no es el último que se va a recibir (MF, More Fragments). Valores incorrectos de parámetros de fragmentación de los datagramas se han venido utilizando típicamente para causar importantes negaciones de servicio a los sistemas e incluso para obtener la versión del operativo que se ejecuta en un determinado host. Por ejemplo. ¿qué le sucedería al subsistema

40
de red implementado en el núcleo de una máquina Unix si nunca recibe una trama con el bit MF reseteado, indicando que es el último de un paquete? ¿se quedaría permanentemente esperándola? ¿y si recibe uno que en teoría no está fragmentado pero se le indica que no es el último que va a recibir? ¿cómo respondería el núcleo del operativo en este caso? Como vemos, si en nuestras máquinas observamos ciertas combinaciones de bits relacionados con la fragmentación realmente tenemos motivos para sospechar que alguien trata de atacamos.
• Dirección origen y destino. Las direcciones de la máquina que envía un paquete y la de la que lo va a recibir también son campos interesantes de cara a detectar intrusiones en nuestros sistemas o en nuestra red. No tenemos más que pensar el tráfico proveniente de nuestra DMZ que tenga como destino nuestra red protegida: es muy posible que esos paquetes constituyan un intento de violación de nuestra política de seguridad. Otros ejemplos clásicos son las peticiones originadas desde Internet y que tienen como destino máquinas de nuestra organización que no están ofreciendo servicios directos al exterior, como un servidor de bases de datos cuyo acceso está restringido a sistemas de nuestra red.
• Puerto origen y destino. Los puertos origen y destino ( especialmente este último) son un excelente indicativo de actividades sospechosas en nuestra red. Aparte de los intentos de acceso no autorizado a servicios de nuestros sistemas, pueden detectar actividades que también supondrán violaciones de nuestras políticas de seguridad como la existencia de troyanos, ciertos tipos de barridos de puertos o la presencia de servidores no autorizados dentro de nuestra red.
• Flags TCP. Uno de los campos de una cabecera TCP contiene seis bits (URG, ACK, PSH, RST, SYN y FIN), cada uno de ellos con una finalidad diferente (por ejemplo, el bit SYN es utilizado para establecer una nueva conexión, mientras que FIN hace justo lo contrario: liberarla). Evidentemente el valor de cada uno de estos bits será O ó 1, lo cual de forma aislada no suele decir mucho de su emisor No obstante, ciertas combinaciones de valores suelen ser bastante sospechosas, por ejemplo, una trama con los dos bits de los que hemos hablado, SYN y FIN, activados simultáneamente sería indicativa de una conexión que trata de abrirse y cerrarse al mismo tiempo.
• Campo de datos. Seguramente, el campo de datos de un paquete que circula por la red es donde más probabilidades tenemos de localizar un ataque contra nuestros sistemas. Esto es debido a que con toda probabilidad nuestro cortafuegos corporativo detendrá tramas cuya cabecera sea sospechosa (por ejemplo, aquellas cuyo origen no esté autorizado a alcanzar su destino o con campos incorrectos), pero rara vez un cortafuegos se parará a analizar el contenido de los datos transportados en la trama. Por ejemplo, una petición como "GET
.. / .. / .. /etc/passwd HTTP/1. o" contra el puerto 80 del servidor Web de nuestra empresa no se detendrá en el cortafuegos, pero muy probablemente se trata de un intento de intrusión contra nuestros sistemas

•
"TI
Acabamos de ver sólo algunos ejemplos de campos de una trama TCP/IP que, al presentar determinados valores, pueden ser indicativos de un ataque. Sin embargo, no todo es tan sencillo como comprobar ciertos parámetros de cada paquete que circula por uno de nuestros segmentos. También es posible y necesario que un detector de intrusos basado en red sea capaz de notificar otros ataques que no se pueden apreciar en una única trama. Uno de estos ataques es la presencia de peticiones que, aunque por sí mismas no sean sospechosas, por su repetición en un intervalo de tiempo más o menos pequeño puedan ser indicativas de un ataque (por ejemplo, barridos de puertos horizontales o verticales). Otros ataques difíciles de detectar analizando tramas de forma independiente son las negaciones de servicio distribuidas (DDoS, Distribured Denial qf Service), justamente por el gran número de orígenes que el ataque tiene por definición.
Según lo expuesto hasta ahora en este punto, puede parecer que los sistemas de detección de intrusos basados en red funcionan únicamente mediante la detección de patrones; realmente, esto no es así: en principio, un detector de intrusos basado en red puede estar basado en la detección de anomalías, igual que lo puede estar uno basado en máquinas. No obstante, esta aproximación es minoritaria; aunque una intrusión generará probablemente comportamientos anormales (por ejemplo, un tráfico excesivo entre el sistema atacante y el atacado) susceptibles de ser detectados y eliminados, con demasiada frecuencia estos sistemas no detectarán la intrusión hasta que la misma se encuentre en un estado avanzado. Este problema hace que la mayor parte de IDS basados en red que existen actualmente funcionen siguiendo modelos de detección de usos indebidos.
Para finalizar este punto dedicado a los sistemas de detección de intrusos basados en red es necesario hablar de las honeynets. Se trata de un concepto muy parecido al de los honeypots, de los que ya hemos hablado, pero extendido ahora a redes completas: redes diseñadas para ser comprometidas, formadas por sistemas reales de todo tipo que, una vez penetrados, permiten capturar y analizar las acciones que está realizando el atacante para así poder aprender más sobre aspectos como sus técnicas o sus objetivos. Realmente, aunque la idea general sea común, existen dos grandes diferencias de diseño entre un tarro de miel y una red de miel: por un lado, esta última evidentemente es una red completa que alberga diferentes entornos de trabajo, no se trata de una única máquina; por otro, los sistemas dentro de esta red son sistemas reales, en el sentido de que no simulan ninguna vulnerabilidad, sino que ejecutan aplicaciones típicas (bases de datos, sistemas de desarrollo) similares a las que podemos encontrar en cualquier entorno de trabajo normal. El objetivo de una honeynet no es la decepción, sino principalmente conocer los movimientos de un pirata en entornos semireales, de forma que aspectos como sus vulnerabilidades o sus configuraciones incorrectas se puedan extrapolar a muchos de los sistemas que cualquier empresa posee en la actualidad; de esta forma podemos prevenir nuevos ataques exitosos contra entornos reales.
En el funcionamiento de una red de miel existen dos aspectos fundamentales y especialmente críticos, que son los que introducen la gran cantidad trabajo de administración extra que una honeynet implica para cualquier organización. Por un lado, tenemos el control del flujo de los datos, es vital para nuestra seguridad garantizar que una vez que un sistema dentro de la honeynet ha sido penetrado, este no se utilice como plataforma de salto para atacar otras máquinas, ni de nuestra organización ni de cualquier otra; la red de miel ha de permanecer perfectamente

42
controlada, y por supuesto aislada del resto de los segmentos de nuestra organización. En segundo lugar, otro aspecto básico es la captura de datos, el monitoroo de las actividades que un atacante lleva a cabo en la ho11ey11et. Recordemos que nuestro objetivo principal era conocer los movimientos de la comunidad pirata para poder extrapolarlos a sistemas reales, por lo que también es muy importante para el correcto funcionamiento de una honeynet una correcta recopilación de datos generados por el atacante. Además, estos datos recogidos nunca se han de mantener dentro del perímetro de la honeynet, ya que si fuera así cualquier pirata podría destruirlos con una probabilidad demasiado elevada.
El concepto de honeynet es relativamente nuevo dentro del mundo de la seguridad y, en concreto, de los sistemas de detección de intrusos. Las herramientas de seguridad ya no se conforman con detectar problemas conocidos, sino que tratan de anticiparse a nuevas vulnerabilidades que aún no se han publicado pero que están presentes en multitud de sistemas. Conocer cuanto antes cualquier exploit usado por los piratas es algo vital si queremos lograr este objetivo.
2.5 DETECCIÓN DE ANOMALÍAS
Desde que en 1980 James P. Anderson propusiera la detección de anomalías como un método válido para detectar intrusiones en sistemas informáticos, la línea de investigación más estudiada, pero no por ello la más extendida en entornos reales, es la denominada detección de anomalías. La idea es a priori muy interesante: estos modelos de detección conocen lo que es normal en nuestra sistema a lo largo del tiempo, desarrollando y actualizando conjuntos de patrones contra los que comparar los eventos que se producen en los sistemas. Si uno de esos eventos (por ejemplo, una trama procedente de una máquina desconocida) se sale del conjunto de normalidad, automáticamente se cataloga como sospechoso.
Los IDS basados en detección de anomalías se basan en la premisa de que cualquier ataque o intento de ataque implica un uso anormal de los sistemas. Pero, ¿cómo puede un sistema conocer lo que es y lo que no es normal en nuestro entorno de trabajo? Para conseguirlo, existen dos grandes aproximaciones: o es el sistema el que es capaz de aprenderlo por sí mismo (basándose por ejemplo en el comportamiento de los usuarios, de sus procesos o del tráfico de nuestra red) o bien se le especifica al sistema dicho comportamiento mediante un conjunto de reglas. La primera de estas aproximaciones utiliza básicamente métodos estadísticos (medias, varianzas), aunque también existen modelos en los que se aplican algoritmos de aprendizaje automático; la segunda aproximación consiste en especificar mediante un conjunto de reglas los perfiles de comportamiento habitual basándose en determinados parámetros de los sistemas ( con la dificultad añadida de decidir cuáles de esos parámetros que con mayor precisión delimitan los comportamientos intrusivos ).
En el primero de los casos (el basado en métodos estadísticos), el detector observa las actividades de los elementos del sistema y genera para cada uno de ellos un perfil que define su comportamiento. Dicho perfil es almacenado en el sistema y se actualiza con determinada

4J
frecuencia. El comportamiento del usuario en un determinado momento se guarda temporalmente en otro perfil y a intervalos regulares se compara con el almacenado previamente en busca de desviaciones que puedan indicar una anomalía.
Los tipos de datos o medidas que pueden ser útiles en la elaboración de estos perfiles
1. Intensidad de la actividad. Reflejan el índice de progreso de la actividad en el sistema, para lo cual recogen datos a intervalos muy pequeños, típicamente entre un minuto y una hora. Estas medidas detectan ráfagas de comportamiento (por ejemplo, una excesiva generación de peticiones de entrada/salida en un cierto intervalo) que en espacios de tiempo más amplios no podrían ser detectadas.
2. Numéricas. Se trata de medidas de la actividad cuyo resultado se puede representar en forma de valor numérico, como el número de archivos leídos por cierto usuario en una sesión o la cantidad de veces que ese usuario se ha equivocado al teclear su contraseña de acceso al sistema.
3. Categóricas. Las medidas categóricas son aquellas cuyo resultado es una categoría individual, y miden la frecuencia relativa o la distribución de una actividad determinada con respecto a otras actividades o categorías. Por ejemplo, cuál es la relación entre la frecuencia de acceso a un determinado directorio del sistema en comparación con la de acceso a otro.
4. Distribución de registros de auditoria. Esta medida analiza la distribución de las actividades generadas en un pasado reciente basándose en los /ogs generados por las mismas. Dicho análisis se realiza de forma ponderada, teniendo más peso las actividades más recientes, y es comparado con un perfil de actividades habituales previamente almacenado, de forma que permite detectar si en un pasado reciente se han generado eventos inusuales.
La segunda aproximación a la que antes hemos hecho referencia es la que consiste en indicar mediante un conjunto de reglas el comportamiento habitual del sistema, es denominada detección de anomalías basada en especificaciones, y fue propuesta y desarrollada inicialmente por Calvin Cheuk Wang Ko y otros investigadores de la Universidad de California en Davis, durante la segunda mitad de los noventa. La idea en la que se sustentan los sistemas de detección de anomalías basados en especificaciones es que se puede describir el comportamiento deseable y normal de cualquier programa cuya seguridad sea critica. Esta descripción se realiza en base a una especificación de seguridad mediante gramáticas y se considera una violación de la seguridad a las ejecuciones de dichos programas que quebranten su respectiva especificación.
Para ver más claramente el concepto de la detección de anomalías basada en especificaciones, podemos pensar en la ejecución de un programa que se puede considerar crítico por ser privilegiado: /bin/passwd. Si conseguimos diferenciar las diferentes ejecuciones de esta orden que se pueden considerar habituales (por ejemplo, cuando un usuario cambia su contraseña sin problemas, cuando se equivoca, cuando el sistema no le deja cambiarla por los motivos típicos),

44
podríamos especificar formalmente cada una de estas secuencias de operación. De esta forma, cada vez que un usuario invoque a /bin/passwd, el sistema de detección monitoreará las operaciones que esa llamada genere y considerará una intrusión a cualquiera que no sea habitual.
La idea de los sistemas de detección de intrusos basados en la detección de anomalías es realmente atractiva, no obstante, existen numerosos problemas a los que estos mecanismos tratan de hacer frente. En primer lugar podemos tener en cuenta las dificultades que existen a la hora de aprender o simplemente especificar lo habitual, el obtener un patrón de tráfico normal en una red no es sencillo, quizás establecer un conjunto de procesos habituales en una única máquina resulte menos complicado pero tampoco se trata de una tarea trivial. Además, conforme aumentan las dimensiones de los sistemas (redes con un gran número de máquinas interconectadas, equipos con miles de usuarios), éstos se hacen cada vez más aleatorios e impredecibles.
Otro gran problema de los sistemas basados en detección de anomalías radica en la política de aprendizaje que éstos sigan; si se trata de esquemas donde el aprendizaje es rápido, un intruso puede generar eventos para conseguir un modelo distorsionado de lo normal antes de que el responsable de los sistemas se percate de ello, de forma que el IDS no llegue a detectar un ataque porque lo considera algo habitual. Si por el contrario el aprendizaje es lento, el IDS considerará cualquier evento que se aleje en lo más mínimo de sus patrones como algo anómalo, generando un gran número de falsos positivos (falsas alarmas), que a la larga harán que los responsables de los sistemas ignoren cualquier información proveniente del IDS, con los evidentes riesgos que esto implica.
2.6 DETECCIÓN DE USOS INDEBIDOS
Dentro de la clasificación de los sistemas de detección de intrusos en base a su forma de actuar, la segunda gran familia de modelos es la formada por los basados en la detección de usos indebidos. Este esquema se basa en especificar de una forma más o menos formal las potenciales intrusiones que amenazan a un sistema y simplemente esperar a que alguna de ellas ocurra Para conseguirlo existen cuatro grandes aproximaciones: los sistemas expertos, los análisis de transición entre estados, las reglas de comparación y el emparejamiento de patrones, y la detección basada en modelos.
Los primeros sistemas de detección de usos indebidos se basaban en los sistemas expertos para realizar su trabajo, en ellos las intrusiones se codifican como reglas de la base de conocimiento del sistema experto, de la forma genérica if-then. Cada una de estas reglas puede detectar eventos únicos o secuencias de eventos que denotan una potencial intrusión y se basan en el análisis, generalmente en tiempo real, de los registros de auditoria proporcionados por cualquier sistema Unix.
La segunda implementación de los sistemas de detección de usos indebidos es la basada en los análisis de transición entre estados. Bajo este esquema, una intrusión se puede contemplar como

45
una secuencia de eventos que conducen al atacante desde un conjunto de estados inicial a un estado determinado, representando este último una violación consumada de nuestra seguridad. Cada uno de esos estados no es más que una imagen de diferentes parámetros del sistema en un momento determinado, siendo el estado inicial el inmediatamente posterior al inicio de la intrusión, y el último de ellos el resultante de la completitud del ataque. Si conseguimos identificar los estados intermedios entre ambos, seremos capaces de detener la intrusión antes de que se haga efectiva.
La tercera implementación es la basada en el uso de reglas de comparación y emparejamiento de patrones. En ella, el detector se basa en la premisa de que el sistema llega a un estado de riesgo cuando recibe como entrada el patrón de la intrusión, sin importar el estado en que se encuentre en ese momento. Dicho de otra forma, simplemente especificando patrones que denoten intentos de intrusión el sistema puede ser capaz de detectar los ataques que sufre, sin importar el estado inicial en que esté cuando se produzca dicha detección, lo cual suele representar una ventaja con respecto a otros modelos de los que hemos comentado.
Actualmente muchos de los sistemas de detección de intrusos más conocidos, como Snort y Rea/Secure, están basados en el emparejamiento de patrones. Utilizando una base de datos de patrones que denotan ataques, estos programas se dedican a examinar todo el tráfico que ven en su segmento de red y a comparar ciertas propiedades de cada trama observada con las registradas en su base de datos como potenciales ataques. Si alguna de las tramas empareja con un patrón sospechoso, automáticamente se genera una alarma en el registro del sistema.
Por último, los sistemas de detección de intrusos basados en modelos consisten de una aproximación conceptualmente muy similar a la basada en la transición entre estados, en el sentido que contempla los ataques como un conjunto de estados y objetivos, pero ahora se representa a los mismos como escenarios en lugar de hacerlo como transiciones entre estados. En este caso se combina la detección de usos indebidos con una deducción o un razonamiento que concluye la existencia o inexistencia de una intrusión. Para ello, el sistema utiliza una base de datos de escenarios de ataques, cada uno de los cuales está formado por una secuencia de eventos que conforman el ataque. En cada momento existe un subconjunto de esos escenarios, denominado de escenarios activos, que representa los ataques que se pueden estar presentando en el entorno. Un proceso denominado anticipador analiza los registros de auditoria generados por el sistema y obtiene los eventos a verificar en dichos registros para determinar si la intrusión se está produciendo. El anticipador también actualiza constantemente el conjunto de escenarios activos, de manera que este estará siempre formado por los escenarios que representan ataques posibles en un determinado momento y no por la base de datos completa.
Los IDS basados en la detección de usos indebidos son en principio más robustos que los basados en la detección de anomalías. Al conocer la forma de los ataques. es teóricamente extraño que generen falsos positivos, sin embargo la generación éstos presenta un problema a la hora de implementar cualquier sistema de detección. No obstante, en este mismo hecho radica su debilidad, sólo son capaces de detectar lo que conocen, de forma que si alguien nos lanza un ataque desconocido para el IDS, éste no nos notificará ningún problema. Es algo similar a los programas antivirus, cada cierto tiempo es conveniente actualizar la versión del antivirus usado,

46
también es conveniente mantener al día la base de datos de los IDS basados en detección de usos indebidos. Aún así, seremos vulnerables a nuevos ataques.
Otro grave problema de los IDS basados en la detección de usos indebidos es la incapacidad para detectar patrones de ataque convenientemente camuflados. Volviendo al ejemplo de los antivirus, pensemos en un antivirus que base su funcionamiento en la búsqueda de cadenas virales, lo que básicamente hará ese programa será buscar cadenas de código hexadecimal pertenecientes a determinados virus en cada uno de los archivos a analizar, de forma que si encuentra alguna de esas cadenas el software asumirá que el archivo está contaminado. Y de la misma forma que un virus puede ocultar su presencia simplemente cifrando esas cadenas, un atacante puede evitar al sistema de detección de intrusos sin más que insertar espacios en blanco o rotaciones de bits en ciertos patrones del ataque.
2.7 SNORT
Snort es un snif.fer capaz de actuar como sistema de detección de intrusos en redes de tráfico moderado. Su facilidad de configuración, su adaptabilidad, sus requerimientos mínimos (funciona en diferentes sabores de Unix) y sobre todo su precio (se trata de un software completamente gratuito que podemos descargar desde su página oficial http://www.snort.org/) lo convierten en una óptima elección en multitud de entornos, frente a otros sistemas como NFR (Network F1ight Recorder) o !SS Rea/Secure que, aunque quizás sean más potentes, son también mucho más pesados e infinitamente más caros.
Para instalar un sistema de detección de intrusos basado en Snort en primer lugar necesitamos evidentemente este programa, que podemos descargar desde su página Web. Además, para compilarlo correctamente es necesario disponer de las librerías libpcap, una interfaz para tratamiento de paquetes de red desde espacio de usuario y es recomendable también, aunque no obligatorio, instalar Libnet, que es una librería para la construcción y el manejo de paquetes de red. Con este software correctamente instalado en nuestro sistema, la compilación de Snort es trivial.
Snort está clasificado como un sistema basado en red y que funciona mediante detección de usos indebidos. Estos usos indebidos se reflejan en una base de datos formada por patrones de ataques. Dicha base de datos se puede descargar también desde la propia página Web de Snort, donde además se pueden generar bases de patrones a medida de diferentes entornos (por ejemplo ataques contra servidores Web, intentos de negaciones de servicio o exploits). El archivo que utilicemos en nuestro entorno será la base para el correcto funcionamiento de nuestro sistema de detección de intrusos.
Una vez hemos compilado e instalado correctamente el programa llega el momento de ponerlo en funcionamiento y es aquí donde se produce, al menos inicialmente, uno de los errores más graves en la detección de intrusos. Por lógica, uno tiende a pensar que el sensor proporcionará mejores

47
resultados cuantos más patrones de ataques contenga en su base de datos, sin embargo esta idea es errónea. En primer lugar, es muy probable que no todos los ataques que Snorl es capaz de detectar sean susceptibles de producirse en el segmento de red monitoreado; si situamos el sensor en una zona desmilitarizada donde únicamente ofrecemos servicio de Web, ¿qué interés tiene tratar de detectar ataques contra DNS? Evidentemente, cuanta más azúcar más dulce, pero si el sensor ha de analizar todo el tráfico, puede ocurrir que mientras trata de decidir si un paquete entre dos máquinas protegidas se adapta a un patrón estamos dejando pasar tramas provenientes del exterior que realmente representan ataques. Hemos de tener presente que la herramienta no detendrá el tráfico que no sea capaz de analizar para hacerlo más tarde, sino que simplemente lo dejará pasar. Así, debemos introducir en la base de patrones de ataques los justos para detectar actividades sospechosas contra nuestra red.
En segundo lugar, pero no menos importante, es necesario estudiar los patrones de tráfico que circulan por el segmento donde el sensor escucha para detectar falsos positivos y para reconfigurar la base de datos o para eliminar los patrones que generan esas falsas alarmas. Si un patrón nos genera un número considerable de falsos positivos, debemos planteamos su eliminación Esto es especialmente crítico si lanzamos respuestas automáticas contra las direcciones atacantes deteniendo todo su tráfico en nuestro cortafuegos, podemos llegar al extremo de detener a simples visitantes de nuestras páginas Web simplemente porque han generado falsos positivos. En un entorno de alta seguridad quizás vale la pena detener muchas acciones no dañinas con tal de bloquear también algunos ataques, aunque constituiría una negación de servicio en toda regla contra los usuarios que hacen uso legítimo de nuestros sistemas.
En resumen, hemos de adaptar a nuestro entorno de trabajo, de una forma muy fina, la base de datos de patrones de posibles ataques. Vale la pena invertir el tiempo que sea necesario en esta parte de la implementación ya que eso nos ahorrará después muchos análisis de falsas alarmas e incluso uno que otro susto.
2.7.1 FORMAS DE USO
Como ya se ha mencionado, Snort tiene muchas características de trabajo que lo hacen poderoso: espionaje de paquetes (sniffing), registro de paquetes (pac/ret logger) y detección de intrusos.
La forma más sencilla para empezar a conocer los modos de trabajo y las opciones de Snort es a través del siguiente comando:
[user@localhost user]t snort -?
-*> Snort! <*-
Version 1.9.0 (Build 209)
By Martin Roesch ([email protected],www.snort.org)
USAGE: snort [-options] <filter options>

48
,,pt1ons:
-.::\ Set alert mode: fast, full, console, or none (alert file alerts only)
-b Log packets in tcpdurnp format (much faster')
-e <rules> Use Rules File <rules>
-e Print out payloads with character data only (no hex)
-d Dump the Application Layer
-e Display the second layer header info
-E Log alert messages to NT Eventlog. (Win32 only)
-f Turn off fflush() calls after binary log writes
-F <bpf> Read BPF filters from file <bpf>
-h <hn> Home network = <hn>
-i <if> Listen on interface <if>
-I Add Interface name to alert output
-k <mode> Checksum mode (all,noip,notcp,noudp,noicmp,none)
-1 <ld> Log to directory <ld>
-L <file> Log to this tcpdump file
-n <cnt> Exit after receiving <cnt> packets
-N Turn off logging (alerts still work)
-o Change the rule testing order to PasslAlertlLog
-o Obfuscate the logged IP addresses
-p Disable promiscuous mode sniffing
-P <snap> Set explicit snaplen of packet (default: 1514)
-q Quiet. Don't show banner and status report
-r <tf> Read and process tcpdump file <tf>
-R <id> Include 'id' in snort intf<id>.pid file name
-s Log alert messages to syslog
-S <n=v> Set rules file variable n equal to value v
-T Test and report on the current Snort configuration
-U Use UTC for timestamps
-v Be verbose
-V Show version number
-W Lists available interfaces. (Win32 only)
-w Dump 802.11 management and control frames
-X Dump the raw packet data starting at the link layer
-y Include year in timestamp in the alert and log files
-z Set assurance mode, match on established sesions (for TCP)
-? Show this information
<Filter Options> are standard BPF options, as seen in TCPDump
El comando anterior nos presenta todas las opciones con las que es posible trabajar. Todas estas opciones están relacionadas unas con otras. Sin embargo, es más sencillo poner el espionaje y registro de paquetes en una misma categoría ya que provee la misma funcionalidad. El formato genérico para este modo es:

[user@localhost user]# snort -v
Running 1n packet dwnp mode
Log directory = /var/log/snort
Initializing Network Interface ethO
--== Initializing Snort ==-Initializing Output Plugins!
Decoding Ethernet on interface ethO
Initialization Complete
-*> Snort! <*-
Version 1.9.0 (Build 209)
By Martin Roesch ([email protected],www.snort.org)
05/21-11:00:28.593943 ARP who-has 192.168.2.92 tell 192.168.2.60
05/21-11:00:28.594419 ARP who-has 192.168.2.8 tell 192.168.2.60
05/21-11:00:28.594544 ARP who-has 192.168.2.93 tell 192.168.2.60
05/21-11:00:30.467265 192.168.2.5:1025 -> 192.168.2.1:139
TCP TTL:128 TOS:OxO ID:16685 IpLen:20 DgmLen:104 DF
***AP*** Seq: Ox6B703 Ack: Ox2266AOC Win: Ox2238 TcpLen: 20
=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=
05/21-11:00:30.467731 192.168.2.1:139 -> 192.168.2.5:1025
TCP TTL:128 TOS:OxO ID:47513 IpLen:20 DgrnLen:1500 DF
2. 7.1.1 Modo sniffer
49
Con esta opcmn -v m1c1amos Snort visualizando en pantalla las cabeceras de los paquetes TCP/IP, es decir, en modo sniffer. Esta opción es el modo verbouse y mostrará las cabeceras IP, TCP, UDP e ICMP.
Si queremos, además, visualizar los campos de datos que pasan por la interfaz de red, añadiremos -d.
[user@localhost user]# snort -vd
Running in packet dump mode
Log directory = /var/log/snort
Initializing Network Interface ethO

50
=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=
05/21-11:06:18.943887 192.168.4.5:3890 -> 192.168.4.15:8080
TCP TTL:128 TOS:OxO ID:33216 IpLen:20 OgmLen: 40 OF***A•••• Seq: OxE3A50016 Ack:
Ox8B3ClE40 Win: OxFAFO TcpLen: 20
=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=
05/21-11:06:18.962018 192.168.4.5:3890 -> 192.168.4.15:8080
TCP TTL:128 TOS:OxO I0:33217 IpLen:20 OgmLen:681 OF
***AP••• Seq: OxE3A50016 Ack: Ox883ClE40 Win: OxFAFO TcpLen: 20
47 45 54 20 68 74 74 70 3A 2F 2F 77 77 77 2E 6F GET http://www.x
60 65 6C 65 74 65 2E 63 6F 60 2E 62 72 2F 73 75 xxxx.corn.br/xx
70 65 72 6F 6D 65 6C 65 74 65 2F 64 6F 77 6E 6C xxxxxxx/downl
6F 61 64 73 2F 64 65 66 61 75 6C 74 2E 61 73 70 oads/default.asp
20 48 54 54 50 2F 31 2E 30 00 OA 55 73 65 72 20 H'.I'TP/1. O .. U ser-
41 67 65 6E 74 3A 20 40 6F 7A 69 6C 6C 61 2F 34 Agent: Mozilla/4
2E 30 20 28 63 6F 60 70 61 74 69 62 6C 65 38 20 .o (compatible;
40 53 49 45 20 36 2E 30 38 20 57 69 6E 64 6F 77 MSIE 6.0; Window
73 20 4E 54 20 35 2E 30 29 20 4F 70 65 72 61 20 s NT 5. O) Opera
37 2E 31 31 20 20 58 65 6E 50 00 OA 48 6F 73 74 7.11 [en] .. Host
3A 20 77 77 77 2E 6F 60 65 6C 65 74 65 2E 63 6F : www.xxxxx.co
60 2E 62 72 OD OA 41 63 63 65 70 74 3A 20 74 65 m.br .. Accept: te
78 74 2F 68 74 60 6C 2C 20 69 60 61 67 65 2F 70 xt/htrnl, irnage/p
6E 67 2C 20 69 60 61 67 65 2F 6A 70 65 67 2C 20 ng, irnage/jpeg,
69 60 61 67 65 2F 67 69 66 2C 20 69 60 61 67 65 irnage/gif, irnage
2F 78 20 78 62 69 74 60 61 70 2C 20 2A 2F 2A 38 /x-xbitrnap, • /*;
71 30 30 2E 31 OD OA 41 63 63 65 70 74 20 4C 61 q=0.1 .. Accept-La
Añadiendo la opción -e, Snort nos mostrará información más detallada al desplegar también las cabeceras a nivel de enlace.
2.7.1.2 Modo Registro de paquetes
Con estas opciones, y dependiendo del tráfico en nuestra red, veremos gran cantidad de información pasar por nuestra pantalla, con lo cual sería interesante registrar y guardar estos datos a disco para su posterior estudio. Entraríamos entonces en Snort en el modo de registro de paquetes.

51
[user@localhost user]# snort -dev -1 /var/log/snort
La opción -1 indica a snort que debe guardar los logs en un directorio determinado, en este caso /var/log/snort. Dentro de esta carpeta se creará una estructura de directorios donde se archivarán los registros. En este modo, además podemos disponer de otras opciones como:
• -h Indicar la IP de la red a registrar
[user@localhost user]# snort -vde -1 ./log -h 192.168.4.0/24
Running in packet logging rnode
Log directory = ./log
• -b Formato de los logs sea en modo binario, es decir, el modo que entiende TCPDump, para estudiar más a fondo con los potentes filtros de estos programas los registros de Snort. La salida del logs en el caso de la opción de salida binaria ya no será una estructura de directorios, si no, un sólo archivo.
[user@localhost user]# snort -1 ./log -b
Running in packet logging rnode
Log directory = ./log
Algunas de las ventajas de utiliz.ar esta opción son: no hará falta indicarle IP alguna de nuestra red (-h), guardará todo en un mismo archivo y recogerá datos de toda nuestra red y tampoco serán necesarias las opciones -de ni la opción -v. Para leer el archivo binario generado es necesario introducir la opción -rnombrearchivo.log.
Otra opción a toma en cuenta es -i para indicar a :mort la interfaz de red usar en el caso de que tengamos dos o más.
[user@localhost user]# snort -vde -i ethO
2.7.1.3 Modo NIDS.
El modo detección de intrusos de red se activa añadiendo a la línea de comandos de Snort la opción -e snort. conf.
[user@localhost user]t snort -dev -1 ./log -h 192.168.4.0/24 -e .. /etc/snort.conf
En el archivo snort.conf, se guarda toda la configuración de: • Las reglas • Preprocesadores • Otras configuraciones necesarias para el funcionamiento en modo NIDS

Con la opción -D indicará a .mor/ que corra como un servicio.
# snort -dev -1 ./log -h 192.168.4.0/24 -e .. /etc/snort.conf -D
Alertas generadas
Snort creará, a parte de la estructura de directorios, un archivo alert.id\· donde almacenará las alertas generadas.
Snort dispone de siete modos de alertas en la línea de ordenes: completo, rápido, socket, syslog, SMB, consola y ninguna.
• Fast. El modo alerta rápida nos devolverá información sobre: tiempo, mensaJe de la alerta, clasificación, prioridad de la alerta, IP y puerto de origen y destino.
[user@localhost user]# snort -A fast -dev -1 ./log -h 192.168.4.0/24 -e
.. /etc/snort.conf
09/19-19:06:37.421286 [**] [1:620:2] SCAN Proxy (8080) attempt [**]
[Classification: Attempted Information Leak] [Priority: 2] ...
.. . (TCP) 192.168.4.3:1382 -> 192.168.4.15:8080
• Full. El modo de alerta completa nos devolverá información sobre: tiempo, mensaje de la alerta, clasificación, prioridad de la alerta, IP y puerto de origen/destino, además de información completa de las cabeceras de los paquetes registrados.
[user@localhost user]# snort -A full -dev -1 ./log -h 192.168.4.0/24 -e
.. /etc/snort.conf
[**] [1:620:2] SCAN Proxy (8080) attempt ["'"*]
[Classification: Attempted Information Leak] [Priority: 2]
09/19-14:53:38.481065 192.168.4.3:3159 -> 192.168.4.15:8080
TCP TTL:128 TOS:OxO ID:39918 IpLen:20 DgmLen:48 DF
******S* Seq: OxE87CBBAD Ack: OxO Win: Ox4000 TcpLen: 28
TCP Options (4) => MSS: 1456 NOP NOP SackOK
Información de la cabecera del paquete:
TCP TTL:128 TOS:OxO ID:39918 IpLen:20 DgmLen:48 DF
******S* Seq: OxE87CBBAD Ack: OxO Win: Ox4000 TcpLen: 28

53
TCP Options (4) => MSS: 145G NOP NOP SackOK
• Socket. Snort manda las alertas a través de un canal para que las escuche otra aplicación. La opción usada es:
# snort -A unsock -e snort.conf
• Console. En este modo de alerta el programa imprime las alarmas en pantalla.
[user@localhost user]# snort -A console -dev -1 ./log -h 192.168.4.0/24 -e
.. /etc/snort.conf
• None. Se desactivan las alarmas.
[user@localhost user]# snort -A none -e snort.conf
• SMB. Permite a Snort realizar llamadas al cliente de SMB 15 y enviar mensajes de alerta a hosts Windows (WinPopUp). Se ha de tener presente que para activar este modo de aJerta se debe compilar Snort con el conmutador de habilitar alertas SMB (enable -smbalerts}.
Además, para usar esta caracteristica enviando un WinPopUp a un sistema Windows, habrá que añadir a la línea de comandos de snort: -M woRKSTATIONs
• Syslog. El programa Snort envía las alarmas al syslog16.
[user@localhost user]# snort -A console -dev -1 ./log -h 192.168.4.0/24 -e
.. /etc/snort.conf -
• Eventlog. Funcionando en este modo se registra las alertas para visualizarse a través del visor de sucesos de un sistema windows. Esta opción se activará mediante -E y es sólo para Win32.
2.7.2 REGLAS
Las reglas Snort las podemos dividir en dos secciones lógicas: cabecera de la regla y opciones.
La cabecera contiene la acción de la regla en sí, los protocolos involucrados, las direcciones IP, las máscaras de red, los números de puerto origen y destino y el destino del paquete o la dirección de la operación. La sección de opciones contiene los mensajes y la información necesaria para la decisión a tomar por parte de la alerta en forma de opciones.
15 Cliente de Samba en Linux para compartir archivos con servidores con plataforma Windows. 16 Manejador de logs del sistema.

54
Para lograr entender la forma en la que las reglas están escritas y, sobretodo, su uso, veamos un ejemplo breve. La siguiente regla está escrita detectar y alertar una exploración de puertos con la utilidad nmap:
alert tcp $EXTERNAL_NET any -> $HOME_NET any (msg:"Exploración ping con
nmap";flags:A;ack:O; reference:arachnids,28;classtype:attempted-recon; sid:628; rev:l;)
Separando la regla, la información de la cabecera es la siguiente: • Acción de la regla: alert
• Protocolo: tcp
• Dirección IP origen: $EXTERNAL _ NET (toda la red) • Puerto IP origen: any ( cualquiera) • Dirección IP destino: $HOME_NET (toda nuestra red) • Puerto IP destino: any (cualquiera) • Dirección de la operación: -> (puede ser->,<-,<>)
La información de la sección de opciones es: • Mensaje: msg
• Opciones: flags:A; ack: O; reference:arachnids, 28;classtype: attempted-recon;
sid:628; rev:l;
El significado de cada una de las opciones es el siguiente:
',- flags:A Establece el contenido de las banderas TCP, en este caso ACK (puede tener varios valores y operadores) .
.,. Ack: o Caso particular para valor ACK=O, es el valor que pone nmap para la exploración a través de ping 7 con TCP.
',- reference: arachnids, 28 Proporciona información adicional en caso de que ya exista una referencia externa.
>-' classtype:attempted-recon Categoria de la alerta según niveles predefinidos y
prioridades.
',- sid: 628 Número de identificación único para esta regla.
~ rev: 1 Identificación de la revisión o versión de la regla.
Otro ejemplo que vale la pena revisar es el siguiente:
17 Comando para conocer si cierta máquina está en línea.

55
alert tcp any any --> 192.168.1.0/24 111 (content:"100 01 86 aSI"; rnsg: "mountd
access";)
Esta regla detecta los intentos de acceso al demonio de administración mo11111d de Unix, el cual tiene diversos problemas de desbordamiento de memoria intermedia que permiten a un atacante remoto obtener privilegios de administrador en los sistemas vulnerables.
Esta regla tiene dos puntos interesantes: el primero nos demuestra que el orden de la sección opciones es indiferente ya que primero están las opciones y después el mensaje. El segundo punto es referente a la opción content, ésta es una de las opciones más importantes ya que nos permite la búsqueda de contenidos dentro del campo datos del paquete IP.
Como podemos apreciar en las dos reglas vistas, la escritura de las reglas que Snort usa para detectar los ataques no es nada sencillo. En este apartado únicamente hemos visto ejemplos sencillos que nos ayudan a tener una idea de cómo están escritas las reglas y cómo deben ser leídas, sin embargo, la creación de las mismas requiere de un amplio conocimiento del ataque que se busca detectar y de todas las opciones que Snort nos presenta para su redacción.

56
3 IMPLEMENTACIÓN
Una vez que hemos hecho un breve repaso de la teoria acerca de cortafuegos y sistemas de detección de intrusos, conocemos las ventajas y desventajas que estas herramientas presentan. Cada una de éstas llevan a cabo una tarea específica pero cuyos alcances están limitados, la función de los cortafuegos es de prevención mientras que la función de los IDS es de detección; la intervención de un humano para interpretar y conectar la infonnación de ambos programas es necesaria para mantener nuestra red protegida ante los diversos intentos de violación de la seguridad.
La comunicación de dos herramientas de este tipo, como iptables y Snort, permitirá, entre otras cosas, que estos programas trabajen virtualmente unidos simulando un sistema de respuesta y/o recuperación ante un ataque.
El Grupo de Trabajo en Detección de Intrusiones (IDWG, lntrusion Detection Working Group) se dedica a trabajar en la definición de formatos de datos y procedimientos de intercambio de información referente a la detección de intrusiones y sistemas de respuesta. Uno de los objetivos principales de esta organización es crear un estándar para la representación de los datos emitidos por los diversos detectores de intrusos que se encuentran en el mercado.
Con este objetivo en mente propusieron un modelo de datos para llamado Formato de Intercambio de Mensajes de Detección de Intrusiones (IDMEF por sus siglas en inglés), el cual también proponen sea implementado en XML.
La implementación de esta propuesta tiene como resultado que el detector de intrusos genere las alertas con el fonnato planteado lo que facilita la lectura y extracción de la infonnación necesaria para tomar medidas ante un ataque. Es decir, una vez generada una alerta, un agente programado para leer las alertas generadas con el formato IDMEF XML tomará datos del ataque, como la dirección IP del supuesto atacante, y configurará el cortafuegos para prohibir el ataque proveniente de dicha dirección.

57
3.1 ARQUITECTURA
Antes de empezar a implementar un esquema de comunicación entre estas herramientas es necesario definir la arquitectura que vamos a usar. Sabemos que el cortafuegos preferentemente va ubicado en el host bastión, pero la pregunta es: ¿dónde colocar el IDS? Una actitud paranoica por nuestra parte nos podría llevar a instalar un IDS en cada computadora o en cada tramo de red. Lo lógico es instalar el IDS en un dispositivo por donde pase todo el tráfico de red que nos interese. Ese punto no es otro que el host bastión, es decir, en donde se encuentra el cortafuegos corporativo. Por tanto, es aquí donde vamos a implementar el primer esquema de detección de intrusos y respuesta automática ante ataques, esta respuesta será habitualmente el bloqueo de la dirección atacante en el propio cortafuegos.
Ahora que hemos decidido en qué computadora implementaremos el detector, una cuestión típica es si debemos emplazarlo detrás o delante del cortafuegos que protege a nuestra red. En principio, si dejamos que el sensor analice el tráfico antes de que sea filtrado en el cortafuegos, estaremos en disposición de detectar todos los ataques reales que se lanzan contra nuestra red, sin ningún tipo de filtrado que pueda detener las actividades de un pirata. No obstante, probablemente lo que más nos interesará no es detectar todos estos intentos de ataque (aunque nunca está de más permanecer informado en este sentido), sino detectar el tráfico sospechoso que atraviesa nuestro cortafuegos y que puede poner en riesgo a nuestros servidores. Por tanto, es recomendable ubicar el sensor de nuestro sistema de detección de intrusos en la zona protegida ya que de cualquier forma, los potenciales ataques que no lleguen al mismo quedarán registrados en los logs del cortafuegos e incluso serán neutralizados en el mismo.
Con las herramientas correctamente instaladas y configuradas ya estamos listos para poner en funcionamiento el sistema. Seguramente hasta ahora no hemos tenido muchos problemas, no obstante, a partir de ahora las cosas se empiezan a complicar un poco ya que comienza la segunda parte, la del tratamiento de la información que nuestro detector de intrusos nos va a proporcionar. Y es que desde este momento el sistema de detección va a empezar a funcionar y a generar logs con notificaciones de posibles ataques o cuanto menos de actividades sospechosas. Es momento de decidir puntos como qué hacer ante la generación de un evento en el mismo y cómo procesar y representar la información recibida de manera que sea útil y entendible tanto por un humano como por otras herramientas como un cortafuegos.
3.2 MODELO DE DATOS IDMEF
El formato de intercambio de mensajes de detección de intrusiones (IDMEF) se proyecta para ser un formato estándar de datos que los sistemas automatizados de la detección de intrusiones pueden utilizar para reportar alarmas sobre eventos sospechosos. El desarrollo de este formato estándar permitirá interoperabilidad entre sistemas comerciales, de software libre y de

58
investigación, permitiendo a los usuarios mezclar y comparar el despliegue de estos sistemas según sus puntos fuertes y débiles para poder obtener una implementación óptima.
El modelo de datos IDMEF es una representación orientada a objetos de los datos de las alertas enviados a los administradores por los sistemas de detección de intrusos Este modelo fue diseñado para proveer una representación estándar de las alertas de manera no ambigua y para permitir la relación entre alertas simples y complejas.
El IDWG propone una implementación del modelo con el lenguaje XML, un lenguaje para describir otros lenguajes, que provee de una aplicación para definir etiquetas propias. XML permite la definición de lenguajes completos con el uso de etiquetas (parecidas a las de HTML) personalizadas para diferentes tipos de documentos y diferentes aplicaciones. Difiere de HTML, en que éste cuenta con un conjunto fijo de identificadores con uso en particular y que debe ser adaptado para los fines requeridos.
La razón principal para la implementación del modelo IDMEF en XML es muy sencilla, la flexibilidad que aporta XML lo hace una buena elección para los fines requeridos: un documento que pueda variar de acuerdo a las condiciones presentadas, dependiendo de varios factores tales como el tipo de ataque o la fuente del ataque. Otras razones más específicas son:
• XML permite el desarrollo de un lenguaje personalizado específicamente con el propósito de describir alertas de detección de intrusos. Además define un método estándar para la extensión del lenguaje, ya sea para revisiones futuras o uso de alguna compañía.
• Las herramientas de software de procesamiento de documentos XML son ampliamente disponibles, tanto de forma comercial como gratuita. Numerosas herramientas y APis para la validación de documentos XML se encuentran disponibles en una gran variedad de lenguajes, entre los que podemos mencionar C, C++, Tcl, Peri, Python y Lisp.
• XML cumple con los requerimientos de IDMEF con respecto a que el formato del mensaje debe soportar filtrado y agregación. La integración de XML con XSL, un lenguaje de estilos, permite que los mensajes sean combinados, descartados y/o reordenados.
• Proyectos de XML en desarrollo proveerán extensiones orientadas a objetos, soporte a bases de datos y otras características útiles. El IDMEF al ser implementado en XML automáticamente hereda todas estas características.
• XML es gratuito y su uso es libre.
La relación entre los principales componentes del modelo de datos se muestra en la siguiente figura. La primera clase para todos los mensajes IDMEF es IDMEF-message~ cada tipo de mensaje es una subclase de esta. Existen dos tipos de mensajes definidos: Alertas y Corazonadas. Dentro de cada mensaje existen subclases utilizadas para entregar información detallada sobre el contenido del mensaje.

59
Es importante recalcar que los modelos de datos no especifican como una alerta debe de ser clasificada o identificada. Por ejemplo, un ataque de exploración de puertos puede ser identificado por un analizador como un ataque contra múltiples objetivos, mientras que otro analizador puede identificarlo como múltiples ataques desde una misma fuente. Aún así, cuando el analizador ha determinado que tipo de alerta mandar, el modelo de datos decide como la será formateada la alerta.
+---------------+ I IDMEF-Message I +---------------+
/ \ 1
+----------------------------+-------+
+-------+ +----------------+ +-----------+ +----------------+ I Alert 1<>-1 Analyzer I Heartbeat l<>-1 Analyzer +-------+ 1
1
1
1
1
1
1
1
1
1
I 1
1
1
1
1
1
1
1
1
1
1
+----------------+ +----------------+
+-----------+ +----------------+ 1 1 +----------------+
<>-1 CreateTime 1 1 <>-1 CreateTime +----------------+ +----------------+
1 1 +----------------+ 1 1 +----------------+
<>-1 DetectTime I l<>-1 AdditionalData I +----------------+ +----------------+
<>-1 AnalyzerTime I +----------------+
+-----------+
+--------+ +----------+ <>-1 Source l<>-1 Node
+--------+ +----------+ +----------+
l<>-1 User 1 +----------+ 1 +----------+ 1<>-1 Process 1 +----------+ 1 +----------+ l<>-1 Service I
+--------+ +----------+ +--------+ +----------+
+----------------+
1
1
1
l<>-1 Target l<>-1 Node
1
I
+-------+
+--------+ +----------+ 1 1 +----------+ I l<>-1 User I 1 1 +----------+ I I +----------+ I l<>-1 Process 1 1 +----------+ 1 1 +--------- + I l<>-1 Service +----------------+ 1 1 +----------+ +----1 Classification I 1 1 +----------+ 1 +----------------+ I l<>-1 FileList 1 1 +----------------+ +--------+ +----------+ 1 +--1 Assessment I
<>----------------------------+ 1 +----------------+ <>------------------------------+ +----------------+ <>---------------------------------1 AdditionalData I
+----------------+

60
3.2.t LA CLASE IDMEF-MESSAGE
Todos los mensajes son parte de la clase IDMl·.:F-message; esto es la primera clase del modelo de datos IDMEF, así como del IDMEF DTD. Tenemos dos tipos (subclases) de los mensajes IDMEF: las alertas y las corazonadas.
Debido a que los documentos DTD no soportan la subclasificación, la relación entre los IDMEFmessage y las subclases Alerta y Corazonada es representada con una relación agregada. Esta es declarada en el IDMEF DTD como sigue:
< ! ENTITY 9, attlist. idmef
version
">
<!ELEMENT IDMEF-Message
(Alert I Heartbeat)*
) >
<!ATTLIST IDMEF-Message
%attlist.idmef;
>
CDATA
La clase de IDMEF-message tiene un solo atributo:
#FIXED '1. o'
• Version. La versión del IDMEF-message. La versión actual es la número 1.0.
3.2.2 LA CLASE ALERT
Generalmente cada vez que el analizador detecta un evento para el que ha sido configurado a encontrar, este manda un mensaje de alerta a su administrador, dependiendo del analizador la alerta puede corresponder a un solo evento o a múltiples eventos. Las alertas suceden asincrónicamente en respuesta a eventos externo.
Las clases que componen una alerta son:
• Analyzer. Exactamente uno. Información de identificación para el analizador que genera la alerta.
• Creation time. Exactamente uno. El tiempo en que la alerta fue creada. De las tres veces que puedan ser provistas con una alerta, esta es la única que es requerida.
• DetectTime. Cero o uno. El tiempo que un evento que generó una alerta fue detectado. En este caso si hay más de un evento, el tiempo en que el primer evento fue detectado. En algunas circunstancias este puede no ser igual al tiempo de creación.
• Analyzertime. Cero o uno. El tiempo corriente en el analizador.

01
• Source. Cero o más. La fuente del evento que generó la alerta.
• lárKet Cero o más. El objetivo del evento que generó la alerta.
• Classification. Uno o más. El nombre de la alerta u otra información que permita al administrador determinar qué es.
• Assesment. Cero o uno. Información sobre el impacto del acontecimiento, de las acciones tomadas por el analizador en respuesta a él y de la confianza del analizador en su evaluación.
• Additional data. Cero o más. Información incluida por el analizador que no cabe en el modelo de los datos. Ésta puede ser un pedazo atómico de datos o una cantidad grande de datos proporcionados a través de una extensión al IDMEF.
+--------------- + Alert
+--------------- + +------------------+ STRING ident <>----------1 Analyzer
+------------------+ +------------------+
<>----------1 CreateTime I +------------------+
0 .. 1 +------------------+ <>----------1 DetectTime I
+------------------+ 0 .. 1 +------------------+
<>----------/ AnalyzerTime / +------------------+
o .. *+------------------+ <>----------1 Source I
+------------------+ o .. *+------------------+
<>----------1 Target +------------------+
l .. *+------------------+ <>----------1 Classification
+------------------+ 0 .. 1 +------------------+
<>----------1 Assessment I +------------------+
o .. *+------------------+ <>----------/ AdditionalData
+------------------+ +---------------+
I \ 1 +----+------------+-------------+
+-------------------+ +-------------------+ ToolAlert I CorrelationAlert I
+-------------------+ +-------------------+
+-------------------+ I OverflowAlert I +-------------------+

62
La relación inherente entre la alerta y las subclases Too/Alerl, Corr<'la1io11Aler1 y Ove1:flowA/er1 se ha substituido por una relación agregada. La alerta se representa en el DTD de XML como sigue:
< 1 ELEMENT Alert
) >
Analyzer, CreateTirne, DetectTirne?, AnalyzerTirne?, Source*,
Target *, Classification+, Assessrnent?, (ToolAlert
OVerflowAlert I CorrelationAlert)?, AdditionalData*
< !ATTLIST Alert
ident CDATA 'o'
>
La clase de alerta tiene un atributo: • ldent. Opcional. Un identificador único para la alerta
3.2.2.1 La Clase ToolAlert
La clase Too/Alert lleva la información adicional relacionada con el uso de las herramientas de ataque o de programas maliciosos como los caballos de Troya. Se puede utilizar por el analizador cuando puede identificar estas herramientas. Su función es agrupar unas o más alertas enviadas juntas anteriormente para poder decir "estas alertas son el resultado de alguien que utiliza esta herramienta."
+------------------+ Alert
+------------------+ I \
1 +------------------+
ToolAlert +------------------+ +-------------------+
1 <>----------1 narne 1 +-------------------+ 1 0 .. 1 +-------------------+ 1<>----------1 comrnand I 1 +-------------------+ I l .. *+-------------------+ l<>----------1 alertident I 1 +-------------------+ I I STRING analyzerid I 1 +-------------------+
+------------------+
La clase de Too/A/ert se compone de tres clases:
• Name. Exactamente uno. STRING. La razón de agrupar las alertas juntas, por ejemplo, el nombre de una herramienta partiailar.

• ( 'ommand Cero o uno. STRING El comando o la operación que la herramienta fue pedida para realizar, por ejemplo, un HackOriflce ping
• Alerlidenl Uno o más. STRING. La lista de los identificadores de alerta que se relacionan con esta alerta. Ya que los identificadores de alertas son únicos a través de las alertas enviadas por un solo analizador, la cualidad opcional del analyzerid de a/ertident se debe utilizar para identificar el analizador del cual la alerta particular vino. Si el analyzerid no se proporciona, la alerta se asume para haber venido del mismo analizador que está enviando el Too/A/ert.
Esto se representa en el DTD de XML como sigue:
<!ELEMENT ToolAlert
name, cormnand?, alertident+
) >
<!ELEMENT alertident
<!ATTLIST alertident
(#PCDATA) >
analyzerid CDATA #IMPLIED
>
3.2.2.2 La Clase CorrelationAlert
La clase CorrelationA/ert lleva la información adicional relacionada con la correlación de la información de las alertas. Se usa para agrupar una o más alertas enviadas anteriormente.
+------------------+ I Alert +------------------+
/ \ 1
+------------------+ I CorrelationAlert I +------------------+ +-------------------+
1<>----------1 name 1 +-------------------+ I l .. *+-------------------+ l<>----------1 alertident 1 +-------------------+ I I STRING analyzerid I 1 +-------------------+
+------------------+
La clase de CorrelationA/ert se compone de dos clases:
• Name. Exactamente uno. STRING. La causa de agrupar las alertas juntas, por ejemplo, un método de correlación particular.

b4
• Alertident. Uno o más. STRING. La lista de los identificadores alertas que son relacionados con esta alerta. Porque los identificadores de alertas son únicos a través de las alertas enviadas por un solo analizador, la cualidad opcional del ana~)lzerid de alertidem se debe utilizar para identificar el analizador de el cual una alerta particular vino. Si el analyzerid no se proporciona, la alerta se asume de haber venido del mismo analizador que está enviando el CorrelationA/ert.
Esto se representa en el DTD de XML como sigue:
<!ELEMENT CorrelationAlert
name, alertident+
) >
<!ELEMENT alertident
<!ATTLIST alertident
analyzerid CDATA
(#PCDATA) >
3.2.2.3 La Clase Overflow Alert
El OverflowAlert lleva la información adicional relacionada con los ataques de desbordamiento. Su función es permitir a un analizador proporcionar los detalles del ataque del desbordamiento sí mismo.
La clase de OverflowAlert se compone de tres clases:
• Program. Exactamente uno. STRING. El programa que el ataque del desbordamiento intento correr ( éste no es el programa que fue atacado).
• Size. Cero o uno. NÚMERO ENTERO. El número de bytes que el atacante envía.
• Buffer. Cero o uno. BYTE[]. Algunos o todos los datos enviados.
+------------------+ Alert
+------------------+ /_\
1
+------------------+ OVerflowAlert
+------------------+ +---------+ (<>----------( program I 1 +---------+ 1 0 .. 1 +---------+ l<>----------1 size I 1 +---------+ I 0 .. 1 +---------+ (<>----------( buffer I 1 +---------+
+------------------+

Esto se representa en el DTD de XML como sigue:
< 'ELEMENT OverflowAlert
prograrn, size?, buffer?
) >
3.2.3 LA CLASE HEARTBEA T
Los analizadores utilizan los mensajes de corazonada para indicar su estado actual a los administradores. La corazonada es para ser enviados en un período regular, cada diez minutos o cada hora. El recibo de un mensaje de corazonada de un analizador indica al administrador que el analizador está en servicio; la carencia de un mensaje de corazonada ( o más probables, la carencia de un cierto número de los mensajes consecutivos de corazonada) indica que el analizador o su conexión de red ha fallado.
Un mensaje de corazonada se compone de varias clases agregadas:
• Analyzer. Exactamente uno. Infonnación de la identificación para el analizador que originó la corazonada.
• CreateTime. Exactamente uno. El tiempo que la corazonada fue creada.
• AnalyzerTime. Cero o uno. El tiempo actual en el analizador.
• Additiona/Data. Cero o más. Información incluida por el analizador que no cabe en el modelo de los datos. Ésta puede ser un pedazo atómico de datos o una cantidad grande de datos proporcionados con una extensión al IDMEF.
+--------------+ Heartbeat
+--------------+ +------------------+ STRING ident l<>----------1 Analyzer
1 +------------------+ 1 +------------------+ l<>----------1 CreateTirne 1 +------------------+ I 0 .. 1 +------------------+ l<>----------1 AnalyzerTirne I 1 +------------------+ I o .. *+------------------+ l<>----------1 AdditionalData I 1 +------------------+
+--------------+

Esto se representa en el DTD de XML como sigue
< 1 ELEMENT Heartbeat
Analyzer, CreateTime, AnalyzerTime?, Add1tionalData*
) >
<!ATTLIST Heartbeat
ident
>
CDATA
La clase de corazonada tiene un atributo:
. o.
• ldent. Opcional. Un identificador único para la corazonada.
3.2.4 LAS CLASES PRINCIPALES
bb
Las clases principales: Analyzer, Source, Target, Cla<isification y Additiona/Data, son las partes principales de las alertas y de las corazonadas.
+-----------+ +----------------+ I Heartbeat 1 +-------1 Analyzer +-----------+ 1 +----------------+ 1 !<>---+--+ +-----------+ 1 1 o .. *+----------------+
1 +-------1 AdditionalData I 1 +----------------+
+-----------+ 1
I Alert I +-----------+ 1
I<>---+ 1
1
1
o .. *+----------------+ +-------1 Source 1 +----------------+ I o .. •+----------------+ +-------1 Target I 1 +----------------+
I<>------+ +-----------+ 1 l .. •+----------------+
+-------! Classification I +----------------+
3.2.4.1 La Clase Analyzer
Esta clase identifica el analiz.ador del cual el mensaje de la alerta o de la corazonada se origina. Solamente un analizador se puede codificar para cada alerta o para cada corazonada y ése debe ser el analiz.ador en el cual la alerta o la corazonada fue originada.
La clase del analizador se compone de dos clases:
• Node. Cero o uno. Información sobre el dispositivo en el cual el analizador reside como la dirección de red o el nombre de la red.

V/
• Process. Cero o uno. Información sobre el proceso en el cual el analizador se está ejecutando
+---------------------+ Analyzer
+---------------------+ 0 .. 1 +---------+ STRING analyzerid l<>----------1 Node I STRING manufacturer 1 +---------+ STRING model o .. 1 +---------+ STRING version STRING class STRING ostype STRING osversion
l<>----------1 Process I 1 +---------+ 1
1
+---------------------+
Esto se representa en el DTD de XML como sigue:
<!ELEMENT Analyzer
Node?, Process?
}>
<!ATTLIST Analyzer
analyzerid
manufacturer
model
version
class
ostype
osversion
>
CDATA
CDATA
CDATA
CDATA
CDATA
CDATA
CDATA
La clase contiene los siguientes atributos:
I O I
#IMPLIED
#IMPLIED
#IMPLIED
#IMPLIED
#IMPLIED
#IMPLIED
• Analyzerid. Opcional. Identificador único para el analizador.
• Mamifacturer. Opcional. Nombre del fabricante.
• Model. Opcional. Modelo del programa.
• Version. Opcional. Versión del programa.
• Class. Opcional. Tipo de programa.
• Ostype. Opcional. Nombre del sistema operativo.
• Osversion. Opcional. Versión del sistema operativo.

68
3.2.4.2 La Clase Classification
En esta clase se proporciona el nombre de una alerta u otra información permitiendo que el administrador determine el tipo de alerta.
Se compone de dos clases:
• Name. Exactamente uno. STRING. El nombre de la alerta a partir del uno de los orígenes enumerados abajo.
• URL. Exactamente uno. STRING. Un URL en el cual el administrador puede encontrar la información adicional sobre la alerta. El documento señalado por al URL puede incluir una descripción profundizada del ataque, de las contramedidas apropiadas u otra información juzgada relevante por el IDS.
+----------------+ I Classification I +----------------+ +------1
STRING origin l<>----------1 name I 1 +------+
+------~ 1 <>----------1 url 1 +------+
+----------------+
Esto se representa en el DTD de XML como sigue:
<!ENTITY % attvals.origin
( unknown I bugtraqid I cve I vendor-specific
">
<!ELEMENT Classification
name, url
)>
<!ATTLIST Classification
origin %attvals.origin; 'unknown'
>
La clase posee un único atributo:
• Origin. Requerido. La fuente de la cual el nombre de la alerta origina. Los valores permitidos para esta cualidad se demuestran abajo. Los valores posibles son bugtraqid, cve, vendor-specific o unknown, siendo éste último el valor predeterminado.

V/
3.2.4.3 La Clase Source
Contiene la información sobre la posible fuente del evento que generó la alerta. Un acontecimiento puede tener más de una fuente, por ejemplo, el ataque de negación de servicio distribuido
Esta clase se compone de cuatro clases:
• Nade. Cero o uno. Información sobre el dispositivo que parece causar los acontecimientos (dirección de red o nombre de la red).
• U-ser. Cero o uno. Información sobre el usuario que parece causar el evento.
• Process. Cero o uno. Información sobre el proceso que parece causar el evento.
• Service. Cero o uno. Información sobre el servicio de red implicado en el evento.
+------------------+ Source
+------------------+ 0 .. 1 +---------+ STRING ident l<>----------1 Node I ENUM spoofed 1 +---------+ STRING interface 1 0 .. 1 +---------+
l<>----------1 User I 1 +---------+ I 0 .. 1 +---------+ l<>----------1 Process I 1 +---------+ 1 0 •• 1 +---------+ \<>----------\ Service I 1 +---------+
+------------------+
Esto se representa en el DTD de XML como sigue:
<!ENTITY % attvals.yesno
( unknown I yes I no
">
<!ELEMENT Source
Node?, User?, Process?, Service?
)>
<!ATTLIST Source
ident
spoofed
interface
>
CDATA
%attvals.yesno;
CDATA
'O'
'unknown'
#IMPLIED

70
Además, se tienen tres atributos:
• /den/ Opcional Identificador único para esta fuente
• Spoofed. Opcional. Una indicación de si la fuente es una trampa. Los valores permitidos para esta cualidad se demuestran abajo. Los valores posibles son sí, no y desconocido.
• Interface. Opcional. Puede ser utilizado por un analizador con múltiples interfaces para indicar la interfaz por la que se detectó el evento.
3.2.4.4 La Clase Target
Aquí se encuentra la información sobre el posible objetivo del evento que generó la alerta. Un acontecimiento puede tener más de un objetivo como en el caso de una exploración de puertos.
Se compone de cinco clases:
• Node. Cero o uno. Información sobre el dispositivo al cual el evento está dirigido.
• User. Cero o uno. Información sobre el usuario a quien se está dirigiendo el evento.
• Process. Cero o uno. Información sobre el proceso al que se dirige el evento.
• Service. Cero o uno. Información sobre el servicio de red implicado en el evento.
• FileList. Cero o uno. Información sobre el archivo implicado en el evento.
+------------------+ Target
+------------------+ 0 .. 1 +----------+ STRING ident l<>----------1 Node I ENUM decoy 1 +----------+ STRING interface I O .. 1 +----------+
1<>----------1 User I 1 +----------+ 1 0 •• 1 +----------+ l<>----------1 Process I 1 +----------+ 1 0 •• 1 +----------+ l<>----------1 Service I 1 +----------+ 1 0 •• 1 +----------+ l<>----------1 FileList I 1 +----------+
+------------------+
'·

Esto se representa en el DTD de XML como sigue
< 1 ENTITY ~ attvals.yesno
r unknown I yes I no
">
<!ELEMENT Target
Node?, User?, Process?, Service?, FileList?
)>
< 1ATTLIST Target
ident
>
de coy
interface
CDATA 'o' %attvals.yesno; 'unknown'
CDATA #IMPLIED
Se tienen tres atributos en esta clase:
• ldent. Opcional. Identificador único para el objetivo.
• Decoy. Opcional. Indicación acerca de si el objetivo es un señuelo o no.
• Interface. Opcional. Interfaz a la que pertenece el objetivo.
3.2.4.5 La Clase Assessment
Se utiliza para proporcionar la valoración del analizador acerca de un acontecimiento, como el impacto, las acciones tomadas en respuesta y la confianza.
+------------------+ Assessment
+------------------+ 0 .. 1 +------------+ l<>----------1 Impact 1 +------------+ I o .. *+------------+ l<>----------1 Action 1 +------------+ 1 0 •. 1 +------------+ l<>----------1 Confidence I 1 +------------+
+------------------+
Se compone de tres clases:
• Impact. Cero o uno. Valoración del impacto.
• Action. Cero o más. Acción de respuesta tomada por la herramienta.

I .:_
• ( 'onfidell(:e Medida de confianza que el analizador tiene en su evaluación del acontecimiento.
Esto se representa en el DTD de XML como sigue:
<!ELEMENT Assessment
Impact?, Action*, Confidence?
) >
3.2.4.6 La Clase AdditionalData
Se utiliza para proporcionar información que no puede ser representada por el modelo de datos. La clase Additiona/Data se puede utilizar para proporcionar los datos en casos donde solamente es necesario enviar pequeñas cantidades de información adicional, también puede ser utilizada para extender el modelo de datos y el DTD para permitir la transmisión de datos complejos.
El elemento Additiona/Data se declara en el DTD de XML como sigue:
<!ENTITY % attvals.adtype
boolean I byte I character date-time I integer
ntpstamp I portlist I real string I xml )
">
<!ELEMENT AdditionalData
<!ATTLIST AdditionalData
type
meaning
>
ANY >
%attvals.adtype;
CDATA
La clase de Additiona/Data tiene dos atributos:
'string'
#IMPLIED
• Type. Requerido. El tipo de dato transportado. Los valores permitidos son boo/ean, byte, character, date-time, integer, ntpstamp, portlist, real, string y xml.
• Meaning. Opcional. Una cadena que describe el significado del contenido del elemento. Estos valores variarán de acuerdo a la implementación.

I .J
3.3 IMPLEMENTACIÓN DEL IDMEF: LIBIDMEF
La librería IDMEF XML conocida como lihidmef es una implementación de la propuesta del IDWG mencionada anterionnente. Esta librería nos permite crear mensajes con el formato deseado a partir de las alertas generadas en un IDS.
Cabe mencionar que libidmef está construida sobre libxm/2, el cual es un proyecto activo y bien respaldado que provee implementaciones de documentos XML con estructuras en lenguaje C. Entre otras características, esta librería permite validación de documentos XML con base en la definición del tipo de documento DTD, es decir, donde se encuentran los lineamientos a seguir para la construcción de nuestros XML. La construcción de libidmef está orientada a proveer una interfaz sencilla para el uso de libxml.
Antes de iniciar la construcción del mensaje, es necesario saber que en el corazón de la librería se encuentra xm/Doc, la cual es una estructura que contiene el árbol con el que los mensajes IDMEF XML serán estructurados. La librería, además, provee la habilidad de construir múltiples mensajes IDMEF de forma concurrente o simultánea, lo que pennite crear, activar y almacenar documentos al mismo tiempo.
El proceso para construir un mensaje con esta librería es el siguiente: 1. Antes de empezar a construir el mensaje IDMEF XML, se debe llamar a la función
globalsinit ( ¡ para inicializar las variables globales. El argumento de entrada de esta función es la ruta en la que se encuentra el DTD.
2. El siguiente paso, es llamar a la función createCurrentDoc ( l para crear e inicializar un nuevo documento xmlDoc y establecerlo como el documento actual. El argumento de entrada de esta función es la versión actual de XML.
3. Ahora estamos listos para empezar con la construcción del mensaje. Hay 3 formas distintas de hacerlo: en la primera, el mensaje entero se construye de una sola vez; en la segunda, se pueden construir los componentes individualmente y unirlos al final; y la tercera es una combinación de las dos anteriores.
Usando la primera alternativa, el mensaje se construye con el siguiente código: void buildMessage(Packet *p)
if (p == NULL)
return NULL;
/* build a new IDMEF message */
theMessage = newIDMEF_Message(
newAttribute("version","1.0"),
newAlert(
newAttribute("ident",idrnef_alertid_str),

newAnalyzer(
) '
newAttr1bute("analyzer1d","IDS DRMBOT"J,
newAttribute("manufacturer","JBOT"),
newAttribute ( "model", "0110"),
newNode(
newAddress(
newAttribute("category","ipv4-addr"),
newSimpleElement("address","192.168.123.234"),
NULL
) ,
NULL
) ,
NULL
neWCreateTime(NULL), /* Current time values set here */
newSource(
) ,
newNode(
) ,
newAddress(
newAttribute("category","ipv4-addr"),
newSimpleElement("address",inet_ntoa(p->iph->ip_src)),
NULL
) , NULL
newService (
newSimpleElement("port",sport),
NULL
) ,
NULL,
newTarget(
newNode(
) ,
) ,
newAddress(
newAttribute("category","ipv4-addr"),
newSimpleElement("address",inet_ntoa(p->iph->ip_dst)),
NULL
) ,
NULL
newService(
newSimpleElement("port",dport),
NULL
) , NULL,
, ....

newClassif1cat1on(
newAttnbute ( "origin", "bugtraqid"),
newSimpleElernent("narne","TELNET bsd exploit client finishing"),
newSimpleElement("url","http://cve.rnitre.org/cgi-bin/cvename.cgi?narne=CAN-
2001-0554"),
NULL
) ;
) '
newAssessment(
newlmpact(
newAttribute("severity","high"),
newAttribute("completion","succeeded"),
newAttribute ( "type", "aclmin"),
NULL
) ' newConfidence(
newAttribute("rating","2"),
NULL
) I
NULL
) I
NULL
) I
NULL
Este método, como ya se ha dicho, requiere que se tenga toda la información antes de construir el mensaje, sin embargo la estructura nos brinda una forma intuitiva para la construcción del mensaje y permite futuras modificaciones de una manera simple. Alternativamente, se puede hacer uso de los otros dos acercamientos mencionados.
4. Antes de poder crear otro mensaje, es necesario llamar a la función clearcurrentDoc ()
para limpiar la estructura del documento. Después de eso, se puede llamar createcurrentDoc ( 1 de nuevo para construir otro mensaje.
Después de haber visto una breve explicación de cómo la librería construye los mensaJes, pasemos a ver cómo trabaja esta librería en conjunto con Snort.
3.4 PLUG-IN
La construcción de mensajes IDMEF XML en Snort se lleva a cabo a través de un plug-in, el cual convierte las alertas generadas en los formatos habituales de Snort a formatos IDMEF XML.

ID
Para el uso de este ¡,l11K-i11, éste debe ser compilado dentro de S11ort y activarlo en el archivo de configuración snort. con f. Dentro de este archivo, en la parte de configuración de los módulos de salida, se debe agregar el pl11K-i11 instalado seguida por una lista de argumentos:
idrnef: $HOME_NET keyl=valuel key2=value2 key3=value3 ...
Los argumentos requeridos son:
1. logro. La ubicación del archivo en donde se escribirán los mensajes IDMEF XML
2. dtd. La ubicación del archivo OTO.
3. analyzer_ id. Un identificador único del IDS.
Los siguientes argumentos son opcionales:
1. category. El dominio en el que se encuentra el IDS. 2. name. El nombre de dominio del equipo en donde se encuentra el IDS. 3. /ocation. La ubicación física del IDS. 4. address. La dirección de red del IDS. 5. netmask. La máscara de red de la dirección IP anterior. 6. address _cat. El tipo o categoría de la dirección dada. 7. homenet_cat. El tipo de dominio en el que se encuentra la red local. 8. homenet loe. La ubicación fisica de la red local. 9. default. La opción de tipo de regla del mensaje IDMEF por defecto. 10. web. La opción de tipo de regla del mensaje IDMEF de Web. 11. overflow. La opción de tipo de regla del mensaje IDMEF de desbordamiento 12. indent. Especifica si el mensaje IDMEF se escribe justificado o no 13. alert _id. Ruta o nombre del archivo que contiene la información de las alertas generadas.
Ejemplos de configuración:
• output idrnef: 123.234.123.0/24 logto=/var/log/snort/idrnef_alerts.log
analyzer_id=IDSl dtd=/path/to/idrnef-message.dtd
• output idrnef: 123.234.123.0/24 logto=/var/log/snort/idrnef alerts.log
analyzer_id=IDSl dtd=/path/to/idrnef-message.dtd category=dns
location=San_Francisco_network address=123.234.123.55 address_cat=ipv4-
addr web=ascii default=hex homenet loc=San Francisco network - -homenet cat=dns
Para tenninar la configuración del plug-i11, también es necesario indicar cuáles son las reglas que deseamos que generen sus alertas con el fonnato IDMEF XML. Esto se hace al agregar la palabra

f f
clave idmef seguida del tipo de alerta a la regla. Los posibles tipos de alerta son: web, overflow
y default. Esto nos permite especificar distintos formatos de salida para cada alerta.
Un ejemplo de lo anterior es:
• alert TCP any any -> any 27665 (msg: "IDS196/trin00-attacker-to
master"; flags: AP; content: "betaalmostdone"; idmef: default;)
El siguiente es un ejemplo de una regla de Snort y del respectivo mensaje IDMEF producido:
alert TCP any any -> any 80 (msg: "IDS297/http-directory-traversall"; flags:
AP; content: " .. /"; reference: arachNIDS,IDS297; idmef: default;)
<IDMEF-Message version="O.l">
<Alert alertid="329440" impact="unknown" version="l">
<Time>
<ntpstamp>Ox3a2d8b3a.Ox0</ntpstamp>
<date>2000-12-05</date>
<tirne>l6:41:30</time>
</Time>
<Analyzer ident="IDSl">
<Node category="dns">
<location>San Francisco Network</location>
<name>supersnort</name>
<Address category="ipv4-addr">
<address>l23.234.123.12</address>
</Address>
</Node>
</Analyzer>
<Classification origin="vendor-specific">
<name>IDS297/http-directory-traversall</name>
<url>http://www.whitehats.com/info/IDS297</url>
</Classification>
<Source spoofed="unknown">
<Node>
<Address category="ipv4-addr">
<address>222.222.lll.ll</address>
</Address>
</Nade>
</Source>
<Target decoy="unknown">
<Nade category="dns">
<location>San Francisco Network</location>
<Address category="ipv4-addr">
<address>l23.234.123.7</address>

</Address>
</Node>
<Service ident="O">
<dport>80</doort>
<sport>l397</sport>
</Service>
</Target>
<AdditionalData meaning="Packet Payload" type="string">GET
.. / .. /stuff/I/shouldnt/be/seeing</AdditionalData>
</Alert>
</IDMEF-Message>
3.5 ESTRATEGIA DE RESPUESTA
78
Una pregunta importante con respecto a nuestro esquema de detección de intrusos es qué hacer con la información obtenida del mismo. Como siempre, tenemos varias posibilidades, por un lado, podemos procesarla manualmente de forma periódica y en función de los datos que nuestros sensores hayan recogido tomar una determinada acción: bloquear las direcciones atacantes en el cortafuegos corporativo, enviar un correo de queja a los responsables de dichas direcciones, realizar informes para nuestros superiores, o simplemente no hacer nada. Dependerá casi por completo de la política de seguridad que sigamos o que tengamos que seguir.
Mucho más interesante que cualquiera de estas respuestas manuales es que el propio sensor sea capaz de generar respuestas automáticas ante lo que él considere un intento de ataque. Si elegimos esta opción, lo más habitual suele ser un bloqueo total de la dirección atacante en nuestro cortafuegos unida a una notificación de cualquier tipo a los responsables de seguridad. Es siempre recomendable efectuar esta notificación (si no en tiempo real, si al menos registrando las medidas tomadas contra una determinada dirección en un /og) por motivos evidentes. Por ejemplo, si bloqueamos completamente el acceso de alguien hacia nuestros sistemas, debemos recordar que es posible que se trate de un usuario autorizado que en ningún momento atacaba nuestras máquinas, a pesar de que el sensor que hemos instalado opine lo contrario. No importa lo seguros que estemos de lo que hacemos ni de las veces que hayamos revisado nuestra base de datos de patrones, nunca podemos garantizar por completo que lo que nuestro IDS detecta como un ataque realmente lo sea.
Contemplando la posibilidad que ofrece el lenguaje XML de permitir la interoperabilidad entre una diversa cantidad de módulos escritos en lenguajes distintos, y aprovechando la existencia de una amplia gama de clases preestablecidas en el lenguaje de programación Java para la lectura de archivos en XML, elaboramos un programa capaz de leer los archivos generados con anterioridad y almacenados en el archivo /var/log/snort/idmef_alerts. log. Dicho programa, además, tiene la capacidad de escribir en un nuevo archivo, /etc/sysconfig/iptables, en el que se

I;,
encuentran almacenadas las distintas reglas del cortafuegos, para bloquear una dirección IP cualquiera, desde la cual se haya detectado un ataque
En Java, existen dos metodologías de lectura e interpretación de archivos XML ampliamente conocidas: DOM y SAX. Mientras que DOM permite una mayor flexibilidad para la lectura de los archivos y las acciones posibles a seguir, SAX es una metodología más sencilla y directa, razón por la cual se prefirió crear el programa utilizando ésta última.
El algoritmo a seguir es el siguiente: Aprovechando las ventajas de la clase DefaultHandler del paquete org. xrnl. sax. helpers (clase extendida por el lector), el archivo XML generado con anterioridad (y almacenado dentro del archivo /var/ log/ snort/ idrnef _ alerts. log) es leído de principio a fin, siguiendo las reglas establecidas en el archivo OTO creado previamente. Dichas reglas permiten comprender al programa las etiquetas XML conforme las lee, y el hecho de que el archivo sea válido o no. El lector contiene instrucciones específicas a seguir para cada elemento y atributo en el momento en el que son leídos. Cabe mencionar que este lector e intérprete está abierto a la posibilidad de anexar a futuro nuevas instrucciones a seguir para cada etiqueta.
En este caso en particular, una vez que el archivo ha sido abierto y el programa comienza su lectura, se espera a la aparición de una o más etiquetas del tipo <Alert>, dentro de las cuales se encuentra una etiqueta indicando la dirección IP del atacante. En cuanto es detectado este parámetro, se procede a la apertura del archivo /etc/sysconfig/iptables, en el cual se encuentran escritas las reglas a seguir para bloquear la dirección IP hostil. A continuación, se busca dentro del archivo la regla correspondiente al bloqueo de direcciones IP, y, escribiendo en él, se añade una nueva regla del tipo:
iptables -A INPUT -s {dirección IP fuente} -j DROP
al archivo, permitiendo que se bloquee la dirección especificada.
El programa repite estos pasos para cada etiqueta <Alert> hallada dentro del archivo /var/log/snort/idmef_alerts. log, hasta concluir. Después de lo cual, permanece residente en memoria, esperando un cierto tiempo especificado, para volver a activarse y reiniciar el algoritmo. De este modo, es posible modificar o añadir el archivo /var/log/snort/idmef_alerts.log mientras el programa queda esperando, para que, al despertar este último, sea capaz de modificar nuevamente el archivo /etc/sysconfig/iptables
y tener así la capacidad de mantener en actualiz.ación constante las reglas del firewall, permitiendo una defensa eficiente contra cualquier posible ataque.
Un correcto esquema de respuesta automática que bloquee la dirección de un presunto atacante debería contemplar los siguientes puntos:
• ¿Qué probabilidad hay de que el ataque detectado sea realmente un falso positivo? No todos los ataques que un sensor detecta tienen la misma probabilidad de serlo realmente.

8U
Por ejemplo. alguien que busca en nuestros servidores Weh un CGI denominado phf18 casi
con toda probabilidad trata de atacar nuestros sistemas; en cambio, una alarma generada porque el sensor detecta un paquete ICMP de formato sospechoso no tiene por qué representar un verdadero ataque Es necesario o cuanto menos recomendable, asignar un peso específico a cada alarma generada en el sensor y actuar sólo en el caso de que detectemos un ataque claro: un evento que denote muy claramente un intento de intrusión o bien varios menos sospechosos pero cuya cantidad nos indique que no se trata de falsos positivos.
• ¿Debemos contemplar direcciones protegidas? Otro punto a tener en cuenta antes de lanzar una respuesta automática contra un potencial atacante es su origen. Si se trata de una dirección externa seguramente la respuesta será adecuada, pero si se trata de una interna a nuestra red o de direcciones de empresas colaboradoras externas la situación no es tan clara. Debemos planteamos que quizás estamos bloqueando el acceso a alguien a quien, por los motivos que sea, no deberíamos habérselo bloqueado. Aunque se trate de cuestiones mas políticas que técnicas, es muy probable que en nuestro IDS debamos tener claro un conjunto de direcciones contra las que no se va actuar. En caso de detectar actividad sospechosa de estas direcciones, podemos preparar un mecanismo que alerte a los responsables de seguridad y, bajo la supervisión del administrador, tomar las acciones que consideremos oportunas.
• ¿Hay un límite al número de respuestas por unidad de tiempo? Seguramente la respuesta inmediata a esta pregunta sería no, a fin de cuentas, si me atacan diez direcciones diferentes en menos de un minuto, ¿qué hay de malo en actuar contra todas bloqueándolas? En principio esta sería la forma correcta de actuar, pero debemos pensar en lo que es normal y lo que no lo es en nuestro entorno de trabajo. ¿Es realmente habitual que suframos ataques masivos y simultáneos desde diferentes direcciones de Internet? Dependiendo de nuestro entorno, se puede considerar una casualidad que dos o tres máquinas diferentes decidan atacamos al mismo tiempo sin embargo una cantidad mayor resulta cuanto menos sospechoso. Un pirata puede simular ataques desde diferentes hosts de una forma más o menos sencilla y si nos limitamos a bloquear direcciones o redes completas, es fácil que nosotros mismos causemos una importante negación de servicio contra potenciales usuarios legítimos, como por ejemplo simples visitantes de nuestras páginas Web o usuarios de correo, lo cual puede representar un ataque a nuestra seguridad más importante que el que causaría ese mismo pirata si simplemente le permitiéramos explorar nuestras máquinas. Si nuestro sensor lanza demasiadas respuestas automáticas en un periodo de tiempo pequeño, el propio sistema debe encargarse de avisar a una persona que se ocupe de verificar que todo es normal.
Teniendo en cuenta los puntos anteriores, debemos diseñar un esquema de respuestas automáticas adecuado. Un algoritmo del funcionamiento de nuestro esquema podría ser el siguiente:
18 Programa que se encuentra en versiones antiguas de Apache y que presenta graves problemas de seguridad.

ESTADO: ·, ;,etección a taque)
31 umbral de respuestas superado: FIN
SI NO
Comprobación IP atacante
SI es IP protegida: FIN
SI NO
Ponderación histórica de gravedad
SI umbral de gravedad superado: ACTUAR
SI NO
REGISTRAR
FSI
FSI
FSI
Como vemos, al detectar un ataque desde determinada dirección, el modelo comprueba que no se ha superado el número de respuestas máximo por unidad de tiempo, por ejemplo, que no se ha bloqueado ya un número determinado de direcciones en las últimas 24 horas, si este umbral ha sido sobrepasado no actuaremos de ninguna forma automática, principalmente para no causar importantes negaciones de servicio, pero si no lo ha sido, se verifica que la dirección IP contra la que previsiblemente se actuará no corresponde a una de nuestras protegidas, por ejemplo a una máquina de la red corporativa: si es así se finaliza. Este finalizar no implica ni mucho menos que el ataque no haya sido detectado y se haya guardado un log del mismo, simplemente que para evitar problemas mayores no actuamos en tiempo real contra la máquina, si corresponde al grupo de protegidas es porque tenemos cierta confianza o cierto control sobre la misma, por lo que un operador puede preocuparse más tarde de investigar la alerta. Si se trata de una dirección no controlada ponderamos la gravedad del ataque, uno con poca posibilidad de ser un falso positivo tendrá un peso elevado mientras que uno que pueda ser una falsa alarma tendrá un peso bajo. Aún así, diferentes ataques de poco peso pueden llegar a sobrepasar nuestro límite si se repiten en un intervalo de tiempo pequeño. Es importante recalcar que son diferentes ataques, ya que si la alarma que se genera es todo el rato la misma debemos planteamos algo ¿es posible que un proceso que se ejecuta periódicamente y que no se trata de un ataque esté todo el rato levantando una falsa misma alarma? La respuesta es sí, y evidentemente no debemos bloquearlo sin más, es más recomendable revisar nuestra base de datos de patrones de ataques para ver por qué se puede estar generando continuamente dicha alarma.
Por último, si nuestro umbral no se ha superado debemos registrar el ataque, su peso y la hora en que se produjo para poder hacer ponderaciones históricas ante más alarmas generadas desde la misma dirección, y si se ha superado el esquema debe efectuar la respuesta automática: bloquear al atacante en el cortafuegos, enviar un correo electrónico al responsable de seguridad, etc. Debemos pensar que para llegar a este último punto, tenemos que estar bastante seguros de que realmente hemos detectado a un pirata, no podemos permitirnos el efectuar respuestas automáticas ante cualquier patrón que nos parezca sospechoso sin saber realmente que se trata de algo hostil a nuestros sistemas.

OL.
Antes de finalizar este punto, es necesario que volver a insistir una vez más en algo que ya hemos comentado, es muy recomendable que ante cada respuesta se genere un aviso que pueda ser validado por un administrador de sistemas o por responsables de seguridad, mejor si es en tiempo real. Por muy seguros que estemos del correcto funcionamiento de nuestro detector de intrusos, nadie nos garantiza que no nos podamos encontrar ante comportamientos inesperados o indebidos y con toda certeza es más fácil para una persona que para una máquina darse cuenta de un error y subsanarlo.

CONCLUSIONES
Las herramientas de seguridad con las que hemos trabajado están clasificadas dentro de las categorías de prevención y detección. Los mecanismos de prevención aumentan la funcionalidad de un sistema durante el funcionamiento normal de éste y, como su nombre lo dice, previenen la ocurrencia de violaciones a la seguridad. Los mecanismos de detección son aquellos que se utilizan para detectar violaciones de la seguridad o intentos de violación. Jptables es un mecanismo de prevención mientras que Snort es un mecanismo de detección. Estas dos herramientas trabajando unidas caen dentro de una nueva categoría, los mecanismos de recuperación y/o respuesta, los cuales se aplican cuando una violación del sistema se ha detectado para retomar a éste a su funcionamiento correcto.
Como podemos ver, la comunicación entre iptables y Snort, permite que ambos programas trabajen virtualmente unidos como una sola solución de seguridad que es capaz de responder automáticamente ante diversos intentos de violación a la seguridad de nuestro sistema
La estrategia de respuesta automática que implementada en este trabajo consistió en el bloqueo de la dirección IP del presunto atacante mediante la reconfiguración del cortafuegos, sin embargo, esto sólo fue un medio para comprobar la efectividad de la comunicación entre ambas herramientas ya que el protocolo de comunicación provee mucha más información que podemos utilizar para detener un ataque contra nuestros sistemas.
Mediante el agente de lectura de los logs en formato IDMEF XML podemos extraer y almacenar toda la información contenida en el mismo, lo que nos brinda grandes posibilidades para tomar las acciones necesarias para detener un posible ataque, además de tener la capacidad de deslindar responsabilidades y de aprender de nuestras vulnerabilidades.
Por otro lado, la propuesta del IDWG respecto al formato de intercambio de mensajes de detección de intrusiones (IDMEF) es tan sólo eso, una propuesta, sin embargo, el objetivo es que ésta se convierta en un formato estándar de datos que los sistemas de detección de intrusos utilicen para reportar alarmas sobre eventos sospechosos

g__¡
La comunicación entre el cortafuegos y el IDS se llevó a cabo con el formato IDMEF XML, io .:uai proporcionó varias ventajas, las alertas contienen la información necesaria para conocer los detalles del ataque, además es posible que el administrador la lea v la entienda con tan sólo un vistazo debido al orden de sus etiquetas y a que éstas son realmente descriptivas.
Otra de las ventajas que debemos tener presente, talvez la más importante, es que el formato IDMEF provee una representación estándar de las alertas de manera no ambigua que permitirá la interoperabilidad de distintos sistemas, como es el caso de esta investigación, en donde la interacción fue entre un cortafuegos y un IDS.
Dicha sintaxis estándar será de gran utilidad no sólo para la interoperabilidad entre herramientas, sino que permitirá representar cualquier tipo de bitácora producida por las diferentes herramientas en el mercado. Actualmente la información relacionada con los eventos acontecidos se encuentra almacenada en una variedad de formatos propietarios haciendo la comparación dificil de llevar a cabo, sin embargo, el modelo IDMEF resuelve este problema facilitando la tarea del análisis de los datos generados.

REFERENCIAS
[ 1] Spafford, Gene y Simson Garfinkel. Practica/ Unix & Internet Security. 2nd Edition. O'Reilly & Associates, Inc. 1996.
[2] Beale, Jay, et al. Snort 2.0 lntrusion Detection. Syngress Publishing, 2003.
[3] Escamilla, Terry. Jntrusion Detectio11: Network Security Beyo11d the Firewa/1. John Wiley & Sons, Inc. 1998.
[ 4] McClure, Stuart, et al. Hackers: Secretos y soluciones para la seguridad de redes. Trad. Jorge Rodríguez Vega. Madrid: Osbome/McGraw-Hill, 2002
[5] Villalón, Antonio. Seguridad en U11ix y Redes. Tesis Universidad de Valencia. España: Julio, 2002.
[6] Russell, P. Rusty. Ne(filterliptables. Noviembre 2003. <http://www.netfilter.org>
[7] Caswell, Brian y Marty Roesch. Snort: The Open Source Network Jntrusion Detection System. Noviembre 2003. <http://www.snort.org>
[8] Curry, David y Hervé Debar. Jntrusion Detection Message Exchange Formal Data Model and Extensible Markup Language (XML) Document Type Definition. Enero 2003. <http://www. ietf org/intemet-drafts/draft-ietf-idwg-idmef-xml-1 O. txt>
[9] McAlemey, Joe. IDMEF XML pluginfor the Snort IDS. Enero 2003 <http://www.silicondefense.com/idwg /snort-idmef/>
[10] McAlemey, Joe y Adam Migus. Libidmef C library implementation ofthe IDMEF XML draft. Junio 2002 <http://www.silicondefense.com/idwg/libidmeflindex.htm>
[ 11] Russell, P. Rusty. Linux iptables HOWTO. Septiembre 1999.

[ 12] Andreasson, Oskar lptah/es fotorial Abril 2003
[ 13] Roesch, Martín y Chris Green. Snort ( lsers Manual. 2003 <http://www. snort .org/docs/writing_ rules/>
[ 14] Bace, Rebecca y Peter Mell. "lntrusion Detection Systems". NIST Special Publicatio11. SP800-31 Noviembre 2001 <http://csrc.nist.gov/publications/nistpubs/800-31/sp800-3 lpdf>
86


















