Jesús Labarta CEPBA-UPCpeople.ac.upc.edu/jesus/multiprocesadores/introduccion.pdf · l Secuencial...
24
1 Multiprocesadores Multiprocesadores Jesús Labarta CEPBA-UPC Jesús Labarta, MP, 2002 Objetivos Objetivos n Conocer sobre multiprocesadores (mas allá de la culturilla de taberna) l Conceptos básicos l Terminología l Problemática n Experiencia práctica l Programación l Análisis del rendimiento
Transcript of Jesús Labarta CEPBA-UPCpeople.ac.upc.edu/jesus/multiprocesadores/introduccion.pdf · l Secuencial...

1
MultiprocesadoresMultiprocesadores
Jesús Labarta
CEPBA-UPC
Jesús Labarta, MP, 2002
ObjetivosObjetivos
n Conocer sobre multiprocesadores (mas allá de la culturilla de taberna)
l Conceptos básicosl Terminologíal Problemática
n Experiencia práctica
l Programaciónl Análisis del rendimiento

2
Jesús Labarta, MP, 2002
TemasTemas
n Paralelismo y multiprocesadores
n Modelos de programación
n Herramientas
n Implementación Memoria compartida
l Coherencia/consistencial Sincronización
n Implementación paso de mensajes
n Interconexión
n Sistema Operativo
Jesús Labarta, MP, 2002
n Desde los dinosaurios
n Hasta los ratones (super)
MultiprocesadoresMultiprocesadores
L3 D
irec
tory
/Con
trol
L2 L2 L2
LSU LSUIFUBXU
IDU IDU
IFUBXU
FPU FPU
FXU
FXUISU ISU

3
Jesús Labarta, MP, 2002
MultiprocesadoresMultiprocesadores
n Desde los grandes centros americanos
l Simulación: física (nuclear), aerodinámica, biología, ...
n Pasando por la industria
l Diseñol Planificación producciónl Bases de datos
n Hasta la cocina
Jesús Labarta, MP, 2002
MultiprocesadoresMultiprocesadores
n TOP 500
l http://www.top500.org/

4
Jesús Labarta, MP, 2002
MultiprocesadoresMultiprocesadores
n TOP 500
l http://www.top500.org/
Jesús Labarta, MP, 2002
MultiprocesadoresMultiprocesadores
n TOP 500
l http://www.top500.org/

5
Jesús Labarta, MP, 2002
MultiprocesadoresMultiprocesadores
n TOP 500
l http://www.top500.org/
Jesús Labarta, MP, 2002
MultiprocesadoresMultiprocesadores
n TOP 500
l http://www.top500.org/

6
Jesús Labarta, MP, 2002
ParalelismoParalelismo
n Expectativa
l más currantesümenos tiempo
ümás trabajo en el mismo tiempo
… .. lineal
Jesús Labarta, MP, 2002
ParalelismoParalelismo
n Realidad
l Reparto del trabajo (balanceo)üA veces no hay
üA veces se repite
l Sobrecarga (overhead)ügeneración del trabajo
üsincronización
n Resultado
l El equipo rinde más que uno solol No siempre de forma lineall A veces mas que la suma de individualidades

7
Jesús Labarta, MP, 2002
Paralelismo: usoParalelismo: uso
n Capability computing
l Abordar grandes problemasüNo solo tiempo (CPUs)
üTambien Memoria, I/O,...
n Capacity computing:
l Throughput. Muchos problemas
Jesús Labarta, MP, 2002
MultiprocesadoresMultiprocesadores
n Que tenemos nosotros
l SGI Origin2000:ü 64 MIPS R10000
l IBM SP:ü : 128 Power3
ü : 32 Power4
l HP (compaq):ü : 12 Alpha 21264
ü : 16 Alpha 21264
… . no estamos en el mapa
l Clusterü 64 Pentiums III
ü 16 Pentiums II
l SMPs pequeñoü 4 Pentiums
ü 4 Itaniums
… pero se puede hacer mucho

8
Jesús Labarta, MP, 2002
Modelos de rendimientoModelos de rendimiento
n Modelo
l Relación entreüparámetros del sistema
ü Indicadores de rendimiento
l UtilüPredecir rendimiento
– Expectativas
üEntender funcionamiento
Si se sabe utilizar …
… mejor cuanto menos coincida con la realidad
Jesús Labarta, MP, 2002
Modelos de rendimientoModelos de rendimiento
n Indicadores de rendimiento
l Tiempo T(p)üSpeed-up S(p) = T(1)/T(p)
üEficiencia ?(p) = S(p)/p
l Throughput ??/T ??∈ {trabajos, iteraciones, problemas...}
n Otros indicadores
l Calidad precioüMFLOP/$
üMFLOP/Watio
üMFLOP/m2

9
Jesús Labarta, MP, 2002
Modelos de rendimientoModelos de rendimiento
n Ley de Amdahl
l T(1) = Tseq + Tparl T(P) = Tseq + Tpar/Pl S(P) = 1/((1-f)+f/P)ü f=Tpar/T(1) fracción paralelizable del programa
l Lo que no se paraleliza, no va mas rápido
… . acaba siendo el factor que limita
Jesús Labarta, MP, 2002
Speed-up: Amdahl’s LawSpeed-up: Amdahl’s Law
S(p) = 1 / (1 - f + (f / p))
Scalability for different sequential fraction
1.00
10.00
100.00
1000.00
1 2 4 8 16 32 64 128 256 512
# processors
Spee
dup
0.995
0.99
0.95
0.9
0.8

10
Jesús Labarta, MP, 2002
Speed-up: OverheadsSpeed-up: Overheads
S(p) = 1 / (1 - f + (f / p)+o)
Scalability for different sequential fractions. Overhead 0.05
0.10
1.00
10.00
100.00
1 2 4 8 16 32 64 128 256 512
# processors
Spee
dup 0.995
0.99
0.95
0.9
0.8
Scalability for different sequential fractions. Overhead 0.0005
0.10
1.00
10.00
100.00
1 2 4 8 16 32 64 128 256 512
# processorsSp
eedup
0.995
0.99
0.95
0.9
0.8
S(p) = 1 / (1 - f + (f / p)+o*p)
Jesús Labarta, MP, 2002
ArchitecturesArchitectures
n Shared Memory
l SMPl NUMA
n Distributed Memory
n Hierarchical mix
l SMP nodes @ Distributed memory

11
Jesús Labarta, MP, 2002
Shared MemoryShared Memory
n SMP (symmetric multiprocessor):
l UMAl Issuesü Interconnection network:
– Aggregated bandwidth: bus, crossbar.– Latency
üCache: coherency, consistency
. . .
Memory
Interconnect
Cache
Processor
I/O
Jesús Labarta, MP, 2002
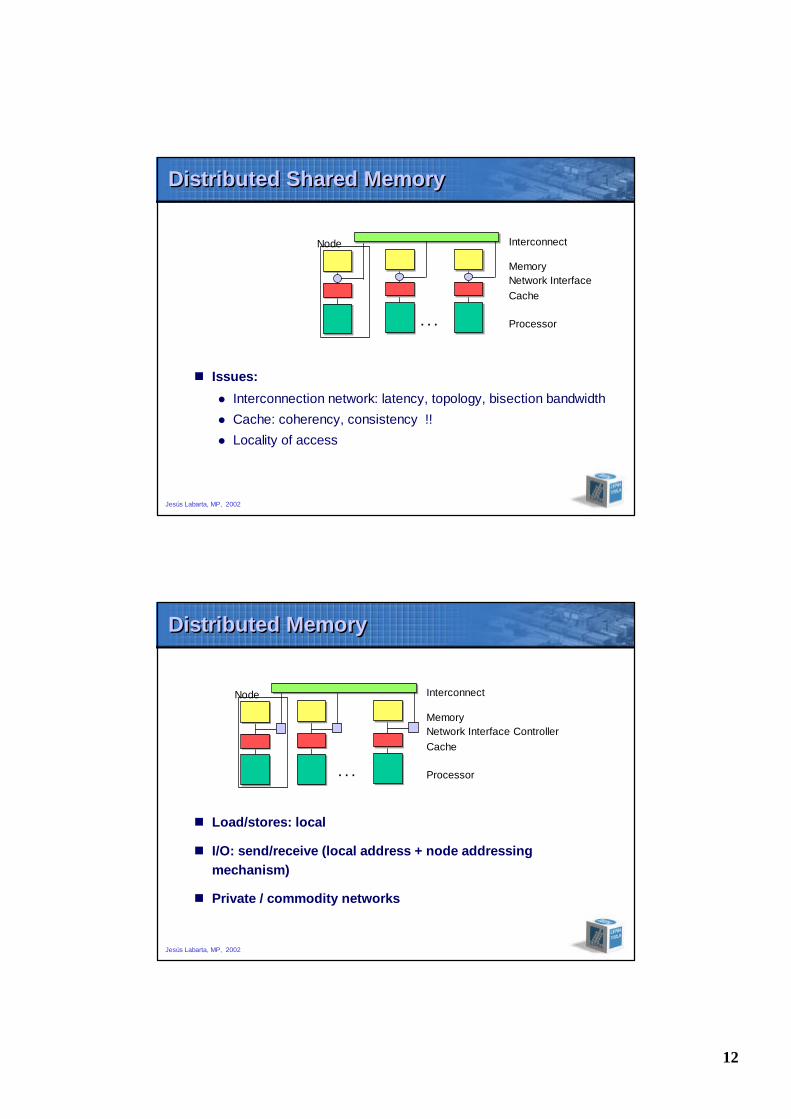
Distributed Shared MemoryDistributed Shared Memory
n Load/stores: local/remote depending on physical address
n NUMA (non-uniform memory access): remote accesses maytake 5-10 times longer
. . .
Memory
Interconnect
Cache
Processor
Node
Network Interface
12
Jesús Labarta, MP, 2002
Distributed Shared MemoryDistributed Shared Memory
n Issues:
l Interconnection network: latency, topology, bisection bandwidthl Cache: coherency, consistency !!l Locality of access
. . .
Memory
Interconnect
Cache
Processor
Node
Network Interface
Jesús Labarta, MP, 2002
Distributed MemoryDistributed Memory
n Load/stores: local
n I/O: send/receive (local address + node addressingmechanism)
n Private / commodity networks
. . .
Memory
Interconnect
Cache
Processor
Node
Network Interface Controller

13
Jesús Labarta, MP, 2002
Distributed MemoryDistributed Memory
n Issuesl Interconnection network:ü latency, topology, bisection bandwidth
ü Injection mechanism
n SMP nodes
. . .
Memory
Interconnect
Cache
Processor
Node
Network Interface Controller
Jesús Labarta, MP, 2002
Modelos de programaciónModelos de programación
n Mecanismos disponibles al programador para expresar laestructura lógica de un programa
n Influye
l Complejidad del programaüCosto de desarrollo
üLegibilidad. Costo de mantenimiento
l Rendimientoü Influenciado por el modelo
üpor la implementación del modelo
üPor la estructura de paralelización

14
Jesús Labarta, MP, 2002
Modelos de programaciónModelos de programación
n Componentes
l Datosl Procesosl Comunicaciónl Sincronizaciónl Entrada/salida
Jesús Labarta, MP, 2002
SecuencialSecuencial
C
D
S
Variable globales:
Variables dinámicas(locales): Visibilidad local Se puede pasar puntero al llamar funciones Vida limitada
Librerias:
malloc: Visible global
Problemas: Desbordamiento pilas Errores difíciles detectar (efecto variable y lejano)

15
Jesús Labarta, MP, 2002
Memoria compartida: espacio @Memoria compartida: espacio @
Variable globales: Unica copia
Variables dinámicas(locales): Acceso normal: privadas Accesibles globalmente (pasar puntero)
Librerias: Exclusión mutua
malloc: Visible global
Problemas: Desbordamiento pilas Errores difíciles detectar (efecto variable y lejano)
C
D
S1
S2
S3
Jesús Labarta, MP, 2002
Memoria Distribuida: espacio @Memoria Distribuida: espacio @
C
D
S
C
D
S
C
D
S
Variables globales: Replicadas: misma dirección lógica mantener consistencia Distribuidas: misma dirección, distinto objeto
Variables dinámicas(locales): privadas (no posibilidad compartir) ~ mismas direcciones lógicas
Librerías: Locales.
malloc: local ~ mismas direcciones lógicas

16
Jesús Labarta, MP, 2002
ModelosModelos
n Memoria compartida
l Pthreadsl OpenMPühttp://www.openmp.org
ühttp://www.compunity.org
n Memoria distribuida
l MPIühttp://www.mpi.org
ühttp://www-unix.mcs.anl.gov/mpi/
Jesús Labarta, MP, 2002
EspectroEspectro
Architecture
DM-MP
NUMA
SMP
Programming model
MPNon coherent SMCoherent SM
SVM
OpenMP@O2000
OpenMP@Alphasever
shmem@T3E
MPI@T3E
MPI@O2000
MPI@Sun

17
Jesús Labarta, MP, 2002
ParalelizaciónParalelización
n Fases
l Descomposiciónl Asignaciónl Orquestaciónl Mapeo
Algorítmico, ideas
Programación, sistema
Jesús Labarta, MP, 2002
n Aspectos básicos de programación en los distintos modelos

18
Jesús Labarta, MP, 2002
Pthreads: programaciónPthreads: programación
Distribuciónde cálculo
Memoria compartida
Double A(30,30)interger thid, j
main() { Do j = 1,30 Do thid=1,num_threads iinf = f(thid) isup = f(thid) create_thread(Loops_body,iinf,isup)}
Loop_body(iinf,isup) { Do i =iinf,isup A(i,j) = 2* A(i,j) A(i,j) = j* A(i,j) A(i,j) = i* A(i,j)}
C
D
S1
S2
S3
Double A(30,30)integer i,j
Do j = 1,30 Do i =1,30 A(i,j) = 2* A(i,j) A(i,j) = j* A(i,j) A(i,j) = i* A(i,j)
Jesús Labarta, MP, 2002
OpenMP: programaciónOpenMP: programación
Double A(30,30)integer i,j
Do j = 1,30 Do i =1,30 A(i,j) = 2* A(i,j) A(i,j) = j* A(i,j) A(i,j) = i* A(i,j)
Distribuciónde cálculo
Secuencial
Double A(30,30)interger i,j
Do j = 1,30C$OMP PARALLEL DOC$OMP PRIVATE (i) Do i =1,30 A(i,j) = 2* A(i,j) A(i,j) = j* A(i,j) A(i,j) = i* A(i,j)
C
D
S1
S2
S3

19
Jesús Labarta, MP, 2002
MPI: programaciónMPI: programación
Distribuciónde datos
Secuencial Memoria distribuida
Double A(10,30)
myrank = quien_soy()Do j = 1,30 Do li =1,10 i=li+myrank*10 A(li,j) = 2* A(li,j) A(li,j) = j* A(li,j) A(li,j) = i* A(li,j)
C
D
S
C
D
S
C
D
S
Double A(30,30)integer i,j
Do j = 1,30 Do i =1,30 A(i,j) = 2* A(i,j) A(i,j) = j* A(i,j) A(i,j) = i* A(i,j)
Jesús Labarta, MP, 2002
EconomíaEconomía
n Precio / rendimiento
n Costes
l Adquisiciónl Mantenimientol Espacio y consumol Gestiónüsystems

20
Jesús Labarta, MP, 2002
Potencia (MFLOPS, MIPS)
Tamaño del problema
1 Procesador
SuperlinealOverhead
Ley Amdahl
Sublineal
Aceleracion (Speedup)
Numero de procesadores
Paralelismo
Ideal
Que se puede esperar?Que se puede esperar?
Jesús Labarta, MP, 2002
Imaginación
Lineal
Discreta
Utilidad
Tiempo de ejecución
= F( practica, imaginación) Utilidad
Numero de procesadores
Superlineal
Sublineal
Ideal
Utilidad
Costo
Econom
ia de e
scala
Disponibles
Supercom
putador
Costo
Economia de escala
DisponiblesSuperc
omputador
Numero de procesadores
Que se puede esperar?Que se puede esperar?

21
Jesús Labarta, MP, 2002
EconomíaEconomía
n Necesidad:
l Usuario ≅ gasüPV=nRT
– P ∝ 1/ V ⇒ Solo si esta muy comprimido empuja de verdad
l Usuario ≠ gas– Una vez expandido es difícil volver atrás
l TendenciasüCOTS: procesadores, redes, software
Jesús Labarta, MP, 2002
Economía: desarrolloEconomía: desarrollo
n Memoria comparida n Memoria distribuida
Effort
Sup
Effort
Sup

22
Jesús Labarta, MP, 2002
HerramientasHerramientas
n Analizar una aplicación (sweep3d)
l Secuenciall Paralela
n Profile
l perfexl ssrun
n Traceo
l Paraverl Dimemasl Paradyn
Jesús Labarta, MP, 2002
HerramientasHerramientas
n Analizar rendimiento de aplicaciones
l Donde están sus cuellos de botellal Información para optimizarla
n Fases:
l Adquisición datosl Análisis

23
Jesús Labarta, MP, 2002
Adquisición de datosAdquisición de datos
n Instrumentación
l Qué:ücódigo usuario
ü librería
üsistema
l Quien:ümanual
ücompilador
üautomático
l Método:ü traceo / muestreo (correlado con … )
üPost-mortem / on-line
Jesús Labarta, MP, 2002
Adquisición de datosAdquisición de datos
n A tener en cuenta
l Perturbación de la ejecución:üCausa: tiempo instrumentación, polución cache, almacenamiento,…
üMinimización: implementación, soporte hardware
üEfecto: conocerlo. Vivir con el.
l Tamaño datos:üProblema almacenamiento y postproceso
üControl de la instrumentación: manual, automático
üProcesado on-line
– Overhead– Reducción información

24
Jesús Labarta, MP, 2002
AnálisisAnálisis
n Objetivo
l Transmitir información al usuario: maximizar
n Enfoque
l Percepciónl Cuantificación
n Presentación
l Qué: magnitudes => vistaüactividad temporal, fallos de cache, rutina, …
l Cómo: modelo de presentaciónüTextual
üGráfico
üsonoro,...
Jesús Labarta, MP, 2002
AplicacionesAplicaciones
n Solver iterativo
n Radix sort
n LU