

Introducción mongodb y desarrollo
57
-
Upload
juan-ladetto -
Category
Technology
-
view
183 -
download
2
Transcript of Introducción mongodb y desarrollo

Un poco de historia
• Las bases de datos relacionales eran la única opción
• Las aplicaciones web tienen picos• Especialmente las aplicaciones transaccionales (e-commerce)
• Los desarrolladores encontraron en memchached principalmente la solución a sus problemas de escalabilidad

Escalando verticalmente
• Las bases de datos no están diseñadas para tener un esquema de datos distribuídos
• Cuando la concurrencia aumenta la “única” manera es escalar verticalmente
• Después entontraron soluciones provistas por los proveedores de base de datos que brindaban soluciones de escalabilidad (master-slave/sharding)• Conocido como ‘scaling out’ o ‘horizontal scaling’

Escalando Base de datos – Master/Slave
• Master-Slave• Todos las escrituras van al master, todas las lecturas se realizan sobre los slaves
• Los reads críticos pueden ser incorrectos ya que las escrituras no se propaganinmediatamente
• Los tamaños de los data sets pueden plantear problemas ya que los master necesitanduplicar información hacia lo slaves.

Transacciones – Propiedades ACID
• Atomic – Todo el trabajo en una transacción se completa o nada de la transacción se realiza
• Consistent – Una transacción transforma la base de datos desde un estado consistente hacia otro estado consistente. La consistencia estádefinida en términos de restricciones.
• Isolated – Los resultados realizados por una transacción no son visibles hasta que la transacción se complete (commit).
• Durable – Los resultados de una transacción terminada sobrevive a fallos

Sistemas distribuidos
• CAP “Theorem”• Consistency: Todos los clientes ven la misma información siempre
• Availability: Cada cliente puede siempre escribir y leer
• Partition tolerance: El Sistema funciona bien aunque tengamos la información distribuída en particiones y alguna partición sufre algunaanomalía
• “CAP theorem” dice que solo podés tener 2 de estas condiciones en un Sistema distribuído
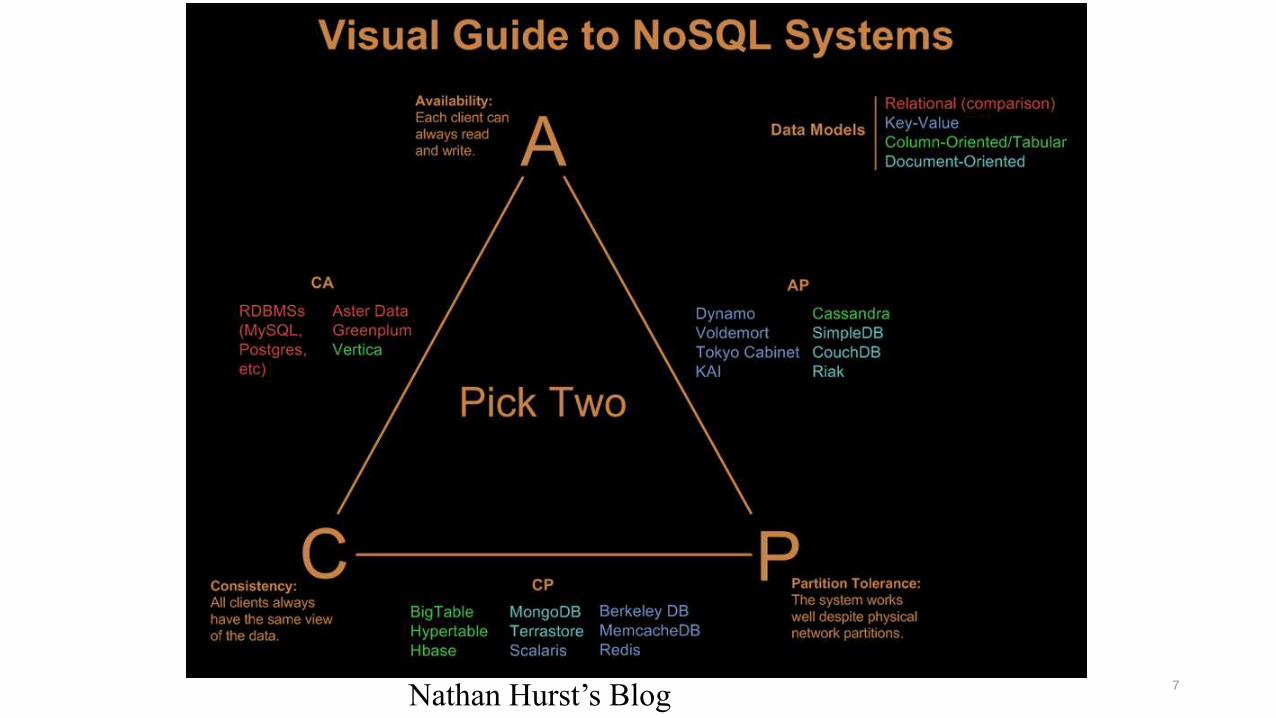
7
Nathan Hurst’s Blog

Propiedades – Propiedades BASE
• Acrónimo opuesto a ACID• Basically Available,
• Soft state,
• Eventually Consistent
• Características• Poca consistencia – los datos leidos pueden no ser los correctos
• Disponibilidad primero
• El mayor esfuerzo por brindar la mejor solución
• Simples y rápidosIn partitioned databases, trading some consistency for availability can lead to dramatic improvements in scalability.Dan Pritchett, Ebay

La aparición de “NoSQL” y sus características
• Grandes volúmenes de información• Google’s “big tables”
• Replicación y distribución escalable• Potencialmente miles de máquinas• Potencialmente distribuídas en todo el mundo
• Las consultas necesitan retornar respuestas rápidamente
• Sistemas con muchísimas consultas y pocos updates
• Inserciones y actualizaciones asincrónicas
• Sin un schema definido
• Responden al esquema transaccional BASE
• Responden al teorema CAP
• Principalmente de código abierto

Una definición de NoSQL
From www.nosql-database.org:Next Generation Databases mostly addressing some of the points: being non-relational, distributed, open-source and horizontal scalable. The original intention has been modern web-scale databases. The movement began early 2009 and is growing rapidly. Often more characteristics apply as: schema-free, easy replication support, simple API, eventually consistent / BASE (not ACID), a huge data amount, and more.

Tipos de base de datos NoSQL
Existen varios tipos de base de datos del tipo NoSQL:
• Column Store – Cada porción guardada contiene datos de una sola columna
• Document Store – guarda un documento organizado por tags
• Key-Value Store – guarda un valor por cada key
• Graph Databases – Persisten relaciones entre nodos

NoSQL: Column Store
• Cada porción de almacenamiento contiene información de una sola columna
• Ejemplos: Hadoop/Hbase• http://hadoop.apache.org/
• Yahoo, Facebook
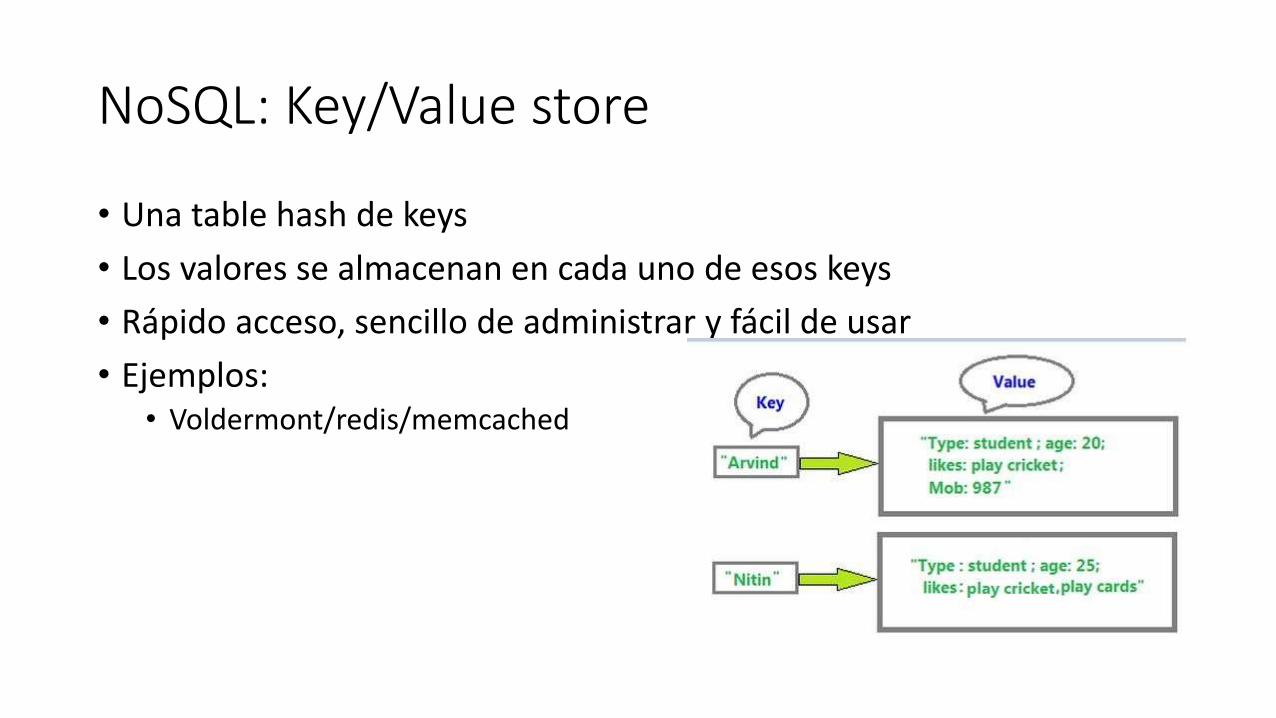
NoSQL: Key/Value store
• Una table hash de keys
• Los valores se almacenan en cada uno de esos keys
• Rápido acceso, sencillo de administrar y fácil de usar
• Ejemplos: • Voldermont/redis/memcached
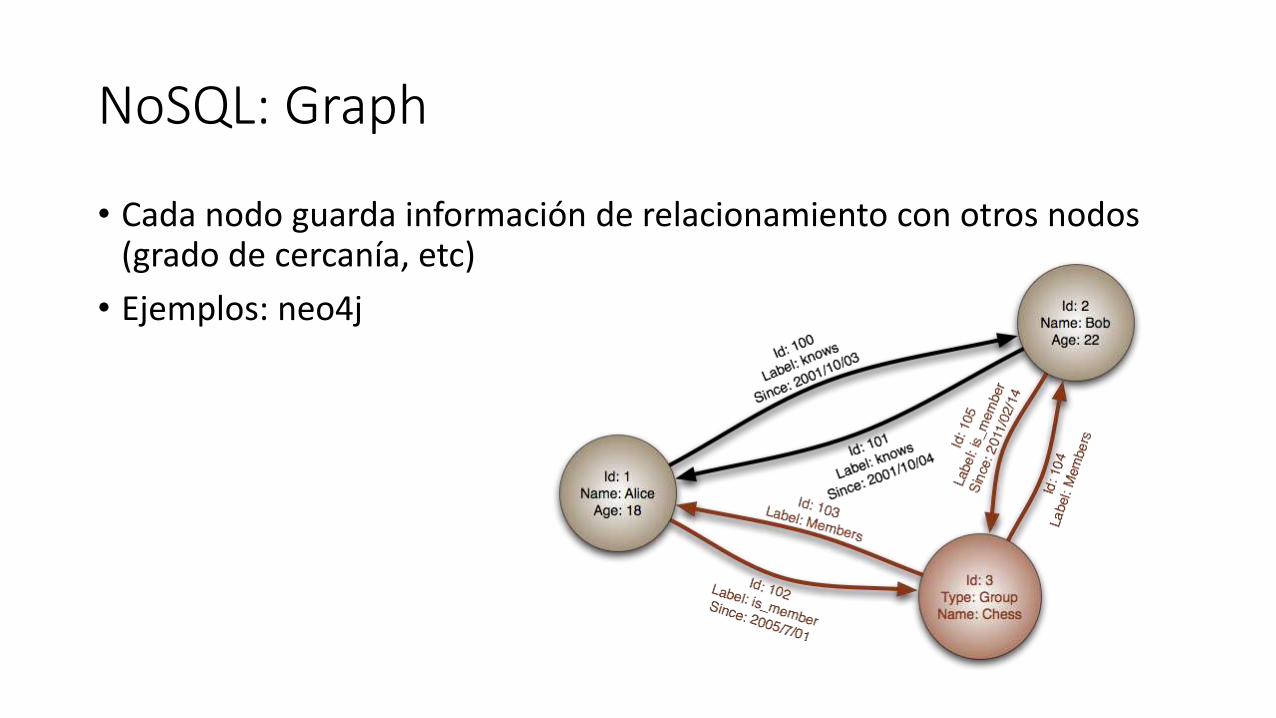
NoSQL: Graph
• Cada nodo guarda información de relacionamiento con otros nodos(grado de cercanía, etc)
• Ejemplos: neo4j
NoSQL: Document store
• Cada key es un documento que puede contener a su vez otrosdocumentos (subdocumentos)
• Ejemplos:
• CouchDB• http://couchdb.apache.org/
• BBC
• MongoDB• http://www.mongodb.org/
• Foursquare, Shutterfly

Qué es mongodb (10gen)
• MongoDB (sacado de mongodb.com):
Es una base de datos para las aplicaciones de hoy, innovativa, de rápidotime to market, que escala globalmente, fácil de operar y seguro.

Beneficios
• Rápido e iterativo desarrollo:• La flexibilidad de los modelos de datos de mongodb y la posibilidad de tener
esquemas dinámicos hacen que sea sencillo para los desarrolladores crear y evolucionar aplicaciones. El provisionamiento automático hacen que la integración y evolución de aplicaciones sea realmente sencilla.
• Modelo de datos flexible:• Los documentos de mongo pueden almacenar y combinar datos de cualquier tipo de
estructura dentro de una misma colección• El acceso a la información es MUY sencilla, pocas condiciones y bien detalladas• Los esquemas de datos se pueden modificar dinámicamente sin downtime.• Menos inversión de tiempo pensando como persistir información y más trabajando
con los mismos• Operaciones del tipo ALTER_TABLE o peor rediseñar los esquemas desde el principio

+Beneficios
• Multi-Datacenter Scalability.• MongoDB puede escalar dentro de un datacenter o a través de multiples datacenters
distribuídos proveyendo nuevos niveles de disponibilidad y escalabilidad. A medidaque las estructuras son más grandes en términos de datos y niveles de acceso, MongoDB escala rápidamente sin downtime y sin que uno tenga que modificar la aplicación para que tome la nueva configuración.
• Conjunto integrado de funcionalidades• Analísis, text search, datos geoespaciales, replicación global, hacen que uno pueda
usar mongodb como “solución” única para muchas aplicaciones del tipo real-time.
• Bajo TCO.• MongoDB corre en servidores de tipo “commodity” y escala horizontalmente como
así verticalmente. Sin costo (open source) pero algunos beneficios si se quiere pagarlicenciamiento.

MondoDB Data Model
19
• Una instalación de MongoDB está compuesta por un conjunto de base de datos. Una base de datoscontiene un conjunto de colecciones. Una coleccióncontiene un conjunto de documentos. Un document es un conjunto de pares de key-value.
RDBMS MongoDB
TableRow(s)IndexJoinPartitionPartition Key
CollectionBSON (binary json) DocumentIndexEmbedding & LinkingShardShard Key

Reglas para crear documentos (estructuras de datos)• Regla 1: Todo documento si o si tiene que tener un _id
• Regla 2: Tamaño máximo de un documento 16 MB
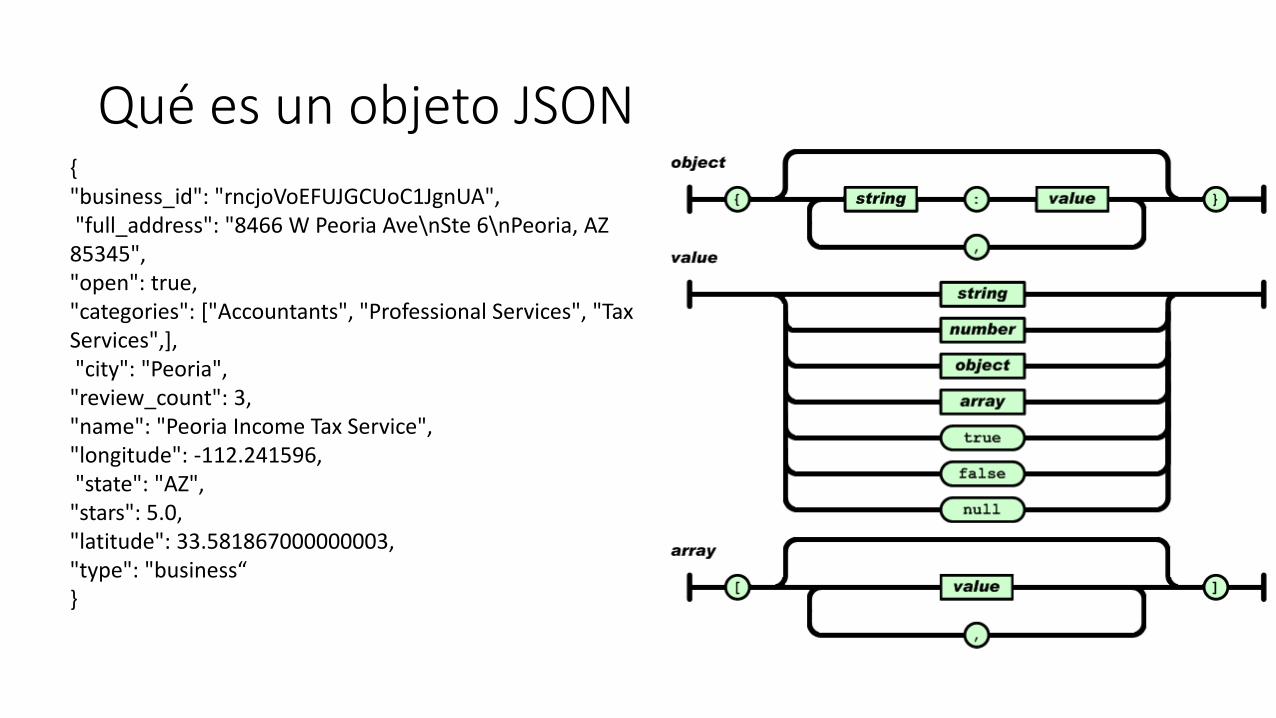
Qué es un objeto JSON{"business_id": "rncjoVoEFUJGCUoC1JgnUA","full_address": "8466 W Peoria Ave\nSte 6\nPeoria, AZ
85345", "open": true, "categories": ["Accountants", "Professional Services", "Tax Services",],"city": "Peoria",
"review_count": 3, "name": "Peoria Income Tax Service","longitude": -112.241596,"state": "AZ",
"stars": 5.0, "latitude": 33.581867000000003, "type": "business“}

MongoDB Data Model
• MongoDB almacena documentos en una representación llamadaBSON (Binary JSON). Generalmente los documentos similares estánorganizados como colecciones.
• Cada documento de MongoDB tiende a tener toda la información quelo representa como un todo. • Ej: data-model y blog (entradas, categorías, tags, usuarios, comentarios).

SQL Statement MongoDB commands
SELECT * FROM table
db.collection.find()
SELECT * FROM tableWHERE artist = ‘Nirvana’
db.collection.find({Artist:”Nirvana”})
SELECT*FROM tableORDER BY Title
db.collection.find().sort(Title:1)
DISTINCT .distinct()
GROUP BY .group()
>=, < $gte, $lt
Obteniendo información
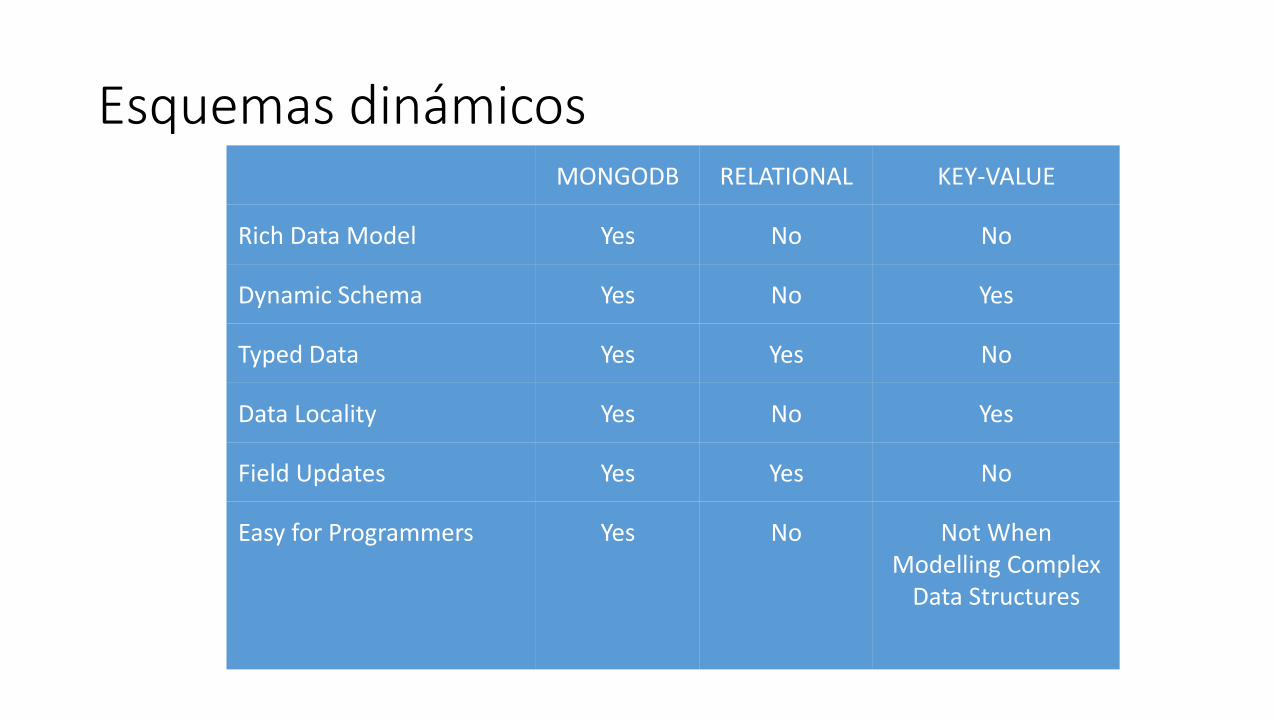
Esquemas dinámicosMONGODB RELATIONAL KEY-VALUE
Rich Data Model Yes No No
Dynamic Schema Yes No Yes
Typed Data Yes Yes No
Data Locality Yes No Yes
Field Updates Yes Yes No
Easy for Programmers Yes No Not When Modelling Complex
Data Structures

Indices
• Indices como en cualquier base de datos es un mecanismoimportantísimo para el correcto procesamiento de información
• Uno puede definir índices de tipo unique, compuestos, para arrays, con ttl, geoespaciales, de texto
• El optimizador de queries de mongo analiza y selecciona el índice máseficiente. (explain al rescate)
• Mongodb puede llegar a utilizar más de un índice para optimizar unaconsulta.

Tipos de consultas
• MongoDB soporta muchos tipos distintos de consultas y ofreceframeworks que ayudan a cumplimentar sus debilidades. Ademásmongodb (siempre que su driver lo soporte) puede devolver no únicamente un documento completo, sino también subdocumentos)• Consultas Key-value
• Consultas de rango
• Consultas Geoespaciales (con índices especiales)
• Consultas del tipo texto (con índices especiales)
• Aggregation Framework
• MapReduce

Consistencia y disponibilidad en MongoDB
Modelo Transaccional
• MongoDB proporciona las propiedades ACID a nivel de documento. • Una o más propiedades pueden ser escritas en una sola operación,
incluyendo updates a multiple subdocumentos y elementos de un array. ACID provisto por mongodb asegura la completa separación cuando unodocumento se está actualizando. Si un error se produce cuando se actualiza la operación hace roll-back y siempre se obtiene una vista consistente del documento.
• Con Write concerns nos permite definir como queremos asegurarnos que la operación realmente se haya producido a distintos niveles.

IN-MEMORY Performance con ON-DISK CAPACITY• MongoDB hace uso extensivo de RAM para optimizar las operaciones
en la base de datos.
• Toda la información es manipulada y mapeada a través de memory-mapped files.
• Leer desde memoria es mucho más rápido que leer de disco
• Muchas veces es suficiente con mongodb y no es necesario otro layer de caching.

ALTA DISPONIBILIDAD - REPLICA SETS
• MongoDB puede mantener multiples copias de información llamadareplicasets usando mecanismos nativos de replicación. Una replica esautónoma y previene downtime. Failover automático elimina lasnecesidades de administradores de intervener manualmente.
• El número de replicas es configurable.
• Una operación sobre una replica puede devolver un ack cuando determinada cantidad de replicasets devuelvan el OK de la operación.

ESCALABILIDAD: AUTO-SHARDING
• MongoDB prove escalabilidad horizontal utilizando una técnicallamada sharding.
• Sharding distribuye información a lo largo del shar which is transparent to applications. Sharding distributes data across multiple physical partitions called shards. Sharding allows MongoDBdeployments to address the hardware limitations of a single server, such as bottlenecks in RAM or disk I/O, without adding complexity to the application. MongoDB automatically balances the data in the cluster as the data grows or the size of the cluster increases or decreases.

Seguridad
• Authentication. Built in o con integración con LDAP, AD, Kerberos, etc
• Authorization. 2 tipos de roles: sobre los datos y sobre las bases de datos.
• Auditoria. For regulatory compliance, security administrators can use MongoDB's native audit log to track access and administrative actions taken against the database.
• Encripción. MongoDB data puede ser encriptadatanto en transmission como en disco. Conexiónvía SSL.

CRUD EN MONGO

Manos a la obra
• Mongo Shell
• Accediendo a mongo a través del driver de c#

Modelado de datos

Diferencias con el esquema tradicional de diseño• Tradicional
• No importa tu aplicación
• Solo importan los datos
• Unicamente relevantedurante el diseño
• Formas normales y desnormalización para performance
MongoDB
• Siempre dependerá de tuaplicación
• No únicamente importan los datos sino como serán usados
• Relevante durante toda la vidaútil de tu aplicación

Modelado de datos con mongodb
El diseño de esquema es evolucionario
• Diseño y desarrollo
• Implementación y monitoreo
• Modificaciones iterativas

3 Componentes para diseñar los esquemas
1. La información que tu aplicación necesita
2. Cómo tu aplicación lee información
3. Cómo tu aplicación persiste información

Patrones de diseño comunesEmbeber para tener los datos a mano
Emb
// Contacto embebido{"_id": 3,“nombre": “Perez, José",“CP": “1007",“telefonos": [ “011-4564-3456", “011-4334-3411" ]}
Ref
// Contact document:{"_id": 3,"nombre": "Perez, José", "CP": "1007"}
// Number documents:{ "contacto_id": 3, “telefono": " 011-4564-3456"}{ "contacto_id": 3, “telefono": "011-4334-3411"}

Patrones de diseño comunesReferenciar para tener flexibilidad o necesidad
Emb
// post embebido{"_id": "Primer Post", "author": "Juan", "text": "Arranco un blog que nunca continuaré", "comments": [{ "author": "Pedro", "text": "Bienvenido!" },...]}db.posts.find({“comments.author”: “Pedro”})
Ref
db.post esquema{"_id": "Primer Post", "author": "Juan", "text": "Arranco un blog que nunca continuaré“}
db.comments esquema{"_id": ObjectId(...),"post_id": “Primer Post","author": “Pedro","text": “Bienvenido! "}db.comments.find({“comments.author”: “Pedro”})
• Límite 16 MB por documento y todo en RAM
• Documentos que crecen se mueven a nuevos lugares

Patrones de diseño comunesReferenciar cuando tenemos relaciones M:N
Referenciado
// db.product esquema
{ "_id": "Mi Producto", ... }
// db.category esquema
{ "_id": "Una Categoria", ... }
// db.product_category esquema
{ "_id": ObjectId(...),"product_id": "Mi Producto","category_id": "Una Categoria" }
Embebido
// db.product esquema
{ "_id": "Mi Producto","categories": [{ "_id": "Una Categoria", ... }...] }
// db.category esquema{ "_id": "Una Categoria","products": [{ "_id": "Mi Producto", ... }...] }
Referenciando ids
// db.product schema
{ "_id": "Mi Producto", "category_ids": [ "Una Categoria", ... ] }
// db.category schema
{ "_id": "Una Categoria" }

Patrones de diseño comunesEsquemas polimórficos
Analicemos con un ejemplo práctico

MongoDBMapReduce – Aggregation Framework

MapReduce
• Qué es?• Posibilidades para buscar y condensar información
• En mongodb• db.collection.mapReduce(mapFunction, reduceFunction, {params})
Juguemos (zips collections):
> var map = function() {emit(this.state, this.pop);}
> var reduce = function(state, pops){ return Array.sum(pops)}
> db.zips.mapReduce(map, reduce, {out: "map_reduce1"})
{
"result" : "map_reduce1",
"timeMillis" : 2376,
"counts" : {
"input" : 29353,
"emit" : 29353,
"reduce" : 346,
"output" : 51
},
"ok" : 1
}
> db.map_reduce1.find()

MapReduceAlgo un poquito más complejo
var map = function () {
for (var i = 0; i< this.scores.length; i++){
var key = this.scores[i].type;
var value = { count:1, score: this.scores[i].score};
emit(key, value);
}}
var reduce = function(type, scores) {
reducedVal = { count: 0, score: 0.0 };
for (var idx = 0; idx < scores.length; idx++) {
reducedVal.count += scores[idx].count;
reducedVal.score += scores[idx].score;
}
return reducedVal;
};
var finalize = function (key, reducedVal) {
reducedVal.avg = reducedVal.score/reducedVal.count;
return reducedVal;
};
db.students.mapReduce( map, reduce,
{
out: { merge: "map_reduce_example" },
query: { name:
{ $gt: 'J' }
},
finalize: finalize
}
)

MapReduceTroubleshooting Map-Reduce Functions
> var map = function (){emit(key, value)}
> var emit = function (key, value){print (key, tojson(value)}
> var doc = db.coll.findOne()
> doc
map.apply(doc)
var reduceFunction1 = function(keyCustId, valuesPrices){}
var myTestValues = [ 5, 5, 10 ];
reduceFunction1('myKey', myTestValues);

mapReduce desde c#
var map = “”;
Var reduce =“”;
var collection = db.GetCollection("movies");
var options = new MapReduceOptionsBuilder();
options.SetFinalize(finalize);
options.SetOutput(MapReduceOutput.Inline);
var results = collection.MapReduce(map, reduce, options);
foreach (var result in results.GetResults())
{
Console.WriteLine(result.ToJson());
}

Aggregation Framework
- Evolución de mapReduce. c++, código compilado, 10x veces más rápido que mapReduce
• Qué es básicamente?• Una serie de transformaciones sobre los documentos de una colección
• Ejecutados en etapas
• El resultado es un cursor o una colección
• Conjunto grande de librerías de funciones• Filtrado, computo, grupo, sumarización
• El resultado de una etapa es enviada a la siguiente
• Las operaciones se ejecutan en un orden secuencial
$match $Project $group $sort

Aggregation FrameworkPipeline Operators
• $match• Filtrar
• $sort• Ordenar Documentos
• $limit / $skip• Paginar documentos
• $redact• Restringir documentos
• $geoNear• Ordenar por proximidad
• $let, $map• Definir variables
• $project• Rearmar documentos
• $group• Sumarizar documentos
• $unwind• Expandir array

Aggregation Framework$match
{subject: "Hello There",words: 218,from: "[email protected]"}
{subject: "I love Hofbrauhaus",words: 90,from: "[email protected]"}
{subject: "MongoDBRules!",words: 100,from: "[email protected]"}
{ $match: {from: "[email protected]"}}
{subject: "MongoDB Rules!",words: 100,from: "[email protected]"}
{ $match: {words: {$gt: 100}}}

Aggregation Framework$project
{_id: 12345,subject: "Hello There",words: 218,from:"[email protected]"to: [ "[email protected]","[email protected]" ],account: "mongodb mail",date: ISODate("2012-08-05"),replies: 3,folder: "Inbox",...}
{ $project: {_id: 0,subject: 1,from: 1}}
{subject: "MongoDB Rules!", from: "[email protected]"}
{ $project: {spamIndex: {$divide: ["$words",
"$replies"]
},user: "$from"
}}
{
_id: 12345,
spamIndex: 72.6666 ,
user: "[email protected]"
}
{ $project: {subject: 1,stats: {replies: "$replies",from: "$from",date: "$date"
}}}
{
_id: 375,subject: "Hello There",
stats: {replies: 3,from: "[email protected]",date: ISODate("2012-08-05")
}}

Aggregate Framework$group
{subject: "Hello There",words: 218,from: "[email protected]"}
{subject: "I love Hofbrauhaus",words: 90,from: "[email protected]"}
{subject: "MongoDB Rules!",words: 100,from: "[email protected]"}
{ $group: {_id: "$from",avgWords: { $avg:"$words" }}}
{_id: "[email protected]",avgWords: 154}
{_id: "[email protected]",avgWords: 100}
{ $group: {_id: "$from",words: { $sum: "$words" },mails: { $sum: 1 }}}
{_id: "[email protected]",words: 308,mails: 2}
{_id: "[email protected]",words: 100,mails: 1}

Aggregate Framework$unwind
{_id: 2222,subject: "2.8 will be great!",to: [ "[email protected]","[email protected]","[email protected]",],account: "mongodb mail"}
{ $unwind: "$to" }
{ subject: "2.8 will be great!",
to: "[email protected]",
account : "mongodb mail” }
{ subject: "2.8 will be great!",
to: "[email protected]",
account : "mongodb mail” }
{ subject: "2.8 will be great!",
to: "[email protected]",
account : "mongodb mail” }

Agregate Framework
• Uso
• collection.aggregate([…], {<options>})• Devuelve un cursor• allowDiskUse, explain• Usar $out para guardarlo en una colección
• db.runCommand({aggregate:<collection>, pipeline:[…]})• Devuelve un documento (16 MB)
• Ejemplos:• db.books.aggregate([{ $project: { language: 1 }},{ $group: { _id: "$language", numTitles: { $sum: 1 }}}])
• { _id: "Russian", numTitles: 1 },
• { _id: "English", numTitles: 2 }
• db.runCommand({aggregate: "books", pipeline: [{ $project: { language: 1 }},$group: { _id: "$language", numTitles: { $sum:1}}}])
• {result : [{ _id: "Russian", numTitles: 1 },{ _id: "English", numTitles: 2 }],“ok” : 1}

Aggregation Framework - Ejemplos
• (zips snippet)

Spatial indexes
• Mongodb almacena información geoespacial con formato geojson
• Veamos algunos ejemplos:
Listar los aeropuertos de un estado> use geo
> var cal = db.states.findOne( {code : "CA"} );
> db.airports.find( { loc : { $geoWithin : { $geometry : cal.loc } } }, { name : 1 , type : 1, code : 1, _id: 0 } );
> db.airports.find( { loc : { $geoWithin : { $geometry : cal.loc } }, type : "International" }, { name : 1 , type : 1, code : 1, _id: 0 }
).sort({ name : 1 });
//y si agregamos un índice espacial?
db.airports.ensureIndex( { "loc" : "2dsphere" } );

Spatial indexes
Interección de planos> use geo
> var cal = db.states.findOne( {code : "CA"} );
db.states.find({ loc : { $geoIntersects : { $geometry : cal.loc } } , code : { $ne : "CA" } }, { name : 1, code : 1 , _id : 0 } );
Proximidaddb.airports.find({loc : {$near : {$geometry : { type : "Point" , coordinates : [-73.965355,40.782865] }, $maxDistance : 20000}}, type : "International"}, {name : 1,code : 1,_id : 0});

Text Search en mongodb
•Algo que está comenzando• http://docs.mongodb.org/manual/reference/operator/qu
ery/text/• db.texto.ensureIndex({ caption : "text" }, { default_language: "english" })
• db.collection.ensureIndex({content: "text", "users.comments": "text", "users.profiles": "text"},{ name: "MyTextIndex" })
• db.collection.ensureIndex({content: "text", "users.comments": "text","users.profiles": "text"},
• { name: "MyTextIndex", weights: {content: 10, "users.comments": 5, "users.profiles": 2} })
• db.texto.find({$text:{$search:”algo”}})


















