
LAB I copia
468
UNIVERSIDAD NACIONAL DE SAN CRISTOBAL DE HUAMANGA FACULTAD DE INGENIERÍA ESCUELA DE INGENIERÍA DE SISTEMAS ADMINISTRACIÓN DE BASES DE DATOS (IS - 421) Ing. Hubner Janampa Patilla INTRODUCCIÓN
-
Upload
ian-alchy-gomez-salvatierra -
Category
Documents
-
view
41 -
download
4
Transcript of LAB I copia

UNIVERSIDAD NACIONAL DE SAN CRISTOBAL DE HUAMANGA
FACULTAD DE INGENIERÍA
ESCUELA DE INGENIERÍA DE SISTEMAS
ADMINISTRACIÓN DE BASES DE DATOS (IS - 421)
Ing. Hubner Janampa Patilla
INTRODUCCIÓN

Todo el mundo guarda los datos. Las grandes organizaciones gastan millones
para cuidar de su nómina de cliente, y los datos de la transacción. Las
sanciones para conseguir que mal son graves: las empresas pueden colapsar,
los accionistas y los clientes pierden dinero, y esto sucede para muchas
organizaciones (compañías aéreas, las juntas de salud, empresas de energía),
no es exagerado decir que incluso la seguridad personal puede ser puesto en
situación de riesgo.
Sin embargo, muchas pequeñas bases de datos pueden encontrarse dentro de
estas grandes organizaciones y también en las pequeñas empresas, clubes
privados. Cuando estos salen mal, no tiene la portada de los periódicos, pero
los costes a menudo son muy graves.
¿Dónde encontramos estas pequeñas bases de datos electrónicas?, en
casa, podríamos seguir en las libretas de direcciones y catálogos de CD; los
clubes deportivos tendrán información sobre los miembros; las pequeñas
empresas podrían mantener sus propios datos de los clientes.
Introducción al diseño de bases de datos
2Hubner Janampa Patilla - Administración
de Bases de Datos - 200924/09/2009

Dentro de las grandes organizaciones, también habrá una serie de pequeños
proyectos para mantener los datos que no es fácilmente o convenientemente
administrado por el gran nivel de todo el sistema de bases de datos.
Los investigadores pueden mantener su propia experimentación y los
resultados de la encuesta; grupos desean administrar sus propias listas o
llevar un registro de equipo; los departamentos podrán mantener sus propias
cuentas detalladas y de presentar un resumen de la organización financiera
del software.
La mayoría de estas pequeñas bases de datos son creados por los usuarios
finales. Se trata de personas cuyo principal trabajo es algo más que un
ordenador profesional. Ellos suelen ser los científicos, administradores,
técnicos, contadores, o maestros, y muchos de ellos tienen sólo modestos
habilidades en hoja de cálculo o base de datos de software.
Las bases de datos resultantes no suelen estar a la altura de las expectativas.
El tiempo y la energía es gastados para crear unos cuadros en una base de
datos de productos, como Microsoft Access, o en la creación de una hoja de
cálculo en un producto, tales como Excel.
3Hubner Janampa Patilla - Administración
de Bases de Datos - 200924/09/2009

Cómo se equivocó
Una base de datos que no cumple las expectativas se convierte en un costoso
ejercicio de manipulación de datos. Es evidente que tienen el costo del tiempo
y esfuerzo gastado en la creación de un insatisfactorio solicitud. Sin embargo,
un problema mucho más grave es la incapacidad para usar los datos valiosos.
Esto es especialmente cierto para los datos de la investigación.
Por desgracia, algunos bastante simples errores en el diseño puede significar
que gran parte del potencial de la información se pierda.
Otro costo oculto viene de inexactitudes en los datos. Pobre diseño de bases
de datos permite que lo que debe evitarse las incoherencias a estar presentes
en los datos. La mala manipulación de las categorías de los datos pueden
producir resúmenes e informes para inducir a error o, para ser burdo, mal.
4Hubner Janampa Patilla - Administración
de Bases de Datos - 200924/09/2009

Problemas con una base de datos no son necesariamente causados por la falta
de conocimiento sobre la base de datos de un producto en sí (aunque esto
eventualmente convertirse en una limitación), pero son a menudo el resultado
de haber escogido mala agrupación de los datos, o en una hoja de cálculo.
Esto se produce por dos razones principales:
• No tener una idea clara de qué tipo de información tiene la base de datos o
una hoja de cálculo.
• No tener un modelo claro de las distintas clases de datos y sus relaciones
el uno al otro
Este curso describe las técnicas para obtener una comprensión precisa de
cómo desarrollar un modelo conceptual de los datos implicados, y cómo
traducir ese modelo en un diseño de bases de datos. Usted aprenderá a
diseñar mejores bases de datos.
Podrás evitar el costo de "hacer mal".
5Hubner Janampa Patilla - Administración
de Bases de Datos - 200924/09/2009

Técnicas de análisis
Mucho análisis y diseño de metodologías se han desarrollado con gran
desarrollo de proyectos en mente. Estas metodologías tienen que abordar las
cuestiones de los costos y los contratos, mantenimiento y seguridad, normas e
interfaces, y el documentación necesaria para un proyecto que es demasiado
grande para cualquier persona o equipo de comprender en total.
El calendario puede significar la participan de mas equipos de proyecto que
podría a su vez cargar más la totalidad de su personal durante el desarrollo, a
fin de que la documentación se convierte en un crítico factor en el éxito del
proyecto.
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009624/09/2009

Determinar el uso
Lo que en cualquier proyecto se requiere es un entendimiento claro de
exactamente lo que la base de datos lograra. A veces, los clientes pueden tomar
delito cuando usted pregunta qué uso le dará a su bases de datos.
Se necesita de cierta disciplina para hacer los preparativos necesarios,
especialmente cuando la necesidad de obtener los datos introducidos soy muy
importantes. Una manera conveniente de capturar los posibles usos para datos
es construir casos de uso o historias de usuario.
Usted puede estar familiarizado con estas ideas, que proceden del Lenguaje
Unificado de Modelado (UML) y la Extrema Programming. Los casos de
uso son de libre formato de texto, que esencialmente describen las cosas desde
el punto de vista de un posible usuario. Por ejemplo, en un caso de uso podría
registrar un estadístico los datos de su trabajo sobre la investigación
experimental que depende de la meteorología.
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009724/09/2009

Crear un modelo de datos
El abismo entre tener una idea básica de lo que su base de datos debe ser capaz
de hacer, y el diseño de las tablas correspondientes, es salvarse por tener un
claro modelo de datos. El modelado de datos implica reflexionar muy
detenidamente sobre los diferentes conjuntos o clases de datos que necesitamos
para una problema particular.
Aquí está un ejemplo simple : una pequeña empresa pueda tener clientes,
productos y pedidos. Tenemos que grabar el nombre del cliente. Que
pertenece claramente a nuestros conjunto de datos de clientes. ¿Y con respecto
a la dirección? Ahora, ¿significa la dirección del cliente de contacto (en cuyo
caso pertenece a los datos de los clientes), o cuando nos envía la orden (en cuyo
caso pertenece la información a la orden)? ¿Qué pasa con el descuento ? ¿Que
le pertenece al cliente (algunos de ellos son clientes de tarjetas de oro), o el
producto, o la orden (20% de descuento para pedidos superiores a $ 4000)?
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009824/09/2009

Obtener las respuestas correctas a estas preguntas es, evidentemente, vital si
va a proporcionar una base de datos útil para usted mismo o su cliente. No es
una buena partida hacer una columna en su hoja de cálculo "Descuento" antes
de tener una comprensión muy precisa de exactamente lo que significa un
descuento en el contexto del problema actual.
Los diagramas de modelado de los datos proporcionan en forma precisa y fácil
interpretar la documentación para obtener respuestas a preguntas tales como
usted se plantea. Aún más importante, el proceso de construcción de un
modelo de datos le lleva a preguntarse las preguntas, en primer lugar. Es
esto, más que cualquier otra cosa, que hace este tipo de modelado de
datos.
Los modelos de datos que va ver en este curso son medianos. Ellos pueden
representar una pequeño problema en su totalidad, pero lo más probable es
que será una pequeña parte de un problema más amplio.
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009924/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200910
Los modelos de datos suelen estar representadas visualmente utilizando
algún tipo de diagrama. Diagramas le permiten tener a una gran cantidad
de información de un vistazo, dándole la capacidad de captar rápidamente la
esencia de un diseño de bases de datos sin tener que leer un montón de texto.
Vamos a utilizar el diagrama de clase de notación UML para representar a
nuestros modelos de datos, pero muchas otras notaciones son igualmente
útiles.
24/09/2009

Implementación de base de datos
Una vez que usted tiene un modelo de datos que apoye a sus casos de uso
(y todos los demás detalles que se han descubierto en el camino), usted sabe
cuán grande es su problema y el tipo de detalle que implica. Ahora tiene una
buena base para el diseño de una adecuada aplicación y la realización de la
aplicación.
Conceptualmente, la traducción del modelo de datos para el diseño de una
base de datos o una hoja de cálculo es simple. En las próximas lecciones ,
vamos a ver la forma de diseñar tablas y relaciones en una base de datos
relacional (como Microsoft Access), que representan la información en el
modelo de datos. Además también veremos cómo esto podría hacerse en uno
base de datos orientado a objetos, y por problemas con no demasiadas clases
de datos, cómo puede capturar parte de la información en un producto de hoja
de cálculo como Microsoft Excel.
Hubner Janampa Patilla - Administración
de Bases de Datos - 20091124/09/2009

La traducción del modelo de datos al diseño de bases de datos es bastante
sencillo, sin embargo, la aplicación real no es tan simple. Una gran cantidad
de trabajo es necesario para asegurar que la base de datos sea útil al usuario
final. Esto significará diseñar una interfaz de usuario con una clara lógica, la
buena entrada de los datos, la capacidad de encontrar rápidamente los datos
de editar o borrar, adaptable y preciso para consultar e informar las
características, la capacidad de importación y exportación de datos, y las
buenas instalaciones de mantenimiento, tales como copia de seguridad y
archivo.
No subestime el tiempo y la experiencia necesario para completar una
aplicación útil incluso para las más pequeñas base de datos. Consideraciones
tales como la interfaz de usuario, mantenimiento, archivo, están fuera del
alcance de este curso, pero estarán bien cubiertas en el aspecto practico del
curso.
Hubner Janampa Patilla - Administración
de Bases de Datos - 20091224/09/2009

CAPÍTULO 1 Qué puede salir mal
Palabras claves, mala gestión y las categoríasInformación repetida
El diseño de un único informeResumen
13Hubner Janampa Patilla - Administración
de Bases de Datos - 200924/09/2009

¿Qué puede salir mal
El problema con una serie de pequeñas bases de datos (y muy probablemente con
muchos grandes queridos) es que la idea inicial de cómo registrar los datos no es
necesariamente la correcta.
A menudo, una tabla o una hoja de cálculo está diseñado para imitar una posible
entrada de datos. Esta práctica puede ser adecuada para resolver el problema
inmediato (por ejemplo, almacenar los datos en alguna parte), sin embargo,
simulando una pantalla de entrada de datos o un informe en su diseño de bases
de datos a menudo causa problemas más adelante. Se puede hacer que sea difícil
o imposible para obtener información para los distintos informes o resúmenes,
no obstante, deben estar disponibles teniendo en cuenta los datos recogidos.
En este capítulo se presentan ejemplos extraídos de la vida real para ilustrar
algunos tipos básicos de los problemas surgidos cuando los datos se almacenan
en las hojas de cálculo mal diseñados o tablas.
Hubner Janampa Patilla - Administración
de Bases de Datos - 20091424/09/2009

Estos son ejemplos reales que he encontrado en mi propio trabajo de diseño.
No proceden de un libro de texto o de un examen de papel. Algunos de los
datos ha sido suprimida o modificadas para proteger la identidad de los
culpables.
Mala gestión de palabras claves y categorías
Un problema común en el diseño de bases de datos es el fracaso para tratar
adecuadamente con palabras clave y categorías. Muchas aplicaciones de bases
de datos implica que los datos se clasifican de alguna manera:
productos o acontecimientos pueden ser de interés para determinadas
categorías de personas, los clientes pueden ser clasificados por edad o los
intereses o los ingresos (o los tres). Al introducir datos, por lo general,
pensar en un tema con su particular lista de categorías o palabras clave. Sin
embargo, cuando usted llegado a la preparación de informes o hacer algunos
análisis, puede que tenga que ver las cosas al revés.
Hubner Janampa Patilla - Administración
de Bases de Datos - 20091524/09/2009

A menudo quieren ver una categoría con una lista de todos sus elementos, o
un título con el número de artículos. Por ejemplo, usted podría preguntar
"¿Cuál es el porcentaje de clientes que son buenos pagadores? "Si las palabras
clave y categorías no son almacenados correctamente inicialmente, estos
informes pueden llegar a ser muy difícil de producir.
Ejemplo 1 describe un caso sobre la información de cómo se utilizan las
plantas, y se registra de una manera que parece razonable a primera vista,
pero que en última instancia no se puede manipular y se le hace muy difícil
crear reportes específicos para cada planta en cuanto a su uso, etc.
Hubner Janampa Patilla - Administración
de Bases de Datos - 20091624/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 200917
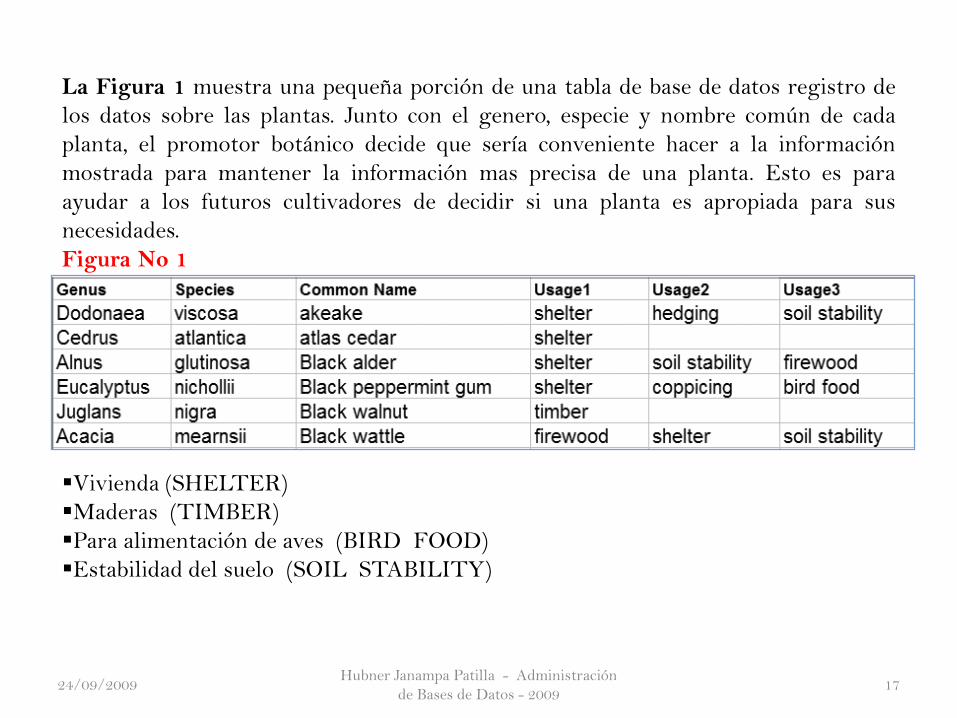
La Figura 1 muestra una pequeña porción de una tabla de base de datos registro de
los datos sobre las plantas. Junto con el genero, especie y nombre común de cada
planta, el promotor botánico decide que sería conveniente hacer a la información
mostrada para mantener la información mas precisa de una planta. Esto es para
ayudar a los futuros cultivadores de decidir si una planta es apropiada para sus
necesidades.
Figura No 1
Vivienda (SHELTER)
Maderas (TIMBER)
Para alimentación de aves (BIRD FOOD)
Estabilidad del suelo (SOIL STABILITY)
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200918
En el Ejemplo 1, la verdadera vergüenza es que todos los datos han sido
recogidos cuidadosamente y entró, pero el diseño del cuadro que hace que sea
imposible dar respuesta a las preguntas obvias convenientemente. El
problema es que el desarrollador no tiene tiempo de dar un paso atrás y
examinar los probables usos de los datos.
El diseño de la base de datos principalmente debe satisfacer su problema
inmediato, que es "necesario para almacenar toda la información que tenemos
sobre cada planta." Antes de embarcarse en la puesta en práctica, habría sido
útil tener en cuenta otros puntos de punto de vista y posibles usos de los
datos. La más obvia de ellas es "Quiero encontrar todas las plantas que
cuentan con este uso en particular‖.
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200919
En el Ejemplo 1, realmente tenemos dos tipos o clases de datos, las plantas
y sus usos, y estamos interesados en las conexiones entre ellos. Las técnicas
de modelado de datos se describe en el resto del curso, que es una forma
práctica de aclarar exactamente qué es lo que usted esperar de sus datos y
ayudar a decidir cuál es el mejor diseño de bases de datos para apoyar eso.
Saltando un poco por delante para ver una solución para la base de datos
planta del problema, puede configurar rápidamente una útil base de datos
relacional mediante la creación de los dos tablas como se muestra en la Figura
1-2.
24/09/2009
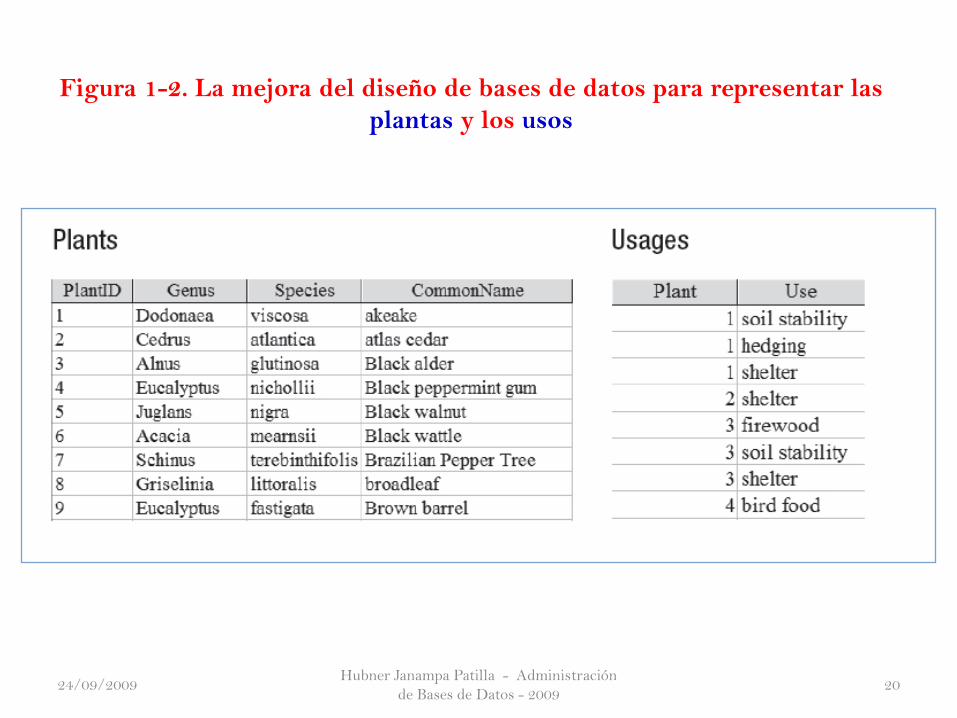
Figura 1-2. La mejora del diseño de bases de datos para representar las
plantas y los usos
Hubner Janampa Patilla - Administración
de Bases de Datos - 20092024/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 20092124/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 20092224/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 20092324/09/2009

Una breve historia de las bases de datos
La Base de datos moderno surgió en el decenio de 1960 gracias a la
investigación en IBM, entre otras empresas. La investigación centrada
principalmente en torno a la automatización de oficinas, en particular la
automatización de almacenamiento de datos y indexación de las tareas que
anteriormente requería una gran cantidad de mano de obra.
La potencia de las computadoras y almacenamiento se ha convertido en mucho
más barato, con lo que el uso de computadoras para los datos de indexación y
almacenamiento era una solución viable. Un pionero en la base de datos de
campo fue Charles W. Bachman, que recibió el Premio Turing en 1973 por
una labor pionera en la tecnología de base de datos. En 1970, un investigador de
IBM llamado Ted Codd publicó el primer artículo sobre las bases de datos
relacionales.
A principios del decenio de 1980, los primeros sistemas de bases de datos
basado en el estándar SQL apareció en las empresas tales como Oracle, con
Oracle, versión 2, y, posteriormente, SQL / DS de IBM, así como una serie de
otros los sistemas de otras empresas.
Hubner Janampa Patilla - Administración
de Bases de Datos - 20092424/09/2009

Lenguaje estructurado de consultas (SQL)
La primera pregunta que hacer es lo que es SQL y cómo utilizarlo con bases
de datos.
SQL tiene tres funciones principales:
❑ Creación de una base de datos y la definición de su estructura.
❑ Consultar a la base de datos para obtener los datos necesarios para
responder a las preguntas.
❑ Seguridad de control de las base de datos.
La definición de estructura de base de datos incluye la creación de nueva base
de datos tablas y campos, el establecimiento de normas de datos
entrada, y así sucesivamente, que se expresa por un sub lenguaje SQL
llamado lenguaje de control de datos (DCL).
Hubner Janampa Patilla - Administración
de Bases de Datos - 20092524/09/2009

La introducción a las consultas SQL
Las consultas SQL son las más comunes en el uso del SQL. Un sub lenguaje
SQL llamado lenguaje de manipulación de datos (DML) se refiere a las
consultas y manipulación de datos.
Por ejemplo, con un base de datos que almacena detalles de los vendedores, las
ventas de automóviles, el tipo vendido, y así sucesivamente, es posible que se
desee conocer el número de coches vendidos por cada vendedor en cada mes y
la cantidad de dinero que hizo la empresa.
Usted puede escribir una consulta SQL a esa pregunta y obtener la respuesta.
Una consulta SQL consiste en diversas declaraciones, cláusulas y
condiciones.
Una declaración es una instrucción o un comando. Una cláusula especifica los
límites a una declaración, los límites que se especifican mediante condiciones.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200926
SELECT CarModel FROM CarSales
WHERE CarSoldDate BETWEEN „May 1 2005‟ AND „May 31 2005‟;
24/09/2009

La comparación de SQL a otros lenguajes de programación
Ahora que sabes para que puedes utilizar SQL, puedes compararlo con otros
lenguajes de programación. Para ser honestos, SQL es bastante diferente de
los lenguas de procedimiento, tales como C + +, Visual Basic, Pascal, y otra
tercera generación de lenguajes de programación, que permiten a los
programadores escribir paso a paso instrucciones diciéndole al ordenador
exactamente qué hacer para lograr un determinado objetivo. Tomando la
venta de automóviles de ejemplo, su objetivo podría ser la de seleccionar toda
la información sobre las ventas realizadas en julio en la sala de exposición
de Nueva York. Muy aproximadamente en su lengua de procedimiento
podría hacer lo siguiente:
1. Las carga de ventas de los datos en la memoria del ordenador.
2. Extracto de los elementos individuales de datos a partir de los datos de
ventas.
3. Revisar para ver si cada uno de los elementos de datos es a partir del mes
de julio y de la sala de exposición de Nueva York.
4. Si es así, entonces hacer una nota de los datos.
Hubner Janampa Patilla - Administración
de Bases de Datos - 20092724/09/2009

5. Volver a la orden del día de los datos y seguir hacia adelante hasta que
todos los temas han sido verificados.
6. Loop a través de los datos y mostrar los resultados de cada uno de ellos.
SQL, sin embargo, es un lenguaje declarativo. En las ventas de automóviles
de ejemplo, si estas usando SQL, usted podría escribir lo siguiente:
SELECT * FROM SalesMadeWHERE SaleDate = “July 2005”AND SalesOffice = “NewYork”

Comprender las normas SQL
Al igual que ocurre con las bases de datos, IBM hizo una gran parte del
trabajo original de SQL. Sin embargo, un montón de otros proveedores de
IBM se ocupa de la norma y desarrollado sus propias versiones del mismo.
Habiendo tantos dialectos diferentes causando bastante dolor de cabeza para
el desarrollador, en 1986 fue aprobado por el organismo de normalización del
Instituto Nacional Estadounidense de Estándares (ANSI) y en 1987 por
la Organización Internacional de Normalización (ISO), que creó un
estándar para SQL. Aunque esto ha ayudado a minimizar las diferencias entre
los diversos dialectos SQL, todavía hay diferencias entre ellos.
Hubner Janampa Patilla - Administración
de Bases de Datos - 20092924/09/2009
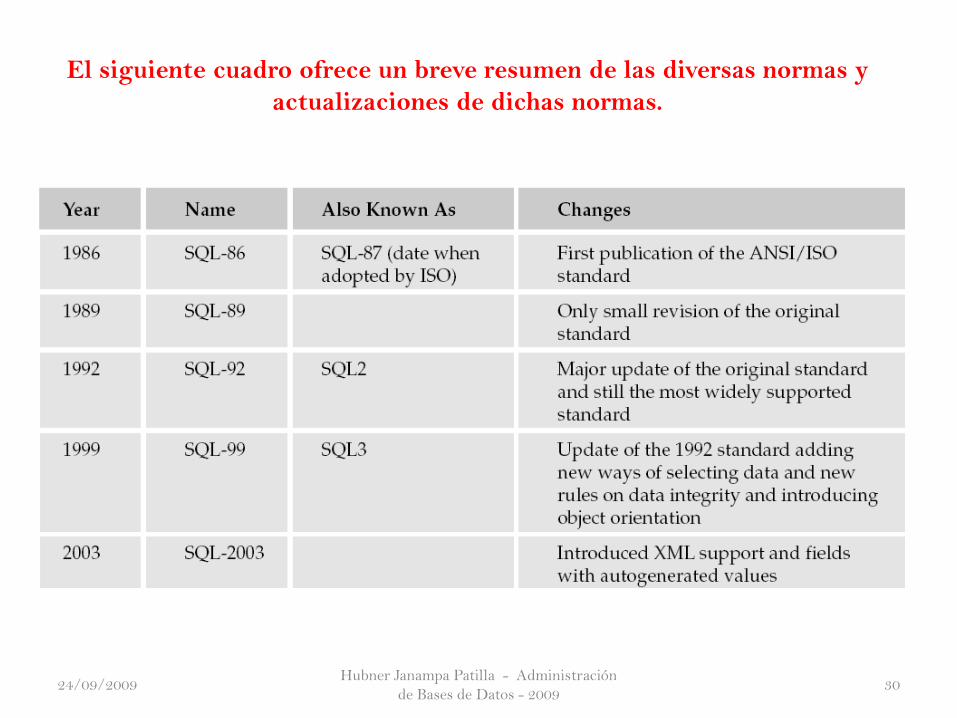
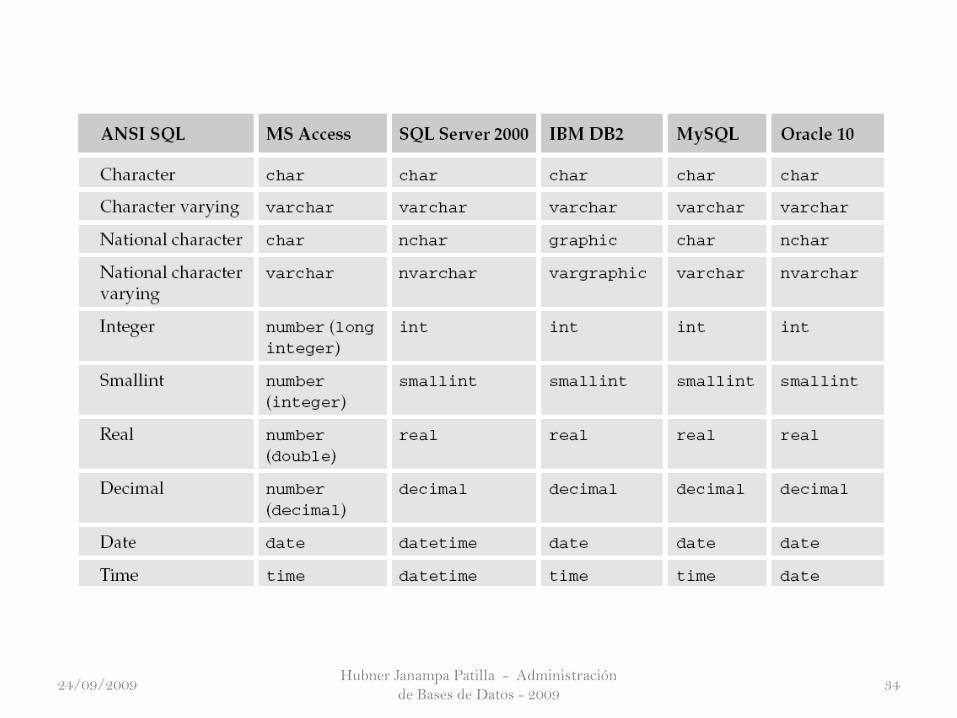
El siguiente cuadro ofrece un breve resumen de las diversas normas y
actualizaciones de dichas normas.
Hubner Janampa Patilla - Administración
de Bases de Datos - 20093024/09/2009

Este curso se concentra en SQL-92, SQL-99, y SQL-2003 debido a que la
mayoría de sus características han sido aplicado a la mayoría de base de datos
relacionales de gestión de sistemas (RDBMS).
Aunque las normas son importantes para ayudar a traer algún tipo de
coincidencia entre los distintos RDBMS, al final del día lo que funciona en la
práctica es lo que realmente cuenta. En lugar de debatir interminablemente
las normas, este curso le proporcionara información para ayudarle en el
mundo real de las bases de datos.
Hubner Janampa Patilla - Administración
de Bases de Datos - 20093124/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 20093224/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200933
CREATE TABLE name_of_table
(
name_of_column column_datatype
)
CREATE DATABASE myFirstDatabase;
Dicho esto, la siguiente sección le muestra cómo crear tu propia base de datos SQL.
24/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 20093424/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 20093524/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 20093624/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 20093724/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 20093824/09/2009

La creación de la base de datos de ejemplo
Usted necesidad de crear un base de datos para almacenar las tablas. Ustedpuede llamar a su base de datos algo así como Club de Cine , aunque elnombre de la BD no es importante. En el apéndice que se dará al final de estapresentación, tiene todas las características necesarias para la creación de unejemplo de base de datos en blanco, ya sea en Access, SQL Server, DB2,MySQL, y Oracle . Una vez que hayas creado la BD Club Cine, es hora deempezar a poblar con tablas.
La premisa básica es que usted está ejecutando un club de película, y quedesea una base de datos que almacena los siguientes información:
❑ Detalles de los miembro del Club, tales como nombre, dirección, fecha de nacimiento, fecha de su adhesión, y la dirección de correo electrónico. ❑ Detalle de asistencia a las reuniones. ❑ Ficha de la película. ❑ Preferencias categoría para los miembros.
Ya ha establecido los detalles de la BD del club, pero ahora anunciare los campos adicionales para las tablas:
Hubner Janampa Patilla - Administración
de Bases de Datos - 20093924/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200940
CREATE TABLE Films
(
FilmId integer,
FilmName varchar(100),
YearReleased integer,
PlotSummary varchar(2000),
AvailableOnDVD char(1),
Rating integer,
CategoryId integer
);
CREATE TABLE Category
(
CategoryId integer,
Category varchar(100)
);
CREATE TABLE FavCategory
(
CategoryId integer,
MemberId integer
);
CREATE TABLE MemberDetails
(
MemberId integer,
FirstName nvarchar(50),
LastName nvarchar(50),
DateOfBirth datetime,
Street varchar(100),
City varchar(75),
State varchar(75),
ZipCode varchar(12),
Email varchar(200),
DateOfJoining datetime
);
CREATE TABLE Attendance
(
MeetingDate datetime,
Location varchar(200),
MemberAttended char(1),
MemberId integer
);
24/09/2009
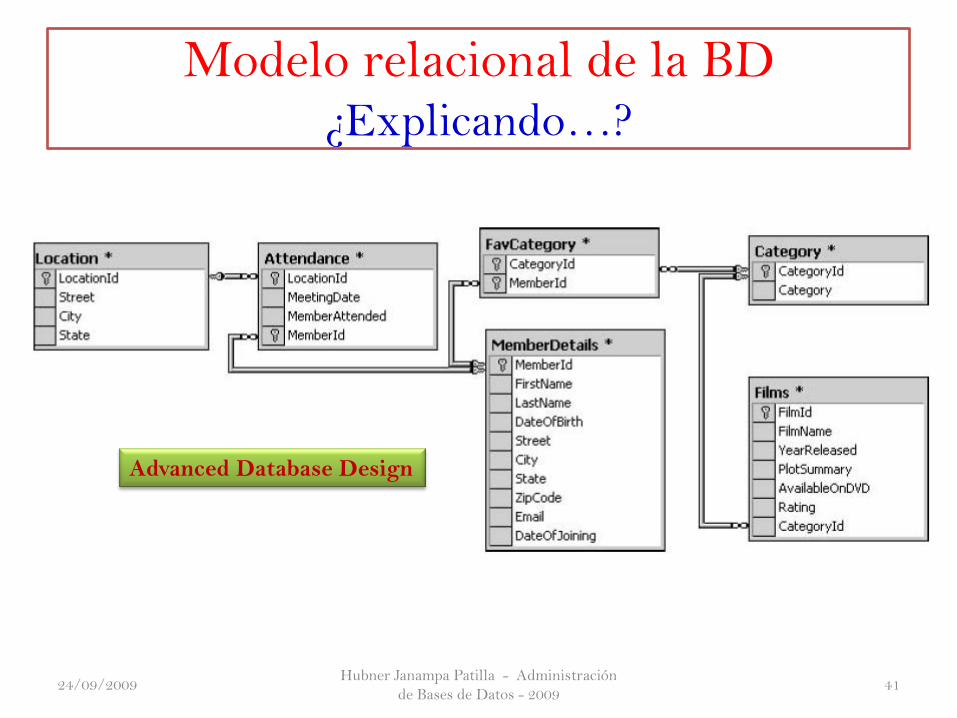
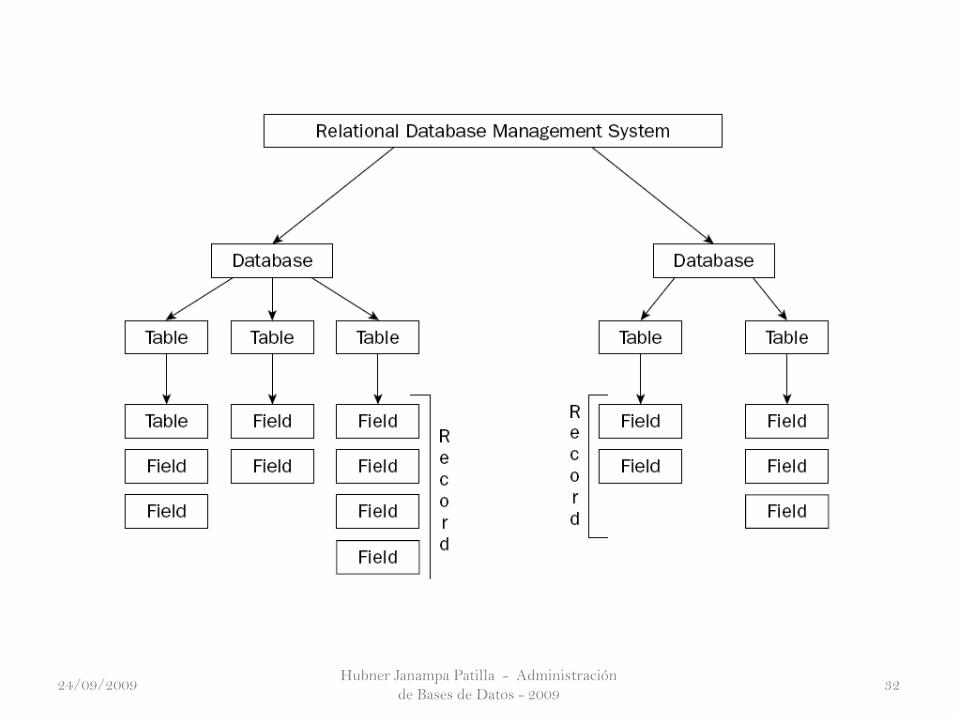
Modelo relacional de la BD¿Explicando…?
Hubner Janampa Patilla - Administración
de Bases de Datos - 200941
Advanced Database Design
24/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 20094224/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200943
ALTER TABLE Attendance
DROP COLUMN Location;
ALTER TABLE Attendance
ADD LocationId integer;
CREATE TABLE Location
(
LocationId integer,
Street varchar(100),
City varchar(75),
State varchar(75)
);
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 20094424/09/2009

Entering Information
Ya se examinó la creación de una base de datos y la adición de tablas, por lo queahora usted está listo para empezar agregando los datos. La mayoría deRDBMS proporcionar herramientas de gestión que permiten ver las tablas ylos registros que poseen, así como también le permite añadir, modificar yborrar los datos. Estas herramientas son muy conveniente cuando se tienepequeñas cantidades de datos o cuando usted está haciendo una prueba de labase de datos.
Sin embargo, usted no suelen introducir datos utilizando las herramientas degestión. Mucho más común es algún tipo de programa o una página Web queactúa como una interfaz agradable en el que el usuario introduce los datos. Estecapítulo se centra en cómo utilizar comandos SQL para insertar, actualizar oborrar datos contenida en una base de datos.
Este capítulo abarca los tres sentencias SQL que se ocupan de alterar los datos.El primero es la declaración INSERT, que introduce nuevos datos. ElUPDATE actualiza los datos existentes en la base de datos. Por último, estecapítulo se refiere a la declaración DELETE, que (sorpresa, sorpresa) suprimeregistros.
Hubner Janampa Patilla - Administración
de Bases de Datos - 20094524/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 20094624/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 20094724/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 20094824/09/2009
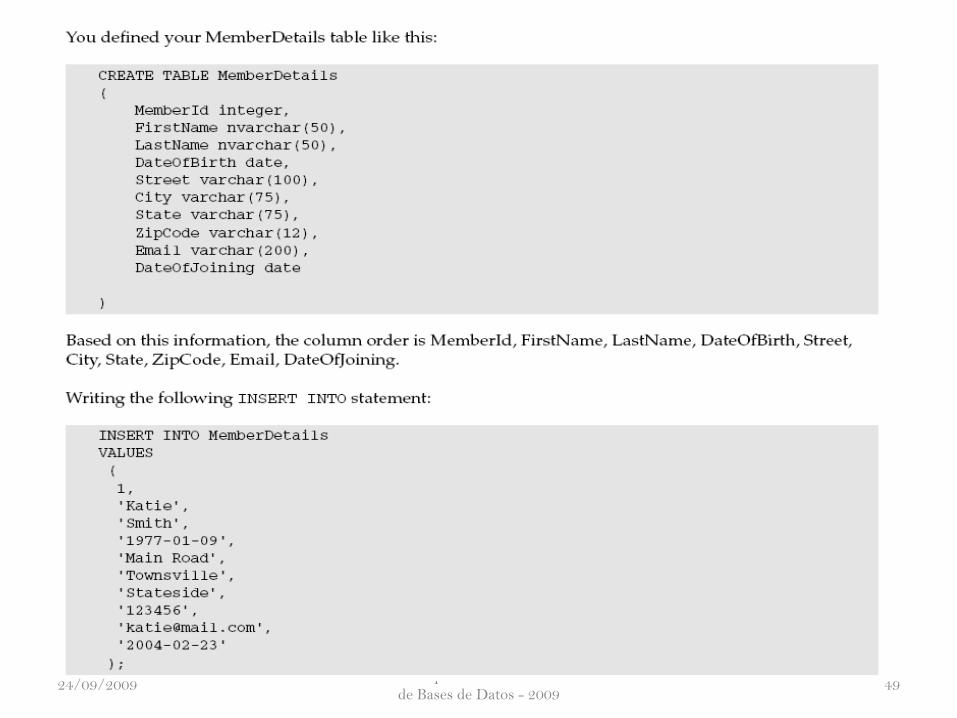
Hubner Janampa Patilla - Administración
de Bases de Datos - 20094924/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200950
Tenga en cuenta que las fechas en la tabla anterior se especifican en el formulario de
año-mes-día, por lo que 23 de febrero de 2004, se introduce como 2004-02-23. El
formato exacto aceptable para cada sistema de base de datos varía no sólo con el
sistema de bases de datos, sino también con la forma en que la base de datos fue
creado e instalado, así como el formato fecha / hora especificado por el propio
ordenador. Sin embargo, el formato año-mes-día no funciona por defecto en la
instalación de Oracle.
Para Oracle, utiliza el formato de day-month_name-year. Por lo tanto, usted
deberá escribir 9 de enero de 1977.
Las ventajas de no nombrar a las columnas de su sentencia INSERT, es que se
salva de escribir y se le hace más corto la sentencia SQL.
24/09/2009

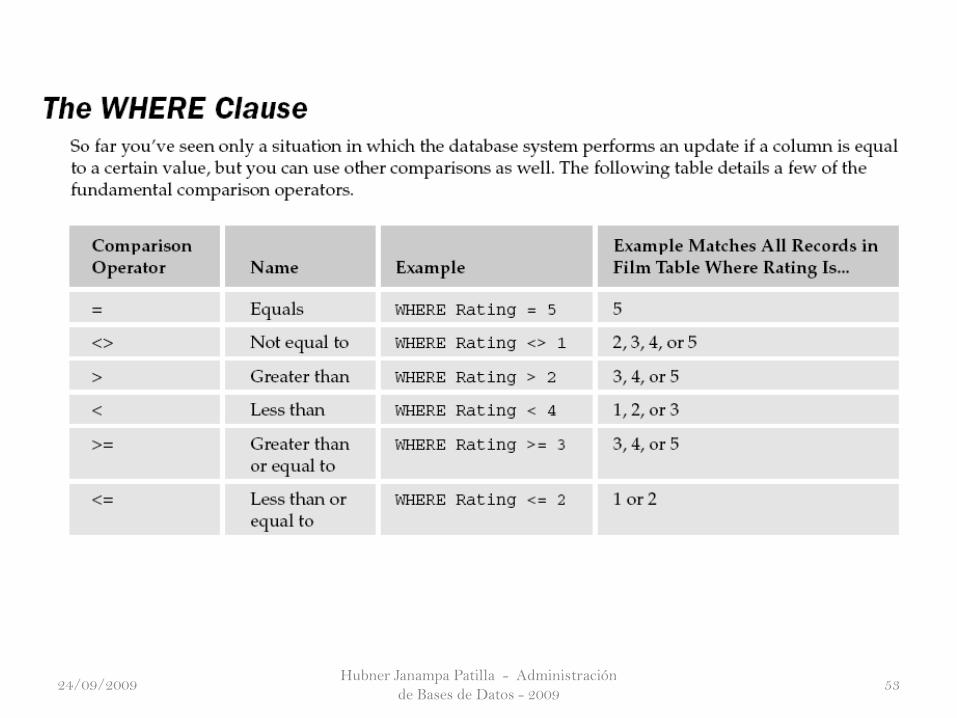
Updating Data
Hubner Janampa Patilla - Administración
de Bases de Datos - 200951
No sólo es necesario añadir nuevos registros, pero en algún momento usted
también tiene la necesidad de cambiar los registros. Para actualizar los
registros, usted utilizara el comando UPDATE. Especificar los registros a
cambiar es la principal diferencia entre la inserción de nuevos datos y
actualizar los datos existentes. Usted especifica que para actualizar los
registros utiliza la cláusula WHERE, que le permite especificar que sólo los
registros de actualización son aquellos en los que una determinada condición
es verdadera.
El comando UPDATE permite la configuración para actualizar los campos. La
sintaxis básica para la actualización es la declaración siguiente:
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 20095224/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 20095324/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 20095424/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 20095524/09/2009

Deleting Data
Hasta ahora, en este capítulo, usted ha aprendido la manera de añadir nuevos
datos y actualizar los datos existentes, por lo que todo lo que queda a aprender
es cómo borrar los datos. La buena noticia es que la supresión de los datos es
muy fácil, y si es necesario, añadir una cláusula WHERE para especificar que
los registros para borrar.
Si desea borrar todos los registros de una tabla, simplemente dejar de lado la
cláusula WHERE, como se muestra en la siguiente declaración:
Hubner Janampa Patilla - Administración
de Bases de Datos - 20095624/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 20095724/09/2009

Hasta el momento usted ha aprendido a crear una base de datos y la forma de
insertar datos en ella, por lo que ahora puede aprender la manera de extraer
los datos de su base de datos. Probablemente, su característica mas potente de
SQL es su capacidad para extraer los datos, y la extracción de datos puede
ser tan simple o complejo como usted requiere.
Usted puede simplemente extraer datos de la misma forma en que fue
introducido en la base de datos, o se puede consultar la base de datos y
obtener respuestas a las preguntas a partir de los datos básicos.
La clave para obtener los datos, es la sentencia SELECT, que en su forma
básica es muy simple y fácil de usar. Sin embargo, a medida que veremos los
capítulos, usted vera los lotes de opciones adicionales que hacen de la
sentencia SELECT muy potente.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200958
Extracting Information
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 20095924/09/2009
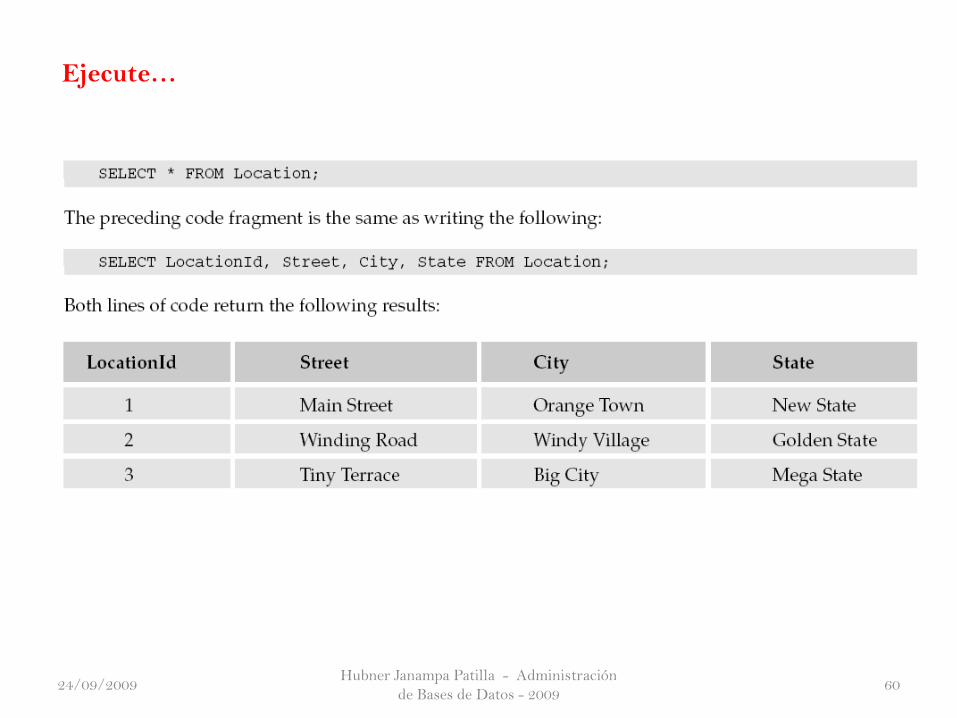
Hubner Janampa Patilla - Administración
de Bases de Datos - 200960
Ejecute…
24/09/2009

Returning Only Distinct Rows
Si desea conocer todos los valores únicos en un registro, ¿cómo ir sobre la
recuperación de ellos?, la respuesta es mediante el uso de la palabra clave
DISTINCT. La palabra clave DISTINCT se añadirá a la declaración del
SELECT, directamente después de la palabra clave SELECT. Por ejemplo, si
alguien le pide de que ciudades proceden los miembros, usted podría intentar
una consulta similar a lo siguiente:
Hubner Janampa Patilla - Administración
de Bases de Datos - 20096124/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200962
Ejecute…
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200963
Ejecute…
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200964
Using Aliases
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200965
Filtering Results with the WHERE Clause
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 20096624/09/2009

Trabajo Practico
Cinco nuevos miembros se han unido al club, por lo que sus datos deben
incluirse en la base de datos. Lo siguiente detalla cómo se deberá añadir los
nuevos miembros para la de base de datos:
1. Introduzca el código SQL en su base de datos, a continuación ejecútelo. Se
incluyen los nuevos miembros y sus categorías preferidas de las películas con
la sentencia INSERT. Tenga en cuenta que si está utilizando Oracle, los
formatos de fecha se debe cambiar de su actual formato de año-mes-día a
día-mes-año.
Hubner Janampa Patilla - Administración
de Bases de Datos - 20096724/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200968
1
24/09/2009
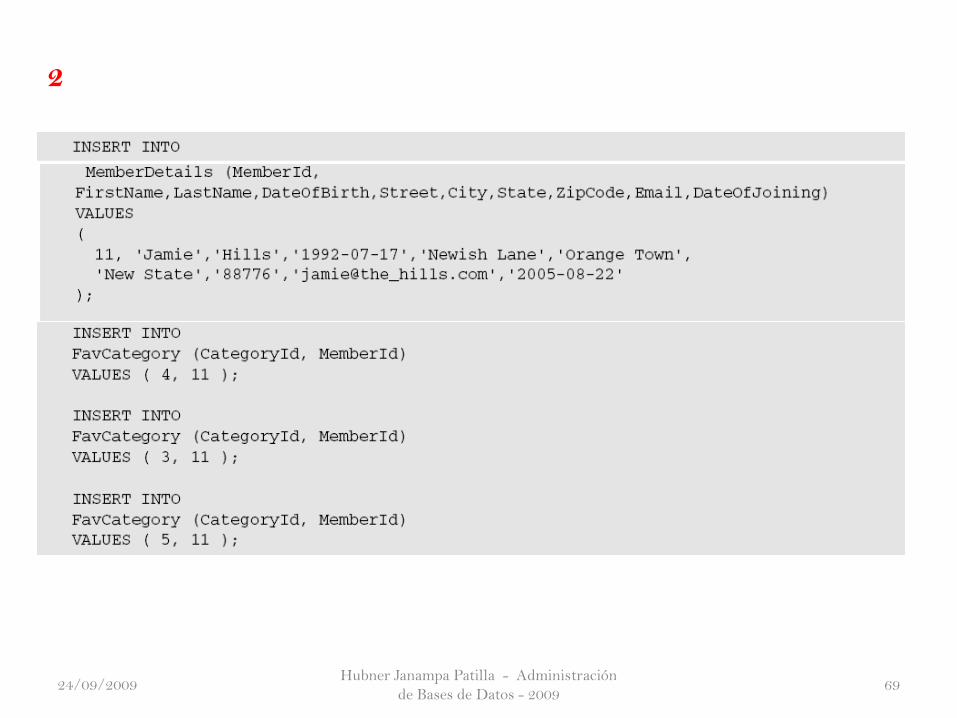
Hubner Janampa Patilla - Administración
de Bases de Datos - 200969
2
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200970
3
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200971
4
24/09/2009
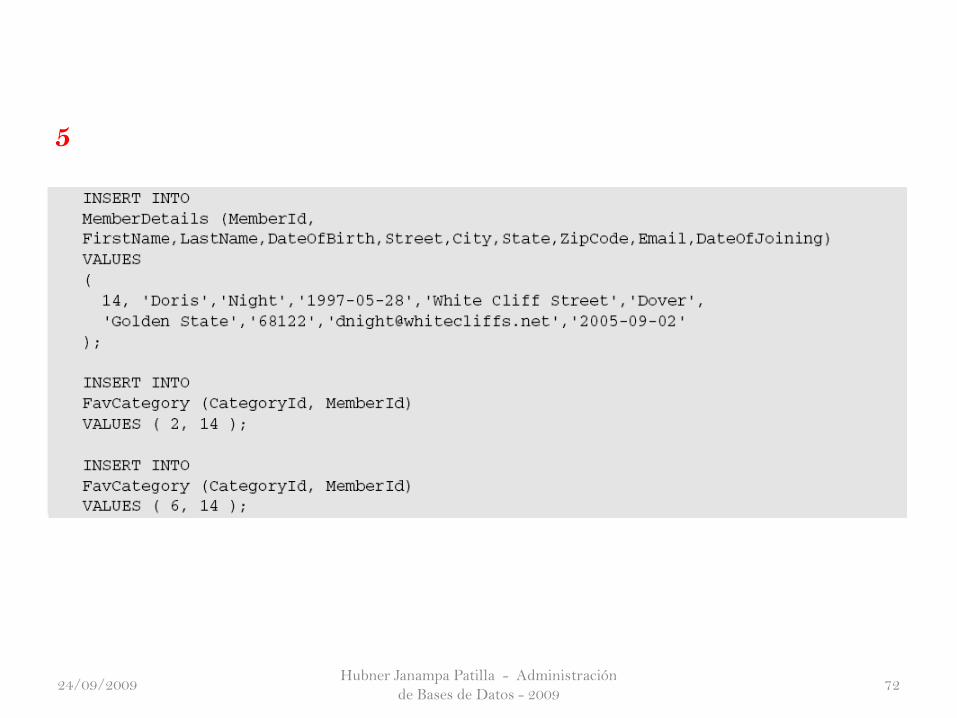
Hubner Janampa Patilla - Administración
de Bases de Datos - 200972
5
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200973
Pruebe las siguientes consultas...
24/09/2009

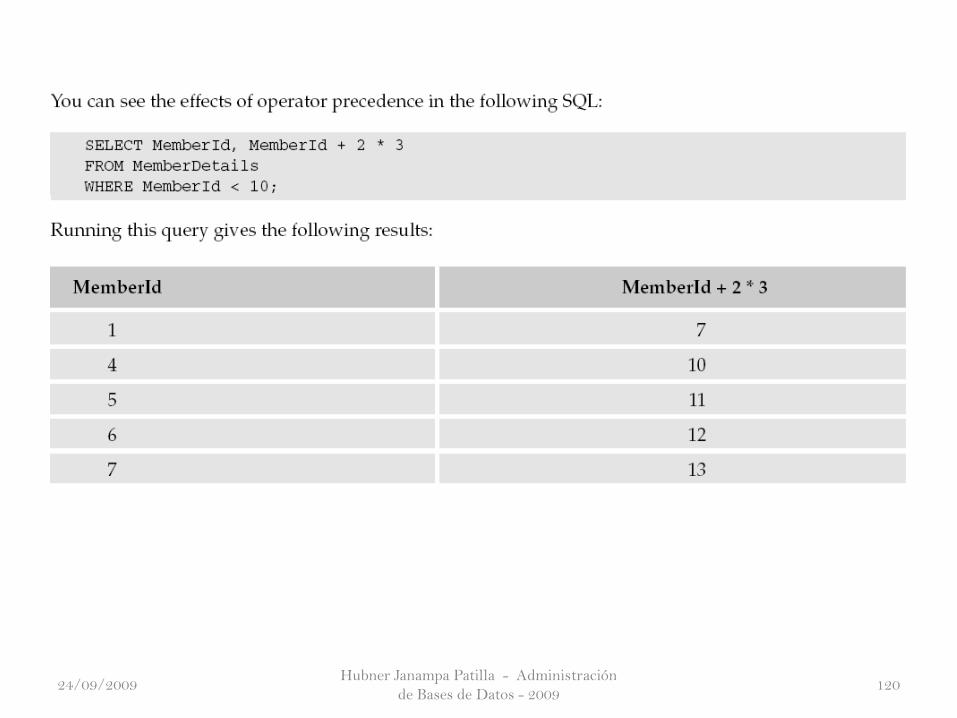
Introducing Operator Precedence
La Declaración Americana de la independencia establece que todos los
hombres son creados iguales, pero no menciona nada sobre los operadores.
Si lo hiciera, tendría que decir que todos los operadores son definitivamente
no iguales. Una jerarquía de los operadores determina qué operador se
evalúa en primer lugar. Si todos los operadores tendrían igual precedencia,
entonces todas las condiciones se interpretan de izquierda a derecha.
Si los operadores son diferentes, entonces los más altos son evaluados
primero, luego el siguiente más alto, y así sucesivamente. En el siguiente
cuadro se detallan todos los operadores lógicos. Su orden en el cuadro
detalla la jerarquía de mayor a menor. Los operadores que figuran en la
misma fila tienen el mismo orden de precedencia, por ejemplo, o si tiene la
misma prioridad como TODOS.
Hubner Janampa Patilla - Administración
de Bases de Datos - 20097424/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200975
Recordar que el operador AND tiene precedencia sobre el operador OR, se
puede adivinar la forma en que la siguiente sentencia SQL seria evaluado.
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200976
Mas ejemplos prácticos sobre la precedencia de operadores…
24/09/2009

El operador BETWEEN le permite especificar un rango, donde el rango es
de entre uno y otro valor.
Hasta ahora, cuando usted necesita para comprobar si hay un valor dentro de
un cierto rango, que utilizó el operador "mayor o igual al “(> =) o el" menor
o igual que "(<=).
Las siguientes sentencias SQL utilizan el operador BETWEEN para
seleccionar las películas con una calificación crediticia entre 3 y 5:
Si utiliza el operador BETWEEN, se puede ver que ofrece exactamente los
mismos resultados que los operadores "mayor o igual a "(> =) y" menor o
igual que "(<=). Es sumamente importante recordar que el operador
BETWEEN es inclusivo, lo que significa que en el anterior código, 3 y 5
también se incluyen en el rango.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200977
BETWEEN Operator
24/09/2009

Puede utilizar BETWEEN con tipos de datos distintos, como texto y las fechas.
También puede utilizar el operador BETWEEN en conjunción con el operador
NOT, en cuyo caso SQL selecciona un valor que no está en el intervalo de valores
especificados, como puede ver en las siguientes sentencias.
Hubner Janampa Patilla - Administración
de Bases de Datos - 20097824/09/2009

Between en acción…
Hubner Janampa Patilla - Administración
de Bases de Datos - 200979
Explique…
Explique…
24/09/2009

LIKE Operator
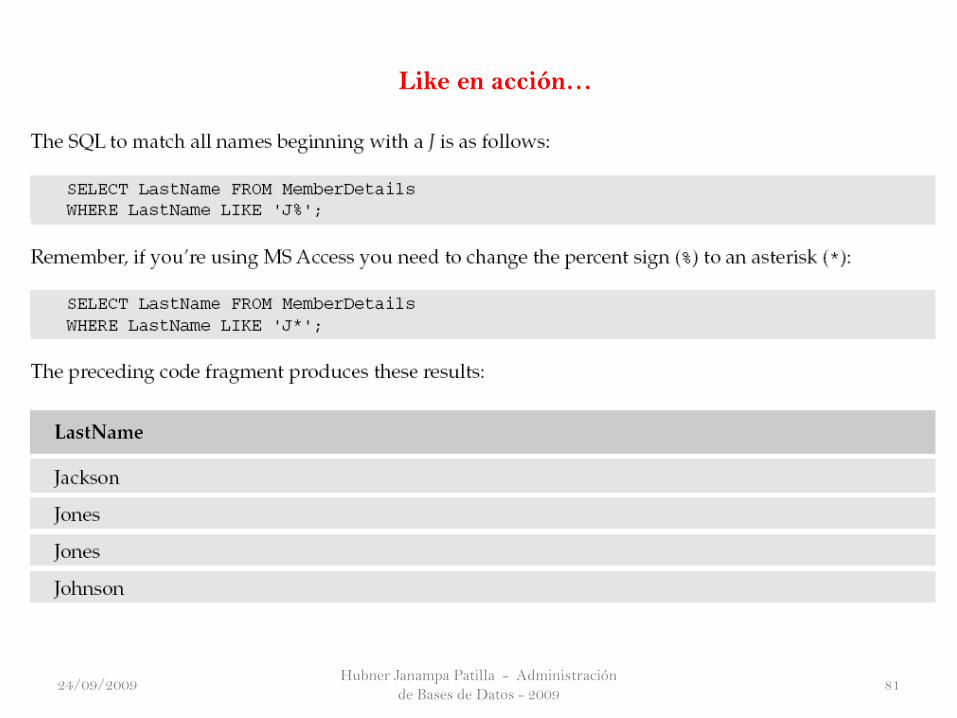
El operador LIKE le permite utilizar caracteres comodín cuando se busca un
personaje sobre el terreno. Un comodín es un carácter que no coincide con un
carácter específico, sino que coincide con cualquier carácter o de cualquier
uno o más caracteres. Un ejemplo de su uso sería averiguar los detalles de
todos los miembros del Club de Película cuyo apellido comienza con J.
En el siguiente cuadro se detallan los dos caracteres disponibles.
Hubner Janampa Patilla - Administración
de Bases de Datos - 20098024/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 200981
Like en acción…
24/09/2009

Nota:
En algunos sistemas de bases de datos, el operador LIKE se distingue entremayúsculas y minúsculas; en otros no lo es. Oracle, por ejemplo, esdistingue entre mayúsculas y minúsculas, por lo LIKE 'J%' sólo coincide con unaJ mayúscula seguida de uno o más caracteres. En el servidor SQL, como 'J%'coincide con una letra en mayúsculas o minúsculas J seguido de uno o máscaracteres.
Hubner Janampa Patilla - Administración
de Bases de Datos - 20098224/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200983
Recuerde que en algunos sistemas de bases de datos, el operador LIKE se
distingue entre mayúsculas y minúsculas, de modo SIMILAR D___s
comienza con un capital D. En otros sistemas coincide con mayúsculas y
minúsculas Ds.
Oracle y DB2 distinguen entre mayúsculas y minúsculas; MS SQL Server,
MySQL, y MS Access no lo distinguen. Asimismo, recuerda que en MS
Access es necesario que usted utilice un signo de interrogación (?) en lugar
del subrayado.
24/09/2009

Desarrolle el siguiente ejercicio práctico
Hubner Janampa Patilla - Administración
de Bases de Datos - 20098424/09/2009
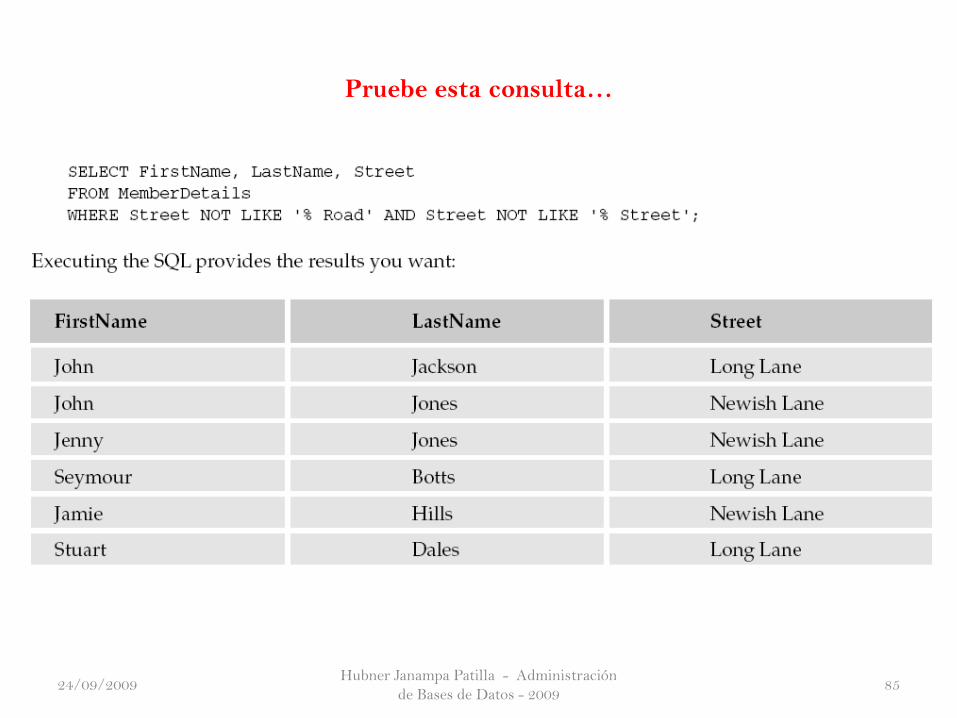
Pruebe esta consulta…
Hubner Janampa Patilla - Administración
de Bases de Datos - 20098524/09/2009

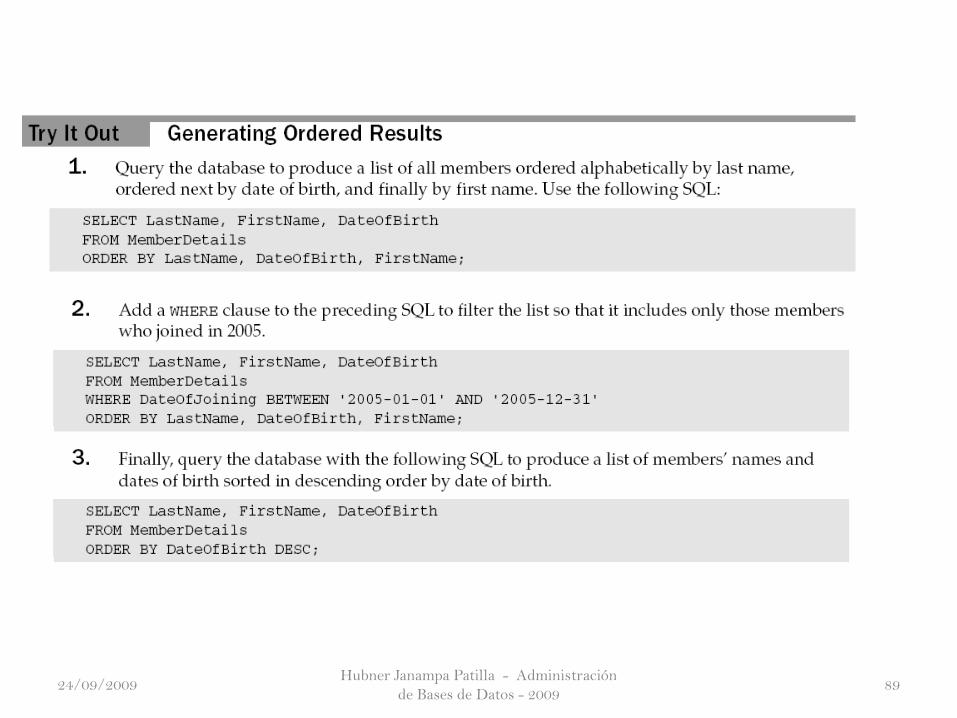
Ordering Results with ORDER BY
Hasta el momento, los resultados de una consulta han llegado,cualquiera que sea su fin la base de datos decide, que suele basarse enla orden en que se introdujeron los datos, a menos que la base de datosestá diseñado de otra manera (como pueden ver en los capítulosposteriores).
Sin embargo, los resultados de una consulta lista en un ordendeterminado (una lista de nombres en orden alfabético o una lista deaños en orden numérico), a menudo viene muy bien. SQL le permiteespecificar el orden de los resultados con la Cláusula ORDER BY.La cláusula ORDER BY va justo al final de la sentencia SELECT. Lepermite especificar la columna o columnas que determinará el ordende los resultados y si la orden es ascendente (el más pequeño amayor) o descendente (mayor a menor).
Hubner Janampa Patilla - Administración
de Bases de Datos - 20098624/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200987
Por ejemplo, la siguiente sentencia SQL muestra una lista de años de lanzamiento de
películas al cine.
Salida:
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200988
Salida:
Ejecute esta sentencia SQL:
24/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 20098924/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200990
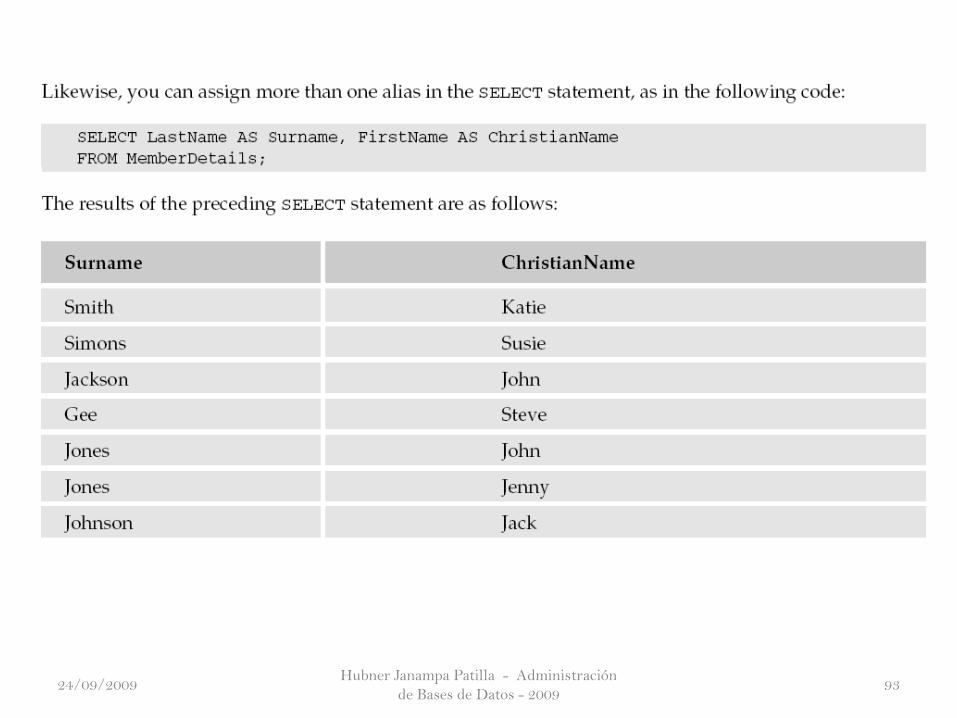
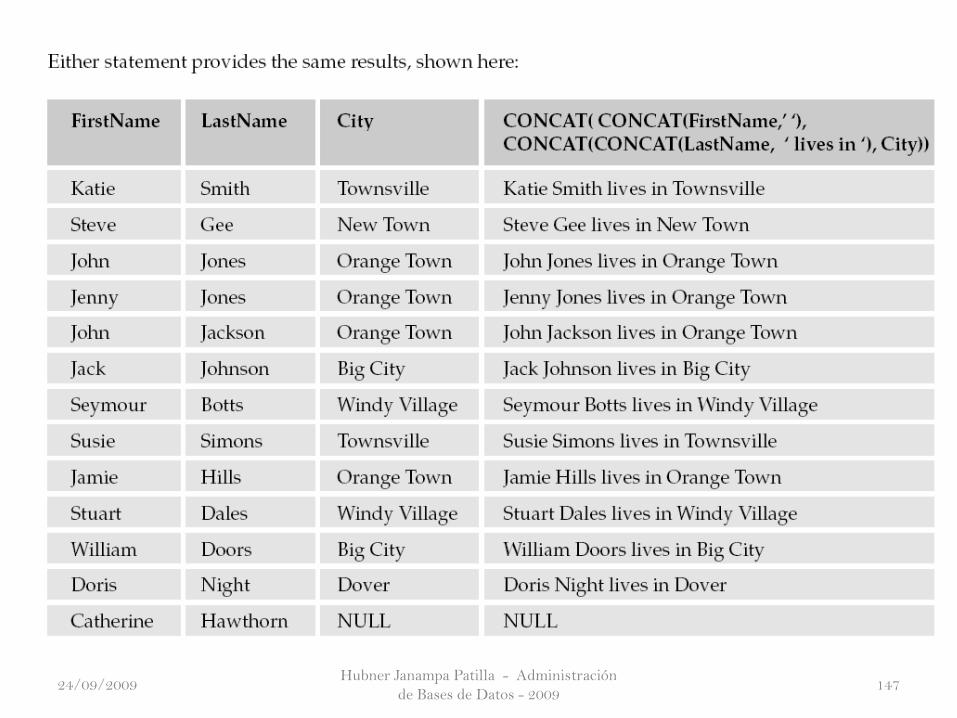
No sólo SQL le permite consultar diversas columnas, sino que también le
permite combinar una o más columnas y dar como resultado la columna con un
alias. Tenga en cuenta que el uso de un alias no tiene ningún efecto sobre la tabla
en sí; usted no crea realmente una nueva columna en la tabla, sólo uno de los
resultados establecidos. Por ejemplo, si usted tiene los datos de ABC y concatenar
a DEF, se obtiene ABCDEF.
Sólo se tratara de concatenar literales de texto o columnas que tienen el tipo de
dato char o varchar.
Por lo tanto, ¿cómo se van concatenando sobre el texto? Por desgracia,
concatenar texto varía en función de la sistema de bases de datos que está
utilizando. Usted simplemente necesita a leer la sección de interés para el sistema
de base de datos que está utilizando.
Joining Columns—Concatenation
24/09/2009
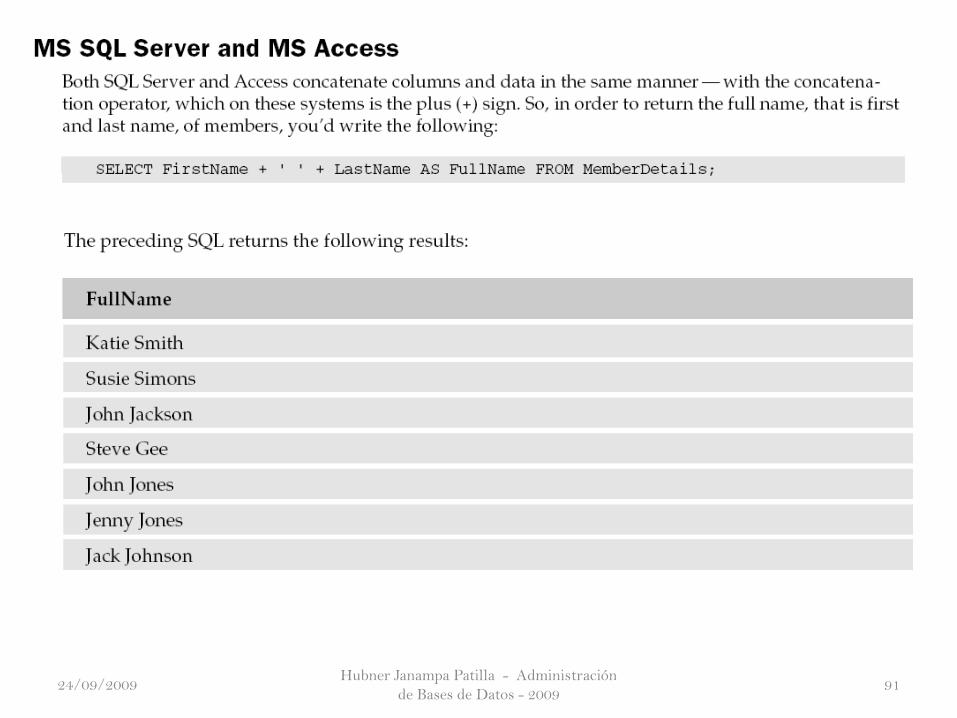
Hubner Janampa Patilla - Administración
de Bases de Datos - 20099124/09/2009
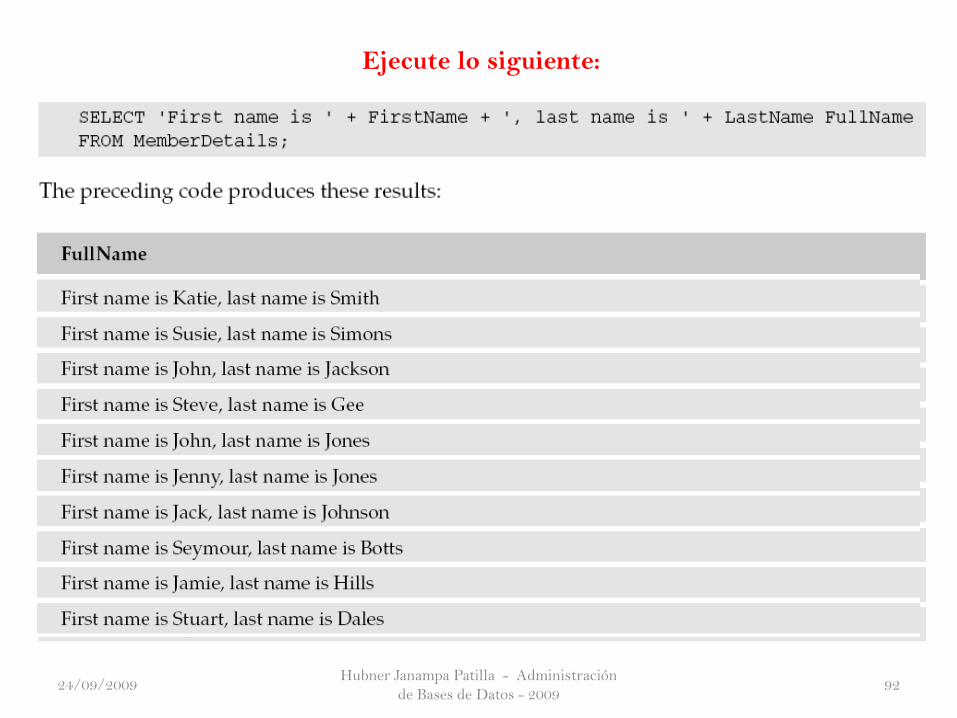
Ejecute lo siguiente:
Hubner Janampa Patilla - Administración
de Bases de Datos - 20099224/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 20099324/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 200994
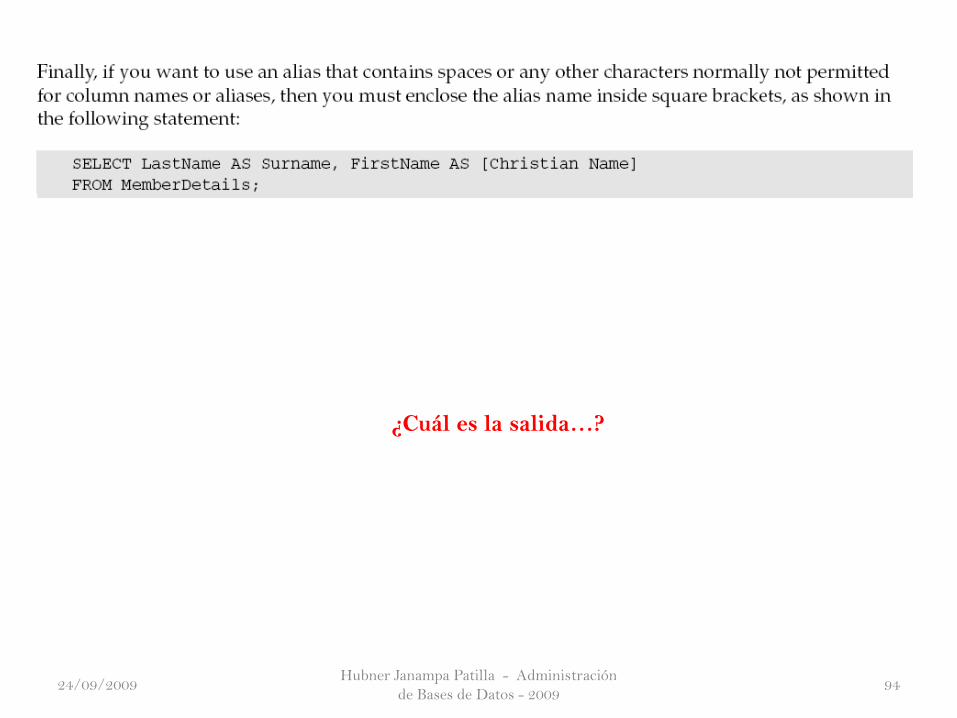
¿Cuál es la salida…?
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 20099524/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200996
Selecting Data from More Than One Table
Usando el SQL que has aprendido hasta el momento, se puede extraer datos de
una sola tabla en la base de datos, que es muy a menudo debido a la limitación
de respuestas que requieren los datos de una o más tablas. Los desarrolladores
de SQL asumen esta limitación y ponen en práctica una forma de unir datos de
más de una tabla en un conjunto de resultados.
El uso de la palabra une no es accidental, en SQL esta palabra clave es JOIN y
hace referencia a la unión de una o más tablas. Posteriormente se examinaran
todos los diferentes tipos de uniones, pero en esta parte se refiere a la más
comúnmente utilizada (y también lo más fácil de usar).
24/09/2009
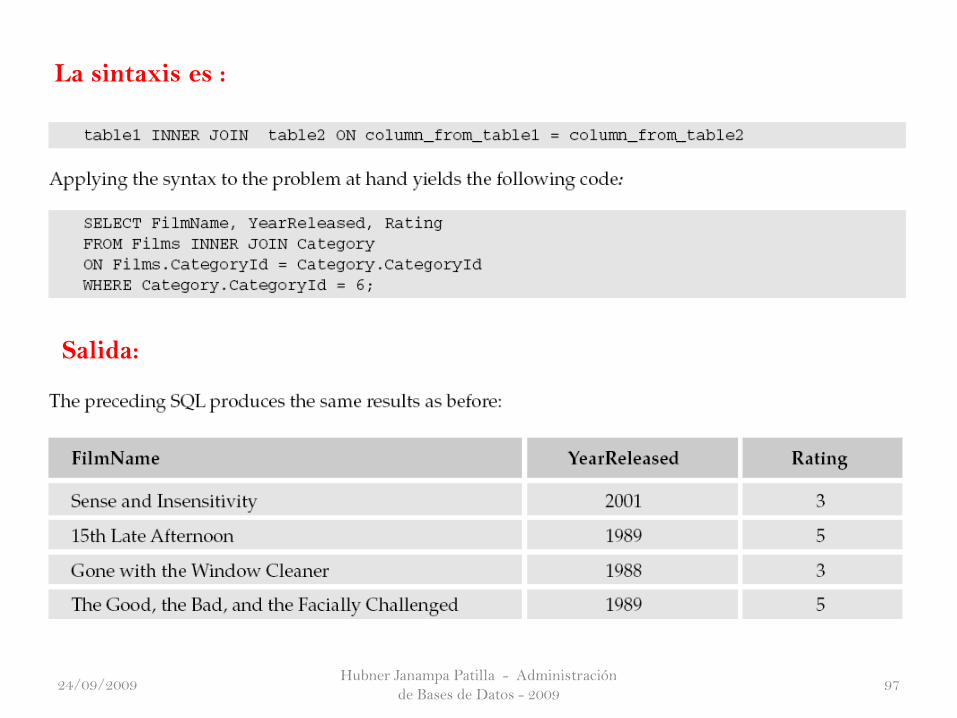
La sintaxis es :
Hubner Janampa Patilla - Administración
de Bases de Datos - 200997
Salida:
24/09/2009
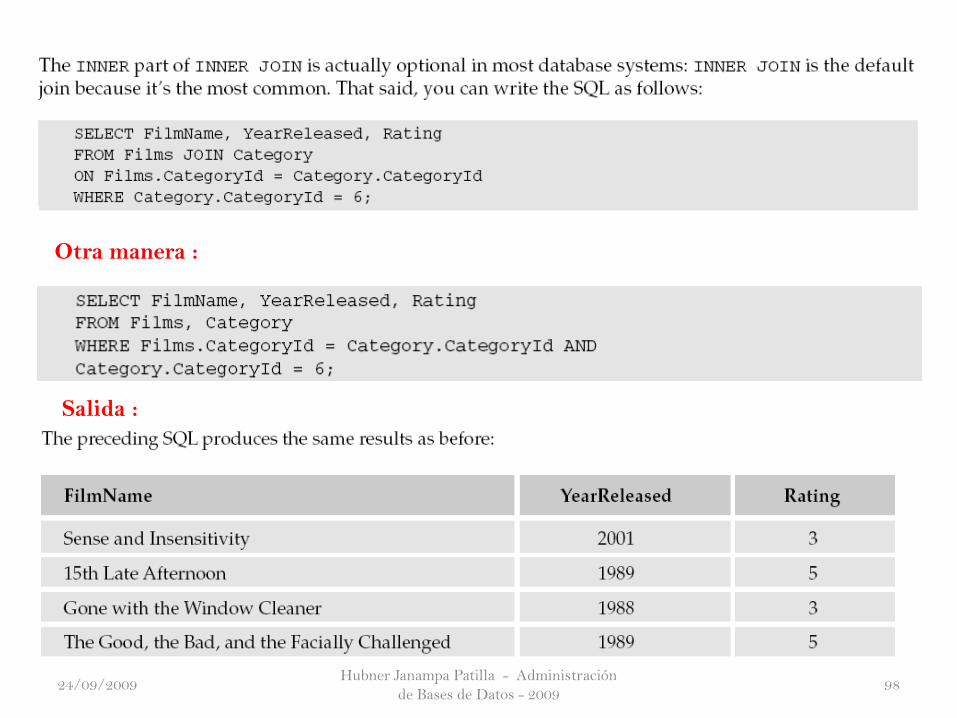
Hubner Janampa Patilla - Administración
de Bases de Datos - 200998
Otra manera :
Salida :
24/09/2009
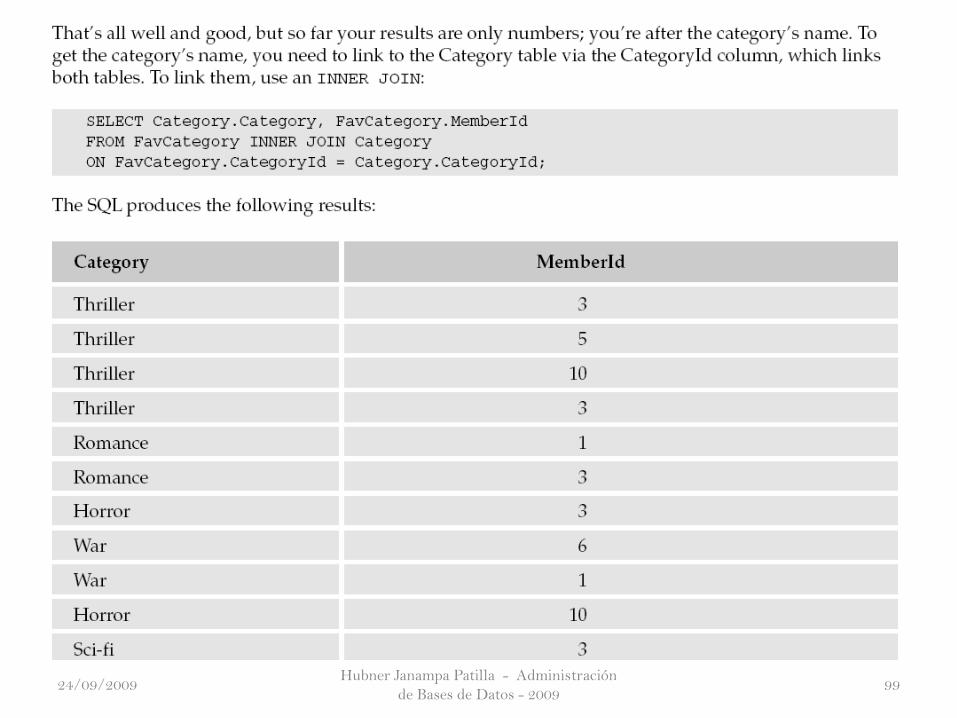
Hubner Janampa Patilla - Administración
de Bases de Datos - 20099924/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 2009100
¿Algo de más complejidad…?
Interprete…
24/09/2009
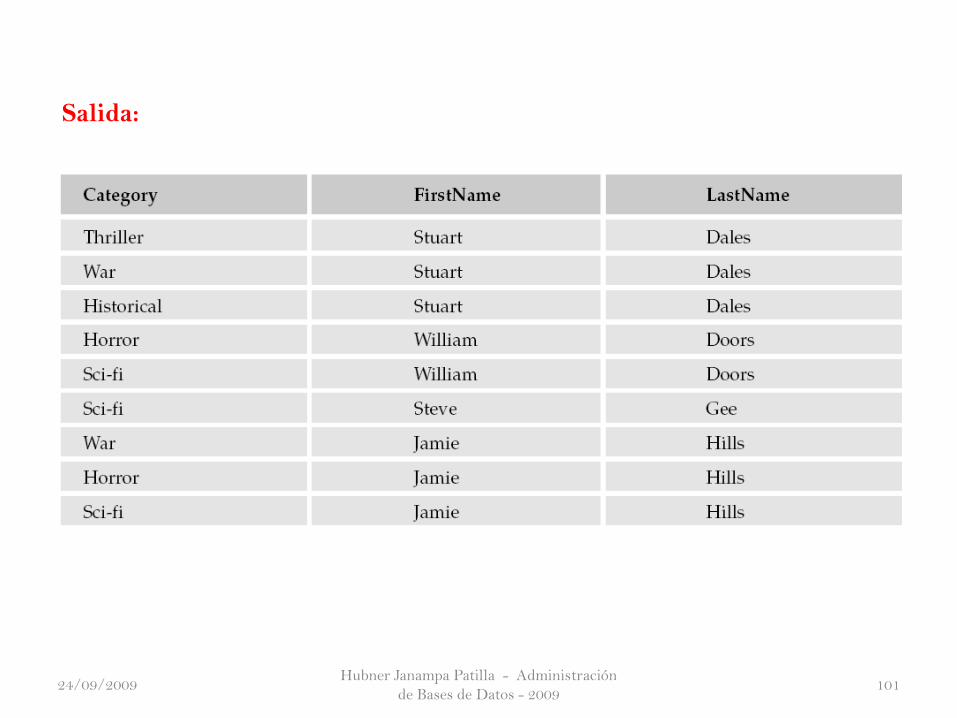
Salida:
Hubner Janampa Patilla - Administración
de Bases de Datos - 200910124/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 2009102
¿Explique…?
24/09/2009
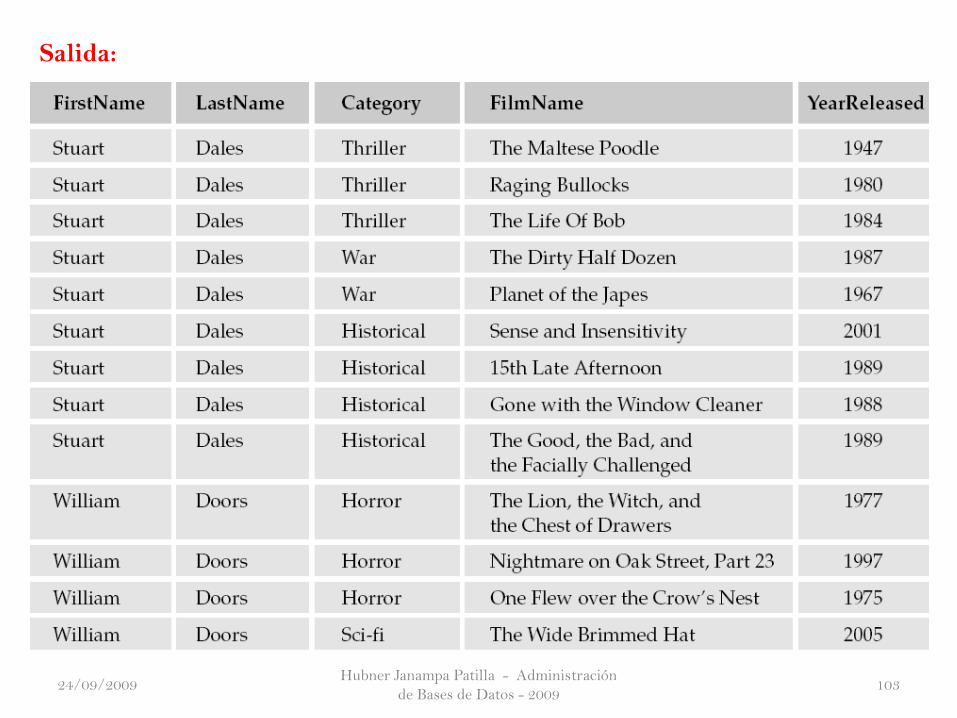
Salida:
Hubner Janampa Patilla - Administración
de Bases de Datos - 200910324/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200910424/09/2009

Advanced Database Design
Este capítulo tiene que ver con mejorar el diseño de una base de datos en
términos de facilidad de gestión, la eficiencia, y limitar los riesgos de
introducción de datos no válidos. El capítulo comienza con un poco de teoría y
se refiere a la práctica, en particular la base de datos del Club de Cine. Se trata
de mejorar la eficiencia en términos de almacenamiento de datos y reducción
al mínimo del espacio perdido.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200910524/09/2009

Normalización
Al inicio del curso se discutió la forma de diseñar la estructura de base de
datos utilizando tablas y campos, a fin de evitar problemas como la
duplicación innecesaria de datos y la imposibilidad de identificar de forma
exclusiva los registros.
Aunque no se pidió la normalización en aquel entonces, que fue el concepto
utilizado. En esta sección se explica la normalización con más detalle y cómo
utilizarlo para crear bien una estructura de bases de datos.
La normalización consiste en una serie de directrices que ayuden a orientar en
la creación de una buena estructura de base de datos. Tenga en cuenta que son
directrices y no reglas a seguir ciegamente. El diseño de bases de datos es,
probablemente, tanto el arte como es la ciencia, y su propio sentido común
es importante, también.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200910624/09/2009

Las directrices de la normalización se dividen en formas normales; pensar de
forma que el formato o la forma en que un estructura de base de datos está
establecido. Examinaremos sólo las tres primeras formas, para ir a la
normalización de una base de datos. El objetivo de las formas normales es
organizar la estructura de base de datos a fin de que cumpla con las normas
de la primera forma normal, la segundo forma normal y, por último, tercera
forma normal.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200910724/09/2009

Primera forma normal
Al inicio del curso caminó a través de algunos pasos básicos para crear una buena
organización de la estructura de la base de datos. En particular, se dijo que usted
debe hacer lo siguiente:
❑ Definir los datos necesarios, porque se convierten en las columnas de una
tabla.
❑ Asegúrese de que no hay repetición de grupos de datos.
❑ Asegúrese de que hay una clave primaria.
Estas normas son aquellas de la primera forma normal, por lo que has cubierto
primera forma normal sin siquiera saberlo.
En la base de datos del club cine, ya cumple con la primera forma normal, pero
para refrescar la memoria, aquí se da un resumen breve de la primera forma
normal.
En primer lugar, debe definir los elementos de información. Esto significa mirar a
los datos que deben almacenarse, la organización de los datos en columnas, definir
qué tipo de dato cada columna contiene, y por último, poner en columnas
relacionadas con los de su propia tabla.Hubner Janampa Patilla - Administración
de Bases de Datos - 200910824/09/2009
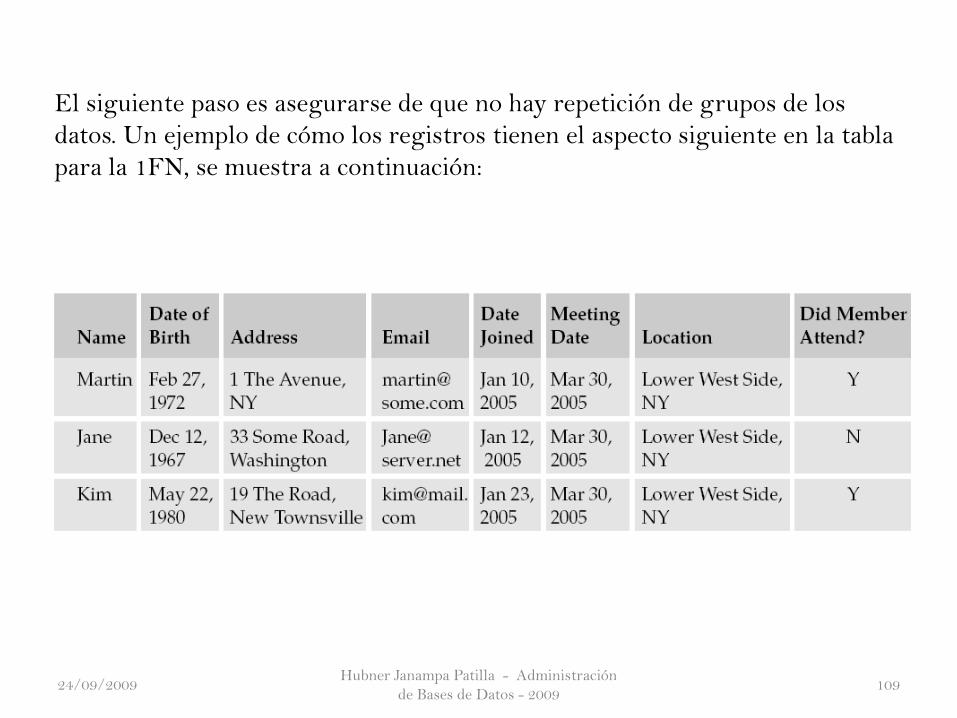
El siguiente paso es asegurarse de que no hay repetición de grupos de los
datos. Un ejemplo de cómo los registros tienen el aspecto siguiente en la tabla
para la 1FN, se muestra a continuación:
Hubner Janampa Patilla - Administración
de Bases de Datos - 200910924/09/2009

Segunda forma normal
Primera forma normal requiere que todas las tablas deben tener una clave
primaria. Esta clave primaria puede constar de uno o más columnas. La
clave principal es el identificador único de ese registro, y la segunda forma
normal establece que no debe haber dependencias parciales de cualquiera de
las columnas de la clave primaria.
Por ejemplo se puede crear una tabla llamada ActorFilms con las siguientes
columnas:
Hubner Janampa Patilla - Administración
de Bases de Datos - 200911024/09/2009
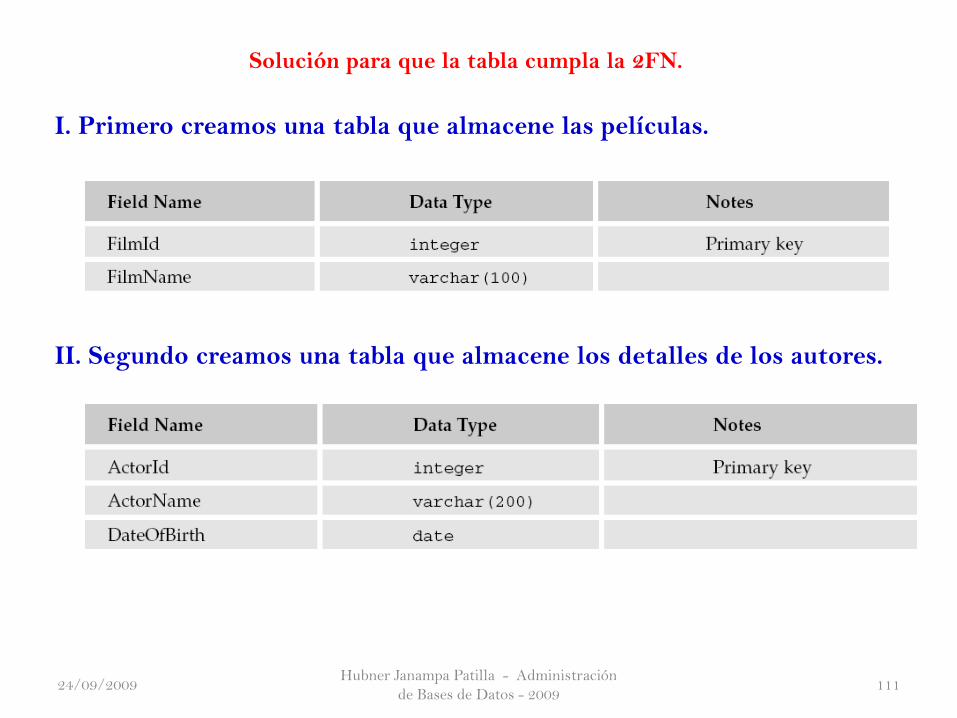
Solución para que la tabla cumpla la 2FN.
I. Primero creamos una tabla que almacene las películas.
II. Segundo creamos una tabla que almacene los detalles de los autores.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200911124/09/2009

III . Finalmente creamos una tercera tabla que almacene los FilmIds Y
ActorIds , para saber que actores protagonizaron que película.
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009112
Ahora las tablas están en segunda forma normal. Puedes buscar en cada tabla
y se puede ver que todas las columnas son vinculado a la clave principal,
salvo que las dos columnas en la tercera tabla componen la clave primaria.
24/09/2009

Tercera forma normal
Tercera forma normal es un poco más opcional, y su uso depende de las
circunstancias.
Una tabla está en tercera forma normal cuando se cumplan las siguientes
condiciones:
❑ Es en la segunda forma normal.
❑ Todos los campos no primarios son dependientes de la clave primaria.
La dependencia de campos no primarios se sitúa entre los datos.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200911324/09/2009
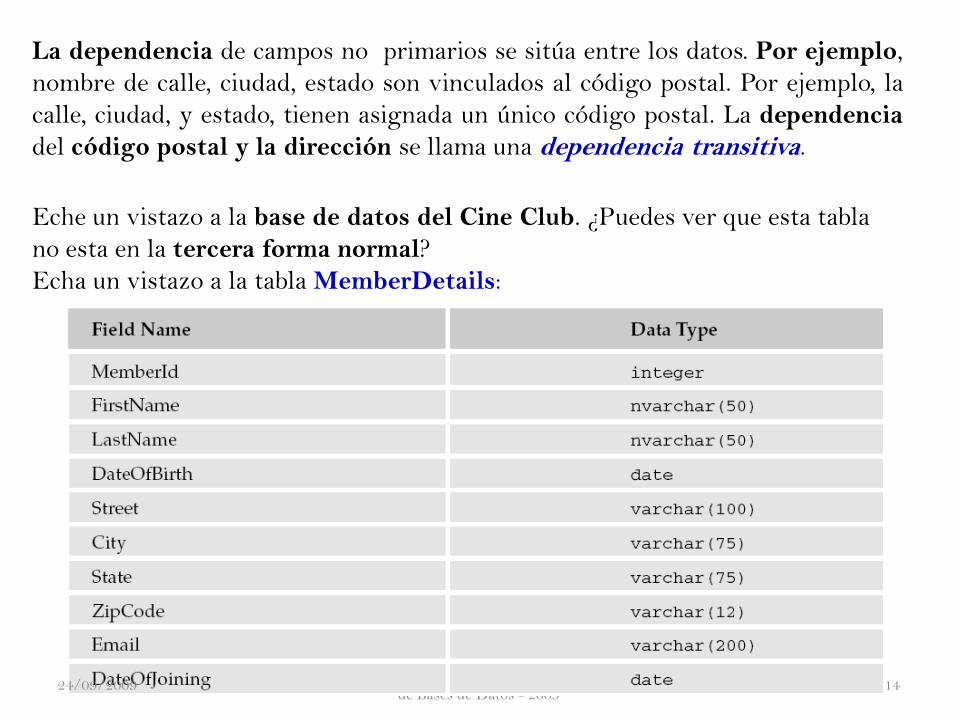
La dependencia de campos no primarios se sitúa entre los datos. Por ejemplo,
nombre de calle, ciudad, estado son vinculados al código postal. Por ejemplo, la
calle, ciudad, y estado, tienen asignada un único código postal. La dependencia
del código postal y la dirección se llama una dependencia transitiva.
Eche un vistazo a la base de datos del Cine Club. ¿Puedes ver que esta tabla
no esta en la tercera forma normal?
Echa un vistazo a la tabla MemberDetails:
Hubner Janampa Patilla - Administración
de Bases de Datos - 200911424/09/2009
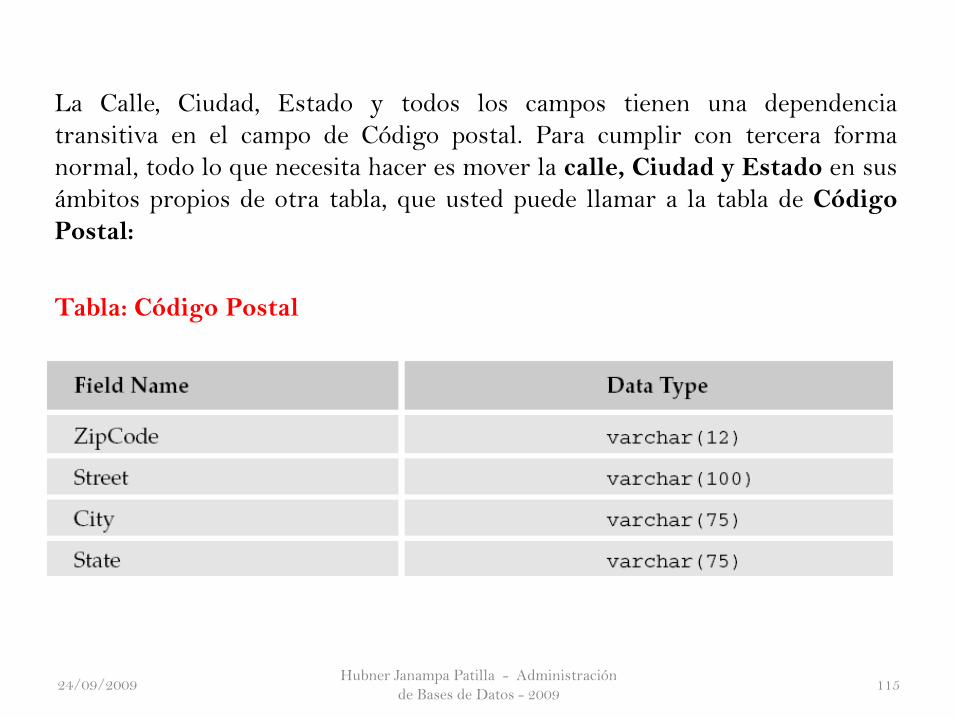
La Calle, Ciudad, Estado y todos los campos tienen una dependencia
transitiva en el campo de Código postal. Para cumplir con tercera forma
normal, todo lo que necesita hacer es mover la calle, Ciudad y Estado en sus
ámbitos propios de otra tabla, que usted puede llamar a la tabla de Código
Postal:
Tabla: Código Postal
Hubner Janampa Patilla - Administración
de Bases de Datos - 200911524/09/2009
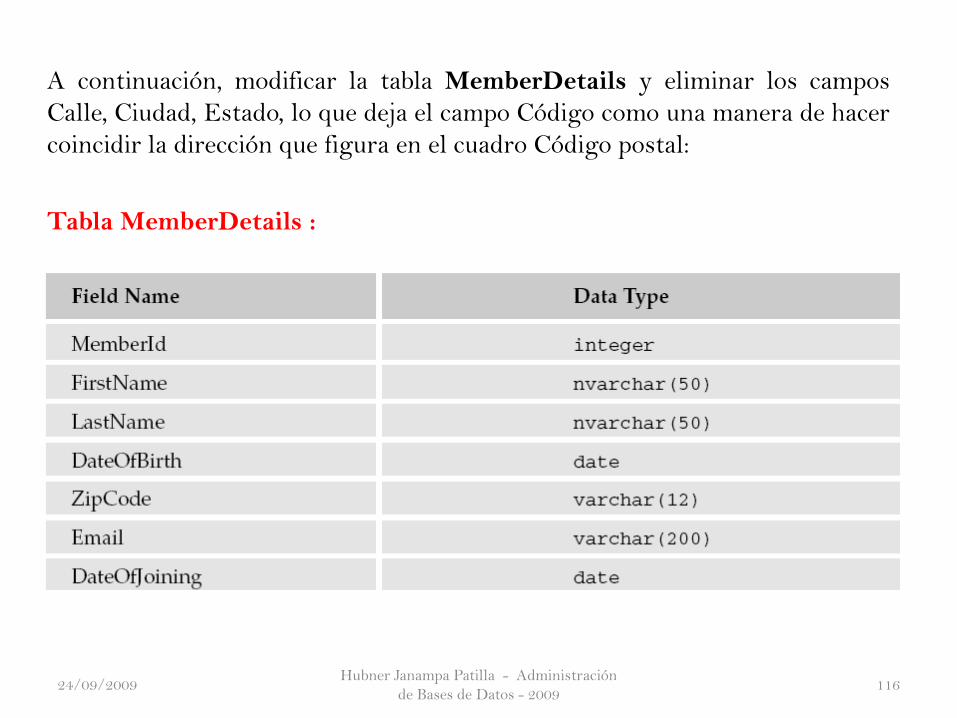
A continuación, modificar la tabla MemberDetails y eliminar los campos
Calle, Ciudad, Estado, lo que deja el campo Código como una manera de hacer
coincidir la dirección que figura en el cuadro Código postal:
Tabla MemberDetails :
Hubner Janampa Patilla - Administración
de Bases de Datos - 200911624/09/2009

Las ventajas de eliminar las dependencias libres son principalmente de
dos tipos. En primer lugar, la cantidad de datos se reduce y la
duplicación, y por tanto, se convierte la base de datos más pequeña. Dos o
más personas que viven en la misma calle en la misma ciudad en la misma
ciudad tienen el mismo código postal.
En lugar de almacenar todos los datos en mas de una vez, almacenar sólo una
vez en la tabla Código postal para que el Código postal se almacene solo una
vez.
La segunda ventaja es la integridad de los datos. Cuando los datos
duplicados cambian hay un gran riesgo de actualización de sólo algunos de
los datos, especialmente si se extiende en una serie de lugares diferentes en la
base de datos. Si la dirección y código postal de los datos se almacenan en tres
o cuatro tablas diferentes, entonces cualquier cambio de los códigos postales
tendría que recorrer todos los registros en las tres o cuatro tablas. Sin
embargo, si se almacenan todos en una sola tabla, entonces usted necesita
cambiar en un solo lugar.
Hay un aspecto negativo sin embargo, el cual añade complejidad y una menor
eficiencia.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200911724/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200911824/09/2009

Los operadores matemáticos básicos
No es ninguna gran sorpresa al enterarse de que los cuatro operadores
matemáticos básicos son multiplicación, división, resta, y además, que se
enumeran en la tabla siguiente, junto con los operadores que SQL utiliza para
ellos representan:
Hubner Janampa Patilla - Administración
de Bases de Datos - 200911924/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 200912024/09/2009

Funciones matemáticas comunes
El estándar SQL (y casi todos las aplicaciones SQL) contiene cuatro funciones
básicas de matemáticas. Sin embargo, una serie de otras funciones
matemáticas existen, que, aunque no en el estándar ANSI SQL, se encuentran
en suficientes implementaciones de bases de datos que vale la pena listar aquí.
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009121
The ABS() Function :
24/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009122
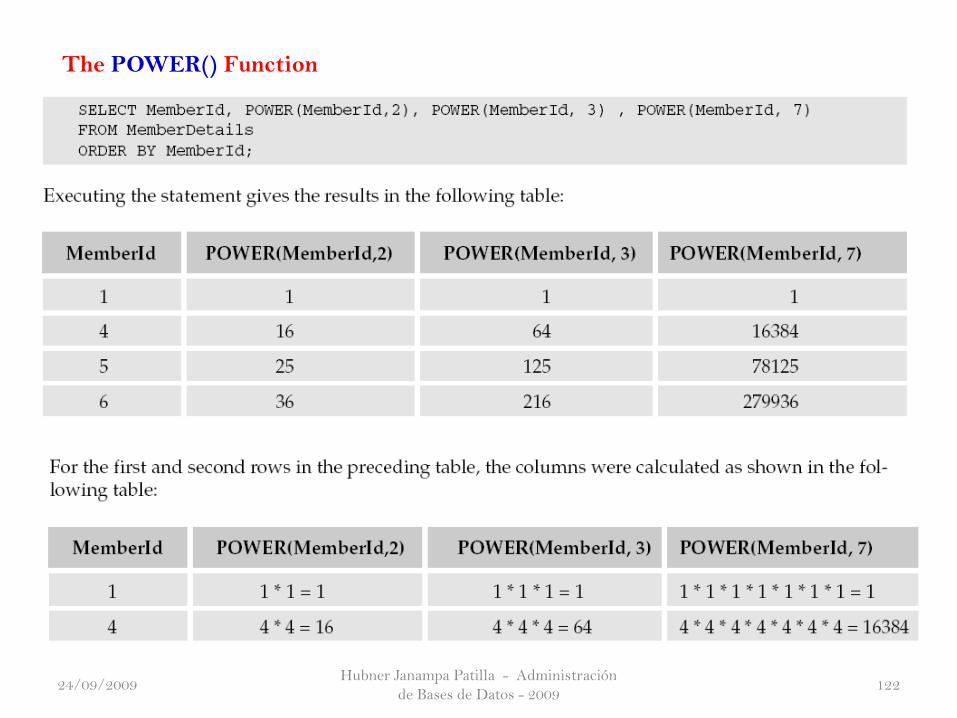
The POWER() Function
24/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009123
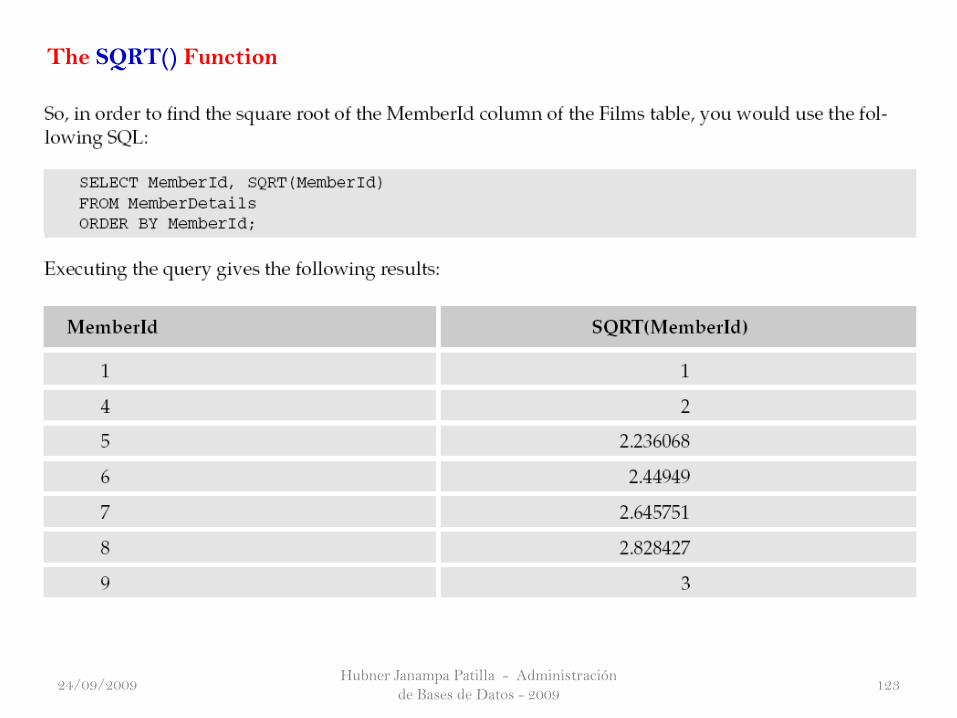
The SQRT() Function
24/09/2009
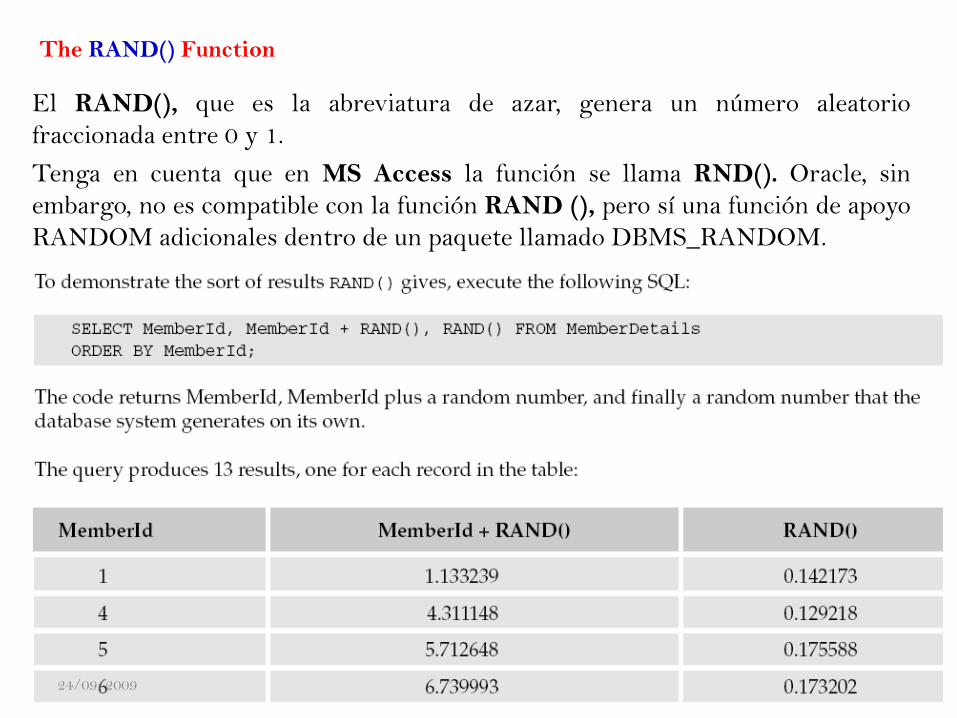
El RAND(), que es la abreviatura de azar, genera un número aleatorio
fraccionada entre 0 y 1.
Tenga en cuenta que en MS Access la función se llama RND(). Oracle, sin
embargo, no es compatible con la función RAND (), pero sí una función de apoyo
RANDOM adicionales dentro de un paquete llamado DBMS_RANDOM.
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009124
The RAND() Function
24/09/2009

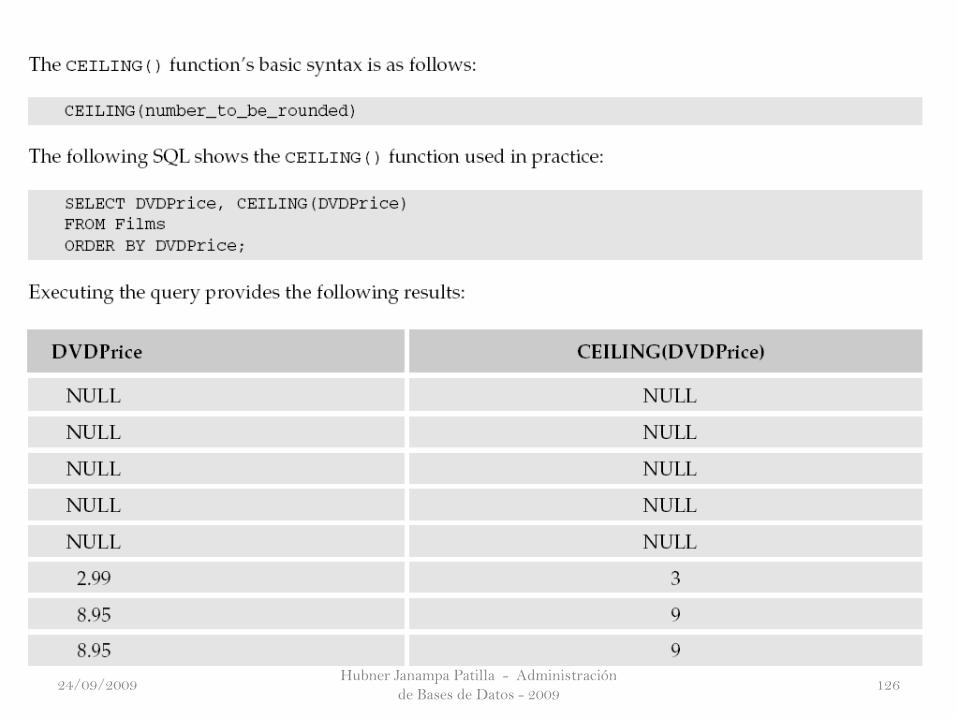
The CEILING() Function
El límite máximo elimina todos los números después del punto decimal y
redondea hasta el próximo número entero más alto. Por ejemplo, 3,35 se
redondeara por exceso al 4; 5,99 redondeado a 6, y -3,35 redondearán por
exceso al -3. Si el redondeo de los números negativos parece extraño (-4 ¿por
qué no en lugar de -3?), Sólo recordar que el límite máximo ronda hasta el
número entero inmediatamente superior; los números negativos que son
más cerca al 0 es superior en valor, por lo que -3 es superior a -4.
En Oracle, el límite máximo se llama CEIL(), pero funciona de la misma
forma, sólo el nombre es diferente. Tenga en cuenta también que el límite
máximo no está soportada en MS Access.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200912524/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 200912624/09/2009

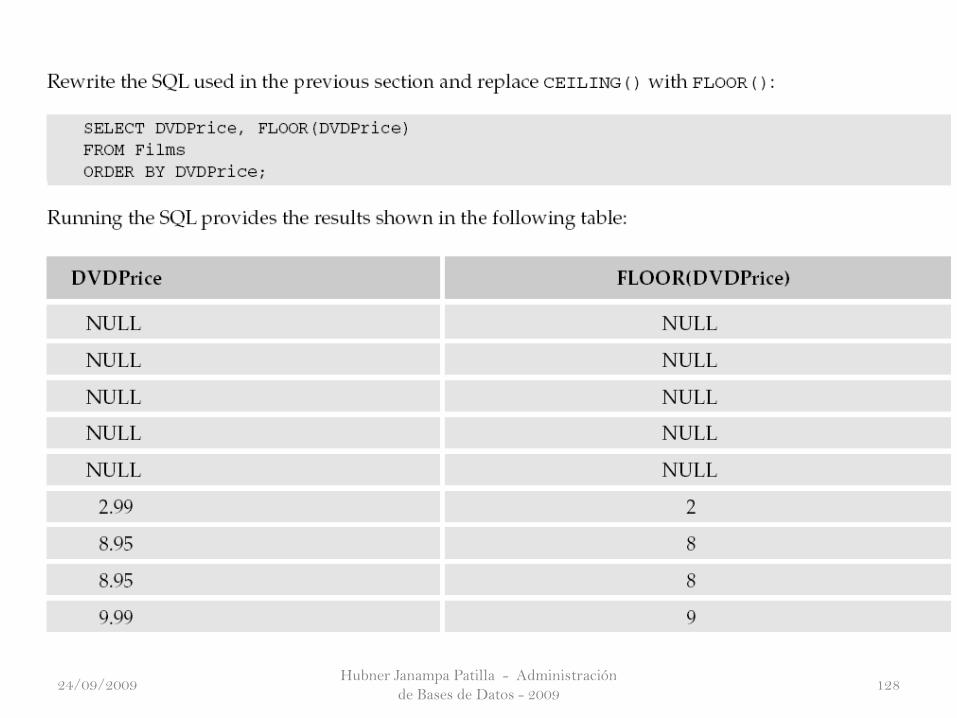
The FLOOR() Function
La función FLOOR() trabaja en el sentido contrario como límite máximo en
el sentido de que los redondeos se realizan al siguiente más bajo valor entero.
Por ejemplo, 3,35 se redondeará hacia abajo a 3; 5,99 redondeará hacia abajo
a 5, y -3,35 redondeará hacia abajo a -4; -4 es inferior a -3. Una vez más
FLOOR() no es compatible con MS Access.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200912724/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 200912824/09/2009

En lugar de redondear siempre como límite máximo o hacia abajo como lo
hace FLOOR(), la función ROUND() redondea basado en los dígitos después
del punto decimal. Si el dígito después del punto decimal es de 4 o menos,
entonces es simplemente eliminado. Si el dígito después del punto decimal es
de 5 o más, entonces el número se redondea al número mayor entero y el
dígito es eliminado. Por ejemplo, 3.55 redondeado a un número entero
utilizando ROUND() sería 4, mientras que 3.42 redondeado a un número
entero que no deberá exceder de 3.
Por lo tanto, -4,6 redondeado al próximo entero es más alto -5. A diferencia
de CEILING() y FLOOR(), la función ROUND() cuenta con el apoyo de MS
Access.
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009129
The ROUND() Function
24/09/2009
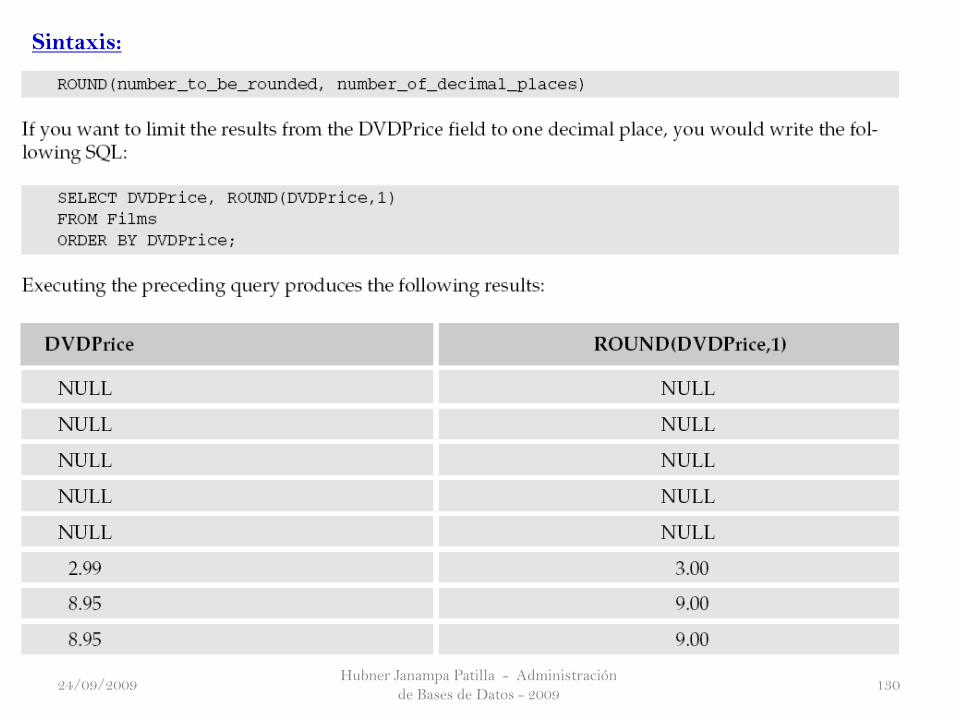
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009130
Sintaxis:
24/09/2009

Introducing String Functions
En esta sección usted camina a través de una serie de funciones muy útiles
que le permiten manipular cadenas y búsqueda basados en los datos. Cadena
de datos es un nombre colectivo para un grupo de caracteres, como el
nombre de una persona o un grupo de números. A pesar de que cada carácter
se almacena en su propia ubicación de memoria, la base de datos le permite
manipular una columna de caracteres al mismo tiempo.
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009131
El SUBSTRING () le permite obtener sólo una parte de una cadena de uno o
más caracteres de la toda la cadena de caracteres. Cuando se utiliza esta
función, es importante recordar que una cadena no es más que un cadena de
caracteres individuales. Por ejemplo, Wrox Press es una cadena, y cada uno
de los personajes son de la siguiente manera:
The SUBSTRING() Function
24/09/2009

El SUBSTRING () trabaja en el carácter. La función toma tres parámetros: la
cadena de la cual se obtiene la subcadena, el primer carácter que debe
obtenerse, y el número de caracteres en total.
Considere la siguiente sintaxis:
MS Access no utiliza el SUBSTRING(). En lugar de ello, emplea el MID(),
que tiene exactamente la misma sintaxis y obra de la misma manera como lo
hace el SUBSTRING(). Así que si estás usando MS Access, dondequiera que
vea SUBSTRING(), basta con sustituirla por MID(). Oracle y DB2 de IBM
apoyan a la función SUBSTRING(), pero ellos lo llaman SUBSTR(). Si está
utilizando Oracle o DB2, dondequiera que vea SUBSTRING(), sustituirla por
SUBSTR ().
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009132
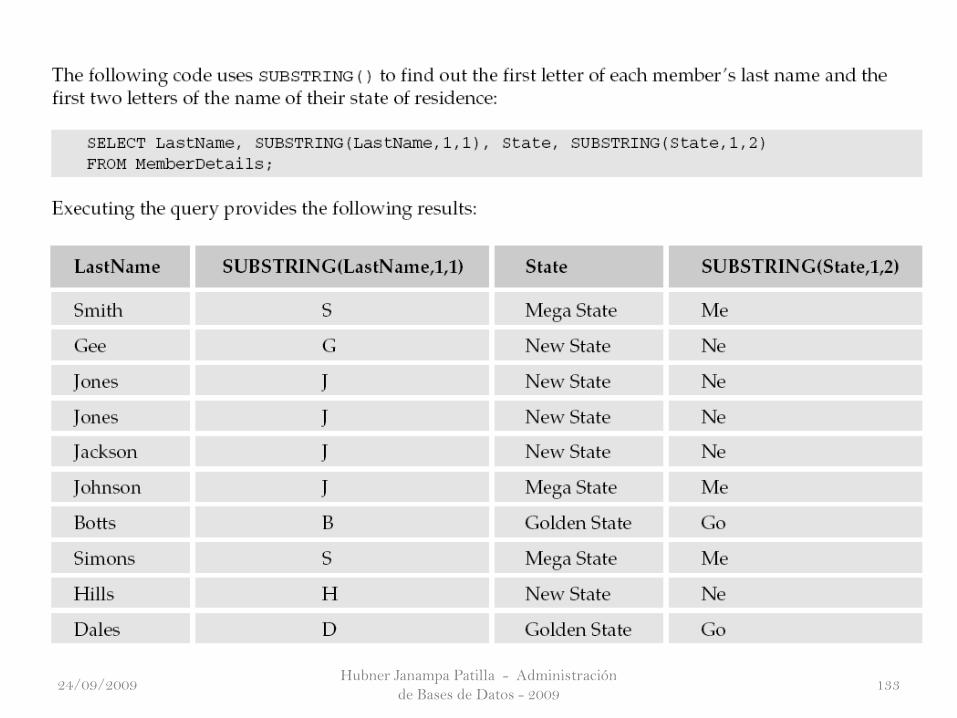
The SUBSTRING() Function
24/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 200913324/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 2009134
Case Conversion Functions
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 2009135
The REVERSE() Function
24/09/2009

Recorte implica la eliminación de caracteres no deseados desde el principio al
final de una cadena. En la mayoría de implementaciones de bases de datos, el
único personaje que se puede recortar es el espacio.
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009136
Funciones TRIM()
Si quieres regresar los caracteres que se insertaron y sin espacios, puedes
recortar los espacios con una de las dos funciones de acabado: LTRIM () o
RTRIM(). LTRIM() elimina los espacios a la izquierda de los caracteres,
mientras que RTRIM() elimina los espacios a la derecha de los caracteres. Por
lo tanto, si desea eliminar los espacios del ejemplo en la tabla definida
anteriormente, usted utilizaría RTRIM ():
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200913724/09/2009
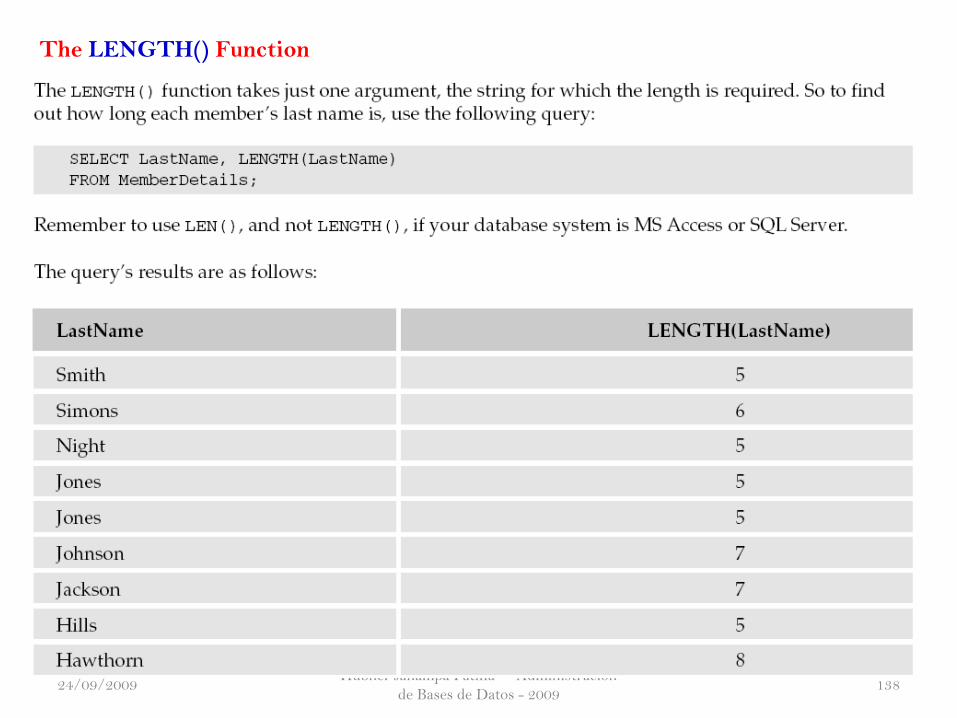
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009138
The LENGTH() Function
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200913924/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200914024/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200914124/09/2009
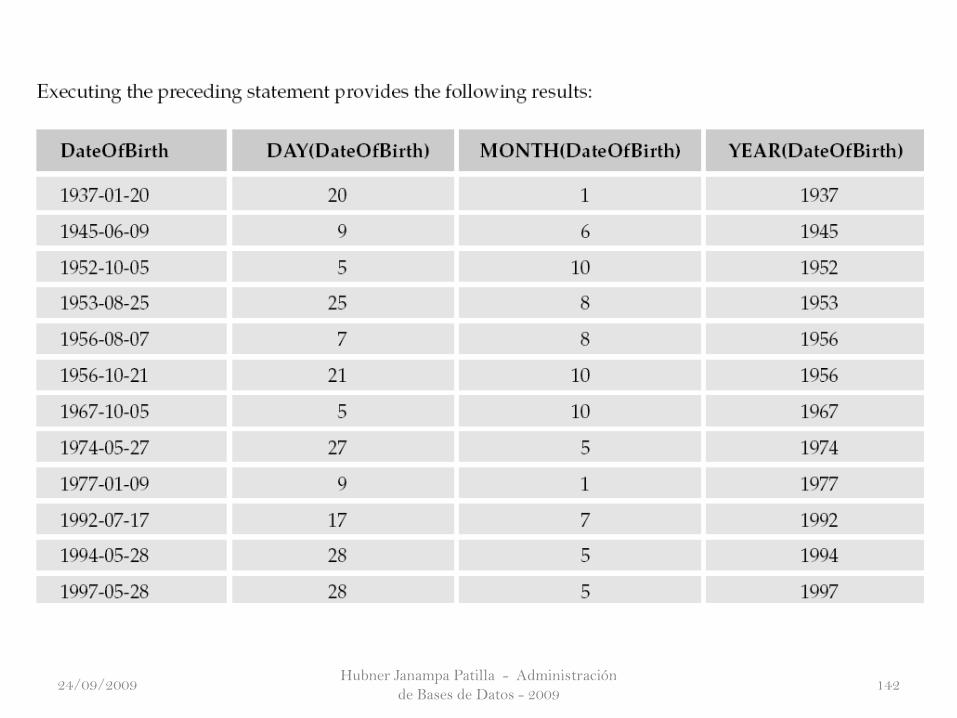
Hubner Janampa Patilla - Administración
de Bases de Datos - 200914224/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 2009143
The CAST() function
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200914424/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 200914524/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200914624/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 200914724/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 2009148
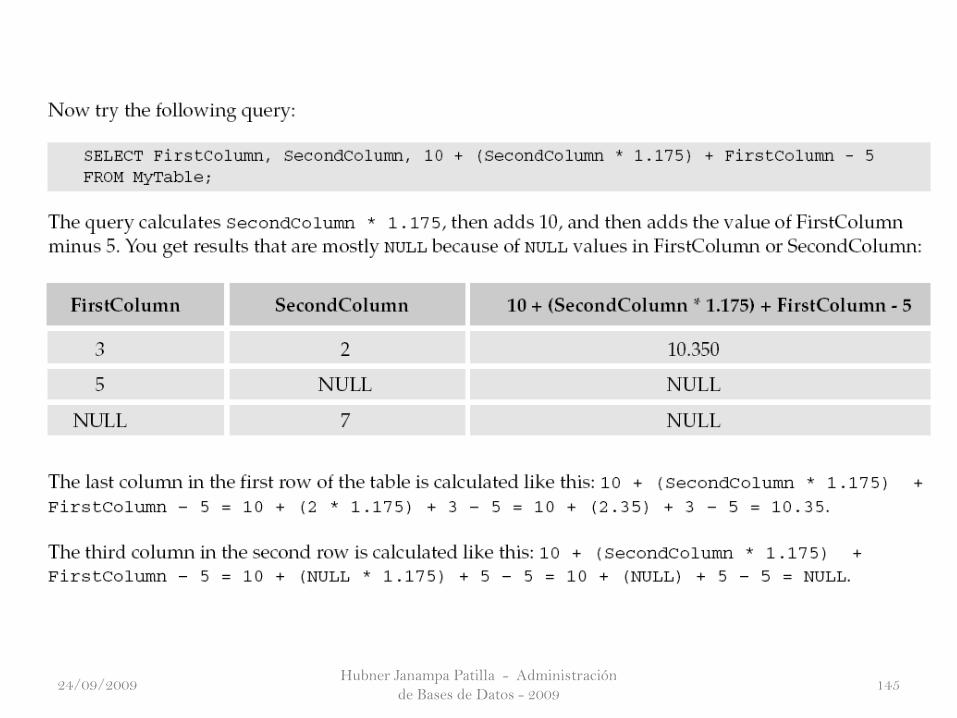
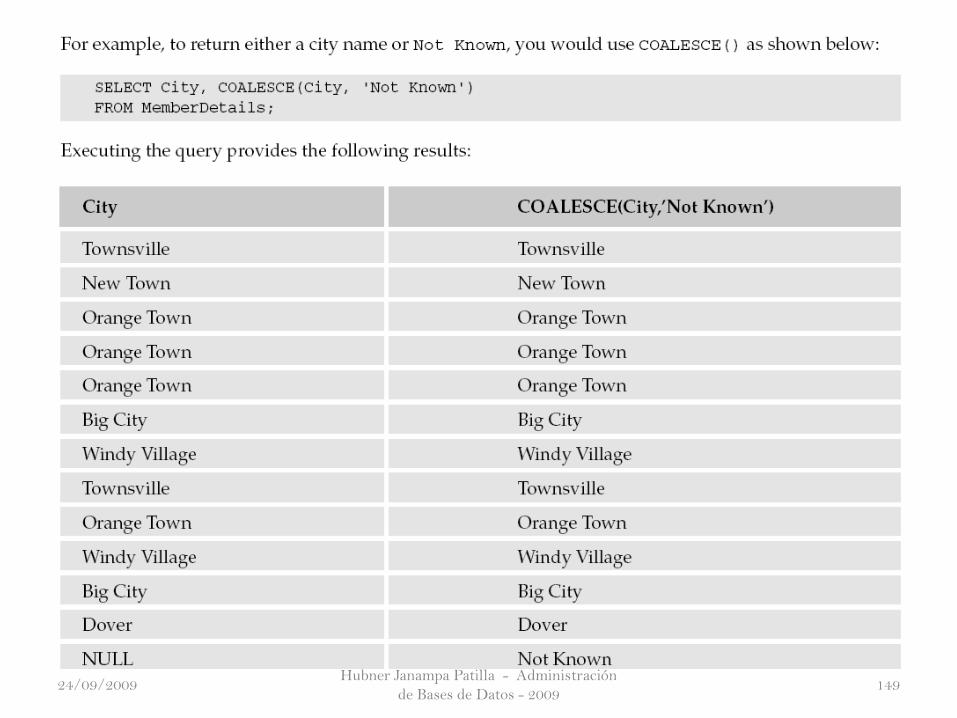
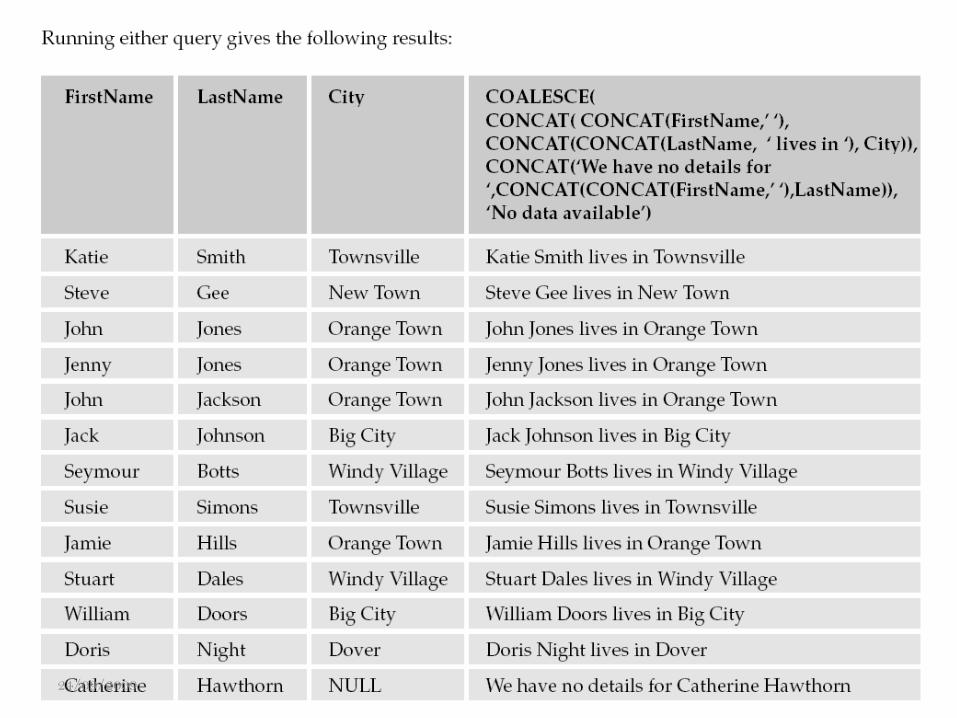
La función COALESCE() devuelve el primer valor NOT NULL de la lista de valores
que le pasa como argumentos.
Si todos los argumentos son NULL, entonces la función devuelve NULL. Tenga en
cuenta que MS Access soporta esta función.
Tenga en cuenta que cada argumento pasado a la función COALESCE() debe ser del
mismo tipo de datos (una cadena o un número) o uno que pueda convertirse. Si obtiene
un error al pasar diferentes tipos de datos como argumentos, entonces utilizar el
CAST().
The COALESCE() Function
24/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 200914924/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 2009150
Veamos como utilizamos COALESCE() con MS SQL SERVER
24/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 200915124/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200915224/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200915324/09/2009

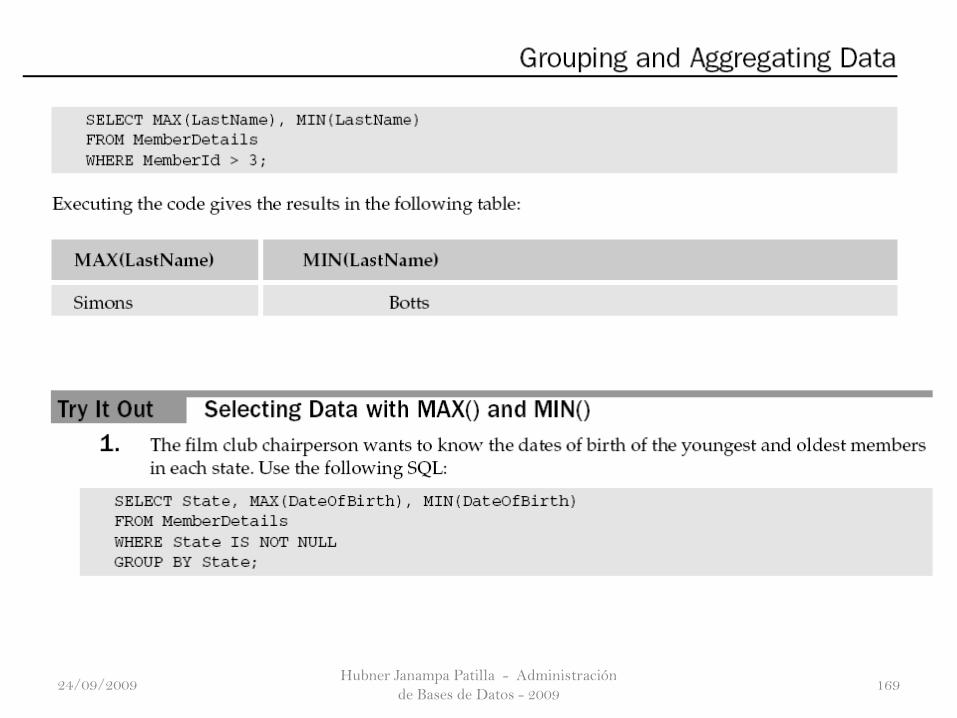
En esta sección se examina la cláusula GROUP BY, que se utiliza enconjunción con el comando SELECT.
Permite que usted agrupe datos idénticos en un subconjunto. La CláusulaGROUP BY es mas poderoso cuando se utiliza con SQL y con el resumen defunciones de agregación. GROUP BY es también muy útil con subconsultas,un concepto examinado en el Capítulo 7.
Example:
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009154
Grouping Results
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200915524/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200915624/09/2009

Resumiendo y agregar los datos
Hasta ahora, los resultados obtenidos de la base de datos han consistido en un
conjunto de registros individuales en lugar de registros que se han resumido
,digamos, incluyendo un promedio de los registros o contando los mismos.
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009157
Counting Results
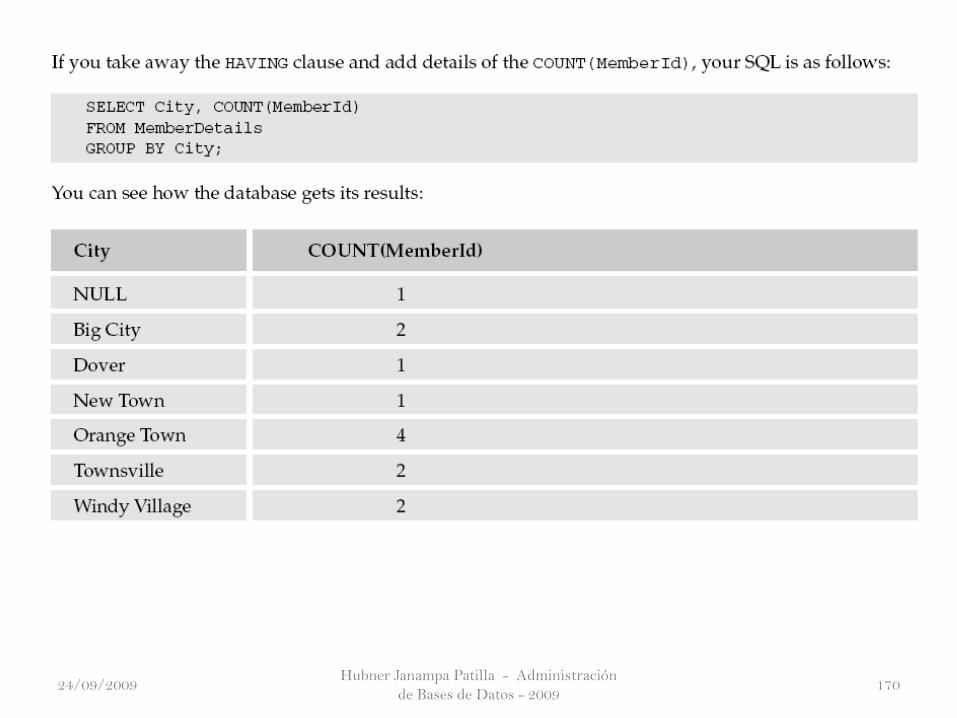
Puede utilizar el COUNT() para contar el número de registros en los
resultados. Dentro de los paréntesis de la función COUNT() inserte el
nombre de la columna que desea contar.
El valor devuelto en los resultados es el número de valores NO NULL en la
columna. Alternativamente, usted puede insertar un asterisco (*), en cuyo caso
todas las columnas de todos los registros de los resultados se cuentan con
independencia de si el valor es NULL o no. La función COUNT() también
puede aceptar las expresiones, por ejemplo COUNT(MemberID +CategoryID ).
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200915824/09/2009
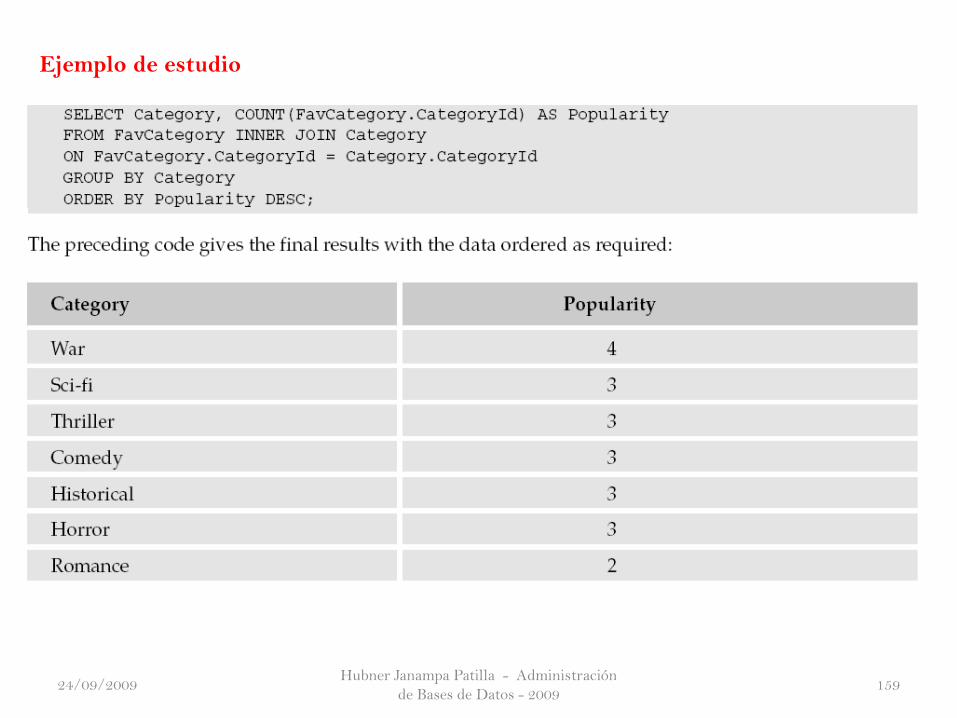
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009159
Ejemplo de estudio
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 2009160
Sin embargo el uso de un alias para el COUNT(FavCategory.CategoryId) en la
sentencia SELECT no es esencial. Usted podría haber logrado los mismos
resultados con este SQL, que es, de hecho, el único que MS Access acepta:
Sin embargo, dar un nombre significativo a la función agregada de los
resultados hace que el código más legible.
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200916124/09/2009

Adding Results
La función SUM() añade todos los valores de la expresión que le pasan como
argumento, ya sea de una columna o el resultado de un cálculo. La sintaxis
básica es la siguiente:
SUM(expression_to_be_added_together)
Hubner Janampa Patilla - Administración
de Bases de Datos - 200916224/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200916324/09/2009

Averaging Results
Si desea averiguar la media de una columna o de una expresión en losresultados, usted necesita utilizar la función AVG(). Esto funciona de lamisma manera que la función SUM (), con la diferencia obvia de que obtieneun valor medio.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200916424/09/2009
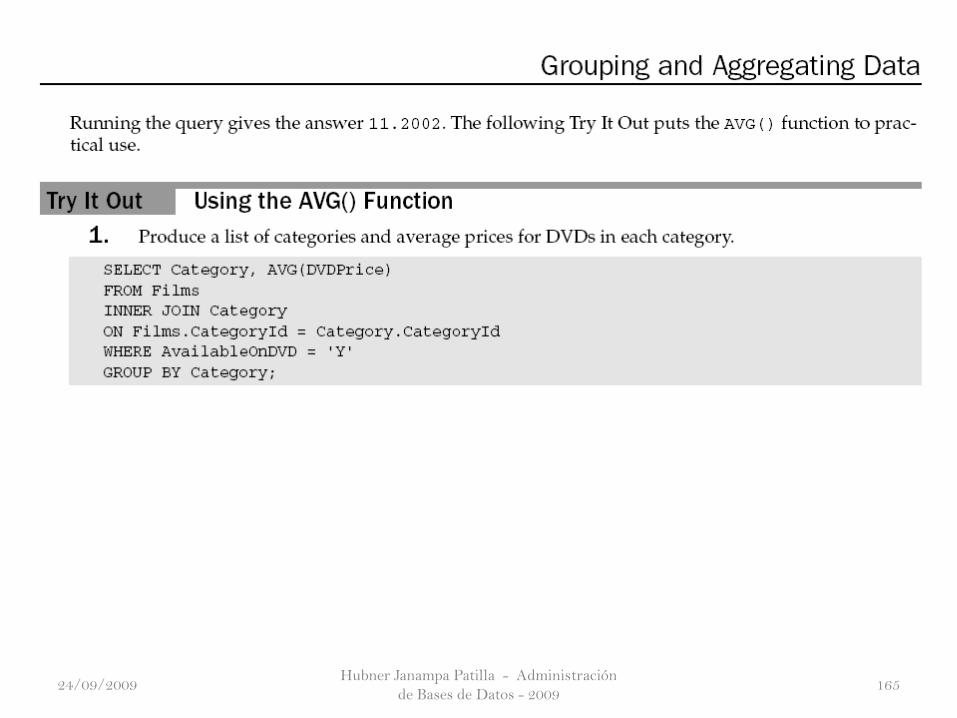
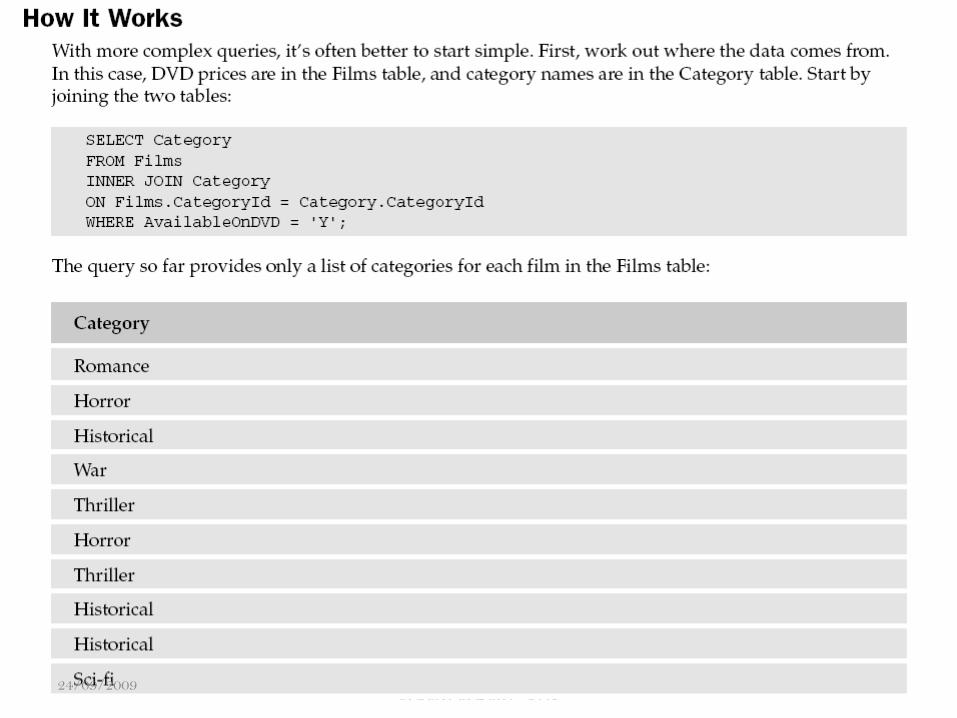
Hubner Janampa Patilla - Administración
de Bases de Datos - 200916524/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 200916624/09/2009
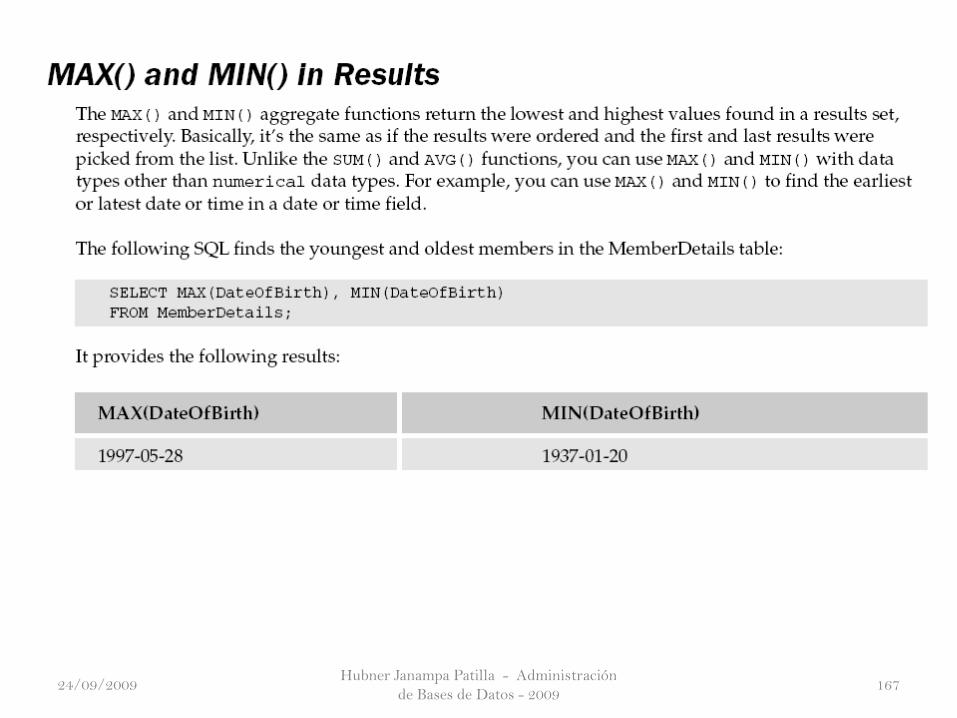
Hubner Janampa Patilla - Administración
de Bases de Datos - 200916724/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200916824/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 200916924/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 200917024/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200917124/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 2009172
En un ejemplo anterior, el presidente del club quiso saber cuántos miembros de su lista
tienen como favorito la categoría de la película. El presidente también quería saber la lista
ordenada de los más populares a los menos populares de elección de la categoría . Sin
embargo, ahora el presidente quiere la lista para incluir sólo aquellas categorías donde
cuatro o más de sus miembros figuran en sus categorías favoritas. Ejecutar el siguiente
SQL para responder a la pregunta del presidente:
24/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 200917324/09/2009

Joins Revisited
Recuerde, un inner join se compone de la palabra clave INNER JOIN, que
especifica que dos tablas se van a unir. Después de la palabra clave INNER
JOIN, se especifique una cláusula, que identifica la condición que debe cumplir
cada tabla. La sintaxis básica de un inner join es la siguiente:
name_of_table_on_left INNER JOIN name_of_table_on_right
ON condition
Hubner Janampa Patilla - Administración
de Bases de Datos - 200917424/09/2009

Usted podría utilizar un non-equijoin, por ejemplo, si usted desea una lista
de las películas puesto en libertad después del año de nacimiento de cada uno
de los miembros que viven en Golden State. El SQL necesario para este
ejemplo es el siguiente (tenga en cuenta que la ejemplo no trabaja en Oracle,
como Oracle no es compatible con el función YEAR().
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009175
Equijoins and Non-equijoins
24/09/2009

Multiple Joins and Multiple Conditions
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009176
Usted puede tener más de una tabla que se sumen a una consulta, lo cual es esencial
cuando usted tiene la necesidad de unir más de dos tablas a la vez. Por ejemplo, si desea
una lista de los nombres de los miembros y los nombres de sus películas favoritas por
categorías, usted necesita unir las tablas MemberDetails, Category, y FavCategory en
la siguiente consulta:
24/09/2009
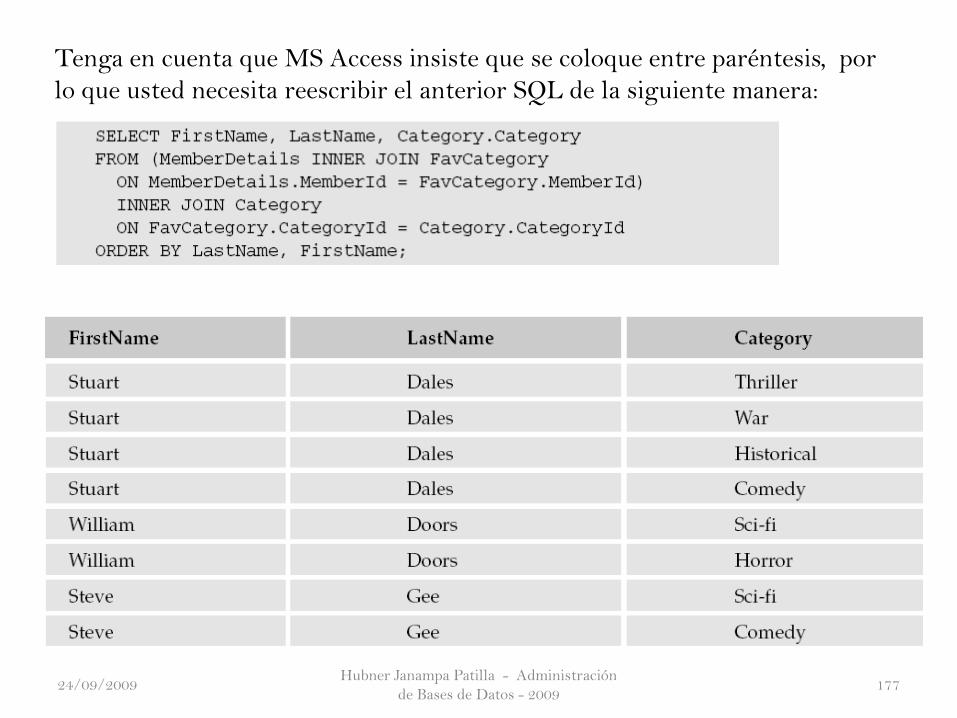
Tenga en cuenta que MS Access insiste que se coloque entre paréntesis, por
lo que usted necesita reescribir el anterior SQL de la siguiente manera:
Hubner Janampa Patilla - Administración
de Bases de Datos - 200917724/09/2009

Vale la pena mencionar que un INNER JOIN en su declaración no se limita a una sola
condición, que puede contener dos o más. Por ejemplo, el siguiente SQL tiene dos
condiciones en la posición de la clausula ON.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200917824/09/2009

Cross Joins
Una unión cruzada suma todas las filas de todas las tablas que figuran en la
unión y se incluyen en los resultados.
Puede definirse una unión cruzada de dos maneras.
La primera manera de crear una unión cruzada es como se muestra en el
siguiente código, donde las tablas Category y Location están unidas
mediante CROSS JOIN:
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009179
Primera Forma:
24/09/2009

La anterior sintaxis es apoyada por Oracle, MySQL y MS SQL Server, pero
no por IBM DB2 o MS Access. Una alternativa para la sintaxis de una
unión cruzada no es más que unirse a la lista todas los tablas, tal y como se
muestra aquí:
Prácticamente todas las bases de datos apoyan la segunda forma, por lo que
es probablemente la mejor manera para llevar a cabo una unión cruzada.
Ambas formas presentan el mismo resultado :
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009180
Segunda Forma:
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200918124/09/2009

En este capítulo se examina cómo puede anidar una consulta dentro de otra.
SQL permite que las peticiones en consultas, o subconsultas, que están dentro
del SELECT. Esto puede sonar un poco extraño, pero las subconsultas pueden
ser muy útiles. El inconveniente, sin embargo, es que pueden consumir una
gran cantidad de procesamiento, disco, memoria y recursos.
A lo largo de este capítulo, verás que hay referencias al exterior e interior de
las subconsultas.
Se muestra a continuación es un estándar de consulta:
Hubner Janampa Patilla - Administración
de Bases de Datos - 200918224/09/2009
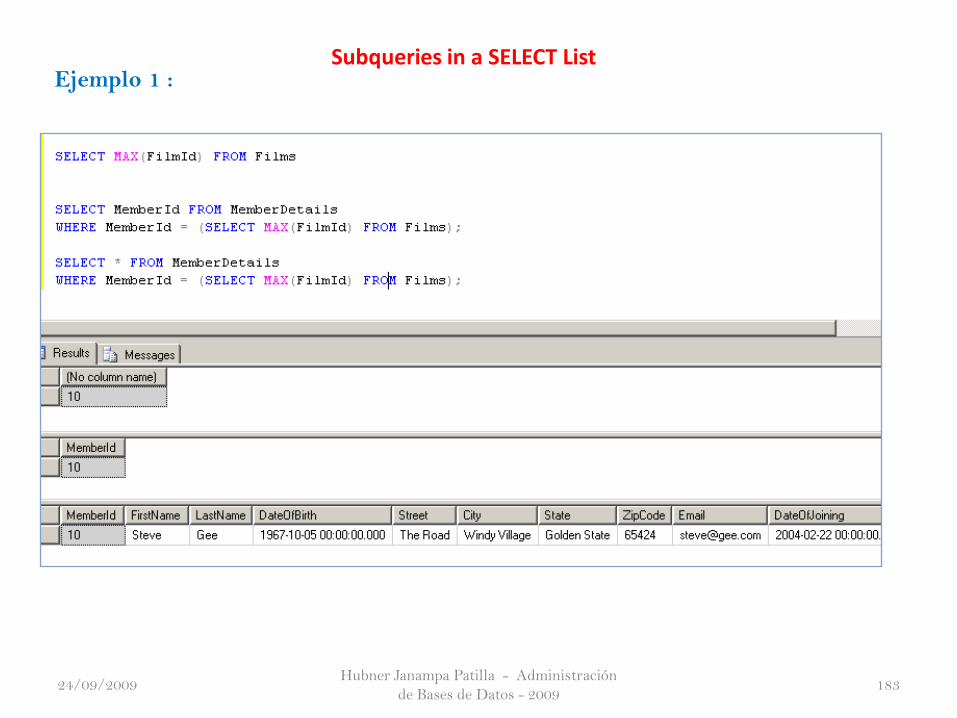
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009183
Ejemplo 1 : Subqueries in a SELECT List
24/09/2009
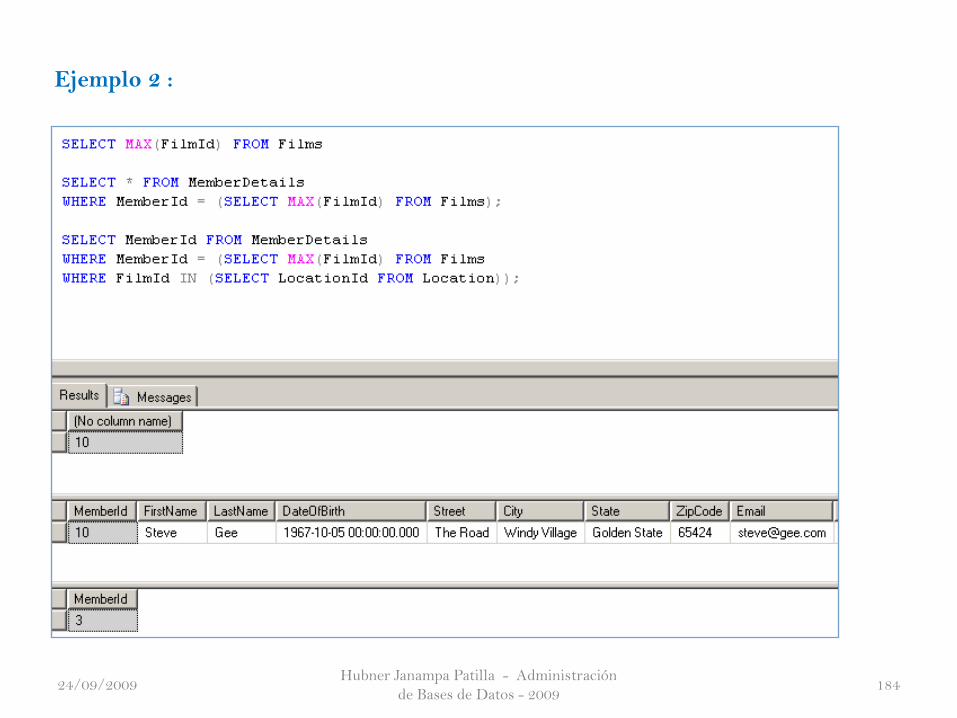
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009184
Ejemplo 2 :
24/09/2009
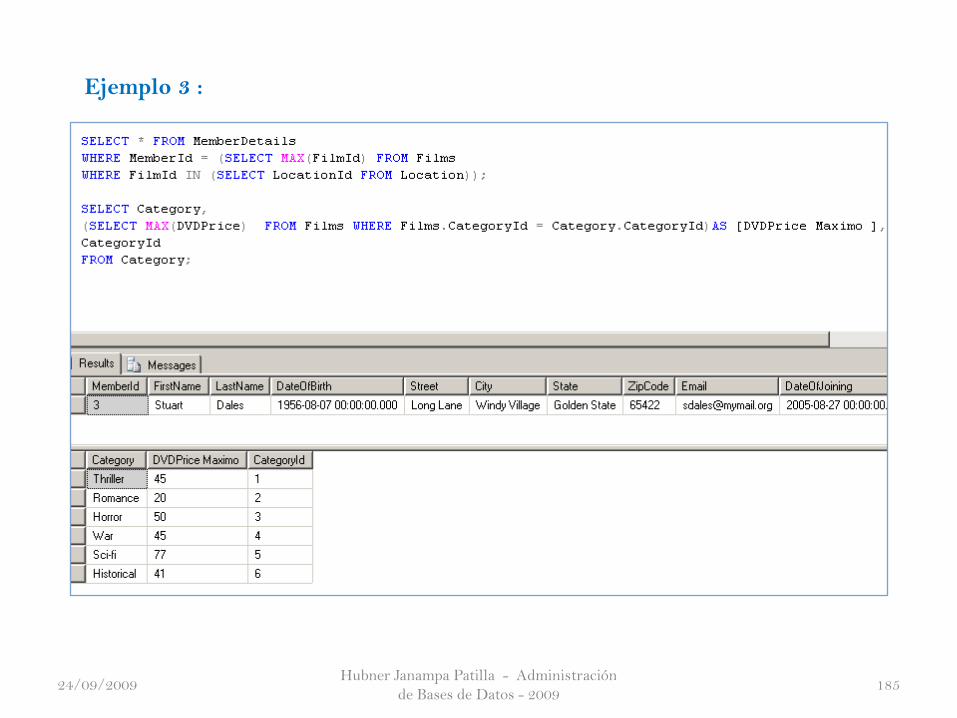
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009185
Ejemplo 3 :
24/09/2009
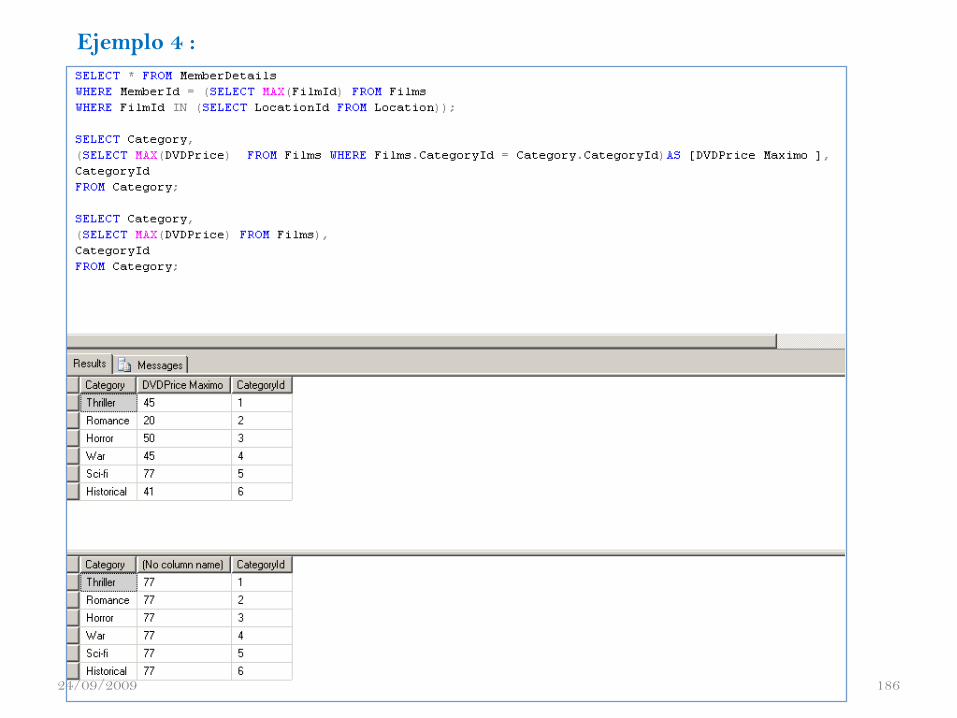
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009186
Ejemplo 4 :
24/09/2009
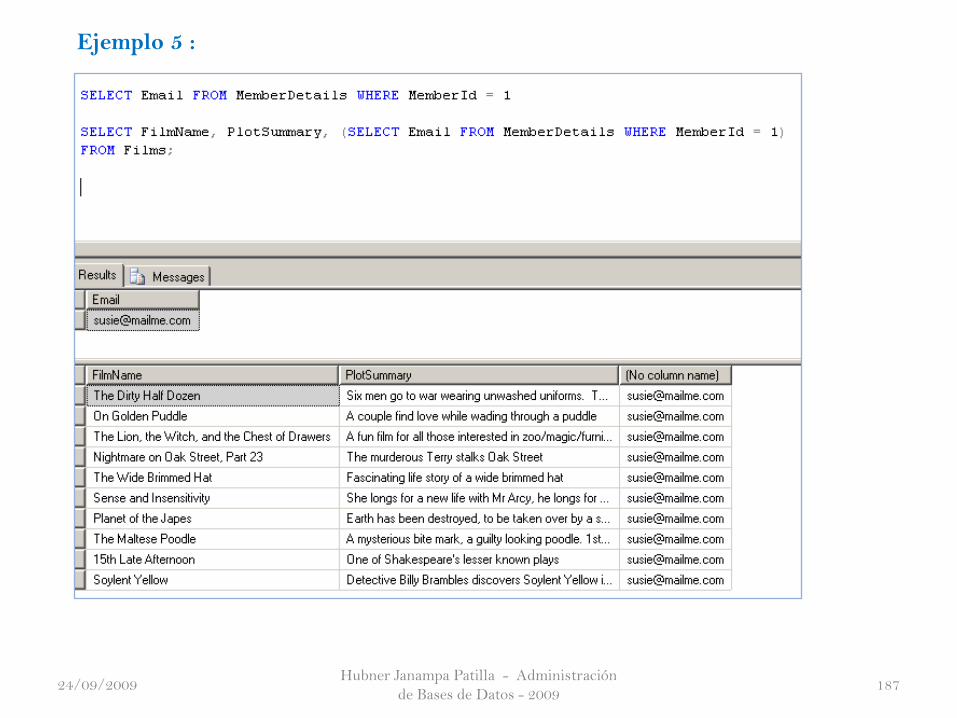
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009187
Ejemplo 5 :
24/09/2009
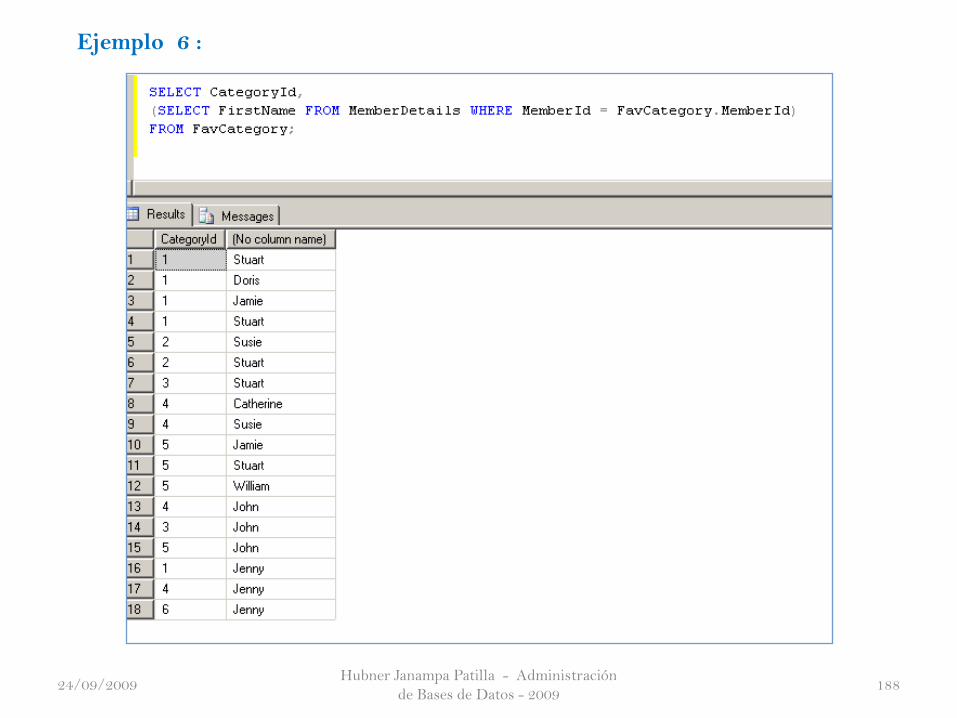
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009188
Ejemplo 6 :
24/09/2009
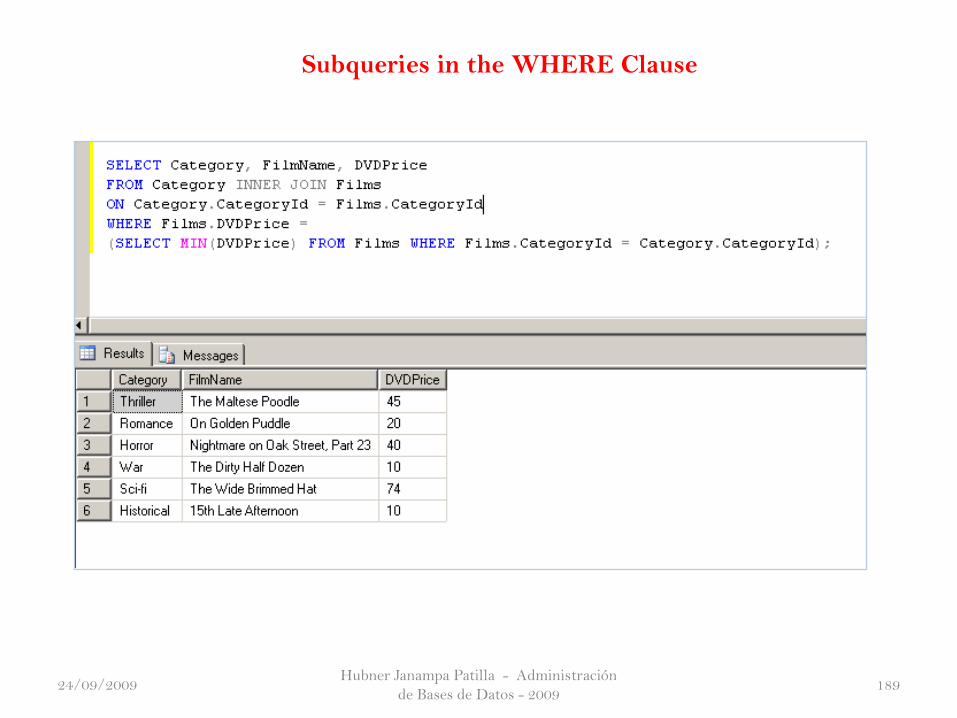
Subqueries in the WHERE Clause
Hubner Janampa Patilla - Administración
de Bases de Datos - 200918924/09/2009
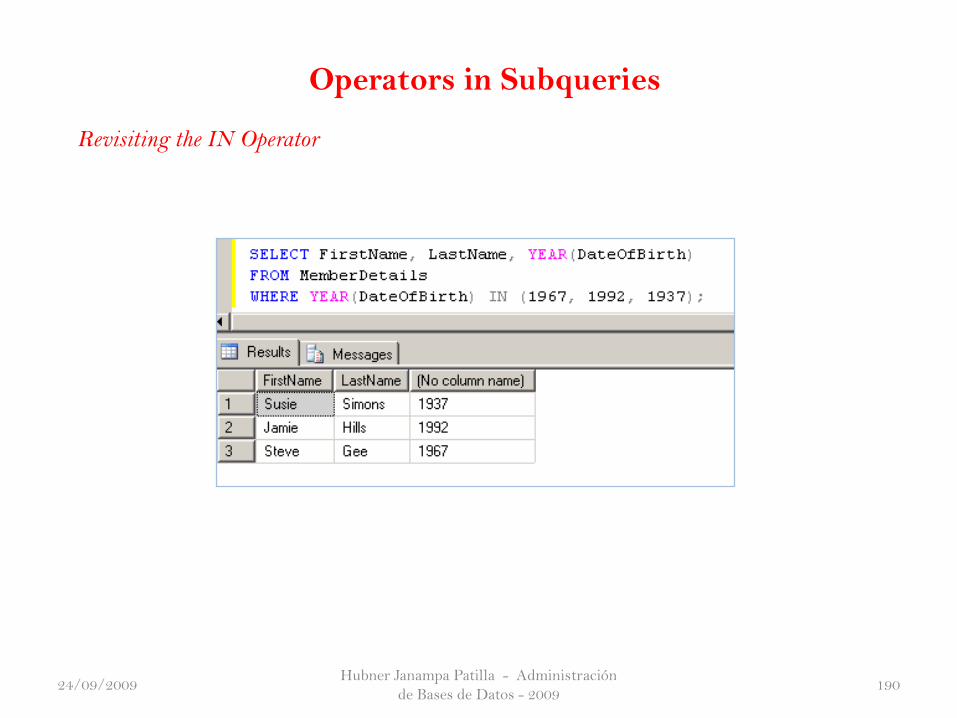
Operators in Subqueries
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009190
Revisiting the IN Operator
24/09/2009
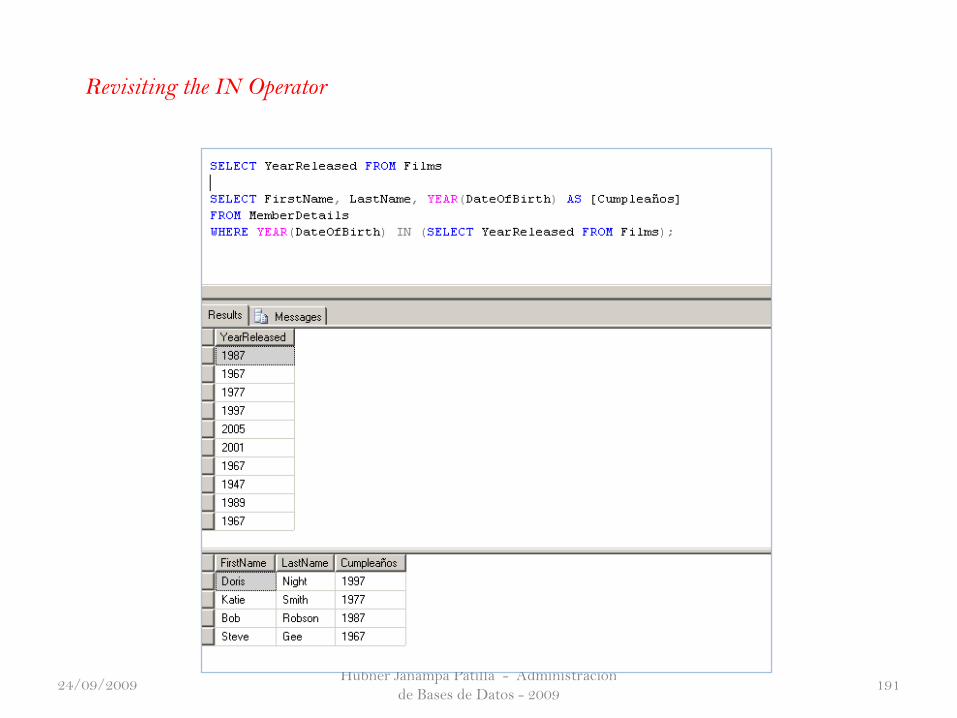
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009191
Revisiting the IN Operator
24/09/2009
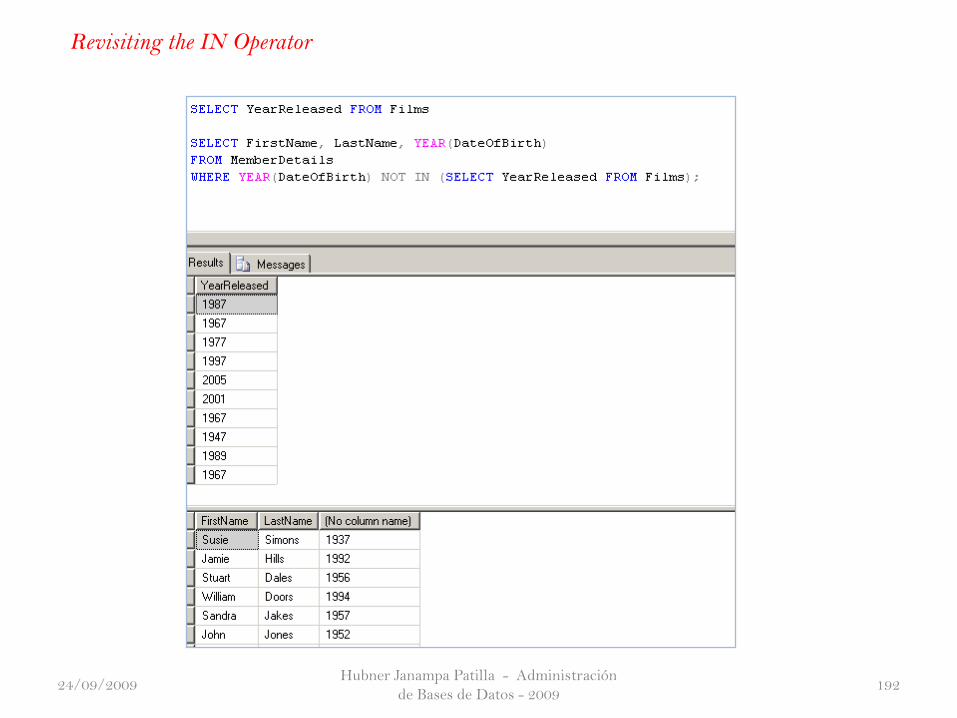
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009192
Revisiting the IN Operator
24/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009193
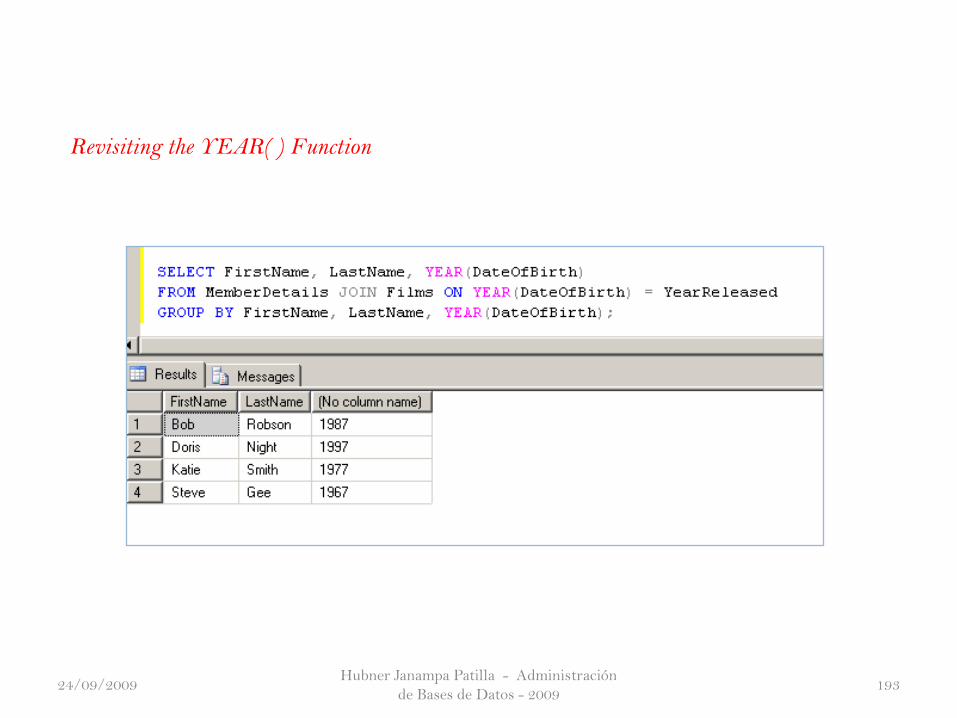
Revisiting the YEAR( ) Function
24/09/2009

Using the ANY, SOME, and ALL Operators
Continuara…
Hubner Janampa Patilla - Administración
de Bases de Datos - 200919424/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200919524/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200919624/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200919724/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200919824/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200919924/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200920024/09/2009

Implementación de procedimientos almacenados
Objetivos
• Describir cómo se procesa un procedimiento almacenado.
• Crear, ejecutar, modificar y eliminar un procedimiento almacenado.
• Crear procedimientos almacenados que acepten parámetros.
• Ejecutar procedimientos almacenados extendidos.
• Crear mensajes personalizados de error.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200920124/09/2009

• Un procedimiento almacenado es una colección con nombre de
instrucciones de Transact-SQL que se almacena en el servidor. Los
procedimientos almacenados son un método para encapsular tareas
repetitivas. Admiten variables declaradas por el usuario, ejecución
condicional y otras características de programación muy eficaces.
SQL Server admite cinco tipos de procedimientos almacenados:
Procedimientos almacenados del sistema (sp_)
Almacenados en la base de datos master e identificados mediante el prefijo
sp_, los procedimientos almacenados del sistema proporcionan un método
efectivo de recuperar información de las tablas del sistema.
Permiten a los administradores del sistema realizar tareas de administración
de la base de datos que actualizan las tablas del sistema aunque éstos no
tengan permiso para actualizar las tablas subyacentes directamente. Los
procedimientos almacenados del sistema se pueden ejecutar en cualquier base
de datos.Hubner Janampa Patilla - Administración
de Bases de Datos - 200920224/09/2009

Procedimientos almacenados locales
Los procedimientos almacenados locales se crean en las bases de datos de los
usuarios individuales.
Procedimientos almacenados temporales
Los procedimientos almacenados temporales pueden ser locales, con nombres
que comienzan por un signo de almohadilla (#), o globales, con nombres que
comienzan por un signo de almohadilla doble (##). Los procedimientos
almacenados temporales locales están disponibles en la sesión de un único
usuario, mientras que los procedimientos almacenados temporales globales
están disponibles para las sesiones de todos los usuarios.
Procedimientos almacenados remotos
Los procedimientos almacenados remotos son una característica anterior de
SQL Server. Las consultas distribuidas admiten ahora esta funcionalidad.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200920324/09/2009

Procedimientos almacenados extendidos (xp_)
Los procedimientos almacenados extendidos se implementan como bibliotecasde vínculos dinámicos (DLL, Dynamic-Link Libraries) que se ejecutan fueradel entorno de SQL Server. Normalmente, se identifican mediante el prefijoxp_. Se ejecutan de forma similar a los procedimientos almacenados.
Los procedimientos almacenados en SQL Server son similares a losprocedimientos de otros lenguajes de programación ya que pueden:
Contener instrucciones que realizan operaciones en la base de datos;
incluso tienen la capacidad de llamar a otros procedimientos almacenados.
Aceptar parámetros de entrada.
Devolver un valor de estado a un procedimiento almacenado o a un
proceso por lotes que realiza la llamada para indicar que se ha ejecutado
correctamente o que se ha producido algún error, y la razón del mismo.
Devolver varios valores al procedimiento almacenado o al proceso por
lotes que realiza la llamada en forma de parámetros de salida.Hubner Janampa Patilla - Administración
de Bases de Datos - 200920424/09/2009

El procesamiento de un procedimiento almacenado conlleva crearlo y
ejecutarlo la primera vez, lo que coloca su plan de consultas en la caché de
procedimientos.
La caché de procedimientos es un bloque de memoria que contiene los planes
de ejecución de todas las instrucciones de Transact-SQL que se están
ejecutando actualmente.
El tamaño de la caché de procedimientos fluctúa dinámicamente de acuerdo
con los grados de actividad.
La caché de procedimientos se encuentra en el bloque de memoria que es la
unidad principal de memoria de SQL Server. Contiene la mayor parte de las
estructuras de datos que usan memoria en SQL Server.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200920524/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 2009206
Los procedimientos almacenados ofrecen varias ventajas. Pueden:
Compartir la lógica de la aplicación con las restantes aplicaciones, lo que
asegura que el acceso y la modificación de los datos se hace de una forma
coherente.
Los procedimientos almacenados pueden encapsular la funcionalidad del
negocio. Las reglas o directivas empresariales encapsuladas en los
procedimientos almacenados se pueden cambiar en una sola ubicación.
Todos los clientes pueden usar los mismos procedimientos almacenados para
asegurar que el acceso y modificación de los datos es coherente.
Apartar a los usuarios de la exposición de los detalles de las tablas de la base de
datos. Si un conjunto de procedimientos almacenados permite llevar a cabo
todas las funciones de negocio que los usuarios necesitan, los usuarios no
tienen que tener acceso a las tablas directamente.
Proporcionar mecanismos de seguridad. Los usuarios pueden obtener permiso
para ejecutar un procedimiento almacenado incluso si no tienen permiso de
acceso a las tablas o vistas a las que hace referencia.24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 2009207
Mejorar el rendimiento. Los procedimientos almacenados implementan
muchas tareas como una serie de instrucciones de Transact-SQL. Se puede
aplicar lógica condicional a los resultados de las primeras instrucciones de
Transact-SQL para determinar cuáles son las siguientes que deben ejecutarse.
Todas estas instrucciones de Transact-SQL y la lógica condicional pasa a ser
parte de un único plan de ejecución del servidor.
Reducir el tráfico de red. En lugar de enviar cientos de instrucciones de
Transact-SQL por la red, los usuarios pueden realizar una operación compleja
mediante el envío de una única instrucción, lo que reduce el número de
solicitudes que se pasan entre el cliente y el servidor.
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200920824/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200920924/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200921024/09/2009
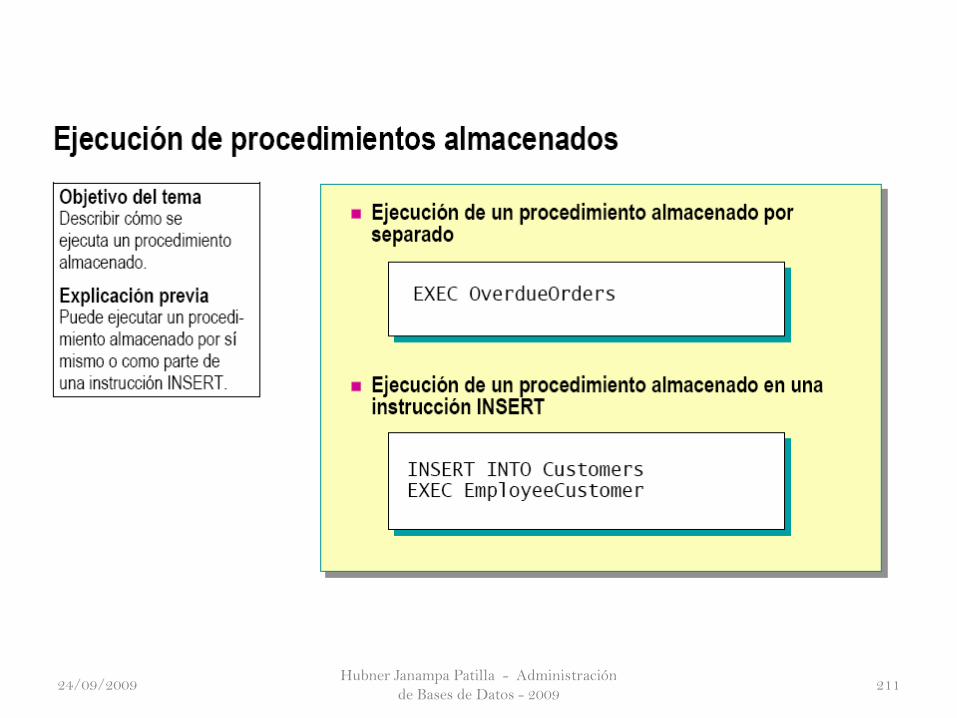
Hubner Janampa Patilla - Administración
de Bases de Datos - 200921124/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200921224/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200921324/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200921424/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200921524/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200921624/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200921724/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200921824/09/2009
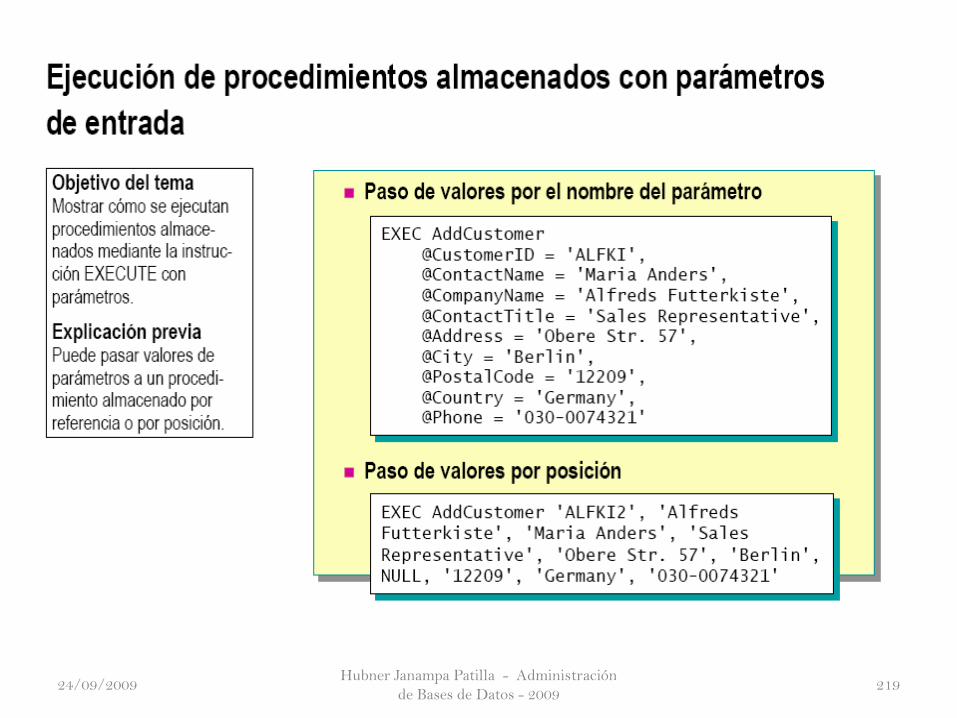
Hubner Janampa Patilla - Administración
de Bases de Datos - 200921924/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200922024/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200922124/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200922224/09/2009
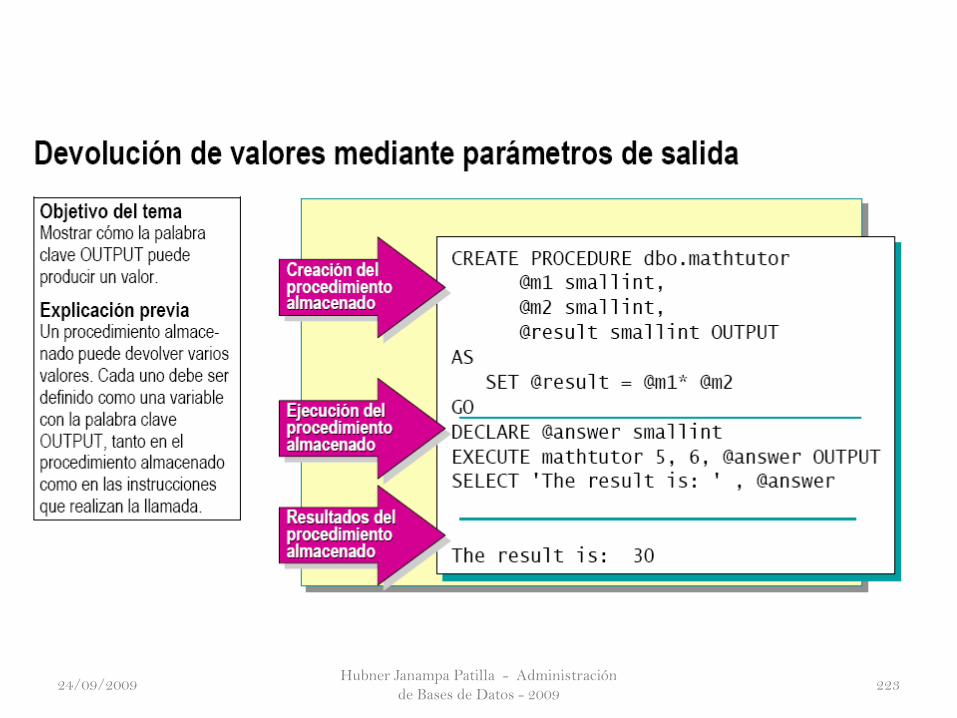
Hubner Janampa Patilla - Administración
de Bases de Datos - 200922324/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200922424/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200922524/09/2009

Continuara …..
Ejercicio
Realice un formulario (VB.Net , C#.Net o
Java) y utilice procedimientos almacenados
para grabar, modificar, y eliminar.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200922624/09/2009

Transact SQL 2005
Hubner Janampa Patilla - Administración
de Bases de Datos - 200922724/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 2009228
Microsoft Sql Server 2005 es un producto con muchas novedadescomparándolo con su antecesor SQL 2000. Sin duda que uno de susmayores cambios ha sido la inclusión del CLR dentro del motor de basede datos.
Nos concentraremos en algunas de las tantas novedades que nos traeMicrosoft SQL 2005 en lo que respecta a Transact-SQL, las cuales seránde mucha utilidad para los desarrolladores de aplicaciones como asítambién para los DBA.
Transact SQL (TSQL) es el lenguaje que usamos para escribir : StoreProcedures – Triggers – Querys – Etc.
Sin dudas que TSQL no dispone de las mismas habilidades y potenciaque puede tener un lenguaje como C# o VB.NET. En Sql2005 veremosun cambio significativo en TSQL el cual nos ayudara en nuestro trabajodiario.
24/09/2009

Numerando Registros (RowId)
En muchas ocasiones es necesario poder obtener una columna con el número
de registro o también poder generar un ranking. Hasta SQL2000 este tipo
de operaciones no eran tan simples de realizar y no disponíamos de
instrucciones directas. En TSQL 2005 disponemos de una serie de
instrucciones las cuales nos hacen el trabajo mucho mas simple y eficiente.
Veamos de qué se trata ello.
Row_Number: Esta nueva función de TSQL nos permitirá numerar los
resultados de una query.
El siguiente ejemplo muestra el uso de esta función:
Hubner Janampa Patilla - Administración
de Bases de Datos - 200922924/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200923024/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200923124/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200923224/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200923324/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200923424/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200923524/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200923624/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200923724/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200923824/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200923924/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200924024/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200924124/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200924224/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200924324/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200924424/09/2009

Introducción a Oracle 11g…..
Continuara…
Hubner Janampa Patilla - Administración
de Bases de Datos - 200924524/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 2009246
Aplicaciones Java con JDBC
24/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 200924724/09/2009
PERSISTENCIA EN JAVA
ENCUENTRO 1SISTEMAS
UNSCH
Hubner Janampa Patilla - Administración
de Bases de Datos - 200924824/09/2009

Hablar con las bases de datos
Ahora veremos la forma en que los programas Java puede interactuar con
otras bases de datos o cualquier base de datos que se puede acceder usando el
Lenguaje de Consulta Estructurado (SQL).
En primer lugar voy a presentar las ideas básicas detrás de bases de datos y la
forma en que almacenar datos.
Esto lleva naturalmente en una discusión sobre SQL, el lenguaje que se
utiliza con muchas bases de datos relacionales para definir consultas de datos y
que es un requisito previo para el acceso a bases de datos en Java.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200924924/09/2009

Entonces usted verá en la Conectividad de bases de datos Java (JDBC),
una biblioteca de clases, lo que proporciona una forma estándar para la
creación y el mantenimiento de un programa en Java para la conexión de una
base de datos.
Una vez que haya una conexión con un base de datos, puede utilizar SQL para
acceder y procesar el contenido.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200925024/09/2009

En este primer encuentro, usted tomará un breve recorrido por los conceptos
de bases de datos, SQL y JDBC. En lo siguiente entraremos en más
profundidad en las capacidades proporcionadas por JDBC y desarrollar una
base de datos de navegación de solicitud. En este encuentro usted aprenderá:
❑ Que son las bases de datos
❑ La razón de ser del JDBC
❑ Cómo escribir un simple programa JDBC
❑ Cuales son los elementos clave de la API de JDBC
Hubner Janampa Patilla - Administración
de Bases de Datos - 200925124/09/2009

JDBC conceptos y la terminología
Para asegurarnos de que tenemos un común entendimiento de la jerga,
primero voy a echar un vistazo a la terminología de la base de datos.
En primer lugar, en general, el acceso a los datos es el proceso de
recuperación o manipular los datos que se toma en local o remoto de un
origen de datos.
Las fuentes de los datos no tienen que ser relacional, pueden venir en una
variedad de diferentes formas.
Algunos ejemplos de fuentes de datos que usted puede realizar el acceso son
los siguientes:
Hubner Janampa Patilla - Administración
de Bases de Datos - 200925224/09/2009

1. Acceso a distancia de una base de datos relacional en un servidor, por
ejemplo, SQL Server
2. Una base de datos local relacional en su ordenador, por ejemplo,
Microsoft Access.
Un archivo de texto en su ordenador.
3. Una hoja de cálculo.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200925324/09/2009

JDBC es, por definición, una interfaz a las fuentes de datos relacionales. Si
bien es concebible que fuentes no relacional pueden ser accesibles a través de
JDBC, se le concentra en las bases de datos relacionales.
Si no ha trabajado antes con bases de datos relacionales, debe todavía ser
capaz de seguir debatiendo frente a esto.
La estructura de una base de datos relacional es bastante lógico y fácil de
aprender, y aunque no pueda proporcionarle una completa información sobre
él, aquí voy a cubrir una cantidad suficiente de los elementos básicos para
hacerlo comprensible, incluso si nunca has trabajado con bases de datos antes.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200925424/09/2009

La base de datos de Java Connectivity (JDBC), provee una biblioteca que
proporciona los medios para que pueda ejecutar sentencias SQL dentro de un
programa Java, para acceder y operar sobre una base de datos relacional.
JDBC esta basada en la interfaz de programación de aplicaciones (API) para
acceso a bases de datos y está destinado a ser un estándar para que los
desarrolladores de Java y base de datos de los proveedores pueden adherirse.
La biblioteca esta en el paquete java.sql. Se trata de un conjunto de clases e
interfaces que proporciona un API uniforme para el acceso a una amplia gama
de bases de datos.
Las operaciones que desee realizar sobre una base de datos relacional se
expresan en un idioma que esta diseñado específicamente para este fin, más
comúnmente conocida como SQL.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200925524/09/2009

SQL no es como un lenguaje de programación convencional, como Java. SQL
es un lenguaje declarativo, lo que significa que SQL le dice al servidor de
base de datos lo que quieres hacer, pero no cómo debe ser el hecho hasta el
servidor.
Cada comando SQL es analizada por el servidor de bases de datos, y la
operación que describe es llevada a cabo por una pieza de software que se
suele hacer referencia como el motor base de datos .
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009256
Un motor de base de datos se asocia con una particular puesta en marcha de
una base de datos relacional, aunque no necesariamente es única. Diferentes
implementaciones de bases de datos comerciales podrán utilizar un motor
común de base de datos.
24/09/2009
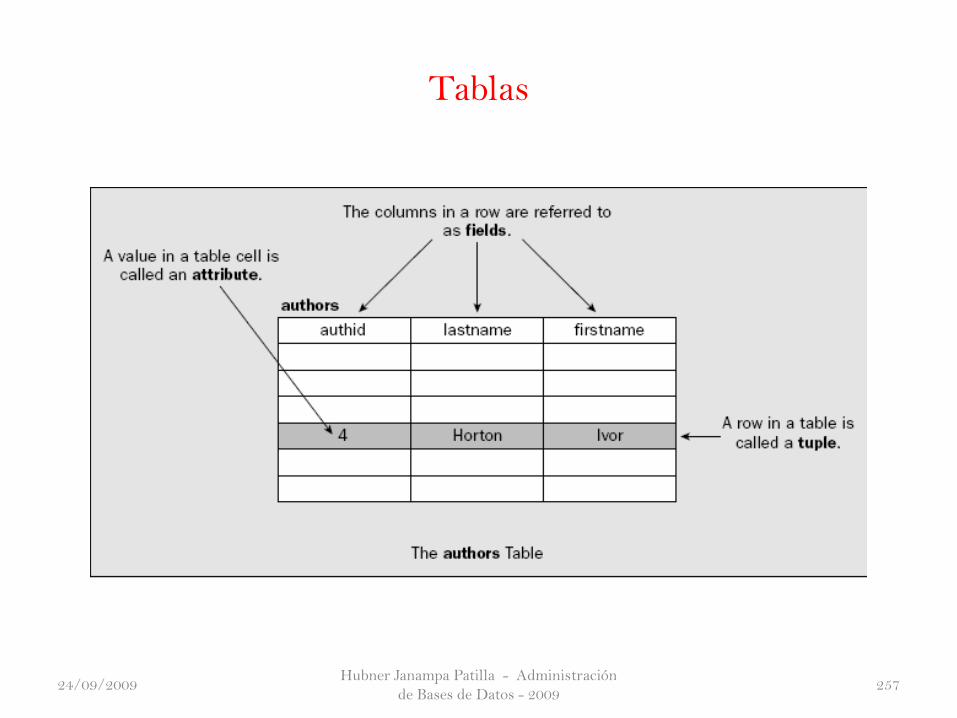
Tablas
Hubner Janampa Patilla - Administración
de Bases de Datos - 200925724/09/2009
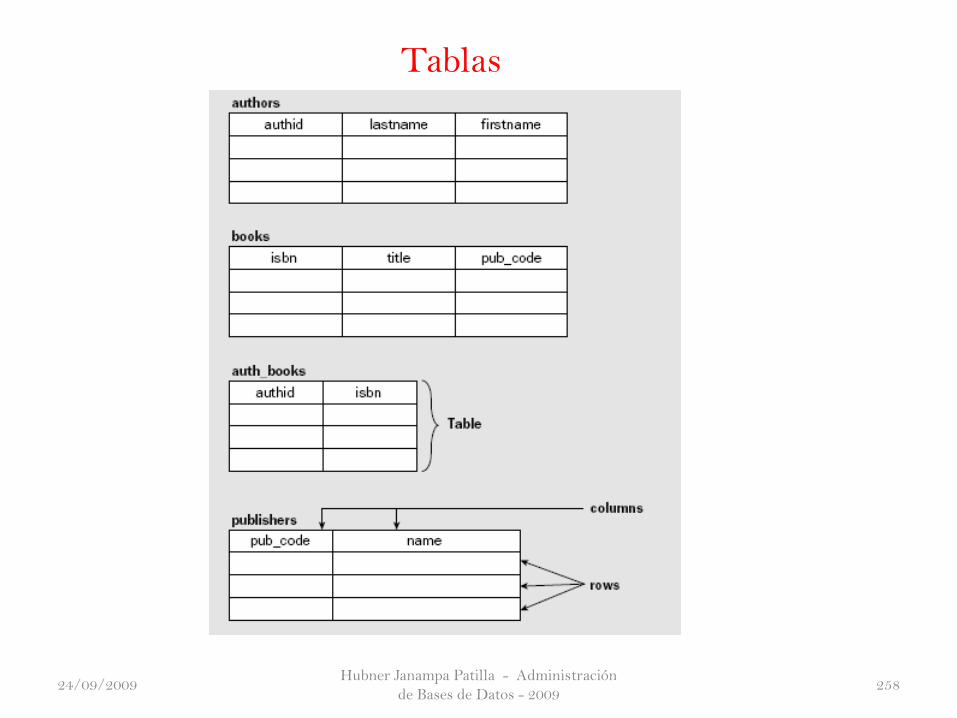
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009258
Tablas
24/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009259
Tablas
24/09/2009

Es un Lenguaje de consulta estructurado (SQL), aceptada
internacionalmente como la norma oficial para el acceso a bases de datos.
Una de las principales razones para la aceptación de SQL como el lenguaje de
consultas relacionales es la arquitectura cliente / servidor que se inició a
finales del decenio de 1980.
Introducción de SQL
Hubner Janampa Patilla - Administración
de Bases de Datos - 200926024/09/2009

SQL es diferente de otros lenguajes de programación que usted puede estar
familiarizado con todo en el sentido de que es declarativo, no de
procedimiento. En otras palabras, usted no usa SQL para definir procesos
complejos, sino usa SQL para cuestión de comandos que definen y manipulan
los datos.
La primera cosa que usted vera de SQL es que es muy legible. La forma en que
cada consulta se ha estructurado se lee como una oración en Inglés. La sintaxis
es fácil de aprender, y las construcciones y los conceptos son muy fácil de
entender.
Veamos el ejemplo de una base de datos que has visto anteriormente la base de
datos technical_library
Hubner Janampa Patilla - Administración
de Bases de Datos - 200926124/09/2009

Sentencias SQL
La mayoría de sentencias SQL y, desde luego, los que usted va a utilizar,
caen claramente en dos grupos:
❑ Lenguaje de definición de datos (DDL), declaraciones que se utilizan
para describir las tablas y los datos que contienen.
❑ Lenguaje de manipulación de datos (DML), declaraciones que se
utilizan para operar sobre los datos de la base de datos.
DML puede dividirse en dos grupos:
❑ SELECT-Las declaraciones que devuelven un conjunto de resultados.
❑ Todo lo demás-Las declaraciones que no devuelven un conjunto de
resultados.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200926224/09/2009

Para crear las tablas en el ejemplo, usted podría utilizar DDL, que define una
sintaxis de comandos tales como CREATE TABLE y ALTER TABLE.
Usted podría utilizar las declaraciones DDL para definir la estructura de la
base de datos.
Para llevar a cabo operaciones en la base de datos de añadir filas a una tabla o
la consulta de los datos, por ejemplo, usted podría utilizar las declaraciones
DML.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200926324/09/2009

He aquí un ejemplo típico de una declaración DDL
Hubner Janampa Patilla - Administración
de Bases de Datos - 200926424/09/2009

La biblioteca JDBC fue diseñado como una interfaz para ejecutar sentencias
SQL, y no como un compromiso de alto nivel capa de abstracción para el
acceso a los datos.
Además permite en gran escala escribir aplicaciones para la interfaz JDBC
sin preocuparse demasiado sobre la base de datos que se desplegará con la
solicitud.
Una aplicación JDBC está bien aislado de las características particulares del
sistema de base de datos que utiliza y, por tanto, no tiene que ser re-
ingeniería de bases de datos específicas.
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009
El paquete JDBC
26524/09/2009
Desde el punto de vista del usuario, una aplicación Java que trabaja con una base
de datos se muestra conceptualmente como:
Hubner Janampa Patilla - Administración
de Bases de Datos - 200926624/09/2009

Conexión con la Base de Datos y consultas elementales
Hubner Janampa Patilla - Administración
de Bases de Datos - 200926724/09/2009

URL y JDBC
Una hace referencia a un URL de recursos electrónicos, tales como una de la pagina de la World
Wide Web o un archivo en un servidor de FTP, que identifica de forma exclusiva ese recurso.
URL desempeñar un papel central en el desarrollo de aplicaciones de red en Java. JDBC utiliza
URLs para identificar los lugares de ambos conductores y fuentes de datos. URL JDBC tienen el
siguiente formato:
JDBC: Subprotocolo: data_source_identifier
El régimen JDBC indica que la URL se refiere a una fuente de datos JDBC. El sub-protocolo
identifica el Driver JDBC para su uso. Por ejemplo, el puente JDBC-ODBC, utiliza el conductor
identificador ODBC.
El driver JDBC dicta el formato de la fuente de datos de identificación. En el ejemplo anterior,
el puente JDBC-ODBC simplemente utiliza el nombre de la fuente de datos ODBC . Para utilizar
el controlador ODBC con la fuente de datos ODBC technical_library, usted podría crear una
URL con el siguiente formato:
JDBC: ODBC: technical_library
En relación a JDBC – ODBC
Existe un vínculo muy estrecho entre la cartografía de la arquitectura JDBC y la Open DataBase
Connectivity (ODBC), fundamentalmente porque se basan en la mismo nivel, el SQL X / Open
CLI; JDBC es mucho más fácil de usar.
Debido a su ascendencia común, comparten algunos importantes componentes conceptuales:
Hubner Janampa Patilla - Administración
de Bases de Datos - 200926824/09/2009

Componentes Conceptuales
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009
Carga el driver de la base de datos y gestiona las conexiones entre la aplicación y el conductor
Traduce llamadas a la API, en las operaciones de una determinada fuente de datos
Una sesión entre una aplicación y una base de datos
La información sobre los datos devueltos, la base de datos, y el conductor
Conjunto Lógico de columnas y filas de los datos devueltos por la ejecución de una declaración
Una sentencia SQL para realizar una consulta o actualización de operación
26924/09/2009

Asumiendo que han seguido las instrucciones dadas al comienzo de la
presentación, y tienen la necesaria base de datos de ejemplo y el
controlador de la base de datos instalado en su máquina, usted está listo
para ver una base JDBC ,programa que involucra los siguientes pasos:
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009
1.Importar las clases necesarias.
2. Cargar el driver JDBC.
3. Identificar el origen de datos.
4. Asignar un objeto de conexión.
5. Asignar una declaración objeto.
6. Ejecuta una consulta mediante la declaración de objeto.
7. Recuperar datos de la devolución del objeto ResultSet.
8. Cerrar el ResultSet.
9. Cerrar la Declaración objeto.
10. Cerrar el objeto Connection.
A lo largo de esta presentación usted acumulara suficiente comprensión
de JDBC para aplicar los elementos esenciales de dicho programa.
JDBC Básico
27024/09/2009
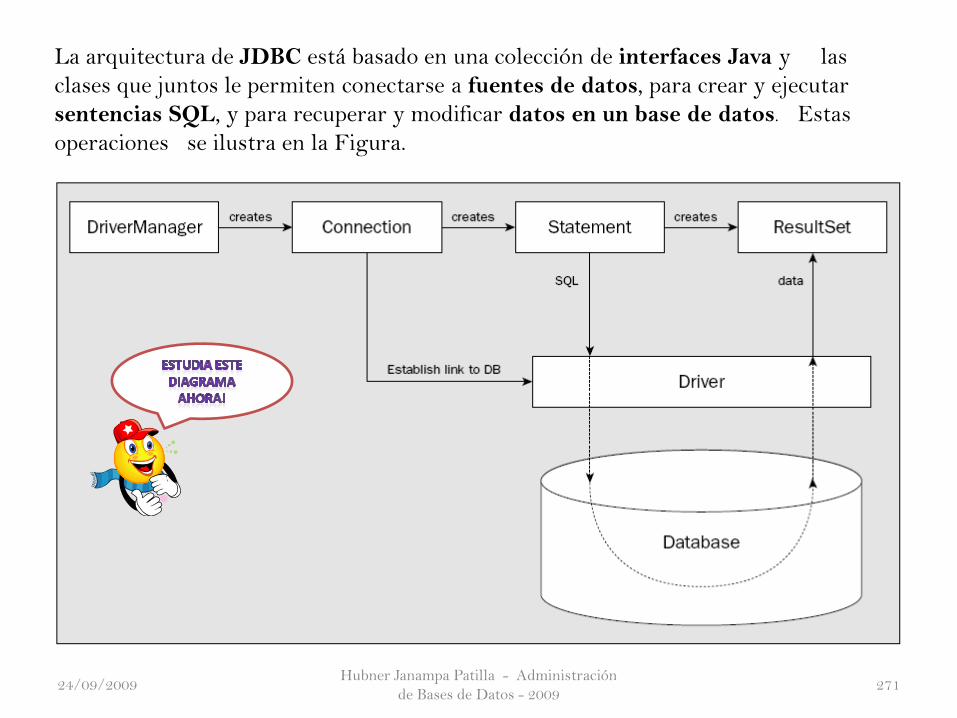
La arquitectura de JDBC está basado en una colección de interfaces Java y las
clases que juntos le permiten conectarse a fuentes de datos, para crear y ejecutar
sentencias SQL, y para recuperar y modificar datos en un base de datos. Estas
operaciones se ilustra en la Figura.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200927124/09/2009

En todos los ejemplos que usted observara en la presentación, utilizara el
puente JDBC-ODBC , sun.jdbc.odbc.JdbcOdbcDriver- conductor -para
acceder al MS Access technical_library.mdb base de datos que he asumido
ha sido creado con un Microsoft Access controlador ODBC como se
describe en la sección anterior.
Veamos como podemos conectar a una base
de datos Ms Access con JDBC-ODBC
Hubner Janampa Patilla - Administración
de Bases de Datos - 200927224/09/2009

package jdbc_odbc;
import java.sql.Connection;import java.sql.DriverManager;import java.sql.SQLException;
public class MakingTheConnection {
public static void main(String[] args) {// Load the driver
try {// Load the driver classClass.forName("sun.jdbc.odbc.JdbcOdbcDriver");// Define the data source for the driver
String sourceURL = "jdbc:odbc:HJP";// Create a connection through the DriverManagerConnection databaseConnection = DriverManager.getConnection(sourceURL);System.out.println("Connection is: "+databaseConnection);
} catch(ClassNotFoundException cnfe) {System.err.println(cnfe);
} catch(SQLException sqle) {System.err.println(sqle);
} }}
Hubner Janampa Patilla - Administración
de Bases de Datos - 200927324/09/2009

Usando el ResultSet de referencia, se puede recuperar el valor de cualquier
columna para la fila actual (tal como se especifica por el cursor) por su
nombre o por posición. También puede determinar la información sobre las
columnas, por ejemplo como el número de columnas devueltas o los tipos de
datos de las columnas. La interfaz ResultSet declara los siguientes métodos
básicos para recuperar una columna de datos para la fila actual, los tipos
utilizados en Java son:
Hubner Janampa Patilla - Administración
de Bases de Datos - 200927424/09/2009

Tenga en cuenta que esta lista no es completa, pero no es probable que
necesite saber acerca de los demás. Para una lista completa de los métodos
disponibles, eche un vistazo a la documentación para la interfaz ResultSet.
Allí están sobrecargadas versiones de cada uno de los métodos se muestra en
el cuadro anterior que ofrecen dos formas de identificación de la columna que
contiene los datos.
La columna se puede seleccionar con el nombre de la columna SQL, como
una cadena o pasando un argumento índice de tipo int, donde la primera
columna tiene el valor índice 1.
Tenga en cuenta que los nombres de columna no se distingue entre
mayúsculas y minúsculas para que "FirstName" es el mismo como
―firstName".
Hubner Janampa Patilla - Administración
de Bases de Datos - 200927524/09/2009

La mayoría de los métodos básicos de acceso a datos son muy flexibles en la
conversión de tipos de datos SQL para tipos de datos Java. Por ejemplo,
si usa getInt() en un campo de tipo CHAR, el método se tratará de analizar
los personajes suponiendo que se especifico un número entero. Del mismo
modo, se puede leer tipos numéricos de SQL usando la getString().
Con todos estos métodos, la ausencia de un valor, lo cual es un NULL SQL,
se devuelve, ya sea como el equivalente de cero, o como nulo, según el objeto
de referencia devuelto. Así, un campo booleano NULL devolverá falso, y una
campo numérico NULL devolverá 0. Si accede a una base de datos y se
produce error cuando ejecuta un getXXX() para un resultset, una excepción
de tipo SQLException se lanzará.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200927624/09/2009

La API de JDBC proporciona el acceso a los metadatos, no sólo para la
conexión de objeto, sino también para la ResultSet objeto. La API de JDBC
proporciona un objeto ResultSetMetaData que le permite mirar los datos
detrás del objeto ResultSet. Si piensa en la prestación de servicios de
navegación interactiva en su aplicaciones JDBC, usted encontrará esta
especialmente útil.
En conjunto de estas clases e interfaces constituyen la mayor parte de los
componentes JDBC. Vamos a poner ahora en práctica con un ejemplo
sencillo.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200927724/09/2009

package JDBC_CONEXION;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;
import java.sql.ResultSet;
public class MakingAStatement {
public static void main(String[] args) {
// Load the driver
try {
// Load the driver class
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
// This defines the data source for the driver
String sourceURL = new String("jdbc:odbc:HJP");
//Crear conexión a través de la DriverManager
Connection databaseConnection =DriverManager.getConnection(sourceURL);
Statement statement = databaseConnection.createStatement();
ResultSet authorNames = statement.executeQuery("SELECT lastname, firstnameFROM authors");
// Salida de datos del resultset
while(authorNames.next()) {
System.out.println(authorNames.getString("lastname")+" "+
authorNames.getString("firstname"));
}
}catch(ClassNotFoundException cnfe) {
System.err.println(cnfe);
}catch(SQLException sqle) {
System.err.println(sqle);
} }
} Hubner Janampa Patilla - Administración
de Bases de Datos - 200927824/09/2009

Configurar el tiempo de inicio de sesión
La clase DriverManager proporciona un par de métodos de acceso para el
período de tiempo de inicio de sesión. Estos permiten que usted especifique
un período de tiempo (en segundos) que limita el tiempo que un driver está
dispuesto a esperar para que inicie la conexión a la base de datos. Los dos
métodos de acceso son los siguientes:
Hubner Janampa Patilla - Administración
de Bases de Datos - 200927924/09/2009

Se especifica que el periodo de tiempo no predeterminado puede ser útil para aplicaciones de que
están teniendo dificultades para la conexión a un servidor de bases de datos remotas. Por
ejemplo, si su aplicación está intentando conectarse con un servidor muy ocupado, la solicitud
podría parecer que han colgado. Puede decirle al DriverManager el fracaso del intento de
conexión cuando especificamos un período de tiempo. El fragmento de código a continuación le
dice al DriverManager a fracasar el intento de acceso después de 60 segundos:
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009280
package jdbc_expire;
import java.sql.Connection;import java.sql.DriverManager;import java.sql.SQLException;
public class jdbc_expire {public static void main(String[] args) {
String driverName = "sun.jdbc.odbc.JdbcOdbcDriver";String sourceURL = "jdbc:odbc:technical_library";
try {Class.forName(driverName);DriverManager.setLoginTimeout(60); // fail after 60 secondsConnection databaseConnection = DriverManager.getConnection(sourceURL);
} catch(ClassNotFoundException cnfe) {System.err.println("Error loading " + driverName);
} catch(SQLException sqle) {System.err.println(sqle);
}}}
24/09/2009

Una vez que la conexión ha sido establecida por la llamada del método
getConnection(), el siguiente paso es crear la declaración de un objeto que le
permite ejecutar una sentencia SQL y recuperar los resultados. Para crear
una declaración de objeto, simplemente llame al método createStatement()
del objeto de conexión.
Una vez que haya creado la declaración de un objeto para ejecutar una
consulta SQL contra la base de datos conectada, pase un objeto String como
argumento para el método executeQuery().
El executeQuery() devuelve un objeto que implementa la interfaz
ResultSet. Como su nombre implica, la interfaz ResultSet le permite
obtener la información de que fue recuperado por la consulta. Tú puedes
pensar en la interfaz ResultSet como un proporcionador de filas, o como una
tabla virtual de resultados. El ResultSet proporciona interiormente un
cursor o puntero lógico para hacer un seguimiento de su fila actual. En un
ResultSet lo primero que regresa es el cursor que se coloca justo antes de la
primera fila de datos. Este mecanismo se ilustra en la Figura.Hubner Janampa Patilla - Administración
de Bases de Datos - 2009
¿Cómo funciona…?
28124/09/2009
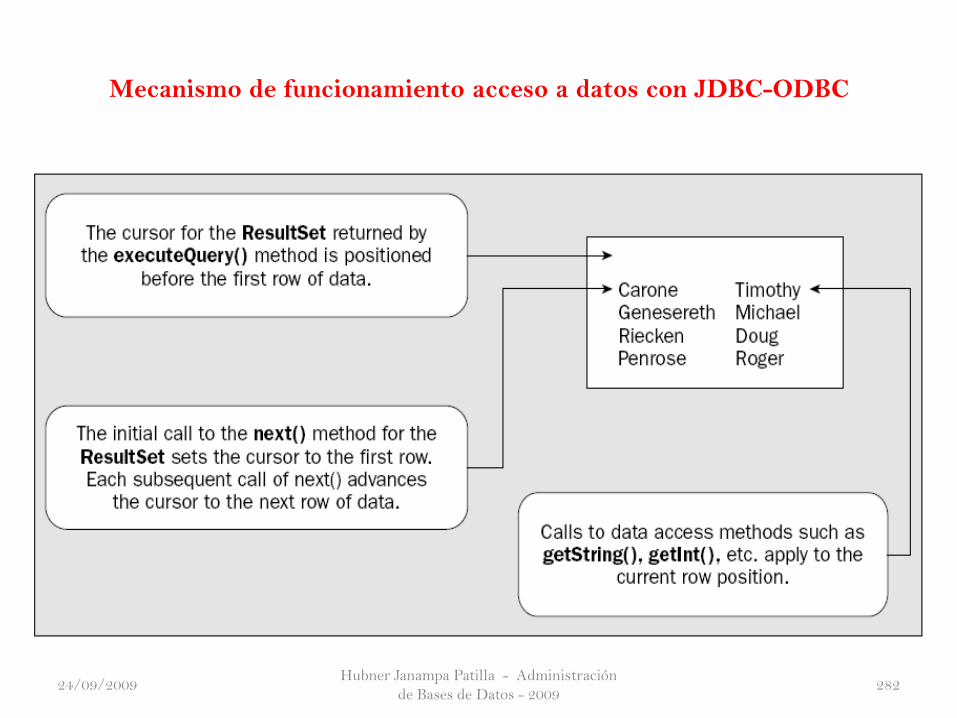
Mecanismo de funcionamiento acceso a datos con JDBC-ODBC
Hubner Janampa Patilla - Administración
de Bases de Datos - 200928224/09/2009

Obtener los metadatos de un Resultset
El método getMetaData() para un objeto ResultSet devuelve una referencia a
un objeto de tipo java.sql.ResultSetMetaData que encapsula los metadatos
para el resultset. La interfaz ResultSetMetaData declara métodos que le
permiten obtener los elementos de los metadatos para el resultset.
El getColumnCount() devuelve el número de columnas en el resultset como
un valor de tipo int.
Para cada columna, se puede obtener el nombre de la columna y el tipo de
columna llamando a los métodos getColumnName() y getColumnType()
respectivamente. En ambos casos, especificar la columna por su valor índice. El
nombre de la columna se devuelve como un objeto String, y el tipo de columna
se devuelve como un valor de tipo int que identifica el tipo SQL.
Los tipos de clase en el paquete publico java.sql define los campos de tipo int
que identifica los tipos SQL, y los nombres de esos miembros de la clase de
datos son los mismos que los tipos que SQL representa como CHAR,
VARCHAR, DOBLE, INT, TIME, y así sucesivamente.Hubner Janampa Patilla - Administración
de Bases de Datos - 200928324/09/2009

Usted podría ver el contenido del valor de los datos de cada fila de un objeto
ResultSet que son del tipo SQL CHAR con el siguiente código:
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009284
De este modo, se puede enumerar los nombres de las columnas en un resultset que eran de tipo CHAR con el siguiente código:
24/09/2009

También puede obtener el nombre del tipo de una columna como una cadenallamando a la getColumnTypeName(). Otro método muy útil esgetColumnDisplaySize(), que devuelve el importe máximo del número decaracteres necesarios para visualizar los datos almacenados en la columna.
Pasará el número de índice de la columna que usted está interesado en como argumento.
El regreso el valor es de tipo INT. Usted puede utilizar este formato paraayudar a la salida de la columna de datos.
Toda una gama de otros métodos de metadatos suministrados por unresultset encontrará en la documentación para la interfazResultSetMetaData.
Aquí hay una lista de unos métodos más que a usted le puede resultar muyútil-que todos ellos requieren un argumento que es el numero de columna detipo int:
Hubner Janampa Patilla - Administración
de Bases de Datos - 200928524/09/2009
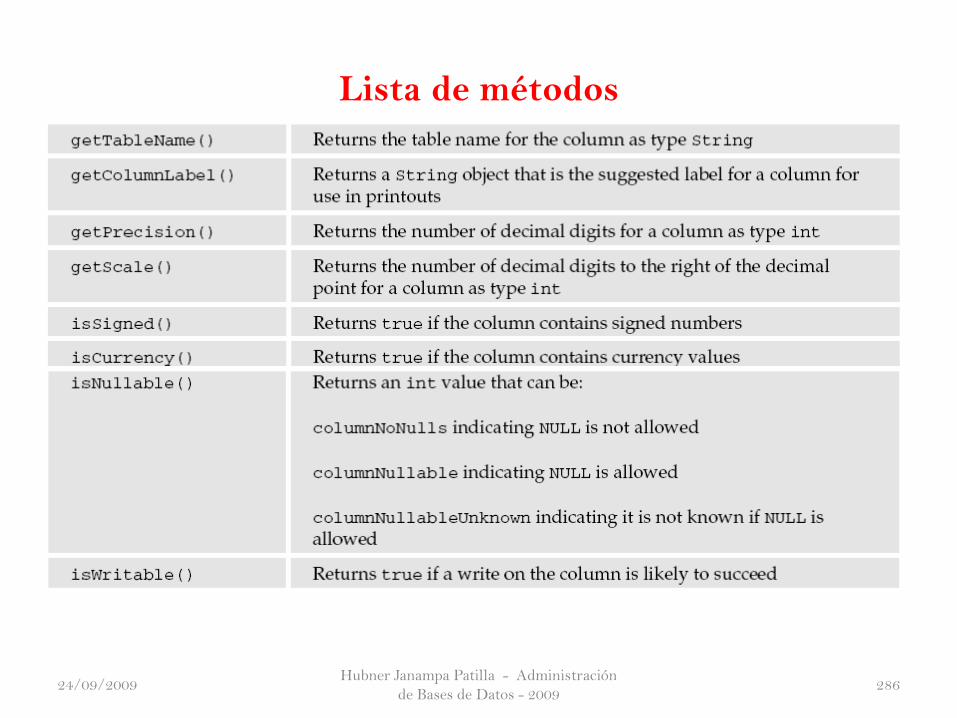
Lista de métodos
Hubner Janampa Patilla - Administración
de Bases de Datos - 200928624/09/2009

EJEMPLO PRACTICO
SISTEMASDISEÑO DE LA
BASE DE DATOS UNSCH
Hubner Janampa Patilla - Administración
de Bases de Datos - 200928724/09/2009

Diseño de tablas de la base de datos
El primer paso en el diseño de las tablas que usted necesita en su base de
datos es decidir qué información desea capturar. Entonces usted puede
diseñar tablas en torno a esa información.
Con la base de datos technical_library, se desea hacer un seguimiento de
los siguientes tipos de cosas:
❑ Libros (Books)
❑ artículos (Articles)
❑ Autores (Authors)
❑ Editores (Publishers)
Para cada una de estas categorías de información, llamados entidades en la
jerga de bases de datos, usted desea grabar un conjunto específico de datos,
como sigue:Hubner Janampa Patilla - Administración
de Bases de Datos - 200928824/09/2009

Ejemplo de acceso a la Base de Datos
Tres formas de recorrer desde Java contra la base de datos mediante el objeto ResulSet y
ResultSetMetaData
Hubner Janampa Patilla - Administración
de Bases de Datos - 200928924/09/2009

package javaapplication26;
import java.sql.Connection;
import java.sql.Statement;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.sql.SQLException;
public class EssentialJDBC {
Connection connection;
Statement statement;
String sourceURL = "jdbc:odbc:technical_library";
String queryIDAndName = "SELECT authid, lastname, firstname FROM authors";
String queryWildcard = "SELECT * FROM authors"; // Select all columns
Hubner Janampa Patilla - Administración
de Bases de Datos - 200929024/09/2009

public static void main (String[] args) {EssentialJDBC SQLExample = new EssentialJDBC(); // Create application objectSQLExample.getResultsByColumnName();SQLExample.getResultsByColumnPosition();SQLExample.getAllColumns();SQLExample.closeConnection();
}public EssentialJDBC() {
// Constructor to establish the connection and create a Statement object...try {
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");connection = DriverManager.getConnection(sourceURL);statement = connection.createStatement();} catch(SQLException sqle) {
System.err.println("Error creating connection");} catch(ClassNotFoundException cnfe) {
System.err.println(cnfe.toString());}
}
Hubner Janampa Patilla - Administración
de Bases de Datos - 200929124/09/2009

void getResultsByColumnName() {// Execute wildcard query and output selected columns...
try {ResultSet authorResults = statement.executeQuery(queryWildcard);int row = 0;while(authorResults.next()) {
System.out.println("Row" + (++row) + ") "+authorResults.getString("authid")+ " " +authorResults.getString("lastname")+ " , "+authorResults.getString("firstname"));
}authorResults.close();} catch (SQLException sqle) {
System.err.println ("\nSQLException-------------------\n");System.err.println ("SQLState: "+ sqle.getSQLState());System.err.println ("Message : " + sqle.getMessage());
}}
Hubner Janampa Patilla - Administración
de Bases de Datos - 200929224/09/2009

void getResultsByColumnPosition() {// Execute ID and name query and output results...
try {ResultSet authorResults = statement.executeQuery(queryIDAndName);int row = 0;while (authorResults.next()) {
System.out.print("\nRow " + (++row) + ") ");for(int i = 1 ; i<=3 ; i++) {
System.out.print((i>1?", ":" ")+authorResults.getString(i));}}authorResults.close(); // Close the resultset} catch (SQLException ex) {
System.err.println("\nSQLException-------------------\n" );System.err.println("SQLState: " + ex.getSQLState());System.err.println("Message : " + ex.getMessage());
}}
Hubner Janampa Patilla - Administración
de Bases de Datos - 200929324/09/2009

void getAllColumns() {// Execute wildcard query and output all columns...
try {ResultSet authorResults = statement.executeQuery(queryWildcard);ResultSetMetaData metadata = authorResults.getMetaData();int columns = metadata.getColumnCount(); // Column countint row = 0;while (authorResults.next()) {
System.out.print("\nRow " + (++row) + ") ");for(int i = 1 ; i<=columns ; i++) {
System.out.print((i>1?", ":" ")+authorResults.getString(i));}}authorResults.close(); // Close the resultset} catch (SQLException ex) {
System.err.println("\nSQLException-------------------\n");
System.err.println("SQLState: " + ex.getSQLState());System.err.println("Message : " + ex.getMessage());
}}
Hubner Janampa Patilla - Administración
de Bases de Datos - 200929424/09/2009

// Close the connection
void closeConnection() {
if(connection != null) {
try {
connection.close();
connection = null;
} catch (SQLException ex) {
System.out.println("\nSQLException-------------------\n");
System.out.println("SQLState: " + ex.getSQLState());
System.out.println("Message : "+ ex.getMessage());
}
}
}
}
Hubner Janampa Patilla - Administración
de Bases de Datos - 200929524/09/2009

El uso de un objeto PreparedStatement
Vamos a poner una declaración preparada en acción. Esto lo veremos en
profundidad en lo que queda del curso. Use el código de ejemplo que ejecuta el
mismo SQL SELECT utilizando tanto el estado y los objetos
PreparedStatement.
Para cada uno de estos, los resultados se mostrarán junto con los metadatos.
En primer lugar se definirá un esquema de la clase StatementTest y sus estados
de sus miembros. En el método main () se ejemplifica el objeto StatementTest
y luego llamar a los métodos doStatement () y doPreparedStatement () para
ese objeto:
Hubner Janampa Patilla - Administración
de Bases de Datos - 200929624/09/2009

package javaapplication27;import java.sql.Connection;
import java.sql.Statement;
import java.sql.PreparedStatement;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.sql.SQLException;
public class StatementTest {
Connection databaseConnection; // Connection to the database
String driverName; // Database driver name
String sourceURL; // Database location
public static void main(String[] args) {
try {
StatementTest SQLExample = new StatementTest();
SQLExample.doStatement();
SQLExample.doPreparedStatement();
} catch(SQLException sqle) {
System.err.println("SQL Exception: " + sqle);
} catch(ClassNotFoundException cnfe) {
System.err.println(cnfe.toString());
} }
Hubner Janampa Patilla - Administración
de Bases de Datos - 200929724/09/2009

public StatementTest() throws SQLException, ClassNotFoundException {driverName = "sun.jdbc.odbc.JdbcOdbcDriver";sourceURL = "jdbc:odbc:technical_library";Class.forName (driverName);databaseConnection = DriverManager.getConnection(sourceURL);
}
public void doStatement() throws SQLException {Statement myStatement = databaseConnection.createStatement();ResultSet myResults = myStatement.executeQuery("SELECT authid, lastname, firstname FROM authors ORDER BY authid");showResults(myResults);
}public void doPreparedStatement() throws SQLException {
PreparedStatement myStatement = databaseConnection.prepareStatement("SELECT authid, lastname, firstname FROM authors ORDER BY authid");ResultSet myResults = myStatement.executeQuery();showResults(myResults);
}
Hubner Janampa Patilla - Administración
de Bases de Datos - 200929824/09/2009

public void showResults(ResultSet myResults) throws SQLException {
// Retrieve ResultSetMetaData object from ResultSet
ResultSetMetaData myResultMetadata = myResults.getMetaData();
// How many columns were returned? (Cuántas columnas fueron devueltos)
int numColumns = myResultMetadata.getColumnCount();
System.out.println(" ---------------------Query Results-------------------------");
// Loop through the ResultSet and get data (Bucle a través del ResultSet y obtener datos)
while(myResults.next()) {
System.out.printf("%-5d", myResults.getInt(1)); // 1st Column only
for(int column = 2; column <= numColumns; column++) {
System.out.print(myResults.getString(column)+" ");
}
System.out.print("\n"); }
System.out.println("\n\n-----------Query Metadata----------------");
System.out.println("ResultSet contains " + numColumns + " columns");
for (int column = 1; column <= numColumns; column++) {
System.out.println("\nColumn "+ column);
System.out.println("column : " + myResultMetadata.getColumnName(column)); // Print the column name
System.out.println(" label : " + myResultMetadata.getColumnLabel(column)); // Print the label name
System.out.println(" display width : " + myResultMetadata.getColumnDisplaySize(column) +"characters"); // Printthe column’s display size
System.out.println(" data type : " + myResultMetadata.getColumnTypeName(column)); // Print the column type
} } }
Hubner Janampa Patilla - Administración
de Bases de Datos - 200929924/09/2009

Proyecto de Aplicación
Software Interactivo – Java/Sql
Persistencia en Java Jdk 1.6
1. Construcción a puro código
2. Construcción con IDE de Netbeans (matisse)
Hubner Janampa Patilla - Administración
de Bases de Datos - 200930024/09/2009

package jdbc_interactivo;import java.awt.BorderLayout;import java.awt.event.WindowAdapter; import java.awt.event.WindowEvent; import java.awt.event.ActionEvent; import java.awt.event.ActionListener; import javax.swing.JFrame; import javax.swing.JTextField; import javax.swing.JTextArea; import javax.swing.JMenu; import javax.swing.JMenuBar; import javax.swing.JMenuItem; import javax.swing.JScrollPane; import javax.swing.JTable; import java.sql.DriverManager; import java.sql.Connection; import java.sql.Statement; import java.sql.SQLException;
public class InteractiveSQL extends JFrame implements ActionListener {public static void main(String[] args) {// Set default values for the command line argsString user = "guest";String password = "guest";String url = "jdbc:odbc:technical_library";String driver = "sun.jdbc.odbc.JdbcOdbcDriver";
// Up to 4 arguments in the sequence database url,driver url, user ID, passwordswitch(args.length) {case 4: // Start here for four arguments
password = args[3];// Fall through to the next case
case 3: // Start here for three argumentsuser = args[2];// Fall through to the next case
case 2: // Start here for two argumentsdriver = args[1];// Fall through to the next case
case 1: // Start here for one argumenturl = args[0];
}
InteractiveSQL theApp = new InteractiveSQL(driver, url, user, password);}
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009
Desarrollo del Sw a puro código
30124/09/2009

public InteractiveSQL(String driver, String url, String user , String password) {super("InteractiveSQL"); // Call base constructorsetBounds(0, 0, 400, 300); // Set window boundssetDefaultCloseOperation(DISPOSE_ON_CLOSE); // Close window operationaddWindowListener(new WindowAdapter() { // Listener for window close
// Handler for window closing eventpublic void windowClosing(WindowEvent e) {
dispose(); // Release the window resources -Suelte la ventana de recursosSystem.exit(0); // End the application
}} );
// Add the input for SQL statements at the topcommand.setToolTipText("Key SQL commmand and press Enter");getContentPane().add(command, BorderLayout.NORTH);
// Add the status reporting area at the bottomstatus.setLineWrap(true);status.setWrapStyleWord(true);getContentPane().add(status, BorderLayout.SOUTH);
// Create the menubar from the menu itemsJMenu fileMenu = new JMenu("File"); // Create File menufileMenu.setMnemonic('F'); // Create shortcutfileMenu.add(clearQueryItem); // Add clear query itemfileMenu.add(exitItem); // Add exit itemmenuBar.add(fileMenu); // Add menu to the menubarsetJMenuBar(menuBar); // Add menubar to the window
// Add listeners for text field and menu itemscommand.addActionListener(this);clearQueryItem.addActionListener(this);exitItem.addActionListener(this);
Hubner Janampa Patilla - Administración
de Bases de Datos - 200930224/09/2009

// Establish a database connection and set up the tabletry {
Class.forName(driver); // Load the driverconnection = DriverManager.getConnection(url, user, password);statement = connection.createStatement();
model = new ResultsModel(); // Create a table modelJTable table = new JTable(model); // Create a table from the modeltable.setAutoResizeMode(JTable.AUTO_RESIZE_OFF); // Use scrollbarsresultsPane = new JScrollPane(table); // Create scrollpane for tablegetContentPane().add(resultsPane, BorderLayout.CENTER);
} catch(ClassNotFoundException cnfe) {System.err.println(cnfe); // Driver not found
} catch(SQLException sqle) {System.err.println(sqle); // error connection to database
}pack();setVisible(true);
}
// Handles action events for menu items and the text field//Tiradores de acción para eventos de los elementos del menú y el campo de textopublic void actionPerformed(ActionEvent e) {Object source = e.getSource();if(source == command) { // Enter key for text field input
executeSQL();} else if(source == clearQueryItem) { // Clear query menu item
command.setText(""); // Clear SQL entry} else if(source == exitItem) { // Exit menu item
dispose(); // Release the window resourcesSystem.exit(0); // End the application
} }
Hubner Janampa Patilla - Administración
de Bases de Datos - 200930324/09/2009

// Executes an SQL command entered in the text fieldpublic void executeSQL() {
String query = command.getText(); // Get the SQL statementif(query == null||query.length() == 0) { // If there's nothing we are done
return;}try {
model.setResultSet(statement.executeQuery(query));status.setText("Resultset has " + model.getRowCount() + " rows.");
} catch (SQLException sqle) {status.setText(sqle.getMessage()); // Display error message
}}
JTextField command = new JTextField(); // Input area for SQLJTextArea status = new JTextArea(3,1); // Output area for status and errorsJScrollPane resultsPane;
JMenuBar menuBar = new JMenuBar(); // The menu barJMenuItem clearQueryItem = new JMenuItem("Clear query"); // Clear SQL itemJMenuItem exitItem = new JMenuItem("Exit"); // Exit item
Connection connection; // Connection to the databaseStatement statement; // Statement object for queriesResultsModel model; // Table model for resultset
}
Hubner Janampa Patilla - Administración
de Bases de Datos - 200930424/09/2009

package jdbc_interactivo;import java.sql.ResultSet;import java.sql.ResultSetMetaData;import java.sql.SQLException;import javax.swing.table.AbstractTableModel;import java.util.Vector;
class ResultsModel extends AbstractTableModel {public void setResultSet(ResultSet results) {
try {ResultSetMetaData metadata = results.getMetaData();
int columns = metadata.getColumnCount(); // Get number of columnscolumnNames = new String[columns]; // Array to hold names// Get the column namesfor(int i = 0; i < columns; i++) {
columnNames[i] = metadata.getColumnLabel(i+1);}// Get all rowsdataRows.clear(); // Empty vector to store the dataString[] rowData; // Stores one rowwhile(results.next()) { // For each row...
rowData = new String[columns]; // create array to hold the datafor(int i = 0; i < columns; i++) { // For each column
rowData[i] = results.getString(i+1); // retrieve the data item}dataRows.addElement(rowData); // Store the row in the vector
}fireTableChanged(null); // Signal the table there is new model data
}catch (SQLException sqle) {
System.err.println(sqle);} }
Hubner Janampa Patilla - Administración
de Bases de Datos - 200930524/09/2009

public int getColumnCount() {
return columnNames.length;
}
public int getRowCount() {
return dataRows == null ? 0 : dataRows.size();
}
public String getValueAt(int row, int column) {
return dataRows.elementAt(row)[column];
}
public String getColumnName(int column) {
return columnNames[column] == null ? "No Name" : columnNames[column];
}
private String[] columnNames = new String[0]; // Empty array of names
private Vector<String[]> dataRows = new Vector<String[]>(); // Vector of rows
}
Hubner Janampa Patilla - Administración
de Bases de Datos - 200930624/09/2009
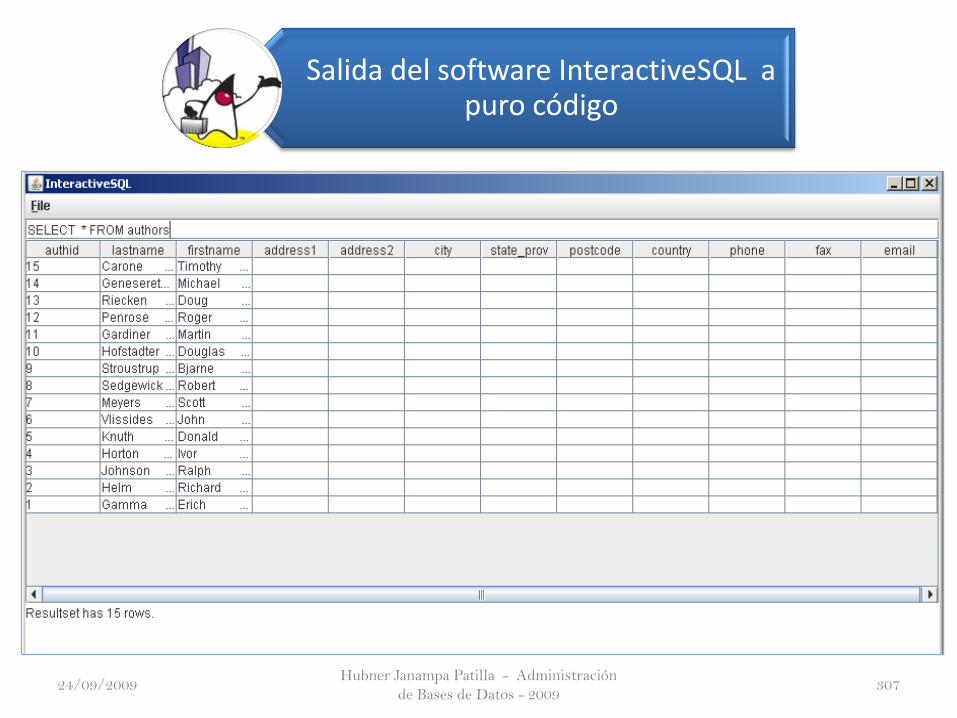
Salida del software InteractiveSQL a puro código
Hubner Janampa Patilla - Administración
de Bases de Datos - 200930724/09/2009

Matisse - Nuevo constructor de GUI para Netbeans
El proyecto Netbeans anunció hace poco la próxima integración de un
nuevo creador de GUI en su plataforma. Este siempre ha sido un punto
destacado en el IDE Netbeans frente a otros IDEs como Eclipse.
Con este nuevo módulo se simplifica todavía más la tarea de construcción
del GUI de una aplicación. En lugar de estar basado en la selección y
ajuste por parte del desarrollador de un layout manager Swing, Matisse
permite la creación en un modo libre de la interface y el propio entorno
infiere el layout manager y el resto de características del mismo, como
reglas de redimensionado, espaciado, etc.
Ahora está disponible una versión preview funcional de Matisse para su
evaluación.
Más información:
• Página de Matisse (http://www.netbeans.org/files/documents/4/475/matisse.html)
• Demo (Flash)
Hubner Janampa Patilla - Administración
de Bases de Datos - 200930824/09/2009

El JDBC en acción
Hubner Janampa Patilla - Administración
de Bases de Datos - 200930924/09/2009

El JDBC en acción
En esta clase voy a extender sobre la base de datos de Java Connectivity(JDBC) y la interfaz de programa de aplicación (API).
En esta presentación usted va a obtener más información acerca de:
❑Mapeo relacional de datos a objetos Java.
❑El mapeo entre SQL y tipos de datos Java.
❑Cómo limitar los datos creada en un resultset
❑Cómo limitar el tiempo dedicado a la ejecución de una consulta
Hubner Janampa Patilla - Administración
de Bases de Datos - 200931024/09/2009

❑Cómo utilizar un objeto PreparedStatement para crear una sentencia
SQL parametrizada.
❑Cómo se puede ejecutar la actualización de bases de datos y borrar sus
operaciones en programas Java
❑ Cómo puede obtener más información de los objetos SQLException.
❑ ¿Qué es un objeto SQLWarning y lo que puedes hacer con ellos?
Hubner Janampa Patilla - Administración
de Bases de Datos - 200931124/09/2009

Tipos de datos y JDBC
ResultSet proporciona una serie de métodos para la recuperación de diferentes
tipos de datos.
Para usar estos de manera eficaz, usted necesita ver a los tipos de datos SQL y
comprender la forma en que java mapea los datos de los distintos tipos en su
programa.
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009312
Mapeo entre Java y tipos de datos SQL
El estándar SQL-92 define un conjunto de tipos de datos que no coinciden
uno por uno con los que están en Java. Ya que al escribir aplicaciones que se
mueven los datos de SQL para Java y viceversa , tendrá que tener en cuenta
cómo JDBC realiza la cartografía. Es decir, lo que necesita saber es el tipo de
dato Java que usted necesita para representar un determinado tipo de dato de
SQL, y viceversa.
24/09/2009
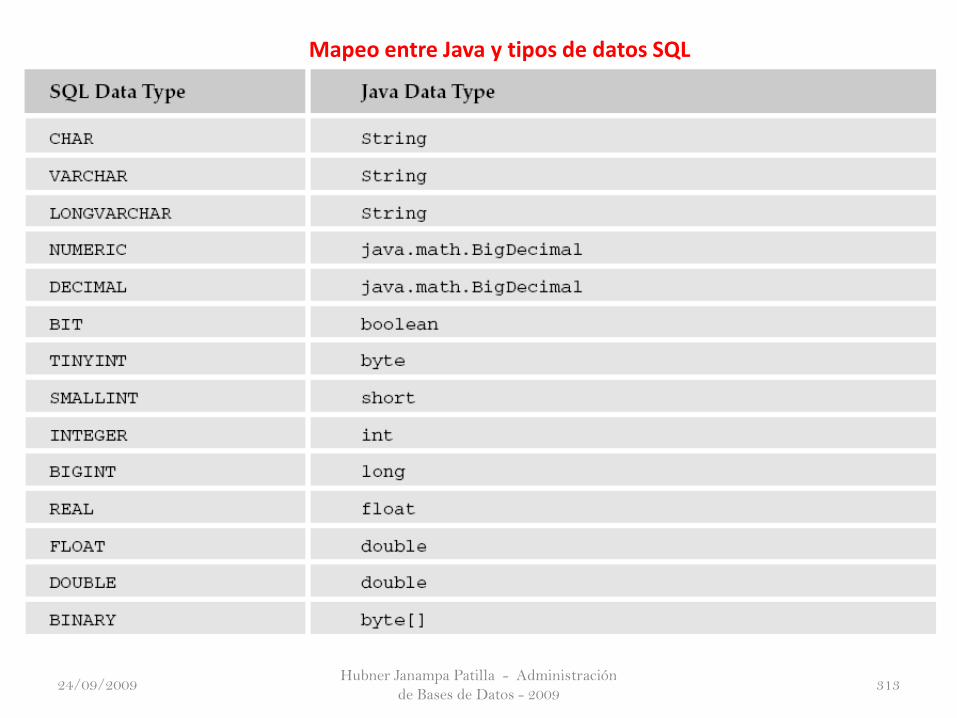
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009313
Mapeo entre Java y tipos de datos SQL
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 2009314
Mapeo entre Java y tipos de datos SQL
24/09/2009
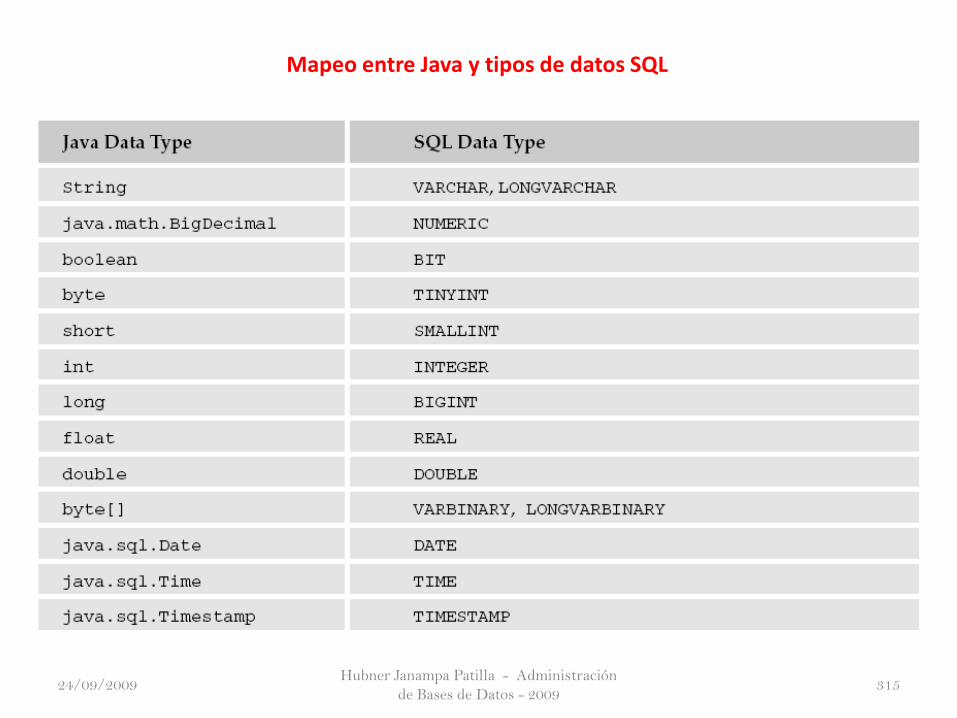
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009315
Mapeo entre Java y tipos de datos SQL
24/09/2009

La forma en que la información se maneja a nivel del objeto suele ser
diferente de la forma en que los datos son almacenada en una base de datos
relacional. En el mundo de los objetos, el principio subyacente es que esos
objetos exhiben las mismas características (información y
comportamiento), como su mundo real de sus homólogos en otros. Es decir,
los objetos en función del nivel del modelo conceptual.
Declaración de Interfaces y ResultSet
Hubner Janampa Patilla - Administración
de Bases de Datos - 200931624/09/2009

Las Bases de datos relacionales, por otra parte, trabaja en el modelo de
datos. Como has visto, las bases de datos relacionales almacenar información
utilizando formularios normalizados, donde los objetos conceptuales como las
facturas y los clientes pueden ser descompuestos en una serie de cuadros. Por
lo tanto,
¿cómo hacer frente al problema de mapeo de objetos a los modelos de
datos relacionales?
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009317
A veces hay una relación directa entre las columnas en una tabla y las
variables miembro en un objeto. En ese caso, la cartografía consiste
simplemente de hacer coincidir los tipos de datos de la base de datos con los
de Java.
24/09/2009
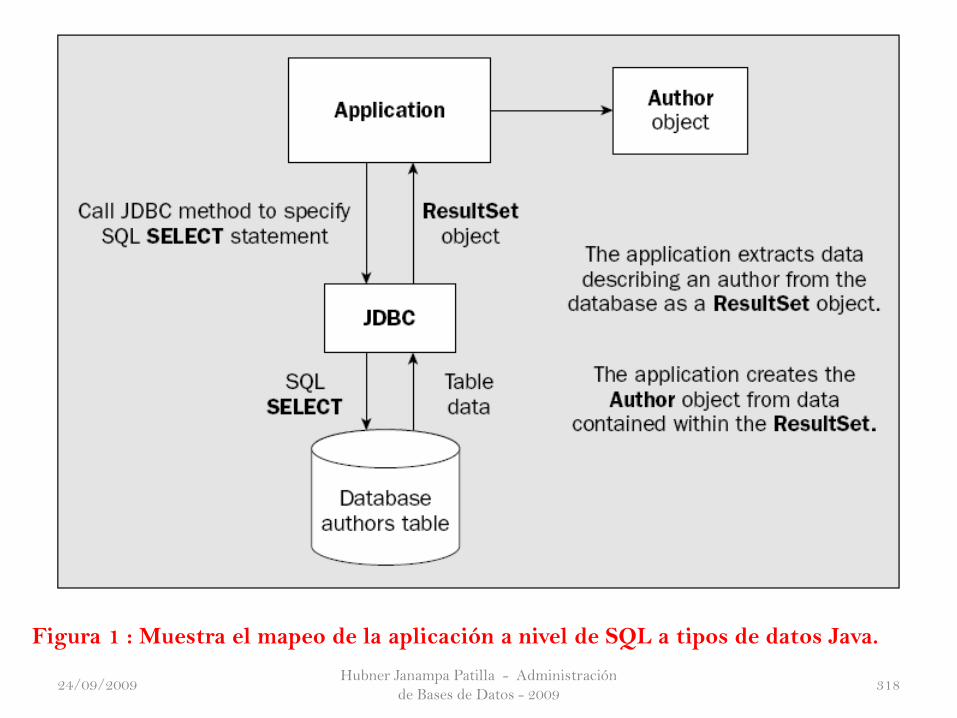
Figura 1 : Muestra el mapeo de la aplicación a nivel de SQL a tipos de datos Java.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200931824/09/2009
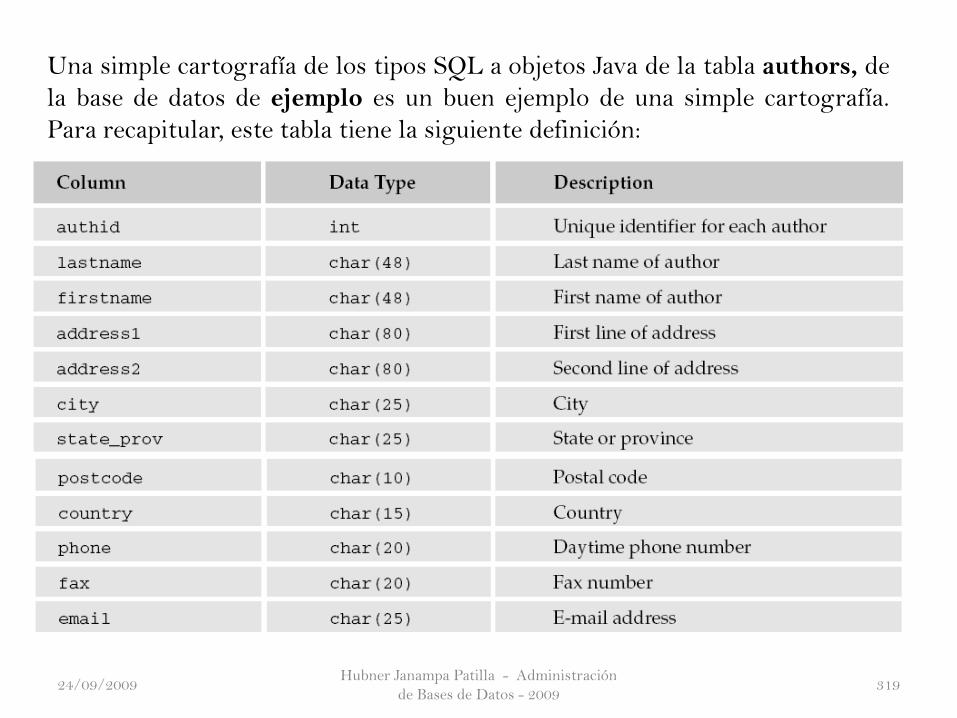
Una simple cartografía de los tipos SQL a objetos Java de la tabla authors, de
la base de datos de ejemplo es un buen ejemplo de una simple cartografía.
Para recapitular, este tabla tiene la siguiente definición:
Hubner Janampa Patilla - Administración
de Bases de Datos - 200931924/09/2009

Vamos a definir una clase Java para encapsular un autor. Tome una mirada
hacia atrás en la tabla que se muestro cómo un Mapa de los tipos SQL a los
tipos de datos Java. Sobre la base de esas asignaciones, se puede definir las
variables miembro de una clase authors, y añadir un constructor, métodos
miembros de acceso, y un toString ():
Hubner Janampa Patilla - Administración
de Bases de Datos - 200932024/09/2009

¿Cómo funciona?
En todo este ejemplo usted debe estar muy familiarizado, pero hay un par de
cosas nuevas que necesito cubrir.
Tenga en cuenta en primer lugar, que hay un paso adicional después de los
datos se lee que crea el autor objeto de llamar su constructor con esos datos.
Asimismo, en el bucle while, ya que cada fila se lee desde el ResultSet, la
aplicación usa los apropiados metodos getXXX() del ResultSet, cuyo
objetivo es realizar la cartografía de SQL a Tipos de datos Java. En cada
una de estas llamadas al método, el argumento es el valor del índice para
seleccionar la columna.
Dado que la consulta selecciona las columnas por su nombre, las columnas en
el resultset será en la misma secuencia como los nombres de columna en la
consulta SQL. Para mostrar los datos de cada objeto Autor, simplemente
llame a System.out.println() y pasar la referencia del objeto Autor a la
misma. Así, se invocan los métodos toString() para el objeto.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200932124/09/2009

package jdbc_accion;
public class Author {
public Author(int authid, String lastname, String firstname, String address[], String city, String state, String postcode, String country, String phone, String fax, String email)
{
this.authid = authid;
this.lastname = lastname;
this.firstname = firstname;
this.address = address;
this.city = city;
this.state = state;
this.postcode = postcode;
this.country = country;
this.phone = phone;
this.fax = fax;
this.email = email;
}
Hubner Janampa Patilla - Administración
de Bases de Datos - 200932224/09/2009

public int getId() {
return authid;
}
public String getLastName() {
return lastname;
}
public String getFirstName() {
return firstname;
}
public String[] getAddress() {
return address;
}
public String getCity() {
return city;
}
public String getState() {
return state;
}
public String getCountry() {
return country;
}
Hubner Janampa Patilla - Administración
de Bases de Datos - 200932324/09/2009

public String getPostCode() {
return postcode;
}
public String getPhone() {
return phone;
}
public String getFax() {
return fax;
}
public String getEmail() {
return email;
}
public String toString() {
return new String("author ID: " + Integer.toString(authid) + "\nname : " + lastname + "," + firstname +"\naddress : " + address[0] + "\n : " + address[1] +" \n : " + city + " " + state + "\n : " + postcode + " " + country +"\nphone : " + phone + "\nfax : " + fax +"\nemail : " + email);
}
int authid;
String lastname;
String firstname;
String address[];
String city;
String state;
String postcode;
String country;
String phone;
String fax;
String email; }Hubner Janampa Patilla - Administración
de Bases de Datos - 200932424/09/2009

package jdbc_accion;
import java.sql.DriverManager;
import java.sql.Connection;
import java.sql.Statement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class TrySimpleMapping {
public static void main (String[] args) {
TrySimpleMapping SQLtoJavaExample;
try {
SQLtoJavaExample = new TrySimpleMapping();
SQLtoJavaExample.listAuthors();
} catch(SQLException sqle) {
System.err.println(sqle);
} catch(ClassNotFoundException cnfe) {
System.err.println(cnfe);
}
}
public TrySimpleMapping() throws SQLException, ClassNotFoundException {
Class.forName (driverName);
connection = DriverManager.getConnection(sourceURL, user, password);
}
Hubner Janampa Patilla - Administración
de Bases de Datos - 200932524/09/2009

public void listAuthors() throws SQLException {
Author author = null;
String query = "SELECT authid, lastname, firstname, address1,"+
"address2, city, state_prov, postcode, country,"+
"phone, fax, email FROM authors";
Statement statement = connection.createStatement();
ResultSet authors = statement.executeQuery(query);
while(authors.next()) {
int id = authors.getInt(1);
String lastname = authors.getString(2);
String firstname = authors.getString(3);
String[] address = { authors.getString(4), authors.getString(5)};
String city = authors.getString(6);
String state = authors.getString(7);
String postcode = authors.getString(8);
String country = authors.getString(9);
String phone = authors.getString(10);
String fax = authors.getString(11);
String email = authors.getString(12);
author = new Author(id, lastname, firstname,
address, city, state, postcode,country, phone, fax, email);
System.out.println("\n" + author);
}
authors.close();
connection.close();
}
Hubner Janampa Patilla - Administración
de Bases de Datos - 200932624/09/2009

Connection connection;
String driverName = "sun.jdbc.odbc.JdbcOdbcDriver";
String sourceURL = "jdbc:odbc:technical_library";
String user = "guest";
String password = "guest";
}
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009327
En este ejemplo se utiliza el JDBC-ODBC Bridge conductor con una fuente
de datos que requieren un nombre de usuario y contraseña. Si usted necesita
un nombre de usuario y contraseña diferente para acceder a esa fuente de
datos, basta con modificar el código en el constructor TrySimpleMapping, y
utilizar el controlador apropiado, la URL y el método getConnection() del
DriverManager.
24/09/2009

El uso de un objeto PreparedStatement
Vamos a poner una declaración preparada en acción a la hora que pasar por
la mecánica del contexto práctico visto. Use el código de ejemplo que ejecuta
el mismo SQL SELECT utilizando tanto el estado y los objetos
PreparedStatement.
Para cada uno de estos, los resultados se mostrarán junto con los metadatos.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200932824/09/2009

package javaapplication27;
import java.sql.Connection;
import java.sql.Statement;
import java.sql.PreparedStatement;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.sql.SQLException;
public class StatementTest {
Connection databaseConnection; // Connection to the database
String driverName; // Database driver name
String sourceURL; // Database location
public static void main(String[] args) {
try {
StatementTest SQLExample = new StatementTest();
SQLExample.doStatement();
SQLExample.doPreparedStatement();
} catch(SQLException sqle) {
System.err.println("SQL Exception: " + sqle);
} catch(ClassNotFoundException cnfe) {
System.err.println(cnfe.toString());
} }
Hubner Janampa Patilla - Administración
de Bases de Datos - 200932924/09/2009

public StatementTest() throws SQLException, ClassNotFoundException {
driverName = "sun.jdbc.odbc.JdbcOdbcDriver";
sourceURL = "jdbc:odbc:technical_library";
Class.forName (driverName);
databaseConnection = DriverManager.getConnection(sourceURL);
}
public void doStatement() throws SQLException {
Statement myStatement = databaseConnection.createStatement();
ResultSet myResults = myStatement.executeQuery(
"SELECT authid, lastname, firstname FROM authors ORDER BY authid");
showResults(myResults);
}
public void doPreparedStatement() throws SQLException {
PreparedStatement myStatement = databaseConnection.prepareStatement(
"SELECT authid, lastname, firstname FROM authors ORDER BY authid");
ResultSet myResults = myStatement.executeQuery();
showResults(myResults);
}
Hubner Janampa Patilla - Administración
de Bases de Datos - 200933024/09/2009

public void showResults(ResultSet myResults) throws SQLException {
// Retrieve ResultSetMetaData object from ResultSet
ResultSetMetaData myResultMetadata = myResults.getMetaData();
// How many columns were returned?
int numColumns = myResultMetadata.getColumnCount();
System.out.println(" ---------------------Query Results-------------------------");
// Loop through the ResultSet and get data
while(myResults.next()) {
System.out.printf("%-5d", myResults.getInt(1)); // 1st Column only
for(int column = 2; column <= numColumns; column++) {
System.out.print(myResults.getString(column)+" "); }
System.out.print("\n"); }
System.out.println("\n\n-----------Query Metadata----------------");
System.out.println("ResultSet contains " + numColumns + " columns");
for (int column = 1; column <= numColumns; column++) {
System.out.println("\nColumn "+ column);
// Print the column name
System.out.println("column : " + myResultMetadata.getColumnName(column));
// Print the label name
System.out.println(" label : " + myResultMetadata.getColumnLabel(column));
// Print the column’s display size
System.out.println(" display width : " + myResultMetadata.getColumnDisplaySize(column) +"characters");
// Print the column’s type
System.out.println(" data type : " + myResultMetadata.getColumnTypeName(column));
} } }Hubner Janampa Patilla - Administración
de Bases de Datos - 200933124/09/2009

Habrá momentos en que la elección entre la utilización de Statement o un
objeto PreparedStatement puede no ser del todo clara. Los objetos
PreparedStatement son grandes cuando:
❑ Es necesario ejecutar la misma declaración varias veces, con la necesidad
de cambiar sólo valores específicos.
❑ La compañía está trabajando con grandes trozos de datos que hacen la
concatenación difícil de manejar.
❑ Usted está trabajando con un gran número de parámetros en la sentencia
SQL que hacen que las cadenas de concatenación sean difíciles de manejar.
Por el contrario, los objetos Statement funcionan bien cuando se tiene las
declaraciones simples y, por supuesto, usted no tiene opción si su driver
JDBC no es compatible con la interfaz PreparedStatement.
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009332
Statement versus PreparedStatement
24/09/2009

La interfaz PreparedStatement
Anteriormente en este apartado, usted vio que usted puede construir cadenas de
SQL sobre la marcha y ejecutar con executeQuery() .
Esa es una manera de introducir los parámetros en una sentencia SQL, pero no
es la única manera, ni es necesariamente el más conveniente. La Interfaz
PreparedStatement provee de un mecanismo alternativo que le permite definir
una sentencia SQL con posicionadores de argumentos. Los Posicionadores son
fichas que aparecen en la sentencia S Q L que se sustituyen.
Este suele ser mucho más fácil que la construcción de una declaración SQL con
valores específicos y luego concatenar cadenas.
Al igual que una declaración de un objeto, se crea un objeto PreparedStatement
llamando a un método del objeto Conexión.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200933324/09/2009

En lugar de llamar al método createStatement() del objeto conexión, llamar
a la prepareStatement() si desea crear un objeto PreparedStatement.
Mientras puede utilizar una declaración objeto de ejecutar cualquier número
de sentencias SQL, el objeto PreparedStatement ejecuta sólo una sentencia
SQL predefinida que tiene definida para los marcadores de posición.
En el argumento se especifica la declaración SQL con cada marcador de
posición por un valor representado por un carácter ? .
Hubner Janampa Patilla - Administración
de Bases de Datos - 200933424/09/2009

Establecer parámetros de consulta
Usted debe fijar valores para todos los marcadores de posición que aparecen en
la declaración de los encapsulados updateLastName de referencia antes de la
declaración puede ser ejecutado. Usted oferta el valor de cada marcador de
posición llamando a uno de los métodos setXXX() de la interfaz
PreparedStatement:
Estos métodos aceptan como mínimo una posición de argumento que identifica
marcador de posición al que usted se refiere y para cada valor de argumento es
sustituido por el marcador de posición.
Los marcadores de posición son indexadas en secuencia de izquierda a derecha
empezando por 1, por lo que la referencia de posición del extremo izquierdo
tiene índice 1, y cualquier marcadores de posición siguiente con el índice de
valor de 2, 3, y así sucesivamente.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200933524/09/2009

El método que usted llama para un marcador de posición, para una entrada
de valor depende del tipo SQL de la columna de destino. Usted debe
seleccionar el método que corresponde al tipo de campo, por lo que
utilizaría setInt () para el tipo INTEGER, por ejemplo.
Una vez que todos los marcadores de posición tienen valores establecidos y
que se ha ejecutado la declaración, usted puede actualizar cualquier
o todos los marcadores de posición (o incluso ninguno) antes de volver a
ejecutar la declaración.
En el siguiente fragmento de código de PreparedStatement muestra el
valor de posición de sustitución en acción.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200933624/09/2009

package sentenciapreparada;
import java.sq l.DriverManager;
import java.sq l.Connection;
import java.sq l.PreparedStatement;
import java.sq l.SQLException;
public class TryPlaceHolders {
public static void main(String[] args) {
try {
String url = "jdbc:odbc:technical_library";
String driver = "sun.jdbc.odbc.JdbcOdbcDriver";
String user = "guest";
String password = "guest";
Class.forName(driver);
Connection connection = DriverManager.getConnection(url,user,password);
String changeLastName = "UPDATE authors SET lastname = ? W HERE authid = ? “ ;
PreparedStatement updateLastName = connection.prepareStatement(changeLastName);
updateLastName.setString(1," Martin"); // Set lastname placeholder value
updateLastName.setInt(2,4); // Set author ID placeholder value
int rowsUpdated = updateLastName.executeUpdate(); // execute the update
System.out.println("Rows affected: " + rowsUpdated);
connection.close();
} catch (ClassNotFoundException cnfe) {
System.err.println(cnfe);
} catch (SQLException sqle) {
System.err.println(sqle); } } }
Hubner Janampa Patilla - Administración
de Bases de Datos - 200933724/09/2009

Cómo funciona los métodos getMaxRows(), getMaxFieldSize(),
getQueryTimeout() de la Interfaz Statement.
Este código es bastante simple. Se crea una conexión usando una URL definida
para una base de datos Access llamada technical_library. Una vez que se
establece la conexión, un objeto Statement es creado, y que usando los métodos
apropiados para el período de tiempo, el máximo tamaño de la columna, y el
número máximo de filas se puede ejecutar . Los tres proporcionan esta
información y tiran una excepción de tipo SQLException si la información no
está disponible, como es el caso con el controlador Microsoft Access.
Para asegúrese de que usted llame a todos los tres métodos, incluso cuando una
excepción es lanzada, cada método de llamada se encuentra en un bloque try
aparte.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200933824/09/2009

package sentenciapreparada;
import java.sql.DriverManager;import java.sql.Connection;import java.sql.Statement;import java.sql.SQLException;
public class TestQueryTimeOut {public static void main(String[] args) {
Statement statement = null;try {
String url = "jdbc:odbc:technical_library";String driver = "sun.jdbc.odbc.JdbcOdbcDriver";String username = "guest";String password = "guest";Class.forName(driver);Connection connection = DriverManager.getConnection(url, username, password);statement = connection.createStatement();System.out.println("Driver : " + driver);
} catch (ClassNotFoundException cnfe) {System.out.println(cnfe);
} catch (SQLException sqle) {System.out.println(sqle);
}
Hubner Janampa Patilla - Administración
de Bases de Datos - 200933924/09/2009

// Put each method call in a separate try block to execute them alltry {
System.out.print("\nMaximum rows :");int maxRows = statement.getMaxRows();System.out.print(maxRows == 0 ? " No limit" : " " + maxRows);
} catch (SQLException sqle) {System.err.print(sqle);
}try {
System.out.print("\nMax field size :");int maxFieldSize = statement.getMaxFieldSize();System.out.print(maxFieldSize == 0 ? " No limit" : " " + maxFieldSize);
} catch (SQLException sqle) {System.err.print(sqle);
}try {
System.out.print("\nTimeout :" );int queryTimeout = statement.getQueryTimeout();System.out.print(queryTimeout = = 0 ? " No limit" : " " + q ueryTimeout);
} catch (SQLException sqle) {System.err.print(sqle);
}}}
Hubner Janampa Patilla - Administración
de Bases de Datos - 200934024/09/2009

Ejecutar DDL y DML
Como ustedes saben, el executeQuery() es el método utilizado para ejecutar una
consulta SQL y que espera que regresen algunos resultados en un resultset.
Como he indicado en el capítulo anterior, hay otros tipos de sentencias SQL que
no devuelven resultados. Estos estados se dividen en dos categorías primarias:
Lenguaje de definición de datos (DDL), y lenguaje de manipulación de datos
(DML).
❑ Las sentencias DDL son las que cambian la estructura de una base de datos,
tales como CREATE TABLE y DROP TABLE.
❑ Las sentencias DML son las que cambian el contenido de la base de datos, tales
como INSERT, UPDATE, y DELETE.
Hasta el momento, todos los ejemplos que usted ha visto, incluida la aplicación
InteractiveSQL, han utilizado la executeQuery(). Si se trató de ejecutar una
sentencia SQL que producen cambios en la base de datos (DML), es decir no
producen un resultset de datos devueltos , el programa InteractiveSQL
provocara una excepción de error.Hubner Janampa Patilla - Administración
de Bases de Datos - 200934124/09/2009

La excepción que contiene el mensaje "No se produjo el ResultSet" se produjo
porque se ejecuta el executeQuery() que espera sólo una sentencia SQL y que genera
resultados en un ResulSet (Nota: incluso cuando una excepción fue arrojado en este
caso, la sentencia SQL sigue siendo ejecutado).
La Declaración prevé la interfaz executeUpdate() método para ejecutar las
declaraciones que cambian el contenido de la base de datos en lugar de regresar los
resultados. Al igual que executeQuery(), el executeUpdate() es un método acepta un
solo argumento de tipo String especificando la sentencia SQL que se va a ejecutar.
Puede utilizar el método executeUpdate() para ejecutar UPDATE, INSERT,
DELETE o sentencias SQL. También se puede utilizar para la ejecución de
declaraciones DDL. El método devuelve un valor de tipo int que indica el número de
filas afectadas por la operación de la base de datos cuando se cambian los contenidos, o
0 para las declaraciones que no alteran la base de datos.
El fragmento de código que figura a continuación ilustra el uso del método
executeUpdate() para agregar una fila a la tabla Authors.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200934224/09/2009

package ExecuteUpdate;import java.sql.DriverManager;
import java.sql.Connection;
import java.sql.Statement;
import java.sql.SQLException;
public class BuildTables {
public static void main(String[] args) {
try {
String username = "guest";
String password = "guest";
String url = "jdbc:odbc:technical_library";
String driver = "sun.jdbc.odbc.JdbcOdbcDriver";
String[] SQLStatements = {"CREATE TABLE online_resources2 (pub_id int, name char(48), url char(80))",
"INSERT INTO online_resources VALUES(1, 'Wrox Home Page','http://www.wrox.com')",
"INSERT INTO online_resources VALUES(2, 'JavaSoft Home Page','http://www.javasoft.com')",
"INSERT INTO online_resources VALUES(3, 'Apress Home Page','http://www.apress.com')",
"INSERT INTO online_resources VALUES(4, 'Addison Wesley Home Page'," +
"'http://www.awprofessional.com')","INSERT INTO online_resources VALUES(5, 'Java Developer Connection'," +
"'http://java.sun.com')"};
Class.forName(driver);
Connection connection = DriverManager.getConnection(url, username, password);
Statement statement = connection.createStatement();
for (String SQLStatement : SQLStatements) {
statement.executeUpdate(SQLStatement);
System.out.println(SQLStatement); }
} catch (ClassNotFoundException cnfe) {
System.err.println(cnfe);
} catch (SQLException sqle) {
System.err.println(sqle);
} } }Hubner Janampa Patilla - Administración
de Bases de Datos - 200934324/09/2009

Resumen
En este capítulo, que ha aplicado las habilidades básicas del JDBC, que
aprendió anteriormente en algunas nuevas formas, amplió su conocimiento
detallado de algunos de los temas que se cubren, e incluso metió en algunos
nuevos. Los elementos más importantes que me introduje en esta presentación
incluyen:
❑ La declaración de una interfaz proporciona métodos que le permiten
limitar el tamaño del campo y el número de filas que se pueden generar en
un resultset. También puede establecer una duración máxima para una
consulta SQL .
Hubner Janampa Patilla - Administración
de Bases de Datos - 200934424/09/2009

Resumen (Cont…)
❑ Un objeto parametrizado PreparedStatement encapsula una sentencia
SQL y proporciona métodos para que usted fije valores para los parámetros
de marcadores de posición, para los parámetros de la sentencia SQL que
están representados por un signo de interrogación (?).
❑ JDBC proporciona un conjunto de asignaciones preferidas entre los tipos
SQL y tipos Java.
❑ Los tipos de datos SQL DECIMAL y NUMERIC son asignados a la
clase de tipo BigDecimal, que es el que se define en el paquete java.math.
Puede utilizar esta clase y la clase BigInteger para aplicaciones que necesitan
de precisión numérica más allá de las capacidades de los tipos primitivos
numéricos.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200934524/09/2009

DEMO
Reportes en Java
Hubner Janampa Patilla - Administración
de Bases de Datos - 200934624/09/2009
Hubner Janampa Patilla - Administración
de Bases de Datos - 200934724/09/2009

Referencia
Professional Eclipse 3 for Java Developers by Berthold DaumNovember 2007.
Professional Java, JDK 5 Edition by W. Clay Richardson, Donald Avondolio, Joe Vitale, Scot Schrager, Mark W. Mitchell, Jeff ScanlonFebruary 2006.
Beginning Java™ 2, JDK™ 5 Edition
Ivor Horton, 2005.
Professional Java JDK 6 Edition by W. Clay Richardson, Donald Avondolio, Scot Schrager, Mark W. Mitchell, Jeff Scanlon January2007.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200934824/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 2009349
Desarrollo de aplicaciones con C# .NET, AJAX , ASP.NET , ORACLE Y MS SQL
24/09/2009

Continuara…
Hubner Janampa Patilla - Administración
de Bases de Datos - 200935024/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 200935124/09/2009

Programación Orientado a Objetos en Java
Hubner Janampa Patilla - Administración
de Bases de Datos - 200935224/09/2009

¿Qué es una clase?
Una clase es una receta para un tipo particular de objetos que define un
nuevo tipo.
Puede utilizar la definición de una clase para crear objetos de esa clase
del tipo que sea, para crear objetos que incorporen todos los componentes
especificados como pertenecientes a esa categoría.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200935324/09/2009

En esencia, una clase de definición es muy simple. Hay sólo dos tipos de cosas
que usted puede incluir en una definición de clase:
I . Campos
Estas son las variables que almacenan datos que suelen distinguir un objeto de
la de otra clase. También se refiere a datos como miembros de una clase.
II. Métodos
Que define las operaciones que puede realizar para la clase.
Los métodos normalmente operan en los campos de las variables de la clase.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200935424/09/2009
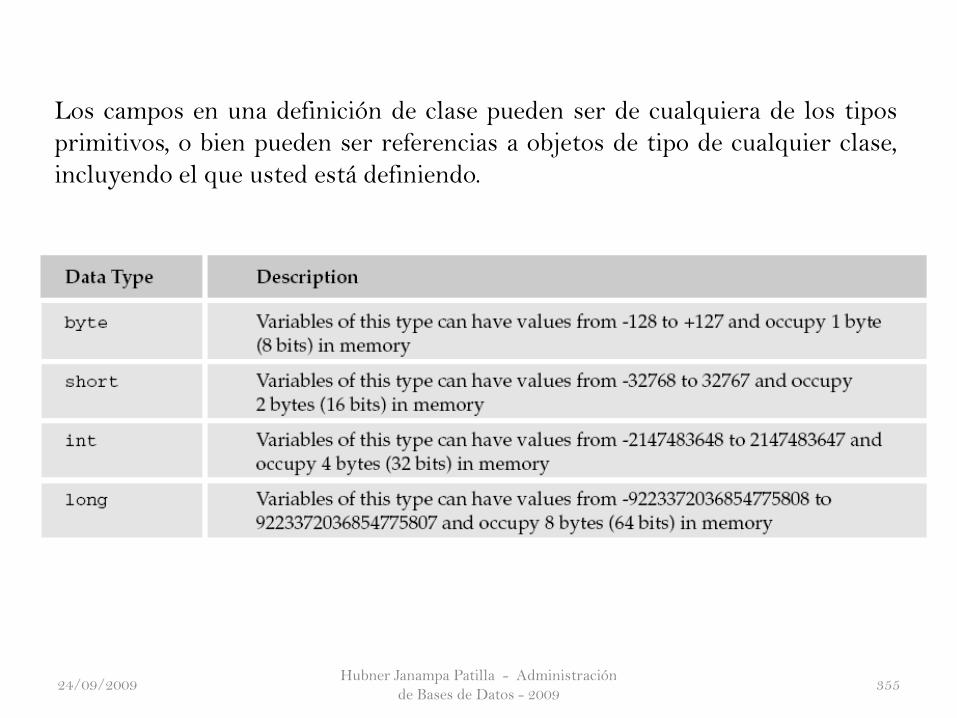
Los campos en una definición de clase pueden ser de cualquiera de los tipos
primitivos, o bien pueden ser referencias a objetos de tipo de cualquier clase,
incluyendo el que usted está definiendo.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200935524/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 2009356
Estructura de una clase
24/09/2009

Tipos de clases
Hubner Janampa Patilla - Administración
de Bases de Datos - 200935724/09/2009
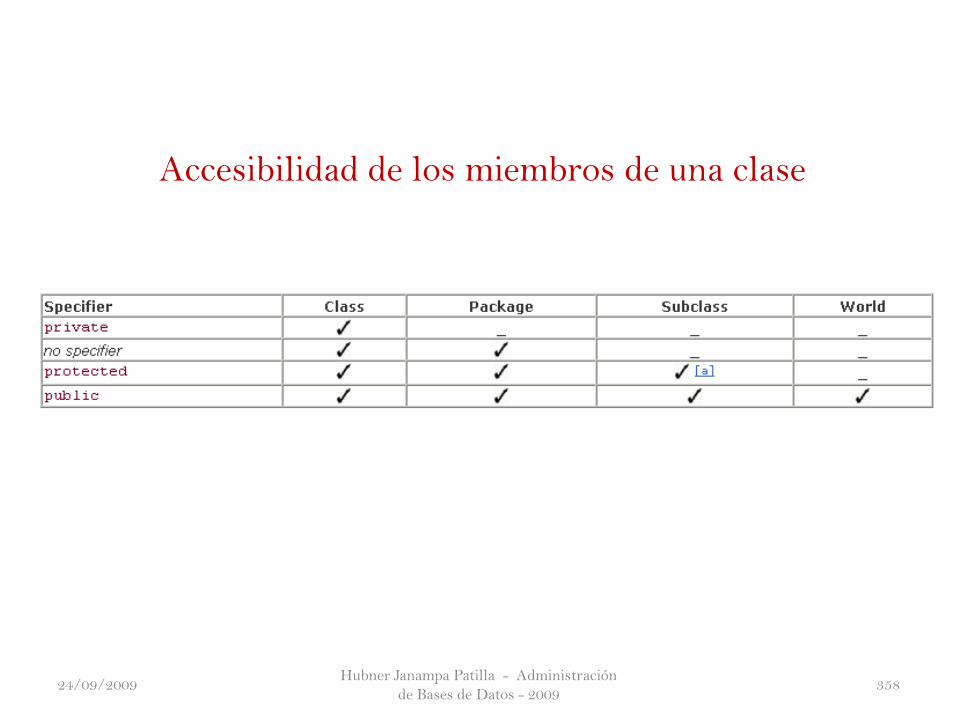
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009358
Accesibilidad de los miembros de una clase
24/09/2009
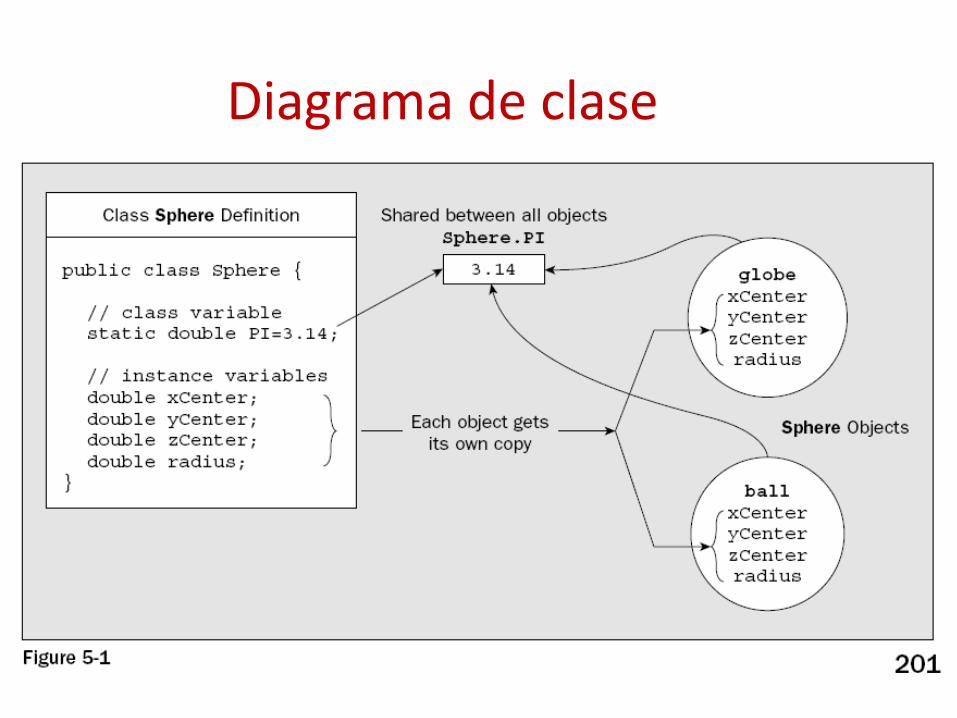
Diagrama de clase

Código de clase en java
360Hubner Janampa Patilla - Administración
de Bases de Datos - 200924/09/2009
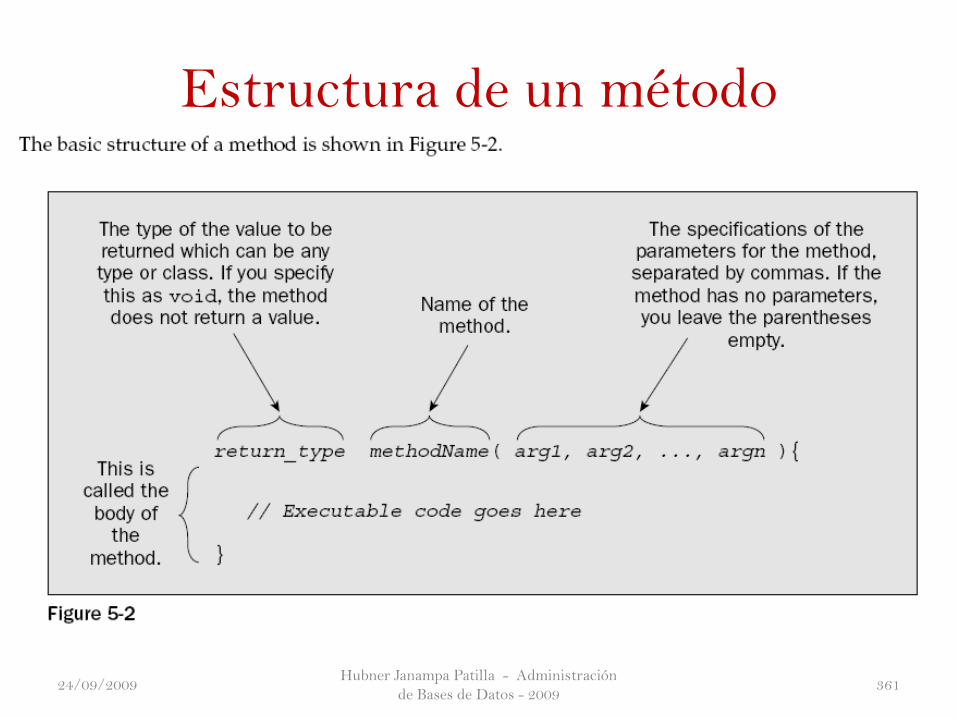
Estructura de un método
361Hubner Janampa Patilla - Administración
de Bases de Datos - 200924/09/2009
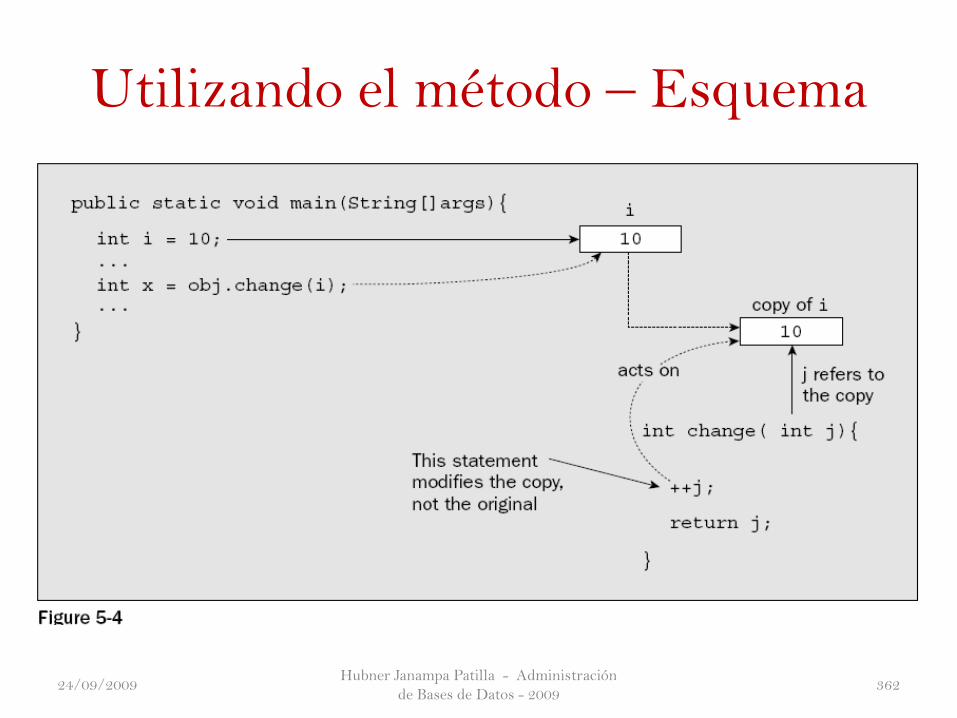
Utilizando el método – Esquema
362Hubner Janampa Patilla - Administración
de Bases de Datos - 200924/09/2009
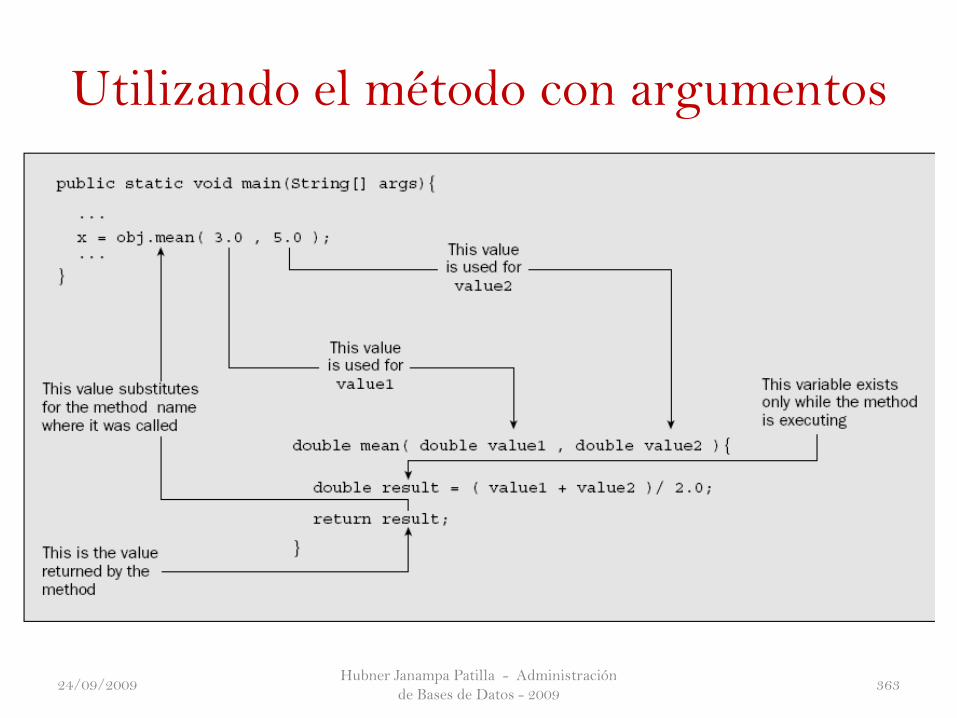
Utilizando el método con argumentos
363Hubner Janampa Patilla - Administración
de Bases de Datos - 200924/09/2009

Trabajo práctico Nº 1 Consideremos las clases mostradas
Clave: Implemente los métodos mostrados
¿Explicando…?
Hubner Janampa Patilla - Administración
de Bases de Datos - 200936424/09/2009

package Sphere;
class Sphere {
static final double PI = 3.14; // Class variable that has a fixed value
static int count = 0; // Class variable to count objects
// Instance variables
double radius; // Radius of a sphere
double xCenter; // 3D coordinates
double yCenter; // of the center
double zCenter; // of a sphere
// Class constructor
Sphere(double theRadius, double x, double y, double z) {
radius = theRadius; // Set the radius
// Set the coordinates of the center
xCenter = x;
yCenter = y;
zCenter = z;
++count; // Update object count
}
// Static method to report the number of objects created
static int getCount() {
return count; // Return current object count
}
// Instance method to calculate volume
double volume() {
return 4.0/3.0*PI*radius*radius*radius;
} }
365Hubner Janampa Patilla - Administración
de Bases de Datos - 200924/09/2009

package Sphere;
class CreateSpheres {
public static void main(String[] args) {
System.out.println("Number of objects = " + Sphere.getCount());
Sphere ball = new Sphere(4.0, 0.0, 0.0, 0.0); // Create a sphere
System.out.println("Number of objects = " + ball.getCount());
Sphere globe = new Sphere(12.0, 1.0, 1.0, 1.0); // Create a sphere
System.out.println("Number of objects = " + Sphere.getCount());
// Output the volume of each sphere
System.out.println("ball volume = " + ball.volume());
System.out.println("globe volume = " + globe.volume());
}
}
366Hubner Janampa Patilla - Administración
de Bases de Datos - 200924/09/2009

Trabajo práctico Nº 2 Consideremos las clases mostradas
Clave: Implemente los métodos mostrados
¿Explicando…?
Hubner Janampa Patilla - Administración
de Bases de Datos - 200936724/09/2009

class Sphere {static final double PI = 3.14; // Class variable that has a fixed
value
static int count = 0; // Class variable to count objects
// Instance variables
double radius; // Radius of a sphere
double xCenter; // 3D coordinates
double yCenter; // of the center
double zCenter; // of a sphere
// Class constructor
Sphere(double theRadius, double x, double y, double z) {
radius = theRadius; // Set the radius
// Set the coordinates of the center
xCenter = x;
yCenter = y;
zCenter = z;
++count; // Update object count
}
// Construct a unit sphere at a point
Sphere(double x, double y, double z) {
xCenter = x;
yCenter = y;
zCenter = z;
radius = 1.0;
++count; // Update object count
}
// Construct a unit sphere at the origin
Sphere() {
xCenter = 0.0;
yCenter = 0.0;
zCenter = 0.0;
radius = 1.0;
++count; // Update object count
}
// Static method to report the number of objects created
static int getCount() {
return count; // Return current object count
}
// Instance method to calculate volume
double volume() {
return 4.0/3.0*PI*radius*radius*radius;
}
}
368Hubner Janampa Patilla - Administración
de Bases de Datos - 200924/09/2009

class CreateSpheres {public static void main(String[] args) {
System.out.println("Number of objects = " + Sphere.getCount());
Sphere esfera1 = new Sphere(4.0, 0.0, 0.0, 0.0); // Create a sphere
System.out.println("Number of objects = " + esfera1.getCount());
Sphere esfera2 = new Sphere(12.0, 1.0, 1.0, 1.0); // Create a sphere
System.out.println("Number of objects = " + Sphere.getCount());
Sphere esfera3 = new Sphere(10.0, 10.0, 0.0);
Sphere esfera4 = new Sphere();
System.out.println("Number of objects = " + Sphere.getCount());
// Output the volume of each sphere
System.out.println(" volume = " + esfera1.volume());
System.out.println(" volume = " + esfera2.volume());
System.out.println(" volume = " + esfera3.volume());
System.out.println(" volume = " + esfera4.volume());
}
}
369Hubner Janampa Patilla - Administración
de Bases de Datos - 200924/09/2009

Trabajo práctico Nº 3 Consideremos las clases mostradas
Clave: Método setTime()
¿Explicando…?
Hubner Janampa Patilla - Administración
de Bases de Datos - 200937024/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 2009371
package clase_time;
public class Time1
{
private int hour; // 0 - 23
private int minute; // 0 - 59
private int second; // 0 - 59
// Establecer un nuevo valor de tiempo de uso de tiempo universal; garantizar que
// los datos sigue siendo coherente mediante el establecimiento de valores no válidos a cero
public void setTime( int h, int m, int s )
{
hour = ( ( h >= 0 && h < 24 ) ? h : 0 ); // validar hora
minute = ( ( m >= 0 && m < 60 ) ? m : 0 ); // validar minutos
second = ( ( s >= 0 && s < 60 ) ? s : 0 ); //validar segundos
}
// convert to String in universal-time format (HH:MM:SS)
public String toUniversalString()
{
return String.format( "%2d:%02d:%02d", hour, minute, second );
}
// convert to String in standard-time format (H:MM:SS AM or PM)
public String toString()
{
return String.format( "%d:%02d:%02d %s",
( ( hour == 0 || hour == 12 ) ? 12 : hour % 12 ),
minute, second, ( hour < 12 ? "AM" : "PM" ) );
}
}
24/09/2009

package clase_time;
public class Time1Test
{
public static void main( String args[] )
{
// create and initialize a Time1 object
Time1 time = new Time1(); // invokes Time1 constructor
// output string representations of the time
System.out.print( "El primer tiempo universal es : " );
System.out.println( time.toUniversalString() );
System.out.print( "El tiempo estandar es :" );
System.out.println( time.toString() );
System.out.println(); // output a blank line
// change time and output updated time
time.setTime( 13, 27, 6 );
System.out.print( "El tiempo universal despúes de setTime es: " );
System.out.println( time.toUniversalString() );
System.out.print( "El tiempo estandar despúes de setTime es : " );
System.out.println( time.toString() );
System.out.println(); // output a blank line
// setTime con valores no correctos
time.setTime( 99, 99, 99 );
System.out.println( " Despúes de intentar asignar un valor incorrecto a setTime, la salida es : " );
System.out.print( "Universal time: " );
System.out.println( time.toUniversalString() );
System.out.print( "tiempo estandar: " );
System.out.println( time.toString() );
}
} Hubner Janampa Patilla - Administración
de Bases de Datos - 200937224/09/2009
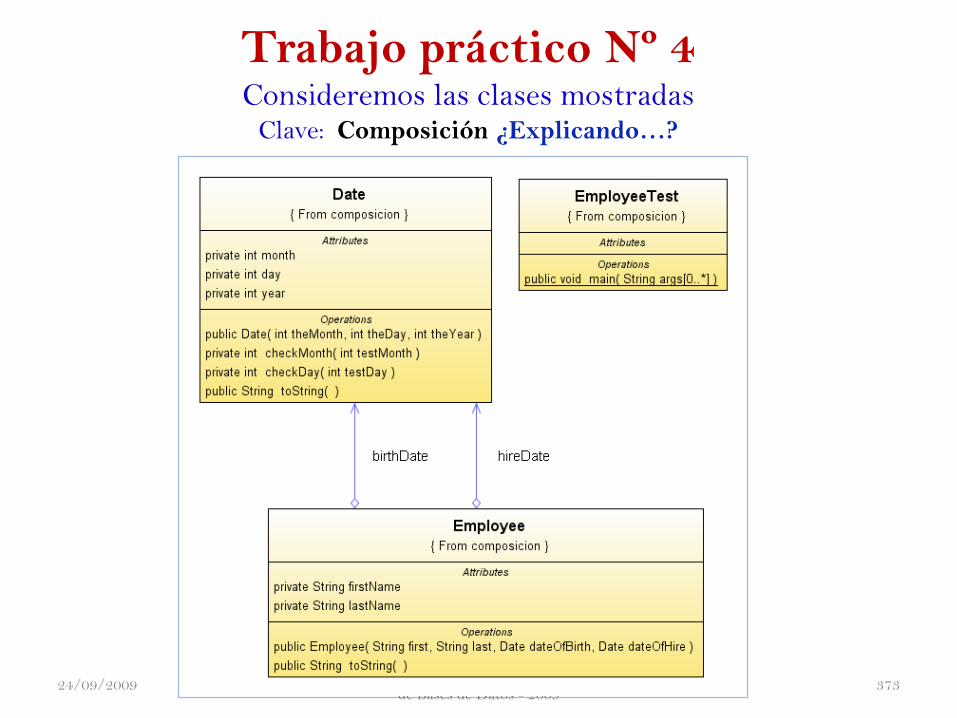
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009373
Trabajo práctico Nº 4Consideremos las clases mostradas
Clave: Composición ¿Explicando…?
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 2009374
package composicion;
public class Date {
private int month; // 1-12
private int day; // 1-31 based on month
private int year; // any year
// constructor: call checkMonth to confirm proper value for
month;
// call checkDay to confirm proper value for day
public Date( int theMonth, int theDay, int theYear )
{
month = checkMonth( theMonth ); // validate month
year = theYear; // could validate year
day = checkDay( theDay ); // validate day
System.out.printf(
"Date object constructor for date %s\n", this );
} // end Date constructor
// utility method to confirm proper month value
private int checkMonth( int testMonth )
{
if ( testMonth > 0 && testMonth <= 12 ) // validate
month
return testMonth;
else // month is invalid
{
System.out.printf(
"Invalid month (%d) set to 1.", testMonth );
return 1; // maintain object in consistent state
} // end else
} // end method checkMonth
// utility method to confirm proper day value based on
month and year
private int checkDay( int testDay )
{
int daysPerMonth[] =
{ 0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31 };
// check if day in range for month
if ( testDay > 0 && testDay <= daysPerMonth[ month ] )
return testDay;
// check for leap year
if ( month == 2 && testDay == 29 && ( year % 400 == 0 ||
( year % 4 == 0 && year % 100 != 0 ) ) )
return testDay;
System.out.printf( "Invalid day (%d) set to 1.", testDay );
return 1; // maintain object in consistent state
} // end method checkDay
// return a String of the form month/day/year
public String toString()
{
return String.format( "%d/%d/%d", month, day, year );
} // end method toString
} // end class Date
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 2009375
package composicion;
public class Employee{
private String firstName;
private String lastName;
private Date birthDate;
private Date hireDate;
// constructor to initialize name, birth date and hire date
public Employee( String first, String last, Date dateOfBirth, Date dateOfHire )
{
firstName = first;
lastName = last;
birthDate = dateOfBirth;
hireDate = dateOfHire;
} // end Employee constructor
// convert Employee to String format
public String toString()
{
return String.format( "%s, %s Hired: %s Birthday: %s", lastName, firstName, hireDate,
birthDate );
} // end method toEmployeeString
} // end class Employee
24/09/2009

package composicion;
public class EmployeeTest{
public static void main( String args[] )
{
Date birth = new Date( 7, 24, 1949 );
Date hire = new Date( 3, 12, 1988 );
Employee employee = new Employee( "Bob", "Blue", birth, hire );
System.out.println( employee );
} // end main
} // end class EmployeeTest
Hubner Janampa Patilla - Administración
de Bases de Datos - 200937624/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 2009377
Trabajo práctico Nº 5Consideremos las clases mostradas
Clave: Polimorfismo ¿Explicando el diagrama de clases?
24/09/2009
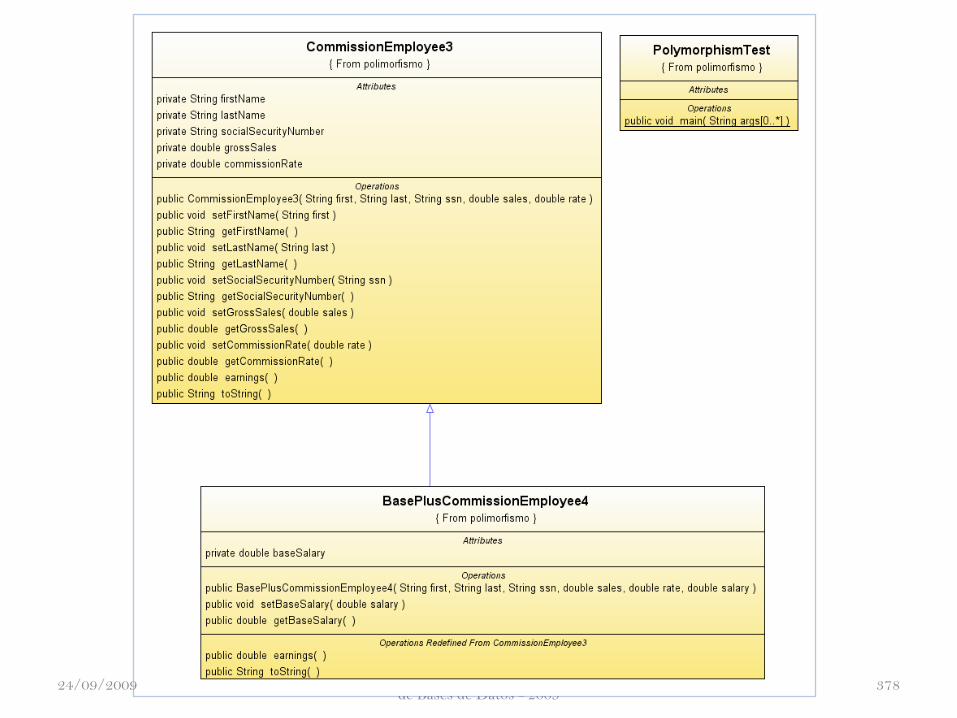
Hubner Janampa Patilla - Administración
de Bases de Datos - 200937824/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 2009379
package polimorfismo;
public class CommissionEmployee3
{
private String firstName;
private String lastName;
private String socialSecurityNumber;
private double grossSales; // Bruto de ventas semanales
private double commissionRate; // commission percentage
// five-argument constructor
public CommissionEmployee3
( String first, String last, String ssn, double sales, double
rate )
{// implicit call to Object constructor occurs here
firstName = first;
lastName = last;
socialSecurityNumber = ssn;
setGrossSales( sales ); // validate and store gross sales
setCommissionRate( rate ); // validate and store commission
rate
} // end five-argument CommissionEmployee3 constructor
// set first name
public void setFirstName( String first )
{
firstName = first;
} // end method setFirstName
// return first name
public String getFirstName()
{
return firstName;
} // end method getFirstName
// set last name
public void setLastName( String last )
{
lastName = last;
} // end method setLastName
// return last name
public String getLastName()
{
return lastName;
} // end method getLastName
// set social security number
public void setSocialSecurityNumber( String ssn )
{
socialSecurityNumber = ssn; // should validate
} // end method setSocialSecurityNumber
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 2009380
// return social security number
public String getSocialSecurityNumber()
{
return socialSecurityNumber;
} // end method getSocialSecurityNumber
// set gross sales amount
public void setGrossSales( double sales )
{
grossSales = ( sales < 0.0 ) ? 0.0 : sales;
} // end method setGrossSales
// return gross sales amount
public double getGrossSales()
{
return grossSales;
} // end method getGrossSales
// set commission rate
public void setCommissionRate( double rate )
{
commissionRate = ( rate > 0.0 && rate < 1.0 ) ?
rate : 0.0;
} // end method setCommissionRate
// return commission rate
public double getCommissionRate()
{
return commissionRate;
} // end method getCommissionRate
// calculate earnings
public double earnings()
{
return getCommissionRate() * getGrossSales();
} // end method earnings
// return String representation of
CommissionEmployee3 object
public String toString()
{
return String.format( "%s: %s %s\n%s: %s\n%s:
%.2f\n%s: %.2f", "commission employee",
getFirstName(), getLastName(), "social security
number", getSocialSecurityNumber(), "gross sales",
getGrossSales(), "commission rate",
getCommissionRate() );
} // end method toString
} // end class CommissionEmployee3
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 2009381
package polimorfismo;public class BasePlusCommissionEmployee4 extends
CommissionEmployee3
{
private double baseSalary; // base salary per week
// six-argument constructor
public BasePlusCommissionEmployee4( String first,
String last, String ssn, double sales, double rate, double
salary )
{
super( first, last, ssn, sales, rate );
setBaseSalary( salary ); // validate and store base salary
} // end six-argument BasePlusCommissionEmployee4
constructor
// set base salary
public void setBaseSalary( double salary )
{
baseSalary = ( salary < 0.0 ) ? 0.0 : salary;
} // end method setBaseSalary
// return base salary
public double getBaseSalary()
{
return baseSalary;
} // end method getBaseSalary
// calculate earnings
public double earnings()
{
return getBaseSalary() + super.earnings();
} // end method earnings
// return String representation of
BasePlusCommissionEmployee4
public String toString()
{
return String.format( "%s %s\n%s: %.2f", "base-salaried",
super.toString(), "base salary", getBaseSalary() );
} // end method toString
} // end class BasePlusCommissionEmployee4
24/09/2009

Hubner Janampa Patilla - Administración
de Bases de Datos - 2009382
package polimorfismo;
public class PolymorphismTest
{
public static void main( String args[] )
{
// assign superclass reference to superclass variable
CommissionEmployee3 commissionEmployee = new CommissionEmployee3( "Sue", "Jones", "222-22-
2222", 10000, .06 );
// assign subclass reference to subclass variable
BasePlusCommissionEmployee4 basePlusCommissionEmployee = new BasePlusCommissionEmployee4(
"Bob", "Lewis", "333-33-3333", 5000, .04, 300 );
// invoke toString on superclass object using superclass variable
System.out.printf( "%s %s:\n\n%s\n\n", "Call CommissionEmployee3's toString with superclass
reference ",
"to superclass object", commissionEmployee.toString() );
// invoke toString on subclass object using subclass variable
System.out.printf( "%s %s:\n\n%s\n\n", "Call BasePlusCommissionEmployee4's toString with subclass",
"reference to subclass object", basePlusCommissionEmployee.toString() );
// invoke toString on subclass object using superclass variable
CommissionEmployee3 commissionEmployee2 = basePlusCommissionEmployee;
System.out.printf( "%s %s:\n\n%s\n", "Call BasePlusCommissionEmployee4's toString with
superclass",
"reference to subclass object", commissionEmployee2.toString() );
} // end main
} // end class PolymorphismTest24/09/2009

Notas del método
con ampliaciones y mejoras
Hubner J.P
Mail: [email protected]
Octubre de 2008
AGILE DEVELOPMENT ICONIX

La receta de Iconix
Hubner Janampa Patilla - Administración
de Bases de Datos - 200938424/09/2009

Método ICONIX
Referencia
• El método original se encuentra en:
Rosenberg, Doug, with Kendall Scott
“Use case driven object modeling with UML. A
practical approach”
Addison Wesley, 1999
• Más información en la página:
http://www.iconix.com
24/09/2009 385Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Método ICONIX
¿Por qué esta versión?
• El texto original incluye muchas disgresiones, generalmente
obsoletas
• El texto supone ciertos conocimientos, que no siempre tienen
los alumnos
• El tratamiento de algunos temas es insuficiente para los usos
modernos
• Por ello se realizó esta versión, que sirva para un primer
curso de desarrollo orientado a objetos y usando UML.
24/09/2009 386Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Enfoque ICONIX
• Modelado de objetos conducido por casos de uso
• Centrado en datos: se descompone en fronteras de datos
• Basado en escenarios que descomponen los casos de uso
• Enfoque iterativo e incremental
• Ofrece trazabilidad
• Uso directo de UML (estándar del Object Management
Group)
24/09/2009 387Hubner Janampa Patilla - Administración
de Bases de Datos - 2009
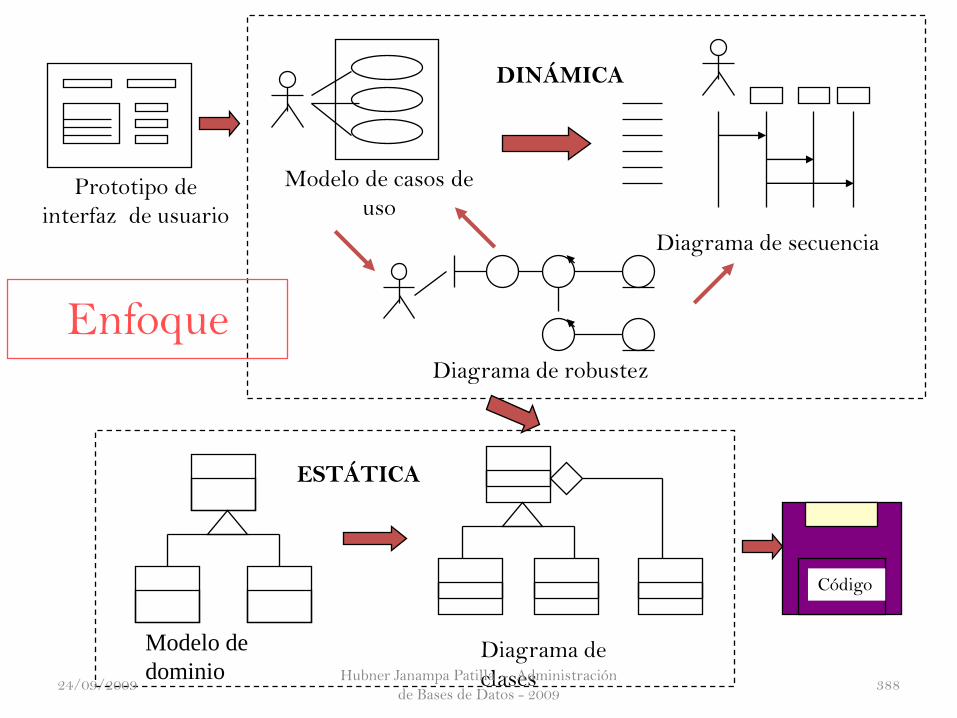
Prototipo de
interfaz de usuario
Diagrama de robustez
Modelo de casos de
uso
Diagrama de secuencia
DINÁMICA
Código
Modelo de
dominioDiagrama de
clases
ESTÁTICA
Enfoque
24/09/2009 388Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Preguntas iniciales
• ¿Quiénes son los usuarios (actores) del sistema y qué
tratan de hacer?
• ¿Cuáles son los objetos del mundo real (dominio del
problema) y las asociaciones entre ellos?
• ¿Qué objetos son necesarios para cada caso de uso?
• ¿Cómo colaboran los objetos en cada caso de uso?
• ¿Cómo se manejan aspectos de tiempo real?
• ¿Cómo se construirá realmente el sistema a nivel de
piezas?
24/09/2009 389Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Características
• Flexible para diferentes estilos y clases de problemas
• Apoyo a la manera de trabajo de la gente
• Guía para los menos experimentados
• Expone los productos anteriores al código de manera
estándar y comprensible
24/09/2009 390Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Pasos principales
I Análisis de requerimientos
• Identificar objetos del dominio y relaciones de agregación y
generalización
• Prototipo rápido
• Identificar casos de uso
• Organizar casos de uso en grupos (paquetes)
• Asignar requerimientos funcionales a casos de uso y objetos
del dominio
• META: revisión de requerimientos
24/09/2009 391Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Pasos principales
II Análisis y diseño preliminar
• Escribir descripciones de casos de uso
– cursos básico y alternos
• Análisis de robustez
– Identificar grupos de objetos que realizan escenario
– Actualizar diagramas de clases del dominio
• Finalizar diagramas de clases
• META: revisión del diseño preliminar
De usuarios hacia sistema
De datos hacia sistema
Detallar a partir de modelos de alto nivel
24/09/2009 392Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Pasos principales
III Diseño
• Asignar comportamiento
• Para cada caso de uso
– Identificar mensajes y métodos
– Dibujar diagramas de secuencia
– Actualizar clases
– (opcional) diagramas de colaboración
– (opcional) Diagramas de estados
• Terminar modelo estático
• Verificar cumplimiento de requerimientos
• META: revisión crítica del diseño
24/09/2009 393Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Pasos principales
IV Implementación
• Producir diagramas necesarios
– Despliegue
– Componentes
• Escribir el código
• Pruebas de unidad e integración
• Pruebas de sistema y aceptación basadas en casos de
uso
• META: entrega del sistema
24/09/2009 394Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Capítulo 2
Modelando el dominio
24/09/2009 395Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Modelado del Dominio
• Dominio del problema: área que cubre las
cosas y conceptos relacionados con el
problema que el sistema deberá resolver
• Modelando el dominio: tarea de descubrir
“objetos” (en realidad clases) que representan
esas cosas y conceptos
• A partir de los datos asociados con
requerimientos se llegará a construir modelo
estático del dominio
24/09/2009 396Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Modelando el dominio
• Fuentes de información:
– Descripción de alto nivel del problema
– Requerimientos de bajo nivel
– Conocimiento de expertos
– Literatura
24/09/2009 397Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Clases y objetos
• Objeto:
– Algo tangible o visible
– Algo que puede aprehenderse intelectualmente
– Algo hacia lo cual se dirigen pensamientos o acciones
• Un objeto tiene:
– Estado
– Comportamiento
– Identidad
24/09/2009 398Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Clases y objetos
• Estado: propiedades y sus valores particulares
• Comportamiento: cómo actúa y responde (a cambios
de estado y paso de mensajes)
24/09/2009 399Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Clases y objetos
• Clase:
– Descripción de un conjunto de objetos que comparten
una estructura, un comportamiento, relaciones y
semántica comunes
• Interfaz:
Vista exterior de una clase; permite contrato acerca de
las responsabilidades que ofrece y exige; aísla el
interior. Es el QUÉ hace
• Implementación:
Vista interior, particular; CÓMO lo hace
24/09/2009 400Hubner Janampa Patilla - Administración
de Bases de Datos - 2009
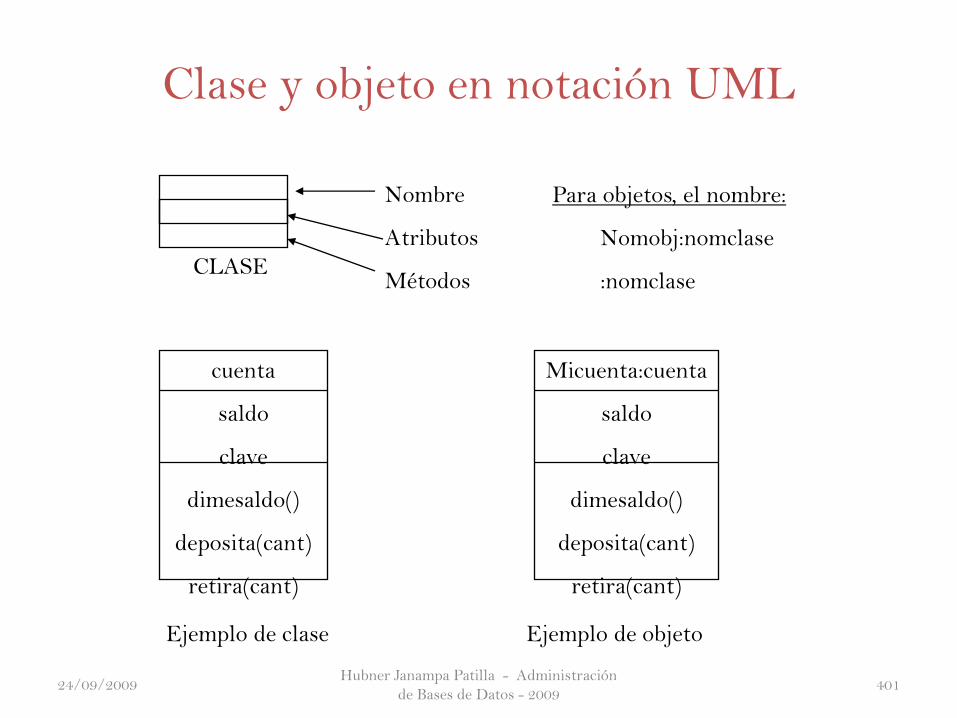
Clase y objeto en notación UML
CLASE
Nombre
Atributos
Métodos
cuenta
saldo
clave
dimesaldo()
deposita(cant)
retira(cant)
Micuenta:cuenta
saldo
clave
dimesaldo()
deposita(cant)
retira(cant)
Ejemplo de clase Ejemplo de objeto
Para objetos, el nombre:
Nomobj:nomclase
:nomclase
24/09/2009 401Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Modelando el dominio
• Procedimiento:
– Tomar documentos disponibles y hacer una lectura
rápida, subrayando los sustantivos y notando frases
posesivas y verbos (uso posterior)
– Los sustantivos y frases nominales se convertirán en
objetos y atributos
– Los verbos y frases verbales se convertirán en
operaciones y relaciones
– Las frases posesivas indican los sustantivos que son
atributos y no objetos
24/09/2009 402Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Modelando el dominio
• Procedimiento (II)
– Formar una lista con los sustantivos y frases
nominales identificados, evitando los plurales y las
repeticiones y ordenándola alfabéticamente
– Revisar la lista eliminando los elementos
innecesarios (irrelevantes o redundantes) o
incorrectos (vagos o conceptos fuera del alcance del
modelo o representan acciones aún cuando parezcan
sustantivos)
– Volver a revisar textos, leyendo entre líneas
24/09/2009 403Hubner Janampa Patilla - Administración
de Bases de Datos - 2009
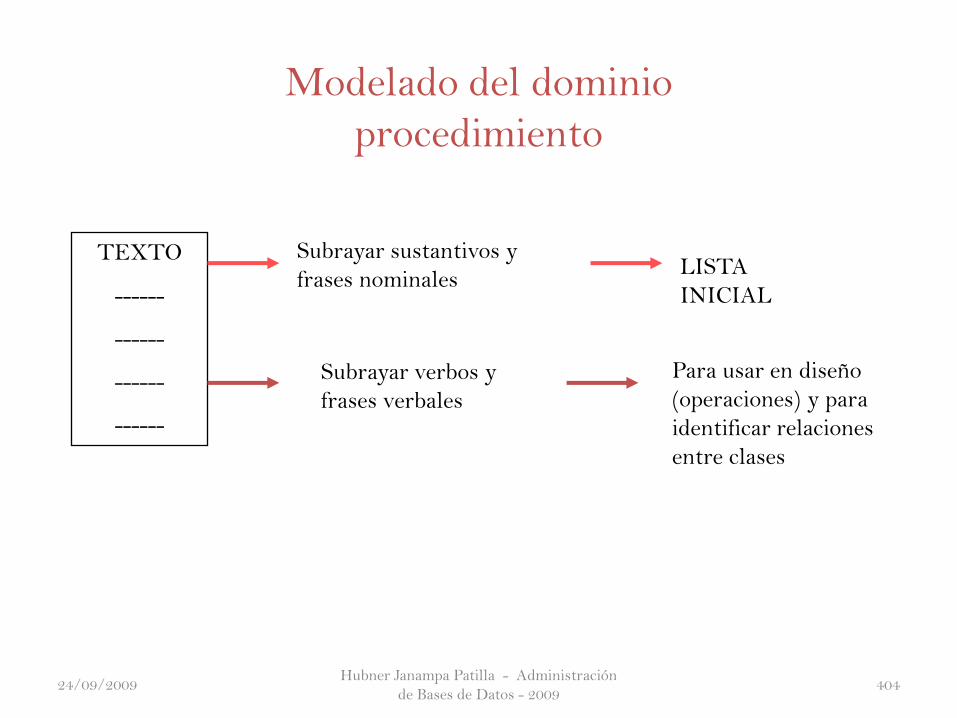
Modelado del dominio
procedimiento
TEXTO
------
------
------
------
Subrayar sustantivos y
frases nominales
Subrayar verbos y
frases verbales
LISTA
INICIAL
Para usar en diseño
(operaciones) y para
identificar relaciones
entre clases
24/09/2009 404Hubner Janampa Patilla - Administración
de Bases de Datos - 2009
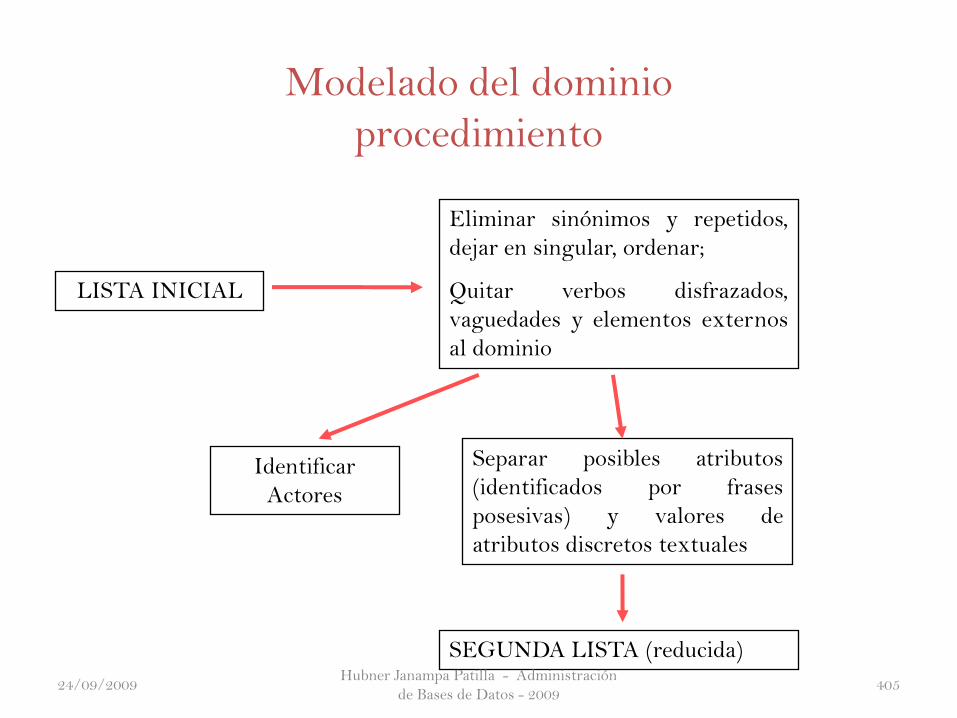
Modelado del dominio
procedimiento
LISTA INICIAL
Eliminar sinónimos y repetidos,
dejar en singular, ordenar;
Quitar verbos disfrazados,
vaguedades y elementos externos
al dominio
Identificar
Actores
Separar posibles atributos
(identificados por frases
posesivas) y valores de
atributos discretos textuales
SEGUNDA LISTA (reducida)
24/09/2009 405Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Modelando el dominio
• Procedimiento (III)
Construir relaciones de generalización
– Una generalización es una relación en la cual una clase es una generalización de otra. También se le llama “tipo-de” o “es-una”. La clase más general se llama Antecesor o Superclase y la otra (refinamiento de la primera) Descendiente o Subclase.
– La subclase hereda los atributos y métodos de la superclase y las asociaciones en que participa. Las puede modificar.
24/09/2009 406Hubner Janampa Patilla - Administración
de Bases de Datos - 2009
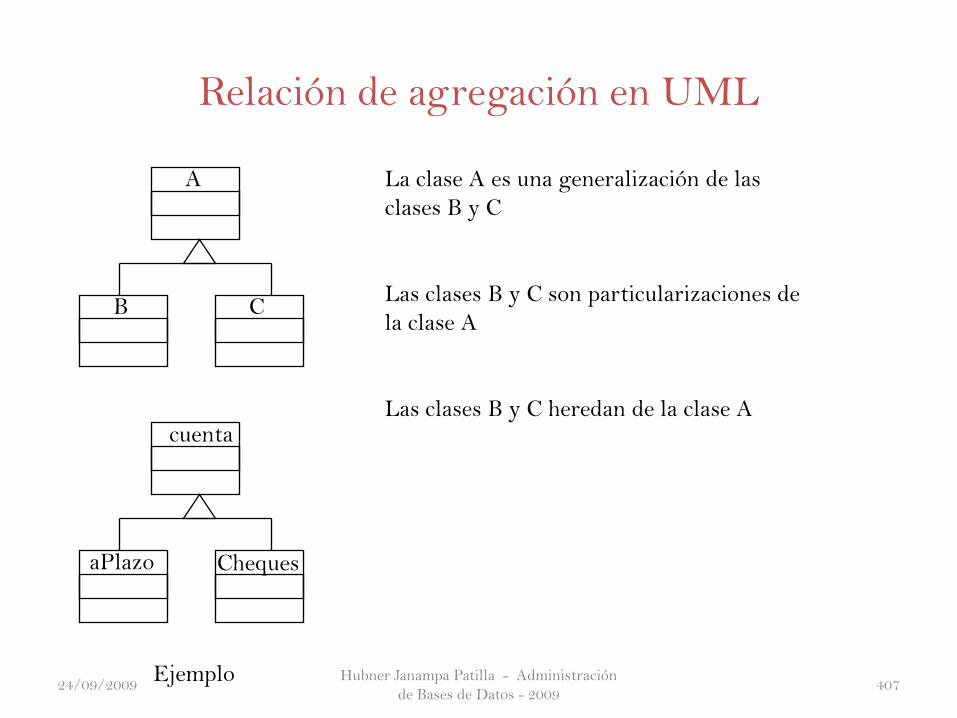
Relación de agregación en UML
A
B C
La clase A es una generalización de las
clases B y C
Las clases B y C son particularizaciones de
la clase A
Las clases B y C heredan de la clase Acuenta
aPlazo Cheques
Ejemplo24/09/2009 407
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Modelando el dominio
• Procedimiento (III)
Establecer asociaciones entre clases
– Una asociación es una relación estática entre dos clases;
indican dependencia, pero no acción (aunque se las nombre
con un verbo)
– Deben ser persistentes (es modelo estático)
24/09/2009 408Hubner Janampa Patilla - Administración
de Bases de Datos - 2009
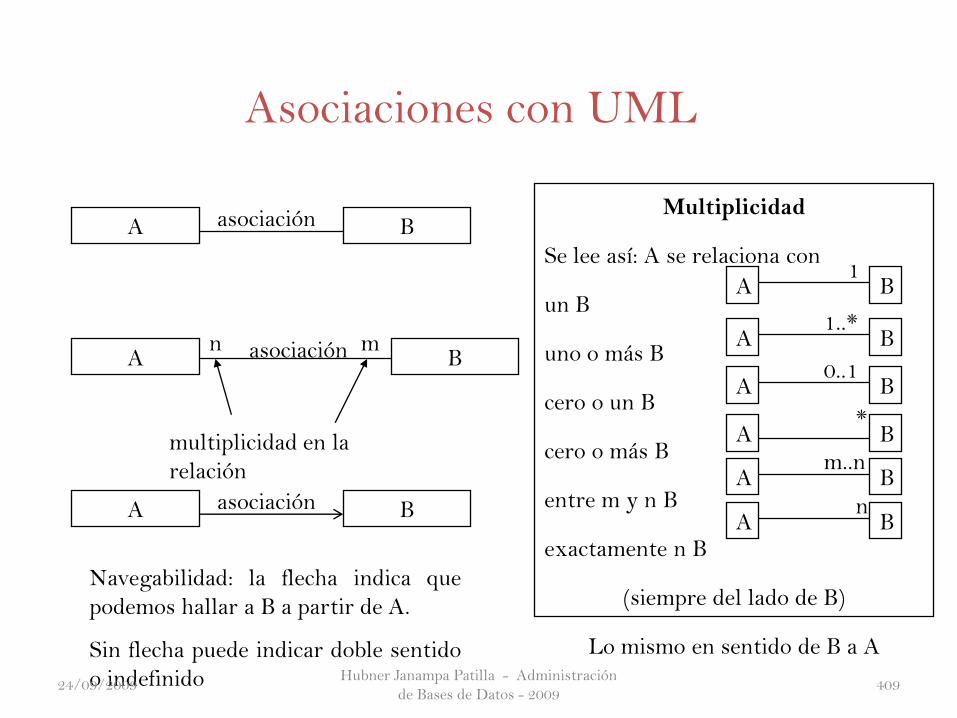
Asociaciones con UML
A Basociación
A Basociaciónn m
multiplicidad en la
relación
Multiplicidad
Se lee así: A se relaciona con
un B
uno o más B
cero o un B
cero o más B
entre m y n B
exactamente n B
(siempre del lado de B)
Lo mismo en sentido de B a A
An
B
A1
B
A1..*
B
A0..1
B
Am..n
B
A*
B
A Basociación
Navegabilidad: la flecha indica que
podemos hallar a B a partir de A.
Sin flecha puede indicar doble sentido
o indefinido24/09/2009 409Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Modelando el dominio
• Procedimiento (III)
Establecer relaciones de agregación
– Una agregación es una relación en la cual una clase está
formada por otras (sus partes)
– A veces se le llama “parte-de”
– En UML se distingue una forma más fuerte llamada
Composición, pero para este método no se hará diferencia
24/09/2009 410Hubner Janampa Patilla - Administración
de Bases de Datos - 2009
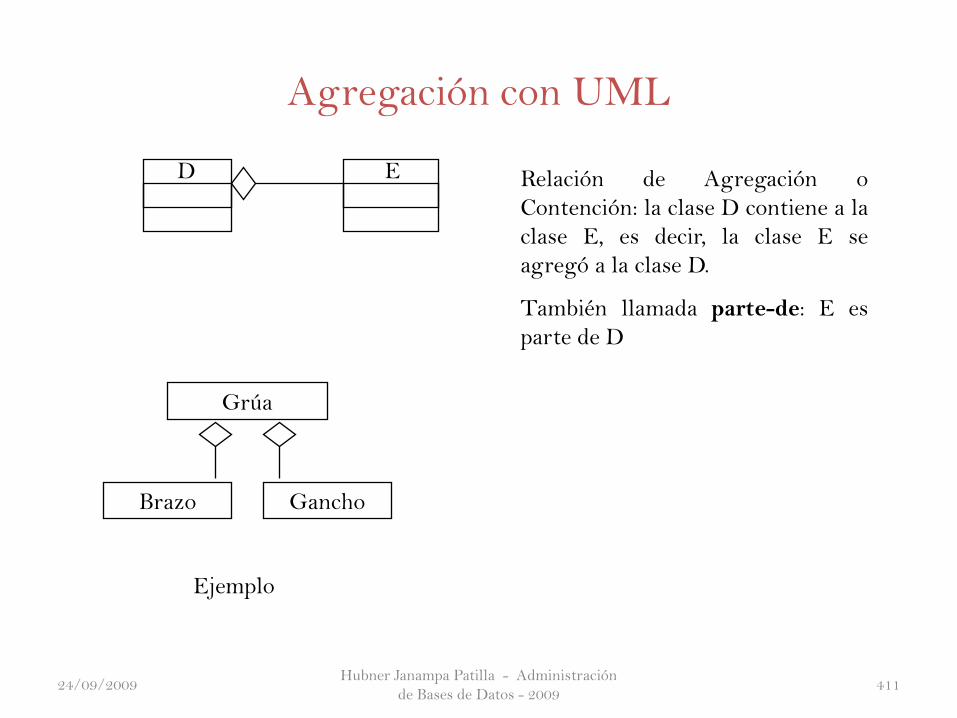
Agregación con UML
D E Relación de Agregación o
Contención: la clase D contiene a la
clase E, es decir, la clase E se
agregó a la clase D.
También llamada parte-de: E es
parte de D
Grúa
Brazo Gancho
Ejemplo
24/09/2009 411Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Modelando el dominio
• Procedimiento (IV)
Clases de asociación
– Una clase de asociación es una variante de las asociaciones muy útil
cuando hay relaciones muchas-a-muchas entre clases
Pueden conseguirse clase del dominio a partir de entidades en
bases de datos preexistentes
Cuando una clase tiene demasiados atributos, conviene dividirla
en clases auxiliares y usar agregación para reunirlas
24/09/2009 412Hubner Janampa Patilla - Administración
de Bases de Datos - 2009
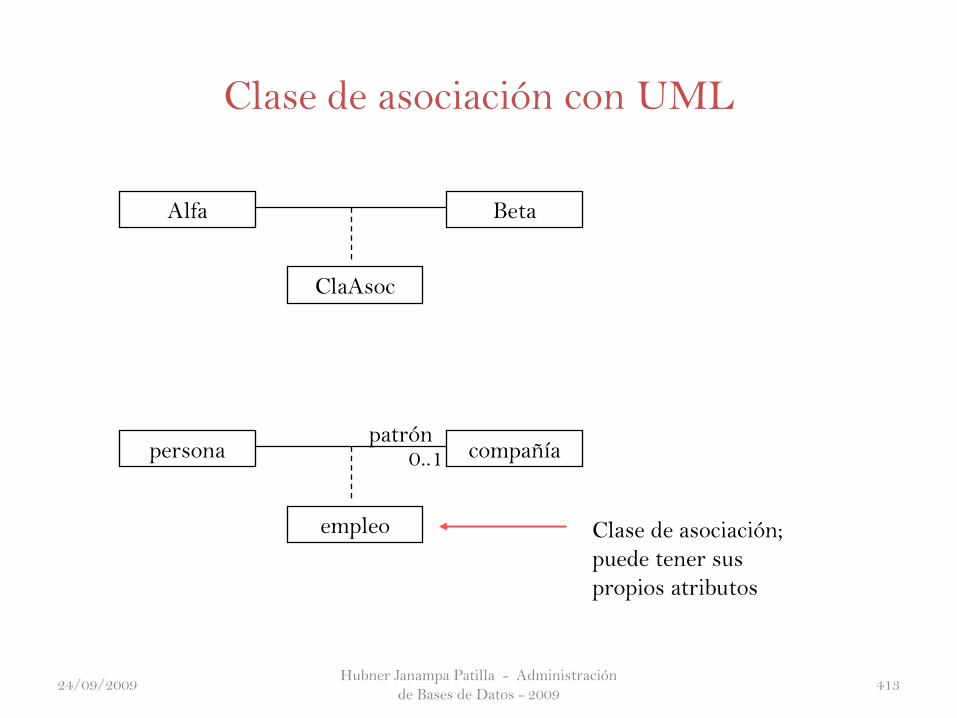
Clase de asociación con UML
Alfa Beta
ClaAsoc
persona compañía
empleo
patrón0..1
Clase de asociación;
puede tener sus
propios atributos
24/09/2009 413Hubner Janampa Patilla - Administración
de Bases de Datos - 2009
Modelado del dominio
procedimiento
SEGUNDA LISTA (reducida)
Diseñar clases básicas,
incluyendo los atributos
identificados Identificar relaciones de
agregación
Identificar otras relaciones
importantes
Incluir multiplicidad en
las relaciones
DIAGRAMA
DE CLASES
Analizar si existen
relaciones de generalización
o agregarlas si es necesario
24/09/2009 414Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Advertencia
No se tarde demasiado en preparar la lista; más
adelante la refinará y completará
24/09/2009 415Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Capítulo 3
Modelado de casos de uso
24/09/2009 416Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Casos de uso
• Buscan capturar los requerimientos del usuario para sistema
nuevo
• Puede ser desde cero o a partir de un sistema anterior
• Especifica escenarios detallados de lo que hace el usuario para
lograr sus fines
• Es la base de todo lo que sigue en este método y otros
semejantes
24/09/2009 417Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Casos de uso
• Definición:
– Un caso de uso es una secuencia de acciones que un
actor (usualmente una persona, pero que puede ser una
entidad externa, como otro sistema o un elemento de
hardware) realiza dentro del sistema para lograr una
meta
24/09/2009 418Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Casos de uso
• Se describe mejor como una frase verbal en presente y en
voz activa.
• Ejemplos:
– Admite paciente,
– Realiza transacción o
– Genera reporte
• Especifica de manera precisa, no ambigua, un aspecto del
uso del sistema sin suponer un diseño o implementación
particulares.
• Toda la funcionalidad del sistema debe estar expresada en
casos de uso
24/09/2009 419Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Casos de uso
• Actor: es un papel realizado por una persona, base de datos
externa, otro sistema.
• Los actores reflejan todas las entidades que deben
intercambiar información con el sistema.
• Varias personas pueden realizar un mismo papel
• Una persona puede jugar varios papeles, en momentos
distintos
• Diagrama de casos de uso: reúne actores y casos de uso
24/09/2009 420Hubner Janampa Patilla - Administración
de Bases de Datos - 2009
Casos de uso
Registra transacción
Genera reporte
Actualiza información
empleado
Usualmente, actores a derecha e izquierda, casos de uso al centro
No cambie símbolos, son parte de un estándar internacional24/09/2009 421
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Casos de uso
Algunos autores separan los actores en dos:
Primarios: los que inician casos de uso
Secundarios: responden a una necesidad del sistema que el
software no puede resolver, no inician la acción.
24/09/2009 422Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Casos de uso
•Existen dos tipos de caso de uso:
• De nivel de análisis: representa comportamiento
común de un grupo de caos
• De nivel de diseño: instancias del anterior, con
comportamiento específico
24/09/2009 423Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Casos de uso
cómo escribirlos
• Escriba un párrafo o más para cada caso de uso, describiendo
su comportamiento
• Si sólo hay una frase, quizá dividió demasiado finamente los
casos de uso y deberían reunirse varios
• Si es demasiado extenso o complicado, quizá debe subdividirlo
• Importa más identificar la mayoría que refinarlos desde el
principio
• Más adelante se descubrirán otros y se refinarán
24/09/2009 424Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Casos de uso
cómo escribirlos
• Recomendación importante:
• Deben guardar estrecha correlación con manual de
usuario y la Interfaz gráfica de usuario (GUI)
• Primero se escribe el manual y luego se trabaja en el
código (como sea: dibujos, texto, prototipo rápido, objetos
de utilería, etc)
24/09/2009 425Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Casos de uso
cómo escribirlos
• En la descripción no detalle demasiado elementos que pueden cambiar más tarde. Por ejemplo, no especifique tipo de botón si puede cambiar por un menú desplegable o una lista para seleccionar.
• Otras fuentes para casos de uso:– Si existe un sistema anterior, use los manuales de usuario para extraer
casos de uso
• Asegúrese que los casos de uso corresponden a lo que efectivamente hacen los usuarios
24/09/2009 426Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Capítulo 4
Análisis de Robustez
24/09/2009 427Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Análisis de Robustez
Identificación de Objetos
• Objetos que participan en cada caso de uso
• Clasificación de objetos:
– Objetos Fronterizos (de limite): objetos con los cuales puede interactuar el usuario – interfaz de usuario -.
– De Entidad: generalmente objetos del modelo de dominio
– De control (controles): intermediarios entre los fronterizos y de entidad.
Objeto
fronterizo
Entidad Control
24/09/2009 428Hubner Janampa Patilla - Administración
de Bases de Datos - 2009
Análisis de Robustez
Relaciones entre objetos
PERMITIDO NO PERMITIDO
24/09/2009 429Hubner Janampa Patilla - Administración
de Bases de Datos - 2009
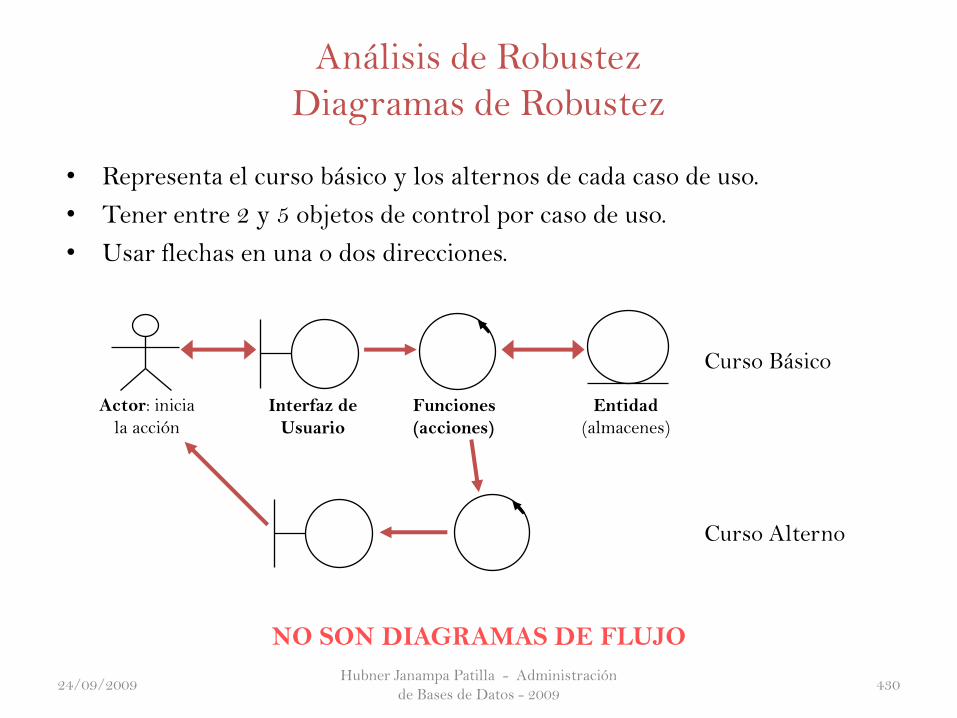
Análisis de Robustez
Diagramas de Robustez
• Representa el curso básico y los alternos de cada caso de uso.
• Tener entre 2 y 5 objetos de control por caso de uso.
• Usar flechas en una o dos direcciones.
Curso Básico
Curso Alterno
NO SON DIAGRAMAS DE FLUJO
Actor: inicia
la acción
Interfaz de
Usuario
Funciones
(acciones)
Entidad
(almacenes)
24/09/2009 430Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Análisis de Robustez
Para qué sirven
• Comprobación de Sanidad: revisar las ideas de los casosde uso (comportamiento razonable).
• Comprobación de entereza: asegurar que en los casos deuso se cubra el camino básico y los posibles caminosalternos.
• Descubrir objetos (si son necesarios)
• Diseño preliminar: los diagramas son la primera vista del nuevo sistema.
24/09/2009 431Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

CAPITULO 5
Modelado de la Interacción
24/09/2009 432Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Modelado de la Interacción
Objetivos
• Construcción de hilos sobre el comportamiento de los
objetos en los casos de uso.
• Tres objetivos:
1. Asignar el comportamiento de los objetos
(fronterizos, entidades y de control).
2. Detallar la interacción entre objetos (por medio
de mensajes).
3. Ubicar los métodos correspondientes a cada clase
(responsabilidades).
24/09/2009 433Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Modelado de la Interacción
Diagramas de Secuencia
• Consta de 4 elementos:
1. Texto del curso de acción (caso de uso).
2. Objetos - se representan con el nombre del
objetos (opcional) y la clase.
3. Mensajes: flechas entre los objetos
4. Métodos: operaciones (objetos de control) –
representados por rectángulos).
24/09/2009 434Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Modelado de la Interacción
Cómo crear un diagrama de Secuencia
1. Copiar texto del caso de uso (parte izquierda).
2. Agregar objetos entidad del diagrama de robustez
(parte superior – derecha).
3. Agregar objetos fronterizos y actores (parte superior –
izquierda).
4. Asignar métodos y mensajes: los objetos de control
pasan a ser métodos de entidades o de objetos
fronterizos (Responsabilidad).
5. Si un objeto de control se necesita, se agrega (Cuando
sólo es intermediario sin actividad propia, se funde con
fronterizo o entidad
24/09/2009 435Hubner Janampa Patilla - Administración
de Bases de Datos - 2009
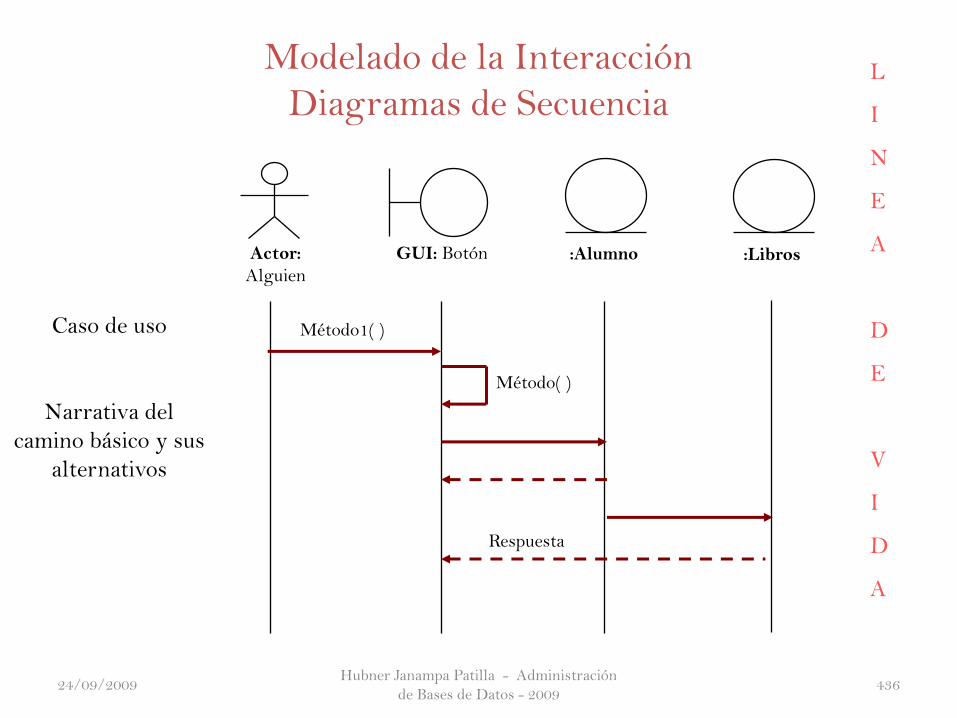
Modelado de la Interacción
Diagramas de Secuencia
Actor:
Alguien
GUI: Botón :Alumno
Caso de uso
Narrativa del
camino básico y sus
alternativos
:Libros
L
I
N
E
A
D
E
V
I
D
A
Método1( )
Método( )
Respuesta
24/09/2009 436Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Modelado de la Interacción
Asignación de métodos – Tarjeta CRC
• Una parte fundamental pero difícil del método es la asignación deresponsabilidades para cada clase.
• Como ayuda existen las tarjetas Clase – Responsabilidad –Colaboración (CRC).
• Estas tarjetas ayudan a decidir y aclarar cuales operaciones(métodos) corresponden a cada clase.
Nombre de clase
Responsabilidades Colaboración
Métodos que están a cargo de esta
claseClases con las que va a
colaborar (relacionadas)
24/09/2009 437Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Modelado de la Interacción
Responsabilidad (Puntos de criterio)
• Al asignar los métodos a cada una de las clases, toma en
cuenta:
1. Reusabilidad: considera que las clases pueden ser
utilizadas en otros proyectos.
2. Aplicabilidad: asignar los métodos realmente necesarios
para la clase y el proyecto.
3. Complejidad: métodos fáciles de construir y de entender.
4. Conocimiento de la implementación
24/09/2009 438Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

CAPITULO 6
Modelado de la Colaboración y Estados
24/09/2009 439Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Modelado de la Colaboración y Estados
• Ayuda a agregar aspectos del comportamiento que tiene el
nuevo sistema.
• Se diseñan comúnmente para sistemas de tiempo real o
sistemas distribuidos.
24/09/2009 440Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Diagramas de Colaboración
• Especifican mas los diagramas de robustez.
• Se apegan más a la situación real.
• Énfasis en el orden de las operaciones entre los objetos del
caso de uso.
• Agrega detalles extras al momento del paso de mensajes
entre los objetos.
24/09/2009 441Hubner Janampa Patilla - Administración
de Bases de Datos - 2009
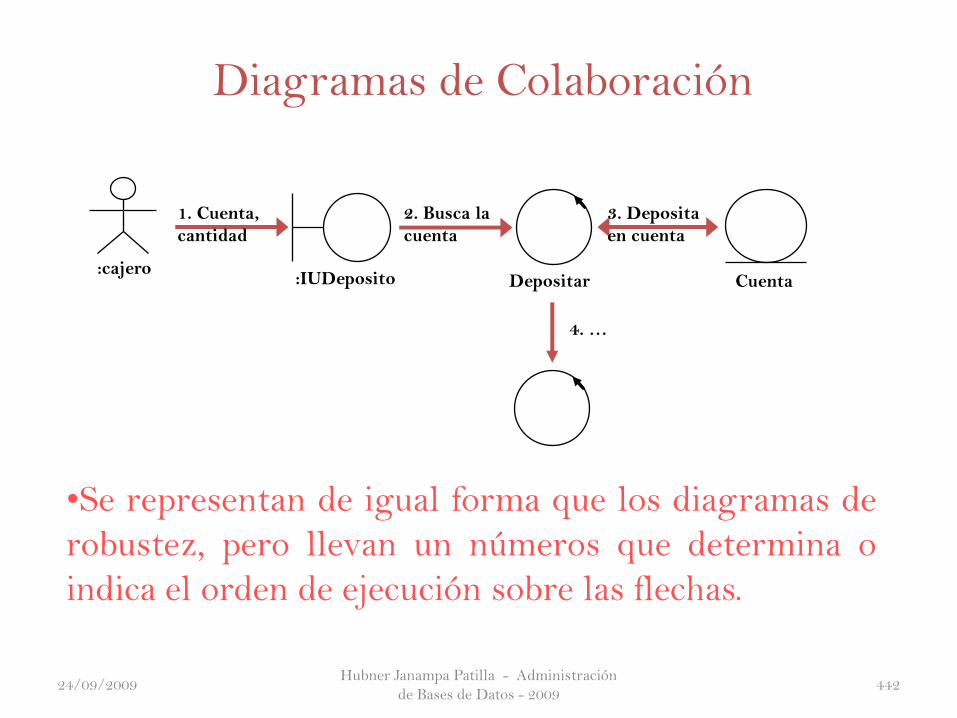
:cajero:IUDeposito Depositar
Diagramas de Colaboración
1. Cuenta,
cantidad
2. Busca la
cuenta
3. Deposita
en cuenta
Cuenta
4. …
•Se representan de igual forma que los diagramas de
robustez, pero llevan un números que determina o
indica el orden de ejecución sobre las flechas.
24/09/2009 442Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Diagramas de Estados
Diagramas de Estado = Máquinas de estado finito =
Autómatas
• Solucionan la representación del comportamiento
dinámico de un objeto o grupo de objetos.
• Muestra el ciclo de vida de los objetos, mediante los
diferentes estados que tiene o pasa un objeto.
24/09/2009 443Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Diagramas de Estados
Elementos
• Estado inicial.
• Estados del objeto = rectángulo redondeado, con el nombre
del estado y las actividades (opcional).
Tipos de actividades o eventos:
a) Inicio – Entrada (Enter): acciones cuando entra al estado.
b) Hacer (Do): acciones mientras esta en el estado.
c) Salida (Exit): acciones cuando sale del estado.
• Transiciones: cambio de estados.
• Estado final.
24/09/2009 444Hubner Janampa Patilla - Administración
de Bases de Datos - 2009
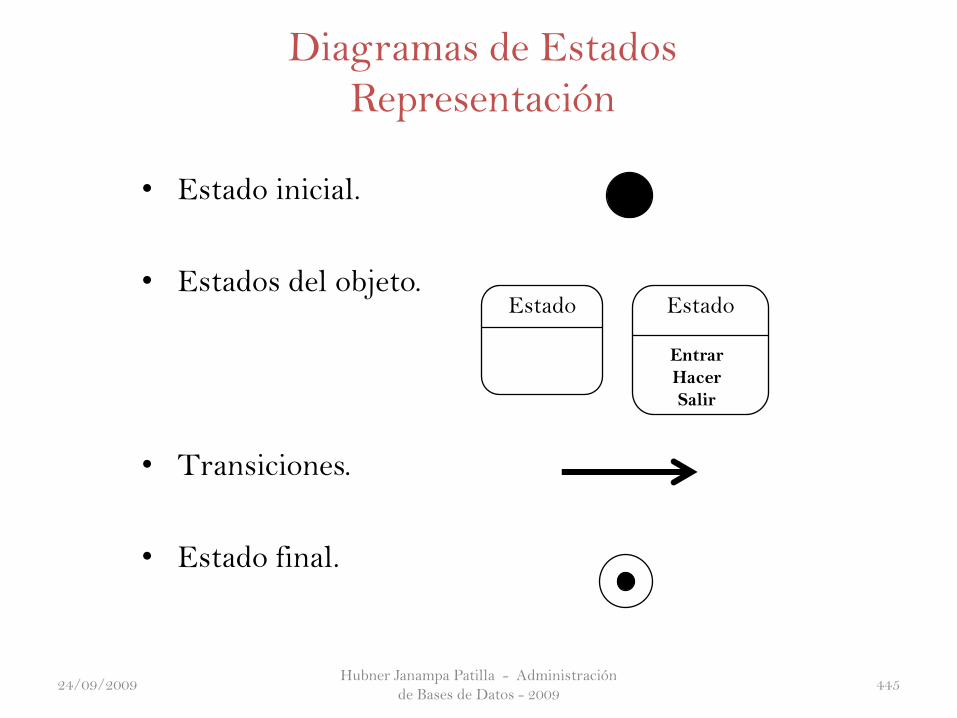
Diagramas de Estados
Representación
• Estado inicial.
• Estados del objeto.
• Transiciones.
• Estado final.
Estado Estado
Entrar
Hacer
Salir
24/09/2009 445Hubner Janampa Patilla - Administración
de Bases de Datos - 2009
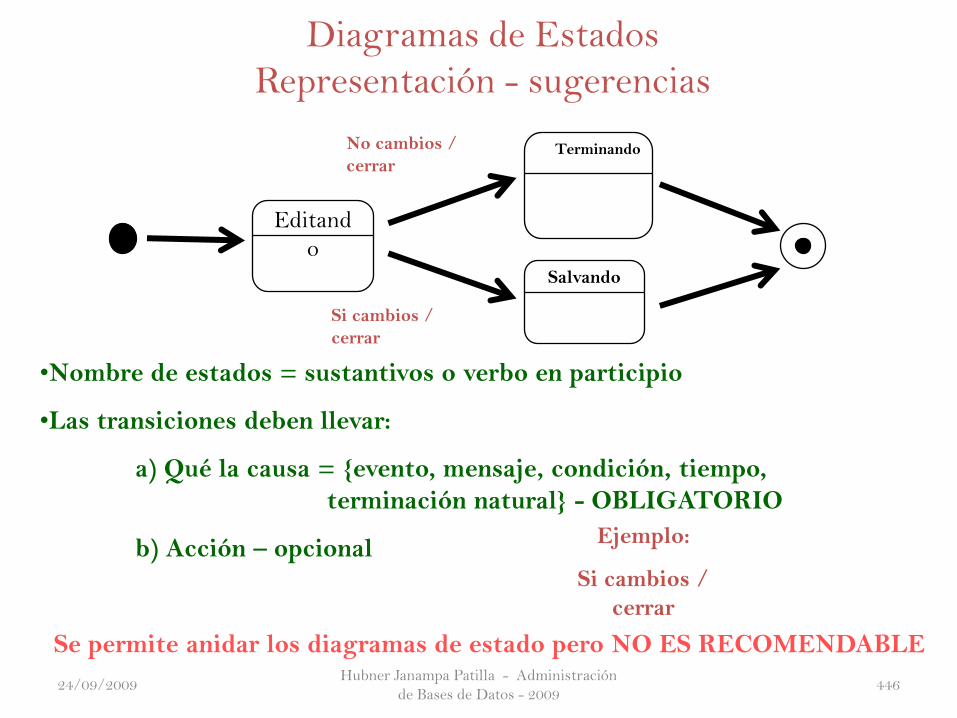
Diagramas de Estados
Representación - sugerencias
Editand
oSalvando
TerminandoNo cambios /
cerrar
Si cambios /
cerrar
•Nombre de estados = sustantivos o verbo en participio
•Las transiciones deben llevar:
a) Qué la causa = {evento, mensaje, condición, tiempo,
terminación natural} - OBLIGATORIO
b) Acción – opcional
Se permite anidar los diagramas de estado pero NO ES RECOMENDABLE
Ejemplo:
Si cambios /
cerrar
24/09/2009 446Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Diagramas de Actividades
• Descienden de los diagramas de flujo, redes de Petri y
de las máquinas de estado.
• Capturan las acciones y los resultados de estas
acciones.
• Representan la secuencia de actividades que se realizan
en un caso de uso (mas detallado, como un diagrama
de flujo).
24/09/2009 447Hubner Janampa Patilla - Administración
de Bases de Datos - 2009
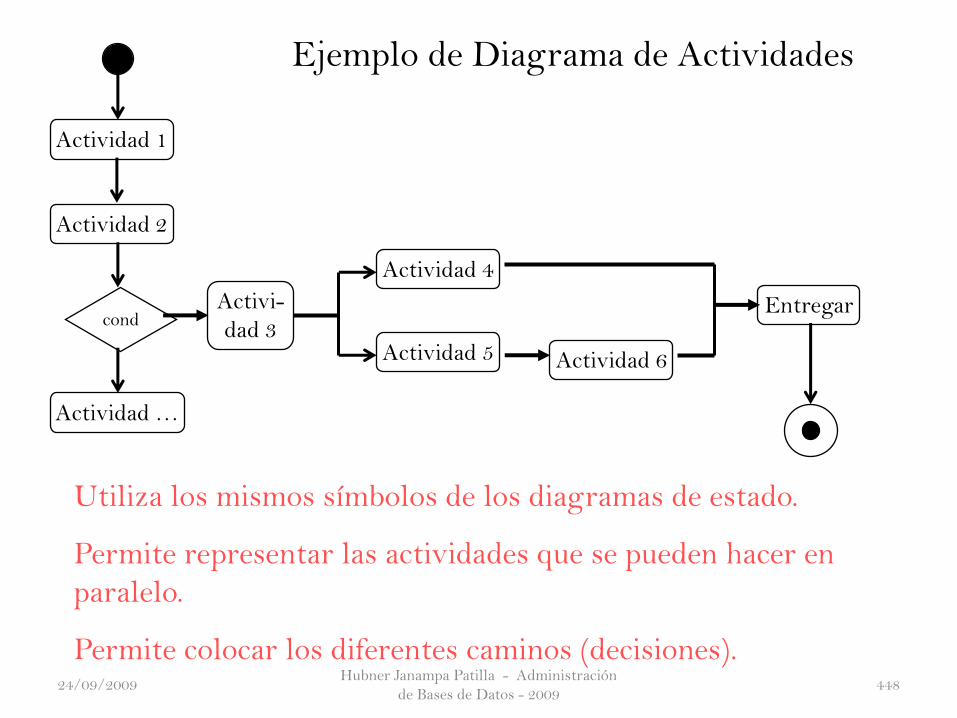
Actividad 1
Actividad 2
Activi-
dad 3
Actividad 4
Actividad 5
Entregar
Actividad 6
Actividad …
cond
Ejemplo de Diagrama de Actividades
Utiliza los mismos símbolos de los diagramas de estado.
Permite representar las actividades que se pueden hacer en
paralelo.
Permite colocar los diferentes caminos (decisiones).24/09/2009 448
Hubner Janampa Patilla - Administración
de Bases de Datos - 2009
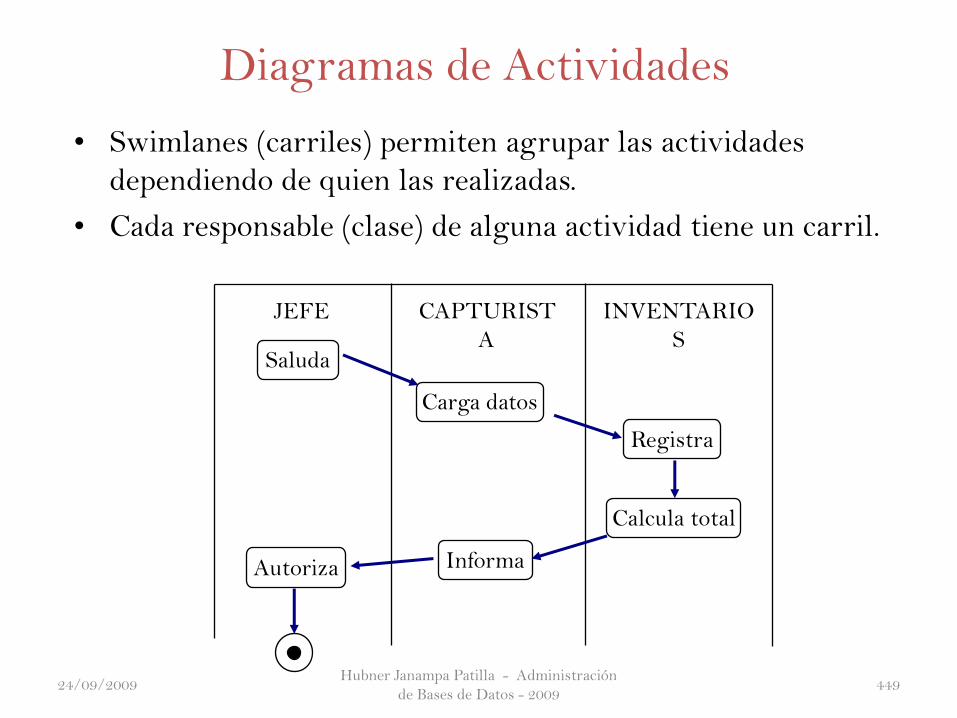
• Swimlanes (carriles) permiten agrupar las actividades
dependiendo de quien las realizadas.
• Cada responsable (clase) de alguna actividad tiene un carril.
Diagramas de Actividades
JEFE CAPTURIST
A
INVENTARIO
SSaluda
Carga datos
Registra
Informa
Calcula total
Autoriza
24/09/2009 449Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Capitulo 7
Requerimientos
24/09/2009 450Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

… Requerimientos
• ¿Qué es un requerimiento?
– Criterio especifico de un usuario que un sistema tiene que satisfacer.
• Los requerimientos definen el comportamiento y funcionalidad requerida por el usuario para un sistema.
• Expresados por frases que incluyen:
1. shall – tiene que, debe que
2. must – debe de, haber de
24/09/2009 451Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

… Requerimientos
• Tipos de requerimientos:
1. Funcionales: “el sistema tiene que generar automaticamente …”.
2. De Datos:
3. De ejecución (desempeño): “El sistema debe de validar los datos que entran…”.
4. De capacidad: “El sistema tiene que mostrarinformación de 10,000 transacciones”.
5. De prueba: “El sistema tiene que permitir hacer transacciones de 50 usuarios al mismo tiempo.
24/09/2009 452Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Casos de Uso <-> Requerimientos
•Los casos de uso son Algunos o Todos los Requerimientos.
•Se sugiere hacer un caso de uso por cada requerimiento funcional,
debido a que:
•Un caso de uso describe una unidad de comportamiento.
•Los requerimientos describen las “reglas” que rigen el
comportamiento del sistema.
•Las funciones son acciones individuales que ocurren dentro del
comportamiento.
Un caso de uso puede satisfacer mas de un requerimiento
(funcional/no funcional), o bien la combinación de varios
casos de uso pueden satisfacer un solo requerimiento.
24/09/2009 453Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Trazabilidad de Requerimientos
•Al iniciar un proyecto se pueden asignar algunos
requerimientos a casos de uso; pero como avanza el
proyecto estos se verifican/validan – trazabilidad.
•Asignación/Trazabilidad son términos importantes a
través de todo el ciclo de vida, debido a que nos ayudan a
determinar si el análisis, diseño cumplen con los
requerimientos deseados.
24/09/2009 454Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Trazabilidad de Requerimientos
•Antes de iniciar la codificación hay que analizar estos aspectos:
•Captura de Datos: encontrar caminos efectivos para capturar
los elementos de cada fase del ciclo de vida.(puedes actualizar o
cambiar algunos elementos de fases del ciclo).
•Análisis de datos y reducción: asegurar que todos los puntos
hechos/asignados son válidos, que todos los requerimientos
fueron asignados y realizados (trace).
•Reporte de datos: documentación del proyecto (reporte de los
resultados de la captura de datos y el análisis y reducción).
24/09/2009 455Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Puntos a realizar…
•Revisa los requerimientos asignados a cada uno de los casos de
uso (todos los requerimientos deben estar asignados entre todos
los casos de uso).
•Verificar que cada requerimiento es realizado en por lo menos
una clase del modelo de dominio.
•Verificar que los requerimientos se satisfacen en por lo menos
un casos de uso (busca entre la descripción de los casos de uso y
los diagramas de secuencia).
•Si realizaste diagramas de colaboración o estado, verifica que el
comportamiento de los diagramas (estados) cumplan con lo
especificado por los requerimientos.
24/09/2009 456Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Capitulo 8
Implementación
24/09/2009 457Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Administración de Proyectos
•Ser listo e ingenioso.
•No desconcentrarse y perder el enfoque en el proceso del
proyecto.
•No utilizar herramientas visuales para generar pruebas
tontas o simples del código.
• Apreciar mas la calidad de código que la cantidad.
24/09/2009 458Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Revisar el modelo de dominio
• Finalizar los diagramas de secuencia y refinar el modelo de
dominio (verificar que los métodos sean concisos y atómicos).
• Realiza:
• Define una lista de argumentos para tus operaciones.
•Define operaciones lógicas
• Asigna clases a componentes si es posible.
24/09/2009 459Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Pruebas
• Para saber si tu sistema es aceptable, realiza pruebas:
• Caja Blanca
• Caja Negra – casos de uso
• Prueba basado en estados (sistemas de tiempo
real).
• Las pruebas deben involucrar grupos lógicos (paquetes) de
casos de uso, pruebas de unidad, de integración y de sistema.
24/09/2009 460Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Métricas
1. Determinar el peso de tus clases, para saber la
complejidad de tus clases.
2. Responsabilidad de una clase – medir el número de
metodos llamados en una clase.
3. Profundidad del árbol – medición de la forma de tu
modelo de dominio (mientras mas profundo sea mas
complejo es).
4. Numero de hijos – tamaño del modelo de dominio.
24/09/2009 461Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

ANEXO
Resumen de símbolos empleados
24/09/2009 462Hubner Janampa Patilla - Administración
de Bases de Datos - 2009
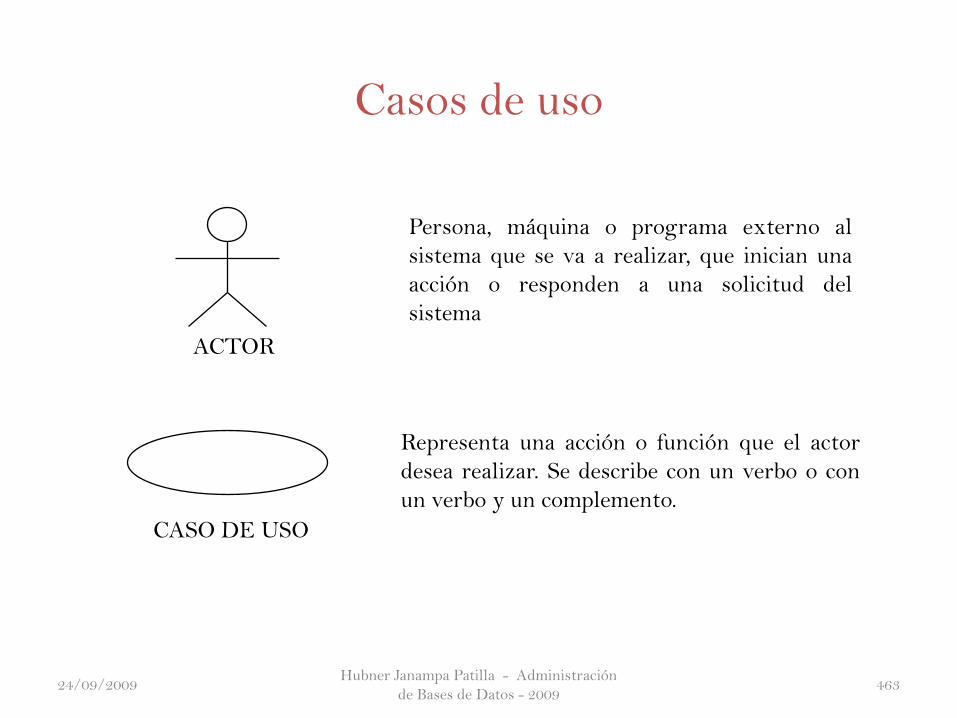
Casos de uso
ACTOR
CASO DE USO
Persona, máquina o programa externo al
sistema que se va a realizar, que inician una
acción o responden a una solicitud del
sistema
Representa una acción o función que el actor
desea realizar. Se describe con un verbo o con
un verbo y un complemento.
24/09/2009 463Hubner Janampa Patilla - Administración
de Bases de Datos - 2009
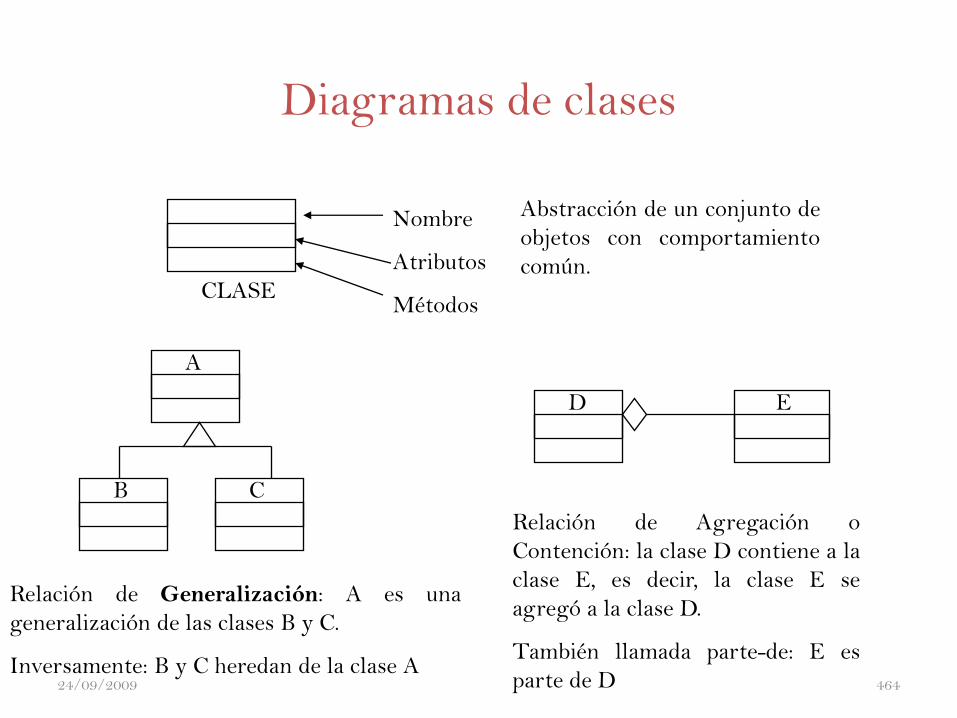
Diagramas de clases
Abstracción de un conjunto de
objetos con comportamiento
común.CLASE
Nombre
Atributos
Métodos
A
B C
Relación de Generalización: A es una
generalización de las clases B y C.
Inversamente: B y C heredan de la clase A
D E
Relación de Agregación o
Contención: la clase D contiene a la
clase E, es decir, la clase E se
agregó a la clase D.
También llamada parte-de: E es
parte de D24/09/2009 464
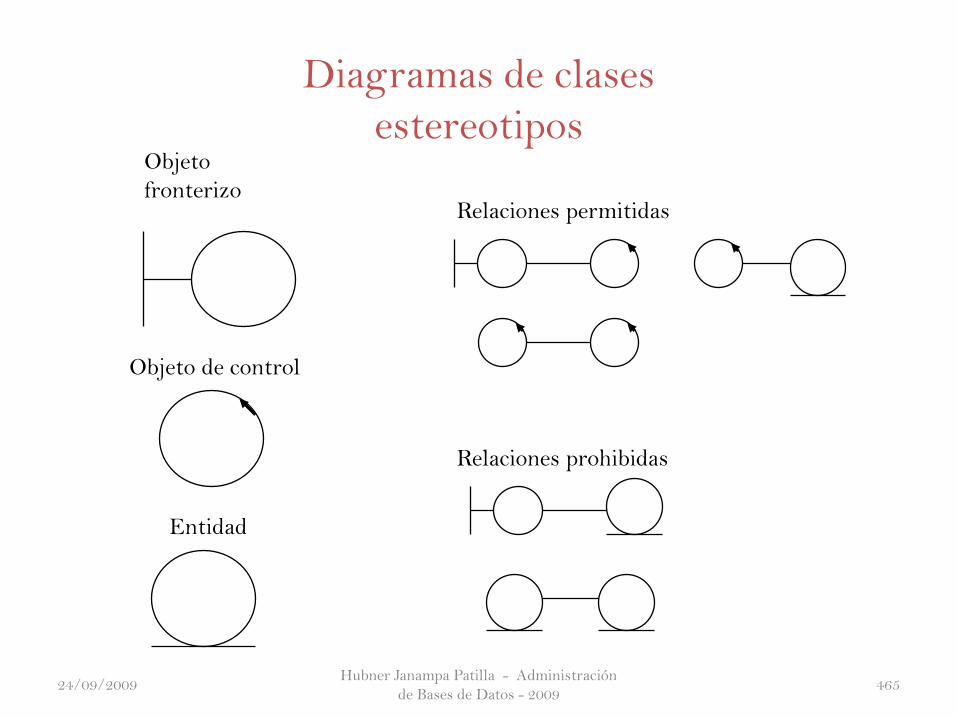
Diagramas de clases
estereotiposObjeto
fronterizo
Objeto de control
Entidad
Relaciones permitidas
Relaciones prohibidas
24/09/2009 465Hubner Janampa Patilla - Administración
de Bases de Datos - 2009
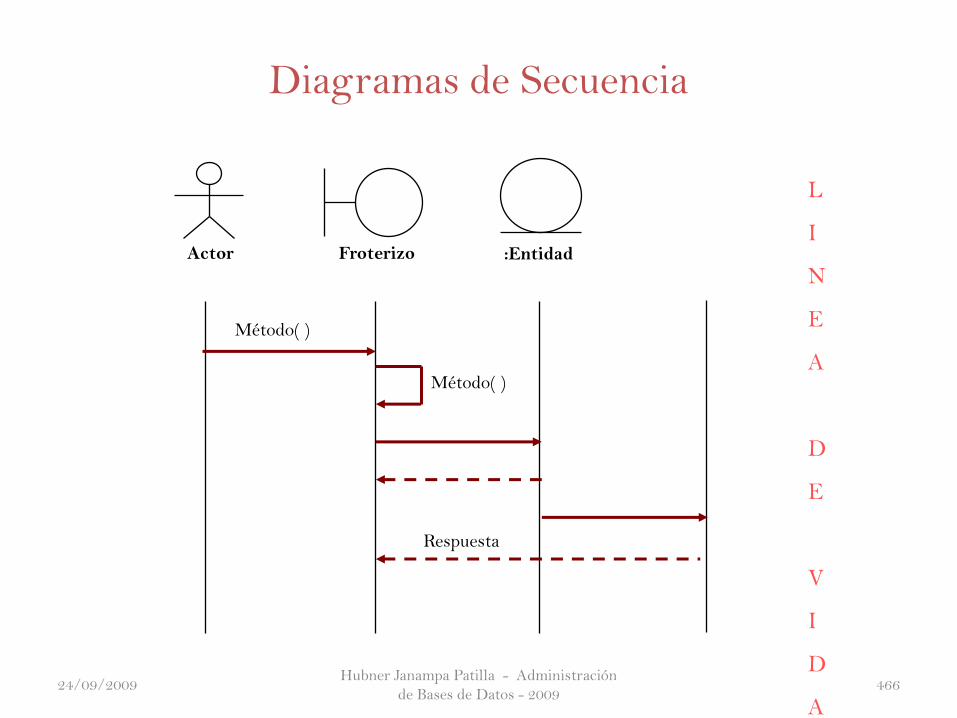
Diagramas de Secuencia
Actor Froterizo :Entidad
L
I
N
E
A
D
E
V
I
D
A
Método( )
Método( )
Respuesta
24/09/2009 466Hubner Janampa Patilla - Administración
de Bases de Datos - 2009
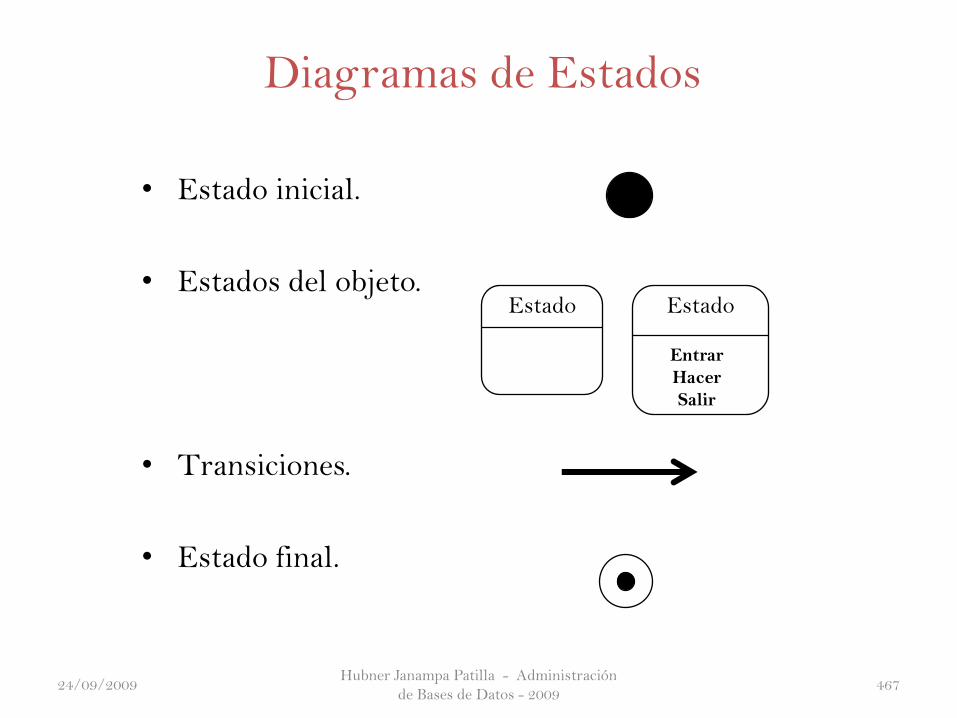
Diagramas de Estados
• Estado inicial.
• Estados del objeto.
• Transiciones.
• Estado final.
Estado Estado
Entrar
Hacer
Salir
24/09/2009 467Hubner Janampa Patilla - Administración
de Bases de Datos - 2009

Bibliografía.
Hubner Janampa Patilla - Administración
de Bases de Datos - 200946824/09/2009


















