
Lib Cazau Metodologia
403
Pablo Cazau Estadística y metodología de la investigación Presentación Capítulo 1: Introducción a la estadística Capítulo 2: Estadística descriptiva Capítulo 3: Probabilidad y curva normal Capítulo 4: Correlación y regresión Capítulo 5: Estadística inferencial Capítulo 6: Investigación e investigación científica Capítulo 7: Tipos de investigación científica Capítulo 8: Causalidad y experimento Capítulo 9: Las etapas de la investigación típica Capítulo 10: Problema, bibliografía, teoría y objetivos Capítulo 11: Hipótesis y variables Capítulo 12: Técnicas de muestreo e instrumentos de medición Capítulo 13: El diseño de investigación Capítulo 14: El procesamiento de los datos Capítulo 15: Redacción y publicación de los resultados Capítulo 16: Investigaciones especiales Referencias bibliográficas de estadística Otras fuentes consultadas para estadística Referencias bibliográficas de metodología Anexos de estadística Anexos de metodología LA FORMA DE CITAR LA PRESENTE BIBLIOGRAFÍA ES LA SIGUIENTE: Cazau Pablo (2011), Estadística y metodología de la investigación. Buenos Aires: Biblioteca Redpsicología. Buenos Aires, Junio 2012. Más informes: [email protected] INDICE GENERAL Presentación PARTE I: ESTADÍSTICA CAPÍTULO 1: INTRODUCCIÓN A LA ESTADÍSTICA 1. DEFINICIÓN Y UTILIDAD DE LA ESTADÍSTICA 2. CLASIFICACIONES DE LA ESTADÍSTICA 3. POBLACIÓN Y MUESTRA 4. ESTRUCTURA DEL DATO 5. LA MEDICIÓN CAPÍTULO 2: ESTADÍSTICA DESCRIPTIVA 1. GENERALIDADES 2. ORDENAMIENTO Y AGRUPACIÓN DE LOS DATOS: MATRICES Y TABLAS 3. VISUALIZACIÓN DE LOS DATOS: GRÁFICOS 4. SÍNTESIS DE LOS DATOS: MEDIDAS ESTADÍSTICAS DE POSICIÓN 5. SÍNTESIS DE LOS DATOS: MEDIDAS ESTADÍSTICAS DE DISPERSIÓN 6. SÍNTESIS DE LOS DATOS: ASIMETRÍA Y CURTOSIS NOTAS CAPÍTULO 3: PROBABILIDAD Y CURVA NORMAL 1. EL CONCEPTO DE PROBABILIDAD 2. ANÁLISIS COMBINATORIO 3. DEFINICIÓN Y CARACTERÍSTICAS DE LA CURVA NORMAL 4. PUNTAJES BRUTOS Y PUNTAJES ESTANDARIZADOS
-
Upload
antonio-vizcarra -
Category
Documents
-
view
196 -
download
1
Transcript of Lib Cazau Metodologia

Pablo CazauEstadística y metodología de la investigación
PresentaciónCapítulo 1: Introducción a la estadísticaCapítulo 2: Estadística descriptivaCapítulo 3: Probabilidad y curva normalCapítulo 4: Correlación y regresiónCapítulo 5: Estadística inferencialCapítulo 6: Investigación e investigación científicaCapítulo 7: Tipos de investigación científicaCapítulo 8: Causalidad y experimentoCapítulo 9: Las etapas de la investigación típicaCapítulo 10: Problema, bibliografía, teoría y objetivosCapítulo 11: Hipótesis y variablesCapítulo 12: Técnicas de muestreo e instrumentos de mediciónCapítulo 13: El diseño de investigaciónCapítulo 14: El procesamiento de los datosCapítulo 15: Redacción y publicación de los resultadosCapítulo 16: Investigaciones especialesReferencias bibliográficas de estadísticaOtras fuentes consultadas para estadísticaReferencias bibliográficas de metodologíaAnexos de estadísticaAnexos de metodología
LA FORMA DE CITAR LA PRESENTE BIBLIOGRAFÍA ES LA SIGUIENTE:Cazau Pablo (2011), Estadística y metodología de la investigación. Buenos Aires: Biblioteca Redpsicología.
Buenos Aires, Junio 2012. Más informes: [email protected]
INDICE GENERAL
Presentación
PARTE I: ESTADÍSTICA
CAPÍTULO 1: INTRODUCCIÓN A LA ESTADÍSTICA
1. DEFINICIÓN Y UTILIDAD DE LA ESTADÍSTICA2. CLASIFICACIONES DE LA ESTADÍSTICA3. POBLACIÓN Y MUESTRA4. ESTRUCTURA DEL DATO5. LA MEDICIÓN
CAPÍTULO 2: ESTADÍSTICA DESCRIPTIVA
1. GENERALIDADES2. ORDENAMIENTO Y AGRUPACIÓN DE LOS DATOS: MATRICES Y TABLAS3. VISUALIZACIÓN DE LOS DATOS: GRÁFICOS4. SÍNTESIS DE LOS DATOS: MEDIDAS ESTADÍSTICAS DE POSICIÓN5. SÍNTESIS DE LOS DATOS: MEDIDAS ESTADÍSTICAS DE DISPERSIÓN6. SÍNTESIS DE LOS DATOS: ASIMETRÍA Y CURTOSISNOTAS
CAPÍTULO 3: PROBABILIDAD Y CURVA NORMAL
1. EL CONCEPTO DE PROBABILIDAD2. ANÁLISIS COMBINATORIO3. DEFINICIÓN Y CARACTERÍSTICAS DE LA CURVA NORMAL4. PUNTAJES BRUTOS Y PUNTAJES ESTANDARIZADOS5. APLICACIONES DE LA CURVA NORMALNOTAS
CAPÍTULO 4: CORRELACIÓN Y REGRESIÓN
1. INTRODUCCIÓN2. EL ANÁLISIS DE CORRELACIÓN3. CÁLCULO GRÁFICO DE LA CORRELACIÓN4. CÁLCULO ANALÍTICO DE LA CORRELACIÓN5. UN EJEMPLO: CONSTRUCCIÓN Y VALIDACIÓN DE TESTS6. EL ANÁLISIS DE REGRESIÓN7. CÁLCULO ANALÍTICO DE LA REGRESIÓN

8. CÁLCULO GRÁFICO DE LA CORRELACIÓNNOTAS
CAPÍTULO 5: ESTADÍSTICA INFERENCIAL
1. INTRODUCCIÓN2. ESTIMACIÓN DE PARÁMETROS3. PRUEBA DE HIPÓTESIS4. EJEMPLOS DE PRUEBAS DE HIPÓTESIS5. EL CONCEPTO DE SIGNIFICACIÓN ESTADÍSTICANOTAS
PARTE II: METODOLOGÍA DE LA INVESTIGACIÓN
CAPÍTULO 6: INVESTIGACIÓN E INVESTIGACIÓN CIENTÍFICA
1. QUÉ ES INVESTIGACIÓN2. TIPOS DE INVESTIGACIÓN3. LA INVESTIGACIÓN CIENTÍFICA4. EL MÉTODO EN LA INVESTIGACIÓN CIENTÍFICA5. EL ENCUADRE EN LA INVESTIGACIÓN CIENTÍFICA6. LA FORMACIÓN DEL INVESTIGADOR CIENTÍFICO
CAPÍTULO 7: TIPOS DE INVESTIGACIÓN CIENTÍFICA
1. INVESTIGACIÓN PURA, APLICADA Y PROFESIONALBases científicas de la investigaciónInvestigación y éticaInterrelaciones entre los tres tipos de investigaciónLos tres tipos de investigación y los contextos de la ciencia2. INVESTIGACIÓN EXPLORATORIA, DESCRIPTIVA, CORRELACIONAL Y EXPLICATIVAInvestigación exploratoriaInvestigación descriptivaInvestigación correlacionalInvestigación explicativaOtras consideracionesUn análisis crítico de la propuesta tipológicaAlgunos ejemplos de investigaciones descriptivas y explicativas3. INVESTIGACIÓN TEÓRICA Y EMPÍRICA4. INVESTIGACIÓN CUALITATIVA Y CUANTITATIVA5. INVESTIGACIONES PRIMARIA Y BIBLIOGRÁFICA6. CONCLUSIONES
CAPÍTULO 8: CAUSALIDAD Y EXPERIMENTO
1. CAUSA Y CAUSALIDADUnicausalidad y policausalidadHacia una definición de causaRequisitos de causalidad2. EL EXPERIMENTODefiniciónMedición de la variable dependienteManipulación de la variable independienteGrupo experimental y grupo de controlExperimento y no experimentoLimitaciones del experimentoExperimento y diseño experimentalValidez interna y validez externa del experimentoLas variables extrañasControl de las variables extrañasPruebas de confirmación y pruebas de refutaciónExperimentos bivariados y multivariadosUn inventario de relaciones entre variables3. LOS CÁNONES DE STUART MILLUna presentación de los métodos de MillCríticas y comentarios a los métodos de MillAntecedentes históricosLos métodos de Mill y los métodos experimentales actuales
CAPÍTULO 9: LAS ETAPAS DE LA INVESTIGACIÓN TÍPICA
CAPÍTULO 10: PROBLEMA, BIBLIOGRAFÍA, TEORÍA Y OBJETIVOS
1. PLANTEO DEL PROBLEMA2. REVISIÓN BIBLIOGRÁFICA3. PLANTEO DEL MARCO TEÓRICO4. PLANTEO DE OBJETIVOS

CAPÍTULO 11: HIPÓTESIS Y VARIABLES
1. HIPÓTESISDefiniciónClasificación de las hipótesisComponentes de la hipótesis: los conceptos2. VARIABLESDefiniciónRelación entre variables y unidades de análisisLa definición conceptual de las variablesClasificación de las variablesCategorización de las variablesLa definición operacional de las variables u operacionalizaciónRelaciones entre la categorización y la operacionalización
CAPÍTULO 12: TÉCNICAS DE MUESTREO E INSTRUMENTOS DE MEDICIÓN
1. DEFINICIÓN DE LA POBLACIÓN2. SELECCIÓN DE LA TÉCNICA DE MUESTREO3. SELECCIÓN DEL INSTRUMENTO DE MEDICIÓN
CAPÍTULO 13: EL DISEÑO DE INVESTIGACIÓN
1. VERSIÓN CAMPBELL Y STANLEYDiseños preexperimentalesDiseños experimentales propiamente dichosDiseños cuasiexperimentales2. VERSIÓN LEÓN Y MONTERODiseños de investigación con encuestasDiseños experimentales con gruposDiseños de N = 1 (diseños de sujeto único)Diseños cuasi experimentales3. VERSIÓN ARNAU GRASDiseños experimentalesDiseños experimentales simplesDiseños experimentales factorialesDiseños experimentales de bloques homogéneosDiseños intrasujeto (o de medidas repetidas)Diseños experimentales no estadísticosDiseños preexperimentalesDiseños cuasiexperimentales4. VERSIÓN SELLTIZ ET AL5. OTRAS VERSIONESVersión KohanVersión Hernández Sampieri et alVersión Lores ArnaizVersión GreenwoodVersión O’Neil6. CONCLUSIONES
CAPÍTULO 14: EL PROCESAMIENTO DE LOS DATOS
1. RECOLECCIÓN DE LOS DATOSLa observaciónLa entrevistaEl cuestionarioEl test2. ORGANIZACIÓN DE LOS DATOSPasos de la organización de los datosEl análisis factorial3. ANÁLISIS DE LOS DATOSEl análisis de la varianza4. INTERPRETACIÓN DE LOS DATOS
CAPÍTULO 15: REDACCIÓN Y PUBLICACIÓN DE LOS RESULTADOS
1. REDACCIÓN DE LOS RESULTADOSLa forma del textoEl contenido del textoLa bibliografíaLa conexión entre una cita bibliográfica y una referencia bibliográficaAlgunos errores posiblesPrecauciones2. PUBLICACIÓN DE LOS RESULTADOS3. COMO HACER UNA MONOGRAFÍA
CAPÍTULO 16: INVESTIGACIONES ESPECIALES

1. INVESTIGACIÓN MÉDICA2. INVESTIGACIÓN GRAFOLÓGICALa cientificidad de la grafologíaLa investigación en grafologíaGrafología y psicologíaConclusiones
REFERENCIAS BIBLIOGRÁFICAS DE ESTADÍSTICA
OTRAS FUENTES CONSULTADAS PARA ESTADÍSTICA
REFERENCIAS BIBLIOGRÁFICAS DE METODOLOGÍA
ANEXOS DE ESTADÍSTICA
ANEXO 1: NOMENCLATURA UTILIZADA EN ESTA GUÍAANEXO 2: TABLA DE ÁREAS BAJO LA CURVA NORMAL ESTANDARIZADATabla 1 – Áreas desde z hacia la izquierdaTabla 2 – Áreas desde z = 0 hacia la izquierda o hacia la derechaANEXO 3: TABLA DE LA DISTRIBUCIÓN t
ANEXOS DE METODOLOGÍA
ANEXO 1. PREGUNTAS MULTIPLE CHOICEANEXO 2. EJERCITACIONES VARIASANEXO 3. EJERCITACIÓN CON INVESTIGACIONESANEXO 4. NORMAS DE PUBLICACIÓN DE LA APA Y COMPARACIÓN CON LAS NORMAS DE VANCOUVERANEXO 5. NORMAS PARA HACER REFERENCIA A DOCUMENTOS CIENTÍFICOS DE INTERNET EN EL ESTILO WEAPAS (LAND, 1998)ANEXO 6. GUÍA PARA MONOGRAFÍAS.

PRESENTACIÓN
El presente texto abarca dos grandes partes: estadística y metodología de la investigación.El material de estadística fue pensado como un manual de consulta para alumnos de diversas carreras universitarias de grado y posgrado que cursan asignaturas donde se enseña la estadística como herramienta de la metodología de la investigación científica. Se brinda aquí un panorama general e introductorio de los principales temas de una disciplina que opera en dos grandes etapas: la estadística descriptiva y la estadística inferencial. También se desarrollan los conceptos de probabilidad y curva normal, básicos para la comprensión de la estadística inferencial, y los conceptos de correlación y regresión vinculados, respectivamente, con las etapas descriptiva e inferencial.El material de metodología de la investigación, fruto de varios años de enseñanza universitaria en los niveles de grado y posgrado, intenta explicar cómo procede el científico cuando investiga la realidad en el ámbito de las ciencias sociales.Esencialmente, la investigación tiene dos etapas: proponer una hipótesis como respuesta a un problema, y luego probarla. Para la primera puede necesitarse intuición y creatividad, y el científico no está tan sujeto a normas como en la segunda etapa, en la cual se requiere un método provisto de reglas específicas que cuidarán que la hipótesis planteada quede efectivamente confirmada (o refutada).El presente texto trata acerca de los pasos concretos que habitualmente da el científico cuando realiza una investigación típica en ciencias sociales, que se presentan en forma panorámica en uno de los capítulos, el 9.La primera edición de este libro (Noviembre 1991) formó parte de la bibliografía obligatoria de la cátedra de Investigación Psicopedagógica II (Carrera de Psicopedagogía. Buenos Aires, Universidad de Belgrano. Profesora titular: Lic. Liliana Hernández).La segunda edición (Julio 2002) formó parte de la bibliografía obligatoria de las cátedras de Metodología de la Investigación (Carrera de Trabajo Social. Buenos Aires, Universidad del Museo Social Argentino. Profesora titular: Lic. Norma Ramljak de Bratti), y Metodología de la Investigación I, II y III (Carrera de Especialista en Ortodoncia. Buenos Aires, Fundación Favaloro y Asociación Argentina de Odontodología. Profesor titular: Lic. Pablo Cazau). También sirvió de base para el desarrollo de investigaciones en la Asociación Panamericana de Grafología.
Pablo Cazau. Buenos Aires, Junio 2012.

PARTE I: ESTADÍSTICA
CAPÍTULO 1: INTRODUCCIÓN A LA ESTADÍSTICA
1. DEFINICIÓN Y UTILIDAD DE LA ESTADÍSTICA
La Estadística es una disciplina que utiliza recursos matemáticos para organizar y resumir una gran cantidad de datos obtenidos de la realidad, e inferir conclusiones respecto de ellos.Por ejemplo, la estadística interviene cuando se quiere conocer el estado sanitario de un país, a través de ciertos parámetros como la tasa de morbilidad o mortalidad de la población. En este caso la estadística describe la muestra en términos de datos organizados y resumidos, y luego infiere conclusiones respecto de la población. Por ejemplo, aplicada a la investigación científica, hace inferencias cuando emplea medios matemáticos para establecer si una hipótesis debe o no ser rechazada.
A veces la estadística ha sido cuestionada por ‘mentir’ distorsionando los datos de la realidad, pero ello no la hace menos científica: en todo caso se trata de un uso tendencioso de la estadística para lograr algún fin. Una errónea lectura de la información estadística puede dar lugar a algunas de las siguientes conclusiones un tanto risueñas: a) La tasa de natalidad es el doble que la tasa de mortalidad; por lo tanto, una de cada dos personas es inmortal. b) El no tener hijos es hereditario; si tus padres no tuvieron ninguno, lo más probable es que tú tampoco los tengas. c) En Nueva York un hombre es atropellado cada diez minutos. El pobre tiene que estar hecho polvo. d) La probabilidad de tener un accidente de tráfico aumenta con el tiempo que pasas en la calle. Por tanto, cuanto mas rápido circules, menor es la probabilidad de que tengas un accidente. e) El 33 % de los accidentes mortales involucran a alguien que ha bebido. Por tanto, el 67 % restante ha sido causado por alguien que no había bebido. A la vista de esto y de lo anterior, esta claro que la forma mas segura de conducir es ir borracho y a gran velocidad.
La estadística puede aplicarse a cualquier ámbito de la realidad, y por ello es utilizada en física, química, biología, medicina, astronomía, psicología, sociología, lingüística, demografía, etc.Cuando en cualquiera de estas disciplinas se trata de establecer si una hipótesis debe o no ser rechazada, no siempre es indispensable la estadística inferencial.Por ejemplo, si sobre 60 veces que se mira un dado, sale un dos 10 veces, no se requiere la estadística para rechazar la hipótesis “el dado está cargado”. Si sale un dos en 58 ocasiones sobre 60, tampoco se necesita la estadística para aceptar la hipótesis “el dado está cargado”. Pero, ¿qué ocurre si el número dos sale 20, 25 o 30 veces? En estos casos de duda, la estadística interviene para determinar hasta qué cantidad de veces se considerará rechazada la hipótesis (o bien desde qué cantidad de veces se la considerará aceptada). En otras palabras, la estadística interviene cuando debe determinarse si los datos obtenidos son debidos al azar o son el resultado de un dado cargado.Otro ejemplo. Si una persona adivina el color (rojo o negro) de las cartas en un 50% de los casos, se puede rechazar la hipótesis “la persona es adivina”. Si, en cambio, acierta en el 99% de los casos el color de las cartas, se puede aceptar la mencionada hipótesis. Los casos de duda corresponden a porcentajes de acierto intermedios, como el 60%, el 70%, etc., en cuyos casos debe intervenir la estadística para despejarlos.La importancia de la estadística en la investigación científica radica en que la gran mayoría de las investigaciones son ‘casos de duda’.
2. CLASIFICACIONES DE LA ESTADÍSTICA
Existen varias formas de clasificar los estudios estadísticos.1) Según la etapa.- Hay una estadística descriptiva y una estadística inferencial. La primera etapa se ocupa de describir la muestra, y la segunda etapa infiere conclusiones a partir de los datos que describen la muestra (por ejemplo, conclusiones con respecto a la población).Tanto la estadística descriptiva como la estadística inferencial se ocupan de obtener datos nuevos. La diferencia radica en que la estadística descriptiva procede a resumir y organizar esos datos para facilitar su análisis e interpretación, y la estadística inferencial procede a formular estimaciones y probar hipótesis acerca de la población a partir de esos datos resumidos y obtenidos de la muestra. Puesto que estas últimas operaciones llevarán siempre a conclusiones que tienen algún grado de probabilidad, la teoría de la probabilidad constituye una de sus herramientas principales. Téngase presente que en sí misma la teoría de la probabilidad no forma parte de la estadística porque es otra rama diferente de la matemática, pero es utilizada por la estadística como instrumento para lograr sus propios objetivos.La estadística descriptiva también incluye –explícita o implícitamente- consideraciones probabilísticas, aunque no resultan ser tan importantes como en la estadística inferencial. Por ejemplo, la elección de un determinado estadístico para caracterizar una muestra (modo, mediana o media aritmética) se funda sobre ciertas consideraciones implícitas acerca de cuál de ellos tiene más probabilidades de representar significativamente el conjunto de los datos que se intenta resumir.Tanto la estadística descriptiva como la inferencial implican, entonces, el análisis de datos. “Si se realiza un análisis con el fin de describir o caracterizar los datos que han sido reunidos, entonces estamos en el área de la estadística descriptiva… Por otro lado, la estadística inferencial no se refiere a la simple descripción de los datos obtenidos, sino que abarca las técnicas que nos permiten utilizar los datos

muestrales para inferir u obtener conclusiones sobre las poblaciones de las cuales fueron extraídos dichos datos” (Pagano, 1998:19).La estadística inferencial se ocupa de problemas como los siguientes: 1) Relación entre muestra y población: estimar parámetros poblacionales a partir de estadísticos muestrales, determinar la probabilidad que una muestra pertenezca a una población, o examinar de si hay diferencia significativa entre muestra y población. 2) Relación entre dos muestras: determinar si hay diferencias significativas entre dos muestras de una población, o determinar si la diferencia entre dos muestras significa que las poblaciones muestreadas son ellas mismas realmente diferentes.Kohan, por su parte, sintetiza así su visión de las diferencias entre ambos tipos de estadística: “Si estudiamos una característica de un grupo, sea en una población o en una muestra, por ejemplo talla, peso, edad, cociente intelectual, ingreso mensual, etc., y lo describimos sin sacar de ello conclusiones estamos en la etapa de la estadística descriptiva. Si estudiamos en una muestra una característica cualquiera e inferimos, a partir de los resultados obtenidos en la muestra, conclusiones sobre la población correspondiente, estamos haciendo estadística inductiva o inferencial, y como estas inferencias no pueden ser exactamente ciertas, aplicamos el lenguaje probabilístico para sacar las conclusiones” (Kohan, 1994:25). Kohan emplea la palabra inductiva porque las inferencias realizadas en este tipo de estadística son razonamientos inductivos, modernamente definidos como razonamientos cuya conclusión es sólo probable.En suma: la estadística descriptiva debe preocuparse de si la muestra está o no bien descripta a partir de los datos de los individuos, mientras que la estadística inductiva se preocupará de establecer la representatividad de la muestra respecto de la población. Más generalmente, la primera es eminentemente descriptiva y no amplía mayormente nuestro conocimiento: mas bien lo resume mediante las medidas estadísticas. En cambio la segunda sí amplía nuestro conocimiento pues lo extiende (con cierto margen de error) a toda la población, y de allí su carácter predictivo.2) Según la cantidad de variables estudiadas.- Desde este punto de vista hay una estadística univariada (estudia una sola variable, como por ejemplo la inteligencia), una estadística bivariada (estudia la relación entre dos variables, como por ejemplo inteligencia y alimentación), y una estadística multivariada (estudia tres o más variables, como por ejemplo como están relacionados el sexo, la edad y la alimentación con la inteligencia).El siguiente esquema ilustra la relación entre dos clasificaciones de la estadística: descriptiva / inferencial y univariada / bivariada.
La estadística descriptiva se ocupa de muestras, y la estadística inferencial infiere características de la población a partir de muestras.A su vez, ambas etapas de la estadística pueden estudiar una variable por vez o la relación entre dos o más variables. Por ejemplo, a) en el caso de la estadística univariada, el cálculo de medidas de posición y dispersión en una muestra corresponde a la estadística descriptiva, mientras que la prueba de la media corresponde a la estadística inferencial; b) en el caso de la estadística bivariada, el análisis de correlación de variables en una muestra corresponde estrictamente hablando a la estadística descriptiva, mientras que el análisis de regresión o las pruebas de hipótesis para coeficientes de correlación (Kohan N, 1994:234) corresponden a la estadística inferencial.3) Según el tiempo considerado.- Si se considera a la estadística descriptiva, se distingue la estadística estática o estructural, que describe la población en un momento dado (por ejemplo la tasa de

nacimientos en determinado censo), y la estadística dinámica o evolutiva, que describe como va cambiando la población en el tiempo (por ejemplo el aumento anual en la tasa de nacimientos).La estadística descriptiva dinámica o evolutiva estudia las llamadas series temporales o cronológicas. Se trata de series determinadas por dos variables, una de las cuales es el tiempo generalmente medido en años. La serie se ordena de acuerdo a la variable tiempo (X) y, en función de su variación, variará la otra variable, que puede ser por ejemplo cantidad de habitantes o temperaturas máximas (Y).De acuerdo a como varía la variable Y, las series cronológicas pueden ser crecientes (cuando Y va aumentando a lo largo del tiempo), decrecientes (cuando Y va disminuyendo a lo largo del tiempo), alternadas (cuando Y aumenta y disminuye cíclicamente), y estacionarias (cuando los valores de Y difieren poco respecto de un valor medio).Las series temporales no sirven solamente para describir la evolución de Y en el tiempo, sino también para hacer predicciones, aunque estas generalmente se hacen a corto plazo porque son muchos los factores que pueden incidir en la evolución de Y, tornándose entonces incierta la predicción.Existen diversos procedimientos para describir o predecir en las series temporales: el método gráfico, el método de los dos promedios, el método de las medias móviles y el método de los cuadrados mínimos.Los diferentes valores que adquiere Y a lo largo del tiempo pueden descomponerse en partes, llamadas componentes de la serie, y que básicamente son cuatro: tres componentes sistemáticos y una componente aleatoria. Los componentes sistemáticos están sujetos a leyes precisas y son la Tendencia (describe como evoluciona Y a corto y largo plazo), el componente Estacional (describe modificaciones repetitivas observables en la evolución de Y en periodos definidos dentro de un periodo mayor), y el componente Cíclico (describe variaciones mayores en la evolución de Y en lapsos repetitivos no definidos dentro de uno mayor). La diferencia entre Estaconal y Cíclico reside especialmente en el tiempo considerado: menor para lo Estacional (por ejemplo cada año hay variaciones estacionales), y mayor para lo Cíclico (por ejemplo cada diez años hay periodos de prosperidad o depresión económica). La componente aleatoria describe la evolución de Y en tanto depende del azar, y es por tanto impredecible.
3. POBLACIÓN Y MUESTRA
Puesto que la estadística se ocupa de una gran cantidad de datos, debe primeramente definir de cuáles datos se va a ocupar. El conjunto de datos de los cuales se ocupa un determinado estudio estadístico se llama población.No debe confundirse la población en sentido demográfico y la población en sentido estadístico.La población en sentido demográfico es un conjunto de individuos (todos los habitantes de un país, todas las ratas de una ciudad), mientras que una población en sentido estadístico es un conjunto de datos referidos a determinada característica o atributo de los individuos (las edades de todos los individuos de un país, el color de todas las ratas de una ciudad).Incluso una población en sentido estadístico no tiene porqué referirse a muchos individuos. Una población estadística puede ser también el conjunto de calificaciones obtenidas por un individuo a lo largo de sus estudios universitarios.La población o universo, definible como el conjunto de todas las unidades de análisis, puede ser finita o infinita, según tenga o no un número determinado de individuos: se puede considerar infinito al conjunto de todos los individuos posibles según su combinación genética. La población también puede ser real o potencial: una población real es el conjunto de todos los argentinos mayores de 18 años y menores de 20, y población potencial es por ejemplo el conjunto de todas las personas que “podrían” utilizar el servicio de psicopatología de un hospital.
En el siguiente esquema pueden apreciarse algunas formas de considerar los datos individuales, según que correspondan a muchas personas o a una sola, y también según que hayan sido recolectados en un instante de tiempo determinado, o bien a lo largo del tiempo.
De muchos individuos De un solo individuoEn un instante de tiempo Notas de todos los alumnos en el
primer parcial de tal mes y tal año.Notas de un solo alumno en el primer parcial de las materias que cursa en ese momento.
A lo largo del tiempo Notas de todos los alumnos durante los 6 años de carrera.
Notas de un alumno a lo largo de los 6 años de carrera.
Los datos de la totalidad de una población pueden obtenerse a través de un censo. Sin embargo, en la mayoría de los casos no es posible hacerlo por razones de esfuerzo, tiempo y dinero, razón por la cual se extrae, de la población, una muestra, mediante un procedimiento llamado muestreo. Se llama muestra a un subconjunto de la población, que puede o no ser representativa de la misma, y que puede estar formada por uno o muchos individuos.Por ejemplo, si la población es el conjunto de todas las edades de los estudiantes de la provincia de Buenos Aires, una muestra podría ser el conjunto de edades de 2000 estudiantes de la provincia de Buenos Aires tomados al azar.Obviamente, hay que asegurarse de que la muestra sea representativa de la población: si se quiere tomar una muestra de los habitantes de una ciudad y sólo se seleccionan veinte enfermos mentales de un hospicio, esta muestra no representará adecuadamente a la población. En cambio si se selecciona la

misma cantidad de sujetos tomando uno de cada 100 de la guía telefónica aquí ya se puede empezar a pensar más en la posibilidad de cierta representatividad, pues están tomados más al azar.Aún así no hay un azar total, pues en la guía no figuran por ejemplo individuos de clase baja (no tienen teléfono); y si se elige por una lista de empadronamiento para votar, allí no figurarán los extranjeros residentes. Un procedimiento bastante aleatorio, en cambio, consiste en elegir un individuo por cada manzana.El tamaño elegido para la muestra es también importante, y variará de acuerdo a cada investigación pudiendo ser el 5%, el 20%, etc., de la población total. Suele ser difícil elegir el tamaño justo, ya que no se puede pecar por defecto (un solo individuo no representa a una ciudad, aún tomándolo al azar) o por exceso (una muestra que sea el 80% de la población es altamente confiable pero no económica, ya que con menos esfuerzo y dinero puede obtenerse una muestra considerablemente más pequeña sin que varíe en forma significativa su grado de representatividad).
Para saber cuando el tamaño de una muestra es aceptable, debe considerarse, además de la varianza poblacional (heterogeneidad de la población), otros dos factores que son el nivel de confianza y el máximo error permitido en las estimaciones (también llamado error muestral).En principio, cuanto más homogénea es la población, menor será el tamaño requerido de la muestra.Para determinar el tamaño de la muestra, deberá primero determinarse un nivel de confianza y un máximo error permitido (valores que determinará el investigador). Una vez conocidos estos valores, se puede determinar el tamaño de la muestra por varios caminos. Por ejemplo (Kohan, 1994:181) (Rubio y otro, 1997:290):a) Utilizar la fórmula de N (tamaño de la muestra), donde el numerador es el producto entre el cuadrado del nivel de confianza y la varianza poblacional, y el denominador el cuadrado del error permitido. Esta fórmula es aplicable sólo en poblaciones infinitas (más de 100.000 elementos), y cuando el procedimiento de muestreo fue aleatorio simple. También hay fórmulas especiales para poblaciones finitas, donde se introduce un factor de corrección con una especificación del tamaño de la población.b) Si no se quiere utilizar una fórmula, puede recurrirse a tablas especiales ya preparadas para estos menesteres, como por ejemplo las tablas de Tagliacarne. Para consultarlas, es preciso conocer antes qué nivel de confianza y qué error muestral será considerado.
Los muestreos se dividen clásicamente en probabilísticos y no probabilísticos. Lo esencial del muestreo probabilístico es que cada individuo de la población total tiene la misma o aproximadamente la misma probabilidad de estar incluído en la muestra. Si se toma una muestra de los habitantes de Londres considerando uno de cada 100 de un listado alfabético, la probabilidad que tiene de haber sido seleccionado el señor Smith es la misma que tiene el señor Brown o cualquier otro (en este caso, la probabilidad del uno por ciento).Hay varias técnicas para realizar muestreos probabilísticos, y todas se basan en la selección de individuos al azar ya que es éste quien presuntamente garantiza la equiprobabilidad. El muestreo puede ser: a) simple: partiendo de toda la población se toman individuos al azar según diversos procedimientos; b) estratificado: previamente se seleccionan en la población estratos (por ejemplo clases sociales: alta, media y baja), y dentro de cada estrato se toman individuos al azar según el muestreo simple; c) por áreas o conglomerados: se delimitan previamente áreas geográficas (provincias, ciudades) y dentro de cada una de ellas se toman individuos al azar según el muestreo simple o estratificado.En el muestreo no probabilístico los individuos de la población no tienen todos la misma probabilidad de aparecer en la muestra, ya que aquí no se hace una estricta selección al azar sino que se toman casos típicos (que se suponen representativos de la media poblacional) o casos en forma accidental (los que tenemos más a mano), etc.Una vez obtenida la muestra (preferiblemente mediante muestreo probabilístico), se procede a describirla, para lo cual se usan ciertas medidas especiales diferentes a las medidas que usamos para medir individuos. Si se quiere describir sujetos individuales se usa una medida individual: Juancito tiene cociente intelectual 110, o Pedrito tiene poco interés en política, etc. Pero, si se quiere describir una muestra se usará lo que se llama una medida estadística. Por ejemplo, tal muestra se compone de sujetos cuyo promedio de cocientes intelectuales es 120, o tal otra muestra tiene un 70% de sujetos con poco interés en política, etc. Como se ve, estas medidas estadísticas son verdaderas síntesis o resúmenes de muchas medidas individuales, y un ejemplo típico es la media aritmética, o sea, un simple promedio.
4. ESTRUCTURA DEL DATO
Los datos son la materia prima con que trabaja la estadística, del mismo modo que la madera es la materia prima con que trabaja el carpintero. Así como este procesa o transforma la madera para obtener un producto útil, así también el estadístico procesa o transforma los datos para obtener información útil. Tanto los datos como la madera no se inventan: se extraen de la realidad; en todo caso el secreto está en recoger la madera o los datos más adecuados a los objetivos del trabajo a realizar. El dato es siempre el resultado de un proceso de medición.De una manera general, puede definirse técnicamente dato como una categoría asignada a una variable de una unidad de análisis. Por ejemplo, “Luis tiene 1.70 metros de estatura” es un dato, donde ‘Luis’ es la unidad de análisis, ‘estatura’ es la variable, y ‘1.70 metros’ es la categoría asignada.Como puede apreciarse, todo dato tienen al menos tres componentes: una unidad de análisis, una variable y una categoría.

La unidad de análisis es el elemento del cual se predica una propiedad y característica. Puede ser una persona, una familia, un animal, una sustancia química, o un objeto como una dentadura o una mesa.Por ejemplo: a) las personas son unidades de análisis si consideramos su edad, su sexo, su inteligencia, su salario o la cantidad de sillas que posee, como variables; b) las sillas son unidades de análisis si consideramos su precio, su color o su estado como variables; c) los colores son unidades de análisis si consideramos su tono o su longitud de onda como variables.La variable es la característica, propiedad o atributo que se predica de la unidad de análisis. Por ejemplo puede ser la edad para una persona, el grado de cohesión para una familia, el nivel de aprendizaje alcanzado para un animal, el peso específico para una sustancia química, el nivel de ‘salud’ para una dentadura, y el tamaño para una mesa.Pueden entonces también definirse población estadística (o simplemente población) como el conjunto de datos acerca de unidades de análisis (individuos, objetos) en relación a una misma característica, propiedad o atributo (variable).Sobre una misma población demográfica pueden definirse varias poblaciones de datos, una para cada variable. Por ejemplo, en el conjunto de habitantes de un país (población demográfica), puede definirse una población referida a la variable edad (el conjunto de edades de los habitantes), a la variable ocupación (el conjunto de ocupaciones de los habitantes), a la variable sexo (el conjunto de condiciones de sexo de los habitantes).La categoría es cada una de las posibles variaciones de una variable. Categorías de la variable sexo son masculino y femenino, de la variable ocupación pueden ser arquitecto, médico, etc., y de la variable edad pueden ser 10 años, 11 años, etc. Cuando la variable se mide cuantitativamente, es decir cuando se expresa numéricamente, a la categoría suele llamársela valor. En estos casos, el dato incluye también una unidad de medida, como por ejemplo años, cantidad de hijos, grados de temperatura, cantidad de piezas dentarias, centímetros, etc. El valor es, entonces, cada una de las posibles variaciones de una variable cuantitativa.
Datos individuales y datos estadísticos.- Un dato individual es un dato de un solo individuo, mientras que un dato estadístico es un dato de una muestra o de una población en su conjunto. Por ejemplo, la edad de Juan es un dato individual, mientras que el promedio de edades de una muestra o población de personas es un dato estadístico. Desde ya, puede ocurrir que ambos no coincidan: la edad de Juan puede ser 37 años, y el promedio de edades de la muestra donde está incluído Juan es 23 años. Por esta razón un dato estadístico nada dice respecto de los individuos, porque solamente describe la muestra o población.Los datos estadísticos que describen una muestra suelen llamarse estadísticos (por ejemplo, el promedio de ingresos mensuales de las personas de una muestra), mientras que los datos estadísticos descriptores de una población suelen llamarse parámetros (por ejemplo, el promedio de ingresos mensuales de las personas de una población) (Kohan N, 1994:143).
5. LA MEDICIÓN
Los datos se obtienen a través un proceso llamado medición. Desde este punto de vista, puede definirse medición como el proceso por el cual asignamos una categoría (o un valor) a una variable, para determinada unidad de análisis y para un determinado lugar y tiempo. Ejemplo: cuando decimos que Martín es varón, estamos haciendo una medición, porque estamos asignando una categoría (varón) a una variable (sexo) para una unidad de análisis (Martín), y aquí y ahora. Como puede verse, la medición va más allá del clásico empleo de la regla y el número.
A veces se ha definido medir como comparar, lo cual puede referirse a diversos tipos de comparación: 1) comparar una cantidad con otra tomada como unidad Sentido clásico de comparación); 2) comparar dos categorías de una misma variable en el mismo sujeto y distinto tiempo; 3) comparar dos categorías de una misma variable en distintos sujetos al mismo tiempo; y 4) categorías de variables distintas (debe usarse puntaje estandarizado), en el mismo sujeto o en sujetos distintos.
Las mediciones individuales recaen sobre sujetos, mientras que las mediciones estadísticas recaen sobre muestras o poblaciones. Así por ejemplo decimos que medimos una muestra A cuando le asignamos la media aritmética 120 respecto de la variable inteligencia. Obviamente, las medidas estadísticas se derivan de las individuales pues no se puede obtener un promedio si desconocemos los valores individuales de los sujetos de la muestra.Para llevar a cabo una medición, necesitamos obligatoriamente tres cosas: a) un instrumento de medición, b) un sistema de medición (o escala), ya que hay diferentes grados de precisión en la medición, y c) un procedimiento para hacer la medición. Nos ocuparemos brevemente de los dos primeros.
Instrumentos de medición.- Un instrumento de medida es un artificio usado para medir. Una balanza es un instrumento para medir peso, un test mide personalidad, inteligencia, aptitud vocacional, etc., un cuestionario mide conocimientos, etc., pero sea cual fuere el instrumento utilizado, para que sea eficaz debe reunir dos requisitos: confiabilidad y validez.

Si la misma balanza hoy me informa que peso 70 kg, mañana 80 kg y pasado 63 kg, es un instrumento poco confiable. Un test puede también ser poco confiable si, respecto del mismo sujeto, arroja resultados dispares en diferentes momentos de administración. Confiabilidad significa, entonces, estabilidad o constancia de los resultados.
Esta constancia no es nunca perfecta. El hecho de que puedan existir ligeras variaciones debidas al azar no compromete la confiabilidad del instrumento de medida, siempre que esas variaciones sean poco significativas. También debemos tener en cuenta los cambios propios del sujeto cuya propiedad medimos. Si el sujeto aumenta de peso o mejora su rendimiento intelectual por un efecto madurativo habrá una variabilidad en los resultados, lo cual no implica necesariamente que el instrumento no sea confiable. En la confiabilidad, como aquí la entendemos, la constancia o la variabilidad en los resultados depende de la labilidad del instrumento mismo, no del sujeto. Por ejemplo si el instrumento tiene una consigna de aplicación ambigua, podrá ser aplicado de manera distinta antes y después, y los resultados podrán ser diferentes.
Un test o cualquier otro instrumento puede ser confiable pero no válido: es válido cuando mide lo que efectivamente pretende medir, lo cual puede parecer una perogrullada pero que no es tal si nos damos cuenta de los casos de instrumentos que querían medir una propiedad y medían otra. Si con un determinado test pretendemos medir memoria pero sólo medimos ansiedad, no es válido. La validez de un test puede establecerse prospectivamente: nos percatamos que un test de aptitud para la ingeniería es válido cuando, andando el tiempo, constatamos que quienes obtuvieron altos puntajes hoy son buenos ingenieros, y quienes sacaron bajos puntajes no lo son.
Para determinar la confiabilidad de una prueba, hay muchos procedimientos, siendo uno de ellos el Coeficiente Alfa de Cronbach.a) ¿Cómo se determina la confiabilidad de un test utilizando la escala alfa de Crombach? Para aplicar el coeficiente alfa de Cronbach se requieren conocimientos y experiencia en estadística. No obstante, con un conocimiento mínimo básico y algo de audacia se puede calcular la fiabilidad de un test mediante el Cronbach utilizando software de estadística como por ejemplo el SPSS (preferiblemente la versión 4), uno de los más conocidos y utilizados para estas cuestiones. La información que debe ingresarse es por lo menos cuantos ítems tiene el test y las respuestas obtenidas de una muestra de sujetos. Si no se dispone del software y se cuenta con cierto conocimiento estadístico, la fórmula para calcular el alfa de Cronbach tiene como numerador el número de ítems de la escala, y como denominador, el producto de dicho número menos 1, multiplicado por el cociente entre la sumatoria de varianzas de los ítems y la varianza de toda la escala. Si se está usando un test ya estandarizado, no hay necesidad de calcular su Coeficiente Cronbach, pues se supone que dicho test es lo suficientemente válido y confiable. Aún así, los creadores de la prueba suelen dar información sobre estas propiedades, incluyendo un coeficiente Cronbach o algún otro que también mida fiabilidad (como el clásico coeficiente Kappa, que mide la equivalencia o concordancia entre observadores, o el coeficiente “r” de correlación de Pearson de la prueba de test-retest, que mide la estabilidad de las respuestas. El Cronbach, por su parte, mide la confiabilidad a partir de la consistencia interna de los ítems, entendiendo por tal el grado en que los ítems de una escala se correlacionan entre sí). En estos casos, en el informe de investigación debe indicarse el coeficiente Cronbach asignado al test utilizado. En cambio, si se ha creado un test o cuestionario ad hoc, será conveniente determinar su fiabilidad mediante el Cronbach para que los lectores sepan cuán confiable o fiable es el test que se está usando. Este coeficiente Cronbach se utilizará, sin embargo, cuando la prueba tenga muchos ítems, ya que lo que evalúa es la confiabilidad a partir de la consistencia interna de los mismos. Si no es así, un técnico estadístico podrá recomendar qué otra prueba de fiabilidad utilizar.b) Qué indica un índice de confiabilidad de 0.9 utilizando dicha escala? Cronbach desarrolló su coeficiente en la década del 50 dentro del contexto de investigaciones educativas. En principio, un Cronbach de 0.90 es bastante alto, con lo cual la confiabilidad de test está prácticamente asegurada y puede ser utilizado sin problemas, ya que está indicando una consistencia interna satisfactoria. En general, se admite que por encima de 0.80, la prueba es confiable. El alfa de Cronbach varía entre 0 y 1 (0 es ausencia total de consistencia, y 1 es consistencia perfecta). El valor 0.90 es satisfactorio si, como dijimos antes, el test tiene muchos ítems. Si el test llegara a tener pocos ítems, se pueden aceptar valores alfa de Cronbach de 0.60 y 0.50 (como sostienen Carmines y Zeller 1979; Pedhazur y Schmelkin 1991). Finalmente, digamos que puede ocurrir que un test tenga varios alfa de Cronbach distintos. Por lo regular esto significa que el test está midiendo una variable compleja, multidimensional, y entonces se ha obtenido un alfa para cada dimensión. No obstante, aún en estos casos puede obtenerse un alfa único para toda la variable.
Puntuación, validez y confiabilidad en los tests psicométricos.- La eficacia de cualquier instrumento de medición, como por ejemplo una balanza o un test, dependerá de su grado de validez y confiabilidad (o fiabilidad, o consistencia). Cuanto más válido y confiable sea el instrumento, mejor medirá la variable. Por ello, quienes construyen el instrumento de medición deben determinar o calcular su grado de validez y confiabilidad.En lo que sigue se describen los conceptos de validez y confiabilidad aplicados a ciertos instrumentos de medición especiales, llamados habitualmente tests psicométricos, es decir, pruebas que permiten medir variables psicológicas en función de algún tipo de puntaje numérico. Por lo tanto, antes explicaremos sucintamente la puntuación, es decir, la asignación de puntajes a los resultados de los tests.1) Puntajes brutos y derivados.- Los números que se asignan a las respuestas de un test se llaman puntajes brutos o directos. Tales puntajes no permiten comparar al sujeto con la población o el grupo normativo representado en un baremo (por ejemplo con los demás sujetos de su misma edad o país), y por ello se requiere transformar los puntajes brutos en puntajes derivados o transformados. Estos ya pueden interpretarse estadísticamente, o sea, permiten comparar al sujeto con los demás de la población, ya que el baremo expresa estadísticamente el desempeño de la población en dicho test.

Ejemplos de puntajes transformados son los puntajes estandarizados, que toman como unidad desviaciones estándar o fracciones de la misma. Algunos ejemplos son el puntaje z (que puede valer entre -3 y +3), el puntaje CI (coeficiente intelectual), la edad mental, el eneatipo (que puede valer entre 1 y 9) y el decatipo (entre 1 y 10).Existen también los puntajes llamados percentiles (que pueden valer entre 1 y 100, y donde cada valor se llama centil o percentil). Por ejemplo si un sujeto obtuvo un percentil 30, ello significa que supera al 30% de la población y el superado por el 70%. Los puntajes derivados pueden transformarse unos en otros. Por ejemplo, un puntaje percentil puede transformarse en uno z o viceversa.2) Validez.- Un instrumento de medición es válido si realmente mide aquello que pretende medir. Si un test pretende medir inteligencia pero mide simplemente memoria, no es válido. En casos de variables simples como el peso no hay mayores problemas para establecer su validez: una balanza mide el peso, pero cuando se trata de variables psicológicas la cuestión de la validez no es tan sencilla.Estadísticamente, la validez suele definírsela como la proporción de la varianza relevante para los fines del test, o sea, la proporción de las pruebas del test atribuibles a la variable que pretende medir. Ello significa que la validez es una cuestión de grado: un test será más válido, entre otras cosas, si tiene más cantidad de pruebas, ítems o subtests que realmente expresan la variable a medir. Téngase presente que la validez no es un atributo del test en sí mismo sino que las inferencias que se hagan a partir de él.La validez no es algo fijo e invariable para todos los tests, sino que dependerá también de lo que el entrevistador quiera medir. Para determinar la validez de un test deben considerarse diferentes aspectos, que algunas veces fueron denominados “tipos” de validez, lo cuales se influencian recíprocamente formando un todo articulado.Pueden mencionarse los siguientes tipos o categorías de validez:a) Validez de contenido.- Un test es válido si el conjunto de sus ítems son una muestra representativa de la variable que pretende medir. Esto es esencial cuando deben hacerse generalizaciones a partir de los resultados del test. Se utiliza especialmente en los tests de rendimiento como por ejemplo un test de vocabulario: un conjunto de expertos seleccionará algunas palabras para incluir en el test de manera tal que representen adecuadamente la totalidad del vocabulario, las cuales pueden elegirse al azar (si se seleccionan sólo palabras muy fáciles, el test disminuye su validez).Un tipo especial de validez de contenido es la validez aparente o de facie: un test tiene validez aparente cuando produce en el sujeto que hace el test la impresión que mide realmente la variable que se quiere medir. Si esto no ocurre no estarán motivados para responder los ítems (por ejemplo porque los juzgan dem asiado inapropiados para su edad o instrucción).b) Validez de constructo.- Es especialmente importante cuando se miden variables complejas definidas desde alguna teoría en particular. No es lo mismo un test que mida inteligencia según Weschler que inteligencia según Piaget: cada uno de ellos da definiciones o constructos diferentes. Un test entonces tendrá menor validez si no están representados en él los diversos aspectos del constructo o variable que propone la teoría, o bien si la teoría de la cual se parte es errónea. Algunos autores actuales consideran que la validez de constructo es la única admisible.Para estimar la validez de constructo se pueden utilizar métodos intraprueba, que ofrecen una llamada validez factorial (por ejemplo examinando el grado de correlación entre los ítems del test, o pidiendo a los sujetos que razonen en voz alta sus respuestas), métodos de manipulación experimental (modificar los valores de la variable a medir y viendo qué efectos producen sobre la puntuación del test), y otros métodos, como por ejemplo la determinación de la validez convergente y la validez discriminante.Hay validez convergente cuando las mediciones del mismo rasgo realizadas con distintos métodos tienen alta correlación, lo cual aumenta la probabilidad de la existencia real del rasgo.Hay validez discriminante cuando las mediciones de distintos rasgos con un mismo método tienen una baja correlación en comparación con la que muestran las medidas del mismo rasgo con diferentes métodos, lo que indica que los rasgos son independientes entre sí, e independientes al sistema de medición utilizado. c) Validez predictiva.- Es el grado en que un test puede predecir el rendimiento o el comportamiento futuro del sujeto. Por ejemplo, en selección de personal un test de liderazgo es válido si, una vez que el postulante entró y obtuvo alto puntaje, a lo largo del tiempo demuestra que efectivamente es un buen líder. Se llama también validez de pronóstico, y se puede estimar a partir de un coeficiente de validez, que correlaciona el puntaje del test con la producción posterior. Esta producción anterior es llamada por algunos autores “criterio” o sea cualquier producción en la vida real, no en un test. Es importante definir la forma en que será medido ese criterio o comportamiento ulterior: algún psicólogo puede medir el liderazgo en términos de influencia real del líder sobre los demás, y otro en términos de si es o no elegido en su trabajo para un puesto de liderazgo.Una variante de la validez predictiva es la validez retrospectiva, donde el test mide algún comportamiento o “criterio” del pasado del sujeto que por alguna razón no es accesible al conocimiento.d) Validez concurrente.- Un test tiene validez concurrente cuando se da una correlación alta entre los puntajes del mismo y otro test que mide lo mismo y que ya fue validado previamente. Por ejemplo el Test A de inteligencia es válido concurrentemente si las puntuaciones de los sujetos sin similares a las puntuaciones de otro Test B de inteligencia ya validado.3) Confiabilidad.- Un test es confiable cuando al ser administrado al mismo sujeto en diferentes momentos, da aproximadamente los mismos puntajes. Si el test se administra en distintos momentos puede ocurrir que varíen las condiciones de cada uno, que pueden atribuirse a que el examinador no aplicó siempre la misma consigna (usualmente explicitada en el manual del test) y/o a que el examinado esté atravesando distintas experiencias (un día está más relajado y atento, otro más angustiado, un mes

maduró o aprendió más que el anterior, un día hay más luz o más humedad ambiental y otro menos, etc.).Incluso aunque siempre se aplique la misma consigna y el examinado esté aproximadamente en las mismas condiciones, los distintos puntajes tienen pequeñas variaciones atribuibles al azar.La confiabilidad de un test es un indicador de la estabilidad del mismo, de su consistencia y del grado de precisión con que mide la variable. Para medir este grado de confiabilidad hay varios procedimientos, como por ejemplo la prueba test-retest (tomar dos o más veces el mismo test y examinar el grado en que se correlacionan los puntajes: el coeficiente de correlación será el coeficiente de confiabilidad); la prueba paralela (tomar al mismo sujeto dos tests distintos que midan lo mismo y examinar el grado de correlación entre ambos puntajes, lo que da un coeficiente de confiabilidad llamado coeficiente de equivalencia); la prueba de las dos mitades (se comparan los puntajes obtenidos en dos mitades del test y se examina su grado de correlación, lo cual indica la consistencia interna del test y su confiabilidad). En esta última prueba ambas mitades deben ser equivalentes (por ejemplo tomar en una los ítems pares y en otra los impares, pues a veces los tests presentan los ítems en un orden de complejidad creciente). Hay otros métodos para determinar la consistencia interna de los tests como el coeficiente de Cronbach, Kuder-Richardson, y el coeficiente Beta, útil para determinar la confiabilidad de una batería de tests (conjunto de tests), que ofrece una medida de la consistencia interna de los puntajes de cada uno.A la obtención de estos diferentes tipos de coeficientes de confiabilidad debe también agregarse una estimación del error estándar de medida (que se obtiene mediante una fórmula), que permite estimar dentro de qué intervalo de puntajes posibles estará el verdadero puntaje. Recordemos que administrar varias veces un mismo test arroja puntajes diferentes debido al azar, es decir, a errores aleatorios o no sistemáticos.Mientras en la confiabilidad influyen los errores aleatorios, en la validez influyen los errores constantes o sistemáticos, pues si un test mide otra variable a la que se pretende medir, arrojará siempre aproximadamente un mismo error.
Escalas de medición.- Se pueden hacer mediciones con mayor o menor grado de precisión. Cuanto más precisa sea la medición, más información nos suministra sobre la variable y, por tanto, sobre la unidad de análisis. No es lo mismo decir que una persona es alta, a decir que mide 1,83 metros.
Los niveles de medición se definen a partir de escalas de medición. Desde el punto de vista de la teoría de la medición, una escala es una línea que representa el campo de variabilidad de una variable. Por ejemplo: la línea indicadora de kilos en una balanza, la línea indicadora de kilómetros en un mapa, la línea indicadora de grados en un termómetro, etc.Los elementos constitutivos de una escala son: a) una longitud, generalmente expresada en centímetros. Por ejemplo, un termómetro de uso clínico puede tener 10 centímetros entre el valor máximo y el valor mínimo de temperatura; b) Un valor mínimo y un valor máximo de la variable, llamados cota inicial y cota final. Por ejemplo: 0 grados y 45 grados centígrados; c) Valores intermedios entre la cota inicial y la final. Por ejemplo: 5-10-15-20-25-30-35-40 grados centígrados; d) Una determinada correspondencia entre la variable a representar (por ejemplo temperatura) y la variable longitud. Por ejemplo: un centímetro representa una variación de 5 grados centígrados. Se llama módulo de la escala al cociente entre la longitud de la escala (numerador) y la resta entre la cota final y la cota inicial (denominador).Existen escalas uniformes, donde el valor representado es siempre proporcional al valor en longitud elegido para representarlo, y escalas funcionales, donde el valor representado nunca lo es, como sucede en las escalas logarítmicas (en este último caso, por ejemplo, 0 cm corresponde a x=10, 4 cm corresponde a x=100, y no a x=40, etc.).
Habida cuenta de que hay maneras más precisas y menos precisas de medir variables, Stevens estableció en 1948 cuatro niveles de medición en orden de precisión creciente: nominal, ordinal, de intervalos iguales y de cocientes o razones. Posteriormente, Coombs agregó otros niveles intermedios: la escala parcialmente ordenada y la escala métrica ordenada.En cada uno de los cuatro niveles de medición, la obtención del dato o resultado de la medición será diferente:
Ejemplos de datos en diferentes niveles de medición
Nivel de medición
Nivel nominal Nivel ordinal Nivel cuantitativo discreto
Nivel cuantitativo continuo
DATO Martín es electricista
Elena terminó la secundaria
Juan tiene 32 dientes
María tiene 70 pulsaciones por minuto
Unidad de análisis
Martín Elena Juan María
Variable Oficio Nivel de instrucción
Cantidad de piezas dentarias
Frecuencia cardíaca
Categoría o valor
Electricista Secundaria completa
32 70
Unidad de medida
------------- ------------ Diente Pulsaciones por minuto

En el nivel nominal, medir significa simplemente asignar un atributo a una unidad de análisis (Martín es electricista).En el nivel ordinal, medir significa asignar un atributo a una unidad de análisis cuyas categorías pueden ser ordenadas en una serie creciente o decreciente (la categoría ‘secundaria completa’ puede ordenarse en una serie, pues está entre ‘secundaria incompleta’ y ‘universitaria incompleta’).En el nivel cuantitativo, medir significa además asignar un atributo a una unidad de análisis de modo tal que la categoría asignada permita saber ‘cuánto’ mayor o menor es respecto de otra categoría, es decir, especifica la distancia o intervalo entre categorías (por ejemplo, la categoría 70 es el doble de la categoría 35).Las variables medibles en el nivel cuantitativo pueden ser discretas o continuas. Una variable discreta es aquella en la cual, dados dos valores consecutivos, no puede adoptar ningún valor intermedio (por ejemplo entre 32 y 33 dientes, no puede hablarse de 32.5 dientes). En cambio, una variable es continua cuando, dados dos valores consecutivos, la variable puede adoptar muchos valores intermedios (por ejemplo entre 1 y 2 metros, puede haber muchas longitudes posibles).Algunas veces una misma variable puede ser considerada como discreta o continua. Por ejemplo, la variable peso es discreta si solamente interesan los pesos sin valores intermedios (50 kg, 51 kg, etc.), mientras que será continua si interesan también los valores intermedios (50,3 kg, 50,35 kg, 50,357 kg, etc.). Obviamente, al considerar una variable como continua se obtendrá mayor precisión, es decir, mayor información.
La precisión es una cualidad importante de la medición. Se pueden hacer mediciones más precisas y menos precisas, o tan precisas como lo permita el instrumento de medición. El primer nivel de medición es el menos preciso, y el último el más preciso. Por ejemplo, una mujer puede estar interesada en ‘medir’ el amor de su pareja, para lo cual podrá interrogarla solicitándole diferentes grados de precisión: ¿me querés? (nivel nominal), ¿me querés más que a la otra? (nivel ordinal), ¿Cuánto me querés, del 1 al 10? (nivel cuantitativo).De la misma manera, diferentes grados de precisión para la variable temperatura pueden ser: A es un objeto caliente (nivel nominal), A es más caliente que B (nivel ordinal), A tiene 25 grados Celsius (nivel cuantitativo). Los ejemplos del amor y de la temperatura ilustran también el hecho de que una variable puede en principio medirse en cualquiera de los niveles de medición.
Los niveles de medición pueden también ser clasificados de acuerdo a un criterio diferente, que afecta específicamente a los dos últimos. Así, los niveles de medición pueden ser clasificados (Stevens) como nominal, ordinal, de intervalos iguales y de cocientes o razones.Estos cuatro niveles son cada vez más precisos y exactos, con lo cual aumenta la información que recibimos al hacer la medición. Somos más precisos y decimos más si afirmamos que Juan tiene 52 años (escalas cuantitativas) que si decimos solamente que es adulto (escalas cualitativas). De idéntica forma, la medición es más precisa si decimos que un objeto cae a 9,8 m/sg2 (escala de cocientes o razones), que si solamente decimos que ese objeto cae más velozmente que otro (escala ordinal).
Cierto día un emperador, que debía invadir una fortaleza, reunión a cuatro de sus espías para que ingresaran en ella y obtuviesen información. Luego de varios días se presentan los cuatro espías con sus respectivos informes. El espía número 1 informa que adentro de la fortaleza hay un jefe. El espía número 2 informa que adentro de la fortaleza hay un jefe que es más alto que el hijo. El espía número 3 informa que adentro de la fortaleza hay un jefe que es dos veces más alto que el hijo. El espía número 4 informa que adentro de la fortaleza hay un jefe que mide 1,90 metros. Los cuatro espías utilizaron respectivamente los cuatro niveles de medición: el primero informó realmente muy poco, en comparación con el último, que proporcionó la información más precisa.De idéntica manera, no es lo mismo decir que ‘es de noche’, ‘es una hora avanzada de la noche’ y ‘son las once de la noche’, siendo ésta última información más precisa que la primera.
Esta precisión creciente es debida a que las propiedades de cada nivel son acumulativas: el nivel 4 tiene las características de los tres anteriores, más alguna nueva. El nivel 3 tiene las características de los dos anteriores, más otras nuevas que harán que ese nivel sea más exacto y por tanto, más informativo acerca de la propiedad o variable a medir.En un sentido genérico, una escala es el conjunto de categorías (o valores) de una variable, conjunto que, como quedó dicho, debe ser exhaustivo y mutuamente excluyente. Estas categorías o valores podemos representarlas gráficamente mediante los puntos de una línea recta para una mejor visualización. Ejemplos:
FIGURA 1

-2° -1° 0° +1° +2° +3°
Escala nominal
Escala ordinal
Escala de intervalos
Escala de cocientes
Ejemplo: religión
Ejemplo: dureza
Ejemplo: temperatura
Ejemplo: altura
Judío Catól Budi Prot Otro
Diam Hierro Cuer Cartón Papel
0 m 1 m 2 m 3 m
Médico Dentista Psicólogo Veterin Ingeniero Arquitecto
Dentista Veterin Psicólogo Médico Arquitecto Ingeniero
Una escala nominal es simplemente un conjunto de dos o más categorías de una variable, sin que interese el orden o la jerarquía entre ellas. La escala nominal de la variable “religión” son sus distintas categorías: judío, católico, etc. El requisito fundamental que deben reunir es que sean distintas entre si de manera que no puede haber dos categorías con el mismo nombre, ni dos categorías que se superpongan (como “cristianos” y “católicos”). Obviamente, además las categorías deben ser homogéneas: todas deben referirse a religiones y no a partidos políticos, oficios o lugares de nacimiento.
Una escala nominal para la variable “profesión” puede representarse de cualquiera de las siguientes maneras, entre otras:
FIGURA 2
Este ejemplo muestra que en una escala nominal no interesa ni el orden en que colocamos las categorías, ni la distancia que hay entre ellas. Si la variable hubiese sido “prestigio de una profesión” aquí sí hubiera importado el orden, pues hay profesiones más prestigiosas y menos prestigiosas. Tampoco la escala nominal informa sobre las distancias entre las categorías: subjetivamente podemos pensar que la “distancia” entre un médico y un dentista no es la misma que hay entre un ingeniero y un arquitecto, pero esta información no nos es suministrada por la escala nominal.Otro ejemplo de variable medible nominalmente es la numeración del 1 al 11 de los jugadores de un equipo de fútbol. Aquí, puesto que las categorías son numéricas podríamos pensar que estamos ante una variable cuantitativa y por tanto medible en los niveles 3 o 4, pero si pensamos así estaremos equivocados. Aquí los números no funcionan como tales en el sentido que no podemos manipularlos aritméticamente sumándolos, restándolos, etc., sino sólo como simples etiquetas: el “1” representa simplemente la palabra “arquero”, el ”10” delantero, etc. Nadie afirmaría que el jugador con el número 6 es dos veces más capaz que el jugador número 3. Los números empiezan a funcionar como indicadores de cantidad recién en las escalas cuantitativas.En la escala ordinal, además de la homogeneidad y la diferenciabilidad entre categorías, importa el orden en que ellas se disponen. Las variables “dureza de los materiales” y “prestigio de una profesión” son ordinales, pues los materiales pueden ordenarse según su dureza y las profesiones de acuerdo a su prestigio. Una escala ordinal para la variable “prestigio ocupacional” puede graficarse de cualquiera de las siguientes formas, entre otras:
FIGURA 3

Basurero Zapatero Ejecutivo
Basurero Zapatero Ejecutivo
1 2 3 4 5 6 7 8 9 10
1 2 3 4 5
1 2 4 8 16
Esto nos muestra que sea cual fuere la forma de representación, siempre ha de respetarse el orden. Este tipo de escalas tiene una ventaja sobre las nominales, pero también tiene una limitación: la escala ordinal me informa si un individuo tiene mayor o menor prestigio ocupacional que otro, pero no me dice “cuánto” en forma objetiva. Esto último es importante porque “subjetivamente” uno podría pensar que un ejecutivo tiene tres veces más prestigio que un zapatero, pero este criterio no sería compartido por otras personas, y una escala ha de ser la misma para todos. Otros ejemplos de variables medibles ordinalmente son el grado de mérito, el grado militar y la gradación de tonos de colores.Según la escala nominal, decimos que hemos hecho una medición simplemente cuando afirmamos que Fulano es médico, y según la escala ordinal cuando afirmamos que Fulano tiene una ocupación más prestigiosa que Zutano, aunque no sepamos cuánto más prestigiosa es. Mientras una escala nominal permite hacer identificaciones, o poner nombres (de allí la expresión “nominal”), la escala ordinal permite hacer comparaciones cualitativas.Las comparaciones cuantitativas, o sea la medición numérica, se hace posible recién con las escalas cuantitativas. Si examinamos las escalas cualitativas (nominales y ordinales) veremos que los intervalos o distancias entre las categorías (o sea las distancias entre los puntos de la recta) son irregulares y no responden a ningún criterio objetivo, aunque sí a muchos subjetivos. En la figura 3 vemos que “zapatero” puede estar más cerca de “basurero” según algunos, o más cerca de “ejecutivo” según otros. La escala ordinal permite comparar profesiones en cuanto a prestigio, pero no permite comparar distancias entre profesiones, o sea no es posible saber cuánto mayor es la distancia de basurero a zapatero respecto de la distancia entre zapatero y ejecutivo.En este sentido, las escalas cuantitativas son aún más informativas. A los requisitos de homogeneidad, diferenciabilidad y orden se agrega uno nuevo: los intervalos deben ser regulares, y más específicamente iguales. Las siguientes tres escalas representan todas ellas intervalos iguales, o sea que los intervalos o distancias entre los puntos están determinados según un cierto criterio matemático:
FIGURA 4
En la primera vemos que los intervalos son iguales, pues la distancia que hay de 1 a 2 es igual a la distancia que hay entre 2 y 3, etc., todo lo cual, dicho matemáticamente, equivale a afirmar que 1-2 = 2-3, etc. Por la misma razón en la segunda escala las distancias también son iguales aunque hayamos tomado intervalos mayores. En la tercera ya parecería que los intervalos no son iguales pues van aumentando cada vez más hacia la derecha, pero si consideramos que se trata de una escala logarítmica (y no lineal como las dos anteriores), veremos que también sus intervalos son iguales según la siguiente serie de igualdades, donde en vez de restar, dividimos:
1 2 4 8------ = ------ = ------ = ------ = etc 2 4 8 16
Esta misma serie, expresada logarítmicamente, es log1-log2 = log2-log3, etc., o sea que en vez de restar números como en la escala lineal restamos logaritmos, pero igualmente sigue cumpliéndose la condición de igualdad de intervalos.

1m 2m 3m 4m 5m
A B C D E
2m 3m 4m 5m 6m
A B C D E
Escala absoluta
Escala relativa0m 1m 2m 3m 4m
Toda escala que tenga intervalos iguales se llama escala métrica, y a este nivel ya sí tiene sentido definir medición más familiarmente como la operación por la cual comparamos una cierta cantidad con otra tomada como nidad. Por ejemplo, decimos que hemos medido el peso de Fulano cuando hemos dicho que pesa 60 kg, o sea, su peso entra 60 veces en la unidad de medida de 1 kg.Estas escalas métricas, típicas de los niveles cuantitativos de medición, siguen conservando las características de diferenciabilidad (o identidad), y orden de la escala ordinal, pero se agregan otras nuevas: no sólo me dice que los pesos 35 kg y 70 kg son distintos (identidad), y no sólo me dice que 70 es un peso mayor que 35 (orden), sino que además me agrega nueva información al decirme: (a) que 70 kg es cuantitativamente tan distinto de 35 kg como 35 kg lo es de 0 kg; y (b) que 70 kg es dos veces más pesado que 35 kg, o sea, me informa acerca de cuánto más pesado es un objeto que otro.Las escalas de intervalos iguales sólo nos pueden dar la información (a), mientras que la escala de cocientes o razones, además, nos suministra la información (b), con lo cual esta última resulta ser más precisa o con mayor contenido informativo.Establezcamos más en detalle las diferencias entre ambas escalas cuantitativas, para lo cual comenzaremos por distinguir las escalas absolutas y las relativas. Supongamos que tomamos cinco objetos cualesquiera y medimos sus alturas, graficando del siguiente modo sus valores respectivos:
FIGURA 5
Es indudable que estas alturas son reales: el objeto A mide efectivamente dos metros, el objeto B tres metros, etc. A estas escalas cuyos números representan realmente el atributo físico las llamamos absolutas y en ellas, obviamente, la cifra 0 corresponderá a la ausencia de altura. Pero supongamos ahora que queremos considerar la altura A, que es dos metros, como altura 0 en forma arbitraria. La escala anterior y la nueva quedarán entonces correlacionadas del siguiente modo:
FIGURA 6
En esta nueva escala el objeto B no tiene realmente un metro de altura: sólo nos dice que B es un metro más alto que A, es decir marca su ubicación respecto de otro objeto. De la misma forma esta escala no dice que A no tenga altura, sino que arbitrariamente le hemos asignado el valor 0 para que sirva de punto de referencia de los demás valores: es una escala relativa o arbitraria. Obviamente, si disponemos de una escala relativa y conocemos además la altura absoluta de uno cualquiera de los objetos, podremos calcular la altura absoluta de los demás (también necesitamos una regla de transformación, pero de esto no nos ocuparemos).También podríamos haber asignado el valor cero no a 2 sino a la media aritmética, que en nuestro ejemplo coincide con 4 metros. La nueva escala relativa quedaría entonces representada del siguiente modo:
FIGURA 7

2m 3m 4m 5m 6m
A B C D E
Escala absoluta
Escala relativa-2m -1m 0m 1m 2m
Estrictamente hablando no tiene sentido decir que algo mide “menos 2 metros” (-2), pues no hay alturas negativas, pero no obstante esa cifra aparecida en la nueva escala nos está diciendo algo: que el objeto A es tan alto con respecto al objeto B como éste con respecto al C, que es la media, y el signo negativo nos indica solamente que la altura de A está por debajo de la media aritmética. Del mismo modo la altura cero no significa aquí ausencia de altura, error que cometió aquel tipo que, cuando le dijeron que hacía cero grado de temperatura exclamó alborozado: “No hace ni frío ni calor!”. Galeno había sugerido como punto cero de temperatura un “calor neutro” que no era ni frío ni calor, pero Galeno estaba en realidad proponiendo una simple convención. Vemos así que la escala de temperatura es un típico ejemplo de escala relativa (con un cero arbitrario).En las escalas de intervalos iguales tenemos escalas relativas (o sea con un cero arbitrario) y en las escalas de cocientes o razones tenemos escalas absolutas (con un cero absoluto o real). El cero arbitrario no corresponde con la ausencia de la magnitud (cero grado no significa ausencia de temperatura), pero el cero absoluto es real (cero metros significa ausencia de altura). Nótese que lo que interesa es la ausencia de la variable, no del individuo. Tanto cero metros como cero cantidad de hijos significa ausencia de altura y ausencia de hijos, y no interesa que el primer valor corresponda a un individuo inexistente y el segundo a una pareja que sí podría existir.Las escalas de cocientes o razones son muy difíciles de encontrar en psicología y en general en las ciencias sociales: en estas disciplinas se manejan variables que, como motivación, inteligencia o aprendizaje, son muy difíciles (o carecería de sentido) identificar su ausencia real, o sea asignarles un cero absoluto, y en general sus valores se consiguen establecer por comparación con otros valores. Efectivamente, existen ciertas variables a las cuales no puede asignársele un ‘cero real’, por cuanto no se considera que esa variable pueda estar ausente en la realidad. Tal es el caso de la ansiedad o la inteligencia: nadie, por menos ansioso o por menos inteligente que sea, puede tener ansiedad o inteligencia nulas.
Pero, más exactamente, ¿porqué las variables psicológicas suelen medirse con escalas relativas y las variables físicas con escalas absolutas? O, si se prefiere, ¿qué nos obliga a medir ciertas variables mediante escalas relativas, cuando en rigor sería preferible usar escalas absolutas por ser más precisas y exactas?Esta interesante cuestión tiene su complejidad, no obstante lo cual orientaremos una respuesta en algún sentido que pueda interesarnos como investigadores en ciencias sociales. Para ello comparemos un físico que debe medir la altura de 10.000 objetos, y un psicólogo que debe medir la inteligencia de 10.000 sujetos de la misma edad. Una vez que hicieron sus respectivas mediciones, cada uno obtiene un promedio: el promedio de alturas es 1,53 metros, y el promedio de inteligencias es 100.Acto seguido, si ahora el psicólogo encuentra una persona y, tras medir su inteligencia encuentra que tiene un valor 60, con justa razón puede decir que tiene una inteligencia inferior a lo normal; pero si el físico encuentra un objeto que mide apenas 0,42 metros no tendrá sentido que diga que su altura es inferior a lo normal o que se trata de un objeto “retrasado” en cuanto a altura. No es este el tipo de comparación que le interesa hacer al físico, pero sí al psicólogo. Este último desea saber si una persona está por encima o por debajo de la media de su edad. Las escalas relativas como la inteligencia toman como punto de referencia no un cero absoluto sino un promedio estadístico al cual puede asignársele tanto el valor 0 como el valor 100 o cualquier otro, y entonces estas escalas relativas son especialmente aptas para comparar la situación de un individuo respecto de otros y ver así si tiene más o si tiene menos inteligencia que el resto. Más aún: si quien mide altura no es un físico sino un médico o un psicólogo (por tanto ya estamos midiendo personas, no objetos), empiezan a cobrar sentido las expresiones “altura normal” o “altura anormal”, por la misma razón que tiene sentido hablar de “inteligencia normal” o “inteligencia anormal”.Quienes construyeron los tests de inteligencia no empezaron eligiendo a un individuo con inteligencia “nula” (o sea, un cero absoluto) y a partir de allí luego los demás valores (10, 20, 30, etc.). Ellos comenzaron eligiendo una gran cantidad de individuos y luego obtuvieron un promedio (supuestamente el promedio de toda la población humana, si acaso la muestra fuese representativa). A dicho promedio le adscribieron convencionalmente el valor 100 y así, si algún nuevo sujeto llegara a obtener cero según esta nueva escala, no significará que no tiene inteligencia (cero absoluto), sino sólo que su capacidad intelectual está muy por debajo de la media poblacional (cero relativo).Hasta aquí puede quedar justificado el uso de escalas relativas en ciencias sociales, pero, entonces, porqué ciertas magnitudes físicas como la temperatura se miden habitualmente en escalas relativas y no absolutas, que ya dijimos serían preferibles? En el caso especial de la temperatura podemos invocar razones históricas y prácticas. Tomemos con la mano un objeto cualquiera: inferimos que tiene una cierta temperatura a juzgar por la sensación térmica que nos produce. Supongamos ahora que el cuerpo que sostenemos se empieza a enfriar. Llegará un momento en que el frío es tan intenso que nuestros dedos se congelan y dejan de funcionar nuestros termorreceptores, o sea, no experimentamos ya ninguna sensación y quedamos anestesiados. Significa esto que el cuerpo no puede seguir enfriándose? No. Puede seguir haciéndolo aunque ya no podamos darnos cuenta por el tacto, y entonces, para averiguarlo, decidimos tomar otro punto de referencia, como por ejemplo su dureza. Podemos así saber si se sigue o no enfriando examinando si su dureza aumenta o no, pero aquí también la dureza

puede tener un límite, y el hecho de que el cuerpo haya alcanzado una dureza máxima y no pueda endurecerse más, ello no significa necesariamente que no pueda seguir enfriándose. De hecho, podemos seguir eligiendo más criterios hasta el infinito, pero la termodinámica ha venido a resolver este problema tomando como punto de referencia no la sensación térmica ni la dureza del cuerpo, sino el movimiento de sus moléculas. Y así, cuando las moléculas cesan todo movimiento el cuerpo ya no podrá seguir enfriándose alcanzando entonces lo que se llama su temperatura absoluta, designada convencionalmente como el cero grado en la escala Kelvin, creada a tal efecto. Esta escala es absoluta porque el cero grado corresponde realmente a la ausencia de temperatura. Podría argumentarse que esto no es así que cero grado está indicando un frío intensísimo en lugar de ausencia de temperatura pero no debemos olvidar que la termodinámica, al crear esta escala, equiparó temperatura a movimiento molecular y no a sensación térmica y entonces el cero grado, al indicar ausencia de movimiento molecular, indica también ausencia de temperatura. Si nuestros termorreceptores pudiesen hipotéticamente percibir la sensación térmica a cero grado Kelvin sin quedar arruinados, seguramente retiraríamos violentamente la mano y nadie podría convencernos de que allí no hay temperatura, pero esto es porque estamos habituados a equiparar temperatura con sensación térmica y no con movimiento molecular. Por lo demás, se supone que el cero absoluto es inalcanzable tanto técnicamente como en teoría, porque si cesara el movimiento molecular la materia dejaría de existir.La idea de equiparar temperatura con movimiento molecular deriva de la teoría cinética del calor del siglo pasado, y sostiene que el movimiento genera calor. Entonces, si las moléculas comienzan a moverse cada vez más rápidamente, el cuerpo empezará a aumentar su temperatura. Obviamente que esto no es más que una teoría: el día de mañana puede aparecer otra que tome como referencia de temperatura no el movimiento sino otro parámetro hoy desconocido, con lo cual se construirá una nueva escala con el cero más alejado y donde el cuerpo podrá seguir enfriándose aún cuando haya cesado todo movimiento molecular. Esto prueba que, en el fondo, el cero absoluto es paradójicamente relativo, pues todo dependerá de qué significado le demos a “temperatura”: si sensación térmica, dureza, movimiento molecular o un parámetro aún no descubierto.Históricamente, la primera escala de temperatura que se creó no fue la escala Kelvin, ya que no existía la idea de vincular la temperatura con el movimiento molecular y construir, sobre esa base, una escala. Pero los físicos necesitaban contar igualmente con alguna que pudiese medir esta magnitud, y fue así que se crearon varias, como la escala centígrada (Celsius), la escala Farenheit y la escala Reamur. La escala Celsius le adjudicó un poco arbitrariamente el cero al punto de congelamiento del agua y el 100 a su punto de ebullición (todo a presión atmosférica normal), dividiéndose luego en 100 partes iguales la escala entre uno y otro valor. Presumiblemente la practicidad de esta escala radica en el hecho de que la mayoría de los objetos que manipulamos o los ambientes donde habitamos están entre 0 y 100 grados Celsius, utilizándose la escala Kelvin sólo para objetos muy fríos. Haciendo las transformaciones necesarias (0 grado Kelvin corresponden a -273 grados Celsius) podríamos usar también la escala Kelvin pero no lo hacemos, entre otras razones, por una cuestión psicológica o de acostumbramiento a las mismas cifras de siempre. En otros casos el desacostumbramiento puede ser menos difícil, y es cuando no hay que habituarse a nuevas cifras sino simplemente a nuevas denominaciones. Tal es el caso del pasaje de los milibares a los hectopascales (escala de presión atmosférica): aquí no se cambió de escala sino de nombre, ya que, por ejemplo, 1008 hectopascales siguen siendo 1008 milibares.
Además del hecho de que una tiene un cero arbitrario y la otra un cero absoluto, hay otra diferencia entre las escalas relativas y absolutas, y que de alguna forma ya empezamos a adelantar.En las escalas de intervalos iguales, que son relativas, no se puede decir que un sujeto con CI 160 tenga el doble de inteligencia que otro de 80, del mismo modo que dos grados no es el doble de temperatura que un grado en la escala Celsius. A lo sumo podemos llegar a decir que la diferencia de inteligencia que hay entre 120 y 140 es la misma que hay entre 100 y 120. En las escalas de cocientes, que son absolutas, podemos obtener en cambio ambos tipos de información como ocurre con las escalas de peso, sonido, longitud o densidad. Además de la inteligencia, otras escalas de intervalos iguales son la energía y las fechas del calendario: del 2 al 4 de junio hay el mismo intervalo temporal que hay entre 4 y 6 de junio, pero carecerá de sentido decir que el 4 de junio es el doble del 2 de junio.Observemos la figura 6. En la escala absoluta sí tiene sentido decir que 6 metros (altura del objeto E) es el doble de 3 metros (la altura de B). O sea, se cumple la igualdad E = 2.B. Si intentamos trasladar esto mismo a la escala relativa esta igualdad no se cumple, pues 4 no es el doble de 1. Para que la expresión E = 2.B valga en la escala relativa debemos sumarle el número 2, que es la distancia que hay entre el cero arbitrario y el absoluto (ya que aquí la escala relativa aparece “corrida” dos lugares). La nueva fórmula para esta escala será E = 2.B + 2, y entonces sí se cumple que 4 = 2.1 + 2. Todo esto es bastante teórico, porque sólo lo podemos hacer si conocemos el corrimiento de la escala relativa respecto de la absoluta, o sea, si conocemos la distancia del cero arbitrario al cero absoluto, cosa que no siempre podemos hacerlo ni tampoco necesitarlo. Desde este punto de vista, la escala absoluta pasa a ser un caso especial de la escala relativa donde la distancia entre los ceros arbitrario y absoluto es nula.Esta clasificación en cuatro niveles ya es clásica y corresponde a Stevens, pero no han faltado otras variantes entre las que podemos mencionar la de Coombs, quien agrega dos niveles más:a) Entre la nominal y la ordinal incluye la escala parcialmente ordenada (figura 8). Se trata en última instancia de una variante de la escala ordinal donde en algunas categorías, como B y C, no se conoce la relación de mayor o menor que tienen entre sí: A es mayor que B o que C, y por otro lado B o C son mayores que D, pero se desconoce si B es mayor, menor o igual a C.
FIGURA 8

A > B > C > D > E Escala ordinal
Escala parcialmente ordenada
BA > > D > E C
b) Entre la ordinal y la de intervalos iguales, Coombs agrega la escala métrica ordenada, una variante de la escala de intervalos iguales donde en vez de ser estos iguales son distintos pero están ordenados creciente o decrecientemente. A diferencia de la escala meramente ordinal, aquí no sólo se ordenan las categorías, sino también los intervalos de acuerdo a su tamaño. Evidentemente informa más que la simple escala ordinal pero menos que la de intervalos iguales propiamente dicha, pues no aclara cuánto mayor es un intervalo que otro.
Siempre estamos haciendo mediciones. Por ejemplo, cuando decimos que tal o cual individuo es católico (medición nominal), o que tal sujeto tiene más mérito que otro (medición ordinal), o cuando decimos que tal otro sujeto tiene 30 años (medición intervalar). Pero la importancia de la medición no reside simplemente en el hecho de que siempre estamos haciendo mediciones, sino en que el acto de medir nos permite conocer cómo varían los fenómenos de la realidad tanto en cantidad como en calidad, lo cual a su vez es muy importante porque es gracias a que existen unas variaciones que dependen causalmente de otras, que podemos organizar nuestro conocimiento del mundo.
CAPÍTULO 2: ESTADÍSTICA DESCRIPTIVA
1. GENERALIDADES
El propósito fundamental de la estadística descriptiva es resumir y organizar una gran cantidad de datos referentes a una muestra (lo más habitual) o a una población. Se supone que los datos resumidos y organizados permiten describir adecuadamente la muestra o la población a los efectos de conocerla y, eventualmente, utilizarlos en la estadística inferencial para obtener conclusiones a partir de ellos.Para resumir y organizar los datos se utilizan diferentes procedimientos, llamados técnicas descriptivas: la matriz de datos permite ordenarlos, las tablas de frecuencias (o tablas de distribución de frecuencias) permiten agruparlos, los gráficos permiten visualizarlos, y las medidas estadísticas y las medidas de asimetría y curtosis permiten resumirlos reduciéndolos a un solo dato.
Secuencia para organizar y resumir datos individuales
A medida que se van utilizando estos procedimientos, los datos van quedando cada vez más resumidos y organizados. El empleo de dichos procedimientos propios de la estadística descriptiva sigue un orden determinado, como puede apreciarse en el siguiente esquema:

DATOS RECOLECTADOS(entrevistas, cuestionarios, tests, etc.)
DATOS ORDENADOS(matriz de datos)
DATOS AGRUPADOS POR FRECUENCIA(tabla de frecuencias)
DATOS AGRUPADOS POR INTERVALOS(tabla de frecuencias por intervalos)
DATOS VISUALIZADOS(gráficos)
DATOS SINTETIZADOS(medidas estadísticas y medidas de asimetría y curtosis)
Como puede verse:a) Los datos quedan recolectados mediante entrevistas, cuestionarios, tests, etc.b) Los datos quedan ordenados mediante una matriz de datos (lo cual permite resumir la información en unas pocas páginas).c) Los datos quedan agrupados mediante tablas de frecuencias (lo cual permite resumir la información en una sola página).d) Los datos quedan visualizados mediante gráficos.e) Los datos quedan sintetizados mediante las medidas estadísticas y otras (lo cual permite resumir la información en uno o dos renglones).Puede entonces decirse que, mediante una matriz de datos, una tabla de frecuencias (1), un gráfico o con medidas estadísticas, etc., la muestra o la población (conjuntos de datos) puede quedar adecuadamente descrita.Estas sucesivas abstracciones estadísticas implican: a) la reducción del espacio físico donde queda guardada la nueva información, y b) la desaparición de considerable información irrelevante.Debe distinguirse el fin o propósito perseguido (por ejemplo ordenar los datos), del medio utilizado para ello, que e la técnica descriptiva (por ejemplo, la matriz de datos).
2. ORDENAMIENTO Y AGRUPACIÓN DE LOS DATOS: MATRICES Y TABLAS
Una vez que los datos han sido recolectados, se procede a continuación a ordenarlos en una matriz de datos y luego a agruparlos en una tabla de frecuencias.La forma de ordenarlos y agruparlos dependerá del tipo de variable considerada. Por ejemplo, si son datos relativos a variables cualitativas (niveles de medición nominal y ordinal), no podremos utilizar tablas de frecuencias por intervalos. El siguiente cuadro indica de qué manera se pueden ordenar y agrupar los datos según cada nivel de medición de la variable:
Ejemplos de organización de los datos según el nivel de medición
Datos ordenados Datos agrupados por frecuencia Datos agrupados por intervalos
Nivel nominal(Ejemplo: variable religión)
Matriz de datosSujeto x (religión)Juan CatólicaPedro CatólicaMaría JudíaAntonio ProtestanteLuis ProtestanteJosé Protestante
Tabla de frecuenciasx (religión) fCatólica 2Judía 1Protestante 3
n = 6
f = frecuencian = tamaño de la muestra
Nivel ordinal(Ejemplo: variable clase social)
Matriz de datosSujeto x (clase
social)Juan AltaPedro MediaMaría MediaAntonio Media
Tabla de frecuenciasx (clase social) f
Alta 1Media 3Baja 2
n = 6

Luis BajaJosé Baja
f = frecuencian = tamaño de la muestra
Nivel cuantitativo(Ejemplo: variable edad)
Matriz de datosSujeto x (edad)Juan 15Pedro 15María 15Antonio 16Luis 16José 16Ana 16Gabriela 16Susana 17Martín 17Sergio 17Pablo 17Daniel 17Graciela 17Daniela 17Beatriz 17Oscar 18Felipe 18Alberto 18Mónica 19Marta 19Mariana 20
Tabla de frecuenciasx (edad) f
15 316 517 818 319 220 1
n = 22
f = frecuencian = tamaño de la muestra
Tabla de frecuencias por intervalos
x (edad) f15-16 817-18 1119-20 3
n = 22
f = frecuencian = tamaño de la muestra
Una vez confeccionada la matriz de datos, se procede luego a resumir aún más esta información mediante una tabla de frecuencias o, si cabe, en una tabla de frecuencias por intervalos. Una tabla de este último tipo se justifica cuando la tabla de frecuencias original es demasiado grande y por tanto de difícil manejo para procesar la información. Sea de la forma que fuere, los datos ordenados según sus frecuencias suelen denominarse distribución de frecuencias (13).
Las tablas de frecuencias contienen tres elementos importantes: las frecuencias, el tamaño de la muestra y los intervalos (en este último caso sólo para variables cuantitativas).
a) Frecuencia.- La frecuencia (f) se define como la cantidad de datos iguales o que se repiten. Por ejemplo: la frecuencia 2 indica que el dato ‘católico’ se repite dos veces, la frecuencia 3 que el dato “clase media” se repite tres veces, y la frecuencia 8 que el dato “17 años” se repite ocho veces.A veces resulta necesario expresar las frecuencias de otra manera, como puede apreciarse en la siguiente tabla ilustrativa:
Tipos de frecuencias que pueden indicarse en una tabla de frecuencias
x (edad) f f% F F% fr Fr
15 3 15% 3 15% 0.15 0.1516 7 35% 10 50% 0.35 0.5017 8 40% 18 90% 0.40 0.9018 2 10% 20 100% 0.10 1
n = 20 n = 100% ------ ------ n = 1 ------
Frecuencia absoluta (f).- Es la cantidad de datos que se repiten. Por ejemplo, la frecuencia 3 indica que hay tres personas de 15 años. La suma de todas las frecuencias absolutas equivale al tamaño de la muestra.Frecuencia porcentual (f%).- Es el porcentaje de datos que se repiten. Por ejemplo, la frecuencia porcentual 15% indica que el 15% de la muestra tiene la edad de 15 años. La suma de todas las frecuencias porcentuales es 100%.Frecuencia acumulada (F).- Es el resultado de haber sumado las frecuencias anteriores. Por ejemplo, la frecuencia acumulada 10 resulta de sumar 7+3, e indica la cantidad de veces que se repiten las edades 16 y 15. La última de todas las frecuencias acumuladas, que en el ejemplo es 20, debe coincidir con el tamaño de la muestra.Frecuencia acumulada porcentual (F%).- Es el porcentaje de las frecuencias acumuladas.

Frecuencia relativa (fr).- A veces también llamada proporción, es el cociente entre la frecuencia de un dato x y la frecuencia total o tamaño de la muestra. En la práctica, el tamaño de la muestra se considera como 1, a diferencia del tamaño de la muestra en la frecuencia porcentual, que se considera 100%.Frecuencia relativa acumulada (Fr).- Es el resultado de haber sumado las frecuencias relativas anteriores. Por ejemplo: la frecuencia relativa 0.90 indica que en 0.90 casos sobre 1 las edades están comprendidas entre 15 y 17 años.Frecuencias parciales y frecuencia total.- Tanto las frecuencias absolutas como las porcentuales o las relativas pueden ser frecuencias parciales o una frecuencia total, siendo ésta última la suma de todas frecuencias parciales.Las frecuencias porcentuales y las frecuencias relativas comparan la frecuencia parcial con la frecuencia total, y sirven para establecer comparaciones entre muestras distintas. Por ejemplo, si en una muestra de 1000 hombres, solo votaron 200, y en una muestra de 600 mujeres solo votaron 200 mujeres, en términos de frecuencias absolutas existe la misma cantidad de votantes masculinos y femeninos, es decir 200, pero en ‘proporción’, las mujeres votaron más (la tercera parte del total) que los hombres (la quinta parte del total). Esta información se obtiene al convertir las frecuencias absolutas en frecuencias porcentuales o en frecuencias relativas (o proporciones).
2) Tamaño de la muestra.- Otro concepto importante es el tamaño de la muestra (n), que designa la cantidad total de datos. Obviamente, la suma de todas las frecuencias f debe dar como resultado el tamaño n de la muestra, por lo que el tamaño de la muestra coincide con la frecuencia total.
3) Intervalos.- Un intervalo, también llamado intervalo de clase, es cada uno de los grupos de valores ubicados en una fila en una tabla de frecuencias. Por ejemplo el intervalo 15-16 significa que en esa fila se están considerando las edades de 15 a 16 años. La frecuencia correspondiente a un intervalo es igual a la suma de frecuencias de los valores en él incluídos (2). Los intervalos presentan algunas características, que son las siguientes:Tamaño del intervalo (a).- También llamado amplitud o anchura del intervalo, es la cantidad de valores de la variable que se consideran conjuntamente en ese intervalo. Por ejemplo, el intervalo 15-16 años tiene una amplitud de 2, puesto que se consideran dos valores: 15 y 16. En otro ejemplo, el intervalo 20-25 años tiene una amplitud de 6, puesto que se consideran seis valores.En general, puede calcularse el tamaño de un intervalo restando el límite superior y el inferior y sumando al resultado el número 1. Por ejemplo, 25 menos 20 da 5, y sumándole 1 da 6.Los ejemplos indicados corresponden a variables discretas, lo que significa que no podrán encontrarse valores intermedios entre dos intervalos. Por ejemplo, entre los intervalos 15-16 y 17-18 no se encontrarán valores intermedios entre 16 y 17 años.Téngase presente que: a) preferiblemente los intervalos deben tener un tamaño constante, de manera tal que no se pueden considerar como intervalos 15-16 y 17-20, porque tienen diferentes tamaños; y b) los intervalos han de ser mutuamente excluyentes, de manera tal que cuando se trata de variables discretas, no pueden definirse los intervalos 15-16 y 16-17, porque el valor 16 años está en ambos intervalos y no se podrá saber con seguridad en qué intervalo ubicar dicho valor.El problema se puede presentar con las variables continuas, donde, por definición, podría aparecer algún valor intermedio entre dos intervalos. Por ejemplo, si se considera la variable continua ‘ingresos mensuales’ y se consideran en ella los intervalos 1000-2000 dólares y 3000-4000 dólares, puede ocurrir que un dato obtenido de la realidad sea 2500 dólares, con lo cual no podrá ser registrado en ningún intervalo. En tal caso se deberían reorganizar los intervalos como 1000-2999 dólares y 3000-4999 dólares, con lo cual el problema estaría resuelto.Desde ya, puede ocurrir que aparezca un ingreso mensual de 2999,50 dólares, en cuyo caso en principio deberían reorganizarse nuevamente los intervalos como 1000-2999,50 dólares y 2999,51-4999 dólares. La forma de reorganizar los intervalos dependerá entonces del grado de precisión que pretenda el investigador o del grado de precisión del instrumento de medición disponible.Límites del intervalo.- Todo intervalo debe quedar definido por dos límites: un límite inferior y un límite superior. Estos límites, a su vez, pueden ser aparentes o reales (Pagano, 1998:38-39). Considérese el siguiente ejemplo:
Límites aparentes Límites reales95-99 94.5-99.590-94 89.5-94.585-89 84.5-89.580-84 79.5-84.575-79 74.5-79.5
Si la variable considerada es discreta, carecerá de sentido la distinción entre límites reales o aparentes. Si se conviene que los valores que la variable puede adoptar son números enteros, se considerarán solamente los intervalos 95-99, 90-94, etc. Estos intervalos son en rigor reales, porque expresan los valores ‘reales’ que puedan haber, que no son fraccionarios.Sólo en el caso de las variables continuas adquiere sentido la distinción entre límites reales y aparentes. Si la variable es continua, deberían tenerse en cuenta los límites reales. Por ejemplo, si un valor resulta ser 94.52, entonces será ubicado en el intervalo 94.5-99.5. Sin embargo, aún en estos casos, lo usual es omitir los límites reales y presentar sólo los límites aparentes (Pagano, 1998:39). En todo caso, los límites

reales se utilizan a veces cuando se intenta transformar la tabla de frecuencias por intervalos en un gráfico.En principio, en ningún caso deberá haber una superposición de valores, como en el caso de los intervalos 20-21 y 21-22, donde el valor 21 está incluído en ambos intervalos, violándose así la regla de la mutua exclusión. Si acaso se presentara esta situación, o bien podrá ser adjudicada a un error del autor de la tabla, o bien deberá traducírsela como 20-20.99 y 21-22.99.Punto medio del intervalo (xm).- Es el valor que resulta de la semisuma de los límites superior e inferior, es decir, el punto medio del intervalo se calcula sumando ambos límites y dividiendo el resultado por dos. Por ejemplo, el punto medio del intervalo 15-20 es 17.5. El punto medio del intervalo sirve para calcular la media aritmética.Intervalos abiertos y cerrados.- Idealmente, todos los intervalos deberían ser cerrados, es decir, deberían estar especificados un límite superior y uno inferior de manera definida. Sin embargo, en algunos casos se establecen también intervalos abiertos, donde uno de los límites queda sin definir. En el siguiente ejemplo, ’18 o menos’ y ’29 o más’ son intervalos abiertos. Obviamente, en este tipo de distribución los intervalos dejan de ser de tamaño constante.
Intervalos18 o menos19-2324-2829 o más
Cantidad de intervalos.- La cantidad de intervalos es inversamente proporcional al tamaño de los mismos: cuanto menor tamaño tienen los intervalos, más numerosos serán.El solo hecho de emplear intervalos supone una cierta pérdida de la información. Por ejemplo, si se considera el intervalo 15-18 años, quedará sin saber cuántas personas de 16 años hay. Para reducir esta incertidumbre, podría establecerse un intervalo menor (15-16 años), pero con ello habrá aumentado la cantidad de intervalos hasta un punto donde la información se procesará de manera más difícil. Consiguientemente, al agrupar los datos hay que resolver el dilema entre perder información y presentar los datos de manera sencilla (Pagano R, 1998:37) (Botella, 1993:54), es decir, encontrar el justo equilibrio entre el tamaño de los intervalos y su cantidad.En la práctica, por lo general (Pagano, 1998:37) se consideran de 10 a 20 intervalos, ya que la experiencia indica que esa cantidad de intervalos funciona bien con la mayor parte de las distribuciones de datos (3).
Se pueden sintetizar algunas reglas importantes para la construcción de intervalos de la siguiente manera:a) Los intervalos deben ser mutuamente excluyentes.b) Cada intervalo debe incluir el mismo número de valores (constancia de tamaño).c) La cantidad de intervalos debe ser exhaustiva (todos los valores deben poder ser incluídos en algún intervalo).d) El intervalo superior debe incluir el mayor valor observado (Botella, 1993:54).e) El intervalo inferior debe incluir al menor valor observado (Botella, 1993:54).f) En variables continuas, es aconsejable expresar los límites aparentes de los intervalos, que los límites reales.
3. VISUALIZACIÓN DE LOS DATOS: GRÁFICOS
Una vez que los datos han sido organizados en tablas de frecuencias, es posible seguir avanzando organizándolos, desde allí, de otras maneras diferentes y con distintos propósitos. Una de estas maneras es la utilización de representaciones gráficas, algunas de las cuales son aptas para representar variables cualitativas (niveles nominal y ordinal) y otras para variables cuantitativas. Al tratarse de esquemas visuales, los gráficos permiten apreciar de un ‘golpe de vista’ la información obtenida.
Diagrama de tallo y hojas
Esta técnica de visualización de datos es aquí mencionada en primer lugar porque puede ser considerada un procedimiento intermedio entre la tabla de frecuencias y el gráfico. Fue creada por Tukey en 1977 (citado por Botella, 1993:59) y presenta, entre otras, las siguientes ventajas: a) permite conocer cada puntuación individual (a diferencia de la tabla de frecuencias por intervalos, donde desaparecen en ellos); y b) puede ser considerada un ‘gráfico’ si hacemos girar 90° el listado de puntuaciones o datos.
A continuación se describe la forma de construir un diagrama de tallo y hojas, tomando como ejemplo la siguiente distribución de datos ordenados:
32-33-37-42-46-49-51-54-55-57-58-61-63-63-65-68-71-72-73-73-73-75-77-77-78-83-85-85-91-93
Tallo
Hojas Procedimiento para realizar el diagrama de tallo y hojas

Varones
Mujeres
100 personas
a) Se construye una tabla como la de la izquierda con dos columnas: tallos y hojas.b) Se identifican cuáles son los valores extremos: 32 y 93.c) Se consideran los primeros dígitos de cada valor: 3 y 9.d) En la columna “tallos” se colocan los números desde el 3 hasta el 9.e) En la columna “hojas” se colocan los segundos dígitos de cada valor que empiece con 3, con 4, con 5, etc.
3 2374 2695 145786 133587 1233357788 3559 13
Girando la tabla obtenida 90° hacia la izquierda, se obtendrá algo similar a un gráfico de barras, que muestra por ejemplo que la mayor concentración de valores es la que comienza con 7.
Una utilidad adicional del diagrama de tallo y hojas es que permite comparar visualmente dos variables, es decir, dos conjuntos de datos en los análisis de correlación, como puede apreciarse en el siguiente ejemplo:
Hojas (Grupo control) Tallo
Hojas (Grupo experimental)
87655 1 944322110 2 124
876655 3 5667788899111000 4 00023344
5 555
Visualmente es posible darse una idea de los resultados del experimento: los datos del grupo experimental tienden a concentrarse en los valores altos, y los del grupo de control en los valores bajos.
Pictograma
Es una representación gráfica en la cual se utilizan dibujos. Por ejemplo, en el siguiente pictograma cada cara puede representar 100 personas:
Sector circular
Representación gráfica de forma circular donde cada porción de la ‘torta’ representa una frecuencia. Para confeccionarlo se parte de una tabla de frecuencias donde están especificadas las frecuencias en grados (f°), las cuales se calculan mediante una sencilla regla de tres simple a partir de las frecuencias absolutas (f).Por ejemplo, si 825 es a 360°, entonces 310 es igual a 360° x 310 dividido por 825, lo cual da un resultado de 135°. Por lo tanto, para representar la frecuencia 310 deberá trazarse un ángulo de 135°.Estos valores pueden verse en el ejemplo siguiente, donde se han representado dos sectores circulares distintos, uno para varones y otro para mujeres:
x(patología)
Sexo Total f°(varones)
f°(mujeres)Varones Mujeres
Angina 310 287 597 135° 113°Bronquitis 297 429 726 130° 169°Sarampión 123 120 243 54° 47°Otras 95 80 175 41° 31°Total 825 916 1691 360° 360°

VaronesMujeres
Bronquitis
Angina
Sarampión
Otras
Bronquitis
Angina Sarampión
Otras
Para realizar estos sectores se traza un ángulo de por ejemplo 130° y dentro de coloca la palabra “bronquitis”, y así sucesivamente.El círculo para mujeres es algo mayor que el círculo para hombres, porque en la muestra hay más mujeres que hombres. Para lograr estos tamaños debe calcularse el radio. Por ejemplo, si se ha elegido un radio masculino de 4 cm, el radio femenino puede calcularse mediante la fórmula siguiente:El radio femenino es igual al radio masculino multiplicado por la raíz cuadrada del n femenino, resultado que se dividirá por la raíz cuadrada del n masculino, donde n = tamaño de la muestra de cada sexo. Si el radio masculino es 4 cm, con esta fórmula se obtendrá un radio femenino de 4,22 cm.
Diagrama de barras
Representación gráfica donde cada barra representa una frecuencia parcial. En el eje de las ordenadas se indican las frecuencias absolutas, y en el eje de absisas se representan los valores de la variable x. De esta manera, las barras ‘más altas’ tienen mayor frecuencia.Existen diferentes tipos de diagramas de barras, de los cuales se ilustran tres: las barras simples, las barras superpuestas y las barras adyacentes. Los dos últimos tipos dan información sobre dos variables al mismo tiempo, que son sexo y estado civil en los ejemplos que siguen:

f
25
20
15
10
5
Barras simples
f
25
20
15
10
5
Solteros Casados Separados x
Barras superpuestas
f
25
20
15
10
5
Solteros Casados Separados x
Barras adyacentes
Solteros Casados Separados x
Adolescentes
Adultos
Las barras también pueden disponerse horizontalmente.Mediante el diagrama de barras pueden representarse variables cualitativas y cuantitativas discretas.
Histograma de Pearson
Utilizado para representar variables cuantitativas continuas agrupadas en intervalos, este gráfico se compone de barras adyacentes cuya altura es proporcional a las respectivas frecuencias parciales. En el ejemplo siguiente, se presenta la tabla de frecuencias por intervalos y su histograma correspondiente:
x (longitud) f1-1.99 32-2.99 53-3.99 2Total 10

f
5
4
3
2
1
1 2 3 4 x
f
5
4
3
2
1
1.5 2.5 3.5 punto medio (xm)
Como pude apreciarse, en las absisas se indican los límites inferiores de los intervalos.Cuando los intervalos no son iguales, en lugar de indicar las frecuencias absolutas pueden indicarse las alturas (h). Esta última se obtiene dividiendo la frecuencia parcial por el tamaño del intervalo correspondiente.
Polígono de frecuencias
Es un gráfico de líneas rectas que unen puntos, siendo cada punto la intersección del punto medio del intervalo (indicado en las absisas) y la frecuencia correspondiente. Tomando el ejemplo anterior, el polígono de frecuencias sería el siguiente:
Un polígono de frecuencias puede obtenerse también a partir del histograma correspondiente. Para ello basta con indicar los puntos medios de cada línea horizontal superior de cada barra del histograma, y luego unirlos con líneas rectas.Otra alternativa para este tipo de diagrama es el polígono de frecuencias acumuladas, donde se indican las frecuencias acumuladas en lugar de las frecuencias habituales.
Ojiva de Galton
Gráfico en el cual se consignan en las ordenadas las frecuencias acumuladas y en las absisas los límites superiores de cada intervalo (aunque también pueden indicarse los puntos medios de cada intervalo). Por ejemplo:
x (longitud) f F1-1.99 3 32-2.99 5 83-3.99 2 10Total 10

F
10
9
8
7
6
5
4
3
2
1 1.99 2.99 3.99 lím superior (Ls)
La ojiva de Galton también puede representar frecuencias acumuladas decrecientes.
4. SÍNTESIS DE LOS DATOS: MEDIDAS ESTADÍSTICAS DE POSICIÓN
Los datos individuales pueden ser sintetizados mediante medidas de posición, medidas de dispersión (ambas se llaman medidas estadísticas), medidas de asimetría y medidas de curtosis. En este ítem se describen las medidas de posición.
Definición
Las medidas de posición pueden ser definidas de diversas formas (4). En esta nota proponemos la siguiente definición: Las medidas de posición son datos estadísticos que intentan representar un conjunto de datos individuales respecto de una variable.Esta definición se refiere a tres cuestiones:
1) Son medidas estadísticas, es decir, no son medidas individuales. Una medida de posición representa a todo un conjunto de datos, y no son los datos individuales. Por ejemplo, un promedio de edades representa a todas las edades del grupo, y no es la edad individual de uno de sus miembros, aunque pueda coincidir numéricamente con ella. Así, si el promedio de edades es 20 años y una de las personas del grupo tiene 20 años, el primer dato es una medida estadística y el segundo una medida individual.En otros términos, las medidas estadísticas no describen individuos, sino poblaciones o muestras. Por ejemplo, no tiene sentido explicar que una persona es anciana porque vive en una población cuyo promedio de edad es 70 años.2) Son medidas representativas, es decir, intentan representar y sintetizar a todas las medidas individuales. El conjunto de todas las medidas individuales puede recibir diversos nombres, tales como muestra y población, con lo cual tiene sentido afirmar proposiciones tales como ‘una medida de posición representa una muestra o una población’.Por ejemplo, es posible representar las notas obtenidas por un grupo de alumnos de diversas maneras:a) El promedio de las notas es de 7.35 puntos (en este caso usamos una medida de posición llamada media aritmética).b) La mitad de los alumnos ha obtenido una nota superior a 6,5 puntos (en este caso utilizamos otra medida de posición llamada mediana).c) La nota que más se ha repetido fue 7 puntos (en este caso usamos la medida de posición llamada modo).La pregunta acerca de cuál de las tres medidas de posición representa ‘mejor’ al conjunto de datos individuales es el problema de la representatividad de la medida de posición, y la estadística suministra, como se verá, diversos criterios para evaluar la mejor forma de representar un cierto número de datos individuales.

3) Son medidas que miden una variable, es decir, algún atributo o propiedad de los objetos. En el ejemplo anterior la variable medida es el rendimiento académico, pero también pueden obtenerse medidas de posición representativas de un conjunto de edades, de profesiones, de clases sociales, de puntuaciones de un test, de cantidad de dientes, etc.De otra manera: no tiene sentido decir que una medida de posición represente un conjunto de personas, pero sí tiene sentido decir que representan las edades de un conjunto de personas.
Características de las principales medidas de posición
Las medidas de posición pueden ser de tendencia central y de tendencia no central. Las primeras “se refieren a los valores de la variable que suelen estar en el centro de la distribución” (Kohan, 1994:69). Por ejemplo: la media aritmética, la mediana y el modo son las más conocidas, pero también está la media aritmética ponderada (útil cuando hay valores que se repiten y que requieren atención diferencial), la media geométrica (Kohan, 1994:71-72), la media armónica, la media antiarmónica, la media cuadrática, la media cúbica, etc.Las medidas de posición no centrales son los cuartiles, deciles y percentiles (Kohan, 1994:79), que reciben genéricamente el nombre de cuantiles o fractiles (5). Los cuantiles se clasifican entonces en cuartiles, quintiles, deciles y percentiles, según que dividan la serie ordenada de valores en cuatro, cinco, diez o cien partes iguales.De acuerdo a Botella (1993:99), las medidas de posición no centrales son datos o valores que ocupan una posición especial en la serie de datos. Cuando una medida de posición es un dato que ocupa un lugar central, la llamamos medida de tendencia central.
En el siguiente cuadro se especifican las definiciones y características principales de las medidas de posición.
Medida Definición CaracterísticasMODO Es el dato o
valor que más se repite, o sea, el de mayor frecuencia.
Resulta útil si hay muchos datos repetidos (altas frecuencias).Puede calcularse cuando hay valores muy extremos.El modo muestral no es un estimador suficiente del modo poblacional porque no incluye todos los datos.En distribuciones multimodales es posible que la muestra no sea homogénea, y que esté constituída por varios estratos.Es posible convertir una distribución multimodal en una modal reorganizando los intervalos.Si una distribución no tiene modo, podría obtenerse reorganizando los datos en intervalos.
MEDIANA Es el dato o valor que divide por la mitad la serie de datos ordenados creciente o decrecientemente, es decir, es el valor central de la serie.
Es la medida más útil en escalas ordinales siempre que los valores centrales sean iguales.No está influenciada por los valores extremos (por ello por ejemplo puede aplicarse desconociendo estos o sea cuando hay límites superiores o inferiores abiertos).Puede usarse cuando hay intervalos abiertos, siempre que el orden de la mediana no se corresponda con ellos.Es útil cuando unos pocos datos difieren mucho del resto.No es útil si hay muchos datos repetidos (altas frecuencias).La mediana muestral no es un estimador suficiente de la mediana poblacional porque no incluye todos los datos.Es útil es distribuciones muy asimétricas (extremos no compensados).La mediana coincide con el Q2 (cuartil 2), el D5 (decil 5) y el P50 (percentil 50) (8).
MEDIA ARITMÉTICA
Es el promedio aritmético de todos los datos o valores.
Está influenciada por los valores extremos (por ejemplo, no puede utilizarse cuando hay valores extremos desconocidos o intervalos abiertos, salvo que estos puedan cerrarse).No conviene cuando los valores extremos son muy altos o muy bajos.Es útil en distribuciones simétricas (con extremos compensados).No puede usarse en escalas nominales ni ordinales.Es siempre superior a la media geométrica y a la media armónica.La media muestral es un estimador suficiente de la media poblacional porque incluye todos los datos.No necesariamente coincide con alguno de los valores.La media aritmética tiene varios otras propiedades (7).
CUANTIL Es el dato o valor que divide la serie ordenada de datos en partes iguales.
Es útil cuando hay gran cantidad de valores.Puede también utilizarse como medida de dispersión.Suelen utilizarse los cuartiles, los deciles y los percentiles.
-Cuartiles Valores que Tres cuartiles dividen la serie en cuatro partes iguales.

dividen la serie en cuatro partes iguales.
-Deciles Valores que dividen la serie en diez partes iguales.
Nueve deciles dividen la serie en diez partes iguales.
-Percentiles Valores que dividen la serie en cien partes iguales.
Noventa y nueve percentiles dividen la serie en cien partes iguales.También se llaman centiles.
Relación entre modo, mediana y media aritmética.- a) La experiencia indica que la relación entre estas tres medidas es: Modo = (3 . Mediana) – (2 . Media aritmética). Esta relación es conocida como la fórmula de Pearson. b) Cuanto más simétrica es una distribución (por ejemplo en una curva normal), más tienden a coincidir los valores de las tres medidas.
Media armónica y media geométrica.- Otras medidas de posición asociadas a la media aritmética son la media armónica y la media geométrica.La media armónica es una medida de posición que suele utilizarse cuando se comparan cantidades constantes de una variable con cantidades variables de otra. Se emplea por ejemplo en física o en música.La media armónica se utiliza en problemas tales como el siguiente: Cuál es la velocidad promedio de un móvil que recorre una trayectoria sobre un cuadrado de 200 km de lado? Las cantidades variables son las velocidades diferentes en cada lado del cuadrado, mientras que la cantidad constante es 200 km. Para calcularla, se utiliza una fórmula donde el numerador es la cantidad de lados (en este caso cuatro), y el denominador es la suma de las inversas de las diferentes velocidades (por ejemplo 1/200 kmh, más 1/150 kmh, etc.).La media geométrica es una medida de posición utilizada en variables tales como tasas de crecimiento, tasas de mortalidad, tasas de interés o cualquier otra expresada en porcentajes. La media geométrica no está tan influenciada por los valores extremos como en la media aritméticaLa media geométrica se utiliza en problemas tales como el siguiente: En un banco se colocan 100$ al 10% en el primer mes, al 6% en el segundo mes, al 4% en el tercer mes y al 8% en el cuarto mes. Cuál es la tasa de interés promedio obtenida?Para calcular la media geométrica, es decir, la tasa de interés promedio, se utiliza la fórmula correspondiente. En este caso se multiplican los valores $110, $106, $104 y $108, que expresan el capital no acumulado más el interés de cada mes, y el resultado se lo eleva a la raíz cuarta (porque son cuatro los meses). El resultado es $106.9 que, restado a $100, da $6.9. Esto significa que la tasa de interés promedio es del 6.9%.
Cálculo analítico de las medidas de posición: fórmulas
Para calcular una determinada medida de posición puede haber diversas fórmulas. La elección de la fórmula adecuada dependerá de la forma en que estén organizados los datos individuales.En principio, los datos pueden estar organizados de cuatro maneras:1) Datos desordenados. Por ejemplo, las edades de un grupo de cuatro personas son 17, 29, 17 y 14. Cuando se recolecta información, generalmente se obtienen datos desordenados, frente a lo cual convendrá ordenarlos.2) Datos ordenados. Por ejemplo, las edades del mismo grupo de personas son 14, 17, 17 y 29, si hemos decidido ordenarlas en forma creciente, aunque también podemos ordenarlas decrecientemente.3) Datos agrupados por frecuencia. Por ejemplo, hay dos edades de 17 años, una edad de 14 años y una edad de 29 años. O, lo que es lo mismo, la frecuencia de la edad 17 es 2, y la frecuencia de las restantes edades es 1.4) Datos agrupados por intervalos. Por ejemplo, hay 3 edades comprendidas en el intervalo 14-17 años, y una edad comprendida en el intervalo 18-29 años.La estadística va agrupando los datos siguiendo el orden anterior. Cuanto más avance en este proceso, más habrá logrado sintetizar y organizar los datos individuales.En el siguiente cuadro se sintetizan las diversas reglas o fórmulas para calcular las medidas de posición, según como estén organizados los datos individuales y según los niveles de medición que admiten. Nótese que en algunos casos no es posible especificar ninguna fórmula, y entonces el cálculo se hará siguiendo la regla indicada para los mismos. Por ejemplo: “para calcular el modo de un conjunto de datos ordenados, debe buscarse el dato o valor que más se repite” (6).

Cálculo de medidas de posición según los niveles de medición que admiten y según la forma de organización de los datos individuales.Preparado por: Pablo Cazau
Medida de posición
Nivel de medición
Datos ordenados Datos agrupados por frecuencia Datos agrupados por intervalos
Modo Nominal Valor que más se repite Valor con la mayor frecuencia ------------Ordinal Valor que más se repite Valor con la mayor frecuencia ------------Cuantitativo Valor que más se repite Valor con la mayor frecuencia f - fant
Mo = Li + ---------------------- . a (f - fant) + (f- fpos)
Mediana Ordinal Valor central de la serie ordenada de valores
Valor que corresponde a la frecuencia acumulada n/2 ------------
Cuantitativo Valor central de la serie ordenada de valores
Valor que corresponde a la frecuencia acumulada n/2 n/2 - Fant
Mn = Li + ---------------------- . a f
Media aritmética
Cuantitativo xX = ----- n
x.f)X = --------- n
xm.f)X = --------- n
Cuartil Cuantitativo Valores que dividen la serie en cuatro partes iguales.Por tanto, hay 3 cuartiles: Q1, Q2 y Q3
Valor que corresponde a la frecuencia acumulada t.n/4, expresión llamada cuartil de orden o Q0 (1)Donde t puede valer 1, 2 o 3.Por tanto, hay 3 cuartiles: Q1, Q2 y Q3
t.n/4 - Fant
Qt = Li + ---------------- . a f
Decil Cuantitativo Valores que dividen la serie en diez partes iguales.Por tanto, hay 9 deciles: desde el D1 hasta el D9
Valor que corresponde a la frecuencia acumulada t.n/10, expresión llamada decil de orden o D0 (1)Donde t puede valer entre 1 y 9.Por tanto, hay 9 deciles: desde el D1 hasta el D9
t.n/10 - Fant
Dt = Li + ---------------- . a f
Percentil Cuantitativo Valores que dividen la serie en cien parte iguales.Por tanto, hay 99 percentiles: desde el P1 hasta el P99
Valor que corresponde a la frecuencia acumulada t.n/100, expresión llamada percentil de orden o P0 (1)Donde t puede valer entre 1 y 99.Por tanto, hay 99 percentiles: desde el P1 hasta el P99
t.n/100 - Fant
Pt = Li + ---------------- . a f
(1) Si no puede identificarse unívocamente una frecuencia acumulada, y por tanto un valor determinado de x, puede ser calculada por interpolación. En realidad, los cuantiles se utilizan preferentemente cuando los datos están agrupados por intervalos.

A continuación, se suministran ejemplos de cómo calcular cada medida de posición teniendo en cuenta las reglas y fórmulas del esquema anterior.
a) Cálculo del modo para datos ordenados (niveles nominal, ordinal y cuantitativo)
Nivel nominal: perro, perro, gato, gato, gato, gato (por tanto, el modo es gato)Nivel ordinal: grande, grande, mediano, mediano, mediano, chico, chico, chico, chico (por tanto, el modo es chico)Nivel cuantitativo: 6, 6, 7, 7, 7, 7, 8, 9, 10, 10, 11 (por tanto, el modo es 7)
b) Cálculo del modo para datos agrupados en frecuencia (niveles nominal, ordinal y cuantitativo)
Nivel nominal Nivel ordinal Nivel cuantitativox (religión) f
Católicos 56Protestantes 78Judíos 45Budistas 24Otros 31
x (dureza) fMuy duro 18Duro 8Intermedio 13Blando 16Muy blando 7
x (edad) f30 años 631 años 1432 años 1933 años 2434 años 15
El modo es “Protestantes” El modo es “Muy duro” El modo es “33” años
Como puede verse, el modo es el valor de la variable x que está más repetido.
c) Cálculo del modo para datos agrupados por intervalos (nivel cuantitativo)
x (cantidad piezas dentarias) f10-18 619-27 828-36 2437-45 2
n=40
Una vez confeccionada la tabla de frecuencias por intervalos, se procede en dos pasos:
a) Se identifica cuál es el intervalo de mayor frecuencia. En este caso, es 28-36.b) Se aplica la fórmula correspondiente:
f - fant
Mo = Li + ---------------------- . a (f - fant) + (f- fpos)
24 - 8Mo = 28 + ---------------------- . 8 = 31.37 piezas dentarias (24 - 8) + (24 - 2)
d) Cálculo de la mediana para datos ordenados (niveles ordinal y cuantitativo)
Para hallar la mediana de un conjunto de datos, primero hay que organizarlos en orden descendente o ascendente. Si el conjunto de datos contiene un número impar de elementos, el central es la mediana. Si hay un número par, la mediana es el promedio de los dos datos centrales.
Ejemplos para el nivel ordinal:
Número impar de datos: alto, alto, alto, alto, medio, medio, medio, medio, medio, medio, bajo (por tanto, la mediana es = medio).Número par de datos: En el nivel ordinal no puede calcularse un promedio si los dos valores centrales son distintos. Si los dos valores centrales son iguales, ese es el valor de la mediana.
Ejemplos para el nivel cuantitativo:
Número impar de datos: 13, 13, 13, 14, 14, 17, 18, 19, 19 (por tanto, la mediana es 14)Número par de datos: 11, 11, 12, 13, 14, 15, 16, 18, 18, 18 (por tanto, la mediana es el promedio entre 14 y 15, o sea 14.5).
e) Cálculo de la mediana para datos agrupados por frecuencia (niveles ordinal y cuantitativo)
x (días) f F
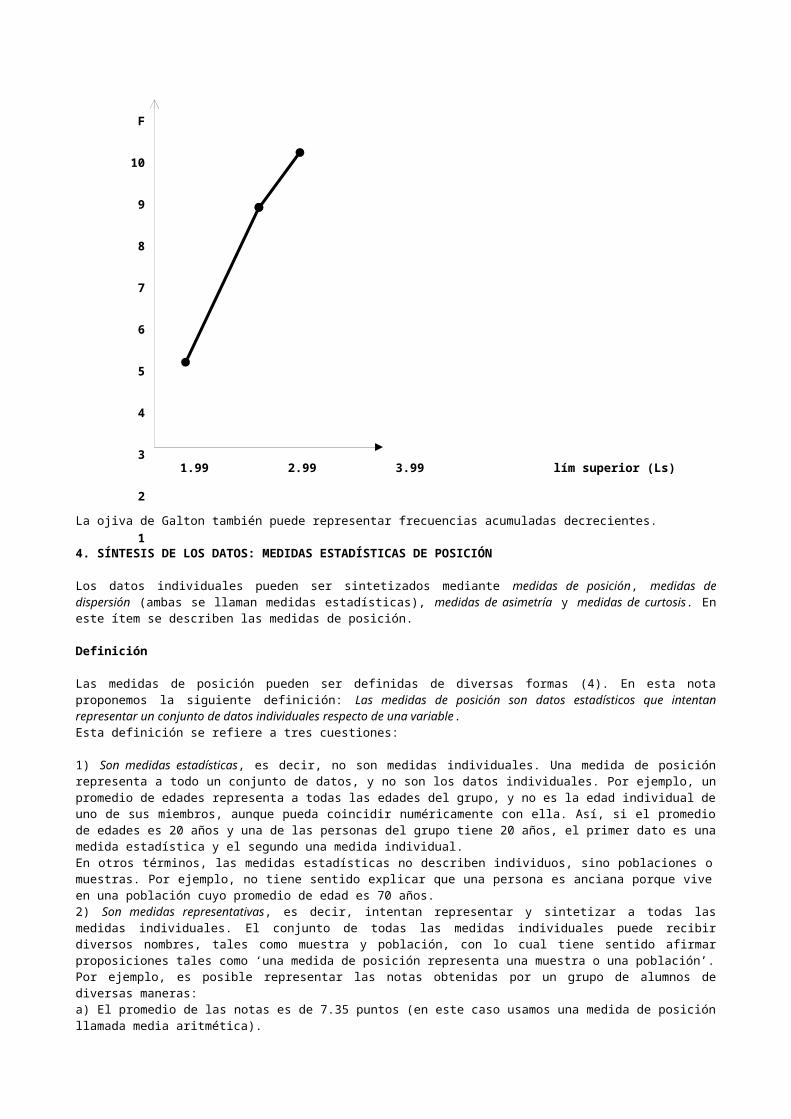
1 7 72 9 163 14 304 10 405 2 42
n = 42
La variable es aquí cantidad de días de posoperatorio.El procedimiento es el siguiente:a) Se calcula la mediana de orden:
Mn0 = n/2 = 42/2 = 21
b) Se identifica cuál es el valor de x que corresponde a la frecuencia acumulada que contiene el valor 21:
Dicha frecuencia acumulada es 30, y, por lo tanto Mn = 3 días
f) Cálculo de la mediana para datos agrupados por intervalos (nivel cuantitativo)
x f F0-3 8 83-6 10 186-9 11 299-12 12 4112-15 9 5015-18 7 5718-21 6 6321-24 5 68
n = 68
Nótese que para calcular la mediana se precisa información sobre frecuencias acumuladas, razón por la cual se ha agregado la columna respectiva.Se procede en dos pasos:a) Se identifica cuál es el intervalo que debe ser considerado, para lo cual se calcula la mediana de orden:
Mn0 = n/2 = 68/2 = 34Tomando en cuenta las frecuencias acumuladas, el valor 34 entra en la frecuencia acumulada 41, y, por lo tanto, el intervalo a considerar será 9-12.b) Se aplica la fórmula de mediana:
n/2 - Fant
Mn = Li + ---------------------- . a f
34 - 29Mn = 9 + ---------------------- . 3 = 10.25 12
Téngase presente que si la variable fuera discreta y medible sólo en números enteros, sería Mn = 10.Si la variable fuese cantidad de materias aprobadas, el alumno con 10 materias aprobadas está en el lugar central de la serie, es decir, habría un 50% de compañeros con menos materias aprobadas y un 50% con más materias aprobadas.
g) Cálculo de la media aritmética para datos ordenados (nivel cuantitativo)
Dados los siguientes dados ordenados: 2-2-3-4-4-4-5-5-6-7-8-10Se puede calcular la media aritmética aplicando la fórmula:
xX = ----- n
X = ---------------------------------------- = --------- = 5 12 12
Página 34 de 314
34

h) Cálculo de la media aritmética para datos agrupados por frecuencia (nivel cuantitativo)
x (edad) f f . x18 3 5419 1 1920 2 4023 4 4225 2 5026 2 5228 2 56
n = 16 363
Nótese que para el cálculo de la media aritmética se ha agregado una columna con los productos de x . f.Se aplica la fórmula de media aritmética:
x.f) 54+19+40+42+50+52+56 363X = --------- = ----------------------------------- = -------- = 22.68 años = 23 años. n 16 16
i) Cálculo de la media aritmética para datos agrupados por intervalos (nivel cuantitativo)
x f xm xm.f0-3 8 1.5 123-6 10 4.5 456-9 11 7.5 82.59-12 12 10.5 12612-15 9 13.5 121.515-18 7 16.5 115.518-21 6 19.5 117.621-24 5 22.5 112.5
n = 68 732.5
Nótese que para el cálculo de la media aritmética se ha agregado una columna con los puntos medios de los intervalos y otra con los productos de las frecuencias por los puntos medios.Se aplica la fórmula de media aritmética:
xm.f) 732.5X = ------------- = ---------- = 10.77 n 68
El método corto y el método clave son dos métodos alternativos para calcular la media aritmética, siendo el último sólo aplicable cuando el tamaño de los intervalos es constante.De acuerdo al método corto, la media aritmética se calcula sumando al punto medio del intervalo de mayor frecuencia, el cociente entre la sumatoria de los productos entre cada frecuencia y la diferencia entre el punto medio de cada intervalo menos el punto medio del intervalo de mayor frecuencia, y la sumatoria de frecuencias (n).De acuerdo al método clave, la media aritmética se calcula sumando al punto medio del intervalo de mayor frecuencia, el producto entre el tamaño del intervalo y un cociente, donde el numerador es la sumatoria de los productos entre las frecuencias y el llamado intervalo unitario (que resulta de dividir la diferencia entre cada punto medio y el punto medio del intervalo de mayor frecuencia, por el tamaño del intervalo), y donde el denominador es la sumatoria de frecuencias (n).
j) Cálculo del cuantil para datos ordenados (nivel cuantitativo)
1-1-1-1-1-2-2-2-3-3-3-3-4-5-6-6-6-6-7-7-8-8-9
Si en la serie anterior resaltamos los tres valores que la dividen en cuatro partes iguales, esos valores serán los cuartiles Q1, Q2 y Q3:
1-1-1-1-1-2-2-2-3-3-3-3-4-5-6-6-6-6-7-7-8-8-9
Q1 = 2Q2 = 3Q3 = 6
Página 35 de 314
35

Sin embargo, es más práctico agrupar los datos por frecuencias o por intervalos, a los efectos del cálculo de los cuantiles (cuartiles, deciles o percentiles).
k) Cálculo del cuantil para datos agrupados por frecuencia (nivel cuantitativo)
x (edad) f F18 3 319 1 420 2 623 4 1025 2 1226 2 1428 2 16
n = 16
Se pueden calcular, por ejemplo, Q1, Q2 y Q3.
El primer paso consiste en averiguar los respectivos cuartiles de orden.
Para Q1 es Q0 = t.n/4 = 1.16/4 = 4Para Q2 es Q0 = t.n/4 = 2.16/4 = 8Para Q3 es Q0 = t.n/4 = 3.16/4 = 12
El segundo y último paso consiste en identificar el valor de x correspondiente al cuartil de orden respectivo.
Q1 = 4Q2 = Está entre 20 y 23Q3 = 25
l) Cálculo del cuantil para datos agrupados por intervalos (nivel cuantitativo)
x (puntaje) f F0-10 1 110-20 3 420-30 5 930-40 6 1540-50 10 2550-60 12 3760-70 13 5070-80 9 5980-90 4 6390-100 3 66
n = 66
Se pueden calcular, por ejemplo, Q3, D7 y P45.
El primer paso consiste en averiguar los cuantiles de orden:
Para Q3 es Q0 = t.n/4 = 3.66/4 = 49.5Para D7 es D0 = t.n/10 = 7.66/10 = 46.2Para P45 es P0 = t.n/100 = 45.66/100 = 29,7
El segundo paso consiste en identificar el intervalo que corresponde al cuantil de orden en la columna de frecuencias acumuladas:
El valor 49.5 corresponde al intervalo 60-70El valor 46.2 corresponde al intervalo 60-70El valor 29.7 corresponde al intervalo 50-60
El tercer y último paso consiste en aplicar la fórmula basándose en la información del intervalo identificado. Si la fórmula pide el dato de la frecuencia acumulada anterior y esta no existe, se coloca 0 (cero).En el ejemplo del cálculo del D7, se aplica la siguiente fórmula:
t.n/10 - Fant
Dt = Li + ------------------- . a f
Página 36 de 314
36

f
5
4
3
2
1
1 4 7 10 x
46.2 - 37D7 = 60 + ---------------- . 11 = 67.78 13
Cálculo visual de las medidas de posición: gráficos
Es posible utilizar un procedimiento gráfico para calcular ciertas medidas de posición, tales como el modo y la mediana. Por ejemplo, el modo se puede calcular a partir de un histograma. La mediana también puede calcularse con un histograma, aunque lo más habitual es hacerlo mediante una ojiva.
a) Cálculo del modo mediante un histograma
Una vez construido el histograma a partir de una tabla de datos agrupados por intervalos:1) Se considera el rectángulo de mayor frecuencia (mayor altura).2) Dentro del mismo se trazan dos rectas como está indicado en el gráfico siguiente.3) Por la intersección de ambas rectas se traza una recta perpendicular al eje de absisas.4) El punto del eje de las absisas por donde pasa la recta perpendicular corresponde al modo (en el ejemplo, el modo es 4.80).
b) Cálculo de la mediana mediante una ojiva
En este caso pueden utilizarse dos procedimientos:1) Una vez trazada la ojiva, a) se ubica en el eje de las ordenadas a la mediana de orden (Mn 0 ); b) por la mediana se orden se traza una recta paralela al eje x hasta que intersecte la ojiva; c) por este punto de intersección se traza una recta paralela al eje y hasta que intersecte el eje x. En este punto estará ubicada la mediana.2) Se trazan en el mismo eje de coordenadas las ojivas creciente y decreciente de la misma distribución de datos. Luego, a) se traza una recta paralela al eje y que pase por la intersección de ambas ojivas y por algún punto del eje x; b) el punto del eje x por donde pasa dicha recta corresponde a la mediana.
Criterios de elección de medidas de posición
1) La elección de una medida de posición debe tener en cuenta el nivel de medición de la variable que se mide:
Nivel nominal Nivel ordinal Nivel cuantitativoModo SI SI SIMediana NO SI. Siempre y cuando los dos
valores centrales con n = par sean iguales. En caso contrario usar el Modo.
SI
Media aritmética
NO NO SI Cuando no haya valores extremos alejados ni valores extremos abiertos. En caso contrario, usar el Modo o la Mediana (*).
Cuantiles NO NO SI
Página 37 de 314
37

(*) Hay al menos tres situaciones donde se preferirá la mediana a la media (Botella, 1993:115): a) cuando la variable es ordinal, b) cuando haya valores extremos que distorsionen la interpretación de la media, y c) cuando haya intervalos abiertos, como en el caso de variables como ingresos mensuales.
2) La elección de una medida de posición debe tener en cuenta la forma en que están organizados los datos. Por ejemplo: “en ocasiones, el azar hace que un solo elemento no representativo se repita lo suficiente para ser el valor más frecuente del conjunto de datos. Es por esta razón que rara vez utilizamos el modo de un conjunto de datos no agrupados como medida de tendencia central. Por esta razón, debemos calcular el modo en datos agrupados en una distribución de frecuencias” (Levin y Rubin, 1996).
3) La elección de una medida de posición de una muestra debe tener en cuenta el grado de fidelidad con que representa a la medida de posición poblacional.Botella (1993:114) afirma, en este sentido, que si no hay ningún argumento en contra, siempre se preferirá la media, no sólo porque permite la utilización de otras medidas estadísticas (por ejemplo el desvío estándar), sino porque es más representativa de la media poblacional que el modo o la mediana con respecto al modo o la mediana poblacional.
5. SÍNTESIS DE LOS DATOS: MEDIDAS ESTADÍSTICAS DE DISPERSIÓN
Definición
Las medidas de dispersión, llamadas también medidas de variabilidad o de variación, son datos estadísticos que informan acerca del grado de dispersión o variabilidad de los datos individuales de una muestra o una población, respecto de una variable. En otras palabras, indican el grado de homogeneidad o de heterogeneidad del conjunto de los datos. Por ejemplo, indican cuán alejados o cuán cercanos se encuentran los datos de algún valor central como la media aritmética: una muestra cuyos datos son 3-4-5 es menos dispersa que una muestra cuyos datos son 1-4-7.
Algunos autores (Botella, 1993:325) han relacionado la dispersión de los datos -para los niveles de medición nominal y ordinal- con los conceptos de entropía y de incertidumbre e incluso han propuesto a la primera como una medida que permite cuantificar la dispersión: a mayor dispersión de los datos, hay mayor entropía y mayor incertidumbre.Por ejemplo, las siguientes dos muestras tienen cada una 40 sujetos que han elegido determinados colores para representar la idea de paz:
Blanco Verde Amarillo Celeste RosaMuestra A: 28 3 3 3 3Muestra B: 8 8 8 8 8
Si habría que adivinar qué color eligió determinado sujeto de la muestra A, cabría proponer el color blanco porque fue el más elegido. En cambio, la incertidumbre aumenta si habría que elegir lo mismo en la muestra B. En esta muestra hay más entropía, es decir, más desorden, mientras que en la muestra A los datos están más ordenados alrededor de un valor muy repetido, como el blanco.La muestra B es más dispersa, es decir, más heterogénea, mientras que la muestra A es menos dispersa, es decir, más homogénea. La homogeneidad no debe relacionarse con la repetición de frecuencias (3-3-3-3) sino con la repetición de valores iguales o muy cercanos entre sí (28 sujetos eligieron blanco).
Una medida de posición no alcanza para describir adecuadamente una muestra. Se obtiene una información más precisa y completa de ella cuando además se utiliza una medida de dispersión.Por ejemplo, la muestra 1 de datos 3-4-5 y la muestra 2 de datos 1-4-7 tienen la misma medida de posición: la media aritmética en ambos casos es 4. Sin embargo, se trata evidentemente de dos muestras diferentes, por cuanto la segunda es más dispersa que la primera, es decir, sus datos están más alejados de la media aritmética.En la primera muestra el promedio de las desviaciones respecto de la media es 1 (de 3 a 4 hay 1, y de 5 a 4 hay 1), mientras que el promedio de las desviaciones en la segunda muestra es 3 (de 1 a 4 hay 3, y de 7 a 4 hay 3). Por lo tanto, ambas muestras pueden representarse de la siguiente manera:
Muestra 1: 4 + 1 (se lee 4 más/menos 1)Muestra 2: 4 + 3 (se lee 4 más/menos 3).
Las medidas de dispersión tienen una importancia adicional porque (Levin y Rubin: 1996): a) Proporcionan información adicional que permite juzgar la confiabilidad de la medida de tendencia central. Si los datos se encuentran ampliamente dispersos, la posición central es menos representativa de los datos. b) A veces resulta indispensable conocer la dispersión de una muestra porque muestras demasiado dispersas pueden no ser útiles para poder sacar conclusiones útiles sobre la muestra. Levin y Rubin indican que, “ya que existen problemas característicos para datos ampliamente dispersos, debemos ser capaces de distinguir los que presentan esa dispersión antes de abordar esos problemas”.
Características de las principales medidas de dispersión
Página 38 de 314
38

En general, las medidas de dispersión más utilizadas sirven para la medición de variables en el nivel cuantitativo. Seguidamente se examinarán las siguientes medidas de dispersión: rango, desviación media, varianza, desvío estándar, desvío intercuartílico y coeficiente de variación.
En el siguiente cuadro se especifican las definiciones y características principales de las medidas de dispersión.
Medida Definición CaracterísticasRANGO Es la diferencia
entre los valores máximo y mínimo de la variable.
De uso limitado, no es una buena medida de dispersión.Es muy sensible a los valores extremos e insensible a los valores intermedios.Está muy vinculada al tamaño de la muestra: es probable que la muestra de mayor tamaño presente mayor rango aunque las poblaciones de referencia tengan igual dispersión (Botella, 1993).Se llama también amplitud.
DESVIACION MEDIA
Es el promedio de las desviaciones de todos los valores respecto de la media aritmética.
Considera desviaciones absolutas, es decir, no las considera con valores negativos (de otro modo, el promedio de las desviaciones, por un teorema de la media aritmética, daría cero). Esto representa una dificultad de cálculo, por lo que se utiliza la varianza.
VARIANZA Es el promedio de los cuadrados de las desviaciones con respecto a la media aritmética.
Es un valor esencialmente no negativo (10).Matemáticamente es buena medida de dispersión, pero da valores muy altos, por lo cual en estadística descriptiva se utiliza el desvío estándar (9).Se apoya en una propiedad de la media aritmética según la cual la suma de los cuadrados de las desviaciones respecto a la media es un valor mínimo.La varianza permite comparar la dispersión de dos o más muestras si sus medias aritméticas son similares (Botella, 1993).Si se suma una constante a un conjunto de valores, la varianza no se modifica (Botella, 1993).Si se multiplica por una constante a un conjunto de valores, la varianza de los nuevos valores el igual al producto de la varianza de las originales por el cuadrado de la constante (Botella, 1993).
DESVIO ESTÁNDAR
Es la raíz cuadrada de la varianza (11)
Es un valor esencialmente no negativo (10).Es la medida de dispersión más utilizada.Se la emplea conjuntamente con la media aritmética como medida de posición.La raíz cuadrada permite compensar el cuadrado de la varianza.Si se suma una constante a un conjunto de valores, el desvío estándar no se modifica (Botella, 1993).Si se multiplica por una constante a un conjunto de valores, el desvío estándar de los nuevos valores el igual al producto del desvío estándar de las originales por el cuadrado de la constante (Botella, 1993).Se llama también desviación típica, o también desviación estándar (Pagano, 1998:71).
DESVIO INTERCUARTILICO
Es la diferencia entre el Q3 y el Q1.
Expresa el rango del 50% central de la serie de valores.Se llama también amplitud intercuartil.
COEFICIENTE DE VARIACION
Es el cociente entre el desvío estándar y la media aritmética.
Permite comparar la dispersión de dos o más muestras con diferentes medias aritméticas: a mayor coeficiente de variación, mayor dispersión.No se expresa en unidades como la variable en estudio (por ejemplo, para edad, no se expresa en años).Puede considerarse como un índice de la representatividad de la media aritmética: cuanto mayor es el coeficiente de variación, menos representativa es la media (Botella, 1993).
Cálculo analítico de las medidas de dispersión: fórmulas
En este ítem se indican las fórmulas para calcular medidas de dispersión, y se suministran ejemplos de cada caso.
Cálculo de las medidas de dispersión según la forma de organización de los datos individualesPreparado por: Pablo Cazau
Medida de dispersión
Datos ordenados Datos agrupados por frecuencia Datos agrupados por intervalos
Rango R = xmay - xmen R = xmay - xmen No
Desviación | x – X | | x – X | . f | xm – X | . f
Página 39 de 314
39

media Dm = --------------- n
Dm = ------------------ n
Dm = -------------------- N
Desvío estándar
( x – X )2
S = ---------------- nEl segundo miembro es a la raíz cuadrada
( x – X )2 . fS = ------------------- nEl segundo miembro es a la raíz cuadrada
( xm – X )2 . fS = ---------------------- nEl segundo miembro es a la raíz cuadrada
Varianza Es el cuadrado del desvío estándar (S2)
Es el cuadrado del desvío estándar (S2)
Es el cuadrado del desvío estándar (S2)
Desvío intercuartílico
DQ = Q3 – Q1 DQ = Q3 – Q1 DQ = Q3 – Q1
Coeficiente de variación
SCV = ----- X
SCV = ----- X
SCV = ----- X
Cuando hay que calcular varianza o desvío estándar poblacionales, se utiliza ‘n’ en el denominador, pero cuando se calculan las correspondientes medidas muestrales (o cuando la muestra es muy pequeña), se utilizará ‘n–1’ (12).
a) Cálculo del rango para datos ordenados y para datos agrupados por frecuencia
Se puede aplicar a estas muestras la fórmula del Rango R = xmay - xmen
Muestra 1: 80, 100, 100, 110, 120. Aquí el rango R es = 120 – 80 = 40.Muestra 2: 30, 50, 70, 120, 180. Aquí el rango R es = 180 – 30 = 150
Como se ve, la muestra 2 es más dispersa porque tiene mayor rango.
No se puede calcular el rango para datos agrupados por intervalos porque se desconocen cuáles son los valores máximo y mínimo.
b) Cálculo de la desviación media para datos ordenados
La serie ordenada de datos puede ser la siguiente: 2, 3, 5, 6, 7, 9, 10Como primer paso se calcula la media aritmética:
2+3+5+6+7+9+10X = --------------------------- = 6 7
Como segundo y último paso, se calcula la desviación media:
| x – X | |2-6| + |3-6| + |5-6| + |6-6| + |7-6| + |9-6| + |10-6| Dm = --------------- = --------------------------------------------------------------------- = 2.29 N 7
c) Cálculo de la desviación media para datos agrupados por frecuencia
A la siguiente tabla de frecuencias (f) deberá agregarse una columna (f.x) para calcular la media aritmética, y luego otras dos columnas (x-X) y (| x-X | . f) para calcular la desviación media:
x f f . x | x - X | | x - X | . f70 45 3150 35 157580 63 5040 25 157590 78 7020 15 1170100
106 10600 5 530
110
118 12980 5 590
120
92 11040 15 1380
130
75 9750 25 1875
140
23 3220 35 115
n = 600 62800 160 8810
Primero se calcula la media aritmética:
Página 40 de 314
40

x.f) 62800X = --------- = ------------ = 104.66 = 105 n 600
Finalmente se calcula la desviación media:
| x – X | . f 8810Dm = ------------------ = ------------ = 14.68 n 600
d) Cálculo de la desviación media para datos agrupados por intervalos
Se procede de la misma manera que en el caso anterior, con la diferencia que en lugar de considerar los valores x, se consideran los puntos medios de los intervalos (xm).
e) Cálculo del desvío estándar para datos ordenados
Para la serie de valores 5, 6, 10, su media aritmética es 7. Una vez conocido este valor, puede obtenerse el desvío estándar de la siguiente forma:
( x – X )2 (5-7)2 + (6-7)2 + (10-7)2
S = Ö ------------------- = Ö ------------------------------------ = Ö 4.66 = 2.2 n 3
f) Cálculo del desvío estándar para datos agrupados por frecuencia
x (edad) f f . x x – X ( x – X )2 ( x – X )2 . f18 3 54 -5 25 7519 1 19 -4 16 1620 2 40 -3 9 1823 4 42 0 0 025 2 50 +2 4 826 2 52 +3 9 1828 2 56 +5 25 50
n = 16 363 185
Primero se calcula la media aritmética, que arroja un valor de X = 23.Finalmente, se aplica la fórmula de desvío estándar:
( x – X )2 . f 185S = Ö ---------------------- = Ö ------------ = Ö 11.56 = 3.2 n 16
Puede también utilizarse una fórmula más sencilla a los efectos del cálculo (Bancroft, 1960:80):
x2.fS = ----------- - (X) 2
n
Donde el primer término del segundo miembro es a la raíz cuadrada.
g) Cálculo del desvío estándar para datos agrupados por intervalos
Se procede del mismo modo que en el caso anterior, con la diferencia que se calcula el punto medio xm de los intervalos en lugar del valor x.
h) Cálculo de la varianza
El procedimiento es el mismo que en el caso del desvío estándar. Sólo debe tenerse presente que la varianza es el cuadrado del desvío estándar.
i) Cálculo del desvío intercuartílico
Dada la siguiente serie, obtener el desvío intercuartílico:
x f0-20 2
Página 41 de 314
41

75 80 85 90 95 100 105 110 115 120 125 130
A
B
Xmín Xmáx
XmáxXmín
Q1 Q3
Q1 Q3
20-40 440-60 560-80 880-100 1
n = 20
Primero se calculan los Q3 y Q1 aplicando la fórmula explicada en medidas de posición.Finalmente, se aplica la fórmula del desvío intercuartílico:
DQ = Q3 – Q1 = 70 – 35 = 35
Una variante es el empleo del desvío semi-intercuartílico, es decir, el desvío intercuartílico dividido dos. Se trata de una medida de dispersión propuesta por Galton en 1889, y que resulta recomendable cuando hay algún valor extremo que pudiera distorsionar la representatividad de la media aritmética (Botella, 1993).
j) Cálculo del coeficiente de variación
Si una muestra tiene una media aritmética 111 y el desvío estándar 18, entonces su coeficiente de variación es:
S 111CV = ----- = ---------- = 0.16 X 18
Cuanto mayor es el CV, mayor es la dispersión.También puede calcularse un coeficiente de variación porcentual, multiplicando CV por 100. En el ejemplo:
CV% = 0.16 . 100 = 16%.
Cálculo visual de las medidas de dispersión: gráficos
Botella (1993:143) menciona dos procedimientos para expresar gráficamente medidas de dispersión: el diagrama de caja y bigotes (Tukey, 1977) y el diagrama de bigotes verticales.
Diagrama de caja y bigotes
Puede apreciarse a simple vista que la distribución de valores B es más dispersa que A no sólo porque la diferencia entre los valores máximo y mínimo (rango) es mayor, sino también porque lo es la diferencia entre los cuartiles primero y tercero.
Diagrama de bigotes verticales
Página 42 de 314
42

Nivel de ansiedad
4° 5° 6° 7° 8° Curso
El gráfico representa las medias aritméticas de nivel de ansiedad de diversos cursos de alumnos. En cada media aritmética se han trazado bigotes verticales que representan los respectivos desvíos estándar. Puede entonces apreciarse, por ejemplo, que a medida que aumenta la media aritmética, tiende también a aumentar el desvío estándar.
6. SÍNTESIS DE LOS DATOS: ASIMETRÍA Y CURTOSIS
Un conjunto de datos o distribución de datos queda exhaustivamente descrito cuando pueden especificarse una medida de posición, una medida de dispersión, un índice de asimetría y un índice de curtosis. Las medidas de asimetría y curtosis se refieren a la ‘forma’ de la distribución y, aunque no son tan importantes como las medidas de posición y dispersión y son muy poco utilizadas, aportan también información sobre la distribución de los valores de una muestra o población.
Asimetría
La asimetría hace referencia al grado en que los datos se reparten equilibradamente por encima y por debajo de la tendencia central (Botella, 1993:169). Por ejemplo, en la siguiente tabla se puede apreciar que en el curso A muchos alumnos obtuvieron buenas notas, en el curso C muchos alumnos obtuvieron bajas notas, y en el curso B están equilibrados.
x (nota) f (curso A) f (curso B) f (curso C)10 5 2 19 10 5 28 15 8 37 22 10 66 16 15 85 12 20 124 8 15 163 6 10 222 3 8 151 2 5 100 1 2 5
n = 100 n = 100 n = 100
Representando las tres distribuciones de datos con curvas en un gráfico con las frecuencias en las ordenadas y los valores de x en las absisas, se obtiene lo siguiente:
Página 43 de 314
43

Curso A Curso CCurso B
Media Modo Modo MediaMediaModo
Asimetría negativa(curva hacia la derecha)
Asimetría cero Asimetría positiva (curva hacia la izquierda)
Han sido propuestos diversos índices de asimetría para cuantificar el grado de asimetría de una distribución de datos. De entre ellos pueden citarse los siguientes (Botella, 1993:170):
Indice de asimetría media-
modo
Indice de asimetría media-mediana
(Kohan, 1994:93)
Indice de asimetría de Pearson
Indice de asimetría intercuartílico
Es la distancia entre la media y el modo, medido en desvíos estándar: X - MoAs = ------------- S
Es la distancia entre la media y la mediana multiplicada por tres, medida en desvíos estándar: X - MnAs= ------------- S
Es el promedio de los valores z elevados al cubo (donde z es el cociente entre la diferencia entre x y la media aritmética, y el desvío estándar).
Es el cociente entre la diferencia Q3-Q2 y Q2-Q1, y la diferencia Q3-Q1
Los tres índices se interpretan de manera similar: si resultan ser números negativos, la curva será asimétrica hacia la derecha, y si dan resultados positivos, la curva será asimétrica a la izquierda. El resultado 0 (cero) indicará asimetría nula (simetría perfecta).Existen otros muchos tipos de curvas: parabólicas, hiperbólicas, bimodales, etc., pero una forma usual es la curva simétrica, llamada también curva normal o campana de Gauss.
Curtosis
La curtosis hace referencia a la forma de la curva de la distribución de datos en tanto muy aguda (mayor apuntamiento o mayor curtosis: leptocúrtica) o muy aplanada (menor apuntamiento o menor curtosis: platicúrtica).
Página 44 de 314
44

Leptocúrtica PlaticúrticaMesocúrtica
Del mismo modo que sucede con la asimetría, también se han propuesto diversos índices de curtosis. Si el índice es positivo, su apuntamiento es mayor que el de una distribución normal y la curva será leptocúrtica, y si es negativo, su apuntamiento es menor y la curva será platicúrtica (Botella, 1993).
NOTAS
(1) Según Botella (1993:49) la “distribución de frecuencias es un instrumento diseñado para cumplir tres funciones: a) proporcionar una reorganización y ordenación racional de los datos recogidos; b) ofrecer la información necesaria para hacer representaciones gráficas; y c) facilitar los cálculos necesarios para obtener los estadísticos muestrales”.(2) Cuando se confecciona una tabla de frecuencias por intervalos con la intención de elaborar gráficos o medidas estadísticas a partir de ella, deben asumirse ciertos supuestos que implican un margen de error, pero que son imprescindibles. Estos supuestos, llamados supuestos de concentración intraintervalo, son dos. a) El supuesto de concentración en el punto medio del intervalo, según el cual todos los valores de la variable son el mismo, a saber, el punto medio del intervalo. b) El supuesto de distribución homogénea, según el cual “los valores incluidos en un intervalo se reparten con absoluta uniformidad en su interior. Es decir, que si en un intervalo hay cinco observaciones [valores observados en la variable] aceptaremos que sus valores son los que tendríamos si partiéramos al intervalo en cinco subintervalos de igual amplitud y asignáramos a cada individuo el punto medio de un subintervalo” (Botella, 1993:56).(3) Hay quienes recurren a la fórmula de Sturges para calcular la cantidad de intervalos que resulta deseable tomar en función del tamaño de la muestra. Esta fórmula es: Número de intervalos = 1 + (log n / log 2), donde n designa el tamaño de la muestra. Por ejemplo, aplicando la fórmula para n = 40, la cantidad deseable de intervalos es 6.3, con lo cual podrán elegirse entre 6 o 7 intervalos. Una vez determinada la cantidad de intervalos, sólo resta dividir el tamaño de la muestra por 6 o 7, de lo que resultará el tamaño de cada intervalo.(4) Por ejemplo, las medidas de posición son aquellas que “caracterizan la posición de un grupo respecto de una variable” (Kohan, 1994:69). Otras definiciones se refieren a la utilidad de estas medidas, y entonces por ejemplo se definen como “índices diseñados especialmente para revelar la situación de una puntuación con respecto a un grupo, utilizando a éste como marco de referencia” (Botella, 1993:83).(5) Estrictamente hablando, ciertos cuantiles como el cuartil 2, el decil 5 y el percentil 50 resultan ser medidas de tendencia central, ya que coinciden con la mediana.(6) Estrictamente, dato y valor no son sinónimos, aunque aquí se emplearán indistintamente ambas expresiones. El valor es uno de los componentes del dato: los otros dos son la unidad de análisis y la variable.(7) Botella (1993:105-111) describe seis propiedades de la media aritmética: 1) La suma de las diferencias de n puntuaciones de la media aritmética, o puntuaciones diferenciales, es igual a cero. 2) La suma de los cuadrados de las desviaciones de unas puntuaciones con respecto a su media es menor que con respecto a cualquier otro valor. 3) Si sumamos una constante a un conjunto de puntuaciones, la media aritmética quedará aumentada en esa misma constante. 4) Si multiplicamos una constante a un conjunto de puntuaciones, la media aritmética quedará multiplicada por esa misma constante. 5) La media total de un grupo de puntuaciones, cuando se conocen los tamaños y medias de varios subgrupos hechos a partir del grupo total, mutuamente exclusivos y exhaustivos, puede obtenerse ponderando las medias parciales a partir de los tamaños de los subgrupos en que han sido calculadas. 6) Una variable definida como la combinación lineal de otras variables tiene como media la misma combinación lineal de las medias de las variables intervinientes en su definición.(8) Equivalencias entre cuantiles (Botella, 1993:89):
Cuartiles
Deciles
Percentiles
D1 P10D2 P20
Q1 P25D3 P30D4 P40
Q2 D5 P50D6 P60D7 P70
Q3 P75D8 P80
Página 45 de 314
45

D9 P90
(9) “Para la varianza, las unidades son el cuadrado de las unidades de los datos. Estas unidades no son intuitivamente claras o fáciles de interpretar. Por esta razón, tenemos que hacer un cambio significativo en la varianza para calcular una medida útil de la desviación, que sea menos confusa. Esta medida se conoce como la desviación estándar, y es la raíz cuadrada de la varianza. La desviación estándar, entonces, está en las mismas unidades que los datos originales” (Levin y Rubin, 1996). La varianza como tal se utiliza más frecuentemente en estadística inferencial (Pagano, 1998:77).(10) “La raíz cuadrada de un número positivo puede ser tanto positiva como negativa. Cuando tomamos la raíz cuadrada de la varianza para calcular la desviación estándar, los estadísticos solamente consideran la raíz cuadrada positiva” (Levin y Rubin, 1996).(11) La desviación estándar nos permite determinar, con un buen grado de precisión, dónde están localizados los valores de una distribución de frecuencias con relación a la media. El teorema de Chebyshev dice que no importa qué forma tenga la distribución, al menos 75% de los valores caen dentro de + 2 desviaciones estándar a partir de la media de la distribución, y al menos 89% de los valores caen dentro de + 3 desviaciones estándar a partir de la media.Con más precisión:Aproximadamente 68% de los valores de la población cae dentro de + 1 desviación estándar a partir de la media.Aproximadamente 95% de los valores estará dentro de + 2 desviaciones estándar a partir de la media.Aproximadamente 99% de los valores estará en el intervalo que va desde tres desviaciones estándar por debajo de la media hasta tres desviaciones estándar por arriba de la media (Levin y Rubin, 1996).(12) Esto se debe a que “los especialistas en estadística pueden demostrar que si tomamos muchas muestras de una población dada, si encontramos la varianza de la muestra para cada muestra y promediamos los resultados, entonces este promedio no tiende a tomar el valor de la varianza de la población, a menos que tomemos n–1 como denominador de los cálculos” (Levin y Rubin, 1996).(13) El concepto de distribución de frecuencias es uno de los más básicos de la estadística descriptiva, y hace referencia a un conjunto de valores de una variable ordenados de acuerdo con sus frecuencias. Las distribuciones de frecuencias pueden expresarse en forma de tablas, gráficos, medidas de posición, medidas de dispersión, de asimetría y de curtosis. Estas últimas cuatro medidas pueden considerarse propiedades o características básicas de una distribución frecuencial.
CAPÍTULO 3: PROBABILIDAD Y CURVA NORMAL
La curva normal es uno de los temas fundamentales de la estadística que utiliza la información provista por la estadística descriptiva y permite el paso a la estadística inferencial en el sentido de proveer una herramienta para obtener conclusiones respecto de la población. La comprensión de este tema exige un conocimiento mínimo de la teoría de la probabilidad.
1. EL CONCEPTO DE PROBABILIDAD
Se entiende por probabilidad el grado de posibilidad de ocurrencia de un determinado acontecimiento. Dicha probabilidad puede calcularse en forma teórica o empírica, a partir de las llamadas probabilidad clásica y frecuencial, respectivamente. El concepto de probabilidad ha demostrado ser de importante utilidad en ciertos enfoques sistémicos, especialmente en los ámbitos de la termodinámica y la teoría de la información.
1. Concepto de probabilidad.- Entendida como medida de la posibilidad de la ocurrencia de un determinado acontecimiento, la probabilidad abarca un espectro que se extiende desde la certeza (el acontecimiento ocurrirá con total seguridad), hasta la imposibilidad (es imposible que el acontecimiento ocurra), pasando por todos los grados intermedios (es muy probable que ocurra, es medianamente probable, es poco probable, etc.).Por ejemplo, el suceso 'obtener un número entre 1 y 6 tirando un dado' equivale a la certeza; el suceso 'obtener un 7 arrojando un dado' equivale a la imposibilidad; y el suceso 'obtener un 2 arrojando un dado' equivale a uno de los grados intermedios de probabilidad.Es habitual representar el grado de probabilidad mediante un número que puede variar entre 1 (certeza) y 0 (imposibilidad). La probabilidad puede entonces valer 1, 0, 0.50, 0.80, etc. Por ejemplo, una probabilidad de 0.1 es muy baja, y una probabilidad de 0.98 muy alta. Una probabilidad intermedia es 0.50 o también, si la expresamos en términos de porcentajes corriendo la coma dos lugares hacia la derecha, obtenemos una probabilidad del 50 por ciento. Tal el caso de obtener una cara arrojando una moneda.Los aspectos más importantes del concepto de probabilidad han sido sintetizados en los llamados axiomas de probabilidad:Axioma 1: Evento seguro.- La probabilidad del conjunto universal o espacio muestral es igual a 1. Por ejemplo, el espacio muestral para un dado es 1, 2, 3, 4, 5, 6.Axioma 2: Evento imposible.- La probabilidad del conjunto vacío es igual a 0. Por ejemplo, que salga un 7 tirando un dado.Axioma 3: Evento aleatorio.- La probabilidad de un evento es un número real mayor o igual que 0 y menor o igual que 1.Axioma 4: Eventos aleatorios compuestos excluyentes.- La probabilidad de un evento más la probabilidad del evento contrario es igual a 1. Por ejemplo, la probabilidad que un dado salga 1 o 2 más la probabilidad que un dado salga 3, 4, 5 o 6 es igual a 1. En símbolos: p + q = 1.
Página 46 de 314
46

2. Probabilidad clásica y probabilidad frecuencial.- Si bien existen diferentes teorías y enfoques acerca de la probabilidad, explicaremos a continuación los dos planteos más habituales, siguiendo un ordenamiento histórico e incluso sistemático: el clásico y el frecuencial. En última instancia, se trata de dos modos diferentes de calcular la probabilidad de la ocurrencia de un fenómeno.a) Probabilidad clásica (Laplace).- Suele también denominarse probabilidad teórica o a priori, y se define como el cociente entre el número de casos favorables y el número de casos equiprobables posibles. Aclaremos esta aparentemente engorrosa definición.Sabemos que un dado tiene seis caras, numeradas del uno al seis. La probabilidad de obtener la cara tres, por ejemplo, es de un sexto, es decir de un caso favorable (porque hay una sola cara con el tres) sobre seis casos equiprobables y posibles (caras 1-2-3-4-5-6). Aplicando la definición de probabilidad, es:
Casos favorables 1p= ----------------------------------------------------- = 0.1666 Casos equiprobables posibles 6
Para poder calcular esta probabilidad necesitamos, obviamente, conocer todos los casos posibles (requisito de exhaustividad), pero además debemos saber que todos esos casos posibles tienen la misma probabilidad de salir (requisito de equiprobabilidad), vale decir, debemos tener la suficiente seguridad de que ninguna cara tendrá mayor o menor probabilidad de salir que otra cara cualquiera, como puede ocurrir, por ejemplo, con los dados 'cargados'.Una aclaración respecto de la expresión 'casos favorables'. Debemos evitar aquí la connotación subjetiva del término. Un caso favorable es simplemente un caso del cual queremos conocer la probabilidad de su ocurrencia. Puede incluso tratarse de un terremoto o una enfermedad, aunque estos eventos no sean 'favorables' desde otro punto de vista más subjetivo.Respecto de la expresión 'casos equiprobables posibles', esta alude al hecho antes indicado de que para calcular una probabilidad en sentido clásico, deben cumplirse los dos requisitos de exhaustividad y equiprobabilidad.Puede suceder, en efecto, que alguno de estos requisitos no se cumpla. 1) Exhaustividad: Este requisito puede no cumplirse en dos casos. Primero, puede ocurrir que al arrojar un dado, este quede parado en equilibrio sobre alguno de sus vértices o aristas. Como posibilidad existe, pero es remotísima. Debido a que esta posibilidad es muy baja, a los efectos prácticos la consideramos nula y seguimos aplicando la definición clásica de probabilidad, como si todos los casos posibles fueran, como en el caso del dado, solamente seis. Segundo, puede ocurrir que no sepamos cuántas caras tiene el dado (en la situación anterior sí sabíamos esta cantidad, descartando las alternativas remotas), aún cuando sepamos que todas tienen la misma probabilidad de salir. En este caso, al desconocer el número de casos posibles, la definición clásica de probabilidad resulta inaplicable, quedándonos la opción de aplicar la probabilidad frecuencial. 2) Equiprobabilidad: Este requisito puede no cumplirse cuando el dado está 'cargado' lo que hace que, por ejemplo, el tres tenga mayores probabilidades de salir que el cuatro. En este caso, podemos calcular la probabilidad mediante la probabilidad frecuencial.En síntesis hasta aquí: cuando ninguno de estos requisitos, o ambos, no pueden cumplirse, nos queda aún la opción de calcular la probabilidad en forma empírica, lo que nos lleva al tema de la llamada probabilidad frecuencial.b) Probabilidad frecuencial.- Suele también denominarse probabilidad empírica o a posteriori, y es definible como el cociente entre el números de casos favorables y el número de casos observados. En un ejemplo, supongamos que no conocemos cuántas caras tiene un dado (es decir desconocemos la cantidad de casos posibles), y queremos averiguar qué probabilidad tiene de salir el uno. Obviamente no podemos decir 'un sexto' o 'uno sobre seis' porque no sabemos cuántas caras tiene el dado. Para hacer este cálculo decidimos hacer un experimento, y arrojamos un dado común de seis caras (aunque nosotros ignoramos este detalle) por ejemplo diez veces, constatando que el uno salió cinco veces, cosa perfectamente posible. Concluímos entonces que la probabilidad de obtener un uno es de cinco sobre diez, es decir, de 0.5. Si tomamos al pie de la letra este valor, podríamos concluir que el dado tiene... ¡2 caras!, cada una con la misma probabilidad de 0.5. Aplicando la definición de probabilidad frecuencial, resulta:
Casos favorables 5p= -------------------------------- = 0.5 Casos observados 10
Otro ejemplo: supongamos que conocemos perfectamente que el dado tiene seis caras, pero no sabemos si las probabilidades de salir son iguales o no para todas ellas, ya que sospechamos que el dado puede estar 'cargado'. Para determinar la probabilidad de salir del número uno hacemos el mismo experimento, dándonos un valor de 0.7. Este valor, si lo tomamos al pie de la letra, nos haría pensar que el dado está preparado para que tenga tendencia a salir el número uno, ya que su probabilidad de ocurrencia es bastante alta.La probabilidad frecuencial se llama también 'a posteriori' debido a que 'sólo después' de hacer nuestra observación o nuestro experimento podemos saber el valor de la probabilidad, y no 'antes', como en el caso de la probabilidad clásica, donde 'antes' de arrojar el dado ya sabemos que la probabilidad de cada cara es de 0.1666.
Página 47 de 314
47

La denominación 'frecuencial' alude al hecho de el cálculo de probabilidades se realiza en base a la frecuencia con que sale una determinada cara o posibilidad, frecuencia que es relativa porque la comparamos con la cantidad de casos observados. Por ejemplo, en nuestro último ejemplo la frecuencia absoluta es 7, porque de 10 veces que arrojamos el dado, 7 veces salió el número deseado. En cambio la frecuencia relativa es 0.7, y resulta de dividir la frecuencia absoluta por el número de casos observados.
Las probabilidades clásica y frecuencial se llaman también probabilidades lógica e inductiva, respectivamente. a) Probabilidad lógica: si yo tengo un dado perfectamente balanceado (o sea que las seis caras tienen la misma probabilidad de salir), no necesitaré arrojarlo para saber qué probabilidad tiene de salir el número 3. Como ya sé que tiene seis caras equiprobables, su probabilidad será de uno sobre seis (p=1/6). b) Probabilidad inductiva: puede ocurrir, sin embargo, que el dado no esté balanceado, o que yo no sepa si el número 3 figura en dos caras y el 5 en ninguna, etc., y sólo sé que tiene 6 caras. A priori, o sea antes de arrojar los dados, en estos casos no puedo saber qué probabilidad tiene el 3 de salir, debido a mi desconocimiento del dado. No obstante tengo un medio de saberlo: arrojo el dado una gran cantidad de veces (cuantas más veces mejor) y voy anotando los números que aparecieron. Si constato que el 3 salió en un 50% de los casos, entonces puedo concluir que la probabilidad será de tres sobre seis (p=3/6=1/2). Este dato no me aclara definitivamente si el dado estaba desbalanceado o si en realidad en tres de sus caras estaba el número 3; sólo me sugiere la probabilidad de aparición del número en cuestión.En suma: en la probabilidad lógica y debido a que conozco el dado, puedo calcular qué probabilidad tiene de salir determinado número sin necesidad de hacer ninguna prueba. Es una probabilidad deductiva, puesto que deduzco de los datos conocidos la probabilidad de cada alternativa. En cambio en la probabilidad inductiva no conozco la naturaleza del dado, y entonces sólo puedo concluir la probabilidad de aparición de un cierto número siguiendo un razonamiento inductivo, vale decir, a partir de los casos observados que fui anotando.Las mismas consideraciones que hicimos con las caras de un dado también podemos hacerlas con los naipes de un mazo y con los individuos de una población. En estadística, puesto que generalmente desconocemos la naturaleza de la población, el tipo de probabilidad empleado es el inductivo.
c) La ley de los grandes números.- También llamada principio de la estabilidad de la frecuencia relativa, nos permite unificar conceptualmente los dos tipos de probabilidad recién examinados, y puede expresarse de la siguiente manera: a medida que aumenta la cantidad de ensayos, el valor de la probabilidad empírica obtenido se va aproximando cada vez más al valor de la probabilidad teórica.
Ley de los Grandes Números
Cantidad de ensayos arrojando una moneda
Probabilidad teórica de salir cara
Probabilidad empírica obtenida para cara
una vez 0.5 02 veces 0.5 0.53 veces 0.5 0.33334 veces 0.5 0.2510 veces 0.5 0.3100 veces 0.5 0.41000 veces 0.5 0.451000000 veces 0.5 0.4999999999999
Siguiendo el esquema adjunto, si arrojamos una moneda por primera vez (primer ensayo), la probabilidad teórica de salir cara es de 0.5, cosa que sabemos más allá de hacer o no esa experiencia. Sin embargo, puede ocurrir que salga ceca, y entonces concluímos que la probabilidad empírica es 0, pues no salió ninguna cara.Al arrojar la moneda por segunda vez, la probabilidad teórica sigue siendo 0.5, ya que el dado no tiene 'memoria': por más que haya salido cien veces cara, la 101° vez sigue teniendo la misma probabilidad de salir cara. La probabilidad empírica, en cambio, nos da por ejemplo también 0.5, porque la primera vez no salió cara pero la segunda sí, con lo cual habrá salido cara la mitad de las veces, o sea hay una probabilidad de 0.5. Al tercer tiro vuelve a aparecer ceca, con lo cual sobre tres tiros habrá salido sólo una cara (la segunda vez), y entonces la probabilidad empírica es de un tercio (0.333).Lo que dice la ley de los grandes números es que, si seguimos aumentando la cantidad de tiros, el valor de la probabilidad empírica se irá aproximando cada vez más a la probabilidad teórica de 0.5, es decir, se verifica una tendencia de la frecuencia relativa a estabilizarse en dicho resultado, y por ello esta ley se llama también principio de la estabilidad de la frecuencia relativa.
La probabilidad (p) varía entre 0 y 1
Imposible Grados intermedios de probabilidad Seguro0 0.25 0.50 0.75 10 1/4 1/2 3/4 1
Probabilidad de extraer un as de espadas de un mazo de cartas francesas
Probabilidad de extraer un naipe de copas de un mazo de cartas españolas
Probabilidad de obtener cara arrojando una moneda
Probabilidad de extraer una bolilla roja de una caja donde hay 3 rojas y una blanca
Probabilidad de extraer una bolilla roja de un bolillero de bolillas rojas
Página 48 de 314
48

d) Probabilidad y variable aleatoria.- Las variables aleatorias son variables donde cada uno de sus valores puede asumir un valor de probabilidad entre 0 y 1. Las variables aleatorias pueden ser discretas o continuas. La variable ‘número del dado’ es discreta, y por ejemplo su valor 2 asume un valor de probabilidad de 1/6.Las distribuciones de probabilidad son modelos donde se emplean variables aleatorias. Por ejemplo la distribución normal (para probabilidad continua), la distribución binomial y la distribución de Poisson (para probabilidad constante), y la distribución hipergeométrica (para probabilidad variable).
3. Algunas aplicaciones del concepto de probabilidad.- La teoría de las probabilidades, importante rama de la matemática, ha permitido encarar la investigación de sistemas, tanto cerrados como abiertos, bajo este relativamente nuevo enfoque. Ejemplos particularmente representativos aparecen en la termodinámica y en la teoría de la información.a) Probabilidad en termodinámica.- La evolución de los sistemas cerrados o abiertos puede medirse según varios parámetros, como por ejemplo el grado de entropía o desorden, pero también según el grado de probabilidad que pueden alcanzar cuando evolucionan hacia estados de equilibrio (como en el sistema cerrado) o hacia estados uniformes (como en el sistema abierto). Así, se dice que la tendencia general de los procesos físicos entendidos como sistemas cerrados apunta a la entropía creciente o estados de creciente probabilidad, mientras que los sistemas abiertos, como por ejemplo los sistemas vivos, consiguen mantenerse en un estado de mínima entropía, es decir, en un estado de alta improbabilidad estadística.b) Probabilidad en Teoría de la Información.- En la Teoría de la Información se emplea tanto la probabilidad clásica como la probabilidad frecuencial. Es posible ilustrar esta cuestión con el siguiente ejemplo (Lichtenthal, 1970): Un forastero llega a un pueblo y pregunta: "¿Lloverá esta tarde?", a lo cual un vecino contesta "sí". Esta respuesta ¿provee mucha información o poca información? Todo depende de quien la reciba.a) Si la respuesta la recibe el mismo forastero, el "Sí" implica bastante información, porque desconoce el clima del pueblo. El "Sí" encierra para él tanta información como el "No", porque, al no conocer el clima habitual de la zona, para él ambas respuestas son igualmente probables (equiprobabilidad), y por consiguiente evalúa la probabilidad de que llueva o no en base a una probabilidad teórica o a priori.b) Si la respuesta la escucha otro vecino, el "Sí" tiene un valor informativo prácticamente nulo porque todos en el pueblo saben que casi siempre llueve por las tardes. No es ninguna novedad el "Sí", es decir encierra poquísima información. En cambio si nuestro vecino hubiese escuchado "No" se sorprendería mucho, y la cantidad de información es mucha. El "Sí" y el "No" no son igualmente probables, cosa que el vecino descubrió por experiencia, por haber vivido un tiempo en el pueblo (la probabilidad es, en este caso, frecuencial, y las posibles alternativas no son equiprobables).Los ejemplos vienen a destacar una idea muy importante que vincula información con probabilidad, y que es la siguiente: el contenido informativo de un mensaje está íntimamente ligado a su improbabilidad o 'valor sorpresa'. Por ejemplo, cuando más nos 'sorprende' la respuesta, o cuando más 'improbable' o 'inesperada' la juzgamos, más información encierra. De aquí una importante definición de información, como aquello que hace disminuir la incertidumbre del receptor. Si al vecino le dicen que "sí lloverá en este pueblo esta tarde" esto no es sorpresa para él, no reduce su incertidumbre y, por consiguiente, apenas si contiene información.
4. Vocabulario.- La teoría de la probabilidad utiliza cierta terminología técnica. Algunos de los principales términos son los siguientes:Espacio muestral: es el conjunto S de todos los resultados posibles de un experimento dado. Por ejemplo, los resultados posibles del experimento de arrojar un dado son 1, 2, 3, 4, 5 y 6.Muestra: es un resultado particular, o sea, un elemento de S. Por ejemplo, arrojar un dado y obtener 4.Espacio finito de probabilidad: se obtiene al asignar a cada muestra de un espacio muestral finito una determinada probabilidad de ocurrencia en forma de número real. La probabilidad de un evento es igual a la suma de las probabilidades de sus muestras. Si en un espacio finito de probabilidad cada muestra tiene la misma probabilidad de ocurrir, se llamará espacio equiprobable o uniforme. Existen también espacios muestrales infinitos.Evento: Un evento A es un conjunto de resultados, o sea, un subconjunto de S. Por ejemplo, un evento puede ser arrojar dos veces un dado obteniéndose por ejemplo un 4 y un 3. Si el evento tiene una sola muestra, se llama evento elemental.El conjunto S o espacio muestral es de por sí un evento (en este caso se lo llama cierto o seguro, pues es seguro que arrojando un dado se obtendrá 1, 2, 3, 4, 5 o 6), mientras que también se considera evento al conjunto vacío (se lo llama imposible: no es posible que no salga ningún número).Se pueden combinar eventos entre sí para formar nuevos eventos, por ejemplo:A unión B es el evento que sucede si y sólo si A o B o ambos suceden.A intersección B es el evento que sucede si y sólo si A y B suceden simultáneamente.A complemento de A’ es el evento que sucede si y sólo si A no sucede. Dos eventos son mutuamente excluyentes cuando no pueden suceder simultáneamente.De una manera más sencilla pueden identificarse los siguientes tipos de eventos:
Eventos Fórmulas (a) EjemploSimple o De un mazo de cartas sacar un 3. p (A) = 4/52 = 0.077
Página 49 de 314
49

elemental casos favorables / casos posibles
Compuestos Excluyentes o alternativos
Contrarios: sacar una carta que sea un 3 o no sea un 3.
p (A o –A) =p (A) + p (-A)
4/52 + 48/52 = 1
No contrarios: sacar una carta que sea un 3 o un as.
p (A o B) =p (A) + p (B)
4/52 + 4/52 = 2/13
No excluyentes o conjuntos
Sacando una sola carta: sacar una carta que sea un 3 y que sea de corazón (c).
p (A y B) = p (A) . p (B)
4/52 . 13/52 = 1/52
Sacando dos o más cartas
Eventos independientes (con reposición): de un mazo sacar dos corazones reponiendo la primera (b).
p (A y B) = p (A) . p (B)
13/52 . 13/52 = 1/16
Eventos dependientes (sin reposición): de un mazo sacar 2 corazones sin reponer (a).
p (A y BsiA) =p (A) . p (BsiA)
13/52 . 12/51 = 0.059
(a) Las fórmulas para eventos excluyentes son el teorema de las probabilidades totales. La fórmula p (A y B) = p (A) . p (B) es el teorema de las probabilidades compuestas para eventos independientes. La fórmula p (A y BsiA) = p (A) . p (BsiA) es el teorema de las probabilidades compuestas para eventos dependientes (probabilidad condicional).(b) Eventos independientes: Se dice que un evento B es independiente de un evento A si la probabilidad de que B suceda no está influenciada porque A haya o no sucedido.(c) Combinando los teoremas de las probabilidades totales de las probabilidades compuestas para eventos independientes, se pueden hacer otros cálculos, como por ejemplo calcular la probabilidad de sacar un 3 o un corazón, pero no ambos (o sea, no un 3 de corazón), mediante la fórmula p (A o B no ambos) = p (A) + p (B) – p (A y B) = 4/52 + 13/52 – (4/52 . 13/52) = 4/13.
2. ANÁLISIS COMBINATORIO
Una de las aplicaciones de la teoría de la probabilidad es el análisis combinatorio, que estudia cuántos grupos distintos de elementos se pueden formar con un número finito de elementos. Por ejemplo: a) cuantos números de tres cifras (grupos) se pueden formar con los elementos 6, 7, 8 y 9 (un ejemplo de número podría ser 768).Por convención, se designa con la letra m al número total de elementos (en el ejemplo son 4), y se designa con la letra n la cantidad de elementos por grupo (en el ejemplo son 3).Los tipos de grupos más importantes que se consideran en el análisis combinatorio son las variaciones (V), las permutaciones (P) y las combinaciones (C), y en ningún caso se considera que los elementos se repiten dentro del grupo (como por ejemplo en 667, donde se repite el 6).En el siguiente cuadro se presentan las definiciones de las variaciones, las permutaciones y las combinaciones, y las respectivas fórmulas para calcular la cantidad de variaciones, permutaciones y combinaciones. Para comprender las mismas, téngase presente el sencillo concepto de factorial. El número factorial de x es aquel que resulta de multiplicar x por cada uno de sus decrecientes hasta llegar al 1. Por ejemplo, el factorial de 4 (que se simboliza 4!) es igual a 24, porque 4! = 4.3.2.1.
Variaciones Permutaciones CombinacionesDefinición: Para que los grupos sean variaciones deben diferir en al menos un elemento (por ejemplo 678-679) o en su orden de sucesión (por ejemplo 678-786).
Definición:Para que los grupos sean permutaciones deben diferir sólo en su orden de sucesión (por ejemplo 678-786).
Definición:Para que los grupos sean combinaciones deben diferir sólo en por lo menos un elemento (por ejemplo 678-679).
Fórmula: Vm,n = m! / (m-n)!
La expresión Vm,n se lee “cantidad de variaciones de m elementos, de n elementos cada variación”.
Fórmula: Pm = m!
La expresión Pm se lee “cantidad de permutaciones de m elementos de m elementos cada permutación”.La permutación es el único caso donde se considera m = n, pues la permutación es un caso especial de variación.
Fórmula: Cm,n = Vm,n / PnCm,n = m! / n! (m-n)!
La expresión Cm,n se llama número combinatorio y se lee “cantidad de combinaciones de m elementos, de n elementos cada combinación”.El número combinatorio es igual a 1 en dos casos: cuando m = n y cuando n = 0.
Ejemplo: ¿Cuántos grupos de 3 personas se pueden formar con 5 candidatos?m = 3n = 5V5,3 = 60 grupos o variaciones.
Ejemplo: ¿Cuántos números de 3 cifras pueden formarse con los dígitos 4, 5 y 6, sin repetir ninguno de ellos?m = n = 3P3 = 6 números o permutaciones.
Ejemplo: ¿Cuántos grupos distintos pueden formarse con los colores A, V y R tomándolos de a dos?m = 3n = 2C3,2 = 3 grupos o combinaciones.
La relación entre la teoría de la probabilidad y el análisis combinatorio reside en que, tomando como punto de partida las fórmulas de la cantidad de variaciones, permutaciones o combinaciones, se puede luego calcular la probabilidad de ocurrencia de uno de los grupos de elementos. Las fórmulas de variaciones, permutaciones o combinaciones indican el número de casos posibles.
Página 50 de 314
50

Experimento binomial.- El número combinatorio puede ser utilizado en los llamados experimentos binomiales, es decir, en experimentos donde se cumplen las siguientes condiciones:
Condiciones EjemploEs una secuencia de repeticiones del mismo ensayo o experimento.
Sacar 3 bolillas de una urna.
Cada ensayo tiene solamente dos resultados posibles (éxito-fracaso).
La bolilla solamente puede salir blanca o negra.
Los ensayos son independientes es decir, no se influyen entre sí.
Antes de sacar la siguiente bolilla se introduce la anterior en la urna (con reposición).
La probabilidad de un resultado (por ejemplo éxito) es igual para todos los ensayos (equiprobabilidad).
Todas las bolillas tienen la misma probabilidad de salir blancas (por ejemplo si se considera blanca como éxito).
La variable es discreta. No hay grados intermedios entre blanco y negro.
La fórmula para calcular la probabilidad de obtener n éxitos con m ensayos es la siguiente:
pn = Cm,n . pn . (1 – p)m-n donde:m = número de ensayos (o n, según otra nomenclatura).n = número de éxitos (o k, según otra nomenclatura).Cm,n = número combinatorio.pn = probabilidad de éxitos.
Ejemplo: ¿cuál es la probabilidad de obtener 6 caras al arrojar una moneda 10 veces?Como m = 10 y n = 6, resulta pn = 0,2050.
En lugar de realizar los cálculos utilizando la fórmula anterior, se puede utilizar una llamada tabla de probabilidades binomiales.
Los experimentos binomiales y la curva normal, que se estudia en el punto siguiente, son dos tipos frecuentes de distribución de probabilidades.
Algunos tipos de distribuciones de probabilidad son los siguientes:1) Distribución normal (para probabilidad continua).- Se representa mediante la curva de Gauss o curva normal, conforma de campana. Es una función unimodal, continua, donde la probabilidad es un área que se acumula de izquierda a derecha, siendo la total igual a 1. La curva es simétrica. Hay tres tipos de distribución normal: no estandarizada, estándar con z y estándar con t. a) Distribución normal no estandarizada.- Sus parámetros son la media aritmética y el desvío estándar. La media aritmética, la mediana y el modo coinciden en el punto central. La variable x puede tomar cualquier valor, positivo o negativo. b) Distribución normal estándar con z.- Caso particular donde la media aritmética asume el valor 0 (cero) y el desvío estándar el valor 1 (uno). c) Distribución normal estándar con t.- La curva es más chata que en el caso anterior, lo que indica mayor dispersión ya que aquí se desconoce el desvío poblacional: al tener menos información, se supone que los valores se distribuyen con mayor dispersión. El aplanamiento de la curva depende del tamaño de la muestra (grados de libertad): cuando éste aumenta, la curva va aproximándose a la forma menos achatada o aplanada de la distribución z.2) Distribución asimétrica de Chi-cuadrado o x2.- Curva asimétrica a la derecha, unimodal, donde x2 asume sólo valores positivos. A medida que aumentan los grados de libertad, la curva se hace cada vez más simétrica. Los grados de libertad dependen de la cantidad de grupos e tratamiento (o sea de las diferentes categorías de la variable: los grados de libertad se expresan como k – 1, donde k = número de categorías de la variable). Chi-cuadrado se usa cuando hay variables nominales.3) Distribución asimétrica de Snedecor o F.- Curva asimétrica a la derecha, unimodal, donde F asume sólo valores positivos. A medida que aumentan los grados de libertad, la curva se hace cada vez más simétrica. F es el cociente entre variancias: F = variancia 1 / variancia 2, y se calcula en base al nivel alfa de significación, los grados de libertad del numerador y los grados de libertad del denominador.4) Distribución binomial (para probabilidad constante).- Considera un esquema de pruebas repetidas con probabilidad constante, donde se realizan experimentos en los cuales se busca obtener x éxitos y n-x fracasos.5) Distribución de Poisson (para probabilidad constante).- Descubierta por Poisson en el siglo 19, considera un esquema de pruebas repetidas con probabilidad constante. Es el caso límite de la probabilidad binomial, donde la probabilidad es constante y los sucesos son independientes. Es totalmente compatible con la distribución binomial, pero solo viene tabulada para números grandes (n = 20 o más) y para probabilidades muy pequeñas (inferiores al 5%), razón por la cual se la llama también distribución de los sucesos raros.La función de probabilidad P(x) de la distribución de Poisson se calcula en base a una tabla especial o bien en base al siguiente cociente:Numerador: producto del número ‘e’ elevado a la menos Lambda, por Lambda elevado a la ‘x’. Lambda es el coeficiente de Poisson una constante igual a n.p. La variable discreta es ‘x’, y el número ‘e’ es igual a 2,71828.Denominador: Factorial de x.Si Lambda es un valor muy pequeño, la curva es marcadamente asimétrica y decreciente. Al crecer Lambda, va tomando forma de campana, o sea se asemeja cada vez más a la distribución normal.6) Distribución hipergeométrica (para probabilidad variable).- Como la distribución binomial, es un esquema de pruebas repetidas, con la diferencia que es con probabilidad variables pues es sin reposición y los sucesos son dependientes. La dispersión es menor que en la distribución binomial, por lo que se la considera una distribución más precisa.
Página 51 de 314
51

f
x70
5
3
1
62 70 84
Gráfico 1 Gráfico 2 Gráfico 3
3. DEFINICIÓN Y CARACTERÍSTICAS DE LA CURVA NORMAL
Si se tomaran nueve personas al azar para medir la variable frecuencia cardíaca, podrían obtenerse, por ejemplo, los siguientes resultados: tres personas con 62, cinco personas con 70 y una persona con 84 pulsaciones por minuto. Representando visualmente esta situación mediante un polígono de frecuencias, se obtiene el gráfico 1.Si se registrara la frecuencia cardíaca de 80 personas más, probablemente se obtendría resultados similares al polígono de frecuencias del gráfico 2. Finalmente, si se consideraran infinito número de personas, la representación visual se asemejaría al gráfico 3, denominado curva normal, curva de Gauss o campana de Gauss (por su forma acampanada).Como puede apreciarse, ciertas variables continuas como la frecuencia cardíaca, la glucemia, la estatura, el peso, la agudeza visual, el cociente intelectual, y otras, tiende a adoptar la forma de una curva normal a medida que aumenta la cantidad de casos observados (3). Aunque esta curva es una idealización, porque no pueden medirse infinitos casos, tiene, como se verá, su utilidad, aún cuando las variables que se estudian desde este modelo no siguen estrictamente la distribución de la curva normal. Pruebas como por ejemplo el chi cuadrado permiten determinar si una distribución es lo suficientemente parecida a una distribución normal como para poder aceptar el modelo de la curva normal para estudiarla. De hecho, muchas variables tienen distribuciones lo suficientemente similares a una distribución normal como para tratarlas como tales sin cometer grandes errores.En relación con estas cuestiones, conviene recordar aquí el teorema del límite central, que dice que cualquiera sea la población de donde se tome una muestra, la distribución de los valores de la muestra se aproximan o asemejan cada vez más a una distribución normal a medida que el tamaño n de la muestra aumenta. En la práctica se consideran normales a las muestras cuyo tamaño es igual o superior a 30.
La curva normal tiene entonces algunas características que son las siguientes:a) Es la idealización de un polígono de frecuencias con tendencia central para una gran cantidad de casos. Por esta razón tiene la apariencia de una curva y no de una línea quebrada, ya que el polígono de frecuencias tiene infinito número de lados.b) Tiene forma de campana: no tiene otras formas similares como puede ser la forma de herradura o la forma de una campana invertida.c) Es simétrica respecto de un eje vertical, lo que las diferencia de otras curvas como por ejemplo la hipérbole equilátera. La simetría de la curva normal implica que la media aritmética, la mediana y el modo coinciden en el punto central. Consecuentemente, la curva normal es unimodal (en cambio, una campana invertida podría ser bimodal). También implica que la distancia del cuartil 1 al cuartil 2 es igual a la distancia entre el cuartil 2 y el cuartil 3.d) Es asintótica respecto del eje x. Esto significa que la curva y el eje de las absisas se cortan en el infinito, lo cual implica que cualquier valor de x tiene potencialmente alguna frecuencia, y ninguna frecuencia igual a 0.e) La curva normal puede adoptar diferentes formas: mesocúrtica, platicúrtica o leptocúrtica.f) Los puntos de inflexión (donde la curva cambia de cóncava a convexa y viceversa) se encuentran en los puntos correspondientes a la media aritmética más/menos un desvío estándar.g) Hay muchas posibilidades de curvas normales, dependiendo de cuáles sean los valores de las medias aritméticas y los desvíos estándar. La más importante es aquella que tiene como media aritmética 0 (cero) y como desvío estándar 1 (la unidad). En este caso, la curva normal se designa como distribución o curva normal estándar o estandarizada.h) Está comprobado que en una curva normal, y siempre idealmente, alrededor de un 68% de los casos posibles están comprendidos entre menos un desvío estándar y más un desvío estándar± alrededor de un 95% están comprendidos entre menos 2 y más dos desvíos estándar± y alrededor
Página 52 de 314
52

de un 99% están comprendidos entre menos tres y más tres desvíos estándar± según lo ilustra el siguiente esquema:
Esto significa por ejemplo que una persona tiene una probabilidad del 68% de tener una frecuencia cardíaca comprendida entre menos un desvío estándar y más un desvío estándar. Si la media aritmética de esta distribución fuera 80 pulsaciones por minuto y el desvío estándar fuera de 10 pulsaciones por minuto, entonces la frecuencia cardíaca de una persona cualquiera tendría un 68% de probabilidades de valer entre 70 y 90 pulsaciones por minuto.Siguiendo el mismo criterio, también puede calcularse la probabilidad de aparición de un valor comprendido entre menos tres desvíos estándar y la media aritmética (99% dividido 2), la probabilidad de aparición de un valor comprendido entre menos dos desvíos estándar y la media aritmética (95% dividido 2), la probabilidad de aparición de un valor comprendido entre menos un desvío estándar y más dos desvíos estándar (68% dividido 2, más 95% dividido 2), y la probabilidad de obtener cualquier otro valor intermedio (como el comprendido entre -1.27 desvíos y +2.56 desvíos), para lo cual se habrá de consultar una tabla especialmente confeccionada para tal efecto.
4. PUNTAJES BRUTOS Y PUNTAJES ESTANDARIZADOS
Antes de hacer referencia a las utilidades prácticas de la curva normal, convendrá aclarar algunos conceptos tales como los de puntaje bruto y puntaje estandarizado.
Para designar los diferentes valores que asume una variable para una determinada unidad de análisis, en estadística descriptiva suele emplearse la expresión ‘dato’. Por ejemplo, un dato puede ser “Juan mide 1.70 metros”. Muchos datos, sin embargo, se distribuyen de acuerdo a una curva normal, y esta clase de datos suelen ser típicamente puntuaciones o puntajes de tests o pruebas de evaluación. Por ejemplo, “Juan obtuvo 90 puntos en el test de inteligencia de Weschler”, o “Pedro obtuvo 7 puntos en el examen de geografía”. Esta es la razón por la cual, en lo que sigue se utilizará la expresión puntaje en lugar de ‘dato’, pero debe tenerse presente que todo puntaje es, siempre, un dato.
Se llama puntaje bruto, directo u original al puntaje obtenido por un sujeto en una prueba. Por ejemplo, podría resultar de la suma de respuestas correctas, valiendo cada una de ellas un punto (Kohan, 1994:138).Los puntajes brutos presentan sin embargo algunos inconvenientes. Por ejemplo: a) Si una persona obtuvo 4 puntos en una prueba académica, podemos suponer que obtuvo un bajo puntaje porque lo comparamos con el puntaje máximo, que es 10. Sin embargo, no nos sirve para comparar a esa persona con el resto de la población, ya que si los demás alumnos obtuvieron en promedio 2 puntos, la calificación 4 será, entonces, alta. b) Si una persona obtuvo 8 puntos en geografía y 5 puntos en matemáticas, podemos suponer que obtuvo más puntaje en geografía. Sin embargo, esta suposición es errónea si
Página 53 de 314
53

resulta ser que el puntaje máximo en geografía es 20 y el puntaje máximo en matemáticas es 6, en cuyo caso habrá obtenido mayor puntaje en matemáticas.Estas y otras dificultades pueden resolverse transformando los puntajes brutos en otros llamados puntajes estandarizados (o también puntajes transformados, porque resultan de haber transformado los puntajes brutos). Estos puntajes estandarizados permitirán, por ejemplo, comparar el puntaje de un sujeto con toda la población, o bien comparar dos puntajes de pruebas con diferentes sistemas de evaluación (1).Los puntajes estandarizados pueden ser lineales o no lineales, según que resulten de transformaciones lineales o no lineales (Kohan, 1994:138). En el primer caso existe una proporcionalidad entre los puntajes brutos y sus correspondientes puntajes estandarizados, ya que la transformación opera según una ecuación lineal o ecuación de primer grado y, por tanto, no ‘deforma’ la distribución de los puntajes brutos.En lo que sigue se describen sucintamente tres ejemplos de puntajes estandarizados de uso frecuente: los puntajes estandarizados z (puntaje reducido), Z (puntaje derivado) y P (puntaje percentil).El puntaje reducido z es “un dato transformado que designa a cuántas unidades de desvíos estándar por arriba o por debajo de la media se encuentra un dato en bruto” (Pagano, 1998:84). Para transformar un dato en bruto x en un puntaje z se utiliza la fórmula: z = (x - X) / s.Pueden destacarse tres características de los puntajes z (Pagano, 1998:86-87): a) tienen la misma forma que el conjunto de datos en bruto; b) la media de los puntajes z es siempre igual a cero; y c) el desvío estándar de los puntajes z es siempre igual a 1.El puntaje derivado Z (también llamado a veces puntaje derivado T) tiene la ventaja sobre el puntaje reducido z que no tiene valores negativos y que pueden despreciarse los decimales por ser una cantidad pequeña (Kohan, 1994:141). Para transformar un puntaje reducido z en un puntaje derivado Z se utiliza la fórmula: Z = (z.10) + 50, ya que este puntaje derivado considera la media aritmética como 50 y el desvío estándar como 10.Existen otras modalidades de puntajes derivados (Botella: 1993:161). Uno muy conocido en psicología es el llamado cociente intelectual o CI, que considera como media aritmética a 100 y como desvío estándar a 15.El puntaje percentil P es un puntaje no lineal y es también de uso frecuente por su facilidad de comprensión, aunque tenga el inconveniente de que su distribución toma una forma que no responde a la realidad de las funciones psicológicas. Para transformar un puntaje z en un puntaje percentil hay que recurrir a una tabla especial, que se describe más adelante.Como se puede apreciar en el esquema siguiente, el puntaje percentil P no es proporcional al resto de los puntajes, pero si lo es respecto de las áreas cubiertas bajo la curva normal, áreas que a su vez indican la probabilidad de ocurrencia de un puntaje cualquiera. En efecto, puede verse que los puntajes percentiles P están concentrados en aquellos lugares donde el área bajo la curva es mayor y, además, cuanto mayor es esta área mayor será el percentil correspondiente.
Las correspondencias entre los diferentes puntajes pueden visualizarse mediante el siguiente esquema (2):
Equivalencias de puntajes brutos y estandarizados
Página 54 de 314
54

50% del áreaprobabilidad = 0.5
P0 P2 P16 P50 P84 P98 P100
0 10 20 30 40 50 60 70 80 90 100
-3s -2s -1s X +1s +2s +3s
-5 -4 -3 -2 -1 0 +1 +2 +3 +4 +5
f (frecuencia) X = media aritméticas = desvío estándarx = puntaje brutoz = puntaje reducidoZ = puntaje derivadoP = percentil
x
z
Z
P
50% del áreaprobabilidad = 0.5
Así por ejemplo, puede apreciarse que un puntaje bruto correspondiente a más un desvío estándar corresponde a un puntaje reducido z de +1, a un puntaje derivado Z de 60, y a un percentil de 84.Especialmente cuando se trata de averiguar valores intermedios (por ejemplo el puntaje bruto correspondiente a más 1.62 desvíos estándar) debe recurrirse al empleo de fórmulas y tablas. El siguiente esquema indica la forma de hacerlo:
Reglas de transformación de puntajes (de utilidad para resolver aplicaciones prácticas de la curva normal)
Página 55 de 314
55

PUNTAJE BRUTO (x) PUNTAJE REDUCIDO (z) AREA EXPRESADA COMO PROBABILIDAD (p)
AREA EXPRESADA COMO PORCENTAJE (%)PUNTAJE DERIVADO (Z)
PERCENTIL (P)m = un número cualquiera entre 0 y 100
z = (x - X) / s
Z = (z.10) + 50
Tabla: entrar por z
Tabla: entrar por p
Multiplicar por 100 Dividir por 100z = (Z-50) / 10
x = (z.s) + X
m% Pm Pm m%
En este esquema, las flechas más gruesas indican los procedimientos habituales en las aplicaciones prácticas de la curva normal, mientras que aquellas y las flechas más finas indican mas bien los procedimientos que se piden en ejercitaciones en cursos de estadística.
5. APLICACIONES DE LA CURVA NORMAL
El modelo matemático de la curva normal tiene varias aplicaciones prácticas, como por ejemplo en psicología y ciencias de la educación. Pagano (1998:81) invoca tres razones principales que explican su importancia en estas disciplinas: 1) Muchas variables psicológicas tienen distribuciones muy semejantes a la curva normal, tales como altura, peso e inteligencia. 2) Muchas pruebas de inferencia empleadas para analizar experimentos tienen distribuciones muestrales que poseen una distribución muestral al aumentar el tamaño de la muestra. 3) Muchas pruebas de inferencia requieren distribuciones muestrales que se asemejen a la curva normal, como la prueba z, la prueba ‘t’ de Student o la prueba F. Consiguientemente, gran parte de la importancia de la curva normal aparece conjuntamente con la estadística inferencial.
En lo que sigue se suministran algunos ejemplos de aplicaciones prácticas de la curva normal con puntajes estandarizados. En primer lugar se expone un problema típico y la forma de resolverlo teniendo en cuenta las reglas de transformación de puntajes (ver esquema anterior). En segundo lugar, se presentan algunas variantes posibles dentro del problema típico u otros.
Problema típico.- La variable ‘peso’ en una población de mujeres adultas tiene una distribución aproximadamente normal, con una media aritmética (X) de 60 kg y un desvío estándar (s) de 6 kg. Calcular la probabilidad de que una mujer adulta de esa población tomada al azar tenga un peso mayor a 68 kg.
Resolución del problema típico.- Cuando el enunciado del problema afirma que la variable tiene una distribución aproximadamente normal, ello significa que puede ser resuelto recurriendo al modelo de la curva normal. A partir de aquí, los pasos para resolverlo son los siguientes:
a) Lo primero que debe especificarse son los datos y las incógnitas. Los datos son tres: la media aritmética (60 kg), el desvío estándar (6 kg), y finalmente un valor de la variable a partir del cual debe estimarse su probabilidad (68 kg). En símbolos:X = 60 kg s = 6 kg x = 68 kgEn este caso el problema solicita resolver una sola incógnita: la probabilidad de que una persona tomada al azar tenga más de 68 kg (también podría haber solicitado averiguar la probabilidad de que tenga menos de 50 kg, o la probabilidad de que tenga entre 40 y 60 kg). En símbolos:p Þ 68 kg > x
Página 56 de 314
56

b) Antes de seguir adelante, siempre convendrá trazar la curva normal y especificar la información revelante para resolver el problema. En este caso es:
Según el esquema de reglas de transformación de puntajes, si a partir de un valor dado de x (68 kg) se quiere calcular su probabilidad p, antes deberá transformarse el valor x a un puntaje reducido z, el cual constituye una incógnita (?) que deberá resolverse.Asimismo se raya el área bajo la curva que se extiende desde 68 hacia la derecha, porque es esa probabilidad (proporcional al área rayada) la que debe averiguarse (es decir, 68 o más).
c) Se aplica la fórmula de transformación del puntaje x en puntaje z:
z = (x - X) / sz = (68 – 60) / 6 = 1.33
d) Se recurre a la Tabla de áreas bajo la curva normal estandarizada para hallar la probabilidad p a partir de z = 1.33. Para ello, puede utilizarse indistintamente la Tabla 1 o la Tabla 2 (ver Anexo).Se utilizará la Tabla 1, donde puede verse que a un valor z = 1.33 corresponde una probabilidad p = 0.9082.
e) Sin embargo, esta tabla indica la probabilidad de z o menos, es decir, la zona rayada hacia la izquierda de z.Por lo tanto, como lo que interesa es la probabilidad de un valor de z o mayor, se restará al valor p = 1 (el total del área bajo la curva) el valor p = 0.9082. En símbolos:Area total 1.0000Menos área hacia la izquierda 0.9082Area hacia la derecha 0.0918Por lo tanto, la probabilidad de que una mujer adulta pese más de 68 kg es de p = 0.0918. Traduciendo la probabilidad a porcentajes, puede decirse que existe un 9.18% de probabilidades de que la mujer pese 68 kg o más. De idéntica manera, puede decirse que el percentil P que ocupa una mujer adulta de 68 kg es, siguiendo las pautas del esquema de reglas de transformación de puntajes: P91 (calculado y redondeado a partir de p = 0.9082), lo cual significa que una mujer que pese 68 kg tiene ‘por debajo’ aproximadamente un 91% de personas que pesan menos que ella.
Algunas variantes posibles.- Los siguientes ocho casos ilustran algunos ejemplos de problemas que pueden resolverse mediante la curva normal y los puntajes estandarizados. El problema típico examinado precedentemente encuadra en el caso 4.En todos estos casos se trata de calcular la probabilidad de ocurrencia de un valor comprendido bajo el área rayada de la curva ya que la probabilidad de ocurrencia del valor es proporcional al área respectiva. Como se verá, en algunos casos conviene más utilizar la Tabla 1 y en otros las Tabla 2 (ver Anexo).
CASO 1 CASO 2
Página 57 de 314
57

CASO 3 CASO 4
CASO 5 CASO 6
CASO 7 CASO 8
Caso 1.- Aquí se trata de averiguar la probabilidad p de que un valor cualquiera de la población corresponda a z = +1.5. Para este caso convendrá utilizar la tabla 1, donde primero se busca el valor +1.5 en la primera columna, y luego se busca su valor de probabilidad, que es p = 0.9332. Nota: si el valor de z hubiese sido +1.56, se busca primero z = 1.5 y luego se busca, en la primera hilera, el valor 0.06 (ya que 1.5 + 0.06 = 1.56). En el entrecruzamiento de 1.5 y 0.06 encontraremos, finalmente, el valor de la probabilidad p = 0.9406.
Caso 2.- En este caso se procede de manera similar que en el caso anterior.
Caso 3.- Aquí se trata de averiguar la probabilidad de que un valor z valga -2 o más. Esta situación exige dos pasos. El primer paso es idéntico al caso 1. Sin embargo, este primer paso calcula la probabilidad de z hacia la izquierda, y lo que se necesita saber es la probabilidad de z hacia la derecha (zona rayada). Como se sabe que la totalidad del área bajo la curva vale 1, para averiguar la zona hacia la derecha bastará con restar 1 de la probabilidad de la zona hacia la izquierda. En esto consiste el segundo y último paso.
Caso 4.- Aquí debe averiguarse la probabilidad de que un valor z valga 1.5 o más. La opción más sencilla es aquí emplear la Tabla1, con la cual se calcula la probabilidad correspondiente a z = +1.5, que es p = 0.9332. Esta probabilidad corresponde a la zona rayada desde z hacia la izquierda, pero como debe averiguarse la probabilidad de z hacia la derecha, deberá restarse 1 menos 0.9332.
Caso 5.- Aquí debe averiguarse la probabilidad de que un valor z esté comprendido entre -2.5 y +1.5. Una forma sencilla de resolver este problema es dividiendo el área rayada en dos: una desde la mitad hacia la izquierda (0 a -2.5) y otra desde la mitad hacia la derecha (0 a +1.5). Se calcula luego la probabilidad de cada área recurriendo a la Tabla 2, y finalmente se suman ambas probabilidades. Nota: para el cálculo de la zona rayada de la mitad hacia la izquierda se buscará en la Tabla 2 el valor z = +2.5, porque es igual al valor z = -2.5 (por ser la curva normal simétrica).
Caso 6.- Este caso es tan sencillo que no requiere el uso de tablas. La probabilidad de la zona rayada es p = 0.5 porque corresponde exactamente a la mitad de toda el área bajo la curva, cuya p es igual a 1 (p = 1 equivale a la certeza).
Página 58 de 314
58

Caso 7.- Aquí debe calcularse la probabilidad de que un valor z esté comprendido entre -2 y -1. En este caso, en lugar de sumar áreas como en el caso 5, deberán restarse áreas. Recurriendo a la Tabla 1, se calcula primero la probabilidad correspondiente a z = -1 (que es p = 0.1587) y luego la probabilidad de z = -2 (que es p = 0.0228). La probabilidad resultante será p = 0.1587 – 0.0228 = 0.1359.
Caso 8.- Aquí debe calcularse la probabilidad de que un valor z esté comprendido entre +1 y +2. Se puede proceder de la misma forma que en el caso 7, es decir, restando las probabilidades correspondientes a z = +2 y z = +1.
NOTAS
(1) Botella (1993:153) refiere que los puntajes estandarizados son útiles en los siguientes casos: a) al hacer comparaciones entre unidades de distintos grupos: se pueden comparar, mediante puntuaciones estandarizadas, distintas observaciones de un mismo sujeto o de sujetos diferentes; b) al hacer comparaciones entre variables medidas de distinta forma, debido a que los puntajes estandarizados son adimensionales. Por ejemplo, comparar una altura expresada en centímetros con otra expresada en metros; y c) al comparar observaciones de distintas variables: por ejemplo, comparar la altura y el peso de un sujeto.(2) En el esquema puede apreciarse que z contempla valores que se extienden a -5 o +5.desvíos estándar. En la práctica, sin embargo, se consideran solamente valores entre -3 y +3 por razones prácticas. En efecto, los valores superiores a +3 o menores a -3 cubren áreas muy pequeñas bajo la curva, es decir, la probabilidad de ocurrencia de puntajes mayores que +3 o menores que -3 son muy improbables, estando muy alejados de la media aritmética.(3) Hay muchas formas en que los datos pueden distribuirse, y en todos esos casos existe cierta regularidad en los mismos. Por ejemplo, hay una tendencia a que la mitad de las veces salga cara arrojando una moneda, y también hay una tendencia a que la mitad de las veces se opte por un producto A y no uno B (suponiendo que lo hay ninguna razón para elegir uno u otro). Estos hechos sugieren que los datos de una manera regular, y los estadísticos propusieron diversos modelos de distribución, uno para cada forma regular de distribución de datos, como por ejemplo el modelo Bernouilli o el modelo binomial.La noción de permanencia estadística (Vessereau A, 1962:15) hace referencia a ciertas uniformidades en los datos de la realidad. Por ejemplo: a) la cantidad de varones y la de mujeres tiende a ser aproximadamente igual; b) el tamaño de las galletitas que fabrica una máquina tiende a ser aproximadamente igual; c) la proporción entre granos esféricos de arvejas y granos arrugados de arvejas tiende a ser del 75% y del 25% aproximadamente, o sea, siempre tiende a encontrarse aproximadamente 75 granos esféricos cada 100, y 25 granos arrugados cada 100; d) la estatura de las personas tienden siempre a estar alrededor de un valor medio, siendo frecuente encontrar estaturas de 1.70 metros pero raro encontrar estaturas de 2 metros.Estas uniformidades sugieren la presencia de leyes que rigen la forma en que se distribuyen los datos. Como hay muchas formas en que los datos pueden distribuirse, también habrá muchas leyes que describen dichas distribuciones. Entre las más conocidas (Vessereau A, 1962:16-24) se cuentan la ley binomial, la ley de Laplace-Gauss y la ley de Poisson. Por ejemplo, la ley de Laplace-Gauss describe las distribuciones que siguen una curva normal: “cuando una magnitud recibe la influencia de una gran cantidad de causas de variación, y estas son todas muy pequeñas e independientes unas de otras, se demuestra que los valores individuales de las mediciones se distribuyen respondiendo a la ley de Laplace-Gauss” (Vessereau A, 1962:20).Otros autores consideran fundamentales a las distribuciones normal, binomial y de Student, y hacen referencia a otras, como la distribución ‘chi cuadrado’ (x2) que, a diferencia de la primeras, no es paramétrica, es decir, no requiere supuestos tan rigurosos acerca de la población, como por ejemplo de que esta se distribuya normalmente (Kohan N, 1994:191).Hay otras leyes que tienen alcance más general, como por ejemplo la ley de distribución de las medias (Vessereau A, 1962:24) que establece que, cualquiera que sea la distribución (binomial, gaussiana, etc.), el desvío estándar de las medias aritméticas de todas las muestras posibles de n elementos disminuye inversamente a la raíz cuadrada de n. Esto significa que cuanto más grandes sean las muestras, menos desviación o dispersión habrá entre sus medias aritméticas.
Teorema de Chebicheff.- Esta desigualdad se aplica a cualquier tipo de distribución (normal o no), hipótesis, ley, etc., y por ello puede actuar como prueba de consistencia. Se emplea cuando no se sabe qué tipo de distribución tiene la muestra o población.Esta desigualdad brinda el límite inferior (probabilidad mínima) de los casos más probables según cualquier ley, teoría, etc. Más concretamente, sirve para determinar la probabilidad mínima de un intervalo centrado en la media, y que abarca tantas dispersiones en menos y tantas en más. Generalmente se toman +2 y -2.La fórmula es:P (m – t . d ≤ x ≤ m + t . d) ≥ 1 – (1/t2)donde:P = Probabilidad mínima.m = Media aritmética.d = Desvío estándar.t = Cantidad de desvíos estándar (en general se toman 2).m – t . d = Límite inferior.m + t . d = Límite superior.x = Valor que está entre ambos límites.m – t . d ≤ x ≤ m + t . d = IntervaloComo se considera generalmente t = 2, resulta ser:P (m – 2. d ≤ x ≤ m + 2 . d) ≥ 0.75Ejemplo de problema.- En una muestra, la media aritmética es 60 y el desvío estándar es 20. Determinar el intervalo de x que abarque por lo menos el 75% de los casos más probables.P (m – 2. d ≤ x ≤ m + 2 . d) ≥ 0.75
Página 59 de 314
59

P (60 – 2. 20 ≤ x ≤ 60 + 2 . 20) ≥ 0.75P (20 ≤ x ≤ 100) ≥ 0.75El intervalo obtenido nos asegura que por lo menos (probabilidad mínima) el 75% de los casos más probables están entre 20 y 100.
CAPÍTULO 4: CORRELACIÓN Y REGRESIÓN
1. INTRODUCCIÓN
El análisis de correlación permite averiguar el tipo y el grado de asociación estadística entre dos o más variables, mientras que el análisis de regresión permite hacer predicciones sobre la base de la correlación detectada.Más concretamente, una vez realizado el análisis de correlación, pueden obtenerse dos resultados: que haya correlación o que no la haya. Si hay correlación, entonces se emprende un análisis de regresión, consistente en predecir cómo seguirán variando esas variables según nuevos valores.Por ejemplo, si sobre la base de haber examinado a 40 alumnos se concluye una alta correlación en sus notas en ambos parciales, conociendo la nota del primer parcial de un alumno número 41, podremos predecir con algún margen de seguridad cuánto se sacará este alumno en el segundo parcial.En general el análisis de correlación se realiza conjuntamente con el análisis de regresión. Mientras el análisis de correlación busca asociaciones, el análisis de regresión busca predicciones, es decir, predecir el comportamiento de una variable a partir del comportamiento de la otra.Así, la correlación y la regresión están íntimamente ligadas. En el nivel más sencillo, ambas implican la relación entre dos variables y utilizan el mismo conjunto de datos básicos, pero mientras la correlación tiene que ver con la magnitud y la dirección de la relación, la regresión se centra en el uso de la relación para hacer una predicción. Esta última es sencilla cuando la relación es perfecta, pero la situación es más compleja si la relación es imperfecta (Pagano, 127).La correlación es útil porque permite hacer predicciones, porque permite establecer correlaciones (paso previo para la determinación de una conexión causal), y para realizar pruebas de confiabilidad de instrumentos de medición como los tests (prueba test-retest) (Pagano, 99).Por último, vale la pena aclarar que en el contexto de un estudio científico, no basta con determinar el grado de correlación entre dos variables en una muestra. Es necesario además establecer, mediante una prueba de significación (por ejemplo la prueba ‘t’), si la correlación establecida en la muestra puede extenderse a toda la población con un determinado nivel de confianza. Esta tarea corresponderá a la estadística inferencial.
Correlación lineal.- Las relaciones entre variables pueden ser de muchos tipos. a) Hay relaciones deterministas que responden a modelos matemáticos teóricos, como por ejemplo la relación entre la intensidad de una corriente y la resistencia del conductor, o bien, la relación entre la factura de consumo de agua y el número de metros cúbicos consumidos. Estas relaciones son habituales en ciencias exactas. b) Otras relaciones no son tan deterministas, pero pueden eventualmente parecerse –sólo parecerse- a algún modelo matemático teórico determinista, en cuyo caso se concluye que ese modelo explica bien la relación, aunque no lo haga perfectamente. Estas relaciones son habituales en las ciencias sociales (Botella, 1993:181).Dentro de los muchos modelos teóricos a los cuales podría ajustarse una relación no determinista se cuentan los modelos lineales, los modelos cuadráticos, los modelos cúbicos, etc. El primero se representa mediante una recta, y los restantes mediante diversos tipos de curva como parábolas e hipérbolas. El presente artículo hará referencia, por razones de simplicidad, a las relaciones lineales y, por tanto, a la correlación lineal.
Correlación y causalidad.- El hecho de que dos variables estén correlacionadas, no significa necesariamente que una sea la causa y la otra el efecto: la correlación no siempre significa causalidad. Entre otras cosas, una alta correlación puede deberse a que ambas variables X e Y dependen cada una independientemente de otra variable Z, y entonces, al variar Z hace variar conjuntamente a X e Y, produciendo un efecto de alta correlación que puede dar la apariencia de causalidad. Por dar un ejemplo: entre memoria visual (X) y memoria auditiva (Y) puede haber una alta correlación, pero ello no significa que la memoria visual sea la causa de la memoria auditiva, ya que ambas pueden estar dependiendo de otro factor Z más general, llámese "memoria", o "cantidad de ARN".Si realizar el análisis de correlación es algo relativamente fácil (se trata de recoger datos y aplicar una fórmula), determinar el vínculo causal suele implicar un procedimiento más laborioso, como por ejemplo la ejecución de un diseño experimental que implique la comparación de dos grupos sometidos a condiciones diferentes y donde haya un control sobre la influencia de variables extrañas.
El siguiente esquema permite visualizar algunos pasos posibles para llevar a cabo un análisis de correlación seguido de un análisis de regresión. El esquema sintetiza, al mismo tiempo, los temas a tratar en el presente artículo.
Página 60 de 314
60

Si las variables son…
CUANTITATIVASSe calcula la correlación con
CUALITATIVAS ORDINALESSe calcula la correlación con
METODO ANALITICOCoeficiente de correlación por rangos de Spearman
METODO ANALITICOCoeficiente de correlación de Pearson
METODO GRAFICODiagrama de dispersión
Se calcula la regresión (predicción) con
Para interpretar mejor este coeficiente, se calcula el coeficiente de determinación
METODO ANALITICOMétodo de los cuadrados mínimos
METODO GRAFICORecta de regresión
2. EL ANÁLISIS DE CORRELACIÓN
“Juan se sacó una buena nota en el primer parcial, y por lo tanto es bastante probable que también saque buena nota en el segundo parcial”. “Esta persona tiene más edad y por lo tanto es más probable que le falte alguna pieza dentaria”. Abundan esta clase de razonamientos en la vida cotidiana, que suelen aceptarse sin demasiada crítica.Sin embargo, en un estudio científico es habitual que estas hipótesis deban ser comprobadas más allá de las certidumbres subjetivas. Para constatar si hay realmente asociación entre dos o más variables cualesquiera, se emplea una herramienta denominada ‘análisis de correlación’, que también evalúa el grado o intensidad en que dichas variables están asociadas. Se examina aquí el caso más sencillo (dos variables), que se estudia dentro de la estadística bivariada.En el siguiente ejemplo se exponen tres posibles distribuciones de frecuencias bivariadas (1) referidas a las primeras y segundas notas de exámenes parciales.
Alumno Tabla 1 Tabla 2 Tabla 3X Y X Y X Y
ABCDEFG
34668910
2556699
34668910
34668910
34668910
2355789
X = Nota del primer parcialY = Nota del segundo parcial
En la Tabla 1 se han consignado las notas de los parciales de un grupo de 7 alumnos ordenadas en forma creciente.Un somero examen visual de la tabla revela que hay bastante asociación entre las variables X e Y: quienes sacaron buena nota en el primer parcial tienden a sacar buena nota en el segundo, y lo mismo para quienes sacaron bajas notas, con lo cual ambas variables tienden a variar concomitantemente o conjuntamente.Sin embargo, debe tenerse presente que la asociación o correlación entre ambas variables no depende de la similitud entre X y Y, sino de la similitud de sus modos de variación. Así, en la Tabla 2 las notas de los primeros y segundos parciales de cada alumno son iguales, y en la Tabla 3 la nota del segundo parcial es diferente, pero siempre menor en un punto. Sin embargo, en ambas tablas la correlación es la misma.
El análisis de correlación busca establecer esencialmente tres cosas:1) Presencia o ausencia de correlación.- Dadas dos o más variables, si existe o no correlación entre ellas. 2) Tipo de correlación.- En caso de existir correlación, si esta correlación es directa o inversa. En la correlación directa, ambas variables aumentan (o disminuyen) concomitantemente, y en la correlación
Página 61 de 314
61

inversa ambas variables varían inversamente, o también puede decirse "en relación inversamente proporcional", lo que significa que cuando una aumenta la otra disminuye, o viceversa (2). En el siguiente esquema se muestran algunos ejemplos de correlación directa e inversa.
Tipos de correlación
Tipo Definición Ejemplos en psicologíaCorrelación directa o positiva
Ambas variables aumentan (o disminuyen) en forma concomitante.
Cociente intelectual/calificación: A mayor CI, mayor calificación obtenida en el examen.Tiempo/retención: A mayor tiempo para memorizar, mayor cantidad de palabras retenidas.Test laboral/rendimiento futuro: A mayor puntaje en un test de aptitud técnica, mayor rendimiento en dicha área dentro de x años (esto es también un modo de estimar la validez predictiva de un test).
Correlación inversa o negativa
Una variable aumenta y la otra disminuye (o viceversa) en forma concomitante.
Edad/memoria: Al aumentar la edad, disminuye la memoria.Numero de ensayos/cantidad de errores: Al aumentar el número de ensayos, disminuye la cantidad de errores.Cansancio/atención: Al aumentar el cansancio disminuye la atención.
3) Grado de correlación.- El grado o ‘intensidad’ de la correlación, es decir, ‘cuánta’ correlación tienen en términos numéricos.
Para hacer todas estas averiguaciones, se puede recurrir a tres procedimientos.a) El método tabular.- Una correlación podría constatarse con la simple visualización de tablas de correlación como las indicadas anteriormente, pero habitualmente las cosas no son tan fáciles, sobre todo porque hay bastante mayor cantidad de datos, y porque estos casi nunca registran los mismos incrementos para ambas variables. Por lo tanto, debe abandonarse la simple visualización de las tablas y utilizar procedimientos más confiables, como los gráficos (diagramas de dispersión o dispersiogramas) y los analíticos (por ejemplo el coeficiente de Pearson).b) El método gráfico.- Consiste en trazar un diagrama de dispersión.c) El método analítico.- Consiste en aplicar una fórmula que permita conocer no sólo el tipo de correlación (directa o inversa) sino también una medida cuantitativa precisa del grado de correlación. La fórmula del coeficiente de Pearson es un ejemplo típico para medir correlación entre variables cuantitativas.
3. CÁLCULO GRÁFICO DE LA CORRELACIÓN
Un gráfico es mucho mejor que una tabla para apreciar rápidamente si hay o no correlación entre variables. Existen varias maneras de graficar la correlación (3), pero aquí se describirá el procedimiento clásico: el diagrama de dispersión. El diagrama de dispersión es básicamente una ‘nube’ de puntos, donde cada punto corresponde al entrecruzamiento de cada par de valores de X e Y. Este diagrama puede realizarse independientemente del cálculo analítico de la correlación.Por ejemplo, el diagrama de dispersión correspondiente a la Tabla 1 se asemeja al diagrama A del esquema de diagramas de dispersión.A este diagrama se ha agregado ‘a ojo’ una línea imaginaria, que viene a representar más o menos el ordenamiento lineal de los puntos (que van desde abajo a la izquierda hacia arriba a la derecha). El diagrama se llama 'de dispersión' porque muestra cuán dispersos (próximos o alejados) están los puntos alrededor de dicha recta. Fácil es advertir que cuanto más alineados estén, más correlación habrá. En el ejemplo A del esquema sobre diferentes diagramas de dispersión, los puntos tienden a ubicarse en las proximidades de la recta imaginaria, lo que indica que están poco dispersos. Si los puntos figurasen más alejados habría más dispersión, y por lo tanto menor correlación entre X e Y.El caso B muestra correlación inversa, pues el ordenamiento de los puntos indican que, a medida que aumenta X, va disminuyendo Y. Así entonces, cuando la línea imaginaria va de abajo a la izquierda hacia arriba a la derecha, hay correlación directa, y cuando va desde arriba a la izquierda hacia abajo a la derecha hay correlación inversa. Dicho más técnicamente, en el primer caso la recta tiene una inclinación o pendiente positiva, y en segundo su pendiente es negativa.El caso C revela, por su parte, que a medida que aumenta Y, los valores de X ni aumentan ni disminuyen, permaneciendo fijos en el valor 5. Por lo tanto no hay correlación. En general no la hay cuando una de las variables no varía (en este caso X permanece constante en el valor 5).El caso D es similar al anterior: allí los valores de Y permanecen constantes en el número 4, mientras va variando X. Tampoco hay correlación.El caso E muestra un ejemplo donde varían ambas variables, pero sin embargo no hay correlación. En esa nube es imposible trazar una línea imaginaria representativa de la orientación de los puntos, simplemente porque no hay tal orientación lineal. Los valores que van asumiendo las variables son en principio aleatorios (varían al azar). Tampoco hay correlación.El caso F nos muestra un caso de correlación perfecta o máxima (en este caso directa), pues no hay dispersión de puntos alrededor de la línea imaginaria: todos están sobre ella. Estas regularidades
Página 62 de 314
62

Y
109876543210
0 1 2 3 4 5 6 7 8 9 10 X
A) Correlación directa
Y
109876543210
0 1 2 3 4 5 6 7 8 9 10 X
B) Correlación inversa
Y
109876543210
0 1 2 3 4 5 6 7 8 9 10 X
C) Sin correlación
Y
109876543210
0 1 2 3 4 5 6 7 8 9 10 X
D) Sin correlación
Y
109876543210
0 1 2 3 4 5 6 7 8 9 10 X
E) Sin correlación
Y
109876543210
0 1 2 3 4 5 6 7 8 9 10 X
F) Correlación directa perfecta
‘perfectas’ no suelen encontrarse fácilmente, ni menos aún en ciencias sociales, porque los fenómenos obedecen siempre a muchas causas que estarán actuando para romper la ‘armonía natural’ entre X e Y.También hay casos de correlación no lineal, donde en lugar de una recta imaginaria se traza una curva. En este artículo se presentan solamente los casos más sencillos, es decir, los casos de correlación lineal, representables mediante rectas.
Diferentes diagramas de dispersión
Si bien una ‘nube de puntos’ puede dar una idea de si hay o no correlación, o de si es directa o inversa, todavía no proporciona información sobre ‘cuanta’ correlación hay. Esta información se obtiene mediante un cálculo analítico.
4. CÁLCULO ANALÍTICO DE LA CORRELACIÓN
La correlación se calcula analíticamente mediante ciertos coeficientes, que serán distintos según se trate de correlacionar variables nominales, ordinales o cuantitativas, y según se trate de otras consideraciones varias.Si bien existen muchos coeficientes de correlación (4), en lo que sigue se explicarán algunos de los más utilizados: el coeficiente de correlación lineal de Pearson (para variables cuantitativas), y el coeficiente de correlación por rangos de Spearman (para variables cualitativas ordinales).
a) Coeficiente de correlación lineal de Pearson
Este coeficiente (que se designa con “r”), fue creado por Karl Pearson (1857-1936) para relacionar variables cuantitativas (es decir, variables que, como “nota de examen”, se miden mediante números).El coeficiente de Pearson es un número comprendido entre -1 y +1, y que posee un determinado signo (positivo o negativo). El valor numérico indica ‘cuanta’ correlación hay, mientras que el signo indica qué ‘tipo’ de correlación es (directa si el signo es positivo, inversa si es negativo). En el siguiente esquema se muestran algunos posibles valores de “r”.
Página 63 de 314
63

Correlación inversa máxima (-1)
Baja correlación inversa (-0.15)
Correlación nula (0)
Alta correlación directa (+0.70)
Correlación directa máxima (+1)
Algunos valores del coeficiente de Pearson
Cuanto más cerca de cero esté el coeficiente de correlación obtenido, tanto menor correlación habrá. Cabría preguntarse: ¿hasta qué valor se considera que hay correlación? ¿desde qué valor no la hay? Esto es una cuestión que depende de varias cosas, y hace a la cuestión de la relatividad del coeficiente de Pearson.En efecto, su interpretación depende de varios factores, como por ejemplo: a) la naturaleza de las variables que se correlacionan; b) la significación del coeficiente; c) la variabilidad del grupo; d) los coeficientes de confiabilidad de los tests; e) el propósito para el cual se calcula r.El valor r = 0,70 puede indicar alta correlación para cierto par de variables, pero baja correlación para otras variables distintas. Otro ejemplo: un r de 0,30 entre estatura e inteligencia o entre tamaño craneal y habilidad mecánica indicaría una correlación mas bien alta, puesto que las correlaciones entre variables físicas y mentales suelen ser mucho más bajas, a menudo iguales a cero. Otro ejemplo: un r de 0,30 entre inteligencia y nota de examen, o entre puntaje en inglés y puntaje en historia es considerada bajísima, ya que los r en estos campos suelen extenderse entre 0,40 y 0,60. Otro ejemplo: semejanzas entre padres e hijos, en cuanto a rasgos físicos y mentales, se expresan por valores entre 0,35 y 0,55, y por lo tanto un r de 0,60 sería alto.Respecto de la fórmula para calcular el coeficiente de correlación de Pearson ("r"), no hay una única manera de presentarla, y la elección de una u otra dependerá de la forma de presentación de los datos. Por ejemplo, si los datos están agrupados en una tabla de frecuencias, se utiliza cierta fórmula (Bancroft, 1960:190), mientras que si los datos no están agrupados en frecuencias, podrán utilizarse cualquiera de las fórmulas indicadas en el siguiente esquema (5):
Fórmula 1 Fórmula 2
{ ( x – X) (y – Y) }r = ± ------------------------------- n x . y
Se usa esta fórmula cuando dan como datos las medias de X e Y y sus respectivos desvíos estándar.
{ ( x – X) (y – Y) }r = ± ------------------------------- ( x – X)2 . (y – Y)2
(El denominador debe elevarse a la raíz cuadrada).Se usa esta fórmula cuando dan como datos las medias aritméticas de X e Y.
Fórmula 3 Fórmula 4 (Z x . Zy)r = ± --------------------- n
Se usa esta fórmula cuando dan como datos los puntajes estandarizados Z.
n (x.y) –x . yr = ------------------------------------------------ n x2 – (x)2 . n y2 – (y)2
(Ambos factores del denominador se elevan a la raíz cuadrada)Se utiliza esta fórmula (llamada fórmula del producto momento) cuando no se conocen ni medias aritméticas ni desvíos estándar.
A continuación se suministra un ejemplo de cómo calcular el coeficiente "r" utilizando la fórmula 2. Se trata de determinar el coeficiente de Pearson para dos variables X e Y (que podrían ser por ejemplo las notas del primero y segundo parcial). También se pide interpretar el resultado.La tabla 1 son los datos dados, mientras que la tabla 2 es una ampliación que debe hacerse para poder obtener más información y poder así aplicar la fórmula:
Tabla 1
Página 64 de 314
64

Alumno X YABCDE
457910
678910
N=5 alumnos
35 40
Tabla 2
x – X y – Y ( x – X) (y – Y) ( x – X)2 (y – Y)2
-3-2023
-2-1012
62026
94049
11011
0 0 16 26 10
X = 7Y = 8
Con los datos obtenidos se aplica ahora la fórmula 2:
{ ( x – X) (y – Y) } 16r = ± ---------------------------------------- = ----------------------- = +0.99raíz de ( x – X)2 . (y – Y)2 raíz de 26,10
Interpretando el resultado, se puede decir que la correlación obtenida es directa o positiva y es además, muy alta.
Coeficientes derivados.- A partir del coeficiente "r" de Pearson (en cualquiera de sus formas) se pueden derivar otros, según la información que se quiera obtener:1) Coeficiente de determinación (r2): es el coeficiente "r" elevado al cuadrado. El coeficiente de determinación indica qué porcentaje de la variación de Y está determinada por las variaciones de X. Por ejemplo, para un "r" de 0,70, hay un coeficiente de determinación de 0,49, lo que significa que el 49% de la variación de Y está determinada por la variación de X.2) Coeficiente de alienación (k): llamado también de no correlación, no indica la correlación sino la falta de correlación entre dos variables (o grado de independencia). Para calcularlo se aplica la fórmula siguiente:r2 + k2 = 1 [1]Por ejemplo, si sabemos que "r" es de 0,50, aplicando la fórmula indicada tenemos que "k" vale 0,86, con lo cual el grado en que falta la correlación resulta ser mayor que el grado en que sí hay correlación.Idénticamente, si "r" vale 1 entonces "k" vale 0, y viceversa. Cuanto mayor es el coeficiente de alienación tanto menor es la correlación, y por tanto menos confiables serán las predicciones que -análisis de regresión mediante- se hagan sobre esa base.3) Coeficiente de indeterminación (k2): es el coeficiente "k" pero elevado al cuadrado. Mide el grado en que la variación de Y no está determinada por la variación de X. La fórmula del coeficiente de indeterminación es deducible de la anterior [1].4) Coeficiente de eficiencia predictiva (E): suele utilizarse para, sabiendo "r", estimar rápidamente el poder predictivo de la correlación "r". Su fórmula es:E = 100 . (1 - 1-r2) donde 1-r2 debe elevarse a la raíz cuadrada.Por ejemplo si la correlación "r" es de 0,50, la eficiencia predictiva será del 13%. Pero cuando "r" sube a 0,98, la eficiencia predictiva será del 80%. La correlación debe ser entonces de 0.87 o más para que la eficiencia predictiva sea mayor al 50%.
Matriz de correlaciones.- En muchas investigaciones se estudian muchas variables, y se intenta cuantificar mediante el coeficiente ‘r’ sus relaciones dos a dos, es decir, las relaciones de cada variable con cada una de las demás (Botella, 1993:202). A los efectos de comparar estos diferentes valores de ‘r’ se traza una matriz de correlación, que puede tener la siguiente forma:
Variable X
Variable Y Variable W
Variable Z
Variable X r = -0.17 r = -0.11 r = -0.30Variable Y r = +0.46 r = +0.17Variable W
r = +0.10
Página 65 de 314
65

Variable Z
La matriz permite visualizar inmediatamente, entre otras cosas, cuáles son los coeficientes de correlación más altos (en este caso, entre Y y W).Nótese que no han sido llenados los casilleros donde se cruzan las mismas variables (por ejemplo X con X), porque carece de sentido hacerlo y su correlación es siempre perfecta y positiva (r = +1).
b) Coeficiente de correlación por rangos de Spearman
Se trata de un coeficiente de correlación utilizado para estudiar la asociación entre dos variables ordinales. Se representa con la letra griega ‘rho’, y sus fórmulas son las siguientes:
Fórmula 1 Fórmula 2
6 d2
= 1 - --------------------------- n (n + 1) (n – 1)
x2 + y2 + d2
= -------------------------------- 2 . Ö x2. y2
La fórmula para obtener x2 o y2 es la misma en ambos casos, y es x2 = y2 = (n3 – n) / 12 En el denominador, la raíz cuadrada afecta a x2. y2
En ciertos casos conviene utilizar la primera fórmula, y en otros casos la segunda. Por ejemplo (Kohan, 1994:256), si no hay empates en los rangos o son muy pocos, se utilizará la fórmula 1, y si hay empates en los rangos, se utilizará la fórmula 2. Para comprender esto, se suministran a continuación dos ejemplos diferentes: uno sin empates y otro con empates.
Ejemplo 1.- En este ejemplo (tomado de Kohan, 1994:256) se utiliza el coeficiente de Spearman para evaluar el grado de asociación entre dos variables ordinales: X (autoritarismo) e Y (búsqueda de status). Por ejemplo, permitirá averiguar si a medida que aumenta el autoritarismo en las personas tiende también a aumentar la búsqueda de status social.Para ello se toma una muestra de 12 sujetos, y se obtienen los siguientes resultados:
Sujeto x (rango por autoritarismo) y (rango por búsqueda de status) d d2
A 2° 3° -1 1B 6° 4° 2 4C 5° 2° 3 9D 1° 1° 0 0E 10° 8° 2 4F 9° 11° -2 4G 8° 10° -2 4H 3° 6° -3 9I 4° 7° -3 9J 12° 12° 0 0K 7° 5° 2 4L 11° 9° 2 4
n = 12 d2 = 52
Esta tabla indica, por ejemplo, que el sujeto A se situó en un segundo lugar en autoritarismo y en un tercer lugar en búsqueda de estatus.Aplicando la fórmula 1, se obtiene un coeficiente de Spearman de 0.82, lo cual sugiere una alta correlación entre autoritarismo y búsqueda de status.
Ejemplo 2.- Aquí se trata de obtener el coeficiente de Spearman cuando hay empates en los rangos. Los empates ocurren cuando dos o más sujetos tienen el mismo rango en la misma variable. Por ejemplo (ver tabla siguiente), los sujetos A y B obtuvieron el mismo puntaje en la variable X (o sea, obtuvieron ambos cero). Otro tanto ocurrió con los sujetos C y D y con los sujetos J y K, siempre en relación a la misma variable X. En el caso de la variable Y todos los puntajes fueron diferentes, y por lo tanto no hubo empates.Cuanto mayor es la cantidad de empates, más conveniente resultará utilizar la fórmula 2.
Sujeto x (rango por autoritarismo) y (rango por búsqueda de status)
d d2
Puntaje Rango Puntaje RangoA 0 (1°) 1.5° 42 3° -1.5 2.25B 0 (2°) 1.5° 46 4° -2.5 6.25C 1 (3°) 3.5° 39 2° 1.5 2.25D 1 (4°) 3.5° 37 1° 2.5 6.25
Página 66 de 314
66
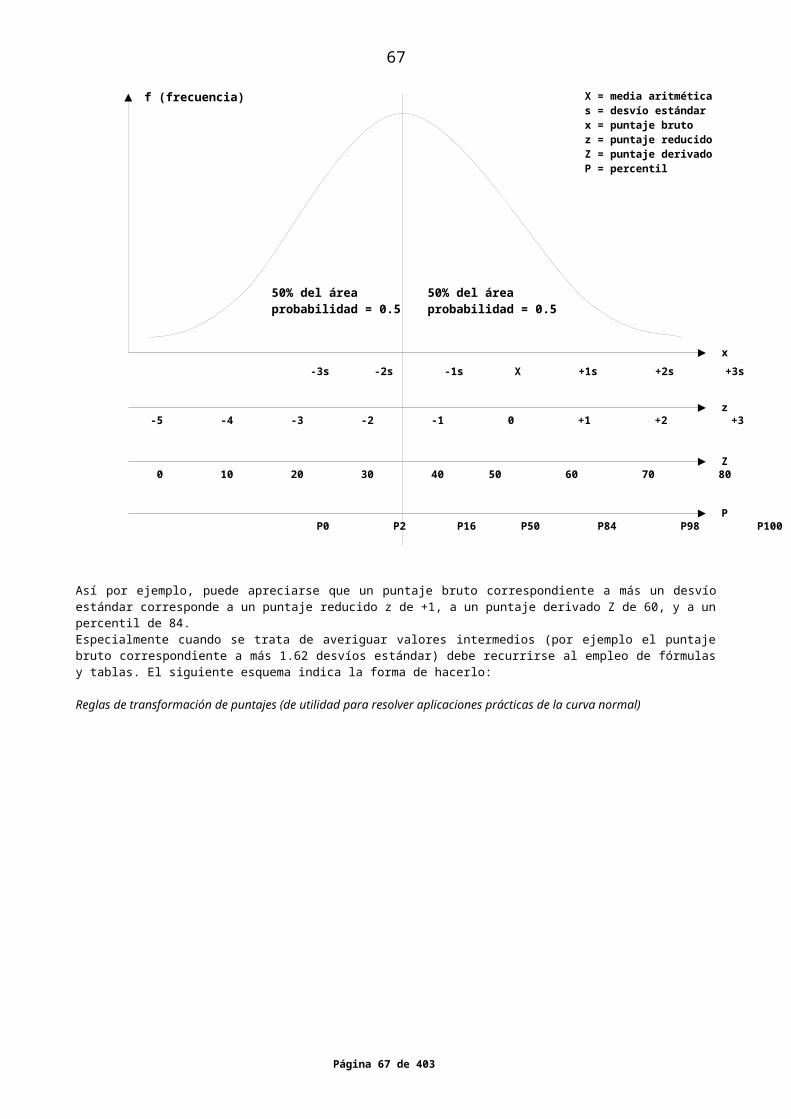
E 3 (5°) 5° 65 8° -3.5 9F 4 (6°) 6° 88 11° -5 25G 5 (7°) 7° 86 10° -3 9H 6 (8°) 8° 56 6° 2 4I 7 (9°) 9° 62 7° 2 4J 8 (10°) 10.5° 92 12° -1.5 2.25K 8 (11°) 10.5° 54 5° -5.5 30.25L 12 (12°) 12° 81 9° 3.5 9
n = 12 d2 = 109.5
Para hallar el coeficiente de Spearman en estos casos, puede procederse se acuerdo a tres pasos:
a) Reasignación de rangos.- En la columna de Puntaje de la variable X se ha agregado entre paréntesis el rango u orden que ocuparía el sujeto. Este agregado sirve al único efecto de determinar el rango definitivo que se le asignará, y que aparece en la columna Rango, de la misma variable.La forma de calcular este rango definitivo es simple. Por ejemplo, si se consideran los sujetos A y B, se suman los rangos 1° y 2°, con lo cual se obtiene el valor 3. Este valor se divide por la cantidad de empates, que en este caso es 2, y se obtiene el valor 1.5, que será el rango definitivo de ambos sujetos.
b) Corrección de la suma de los cuadrados.- Para poder aplicar la fórmula 2, y puesto que hay empates, deben modificarse los valores de x2 y de y2 es decir, las sumatorias de los cuadrados de los valores de cada variable.Para modificar dichos valores deben restarse a ellos E, cuyo valor se entiende a partir de la siguiente fórmula donde dicho factor se ha restado:
n3 – n 123 – 12 23 – 2 23 – 2 23 - 2x2 = --------- - E = ------------ - ( --------- + --------- + --------- ) = 143 – 1.5 = 141.5 12 12 12 12 12
El valor 2 significa que hay sido dos los valores empatados. En este caso, los empates se han dado en tres oportunidades (sujetos A-B, C-D y J-K), y por ello se suman los tres cocientes.Como en la variable Y no se han verificado empates, el cálculo no incluirá el factor de corrección:
n3 – n 123 – 12y2 = --------- = ------------ = 143 12 12
c) Aplicación de la fórmula 2.- Se aplica la fórmula con los valores corregidos del siguiente modo:
x2 + y2 + d2 141.5 + 143 – 109.5 = -------------------------------- = ------------------------------ = 0.616 2 . Ö x2. y2 2 Ö 141.5 . 143
Si no se hubieran introducido las correcciones indicadas, el valor del coeficiente de Spearman “hubiera sido más elevado, aunque en este caso la diferencia es poco importante y sólo conviene corregir cuando hay gran cantidad de empates” (Kohan, 1994:258).
5. UN EJEMPLO: CONSTRUCCIÓN Y VALIDACIÓN DE TESTS
El análisis de correlación se aplica en muchos ámbitos de la psicología, como por ejemplo en la teoría factorialista de la inteligencia, en el análisis de actitudes en psicología social, y también en la construcción de pruebas psicodiagnósticas (6).Como ejemplo, a continuación se inventará un test, no sólo para ver como se realiza esta tarea, sino también para ver el modo en que interviene en este proceso el análisis de correlación.La idea de construir un supuesto “Test de personalidad de Pérez” pudo haber comenzado al leer los diversos trastornos de personalidad del DSM-IV. Uno de ellos es el trastorno narcisista, otro el trastorno esquizoide, y así sucesivamente. El DSM-IV propone diversos criterios para identificarlos, pero aquí se ha elegido otro camino: tomar un test creado ad hoc.Pensando en la cuestión, cabe imaginarse que un individuo narcisista podría muy bien estar cómodo con un dibujo como el esquema 6, donde aparece un gran punto rodeado de otros más pequeños que lo admiran, mientras que un esquizoide preferiría el esquema 7, representativo de un patrón de distanciamiento de las relaciones sociales.
Página 67 de 314
67

Esquema 6 Esquema 7
Acto seguido, se eligen mil sujetos con diagnósticos diversos de personalidad y se les pregunta qué dibujo les gusta más. Aquí es donde interviene el análisis de correlación, que permitirá ver el grado de asociación entre el diagnóstico y el dibujo elegido. Una muy alta correlación aparecería, por ejemplo, si gran cantidad de sujetos con trastorno narcisista eligen el esquema 6, con lo cual, en lo sucesivo se podrá tomar este test sin necesidad de explorar sus conductas y ver si cumplen los criterios del DSM-IV, un trámite que suele ser arduo.Desde ya, construir un test exige una gran cantidad de controles y precauciones que no vienen al caso exponer aquí. Por ejemplo, debe determinarse su validez y su confiabilidad. El análisis de correlación permite, precisamente, determinar por ejemplo un tipo especial de validez: la validez predictiva, que pueden verse claramente en las pruebas de orientación vocacional.Así, por ejemplo, una forma de establecer si un test de este tipo evalúa la vocación de un sujeto, es esperar varios años y ver si ese sujeto tuvo éxito en la profesión sugerida por el test. Como puede apreciarse, aquí se recurre nuevamente al análisis de correlación, al compararse la profesión diagnosticada con la profesión elegida exitosamente. Una alta correlación entre ambas variables es indicador de la validez predictiva del test en cuestión.El análisis de correlación permite también determinar otros tipos de validez como la validez inter-test, que compara los resultados de un test vocacional con otro test vocacional. Si ambos arrojan aproximadamente los mismos resultados en un conjunto de sujetos, entonces tienen validez inter-test, comparación que fue posible por un análisis de correlación.
6. EL ANÁLISIS DE REGRESIÓN
El objetivo del análisis de regresión es establecer una predicción acerca del comportamiento de una variable Y conociendo el correspondiente valor de X (o viceversa) y el grado de correlación existente entre ambas variables.Para ello es preciso conocer la llamada recta de regresión (7), que es la recta imaginaria que mejor representa el conjunto de pares de valores de las variables X e Y. En el siguiente eje de coordenadas, están representados por ejemplo cinco de esos pares de valores, mediante cinco puntos. La recta de regresión dibujada sería la que mejor representa esos puntos, por cuanto la distancia de los puntos a la recta (representada con una línea punteada) es la mínima. Esta distancia recibe el nombre de regresión, de manera tal que cuanto menor es la regresión de los puntos, mayor será la correlación entre ellos.
Página 68 de 314
68
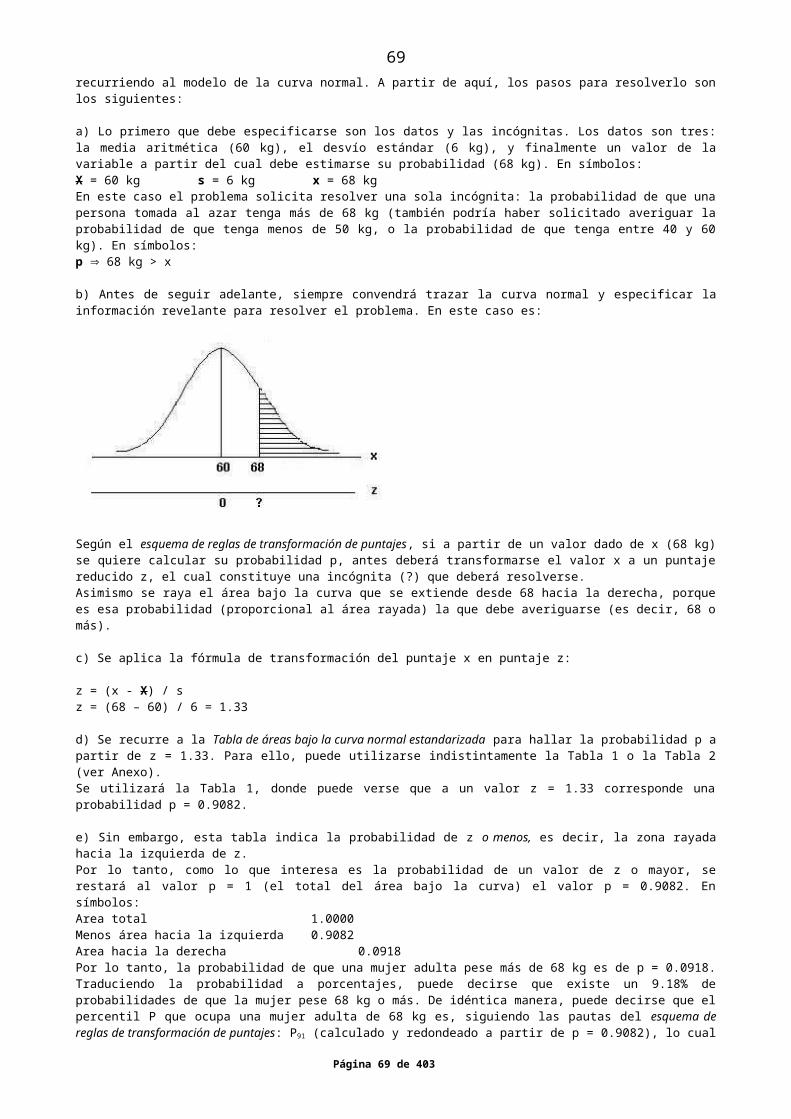
x
y Recta de regresión
La recta de regresión es, de muchas rectas posibles, la que mejor representa la correlación o, más técnicamente, es la única que hace mínima la suma de los cuadrados de las desviaciones o distancias de cada punto a la recta. Es, además, la mejor manera de poder hacer predicciones.Las desviaciones de los puntos respecto de la recta se adjudican a factores no controlados (que suelen ser particularmente importantes en las ciencias sociales), y se parte del supuesto de que si no hubiera factores extraños que afecten la relación entre X e Y, entonces no habría desviaciones y la correlación sería perfecta.La recta de regresión puede trazarse ‘a ojo’, pero este procedimiento no tiene precisión. El análisis de regresión propone un método mucho más preciso, consistente en hallar la recta de regresión por una vía analítica.Este cálculo de la recta de regresión consiste en hallar la ecuación de la recta de regresión, y eventualmente luego dibujándola en un diagrama de coordenadas cartesianas. Una vez en posesión de esta ecuación, podrán hacerse predicciones a partir de la ecuación misma o bien a partir de la recta trazada en el diagrama de coordenadas.Ambos procedimientos serán examinados a continuación con los nombres de cálculo analítico de la regresión y cálculo gráfico de la regresión, respectivamente.
7. CÁLCULO ANALÍTICO DE LA REGRESIÓN
El cálculo analítico de la regresión consiste en averiguar la ecuación de la recta de regresión. Ello permitirá realizar predicciones en base a dicha ecuación.Una vez que se cuenta con un determinado conjunto de pares de valores obtenidos de la realidad, puede determinarse la ecuación de la recta que los representan por dos métodos: el método de los cuadrados mínimos, y el método de las desviaciones.Antes de examinarlos, debe tenerse presente que la forma general de una ecuación de una recta es y = a + b.x (8). Determinar la ecuación de la recta significa asignarle un valor al parámetro ‘a’ y otro valor al parámetro ‘b’. Los métodos indicados tienen como fin determinar el valor de ambos parámetros.
a) Método de los cuadrados mínimos.-
La ecuación de la recta que tiene la forma y1 = a + b . x1 se obtiene averiguando los valores a y b. Una vez obtenidos ambos valores, puede realizarse una predicción cualquiera: a partir de x1 como el valor conocido, se puede predecir el valor de y1.Las fórmulas para el cálculo de a y b son las siguientes:
n (x.y) – x . yb = ------------------------------ n x2 - ( x)2
a = Y - b . X (donde Y y X son las respectivas medias aritméticas)
Como puede apreciarse, primero debe calcularse b, ya que para calcular a se requiere conocer b.
b) Método de las desviaciones.-
La ecuación de la recta se obtiene a partir de la siguiente expresión:
y = r . (Sy / Sx) . (x - X) + Y
En esta ecuación de la recta, la expresión r . (Sy / Sx) se llama coeficiente de regresión.
Página 69 de 314
69
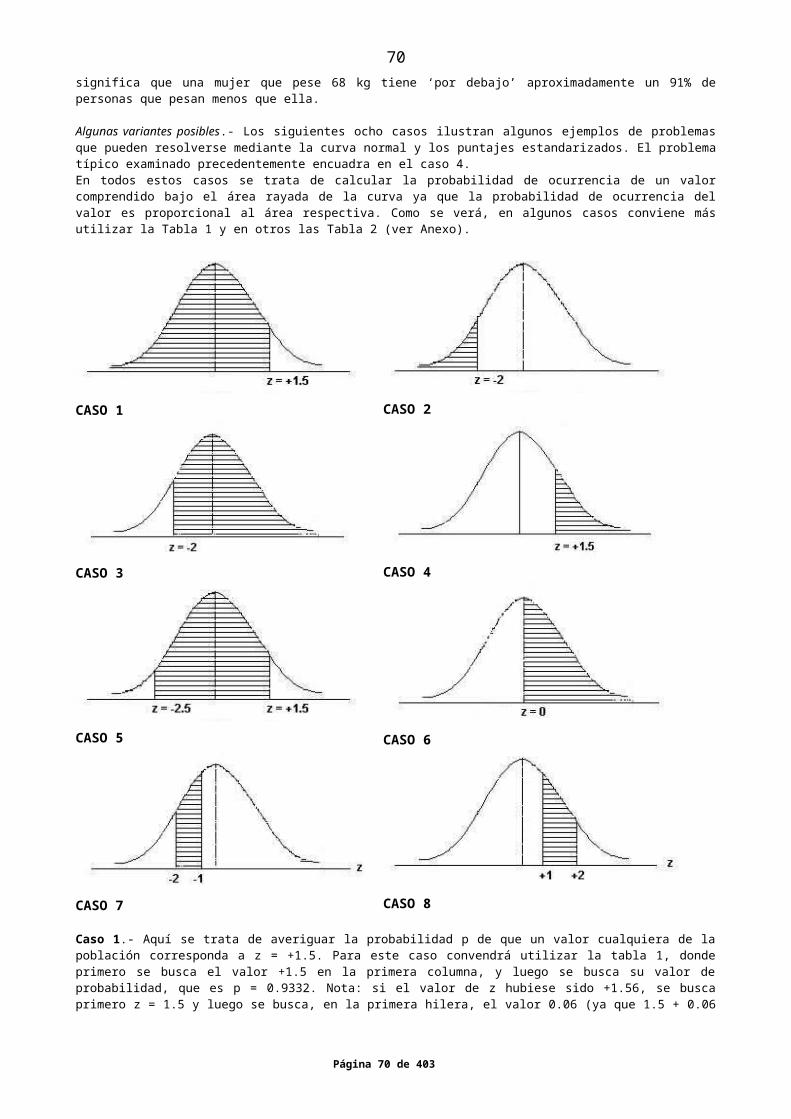
Como puede apreciarse, la aplicación del método de las desviaciones requiere conocer las medias aritméticas y los desvíos estándar de X e Y. También requiere conocer el coeficiente de correlación r, para lo cual resulta aquí recomendable utilizar la fórmula número 1.
Ejemplo de predicción en base a la ecuación de la recta.- Si se dispone ya de una ecuación de la recta, será muy sencillo hacer una predicción del valor de y en función del valor de x.En cambio, si debe hacerse esa predicción a partir de una simple lista de pares de valores correlacionados, primero deberá obtenerse la ecuación de la recta, para lo cual, a su vez –si la idea es aplicar el método de las desviaciones- deben conocerse las medias aritméticas de x e y, los desvíos estándar de x e y, y la correlación r entre x e y.Considérese la siguiente lista de pares de valores ordenados:
Sujeto X (edad) Y (puntaje test)A 2 55B 3 60C 5 65D 6 80E 6 85F 8 75
A los efectos de poder obtener información sobre las medias aritméticas, los desvíos estándar y el coeficiente de correlación (necesarios para calcular la ecuación de la recta), se amplía la tabla anterior de la siguiente manera:
Sujeto X (edad) Y (puntaje test) (X-X) (Y-Y) (X-X) (Y-Y)A 2 55 -3 -15 45B 3 60 -2 -10 20C 5 65 0 -5 0D 6 80 1 10 10E 6 85 1 15 15F 8 75 3 5 15
Total 30 420 --- --- 105
Aplicando la fórmula correspondiente, se obtienen las medias aritméticas de X e Y (que son 5 y 70).Aplicando la fórmula correspondiente, se obtienen los desvíos estándar de X e Y (que son 2 y 10.8).Aplicando la fórmula 1, se obtiene el coeficiente de correlación (que es r = +0.81).Finalmente, se obtiene la ecuación de la recta utilizando el método de loas desviaciones:
y = r . (Sy / Sx) . (x - X) + Yy = 0.81 (10.8 / 2) . (x – 5) + 70
Esta expresión se transforma de manera tal que adopte la forma típica de la ecuación de la recta, con lo cual se obtiene:
y = 47.85 – 4.43 . x
Una vez que se cuenta con la ecuación de la recta, ahora sí pueden hacerse predicciones. Por ejemplo, si a un niño que 10 años se le toma el test, ¿cuál será el puntaje más probable que obtendrá?
y = 47.85 – 4.43 . xy = 47.85 – 4.43 . 10 = 92.15y = 92.15
8. CÁLCULO GRÁFICO DE LA REGRESIÓN
El cálculo gráfico de la regresión consiste en trazar la recta de regresión en base a la ecuación de la recta obtenida en el cálculo analítico. Ello permitirá realizar predicciones en base a dicha recta trazada en el diagrama de coordenadas cartesianas.La recta de regresión, como toda recta, puede determinarse por dos puntos. Un punto es la ordenada al origen, y el otro punto es la intersección de las medias aritméticas de x e y. Este último punto se llama baricentro.Tomando el ejemplo anterior, la ordenada al origen es 47.85, mientras que el baricentro queda determinado por las medias aritméticas 5 y 70, con lo cual la recta de regresión será la siguiente:
Página 70 de 314
70

Y
908070605040302010
0
0 1 2 3 4 5 6 7 8 9 10 X
Y
908070605040302010
0
0 1 2 3 4 5 6 7 8 9 10 X
Ejemplo de predicción en base a la recta del diagrama cartesiano.- Considerando solamente la recta dibujada, puede hacerse una predicción (método gráfico). Por ejemplo, si se sabe que x = 7, puede predecirse que el valor de y será 82 de la siguiente manera:
Error estándar de la predicción.- En el ejemplo anterior la predicción realizada es sólo probable, lo que significa que se está cometiendo algún error en la estimación del valor y. Ello es así porque se ha calculado el coeficiente de correlación r y la ecuación de la recta de regresión en base a una muestra (en este caso de apenas seis sujetos) y con esta información se está intentando predecir un valor nuevo que no está en la muestra, es decir, que pertenece a la población. Además, se está suponiendo (Kohan N, 1994:228) que la muestra ha sido tomada al azar, y que ambas variables se distribuyen normalmente.Es posible estimar el error estándar cometido en base a la siguiente expresión:
esty = y . Ö 1 – r2
Esto es, el error estándar es igual al desvío estándar poblacional multiplicado por la raíz cuadrada de la diferencia entre 1 y el cuadrado del coeficiente de correlación.En el ejemplo anterior, el desvío estándar valía 10.8 y el coeficiente de correlación valía 0.82. Reemplazando, se obtiene:
esty = . Ö 1 – 0.822 = 6.2
Esto significa que el valor de y predicho y = 82, estará en un 68% de los casos entre 82 ± 6.2, es decir entre 88.2 y 75.8. O si se quiere, hay un 68% de probabilidades que el valor de y se encuentre entre 88.2 y 75.8. Desde ya, también puede calcularse este intervalo de confianza en base a un 95% o un 99% de probabilidades, en cuyo caso el intervalo de confianza deberá ser mayor.
NOTAS
(1) Una distribución de frecuencias bivariada es un conjunto de pares de valores, correspondientes a dos variables observadas conjuntamente, con sus respectivas frecuencias. Cuando la distribución se registra en una tabla de doble entrada se obtiene una tabla de contingencia. En cada celda de esta tabla se indica la frecuencia con que se observó cada par de valores.(2) Algunos autores (por ejemplo Botella, 1993:183), clasifican en tres los casos posibles de relación lineal entre variables. a) Relación lineal directa: se dice que dos variables X e Y mantienen una relación lineal directa cuando los valores altos en Y tienden a emparejarse con valores altos en X, los valores intermedios en Y tienden a emparejarse con valores intermedios en X, y los valores bajos en Y tienden a emparejarse con valores bajos en X. Por ejemplo: la relación entre inteligencia y rendimiento. b) Relación lineal inversa: se dice que dos variables X e Y mantienen una
Página 71 de 314
71

relación lineal inversa cuando los valores altos en Y tienden a emparejarse con valores bajos en X, los valores intermedios en Y tienden a emparejarse con valores intermedios en X, y los valores bajos en Y tienden a emparejarse con valores altos en X. Por ejemplo: la relación entre tiempo y errores. c) Relación lineal nula: se dice que hay relación lineal nula entre dos variables cuando no hay un emparejamiento sistemático entre ellas en función de sus valores. Por ejemplo: la relación entre estatura e inteligencia.(3) Otra forma de apreciar gráficamente la correlación es mediante el ángulo de correlación: dadas las dos rectas y1 = a + b . x1 y x1 = a + b . y1 , el punto donde se intersectan se llama centroide. El ángulo entre ambas rectas se llama ángulo de correlación. Cuanto menor es este ángulo, más correlación hay (Kohan, 1994:224).(4) Además del clásico coeficiente "r" de Pearson, existen otros también destinados a medir el grado de asociación entre variables. En el esquema siguiente se resumen algunos ejemplos. No deben confundirse los coeficientes derivados del coeficiente de Pearson, con estos otros coeficientes de correlación, que en general fueron diseñados de manera diferente o para otros propósitos.
Nombre Condiciones de aplicaciónCoeficiente de Pearson Se aplica sobre variables cuantitativas (de intervalos iguales o de cocientes). Además, las
variables deben estar distribuidas normalmente, o al menos tratarse de distribuciones bastante simétricas respecto de la media.Se llama también coeficiente de correlación producto-momento de Pearson.
Coeficiente Q de Yule De fácil cálculo e interpretación como el anterior, pero su uso se limita a dos variables nominales, con dos categorías cada una.
Coeficiente de asociación (gamma) de Goodmann y Kruskal
Se utiliza sobre todo cuando son muchas observaciones y muy pocos valores ordinales alcanzados por ellas. Se busca computando las concordancias e inversiones en las ordenaciones que representan las dos variables y se aplica la fórmula.
Coeficiente (Rho) de Spearman
No es más que el coeficiente de Pearson aplicado a variables ordinales.
Coeficiente Etha Utilizado para variables cuantitativas (de intervalos iguales o de cocientes), debe reunir dos requisitos: que la curva de distribuciones sea bastante simétrica y unimodal, y que la asociación de variación sea al menos aproximadamente rectilínea.
Coeficiente de correlación múltiple
Para correlacionar simultáneamente más de dos variables.
Coeficiente Phi Para variables nominales.
Otros coeficientes son: el Coeficiente (Tau) de Kendall (Kohan, 1994:260), el Coeficiente de Wilcoxon, el Coeficiente de Flanagan, el Coeficiente de correlación multiserial de Jaspe, el Coeficiente T de Tschuprow, el Coeficiente de correlación tetracórica (Kohan, 1994:281), etc.Un ejemplo de aplicación del Coeficiente Q de Yule (poco usado hoy en día) es el cálculo de la correlación entre dos variables nominales con dos categorías cada una: por un lado sexo (masculino-femenino) y por el otro nivel de ingresos (alto-bajo). Primero, se construye una tabla de doble entrada que organice la información obtenida en la muestra. Por ejemplo:
Alto
Bajo
Masculino
A B
Femenino
C D
Segundo, aplicar la fórmula de Q:
A.D – B.CQ = ---------------- A.D + B.C
Los valores de Q varían entre -1 y +1 y se interpretan igual que el clásico coeficiente ‘r’ de Pearson.Eventualmente, también podrá establecerse la significación del coeficiente de correlación obtenido recurriendo a la prueba de t Student. La fórmula de ‘t’ que puede utilizarse lleva como numerador el producto de ‘r’ por la raíz cuadrada de N-2 (N es el tamaño de la muestra), y el denominador es la raíz cuadrada de 1-r2.Todos los coeficientes de correlación pueden aplicarse en psicología, por ejemplo, en experimentos sobre el aprendizaje, en la teoría factorialista de Spearman, y en psicometría cuando por ejemplo debemos establecer el grado de correlación entre dos tests, o el grado de correlación de un mismo test tomado en dos momentos diferentes.(5) “En algunos textos de estadística se describen fórmulas abreviadas para facilitar los cálculos cuando se dispone de un número grande de pares de valores. La disponibilidad actual de calculadoras de mesa y ordenadores personales hacen innecesarias estas fórmulas” (Botella, 1993:193).(6) La construcción de tests puede llevarse a cabo para realizar una investigación ad hoc para la cual no hay instrumentos de medición conocidos, o bien para crear una prueba que pueda ser utilizada por otros en diferentes circunstancias, aunque esto último es más raro en un mercado sobresaturado de pruebas psicométricas y proyectivas donde es realmente muy difícil posicionar un test que pueda representar una mejora respecto de los anteriores.(7) También puede ser una curva, pero en este artículo se describe solamente la regresión lineal, que se representa mediante una recta.(8) El valor ‘a’ es la ordenada al origen, y el valor ‘b’ es el coeficiente angular o pendiente de la recta, que equivale a la tangente del ángulo alfa (formado por la recta y otra recta paralela a la absisa). La ecuación de la recta también puede representarse como x = a + b.y, en cuyo caso el parámetro ‘a’ significará la absisa al origen. En este artículo no se considerará esta segunda expresión por razones de simplicidad, y por cuanto la idea es poder predecir un valor y en función de un valor x, y no un valor x en función de un valor y. Así, la ecuación y = a + b.x permite predecir cuánto valdrá y en función de x, mientras que la ecuación x = a + b.y permite predecir cuánto valdrá x en función de y.Ambas rectas de regresión se cortan en un punto llamado centroide, y “la correlación entre las dos variables está dada por el ángulo entre las dos rectas: si este ángulo vale 0, la correlación es 1” (Kohan N, 1994:224).
Página 72 de 314
72

CAPÍTULO 5: ESTADÍSTICA INFERENCIAL
1. INTRODUCCIÓN
A diferencia de la estadística descriptiva, la estadística inferencial va más allá de la mera descripción de la muestra por cuanto se propone, a partir del examen de ésta última, inferir una conclusión acerca de la población, con un cierto nivel de confianza (o, complementariamente, con un cierto nivel de error).Las muestras de las cuales se ocupa la estadística inferencial son muestras probabilísticas, es decir, aquellas en las cuales es posible calcular el error cometido al estimar una característica poblacional (Kohan N, 1994:144) (1).Clásicamente, la estadística inferencial se ocupa de dos cuestiones: la estimación de parámetros y la prueba de hipótesis, aunque “por lo general, la mayoría de las aplicaciones de la estadística inferencial pertenecen al área de la prueba de hipótesis” (Pagano, 1998:209).De acuerdo al mismo autor (1998:155), en la estimación de parámetros el investigador busca determinar una característica de la población a partir de los datos de la muestra. Por ejemplo, tomando la variable edad, podría concluir que la probabilidad de que el intervalo 40–50 contenga la media de la población es de 0.95.En cambio en la prueba de hipótesis, el investigador reúne datos en una muestra para validar cierta hipótesis relativa a una población. Ejemplos: a) para validar la hipótesis de que la media poblacional no tiene una diferencia significativa con la media muestral, toma ambas medias y las compara estadísticamente mediante la prueba de la media; b) para validar la hipótesis de que en la población el método de enseñanza A es mejor que el B, el investigador toma dos muestras de alumnos y a cada uno le aplica un método de enseñanza diferente. El tipo de conclusión que se busca aquí podría ser que las mayores calificaciones en un grupo que en otro se deben al método de enseñanza aplicado y no al azar, y, además, que dicha conclusión no se aplica sólo a la muestra sino a toda la población.En la estadística inferencial se pueden hacer inferencias espaciales e inferencias temporales. Una inferencia espacial implica suponer, a partir de la muestra, cómo es la población total. Una inferencia temporal es un caso especial donde, a partir de ciertos datos actuales podemos inferir o suponer ciertos otros datos que podamos obtener en el futuro, vale decir una población potencial.
2. ESTIMACIÓN DE PARÁMETROS
Esta tarea consiste en, partiendo de ciertos valores de la muestra llamados estadísticos o estadígrafos (por ejemplo la media aritmética muestral), inferir ciertos otros valores de la población llamados parámetros (por ejemplo la media aritmética poblacional o esperanza).Ello es así porque en general lo que interesa es la población, no la muestra. Cuando un investigador observa que en una muestra el 80% de las personas lee el diario, le interesará averiguar a partir de allí qué porcentaje o proporción de la población lee el diario, ya que por ejemplo su interés es editar un nuevo periódico. De la misma forma, cuando un investigador observa que la media aritmética muestral de la frecuencia cardíaca es 80 pulsaciones por minuto, le interesará averiguar si ello se cumple también en la población, ya que por ejemplo su interés puede ser comparar la frecuencia cardíaca de sus pacientes con toda la población para decidir sobre su salud en base a un criterio estadístico.Como puede verse, lo más habitual es inferir medias aritméticas (promedios) y proporciones (porcentajes). Así, a partir de la media aritmética muestral se infiere la media aritmética poblacional, y a partir de la proporción observada en la muestra se infiere la proporción en la población.Existen dos tipos de estimación de parámetros: la estimación puntual y la estimación intercalar (Pagano R, 1998:304).La estimación puntual consiste en inferir un determinado valor para el parámetro. Por ejemplo, inferir que la población debe tener puntualmente una media aritmética de 80.La estimación intervalar consiste en inferir dentro de qué intervalo de valores estará el parámetro con un determinado nivel de confianza. Por ejemplo, inferir que la población debe tener una media aritmética entre 75 y 83, con un nivel de confianza de 0.95 (esto es, hay un 95% de probabilidades de que el parámetro poblacional se encuentre entre 75 y 93) o, si se quiere, con un nivel de riesgo (4) de 0.05 (esto es, hay un 5% de probabilidades de que el parámetro no se encuentre entre esos valores).En general, resulta mucho más riesgoso afirmar que el parámetro vale 80 que afirmar que vale entre 75 y 83. Por esta razón, se prefiere bajar este riesgo y establecer un intervalo de confianza, que podrá ser de 0.90, 0.95, 0.99, etc., según elija el investigador.Hay diferentes procedimientos de estimación de parámetros, según se trate de estimar medias o proporciones, o según se trate de estimar parámetros de variables cualitativas (con dos categorías o con más de dos categorías) o cuantitativas. En lo que sigue se dan algunos ejemplos combinados.
Estimación de la media poblacional para variables cuantitativas.- Conociendo la media muestral, es posible averiguar con un cierto nivel de confianza (por ejemplo 0.95), entre qué valores de la variable estará la media poblacional. Estos valores se llaman límite superior del intervalo (Ls) y límite inferior del intervalo (Li).Para obtener ambos valores se utilizan las siguientes fórmulas:
Página 73 de 314
73

Ls = X + z . (S / Ö n) Li = X - z . (S/ Ö n)
Donde:
Ls = Límite superior del intervalo de confianza.Li = Límite inferior del intervalo de confianza.X = Media aritmética muestral.S = Desvío estándar muestral.n = Tamaño de la muestra. Si se trata de una muestra chica (menor a 30) se considera n-1.(S / Ö n) = Desvío estándar poblacional. Cuando no tenemos el desvío estándar de la población (hecho muy frecuente) se utiliza el desvío muestral (Rodríguez Feijóo N, 2003).z . (S/ Ö n) = Error muestral o estándar (error que puede cometerse al inferir la media poblacional) (3).z = Puntaje estandarizado que define el nivel de confianza. Si se desea un nivel de confianza de 0.90, debe consignarse z = 1.64. Si se desea un nivel de confianza de 0.95, debe consignarse z = 1.96. Si se desea un nivel de confianza de 0.99, debe consignarse z = 2.58. Para valores intermedios de nivel de confianza, pueden consultarse las tablas de áreas de z (ver capítulo sobre probabilidad y curva normal).
Ejemplo (Rodríguez Feijóo N, 2003).- En una muestra probabilística de 600 niños de 10 años de Capital Federal el cociente intelectual promedio obtenido fue de 105 con una desviación estándar de 16. Con un intervalo de confianza del 95%, ¿entre qué límites oscilará el CI promedio de los niños de 10 años de Capital Federal?Ls = X + z . (S / Ö n) = 105 + 1.96 (16 / Ö 600) = 106.27Li = X - z . (S/ Ö n) = 105 - 1.96 (16 / Ö 600) = 103.73Respuesta: con un riesgo de 5% de equivocarse en la estimación, el CI promedio de los niños de 10 años de Capital Federal oscila entre 103.73 y 106.27 puntos.
Estimación de proporciones para variables cualitativas de dos categorías (Kohan N, 1994:166).- Conociendo la proporción muestral, es posible averiguar con cierto nivel de confianza (por ejemplo 0.99) entre qué proporciones estará la proporción poblacional. Téngase presente que una variable con dos categorías es una variable que tiene solamente dos posibilidades de variación (por ejemplo: el sexo).Para obtener los límites superior e inferior del intervalo de confianza, se utilizan las siguientes fórmulas:
Ls = p + z . (Ö p . q / n)
Li = p - z . (Ö p . q / n)
Nota: La raíz cuadrada afecta a p, q y n.
Donde:
Ls = Límite superior del intervalo de confianza.Li = Límite inferior del intervalo de confianza.p = Proporción muestralz = Puntaje estandarizado que define el nivel de confianza. Si se desea un nivel de confianza de 0.90, debe consignarse z = 1.64. Si se desea un nivel de confianza de 0.95, debe consignarse z = 1.96. Si se desea un nivel de confianza de 0.99, debe consignarse z = 2.58. Para valores intermedios de nivel de confianza, pueden consultarse las tablas de áreas de z (ver capítulo sobre probabilidad y curva normal).q = Proporción que falta para llegar al 100%. Por ejemplo: si p es 65%, entonces q = 35%).n = Tamaño de la muestra. Si se trata de una muestra chica (menor a 30) se considera n-1.
Ejemplo.- En una muestra probabilística de 100 personas, el 20% son masculinos. Con un intervalo de confianza del 99%, ¿entre qué proporciones oscilará el porcentaje de masculinos en la población?Ls = 20% + 2.58 . (Ö 20 . 80 / 100) = 30.3%Li = 20% – 2.58 . (Ö 20 . 80 / 100) = 9.7%Respuesta: con un riesgo de 1% de equivocarse en la estimación, la proporción de masculinos en la población oscila entre el 9.7% y el 30.3%.
3. PRUEBA DE HIPÓTESIS
Las pruebas de hipótesis se utilizan para probar alguna hipótesis en investigación científica (10). Cuando el investigador propone una hipótesis, su deseo será poder confirmarla (porque él mismo la propuso o porque cree intuitivamente en ella). Si decide hacer una prueba estadística para salir de dudas, entonces realizará una prueba de hipótesis y establecerá dos hipótesis estadísticas: su propia hipótesis, a la que convertirá en hipótesis alternativa, y la opuesta, que llamará hipótesis nula, y la tarea consistirá en intentar probar esta última. Si la rechaza, aceptará la alternativa, y si la acepta, rechazará la alternativa (7).
Página 74 de 314
74

Existe una gran variedad de pruebas de hipótesis, pero todas ellas tienen en común una determinada secuencia de operaciones, que son las siguientes:
1) Formulación de la hipótesis de investigación y obtención de los datos.- El investigador comienza formulando la hipótesis que pretende probar. Por ejemplo, que una determinada droga cura una enfermedad. Luego, diseña un experimento y lo ejecuta para obtener datos que permitan aceptar o no la hipótesis. Por ejemplo, administra la droga a un grupo y al otro no, para comparar los resultados.Estrictamente, este primer paso no forma parte de la prueba estadística de la hipótesis pero es una condición necesaria para realizarla, y ello por tres motivos: a) si no hay datos empíricos, no puede realizarse ningún estudio estadístico, del mismo modo que si no hay combustible, el motor no funcionará; b) si los datos obtenidos en el experimento o en la observación son lo suficientemente convincentes como para aceptar o rechazar la hipótesis de investigación, no será necesario emplear una prueba estadística de hipótesis, con lo cual, este primer paso permite decidir si cabe o no aplicarla, aún cuando se sepa que en la inmensa mayoría de los casos sí cabe hacerlo. Por ejemplo, si el 100% de los pacientes tratados con una droga se cura, mientras que el 100% de los pacientes no tratados sigue enfermo, es posible concluir, sin la ayuda de la estadística, que cabe aceptar la hipótesis de investigación según la cual la droga cura. Sin embargo, en la realidad no suelen obtenerse datos tan auspiciosos, por lo que se requiere una prueba estadística; y c) para obtener datos se utiliza un determinado diseño de investigación, y la elección de la prueba estadística de hipótesis más adecuada dependerá del tipo de diseño de investigación utilizado.
En suma, “es importante saber qué diseño está usando el investigador, cuáles son las variables que puede controlar y en función de esto buscar la prueba estadística adecuada” (Kohan, 1994:357).
2) Formulación de la hipótesis alternativa y la hipótesis nula.- Si la prueba estadística resulta necesaria, la hipótesis de investigación es reformulada en términos estadísticos, obteniéndose la hipótesis alternativa (Ha). A continuación, se formula, en los mismos términos, la hipótesis nula (Ho), que es la opuesta de la alternativa. Ambas reformulaciones incluyen consideraciones del tipo “hay o no hay una diferencia significativa entre…”.Por ejemplo, si la hipótesis de investigación sostiene que la droga cura, la hipótesis alternativa dirá que hay una diferencia significativa entre los resultados del grupo de pacientes tratado y el grupo de pacientes no tratado. Por lo tanto, la hipótesis nula sostendrá que no hay una diferencia significativa entre ambos grupos. En este caso, además, la Ha plantea un cambio (la droga cura), mientras que la Ho plantea la permanencia de un estado (la droga no cura).
Lo que siempre se intentará probar es la hipótesis nula para un determinado nivel de significación o de riesgo. Si rechazamos la hipótesis nula aceptamos la alternativa, y si no rechazamos la hipótesis nula, rechazamos la alternativa, ya que ambas son mutuamente contradictorias (8).Al estimar parámetros o probar hipótesis pueden cometerse errores. Suelen describirse dos tipos de errores (Kohan N, 1994:178):El error Tipo I consiste en rechazar la hipótesis nula cuando en realidad es verdadera. O sea, creer que la muestra NO es representativa de la población, cuando sí lo es. Es el error del desconfiado.El error Tipo II consiste en aceptar la hipótesis nula cuando en realidad es falsa. O sea, creer que la muestra SI es representativa de la población, cuando no lo es. Es el error del ingenuo.La probabilidad de cometer el error I se simboliza con la letra griega alfa (a), y la probabilidad de cometer el error II se simboliza con la letra griega beta (b) (Kohan N, 1994:185).Estos errores no son errores que cometan inadvertidamente los investigadores. Como la hipótesis nula se rechaza o se acepta en base a determinado nivel de significación o de riesgo de equivocarse, siempre habrá algún riesgo de error, que podrá ser mayor o menor según el nivel de riesgo elegido, pero que no obliga necesariamente a invalidar los resultados. Debe tenerse presente que siempre que se concluya algo sobre la población a partir de la muestra, el procedimiento estará teñido de algún grado de incertidumbre, es decir, siempre habrá algún grado de probabilidad de cometer alguno de los dos tipos de errores.
3) Selección de la prueba de hipótesis más adecuada.- Quedó dicho que hay una gran cantidad de pruebas de hipótesis y su elección “depende de la hipótesis alternativa que se formule, del número de casos examinados, del nivel de medición utilizado, etc” (Kohan N, 1994:176). Por ejemplo, a) si la hipótesis es direccional (es decir, especifica una relación de ‘mayor que’ o bien una relación de ‘menor que’), se utilizará una prueba de hipótesis de una cola, mientras que si la hipótesis es no direccional (indica una relación de “diferente a”), se utilizará una prueba de hipótesis de dos colas (11); b) si se conoce el desvío estándar poblacional, puede aplicarse la prueba z, mientras que si solamente se conoce el desvío estándar muestral, se aplicará la prueba t de Student; c) si se opera con variables medidas en un nivel nominal, puede utilizarse la prueba de chi cuadrado; si se trabaja con muestras muy pequeñas (por ejemplo de 5 a 10 datos), la prueba t de Student es útil. Señala Vessereau que se trata de un aporte importante por cuanto “durante mucho tiempo se ha creído que era imposible sacar buen partido de las muestras muy pequeñas” (Vessereau A, 1962:33); d) La prueba ANOVA (análisis de varianza): “así como se pueden comparar las medias de dos muestras, existen pruebas que permiten confrontar su variabilidad (varianza o desviación típica). Estas pruebas sirven, entre otras, para resolver los problemas siguientes: 1) Reconocer si un grupo de muestras es homogéneo; y 2) determinar, en la variabilidad de una población de medidas, la parte que corresponde al azar y la que debe atribuirse a causas de variación sistemáticas, llamadas causas controladas o asignadas” (Vessereau A, 1962:38).
Página 75 de 314
75

-3-2-10+1+2+3
z
-3-2-10+1+2+3
t
4) Determinación del nivel de significación.- El nivel de significación a es la probabilidad de rechazar Ho siendo esta verdadera (error tipo I). Cada investigador elige su nivel de significación, es decir, su probabilidad de equivocarse en el sentido indicado. Por ejemplo, puede elegirse un 5% o un 1% de probabilidad de error (o, lo que es lo mismo, un 95% o un 99% de probabilidad de no equivocarse).Señala Kohan (1994:177) que el nivel de significación elegido dependerá de la importancia práctica de la investigación. Por ejemplo, para un estudio sobre los efectos de una droga en el sistema nervioso se usará un nivel de significación muy bajo, como por ejemplo un 0.01%, lo que minimiza al extremo su probabilidad de producir intoxicación.Lo usual es especificar un nivel de significación a (probabilidad de cometer el error tipo I) y no el nivel de significación b (probabilidad de cometer el error tipo II).Una aclaración más detallada del concepto de significación estadística puede consultarse más adelante en este mismo capítulo.
5) Determinación del tamaño de la muestra.- En principio, el tamaño de la muestra n ya fue determinado en el momento de elegir y ejecutar el diseño de investigación: cuanto mayor haya sido el tamaño de la muestra elegido, menor será el error de a (Kohan, 1994:178). Sin embargo, también puede procederse al revés: si se elige un determinar nivel a, puede determinarse por medios matemáticos el tamaño de la muestra n adecuado a ese nivel (Kohan N, 1994:181-185). Así, por ejemplo, en general si el investigador desea un menor margen de error, deberá aumentar el tamaño de la muestra.Además del tamaño de la muestra, deberán también determinarse la curva operativa característica (Kohan N, 1994:180) y el poder de eficiencia de la prueba (o también potencia), definido este último como la probabilidad de rechazar la hipótesis nula cuando es realmente falsa. Por consiguiente, el poder de eficiencia se define como 1 - b, es decir, 1 menos la probabilidad del error II (no rechazar la hipótesis nula cuando es realmente falsa) (Kohan N, 1994:185). Téngase presente:
a Nivel de error tipo I Es la probabilidad de cometer el error tipo I.Probabilidad de rechazar la Ho cuando es verdadera.
1 - a Nivel de confianza Es la probabilidad de NO cometer el error tipo I.Probabilidad de NO rechazar (aceptar) la Ho cuando es verdadera.
b Nivel de error tipo II Es la probabilidad de cometer el error tipo II.Probabilidad de NO rechazar (aceptar) la Ho cuando es falsa.
1 - b Nivel de confianza Es la probabilidad de NO cometer el error tipo II.Probabilidad de rechazar la Ho cuando es falsa. Se llama poder de eficiencia o potencia de la prueba.
6) Determinación de la distribución muestral de la prueba estadística para Ho.- Señala Kohan (1994:186-187) que cuando un investigador eligió una prueba estadística, necesita saber cuál es su distribución muestral, que es una distribución teórica que se obtendría si se sacaran al azar todas las muestras posibles del mismo tamaño de una población (12). El conocimiento de esta distribución muestral permite estimar la probabilidad de la ocurrencia de ciertos valores.
7) Definición de la zona de rechazo.- Sobre la base de los puntos 3, 4, 5 y 6 deberá ahora establecerse la zona de rechazo de la Ho. Para una mejor comprensión de este concepto, se puede trazar una línea horizontal sobre la cual se podrán definir las zonas de rechazo y de no rechazo de la Ho. En esa línea horizontal se indicarán valores que van desde -3 hasta +3, pasando por el 0 (cero). Estos valores corresponden a puntajes estandarizados, como por ejemplo z, si la prueba estadística elegida es la prueba z, o t, si la prueba elegida es la prueba t de Student:
Las zonas de rechazo se definirán según se trate de pruebas de hipótesis de una cola (hipótesis direccionales) o de dos colas (hipótesis no direccionales), según el siguiente esquema:
Página 76 de 314
76

z
z
Prueba de una cola a la izquierda
z
Prueba de una cola a la derecha
Prueba de dos colas
Zona de rechazo Zona de aceptación
Zona de rechazoZona de aceptación
Zona de rechazoZona de rechazo Z de aceptación
z
Zona de rechazo de la Ho Zona de aceptación de la Ho
z teórico = -1.65z empírico = -1.80-1.65-1.80
Para determinar una zona de rechazo (o también zona crítica) es preciso indicar un determinado valor de z (o de t) que sirva para delimitar la zona de rechazo (a) de la zona de aceptación (1 - a). Ese valor recibe el nombre de ‘z teórico’, ‘z crítico’ o ‘punto crítico’, que se calcula en base a una tabla de z (o de t) y en base al nivel de significación elegido.Existe una relación básica entre a, b y el tamaño de muestra n. Puesto que a es la probabilidad de que la estadística de prueba (por ejemplo el z empírico) caiga en la región de rechazo, un incremento en el tamaño de esta región aumenta a, y simultáneamente disminuye b, para un tamaño de muestra fijo. El reducir el tamaño de la región de rechazo disminuye a y aumenta b. Si se aumenta el tamaño de muestra entonces, se tiene más información en la cual basar la decisión y ambas a y b decrecerán.
8) Decisión final (6).- Si el dato empírico (llamado ‘z empírico’) obtenido ‘cae’ dentro de la zona de rechazo, se rechaza la Ho y por tanto se acepta la Ha. En cambio, si el dato ‘cae’ fuera de esta zona de rechazo, no se rechaza (se acepta) la Ho, siempre para un nivel de significación elegido (Kohan N, 1994:189). Por ejemplo:
En este ejemplo, se puede apreciar que el z teórico delimita las zonas de rechazo y aceptación de la Ho. Como de los datos del experimento resultó un z empírico ubicado dentro de la zona de rechazo, se decide rechazar la Ho y, por lo tanto, se acepta la Ha.
Sintéticamente, el procedimiento básico general para realizar las pruebas de hipótesis con z o t es el siguiente:1) Se hace un listado con los datos disponibles: tamaño de la muestra, media muestral, desvío poblacional (o desvío muestral si no está el desvío poblacional: en el primer caso se aplica z, y en el segundo t), el nivel de significación alfa, y el número de colas (una cola a la izquierda o a la derecha en hipótesis direccionales del tipo “menor que” o “mayor que”; dos colas en hipótesis no direccionales).2) Se dibuja la curva normal y se marca el valor o los valores de z crítico (o t crítico), rayando la parte correspondiente.3) Se calcula el z o t empírico (por fórmula).4) Se calcula el z o t crítico (por tabla).5) Se indica en el dibujo el z o y empírico. Si cae dentro de la zona rayada o crítica, se rechaza la hipótesis
nula, y si cae fuera de la zona rayada o crítica, no se rechaza la hipótesis nula.
4. EJEMPLOS DE PRUEBAS DE HIPÓTESIS
Página 77 de 314
77

z
Zona de rechazo de la Ho Zona de aceptación de la Ho
z teórico = -1.64z empírico = -1.8-1.64-1.8
Existe una enorme cantidad de tipos de pruebas de hipótesis, adaptables a diversas necesidades y objetivos. En lo que sigue se suministran ejemplos de algunas de las pruebas más frecuentes.
1) Prueba de la media.- Aquí no hay que estimar un intervalo para la media poblacional (como en la estimación de parámetros), sino probar la hipótesis según la cual no hay diferencia estadísticamente significativa entre la media poblacional y la muestral. Esta prueba, llamada también prueba de la media, se entiende cabalmente a partir de un conocimiento mínimo sobre distribución muestral y teorema central del límite (12).Existe una gran diversidad de pruebas de la media, según que se conozca o no se conozca el desvío estándar poblacional (en cuyo caso se utiliza una prueba z o una prueba t, respectivamente), según que la hipótesis sea direccional (prueba de una cola) o no direccional (prueba de dos colas), y según se aplique a una sola muestra (Pagano R, 1998:293) o a dos muestras (Pagano R, 1998:317).
Ejemplo.- Se supone que la estatura media de la población de alumnos de una universidad es menor que 1.68 m, y su desvío estándar poblacional es de 0.10 m. Se cuenta con una muestra de 36 alumnos, con una media muestral de 1.65 m. Probar la hipótesis con un nivel de significación o riesgo del 5%.
Resolución.- a) En primer lugar convendrá ordenar los datos que suministra el problema:
Tamaño de la muestra (n) = 36. Media aritmética de la población () = 1.68 m.Media aritmética de la muestra (X) = 1.65 m. Desvío estándar de la población () = 0.10 m.Nivel de significación (a) = 5% = 0.05.
b) En segundo lugar, se establecen la hipótesis alternativa y la hipótesis nula.La hipótesis alternativa (Ha) sostiene que la media poblacional es menor que 1.68 m, o sea < 1.68 m.Nótese que, primero, la Ha siempre se refiere a la población, no a la muestra; segundo, es la hipótesis deseable por el investigador y por tanto la que se quiere probar; tercero, en este caso particular la hipótesis se refiere a una permanencia, no a un cambio, ya que sostiene que la estatura media poblacional sigue siendo menor que 1.68 m. a pesar de la muestra, que parece sugerir lo contrario; de esto último se desprende, en cuarto lugar, que la muestra no sería representativa de la población, es decir, la diferencia entre muestra y población sería significativa y en este caso debida al azar.La hipótesis nula (Ho) sostiene que la media poblacional es igual a 1.68 m, o sea = 1.68 m. Estrictamente hablando la Ho, por ser la opuesta a la Ha, debería proponer > 1.68 m, pero en la práctica se utiliza la igualdad.La hipótesis nula (Ho) sostiene que la diferencia entre la media muestral y la media poblacional no es estadísticamente significativa para el nivel de significación del 5%, o sea, la muestra es representativa de la población.
2) Se calcula el z empírico mediante la siguiente fórmula:
X - 1.65 – 1.68ze = -------------- = ------------------ = - 1.8 / Ön 0.10 / Ö36
3) Se calcula el z teórico mediante la tabla de z para un nivel de significación del 5%. Como se trata de una hipótesis alternativa direccional que especifica una dirección de ‘menor que’, se emplea la tabla de áreas de z hacia la izquierda (ver apéndice).Puesto que se pide un nivel de significación del 5%, traduciendo este valor a probabilidades obtenemos 0.05. A continuación, se busca el valor de z que corresponde aproximadamente a esa probabilidad. Hay dos valores que se aproximan idénticamente: 0.0505 y 0.0495. Eligiendo arbitrariamente el primero, se obtiene:
zt = -1.64
4) Se define la zona de rechazo mediante zt y se indica el valor de ze:
Página 78 de 314
78

5) Como ze cae dentro de la región de rechazo o región crítica, entonces se rechaza la Ho, y por lo tanto, se acepta la Ha según la cual la estatura media poblacional es menor que 1.68 m. En este caso se puede estar cometiendo un error tipo I, es decir, rechazar la Ho cuando es verdadera, con una probabilidad de a = 0.05 (o si se quiere, existe una probabilidad del 5% de estar rechazando la Ho cuando es verdadera).
2) Prueba de hipótesis de correlación (13).- La prueba de hipótesis que permite estudiar la significación de una correlación entre dos variables intenta probar la hipótesis nula que sostiene que la correlación entre las dos variables será cero en la población origen. Las hipótesis estadísticas de esta prueba son:Ho) = 0Ha) 0La significación del coeficiente de correlación se estudia por medio de la distribución t de Student. Para
ello se obtiene el valor de:
que se sitúa bajo la distribución t (n-2,).
Ejemplo.- Sean, a efectos didácticos, las siguientes seis observaciones obtenidas en dos variables X e Y:
X Y101012121416
131612171515
Resolución.- Aplicando la expresión del coeficiente de correlación lineal de Pearson, se obtiene r = 0.1225.Si se quiere contrastar la hipótesis nula Ho) = 0, se deberá estudiar la significación del valor r obtenido.Para estudiar su significación se debe transformar, en primer lugar, el valor de la correlación en un valor t (t empírico) y, en segundo lugar, comparar dicho valor con el valor de las tablas de la t de Student (t teórico) con n-2 grados de libertad (ver Tabla t en Anexo).
El valor proporcionado por las tablas es t (4, 0.05)= 2.776.Así, puesto que el valor obtenido es inferior al de las tablas se concluye que los datos no aportan información para rechazar la hipótesis nula Ho en función de la cual las dos variables no están correlacionadas en la población origen de la muestra.
Panorama final.- El siguiente cuadro describe algunas de las principales pruebas de hipótesis:
Prueba H (0) H (A) Zona de rechazo
Valor empírico (se calcula por fórmula)
Valor crítico (se calcula por tabla)
zPuntaje reducido.Se utiliza cuando se conoce el desvío poblacional.
m = x m < x A la izquierda del punto crítico (una cola a la izquierda)
z =Numerador: media muestral menos media poblacional.Denominador: desvío poblacional dividido por la raíz cuadrada de n.
Calcular por tabla en base a a
m = x m > x A la derecha del punto crítico (una cola a la derecha)
m1 = m2 m1 ≠ m2 Dos colast (n-1)t de Student con n-1 grados de libertad.Se utiliza cuando se desconoce el desvío poblacional pero sí el desvío muestral (s).
m = x m < x A la izquierda del punto crítico (una cola a la izquierda)
t =Numerador: media muestral menos media poblacional.Denominador: desvío muestral s dividido por la raíz cuadrada de
Calcular por tabla en base a a y a n-1
m = x m > x A la derecha del punto crítico (una cola a la
Página 79 de 314
79

derecha)n.m1 = m2 m1 ≠ m2 Dos colas
X2
Chi cuadrado.Busca si hay diferencia significativa entre muestra y población.Sólo para variables cualitativas.
f (0) = f (e) f (0) ≠ f (e) A la derecha del punto crítico (una cola a la derecha)
X2 = Sumatoria deNumerador: cuadrado de la diferencia entre f (0) y F (e) Denominador: F (e)
Calcular por tabla en base a a y a k-1
FF de Snedecor o ANOVA.Busca si hay diferencias significativas entre medias de muestras o poblaciones.Busca decidir si la variación entre tratamientos prevalece sobre la variación aleatoria.
m1 = m2 = m3
m1 ≠ m2 ≠ m3
(o al menos dos distintas)
A la derecha del punto crítico (una cola a la derecha)
F =Numerador: variancia entre grupos.Denominador: variancia en cada grupo.(F se calcula por computadora).
Calcular por tabla en base a a, a k-1 y a n-k
z y t corresponden a distribuciones normales.X2 y F corresponden a distribuciones asimétricas a la izquierda.
Símbolos:x = Valor de la media poblacional.m = Media poblacional o esperanza.n = Tamaño de la muestra.a = Nivel de significación.n-1 = Grados de libertad.F (0) = Frecuencia observada.F (e) = Frecuencia esperada.k-1 = Grados de libertad (N° de categorías menos uno).n – k = Grados de libertad.ANOVA = Análisis de la variancia. La variancia entre grupos consiste en las distintas respuestas de la VD ante la aplicación de los distintos niveles de la VI. La variancia en cada grupo consiste en las generadas por las diferencias individuales y otras eventualidades del experimento. Por ejemplo, esta prueba permite indagar si el aerobismo o la caminata mejoran el funcionamiento cardiovascular. La hipótesis nula considera aquí que no hay diferencias en cuanto a funcionamiento cardiovascular entre el grupo aeróbico, el grupo caminante y el grupo control (m1 = m2 = m3).
5. EL CONCEPTO DE SIGNIFICACIÓN ESTADÍSTICA
En este ítem se ofrecen mayores detalles este importante concepto de la estadística inferencial, con un tercer ejemplo de prueba de hipótesis.Uno de los fines de la estadística inferencial consiste en determinar si la diferencia entre dos conjuntos de datos es o no significativa. En el contexto de la investigación científica, ambos conjuntos de datos pueden consistir en dos muestras (por ejemplo entre el grupo experimental y el grupo de control), o bien entre una muestra y una población de la que fue extraída.
1) Diferencia entre muestras.- Cuando la investigación incluye un diseño experimental, es sabido que las muestras (entonces designadas como grupo experimental y grupo de control), en general exigen un tratamiento estadístico antes y después de la manipulación, es decir, antes y después de su exposición a la influencia de la variable experimental “x”.
a) Antes de aplicar “x” lo que se exige es que no haya diferencias significativas entre los grupos experimental y de control, tanto en lo referente a “x” como en las variables de control (es decir a las variables extrañas relevantes que requieren ser controladas).b) Después de aplicar “x”, lo que se espera como deseable (para aceptar la hipótesis de investigación) es que haya diferencias significativas en cuanto a “x” entre ambos grupos. La teoría de las muestras (2) “es útil para poder determinar si las diferencias observadas entre dos muestras son realmente debidas al azar o si son significativas, lo que puede llevar a un proceso de toma de decisiones gracias a las pruebas de ‘hipótesis’ y de ‘significación’ que se pueden hacer” (Kohan N, 1994:144).
2) Diferencia entre muestra y población.- Queda, no obstante, otra tarea adicional para la estadística inferencial: establecer si las conclusiones obtenidas para la muestra experimental, luego de la exposición a “x”, pueden extenderse lícitamente a toda la población, habida cuenta de que la ciencia busca un
Página 80 de 314
80
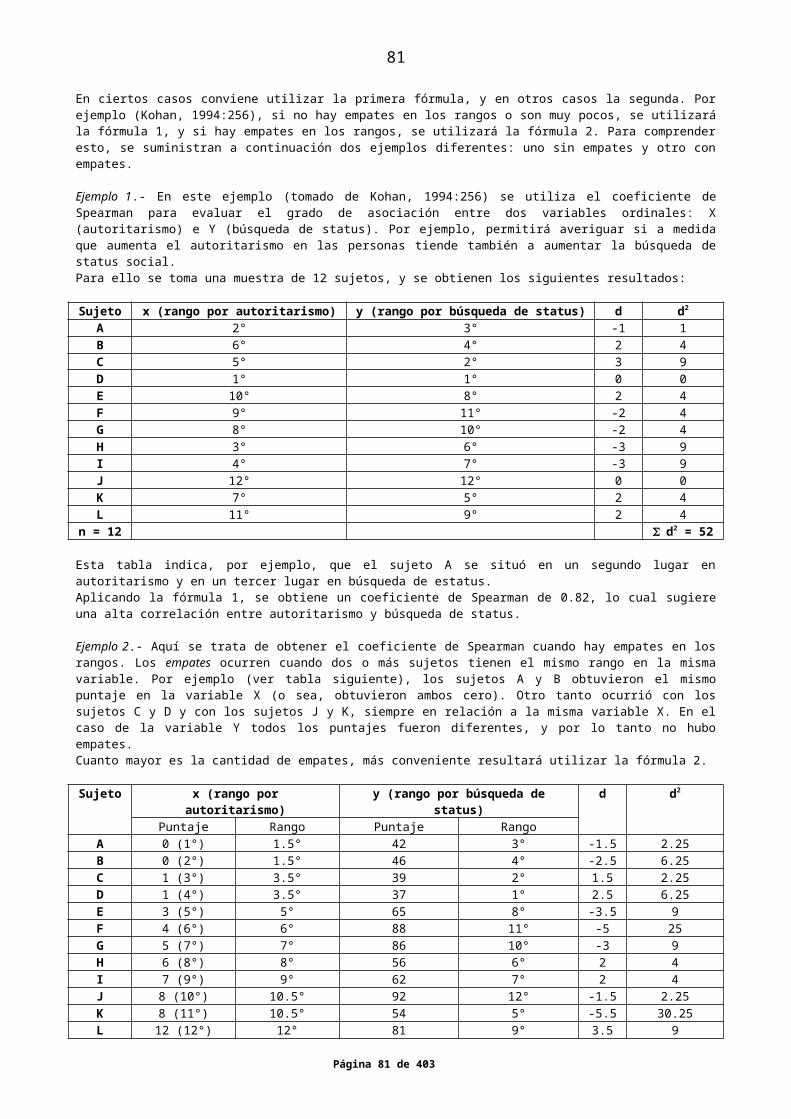
conocimiento válido y universal. Esta tarea es lo que Kohan describe como “probar hipótesis válidas para la población correspondiente, conociendo la información de las muestras” (Kohan N, 1994:144). La misma autora indica que para que las conclusiones que se obtienen a partir de las muestras sean válidas, éstas deben ser representativas de la población.
El objetivo de este ítem es explicar con un ejemplo de qué manera se puede alcanzar el objetivo 1b, es decir, como se puede probar si hay o no diferencias significativas entre un grupo experimental y un grupo de control.Los resultados de un experimento requieren un tratamiento estadístico que permita orientar al investigador acerca de si la hipótesis de investigación debe ser rechazada o no rechazada, para lo cual deberá establecer convencionalmente un determinado nivel de significación que permita diferenciar resultados estadísticamente significativos de resultados estadísticamente no significativos. Seguidamente se explica en detalle esta aseveración.
En los informes de investigación suelen aparecer expresiones del tipo " los resultados del experimento son estadísticamente significativos". Seguidamente se aclarará en forma intuitiva qué quiere decir esto, siguiendo los lineamientos didácticos de León y Montero (1995:105-130).Supóngase un sencillo experimento, donde se trata de probar si un choque emocional altera o no el recuerdo de los sucesos inmediatamente anteriores al mismo.Para ello, se tomaron dos grupos de estudiantes: el grupo experimental presenció una película donde había una escena violenta, y el grupo de control presenció la misma película pero sin la escena violenta.Los resultados fueron los siguientes: el grupo sometido al choque emocional lograba luego recordar un promedio de 10, mientras que el grupo sin choque emocional lograba recordar más sobre las escenas del film: por ejemplo, un promedio de 15. Esquemáticamente:
Grupo Choque emocional
Recuerdo
Grupo I (vieron escena violenta) SI 10Grupo II (no vieron escena violenta) NO 15
Lo que debe ahora establecerse es si esta diferencia en los recuerdos entre 10 y 15 es o no significativa, es decir, si va o no más allá del simple azar. Si se concluye que NO es significativa, entonces las diferencias entre 10 y 15 se deben al azar, pero si se concluye que SI es una diferencia significativa, entonces no debe descartarse la influencia del choque emocional sobre la memoria. La expresión 'significativa' quiere decir una diferencia lo suficientemente grande como para pensar que el choque emocional influye sobre los recuerdos.En principio, para averiguar si la diferencia es o no significativa, puede apelarse a dos procedimientos, que podrían llamarse el procedimiento intuitivo y el procedimiento estadístico.a) El procedimiento intuitivo es muy simple: se advierte que la diferencia entre ambos grupos es 15-10=5, y entonces se piensa: "evidentemente, hay una diferencia significativa". Si ambos grupos hubiesen obtenido 15, se pensaría que no habría diferencia significativa y entonces se concluiría que el choque emocional no influye sobre el recuerdo.Como puede notarse, este procedimiento intuitivo tiene el problema de la subjetividad en la estimación de los resultados. Tal vez para otro investigador no hubiese sido significativa la diferencia de 5 sino una diferencia mayor, como por ejemplo 8. Ambos investigadores polemizarían fundamentando sus argumentaciones sobre la base de simples impresiones o creencias, es decir, jamás llegarían a un acuerdo, y, en el mejor de los casos, acordarían buscar un procedimiento más objetivo. En este caso contratarían a un técnico en estadística para que hiciera una estimación como la que ahora se pasa a explicar.b) El procedimiento estadístico es más complejo que el anterior: en lugar de intentar averiguar si la diferencia entre las promedios 15 y 10 es "intuitivamente significativa", lo que intentará probar es si la diferencia es "estadísticamente significativa".Cabe aquí anticipar algo que señalan León y Montero: "Encontrar una diferencia de valores que no es estadísticamente significativa equivale a decir que esa diferencia la hemos encontrado por casualidad. O lo que es lo mismo, si repitiéramos el proceso, el promedio de diferencias encontradas sería cero".¿Qué significa esta última expresión? Significa que si se hicieran otros experimentos con otros grupos, puesto que las diferencias que se obtienen obedecen a la casualidad, una vez se podría encontrar una diferencia de 5, otra vez una diferencia de 3, otra vez una diferencia de -4, etc., es decir, saldrían números al azar cuyo promedio tendería a cero, puesto que si dicho promedio tendiese a 5, entonces los resultados ya podrían ser pensados como significativos.
A partir del ejemplo, se puede ahora examinar el concepto de significación estadística, central dentro de la teoría de las muestras (5).León y Montero proponen imaginar por un momento una variante del experimento anterior, donde ninguno de los dos grupos fue expuesto al choque emocional, es decir, ambos grupos vieron la misma película sin la escena violenta.Desde ya, este experimento carece de sentido, porque lo que interesa es ver si hay o no diferencias entre dos grupos en lo concerniente a capacidad de recordar, sometidos cada uno a 'diferentes' condiciones
Página 81 de 314
81

experimentales (uno vio la escena violenta y el otro no). Sin embargo, analizar lo que sucedería en este experimento imaginario resultará útil para entender la idea de significación estadística, como enseguida se verá.En este experimento imaginario, puesto que ambos grupos no recibieron el estímulo violento, es esperable que los rendimientos mnémicos sean iguales, o por lo menos aproximadamente iguales, porque siempre cabe la posibilidad de la intervención de pequeñas variables no controladas.Repitiendo varias veces el experimento, una vez podríamos obtener una diferencia de 0, otra vez una diferencia de 0.5, otra vez una diferencia de -1, etc. Si el experimento se repitiese diez mil veces, es razonable pensar que habría muy pocos casos donde la diferencia fuese muy extrema (por ejemplo 7 o -7), y muchos casos próximos a una diferencia de 0. Las diferencias obtenidas en los diez mil experimentos podrían resumirse, según este criterio, en la tabla 1.
Tabla 1
Diferencias entre los 2 grupos
Cantidad de experimentos (frecuencias)
7 56 255 904 2803 6802 12001 16900 2000-1 1700-2 1190-3 720-4 290-5 100-6 26-7 4
Total 10.000
Los resultados de la tabla 1 permiten ver, en efecto, que hay muy pocos experimentos donde la diferencia entre grupos es muy grande (en apenas 5 experimentos la diferencia fue 7), mientras que hay muchos experimentos donde la diferencia entre grupos es nula (hay 2000 experimentos donde la diferencia fue 0).La tabla también informa sobre lo siguiente:a) La cantidad de casos que obtuvieron como diferencia entre +1 y -1 fue de 5.390 casos (que resulta de sumar 1690 + 2000 + 1700). Ello representa el 53,9% más próximo a cero del total de casos.b) La cantidad de casos que obtuvieron como diferencia entre +3 y -3 fue de 9180 casos. Esto representa el 91,8% más próximo a cero del total de casos, y se puede graficar mediante una curva normal tal como aparece en el gráfico 1. En este gráfico se puede visualizar fácilmente que el 91,8% de los experimentos obtuvo una diferencia de -3 hasta +3.
Gráfico 1
Página 82 de 314
82

Una vez hechos estos cálculos, ahora cabe hacerse una pregunta fundamental: ¿dentro de qué intervalo de diferencias cabría admitir que las diferencias responden al simple azar? ¿Dentro del intervalo -1 y +1? ¿Dentro del intervalos -3 y +3? Por las dudas, se considerará convencionalmente este último intervalo. Esto quiere decir, por ejemplo, que si en un experimento se obtuvo una diferencia de 2, entonces se considerará que dicha diferencia se debe al azar (pues 2 está entre -3 y +3), mientras que si en otro experimento se obtuvo una diferencia de 6, entonces se considerará que dicha diferencia no se debe al azar (pues 6 está fuera del intervalo entre -3 y +3), es decir, se considerará que la diferencia es 'estadísticamente significativa'.Supóngase ahora el experimento original, donde un grupo era sometido al estímulo violento y el otro no, es decir, donde los grupos son sometidos a diferentes condiciones experimentales.En uno de dichos experimentos se ha obtenido, por ejemplo, una diferencia de 2.5; por lo tanto, deberá concluirse que esta diferencia no es 'estadísticamente significativa' porque está comprendida dentro del 91,8% de los casos más próximos a cero (o sea, entre -3 y +3), según la convención propuesta.En cambio, si la diferencia encontrada en otro experimento de este tipo hubiese sido de 5, este valor cae fuera del intervalo entre -3 y +3, y por lo tanto es 'estadísticamente significativo' (ver gráfico 2). Desde ya, para decidir esto se ha considerado que el porcentaje que permite discriminar lo que es significativo de lo que no lo es era 91,8%. Si se hubiese elegido el 99%, una diferencia de 5 como resultado hubiese resultado estadísticamente no significativa.Señalan León y Montero: "el investigador [es quien] determina el porcentaje que sirve para discriminar la significación de la no significación. Este tanto por ciento se denomina 'nivel de confianza', y tiene sus valores más frecuentes entre 95% y 99%". Cuanto mayor es el porcentaje elegido, más exigente deberá ser en cuanto a la tipificación de un resultado como estadísticamente significativo.En los informes de investigación, en vez de citarse el nivel de confianza, se suele citar su complementario, que es el 'nivel de significación' o 'nivel de riesgo'. En el caso del ejemplo, si el nivel de confianza era del 91,8%, el nivel de significación o de riesgo será lo que falta para completar 100%, es decir, el 8,2% (ver gráfico 2). Más aún, inclusive, es frecuente expresar este nivel de significación no en términos de porcentajes sino en términos de probabilidad, con lo cual, en vez de afirmarse 8,2%, se afirmará 0.082.
Gráfico 2
Página 83 de 314
83

Las expresiones 'confianza' y 'riesgo' resultan esclarecedoras para entender estos conceptos: si un experimento cae dentro del nivel de confianza se puede decir con tranquilidad, con 'confianza', que los resultados no son estadísticamente significativos, pero si cae dentro del nivel de riesgo, el investigador se estaría 'arriesgando' a sostener que los resultados son estadísticamente significativos, es decir, a aceptar la hipótesis según la cual un choque emocional efectivamente influye sobre los recuerdos.León y Montero indican que encontrar diferencias estadísticamente significativas no es el propósito final del investigador, ni lo más importante. Lo que el investigador persigue es en realidad determinar la significación teórica, más que la significación estadística que le sirve como medio, es decir, si resulta o no relevante para alguna finalidad. Así por ejemplo, si se ha constatado que un tratamiento para adelgazar produce una pérdida de 2 Kg, esto puede ser estadísticamente significativo, pero mientras que para un investigador nutricionista será además también importante desde el punto de vista teórico, para un vendedor de esa dieta no, porque 2 Kg. no le proporciona un buen argumento de venta.Una última acotación. Podría ocurrir que algunos investigadores que hicieran el experimento del choque emocional hubiesen obtenido diferencias extremas, como por ejemplo -7 o +7, mientras que otros hubiesen obtenido diferencias más próximas a cero, con lo cual los primeros hubiesen aceptado la hipótesis del choque emocional, mientras que los segundos la hubiesen rechazado. Este desacuerdo entre investigaciones puede ocurrir, con lo cual deberá emprenderse lo que se llama un 'meta-análisis', es decir, un procedimiento que permita integrar los resultados acumulados de una serie de investigaciones.
NOTAS
(1) Las muestras no probabilísticas “solo suelen usarse como primera aproximación en trabajos piloto, pero no puede saberse cuán confiables son sus resultados” (Kohan N, 1994:146).(2) “Toda teoría de las muestras es una estadística ‘inferencial’, pues se ‘infieren’ a partir de los valores estadísticos hallados en las muestras los valores paramétricos más probables para las poblaciones de las cuales hemos extraído las muestras” (Kohan N, 1994:145).(3) Cuanto mayor es el error estándar, mayor es el intervalo de confianza. El error estándar es mayor cuando z es mayor, o sea, cuanto menor es el riesgo que se quiere correr; cuando n es menor (si se quiere más precisión se necesitará una muestra más grande), y cuando S es mayor. En síntesis: cuanto menor es el riesgo que se quiere correr, cuanto menor es el tamaño de la muestra y cuanto mayor es el S (desvío estándar muestral), mayor será el intervalo de confianza.(4) Este nivel de riesgo es también llamado nivel de significación (Rodríguez Feijóo N, 2003).(5) "La teoría sobre las muestras... es útil [entre otras cosas] para poder determinar si las diferencias observadas entre dos muestras son realmente debidas al azar o si son significativas, lo que puede llevar a un proceso de toma de decisiones gracias a las pruebas de hipótesis y de significación que se pueden hacer" (Kohan N, 1994:144).(6) La prueba de hipótesis tiende a ser denominada en la actualidad teoría de la decisión (Kohan N, 1994:173). Con ello se quiere significar que la prueba de hipótesis se lleva a cabo sobre la base de una teoría llamada teoría de la decisión.(7) Un experimento clásico para probar la hipótesis del investigador es comparar dos muestras: el grupo experimental y el grupo de control. Si hay diferencia significativa entre la muestra experimental y la muestra de control, entonces NO hay diferencia significativa entre la muestra experimental y la población.(8) Puede llamar la atención que el investigador no pruebe directamente su hipótesis alternativa sino que lo haga indirectamente, probando la hipótesis nula. ¿Por qué proceder para apoyar una teoría mostrando que hay poca evidencia para apoyar la teoría contraria? ¿Por qué no apoyar directamente la hipótesis alternativa o de investigación? La respuesta está en los problemas para evaluar las posibilidades de decisiones incorrectas.
Página 84 de 314
84

El argumento que en general puede encontrarse en los textos de estadística es el siguiente: Si la hipótesis de investigación es verdadera (por ejemplo una vacuna cura el resfriado), la prueba de la hipótesis nula (la contraria a la hipótesis de investigación) deberá conducir a su rechazo. En este caso, la probabilidad de tomar una decisión incorrecta corresponde a a cuyo valor fue especificado al determinar la región de rechazo. Por lo tanto, si se rechaza la hipótesis nula (que es lo deseable) se conoce inmediatamente la probabilidad de tomar una decisión incorrecta. Esto proporciona una medida de confianza de la conclusión.Supóngase que se utiliza el razonamiento opuesto, probando la hipótesis alternativa (de investigación) de que la vacuna es efectiva. Si la hipótesis de investigación es verdadera, la estadística de prueba probablemente caerá en la región de aceptación (en lugar de la de rechazo). Ahora, para encontrar la probabilidad de una decisión incorrecta de debe evaluar b, la probabilidad de aceptar la hipótesis nula cuando esta es falsa. A pesar de que esto no representa un gran esfuerzo para el problema de la vacuna contra el resfriado, es un trabajo adicional que se debe hacer y en algunos casos es muy difícil calcular b.Así que, para resumir, es mucho más fácil seguir el camino de la “prueba por contradicción”. Por lo tanto, el estadístico elegirá la hipótesis contraria a la de la investigación como hipótesis nula y su deseo es que la prueba conduzca a su rechazo. Si es así, el estadístico conoce el valor de a y tiene una medida inmediata de la confianza que se puede depositar en esta conclusión.(9) Autores como Hernández Sampieri et al (1996:91) nos ofrecen una interesante tipología de hipótesis nulas que contemplan varias posibilidades. Concretamente, hacen referencia a: 1) hipótesis nulas descriptivas de una variable que se va a observar en un contexto (por ejemplo “la expectativa de ingreso mensual de los trabajadores de la corporación T no oscila entre 50.000 y 60.000 pesos colombianos”); 2) hipótesis que niegan o contradicen la correlación entre dos o más variables (por ejemplo “no hay relación entre la autoestima y el temor de logro”); 3) hipótesis que niegan que haya diferencia entre grupos (por ejemplo “no existen diferencias en el contenido de sexo en las telenovelas S, L y M”); y 4) hipótesis que niegan la relación de causalidad entre dos o más variables (por ejemplo “la percepción de la similitud en religión, valores y creencias no provoca mayor atracción física”).A nuestro entender, una visión más completa de las hipótesis nulas debería considerar al menos cuatro sentidos, que podemos designar respectivamente en términos de hipótesis nula de estimación, hipótesis nula de correlación, de causalidad y de validez externa: a) La hipótesis nula de estimación vendría a afirmar que los estadísticos muestrales no son representativos de los parámetros poblacionales.b) La hipótesis nula de correlación vendría a afirmar que no existe una correlación significativa entre dos o más variables. El nivel de significación es en estos casos el que establece a priori el investigador cuando califica ciertos intervalos del coeficiente de correlación como ‘alto’, ‘medio’, ‘bajo’, etc.c) La hipótesis nula de causalidad vendría a afirmar que los cambios en la variable dependiente Y no son adjudicables a los cambios de la variable independiente X. Pagano, por ejemplo, refiere que la hipótesis nula indica que la variable independiente no influye sobre la variable dependiente (Pagano, 1998:212). Este segundo sentido de hipótesis nula es el más frecuentemente mencionado en los tratados sobre el tema.d) La hipótesis nula de validez externa vendría a indicar que las conclusiones obtenidas en la muestra no son extensibles -con el nivel confianza requerido- a toda la población. Este tipo de hipótesis vendría entonces a negar la validez externa de un experimento, entendiendo aquí validez externa como requisitos de los diseños experimentales tal como por aparecen en gran parte de la bibliografía sobre el tema (por ejemplo Campbell D y Stanley J, 1995:16). Autores como Tamayo parecerían considerar este sentido de hipótesis nula cuando la incluyen dentro de las hipótesis estadísticas, definiendo éstas últimas como suposiciones sobre una población que se realizan a partir de los datos observados, es decir, de una muestra (Tamayo M, 1999:120).La hipótesis nula de estimación corresponde a la primera tarea de la estadística inferencial: la estimación de parámetros. Las hipótesis nulas de correlación y de causalidad corresponderían a la prueba de hipótesis donde se busca establecer si ‘y’ se debe a ‘x’ y no al azar, y la hipótesis nula de validez externa corresponderían a la prueba de hipótesis donde se busca generalizar los resultados a toda la población.(10) Debe diferenciarse la hipótesis de investigación (H), la hipótesis alternativa (H a) y la hipótesis nula (Ho). La hipótesis de investigación resulta, según Vessereau (1962:28), de consideraciones teóricas o bien está sugerida por los datos mismos. A los efectos de probar la hipótesis de investigación, deberá dársele una ‘forma’ estadística, con lo cual se convierte en la hipótesis alternativa (esta ‘forma’ estadística significa que incluye por ejemplo alguna afirmación acerca de ‘si hay o no diferencias significativas’). A su vez para probar esta hipótesis alternativa deberá probarse la hipótesis nula, que no es otra cosa que la negación de la hipótesis alternativa.
Más concretamente, “por lo general, la hipótesis de investigación predice una relación entre dos o más variables (por ejemplo, que los niños que tienen mayor dominio del ojo izquierdo obtendrán puntajes de rendimiento en lectura bastante inferiores a los de los otros alumnos). Para probar esta hipótesis de manera estadística, el investigador debe transformarla en hipótesis alternativa y luego negarla mediante la hipótesis nula. La hipótesis nula no siempre refleja las expectativas del investigador en relación con el resultado del experimento. Por lo general, se opone a la hipótesis de investigación, pero se la utiliza porque resulta más apropiada para la aplicación de los procedimientos estadísticos. La hipótesis nula determina que no existe relación entre las variables consideradas (por ejemplo, en lo que respecta al rendimiento en la lectura, no hay ninguna diferencia entre los niños que poseen mayor dominio del ojo izquierdo y los demás). Por lo general, cuando se formula una hipótesis nula, se espera que sea rechazada. Si esto último ocurre, se acepta la hipótesis de investigación” (Van Dalen: 189-190).
(11) Las pruebas de una cola y dos colas también se llaman pruebas de un extremo y dos extremos, o también unilaterales y bilaterales, o también one tailed test o two tailed test.(12) Dada una población de la cual se conoce su media aritmética, por ejemplo 70, su varianza, y su tamaño N, por ejemplo 4, puede llevarse a cabo el siguiente procedimiento: a) primero se sacan todas las muestras posibles del mismo tamaño. La cantidad de muestras posibles se puede calcular mediante un número combinatorio, y así, por ejemplo, de una población de N = 4, se pueden obtener un total de 6 muestras de n = 2. b) A continuación se calculan las medias aritméticas de cada una de las muestras posibles, con lo cual se obtiene una distribución muestral de medias aritméticas. Por ejemplo, las medias aritméticas de las 6 muestras pueden ser: 50, 60, 70, 80 y 90. c) Seguidamente se calcula la media aritmética de todas estas medias aritméticas, y se obtiene un valor de 70. Como puede apreciarse, esta media de todas la medias muestrales coincide con la media poblacional.La estadística ha demostrado que esta distribución de medias de todas las medias muestrales sigue el modelo de la curva normal, y se ha establecido así el teorema central de límite, que dice que si se sacan repetidamente muestras de tamaño n de una población normal de cierta media y cierta varianza, la distribución de las medias muestrales será normal con una media igual a la media poblacional y con una varianza igual a la varianza poblacional dividido n. Desde ya, la precisión de la aproximación mejora al aumentar n.
Página 85 de 314
85

De todo ello se desprende que si se selecciona una muestra cualquiera y ésta tiene una determinada varianza (o sea, un determinado desvío estándar respecto de la media de las medias), se habrá cometido un determinado error, llamado en este caso error estándar, por haber trabajado con una muestra en lugar de haberlo hecho con la población. La fórmula del error estándar no es otra cosa que el desvío estándar de la muestra en cuestión, lo que es igual al desvío estándar poblacional dividido por la raíz cuadrada del tamaño n de la muestra (Rodríguez Feijóo, 2003) (Kohan N, 1994:150-153).(13) Extraído de http://www.bibliopsiquis.com/psicologiacom/vol5num1/2815/. Otro ejemplo de prueba de hipótesis de correlación puede encontrarse en Kohan (1994:234).
Página 86 de 314
86

PARTE II: METODOLOGÍA DE LA INVESTIGACIÓN
CAPÍTULO 6: INVESTIGACIÓN E INVESTIGACIÓN CIENTÍFICA
La investigación -más allá de si es científica o no lo es- es un proceso por el cual se enfrentan y se resuelven problemas en forma planificada, y con una determinada finalidad. Una forma de clasificar los diferentes tipos de investigación en general es a partir de su propósito o finalidad: fines distintos corresponden a diferentes tipos de investigación.Toda investigación, y en particular la investigación científica, tiene un determinado método y un determinado encuadre, que serán descritos en este capítulo donde además se sugiere, finalmente, un proyecto para la formación de investigadores científicos.
1. QUÉ ES INVESTIGACIÓN
Partiendo de una definición simple, pero no menos correcta, puede decirse que la investigación es un proceso por el cual se enfrentan y se resuelven problemas en forma planificada, y con una determinada finalidad. En esta definición deben destacarse cuatro ideas importantes: "proceso", "problema", "planificada" y "finalidad".
1) Proceso.- Como muchas palabras que terminan en ‘ción’, investigación puede designar dos cosas: la acción de investigar, o bien el efecto, resultado o producto de esa acción. En nuestra definición adoptamos el primer sentido, es decir, un sentido más dinámico y menos estático: la investigación es algo que hace la gente, acciones que requieren tiempo.Que la investigación sea un proceso significa que no es algo que ocurra instantáneamente, sino que se da a lo largo de un tiempo, es decir que tiene una secuencia cronológica. Hay algunas investigaciones que duran unos pocos minutos, como investigar quien me escondió los zapatos, unas pocas horas o días, como podría ser investigar cómo ocurrió un accidente callejero, mientras que otras llevan varios años, como la investigación de la eficacia de una cierta droga para curar cierta enfermedad.
2) Problema.- En nuestra definición hablamos deliberadamente de 'problema', y no empleamos palabras como misterio o enigma, por cuanto ellas tienden a sugerir cuestiones que aceptamos como insolubles, como cuando se dice el misterio de la Santísima Trinidad, o el misterio de María, una mujer que, siendo virgen, parió un hijo. Por tanto, el problema que genera la investigación debe ser, por lo menos en principio, solucionable -sea en el grado que sea-, si no, no hay investigación posible. La investigación implica no sólo enfrentar un problema sino también resolverlo, pues de otra forma la investigación no se completa como proceso: un investigador es un buscador de soluciones o si se quiere, un disolvedor de misterios.Si solamente nos ocupáramos de enfrentar problemas sin resolverlos, haríamos como Fabio Zerpa con el asunto de los platos voladores y como Charles Berlitz con el Triángulo de las Bermudas, para quienes cuantos más misterios sin resolver haya, tanto mejor: es lo que podemos llamar una anti-investigación, porque el fin no es solucionar misterios sino multiplicarlos. De alguna forma ellos saben de la fascinación que ejercen los misterios sobre las personas, y de esa manera pueden vender muchos libros: Bunge llamaba a estos personajes "traficantes de misterios". Desde ya, estos traficantes de misterios ofrecen soluciones, como por ejemplo cuando dicen que las pirámides fueron construidas por extraterrestres, pero la solución vuelve a encerrar un misterio aún mayor, como por ejemplo de dónde vinieron o quienes eran aquellos presuntos extraterrestres. Estos traficantes seducen con lo misterioso, insisten en el enigma, no en la solución. La investigación científica procura resolver problemas, aunque detrás de ellos encuentra problemas más grandes. Sin embargo, no insisten en el enigma sino en la solución.Etimológicamente, 'investigar' significa buscar, indagar. En inglés, investigación se dice 'research', y precisamente 'search' significa buscar. Desde ya se trata, como hemos indicado, de una búsqueda de soluciones.En nuestra definición habíamos dicho que la investigación implica enfrentar y resolver problemas. Ya hemos aclarado que 'resolver' problemas significa encontrarles soluciones. Aclaremos ahora un poco más que significa 'enfrentar' problemas.Tanto en la vida cotidiana como en la investigación científica enfrentamos problemas, pero mientras en la primera los problemas se presentan muy a pesar nuestro, en la ciencia los buscamos y los formulamos deliberadamente. El científico, a diferencia del hombre común, es un problematizador por excelencia, es alguien que está 'mentalizado' para detectarlos. Mario Bunge decía que una de las tareas del investigador es tomar conocimiento de problemas que otros pueden haber pasado por alto. Por ejemplo, en la vida cotidiana nadie se plantea el problema de por qué se cae una manzana cuando la soltamos, salvo que sea Newton y se haya sentado debajo del manzano: "el trabajo científico consiste, fundamentalmente, en formular problemas y tratar de resolverlos" (Ander-Egg E, 1987:139).Ahora bien, sea que los problemas se busquen deliberadamente (como en la ciencia) o se encuentren inopinadamente (como en la vida cotidiana), el denominador común es le hecho de que el problema debe ser enfrentado. La distinción entre buscar y encontrar puede tener una importancia psicológica, pero es secundaria a los efectos de lo que aquí queremos ver, es decir, lo que es común a cualquier investigación.
Página 87 de 314
87

Lo importante será para nosotros que en la investigación se 'enfrentan' problemas, sea que estén buscados deliberadamente, sea que hayan sido encontrados 'sin querer'.En general, en los manuales de metodología de la investigación suele insistirse en el papel protagónico del problema en la investigación, tal como podemos encontrarlo por ejemplo en Selltiz. El mismo Bunge también insiste en ello, dándonos una versión de investigación con reminiscencias darwinianas, cuando la define como un proceso que "consiste en hallar, formular problemas y luchar contra ellos" (Bunge M, 1970:185). En síntesis, si tuviésemos que condensar en una fórmula muy simplificada qué es la investigación, podríamos decir: "investigación = problema + resolución".Como podemos advertir, no puede haber investigación sin un problema, pero, ¿puede haber un problema sin investigación? Respuesta: puede haberlo, como por ejemplo en los casos de resolución de problemas en forma automática, ya que la investigación implica una forma planificada de resolución, como enseguida veremos. Otro ejemplo puede ser agrandar el problema (la anti-investigación de Fabio Zerpa), y otro ejemplo es cuando hay un problema pero no hay una inquietud por resolverlo. Yo tuve una novia que decía: "si un problema no tiene solución, para qué hacerse problema?, y si tiene solución, para qué hacerse problema?" Nunca supe si el problema que la desvelaba era yo, entre otras cosas porque no me dio tiempo: salimos solamente tres días.
3) Planificación.- El tercer concepto incluído en nuestra definición de investigación es el de planificación: concretamente, cuando decimos que la investigación implica resolver un problema en forma planificada. Para Bunge, el término 'problema' designa "una dificultad que no puede resolverse automáticamente, sino que requiere una investigación, conceptual o empírica" (Bunge M, 1970:195). Esto nos suscita la idea de que hay por lo menos dos formas de resolver problemas: automática y planificada.a) Resolución automática.- Un problema puede ser resuelto automáticamente, lo que significa que no exige mayormente esfuerzo intelectual, ingenio, creatividad o planificación. Podemos mencionar tres modalidades de resolución automática de problemas: inmediata, rutinaria y aleatoria.En la resolución inmediata, apenas aparece el problema aparece la solución. Si tengo necesidad de una birome, la tomo del bolsillo y se acabó el problema, es decir, no necesito hacer una 'investigación' para buscar la birome (la investigación, como veremos, supone una resolución planificada). Si mi problema es conocer el origen del universo, puedo tener una solución inmediata que me es provista por mi cosmovisión: lo creó Dios y punto. El dogma religioso suele prohibir la investigación: las verdades están dadas, no hay que buscarlas en ningún lado.La resolución rutinaria implica llevar a cabo una serie de actividades en forma ordenada, mecánica o predeterminada. Muchas actividades cotidianas son rutinarias: si tengo que preparar la comida de todos los días, si tengo que entrar al auto, arrancarlo y andar, o si debo tomar el colectivo todos los días para ir a trabajar, ejecuto una serie de pasos ordenados, incluso sin pensarlos demasiado, en forma automática. Nadie diría que preparar la comida de todos los días es 'hacer una investigación': resolver un problema cotidiano no implica necesariamente investigar. Otro ejemplo: un cirujano que realiza su operación número mil de vesícula ya la hace casi con los ojos cerrados, en forma automática y rutinaria, y por ende no investigó nada.La diferencia que puede haber entre la resolución rutinaria y la inmediata es tal vez solamente que la primera requiere cierto tiempo y, es, por lo tanto, un proceso.Finalmente, la resolución aleatoria consiste en encontrar una solución de manera fortuita, incluso sin haberla buscado. Podemos por ejemplo tener problemas de dinero, y encontramos en la calle cien pesos. Aquí nadie diría que hemos realizado una investigación para resolver nuestro problema económico.b) Resolución planificada.- Como podemos imaginarnos, una resolución planificada no es una resolución automática: exige cierto esfuerzo, exige cierta dosis de creatividad, exige trazarnos estrategias y tácticas. Como su nombre lo indica, exige trazarnos un 'plan' para resolver el problema, precisamente porque no podemos resolverlo automáticamente.Cuando pierdo el botón de la camisa o los documentos y no puedo resolver el problema de manera automática, inicio una 'investigación', pero previamente hago una planificación, por muy inconciente o rudimentaria que pueda ser, es decir, me organizo, me trazo un plan: primero busco en el piso, después en la casa, después en los lugares donde estuve, para lo cual a su vez pudo llamar por teléfono a esos lugares o ir personalmente, etc.La investigación supone una planificación, pero la planificación sola no es investigación, porque requiere también la ejecución del plan. Planificar sin ejecutar es como hacer el plano de una casa sin construirla.La planificación, a su vez, supone una organización y un método, pero no toda organización metódica de actividades supone planificación: la resolución rutinaria de problemas implica una organización de las conductas y un método, pero su mismo carácter rutinario hace innecesaria una planificación previa. Debemos entonces preguntarnos cómo debe ser esta organización metódica para que podamos hablar propiamente de una necesidad de planificación, esto es, para que podamos hablar propiamente de investigación.Ciertos autores (Matus C, 1985) distinguen entre planificación normativa y planificación estratégica, y aclaramos ante todo que lo que aquí estamos llamando planificación corresponde con éste último sentido.Una 'planificación' normativa implica diseñar un plan en forma inflexible y rígida, sin tener en cuenta las posibles variaciones y sorpresas que la realidad pueda presentarnos. No admite ni prevé cambios sobre la marcha. Se trata de una planificación que pretende actuar sobre la realidad como Procusto, quien en lugar de construir un lecho acorde con las dimensiones del hombre, cortaba a éste para ajustarlo al lecho.Una planificación estratégica, al revés, considera los imprevistos e instrumenta los modos de adaptarse a ellos introduciendo cambios en el plan original. Un físico norteamericano, Robert Oppenheimer, decía que
Página 88 de 314
88

investigar significa pagar la entrada por adelantado y entrar sin saber lo que se va a ver. Como el lector habrá advertido, una planificación normativa no es en realidad tal, y está más bien relacionada con la forma rutinaria de resolver problemas. La investigación, en suma, implica una planificación, sobreentendiéndose que se trata de una planificación estratégica y no normativa.La planificación implica trazar un plan constituído por pasos sucesivos para resolver el problema. A grandes rasgos, estos pasos deben incluir la formulación adecuada del problema (para tener claro qué es lo que requiere una solución), la especificación de los medios para recolectar, seleccionar, comparar e interpretar la información -necesaria para resolver el problema-, de la forma más sencilla, breve y económica posible. Decía Pedro Laín Entralgo: "el buen investigador ha de tener a la vez ideas nuevas, buena información y buena técnica de trabajo. A los malos investigadores les falta siempre uno por lo menos de esos tres requisitos". El autor pensaba en la investigación científica, pero sus requisitos son igualmente aplicables a cualquier otro tipo de investigación, por más cotidiana e intrascendente que pueda ser.Como dijimos, la investigación implica entre otras cosas saber seleccionar la información pertinente, y buscarla en la forma más sencilla posible.Así, seleccionamos aquella información que juzgamos atingente o pertinente al problema. Si mi problema es encontrar el botón que perdí, información no pertinente será por ejemplo la cantidad de satélites de Júpiter, e información pertinente será qué clase de objetos hay detrás del sillón.La investigación debe también buscar la sencillez (y hasta la elegancia), cuestión importante porque muchas veces se piensa que una investigación es algo complicado: indudablemente muchas investigaciones son complicadas, pero ello no se debe a que el investigador se proponga deliberadamente sembrar dificultades. Por ejemplo, en una investigación a veces debemos tomar una muestra que ya es representativa con 100 personas. Si tomamos 200 personas estamos complicando innecesariamente la investigación, ya que se nos hace más lenta y más costosa.c) Una relación entre resolución automática y resolución planificada.- Cualquier tipo de investigación, sea del hombre común en su vida o el científico en su laboratorio, implica siempre, como hemos visto, una forma planificada de resolver el problema que la generó. Sin embargo, en el curso de la misma suelen aparecer secundariamente formas automáticas de resolución de problemas. Las investigaciones reales incluyen formas planificadas y formas automáticas de resolución, pero con la importante aclaración que la intención principal de la investigación es la planificación, no la resolución automática.Por ejemplo, la resolución aleatoria puede darse en el curso de una resolución planificada: Pasteur encontró la manera de 'pasteurizar' la leche por azar. Un día sin querer se le cayó el preparado con bacterias patógenas y luego comprobó que habían muerto todas por el brusco cambio de temperatura, consecuencia de esta caída. Esto del azar es un poco relativo, porque, como decía Claude Bernard, el eminente investigador del siglo XIX: quien no sabe lo que busca, no comprenderá lo que encuentra. Esto es importante porque si alguna vez encaramos una investigación, no es raro que resolvamos el problema central o algún problema secundario en forma aleatoria, pero sabremos interpretarlos porque tenemos en mente una investigación planificada en la cual sabemos lo que buscamos.En otro ejemplo menos científico, puede ocurrir que mientras investigamos dónde perdimos los documentos, nos sentamos a pensar y advertimos que lo hemos hecho encima de ellos: intentamos una resolución planificada, pero desembocamos -por azar- en una resolución aleatoria.Del mismo modo, la investigación incluye modos inmediatos y modos rutinarios de resolución de problemas. Mientras un científico investiga, resuelve en forma inmediata el problema de ponerse los anteojos, y resuelve en forma rutinaria muchas de sus actividades, como por ejemplo resolver mediante un algoritmo matemático el nivel de significación estadístico para los resultados de un experimento, tanto que incluso deja que se encargue de la tarea una computadora.
4) Finalidad.- La definición, por último, hace alusión a una finalidad. Toda investigación es una actividad humana intencional, y persigue siempre un propósito específico, más allá del fin genérico que es resolver un problema. La diversidad de finalidades es lo que nos dará la diversidad de investigaciones, es decir, los diferentes tipos de investigación. Veamos algunos ejemplos.
2. TIPOS DE INVESTIGACIÓN
La cantidad de tipos de investigación que se pueden hacer es prácticamente infinita. Vamos a recorrer solamente algunos ejemplos representativos.
1) La investigación cotidiana.- La investigación es un proceso que se infiltra e muchas de nuestras actividades diarias: investigamos cuando estudiamos, cuando jugamos, cuando aprendemos algo, cuando vamos a un boliche bailable a 'investigar', cuando 'investigamos' al vecino, etc. La investigación es una actividad que suele infiltrarse dentro de otras actividades. Por lo tanto, no se necesita ser un científico para ser un investigador.Las investigaciones cotidianas son aquellas que realizamos todos los días, y en este sentido amplio, todos somos investigadores. Si yo llego a mi casa y me encuentro con que perdí los documentos, voy a iniciar una investigación para encontrarlos. Están aquí todos los elementos de una investigación: hay un problema (perdí los documentos), hay una finalidad (quiero encontrarlos) y hay un intento por solucionar el problema en forma planificada: empiezo a averiguar en todos los lugares donde estuve, pregunto por teléfono, dejo dicho que si los encuentran me avisen, etc., etc.
Página 89 de 314
89

2) La investigación infantil.- No se trata de la investigación que podemos hacer nosotros como psicólogos 'sobre' el niño, sino de las investigaciones hechas 'por' el niño cuando indaga la realidad para satisfacer su natural curiosidad o para adaptarse mejor a ella. El niño es, no cabe duda, un investigador nato, y esto ya lo destacaron pensadores como Piaget y Freud.Para Piaget el niño es un verdadero investigador de la realidad: ya desde muy pequeño debe enfrentar problemas, los intenta resolver y lo hace en forma planificada con un fin: la adaptación. No es la planificación de un adulto, pero es también planificación porque el niño, a su manera y en su nivel, también se organiza y al mismo tiempo gracias a ello también va organizando su actividad del mundo y su conocimiento de éste.Freud también habla de los niños investigadores al hablar de la 'investigación sexual infantil', es decir, cuando indagan su sexualidad elaborando y poniendo a prueba sus teorías sexuales infantiles. Freud no dice 'creencias infantiles' sino 'teorías infantiles'. Si el niño tuviese simplemente creencias, creería dogmáticamente en ellas y por tanto ni se preocuparía por iniciar una investigación. Lo que el niño arma son teorías, es decir, hipótesis, suposiciones y, como tales, se preocupará por ponerlas a prueba. Por ejemplo, no acepta sin más la teoría de la castración: necesita verificarla, por ejemplo, espiando a la hermanita a ver si es cierto que a las mujeres le cortaron el pito o no. Esto implica hacer una investigación. Desde ya, un niño de cinco años no necesita dominar el pensamiento hipotético-deductivo del que habla Piaget para hacer investigaciones: ni sus hipótesis ni sus procedimientos para verificarla están tan formalizados como en el adolescente, pero esto no le impide investigar y considerar a sus ideas como entidades que han de ser comprobadas en la realidad.
3) Otros tipos de investigación.- Encontramos también investigaciones periodísticas (donde el problema puede residir en averiguar qué individuos se dedican a la corrupción en el gobierno), investigaciones administrativas (donde el problema puede residir en averiguar qué funcionario fue el responsable de tal o cual acto administrativo), investigaciones criminales (como averiguar quién es el asesino), investigaciones judiciales (como resolver la imputabilidad o no de un acusado en el fuero penal, o la magnitud de la pena, etc.), investigaciones de mercado (el llamado 'marketing', para detectar perfiles de clientes potenciales), investigaciones literarias, filosóficas, científicas, etc.
Desde ya, el hecho de llamar 'investigaciones' a tanta diversidad de actividades humanas obedece a que tienen ciertos caracteres en común, caracteres que hemos resumido en nuestra definición general. Por algo Irving Copi (1974:493) traza una interesante analogía entre la investigación científica y la investigación policial que llevó a cabo Sherlock Holmes en uno de los cuentos de Conan Doyle. Y por algo Sigmund Freud traza también un paralelismo entre la investigación analítica y la investigación judicial (Freud S, 1906).
3. LA INVESTIGACIÓN CIENTÍFICA
Este tipo de investigación debe definírsela por su finalidad y por su método al mismo tiempo: la investigación científica se caracteriza por buscar un conocimiento cada vez más general, amplio y profundo de la realidad aplicando el llamado método científico. Este último se caracteriza porque es fáctico, trasciende los hechos, se atiene a reglas, utiliza la verificación empírica, es autocorrectivo y progresivo, presenta formulaciones generales, y es objetivo (Ander-Egg E, 1987:43). El producto final de la aplicación del método científico es la ciencia, definida como “un conjunto de conocimientos racionales, ciertos o probables, que obtenidos de manera metódica y verificados en su contrastación con la realidad se sistematizan orgánicamente haciendo referencia a objetos de una misma naturaleza, cuyos contenidos son susceptibles de ser transmitidos” (Ander-Egg E, 1987:33).En suma, la investigación científica es “un procedimiento reflexivo, sistemático, controlado y crítico que tiene por finalidad descubrir o interpretar los hechos y los fenómenos, relaciones y leyes de un determinado ámbito de la realidad” (Ander-Egg E, 1987:57).
Es habitual definir la investigación científica como el motor de la ciencia, el seudópodo que extiende el conocimiento hacia regiones desconocidas, o, menos metafóricamente, que es el procedimiento por el cual planteamos y verificamos hipótesis y teorías para que luego, los profesionales puedan aplicarlas exitosamente con una finalidad práctica, y los docentes difundirla a las nuevas generaciones. Sin embargo, las cosas no son tan ideales. Preferimos decir que el conocimiento científico no es de ninguna manera el mejor conocimiento, ni aún tampoco el que ha tenido mayores éxitos en cuanto a resultados prácticos se refiere. Por ejemplo: a) muchos procedimientos terapéuticos no mejoraron y aún empeoraron a los pacientes; b) muchos procedimientos no científicos practicados por curanderos han demostrado ser más eficaces. Como dice Feyerabend, "actualmente la ciencia no es superior a otras ideologías gracias a sus méritos, sino porque el show está montado a su favor".Muchas publicaciones científicas forman parte de ese show, en la medida en que tienden a hipervalorar los procedimientos de investigación científica de la psicología, rescatando en ellos su ajuste a los canones de cientificidad consensualmente reconocidos. Sin embargo, procuramos también no mostrar el método científico ni como infalible ni como el único posible, como así tampoco afirmamos sin más, en el otro extremo, que la ciencia es deleznable. En lugar de ello, intentamos describir y comprender la principal herramienta del investigador, llamada 'método científico', hurgando al mismo tiempo en sus limitaciones y en sus posibilidades.
Etapas.- No siempre los tratadistas del método científico siguen el mismo orden en sus etapas, por lo cual hay diversidad de esquemas. Casi la totalidad están de acuerdo en tres pasos fundamentales: tema, problema, metodología (Kerlinger, Ander Egg, Vandalen y Meyer, Morales, Arias G. Mc Guigan, Castro,
Página 90 de 314
90

Ackoff, Garza, Pozas, Brons, Galtung, Tamayo y Tamayo, Asti, Vera, Parinas, entre otros). Entre los más conocidos tenemos (Tamayo, 1999:170):
Esquema Ackoff a) Planteamiento del problema.b) Marco teórico.c) Hipótesis.d) Diseño.e) Procedimiento de muestreo.
f) Técnica y obtención de datos.g) Guía de trabajo.h) Análisis de los resultados.i) Interpretación de los resultados.j) Publicación de los resultados.
Esquema Pozas a) Planteamiento de la investigación.b) Recolección de datos.
c) Elaboración de los datos.d) Análisis.
Esquema Vázquez-Rivas
a) Planteamiento.b) Levantamiento de datos.
c) Elaboración.d) Análisis.
Esquema Pardinas
a) Teoría.b) Observación.c) Problema.d) Hipótesis.e) Diseño de prueba.
f) Realización del diseño de prueba.g) Conclusiones.h) Bibliografía.i) Notas.j) Cuadros y tablas.
Esquema Brons a) Especificación, delimitación y definición del problema.b) Formulación de la hipótesis.c) Toma, organización, tratamiento y análisis de los datos.d) Conclusiones.e) Confirmación o rechazo de los hijos.f) Presentación del informe.
Esquema Tamayo
a) Elección del tema (planteamiento inicial).b) Formulación de objetivos (generales, específicos)c) Delimitación del tema (alcances y límites, recursos).d) Planteamiento del problema (descripción, elementos, formulación).e) Marco teórico (antecedentes, definición de términos básicos, formulación de hipótesis, operacionalización de variables).f) Metodología (población y muestra, recolección de datos, procesamiento de datos, codificación y tabulación).g) Análisis de la información y conclusiones.h) Presentación del informe de investigación.
Sea cual fuere la secuencia de pasos del método científico, el éxito de cualquier empresa científica depende de tres elementos: “una clara identificación de los objetos a investigar, una teoría imaginativa que explique cómo se relacionan, y una idea precisa de los problemas concretos vinculados con la evidencia y las pruebas más adecuadas al tema de estudio” (Lazarsfeld, 1984:11).
4. EL MÉTODO EN LA INVESTIGACIÓN CIENTÍFICA
En ciertas ocasiones y en el contexto de la actividad científica en sentido amplio (investigación, ejercicio profesional, etc.) resulta importante distinguir métodos de técnicas en términos de la siguiente convención: métodos son procedimientos generales y técnicas son procedimientos específicos aplicados en el marco de un método.Pocas palabras se utilizan de una forma tan diversa y generalizada como 'método' y 'técnica'. Generalizada porque se emplean en todas las artes y todas las ciencias, y diversa porque suelen adjudicárseles significados diferentes. Suelen ser además vocablos que se utilizan sin ser definidos explícitamente, de la misma manera que no nos sentimos obligados a definir la palabra 'ventilador' cuando hablamos de los ventiladores.Hemos de reconocer que muchas veces no es necesario definir los términos 'método' y 'técnica' cuando los empleamos en la vida cotidiana, en las artes o en la ciencia, pero puede resultar importante especificar sus respectivos significados en aquellas ocasiones en las cuales: a) se utilicen ambos términos para describir procedimientos en el contexto de la actividad científica; b) se utilicen ambos términos con sentidos diferentes; y c) cuando sea necesario diferenciarlos si con ello se clarifican aquellos procedimientos.Por empezar, convengamos en que tanto el método como la técnica se refieren a procedimientos para hacer o lograr algo, es decir, son medios orientados hacia un fin. Tal es el sentido que recogen las definiciones lexicográficas a partir de los usos más habituales: "técnica es un conjunto de procedimientos de un arte o ciencia"; "método es el orden que se sigue en las ciencias para investigar y enseñar la verdad" (Diccionario Aristos, 1968).Vamos ahora a la diferencia básica entre método y técnica: un método es un procedimiento general orientado hacia un fin, mientras que las técnicas son diferentes maneras de aplicar el método y, por lo tanto, es un procedimiento más específico que un método. Por ejemplo: hay un método general para asar la carne, aunque pueden usarse diferentes técnicas: a la parrilla, al horno, a la cacerola, con un horno de microondas, etc.Esta distinción entre método y técnica como procedimiento general y específico respectivamente, es la más aceptada y reconocida dentro de la comunidad científica. Greenwood señala, por ejemplo, al hablar de métodos y técnicas de investigación, que "un método puede definirse como un arreglo ordenado, un plan general, una manera de emprender sistemáticamente el estudio de los fenómenos de una cierta disciplina. Una técnica, por el contrario, es la aplicación específica del método y la forma específica en
Página 91 de 314
91

que tal método se ejecuta" (Greenwood, 1973:106). Greenwood hace una analogía diciendo que el método es a la técnica como la estrategia a la táctica, es decir, la técnica está subordinada al método: es un auxiliar de éste.Bunge sigue la misma orientación para distinguir método de técnica, cuando señala por ejemplo que "la ciencia es metodológicamente una a pesar de la pluralidad de sus objetos y de las técnicas correspondientes" (Bunge, 1969:36), o que "la diversidad de las ciencias está de manifiesto en cuanto atendemos a sus objetos y sus técnicas; y se disipa en cuanto se llega al método general que subyace a aquellas técnicas" (Bunge, 1969:38).El mismo autor (1969:24) distingue métodos generales y métodos especiales, y tiende a reservar el nombre de técnicas en relación con estos últimos destacando, de esta forma, el carácter de especificidad de la técnica en relación al método.En suma, para Bunge: "el método científico es la estrategia de la investigación científica: afecta a todo el ciclo completo de investigación y es independiente del tema en estudio. Pero, por otro lado, la ejecución concreta de cada una de esas operaciones estratégicas dependerá del tema en estudio y del estado de nuestro conocimiento respecto a dicho tema. Así, por ejemplo, la determinación de la solubilidad de una sustancia dada en el agua exige una técnica esencialmente diversa de la que se necesita para descubrir el grado de afinidad entre dos especies biológicas" (Bunge, 1969:31).Por tanto, si hemos de respetar la convención precedente, resultará correcto decir "utilicé esta técnica para aplicar este método", y resultará incorrecto decir "utilicé este método para aplicar esta técnica" (aún cuando en esta última expresión se entienda método como un conjunto de pasos para aplicar la técnica).Veamos algunos ejemplos donde cabe hacer distinciones entre método y técnica:Ejemplo 1: psicoterapia.- Hay un método general para curar a un paciente: escuchar su problema, intervenir terapéuticamente, verificar la cura, etc. A partir de este procedimiento genérico, cada terapeuta instrumentará diferentes técnicas (las que dependerían del marco teórico que utilice, de sus preferencias personales, de su adecuación al paciente y al problema, etc.). Por ejemplo la técnica de la prescripción del síntoma, la técnica de la asociación libre, la técnica de la desensibilización sistemática, la técnica Phillips 66 para terapia grupal, la técnica de la interpretación onírica, la hipnosis, etc.Ejemplo 2: matemáticas.- Hay un método general para realizar una operación de suma, que básicamente consiste en relacionar dos o más elementos llamados sumandos y generar un tercero llamado resultado. Para ello pueden utilizarse diferentes procedimientos llamados técnicas: sumar mentalmente, sumar con una calculadora, sumar con los dedos, sumar con un ábaco, etc., y hasta pedirle a otra persona que haga la suma por uno. Suelen denominarse algoritmos a cada una de estas formas diferentes de realizar un cálculo.Ejemplo 3: metodología de la investigación.- Dentro del método general de recolección de datos, se pueden utilizar diferentes técnicas: la entrevista, el cuestionario, el test, la observación, etc. También, dentro del método de muestreo hay diferentes técnicas: el muestro estratificado, el muestreo por conglomerados, etc.Ejemplo 4: ciencias naturales.- En astronomía, dentro del método general de observación de los astros, se pueden implementar diferentes técnicas: utilizar un telescopio reflector, un radiotelescopio, etc. En biología, dentro del método general de observación microscópica, puede usarse la técnica del microscopio óptico, la del microscopio electrónico, etc.Así como dentro de un mismo método se pueden usar técnicas diferentes, también dentro de diferentes métodos se pueden usar las mismas técnicas. Por ejemplo, la técnica de los tests se puede usar dentro de un método para diagnosticar (en la clínica) o en el contexto de un método para verificar una hipótesis (en la investigación). De la misma manera, la técnica del horno de microondas puede ser utilizada dentro del método general para asar carne, o también dentro del método general para llevarle la contra a mi suegra (por cuanto a ella no le gusta que la comida se haga en esa clase de artefactos).Una técnica inadecuada puede arruinar un buen método, y, alternativamente, un mal método puede echar a perder una buena técnica. Por ejemplo, la observación participante es una buena técnica, pero si con ella se procurar verificar experimentalmente una hipótesis, se arruina el método experimental y se desaprovecha la técnica El fin de la técnica debe ser congruente con el fin del método dentro del cual se utiliza.Esta última cuestión tiene relación con la eficiencia y la eficacia de la técnica. Decimos que alguien es eficiente cuando hace bien las cosas, y que es eficaz cuando consigue lo que se propone, es decir, la eficiencia tiene que ver con los medios, y la eficacia con los fines. Considerando estas diferencias, podemos decir que tanto los métodos como las técnicas pueden ser eficientes y eficaces: eficientes si están bien aplicados, y eficaces si alcanzan el fin que se propusieron. Como hemos dicho antes, una técnica puede ser eficiente pero no eficaz, es decir, puede estar bien usada pero ser irrelevante respecto del fin general del método donde está inscripta.Por último, resulta importante destacar que si el método alude a un procedimiento general y la técnica a uno específico, forzosamente habrán de ser términos relativos. Por ejemplo, un mismo procedimiento podrá ser considerado general en relación a otro más específico, o viceversa. Así, la hipnosis es una técnica si lo inscribimos dentro del método terapéutico, pero será un método si intentamos discriminar diferentes formas de hipnotizar (con la mano, con un objeto pendular, con un casete subliminal, etc.) las que, entonces, habremos de considerar técnicas.De la misma forma, la técnica del microscopio óptico es tal en relación al método general de observación de células, pero es un método en relación con las diferentes maneras de implementarlo: la técnica de la hematoxilina-eosina, etc.
Página 92 de 314
92

5. EL ENCUADRE EN LA INVESTIGACIÓN CIENTÍFICA
Entre otras funciones, el encuadre es un sistema de reglas que nos suministra, tanto en la clínica como en la investigación, un telón de fondo fijo o constante que nos permite detectar con facilidad las posibles variaciones en aquellos aspectos de la situación que pueden interesarnos.
Una mosca viajera.- ¿Dónde podemos detectar mejor una mosca caminando? ¿Cuándo camina sobre una pantalla donde están proyectando una película, o cuando camina sobre un cuadro colgado de la pared? Evidentemente podremos ver con mayor facilidad el desplazamiento de la mosca sobre un cuadro porque éste, al ser estático, permite visualizar más fácilmente cualquier cosa que se mueva. En una pantalla, en cambio, el movimiento de las imágenes nos dificulta ver el movimiento de la mosca, porque... todo se está moviendo.Hasta aquí, podemos ir sacando la siguiente conclusión: si yo quiero detectar variaciones (como el desplazamiento de una mosca), tengo que contar con un fondo fijo y constante (como por ejemplo un cuadro), es decir, tengo que hacer un 'encuadre' (poner en un cuadro).En las situaciones clínicas e investigativas trabajamos con variables, es decir, con atributos del sujeto que se supone que variarán. Y para detectar esas variaciones de las variables deberé armar un fondo de constancia y fijeza, llamado encuadre. Se trata de una de las funciones del encuadre, y para comprenderla mejor veamos algunos ejemplos.
Encuadre psicoterapéutico.- Imaginemos que con nuestro paciente no establecemos ningún encuadre definido: quedamos en que él puede venir cuando se le antoja, a la hora que quiera, nosotros podemos o no atenderlo ese día según nuestras ganas, pudiéndolo hacer en la cocina o en el garaje. Y encima de todo, nuestro paciente puede pagarnos lo que él quiera y cuando quiera. Tampoco establecemos las reglas de juego dentro de la sesión: si quiere asociar libremente que lo haga, y si no, no. Por nuestra parte, mientras tanto tenemos derecho a hacernos una siesta o mirar el programa de Tinelli por la televisión.En este contexto no podemos evaluar, por ejemplo, variables importantes como son las resistencias o las transferencias del paciente. No podremos saber si llegó tarde porque no hay encuadre o porque tiene resistencias, como así también será difícil saber si nuestra paciente se quita la blusa en nuestra cocina por una falta de encuadre o por una intensificación de la transferencia positiva, otra variable indispensable en el tratamiento analítico.En cambio, procedamos ahora a establecer un encuadre: fijamos reglas como horarios definidos, comportamientos en la sesión, honorarios, etc. Cuando todo esto se mantiene constante o fijo, cualquier variación en la resistencia o en la transferencia será inmediatamente detectada. Por ejemplo, si tras haber fijado un encuadre determinado, la paciente se quita la blusa, es decir, no respeta cierta regla del encuadre, entonces no habremos de pensar que falta un encuadre, sino que la transferencia positiva se ha manifestado. En cuanto a las resistencias, una medida de esta puede darla la magnitud de las violaciones al encuadre: y si no hay encuadre, resultará más difícil evaluar la resistencia. O para decirlo en otras palabras: si no creamos como fondo un marco de conductas esperables, nos resultará más difícil identificar conductas inesperadas o llamativas, y es así que un psicótico puede pasar mucho más desapercibido en una murga que en un grupo de estudio, donde el encuadre es menos flexible o permisivo.
El encuadre en psicoanálisis.- Señala Freud en la Conferencia 28, que “la cura analítica impone al médico y enfermo un difícil trabajo que es preciso realizar para cancelar unas resistencias internas”. Pero este trabajo al que Freud se refiere, para ser fructífero, debe realizarse bajo determinados condiciones, que implican ‘obligaciones’ que debe cumplir el analista (abstinencia, etc.), el paciente (asociar libremente, etc.) y ambos en un contrato que establece tiempo, honorarios, cantidad de sesiones, y que contribuyen a garantizar que dicho trabajo se realizará sin mayores obstáculos.Un ejemplo de situación que puede amenazar este encuadre pactado entre paciente y analista es la intromisión de la familia del primero. Freud, en la Conferencia 28 más adelante, ofrece un ejemplo de una mujer a quien tuvo ocasión de tratar, pero el encuadre fue afectado por la intromisión de su madre, y el tratamiento no pudo proseguir: “la madre tomó rápidamente su decisión: puso fin al dañino tratamiento”. Esto viola el encuadre porque la paciente ya no está en condiciones de pactar libremente con el analista un conjunto de obligaciones que son las que permitirán el análisis.Otros ejemplos los suministra Freud en sus artículos sobre la transferencia, donde la paciente se enamora del analista y, lejos de interpretarse esta situación como transferencial, analista y paciente se convierten en amantes violando el primero la regla de la abstinencia, una de las reglas del encuadre.Dentro del encuadre está contemplado por ejemplo el tiempo y el dinero. Indica Freud que debe darse al paciente una hora determinada, que le pertenece por completo, y paga por ella aunque no la use. De otro modo puede empezar a aprovechar para faltar, lo cual pone de manifiesto la importancia del encuadre para el tratamiento. Sólo en casos extremos, como alguna enfermedad orgánica, podemos suspender momentáneamente esta regla.En casos leves pueden bastar tres horas semanales: si son más espaciadas cuesta más seguir la vida actual del paciente, con riesgo para la cura, lo cual destaca nuevamente la importancia del encuadre para el tratamiento.El encuadre también debe incluir honorarios. Freud reconoce haber hecho tratamientos gratuitos con el fin de eliminar toda fuente de resistencia, pero tal actitud no fue beneficiosa, pues la gratuidad intensifica mucho algunas resistencias del neurótico: en las mujeres, por ejemplo la tentación implicada en la transferencia, y en hombres jóvenes, la rebeldía contra el deber de gratitud, vinculada al complejo del padre. La ausencia de honorarios hace perder la relación entre médico y paciente todo carácter oral, quedando éste privado de un motivo principal para la cura.
Página 93 de 314
93

El tratamiento analítico moviliza la energía preparada para la transferencia para luchar contra las resistencias, y muestra al paciente los caminos para canalizarla. Un encuadre adecuado permite cumplir con estas tareas.
En el caso de investigaciones que indagan la eficacia de tratamientos, está descontada entonces la importancia de fijar un mismo encuadre en todos los casos, para que influyan lo menos posibles las variables extrañas ajenas al tratamiento.
Encuadre experimental.- El experimento es un procedimiento incluido en las investigaciones científicas típicas. Aunque no es tan habitual denominarlo encuadre, también en una situación experimental existe la necesidad de crear un telón de fondo constante para poder identificar, por contraste, la variación de las variables. O'neil ha definido un experimento como un modelo particular de variación y constancia con lo cual quería decir que un experimento consiste en hacer variar una variable para ver como varía otra, pero manteniendo todos los demás factores constantes.Si quiero saber si influye o no la música funcional sobre el rendimiento de los empleados, haré variar la variable música funcional y veré si hay una variación concomitante en los rendimientos, pero para ello tuve que mantener constantes otras variables que podrían también haber influido en el rendimiento, como el salario. Si en el medio del experimento aumento todos los sueldos, no podré saber si la variación en los rendimientos obedece al salario o al cambio en la música funcional.
Encuadre psicodiagnóstico.- Otro ejemplo de encuadre en el contexto de la metodología de la investigación es el referido al empleo de los instrumentos de medición. La toma de un test puede realizarse con fines clínicos, laborales, forenses, etc., pero también con fines de investigación del test mismo, como por ejemplo cuando la prueba en cuestión está recién inventada y atraviesa aún un periodo de prueba donde constataremos su validez y su confiabilidad. Puede también servir a fines puramente estadísticos, como cuando queremos determinar la media de cociente intelectual de una población dada, o a fines de investigación pura, como cuando queremos verificar la hipótesis según la cual los tiempos de reacción a una consigna son directamente proporcionales a la ansiedad, con el fin de obtener una ley general del funcionamiento psíquico.En cualquiera de los casos indicados es preciso también un encuadre. Por ejemplo, forma parte del encuadre la manera de administrar la consigna, que debe ser siempre la misma. No es lo mismo decir "dibuje SU familia" a decir "dibuje UNA familia", o a decir "Dibuje su familia haciendo algo". Si a todas las personas a quienes le tomo el mismo test le administro consignas diferentes, no podré contar con un mismo patrón para comparar sus respectivas respuestas. Una misma consigna para todos permite, en efecto, asegurarnos de que las variaciones en las respuestas responderán a variaciones individuales de los sujetos, y no a variaciones en las consignas. ¿Porqué? Porque lo que nos interesa es precisamente la variabilidad individual, es decir, aquello que es propio de cada persona.También forma parte del encuadre del proceso psicodiagnóstico el comportamiento del psicólogo durante la toma. Si en el medio de una administración yo empiezo a comportarme en forma rígida y autoritaria o de manera excesivamente permisiva y familiar, no sabré si las nuevas respuestas del sujeto derivan de su peculiar funcionamiento psíquico frente a las consignas de los tests, o de mis nuevos comportamientos.Desde ya, yo puedo inventar un nuevo encuadre donde en el medio de la toma cambio ex profeso mi comportamiento, pero en este caso deberé aplicar el mismo encuadre en todas las tomas y recién entonces podré comparar, sobre este fondo constante, la variabilidad inter- individual.
Otras funciones del encuadre.- Siempre nos manejamos con encuadres, aún en la vida cotidiana: este encuadre son las reglas de convivencia. Es esperable que cuando llamamos por teléfono a alguien nos diga "Hola", y es esperable que cuando dos personas se presentan se extiendan la mano. En este marco de conductas predecibles, cualquier anomalía, cualquier variación será inmediatamente detectada, cosa que no sucede cuando no hay reglas y cualquier cosa puede esperarse de cualquiera en cualquier momento.En estos casos, las funciones del encuadre social son variadas: puede servir para regular y tornar predecible el comportamiento ajeno ("no tengo que temer al otro si me acerco a saludarlo, pues estoy casi seguro que responderá mi saludo amistosamente"), para identificarse con un grupo de pertenencia ("Yo te saludo dándote la mano porque somos de la misma cultura"), etc., etc.Pero fuera de estos encuadres socialmente instituidos, hemos mencionado otros encuadres ad hoc (o sea, construidos especialmente para ciertas situaciones especiales), como el terapéutico y el psicodiagnóstico. Tales encuadres suelen tener además otras funciones, entre las cuales podemos citar dos como ejemplo. Una primera función del encuadre es la de proveer un marco disciplinario que otorgue seriedad y obligue a un compromiso con la tarea. Si decimos a un paciente que venga cuando quiera, la tarea terapéutica puede perder importancia a su consideración, es decir, puede pensar que la cura es una joda. Otras veces un encuadre, y sobre todo si es menos flexible, servirá como metamensaje para aquellos pacientes que no les gusta someterse a ninguna disciplina y que necesitan alguien que les ponga límites, o para aquellos otros que consideran que pueden controlar el tratamiento introduciendo las variaciones que se les antoje en las reglas del encuadre.Una segunda función es el hecho de que un encuadre contribuye a que tanto paciente como terapeuta puedan organizarse la vida racionalmente. En general, todas nuestras actividades cotidianas están regladas en cuanto a horarios, días, etc. aún las que pueden parecer más espontáneas como la planificación del tiempo libre. Si no establecemos ningún encuadre en un tratamiento y nuestro paciente
Página 94 de 314
94

puede venir cuando se le antoja, deberemos estar todo el día esperando al paciente por las dudas que se le ocurra aparecer, y mientras tanto nosotros no podremos hacer ninguna otra actividad. O bien si la hacemos, el paciente nunca estará seguro de encontrarnos cuando venga a visitarnos.
6. LA FORMACIÓN DEL INVESTIGADOR CIENTÍFICO
La actividad científica es una empresa que tiene tres protagonistas principales: el investigador, el docente y el profesional. Mientras el primero desarrolla hipótesis, las pone a prueba y construye teorías, el docente transmite este conocimiento a los futuros profesionales, quienes lo aplicarán con un fin práctico.Existen carreras para ser profesional (todas las carreras de grado como Medicina, Psicología, Ingeniería, Derecho, Agronomía, etc.). Existen también carreras para ser Profesor (los Profesorados), pero no han sido desarrolladas con la misma atención y dedicación las carreras para ser Investigador.Conviene hacer una diferencia entre una carrera, o una maestría de Investigador Científico y un Doctorado, tal como estos últimos se implementan en las Universidades, habida cuenta que en estos últimos existen asignaturas vinculadas con la Metodología de la Investigación, y hay además que presentar un trabajo de investigación como tesis.1°) Un Doctorado incluye asignaturas propias de la carrera de origen, y por lo tanto todos los alumnos están graduados en la misma disciplina. En cambio, en una maestría de Investigador Científico todas las asignaturas están relacionadas con la investigación, sea cual fuere esta, y por lo tanto será posible encontrar entre sus alumnos una diversidad de profesiones distintas o diferentes intereses disciplinares.2°) En un Doctorado suele no privilegiarse la enseñanza práctica de la investigación. Para hacer la tesis, los alumnos deben recurrir o bien a terceros, o bien a un padrino de tesis que tenga la buena voluntad de asistirlo. En cambio, en una carrera de investigador científico el objetivo fundamental es formar investigadores, sea cual fuese la disciplina que dominen, y, en última instancia, profesionalizar esta actividad. Los docentes comparten así más la responsabilidad de la formación de sus alumnos, los futuros investigadores.La Maestría de Investigación Científica que proponemos puede cumplirse en dos años, con un título intermedio de Auxiliar en Investigación Científico al año, y de Investigador Científico al finalizar los estudios.Como requisitos de ingreso, puede considerarse la posibilidad de tomar dos exámenes, donde se evaluarán:a) Conocimientos de computación (Entorno Windows, Aplicaciones Word, Access y Excel o equivalentes, y búsqueda bibliográfica vía Internet). Quienes no dominen estos temas, pueden cursar una asignatura de Informática antes del comienzo del año lectivo de la carrera o al menos durante el primer año de la misma.b) Formación intelectual: no son pruebas psicométricas en el sentido tradicional, donde se evalúe el cociente intelectual, ni tampoco un examen de conocimientos generales, sino pruebas de manejo de situaciones e ideas. Generalmente, quienes más posibilidades tienen de pasar esta prueba son aquellos que tienen un título de grado, es decir, una formación científica previa. No se trata, entonces, de un examen para el cual haya que 'prepararse' en base a un programa, ya que lo que evalúa es la educación del pensamiento gestada a lo largo de los años, incluso desde la infancia y la adolescencia. El principal objetivo de esta evaluación es averiguar si la persona tiene dotes naturales mínimas para la investigación: curiosidad, espíritu crítico, disciplina intelectual, creatividad, disposición para incorporar nuevas maneras de pensar, etc.
Exponemos seguidamente los lineamientos generales de un proyecto de Plan de Estudios para una Maestría de Investigador Científico, que contempla una duración de dos años y la posibilidad de obtener un título intermedio de Auxiliar. La inquietud apunta a la posibilidad de profesionalizar una actividad que, hoy por hoy, suele ejercerse a fuerza de experiencia, intuición y autoaprendizaje.En el siguiente recuadro se indica un sistema tentativo de materias, distribuidas en cuatro cuatrimestres. A continuación, damos algunas especificaciones sobre sus contenidos.
MAESTRIA EN INVESTIGACION CIENTIFICA: ASIGNATURAS
PRIMER CUATRIMESTREIntroducción a la Investigación CientíficaInvestigación BibliográficaEstadística DescriptivaSEGUNDO CUATRIMESTREInvestigación Empírica I (Campo)Estadística InferencialTeoría de la Medición
TERCER CUATRIMESTREInvestigación Empírica II (Experimental)Investigación TeóricaModelos Elucidatorios y HeurísticosCUARTO CUATRIMESTREModelos FormalesCorrientes EpistemológicasHistoria de la Investigación científica
a) Introducción a la Investigación Científica: Asignatura que presenta e introduce en el plan de estudios de la maestría, explicando los lineamientos generales de la investigación. La materia intentaría resumir todo lo que se verá en los dos años, para que el alumno pueda tener una visión global de los temas que irá viendo después.b) Investigación Bibliográfica: Habitualmente, toda investigación comienza con una búsqueda bibliográfica de información sobre el tema que se quiere investigar ('review'), lo que incluye no solamente buscar y seleccionar ideas de otros pensadores, sino también las propias. A partir de esta investigación
Página 95 de 314
95

bibliográfica, la indagación podrá continuar con una investigación teórica, con una investigación empírica de campo o con una investigación empírica experimental, tres posibilidades contempladas en asignaturas subsiguientes.c) Investigación Empírica I (Campo): Paralelamente a la explicación de conceptos teóricos (problema, hipótesis, ley, teoría) y de conceptos básicos sobre investigación de campo, los alumnos llevarán a cabo bajo supervisión docente un trabajo de investigación de campo.d) Investigación Empírica II (Experimental): Junto al desarrollo de conceptos teóricos (explicación, predicción, acción tecnológica, observación, teoría del diseño experimental, inferencia científica), los alumnos realizarán una investigación experimental bajo supervisión docente. Los conceptos teóricos indicados para esta asignatura y para la anterior no necesariamente tienen relación con las investigaciones experimentales o de campo, respectivamente. Mas bien los hemos distribuido en ambas materias porque todos ellos no pueden ser vistos en una sola. Los conceptos seleccionados siguieron el plan del texto de M. Bunge, "La investigación científica: su estrategia y su filosofía" (Barcelona, Ariel, 1971). Esta obra está diseñada para cursos, e incluye un panorama muy completo de la investigación científica, por lo que puede servir como bibliografía de referencia básica a lo largo de toda la carrera. Incluye también más de 500 problemas para resolver como práctica.e) Investigación teórica: Mientras la investigación empírica confronta ideas con la realidad, la investigación teórica confronta ideas entre sí en un nivel de abstracción mayor. En esta asignatura puede también incluirse la cuestión acerca de cómo organizar y redactar un informe o un artículo científico (temática que también se aplica en relación con las investigaciones bibliográficas y empíricas).f) Corrientes Epistemológicas: Abarca la historia de la epistemología desde los Segundos Analíticos del Organon aristotélico, hasta un análisis detallado de las corrientes contemporáneas: Husserl, Bachelard, Piaget, Hempel, Carnap, Reichenbach, Popper, Feyerabend, Lakatos, Kuhn, etc. Como bibliografía de referencia puede utilizarse: Losee J., "Introducción histórica a la filosofía de la ciencia", Madrid, Alianza, 1972, así como textos clásicos: los "Segundos Analíticos" del "Organon" de Aristóteles, Kuhn T., "La estructura de las revoluciones científicas", Feyerabend P., "Tratado contra el método", Bachelard G., "La formación del espíritu científico", "Popper K., "La lógica de la investigación científica" y "El desarrollo del conocimiento científico", etc.g) Teoría de la medición: Tomando como referencia los niveles de medición de Stevens (1948), esta asignatura explica qué significa medir, qué es un instrumento de medición y cuáles son sus diferencias y semejanzas con un instrumento de observación; los requisitos de tales instrumentos, tales como la validez y la confiabilidad; y una explicación detallada de las propiedades matemáticas de cada nivel de medición. Asimismo, se podrán examinar los problemas particulares de medición que presenta cada tipo de ciencia.h) Modelos Elucidatorios y Heurísticos: Los modelos elucidatorios proveen un marco para aprender a definir. Ellos son, por ejemplo, el fenomenológico, basado en la epistemología husserliana, y el empírico, basado en la epistemología neopositivista. Los modelos heurísticos proveen marcos de referencia para el desarrollo de la creatividad, como por ejemplo los modelos estructural, dialéctico, hermenéutico, y los modelos visuales analógicos (simulación computarizada, etc.). Los modelos elucidatorios detienen el pensamiento fijándolo en definiciones, mientras que los modelos heurísticos estimulan el movimiento de las ideas, son más dinámicos. Los primeros aíslan ideas, los segundos las relacionan.i) Modelos Formales: Provee marcos de referencia para la construcción de modelos, teorías y esquemas de planificación en investigación científica. Teoría de Conjuntos, Teoría de la Probabilidad, Teoría de los Juegos, Teoría de la Información, Cibernética, Lógica formal, Teoría General de los Sistemas, Modelos Inferenciales en la Ciencia, Camino Crítico, Modelos Estocásticos, Modelos Aleatorios, etc.j) Historia de la Investigación científica: Aborda un enfoque particular dentro de la historia de la ciencia, a saber, deteniéndose en la descripción y análisis de las investigaciones más sobresalientes de la historia del conocimiento: Galileo, Harvey, Mendel, Maxwell, Freud, etc.Según la teoría del aprendizaje social de Bandura, es posible aprender a investigar observando cómo los demás lo hicieron, y no leyendo un artículo que resume los resultados de una investigación, ya que en éste último no suelen figurar las marchas, contramarchas, obstáculos y vacilaciones que inevitablemente están siempre presentes en cualquier emprendimiento científico. Se procura que el alumno se lleve una imagen real, y no ideal, de la investigación.k) Estadística descriptiva e Inferencial: Incluye los contenidos típicos de la asignatura homónima de carreras universitarias como Psicología, Sociología, Economía, etc., sólo que vistos desde el punto de vista que puede interesar al investigador, es decir, principalmente como herramienta para establecer el grado de confianza de las conclusiones obtenidas en experimentos. Se puede hacer hincapié en el estudio de variables temporales y aleatorias, así como en el análisis de correlación y regresión y en las pruebas de significación, herramientas de uso frecuente en las investigaciones.
Página 96 de 314
96

CAPÍTULO 7: TIPOS DE INVESTIGACIÓN CIENTÍFICA
Diversas clasificaciones se han propuesto para construir o contribuir a una taxonomía de la investigación científica. En el presente capítulo se pasa revista a algunas de ellas, de amplia difusión, que han utilizado diversos criterios tales como el objetivo o propósito de la investigación: a) investigaciones pura, aplicada, profesional; b) investigaciones exploratoria, descriptiva, correlacional y explicativa; c) investigaciones teórica y empírica; d) investigaciones cualitativa y cuantitativa; y e) investigaciones primaria y bibliográfica.
1. INVESTIGACIÓN PURA, APLICADA Y PROFESIONAL
La investigación científica pura tiene como finalidad ampliar y profundizar el conocimiento de la realidad; la investigación científica aplicada se propone transformar ese conocimiento 'puro' en conocimiento utilizable; la investigación profesional suele emplear ambos tipos de conocimiento para intervenir en la realidad y resolver un problema puntual.Lo que habitualmente se llama investigación científica engloba solamente las dos primeras, en la medida en que ellas buscan obtener un conocimiento general, y no meramente casuístico, ya que la investigación pura (o básica) busca ampliar y profundizar el conocimiento de la realidad.
Ejemplo 1) En psicología, la investigación pura investiga el mecanismo de la proyección. La investigación aplicada busca, utilizando como marco teórico el conocimiento puro, un saber general que pueda utilizarse prácticamente. Por ejemplo, investigar alguna técnica de diagnóstico sobre la base del concepto freudiano de proyección, como podría ser un test proyectivo. Finalmente, la investigación profesional consiste en intervenir en la realidad. Por ejemplo, diagnosticar una situación usando la técnica proyectiva descubierta y validada en la investigación aplicada.Ejemplo 2) Un bioquímico estudia en su laboratorio la estructura molecular de ciertas sustancias (investigación pura); luego, otro investigador utiliza este conocimiento para probar la eficacia de ciertas sustancias como medicamentos (investigación aplicada); finalmente, el profesional hará un estudio para determinar si a su paciente puede o no administrarle el medicamento descubierto (investigación profesional).Ejemplo 3) Los matemáticos desarrollan una teoría de la probabilidad y el azar (investigación pura); luego, sobre esta base, los especialistas en diseño experimental y en estadística investigan diversos tipos de diseños experimentales y pruebas estadísticas (investigación aplicada); finalmente, un investigador indagará la forma de utilizar o adaptar estos diseños y pruebas a la investigación concreta que en ese momento esté realizando (investigación profesional).Ejemplo 4) Los antropólogos estudian el problema de la transculturación y su influencia en el aprendizaje escolar de niños que llegan a una nueva cultura (tales problemas suelen provenir, por ejemplo, cuando un maestro argentino enseña a un niño que viene de una cultura diferente, donde no coincide la lógica de la enseñanza con la lógica de apropiación del conocimiento idiosincrásica del niño, o sea, no coinciden la forma de enseñar con la de aprender). Un investigador aplicado diseña técnicas especiales para enseñar a estos niños facilitándoles el aprendizaje, y un profesional investiga la forma de aplicarlas a ese caso particular.
Investigación pura Investigación aplicada Investigación profesionalQué busca Busca el conocimiento por
el conocimiento mismo.Busca recursos de aplicación del conocimiento obtenido en la investigación pura.
Busca intervenir en la realidad utilizando los resultados de los otros dos tipos de investigación.
Qué hace Generaliza. Generaliza. Singulariza.
Diferencias más específicas
"Se realiza con el propósito de acrecentar los conocimientos teóricospara el progreso de una determinada ciencia, sin interesarsedirectamente en sus posibles aplicaciones o consecuencias prácticas;es más formal y persigue propósito teóricos en el sentido de aumentarel acervo de conocimientos de una determinada teoría" (Ander-Egg, 1987:68).
Guarda íntima relación con la investigación pura o básica, puesdepende de sus descubrimientos y avances y se enriquece con ellos."Se trata de investigaciones que se caracterizan por su interés en laaplicación, utilización y consecuencias prácticas de los conocimientos"(Ander-Egg, 1987:68).
Utiliza las ideas elaboradas en la investigación aplicada con el fin de resolver un problema singular y concreto.
Ejemplo en psicología
Elaborar una teoría de la personalidad.
Construir un test en base a una teoría de la personalidad.
Investigar un paciente usando un test de personalidad.
Ejemplo en física
Elaborar una teoría de la superconductividad.
Ensayar materiales superconductivos.
Resolver un problema de instalación eléctrica usando
Página 97 de 314
97

superconductores.
1. Investigación pura o básica.- La investigación pura busca el conocimiento por el conocimiento mismo, más allá de sus posibles aplicaciones prácticas. Su objetivo consiste en ampliar y profundizar cada vez nuestro saber de la realidad y, en tanto este saber que se pretende construir es un saber científico, su propósito será el de obtener generalizaciones cada vez mayores (hipótesis, leyes, teorías).Algunos autores ofrecen su propia definición de investigación pura.Para Ander-Egg (1987:68), es la que se realiza con el propósito de acrecentar los conocimientos teóricos para el progreso de una determinada ciencia, sin interesarse en sus posibles aplicaciones o consecuencias prácticas; es más formal y persigue propósitos teóricos en el sentido de aumentar el acervo de conocimientos de una teoría.Para Rubio y Varas, “tiene como finalidad primordial avanzar en el conocimiento de los fenómenos sociales y elaborar, desarrollar o ratificar teorías explicativas, dejando en un segundo plano la aplicación concreta de sus hallazgos. Se llama básica porque sirve de fundamento para cualquier otro tipo de investigación” (Rubio y Varas, 1997:120).Según Tamayo, recibe también el nombre de pura y fundamental. Tiene como fin la búsqueda del progreso científico, mediante el acrecentamiento de los conocimientos teóricos, sin interesarse directamente en sus posibles aplicaciones o consecuencias prácticas; es de orden formal y busca las generalizaciones con vista al desarrollo de una teoría basada en principios y leyes (Tamayo, 1999:129).Afirmar que la simple curiosidad o el placer por conocer cuestiones que suelen carecer de utilidad práctica inmediata, es una motivación frecuente para la investigación pura puede sugerir que se trata de investigaciones inútiles. Luego de haber presenciado como Faraday exponía los resultados de una investigación pura, una señora le preguntó para qué servían todas esas cosas, a lo cual el físico inglés le respondió: “Señora, ¿para qué sirve un niño recién nacido?”.Hacen investigación pura, por ejemplo, un astrofísico que indaga el origen del universo, un psicólogo social que estudia el problema de la discriminación, un psicólogo que estudia el aprendizaje para establecer las leyes que lo rigen, un físico que explora la estructura subatómica de la materia o las vinculaciones de esta con la energía, un biólogo que intenta desentrañar los orígenes de la vida, un geólogo que investiga la estructura interna de la tierra, etc.
2. Investigación aplicada.- La investigación aplicada busca o perfecciona recursos de aplicación del conocimiento ya obtenido mediante la investigación pura, y, por tanto, no busca la verdad, como la investigación pura, sino la utilidad. En otras palabras, se trata aquí de investigar las maneras en que el saber científico producido por la investigación pura puede implementarse o aplicarse en la realidad para obtener un resultado práctico. "En las ciencias aplicadas -nos dice M. Bunge- las teorías son la base de sistemas de reglas que prescriben el curso de la acción práctica óptima" (Bunge, 1969:683).La investigación aplicada guarda íntima relación con la investigación básica “pues depende de los descubrimientos y avances de ella y se enriquece con ellos. Se trata de investigaciones que se caracterizan por su interés en la aplicación, utilización y consecuencias prácticas de los conocimientos” (Ander-Egg, 1987:68).
A modo de ejemplo, pueden mencionarse cuatro maneras distintas cómo la investigación aplicada puede obtener resultados prácticos: materiales, artefactos, técnicas y campos.
a) Materiales.- Utilizando como marco teórico los resultados de la investigación básica, se pueden crear o perfeccionar nuevos materiales o sustancias que tengan alguna utilidad. Por ejemplo un nuevo medicamento, un novedoso material superconductivo que permita conducir la electricidad con el mínimo posible de disipación de calor (lo que redunda en el fin utilitario de ahorrar energía), un novedoso material lo suficientemente inocuo o maleable que como para que pueda reemplazar a la plastilina con que los chicos juegan, etc.
b) Artefactos.- La investigación aplicada busca también inventar o perfeccionar máquinas, un motor de automóvil que gaste menos, nuevas máquinas-herramientas, el detector de mentiras, etc. La rueda fue el resultado de una de las primeras investigaciones aplicadas que realizó el hombre, aún cuando no tuviera bases científicas explícitas en la investigación pura (que en aquella época, por lo demás, no existía).
c) Técnicas.- La investigación aplicada se propone también descubrir nuevas técnicas, o perfeccionar las ya existentes para mejorar su efectividad o adaptarlas a nuevos propósitos. Todas tienen sus alcances y sus limitaciones, y en todos los casos, debemos investigar su validez y su confiabilidad.Las técnicas, que se definen lexicográficamente como conjuntos de procedimientos de un arte o ciencia, pueden clasificarse con arreglo a varios criterios. Por ejemplo encontramos técnicas puramente verbales (vgr. el test desiderativo), y técnicas que emplean materiales (vgr. el test de Rorschach, que utiliza láminas), la técnica de la hora de juego diagnóstica que emplea juguetes, o, fuera de la psicología, la técnica de la hematoxilina (para visualizar estructuras microscópicas, donde se utiliza dicha sustancia).Propondremos aquí, sin embargo, otro criterio especialmente importante. De acuerdo a su finalidad, podemos agruparlas en técnicas de in-put y técnicas de out-put. En efecto, el valor instrumental de una técnica reside en su capacidad para obtener datos de la realidad (in put), o bien en su capacidad para operar sobre ella (out put).
Página 98 de 314
98

Técnicas de in put son, por ejemplo, las técnicas de recolección de datos (entrevistas, cuestionarios, asociación libre, etc.) que son -strictu sensu- también técnicas de medición. Todas estas técnicas sirven para ingresar información acerca de la realidad, y por ello también podremos incluir la técnica del detector de mentiras, del detector de radiactividad, del detector de metales, el empleo del termómetro o el barómetro, la técnica del carbono-14 para averiguar la antigüedad de los fósiles, etc. En psicología, las técnicas de in put son, en general, las llamadas técnicas diagnósticas, como un test, mientras que en didáctica podemos mencionar las técnicas de evaluación del aprendizaje o la enseñanza.Las técnicas de out put tienen como prototipo en psicología las técnicas terapéuticas, porque con ellas pretendemos operar, es decir, producir algún efecto en la realidad, sea para modificarla o mantenerla sin cambios. En didáctica, una técnica audiovisual, por ejemplo, busca producir un cambio en los alumnos, ayudándolos a construir sus objetos de conocimiento, y lo mismo es aplicable a cualquier técnica que sirva para enseñar mejor. En oratoria, las técnicas de persuasión son técnicas de out put, mientras que en ingeniería encontramos por ejemplo las técnicas metalúrgicas y siderúrgicas, que buscan producir un cambio, una transformación en los metales para adaptarlos a usos específicos. En astronomía es difícil encontrar técnicas de out put, puesto que el astrónomo no puede producir cambios en el universo, alterar la órbita de un planeta y hacer estallar un meteorito que se acerca peligrosamente a la tierra. Las técnicas astronómicas son -por ahora- fundamentalmente de in put, es decir, técnicas para ingresar información, para saber más, acerca de los astros.Un ejemplo histórico de investigación de técnicas de out put, y más concretamente de técnicas terapéuticas lo tenemos en Sigmund Freud, cuando sucesivamente fue probando y descartando diversas técnicas, pasando por la hipnosis, por la técnica del apremio hasta llegar, finalmente, a la interpretación.Este último ejemplo viene a mostrarnos que ciertas técnicas pueden funcionar con técnicas de in put y/o como técnicas de out put al mismo tiempo Para Freud, la interpretación era una técnica que le servía tanto para hacer investigación, es decir para incorporar información sobre el funcionamiento del psiquismo (in put), como también para producir un efecto terapéutico en el paciente (out put).Otro ejemplo de técnica mixta es la evaluación mediante un examen final. A primera vista, parecería que tomar examen es una técnica de in put, en cuanto el docente busca ingresar información acerca del desempeño del alumno. Sin embargo, un examen tiene también las características de una técnica de out put, más allá de la intención del docente, por cuanto incide en el aprendizaje: el alumno suele tener, en los exámenes, no sólo la oportunidad de averiguar lo que no sabe, sino también eventualmente la de aprenderlo. Lo mismo sucede con los llamados exámenes a 'libro abierto', que son, en realidad, exámenes a 'cerebro abierto'. Y en particular, cuando se trata del último examen de la carrera, se acentúa aún más su carácter de técnica de out put, en la medida que parece ejercer un efecto constituyente sobre el alumno al convertirlo, en virtud de un mero acto administrativo, nada menos que en un profesional.El hecho de que ciertas técnicas funcionen inevitablemente -y a veces también inadvertidamente- como técnicas de in put y de out put al mismo tiempo, puede originar ciertas dificultades metodológicas. En este sentido, cabe mencionar la influencia de la pre-medida en los diseños experimentales y, más clásicamente, la dificultad metodológica advertida por Heisenberg en su principio de incertidumbre. En su interpretación subjetivista, este principio establece que en toda medición física influye inevitablemente sobre lo observado el observador, lo que significa que, al pretender aplicar una técnica de medición (in put) estamos al mismo tiempo ejerciendo una influencia sobre el fenómeno observado (out put).La importancia de la creación y la revisión de técnicas dentro de la investigación aplicada reside al menos en dos cuestiones: a) Las técnicas de recolección de datos debieran ser hoy más importantes que nunca, ya que estamos en la era de la globalización y la informática, donde la cantidad de información que recibimos es monstruosa. Entre otros, Alvin Toffler advirtió acerca de los peligros que entraña esta situación para el psiquismo; b) muchas de las técnicas de recolección de información que usamos venimos usándolas y arrastrándolas como un mal hábito desde la primaria en nuestra profesión actual. Por ejemplo, el psicólogo que siempre vino usando una técnica obsesiva donde no descuida ningún detalle, seguirá con la técnica obsesiva cuando deba realizar una entrevista. Se hace entonces emprender una investigación aplicada para revisar estas técnicas, cuestionarlas, criticarlas, mejorarlas, examinar sus alcances y sus limitaciones.Inclusive, también pueden inventarse nuevas técnicas que antes jamás habían usado y ponerlas a prueba, como un nuevo test o una nueva técnica de entrevista.Por último, digamos que una manera de examinar críticamente las técnicas consiste en investigar su adecuación con respecto:1) a su finalidad: una técnica que detecta especialmente actos fallidos no sirve cuando la finalidad es tomar apuntes en una clase, pero sí cuando estamos en una entrevista o en una sesión usando un marco teórico psicoanalítico. En otro ejemplo, un test, por ejemplo, es más adecuado a la finalidad diagnóstica, pronóstica o de evaluación de un tratamiento que a la finalidad del tratamiento en sí, porque suponemos que un test no cura pero sí puede diagnosticar, pronosticar o evaluar progresos en un tratamiento;2) al sujeto sobre el que se aplica la técnica: para anotar lo que dice un profesor que habla muy rápido, tal vez lo mejor sea una técnica de grabación, y para un profesor aburrido, la técnica onírica. Y en el ámbito del ejercicio profesional, no podemos administrar el CAT a un adulto porque es un test hecho para niños;3) al sujeto que aplica la técnica: uno va eligiendo o adaptando una técnica también de acuerdo a su idiosincrasia, personalidad o estilo de conducta. No se puede forzar a usar una técnica obsesiva a un histérico. No estamos hablando aquí de patologías, sino de formas de ser, pues todos nosotros somos
Página 99 de 314
99

algo histéricos, algo fóbicos o algo obsesivos, y la cuestión está en poder aprovechar productivamente estas tendencias empleando en la profesión la técnica más útil;4) al marco teórico desde donde estén operando: la técnica tiene también que ser compatible con la teoría que hemos adoptado. Ciertas técnicas psicométricas se adaptan a un marco teórico piagetiano, las técnicas proyectivas son más apropiadas para un marco psicoanalítico, etc. No se trata simplemente de usar la técnica que prescribe la teoría, sino también se puede usar técnicas de otra teoría: lo importante es que no haya incompatibilidad. Por ejemplo, en principio no podríamos usar la técnica conductista de la desensibilización sistemática si estamos en un marco psicoanalítico, porque mientras esa técnica busca eliminar el síntoma, la teoría, al revés, busca mantenerlo para poder analizarlo.
d) Campos.- De lo que aquí se trata es de pensar y ensayar nuevos campos de aplicabilidad del saber puro. Por ejemplo, los principios de la física pueden aplicarse a la aeronáutica, a la construcción de barcos, de ferrocarriles, a la tecnología médica, etc. Si tomamos como ejemplo las disciplinas de la salud, como la psicología, los campos pueden clasificarse por lo menos según tres criterios:a) El campo de la prevención primaria, de la prevención secundaria y el de la terciaria. Un psicopedagogo no tiene por qué estar constreñido al campo de la prevención secundaria, cuando también puede intervenir a nivel de prevención primaria, por ejemplo, detectando precozmente dificultades de aprendizaje.b) El campo institucional, el campo grupal, el campo de lo individual. Aquí se trata de investigar si la psicopedagogía -por caso- es aplicable o no a situaciones donde quien tiene problemas de aprendizaje ya no es un individuo, sino un grupo o aún una institución. En el campo institucional puede investigarse por qué una institución no aprende, o bien en qué medida un problema institucional puede generar problemas individuales o grupales de aprendizaje, en las personas o en los grupos que la integran.c) El campo clínico, el campo judicial y el campo laboral son también posibilidades de investigación aplicada, ya que cada uno plantea problemas y procedimientos diferentes.d) Otros campos son la infancia, la adultez y la senectud. Por ejemplo, el psicopedagogo no tiene por qué atender solamente niños en edad escolar, pues también pueden tener problemas de aprendizaje los adultos (por ejemplo para aprender su trabajo).En fin, hay muchos otros campos para explorar, y muchos de ellos pueden encontrarse en las llamadas "incumbencias" profesionales, que aparecen por ejemplo en los planes de estudio de las carreras, y dicen para qué está habilitado un profesional, qué cosa puede hacer y qué cosas no. También aparece en las leyes: para las incumbencias del psicólogo está por ejemplo la Ley de Ejercicio Profesional de la Psicología, donde habla de campos de aplicación en el área docente, educacional, forense, laboral, etc.
3. Investigación profesional.- La clasificación clásica divide la investigación en pura y aplicada, pero en este ítem se incluye también la investigación profesional, que debe ser diferenciada de la investigación aplicada. De hecho, algunos autores parecen incluir dentro de la investigación aplicada algunas características de la investigación profesional. Por ejemplo, en el caso de las ciencias sociales, Ander-Egg (1987) describe la investigación aplicada diciendo que busca "el conocer para hacer, para actuar (modificar, mantener, reformar o cambiar radicalmente algún aspecto de la realidad social). Le preocupa la aplicación inmediata sobre una realidad circunstancial antes que el desarrollo de teorías. Es el tipo de investigación que realiza de ordinario el trabajador o promotor social; en general, comprende todo lo concerniente al ámbito de las tecnologías sociales que tienen como finalidad producir cambios inducidos y/o planificados con el objeto de resolver problemas o de actuar sobre algún aspecto de la realidad social" (Ander-Egg, 1987:68).
La investigación profesional se propone intervenir en la realidad utilizando los resultados de la investigación pura y aplicada. Como esta tarea la realiza alguien a quien habitualmente llamamos 'profesional' (un médico, un abogado, un ingeniero, un psicólogo clínico, etc.), hemos denominado con el mismo término a este tipo de investigación.La investigación profesional es así inherente a una profesión, a una práctica profesional. Un médico, un psicopedagogo, un abogado debe investigar el caso que le presentan. En cambio, la investigación científica no necesariamente está ligada a la práctica de una profesión: un profesional puede o no dedicarse, además, a investigar en el sentido científico. De hecho, hay investigadores científicos dedicados exclusivamente a esta actividad, y nunca ejercieron la profesión. La investigación profesional se pone en marcha cuando un profesional es convocado para resolver un problema concreto sin intentar generalizaciones, y por lo cual cobrará honorarios. En cambio, el investigador puro o el aplicado, busca generalizar y su retribución no se suele consignar como honorarios sino como sueldo.La investigación profesional se propone obtener algún resultado (un diagnóstico, una curación, resolver un problema de aprendizaje, construir un edificio, etc.) en relación con un caso único y determinado: no busca generalizar, aunque para ello pueda utilizar los saberes generales obtenidos en la investigación pura y la aplicada: en el curso de los dos últimos siglos la enorme mayoría de las innovaciones técnicas han sido precedidas por investigaciones aplicadas, las que a su vez lo han sido por resultados básicos.La investigación profesional es, entonces, singular, en el sentido de que su finalidad no es obtener un conocimiento general, sino un conocimiento aplicable a un solo caso, a saber, aquel que se debe resolver en ese momento: planificar una clase, en el caso del docente, averiguar el origen de un problema de aprendizaje en el caso del psicopedagogo, construir un puente en el caso de un ingeniero, resolver un pleito en el caso de un abogado.
Página 100 de 314
100
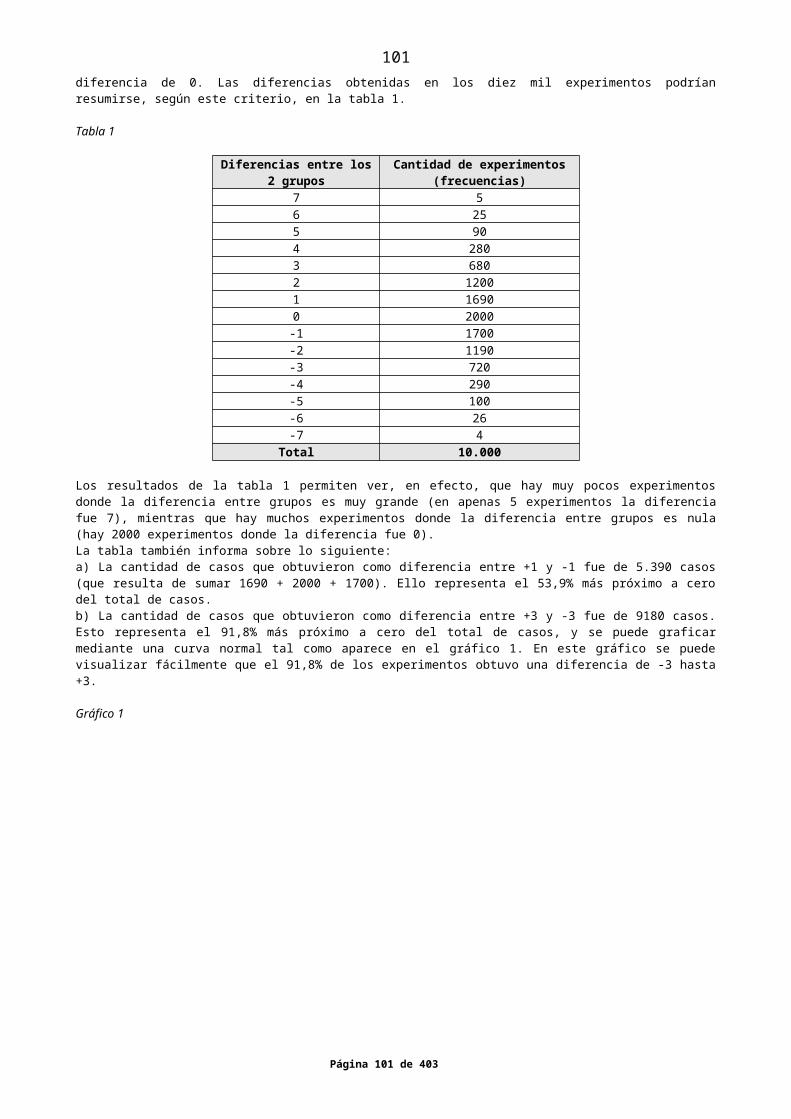
En oposición a la investigación profesional, la investigación pura no necesariamente está urgida por resolver un situación práctica. En este nivel, un científico puede iniciar una investigación motivado solamente por su curiosidad, lo que no quiere decir que en ciertos casos, como en algunas investigaciones aplicadas, haya de por medio un propósito práctico para el cual el investigador haya sido convocado por alguna institución. En este sentido, la investigación aplicada está a mitad camino entre la investigación pura y la profesional, ya que en la investigación aplicada no siempre hay tanta urgencia por resolver inmediatamente un problema: las técnicas pueden investigarse y proponerse hoy, pero empezar a usarse más tarde, cuando los profesionales adquieren información sobre ellas.Hay una relación importante entre la investigación profesional y la científica propiamente dicha (que incluye la pura y la aplicada): los resultados de la investigación casuística del profesional, cuando no son archivados y olvidados, pueden servir como elemento de juicio para llegar a generalizaciones más vastas mediante inducciones galileanas (a partir de un solo caso) o baconianas (a partir de varios). Freud, por caso, investigó los casos de Dora y de Schreber con el fin de ampliar y profundizar su teoría de los sueños y su teoría de la psicosis, respectivamente.En oposición a la investigación profesional, la investigación científica (pura, aplicada) busca siempre generalizar, e incluso para ello hasta puede partir de los datos de un caso singular abordado por un profesional, pero en este punto no estará haciendo una investigación profesional, sino una investigación científica. "Las prácticas profesionales no están sometidas al doble imperativo de la universalización y la validación de sus conclusiones cognoscitivas: les basta con alcanzar una adecuada 'eficacia local, particular', lograda en los marcos del problema práctico que intentan resolver..." (Samaja J, 1995:32).Tomemos el caso de la percepción. Al investigador científico le interesa estudiar los fenómenos perceptivos con el fin de llegar a una comprensión general de la percepción, incluso a formular hipótesis o teorías sobre la misma, como hicieron por ejemplo teorías como la Gestalt o el New Look. En cambio, al investigador profesional le interesa solamente la percepción de su paciente: si está alterada o no, si tiene alteraciones cualitativas o cuantitativas, etc., y todo ello no para extraer conclusiones sobre la percepción en general, sino como parte de un diagnóstico de la situación del paciente, lo que a su vez le servirá para planificar un tratamiento.Otro ejemplo de investigación profesional es la investigación docente, cuando por ejemplo debe planificar una clase o un curso: debe hacer investigaciones bibliográficas, investigación sobre técnicas didácticas, buscar el mejor ejemplo para una idea, etc., todo ello con vista a resolver esa clase o ese curso en particular.Las investigaciones clínicas que hace un psicopedagogo son también ejemplos de investigación profesional. Por ejemplo, en un problema de aprendizaje, ¿se trata de un problema de transculturación? ¿O tal vez se trata de un problema institucional, en cuyo caso la escuela misma anda mal, y esto se refleja en el aprendizaje de los alumnos? ¿O tal vez el problema tiene su origen en una cuestión familiar, o en una simple cuestión de retraso madurativo, o en una cuestión orgánica que requiere la atención de un neurólogo? ¿Tal vez el problema está en una maestra que utiliza el 'horóscopo piagetiano' (una mala interpretación de la teoría piagetiana) y que exige demasiado a un niño que teniendo 8 años no sabe aún clasificar o seriar? Todos estos interrogantes, entre otros, son los que pondrán en marcha la investigación profesional.
La investigación profesional se corresponde aproximadamente con lo que otros autores llaman investigación-acción participativa, en el contexto de investigaciones en ciencias sociales.“La Investigación-Acción Participativa puede considerarse como un proceso que lleva a cabo una determinada comunidad para llegar a un conocimiento más profundo de sus problemas y tratar de solucionarlos, intentando implicar a todos sus miembros en el proceso” (Pérez Serrano, 1990:134).La finalidad de la Investigación-Acción Participativa es de interés para la población, no sólo para una institución determinada: conocer para actuar, sensibilizar e implicar a la población, transformar la propia realidad. Quienes investigan? Los investigadores, técnicos y la población (destinataria de la acción). Cómo se diseña y ejecuta? Los grupos de trabajo diseñan y realizan todas las fases del análisis de la realidad. Cuál es su ámbito? Son ámbitos locales como barrios, zonas rurales, grupos, etc (Rubio y Varas, 1997:123).
Independientemente de las investigaciones profesionales que realiza, el profesional puede también tener la intención de llevar a cabo o participar en investigaciones puras o aplicadas, motivado por el placer o la curiosidad, o tal vez por una finalidad más prosaica relacionada con abultar el currículum o aumentar sus ingresos.Cevallos García y otros (2004) llevaron a cabo un estudio para conocer la actividad investigadora de un grupo de médicos, sus actitudes hacia la investigación y las dificultades que habían encontrado para investigar. Respondieron el cuestionario 174 médicos de ambos sexos con una edad promedio de 43 años, habiéndose obtenido los siguientes resultados: a) en los últimos 5 años, casi la mitad de los profesionales había publicado un trabajo científico y el 38% había presentado comunicaciones a congresos; b) la actitud hacia la investigación reveló que era ‘apenas aceptable’; y c) las dificultades encontradas para investigar fueron, desde las más importantes a las menos importantes: la presión asistencial, la escasez de tiempo, las deficiencias estructurales, la ausencia de líneas de investigación multicéntricas, la falta de incentivación y preparación, y la ausencia de motivación.
Bases científicas de la investigación
Si bien estamos presuponiendo que estos tres tipos de investigación tienen todas una base científica, existieron o existen situaciones en la cuales ello no se cumple, o no se cumple totalmente.
Página 101 de 314
101

Por ejemplo, un gurú pudo haber inventado o perfeccionado una técnica de curación basándose en la intuición: hizo investigación aplicada pero sin base científica.También pueden encararse investigaciones profesionales sin una base científica. En nuestro país, para rehabilitar a los alcohólicos la institución Alcohólicos Anónimos no admite médicos, ni psicólogos ni ningún otro profesional, sino solamente a ex-alcohólicos. Yendo un poco más lejos en el tiempo, los pueblos primitivos construían puentes sin tener conocimientos teóricos de estática (una rama de la física que estudia los cuerpos en reposo), utilizando para ello la intuición, y una experiencia de fracasos acumulada a lo largo del tiempo.Inclusive más: un profesional puede tener una buena base de conocimiento científico porque se recibió en la universidad pero, con el tiempo, poco a poco puede ir utilizando cada vez más su saber cotidiano y menos el científico, en parte porque no se actualiza y, por tanto, puede seguir utilizando teorías que en el ínterin ya fueron refutadas.Un ejemplo de investigación psicopedagógica no científica es la que realiza la madre cuando trata de averiguar por qué su hijo tiene problemas de aprendizaje, y cuando formula hipótesis al respecto. A su manera ella también está haciendo una investigación psicopedagógica, pero no podemos decir que sea científica.Todas estas investigaciones pueden tener indudable éxito, desde ya, pero no discutiremos aquí este importante problema de status del saber científico en relación con otros saberes, un tema del que, entre otros, se ocupó Paul Feyerabend.Y una última observación. Si bien la investigación aplicada o la profesional pueden no estar basadas en las teorías científicas producto de la investigación pura, ellas mismas podrían ser consideradas en sí mismas científicas por utilizar un 'método' científico (Bunge, 1969:685). Bunge distingue, por caso, teorías científicas, teorías tecnológicas sustantivas y teorías tecnológicas operativas. Podríamos relacionar estos tres tipos de teorías con los tres tipos de investigación que hemos descrito, en los siguientes términos. Las teorías científicas son elaboradas por la investigación pura, y orientan o pueden orientar los otros dos tipos de investigación, las cuales están guiadas, además, por teorías propias: la teoría tecnológica sustantiva orientaría la investigación aplicada, y la teoría tecnológica operativa la investigación profesional.
Investigación y ética
Cierta imagen clásica del científico que indaga a nivel de investigación pura o básica es aquella que lo pinta encerrado en una torre de cristal, y que está más allá del bien o del mal, por cuanto sus fines son desinteresados: le interesa conocer para satisfacer su curiosidad, independientemente de si su obra se utilizará para el bien o el mal. Desde este punto de vista, la investigación aplicada está más comprometida éticamente, por cuanto aquí ya no se produce simplemente conocimiento sino técnicas o artefactos para operar sobre la realidad: una cosa es inventar un misil, y otra un marcapasos. Sin embargo, todavía existe a este nivel un cierto grado de independencia, desde que se pueden inventar técnicas o artefactos que, como el rayo láser, puede servir para el bien o para el mal.En la investigación profesional, en cambio, el compromiso ético es insoslayable, porque a este nivel ya no se inventan técnicas o artefactos, sino que directamente se las utiliza.Lo dicho no nos debe hacer pensar, sin embargo, que el investigador puro no tiene un compromiso ético con la sociedad, en la medida en que debe poder prever o imaginar el uso que podrá dársele al conocimiento que produce. Einstein, por caso, parece no haber previsto el uso que se le dio en Hiroshima y Nagasaki a su conocida fórmula de interconvertibilidad de la masa y la energía. De hecho, cuando se enteró del desastre producido por la bomba atómica, se arrepintió públicamente.En suma: en cualquiera de los tres tipos de investigación existe una responsabilidad en lo que se produce como saber, en lo que se diseña o en lo que se hace, con lo cual, la actividad de investigar tiene siempre implicancias éticas.Un ejemplo bastante extendido es aquel donde se realiza 'mal' una investigación en forma deliberada con el fin de obtener algún resultado ventajoso en algún sentido (una 'mala' investigación es aquella que no está de acuerdo con los patrones de procedimiento vigentes en cada época. Por ejemplo, una investigación que presenta como definitivos resultados que son provisorios, o como verdaderos resultados que son equivocados). Tomemos dos casos reales:a) Muchas investigaciones incompletas o insuficientes sobre nuevos medicamentos son presentadas por algunos laboratorios como investigaciones concluidas, y por una razón comercial lanzan prematuramente al mercado remedios aún no suficientemente probados en seres humanos. En estos casos, a veces se utilizan como conejillos de Indias a la gente de los países sub-desarrollados para probar la eficacia de medicamentos por los que luego pagarán fortunas en los países desarrollados.b) Ciertas investigaciones de sondeos de opinión suelen ser tendenciosas, siendo contratadas especialmente por partidos políticos que compran encuestas 'arregladas' para su propio beneficio. Este procedimiento es una forma éticamente cuestionable de aplicar una hipótesis verificada por la Escuela del New Look, según la cual tendemos a opinar como lo hace la mayoría y, por lo tanto, 'si según tal encuesta de opinión tanta gente vota a Fulano será por algo, entonces yo también lo votaré'.Otro caso similar está representado por aquella investigación tendenciosa que intentaba persuadir a los ricos a estudiar en universidades privadas, en vez de en las públicas, mostrando que quienes más poder adquisitivo tenían, eran los que precisamente estudiaban en universidades privadas. Para ello, tomaron como indicadores de nivel de vida cosas como la casa donde vivía, si tenía o no electrodomésticos caros, el barrio de residencia, etc., con lo cual entraban en esta categoría una gran cantidad de gente (léase:
Página 102 de 314
102

4 5
6
1
2
3
hijos de gente pudiente) que por sí mismos no tenían en realidad ningún patrimonio personal. Esta investigación tendía a contrarrestar la tendencia a estudiar en universidades públicas, famosas por su prestigio y nivel académico.Con el mismo criterio utilizado por los promotores de la educación privada, también podríamos promocionar la educación pública bajo el lema: "Estudia en la UBA: millones de alumnos no se pueden equivocar", por parafrasear al humorista inglés Benny Hill, cuando dijo: "Coma en el restaurant de Harry: millones de moscas no se pueden equivocar".
Interrelaciones entre los tres tipos de investigación
La investigación profesional puede estar orientada o guiada por un marco teórico producido por la investigación pura y la investigación aplicada (flechas 4 y 5). A partir de las hipótesis generadas en ellas, la investigación profesional generará sus propias hipótesis, que convendrá denominar 'hipótesis casuísticas' por cuanto, a diferencia de las hipótesis propiamente dichas, no es general y está destinada a explicar solamente un caso en especial. Así, no es lo mismo explicar el proceso de la percepción en general, que explicar por qué un determinado paciente percibe como lo hace, explicación que es inaplicable a otro paciente.La investigación pura puede alimentarse de los datos producidos durante una investigación profesional (flecha 6). La obra de Freud nos ofrece abundantes ejemplos: él construyó una teoría acerca del funcionamiento psíquico en general, sobre la base de los datos que fue recolectando en su práctica profesional.La investigación pura está también influenciada por los resultados de la investigación aplicada (flecha 1). Por ejemplo, la técnica del carbono-14 para estimar la antigüedad de los fósiles, un producto de la investigación aplicada, contribuyó a modificar las teorías sobre el origen de la vida, a propósito del reciente descubrimiento, en la Antártida, de los restos de un meteorito proveniente del planeta Marte. En otro ejemplo, la técnica de la interpretación contribuyó a impulsar la investigación pura en psicoanálisis, del mismo modo que la técnica del taquitoscopio permitió verificar ciertas hipótesis de la teoría del New Look.La investigación aplicada suele utilizar los resultados de la investigación pura (flecha 2), como cuando se diseña un nuevo motor sobre la base de los principios de la termodinámica, o cuando se prueban nuevos medicamentos sobre la base de ciertas propiedades químicas de algunas sustancias, descubiertas en el curso de la investigación pura.Finalmente, la investigación aplicada recibe el aporte de la investigación profesional (flecha 3) en la medida en que, por ejemplo, esta última aporta elementos de juicio para evaluar la validez o la confiabilidad de técnicas diagnósticas o terapéuticas.
Interrelaciones entre investigación pura, aplicada y profesional
Los tres tipos de investigación y los contextos de la ciencia
En otra oportunidad (Cazau, 1996:20) nos hemos referido a los contextos de la ciencia como etapas o vicisitudes que atraviesa el conocimiento científico. En este devenir, intervienen los tres tipos de investigación descriptos, del modo en que se indica en el siguiente esquema. Analicemos en él columna por columna.
Contextos Roles Tipos de investigación Tipos de cienciaDescubrimiento y justificación
Investigador científico Investigación Pura o Aplicada Ciencia Pura o Aplicada
Difusión Transmisor/Receptor Investigación didáctica Saber TranspuestoAplicación Profesional Investigación Profesional Ciencia Aplicada
Página 103 de 314
103

Columna 1: Los cuatro contextos de la ciencia (descubrimiento, justificación, difusión y aplicación) se cumplen tanto en la actividad científica como en la vida cotidiana. Demos un ejemplo simple en este último caso. Una madre se encuentra con un problema: su hijo no aprende. A partir de aquí ella intentará responder a este problema formulando una hipótesis, como por ejemplo que su hijo no aprende porque no lo castigan (contexto de descubrimiento). Hace la prueba, es decir le prohíbe las vacaciones o las golosinas si no estudia bien, y la cosa funciona (contexto de justificación). Comunica esto a sus amigas (contexto de difusión), quienes luego utilizan esta información con sus propios hijos (aplicación).Estas cuatro etapas se cumplen también en la vida científica. Hay, sin embargo, por lo menos tres diferencias entre la actividad cotidiana y la actividad científica. a) El proceder científico es más riguroso con la prueba de la hipótesis: el científico es una especie de neurótico obsesivo que hace sus verificaciones con el máximo rigor, cosa que no sucede en la vida cotidiana, donde incluso hasta aceptamos nuestras hipótesis como verdades absolutas. Por ejemplo, la teoría de la madre del ejemplo es un equivalente de la teoría del refuerzo negativo de un Skinner, cuyas pruebas están llenas de controles experimentales. El resultado es que la hipótesis de Skinner está mucho mejor probada que la de la vida cotidiana. b) En la actividad científica, el conocimiento obtenido es incluído en el marco de una teoría más amplia que permite sistematizar el saber, por ejemplo, dentro de una teoría del aprendizaje.En la vida cotidiana, el conocimiento por ejemplo que a los chicos que andan mal hay que castigarlos no es incluído explícitamente dentro de una teoría, de un sistema hipotético-deductivo sino que se mantiene aislado, escindido del resto del saber. c) En tercer lugar, doña Rosa formula y pone a prueba sus hipótesis con un fin exclusivamente utilitario (que su hijo estudie bien), y no lo hace por una cuestión de simple curiosidad intelectual. En la actividad científica hay siempre una inquietud por conocer, además de una intención utilitaria.Columna 2: La investigación pura se ocupa básicamente de descubrir hechos, problemas o hipótesis, y de justificar (poner a prueba) estas últimas. La investigación aplicada procede de igual manera pero con técnicas, materiales, etc., correspondiendo en estos casos hablar mas bien de invención que de descubrimiento. Los resultados de estos dos tipos de investigación son utilizados en la investigación profesional, cuyos resultados a su vez pueden servir de fuente de datos para la investigación pura y aplicada (doble flecha).Columna 3: Los investigadores científicos -puros o aplicados- producen conocimiento, los profesores lo transmiten, los alumnos los reciben y los profesionales los aplican. Los alumnos tienen varias posibilidades: no solamente pueden convertirse en profesionales, que es lo que ocurre en la mayoría de los casos, sino que también podrán convertirse en profesores, en investigadores puros y en investigadores aplicados.Estos diferentes roles pueden aclararse más mediante la metáfora del 'edificio de la ciencia'. Hay rascacielos como la física, pero hay también ranchitos como la parapsicología, una ciencia que está en pañales (o una protociencia como diría M. Bunge), donde hay muchos hechos constatados pero pocas teorías. La psicología vendría a ser un edificio estándar pero de varios pisos. No es un rancho, pero tampoco un rascacielos.Si la ciencia fuera un edificio, el profesional es el que vive en los departamentos, el investigador puro es el constructor del edificio, y está en los sótanos vigilando que el edificio no se caiga; mientras tanto, el investigador aplicado refacciona o amplía el departamento para hacerlo más habitable, y el docente vendría a ser el que los muestra a los futuros adquirentes (alumnos) para vendérselos, y por ello la docencia es una profesión que exige, como la del vendedor, capacidad persuasiva. También podríamos ubicar a los usurpadores de viviendas, es decir, quienes, por ejemplo como los manosantas y astrólogos, se hacen pasar como psicólogos pero que no lo son porque no están habilitados por el Estado, es decir, no han comprado su vivienda 'por derecha'. Adviertan entonces la diferencia entre el investigador, que construye ciencia, y el profesional, que la usa. Finalmente, los clientes de los profesionales serían las visitas que estos reciben en sus departamentos.Finalmente, hemos incluído una categoría especial de investigación, la investigación didáctica, que indaga las maneras en que se transmiten los conocimientos desde el contexto de descubrimiento y justificación hacia el contexto de aplicación, y viceversa.Columna 4: Las ciencias puras son aquellas donde se realizan investigaciones puras, y las ciencias aplicadas, son aquellas donde se investigan nuevas herramientas para optimizar la aplicación del conocimiento o extenderlo a otros campos. Algunos ejemplos pueden verse en el siguiente esquema.
Puras AplicadasMatemáticas EstadísticaFísica IngenieríaQuímica FarmaciaBiología Medicina, Veterinaria, Agronomía, etc.Psicología Psicopedagogía, etc.Derecho Abogacía
Piaget trabajó por ejemplo en el campo de la investigación pura: él estudió la inteligencia y no encontramos en él un estudio sistemático de sus implicancias pedagógicas o educativas, lo cual hubiera sido investigación aplicada. Freud en cambio, trabajó en los dos campos: en la investigación pura estudió los procesos inconcientes, las pulsiones, los afectos, y en la investigación aplicada pensó y ensayó nuevas técnicas terapéuticas, como el apremio o la interpretación.
Página 104 de 314
104

Si por ciencia aplicada entendemos también la aplicación del conocimiento, deberemos incluir en ella a la investigación profesional: si bien esta última es casuística (no busca un saber general, como la ciencia propiamente dicha), es 'ciencia' en tanto utiliza un procedimiento científico para validar sus hipótesis casuísticas, y es 'aplicada' en tanto usa como marco teórico el saber de la ciencia pura. Finalmente, en el contexto de difusión no encontramos un saber puro sino una transposición de ese saber en un saber enseñable y enseñado (Chevallard, 1997).
2. INVESTIGACIÓN EXPLORATORIA, DESCRIPTIVA, CORRELACIONAL Y EXPLICATIVA
Según su alcance, las investigaciones pueden ser exploratorias, descriptivas, correlacionales o explicativas. Estos tipos de investigación suelen ser las etapas cronológicas de todo estudio científico, y cada una tiene una finalidad diferente: primero se 'explora' un tema para conocerlo mejor, luego se 'describen' las variables involucradas, después se 'correlacionan' las variables entre sí para obtener predicciones rudimentarias, y finalmente se intenta 'explicar' la influencia de unas variables sobre otras en términos de causalidad.Hyman clasifica las encuestas en tres grandes tipos (Hyman, 1955:100-101): descriptivas, explicativas y predictivas, aunque se ocupará en detalle solamente de las dos primeras.
Autores como Hyman (1955) se limitan a clasificar las investigaciones como descriptivas y explicativas, denominándolas metonímicamente como ‘encuestas descriptivas y explicativas’ por cuanto la herramienta principal de recolección de datos es la encuesta. Este autor establecerá una diferencia entre las encuestas descriptivas y las explicativas, aunque señala que tal distinción, si bien real, no es siempre factible, pues "muchas encuestas reúnen características combinadas de descripción y explicación" (Hyman, 1955:24). Su intención, al explicar separadamente los principios de cada una, ha sido mas bien didáctica.
Más concretamente: dentro de las diferentes formas de clasificar los tipos de investigación en ciencias sociales, una tipología posible las clasifica, según el alcance de la investigación, en investigaciones exploratorias, descriptivas, correlacionales y explicativas. La clasificación pertenece a Gordon Dankhe (1986) y aquí la explicitaremos basándonos en una síntesis realizada por Hernández Sampieri y otros (1991).En la práctica, cualquier estudio puede incluir aspectos de más de una de estas cuatro clases de investigación, pero los estudios exploratorios ordinariamente anteceden a los otros porque sirven para empezar a conocer el tema. A partir de allí se inicia una investigación descriptiva, que por lo general fundamentará las investigaciones correlacionales, las que a su vez proporcionan información para llevar a cabo una investigación explicativa. Una investigación puede entonces comenzar siendo exploratoria, después ser descriptiva y correlacional, y terminar como explicativa.No se puede hacer un estudio explicativo si antes, uno mismo u otro investigador no realizó antes un estudio descriptivo, como tampoco podemos iniciar este último sin que alguien antes haya hecho una investigación exploratoria. La historia de la ciencia nos muestra, primero, que una de estas etapas puede durar años y puede haber quedado "olvidada" hasta que alguien retoma la siguiente etapa; y segundo, que los límites entre una y otra etapa no son temporalmente exactos, pudiendo a veces superponerse.Las tres etapas persiguen propósitos diferentes: la investigación exploratoria identifica posibles variables, la investigación descriptiva constata correlaciones entre variables, y la investigación explicativa intenta probar vínculos causales entre variables.
Más concretamente: en la investigación exploratoria buscamos información sobre algún tema o problema por resultarnos relativamente desconocido, como por ejemplo la cuestión de los prejuicios raciales. Este estudio culmina cuando hemos obtenido el conocimiento suficiente como para hacer un listado de los diferentes factores que suponemos vinculados con el prejuicio racial, como por ejemplo educación recibida, religión, zona de residencia, edad, sexo, filiación política, etc. En la investigación descriptiva buscaremos correlacionar estadísticamente cada uno de esos factores con el factor prejuicio racial, y termina cuando hemos constatado ciertas correlaciones lo suficientemente significativas como para sospechar la existencia de un vínculo causal. Por último, en la investigación explicativa intentaremos probar nuestra sospecha anterior, por ejemplo realizando un experimento que me permita concluir si el o los factores considerados son o no causa de la actitud prejuiciosa hacia personas de otras razas.
Señala Hyman que "los hallazgos de las encuestas descriptivas constituyen una guía para teorizar en las explicativas; la capacidad de conceptualizar un fenómeno, que es de enorme importancia en las encuestas descriptivas, resulta fundamental en las encuestas explicativas, ya que el mismo poder de conceptualización debe extenderse al problema de las variables independientes" (Hyman, 1955:116-117). Por lo común, a la encuesta descriptiva se la relega a un segundo plano, otorgándosele un valor puramente empírico y de aplicación. En contraste, a las encuestas explicativas se les otorga gran valor, dada la gran aceptación de su papel en las ciencias sociales (Hyman, 1955:102).
Investigación exploratoria
El objetivo de una investigación exploratoria es, como su nombre lo indica, examinar o explorar un tema o problema de investigación poco estudiado o que no ha sido abordado nunca antes. Por lo tanto, sirve para familiarizarse con fenómenos relativamente desconocidos, poco estudiados o novedosos,
Página 105 de 314
105

permitiendo identificar conceptos o variables promisorias, e incluso identificar relaciones potenciales entre ellas.La investigación exploratoria, también llamada formulativa (Selltiz), permite conocer y ampliar el conocimiento sobre un fenómeno para precisar mejor el problema a investigar. Puede o no partir de hipótesis previas, pero al científico aquí le exigimos flexibilidad, es decir, no ser tendencioso en la selección de la información. En la investigación exploratoria se estudian qué variables o factores podrían estar relacionados con el fenómeno en cuestión, y termina cuando uno ya tiene una idea de las variables que juzga relevantes, es decir, cuando ya conoce bien el tema. Por ejemplo, cuando apareció por primera vez el Sida hubo que hacer una investigación exploratoria, porque había un desconocimiento de este tema. Otros ejemplos son investigar el tema drogadicción para quien no lo conoce, o el tema salud mental en relación con el entorno social. La investigación exploratoria tiene otros objetivos secundarios, que pueden ser familiarizarse con un tema, aclarar conceptos, o establecer preferencias para posteriores investigaciones. La información se busca leyendo bibliografía, hablando con quienes están ya metidos en el tema, y estudiando casos individuales con un método clínico. Blalock destaca la técnica de la observación participante como medio para recolectar información. Es importante que la investigación exploratoria esté bien hecha, porque si no puede echarse a perder la subsiguiente investigación descriptiva y la explicativa.Hernández Sampieri y otros (1996:71) indican que los estudios exploratorios tienen por objeto esencial familiarizarnos con un tópico desconocido o poco estudiado o novedoso. Esta clase de investigaciones sirven para desarrollar métodos a utilizar en estudios más profundos. De hecho, una misma investigación puede abarcar fines exploratorios, en su inicio, y terminar siendo descriptiva, correlacional y hasta explicativa: todo según los objetivos del investigador.En su momento, fueron investigaciones exploratorias las primeras investigaciones sobre el Sida, sobre las vinculaciones potenciales entre histeria y sexualidad (Sigmund Freud), sobre el rendimiento de los obreros en las fábricas (Elton Mayo), etc. En su momento, cuando nada se sabía sobre estas cuestiones, se emprendieron investigaciones para 'explorar' dichos temas y problemas.En un estudio exploratorio se puede partir de una hipótesis previa, o sea, podemos tener alguna idea previa sobre qué factores están vinculados con la drogadicción. Pero esta idea vaga es una guía muy general y sólo nos sirve para descartar la influencia de factores tales como si hay o no atmósfera en Júpiter, por dar un ejemplo; no nos debe servir para descartar otros posibles factores relevantes (o que podrían serlo), tales como la inestabilidad política, social o económica de los países donde aparece la drogadicción.
Investigación descriptiva
En un estudio descriptivo se seleccionan una serie de cuestiones, conceptos o variables y se mide cada una de ellas independientemente de las otras, con el fin, precisamente, de describirlas. Estos estudios buscan especificar las propiedades importantes de personas, grupos, comunidades o cualquier otro fenómeno.Las investigaciones descriptivas constituyen una "mera descripción de algunos fenómenos" (Hyman, 1955:100), como por ejemplo describir la conducta sexual del hombre norteamericano, describir los sentimientos del público hacia los programas radiales, o describir la opinión norteamericana sobre la bomba atómica”. Su objetivo central es "esencialmente la medición precisa de una o más variables dependientes, en alguna población definida o en una muestra de dicha población" (Hyman, 1955:102). "La conceptualización eficaz del fenómeno a estudiar constituye el problema teórico fundamental que se plantea al analista de una encuesta descriptiva" (Hyman, 1955:129).Los estudios descriptivos (Hernández Sampieri y otros, 1996:71) sirven para analizar como es y se manifiesta un fenómeno y sus componentes (ejemplo, el nivel de aprovechamiento de un grupo, cuántas personas ven un programa televisivo y porqué lo ven o no, etc.).Un ejemplo típico de estudio descriptivo es un censo nacional, porque en él se intenta describir varios aspectos en forma independiente: cantidad de habitantes, tipo de vivienda, nivel de ingresos, etc., sin pretender averiguar si hay o no alguna correlación, por ejemplo, entre nivel de ingresos y tipo de vivienda.Otro ejemplo de investigación descriptiva puede ser aquella que intenta averiguar qué partido político tiene más seguidores, o qué imagen posee cada partido político en la población, o cuántas personas hacen psicoterapia en una determinada ciudad, o el índice de productividad de una fábrica, o la cantidad de varones y mujeres que miran televisión, etc. Medir los diferentes aspectos de la personalidad de un sujeto (hipocondría, depresión, sociabilidad, etc.) es también un estudio descriptivo.Mientras los estudios exploratorios buscan descubrir variables, los descriptivos buscan describirlas midiéndolas, y, por tanto, requieren mayor conocimiento del tema para saber qué variables describir y cómo hacerlo.Los estudios descriptivos pueden ofrecer también la posibilidad de hacer predicciones incipientes, aunque sean rudimentarias. Por ejemplo, si sabemos el promedio de horas que miran TV los niños de la ciudad X, podemos predecir con cierta probabilidad el tiempo que mirará TV un niño determinado de dicha ciudad. Otro ejemplo: si sabemos, en base a una muestra, cuánta gente votará a tal partido, podemos predecir con cierto margen de probabilidad o error, si triunfará en las elecciones.Según Hyman, el objetivo fundamental de las encuestas de predicción no es describir ni explicar una situación 'actual', sino hacer una estimación de algún estado de cosas 'futuro' (Hyman, 1955:101). El mismo autor proporciona un ejemplo de investigación predictiva, que tuvo lugar en EEUU cuando el
Página 106 de 314
106

gobierno patrocinó una encuesta que sirviese para orientar la política del control de la inflación. Se buscaba información que permitiese pronosticar el curso de los rescates de bonos de guerra durante el próximo año. La idea era recabar información directamente de las personas, porque hasta entonces los datos surgían de índices globales, como la renta nacional, etc., que no arrojaban luz sobre el efecto diferencial que ciertos factores ejercen sobre los distintos sectores de la población, ni indicaban las distintas motivaciones que los impulsaban. La información necesaria para formular el pronóstico debía obtenerse analizando: a) datos económicos sobre la tenencia de bonos y datos inferidos sobre la vulnerabilidad económica de la familias, y b) datos psicológicos sobre factores cognitivos o motivacionales en que se fundaba la compra y conservación o rescate de bonos, en relación con los diversos procesos económicos previstos en el país. Entre otras cosas, se pudo pronosticar por ejemplo que la reaparición de bienes de consumo no sería muy significativa, ya que los tenedores de bonos querían conservarlos hasta su amortización.
Investigación correlacional
Tiene como finalidad medir el grado de relación que eventualmente pueda existir entre dos o más conceptos o variables, en los mismos sujetos. Más concretamente, buscan establecer si hay o no una correlación, de qué tipo es y cuál es su grado o intensidad (cuán correlacionadas están).En otros términos, los estudios correlacionales pretenden ver cómo se relacionan o vinculan diversos fenómenos entre sí (o si no se relacionan) (Hernández Sampieri y otros, 1996:71).Por ejemplo, un estudio correlacional tratará de averiguar si hay alguna relación entre motivación y productividad laboral para los mismos sujetos (obreros de una fábrica), o si hay o no alguna relación entre el sexo del cónyuge alcohólico y el número de divorcios o abandonos generados por el alcoholismo, o si hay alguna relación entre el tiempo que se dedica al estudio y las calificaciones obtenidas.Consiguientemente, el propósito principal de la investigación correlacional es averiguar cómo se puede comportar un concepto o variable conociendo el comportamiento de otra u otras variables relacionadas, es decir, el propósito es predictivo. Por ejemplo, si yo se que la ocupación y la preferencia de voto están correlacionadas, puedo predecir que los obreros tenderán a votar a determinado partido político más que a otro. No se trata de una predicción incipiente como en la investigación descriptiva, porque en los estudios correlacionales la predicción está apoyada en evidencias más firmes, a saber, en la constatación estadística de un vínculo de correlación.Señalan Hernández Sampieri et al (1991) que la investigación correlacional tiene un cierto valor explicativo, que es parcial. Decir que los estudiantes obtuvieron mejores calificaciones 'porque' estudiaron más tiempo es una explicación, pero parcial, porque hay muchos otros factores que pudieron hacer incidido en sus buenas calificaciones.Los mismos autores advierten sobre la posibilidad de encontrar lo que ellos llaman "correlaciones espurias", es decir, correlaciones existentes entre variables pero que en realidad no expresan causalidad. Por ejemplo, hay una alta correlación entre estatura e inteligencia, pero ello no nos autoriza a sostener que la estatura es la 'causa' de la inteligencia, o a decir que una persona es inteligente debido a su altura.
Investigación explicativa
Las investigaciones descriptivas y correlacionales constituyen una mera descripción de algunos fenómenos, para lo que se centran en la medición de una o más variables dependientes en alguna población o muestra. La investigación explicativa, en cambio, va más allá tratando de encontrar una explicación del fenómeno en cuestión, para lo cual busca establecer, de manera confiable, la naturaleza de la relación entre uno o más efectos o variables dependientes y una o más causas o variables independientes.Así entonces, este tipo de investigación va más allá de la simple descripción de la relación entre conceptos, estando dirigido a indagar las causas de los fenómenos, es decir, intentan explicar por qué ocurren, o, si se quiere, por qué dos o más variables están relacionadas. No es lo mismo decir que ocupación y preferencia política están relacionadas, a explicar por qué lo están en términos de un vínculo causa-efecto.Las investigaciones explicativas son más estructuradas que las anteriores, y proporcionan además un 'sentido de entendimiento' del fenómeno en estudio, es decir, procuran entenderlo a partir de sus causas y no a partir de una mera correlación estadística verificada con otras variables.Algunos llaman 'experimental' a la investigación explicativa. Hernández Sampieri et al (1991) sostienen que si bien la mayoría de las investigaciones explicativas son experimentales, ciertos estudios no experimentales pueden aportar evidencia para explicar por qué ocurre un fenómeno, proporcionando así "un cierto sentido de causalidad".
Hyman, en su análisis de las investigaciones explicativas, sostiene que lejos de intentar la mera descripción de un fenómeno como en las encuestas descriptivas, las encuestas explicativas tratan de encontrar una explicación' del mismo (Hyman, 1955:100). En las encuestas explicativas, "se establece de manera confiable la naturaleza de la relación entre uno o más fenómenos (variables dependientes) y una o más causas (variables independientes)" (Hyman, 1955:100).Los procedimientos para analizar encuestas explicativas "deben proporcionar pruebas confiables de la relación entre el fenómeno y una o más causas o variables independientes y, por tanto, solucionar el problema general del analista: hallar una explicación" (Hyman, 1955:229). La encuesta explicativa "sigue
Página 107 de 314
107

el modelo de los experimentos de laboratorio, con la diferencia fundamental de que procura representar este diseño en un medio natural. En vez de crear y manejar las variables independientes cuyo efecto hay que descubrir, el analista de encuestas debe encontrar en el medio natural casos en que se den dichos factores. Mediante la medición de su presencia y magnitud, es posible establecer, en el curso del análisis, su relación con el fenómeno. La restricción del universo abarcado y el diseño de la muestra proporcionan la técnica básica mediante la que se excluyen otras fuentes de variación del fenómeno en la encuestas explicativa" (Hyman, 1955:117).Clasificación de las investigaciones explicativas.- Hyman clasifica las encuestas explicativas en tres grandes grupos, que son los siguientes:a) Encuestas teóricas o experimentales.- Aquí, "la tarea adopta fundamentalmente la forma de verificación de una 'hipótesis específica' derivada de alguna teoría más amplia, en tanto determinante especial del fenómeno" (Hyman, 1955:100).b) Encuestas de evaluación o programáticas.- Son aquellas donde "los factores que 'han sido o pueden ser manejados por un organismo de acción social' se estudian desde el punto de vista de la ayuda que brindan para determinar el fenómeno. Aquí el objetivo inmediato es la aplicación, modificación o cambio de algún estado de cosas o fenómeno, tomando como base el conocimiento probado de los factores en juego. Tal fue el caso de la investigación sobre el ausentismo: auspiciada por el gobierno, los hallazgos debían facilitar recomendaciones acerca de las medidas correctivas a adoptar en los talleres o en un ambiente más amplio, mediante su manipulación. Esto no significa que el planeamiento básico de esas investigaciones no involucre consideraciones teóricas [como en las encuestas teóricas o experimentales], sino simplemente que los determinantes específicos que en última instancia constituyen el foco del análisis son entidades manipulables" (Hyman, 1955:100).c) Encuestas de diagnóstico.- "Implica una búsqueda de causas posibles en un ámbito relativamente desconocido" (Hyman, 1955:100).Algunas diferencias entre los tres subtipos de investigaciones explicativas.- 1) A diferencia de las encuestas teóricas o experimentales, donde se busca verificar una hipótesis específica sobre los 'determinantes especiales' del fenómeno, a las encuestas de evaluación y de diagnóstico incumbe "verificar la 'contribución de una serie de factores' a la causalidad de un fenómeno" (Hyman, 1955:100).2) La encuesta programática o de evaluación "hace hincapié en los modos de análisis denominados 'especificación' y 'explicación' (...). Además, la encuesta teórica pone el énfasis en el modo de análisis llamado 'interpretación'" (Hyman, 1955:101). La especificación, la explicación y la interpretación son tres modos de análisis que Hyman desarrolla más adelante, en el capítulo 7 titulado "La introducción de variables adicionales y la elaboración del análisis". Estos tres modos de análisis reciben en Hyman el nombre genérico de 'elaboración', y consisten básicamente en introducir variables adicionales para explorar con mayor detalle la original relación X-Y. No se desarrolla aquí este punto, pero para que el lector pueda tener una idea aproximada del tema, hemos diseñado el esquema, que intenta resumir las ideas de Hyman al respecto.
En la explicación, el factor de prueba es una variable antecedente, en la interpretación es una variable interviniente. En la especificación se indica bajo qué circunstancias (variables contextuales) la relación original X-Y es menos o más pronunciada (Hyman, 1955:352). Se volverá sobre este tema cuando se examinen más adelante algunos ejemplos de relaciones entre variables.3) Las encuestas programáticas y teóricas acentúan la importancia de que la 'confiabilidad de las conclusiones esté rigurosamente garantizada', en tanto que la encuesta de diagnóstico puede reservar menos recursos a esas garantías y tratar de alcanzar, en un amplio ámbito, comprensión o 'evidencia sugestiva'" (Hyman, 1955:101).4) "La estructura conceptual de la encuesta teórica será más 'abstracta', mientras que la encuesta programática o de evaluación utilizará variables más 'concretas', y la de diagnóstico participará de ambos niveles de conceptualización" (Hyman, 1955:101).
Página 108 de 314
108

Otras consideraciones
1. ¿Una investigación, puede incluir elementos de los diferentes tipos de estudio indicados?Muchas veces cuando se dice que un estudio es descriptivo, o correlacional, etc., esto no significa necesariamente que no incluya elementos o características de otros tipos de investigación. Además, una investigación puede comenzar siendo descriptiva y terminar siendo luego correlacional.Inclusive más: un estudio puede comenzar siendo explicativo porque procura averiguar la causa de la evasión de impuestos, pero luego, al revisarse la literatura. se comprueba que no hay nada investigado sobre el tema, con lo cual debe continuar investigando de manera exploratoria, pues se trata de indagar en un tema relativamente desconocido.2. ¿De qué depende que una investigación comience como exploratoria, descriptiva, correlacional o explicativa? Que una investigación comience como exploratoria, descriptiva, correlacional o explicativa dependerá del estado de conocimiento sobre el tema a investigar (lo que podemos saber a partir de la revisión de la literatura), y del enfoque que el investigador pretenda darle a su estudio.La revisión de la literatura sobre el tema puede revelarnos, en primer lugar, que no hay antecedentes sobre el tema, o que ellos son inaplicables a lo que queremos estudiar, en cuyo caso iniciaremos una investigación exploratoria.En segundo lugar, puede revelarnos que ciertos estudios descriptivos han detectado y definido ciertas variables, en cuyo caso podremos iniciar un estudio descriptivo. En tercer lugar la revisión de la literatura puede revelarnos la existencia de una o varias relaciones entre conceptos o variables, en cuyo caso podremos emprender una investigación correlacional. En cuarto y último lugar, la literatura puede revelarnos que hay una o varias teorías aplicables a nuestro problema, con lo cual podremos comenzar un estudio explicativo.El enfoque que el investigador busque darle a su estudio también determinará el tipo de investigación que elegirá: a veces el propósito es simplemente describir, otras veces correlacionar, otras veces buscar causas, etc.3. ¿Cuál es de los cuatro tipos de investigación es mejor? Las cuatro son igualmente válidas e importantes, por cuanto todas han contribuido al avance de la ciencia, porque han aumentado y profundizado el conocimiento del fenómeno en estudio.
Un análisis crítico de la propuesta tipológica
La tipología de Dankhe representa un importante avance conceptual al discriminar las investigaciones descriptivas como diferentes de las correlacionales. De hecho, hay innumerables ejemplos de investigaciones descriptivas que no llegan a ser correlacionales, entre otras cosas porque no está como objetivo de la investigación establecer relaciones entre variables. Por ejemplo, los censos describen el estado de variables demográficas como sexo, edad, ocupación, salario, número de hijos o vivienda, sin intentar relacionarlas entre sí. En otro ejemplo, una empresa encuestadora es contratada por algún medio de comunicación para que investigue el estado de la variable preferencia política de la población: en estos casos su único objetivo es describir la variable en cuestión, sin intentar establecer qué tipo de relación puede tener con edad, sexo, etc. A lo sumo, podrá cruzar la variable preferencia política con ellas, pero sin intentar un cálculo de su grado de correlación mediante coeficientes especiales como pueden ser el coeficiente Pearson, el coeficiente Spearman, tarea que ya caer dentro de los objetivos de una investigación correlacional, que es en este caso poder hacer predicciones confiables. Por otro lado, nos permitiremos discrepar con los autores en algunas cuestiones relacionadas con los objetivos de una investigación explicativa que, a nuestro entender, son presentados como demasiado laxos.
Esquema 6 - Tipologia de Dankhe (1986)
Tipo de investigación
Esquema Propósitos
Exploratoria X YX ------ Y
- Identifican variables promisorias- Sugieren relaciones potenciales entre variables
Descriptiva X YX ------ Y
- Describen -miden- las variables identificadas- Pueden sugerir relaciones potenciales entre variables (predicciones rudimentarias)
Correlacional X ------ Y - Determinan correlación entre variables(predicciones más firmes)Explicativa X -----> Y - Sugieren vínculos causas entre las variables. O sea, buscan
explicar por qué están correlacionadas (explican una variable a partir de otra/s)
Una investigación explicativa no se limita a sugerir vínculos causales entre variables sino que, fundamentalmente, se propone probarlos, para lo cual debe constatar que se cumplen los tres requisitos básicos que definen un vínculo de ese tipo: primero, que haya correlación significativa (lo que ya fue probado en la investigación correlacional), segundo, que la supuesta causa ocurra antes que el efecto, y tercero, que haya suficientes motivos para descartar la influencia de otros posibles factores causales, además del que se estudia. La investigación explicativa se centra particularmente en esta última cuestión, y el recurso casi obligado para ello es el experimento.
Página 109 de 314
109

Según algunos autores, la investigación correlacional tendría un cierto valor explicativo porque proporciona 'explicaciones parciales', entendiendo por tales las que informan acerca de un único factor, y no de todos los factores que inciden en un fenómeno. A nuestro entender, un análisis de correlación no intenta probar un vínculo causal, sino constatar estadísticamente un nivel de asociación entre variables. Por lo tanto, si algún sentido tiene la expresión 'explicación parcial' aplicada al análisis de correlación, éste sólo puede consistir en que la presencia de correlación es sólo uno de los tres requisitos del vínculo causal antes indicados.Debido a que un análisis de correlación, por último, no intenta probar conexiones causales, no resulta feliz la expresión 'correlación espuria', utilizada por algunos autores. Según estos, entre dos variables pueden existir 'correlaciones espurias', lo que ocurre cuando, a pesar de existir entre ambas existe una alta correlación, no están vinculadas causalmente, como el caso de la estatura y la inteligencia. A nuestro entender, lo correcto sería decir 'causalidad espuria' porque en el caso indicado no hay duda de que hay correlación y, en todo caso, lo que se pone en tela de juicio es la presencia o no de un vínculo de causalidad.
Algunos ejemplos de investigaciones descriptivas y explicativas
Hyman suministra algunos ejemplos de investigaciones descriptivas y explicativas realizadas entre 1938 y 1946 en los EEUU. El lector podrá apreciar en estos ejemplos algunas de sus características generales:a) Tamaño grande: se estudia un gran número de casos, del orden de los miles (Hyman, 1955:45).b) Tarea colectiva: Salvo una excepción, la investigación no fue llevada a cabo por un estudioso, sino por una organización compuesta por muchas personas (Hyman, 1955:58).c) Patrocinio y subvención: A veces, el problema en estudio no es el resultado de la elección individual de un investigador, sino que surge de las necesidades de la otra parte interesada, que patrocina y respalda la investigación (Hyman, 1955:71).d) Temas controvertibles: por lo común las encuestas giran alrededor de temas controvertibles, y el marco social donde se emprenden y cualquier solución propuesta están generalmente cargado de conflictos (Hyman, 1955:90).
Esquema 7- Ejemplos de Hyman (1955) de investigaciones descriptivas y explicativas
Encuesta Sub-tipo EjemplosDescriptiva Encuesta N° 2: La opinión pública y la bomba atómica
Encuesta N° 3: Opinión norteamericana sobre la radio comercialEncuesta N° 5: Conducta sexual de los norteamericanos
Explicativa Teórica o experimental Encuesta N° 4: Prejuicio y personalidadEncuesta N° 6: Conciencia de clase
De evaluación o programática Encuesta N° 1: Ausentismo industrialDe diagnóstico No hay ejemplos
Encuesta número 1: Ausentismo industrial.- Cierto organismo estatal de EEUU se propuso investigar ciertos hechos relacionados con la naturaleza y alcance del ausentismo en la industria bélica, así como también determinar algunos de los factores que incidían en él. Se vio que a menudo se identificaba el ausentismo con mala voluntad por trabajar, y se lo consideraba un mal nacional que amenazaba el poderío bélico nacional. Los analistas encontraron que casi nunca se distinguía ausencia voluntaria de involuntaria, y que el tema se trataba en voz baja.Se entrevistaron 1800 individuos (100 de 18 fábricas diferentes), y se computaron los índices de ausentismo por fábrica y por individuo. Las variaciones en estos índices se relacionaron con las características de los obreros, con sus condiciones de trabajo y con el grado de satisfacción que sentían respecto de la planta y de la comunidad, todos factores determinados en las entrevistas. Otros factores se determinaron mediante observación, como las condiciones objetivas internas de la planta y la comunidad.Encuesta número 2: La opinión pública y la bomba atómica.- Una institución planeó sondear la opinión de los norteamericanos respecto de la bomba atómica y las cuestiones internacionales, con el fin de incorporar más elementos de juicio para diseñar una política nacional al respecto. Una institución sondeó la opinión de una muestra de 3000 personas, y otra una de 600 personas.Se buscó indagar qué conocimiento tenían sobre la bomba atómica, su existencia, su modo de fabricación, los responsables de la misma, los países que la poseían, su grado de preocupación y sus actitudes frente al control internacional de dicha arma. También se indagó opinión sobre relaciones internacionales, como la relación del país con la ONU, con Rusia y con otros países.Encuesta número 3: Opinión norteamericana sobre la radio comercial.- La Asociación de Radiodifusoras se propuso hacer una encuesta para determinar los puntos fuertes y débiles de la radio y averiguar qué lugar ocupaba estas en las preferencias del público, con el fin de elaborar un plan de radiodifusión.Se constató que ciertos individuos y grupos criticaban el carácter comercial de la radio y el descuido de su responsabilidad pública al no elevar el nivel cultural de sus programas.Se hicieron entrevistas personales a 2500 personas, buscándose indagar si ciertos programas y publicidades resultaban satisfactorios a la gente, y se investigaron actitudes frente al control de la radio
Página 110 de 314
110

por parte del estado. Se indagó también la actitud de la gente frente a otros medios no radiales. Las opiniones se relacionaron con las características personales de los entrevistados, como la frecuencia con que escuchaban radio, el nivel de instrucción, sexo, edad, zona de residencia, etc.Encuesta número 4: Prejuicio y personalidad.- Una institución decidió investigar el problema del prejuicio, lo que incluía un estudio tendiente a demostrar que ciertos factores de la personalidad del hombre moderno lo predisponen a exhibir hostilidad hacia grupos raciales y religiosos. El propósito primario no fue utilizar los resultados para hacer un programa contra el antisemitismo, sino contribuir al conocimiento de las fuentes del antisemitismo, intentando probar empíricamente varias hipótesis acerca de lo correlatos del fenómeno del prejuicio.La orientación teórica de los investigadores los llevó a concluir que el antisemitismo formaba parte de una pauta más generalizada de sentimientos prejuiciosos, que integraba a su vez una pauta amplia y coherente de convicciones políticas y sociales. Se consideró que los sentimientos autoritarios eran consecuencia de un síndrome más básico de personalidad, derivado a su vez de experiencias infantiles. Mediante cuestionarios, se indagaron a 2000 personas sobre antisemitismo, etnocentrismo, ideología político económica y ciertos rasgos más básicos de personalidad. Luego, se entrevistó una muestra menor de personas que exhibían tipos particulares de actitudes que surgían de los cuestionarios, para determinar en detalle sus rasgos de personalidad y su historia y verificar las hipótesis principales.Encuesta número 5: Conducta sexual de los norteamericanos.- Kinsey y colaboradores realizaron entrevistas para informarse sobre el comportamiento sexual del norteamericano y establecer cuáles son los factores que explicaban las diferencias individuales y grupales en cuanto a conducta sexual. Se confeccionó el Informe Kinsey en base a 5.300 entrevistas a varones blancos. Se procuró que en los investigadores no influyeran prejuicios sobre lo que era sano o enfermo en la elección de historias o selección de ítems. Fue una investigación que encontró resistencias y críticas en la sociedad, dado lo controvertido del tema. Se obtuvo información sobre la historia de las conductas sexuales de cada interrogado, y sobre sus características personales. Se describió la conducta sobre todo en función del orgasmo, determinando su intensidad y frecuencia por distintas vías (masturbación, emisión nocturna, desahogo homosexual, relaciones premaritales, extramaritales o maritales, etc.). Se relacionó el desahogo total, la suma de las conductas sexuales y los modos específicos de desahogo con factores como la edad, la educación, la religión, el lugar de residencia y otros.Encuesta número 6: Conciencia de clase.- R. Centers proyectó una encuesta buscando probar una teoría según la cual el status y el rol de una persona respecto de los procesos económicos le imponen ciertas actitudes, valores e intereses vinculados con su rol y status en la esfera política y económica. Además, el status y el rol del individuo, en relación con lo económico, despiertan en él la conciencia de pertenencia a una clase social que comparte esas actitudes, valores e intereses.La finalidad de esta investigación era teórica, consistiendo en proporcionar una prueba objetiva de las hipótesis específicas deducidas de esta teoría general del grupo de interés en la clases sociales. Centers se interesaba tanto por el conflicto de clases, como por la contribución que podían aportar los científicos sociales para comprender mejor las crisis, trastornos y cambios sociales.Se entrevistaron 1.200 individuos adultos, blancos y de sexo masculino, y, a fin de verificar la teoría, se confeccionó un cuestionario que abarcó tres áreas: la orientación básica en materia político económica de los encuestados, la identificación subjetiva del interrogado con una clase social, y la posición objetiva de cada persona según su nivel de vida, ocupación y grado de poder o control ejercido sobre otros. La verificación de la teoría entrañó correlacionar los distintos índices de estratificación con las medidas de conciencia de clase y de ideología político económica.
3. INVESTIGACIÓN TEÓRICA Y EMPÍRICA
Es posible distinguir dos actividades diferentes y complementarias en el ámbito de la investigación científica: la investigación teórica, que compara ideas entre sí, y la investigación empírica, que compara las ideas con la realidad.El escenario clásico de la investigación teórica es la biblioteca, y el de la investigación empírica el laboratorio. En rigor, la gran mayoría de los investigadores desarrollan al mismo tiempo una actividad teórica y empírica, y la diferencia está mas bien en el énfasis en que ponen en cada una de ellas: hay investigadores mas bien orientados hacia la teoría, y otros hacia la experiencia en la realidad.En una aproximación grosera, podemos decir que la investigación teórica es una actividad por la cual relacionamos ideas entre sí, mientras que la investigación empírica se centra en confrontar las ideas con la realidad. Y así, cuando el investigador toma contacto con una idea -sea porque se le ocurrió a él o porque la leyó en algún lado-, tiene a partir de allí dos opciones: relacionar esa nueva idea con otras que ya conoce (investigación teórica), o intentar examinarla o probarla a la luz de los hechos (investigación empírica).
Dentro de la investigación empírica suele distinguirse la investigación de laboratorio y la investigación de campo, según el lugar donde los sujetos son investigados. En la investigación de campo se estudia a los individuos en los mismos lugares donde viven, trabajan o se divierten, o sea, en su hábitat natural. Si se quiere saber cómo influye la televisión en la educación infantil se utilizarán datos sobre niños que ven (o no) televisión en sus hogares. A nadie se le ocurriría encerrar durante meses o años a varios niños en un laboratorio mirando televisión, para ver como evoluciona su educación. Del mismo modo, tampoco se podría provocar un terremoto en una habitación para ver cómo reacciona la gente allí ubicada (salvo que se invente un sofisticado sistema de simulación de sismos, pero esto ya sería costoso): sólo se puede encarar este estudio a través de una investigación de campo,
Página 111 de 314
111

o sea en el lugar natural donde estos fenómenos ocurren. Técnicas típicas de recolección de datos en las investigaciones de campo son las encuestas o la observación participante.La investigación de laboratorio, en cambio, 'saca' a los sujetos de sus lugares naturales, los 'aísla' de su entorno llevándolos a un lugar especial, el laboratorio, y que no necesariamente debe tener azulejos o probetas. Un ejemplo de laboratorio en psicología es la cámara Gesell, o habitación donde por ejemplo se deja jugar libremente a los niños mientras estudiamos sus reacciones a través de un vidrio que permite verlos, y sin que ellos puedan advertir la mirada del investigador. Las investigaciones de laboratorio encuentran su justificación en que permiten aislar el fenómeno de influencias extrañas, de manera tal que, aplicado el estímulo, cualquier cambio en las respuestas ha de deberse con mucha mayor probabilidad a dicho estímulo y no a otras variables extrañas. En la investigación de campo los fenómenos en estudio están más expuestos a estas influencias externas, mientras que en las investigaciones de laboratorio puede aislárselos más de ellas.Téngase presente que también puede introducirse un estímulo en una investigación de campo, es decir, lo que se llama experimento puede realizarse también en este contexto. Refiere Vander Zanden (1986:619) que el experimento puede ser de laboratorio o de campo. En el primer caso se efectúa en un recinto especial para controlar las condiciones con más cuidado. En el segundo se realiza el experimento en el mundo real, introduciendo en la vida cotidiana de las personas la variable independiente.Cierto tipo de investigaciones se prestan para planificarse indistintamente como de laboratorio o de campo. Así, si se quiere saber cómo influyen los ruidos sobre el estrés, hay dos alternativas: a) llevar dos grupos de personas a un lugar especial aislado, donde se los somete a uno a ruidos fuertes y al otro a ruidos débiles, midiendo luego en ambos el estrés resultante (investigación de laboratorio); b) medir directamente el estrés en personas que viven en lugares de mucho ruido y en lugares de poco ruido, para evaluar la diferencia (investigación de campo).
Tomando como ejemplo al creador del psicoanálisis, podemos decir que hay un Freud teórico y un Freud empírico. El primero es el que compara ideas de diversas teorías, o ideas dentro del mismo psicoanálisis. En otras palabras, es un Freud más centrado en examinar relaciones entre ideas, conceptos, hipótesis, teorías, y de aquí que gran parte de la investigación teórica sea investigación bibliográfica (la otra parte no implica contacto con libros, ya que se refiere a la comparación entre ideas nunca publicadas, fruto de la imaginación del científico).El Freud empírico, en cambio, es que está en contacto directo con pacientes en la clínica a los efectos de poder descubrir o probar sus hipótesis, es decir, está más directamente centrado en buscar inspiración en los hechos para construir una teoría o en la confrontación de la teoría con la realidad.Por ejemplo, el Freud teórico (Freud S, 1916) establece una comparación entre los sueños, actos fallidos o actos sintomáticos, con los síntomas neuróticos: al comparar ideas entre sí está haciendo investigación teórica. En cambio el Freud empírico (Freud S, 1909) es el que toma contacto con los pacientes intentando verificar sus hipótesis sobre el síntoma, sobre los sueños o sobre los actos fallidos.En última instancia, la existencia de ambos modos de investigar se justifica a partir de la necesidad de satisfacer dos exigencias igualmente importantes en el conocimiento científico: la coherencia lógica de las ideas (investigación teórica), y la adecuación de las mismas con la realidad (investigación empírica).Centrarse exclusivamente en probar las hipótesis mediante los hechos implica el riesgo de descuidar la conexión lógica entre las mismas hipótesis, con lo cual no puede organizarse el conocimiento en teorías, es decir, en sistemas hipotético-deductivos donde unas ideas están conectadas con otras por deducción. Y al revés, concentrarse exclusivamente en armar una teoría lógicamente coherente mediante la comparación de ideas, implica el riesgo de construir un sistema especulativo que no tiene nada que ver con la realidad, es decir, de armar una teoría perfectamente lógica pero también perfectamente falsa.La relación entre investigación empírica e investigación teórica puede comprenderse mejor a partir de la siguiente secuencia natural del proceso general de la investigación: a partir del examen de los hechos, los científicos emprenden una investigación empírica (típicamente exploratoria) que desembocará en la elaboración de una hipótesis o teoría. Esta a su vez requiere ser verificada, para lo cual se vuelve a realizar una investigación empírica con ese propósito (típicamente explicativa).En este esquema, las investigaciones teóricas aparecen cuando a) un científico se propone comparar hipótesis o teorías entre sí en términos de nivel de verificación, simplicidad, coherencia lógica y otros parámetros, o b) cuando un científico se propone comparar investigaciones empíricas entre sí en términos de capacidad predictiva, nivel de verificación, calidad metodológica y otos parámetros (actividad habitualmente llamada metaanálisis). Para cualquiera de estas actividades, al investigador le basta con la consulta de libros y revistas especializadas, de allí que su tarea sea eminentemente una investigación bibliográfica.La importancia del segundo tipo de estudio teórico, es decir, la ‘investigación sobre investigaciones’ es que pone al descubierto sus fortalezas y debilidades. Por ejemplo (Anónimo, 2005), una revisión de los estudios más importantes publicados entre 1990 y 2003 en revistas científicas influyentes revelaron que casi un tercio de los mismos mostraron resultados contradictorios o débiles. En dicha revisión se indicó que los hallazgos contradictorios y potencialmente exagerados son muy comunes en la investigación clínica, por lo que tanto médicos como pacientes no deben poner tantas esperanzas en un solo estudio porque los tratamientos suelen volverse obsoletos. Por ejemplo, un estudio contradictorio halló que el óxido nítrico no aumentaba la sobreviva de pacientes respiratorios, a pesar de las confirmaciones previas, y que las terapias hormonales de reemplazo para mujeres menopáusicas demostraron tener un efecto adverso como protectores de enfermedades cardiovasculares, cuando antes se había concluido lo contrario. Tampoco la vitamina E logró prevenir los infartos.
4. INVESTIGACIÓN CUALITATIVA Y CUANTITATIVA
Página 112 de 314
112

Cook y Reichardt hacen referencia a dos métodos de investigación: los cualitativos y los cuantitativos. Los autores sostienen al respecto dos cuestiones:
a) El que un investigador utilice uno u otro método no depende del paradigma que sostenga. De hecho, se han utilizado métodos cualitativos dentro de paradigmas cuantitativos, y viceversa. Los autores suministran ejemplos de ello en relación con los diversos ítems que los diferencian (ítems que se indican en el esquema 8). Del paradigma cualitativo se dice que postula una concepción global fenomenológica, inductiva,
estructuralista, subjetiva, orientada al proceso y propia de la antropología social. Del paradigma cuantitativo, en cambio, se dice que posee una concepción global positivista,
hipotético-deductiva, particularista, objetiva, orientada a los resultados y propia de las ciencias naturales.
De acuerdo con algunos autores (Rubio J y Varas J, 1997:237), el método cualitativo opera “en dos momentos: 1) en un primer momento el investigador intenta (mediante grupos de discusión, entrevistas abiertas, historias de vida, etc.) reproducir los discursos de determinado grupo social, comunidad o colectivo. O en su caso, produce o recopila documentos (relatos históricos, biográficos, tradiciones orales, etc.) referidos al ámbito o población en la que se centra la investigación. 2) Posteriormente, se analiza e interpreta la información recogida”.
Esquema 8 – Paradigmas de la investigacion cualitativa y cuantitativa (Cook y Reichardt).
Paradigma cualitativo Paradigma cuantitativoAboga por métodos cualitativos. Aboga por métodos cuantitativos.Fenomenalismo y Verstehen (comprensión): interesado en comprender la conducta humana desde el propio marco de referencia de quien actúa.
Positivismo lógico: busca los hechos o causas de los fenómenos sociales, prestando escasa atención a los estados subjetivos de los individuos.
Observación naturalista y sin control. Medición penetrante y controlada.Subjetivo. Objetivo.Próximo a los datos; perspectiva 'desde dentro'. Al margen de los datos; perspectiva 'desde fuera'.Fundamentado en la realidad, orientado a los descubrimientos, exploratorio, expansionista, descriptivo e inductivo.
No fundamentado en la realidad. orientado a la comprobación, confirmatorio, reduccionista, inferencial e hipotético deductivo.
Orientado al proceso Orientado al resultado.Válido: datos 'reales', 'ricos' y 'profundos'. Fiable: datos 'sólidos' y repetibles.No generalizable: estudios de casos aislados. Generalizable: estudios de casos múltiples.Holista. Particularista.Asume una realidad dinámica. Asume una realidad estable.
b) La oposición radical entre ambos tipos de método no tiene sentido, y resaltan los beneficios potenciales del empleo conjunto de ambos métodos. Se mencionan tres razones por las cuales pueden emplearse conjuntamente ambos métodos: Objetivos múltiples, que obligan a usar diferentes métodos. Los dos métodos pueden vigorizarse mutuamente, brindando cada uno lo que el otro no puede dar. Como ambos métodos tienen prejuicios, sólo cabe llegar a la verdad usando técnicas diferentes con
las que se harán triangulaciones.Usar ambos métodos tiene también sus desventajas: a) puede ser caro, b) puede suponer demasiado tiempo, y c) se puede carecer de adiestramiento en ambos métodos.
5. INVESTIGACIONES PRIMARIA Y BIBLIOGRÁFICA
Un último criterio para clasificar las investigaciones guarda relación con la fuente de los datos consultados. En este sentido, los datos pueden ser clasificados como primarios o secundarios. Los datos primarios son aquellos obtenidos directamente de la realidad por mismo investigador mediante la simple observación o a través de cuestionarios, entrevistas, tests u otro medio. Los datos secundarios son los datos obtenidos de otras personas o instituciones (censos, estudios empíricos de otros investigadores, metaanálisis, etc.). A veces el interés de un investigador recae sobre este segundo tipo de fuentes, y ello por motivos muy diversos: a) no requieren tanto costo y esfuerzo como la obtención de los datos primarios, b) no hay datos primarios disponibles, o c) necesidad de relacionar, sintetizar o integrar diversas investigaciones basadas en datos primarios, tal como ocurre por ejemplo en los llamados metaanálisis. En cualquier caso, el investigador habrá de asegurarse que no hay razones para desconfiar de la verosimilitud de los datos secundarios.Por ejemplo, si un investigador hace un seguimiento de un grupo de pacientes para verificar si un tratamiento farmacológico da resultados, está utilizando datos primarios. En cambio, si un investigador hace una recopilación, una síntesis o una valoración de diversas investigaciones sobre ese tratamiento farmacológico, estará utilizando datos secundarios.
Página 113 de 314
113

En función de lo anterior, es posible entonces clasificar las investigaciones en primarias, si utilizan principalmente datos primarios, y en bibliográficas, si utilizan principalmente datos secundarios, por cuanto la fuente de los datos secundarios se halla en material publicado (libros, revistas, etc.). En la práctica, si bien muchas investigaciones se centran en los datos primarios, pueden también utilizar datos secundarios. Es el caso del médico que además de obtener datos a partir de síntomas y signos (datos primarios), los obtiene a partir de informes de laboratorio clínicos o de comunicaciones de familiares (datos secundarios).
6. CONCLUSIONES
El propósito principal de de la exposición de diversas clasificaciones de las investigaciones es el de proveer un marco de referencia para tipificar una investigación en particular, sea que ya esté realizada, sea que deba aún realizarse. Así, por ejemplo, una determinada investigación puede ser tipificada como pura, explicativa teórica y primaria, si lo que busca es: a) realizar un estudio sobre conocimiento básico, b) suministrar pruebas de vínculos causales, c) elaborar una teoría sobre el tema elegido y d) basarse principalmente en datos obtenidos directamente de la realidad en vez de consultar información secundaria.
Pura Exploratoria Empírica PrimariaBibliográfica
12
Teórica PrimariaBibliográfica
34
Descriptiva Empírica PrimariaBibliográfica
56
Teórica PrimariaBibliográfica
78
Correlacional Empírica PrimariaBibliográfica
910
Teórica PrimariaBibliográfica
1112
Explicativa Empírica PrimariaBibliográfica
1314
Teórica PrimariaBibliográfica
1516
Aplicada Exploratoria Empírica PrimariaBibliográfica
1718
Teórica PrimariaBibliográfica
1920
Descriptiva Empírica PrimariaBibliográfica
2122
Teórica PrimariaBibliográfica
2324
Correlacional Empírica PrimariaBibliográfica
2526
Teórica PrimariaBibliográfica
2728
Explicativa Empírica PrimariaBibliográfica
2930
Teórica PrimariaBibliográfica
3132
El esquema intenta ordenar 32 tipos de investigación combinando algunos de los criterios de clasificación propuestos. En el mismo no se ha considerado el criterio que las clasifica como cualitativas y cuantitativas, principalmente porque en rigor toda investigación tiene en mayor o menor medida algo de ambos aspectos. Por ejemplo, en las investigaciones exploratorias tiende a predominar el aspecto cualitativo, y en las investigaciones correlacionales o explicativas el aspecto cuantitativo.Debe tenerse presente, por último, que estos ‘tipos’ de investigación no suelen encontrarse en la práctica en estado puro: una investigación típica no suele solamente primaria y empírica sino también bibliográfica y teórica, por cuanto es habitual que esté precedida por una revisión de la literatura y pueda incluir alguna consideración acerca de la teoría de base. Si fue clasificada como primaria y empírica es al solo efecto de destacar que tales fueron sus propósitos principales.
Página 114 de 314
114

CAPÍTULO 8: CAUSALIDAD Y EXPERIMENTO
Antes de comenzar a describir las etapas de la investigación típica que constituyen la esencia de la metodología de la investigación, será conveniente incursionar brevemente en los conceptos de causalidad y experimento para comprender mejor el resto del libro.Típicamente el experimento es el dispositivo creado por el investigador para probar una relación causal y cabe enmarcarlo, en ese sentido, dentro de una investigación explicativa. En el presente capítulo se enfocará la causalidad desde un punto de vista más metodológico que epistemológico, es decir, atendiendo a las maniobras que realiza el investigador para probar la causalidad y no al concepto de causalidad en sí tal como es utilizado en tanto referente teórico de la actividad científica. Se hará también una breve reseña histórica de los métodos de Stuart Mill, importante antecedente de las actuales concepciones de causalidad y experimento.
1. CAUSA Y CAUSALIDAD
Unicausalidad y policausalidad
Respecto de la causalidad se pueden sustentar tres posiciones distintas: a) todo fenómeno tiene una sola causa (principio de unicausalidad); b) algunos fenómenos se deben a una sola causa, pero otros a varias; y c) todo fenómeno obedece a muchas causas (principio de policausalidad).El sentido común sostiene habitualmente la primera postura. En la vida cotidiana las personas suelen basarse en este supuesto cuando afirman o creen en enunciados tales como "coma manzanas y adelgazará", o "si estoy enojado se debe simplemente a que usted me hizo enojar", etc., o bien "no aprobé el examen porque el profesor se ensañó conmigo". Si las personas se mantienen en esta ilusión de la única causa se debe probablemente a que, entre otras razones, en la fantasía podrán controlar la ocurrencia o la no ocurrencia de los acontecimientos dominando un solo factor, o sea de la forma más sencilla. Si alguien piensa que se resfrió simplemente porque se desabrigó, podrá supuestamente controlar el resfrío abrigándose bien.La psicología conoce bien esta tendencia. De Vega refiere que “el hombre de la calle utiliza un ‘principio de parsimonia’ intuitivo cuando busca explicaciones causales a los fenómenos. Tendemos a sobreestimar el valor de las atribuciones unicausales, a conformarnos con una sola causa plausible, minimizando otras causas concurrentes” (De Vega, 1984).
El principio de unicausalidad es utilizado también tendenciosamente para manipular la opinión pública y difundir información falsa. Cierto ministerio argentino sugiere la idea que diversas afecciones tumorales y cardíacas están ‘causadas’ por el cigarrillo. Hace ya mucho tiempo que la ciencia abandonó la idea de la causa única. Ningún fenómeno, por más sencillo que sea, tiene una sola causa. En las afecciones indicadas intervienen gran cantidad de factores que, cuando se dan juntos, producen la enfermedad. Por lo tanto, esta ocurre cuando la persona fuma, tiene una cierta disposición genética a contraer cáncer, cuando tiene altos niveles de colesterol, sobrepeso o estrés, entre otros. Esto explica porqué personas que no son fumadores activos ni pasivos tienen cáncer, y personas que fumaron siempre no contraen cáncer.Es probable que la no referencia al estrés, al smog ni al sobrepeso se deba a que el mismo Estado es en parte responsable del estrés de los ciudadanos y del smog circulante, y a que algunos funcionarios encargados de planificar estrategias preventivas padecen ellos mismos de sobrepeso. En suma: el cigarrillo parece cargar con toda la culpa de cánceres e infartos quedando en la penumbra los demás factores indicados, con lo cual queda desvirtuada la realidad de las cosas.
Sin embargo, cuando se empieza a advertir que las cosas no son tan sencillas se comienza a sostener insensiblemente la segunda postura, pero la tercera posición ya es sustentada por la actitud científica. Años de investigaciones enseñan que la realidad es bastante más compleja de lo que se supone y que cualquier fenómeno, por simple y anodino que parezca, obedece a muchas causas que actúan conjuntamente para producirlo. Se podría pensar que la rotura de un vidrio tiene una sola causa: la piedra arrojada contra él. Este acontecimiento obedece sin embargo a muchas razones que intervienen simultáneamente: el arrojar la piedra, su dureza, su trayectoria, su velocidad, la fragilidad del vidrio, el propio instinto de agresión, etc. etc. Conocí un niño que habiendo roto una ventana, se justificó diciendo "qué culpa tengo yo si el vidrio es frágil". Podría también haber dicho, apelando a otra posible causa, "qué culpa tengo yo si el vidrio se interpuso en la trayectoria de la piedra".En suma: si se pretende ser un poco objetivo, debe admitirse que la realidad es compleja y aceptar que un fenómeno responde a una multiplicidad de causas que, actuando conjuntamente, producirán el fenómeno en cuestión. Pero, debido a que tampoco conocemos todas las causas que lo producen, sólo podremos decir que la intervención de las causas conocidas simplemente aumenta mucho la probabilidad de que el fenómeno ocurra.Cabe, por último, una pregunta: ¿si los científicos aceptan el principio de policausalidad, porqué muchas investigaciones científicas consideran sólo una causa? Es posible citar dos razones importantes: a) es imposible poner a prueba simultáneamente todas las causas posibles (entre otras cosas porque se desconocen), por lo que el científico decide probar uno por uno cada factor causal en investigaciones separadas e independientes; b) al científico suelen interesarle, por razones prácticas, sólo ciertos factores causales y en ocasiones uno solo. Sostenía Freud (1915) que en la causación de la neurosis intervienen varias causas, como los factores constitucionales heredados y los conflictos sexuales infantiles. Freud, sin
Página 115 de 314
115

Tranquilidad (X) Aprobar (Y)
Haber estudiado (X)
Profesor tolerante (X)
embargo, se centró en este último factor, porque ese era su interés, aunque, por lo demás, poco podía estudiarse sobre el factor constitucional en aquel entonces.
Si bien los científicos suponen el principio de causalidad múltiple, intimamente anhelan a buscar una única causa y, en el caso de los físicos, una única fórmula que permita explicar el todo. Newton unificó la mecánica terrestre con la mecánica celeste creando su mecánica clásica. Maxwell unificó la electricidad y el magnetismo en su teoría del electromagnetismo, aunque no pudo resumirlo en una sola fórmula sino en cuatro. Einstein unificó la teoría de la gravedad de Newton y su propia teoría sobre la velocidad de la luz en su teoría general de la relatividad o teoría del espacio-tiempo, y hasta el final de sus días intentó unirla a su vez con el electrognetismo con la esperanza que lograr la fórmula que lo explicase todo, pero no lo logró.De todas maneras tampoco lo iba a explicar todo porque aún quedaba por incluir esa realidad subatómica infinitamente pequeña de la que daba cuenta la teoría cuántica, que siempre Einstein ignoró olímpicamente porque no tenía nada que ver con su visión determinista del universo.El estudio de las realidades infinitamente pequeñas como las fuerzas nucleares fuertes y débiles mostró que la gravedad misma no era una fuerza tan intensa: si un objeto cae desde un décimo piso no sigue cayendo hasta el centro de la tierra porque lo detendrá un pavimento, compuesto por átomos unidos por fuerzas nucleares fuertes y débiles, que, entonces, son capaces de detener la fuerza gravitacional.Hoy en día los físicos buscan todavía una teoría que lo unifique todo: la relatividad general y la mecánica cuántica o, si se quiere, una fórmula que sintetice las cuatro fuerzas fundamentales de la naturaleza: la fuerza nuclear fuerte, la fuerza nuclear débil, el electromagnetismo y la gravedad, y parece que un candidato potable es la teoría de las cuerdas, supuestamente elaborada por físicos igualmente cuerdos. Según esta teoría toda la realidad, desde las mínimas partículas terrestres hasta las estrellas más lejanas, están compuestas del mismo ‘material’: cuerdas increíblemente pequeñas que vibran de diferentes maneras, diferencias que dan lugar a los distintos tipos de partículas hasta ahora descubiertas por los físicos.
Hacia una definición de causa
Dentro de este principio de policausalidad es posible ahora intentar una definición de causa en los siguientes términos.Según el supuesto de la policausalidad, un efecto es producido por varias causas. Las causas que determinan aprobar un examen son varias: haber estudiado, no estar nervioso, un profesor tolerante, etc. Esquemáticamente, X representan las causas, e Y el efecto:
Indudablemente que estudiar es una condición necesaria, pero aún no es suficiente para aprobar, pues puede ocurrir que los nervios nos traicionen o el profesor sea muy exigente. Otro tanto podemos decir de los otros factores: tener un profesor tolerante es condición necesaria pero no suficiente, pues además debemos haber estudiado y no estar nerviosos. Del mismo modo, la sola intervención del factor tranquilidad, si bien necesario, no alcanza a ser suficiente por los mismos motivos anteriores. Nuestra primera conclusión es entonces esta: cada uno de los factores causales, considerados en forma independiente, son una condición necesaria pero no suficiente.Sin embargo, si ahora en vez de considerarlos independientemente los consideramos “conjuntamente”, las cosas cambian, porque si todos esos factores se dan juntos entonces aprobamos el examen. Todos ellos juntos son entonces una condición suficiente, lo que nos lleva a nuestra segunda conclusión: si consideramos a los factores causales conjuntamente, funcionan como condición suficiente. De todo lo dicho se desprende que una condición suficiente es el conjunto de todas las condiciones necesarias.En general, por causa entenderemos toda condición necesaria y suficiente para que ocurra un fenómeno. Condición necesaria es aquella que si no está, el efecto no se produce. Estudiar es condición necesaria porque si no estudiamos, no aprobamos. Del mismo modo cierta capacidad mental es condición necesaria para el aprendizaje (una piedra no puede aprender), y también es condición necesaria para ser drogadicto haber tenido alguna experiencia con drogas.En cambio una condición suficiente es aquella que si está, el fenómeno se produce. Condición suficiente es la suma de estudiar, estar tranquilo y tener un profesor tolerante, pues si se dan estos tres factores aprobamos. Podemos decir también que una condición suficiente para la ceguera es la destrucción del nervio óptico, o que un conflicto grupal es condición suficiente para su bajo rendimiento.En la investigación científica, las condiciones necesarias son importantes porque permiten excluir factores irrelevantes, y las condiciones suficientes porque permiten incluirlos.
Página 116 de 314
116

Selltiz, Wrightsman, Deutsch, y Cook (1980) dicen que en la práctica es, sin embargo, muy difícil encontrar condiciones necesarias y suficientes: la destrucción del nervio óptico no es la única condición necesaria y suficiente para la ceguera, pues ésta puede existir aún cuando no se haya destruido dicho nervio, o sea, puede haber otras condiciones distintas que produzcan este efecto. Por ello el científico debe buscar una constelación de otras posibles causas (además de la necesaria y suficiente), y que suelen clasificarse como condiciones contribuyentes, contingentes y alternativas. Veamos un ejemplo, tomado de los autores mencionadosEs condición necesaria y suficiente de la drogadicción el hecho de no poder el sujeto suspender voluntariamente el consumo de drogas: si no puede suspender este consumo el sujeto es drogadicto, pero nadie que investigue sobre las causas de la drogadicción se puede conformar con esta única explicación. Buscará entonces causas contribuyentes (ausencia de padre), contingentes (el habitual consumo de drogas en el barrio), y alternativas (presencia de un padre hostil).Condición contribuyente es aquella que aumenta las probabilidades de ocurrencia del fenómeno, pero no lo hace seguro. La ausencia de padre aumenta las probabilidades que el adolescente sea drogadicto.Sin embargo, esta condición contribuyente podrá funcionar efectivamente como causa siempre y cuando en el barrio el consumo de droga sea habitual (condición contingente). Y así, una condición contingente es una situación especial en la cual la condición contribuyente puede realmente actuar como causa. En suma: en las vecindades donde el uso de drogas está generalizado (condición contingente), la ausencia del padre del adolescente (condición contribuyente), contribuye o ayuda a aumentar las probabilidades de que el muchacho sea drogadicto. Decimos que ‘aumenta’ su probabilidad pero no lo hace 100% seguro, porque además el sujeto debe no poder desprenderse voluntariamente de su hábito (condición suficiente).La condición contribuyente (ausencia del padre) tiene una condición alternativa (presencia de un padre que trata en forma hostil o indiferente al sujeto). En rigor esta última es también una condición contribuyente en tanto también aumenta la probabilidad que el hijo sea drogadicto. Lo que interesa entonces destacar acá, según nuestro parecer, es que si una condición contribuyente tiene alguna condición alternativa que es también capaz de producir el fenómeno, entonces aumentan aún más las probabilidades de que este ocurra pues ambas condiciones cubrieron todo o casi todo el espectro de posibilidades de la situación del padre.
Requisitos de causalidad
En toda investigación explicativa lo que se hace es una prueba de causalidad, y para poder probar que realmente la relación X-Y es causal deben cumplirse obligatoriamente tres requisitos:1) Variación concomitante (correlación).- X (causa) e Y (efecto) deben variar conjunta o concomitantemente. Sin embargo, hay muchas situaciones donde dos variables aparecen estadísticamente correlacionadas, pero que sin embargo, carecen de todo vínculo causal. Por ejemplo, pues puede ocurrir que X e Y varíen en el mismo sentido sólo porque son ambas efectos de una causa desconocida Z. Evidentemente puede haber una alta correlación entre el hecho de que un profesor comience una clase a las 20 horas y otro, en la misma aula, lo haga a las 22 horas, pero ello no significa que la primera situación sea la causa de la otra. En estos casos, ambas variables dependen de una tercera, que es la organización horaria de la universidad.De la misma manera, hay una alta correlación entre los hechos “amanece en Buenos Aires” y “amanece en Chile”, ya que cada vez que amanece en Buenos Aires, poco después también amanece en Chile. Sin embargo, nadie se animaría a decir que lo primero es la causa de lo segundo. La tercera variable de la cual dependen ambas es, en este caso, la rotación de la tierra.Existe cierta tendencia muy humana a considerar que las simples correlaciones estadísticas indican una relación causal. Antiguamente, se pensaba que cuando ocurrían ciertos fenómenos como un viento que soplaba del este, el resultado era que a los nueve meses se producía el nacimiento de un hijo, ya que se había atendido a la correlación viento-nacimiento. Obviamente se trata este de un caso de correlación sin causalidad, ya que el viento, si bien podía estar asociado por un nacimiento, nadie hoy en día diría que el viento es la causa del mismo. Y es que a nadie se le había ocurrido por entonces relacionar el coito con el nacimiento: hoy sabemos que la relación coito-nacimiento no sólo es una correlación sino que además también es un vínculo causal.
Alternativamente, puede ocurrir que X e Y no aparezcan en un primer momento correlacionadas, pero ello no significa que no estén conectadas causalmente, ya que otras variables que no podemos controlar en ese momento pueden estar distorsionando la correlación subyacente (como por ejemplo errores de medición). Estas situaciones especiales no deben hacernos pensar que puede haber causalidad sin correlación: allí donde hay causalidad siempre ha de haber correlación, aunque ésta pueda aparecer encubierta.
La existencia de una correlación (encubierta o no) es condición necesaria para que hay un vínculo causal, pero aún no suficiente, porque además deben cumplirse los restantes dos requisitos.2) Ordenamiento temporal.- Para que X sea causa de Y es preciso que la causa X ocurra cronológicamente antes que el efecto Y, o por lo menos simultáneamente con él. No se rompe primero el vidrio y después tiramos la piedra. Robert Koch, bacteriólogo alemán, bromeaba con que había un solo caso donde la causa sigue al efecto, y es cuando el médico va detrás del féretro de su paciente.
Página 117 de 314
117

3) Eliminación de otros posibles factores causales.- Para que X sea causa de Y es preciso haber constatado que no hay otras causas ejerciendo influencia sobre el efecto Y. Si la tarea de establecer la correlación era propia de una investigación descriptiva, el trabajo de eliminar la influencia de otros posibles factores causales es ya lo más característico de una investigación explicativa. En este contexto, los experimentos son los dispositivos más aptos para ejercer un control sobre las variables extrañas.
2. EL EXPERIMENTO
Definición
En un sentido amplio, es toda modificación introducida deliberadamente en la realidad con el fin de examinar sus efectos o consecuencias. Ejemplo: cuando un niño intenta averiguar si su llanto atrae a su mamá, está realizando un experimento. Un tipo especial de experimento es el experimento científico, donde se manipula una variable con el fin de examinar sus efectos en otra variableClásicamente, un experimento es un dispositivo para probar un vínculo causal, para lo cual: a) el investigador hace intervenir deliberadamente la posible causa (variable independiente) para ver si influye sobre el efecto (variable dependiente), y b) al mismo tiempo controla la incidencia de otras posibles causas (variables extrañas). Si estas otras causas no influyen o están controladas, entonces aumenta la presunción de que lo que hizo variar el efecto fue la única causa que se hizo intervenir deliberadamente. En suma: un experimento es una situación provocada y controlada.O´neil (1968) da una excelente definición de experimento cuando dice que es un modelo particular de variación y constancia, es decir, en todo experimento se hace variar X para ver cómo varía Y, mientras se mantienen constantes todos los otros posibles factores extraños.
La investigación explicativa puede denominarse, según Hyman, teórica o experimental. Este autor parece considerar como sinónimos ambos términos, pero a nuestro criterio cabe hacer una diferencia: en la investigación experimental buscamos confrontar una hipótesis con la realidad, mientras que en la investigación teórica buscamos confrontar hipótesis entre sí.Según el mismo autor (1984:100), además del propósito teórico o experimental, una investigación explicativa puede apuntar a objetivos más prácticos, de aquí que también existan, de acuerdo a denominaciones de Hyman, estudios explicativos de diagnóstico, de predicción, y de evaluación o programáticos. En este texto centraremos nuestra atención en la tarea principal: la prueba de la hipótesis causal.En otro orden de cosas, si bien lo que caracteriza la investigación científica es la identificación de las causas de los fenómenos, en nuestras investigaciones cotidianas –no científicas- muchas veces no nos tomamos esta molestia. De hecho, podemos resolver muchos problemas sin conocer las causas que los ocasionan, como por ejemplo: a) Golpeamos duramente el teléfono… y anda!!!; b) Reemplazamos un electrodoméstico que no anda por otro que sí funciona; c) Si la PC anda mal muchos técnicos ni se preocupan por averiguar la causa: directamente formatean el disco rígido y reinstalan todos los programas. Estas actitudes son también observables en los ámbitos que suponemos científicos: la esquizofrenia o la epilepsia puede curarse con un electroshock, lo que no presenta gran diferencia con arreglar un teléfono golpeándolo.
Campbell y Stanley (1995:9) definen un experimento como aquella "parte de la investigación en la cual se manipulan ciertas variables [llamadas variables experimentales] y se observan sus efectos sobre otras [llamadas variables dependientes]". En todo experimento se debe tomar la precaución de que sobre la variable dependiente no influya ningún otro factor (que los autores llaman variable externa), para poder estar razonablemente seguros que el efecto producido se debe a la variable experimental. Finalmente, se tomarán ciertos otros recaudos que aseguren que los resultados del experimento podrán generalizarse a toda la población.Consiguientemente, los tres tipos de variables involucradas en un experimento son:a) Variable experimental: Variable que se manipula para conocer cuales son sus efectos sobre otra. Campbell y Stanley también suelen referirse a ella con el nombre de estímulo experimental, y se la designa con la letra X.b) Variable dependiente: Variable sobre la cual supuestamente influye la variable experimental, y suele designársela con la letra Y. Campbell y Stanley no utilizan estas denominaciones, y suelen referirse a las variables dependientes como los 'efectos' que se observan o miden (por ello las designan con la letra O, que indica un proceso particular de observación o medición).Por ejemplo, cuando los autores mencionados esquematizan un diseño en la forma O1--X--O2, están queriendo decir que primero se observa o mide la variable dependiente (O1), luego se aplica el estímulo experimental (X), y finalmente se observa o mide si hubo o no algún cambio en la variable dependiente (O2).c) Variable externa: Variable que, de no ser controlada en el experimento, podría generar efectos que se confundirían con el del estímulo experimental (Campbell y Stanley, 1995:17). Campbell y Stanley suelen también referirse a ellas con el nombre de hipótesis rivales (Campbell y Stanley, 1995:20), mientras que otros autores como Selltiz y otros (1965) las llaman hipótesis alternativas. Algunos autores (Arnau Gras J, 1980) llaman a las variables externas, variables 'extrañas', que es la denominación que se utilizará preferentemente en este libro.Mediante un breve ejemplo se puede ilustrar el papel de las variables experimentales, dependientes y extrañas. Si quisiéramos hacer un experimento para probar cierto método educacional correctivo, podríamos aplicarlo a un grupo de alumnos durante un tiempo, y luego observar y medir la mejoría producida. Sin embargo, puede ocurrir que la mejoría no obedezca al método correctivo empleado, sino a un factor de maduración que hizo que durante el tiempo que duró la experiencia los alumnos hicieron
Página 118 de 314
118

una remisión espontánea de sus dificultades escolares. La hipótesis que sostiene que la mejoría obedece a una remisión espontánea se convierte así en una hipótesis rival que compite con la hipótesis de investigación (que dice que la mejoría es debida al método correctivo).En este ejemplo, la variable experimental es el método correctivo, la variable dependiente es la mejoría de los alumnos, y la variable externa es la maduración. Se hace preciso controlar la influencia de esta última variable, porque de otro modo no podríamos saber si la mejoría obedeció a ella o al método correctivo.Téngase presente entonces, que la variable independiente (VI) se manipula, la variable dependiente (VD) se mide, y la variable extraña o externa (VE) se controla. Son tres operaciones diferentes: cuando se manipula la VI se ha hace variar a voluntad del investigador, y para ver si produce algún efecto sobre la VD, esta deberá ser medida. Al mismo tiempo, se procurará anular la influencia de las VE, es decir, se las controlará.
Medición de la variable dependiente
En algunos experimentos la variable dependiente se mide antes y después de la aplicación de la variable independiente, para constatar si hubo alguna variación en ella. En otros, se mide solamente después. En un sentido muy amplio, las variables independientes también se miden, entendiendo medición como asignación de una categoría. Precisamente cada categoría de la variable independiente suele denominársela tratamiento experimental.
Manipulación de la variable independiente
Hay dos formas de manipular la variable independiente: cuando el investigador provoca la variación de la variable está haciendo una manipulación de facto, mientras que cuando selecciona variaciones ya producidas naturalmente está haciendo una manipulación ex post facto, expresión latina que significa "después de ocurrido el hecho". Esta terminología se propone en este libro. Muchas veces la VI se manipula ex post facto por existir cuestiones prácticas o éticas que impiden la manipulación de facto. También depende del tipo de investigación experimental emprendido: en las investigaciones de laboratorio se realizan manipulaciones de facto, mientras que en las investigaciones de campo pueden realizarse ambos tipos de manipulación.Ejemplo 1) Para estudiar la incidencia del estado civil de los padres en la condición de drogadicción filial, se seleccionan de la población dos grupos: uno de padres casados y otro de padres divorciados. Se trata de una manipulación ex post facto, porque los padres ya estaban casados o divorciados antes del estudio. Si hipotéticamente se hubiera realizado una manipulación de facto, el investigador habría pedido a ciertos padres que se divorciaran para ver la incidencia de este estado civil en la drogadicción de los hijos. Nótese la diferencia: en el segundo caso se ha "provocado" deliberadamente el divorcio, mientras que en el primero se han "seleccionado" casos de divorcio ya ocurridos naturalmente.Ejemplo 2) La indagación de la relación ruido-hipoacusia puede llevarse a cabo como investigación de campo o como investigación de laboratorio. En este último caso se lleva a los sujetos a un lugar especial -el laboratorio- y un grupo es expuesto a los ruidos y el otro no (manipulación de facto). En la investigación de campo, en cambio, los ruidos o los no-ruidos ya están en los lugares naturales donde la gente vive (manipulación ex post facto), con lo cual bastará con seleccionar el grupo experimental en la población con ambiente ruidoso, y el grupo de control en la población de entorno más silencioso.Ejemplo 3) Como tercer ejemplo se pueden mencionar investigaciones que indagan la influencia del método de aprendizaje de lectoescritura (variable independiente) sobre el rendimiento del alumno en lectoescritura (variable dependiente). Concretamente, se trata de averiguar si es más eficaz el método silábico o el método global, eficacia medible a partir de los respectivos rendimientos de los alumnos.Una investigación como la descrita puede realizarse, de dos maneras: a) Manipulación ex post facto: se seleccionan alumnos o ex-alumnos de escuelas donde ya se hayan implementado los método silábico y global, y se procede a comparar los respectivos rendimientos. b) Manipulación de facto: se seleccionan dos escuelas y se les propone aplicar, desde el comienzo del ciclo lectivo, una el método silábico y otra el método global, y después de uno o dos años se analizan los rendimientos de los alumnos en cada una de esas instituciones educativas.A este último tipo de manipulación pueden oponérsele objeciones de tipo ético, porque se está exponiendo a la población de una de las escuelas a un método que considerado ineficaz y por ende perjudicial para los propósitos educativos.Ejemplo 4) Un ejemplo de manipulación de facto en una investigación de campo ocurrió durante el "experimento" llevado a cabo por Orson Welles (aunque su intención no haya sido hacer una investigación sino lograr un efecto espectacular), cuando un buen día se le ocurrió transmitir por la radio una falsa noticia: estaban descendiendo platillos voladores en las afueras de la ciudad, y los extraterrestres se acercaban amenazantes para invadir el planeta. Durante mucho tiempo se comentó el descomunal efecto que produjo en la gente, que huyó despavorida y hubo incluso algunos suicidios. Se trata de un ejemplo donde la manipulación de la variable independiente (invasión extraterrestre) fue ejercida de facto, es decir, se provocó su presencia deliberadamente, y terminó ejerciendo su influencia sobre la variable dependiente (conducta de la población) en la forma indicada.
Grupo experimental y grupo de control
Página 119 de 314
119

Muchos experimentos comparan dos grupos. Una vez extraída una muestra de una población, dentro de la misma se seleccionan al azar dos grupos: el grupo experimental y el grupo de control. Se llama grupo experimental al que se somete a la influencia del posible factor causal que interesa (X), o sea a la influencia de la variable independiente o experimental, y se llama grupo de control a cualquier otro grupo usado como referencia para hacer comparaciones. Habitualmente los grupos de control son aquellos a los que no se somete a la influencia del posible factor causal. Ejemplo: a los efectos de investigar el estrés, el grupo experimental es el sometido a distintas intensidades de ruidos, y el grupo de control no. Otra posibilidad sería que a los diferentes grupos se los sometiera a diferentes intensidades de sonidos, en cuyo caso todos serían experimentales porque recibirían la influencia de X, pero al mismo tiempo serían grupos de control porque permitirían establecer comparaciones.Por último, hay investigaciones donde se utiliza un solo grupo. En estos casos, este grupo funcionará como grupo experimental cuando recibe la influencia de X, y en otro instante de tiempo funcionará como grupo de control cuando no recibe esa influencia.
Experimento y no experimento
Un experimento implica siempre en mayor o menor medida crear una situación controlada, donde mantenemos constantes ciertos factores y hacemos variar otros. Pero a veces, para probar una hipótesis, no podemos recrear una tal situación, y debemos esperar a que ocurra espontáneamente. Esto se aplicaría por ejemplo en el caso de querer verificar la hipótesis de la periodicidad de las manchas solares o de los eclipses, en cuyo caso no tenemos otro remedio que esperar una determinada fecha para ver si se producen o no, y para colmo tampoco se pueden mantener constantes todos los otros posibles factores extraños.En cambio si lo que se quiere es verificar la temperatura de ebullición del agua, aquí sí se puede crear una situación donde se pone a hervir agua y se comprueba con un termómetro a qué temperatura se transformará el vapor, manteniendo al mismo tiempo constantes otros factores como presión atmosférica, cantidad de solutos disueltos, etc. Esta última es, entonces, una investigación claramente experimental, mientras que el caso anterior del eclipse corresponde a una investigación no experimental.
Limitaciones del experimento
En las investigaciones no experimentales debe esperarse a que ocurra el fenómeno para luego estudiarlo, y por ello se las llama también investigaciones ex-post-facto (después de ocurrido el hecho). No es costumbre provocar la drogadicción para estudiar luego sus consecuencias, así como tampoco se suele provocar un plenilunio (luna llena) para ver cómo influye sobre el comportamiento criminal de las personas, con lo cual en estos dos últimos casos no puede emplearse un experimento.Realizar experimentos en ciencias sociales presenta algunas dificultades especiales: a) experimentar con seres humanos suele tener una limitación ética. La alternativa podría ser encarnizarse con animales no humanos, pero aquí surge otra dificultad: puede desconocerse hasta qué punto las conclusiones obtenidas sobre animales son extensibles a los seres humanos. De hecho este problema se presenta aún en ciencias biológicas, cuando se investigan nuevas drogas para curar enfermedades; b) el ser humano es particularmente complejo, y por lo tanto puede resultar problemático que un experimento pueda controlar una mayor cantidad de variables extrañas.
Experimento y diseño experimental
El diseño experimental es un plan general para hacer un experimento, de la misma manera que el plano de una casa es un plan para construirla. O’neil (1968) define experimento como un modelo particular de variación y constancia, definición aplicable también al diseño experimental. Es particular porque se aplica a una muestra concreta, no a toda la población, con lo cual luego deberá resolverse si las conclusiones obtenidas para la muestra son igualmente aplicables a toda la población, tarea que competerá a la estadística inferencial.También es un modelo de variación, porque el experimento consiste en hacer variar la variable independiente X para ver si también varía la variable dependiente Y. Es también un modelo de constancia porque al mismo tiempo que se hace variar las variables principales se deben controlar la influencia de las variables extrañas, lo que puede hacerse manteniéndolas en valores constantes.
Validez interna y validez externa del experimento
Es posible probar dentro de los estrechos límites del laboratorio que el ruido produce estrés (validez interna), pero, ¿la conclusión es aplicable a todas las otras personas que no participaron del experimento (validez externa)?Siguiendo cierta nomenclatura clásica, se dice que un experimento tiene "validez interna" cuando puede probar, con cierto margen de confiabilidad, que X es la causa de Y, y que el efecto Y no obedece a otros factores tales como el azar o la influencia de variables extrañas. Asimismo, se dice que un experimento tiene "validez externa" cuando sus resultados pueden, también con cierto margen de confiabilidad, generalizarse a toda la población, es decir, cuando hay una cierta seguridad que durante el experimento no están ejerciendo influencia ciertos factores que, se supone, tampoco actúan en la población. Validez
Página 120 de 314
120

externa es, entonces, sinónimo de representatividad de la muestra experimental, y su importancia reside en que la representatividad permite la generalización y ésta, a su vez, aumenta la capacidad predictiva de la hipótesis.
En los términos de Campbell y Stanley, la validez interna es la "mínima imprescindible, sin la cual es imposible interpretar el modelo: ¿introducían, en realidad, una diferencia los tratamientos empíricos en este caso experimental concreto?. [Por su parte], la validez externa "plantea el interrogante de la posibilidad de generalización: ¿a qué poblaciones, situaciones, variables de tratamiento y variables de medición puede generalizarse este efecto?" (Campbell y Stanley, 1995:16). Por consiguiente, de acuerdo a Campbell y Stanley las variables 'externas' conciernen a la validez 'interna', aclaración que hacemos para evitar que el lector se confunda al respecto (razón por la cual se prefiere en este libro la denominación variable extraña).
Arnau Gras indica que "el problema surge cuando se produce una incompatibilidad entre ambos tipos de validez. En efecto, los controles que se utilizan para asegurar la validez interna tienden a comprometer la validez externa, es decir, a medida que se aumentan las restricciones sobre la situación experimental, desfiguramos totalmente el contexto y limitamos automáticamente la representatividad de la misma. Esto llevará, sin duda, a preguntarse, en el caso que se hallen comprometidos los dos tipos de validez, cuál de los dos deberá prevalecer. Según Campbell (1957), la respuesta es clara: deberá darse prioridad a la validez interna. Siempre será mejor para la ciencia conseguir probar hipótesis que sacrificarlas en aras de generalizaciones vagas o imprecisas" (Arnau Gras J, 1980:350-352).No obstante, debe tenerse presente que Campbell y Stanley siguen considerando como objetivos dignos de alcanzar a los diseños ricos en una y otra validez. "Así ocurre, particularmente, respecto de la investigación sobre métodos de enseñanza, donde el desiderátum será la generalización a situaciones prácticas de carácter conocido" (Campbell y Stanley, 1995:17).Finalmente, ¿hasta qué punto pueden resolverse los problemas de la validez interna y la validez externa en un diseño experimental? Al respecto, Campbell y Stanley señalan que mientras "los problemas de validez interna son susceptibles de solución dentro de los límites de la lógica de la estadística probabilística, los de validez externa no pueden resolverse en estricto rigor lógico en una forma nítida y concluyente" (Campbell y Stanley, 1995:39), habida cuenta de que, como dijo Hume, 'la inducción o generalización nunca tiene una plena justificación lógica', es decir, los resultados del experimento no pueden generalizarse concluyentemente a toda la población.Campbell y Stanley sugieren una solución a este problema de validez externa, que consiste en procurar la máxima similitud entre experimentos y condiciones de aplicación (que sea compatible con la validez interna), por cuanto la generalización resulta más 'válida' cuanto más se asemeje la situación experimental y la situación con respecto a la cual se desea generalizar. El fundamento de este procedimiento se encuentra en la hipótesis de Mill acerca de la legalidad de la naturaleza, y que Campbell y Stanley describen como el supuesto del 'aglutinamiento': "cuanto más cercanos se hallan dos acontecimientos en tiempo, espacio y valor..., más tienden a ajustarse a las mismas leyes" (Campbell y Stanley, 1995:40).
Las variables extrañas
Cuando se intenta averiguar si X es la causa de Y casi siempre existe la sospecha de que hay otras variables ajenas al experimento en sí que pueden estar ejerciendo también influencia sobre Y, y entonces podrá ocurrir que Y varía por influencia de esas otras variables ajenas y no por X. Por lo tanto, deben ‘anularse’ al máximo estas influencias extrañas para saber si realmente la variación de Y se debe o no a X. Si por caso el interés está en averiguar la influencia causal de la educación (X) sobre la inteligencia (Y), se procurará anular la influencia de variables extrañas como por ejemplo la alimentación, pues cabe la sospecha que la inteligencia también depende de ella. Nótese que se trata de una simple anulación metodológica pues no se está anulando la condición causal de la alimentación como tal, sino sólo su influencia (de hecho, los niños del experimento continúan alimentándose).Las variables extrañas también han sido denominadas variables de control, factores de prueba, etc. y ha sido representada con diversos símbolos: con la letra “t” (Hyman, 1984:346), con la letra "z" (Blalock (1982:26), etc., adaptándolas a contextos particulares.Las variables extrañas han sido clasificadas de diversas maneras, de las cuales se explicarán dos: a) las variables pueden ser organísmicas y situacionales, según dependan de los individuos o de la situación, y b) las variables extrañas (Campbell y Stanley, 1995) pueden ser fuentes de invalidación interna o fuentes de invalidación externa, según estén afectando, respectivamente, la validez interna o la validez externa.
a) Variables extrañas organísmicas y situacionales.- Las variables organísmicas son factores que dependen del sujeto mismo, tales como sus experiencias pasadas y los cambios debidos a la maduración o al desarrollo. Si se quiere indagar la influencia de los premios o castigos (X) sobre el aprendizaje (Y), puede ocurrir que el sujeto aprenda mejor debido a sus cambios madurativos (variable extraña) y no a los refuerzos, sobre todo si el experimento implica un seguimiento de niños muy pequeños a lo largo de varios meses. Del mismo modo, si se quiere conocer la influencia del ruido (X) sobre el estrés (Y), puede ocurrir que ciertos sujetos sean hipersensibles a los ruidos por alguna experiencia traumática o simplemente por factores constitucionales, y entonces revelen mayor nivel de estrés debido a su hipersensibilidad (variable extraña).
Página 121 de 314
121

Las variables situacionales son factores que dependen del ambiente. Al investigar cómo influye el ruido sobre el estrés, puede ocurrir que los sujetos elegidos para el experimento habiten en un país económicamente inestable, con lo cual el estrés se verá influenciado también por esta condición (variable extraña), con lo que se corre el riesgo de no saber si el estrés se debe al ruido o a la inestabilidad económica.Un caso muy especial de variable situacional son las variables derivadas del experimento, ya que muchas veces ocurre que es el mismo experimento quien influye sobre Y. Al investigar el vínculo ruido-estrés puede ocurrir que el sujeto, al sentirse como una especie de ‘conejillo de Indias’, por ese solo hecho aumente su nivel de estrés. Quizás estamos usando una amenazadora máquina para medir su estrés y el individuo se estresa con sólo mirarla, con lo cual no se podrá saber si tal estrés se debe al experimento mismo o a los ruidos. Esta influencia que puede ejercer la misma situación experimental es llamada ‘acción retroactiva’ por O’neil, ‘influencia de la pre-medida’ por Selltiz, ‘efectos de las mediciones previas’ según Blalock, etc., pero todas esas denominaciones apuntan a la misma idea.
Un conocido ejemplo de influencia del experimento y que preocupó durante mucho tiempo a los médicos fue la llamada ‘hipertensión del guardapolvo blanco’. Cuando el médico intentaba tomarle la presión a una persona, la sola presencia del galeno munido de un tensiómetro bastaba para que la presión subiera espontáneamente, con lo cual el médico nunca podía saber si la hipertensión era un signo patológico o simplemente un momentáneo aumento de la presión ante la visión del guardapolvo blanco y el instrumento de medición.Otro ejemplo aparece en Blalock (1982). Un grupo de obreras aumentó su rendimiento laboral pero no debido a que había mayor iluminación y horarios de descanso, como se pensaba, pues cuando estos factores se suprimieron, el rendimiento no decayó. Este se debía en realidad a que fueron separadas y aisladas para realizar el experimento: esto las halagó pues creían estar siendo objeto de un trato preferencial, y entonces aumentaron su rendimiento.Los factores debidos al experimento mismo no se ven sólo en el ámbito de las ciencias sociales: pueden detectarse también en experimentos de microfísica cuando se trata de averiguar la causa de ciertas características de las partículas subatómicas. Una de las interpretaciones del principio de incertidumbre de Heisenberg dice que, cuando el físico quiere observar la trayectoria de una partícula subatómica, su sola presencia material hace que esa trayectoria se modifique, con lo cual nunca puede saber hasta qué punto depende de su presencia física o de otro factor que en ese momento resulte importante investigar.
b) Factores de invalidación interna y externa como variables extrañas.- La validez interna queda comprometida cuando en el experimento están ejerciendo influencia ciertos factores llamados 'variables extrañas', además de X. Por ello, estas variables extrañas son denominadas 'fuentes de invalidación interna'. Se trata de factores que por sí solos pueden "producir cambios susceptibles de confundirse con los resultados de X" (Campbell y Stanley, 1995:38).Del mismo modo, la validez externa queda comprometida cuando en el experimento están ejerciendo influencia ciertos otros factores, que, por ello, son denominados 'fuentes de invalidación externa'. Estas amenazas a la validez externa "pueden considerarse efectos de interacción entre X y alguna otra variable" (Campbell y Stanley, 1995:38) relacionada con la situación experimental, con lo cual la influencia que ejercen valen sólo para el experimento, no para toda la población.El experimento ideal sería aquel que puede controlar la influencia de la totalidad de las fuentes de invalidación interna y externa. En la práctica, sin embargo, los diseños experimentales pueden controlar sólo algunas fuentes de invalidación, y otras no. El esquema 2 muestra precisamente qué fuentes de invalidación interna y externa pueden ser controladas por cada diseño experimental (en este caso aparece el signo más +), y qué fuentes no pueden controlar (en este caso aparece el signo menos -). Como puede observarse en el esquema, los diseños experimentales propiamente dichos son, en general, los que mejor controlan las fuentes de invalidación interna, porque han sido pensados precisamente para ello. De hecho, son los diseños que más recomiendan los autores del esquema (Campbell y Stanley, 1995:31).A continuación se explicarán algunas de las más corrientes fuentes o factores de invalidación mencionados por Campbell y Stanley. Los autores describen un total de 12 fuentes: las primeras 8 son fuentes de invalidación interna, y las últimas 4 son fuentes de invalidación externa (esquema 2).
1) Historia.- Acontecimientos específicos ocurridos entre la primera y la segunda medición, además de la incidencia de la variable experimental (Campbell y Stanley, 1995:17). "Como es obvio, estas variables suelen manifestarse con mayor frecuencia en experimentos a largo plazo" (Arnau Gras J, 1980:350-352). La variable historia es la contrapartida de lo que en el laboratorio físico y biológico ha sido denominado "aislamiento experimental" (Campbell y Stanley, 1995:79).
Un ejemplo de intervención de la variable extraña ‘historia’ puede ser el siguiente. Supóngase que se quiere saber si determinada droga produce o no una disminución de un tumor. Supóngase también que, en lugar de elegir animales, para ello, se elige un grupo de personas y, antes de comenzar el experimento, se les mide el tamaño del tumor (esto es lo que Campbell y Stanley llamarían primera medición). A continuación se manipula la variable independiente ‘droga’ administrándoles a estas personas determinado medicamento. Luego de un tiempo de dos meses, se pide a los sujetos que vuelvan al hospital para medirles nuevamente el tamaño del tumor (segunda medición) para ver si aumentó, si disminuyó o si sigue igual.Supóngase que los tumores hayan disminuido significativamente de tamaño. En este punto, un investigador un poco apresurado concluiría que su droga surtió efecto, pero, si fuese más cuidadoso, consideraría la posibilidad de la intervención de la variable extraña ‘historia’. En efecto, tal vez la disminución del tumor no obedeció a la droga (o solamente a ella), sino al hecho de que durante esos dos meses los pacientes iniciaron por propia voluntad una dieta estricta, y que fue esta variable extraña la que en realidad produjo el efecto deseado.
Página 122 de 314
122

2) Maduración.- Procesos internos de los participantes, que operan como resultado del mero paso del tiempo, y que incluyen el aumento de edad, el hambre, el cansancio y similares (Campbell y Stanley, 1995:17). El término abarca, entonces, "todos aquellos procesos biológicos o psicológicos que varían de manera sistemática con el correr del tiempo e independientemente de determinados acontecimientos externos" (Campbell y Stanley, 1995:21).3) Administración de tests.- Influencia que ejerce la administración de un test sobre los resultados de otro posterior (Campbell y Stanley, 1995:17). "Las medidas tomadas de los sujetos o los tests previamente suministrados, a fin de obtener datos para la posible formación de grupos, pueden influir en los resultados finales, independientemente de la acción del tratamiento" (Arnau Gras J, 1980:350-352).4) Instrumentación.- Cambios en los instrumentos de medición o en los observadores o calificadores participantes que pueden producir variaciones en las mediciones que se obtengan (Campbell y Stanley, 1995:17). La expresión se refiere entonces a "las variaciones autónomas en el instrumento de medición que podrían ser la causa de una diferencia O1-O2" (Campbell y Stanley, 1995:24).En un sentido muy amplio podrían incluirse aquí los prejuicios de los mismos investigadores. Rollo May (1990:25) describe un experimento realizado por Robert Rosenthal, de la Universidad de Harvard, destinado a comprobar cómo influyen los prejuicios del investigador en los resultados de su experimento.Para ello, seleccionó tres grupos de estudiantes avanzados de la carrera de psicología, informándoles que habrían de participar en un experimento con ratas que debían recorrer un laberinto.Al primer grupo de estudiantes les informó que las ratas con las que trabajarían eran muy inteligentes, al segundo grupo no les dijo nada sobre la inteligencia de las ratas, y al tercer grupo les advirtió que sus ratas eran especialmente tontas.En realidad, todas las ratas eran aproximadamente iguales en cuanto a su capacidad, y a pesar de ello los resultados del experimento fueron sorprendentes. Las ratas del primer grupo se desempeñaron en el laberinto significativamente mejor que las demás, mientras que las del tercer grupo (supuestamente tontas) fueron las de peor rendimiento, incluso con un mal desempeño realmente llamativo.Rosenthal y sus colegas han repetido este experimento con muchas variantes, incluyendo pruebas donde en vez de ratas se trabajaba con seres humanos. La conclusión fue entonces la siguiente: no hay duda que el 'prejuicio', o la expectativa del experimentador influye en el rendimiento de los sujetos de prueba, a pesar de haberse adoptado todos los recaudos necesarios para que los distintos experimentadores dieran exactamente las mismas instrucciones a sus sujetos.La pregunta que faltaba responder era: ¿pero entonces, cómo se comunica la expectativa del experimentador a las ratas u otros sujetos? Al parecer, concluye el equipo de Rosenthal, lo más probable es que sea mediante movimientos corporales. Rosenthal está ahora tratando de determinar qué movimientos son esos y qué y cómo se comunica información a través de los mismos. Para otros pensadores, además de los movimientos corporales influiría también el tono y la inflexión de la voz, y el lenguaje subliminal infinitamente matizado con el cual nos comunicamos sin saber que suele ser significativo.5) Regresión estadística.- Opera allí donde se han seleccionado los grupos sobre la base de sus puntajes extremos (Campbell y Stanley, 1995:17). Estos puntajes extremos (sean muy altos o muy bajos) hacen surgir una diferencia entre el pretest y el postest más allá de los efectos de la variable experimental, diferencia adjudicable al fenómeno de la regresión estadística.El concepto de regresión fue planteado por Francis Galton (1822-1911) cuando observó que los hijos de padres altos tienden a ser menos altos, y los hijos de padres bajos tienden a ser menos bajos que sus progenitores. Es decir, la talla de los descendientes tiende hacia la estatura media de la población, movimiento regresivo que Galton expresó en su principio de regresión. Este autor atribuyó el fenómeno como una previsión de la naturaleza destinada a proteger la raza contra los extremos. Posteriormente, Karl Pearson retomó estas investigaciones ideando la ecuación de regresión, que permite hacer predicciones o estimaciones de una variable sobre la otra.Arnau Gras explica esta fuente de invalidación en los siguientes términos (1980:350-352): supongamos que se aplicó un test de rendimiento, y se han seleccionado los sujetos con puntajes más altos (por ejemplo, superiores al centil 85). Si a estos sujetos, luego de la aplicación de X, se les toma un segundo test, la puntuación media que obtendrán tenderá a desplazarse hacia la media de la población original, o sea, tenderán a bajar.Lo mismo hubiese sucedido si se elegían los puntajes más bajos: en el segundo testo la media del grupo, baja en el primer test, se desplazaría hacia la media real de la población, o sea, sería mayor en este segundo test. Los efectos de regresión estadística tienen como causas principales el azar, o bien, las propias deficiencias de los instrumentos de medición.La regresión estadística es una fuente de invalidación, entonces, porque es una causa de la diferencia de puntajes entre un primer test y un segundo test, cuando en realidad la causa que nos interesa realmente comprobar es la de X: al haber regresión estadística, los resultados quedan distorsionados por este factor. El esquema 1 nos ilustra más claramente el fenómeno de la regresión estadística.
Esquema 1 – El fenómeno de la regresión estadística en los diseños experimentales
A 100 90 80 70 60 50 40 30 20 10 0 La media aritmética de una población tiene un valor 50.
B 100 90 80 70 De esa población se extrae un grupo con puntajes altos, donde la media aritmética es 85.
C 95 85 75 65 Más tarde, se vuelve a medir a éste último grupo, obteniéndose una
Página 123 de 314
123

media aritmética menor (82,5), más aproximada a la media poblacional 50.La diferencia de puntajes entre B y C se debe al fenómeno de la regresión estadística y, de haberse aplicado X entre el pretest B y el postest C, la regresión puede confundirse con los efectos de X.
6) Selección: sesgos resultantes en una selección diferencial de participantes para los grupos de comparación (Campbell y Stanley, 1995:17). Dice Arnau Gras: "la selección diferencial de los sujetos determina en muchos casos que los resultados acusen más bien las diferencias existentes entre los grupos, que la acción del tratamiento experimental. Si se quiere probar, por ejemplo, la eficacia de un nuevo método para el aprendizaje de lectura y se eligen para ello dos clases de alumnos de primer curso, puede ocurrir, independientemente del método, que el grupo experimental tenga más habilidad para la lectura que el grupo control" (Arnau Gras J, 1980:350-352).7) Mortalidad experimental.- O diferencia en la pérdida de participantes de los grupos de comparación (Campbell y Stanley, 1995:17), lo que implica por ejemplo casos perdidos, y casos para los cuales sólo se dispone de datos parciales (Campbell y Stanley, 1995:36). Esta fuente de invalidación es más importante si se produce en sujetos ubicados en los extremos de la distribución (Arnau Gras J, 1980:350-352).Señala Arnau Gras que "esta posibilidad es muy alta en aquellos experimentos que se programan para periodos prolongados. Los sujetos pueden enfermar o cansarse, y no acudir cuando se aplican los tratamientos" (Arnau Gras J, 1980:350-352). Aclaramos que mortalidad experimental significa, entonces, que los sujetos han 'muerto' a los efectos del experimento, y no necesariamente que hayan fallecido.8) Interacción de selección y maduración, etc.- En algunos de los diseños cuasiexperimentales de grupo múltiple, como el diseño 10, se confunde con el efecto de la variable experimental (Campbell y Stanley, 1995:17). Arnau Gras señala al respecto que "la interacción entre selección y maduración, entre selección e historia y otras condiciones puede comprometer seriamente la validez de los resultados experimentales. Puede ocurrir, por ejemplo, que si bien tanto el grupo experimental como el de control han presentado puntuaciones similares en el pretest, dado que el grupo experimental se halla más motivado, o muestre más rapidez en captar las explicaciones, obtiene un rendimiento superior en el retest que el grupo control, independientemente del tratamiento" (Arnau Gras J, 1980:350-352).
Esquema 2 – Fuentes de invalidación para diseños experimentales según Campbell-Stanley (Preparado por Pablo Cazau)
Fuentes de invalidación para diseños experimentales según Campbell y Stanley (preparado por Pablo Cazau)
Estos cuadros se presentan con renuencia, pues pueden resultar ‘demasiado útiles’ si se llega a confiar en ellos y no en el texto del libro. Ningún indicador de + o – debe respetarse, a menos que el lector comprenda por qué se lo ha colocado (Nota de Campbell y Stanley).
Signo negativo: imperfección definidaSigno positivo: factor controladoSigno interrogación: posible causa de preocupaciónEspacio en blanco: factor no pertinente
Fuentes de invalidación interna(1) Historia(2) Maduración(3) Tests(4) Instrumentación(5) Regresión(6) Selección(7) Mortalidad(8) Interacción
Fuentes de invalidación externa(9) Interacción de tests y X(10) Interacción de selección y X(11) Dispositivos reactivos(12) Interferencia de X múltiples
1 2 3 4 5 6 7 8 9 10 11 12
Diseñospreexperimentales
1. Estudio de casos con una sola medición
- - -
2. Diseño pretest-postest de un solo grupo
- - - - ? + + - - - ?
3. Comparación con un grupo estático
+ ? + + + - - - -
Diseñosexperimentales propiamente dichos
4. Diseño de grupo de control pretest-postest
+ + + + + + + + - ? ?
5. Diseño de 4 grupos de Solomon
+ + + + + + + + + ? ?
6. Diseño de grupo de control con postest únicamente
+ + + + + + + + + ? ?
Diseñoscuasiexperimentales
7. Experimento de series cronológicas
- + + ? + + + + - ? ?
8. Diseño de muestras cronológicas equivalentes
+ + + + + + + + - ? - -
9. Diseño de materiales equivalentes
+ + + + + + + + - ? ? -
10. Diseño de grupo de control no equivalente
+ + + + ? + + - - ? ?
11. Diseños compensados + + + + + + + ? ? ? ? -12. Diseño de muestra separada pretest-postest
- - + ? + + - - + + +
Página 124 de 314
124

12a. Variante a del diseño 12
+ - + ? + + - + + + +
12b. Variante b del diseño 12
- + + ? + + - ? + + +
12c. Variante c del diseño 12
- - + ? + + + - + + +
13. Diseño de muestra separada prestest-postest con grupo de control
+ + + + + + + - + + +
13a. Variante a del diseño 13
+ + + + + + + + + + +
14. Diseño de series cronológicas múltiples
+ + + + + + + + - - ?
15. Diseño de ciclo institucional recurrente (diseño de retazos)02 < 01 y 05 < 0402 < 0302 < 0406 = 07 y 02y = 02o
+--
---+
+-+
+??
???
-++
?+?
-
+-+
???
++?
16. Análisis de discontinuidad en la regresión
+ + + ? + + ? + + - + +
9) Interacción de tests y X.- Cuando un pretest podría aumentar o disminuir la sensibilidad o la calidad de la reacción del participante a la variable experimental, haciendo que los resultados obtenidos para una población con pretest no fueran representativos de los efectos de la variable experimental para el conjunto sin pretest del cual se seleccionaron los participantes experimentales (Campbell y Stanley, 1995:18).En otras palabras, "el efecto reactivo o interactivo del pretest puede restringir la posibilidad de generalización de los resultados experimentales. La previa aplicación de un test puede incrementar o disminuir la sensibilidad de un grupo de sujetos en relación con la variable independiente. De ahí que los resultados obtenidos de un experimento en el que los sujetos han sido sometidos a una previa prueba, no podrán ser representativos del efecto de la variable experimental para una población que no ha sido sometida a dicha prueba" (Arnau Gras J, 1980:350-352).10) Interacción de selección y X.- Este factor hace referencia a los efectos de interacción de los sesgos de selección y la variable experimental (Campbell y Stanley, 1995:18). Se trata, en rigor, de un problema en el muestreo, es decir, en la selección de las muestras para el experimento. Dice Arnau Gras:"Si los grupos experimental y de control no han sido seleccionados al azar de la población de donde proceden, los resultados difícilmente podrán extenderse a toda la población. Sobre todo si se parte de grupos naturales o muestras no representativas es posible que determinado tratamiento interactúe con el grupo experimental debido a sus características particulares" (Arnau Gras J, 1980:350-352).11) Dispositivos reactivos.- O efectos reactivos de los dispositivos experimentales, que impedirían hacer extensivo el efecto de la variable experimental a las personas expuestas a ella en una situación no experimental (Campbell y Stanley, 1995:18).El efecto interactivo "suele ocurrir en aquellos experimentos en los que por parte de los sujetos se da una predisposición a participar de ellos. Ejemplo típico de este efecto lo encontramos en aquellos experimentos que se realizan con estudiantes de primer año de especialidad, o bien, con sujetos voluntarios. Los sujetos voluntarios difieren considerablemente de los sujetos no voluntarios y, consecuentemente, no constituyen una muestra representativa. Este extremo atenta contra el principio del muestreo probabilístico. De ahí que los resultados obtenidos de las situaciones en que los sujetos o bien están predispuestos, o bien, tienen cierta familiaridad con las técnicas experimentales, no pueden ser considerados como representativos" (Arnau Gras J, 1980:350-352). El factor reactividad se refiere también a que, por ejemplo, el mismo hecho de hacer una medición previa, ya es un estímulo para el cambio. Por ejemplo, en un experimento sobre terapia para el control del peso, el pesaje inicial puede funcionar por sí mismo como estímulo para adelgazar, aun sin tratamiento curativo alguno (Campbell y Stanley, 1995:24).12) Interferencia de X múltiples.- Pueden producirse cuando se apliquen tratamientos múltiples a los mismos participantes, pues suelen persistir los efectos de tratamientos anteriores. Este es un problema particular de los diseños de un solo grupo de tipo 8 o 9 (Campbell y Stanley, 1995:18).Para Arnau Gras, este factor viene a ser una ampliación de lo afirmado en el anterior. "Así, en aquellos casos en que el experimento exige una exposición repetitiva a dos o más tratamientos, es posible que la acción de los tratamientos anteriores interactúe con los tratamientos posteriores, a no ser que su acción quede eliminada con el tiempo. Siempre que precisamente no interese conocer el efecto de esta exposición sucesiva, como ocurre en los experimentos sobre el aprendizaje y la transferencia" (Arnau Gras J, 1980:350-352).La selección de las técnicas de control de las variables extrañas es sumamente importante al diseñar un experimento, razón por la cual se desarrollará a continuación más en detalle esta cuestión.
Página 125 de 314
125

Control de las variables extrañas
Una de los propósitos principales de un experimento clásico es el control de las variables extrañas de manera tal que no ejerzan influencia sobre la variable dependiente, o al menos que se conozca su grado de influencia sobre ella para luego descontarlo.Métodos para controlar variables extrañas son los siguientes:a) Eliminación.- Cuando se sabe que existe una variable extraña que puede alterar los resultados de la investigación, se puede simplemente eliminarla (Pick y López, 1998). Sin embargo, este procedimiento es muy difícil de aplicar porque las variables, en tanto atributos de los fenómenos, no pueden eliminarse sin más. En un ejemplo, nadie puede eliminar los vientos porque ellos podrían influir sobre el estado de ánimo de las personas (variable dependiente) además del estado civil (variable independiente).b) Evitación.- Aunque una variable no pueda eliminarse, puede realizarse el experimento en aquellas situaciones donde la variable extraña no actúa. Siguiendo con el ejemplo, sería estudiar el vínculo entre estado civil y estado de ánimo en lugares donde no sopla viento.c) Constancia.- Si la variable extraña no puede eliminarse ni evitarse, puede implementarse una situación donde se mantenga en valores constantes. Siguiendo con el ejemplo, en un lugar donde sopla el mismo viento en forma permanente, cualquier variación en el estado de ánimo de las personas podrá ser entonces atribuida a las diferencias en el estado civil.En otro ejemplo (O’Neil, 1968), al estudiarse la incidencia del nivel escolar en la amplitud del vocabulario, puede seleccionarse una muestra con alumnos de la misma escuela, con aproximadamente el mismo coeficiente intelectual, y con padres con similar amplitud de vocabulario, etc., todas variables extrañas que también pueden influir sobre la amplitud de vocabulario de los niños.Esta técnica de control se emplea también en física, cuando por ejemplo se desea estudiar la relación entre volumen y temperatura de un gas, manteniendo la presión ‘constante’.En los casos de experimentos con un grupo experimental y otro de control, se pueden mantener constantes los valores de las variables extrañas en ambos grupos mediante la técnica del apareamiento (o control por apareo de pares, o equiparación por igualación) (Campbell y Stanley, 1995:17) (Greenwood, 1973:109) (McCall, 1923) (Fisher, 1925), mediante la cual se forman grupos equivalentes, asignando al azar a cada grupo pares de sujetos con características psicológicas iguales (Tamayo, 1999:54). De esta forma la única diferencia entre ambos grupos será que uno recibe la influencia de la variable independiente y el otro no, pudiéndose así llegar a una conclusión más segura respecto de su influencia sobre la variable dependiente.La técnica del apareamiento, más concretamente, consiste en: primero, elegir dos sujetos que sean lo más iguales posibles en cuanto a las variables consideradas relevantes; segundo, empezar a formar con uno de ellos el grupo experimental y con el otro el grupo de control; tercero, hacer lo mismo con nuevos pares de sujetos, hasta formar los dos grupos. Este procedimiento asegura, obviamente, la igualdad de ambos grupos, con lo cual se habrá podido controlar la influencia de las variables extrañas.Un ejemplo muy simple: si se quiere probar la eficacia de un determinado método de enseñanza, se eligen dos grupos de alumnos, pero, antes de utilizar con uno de ellos el método en cuestión, se igualan por emparejamiento o apareamiento: se toman dos sujetos que tengan la misma inteligencia o la misma motivación (variables relevantes extrañas que también pueden influir sobre el rendimiento escolar) y se envían uno a cada grupo. Se hace lo mismo con otra pareja de sujetos, y así sucesivamente. Con ello, ambos grupos habrán quedado igualados, en el sentido de que tendrán más o menos la misma inteligencia, la misma motivación, etc., con lo cual, luego del experimento, cualquier variación entre los dos grupos, en cuanto a rendimiento escolar, podrá ser adjudicada al método de enseñanza y no a otras variables extrañas como las indicadas.d) Balanceo.- Cuando las variables extrañas no pueden mantenerse constantes se prepara un dispositivo de balanceo y de contrabalanceo donde de alguna manera los efectos de una variable extraña se compensen con los efectos de otra, con lo cual ambas se anulan en el conjunto. Un ejemplo de contrabalanceo (Pick y López, 1998), aparece en ciertas investigaciones donde se pide a los sujetos que respondan varias veces a un mismo estímulo o a varios estímulos diferentes. Esta serie de respuestas puede provocar en los mismos dos reacciones: por un lado, fatiga, porque los sujetos se cansan de estar respondiendo; por otro lado, aprendizaje, ya que después de presentar dos o tres veces el mismo estímulo el sujeto ya sabe cómo responder. Para evitar estos problemas, los grupos se pueden subdividir en subgrupos para que los efectos de la fatiga y/o aprendizaje queden anulados.El balanceo de las variables extrañas se lleva a cabo mediante un procedimiento similar al diseño experimental del cuadrado latino (véase más adelante en este libro) con la salvedad que en este se balancea variables independientes, no extrañas.e) Aleatorización.- Consiste en seleccionar a los sujetos al azar (Campbell y Stanley, 1995:17) (Greenwood, 1973:109) (McCall, 1923) (Fisher, 1925). Propuesto por Fisher pero anticipado por McCall en la década del '20, se trata de un procedimiento que "sirve para lograr, dentro de límites estadísticos conocidos, la igualdad de los grupos antes del tratamiento" (Campbell y Stanley, 1995:18). Esta técnica de control “es una de los más sencillas y más utilizadas en ciencias sociales, sobre todo cuando se llevan a cabo estudios experimentales. Se parte del postulado de que si la selección y distribución de sujetos en grupos de control fue hecha al azar, podemos inferir que las variables extrañas, desconocidas por el investigador, se habrán repartido también al azar en ambos grupos, y así quedarán igualadas” (Pick y López, 1998).Por ejemplo, si se quiere estudiar la influencia del ruido sobre el estrés, los sujetos elegidos no podrán ser ‘todos’ ellos veteranos de guerra o bien ‘todos’ ejecutivos, porque entonces las variables extrañas
Página 126 de 314
126

‘experiencias traumáticas’ y ‘tipo de ocupación’ estarán también influyendo sobre los niveles de estrés. En cambio si se toman los sujetos al azar (donde entrarán verosímilmente veteranos y no veteranos, ejecutivos y no ejecutivos), esto se supone que garantizará la heterogeneidad del grupo en cuanto a experiencias traumáticas y ocupaciones, con lo que la influencia de éstas se reducirá considerablemente hasta un nivel aceptable donde su intervención no resulta significativa, ya que ambos grupos (experimental y de control) tendrán aproximadamente la misma proporción de veteranosLa ventaja de la aleatorización no reside en su sencillez sino también en que permite controlar al mismo tiempo gran cantidad de variables extrañas, incluso aquellas que son desconocidas para el investigador. Como no se pueden mantener constantes tantas variables extrañas al mismo tiempo, se puede lograr el mismo control mediante la aleatorización, situación en la cual si bien no se mantienen constantes sus valores, sus fluctuaciones quedan razonablemente neutralizadas.Cabría preguntarse: ¿para qué recurrir a la aleatorización, si se puede controlar las variables extrañas manteniéndolas constantes? Sería como decir que al estudiar el vínculo ruido-estrés se seleccionan solamente a veteranos de guerra (es decir se mantiene constante la variable extraña ‘experiencias traumáticas pasadas’) y entonces, cualquier variación en el grado de estrés entre los que recibieron ruidos y los que no, se deberá solamente al factor ruido ya que ambos grupos, al ser todos veteranos de guerra, están en igualdad de condiciones.Esta solución sería viable si fuese solamente una la variable extraña que hay que controlar, pero habitualmente son muchas y realmente resulta muy difícil, cuando no imposible, mantenerlas constantes a todas, o sea, reunir un grupo homogéneo respecto de todas las variables extrañas. De hecho, ya poder seleccionar un grupo donde todos sean veteranos de guerra y al mismo tiempo todos ejecutivos es bastante engorroso. Se elige entonces el procedimiento de la aleatorización: el azar, como la muerte, es el gran nivelador, y por sí solo es capaz de colocar en igualdad de condiciones a todos los sujetos de un experimento.La aleatorización presenta la ventaja de su fácil implementación, pero también que permite igualar los grupos con respecto a muchas variables extrañas, incluso aquellas que son desconocidas por el investigador. Se ha adjudicado el mérito de haber introducido esta técnica de control a Fisher, pero McCall es en rigor el precursor, cuando dijo un par de años antes que "así como se puede lograr la representatividad por el método aleatorio [...] también se puede conseguir la equivalencia por el mismo medio, siempre que el número de sujetos sea lo suficientemente grande" (McCall, 1923).La aleatorización es una técnica que Campbell y Stanley prefieren al clásico método de la igualación por equiparación (Campbell y Stanley, 1995:18). Es posible también una combinación de equiparación y aleatorización para obtener mayor precisión estadística, como en el caso de la técnica del 'bloqueo' (Campbell y Stanley, 1995:10; 35/36).f) Distribución de frecuencias.- La técnica de la distribución de frecuencias (Greenwood, 1973) intenta igualar los grupos a partir de armar dos que tengan aproximadamente las mismas medidas estadísticas, como por ejemplo, que ambos tengan la misma media aritmética y el mismo desvío estándar respecto de las variables consideradas relevantes.
Pruebas de confirmación y pruebas de refutación
Dos tipos de sospechas pueden poner en marcha una investigación explicativa, y, en particular, un experimento: primero, se puede sospechar que cierto o ciertos factores SÍ son la causa de un fenómeno; segundo, que cierto factor NO es la causa de un fenómeno dado a pesar de las apariencias (por ejemplo, a pesar de la alta correlación). En el primer caso se emprende una prueba de confirmación, y en el segundo caso, una prueba de refutación.a) Si el investigador piensa que uno o varios factores son causa de cierto efecto, está haciendo una prueba de confirmación. Una prueba de confirmación no es una prueba donde se confirma una hipótesis, ya que el resultado puede confirmar o refutar la hipótesis (aceptación o rechazo), sino una prueba diseñada con la ‘intención’ de confirmar la sospecha de causalidad. Si una prueba de confirmación fuese una prueba donde se confirma una hipótesis, ¿para qué realizarla si ya se conoce el resultado?b) Si el investigador piensa, en cambio, que un cierto factor no es la causa de un fenómeno a pesar de la alta correlación constatada entre ambas, entonces estará emprendiendo una prueba de refutación, como por ejemplo la llamada prueba de espureidad (o prueba de falsedad, pues se busca probar que a pesar de parecer verdadera, la “causa” no lo es). La prueba de espureidad tiene la estructura de un experimento crucial, donde se busca decidir entre dos hipótesis alternativas y donde una de ellas debe quedar refutada.Una prueba de refutación no es, entonces, una prueba donde se refuta una hipótesis sino sólo donde se intenta refutarla, pudiéndose o no tener éxito en dicho intento. La sospecha que pone en marcha este tipo de investigación puede surgir antes, durante o después de una prueba de confirmación. A veces en el curso de la investigación y antes de poder confirmar o rechazar la hipótesis, puede surgir una fuerte sospecha de que X no es la causa de Y sino Z, o sea, otra variable. En este punto se podrán abandonar los intentos originales por confirmar y emprender una prueba de refutación, consistente en tratar de demostrar que X no es la causa sino Z.Si bien una investigación puede estar orientada hacia la modalidad confirmatoria o hacia la modalidad refutatoria, cuando luego deben aplicarse pruebas estadísticas que apoyen las conclusiones se sigue clásicamente el esquema de la refutación planteándose la denominada hipótesis nula.
Experimentos bivariados y multivariados
Página 127 de 314
127

X Y X2 Y
X1
Xn
Experimentobivariado
Experimentomultivariado
El experimento clásico es bivariado, es decir, procura probar la conexión entre una variable independiente (causa X) y una variable dependiente (efecto Y). Tal es el caso del abordaje de hipótesis como "la memoria depende de la edad", "ambientes con música aumentan el rendimiento laboral", etc., o de aquellas otras que la divulgación científica suele expresar más literariamente como "el mal humor es una hormona" y "la tristeza atrae a los virus".Ejemplos de relaciones bivariadas son las siguientes:
X = Edad Y = Memoria X = Incentivo Y = RendimientoX = Nivel económico Y = Hábitos alimenticios X = Nivel
socioeconómicoY = Inteligencia
X = Area geográfica Y = Drogadicción X = Cantidad de ensayos Y = Número de erroresX = Método de enseñanza
Y = Rapidez del aprendizaje
X = Deserción escolar Y = Drogadicción
X = Proximidad elecciones
Y = Voto decidido X = Frustración Y = Agresión
X = Padres separados Y = Deserción escolar X = Drogadicción Y = Soledad
Sin embargo, según las necesidades y posibilidades de la investigación, también puede contemplar el estudio de más de una variable independiente o más de una dependiente, en cuyo caso se habla de experimentos multivariados, múltiples o factoriales. Tanto los experimentos bivariados como los multivariados requieren el control de las variables extrañas.
Como indican Campbell y Stanley (1995:14), los diseños que estudian una sola variable por vez resultan demasiado lentos para la investigación de ciertos temas como al aprendizaje. Desde la década del ’50 en adelante tiende a enfatizarse la importancia de considerar diseños multivariados, sea que consistan en estudiar varias variables independientes a la vez, sea que consistan en estudiar varias variables dependientes, sea que consistan en ambas cosas simultáneamente. Uno de los pioneros de estos enfoques fue Fisher, cuyos procedimientos eran multivariados en el primer sentido y bivariados en el segundo.
Por lo general, en los experimentos multivariados la variable dependiente (Y) sigue siendo una sola, y lo único que aumenta es el número de variables independientes o experimentales (X1, X2, X3, etc.), pues lo que se busca investigar son varios posibles factores causales al mismo tiempo, con el objeto de probar cuál o cuáles de ellos influyen como causa y en qué medida lo hacen. Ejemplos de investigaciones multivariadas son la indagación simultánea de la edad, el sexo y la situación familiar como posibles causas de la drogadicción. O la música, el color de las paredes y la temperatura ambiente como posibles factores que influyen sobre el rendimiento laboral.Tales diseños multivariados se justifican por ejemplo cuando: a) no se puede aislar y controlar en la realidad las distintas variables independientes, con lo que no queda otro remedio que considerarlas conjuntamente mediante un diseño múltiple; b) cuando resulta menos costoso en tiempo y dinero tratar conjuntamente todas las variables en lugar de hacer varios diseños bivariados separados (como X1-Y, X2-Y, etc.). Ejemplos de relaciones multivariadas son las siguientes:
Ejemplo 1 Ejemplo 2 Ejemplo 3Variables independientes o experimentales
X1 = Número de palabras a recordarX2 = Nivel de ansiedad
X1 = Variedad vegetalX2 = Tipo de sueloX3 = Clima
X1 = Método de enseñanzaX2 = Personalidad profesorX3 = Proximidad exámenes
Variable dependiente
Y = Memoria Y = Velocidad de crecimiento
Y = Rendimiento escolar
En síntesis:
Un inventario de relaciones entre variables
Dentro del esquema de un experimento bivariado y, con mayor razón, dentro de uno multivariado, existen muchas posibilidades de combinación entre variables. Sin pretender ser exhaustivos, los siguientes son algunos ejemplos de ellas:
Página 128 de 314
128

X1 X
Esquemas lineales
X2 Xn X
3 X
Xn
X
4 X
Xn
X X
5
X
Xn
X 6
X
Xn
X
X
Xn
7
X
Xn
X X 8
X
Xn
X X
9 X Y
z
Esquemas cibernéticos
X10 X
X
11
X
X 12 X X
X X
Xn significa “una X o más”
Se han clasificado estos diferentes esquemas en lineales y cibernéticos. Estos últimos estudian específicamente procesos de feedback o retroalimentación: no es lo mismo estudiar como influye la alimentación en la inteligencia (esquema lineal X à Y), que estudiar como ambas variables se influyen mutuamente (X ßà Y).Nótese que en ninguno de los esquemas se utiliza la letra Y, que representa la variable dependiente o efecto. En realidad en cualquiera de estos esquemas se puede sustituir alguna X por Y, siempre y cuando a la Y ‘llegue’ una flecha y al mismo tiempo ‘no salga’ ninguna flecha de ella. Estas sustituciones, sin embargo, carecerían de sentido en los esquemas cibernéticos, donde todas las variables son al mismo tiempo independientes y dependientes, pues todas ellas influyen y son influidas.
Página 129 de 314
129

Nivel de educación Interés en política Intención de voto
z YX
Ejemplo 1) Este es el esquema clásico más simple, donde se procura investigar la influencia que ejerce la variable independiente X sobre la variable dependiente Y. Por ejemplo, la influencia de las fases lunares sobre el comportamiento agresivo.Mediante este esquema puede llevarse a cabo, por ejemplo, una investigación para averiguar si el sexo influye en la forma de percibir los mensajes publicitarios.Se pueden tomar dos grupos de personas: uno de hombres y otro de mujeres, preferiblemente elegidos al azar, y pedirles que opinen sobre un mismo mensaje publicitario que se le entrega recortado de un diario o revista. Como ítems para este instrumento de medida (en este caso un cuestionario), se le pueden preguntar qué fue lo que más le llamó la atención del aviso (imagen, texto, colores, etc.), si lo consideran interesante (mucho, poco, nada), qué cree que intenta decir el mensaje (vender, sugerir, seducir, enseñar, etc.), y cualquier otro ítem que también evalúe específicamente la forma de percibir. Una vez contestados todos los cuestionarios, se comparan las respuestas masculinas y femeninas intentando averiguar si las diferencias son significativas (no debidas al azar, por ejemplo). Finalmente, convendrá que el mensaje publicitario elegido sea neutro respecto del sexo, o sea, que publicite un producto o servicio tanto para hombres como para mujeres (una aspirina, un viaje al Caribe, etc.), para que luego las diferencias en las respuestas no sean adjudicadas a la índole del mensaje sino a las características personales de los sujetos.
Ejemplo 2) En este esquema se introduce una variable interviniente, así llamada porque ‘interviene’ entre otras dos de manera tal que es efecto de la primera pero a la vez causa de la segunda.Por ejemplo, es lugar común considerar que el frío es la causa de la gripe. Sin embargo, esta relación no es tan directa: en rigor, podría pensarse que el frío hace que las personas busquen los lugares cerrados (variable interviniente), lo cual a su vez aumentaría la probabilidad de contagio gripal.Hyman (1984:353-356) propone un ejemplo de variable interviniente. Originalmente, los datos de una investigación descriptiva pueden hacer sospechar que el nivel de educación de las personas (X) es lo que determina sus intenciones de voto (Y) o sea, sus intenciones por participar activamente del sistema democrático, sea porque la educación enseña la importancia del voto, sea porque simplemente se advirtió una alta correlación entre ambos factores (personas poco instruidas tienden a no votar, personas instruidas tienden a querer votar). Esta sospecha surge del siguiente cuadro:
Cuadro I Intención de votoSecundario
92%
Primario 82%
Puede sin embargo suponerse que en realidad entre X e Y se interpone una variable interviniente: el interés en política (z), de forma tal que el nivel de educación determina el interés en política y recién éste es la causa directa de la intención de votar:
Para examinar entonces esta nueva relación entre interés en política e intención de voto se recolectó la siguiente información, que revela la existencia de un factor causal más directo (el interés en política):
Cuadro II Intención de votoSecundari
oPrimario
Mucho interés 99% 98%Moderado interés
93% 90%
Poco interés 56% 59%
Se podría aquí argumentar que en rigor el nivel educativo es también causa, aunque indirecta, de la intención de votar. Esto es admisible, pero también es cierto que lo que al científico le interesa a veces es una causa más directa para poder controlar mejor la aparición o la no aparición de Y. Es más difícil controlar la intención de votar a partir del nivel educativo pues puede ocurrir que cierto tipo de educación no despierta interés en política. En cambio el interés político es más seguro para controlar la intención de voto. Esta es sólo una razón práctica para elegir causas directas, pero hay también una razón teórica: no aumenta en mucho el conocimiento de un fenómeno sus causas remotas.
Página 130 de 314
130

Efectivamente, cuanto más indirecta o remota sea la causa menor interés tendrá para el científico: una causa remota de la drogadicción es por ejemplo la existencia del sol, ya que si no hay sol no hay fotosíntesis, y por lo tanto no hay plantas, y por lo tanto no habrá ni cocaína ni marihuana, con lo cual no habrá drogadicción. La explicación de la adicción a las drogas por el sol resulta ser inatingente.
Ejemplo 3) Una investigación que siga este esquema podría consistir en averiguar cómo influyen sobre el rendimiento escolar el método de enseñanza, la personalidad del profesor y la proximidad de los exámenes. Para examinar todas estas variables a la vez hay varias técnicas, de las cuales puede citarse a modo de ejemplo la técnica del cuadrado latino.Antes de ser utilizado en la investigación experimental, el cuadrado latino era un simple entretenimiento que en la época medieval reemplazaba a la televisión, sólo que hacía pensar. Consistía en disponer en una tabla cuadrada letras de tal forma que ninguna de ellas podía repetirse en ninguna columna –vertical- ni hilera –horizontal-. Por ejemplo, si las letras eran A, B y C, el cuadrado latino se solucionaba del siguiente modo:
A B CC A BB C A
Aquí la letra A aparece sólo una vez en cualquier columna o hilera, y lo mismo sucede con las letras B y C. Una vez resuelto, se intentarían luego pruebas más difíciles utilizando por ejemplo cuatro columnas, cuatro hileras y cuatro letras, y así sucesivamente.Con el cuadrado latino, en el ejemplo indicado, se investigan cuatro variables (tres independientes y una dependiente), y el número de columnas o hileras guarda relación no con el número de variables sino con el número de categorías de las mismas. Si se quiere estudiar la influencia de tres variables independientes (método de enseñanza, personalidad del profesor y proximidad de los exámenes) sobre la variable dependiente (rendimiento escolar), y tomar tres categorías para cada una de esas variables, puede organizarse el experimento sobre la base del siguiente cuadrado:
Examen lejano Examen intermedio
Examen próximo
Profesor A M1 M2 M3Profesor B M2 M3 M1Profesor C M3 M1 M2
En este cuadrado quedaron formados nueve casilleros. En la práctica, esto significa que se han tomado nueve grupos de alumnos, y así por ejemplo el primer grupo está formado por alumnos que tienen el profesor A, cuyos exámenes están lejanos, y con los cuales se utilizó el método de enseñanza M1, y así sucesivamente con los demás grupos. Obsérvese que los números 1, 2 y 3, las tres categorías de la variable método de enseñanza, han sido dispuestas de acuerdo al criterio del cuadrado latino: no se repite ninguna cifra ni por hilera ni por columna. Esto resulta muy importante porque ‘mezcla’ todas las variables y categorías lo suficiente como para que no haya predominio de ninguna en especial en el conjunto de los nueve grupos. Así por ejemplo, si en lugar de haber puesto en la primera hilera horizontal M1, M2 y M3 se hubiese puesto M1, M1 y M1, en esa hilera habría un neto predominio del método de enseñanza 1 y del profesor A. En cambio, con la disposición del cuadrado latino se procura que no aparezcan estos predominios.Obviamente el cuadrado no contempla todas las posibilidades de combinación, pues faltan por ejemplo los grupos con profesor A, cercanía de exámenes y método de enseñanza 1. Esta y otras posibilidades fueron anuladas para evitar el predominio anteriormente citado, y los nueve grupos seleccionados bastan para poder emprender la investigación con ellos sin considerar los 27 posibles, con el consiguiente ahorro de esfuerzo, tiempo y dinero.El hecho de que no aparezcan los predominios indicados tiene un motivo fundamental. Siguiendo con el ejemplo anterior, si en la primera hilera aparecen predominando el profesor A y el método de enseñanza 1, un muy alto rendimiento escolar en esos tres grupos no se sabría si atribuirlo al profesor o al método de enseñanza, con lo cual habríase desvirtuado el propósito del experimento, a saber, conocer el grado de influencia causal de cada uno de los factores considerados.Una vez que se ha seguido durante meses la evolución de los nueve grupos formados, hipotéticamente pueden haberse obtenido los siguientes valores de rendimiento escolar:
Examen lejano Examen intermedio
Examen próximo
Profesor A 9 5 2Profesor B 6 1 8Profesor C 3 8 4
Estos valores no son frecuencias sino índices de rendimiento escolar, que pueden resultar por ejemplo del promedio de calificaciones de los alumnos de cada grupo. Por ejemplo, 9 fue el promedio de calificaciones obtenido por el grupo con profesor A, examen lejano y método de enseñanza 1.
Página 131 de 314
131

Religión
Tipo de ocupación
Preferencia política
z
YX
¿Cómo se analiza esta información? El primer lugar se puede comenzar observando dónde están las calificaciones más altas (8-8-9), y se ve que coinciden justamente con los grupos donde se aplicó el método de enseñanza 1. En segundo lugar se puede observar dónde están las calificaciones más bajas (1-2-3), que aparecen en los grupos donde se usó el método de enseñanza 3. Ambas observaciones sugieren que el factor método de enseñanza es muy importante para el rendimiento escolar, y además que las otras dos variables tienen escasa influencia, ya que por ejemplo tanto en los grupos con bajas calificaciones como en los de altas calificaciones, existieron diversos profesores y diversos grados de proximidad temporal al examen. Además, por ejemplo, cada profesor tuvo alumnos con rendimientos muy disímiles en sus respectivos tres grupos.Los resultados de la investigación también podrían haber sido estos otros:
5 4 1 6 5 64 5 1 7 6 59 4 2 5 6 6Caso A Caso B
En el caso A pueden sacarse dos conclusiones importantes: primero, que el rendimiento escolar aumenta notablemente con la feliz combinación del profesor C que imparte el método de enseñanza 3 lejos de los exámenes (promedio de calificaciones 9), con lo cual pueden organizarse las clases en un colegio con estos criterios; y segundo, que la proximidad de los exámenes disminuye notablemente el rendimiento escolar, pues allí las calificaciones fueron bajas (1-1-2) en comparación con las calificaciones de los otros grupos.En el caso B el análisis de los datos revela que ninguno de los tres factores es más importante que el otro, ejerciendo todos ellos una influencia más o menos igual, que hasta incluso podría ser nula. En el análisis de los datos es tan importante darse cuenta qué dicen como qué no dicen, y así, el caso B no informa acerca del porqué de las calificaciones regulares (5-6-7), lo cual puede atribuirse a alguna variable contextual como por ejemplo la edad de los alumnos: en la adolescencia, se piensa en cualquier cosa menos en estudiar.
Ejemplo 4) Este esquema resulta ser una combinación de los esquemas 1 y 3.
Ejemplo 5) Teóricamente cabe la posibilidad de investigar simultáneamente dos variables dependientes (dos efectos) de una única causa. Tal es el caso del enunciado "el ruido produce estrés y también hipoacusia", pero en estas situaciones lo habitual es desglosar el enunciado en dos hipótesis diferentes ("el ruido produce estrés" y "el ruido produce hipoacusia") y emprender dos investigaciones diferentes y bivariadas, con lo que se vuelve al primer esquema simple (ejemplo 1). Y si bien es posible también desglosar una investigación bivariada en varias bivariadas, si se prefiere la primera es porque ahorra tiempo y esfuerzo o porque no es posible separar en la realidad la influencia de las otras posibles causas.El esquema del ejemplo 5 sirve también para probar relaciones espúreas. Blalock (1982:78) cita un ejemplo donde se constató una alta correlación entre la religión y la preferencia política, lo que llevó a pensar que era la religión no que determinaba a ésta última. No obstante, se sospechó que en realidad la influencia provenía del tipo de ocupación, o sea de si las personas eran empleados u obreros. El esquema correspondiente es:
Los datos que llevaron a la suposición de un vínculo causal entre X e Y habían surgido del cuadro siguiente, donde figuran por igual obreros y empleados sin discriminar, ya que aún no se sospechaba la influencia del tipo de ocupación:
Protestantes CatólicosRepublicanos 62% 38%Demócratas 38% 62%
Cuando se empezó a pensar en la espureidad de este vínculo entre religión y preferencia política se construyeron dos nuevos cuadros con la misma muestra de sujetos que había servido para el primero: uno con empleados solamente y otro con sólo obreros, siendo los resultados los siguientes.
Página 132 de 314
132

Tiempo de ausencia
Tipo de ocupación
Estrés
z
YX
Empleados Protestantes CatólicosRepublicanos 56% 24%Demócratas 14% 6%
Obreros Protestantes CatólicosRepublicanos 6% 14%Demócratas 24% 56%
Estos datos muestran que efectivamente el vínculo X-Y es espúreo, y además agrega elementos de juicio favorables a la hipótesis del tipo de ocupación como factor causal. Este segundo ejemplo nos muestra además que el cuadro trivariado del primer ejemplo puede ser desglosado en dos cuadros bivariados, uno para cada categoría de la variable adicional.Las pruebas de espureidad pueden establecer inequívocamente que la relación X-Y no es causal, pero algunas veces no alcanzan para probar simultáneamente que Z sea la causa real de Y, con lo cual el investigador se ve obligado a recurrir a algún tipo de diseño experimental bivariado para llevar a cabo esta última prueba de confirmación, o bien a realizar una nueva prueba de espureidad si se sospecha de una nueva variable adicional Z’, como factor causal real.Otro ejemplo donde puede probarse una relación espúrea es el siguiente: una investigación descriptiva reveló que existía una alta correlación entre el estrés y el tiempo en que las personas estaban fuera del hogar. En un primer momento se sospechó que el estrés se debía a esas prolongadas ausencias, pero por uno u otro motivo fue creciendo en el investigador la sospecha de que el tiempo de alejamiento (variable independiente) no era la causa del estrés (variable dependiente) sino el tipo de ocupación de la persona (variable adicional), y que si las dos primeras estaban altamente correlacionadas era porque sobre ellas actuaba independiente y simultáneamente el tipo de ocupación (o sea, el tipo de ocupación influye tanto sobre el estrés como sobre el tiempo de alejamiento del hogar). Esquemáticamente:
En este esquema las dos flechas llenas indican que efectivamente Z es causa de X y de Y, y la flecha punteada indica que la relación X-Y es espúrea, es decir, aparenta ser un vínculo causal pero no lo es. Pero, ¿cómo se ha procedido para llegar a esas conclusiones?La alta correlación existente entre X e Y, que había hecho suponer al investigador que existía un vínculo causal, surgió originalmente a partir de la lectura del cuadro siguiente:
% de estresadosMás tiempo fuera del hogar 80%Menos tiempo fuera del hogar
60%
Una vez que se afianzó la creencia de que este vínculo sólo tiene apariencia de causal pero en realidad no lo es (relación espúrea), y de que la causa parecía ser en realidad el tipo de ocupación, el investigador procedió a recoger los datos en un segundo cuadro pero, esta vez, incluyendo la variable adicional Z para ver si se producía algún cambio:
% de estresadosMás tiempo fuera del
hogarMenos tiempo fuera del
hogarEjecutivos 81% 78%No ejecutivos 62% 61%
Este nuevo cuadro –trivariado- confirma la espureidad del vínculo original X-Y. En efecto, aquí se aprecia que la diferencia en el porcentaje de estresados entre los que están más tiempo y menos tiempo fuera del hogar (81% y 78%, o bien 62% y 61%), no es significativa si la comparamos con la diferencia en el porcentaje de estresados entre los ejecutivos y los no ejecutivos (81% y 62%, o bien 78% y 61%), todo lo cual indica que el estrés no es debido al mayor o menor tiempo fuera del hogar sino al tipo de ocupación.
Página 133 de 314
133

Sexo Carrera
País
X Y
z
Más concretamente, vemos que la diferencia en cuanto a porcentaje de estresados entre ejecutivos y no ejecutivos es del 19% (que resulta de restar 81% y 62%), diferencia que es grande en comparación con la diferencia en el porcentaje de estresados entre los que están más tiempo y menos tiempo alejados del hogar, que es apenas del 3% (resultado de restar 81% y 78%).Hyman la denomina variable antecedente (z) porque ocurre ‘antes’ que X e Y.Otro ejemplo de variable antecedente son los factores genéticos. El hecho de que se haya encontrado una alta correlación entre la raza (X) y ciertos tipos de cáncer (Y) no prueba necesariamente que la raza sea la causa de esas patologías: raza y cáncer dependen de factores genéticos (Z), por ejemplo: si se piensa que entre X e Y hay una relación causal es porque se constató alta correlación, pero ésta puede deberse simplemente a que raza y cáncer están determinados por el mismo cromosoma, portador al mismo tiempo del gen del color de piel (raza) y del gen que predispone al cáncer.Otro investigador podrá sospechar otra cosa: que el cáncer se debe a la raza y que los factores genéticos no influyen, si por ejemplo piensa que el color de piel hace que los rayos ultravioletas solares penetren más profundamente en los tejidos y tengan más probabilidades de producirles lesiones malignas. En estos casos la investigación estará encaminada a probar que X es causa de Y, en lugar de intentar probar que no lo es por existir otro sospechoso más convincente (z).
Ejemplos 6 y 7) Estos esquemas resultan ser combinaciones de otros esquemas.
Ejemplo 8) Este caso es citado por caso por Blalock (1982:82) como ejemplo de complicación de fuentes de espureidad: el vínculo entre religión (X superior) y preferencia política (Xn) puede obedecer a dos causas comunes (X izquierda y X derecha): la religión y la región del país.
Ejemplo 9) Este esquema ilustra lo que Hyman llama variable contextual. Una investigación descriptiva realizada en cierto país (variable contextual) ha revelado que hay una alta correlación entre el sexo de los estudiantes y la carrera que estos eligen, ya que por ejemplo los hombres se orientan sobre todo hacia la ingeniería y las mujeres hacia la psicología:
Suponiendo que la investigación haya sido hecha a escala internacional, puede llegarse a advertir que la relación sexo-carrera sufre variaciones según el país considerado. Podríase quizás constatar que en los países socialistas aumenta la proporción de mujeres que estudian ingeniería, etc. Sobre la original relación X-Y está entonces actuando una variable contextual (país), la que obviamente no se tendrá en cuenta si la investigación es sólo a nivel nacional, en cuyo caso deja de ser variable adicional y pasa a ser una constante.Por lo general las variables contextuales son espacio-temporales. La relación sexo-carrera no sólo puede depender de la región o país, sino también de la época considerada: hace 60 o 70 años la proporción de mujeres que estudiaban medicina era considerablemente menor.
Ejemplo 10) Algunas relaciones causales pueden darse en cualquiera de ambos sentidos: si bien es cierto que el incentivo aumenta el rendimiento, un mejor rendimiento puede a su vez funcionar como incentivo. O también la droga hace que un adolescente falte al colegio, y a su vez la ausencia del colegio hace que vaya a otros lugares donde puede adquirir el hábito. En última instancia cuál de los dos factores será considerado causa depende de la decisión del investigador, lo que viene a mostrar que fuera de todo contexto no se puede saber si una variable dada es independiente o dependiente, y sólo se sabrá viendo cómo está relacionada con otra variable: si como causa o como efecto. El solo hecho de pensar que la variable ‘conducta’ en psicología es dependiente (bajo el supuesto que la psicología estudia las causas de la conducta), no debe excluir la posibilidad de que, en este mismo ámbito, pueda ser considerada a veces como independiente, en la medida que se pretenda investigar cómo influye, por caso, el comportamiento sobre la autoestima.En algunos de sus escritos Freud consideró al síntoma en su doble aspecto de causa y efecto. Lo entendió como efecto cuando sugirió que un sentimiento de culpa o una intensa fijación anal (causa) puede hacer que el paciente sea un maniático de la limpieza (síntoma-efecto); y lo entendió como causa, cuando agregó que su manía por la limpieza (síntoma-causa) puede tornarse tan insoportable para el mismo sujeto que se defienda de ella con una extrema suciedad (efecto, o síntoma secundario).
Página 134 de 314
134

X Y
z
Variable antecedente Variable interviniente Variable contextual
z YX X Y
z
EJEMPLO 5 EJEMPLO 2 EJEMPLO 9
Ejemplos 11 y 12) Estos esquemas resultan ser complejizaciones del esquema 10. Estas variantes admiten aún esquemas más complejos donde intervienen 5, 10 o 30 variables al mismo tiempo con realimentaciones positivas y negativas. Por ejemplo: en una ciudad cuando aumenta el número de habitantes aumenta la cantidad de basura; cuando ésta aumenta se incrementa la cantidad de bacterias, y esto a su vez provoca un aumento en las enfermedades infecciosas. Este incremento de enfermedades a su vez hace descender el número de habitantes, lo que a su vez hará descender la cantidad de basura, y así sucesivamente.
Finalmente, puede consignarse que:a) Los ejemplos 2 y 5 son algunas de las formas en que puede presentarse una prueba de espureidadb) Los ejemplos 5, 2 y 9 respectivamente, indican según Hyman (1984:351) tres maneras en que las variables extrañas, que él llama aquí variables adicionales (z), pueden estar ejerciendo su influencia:
Los esquemas nos muestran que z actúa como variable antecedente cuando ocurre cronológicamente antes de X; que actúa como variable interviniente cuando ocurre después de X; y que actúa como variable contextual cuando ocurre al mismo tiempo (simultáneamente) que X.
3. LOS CÁNONES DE STUART MILL
En el siglo pasado, John Stuart Mill presentó una serie de procedimientos destinados a descubrir y a probar conexiones causales, basándose en las ideas de Francis Bacon y algunos autores medievales. En el presente ítem se explican estos métodos con ejemplos, se exponen comentarios sobre ellos, algunas de las críticas que han recibido, y se reseñan brevemente sus antecedentes históricos con el fin de completar la información sobre los conceptos de causalidad y experimento desde un punto de vista histórico.John Stuart Mill (1806-1873), filósofo, psicólogo y metodólogo de la ciencia británico, tuvo que esperar más de veinte años en poder casarse con su novia Harriet Taylor, durante los cuales debió sufrir los prejuicios victorianos de la época. Fue, tal vez por eso, un ardiente defensor de los derechos de las mujeres a decidir por sí mismas y no por las presiones sociales (entre otras cosas defendió el sufragio femenino), y fue también tal vez por ello que, decidido a indagar las causas de tal demora, planteó sus famosos cánones para descubrir y probar vínculos causales.
Una presentación de los métodos de Mill
Comenzaremos dando una explicación sencilla de cada uno de los métodos de Stuart Mill, para lo cual nos guiaremos siguiendo el esquema 1. Asimismo, utilizaremos un mismo ejemplo hipotético para todos los métodos, para simplificar la explicación.El ejemplo en cuestión es el siguiente: se trata de utilizar los métodos de Mill para descubrir y probar las causas de los problemas de aprendizaje en los niños (fenómeno). Entre las causas posibles están A (mala alimentación), B (el colegio), C (el maestro), y D (los vínculos familiares). Antes de ver cómo se aplican a este problema los métodos de S. Mill, hagamos una breve aclaración sobre la expresión "circunstancias antecedentes" que aparece en el esquema 1.En principio, la expresión 'antecedentes' puede tener dos sentidos distintos, que podemos designar como ontológico y metodológico: 1) en un sentido ontológico, circunstancias antecedentes son circunstancias que ocurren temporalmente 'antes' que el fenómeno (Copi, 1974:431). Por ejemplo, el ruido se produce antes que la reacción de estrés; y 2) en un sentido metodológico, circunstancias antecedentes puede aludir a que son circunstancias que deben formularse 'antes' de la aplicación del método (por ejemplo, esta interpretación es mencionada por Losee como una condición de aplicabilidad del método de la diferencia en Losee, 1979:158). Por ejemplo, antes de investigar sobre el estrés, debemos especificar al ruido como un factor con él relacionado.
Página 135 de 314
135

Mill considera el primer sentido pues 'causa' es, para él, el antecedente necesario e invariable de un fenómeno (Fatone, 1969:167). El hecho de que, como veremos, Mill defina sus métodos en términos de "la circunstancia es la causa (o el efecto) de...", alude simplemente a que sus métodos sirven tanto para buscar la causa de un efecto, como para buscar el efecto de una causa, es decir, más genéricamente, para estudiar en qué concuerdan o en qué difieren casos diferentes (Fatone, 1969:167).El segundo sentido es igualmente compatible con la posición de Mill, porque no contradice su pretensión de que los métodos permiten 'descubrir' causas, lo cual puede hacerse perfectamente antes de la fase probatoria, o fase de aplicación propiamente dicha del método. Finalmente, diferenciemos circunstancia antecedente de circunstancia común y circunstancia relevante. Circunstancias comunes son aquellas circunstancias antecedentes que aparecen cuando también aparece el fenómeno. Por su parte, las circunstancias antecedentes elegidas se supone que son circunstancias relevantes a los efectos de la explicación del fenómeno.
Esquema 1: Los métodos de Stuart Mill
Método Casos Circunstancias Antecedentes
Fenómeno Conclusión
Concordancia N°1N°2 N°3
A B CB CC
XXX
C es causa (o efecto) probable de X
Diferencia N°1N°2
A B B
X no-X
A es causa (o efecto) probable de X
Conjunto de concordancia y diferencia
N°1N°20N°3
A B CB C C
XX no-X
B es causa (o efecto) probable de X
Residuos N°1 A B CSe sabe que ASe sabe que B
X Y Z X Y
C es causa (o efecto) probable de Z
Variación concomitante
N°1N°2
A B2A B
X2X
A es causa (o efecto) probable de X
A: Mala alimentación X: Problema de aprendizajeB: Colegio Y: Problema de conducta en la escuelaC: Maestro Z: Problema de conducta en la casa
1. Método de la concordancia (o del acuerdo).- "Si dos o más casos del fenómeno que se investiga tiene sólo una circunstancia en común, esa circunstancia es la causa (o el efecto) del fenómeno en cuestión". Las definiciones de los métodos son prácticamente textuales de Stuart Mill (1843).
Siguiendo el esquema adjunto, vemos que en el primer caso se trata de un niño con problemas de aprendizaje (X). Este fenómeno se presenta con ciertas circunstancias en común: este niño tiene mala alimentación (A), va a un determinado colegio (B) y tiene determinado maestro (C).Pero hemos avanzado poco: cualquiera de esos tres factores puede o no estar relacionado con el problema de aprendizaje. Para empezar a sacar algunas conclusiones, entonces, debemos seguir examinando otros casos.En el segundo caso, tenemos otro niño con el mismo problema de aprendizaje, sólo que el factor A no está presente, pues está bien alimentado, pero sin embargo los otros dos sí, pues concurre al mismo colegio y tiene el mismo maestro que el niño del primer caso. Hasta aquí, en principio se pueden concluir dos cosas: a) que el factor A no es la causa del problema de aprendizaje, pues éste se produce estando o no estando presente dicho factor; y b) que la causa del problema de aprendizaje queda circunscripto a los factores B y C, o a alguno de ellos.Sin embargo, la conclusión que nos debe interesar hasta ahora, de acuerdo al espíritu de los métodos de Mill, es la segunda: se trata de procedimientos que no intentar probar que un factor NO es causa de otro, sino que probar que un factor SI lo es. A diferencia del enfoque popperiano, aquí el propósito de la investigación no es refutar sino probar factores, aún cuando un resultado de esta prueba pueda desembocar secundariamente en una refutación.Retomando: como todavía nuestra conclusión no es satisfactoria (no sabemos si el factor causal es B o C), pasamos a examinar un tercer caso, donde está presente como circunstancia solamente C, y vemos que el efecto 'problema de aprendizaje' sigue produciéndose. Ahora sí podemos concluir que C tiene importancia causal respecto de X, porque hay una 'concordancia': cada vez que aparece C aparece X, cuando todos los demás factores varían.Veamos este otro ejemplo: "Es interesante señalar que uno de los síntomas frecuentes de los casos de extrema angustia ante el combate es una inhibición del lenguaje, que puede ir desde la mudez completa hasta la vacilación y el tartamudeo. Análogamente, el que sufre de pánico escénico agudo es incapaz de hablar. Muchos animales tienden a dejar de emitir sonidos cuando están atemorizados, y es obvio que esta tendencia tiene un valor adaptativo, al impedirles atraer la atención de sus enemigos. A la luz de estos elementos de juicio, cabría sospechar que el estímulo del temor tiene una tendencia innata a provocar la respuesta de una suspensión de la conducta vocal" (John Dollard J y Millar N, "Personalidad y psicoterapia", citado por Copi, 1974:428). El esquema sería el siguiente:
Página 136 de 314
136

Caso Circunstancia Antecedente
Fenómeno
Caso 1 A B MudezCaso 2 A C MudezCaso 3 A D Mudez
A: temor, angustia, pánico.B: estar en combate.C: estar en un escenario.D: un animal en su hábitat.
Los factores variables, es decir, las circunstancias que no están siempre presentes cada vez que se produce mudez son los lugares: una batalla, un escenario, una selva, pero el factor común es siempre el temor, de lo cual se concluye la relación causal entre el temor y la mudez: en todos los casos, ambos factores 'concuerdan'.Otro ejemplo: "Se observó que los habitantes de varias ciudades presentaban una proporción mucho menor de caries dentales que el término medio de toda nación y se dedicó cierta atención a tratar de descubrir la causa de este fenómeno. Se halló que las circunstancias propias de estas ciudades diferían en muchos aspectos: en latitud y longitud, en elevación, en tipos de economía, etc. Pero había una circunstancia que era común a todas ellas: la presencia de un porcentaje raramente elevado de flúor en sus aguas, lo que significaba que la dieta de los habitantes de esas ciudades incluía una cantidad excepcionalmente grande de flúor. Se infirió de ello que el uso de flúor puede causar una disminución en la formación de caries dentales y la aceptación de esta conclusión condujo a adoptar tratamientos a base de flúor, para este propósito, en muchas localidades (Copi, 1974:427).
2. Método de la diferencia.- "Si un caso en el cual el fenómeno que se investiga se presenta y un caso en el cual no se presenta tienen todas tienen todas las circunstancias comunes excepto una, presentándose ésta solamente en el primer caso, la circunstancia única en la cual difieren los dos casos es el efecto, o la causa, o una parte indispensable de la causa de dicho fenómeno".
En el primer caso, hay un niño con problemas de aprendizaje (X) que tiene mala alimentación (A) y que va a un determinado colegio (B).En cambio, en un segundo caso está la situación de un niño sin problemas de aprendizaje (no-X), con buena alimentación pero que va al mismo colegio.Del análisis de ambos casos se puede concluir que A es la causa del problema, porque cuando aparece A el fenómeno se produce y cuando no aparece A el fenómeno no se produce (o si se quiere, porque la 'diferencia' entre la producción y la no producción del fenómeno radica en A).Ejemplo: "En 1861, Pasteur finalmente aportó una prueba general contra la generación espontánea. Hizo hervir un caldo de carne en un frasco con un cuello delgado muy largo hasta que no quedó ninguna bacteria. Esto se probaba por el hecho de que podía mantener el caldo en el frasco durante un periodo indefinido sin que se produjeran cambios, pues el estrecho cuello no permitía que nada penetrara en él. Luego rompió el cuello y en pocas horas aparecieron microorganismos en el líquido, y la carne estaba en plena descomposición. Probó que el aire transportaba tales organismos filtrándolo dos veces con filtros estériles y mostrando que podía provocar la putrefacción con el primer filtro, pero no con el segundo (H Pledge, "La ciencia desde 1500". Citado por Copi, 1974:433).
3. Método conjunto de la concordancia y la diferencia.- "Si dos o más casos en los cuales aparece el fenómeno tienen solamente una circunstancia en común, mientras que dos o más casos en los cuales no aparece no tienen nada en común excepto la ausencia de esta circunstancia, la circunstancia única en la cual difieren los dos grupos de ejemplos es el efecto, o la causa, o parte indispensable de la causa del fenómeno".
Este método resulta de aplicar la concordancia y la diferencia en una misma investigación. Por ejemplo: a) Aplicando el método de la concordancia a los casos 1 y 2, se concluye provisoriamente que la causa del problema de aprendizaje puede ser B o C. b) Para decidir cuál de estos dos factores es la causa, aplicamos ahora el método de la diferencia a los casos 2 y 3, donde podemos concluir que la causa del problema es B.El método de la diferencia y el método conjunto de la concordancia y la diferencia son los dos únicos procedimientos donde contamos con fenómenos o efectos que NO se han producido (no-X).Ejemplo: "Eijkman alimentó a un grupo de pollos exclusivamente con arroz blanco. Todos ellos desarrollaron una polineuritis y murieron. Alimentó a otro grupo de aves con arroz sin refinar. Ni uno solo de ellos contrajo la enfermedad. Luego reunió los residuos del refinamiento del arroz y alimentó con ellos a otros pollos polineuríticos, que al poco tiempo se restablecieron. Había logrado asignar con exactitud la causa de la polineuritis a una dieta defectuosa. Por primera vez en la historia, había conseguido producir experimentalmente una enfermedad debida a deficiencias de alimentación y había podido curarla. Fue un trabajo notable, que dio como resultado medidas terapéuticas inmediatas (Jaffe B, "Avanzadas de la ciencia". Citado por Copi, 1974:436).
Página 137 de 314
137

4. Método de los residuos.- "Restad de un fenómeno la parte de la cual se sabe, por inducciones anteriores, que es el efecto de ciertos antecedentes, y entonces el residuo del fenómeno es el efecto de los antecedentes restantes".
El primer caso corresponde a un niño con mala alimentación (A), que va a un determinado colegio (B) y que tiene determinado maestro (C). Este niño presenta problemas de aprendizaje (X), problemas de conducta en la escuela (Y) y problemas de conducta en el hogar, es decir, se trata de una configuración de tres fenómenos discriminables y relacionados entre sí.Por los resultados de investigaciones anteriores, sabemos que A es la causa de X, y que B es la causa de Y. Por lo tanto, C será la causa de Z, por ser el factor 'residual' de un fenómeno también 'residual'.Como puede apreciarse, este método sólo puede aplicarse cuando se aplicó alguno de los otros métodos de Mill, gracias a los cuales se había podido concluir que A es causa de X y que B es causa de Y.Un ejemplo muy citado de este método es el descubrimiento del planeta Neptuno por Adams y Le Verrier. Se había estudiado el movimiento del planeta Urano con ayuda de las teorías de Newton, y se bosquejó su órbita en la suposición de que el Sol y los planetas interiores a ella eran los únicos cuerpos que influían sobre ella. Pero las posiciones de Urano obtenidas por cálculo no coincidían con las observadas.Suponiendo que estas diferencias podrían explicarse por la acción gravitacional de un planeta exterior a la órbita de Urano, se calculó la posición de tal planeta hipotético (cuya conducta se ajustaría a los principios comunes de la mecánica celeste), tomando como base para el cálculo las perturbaciones en el movimiento de Urano. En las cercanías del lugar calculado fue descubierto, en efecto, el planeta Neptuno. Dicho descubrimiento se acredita por ese motivo al método de los residuos (Cohen y Nagel, 1979:87-88).El método de los residuos resulta particularmente útil en aquellos casos donde no podemos encontrar un caso donde falte alguna posible causa, o donde las posibles causas no pueden ser eliminadas por experimentación. En el ejemplo del problema de aprendizaje, cuando no es posible encontrar ni producir ningún caso en el cual falte A, B o C.Fatone da otro ejemplo: "el péndulo puede ser sustraído a la influencia de una montaña, pero no a la influencia de la tierra, para ver si seguirá oscilando en caso de que la acción de la tierra fuera suprimida" (Fatone, 1969:168).
5. Método de la variación concomitante.- "Un fenómeno que varía de cualquier manera, siempre que otro fenómeno varía de la misma manera es, o una causa, o un efecto de este fenómeno, o está conectado con él por algún hecho de causalidad".
En los dos casos aquí considerados, el problema de aprendizaje (X) del niño tiene como circunstancias comunes tanto la mala alimentación (A) como el colegio donde concurre (B).Así las cosas no podemos concluir nada, salvo que podamos constatar que cuando aumenta la alimentacíón deficitaria, también se agrava correlativamente el problema de aprendizaje. Esquemáticamente: si la mala alimentación aumenta al doble (2A) y correlativamente el problema de aprendizaje se agrava también al doble (2X), entonces podemos concluir que A es la causa de X, porque se ha producido una 'variación concomitante' entre A y X: a medida que se incrementa un factor, se incrementa el efecto.Como podemos apreciar, este es el único método de los cinco que introduce un análisis cuantitativo del problema: los cuatro métodos anteriores implicaban una consideración cualitativa, es decir, de 'presencia' o 'ausencia' de factores, y no de cambios cuantitativos en los mismos.Ejemplo: El fenómeno de las mareas puede podría producirse por la atracción gravitacional de la luna o por la presencia de estrellas fijas. Sin embargo, cuando se produce un cambio en la atracción gravitacional lunar, también se produce una alteración en el nivel del mar. De esta manera, se puede concluir que las mareas están producidas por la atracción gravitacional lunar.
Críticas y comentarios a los métodos de Mill
Los cánones de Mill estaban destinados a averiguar las relaciones de causalidad, esto es, los "antecedentes invariables e incondicionales" de todos los fenómenos (Ferrater Mora, 1979:2228). La expresión 'averiguar' alude aquí tanto a descubrir relaciones causales, como a probarlas.En efecto, Stuart Mill había propuesto sus métodos como instrumentos de 'descubrimiento' de conexiones causales, y como procedimientos de 'prueba' de las mismas. Una buena parte de las críticas apuntan precisamente a estas dos pretensiones, que examinaremos por separado. Un examen más completo de estas críticas pueden encontrarse en (Copi, 1974:451-459) y en (Cohen y Nagel, 1979:72-90).
1. Los métodos de Mill como instrumentos para descubrir conexiones causales.- Imaginemos que, aplicando el método de la concordancia para averiguar las causas del problema de aprendizaje, consideramos un cuarto caso donde incluimos una nueva circunstancia antecedente D (por ejemplo, ser drogadicto), y que había estado presente también en los tres casos anteriores. En esta nueva situación, el esquema sería el siguiente:
Caso 1 ABCD XCaso 2 BCD XCaso 3 CD XCaso 4 D X
Página 138 de 314
138

Si constatamos que el problema de aprendizaje (X) se produce también en presencia del factor D, concluiremos entonces que D es la causa de X.Por lo tanto, cuando habíamos aplicado el método de la concordancia considerando solamente los tres primeros casos, habíamos concluido erróneamente que la causa era C, debido a que no habíamos considerado 'todos' los factores atinentes o relevantes a la cuestión. El método no nos ayuda entonces a 'descubrir' nuevos posibles factores atinentes, entre los cuales podría estar la 'verdadera' causa.Esta crítica es extensible a los demás métodos. Como indica Copi, "los métodos no pueden usarse a menos que se tengan en cuenta todas las circunstancias atinentes al fenómeno. Pero las circunstancias no llevan rótulos que digan 'atinente' o 'no atinente'. Los problemas de atinencia son problemas relativos a la 'conexión causal', algunos de los cuales, al menos, deben hallarse resueltos 'antes' de que sea posible aplicar los métodos de Mill. Por consiguiente, los métodos de Mill no son 'los' métodos para descubrir conexiones causales, pues algunas de estas conexiones deben ser conocidas previamente a toda aplicación de esos métodos" (Copi, 1974:456).Críticas similares formulan Cohen y Nagel (1979:89), cuando sostienen que para que los métodos de Mill sirvan para descubrir causas, deben incluir entre las circunstancias antecedentes la causa verdadera: "si no hemos tenido la fortuna de incluirla, eliminaremos todas las alternativas sin descubrir la causa de X".El problema no pasa solamente por no haber seleccionado todos los factores atinentes, sino que también puede pasar por haberlos seleccionado mal. Un ejemplo particularmente risueño nos lo suministra Copi (1974:453): tomo whisky con soda y me emborracho, tomo vino con soda y me emborracho, tomo ron con soda y me emborracho, y tomo gin con soda y también me emborracho. Por lo tanto, lo que me emborracha es la soda, porque concuerda siempre la soda con la borrachera.Esta mala selección de los factores relevantes me impide descubrir la verdadera causa de la borrachera, lo que ilustra otro aspecto del problema de los métodos de Mill para descubrir conexiones causales. En realidad, el factor concordante que habría que haber seleccionado es el componente de alcohol presente en todas las bebidas consideradas.
2. Los métodos de Mill como reglas para probar conexiones causales.- Copi (1974:457-459) sostiene dos razones para negarles valor demostrativo a los cánones de Mill.a) Puesto que los métodos, como hemos visto en el parágrafo anterior, no pueden ayudarnos a seleccionar todos los factores atinentes, la afirmación de que uno de los factores considerados es la causa del fenómeno no tiene valor de prueba. El experimento de la soda que emborracha no logró probar la causa de la borrachera.b) Las correlaciones entre factores y fenómenos no siempre son prueba de un vínculo causal, y los métodos de Mill, especialmente el de las variaciones concomitantes, concluyen un vínculo causal allí donde hay una simple correlación. Por ejemplo (Copi, 1974:458), el hecho de que la velocidad diaria del viento en Chicago varíe proporcionalmente durante un año o más con la tasa de nacimientos en la India, no indica que un factor sea la causa del otro.Desde ya, cuanto mayor sea el número de casos donde hay correlación, tanto mayor será la probabilidad que dicha relación sea causal, pero, como no se pueden examinar todos los casos posibles, las conclusiones nunca serán seguras. Tal el tipo de cuestionamiento que hace Copi a los métodos de Mill como instancias de prueba de conexiones causales: los métodos de Mill son inductivos, no deductivos, y por tanto nunca podrán conferir necesariedad a un vínculo causal.Este tipo de crítica podemos incluso encontrarla varios siglos antes, cuando Nicolás de Autrecourt (siglo XIV) cuestiona el método de la concordancia propuesto por entonces diciendo que no puede establecerse que una correlación cuya vigencia se ha observado deba continuar manteniéndose en el futuro, con lo cual no se puede conseguir conocimiento necesario de las relaciones causales (Losee, 1979:52). En la misma línea de pensamiento se inscribe la conocida posición escéptica de Hume (1711-1776) al respecto (Losee, 1979:110).Tengamos presente, por último, que la presencia de correlación no asegura que haya un vínculo causal, por cuanto la correlación entre los fenómenos estudiados podría muy bien deberse a que son efectos de una misma causa. Stuart Mill había llegado a advertir esto cuando consideró los fenómenos altamente correlacionados del día y de la noche (Losee, 1979:164): en realidad, dicha correlación obedece a que ambos fenómenos dependen de ciertas condiciones, como por ejemplo la rotación diurna de la tierra, lo que viene a mostrarnos que Mill tuvo conciencia de las limitaciones de sus métodos. Examinémoslas brevemente.
3. La autocrítica de Stuart Mill.- Los diversos cuestionamientos que hemos detallado apuntan, en general, al mal uso de los métodos más que al pensamiento original de Stuart Mill, por cuanto éste ya se había percatado acerca de los alcances y las limitaciones de ellos.Mill había propuesto sus métodos como reglas para probar conexiones causales, pero "en sus momentos más prudentes, sin embargo, restringió la prueba de la conexión causal a aquellos argumentos que satisfacían el método de la diferencia" (Losee, 1979:165). Además, Mill sostuvo que el método de la diferencia era el más importante en cuanto a su potencial para descubrir causas, y que, en este sentido, contrastaba con el método de la concordancia, que tenía dos importantes limitaciones (Losee, 1979:158-159). El primer lugar, el método de la concordancia sólo sirve cuando se hizo un inventario exacto de las circunstancias relevantes, con lo cual su éxito depende de las hipótesis previas sobre las circunstancias relevantes. En nuestro ejemplo del problema de aprendizaje, ya hemos dicho que si no incluímos el factor
Página 139 de 314
139

drogadicción como causa y éste factor es efectivamente causal, las conclusiones seguirán un camino equivocado.En segundo y último lugar, el método de la concordancia no sirve si está funcionando una pluralidad de causas. "Mill reconoció que un tipo determinado de fenómenos puede ser el efecto de diferentes circunstancias en diferentes ocasiones" (Losee, 1979:158-159). Por ejemplo, en la siguiente situación:
Caso
Circunstancias antecedentes
Fenómenos
1 ABEF abe2 ACD acd3 ABCE afg
es posible que B causara 'a' en los casos 1 y 3, y que D causara 'a' en el caso 2. Debido a que esta posibilidad existe, sólo se puede concluir que es probable que A sea la causa de 'a'.En general, Stuart Mill estableció la limitación de sus métodos en su carácter inductivo. En efecto, Para él, "la lógica debe estudiar principalmente la teoría de la inducción como el único método adecuado para las ciencias. Los conocimientos científicos son producto de la inducción, pues las mismas generalidades ideales que se suponen adquiridas 'a priori' son el resultado de generalizaciones inductivas. La previsión de los fenómenos tiene, por tanto, un carácter probable [que] no es nunca seguridad definitiva" (Ferrater Mora, 1979:2227-2228).
4. Reivindicación de los métodos de Mill.- Copi los cuestiona los métodos de Mill como instancias de descubrimiento y de prueba, pero los reivindica diciendo que, si se agrega una hipótesis adicional que postule un universo finito de causas, pueden obtenerse conclusiones seguras o necesarias, es decir, fundadas en la deducción, y no en la inducción (los métodos de Mill son esencialmente inductivos). En el ejemplo del problema de aprendizaje, si agregamos como premisa adicional que las 'únicas' causas posibles del problema de aprendizaje X son A, B y C, entonces la conclusión de que C es la causa efectiva es necesaria.Así presentados, los métodos de Mill "aparecen como instrumentos para someter a ensayo la hipótesis. Sus enunciados describen el método del 'experimento controlado', que constituye un arma indispensable de la ciencia moderna" (Copi, 1974:461). Copi redondea su reivindicación, señalando que si bien las leyes causales nunca pueden ser descubiertas con los métodos de Mill, ni pueden estos establecer 'demostrativamente' [deductivamente] su verdad, estos métodos "constituyen los modelos básicos a los cuales debe adecuarse todo intento por confirmar o refutar, mediante la observación o el experimento, una hipótesis que confirme una conexión causal" (Copi, 1974:464).Cohen y Nagel también cuestionan los métodos como procedimientos de descubrimiento y de prueba, pero los reivindican indicando que, aunque no pueden servir para probar causas, sirven para eliminar otras. Copi dice: "los métodos de Mill son esencialmente eliminatorios". En el ejemplo del problema de aprendizaje, aunque métodos como el de la concordancia no prueban con certeza que C es la causa de X, sí prueban con certeza que A y B no lo son.Cohen y Nagel señalan, así, que los métodos de Mill "son de indudable valor en el proceso de llegar a la verdad, pues al eliminar las hipótesis falsas, restringen el campo dentro del cual podemos encontrar las verdaderas. Y aún cuando no logren eliminar todas las circunstancias irrelevantes, nos permiten establecer (con cierta aproximación) de modo tal las condiciones para la producción de un fenómeno que podamos distinguir aquella hipótesis que, desde el punto de vista lógico, es preferible a sus rivales" (Cohen y Nagel, 1979:90).
Antecedentes históricos
Stuart Mill no es del todo original al plantear sus métodos. Su mérito reside en haber revisado, sistematizado y propagandizado las ideas al respecto de Francis Bacon quien, a su vez, tampoco fue el primero en formular los métodos inductivos, ya que encontramos importantes antecedentes en algunos pensadores medievales, como por ejemplo en Robert Grosseteste, Juan Duns Escoto o Guillermo de Occam.Consiguientemente, podemos trazar dos etapas históricas hasta desembocar en los métodos de Mill del siglo XIX: los medievales y Francis Bacon (después de Bacon y antes de Stuart Mill, el inglés David Hume había escrito ocho reglas "para juzgar sobre causas y efectos", entre las cuales estaban los métodos de la concordancia, de la diferencia y de las variaciones concomitantes. Ver Losee, 1979:115). Para todo ello, nos guiaremos por el esquema 2.
Esquema 2: Algunos antecedentes históricos de los métodos de Mill
Grosseteste(1168-1253)
Duns Escoto(1265-1308)
G. de Occam(1280-1349)
Galileo(1564-1642)
F. Bacon(1561-1626)
Concordancia B FDiferencia C GConjunto A DV.Concomitant E H
Página 140 de 314
140

e
(Para las letras mayúsculas, remitirse al texto).
1. Los medievales.- A) Grosseteste contribuyó a desarrollar nuevas técnicas inductivas para descubrir principios explicativos. Sugirió por ejemplo un procedimiento para saber si una hierba tenía efecto purgante: debían examinarse numerosos casos donde se administrase la hierba en condiciones donde no hubiera otros agentes purgantes. Se trata (Losee, 1979:42) de un procedimiento inductivo que luego describiría Stuart Mill como el método conjunto de la concordancia y la diferencia.B) Duns Escoto propuso el método de la concordancia, pero le asignó méritos muy modestos: sostenía que, si cada vez que se daba la circunstancia A se producía el efecto X, variándose todas las otras circunstancias, el científico estaba autorizado a afirmar que A 'puede' ser la causa de X, pero no a que necesariamente A 'debe' ser su causa (Losee, 1979:43). Escoto habló de 'uniones disposicionales' entre un efecto y su circunstancia antecedente, es decir, de uniones constatadas en la experiencia y que, como tales, no podían ser consideradas uniones necesarias.C) Nos cuenta Losee: "Occam formuló un procedimiento para extraer conclusiones acerca de las uniones disposicionales siguiendo un Método de la Diferencia. El método de Occam consiste en comparar dos casos: un caso en que el efecto está presente, y un segundo caso en que el efecto no está presente. Si se puede mostrar que existe una circunstancia que está presente cuando el efecto está presente, y ausente cuando está ausente [...], entonces el investigador está autorizado a concluir que la circunstancia 'puede ser' la causa del efecto"."Occam mantenía que, en el caso ideal, el conocimiento de una unión disposicional podía establecerse sobre la base de solamente una asociación observada. Señalaba, sin embargo, que en un caso así se debe estar seguro de que todas las demás causas posibles del efecto en cuestión no están presentes. Observó que, en la práctica, es difícil determinar si dos conjuntos de circunstancias difieren sólo en un aspecto. Por esta razón, instaba a investigar muchos casos, con el fin de minimizar la posibilidad de que un factor no localizado sea el responsable de la aparición del efecto" (Losee, 1979:43).D) Crombie (1979:36) indica que Occam también propuso un método similar al luego conocido como método de la concordancia y la diferencia. Mediante dicho procedimiento, Occam pensó que, ya que el mismo efecto podía tener diferentes causas, era preciso eliminar las hipótesis rivales.E) En su "Diálogo sobre los dos sistemas principales del mundo" (1632), Galileo hace discutir a Salviati (que representa el pensamiento de Galileo) y a Simplicio (que representa a los aristotélicos). Refiere Crombie (1979:126-127) que en este texto Galileo habla de un procedimiento igual al método de las variaciones concomitantes de Stuart Mill (o al método de los grados de comparación de Bacon), cuando dice: "Así digo que si es verdad que un efecto puede tener solamente una causa, y si entre la causa y el efecto hay una conexión precisa y constante, entonces cuando quiera que se observe una variación precisa y constante en el efecto, debe haber una variación precisa y constante en la causa". Para ejemplificar el procedimiento, Galileo nos suministra el ejemplo de las mareas, que hemos explicado brevemente más arriba.Sin embargo (Losee, 1979:65), Galileo no avaló los otros métodos de Bacon: las hipótesis sobre idealizaciones no pueden obtenerse de la inducción por enumeración simple ni por los métodos de la concordancia y la diferencia, siendo preciso que el científico intuya qué propiedades de los fenómenos son la base adecuada para la idealización, y qué propiedades pueden ignorarse.
2. Francis Bacon.- Bacon propondrá sus 'tablas' como un nuevo procedimiento inductivo que reemplazaría al hasta entonces conocido método de la inducción por simple enumeración, también llamado inducción incompleta. En su "Novum Organum", nos cuenta que "esta especie de inducción que procede por la vía de la simple enumeración no es sino un método de niños, que no conduce sino a conclusiones precarias y que corre los más grandes riesgos por parte del primer ejemplo contradictorio que puede presentarse; en general, se pronuncia según un número de hechos demasiado pequeño, y solamente de esa especie de hechos que se presentan a cada instante. Pero la inducción verdaderamente útil en la invención y en la demostración de las ciencias y de las artes hace una elección entre observadores y las experiencias, separando de la masa, por exclusiones y rechazos convenientes, los hechos no concluyentes; luego, después de haber establecido proposiciones en número suficiente, se detiene al fin en las afirmativas y se atiene a estas últimas" (Bacon F, "Novum Organum", I, 105).Para aclarar estas ideas de Bacon, retomemos brevemente el ejemplo del problema de aprendizaje y veamos cómo podría resolverse mediante la inducción por enumeración simple y por la inducción baconiana.a) Inducción por enumeración simple: el primer niño pertenece al colegio B, y tiene problemas de aprendizaje; el segundo niño también pertenece al colegio B y también tiene problemas de aprendizaje; y así sucesivamente con otros niños. Por lo tanto, se concluye que la causa del problema de aprendizaje es el colegio B.b) Inducción baconiana: usando por ejemplo el método de la concordancia, vemos que el primer niño pertenece al colegio B, tiene al maestro C y tiene mala alimentación, y vemos que tiene problemas de aprendizaje. El caso del segundo niño es igual, pero está bien alimentado, y el caso del tercer niño es igual pero está bien alimentado y no va al colegio B. Por lo tanto, puesto que en los tres casos concuerda siempre el maestro C, esta será probablemente la causa del problema de aprendizaje. Esta conclusión es más firme que aquella otra ofrecida por el método de la inducción por enumeración simple. Ciertos autores (por ejemplo Fatone 1969:165) han declarado que la propuesta de F. Bacon se opone a la
Página 141 de 314
141

inducción llamada completa, consistente en derivar del total de casos una afirmación general que vale precisamente para todos esos casos.En rigor, la propuesta de Bacon iba tanto contra la inducción por enumeración simple como contra la inducción completa o matemática. Para él, ni la experiencia bruta ni los razonamientos vacíos, respectivamente, son el camino de la ciencia. El científico no debe ser, decía Bacon en el libro 1, aforismo 95 del "Novum Organum", ni una hormiga, que lo único que hace es almacenar (comida = información), ni una araña que teje redes con material fabricado por ella misma. El científico debe estar en el punto medio: debe ser una abeja que extrae materiales en los jardines, pero luego puede elaborar esa materia prima con un 'arte que le es propio'. Esta elaboración de la información que nos brinda la naturaleza es posible gracias a la utilización de una nueva herramienta (un 'novum organon'), constituído fundamentalmente por las 'tablas', antepasados directos de los 'métodos' de Mill.Las 'tablas' de Bacon son tres: de presencia, de ausencia y de comparación, y corresponden, respectivamente, a los métodos de la concordancia, de la diferencia y de las variaciones concomitantes (F, G y H del esquema 2)."En la tabla de presencia se registrarán todos los casos diferentes en que se da el mismo fenómeno; en la de ausencia, los casos en que el fenómeno que interesa no se da a pesar de que tienen circunstancias comunes con aquel en que se da; en la tabla de comparación, los casos en que el fenómeno presenta variaciones o diferencias [...]. Así fundaba Bacon el método, que consiste en buscar los fenómenos tales que: cuando se da uno de ellos se da el otro; cuando no se da uno de ellos no se da el otro; y cuando uno de ellos varía, varía el otro. Comprobada esta triple relación, podía enunciarse la relación forzosa que existía entre los hechos" (Fatone, 1969:166).
Los métodos de Mill y los métodos experimentales actuales
A partir de Stuart Mill, los métodos para probar conexiones causales siguieron evolucionando de manera notable hasta muy entrado el siglo XX. En tren de establecer una comparación entre los cánones de prueba de Mill y los actuales, podemos trazar, en forma muy escueta, el siguiente panorama.Los métodos experimentales actuales presentan una gran semejanza con los métodos de la diferencia y de la variación concomitante, mientras que tienen poco que ver con los métodos de la concordancia y de los residuos.La semejanza con el método de la diferencia radica en que precisamente en los modelos experimentales actuales, una situación típica es aquella donde se comparan dos grupos: a uno se lo somete a la influencia de un posible factor causal A y al otro no, en la esperanza de que luego el primer grupo presente el efecto X y el segundo no. La semejanza con el método de la variación concomitante radica en el análisis cuantitativo, típico de los métodos actuales. Muchas veces no basta con someter a un grupo a la influencia de un posible factor causal A, sino que además se introducen variaciones cuantitativas en dicho factor para ver si se produce una variación concomitante en el efecto X. Un ejemplo son los experimentos sobre nuevas drogas para curar enfermedades.El método de los residuos no guarda relación con los métodos actuales sencillamente porque no se trata de un procedimiento experimental. Hemos ya dicho que uno de los motivos por los cuales se utilizaba este método era para investigar situaciones donde no se podían introducir cambios artificialmente.El método de la concordancia, por último, es bastante diferente a ciertos procedimientos experimentales actuales típicos. Mediante el método de Mill, comparábamos distintos casos donde se produce el efecto X y donde hay diferentes causas posibles. Por ejemplo, en un caso tenemos las causas posibles A-B-C y el efecto X. En cambio, en el procedimiento actual no se hace un descarte progresivo de causas hasta que quede, por ejemplo, C. En su lugar, se selecciona previamente la causa C y se la somete a prueba y los demás factores (A y B) son tratados como variables extrañas, buscándose controlar su influencia con procedimientos tales como la aleatorización. Un pionero de este procedimiento fue Fisher, que lo propone alrededor de 1925 (Fisher, 1954).
Página 142 de 314
142
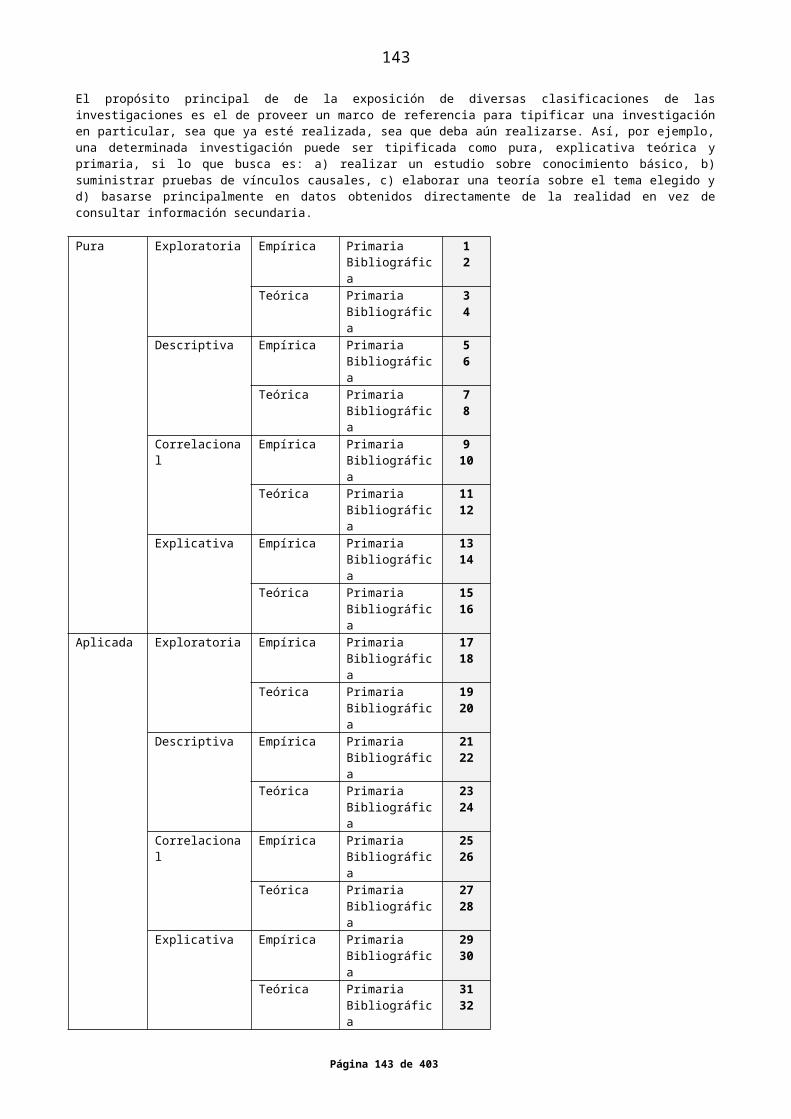
CAPÍTULO 9: LAS ETAPAS DE LA INVESTIGACIÓN TÍPICA
A lo largo del presente texto se explicarán los pasos o etapas de una investigación típica, es decir, empírica. Este tipo de investigación podrá ser pura o aplicada, pero en general seguirá la pauta de una investigación correlacional o explicativa, primaria y cuantitativa.Cada etapa será tratada en detalle en los siguientes capítulos de este libro:
Etapas de la investigación típica (visión panorámica) Capítulo1) Planteo del problema2) Revisión bibliográfica3) Planteo del marco teórico4) Planteo de objetivos
Capítulo 10
5) Formulación de la hipótesis6) Identificación, categorización y operacionalización de las variables
Capítulo 11
7) Definición de la población8) Selección de la técnica de muestreo9) Selección o construcción de los instrumentos de medición
Capítulo 12
10) Selección del diseño de investigación Capítulo 1311) Recolección y organización de los datos12) Análisis e interpretación de los datos
Capítulo 14
13) Presentación de los resultados Capítulo 15
En el presente capítulo se presenta una primera vista panorámica de las etapas de una investigación típica, y que habitualmente se cumplen en la mayoría de las investigaciones que podemos encontrar en las publicaciones científicas.Así es que a continuación se explica brevemente cada etapa utilizando un ejemplo único: una investigación que indague acerca de las relaciones entre estado civil y estado de ánimo. Téngase presente que, dependiendo de cada investigación en particular, algunos de los pasos indicados pueden saltearse, cambiarse el orden, e incluso volver sobre alguno de los pasos anteriores.
1) Planteo del problema.- El problema se expresa mediante una pregunta, la cual deberá ser contestada en la investigación. Por ejemplo: “¿Existe alguna relación significativa entre estado civil y estado de ánimo?”.Debe diferenciarse el problema del tema. El tema de la investigación es básicamente la variable dependiente. En nuestro ejemplo, cualquiera de ambas podría serlo: el estado civil puede depender del estado de ánimo (estoy triste por lo tanto me divorcio) o el estado de ánimo puede depender del estado civil (estoy soltero y por lo tanto estoy alegre). En este paso, por tanto, deberemos decidir cuál será nuestra variable dependiente. Por ejemplo, elegimos estado de ánimo.
2) Revisión bibliográfica.- Su función básica es la de conocer qué soluciones dieron otros autores al mismo problema o problemas similares que pretendemos resolver en nuestra investigación. Emprendemos aquí la ardua tarea de revisar todo las investigaciones realizadas concernientes a la relación entre estado de ánimo y estado civil, para lo cual deberemos recorrer bibliotecas, la red Internet, etc. La idea es hacer una síntesis de todo lo encontrado utilizando solamente los abstracts de las investigaciones encontradas. Tal vez podríamos encontrarnos con que nuestra investigación ya fue realizada, pero ello no debe desilusionarnos: por lo general nuestra investigación partirá de muestras diferentes, utilizará otros instrumentos de medición, etc., lo cual la convierte en una investigación original que complementará la ya realizada. En todo caso, en nuestro informe final consignaremos en qué medida nuestra investigación coincide o no con los resultados de otras investigaciones, y qué razones podrían dar cuenta de las diferencias.
3) Planteo del marco teórico.- Las variables elegidas han de ser definidas dentro de un marco teórico. Por ejemplo, para definir ‘estado civil’ podemos tomar como referencia el Código Civil del país donde hacemos la investigación, mientras que para definir ‘estado de ánimo’ podremos tomar el DSM-IV. Otros ejemplos de marcos teóricos para otras variables pueden ser el psicoanálisis, el cognitivismo, la teoría de la gestalt, la teoría del aprendizaje de Skinner, etc. En suma, en este caso se sintetizarán los marcos teóricos utilizados, mientras que las definiciones teóricas de las variables se especifican en un paso ulterior
4) Planteo de objetivos.- Supondremos que en nuestro ejemplo realizaremos una investigación de campo, experimental, descriptivo-explicativa y con datos principalmente primarios.Suelen especificarse un objetivo general y objetivos específicos. En nuestro ejemplo, el objetivo general podría ser ‘probar si existe o no una relación significativa entre estado civil y estado de ánimo’, y algunas objetivos más específicos podrían ser ‘revisar las investigaciones recientes sobre el tema’, ‘discutir las diferencias encontradas con otras investigaciones sobre el mismo tema’, o ‘examinar la incidencia de las variables edad y nivel de instrucción en la muestra seleccionada’.
Página 143 de 314
143

5) Formulación de la hipótesis.- La hipótesis es nuestra respuesta tentativa al problema, y puede formularse en forma general y específica. La forma general sería “existe una relación significativa entre estado civil y estado de ánimo”. Un ejemplo de hipótesis más específica sería “las personas solteras tienden a sufrir estados depresivos”. En una hipótesis específica, pueden ‘especificarse’ varias cosas: el vínculo entre las variables (en vez de decir ‘existe una relación entre…” decimos “…es la causa de…”), alguna categoría de alguna variable (en vez de ‘estado civil’ decimos ‘casado’), o alguna dimensión o indicador de alguna variable (en vez de ‘estado de ánimo’ decimos ‘presentan desinterés por el mundo exterior’). Normalmente, la hipótesis que será verificada en la investigación es la hipótesis general.Si hemos decidido que nuestra investigación sea exploratoria, en lugar de una hipótesis pueden realizarse algunas conjeturas acerca de las variables o factores relevantes vinculadas con el tema. Las conjeturas son meras sospechas que luego, si se encuentran suficientes elementos de juicio para considerarlas dignas de ser probadas, serán convertidas en hipótesis.
6) Identificación, categorización y operacionalización de las variables.- Respecto de la identificación, nos preguntaremos qué variables principales vamos a considerar: ‘estado civil’ y ‘estado de ánimo’. Seguidamente, las clasificamos según diversos criterios: simples o complejas, manifiestas o latentes, organísmicas o situacionales, etc. En general, las clasificaciones que no pueden obviarse son: independiente o dependiente (‘estado civil’ será independiente y ‘estado de ánimo’, dependiente), y cualitativa o cuantitativa. Esta última clasificación es importante porque especifica en qué nivel de medición la mediremos. Por ejemplo, ‘estado civil’ será una variable cualitativa nominal, mientras que ‘estado de ánimo’ será una variable cualitativa ordinal. En principio no tendría mucho sentido clasificar ‘estado civil’ como ordinal, porque no podemos decir “más casado”, “algo casado” o “nada casado”.Respecto de la categorización, asignaremos categorías a las variables (para ‘estado civil’ pueden ser ‘soltero’, ‘casado’, ‘separado de hecho’, ‘divorciado’, ‘juntado’, ‘viudo’, etc., y para ‘estado de ánimo’ pueden ser ‘muy deprimido’, ‘deprimido’, ‘alegre’ y ‘muy alegre’).En cuanto a la operacionalización, si las variables son complejas seleccionaremos dimensiones e indicadores. Dimensiones de ‘estado de ánimo’ podrían ser ‘manifestaciones físicas’ y ‘manifestaciones psíquicas’, y sus respectivos indicadores, ‘postura corporal’ e ‘interés por el trabajo’. Como ‘estado civil’ es una variable simple, seleccionaremos un solo indicador. Por ejemplo, aquello que nos responde el sujeto cuando le preguntamos por su estado civil.
7) Definición de la población.- Especificamos la población que queremos estudiar. Por ejemplo, todas las personas entre 20 y 60 años que vivan en la ciudad de Buenos Aires en un mes y año determinado. Por lo tanto, nuestra unidad de análisis serán personas (y no por ejemplo grupos o familias). La definición de la población supone siempre especificar sus componentes, llamados unidades de análisis.
8) Selección de la técnica de muestreo.- Podríamos elegir una muestra de tipo probabilístico: elegimos al azar una cierta cantidad de números telefónicos. Hay otros procedimientos menos aconsejables porque no son aleatorios, como elegir a las personas que conocemos de nuestro entorno (familiares, amigos, vecinos, etc.). Es estos casos la muestra estará sesgada por nuestras preferencias y por un determinado estrato social o zona geográfica.Las muestras serán diferentes según el tipo de investigación a realizar. En un estudio descriptivo puede utilizarse una muestra de 1000 personas extraídas de la población, y a las cuales encuestaremos. En un estudio explicativo experimental, las muestras consistirán por ejemplo en dos grupos: el primero conformado por personas solteras, y el segundo por personas casadas. También podemos elegir tantos grupos como categorías tenga la variable ‘estado civil’.
9) Selección o construcción de los instrumentos de medición.- Hay varios tests que miden estado de ánimo, como por ejemplo el Cuestionario de Depresión. Si no hemos encontrado ningún instrumento apto para medir nuestras variables, deberemos construirlos nosotros mismos. En nuestro ejemplo, deberemos construir un test para medir ‘estado de ánimo’. Para medir ‘estado civil’ obviamente no se requiere ningún test: basta con preguntarle a la persona cuál es su estado civil.La construcción de nuestro test implicará cumplir estos pasos: a) Seleccionar los ítems, es decir, las preguntas o las pruebas que incluirá. Para nuestro ejemplo, uno de los ítems puede ser la pregunta “¿Se siente triste la mayor parte de los días?”. b) Categorizar los ítems, es decir, establecer las respuestas posibles que podrá responder cada sujeto en cada ítem. Por ejemplo para el ítem anterior, las posibles categorías pueden ser “sí” y “no”. c) Construir un sistema de puntuación de las respuestas. Por ejemplo asignamos arbitrariamente el número 1 si contestó que sí y 0 si contestó que no. Luego, sumando todos los puntos de cada ítem, deberemos obtener un índice, en este caso, un índice de estado de ánimo. También aquí estableceremos como interpretar estos índices. Por ejemplo, si obtuvo más de 20 categorizaremos al sujeto como “muy deprimido”, si obtuvo entre 15 y 19 puntos lo ubicaremos como “deprimido”, y así sucesivamente. d) Finalmente determinaremos la validez y la confiabilidad del instrumento así construido.
10) Selección del diseño de investigación.- Como estamos suponiendo que nuestra investigación es explicativa y además indaga una sola variable causal, se podrían elegir alguno de los seis diseños experimentales bivariados que propone Selltiz, fundamentando además esta elección.
Página 144 de 314
144

11) Recolección y organización de los datos.- Para la recolección de los datos, aplicamos o administramos los instrumentos de medición. Tomamos a los sujetos elegidos un test de estado de ánimo y les preguntamos su estado civil. De todos los pasos de esta investigación, este es el único en el cual tomamos contacto con los sujetos del estudio. Todos los otros pasos los podemos realizar solos en nuestro lugar de trabajo.La organización de los datos, supone realizar ciertas operaciones como la construcción de una matriz de datos, la tabulación, la graficación y la obtención de medidas estadísticas de posición y de dispersión.a) Construcción de la matriz de datos.- Organizamos y sintetizamos toda la información obtenida en una matriz, que, en nuestro ejemplo puede asumir la siguiente forma:
Sujeto Estado civil
Estado de ánimo
A Soltero Muy deprimidoB Soltero AlegreC Casado DeprimidoEtc Etc Etc
En el caso de tratarse de variables cuantitativas, en esta matriz se consignarán en las columnas de las variables los puntajes brutos, los puntajes estandarizados y/o los percentiles. Por ejemplo, si utilizamos el WISC-III para medir inteligencia en niños, Juancito pudo haber obtenido respectivamente 121, 114 y 82.b) Tabulación.- Toda la información de la matriz de datos la organizamos aquí en una tabla de doble entrada, es decir, una tabla que permita cruzar las dos variables en juego:
Muy deprimido
Deprimido
Alegre
Muy alegre
TOTALES
Soltero 7 ? ? ? ?Casado ? ? ? ? ?Separado de hecho
? ? ? ? ?
Divorciado ? ? ? ? ?Juntado ? ? ? ? ?Viudo ? ? ? ? ?TOTALES ? ? ? ? ?
Por ejemplo, hemos colocado la frecuencia 7 en el primer casillero porque hemos encontrado siete casos de sujetos solteros muy deprimidos.c) Graficación.- Opcional. Sirve para presentar la información de las tablas de una forma más intuitiva y rápidamente comprensible.d) Obtención de medidas de posición, dispersión y correlación.- Generalmente pueden obtenerse a partir de la tabla de doble entrada. Como en el ejemplo que estamos siguiendo las variables no son cuantitativas, no podremos utilizar la media aritmética ni el desvío estándar. Deberemos usar medidas estadísticas para variables cualitativas, como el modo o la mediana (medidas de posición), y otras. Por ejemplo, si la categoría que más se repite para la variable ‘estado de ánimo’ es ‘alegre’, entonces ‘alegre’ es el modo. Las medidas de correlación, finalmente, permiten organizar la información acerca de la relación entre dos o más variables (en este caso, entre estado civil y estado de ánimo).
12) Análisis e interpretación de los datos.- Respecto del análisis de los datos, de acuerdo a los fines que nos hayamos propuesto y si resultare necesario, podremos optar por varias posibilidades dentro de la amplia gama de pruebas estadísticas tales como la prueba t, la prueba z, etc., tarea que generalmente se confía a algún especialista en estadística. Tales pruebas tienen como finalidad ofrecer una prueba matemática que permita decidir si aceptaremos o rechazaremos nuestra hipótesis.La interpretación de los datos es opcional pero recomendable. En este paso arriesgamos algunas conjeturas personales acerca del porqué de la asociación detectada entre ambas variables. Por ejemplo, hemos encontrado una alta asociación entre ‘alegría’ y ‘casado’ quizá porque el matrimonio permite compartir trances y dificultades más fácilmente, con lo cual hay menor margen para la depresión. La interpretación de los datos puede hacerse desde algún marco teórico existente o bien, si somos audaces e imaginativos, podemos crear nuestro propio marco teórico porque no hay ninguno que nos satisfaga.
13) Presentación de los resultados.- Mientras fuimos cumpliendo los pasos anteriores, es muy probable que hayamos escrito varias hojas en borrador. Con este material redactamos nuestro informe final, luego el abstract o resumen del mismo, luego seleccionamos un título para nuestro informe y, finalmente, publicados los resultados (por ejemplo enviándolos a una revista científica).Este proceso se realimenta continuamente: en cuanto damos a conocer nuestro trabajo a la comunidad científica, desde ese momento entra a formar parte de la bibliografía existente sobre el tema y, por tanto, será consultado por otro investigador que se encuentre en la etapa de la revisión bibliográfica.
Este libro presentará en los capítulos siguientes cada etapa de la investigación con mayor detalle, tal como puede apreciarse en el siguiente esquema:
Página 145 de 314
145

Etapas de la investigación típica (visión más detallada) Capítulo1) Plantear del problema2) Revisar bibliográfica3) Plantear del marco teórico4) Plantear de objetivos
Capítulo 10
5) Plantear la hipótesis6) Clasificar la hipótesis7) Definir las unidades de análisis8) Definir conceptualmente las variables9) Clasificar las variables10) Definir operacionalmente las variables11) Categorizar las variables
Capítulo 11
12) Definir de la población13) Seleccionar la técnica de muestreo14) Seleccionar o construir los instrumentos de medición
Capítulo 12
15) Selección del diseño de investigación Capítulo 1316) Recolectar los datos17) Organizar los datos18) Analizar los datos19) Interpretar los datos
Capítulo 14
20) Redactar de los resultados21) Publicar los resultados
Capítulo 15
Página 146 de 314
146

CAPÍTULO 10: PROBLEMA, BIBLIOGRAFÍA, TEORÍA Y OBJETIVOS
En este capítulo se describirán los cuatro primeros pasos de una investigación típica: el planteo del problema que la investigación debe resolver, la revisión bibliográfica, el planteo del marco teórico y el planteo de los objetivos de la investigación.
1. PLANTEO DEL PROBLEMA
El problema de investigación es aquel que la investigación busca resolver, y por tanto el que dará sentido a ésta. El problema suele ser definido también como toda “situación considerada como difícil de resolver, y que por tanto necesita de la investigación para resolverse” (Tamayo, 1999:169), o como aquel “ámbito de la investigación para el que la ciencia no tiene todavía una solución satisfactoria” (León y Montero, 1995:22). Autores como Tamayo destacan que el problema encierra aspectos conocidos y desconocidos, y que la idea es descubrir los desconocidos que integran la situación problemática” (Tamayo, 1999:169).
Formulación.- Si la investigación científica es un automóvil, el combustible que la alimenta son los hechos. Pero lo que la pone en marcha no es un hecho sino un problema y, obviamente, la intención del investigador por resolverlo. Lewis Carroll, en "Alicia en el país de las maravillas", hace decir a uno de sus personajes que "como no tenía respuesta para ninguno de sus problemas, el modo de formularlos no importaba demasiado". Pero en el caso de la investigación científica sí interesa cómo se planteará el problema. La importancia de formularlo correctamente fue alguna vez destacada por Claude Bernard, cuando dijo que el experimentador que no sabe lo que está buscando, no comprenderá lo que encuentra.La correcta formulación de un problema supone:a) Expresarlo en forma de interrogante. La pregunta es la forma gramatical que asume el problema.b) Expresarlo en forma lo suficientemente concreta como para que pueda ser resuelto efectivamente por la vía científica, es decir, para que sea solucionable científicamente. Así, el problema de la existencia de Dios no es lo suficientemente concreto pues no hay investigación científica que pueda resolverlo, siendo mas bien un problema filosófico. Señalan Selltiz y otros (1980) que el problema debe reducirse a dimensiones manejables o a un cierto número de sub-tareas, cada una de las cuales debe ser abordada en un solo estudio.c) Expresarlo en forma lo suficientemente clara como para saber qué datos buscar para resolverlo. Así, el problema de si el perro del comisario ladra o no, además de ser un problema cotidiano y no científico, no es lo suficientemente claro ya que no especifica si el comisario "tiene" un perro o si el comisario "es" un perro, con lo cual no se sabrá qué datos buscar para resolverlo: si los datos sobre el perro o los datos sobre su dueño. Del mismo modo, no puede decirse simplificadamente "voy a investigar el problema de la droga". Esta es una afirmación ambigua que puede apuntar tanto al problema de cuáles son las causas de la drogadicción como al problema de cómo fabricar droga sin que se entere la policía. En cambio, problemas bien planteados son por ejemplo: ¿qué incentiva el rendimiento escolar?, o ¿influye la educación recibida sobre la ideología política de las personas? Se trata de problemas solucionables y donde se sabe el tipo de información a buscar para resolverlos.
El problema es del investigador.- Conviene distinguir claramente el problema que llevó a hacer la investigación, del problema que se busca resolver con la investigación. Por ejemplo, una cosa es el problema que tienen las personas que no pueden superar su miedo a volar, y otra es el problema de examinar la eficacia de tratamientos para perder ese miedo. El primero es un problema de la población, que engendra o motiva un nuevo problema, el del investigador.
La justificación del problema.- En muchos informes de investigación se especifica porqué es importante el abordaje del problema. Esta justificación no se refiere a la importancia personal que el problema puede tener para el investigador, sino a la importancia que tiene para la comunidad científica y la población en general. Se supone que resolver el problema implicará aumentar en amplitud y profundidad el conocimiento de la realidad, o bien prestar algún beneficio práctico inmediato. Así, aunque un problema puede ser muy importante en tales sentidos, no alcanza a justificarse si su investigación es ‘más de lo mismo’, es decir, si ya hay una gran cantidad de investigaciones que trataron la cuestión de la misma manera.La justificación es lo que orienta la elección del problema, que puede seleccionarlo el mismo investigador o la institución para la cual trabaja.Señalan Hernández Sampieri R y otros (1996:17) que los criterios principales para evaluar el valor potencial de una investigación son: conveniencia, relevancia social, implicaciones prácticas, valor teórico y utilidad metodológica. Agregan que el planteamiento de un problema de investigación científico no puede incluir juicios morales o estéticos, pero debe cuestionarse si es o no ético llevarlo a cabo.
El problema y el tema.- Debe distinguirse claramente el problema del tema de investigación. Un tema puede ser el insomnio, mientras que los problemas que pueden tratarse dentro de esa amplia temática pueden ser ¿existen tratamientos eficaces contra el insomnio? ¿cuáles son las causas del insomnio? o ¿hay alguna relación entre insomnio y sedentarismo? Cuando la investigación contempla variables independientes y dependientes, es habitual considerar al tema como la variable dependiente.
Página 147 de 314
147

Problema e hipótesis.- Mientras que el problema es la pregunta, la hipótesis es la respuesta tentativa. Señalan Selltiz y otros (1980) que si no hay suficientes conocimientos para proporcionar una base para hacer una hipótesis, como ocurre en los estudios exploratorios, la formulación del problema incluirá una indicación de las áreas sobre las que se desea establecer una hipótesis. En cambio si ya existen conocimientos relevantes concernientes al problema, la formulación de éste último incluirá hipótesis como guía para la recogida de datos y para su análisis, y como medio para poder relacionar el estudio con otros similares o con un cuerpo de teoría en general.Señalan Hernández Sampieri R y otros, (1996:17) que plantear el problema de investigación es afinar y estructurar más formalmente la idea de investigación, desarrollando tres elementos: objetivos de investigación, preguntas de investigación y la justificación de ésta. Los tres elementos deben ser capaces de guiar a una investigación concreta y con posibilidad de prueba empírica. Los objetivos y preguntas de investigación deben ser congruentes entre sí e ir en la misma dirección. 3. Los objetivos establecen qué pretende la investigación, las preguntas nos dicen que respuestas deben encontrarse mediante la investigación y la justificación nos indica porqué debe hacerse la investigación.
2. REVISIÓN BIBLIOGRÁFICA
Sólo cuando se tiene el claro el problema a resolver en la investigación, se pueden comenzar a buscar qué otras soluciones o respuestas se dieron al mismo. La importancia de esta revisión bibliográfica reside en que: a) permite saber si otras investigaciones ya han resuelto eficazmente el problema, con lo cual toda nueva investigación será superflua. En raro encontrar esta situación porque un problema científico en rigor no termina nunca de resolverse toda vez que siempre podrán aportarse nuevos elementos de juicio para reforzar la hipótesis o para refutarla; b) permite detectar investigaciones que hayan resuelto el problema solo parcialmente, con lo cual la nueva investigación intentará completar la respuesta. Por ejemplo, puede ocurrir que un problema haya sido tratado solamente en un estudio exploratorio, con lo cual la nueva investigación intentará continuarlo mediante una investigación descriptiva.Para Tamayo, la revisión bibliográfica “es el fundamento de la parte teórica de la investigación, y permite conocer a nivel documental las investigaciones relacionadas con el problema planteado. Presenta la teoría del problema aplicada a casos y circunstancias concretas y similares a las que se investiga” (Tamayo, 1999:186).
3. PLANTEO DEL MARCO TEÓRICO
En el marco teórico se expresan “las proposiciones teóricas generales, las teorías específicas, los postulados, los supuestos, categorías y conceptos que han de servir de referencia para ordenar la masa de hechos concernientes al problema o problemas que son motivo de estudio e investigación. También, en las investigaciones avanzadas, puede ser el encuadre en que se sitúan las hipótesis a verificar” (Ander-Egg, 1987:154).Destacan Hernández Sampieri y otros (1996:54) que para elaborar el marco teórico es necesario detectar, obtener y consultar la literatura y otros documentos pertinentes para el problema de investigación, así como extraer y recopilar de ellos la información de interés. La construcción del marco teórico depende de lo que encontremos en la revisión de la literatura: a) que existe una teoría completamente desarrollada que se aplica a nuestro problema de investigación, b) que hay varias teorías que se aplican al problema de investigación, c) que hay generalizaciones empíricas que se aplican a dicho problema o d) que solamente existen guías aún no estudiadas e ideas vagamente relacionadas con el problema de investigación. En cada caso varía la estrategia para construir el marco teórico. Con el propósito de evaluar la utilidad de una teoría para nuestro marco teórico podemos aplicar cinco criterios: a) capacidad de descripción, explicación y predicción, b) consistencia lógica, c) perspectiva, d) fructificación y e) parsimonia. 8. El marco teórico orientará el rumbo de las etapas subsecuentes del proceso de investigación (Hernández Sampieri R y otros, 1996:54).Las funciones que se atribuyen al marco teórico son, entre otras, a) delimitar el área de la investigación; b) sugerir guías de investigación; c) compendiar los conocimientos existentes en el área que se va a investigar; d) Expresar proposiciones teóricas generales (Tamayo, 1999:139).El marco teórico incluye también las definiciones de los principales conceptos de la investigación, por cuanto en rigor toda definición es una teoría acerca de lo definido, en tanto se consideren las llamadas por Copi (1974) definiciones teóricas.Destacan Selltiz y otros (1980) que sean o no establecidas las hipótesis, la investigación requiere una definición de conceptos a utilizar en la organización de los datos. Algunas de estas definiciones serán formales: dan a conocer la naturaleza general del proceso o fenómeno a indagar y su relación con otros estudios o con la teoría científica existente. Otras serán definiciones de trabajo, las cuales permiten la recogida de datos que el investigador está dispuesto a aceptar como índice de sus conceptos (Selltiz y otros, 1980). Debe aclararse que las definiciones teóricas se explicitan en el marco teórico, mientras que las definiciones operacionales se explicitan más adelante, cuando se definen las variables.
4. PLANTEO DE OBJETIVOS
Página 148 de 314
148

Si el problema asume gramaticalmente la forma de una pregunta, los objetivos tienen la forma gramatical de un verbo en infinitivo. Como el objetivo supone acciones a realizar, deben ser expresados mediante verbos, tales como ‘explorar’, describir’, ‘correlacionar’ o ‘probar’.El planteo de objetivos supone entonces elegir qué tipo de investigación se realizará. ¿Será un estudio exploratorio, descriptivo, explicativo o una combinación de ellos? ¿Será una investigación primaria o bibliográfica?A veces se especifica un objetivo general y objetivos específicos. Estos últimos corresponden a las diversas sub-tareas en las cuales se descompone la tarea principal, o bien pueden hacer referencia a otros objetivos fuera del problema de investigación pero que por alguna razón han sido considerados dentro de la misma.
Página 149 de 314
149

CAPÍTULO 11: HIPÓTESIS Y VARIABLES
Las investigaciones típicas comienzan planteando una hipótesis que deberá ser probada. La excepción son las investigaciones exploratorias, donde el poco o nulo conocimiento sobre el tema a investigar puede impedir su formulación: a veces sólo se alcanzan a plantear conjeturas que podrán o no convertirse en hipótesis. La diferencia radica en que la conjetura no está apoyada por suficientes elementos de juicio como para merecer el esfuerzo de diseñar una investigación que la pondría a prueba.Según Hernández Sampieri y otros, (1996:103), en efecto, hay investigaciones que no pueden formular hipótesis porque el fenómeno a estudiar es desconocido o se carece de información para establecerlas, pero ello sólo ocurre en los estudios exploratorios y en algunos estudios descriptivos.Para poder probar una hipótesis, debe estar adecuadamente formulada, y deberán estar identificados sus componentes básicos: las unidades de análisis y las variables. En el caso de éstas últimas, en particular, deberán estar adecuadamente definidas y categorizadas.Más concretamente, los pasos que deben cumplirse en esta etapa de la investigación son los siguientes:1) Plantear la hipótesis.2) Clasificar la hipótesis.3) Definir las unidades de análisis.4) Definir conceptualmente las variables.5) Clasificar las variables.6) Definir operacionalmente las variables.7) Categorizar las variables.
1. HIPÓTESIS
Definición
La hipótesis es básicamente una respuesta tentativa al problema de investigación. Si el problema es ¿porqué lloran los bebés?, una hipótesis puede ser “los bebés lloran porque tienen hambre”, o “los bebés lloran porque no ven a la madre”, etc. De esta forma, un mismo problema puede ser respondido con varias hipótesis.Entre las principales características de las hipótesis pueden mencionarse las siguientes:
1) Una hipótesis es una proposición general, sintética y verificable. Es una proposición, o sea una afirmación (o negación) acerca de algo. Cuando se dice “aprendizaje” no se está afirmando ni negando nada, pero cuando se dice que “el aprendizaje es estimulado con premios” aquí ya se está afirmando algo. Aunque también una negación es una proposición (“el aprendizaje no es estimulado por premios”), lo habitual en la ciencia es la formulación de hipótesis en forma positiva o afirmativa.Mientras los problemas se expresan mediante preguntas, las hipótesis se expresan mediante proposiciones.De los varios tipos de proposiciones que hay, y siguiendo la tradición aristotélica del Organon, las hipótesis suelen expresarse como proposiciones hipotéticas, y, más concretamente (León y Montero, 1995:22), en la forma condicional <Si… entonces…>. La proposición categórica “Los bebés lloran porque tienen hambre” puede convertirse en la proposición hipotética “Si X es un bebé que llora, entonces X tiene hambre”.La proposición hipotética debe además ser general: se supone y pretende que la hipótesis sea aplicable a todos los individuos (incluso a los desconocidos, con lo que la hipótesis tiene también un carácter predictivo). El anterior ejemplo sobre el aprendizaje es una proposición general; en cambio, "Juancito aprende más cuando es premiado" es singular, y en este sentido no es una hipótesis. A lo sumo podrá ser una proposición deducible de una hipótesis ("el aprendizaje aumenta con los premios") cuando no el resultado de una observación. El requisito de la generalidad deriva de una exigencia del conocimiento científico que dice que tiene que ser general pues esto no sólo aumenta el saber sobre la realidad sino que además, al ser predictivo, tiene una mayor utilidad práctica.
El requisito de la generalidad es importante para diferenciarlo del sentido del término ‘hipótesis’ que suele utilizarse en la vida cotidiana. Si alguien no llega a la cita, buscamos alguna hipótesis para explicar esta situación: había huelga de transportes, tuvo un accidente, se quedó dormido leyendo este libro, etc. Son todas respuestas tentativas que después podrán o no verificarse o no. Sin embargo, esta hipótesis no es general sino singular, porque está destinada a dar una respuesta a ese problema específico (aquí y ahora alguien no llegó a la cita), y es inaplicable a todos los casos donde alguien no llega.
La hipótesis también debe ser una proposición sintética. De acuerdo con cierta clasificación de inspiración kantiana (Mc Guigan, 1978:53), las proposiciones pueden ser analíticas, contradictorias y sintéticas.Las proposiciones analíticas son siempre verdaderas: "lo que es, es", o "el triángulo tiene tres ángulos", etc. Las proposiciones contradictorias son siempre falsas: "una empanada no es una empanada", "un cuadrilátero tiene cinco lados", etc. Lo característico de estas proposiciones es que se conoce su verdad o su falsedad simplemente por el examen de la misma proposición, con lo que no se requiere confrontarlas con la realidad: no se precisa observar un triángulo para saber que tiene tres ángulos, porque el significado de triángulo ya lo implica.
Página 150 de 314
150

Si en las proposiciones analíticas (o contradictorias) se tiene siempre la certeza de su verdad (o falsedad), en las proposiciones sintéticas no es posible saber de antemano (o "a priori") si son verdaderas o falsas. Por ejemplo "el lápiz es azul", o "la frustración genera agresión". Puesto que se desconoce su verdad o falsedad, requerirán entonces ser verificadas empíricamente, lo que constituye otra de las características de una hipótesis.Pero para poder verificar una proposición sintética esta deberá ser, obviamente, verificable. "Lucifer vive en el infierno" es una proposición sintética pues no se sabe de antemano si esto es cierto o no, pero no es verificable pues no se cuenta con ninguna experiencia que pueda probarlo. Cabe recordar que una hipótesis es una respuesta a un problema, y si se desea que éste sea solucionable se deberá buscar una respuesta verificable. "La frustración genera agresión" sí es verificable, por ejemplo dando a las personas ciertos problemas para resolver que en realidad son insolubles, y luego medir sus niveles de agresión. Es entonces posible administrar estímulos frustrantes y observar luego si aparecen o no respuestas agresivas.Para que una hipótesis sea verificable, deben poder extraerse de ella consecuencias lógicas y por esa vía comprobar su acuerdo con los hechos conocidos o desconocidos. Así, la hipótesis “todos los cuervos vuelan” es verificable porque puede deducirse de ella el enunciado verificable “este cuervo vuela”.
2) Las hipótesis surgen de una teoría previa y a veces también de la experiencia. Aunque formular una hipótesis requiere cierta dosis de creatividad, se basa siempre en una teoría previa, implícita o explícita.Así, para responder a la pregunta ¿por qué los bebés se chupan el dedo?, puede plantearse la hipótesis de la alucinación de pecho o la hipótesis de la reacción circular primaria. En el primer caso se ha tomado como referencia la teoría freudiana, y en el segundo caso la teoría piagetiana. En otro ejemplo, frente al problema de porqué existe el dolor, puede plantearse la hipótesis de que se trata de un aviso natural de alguna enfermedad para alertar al sujeto y poder combatirla, lo cual supone una teoría acerca del funcionamiento de los seres vivos.Las hipótesis científicas requieren que las teorías de base estén claramente explicitadas, y por esta razón se suele requerir que en la presentación de una tesis se incluya el marco teórico.A veces las hipótesis surgen de la experiencia. Luego de haber visto muchas veces que luego del relámpago viene el trueno, se puede formular la hipótesis “El relámpago es la causa del trueno”, hipótesis que supone también un marco teórico que, en este caso, podría ser la teoría de que todo tiene una causa, o la teoría de que la sucesión regular de dos sucesos supone causalidad.
Hernández Sampieri y otros (1996:103), refieren que las hipótesis surgen normalmente del planteamiento del problema y la revisión de la literatura, y algunas veces de teorías. Por su parte, Selltiz y otros (1980) señalan que una hipótesis puede originarse a partir de cuatro fuentes: como una simple sospecha, como resultado de otros estudios, como consecuencia lógica de una teoría, o finalmente como resultado de la observación de ciertas relaciones entre variables. Tanto si nace de una sospecha como si surge de estudios anteriores, la hipótesis estará aislada de un cuerpo de teoría, lo cual no sucede cuando la hipótesis surge como consecuencia lógica de una teoría. En realidad puede cuestionarse esta última afirmación: toda hipótesis está conectada con algún cuerpo de teoría, aunque no se trate de una teoría científica sino de un simple cuerpo de creencias, que en sentido amplio es también una teoría.
3) Las hipótesis científicas han de ser relevantes, en el sentido que procuran dar explicaciones "esperables" de acuerdo al contexto donde se trabaja. En un contexto científico no puede afirmarse como hipótesis que "la neurosis se debe a que existe el universo". Indudablemente esto no carece de sentido, porque si no habría universo no habría personas y por lo tanto tampoco neuróticos, pero ésta no es la explicación esperable en un contexto psicológico. Del mismo modo, en el contexto de la química sería irrelevante explicar un incendio diciendo que se debió a que se quería cobrar el seguro. La explicación relevante en el mismo contexto es aportada por la teoría de la combustión.
4) Tras la aparente complejidad de su indagación, el científico trata de buscar la solución más sencilla, por lo que las hipótesis que plantea suelen ser simples. De hecho, dadas dos hipótesis alternativas que fueron ambas verificadas con la misma fuerza, se tiende a preferir la más simple, o sea, aquella que con los mismos elementos explica más, o aquella que muestra una realidad más armónica y uniforme, o hasta incluso aquella que resulta psicológicamente más entendible o más plausible.
5) Algunas veces se proponen varias hipótesis para resolver un problema (multiplicidad), y luego se va haciendo una selección sobre la base de los elementos de juicio a favor o en contra de cada una de ellas. Hempel (1977) cita un ejemplo donde para resolver el problema de por qué las mujeres parturientas contraían la fiebre puerperal, se habían propuesto seis hipótesis alternativas.
6) Las hipótesis son proposiciones tentativas acerca de las relaciones entre dos o más variables (Hernández Sampieri y otros, 1996:103), aunque también la hipótesis puede hacer referencia a una sola variable, como por ejemplo en “la mayoría de los pacientes psicóticos presentan delirios”, como en las investigaciones descriptivas. En las investigaciones correlacionales y explicativas, la hipótesis permite al investigador relacionar variables entre sí para determinar cómo varían unas en función de otras y, de esta manera, ampliar y profundizar su comprensión de la realidad.
Clasificación de las hipótesis
Página 151 de 314
151

De las diversas taxonomías existentes, dos clasificaciones pueden ser de interés para la metodología de la investigación.
1) La primera clasificación las ordena en hipótesis descriptivas, correlacionales y explicativas o causales, según correspondan a investigaciones descriptivas, correlacionales o explicativas, respectivamente.Las hipótesis descriptivas, por tanto, se refieren a una sola variable, como por ejemplo “la mayoría de los grupos humanos tienen alta cohesión”, donde la variable es cohesión grupal.Las hipótesis de correlación afirman una cierta asociación estadística o concomitancia entre dos o más factores o variables, como "a mayor cohesión grupal mayor eficacia laboral". Esta hipótesis dice que cuanto más unido es un grupo mejor trabaja, o sea informa que los factores cohesión y eficacia están altamente correlacionados: cuando aumenta uno también aumenta el otro. La correlación podrá ser directa (ambos factores aumentan, o ambos disminuyen), o inversa (uno aumenta y el otro disminuye, o viceversa).Sin embargo, la hipótesis no dice explícitamente que un factor sea la causa del otro (aunque pueda uno suponerlo íntimamente o leerlo entre líneas), o sea que explícitamente no está formulada como hipótesis causal. Hubiera sido así en la hipótesis "la causa de la eficacia laboral es la cohesión grupal", o "la cohesión grupal determina la eficacia laboral", donde la expresión "determina" ya sugiere en forma explícita la idea de un vínculo causa-efecto. Las hipótesis causales tienen mayores pretensiones: no solamente afirman que dos factores se encuentran correlacionados sino que además arriesgan la idea que hay un vínculo causal entre ellos, o sea uno es la presunta causa y el otro el efecto. Las hipótesis de este tipo son claramente explicativas (explican la eficacia a partir de la cohesión), mientras que las hipótesis de correlación son mas bien descriptivas, pues resumen las observaciones realizadas sobre cierta cantidad de grupos donde se constató una cierta regularidad entre la cohesión y la eficacia.Normalmente, las hipótesis de correlación van surgiendo en el transcurso de una investigación descriptiva, pero a medida que avanza esta descripción el investigador puede ir alimentando la sospecha de que entre ciertos factores no sólo hay una correlación sino también una relación causal, que deberá ser probada mediante una investigación explicativa.Cuando autores como Selltiz y otros (1980) señalan que la función de la hipótesis es sugerir explicaciones de ciertos hechos y orientar la investigación de otros, están probablemente indicando la función de las hipótesis explicativas por un lado, y de las hipótesis descriptivas y correlacionales por el otro.
2) La segunda clasificación ordena las hipótesis en hipótesis sustantivas e hipótesis estadísticas. Las primeras son propiamente las hipótesis que se quiere probar en la investigación. Cuando esta prueba requiere un procedimiento estadístico, entonces la hipótesis sustantiva se traduce al lenguaje de la estadística y se trabaja sobre ella desde este punto de vista.Otros autores ofrecen clasificaciones ligeramente diferentes encuadrables en este segundo criterio clasificatorio.Por ejemplo, Mora y Araujo (1971) refieren que “en la investigación usamos dos tipos de hipótesis: sustantivas y auxiliares. Las sustantivas relacionan las variables que queremos estudiar. Las auxiliares pueden ser de validez o estadísticas. Las hipótesis de validez relacionan las variables conceptuales o latentes con los indicadores u observaciones. Las hipótesis estadísticas relacionan las unidades de análisis observadas con el universo al que pertenecen. Los problemas de medición tienen que ver con las hipótesis auxiliares de validez”.Otros autores (Hernández Sampieri y otros, 1996:103) indican que las hipótesis se clasifican en: a) hipótesis de investigación, b) hipótesis nulas, c) hipótesis alternativas. A su vez, las hipótesis de investigación se clasifican de la siguiente manera:
a) Hipótesis descriptivas del valor de variables que se van a observar en un contexto.b) Hipótesis correlacionales
Hipótesis que establecen simplemente relación entre las variables
BivariadasMultivariadas
Hipótesis que establecen cómo es la relación entre las variables (hipótesis direccionales)
BivariadasMultivariadas
c) Hipótesis de la diferencia de grupos
Hipótesis que sólo establecen diferencia entre los grupos a comparar.Hipótesis que especifican a favor de qué grupo, de los que se comparan, es la diferencia.
d) Hipótesis causales
BivariadasMultivariadas Hipótesis con varias variables independientes y una dependiente.
Hipótesis con una variable independiente y varias dependientes.Hipótesis con varias variables tanto independientes como dependientes.Hipótesis con presencia de variables intervinientes.Hipótesis altamente complejas.
“Puesto que las hipótesis nulas y las alternativas se derivan de las hipótesis de investigación, pueden clasificarse del mismo modo pero con los elementos que las caracterizan. Las hipótesis estadísticas son la transformación de las hipótesis de investigación, nulas y alternativas en símbolos estadísticos. Se clasifican en: a) hipótesis estadísticas de estimación, b) hipótesis estadísticas de correlación, y c) hipótesis estadísticas de la diferencia de grupos” (Hernández Sampieri y otros, 1996:103).
Página 152 de 314
152

Estos mismos autores agregan que la formulación de hipótesis va acompañada de las definiciones conceptuales y operacionales de las variables contenidas dentro de las hipótesis, lo que puede considerarse en relación con las llamadas hipótesis de validez mencionadas por Mora y Araujo (1971).
Componentes de la hipótesis: los conceptos
Desde el punto de vista lógico la proposición es una estructura intermedia entre el concepto y el razonamiento: varios conceptos constituyen una proposición, y varias proposiciones un razonamiento. Por consiguiente la hipótesis, al ser una proposición, puede descomponerse en sus elementos constitutivos llamados conceptos. El concepto (Selltiz y otros, 1980) es una representación abreviada de una diversidad de hechos, o sea que su utilidad es la de simplificar el pensamiento, y sirven para organizar los datos y relacionarlos entre sí.
No debe confundirse el concepto con el término: el primero es una idea, mientras que el segundo es una mera palabra. Muchas teorías utilizan el mismo término como por ejemplo, "transferencia", pero cada una lo conceptualiza de diferente manera y entonces son conceptos diferentes: una cosa es la transferencia en el psicoanálisis, otra en las teorías del aprendizaje, y otra el ARN de transferencia en biología. Otro tanto puede decirse del término "resistencia", que puede apuntar a un concepto de la física o del psicoanálisis.
Si bien se emplean conceptos en la vida cotidiana ("golosina", "alegría"), y los hay también en la filosofía ("ente", "alma"), los conceptos que aquí interesan son aquellos que pueden ser tratados científicamente, y que suelen ser llamados constructos.
Respecto del constructo, indica Arnau Gras (1980) que la mejor forma en que el científico limita su objeto de observación es mediante el concepto, una abstracción hecha de algún aspecto o rasgo que presentan las cosas observadas. Por ejemplo: inteligencia, rendimiento, agresión, emoción, tendencia, etc. El constructo es un concepto creado deliberadamente con fines científicos y que, a diferencia del concepto propiamente dicho, posee dos características: a) se relaciona con otros constructos (aspecto relacional), y b) puede observarse y medirse (aspecto reductivo).Para Arnau Gras (1980:129), si un concepto puede observarse y medirse, y si puede vinculárselo con otros conceptos a través de una hipótesis, entonces puede usárselo en la investigación científica y recibe el nombre de "constructo".
Por ejemplo, en la hipótesis "en la provincia de Buenos Aires, a mayor densidad poblacional menor solidaridad entre los habitantes", los conceptos que la componen son: "área geográfica", "densidad poblacional", "solidaridad", “habitantes” y la relación “a mayor… a menor”.Los conceptos de una hipótesis pueden clasificarse de la siguiente manera:
Conceptos objetivos
Primera clasificación
Empíricos: Son directamente observables.Teóricos: Son indirectamente observables.
Segunda clasificación
Unidades de análisis: Son los objetos (o sujetos a estudiar).Variables: Son las propiedades de los objetos.
Conceptos relacionales
Relacionan conceptos objetivos entre sí.
a) Conceptos objetivos y relacionales.- Como puede apreciarse en el ejemplo anterior, algunos conceptos se refieren a entidades (habitantes) y propiedades de estas entidades (ser solidarios), mientras que otros simplemente relacionan dichos conceptos (a mayor… a menor). Alguna vez la lógica medieval los denominó, respectivamente, conceptos categoremáticos y sincategoremáticos.En otro ejemplo: la hipótesis “hay una asociación significativa entre inteligencia y rendimiento escolar” contiene como términos objetivos ‘inteligencia’, ‘rendimiento escolar’ y, tácitamente, ‘alumnos’. Contiene además el término relacional ‘hay una asociación significativa entre…’.
b) Conceptos empíricos y teóricos.- Los conceptos tienen diversos grados de abstracción, desde los más empíricos como ‘perro’ o ‘sexo’ a los más abstractos como ‘inteligencia’ o ‘personalidad’: los primeros son directamente observables, y los segundos no, pero pueden traducirse a otros conceptos más empíricos mediante un proceso llamado operacionalización. Por ejemplo, traducir ‘inteligencia’ como ‘habilidad para el cálculo’. Los conceptos involucrados en una hipótesis deben poder observarse y medirse.Un concepto es tanto más teórico cuanto más distancia hay entre el concepto y el objeto de la realidad representado, y, como indican Selltiz y otros (1980), más posibilidad de falsas interpretaciones del mismo hay.Esta primera clasificación de conceptos objetivos se relaciona con la segunda clasificación de conceptos objetivos de la siguiente manera: mientras las unidades de análisis de consideran habitualmente conceptos empíricos, las variables pueden ser conceptos teóricos o empíricos.
c) Unidades de análisis.- Las unidades de análisis son los elementos cuyas propiedades se quieren investigar. En psicología, unidades de análisis pueden ser personas, grupos, familias, instituciones, y hasta funciones psíquicas como la percepción, la memoria, etc. Cuando debe especificarse la población que se estudiará, es decir, el conjunto de las unidades de análisis, se especifican también estas, y, por
Página 153 de 314
153

caso, en lugar de decir genéricamente ‘personas’ se puede decir ‘adultos mayores de 65 años, masculinos y que viven en Argentina’, o bien ‘pacientes con medicación antidepresiva registrados durante 2005 en el Hospital Durand’.En biología las unidades de análisis pueden ser organismos vivientes, ecosistemas, células, etc. En física átomos o partículas subatómicas, en astronomía, estrellas, planetas o galaxias, etc.Entre los conceptos objetivos también están las variables, cuya importancia exige un tratamiento más extenso en el siguiente ítem.
2. VARIABLES
Definición
Las variables (V) son atributos, propiedades o características de las unidades de análisis (UA), susceptibles de adoptar distintos valores o categorías. Ejemplos de variables como atributos de las personas son la edad, el sexo, la inteligencia, la estatura, la personalidad, la memoria, la zona de residencia, la ocupación, el grado de solidaridad, el color de cabello o el estado civil. Ejemplos de atributos de una población son la densidad y el tamaño.Los valores o categorías de la variable pueden variar tanto entre sujetos (unos pueden ser más inteligentes que otros), como en el mismo sujeto a lo largo del tiempo (por ejemplo la edad). Se las llama variaciones interindividuales y variaciones intraindividuales.
Las variaciones interindividuales son propias de lo que en psicología evolutiva se llaman estudios transversales (se realizan en un aquí y ahora), mientras que las variaciones intraindividuales conciernen mas bien a estudios longitudinales (que se realizan a lo largo del tiempo).El sexo puede variar de una persona a otra, pero no dentro de la misma persona (salvo que se haga una operación para cambiar de sexo). La preferencia por un equipo de fútbol varía de una persona a otra, pero no suele variar con el tiempo dentro de la misma persona. La edad, finalmente, es una variable que varía tanto interindividualmente como intraindividualmente. Lo que nunca puede suceder, por una cuestión lógica, es que haya variables que varíen dentro de una persona y que no puedan nunca variar de una persona a otra. La razón es que si la propiedad varía dentro de la misma persona, existe la posibilidad de que dos personas tengan diferentes valores para esa variable, con lo cual habrá una variación interindividual.
La variable puede variar de dos formas: si es asunto de presencia o ausencia, la variación es factorial, y si es asunto de grados, es funcional (O’Neil, 1968). Por ejemplo, la variable ‘terremoto’ puede adoptar dos valores: sí (presencia) o no (ausencia). En cambio la variable ‘cantidad de hijos’ puede adoptar diversos grados: 1, 2, 3, 4, etc. Muchas variables admiten ambos tipos de variación, según el interés del investigador: la variable ‘cantidad de hijos’ por ejemplo, puede variar factorialmente, si se eligen arbitrariamente los valores ‘con hijos’ (presencia) y ‘sin hijos’ (ausencia).Finalmente, refieren Selltiz y otros (1980) que las variables (y, en general, los conceptos) pueden definirse de dos maneras: formalmente (para relacionarlos con la teoría), y prácticamente (para vincularlos con los hechos y poder hacer la investigación). O sea que de los conceptos pueden darse definiciones formales y definiciones de trabajo. La definición de trabajo de Selltiz no es otra cosa que la definición operacional y el proceso de llegar a ella se llama operacionalización.
Relación entre variables y unidades de análisis
Se enumeran a continuación algunas reglas básicas de investigación, concernientes a las precauciones que deben tomarse al establecer relaciones entre unidades de análisis y variables.
1) Unidades de análisis y variable son conceptos diferentes pero relacionados.- La diferencia entre una unidad de análisis y una variable es la misma que hay entre una cosa y una propiedad. Una cosa puede ser una mesa, y una propiedad puede ser su color, forma o tamaño. Una cosa puede ser un metal, y una propiedad su maleabilidad. Una cosa puede ser un conejo, y una propiedad su talla o el estado de su sistema inmunológico. Una cosa también puede ser una persona y como propiedades tener el sexo, la inteligencia, la preferencia política, la edad, la raza, etc.Ahora bien: la cosa es la unidad de análisis, mientras las propiedades son las variables, con lo cual éstas últimas resultan ser atributos, propiedades o características de las unidades de análisis.Una investigación puede trabajar, por ejemplo, con 200 unidades de análisis (200 personas) y con sólo dos variables (peso y talla); otra investigación puede trabajar con 30 unidades de análisis (30 estudiantes) y cuatro variables (rendimiento, tipo de enseñanza recibida, personalidad e inteligencia); y así sucesivamente.
2) Unidades de análisis y variables son conceptos relativos.- Lo que en una investigación es una unidad de análisis, en otra puede funcionar como variable: si ‘persona’ es una cosa, entonces ‘memoria’ puede ser una variable; pero si ‘memoria’ es la cosa, entonces ‘capacidad de almacenamiento’ puede ser una variable. Dentro de una misma investigación el mismo concepto no puede ser ambas cosas, o sea, unidad de análisis y variable al mismo tiempo. Por ejemplo, al investigar en los individuos la relación entre inteligencia y alimentación, claramente inteligencia es una variable. Sin embargo, en las investigaciones emprendidas por Charles Spearman, por citar un ejemplo histórico, la inteligencia es considerada la
Página 154 de 314
154

unidad de análisis, de la cual se estudian algunas variables mediante el análisis factorial, como la inteligencia verbal y la inteligencia manual, en sus mutuas relaciones.Las siguientes afirmaciones ilustran la relatividad de las ideas de unidad de análisis y variable.
“Juan (UA) es inteligente (V)”“La inteligencia (UA) es inteligencia verbal (V)”“La inteligencia verbal (UA) es comprender palabras (V)”.
La transformación de una variable en unidad de análisis (por ejemplo “inteligencia” en la primera afirmación se transforma en “inteligencia” en la segunda afirmación) tiene, sin embargo, un límite. Este límite aparece cuando una variable ya no se puede transformar más en unidad de análisis. En el ejemplo, la variable empírica "comprensión de palabras" no puede ya ser considerada unidad de análisis porque no se pueden seguir extrayendo variables de ella. En este caso, decimos que la variable se ha convertido en un indicador. El concepto de indicador será examinado al tratar el tema de la operacionalización.Un último ejemplo donde un mismo concepto puede ser entendido como una unidad de análisis o como una variable es el siguiente: un sonido en tanto 'propiedad de algo' es una variable (por ejemplo propiedad de un sonajero), pero en tanto 'elemento que tiene una propiedad' es una unidad de análisis (por ejemplo el sonido tiene altura, intensidad o timbre).
3) La variable debe ser un atributo atingente o congruente con la unidad de análisis.- Esto significa que la variable elegida tiene que ser efectivamente una propiedad de la unidad de análisis considerada. Por ejemplo, no tiene sentido decir que el estado civil es una característica de un grupo, o que el sexo sea una propiedad de una organización. Desde ya, puede ocurrir que una misma variable sea aplicable a más de una unidad de análisis: la cohesión puede predicarse tanto de una pareja, como de un grupo o una organización. Ejemplos de unidades de análisis y variables en psicología son:
Unidad de análisis VariablesIndividuo Edad, inteligencia, personalidad, preferencia sexual, etc.Pareja Estado civil, diferencia de edades, promedio de edades, personalidad del cónyuge
masculino, coincidencia de personalidades, cantidad de hijos, etc.Grupo Cohesión, tamaño, tipo de liderazgo, productividad, etc.Organización Cultura organizacional, antigüedad, grado de apertura al exterior, etc.
4) Toda investigación debe incluir al menos una unidad de análisis, y cada unidad de análisis una variable.- Carece de sentido decir "voy a iniciar una investigación sobre las personas": hay que aclarar qué aspectos o características de las personas vamos a investigar, aún cuando luego se cambien sobre la marcha.Una investigación sencilla puede considerar solamente un tipos de unidad de análisis y una variable (ejemplo, indagar las preferencias políticas de los estudiantes). Una investigación más compleja puede incluir dos unidades de análisis, cada una con su o sus correspondientes variables (ejemplo, indagar la relación entre la inteligencia de las personas y el grado de cohesión de los grupos que integran).
La definición conceptual de las variables
Para poner a prueba la hipótesis es preciso dar una definición conceptual de las variables que contiene. Ello permitirá luego clasificarlas, operacionalizarlas y categorizarlas.En la vida cotidiana lo habitual es usar las palabras, no definirlas. De hecho, a la hora de definirlas se suelen encontrar dificultades, en parte por falta de entrenamiento. Así, cuando se intenta definir ‘profesión’ se dice ‘profesión’ es lo que uno hace’, lo cual puede confundirse con ‘oficio’ o ‘hobby’.En la investigación científica se exigen definiciones explicitas y desprovistas de ambigüedad y, además, preferiblemente definiciones conceptuales, es decir, que indiquen atributos esenciales y no se limiten a dar ejemplos.Una definición conceptual de la variable ‘ausentismo laboral’ puede ser ‘el grado en el cual un trabajador no se reporta a trabajar a la hora programada para hacerlo’ (Hernández Sampieri y otros, 1996:102). Por tanto, una definición conceptual no otra cosa que el significado de la palabra, significado que surge a partir del marco teórico utilizado (y por ello algunos autores llaman definición teórica a la definición conceptual). Por ejemplo, la variable inteligencia será definida conceptualmente según que se considere la teoría de Piaget, la teoría de Weschler o la teoría de Gardner.Otras veces la variable es definida lexicográficamente, es decir, apelando a la definición del diccionario común. Así, la variable ‘sexo’ puede definirse como ‘condición orgánica que distingue al hombre de la mujer’. A partir de allí, la sociología ampliar la definición y en función de ella buscará algún indicador sencillo, como por ejemplo la información que ofrece el documento de identidad, mientras que la medicina considerará otra definición y buscará varios indicadores: la cromatina (sexo cromatínico), los cromosomas X e Y (sexo cromosómico), la estructura de los genitales (sexo gonadal) y la apariencia externa (sexo fenotípico) Esta diferente tipificación del sexo hará entonces que la primera variable sea clasificada como simple y la segunda como compleja. También hará que se den diferentes definiciones operacionales de las variables y que se las categorice de manera diferente (‘masculino’ y ‘femenino’ en el primer caso, y en el segundo caso ‘masculino normal’, ‘femenino normal’, ‘síndrome de Turner’,
Página 155 de 314
155

‘síndrome de Klinefelter’, ‘seudohermafroditismo masculino’, etc.). Por tanto, dar una definición conceptual de la variable es lo que permitirá luego clasificarla, operacionalizarla y categorizarla.
Clasificación de las variables
Las variables se pueden clasificar según diversos criterios:
Criterio Tipos de variablesSegún su función en la investigación Independientes / Dependientes / ExtrañasSegún su nivel de medición Cualitativas / Cuantitativas (discretas y continuas)Según su ámbito de acción Organísmicas / SituacionalesSegún su distancia al plano empírico Empíricas o manifiestas / Teóricas o latentesSegún su nivel de complejidad Simples / ComplejasSegún su manipulación Activas / Asignadas
a) Según su función en la investigación.- Las variables pueden ser independientes, dependientes y extrañas. Se trata de variables relevantes porque por uno u otro motivo deben ser tenidas en cuenta en las investigaciones. La variable independiente (VI) es la que hace variar el investigador para ver si se produce también una variación en la variable dependiente (VD). Esta última entonces se define como la variable que varía o puede variar con la VI: la variable dependiente no necesariamente debe variar, pero sí es cierto que sobre ella recae una expectativa de variación. Finalmente, la variable extraña (VE) es aquella que también puede hacer variar la variable dependiente pero que se la controla para que no lo haga, o, al menos, para conocer su grado de influencia para luego descontarlo del efecto de la variable independiente.En las hipótesis causales, la VI es la posible causa y la VD es el posible efecto, mientras que en las hipótesis correlacionales, puede decirse que la VI es aquella de la cual se sospecha que es la causa, aunque dicha hipótesis no la plantee explícitamente como tal.En síntesis hasta aquí: la variable dependiente es aquella que supuestamente depende de otra variable, llamada independiente, y la variable independiente es aquella de la cual supuestamente depende la variable dependiente. En la hipótesis que dice que "nuestra impresión de las personas depende de cómo hablan" se está considerando que la impresión es la variable dependiente y el modo de hablar la variable independiente.
Un tema clásico de la tradición científica norteamericana de la década del ’40 fue las investigaciones sobre la relación entre frustración y agresión. Un experimento típico consistió, por ejemplo, en reunir un grupo de personas y darles para resolver problemas que eran en realidad insolubles, aunque no se les informaba de esto último. A medida que estas personas intentaban resolver los problemas, iba incrementándose su frustración, y, algunos antes y otros después, empezaban a manifestar comportamientos agresivos con diferentes modalidades e intensidades contra quienes les habían propuesto los problemas, lo que venía a sugerir que la frustración producía agresión. Fuera de estas situaciones experimentales, en la vida cotidiana no es impensable suponer que cuando a una persona no le ofrecen un trabajo que le habían prometido, o cuando no es correspondida en su amor (frustración), puede desarrollar hacia el otro un comportamiento agresivo en una amplia gama que va desde la calumnia hasta el ataque físico.En este contexto, se dice que la agresión depende de la frustración y, por lo tanto, que la agresión es la ‘variable dependiente’ porque depende de la otra variable que es la frustración, mientras que esta última será la ‘variable independiente’ porque es la que supuestamente ‘hace variar’ la agresión. La expresión ‘supuestamente’ se aplica aquí porque un objetivo central de la investigación será determinar si hay o no una relación entre X e Y, es decir, corroborar o refutar la hipótesis original.
En psicología, la variable dependiente es por lo común la respuesta de la persona y, según Arnau Gras (1980), puede adoptar cualquiera de estas caracterizaciones: 1) una reacción concreta, como la muscular o la glandular, 2) un movimiento manifiesto y externo, como levantar una pata, donde están involucrados varios músculos, 3) una respuesta global en función de un fin, como presionar una barra para abrir una caja, sin importar qué órgano o grupo muscular se empleó, 4) una respuesta a una necesidad, como por ejemplo la conducta de ataque, y 5) respuestas amplias y complejas, como la ansiedad, el poder.Respecto de las variables extrañas, el tema ya fue tratado en otro capítulo, donde habían quedado clasificadas como organísmicas y situacionales y como fuentes de invalidación interna y externa.Cabe reiterar, finalmente, tres importantes cuestiones que giran en torno a la relación entre la variable independiente X y la variable dependiente Y:1) ¿Cómo se decide cuál es la variable independiente y cuál la dependiente? En principio, el criterio consiste en pensar cuál es la causa y cuál el efecto. Cuando se quiere investigar si tal droga produce o no la curación de una enfermedad, la droga será claramente la causa (o la supuesta causa), y la curación el efecto, es decir, la variable independiente X será la droga, y la variable dependiente Y será el efecto curativo.Hay casos, sin embargo, donde cualquiera de ambas variables podría ser la causa o el efecto de la otra. Así por ejemplo, en principio, podría suponerse que la agresión depende de la frustración, pero también, y con el mismo fundamento, que la frustración depende de la agresión (por ejemplo, cuanto más agresiva es una persona más será reprimida y, por ende, más frustrada se sentirá). Indudablemente, se tiene todo el derecho de elegir una u otra posibilidad, y de esta elección dependerá qué se considerare como X y qué como Y, orientando esta elección, en consecuencia, toda la investigación.
Página 156 de 314
156

Sea cual fuere la variable elegida como la posible causa (X), un requisito indispensable para poder avanzar en la investigación es que dicha variable debe poder ser manipulada por el investigador, es decir, éste debe poder hacerla variar a voluntad, para ver si se produce o no una variación en la variable dependiente Y, o efecto.Cierto tipo de investigaciones no se interesan, sin embargo, por indagar una relación causa-efecto, sino simplemente por averiguar si dos variables están o no asociadas estadísticamente, es decir, si ‘suelen darse juntas’. En estos casos, la elección de la variable independiente no se realizará en función de pensarla como ‘la causa’, sino de pensarla como aquella variable que puede ser manipulada por el investigador para establecer su grado de asociación estadística con la variable dependiente.Este tipo de investigaciones suelen perseguir una finalidad exclusivamente práctica (pues no buscan indagar vínculos de causalidad). Ejemplos típicos son las investigaciones de mercado: a una empresa puede interesarle si hay o no asociación estadística entre el nivel socioeconómico de las personas y el color que prefieren en los envases de la leche, porque de ello dependerá en qué barrios distribuirá los envases de tal o cual color, y, con ello, podrán maximizarse las ventas.2) ¿Qué significa la expresión "depende"? Como quedó sugerido, que Y depende de X puede significar dos cosas: una dependencia estadística o una dependencia causal. Una cosa es que dos variables ‘se den habitualmente juntas’ sin que necesariamente una sea la causa y otra el efecto (dependencia estadística), y otra es que dos variables estén relacionadas como causa y efecto (dependencia causal).El color de la piel y la forma del cráneo son variables que están bastante asociadas estadísticamente: las personas de piel negra son dolicocéfalas, las de piel amarilla son braquicéfalas y las de piel blanca son mesocéfalas. Esto no significa que el color de la piel sea la causa de la forma del cráneo, ni que la forma del cráneo sea la causa del color de la piel: simplemente, ambas variables suelen ‘darse juntas’ o, dicho en términos más técnicos, existe entre ellas una alta correlación.En cambio, el color de la piel y la aceptación social, además de estar asociadas estadísticamente (los negros no son aceptados en ciertos barrios, etc.), hay también una dependencia causal: ciertas personas son aceptadas o rechazadas ‘debido a’ su color de piel.De lo dicho se desprende que una dependencia estadística no prueba necesariamente que haya una dependencia causal. Para que hay una dependencia causal deben cumplirse, además de la dependencia estadística, otra serie de condiciones, como por ejemplo la antecedencia temporal (la causa nunca puede ocurrir después del efecto).En ocasiones suele asignarse sin más un vínculo causal a una mera asociación estadística o correlacional. Refieren Campbell y Stanley que "si pasamos revista a las investigaciones sobre educación, pronto nos convenceremos de que son más los casos en que la interpretación causal de la información correlacional se exagera que aquellos en que se la desconoce..." (Campbell y Stanley, 1995:124).3) Habida cuenta que la variable dependiente es aquella que depende de la independiente, ¿de qué depende a su vez la variable independiente? La variable independiente tiene dos fuentes posibles de variación: la variación natural y la variación provocada.Con variación natural queremos decir que, en la realidad, siempre es posible considerar que sobre la variable independiente actúan otras variables, lo que no es sino un caso particular del principio general que sostiene que, al estar todas las variables relacionadas, cualquier variable influye sobre otras, y a su vez recibe la influencia de otras tantas.Por ejemplo, así como la variable dependiente ‘agresión’ puede recibir la influencia de la variable independiente ‘frustración’, esta última también puede recibir la influencia de la variable ‘educación’ (si consideramos que cierto tipo de educación enseña al sujeto a tolerar mejor la frustración), de la variable ‘edad’ (si consideramos que un niño se frustra más fácilmente que un adulto), de variables de índole bioquímica (si consideramos que la presencia de determinados neurotransmisores pueden acentuar o no la tolerancia a la frustración), etc.Todas estas variables que influyen o influirían sobre la variable independiente ‘frustración’ ejercer su acción en forma natural, es decir, sin la presencia de alguien (un investigador) que las haga variar deliberadamente. Cuando esto ocurre, podemos hablar de una variación provocada. Las variaciones provocadas tienen sentido entonces en una situación experimental donde hay un investigador que deliberadamente haga variar la variable para producir un determinado efecto sobre la frustración, con el fin de estudiar científicamente la naturaleza de la relación entre ellas.
b) Según su nivel de medición.- Las variables pueden ser cualitativas o cuantitativas según que se midan no numéricamente o numéricamente. Las variables ‘religión’ o ‘sexo’ son cualitativas, mientras que las variables ‘edad’ o ‘peso’ son cuantitativas. Sin embargo, dependerá de una decisión del investigador considerar una variable como cualitativa o cuantitativa, según su criterio. Si considera para ‘estatura’ los valores ‘alta’, ‘media’ y ‘baja’ la estará considerando cualitativa; no así si selecciona los valores ‘1,60m’, ‘1,70m’, etc. Si se desea tener precisión en la medición, deberá preferirse siempre que se pueda el nivel cuantitativo.En las variables cuantitativas, los números deben ser empleados como indicadores de cantidad, no como simples etiquetas. La variable ‘jugador de fútbol’ admite como categorías ‘defensor’, ‘atacante’, ‘mediocampista’, etc., pero también pueden expresarse con los números 1 al 11, lo cual no significa que esta variable sea cuantitativa.Las variables cuantitativas pueden a su vez ser discretas y continuas según como sea la escala numérica. Por ejemplo, si sólo se registran números enteros, es una variable discreta (por ejemplo ‘cantidad de hijos’), pero si se registran además números intermedios fraccionarios hasta donde el instrumento de medición lo permita, es una variable continua (por ejemplo ‘tiempo’, que puede admitir los valores ‘una
Página 157 de 314
157

hora’, ‘una hora y 10 minutos’ y ‘una hora, 10 minutos y 25 segundos’). En las variables continuas es siempre posible agregar otro valor entre dos valores dados cualesquiera hasta donde el instrumento lo permita, porque hay instrumentos más precisos y menos precisos.
c) Según su ámbito de acción.- Las variables pueden ser organísmicas y situacionales. Las primeras son propias del sujeto (temperamento, tolerancia a la frustración, etc.), mientras que las segundas son propias del ambiente o la situación que rodea al sujeto (clima político, clima meteorológico, tipo de tarea a realizar, etc.). Señala Arnau Gras (1980) que la variable situacional son estímulos provenientes del medio físico o social, como la modalidad o tipo de tarea a realizar. Las organísmicas suponen cualquier característica biológica, fisiológica o psicológica del organismo. Por ejemplo historias de refuerzo, emotividad, actitudes, motivos, etc.Variables organísmicas o situacionales pueden ser las variables independientes (Arnau Gras, 1980), las variables dependientes y las variables extrañas.
d) Según su distancia al plano empírico.- Las variables pueden ser empíricas -o manifiestas- y teóricas -o latentes-. Las primeras pueden observarse y medirse directamente (por ejemplo ‘color de ojos’) mientras que las segundas sólo pueden observarse y medirse indirectamente traduciendo sus términos abstractos a términos empíricos. ‘Inteligencia’ es una variable teórica porque sólo puede medirse a través de sus indicadores empíricos, como por ejemplo "aptitud para comprender refranes".
e) Según su nivel de complejidad.- Las variables pueden ser simples o complejas. Esta clasificación es correlativa de la anterior: las variables simples son empíricas, y las variables complejas son teóricas. Las variables simples son aquellas que, para conocerlas, requieren un solo indicador (para conocer la edad de una persona basta con preguntarle, o bien basta con mirar su documento de identidad, o bien mirar su partida de nacimiento, etc.). En cambio las variables complejas requieren de varios indicadores (para conocer la inteligencia de una persona le aplicamos un test donde hay varios ítems).
f) Según su manipulación.- Las variables pueden ser activas o asignadas según como sean manipuladas, entendiendo por manipulación la acción que realiza el investigador de cambiar sus valores. Refiere Arnau Gras (1980) que una variable es activa si el experimentador puede manipularla directamente (premios, castigos) y por ello se la llama también variable experimental. La variable asignada en cambio, resulta difícil o imposible de manipular, como las variables organísmicas. Se las llama asignadas pues se manipulan por selección de los sujetos, pero no pueden ser provocadas directamente por el experimentador. Así, cuando investiga una variable activa, se eligen los grupos al azar pero cuando emplea una asignada, se seleccionan dos grupos que difieren en las categorías de dicha variable.
g) Otras clasificaciones.- a) Lazarsfeld y Menzel (citados por Korn, 1969) clasifican las variables según el tipo de unidad de análisis al que se refieren. Hay variables que son propiedades de unidades de análisis muy amplias (como las propiedades de un grupo o una sociedad), y otras que son propiedades de sujetos individuales. b) Arnau Gras (1980) utiliza un criterio ‘teórico-explicativo’ según el cual las variables pueden ser estímulos, respuestas o variables intermediarias entre el estímulo y la respuesta. Las variables estímulo son cualquier aspecto mensurable del ambiente físico o social, presente o pasado, que puede afectar la conducta del organismo. Las variables de respuesta son las medidas obtenidas de diversos aspectos de la conducta de los sujetos. Las variables intermediarias son los procesos que se intercalan entre las dos anteriores, aunque no todos los psicólogos admiten la necesidad de tales variables.
Estudiar cómo varían las variables permite obtener conclusiones sobre la aceptación o rechazo de la hipótesis. Este paso fundamental, sin embargo, no puede llevarse a cabo si antes no se ha sometido a todas las variables de la hipótesis a un doble proceso: la operacionalización o definición operacional y la categorización.
Categorización de las variables
Es la adjudicación de categorías o valores a una variable. A su vez, las categorías o valores son las diferentes posibilidades de variación que una variable puede tener. Por ejemplo, las categorías de ‘clase social’ pueden ser ‘alta’, ‘media’ y ‘baja’, y los valores de ‘tiempo de reacción’ pueden ser ‘un segundo’, ‘dos segundos’, etc.
Se acostumbra a llamar categorías a aquellas que no admiten un tratamiento cuantitativo por medio de cálculos, y por lo tanto regularmente se expresan en palabras. Tales son las categorías de clase social, de raza, de partido político, etc. En cambio suelen llamarse valores a las posibilidades de variación cuantitativa, por lo que han de expresarse numéricamente. Es el caso de las variables cuantitativas peso, altura, ingreso mensual, edad, número de hijos, cantidad de ingesta diaria de alcohol, etc.
La elección del conjunto de categorías o valores dependerá de la naturaleza de la variable, del objetivo de la investigación y del grado de precisión que se quiere alcanzar.Respecto de la naturaleza de la variable, no pueden elegirse ‘verde’ o ‘amarillo’ como categorías de la variable ‘ocupación’. Respecto del objetivo de la investigación, señala Korn (1969) que el sistema de
Página 158 de 314
158

categorías elegido debe tener relevancia para el contexto donde se aplicará, ya que toda variable tiene una amplitud de variación teóricamente mucho mayor que la que resulta relevante en cada situación específica. Si acaso el estudio se centra en un país donde sólo hay dos clases sociales netamente diferenciadas, entonces sólo se indicarán dos categorías. Respecto del grado de precisión deseable, muchas veces puede aumentarse este eligiendo categorías intermedias, y agregar a las clases alta, media y baja las categorías ‘media alta’ y ‘media baja’.El investigador tiene una cierta libertad para elegir las categorías de su variable. No obstante ello, y sea cual fuese el sistema de categorías seleccionado, éste debe reunir dos requisitos: a) las categorías deben ser mutuamente excluyentes. No puede decirse que las categorías de la variable ‘religión’ son ‘cristianos’ y ‘católicos’ porque hay una superposición en las mismas; b) deben ser además exhaustivas, o sea deben agotar todas las posibilidades de variación, con lo cual no podría decirse que las categorías de la variable ‘raza’ son solamente ‘blanca’ y ‘negra’. Hay veces en que son muchas las categorías que habría que agregar para cumplir con este requisito, en cuyo caso pueden agruparse a todas las restantes bajo una categoría residual caratulada como ‘Otras’.Estos dos requisitos sirven en la medida en que permiten ubicar a cualquier sujeto en una y sólo una categoría sin que surjan dudas. Si hay que ubicar al Papa no se sabrá si ponerlo en ‘cristianos’ o ‘católicos’, de aquí que pueda también definirse la exclusión mutua como la imposibilidad de que un sujeto cualquiera pueda adquirir más de un valor de la variable. En el caso de la variable ‘ocupación’, puede ocurrir que un individuo sea al mismo tiempo ‘médico’ y ‘psicólogo’, en cuyo caso se podrán abrir categorías mixtas (por ejemplo ’médico y psicólogo’) con lo que queda igualmente salvado el requisito de la mutua exclusión.De idéntica forma y para el segundo requisito, si hay que ubicar a un japonés y sólo se cuenta con las categorías ‘blanco’ y ‘negro’ no se podrá hacerlo por falta la categoría ‘oriental’; de aquí que también podamos definir la exhaustividad como la imposibilidad de no poder categorizar a un sujeto cualquiera.
La definición operacional de las variables u operacionalización
Definir operacionalmente una variable es especificar qué operaciones o actividades debe realizar el investigador para medirla. Estas operaciones se llaman indicadores, y, cuando recogen información de la realidad son capaces de convertirla en datos.Las variables simples se operacionalizan con un solo indicador, mientras que las variables complejas requieren varios indicadores.
a) Operacionalización de variables simples.- Por ejemplo, operacionalizar la variable ‘sexo’ significa especificar qué actividad realizará el investigador para medirla: mirar el documento de identidad, preguntar al sujeto cual es su sexo, observar su aspecto físico general, observar si tiene o no la nuez de Adán, observar sus genitales externos, etc. Estas diversas operaciones se llaman indicadores.Desde ya, el investigador no realizará todas esas operaciones, sino que elegirá alguna que suponga confiable y representativa de la variable. Nadie elegiría como indicador ‘observar si tiene o no pantalón’, sino mas bien ‘preguntar al sujeto cual es su sexo’. Y si acaso existiesen razones para dudar de su respuesta, podrá optarse por un indicador más confiable: ‘mirar el documento de identidad’.
La definición operacional “es el conjunto de procedimientos que describe las actividades que un observador debe realizar para recibir las impresiones sensoriales (sonidos, impresiones visuales o táctiles, etc.) que indican la existencia de un concepto teórico en mayor o menor grado (Reynolds, 1971:52).La definición operacional entonces, indica operaciones para medir una variable, y, aunque estas operaciones serán denominadas en el presente libro indicadores, no todos los autores coinciden con esta convención lingüística o no son explícitos respecto a ella.Por ejemplo: a) un indicador es una propiedad manifiesta u observable que se supone está ligada empíricamente, aunque no necesariamente en forma causal, a una propiedad latente o no observable que es la que interesa (Mora y Araujo, 1971); b) se denomina indicador a la definición que se hace en términos de variables empíricas de las variables teóricas contenidas en una hipótesis (Tamayo, 1999:126); c) un indicador de una variable es otra variable que traduce la primera al plano empírico (Korn, 1965). Por su parte, Hernández Sampieri y otros (1996:242) llaman indicador al dato obtenido con la operación.
Otros ejemplos de operacionalización de variables simples son las siguientes:
Variable simple IndicadorDentición Observar la cantidad y el tipo de piezas dentarias de una persona’Ambulación Medir el número de veces que una rata cruza una línea marcada en el piso
(Lores Arnaiz, 2000).Estrés Medir el nivel de cortisol (Lores Arnaiz, 2000).Ausentismo laboral Revisar de las tarjetas de asistencia al trabajo, durante el último trimestre
(Hernández Sampieri y otros, 1996:102).Profesión Preguntarle al sujeto cuál es su profesión.Enuresis nocturna Averiguar cuantas noches por mes y cuantas veces cada noche se orina
involuntariamente.Peso Observar el registro en la balanza.Frecuencia cardíaca Tomar el pulso y contar la cantidad de pulsaciones por minuto.Grado de alfabetización Obtener el porcentaje de analfabetos sobre el total de la población (Korn,
Página 159 de 314
159

1965).
Cuando se realiza la operación especificada como indicador, se obtiene un dato, el cual a su vez permitirá ubicar al sujeto en alguna categoría de la variable:
Variable simple Indicador Dato CategoríaPeso Observar el registro en la balanza. 89 Kg 80-90 Kg
Diversas técnicas pueden utilizarse para operacionalizar variables, como por ejemplo la observación (utilizada por ejemplo en la operación ‘mirar la apariencia de la persona’), los tests psicométricos o proyectivos (utilizada por ejemplo en la operación ‘tomar un test’), las técnicas conductuales (utilizadas por ejemplo en la operación ‘dar un estímulo táctil a una persona’), las técnicas psicofisiológicas (utilizadas por ejemplo en la operación ‘registrar las respuestas eléctricas del tejido vivo’), las técnicas anatómicas (utilizadas por ejemplo en la operación de ‘hacer una disección del lóbulo frontal’), el cuestionario (utilizada por ejemplo en la operación ‘preguntar al sujeto cuál es su profesión’), etc.
b) Operacionalización de variables complejas.- A diferencia de las variables simples, la operacionalización de variables complejas supone especificar varias operaciones o indicadores, y a veces muchos. Por ejemplo, la variable inteligencia se explora a través de tantos indicadores como pruebas o preguntas tenga el test de inteligencia. Uno puede ser ‘pedir al sujeto que arme un rompecabezas’, otro puede ser ‘pedirle al sujeto que explique el significado de una palabra’, otro ‘pedirle al sujeto que haga una operación aritmética’, etc.De la misma forma, la variable clase social se explora a través de indicadores tales como ‘preguntar al sujeto cual es su ingreso mensual’, ‘preguntarle si utiliza o no tarjeta de crédito’, ‘preguntarle en qué barrio vive’, ‘preguntarle por su nivel de instrucción’, ‘preguntarle por su ocupación’, etc.En ciertos países y culturas las personas de distinta clase social se visten inexorablemente en forma muy distinta, y basta este solo indicador para saber enseguida a qué clase social pertenece una persona sin necesidad de investigar su nivel económico, el prestigio de su ocupación, su nivel de educación, etc. En estos casos ‘clase social’ pasa a ser una variable simple y se la mide con un único indicador, que puede ser la operación ‘observar como se viste la persona’.Cuando una variable sólo puede ser medida a través de tests, cuestionarios o entrevistas, seguramente se trata entonces de una variable compleja. Nadie administraría un test a una persona para conocer su edad o su estatura.Dos cuestiones más deben ser tratadas a propósito de la operacionalización de las variables complejas: la selección de los indicadores y la especificación de las dimensiones.
Respecto de la selección de los indicadores, debe partirse de la base que el universo de indicadores es amplio y complejo. A medida que la discusión del concepto se amplía, se va modificando su definición conceptual y el número de indicadores posibles se aumenta, lo cual se denomina comúnmente universo de indicadores (Tamayo, 1999:126).Un problema que debe resolverse es como seleccionar los indicadores necesarios y suficientes para medir adecuadamente la variable. En principio, dos muestras diferentes de indicadores pueden ser igualmente eficaces para medirla, como lo sugiere la teoría de la intercambiabilidad de índices, basada en la experiencia de que, dado un gran universo de ítems o indicadores, cualquiera que sea la muestra elegida para formar el instrumento clasificatorio, no se hallarán grandes diferencias (Lazarsfeld, 1980).En la práctica, la selección de indicadores se basa en parte en la intuición (Mora y Araujo, 1971), y en parte en criterios más objetivos (Lazarsfeld, 1980): elegir indicadores altamente correlacionados con la variable (indicadores expresivos) o indicadores que supuestamente son el efecto de la variable o causa (indicadores predictivos).Por ejemplo (Lazarsfeld, 1980), al buscar indicadores de la variable ‘antisemitismo’ pueden seleccionarse dos tipos de indicadores, o una mezcla de ambos: a) ‘la obediencia y el respeto a la autoridad son las virtudes más importantes que debe aprender un niño’. Esta es una afirmación que figura en un cuestionario que mide antisemitismo y el sujeto debe responder si está o no de acuerdo. Pero este indicador no expresa directamente la variable ‘antisemitismo’ sino ‘autoritarismo’, y si es seleccionado es solamente porque se sabe que hay una alta correlación entre ambas variables; b) ‘la mayoría de la gente no se da cuenta hasta qué punto nuestras vidas están regidas por las conspiraciones de los políticos’. Este indicador ya expresa directamente el antisemitismo, y está en una relación de causa-efecto con el mismo: el grado de antisemitismo es la causa de que la persona responda si está o no de acuerdo con dicha afirmación.Lazarfeld (1980) llama al primer tipo indicador expresivo, y al segundo indicador predictivo pues sólo se puede predecir una respuesta con cierta seguridad sobre la base de un vínculo causal. El mismo autor sugiere buscar primero indicadores expresivos y luego indicadores predictivosPor ejemplo para la variable ‘personalidad autoritaria’ se buscan primero indicadores expresivos; por ejemplo indicadores de ‘convencionalismo’, supuestamente correlacionado con ‘personalidad autoritaria’ (¿cómo decoraría su pieza?, ¿qué sentimientos le inspira el pelo corto y el pelo corto y el lápiz labial en la mujer?), indicadores de ‘superstición’, también supuestamente correlacionada con la variable principal (¿cree en profecías?), etc. Finalmente se buscan indicadores predictivos (¿quiénes fueron las personalidades más destacadas de Alemania? ¿cuál es la mejor forma de gobierno?, etc.) (Lazarsfeld, 1980).
Página 160 de 314
160

Dimensión 2
Variable
Indicador 1
Dimensión 1 Dimensión 3
Indicador 3
Indicador 2 Indicador 1 Indicador 2
Otras reglas útiles para seleccionar indicadores son las siguientes (Mora y Araujo, 1971): a) seleccionar indicadores redundantes (preguntas de un cuestionario que indagan los mismo de diferente forma para ver si el sujeto se contradice), y b) seleccionar indicadores muy diferentes entre sí para cubrir todo el espectro de dimensiones de la variable o todo el espectro de características del sujeto que responde (en un cuestionario incluir preguntas personales mezcladas con preguntas impersonales).
Respecto de la especificación de las dimensiones, muchos autores señalan que, en el caso de las variables complejas, resulta necesario o conveniente especificar dimensiones y luego, desde allí, especificar los indicadores. Mientras que algunos autores (Hernández Sampieri y otros, 1996:100) se limitan a las definiciones conceptuales y operacionales, otros (Tamayo, 1999:159) (Korn, 1969) indican que los pasos de la operacionalización de una variable compleja son la definición nominal, la definición real (o enumeración de dimensiones) y la definición operacional (o enumeración de indicadores). Definir teóricamente, realmente y operacionalmente una variable permitiría entonces traducirla en propiedades observables y medibles, descendiendo cada vez más desde lo general a lo singular.El esquema correspondiente sería:
Las dimensiones son aspectos o facetas de una variable compleja. Por ejemplo, dimensiones de inteligencia podrían ser inteligencia verbal, inteligencia manual e inteligencia social; dimensiones de memoria podrían ser memoria visual, memoria auditiva y memoria cinética, o también memoria de corto plazo y memoria de largo plazo; dimensiones de clase social podrían ser nivel socio-económico y nivel de instrucción; dimensiones de creatividad podrían ser creatividad plástica y creatividad literaria, etc. Pueden también establecerse subdimensiones, como por ejemplo las subdimensiones creatividad en prosa y creatividad en poesía para la dimensión creatividad literaria. Cuanta más cantidad y niveles de dimensiones y subdimensiones requiere una variable, tanto más compleja será ésta.
La selección de las dimensiones dependerá de cómo se haya definido conceptualmente la variable. Si en la definición de clase social se ha recalcado la importancia del nivel económico y del nivel de instrucción, pueden adoptarse estos dos aspectos como dimensiones, es decir, se piensa que lo económico y lo educativo es algo importante para saber a qué clase social pertenece una persona. De idéntica manera, si se adopta la teoría de Gardner de las inteligencias múltiples para dar una definición conceptual de inteligencia, entonces corresponderá elegir como dimensiones inteligencia verbal, matemática, artística, intrapersonal, interpersonal, kinestésica, etc.
Una vez que se han identificado las dimensiones, el proceso continúa seleccionando indicadores para cada dimensión o subdimensión, lo cual es una manera de organizar los indicadores asegurándose de no omitir ningún aspecto relevante de la variable.Como puede apreciarse, a medida que se especifican dimensiones y luego indicadores, hay un acercamiento cada vez mayor al plano empírico. Para la variable ‘clase social’ se pasa, por ejemplo, de la dimensión ‘nivel socio-económico’ a la subdimensión ‘nivel económico’, y desde aquí al indicador ‘preguntar cual es su patrimonio actual’ o al indicador ‘preguntar si es propietario’, que constituirán elementos de juicio para decidir a qué clase social pertenece el sujeto.
Si un profano pregunta qué es la inteligencia y recibe una definición teórica o conceptual, mucho no habrá entendido, pero si le enumeran dimensiones como inteligencia verbal, manual o social, habrá comprendido algo más porque es algo más próximo a la realidad; y finalmente, su comprensión será más completa si se mencionan indicadores como preguntar si sabe utilizar palabras, si es hábil con las manos, si es hábil para tratar con personas, si puede encontrar el absurdo en frases del tipo ‘qué lástima que el sol se ponga de noche porque ese es justo el momento donde más lo necesitamos!’ o ‘como llovía, Juan se sumergió en el río para no mojarse’.
Conviene aclarar también que un mismo indicador puede corresponder a dos dimensiones distintas. Por ejemplo el indicador ‘preguntar a qué colegio asiste’ puede corresponder a ‘nivel de instrucción’ pero también a ‘nivel socio-económico’.Conviene también aclarar que lo que en una investigación es considerada una dimensión, en otra puede funcionar como variable principal. Por ejemplo, en un estudio sobre creatividad, ‘creatividad literaria’ será
Página 161 de 314
161

una dimensión, pero en un estudio más específico sobre creatividad literaria, esta pasará a ser la variable.
Relaciones entre la categorización y la operacionalización
Las dimensiones, subdimensiones e indicadores de una variable son a su vez, estrictamente hablando, también variables, porque son susceptibles de variar según sus propias categorías. Por ejemplo, la dimensión ‘nivel de instrucción’ puede variar como primaria, secundaria o universitaria, y por ende es una variable. A medida que se pasa de las dimensiones a las subdimensiones y de estas a los indicadores, dichas variables se tornan cada vez menos simples y más empíricas o manifiestas.El siguiente esquema ilustra la idea de que las variables, dimensiones, subdimensiones e indicadores pueden todos categorizarse. Por ejemplo, para la variable ‘actitud discriminatoria’ se pueden especificar tres categorías: alta, media y baja. Para la subdimensión ‘discriminación sexual hacia el sexo opuesto’ también, y para el indicador ‘discriminación sexual en la elección de puestos’ (por ejemplo, ‘preguntar al sujeto si deben darse puestos de trabajo a hombres o a mujeres’), se han indicado dos categorías: hombre y mujer. Cuando el sujeto elige una de las categorías (por ejemplo ‘hombre’) se dice que se ha obtenido un dato.
Suele a veces confundirse categorías con dimensiones, y al respecto deben tenerse en cuenta las siguientes precisiones:a) A un determinado sujeto puede incluirselo solamente en una categoría (o es de clase alta, o es de clase baja, o es de clase media, etc.), mientras que el mismo sujeto incluye todos los aspectos o dimensiones (tiene determinado nivel socio-económico, determinado nivel de instrucción, etc.).b) Lo anterior de debe a una cuestión lógica: las categorías son excluyentes (‘o’) y las dimensiones están en conjunción (‘y’). Para la variable ‘clase social’ se habla de alta o baja, pero en las dimensiones se habla de nivel-socioeconómico y nivel de instrucción. El ‘o’ indica exclusión mutua, y el ‘y’ indica conjunción.c) Dos variables relacionadas en una hipótesis pueden tener distintas categorías pero no las mismas dimensiones, pues serían la misma variable.d) Las categorías son los valores posibles de una variable, mientras que las dimensiones son los aspectos discernibles que sirven para describirla.
Página 162 de 314
162

CAPÍTULO 12: TÉCNICAS DE MUESTREO E INSTRUMENTOS DE MEDICIÓN
En este capítulo se desarrollarán los siguientes pasos de la investigación científica típica: a) definir la población, b) decidir como extraer de ella una muestra, y c) seleccionar o construir los instrumentos de medición que se aplicarán a los individuos seleccionados.
1. DEFINICIÓN DE LA POBLACIÓN
Antes de seleccionar la técnica de muestreo adecuada al problema y a los objetivos de la investigación, se requiere definir la población y las unidades de análisis que la compondrán. Las unidades de análisis son aquellas entidades cuyas propiedades son las variables que quieren estudiarse. Las unidades de análisis pueden ser personas (alumnos, pacientes, líderes, payasos, soldados, etc.), organizaciones (comerciales, no gubernamentales, hospitales, medios de comunicación, etc.), familias, grupos de autoayuda, etc. Deben también definirse sus propiedades y sus coordenadas de lugar y tiempo. Por ejemplo, una población estará constituida por todos los alumnos varones de quinto grado de las escuelas públicas (propiedades) de la ciudad de Buenos Aires (lugar) durante el año 2005 (tiempo).
2. SELECCIÓN DE LA TÉCNICA DE MUESTREO
Una técnica de muestreo es un procedimiento para extraer una muestra de una población, mientras que una muestra es una parte de la población que está disponible, o que se selecciona expresamente para el estudio de la población.
Representatividad de la muestra.- Es deseable y hasta imprescindible que una muestra sea representativa de la población. Cuatro mujeres no es una muestra representativa de los habitantes de una ciudad, porque las mujeres son la mitad de los habitantes. Que la muestra sea representativa es importante porque luego se podrán extender a toda la población las conclusiones que se hayan extraído de ella.De acuerdo a Tamayo (1999:185), son cuatro las condiciones que garantizan la representatividad de una muestra: a) definir y delimitar la población a la que deben extenderse las conclusiones obtenidas a partir de la muestra; b) garantizar que cada unidad de población tenga igual probabilidad de ser incluida en la muestra; c) utilizar un muestreo no viciado por posibles relaciones existentes entre las unidades de población; y d) tomar una muestra amplia a fin de reducir al máximo el error de muestreo.De una manera más simplificada, puede decirse que una muestra es representativa si: a) si tiene un tamaño adecuado, y b) si fue elegida al azar. Esta última condición introduce el tema de las diferentes técnicas de muestreo, clasificables como probabilísticas y no probabilísticas.
Tamaño de la muestra.- El tamaño de la muestra es “la cantidad de datos que serán extraídos de la población para formar parte de la muestra” (Valdés F, 1998).Si bien existen procedimientos matemáticos para calcular el tamaño de una muestra, esta tarea puede a veces tornarse compleja dado el tipo de problema a investigar y la población considerada. Hernández Sampieri (1996:228) sugieren tomar como referencia los tamaños de muestra elegidos por otros investigadores. Por ejemplo, es habitual que para poblaciones nacionales (por ejemplo un país) se tome una muestra al azar no menor a 1000 sujetos, mientras que para poblaciones regionales (por ejemplo una provincia, una ciudad), se consideren de 300 a 700 sujetos para estudios sobre conducta y actitudes, de 500 sujetos para estudios médicos, y de 100 sujetos para experimentos de laboratorio y estudios económicos.Señala Tamayo (1999:198) que el tamaño de la muestra depende del grado de error que sea tolerable en las estimaciones muestrales y de los objetivos de investigación. En otras palabras, si uno está dispuesto a tolerar un mayor error, puede tomar una muestra de menor tamaño por cuanto será menos representativa.En general, el tamaño de la muestra no debe ser ni muy grande (porque entonces, si bien es representativa, supone un esfuerzo adicional inútil trabajar con ella), ni muy pequeña (porque entonces puede no ser representativa). La estadística ha desarrollado ciertas fórmulas especiales para calcular tamaños de muestra de acuerdo al grado de error que se está dispuesto a cometer, al grado de homogeneidad de la muestra y a otras consideraciones. Refiere Tamayo (1999:147) que a mayor grado de heterogeneidad de las unidades de población y menor tamaño de la muestra, mayor probabilidad de que ésta resulte insuficiente.El tamaño de la muestra se calcula con base a la varianza de la población y la varianza de la muestra. Esta última expresada en términos de probabilidad de ocurrencia. La varianza de la población se calcula con el cuadrado del error estándar, el cual determinamos. Cuanto menor sea el error estándar, mayor será el tamaño de la muestra (Hernández Sampieri y otros, 1996:233).
Técnicas de muestreo.- Las técnicas para recoger muestras pueden clasificarse de acuerdo a dos criterios diferentes:
Página 163 de 314
163

a) Según el número de muestras tomadas de la población, los muestreos pueden ser simples, dobles o múltiples (Rodas y otros, 2001) según que elijan una muestra, dos muestras o más de dos muestras. A veces es preciso extraer una segunda muestra cuando los resultados de la primera no alcanzan o no son definitivos. Por ejemplo el investigador toma una segunda muestra al azar entre aquellos que no respondieron un cuestionario y entrevista a los sujetos seleccionados a fin de obtener la información y mayor confiabilidad de los datos (Tamayo, 1999:148). En otro ejemplo, “al probar la calidad de un lote de productos manufacturados, si la primera muestra arroja una calidad muy alta, el lote es aceptado; si arroja una calidad muy pobre, el lote es rechazado. Solamente si la primera muestra arroja una calidad intermedia, será requerirá la segunda muestra (Rodas y otros, 2001).Los muestreos dobles o múltiples pueden a su vez ser transversales o longitudinales, según que las muestras sean extraídas simultánea o sucesivamente en el tiempo. Algunos autores (Tamayo, 1999:148) denominan a estos últimos muestreos cronológicos, como el caso donde se requieren extraer varias muestras de conducta a lo largo del tiempo, a intervalos regulares, con el fin de estudiar su evolución.Otros ejemplos de muestreos dobles o múltiples son los muestreos estratificados o los muestreos por conglomerados, que serán mencionados más adelante como modalidades de los muestreos probabilísticos.
b) Según el modo de elegir los individuos de la muestra, los muestreos pueden ser de dos grandes tipos: probabilísticos (los individuos son elegidos al azar), y no probabilísticos (no elegidos al azar). En el primer caso, cualquier individuo tiene la misma probabilidad de ser incluido en la muestra, y en el segundo caso no. Además, en el primer caso la generalización de los resultados a toda la población es más válida que en el segundo.En los muestreos probabilísticos “pueden usarse tres procedimientos de selección: la tómbola, la tabla de números random (al azar) y la selección sistemática. Todo procedimiento de selección depende de listados, ya sea existentes o construidos ad hoc, como por ejemplo el directorio telefónico, listas de asociaciones, listas de escuelas oficiales, etc. Cuando no existen listas de elementos de la población se recurren a otros marcos de referencia que contengan descripciones del material, organizaciones o sujetos seleccionados como unidades de análisis. Algunos de estos pueden ser los archivos, hemerotecas y los mapas” (Hernández Sampieri y otros, 1996:233).Algunos tipos de muestreo probabilístico o aleatorio son los siguientes:Muestreo simple.- Se eligen los individuos utilizando, por ejemplo, una tabla de números aleatorios. Refieren Rodas y otros (2001) que si la población es infinita, esta tarea se torna imposible, por lo cual se recurre a otros tipos de muestreo aleatorio como el sistemático, el estratificado o el muestreo por conglomerados.Muestreo sistemático.- Consiste en la selección de las unidades de muestreo de acuerdo con un número fijo k, es decir, se elige una unidad cada k veces (Tamayo, 1999:150). Más específicamente, “una muestra sistemática es obtenida cuando los elementos son seleccionados en una manera ordenada. La manera de la selección depende del número de elementos incluidos en la población y el tamaño de la muestra. El número de elementos en la población es, primero, dividido por el número deseado en la muestra. El cociente indicará si cada décimo, cada onceavo, o cada centésimo elemento en la población va a ser seleccionado. El primer elemento de la muestra es seleccionado al azar. Por lo tanto, una muestra sistemática puede dar la misma precisión de estimación acerca de la población, que una muestra aleatoria simple cuando los elementos en la población están ordenados al azar” (Rodas y otros, 2001). El muestreo sistemático se llama también muestreo a intervalos regulares (Tamayo, 1999:147).Muestreo estratificado.- Se divide la población en estratos (por ejemplo por clase social, por edades, etc.) y de cada estrato, que es más homogéneo que la población, se extrae una muestra mediante muestreo aleatorio simple o sistemático. En general, la estratificación aumenta la precisión de la muestra, es decir, presenta menor error muestral que el muestreo simple (Vallejo Ruiloba J y otros, 1999:70) (Hernández Sampieri y otros, 1996:233) (Rodas O y otros, 2001).Cuando la cantidad de individuos seleccionada en cada estrato es proporcional a la cantidad total del estrato poblacional, se habla de muestreo proporcional. En oposición, en un muestreo no proporcional el número de casos sacado de cada uno de los diversos estratos del universo en cuestión no guarda relación con el número de unidades del estrato (Tamayo, 1999:149).
Muestreo por conglomerados.- Se divide la población en conglomerados, generalmente geográficos como por ejemplo en barrios o en ciudades, y de cada uno se extrae una muestra mediante un procedimiento aleatorio simple o sistemático, pudiendo no considerarse en el proceso algunos conglomerados.Si bien es útil para poblaciones grandes (Vallejo Ruiloba y otros, 1999:70), usualmente es menos preciso o sea, tiene mayor error muestral que los otros procedimientos, a igual tamaño de la muestra (Vallejo Ruiloba y otros, 1999:70). Sin embargo, “una muestra de conglomerados puede producir la misma precisión en la estimación que una muestra aleatoria simple, si la variación de los elementos individuales dentro de cada conglomerado es tan grande como la de la población” (Rodas y otros, 2001).El muestreo por conglomerado generalmente se halla incluído en un procedimiento polietápico (véase más adelante).Muestreo polietápico.- “Es una combinación encadenada de otros tipos de muestreo aleatorio y se utiliza en los muestreos muy grandes. Es complejo y requiere para la interpretación de los resultados transformaciones únicamente disponibles en programas muy específicos” (Vallejo Ruiloba y otros, 1999:70).
Página 164 de 314
164

Criterio Tipo de muestreoSegún el número de muestras
SimpleDobleMúltiple
Según el modo de elegir a los individuos
Probabilístico o aleatorio
SimpleSistemáticoEstratificadoPor conglomeradosPolietápico
No probabilístico o no aleatorio
AccidentalIntencional
Mixto Combina probabilísticos y no probabilísticos.
En el muestreo no probabilístico los individuos no tienen la misma probabilidad de ser incluidos en la muestra, o al menos no puede conocerse dicha probabilidad, por cuanto la selección depende de algún criterio del investigador diferente a la elección por azar. Por ello, según Hernández Sampieri y otros (1996:233) se llaman también muestreos dirigidos, y según Rodas (2001) muestreos de juicio. De acuerdo a Vallejo Ruiloba y otros (1999:70), se trata de muestreos no aleatorios por cuanto la elección de los sujetos no es debida al azar.Los muestreos no probabilísticos son válidos si un determinado diseño de investigación así lo requiere, pero sin embargo, si bien los resultados son generalizables a la muestra en sí o a muestras similares, no son generalizables a una población (Hernández Sampieri y otros, 1996:233).Algunos tipos de muestreo no probabilístico o no aleatorio son los siguientes:Muestreo accidental.- Consiste en tomar casos hasta que se complete el número de elementos deseados, es decir, hasta que la muestra alcanza el tamaño precisado (Tamayo, 1999:147). Por ejemplo, seleccionar una muestra de sujetos voluntarios para estudios experimentales y situaciones de laboratorio (Hernández Sampieri y otros, 1996:233).Muestreo intencional.- O sesgado, donde el investigador selecciona los elementos que a su juicio son representativos, lo cual exige un conocimiento previo de la población que se investiga para poder determinar categorías o elementos que se consideran como tipo o representativos del fenómeno que se estudia (Tamayo, 1999:148). Por ejemplo seleccionar una muestra de sujetos expertos en estudios exploratorios, o una muestra de sujetos-tipo en otra clase de estudios (Hernández Sampieri y otros, 1996:233).Existen aún otras técnicas no probabilísticas, como por ejemplo el muestreo por cuotas, frecuente en estudios de opinión y mercadotecnia (Hernández Sampieri y otros, 1996:233).
Finalmente, en el muestreo mixto se combinan diversos tipos, probabilísticos y no probabilísticos; por ejemplo, pueden seleccionarse las unidades de la muestra aleatoria y luego aplicarse el muestreo por cuotas (Tamayo, 1999:149).Las técnicas de muestreo no son procedimientos ciegos, estando guiados por una teoría del muestreo, o estudio de las relaciones existentes entre una población y muestras extraídas de la misma. Esta teoría permite, por ejemplo: a) estimar cantidades desconocidas tales como los parámetros poblacionales, a partir de los estadísticos muestrales, o b) determinar si las diferencias observadas entre dos muestras son debidas al azar, o si son realmente significativas.
3. SELECCIÓN DEL INSTRUMENTO DE MEDICIÓN
Todo instrumento de medición intenta medir algo. Este algo es algún aspecto recortado de la realidad, habitualmente designado como variable. Como la variable puede adoptar diferentes valores, el instrumento de medición informará acerca de qué valor adoptó la variable aquí y ahora, en esta persona o en este objeto. Ejemplos de instrumentos de medición clásicos en las ciencias naturales son el barómetro (mide la presión atmosférica), la balanza (mide el peso), el cronómetro (mide la duración), el tensiómetro (mide la presión arterial), etc.Las ciencias sociales disponen también de una amplia gama de instrumentos de medición, como por ejemplo los tests psicométricos (pueden medir inteligencia), los tests proyectivos (pueden medir personalidad, gravedad de la patología mental, etc.), los cuestionarios (pueden medir actitudes, personalidad, estado de ánimo, intereses vocacionales, etc.), o los exámenes (pueden medir el rendimiento del alumno). Las entrevistas e incluso la simple observación pueden ser considerados instrumentos de medición. Por ejemplo, la observación del juego de un niño durante una hora (la llamada ‘hora de juego diagnóstica’) permite medir variables como tolerancia a la frustración, creatividad, etc.Un mismo instrumento de medición puede ser utilizado de diversas maneras. Por ejemplo un cuestionario puede administrarse en forma personal, por teléfono o por correo (Hernández Sampieri y otros, 1996:338). Esto es importante porque todo instrumento de medición va acompañado de ciertas instrucciones acerca de cómo debe ser administrado y como debe ser analizado. La administración es el proceso que transforma información en datos, mientras que el análisis transforma los datos en conclusiones significativas acerca de la variable medida.Algunos instrumentos de medición son tan genéricos que pueden utilizarse en todas las disciplinas: una regla puede medir la longitud de una planta en botánica o la altura de una letra en grafología, mientras
Página 165 de 314
165

que un cronómetro puede medir la velocidad de un automóvil en cinemática o el tiempo de reacción en psicología. Ello se debe a que el espacio y el tiempo son ejemplos de magnitudes fundamentales que impregnan toda la realidad.La medición de las variables puede realizarse mediante un instrumento de medición ya existente, o bien, si no existe o no hay garantías de su validez y confiabilidad, mediante un instrumento construido ad hoc. Según Hernández Sampieri y otros (1996:338), los pasos genéricos para construir un instrumento de medición son: 1) Listar las variables a medir. 2) Revisar sus definiciones conceptuales y operacionales. 3) Elegir uno ya desarrollado o construir uno propio. 4) Indicar niveles de medición de las variables (nominal, ordinal, por intervalos y de razón). 5) Indicar como se habrán de codificar los datos. 6) Aplicar prueba piloto. 7) Construir la versión definitiva. La prueba piloto consiste en aplicar el instrumento a un número pequeño de casos para examinar si está bien construido (por ejemplo, en un cuestionario si las preguntas serán entendidas por los sujetos).
Errores en la medición.- Al medir se pueden cometer dos tipos de errores a) sistemáticos o de sesgo o constantes: un error constante es introducido en la medida por algún factor que sistemáticamente afecta a la característica a medir o al propio proceso de medida, y por ello suele pasar desapercibido; b) variables o al azar: debidos a influencias pasajeras, sea que procedan de la misma persona y del procedimiento de medida (Selltiz y otros, 1980). Por ejemplo, cuando se aplica un test para medir inteligencia, se comete un error constante cuando se lo toma siempre en lugares ruidosos, con lo cual el resultado no reflejará solamente la inteligencia sino también la tensión derivada del ambiente. En cambio, se comete un error variable cuando algunas de las personas están muy cansadas.Del mismo modo, al medir la longitud de una mesa se comete un error constante cuando las marcas de la regla no son exactamente de un centímetro, y un error variable cuando el investigador se distrae momentáneamente al efectuar la medición.Lo ideal sería que los resultados de una medición reflejen solamente la característica o propiedad que se está midiendo, pero desgraciadamente puede haber otros factores no controlados o desconocidos que pueden desvirtuar el proceso de medición, haciéndole perder precisión. Selltiz y otros (1980) agrupan en nueve las posibles fuentes de variaciones en los resultados o puntuaciones de los instrumentos de medida, y que son fuentes de error:
1. Verdaderas diferencias en la característica que se intenta medir: idealmente las diferencias medidas que se obtienen reflejan las verdaderas diferencias entre los individuos. Se trataría del único caso donde la medición no es errónea.2. Verdaderas diferencias en otras características relativamente estables del individuo, que afectan su puntuación: variables como la inteligencia pueden contaminar medidas sobre la característica ‘actitud’.3. Diferencias debidas a factores personales transitorios, como humor, fatiga, grado de atención, etc., que son pasajeros.4. Diferencias debidas a factores de situación: la entrevista a una ama de casa puede estar influida por la presencia del esposo.5. Diferencias debidas a variaciones en la administración: la forma de obtener la medida puede influir en ésta, como cuando el entrevistador cambia el tono de la pregunta, añade preguntas, etc.6. Diferencias debidas al método de muestreo de los ítems: una entrevista o cuestionario contiene sólo algunas preguntas de todas las posibles. El tamaño de esta muestra influirá también sobre la medida.7. Diferencias debidas a la falta de claridad del instrumento de medida: los sujetos pueden interpretar de distinta forma las preguntas por estar expresadas ambiguamente.8. Diferencias debidas a factores mecánicos tales como rotura de lápices, preguntas poco legibles, falta de espacio para responder, etc.9. Diferencias debidas a factores en el análisis: como los errores que comete el investigador al tabular, puntuar y analizar los datos obtenidos.
Generalmente la construcción de un cuestionario exige mucha atención, rigor, y conocimientos de estadística suficientes para examinar su validez y su confiabilidad. Señalan Mora y Araujo (1971) que un mal resultado de la investigación puede deberse a que se partió de una hipótesis equivocada o bien que se usaron malos instrumentos de medición.Consiguientemente, toda medida debe reunir dos requisitos: validez y confiabilidad (o confianza). La validez puede estar afectada tanto por errores constantes como variables, pero la confiabilidad generalmente está afectada por errores variables (Selltiz y otros, 1980).
Generalidades sobre validez y confiabilidad.- Validez y confiabilidad son dos requisitos que debe reunir todo instrumento de medición para cumplir eficazmente su cometido, es decir, medir. La validez implica relevancia respecto de la variable a medir, mientras que la confiabilidad implica consistencia respecto de los resultados obtenidos.Como instrumento de medición del aprendizaje, la prueba escrita debe ser válida y debe ser confiable.Es posible imaginarse una prueba escrita algo grotesca, donde el alumno debe contestar cinco preguntas en un minuto. ¿Podemos pensar que esta prueba mide el nivel de aprendizaje alcanzado? ¿No estará midiendo en realidad la velocidad de escritura, o la paciencia del alumno? En este caso la prueba no es válida, porque está midiendo otra cosa que nada tiene que ver que lo que originalmente se quería medir.
Página 166 de 314
166

Consiguientemente, se dice que un instrumento es válido cuando mide lo que pretende medir. Si la prueba escrita mide realmente el aprendizaje alcanzado, entonces es válida.Cabe imaginar ahora una prueba escrita válida, donde el alumno debe elaborar la respuesta a dos o tres preguntas en dos horas. Cuando esta prueba escrita es corregida por el profesor A, el B y el C, aparecen tres notas distintas, y hasta incluso uno de los profesores aprueba al alumno y los otros no. Los tres profesores son concientes de que están midiendo la misma variable -aprendizaje- por lo que la prueba es válida, pero sin embargo... no es confiable, porque los resultados son dispares. La prueba hubiese sido confiable si, por ejemplo, hubiera utilizado el sistema de multiple choice, en cuyo caso las notas de todos los profesores hubiese sido la misma por haber aplicado todos ellos el mismo criterio estándar de evaluación (esto no significa que una prueba deba siempre utilizar el sistema de multiple choice). Consiguientemente, se dirá que un instrumento de medición es confiable (o fiable) cuando presenta cierta consistencia o constancia en los resultados.En lo que sigue, se harán algunas otras consideraciones respecto de cómo pueden determinarse la validez y la confiabilidad en los tests psicológicos, siguiendo el ordenamiento propuesto en (Casullo, 1980).
Validez.- Un test psicológico es válido cuando efectivamente mide lo que pretende medir. Si en un supuesto test de creatividad, las preguntas son del tipo "en qué año Colón descubrió América", el test no estará midiendo creatividad sino memoria o cultura general. No es válido porque no mide lo que efectivamente pretendía medir. Debido a que debemos saber lo que el test mide, tal vez sea preferible definir la validez, tal como lo sugiere Anastasi (1976) como el grado en que conocemos lo que el test mide.La validez de un test puede establecerse de diversas maneras, correspondiendo a cada una de ellas un tipo de validez distinto. En este sentido, se puede hablar de cuatro tipos de validez:a) Validez predictiva.- Se puede establecer la validez de un test viendo si el desempeño posterior del sujeto para la variable medida se corresponde con los puntajes obtenidos en el test. Por ejemplo, un test vocacional es válido si las profesiones en las cuales los sujetos tuvieron éxito corresponden a las profesiones sugeridas por el test. Obviamente, para saber si el test vocacional resultó válido, habrá que esperar, en este caso, varios años.Otras veces, tal vez no sea necesario esperar tanto, tal como sucede en los tests que permiten conocer la propensión a sufrir desórdenes emocionales, o en los tests que permiten conocer el grado en que cierto tratamiento psiquiátrico puede o no beneficiar a un paciente.b) Validez concurrente.- Se puede establecer la validez de un test examinando el grado de correlación de sus puntajes con los puntajes de otro test que mide la misma variable. En otras palabras, la validez se evalúa aquí en términos de 'concurrencia' de puntajes de tests diferentes.Por ejemplo, "se ha estudiado la validez concurrente de la Escala de Inteligencia Weschler comparando los puntajes obtenidos en ella con los obtenidos en la prueba Stanford Binet por los mismos sujetos" (Casullo, 1980). Como podemos apreciar, la validez concurrente se puede determinar sólo a partir de haber constatado la validez de otro tipo de prueba que mide lo mismo. Como no puede hacerse una 'regresión al infinito', este otro tipo de prueba debe haber sido validada de acuerdo a un criterio distinto al criterio de concurrencia.
Una cuestión relacionada con la validez concurrente es el empleo en un test de indicadores de otra variable diferente, pero que está altamente correlacionada con la variable que intenta medir el test. Lazarsfeld (1980), por ejemplo, habla de los indicadores expresivos, los que, a diferencia de los predictivos (que miden la variable directamente), la miden indirectamente a través de otra variable con la cual está altamente correlacionada. Por ejemplo, se puede medir la variable 'antisemitismo' recurriendo a indicadores de otra variable correlacionada, por ejemplo 'autoritarismo', mediante indicadores del tipo "La obediencia y el respeto a la autoridad son las virtudes más importantes que debe aprender un niño".
c) Validez de contenido.- Un tests tiene validez de contenido si los diferentes ítems o contenidos que lo componen (pruebas, preguntas, etc.) son una muestra representativa de la variable o constructo que se pretende medir. Si un test de inteligencia incluye una sola prueba (por ejemplo construir un rompecabezas), esa prueba mide efectivamente inteligencia pero no tiene validez de contenido porque no es por sí sola representativa de la inteligencia del sujeto: debe también incluir otras pruebas para medir otros tipos de inteligencia como por ejemplo la inteligencia social, o habilidad para relacionarse con las personas.En otro ejemplo, "una prueba o examen parcial que se elabore para evaluar el aprendizaje de los contenidos de las tres primeras unidades o temas de un programa debe incluir ítems que abarquen todos los contenidos y objetivos de esa parte del programa" (Casullo, 1980). De igual forma, al diseñar una entrevista para diagnosticar una depresión mayor, por ejemplo, ella debe incluir todos los criterios que el DSM-IV establece para esa categoría. En caso contrario, la entrevista como instrumento de medición carecerá de validez de contenido.
La validez de contenido plantea el problema de la adecuada selección de indicadores en la construcción de un test, es decir, de su grado de representatividad. Lazarsfeld (1980) señala al respecto que la teoría de la intercambiabilidad de los índices se basa en que la experiencia ha demostrado que, dado un gran número de ítems o indicadores, cualquiera que sea la muestra elegida para construir el instrumento de medición, no se hallarán grandes diferencias. Si las hay o no dependerá, en todo caso, de la certeza de la inferencia de
Página 167 de 314
167

características latentes a partir de los datos manifiestos, lo cual a su vez depende de varios factores, entre los que se puede citar el grado en que la pregunta - indicador está sujeta a interpretaciones diversas.
d) Validez de constructo.- También llamada validez estructural (Casullo, 1980), la validez de constructo implica que los distintos indicadores o pruebas de un test son el producto de una buena operacionalización, es decir, cuando reflejan la definición teórica de la variable que se pretende medir. Por caso, de una concepción piagetiana de inteligencia no surgirán las mismas pruebas que de una concepción weschleriana.Según Casullo, este es el tipo de validez básico que debe tenerse en cuenta al diseñar instrumentos de medición: "la validez estructural supone básicamente que la técnica psicométrica tenga definido claramente el constructo teórico que pretende medir, pueda operacionalizarlo a través de indicadores coherentes y a partir de ellos se puedan obtener índices" (Casullo, 1980).Cuando el conjunto de indicadores de un test se obtuvo mediante el procedimiento estadístico llamado análisis factorial, hablamos entonces de validez factorial del test.
Confiabilidad.- La confiabilidad se logra cuando aplicada una prueba repetidamente a un mismo individuo o grupo, o al mismo tiempo por investigadores diferentes, da iguales o parecidos resultados (Tamayo, 1999:68). Más concretamente, un test psicológico es confiable cuando, aplicado al mismo sujeto en diferentes circunstancias, los resultados o puntajes obtenidos son aproximadamente los mismos. Veamos tres cuestiones que son importantes en esta definición: el 'mismo' sujeto, las 'diferentes' circunstancias, y los resultados 'aproximadamente' iguales.Con respecto a la primera cuestión, es obvio y hasta esperable que si tomo un test a 'diferentes' personas obtenga puntajes diferentes. Si todas las personas tuviesen la misma inteligencia, carecería de sentido tomarles un test. También es esperable que cuando le tomamos el test a una 'misma' persona en diferentes circunstancias, me de aproximadamente el mismo puntaje. En caso contrario la prueba no es confiable, por lo que entonces la confiabilidad se determina tomando el test a la misma persona, no a personas diferentes.Con respecto a la segunda cuestión, las diferentes circunstancias en que se toma la prueba a la misma persona pueden ser varias: en diferentes instantes de tiempo, con diferentes administradores del test, con diferentes evaluadores de los resultados, en diferentes ambientes físicos, etc. Si, a pesar de todas estas condiciones diferentes, un mismo sujeto obtiene mas o menos el mismo puntaje, el test resulta altamente confiable. No obstante ello, tampoco de trata de tentar al diablo: los tests incluyen siempre elementos que intentan asegurar la confiabilidad, como por ejemplo la consigna que prescribe que el administrador deberá hacer determinada pregunta y no otra, que deberá responder a preguntas del sujeto de determinada manera y no de otra, que deberá tomar el test en un ambiente sin ruidos, etc., todo ello para que no influya la forma peculiar de administrar el test sobre el puntaje.Como señala Casullo, "cuando pretendemos mantener constantes o uniformes las condiciones en las que se toma una prueba, controlando el ambiente, las instrucciones, el tiempo, el orden de las preguntas, lo que intentamos es reducir la varianza de error a los efectos de que los puntajes sean más confiables" (Casullo, 1980).Con respecto a la tercera cuestión, no podemos esperar que los resultados sean exactamente los mismos, es decir, siempre habrá una 'varianza', es decir, una variación en los resultados. El problema es decidir si esa variación es lo suficientemente pequeña como para decidir que el test es confiable o, si por el contrario, refleja un problema de confiabilidad, es decir, es lo suficientemente grande como para declararla no confiable. En otras palabras y como dice Anastasi (1976), toda medida de confiabilidad de un instrumento de medición denota qué proporción de la varianza total en los puntajes es varianza de error. Más claramente: cuando medimos una variable, como por ejemplo autoconcepto o inteligencia, debemos estar relativamente seguros de saber en qué medida el puntaje refleja realmente el estado de la variable y en qué medida es el resultado de otras variables extrañas como fatiga, sesgos del evaluador, ansiedad, etc. Señala al respecto Casullo que "el 'puntaje verdadero' podría determinarse haciendo un promedio de los puntajes obtenidos en distintas evaluaciones sucesivas de la variable en cuestión" (Casullo, 1980), ya que se supone que cada puntaje obtenido es resultado tanto de la variable a medir como de la influencia de otros factores. La parte del puntaje debido a la influencia de la variable suele llamarse varianza 'verdadera' y la parte del puntaje que resulta de los otros factores suele llamarse varianza de error, la que está expresando el error de medición. La varianza verdadera más la varianza de error se llama varianza total. Para determinar la confiabilidad de un test se utiliza el análisis estadístico de correlación. En general, cuanto más alta es la correlación entre los diferentes puntajes obtenidos por un mismo sujeto, más confiable resulta el test. En muchos tests, y luego de haber sido probados muchas veces, se puede obtener un coeficiente de confiabilidad para dicho test, lo cual a su vez permite evaluar los límites razonables del puntaje verdadero en base a cualquier puntaje obtenido.
Para quienes tengan cierto conocimiento de curvas normales, la expresión e = s . 1 - r me indica el error de medición aceptable (e) que puedo cometer al evaluar un puntaje de una variable en base a una muestra o población con un determinado desvío estándar (s) y con un instrumento de medición cuyo coeficiente de confiabilidad es (r). Por ejemplo, si el desvío estándar es 15 y el coeficiente de confiabilidad es 5, aplicando la fórmula obtengo un error de medición de 5. Esto significa que si el verdadero puntaje de un sujeto es 110, podemos esperar que al serle administrada la prueba obtenga un puntaje entre 105 y 115 (o sea entre menos 5 y más 5) en el 68% de los casos (68% porque hemos considerado un solo desvío estándar).
Página 168 de 314
168

El requisito de la confiabilidad supone que la variable a medir se mantiene estable en el tiempo. Esto, sin embargo, no siempre es aplicable, como por ejemplo cuando se administran sucesivas pruebas de estado de ansiedad a lo largo de un tratamiento psicoterapéutico. En estos casos lo que se espera es que los puntajes vayan cambiando, no que se mantengan similares.Veamos diferentes maneras en que puede determinarse la confiabilidad de un test.a) Repetición de test.- Consiste en volver a tomar la misma prueba al mismo sujeto o grupo de sujetos: esta segunda prueba se llama retest. Un ejemplo de la técnica de test-retest puede ser la siguiente: primero tomamos una prueba de aptitud matemática a un grupo de alumnos (test), y luego, al día siguiente, volvemos a tomar la misma prueba aunque con diferentes contenidos (retest). Cuanto más 'iguales' sean los puntaje obtenidos por cada alumno, tanto más confiable es la prueba. Notemos que entre el primero y el segundo día las condiciones pudieron haber cambiado de manera tal de incidir sobre los resultados de la segunda prueba. Por ejemplo, un alumno recibió una mala noticia y no pudo concentrarse en la segunda evaluación, sacando un puntaje mucho menor. Otros factores pudieron haber sido variaciones climáticas, ruidos repentinos, etc., o incluso la incorporación de nuevos conocimientos si la segunda prueba tuvo el carácter de un examen recuperatorio.En general, cuanto más tiempo transcurra entre la primera y la segunda administración de la prueba, más factores pueden estar influyendo sobre los puntajes de la segunda, más distintos serán con respecto a la primera y, por tanto, menos confiable será la prueba.Según Casullo, "es posible citar ejemplos de tests psicológicos que muestran una alta confiabilidad tras periodos de pocos días, la cual disminuye cuando el intervalo se extiende a diez o quince años" (Casullo, 1980), sobre todo si en el transcurso de ese largo periodo de tiempo los sujetos maduraron o aprendieron cosas nuevas.
En general, "se sugiere que el intervalo entre la repetición de las pruebas (test-retest) para todas las edades no sea mayor que seis meses. Este procedimiento nos permite hablar de la 'estabilidad' de las mediciones obtenidas administrando una técnica psicométrica.Contesta a la pregunta relativa a en qué medida las mediciones resultan estables a lo largo de un periodo de tiempo. Una alta confiabilidad de este tipo nos dice que las personas mantienen sus posiciones uniformes en el rango de la variable psicológica que intenta medir la técnica (aprendizaje, autocontrol o ansiedad estado). Esta forma de determinar la confiabilidad presenta algunas dificultades, como por ejemplo: a) la práctica puede causar un rendimiento diferente en el retest, y b) si el intervalo es corto las personas pueden recordar las respuestas" (Casullo, 1980).
b) Formas equivalentes.- Se puede establecer la confiabilidad de una prueba administrándola en diferentes momentos al mismo sujeto, pero tomando la precaución de que la prueba sea diferente en cuanto a los contenidos aunque equivalente en cuanto a la forma. Por ejemplo, tomar dos exámenes escritos sobre diferentes temas, pero con la misma cantidad de preguntas, el mismo grado de dificultad, el mismo tipo de preguntas, etc.Esta forma de medir la confiabilidad tiene sus limitaciones; por ejemplo, si pensamos que la práctica influye en los puntajes del segundo examen, o sea, si los alumnos adquieren cierta destreza en la primera prueba que hará subir los puntajes en la segunda.c) División por mitades.- Se puede establecer la confiabilidad de un test dividiéndolo en dos partes equivalentes (equivalentes en grado de dificultad, etc.) y asignando un puntaje a cada parte. Si ambos puntajes son muy similares para un mismo sujeto, el test no sólo tiene confiabilidad sino también consistencia interna. Esto último no podía constatarse con la técnica test-retest ni con la administración de formas equivalentes.Otras veces se divide la prueba en tantas partes como ítems tenga, como hicieron Kuder y Richardson, lo que permite examinar cómo ha sido respondido cada ítem en relación con los restantes (Casullo, 1980). Tengamos presente que cuando hablamos de consistencia interna nos podemos referir a consistencia de los ítems o a consistencia de las respuestas del sujeto: la confiabilidad tiene relación directa con el primer tipo de consistencia.
Página 169 de 314
169
CAPÍTULO 13: EL DISEÑO DE INVESTIGACIÓN
Un diseño de investigación científica es básicamente un plan para recolectar datos, aunque algunos autores incluyen también un plan para analizar los datos, fundamentalmente una prueba estadística. El plan de recolección ha de ser lo más sencillo y económico posible, aunque ello no debe hacer pensar que un diseño de investigación se pueda ejecutar en horas o días: una investigación puede llevar meses y años.Existe amplia bibliografía al respecto que propone una gran diversidad de criterios de clasificación de los diseños de investigación, especialmente para las ciencias sociales donde el objeto de estudio es más complejo.Muchas veces los investigadores, a la hora de elegir un diseño, se encuentran con esa gran cantidad de propuestas, donde incluso llegan a mencionarse los mismos diseños con denominaciones diferentes. El presente artículo tiene como finalidad presentar algunas taxonomías de diseños de investigación en ciencias sociales que orienten al investigador para construir un árbol de decisión cuando deba elegir el que más se adapta a sus objetivos (por ejemplo realizar una investigación exploratoria, descriptiva, correlacional o explicativa) y a los recursos con que cuenta (por ejemplo sujetos de experimentación, técnicos en estadística, etc.).Se ha presentado en primer lugar la versión Campbell y Stanley por ser un referente clásico, consultado por la mayoría de los autores de las restantes versiones aquí presentadas. Si bien estos diseños han surgido principalmente de las ciencias sociales, algunos de ellos son aplicables también en la física, la química, la biología y demás ciencias naturales.
1. VERSIÓN CAMPBELL Y STANLEY
Donald Campbell y Julian Stanley presentaron en 1963 una sistematización de diseños de investigación experimental para las ciencias sociales. Los autores describen un total de dieciséis diseños experimentales (agrupados en tres pre-experimentales, tres experimentales propiamente dichos y diez cuasi-experimentales), y examinan su validez interna y externa tomando en consideración un total de doce fuentes corrientes de invalidación que amenazan las inferencias válidas.Los 16 diseños experimentales descriptos por Campbell y Stanley, son clasificados en tres grupos (esquema 1).a) Diseños preexperimentales: son 3, y no son recomendados por los autores.b) Diseños experimentales propiamente dichos: son 3, y son recomendados especialmente por esos autores.c) Diseños cuasiexperimentales: son 10, y son recomendados por Campbell y Stanley si no es posible aplicar uno mejor.
Esquema 1 – Diseños experimentales versión Campbell-Stanley (Preparado por Pablo Cazau)
TIPO NOMBRE ESQUEMADiseñospreexperimentales
1. Estudio de casos con una sola medición
X 0
2. Diseño pretest-postest de un solo grupo
01 X 02
3. Comparación con un grupo estático
X 01---------------------------- 02
Diseñosexperimentales propiamente dichos
4. Diseño de grupo de control pretest-postest
R 01 X 02R 03 04
5. Diseño de 4 grupos de Solomon
R 01 X 02R 03 04R X 05R 06
6. Diseño de grupo de control con postest únicamente
R X 01R 02
Diseñoscuasiexperimentales
7. Experimento de series cronológicas
01 02 03 04 X 05 06 07 08
8. Diseño de muestras cronológicas equivalentes
X10 X00 X10 X00 etc
9. Diseño de materiales equivalentes
MaX10 MbX00 McX10 MdX00 etc
10. Diseño de grupo de control no equivalente
0 X 0-------------------0 0
11. Diseños compensados X10 X20 X30 X40-------------------------X20 X40 X10 X30-------------------------X30 X10 X40 X20-------------------------X40 X30 X20 X10
Página 170 de 314
170

12. Diseño de muestra separada pretest-postest
12R 0 (X)R X 0
12aR 0 (X)R X 0-----------------------------R 0 (X)R X 0
12bR 01 (X)R 02 (X)R X 03
12cR 01 X 02R X 03
13. Diseño de muestra separada pretest-postest con grupo de control
13R 0 (X)R X 0----------------------------R 0R 0
13aR 0 (X)R 0 X 0-------------------R 0 (X) R’R 0 X 0-------------------R 0 (X)R 0 X 0R 0R 0-------------------R 0 R’R 0-------------------R 0R 0
14. Diseño de series cronológicas múltiples
0000 X 00000000 0000
15. Diseño de ciclo institucional recurrente (diseño de retazos)
Clase A X 01Clase B 02 X 03
Esquema más preciso:A X 01----------------------------B1 R02 X 03B2 R X 04----------------------------C 05 X-- -- -- -- -- -- -- -- -- ---CGPC B 06CGPC C 07
16. Análisis de discontinuidad en la regresión
---------------------------------------
Para indicar grupos igualados por aleatorización se emplea el símbolo R (inicial de 'randomización'), y están presentes solamente en los diseños experimentales propiamente dichos, porque la aleatorización es un requisito esencial para que un diseño sea experimental. Otro requisito es la presencia de grupos de control. En el diseño 3, que es preexperimental, se utiliza un grupo de control, pero estos no están igualados por aleatorización, sino por otros procedimientos que suelen conducir a inferencias erróneas (Campbell y Stanley, 1995:18).
Diseños preexperimentales
Se trata de diseños que no son recomendados por Campbell y Stanley, pero que dichos autores emplean fundamentalmente para "ilustrar los factores de validez que requieren control" (Campbell y Stanley, 1995:139).
Diseño 1: Estudio de un caso con una sola medición.- Este diseño consiste en tomar un solo grupo por vez, someterlo a la acción de algún agente o tratamiento (X) que supuestamente provoque algún cambio, para luego proceder a estudiarlo (O).En estos estudios, "se compara implícitamente un caso único, cuidadosamente estudiado, con otros acontecimientos observados de manera casual y recordados. Las inferencias se fundan en expectaciones generales de cuáles hubieran sido los datos de no haberse producido X, etc." (Campbell y Stanley, 1995:19). Se nos ocurre el siguiente ejemplo: 'este grupo de alumnos anda mejor ahora (O) que hay otro profesor (X)'. Campbell y Stanley asignan a este diseño un valor científico casi nulo por cuanto adolece de una importante falta de controles, y sostienen que, en lugar de haberse dedicado tanta energía al estudio intensivo del caso, se podría haberla derivado hacia el estudio comparativo con otro grupo de alumnos que hubieran seguido con el profesor anterior.Diseño 2: Diseño pretest - postest de un solo grupo.- Este diseño consiste, primero, en observar o medir un determinado grupo (O1); segundo, introducir un factor que supuestamente producirá algún cambio en el mismo (X); y por último, volver a observar o medir (O2) el grupo luego de haber aplicado X, para ver si se registró el cambio esperado.El problema que presenta este diseño, juzgado por los autores como un "mal ejemplo", es que pueden intervenir variables externas que ocasionen el cambio, independientemente de X. "Tales variables ofrecen hipótesis aceptables que explican una diferencia O1 -- O2 opuesta a la hipótesis de que X causó la diferencia" (Campbell y Stanley, 1995:20). Tales hipótesis aceptables son entonces hipótesis rivales, y entre ellas se pueden mencionar la historia, la maduración, la administración de tests, la instrumentación y, en algunos casos, la regresión estadística.
Página 171 de 314
171

En lo concerniente al factor historia, debe tenerse presente que "entre O1 y O2 pueden haber ocurrido muchos otros acontecimientos capaces de determinar cambios, además de la X sugerida por el experimentador.Si el pretest (O1) y el postest (O2) se administraron en días distintos, los acontecimientos intermedios pueden haber causado la diferencia. Para convertirse en una hipótesis rival 'aceptable', tal acontecimiento debería haber afectado a la mayor parte de los estudiantes que integran el grupo examinado" (Campbell y Stanley, 1995:20). Por ejemplo, en 1940 se investigó si la propaganda nazi (X) influía o no en las actitudes de los alumnos. Estos cambios, efectivamente, se verificaron, pero no pudo saberse si se debieron a la propaganda nazi o al hecho de que entre O1 y O2 se produjo la caída de Francia (factor de invalidación 'historia').En lo relativo a la maduración, "es probable que entre O1 y O2 los estudiantes hayan aumentado de edad, apetito, fatiga, aburrimiento, etc., y acaso la diferencia obtenida refleje ese cambio y no el de X" (Campbell y Stanley, 1995:21). En cuanto al factor administración de tests, cabe consignar que, por ejemplo en pruebas de rendimiento e inteligencia, los sujetos suelen desempeñarse mejor en el segundo test que en el primero, con lo cual no puede saberse si el mejor desempeño en el postest obedece a la toma del pretest o a X.En lo referente a la instrumentación de pruebas, Campbell se refiere a un 'deterioro de los instrumentos' de medición en el intervalo entre el prestest O1 y el postest O2. Por ejemplo, si se trata de observar cómo los alumnos participan en el aula, los observadores pueden observar de manera diferente la segunda vez (O2), como por ejemplo, ser más hábiles o ser más indiferentes en sus observaciones. Otro caso es cuando los observadores o administradores de tests son personas distintas en O1 y O2, también causa posible de diferencias entre ambas mediciones más allá del efecto de X.Por último, en lo relativo al factor regresión estadística, "si en una prueba correctiva se seleccionan alumnos para un experimento especial porque han tenido puntajes particularmente bajos en el test de rendimiento escolar (O1), en una prueba posterior en que se adopte la misma forma de antes u otras similar a ella, casi con seguridad O2 tendrá para ese grupo un promedio más elevado que O1. Este resultado confiable no se deberá a ningún efecto genuino de X, a ningún efecto de la práctica de test y retest, etc. Es mas bien un aspecto tautológico de la correlación imperfecta entre O1 y O2" (Campbell y Stanley, 1995:24-25).Cuanto menor sea el grado de correlación entre O1 y O2, mayor será la regresión hacia la media. Los efectos de regresión son entonces acompañamientos inevitables de la correlación imperfecta de test-retest para grupos "seleccionados por su ubicación extrema" (Campbell y Stanley, 1995:27-28).Diseño 3: Comparación con un grupo estático.- Es un diseño en el cual se compara un grupo que ha experimentado X, con otro grupo que no ha experimentado X (llamado grupo estático). Ejemplos: la comparación de sistemas escolares con maestros universitarios (X), con otros sistemas con maestros no universitarios; la comparación de alumnos que reciben cursos de lectura veloz (X), con otros que no los reciben; la comparación entre quienes ven determinado programa de televisión (X), con otros que no lo ven.El lector advertirá cierta semejanza con el diseño 6 (ver esquema 1), pero hay una diferencia: en el diseño 3 no se ha tomado la precaución de asegurarse la equivalencia de ambos grupos mediante un método como la aleatorización, precaución que sí se tomó en el diseño 6. Por lo tanto, un factor no controlado por el diseño 3 es la selección previa de los sujetos de los grupos. Así, en este diseño, "si hay diferencias entre O1 y O2, ello bien puede deberse al reclutamiento diferencial de las personas que componen los grupos: estos podrían haber diferido aun sin la presencia de X" (Campbell y Stanley, 1995:29).Otro factor no controlado por el diseño 3 es la mortalidad experimental. Aún cuando se hubiera tomado la precaución de igualar los grupos, persiste el problema del abandono selectivo de personas de uno de los grupos (mortalidad experimental).
Diseños experimentales propiamente dichos
Los diseños experimentales propiamente dichos que siguen son los recomendados en la actualidad por la literatura metodológica y por Campbell y Stanley (Campbell y Stanley, 1995:31). Se trata de diseños con un gran poder de control de variables externas (extrañas).
Diseño 4: Diseño de grupo de control pretest - postest.- Este diseño clásico consiste en utilizar dos grupos equivalentes logrados por aleatorización (R), hacerles un pre-test a ambos (O1 y O3), aplicarle X al grupo experimental, y finalmente hacerles un post-test a ambos a ver si hubo alguna variación como consecuencia del tratamiento experimental X.Con este diseño se pueden controlar una gran cantidad de fuentes de invalidación interna. Por ejemplo:a) La historia "se controla en la medida en que los acontecimientos históricos generales que podrían haber producido una diferencia del tipo O1-O2 causarían también una diferencia del tipo O3-O4" (Campbell y Stanley, 1995:32). La precaución que debe tomarse en estos casos es que las historias 'intrasesionales' de cada grupo no sean tan diferentes entre sí como para que se conviertan verosímilmente en una hipótesis rival a la hipótesis de investigación de que X es la causa de la variación.b) La maduración y la administración de tests "están controladas en el sentido de que su manifestación en los grupos experimentales y de control debería ser igual" (Campbell y Stanley, 1995:34).c) La instrumentación "se controla con facilidad cuando se dan las condiciones para el control de historia intrasesional, en particular cuando se logra la O por medio de reacciones de los estudiantes a un
Página 172 de 314
172

instrumento fijo, como una prueba impresa" (Campbell y Stanley, 1995:34). El problema es más grave cuando se recurre, en cambio, a observadores y entrevistadores, ya que diversos son los factores que pueden sesgar sus puntajes o registros.d) La regresión "se controla, en lo que a diferencia de medias concierne y por muy extremo que sea el grupo en los puntajes pretest, si tanto el grupo experimental como el de control se asignan al azar, tomándolos de este mismo conjunto extremo. En tales casos, el grupo de control regresiona tanto como el experimental" (Campbell y Stanley, 1995:34-35).e) La selección se controla asegurando la igualdad de los grupos mediante la aleatorización. Campbell y Stanley discuten aquí el valor de otro procedimiento para asegurar esta igualdad, la equiparación (Campbell y Stanley, 1995:36), señalando su ineficacia como "único" procedimiento, pudiéndose obtener mayor precisión estadística cuando se lo combina con la aleatorización, procedimiento mixto llamado "bloqueo" (por ejemplo, asignar estudiantes a pares equiparados y asignando luego al azar un miembro de cada par al grupo experimental y otro al de control).f) Respecto de la mortalidad, "los datos de que disponemos gracias al diseño 4 permiten establecer qué mortalidad explica aceptablemente la ganancia O1-O2" (Campbell y Stanley, 1995:36), ya que suele ser precisamente en el grupo experimental donde se exige la concurrencia de los sujetos para su exposición a X. La distinta concurrencia en el grupo experimental y en el de control produce una mortalidad que puede introducir sutiles sesgos. Examinemos ahora los factores que, en este diseño 4, atentan contra la validez externa, recordando que estas amenazas a la validez externa pueden considerarse como efectos de interacción entre X y alguna otra variable.a) Interacción de tests y X.- La toma de un pretest puede influir sobre los resultados del experimento, lo que llevó a algunos experimentadores a elegir el diseño 6, que omite el pretest."Cuando se emplea un test con procedimientos muy poco usuales, o cuando el test implica engaño, reestructuración conceptual o cognitiva, sorpresa, tensión, etc., los diseños con grupos no sometidos a pretest [como el diseño 6] continúan siendo muy convenientes, aunque no imprescindibles" (Campbell y Stanley, 1995:42).b) Interacción de selección y X.- El origen de este factor -como se dijo más arriba- se encuentra en la obtención de muestras no representativas. Al respecto, comentan Campbell y Stanley que este diseño 4, "dentro del ámbito de las actitudes sociales, es tan exigente en lo que a cooperación por parte de los participantes se refiere, que en definitiva la investigación sólo se hace con un público cautivo en vez de realizarla con ciudadanos comunes, que son a quienes quisiéramos referirnos. En una situación de esta índole, el diseño 4 merecería un signo negativo en cuanto a selección [ver esquema 2]. No obstante, en la investigación pedagógica nuestro universo de interés está constituído por un público cautivo para el cual se pueden obtener diseños 4 de elevada representatividad" (Campbell y Stanley, 1995:44).c) Otras interacciones con X.- Las interacciones de X con los demás factores (mortalidad, tests, maduración, historia, excepto regresión, que no interacciona con X), pueden también examinarse como amenazas a la validez externa. Esos distintos factores no fueron incluidos como encabezamientos de columnas del esquema 2, porque "no ofrecen bases firmes de discriminación entre diferentes diseños" (Campbell y Stanley, 1995:45).d) Dispositivos reactivos.- El hecho de tener conciencia de participar de un experimento, predispone a los sujetos de una forma que no se da en situaciones no experimentales o naturales, lo cual dificulta la generalización de los resultados.Sin embargo, no por ello debe abandonarse la investigación, sino mas bien mejorarla evitando la incidencia de estos dispositivos reactivos, para lo cual Campbell y Stanley ofrecen diversas sugerencias (Campbell y Stanley, 1995:45).Diseño 5: Diseño de cuatro grupos de Solomon.- Aunque el diseño 4 se usa más, el diseño 5 tiene más prestigio y fue el primero en considerar explícitamente los factores de validez externa.Como se ve en el esquema 3, este diseño usa cuatro grupos: a los dos del diseño 4 se agregan otros dos, -experimental y de control sin pretest-, lo que permite determinar tanto los efectos principales de los tests como la interacción entre ellos y X (y por esto permite controlar el factor de invalidación externa 'interacción de tests y X'). "De ese modo, no sólo se aumenta la posibilidad de generalizar, sino que además se repite el efecto de X en cuatro formas diferentes: O2>O1, O2>O4, O5>O6 y O5>O3. Las inestabilidades concretas de la experimentación son tales que, si esas comparaciones concuerdan, el vigor de la inferencia queda muy incrementado" (Campbell y Stanley, 1995:53).Diseño 6: Diseño de grupo de control con postest únicamente.- Este diseño no utiliza pretest, por cuanto aquí se considera que la simple aleatorización R es suficiente para asegurar la igualdad de los grupos, y en tal sentido el diseño 6 resulta preferible al 4 o al 5, donde deben tomarse pretests. Además, hay casos donde no se pueden tomar pretest, respondiendo este diseño a esta necesidad. Campbell y Stanley examinan algunas ventajas y desventajas del diseño 6 con respecto al 4 o al 5, pero, en general, recomiendan el empleo del 6 (Campbell y Stanley, 1995:55).
Los diseños factoriales emplean recursos de los diseños 4, 5 y 6, pero ase aplican a situaciones donde estudia más de una variable experimental X. Así, "sobre la base conceptual de los tres diseños anteriores, pero en particular el 4 y el 6, pueden ampliarse las complejas elaboraciones típicas de los diseños factoriales de Fisher, agregando otros grupos con otras X" (Campbell y Stanley, 1995:57). Los diseños factoriales presentan problemas especiales relacionados con la interacción, las clasificaciones inclusivas y cruzadas, y los modelos factoriales finitos, fijos, aleatorios y mixtos.
Diseños cuasiexperimentales
Página 173 de 314
173

Un diseño cuasiexperimental es un diseño en el cual no hay un control experimental total o perfecto, tal como se podría conseguir en un diseño experimental auténtico o propiamente dicho (Campbell y Stanley, 1995:70 y 139)."Son muchas las situaciones sociales donde el investigador puede introducir algo similar al diseño experimental en su programación de procedimientos para la recopilación de datos (por ejemplo, el cuándo y el a quién de la medición), aunque carezca de control total acerca de la programación de estímulos experimentales (el cuándo y el a quién de la exposición y la capacidad de aleatorizarla), que permita realizar un auténtico experimento. En general, tales situaciones pueden considerarse como diseños cuasiexperimentales" (Campbell y Stanley, 1995:70).Debido a que se carece de un control experimental total, es imprescindible que el investigador conozca a fondo las variables que su diseño no controla, y con este fin Campbell y Stanley confeccionaron la lista de verificación de fuentes de invalidación que figuran en el esquema 2 (Campbell y Stanley, 1995:70).No obstante sus imperfecciones, los autores recomiendan utilizar diseños cuasiexperimentales en aquellas configuraciones donde no haya modo alguno de recurrir a mejores diseños experimentales (Campbell y Stanley, 1995:11, 71 y 139). A continuación, se examinan tres diseños experimentales unigrupales, o sea donde se trabaja con un solo grupo; los cinco que le siguen son diseños multigrupales (Campbell y Stanley, 1995:71).Diseño 7: Experimento de series cronológicas.- En lo esencial, consiste "en un proceso periódico de medición sobre algún grupo o individuo y la introducción de una variación experimental en esa serie cronológica de mediciones" (Campbell y Stanley, 1995:76). Fue muy utilizado en ciencias físicas y biológicas, aunque también se lo empleó alguna vez en ciencias sociales, como por ejemplo en los experimentos sobre factores que influyen sobre la producción industrial (Campbell y Stanley, 1995:77).El más grave inconveniente del diseño 7 es la imposibilidad de controlar el factor historia, es decir, la hipótesis rival de que no sea X lo que provocó el cambio sino otro acontecimiento más o menos simultáneo (7 Campbell y Stanley, 1995:9), como por ejemplo los efectos meteorológicos, aunque tal vez convendría más mencionar -aunque sean análogos al factor maduración- cambios periódicos referidos a costumbres institucionales como ciclos semanales de trabajo y pago de salarios, de trabajo y vacaciones, fiestas escolares, etc. (Campbell y Stanley, 1995:81).Otros factores que atentan contra la validez interna están, no obstante, controlados: por ejemplo la maduración, por ser generalmente un proceso uniforme y regular del que no es esperable que cambie mucho precisamente en el momento de aplicar X. Lo mismo vale para los tests: no es esperable que se produzca en ellos un error de medición precisamente entre O4 y O5.Por su parte, "los efectos de la regresión suelen consistir en una función negativamente acelerada del tiempo transcurrido, razón por la cual no son aceptables como explicaciones de un efecto en O5 mayor que los efectos en O2, O3 y O4" (Campbell y Stanley, 1995:82). En cuanto a la selección como fuente de efectos principales, es obvio que quedará controlada si "en todas las O están implicadas las mismas personas" (Campbell y Stanley, 1995:82), cosa que también resulta válida para el diseño 2.Campbell y Stanley recomiendan utilizar este diseño, pero adoptando la precaución de no realizar un experimento único, que nunca es concluyente. Aún no utilizando un grupo de control, es preciso que varios investigadores repitan el diseño 7 en muchos lugares distintos (Campbell y Stanley, 1995:83).Diseño 8: Diseño de muestras cronológicas equivalentes.- Se trata de un diseño con un solo grupo que utiliza dos muestras equivalentes de sesiones, con la variable experimental en una de ellas y no en la otra. El modelo puede verse en el esquema 3, aunque la intención es obtener una alternancia aleatoria, y no regular como lo sugiere dicho esquema. Este diseño puede ser considerado como una variante del diseño 7, donde la diferencia está en que se introduce la variable experimental en forma reiterada, y no una sola vez (Campbell y Stanley, 1995:86).Empleado correctamente, se trata de un diseño en general válido internamente. "La historia, que es el principal inconveniente del experimento con series cronológicas, se controla presentando X en numerosas sesiones separadas, haciendo así improbable en extremo cualquier otra explicación fundada en la coincidencia de acontecimientos externos. Las otras fuentes de invalidación se controlan con la misma lógica detallada a propósito del diseño 7" (Campbell y Stanley, 1995:87).En cuanto a la validez externa, uno de los factores de invalidación externa no controlados por este diseño es la interferencia de X múltiples (o sea, cuando se presentan muchos niveles de X para el 'mismo' conjunto de personas.Por ejemplo, si X1 tiene algún efecto prolongado que llega a influir en los periodos sin X (o X0), como parece por lo común probable, este diseño 8 puede subestimar el efecto de X1. Y "por el contrario, el hecho mismo de que se produzcan frecuentes desplazamientos puede incrementar el valor del estímulo de una X, excediendo al que se daría en una presentación continua y homogénea. En [cierto estudio], las melodías hawaianas influirían sobre el trabajo de manera bastante diferente si se las intercalase durante todo un día entre otras formas de música, que si constituyen el único 'alimento' musical" (Campbell y Stanley, 1995:88).Diseño 9: Diseño de materiales equivalentes.- Este tipo de diseño se aplica "allí donde la índole de las variables experimentales sea tal que los efectos son permanentes, y los distintos tratamientos y repeticiones de ellos deben aplicarse a un contenido no idéntico" (Campbell y Stanley, 1995:90).Por ejemplo, si queremos averiguar la incidencia del tipo de aprendizaje X (masivo o distribuido), en una primera etapa damos a un sujeto o un grupo una lista de palabras para aprender en forma masiva. Luego, en un segundo momento donde la consigna es aprender en forma distribuida, no podremos darles al mismo sujeto o grupo la misma lista de palabras, porque ya las habrán aprendido. Por lo tanto, le
Página 174 de 314
174

damos un 'material equivalente', por ejemplo, otro listado de palabras que sea equivalente al primero (palabras de igual número de sílabas, de igual familiaridad, etc.)."A semejanza del diseño 8, el diseño 9 tiene validez interna en todos los puntos, y en general por los mismos motivos" (Campbell y Stanley, 1995:92). Sin embargo, el diseño presenta limitaciones en cuanto a la validez externa. Por ejemplo, en cuanto al factor interferencia de X múltiples, la validez externa está comprometida por la interferencia entre los niveles de la variable experimental o entre los materiales (Campbell y Stanley, 1995:92).Diseño 10: Diseño de grupo de control no equivalente.- Es un diseño muy usado en investigación educacional, y "comprende un grupo experimental o otro de control, de los cuales ambos han recibido un pretest y un postest, pero no poseen [a diferencia del diseño 4] equivalencia preexperimental de muestreo" (Campbell y Stanley, 1995:93). O sea, los sujetos que se toman de una población común no son asignados en forma aleatoria a uno y otro grupo, sino que constituyen entidades formadas naturalmente (como una clase de alumnos), tan similares entre sí pero no tanto como para que se pueda prescindir del pretest."Cuanto más similares sean en su reclutamiento el grupo experimental y el de control y más se confirme esa similitud por los puntajes del pretest" (Campbell y Stanley, 1995:94) más eficaz es el control.Entonces, dos cosas deben aclararse con respecto al diseño 10: primero, no debe confundírselo con el diseño 4 por las razones ya apuntadas, y segundo y a pesar de ello, debe admitirse que el diseño 10 es utilizable en muchas ocasiones donde no podemos usar los diseños 4, 5 o 6 (94).Diseño 11: Diseños compensados.- Abarcan todos aquellos diseños "en los cuales se logra el control experimental o se aumenta la precisión aplicando a todos los participantes (o situaciones) la totalidad de los tratamientos" (Campbell y Stanley, 1995:99).Un ejemplo es el cuadrado latino. En el esquema 3, las cuatro filas corresponden a cuatro grupos (o individuos) distintos. A cada grupo se lo va exponiendo a diferentes valores de la variable experimental X a lo largo de cuatro sucesivos tratamientos (las cuatro columnas). En otras palabras, cada grupo (o sujeto) pasa por todas las condiciones experimentales. "Obsérvese que cada tratamiento (o X) sólo se da una vez en cada columna y cada fila" (Campbell y Stanley, 1995:100): esta disposición permite 'compensar' los resultados de un grupo (o de un tratamiento) con el de otros grupos (o tratamientos), lo que a su vez permite inferir que las diferencias obtenidas en los distintos tratamientos experimentales (X1, X2, X3 y X4) no son debidas ni a discrepancias grupales iniciales ni a efectos de la práctica, la historia, etc.Diseño 12: Diseño de muestra separada pretest - postest.- Señalan Campbell y Stanley que para grandes poblaciones (ciudades, fábricas, escuelas, cuarteles), "suele ocurrir que, aunque no se pueden segregar subgrupos en forma aleatoria para tratamientos experimentales diferenciales, cabe ejercer algo así como un control experimental completo sobre el 'momento de aplicación' y los 'destinatarios' de la O, utilizando procedimientos de asignación aleatoria" (Campbell y Stanley, 1995:103).Este control está posibilitado por el diseño 12 que consiste, básicamente, en medir una muestra antes de X, y otra equivalente después de X. Guarda cierta semejanza con el diseño 2, pero a diferencia de éste, el diseño 12 puede controlar los factores tests e interacción de tests y X.Algunas variantes del este diseño (12a, 12b y 12c, ver esquema 3) permiten controlar otros factores de invalidación. Por ejemplo, el diseño 12a controla la historia pues "si el mismo efecto se da en varias ocasiones, la posibilidad de que sea resultado de acontecimientos históricos coincidentes se torna menos probable" (Campbell y Stanley, 1995:104). Asimismo, el diseño 12b permite controlar la maduración, y el diseño 12c otros factores como la mortalidad.En general, todas estas variantes del diseño 12 "pueden resultar superiores en validez externa... respecto de los experimentos propiamente dichos de los diseños 4, 5 y 6. Estos diseños no requieren gran cooperación de los participantes, ni que estén disponibles en ciertos lugares y momentos, etc., de modo que se puede utilizar un muestreo representativo de poblaciones previamente determinadas" (Campbell y Stanley, 1995:106).Diseño 13: Diseño de muestra separada prestest - postest con grupo de control.- Se trata del diseño 12 al cual se le agrega un grupo de control, constituído por grupos comparables (aunque no equivalentes). Se trata de un diseño parecido al 10, "sólo que no se vuelve a someter a test a las mismas personas y, por lo tanto, se evita la posible interacción entre la administración de tests y X" (Campbell y Stanley, 1995:107).La variante 13a controla perfectamente, como ningún otro diseño, tanto la validez interna como la externa, con lo cual cabe considerarlo como un diseño experimental propiamente dicho aunque, que se sepa, nunca fue utilizado. Su esquematización (esquema 3) se ve complicada por los dos niveles de equivalencia (R y R') que implica (Campbell y Stanley, 1995:107).Diseño 14: Diseño de series cronológicas múltiples.- Se trata del diseño 7 al que se le ha agregado un grupo de control. "En los estudios de grandes cambios administrativos por medio de datos en series cronológicas, al investigador le conviene buscar una institución similar no sujeta a X [grupo de control], de la cual tomar una serie cronológica de «control» análoga (idealmente, con X asignada al azar)" (109). Para Campbell y Stanley, se trata de un excelente diseño cuasiexperimental, acaso el mejor de los más viables, y es particularmente apropiado para investigaciones en establecimientos educativos (Campbell y Stanley, 1995:110).Diseño 15: Diseño de ciclo institucional recurrente (o diseño de retazos).- Se trata de un diseño apto para aquellas situaciones donde se presenta en forma cíclica, a cada nuevo grupo de participantes, cierto aspecto de un proceso institucional, como por ejemplo y típicamente, un programa de adoctrinamiento.
Página 175 de 314
175

Este diseño intenta reunir las ventajas respectivas de los diseños 2 y 3 (ya que signos positivos y negativos son mayoritariamente complementarios, como se ve en el esquema 2). En efecto, en el diseño 15 "pueden medirse a la vez un grupo expuesto a X con otro que va a serlo; esa comparación entre O1 y O2 corresponde así al diseño 3. La segunda medición del personal de la Clase B, un ciclo después, nos da el segmento de diseño 2" (Campbell y Stanley, 1995:112). De esta manera, también, el diseño 15 puede combinar estudios transversales (comparando dos grupos al mismo tiempo entre sí) con estudios longitudinales (comparación a través del tiempo).Se supone que en este diseño se podrá aplicar el postest O1 al mismo tiempo que el pretest O2 a otro. No siempre ocurre así: la variante presentada en el esquema 2 ilustra esta situación y se trata de una representación más precisa del diseño 15, correspondiente al caso típico de una situación escolar (Campbell y Stanley, 1995:116).Diseño 16: Análisis de discontinuidad en la regresión.- Campbell y Stanley ilustran este diseño con una investigación (Campbell y Stanley, 1995:118) donde se trató de averiguar si recibir un premio (una beca, etc.) incidía o no en el desempeño posterior del estudiante (en cuanto a logros, actitudes, etc.). Como el premio se otorga sólo a los alumnos más calificados, el problema que se presenta es que resulta difícil evaluar la incidencia del premio porque los alumnos más calificados igualmente tendrían mejor desempeño, aún sin premio, dados sus buenos antecedentes en calificaciones.Según cabe entender a partir de la muy breve explicación que nos suministran los autores, el diseño 15 intenta averiguar si hay o no discontinuidad en la línea de regresión. Por ejemplo, un alumno con calificación 5 tendrá luego un desempeño 5, uno con calificación 6 tendrá un desempeño de 6, y así sucesivamente, lo que permite predecir -mediante análisis de regresión- que alguien con calificación 8 tendrá desempeño 8. Si este alumno con calificación 8 recibió un premio, y si su desempeño resulta ser 10 en vez de 8, se habrá producido una discontinuidad en la secuencia regresiva, y habremos podido demostrar el efecto del premio.
2. VERSIÓN LEÓN Y MONTERO
León y Montero distinguen los métodos descriptivos (observación y encuesta), los métodos experimentales (diseños experimentales con grupos), y los métodos propios de la investigación aplicada (diseños de sujeto único y diseños cuasi experimentales).
De una manera un tanto arbitraria pero que sirve como criterio de organización, los métodos de investigación en psicología y educación pueden ser clasificados de acuerdo a los objetivos que persiguen de la siguiente manera, teniendo en cuenta que los autores califican a los métodos de investigación como planes para la obtención de datos (León y Montero, 1995:15), y a los diseños como “elaboraciones de un plan de actuación una vez que se ha establecido el problema de investigación” (León y Montero, 1995:14). No aparece clara la diferencia entre método y diseño, pero debería entenderse que ambos son planes para obtener datos, sólo que los diseños son procedimientos más específicos enmarcados dentro de algo más amplio, el método, el cual depende del objetivo de la investigación:
Objetivos de la investigación Diseños de investigación (planes para la obtención de datos)Métodos descriptivos Observación
Diseños de investigación con encuestasMétodos experimentales Diseños experimentales con gruposInvestigación aplicada Diseños de N = 1 (diseños de sujeto único)
Diseños cuasi experimentales
La observación puede funcionar también como un modo de acceder a problemas de investigación. De hecho, muchas veces se comienza a investigar haciendo observaciones cada vez más sistemáticas para delimitar problemas y elaborar hipótesis sobre lo observado (León y Montero, 1995:16).
Diseños de investigación con encuestas
Se define encuesta como una “investigación destinada a conocer características de una población de sujetos a través de un conjunto de preguntas” (León y Montero, 1995:98).
Diseños transversalesDescriben una población en un momento dado.
Por ejemplo, investigar si hay relación entre ser fumador y tener padres fumadores.
Diseños longitudinalesDescriben una población a lo largo del tiempo, en varios momentos. Por ejemplo, investigar como cambia la intención de voto a lo largo de una campaña electoral.
Muestreos sucesivos con grupos de sujetos distintosLa misma encuesta se aplica más de una vez a muestras distintas. Se puede entender como una sucesión de estudios transversales. Por ejemplo investigar cambios en la actitud hacia el tabaco.Diseño de panelLa misma encuesta se aplica más de una vez a la misma muestra. A diferencia del anterior, este diseño se puede determinar qué sujetos han cambiado y quienes no (cuando los sujetos son distintos sólo se puede hablar de un cambio general en la población).
Página 176 de 314
176

Diseño de cohorteSe encuesta varias veces a los mismos sujetos, seleccionados por algún acontecimiento temporal que los identifica, como la edad, el haber estado en una guerra, haber pasado hambre, etc. Por ejemplo, investigar como distintas generaciones, afectadas por diferentes dictaduras, reaccionan ente los valores democráticos.
Diseños experimentales con grupos
Son diseños experimentales donde se comparan dos o más grupos, formados por distintos sujetos o por los mismos sujetos. Los grupos de sujetos distintos se llaman también ‘grupos independientes’ (Shaughnessy y Zechmeister, 1990), pero León y Montero prefieren obviar esta nomenclatura, que clasifican los diseños experimentales con grupos del siguiente modo:
Diseños simplesEstudian una sola variable independiente (León y Montero, 1995:192).
Diseños con grupos de sujetos distintos (a)
Diseño de grupos aleatoriosLos sujetos son asignados al azar a cada uno de los grupos (León y Montero, 1995:134).Diseño de grupos aleatorios con bloquesSe busca que los grupos sean lo más similares posibles mediante el control de una o varias variables (León y Montero, 1995:136,155) (b).
Diseños con grupos con los mismos sujetos (o intra-sujeto, o de medidas repetidas) (c)
Diseños complejosEstudian más de una variable independiente (León y Montero, 1995:192)
Diseños factoriales (d)Se consideran más de una VI, y se crean tantos grupos como combinaciones de los niveles de las VI (León y Montero, 1995:221).
(a) Los diseños de grupos aleatorios y de grupos aleatorios con bloques pueden ser considerados de aplicación general, pero hay diseños para ciertos problemas especiales, como por ejemplo el diseño de control por placebo o diseño ciego (a un grupo se administra la medicina verdadera y al otro un sustituto), y el diseño del doble ciego (ni el experimentador ni los sujetos saben quienes reciben la medicina y el placebo) (León y Montero, 1995:143).
(b) Algunos ejemplos de diseño de grupos aleatorios con bloques son los siguientes (León y Montero, 1995:138-143):1- Varios sujetos por nivel y bloque.- Debe averiguarse la incidencia de la inteligencia sobre el rendimiento actual, y debe controlarse la variable extraña rendimiento anterior. Para ello, se crean tres bloques de sujetos: con rendimiento anterior alto, medio y bajo. Luego, de cada bloque se eligen al azar sujetos que irán al grupo experimental o al grupo de control (por ejemplo si hay cuatro sujetos por bloque, se asignan dos a un grupo y dos al otro).La variable extraña ha quedado ‘bloqueada’. Este diseño sirve especialmente cuando los grupos son pequeños, ya que en grupos grandes la probabilidad de que la asignación aleatoria sin bloques produzca una distribución descompensada es muy pequeña.2- Un sujeto por nivel y bloque.- Es el mismo caso anterior, solamente que se asignan solamente dos sujetos por cada bloque, iguales respecto de la variable extraña, y luego se asignan al azar a los grupos experimental y de control. Tiene la ventaja de producir grupos más iguales, y por tanto aumenta la sensibilidad del experimento.3- Camada.- Los bloques se forman con sujetos de una misma camada (por ejemplo mellizos, trillizos, etc.). Ellos formarán un bloque natural 4- Gemelos.- En lugar de camadas se utilizan gemelos, que son ‘más iguales’ que los mellizos debido a su carga genética más similar.
(c) En los diseños con grupos con los mismos sujetos pueden producirse efectos distorsionantes debidos a la práctica, al orden de presentación de los tratamientos, a la fatiga y a la motivación (León y Montero, 1995:164).Sin embargo la misma práctica puede ser objeto de estudio, como en los experimentos sobre el aprendizaje, donde a lo largo del tiempo se repite la misma condición, presentándose una misma situación al mismo grupo de sujetos. La VI será el número de ensayos, y la VD el número de errores (León y Montero, 1995:167).En los diseños intra-sujeto se utilizan diferentes técnicas de control, que se utilizan en el contexto de dos estrategias principales: a) amortiguar un posible efecto distorsionador debido al orden de presentación de los distintos tratamientos experimentales; b) si se conoce la cuantía del efecto distorsionador del orden de presentación, entonces se evalúa dicha cuantía para restarlo del efecto de la variable principal.Las técnicas de control son: la aleatorización por bloques (responde a la primera estrategia), el reequilibrado (se aplica dentro de las dos estrategias), y el diseño de cuadrado latino (responde a la segunda estrategia).
Página 177 de 314
177

Las tres técnicas de control del efecto de orden de presentación de los tratamientos experimentales son (León y Montero, 1995:189):Aleatorización por bloques.- “Cada tratamiento se aplica más de una vez. Se establecen bloques de tratamientos de tamaño igual al número de valores de la variable independiente VI. Dentro de cada bloque se incluye, en orden aleatorio, una tarea de cada condición experimental”.Reequilibrado.- “Hacer una repetición de la secuencia de presentación de los tratamientos en orden inverso. Dicha inversión puede hacerse con los mismos sujetos o con sujetos distintos”.Diseño de cuadrado latino.- El control se lleva a cabo mediante la selección de un grupo de secuencias de presentación de entre todas las posibles. Se eligen tantas secuencias como tratamientos haya en el experimento, de tal modo que se cumpla la condición de que un tratamiento experimental sólo aparezca una vez en cada posición dentro del conjunto de secuencias elegidas”.
(d) Los diseños factoriales son aquellos diseños con más de una VI donde todos los niveles de una variable se combinan con los niveles del resto de las variables. Por ejemplo, un diseño 2x2 supone dos VI, cada una con dos valores (sexo es varón o mujer, distracción es sí o no), y sería el caso más sencillo (León y Montero, 1995:193). La estrategia del diseño factorial permite observar como se comporta una variable bajo todas las condiciones de la otra, lo que es una ventaja respecto de hacer, por ejemplo, dos diseños simples consecutivos, que dejarían fuera algunas combinaciones cruciales (León y Montero, 1995:198). Los diseños factoriales admiten muchas extensiones además del simple 2x2. Por ejemplo, se puede hacer uno de 7x9, aunque para ello se requerirían muchos sujetos, habida cuenta que al menos 10 sujetos debe haber en cada grupo, con lo cual debería contarse con 7x9x10 = 630 sujetos (León y Montero, 1995:198).En el contexto de los diseños complejos, los autores destacan especialmente el concepto de interacción, que es el efecto adicional de la VD a la suma de los efectos individuales de las variables independientes (León y Montero, 1995:202). Estos efectos, que pueden ocurrir entre dos o más variables independientes, pueden detectarse mediante un análisis estadístico de varianza en términos de si son o no estadísticamente significativos para determinado nivel de significación (León y Montero, 1995:208).Hay casos especiales de interacción, donde aparece pero no puede ser explicada teóricamente. Un caso especial de interacción es el efecto suelo (o techo), que aparece en la VD si a partir de cierto valor no es posible obtener otros más bajos (o más altos), permaneciendo constantes a pesar de la variación de VI (León y Montero, 1995:221)
Técnicas de análisis estadístico para diseños con grupos de sujetos distintos .- a) En los diseños de grupos aleatorios, si son dos grupos se utiliza la diferencia de medias de gruidos independientes y si son más de dos grupos, se usa el análisis de varianza de un factor. b) En los diseños de grupos aleatorios con bloques se utilizan las técnicas anteriores, sólo que el criterio de bloque ayuda a disminuir la varianza debida al error: sólo habrá que restarle la varianza debida a la variable bloqueada (León y Montero, 1995:153).
Técnicas de análisis estadístico para diseños con grupos con los mismos sujetos.- La técnica más utilizada es el análisis de varianza, y más concretamente el análisis de varianza de un factor con medidas repetidas, técnica que se utiliza cuando se emplea la aleatorización o el reequilibrado como técnica de control. En el segundo caso se asume que no se quiere analizar estadísticamente el efecto debido al orden. Finalmente, si la VI tiene sólo dos valores se puede analizar la diferencia entre grupos mediante la t de Student para datos apareados (León y Montero, 1995:187).
Técnicas de análisis estadístico para diseños complejos.- Se utiliza el análisis de varianza, para lo cual debe tenerse en claro la cantidad de VI involucradas, especificando las que sean de medidas repetidas. Si se trata de grupos aleatorios x grupos aleatorios, se usa el análisis de varianza de dos factores. Si se trata de grupos aleatorios x medidas repetidas, en análisis de varianza de dos factores, uno con medidas repetidas, y si se trata de medidas repetidas x medidas repetidas, el análisis de varianza de medidas repetidas con dos variables (León y Montero, 1995:220).
En los diseños experimentales con grupos lo ideal es asignar sujetos al azar a cada grupo. Sin embargo, en la práctica esto no es posible, ya que se cuenta con grupos ya formados (por ejemplo alumnos de un aula). En estos casos en lugar de asignar sujetos al azar se asignan grupos al azar, lo que igualmente permite el control de variables extrañas, aunque en menor medida (León y Montero, 1995:147).
Requisitos de los diseños experimentales.- Las propiedades que deben exigirse a un experimento son la fiabilidad, la sensibilidad, la validez externa y la validez interna. “Los experimentos son fiables cuando al repetirse se obtienen los mismos resultados, pero lo que hace que se obtengan los mismos resultados es que el experimento estuviera bien controlado” (León y Montero, 1995:119). Respecto de la sensibilidad, se espera que los aparatos, los registros, las unidades de medida sean lo suficientemente sensibles como para detectar los cambios en las conductas (León y Montero, 1995:120). La validez interna se refiere al grado de seguridad con el que se pueden establecer las causas de las variaciones, y la validez externa consiste en el poder de generalización de los resultados obtenidos (León y Montero, 1995:121).
Diseños de N = 1 (diseños de sujeto único)
Página 178 de 314
178
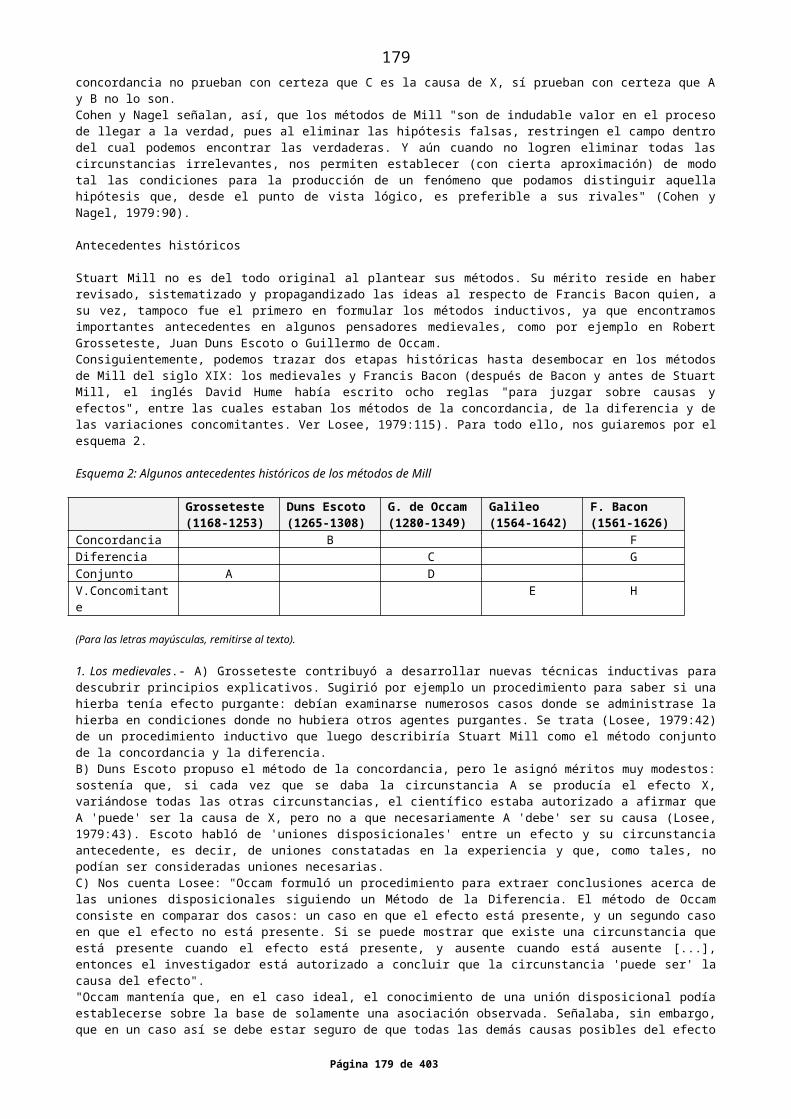
Son diseños donde se estudia un solo caso, como por ejemplo un paciente. El ejemplo típico es el llamado estudio de casos, donde se describe en forma detallada las características de un individuo en condiciones especiales. Por ejemplo, en el caso de un paciente se narran su evolución asociada a sucesivas intervenciones del terapeuta. Estos diseños normalmente no tienen control sobre las variables extrañas, y sirven también para sugerir nuevas hipótesis. Freud y Piaget, entre otros, lo han utilizado (León y Montero, 1995:228).Si en los diseños que estudian grupos se hace referencia a pre-medidas y posmedidas, en los diseños de sujeto único puede tener importancia también referirse a lo que podemos llamar intra-medidas, con lo cual incluirán tres tipos de medidas: medidas ‘antes’, medidas ‘mientras’ y medidas ‘después’, referidas a series de mediciones de la variable dependiente antes de la aplicación del tratamiento (línea de base), durante la aplicación del tratamiento (que a veces puede durar semanas, meses o años), y después de la aplicación del tratamiento (fase de seguimiento).Mientras los diseños de investigación por encuestas y los diseños experimentales con grupos deben lidiar contra las diferencias individuales de los sujetos (si estas persisten a pesar del control de variables son consideradas como errores), los diseños de sujeto único no tienen este problema, y se basan en la idea según la cual si un fenómeno es lo suficientemente básico se tendrá que producir en el resto de los sujetos. Por ejemplo, fueron utilizados en el análisis del condicionamiento operante por Skinner (León y Montero, 1995:226).
Diseño ABPrimero se establece una línea de base sin tratamiento (A) y una vez estabilizada se produce la intervención midiendo la nueva serie (B) (León y Montero, 1995:239).Diseño ABABProcede en cuatro fases, donde A es sin tratamiento y B es con tratamiento. Admite variantes, como BAB y ABA. El diseño ABA se llama ‘de vuelta atrás’, y sirve para, una vez retirado el tratamiento, examinar si hubo otras variables que actuaron simultáneamente (León y Montero, 1995:241).Diseños de línea base múltiplePlan experimental donde varias conductas se registran simultáneamente y donde se aplica el mismo tratamiento pero de forma escalonada. Es una extensión del AB donde no puede realizarse una retirada del tratamiento (León y Montero, 1995:253) (a).
(a) Un ejemplo es el siguiente (León y Montero, 1995:246). Una madre quiere que su hija dedique más tiempo al clarinete, al campamento y a la lectura. En la primera semana se establecieron líneas base de las tres conductas donde la madre sólo se limitaba a recomendarle que dedicara 30 minutos a cada una. A la segunda semana la madre empezó a premiar el clarinete, pero no las otras conductas, y se vio que la hija aumentaba su tiempo con el clarinete mientras que las otras conductas se mantenían en la línea de base. A la tercera semana sumó un premio al campamento y ocurrió otro tanto, y a la cuarta semana sumó un premio a la lectura, habiendo ocurrido lo mismo.
Los diseños de sujeto único se utilizan: a) cuando solo se dispone de un sujeto; b) cuando es difícil encontrar sujetos para un grupo de control, ya que en el diseño de sujeto único el paciente es su propio control; c) cuando se busca comprobar la eficacia de una intervención terapéutica; y d) cuando la investigación es sobre procesos muy básicos o con clara base biológica (por ejemplo que la emetina produzca náuseas, para que luego sirva como tratamiento contra el alcoholismo) (León y Montero, 1995:234).Las tres fases básicas de los diseños de sujeto único son: establecer la línea de base, aplicar la intervención, e interpretar los resultados. Si se trata de un diseño para probar la eficacia de la emetina para el alcoholismo, establecer la línea de base implicará realizar mediciones previas al experimento para examinar la tendencia de consumo de alcohol del sujeto o bien su variabilidad, que puede permanecer en la misma cuantía (León y Montero, 1995:236).Un diseño de sujeto único puede cumplir perfectamente los tres criterios de causalidad: que VI anteceda al VD, que haya covariación entre ambas, y que puedan descartarse otras posibles causas además de VI (León y Montero, 1995:229).
Validez de los diseños de sujeto único.- La validez interna de estos diseños depende del correcto control de variables extrañas, y valen las consideraciones para los diseños de grupos, aunque debe recordarse la importancia de variables como historia, maduración, efecto experimentador, etc. Sin embargo, debe tenerse presente que en los diseños de sujeto único las puntuaciones no son independientes, ya que dependen de las anteriores.El diseño AB encierra dificultades, por ser difícil desechar la influencia de variables extrañas, aunque puede acumularse evidencia con más sujetos equiparados. También es importante la interacción entre sujeto y tratamiento, pues no todos los sujetos responden del mismo modo al mismo, sea cual fuere.La validez externa está en tela de juicio, porque mal puede representar a toda la población un solo sujeto. Sin embargo: a) puesto que estos diseños se usan en el ámbito clínico, los sujetos suelen representar bastante bien a la población a la que pertenece (por ejemplo un fóbico); y b) los cambios producidos por el tratamiento son tan grandes que hay margen de sobre para esperar que se produzcan en otros sujetos (León y Montero, 1995:247).El empleo de los diseños de sujeto único es inadecuado en cuatro casos: a) cuando puede utilizarse un diseño de grupos; b) cuando la variabilidad de la conducta en la línea de base es muy grande; c) cuando
Página 179 de 314
179

se precisa un informe sobre la eficacia de un tratamiento para utilizarlo en forma generalizada; y 4) cuando hay que hacer estudios comparativos de la eficacia de varios tratamientos alternativos (no se puede decir que un tratamiento es mejor que otro porque un sujeto mejoró) (León y Montero, 1995:248).
Técnicas de análisis estadístico para diseños de sujeto único.- Son técnicas bastante más complejas que las empleadas en diseños de grupos, por lo que a veces se recurre a una apreciación no estadística observando la evolución del tratamiento en las gráficas, que deben registrar un número grande de observaciones por serie (sin y con tratamiento), y registrar si en la línea de base hubo cambios en la tendencia (a subir, a bajar, etc.), y en el nivel (mayor o menor que los valores en el tratamiento) (León y Montero, 1995:249).
Diseños cuasi experimentales
Los diseños cuasi experimentales presentan más dificultades para establecerse su validez interna, pero menos dificultades para establecerse su validez externa. Típicamente suelen utilizarse en psicología del desarrollo (en diseños evolutivos la edad es la VI) y en programas de valoración de tratamientos o intervenciones.León y Montero presentan dos criterios para clasificar los diseños cuasi experimentales:
Criterio clásico(Cook y Stanley, 1979)
Diseño pre-post con un solo grupoDiseño pre experimental donde se utiliza una única medida, en un solo grupo, antes y después de la aplicación del tratamiento para evaluar los cambios producidos por éste (León y Montero, 1995:280).Diseño pre-post con grupo de control ‘no equivalente’Diseño cuasi experimental donde el grupo de control no se ha formado mediante asignación aleatoria. Esto hace que haya mayor incidencia de las potenciales amenazas a la validez interna de la investigación (León y Montero, 1995:280).Diseño de series temporales interrumpidas con grupo de control ‘no equivalente’Diseño cuasi experimental donde se utilizan series de medidas repetidas antes y después del tratamiento en un grupo, el experimental. Al mismo tiempo se toman medidas en otro grupo de control, que no recibe el tratamiento. La creación de ambos grupos no es mediante asignación aleatoria (León y Montero, 1995:280).
Criterio ex post facto(Dunham, 1988)
Diseño ex post facto prospectivoDiseño donde se seleccionan grupos de sujetos con diferentes valores en la VI y se les compara en la VD (León y Montero, 1995:280).Diseño ex post facto retrospectivoDiseño donde se selecciona a los sujetos según sus características en la VD para, de forma retrospectiva, buscar VI explicativas de la VD (León y Montero, 1995:280).
a) Criterio clásico.- Los diseños cuasi experimentales fueron sistematizados por Campbell y Stanley (1966) y por Cook y Campbell (1979), mientras León y Montero presentan algunos de estos diseños más utilizados en psicología y educación, basándose en la versión Cook y Stanley.Estos últimos presentan 17 tipos de diseños cuasi experimentales agrupados en tres grandes bloques: diseños pre experimentales, diseños con grupo de control no equivalente, y diseños de series temporales interrumpidas, bloques que suponen una ordenación según el grado de interpretabilidad de los resultados en términos de causación. León y Montero presentan solo un ejemplo de cada bloque.Un pre experimento “es un diseño cuasi experimental donde la posibilidad de establecer relaciones causales entre la VI y la VD está muy limitada por la falta de control experimental y la falta de manipulación de la VI” (León y Montero, 1995:280).Un cuasi experimento “es un plan de recogida de datos donde el investigador, siguiendo un proceso similar al del experimento, o bien no puede manipular la variable de su interés o bien no tiene la capacidad de control requerida en un experimento” (León y Montero, 1995:280).Hay situaciones donde no se puede manipular la VI, como por ejemplo no se puede pedir a una familia que interactúe con sus hijos de manera tal de producirles un trastorno esquizofrénico. Para estos casos pueden servir los diseños cuasi experimentales (León y Montero, 1995:258-262):
Diseño pre-post con un solo grupo.- Por ejemplo, en un grupo de 30 pacientes, medir antes y después la severidad del trastorno esquizofrénico del entrenamiento de sus familias durante seis meses para que ofrezcan una interacción afectiva adecuada.Diseño pre-post con grupo de control ‘no equivalente’.- Una mejora metodológica respecto del diseño anterior supone introducir un grupo de control, sólo que en este no se hizo una asignación aleatoria del mismo por ser muy difícil, en la realidad, conseguir un grado aceptable de semejanza.Diseño de series temporales interrumpidas con grupo de control ‘no equivalente’.- Consiste en establecer una línea base en dos grupos mediante una serie de medidas durante cierto tiempo. Luego, se aplica el tratamiento al grupo experimental y se registra una nueva serie de medidas en ambos grupos. Aunque el
Página 180 de 314
180

grupo de control no es equivalente, este diseño supone una mejora metodológica pues las premedidas detectarían una supuesta tendencia a la mejoría por causas ajenas al tratamiento, por ejemplo las debidas al apoyo familiar.
b) Criterio ex post facto.- Este criterio, establecido por Dunham (1988) define diseño ex post facto como aquel donde se selecciona a los sujetos por sus características personales cuando alguna de ellas es considerada como VI y no puede ser manipulada (León y Montero, 1995:280).El nombre deriva de que los sujetos son elegidos para la investigación por sus características (sexo, edad, rasgos de personalidad, etc.), esto es, ‘después del hecho’ de haberlas adquirido. En otras palabras, no se asignan aleatoriamente a los sujetos a los valores de la VI sino que se los selecciona por poseer ya un determinado valor en dicha variable. Cuando se trabaja con variables del organismo, se habla de ‘grupos naturales’.
Diseño ex post facto prospectivo.- Se seleccionan grupos con diferentes valores de VI y se los compara respecto de la VD. Por ejemplo, sujetos previamente clasificados como “muy motivados por el logro” y “poco motivados por el logro” mostraron preferencias distintas en un juego donde la probabilidad de ganar dependía de sus elecciones.Diseño ex post facto retrospectivo.- Se selecciona una muestra de sujetos según sus características respecto de la VD y luego, de forma retrospectiva, se buscan posibles VI explicativas. Por ejemplo, seleccionar un grupo de esquizofrénicos con diversos grados de severidad, y luego estudiar sus historias anteriores de interacción familiar. El problema aquí no es solo que puede influir las expectativas del investigador, sino también el hecho de estar buscando una causa que no es, pues puede ocurrir que la verdadera causa, en el ejemplo, sea genética, y lo que produce esquizofrenia no es la interacción familiar sino rasgos psicóticos de alguno de los padres (León y Montero, 1996:264).
Validez de los diseños cuasi experimentales.- a) Validez interna: la validez interna está limitada porque el investigador no puede manipular VI ni asignar aleatoriamente a los sujetos a las condiciones experimentales. Amenazas a la validez interna son la historia, la adaptación a las pruebas, los instrumentos, la regresión a la media, etc. b) Validez externa.- Suele considerarse que está asegurada porque en muchos casos de diseños cuasi experimentales se trabaja en contextos naturales. Sin embargo, debe considerarse que la validez externa puede comprometerse por otras razones además de trabajar en situaciones artificiales, como por ejemplo cuando la muestra no es representativa (muchas investigaciones cuasi experimentales trabajan con sujetos voluntarios) (León y Montero, 1995:274).
Técnicas de análisis estadístico para diseños cuasi experimentales.- La mayoría de los datos en estos diseños se analizan mediante pruebas estadísticas de comparación entre dos o más muestras. Cuando las muestras son más de dos o las VI son también plurales, se utiliza el análisis de varianza. Por ejemplo, en los diseños con más de una medida al mismo grupo se utilizará el modelo de medidas repetidas. Cuando este tipo de medida se combina con la de un grupo de control, se puede aplicar el diseño mixto (factor Inter.-sujetos y factor intra-sujetos) o un análisis de covarianza. En este segundo caso se utiliza la medida del pretest, en ambos grupos, como covariable de la medida en el postest. O sea, antes de comparar a los dos grupos en el postest, se elimina la parte de la varianza debida a su situación en el momento del pretest. Otra técnica muy utilizada, el diseños retrospectivos, es la regresión, simple o múltiple (León y Montero, 1995:276).
3. VERSIÓN ARNAU GRAS
Arnau Gras (1980) presenta la siguiente clasificación de diseños de investigación, en parte basada en Campbell y Stanley (1966):
Diseños experimentales simples(o unifactoriales)
Diseños bivalentes(VI asume dos valores)
Diseños de dos grupos al azar: a) Diseño de antes y después. b) Diseño de sólo después. c) Diseño de Solomon.
Diseños multivalentes(VI asume más de dos valores)
Diseños multigrupo totalmente al azar
Diseños experimentales factoriales
Diseños para dos VI Modelo factorial fijoModelo factorial al azarModelo factorial mixto
Diseños experimentales de bloques homogéneos
Diseños de dos grupos apareadosDiseños de doble bloqueo (cuadrado latino y cuadrado grecolatino)Diseños de bloques al azar
Diseños intrasujeto (o de medidas repetidas)
Diseños de tratamiento por sujetosDiseños factoriales intrasujetos (o diseño tratamiento por tratamiento por sujetos)Diseños factoriales mixtos (tratamiento intra e intersujeto):Diseños contrabalanceados
Página 181 de 314
181

Diseños experimentales no estadísticos
También llamados conductuales
Diseños preexperimentales
Diseños de grupo único Diseños de un solo grupo sin repeticiónDiseños de antes y después de un solo grupo
Diseños de comparación estática
Diseños cuasiexperimentales
Diseños de series temporalesDiseños de antes y después de grupo de control no equivalente
Diseños experimentales
Desde que Fisher sentó las bases para los diseños factoriales en 1935, se establece una diferencia entre los diseños simples (o de factor único o de una sola VI) y los diseños factoriales (de dos o más factores o de dos o más VI) (Arnau Gras, 1980:356).Según el número de factores independientes y la cantidad de tratamientos, Arnau Gras (1980:359) clasifica los diseños experimentales en bivalentes, multivalentes y factoriales. Los dos primeros son diseños simples, y todos ellos son diseños de grupos al azar. Estos últimos es una categoría de diseños donde los individuos son asignados al azar a los grupos, y donde cada condición experimental es aplicada en forma independiente a cada grupo (y por ello se llaman también diseños de grupos independientes). Entre los diseños de grupos al azar se cuentan los diseños bivalentes, multivalentes y factoriales (Arnau Gras, 1980:369).Se menciona también la clasificación de Castro (1975), que divide los diseños experimentales en univariables o multivariables, según que utilicen una o más VI., los que incluyen a su vez diversas categorías:
Diseños univariables(Estudian una VI)
Diseños bicondicionales.Diseños multicondicionales.
Diseños multivariables(estudian dos o más VI)
Diseños reversibles multivariables.Diseños factoriales.Diseños jerárquicos.Diseños incompletos.
Diseños experimentales simples
Heredados de la física, en ellos sólo se varía un único factor, manteniéndose constante el resto. En cambio en psicología, la mayoría de las variables están directamente relacionadas con las restantes, y el hecho de variar una de ellas implica la alteración de las otras, por lo que la aplicación de diseños simples presenta problemas, que son básicamente dos: a) los resultados son ambiguos porque no se sabe bien qué variable afecta el fenómeno, y b) puede haber interacción, lo que afecta especialmente la validez externa del diseño (Arnau Gras, 1980:353-354).Diseños bivalentes.- Aquellos donde la VI asume solamente dos valores. Tienen utilidad exploratoria, y tienen dos riesgos: a) el posible desconocimiento inicial sobre la relación entre variables: según los valores elegidos para VI, pueden dar resultados opuestos; y b) no pueden generalizarse los resultados más allá del experimento.El paradigma de experimentación de los diseños de factor único bivalentes es aquel donde se compara un grupo experimental con otro de control. Los sujetos son elegidos al azar de la población, y luego son asignados al azar a cada grupo (Arnau Gras, 1980:370). Sus tres modalidades (antes y después, sólo después y Solomon), tienen cada una sus ventajas e inconvenientes (Arnau Gras, 1980:379-376).Diseños multivalentes.- Plan experimental para dos o más valores de VI. Se llaman también diseños funcionales. Son más precisos que los anteriores para identificar la posible relación VI-VD y para establecer relaciones cuantitativas entre ellas (Arnau Gras, 1980:364). En particular, el diseño multigrupo totalmente al azar de sólo después supone emplear tantos grupos como valores tenga VI (Arnau Gras, 1980:376).
Diseños experimentales factoriales
Los diseños factoriales son disposiciones donde se estudia la acción conjunta de dos o más VI, llamadas también factores. Si es completo, habrá tantos grupos como posibles combinaciones entre los tratamientos experimentales. Suponen un gran ahorro de tiempo y costos respecto de los diseños anteriores, suministran más información que los diseños simples, permite calcular interacción entre variables, y son más realistas, especialmente en psicología donde la conducta está determinada por varios factores (Arnau Gras, 1980:364 y 386).Un ejemplo es el diseño factorial de 2x3. Esto significa que indaga dos VI (pues hay dos números), que la primera tiene dos categorías y la segunda tiene tres categorías, con lo cual quedarían formados seis grupos experimentales, cada uno representando una combinación de valores de ambas variables (Arnau Gras, 1980:387).Efectos principales y secundarios.- En los diseños factoriales no sólo se examinan los efectos principales o efectos de cada VI en forma independiente, sino también los efectos secundarios, también llamados
Página 182 de 314
182

efectos simples o efectos de interacción, como por ejemplo el efecto de interacción entre dos de las VI (Arnau Gras, 1980:388).Modelos factorial fijo, al azar y mixto.- En el modelo factorial fijo el investigador ha elegido de antemano o a priori los valores de las VI, mientras que en el modelo factorial al azar, los valores de VI fueron elegidos aleatoriamente de la población general (por ejemplo elegir tratamientos al azar, si acaso el investigador no tuviese alguna preferencia por alguno de ellos). Un modelo mixto utiliza ambos criterios (Arnau Gras, 1980:398).Principio del confundido.- Como puede apreciarse, los diseños factoriales pueden llegar a incluir una gran cantidad de grupos experimentales. El riesgo que se corre es que la VI puede quedar contaminada o confundida, es decir, su cambio va acompañado sistemáticamente por el cambio de otro factor no controlado (efecto de confusión). Por ejemplo la VI nivel socioecónomico constituye una variable confundida si varía sistemáticamente con posibilidades económicas futuras o escaso nivel cultural (variables extrañas) cuando se trata de examinar su incidencia sobre la VD preferencia vocacional (Arnau Gras, 1980:402).
Diseños experimentales de bloques homogéneos
Cuando los sujetos son muy distintos entre sí aumenta la posibilidad de error al inferir relaciones causales, lo cual puede compensarse o bien utilizar grupos de gran tamaño, o bien utilizar un único sujeto, o bien utilizar diseños de bloques para reducir las diferencias individuales (Arnau Gras, 1980:407).Esta técnica consiste e formar grupos homogéneos o bloques, cuyos sujetos presentan valores iguales que eliminan la heterogeneidad intrabloque. Por ejemplo un bloque puede estar formado por pacientes fóbicos, otro por pacientes obsesivos, etc. En este caso la variable de bloqueo es diagnóstico (Arnau Gras, 1980:408). Los bloques pueden estar formados por un grupo de sujetos o por un solo sujeto (Arnau Gras, 1980:413), y la técnica del bloqueo puede utilizar para diseños simples o diseños factoriales (Arnau Gras, 1980:432).Diseños de dos grupos apareados.- Los grupos se equiparan mediante la técnica del apareamiento, que consiste en asignar al azar, a cada uno de los grupos, pares de sujetos con características similares en relación con la VD (Arnau Gras, 1980:415).El apareamiento se puede realizar de diversas formas (Arnau Gras, 1980:420): aparear sujetos con alguna característica similar altamente correlacionada con la VD, aparear sujetos con características psicológicas similares, aparear sujetos, o aparear sujetos mediante otras técnicas como el control acoplado (Arnau Gras, 1980:421) o el rendimiento previo (Arnau Gras, 1980:422).Diseños de doble bloqueo.- En este caso se consigue reducir aún más el error, por cuanto se clasifica a los sujetos de acuerdo a dos criterios, y no a uno, con lo cual se pueden controlar dos fuentes de variación extraña (Arnau Gras, 1980:423). El ejemplo típico es el diseño del cuadrado latino. Un ejemplo podría ser aplicarlo utilizando nivel de ansiedad y hora del día como variables extrañas de bloqueo, formar un cuadro de doble entrada con nueve casilleros (ya que se asignaron 3 valores a ansiedad y 3 a hora del día). A continuación, se forman nueve grupos de sujetos que son sometidos a distintos valores de VI (distintos tratamientos, por ejemplo memorizar una lista de palabras de diferente longitud), para ver como varía la VD (memoria). El cuadrado grecolatino supone la superposición de dos cuadrados latinos: se estudian dos VI en lugar de una, siendo cada casillero alguna combinación de dos valores de ambas variables (Arnau Gras, 1980:432).Diseños de bloques al azar.- Se ha comprobado que no hay diferencias notables en cuanto a los resultados en la aplicación de estos diseños y los diseños de grupos apareados (Arnau Gras, 1980:436).
Diseños intrasujeto (o de medidas repetidas)
Son aquellos en los que el sujeto es considerado como su propio control. Así, se aplican al mismo sujeto todas las condiciones experimentales. Cada sujeto constituye un solo bloque y la técnica del bloqueo es llevada hasta sus últimas consecuencias y como ello, la homogeneidad intrabloque aumenta la eficacia y sensibilidad del experimento (Arnau Gras, 1980:437). Son importantes los efectos de orden en esta clase de diseños, ya que el mismo puede hacer que las respuestas de los sujetos varpien más en función de ensayos previos que el función de las diferencias de los tratamientos (Arnau Gras, 1980:446). Hay varios tipos de estos diseños:Diseños de tratamiento por sujetos.- Diseño donde se aplican todos los tratamientos (o sea todos los niveles de la VI) a cada uno de los sujetos, con el fin de minimizar la incidencia de las diferencias individuales. (Arnau Gras, 1980:438). Ello permite también realizar un análisis de tendencias (Arnau Gras, 1980:441).Diseños factoriales intrasujetos (o diseño tratamiento por tratamiento por sujetos).- Diseño donde se manipulan dos o más VI y se aplica cada combinación de tratamientos en un orden sucesivo, a cada sujeto. Se trata de un diseño que se ajusta a la estructura lógica de los diseños de tratamiento por sujetos a de bloques al azar.Diseños factoriales mixtos (tratamiento intra e intersujeto).- Disposición experimental donde algunas comparaciones de los tratamientos son intrasujetos y otras intersujetos. Los valores de una de las VI se aplican a cada uno de los sujetos (variable intrasujeto) y los valores correspondientes a una segunda o más VI, se aplican a diferentes grupos de sujetos (variables intersujetos). Presenta las siguientes variedades: a) Diseños bifactoriales: se combinan dos factores independientes. El primer factor reaplica en todos sus valores a cada sujeto, y el segundo se aplicará al azar a diferentes grupos de sujetos, según
Página 183 de 314
183

la cantidad de niveles Suele utilizarse en experimentos sobre aprendizaje y extinción (Arnau Gras, 1980:447). b) Diseños trifactoriales: extensión lógica del anterior donde se pueden emplear dos disposiciones básicas. Primero, se aplican todos los valores de una VI a cada sujeto, mientras que las otras dos VI se aplican intersujetos. Segundo, se toman dos VI de medidas repetidas o intrasujeto, dejando la tercera como variable intersujetos (Arnau Gras, 1980: 450). c) Diseños con técnica de bloqueo: combinación de un diseño intrasujeto con un diseño de bloques al azar (Arnau Gras, 1980:454).Diseños contrabalanceados.- Si bien son considerados por Arnau Gras (1980:469) en el capítulo correspondiente a diseños preexperimentales y cuasiexperimentales, este autor los considera una extensión de los diseños intrasujeto. El contrabalanceo permite compensar los posibles efectos positivos o negativos que se producen en una sucesión continua de tratamientos (Arnau Gras, 1980:465).
Diseños experimentales no estadísticos
En los diseños experimentales estadísticos hay un control estadístico de las diferencias individuales. Este esquema fue consolidado por Fisher hacia 1935, quien consideró el análisis estadístico y el diseño experimental como dos caras de la misma realidad. A este esquema se contrapone el análisis experimental de la conducta, de inspiración skinneriana, donde se considera que la variabilidad de la conducta no es algo inherente a ella o a los sujetos sino a factores que la controlan, siendo entonces el propósito descubrir mediante manipulación experimental, los factores responsables de dicha variabilidad (Arnau Gras, 1980:470).Los aspectos más importantes de estos diseños son: a) preferente interés por la variabilidad intrasujeto; b) despojar sal diseño de toda regla o norma previa a seguir; c) empleo preferente de sujetos únicos; d) el control, como manipulación y eliminación de variables, es uno de sus objetivos básicos; e) el concepto de línea de base o estado de conducta estable es la base de contrastación de los cambios operados en la conducta por manipulación de variables; f) la reversibilidad del proceso conductual, adquiere, en este contexto, un auténtico valor demostrativo de la efectividad de los tratamientos (Arnau Gras, 1980:472).
Diseños preexperimentales
Estos diseños, que son aproximaciones experimentales, presentan serios problemas para ejercer un control experimental, según Campbell y Stanley (1966). Entre ellos se pueden mencionar los siguientes:Diseños de un solo grupo sin repetición.- Diseño de grupo único donde a un grupo al azar o formado naturalmente se aplica la VI si medida previa, y luego se realiza la posmedida (Arnau Gras, 1980:457).Diseños de antes y después de un solo grupo.- Diseño de grupo único donde un grupo formado por algún sistema de muestreo se le aplica una premedida, un tratamiento con VI, y una posmedida (Arnau Gras, 1980:458).Diseños de comparación estática.- Permite comparar la posmedida de dos grupos sin premedida, aplicando VI sólo a uno de ellos. Como los grupos fueron elegidos por selección, no hay una garantía que antes de la aplicación de VI los grupos sean equivalentes (Arnau Gras, 1980:459).
Diseños cuasiexperimentales
Si en los diseños preexperimentales hay un defecto básico que invalida cualquier resultado, en los cuasiesperimentales se constata un defecto básico de control de las condiciones experimentales, pero pueden ofrecer la posibilidad de obtener resultados científicamente válidos (Arnau Gras, 1980:460).Se pueden mencionar como diseños cuasiexperimentales los siguientes:Diseños de series temporales.- A un grupo formado por selección (no por azar), se aplica una serie de premedidas en el tiempo, luego se aplica VI, y finalmente se aplica otra serie de posmedidas en el tiempo.Diseños de antes y después de grupo de control no equivalente.- Se comparan dos grupos no formados por azar: se les toman a ambos una premedida y una posmedida, sólo que uno se le aplica el tratamiento VI y al otro no.
4. VERSIÓN SELLTIZ ET AL
Selltiz, Jahoda, Deutsch, Cook (1980) describen, entre otros, los diseños experimentales divariados, entre los cuales hay varios tipos, pero el objetivo es siempre probar la relación X-Y como causal. Cuando sospechamos que realmente hay pocas variables extrañas utilizaremos un diseño más simple, pero cuando no es así nos vemos obligados a tomar más recaudos mediante un diseño más complejo. Los diseños descritos por los autores son seis y no son los únicos posibles, y muchas de las ejemplificaciones no corresponden a ellos.En el esquema siguiente se resumen los distintos tipos de diseños experimentales divariados mencionados por los autores indicados, desde el más sencillo al más complejo. Todos los grupos fueron tomados al azar, y se supone además que están ejerciendo influencia variables adicionales o extrañas al experimento: de otro modo no tendría sentido usar estos diseños, cuyo propósito es precisamente controlarlas.
Diseños experimentales bivariados (Versión ligeramente modificada por el autor de Selltiz-Jahoda-Deutsch-Cook)
Página 184 de 314
184

Tipo de diseño Grupos Y antes
X Y después
Cambio (d) Interacción (I)
Ejemplos
I. Solo después ExperimentalControl
--------
X----
Y2Y’2
d = Y2-Y’2 ---- X = Proyección de un film de guerraY = Opinión sobre la guerra
II. Antes y después con un grupo
Experimental Y1 X Y2 d = Y2-Y1 ---- X = FrustraciónY = Constructividad lúdica
III. Antes y después con grupos intercambiables
ExperimentalControl
----Y’1
X----
Y2----
d = Y2-Y’1 ---- X = Campaña publicitariaY =Efectividad de la campaña
IV. Antes y después con un grupo de control
ExperimentalControl
Y1Y’1
X----
Y2Y’2
d = Y2-Y1d’ = Y’2-Y’1
---- X = Proyección de un film de guerraY = Opinión sobre la guerra
V. Antes y después con dos grupos de control
ExperimentalControl IControl II
Y1Y’1
(Y’’1)
X----X
Y2Y’2Y’’2
d = Y2-Y1d’ = Y’2-Y’1d’’ = Y’’2-Y’’1
I = d – (d’+d’’)
X = Curso de entrenamiento en relaciones humanasY = Opinión sobre las relaciones humanas
VI. Antes y después con tres grupos de control
ExperimentalControl IControl IIControl III
Y1Y’1
(Y’’1)(Y’’’1)
X----X
----
Y2Y’2Y’’2Y’’’2
d = Y2-Y1d’ = Y’2-Y’1d’’ = Y’’2-Y’’1d’’’ = Y’’’2-Y’’’1
I = d – (d’+d’’-d’’’)
-----
En la versión Selltiz-Wrightsman-Cook solamente figuran los diseños 1, 4 y 6. En dicha versión, el esquema 4 se llama “diseño simple” y el 6 se llama “diseño ampliado” o “esquema de los cuatro grupos de Solomon”. Esta última denominación figura en ambas versiones.
En este esquema observamos las expresiones “Y antes”, “X” e “Y después”. Si retomamos el ejemplo de la relación ruido-estrés, “Y antes” significa la medición del estrés antes de aplicar el ruido (o premedida de Y), “X” significa aplicación del estímulo sonoro, e “Y después” indica la medición del estrés después de haber aplicado dicho estímulo (posmedida de Y). Esta última medición debe realizarse para constatar si hubo o no alguna diferencia.En función de lo dicho encontraremos dos tipos de diseño bivariado: a) de sólo después, donde no tomamos la premedida, sino solamente aplicamos el ruido y luego medimos el estrés; y b) de antes y después, donde tomamos tanto la premedida como la posmedida. Se trata de diseños más complejos y, como se ve en el esquema, admiten cinco variantes.
1) Diseño de sólo después.- Es un diseño sencillo donde trabajamos con un grupo experimental y otro de control, sin haber tomado a ninguno la premedida. Lo que hacemos es someter a estímulos sonoros (X) al grupo experimental, y luego averiguamos las posmedidas de estrés en ambos grupos (Y2 e Y’2). Si hay diferencia significativa entre ambas medidas de estrés, cabe pensar entonces que X es la causa de Y. En otras palabras, la diferencia “d” (ver columna de ‘cambio’) debe ser distinta a cero. En principio, cuanto más diferente de cero sea “d”, tanto más probable es la influencia de X como factor causal. Si “d” da cero o valores muy próximos a cero no hubo cambio, o sea el nivel de estrés en ambos grupos es igual, de donde pensamos que el factor ruido no tuvo influencia causal. Supongamos un ejemplo numérico:
Grupo Y antes X Y después CambioExperimentalControl
--------
X----
2015
d = 20-15 = 5
En este experimento imaginario el nivel de estrés de quienes sufrieron ruidos es 20 (por ejemplo 20 ml de adrenalina en sangre), y el nivel de los que no sufrieron los ruidos es 15. Aparece una diferencia significativa, que es 5, y por lo tanto concluimos que el ruido ejerce influencia causal.Cuando aplicamos este diseño, estamos suponiendo que los niveles de estrés antes del ruido (premedidas) son aproximadamente iguales en ambos grupos y que tienen en este caso el mismo valor 15, pues ambos grupos fueron extraídos de la misma muestra, se suponen homogéneos entre sí y los sujetos fueron elegidos al azar. De esta forma el grupo de control, al no haber sido expuesto a ruidos, seguirá manteniendo el valor 15 de estrés, pero no así el grupo experimental. Esquemáticamente, la situación sería así:
Página 185 de 314
185

Grupo Y antes X Y después CambioExperimentalControl
(15)(15)
X----
2015
d = 20-15 = 5
El valor 15 entre paréntesis indica que sólo suponemos dicho valor para ambos grupos antes de aplicar el ruido, pues en realidad en este tipo de diseño no hemos tomado efectivamente las premedidas. Si tenemos fuertes razones para suponer que las premedidas son iguales, no nos molestaremos en tomarlas, pero puede ocurrir que tengamos alguna duda y, al medirlas, comprobamos que en realidad son bastante distintas, como sería en el siguiente ejemplo hipotético:
Grupo Y antes X Y después CambioExperimentalControl
(20)(15)
X----
2015
d = 20-15 = 5
Si las cosas ocurren así, entonces nos hemos equivocado al suponer que el ruido causa el estrés, ya que en el grupo experimental el nivel de estrés antes y después del ruido es igual. Por lo tanto, cuando tenemos suficientes razones para sospechar que las premedidas son distintas, debemos tomarnos la molestia de medirlas, y entonces ya no estaremos utilizando el diseño de sólo después, sino cualquiera de los diseños de antes y después.En esta clase de diseños sí habrá de interesarnos tomar las premedidas y, cuando lo hacemos, pueden suceder dos cosas: a) que las premedidas sean iguales, situación que es la más deseable porque de entrada pone en el mismo nivel a todos los grupos respecto de la variable Y (estrés). Fueron grupos bien elegidos y proseguimos el experimento con ellos sin cambiarlos; b) que las premedidas sean distintas entre sí, en cuyo caso volveremos a seleccionar otros grupos que sean homogéneos respecto de sus premedidas, a efectos de nivelarlos. Otra posibilidad sería continuar con los grupos originales desiguales, pero en esta situación habremos de tener en cuenta sus diferencias al momento de la evaluación de los resultados finales.
Antes de examinar los diseños de antes y después, demos un ejemplo de diseño de sólo después (Selltiz). El problema que generó la investigación fue saber hasta qué punto la proyección de un film de guerra (X) influía sobre la opinión de las personas sobre los temas bélicos (Y). Antes de la proyección del film al grupo experimental, se partió de la base de que las personas de ambos grupos (experimental y de control) tenían más o menos las mismas opiniones sobre la guerra, con lo cual no era necesario tomar las premedidas de Y. Acto seguido se proyectaron varios films de guerra sólo al grupo experimental, y después se hicieron encuestas sobre opiniones de temas bélicos a ambos grupos: si había diferencia significativa entre estas opiniones, entonces se comprobaba la influencia causal de la proyección del film, y si no, no.
2) Diseño de antes y después con un grupo.- Es el diseño más sencillo en cuanto utilizamos un solo grupo: el experimental. En él, medimos el estrés antes del estímulo sonoro (Y1), aplicamos este estímulo (X), y volvemos a medir el estrés después (Y2). Si hay diferencia significativa entre Y2 e Y1, entonces el ruido es factor causal del estrés.
Selltiz da un ejemplo para el tipo de diseño 2. Se puede averiguar qué influencia tiene la frustración (X) sobre la constructividad en el juego en los niños, para lo cual se ubican infantes con juguetes en una habitación donde el investigador puede observarlos a ellos pero no estos a él. Los niños comenzarán a jugar, y se evalúa luego de cierto tiempo el grado de constructividad que despliegan. Luego se los somete a estímulos frustrantes (ocultarles los juguetes, mostraeles juguetes más nuevos pero que no pueden tocar, etc.) y se mide después nuevamente el grado de constructividad cuando sigan jugando para saber si hubo o no alguna variación significativa. Este experimento resulta también útil para evaluar el grado de sadismo del investigador.
La simplicidad de este diseño radica en que el investigador que lo utiliza supone que las distintas variables extrañas que pueden actuar sobre el estrés están razonablemente controladas o anuladas por la simple aleatorización, y no es necesario entonces el empleo de grupos de control. Sin embargo, si sospechamos que esas variables sí están ejerciendo su influencia, entonces deberemos usar diseños más complejos, que enseguida veremos. Entre estas variables extrañas hay dos que son particularmente importantes: la influencia de la premedida y la interacción. Si creemos que la variable que interviene es solamente la premedida, optaremos por realizar un experimento según el diseño de antes y después con grupos intercambiables.
El diseño II presenta algunas insuficiencias que pueden compensarse utilizando un diseño I. Yabo (1971) describe una situación en la cual primero se pensó en utilizar un diseño II, pero luego se lo completó con un diseño I.Para probar cuál es el efecto de una droga sobre la presión arterial en individuos hipertensos, a un grupo determinado de individuos con hipertensión se les mide la presión arterial antes y después de la administración de la droga, registrando así la diferencia observada.Cualquiera sea el sentido de la diferencia, ésta se puede atribuir a: 1) El efecto de la droga. 2) Otros factores que cambien la presión arterial entre el pretest y el postest, sin que la droga tenga ninguna participación. 3) Al azar, es decir que la diferencia observada sea consecuencia de la variabilidad biológica que no tiene una clara explicación, pero que siempre puede estar presente ya que es una propiedad de la naturaleza. 4) A la combinación de dos o más de las causas enumeradas anteriormente.La segunda de estas causas posibles puede eliminarse si al mismo tiempo que en el grupo tratado (I), se observan los cambios de la presión arterial en otro grupo (II) de hipertensos (aquí se aplicaría el diseño I), con
Página 186 de 314
186

los cuales se procede en similar forma que con el grupo I, pero con la única diferencia de que no se les administra la droga sino un placebo. Este grupo II es el grupo “testigo” o “control”.Si analizamos los cambios de presión arterial en el grupo tratado y al mismo tiempo los del grupo testigo, la diferencia que podemos observar entre ambos grupos se puede atribuir ahora a: 1) El efecto de la droga. 2) El efecto del azar. 3) La combinación de las dos causas antes mencionadasPara eliminar al azar como causa de los efectos observados, se procedió luego a realizar una prueba o test de significación estadística.
3) Diseño de antes y después con grupos intercambiables.- Se trata de un diseño especial para el control de la influencia de la premedida de Y. el sólo hecho de tomar una premedida del estrés puede hacer aumentar el estrés de la persona (por ejemplo por sentirse investigada). Por lo tanto habrá aquí dos factores concurrentes que producen estrés: la premedida y el ruido. Si queremos eliminar la influencia de la premedida recurrimos a un expediente muy simple: sencillamente no la tomamos. En el esquema general de los diseños experimentales bivariados se aprecia, efectivamente, que el grupo experimental no es premedido: solamente es expuesto a X y luego posmedido.Sin embargo, necesitamos conocer el valor de la premedida del grupo experimental, y entonces recurrimos a un procedimiento también sencillo: le tomamos la premedida a otro grupo (grupo de control), el cual, por haber sido tomado de la misma muestra que el grupo experimental, existe suficiente seguridad estadística de que ambos grupos tendrán aproximadamente las mismas premedidas, o sea, el mismo nivel previo de estrés. Por lo tanto el valor de la premedida del grupo de control (Y’1) podremos considerarlo como si fuese el valor de la premedida del grupo experimental, con lo cual sólo nos resta comparar si ésta última y la posmedida son o no iguales: si la diferencia se aproxima a cero, entonces el ruido no influye como causa, y en caso contrario, sí. La única utilidad que entonces tiene aquí el grupo de control es la de proveernos de un dato premedido.Notemos también que en este tipo de diseño la diferencia ‘d’ se obtiene comparando una premedida con una posmedida, en contraste con el diseño de sólo después donde comparábamos dos posmedidas.
Supongamos que queremos hacer una campaña publicitaria para vender relojes que funcionen con energía solar. Si queremos saber si fue o no efectiva podemos hacer una encuesta antes de la campaña preguntándoles a las personas sus preferencias en materia de relojes de distinto tipo, y luego otra encuesta después de la campaña para ver si las preferencias cambiaron o no como consecuencia de la misma.Pero, el sólo hecho de hacer una encuesta antes puede estar ya influenciando (influencia de la premedida) en el sentido que las personas podrán poner mayor interés en la campaña posterior, con lo cual ésta ya no será la campaña original (o bien la opinión previa puede influir en la opinión posterior por cierta tendencia de las personas a responder siempre lo mismo). Para evitar esa influencia, la encuesta previa la hacemos con personas de la misma población pero que vivan fuera del alcance de la campaña publicitaria, con lo cual la encuesta posterior (posmedida) reflejará en el grupo experimental solamente la efectividad de la campaña, sin la influencia de la encuesta previa. Este experimento es entonces un ejemplo de aplicación del diseño de antes y después con grupos intercambiables.
4) Diseño de antes y después con un grupo de control.- Es muy similar al esquema de sólo después, con la única diferencia que aquí hemos tomado las premedidas para asegurarnos de la igualdad de condiciones de ambos grupos. Para que con este nuevo diseño podamos probar que X es causa de Y, deberán verificarse simultáneamente dos condiciones: que d sea distinto de cero, y que d’ sea igual o muy próximo a cero. Ejemplo:
Grupo Y antes X Y después CambioExperimentalControl
1515
X----
2015
d = 20-15 = 5d’ = 15-15 = 0
Este diseño nos sirve especialmente, entonces, para averiguar cómo son las premedidas entre sí de ambos grupos, pero no permite controlar si hay o no influencia de la interacción, influencia de la premedida, u otras influencias. Por lo tanto, lo aplicaremos cuando tenemos fuertes razones para pensar que todas estas variables extrañas no están ejerciendo influencia significativa.
Un ejemplo de aplicación del diseño IV de Selltiz es un estudio en el cual se intenta demostrar la influencia del conflicto cognitivo en la adquisición de la noción de izquierda-derecha (Dalzon, 1988). La hipótesis que se intentaba probar era que los niños podrían adquirir más rápidamente la noción de cuales son los lados izquierdo y derecho tanto para él mismo como para los demás, si interactuaba con otros niños de manera tal que se generaran entre ellos conflictos y discusiones acerca de cual es el lado izquierdo y cual el derecho.Para ello se tomaron dos grupos de 28 niños cada uno: a los niños del grupo experimental se los hizo interactuar entre sí en una situación artificial donde estaban obligados a discutir entre ellos cual era la izquierda y cual la derecha, y al grupo de control no. Ambos grupos fueron premedidos respecto de su nivel de adquisición de la noción de izquierda-derecha, y luego, en la posmedida, se comprobó que el grupo experimental había adquirido la noción cognitiva más rápidamente que los niños del grupo de control.
5) Diseño de antes y después con dos grupos de control.- El propósito central de este tipo de diseño es el de controlar la influencia de la interacción, y entonces lo aplicamos cuando sospechamos su existencia. El diseño puede medir también la influencia de la premedida; efectivamente, notemos que aquí la situación de los grupos de control II y I es igual a la situación de los dos grupos del diseño 3, el cual servía precisamente para el control de esta variable extraña.
Página 187 de 314
187

Aclaremos el concepto de interacción. Supongamos que el hambre (X) produce agresividad (Y), como pueden sugerirlo los saqueos a los supermercados en épocas de crisis. Si pudiésemos disponer de un ‘agresivómetro’, supongamos que el hambre produce una agresividad de 3. Por otro lado, otras observaciones nos pueden sugerir que también la fatiga produce agresividad: si la película es muy larga el público se puede enojar. Supongamos que aquí la fatiga produce agresividad 1. El sentido común puede sugerirnos que, si los factores hambre y fatiga actúan conjuntamente, el sujeto responderá con una agresividad 4 (3 por hambre y 1 por fatiga). Esquemáticamente:
X YHambreFatigaHambre + fatiga
Agresividad 3Agresividad 1Agresividad 4
Sin embargo, puede ocurrir que estos efectos no sean aditivos. Si un individuo está hambriento y encima fatigado, probablemente no le quede mucha energía para ser agresivo, y entonces en estos casos podemos obtener un valor 0.5 para su agresividad. Qué ha ocurrido? Las variables hambre y fatiga han interactuado, o sea produjeron un efecto inesperado, no aditivo: la agresividad resultante fue mucho menor a la esperada, aunque en otros casos los efectos pueden ser mayores que la simple suma, vale decir que al interactuar, las variables potencien sus efectos como en el caso del consumo simultáneo de alcohol y drogas. El primero produce daño cerebral 7 (una cifra cualquiera) y las segundas daño cerebral 9; pero, si ambos factores actúan juntos, el daño cerebral no será 16 sino 30.Definiremos entonces interacción como toda situación en la cual dos o más variables, por el solo hecho de actuar conjuntamente sobre un efecto, producen una influencia no aditiva sobre éste, sea reduciéndolo, sea potenciándolo. Se trata entonces de efectos combinados que van más allá de los simples efectos aditivos. Otros autores dan definiciones similares. Una de ellas, por caso, afirma que entre dos variables ocurre interacción cuando el efecto que ejerce una de ellas en la variable dependiente ‘cambia’ conforme los valores que adquiere la otra, es decir, cuando la acción de una de las variables depende de cómo actúa una segunda (definición de Reuchlin citada en Arnau Gras, 1980:392).La consideración de la interacción puede tener gran importancia práctica. Piénsese, por ejemplo, en la posibilidad de que dos tratamientos combinados (psicoterapia y farmacoterapia) puedan producir efectos curativos que van más allá de la simple suma de los efectos curativos de cada tratamiento.
Blalock (1982:85) cita un ejemplo para comparar los efectos aditivos (que este autor y otros varios llaman ‘efectos principales’) con los efectos de interacción. Las variables educación, sexo y raza determinan aditivamente el ingreso mensual: 2000 dólares por tener título secundario, más 2000 dólares por ser varón, más 2000 dólares por ser blanco.Sin embargo esta aditividad puede distorsionarse, o sea pueden aparecer efectos de interacción, como por ejemplo cuando la diferencia de ingresos entre blancos y negros es pequeña para un bajo nivel educacional, pero mayor en los altos niveles de educación. Así, si un blanco posee solamente título primario, su sueldo por ser blanco se acercará más al sueldo de un negro con primaria y ganará en tal concepto sólo 500 dólares más (y no 2000). Están aquí interactuando las variables educación y raza produciendo un efecto no aditivo sobre el ingreso mensual.
Traslademos ahora el concepto de interacción al diseño 5. En este caso lo que queremos averiguar es si hay o no interacción entre la premedida (Y1) y la variable experimental (X), es decir, si producen o no un efecto no aditivo sobre la posmedida (Y2). Por lo tanto, la sospecha estará recayendo solamente en el grupo experimental, único grupo donde ambos factores actúan conjuntamente.Para saber si existe o no interacción, primero averiguaremos los efectos que producen independientemente Y1 y X, o sea, cuando actúan solos, lo que podemos saber mediante los grupos de control I y II respectivamente. Vemos así que el diseño 5 hace posible la separación de la influencia de la variable experimental de la influencia de la premedida, aún cuando haya interacción entre ellas. Aclaremos que en el grupo de control II la premedida no fue efectivamente tomada (pues sólo nos interesa la influencia de X), pero como necesitamos igualmente conocer su valor, simplemente la inferimos a partir de las premedidas de los otros dos grupos, pudiendo ser un simple promedio de ellas. En el esquema general de diseños experimentales bivariados, los paréntesis significan que se trata de una premedida inferida. Comparemos ahora los siguientes dos ejemplos: uno donde no hay interacción y otro donde sí la hay.
Cuadro A (sin interacción)
Grupo Y antes X Y después Cambio Interacción
I = d – (d’ + d’’)I = 25 – (0 + 25) = 0
ExperimentalControl IControl II
1515
(15)
X----X
401540
d = 25d’ = 0d’’ = 25
Página 188 de 314
188

Cuadro B (con interacción)
Grupo Y antes X Y después Cambio Interacción
I = d – (d’ + d’’)I = 25 – (0 + 5) = 20
ExperimentalControl IControl II
1515
(15)
X----X
401520
d = 25d’ = 0d’’ = 5
El grupo de control I detecta si hay o no influencia de la premedida (pues allí no se aplica ruido y mucho menos interviene la interacción entre premedida y ruido). Si comprobamos que efectivamente no existe esta influencia (como en los cuadros A y B), cualquier diferencia entre las posmedidas del grupo de control II y el grupo experimental será debida a la interacción (tal como ocurre en el cuadro B). En el caso de constatarse la existencia de interacción, el experimento deberá complejizarse para poder ponderar su influencia según qué valores asuman las variables interactuantes (pues puede ocurrir que para determinados valores la interacción quede anulada, para otros potencie sus efectos y para otros los reduzca por debajo de lo aditivamente esperable).A partir de lo dicho fácil es darse cuenta que puede haber influencia de la premedida sin que haya interacción (caso donde la premedida y X dan efectos simplemente aditivos), pero no puede haber interacción sin influencia de la premedida (pues en estos diseños precisamente la interacción se establece entre la premedida y X). En los cuadros A y B, observando los valores del grupo de control I nos damos cuenta que no hubo influencia de la premedida, lo cual no significa que ésta pueda empezar a ejercer influencia a propósito de su acción conjunta con X en el grupo experimental.Muchas veces con sólo mirar los valores de los cuadros podemos saber intuitivamente si hubo o no interacción, pero si queremos conocer cuantitativamente su valor preciso aplicaremos la fórmula de la interacción (ubicada a la derecha de los cuadros A y B): a medida que el resultado se aproxime a cero, la interacción será cada vez menor. Cuando el valor obtenido es cero, no la hay.
Selltiz cita un ejemplo de diseño 5, donde los investigadores trataron de averiguar si los cursos de entrenamiento en relaciones humanas (X) influían o no sobre la información y opinión sobre temas de relaciones humanas en las personas que hicieron dichos cursos. Se supuso que podía haber interacción entre la premedida (encuesta previa al curso) y la variable experimental (curso), y entonces se utilizaron otros dos grupos: uno hizo directamente el curso sin encuesta previa (grupo de control II), y el otro fue sometido a esta encuesta previa sn hacer el curso (grupo de control I), con lo cual pudieron medirse esas influencias en forma independiente.
6) Diseño de antes y después con tres grupos de control.- Además de medir la influencia de la interacción y de la premedida, este diseño tiene la ventaja adicional de poder controlar la influencia de otras variables extrañas desconocidas, tanto organísmicas (cambios madurativos, etc.) como situacionales (clima, etc.) que eventualmente puedan también estar ejerciendo su influencia.Este sexto diseño es igual al anterior excepto que tiene agregado un grupo de control III, que es precisamente el que nos permite averiguar si influyen o no las otras variables adicionales. En él volvemos a encontrar una premedida inferida, o sea un premedida no tomada pero cuyo valor se supone similar a las premedidas tomadas en los otros grupos. La necesidad de contar con este valor deriva del hecho que necesitamos compararlo con la posmedida correspondiente para ver si existe o no una diferencia d’’’.El razonamiento que debe hacerse entonces es el siguiente: sobre la posmedida del grupo de control III nunca podrá ejercer su influencia ni la premedida ni la variable experimental, pues no fueron aplicadas, ni mucho menos la interacción entre ellas. Por lo tanto, cualquier diferencia que aparezca entre la premedida inferida Y’’’1 y la posmedida Y’’’2 será debida a la influencia de las otras variables adicionales, lo cual nos permite entonces detectar sus intervenciones.
En el diseño VI cabe preguntarse ¿por qué, si el grupo de control III no mide interacción, en la fórmula de interacción aparece el valor d’’’? Al respecto debe tenerse presente que d’’’ mide la influencia de variables desconocidas, y entonces pueden suceder dos cosas: a) d’’’ igual a 0. En este caso no hay problema, pues en la fórmula de interacción desaparece. b) d’’’ distinto de 0. Esto significa que las variables extrañas desconocidas influyen. Y si influyen en el grupo de control III, también lo hacen en los grupos restantes. Por tanto, para evaluar la interacción en d, d’ y d’’ es preciso descontar la influencia de las variables desconocidas.
En síntesis: los tipos de diseño experimental aquí examinados están destinados a probar si X es factor causal de Y mediante el control de las variables adicionales. Estas últimas son fundamentalmente la influencia de la premedida, la interacción, y otras posibles variables que pueda haber.Cuando consideramos que las variables adicionales ya están controladas de antemano y suponemos que las premedidas son iguales o controlables, aplicamos el diseño 1. Cuando no conocemos las premedidas y creemos que son distintas, nos sacaremos la duda aplicando los diseños de antes y después 2 y 4. Cuando sospechamos que además puede ejercer influencia la premedida, aplicamos el diseño 3. Cuando pensamos que interviene la interacción, aplicamos el diseño 5 y finalmente, cuando creemos que además de la premedida y la interacción intervienen otros factores que es preciso también controlar, nos decidiremos por el diseño 6.Cómo averiguar qué tipo de diseño fue aplicado en un experimento dado? Para saberlo podemos contar con una regla práctica: si en el experimento no se tomaron premedidas, se aplicó el diseño 1, y si efectivamente fueron tomadas, quedan los diseños 2 al 6. Si se trabajó con un solo grupo se usó el
Página 189 de 314
189

diseño 2, con tres grupos el diseño 5 y con cuatro grupos el diseño 6. Restan los diseños 3 y 4, ambos con dos grupos. Reconocemos la aplicación del diseño 3 si se tomó una sola premedida (al grupo de control), y fue usado el diseño 4 si se tomaron las premedidas en ambos grupos.
5. OTRAS VERSIONES
En una apretada síntesis, se presentan a continuación otras versiones que, muy a grandes rasgos, coinciden con las versiones presentadas precedentemente. Téngase presente que casi todos los autores provienen de las ciencias sociales, y especialmente de la psicología. En particular, Kohan es una autora especialista en estadística.
Versión Kohan
Según el grado de control de las variables, cabe distinguir tres tipos de investigación: por observación natural, por evaluación sistemática y por manipulación experimental (Kohan, 1994:357-359).1) Observación natural.- Implica observar naturalmente sin artificios la conducta en algún atributo o variable que interese. No existe un control activo ni sobre los estímulos (VI) ni sobre las respuestas (VD). Lo único que puede hacerse es controlar algo las variables extrañas para que no contaminen las relaciones que se supone existen entre VI y VD.2) Evaluación sistemática.- Supone inducir a los sujetos a que expresen sus tendencias exponiéndolos a una evaluación sistematizada igual para todos con estímulos controlados, como tests, etc. El investigador trata de controlar los sujetos sólo en parte. Se trata de que estos produzcan respuestas que se cree reflejan sus características preexistentes, sin afectarse deliberadamente la naturaleza del atributo del cual dependen las respuestas.3) Manipulación experimental.- El investigador busca influir los determinantes de las respuestas y también trata de lograr un control definido sobre las variables extrañas que pueden contaminar la experiencia manteniéndolas constantes o variándolas sistemáticamente.
Tipos de diseños de investigación.- Un diseño de investigación “es un plan, una estructura y una estrategia de investigación concebido para dar respuesta a los interrogantes puestos por la investigación y controlar la variancia” (Kohan, 1994:359). Los diseños pueden clasificarse del siguiente modo:
Ex post factoExperimentales Estudian una
VIDiseño simple con sujetos elegidos al azar.Diseño de los sujetos apareados al azar.Apareamiento de sujetos por un atributo correlacionado con la VD.Empleo de los sujetos como su propio control.Diseño de tipo test ‘antes-después’ con grupo de control.Diseño ‘antes-después’ combinado con diseño ‘solo-después’.
Estudian dos o más VI
Diseño de tratamiento de niveles.Diseños factoriales.
Diseños ex post facto.- No se pueden manipular las VI o asignar sujetos a tratamientos a criterio del investigador, porque la VI ya ha ocurrido. El investigador comienza con la observación de la VD y retrospectivamente estudia la o las VI para analizar sus posibles efectos sobre la primera. En sociología, psicología, educación antropología y ciencias políticas una gran proporción de la investigación ha sido ex post facto. Este tipo de investigación tiene tres debilidades: no puede manipular VI, no puede aleatorizar, y tiene el riesgo de una interpretación inadecuada (Kohan, 1994:362-363).
Diseños experimentales.- Son aquellos donde el investigador mismo determina quién debe ser asignado a qué condiciones. Una investigación es verdaderamente científica cuando el investigador puede manipular y controlar una o más VI y observa la VD para ver si existe variación concomitante con la manipulación de la o las VI. Existe una gran diversidad de diseños, de los cuales Kohan (1994:363-373) menciona los que juzga fundamentales:Diseño simple con sujetos elegidos al azar.- Requiere dos grupos de sujetos: experimental y de control que se seleccionan al azar de una misma población y luego se asignan aleatoriamente a las dos condiciones experimentales (o diferentes valores de la VI). Si hay diferencia entre las medias de los grupos, la prueba estadística a utilizar será z o t, según el número de casos (Kohan, 1994:364).Diseño de los sujetos apareados al azar.- Si no puede utilizarse el azar para obtener grupos equivalentes, se utiliza la técnica del apareamiento de los sujetos: las mediciones previas de VD se aparean y cada integrante de la pareja es asignada al azar a uno de ambos grupos. Un ejemplo de prueba estadística que puede aplicarse es la prueba t (Kohan, 1994:364).Apareamiento de sujetos por un atributo correlacionado con la VD.- Se utiliza cuando no es posible aparear los sujetos con un pretest de VD, pero sí con otra característica correlacionada con ella. Ejemplo,
Página 190 de 314
190

si los niños son muy pequeños como para producir medidas estables de inteligencia, se pueden aparear según el nivel educacional de los padres (Kohan, 1994:366).Empleo de los sujetos como su propio control.- Una de las mejores maneras en que puede reducirse el error debido a diferencias individuales entre los sujetos es que ellos mismos sea su propio control, es decir, son medidos sucesivamente bajo un tratamiento experimental y luego bajo otro. El problema es que los efectos de orden en que son presentados los tratamientos pueden influir en los resultados, que puede resolverse mediante el contrabalanceo: se sigue un orden para la mitad de los sujetos tomados al azar, y el orden inverso para la otra mitad. Se menciona la prueba t como ejemplo para evaluar los resultados (Kohan, 1994:367).Diseño de tipo test ‘antes-después’ con grupo de control.- Se cuenta con un grupo de control tomado al azar de la población que no reciba tratamiento o que reciba un tratamiento neutro tipo placebo. Se comparan las medidas de pretest y postest entre ambos grupos, y puede utilizarse el apareamiento para formar grupos equivalentes, lo que es aún mejor. La prueba t es mencionada como prueba estadística en estos casos (Kohan, 1994:370).Diseño ‘antes-después’ combinado con diseño ‘solo-después’.- Permite el control de la interacción entre pretest y VI (Kohan, 1994:371). y equivale al diseño de Solomon. Como prueba estadística puede utilizarse t para comparar las medias de los diversos grupos entre sí, que son cuatro: dos experimentales o dos de control.Diseño de tratamiento de niveles.- El efecto sobre la VD del principal tratamiento experimental se evalúa en cada uno de los diversos ‘niveles’ de una o más VI, distintos niveles que pueden ser grupos de sujetos naturales (por ejemplo niños inteligentes y retardados). En otro ejemplo, se puede utilizar este diseño para evaluar el tratamiento psicoterapéutico en histeria, ansiedad y obsesión, utilizando en cada uno de los tres niveles un grupo experimental y uno de control (Kohan, 1994:372).Diseños factoriales.- En estos casos el interés recae sobre el efecto separado o interactivo de dos o más VI. Suelen requerir pruebas estadísticas de análisis de variancia y análisis factoriales, más complejas (Kohan, 1994:373).
Técnicas estadísticas.- Las técnicas estadísticas se utilizan en los tres grandes tipos de investigación, y con diversos propósitos: para seleccionar muestras, para evaluar respuestas mediante construcción de tests o cuestionarios, para evaluar su validez y confiabilidad, o para controlar variables (Kohan, 1994:359). Es importante “saber qué diseño está usando el investigador, cuáles son las variables que puede controlar y en función de esto buscar la prueba estadística apropiada” (Kohan, 1994:357).
Versión Hernández Sampieri et al
Tipos de investigación.- Los autores describen cuatro tipos de investigación: la investigación exploratoria, descriptiva, correlacional y explicativa (Hernández Sampieri et al, 1996:57). En los primeros no se formulan hipótesis, en los segundos se formulan hipótesis descriptivas de una variable, en los terceros hipótesis correlacionales y de diferencia de grupos cuando estas últimas no expliquen la causa que provoca tal diferencia, y en los últimos hipótesis causales. Una misma investigación puede abarcarse algunas o todas las hipótesis indicadas (Hernández Sampieri et al, 1996:96-97).
Diseños de investigación.- Un diseño de investigación es un plan o estrategia para responder a las preguntas de investigación, le señala lo que debe hacer para alcanzar sus objetivos y analizar la certeza de la hipótesis formulada. Se pueden clasificar en diseños experimentales y no experimentales (Hernández Sampieri et al, 1996:108-109). Los autores referidos clasifican los diseños experimentales siguiendo la versión Campbell y Stanley (1966), como diseños preexperimentales, experimentales ‘puros’ o verdaderos, y cuasi experimentales. Respecto de los diseños no experimentales, Hernández Sampieri et al (1996:187) los clasifican como transeccionales y longitudinales. Más concretamente:
Diseños experimentales(Campbell y Stanley, 1966)
PreexperimentalesExperimentales purosCuasiexperimentales
Diseños no experimentales Transeccionales o transversales(uno o más grupos)
DescriptivosCorrelacionales/causales
Longitudinales(un grupo)
De tendencia (trend)De evolución (cohort)De panel
Diseños experimentales.- “1) En su acepción más general, un experimento consiste en aplicar un estímulo a un individuo o grupo de individuos y ver el efecto de ese estímulo en alguna(s) variable(s) del comportamiento de éstos. Esta observación se puede realizar en condiciones de mayor o menor control. El máximo control se alcanza en los <experimentos verdaderos>. 2) Deducimos que un estímulo afectó cuando observamos diferencias –en las variables que supuestamente serían las afectadas- entre un grupo al que se le administró dicho estímulo y un grupo al que no se le administró, siendo ambos iguales en todo excepto en esto último. 3) Hay dos contextos en donde pueden realizarse los experimentos: el laboratorio y el campo. 4) En los cuasiexperimentos no se asignan al azar los sujetos a los grupos experimentales, sino que se trabaja con grupos intactos. 5) Los cuasiexperimentos alcanzan validez interna en la medida en que demuestran la equivalencia inicial de los grupos participantes y la
Página 191 de 314
191

equivalencia en el proceso de experimentación. 6) Los experimentos <verdaderos> constituyen estudios explicativos, los preexperimentos básicamente son estudios exploratorios y descriptivos; los cuasiexperimentos son –fundamentalmente- correlacionales aunque pueden llegar a ser explicativos” (Hernández Sampieri et al, 1996:182).
Diseños no experimentales.- La investigación no experimental es aquella que se realiza sin manipular deliberadamente variables, y donde se observan fenómenos tal y como se dan en su contexto natural, para después analizarlos (Hernández Sampieri, 1996:189). Según el número de momentos en el tiempo donde se recolectan datos, los diseños no experimentales pueden ser transeccionales o transversales, y longitudinales.“1) La investigación no experimental es la que se realiza sin manipular deliberadamente las variables independientes, se basa en variables que ya ocurrieron o se dieron en la realidad sin la intervención directa del investigador. Es un enfoque retrospectivo. 2) La investigación no experimental es conocida también como investigación expost-facto (los hechos y las variables ya ocurrieron) y observa variables y relaciones entre éstas en su contexto natural. 3) Los diseños no experimentales se dividen en transeccionales y longitudinales. 4) Los diseños transeccionales realizan observaciones en un momento único en el tiempo. Cuando miden variables de manera individual y reportan esas mediciones son descriptivos. Cuando describen relaciones entre variables con correlacionales y si establecen procesos de causalidad entre variables son correlacionales / causales. 5) Los diseños longitudinales realizan observaciones en dos o más momentos o puntos en el tiempo. Si estudian a una población son diseños de tendencia, si analizan a una subpoblación o grupo específico son diseños de análisis evolutivo de grupo y si estudian a los mismos sujetos son diseños de panel. 6) La investigación no experimental posee un control menos riguroso que la experimental y en aquella es más complicado inferir relaciones causales. Pero la investigación no experimental es más natural y cercana a la realidad cotidiana. 7) El tipo de diseño a elegir se encuentra condicionado por el problema a investigar, el contexto que rodea a la investigación, el tipo de estudio a efectuar y las hipótesis formuladas” (Hernández Sampieri et al, 1996:204).
Correspondencia entre tipos de investigación, hipótesis y diseños de investigación.- Un estudio o investigación puede iniciarse como exploratorio, descriptivo, correlacional o explicativo. El tipo de estudio nos lleva a la formulación de cierta clase de hipótesis, y estas a la selección de un determinado diseño de investigación (Hernández Sampieri, 1996:202). Esquemáticamente:
Investigación Hipótesis DiseñoExploratorio No se establecen, lo que se pueden formular son
conjeturas iniciales.Transeccional descriptivo.Preexperimental.
Descriptivo Descriptivas.Correlacional De diferencia de grupos sin atribuir causalidad. Cuasiexperimental.
Transeccional correlacional.Longitudinal (no experimental).
Correlacionales.
Explicativo De diferencia de grupos atribuyendo causalidad. Experimental.Cuasiexperimental, longitudinal y transeccional causal (cuando hay bases para inferir causalidad, un mínimo de control y análisis estadísticos apropiados para analizar relaciones causales).
Causales.
Versión Lores Arnaiz
Como otras ciencias empíricas, la investigación en psicología utiliza métodos correlacionales y experimentales para alcanzar sus objetivos, que son producir conocimientos contrastables sobre el funcionamiento de la mente humana en sociedad (Lores Arnaiz, 2000).Mientras el método correlacional busca probar una hipótesis correlacional, el objetivo del método experimental es poner a prueba una hipótesis funcional, entendida esta como una afirmación que establece una relación funcional entre variables.Ejemplo de hipótesis funcional: "El hecho de que los padres tengan esquizofrenia influye en que sus hijos biológicos también la padezcan, a través de factores genéticos".Los métodos experimentales en sentido amplio abarcan la observación controlada, el experimental propiamente dicho, y el cuasi-experimental.Más específicamente, los diseños experimentales propiamente dichos buscan someter a prueba una hipótesis funcional (por ejemplo, la falta de serotonina disminuye el sueño). Es un proceso de toma de decisiones acerca de un conjunto de procedimientos cuyo objetivo central es garantizar, en el máximo grado posible, la validez interna del experimento.Un experimento tiene por fin poner a prueba una hipótesis, entendida esta como una afirmación que establece una relación funcional entre variables. Al menos una de las variables se refiere a un constructo hipotético, una propiedad inobservable directamente (inteligencia, memoria, etc.). Los constructos deben definirse conceptual y operacionalmente. No se pueden explicar fenómenos sólo en base a sus aspectos observables: esto es una simple descripción.
Página 192 de 314
192

Un buen diseño experimental debe reunir tres condiciones:1) Debe hacer variar al menos una VI para evaluar sus efectos sobre la VD.2) Debe poder asignar los sujetos a diferentes condiciones o tratamientos experimentales.3) Debe poder controlar las variables pertinentes.
La tabla siguiente sintetiza los diversos métodos y los tipos de diseño que abarca cada uno.
Métodos Clasificación de diseñosCorrelacional CorrelacionalesObservación controladaExperimental propiamente dicho one-way (estudian una VI)
Primer criterioDiseño de dos grupos (VI asume 2 valores).Diseño multinivel (VI asume más de 2 valores).Segundo criterioDiseño de solo post-test.Diseño de pre-test y post-test.Tercer criterioDiseño de grupos aleatorios.Diseño de asignación aleatoria apareada (intersujetos) o también diseño de sujetos apareados aleatoriamente distribuidos.Diseño de medidas repetidas (intrasujetos). Un solo grupo sirve para todas las condiciones experimentales.
Experimental propiamente dicho factoriales (estudian dos o más VI)
Primer criterioDiseño two-way (estudian 2 VI) Ejemplos: 2x2, 3x3, 4x2, etc. Ejemplo: 2x2 significa dos valores para cada una de las dos VI. Por lo tanto, tiene 4 combinaciones posibles.Diseño three-way (estudian 3 VI) Ejemplos: 2x2x2, 2x2x4, etc.Diseños que estudian 4 o más VI.Segundo criterioDiseño de grupos aleatorios.Diseño aleatorizado de sujetos apareados, o también diseño de sujetos apareados distribuidos aleatoriamente.Diseño de medidas repetidas (intrasujeto).Diseño mixto (combina los dos últimos) o también diseño inter-intrasujetos (split-plot).
Cuasi-experimental
Diseño de serie de momentos interrumpida.Diseño de serie de momentos interrumpida, con una reversión.Diseño de serie de momentos interrumpida, con grupo control.
Sujeto único Diseños ABA.Diseños con múltiples valores de la VI.Diseños de línea de base múltiple.
Método correlacional.- Los diseños correlacionales son aquellos en los que se emplea el método correlacional.El objetivo del método correlacional es poner a prueba una correlación (o hipótesis correlacional), entendida esta como una afirmación que indica que entre dos o más variables hay una cierta asociación estadística (o también, que tal asociación se establece con un cierto valor de probabilidad).Ejemplo de hipótesis correlacional: "Que el padre de una persona sea esquizofrénica aumenta la probabilidad de que su hijo posea esa enfermedad".Este método utiliza para establecer correlaciones entre variables estadísticos como los coeficientes de correlación, chi cuadrado o t de Student.En el método correlacional no se manipulan VI.El método correlacional por sí solo no da direccionalidad a la relación entre variables.
Observación controlada.- Puede distinguirse entre observación sistemática y no sistemática.Observación no sistemática o preliminar.- Es importante porque a) provee material bruto para formular preguntas o hipótesis, y b) cuando los problemas o sujetos son nuevos para el investigador.Observación sistemática.- Puede utilizarse para operacionalizar variables, y debe estar precedida por una observación no sistemática.
Descripción de la conducta.- Para describir la conducta debe diferenciarse su estructura (apariencia, forma física o patrón temporal), y sus consecuencias (efectos que produce sobre el ambiente, otros sujetos o sobre el mismo sujeto).Elección de categorías.- La conducta es una corriente continua de movimientos y eventos, y para ser medida debe dividirse tal corriente en unidades o categorías discretas. Algunas veces tales categorías son naturales claramente distinguibles, pero otras las construye el investigador en base a hipótesis previas.Para construir categorías debe tenerse en cuenta: a) usar un número suficiente de categorías, b) definir con precisión cada una, para lo cual hay definiciones operacionales y definiciones ostensivas. Estas
Página 193 de 314
193

últimas dan un ejemplo de un caso al que la categoría se aplica, c) las categorías deben ser independientes, no superponerse, y d) deben ser homogéneas, compartir las mismas propiedades.Reglas de registro.- De la conducta puede hacerse un registro continuo (de todas sus ocurrencias, o sea cada ocurrencia de la conducta indicando el momento en que sucede), o bien un muestreo de tiempo (la conducta es muestreada periódicamente, por ejemplo mediante elección de puntos muestrales. Por ejemplo, la conducta ocurrió en 40 de los 120 puntos de muestreo, siendo entonces el puntaje 0.33).Tipos de medida de la conducta.- Las observaciones conductuales arrojan usualmente cuatro tipos de medida: latencia (tiempo entre estímulo y primera conducta), frecuencia (número de ocurrencias por unidad de tiempo), duración (tiempo que dura una ocurrencia singular) e intensidad (medible de diversas formas, como por ejemplo por el número de actos componentes por unidad de tiempo empleado en ejecutar la actividad).Al elegir el tipo de medida, debe distinguirse entre dos tipos de patrones conductuales: a) los eventos (patrones de conducta de corta duración, puntuales) y b) los estados (de mayor duración, como actividades prolongadas, posturas corporales, etc.).Métodos de registro.- Al decidir sobre como registrar la conducta, deben tenerse en cuenta dos niveles de decisión: las reglas de muestreo (qué sujetos observar y cuándo), y las reglas de registro (como registrar la conducta).Las reglas de muestreo pueden ser ad limitum (se toma simplemente nota de lo que se ve y parece relevante), focal (se observa un sujeto durante cierto lapso de tiempo y se registran todas sus conductas), panorámico (se escanea o censa rápidamente un grupo entero de sujetos a intervalos regulares y se registra la conducta de cada sujeto en ese instante), y muestreo de conducta (mirar el grupo entero y registrar la ocurrencia de un tipo particular de conducta y los sujetos que las ejecutan).
Diseño experimental propiamente dicho one-way.- Son aquellos que estudian una sola VI. Ejemplos:Diseño multinivel: estudio de la influencia del SN sobre el sistema inmune en las ratas.Diseño de asignación aleatoria apareada: estudio de la influencia de la cafeína sobre la memoria.Diseño de medidas repetidas: impacto del estrés de la viudez sobre el sistema inmune.
Ventajas de los diseños con pretest:1. Puede determinarse que antes de VI los grupos no diferirán respecto de la VD.2. Permite analizar el cambio comparando pretest con postest.3. Tienen más probabilidad de detectar los efectos de VI.El inconveniente es la sensibilización que puede generar el pretest en los sujetos. Una forma de controlar esta amenaza es dividiendo cada grupo en dos mitades: a uno se le toma pretest y al otro no, y se ven luego las diferencias con los respectivos postest.
Diseño experimental propiamente dicho factoriales (estudian dos o más VI).- Los diseños factoriales se usan para estudiar los efectos individuales y combinados de dos más VI (o factores), dentro de un mismo experimento.Su principal ventaja es que permiten detectar interacciones, además de detectar, como lo hacen los diseños one-way, los efectos principales de VI, y la varianza de error.
Interpretación de efectos principales e interacciones.- Los efectos principales son debidos a las VI. Así, un diseño factorial con dos VI tendrá dos efectos principales.Las interacciones son efectos combinados de dos o más VI.Si se muestra que hay interacción entre las VI, esto impide hablar de efectos principales de cada una de las VI. El hecho de que una interacción entre VI impida hablar de efectos principales depende de si tal interacción cualifica o no los efectos principales.Se dice que una interacción cualifica un efecto principal si los efectos de una variable desaparecen o se invierten según el valor de la otra VI. Si el efecto principal es cualificado por la interacción, no puede interpretarse, esto, es, no puede afirmarse nada con respecto al mismo.Pueden darse cinco casos, que se describen a continuación en base a un ejemplo.
Ejemplo: se consideran dos VI (A = tamaño del aula y B = método de enseñanza), para estudiar como influyen estas dos variables sobre el rendimiento escolar, y eventualmente para ver si interaccionan entre sí.
A1 (aula grande) A2 (aula chica)B1 (método 1) A1 B1 A2 B1B2 (método 2) A1 B2 A2 B2
1) A y B tienen efectos principales, pero no hay interacción. No hay interacción porque la variable A tiene los mismos efectos bajo las condiciones B1 y B2, y la variable B es igual para A1 y A2.2) A y B mantienen sus efectos principales pero además hay interacción entre ellas. Para los sujetos en la condición A1, el efecto de B es pequeño, mientras que en la condición A2, el efecto de B es más pronunciado. En este caso la interacción no cualifica los efectos principales, ya que ele efecto principal de B está presente tanto bajo A1 como bajo A2 (simplemente es más fuerte bajo A2 que bajo A1).3) A y B mantienen sus efectos principales, hay interacción entre ellas pero además ésta cualifica a los efectos principales. Aunque los sujetos en la condición B1 tienen más puntaje que la condición B2 (hay un
Página 194 de 314
194

efecto principal de B), la interacción muestra que este efecto solo ocurre realmente para la condición A2. Bajo A1, no tienen efecto bajo A1, pero si bajo A2, o sea, la única combinación donde B hace efecto es A2B1. En un caso así, interpretar el efecto principal de B sería confuso, porque esta variable solo tiene efecto para los sujetos en la condición A2. Sería factible interpretar el efecto principal de A, en cambio, porque A1 es más bajo que A2 en las dos condiciones: B1 y B2.4) Interacción cruzada: es otro caso de interacción que cualifica los efectos principales. Una VI tiene efectos opuestos sobre la VD, según el valor de la otra VI. Si los sujetos reciben A1, B2 arroja mejores puntajes que B1. Si reciben A2, B2 arroja puntajes peores que B1. Dadas estas relaciones, los efectos principales carecen de significado: la interacción impide la interpretación.5) No hay efectos principales de las VI pero sí hay interacción entre ellas. Si los sujetos reciben A1, los valores de B2 son mejores que los de B1; si reciben A2, los valores de B2 son peores que B1. Si los sujetos reciben B1, los puntajes son mejores en A2 que en A1, y si los sujetos reciben B2, los puntajes son peores en A2 que en A1.
Diseños cuasiexperimentales.- Difieren de los diseños experimentales en que no controlan con la misma eficacia las variables extrañas, es decir, no cumplen del todo con la tercera condición de causalidad (las otras dos son antecedencia temporal y correlación).Los diseños cuasiexperimentales de series de momentos miden la variable dependiente repetidas veces antes, y repetidas veces después de la aplicación de la variable independiente (que en estos casos se llama variable cuasi-independiente).
Los diseños cuasi-experimentales abarcan tres tipos:Diseño de serie de momentos interrumpida.- Se obtienen repetidas medidas pretest y, luego de aplicar VI, repetidas medidas postest. Por ejemplo, permite estudiar la eficacia de un programa de intervención comunitaria para reducir la iniciación al consumo de drogas.Gracias a este diseño se pueden identificar posibles efectos de VI contra el fondo de otros cambios debidos a variables pertinentes no controlables, como la madurez de los sujetos.Diseño de serie de momentos interrumpida, con una reversión.- Igual an anterior, con la diferencia que la VI es primero introducida pero luego retirada, haciéndose premedidas y posmedidas de VD respecto del momento de retirar VI. Permite controlar la influencia de variables extrañas históricas. Para aumentar el control de dichas variables, puede reintroducirse la VI y retirarse nuevamente. En este caso, hablamos de un diseño de series de momentos interrumpida con replicaciones múltiples.Este diseño tiene tres limitaciones: a veces no se puede retirar VI; el efecto de algunas VI permanece luego de ser retiradas; y el retiro de una VI puede producir cambios por sí mismo, que no se deben a esa variable.Diseño de serie de momentos interrumpida, con grupo control.- Se trata de aplicar los diseños anteriores a otro grupo que actúa como control, lo que aumenta la validez interna del diseño.
Diseños de sujeto único.- En estos casos, la unidad de análisis es un solo sujeto. Esto los diferencia de los diseños experimentales y cuasi-experimentales, donde la unidad de análisis es el grupo, es decir, se evalúan los efectos de las variables comparando dos o más grupos de sujetos. Sus resultados se suelen presentar mediante gráficos.Si bien no son tan utilizados como los diseños de grupo, surgieron como respuesta a las críticas formuladas en estos últimos, especialmente por B. Skinner. Estas críticas se centran en tres cuestiones:a) Varianza de error: Buena parte de la varianza de error en diseños de grupo no refleja la variabilidad de la conducta por sí misma sino que es creada por el mimo acto de agruparlos. La varianza de error es en parte producto de las diferencias individuales, antes que variaciones reales en los sujetos, y refleja factores que no han sido controlados.b) Generalización: Se supone que el diseño grupal minimiza el impacto de las respuestas idiosincrásicas. Sin embargo, estos diseños presentan un promedio de las respuestas que no refleja con precisión la respuesta de ningún sujeto en particular.c) Confiabilidad: Los diseños de grupo no intentan determinar si el efecto de VI es confiable, es decir, si se obtendrá en otra ocasión. La replicación de un experimento por otros equipos es común, pero dentro del experimento, es rara. Los diseños de sujeto único, al introducir y retirar la VI varias veces, hacen una replicación intrasujeto.Limitaciones: a) No son útiles cuando la reversión (retiro de VI) produce un efecto duradero en la conducta; b) No poseen gran validez externa pues sus efectos sólo se aplican a sujetos similares a los seleccionados; c) No son apropiados para estudiar interacciones entre variables; d) Razones éticas impiden a veces la reversión de un tratamiento; y e) Estos diseños no pueden analizarse mediante estadística inferencial (test t o test F) porque no utilizan promedios grupales.
Los diseños de sujeto único pueden clasificarse del siguiente modo:Diseños ABA.- O diseño de reversión. Intenta demostrar que una VI produce un efecto, y luego, al retirarla, que no lo produce más. La letra A se refiere al momento donde VI o actúa, y B al momento donde sí actúa. Este diseño admite variantes para aumentar su eficacia: ABAB, ABABABA, etc. En varios sentidos, se trata de diseños de series de momentos pero sobre un solo sujeto.Diseños con múltiples valores de la VI.- A diferencia de los anteriores, donde se asigna a VI los valores presencia o ausencia, estos diseños admiten diversos valores de VI, resultando así por ejemplo un diseño tipo ABACA, donde B y C representan dos valores distintos de VI.
Página 195 de 314
195

Diseños de línea de base múltiple.- A veces el efecto de una VI no desaparece cuando es retirada (como cuando se enseña al sujeto una estrategia de afrontamiento contra el estrés). El diseño resuelve este problema: estudia varias conductas simultáneamente y, después de obtener una línea de base de cada una, se introducen niveles de VI que se supone afectan sólo a una de esas conductas. Al medir varias conductas, el investigador puede mostrar que VI afecta una conducta pero no a otras.
Otras diferencias importantes entre los métodos.- Son las siguientes:
Método Requisitos de causalidadCorrelación Antecedencia temporal Exclusión de variables
extrañasCorrelacional Sí No NoExperimental Sí Sí SíCuasi-experimental Sí Sí No
Método Teoría de la que deducir hipótesis
Hipótesis Variables Manipulación
Control de variables pertinentes
Fase
Observación controlada
No Se plantean varias tentativas
Candidatas a VI y VDV. pertinentes
Artificial Sí Exploratoria
Experimental
Sí Hipótesis funcional
VI-VDV. pertinentes
Artificial Sí Probatoria
Cuasi experimental
Sí Hipótesis funcional
VI-VDV. pertinentes
Natural No total Probatoria
Correlacional No Hipótesis de asociación luego del análisis de datos
Variables a asociar
No No Exploratoria
Versión Greenwood
Para Greenwood (1973), el investigador puede elegir el método de investigación empírica más adecuado para el fenómeno o la hipótesis en que está interesado. Cabe distinguir método y técnica del modo siguiente: un método es un arreglo ordenado, un plan general, una manera de emprender sistemáticamente el estudio de los fenómenos de una cierta disciplina. Una técnica, en cambio, es la aplicación específica del método y la forma específica en que el método se ejecuta. Así, la técnica es un auxiliar del método, está subordinada a él. Por ejemplo, hay técnicas de observación y de análisis de los datos, como el muestreo, la observación participante, los tests proyectivos, la entrevista, el cuestionario por correo, etc.Se describen a continuación los tres principales métodos en la investigación social empírica. Ellos tienen sus paralelos en las disciplinas físicas y biológicas: el método experimental con el método de laboratorio, el método de encuesta con el método epidemiológico, y el método de estudio de caso con el método clínico.
Método experimental.- Es un procedimiento lógico para la selección de los sujetos de estudio, la realización de observaciones, la recolección de datos y la organización de la evidencia, destinado a comprobar una relación causal entre dos factores.Características.- a) Requiere un estado de contrastes.- Un experimento necesita al menos dos grupos de individuos, uno de los cuales (el grupo experimental) está sometido a un cierto factor y el otro no (grupo de control), factor llamado exposición, estímulo, tratamiento o variable independiente. b) Identificación de las consecuencias del contraste.- Se comparan los resultados en ambos grupos respecto de la variable dependiente, evaluándose si las diferencias han sido debidos al azar o a una relación causal. Se hacen mediciones no sólo después de la introducción de la variable independiente, sino también antes, para asegurarnos que la variable dependiente no precede a la independiente. Además, deben hacerse controles para verificar que el cambio en la variable dependiente no es debida a otras variables, además de la independiente. O sea: c) Control de influencias extrañas.- Se deben idear ciertos mecanismos para controlar la influencia de otros elementos que también pueden producir los resultados diferenciales entre el grupo experimental y el de control, elementos que pueden referirse a las características de la unidades de estudio y al ambiente en que se hizo el experimento.Técnicas de control.- a) Igualación por parejas o emparejamiento.- Cada unidad elegida para el grupo experimental debe tener su contrapartida perfectamente igual en otra elegida para el grupo de control,
Página 196 de 314
196

respecto de las variables pertinentes a la variable dependiente. b) Distribución de frecuencias.- Consiste en igualar ambos grupos según ciertos parámetros estadísticos como promedio, variación y proporciones, respecto de las variables pertinentes a la variable dependiente. c) Randomización o aleatorización.- Consiste en asignar las unidades a los conjuntos experimental y de control según algún procedimiento al azar, lo que garantiza que las diferencias entre ambos conjuntos sean adjudicables al azar.Las dos primeras técnicas son las más difíciles de emplear, y contribuyen a incrementar la sensibilidad del experimento (este es sensible cuando puede registrar pequeños efectos sobre la variable dependiente atribuibles a la independiente y que, de otra forma, se verían oscurecidos por la influencia de factores externos), mientras que la última asegura su validezTipos de experimentos.- Hay cuatro tipos principales de experimentos. a) Experimento de laboratorio.- Se realiza en un ambiente muy bien controlado. El investigador selecciona los sujetos, señala la naturaleza, intensidad, tiempo, duración y dirección de la variable independiente, etc. Sin embargo es artificial, lo que provoca ciertas dudas sobre la aplicabilidad de sus resultados a la realidad social. b) Experimento de campo.- Se realiza, a diferencia del anterior, en un ámbito real, es decir en una situación social que esté sucediendo, con lo cual la única manipulación del investigador es introducir la variable independiente. Estos experimentos suelen realizarse con prácticos, encargados de, por ejemplo, administrar algún diagnóstico o tratamiento a pacientes. c) Experimento natural.- El investigador estudia algún cambio social cuyo suceso se ha anticipado y que cumple con los tres requisitos del experimento antes mencionados. El investigador no introduce la variable independiente: espera a que aparezca porque la ha anticipado. Los experimentos de laboratorio, de campo y natural se llaman proyectados, mientras que el experimento ex post facto es no proyectado. La diferencia está en que en los proyectados, el investigador puede observar las unidades de estudio antes que aparezca la variable independiente, de manera que puede apreciar como evoluciona y qué efectos produce ésta en el tiempo. d) Experimento ex post facto.- El investigador observa las unidades de estudio sólo después que la variable independiente ha ocurrido, por lo debe ir hacia atrás en el tiempo intentando reconstruir las etapas iniciales que no le fue posible observar. Así, los experimentos proyectados se planifican antes del hecho, y los ex post facto después que se ha producido el hecho.Los cuatro tipos de experimentos fueron mencionados según un orden decreciente en cuanto al grado de control sobre las unidades de estudio, la variable independiente y el ambiente, dándose el máximo control en el experimento de laboratorio.
Método de la encuesta.- Consiste en la observación, por medio de preguntas, de poblaciones numerosas en situaciones naturales con el fin de obtener respuestas susceptibles de analizarse cuantitativamente. A diferencia del experimento, la encuesta nació en las ciencias sociales en el siglo XIX.Características.- a) Poblaciones numerosas.- De las cuales suele extraerse una muestra realizándose, entonces, una encuesta muestral. Mientras más grande y representativa sea la muestra, más confiables serán las generalizaciones a la población. b) Datos primarios.- O sea, sólo pueden obtenerse directamente a través del contacto con los individuos implicados, mediante entrevistas y/o cuestionarios. c) Análisis cuantitativo.- La información se clasifica en categorías y se pone en tablas para poder ser analizada cuantitativamente.Tipos de encuesta.- Existen las encuestas descriptivas y las explicativas. La encuesta descriptiva busca determinar la distribución de un fenómeno en una población, y su resultado es la afirmación de un hecho. La encuesta explicativa, en cambio, busca las razones de tal distribución, con lo cual el resultado es una explicación del hecho observado.Mientras la encuesta explicativa suele estar guiada por una hipótesis explícita, la descriptiva por lo general no lo está. Además, mientras la encuesta descriptiva debe utilizar muestras representativas y heterogéneas, la explicativa puede utilizar muestras no representativas y homogéneas. En general, la mayoría de las encuestas combinan rasgos de la descriptiva y de la explicativa. Así, cuando es una encuesta descriptiva surge alguna hipótesis, el investigador vuelve sobre los datos originales haciendo un análisis secundario mediante submuestras con el fin de constatar las relaciones causales sugeridas en la hipótesis, convirtiéndola en una encuesta explicativa.
Método del estudio de caso.- Consiste en el examen intensivo, en amplitud y profundidad, de una unidad de estudio (un individuo, un grupo, una comunidad, una asociación, un acontecimiento, una cultura) empleando todas las técnicas disponibles para ello. Se busca la comprensión del fenómeno como un todo. Este método surgió en las prácticas clínicas.Características.- a) Intensidad.- Es un método intensivo tanto en amplitud como en profundidad. Amplitud significa que logra cubrir tantos aspectos del fenómeno como sea posible, pues busca una comprensión completa y total del mismo. Profundidad significa que el método se mueve hacia atrás en el tiempo para conocer las circunstancias por las cuales el caso llegó al estado actual. b) Oportunismo.- El método no obliga a usar determinadas técnicas para recoger datos, teniendo completa libertad para ello, y en el orden que se prefiera. El oportunismo más la intensidad permiten obtener una enorme cantidad de información sobre el caso estudiado. c) Análisis heterodoxo.- Dada la variedad y diversidad de las técnicas de recolección de datos usadas, los datos que se obtienen son desusadamente variados y ricos, y pueden analizarse sistemática e intuitivamente.
Evaluación de los tres métodos empíricos.- Normalmente, cada investigador se especializa en uno de los tres métodos indicados, y tiende a considerarlo como el mejor. Sin embargo, cada uno tiene sus virtudes pero también sus limitaciones.
Página 197 de 314
197

Método experimental.- Su principal virtud es que puede confiarse en él para determinar si una relación causal existe o no entre la variable independiente y la dependiente, por cuanto permite constatar el orden temporal de las variables y la exclusión de otras causas posibles. Es el mejor método para probar una hipótesis causal.En este método pueden operacionalizarse fácilmente las variables, y posee además gran versatibilidad pues hay muchos diseños experimentales posibles entre los que elegir.Su defecto principal radica en que es muy difícil de aplicar, especialmente en su forma más pura y rigurosa. Segundo, el experimento debe contar con la cooperación o conciencia de estar participando en un experimento por parte de los sujetos. Tercero, en un laboratorio es muy difícil reproducir con todo su vigor las fuerzas sociopsicológicas que actúan normalmente sobre las personas: el mundo real no puede duplicarse en el laboratorio. Cuarto, el experimento es inapropiado en la etapa exploratoria o inicial de la investigación, pues requiere un cabal conocimiento del fenómeno en estudio.Método de la encuesta.- Como primera ventaja, este método permite obtener generalizaciones confiables sobre uniformidades sociales porque las muestras son muy numerosas. En segundo lugar, evita algunos problemas del método experimental como la artificialidad.Un primer defecto del método de encuesta es su falta de intensidad: el contacto con los sujetos es superficial y breve. Segundo, sólo se hacen preguntas susceptibles de analizar cuantitativamente con respuestas previstas de antemano. Tampoco es un método ideal para establecer conexiones causales pues es difícil obtener datos sobre ordenamiento temporal de variables y exclusión de otras causas posibles. Otra desventaja es la autoselección (algunos encuestados pueden elegir inconcientemente sufrir o no la experiencia cuyos resultados se observan), entendiendo por tal la variable que favorece y desfavorece la aparición del fenómeno en estudio, y esta variable no está controlada en la encuesta, aún en la explicativa, o sea, no satisface el criterio de causalidad de exclusión de otras causas posibles.Método del estudio de caso.- Su principal virtud es que permite una comprensión profunda y completa del fenómeno. En segundo lugar, resulta muy valioso como método exploratorio. En cambio, sus limitaciones tienen que ver, primero, con la falta de rigor característico del aspecto analítico de este método y su dependencia casi exclusiva de la capacidad de síntesis del investigador para imponer un cierto orden en la gran masa de datos. Pero, aún cuando la interpretación sea confiable, subsiste una segunda limitación: sus resultados no son generalizables a otros casos, ni mucho menos a la población.
La clasificación de los métodos de investigación social empírica propuesta por Greenwood puede sintetizarse en el siguiente cuadro:
Método Experimental Encuesta Estudio de casoCaracterísticas Estado de contrastes.
Identificación de las consecuencias del contraste.Control de influencias extrañas mediante igualación por parejas, distribución de frecuencias o randomización.
Poblaciones numerosas.Datos primarios.Análisis cuantitativo.
Intensidad en amplitud y profundidad.‘Oportunismo’: libertad para emplear técnicas.Análisis heterodoxos: datos ricos y variados.
Tipos Proyectados:De laboratorio.De campo.Natural.No proyectados:Expost-facto.
Descriptiva.Explicativa.
Ventajas Detecta conexiones causales.OperacionabilidadEspecificidad.Versatibilidad.
Resultados generalizables.No es artificial.
Comprensión profunda.Carácter exploratorio.
Desventajas Difícil de aplicar.Sujetos deben cooperar.Artificialidad.No apto para investigaciones exploratorias.
Falta de intensidad.Selecciona preguntas.No detecta causalidad.Autoselección.
Sin rigor analítico.No generalizable.
Versión O’Neil
O’Neil (1968:28) sostiene que los principales métodos de observación empleados en la psicología son los métodos experimentales y los métodos no experimentales. En los primeros, “el control se ejerce sobre las condiciones en que ocurre el acontecimiento estudiado”, lo que no ocurre en los métodos no experimentales. Dentro de los métodos no experimentales, a su vez, pueden distinguirse los métodos de estudio de caso y los métodos de sondeo (o encuesta). Los métodos no experimentales pueden considerarse como aquellos que se refieren al establecimiento de hechos representativos, lo que no significa que no estén orientados por hipótesis o no se refieran a la comprobación de hipótesis., pero, “en general, la hipótesis para comprobar se refiere al hecho que se establece (o su opuesto) y no a algo que implica ese hecho” (O’neil, 1960:5).
Página 198 de 314
198

a) Métodos experimentales.- La expresión ‘control de las condiciones’ se refiere a las circunstancias importantes del acontecimiento, o a si su observación ha sido constante o modificada de un momento a otro y de una manera establecida. La característica distintiva del experimento es “un modelo de constancia y variación de una ocasión a otra” (O’neil, 1960:31). La función característica del experimento es la comprobación de hipótesis, pero también tiene otras funciones como por ejemplo indagar cuales son los movimientos típicos de los recién nacidos, o bien que respuestas pueden despertarse en el neonato y mediante qué estímulos (O’neil, 1960:33),Existen tres tipos de técnicas para ejercer el control sobre las condiciones: manipulativas, selectivas y estadísticas. Por ejemplo, un experimento donde se quiere averiguar como influye el nivel de escolaridad sobre la amplitud del vocabulario. Un experimento manipulativo consistiría en medir el vocabulario en niños de diferente escolaridad pero de similar influencia parental (pues se supone que el vocabulario de los padres es otra variable que incide sobre el vocabulario del niño) y en escuelas equivalentes. Como este experimento es difícil que realizar, puede aplicarse entonces una técnica selectiva, donde seleccionamos de entre la gente joven con la que contamos, aquellos de inteligencia semejante, padres similares y diferentes niveles de escolaridad, con lo que obtenemos una muestra bastante semejante a la obtenida con la técnica manipulativa. Sin embargo, estas muestras pueden resultar demasiado pequeñas, con lo cual puede utilizarse la técnica estadística: se toman a todas las personas con que contamos, medimos su inteligencia, el vocabulario de los padres, la escolaridad y el vocabulario de los sujetos, aplicando a estas medidas coeficientes de correlación entre cada par de variables (O’neil, 1960:39).b) Métodos no experimentales: estudio de caso.- Tiene por objeto describir de manera completa al sujeto individual, lo típico de él. Dos variedades importantes de estudios de caso son los estudios biográficos y los estudios clínicos, ya que sambos producen una descripción del individuo a partir de una gran cantidad de observaciones diversas (O’neil, 1960:50).c) Métodos no experimentales: encuesta.- Tiene por objeto descubrir lo que es típico de un grupo de sujetos. Se han planteado algunos tipos, como los estudios de campo, los estudios de desarrollo y los estudios diferenciales. “Un estudio de campo es una encuesta llevada a cabo sobre el terreno, en los lugares habituales donde viven los sujetos; un estudio de desarrollo busca demostrar algún cambio típico, durante algún lapso de la vida, en el curso de la conducta; y un estudio diferencial busca señalar las diferencias o las semejanzas entre algunas clases de hechos, por ejemplo, el sexo, la raza, la edad y la clase social. Los tres tipos de encuesta tienen en común que las diversas situaciones estudiadas se toman como representativas de una clase más numerosa, a la cual pertenecen” (O’neil, 1960:58).
6. CONCLUSIONES
La gran diversidad de criterios taxonómicos presentados obliga al investigador no conocedor de estos temas a realizar un considerable esfuerzo de búsqueda y selección del diseño más apropiado.Con el fin de trazar un esbozo de árbol de decisión, se propone buscar y seleccionar un diseño de investigación en base a las siguientes preguntas:Si el investigador no ha planteado una hipótesis causal, puede orientarse respondiendo a las siguientes preguntas:a) ¿Se desea realizar un estudio simplemente exploratorio, sin hipótesis previas y sin haber identificado variables? Convendrá entonces elegir la observación o la encuesta, teniendo presente que estas técnicas también pueden utilizarse en estudios descriptivos, correlacionales o explicativos. El diseño observacional puede consistir en una observación o en observaciones sucesivas a lo largo del tiempo, y pueden utilizarse también los diseños preexperimentales de Campbell y Stanley.b) ¿Se desea estudiar una simple asociación estadística entre variables sin intentar probar un nexo causal? Entonces se podrá optar por el diseño de encuestas o por los métodos correlacionales descritos por autores como Lores Arnaiz o Hernández Sampieri.c) ¿Se desea estudiar a fondo un caso sin intentar extraer conclusiones generales para toda la población? Para ello está especialmente indicado el método de estudio de caso descrito por Greenwood o por O’neil. A diferencia de los diseños de sujeto único, no buscan obtener generalizaciones a toda la población sino explorar en profundidad un caso particular.Si el investigador ha planteado una hipótesis causal que desea probar y ha identificado variables relevantes, puede ahora responder a los siguientes interrogantes:d) ¿Se cuenta con un sujeto único o con un grupo de sujetos? En estos casos el investigador seleccionará diseños de sujeto único o de grupo.e) ¿Cuántas variables independientes (VI) serán estudiadas? Si se estudia una sola, el investigador elegirá un diseño simple, o univariado (o divariado, según Selltiz), y si estudia dos o más, entonces elegirá alguno de los diseños factoriales o multivariados.f) ¿Se quiere ser exigente respecto del control de las variables extrañas? Convendrá entonces elegir un diseño experimental propiamente dicho de la versión Campbell y Stanley. Los diseños cuasiexperimentales de la misma versión ofrecen menor control de aquellas variables, pero aumentan la validez externa.g) ¿Se quiere estudiar un fenómeno aquí y ahora, o a lo largo del tiempo? Para ello se podrán seleccionar diseños experimentales o diseños no experimentales, y, dentro de estos últimos, diseños transeccionales o longitudinales en la versión de Hernández Sampieri.
Página 199 de 314
199

CAPÍTULO 14: EL PROCESAMIENTO DE LOS DATOS
Una vez cumplidas las etapas anteriores, llega ahora el momento de tomar contacto con la realidad, es decir, con los sujetos de la investigación, lo que implicará generar los primeros datos. En sentido amplio, el procesamiento de los datos abarca cuatro etapas: la recolección, la organización, el análisis y la interpretación de los datos. En el presente capítulo se suministra información acerca de cómo proceder en cada una de esas instancias sobre la base del conocimiento adquirido en capítulos anteriores y sobre la base de algunos nuevos conocimientos.En el contexto de la investigación científica, un dato es un fragmento de información obtenido de la realidad y registrado como tal con el fin de contribuir a resolver el problema de investigación. Un dato se expresa habitualmente en forma de enunciados afirmativos del tipo “Juan obtuvo 80 puntos en el test A”, “La media aritmética del pretest del grupo experimental es 75”, “La mitad de la muestra seleccionada es de sexo masculino”, etc. El dato es entonces eminentemente descriptivo, y puede referirse a un individuo o a una muestra.Los datos pueden buscarse en forma directa o bien ser tomados de otras investigaciones o fuentes confiables. En cualquier caso, los datos deben ser objetivos, es decir, reflejar fielmente la realidad. En un sentido estricto, cualquier conclusión probabilística a partir del análisis o la interpretación de los datos no es un dato sino una suposición o inferencia.Las cuatro etapas del procesamiento de los datos se cumplen en mayor o menor medida en las investigaciones exploratorias, descriptivas, correlacionales y explicativas. Por ejemplo, en las investigaciones exploratorias la etapa de la recolección de datos es la más importante.
1. RECOLECCIÓN DE LOS DATOS
Los datos se obtienen de la realidad mediante los llamados instrumentos de recolección de datos. Por ejemplo, el dato ‘Juan es inteligente’ puede obtenerse a través de una observación, de una entrevista, de un cuestionario o de un test, que son instrumentos típicos de las ciencias sociales y, en particular, de la psicología. En otras disciplinas pueden encontrarse otros instrumentos de recolección de datos como el telescopio, el termómetro, el espectrógrafo, el estetoscopio o la balanza.Todos los instrumentos de medición mencionados en capítulos anteriores son al mismo tiempo y forzosamente instrumentos de recolección de datos, por cuanto medir supone obtener datos.En el presente ítem se pasará una somera revista a los principales instrumentos de recolección de datos en ciencias sociales y a algunas precisiones sobre la forma de obtener datos correctamente con ellos. Se hará referencia a la observación, la entrevista, el cuestionario y el test.
La observación
La observación científica es aquella observación que se realiza como parte de un proyecto de investigación científica. Se caracteriza porque tiene objetivos definidos y concretos, y porque deliberadamente procura ser objetiva. En este ítem se examinan cuestiones relativas al registro de la observación, los tipos de observación, las precauciones en el empleo de esta técnica de recolección de datos y algunas de sus ventajas y limitaciones.
Introducción.- Sin ser científicos, todos los días las personas tienen oportunidad de observar: observan a su alrededor mientras hacen cola en el banco, mientras asisten a un acto patriótico, mientras viajan en colectivo, mientras aguardan una cita, mientras están en un velorio o cuando asisten a una fiesta.En una gran cantidad de casos como estos no se observa con un propósito determinado: se deja vagar la vista simplemente porque se prefiere tener los ojos abiertos en lugar de tenerlos cerrados. Algunas de las cosas que observan llaman más la atención, pero al siguiente momento la vista o el oído se apartó de ellas y dirigiendo la atención hacia otras, un poco aleatoriamente. Estas observaciones no tienen un propósito definido y son bastante fortuitas y poco estructuradas, en el sentido de que se atiende aquí y allá situaciones diversas, sin orden ni preferencias.Pero en la vida cotidiana existen también otros tipos de observación donde se sabe exactamente qué se quiere observar, siendo la observación más deliberada y atenta. Es el caso de la persona que observa atentamente cuando sus hijos cruzan la calle, o la que espía a su cónyuge para ver qué hace cuando cree estar solo, o la que atiende las características de las calles para orientarse correctamente, o la persona voyeurista que se complace en observar una escena erótica.Este tipo de observaciones son observaciones cotidianas: pueden tener o no un propósito definido, y son observaciones que llevan a cabo todas las personas fuera de todo objetivo científico. Cuando una observación se realiza dentro del marco de una investigación científica, cabe denominarla observación científica.
La observación científica.- La observación científica apunta a fines, objetivos o propósitos determinados: puede servir como fuente de inspiración de hipótesis (y entonces es menos estructurada o sistemática), como procedimiento para comprobación de hipótesis, (entonces será más sistemática y controlada), etc. Dice Kaplan que “la observación científica es búsqueda deliberada, llevada con cuidado y premeditación, en contraste con las percepciones casuales, y en gran parte pasivas, de la vida cotidiana” (Ander-Egg, 1987:197).
Página 200 de 314
200

En la literatura sobre el tema, sin embargo, se suele denominar observación científica a la observación sistemática y estructurada, es decir, aquella especialmente apta para la comprobación de hipótesis. Así, por ejemplo, León y Montero refieren que para que la observación sea científica debe ser sistemática (León O y Montero I, 1995), mientras que otros autores señalan que la observación científica “necesita de intencionalidad y sistematicidad para poder conseguir resultados rigurosos y adecuados” (Rubio J y Varas J, 1997:403).Aquí se considerará a la observación científica en un sentido un poco más amplio, de manera tal que incluya tanto las observaciones poco estructuradas y más libres, especialmente útiles para descubrir hipótesis, como las observaciones más estructuradas y pautadas, especialmente útiles para su verificación. Por ejemplo: observar libremente todo lo que ocurre en un grupo de adolescentes con el fin de descubrir porqué se drogan es un ejemplo del primer tipo, mientras que observar ciertas conductas específicas de un grupo de adolescentes con el fin de probar o no que ellos se drogan porque están ansiosos, es un ejemplo del segundo tipo.Es así entonces que puede definirse la observación científica como toda aquella observación que se realiza como parte de un proyecto de investigación científica. Se caracteriza porque tiene objetivos definidos y concretos, y porque deliberadamente procura ser objetiva.La observación es un procedimiento de percepción a través de los sentidos del investigador (especialmente la vista y el oído), y no mediante relatos orales o escritos de otras personas, e implica un examen de fenómenos actuales tal como tienen lugar en un aquí y ahora, y no de fenómenos pasados (Sierra Bravo R, 1979).La observación comporta siempre cinco elementos: el sujeto que observa, lo observado, los medios (sentidos como la vista u oído), los instrumentos (medios que sirven de apoyo a los anteriores), y el marco teórico (que guía la observación) (Ander-Egg, 1987:198).Utilizada científicamente, la observación es al mismo tiempo un instrumento de recolección de datos y un instrumento de medición. Por ejemplo, cuando observamos jugar a un niño no solamente estamos recogiendo información (“este niño rompe los juguetes que no le gustan”) sino que también estamos midiendo su conducta (por ejemplo, adjudicándole un valor a su conducta: “es muy agresivo”, “medianamente agresivo” o “poco agresivo”). En cuanto la observación recoge datos y mide comportamientos, la información deberá quedar registrada.
Observación y registro.- La observación científica tiene, como cualquier tipo de observación, dos etapas básicas: la observación propiamente dicha y el registro de lo observado. Algunos autores llegan a dar tanta importancia a esta última etapa que directamente definen la observación en términos de registros, como por ejemplo cuando sostienen que la observación “consiste en el registro sistemático, válido y confiable de comportamientos o conducta manifiesta“(Hernández Sampieri y otros, 1996:316).Siempre que se observa algo, simultánea o sucesivamente se está también registrándolo, es decir, representando la observación mediante algo que la mantiene perdurable en el tiempo, mediante algo que deja constancia de lo observado. Cuando se observa la calle en un paseo, lo observado queda registrado en la memoria, más allá de la voluntad y más allá de si luego se utilizará o no ese registro para recordar lo observado. Sin embargo, el mero registro mnémico, en el contexto de las observaciones científicas, tiene dos inconvenientes: no es fiable y no es público. No es fiable porque los datos de la memoria se alteran con el tiempo, y no es público porque ningún otro investigador puede consultar la memoria de un observador cuando lo desee. Por lo tanto, la observación científica requiere algún tipo de registro de la información que sea fiable y público. Por ejemplo, una grabación de sonido o video, o un escrito que describe o narra lo observado. En el primer caso el registro se realiza mientras se observa, y en el segundo caso luego de haber observado.Los registros suelen clasificarse en dos grandes grupos: los registros narrativos y los registros de planilla. Estos últimos también suelen denominarse registros de conducta (Rubio J y Varas J, 1997:422) o registros de código arbitrario (León O y Montero I, 1995).En el registro narrativo el observador se limita a contar lo que ha observado en forma de relato descriptivo. El registro narrativo de una observación podría comenzar por ejemplo, así: “Nos reunimos por la mañana temprano y fuimos al aula que nos habían indicado. Cuando entramos, los alumnos estaban todos conversando entre sí, mientras el docente escribía en el pizarrón…”.En el registro de planilla, el observador no cuenta una historia sino que “llena” una planilla o formulario con ciertos variables, indicadores y categorías establecidas de antemano. Así, por ejemplo, puede haber un casillero que solicite cantidad de alumnos de la clase observada, otro para el promedio de edad de los alumnos, otro donde el observador deberá elegir llenar el casilleros “Sí”, “No” o “Más o menos” frente a la pregunta “Los alumnos se mostraron ansiosos cuando el profesor les explicó la tarea que tenían que realizar?”, etc. En este último ejemplo, la variable puede ser “ansiedad” y las categorías los diferentes valores que pueden adjudicarse a la ansiedad, es decir, “Sí”, ”No” y “Más o menos”. Eventualmente, también pueden codificarse estas diferentes categorías adjudicando arbitrariamente el valor 2 a “Sí”, el valor 0 a “No”, y el valor 1 a “Más o menos”.En el código arbitrario se organiza la información en una planilla con datos de interés (por ejemplo cantidad de alumnos, etc.). El código arbitrario es un sistema de categorías arbitrarias elaboradas por el investigador para registrar los elementos de su interés en el fenómeno observado (León y Montero, 1995). Bakeman y Gottman (1986) recomiendan los siguientes puntos para elaborar un código de observación:
Página 201 de 314
201

1) Nunca observar sin una pregunta previa claramente formulada.2) Seleccionar el o los niveles de análisis adecuados para buscar una respuesta.3) Hacer una observación asistemática para recoger información en forma narrativa para ir descubriendo categorías de análisis.4) Procurar usar categorías dentro del mismo nivel de molaridad-molecularidad, que sean homogéneas y lo suficientemente detalladas.5) El código debe estar formado por categorías exhaustivas y excluyentes entre sí.6) Realizar finalmente un proceso de depuración, mediante la contrastación empírica, antes de considerar que se ajusta a sus intereses como investigador.
En otro ejemplo (Hernández Sampieri y otros, 1996:316), para investigar la influencia del conocimiento acerca del retraso mental sobre la conducta frente al retrasado mental, las categorías a considerar pueden ser distancia física, movimientos corporales de tensión, conducta visual y conducta verbal.Como puede apreciarse, en el registro de planilla la información está más organizada, está más sistematizada en términos de qué aspectos de lo observado resultan relevantes, mientras que el registro narrativo es más libre.Las variables, indicadores y categorías se seleccionan siempre en función del marco teórico que sustente el observador-investigador: marcos teóricos distintos dan lugar a categorías de observación diferentes. Por ejemplo (León O y Montero I, 1995), si se observa el comportamiento verbal de un niño pequeño, se puede utilizar el marco teórico de Piaget o el de Vygotski. En el primer caso se tomará en consideración el concepto de habla egocéntrica (para Piaget primero se aprende a hablar, luego se habla solo y finalmente se empieza a hablar para o con los demás), y en el segundo caso se considerará el concepto de habla privada (para Vygotski, primero se empieza hablando para y con los demás, y luego el habla se usa para comunicarse con uno mismo, el habla se internaliza y forma los rudimentos del pensamiento verbal).Cuando se trata de observar conductas mediante un registro de planilla, los investigadores suelen utilizar cinco aspectos o dimensiones de las mismas: ocurrencia, frecuencia, latencia, duración e intensidad (León O y Montero I, 1995). La ocurrencia informa sobre si determinado fenómeno ocurrió o no durante la observación. La frecuencia nos indica el número de veces que un determinado dato de observación aparece durante la misma. Otra medida posible de obtener es la latencia, o tiempo que transcurre entre un estímulo y la aparición de la reacción o respuesta al mismo. La duración es el tiempo durante el cual se manifiesta el fenómeno observado, y la intensidad es la fuerza con que el fenómeno aparece en un momento dado. Por ejemplo, la intensidad de la conducta agresiva.
Tipos de observación.- Diferentes autores (Ander-Egg, 1987:201) (Rubio J y Varas J, 1997:404) (León O y Montero I, 1995) nos ofrecen distintas clasificaciones de los tipos de observación. En lo que sigue se proponen varios criterios importantes a tener en cuenta cuando se trate de ubicar cualquier observación en alguna categoría.
a) Según la participación del observador, la observación puede ser participante o no participante (Hernández Sampieri y otros, 1996:321) (León O y Montero I, 1995). La primera también se denomina interna y la segunda externa.En sentido amplio, observación participante es aquella en la cual el observador ejerce influencia sobre el sujeto observado, lo cual puede ocurrir de dos maneras: a) observando la conducta del sujeto sabiendo éste que es observado, o b) interactuando con el sujeto sin que este advierta que es investigado.En la observación participante el observador interactúa con los sujetos que observa, es decir, es parte de la situación observada, lo que no ocurre en la observación no participante, donde el observador permanece ajeno a dicha situación. Por ejemplo, no es lo mismo observar la conducta de un bebé mientras el observador está jugando con él, que cuando lo mira a través del vidrio de una cámara Gesell. Un ejemplo típico de observación participante lo ofrece la etnografía, cuando el observador convive con los indígenas a quienes desea observar. Se trata de una observación activa pues el observador participa en forma directa e inmediata de la situación, por ejemplo, asumiendo algún rol dentro del grupo observado. Esta participación puede ser natural, cuando el observador ya pertenece al grupo observado, o artificial, cuando se integra al grupo para hacer la investigación.En sentido amplio, observación participante es aquella en la cual el observador ejerce influencia sobre el sujeto observado, lo cual puede ocurrir de dos maneras: a) observando la conducta del sujeto sabiendo éste que es observado, o b) interactuando con el sujeto sin que este advierta que es investigado.La observación participante permite (León O y Montero I, 1995) acceder a información que no podría adquirir un observador externo, no participante.
He aquí algunas definiciones de observación participante.“Procedimiento para la recolección de datos en el cual el investigador se introduce en el medio natural y dedica buen tiempo a notar y observar lo que allí sucede, y a veces a interactuar con las personas que estudia” (Vander Zanden J, 1986:623).La “observación participativa es un método para conducir la investigación descriptiva en el cual el investigador se convierte en un participante de la situación a fin de comprender mejor la vida de ese grupo” (Woolfolk, 1996:14).
En el caso de la observación no participante, el observador puede estar oculto o bien a la vista. Por ejemplo, cuando se observa el comportamiento de los alumnos en una clase, ellos saben que el observador está allí, que es alguien ‘de afuera’ que llegó quién sabe con qué intenciones. En estos casos
Página 202 de 314
202

debe tenerse en cuenta la reactividad (León O y Montero I, 1995), es decir, la posibilidad de estar observando un fenómeno sesgado o influido por la propia presencia del observador, cuestión que en otro ámbitos como la física cuántica ha sido destacado en el llamado principio de incertidumbre de Heinsenberg. Lo ideal, aunque difícil de realizar, es que el observador pase desapercibido. Si ello no ocurre, se esperará a que el observado se habitúe a la presencia del observador.
De acuerdo a otros autores (León y Montero, 1995), según el grado en que el observador interviene en la situación observada, la observación puede ser: observación natural, observación estructurada y experimento de campo. Por observación natural se entiende aquella donde el observador es un mero espectador de la situación, sin que intervenga de modo alguno en el curso de los acontecimientos observados. Además, tal situación es natural o sea se produce dentro del contexto usual donde surgen los fenómenos a observar.En la observación estructurada el observador busca estructurar una situación para obtener una mayor claridad en sus datos. Por ejemplo, observar niños pero proponiéndoles una tarea para realizar. En el caso del experimento de campo, el nivel de estructuración es mucho mayor aunque se mantiene el propósito de realizar la observación en un contexto natural (de ahí el nombre ‘campo’). Un experimento de campo implica la creación de al menos dos situaciones distintas de observación, de tal modo que las diferencias esperables entre ambas sean atribuibles a la causa que está investigando.
b) Según el número de observadores, la observación puede ser individual o grupal (también llamada colectiva o en equipo).La observación individual la realiza una sola persona, mientras que la observación grupal es llevada a cabo por varias personas. En este último caso, pueden darse varias posibilidades, como por ejemplo: 1) cada integrante del grupo de observadores observa la situación en días diferentes; 2) todos los integrantes observan la misma situación al mismo tiempo, lo cual resulta especialmente útil cuando se trata de corregir posibles diferencias subjetivas entre ellos; y 3) todos los integrantes observan la misma situación al mismo tiempo pero cada cual con la consigna de observar diferentes aspectos de la situación. Por ejemplo: un observador puede atender la conducta corporal y otro la conducta verbal.
c) Según el grado de sistematización de los datos, la observación puede ser sistemática o no sistemática (o, según otras terminologías, estructurada y no estructurada). Algunos autores (Rubio J y Varas J, 1997) incluyen categorías intermedias y se refieren a observaciones no sistematizada, sistematizada y muy sistematizada.En la observación sistemática el observador cuenta con esquemas elaborados acerca de lo que observará, que definen y limitan el campo de la observación. Implica delimitar de antemano tanto el campo a estudiar (lugares y sujetos) así como los aspectos concretos o conductas a observar.Algunos autores (González G, 1990) definen directamente la observación en términos de esta característica, cuando dicen que la observación comprende el registro de los patrones conductuales de personas, objetos y sucesos en forma sistemática para obtener información sobre el fenómeno de interés.León y Montero indican que una condición para que una observación sea científica es que debe ser sistemática, es decir, se debe hacer de tal modo que de lugar a datos susceptibles de ser obtenidos –replicados- por cualquier otro investigador. Para garantizar esta sistematicidad es preciso que haya procedimientos para evitar que los datos puedan ser sesgados por una definición ambigua de lo que se observará (el habla privada, por ejemplo), por la forma de registrar los datos (mientras se observa o al final), por el momento de la observación (no es lo mismo observar niños por la mañana que por la tarde), por los sujetos observados (a qué niños observar). En suma, todos los observadores deben respetar las mismas condiciones: qué observar, como observar, cuándo observar y a quiénes observar (León y Montero, 1995).La observación no sistemática es más libre en el sentido que no se establece de antemano con precisión que se buscará observar, y por ello resulta especialmente apta para investigaciones exploratorias donde, por no existir mucho conocimiento del tema, el observador abre todos sus sentidos y posibilidades para conocer el fenómeno.
d) Según el grado de artificialidad de la situación observada, la observación puede ser natural o artificial. Esta última se llama también observación de laboratorio.Mientras en la observación natural observamos una situación que ocurre espontáneamente, que forma parte de la vida real, en la observación artificial el investigador crea una situación especialmente para ser observada. No es lo mismo observar como las personas reaccionan en la calle frente a un accidente casual, que seleccionar a un grupo de personas en un lugar determinado y exponerlas a presenciar un accidente provocado por el investigador. En este último caso, la situación no ocurre en forma espontánea y natural, sino que es inducida o provocada.Las observaciones artificiales son típicas de los experimentos de laboratorio. Por ejemplo, cuando se aisla a un grupo de niños en una cámara Gesell y, en un momento dado se les suministra juguetes y luego se les quita, con el fin de averiguar como influyen los niveles de frustración sobre la forma de jugar de los niños.Ciertos autores ofrecen su propia definición de observación natural. Por ejemplo, para León y Montero la observación natural incluye también la condición de ser una observación no participante: por observación natural entienden aquella donde el observador es un mero espectador de la situación, sin que intervenga
Página 203 de 314
203

de modo alguno en el curso de los acontecimientos observados. Además, tal situación es natural, o sea, se produce dentro del contexto usual donde surgen los fenómenos a observar (León O y Montero I, 1995).Para Vander Zanden, en la observación naturalista se observa y registra el comportamiento de las personas tal como se produce dentro de su marco natural. Es importante aquí la observación participante, donde el investigador se introduce dentro del grupo que va a estudiar, a veces interactuando también él con las personas en estudio. Una variante es el experimento por demostración (Garfinkel) donde el investigador introduce una perturbación dentro de las interacciones para ver cómo las personas reaccionan (Vander Zanden, 1986).
e) Según el tipo de información que se busca, la observación puede ser cualitativa o cuantitativa. La observación cualitativa procede en forma poco estructurada, priorizando los aspectos relacionales y significativos de la conducta, sin detenerse en su frecuencia y regularidad. Es útil en estudios exploratorios sobre un fenómeno desconocido. La observación cuantitativa, en cambio, busca el registro y recuento de conductas con la intención de ofrecer tipos o perfiles de comportamientos, regularidades y predicciones en torno a la frecuencia con que aparece un rasgo, acción o conducta. Es típica en la observación más sistematizada.Por ejemplo, en una observación cualitativa se describirá una conducta atendiendo a sus peculiaridades únicas, mientras que en una observación cuantitativa se describirá simplemente cuantas veces ha aparecido esa conducta durante el tiempo de observación.Rubio y Varas refieren que los registros narrativos son más aptos para obtener información cualitativa, y suelen ser empleados en observaciones no sistemáticas. En cambio los registros de planilla son más aptos para obtener información cuantitativa, y son típicos de las observaciones más sistemáticas (Rubio J y Varas J, 1997:422).
Hay aún otras clasificaciones, como por ejemplo según la forma de obtención de los registros puede ser personal y mecanizada, y según su campo de aplicación, puede ser auditorías, análisis comunicacional y análisis de vestigios (González G, 1990).
Precauciones en el empleo de la observación.- a) Técnicas de muestreo en la observación.- ¿Cuando observar, a quién observar y dónde hacerlo? Respecto del a quién, se elige siempre una muestra de sujetos, no a toda la población, pero ella debe ser representativa, es decir, recoger todas las características relevantes de la población. Respecto del cuándo observar, hay un muestreo de tiempo, es decir, elegir el lapso de tiempo que se observará (todo el día, por la mañana, etc.). Este muestreo de tiempo puede ser sistemático (selección racional del periodo de observación) o aleatorio (al azar). Una vez seleccionados los periodos de observación, deberá luego decidirse si el registro de lo observado se hará en forma continua o por intervalos. Y respecto del dónde observar, debe realizarse un muestreo de situaciones (también puede ser sistemático o aleatorio), y aquí la muestra debe también ser representativa (León O y Montero I, 1995).En general conviene elegir una muestra representativa de la población y del tiempo de observación. Si se elige observar alumnos con problemas de motricidad, tal vez no sean una muestra representativa de toda la población estudiantil. A veces, sin embargo (Rubio J y Varas J, 1997:430), pueden seleccionarse casos únicos, casos extremos, casos comparables entre sí, etc. Del mismo modo, si se elige observar solamente dos minutos, tal vez ese lapso no represente todo lo que sucede en la clase, y sí puede ser una muestra temporal representativa tomar varios intervalos de diez minutos al azar.b) Validez y confiabilidad.- Hasta donde sea posible, debe procurarse que la observación sea válida y confiable. Validez y confiabilidad son los dos requisitos básicos de todo instrumento de medición. León y Montero explican que la confiabilidad se refiere a que el procedimiento de recogida de datos ha de llevar siempre a la obtención de la misma información, dentro de una situación dada, independientemente de quién recoja los datos o del momento en que se recojan.El grado de acuerdo es el medio más usual para estudiar la fiabilidad. Existen varios índices para calcular este acuerdo, como por ejemplo el porcentaje de acuerdo (porcentaje de veces que dos observadores han coincidido en lo observado) y el coeficiente Kappa de Cohen (toma en cuenta que algunos de los acuerdos pueden ser debidos al azar).Por validez se entiende que dicho procedimiento recoja los datos que realmente pretende recoger. La validez se suele estudiar en relación a tres aspectos diferentes de la misma. La validez de contenido estudia si la selección de conductas recogidas en un código es una muestra representativa del fenómeno a estudiar. La validez de constructo indica en qué medida un código de observación es congruente con la teoría desde la que se formuló el problema. Y la validez orientada al criterio establece en qué medida un código detecta las posibles variaciones del fenómeno a observar (sensibilidad del código) (León O y Montero I, 1995).c) Etica.- Adoptar una actitud de respeto hacia las personas observadas. Cuando sea necesario dar a las personas una explicación de las tareas de observación (Ander-Egg, 1987:198).d) Los detalles.- Utilizar indicios y percepciones a partir de pequeños detalles. Aunque leves, las impresiones ayudan a la comprensión del todo (Ander-Egg, 1987:198).e) Identificación de la unidad de análisis.- Deberá tenerse en claro a quién se observará: a las personas, al grupo en su conjunto, a un colectivo (conjunto de personas que no llegan a formar un grupo), a un barrio, etc. En función de la unidad de análisis se establecerán las variables a considerar. Por ejemplo, si se estudian grupos interesarán propiedades tales como la cohesión, que no correspondería adjudicar a las personas individualmente. En cambio, si la idea es estudiar personas, variables a considerar podrían ser
Página 204 de 314
204

el sexo o la personalidad, cualidades que no se podrían adjudicar a un grupo. Existen, sin embargo, variables que en principio pueden adjudicarse tanto a personas como a grupos, como por ejemplo los estilos de aprendizaje.
Ventajas y limitaciones de la observación.- Tanto como instrumento de recolección de datos como instrumento de medición, la observación presenta ciertas ventajas y ciertas limitaciones en relación con otros instrumentos como pueden ser la entrevista, el cuestionario o los tests.
Algunas ventajas de la observación pueden ser las siguientes (Hernández Sampieri y otros, 1996:321) (Ander-Egg, 1987:206):1) No es obstrusiva, es decir, este instrumento de medición no estimula el comportamiento de los sujetos, como puede hacerlo un cuestionario. Simplemente registra algo que fue estimulado por factores ajenos al instrumento de medición.2) Acepta material no estructurado.3) Puede trabajar con grandes volúmenes de datos.4) Permite obtener información independientemente del deseo o no de las personas de ser observadas.5) Permite obtener información teniendo en cuenta el contexto en que ocurre.6) Permite obtener información sin intermediarios, de ‘primera mano’, sin distorsiones.
Entre las limitaciones de la observación se pueden consignar (Ander-Egg, 1987:207):1) El observador suele proyectar su ecuación personal sobre lo observado. El sesgo en la observación está también influido por las propias expectativas del observador acerca de lo que verá (León O y Montero I, 1995).2) No es sencillo separar los hechos observados de la interpretación de los hechos.3) El observador puede influir sobre lo observado provocando conductas atípicas, inhibiciones, exhibicionismo, etc., en los observados.4) Se corre el riesgo de hacer generalizaciones no válidas a partir de situaciones no representativas.
Observación e hipótesis.- En general, se admite que toda observación es selectiva, en el sentido de que está orientada o guiada por expectativas previas acerca de cómo es la realidad, es decir, por hipótesis previas. Si se observa una biblioteca donde algún libro está en alguna posición anómala, la atención se dirige más rápidamente a ese libro: de alguna manera el observador se siente conmovido o alarmado porque hay algo que se contradice con su expectativa acerca de lo que es una biblioteca. En estos casos, dos cursos posibles de acción pueden ser los siguientes: o bien se coloca ‘bien’ el libro (se modifica la realidad), o bien se cambia la hipótesis acerca de lo que es una biblioteca (se cambia la teoría).Puede concluirse que entre observación e hipótesis hay una realimentación: la observación sugiere nuevas hipótesis, pero también las hipótesis previas orientan la observación.
La entrevista
Definición.- Es una situación en la cual el investigador y el o los entrevistados mantienen un diálogo cara a cara con el fin de obtener datos para una investigación. Por ejemplo, en una investigación exploratoria permite recabar información de cualquier persona que esté inmersa en el tema a investigar. Si se investiga drogadicción, podrán entrevistarse a drogadictos, padres hermanos o amigos de drogadictos, expertos en drogadicción, ex-drogadictos, etc.Tamayo (1999:94) la define como un conjunto de preguntas realizadas en forma oral que hace el investigador a un sujeto para obtener información, y que son anotadas por el primero.El tiempo de duración de la entrevista puede extenderse desde alrededor de 20 minutos hasta varias horas, y puede desarrollarse en una o varias reuniones con una frecuencia a determinar por el investigador. Como sucede con cualquier instrumento de recolección de datos, es importante que la información obtenida quede registrada de manera que pueda ser consultada por otros investigadores: en forma escrita, en forma electrónica (audio, video), etc.
Clasificación.- De acuerdo al número de entrevistados, la entrevista puede ser individual o grupal (Tamayo, 1999:94), y de acuerdo a su grado de estructuración, pueden ser estructuradas y no estructuradas.La entrevista estructurada es aquella que se hace de acuerdo a la estructura de la investigación; puede ser de orden flexible o rígido. Las rígidamente estructuradas son de orden formal y presentan un estilo idéntico del planteamiento de las preguntas y en igual orden a cada uno de los participantes. Son flexibles cuando conservan la estructura de la pregunta, pero su formulación obedece a las características del participante (Tamayo, 1999:95).La entrevista no estructurada es aquella en la que la pregunta puede ser modificada y adaptarse a las situaciones y características particulares del sujeto. El investigador puede seguir otras pautas al preguntar. No se trabaja este tipo de entrevistas cuando se va a verificar hipótesis, pues resulta difícil la cuantificación de los datos obtenidos (Tamayo, 1999:95).Selltiz y otros (1980) clasifican las entrevistas en: entrevista estándar de pregunta abierta (estructurada), entrevista dirigida (parcialmente estructurada), entrevista clínica (parcialmente estructurada), entrevista profunda (parcialmente estructurada), y entrevista no dirigida (no estructurada). Estos autores ponen el énfasis en la forma de entrevistar: desde la situación donde se deja que el entrevistador hable
Página 205 de 314
205

libremente, hasta la situación donde el entrevistador debe ceñirse a responder determinadas preguntas. En las preguntas abiertas el entrevistado puede responder lo que desee, mientras que en las preguntas cerradas debe optar por alguna respuesta predeterminada (sí/no, etc.).Los mencionados autores refieren que en la entrevista dirigida se sabe de antemano qué tema se va a estudiar del sujeto. En la entrevista clínica se incluye además una exploración del pasado, y en la entrevista profunda las motivaciones íntimas del sujeto. La entrevista no dirigida implica un entrevistador que sirve mas bien como catalizador o continente del sujeto.
Precauciones.- Los ‘no sé’ o las faltas de respuesta pueden deberse realmente a una real ignorancia o a una falla en la entrevista. Si se deben a lo primero, deben incluirse en la tabla como una categoría más (del tipo ‘no sabe’). Si se deben a lo segundo, deben mejorarse las entrevistas para evitar esos errores, pero si aún así persisten, se investigará si se dan al azar con igual frecuencia en todos los grupos de interrogados. Si es así, los ‘no sé’ y las faltas de respuesta pueden excluirse del cuadro o tabla (Zeisel, 1986).
El cuestionario
Definición y clasificación.- Es un instrumento de recolección de datos “formado por una serie de preguntas que se contestan por escrito a fin de obtener la información necesaria para la realización de una investigación” (Tamayo, 1999:70). Los cuestionarios son especialmente aptos para explorar determinadas variables, como por ejemplo clase social o actitudes. Nadie utilizaría un cuestionario para indagar la variable ‘modalidad de juego’ en un niño, que se explora mediante la observación, del mismo modo que nadie intentaría averiguar la clase social de una persona observando su comportamiento durante un día entero.Los cuestionarios pueden clasificarse según varios criterios, de los cuales cabe mencionar dos: a) según el tipo de pregunta, y b) según quien escribe las respuestas.De acuerdo al primer criterio, los cuestionarios pueden ser estructurados (todas preguntas cerradas), semiestructurado (preguntas abiertas y cerradas), y no estructurado (todas preguntas abiertas). En general (González, 1990), las preguntas que se hacen pueden ser sencillas y destinadas a averiguar variables demográficas como sexo, edad o nivel de instrucción, preguntas sobre intereses, actitudes, opiniones, y preguntas de control destinadas a detectar contradicciones en las respuestas.De acuerdo al segundo criterio, los cuestionarios pueden ser autoadministrables, cuando el sujeto mismo registra sus respuestas, o heteroadministrables, cuando es el investigador quien las anota. Estos últimos suelen llamarse encuestas, si se entiende por encuesta un “instrumento de observación formado por una serie de preguntas formuladas y cuyas respuestas son anotadas por el empadronador” (Tamayo, 1999:94). Otros autores asignan al término otros significados, como por ejemplo Vander Zanden (1986:619), que incluye dentro de las encuestas los cuestionarios escritos pero también las entrevistas.Los métodos para tomar encuestas pueden ser de cuatro tipos: telefónica, por correo, personal (en el hogar, interceptación en centros comerciales), y por computadora (red Internet, etc.) (González G, 1990).
Construcción de cuestionarios.- Una vez que se ha definido operacionalmente una variable en términos del indicador “administrar un cuestionario”, se procede a continuación a tomarlo o administrarlo si ya existe y es lo suficientemente válido y confiable. En el caso de no disponerse de él, el investigador deberá construir un cuestionario ad hoc. El cuestionario debe ser fácilmente comprensible para el sujeto que responde, de manera tal que pueda entender enseguida no sólo las preguntas sino también la organización misma del cuestionario.Los pasos fundamentales de la construcción de un cuestionario son:1) Seleccionar las preguntas.- El conjunto de preguntas elegido debe cubrir todas las dimensiones de la variable. Si para explorar la clase social hay una sola pregunta del tipo ¿qué marca de calzoncillos usa?’, este solo interrogante no alcanza para decidir sobre el estrato social del encuestado, porque tal vez los de clase media y baja usen las mismas marcas, y porque hay otras cosas que definen también una clase social. Por lo tanto, las preguntas deben apuntar a explorar todas las facetas de la variable, es decir, sus diversas dimensiones y subdimensiones: nivel de ingresos, nivel de instrucción, etc., obviándose al mismo tiempo las preguntas irrelevantes del tipo ‘¿le gusta el café amargo o dulce?’ porque nada nos dice sobre la clase social. En este primer paso también se definirán cuales serán preguntas abiertas y cuales cerradas, o si sólo habrá preguntas abiertas o sólo cerradas.Es preciso también incluir al comienzo del cuestionario preguntas que informen sobre datos básicos: nombre (si no es anónimo), edad, sexo, o nivel de instrucción, a elección del investigador. El cuestionario incluirá también un casillero para la fecha de administración y otro para su numeración.2) Ordenar las preguntas.- El orden suele ser importante no sólo porque algunas preguntas siguen una secuencia lógica sino también porque las organiza de forma tal que las preguntas similares aparezcan distanciadas entre sí. Además, a veces conviene evitar que las preguntas que exploran una misma dimensión de la variable estén juntas, y otras veces conviene hacerlo.3) Clasificar las respuestas posibles.- Las preguntas deben estar hechas de tal forma que sea posible clasificar sus respuestas según algún criterio. Si se trata de preguntas cerradas, deben especificarse una lista de respuestas posibles, de la cual el sujeto elegirá alguna haciendo por ejemplo una cruz en el casillero correspondiente.Si la pregunta es ‘¿tiene el secundario aprobado?’, las respuestas posibles serán ‘sí’ o ‘no’. Si la pregunta es ‘¿qué nivel de instrucción tiene?’ se podrán clasificar las respuestas posibles como ‘primaria’,
Página 206 de 314
206

‘secundaria’ y ‘universitaria’, y hasta agregar, para obtener mayor precisión, ‘primaria incompleta’, ‘secundaria incompleta’ y ‘universitaria incompleta’. Si la pregunta es ‘¿qué opinión le merecen los negros?’, las respuestas posibles podrían ser ‘buena’, ‘regular’ o ‘mala’. Los cuestionarios también pueden incluir afirmaciones en lugar de preguntas, frente a las cuales el sujeto podrá dar como posibles respuestas ‘muy de acuerdo’, ‘de acuerdo’ o ‘en desacuerdo’.
Siguiendo a Coombs (citado en González G, 1990) las escalas de medición de variables psicológicas pueden clasificarse en dos tipos: escalas de autoclasificación (se le pide al sujeto que se sitúe en una posición a lo largo del continuo de la variable que se está midiendo) y escalas de clasificación objetal (se le pide al sujeto que ubique uno o más objetos a lo largo del continuo de la variable que se está midiendo). Ejemplos son los siguientes:
Autoclasificación Escala LikertEscala ThrustoneEscala BogardeEscala Guttman
Se utilizan clásicamente para medir las actitudes y sus tres componentes (afectivo, ideacional y volitivo), midiendo tanto su dirección como su intensidad.
Clasificación objetal
Comparativas Orden-rangoComparación pareadaClasificación QSuma constante
No comparativas Clasificación continuaClasificación por partidas Diferencial semántico
Escala de Stapel
Escalas de autoclasificaciónEscala Likert.- Se presentan una serie de afirmaciones (por ejemplo ‘las escuelas municipales funcionan bien’) y se pide al encuestado su grado de acuerdo o desacuerdo con dicha afirmación (por ejemplo muy de acuerdo, de acuerdo, ni acuerdo ni desacuerdo, desacuerdo, muy en desacuerdo). En otro ejemplo, preguntas ‘tipo Likert’ son las siguientes: ‘La atención al cliente le resulta: satisfactoria, regular, insatisfactoria’ (marcar lo que corresponda).Escala Thurstone.- Se enumeran una serie de afirmaciones en torno a un tema de investigación, y se indica si se está o no de acuerdo. Por ejemplo, una afirmación de la serie podría ser: ‘Casi todos los comerciales de TV me son indiferentes’.Escala Bogardus.- Esta escala tenía por objetivo estudiar relaciones entre grupos étnicos, y por ello se la conoce como escala de distancia social. Luego se extendió al estudio de relaciones entre clases sociales, grupos ocupacionales y minorías. Un ejemplo es la escala de distancia racial, donde la persona debe ubicar diferentes ítems (por ejemplo ‘se casaría con’, ‘tendría como amigos a’, etc dentro de alguna categoría como judío, negro, indio, blanco europeo, chino, mestizo).
Escalas comparativasOrden-rango.- Se le presentan al entrevistado un conjunto de objetos en forma simultánea (por ejemplo marcas) y se le pide que los ordene o clasifique según algún criterio como calidad, confiabilidad, diseño, precio, etc.)Comparación pareada.- Se le presentan al entrevistado pares de objetos y se le pide que seleccione uno de acuerdo a un criterio (sabor, aroma, diseño, textura, precio, etc.). Por ejemplo, se presentan seis pares de bebidas gaseosas y señala cual de cada par prefiere por su sabor.Clasificación Q.- Se utiliza para discriminar con rapidez entre una cantidad relativamente grande (30-40) de objetos, los que pueden ser productos, marcas, personas, ideas o afirmaciones. Se le presentan al entrevistado el conjunto completo de objetos y se le pide que los clasifique en base a su similitud con un número limitado de clases o grupos. Ejemplo: clasifique una lista de automóviles en alguno de los siguientes grupos según el uso principal que le daría: automóvil de uso ciudadano, de uso profesional, de uso familiar, para divertirse y para viajar.Suma constante.- Se pide al entrevistado que distribuye un conjunto de conceptos en una cantidad fija, como por ejemplo 100 (cien). El objetivo es medir la importancia relativa que tiene cada objeto para el entrevistado. Por ejemplo, asignar un valor a las siguientes características en función de su importancia cuando debe comprarse un auto: precio, motor, equipamiento, consumo, apariencia externa. Los valores deben sumar 100.
Escalas no comparativasA través de estas escalas se propone a los entrevistados que hagan clasificaciones de objetos de manera independiente, sin compararlos con otros, según ciertos criterios. No se comparan los objetos entre sí, sino que se evalúa uno por vez. O sea, no se demanda al entrevistado un juicio condicional, pues el juicio sobre un objeto ya no está condicionado por el objeto de comparación.Clasificación continua.- Los encuestados califican los objetos marcando sobre una línea recta continua su posición respecto al tema objeto de investigación. Dicha línea puede estar representada únicamente por dos extremos (por ejemplo ‘nada amables’ y ‘muy amables’, si se investiga la amabilidad del personal de una empresa), o pueden indicarse graduaciones dentro de dicho continuo. Asimismo, pueden utilizarse una graduación numérica y otra verbal para facilitar la respuesta del encuestado.Clasificación por partidas.- Suelen utilizarse la medir la imagen de una empresa. Por ejemplo el diferencial semántico y la escala de Stapel.Diferencial semántico.- Es una escala bipolar, donde el sujeto debe ubicar a una empresa entre dos polos, como por ejemplo ‘confiable’ y ‘no confiable’, en algún punto intermedio entre ambos. Se asigna el valor 0 (cero) a la categoría media, y valores negativos y positivos hacia ambos lados. Generalmente se evalúan entre 7 y 8 dimensiones, una de las cuales puede ser confiabilidad.Escala de Stapel.- Es una escala unipolar, donde la persona debe ubicar por ejemplo la confiabilidad en una escala de menos 5 a más cinco, pasando también por el cero. Evita el problema de definir adjetivos o frases bipolares.
Página 207 de 314
207

Las respuestas posibles a las preguntas abiertas son también susceptibles de clasificación, sólo que no será el sujeto quien elija una opción sino el mismo investigador, a partir de la información libre proporcionada por el sujeto. Así, frente a la pregunta ‘¿cuál es su opinión sobre la infidelidad?’, el sujeto podrá explayarse todo lo que quiera, pero su respuesta deberá poder ser ubicada en alguna alternativa: como ‘de acuerdo’, ‘en desacuerdo’, etc., o bien ‘la defiende’, ‘la ataca’, etc.4) Codificar las respuestas posibles.- La codificación consiste en asignarle un valor (generalmente un número) a cada respuesta posible. Por ejemplo, si el sujeto respondió la primera opción que se asignarán 5 puntos, y si respondió a la segunda, 10 puntos. En general, el número indica la importancia de la respuesta, pero puede tener otras finalidades.5) Especificar un procedimiento para construir un índice.- El índice es “una medida compleja que se obtiene combinando los valores obtenidos por un individuo en cada uno de los indicadores propuestos para la medición de una variable” (Korn, 1969). Adaptando esta definición a un cuestionario, puede decirse que un índice es un valor (generalmente un número) que representa y sintetiza todos los valores de las respuestas obtenidas. Así, si para un sujeto se codificó con 5 la primera respuesta, con 10 la segunda y con 3 la tercera, el índice resultará por ejemplo de la suma, es decir, 18.La forma de construir el índice debe quedar especificada claramente. Hay muchas formas de construir índices: además de la simple suma o de simple promedio aritmético está también el promedio ponderado, donde se asigna mayor peso a ciertas preguntas a los efectos del conteo final. Otras veces se extraen previamente subíndices, uno para cada dimensión, para luego resumirlos en el índice final, tal como puede verse en el test WISC de inteligencia que, aunque no es un cuestionario, tiene la misma organización al respecto.La utilidad del índice no consiste sólo en resumir mucha información en una sola cifra, sino muchas veces también compensar estadísticamente la inestabilidad de las respuestas: factores como la falta de atención o el desinterés pueden malograr algunas respuestas, y en el índice pueden quedar compensados esos pobres resultados con otras respuestas donde se puso mayor interés y concentración, y donde se obtuvieron resultados óptimos.Pero la utilidad principal del índice es que permite ubicar al sujeto en alguna categoría de la variable medida por el cuestionario. Por ejemplo, si el índice obtenido por el sujeto A es 56, entonces será ubicado en la categoría ‘muy discriminador’ de la variable ‘discriminación social’. Al construirse el cuestionario, también debe quedar especificado un criterio para efectuar esta clasificación.6) Administrar una prueba piloto.- Permite probar si el cuestionario fue bien construido, y modificarlo si es necesario. Este paso es importante porque permite, entre otras cosas, averiguar si las preguntas podrán ser bien comprendidas por los sujetos.7) Establecer la validez y la confiabilidad del instrumento construido.- Se trata de una tarea ardua que suele exigir la administración del cuestionario a una gran cantidad de personas, el empleo de pruebas estadísticas especializadas y la confección de baremos.
Cuestionario y entrevista.- Ambos instrumentos tienen algunas diferencias. Por empezar el cuestionario es escrito y la entrevista es oral. Luego, el cuestionario puede ser individual o colectivo (se puede administrar a muchas personas al mismo tiempo por un solo investigador), mientras que la entrevista es individual (o a lo sumo grupal).Refieren Selltiz y otros (1980) que el cuestionario es además menos oneroso, requiere menos habilidades del recolector de los datos, puede alcanza a poblaciones numerosas por ser colectivo, y pone al sujeto en una actitud menos obligada para responder inmediatamente. La entrevista, por su parte, es más flexible pues se pueden cambiar, agregar o modificar preguntas, informa no sólo sobre lo que el sujeto dice sino sobre cómo lo dice, y permite tener acceso a personas analfabetas o poco instruidas.La desventaja de los cuestionarios y entrevistas es que son inaplicables cuando las personas no quieren o no pueden contestar sinceramente, en cuyo caso se recurrirá a la observación o a los tests.
El test
Definición y clasificación.- La palabra test remite a prueba, ensayo, examen, y consiste en someter a los sujetos a una situación estímulo donde habrán de dar ciertas respuestas. Difiere del cuestionario en alguno o en todos los siguientes aspectos: a) los estímulos no son solamente preguntas, como en los cuestionarios, sino situaciones, como por ejemplo presentar una imagen para inventar una historia en torno a ella (por ejemplo el TAT o el TRO); b) los estímulos son lo suficientemente herméticos como para que el sujeto desconozca qué está midiendo el investigador (por ejemplo las láminas del Test de Rorschach); esto es útil porque evita que el sujeto manipule la información que ofrece sobre sí mismo y porque permite conocer más rápidamente aquellos aspectos que el sujeto desconoce de sí y que nunca podría haber suministrado en una entrevista o un cuestionario (o que hubiese tardado más en hacerlo), donde el sujeto expresa lo que conoce de sí; c) las respuestas de los sujetos no son solamente verbales sino que también pueden ser no verbales: realizar un dibujo, dramatizar una situación, resolver un problema aritmético, resolver una situación simulada, etc.Suelen clasificarse los tests psicológicos en tests psicométricos y tests proyectivos. Los primeros están diseñados para estudiar capacidades como la inteligencia, mientras que los segundos para explorar la personalidad y los aspectos más inconcientes de los sujetos. También puede clasificárselos de acuerdo al tipo de respuesta en verbales (el sujeto responde con palabras), gráficos (el sujeto debe dibujar o copiar un dibujo) y de acción (el sujeto debe jugar, dramatizar una situación, etc.).
Página 208 de 314
208

Los tests en la investigación.- Los tests en general pueden ser utilizados en la clínica o en la investigación. En el primer caso, se puede buscar establecer un diagnóstico, realizar una orientación vocacional o una selección de personal. En el segundo caso, se busca obtener un conocimiento más general que trascienda el interés inmediato sobre un caso particular. Cuando a una persona se le administra un test de inteligencia y otro de personalidad, la finalidad es clínica si solamente se procura conocer su aptitud para un puesto de trabajo o su nivel de imputabilidad en una causa penal. En cambio, la finalidad será investigativa si se procura, por ejemplo, comparar los resultados con el de otras personas para ver si hay alguna relación entre personalidad e inteligencia, más allá de los casos particulares (investigación básica) o para probar la validez inter-test de alguna de ambas pruebas (investigación aplicada).
Construcción de tests.- Del mismo modo que con los cuestionarios, si no se dispone de tests debidamente estandarizados que se adapten a los propósitos de la investigación, deberá emprenderse la ardua tarea de construir uno. Se trata de una tarea más compleja que la construcción de un cuestionario, aunque algunas de las indicaciones para construir cuestionarios pueden servir para la construcción de tests. Por ejemplo, en los tests también se suelen codificar las respuestas posibles y se especifica un procedimiento para obtener un índice. Por ejemplo, en el test de inteligencia de Weschler el índice a construir es una medida del Cociente Intelectual (CI). Además, como ocurre con cualquier instrumento de medición, también el test ha de ser válido y confiable. Un test de inteligencia no puede diseñarse un test de inteligencia con la sola pregunta ‘¿es usted inteligente?’, porque, si bien puede ser confiable, no es válido ya que en realidad podría estar midiendo otras variables como la autoestima.
2. ORGANIZACIÓN DE LOS DATOS
Cuando termina la etapa de la recolección de datos, generalmente el resultado es una gran masa de información sin organizar, como por ejemplo quinientos cuestionarios respondidos, o diez cintas de audio con transcripciones de entrevistas, o una montaña de radiografías o análisis clínicos de laboratorio.Antes de ser analizados, es necesario organizar y resumir todos los datos de una manera que pueda ser útil a los propósitos de la investigación y, si bien hay recomendaciones generales, la organización de la información tendrá sus propias peculiaridades según se trate de información cualitativa o de información cuantitativa, es decir, constituida respectivamente por datos no numéricos y por datos numéricos.
Pasos de la organización de los datos
Como habitualmente las investigaciones incluyen en mayor o menor medida información cuantitativa, o generan información cuantitativa a partir de información cualitativa, a continuación de reseñarán sucintamente los pasos para organizar este tipo de información:
1) Construcción de una matriz de datos.- En un primer paso se lleva toda la información relevante a una matriz de datos. Por ejemplo, la información relevante de 85 tests de inteligencia puede volcarse en una matriz del siguiente modo:
N° Sujeto Edad
Sexo CI (Cociente intelectual)
1 Juan 32 Masculino
105
2 María 24 Femenino
120
3 Pedro 18 Masculino
85
4 Antonio
35 Masculino
110
85 Etc
Como puede apreciarse, la matriz de datos típica incluye una columna con la identificación de los sujetos y otras tantas columnas correspondientes a las variables de interés.
2) Construcción de tablas y cuadros.- En un segundo paso se resume aún más la información en tablas y en cuadros. Las tablas contienen información sobre una variable, como por ejemplo sobre el Cociente Intelectual:
CI f (frecuencia)menos de 90 2591-110 20111-130 18más de 131 22Total 85
Página 209 de 314
209

En las tablas desaparecieron los elementos identificatorios de los sujetos (por ejemplo sus nombres), quedando solamente indicadas las frecuencias con que aparecen las categorías de la variable. Por ejemplo, hay 25 sujetos que obtuvieron menos de 90 como Cociente Intelectual.Las tablas son particularmente útiles para las investigaciones descriptivas, que estudian una sola variable, pero en las investigaciones correlacionales y explicativas, donde se busca examinar la relación entre dos o más variables, será necesaria la construcción de cuadros, o elementos que relacionan variables:
Alta Media Baja Total-90 30 40 70 14090-110 55 55 50 160+110 80 50 20 150Total 165 145 140 450
El cuadro indica, por ejemplo, que hay 30 sujetos que tienen menos de 90 de CI y que pertenecen a la clase alta. El cuadro del ejemplo relaciona entonces las variables CI con clase social. Se trata de un cuadro bivariado, pero también hay cuadros trivariados y multivariados.Tanto las tablas como los cuadros deben tener un encabezamiento que incluya información sobre las variables, las unidades de análisis y el lugar y el momento de la recolección de la información. El cuadro del ejemplo podría tener el siguiente encabezamiento: “Cuadro I: Inteligencia según clase social en adolescentes de la Ciudad de Buenos Aires, año 1980”.Tanto en las tablas como en los cuadros los elementos propiamente informativos son las frecuencias, o número de sujetos incluidos en las categorías.Hay varios tipos de frecuencias. En los siguientes ejemplos, por ejemplo la cifra 30, que significa que hay 30 sujetos de clase alta con CI inferior a 90; o la cifra 145, indicadora que hay 145 adolescentes de clase media; o la cifra 450, que indica el número total de casos de la muestra. Estos tres ejemplos corresponden, respectivamente, a las llamadas frecuencias condicionales, marginales y totales. La frecuencia condicional corresponde al entrecruzamiento de dos categorías distintas, y la frecuencia marginal sólo a una. Así, 20 es frecuencia condicional y 150 frecuencia marginal.Puede verse que las frecuencias marginales resultan de la suma de las frecuencias condicionales correspondientes, y pueden ser horizontales (como 140, resultado de sumar 30, 40 y 70) o verticales (como 145, que resulta de sumar 40, 55 y 50). La suma de las frecuencias marginales horizontales debe ser igual a la suma de las frecuencias marginales verticales, y esa cifra debe equivaler a la frecuencia total (tamaño de la muestra).Un cuadro bivariado puede también incluir la misma información pero bajo la forma de frecuencias acumuladas (horizontales o verticales), frecuencias porcentuales (horizontales o verticales) y frecuencias porcentuales acumuladas (también horizontales o verticales). El esquema siguiente ejemplifica estas alternativas:
Ejemplos de frecuencias
Alta Media Baja Total-90 30 40 70 14090-110 55 55 50 160+110 80 50 20 150Total 165 145 140 4501. Frecuencias absolutas
Alta Media Baja Total-90 30 70 140 -90-110 55 110 160 -+110 80 130 150 -Total 165 310 450 -2. Frecuencias acumuladas horizontales
Alta Media Baja Total-90 30 40 70 14090-110 85 95 120 300+110 165 145 140 450Total - - - -3. Frecuencias acumuladas verticales
Alta Media Baja Total-90 21% 29% 50% 100%90-110 34% 34% 32% 100%+110 53% 33% 14% 100%Total - - - -4. Frecuencias porcentuales horizontales
Alta Media Baja Total-90 18% 28% 50% -90-110 33% 38% 36% -+110 49% 34% 14% -Total 100% 100% 100% -5. Frecuencias porcentuales verticales
Alta Media Baja Total-90 21% 50% 100% -90-110 34% 68% 100% -+110 53% 86% 100% -Total - - - -6. Frecuencias porcentuales acumuladas horizontales
Alta Media Baja Total-90 18% 28% 50% -90-110 51% 66% 86% -+110 100% 100% 100% -Total - - - -7. Frecuencias porcentuales acumuladas verticales
Página 210 de 314
210

Como puede verse, la misma información del cuadro original 1 puede expresarse, según las necesidades de la investigación, de seis maneras diferentes. He aquí algunos ejemplos de cómo han de leerse las distintas posibilidades:a) La cifra 110 del cuadro 2 indica que hay 110 individuos de clase media con 110 o menos de CI. En cambio la cifra 95 del cuadro 3 indica que hay 95 sujetos con CI entre 90 y 110 y que además pertenecen a las clases media y alta. En el primer caso la acumulación se hizo horizontalmente y en el segundo verticalmente.b) La cifra 53% del cuadro 4 indica que sobre el total de sujetos con CI superior a 110, el 53% son de clase alta. En cambio la cifra 49% del cuadro 5 indica que sobre el total de sujetos de clase alta, un 49% posee un CI superior a 110. También en ambos cuadros los porcentajes se calcularon horizontal y verticalmente, en forma respectiva. Una importante utilidad que tienen los porcentajes es que permiten igualar las frecuencias con respecto a una base común (el 100%):
Edad Primaria Secundaria Total30 años 12 142 15440 años 18 18 3650 años 30 - 30Total 60 160 220Cuadro I – Frecuencias absolutas
Edad Primaria Secundaria Total30 años 20% 89% -40 años 30% 11% -50 años 50% - -Total 100% 100% -Cuadro II – Frecuencias porcentuales
En el Cuadro I hay dos frecuencias absolutas iguales (18 y 18), pero ellas no tienen el mismo significado estadístico, pues un 18 se tomó sobre un total de 60 personas (escolaridad primaria) y el otro sobre un total de 160 (escolaridad secundaria). Si se igualan 60 y 160 en una base común (100%) como en el Cuadro II, se ve que en realidad uno de los 18 representa el 30% del total y el otro tan sólo el 11% del otro total. Esto permite evaluar a simple vista qué proporción de sujetos de 40 años hay en cada nivel de escolaridad: si bien la cantidad absoluta de sujetos es la misma (Hyman, 1984:353-356), hay mayor proporción de sujetos primarios que secundarios.c) La cifra 50% del cuadro 6 indica que el 50% de los sujetos con CI inferior a 90 pertenecen a las clases alta y media. La cifra 28% en cambio, en el cuadro 7, expresa que el 28% de los sujetos de clase media tiene CI inferior a 90. Las acumulaciones de los porcentajes se realizaron en forma horizontal y vertical, respectivamente. Obsérvese que la información del cuadro 6 no es la misma que la del cuadro 7, pero es igualmente verdadera. La elección de una u otra información dependerá de qué información nos interese más o, incluso, hay quienes utilizan esta posibilidad de elegir con el propósito de convencer o persuadir. Por ejemplo, si se quiere persuadir a alguien que el cigarrillo es pernicioso para la salud, preferiré decirle que el 90% de los cánceres de pulmón son ocasionados por el cigarrillo a decirle que sólo el 10% de los fumadores mueren de cáncer de pulmón, siendo que ambas afirmaciones son igualmente verdaderas.
3) Graficación.- La misma información que se obtiene a partir de tablas y cuadros puede también presentarse en forma de gráficos para una mejor visualización, y supone otra forma de organizar y resumir la información a partir de tablas o cuadros. El siguiente ejemplo ilustra la manera de traducir una tabla en un gráfico:
Edad Frecuencia (f)17 7018 11019 14020 160Total
480
Gráfico
Página 211 de 314
211

f
160150140130120110100090080070
17 18 19 20 Edad
4) Obtención de medidas estadísticas.- Es posible e incluso a veces necesario resumir aún más la información, hasta reducirla a una o dos cifras llamadas medidas estadísticas. Se trata de medidas que describen a la muestra y no ya a los sujetos, descritos por medidas individuales. No es lo mismo decir que Juan tiene 30 años (medida individual), a decir que la muestra de sujetos tiene una media aritmética o promedio de 25 años (medida estadística).Las medidas estadísticas pueden describir una sola variable (como las medidas de posición y las medidas de dispersión), o pueden describir la relación entre dos o más variables (como los coeficientes de correlación). El simple promedio o media aritmética es un ejemplo de medida estadística de posición, o sea, describe una sola variable.
El análisis factorial
El análisis factorial es un procedimiento ya clásico para resumir y organizar la información relativa a las relaciones entre muchas variables. Estrictamente hablando y a pesar de su denominación, no supone analizar datos sino solamente organizarlos, sin perjuicio que luego se pueda realizar un análisis de los resultados obtenidos utilizando pruebas las pruebas de la estadística inferencial.En este ítem se presenta el análisis factorial solamente como otro ejemplo de cómo pueden ser resumidos y organizados los datos.Muchas investigaciones en psicología y ciencias sociales obligan a considerar las mutuas interrelaciones entre muchos factores. El análisis factorial es un procedimiento matemático que permite correlacionar muchos factores entre sí. Ha sido diseñado específicamente para resolver problemas en psicología y en ciencias sociales, y un ejemplo típico aparece en la teoría factorialista de la inteligencia de Charles Spearman (1863-1945), a quien suele reconocérselo como el fundador del método. Si bien existieron posteriores desarrollos que incluyeron nuevas perspectivas y aplicaciones, en lo que sigue se ilustra el análisis factorial muy simplificadamente, tomando dos ejemplos: uno de la psicología de la inteligencia, y el otro de la psicología social. El examen de estos ejemplos bastará para adentrarse en la comprensión de los lineamientos del método, por lo que se obviará una introducción teórica.
El análisis factorial de la inteligencia.- Situémonos por un momento en el lugar de Spearman: estamos decididos a iniciar una investigación sobre la inteligencia. En sí misma, como concepto teórico la inteligencia no es algo que pueda observarse directamente, y por lo tanto sólo podemos poner nuestra atención en comportamientos observables. Pero, ¿cuáles comportamientos? Seguramente no elegiríamos el movimiento automático de la pierna en el reflejo rotuliano, ya que no lo suponemos un comportamiento indicador de inteligencia. Tampoco elegiríamos el llanto espontáneo de una persona frente a una situación dolorosa e imprevista. Esto significa que haremos una selección previa de aquellos comportamientos que, según nuestras suposiciones, son indicadores de la inteligencia de la persona, como por ejemplo realizar una suma aritmética, agrupar varios objetos según atributos en común, armar un rompecabezas, defender un argumento, discernir significados de vocablos, etc.Todas estas conductas que, suponemos son expresión de 'algo' llamado inteligencia las denominaremos, siguiendo la terminología de Spearman, habilidades. Precisamente, una obra de referencia obligada de Spearman editada en castellano se titula "Las habilidades del hombre".Nuestro paso siguiente consistirá en hacer un listado de todas estas habilidades, y armar una especie de test compuesto de tantas pruebas como habilidades querramos medir en las personas. Por ejemplo, una prueba puede consistir en realizar una suma, otra en armar un rompecabezas, otra en buscar sinónimos para una palabra dada, etc. Incluso incluiremos una prueba de memorización, si acaso suponemos que la memoria tiene alguna vinculación con la inteligencia.Una vez listo el test, procedemos a administrarlo a una gran cantidad de personas, y a continuación realizamos la evaluación de las respuestas obtenidas o de las pruebas realizadas, asignando un puntaje a
Página 212 de 314
212

G
E2
G
G
E1
G
E3 E1 = Buscar sinónimosE2 = Armar oracionesE3 = Manejar vocabulario
CorrelaciónCausalidad
G = Factor generalE = Factor específico
cada prueba y para cada sujeto. A partir de aquí comienza lo que puede llamarse un análisis de correlación, que es el elemento fundamental del análisis factorial. ¿Qué significa hacer un análisis de correlación? Básicamente, significa comparar los puntajes de dos habilidades entre sí a los efectos de ver si entre ellas hay algún grado de variación concomitante. Por ejemplo, tras haber comparado los puntajes de habilidad para sinónimos con los puntajes de habilidad para redactar oraciones, hemos verificado que entre ellas se da una alta correlación: los sujetos que tienen alto puntaje en una habilidad suelen tenerlo también en la otra, y los sujetos que obtuvieron poco puntaje en una habilidad, suelen tener bajo puntaje también en la otra.El objetivo inmediato de este análisis es establecer un grado de correlación para cada par de habilidades, y como estas son muchas, el lector podrá imaginarse la magnitud de la tarea. De hecho, hacer todos estos cálculos le llevó a Spearman nada menos que 21 años (desde 1904 hasta 1925), hasta que finalmente pudo presentar su mapa de la inteligencia.El grado de correlación puede medirse mediante el llamado coeficiente de Pearson (r), que puede asumir valores entre -1 y +1. Un valor r=0 indica ausencia de correlación, y un valor r=0,90 estará indicando un alto grado de correlación, mientras que r=1 es la correlación perfecta, que prácticamente no existe en la realidad. Es así que a cada par de habilidades puede asignársele un determinado valor de r. Por ejemplo, entre las habilidades para buscar sinónimos y para redactar oraciones, hemos encontrado una correlación de 0,90 (por dar un ejemplo cualquiera).Spearman empezó concentrando su atención en las correlaciones significativas. A partir de aquí, frente a una alta correlación entre dos habilidades podríamos pensar dos posibilidades:a) Si ambas varían en forma concomitante, es porque entre ellas existe un vínculo causal. Por ejemplo: la habilidad para buscar sinónimos es la 'causa' de saber armar oraciones. Hay al menos dos importantes razones para abandonar esta primera posibilidad. En primer lugar la correlación, si bien es condición necesaria para que haya un vínculo causal, no es aún suficiente, vale decir, la correlación no prueba por sí sola la causalidad. En segundo lugar, subjetivamente nos cuesta creer que la habilidad para buscar sinónimos sea la causa de saber armar oraciones, o que la habilidad para armar rompecabezas sea la causa de saber dibujar. De hecho, podemos conocer alguna persona que arma bien rompecabezas pero que dibuja mal. Por consiguiente, ni nos molestaremos en intentar probar un vínculo causal que de entrada no creemos plausible.b) La segunda posibilidad sería considerar que, si ambas habilidades varían en forma concomitante, no es porque una sea causa y otro efecto sino porque ambas dependen de un tercer factor común a ambas, es decir de un tercer factor que actúa o interviene unilateralmente sobre cada una de ellas. Esta segunda línea de pensamiento fue la que adoptó Spearman como hipótesis de trabajo. Supuso que si dos habilidades están de alguna forma correlacionadas, es porque ambas dependen de algún factor en común, llamado factor general. La dependencia causal ya no está entre dos habilidades, sino entre una habilidad (efecto) y un factor que la determina (causa).Examinemos el esquema 1, que podría sintetizar las conclusiones de una investigación preliminar, en la cual se han correlacionado entre sí las habilidades 1, 2 y 3 tomadas de a dos (diádicamente). Es decir, se correlacionaron 1-2, 2-3 y 1-3, y, al comprobarse alta correlación, se concluye que todas ellas dependen de un factor general común (G). Sin embargo, estas correlaciones estadísticas no son perfectas, lo que hace pensar que también hay factores específicos (E) propios de cada habilidad, que las hace diferentes entre sí.
Esquema 1
En suma hasta aquí: cada habilidad está determinada por dos factores: un factor general común G, que es lo que tiene en común con otras habilidades, y un factor específico E, propio de esa única habilidad. El factor G determina que haya correlación entre habilidades, y el factor E determina que haya diferencias entre ellas. Desde ya, esos factores no se ven a simple vista como se puede ver una habilidad concreta, sino que son abstracciones que nos permiten ir organizando el conjunto de las habilidades con la finalidad de construir una teoría coherente de la inteligencia.En una primera etapa de su investigación, Spearman trabajó solamente con los factores G y E, y por ello su teoría fue denominada teoría bifactorial de la inteligencia. Sin embargo, en investigaciones ulteriores Spearman incluyó un tercer factor, el factor C o factor grupal común, con lo cual su teoría dejó de ser
Página 213 de 314
213

G
C1
E1
G
C1
E2
G
C1
E3
G
C2
E4
G
C2
E5
G
C2
E6
G
C3
E7
G
C3
E8
G
C3
E9
G
C1
G
C2
G
C3
G
Correlación muy altaCorrelación no tan altaCausalidad
Habilidades hipotéticas
Habilidades observadas
E1 = Buscar sinónimosE2 = Armar oracionesE3 = Manejar vocabulario
G = Factor general (de todas las habilidades). Ej: InteligenciaC = Factor común (a algunas habilidades). Ej: Factor verbalE = Factor específico (propio de cada habilidad).
E4 = Saber sumarE5 = Calcular raícesE6 = Resolver ecuaciones
E7 = Armar rompecabezasE8 = Saber dibujarE9 = Etc
bifactorial y pasó a ser multifactorial. Con la introducción de este tercer factor, el mapa de las habilidades comenzó a adoptar más la estructura que indicamos en el esquema 2.
Esquema 2 – Matriz sencilla para el análisis factorial de Spearman
La introducción de estos nuevos factores intermedios quedaba justificada porque Spearman había notado una muy alta correlación entre 1-2-3, y por otro lado una muy alta correlación entre 4-5-6, pero la correlación no era tan alta cuando se comparaban habilidades de ambos grupos, por ejemplo en 1-5 o en 2-4. Esto llevó a pensar que las habilidades podían agruparse, dependiendo cada grupo de habilidades de un factor común C que no estaba en otro grupo. Así por ejemplo, las habilidades para sinónimos, para armar oraciones y para utilizar vocabulario estaban entre sí muy correlacionadas y por tanto dependían del factor común C1, llamado factor verbal. Otro tanto ocurría con otro grupo de habilidades (suma, proporciones y ecuaciones) que entonces dependían de otro factor común C2 llamado factor numérico, ya que este segundo grupo no estaba tan correlacionado con el primero, y entonces debía pensarse en factores comunes distintos.Sin embargo, si bien no se constataba una muy alta correlación entre habilidades de distintos grupos, persistía no obstante una correlación significativa entre ellas, lo que hizo pensar que, en realidad, los factores comunes debían depender a su vez de un factor más general, el factor G, presente en todos los grupos y en todas las habilidades. Este factor G es precisamente la inteligencia, entendida entonces como una habilidad general abstraída a partir de muchas habilidades efectivamente observadas.La conclusión obtenida por Spearman fue entonces, la siguiente: la inteligencia está determinada por un factor general G común a todas las habilidades, por varios factores C comunes a ciertos grupos de habilidades, y por un factor E propio de cada habilidad. Con este planteo, Spearman procuró ofrecer una solución ecléctica a las concepciones que por entonces circulaban sobre la inteligencia: la teoría monárquica (la inteligencia depende un único factor), la teoría oligárquica (la inteligencia depende de unos pocos factores separados o de varias facultades diferenciadas), y la teoría anárquica (la inteligencia sólo puede describirse como un conjunto de múltiples habilidades independientes entre sí). Fue así que le dio la razón a la teoría monárquica introduciendo el factor G, a la teoría oligárquica introduciendo los factores C, y a la teoría anárquica proponiendo los factores E.El factor G fue entendido como la energía subyacente, constante y común a todas las operaciones psíquicas, mientras que en el otro extremo, los factores específicos eran las máquinas o dispositivos especiales -propios para cada habilidad- mediante los cuales actuaba la energía G. Además, G es un factor intraindividualmente constante e interindividualmente variable (pues la inteligencia sólo varía de
Página 214 de 314
214

G
F1
P1 P4P2 P3 P5 P8P6 P7 P9 P12P10 P11
F2 F3
Correlación muy altaCorrelación no tan altaCausalidad
G = Factor general. Ejemplo: Conservadorismo político.F = Factores comunes a varias actitudes. Por ejemplo:F1 Conservadorismo económicoF2 Libertades cívicasF3 Relaciones internacionalesP = Actitudes específicas.
una persona a otra), y E es un factor variable intra e interindividualmente (dentro del sujeto varía según sus diferentes habilidades, y en comparación con otros sujetos está claro que las personas tienen diferentes rendimientos en cada habilidad).La idea original de Spearman fue desarrollada profusamente en nuevas investigaciones sobre la inteligencia que, por ejemplo produjeron la teoría multimodal de Thorndike y Thompson, y el análisis factorial múltiple de Thurstone y otros (Bernstein, 1979:512). También se utilizó el método en otros ámbitos, como por ejemplo en la investigación de las actitudes en psicología social (Blalock, 1971:109-114).
El análisis factorial de las actitudes.- Las actitudes en psicología social pueden medirse mediante cuestionarios, de manera que, a diferencia del caso anterior de la inteligencia, aquí no administraremos tests. Por tanto, en lugar de pruebas haremos preguntas, y en vez de ejecuciones obtendremos respuestas. Y obviamente, en vez de habilidades buscaremos correlacionar actitudes. Tomaremos un ejemplo hipotético de Blalock (1971:109-114), e iremos razonando del mismo modo como lo hicimos en el caso de Spearman.Supongamos que, en vez de la inteligencia, queremos investigar una actitud: el conservadorismo político (esquema 3). Confeccionamos un cuestionario con 12 preguntas (de la P1 a la P12), cuatro de las cuales ponen de manifiesto el conservadorismo económico (F1), otras cuatro las libertades cívicas (F2), y las restantes cuatro las relaciones internacionales (F3). Elegimos estos tres aspectos porque, según nuestro entender, pueden poner de manifiesto la variable general 'conservadorismo político'. A partir de aquí confeccionamos las 12 preguntas específicas. Por ejemplo, una pregunta donde suponemos se manifiesta el factor conservadorismo económico sería "¿Está conforme con el actual programa de seguridad social?". Sería la pregunta P1.
Esquema 3 – Análisis factorial de actitudes
Luego de haber administrado el cuestionario a una gran cantidad de sujetos, procedemos a correlacionar las diferentes respuestas del cuestionario entre sí. Si nuestra primera y provisoria clasificación de la variable general en las tres dimensiones F1, F2 y F3 fuese correcta, deberíamos obtener los siguientes resultados: a) Una muy alta correlación entre las respuestas P1 a P4, así como entre las respuestas P5 a P8, y entre las respuestas P9 a P12. b) Una correlación menor entre los tres grupos de respuestas anteriores, lo que probaría la relativa independencia de los factores F1, F2 y F3, y, por ende, estaría justificado separarlos en tres dimensiones de la variable. Si bien la correlación entre estos factores es menor en comparación con las correlaciones entre respuestas específicas, no resulta tan baja como para pensar que son totalmente independientes, ya que todos dependen de la variable general 'conservadorismo político'.En general, si se cumplen las condiciones a y b, habremos justificado nuestra clasificación de la variable en los tres factores, y las correspondientes respuestas dentro de cada factor. El análisis factorial realizado nos permitió, así, corroborar nuestras presunciones acerca de la estructura interna de la variable general (es decir, su modo de estar subdividida en factores), con lo cual podemos administrar un cuestionario basado en ese criterio para medir actitudes en las personas que tenga cierto grado de validez.Desde ya, que las correlaciones nunca serán perfectas. Por ejemplo, las correlaciones entre las respuestas de un mismo factor no llegan a ser totales porque siempre cada respuesta tiene factores específicos. Así por ejemplo, un sujeto muy prejuicioso en general pudo haber entablado cordiales relaciones con negros por formar con ellos parte del mismo equipo de fútbol, y por ende no presentar objeciones frente a la pregunta de la integración racial en los deportes.
Página 215 de 314
215

El esquema que hemos presentado puede presentar muchas variantes o complicaciones. Solamente indiquemos una, pero no especificaremos el complejo procedimiento factorial que se usa para este caso: puede ocurrir que una misma pregunta dependa simultáneamente de dos factores. Por ejemplo, la pregunta sobre si los miembros del partido comunista deben ser encarcelados o deportados, indica tanto el factor libertades cívicas (por lo de encarcelados), como el factor relaciones internacionales (por lo de deportados).
3. ANÁLISIS DE LOS DATOS
La obtención de tablas, cuadros, gráficos o medidas estadísticas no son más que pasos preparatorios para el análisis de los datos. El análisis de los datos tiene como finalidad extraer conclusiones acerca de la hipótesis de investigación a partir de los datos organizados y resumidos en el paso anterior. Tamayo (1999:53), por ejemplo, lo define como el procedimiento práctico que permite confirmar las relaciones establecidas en las hipótesis. Otros autores refieren finalidades similares, cuando señalan que el propósito del análisis es resumir las observaciones realizadas previamente en forma tal que den respuestas a los interrogantes de la investigación (Selltiz y otros, 1980).
Señalan Selltiz y otros (1980) que si bien el análisis y la interpretación de los datos son la última parte de la investigación, normalmente en los comienzos de la misma se realizan análisis e interpretaciones orientadoras de la misma. Ningún estudio científico debería planificarse sin una anticipación de lo que se hará cuando se tengan los datos, o sin haber considerado la posible interpretación de los hallazgos obtenidos. Si no se procede así el investigador encontrará que no puede hacer el análisis al final porque le faltan los datos relevantes.
A veces el análisis puede realizarse solamente a partir de la lectura de tablas, cuadros, gráficos o medidas estadísticas. Por ejemplo, puede obtenerse una conclusión razonablemente segura sobre la relación entre inteligencia y alimentación cuando un cuadro informa que existe un 90% de sujetos inteligentes entre los bien alimentados y un 5% de sujetos inteligentes entre los mal alimentados, y donde los sujetos fueron tomados al azar de la población. El análisis concluirá entonces que estos resultados de la muestra reflejan adecuadamente la situación de toda la población.Sin embargo, en la mayoría de los casos los resultados no son tan contundentes, y requieren un análisis estadístico. Tal vez el ejemplo más representativo de este tipo de análisis sea el análisis de la varianza.
El análisis de la varianza
La varianza es una medida de las variaciones que sufre la variable dependiente cuando esta es considerada dentro de una situación experimental. La varianza primaria es aquella que puede atribuirse a la influencia de la variable independiente, mientras que la varianza secundaria es debida a otros factores extraños, los que requerirán ser controlados. No debe confundirse con la varianza entendida como medida de dispersión, que es una noción de la estadística descriptiva.Al hacer un experimento para determinar el grado de influencia que ejercen los ruidos sobre el estrés, se podrían tomar dos grupos de personas: e grupo experimental sería sometido a cierta intensidad sonora, mientras que grupo de control no sería sometido a esa intensidad.Midiendo el nivel de estrés en ambos grupos luego de haber aplicado el ruido, se podría determinar si éste ejerció influencia o no. Por ejemplo, si hay más nivel de estrés en el grupo experimental que en el grupo de control, se podría pensar que el ruido fue el causante de la diferencia.Si la varianza son las variaciones sufridas por la variable dependiente, en el ejemplo, son las variaciones que puede sufrir el nivel de estrés entre el grupo experimental y el grupo de control. Si la diferencia en el nivel de estrés encontrada entre ambos grupos es 5, entonces 5 es la varianza.Sin embargo, las cosas no resultan nunca tan sencillas. De hecho, y aún en el transcurso de una situación controlada como la experimental, sobre el efecto estrés suele influir no solamente el ruido sino también toda una serie de otros factores que suelen designarse como variables extrañas.Estas otras fuentes de variación inciden también en la varianza, con lo cual ésta última no es debida solamente al ruido sino además también a esos otros factores que siempre o circunstancialmente estarán presentes.Tiene sentido entonces distinguir dos componentes de la varianza: una parte de la varianza que es debida a la influencia de la variable independiente ruido, y otra parte que es debida a los factores o variables extrañas. Puede convenirse en denominar 'varianza primaria' a la parte de la varianza que es debida a la influencia de la variable independiente, 'varianza secundaria' a la parte de la varianza que es debida a factores extraños, y finalmente, 'varianza total' a la suma de la varianza primaria y la secundaria.Los resultados que se obtienen en un experimento corresponden a la varianza total, con lo cual es tarea del investigador discriminar qué parte de esta varianza total es la varianza primaria, porque sólo ella nos dará una medida del grado de influencia que ejerce la variable independiente sobre la variable dependiente, o, en otras palabras, sólo ella permitirá corroborar o rechazar la hipótesis experimental (que en el ejemplo sería 'el ruido incide sobre el estrés').En un experimento se deberían poder 'controlar' todos los otros factores extraños para que no influyan, o, por lo menos, conocer su valor para poder luego descontarlo de la varianza total.Arnau Gras (1980) clasifica todos estos factores extraños que pueden incidir sobre los valores de la variable dependiente en tres grandes grupos: a) Los que proceden del sujeto: edad, sexo, herencia, estado actual del organismo, y demás variables subjetivas; b) Los que proceden del ambiente; y c) Los
Página 216 de 314
216

que proceden de la misma situación experimental: actitudes, expectativas y procedimientos del investigador, así como el sistema de medición empleado.La teoría de los diseños experimentales provee una cierta cantidad de técnicas de control de todas estas variables extrañas, como la aleatorización. Si los sujetos del grupo experimental y del grupo de control fueron seleccionados al azar, puede estarse razonablemente seguros que también estarán distribuidos al azar los valores de las variables extrañas, y que esa distribución será aproximadamente igual en ambos grupos.Puede ocurrir que no tome la precaución de aleatorizar, por ejemplo incluyendo deliberadamente dentro del grupo experimental a veteranos de guerra y dentro del grupo de control a empleados administrativos. Con ello, no podrá saberse si la diferencia de estrés entre ambos grupos (varianza) es debida al ruido o a la condición laboral.En cambio, si se toma la precaución de elegir a los sujetos al azar, quedarán distribuidos aleatoriamente en ambos grupos tanto los veteranos como los empleados. En otras palabras, la 'mezcla' de ambas condiciones laborales será aproximadamente la misma en los dos grupos, con lo cual, al ser entonces equivalentes, cualquier diferencia del estrés entre ellos podrá ser adjudicada a la variable independiente ruido.Finalmente, cabe consignar que dentro de la varianza secundaria suele distinguirse una varianza sistemática y una varianza del error. A diferencia de la primera, esta última es impredecible, ya que es el conjunto de fluctuaciones en los valores de la variable dependiente como consecuencia del azar.Lores Arnaiz (2000) distingue los siguientes tipos de varianza:
Tipo de varianza Fuente de la varianzaSistemática Primaria o de tratamiento: es aquella que
refleja los efectos de la manipulación directa de la VI (Arnau Gras, 1980:148).
VI (Variable independiente)
Secundaria o confundida: es aquella que refleja los efectos de las variables extrañas (no conocidas), confundidas o pertinentes (conocidas) que no han sido controladas y, por tanto, están afectando la validez interna (validez interna es el grado en que controlamos adecuadamente las variables pertinentes).
Variables confundidas o pertinentes.Hay 9 ejemplos: asignación sesgada de los sujetos a las condiciones experimentales; variables confundidas; pérdida diferencial de sujetos durante el estudio; sensibilización debida al pre-test; historia; maduración; expectativas del experimentador; deseabilidad; efectos placebo.
No sistemática
De error: fluctuaciones en los valores obtenidos debidos al azar (Arnau Gras, 1980:149).
Factores debidos al azar.Hay 5 ejemplos: diferencias individuales preexistentes; estados transitorios; factores ambientales; tratamiento diferencial; error de medición.
En suma: los investigadores recurren a la estadística inferencial para determinar si las diferencias observadas entre las medias de los grupos son mayores a lo esperable sobre la base de la sola varianza de error. Para ello suelen utilizar el análisis de varianza (ANOVA) que, por ejemplo, permite saber si la VI ejerce influencia examinando si hay mayor varianza que la debida a la varianza secundaria y a la varianza de error. En ANOVA se calcula un test-F: cuanto mayor es la varianza entre grupos en relación a la varianza intra grupo, mayor será F y más probable que la VI sea la que crea las diferencias entre los grupos (Lores Arnaiz, 2000).
4. INTERPRETACIÓN DE LOS DATOS
Las conclusiones del análisis de los datos pueden a su vez ser interpretadas, es decir, pueden asignárseles algún significado en el contexto de alguna creencia o teoría, o al ser comparadas con los resultados de otras investigaciones, lo que hace que el conocimiento se amplíe y profundice.Por ejemplo una alta correlación entre inteligencia y clase social podrá ser interpretada de manera muy distinta por una teoría ambientalista y por una innatista: la primera insistirá en que la inteligencia en clases altas obedece a que los niños están mas estimulados (hacen más viajes, tienen más juguetes, etc.), mientras que la segunda planteará la existencia de mejores genes en las personas de clase alta.Mientras el análisis requiere un procedimiento minucioso y objetivo, en la interpretación el investigador puede permitirse dejar volar la imaginación para arriesgar explicaciones posibles de lo analizado, y que luego serán o no sometidas a prueba en ulteriores estudios.Destacan Selltiz y otros (1980) que el objetivo de la interpretación es buscar un significado más amplio a las conclusiones del análisis mediante su conexión con otros conocimientos disponibles. Refieren también que la interpretación como ampliación del conocimiento tiene dos aspectos principales: primero la continuidad, es decir establecer una continuidad en la investigación social a través de la conexión de los resultados de un estudio con otros. Segundo, el establecimiento de conceptos aclaratorios, es decir, se pueden empezar a construir teorías acerca del porqué de los hechos observados.
Página 217 de 314
217
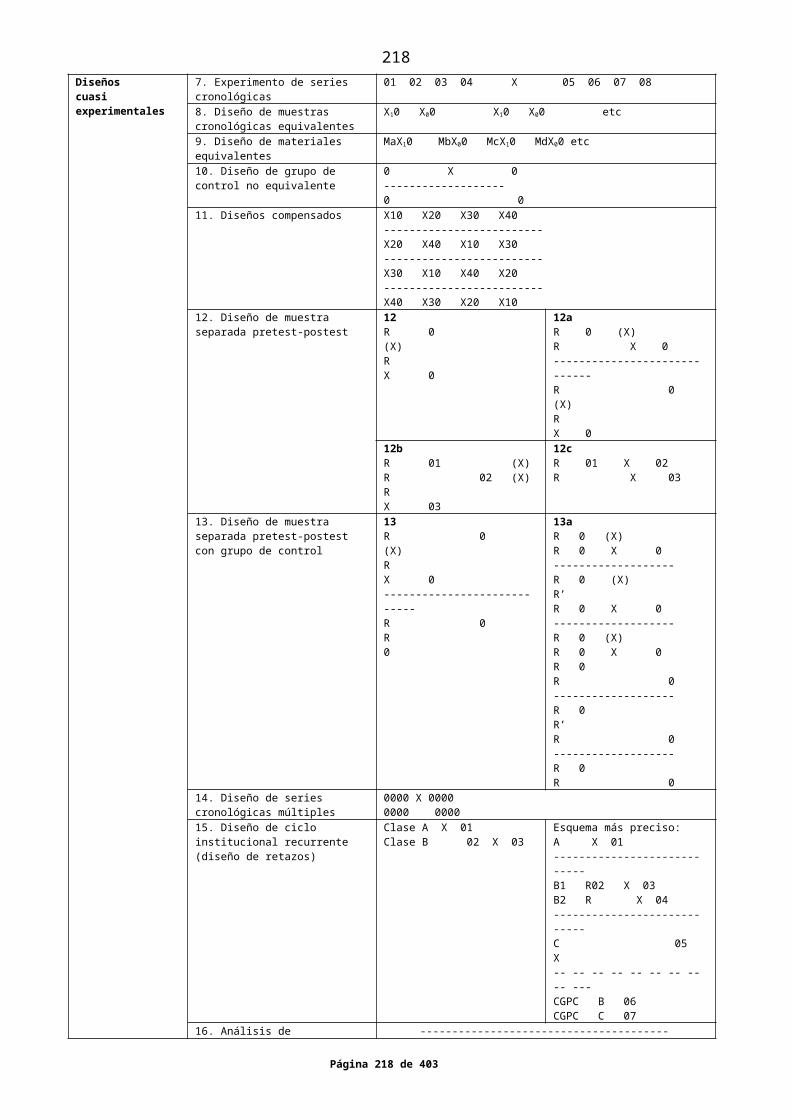
Por último, en una investigación puede suceder que hayan quedado datos sin elaborar. Selltiz y otros (1980) destacan que estos datos pueden sin embargo ser utilizados en el análisis y la interpretación sin tener en cuenta si fueron o no cuantificados en todos los aspectos. El uso de datos no elaborados a lo largo del análisis cumple dos funciones distintas: ilustrar el rango de significación adjudicado a cualquier categoría (ya que la exactitud con que pueden ser definidas las categorías depende de los datos sin elaborar), y estimular nuevos puntos de vista (por ejemplo aclarar la naturaleza de las relaciones entre variables ya descubiertas en el análisis, o estimular hipótesis para investigaciones posteriores).
Página 218 de 314
218

CAPÍTULO 15: REDACCIÓN Y PUBLICACIÓN DE LOS RESULTADOS
Una vez completado su estudio, el investigador puede tener interés en comunicar sus resultados a la comunidad científica nacional o internacional, y entonces emprende la última tarea, la redacción de un informe final, que habitualmente aparecerá publicado en las revistas especializadas como un artículo científico, será leído en algún congreso, o, si es ampliado y profundizado, tomará la forma de un libro.Un informe de investigación es un “documento escrito en el que el investigador relata cuidadosamente todos los pasos seguidos en la investigación, los resultados obtenidos y sus conclusiones con respecto al problema estudiado” (León y Montero, 1995:22).El intercambio de información entre los científicos es importante porque cualquiera de ellos puede saber qué se investigó y qué no se investigó sobre tal o cual tema en el mundo, lo que a su vez evita repetir experimentos o inventar hipótesis ya inventadas, y disponer de nuevas fuentes de inspiración para continuar investigaciones o plantear nuevos problemas e hipótesis.Una idea científica suele recorrer tres pasos: la elaboración, la redacción y la publicación. Las dos primeras etapas suelen realimentarse entre sí: a medida que se piensa o elabora se van redactando los resultados, y a medida que se redactan, van surgiendo nuevas ideas o corrigiéndose otras, ya que escribir, como quedó indicado, es pensar de otra manera.Sin embargo, hay algo que puede llamarse la ‘redacción final’, donde se detiene todo proceso de elaboración para permitir que la idea pueda finalmente ser dada a conocer a la comunidad científica, es decir, pueda ser publicada.Respecto de esta última etapa, cabe consignar que cuando de trata de presentar un trabajo científico que tenga como destino ser publicado, normalmente el editor impondrá como condición -o simplemente recomendará- ciertos requisitos de presentación. Estos requisitos son diferentes en cada caso, pues cada editorial, cada revista científica o cada sitio de Internet establecen sus propias pautas. Cuando el destino del trabajo no es su publicación sino simplemente su presentación en una cátedra con fines de evaluación, los profesores también acostumbran a indicar a los alumnos sus propios requisitos de presentación mediante un sistema de pautas más personalizado.El presente capítulo ofrece algunas consideraciones útiles para quienes deban redactar y publicar trabajos científicos, sea en forma artículo, libro o tesina / tesis académica. Resulta, entonces, indicado para investigadores y estudiantes de grado y de doctorado.
1. REDACCIÓN DE LOS RESULTADOS
Escribir es una manera de hacer muchas cosas. Es una manera de trascender, porque el papel dura más que el cerebro; es una manera de decidir, cuando se redacta un testamento; es una manera de amar, cuando se envía una poesía; es una manera de olvidar, al hacer anotaciones en la agenda; es una manera de descargarse cuando no hay nadie que pueda consolar; es una manera de castigar: los alumnos suelen quejarse de las tareas escritas, tal vez como resabio de aquella época en la que debían escribir cien veces “no debo...".Pero escribir es también una forma de pensar, diferente de la empleada al hablar. Muchas personas prefieren hablar en vez de escribir. Y se trata realmente de dos cosas distintas porque:a) Muchas veces se animan a decir cosas pero no a escribirlas: a las palabras se las lleva el viento y existe la posibilidad de corregir errores sobre la marcha haciendo un feedback con las expresiones faciales del interlocutor (por ejemplo un profesor). Otras veces suelen decirse cosas que son obvias y escribir las no obvias, pero con frecuencia es necesario también decir por escrito lo que es obvio, ya que puede no serlo para el lector.b) Muchas otras veces, por el contrario, se escriben cosas que jamás a la persona se le hubiera ocurrido decir en forma oral, sobre todo porque el acto mismo de la escritura genera un clima que obliga a pensar con una organización y una precisión que no se suele poner en juego en el coloquial y versátil acto de hablar.Muchos alumnos deberían aprender a leer y escribir por segunda vez, aunque más no sea para educar el pensamiento en el rigor y la organización. "La lectura produce personas completas; la conversación, personas dispuestas; y la escritura, personas precisas", dijo Francis Bacon.
La forma del texto
Todo texto tiene un contenido y una forma. El contenido se refiere a ‘qué’ se dice, mientras que la forma a ‘cómo’ se lo dice (estilo literario, modalidad de organización del texto, etc.).Los libros y los artículos publicados en revistas científicas admiten diferentes clasificaciones de formato. Los libros pueden tener una organización lógica, cronológica o narrativa, mientras que los artículos pueden responder a un formato técnico o a uno narrativo. En cualquier caso, lo que organiza primariamente el texto, lo que le da su ‘primera’ forma son los títulos. Asimismo, el texto principal puede incluir también textos accesorios, como por ejemplo los anexos y las notas al pie.
El formato de libros.- Un libro puede estar organizado de tres maneras básicas: en forma lógica, en forma cronológica o en forma alfabética, o bien en algunas de sus posibles combinaciones, teniendo cada una sus ventajas y desventajas.
Página 219 de 314
219

a) Organización lógica.- Muchos textos están organizados lógicamente, como el caso de los llamados ‘manuales’. Un ejemplo podría estar representado por aquel libro en cuyo primer capítulo se exponen los conceptos más importantes de una disciplina, mientras que los restantes abordan en detalle cada uno de aquellos conceptos.Esta modalidad expositiva es 'lógica' porque sigue el modelo del razonamiento deductivo, (de lo general a lo particular), del modelo inductivo (de lo particular a lo general), o bien, más frecuentemente, el de una combinación de ambos (por ejemplo, el ordenamiento de los capítulos es deductivo, pero dentro de cada capítulo hay ordenamientos inductivos).Bruner (1996) habla de dos modalidades de pensamiento: la paradigmática o lógico-científica, que corresponde a la organización lógica del texto, y la narrativa, que corresponde a la organización cronológica. La primera forma de funcionamiento cognitivo, o, en este caso, de exposición de un tema, "trata de cumplir el ideal de un sistema matemático, formal, de descripción y explicación. Emplea la categorización o conceptualización y las operaciones por las cuales las categorías se establecen, se representan, se idealizan y se relacionan entre sí a fin de constituir un sistema" (Bruner, 1996:24).La modalidad lógica ofrece la ventaja de mostrar la arquitectura deductiva de las ideas. En cambio, no muestra cómo esas ideas han ido elaborándose en el tiempo (modalidad cronológica) ni suministra pistas para buscar rápidamente un determinado concepto (modalidad alfabética).
b) Organización cronológica.- En este caso, los sucesivos capítulos narran una historia que habitualmente va desde los acontecimientos más antiguos (primeros capítulos) hasta los más actuales (últimos capítulos). Ejemplos típicos de esta modalidad expositiva son las biografías, y las 'historias': la historia de la humanidad, la historia del psicoanálisis, la historia de las instituciones, etc."El objeto de la narrativa son las vicisitudes de las intenciones humanas" (Bruner, 1996:27), nos dice acertadamente este autor cuando define su segunda forma de pensamiento, la forma narrativa, y que corresponde a lo que aquí se llama organización cronológica del texto. A diferencia de lo que ocurre en la organización lógica, en una narración los protagonistas no son tanto los conceptos y sus mutuas relaciones, como las personas y las acciones que ellas realizan. Por ejemplo, en la modalidad lógica un pensamiento puede surgir como consecuencia lógica de un pensamiento anterior, mientras que en la modalidad narrativa, un pensamiento puede surgir como consecuencia de haber sido rectificado o criticado un pensamiento anterior, del mismo o de otro autor-actor. En un caso, el "luego" describe una secuencia lógica, y en el otro, una secuencia temporal.La ventaja de la modalidad cronológica es que permite mostrar cómo han ido construyéndose los diferentes conceptos a lo largo del tiempo, mientras que su desventaja es que no muestra una visión de conjunto, es decir, cómo las diferentes ideas están organizadas en un sistema inductivo o deductivo.Por ejemplo, un texto que intente dar un panorama de la teoría psicoanalítica, puede organizarse lógicamente desde los principios más teóricos hasta las aplicaciones más prácticas de la teoría, o puede organizarse cronológicamente narrando las vicisitudes del pensamiento de Freud desde 1890 hasta su muerte. El primer caso se centra en la teoría en abstracto, y el segundo en cómo su creador ha ido construyéndola.Otro ejemplo de ambas modalidades aparecen en los artículos periodísticos: la crónica de un hecho policial asume normalmente la modalidad cronológica, mientras que un artículo editorial, la modalidad lógica.
c) Organización alfabética.- Está basada en el ordenamiento convencional del alfabeto, y los ejemplos típicos son los 'diccionarios' especializados: de filosofía, de psicología, de economía, de mineralogía, etc.La ventaja de este tipo de presentación es que, al estar basada en un código compartido entre autor y lector (el orden alfabético) permite el rápido acceso a determinadas ideas o recortes conceptuales, mientras que su desventaja radica en que ofrece una visión fragmentada del conjunto.
Combinaciones posibles.- En la práctica, las modalidades lógica, cronológica y alfabética suelen ir combinadas de diferentes maneras. Estas diferentes formas de combinar modalidades pueden clasificarse en dos grandes tipos: integradas y separadas.
1) Modalidades integradas.- Esta alternativa se refiere a aquellos libros en los cuales dos o más modalidades están integradas en el mismo texto. Algunos ejemplos son los siguientes:a) Ordenamiento cronológico integrado en un ordenamiento lógico: en el transcurso de una exposición lógica, aparecen fragmentos de ordenamiento cronológico. Por ejemplo, al describirse una clasificación de minerales, se incluye la historia del descubrimiento de cada uno de ellos.b) Ordenamiento lógico integrado en un ordenamiento alfabético: en el contexto de un ordenamiento alfabético, se incluyen referencias que ayudan o invitan al lector a hacer un ordenamiento lógico. Son las clásicas referencias cruzadas o bien las referencias hipertextuales de los diccionarios informatizados.El recurso utilizado por Laplanche y Pontalis para organizar su "Diccionario de Psicoanálisis" consiste, por ejemplo, en referencias del tipo "véase esta palabra", o también asteriscos para designar vocablos a los que en el diccionario se les ha dedicado un artículo. "De este modo - dicen los autores- desearíamos a invitar al lector a establecer, por sí mismo, relaciones significativas entre los conceptos y a orientarse en las redes de asociaciones del lenguaje psicoanalítico. Con ello creemos haber evitado un doble peligro: la arbitrariedad a que podría conducir una clasificación puramente alfabética y al riesgo, más frecuente, del dogmatismo ligado a las exposiciones de tipo hipotético-deductivo" (Laplanche y Pontalis, 1981:XIV).
Página 220 de 314
220

2) Modalidades separadas.- Esta alternativa hace referencia a aquel libro donde las modalidades están netamente separadas, ocupando dos partes distintas del espacio físico del mismo. Generalmente se trata de solamente dos modalidades, donde una de las cuales es la principal y la otra la accesoria. Esto significa que estos libros tienen una organización primaria (por ejemplo lógica) y una organización secundaria (por ejemplo alfabética). En el esquema adjunto aparecen algunos ejemplos posibles, que pasamos a describir brevemente.a) Este primer ejemplo corresponde al formato clásico. Se trata de los libros primariamente organizados en forma lógica, pero que incluyen secundariamente, al final, una organización alfabética en forma de índice analítico o, en algunos casos, un simple glosario. Un ejemplo de este último caso es "Introducción a la obra de Melanie Klein" (Segal H, 1987), donde su autora, Hanna Segal, agrega al final un glosario alfabéticamente ordenado de los principales conceptos utilizados en el texto.b) La organización primaria puede ser también cronológica y, secundariamente, incluir al final un índice analítico que organiza el libro en forma alfabética. Tal el caso de las obras completas de Freud editadas por Amorrortu, donde los artículos de Freud se exponen cronológicamente, y donde en el último tomo figura un extenso y detallado índice analítico. Otros ejemplos son los textos de historia de Losee (1979) y de Hull (1978).c) Esta variante aparece por ejemplo en el "Diccionario de Psicoanálisis" de Laplanche y Pontalis, donde la organización primaria es alfabética, pero la secundaria también, ya que al final incluye un índice analítico que, por lo demás, es más detallado que la simple lista de los artículos del diccionario.Las combinaciones d, e y f parecen no haber sido utilizadas nunca, lo que llama la atención por cuanto presentan ciertas ventajas que no tienen las combinaciones tradicionales.El autor de esta Guía publicó un Diccionario de "Teoría General de los Sistemas" con un triple organización: la organización primaria es alfabética, la secundaria es lógica y la terciaria es nuevamente alfabética (índice analítico). La organización lógica, que figura como un Apéndice, ofrece otra opción de lectura del Diccionario y consiste, básicamente, en el Índice General que el autor hubiese hecho, de organizar primariamente el texto en forma lógica. Tal Índice General está organizado en capítulos, y en cada uno hay subtítulos, que corresponden a los diversos artículos del Diccionario. El interesado, si opta por una lectura lógica, no tiene más que ir leyendo dichos artículos en el orden indicado en el mencionado Índice General. A modo de auxilio para armar la trama lógica de la teoría, al final de cada artículo del Diccionario, se incluye un denominado 'párrafo de conexión', que muestra la articulación con el siguiente artículo que deberá ser leído.
El formato de artículos.- Entre las diversas maneras de redactar un informe científico, pueden encontrarse dos formatos típicos: el formato técnico y el formato narrativo, siendo el primero de ellos exigido en la mayoría de los ámbitos donde se evalúan oficialmente investigaciones. Quien no utiliza esta retórica de corte positivista, tal vez no podrá escalar posiciones en la pirámide de la comunidad científica.Una recorrida por diferentes informes científicos permite distinguir, entre otros, un formato narrativo y un formato técnico.
Otros formatos que aquí no se considerarán son el formato coloquial y el formato periodístico. El formato coloquial es esencialmente oral y el ejemplo típico son clases o conferencias. Es más informal y el discurso no suele estar tan organizado como en un material escrito donde generalmente se ha cuidado de utilizar un lenguaje más riguroso y de estructurar las ideas en forma más coherente, como por ejemplo mediante el empleo de títulos. El estilo oral está estructurado temporalmente, porque las palabras pronunciadas tienen duración, de aquí la utilización de muletillas del tipo "ahora veremos..." o "si nos queda tiempo...", etc. En cambio, el estilo escrito está organizado espacialmente, porque las palabras escritas ocupan un lugar físico (en el papel o en la pantalla de la computadora). Por ello, las muletillas típicas son, por ejemplo, "más arriba dijimos", o "aquí veremos...", etc.Con el tiempo, las clases o conferencias podrán transformarse en discurso escrito: apuntes impresos, artículos científicos, libros, etc. Para ello, suelen antes pasar por una etapa intermedia: la clase desgrabada, que, si bien es escrita, mantiene la estructura temporal, el lenguaje poco riguroso y la organización informal.El formato periodístico es el que aparece en diarios o revistas de interés general o de divulgación científica. Sus destinatarios son el público profano, y por ello el lenguaje empleado no es tan riguroso y, con frecuencia, más llamativo e impactante.
Un ejemplo típico del formato narrativo es el informe de casos. El propósito no es aquí alcanzar generalizaciones sino profundizar en la comprensión de algún caso en particular. El informe de casos da cuenta de lo único e irrepetible, y, aún cuando el objetivo a largo plazo sea la construcción de una teoría, no teme introducir puntos de vista subjetivos o impresiones personales si ello puede contribuir a la comprensión del caso. Según Zeller, "a través de la destreza artística con que produce su narrativa de caso, el científico social se convierte en algo más que un narrador objetivo de experiencias: se convierte en un filtro narrativo a través del cual se modela la experiencia y se le da sentido" (Zeller N, 1995:312).El formato narrativo aparece típicamente en los artículos freudianos sobre el caso Juanito, el caso Schreber o el Hombre de las Ratas. También puede encontrárselo no ya en informes sino en la forma de redactar programas analíticos para asignaturas. Slapak, por ejemplo, plantea esta situación como un obstáculo que impide identificar con claridad qué contenidos se proponen para enseñar, toda vez que muchos profesores utilizan "modalidades narrativas, con frases extensas, adjetivadas, a partir de las cuales no es posible determinar de manera directa cuáles son los conceptos que se propone desarrollar" (Slapak, 1996:140).El formato técnico es bien diferente. Dentro de sus múltiples variantes, una típica es aquella donde se exponen los resultados de una investigación empírica con la apoyatura estadística que permita realizar
Página 221 de 314
221

predicciones con un determinado margen de error, también especificado (de allí que sea frecuente la designación de variables independientes como 'predictores'). En ellos se procura describir el experimento realizado con el fin de que otros investigadores puedan repetirlo, garantizándose así una cierta objetividad en los procedimientos y las conclusiones.Un paper típico en formato técnico incluye los siguientes títulos: "Abstract" (donde se resume en no más de una carilla el artículo), "Marco teórico", "Método" (muestra seleccionada, procedimientos de medida, instrumentos de medición usados, especificación de los procedimientos estadísticos inferenciales utilizados, tales como tests de hipótesis o análisis de regresión, etc.), "Resultados" (análisis estadístico de los datos obtenidos, generalmente volcados en cuadros de doble entrada, etc.), "Discusión" (donde entre otras cosas se comparan los resultados con otras investigaciones sobre el mismo tema, o se aprecia en qué medida los resultados confirman la teoría, etc.), y "Conclusiones" (donde entre otras cosas se especifican los alcances y limitaciones de la investigación realizada, se sugieren nuevas líneas de investigación, etc.). En ocasiones, los ítems "Conclusiones" y "Discusiones" son equivalentes, utilizándose cualquier denominación indistintamente. La discusión es una “reflexión que realiza el investigador en relación a las implicaciones que los datos obtenidos en su investigación tienen para su hipótesis” (León y Montero, 1995:22).
El informe propiamente dicho no necesita obligatoriamente explicar todas las vicisitudes, marchas y contramarchas de la investigación, siendo suficiente explicar en forma clara pero rigurosa los objetivos de la investigación emprendida, las conclusiones obtenidas, los elementos de juicio que las avalan y las técnicas empleadas en la investigación, el tipo de diseño, las características de los instrumentos de medición utilizados, etc. Incluso la exposición puede ser amena sin que por ello el informe deba transformarse en un artículo de divulgación científica, más destinado a al público general que al público especializado. Además, un texto científico tiene ciertas características que no tiene un texto literario como una novela o una poesía, ya que su finalidad primaria no es la de expresar estéticamente sentimientos o dar rienda suelta a la fantasía, sino la de comunicar información.
Los orígenes de este formato técnico se remontan a la década del ’40. Luego de la segunda guerra mundial se produjo un gran desarrollo de la investigación, sobre todo en EEUU, y los editores de las revistas comenzaron a exigir artículos sintéticos y bien organizados para aprovechar al máximo el espacio. Cada artículo debía tener: Introducción (¿qué se estudió?), Método (¿cómo se estudió?), Resultados (¿cuáles fueron los hallazgos?) y Discusión (¿qué significan los resultados?). Este esquema tiene entonces las siglas IMRYD. Este esquema facilitaba el trabajo de los revisores, pero también el de los lectores que podían encontrar rápidamente lo que buscaban, y el de los autores en tanto contaron con un esquema que les permitió organizar su escrito. Prácticamente hoy en día todas las revistas científicas se basan en sus artículos en el esquema IMRYD, al que suele agregarse un abstract o resumen, conclusiones y referencias bibliográficas.
El abstract o resumen “debe dar cuenta en forma clara y simple del contenido de la obra. El orden recomendable de presentación es el siguiente: Una formulación precisa y concisa del objetivo de la investigación, una breve descripción de la metodología y formulación general de las conclusiones o resultados obtenidos. El resumen debe ser informativo y expresar en un mínimo de palabras, el mayor número posible de información sobre el contenido del trabajo (máximo una página)” (Droppelmann, 2002).No es lo mismo el resumen del informe, y las conclusiones que suelen figurar al final del mismo:a) La conclusión hace referencia a las consecuencias más importantes de la investigación realizada, sea que consistan en los nuevos problemas que plantea, en las soluciones prácticas que pueda ofrecer, en su repercusión para la ampliación, la reconsideración o la refutación de las teorías científicas establecidas que sirvieron de marco de referencia a la investigación, etc. b) Mientras una conclusión adelanta consecuencias, un resumen comprime información. El resumen es un texto que reduce el artículo a las ideas principales dejando de lado las secundarias, y permite al lector darse una idea de su contenido en un tiempo bastante más breve. Un resumen es una síntesis analítica, una conclusión es una síntesis dialéctica. A veces se emplea también la palabra ‘abstract’, aunque generalmente ésta se aplica a un resumen algo más lacónico y ubicado al comienzo del artículo.
En este esquema, particularmente importantes son los métodos utilizados para hacer la investigación. Para evitar las críticas a sus investigaciones, Pasteur publicaba sus resultados incluyendo los métodos utilizados con gran detalle, de modo que otros investigadores pudieran reproducir sus resultados. Hoy en día la reproducibilidad de los experimentos es fundamental en la ciencia.No todos los que publican informes científicos tienen conocimiento de este formato, en cuyo caso suelen recurrir a lo que alguna vez les enseñaron siendo estudiantes cuando debían hacer una monografía, utilizando entonces el clásico esquema de "Introducción", "Desarrollo" y "Conclusiones".La prueba de fuego de todo aspirante a publicar en una revista científica especializada es la confección de la tesis de doctorado, siendo habitual que también a ellas se les exija el formato técnico. Por ejemplo, una tesis de doctorado de 400 páginas en la Universidad de Colorado (Massonnat-Mick G, 1999), fue estructurada en las siguientes partes: Abstract, Reconocimientos, Introducción, Revisión de la literatura (que incluye referencias al marco teórico utilizado), Análisis, Síntesis, Validación e Implementación (que incluye los procedimientos estadísticos utilizados para la validación de la hipótesis), Resultados, Recomendaciones y Conclusiones, y Apéndices.Si bien cada centro de investigación o cada universidad específica sus propias pautas para la presentación de informes, se puede aquí mencionar una propuesta típica de informe técnico que ha codificado la retórica de la investigación tradicional o "positivista" (Zeller, 1995:295).
Página 222 de 314
222

Se trata de la propuesta del APA Publication Manual (Bazerman C, 1987), que, según Zeller, se ha convertido en el manual de estilo para gran parte de las ciencias sociales y también para la investigación en ciencias de la educación. La misma autora señala que las convenciones APA para la redacción "están destinadas a crear la apariencia de objetividad (ausencia de parcialidad o sesgo) de modo que la retórica de los informes o artículos de investigación sean consistentes con la metodología en la que se basan. Según Bazerman estas convenciones incluyen 1) el uso del punto de vista en tercera persona, es decir, del punto de vista objetivo; 2) el énfasis en la precisión, tomando la ciencia matemática como modelo; 3) la evitación de metáforas y otros usos expresivos del lenguaje; y 4) la práctica de apoyar toda afirmación en una prueba experimental y empírica tomada de la naturaleza" (Zeller, 1995:296).La misma autora destaca la importante influencia de este tipo de formato, refiriendo que incluso se ha llegado a la paradoja de que muchos investigadores no positivistas que rechazan la objetividad en las ciencias humanas, ellos mismos han utilizado formatos técnicos en la redacción de sus informes.Para Zeller, el formato técnico y el narrativo representan estrategias retóricas diferentes que se apoyan en dos supuestos fundamentales: "el primer supuesto es que el principal objetivo de un informe de casos [narrativo] es crear comprensión (versus predicción y control). El segundo supuesto es que una narrativa de caso, a diferencia de un informe técnico de investigación, debe ser un producto en vez de un registro de la investigación" (Zeller, 1995:295).Ya desde los mismos títulos de los informes puede identificarse el formato: no es lo mismo títulos de tipo "El hombre de los lobos" o "La crisis negra o el día que me llamaron racista (glup)", que los títulos "Factores intrapsíquicos e interpersonales relacionados con el bienestar psicológico del adolescente en familias con madrastra o padrastro", o "Validación de un procedimiento informatizado para la evaluación de las estrategias de resolución de una tarea de visualización espacial".Finalmente, cabe consignar que el formato técnico donde se expone el título, el abstract y el cuerpo del informe facilita enormemente su búsqueda en el inmenso océano de información que circula en Internet o en las bibliotecas. Así, si lo que se busca es por ejemplo información sobre las relaciones entre familia y drogadicción, no deberán leerse todos los informes en su totalidad, sino solamente sus títulos. Sobre 3000 títulos seleccionados se podrán elegir 300, de los cuales se leerán solamente los abstracts. Una nueva selección en función de estos últimos finalmente, podrá conducir a considerar apenas 30 informes, que sí podrán leerse con mayor detenimiento.
La titulación de los textos.- Los títulos de un texto científico, al igual que los de uno literario, son los anfitriones del lector, pausas para descansar, y la primera impresión que se lleva el lector sobre el escrito; pero, ante todo, son los organizadores primarios de la información en tanto recursos centrales para la comprensión del texto.Cuando se lee un texto donde los títulos están adecuadamente colocados, su comprensión se torna más fácil porque la información está más organizada. Los títulos son recursos que permiten organizar la información tanto al lector como al autor del texto, siempre y cuando, desde ya, unos y otros reconozcan su importancia para tal fin.A los títulos se los puede denominar organizadores primarios no sólo porque son los primeros elementos a los que recurre el lector para comprender lo que lee, sino también porque son los que organizan la información en sus partes más genéricas o principales. Los organizadores secundarios, en cambio, son los términos sincategoremáticos o relacionales incluidos en los párrafos: términos sincategoremáticos son aquellos que relacionan ideas, frases, etc., como por ejemplo 'por lo tanto', 'porque', las conjunciones ilativas, las preposiciones, etc.De lo dicho se desprende que cuando un texto tiene cierta extensión (por ejemplo un libro, un capítulo de un libro, o un artículo), resulta fundamental fragmentarlo. La titulación es el proceso de fragmentación consistente en dividirlo en partes jerárquicas, o simplemente diferentes, mediante el empleo de títulos explícitos o implícitos, con el fin de facilitar al lector la organización y la comprensión de la información recibida.
Respecto de la importancia de los títulos, puede indicarse lo siguiente:
a) Los títulos ayudan a ubicar al lector en cada parte del texto.- Un título es un anfitrión que invita al lector a entrar en él y recorrer sus diversas partes. En este sentido, la titulación de un artículo es un proceso similar a la señalización vertical de una ruta o de un shopping: cada título es un cartel indicador que muestra al lector dónde está ubicado en el texto, del mismo modo que muestra al conductor su ubicación en la ruta o al visitante su lugar en el centro comercial. Títulos como "Introducción" pueden ser equivalentes a "Entrada", mientras que el "Resumen" puede ser la "Salida" o el plano de la ruta o el shopping.b) Los títulos son medios para la comprensión del texto que subsumen.- Tómese el lector la molestia de leer el siguiente párrafo:
"En realidad el procedimiento es bastante simple. Primero usted dispone las cosas en grupos diferentes. Naturalmente, una pila puede ser suficiente, dependiendo de cuanto haya que hacer. Si usted tiene que ir a alguna parte debido a la falta de medios, éste sería el siguiente paso, y en caso contrario todo está bien dispuesto. Es importante no enredar las cosas. Es decir, es mejor hacer pocas cosas a la vez, que demasiadas. De momento esto puede no parecer importante, pero las cosas pueden complicarse fácilmente. Un error también puede costar caro. Al principio todo el procedimiento parece complicado. Pronto, sin embargo, llegará a ser simplemente otra faceta de la vida. Es difícil prever un fin o necesidad de esta tarea en el futuro inmediato, pero nunca se sabe. Cuando el procedimiento se ha completado se dispone de nuevo el material en grupos diferentes.
Página 223 de 314
223

Luego pueden colocarse en sus lugares adecuados. Eventualmente pueden usarse de nuevo y todo el ciclo completo se repite."
Probablemente haya entendido poco o nada, por no saber de qué se está hablando, lo que además influye en la calidad del recuerdo del texto y de su posterior evocación.Proponemos ahora al lector que vuelva a leer el párrafo, pero ahora con el título "El lavado de la ropa", y podrá comprobar cómo habrá aumentado la comprensión del material y, desde ya, su fijación mnémica.El ejemplo forma parte de un experimento llevado a cabo por Bransford y Johnson (1973, citado por De Vega, 1984) destinado a evaluar la importancia del carácter constructivo y contextual de la comprensión. Para la psicología cognitiva, en efecto, los títulos tienen el valor de un 'índice contextual lingüístico' que permite reducir la ambigüedad de un texto, facilitando enormemente su comprensión.En otro ejemplo, alguna vez al encender la radio no se pudo dilucidar de qué estaba hablando la persona, y recién se puede comprenderlo cuando el locutor tiene la delicadeza de decirnos que "acaba de hablar Fulano sobre tal tema", es decir, cuando nos suministró un título.Normalmente, cuando se habla con otra persona se suprime mucha información tácita por una cuestión de economía, por saber que esa información llegará al interlocutor por el contexto, que funciona como título. Por ejemplo, si alguien está con el mecánico viendo el motor del auto, no dice "sale humo del motor", sino simplemente "sale humo", expresión ésta última que, fuera de todo contexto, carece de una significación precisa.c) Los títulos responden a expectativas del lector.- Los lectores tienen una expectativa acerca de que habrán de encontrar títulos que los guiarán, como por ejemplo 'Introducción', 'Desarrollo' o 'Conclusión'. Estas estructuras que guían la producción y comprensión de discursos son llamadas por los psicólogos cognitivos esquemas de dominios (De Vega, 1984) y, cuando un texto no satisface estas expectativas alejándose de los esquemas convencionales, la comprensión puede resultar más ardua.
Respecto de los niveles de titulación, puede decirse lo siguiente:
Los títulos están habitualmente ordenados por niveles para indicar al lector cuales son las ideas principales y las secundarias, aunque la correlatividad de los títulos suele indicar también una secuencia narrativa. Estos niveles son:
1- Título del libro2- Subtítulo del libro3- Título del capítulo o artículo4- Subtítulo/s del capítulo o artículo5- Asterisco o equivalentes (interlineado mayor)6- Comienzos de párrafo
Los cuatro primeros niveles son títulos explícitos, y los dos últimos corresponden a títulos implícitos.El nivel 4 admite diferentes subniveles: por ejemplo, pueden establecerse subtítulos dentro de un subtítulo más general. En el primer subtítulo de la presente nota, por caso, hemos incluído tres subtítulos indicados con las letras a, b y c.A partir del nivel 5 ya no hay títulos establecidos en forma explícita, sino equivalentes de títulos, y pueden existir o no. Por ejemplo, un asterisco o un interlineado más destacado que separa párrafos es interpretado por el lector como un límite entre dos fragmentos de texto que hablan de cosas diferentes dentro del mismo tema.Cuando no hay subtítulos, o cuando el lector intenta comprender un texto subsumido en un subtítulo, suele utilizar las primeras palabras de cada párrafo para ordenar su lectura. El autor debe aprovechar esta tendencia del lector y utilizar los comienzos de párrafos como títulos de último nivel. Comienzos de párrafo útiles son por ejemplo "En resumen...", "Haremos aquí una breve pausa para aclarar...", "Veamos algunos ejemplos de...", "Retomando lo que decíamos...", etc.
Respecto a cómo titular correctamente, puede darse las siguientes indicaciones útiles para redactar y ubicar los títulos de manera que puedan cumplir mejor su función de organizar y ayudar a la comprensión del texto.a) La cantidad de títulos no debe ser ni muy breve ni muy extensa.- Los lectores suelen perderse en un artículo tanto cuando carece de títulos, como cuando tiene demasiados. Aunque el logro del equilibrio justo depende de la habilidad del autor, una proporción más o menos razonable podría ser un subtítulo cada dos carillas, si se trata de un paper de extensión estándar (unas 20 carillas).b) Los títulos no deben ser, en lo posible, expresiones metafóricas.- Algunos títulos de artículos de divulgación científica suelen impactar apelando a las emociones o a la sensibilidad del lector, como "Un banquete delicioso" para un artículo que habla de bulimia, o "La naturaleza juega al bingo" para otro que versa sobre la teoría de la probabilidad. Informes científicos con títulos literarios hacen que el lector no pueda darse una idea rápida del contenido del artículo y así, en lugar de "Un banquete delicioso", convendrá colocar "La bulimia", un título más aburrido pero también más práctico.c) No debería abusarse de los subtítulos.- Hay textos que tienen subtítulos de subtítulos de subtítulos..., lo cual tiende a confundir al lector al sumergirlo en una maraña de relaciones que dificultan la comprensión. En caso de tener que utilizarse dos o tres niveles de subtítulos, como suele ocurrir en escritos extensos como las tesis, deben usarse indicadores de nivel. Ejemplo 1: utilizar números para los títulos de mayor
Página 224 de 314
224

nivel, y letras para los del nivel siguiente. Ejemplo 2: usar mayúsculas para los títulos de mayor nivel, y minúsculas para los de menor nivel. Ejemplo 3: usar negritas para los títulos de mayor nivel, y cursiva o bastardilla para los del nivel siguiente. Ejemplo 4: usar letras más grandes para unos y letras más chicas para otros.d) Cuidar la relación entre comienzos de párrafo.- Hay autores que por ejemplo comienzan un párrafo con la expresión "en primer lugar..." y luego, en el resto del texto, no aparece ningún "en segundo lugar" o "en último lugar".e) Los títulos deben atender a las expectativas estándar de los lectores .- Tres supuestos tácitos del lector deben tenerse en cuenta: 1) Lo que está expresado con mayúsculas o en letras más grandes es más importante que lo que está en minúsculas o en letras más chicas (salvo en los contratos, donde la letra chiquita suele ser lo más importante). 2) Lo que está dicho primero es lo más importante. Cuando un artículo está dividido en títulos de igual nivel, se tiende a pensar que lo dicho primero es lo más importante. Esto no es siempre así, porque a veces un artículo comienza con algo poco importante pero que impacta, con el fin de que el lector continúe leyendo por inercia. Esto es perfectamente lícito, siempre y cuando quien escribe el artículo suministre luego pistas claras acerca de qué es lo importante y lo que no. 3) El texto que figura a continuación de un título habla acerca de lo que el título dice. Esto que puede parecer una tontería no es a veces tenido en cuenta por el autor, generando en el lector incongruencias que lo obligan a realizar un esfuerzo adicional para reorganizar la información que recibe.f) Hacer un esquema previo de los títulos.- Esta precaución no sólo ayuda a organizar la redacción de las ideas, sino que también garantiza bastante la titulación correcta.
Las notas al pie.- Las notas al pie son anotaciones que figuran al final de una página o bien al final del libro o del artículo, y que brindan al lector algún tipo de información adicional, como referencias bibliográficas de citas, pero especialmente aclaraciones o comentarios que no hacen al tema principal del texto. Alguien dijo: "las grandes batallas de la antigüedad suelen quedar transformadas, con el tiempo, en una simple nota al pie".
Aclaraciones preliminares.- Antes de describir qué usos puede darse a las notas al pie, se describen a continuación algunas de sus características generales.a) Cada vez que en el texto principal de un artículo o un libro figura una llamada, ella suele remitir a lo que se llama una nota al pie, que puede estar "al pie de la página" o "al pie del artículo". Conviene colocar la nota al pie al final de la página por una razón de comodidad de lectura. Cuando la nota al pie está al final del artículo o del libro ello obliga al lector a pasar páginas y buscar la nota en el final, interrumpiendo la continuidad de la lectura.b) La nota al pie debe tener un formato diferente al texto principal, para quedar bien individualizada. Generalmente, en las notas al pie se utiliza una tipografía más pequeña, y suele estar separada del texto principal por una breve línea.c) Obviamente, toda nota al pie comienza con una llamada, que debe ser exactamente igual a la llamada respectiva que figura en el texto principal. Por ejemplo, la llamada ‘(1)’ del texto principal remite a la nota al pie que comienza con la llamada ‘(1)’.d) Las notas al pie derivan habitualmente del texto principal, pero también de los títulos de dicho texto, en cuyo caso suele utilizarse el asterisco (*) como llamada.e) No debe abusarse de las notas al pie. En lo posible, el redactor deberá utilizar el mínimo necesario para sus fines. Por ejemplo, un escrito lleno de notas al pie y donde el texto principal ocupa un espacio menor puede hacer dudar al lector acerca de donde está el contenido del artículo: si en el texto principal o en las notas al pie.
Usos más habituales de la nota al pie.- A continuación pueden apreciarse varios ejemplos de notas al pie, que ilustran algunos de los usos más habituales de este recurso expositivo.
Ejemplo de texto con notas al pie Notas al pie del textoLa medicina hipocrática (*)Por Juan Pérez (**)
Hipócrates puede muy bien ser considerado como un representante típico de la medicina griega. Como señala acertadamente Asúa, "es posible captar el carácter esencial de la actividad médica griega concentrándonos en la figura de Hipócrates de Cos" (1). Hipócrates tenía una actitud naturalista. Por ejemplo, en su tratado "La enfermedad sagrada", establece que "la epilepsia no es causada por la posesión de espíritus malignos" (2), sino que invoca causas naturales. Sin embargo, "debe tenerse en cuenta que esta actitud no significaba romper con la religión oficial griega" (3) ya que el mismo tratado aclara que las enfermedades están, en última instancia, bajo el control de los dioses (4).La novedad que introduce la escuela de Hipócrates es que rompe con la idea de la enfermedad como posesión, idea muy difundida en las culturas arcaicas y en especial en Babilonia, donde se utilizaba el recurso del exorcismo (5).
(*) El presente artículo resume los conceptos vertidos por el autor en una conferencia dictada en la Universidad Nacional de La Plata, en abril de 1988.(**) Médico legista. Prof. Adjunto de la Cátedra de Historia de la Medicina de la Facultad de Medicina de la Universidad de Buenos Aires.
(1) Asúa Miguel de, "El árbol de las ciencias", Fondo de Cultura Económica, Bs. As., 1996, p. 21.(2) Idem, p. 22.(3) Loc. Cit.(4) Cfr. Hull L, "Historia y filosofía de la ciencia", Ariel, Barcelona, 1978, 4° edición, p. 124.(5) En la época de Hipócrates coexistía con su escuela otra que era la medicina sacerdotal o teúrgica. Aquí nos referiremos solamente a la escuela "médica" de Hipócrates.
Página 225 de 314
225

Entre los usos más difundidos de las notas al pie se cuentan los siguientes.1) Indicar la fuente bibliográfica de una cita.- Tal el ejemplo de la nota al pie ‘(1)’. En la misma, también se puede obviar la editorial, el lugar, y el año de edición de la fuente, ya que esa información puede estar ya incluída en las referencias bibliográficas, al final del artículo o libro.La nota al pie ‘(2)’ remite a la misma fuente bibliográfica inmediatamente anterior. En estos casos, suele utilizarse indistintamente "Idem", "Id.", "Ibidem" o "Ibid.", expresión latina que significa "el mismo". La nota al pie ‘(3)’ remite no sólo a la misma fuente bibliográfica inmediatamente anterior, sino además también a la misma página, puesto que la expresión "Loc. Cit.", del latín "Locus citate", significa "lugar citado". Si la fuente bibliográfica no es inmediatamente anterior, se puede consignar, por ejemplo, "Asúa, M. ‘El Árbol de las ciencias’, loc. cit.", para que el lector sepa a qué texto se hace referencia.Suele usarse también otra expresión, "op. cit.", que significa en latín "opus citate" (obra citada), en los casos donde se vuelve a mencionar una fuente bibliográfica indicada anteriormente. Por ejemplo: "Asúa M., op. cit., p. 49".Todas las especificaciones precedentes se aplican tanto a las citas textuales como a las no textuales (en el ejemplo del recuadro, se han indicado solamente citas textuales).2) Remitir a un texto no citado específicamente.- La nota al pie ‘(4)’ del ejemplo comienza con la expresión "Cfr.", abreviatura de "confiérase" o "confróntese". Ella remite al lector al texto indicado en la nota y da a entender que en dicho texto hay algo que, aunque no fue citado explícitamente en el texto principal, está de alguna forma relacionado con lo que se está diciendo.También pueden utilizarse las expresiones "Cf." o "Véase", y pueden incluso remitir a otros lugares del mismo texto que el lector está leyendo, como por ejemplo cuando en una nota al pie aparecen expresiones como "(9) Véase más arriba el segundo ejemplo", o "(9) Véase capítulo 4".3) Agregar información adicional.- Tal el ejemplo de la nota al pie ‘(5)’, donde la información no fue incluida en el texto principal para no obstaculizar la continuidad en la lectura. En general, se puede leer un artículo prescindiendo de las notas al pie, y con la seguridad de haberse informado respecto de las ideas principales de su autor. Otros ejemplos de notas al pie que agregan información adicional son: "Ptolomeo también fue autor de una famosa obra de astrología, el Tetrabiblos", o "Las artes liberales para Varrón eran nueve: retórica, gramática, dialéctica, aritmética, geometría, música, astronomía, medicina y arquitectura. Casiodoro (490-585 d.C.) eliminó del canon las dos últimas, dando origen a la tradición de las siete artes liberales", etc.4) Agregar sucintamente algún punto de vista diferente al que se plantea en el texto principal.- Ejemplos de este tipo de notas al pie pueden ser las siguientes: "No coincidimos con este planteo de Collins, por cuanto...", o "Esta es la oportunidad de rectificar una opinión que había desarrollado tiempo atrás...", etc. Desde ya, una nota al pie puede tener otras muchas utilidades, dependiendo ello de la imaginación del redactor y de su habilidad para distinguir qué tiene sentido incluir como nota al pie, y qué no.
El contenido del texto
El contenido de un texto científico puede expresar los resultados de tres tipos de investigación: una investigación teórica, una bibliográfica, y una empírica. En la investigación teórica la tarea principal es relacionar diversas ideas entre sí, mientras que en la investigación empírica es central relacionar ideas con hechos. La investigación bibliográfica suele estar incluida en ambas, pero también puede constituir una investigación independiente. En cualquier caso, su propósito principal es exponer las diversas teorías y/o investigaciones que se han llevado a cabo sobre un determinado tema, como por ejemplo sobre el sentido de una palabra, o sobre los resultados de algún tipo especial de terapia.En el presente ítem se incluye un ítem sobre la importancia de las definiciones en tanto estas permiten organizar primariamente el contenido de la información, del mismo modo que los títulos organizan primariamente su forma.
La investigación teórica.- Una investigación teórica permite explorar diferentes puntos de vista de diversos autores, examinando sus concordancias, sus diferencias y el grado en que fundamentan sus afirmaciones, tanto si se trata de una fundamentación lógica como de una fundamentación empírica.Una investigación teórica puede incluir una investigación bibliográfica, pero va más allá de ella, por cuanto no se limita a exponer diferentes puntos de vista sino también a analizarlos, cuestionarlos, defenderlos, compararlos y, eventualmente, proponer un enfoque teórico alternativo.Una investigación teórica no es empírica, pero puede exponer resultados de investigaciones empíricas con el fin de ilustrar o fundamentar asertos teóricos.
La investigación bibliográfica.- La investigación bibliográfica es aquella etapa de la investigación científica donde se explora qué se ha escrito en la comunidad científica sobre un determinado tema o problema. Si una investigación bibliográfica forma parte de una investigación más general de tipo empírico, ella se incluye, entre otras cosas, para apoyar la investigación que se desea realizar, evitar emprender investigaciones ya realizadas, tomar conocimiento de experimentos ya hechos para repetirlos cuando sea necesario, continuar investigaciones interrumpidas o incompletas, buscar información sugerente, seleccionar un marco teórico, etc.A continuación se exponen algunas indicaciones a tener en cuenta al emprender este tipo de investigación, principalmente en lo concerniente a qué hay que consultar, y cómo hacerlo.
Página 226 de 314
226

a) ¿Qué bibliografía consultar?.- A la hora de resolver este problema, se pueden diferenciar tres niveles de bibliografía, de acuerdo al tipo de destinatario para el que fue diseñada: la bibliografía para el público en general, la bibliografía para aprendices o alumnos, y la bibliografía para profesionales e investigadores.a) Bibliografía para el público en general.- Se incluye aquí aquel material destinado a todas las personas, profanos o no profanos. En esta categoría están los diccionarios 'comunes', los diccionarios enciclopédicos, las enciclopedias, y los artículos de divulgación científica que se publican en diarios y revistas de interés general. Desde ya, entre estos artículos de divulgación habrá material de dispar lecturabilidad: algunos podrían ser de 'fácil' lectura, como un artículo sobre el ataque de pánico publicado en una revista femenina, y otros algo más 'sesudos' como el que habla de la estructura del universo en una revista de divulgación científica.b) Bibliografía para aprendices o alumnos.- Cabe incluir aquí todo aquel material diseñado especialmente para la enseñanza sistemática y, por tanto, sus destinatarios son aprendices o alumnos. Por ejemplo, los manuales y tratados generales sobre alguna disciplina, las publicaciones internas de las cátedras, las clases desgrabadas de los profesores, textos indicados por los docentes como bibliografía, etc. Los diccionarios especializados (por ejemplo de filosofía, de psicoanálisis, de electrónica, etc.) fueron diseñados para alumnos pero también para profesionales e investigadores.c) Bibliografía para profesionales e investigadores.- Se incluyen aquí fundamentalmente los artículos especializados que aparecen en Journals o revistas destinadas a profesionales e investigadores, como así también las comunicaciones hechas en Congresos o Simposios, tesis de doctorado, etc. La lectura de este tipo de material supone habitualmente bastante conocimiento previo, por lo que no es común que sea consultado por alumnos novatos, ni menos aún por el público profano.En general, hay siempre alguien que avala la calidad de lo publicado, más allá de si lo hace bien o mal. Por ejemplo, un diccionario está avalado por la editorial que lo publica, y difícilmente se podría encontrar en él una leyenda que aclarase que el editor no sea hace responsable por las definiciones propuestas. De idéntica forma, un manual está avalado por el profesor que lo recomienda, y una clase desgrabada suele estar corregida por el docente que la dictó. Los artículos publicados en revistas especializadas están avalados en cuanto a su nivel de 'cientificidad' por un comité editor.Otras veces, no hay nadie que ostensiblemente se hace responsable de avalar un escrito, siendo el ejemplo más patético al respecto la bibliografía que circula libremente por Internet. De hecho, cualquiera puede escribir cualquier cosa, incluso utilizando una engañosa sintaxis científica y un engañoso vocabulario del mismo tenor, y enviarlo desaprensivamente a rodar por la autopista informática.Pero ¿qué tipo de material debería utilizarse en una investigación bibliográfica con fines de investigación científica? En principio, considero que el investigador no debería descartar ninguno de los tres niveles de lectura: se puede encontrar material muy valioso en un artículo de divulgación científica, y material de baja calidad en un artículo especializado. El diccionario 'común' resulta muchas veces imprescindible a la hora de tener que definir conceptos, aún cuando no sea luego citado.En suma: en principio se puede consultar todo lo considerado relevante, y en el nivel que sea. En todo caso, la restricción no pasa por lo que se consulta, sino por lo que finalmente se cita como bibliografía consultada.b) ¿Qué se cita de lo que se consulta?.- Al respecto, pueden servir las siguientes observaciones:a) Conviene no citar revistas de divulgación científica, porque a los ojos de muchos lectores y evaluadores, el material puede perder prestigio, seriedad o credibilidad. La razón principal es la creencia de que los artículos de divulgación científica son seleccionados más por su interés comercial que por su rigor científico o, si se quiere, más por su capacidad para impresionar que por su capacidad para respaldar lo que se afirma. Con esto no se descalifica la divulgación científica. De hecho algunas de ellas suelen publicar artículos firmados por investigadores de amplio reconocimiento académico en la misma comunidad científica, como por ejemplo Paul Davies o Carl Sagan. Se aconseja, por lo tanto, citar aquella parte de la bibliografía consultada que abarca diccionarios de todo tipo, manuales y, en especial, libros y artículos especializados.b) No debería incluirse bibliografía no consultada, lo que a veces se hace para 'abultar' la lista pretendiendo con ello dar al escrito mayor prestigio o, en el caso de alumnos que presentan monografías, dar la impresión de haber 'trabajado' más.c) A veces, se menciona un texto que jamás se tuvo entre las manos, pero que aparece citado en algún libro efectivamente consultado. Se trata de un 'hurto lícito' de citas donde se usa al autor como un empleado, ya que fue él quien se tomó el trabajo de buscar la bibliografía. Es un recurso legítimo siempre y cuando: a) se esté razonablemente seguro de la fidelidad de la mención bibliográfica ajena, y b) cuando su empleo esté estrictamente justificado, es decir, no utilizar citas bibliográficas de otros libros 'porque sí'.d) Una creencia muy extendida, sobre todo entre los alumnos que realizan trabajos escritos, es que si se cita un libro, uno debe conocer a fondo 'todo' el libro, porque "tal vez puedan preguntarme cualquier cosa sobre él". Desde ya, no hay que saber detalladamente todo el libro consultado, aunque sí conocer aquella parte que fue efectivamente utilizada, que bien pudo haber sido un simple párrafo.c) ¿Cómo buscar la bibliografía?.- Dankhe (citado por Hernández Sampieri, 1991:23) propone otro criterio para clasificar las fuentes de información bibliográfica, distinguiendo fuentes primarias, secundarias y terciarias. Una fuente primaria es por ejemplo un libro, o un artículo de una revista. Una fuente secundaria es un listado de fuentes primarias, como por ejemplo ciertas publicaciones periódicas que reportan y/o comentan brevemente artículos, libros, tesis, ponencias, etc. publicadas en determinado lapso de tiempo o para determinadas disciplinas científicas. Una fuente terciaria agrupa o compendia, a su vez, fuentes secundarias, como por ejemplo un catálogo de revistas periódicas.
Página 227 de 314
227

Esta clasificación resulta útil para decidir por dónde comenzar la investigación bibliográfica. En general, conviene hacerlo por las fuentes terciarias para ver qué revistas publican material sobre el tema que interesa; luego, se pasa a las fuentes secundarias para localizar, dentro de las revistas, la información pertinente. Finalmente, las fuentes primarias así seleccionadas proveerán la información directa.Hernández Sampieri y otros (1991:27) ofrecen tres recomendaciones para buscar la bibliografía que interesa: a) acudir directamente a las fuentes primarias u originales, cuando se conozca bien el área de conocimiento en donde se realiza la revisión de la literatura; b) acudir a expertos en el área para que orienten la detección de la literatura pertinente y a fuentes secundarias, y así localizar las fuentes primarias (que es la estrategia más común); y c) acudir a fuentes terciarias para localizar fuentes secundarias y lugares donde puede obtenerse información, y a través de ellas detectar las fuentes primarias de interés.El "Member Catalog" de la New York Academy of Sciences (www.nyas.org) es un ejemplo de fuente terciaria para ciencias biológicas, por ejemplo. En el ámbito de la psicología, pueden mencionarse el "Index of Psychoanalitic writting", el "Bibliographic Guide of Psychologie", los "Psycological Abstracts" que se publican desde 1927, así como índices de todas las revistas publicadas hasta la fecha en español o en otro idioma, etc."Psycological Abstracts" es una revista de resúmenes elaborada sobre más de mil revistas científicas a nivel internacional. Se publica cada seis meses y contiene no sólo resúmenes de artículos sino información de libros, capítulos de libros y otros tipos de documento. León y Montero (1993:299) advierten, sin embargo, que nadie suele empezar a estudiar un tema buscando artículos en los "Psychological Abstracts", y, de hacerlo, descubriría que el volumen de lo publicado sólo en los últimos diez años sobre el más específico de los temas es tal, que no terminaría de leerlo en todo el tiempo que había previsto para la investigación. No obstante, cabe consignar que puede ser de utilidad para quienes ya son expertos en el tema o bien para aquellos que buscan obtener, solamente a partir de títulos, un panorama somero de lo publicado sobre el tema. Por lo demás y afortunadamente, el almacenamiento de la información en soportes magnéticos tipo CD-Rom está facilitando mucho la búsqueda.Otra fuente terciaria es el "Annual Review of Psychology", donde un grupo de investigadores revisan lo escrito sobre una temática ordenándolo, comentándolo o criticándolo. Al consultar este tipo de material, no debe pensarse que la bibliografía publicada más recientemente es necesariamente la más actualizada.De hecho, existen artículos fechados hace ochenta años con un increíble nivel de actualidad, y otros publicados hace muy poco pero que no agregan nada nuevo a lo que se viene diciendo desde hace mucho, ni en cuanto al contenido ni en cuanto a la forma de exponerlo.Una vez identificada la fuente primaria de información (el libro, el artículo o la ponencia que interesa), comienza ahora la tarea de la consulta bibliográfica propiamente dicha.d) ¿Cómo consultar la bibliografía?.- El principal problema que debe encararse al consultar un texto es el procesamiento de la información. En efecto, la comprensión de textos expositivos científicos o técnicos es una tarea cognitivamente exigente, no sólo porque el lector debe poseer y ser capaz de invocar grandes cuerpos de conocimiento especializado, sino también porque debe ser capaz de realizar una variedad de procesos de lectura y administración de memoria (Britton y otros, 1985).La cuestión, sin embargo, no depende solamente del lector sino también de quien escribió el texto. Hay artículos que son muy complejos, y no por el tema sino por la forma en que fueron escritos.Por ejemplo, un artículo es más fácil de comprender si está dividido en subtítulos, o si tiene un resumen al final, o si el autor expone sus ideas en forma ordenada. En términos cognitivos, se dice que el texto en cuestión creó las condiciones para ahorrar los recursos de memoria, para reasignarlos al proceso de comprensión e integración.Cuando se lleva a cabo una investigación bibliográfica, desde un punto de vista cognitivo la mente realiza fundamentalmente tareas de ingreso de información (in put) y de procesamiento. En cambio, cuando se exponen los resultados de la investigación pasan a un primer plano la tarea de egresar la información (out put). Por consiguiente, la investigación bibliográfica exige habilidades vinculadas con el in put y el procesamiento, y en particular, la consulta bibliográfica tiene más que ver con éste último. Por ejemplo: El input tiene relación con buscar, percibir, escuchar, oír, leer, memorizar, retener, seleccionar. El procesamiento tiene que ver con analizar, definir, relacionar, comprender, comentar, criticar, crear, comparar, entender, concluir, inferir, razonar, ordenar, organizar, deducir, suponer, inducir, problematizar, opinar. Las habilidades para redactar informes científicos, en cambio, se centran en el output: exponer, enunciar, mentar, decir, escribir, hablar, mostrar, redactar, informar, comunicar, esquematizar, graficar, concluir, resumir.Durante la consulta bibliográfica, el texto puede leerse de dos maneras: secuencialmente o estructuralmente. La lectura secuencial es un pésimo hábito que algunos arrastran desde la primaria, cuando los obligaban a leer palabra por palabra o línea por línea. Lee secuencialmente quien comienza leyendo el material desde la primera línea, y no para hasta la última.La lectura estructural, en cambio, supone leer títulos y organizar el texto a partir de allí, supone trazarse un mapa mental del texto para saber adonde apunta y cuáles son las ideas principales. Una forma de lectura estructural es, por ejemplo, leer el título del artículo y a continuación el resumen, que puede figurar al final. Otra manera es intentar hacer una red conceptual relacionando los títulos y subtítulos entre sí.Una vez realizada esta lectura estructural, se decide si interesa o no seguir profundizando en el texto. En caso afirmativo, se seleccionan los párrafos más interesantes en base a una rápida lectura de las palabras iniciales. Una vez seleccionados los párrafos, se deberá atender no sólo en el contenido informativo, sino la forma en que la información es presentada: en cada párrafo, ¿el autor se propone
Página 228 de 314
228

analizar, comparar, criticar, clasificar, definir, opinar, sintetizar, defender una idea, o qué? A continuación se enumeran algunas de estas operaciones que deberán tenerse en cuenta para procesar la información.
Algunas operaciones que requieren ser identificadas en una consulta bibliográfica .- Los párrafos que se seleccionan en un texto para consulta bibliográfica pueden tener diferentes propósitos. Conocerlos ayudará a utilizar la bibliografía en forma pertinente:
ANALIZAR Descomponer en partes una cosa y considerarlas de a una. Ejemplos: clasificar, describir.CITAR Mencionar las ideas de otra persona o personas.COMPARAR Señalar las semejanzas y/o diferencias entre dos o más cosas o ideas. Confrontar.CONCLUIR Hacer un 'cierre' del texto, resolver de alguna manera lo dicho destacando consecuencias o aspectos significativos, o, especialmente, combinar ideas ya expuestas para construir una idea nueva.CRITICAR Cuestionar o rechazar una idea mediante respaldos argumentativos. En sentido amplio, criticar implica analizar los pro y los contra de una afirmación, discutir, evaluar.DEDUCIR Extraer una conclusión lógicamente necesaria de una o más premisas.DEFENDER Apoyar una idea mediante respaldos argumentativos.Destacar, aceptar, apreciar, reivindicar, valorar.DEFINIR Explicar brevemente el significado de una palabra.DESCRIBIR Enumerar las características de una cosa o situación.EJEMPLIFICAR Mencionar casos o situaciones más o menos concretas que correspondan a una idea o a un caso más general. Ilustrar, mostrar.EXPLICAR Dar cuenta de un hecho o situación relacionándolo con causas, finalidades, motivos, antecedentes, consecuencias, implicaciones, etc.HISTORIZAR Trazar la reseña histórica de la evolución de una idea.INDUCIR Extraer una conclusión más general y de carácter probable a partir de casos particulares. Generalizar.OPINAR Formular un juicio sin fundamentarlo rigurosamente. Conjeturar, suponer.PROBLEMATIZAR Formular preguntas o problemas, más allá de si en el texto se ofrecen o no respuestas o soluciones.REFERIR Remitir a otra parte del texto. Ejemplo: anunciar o informar acerca del tema del texto siguiente.RESUMIR Abreviar un texto en sus ideas principales y respetando el orden de la exposición original.SINTETIZAR Puede significar resumir o concluir, según se trate, respectivamente, de una síntesis analítica o de una síntesis dialéctica. Ver Resumir y Concluir.SUGERIR Instar al lector a que piense o haga determinada cosa. Convencer, persuadir.
e) ¿Cómo registrar la bibliografía consultada?.- A medida que se va consultando la bibliografía, también se va al mismo tiempo registrándola. La forma tradicional de hacerlo es en fichas, aunque también pueden usarse cuadernos, libretas u hojas sueltas. En rigor, no importa mucho la manera en cómo se registra la información, lo que además depende de cada cual (Hernández Sampieri, 1991:30-37). Sin embargo, y sea cual fuese la técnica empleada, deberá discriminarse bien si lo que se registra es un resumen de lo consultado, una cita textual, un comentario, o una crítica, una idea suelta del consultor del material.La investigación bibliográfica termina en principio con el registro de lo consultado, y hasta ahora la labor ha consistido apenas en reunir algunas piezas del rompecabezas, no en armarlo, cosa que será la labor de toda la investigación en su conjunto hasta su presentación por escrito en un informe final.
Finalmente, puede resultar útil listar algunas preguntas que pueden hacerse al leer un texto científico o filosófico: ¿qué dice realmente?, ¿qué oculta?, ¿qué disimula?, ¿qué simplifica?, ¿qué ignora?, ¿qué presupone?, ¿qué falsea?, ¿a qué nos induce?, ¿qué acentúa?, ¿qué niega?, ¿qué provoca?, etc.
La investigación empírica.- La investigación científica empírica tiene básicamente cinco etapas. Primero, se definen algunas cuestiones generales como el tema, el problema, el marco teórico a utilizar, etc. Segundo, se procede a hacer una investigación bibliográfica, básicamente para ver qué se ha escrito sobre la cuestión. Tercero, se traza un proyecto de investigación empírica. Cuarto, se ejecuta lo proyectado. Quinto, se exponen los resultados, usualmente por escrito.La investigación empírica actual suele consistir en un intento por refutar una hipótesis por medios estadísticos, en lugar de confirmarla por medios menos objetivos, y de aquí que todo escrito que plasma una investigación empírica tiene la forma de un ensayo de refutación.El ensayo de refutación es un escrito en el cual se plantea una idea o hipótesis y se la intenta refutar, o demostrar su falsedad, sobre la base de elementos de juicio lógicos y/o empíricos desarrollados en el mismo. Un ejemplo típico es aquel artículo en el cual se intenta refutar o ‘rechazar’ una hipótesis nula mediante pruebas empíricas.Refutar no significa demostrar la verdad de una idea considerada falsa, sino demostrar la falsedad de una idea considerada verdadera. Algunos casos donde en algún sentido puede aplicarse la idea de refutación son los siguientes: a) Mayéutica: el método socrático que obligaba al interlocutor a ir reconociendo gradualmente la falsedad de una opinión tomada por cierta. b) Demostración por el absurdo: utilizada típicamente en matemáticas, intenta demostrar la falsedad de un enunciado ‘p’ demostrando la verdad de su contradictorio ‘no-p’. Este procedimiento ha sido llamado ‘indirecto’ porque, en lugar de probar que un enunciado es verdadero en forma ‘directa’, intenta hacerlo demostrando la falsedad de su contradictorio. c) Pruebas judiciales: en ciertos sistemas jurídicos se presume que el acusado es inocente, con lo cual la tarea del fiscal acusador consistirá en demostrar que la afirmación ‘el acusado es inocente’ es falsa, es decir, deberá intentar refutarla.
Página 229 de 314
229

Pero fuera del campo filosófico, matemático o jurídico, en el territorio de las ciencias fácticas la refutación tiene una larga historia que culmina con la propuesta popperiana según la cual la gran tarea del científico no es probar la verdad de la teoría sino su falsedad, procedimiento llamado entonces refutación o falsación.En este sentido, las hipótesis refutadas tienen su utilidad, pues “al eliminar cada una de las hipótesis falsas, el investigador va estrechando el campo en el cual deberá hallar una respuesta” (Deobold, 1985:193). Por otro lado, las hipótesis confirmadas no son necesariamente verdaderas: simplemente, no se ha encontrado evidencia para refutarla.En muchas ocasiones, elegir refutar en vez de confirmar obedece a una cuestión más práctica: desde el punto de vista estadístico es mucho más fácil intentar refutar que confirmar.Un ejemplo típico de utilización de este procedimiento es el paper que se publica en una revista científica y donde el o los investigadores ponen a prueba su hipótesis utilizando un procedimiento de refutación desarrollado con herramientas estadísticas. Se trata de una exigencia metodológica habitual en los casos de artículos científicos y tesis de doctorado, aunque por su complejidad no suele ser requisito en evaluaciones académicas menores como las monografías que se piden durante una carrera de grado.Se trata de un camino en cierta forma reñido con el sentido común. El sentido común dice, en efecto, que se debe tratar de probar la hipótesis de investigación, en vez de intentar refutar la hipótesis opuesta (llamada hipótesis nula). En otras palabras, es el que dice que se debe tratar de probar que una droga es efectiva para una enfermedad, en vez de refutar la hipótesis de que no es efectiva: “la hipótesis nula no siempre refleja las expectativas del investigador en relación con el resultado del experimento. Por lo general, se opone a la hipótesis de investigación, pero se la utiliza porque resulta más apropiada para la aplicación de procedimientos estadísticos” (Deobold, 1985:189).No se explicará aquí porqué resulta mejor refutar la hipótesis opuesta que probar directamente la propuesta. De hecho entender esta cuestión no es nada fácil. En su lugar, se ofrece un sencillo ejemplo para dar cuenta en líneas generales de este proceso.Supóngase que se quiere averiguar si una persona tiene poder de adivinación, y para ello se diseña un experimento donde se le pide que diga si una moneda saldrá cara o ceca, antes de arrojarla el investigador. Se decide realizar esta prueba 100 veces con la misma persona (cuanto más elevado sea el número de pruebas tanto mejor. Por ejemplo, si se realizan solamente dos pruebas y en ambas el sujeto adivinó, no por ello concluiremos que tiene el poder de adivinar, porque pudo haberlo hecho por azar. En cambio, si adivinó en las 100 pruebas, ya debemos empezar a pensar en un poder de adivinación real). Hay, entre otros, tres posibles resultados del experimento:1) Acertó en el 50% de los casos.- Se piensa aquí que esta persona no tiene poder de adivinación, y que en los casos en que acertó, lo hizo por azar.2) Acertó en el 100% de los casos.- Decididamente, esta persona tiene poder de adivinación! Este resultado no puede explicarse por el simple azar. (Existe otra posibilidad: que la persona haya acertado en el 0% de los casos, es decir, que no haya acertado ni uno solo. Cabe pensar aquí que estos resultados tampoco pueden deberse al simple azar, y que esta persona tiene también un gran poder de adivinación.... pero para adivinar aquel evento que ¡no se producirá!).3) Acertó en el 75% de los casos.- Acá se presenta un problema, porque este 75% se encuentra a mitad camino entre el 50% y el 100%. El dilema es, entonces, qué conclusión sacar: ¿la persona acertó por azar o bien es realmente adivina?Todo el mundo estaría de acuerdo con las dos primeras conclusiones, pero no todos opinarían lo mismo en este tercer caso: tal vez para unos lectores el 75% de aciertos no significa adivinación, mientras que para otros lectores sí. Se necesita, entonces, ponerse todos de acuerdo en base a un criterio único, objetivo y compartido. La elección de este criterio, que en estadística de la investigación se relaciona con el concepto de niveles de significación (alfa y beta), dependerá de cuanto estemos dispuestos a equivocarnos. Por ejemplo, si elegimos 90% (muy cerca del 100% del poder de adivinación) hay un riesgo muy alto de equivocarnos al concluir que la persona no tiene poder de adivinación (es decir, los resultados se deben al azar), o bien una alta probabilidad de acertar si concluimos que sí tiene poder adivinatorio (los resultados no se deben al azar).Supóngase ahora que todos se han puesto de acuerdo en considerar el 75% como el límite entre el poder de adivinación y el azar: si la persona acierta en un 75% o más de los casos, es adivina, y si no, acordarán en que acertó por azar. Considerando este 75% y una muestra de tamaño fijo, se pueden plantear dos hipótesis diferentes:La hipótesis de investigación: “la persona es adivina”.La hipótesis nula: “la persona no es adivina”.En principio, si la persona acierta en un 75% o más de las veces, se acepta la hipótesis de investigación y se rechaza la hipótesis nula (o al revés, si acierta en menos del 75% de las veces, se rechaza la hipótesis de investigación y se acepta la hipótesis nula).Sin embargo, aunque la decisión de aceptar la hipótesis de investigación y la decisión de rechazar la nula son formalmente equivalentes (una implica la otra), no lo son desde el punto de vista estadístico: como quedó dicho, es más fácil intentar el rechazo de la nula que la aceptación directa de la hipótesis de investigación. Si la nula se rechaza, se concluye que no hay motivos para desechar la hipótesis de la investigación, y si la nula no se rechaza, se concluirá que no hay motivos para aceptar la hipótesis de investigación.El ejemplo no aclara el proceso estadístico de refutación en mayor detalle, pero bastará para dar alguna idea de su complejidad.
Página 230 de 314
230

La importancia de las definiciones.- Como los carteles indicadores de las rutas, las definiciones expresan el estado actual del conocimiento que se tiene sobre una región geográfica, es decir, sobre una disciplina científica. Y a la hora de transmitir el saber, también suelen cumplir la función de consagrar la validez del conocimiento, compactándolo en un enunciado cerrado e inviolable.Originalmente, definir significa trazar un límite, una frontera entre lo que es y lo que no es. El diccionario lexicográfico dice, en efecto, que una definición es una proposición que fija con claridad y exactitud el significado de una palabra o la naturaleza de una cosa.El análisis sistemático de la definición comenzó con el Organon aristotélico. En su primera parte, las "Categorías", Aristóteles habla de su clásica concepción de la definición como especificación de un género próximo y una diferencia específica. Así, durante siglos pudo definirse al hombre como "animal (género) racional (diferencia)".Desde entonces, mucha agua ha corrido bajo el puente, y diversos fueron los puntos de vista con que la definición fue analizada a lo largo de los siglos. En este ítem se rescata cierta perspectiva epistemológica, por cuanto que trataremos de las definiciones que se dan en las ciencias, no en la vida cotidiana, y por cuanto son enunciados a través de los cuales se intenta transmitir el saber y sobre todo organizarlo primariamente.
1. La definición como estado actual del conocimiento.- Es posible trazar una analogía entre la definición, y un elemento de señalización vertical, es decir, un cartel indicador de los que aparecen en las rutas. Pueden contemplarse las siguientes dos posibilidades:1) Estamos transitando una ruta y nos topamos con un cartel indicador de una curva, un puente, una estancia, una ciudad, un país, un aeródromo. Esto equivale a decir que estamos metiéndonos en una ciencia que ya recorrieron otros, y donde cada tanto encontramos una definición que es el equivalente del cartel indicador.Por ejemplo, tomamos por primera vez un libro de química y encontramos la definición de química, de molécula, de átomo, de hidrocarburo, de ácido, etc., que nos van indicando los diversos temas - regiones- que estamos recorriendo. La definición de química es evidentemente muy importante, y equivale al cartel que indica la frontera entre un país y otro (entre una ciencia y otra): del mismo modo que el cartel que dice "Chile" nos indica que hasta aquí estamos en la Argentina, pero desde aquí en más entramos en otro país, la definición de química nos muestra que hasta aquí estamos en la química, pero desde aquí en más ya entramos en la física o en la biología.De la misma manera, los carteles indicadores de ciudades pueden ser equivalentes a las definiciones más específicas, como la de ácido o base. Todos estos carteles ya fueron colocados por los primeros científicos que transitaron la química, como Lavoisier, Dalton, y otros.2) En una segunda posibilidad, estamos ahora en un bosque o una selva absolutamente virgen donde nunca antes el hombre ha pasado. Desde ya, no hallamos ningún cartel indicador, y no sabemos con qué nos encontraremos detrás de cada árbol.En este caso, estamos en la situación de aquellos científicos pioneros que incursionaron por primera vez en el conocimiento y fundan una determinada disciplina. Como ellos, nos vemos en la obligación de colocar los primeros carteles, es decir, dar definiciones fundacionales como la que dio Aristóteles de la Física en el siglo IV AC, la que dio Comenio de la Didáctica en el siglo 17 (Barco, 1989:8), o la que dio Comte de la Sociología en el siglo 19 (Timasheff, 1969:15).También puede ocurrir que estemos en un territorio conocido, como por ejemplo en la Psicología, pero sin embargo decidimos no visitar el rancho de Skinner o la estancia de Watson, y nos salimos de nuestra ruta habitual intentando explorar otras zonas, con lo cual podemos encontrarnos con la sorpresa de un lugar totalmente virgen, a juzgar, por ejemplo, por la inexistencia de carteles indicadores. Tal lo que le pasó a Freud cuando andaba por las rutas tradicionales de la psicología y decidió ir a explorar un campo donde habitaban a la intemperie varias histéricas. "Esto es algo nuevo", se dijo, y acto seguido instaló un gran cartel que decía "Psicoanálisis". Tal vez antes que él pasaron otros por ese territorio, pero no tuvieron la precaución de instalar carteles y, por tanto, para los viajeros que venían después ese territorio siguió siendo inexplorado. Freud había tomado la misma precaución que los que pusieron carteles fundacionales cuando llegaron a la cima del Everest, al Polo, o a la Luna.Ahora bien. Tanto si el cartel indicador ya fue puesto por otros como si lo hemos colocado nosotros por primera vez, ese cartel está siempre situado en una determinada región geográfica a la que pretende describir o representar.Sin embargo, la cuestión se complica cuando advertimos que en realidad, la región geográfica representada cambia continuamente, sea por un proceso natural (como cuando una inundación hace aparecer una nueva laguna), sea por la intervención humana (como cuando alguien decide fundar una ciudad, o bien abandonarla a su suerte convirtiéndola en un pueblo fantasma).En estos casos, los carteles que había antes del cambio producido resultan obsoletos, y se torna necesario cambiarlos para que puedan seguir representando la región. Cuando en el siglo XIX comenzaron los primeros experimentos con tubos de rayos catódicos, se comenzó a sospechar que existían 'dentro' del átomo ciertas otras partículas más pequeñas: los electrones y los protones. Este descubrimiento de un nuevo 'pueblo' obligó a cambiar el cartel indicador: se abandonó la vieja definición de átomo como partícula última e indivisible (a=no, tomo=división), y se comenzó a delinear la nueva definición que terminó de redondearse con el modelo atómico de Thompson. Nuevos descubrimientos modificaron a su vez estas definiciones, y aparecieron sucesivamente los carteles indicadores del modelo de Rutherford, el modelo de Bohr-Summerfeld y, finalmente, el modelo atómico actual. Y así, quien hoy en día abre un tratado de química, encontrará los viejos carteles abandonados junto al camino (las
Página 231 de 314
231

definiciones que aparecen en las reseñas históricas de la química), pero también los carteles vigentes, bien erguidos y visibles (las definiciones actuales).Las modificaciones que sufren las regiones geográficas son una metáfora para designar las transformaciones que sufre nuestro objeto de conocimiento a medida que incorpora nuevos descubrimientos y nuevas hipótesis. Como se presupone que la ciencia siempre se topará con ellos, debemos considerar que las definiciones son siempre abiertas, es decir, susceptibles de modificación, y que lo que hacen no es más que expresar el estado actual de nuestro saber, no el saber definitivo.
2. La definición como saber cerrado.- Las definiciones entendidas como expresión del estado actual de un saber tienen también su aspecto amenazante, cuando por ejemplo son utilizadas para mostrar, transmitir, establecer un conocimiento como definitivo y cerrado, que no admite revisiones: "partir de una definición puede resultar estéril; las definiciones se constituyen en puntos de llegada o parámetros para "dictaminar" sobre la validez o no de algo, e impiden el paso a una reflexión amplia" (Rodríguez Ousset, 1994:4). No por nada "definición" y "definitivo" tienen la misma raíz. El sentido de definición como instancia concluida y cerrada es recogida en el arte, cuando por ejemplo se habla de debe darse una definición para indicar que debe concluirse una obra.Las definiciones cerradas suelen aparecer en las ciencias exactas y en las ciencias naturales, como por ejemplo cuando se define cuadrilátero o ser viviente, y ello se debe a que representan territorios bastante conocidos. Las definiciones abiertas son, en cambio, más características de las ciencias sociales, y no es infrecuente encontrar textos donde -en este ámbito- el autor se resiste a dar una definición, sea invocando la inmadurez de la disciplina tratada (la definición sería prematura), sea invocando la complejidad de su objeto de estudio (la definición sería simplista o artificial). En lugar de ello, abundan disquisiciones orientadas mas bien a desarmar definiciones que a construirlas.De más esta decir, finalmente, que si en las ciencias sociales no aparecen definiciones precisas y contundentes, es porque ellas remiten a un territorio poco explorado y sus carteles indicadores habrán ser, necesariamente, provisorios e inciertos. Después de todo, las ciencias sociales han comenzado a ser exploradas sistemáticamente hace dos siglos, mientras que el país de las ciencias naturales viene siendo transitado desde muchos tiempo atrás.
La bibliografía
La investigación científica actual es un trabajo de equipo en el doble sentido sincrónico y diacrónico: sincrónico porque en una misma investigación participan simultáneamente varios científicos, y diacrónico porque las nuevas investigaciones toman como referencia investigaciones anteriores, y son a su vez referentes de nuevos estudios de manera sucesiva en el tiempo.El hecho de que toda investigación se articula con estudios anteriores queda plasmado en dos elementos fundamentales de todo escrito científico: las citas bibliográficas y las referencias bibliográficas. Mientras las primeras exponen ‘qué’ información se obtuvo de investigaciones anteriores, las segundas indican ‘donde’ puede ser encontrada.
Las citas bibliográficas.- La cita bibliográfica es un texto de otro autor que se introduce en el discurso para desarrollar o fundamentar lo que se está diciendo, o bien como referencia para discutir un punto de vista diferente. Para citar un autor, existen ciertas normas de uso habitual que es preciso conocer para facilitar la comunicación dentro de la comunidad científica.
1. Sobre el aspecto formal de las citas.- En el cuadro adjunto, se trascribe un fragmento de discurso científico en el cual están representados los principales elementos que deben ser tenidos en cuenta en el momento de insertar una cita bibliográfica.
Algunos elementos de las citas bibliográficas (ejemplo)
1 En el año 1632 aparece publicado el2 "Diálogo sobre los dos máximos sistemas3 del mundo", donde Galileo hace hablar a4 tres personajes: Simplicio, defensor del5 sistema ptolemaico, Salviati, defensor del6 sistema copernicano, y Sagredo, un7 personaje neutral que busca información8 o, según Babini,"algo así como el árbitro9 en la discusión entre los defensores de10 «los dos máximos sistemas» del mundo11 [la bastardilla es nuestra]"¹.12 En el libro, se proponen13 "indeterminadamente las razones14 filosóficas y naturales [científicas] tanto15 para la una como para la otra parte, y en16 la cual (...) resaltan claramente las17 intenciones del autor en favor del sistema18 sistema copernicano"².19 Babini refiere que el libro no estaba20 escrito en latín, como entonces se
Renglón 8-11: El texto entre comillas es un ejemplo de cita bibliográfica.Renglón 8: La palabra 'árbitro' no aparece originalmente en bastardilla. Se ha puesto en bastardilla para destacarla, pero para ello, se debió agregar al final de la cita y entre corchetes, la indicación del renglón 11.Renglón 16: Se ha insertado en la cita la expresión '(...)', que significa que se ha omitido parte del texto original. Esta simplificación se llama elipsis.Renglón 19-23: Esto es una cita no textual, es decir, se cita lo que dijo un autor aunque no se hace textualmente, y por tanto no va entre comillas.Renglón 24: Se ve aquí como en la trascripción del texto se ha respetado la bastardilla del autor.Renglón 25: Se ha insertado la expresión '[sic]' que significa 'textual', para dar a entender que es correcta la trascripción de la palabra o expresión inmediatamente anterior de la cita. Se incluye dicha expresión cuando puede haber
Página 232 de 314
232

21 acostumbraba para los textos científicos,22 sino en italiano, lo que permitió que fuese23 leído por todo el mundo muy rápidamente.24 Señala Babini: "La aparición del Diálogo25 desata una tormenta tan envolvente [sic]26 como inesperada: Galileo es acusado27 directamente, se le cita y se le obliga a28 comparecer, viejo y enfermo, ante la29 Inquisición en Roma [en 1633] y se le30 dicta sentencia..."³.
alguna duda sobre si se transcribió bien una palabra o expresión.Renglón 29: Se ha interpolado el año para aclarar la información, aunque no figure en el texto original. Esta interpolación se hace con corchetes.Renglones 11-18-30: En estos tres renglones puede apreciarse un número superíndice al final de cada cita, que remite a la nota al pie, es decir, a la fuente de donde la cita se extrajo.
1) Citas textuales.- Cuando se transcribe textualmente a otro autor, el fragmento debe figurar entre comillas para que quede claro donde empieza y donde termina lo que dice el autor y lo que dice el redactor del trabajo. Ejemplos de citas bibliográficas textuales aparecen en los renglones 8-11, 13-18 y 24-30.La cita textual puede comenzar con mayúscula, como por ejemplo cuando se cita desde el comienzo de un párrafo (renglón 24), o bien con minúscula, cuando, aunque se cite también desde el comienzo de un párrafo, se desea incluirla dentro del párrafo que se está redactando (renglón 8).La cita textual supone una trascripción exacta, lo que incluye también signos de puntuación, subrayados, etc. y hasta incluso errores de traducción que han sido juzgados como tales.2) Citas no textuales.- A veces, el fragmento a citar textualmente es demasiado extenso, lo que podría dificultar la continuidad del discurso. En estos casos, se puede citar al autor no textualmente sino haciendo una breve paráfrasis (interpretación amplificativa de un texto para ilustrarlo e explicarlo) de lo dicho. Ejemplos de citas no textuales aparecen en los renglones 19-23 y 1-8.Tanto si la cita es textual como no textual, hay quienes no la incluyen en el cuerpo principal del texto sino aparte, en una nota al pie. Otros redactores la incluyen dentro del cuerpo principal pero como un párrafo entero separado del anterior y del siguiente por un ‘punto y aparte’, y habitualmente con una tipografía más pequeña y/o una sangría (espacio en blanco ubicado antes de cada renglón o de cada párrafo). Estas opciones quedan a criterio de cada redactor.3) Llamadas.- Son símbolos que remiten al lector a una nota al pie de la página o al final del artículo (aunque esto último suele dificultar la lectura por obligar al lector a consultar otra página diferente a la que está leyendo). Aunque este símbolo puede ser un asterisco (*) o cualquier otro, usualmente se trata de números indicados como superíndice (²) y ordenados correlativamente conforme van apareciendo en el texto. Los ejemplos figuran en los renglones 11, 18 y 30. Las llamadas siempre se insertan al final de una cita textual, pero pueden también insertarse al final de una cita no textual.Téngase presente que una llamada no es ni una cita bibliográfica ni una nota al pie, sino el nexo entre ambas. Existen, sin embargo, ciertos casos donde una expresión puede ser considerada al mismo tiempo una llamada y una cita bibliográfica, como por ejemplo la expresión ‘(Collins, 1983b)’. Dicha expresión remite al lector a información sobre un texto que figura en la bibliografía consultada (referencias bibliográficas), y donde la letra ‘b’ indica que se trata de un segundo libro o artículo del mismo autor (Collins) y de la misma fecha.4) Elipsis.- Las elipsis u omisiones de texto dentro de una cita se indican mediante puntos suspensivos entre paréntesis, como puede verse en el renglón 16. Este recurso se utiliza cuando se desea omitir una parte del texto consultado porque no es relevante para lo que se está diciendo, y en especial cuando el texto a omitir es una extensa consideración que podría interrumpir la lectura, distrayendo al lector del tema fundamental.Por la misma razón, también puede dejarse deliberadamente una cita incompleta, en cuyo caso se agregan al final de la misma puntos suspensivos (renglón 30).5) Caracteres especiales.- Pueden denominarse caracteres especiales a toda aquella característica tipográfica que aparece en el texto original a citar. En estos casos, cuando se transcribe textualmente la cita es norma respetar tal cual estas características originales del autor citado.Ejemplos de caracteres especiales son expresiones en bastardilla (renglones 8 y 24), entrecomillados (renglón 10), expresiones subrayadas, expresiones destacadas en negrita, signos de puntuación, etc. En el caso de los entrecomillados, es importante que se empleen dos tipos diferentes de comillas para la misma cita: aquellas que definen la cita textual propiamente dicha, y aquellas que están incluidas por el autor citado dentro de la cita. Las computadoras suelen tener ambos tipos de comillas (" y «»).6) Interpolaciones.- A diferencia de los caracteres especiales, que figuran en el texto original a citar, las interpolaciones son elementos incluidos ex profeso dentro de la cita para una mejor comprensión de la misma, y siempre van entre corchetes: no se usan paréntesis porque podrían confundirse con otros paréntesis que pueden formar parte de la misma cita. Ejemplos de interpolaciones aparecen en los renglones 11, 14, 25 y 29.Las interpolaciones de los renglones 14 y 29 son aclaraciones que facilitan la comprensión de la cita, o que contextualizan las ideas allí expresadas. La interpolación del renglón 11 tiene carácter aclaratorio, y advierte al lector acerca de una modificación introducida en la cita original. Hay redactores que suelen incluir interpolaciones del tipo [la bastardilla no es nuestra], cuando piensan que puede haber dudas en el lector acerca de si la bastardilla estaba o no en el texto original.La interpolación del renglón 25 es la expresión ‘sic’ (que en latín significa ‘así’), y deberíamos utilizarla para aclarar que el texto original figura realmente ‘así’, a pesar de algún supuesto error o algo extraño en el mismo. En el ejemplo indicado, la expresión ‘sic’ fue incluída para advertir al lector que la palabra
Página 233 de 314
233

‘envolvente’ existe tal cual en el original, habida cuenta que dicho adjetivo no parece ser el correcto en el discurso del autor citado.7) Modificaciones.- Al igual que las interpolaciones, son elementos que introducimos en el texto original, pero no agregando algo sino modificándolo. Un ejemplo aparece en el renglón 8, donde la modificación consistió en expresar en bastardilla una palabra que en el original no lo estaba. Las modificaciones siempre deben ser aclaradas como tales mediante una interpolación (renglón 11), porque las bastardillas, así como las negritas o los subrayados, son también portadores de sentido.
2. Sobre el empleo correcto de las citas.- La evaluación crítica de un texto científico incluye también la consideración de las citas bibliográficas, existiendo ciertas normas que no solamente conciernen a su presentación formal, sino también a su cantidad y a su calidad.1) La cantidad de las citas bibliográficas.- El principal defecto de un escrito científico no es la ausencia de citas bibliográficas, sino su exceso, ya que un trabajo científico puede no tener citas bibliográficas pero sí referencias bibliográficas (lo que se aprecia en la bibliografía consultada que figura al final del mismo).Si bien no hay fórmulas absolutas que prescriban cuántas citas debe incluir un discurso (esto queda al sano criterio del redactor), debe evitarse la exageración. Hay redactores que tienen una auténtica adicción a las citas, tal vez porque, al no poder dejar de dudar del verdadero sentido de los textos consultados, se empeñan en trascribirlos tal cual... por las dudas.Otros, especialmente quienes en su carácter de alumnos deben redactar una monografía, creen que incluyendo muchas citas puede hacer que el profesor piense que han consultado mucha bibliografía. Sin embargo, el efecto producido es inverso: el docente se llevará probablemente la impresión de que, con tantas citas, el alumno en realidad no tenía mucho para decir de su propia cosecha.El gran problema del exceso de citas, o de las citas demasiado extensas, es que se pueden perder la continuidad y la agilidad en la lectura, demorándola o dificultándola inútilmente. Un ejemplo extremo es aquel donde se incluye en el texto una cita textual donde el autor citado cita a su vez textualmente a otro autor, con lo cual el agotado lector empieza a no saber muy bien quién dijo qué cosas.Si se pueden evitar citas bibliográficas textuales, tanto mejor: a veces favorece más la agilidad en la lectura una breve cita no textual que una más larga cita textual.2) La calidad de las citas bibliográficas.- Tampoco aquí hay fórmulas absolutas para seleccionar las citas que se utilizarán, pero valgan tres recomendaciones:a) Las citas deben ser pertinentes, es decir, deben estar directamente relacionadas con el tema tratado o con lo que se quiere demostrar. Si hay alguna cita que se quiere incluir sí o sí pero no tiene relación directa con el tema, puede tratarse como una nota al pie, fuera del texto principal, preferiblemente indicando que no se trata de una cuestión relevante al tema tratado en el escrito.b) Las citas no deben ser arrancadas de su contexto original, ya que así podría falsearse la intención del autor citado. La descontextualización se realiza a veces deliberadamente para lograr un título impactante (en las notas periodísticas, no es raro escuchar que un entrevistado se queje porque tal o cual afirmación suya ha sido descontextualizada), y a veces para conseguir mayor ‘fundamentación’ para las propias ideas del redactor, haciéndole decir al autor citado cosas que él no dijo.c) En lo posible, deben utilizarse citas de los autores originales, para evitar aquello de "fulano dijo que mengano dijo que zutano dijo...". Si no se cuenta con el texto del autor original, hay quienes, sin más, eligen copiar una cita de otro autor que a su vez lo cite.
Finalmente, las citas bibliográficas pueden ser utilizadas para armar el esqueleto de un escrito. Es posible incluso comenzar una monografía, aún antes de tener una idea completa del tema, con una selección de citas bibliográficas aisladas que parecen pertinentes, y que luego, convenientemente conectadas con el hilo del propio discurso y las ideas propias, se constituyan en el texto definitivo.
Las referencias bibliográficas.- La mención de la bibliografía consultada en un trabajo científico debe ajustarse a ciertas pautas, para que la comunicación entre investigadores pueda ser fluida y sencilla. En lo que sigue, se especifican algunas normas importantes.Todo escrito científico debe incluir al final un detalle de las fuentes bibliográficas utilizadas, éditas o inéditas, para que el lector pueda identificar rápidamente el recorrido de la investigación bibliográfica del autor y obtener, a partir de allí, diversas conclusiones, tales como por ejemplo su orientación teórica o la calidad y cantidad del material consultado.Más allá de que muchas veces el autor no incluye toda la bibliografía que debería o que desearía, sino la que puede, el sentido de las menciones bibliográficas radica en que la investigación científica es una empresa colectiva donde todos se basan en la obra de los demás.A continuación, se detalla un formato habitual para la mención de libros, artículos en libros, artículos en revistas, artículos sueltos y materiales inéditos, con los respectivos ejemplos. Téngase en cuenta que estas indicaciones no tienen consenso universal. En los Anexos 4 y 5 el lector encontrará otros formatos alternativos.
Para la mención de libros, el orden es el siguiente:
a) Autor/es: Se coloca el apellido primero y luego el nombre de pila completo, si se conoce. Si son dos autores, se unen los nombres con la conjunción 'y', y si son más de dos, puede agregarse 'y otros'. Esta última expresión suele también colocarse en latín como 'et al.'. El orden en que se escriben los nombres de los autores corresponde al orden en que aparecen en la portada del libro.
Página 234 de 314
234

b) Fecha de la primera publicación: Por lo general, al dorso de la primera página impresa con el título del libro, figuran una serie de datos importantes, entre los que figura el año en que fue publicado por primera vez, muchas veces en el idioma original como el inglés o el francés. Esta fecha suele no coincidir con la fecha de la edición del libro actual, y se colocará entre paréntesis luego del nombre del autor (acompañada del mes, si se conociera).Cuando hay dos libros que tienen la misma fecha de primera publicación, se diferenciarán ambos agregando al año letras minúsculas desde la "a" en adelante (ver en ejemplos los textos de M. Klein).Excepcionalmente, puede ocurrir que la fecha de la primera publicación sea reciente (por ejemplo 1988), en comparación con la fecha en la cual el texto fue publicado por primera vez hace mucho tiempo. En estos casos, al final de toda la mención se coloca entre paréntesis la expresión "Obra publicada en 1723".Por último: la importancia de incluir la fecha de la primera publicación es que orienta al lector acerca de cuándo tuvo conocimiento la comunidad científica de la obra del autor en cuestión.c) Título: El título del libro deberá ir destacado con negrita o bien subrayado. Se recomienda no destacarlo en bastardilla (o cursiva o itálica, que son sinónimos) porque puede ocurrir que el título original incluya alguna palabra en este tipo de letra. A continuación del título puede también incluirse el sub-título, destacado o no en la forma antedicha.d) Lugar: El lugar de la edición del libro se refiere a una ciudad, no a un país. A veces, en el libro figuran varias sedes diferentes de la misma editorial (por ejemplo Paidós tiene sedes en Barcelona, México y Buenos Aires). En estos casos se cita la ciudad donde se imprimió el libro.e) Editorial: Se cita la editorial, como por ejemplo "Ediciones Nueva Visión" o "Amorrortu editores", es decir, tal como figura en el libro. No es necesario agregar la Colección de la editorial a la que el libro pertenece (por ejemplo, Colección Psicología Profunda). Tampoco es obligatorio incluir las expresiones “Editorial” o “Ediciones”.f) Fecha de publicación: Esta se refiere a la fecha de publicación del libro que se ha utilizado como consulta. Téngase presente que esta fecha corresponde siempre a la última edición, y, si la última edición hubiese tenido varias reimpresiones, a la fecha de la última reimpresión. La diferencia entre edición y reimpresión se refiere a que en el primer caso hubo cambios en el libro, que pueden haber sido muy importantes o no, mientras que en la reimpresión, el libro volvió a imprimirse sin ningún cambio o modificación (por ejemplo, con el fin de cubrir una mayor demanda).Los elementos indicados son necesarios y suficientes para la mención del libro consultado. Algunas veces se agregan, luego de la última fecha de publicación, otros datos: el número de edición, y/o la indicación del capítulo o las páginas consultadas. Suele utilizarse la abreviatura 'p.' para 'página' y 'pp.' para 'páginas'. En este último caso, pueden indicarse páginas distintas (por ejemplo pp. 35 y 78), o un intervalo de páginas (por ejemplo pp. 35-40).
Ejemplos
Gill M y Rapaport D (1953) Aportaciones a la teoría y la técnica psicoanalíticas, México, Pax, 1962.Klein Melanie (1932a) The Psychoanalysis of children, Nueva York, Grove Press, 1960.Klein Melanie (1932b) Algunas conclusiones teóricas sobre la vida emocional del lactante, Buenos Aires, Nova, 1955.Stern Daniel N (1985, mayo) El mundo interpersonal del infante, Buenos Aires, Paidós, 1991.
Para la mención de artículos en libros, el orden es el siguiente:
a) Autor/es del artículo: Valgan aquí las mismas consideraciones del ítem anterior.b) Fecha de la primera publicación: Idem anterior. Cabe aclarar simplemente que se refiere a la fecha de la primera publicación del artículo, no del libro donde está incluído.c) Título del artículo: Es habitual destacarlo entre comillas.d) Autor/es del libro: Luego de la preposición 'En' se escribe el apellido y el nombre del autor del libro. Como se trata de un libro que incluye artículos, generalmente se trata de un compilador o un editor que interviene como compilador. En estos casos, luego del nombre se coloca entre paréntesis 'comp.' o 'ed.'. En los casos donde todos los artículos del libro son del mismo autor (por ejemplo en las Obras Completas), no se especificará el apellido del mismo.e) Título del libro: Es habitual resaltarlo con letra cursiva.f) Lugar, editorial y fecha de publicación del libro: Valen las mismas indicaciones que para cualquier libro. Al final de todo, es común citar el intervalo de páginas que abarca el artículo.Un caso especial son los artículos incluidos en enciclopedias, en cuyo caso la mención bibliográfica sigue el modelo del ejemplo. Nótese que debe especificarse el volumen y la página donde figura el artículo consultado.
Ejemplos
Freud S (1914) "Introducción al narcisismo". En Obras Completas, Buenos Aires, Amorrortu, 1995, XIV, 65-98.Klein M (1969) "Sobre el sentimiento de soledad". En El sentimiento de soledad y otros ensayos, Buenos Aires, Hormé, 1969, pp. 154-180.Rud C (1994) "La psicoterapia del Acercamiento Centrado en la Persona". En Sánchez Bodas A. (ed.), Psicoterapias en Argentina, Buenos Aires, Holos, 1994, pp. 196-236.Smith J "Thermodynamics", Encyclopedia Britannica, 1957, Vol. 23, p. 192.
Para la mención de artículos en revistas, el orden es el siguiente:
Página 235 de 314
235

Valen las mismas indicaciones que en la mención de artículos incluidos en libros. Téngase presente que muchas veces deberán indicarse el volumen o tomo de la revista, y el número de la revista incluído en ese tomo, separados por una coma (por ejemplo XXV, 5). También téngase presente que muchas veces, en el caso de una revista no se cita una editorial sino la institución que la edita. Si se trata de diarios, no se cita editorial.
Ejemplos
Garma A (1968) "El pensar amplio en los sueños". En Revista de Psicoanálisis, Asociación Psicoanalítica Argentina, 1968, XXV, 1, 9-26.Glover E (1931) "The Therapeutic effect of inexact interpretation: a contribution to the theory of suggestion". En Int. J. Psychoanal, 1931, XII, 4, 399-411.Lacan J (1953) "Algunas reflexiones sobre el yo". En Uno por uno (Revista Mundial de Psicoanálisis), 1994-95, 41, 7-21.Romeo C "Por una ética de los trasplantes", El País, Madrid, 25 de noviembre de 1984, Sección Opinión, pp. 14-15.
Para la mención de artículos sueltos y material inédito, el orden es el siguiente:
Aquí se incluyen tanto los libros que aún están en proceso de edición (en cuyo caso se coloca entre paréntesis la expresión 'en prensa'), como las clases o materiales bibliográficos especialmente preparados para alumnos, que conforman las llamadas publicaciones internas de una cátedra. En estos casos se suele utilizar, más que por tradición que por otra cosa, la expresión 'mimeografiado', en alusión a un sistema de impresión hoy en desuso y hace tiempo reemplazado por el fotocopiado.La expresión 'inédito', que significa no editado, se utiliza en casos como clases o escritos de un solo ejemplar, sean del profesor-autor o de algún alumno.
Ejemplos
Cavell M (en prensa) The self and separate minds, Nueva York, New York University Press.Giménez J "Teórico N°7 del 13/6/87", Materia: "Técnicas Exploratorias de la Personalidad", CEP-UBA, Buenos Aires, 1988, mimeografiado.Lacan J "La angustia", Clase del 30 de enero de 1963, inédito.
La conexión entre una cita bibliográfica y una referencia blbiográfica
Cuando en el texto se incluye una cita bibliográfica, textual o no, también se incluye un elemento, generalmente entre paréntesis, que permite remitir al lector a la referencia bibliográfica completa de donde la cita se obtuvo. Existen diferentes normas para incluir este tipo de conexión, y probablemente la más utilizada actualmente sea el llamado estilo Harvard.Para aplicar este formato pueden seguirse los siguientes pasos:
1) Se escribe la cita, es decir, un fragmento de texto tomado de otro autor, y a continuación, entre paréntesis, se indica el apellido del autor y el año de publicación del texto utilizado. Por ejemplo:
Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum (González 2005).
Existen algunas reglas adicionales:a) Cuando se considere apropiado, puede agregarse el número de página luego del año. Por ejemplo: (González 2005, p. 23) o también (González 2005:23).b) Si se menciona el nombre del autor, basta con especificar a continuación y entre paréntesis el año y eventualmente la página. Por ejemplo: Como indica González (2005), lorem ipsum dolor sit amet…c) Si un texto tiene dos autores, se menciona a ambos. Por ejemplo: (González & Pérez 2007).d) Si un texto tiene tres o más autores, se menciona al primero y luego se agrega “et al.” en cursiva (que en latín significa “y otros”). Por ejemplo: (González et al. 2004).e) Si se menciona más de una obra publicada en el mismo año por los mismos autores, se agrega al año una letra minúscula empezando con la a, luego la b, etc. Por ejemplo: (González 2005a).f) Si no hay especificación de año, se escribe “s.a.” (sin año). Por ejemplo: (González s.a.)7) Si no hay autor, como puede suceder por ejemplo en un artículo periodístico, se menciona el título del artículo. Por ejemplo: (La vida de las abejas 2001).g) Si se consultó una reedición actual de un libro antiguo, puede especificarse antes la fecha de la publicación original entre corchetes, lo que permite al lector entender la cronología de las publicaciones. Por ejemplo: (Darwin [1862] 2003).
2) Se escribe la referencia bibliográfica completa indicándose autor, año, título (en cursiva), lugar de edición y editorial. Por ejemplo: González Juan (2005b). Biología humana. Barcelona: Herder.
Página 236 de 314
236

Esta referencia completa deberá ser incluida en una lista ordenada alfabéticamente al final del trabajo que puede llevar el título de “Referencias bibliográficas”, “Bibliografía consultada”, “Fuentes bibliográficas consultadas”, u otra.
Independientemente del estilo Harvard, si se cita a un autor A que a su vez es citado por otro autor B, puede escribirse por ejemplo (González 2005, citado por Pérez 2007).
2. PUBLICACIÓN DE LOS RESULTADOS
La fase final de una investigación es la publicación de sus resultados para ser utilizados como puntos de partida o referencia para nuevas investigaciones. Pero un afán narcisista o la simple necesidad de obtener un mejor empleo mueven a los científicos a publicar -sea como sea- esos resultados en revistas de renombre, aún cuando a veces los procedimientos estén reñidos con la ética y con el profesionalismo. La selección de los trabajos tampoco suele resultar todo lo objetiva que sería deseable.Una importante universidad privada argentina utiliza una matriz de evaluación de antecedentes para todos aquellos profesores que deseen acceder a algún cargo docente en la institución. Uno de los ítems se refiere a la actividad académica, e incluye una evaluación de los trabajos publicados por el candidato, proponiéndose una distinción, por un lado entre ser el autor, el coautor, o un mero compilador, y por el otro entre haber publicado en una revista con referato o sin referato.Respecto de esta última cuestión, es obvio que no es lo mismo haber publicado un artículo científico en un periódico de barrio, que haberlo hecho en una revista de la talla de "Science", "Psysics Today" o "Nature", donde los artículos son estrictamente -y supuestamente- seleccionados según su calidad académica por un referi.El afán por publicar en estas revistas es grande, ya que quienes salen en sus páginas no tardan en recibir ofertas de trabajo y diversas colaboraciones. A 1995, existían más de 40.000 revistas y periódicos especializados que cubren casi todos los campos de investigación, publicándose anualmente en ellos más de un millón de artículos.Cada revista tiene su propio equipo de "reviewers" o revisores, verdaderos referis encargados de evaluar la calidad y originalidad de los materiales presentados detectando posibles plagios o repeticiones. A veces, estos revisores siguen criterios mas bien subjetivos como la coherencia del trabajo con la línea editorial, la nacionalidad, el renombre o la 'moda' de los autores, lo cual puede dejar de lado resultados de investigaciones verdaderamente originales o promisorias.Otros investigadores optan por publicar un libro -en ocasiones hasta arriesgando su propio capital-, para lo cual hay dos opciones: o bien recurren a cualquier editorial que acceda a la publicación mientras el autor pague, o bien a ciertas otras editoriales que -sin dejar de lado tampoco el afán comercial- suelen revisar la calidad del trabajo y lo avalan con su propio renombre.Sea como fuere, el ansia por publicar suele convertirse en una verdadera obsesión que a veces produce resultados deplorables, tales como trabajos sin rigor científico, o bien muy rigurosos, pero plagiados.
Veamos algunos ejemplos (Daniels, 1994).1) "No hace mucho que el doctor Jerome Jacobstein, del Colegio Médico de la Universidad de Cornell, testificó ante el Congreso de EEUU que el 25% de todos los comunicados científicos podrían estar basados en parte en datos que han sido ocultados o manipulados intencionalmente. Célebre es el caso del oncólogo iraquí Elías A. K. Alsabti, que en los años setenta consiguió un impresionante currículum capaz de acomplejar a cualquiera. Su técnica consistía en dedicarse a calcar trabajos publicados en revistas de prestigio y enviarlos con una redacción distinta a boletines de menor difusión. Así se hizo con más de un centenar de informes y comunicados, pero se sospecha que no fue autor de ninguno".2) "Tampoco es un secreto que determinados revisores a los que las revistas envían los trabajos originales se aprovechan de estos documentos para utilizarlos en sus investigaciones personales. Incluso pueden retrasar su opinión y menospreciar su calidad para hacer públicos antes sus resultados o los de sus amigos. Los matemáticos recuerdan con cierto recelo a su colega francés Augustin-Louis Cauchy (1789-1857), que se inspiraba en los originales que la revista "Comptes Rendus de l'Académie des Sciences" le remitía para darles el visto bueno".
Pero publicar un artículo no es la única forma de adquirir prestigio. También se puede procurar de alguna forma que otros autores lo citen a uno. Pérez Mercader, físico teórico del Instituto Nacional de Técnica Aeroespacial de España (Daniels, 1994), señala que muchas veces el impacto de un investigador no depende del número de veces que es citado en otros artículos, porque esto depende de una camarilla de autores que acuerdan citarse mutuamente. A Pérez Mercader mismo le sucedió que un colega suyo le advirtió que si no lo citaba, él también dejaría de citarlo.Las mismas revistas científicas también adquieren prestigio en función de la frecuencia con que son citadas en otras publicaciones y, en este sentido, se les otorga un determinado factor de impacto (Daniels, 1994): si un científico publica un artículo en una revista con un alto factor de impacto, obtendrá seguramente más puntos para sumar a su currículum.Una última oportunidad que tiene el investigador ávido de reconocimiento es enviar su material a través de Internet, lo cual tiene, desde su perspectiva, una ventaja y una desventaja: es conocido mundialmente pero su artículo, aún siendo original y valioso, podrá no ser apreciado en su justa medida por carecer de referatos.
Página 237 de 314
237

3. COMO HACER UNA MONOGRAFÍA
El presente material pretende ser una guía orientativa que ofrece al alumno pautas para la realización de una monografía en el transcurso de su carrera. No es un escrito ‘mágico’: se aprende a hacer una monografía haciéndola, no leyendo como se hace, pero es una buena manera de comenzar.En el contexto de la educación formal, una monografía es un trabajo escrito original referido a un tema puntual que permite evaluar el aprendizaje del alumno y acreditar sus estudios. Generalmente debe ser presentada hacia el final de un ciclo de estudios, como por ejemplo hacia el final de la cursación de una asignatura o hacia el final de la carrera.Las monografías incluyen información obtenida de diferentes fuentes, pero también un análisis crítico y objetivo de la misma, y una conclusión.Una monografía es un trabajo personal: dos alumnos pueden tratar el mismo tema puntual pero serán dos monografías diferentes porque estarán encarados de manera distinta. Es también un trabajo original porque aporta nueva información o una nueva mirada a la comunidad científica, por modesta que pueda resultar.Cuando se trata de diferenciar una monografía de una tesis, una tesina, un artículo científico o un artículo de divulgación científica, no hay un acuerdo universal. Sin embargo, existe cierto consenso en los siguientes puntos:a) Las monografías, tesinas y tesis son elaboradas por alumnos de carreras de grado o posgrado. Suele llamarse monografía al trabajo de menor envergadura presentado en cualquier momento de la carrera y dentro de una asignatura determinada; suele llamarse tesina al trabajo final de una carrera, especialmente de grado; y suele llamarse tesis al trabajo de mayor envergadura que se presenta al final de ciertos posgrados de mayor categoría académica, típicamente el doctorado.2) Los artículos científicos y los artículos de divulgación científica son realizados por profesionales. Las diferencias radican en dos puntos: primero, los artículos científicos se publican en revistas especializadas destinados a otros profesionales; además, son realizados por profesionales del área respectiva (por ejemplo un artículo científico sobre maloclusiones será hecho por un odontólogo). Y segundo, los artículos de divulgación científica son publicados en revistas de interés general (por ejemplo la revista “Muy interesante”) y por tanto utilizan un lenguaje más asequible al gran público; además, suelen ser hechos por periodistas científicos que no necesariamente son profesionales del área respectiva.Para realizar un artículo de divulgación científica, el periodista puede a su vez consultar artículos científicos o realizar entrevistas a científicos si considera que el tema es lo suficientemente interesante como para captar el interés del lector.
Tipos de monografía.- Pueden diferenciarse dos grandes tipos de monografía:a) Bibliográfica: supone buscar, ordenar y analizar la bibliografía existente sobre un tema determinado, para luego volcar los resultados por escrito. La revisión bibliográfica debe ser lo más exhaustiva posible de manera tal que refleje los diversos puntos de vista sobre el tema.b) Empírica: supone buscar, ordenar y analizar información obtenida directamente de la realidad sobre un tema determinado, para luego volcar los resultados por escrito. La investigación empírica debe ser lo más objetiva posible sin tergiversar los hechos. Un ejemplo entre muchos podría ser la presentación de un caso clínico.La diferencia fundamental entre ambos tipos de monografía es que en el primer caso la información se obtiene principalmente a partir de datos secundarios, y en el segundo caso, principalmente a partir de datos primarios.Datos primarios son aquellos obtenidos directamente de la realidad, como por ejemplo la información sobre un caso clínico que haya atendido el autor de la monografía, o también lo que piensa personalmente sobre ese caso.Datos secundarios son aquellos obtenidos de otros autores. Por ejemplo, “lo que dice la bibliografía”. La bibliografía consultada puede estar a su vez basada en datos primarios, o también en datos secundarios (como el caso de la bibliografía basada a su vez en otras fuentes bibliográficas).
La función del tutor.- En ocasiones, el alumno recibe la ayuda de un profesional para realizar la monografía, llamado tutor, que podrá elegir él mismo entre los docentes de la carrera, o entre otros profesionales conocedores del tema de la monografía y conocedores de cómo se realiza una monografía.Las funciones del tutor son las que acompañar a su alumno a lo largo de todo el proceso de investigación, desde la realización del proyecto hasta la redacción final, en actividades tales como las de sugerir, ayudar, recomendar, asesorar o guiar al alumno en su tarea. El alumno podrá pedir al tutor que revise el trabajo en cualquier momento. Generalmente cuando el tutor considera que el trabajo está en condiciones de ser presentado, escribe una nota a las autoridades académicas informando de esta situación.Lamentablemente en la práctica hay varios tipos de tutores: los que, aún siendo excelentes profesionales no saben bien como se hace una monografía, los que son demasiado exigentes y corrigen interminablemente (y a veces arbitrariamente) el trabajo del alumno, imponiéndole eventualmente un tema sin más explicaciones, y aquellos que se despreocupan casi totalmente instruyendo al alumno que cuando termine de hacer la monografía, venga a verlo y él le firmará la nota para poder presentarla ante las autoridades académicas.
Página 238 de 314
238

La evaluación de la monografía.- La evaluación de la monografía la lleva a cabo el mismo alumno, su tutor, y las autoridades académicas encargadas de la aprobación final o acreditación.Algunos criterios de evaluación frecuentes que utilizan las autoridades académicas son los siguientes:1) Aspectos formales: Presentación general, claridad expositiva, cuidado de la sintaxis y la ortografía, citas y referencias bibliográficas correctas, paginación, fecha, títulos y subtítulos claros, presencia de índice, etc.2) Aspectos de contenido: Nivel de fundamentación o argumentación, es decir, el grado en que el alumno apoya teórica o empíricamente cada afirmación que realiza, definiciones de conceptos principales, adecuación de los títulos al texto, calidad de la elaboración personal, relevancia de la información, calidad de las conclusiones, cantidad y calidad de las fuentes bibliográficas utilizadas, etc.
Manos a la obra: como hacer la monografía
Tomaremos como ejemplo el caso de una monografía de revisión bibliográfica, que es el típico. Para realizar una monografía de este tipo deben seguirse una serie de pasos ordenados, que a grandes rasgos son los siguientes:
1) Preparar una hoja en blanco.- Hacer una monografía supone pensar, pero este pensamiento debe escribirse. Cualquier idea que el alumno tenga la irá volcando en una hoja de papel en blanco. No es preciso que cuide la redacción ni la organización, siendo suficiente con anotar ideas sueltas, como por ejemplo el tema, un índice tentativo, el nombre de la biblioteca donde se piensan hacer consultas, etc. Un error frecuente es, en esta primera etapa, gastar energías en redactar impecablemente párrafos enteros del trabajo.En un comienzo, entonces, las piezas del rompecabezas estarán sueltas, y hasta faltarán algunas de ellas. A medida que el pensamiento se organice, irán tachándose ideas, se irán clasificando y organizando cada vez mejor. Si es preciso, se tirará la hoja en blanco y se escribirá otra, siendo conveniente guardar las hojas dentro de una carpeta destinada solamente a la monografía. Naturalmente, en vez de una hoja escrita puede utilizarse un procesador de textos, tipo Word, que presenta grandes ventajas.
2) Elegir el tema.- El tema puede ser asignado por el profesor, pero también puede elegirlo el alumno. Sea cual fuese el tema elegido, deberá cumplir dos condiciones:a) Ser atingente a los estudios que se están cursando. Por ejemplo, un alumno de ortodoncia no puede desarrollar un tema de ortopedia. Las carreras o cursos generalmente explicitan sus objetivos, lo cual puede servir al alumno para orientarse respecto al tema a elegir. Por ejemplo, los objetivos de cierta carrera de especialización en Ortodoncia son los siguientes: “Diagnóstico, prevención, intercepción y tratamiento de todas las formas de maloclusión. Aprendizaje de distintas técnicas ortodóncicas. Manejo de aparatología fija y removible”.b) Ser puntual. La Ortodoncia a secas es un tema demasiado amplio. Ejemplos de temas más específicos pueden ser:
“La mordida abierta y su relación con los hábitos bucales”.“Tratamiento de las maloclusiones de clase III”.“El hábito de la succión digital”.“Etiología de las maloclusiones”.“Tratamiento ortodóncico en pacientes con enfermedades sistémicas”.“Respuesta del hueso perimplantario a la carga ortodóncica”.“Intrusión incisiva en la corrección de la mordida profunda”.“Diferencias entre la percepción estética del paciente y del ortodoncista”.“Correlación de medidas cefalométricas entre pacientes y sus progenitores”.“Eficacia de la aparatología oral en pacientes con apnea obstructiva del sueño”.“Valoración de la distracción osteogénica en la sínfisis mandibular”.“Aumento del ancho del arco dentario superior en dentición mixta y permanente temprana”.
El tema no sólo deberá ser pensado sino también escrito en una hoja de papel. La expresión escrita del tema es el título de la monografía. En un comienzo el título, y consiguientemente el tema, no son necesariamente los definitivos, pudiendo ser cambiados total o parcialmente.Si no se encuentra tema, puede buscarse inspiración leyendo material bibliográfico (búsqueda explotaria) o consultando a personas expertas.Para elegir un tema debe haber suficiente información bibliográfica, y además esta debe ser asequible. Esto último significa que esté al alcance físico del autor, que éste pueda comprenderla, que esté escrita en un idioma que conoce, que disponga de tiempo suficiente para consultarla, etc.El tema, además, preferiblemente responder a los intereses del autor, es decir “debe ser interesante”. También debe ser útil en algún sentido a quienes leerán el trabajo, sea que se trate de la comunidad científica, sea que se trate de público en general.El siguiente cuadro permite verificar rápidamente si se han cumplido todos los requisitos para elegir definitivamente el tema:
¨ El tema es atingente. ¨ El tema queda claramente expuesto en un título.
Página 239 de 314
239

¨ El tema es puntual o específico. ¨ El tema presenta algún interés para el autor.¨ Hay suficiente bibliografía, y es asequible. ¨ El tema es útil para los demás.
3) Buscar información.- En el paso anterior ya pudo haber comenzado el proceso de búsqueda bibliográfica, pero entonces servía solamente para elegir un tema. Una vez seleccionado éste, ahora comienza una ‘segunda’ búsqueda que permitirá recoger toda la información necesaria para realizar la monografía, y que puede incluir no sólo bibliografía sino también testimonios de personas, fotografías, etc.Quizá el autor encuentre bibliografía sobre el tema que no piensa utilizar, pero igualmente la tendrá en cuenta para ofrecerla al lector interesado en profundizar el tema tratado.Una correcta búsqueda bibliográfica tiene en cuenta los siguientes aspectos:a) Las fuentes bibliográficas deben ser confiables, en el sentido de incluir información veraz y rigurosa. En general, estos criterios los cumplen los diccionarios, los libros de texto y los artículos publicado en revistas científicas.b) Las fuentes bibliográficas deben ser preferiblemente ‘de primera mano’. Por ejemplo, si debe citarse una idea de Pérez, es mejor ir al libro escrito por Pérez y no extraer su idea en un artículo de otro autor. Esta es la razón por la cual no convendrá considerar como fuente bibliográfica artículos publicados en diarios o revistas de interés general.c) Cuando se extrae alguna idea o párrafo de un libro o artículo, no es necesario leer todo el artículo o todo el libro, pero sí tener una idea global de los mismos. Esta idea global suele figurar bajo el rótulo “resumen” o “abstract”.d) Debe descartarse la información irrelevante, o sea la que no tiene relación directa con el tema.e) Debe descartarse la información redundante, como por ejemplo una definición igual o similar encontrada en otra fuente, salvo que se desee enfatizar que muchos autores coinciden en esa definición o esa idea.f) Cuando sea posible, conviene seleccionar algún libro o artículo de lectura imprescindible porque trata el tema de una manera completa y ordenada. Por ejemplo, el artículo de un diccionario enciclopédico. Su lectura permite tener una visión global del tema de la monografía y eventualmente permite obtener otras fuentes, citadas en las referencias bibliográficas.Una búsqueda bibliográfica es correcta, en suma, si cumple estos requisitos:
¨ Es información relevante. ¨ Es completa: consideró todos los aspectos del tema.¨ No es información redundante. ¨ Las fuentes son confiables.
4) Transcribir la información encontrada.- Cuando la bibliografía buscada es finalmente localizada o encontrada, ahora deberá ser transcripta a otro lugar, preferiblemente a un procesador de textos, como por ejemplo el Word. La trascripción es el proceso por el cual se transforma la información encontrada en citas bibliográficas.Hay diversas formas de transcribir la información: utilizar el comando ‘copiar y pegar’, si la información original está en Internet, o tipeando a mano si está en una publicación impresa. Nada hay de malo en copiar y pegar siempre y cuando no se cometa plagio al no citar la fuente de consulta. Hoy en día, los motores de búsqueda de Internet permiten a las autoridades académicas detectar si se cometió o no plagio.Si se hace una trascripción textual, el material copiado debe ser puesto entre comillas, pero también puede hacerse una trascripción no textual, que va sin comillas. Esta última se realiza, por ejemplo, cuando puede decirse lo mismo con otras palabras más claras, o cuando quiere resumirse la información, pero en cualquier caso el mismo autor de la monografía es quien deberá hacer la redacción.En una época pasada la información se transcribía a un soporte de cartulinas rectangulares llamadas ‘fichas’. Hoy en día la tecnología ofrece una herramienta mucho más útil: un procesador de textos. Consiguientemente, todas las citas bibliográficas se irán volcando a un archivo Word u otro a medida que se vayan encontrando.Convendrá separar las citas bibliográficas claramente unas de otras mediante espacios en blanco. Cada cita tiene tres partes: en primer lugar la trascripción, textual o no, del material; en segundo lugar, a continuación en punto seguido y entre paréntesis, el apellido del autor consultado, el año de edición de la fuente, y optativamente la página; y en tercer lugar, la referencia bibliográfica donde figurarán los datos completos de la fuente consultada.Un ejemplo de cita bibliográfica puede ser el siguiente:
“Las causas [de la deglución atípica] pueden agruparse en tres encabezamientos (1): (a) trastornos de la erupción dentaría y crecimiento alveolar […]; (b) interferencia mecánica con la erupción y crecimiento alveolar, por ejemplo, un hábito de succión digital; y (c) displacía esquelética vertical [sic]. Esta última, aunque se ve con menos frecuencia, es un problema muy diferente y mucho más fácil de tratar” (Gregoret, 1997:118).Gregoret Jorge (1997) Ortodoncia Y Cirugía Ortognática. Barcelona: Editorial Espaxs. 3º Edición.
En este caso se trata de una cita textual, porque está entre comillas. A veces, también entre comillas, se escribe la cita en bastardilla (llamada también cursiva).Se han incluido, a modo de ejemplo, los diversos casos donde deben utilizarse los corchetes []. Estos casos son principalmente tres:
Página 240 de 314
240

- Cuando se quiere agregar un comentario breve o una aclaración. Ejemplo: [de la deglución atípica].- Cuando hay párrafos intermedios no transcritos. Ejemplo: […].- Cuando existe la sospecha de un error en el texto original. En estos casos se incluye la expresión [sic], que significa “así, de esta manera”, dando a entender que no se trata de un error de trascripción del autor de la monografía.Si el autor de la monografía decide incluir una nota al pie, en el ejemplo de cita bibliográfica también se ha incluido la forma de hacerlo, que aparece como la expresión (1) luego de la palabra ‘encabezamientos’. Dicha expresión (1) se repite al pie de la página y se agrega información adicional para no recargar el texto con explicaciones secundarias. Esta información no debe ser muy extensa, y puede consistir en una aclaración más detallada de un concepto, en una aclaración acerca de en qué otro lugar de la monografía se puede encontrar información similar o relacionada, etc.
El paso final de la trascripción de la bibliografía consiste en lo siguiente:a) Al final de todas las citas crear el título “Referencias bibliográficas”.b) Utilizar la secuencia “cortar y pegar” del procesador de textos para cortar las referencias bibliográficas de cada cita y agruparlas bajo este nuevo título. Con ello se obtendrá un listado de toda la bibliografía consultada.c) Tras haber seleccionado todo el listado, utilizar el comando “ordenar” (en el menú “Tabla” del Word) para ordenarlo alfabéticamente. Un resultado posible de estas operaciones puede ser el siguiente:
De Nova García M y col, Succión digital: factor etiológico de maloclusión. Revista Odontología Pediátrica, 1993; 2(1):85-90.Díaz Fernández José Manuel (2004) Velázquez Blez Rodolfo y Pérez Noel, Mordida Abierta, dicción y rendimiento Escolar. Disponible en www.ortodoncia.ws. Consultado el 22/10/2006.Fernández Parra A, Gil Roales-Nieto J (1994) Odontología conductual. Barcelona: Martinez Roca.Gregoret Jorge (1997) Ortodoncia Y Cirugía Ortognática. Barcelona: Editorial Espaxs. 3º Edición.Segovia M (1988) Interrelaciones entre la odontoestomatología y la fonoaudiología. La deglución atípica. Buenos Aires: Ed Médica Panamericana.
Este ejemplo ilustra la forma en que debe hacerse la referencia bibliográfica según se trate de un libro (por ejemplo el de Gregoret), de un artículo dentro de una revista científica (por ejemplo el de De Nova), o de un material consultado en Internet (por ejemplo el caso de Díaz Fernández).En el caso de una revista científica, al final se consigna el nombre de la revista, el tomo o el número de año (2 en el ejemplo) y el número de la revista dentro del tomo o año (1 en el ejemplo), seguido de las páginas donde comienza y termina el artículo.Cuando sea posible, siempre debe ponerse el apellido y nombre completo del autor, sin iniciales.Debe indicarse el número de edición si se trata de la 2º edición en adelante. Este año no debe confundirse con la fecha de impresión, ya que un libro pudo haber tenido sucesivas reimpresiones de una misma edición.Aunque no hay una norma universal para redactar las referencias bibliográficas, los ejemplos aquí indicados responden a ciertos estándares internacionales de empleo común en los trabajos científicos.
5) Clasificar la información transcripta.- Hasta ahora se cuenta con una cierta cantidad de citas bibliográficas ordenadas un poco arbitrariamente, según ‘se fueron encontrando”.Llega ahora el momento de clasificar o encasillar todas las citas en categorías, que básicamente son las siguientes:
INTRODUCCIÓN DESARROLLO CONCLUSIONES REFERENCIAS BIBLIOGRÁFICAS ANEXOS
Se trata de la estructura clásica de una monografía. Cada categoría tiene un título (por ejemplo “Introducción”). Por tal razón deberá comenzarse tipeando estos títulos, y luego colocar bajo cada uno de ellos las citas que el autor piensa incluir. El título “Referencias bibliográficas” es el único que ya había sido incluido en pasos anteriores.Dentro de la “Introducción” se incluyen citas referentes a cuestiones como la presentación del tema, los objetivos de la monografía, la justificación de la elección del tema (importancia, utilidad, etc.), definiciones importantes y/o marcos teóricos utilizados.Dentro del “Desarrollo” se incluirán gran cantidad de citas. Debe aquí recordarse que esta parte es central y es la que ocupará el mayor número de páginas del trabajo (por lo menos un 70% del mismo).El Desarrollo suele incluir lo que se llamada el “estado del arte”, es decir, el estado actual de la cuestión tratada en la monografía: qué se sabe y qué no se sabe del tema, cuáles son las últimas investigaciones al respecto, etc.Dentro de las “Conclusiones” pueden incluirse citas aunque es poco frecuente, porque se refieren a cuestiones tales como un breve resumen del desarrollo, planteo de problemas pendientes abiertos, aportes personales y síntesis creativas en torno al tema tratado.
Página 241 de 314
241

Los “Anexos” o “Apéndices” se incluyen sólo si es necesario ubicar en algún lugar información complementaria de cierta extensión que, de haberla colocada en el cuerpo principal del trabajo, hubiese dificultado la fluidez de la lectura. A nadie le gusta leer un texto que de pronto se ‘vaya por las ramas’, para luego retomar el tema más adelante.Para completar este paso, pueden incluirse subcategorías mediante subtítulos dentro de la “Introducción” y, especialmente, dentro del “Desarrollo”, que serán elegidas por el autor de la monografía de acuerdo a cómo haya decidido organizar la exposición. Las citas bibliográficas, entonces, serán a su vez ubicadas dentro de estas subcategorías.Finalmente, se ubican al comienzo los diferentes títulos y subtítulos ordenados, formándose así el primer índice o sumario tentativo. El ordenamiento en títulos o subtítulos facilita enormemente la comprensión del texto.
6) Redactar un primer borrador.- Hasta ahora se dispone de un primer esquema o esqueleto de la monografía: un conjunto de citas bibliográficas organizadas bajo los títulos Introducción, Desarrollo, Conclusiones y Anexos, de las cuales se separaron las correspondientes referencias bibliográficas ordenadas bajo el título homónimo.A partir de este paso ya no se copia más texto: hay que empezar a crearlo, por lo que el autor de la monografía deberá apelar a sus habilidades para la redacción.Nadie escribe todo bien de entrada: conviene empezar a redactar sin preocuparse demasiado por los aspectos sintácticos u ortográficos para concentrar la energía en “qué” se dice más que en “cómo” se lo dice. Escribir es otra manera de pensar, es decir, de relacionar, organizar, clasificar, comparar, cuestionar o crear.Los párrafos nuevos que serán redactados por el autor se irán intercalando con los párrafos que contienen las citas bibliográficas, de manera tal de comenzar a armar un texto coherente e hilado. Algunos nuevos párrafos se destinarán para presentar el tema, otros para indicar los objetivos del trabajo, otros para justificar la elección del tema, otros para conectar o unir dos o más citas bibliográficas, otros para vertir alguna opinión personal que surja durante este proceso, etc.El primer borrador es, en síntesis, lo que su nombre indica: un texto que luego será sometido a una revisión más intensiva y detallada.
7) Hacer la redacción definitiva.- En esta etapa, el autor revisa nuevamente todo lo escrito. Se trata al mismo tiempo de una segunda lectura y de una segunda escritura donde se harán varios tipos de revisión, como por ejemplo controlar la ortografía (ejemplo: un acento correcto) y la sintaxis (por ejemplo una frase bien armada y entendible, o el correcto empleo de comas y puntos).Durante la redacción se tendrá en cuenta que el lector de la monografía es alguien que supuestamente desconoce el tema, con lo cual el autor deberá ejercitar sus dotes de docente para explicarlo de la manera más clara y organizada posible, sin ‘irse por las ramas’ desviándose del tema central. Si para ello o para completar la información debe ampliarse la búsqueda bibliográfica, se adicionarán las citas bibliográficas faltantes.Siempre es preferible redactar en tercera persona (ejemplo: no decir “yo sostengo” sino “el autor de esta monografía sostiene”).Toda opinión personal debe estar fundamentada racionalmente, fundamentación que también se explicita redactándola. No se puede afirmar “me parece que esto es así por una corazonada”.También se controlará que haya una ilación entre títulos entre sí, subtítulos entre sí y párrafos entre sí, y que la numeración de títulos y subtítulos sea correlativa. También se verificará que los textos tengan relación con el título o subtítulo donde están incluidos.Ningún conjunto de reglas asegura el éxito de la escritura: sólo la práctica lo hace. No obstante, será útil repasar algunos ítems para asegurarse que el proceso de redacción definitiva se ha cumplido correctamente:
¨ Párrafos y oraciones no son demasiado largos. ¨ La redacción está en tercera persona. ¨ El autor no se ‘fue por las ramas’. ¨ Las opiniones están fundamentadas.¨ La ortografía y la sintaxis son correctas. ¨ La numeración de títulos es correlativa.¨ Hay adecuación entre títulos y texto. ¨ Hay una ilación general de todo el texto.
8) Editar el formato.- El último paso consiste en definir los aspectos formales de la presentación del trabajo: establecer el tamaño de los márgenes, elegir el tamaño y tipo de letra definitivo para los títulos y el texto (cuidando que los títulos tengan mayor tamaño o se destaquen más), numerar las páginas, definir el tamaño del papel, establecer el interlineado, las sangrías, etc., de acuerdo a las especificaciones de la consigna, si las hubiere.Conviene que los títulos generales (Introducción, Desarrollo, Conclusiones, Referencias bibliográficas y Anexos) figuren en una página nueva.El trabajo puede ser entregado en forma impresa y/o electrónica (disquete, CD o vía e-mail), según lo soliciten las autoridades. En este último caso, se utilizarán archivos de uso habitual y común, como por ejemplo los generados con el procesador Word.Cada institución suele especificar sus propias normas de formato, mientras que otras se acogen a estándares internacionales. Para este trabajo se han seleccionado algunas normas que facilitan la lectura de la monografía y le otorgan cierta estética a la presentación. El autor de la monografía podrá comprobar si cumple con estas normas verificando los siguientes ítems:
Página 242 de 314
242

¨ Hojas tamaños A4. ¨ Títulos generales en una nueva página.¨ 2,5 cm en los cuatro márgenes. ¨ Fuente: Times New Roman.¨ Páginas numeradas, excepto la primera. ¨ Tamaño de letra para títulos: 18 negrita.¨ Interlineado 1,5 (Word). ¨ Tamaño de letra para sub-títulos: 12 negrita.¨ Sangría de 1 cm en la primera línea. ¨ Tamaño de letra para texto: 12 normal.
En síntesis: hacer una monografía es como pararse frente a muchas paredes (muchas fuentes bibliográficas), separar de cada pared los ladrillos relevantes (para el tema), amontonar los ladrillos seleccionados (las citas bibliográficas) y finalmente construir con ellos una nueva y original pared donde se han agregado nuevos ladrillos (la opinión personal del autor) y donde se los ha unido mediante un nuevo cemento (la forma peculiar de organizar el material utilizada por el autor).
CAPÍTULO 16: INVESTIGACIONES ESPECIALES
Si bien la metodología de la investigación científica ofrece pautas generales aplicables a cualquier disciplina científica, desde la física teórica hasta la antropología, cada una de estas, al tener su propia especificidad, obliga al investigador a adaptar su metodología a sus respectivos objetos de estudio. En este capítulo se ofrecen dos ejemplos aplicados a disciplinas diferentes: la investigación médica y la investigación grafológica.
1. INVESTIGACIÓN MÉDICA
Si por medicina se entiende el arte y la ciencia de diagnosticar y tratar enfermedades, las investigaciones médicas se ocuparán de resolver problemas relativos al diagnóstico y al tratamiento de las enfermedades tanto a nivel individual como poblacional, entendiendo la palabra ‘tratamiento’ en su sentido más amplio, a saber, la prevención primaria, secundaria y terciaria de la enfermedad.Lo que habitualmente se llama investigación médica no se refiere a la investigación profesional que desarrolla un determinado médico con su paciente para resolver su problema, sino a la investigación de la enfermedad con el fin de ampliar y profundizar el conocimiento general sobre las enfermedades, tanto en los aspectos diagnósticos como terapéuticos. Más allá de su fin práctico, la investigación profesional puede proveer datos para realizar una investigación de este último tipo. Es el caso del médico que desarrolla dos tipos de actividades: por un lado se dedica a tratar pacientes, como lo hace la mayoría de los médicos, pero por el otro lado puede utilizar todas las historias clínicas y conocimientos obtenidos en su vida profesional para desarrollar una investigación básica o aplicada, como por ejemplo hacer un recuento del porcentaje de éxitos de determinado tratamiento o determinada droga, de la frecuencia de determinados diagnósticos, de las actitudes de los pacientes frente a su enfermedad, de la cantidad y calidad de efectos colaterales de determinado medicamento, etc., conocimiento que ya no será útil sólo a sus pacientes particulares sino a toda la población, y por tanto pasará a ser patrimonio del saber médico general.
La investigación aplicada en medicina.- Se propone fundamentalmente estudiar la eficacia de nuevos o conocidos procedimientos diagnósticos o terapéuticos.Las investigaciones diagnósticas en medicina pueden tener al menos dos finalidades diferentes: a) explorar la eficacia de procedimientos diagnósticos nuevos y ya conocidos (tomografía computada, EEG, ECG, resonancia magnética, etc.), y b) establecer nuevas taxonomías más útiles o revisar las anteriores. En este último sentido, cabe mencionar a la CIE (Clasificación Internacional de Enfermedades) como el último esfuerzo en este sentido. En cualquier caso, el investigador deberá tener el claro el criterio de clasificación, que puede estar basado en los síntomas, en las causas o en los tratamientos. Este último criterio es cuestionado porque se basa en una consideración meramente lucrativa, al clasificar las enfermedades de acuerdo al tipo de medicamento que el paciente puede comprar.La investigación sobre clasificación de enfermedades basadas en los síntomas suele utilizar un diseño de investigación correlacional, que permite discernir la frecuencia con la cual aparecen ciertos síntomas en forma conjunta definiéndose de esta manera síndromes específicos.Las investigaciones terapéuticas tienen como finalidad examinar la eficacia de tratamientos nuevos o ya conocidos en los campos de la prevención secundaria y terciaria, y poner a prueba la eficacia de planes de prevención primaria.Para ello suelen utilizarse diseños de investigación de sujeto único y diseños de investigación de grupos, donde se compara un grupo de pacientes antes y después de la aplicación del tratamiento, o bien donde se comparan dos o más grupos de pacientes. Por ejemplo, un grupo que recibe el tratamiento, otro grupo que no recibe ningún tratamiento, y otro que recibe un placebo.Por su pare, los planes de prevención primaria se pueden poner a prueba mediante diseños longitudinales donde se compara el comportamiento o las actitudes de la población antes y después de haber realizado una campaña de concientización.
La investigación básica en medicina.- Todos los ejemplos anteriores correspondían a la investigación aplicada, pero existe un campo muy importante dentro de la medicina relacionado con la investigación básica, y que puede estar a cargo de médicos, bacteriólogos, especialistas en biología molecular o en
Página 243 de 314
243

ingeniería genética. Su finalidad es la ampliar y profundizar las ciencias básicas de la medicina: la física, la química y la biología. Por ejemplo, cuando un médico investiga la eficacia de un tratamiento contra la diabetes está haciendo investigación aplicada, pero cuando investiga el proceso bioquímico de la formación de insulina en el organismo, está haciendo investigación básica o pura. Los resultados de la investigación básica, a diferencia de los resultados de la investigación aplicada, pueden no tener una aplicación inmediata, y servir quizás mucho tiempo después. En el campo de la física se plantea una situación similar: la investigación básica puede ocuparse de los agujeros negros, pero este saber recién podrá ser útil en un futuro distante, cuando se desarrollen los viajes espaciales más allá del sistema solar.
La investigación profesional en medicina.- Esta modalidad se propone resolver una cuestión práctica y puntual: diagnosticar y/o tratar a un determinado paciente que se presenta a la consulta. En este ámbito, una cuestión central concierne al soporte de las decisiones clínicas.Continuamente estamos tomando decisiones, tanto en la vida cotidiana como en la labor profesional. En la vida diaria, por ejemplo, tomamos decisiones acerca de hoy deberemos salir o no con el paraguas, o si debemos casarnos o no con determinada persona.En la labor profesional, gran parte de las decisiones que deben tomarse tienen que ver con el diagnóstico y con el tratamiento. En el caso del diagnóstico, debemos decidir qué patología presenta el paciente a partir de sus síntomas, signos y síndromes, ya que por ejemplo un mismo síndrome puede referirse a muchas patologías diferentes. En el caso del tratamiento, debemos decidir cuál es el mejor procedimiento terapéutico para esta patología, para este paciente y para este momento de su historia clínica.El proceso psicológico mediante el cual tomamos decisiones es básicamente igual en ambos casos, y también en los dos casos las consecuencias de las decisiones pueden ser nimias o muy importantes. Una decisión equivocada en la clínica suele ser importante porque afectará la salud del paciente y nuestro prestigio profesional siempre bajo amenaza del fantasma de la mala praxis.El problema del soporte de las decisiones clínicas consiste en examinar en base a qué consideraciones hemos tomado las decisiones, lo que nos lleva al problema del fundamento de la decisión clínica.A los efectos de introducir un cierto ordenamiento, se proponen aquí seis tipos de soportes diferentes que pueden fundamentar las decisiones clínicas.1) El azar.- En la vida cotidiana a veces se toma deliberadamente una decisión al azar, lo cual puede ocurrir porque evita el esfuerzo de pensar, o cuando las probabilidades de ocurrencia de un fenómeno son aproximadamente equivalentes. Por ejemplo, si existen más o menos las mismas probabilidades de lluvia y de buen tiempo, podemos dejar que una moneda decida si saldremos o no con paraguas.En la clínica las decisiones libradas al azar son muchos menos frecuentes, porque las consecuencias de las decisiones suelen ser importantes.2) La experiencia.- Quien fundamenta sus decisiones en la experiencia suele decir: “hace 15 años que vengo aplicando el mismo tratamiento y siempre me ha dado resultado”, o bien, “siempre que tal paciente viene con tal o cual conjunto de síntomas, luego constato la exactitud de tal o cual diagnóstico”.3) La intuición.- La intuición puede ponerse en juego cuando no hay suficiente experiencia. Es el caso del profesional que dice: “me da la impresión que este tratamiento será eficaz para este paciente, aunque nunca lo haya aplicado a nadie”.4) La autoridad basada en la experiencia o la intuición.- También pueden fundamentarse las decisiones clínicas en base a la opinión de una autoridad reconocida y valorada. Es el caso del quien sostiene “este tratamiento es eficaz porque me lo dijo un profesor cuando estudiaba”, o “porque el manual de procedimientos quirúrgicos lo recomienda”, o “porque el vendedor de los insumos para este tratamiento insiste en su eficacia”, o “porque así lo dice el prospecto que acompaña el medicamento”, o incluso “porque lo decía mi abuela que de esto sabe mucho”.Cuando uno se inicia en la profesión no cuenta con suficiente experiencia clínica, y entonces recurre a la autoridad, y más concretamente a lo que le enseñaron los profesores en la universidad. Conforme pasa el tiempo, la experiencia comienza a tener más peso e incluso puede entrar en conflicto con la autoridad, como cuando uno dice “lo que veo en el consultorio no tiene nada que ver con lo que me enseñaron”.El problema de confiar en una autoridad reside principalmente en que esa autoridad bien pudo haber aconsejado tal o cual decisión guiándose exclusivamente por su experiencia o su intuición, con lo cual tiene la misma fortaleza o endeblez de estas últimas.5) La autoridad basa en la evidencia científica.- En estos casos se toma una decisión en base a una autoridad que a su vez se apoyó en un soporte generalmente más seguro: la evidencia científica. En el caso de las decisiones diagnósticas, a veces fundamentamos un diagnóstico porque hemos constatado que el paciente cumple con los criterios de la CIE-10 de determinada patología. Aquí se reconoce la autoridad del comité que redactó esta CIE (Clasificación Internacional de Enfermedades).En el caso de las decisiones terapéuticas se toma como autoridad a los autores de artículos de publicaciones científicas periódicas o a los autores de libros, aun cuando en este último caso no suele haber un comité evaluador de la calidad científica del material.Normalmente, las revistas especializadas publican artículos con resultados de investigaciones avaladas por un comité evaluador que garantiza la originalidad y la autenticidad de las mismas, ya que siempre existe el riesgo que alguna investigación: a) jamás se haya realizado; b) sea una simple copia de una investigación antigua perdida en el olvido; c) sea una investigación con resultados modificados deliberadamente (‘dibujados’) para favorecer determinados intereses; o d) carezca de los mínimos requisitos de aplicación del método científico.Para evitar la publicación de resultados con estas características, las revistas científicas tienen ‘referato’, es decir, cuentan con un comité evaluador que garantiza que no se cometieron las mencionadas
Página 244 de 314
244

irregularidades. Desde ya, subsiste el problema acerca de si dicho comité evaluador, y por ende la revista científica misma, es o no confiable, para lo cual existe un Current Index o listado de revistas científicas confiables, del mismo modo que hay un listado de universidades confiables. Normalmente debiéramos confiar en tales listados porque están respaldados o bien por un comité de investigadores neutrales de amplia trayectoria científica y ética, o por alguna entidad estatal responsable de la calidad del trabajo científico.6) La evidencia científica directa.- Una decisión clínica puede también estar respaldada o fundamentada en una investigación en la que ha participado el mismo profesional y que ha respetado el canon del método científico. Esto es lo que podemos llamar evidencia científica directa, y aparece en aquellos casos en que decidimos aplicar determinado tratamiento “porque hemos demostrado su eficacia bajo rigurosas condiciones experimentales”.Ahora bien, ¿qué es lo que hace que una investigación científica ofrezca resultados más confiables que la simple experiencia o la simple intuición? Entre los requisitos metodológicos deseables se cuentan la validez externa y la validez interna.Un experimento que se precie de científico debe tener lo que en la jerga de la teoría de la investigación se llama validez externa: los resultados obtenidos en la muestra deben poder extenderse con cierto margen de confianza a toda la población. Por ejemplo, el hecho de que cierto tratamiento ortodóncico sea efectivo en el 90% de los casos de la muestra, no necesariamente permite concluir ese porcentaje de eficacia a toda la población, salvo que se tomen ciertos recaudos, como por ejemplo que la muestra estudiada sea representativa de la población. Por ejemplo, una muestra de dos pacientes no puede ser representativa de los 10 millones de pacientes de un país. Se trata de un error que a veces cometen quienes fundan sus decisiones clínicas en la experiencia generalizando prematuramente: resulta peligroso inferir la eficacia de un tratamiento porque se tuvo éxito con un paciente.Un experimento debe tener también la llamada validez interna. Un experimento tiene validez interna cuando ha podido controlar razonablemente la influencia de variables extrañas. Si queremos medir la influencia de un ambiente amenazante (como el de algunos consultorios) sobre los niveles de estrés, podríamos comparar dos grupos: al grupo experimental se lo atiende en consultorios de entorno amenazante, y al grupo de control no, y luego se miden las diferencias en los niveles de estrés. Si son diferencias significativas, entonces concluimos que el entorno de atención ejerce su influencia.Sin embargo, esto no garantiza nada, porque bien pudo haber ocurrido que el grupo sometido al ruido estuviese integrado por ejecutivos, y el otro no, con lo cual no podríamos saber si los altos niveles de estrés se deben al ruido ambiental o a las profesión de ejecutivo, que en este caso operaría como variable extraña.Algunas otras condiciones deseables de un experimento, relacionadas con lo anterior, son la randomización, el empleo de grupos en lugar de casos únicos y la asignación de un determinado nivel de confianza.Del total de profesionales que obtienen títulos de grado apenas un ínfimo porcentaje se dedica a la investigación científica. La gran mayoría se embarca en el ejercicio de la profesión, con lo cual, al no desarrollar actividades de investigación no tienen acceso a la evidencia científica directa, y recurren entonces a la experiencia, la intuición o la autoridad para fundamentar sus decisiones clínicas.En algunos casos, como por ejemplo cuando se trata de diagnósticos sencillos, la simple experiencia suele ser suficiente para avalar nuestras decisiones. Cuando un paciente tiene temperatura y escalofríos en una determinada época del año, un somero examen nos conduce a diagnosticar gripe, y efectivamente acertamos porque la gripe es una patología muy habitual: la experiencia nos ha sido útil.Si bien pueden tomarse decisiones exitosas en base a la experiencia, la intuición o la autoridad basada en ellas, estas presentan algunos problemas sobre los cuales es necesario alertar.1) En primer lugar, tenemos una cierta tendencia a sobrevalorar nuestra experiencia o nuestra intuición, en parte por una cuestión narcisista (después de todo ‘nuestra intuición no puede fallar’), y en parte por comodidad: es mucho más fácil recurrir a ellas que hacer un tedioso experimento científico para avalar nuestras decisiones.2) En segundo lugar, tenemos una tendencia a no tener en cuenta los casos que contradicen nuestra suposición. Por ejemplo, cuando se trata de decidir sobre un tratamiento que nuestra intuición recomienda, tendemos a ‘olvidar’ los casos en que el tratamiento fracasó. No se trata de un olvido deliberado, sino inconciente, es decir, está más allá de nuestra voluntad conciente.3) En tercer lugar, puede ocurrir que el número de casos que conforman nuestra experiencia clínica no constituyan una muestra representativa, sea porque es muy pequeña, sea porque está sesgada. Por ejemplo, el hecho que un tratamiento haya tenido éxito en dos casos no prueba que lo tendrá en todos los casos. Y del mismo modo, en el caso de la muestra sesgada, el hecho que el tratamiento haya sido exitoso en adultos, no prueba que pueda serlo para todas las edades.4) En cuarto lugar, recurrir a una autoridad para avalar nuestras decisiones no tiene en principio nada de malo, salvo que la opinión autorizada se base en la simple experiencia o intuición o esté basada en algún afán especial por promocionar determinado tratamiento o vender determinada droga.Tal vez la única situación donde se puede razonablemente confiar en la autoridad es cuando ha acumulado una gran experiencia clínica, o cuando su opinión se funda en los resultados de investigaciones científicas.La intuición o la experiencia no son los malos de la película ni la evidencia científica el bueno. Desarrollar el juicio clínico supone a) aprender a reconocer cuando, al tomar una decisión, se puede confiar en uno u otro tipo de fundamento, y b) acostumbrarse a la idea que no siempre la primera decisión es la mejor.
Página 245 de 314
245

La medicina basada en la evidencia.- Ante una duda, el profesional suele recurrir a los conocimientos adquiridos en la carrera, a su propia experiencia clínica, a la opinión de un colega o, más raramente, consultará resultados de investigaciones en alguna publicación científica. En este último caso, el profesional debe contar con cierto conocimiento acerca de cuáles investigaciones proporcionan evidencia más segura, sea que se trate de ejecutar un plan preventivo, realizar un diagnóstico, establecer un tratamiento curativo o de rehabilitación, o hacer un pronóstico.Con el fin de procurar a los profesionales este conocimiento, en la Universidad McMaster de Canadá (Guyatt G y otros, 1992) se ha propuesto la llamada Medicina basada en la Evidencia (MBE), para que la práctica médica cotidiana se fundamente sobre estudios científicos actualizados de la mejor calidad metodológica. Entre otras cosas supone la lectura crítica de textos y artículos médicos y la revisión sistemática de la evidencia existente, porque el razonamiento médico tradicional resulta insuficiente para tomar decisiones clínicas. Sin embargo, no desvaloriza la experiencia clínica del profesional ni las preferencias del paciente.La MBE ha establecido varios niveles de evidencia que ayudan al profesional a valorar la solidez de la prueba. A cada nivel de evidencia se corresponde un grado de recomendación, tal como se presenta en la siguiente tabla (preparada por Pablo Cazau a partir de la US agency for Health Care Policy Research):
Niveles de evidencia Grados de recomendaciónIa: La evidencia proviene de meta-análisis de ensayos controlados, aleatorizados, bien diseñados. Ib: La evidencia proviene de, al menos, un ensayo controlado aleatorizado.
Extremadamente recomendable.
IIa: La evidencia proviene de, al menos, un estudio controlado bien diseñado sin aleatorizar. IIb: La evidencia proviene de, al menos, un estudio no completamente experimental, bien diseñado, como los estudios de cohortes. Se refiere a la situación en la que la aplicación de una intervención está fuera del control de los investigadores, pero su efecto puede evaluarse.
Recomendación favorable.
III: La evidencia proviene de estudios descriptivos no experimentales bien diseñados, como los estudios comparativos, estudios de correlación o estudios de casos y controles.
Recomendación favorable pero no concluyente.
IV: La evidencia proviene de documentos u opiniones de comités de expertos o experiencias clínicas de autoridades de prestigio o los estudios de series de casos.
Consenso de expertos, sin evidencia adecuada de investigación.
Para comprender algunos términos técnicos incluidos en esta tabla, valgan las siguientes aclaraciones:1) Un ensayo controlado es una investigación donde las variables extrañas o ajenas a las estudiadas han sido razonablemente controladas.2) Un estudio de casos control permite comparar grupos de enfermos o no enfermos según la presencia de una determinada característica o exposición a algún factor.3) Un estudio de serie de casos clínicos identifica y describe un conjunto de casos clínicos que aparecieron en un intervalo de tiempo. Si se trata de patologías desconocidas, puede contribuir a caracterizarlas.4) Una cohorte es un conjunto de individuos de una población que comparten la experiencia de un mismo acontecimiento, en un determinado lapso temporal. Típicamente es un grupo de nacidos en un determinado período, como por ejemplo entre 1985 y 1989, pero puede referirse a otro acontecimiento. En un estudio de cohorte los individuos que componen los grupos de estudio se seleccionan según la presencia de una determinada característica. Estos individuos no tienen la enfermedad en estudio y son seguidos durante un tiempo para observar la frecuencia con que la enfermedad aparece en cada uno de los grupos.5) Un meta-análisis “es un estudio basado en la integración estructurada y sistemática de la información obtenida en diferentes estudios clínicos, sobre un problema de salud determinado. Consiste en identificar y revisar los estudios controlados sobre un determinado problema, con el fin de dar una estimación cuantitativa sintética de todos los estudios disponibles. Dado que incluye un número mayor de observaciones, un metaanálisis tiene un poder estadístico superior al de los ensayos clínicos que incluye” (http://es.wikipedia.org/wiki/).Aunque a veces se toman como sinónimos, algunos autores (Guerra y otros, 2003) consideran que los meta-análisis son un caso particular de las llamadas revisiones sistemáticas. Señalan que el término meta-análisis “debe aplicarse únicamente cuando los trabajos incluidos en la revisión a juicio de los investigadores se pueden combinar razonablemente efectuando una síntesis estadística cuantitativa de sus resultados para obtener una estimación combinada de los efectos descritos en los estudios individuales. Por tanto, la revisión sistemática constituye un proceso de investigación más amplio, que va desde la formulación del objetivo hasta la interpretación de los resultados, incluyendo la fase de análisis estadístico cuando haya sido posible la agregación cuantitativa de los datos” (Guerra y otros, 2003).Está claro que las revisiones sistemáticas son estudios secundarios, porque se ocupan de estudiar los estudios primarios. Son muy útiles cuando el clínico necesita una respuesta rápida a sus dudas y no cuenta con tiempo suficiente para revisar la gran cantidad de investigaciones sobre un mismo tema y para realizar nuevas. Sin embargo Guerra y otros (2003) indican que no deben utilizarse cuando se trata de aprobar o no un fármaco nuevo, cuando un efecto insignificante puede volverse relevante al combinar varios estudios con efectos irrelevantes o de mala calidad, o cuando se intenta frenat la realización de investigaciones originales, entre otras razones.
Los niveles de evidencia y grados de recomendación indicados en la tabla precedente deben tomarse como criterios muy genéricos, ya que existen niveles de evidencia y grados de recomendación más específicos aplicados a intervenciones preventivas y terapéuticas, y a indagaciones donde deben hacerse
Página 246 de 314
246

diagnósticos, pronósticos, evaluación de factores de riesgo y evaluaciones económicas. Para estas diversas alternativas puede consultarse a Primo J (2003).
2. INVESTIGACIÓN GRAFOLÓGICA
La cientificidad de la grafología
En su sentido habitual, el término ‘grafología’ designa: a) Una teoría acerca de la relación entre la escritura y el psiquismo, y b) una técnica para analizar la escritura, basada en la teoría, con el fin de diagnosticar aspectos mentales.Aquí nos interesará la grafología como teoría, y una cuestión que puede suscitarse al respecto es si se trata de una teoría científica o no.Muchas de las definiciones del término ‘grafología’ que podemos encontrar en los textos especializados en este tema hacen hincapié en que se trata de una disciplina científica. Así por ejemplo:
La grafología “es la ciencia que tiene por objeto el estudio del carácter, del temperamento y de la personalidad, mediante el análisis e interpretación de los aspectos de movimiento, espacio y forma en la escritura manuscrita” (Vels, 1991:39).
La grafología “es el estudio científico de la expresión del carácter a través de la escritura, y comienza con la psicología de la personalidad. Esta se manifiesta en todas y cada una de las expresiones del comportamiento humano, especialmente en los movimientos infinitamente delicados de la mano que guía la pluma sobre el papel” (Marcuse, 1974:53).
Hay quienes opinan, sin embargo, que la teoría grafológica no es científica porque se apoya en la intuición, en la experiencia, o en la apelación a la autoridad. Así por ejemplo, la afirmación según la cual “la presencia del trazo horizontal en la letra ‘t’ es indicadora de fuerza de voluntad” podría ‘fundamentarse’ de tres maneras:
La intuición sostiene la verosimilitud de esta afirmación argumentando que para escribir el trazo horizontal de la letra debe levantarse el lápiz y ello requiere esfuerzo de voluntad. Una objeción a este argumento: se trata de una simple impresión subjetiva y, como tal, puede fallar.
La experiencia cotidiana sostiene la afirmación argumentando que “en todas las personas en quienes advertí la ausencia del trazo horizontal, pude verificar escasa fuerza de voluntad”. Una objeción a este argumento: la cantidad de personas observadas puede ser insuficiente y por tanto no cabe generalizar.
La apelación a la autoridad sostiene la afirmación diciendo que pertenece a una ‘reconocida’ autoridad en el tema. Una objeción a este argumento: esa autoridad bien podría haberse fundado, para enunciarla, en la intuición o la experiencia.
Según la ortodoxia del método científico, entonces, si las teorías grafológicas están avaladas por simples certidumbres subjetivas o por la experiencia diaria, entonces son dudosas o inciertas y no cabe considerarlas científicas.No es el objetivo de este ítem discutir si en el estado actual las teorías grafológicas tienen o no cientificidad, sino establecer algunos lineamientos generales del procedimiento para validarlas según y conforme el canon científico.
La investigación en grafología
Toda investigación científica implica dos actividades diferentes: inventar teorías, y probarlas. En el caso de la investigación grafológica, las hipótesis o teorías que surgen de la intuición o la experiencia no deben descartarse. De hecho, “los primitivos grafólogos franceses conseguían hacer buenas diagnósticos psicológicos, lo cual se debía probablemente a su imaginación innata y conocimiento intuitivo de la naturaleza humana y no a los medios empleados” (Marcuse, 1974:12). Pero si bien estas intuiciones no deben descartarse, deberían probarse científicamente, lo que les otorgaría mayor certeza.Por ejemplo, una prueba estadística puede avalar la afirmación del vínculo entre el trazo horizontal de la letra ‘t’ y la fuerza de voluntad, sobre la base de una muestra representativa de la población y sobre la base de haber constatado mediante coeficientes de correlación que hay una asociación significativa entre escribir el trazo horizontal y la fuerza de voluntad.La importancia de la investigación grafológica no reside solamente en que pueden probarse científicamente diversas impresiones subjetivas y creencias basadas en experiencias personales, sino también en que la investigación contribuye a que el grafólogo pueda lograr un reconocimiento científico de su actividad, más allá del reconocimiento social y del reconocimiento legal. Parte de este reconocimiento científico se logra, por ejemplo, difundiendo las investigaciones realizadas en Congresos y en revistas especializadas donde comisiones evaluadoras garantizan la cientificidad de los trabajos presentados, evitándose la publicación de investigaciones ‘inventadas’, ‘copiadas’ o ‘modificadas tendenciosamente’.
Página 247 de 314
247

SITUACION(Variable independiente)
PERSONA(Variable independiente)
ESCRITURA(Variable dependiente)
Escritura, persona y situación.- Uno de los primeros pasos para iniciar una investigación grafológica es establecer cuáles son las variables fundamentales que considera la grafología. Estas variables son al menos tres:
Esquema 1 – Variables principales en grafología
Este esquema no es más que una derivación de cierta hipótesis general en psicología según la cual la conducta C es función de la persona P y el ambiente A, y donde además se especifica que entre P y A hay una interrelación. Autores como Kurt Lewin han dado forma matemática a esta idea mediante la expresión C = F (P ó A). Véase Lewin K, La teoría del campo en la ciencia social. Buenos Aires: Paidós, capítulo 1.
La escritura es una variable dependiente porque se supone que ‘depende’ de ciertos factores como la persona y la situación, que entonces se designan como variables independientes. Así, por ejemplo, el hecho de que un sujeto escriba con determinados rasgos se debe no sólo a su modo de ser (una personalidad histérica, por ejemplo) sino también a la situación en el momento de escribir (la birome escribe mal). La división entre persona y situación, hay que reconocerlo, es un tanto artificial. Por ejemplo, la educación recibida es desde cierto punto de vista un factor personal, y desde otro un factor situacional.Incidentalmente, en el campo de la grafoterapia estas variables pueden cumplir funciones diferentes. Esta aplicación, introducida en el siglo XX, permite “corregir las dificultades caracterológicas por medio de la escritura” (Echevarría, 1992:35), y supone que la forma de escribir puede incidir sobre la persona generando cambios en ella. Desde esta perspectiva, la variable escritura será considerada variable independiente porque se considera que influye sobre las variables personales, que pasan a ser, entonces, dependientes.En el campo grafodiagnóstico, se supone que las variables independientes son causas, y la variable dependiente el efecto. Ya desde su nacimiento, la grafología ha advertido la importancia de estas variables. Klages, por ejemplo, a fines del siglo XIX, formula una teoría general de la escritura como medio de expresión de vivencias psicológicas sosteniendo, por ejemplo, que la escritura está determinada por factores del momento, por el desarrollo del carácter y por factores inconcientes (como el del hijo que escribe a imagen y semejanza de su progenitor) (Marcuse, 1974:15). Los factores del momento corresponden a la variable situación, y los dos factores restantes a la variable persona.De acuerdo a cierta nomenclatura de la metodología de la investigación, las tres variables mencionadas son variables complejas, es decir, presentan varias facetas o aspectos. La variable persona, en un sentido muy amplio, puede incluir capacidades, actitudes, comportamientos y hasta la edad, el sexo y la salud física y mental. La variable situación se refiere a factores sociales, escolares, familiares, circunstanciales, etc., y, del mismo modo, la variable escritura presenta como aspectos la distribución, la disposición, la proporción o la altura. Cada uno de los aspectos de las variables recibe el nombre de dimensión o factor. Por ejemplo, los factores personales indicados para la variable persona.A continuación, describiremos más detalladamente estas tres variables.
1) Persona.- Más allá de las diferentes definiciones que ofrece cada teoría psicológica sobre este término, esta primera variable abarca todo lo que habitualmente se llaman factores personales, es decir, aquellos factores que están presentes en el sujeto, que le pertenecen per se.Sea cual fuere la definición que se asigne a cada uno, ejemplos de estos factores personales son la personalidad, el carácter, el temperamento, las actitudes, la herencia, el sistema nervioso, el sexo, la edad, etc.Por ejemplo personas con diferentes temperamentos escribirán de manera diferente (Echevarría, 1992:16). Asimismo, la edad es otra característica intrínseca a la persona, por cuanto el mismo sujeto no escribe igual de niño que de adulto, e incluso no escribe igual en sus diferentes periodos evolutivos infantiles. Así, por ejemplo, ciertos autores consideran que la escritura infantil está relacionada con las diferentes etapas evolutivas del niño (Echevarría, 1992:14).Conociendo la escritura de un sujeto, pueden inferirse estos factores personales. Por ejemplo, “aunque el análisis de la escritura infantil exige la desviación de algunas de las normas impuestas para el análisis en los adultos, es posible aplicarlas en líneas generales, con excepción de la regularidad y firmeza de los trazos, ausentes en los niños” (Marcuse, 1974:99).
Página 248 de 314
248

2) Situación.- Los factores situacionales son aquellos originados en el ambiente de la persona. Puede suponerse que la escritura depende de factores sociales, escolares, familiares y estados transitorios situacionales.Los factores sociales inciden sobre la forma de escribir según cada cultura o época. Por ejemplo, una de las primeras expresiones gráficas del niño es el garabato, y sólo después, alrededor de los cinco años, el niño comienza a escribir. Importa aquí destacar que mientras el garabato es una actividad espontánea, la escritura es una actividad aprendida y por lo tanto tendrá en mayor medida la impronta de la cultura.La influencia de la escuela reside en como la persona es educada para escribir en la educación formal. No escribe igual una persona que estudió caligrafía que otra que no lo hizo. De igual manera, la influencia familiar puede apreciarse, por ejemplo, en el modelo de escritura tomado de los padres o los hermanos.Respecto de los estados transitorios situacionales, finalmente, algunos autores los llaman factores circunstanciales y son todos aquellos que tienen que ver con las condiciones físicas de la escritura: “si omitimos los cambios en la escritura producidos por factores circunstanciales, como pueden serlo una pluma gastada, tinta demasiado espesa o fluida, papel grueso o una superficie de apoyo rugosa, la causa principal de las variaciones en la escritura son psicológicas” (Marcuse, 1974:19). Cabe incluir en este factor también a otros estados transitorios como las condiciones climáticas del momento, la sonoridad ambiental, etc., todos ellos atributos físicos del entorno, e incluso también al clima psicológico al instante de producir la escritura.
3) Escritura.- La escritura, como variable compleja, está conformada por varios aspectos o dimensiones, como por ejemplo (Vels, 1991:51) la distribución (ordenada, desordenada, etc.), la disposición (regular, irregular, etc.), la proporción (proporcionada, desproporcionada, etc.), la altura (grande, pequeña, etc.), la amplitud (ancha o estrecha, etc.), la tensión (firme, floja, etc.), la ejecución (redonda, angulosa, etc.), la cohesión (ligada, desligada, etc.), y otras.Cada dimensión o aspecto de la escritura presenta a su vez posibles valores, llamados categorías, y que en el párrafo anterior aparecían entre paréntesis. Esquemáticamente:
Esquema 2 – Algunas dimensiones y categorías de la variable escritura
Dimensiones
Categorías
Distribución Ordenada, desordenada, etcDisposición Regular, irregular, etcProporción Proporcionada, desproporcionada,
etcAltura Grande, pequeña, etcAmplitud Ancha o estrecha, etcTensión Firme, floja, etcEjecución Redonda, angulosa, etcCohesión Ligada, desligada, etcEtc Etc
Sólo las categorías o una combinación de ellas son susceptibles de interpretación. Por ejemplo: 1) la escritura ancha corresponde a “sujetos con tendencia muy marcada a la expansión, a la convivencia con otros “ (Vels, 1991:65); 2) la escritura angulosa, ordenada y regular indica “conciencia profesional, integridad moral, disciplina, perseverancia” (Vels, 1991:65).Finalmente, cabe consignar que las diversas dimensiones de las variables persona y situación también son susceptibles de categorización. Por ejemplo, la dimensión temperamento de la variable persona puede incluir las categorías sanguíneo, flemático, nervioso y colérico (Echevarría, 1992:16), mientras que la dimensión escolaridad de la variable situación puede incluir los niveles primario, secundario o la universidad.
Estabilidad e inestabilidad.- En el parágrafo anterior habíamos clasificado los factores que influyen en la escritura en factores personales y factores situacionales subsumiéndolos, respectivamente, bajo las denominaciones ‘persona’ y ‘situación’.Sin embargo, también es posible clasificar los mismos factores en factores estables y factores inestables, un criterio muy utilizado, por lo demás, en grafología en la medida en que el grafólogo es conciente que sobre la escritura están actuando, además de factores estables, ciertos factores transitorios o accidentales (factores inestables), como el tipo de papel sobre el cual se escribe, el estado de ánimo predominante al momento de escribir o cierto dolor de cabeza que afectó al sujeto en ese momento.Como lo ilustra el siguiente esquema, entre ambas clasificaciones no hay una correspondencia unívoca, y por lo tanto no debe pensarse que los factores personales son los factores estables o que los factores situacionales son los factores inestables. En realidad, los factores personales pueden ser tanto estables como inestables, y otro tanto cabe decir de los factores situacionales.
Esquema 3 – Factores estables e inestables de la escritura
Variables Dimensiones o factores (ejemplos) Condición
Página 249 de 314
249

Persona(factores personales)
PersonalidadTemperamentoCarácterEdadSexoSalud
Factores estables
Estados personales transitorios Factores inestablesSituación
(factores situacionales)Estados situacionales transitorios CulturaEscolaridadFamilia
Factores estables
Llamaremos factores estables a aquellos que tienen cierta permanencia en el tiempo, mientras que los factores inestables son más cambiantes o fluctuantes, incluso de una hora a otra, de un día para otro, y hasta de un mes a otro en el caso de situaciones de duelo. Los primeros serían los responsables del grafismo habitual, mientras que los segundos incidirían en los cambios o alteraciones momentáneas de la escritura.Como se aprecia en el esquema, los factores inestables puede ser estados personales transitorios (un dolor de cabeza, un estado de excitación momentáneo) o estados situacionales transitorios (una birome que funciona mal, la percepción de una discusión violenta en el entorno).Los grafólogos son bien concientes de la incidencia de los factores inestables: “si no conocemos las circunstancias en que se produjo la muestra no nos es posible dar a la escritura la interpretación adecuada a los factores extraños a la personalidad del individuo que pueden haber afectado la fluencia de la escritura” (Marcuse, 1974:64).Del mismo modo, Klages sostenía que una situación de alegría pone al individuo en un estado de exaltación que lo lleva a escribir en ese momento con letras más grandes y a mayor velocidad, del mismo modo que un estado melancólico produce un efecto inverso, denominando a este factor ‘motivación personal’, también cambiante, porque cambia no sólo con el desarrollo del carácter sino por influencia de impresiones externas (Marcuse, 1974:14).Es también conocida la diferencia entre los factores estables e inestables de la persona. Así, ciertos tests psicológicos distinguen lo ‘permanente’ del sujeto, de lo que varía según cada momento o circunstancia (el ‘como es’ y el ‘como está’), como por ejemplo los tests que miden, respectivamente, la ansiedad-rasgo y la ansiedad-estado.Si unificamos ambas clasificaciones de los factores que inciden en la escritura, en suma, obtendremos los siguientes tipos: factores personales estables, factores personales transitorios, factores situacionales estables, y factores situacionales transitorios.Diferentes enfoques dentro de la grafología dan prioridad a cierto tipo de factores y descartan otro cierto tipo de factores. Por ejemplo:
Prioridad de los factores personales estables: “una mala pluma, una mala tinta, un apoyo insuficiente del brazo o una mesa que se mueve, una postura incómoda, un estado anormal de fatiga, depresión o excitación, por ejemplo, pueden causar una deformación importante del grafismo habitual. Por tanto, conviene asegurarse de que se analiza el grafismo corriente en el sujeto, es decir, sin influencias externas o internas perturbadoras” (Vels, 1991:47).
Prioridad de algunos factores personales estables y descarte de otros del mismo tipo: algunos autores (Marcuse, 1974:39) incluyen a la lateralidad manual (condición de zurdo o diestro) entre los factores cuya influencia debe ser descartada cuando se analiza la escritura. En otro ejemplo, algunos autores priorizan el análisis de la personalidad, otros del temperamento y otros de la salud, sean cuales fueren las definiciones que asignan a estos términos.
En general, la tendencia dominante es la de analizar la escritura en términos de factores personales estables, descartándose los factores personales inestables y los factores situacionales.El lector puede ir entonces comprendiendo que los factores que se descartan deben ser controlados o neutralizados en cuanto a su influencia sobre la escritura, importando solamente los factores priorizados.En la nomenclatura de la metodología de la investigación, los factores priorizados se designan como variables independientes (propiamente dichas), y los factores que deben ser descartados y neutralizados se designan como variables externas.La denominación ‘variable externa’ puede encontrarse en Campbell y Stanley (1995:17) aunque otros autores las han llamado variables extrañas (Cortada, 1994:360; Tamayo, 1999:213) y variables de control. Esta última denominación enfatiza la necesidad de ‘controlar’ estos factores extraños al analizar la escritura, en el sentido de neutralizar su influencia, para lo cual pueden emplearse las diversas técnicas de control descriptas en los manuales de procedimiento científico tales como la anulación, la sustracción, el emparejamiento o la aleatorización.Por ejemplo, la anulación del factor situacional inestable “papel rugoso” consiste simplemente en anular este tipo de papel. A veces, no es posible anular un factor situacional inestable, en cuyo caso se consigna su incidencia en la escritura para luego separarlo de los efectos de los factores estables (sustracción).
Página 250 de 314
250
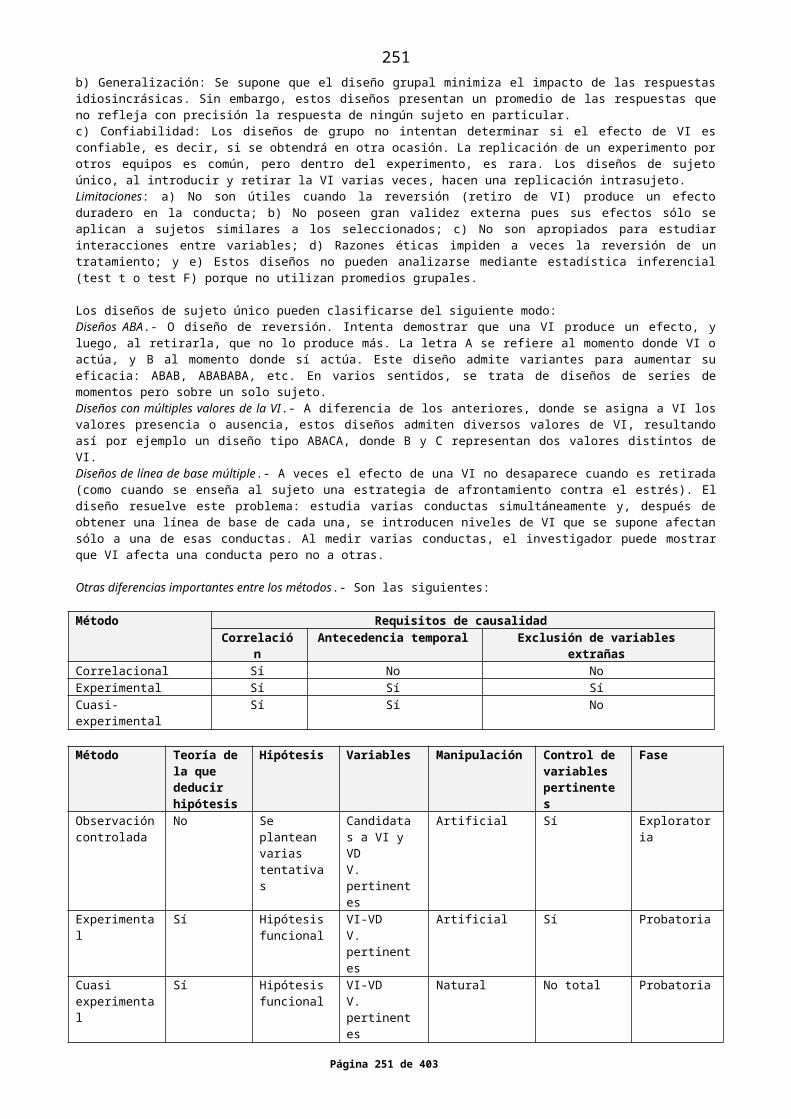
Rasgo grafológico Rasgo grafológico
Rasgo personalRasgo personal
1 1
2
3
La relación entre factores personales estables y la escritura.- Puesto que por lo general el análisis grafológico intenta vincular la escritura con los factores personales estables, en lo que sigue nos concentraremos en este caso.“Los primeros intentos sistematizados de relacionar los rasgos caligráficos del individuo con las características de su personalidad fueron emprendidos en Italia en el siglo 17 por Camilo Baldi” (Marcuse, 1974:11).Desde entonces hasta la actualidad, los grafólogos han considerado no solamente las relaciones entre un rasgo de escritura y un rasgo de la persona, por ejemplo un rasgo de personalidad, sino también, subsidiariamente, las relaciones de los rasgos de escritura entre sí y las relaciones de los rasgos de personalidad entre sí. En el siguiente esquema ilustramos estas tres posible relaciones:
Esquema 4 - Relaciones importantes en grafología
Relación 1.- La escuela de Michon del siglo 19 planteaba que si por ejemplo, “analizando la caligrafía de veinte personas valerosas hallaban un trazo determinado común, como una ‘a’ abierta u otro rasgo especial, decidían calificar ese trazo como representación del valor personal” (Marcuse, 1974:12). Los textos de grafología ilustran profusamente este tipo de correspondencias.Relación 2.- Entre los diferentes aspectos de la escritura de una persona puede haber ciertas correspondencias. Puede haber un paralelismo entre el punto de la letra ‘i’ y la barra de la letra ‘t’. Si ambos elementos están altos, significa idealismo y optimismo. También puede no haber un paralelismo, en cuyo caso hay represión y artificialidad concientes (Marcuse, 1974:87).Relación 3.- Los estudios factorialistas de la inteligencia y ciertos enfoques en psicología social, por dar dos ejemplos, han puesto de manifiesto que diferentes aspectos de la persona pueden estar asociados más allá de lo esperable por azar. Así, por ejemplo, la característica ‘ser racista’ suele estar asociada con la característica ‘ser autoritario’, o la característica ‘ser hábil para sumar’ suele estar asociada con ‘ser hábil para multiplicar’.Allport y Vernon han destacado estos tres tipos de relación cuando en 1931 dirigieron experimentos sobre grafología basando sus investigaciones en tres supuestos: que la personalidad es consistente, que los movimientos físicos expresivos (por ejemplo la escritura, la expresión facial, la forma de caminar, etc.) son expresiones de la personalidad, y que los movimientos son consistentes con determinada personalidad y entre sí (Marcuse, 1974:16).El análisis de la escritura puede aplicarse a su conjunto, a una determinada palabra, a una determinada letra, a la firma, etc. En los casos en que se analiza la escritura en su conjunto (por ejemplo una carta manuscrita), que son los casos más habituales, puede optarse por un marco teórico elementalista o por uno totalista.Ya en los comienzos de la grafología francesa es posible identificar estas dos tendencias opuestas. Michon y su escuela representa la orientación elementalista, según la cual “el carácter era un mosaico de cualidades y propiedades personales, cada una de ellas relacionada directamente con determinado rasgo caligráfico, que podía ser sumado a otros para completar cierta apreciación del carácter” (Marcuse, 1974:12).Crepieux-Jamin, discípulo de Michon, se opuso a esta orientación planteando un totalismo cuando expresó “la necesidad de considerar cada uno de los rasgos como parte del sistema general, manteniendo que cada uno de ellos contribuía en diferentes grados a la interpretación del conjunto” (Marcuse, 1974:13).En esta misma línea se desarrolló la grafología alemana de fines del siglo XIX. Por ejemplo Meyer consideraba que los signo grafológicos no tenían un significado especial, “sino que se los interpretaba como resultantes de una funcion única, fundamental, capaz de expresarse de diversas maneras” (Marcuse, 1974:14). Lavater escribía, en el siglo XVIII, que “si toda la escritura en su conjunto es de aspecto armónico, resulta sencillo especular sobre la naturaleza armoniosa del escritor” (Marcuse, 1974:11).
Estandarizaciones.- Para que la investigación grafológica sea posible, se requieren al menos dos tipos de estandarización previas: la estandarización del procedimiento de recolección de datos, y la estandarización del procedimiento de análisis de los datos. La primera asegura de todos los investigadores recogerán la información de la misma manera, mientras que la segunda garantiza que
Página 251 de 314
251

todos los investigadores utilizarán los mismos criterios para analizarla. Estas uniformidades permiten, entre otras cosas, que las investigaciones de diferentes grafólogos puedan compararse entre sí.
Estadarización del procedimiento de recolección de datos.- El procedimiento básico para recoger información en grafología es pedirle al sujeto una muestra de su escritura. En este sentido, todos los grafólogos a nivel mundial deberían acordar un mismo patrón, como por ejemplo, que la persona escriba en un ambiente tranquilo, que no esté cansada, que lo haga con un determinado tipo de lapicera o birome, que lo haga en un papel de tamaño estándar (A4, carta, oficio, etc.) de determinado color, de determinado gramaje, desprovisto de líneas, etc.Esta modalidad de estandarización tiene como finalidad minimizar la influencia de los factores inestables o transitorios que condicionan la escritura. De hecho, se aplica en los tests proyectivos como el Bender o el HTP y, como la escritura tiene las características de una prueba proyectiva, no hay razón para excluirla de los procedimientos de estandarización mencionados.
Estandarización del procedimiento de análisis de los datos.- Cuando se analiza la escritura es corriente hacer apreciaciones del tipo ‘escritura grande’ o ‘distancia entre líneas pequeña’, etc. La pregunta que surge aquí es qué se considera grande y qué se considera pequeño. Como estos adjetivos pueden ser interpretados de diferente manera según cada grafólogo, ha sido necesario establecer patrones que sirvan como marco de referencia. Autores como Vels se refieren a ellos calificándolos como ‘módulos patrón’ (Vels, 1991:45). Ejemplos de módulos-patrón son: “escritura normal se considera la que está entre 2,5 mm y 3 mm”, “la distancia entre líneas normal es tres o cuatro veces la altura de las letras m, n y u del tipo de letra que se utilice”, etc. Desde ya, es importante que haya consenso respecto de estas normas entre todos los grafólogos, de manera tal que, cuando uno de ellos lee el trabajo de otro, pueda estar seguro que compartirá el mismo significado para ‘grande’ o ‘pequeño’.¿Qué ocurriría si diez grafólogos analizaran la misma escritura? Habría que hacer el experimento para ver los resultados, pero puede conjeturarse que habría diferencias entre los informes porque también el grafólogo proyecta sus propias creencias y formas de ver el mundo. Sin embargo, esas diferencias serían apenas matices si todos los grafólogos utilizan la misma teoría para analizar la producción escrita. La gran semejanza detectada entre los diez análisis prueba que utilizaron la misma teoría, pero no que esa teoría sea la correcta. El experimento imaginario puede haber arrojado otro resultado: que los diez informes sean manifiestamente diferentes (por ejemplo según uno de ellos el sujeto es valiente, mientras que según otro es cobarde). Estos resultados no pueden entonces compararse entre sí, por lo cual se requiere también una estandarización del marco teórico, incluido dentro de la estandarización del procedimiento de análisis.
Grafología y psicología
La grafología, en tanto análisis de la escritura para obtener un conocimiento de la personalidad, utiliza como marco de referencia teórico a la psicología. En términos de formación académica, la grafología se centra en el estudio de la escritura, mientras que la psicología es más abarcativa porque comprende el estudio del psiquismo humano. En términos de incumbencias, el grafólogo no puede tratar pero el psicólogo sí, del mismo modo que el psicólogo no puede prescribir medicamentos pero el psiquiatra sí.Pero, ¿qué ocurre como la labor diagnóstica? Diagnosticar significa ubicar a una persona en alguna categoría. Por ejemplo:a) al decir que Juan es agresivo, estamos ubicándolo en la categoría ‘agresividad’.b) al decir que Juan es neurótico obsesivo, estamos ubicándolo en la categoría ‘neurosis obsesiva’.Se trata de dos categorías muy diferentes: la agresividad, la bondad, la avaricia, la valentía son simples características de la personalidad, normales o anormales, mientras que neurosis obsesiva o esquizofrenia paranoide son patologías (o trastornos mentales, o entidades nosológicas). Para diagnosticar una patología se requiere otra formación que va más allá del conocimiento grafológico, salvo que el grafismo en su conjunto sea un indicador patognomómico. En psicopatología se acepta en general que no hay indicadores de este tipo. Por ello el grafólogo puede diagnosticar características de la personalidad, pero no patologías (y en este último caso solamente como conjetura, comunicable o no a otra persona).Para realizar diagnósticos, el grafólogo utiliza la técnica grafológica, mientras que el psicólogo utiliza, entre otras, las técnicas proyectivas gráficas.Tanto en la técnica grafológica como en las técnicas proyectivas gráficas utilizadas habitualmente en psicología (HTP, Dos personas, etc.), se atiende a los aspectos formales del grafismo (emplazamiento, tamaño, trazo, etc.), y además se parte del supuesto que el sujeto proyecta aspectos de su intimidad psíquica o de su mundo interno en su producción. La diferencia radica en que ambas técnicas utilizan teorías diferentes para analizar o interpretar la producción gráfica: la técnica grafológica se basa principalmente en teorías grafológicas, mientras que las técnicas proyectivas se fundan principalmente en la teoría psicoanalítica. Esta última circunstancia requiere que la técnica proyectiva atienda, además de los aspectos formales, a los aspectos de contenido. En la técnica grafológica, en cambio, se atiende a ‘como’ la persona escribe’, y no sobre ‘qué’ escribe.En suma, puede decirse que la técnica grafológica es una técnica proyectiva porque parte del supuesto de la proyección, en el más amplio sentido de esta palabra, pero por otro lado no es una técnica proyectiva porque no analiza los resultados desde la teoría psicoanalítica.A partir de lo dicho se abren dos posibilidades: que un psicólogo pueda utilizar una técnica grafológica, o, al revés, que un grafólogo pueda utilizar una técnica proyectiva clásica de la psicología.
Página 252 de 314
252

El primer caso podría presentarse en el Test de las Dos personas, donde el psicólogo debe analizar no solamente el dibujo sino también la historia que el sujeto escribe sobre lo dibujado. El análisis que hace no se refiere solamente al contenido de la historia sino también a algunos aspectos formales, como por ejemplo el emplazamiento, realizando entonces aquí una labor algo similar a la del grafólogo, aunque, desde luego, no se trata de un análisis grafológico tal como es entendido en grafología.El segundo caso sólo es posible si el grafólogo tiene la suficiente formación psicoanalítica para analizar una técnica proyectiva gráfica. Este problema tiene que ver con las incumbencias del grafólogo, vale decir con aquello que puede hacer o aquello que no puede hacer. El problema reside en quién será quien defina estas incumbencias: su formación académica (por ejemplo si el programa de estudios incluye o no la teoría psicoanalítica), una ley que defina incumbencias, una autoridad reconocida de la grafología, una asociación de profesionales grafólogos, o bien cada grafólogo en particular según su particular visión de su propio rol.Detrás de las incumbencias se esconde una cuestión más profunda: el reparto del poder entre diferentes tipos de profesionales, llámeselos psicólogos, psiquiatras, tarotistas o grafólogos, sin ánimo de comparación. El otorgamiento de este poder proviene de varias fuentes (los reconocimientos sociales, académicos, legales) y varía de una época a otra y de un país a otro. En Chile un psicólogo es un simple auxiliar del médico, del mismo modo que puede serlo un enfermero, pero en Argentina tiene una cuota mayor de poder. Es posible que un grafólogo experimente, respecto del psicólogo, un cierto sentimiento de inferioridad, incluso aunque no se sienta su auxiliar.Otra cuestión tiene relación con la etimología del vocablo ‘grafología’. El estudio del grafismo, en un sentido amplio, puede hacer referencia a los dibujos o a la escritura. Históricamente, la especie humana ha producido primeramente dibujos, y estos fueron transformándose progresivamente en escritura alrededor del año 4000 AC, habiendo pasado por etapas intermedias donde el grafismo fue en parte dibujo y en parte escritura.Los fundadores de la grafología han establecido claramente que su objeto de estudio es la escritura, no el dibujo o, si se quiere, ese dibujo especial llamado letra: no es lo mismo dibujar un círculo que dibujar la letra o (Cazau, 2006).
Conclusiones
En el presente trabajo hemos esbozado algunas de las condiciones mínimas indispensables para poder iniciar una investigación en el campo de la grafología: 1) en primer lugar el grafólogo ha de considerar el espectro de posibles factores personales y situacionales, estables e inestables, para poder elegir cuál o cuales de ellos someterá a estudio; 2) en segundo lugar debe considerar las tres posibles relaciones entre rasgos personales y rasgos grafológicos para elegir cuál o cuales de ellas investigará; y 3) en tercer lugar debe tomar las precauciones necesarias para estandarizar los procedimientos de recolección y análisis de los datos.Puede ser importante aclarar, finalmente, que las pautas de investigación aquí presentadas se aplican especialmente a la investigación científica propiamente dicha, más allá que también puedan aplicarse a la investigación profesional. Llamamos investigación profesional a la que emprende un grafólogo con fines diagnósticos con una determinada persona que contrata sus servicios. En cambio, la investigación científica propiamente dicha tiene como fin aumentar y profundizar el saber grafológico. Para ello también aquí se necesita contar con personas, pero, en este caso, tal vez no sea tan fácil conseguir que se presten gratuita o voluntariamente a una investigación, salvo que se ofrezca como contraprestación un análisis grafológico con fines diagnósticos u otro tipo de beneficio.Un grafólogo que se dedica a su profesión, a lo largo del tiempo puede reunir material importante como para ser utilizado en protocolos de investigación científica, realizando él mismo la investigación o suministrando sus datos a otros investigadores.
Página 253 de 314
253

REFERENCIAS BIBLIOGRÁFICAS DE ESTADÍSTICA
Bancroft H (1960) Introducción a la bioestadística. Buenos Aires: Eudeba.Botella R (1993) Análisis de datos en psicología I. Buenos Aires: Paidós.Campbell D y Stanley J (1995), Diseños experimentales y cuasiexperimentales en la investigación social. Buenos Aires: Amorrortu.Hernández Sampieri R, Fernández Collado C y Baptista Lucio P (1996), Metodología de la investigación. México: McGraw-Hill.Kohan N (1994) Diseño estadístico. Buenos Aires, Eudeba.Lichtenthal S, Qué es la teoría de la información. Buenos Aires, Revista Ciencia Nueva, N° 3, 1970.León O y Montero I (1995) Diseño de investigaciones (Introducción a la lógica de la investigación en Psicología y Educación), Madrid, McGraw-Hill.Levin R y Rubin D (1996) Estadística para administradores. Prentice Hall, 6° ed.Pagano R (1998) Estadística en las ciencias del comportamiento. México: Internacional Thomson. 5° edición.Rodríguez Feijóo N (2003) Estadística social.Rubio M y otro (1997) El análisis de la realidad en la intervención social. Madrid: Editorial CCS.Tamayo M (1999), Diccionario de la investigación científica. México: Limusa.Van Dalen D y Meyer W, Manual de técnica de la investigación educacional.Vessereau A (1962) La estadística. Buenos Aires: Eudeba.
OTRAS FUENTES CONSULTADAS PARA ESTADÍSTICA
Ander-Egg E (1987) Técnicas de Investigación social. Buenos Aires: Hvmanitas, 21 edición.Cuidet C (1969) Nociones básicas para el tratamiento estadístico en los tests mentales. Buenos Aires: Opfyl.Garrett H (1966) Estadística en Psicología y Educación. Buenos Aires: Paidós.
REFERENCIAS BIBLIOGRÁFICAS DE METODOLOGÍA
American Psychological Association (APA) (1994). Publication manual of the American Psychological Association (4th ed.). Washington, D. C. http://www.apa.orgAnastasi A (1976) Tests psicológicos. Madrid: Aguilar, 3° edición.Ander-Egg E (1987) Técnicas de investigación social. Buenos Aires: Hvmanitas, 21° edición.Anónimo (2005) Son refutados un tercio de los estudios médicos. Buenos Aires, Diario La Nación, 15 de julio de 2005.Arnau Gras J (1980) Psicología experimental. Un enfoque metodológico. México: Trillas.Bakeman E y Gottman J (1986) Observación de la interacción: introducción al análisis secuencial. Madrid: Morata.Barco Susana, "Estado actual de la pedagogía y la didáctica", en Revista Argentina de Educación, N° 12, Buenos Aires, 1989.Bazerman C (1987) "Codifying the social scientific style: The APA Publication Manual as a behaviorist rhetoric", en J. Nelson, A. Megill y D. McCloskey, eds., "The rhetoric of de human sciences: Language and argument in scholarship and public affairs" (págs. 125-44), Madison, University of Wisconsin Press.Bernstein J, La psicología factorial: Spearman. Incluído en Heidbreder E (1979) Psicologías del Siglo XX. Buenos Aires: Paidós.Blalock H (1971) Introducción a la investigación social. Buenos Aires: Amorrortu.Blalock H (1982) Introducción a la investigación social. Buenos Aires: Amorrortu.Britton B, Glynn S. y Smith J, "Cognitive demands of processing expository text". En: Bruce K. Britton y John Black (Eds.), "Understanding expository text", pp. 227-248. Hillsdale, New Jersey, Lawrence Erlbaum Associates, 1985. Existe traducción en castellano: "Exigencias cognitivas para el procesamiento de textos expositivos", publicación interna de la cátedra de Psicología General II de la Facultad de Psicología de la Universidad de Belgrano, 1998. Traducido y abreviado por Carlos Molinari Marotto.Bruner Jerome (1996) Realidad mental y mundos posibles. Barcelona: Gedisa.Bunge M (1969-1970) La investigación científica: su estrategia y su filosofía. Barcelona: Ariel.Campbell D y Stanley J (1966) Experimental and quasi-experimental design for research. Chicago: Rand McNally.Campbell D y Stanley J (1995) Diseños experimentales y cuasiexperimentales en la investigación social. Buenos Aires: Amorrortu.Castro L (1975) Diseño experimental sin estadística. México: Trillas.Casullo M y otros (1980) Teoría y técnicas de evaluación psicológica. Buenos Aires: Psicoteca.Cazau P (1996) El contexto de difusión en la ciencia y la psicología. Buenos Aires: Publicación de la Secretaría de Cultura de la Facultad de Psicología (Universidad de Buenos Aires).Cazau P (2006) Exposición sobre los fundamentos de la grafología. Mesa-Debate organizada por la Sociedad Panamericana de Grafología, Buenos Aires, 24-11-2006.Cevallos García C y otros, Investigación en atención primaria: actitud y dificultades percibidas por nuestros médicos. En Atención Primaria. 2004 Dic; 34 (10):520–524.Chevallard Y (1997) La transposición didáctica: del saber sabio al saber enseñado. Buenos Aires: Aiqué.Cohen M y Nagel E (1979) Introducción a la lógica y al método científico (Vol. II: Lógica aplicada y método científico). Buenos Aires: Amorrortu.Cook T y Campbell D (1979) Quasi-experimentation design and analysis issues for the field settings. Boston: Houghton Mifflin.Cook y Reichardt, Métodos cualitativos y cuantitativos en investigación evaluativo.Copi I (1974) Introducción a la lógica. Buenos Aires: Eudeba, 15° edición.Corripio Fernando (1988) Dudas e incorrecciones del idioma. México: Larousse.Crombie A (1979) Historia de la Ciencia: de San Agustín a Galileo (Tomo 2). Madrid: Alianza, 2° edición.Dalzon C (1988) Conflicto cognitivo y construcción de la noción derecha-izquierda. Incluido en Perret A y Nicoles M (1988), Interactuar y conocer. Desafíos y regulaciones sociales en el desarrollo cognitivo. Buenos Aires: Miño y Dávila.Daniels F, Publicar a cualquier precio. Buenos Aires, Revista Muy Interesante N° 100, Febrero de 1994.De Vega J (1984) Introducción a la psicología cognitiva. Madrid: Alianza.
Página 254 de 314
254

Deobold B y otros (1985) Manual de técnica de la investigación educacional. Buenos Aires: Paidós.Diccionario Aristos (1968). Barcelona: Ramón Sopena.Droppelmann A (2002), Procedimientos para la elaboración de proyecto y tesis de grado y proceso de titulación (Reglamento interno).Dunham P (1988) Research methods in psychology. Nueva York: Harper & Row.Echevarría María Elina (1992) Grafología infantil. Comprendiendo a los niños a través de su escritura y dibujos. Madrid: EDAF.Fatone V (1969) Lógica e introducción a la filosofía. Buenos Aires: Kapelusz, 9° edición.Ferrater Mora J (1979) Diccionario de Filosofía. Madrid: Alianza.Fisher R (1925) Statistical methods for research workers. London: Oliver & Boyd. (Hay edición castellana de este clásico: "Tablas estadísticas para investigadores científicos”. Madrid: Aguilar, 1954, 2° edición).Fisher R (1954) Tablas estadísticas para investigadores científicos. Madrid: Aguilar, 2° edición.Freud S (1906) La indagatoria forense y el psicoanálisis. Obras Completas, Tomo IX. Buenos Aires: Amorrortu, 1993.Freud S (1909) Análisis de la fobia de un niño de cinco años (Caso Juanito). En Obras Completas. Buenos Aires: Amorrortu.Freud S (1915) Los caminos de la formación del síntoma (Conferencia 23). En Obras Completas, Tomo XVI. Buenos Aires: Amorrortu, 1995.Freud S (1916) Psiquiatría y psicoanálisis (Conferencia 16). Obras Completas. Buenos Aires: Amorrortu.González G (1990) Estudios de mercado: módulo 2. Publicación interna de la cátedra Estudios de mercado. Buenos Aires: Universidad de Belgrano.Greenwood E (1973) Metodología de la investigación social. Buenos Aires: Paidós.Guerra J y otros (2003) Las revisiones sistemáticas, niveles de evidencia y grados de recomendación. Disponible en www.fisterra.com.Guyatt G y otros, Evidence-Based Medicine. A new approach to teaching the practice of medicine. JAMA 1992;268:2420-2425.Hempel C (1977) Filosofía de la ciencia natural. Madrid: Alianza Editorial. 3° edición.Hernández Sampieri R Fernández Collado C y Lucio P (1996) Metodología de la investigación. México: McGraw-Hill.Hull L (1978) Historia y filosofía de la ciencia. Barcelona: Ariel, 4° edición.Hyman Herbert (1984), Diseño y análisis de las encuestas sociales. Buenos Aires: Amorrortu.Kohan N (1994) Diseño estadístico para investigadores de las ciencias sociales y de la conducta. Buenos Aires: Eudeba.Korn F (1965) Qué es una variable en la investigación social. Buenos Aires: Facultad de Filosofía y Letras de la Universidad de Buenos Aires, ficha OPFYL N° 476.Korn F (1969) El significado del término variable en sociología. Artículo incluido en Korn F y otros, “Conceptos y variables en la investigación social”, Buenos Aires, Nueva Visión, 1969. Land, T [a.k.a. Beads] (1998, 15 Octubre). Web extension to American Psychological Association Style (WEAPAS) (Rev. 1.6) [Documento WWW] http://www.beadsland.com/weapas/ Este documento propone una extensión al Apéndice 3-A (APA; 1994, pp. 189-222), integrando los estándares de Internet para los URL (Uniform Resource Locators) (Graham, 1995), tal y como son usados en la World Wide Web (WWW) (W3C, 1995). La extensión propuesta aquí es una alternativa a los patrones sugeridos para los recursos de red (APA, 1994, p. 218 - 220, 1998; Dewey, 1996).Laplanche J y Pontalis J (1981) Diccionario de Psicoanálisis. Barcelona: Labor. 2° edición.Lazarsfeld P (1984) Palabras preliminares a Hyman H (1984) Diseño y análisis de las encuestas sociales. Buenos Aires: Amorrortu.Lazarsfeld Paul (1980) Origen y desarrollo de las variables sociológicas. Artículo incluído en Korn F (ed) (1980) Conceptos y variables en la investigación social”. Buenos Aires: Nueva Visión.León O y Montero I (1995) Diseño de investigaciones. Introducción a la lógica de la investigación en psicología y educación. Madrid: McGraw Hill.Lores Arnaiz M (2000) Módulos de Metodología de la investigación psicológica (Cátedra de Metodología de la Investigación, Facultad de Psicología, Universidad de Buenos Aires).Losee J (1979) Introducción histórica a la filosofía de la ciencia. Madrid: Alianza, 2° edición.Marcuse Irene (1974) Grafología. Estudio y guía de la personalidad a través de la escritura. Buenos Aires: Glem. 2° edición.Massonnat-Mick Graciela, "An Evaluation of the success of the privatization of Aerolíneas Argentinas (AR)", Colorado Technical University, Denver, Colorado, June 1999.Matus C (1985) Planificación, libertad y conflicto. Caracas: Ediciones Iveplan.McCall W (1923) How to experiment in education. New York: Macmillan.Mora y Araujo (1971) Medición y construcción de índices. Buenos Aires: Nueva Visión.Normas de Vancouver. International Committee of Medical Journal Editors (1993). Uniform requirements for manuscripts submitted to biomedical journals.Nuevo Pequeño Larrousse Ilustrado. París: Librería Larrouse, 1961.O’Neil W (1968), Introducción al método en psicología. Buenos Aires: Eudeba, 2° edición.Pérez Serrano G (1990), Investigación-Acción. Aplicaciones al campo social y educativo. Madrid: Dykinson.Pick S y López A (1998), Cómo investigar en ciencias sociales. Buenos Aires: Trillas.Primo J (2003), Niveles de evidencia y grados de recomendación. Ponencia presentada en el Symposium “Gestión del conocimiento y su aplicación en la Enfermedad Inflamatoria Crónica Intestinal”, organizado por el Grupo Español de Trabajo en Efneremdad de Crohn y Colitis Ulcerosa. Valencia, 24 enero 2003.Reynolds (1971), A primer in theory construction. Indianapolis: The Bobbs-Merill Company Inc.Rodas O y otros (2001) Teoría básica del muestreo. Disponible en www.monografias.com/trabajos11Rodríguez Ousset Azucena, Problemas, desafíos y mitos en la formación docente, en Revista Perfiles Educativos N° 63, México, UNAM, 1994.Rollo May (1990) El dilema del hombre. México: Gedisa.Rubio J y Varas J (1997), El análisis de la realidad, en la intervención social. Métodos y técnicas de investigación. Madrid: Editorial CCS.Samaja J (1995) Epistemología y metodología: Elementos para una teoría de la investigación científica. Buenos Aires: Eudeba, 3° edición.Segal Hanna (1987) Introducción a la obra de Melanie Klein. Buenos Aires: Paidós.Selltiz, Jahoda, Deutsch y Cook (1980) Métodos de investigación en las relaciones sociales. Madrid: Rialp. Existe una versión similar de este texto, cuyos autores son Selltiz, Wrightsman, Deustch y Cook.Shaughnessy J y Zechmeister E (1990) Research methods in Psychology. Nueva York: McGraw-Hill, 2da. edición.
Página 255 de 314
255

Sierra Bravo R (1979) Técnicas de investigación social. Madrid: Paraninfo.Slapak Sara, Tecnologías de gestión para la innovación curricular. Investigaciones en Psicología, Revista del Instituto de Investigaciones de la Facultad de Psicología de la Universidad de Buenos Aires, Año 1 – N° 1, 1996.Stuart Mill John (1843) A System of Logic. Londres: Longmans Green, 1865.Tamayo M (1999) Diccionario de investigación científica. México: Limusa.Timasheff Nicholas (1969) La teoría sociológica. México: FCE, 1969, 5° edición.Valdés F (1998) Comprensión y uso de la estadística. Glosario. Universidad Rómulo Gallegos.Vallejo Ruiloba J y otros (1999) Introducción a la psicopatología y la psiquiatría. Barcelona: Masson, 4° edición.Vander Zanden J (1986) Manual de Psicología Social. Barcelona: Paidós.Vels Augusto (1991) Diccionario de grafología y términos psicológicos afines. Barcelona: Herder. 4° edición.Wainerman C y otro (2001) La trastienda de la investigación. Buenos Aires: Lumiere.Woolfolk A (1996) Psicología educativa. México: Prentice-Hall Hispanoamericana.Yabo R, Bioestadística. Buenos Aires: Revista Ciencia Nueva, Año II, N° 13, Noviembre 1971.Zeisel H (1986) Dígalo con números. México: FCE.Zeller Nancy (1995) La racionalidad narrativa en la investigación educativa, incluido en McEwan H y Egan K (comp) (1998) La narrativa en la enseñanza, el aprendizaje y la investigación. Buenos Aires: Amorrortu.
Página 256 de 314
256

ANEXOS DE ESTADÍSTICA
ANEXO 1: NOMENCLATURA UTILIZADA EN ESTA GUÍA
Muchos de los símbolos que se emplean en estadística no son universales. En la siguiente lista se presentan los símbolos que se utilizan en esta Guía, y también se incluyen los símbolos de las letras del alfabeto griego.Hay ciertas reglas que suelen ser universales, como por ejemplo, las letras griegas siempre se refieren a parámetros de la población y las letras latinas se refieren a estadísticos de la muestra (Levin y Rubin, 1996).
Símbolo Conceptoh Altura
CV Coeficiente de variaciónCV% Coeficiente de variación porcentual
Q0 Cuartil de ordenQt Cuartil t (ejemplo: Q3 = Cuartil 3)D0 Decil de ordenDt Decil t (ejemplo: D9 = Decil 9)Dm Desviación mediaS Desvío estándar muestral Desvío estándar poblacionalf Frecuencia absolutaF Frecuencia acumulada
Fant Frecuencia acumulada anteriorF% Frecuencia acumulada porcentualFpos Frecuencia acumulada posteriorFr Frecuencia acumulada relativafant Frecuencia del intervalo anteriorfpos Frecuencia del intervalo posteriorf° Frecuencia expresada en gradosf% Frecuencia porcentualfr Frecuencia relativa
As Indice de asimetríaLi Límite inferior del intervaloLs Límite superior del intervalo
xmay Mayor valor de la variableX Media aritmética muestral de xY Media aritmética muestral de y Media aritmética poblacional (esperanza)
Mn MedianaMn0 Mediana de ordenxmen Menor valor de la variableMo Modo
t Número de decil o del percentilP0 Percentil de ordenPt Percentil t (ejemplo P99 = Percentil 99)p ProbabilidadZ Puntaje estandarizada derivadoz Puntaje estandarizado reducidoxm Punto medio del intervaloR Rango o amplitudDQ Rango o desvío intercuartílico Sumatorian Tamaño de la muestraN Tamaño de la poblacióna Tamaño o amplitud del intervalo| Valor absoluto
xn Variable (cualquier valor de una…)x1 Variable (determinado valor de una…)
x, y Variables (letras que designan…)
Página 257 de 314
257

S2 Variancia muestral Variancia poblacionalLs Límite superior del intervalo de confianzaLi Límite inferior del intervalo de confianzaH Hipótesis de investigación
Ho Hipótesis nulaHa Hipótesis alternativaa Probabilidad de cometer un error Tipo Ib Probabilidad de cometer un error Tipo II
1 - a Probabilidad de NO cometer el error tipo I1 - b Probabilidad de NO cometer el error tipo II
ze z empíricozt z teórico o crítico
Alfabeto griegoNombre Mayúscula Minúscula Nombre Mayúscula Minúscula Nombre Mayúscula Minúscula
alfa iota ro beta kappa sigma gamma lambda tau delta mi ípsilon épsilon ni fi dseta xi ji eta ómicro
n psi
zeta pi omega
ANEXO 2: TABLA DE ÁREAS BAJO LA CURVA NORMAL ESTANDARIZADA
Las siguientes tablas representan dos maneras diferentes de proporcionar una misma información, a saber, la relación entre el puntaje reducido z con la probabilidad p de ocurrencia del valor z. El valor de esta probabilidad es proporcional al área correspondiente bajo la curva.Por ejemplo, dado un valor z, las tablas permite conocer qué probabilidad tiene que darse ese valor o más o ese valor o menos, en un individuo elegido al azar. Desde ya, a la inversa, también permite conocer qué valor z corresponde a una determinada probabilidad. Los valores z figuran en la primera columna, mientras que los diferentes valores de probabilidad figuran en las columnas restantes.
Por ejemplo:a) Siguiendo la Tabla 1, un puntaje reducido z = +1.26 o menor tiene una probabilidad de ocurrencia de p = 0.8962 (el área bajo la curva normal corresponde al 89.62% de total del área).b) Siguiendo la Tabla 2, un puntaje reducido z situado entre z = 0 y z = +1.26 tiene una probabilidad de ocurrencia de p = 0.3962 (el área bajo la curva normal corresponde al 39.62% del total del área).
Arriba de cada tabla puede observarse un esquema de la curva normal. Las áreas rayadas indican las áreas que cada tabla permite calcular. Por ejemplo, la Tabla 1 permite calcular áreas desde z hacia la izquierda, y la Tabla 2 calcula áreas entre z y el centro de la distribución (z = 0).Nótese que el título asignado a la Tabla 2 es “Áreas desde z = 0 hacia la izquierda o hacia la derecha”. Esto significa que, debido a la perfecta simetría de la curva normal, una distancia entre z = +1.26 y 0 da la misma probabilidad que la distancia z = -1.26 y 0.
Tabla 1 – Áreas desde z hacia la izquierda
zProbabilidad (p)
0.00 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09
-3.4 .0003 .0003 .0003 .0003 .0003 .0003 .0003 .0003 .0003 .0002
-3.3 .0005 .0005 .0005 .0004 .0004 .0004 .0004 .0004 .0004 .0003
-3.2 .0007 .0007 .0006 .0006 .0006 .0006 .0006 .0005 .0005 .0005
Página 258 de 314
258

-3.1 .0010 .0009 .0009 .0009 .0008 .0008 .0008 .0008 .0007 .0007
-3.0 .0013 .0013 .0013 .0012 .0012 .0011 .0011 .0011 .0010 .0010
-2.9 .0019 .0018 .0017 .0017 0016. .0016 .0015 .0015 .0014 .0014
-2.8 .0026 .0025 .0024 .0023 .0023 .0022 .0021 .0021 .0020 .0019
-2.7 .0035 .0034 .0033 .0032 .0031 .0030 .0029 .0028 .0027 .0026
-2.6 .0047 .0045 .0044 .0043 .0041 .0040 .0039 .0038 .0037 .0036
-2.5 .0062 .0060 .0059 .0057 .0055 .0054 .0052 .0051 .0049 .0048
-2.4 .0082 .0080 .0078 .0075 .0073 .0071 .0069 .0068 .0066 .0064
-2.3 .0107 .0104 .0102 .0099 .0096 .0094 .0091 .0089 .0087 .0084
-2.2 .0139 .0136 .0132 .0129 .0125 .0122 .0119 .0116 .0113 .0110
-2.1 .0179 .0174 .0170 .0166 .0162 .0158 .0154 .0150 .0146 .0143
-2.0 .0228 .0222 .0217 .0212 .0207 .0202 .0197 .0192 .0188 .0183
-1.9 .0287 .0281 .0274 .0268 .0262 .0256 .0250 .0244 .0239 .0233
-1.8 .0359 .0352 .0344 .0336 .0329 .0322 .0314 .0307 .0301 .0294
-1.7 .0446 .0436 .0427 .0418 .0409 .0401 .0392 .0384 .0375 .0367
-1.6 .0548 .0537 .0526 .0516 .0505 .0495 .0485 .0475 .0465 .0455
-1.5 .0668 .0655 .0643 .0630 .0618 .0606 .0595 .0582 .0571 .0559
-1.4 .0808 .0793 .0778 .0764 .0749 .0735 .0722 .0708 .0694 .0681
-1.3 .0968 .0951 .0934 .0918 .0901 .0885 .0869 .0853 .0838 .0823
-1.2 .1151 .1131 .1112 .1093 .1075 .1056 .1038 .1020 .1003 .0985
-1.1 .1357 .1335 .1314 .1292 .1271 .1251 .1230 .1210 .1190 .1170
-1.0 .1587 .1562 .1539 .1515 .1492 .1469 .1446 .1423 .1401 .1379
-0.9 .1841 .1814 .1788 .1762 .1736 .1711 .1685 .1660 1635. 1611.
-0.8 .2119 .2090 .2061 .2033 .2005 .1977 .1949 .1922 .1894 .1867
-0.7 .2420 .2389 .2358 .2327 .2296 .2266 .2236 .2206 .2177 .2148
-0.6 .2743 .2709 .2676 .2643 .2611 .2578 .2546 .2514 .2483 .2451
-0.5 .3085 .3050 .3015 .2981 .2946 .2912 .2877 .2843 .2810 .2776
-0.4 .3446 .3409 .3372 .3336 .3300 .3264 .3228 .3192 .3156 .3121
-0.3 .3821 .3783 .3745 .3707 .3669 .3632 .3594 .3557 .3520 .3483
-0.2 .4207 .4168 .4129 .4090 .4052 .4013 .3974 .3936 .3897 .3859
-0.1 .4602 .4562 .4522 .4483 .4443 .4404 4364. 4325. 4286. 4247.
-0.0 .5000 .4960 .4920 .4880 .4840 .4801 .4761 .4721 .4681 .4641
0.0 .5000 .5040 .5080 .5120 .5160 .5199 .5239 .5279 .5319 .5359
0.1 .5398 .5438 .5478 .5517 .5557 .5596 .5636 .5675 .5714 .5753
0.2 .5793 .5832 .5871 .5910 .5948 .5987 .6026 .6064 .6103 .6141
0.3 .6179 .6217 .6255 .6293 .6331 .6368 .6406 .6443 .6480 .6517
0.4 .6554 .6591 .6628 .6664 .6700 .6736 .6772 .6808 .6844 .6879
0.5 .6915 .6950 .6985 .7019 .7054 .7088 .7123 .7157 .7190 .7224
0.6 .7257 .7291 .7324 .7357 .7389 .7422 .7454 .7486 .7517 .7549
0.7 .7580 .7611 .7642 .7673 .7704 .7734 .7764 .7794 .7823 .7852
0.8 .7881 .7910 .7939 .7967 .7995 .8023 .8051 .8078 .8106 .8133
0.9 .8159 .8186 .8212 .8238 .8264 .8289 .8315 .8340 .8365 .8389
1.0 .8413 .8438 .8461 .8485 .8508 .8531 .8554 .8577 .8599 .8621
1.1 .8643 .8665 .8686 .8708 .8729 .8749 .8770 .8790 .8810 .8830
1.2 .8849 .8869 .8888 .8907 .8925 .8944 .8962 .8980 .8997 .9015
1.3 .9032 .9049 .9066 .9082 .9099 .9115 .9131 .9147 .9162 .9177
1.4 .9192 .9207 .9222 .9236 .9251 .9265 .9279 .9292 .9306 .9319
1.5 .9332 .9345 .9357 .9370 .9382 .9394 .9406 .9418 .9429 .9441
Página 259 de 314
259

1.6 .9452 .9463 .9474 .9484 .9495 .9505 .9515 .9525 .9535 .9545
1.7 .9554 .9564 .9573 .9582 .9591 .9599 .9608 .9616 .9625 .9633
1.8 .9641 .9649 .9656 .9664 .9671 .9678 .9686 .9693 .9699 .9706
1.9 .9713 .9719 .9726 .9732 .9738 .9744 .9750 .9756 .9761 .9767
2.0 .9772 .9778 .9783 .9788 .9793 .9798 .9803 .9808 .9812 .9817
2.1 .9821 .9826 .9830 .9834 .9838 .9842 .9846 .9850 .9854 .9857
2.2 .9861 .9864 .9868 .9871 .9875 .4878 .9881 .9884 .9887 .9890
2.3 .9893 .9896 .9898 .9901 .9904 .9906 .9909 .9911 .9913 .9916
2.4 .9918 .9920 .9922 .9925 .9927 .9929 .9931 .9932 .9934 .9936
2.5 .9938 .9940 .9941 .9943 .9945 .9946 .9948 .9949 .9951 .9952
2.6 .9953 .9955 .9956 .9957 .9959 .9960 .9961 .9962 .9963 .9964
2.7 .9965 .9966 .9967 .9968 .9969 .9970 .9971 .9972 .9973 .9974
2.8 .9974 .9975 .9976 .9977 .9977 .9978 .9979 .9979 .9980 .9981
2.9 .9981 .9982 .9982 .9983 .9984 .9984 .9985 .9985 .9986 .9986
3.0 .9987 .9987 .9987 .9988 .9988 .9989 .9989 .9989 .9990 .9990
3.1 .9990 .9991 .9991 .9991 .9992 .9992 .9992 .9992 .9993 .9993
3.2 .9993 .9993 .9994 .9994 .9994 .9994 .9994 .9995 .9995 .9995
3.3 .9995 .9995 .9995 .9996 .9996 .9996 .9996 .9996 .9996 .9997
3.4 .9997 .9997 .9997 .9997 .9997 .9997 .9997 .9997 .9997 .9998
Tabla 2 – Áreas desde z = 0 hacia la izquierda o hacia la derecha
zProbabilidad (p)
0.00 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09
0.0 .0000 .0040 .0080 .0120 .0160 .0199 .0239 .0279 .0319 .0359
0.1 .0398 .0438 .0478 .0517 .0557 .0596 .0636 .0675 .0714 .0754
0.2 .0793 .0832 .0871 .0910 .0948 .0987 .1026 .1064 .1103 .1141
0.3 .1179 .1217 .1255 .1293 .1331 .1368 .1406 .1443 .1480 .1517
0.4 .1554 .1591 .1628 .1664 .1700 .1736 .1772 .1808 .1844 .1879
0.5 .1915 .1950 .1985 .2019 .2054 .2088 .2123 .2157 .2190 .2224
0.6 .2258 .2291 .2324 .2357 .2389 .2422 .2454 .2486 .2518 .2549
0.7 .2580 .2612 .2642 .2673 .2704 .2734 .2764 .2794 .2823 .2852
0.8 .2881 .2910 .2939 .2967 .2996 .3023 .3051 .3078 .3106 .3133
0.9 .3159 .3186 .3212 .3238 .3264 .3289 .3315 .3340 .3365 .3389
1.0 .3413 .3438 .3461 .3485 .3508 .3531 .3554 .3577 .3599 .3621
1.1 .3643 .3665 .3686 .3708 .3729 .3749 .3770 .3790 .3810 .3830
1.2 .3849 .3869 .3888 .3907 .3925 .3944 .3962 .3980 .3997 .4015
1.3 .4032 .4049 .4066 .4082 .4099 .4115 .4131 .4147 .4162 .4177
1.4 .4192 .4207 .4222 .4236 .4251 .4265 .4279 .4292 .4306 .4319
1.5 .4332 .4345 .4357 .4370 .4382 .4394 .4406 .4418 .4429 .4441
1.6 .4452 .4463 .4474 .4484 .4495 .4505 .4515 .4525 .4535 .4545
Página 260 de 314
260

1.7 .4554 .4564 .4573 .4582 .4591 .4599 .4608 .4616 .4625 .4633
1.8 .4641 .4649 .4656 .4664 .4671 .4599 .4608 .4616 .4625 .4633
1.9 .4713 .4719 .4726 .4732 .4738 .4744 .4750 .4756 .4761 .4767
2.0 .4772 .4778 .4783 .4788 .4793 .4798 .4803 .4808 .4812 .4817
2.1 .4821 .4826 .4830 .4834 .4838 .4842 .4846 .4850 .4854 .4857
2.2 .4961 .4864 .4868 .4871 .4875 .4878 .4881 .4884 .4887 .4890
2.3 .4893 .4896 .4898 .4901 .4904 .4906 .4909 .4911 .4913 .4916
2.4 .4918 .4920 .4922 .4925 .4927 .4929 .4931 .4932 .4934 .4936
2.5 .4938 .4940 .4941 .4943 .4945 .4946 .4948 .4949 .4951 .4952
2.6 .4953 .4955 .4956 .4957 .4959 .4960 .4961 .4962 .4963 .4964
2.7 .4965 .4966 .4967 .4968 .4969 .4970 .4971 .4972 .4973 .4974
2.8 .4974 .4975 .4976 .4977 .4977 .4978 .4979 .4979 .4980 .4981
2.9 .4981 .4982 .4982 .4983 .4984 .4984 .4985 .4985 .4986 .4986
3.0 .4987 .4987 .4987 .4988 .4988 .4989 .4989 .4989 .4990 .4990
3.1 .4990 .4991 .4991 .4991 .4992 .4992 .4992 .4992 .4993 .4993
3.2 .4993 .4993 .4994 .4994 .4994 .4994 .4994 .4995 .4995 .4995
3.3 .4995 .4995 .4995 .4996 .4996 .4996 .4996 .4996 4996. .4997
3.4 .4997 .4997 .4997 .4997 .4997 .4997 .4997 .4997 .4997 .4998
ANEXO 3
TABLA DE LA DISTRIBUCION t (Student)
Grado de libertad
Nivel de probabilidad para pruebas de una cola0.10 0.05 0.025 0.01 0.005 0.0005Nivel de probabilidad para pruebas de dos colas0.20 0.10 0.05 0.02 0.01 0.001
1 3.078 6.314 12.706 31.821 63.657 636.6192 1.886 2.920 4.303 6.965 9.925 31.5983 1.638 2.353 3.182 4.541 5.841 12.9414 1.533 2.132 2.776 3.747 4.604 8.6105 1.476 2.015 2.571 3.365 4.032 6.8596 1.440 1.943 2.447 3.143 3.707 5.9597 1.415 1.895 2.365 2.998 3.499 5.4058 1.397 1.860 2.306 2.896 3.355 5.0419 1.383 1.833 2.262 2.821 3.250 4.781
10 1.372 1.812 2.228 2.764 3.169 4.58711 1.363 1.796 2.201 2.718 3.106 4.43712 1.356 1.782 2.179 2.681 3.055 4.31813 1.350 1.771 2.160 2.650 3.012 4.22114 1.345 1.761 2.145 2.624 2.977 4.14015 1.341 1.753 2.131 2.602 2.947 4.07316 1.337 1.746 2.120 2.583 2.921 4.01517 1.333 1.740 2.110 2.567 2.898 3.96518 1.330 1.734 2.101 2.552 2.878 3.92219 1.328 1.729 2.093 2.539 2.861 3.88320 1.325 1.725 2.086 2.528 2.845 3.85021 1.323 1.721 2.080 2.518 2.831 3.81922 1.321 1.717 2.074 2.508 2.819 3.79223 1.319 1.714 2.069 2.500 2.807 3.76724 1.318 1.711 2.064 2.492 2.797 3.74525 1.316 1.708 2.060 2.485 2.787 3.72526 1.315 1.706 2.056 2.479 2.779 3.70727 1.314 1.703 2.052 2.473 2.771 3.69028 1.313 1.701 2.048 2.467 2.763 3.67429 1.311 1.699 2.045 2.462 2.756 3.65930 1.310 1.697 2.042 2.457 2.750 3.64640 1.303 1.684 2.021 2.423 2.704 3.551
Página 261 de 314
261

60 1.296 1.671 2.000 2.390 2.660 3.460120 1.289 1.658 1.980 2.358 2.617 3.373
Infinito 1.282 1.645 1.960 2.326 2.576 3.291(Fuente: Kohan, 1994:519).
ANEXO 3: EJERCITACIÓN
Sumario
Ejercicios de Ejercicios con respuesta (total o parcial) Ejercicios sin respuestaEstadística descriptiva 104–105–106–107–108–109–113-114–115–116–
118-119- 122–123–124–125–126–127–128–129–130–131–132–133–134–135–136–137-138-139-140-141-142
101–102–103–110–111-112–117-120–121
Probabilidad 201–202–203–204–205-206-207-208-209-210-211-212
-----------------------
Curva normal 301–305-306-307-308-309-310-311 302–303–304Correlación y regresión 406–407-410–411–412–413-414-415 401–402–403–404–405–408-409Estadística inferencial 502-503-504-505-506-507-508-509-510-513-514-
515-516-517501-511-512
EJERCICIOS DE ESTADÍSTICA DESCRIPTIVA
101) Un investigador preguntó a un grupo de personas su opinión sobre la privatización de cierta empresa del estado. Las respuestas fueron las siguientes:
Indeciso – Muy en desacuerdo – Indeciso – Muy en desacuerdo – Indeciso – De acuerdo – En desacuerdo – De acuerdo – De acuerdo – En desacuerdo – Indeciso – De acuerdo – En desacuerdo – De acuerdo – En desacuerdo – En desacuerdo – En desacuerdo – Indeciso –De acuerdo – Indeciso – Muy en desacuerdo – Indeciso – De acuerdo – De acuerdo – Muy de acuerdo – Indeciso – Muy de acuerdo – Indeciso – Indeciso – Muy de acuerdo – Indeciso – Muy en desacuerdo – Indeciso.
a) Presente estos datos en una tabla de frecuencias especificando frecuencias, frecuencias porcentuales, frecuencias relativas y frecuencias porcentuales y relativas acumuladas.b) Grafique la tabla en un gráfico de barras y en un gráfico sectorial.
102) En la tabla que sigue se recogen los pesos (en libras) de 40 estudiantes varones de una universidad.
138 164 150 132 144 125 149 157146 158 140 147 136 148 152 144168 126 138 176 163 199 154 165146 173 142 147 135 153 140 135161 145 135 142 150 156 145 128
a) Construir una tabla de distribución de frecuencias.
103) Un grupo de niños de 8 años de edad obtuvo los siguientes puntajes en el test de las matrices Progresivas de Raven.
43 40 38 33 32 41 32 37 44 46 40 8 31 4833 33 41 39 19 50 38 29 38 37 44 31 36 3442 31 42 40 40 44 45 36 10 39 44 32 27 4032 49 43 29 26 24 20 39 33 41 13 24 9 2223 23 34 44 21 25 28 34 18 36 36 27 34 2135 18 41 28 49 30 37 26 21 26 31 44 43 3341 12 35 20 38 32 25 36 41 18 25 25 30 2432 49 43 29 26 24 20 39 33 41 13 24 9 2218 36 32 38
a) Elabore una tabla de distribución de frecuencias con intervalos = 5. Indique las frecuencias y las frecuencias acumuladas relativas.b) Elabore una tabla de distribución de frecuencias con intervalos = 10. Indique las frecuencias y las frecuencias acumuladas relativas.
Página 262 de 314
262

104) Dada la siguiente tabla de frecuencias:
x (edad) f18-20 721-23 424-26 227-29 430-32 133-35 2
20
a) Obtenga las frecuencias porcentuales, las frecuencias acumuladas (crecientes y decrecientes), las porcentuales acumuladas (crecientes y decrecientes) y las frecuencias relativas. Agregue columnas para incluirlas.
105) Dada la siguiente tabla de frecuencias:
x f70-77 478-85 486-93 294-101 3102-109 3
n=16
a) Obtenga las frecuencias relativas, las frecuencias porcentuales, las frecuencias relativas acumuladas, las frecuencias porcentuales acumuladas y los puntos medios de cada intervalo. Agregue columnas para incluir todo.
106) Dada la siguiente tabla de frecuencias:
x (peso en libras) f118-126 3127-135 5136-144 19145-153 12154-162 5163-171 4172-180 2
n=50
a) Obtenga las frecuencias acumuladas y las frecuencias acumuladas porcentuales. Agregue columnas para incluirlas.
107) Dados los siguientes datos:
61 34 34 19 8451 51 61 34 1951 19 19 19 3451 34 34 51 34
a) Ordenar los datos en una tabla de frecuencias sin intervalos.b) Calcular la media aritmética, el modo y la mediana.
108) A partir de la siguiente matriz de datos:
Alumnos X (edad)AbelOscarElenaMartínJuanLuisMaría
292417551776
Página 263 de 314
263

PepeMartaLucíaFabiánInésGabrielaCarolina
42252517552525
N=14
a) Construir una tabla de frecuencias.b) Construir una tabla de frecuencias por intervalos de tamaño 5.c) Dibujar un gráfico de barras.d) Obtenga la media aritmética y el desvío estándar.
109) Calcular la media aritmética, la mediana, el modo y el desvío estándar para las siguientes series de datos:
a) 11-5-8-4-13-7-14-13-6b) 11-5-8-4-13-7-95-13-6c) 42 44 45 47 48 52 53 55 56 58d) 2 3 5 8 9 91 92 95 97 98e) 103-105-98-89-110-117-120f) 17-20-22-18-19-27-45g) 70-62-80-55-93h) 4-7-7-8-9-10-11-13i) La serie de datos de la siguiente tabla:
x f100-149 20150-199 48200-249 80250-299 36300-349 16
n = 200
j) La serie de datos de la siguiente tabla:
x f40-42 243-45 1046-48 2549-51 852-54 5
n = 50
110) Calcular el modo y la mediana en la siguiente distribución:
Nivel de instrucción fPrimario 4Secundario 8Universitario 5
n=17
111) Calcular el modo y la mediana en la siguiente distribución:
Estímulo f f%Visual 20 40Auditivo 12 24Olfativo 8 16Mecánico 10 20
50 100
112) Calcular el cuartil 1, el decil 7 y el percentil 88 para la siguiente distribución de frecuencias:
x (edad) f15-16 61
Página 264 de 314
264

17-18 11819-20 30
n = 209
113) Responder las siguientes preguntas:
a) ¿Qué cuartil, qué decil y qué percentil coinciden con la mediana?b) ¿Qué percentil corresponde al Q3?
114) Calcular la media aritmética, la mediana, el modo y el desvío estándar en las siguientes distribuciones:
a)
X (edad) f x.f12 10 12013 12 15614 14 19615 16 24016 12 19217 12 20418 4 72
80 1180
b)
X f Xm Xm . f0-2 1 1 12-4 3 3 94-6 6 5 306-8 7 7 498-10 3 9 27
20 116
c)
X f X . f
3 4 124 6 245 7 356 3 18
20 89
115) Para hacer un perfume se requieren 360 horas de mano de obra no calificada, 120 horas de semicalificada y 60 horas de calificada, siendo los salarios por categoría los siguientes: 10$ la hora, 20$ la hora y 30$ la hora, respectivamente.
x f x.f10
360 3600
20
120 2400
30
60 1800
N = 540 7800
a) Cuál es el salario medio horario de todos lo operarios?
116) Dada la siguiente información, obtenga las frecuencias relativas y decida en función de ellas si fueron los hombres o las mujeres quienes proporcionalmente votaron más por el candidato A:
Cuadro I – Voto femenino
Candidato fCandidato A 300
Página 265 de 314
265

Candidato B 230En blanco 10Total 540
Cuadro II – Voto masculino
Candidato fCandidato A 300Candidato B 190En blanco 270Total 760
117) Calcular gráficamente el modo (mediante un histograma) y la mediana (mediante una ojiva) de la siguiente distribución:
x (edad) f f ac18-20 6 621-23 4 1024-26 4 1427-29 2 16
n=16
118) En una muestra de 800 escolares se desea saber qué número de orden tiene aquel que por su puntaje obtuvo el percentil 60. Indique a qué número de escolares supera y por cuántos es superado.
119) Responda las siguientes preguntas:
a) Cuál es el percentil que coincide con el decil 7?b) Cuál es el percentil que coincide con el decil 8?
120) En base a los siguientes datos, construya una tabla de distribución de frecuencias para cada una de las tres variables, indicando en cada una, la frecuencia (f), la frecuencia acumulada (f.ac.), la frecuencia porcentual (f %), y la frecuencia porcentual acumulada (f.ac. %). Para la variable intervalar utilice intervalos de amplitud 3.
Alumno Edad
Religión Clase social
1 19 católica alta2 22 judía media3 21 protestante baja4 22 judía media5 21 católica media6 26 judía alta7 20 católica media8 19 católica baja9 19 protestante media10 21 judía baja11 21 católica media12 23 judía media13 23 católica media14 20 protestante baja15 21 protestante alta16 24 católica alta17 26 católica baja18 25 judía media19 19 católica media20 24 musulman
amedia
21 21 judía alta22 27 judía media23 23 católica media24 20 católica media25 21 protestante alta
Página 266 de 314
266

121) Obtenga los números de proporción de las siguientes tablas, y sobre esa base indicar cuál de ambos grupos de alumnos tiene mayor proporción de aprobados:
f (grupo A) f (grupo B)Aprobados 200 350Reprobado
s90 480
Total 290 830
122) Una comisión integrada por profesionales de la salud, de la educación y padres, de una pequeña localidad del interior, está interesada en conocer el nivel de consumo de alcohol en sus adolescentes. Para ello llevaron a cabo una encuesta anónima a 10 varones y 10 mujeres elegidos al azar de distintas zonas de la localidad. Se los interrogaba sobre la cantidad y tipo de bebida alcohólica que consumían aproximadamente por semana durante el verano. Luego se convertían a cantidad neta de alcohol etílico.A continuación se exhibe la lista donde se registra para cada sujeto el número de encuestado, sexo y cantidad aproximada de alcohol consumida semanalmente durante el verano.(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
Código
Género
Consumo semanal de alcohol en litros
1 f 0,22 f 0,063 m 0,484 f 05 m 0,0756 f 0,147 f 0,18 m 0,449 m 0.4210 m 0,711 f 0,0412 f 013 f 0,114 m 0,315 m 0,516 f 0,0517 m 0.4818 f 0,02519 m 020 m 0.45
a) ¿Cuál es la población de individuos y cuál la de observaciones?b) ¿Quiénes constituyen la muestra de individuos y quiénes la de observaciones?c) Menciones la variable de interés y clasifíquela.d) Mencione qué nivel de medición se utilizó e indique los valores de la escala. e) Indique la posible fuente sistemática que provoque variaciones previsibles en la cantidad de alcohol consumida por los adolescentes.f) Ordene la información dada de manera que aparezca exhibida dicha fuente sistemática.g) Enuncie posibles fuentes fortuitas de variación y distinga entre ellas las que son susceptibles de ser estudiadas como sistemáticas.
123) Enuncie algunas fuentes de variación que puedan afectar la calificación en el parcial de estadísticas y distinga las que son susceptibles de ser estudiadas como sistemáticas, Explique cómo exhibiría la información si quisiera mostrar que la asistencia a las teorías es una fuente sistemática de variación.(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
124) Un equipo de psicopedagogos desea estudiar las habilidades adquiridas en el aprendizaje escolar de la lectoescritura mediante una prueba de rendimiento (en la escala usual de 1 a 10) y el nivel de agresividad (bajo, normal, alto) de niños provenientes de hogares carecientes del gran Buenos Aires.Determine la población, las unidades, las características a estudiar y su nivel de medición, las variables estadísticas, su clasificación y sus valores.
Página 267 de 314
267

(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
125) Clasificar las siguientes variables e indicar el nivel de medición de las escalas adoptadas.a) Calificación de 8 individuos de un grupo según su posición en rendimiento: 1 al de mayor rendimiento, 8 al de menor rendimiento.b) Psicodiagnóstico correspondiente a un paciente según los cuadros clínicos (neurosis, psicosis, etc.).c) Nacionalidad del sujeto.d) Cantidad de palabras correctamente leídas por un disléxico en un minuto.e) Cociente intelectual. (Binet-Stern).f) Tiempo que tarda un alumno de Psicología en concluir su carrera.g) Temperatura en grados centígrados en Capital Federal a las 0 horas.h) Orden de mérito obtenido por un aspirante en un concurso.i) Edad de una persona.(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
126) Para comparar la eficiencia de un método de autoinstrucción con el tradicional en la enseñanza del tema “Prueba de hipótesis” se han elegido al azar 40 alumnos de la cátedra 1 de estadística del primer cuatrimestre de 1993. Fueron asignados aleatoriamente 20 a cada modalidad de enseñanza. Los resultados de su posterior evaluación son:(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
Número de alumnos
Clasificación
Método tradicional
Método de autoinstrucción
3 1 14 5 15 7 16 4 27 3 78 59 310 1
a) Lea la información de la tabla.b) Determine quiénes constituyen la población y quiénes la muestra de individuos y de observaciones.c) Mencione la variable estadística y clasifíquela.d) ¿Observa alguna tendencia en las observaciones que den cuenta de la existencia de una fuente sistemática devariación? ¿Cuál?e) ¿Todas las calificaciones obtenidas bajo el método de autoinstrucción fueron mayores que las obtenidas bajo elmétodo tradicional? ¿A qué atribuye esto?f) Mencione posibles fuentes fortuitas de variación que afecten la calificación.g) Explique a partir de d) y e) por qué se acudió a una serie de observaciones en cada grupo para compararlos en lugar de usar un solo representante de cada grupo.
127) Los datos de este ejercicio fueron obtenidos de un largo estudio por Mr. Joseph Raffaele, de la Universidad de Pittsburg, para analizar la comprensión lectora (C) y la rapidez lectora (R), usando los puntajes obtenidos en los subtests del IOWA, TEST OF BASIC SKILLS. Después de seleccionar aleatoriamente 30 estudiantes y dividirlos al azar en 6 submuestras de tamaño 5, los grupos fueron asignados aleatoriamente a dos tratamientos (clases abreviadas y clases no abreviadas) y tres maestros. Los datos son:(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
Maestro 1
Clases abreviadas
Clases no abreviadas
R C R C10 21 9 1412 22 8 159 19 11 1610 21 9 1714 23 9 1711 23 11 15
Página 268 de 314
268

Maestro 2
14 27 12 1813 24 10 1615 26 9 1714 24 9 18
Maestro 3
8 17 9 227 15 8 1810 18 10 178 17 9 197 19 8 19
a) Indique cuáles son las posibles fuentes sistemáticas de variación.b) Mencione las características a estudiar, su nivel de medición, las variables estadísticas y su clasificación.c) Menciones posibles fuentes fortuitas de variación.
128) Ejercicio para reflexionar y discutir en conjunto. En una revista se publicó un test para la autoevaluación de la actitud solidaria. Consistía en 40 ítems con dos opciones:Una corresponde a una actitud solidaria y la otra no. El puntaje que se autoasigna el individuo corresponde a la cantidad de respuestas que denotan una actitud solidaria.Suponiendo que Enrique, Luis y Matías, hayan obtenido 30 puntos, 40 puntos y 20 puntos respectivamente (y hayan sido totalmente honestos consigo mismos):(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
a) Responda justificando las respuestas ¿Considera que tiene sentido afirmar que…a1) …la actitud solidaria de Enrique difiere de la de Luis en la misma medida que difiere de la actitud solidaria de Matías?a2) … Luis es el doble de solidario que Matías?b) Menciones la característica objeto de estudio, su nivel de medición, el instrumento de medición y la variable estadística.
129) Al registrarse el puntaje de 5 sujetos en una prueba de razonamiento lógico y el tiempo empleado para resolverla se obtuvieron las siguientes observaciones apareadas:(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
Puntaje X (sobre un total de 20): 15 13
20 15 18
Tiempo Y (en minutos: 60 55
68 50 65
Verificar si son iguales o no las siguientes expresiones. En caso de ser iguales decidir si lo son para cualquier conjunto de observaciones.
a) å x i y åx i i i =
b) å yi y å yi
i = i =
c) å xi yi y å xi å y i = 1 i = 1
130) Los siguientes resultados fueron expresados mediante un diagrama circular, y se refieren a una encuesta de opinión llevada a cabo sobre 510 personas de Capital Federal y Gran Buenos Aires (Clarín, 9/1/94):(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
“Cómo quieren ser gobernados los argentinos”46% Presidente controlado por el Congreso.24% Presidente con amplios poderes de decisión.20% Presidente acompañado por un Primer Ministro.10% No sabe / No contesta.Fuente: Estudio Graciela Romer y Asociados.
Página 269 de 314
269

a) Menciones la variable y sus valores.b) ¿Está de acuerdo con el título del recuadro?c) Indique qué ángulo corresponde a cada sector.d) ¿Cuántas personas sustentan cada opinión?
131) A partir de los datos de la siguiente tabla (Clarín, 9/1/94)(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
¿QUIÉN DEBE DESTITUIR AL JEFE DE GABINETE?Según voto para diputados 1993. En porcentajes
La Cámara de Diputados
La Asamblea Legislativa
El Presidente N/SN/C
PJ 21 19 35 25UCR 22 31 12 23
MODIN 47 16 11 26FRENTE GRANDE 38 51 5 5U. SOCIALISTA 40 20 20 20
TOTAL 27 27 21 25FUENTE: Estudio Graciela Römer y Asociados
a) Mencione la variable y la fuente sistemática de variación.b) Confecciones un diagrama circular para la distribución de frecuencias sobre el total de encuestados.c) Elija un diagrama para comparar las opiniones de los votantes de PJ con los de la UCR.
132) En cierta comisión de Estadística la media de las calificaciones del primer parcial fue de 6 para las mujeres y de 5 para los varones. Calcular la media de todas las calificaciones de dicha comisión sabiendo que corresponden a 20 mujeres y 10 varones.(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
133) En una empresa el personal está categorizado según se indica a continuación:(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
Categorías
Salario Número de empleados
1 $ 300 122 $ 500 313 $ 700 274 $ 1.200 75 $ 2.000 46 $ 4.000 27 $ 6.000 3
a) Calcule la mediana de las categorías.b) Calcule la mediana y la media del sueldo.c) Si quisiera representar la escala salarial de la empresa ¿cuál de las dos medidas utilizaría en caso de ser i) sindicalista?, ii) directivo?, iii) economista objetivo?
134) Una muestra de 100 personas adultas alcanza en la variable:X = “Peso” un desvío estándar de 25 Kg. Y en la variable Y = “Estatura” un desvío estándar de 0,15 m.¿Podemos afirmar que la variabilidad en este grupo es mayor en la variable X que en la variable Y? Justifique la respuesta.(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001). (Adaptación de Botella 5.4.9 - Página 144).
135) Una muestra de 100 varones obtiene una media de 14 y una varianza de 16 en la variable X = “Cantidad de respuestas correctas” referidas a 20 preguntas de un cuestionario sobre fútbol; mientras que una muestra de 100 mujeres obtiene una media de 7 y una varianza de 9 en la misma variable. ¿Podemos afirmar que los varones varían más que las mujeres en dicha variable? Justifique la respuesta.(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001). (Adaptación de Botella 5.4.10 - Página 144).
136) Los alumnos de una comisión de Escuela Francesa obtuvieron las calificaciones que se muestran en las siguientes tablas:
Página 270 de 314
270

(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
FrecuenciaCalificació
n1º parcial 2º parcial
3 2 14 4 15 7 26 6 47 3 68 2 89 1 310 1 1
1. Gratifique ambas distribuciones de modo que puedan ser comparadas y responda sin hacer cálculos:a) ¿En qué parcial la comisión obtuvo mejor rendimiento?b) ¿Qué parcial discriminó mejor a los alumnos de mejor rendimiento? ¿Y a los de peor rendimiento? ¿Cómo debería ser la forma de la distribución para discriminar por igual a los alumnos de mejor y peor rendimiento? Explique la vinculación entre el tipo de asimetría de la distribución de los puntajes y el efecto discriminatorio de la prueba.2. Cuantifique la asimetría de Pearson y la curtosis en ambas distribuciones y compárelas. (Use la calculadora y aproxime la media y el desvío a un decimal para facilitar los cálculos).
137) En su artículo “La estadística al servicio de la evaluación en pruebas de rendimiento”, la Licenciada Floralba Cano de Becerra aconseja tomar pruebas que produzcan puntajes con asimetría positiva al inicio del curso y asimetría negativa en los exámenes finales. ¿Sobre qué criterio se apoya esta sugerencia?(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
138) En un centro de psicopedagogía clínica, 20 niños disléxicos recibirán el mismo tratamiento de los terapeutas A y B. Cada uno atenderá a 10 de ellos. Al final del tratamiento se les toma un test cuyos mayores puntajes están vinculados a mayor cantidad de palabras incorrectamente leídas. Los resultados obtenidos por ambos terapeutas son resumidos a continuación:(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
Terapeuta APuntaje Frecuenci
a3 44 15 36 17 1
Terapeuta B
x = SMdn = 5,5
Mo = 7S = 1, 44CV = 24
Basándose en los resúmenes adecuados responda:a) ¿Qué grupo obtuvo mejores resultados en el test?b) ¿Puede afirmarse que el terapeuta A es más eficiente que el terapeuta B? Justifique.
139) Con el fin de decidir entre dos propuestas publicitarias A y B de cierto producto destinado a los adolescentes de Capital Federal, se eligieron 120 de ellos aleatoriamente, los que fueron divididos, también al azar, en dos grupos de 60. Cada grupo vio solo un tipo de propuesta y después debió asignar a la marca del producto una posición en el ranking entre las otras marcas competidoras.(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).Los resultados obtenidos fueron:
Página 271 de 314
271

Número de sujetosRankin
gPropuesta A Propuesta B
1 29 122 20 183 11 30
a) i) Indique quiénes constituyen la población de individuos y quiénes la muestra de individuos. ii) Determine quiénes constituyen las poblaciones de observaciones (¿Son reales o hipotéticas?) y quiénes las muestras de observaciones. b) Menciones la variable estadística, clasifíquela e indique el nivel de medición utilizado.c) ¿Observa alguna tendencia en las observaciones que den cuenta de la existencia de una fuente sistemática de variación? En caso afirmativo explique dicha tendencia y menciones la fuente sistemática de variación.d) Represente con un diagrama adecuado la distribución de frecuencias porcentuales correspondientes al ranking asignado al producto, sin discriminar el tipo de propuesta publicitaria.e) ¿Qué porcentaje de sujetos no le asignó el primer lugar en el ranking a la marca en cuestión?
140) Los siguientes datos corresponden a la cantidad de errores cometidos por un niño disléxico en la lectura de 15 párrafos breves de diferentes textos.(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
3_4_7_3_4_5_3_4_6_5_2_1_2_4_5
a) Presente la información en una tabla de frecuencias absolutas y calcule las medidas de tendencia central, los cuartiles, el desvío estándar y los índices de asimetría y curtosis.b) ¿En qué porcentaje de ocasiones el niño cometió como máximo cuatro errores?
141) Una agencia de viajes cordobesa está interesada en conocer la frecuencia anual de viajes a países limítrofes de ejecutivos de la pequeña y mediana empresa de la ciudad de Córdoba durante el último año. Para ello toma una muestra aleatoria de 30 ejecutivos de la primera y 15 de la segunda y obtiene los resultados que siguen:(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
Número de ejecutivosNúmero de viajes Pequeña
empresaMediana empresa
0 6 -1 10 42 7 23 4 34 2 35 - 26 - 17 1 -
a) i) Indique quiénes constituyen la población de individuos y quiénes la muestra de individuos. ii) Determine quiénes constituyen las poblaciones de observaciones (¿Son reales o hipotéticas?) y quiénes las muestras de observaciones. b) Menciones la variable estadística, clasifíquela e indique el nivel de medición utilizado.c) Explique qué tendencia siguen las observaciones que da cuenta de la existencia de una fuente sistemática de variación y menciones dicha fuente. ¿Todas las observaciones responden a lo previsto? ¿A qué se atribuye esto?. Explique.d) Represente en un solo gráfico la distribución de frecuencias para cada tipo de empresa de modo que puedan ser comparadas.e) ¿Qué porcentajes de sujetos realizó por lo menos dos viajes en el último año?
142) A continuación presentamos una tabla con la distribución de frecuencias de las calificaciones finales en lengua de niños de 7º grado del turno mañana y también algunos resúmenes estadísticos correspondientes al turno tarde.(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
TURNO MAÑANACalificación Frecuenci
Página 272 de 314
272

a0,5___2,5 12,5___4,5 24,5___6,5 86,5___8,5 7
8,5___10,5 2
TURNO TARDEx = 5,01s = 1,86Md = 5,4n = 25
a) ¿Qué grupo parece haber tenido mayor rendimiento? ¿Por qué?b) ¿En qué grupo hay mayor variabilidad relativa a la media?
EJERCICIOS DE PROBABILIDAD
201) Responder los siguientes problemas de teoría de la probabilidad:
a) ¿Qué probabilidad hay, al arrojar un dado, que salga 5 o un número mayor?b) ¿Qué probabilidad hay, al arrojar un dado, que salga un número par?c) ¿Qué probabilidad hay, al arrojar un dado, que salga menos de 3?d) ¿Qué probabilidad hay de sacar un rey de un mazo de 40 cartas?e) ¿Qué probabilidad hay, al arrojar un dado, que salga mayor de 7?f) ¿Qué probabilidad hay, al arrojar un dado, que salga un número entre 1 y 6?g) ¿Qué probabilidad hay, al arrojar un dado, que no salga el número 5?h) ¿Qué probabilidad hay de no sacar un corazón de un mazo de 52 cartas francesas?
202) Responder los siguientes problemas de teoría de la probabilidad:
a) ¿Qué probabilidad hay de sacar dos caras arrojando dos monedas?b) ¿Qué probabilidad hay de sacar con un tiro de dos monedas, dos caras o dos cecas indistintamente?c) Se arroja una moneda y un dado. ¿Qué probabilidad hay de obtener una cara y un 3?d) ¿Qué probabilidad hay, al arrojar dos dados, de obtener dos 5?e) ¿Qué probabilidad hay, al arrojar dos dados, de obtener al menos un 5?f) ¿Qué probabilidad hay, al arrojar dos dados, de obtener dos números iguales?g) ¿Qué probabilidad hay, al arrojar dos dados, de obtener un número par y otro impar?h) ¿Qué probabilidad hay, al arrojar dos dados, de obtener dos números cuya suma sea 10?i) De un mazo de 40 cartas, cual es la probabilidad de sacar tres cartas que sean tres espadas, sin reposición?j) De un mazo de 40 cartas, cual es la probabilidad de sacar tres cartas que sean tres espadas, con reposición?k) Un bolillero contiene 7 bolillas rojas y 3 azules. Se sacan dos bolillas sucesivamente sin reposición. Calcular la probabilidad de que ambas sean rojas.l) Un bolillero contiene 7 bolillas rojas y 3 azules. Se sacan dos bolillas sucesivamente con reposición. Calcular la probabilidad de que ambas sean rojas.
203) En una muestra de 380 personas, hay varones y mujeres con ojos claros y oscuros según las siguientes cantidades:
Ojos claros Ojos oscuros Total
Varones
60 170 230
Mujeres 100 50 150Total 160 220 380
a) Al elegir una persona al azar, qué probabilidad tiene de ser mujer o tener ojos claros, indistintamente?b) Qué probabilidad tiene de ser mujer o de tener ojos claros, pero no ambas cosas?c) Qué probabilidad tiene de ser un varón de ojos claros?d) Sabiendo que la persona elegida es varón, ¿qué probabilidad tiene de tener ojos oscuros?
204) Responder los siguientes problemas de análisis combinatorio (variaciones):
Página 273 de 314
273

a) ¿De cuántas maneras distintas pueden ubicarse 6 personas en el primer asiento de dos personas de un ómnibus?b) ¿Cuántos números distintos de 3 cifras pueden formarse con los números del 1 al 9 sin repetir ninguno de ellos?c) En la pregunta anterior, ¿cuántos de esos números son mayores que 900?
205) Responder los siguientes problemas de análisis combinatorio (permutaciones):
a) ¿Cuántos números distintos de 9 cifras pueden formarse con los números del 1 al 9 sin repetir ninguno de ellos?b) ¿Si recibimos 7 cartas de un mazo, de cuántas formas podemos ordenarlas en la mano?c) ¿Cuantos anagramas se pueden formar con las letras de la palabra ARTE?d) ¿De cuantas maneras puede sacarse una foto una familia de 6 personas de frente?e) En el ejercicio anterior, ¿de cuantas maneras el padre y la madre aparecen juntos?
206) Responder los siguientes problemas de análisis combinatorio (experimento binomial):
a) ¿Cuál es la probabilidad de obtener dos ases tirando el dado 3 veces?b) En una urna hay 7 bolillas blancas y 5 negras. Se sacan sucesivamente 3 bolillas con reposición. ¿Cuál es la probabilidad de que salgan 2 bolillas blancas?c) En un bolso hay dos monedas de plata y tres de oro. Se realizan 5 extracciones. ¿Cuál es la probabilidad de sacar tres veces monedas de plata?d) El 30% de los estudiantes se opone a pagar una cuota. Tomando 25 estudiantes, calcular la probabilidad que aparezcan 5 estudiantes que se opongan a pagar la cuota.
207) Sabiendo Por experiencias previas que el 70 % de los alumnos de Psicología de la UBA promociona Estadística y suponiendo que esta proporción se mantenga el presente cuatrimestre, calcule la probabilidad de que en una muestra aleatoria de 10 alumnos:(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
a) Por lo menos uno no promocione.b) No promocionen cinco.c) Promocionen por lo menos la mitad.d) No promocionen a lo sumo dos.e) Promocionen más de cuatro y menos de ocho.
208) Una prueba de percepción visual consiste en responder a cuál de dos matices, previamente presentados, corresponde el color verde que aparece sucesivamente en 12 estampados diferentes. El resultado de la prueba se considera “muy satisfactorio” cuando se ha respondido acertadamente en, por lo menos, 9 de las 12 presentaciones.En prácticas previas un sujeto ha logrado acertar el 80 % de las presentaciones. ¿Cuál es la probabilidad de que al realizar la pruebaa) obtenga el resultado “muy satisfactorio”b) no obtenga el resultado “muy satisfactorio” suponiendo que contestó completamente al azar en todos los casos?(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
209) Gastón se recibió recientemente de psicólogo y va a abrir un consultorio pero no se siente muy seguro en la atención de casos con síndrome de depresión. Consultando entre sus colegas obtuvo la siguiente información:
Consulta A Consulta B Consulta C Consulta DCasos con síndrome de depresión
3 5 15 7
Total de pacientes 30 55 135 80
En el hipotético caso que al consultorio de Gastón acudieron 9 pacientes ¿qué probabilidad le asignaría al hecho de que:a) Alguno tenga síndrome de depresión?b) Más de la mitad no tenga síndrome de depresión?(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
210) En cierta región de una provincia argentina Ignacio (sociólogo) y Lucía (maestra) están estudiando el fenómeno de la deserción escolar a nivel primario. De una encuesta del último año a varias escuelas obtuvieron la siguiente información:
Página 274 de 314
274

Causas de deserción Número de casos
Necesidad de trabajar 180Distancia a la escuela 40
Enfermedad 55Dificultades intelectuales
20
Otros 5
Habiendo iniciado el año lectivo en dichas escuelas un total de 6.000 alumnos.Ignacio se pregunta qué probabilidad tendrá de que entre 12 niños que abandonen la escuela en año entrante, más de la tercera parte lo haga debido a la necesidad de trabajar.Lucía se pregunta con qué probabilidad concluirá el año conservando a sus 15 alumnos.Suponiendo que el año entrante tenga un comportamiento similar al anterior con respecto al fenómeno de la deserción, responda aa) Ignaciob) Lucía(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
211) Sabiendo por experiencia que sólo 4 de cada 10 personas que comienzan un determinado tratamiento perseveran en él: ¿Cuál es la probabilidad de que una muestra aleatoria de 8 personas que comienzan un tratamiento…?a) ¿Persevere más de la mitad?b) ¿Persevere por lo menos uno?c) ¿No persevere a lo sumo la mitad?(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
) Una investigación sobre la puntualidad del personal llevada a cabo sobre 3 empresas que se consideran representativas en determinada ciudad arrojó los siguientes resultados:(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
Empresa A Empresa B Empresa CImpuntuales 30 14 19
Puntuales 68 38 41
Una empresa de la misma ciudad va a contratar 5 nuevos empleados. ¿Qué probabilidad le asigna al hecho de que…?a) ¿Todos sean puntuales?b) ¿A lo sumo dos sean impuntuales?c) ¿Por lo menos uno sea puntual?
EJERCICIOS DE CURVA NORMAL
301) En una distribución normal de puntajes de una prueba, un alumno obtuvo 19 puntos. Si la media de la distribución es de 20 puntos y el desvío estándar es de 2 puntos, ¿qué percentil le corresponde?
302) En una distribución normal de puntajes de una prueba un alumno x obtuvo el percentil 80. Si la media de la distribución es de 30 puntos y el desvío estándar es de 2 puntos, ¿qué puntaje obtuvo en la prueba?
303) El puntaje obtenido en un test de aprendizaje de una población de adolescentes es aproximadamente normal, con media 80 y desvío estándar 5.
a) Debe hacerse una clasificación en tres categorías:
A = constituida por el 20% de los puntajes bajos.B = constituida por el 10% de los puntajes altos.C = constituida por el resto (70%).
Hallar los puntajes brutos que separan las tres categorías.
b) Si el tamaño de la población es n = 3000, ¿cuántos adolescentes estarán por debajo del puntaje 86?c) Qué percentil corresponde al puntaje 82?
Página 275 de 314
275

d) Qué valor de z corresponde al percentil 78?
304) En un test de aptitud para las matemáticas cuyos puntajes se distribuyen normalmente con media aritmética 5 y desvío estándar 1.5, un individuo obtuvo 4 puntos. En un test de aptitud para idiomas cuyos puntajes se distribuyen normalmente con media aritmética 6 y desvío estándar 2, el mismo individuo obtuvo 4.5 puntos.
a) En cual de las dos pruebas demostró mayor aptitud?b) Qué porcentaje de alumnos obtuvo hasta 4 puntos en matemáticas?c) Hasta qué puntaje obtuvo el 80% inferior de los casos en matemáticas?
305) Para una media aritmética 30 y un desvío estándar 5, ¿cuál es el valor de x que corresponde al 20% de los mejores dotados?
306) Utilizando la distribución normal, calcular:
a) ¿Hasta qué valor de z habrá que incluir para considerar los 2000 inferiores de un total de 2500?b) ¿Desde qué valor de z habrá que tomar, si se quieren incluir los 900 casos superiores sobre un total de 1000?c) Sobre un total de 2000 se quieren tomar los 1900 centrales. ¿Qué valores de z los limitan?
307) El puntaje T de Esteban en un test de creatividad es de 70 y su puntaje z en otro de memoria es de 2,5. Tomando como referencia a los grupos normativos ¿es Esteban más creativo que memorioso o al revés? Justifique.(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
308) Suponiendo que los puntajes en una prueba de razonamiento verbal se distribuyen con media 12 y desvío estándar 3 en un grupo normativo, calcule:
a) El rango percentilar de un sujeto que obtiene 14 puntos.b) El puntaje correspondiente al sujeto que es superado por el 90 % del grupo.c) El centil 95.(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
309) Para ingresar a cierta universidad se debe rendir un examen de ingreso y solo hay cupo para el 20 % de los aspirantes. Suponiendo que los puntajes se distribuyan normalmente en el grupo de aspirantes con media 60 y desviación estándar 15 ¿Qué nota mínima de aprobación debe fijarse?(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
310) Los puntajes en un test de creatividad se distribuyen normalmente con media 65 y desvío estándar 10 puntos en un grupo normativo de 600 personas. Los sujetos se consideran según los siguientes criterios:Poco creativos si exceden dos desvíos por debajo de la media.Algo creativos si están a menos de dos desvíos por debajo de la media.Creativos si están a menos de dos desvíos pon encima de la media. Muy creativos si están en más de dos desvíos por encima de la media.Calcule:a) La cantidad de individuos del grupo normativo correspondiente a cada categoría.b) El puntaje de los individuos que pertenecen al 2 % más creativo.c) Cómo es clasificado un sujeto que obtuvo 80 puntos.d) El puntaje correspondiente al tercer centil.(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
311) Un peso inferior al kilo o superior a los cuatro kilos al nacer, puede considerarse riesgoso en una población determinada. Suponiendo que los pesos se distribuyan normalmente en los recién nacidos con media 2,8 y desvío 0,6 kilogramos, calcule la probabilidad de que un recién nacido.a) Está dentro del grupo de riesgob) Pese entre 2 y 3 kilogramos.(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
EJERCICIOS DE CORRELACIÓN Y REGRESIÓN
Página 276 de 314
276

401) Dados los siguientes pares de valores:
x 1 2 3 4 5 6 7 8y 14 14 13 12 12 10 9 9
a) Obtener el coeficiente de correlación e interpretarlo.b) Hacer el diagrama de dispersión e interpretarlo.c) Calcular el valor de y1 para x1 = 12d) Trazar la recta de regresión.
402) Dados los siguientes tres grupos de pares de valores:
x y x y x y56 5
929 2 9
535
48 72
25 8 89
14
40 65
18 5 82
26
30 62
17 7 80
37
29 40
12 14 74
39
25 36
10 24 66
27
a) Graficar los diagramas de dispersión y estimar aproximadamente la correlación existente en cada uno.b) Calcular los tres coeficientes de correlación de Pearson, eligiendo la fórmula más adecuada.c) Comparar los resultados obtenidos con las estimaciones hechas en el punto a).
403) Los siguientes valores corresponden a la edad del esposo y la esposa en 5 matrimonios:
x 25
42 30
54 62
y 19
35 29
53 61
a) Obtener el coeficiente de correlación y determinar en base a él si la correlación es positiva o negativa, y si es alta o baja.b) Obtener el diagrama de dispersión correspondiente.c) Calcular el valor de Y 1 para X 1 = 45.d) Trazar la recta de regresión correspondiente.
404) Se ha tomado una prueba de aptitud numérica y verbal a 6 niños, siendo los puntajes obtenidos los siguientes:
Sujeto A B C D E FAptitud Numérica
14
9 25
34 15
23
Aptitud verbal 18
7 23
32 19
21
a) Obtener el coeficiente de correlación y determinar en base a él si la correlación es positiva o negativa, y si es alta o baja.b) Obtener el diagrama de dispersión correspondientec) Calcular el valor Y 1 para X 1 = 6.d) Trazar la recta de regresión correspondiente.
405) Dados los siguientes pares de valores:
x 1 2 3 4 5 6 7 8y 14 14 13 12 12 10 9 9
a) Obtener el coeficiente de correlación y determinar en base a él si la correlación es positiva o negativa, y si es alta o baja.b) Obtener el diagrama de dispersión correspondiente.c) Calcular el valor Y 1 para X 1 = 12.
Página 277 de 314
277

d) Trazar la recta de regresión correspondiente.
406) Se desea saber si existe algún tipo de asociación entre razonamiento verbal y redacción. Para ello se tomaron 10 sujetos y se le tomaron dos pruebas a cada uno para las aptitudes específicas, obteniéndose los resultados indicados en la tabla adjunta. Aplicar el coeficiente de Pearson e interpretar el resultado.
SUJETO A B C D E F G H I JPUNTAJE X 50 52 46 47 47 54 51 4
444 45
PUNTAJE Y 49 45 47 49 43 48 51 46
42 40
407) Si se ha tomado una prueba de aptitud verbal y otra numérica, se desea saber si ambas variables están asociadas entre sí después de haberse obtenido los datos de la tabla adjunta. Calcule el coeficiente de Pearson e interprete el resultado.
SUJETO A B C D E FRENDIMIENTO EN APTITUD NUMÉRICA 14 9 25 3
415 23
RENDIMIENTO EN APTITUD VERBAL 18 7 23 32
19 21
408) La tabla adjunta presenta las notas obtenidas por 10 alumnos en los parciales de una materia.
a) Realizar el diagrama de dispersión.b) Indicar qué tipo de correlación hay leyendo solamente el diagrama. Justificar.
A B C D E F G H I Jx (primer parcial) 1 2 8 7 9 6 9 6 5 9y (segundo parcial) 2 4 9 7 8 5 9 8 4 9
409) Ocho sujetos fueron sometidos a una prueba de memoria. Debían memorizar una lista de 30 palabras en cierto tiempo estipulado, y los resultados se exponen en la tabla adjunta.
Sujeto Tiempo (en minutos) Número de palabras recordadas
A 2 12B 5 23C 7 26D 6 25E 4 21F 3 15G 1 8H 8 28
a) Construya el diagrama de dispersión, determinar si hay o no correlación y si ésta es directa o inversa. Justificar.
410) Para las tres tablas adjuntas:
X Y56 5948 7240 6530 6229 4025 36
X Y29 225 818 517 712 1410 24
Página 278 de 314
278

X Y95 3589 1482 2680 3773 3967 27
a) Hacer los diagramas de dispersión correspondientes.b) Determinar cuál de los tres casos tiene mayor correlación y cuál menor correlación (independientemente del signo), utilizando el coeficiente de Pearson.
411) Se suministra a diez alumnos una batería de tests para estudiar simultáneamente su rendimiento en distintas áreas, siendo los resultados los que figuran en la tabla adjunta.
ALUMNO
CI LECTURA MÚSICA FÍSICA
A 120 28 53 28B 108 32 48 25C 103 37 45 22D 100 41 44 19E 100 38 40 20F 96 15 36 15G 90 17 36 17H 86 28 31 15
a) Calcular las intercorrelaciones entre pares de variables y presentar los resultados en una matriz de correlación (utilice el coeficiente de Pearson).b) ¿En qué difiere este procedimiento del empleado con el coeficiente de correlación múltiple?
412) En un grupo de matrimonios el coeficiente de correlación entre las variables “edad del marido” y “edad de la esposa” fue de 0.96. Significa ello que en la mayor parte de los matrimonios considerados, marido y mujer, ¿son de una misma edad?
413) Se ha pedido a dos jueces que ordenen en forma independiente a seis sujetos en relación con su grado de peligrosidad. Los ordenamientos resultantes se indican en la tabla adjunta. Calcular la correlación existente entre ambos ordenamientos, utilizando el coeficiente Rho de Spearman.
Juez 1 F C E D A BJuez 2 C E F D B A
414) ¿Existe el mismo grado de correlación en las cuatro tablas siguientes? En caso negativo, ¿en cuál hay mayor correlación? (No utilizar ni gráficos ni fórmulas: solamente observar las tablas.).
X Y X Y X Y X Y1 1 1 6 1 2 1 162 2 2 7 2 4 2 143 3 3 8 3 6 3 124 4 4 9 4 8 4 105 5 5 10 5 10 5 86 6 6 11 6 12 6 67 7 7 12 7 14 7 48 8 8 13 8 16 8 2
415) Si un test es confiable se espera que arroje puntuaciones más o menos estables cuando es administrado a un mismo individuo en diferentes momentos pero en similares condiciones. Si así sucediera, la correlación lineal entre los puntajes de los individuos, la primera vez que fueron evaluados (test) y la segunda vez (retest), debería ser alta.(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).A continuación se exhibe un listado con los resultados obtenidos después de haber aplicado el método test-retest para estudiar la confiabilidad de una prueba de memoria.
a) Dibuje el diagrama de dispersión e indique qué sugiere en relación a la confiabilidad de la prueba.
Página 279 de 314
279

b) Mediante el uso de un coeficiente adecuado precise el análisis hecho en a) y decida si la prueba es o no confiable.
SUJETO PUNTAJE EN EL TEST PUNTAJE EN EL RETESTNéstor 10 7Ana María
6 9
Silvia 7 8Andrea 9 7Eduardo 6 10Liliana 6 8Gustavo 8 5Cristina 7 6Flavia 8 8Alejandro 4 6
EJERCICIOS DE ESTADÍSTICA INFERENCIAL
501) El rector de una universidad piensa que durante los últimos años, la edad promedio de los estudiantes que asisten a esta institución ha cambiado. Para probar dicha hipótesis, se realiza un experimento en el cual se mide la edad de 150 alumnos elegidos al azar entre todos los estudiantes de este centro de educación superior. La edad promedio es de 23.5 años. Un censo realizado en la universidad, unos cuantos años antes del experimento, reveló una edad promedio de 22.4 años, con una desviación estándar de 7.6 (Fuente: Pagano R., Estadística para las ciencias del comportamiento", International Thomson Editores, México, 1999, 5ta. edición, pág. 280).
a) Cuál es la hipótesis alternativa no direccional?b) Cuál es la hipótesis nula?c) Utilizando Alfa = 0.05, cuál es la conclusión?
502) Una muestra de 36 alumnos tiene una media de 7, mientras que el desvío poblacional es de 1. Determinar, para una probabilidad del 95%, el intervalo de confianza correspondiente.
503) El puntaje medio en un test de habilidad numérica es de 65 puntos en una población normativa cuya desviación típica es 10. Una muestra aleatoria de 9 sujetos extraída de dos divisiones de 6º grado de una escuela, arrojó una media de 60 puntos. Suponiendo que los puntajes en dichas divisiones se distribuyen de manera aproximadamente normal con la misma desviación que la población normativa, ¿hay suficiente evidencia de que el rendimiento medio de los niños de sexto grado es inferior al del grupo normativo? Usar un nivel de significación del 1 %.(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
504) El tiempo medio de reacción ante un determinado estímulo fue de 11 centésimas de segundo en una muestra de 16 personas. ¿Son estos datos consistentes con la hipótesis de que el tiempo de reacción se distribuye normalmente con media 10 y desvío 4 centésimos por segundo? Usar un nivel de significación del 10 %.(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
505) Un docente implementa un nuevo método didáctico para la enseñanza de un determinado tema que, él espera, aumentará en rendimiento medio de sus alumnos. Históricamente este era de 5,5 puntos. El resultado de la evaluación sobre sus 25 alumnos arrojó una media de 6,3 puntos con un desvío estándar de 2 puntos. ¿Puede afirmarse que el nuevo método fue eficaz? Usar un nivel de significación del 5 % y suponer que los puntajes se distribuyen normalmente.(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
506) Algunos trabajos sobre memoria icónica indican que el promedio de letras recordada por un sujeto normal es de 4,5. Los trabajos que se vienen realizando en la Universidad Autónoma de Madrid no están de acuerdo con tal hipótesis. Deseamos pues, contrastar la hipótesis de que = 4,5, para lo cual seleccionamos una muestra aleatoria simple de veinticinco sujetos universitarios, psicólogos de la Universidad Autónoma de Madrid, y encontramos que el promedio de palabras recordadas (tras exposición taquistoscópica) es de 3, con una
Página 280 de 314
280

desviación típica de 1,3. Utilizando = 0,01 realice la prueba correspondiente suponiendo la distribución normal de los puntajes.(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
507) Este ejercicio se refiere a datos reales extraídos de una investigación de Ayala y otros (1990), “Estimulación temprana: Su influencia sobre el desarrollo intelectual de niños de 2 a 4 años”, Avances en Psicología Clínica Latinoamericana, 8: 115-124 (1990).Para probar la eficacia de un programa de investigación temprana (P.E.T.) se suministró un test de CI a un grupo control y a un grupo experimental antes de iniciar el programa y después de un año de aplicación del mismo sobre el grupo experimental. Ambos grupos quedaron determinados por la asignación aleatoria de niños de 2 a 4 años que asisten al Hogar Infantil “Copetín” de la ciudad de Pamplona, Colombia.
I. Pruebe, al 1 %, las hipótesisa) El C.I, aumenta, en promedio, en los niños que reciben el P.E.T.b) No hay evidencias de que aumente el C.I. medio de los niños que no reciben el P.E.T.II. ¿Por qué es necesario usar un grupo control?
DATOSGRUPO CONTROLPre-test: 86, 135, 70, 98, 111, 109, 96, 92, 117, 142, 107, 103, 105, 116, 80.Post-test: 110, 112, 104, 106, 118, 103, 110, 129, 109, 117, 118, 102, 124, 121, 131.GRUPO EXPERIMENTALPre-test: 108, 125, 105, 111, 126, º105, 92, 90, 104, 87, 104, 104, 127, 102, 100.Post-test: 157, 147, 134, 138, 154, 127, 127, 129, 124, 132, 124, 133, 128, 144, 157.(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
508) Con el fin de estudiar el posible influjo del tipo de instrucciones en la ejecución de una prueba, se seleccionarán aleatoriamente trece sujetos. Se les suministra la prueba a cinco tras darles instrucciones breves y sencillas y al resto tras darles instrucciones largas y explícitas. A la vista e los resultados, compruebe, a un nivel de significación de 0,10, si las instrucciones influyen en el rendimiento en dicha prueba.(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
Grupo A (instrucciones breves): 1 3 6 7 8Grupo B (instrucciones largas): 3 5 6 5 8 9 8 4Realice el procedimiento explicitando los supuestos que lo hacen válido.
509) Se ha llevado a cabo un experimento para corroborar si los dibujos facilitan el aprendizaje de palabras en niños pequeños según sostiene cierta escuela pedagógica. Se seleccionó aleatoriamente veinte niños del último curso de preescolar para que aprendan palabras ilustradas con sencillos dibujos o para que las aprendan (las mismas palabras) sin ilustración. Se asignaron al azar diez sujetos a cada método. Tras varios ensayos se determinó el dominio sobre dichas palabras, midiendo el número de respuestas correctas de cada niño (Adaptado de un ejercicio de San Martín Castellanos).(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
a) Explicite los supuestos necesarios para probar estadísticamente la hipótesis. Justifique por qué se aleatorizó para formar los grupos.b) A la vista de los resultados que se siguen pruebe la hipótesis con un nivel de significación de 0,10.Grupo con ilustración: 10, 13, 19, 25, 22, 23, 21, 20, 17, 20.Grupo sin ilustración: 16, 17, 20, 11, 10, 12, 10, 11, 12, 13.
510) Se desea investigar si el nivel de estrés difiere entre las personas que desempeñan tareas ejecutivas y aquéllas que trabajan en relación de dependencia. Para ello se tomaron dos muestras aleatorias de 16 ejecutivos y 16 empleados y se les suministró un test de ansiedad. Por la manera en que se construyó la escala, los psicólogos consideran que para que una diferencia de puntajes en el nivel de estrés sea interpretable como una diferencia real en sí mismo, ésta debe ser superior a dos puntos. En otras palabras, el umbral es de dos puntos.Los resultados maestrales arrojaron un nivel de estrés de 55 puntos para los ejecutivos con un desvío estándar de 6 puntos y una media de 50 con un desvío de 7 puntos para los empleados. Suponiendo la igualdad de varianzas responda:(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
Página 281 de 314
281

a) ¿Es la diferencia observada en el nivel de estrés entre ambos grupos estadísticamente significativa al 5 %?b) ¿Puede decirse de a) la significación psicológica; esto es, que un grupo está más estresado que otro?c) ¿Qué hipótesis estadísticas debería plantear para poder deducir que los ejecutivos están más estresados que los empleados? Haga la prueba correspondiente.d) Formule una conclusión general.
511) En el primer cuatrimestre de 1994 los profesores de la Cátedra II de Estadística efectuamos una encuesta a los alumnos asistentes a las clases teóricas en las tres bandas horarias. Entre otras cosas, los interrogamos sobre su predisposición hacia la materia y su opinión sobre la utilidad de la misma en psicología. Los resultados (reales) se exhiben a continuación.(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
Predisposición Muy mala
Mala
Indiferente Buena
Muy buena
Número de alumnos 8 43 52 138 9
Opinión sobre la utilidad de la estadística en psicología.
58% útil.16.4% no sabe.12.8% poco útil.11.6% muy útil.0.8% completamente inútil.
Considerando al conjunto de alumnos encuestados como una muestra aleatoria de una población hipotética mayor, pruebe las siguientes hipótesis al 1 %.a) Más de la mitad tiene una buena o muy buena predisposición hacia la Estadística.b) Menos de la cuarta parte de los que tienen opinión formada la consideran poco útil o inútil.
512) Una firma hace un estudio de mercado con el fin de decidir si es necesario o no aumentar la publicidad el siguiente año. Como un aumento de publicidad implicaría un importante aumento del presupuesto para ese fin, la empresa quiere evitar la posibilidad de lanzar una campaña innecesariamente.La campaña será lanzada solo si menos de 45 % de la población consume el producto de la firma.De 400 personas encuestadas, seleccionadas al azar de distintos distritos de Capital Federal, 168 afirmaron consumir el producto.¿Qué decisión tomará la firma al nivel del 5 %?(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
513) Los puntajes en una prueba objetiva de rendimiento escolar siguen la distribución normal con media 15 puntos y varianza 11,25 bajo el supuesto de responder todos los ítems al azar.Un docente toma la prueba a un curso de 36 alumnos y obtiene un puntaje medio de 16,5 puntos. ¿Puede descartar, a un nivel del 1 %, la posibilidad de que sus alumnos hayan respondido al azar?(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
514) Una prueba de oído musical consiste en reproducir el sonido de la nota “la” (que corresponde a una frecuencia de 440) luego de oírla.Un grupo de 10 personas elegidas aleatoriamente e independientemente entre profesionales que se dedican a la afinación de instrumentos musicales, realizó la prueba y de las 10 emisiones se obtuvo una frecuencia media de 435 con un desvío estándar de 11. ¿Puede afirmarse que la frecuencia media de las notas que emitirían los profesionales de la población muestreada difiere de 440 al nivel del 10 %? Suponga la distribución normal de las frecuencias emitidas.(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
515) Un conjunto de sujetos evaluó la culpabilidad del protagonista de un episodio delictivo imaginario en una escala de 1 a 5. Después de proyectar un video con debate sobre las circunstancias inherentes a la vida del personaje volvieron a evaluarlo.A partir de los resultados obtenidos que se muestran a continuación ¿Puede inferir al 5 % que el debate sobre el tema a partir del video modifica la atribución de culpas tendiendo a atenuarla?(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
Atribución de culpas
Página 282 de 314
282

Sujeto Pre-video Post-video1 2 22 2 13 3 24 4 35 3 36 3 37 4 48 3 29 2 110 1 2
516) En una escuela bachiller de varones y en otra de mujeres se suministró un test de habilidad mecánica. En cada escuela se obtuvo una distribución aproximadamente normal de los puntajes con una diferencia de medias de 6 puntos a favor de los varones.Posteriormente se seleccionó una muestra aleatoria de cada escala formada por 10 estudiantes elegidos al azar entre las distintas divisiones y se los entrenó durante un período determinado después de lo cual se les volvió a suministrar una prueba para evaluar las mismas habilidades. Se obtuvo una media de 65 puntos para los varones y de 61 para las mujeres con desviaciones típicas de 10 y 12 puntos respectivamente.Para probar la hipótesis de que la diferencia entre los géneros se reduciría a, por lo menos, la mitad si los estudiantes de ambas escuelas recibieran el mismo entrenamiento…¿Qué hipótesis estadísticas tendría que plantear si quisiera tener una baja probabilidad de equivocarse en el sentido de no detectar que efectivamente la diferencia disminuiría?Conteste a los puntos mencionados suponiendo que no se haya alterado la normalidad de los puntajes después del entrenamiento y que los puntajes se distribuyen con igual varianza en ambos géneros.Use un nivel de significación del 10 %.(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
517) Usando los datos que se muestran en el cuadro pruebe las siguientes hipótesis al 5 %:a) Menos de la quinta parte de las mujeres consideran que ellas tienen oportunidades laborales de mejor paga.b) Más del 40 % cree que los varones tienen mayor reconocimiento de los jefes.c) Más del 30 % de las que tienen opinión formada sostienen que ambos -varones y mujeres- tienen las mismas oportunidades de ascensos en empresas privadas.d) La mitad de las mujeres que tienen opinión formada consideran que los varones tienen oportunidades de conseguir empleo.La Nación, revista, 4/9/1994
OPORTUNIDADES LABORALES(En porcentaje)
De mejor paga 44 18 33 5 100De reconocimiento de los jefes 45 17 33 6 100
De reconocimiento de los compañeros 44 16 30 10 100De ascensos (en empresas privadas) 44 16 30 10 100De ascensos (en empresas públicas) 40 15 33 12 100
De conseguir empleo 44 16 29 11 100Fuente: Consejo Nacional de la Mujer. Sobre un total de 1200 mujeres consultadas
(Fuente: Guía de Trabajos prácticos de la cátedra de Estadística de la Facultad de Psicología de la Universidad de Buenos Aires, 2001).
RESPUESTAS A LOS EJERCICIOS
104)
x (edad)
f f% f ac (creciente)
f% ac (creciente)
f ac (decreciente) f% ac (decreciente) fr
18-20 7 35% 7 35% 20 100% 0.3521-23 4 20% 11 55% 16 80% 0.2024-26 2 10% 13 65% 14 70% 0.1027-29 4 20% 17 85% 10 50% 0.2030-32 1 5% 18 90% 9 45% 0.0533-35 2 10% 20 100% 7 35% 0.10
20 100% 1.00
105)
Página 283 de 314
283

x f fr f% fr ac F% PM70-77 4 0.25 25% 0.25 25% 73.578-85 4 0.25 25% 0.50 50% 81.586-93 2 0.12 12% 0.62 62% 89.594-101 3 0.19 19% 0.81 81% 97.5102-109 3 0.19 19% 1 100% 104.5
n=16
1 100%
106)
x (peso en libras) f f ac F%118-126 3 3 7.5%127-135 5 8 20%136-144 19 27 42.3%145-153 12 39 72.2%154-162 5 44 85%163-171 4 48 95%172-180 2 50 100%
n=50
107a)
x (edad) f (frecuencia)____________________
19 534 751 561 284 1
____________________n = 20
108)
X (edad) f67172425294255
11314112
N=14
X (edad) f6-2526-4546-65
1022
N=14 N=14
Gráfico de barras
109)
Media Mediana Modo Desvíoa)b)c)
Página 284 de 314
284

d)e)f) 23.86g) 70h) 8.50i)j)
113)
a) Q2, D5 y P50b) P75)
114)
Media
Mediana
Modo
Desvío
a) 14.75b) 5,8c) 4,45
115)
a) 14.4$ por hora.
116)
Cuadro III – Voto femenino
Candidato fr
Candidato A 0.55Candidato B 0.43En blanco 0.02Total 1.00
Cuadro IV – Voto masculino
Candidato fr
Candidato A 0.39Candidato B 0.25En blanco 0.36Total 1.00
El voto femenino fue proporcionalmente mayor.
118)
El percentil de orden es 480. Supera a 479 y es superado por 320.
119)
a) 70b) 80
122) a) La población objeto de estudio es el conjunto de los adolescentes de la localidad donde se llevó a cabo la experiencia. La población de observaciones es el conjunto de números que representan a las cantidades de alcohol medido en litros correspondientes al consumo semanal aproximado de cada adolescente durante el verano.b) La muestra de individuos está formada por los 20 adolescentes que fueron escogidos para la encuesta y la deobservaciones, por sus correspondientes consumos de alcohol.c) La variable es la cantidad de alcohol que consume por semana un adolescente durante el verano. Es una variable cuantitativa continua.
Página 285 de 314
285

d) El nivel de medición es de razón, ya que las diferencias entre los números obtenidos por las mediciones tienen significado: diferencias en el consumo de alcohol. El cero no es convencional, es absoluto porque significa ausenciadel consumo (en cualquier unidad que se tome). El rango de valores de la escala son todos los números negativos.e) La posible fuente de variación sistemática es el género: podría suponerse que los consumos difieren entre los sexos (o, más aun, que los consumos del sexo femenino (f) tiendan a ser inferiores que en el masculino (m).Esto puede constituir una hipótesis por probar; si el experimentador lo probara, afirmaría que efectivamente el sexo es una fuente sistemática de variación.f) Ordenando los consumos de menor a mayor e indicando a cuántas mujeres o varones corresponden dichos consumos puede tenerse una primera idea acerca de la verosimilitud de la hipótesis de que el género es una fuente de variación.
Cantidad de varones y mujeres
Consumos
Mujeres Varones
0 2 10,025 10,04 10,05 10,06 10,075 1
0,1 20,14 10,2 10,3 1
0,42 10,44 10,45 10,48 20,5 10,7 1
Los mayores consumos corresponden a los varones. Se observa una “tendencia” de la variable “cantidad de alcohol consumida” a adoptar valores más altos dentro del conjunto de los varones que de las mujeres, lo cual no quiere decir que todas las mujeres consuman menos alcohol que todos los varones: la encuestada 1 consume 0,2 litros, mientras que el encuestado 19 no consume alcohol. Esto muestra que no toda la variabilidad en el consumo se debe al género hay otras fuentes de variación no registradas en esta experiencia: las fuentes fortuitas. Ellas hacen necesario utilizar una serie de observaciones dentro de cada grupo (varón, mujer) a fin de poder detectar el efecto de la fuente sistemática.g) Posibles fuentes fortuitas de variación son: edad, clase social, predisposición genética, nivel de autoestima, antecedentes familiares, nivel de receptibilidad de la publicidad, etc. Tal vez podrían imaginarse (hágalo) experimentos para probar si tales factores son o no fuentes de variación. Si se prueba, serían fuentes sistemáticas. Posiblemente sea difícil imaginar un experimento para medir en cada persona el nivel de receptibilidadde la publicidad; si no se pudiera medir sería siempre considerada como una posible fuente fortuita de variación. 123)
Algunas fuentes de variación podrían ser: la capacidad de cada alumno, el docente que corrige, el método de estudio, el tiempo dedicado al estudio, el nivel de ansiedad en el momento del examen, la dificultad propia de cada examen (en el caso que se tome un examen distinto para cada banda horaria), circunstancias individuales previas al examen, etc. Todas, salvo la última, pueden ser estudiadas como sistemáticas.La asistencia a las teóricas como fuente sistemática de variación se podría visualizar presentando la información en una tabla como la del ejercicio resuelto, poniendo la calificación en el lugar del consumo y la asistencia o no asistencia a las teóricas en lugar del género.
124)
La población consiste en los niños escolarizados provenientes de hogares del Gran Buenos Aires.Las unidades son cada uno de dichos niños.
Página 286 de 314
286

Las características que se desean estudiar son “habilidades adquiridas en el aprendizaje de la lectoescrtitura” y “nivel de agresividad”.El nivel de medición de la primera puede considerarse intervalar si se representa por el rendimiento entendido como cantidad de respuestas correctas en la prueba. Si ésta no se admite como una correspondencia razonable con la cantidad de habilidades adquiridas, podría tratarse en un nivel ordinal.El nivel de medición de los puntajes asignados a habilidades intelectuales o a características psicológicas en los tests, es un tema de discusión entre los especialistas.El nivel de medición de la “agresividad” es claramente ordinal por la escala adoptada.Las variables estadísticas son: “calificación en la prueba de habilidades en lectoescritura” y “nivel de agresividad”. La misma discusión referida al nivel de medición del rendimiento cabe para clasificar a la variable “calificación en la prueba”.Si se adopta un modelo donde “habilidad adquirida en lectoescritura” se considera medible en el nivel en el nivel intervalar, la calificación en la prueba es una variable cuantitativa discreta cuyos valores son los números del 1 al 10 (enteros o no según la precisión adoptada) aunque la naturaleza de la característica sea continua; si solo se admite un nivel ordinal para medirla, los valores de la calificación no indicarían cantidad, sino un rango, con lo que la calificación sería cuasi-cuantitativa. El “nivel de agresividad” es cuasi-cuantitativo y sus valores son “bajo, medio y alto”.
125)
a) Cuasi-cuantitativa, nivel ordinal.b) Cualitativa, nivel nominal.c) Cualitativa, nivel nominal.d) Cuantitativa discreta, nivel de razón.e) Cuantitativa continua, nivel intervalar o Cuasi-cuantitativa, nivel ordinal (es discutible).f) Cuantitativa continua, nivel de razón (el cero de la escala no tiene por qué ser un valor posible para la variable).g) Cuantitativa continua, nivel intervalar.h) Cuasi-cuantitativa, nivel ordinal.i) Cuantitativa discreta (pues se considera en años o meses enteros), nivel de razón. El cero es una convención de ladefinición de “edad” pero no una convención de la escala. En nuestra cultura la definimos como tiempo de vida a partir del nacimiento.
126)
a) Hay un alumno instruido con el método tradicional que obtuvo una calificación de 3 puntos, cinco alumnos instruidos con el método tradicional, obtuvieron una calificación de 4, siete alumnos obtuvieron 7 con el método de autoinstrucción, etc.b) La población de individuos está integrada por la totalidad de los alumnos de la cátedra 1 de Estadística que cursaron la materia en el primer cuatrimestre de 1993.Hay dos poblaciones hipotéticas de observaciones: una está formada por las calificaciones correspondientes a dichos alumnos si éstos hubieran sido instruidos por el método tradicional; la otra población hipotética la integran las calificaciones bajo el método de autoinstrucción sobre la misma población de individuos.Hay dos muestras de individuos, cada una de 20 alumnos, que son los que participaron de la experiencia y dos muestras de observaciones que corresponden a su calificación según el método de instrucción, las cuales están registradas en la tabla.c) La variable estadística es la calificación obtenida por los alumnos en la evaluación acerca del tema “prueba de hipótesis”. Es una variable cuantitativa discreta.d) Sí. Las calificaciones tienden a ser mayores para el grupo correspondiente al método de autoinstrucción. Aparentemente el método de instrucción es una fuente sistemática de variación para la calificación. Decimos “aparentemente” porque llegamos a la conclusión por simple inspección ocular (más adelante veremos métodos adecuados de decisión estadística).e) No, debido a las fuentes fortuitas de variación.f) Capacidad individual, preferencia del sujeto a recibir un determinado tipo de instrucción, el docente a cargo de cada uno de los métodos, etc.g) Si no existieran fuentes fortuitas de variación y toda la variabilidad en la calificación de debiera al método, entonces todas las calificaciones coincidirían dentro del mismo método y bastaría tomar una observación de cada uno para compararlos. Pero al existir otras fuentes de variación, es necesario hacer una “serie de observaciones” para que el efecto de las fuentes fortuitas se vea compensado en el conjunto y deje ver la tendencia en el comportamiento de la variable. Por ejemplo: si se hubiera tomado una sola observación de cada grupo, podría haber ocurrido que se eligiera el alumno que se sacó 7 con el método tradicional y el que se sacó 4 con el de autoinstrucción: no se sabría entonces se estas calificaciones son debidas a que el método tradicional es mejor o a que al azar hizo que un alumno más inteligente recibiera el método tradicional. Pero cuando a cada método se asigna al azar un conjunto de individuos, es poco probable que todos los más inteligentes queden en uno de ellos y el efecto de la inteligencia se verá compensado en dicho conjunto sin ocultar el efecto de la fuente sistemática.
127)
Página 287 de 314
287

a) Las posibles fuentes sistemáticas de variación son la modalidad de la clase y el maestro.b) Las características a estudiar son: “rapidez lectora”. El nivel de medición es de razón para la primera y discutible para la segunda: ordinal o intervalar (el tratamiento estadístico posterior de ella hace el autor corresponde al nivel intervalar).Las variables estadísticas son: “calificación en rapidez lectora” -cuantitativa discreta, aunque la característica es continua- y “calificación en comprensión lectora” -cuasicuantitativa o cuantitativa discreta según el nivel de medición adoptado-. c) Posibles fuentes fortuitas de variación son: la capacidad individual, en entrenamiento extra-escolar, el nivel cultural de los estudiantes, etc.
128)
a) 1) y a 2) No parece razonable cuantificar la actitud solidaria al punto de pretender dar una métrica de la diferencia en solidaridad entre uno u otro.b) La característica que merece estudiar es la actitud solidaria, y su nivel de medición es ordinal, pues tiene sentido pensar que una persona es más o menos solidaria que otra, inclusive podría decirse “mucho más” o “mucho menos” solidaria; es decir, podría pensarse en la proximidad o distancia entre las personas en cuanto a su actitud solidaria en términos “ordinales”, pero cuantificarla con la precisión que supone el nivel intervalar, parece muy pretencioso. Parece más razonable interpretar los puntajes los puntajes como rangos que como cantidades.El instrumento de medición es el test de autoevaluación y la variable estadística es la “cantidad de respuestas que denotan una actitud solidaria”. Obsérvese que si se tomara esta variable como objeto de estudio es la misma sin remitirnos al significado en términos de la característica que representa, correspondería al nivel de razón, ya que es una variable intrínsecamente cuantitativa (cantidad de respuestas…) y el cero no es arbitrario, significa que el individuo no dio ninguna respuesta que denotara una actitud solidaria. Si a la variable se le diera un tratamiento estadístico correspondiente al nivel de razón, habría que tener en cuenta que todo lo que se concluye referirá al puntaje pero no a la característica de interés.
129)
a) y c) Son distintas, b) Siempre son iguales. Propiedad distributiva.
130)
a) La variable es “opinión de los argentinos (Capital Federal y Gran Buenos Aires) con respecto a la manera que quieren ser gobernados”. Sus valores son: Presidente controlado por el Congreso, Presidente con amplios poderes, Presidente acompañado por un primer ministro y No sabe/No contesta.b) El título sugiere que la información representa la opinión de los argentinos cuando en realidad solo se interrogó a los habitantes de Capital Federal y Gran Buenos Aires.c) Los ángulos son 165° 36’ (46 %), 86° 24’ (24 %), 72° (20 %), 36’’ (10 %).d) 235, 122, 102 y 51 (correspondientes al orden de c).
131)
a) La variable es “opinión de los votantes respecto de quién debe destituir al jefe de gabinete”. Sus valores son: La Cámara de Diputados, la Asamblea Legislativa, el Presidente y No sabe/No contesta. La fuente sistemática de variación es “partido político”.b) Los ángulos son: 87° 12’, 97° 12’, 75° 36’ y 90°.c) Una posibilidad es el diagrama de rectángulos adyacentes.
132)
X = 17/3 = 5,67
133)
a) Categoría mediana: es el par (2,3).b) Salario mediano = $ 600 (lo tomamos como representante del intervalo (500, 700)). Salario medio = $ 934,88c) i) La mediana, ii) la media, iii) la mediana.
134)
No, porque no son comparables. Las variables se refieren a magnitudes diferentes.
135)
Página 288 de 314
288

No es lo más adecuado comparar las varianzas en términos absolutos, sino en relación a la media cuando el nivel de medición lo permite. Como la “Cantidad de respuestas correctas” corresponde al nivel de razón, podemos calcular el coeficiente de variación.
Para los varones CV = 2/7 = 28,6Para las mujeres CV = 3/7 = 42,9La variabilidad relativa es mayor en las mujeres.
136)
1.a) En el segundo parcial se obtuvo mejor rendimiento que en el primero pues, visualmente, se observa que la distribución es asimétrica para el segundo parcial y asimétrica positiva para el primero.b) El primer parcial discriminó más a los alumnos de mejor rendimiento, el segundo parcial discriminó más a los de peor rendimiento. Para discriminar a los de mejor y peor rendimiento por igual la forma de la distribución debería ser simétrica.En una distribución asimétrica positiva los puntajes más altos son poco frecuentes; por lo que un alumno que obtiene uno de tales puntajes se destaca del resto, ya que pertenece a un grupo minoritario extremo. En una distribución asimétrica negativa se da la misma situación en sentido contrario y se destacan los de peor rendimiento. Si la distribución fuera simétrica, el grupo minoritario estaría conformado por los alumnos con puntajes extremadamente altos o bajos en la misma proporción, por lo que se destacarían del resto por igual.
2.Primer parcial: asimetría = 0,666 curtosis = 0,06894Segundo parcial: asimetría = -0,674 curtosis = 0,13835Ambas distribuciones tienen casi el mismo grado de asimetría pero en sentido contrario. Es algo más cúrtica la distribución en el segundo parcial.
137)
Si al principio del curso los puntajes se distribuyen con asimetría positiva son pocos los alumnos que obtendrán los mayores puntajes y no tan pocos los que podrían sacar una nota baja. La intención sería incentivar al alumno desde el inicio del curso para que se esfuerce en no reprobar o en merecer notas excelentes. En cambio, en un examen final, interesa que las calificaciones bajas de reprobación sean infrecuentes y no tanto las excelentes; para que si alguien reprueba se tenga la tranquilidad de que es porque realmente lo merece al destacarse por su mal rendimiento.
138)
a) Obtuvo mejor resultado el grupo del terapeuta A ya que su media es 4,4; o sea, menor que la del grupo del terapeuta B.b) No puede afirmarse esto porque:*No se sabe si ambos grupos tenían el mismo nivel de dificultad al momento de comenzar el tratamiento ya que no se hizo un pre test. Tampoco fueron aleatorios como para suponer una distribución homogénea en los grupos.*Aunque los dos grupos estuvieran en condiciones semejantes de partida, habría que investigar si la diferencia entre las medias es suficientemente grande en relación a su variabilidad de muestra en muestra.
139)
a) i) Población de individuos: Totalidad de adolescentes de Capital Federal. Muestra de individuos: Los 120 adolescentes seleccionados para la experiencia. ii) Poblaciones de observaciones: Una población es el conjunto de todos los rankings que los adolescentes de Capital Federal le asignaron al producto de haber sido expuestos a la propuesta publicitaria A. La otra población Es la de los rankings que dichos adolescentes asignarán al producto de haber recibido la propuesta publicitaria B. Por como están definidas estas dos poblaciones, son claramente hipotéticas. Las muestras de observaciones son también dos y corresponden a cada población hipotética. Están constituidas Por los rangos asignados efectivamente por los adolescentes de Capital Federal seleccionados para la Experiencia que vieron la publicidad tipo A y los asignados por los que vieron la publicidad tipo B.b) La variable estadística es “Ranking asignado al producto entre las dos marcas competidoras”. Es cuasicuantitativa y el nivel de medición utilizado es el ordinal.
Página 289 de 314
289

c) Casi la mitad de los adolescentes que recibieron la propuesta A votaron en primer lugar al producto y casi la tercera parte de los mismos le asignaron el tercer lugar, mientras que estas proporciones se invierten en el caso de los mismos que tuvieron la propuesta B. De modo que la tendencia es posicionar mejor al producto si se ha recibido la propuesta A. Por tanto el tipo de propuesta publicitaria parece ser una fuente sistemática de variación.d) Los porcentajes son 32,4, 21,6 y 34,2 para los lugares 1, 2 y 3 respectivamente. Pueden representarse en un diagrama de rectángulos o bien en uno circular mientras se indique a qué rango corresponde cada sector.e) El 65,8 %.
140)
a) x = 3,86 Md = 5 Mo = 4 Q1 = 3 Q3 = 5 s = 1,54 As = 0,11 Cu = -0,47b) 66,67 %
141)
a) i) Población de individuos: La totalidad de ejecutivos de la pequeña o mediana empresa de la ciudad de Córdoba. Muestra de individuos: Los 45 ejecutivos seleccionados para la encuesta. ii) Las poblaciones de observaciones son dos: Una es la formada por todos los números que indican cuántas veces viajó el último año a un país limítrofe cada ejecutivo de la pequeña empresa de la ciudad de Córdoba (haya o no sido seleccionado para la encuesta). La otra población está definida de la misma manera para los ejecutivos de la mediana empresa. Por cómo están definidas, son poblaciones reales. Hay dos muestras de observaciones reales que se corresponden con cada una de las poblaciones: una es la de los 30 números que representan cuántas veces viajó a un país limítrofe el último año cada uno de los ejecutivos encuestado de la pequeña empresa y la otra es la definida de manera análoga sobre los 15 encuestados de la mediana empresa.b) La variable estadística es “Número de viajes a países limítrofes realizados por el ejecutivo en el último año”. Es una variable cuantitativa discreta y el nivel de medición es de razón.c) Para poder comparar ambos grupos es necesario usar las frecuencias porcentuales o las relativas, ya que son dos muestras de diferente tamaño. Puede observarse que las frecuencias porcentuales tienden a acumularse en los valores más bajos de la variable para el caso de los ejecutivos de la pequeña empresa y hacia valores más altos en el otro grupo. Por lo que el tipo de empresa parece ser una fuente sistemática de variación para la frecuencia de los viajes de los ejecutivos en cuestión: los ejecutivos de la pequeña empresa suelen viajar menos que los de la mediana empresa. Se podrían enunciar algunas hipótesis que expliquen esto; por ejemplo: cabe esperar que el nivel adquisitivo sea más alto en el grupo de la mediana empresa, lo que facilita la posibilidad de viajar; o porque la mayor envergadura de tales empresas las pone en la necesidad de vincularse con otras empresas extranjeras.No todas las observaciones responden a esta tendencia, ya que vemos que el único ejecutivo que más ha viajado entre todos (7 viajes) es de la pequeña empresa. Esto puede atribuirse a fuentes fortuitas de variación; por ejemplo: que tal ejecutivo tenga familiares cercanos en un país limítrofe, o que tenga un ingreso económico muy alto que no necesariamente proviene de su empresa.d) Hay que realizar un diagrama de barras adyacentes usando las frecuencias porcentuales.e) 55,56 %.
142)
El turno mañana tiene mejor rendimiento ya que, resumiendo sus mayores puntajes con las medidas de tendencia central, vemos que son mayores que el turno tarde: x = 6,2 y Md = 6,25.La mayor variabilidad relativa a la media es en el turno tarde pues su coeficiente de variación es de 37 mientras que a la mañana es 31.
201)
a) 2/6 = 0.33b) 3/6 = 0.5c) 2/6 = 0.33d) 4/40 = 0.10e) 0/6 = 0f) 6/6 = 1g) 1 – p = 1 – 1/5 = 5/6.
Página 290 de 314
290

h) 1 – p = 1 – 13/52
202)
a) p(A) . p(B) = ½ . ½ = ¼b) p (A) + p(B) = ¼ + ¼ = ½c) p (C) . p(3) = ½ . 1/6 = 1/12d) p (5) . p (5) = 1/6 . 1/6 = 1/36e) p = 11/36f) p = 1/6g) p = 9/36 = ¼h) p = 3/36 = 1/12.i) p (A) . p (B) . p(C) = 10/40 . 10/40 . 10/40 = 0.016j) p (A) . p (BsiA) . p (CsiAyB) = 10/40 . 9/39 . 8/38 = 0.012k) 7/10 . 6/9 = 0.47l) 7/10 . 7/10 = 0.49
203)
a) p (A) + p (B) = 150/380 + 160/380 = 0.82b) p (A) + p (B) – p (AyB) = 150/380 + 160/380 – 100/380 = 0.55c) 60/380 = 0.16d) 60/230 = 0.26
204)
a) V6,2 = 30.b) V9,3 = 504.c) V8,2 = 56 (Para ser mayor de 900 la primera cifra siempre será 9, y por lo tanto solo resta ubicar dos cifras tomadas de las 8 restantes, pues el 9 no puede repetirse).
205)
a) P9 = 362.880b) P7 = 5040.c) P4 = 24.d) P6 = 720.e) 5.2.P4 = 240 (pues hay 5 posibilidades en que aparezcan juntos: en los dos primeros lugares, en el segundo y tercer lugar, etc.).
206)
a) m = 3, n = 2 y p = 1/6. Por lo tanto la probabilidad es 0.072.b) m = 3, n = 2 y p = 7/12. Por lo tanto, la probabilidad es 0.42.c) m = 5, n = 3 y p = 2/5. Por lo tanto, la probabilidad es 0.23.d) m = 25, n = 5 y p = 1/3. Calcule la probabilidad aplicando la fórmula.
207)
a) 0,972, b) 0,103, c) 0,952, e) 0,57
208)
a) 0,794, b) 0,927
209)
a) 0,613, b) 0,999
210)
a) 0,944, b) 0,463
211)
a) 0,174b) 0,983c) 0,406
Página 291 de 314
291

212)
a) 0,168b) 0,837c) 0,998
301)
P31
305)
x = 30.59
306)
a) z = 0.84 b) z = -1.28c) z = +1.96 y z = -1.96
307)
Como el puntaje T tiene media 50 y desvío estándar 10, el puntaje z de Esteban en creatividad es 2; de modo que supera a la media del grupo normativo en dos unidades de desvío mientras que en el test de memoria la supera en dos desvíos y medio. Por tanto podemos decir que es más memorioso que creativo, tomando como referencia a los grupos normativos.
308)
a) 74,86, b) 8,16, c) 16,95
309)
72,75
310)
a) Hay 14, 286, 286 y 14 personas en los respectivos grupos.b) 85,5.c) Creativo, pues está a un desvío y medio por encima de la media.d) 46,2.
311)
a) 0,0241b) 0,5375
406)
Respuesta: r = + 0,63.Por lo tanto, hay cierta correlación.
407)
Respuesta: r = + 0.92.Por lo tanto, muy alta correlación directa.
410)
a) b) 0,78 * 0,82 * 0,18
411)
a)
r CI LECTURA MÚSICA FÍSICACI 0.42 0,91 0,86LECTURA 0,56 0,49
Página 292 de 314
292

MÚSICA 0,95FÍSICA
b) Con este método se correlacionan de a 2 variables por vez y con la correlación múltiple varias simultáneas.
412)
No.
413)
Sujetos JUEZ 1 JUEZ 2 D (Dif) D 2
A 5º 6º -1 1B 6º 5º 1 1C 2º 1º 1 1D 4º 4º 0 0E 3º 2º 1 1F 1º 3º -2 4
8
Spearman = 0.77 (hay correlación, pero algo débil).
414)
En las cuatro tablas existe la misma correlación.
415)
b) No se observa clara tendencia lineal en los puntos y, si se ajustara a una recta, aparentemente tendría una pendiente negativa; con lo cual el test no parece ser confiable.c) r = -0,19. El test no es confiable ya que, de haber alguna relación lineal entre las variables, ésta sería de sentido inverso al que se espera; es decir: los sujetos con puntajes altos en el test tienden, en alguna medida, a bajarlos en el retest y recíprocamente.
502)
Límite superior = 7.33 y límite inferior = 6.67. Por lo tanto, la media poblacional estará comprendida entre 7.33 y 6.67 con una probabilidad del 95%.
503)
Es una prueba unilateral a izquierda.El valor observado del estadístico de prueba es e = -1,5.El valor crítico es el centil 1, z0,01 = 2,33 aproximadamente.La decisión es no rechazar la hipótesis nula.Conclusión: Los resultados observados no dan suficiente evidencia de que el rendimiento medio de los alumnos de sexto grado sea inferior al del grupo normativo. Si bien la media muestral es inferior a 65 esta diferencia puede deberse al azar; es decir, no es estadísticamente significativa.
504)
Es una prueba bilateral.El valor observado del estadístico de prueba es e = 1.Los valores críticos son los centiles 5 y 95, z0,05 = -1,645 y z0,95 = 1,645 respectivamente.La decisión es no rechazar la hipótesis nulaConclusión: Los datos son consistentes con la hipótesis de que los puntajes se distribuyen normalmente con media 10 y desvío 4, ya que no han conducido a rechazarla.
505)
Es una prueba unilateral a derecha.El valor observado del estadístico de prueba es e = 2.El punto crítico en el centil 95, t24; 0,95 = 1,711.La decisión de rechazar la hipótesis es nula.Conclusión: Aceptamos que el rendimiento medio de los alumnos que se instruyeron con el nuevo método, es mayor que el histórico, con un nivel de significación del 5 %, es decir, que aproximadamente 5 de cada 100 veces que se realice este procedimiento se optaría por esta decisión incorrectamente.
Página 293 de 314
293

ComentarioEn psicología se acostumbra a decir en estos casos, para resumir, que la media es significativamente mayor.No debe entenderse la expresión “significativamente mayor” como que la media poblacional es mucho mayor que 5,5, cosa que podría sugerir la palabra “significativamente”. El método de prueba de hipótesis utilizado solo permite afirmar, con bajo riesgo de error, que la media poblacional es “mayor” que 5,5 y no “en qué medida mayor”.Cabe aclarar que la población a la que hemos hecho referencia en este ejercicio no es una población real sino hipotética; ya que está formada por todos los alumnos de características similares a los que fueron evaluados que podrían recibir el nuevo método de enseñanza.
506)
Es una prueba bilateral.El valor observado del estadístico de prueba es de e = -5,77.Los valores críticos son t24; 0,005 = -2,797 y t24; 0,995 = 2,797La decisión es rechazar la hipótesis nula.Conclusión: El promedio de letras recordadas por los sujetos de la Universidad Autónoma de Madrid es distinto de 4,5 al nivel del 1 %. Por el signo negativo del estadístico podemos deducir que es menor con el mismo nivel de significación.
507)
I. a) Debemos probar estadísticamente al 1 % que, en promedio, los niños aumentarían sus puntajes CI en el post-test si recibieran un programa de estimulación temprana; para lo cual contamos con una muestra de 15 niños sobre los que se llevó a cabo la experiencia (grupo experimental). Nuestra hipótesis se refiere, pues, a una población hipotética: la de los niños de 2 a 4 años de características similares a los de la muestra, sometidos a un P.E.T.Si definimos la variable D = Diferencia entre las puntuaciones del post-test y pre-test de cada niño, lo que debemos poner a prueba, al 1 %, son las siguientes hipótesis estadísticas:Ho: µD = 0 (Los CI de los niños después del P.E.T. no difieren, en promedio, de los iniciales).H1: µD > 0 (Los CI, en promedio, aumentan si los niños reciben el P.E.T.).uD denota la media de las diferencias entre los CI obtenidos en el post-test y pre-test.Por lo tanto el procedimiento es el correspondiente a una media poblacional con desvío desconocido para la variable D cuyos valores maestrales son:D: 49, 22, 29, 27, 28, 22, 35, 39, 20, 45, 20, 29, 1, 42, 57.El estadístico de prueba es E = D – O que, bajo Ho, sigue la distribución t de Student con 14 grados de libertad. S’D/ √15 El valor crítico, que determina una zona de rechazo de Ho unilateral a derecha, es t14,099 = 2,624.Como el valor observado de la media D es 31 y el de S’D es 13,97, el valor observado del estadístico de prueba resulta: 31 E = = 8,59 13,97/√15Puesto que 8,59 > 2,624 se rechaza Ho; es decir, hubo aumento estadísticamente significativo de CI medio en los niños del grupo experimental.
I. b) Es una prueba unilateral a derecha. El valor observado del estadístico de prueba es e = 1,78. El valor crítico es t14; 0,99 = 2,624 La decisión es no rechazar la hipótesis nula.Conclusión: No hay evidencias, al 1 %, de que haya aumentado el CI medio de los niños que no recibieron el P.E.T.II. Es necesario usar un grupo control para poder atribuir los cambios observados (en este caso el aumento del CI) al factor que define al grupo experimental: haber recibido el P.E.T.
ComentarioHaremos una crítica al análisis estadístico anterior el cual fue hecho así por los autores del artículo.La conclusión global de los autores es que el P.E.T. es eficaz porque han probado estadísticamente que, en promedio, el grupo experimental aumentó su CI mientras que el control no.1º) Esta afirmación proviene de dos pruebas de hipótesis llevadas a cabo por separado en a) y b); cada una con su nivel de significación (0,01); por lo que la afirmación simultánea de ambas cosas no obedece a un nivel de significación global conocido. Siempre que sea posible, deben tratarse todos los datos del experimento conjuntamente, a fin de que la decisión final obedezca a un único nivel de significación.2º) Los niños que no recibieron el P.E.T. tuvieron durante un año la estimulación ordinaria propia de un hogar infantil, por lo que podría esperarse en ellos también un aumento del CI. De hecho el lector puede verificar que hay un aumento estadísticamente significativo al 5 %. Esto no hace menos cierto que el P.E.T. sea eficaz, pues la eficacia del mismo no radica en que es único de los dos que aumenta el CI, sino
Página 294 de 314
294

que lo aumenta en mayor medida que el programa usual. Luego, nuestra segunda crítica se dirige hacia las hipótesis estadísticas planteadas por los autores. Consideramos que es más acertado plantear que la diferencia entre los CI del pos-test y pre-test es, en promedio, mayor para el grupo experimental que para el grupo control. Esto es, en símbolos:
H0: µDE = µDC
o equivalente H1: µDE > µDC
HO: µDE - µDC = 0H1: µDE - µDC > 0Donde µDE y µDC denotan las medias de las diferencias entre los CI obtenidos en el post-test y pre-test por los grupos experimental y control respectivamente.De este modo con una sola prueba de hipótesis podemos arribar a una conclusión respecto de la eficacia del P.E.T.
508)
Hay que suponer que los puntajes se distribuyen normalmente en cada población hipotética pues las muestras son de tamaño pequeño, y que tienen la misma varianza (aunque se desconozca). También hay que suponer la independencia entre las muestras.Es una prueba unilateral.El valor observado del estadístico de prueba es e = -0,71.Los valores críticos son t11; 0,05 = -1,796, t11; 0,95 = 1,795.La decisión es no rechazar la hipótesis nula.Conclusión: No hay evidencia de que el tipo de instrucción influya en el rendimiento de los alumnos en las pruebas con un nivel del 10 %.
509)
a) Los supuestos son: normalidad de los puntajes, igualdad de varianzas e independencia de las muestras.La aleatorización es un recurso para lograr la independencia de las muestras.b) Es una prueba unilateral.El valor observado del estadístico de prueba es e = 2,22.El valor crítico es t18; 0,90 = 1,33.La decisión es rechazar la hipótesis nula.Conclusión: Las ilustraciones favorecen el aprendizaje de las palabras al nivel del 10 %.
510)
a) Es una prueba bilateral.El valor observado del estadístico de prueba es = 2,17.Los valores críticos son t30 ; 0,025 = -2,042 y t30; 0,975 = 2,042.La diferencia es significativa y, por el signo de e, concluimos que el puntaje en estrés es mayor en los ejecutivos que en los empleados.b) No puede inferirse que los ejecutivos estén más estresados que los empleados pues basta con que el puntaje sea mayor: debe superarlo en por lo menos dos puntos para que la diferencia tenga una significación psicológica, es decir, debe superar el umbral.c) Deberían plantearse las hipótesis:
Ho: µej - µem = 2H1: µej - µem > 2o equivalente
Ho: µej - µem – 2 = 0H1: µej - µem – 2 > 0
El estadístico esX1 – X2 - 2
E = √Sc
2 (1/16 + 1/16)
donde Sc2 es la varianza combinada. En este caso su cálculo es sencillamente el promedio simple de
ambas varianzas por provenir de muestras del mismo tamaño.El valor observado del estadístico de prueba es e = 1,3.
Comentario:En estas situaciones, antes de tomar una decisión basándose en no rechazar la hipótesis nula, suele hacerse suele hacerse un estudio de la potencia. En este problema sería conveniente estudiar con qué probabilidad la empresa puede equivocarse en no hacer publicidad en algún caso que considere grave
Página 295 de 314
295

equivocarse, supongamos, cuando la verdadera proporción de sujetos que consumen el producto es, por ejemplo, 40 %. Si la potencia en este caso es alta, (o sea, si hay baja probabilidad de equivocarse), la empresa puede decidir con más tranquilidad no hacer publicidad, ya que está suficientemente protegida contra la posibilidad de equivocarse en este sentido (error del tipo II).En realidad, en la práctica, el procedimiento es al revés: se hace el estudio de la potencia previamente a tomar los datos, ya que su cálculo no depende de los mismos, con el fin de investigar qué tamaño muestral elegir para lograr una potencia alta en los casos de interés.
513)
Es una prueba bilateral.El valor observado del estadístico de prueba es e = 2,68.Los valores críticos son: z0,005 = -2,575 y z0,995 = 2,575.La decisión es rechazar la hipótesis de que la media del grupo coincide con la media por azar.Conclusión: Puede descartarse, a nivel del 1 %, la posibilidad de que los alumnos hayan contestado por azar.
514)
Es una prueba bilateral.El valor observado del estadístico de prueba es e = -1,44.Los valores críticos son t9; 0,05 = -1,833 y t9; 0,95 = 1,833La decisión es no rechazar la hipótesis nula.Conclusión: La diferencia observada puede atribuirse a razones fortuitas y no necesariamente a que los profesionales, en promedio, emitan una frecuencia de la correcta para la nota “la”.
515)
Es una prueba unilateral para una diferencia de medias de datos apareados.El valor observado del estadístico de prueba es e = -2,24.El valor crítico es t9; 0,05 = -1,833.La decisión es rechazar la hipótesis nula.Conclusión: La media de los puntajes en la asignación de culpa es estadísticamente inferior después de la proyección del video con debate que antes, al 5 %; lo que podría indicar que los sujetos se vieron en alguna medida influidos por dicha proyección y atenuaron su juicio.Comentario: Nótese que el nivel de medición es esencialmente ordinal, aunque se hace un tratamiento estadístico propio del nivel intervalar. Es uno de los tantos casos donde se comete un cierto abuso en el análisis estadístico, el cual podría justificarse si se supone que hay una cierta idea de “equidistancia” -aunque no del todo precisada- entre los cinco valores de la escala. Existen métodos estadísticos más adecuados a estas situaciones: por ejemplo, pruebas de hipótesis sobre la mediana, que exceden el nivel de este curso.
516)
a) Ho: µ1 - µ2 < 3 H1: µ1 - µ2 > 3b) El valor observado del estadístico de prueba es e = 0,175. El valor crítico es t18; 0,90 = 1,33. La decisión es no rechazar la hipótesis nula.Conclusión: No hay evidencias, al 10 %, de que la habilidad media de los varones supere a la de las mujeres en más de tres puntos.
517)
a) Es una prueba unilateral. H1: P < 0,2. El valor observado del estadístico de prueba es e = -1,732. El valor crítico es z0,05 = -1,645. La decisión es rechazar la hipótesis nula.Conclusión: Menos de la quinta parte de las mujeres consideran que ellas tienen oportunidades laborales de mejor paga.
b) Es una prueba unilateral. H1: P > 0,4. El valor observado del estadístico de prueba es e = 3,536. El valor crítico es z0,95 = 1,645. La decisión es rechazar la hipótesis nula.Conclusión: Más del 40 % de las mujeres cree que los varones tienen mayor reconocimiento de los jefes.
c) Es una prueba unilateral. H1 : P > 0,3. n = 1080. e = 2,388. z,0,95 = 1,645. Se rechaza Ho. Más del 30 % de las mujeres que tienen opinión formada
Página 296 de 314
296

sostiene que las personas de ambos géneros tienen las mismas oportunidades de ascensos en empresas privadas.
d) Es una prueba bilateral. n = 1068. e = -0,367. z0,025 = -1,96. z0,975 = 1,96. No se rechaza H0. No hay evidencias que contradigan que la mitad de las mujeres con opinión formada cree que los varones tienen mejores oportunidades de conseguir empleo.
Página 297 de 314
297

ANEXOS DE METODOLOGÍA
ANEXO 1. PREGUNTAS MULTIPLE CHOICE
1) ¿Qué es una variable experimental?
a) La que manipula el investigador.b) La que supuestamente influye sobre la variable dependiente.c) La variable independiente.d) Todas las anteriores son correctas.e) Ninguna de las anteriores es correcta.
2) ¿A qué se llama validez de un instrumente de medida?
a) Es válido si tiene alta precisión.b) Es válido si arroja los mismos resultados para el mismo sujeto en diferentes oportunidades.c) Es válido si mide efectivamente lo que pretende medir.d) Todas las anteriores son correctas.e) Ninguna de las anteriores es correcta.
3) Probar una hipótesis causal de objetivo de:
a) La investigación exploratoria.b) La investigación descriptiva.c) La investigación correlacional.d) La investigación explicativa.e) Ninguna de las anteriores es correcta.
4) ¿Cuál de las siguientes afirmaciones describe mejor la relación que hay entre un vínculo de correlación y un vínculo causal?
a) La correlación es condición necesaria pero no suficiente para probar un vínculo causal.b) La correlación es condición necesaria y suficiente para probar la conexión causal.c) Si no hay conexión causal no puede haber correlación.d) Las respuestas a y c son correctas.e) Si hay conexión causal puede o no haber correlación.
5) ¿Cuál de estos sistemas de categorías no cumple con el requisito de la exhaustividad?
a) Masculino-femenino (sexo).b) Alta-media-baja (clase social)c) 80 a 100, 101 a 120, 121 a 140 (cociente intelectual).d) Todos los anteriores.e) Buena-mala (memoria).
6) ¿Cuál de estas afirmaciones es la más correcta?:
a) Varias categorías forman un indicador.b) Varias dimensiones forman una categoría.c) Varias dimensiones forman un indicador.d) Varios indicadores forman una categoría.e) Varios indicadores forman un índice.
7) ¿Para qué sirve una prueba de espureidad?
a) Para probar que no hay correlación entre X e Y.b) Para probar que no hay conexión causal aun cuando no haya correlación.c) Para probar que la correlación entre X e Y no se debe a una relación causal.d) Para probar que entre X e Y hay realmente conexión causal aunque no lo parezca.e) Las respuestas a y b son correctas.
8) ¿Qué variables pueden influir sobre la variable independiente?
a) La influencia de la pre-medida.b) La interacción.c) Cambios madurativos en los sujetos.d) Todas las anteriores.e) Ninguna de las anteriores.
9) ¿Cuál es la afirmación correcta?
a) Una investigación experimental nunca puede ser una investigación de campo.b) Una investigación exploratoria nunca puede ser experimental.c) Una investigación descriptiva es siempre previa a una investigación exploratoria.d) Ninguna de las anteriores.e) Una investigación descriptiva es siempre correlacional.
Página 298 de 314
298

10) Operacionalizar una variable significa:
a) Especificar su indicador si es una variable simple.b) Especificar sus indicadores y dimensiones si es una variable compleja.c) Especificar sus categorías o valores.d) Las respuestas a y b son correctas.e) Especificar el nivel de medición que le corresponde.
11) El muestreo probabilístico:
a) No permite calcular el error muestral.b) Implica que cualquier sujeto tiene la misma probabilidad de integrar la muestra.c) Permite obtener muestras más representativas.d) Las respuestas a, b y c son correctas.e) Las respuestas b y c son correctas.
12) La interacción es:
a) Una variable extraña o factor de invalidación interno de un experimento.b) Una relación entre variables independientes.c) Una relación entre variables dependientes.d) Una relación entre una variable independiente y otra dependiente.e) Las respuestas a y b son correctas.
13) La variable “tolerancia a la frustración” es:
a) Organísmica y activa.b) Activa y situacional.c) Organísmica y asignada.d) Asignada y situacional.e) Ninguna de las anteriores es correcta.
14) Un indicador es:
a) Una variable empírica.b) Un índice complejo.c) Aquello que se identifica en una definición real.d) Una pregunta en un cuestionario.e) Las respuestas a y d son correctas.
15) El objetivo de un estudio exploratorio puede ser:
a) Familiarizarse con el tema a estudiar.b) Ampliar el conocimiento del tema.c) Aclarar conceptos y establecer preferencias para posteriores investigaciones.d) Todas las anteriores son correctas.e) Solamente a y b son correctas.
16) Buscar una asociación estadística entre las variables es un objetivo de:
a) El análisis de los datos.b) Un estudio correlacional.c) Un estudio explicativo.d) Es un estudio exploratorio.e) Las respuestas a y b son correctas.
17) ¿Qué criterios se usan para probar una conexión causal?
a) Variación concomitante, orden temporal y eliminación de otros posibles factores causales.b) Correlación, orden temporal e interacción.c) Correlación y orden temporal.d) Control de variables extrañas y aleatorización.e) Control de variables extrañas, aleatorización y uso de grupos de control.
18) El diseño de antes y después con dos grupos de control (Selltiz) se usa cuando:
a) Se quiere controlar cualquier variable extraña.b) Se quiere conocer la influencia de la pre-medida.c) Se quiere conocer la influencia de la interacción.d) Todas las anteriores son correctas.e) Ninguna de las anteriores es correcta.
19) La observación participante es:
a) Una técnica de estudios exploratorios.b) Una técnica de recolección de datos.c) Una técnica donde el investigador participa activamente del fenómeno a estudiar.
Página 299 de 314
299

d) Todas las anteriores son correctas.e) Las respuestas b y c son correctas.
20) Si la hipótesis de un diseño experimental tiene 3 variables…
a) Una es la independiente, otra la dependiente y otra es la premedida.b) Son dos independientes y la otra es dependiente.c) Dos son dependientes y la otra independiente.d) Dos son independientes y la otra es interviniente.e) Ninguna de las anteriores es correcta.
21) ¿En qué tipo de esquema experimental (Selltiz) interesa conocer la diferencia entre la pre-medida del grupo de control y la post-medida del grupo experimental?
a) En el esquema de solo después.b) En esquema de antes y después con un grupo de control.c) En esquema de antes y después con grupos intercambiables.d) Las respuestas b y c son correctas.e) Ninguna de las anteriores es correcta.
22) ¿Qué afirmación es más correcta?
a) La VI se controla, la VD se manipula y la VE se mide.b) La VI se manipula, la VD se mide, y la VE se controla.c) La VI se mide, la VD se controla, y la VE se manipula.d) Todas las variables se controlan.e) Ninguna de las anteriores es correcta.
23) Un test es válido cuando:
a) Pretende medir inteligencia y efectivamente mide inteligencia.b) En el mismo sujeto arroja aproximadamente los mismos resultados.c) Las respuestas a y b son correctas.d) Cuando fue probado un número suficiente de veces como para poder ser usado en la clínica.e) Ninguna de las anteriores es correcta.
24) Un experimento tiene validez interna cuando:
a) Se pueden extender sus resultados a toda la población.b) Puede controlar mejor las variables extrañas.c) Ha logrado probar sin ninguna duda la influencia de la VI.d) Las respuestas a y b son correctas.e) Las respuestas a, b y c son correctas.
25) ¿Para qué se necesita conocer la pre-medida?
a) Cuando se sospecha que las pre-medidas de los grupos experimental y de control son iguales.b) Cuando se sospecha que las pre-medidas de los grupos experimental y de control son diferentes.c) Cuando se sospecha que existe interacción.d) Las respuestas a y c son correctas.e) Las respuestas b y c son correctas.
26) ¿Qué es una condición contribuyente?
a) Es una condición necesaria pero no suficiente.b) Es una condición que aumenta la probabilidad que se produzca un determinado fenómeno, pero no lo hace seguro.c) Es la serie de condiciones bajo las cuales una determinada variable es causa contribuyente.d) Las respuestas b y c son correctas.e) Es una condición necesaria y suficiente.
27) Si se quiere probar que la relación X-Y es causal…
a) Se hace una prueba de espureidad.b) Se aplica un diseño experimental.c) Se busca anular la influencia de otras variables.d) Las respuestas a y c son correctas.e) Las respuestas b y c son correctas.
28) La premedida es:
a) Una medida de la variable independiente.b) Una medida de la variable dependiente.c) Una medida que se realiza antes de la aplicación de la variable dependiente.d) Cualquiera de las anteriores es correcta.e) Ninguna de las anteriores es correcta.
29) Una variable simple:
Página 300 de 314
300

a) No tiene dimensiones ni indicadores.b) Tiene pocas dimensiones y muchos indicadores.c) Es una variable empírica.d) Tiene pocos indicadores y pocas dimensiones.e) Tiene una sola dimensión.
30) Una frecuencia es:
a) Un número que indica cantidad de unidades de análisis.b) Un número indicativo del tamaño de la muestra.c) Una medida estadística de dispersión.d) Un número que resulta del entrecruzamiento de dos categorías.e) Todas las anteriores son correctas.
Respuestas a los Multiple Choice
1 D 6 E 11 E 16 B 21 C 26 B2 C 7 C 12 E 17 A 22 B 27 E3 D 8 E 13 C 18 C 23 A 28 B4 A 9 E 14 E 19 D 24 B 29 C5 C 10 D 15 D 20 B 25 E 30 A
ANEXO 2. EJERCITACIONES VARIAS
1) Analizar los datos de los siguientes cuadros:
Cuadro 1. Carrera elegida según sexo en la Provincia de Buenos Aires (1995)
Humanidades
Técnicas
Total
Varones
350 2300 2650
Mujeres 1200 240 1440Total 1550 2540 4090
Cuadro 2. Afiliación política según nivel de institución en adultos de Capital Federal (1997)
Nivel de instrucción
% afiliados
Primaria 60 %Secundaria 25 %Terciaria 15 %
Total 100 %
Cuadro 3. Deserción escolar según clase social en alumnos del partido de La Matanza en el período 1980-1995
Deserción durante 1º a 4º
Deserción durante 5º a 7º
Clase AClase BClase C 1Clase C 2Clase C 3Clase DClase E
2 %5 %6 %8 %
10 %19 %50 %
3 %4 %7 %7 %
13 %17 %49 %
Total 100 % 100 %
Cuadro 4. Cantidad de palabras memorizadas en 5 minutos de exposición, según edad
0-3 4-7 8-11 Total10 años15 años20 años
50 %20 %10 %
33 %30 %25 %
17 %50 %65 %
100 %100 %100 %
Cuadro 5. Porcentaje de oyentes según edad y tipo de programa
Tipo de programa radial EdadJóvenes Viejos
Programas religiosos 17% 26%Programas de discusión 34% 45%Programas de música clásica
30% 29%
Total de casos 1000 1300
Cuadro 6. Porcentaje de oyentes según edad, nivel de educación y tipo de programa radial
Página 301 de 314
301

Tipo de programa radial EducaciónAlta BajaEdad Edad
Jóvenes Ancianos
Jóvenes Ancianos
Programas religiosos 9% 11% 29% 32%
Programas de discusión 40% 55% 25% 40%Programas de música clásica
32% 52% 28% 19%
2) Lea atentamente cada ítem y, para cada uno, responda las consignas de abajo.
a) Una investigación demostró que las personas tendían a atribuir sus éxitos a factores internos y sus fracasos a factores externos.b) Una investigación realizada en EEUU, reveló que la creatividad disminuía cuando las personas cumplían menos horas de sueño.c) Una investigación estudió cómo incide la situación familiar en niños de escolaridad primaria sobre el fracaso escolar.d) Un estudio de Asch mostró que a partir de un solo rasgo central (por ejemplo, si es afectuoso o frío) coloreamos toda nuestra impresión sobre una persona, quedando los otros rasgos en segundo plano.e) En una empresa se observó que desde hace tres meses el rendimiento promedio de los obreros bajó sensiblemente. Se atribuyó esto al hecho de que hace justamente tres meses se decidió suspender por economía la música funcional de la planta, y destinar el dinero a pintar los interiores de la fábrica con otro color (antes era verde y ahora celeste).f) A 200 personas se las interrogó con un cuestionario acerca de su opinión sobre el aborto, y se comprobó que estas opiniones eran sustancialmente diferentes en 35 e ellas, que eran justamente las únicas que habían tenido al menos una experiencia personal (ella o su pareja habían abortado al menos una vez).
a) Identificar variables independientes X variables dependientes Y.b) Clasificar y categorizar ambas variables.c) Proponer un indicador para alguna de las variables.d) Construir un cuadro con frecuencias que confirmen la hipótesis del enunciado.e) ¿Qué tipo de diseño de investigación se utilizó o podría utilizarse?
3) Una investigación para indagar la relación entre el rendimiento escolar y el tipo de vínculo conyugal de los padres arrojó los siguientes resultados:
Padres casados
Padres separados
Total
Buen rendimiento 88 45 133Mediano rendimiento
51 37 88
Bajo rendimiento 25 78 103Total 164 160 324
a) ¿Cuál es X y cuál es Y?b) ¿Cuál es el tamaño de la muestra?c) ¿Cuál es la unidad del análisis?d) Extraer las frecuencias porcentuales verticales y las horizontales.e) ¿Qué significado empírico tienen las cifras 51 y 103?f) ¿Qué conclusiones sacaría de la lectura del cuadro?
4) Una investigación arrojó los siguientes resultados:
50 estudiantes secundarios tienen un CI entre 149-130.13 estudiantes universitarios tienen un CI entre 109-90.El tamaño de la muestra es 350.El total de estudiantes secundarios con CI 149-130 es de 170.85 estudiantes secundarios tienen un CI entre 109-90.El total de alumnos universitarios en de 190.
a) ¿Cuál es la unidad de análisis?b) ¿Cuál es X y cuál es Y, y cuáles son sus categorías?c) ¿En qué nivel de medición se miden esas variables?d) A partir de los datos expuestos, construya un cuadro indicando todas las frecuencias.e) ¿Qué conclusiones puede sacar de la lectura de la tabla?
5) El cuadro I parece mostrar que el nivel educacional influye sobre la intención de votar.
Cuadro I
Intención de votarSecundari
a92 %
Primaria 82 %
Cuadro II
Página 302 de 314
302

Intención de votarSecundario
Primario
Mucho interés 99 % 98 %Mediano interés
93 % 90 %
Poco interés 56 % 59 %
¿El cuadro II confirma la anterior suposición? ¿O muestra que en realidad lo que influye directamente sobre la intención de votar es el interés político? ¿Por qué?
6) Determinar qué variable no presenta correlación con la variable de sexo.
% de mujeresCarreras humanísticas
Carreras técnicas
1930
53 % 52 %
1950
66 % 65 %
1970
78 % 79 %
7) En los siguientes casos indicar cuál es la variable independiente y cuál la dependiente:
Aprendizaje – Necesidad de aprobación.Lugar geográfico – Clima.Fuerza de una hipótesis – Frecuencia de confirmación pasada.Personalidad – Conducta.Temor – Acatamiento a una norma.Inteligencia – Alimentación en la infancia.
8) En un estudio se buscaron correlacionarlas variables deserción escolar, drogadicción, clase social y zona geográfica, y se resumieron los resultados en varias cuadros bivariados.
a) ¿Cuál podría ser la variable dependiente, y cuáles las independientes?b) ¿Es un estudio exploratorio, descriptivo o explicativo?
9) Una investigación en EEUU arrojó los siguientes resultados:
El 62 % de los protestantes son republicanosEl 65 % de los católicos son demócratasEl 80 % de los republicanos son empleadosEl 80 % de los demócratas son obreros
a) Partiendo de la base que esta investigación fue hecha para saber qué factores influyen sobre la preferencia política, especifique cuál es la variable dependiente.b) ¿Cuáles son las variables independientes?
10) Se desea averiguar qué tipo de programas de radio (música clásica, religioso, de discusión) escuchan los adultos según el sexo.
a) Confeccionar el cuestionario tipo para recolectar datos.b) Administre los cuestionarios a 20 personas.b) Vuelque la información obtenida en una matriz de datos.c) Resuma los datos de esta matriz en un cuadro bivariado.e) Analice el cuadro obtenido.
11) Construya un cuadro bivariado que muestre que existe una correlación en la siguiente hipótesis: “Cuanto más satisfecho está el obrero con su trabajo, mayor participación tiene en actividades comunitarias”. Obtenga previamente dos categorías para cada variable.
ANEXO 3. EJERCITACIÓN CON INVESTIGACIONES
Los siguientes resúmenes de investigaciones pueden servir de ejercitación para aprender a identificar variables independientes, dependientes y extrañas, tipos de diseños de investigación, tipos de muestreo, tipos de instrumentos de medición, formas de cumplir las diferentes etapas de la investigación y otros conceptos explicados en este libro. Las investigaciones 1 a 18 son de Psicología, y las investigaciones 19 a 26 son de Odontología.
1) El 66 por ciento de los superdotados tiene bajo rendimiento escolar
Aunque resulte paradójico, el fracaso escolar puede ser consecuencia de una elevada inteligencia. Así se desprende de las estadísticas. En España, alrededor del 2 por ciento de la población escolar es superdotada. Es decir, en cada clase, al menos un niño tiene un coeficiente intelectual por encima de los 130 puntos. Sin embargo, el 66 por ciento de estos tiene un bajo rendimiento escolar que la mayoría de las veces desemboca en fracaso.
Página 303 de 314
303

En España, se calcula que alrededor del 2 por ciento de la población escolar es superdotada, lo que significa que uno de cada 25 niños puede serlo. Es decir, en cada clase puede haber al menos uno de estos alumnos. Sin embargo, a pesar de su inteligencia, el 66 por ciento de los superdotados tiene un bajo rendimiento escolar, que, en muchos casos, llega incluso al fracaso, según datos de los últimos estudios internacionales. «Este porcentaje tan elevado se debe a que en las clases ordinarias, se aburren al no disponer de los recursos técnicos y materiales necesarios para desarrollar sus capacidades», explica el presidente de la Asociación Española de Superdotados y con Talento (AEST), Esteban Sánchez. El fracaso escolar radica también en el hecho de que no cuentan con profesores preparados, así como la inexistencia de tareas apropiadas donde poder demostrar sus habilidades. La desmotivación ante los trabajos, el aburrimiento y las escasas posibilidades para desarrollar su creatividad hacen que en muchas ocasiones el profesor califique al niño de «poco brillante». «Es lógico pensar que todos los niños superdotados, desde que entran en la escuela presenten un bajo rendimiento escolar, ya que la enseñanza no se ajusta a su nivel de aprendizaje», explica la directora del centro «Huerta del Rey», Yolanda Benito, en un extenso informe publicado por este centro. Un claro ejemplo es la contestación que un niño de 5 años daba a sus compañeros: «Vosotros empezar a hacer los deberes que yo os pillo». I. Gallego. Recorte del diario ABC, de Madrid. http://www.eltercertiempo.net/recortes/recort10.htm
2) El trato en el trabajo se refleja en la casa
Cuando los padres llegan a casa, generalmente tienen dos alternativas: estar relajados, con ganas de compartir y jugar con sus hijos o sentirse cansados, agobiados y lo único que ambicionan es estar solos.Según un reciente estudio, el comportamiento que tenga cada padre en el hogar está estrechamente relacionado con la forma en que lo tratan en su trabajo.Los padres cuyos trabajos están claramente definidos, que tienen autonomía y jefes comprensivos tienden a tener una mayor autoestima y tratan a sus hijos con más aceptación y cariño, de acuerdo con el estudio de la Universidad de Illinois, EEUU. Asimismo tienden a usar un sistema de disciplina menos estricto.La investigación que se basó en 59 personas donde ambos padres trabajan muestra una fuerte relación entre condiciones de trabajo, autoestima y paternidad.Estos resultados son similares a los de un estudio realizado entre profesionales que también evidencia que los padres que están bien en su trabajo y se sienten "buenos proveedores" tienen una relación más cariñosa con sus hijos. A la inversa, "los hombres que tienen días estresantes y agotadores, tienden a llegar a casa y aislarse" de los otros miembros de la familia, dice la Dra. Maureen Perry-Jenkins, coautora del estudio.Investigaciones del Instituto de la Familia y el Trabajo, de Nueva York, afirma que las familias con frecuencia sufren el impacto del estrés del trabajo. Richard Capuzzo, administrador de una panadería, a menudo sale en bicicleta con sus hijas y después del trabajo pasa a buscar a su pequeña de tres años del jardín de infantes. Pero cuando antes trabajaba en una imprenta, llegaba a casa tan cansado que se aislaba.La Dra. Perry-Jenkins dice que la investigación sugiere que los esfuerzos de los empleadores para crear un ambiente de trabajo sano y justo también ayuda a mejorar la vida familiar de sus empleados.Sin indicación de fuente.
3) Leer el diario mejora a la gente
La lectura del diario ejerce una influencia moderadora y actúa como una fuerza estabilizadora sobre la cultura política de un país.La televisión no sólo inhibe la voluntad de las personas para participar activamente como miembros de la sociedad sino la confianza en el prójimo y en el gobierno. A estas conclusiones llegaron -por lo menos para los Estados Unidos- los sociólogos y demógrafos después de recientes estudios sobre comportamiento social y consumo de los diversos medios de comunicación.El profesor de Harvard Robert D. Putnam rompió filas respecto de sus colegas durante la conferencia anual de la Asociación Norteamericana de Ciencias Políticas, celebrada en Chicago. Sus colegas discutían principalmente si la victoria republicana en las elecciones legislativas de 1994 representó el comienzo de una nueva etapa o si fue un resultado accidental. Putnam sostiene que desde la irrupción de la TV en los años cincuenta, la confianza y el compromiso social -el "capital social" de los Estados Unidos- comenzaron a debilitarse gradualmente.Confianza y compromiso.- El profesor Putnam observó que inclusive entre las personas de distinto nivel de educación había una interrelación entre la cantidad de tiempo que la gente pasaba frente al aparato de TV y el grado de predisposición que poseían para incorporarse a un grupo social y el grado de confianza -incluyendo la confianza política- que tenían en su gobierno.Esto significa que los niveles de compromiso y confianza disminuyeron en relación con la cantidad de tiempo frente al televisor. Putnam descubrió también cierta diferencia entre las generaciones nacidas antes de la Segunda Guerra Mundial, más comprometidas y satisfechas, y las que nacieron después y quedaron expuestas a la TV. El profesor de Harvard está convencido de que cuanto más uno lee diarios, tanta más confianza tiene, mientras que cuanto más mira televisión, tanta menos confianza adquiere.Una reciente encuesta realizada por la Universidad de Ohío junto con el Servicio de Noticias Scripps Howard reveló resultados similares. El sondeo mostró una clara relación entre el consumo de noticias y la participación electoral. El 76% de las personas que habitualmente seguían las alternativas de la política internacional por televisión y en los diarios votó en las últimas elecciones legislativas norteamericanas. El porcentaje de los votantes indiferentes a las noticias fue sólo la mitad. Sin embargo, los demógrafos descubrieron que un número desproporcionadamente elevado de personas de este grupo estaba disconforme con el Gobierno, las leyes y la Constitución.Años de lectura.- La encuesta reveló que cuanto más años tiene la gente, tanto mayor es la probabilidad de que lean diarios y voten en las elecciones. Sin embargo, no se puede culpar a la TV por la baja afluencia de votantes en las elecciones norteamericanas -generalmente entre 50 y 60%- porque antes de que existiera la televisión las cifras eran inclusive más bajas.La encuesta de la Universidad de Ohío apuntala la opinión de Putnam de que la TV lleva a tener menos confianza en los políticos y funcionarios del gobierno. Indicó que los lectores de diarios tienden a tener un criterio más equilibrado y positivo de las cosas que quienes sólo miran televisión. Curtis Gans, director de la Comisión para el estudio del electorado norteamericano, cree tener una explicación: "La información que reciben los lectores del diarios no es tan generalizada y simplificada. La influencia de los medios visuales no es liberal ni conservadora, sino visual. La TV nos presenta imágenes de las luchas de poder en lugar de mostrar los aspectos sustanciales de la obra de gobierno". El actual ánimo político no parece reflejar realmente un creciente sentimiento contra las altas esferas políticas de
Página 304 de 314
304

Washington, una pérdida de confianza tanto en los demócratas, que predominan en la Casa Blanca, como en los republicanos, cuyo predominio se halla en el Congreso. Hace poco, una encuesta realizada por el diario The New York Times y la CBS News indicó que el 55% del electorado vería con beneplácito la aparición de un nuevo partido independiente. De acuerdo con la mayoría de los consultados, su misión debería "representar al pueblo".Los demógrafos hablan acerca de uno de los niveles más bajos del ánimo pólítico del electorado norteamericano en los últimos tiempos. El 59% de los consultados no consiguió nombrar a un solo político norteamericano de su admiración y solamente el 6% nombró al presidente. El 79% incluso fue de la opinión de que el gobierno estaba controlado por un reducido grupo de gente influyente con intereses específicos y que los utilizaban para su propio beneficio. La alienación entre los gobernantes y los gobernados en los Estados Unidos no es un descubrimiento. Lo novedoso, sin embargo, es que el profesor Putnam cree haber identificado lo que por lo menos es en parte responsable de esa alienación: la TV norteamericana. Los primeros capítulos de la serie "La telecracia" están en el aire.Diario La Nación, Buenos Aires.
4) Lo peor de los viajes puede ser la vuelta
Olvídese de la ansiedad de separación. Llegar a casa a veces es lo más difícil. Los matrimonios pueden fracasar cuando uno de los esposos viaja extensamente. Pero la tensión puede aumentar no cuando están separados, sino cuando están juntos.Una investigación sobre viajes de trabajo y separación familiar del doctor en Psicología de la Universidad de Carolina del Sur, Frederic Medway, descubrió que algunos trabajadores no llegan de sus viajes con la mejor de las sonrisas. "Las parejas de algunos ejecutivos se han quejado que cuando sus esposos vuelven a casa después de un largo viaje, lo primero que dicen es 'Dónde está el correo?' y a la esposa le dan ganas de decir '¿Y yo que soy, una foto en la pared?'", relata el Dr. Medway. Típicamente, las peleas ocurren porque el que viaja y el que se queda en casa tienen diferentes percepciones sobre lo que realmente pasa en un viaje de negocios. Lo que para el viajero son una serie de aburridos aeropuertos y hoteles solitarios, para el que se queda son comidas elegantes y aventuras de cinco estrellas.Lo que es más, ambos creen que merecen algún tipo de compensación. El que se quedó lidiando con el mantenimiento de la casa y el cuidado de los hijos quiere salir a comer afuera y recibir regalos. Por su parte, el cansado viajero desea una comida hecha en casa y tiempo para relajarse. Según el Dr. Medway los hoteles pueden regalar juguetes que no sean muy caros para los niños que quedaron en casa, pero lo más importante es que ambos esposos se comuniquen mejor sobre lo que hacen mientras el otro está de viaje.Sin indicación de fuente.
5) Actitudes frente a la delincuencia
La participación de la sociedad en actividades de prevención de la delincuencia depende tanto del conocimiento, como de las actitudes que la colectividad tiene sobre estas iniciativas preventivas. De dichos conocimientos y actitudes depende la colaboración de la ciudadanía. Pero también los profesionales ligados directa o indirectamente a la delincuencia tienen su importancia.Opinión pública y delincuencia.- Algunas investigaciones mostraron una actitud negativa de la opinión pública hacia los delincuentes, mientras otras revelaron que los consideraban personas normales, capaces de modificar su comportamiento.La opinión pública ve la delincuencia como el producto de muchas causas, y distintas según cada delito. Por ejemplo las violaciones eran adjudicadas a inestabilidad mental y educación deficiente, los robos a la influencia ambiental, etc. Se vio también que las personas autoritarias y conservadoras tienden a promover el 'castigo' de los delincuentes, y quienes apoyan mas bien una rehabilitación son aquellos que ven en la delincuencia causas sociales y económicas.Son diversas las actitudes hacia la gravedad de los delitos, la severidad de los castigos y el tratamiento de los delincuentes. Así, la percepción de los delitos depende del nivel educativo-cultural: cuanto mayor nivel cultural, menos prejuicios y más flexibilidad hay ante el delincuente. En general, sin embargo, la opinión pública es más severa que los jueces cuando se trata de castigar al delincuente.Los delitos violentos son los que más llaman la atención de los ciudadanos, estimulados a su vez por los medios de comunicación. La delincuencia de cuello blanco parece ser considerada menos grave por la opinión pública.Las investigaciones sobre actitudes hacia la delincuencia deben ser en general más precisas y cuidadosas para poder ser tenidas en cuenta a la hora de instrumentar políticas de justicia penal. Por ejemplo, deben especificar los tipos de actitudes sobre tipos de delincuente y formas de delincuencia.Actitudes de profesionales relacionados con la delincuencia.- Los profesionales de la salud presentan en general actitudes desfavorables hacia pacientes etiquetados como delincuentes o psicópatas. Otras investigaciones revelaron que en el momento de tratarlos, se vieron actitudes favorables en psiquiatras y asistentes sociales. Los médicos en particular tienden a adjudicar a la delincuencia causas orgánicas, como por ejemplo el consumo de estupefacientes.Por su parte los funcionarios de las cárceles son más benevolentes al juzgar la delincuencia, y lo mismo respecto de los policías, aunque hay variaciones según cada establecimiento penitenciario. Asimismo y en oposición a los profesionales de la salud, los funcionarios carcelarios y policías tienen actitudes menos favorables hacia las causas socioambientales y las medidas de prevención y los tratamientos rehabilitadores.En cuanto a la actitud de los funcionarios judiciales, estas varían según el nivel educacional y su ocupación. Los jurados de mayor nivel educativo tienen actitudes menos estereotipadas hacia la delincuencia, y tienden a considerar cada caso particular. Los abogados defensores tienden por su parte a considerar menos culpables a los delincuentes, y los jueces mostraron actitudes neutras; estos últimos también adjudican las causas de la delincuencia al área socioambiental.Conclusiones.- En general, la opinión pública es favorable a la rehabilitación de los presos. Los profesionales de los medios de comunicación ejercen mucha influencia sobre las medidas de prevención y tratamiento de los delincuentes, e influyen sobre la opinión pública al respecto.Ortet y Fabregat, “La delincuencia: opinión pública y actitudes de profesionales”.
6) Relación entre la fecha del cumpleaños y la fecha de muerte
Casi la mitad de la gente muere en los tres meses posteriores a su último cumpleaños, según un estudio dirigido por un sociólogo de la Universidad Brigham Young, Phillip Kunz. Tras examinar 747 muestras aleatorias de obituarios publicados en Salt Lake City durante 1975, Kunz encontró que el 46 por ciento de las muertes ocurría dentro de los tres primeros meses que seguían a su cumpleaños, y el 77 por ciento durante los primeros seis meses. Sólo el 8 por
Página 305 de 314
305

ciento fallecía durante los tres meses anteriores a este aniversario. La gente parece mirar hacia el futuro, y ve en los cumpleaños una meta que debe alcanzar. El periodo que sigue a la celebración es anticlimático, decepcionante, y puede llevar a la depresión y a la pérdida de las ganas de vivir.Isaac Asimov, en Muy Interesante N° 59, Bueno Aires, Setiembre 1990.
7) Hamacando al bebé
Los bebés prematuros crecen mejor si son balanceados en una hamaca en lugar de estar en una cuna, reveló un estudio holandés.En una investigación realizada en el Hospital de Niños de Wilhemins, en Utrecht, se mantuvo a 50 niños en incubadoras-hamacas durante sus primeras semanas de vida. El psicoterapeuta Paul Helders dijo que se mostraron más vivaces y respiraban más acompasadamente que los bebés mantenidos en las incubadoras corrientes. En su primer año también crecieron más que otros bebés, agregó. Helders empezó a pensar en las hamacas luego de estudiar el comportamiento fetal en el vientre materno y advertir que los bebés se veían como si estuvieran suspendidos de una hamaca.Posteriormente, durante el embarazo, los bebés se balancean en el vientre con el movimiento de sus madres. El hospital planea introducir hamacas en todas sus incubadoras.Diario La Nación, Buenos Aires, 28-3-89.
8) Efectos del avenimiento en los hijos
Un equipo de 20 médicos, psicólogos y especialistas en computación de la Universidad de Chile, dirigido por el Dr. Eyrer Klorman -actualmente profesor de posgrado de la UB- realizó durante dos años y medio una exploración de los efectos psíquicos en hijos de matrimonios bien avenidos, mal avenidos y separados. Entre las conclusiones más salientes se señalan estas:En relación con los hijos de matrimonios mal avenidos, los de parejas bien avenidas se ven a sí mismos como menos tímidos, menos agresivos, menos temerosos, menos deprimidos, más conformes con su propio sexo; se sienten más satisfechos con la pareja parental y queridos por ambos padres por igual.Las madres los notan con menor necesidad de llamar la atención y menos dependientes. A su vez los hijos de separados muestran conductas semejantes a los de mal avenidos; pero a diferencia de ellos, la madre es para ellos la fuente principal de afecto, y sienten lejano al padre. Tales niños parecen compensar esto último con el apoyo en un amigo de igual edad.Fantasías.- En relación con la separación los niños, sobretodo los preescolares y escolares, tienen fantasías de culpa a pesar de intuir o conocer las causas aducidas por sus padres. El verdadero motivo sería, según ellos, el haberles hecho la vida imposible.Una fantasía que se encontró desde los preescolares hasta los adolescentes es la recomposición de la pareja, aunque los padres hubieran establecido otros vínculos.Polos.- En los resultados de la investigación, en un polo quedaron los hijos de los matrimonios bienavenidos, y en el otro los de mal avenidos o separados. Los contrastes entre ambos campos son notorios, tanto en el rendimiento intelectual como en el comportamiento en general.Método.- La muestra se conformó así: en diferentes zonas de Santiago de Chile, en colegios de clase alta, media y baja se aplicaron a 1080 padres tres instrumentos: hoja de registro (identificación, ocupación, etc.),escala de clasificación social (estrato socioeconómico y educacional), escala de ajuste diádico para padres casados, que evalúa la aveniencia según el consenso de pareja, satisfacción de la relación, y cohesión (objetivos y actividades compartidas), y escala de ajuste diádico para padres separados.Selección.- De las 1080 familias se eligieron 270: 90 de clase alta, 90 de media y 90 de baja. Se hizo por computadora que la muestra comprendiera por partes iguales: 1) separación, buen avenimiento, mal avenimiento; 2) preescolares, escolares, adolescentes. La mitad, varones. Se cruzaron las variables y se consiguió una gran riqueza de datos.Desarrollo.- La investigación se desarrolló sobre las siguientes variables: status marital (separados, bien avenidos, mal avenidos); nivel socioeconómico; nivel de estudios; sexo. Se evaluaron las influencias de estas variables en el área física, intelectual y psicológica de los niños. A cada familia se le aplicaron estos instrumentos: Anamnesis (según pautas, la madre informa sobre el niño y la familia; entrevista al niño semiestructurada); entrevista (a casados, a separados. Pautada); entrevista a la madre sobre la vida social del niño; al profesor; entrevista a la madre y al padre sobre la relación con el hijo (actividades compartidas); tests de inteligencia; observación clínica del niño; entrevistas clínicas a padres e hijos para completar datos.Repitientes.- Como último resultado de interés general: el rendimiento intelectual es similar en los tres grupos por situación matrimonial, y se ve afectado por la pobreza, aunque sigue la distribución normal.En el número de repeticiones escolares, el grupo que más incurre en ellas es el de hijos de matrimonios malavenidos, seguidos muy de cerca por los de matrimonios separados. El que presenta menor número de repitientes es el de hijos de bien avenidos. Igual tendencia se observa con respecto a dificultades en concentración y atenciónDiario La Nación, Buenos Aires.
9) Dormir poco reduce la creatividad
Un estudioso británico, el Dr. James Horne, especializado en la investigación sobre el sueño y afecciones vinculadas con el mismo, asegura que el dormir poco afecta notablemente las capacidades creativas en el trabajo, Sobre todo perjudicaría la capacidad de enfrentar situaciones nuevas con rapidez mental y buen manejo de los problemas.Así lo informa una nota del "New York Times", transcripta por ANSA. Una sola noche de sueño perdido, por ejemplo, afecta seriamente la flexibilidad, espontaneidad y originalidad que permiten alas personas cambiar de perspectiva y romper esquemas fijos.Horne, especialista en psico-fisiología de la Universidad de Loughborough, en Inglaterra, dijo que su hallazgo parece corroborar la opinión generalizada que asigna al sueño una función de recuperación de la corteza cerebral frente al desgaste durante el día, cuando el individuo está despierto y en acción. La mente, con la pérdida de una noche de sueño, se vuelve más rígida y el sujeto se aferra a los esquemas ya conocidos no atinando a renovarse.Horne estudió a 24 estudiantes saludables determinando tiempos de razonamiento, flexibilidad, originalidad de pensamiento, capacidad de elaboración de ideas. Un test mostraba la foto de una persona ejecutando una acción ambigua. Los estudiantes debían escribir todas las preguntas que surgían en su mente y que pudieran ayudar a explicar la situación. Otro test incluyó preguntas como: ¿cuántas utilidades existen para una caja de cartón?, o ¿cuáles
Página 306 de 314
306

serían las consecuencias de algún suceso hasta ahora no imaginable, por ejemplo, si las nubes tuvieran líneas colgando de ellas y llegando hasta la Tierra? Los estudiantes fueron divididos en dos grupos. En los tests iniciales la respuesta, los resultados generales, fueron más o menos iguales. Luego un grupo pasó una noche en vela y el otro durmió. El día siguiente el rendimiento del grupo desvelado fue mucho más bajo y preguntas, respuestas e ideas se mostraron menos originales.El doctor Horne señaló que el hallazgo tiene utilidad para la conducta de los estudiantes antes del examen. El pasar una noche entera estudiando para saber más en el examen del día siguiente podría ser útil para responder a preguntas de elección múltiple, pero no en absoluto si hay que disertar sobre un tema o analizar un problema nuevo. También para los trabajadores en cuya tarea es importante la comunicación oral, las noches en vela pueden ser perjudiciales pues su vocabulario se restringirá y se aplicarán los esquemas ya conocidos, faltando originalidad.Diario La Prensa, Buenos Aires, 1989.
10) Terapia familiar y enuresis
Resumen.- En este trabajo se describe un abordaje familiar para el tratamiento de la enuresis. La estrategia utilizada focaliza la terapia en el nivel del problema real (más allá de la enuresis), abarcando los aspectos individuales y de los contextos familiar y social que mantienen la disfuncionalidad. Un contexto terapéutico que fortalece la competencia familiar, consigue que la familia se sienta artífice de los cambios y que el niño se encuentre motivado para desarrollar sus posibilidades y alcanzar un nivel de comportamientos acordes a su edad. Se inicia así un proceso de crecimiento familiar que favorece la resolución del síntoma. Sobre un total de 40 casos tratados en periodos de 3 a 12 meses, se logró modificar en 37 de ellos los aspectos disfuncionales del sistema con el consiguiente levantamiento del síntoma” (Burrone y Capelluto, 1987:9).Burrone T y Capelluto D, Terapia familiar y enuresis. Buenos Aires: Revista Sistemas familiares. Diciembre 1987, páginas 9-15.
11) Obediencia a órdenes criminales
Stanley Milgram señala que la obediencia a la autoridad, una característica tradicionalmente alabada como virtud, toma un aspecto nuevo cuando sirve a una causa malévola y, lejos de quedar como virtud se transforma en un pecado atroz.Para poder estudiar más de cerca el acto de obedecer, Milgram realizó un experimento en la Universidad deYale que involucró más de mil participantes y fue repetido en varias universidades.En síntesis, el experimento consiste en lo siguiente: una persona concurre a un laboratorio de psicología y le dicen que ejecute una serie de actos que entran cada vez más en conflicto con su conciencia. ¿Hasta cuándo el participante cumplirá con las instrucciones del experimentador antes de negarse a ejecutar las acciones que se le exigen?Los detalles del experimento son los siguientes: dos personas concurren al laboratorio de psicología para participar en un estudio de memorización y aprendizaje. Uno de ellos es designado como "maestro" y el otro como "alumno". El experimentador explica que el estudio trata de los efectos del "refuerzo negativo" sobre el aprendizaje. Al "alumno" lo llevan a un cuarto, lo sientan en un sillón, le sujetan los brazos para evitar el movimiento excesivo y le fijan un electrodo en la muñeca. Le dicen que debe aprender una lista de pares de palabras y cada vez que comete un error recibe un refuerzo "negativo". La cualidad civilizada del lenguaje enmascara el hecho sencillo de que el hombre va a recibir una descarga eléctrica.El verdadero centro del experimento es el "maestro". Después de observar cómo atan al "alumno" al sillón, el "maestro" es llevado al cuarto principal del experimento y lo sientan delante de un impresionante generador de corriente. Lo más notable de este aparato es una línea horizontal compuesta por 30 llaves que indican la potencia de la descarga que varía entre 15 y 450 volts, con incrementos de a 15 volts. Hay también títulos que varían entre "descarga leve" y "peligro-choque severo". Al "maestro" se le dice que debe administrar el test de aprendizaje al "alumno" leyendo la primera palabra de cada par; cuando el "alumno" responde correctamente recitando la segunda palabra del par, el "maestro" sigue con el ítem siguiente; cuando el "alumno" da una respuesta incorrecta, el "maestro" debe castigarlo aplicándole una descarga eléctrica empezando por el nivel más bajo (15 volts) y aumentando de nivel cada vez que el "alumno" comete un error, pasando por 30 volts, 45 volts, etc.El "maestro" es un sujeto verdaderamente ingenuo que ha venido al laboratorio para participar de un experimento. El "alumno", la víctima, es un actor que en realidad no recibe ninguna descarga.El objetivo del experimento es simplemente averiguar hasta donde procederá una persona en una situación concreta y mensurable en la cual le ordenan infligir cada vez más dolor a la víctima que protesta. ¿A qué punto rehusará el sujeto obedecer al experimentador? El conflicto surge cuando el hombre que recibe la descarga empieza a manifestar desagrado. Antes de los 75 volts no hay respuesta de protesta. A los 75, el "alumno" gruñe. A los 120 se queja verbalmente; a los 150 exige que lo saquen del experimento. A medida que las descargas se elevan, sus protestas se acentúan y son cada vez más intensivas y emocionales. A los 285 volts su respuesta sólo puede describirse como un grito de agonía.La cualidad angustiosa del experimento se oscurece bastante en las palabras escritas. Para el "maestro" la situación no es un juego: el conflicto es intenso y manifiesto. Por un lado el sufrimiento patente del "alumno" lo presiona para que desista. Por el otro el experimentador, una autoridad legítima con quien el sujeto se siente algo comprometido, le ordena que siga. Cada vez que el "maestro" vacila en administrar una descarga, el experimentador aplica sucesivamente cuatro estímulos verbales: "siga, por favor", "el experimento requiere que usted siga", es absolutamente necesario que usted siga", y finalmente "usted no tiene otra alternativa más que seguir".Para desenredarse de la situación, el sujeto debe hacer una ruptura clara con la autoridad. El objetivo de esta investigación es encontrar cuándo y cómo la gente desafiaría la autoridad frente a un imperativo moral claro.Vander Zanden J, "Manual de Psicología social", Barcelona, Paidós, 1986.
12) Sueños de los animales
Casi todo el mundo ha visto a los animales domésticos, mientras duermen, gimotear, crispárseles los bigotes y agitar las patas en una aparente persecución de conejos imaginarios. ¿Pero realmente sueñan? Puesto que los animales no pueden despertarse a la mañana y describir sus sueños, la cuestión parecía irresoluble.Pero, recientemente, el doctor Charles Vaughan, de la Universidad de Pittsburgh, concibió un ingenioso experimento para que los animales puedan informarnos, finalmente, si en realidad sueñan. Se colocamos monos rhesus en cabinas frente a una pantalla, y se les enseñó a presionar una barra toda vez que veían una imagen en la pantalla. Luego se
Página 307 de 314
307

conectaron los monos a una máquina encefalográfica y se los colocó nuevamente en sus cabinas especiales. Poco después de dormirse, el EEG registró los rostros especiales que produce el cerebro dormido de los monos. Pero lo más importante fue que, mientras dormían los monos presionaban ansiosamente las barras. Evidentemente veían imágenes en las pantallas de sus mentes: soñaban. O al menos, es lo que cree el doctor Vaughan.Copi I (1974), Introducción a la lógica. Buenos Aires: Eudeba. 15ª edición, página 528.
13) Fuentes de error en el razonamiento silogistico
Los autores describen en este artículo un experimento donde se muestra que los sujetos que están realizando una tarea de razonamiento no responden de una forma no lógica (como sostiene la hipótesis del efecto atmósfera), sino que atienden a la estructura lógica del material. No obstante esto, los sujetos pueden cometer dos tipos de error: a) pueden interpretar erróneamente las premisas en el sentido de que una proposición que debe tomarse como si se refiriera a múltiples relaciones posibles se toma, por el contrario, como haciendo referencia sólo a una de esas relaciones; y b) el sujeto puede deducir de las premisas sólo una relación en casos en los que resulta necesario deducir múltiples relaciones posibles. Así, los sujetos no son alógicos: la interpretación de la premisa elegida “es” una de las interpretaciones posibles, y la relación deducida “es” una de las relaciones que se pueden deducir.Más detalles:En este artículo se describe un experimento –supervisado por Henle- que intenta refutar la hipótesis del efecto atmósfera, que es una de las teorías “no lógicas” sobre el pensamiento. En efecto, los autores describen en este artículo un experimento donde se muestra que los sujetos que están realizando una tarea de razonamiento no responden de una forma no lógica (como sostiene la hipótesis del efecto atmósfera), sino que atienden a la estructura lógica del material.No obstante esto, los sujetos pueden cometer dos tipos de error:a) pueden interpretar erróneamente las premisas en el sentido de que una proposición que debe tomarse como si se refiriera a múltiples relaciones posibles se toma, por el contrario, como haciendo referencia sólo a una de esas relaciones; (por ejemplo “Todo A es B” puede interpretarse como “Todo A es B y todo B a A”, o bien como “Todo A es B pero no todo B es A”).b) pueden deducir de las premisas sólo una relación en casos en los que resulta necesario deducir múltiples relaciones posibles. Así, los sujetos no son alógicos: la interpretación de la premisa elegida “es” una de las interpretaciones posibles, y la relación deducida “es” una de las relaciones que se pueden deducir.El experimento consistió en lo siguiente. Se tomaron dos grupos de personas:El grupo T, al que se le dieron silogismos tradicionales.El grupo M, al que se le dieron silogismos modificados.La diferencia radica en que los silogismos modificados tienen premisas unívocas, es decir, no pueden ser interpretadas erróneamente, con lo cual, si en el grupo M se cometen errores, entonces deben ser adjudicados no a la interpretación errónea de las premisas sino a la deducción de una sola de las posibles conclusiones deducibles.La fuente de error en el caso M no está en la incapacidad para deducir una relación a partir de las premisas (esto lo hacen muy bien como se muestra en el primer grupo). Mas bien el problema parece deberse a su fracaso para deducir las múltiples relaciones posibles y en decidirse por una respuesta que sea apropiada para todas esas relaciones.Este tipo de razonamiento incompleto es semejante al tipo de pensamiento cotidiano del tipo “puede ser”. Por ejemplo, a partir de cierto conocimiento sobre automóviles y sabiendo que acaba de llover, podemos inferir que no arranca porque los cables están húmedos. Si este análisis se muestra insuficiente podemos considerar otras alternativas. sin embargo, en un silogismo no existe retroalimentación y los sujetos quedan satisfechos con la conclusión a la que llegaron.Ceraso J y Provitera A, Fuentes de error en el razonamiento silogístico, artículo incluído en “Investigaciones sobre lógica y psicología” (traducido de “Sources of error in syllogistic reasoning”, Cognitive Psychologie, 2, 1971, 400-410).
14) Experiencias infantiles
Se ha dicho que las experiencias infantiles similares pueden originar características psíquicas comunes en ciertas categorías de individuos.Actualmente hay bastante acuerdo en que un aspecto aislado de la experiencia infantil no es significativo, a menos que sea reforzado por otras experiencias con un significado psicológico similar. Por ello últimamente han recibido consideración más que el destete o la edad en que se inculcan ciertos hábitos higiénicos, aspectos más globales de la crianza, como la severidad o indulgencia general, el grado de afecto que recibe el niño, principalmente de su madre, y el cuidado y protección que se le brinda. Este camino parece ser más fructífero, aún cuando estas cualidades o dimensiones son difíciles de medir. Hay ya alguna evidencia de que los niños difieren significativamente en varias características psíquicas según el grado en que su crianza puede caracterizarse respecto del afecto materno, la protección y la severidad del control familiar. Así, el afecto materno desalienta la agresividad y favorece la formación de la conciencia moral, y la libertad estimula el desarrollo intelectual.Adaptado de A de Babini, 1965. Educación familiar y status socio-económico. Instituto de Sociología.
15) Contacto con otras culturas y cambio de actitud
El contacto con otras culturas influye sobre los cambios de actitudes de las personas en el sentido de una mayor tolerancia y aceptación de puntos de vista diferentes al propio. Así por ejemplo, (Asch, 1959) la integración de soldados negros en compañías de infantería compuestas por blancos y su posterior actuación conjunta en el frente de guerra, produjo modificaciones de actitudes en estos últimos, favorables a dicha innovación. Sólo un 7% de los blancos integrados se mostró en oposición a tal medida contra un 62% de respuestas desfavorables obtenidas de divisiones íntegramente blancas.Un estudio experimental (Mc Guigan, 1968) realizado con alumnos americanos que estudiaron durante un año en Francia conviviendo con familias de este país, reveló en ellos una evidente disminución de sus prejuicios, sentimientos menos favorables a los norteamericanos y más favorables a los franceses, un mejor ajuste social y un mayor desarrollo de sus valores sociales.Las experiencias directas vividas "por los sujetos frente a situaciones donde tal vez deban reestructurar su repertorio de significados, disolver sus estereotipos y revisar conciente o inconcientemente los motivos que los llevan a aceptar o rechazar algún objeto referente, serán componentes obligados de todo programa que tienda al logro de ese tipo de objetivos" (Lafourcade, 1980).
Página 308 de 314
308

Asch Salomon (1959) Social Psychology. Prentice Hall Inc. Englewood Cliffs, Nueva Jersey, 5ta edición. (Traducción castellana: Eudeba, Buenos Aires, 1964, págs. 585-587).Mc Guigan F, Psychological changes related to intercultural experiences. Psychological report, 1958, 4.Lafourcade P (1980) Planeamiento, conducción y evaluación de la enseñanza superior. Buenos Aires: Kapelusz.
16) Efectos de la frustración en los juegos infantiles
Barker, Dembo y Lewin (1941) estudiaron los efectos de la frustración en los juegos de niños. Primero efectuaron la observación de niños de 5 años durante su juego normal. Cada niño fue llevado a una habitación donde encontraba juguetes sencillos con los que se le permitía jugar durante media hora. Durante dicho tiempo su juego iba siendo clasificado por un observador sobre una escala de 'constructividad'. A continuación se elevaba una pared corrediza; en la parte de la habitación ahora expuesta había una atractiva colección de juguetes. Cuando el niño se hallaba totalmente sumergido con ellos, el investigador tomaba al niño de la mano y lo llevaba a la parte de la habitación donde había estado jugando anteriormente, y cerraba con llave los juguetes detrás de una red a través de la cual el niño podía seguir viendo los nuevos juguetes.El juego del niño con los primeros juguetes fue puntuado nuevamente con el criterio de constructividad durante un periodo de media hora.La conclusión general fue que la frustración producía una regresión en el nivel de funcionamiento intelectual y aumentaba la infelicidad, inquietud y destructividad de los niños. La diferencia en puntuación de constructividad del juego durante los periodos de prefrustración y posfrustración fue tomada como evidencia del grado de regresión inducida por la experiencia frustrada. Al finalizar la experiencia, se permitió a los niños jugar cuanto desearan con los nuevos juquetes, con el fin de borrar los efectos de la frustración.Selltiz y otros, 1980, Métodos de Investigación en las relaciones sociales, Madrid, Rialp, págs.138-139.
17) Cuentos para olvidar
Un grupo de investigadoras argentinas diseñaron una serie de experimentos para identificar qué características hacen que unos mensajes sean más fáciles de recordar que otros, y qué tipo de textos permiten recuperar mayor cantidad y mejor calidad de información.El proyecto se desarrolló dentro de una línea de investigación destinada a mejorar la calidad de la enseñanza. En una de las experiencias, los investigadores solicitaron a 44 niños de tercer grado que leyeran atentamente tres cuentos cortos, y los contaran luego a otra persona.Utilizaron la fábula del zorro y la cigüeña, un cuento folclórico de un sapo que con su astucia ganó una batalla a un burro soberbio y una adaptación de un capítulo de Dailan Kifki, un elefante que busca nuevo dueño. Los chicos recuperaron suficiente información y pudieron contar el primer relato, pero fracasaron en los otros dos cuentos, especialmente en el del elefante, que no pudieron resumir ni volver a contar.“En una segunda etapa, utilizamos modelos que podrían predecir si el mensaje será comprendido, interpretado y recordado y señalar en qué lugares de los dos textos podrían presentarse problemas”, dice Signorini, una de las investigadoras.“Los modelos mostraron que la historia del zorro y la cigüeña podría ser comprendido y recordado con mayor facilidad que los otros dos relatos porque la fábula respeta la estructura tradicional de los cuentos, presenta los hechos estrechamente ligados entre sí por sus relaciones causales, y además, su formato facilita a los lectores la representación mental del texto”, puntualizó Marro, otra de las investigadoras.Fragmento de un artículo publicado en el diario Clarín, Buenos Aires.
18) En el principio, la palabra
Investigaciones recientes demuestran que hablar regularmente a los bebés durante el primer año de vida, tiene un profundo efecto positivo en el desarrollo de su cerebro y de su aptitud para aprender. El número de palabras dirigidas a las criaturas al día, constituye el estímulo más poderoso para agudizar la inteligencia y avivar la capacidad de razonar, de resolver problemas y de relacionarse con los demás. Cuantos más vocablos por hora escuche el pequeño, mejor. Las palabras no tienen que ser complicadas ni esotéricas, basta con que sean pronunciadas en tono afirmativo por un ser humano afable, atento, interesado y envuelto emocionalmente con el bebé. Los mensajes transmitidos por la radio o el televisor no tienen este impacto saludable.Los cimientos del pensamiento racional se establecen en los primeros meses de existencia, mucho antes de que la criatura muestre signo alguno de distinguir entre una idea abstracta, como ‘mañana’ o ‘ayer’ y su chupete. El cerebro del recién nacido está esperando ansiosamente recibir los primeros estímulos del nuevo entorno para configurar las conexiones entre los millones de neuronas que forman el entramado de materia gris que le va a permitir ser perceptivo, inteligente, adaptable y creativo (…).Los niños progresan más cuando están rodeados de personas que no solo son responsables y cariñosas, sino además habladoras (…). De todo lo cual se deduce la conveniencia de promover proyectos educativos para padres y cuidadores, lo mismo que programas de intervención precoz que fomenten la comunicación y el dinamismo verbal, tanto en el seno de la familia como en las guarderías.Vivimos en un océano de palabras, pero, como pasa a los peces en el agua, casi nunca somos concientes de que éstas enlazan nuestras actividades y fraguan las relaciones. Y en el caso de nuestros bebés, las palabras tienen además el poder de configurar las facultades del alma y, de paso, decidir su suerte.De la nota “El poder de las palabras”, por Luis Rojas Marcos en “El País Semanal”, de Madrid.
19) Prueba de susceptibilidad antimicrobiana de un material de obturación endodóntica
Resumen.- Los Estudios y ensayos de laboratorio “in vitro” realizados en el presente trabajo por P. L. R. M. (pasta lentamente reabsorbible de Maisto) confirman un efecto bacteriostático con todas las cepas de microorganismos estudiados: Fusobacterium periodonticum ATCC 33693 Prevotella Melaninogenica ATCC 439822 Porphyromonas endodontalis ATCC 35406 Staphylococcus sp, Streptococcus viridans y Streptococcus Grupo A, en períodos de 0 a 56 días y valores de 1 g hasta 0.5 mg/ml.Sierra L y otros. En Revista de la Sociedad Odontológica de La Plata. Año XIV, N 28, págs 25-29. Agosto 2001.
Página 309 de 314
309

20) Antibioticoterapia recibida por pacientes antes de su primera consulta a un especialista en Cirugía y Traumatología Buco Máximo Facial.
Resumen.- En el presente trabajo se realiza un estudio epidemiológico de 5009 pacientes atendidos en el Servicio de Odontología, Cirugía y Traumatología Buco Máximo Facial del H.I.E.A. y C. San Juan de Dios de La plata y en la asignatura Cirugía B de la Facultad de Odontología de la Universidad Nacional de La Plata, desde abril de 1997 a marzo de 1999. En dicho relevamiento se enfatizó la cantidad de pacientes que recibieron Antibioticoterapia antes de la primera consulta, cuál fue la droga re3cibida y si el paciente presentaba o no una intención que justificara su administración.Bercini C y otros. En Revista de la Sociedad Odontológica de La Plata. Año XIV, N 28, págs 25-29. Agosto 2001.
21) Selladores a base de ionómeros vítreos y resinas: estudio clínico comparativo en condiciones de campaña.
Resumen.- El objetivo de este trabajo consistió en comparar la eficacia de un sellador de autocurado a base y otro a base de ionómeros vítreos en condiciones de campaña. A los 24 meses de la única aplicación de ambos materiales, los selladores de resina presentaron una retención del 88,37 % y 81,98 % para maxilar superior e inferior respectivamente, siendo la misma del 25 % y 22,09 % en el caso de los selladores de ionómeros. No se registraron diferencias significativas en el desempeño de ambos materiales como preventivos de caries de fosas y fisuras.Esquivel S. En Revista de la Sociedad Odontológica de La Plata. Año XIV, N 28, págs 25-29. Agosto 2001.
22) Agrandamiento gingival inducido por ciclosporina. Forma de abordar su tratamiento
Resumen.- El objetivo del presente trabajo es difundir una opción de tratamiento válida para los agrandamientos gingivales farmacodependientes en especial los producidos por la ingesta de un potente inmunosupresor como es la ciclosporina A. El plan de tratamiento expuesto en este trabajo se basa en la evidencia científica disponible en la actualidad, tratando de resaltar la importancia que tiene el control de la enfermedad periodontal y las citas de mantenimiento para el éxito y estabilidad a largo plazo.Feser G y otros. En Revista de la Asociación Odontológica Argentina. Vol 93, N 1 / 45-46. Enero-Marzo 2005.
23) Caninos extralargos: análisis de su frecuencia e inconvenientes para el tratamiento endodóntico
Resumen.- La presencia de un canino o cualquier otra pieza dentaria que requiera un tratamiento endodóntico, y cuya raíz supere en longitud las medidas máximas con que son fabricados los instrumentos convencionales, puede crear un inconveniente serio para la realización de un tratamiento exitoso. En este trabajo, se analizaron las medidas anatómicas longitudinales de una muestra de 280 caninos superiores humanos extraídos, observándose que el 13,21 % presentaban longitudes que superaban los 31,0 mm. Estas medidas se incrementabas cuando las piezas analizadas presentaban diferentes grados de curvatura radicular. La importancia de informar acerca de este tipo de anomalía, radica en que si bien se presenta con poca frecuencia en la práctica, puede ocurrir, y el profesional deberá conocer cabalmente las variaciones morfológicas que pueden presentarse con el objeto de estar preparado para tratar adecuadamente el conducto radicular en toda su longitud.Zmener O y otros. En Revista de la Asociación Odontológica Argentina. Vol 93, N 1 / 13-16. Enero-Marzo 2005.
24) Candidiasis oral multifocal crónica
Resumen.- La Candidiasis es la patología micótica más conocida por el patólogo oral, siendo la misma marcadora de inmunodeficiencia. Es importante su seguimiento para determinar las circunstancias que permitieron su proliferación. En el presente trabajo se expone un caso clínico de un paciente masculino de 36 años con Candidiasis crónica hiperplásica con diferentes localizaciones intra orales, en un paciente inmunodeprimido.Godoy R y otro. En Revista de la Asociación Odontológica Argentina. Vol 92, N 5 / 425-428. Octubre-Diciembre 2004.
25) Análisis de la calidad de la obturación de perforaciones radiculares, obtenida por medio del sistema de gutapercha termoplastizada Thermafil Plus. Segunda parte
Los objetivos de este trabajo fueron evaluar la capacidad del sistema Thermafil Plus para obtener simultáneamente conductos radiculares curvos y perforaciones laterales artificiales en vitro y analizar el sellado marginal en las perforaciones obturadas.Resumen.- Se realizadon perforaciones radiculares en la cara mesial del conducto mediovestibular de 34 molares inferiores, que fueron previamente preparados con Orifice Shapers e instrumentos rotatorios ProFile 0,04 y 0,06. Los especimenes fueron preparados en dos grupos de 17 cada uno, obturando los conductos radiculares y las perforaciones de la siguiente forma: Grupo 1: sistema de gutapercha termoplastizada Thermafil Plus; Grupo 2: técnica de condensación lateral de conos de gutapercha. En ambos casos, se utilizó AH-26 como sellador. En comparación con la técnica de condensación lateral, el sistema Thermafil Plus permitió obtener obturaciones radiográficamente más densas y mejor adaptadas a las paredes dentinarias, si bien se registró una mayor proporción de sobreobturaciones. La densidad radiográfica de material que obtura las perforaciones, la observación microscópica del material detectado en la desembocadura de las mismas sobre la superficie radicular y el análisis del sellado marginal obtenido en las perforaciones, revelaron que el sistema Thermafil Plus resultó ser significativamente más efectivo (p<0,05) para obturar simultáneamente conductos radiculares curvos y perforaciones radiculares realizadas en forma experimental.Zmener O y otros. En Revista de la Asociación Odontológica Argentina. Vol 90, N 3. Junio-Julio-Agosto 2002.
26) Características de la oclusión en niños con dentición primaria de la Ciudad de México
Resumen.- El fenómeno más dinámico que se observa en la boca es el de la oclusión dental. Las características de la oclusión durante la dentición primaria se consideran precursoras de las características de la oclusión de la dentición permanente, de ahí la importancia de su comprensión y entendimiento.Objetivo.- El propósito de este trabajo fue conocer las características de la oclusión dental durante la dentición primaria en un grupo de niños mexicanos de un nivel socio-económico medio bajo.Muestra.- Se revisaron 42 niños y 58 niñas, entre tres y cinco años de edad con dentición temporal completa.
Página 310 de 314
310

Material y métodos.- Se realizó un estudio observacional, prolectivo, transversal y descriptivo. Las características de la oclusión se observaron en modelos de estudio y los datos se analizaron estadísticamente por medio del programa SPSS y la prueba de Ji cuadrada con un nivel de confianza del 95 %.Resultados.- La forma del arco más frecuente fue la ovoide en 71 % de los niños y 74 % en las niñas en el maxilar, en la mandíbula 81 % para las niñas y 64 % para los niños. Los espacios primates invertidos se observaron en 7 % de los niños y 22 % de las niñas. La sobremordida vertical aumentada se presentó en 57 % de los niños y 55 % de las niñas, la sobremordida horizontal ideal con 52 % para los niños y 59 % para las niñas. La relación canina Clase I representó el 88 % en niños y 85 % en niñas. El plano terminal mesial en 79 % de los niños y 81 % de las niñas, el plano terminal recto se observó en 12 % de los niños y 16 % en las niñas.Conclusiones.- Las características consideradas como ideales pueden tener variaciones debido a las características raciales de los individuos sin que esto represente una alteración en la oclusión o desarrollo de la misma.Sema Medina C y Silva Meza, R. En Rev ADM 2005; LXII (2): 45-51.
ANEXO 4. NORMAS DE PUBLICACIÓN DE LA APA Y COMPARACIÓN CON LAS NORMAS DE VANCOUVER
Se ofrece aquí una síntesis de los requisitos de uniformidad para manuscritos que deben presentarse a revistas científicas de acuerdo a las normas de publicación de la APA (American Psychological Association, 1994). Se establecen también, con fines ilustrativos, algunas comparaciones con las normas de Vancouver para publicación en revistas biomédicas.
1. Formato básico
El trabajo se presentará mecanografiado por una sola cara, a doble espacio en papel tamaño DIN A4 (212x297 mm), en dos copias y en disco de 3.5 pulgadas para ordenador compatible IBM-PC, formateado en procesador de textos Microsoft Word o WordPerfect (indicando el nombre del procesador utilizado y su versión. Por ejemplo, “Word 2000”).Las normas de Vancouver (1993), para revistas biomédicas, por su parte, establecen que el material se imprimirá en papel blanco A4, con márgenes de por lo menos 25 mm, escribiéndose en su totalidad sobre una cara del papel y a doble espacio. Cada epígrafe comenzará en hoja aparte, y las páginas se numerarán en forma consecutiva, empezando por la del título sobre el ángulo superior o inferior derecho de cada página.
2. Primera y segunda página
En la primera página se consignará el título del estudio, nombre y apellidos de los autores, centro de trabajo, dirección postal de contacto, número de teléfono y, si correspondiera, número de fax y correo electrónico.En la segunda página se incluirá el título del trabajo en español y en inglés; un resumen en castellano y en inglés (con una extensión no superior a las 250 palabras); y a continuación cuatro palabras-clave en castellano y en inglés. Por su parte, las normas de Vancouver establecen lo siguiente.La primera página contendrá: a) el título del artículo, conciso pero informativo; b) nombre y apellidos de cada autor, acompañados de sus grados académicos más importantes y su afiliación institucional; c) nombre del departamento/s y la institución/es o instituciones a los que se debe atribuir el trabajo; d) declaraciones de descargo de responsabilidad, si las hay; e) nombre y dirección del autor que se ocupará de la correspondencia relativa al manuscrito; f) nombre y dirección del autor a quien se dirigirán las separatas o nota informativa de que los autores no las proporcionarán; g) origen del apoyo recibido en forma de subvenciones, equipo o medicamentos.Como nota al pie de la primera página o como apéndice del texto, una o varias declaraciones especificarán: a) las colaboraciones que deben ser reconocidas pero que no justifican la autoría, tales como el apoyo general del jefe del departamento; b) la ayuda técnica recibida; c) el agradecimiento por el apoyo financiero y material, especificando la índole del mismo; y d) las relaciones financieras que puedan suscitar un conflicto de intereses. La segunda página incluirá un resumen (que no excederá las 150 palabras de extensión si es un resumen ordinario o las 250 si es uno estructurado). En él se indicarán los propósitos del estudio o investigación; los procedimientos básicos que se han seguido; los resultados más importantes (datos específicos y, de ser posible, su significación estadística); y las conclusiones principales. Hágase hincapié en los aspectos nuevos e importantes del estudio o las observaciones.A continuación del resumen agréguense de 3 a 10 palabras o frases cortas clave que ayuden a los indicadores a clasificar el artículo. Para este fin pueden usarse los términos de la lista "Medical Subject Headings" (MeSH) del "Index Medicus".
3. Extensión y organización general
La APA sugiere las siguientes pautas en cuanto a extensión y organización del trabajo:
TIPO DE TRABAJO EXTENSION ORGANIZACION (TITULOS)Trabajos de investigación y Estudio de casos
La extensión máxima aceptada será de 20 páginas, excluyendo tablas, notas y figuras.
Introducción, Método, Resultados, Discusión / Conclusiones, Notas y Referencias bibliográficas.
Trabajos de revisión teórica La extensión máxima aceptada será de 20 páginas, excluyendo tablas, notas y figuras.
Planteamiento del problema, Desarrollo del tema, Discusión / Conclusiones y Referencias bibliográficas.
Comunicación de experiencias profesionales, Recensiones y Noticias
La extensión máxima será de 5 páginas, y 10 referencias bibliográficas.
Para ver con mayor detalle qué debe incluirse en cada título, cabe considerar las prescripciones sugeridas por las normas de Vancouver, a grandes rasgos igualmente aplicables a los trabajos de psicología.El texto de los artículos de observación y experimentales se divide, generalmente, en secciones que llevan estos encabezamientos: Introducción, Métodos, Resultados y Discusión (para la APA, los títulos Discusión y Conclusión
Página 311 de 314
311

pueden emplearse en forma indistinta para el mismo texto). En los artículos largos puede ser necesario agregar subtítulos dentro de estas divisiones. Por ejemplo, dentro del título Resultados puede incluirse el subtítulo Estadísticas.
a) Introducción.- Aquí se expresa el propósito del artículo. Resuma el fundamento lógico del estudio u observación. Mencione las referencias estrictamente pertinentes, sin hacer una revisión extensa del tema. No incluya datos ni conclusiones del trabajo que está dando a conocer. b) Métodos.- Aquí se describe claramente la forma como se seleccionaron los sujetos observados o que participaron en los experimentos. Identifique los métodos, aparatos y procedimientos, con detalles suficientes para que otros investigadores puedan reproducir los resultados. Proporcione referencias de los métodos acreditados, incluyendo los de índole estadística. Identifique exactamente todos los medicamentos y productos químicos utilizados, sin olvidar nombres genéricos, dosis y vías de administración.No use el nombre, las iniciales ni el número de historia clínica de los pacientes, especialmente en el material ilustrativo.Estadística.- Describa los métodos estadísticos con detalle suficiente para que el lector versado en el tema y que tenga acceso a los datos originales, pueda verificar los resultados informados. Siempre que sea posible, cuantifique los resultados y preséntelos con indicadores apropiados de error o incertidumbre de la medición (por ejemplo intervalos de confianza). No dependa exclusivamente de las pruebas de comprobación de hipótesis estadísticas, tales como el uso de los valores 'p' que no transmiten información cuantitativa importante. Proporcione los detalles del proceso de aleatorización de los sujetos.Informe sobre las complicaciones del tratamiento. Especifique el número de las observaciones. Mencione las pérdidas de sujetos de observación. Siempre que sea posible, las referencias sobre diseño del estudio y métodos estadísticos serán de trabajos vigentes, más bien que de los artículos originales donde se describieron por vez primera. Especifique cualquier programa para procesar la información estadística que se haya empleado. Limite el número de cuadros y figuras al mínimo necesario para explicar el tema central del artículo. Usar gráficas en vez de las tablas resulta más didáctico. Defina los términos, las abreviaturas y la mayor parte de los símbolos estadísticos. c) Resultados.- Aquí se presentan los resultados siguiendo una secuencia lógica mediante texto, tablas y figuras. No repita en el texto los datos de los cuadros o las ilustraciones: destaque o resuma sólo las observaciones importantes. Describa lo que ha obtenido sin incluir citas bibliográficas.d) Discusión.- Haga hincapié en los aspectos nuevos e importantes del estudio y en las conclusiones que se derivan de ellos. No repita con pormenores los datos u otra información, ya presentados en las secciones de introducción y resultados.Explique también aquí el significado de los resultados y sus limitaciones, incluyendo las consecuencias para la investigación futura. Relacione las observaciones con otros estudios pertinentes. Establezca el nexo de las conclusiones con los objetivos del estudio, pero absténgase de hacer afirmaciones generales y extraer conclusiones que no estén completamente respaldadas por los datos. Proponga nuevas hipótesis cuando haya justificación para ello, pero identificándolas claramente como tales. Cuando sea apropiado, puede incluir recomendaciones.
4. Referencias bibliográficas
Todas las referencias bibliográficas se insertarán en el texto (nunca a pie de página) e irán en minúsculas (salvo la primera letra). Todas estas referencias aparecerán alfabéticamente ordenadas luego en "Referencias bibliográficas". Todas las citas se ajustarán a las normas de publicación de trabajos de la American Psychological Association (1994) en su "Publication Manual" (Washington, 1994).A continuación se recuerdan las normas generales para elaborar los tres tipos básicos de referencias, y las referencias a material consultado en Internet:
a) Libros.- Autor (apellido -sólo la primera letra en mayúscula-, coma, inicial de nombre y punto; en caso de varios autores, se separan con coma y antes del último con una "y"), año (entre paréntesis) y punto, título completo (en letra cursiva) y punto; ciudad y dos puntos, editorial.Ejemplos:Apellido, I., Apellido, I. y Apellido, I. (1995). Título del Libro. Ciudad: Editorial. Tyrer, P. (1989). Classification of Neurosis. London: Wiley.
b) Capítulos de libros colectivos o actas.- Autores y año (en la forma indicada anteriormente); título del capítulo, punto; "En"; nombre de los autores del libro (inicial, punto, apellido); "(Eds.),", o "(Dirs.),", o "(Comps.),"; título del libro en cursiva; páginas que ocupa el capítulo, entre paréntesis, punto; ciudad, dos puntos, editorial.Ejemplos:Autores (año). Título del Capítulo. En I. Apellido, I. Apellido y I. Apellido (Eds.), Título del Libro (págs. 125-157). Ciudad: Editorial. Singer, M. (1994). Discourse inference processes. En M. Gernsbacher (Ed.), Handbook of Psycholinguistics (pp. 459-516). New York: Academic Press.
c) Artículos de revista.- Autores y año (como en todos los casos); título del artículo, punto; nombre de la revista completo y en cursiva, coma; volumen en cursiva; número entre paréntesis y pegado al volumen (no hay blanco entre volumen y número); coma, página inicial, guión, página final, punto.Ejemplos:Autores (año). Título del Artículo. Nombre de la Revista, 8(3), 215-232. Gutiérrez Calvo, M. y Eysenck, M.W. (1995). Sesgo interpretativo en la ansiedad de evaluación. Ansiedad y Estrés, 1(1), 5-20.
d) Material consultado en Internet.- Véase Anexo 2.
Se examinan a continuación las normas de Vancouver respecto de las referencias bibliográficas.Las referencias deben numerarse consecutivamente, siguiendo el orden en que se mencionan por primera vez en el texto. En éste, en las tablas y en las ilustraciones, las referencias se identificarán mediante números arábigos (o superíndice) entre paréntesis.Como referencias no deben utilizarse resúmenes, 'observaciones inéditas' o 'comunicaciones personales', aunque sí se pueden incluir los artículos aceptados aunque todavía no publicados.
Página 312 de 314
312

A continuación, y siempre siguiendo el criterio de Vancouver, se especifican las formas de citar las referencias bibliográficas.
Tipo de material de referencia
Ejemplo
a) Artículo de revista.- Inclúyase el nombre de todos los autores cuando sean seis o menos; si son siete o más, anótese solo el nombre de los seis primeros y agréguese "et al".
You CH, Lee KY, Chey RY, Menguy R. Electrogastrographic study of patients with unexplained nausea, bloating and vomiting. Gastroenterology 1980; 79(2): 311-314.
b) Artículo que ha sido comentado en otro trabajo.
Kobayashi Y, Fujii K, Hiki Y, Tateno S, Kurokawa A, Kamiyama M. Steroid therapy in IgA nephropathy:a retrospective study in heavy proteinuric cases (ver comentarios). Nephron 1988; 48: 12-17. Comentado en: Nephron 1989; 51 289-91.
c) Libros (Individuos como autores).
Colson JH, Armour WJ. Sports injuries and their treatment. 2nd rev ed. London: S Paul, 1986.
d) Libros (Directores o compiladores como autores).
Diener HC, Wilkinson M, editores. Drug-induced headache. New York: Springer-Verlag, 1988.
e) Capítulos de libros. Weinstein L, Swartz MN. Pathologic properties of invading microorganismos. En: Sodeman WA, Sodeman LA, editores. Pathologic physiology: mechanisms of disease. Philadelphia: Saunders, 1974: 457-472.
f) Actas de conferencias. Vivian VL, editor. Child abuse and neglect: a medical community response. Proceedings of the First AMA National Conference on Child Abuse and Neglect; 1984 Mar 30-31; Chicago. Chicago: American Medical Association, 1985.
g) Tesis Doctoral. Youssef NM. School adjustment of children with congenital heart disease (Tesis Doctoral). Pittsburgh (PA): Univ of Pittsburgh, 1988.
h) Trabajos inéditos. Lillywhite HB, Donald JA. Pulmonary blood flow regulation in an aquatic snake. Science. En prensa.
5. Citas textuales, tablas y figuras
Toda cita textual debe ir entre comillas y con indicación del apellido del autor(es) del texto, año de publicación y página(s) de donde se ha extraído, todo ello entre paréntesis.Las tablas y figuras no se incluirán en el texto, sino en hojas separadas que permitan una buena reproducción. Además, una hoja final incluirá los títulos y leyendas de figuras y tablas, correlativamente numeradas, a las que se refieren las figuras/tablas correspondientes. En el texto se debe marcar el lugar o lugares donde han de insertarse.
ANEXO 5. NORMAS PARA HACER REFERENCIA A DOCUMENTOS CIENTÍFICOS DE INTERNET EN EL ESTILO WEAPAS (LAND, 1998)
a) Autores.- Los documentos de la World Wide Web que indican que son "mantenidos", generalmente se refieren al autor con el apelativo de Maintainer (Maint), aunque también puede usarse más genéricamente Editor (De).Los autores de los documentos en Internet pueden ser identificados de dos maneras: a partir de las direcciones electrónicas, y a partir de los llamados alias/títulos.Dirección electrónica como autor.- Ante todo, deben revisarse todos los vínculos que puedan conducir a la identificación del autor del documento (por ejemplo los que digan "comentarios a", "home" o "sobre el autor"). Si la página web sólo presenta un vínculo hacia una dirección electrónica y no hay otra información que sugiera la identificación del autor, esta dirección electrónica se puede usar para llenar la posición del autor. Si aparecen en cambio alias genéricos (como webmaster, maintainer, etc.), se considera la organización a la que representa el documento (usualmente identificable en el dominio del servidor en que se encontró el documento) como el autor grupal o corporativo del documento. Esta organización también puede ser ubicada en la sección de direcciones, unida a una dirección electrónica.Los envíos de noticias y otros documentos que son sólo identificables por una dirección electrónica remitente también pueden usar ésta como identificación del autor.Cuando se citen las referencias que contienen direcciones electrónicas en el lugar de los autores, se debe escribir la dirección completa como si fuera el apellido.Alias/títulos como autor.- También aquí, ante que nada todos los potenciales vínculos que conduzcan a la identificación del nombre real del autor deben ser explorados antes de usar un alias como autor.Si un autor es conocido ampliamente por su título y además se conoce su nombre real, éste puede ser incluído entre corchetes inmediatamente después del nombre real, en la posición del autor. En tales casos, la abreviación "a.k.a." (Also Known As) debe ser utilizada para indicar que es el alias.La primera letra de un alias debe ser puesta en mayúsculas. Sin embargo, algunos alias usan estructuras léxicas no convencionales para identificarse (ej. ENiGmA, mrEd), en cuyo caso esta estructura debe conservarse para asegurar la identificación (así, la primera letra se mantendría como el original). Si se identifica un alias como autor, debido a que el nombre real no se ha podido determinar, y además se conoce la dirección electrónica, ésta se incluye entre corchetes después del alias.
b) Fechas.- Tengamos presente en primer lugar que, a diferencia de las publicaciones "en papel", los documentos de red pueden ser actualizados o modificados por sus autores en cualquier momento, por lo que la fecha de esta modificación será la que tendremos en cuenta.
Página 313 de 314
313

Las referencias a los artículos mensuales, que no se modifican una vez que se han distribuido, necesitan sólo la determinación del año y mes de publicación. Si la publicación es una revista (Journal) reconocida, con volumen y número de edición, sólo se necesita escribir el año. Los artículos de periódicos deben ser identificados no sólo con la fecha, sino también la hora, para distinguirlos de otros artículos del mismo tema y del mismo autor. El formato para tales referencias tiene la forma de "(Año, Mes Día, GMT Hora:Minuto:Segundo)", en la que GMT es la hora del Meridiano de Greenwich y la Hora está expresada en el estilo de un reloj de 24 horas. Los documentos de red que no ofrecen información de cuando fueron creados o modificados deben ser considerados como versiones re-publicadas o trabajos sin fecha inicial de publicación (APA, 1994, p. 173), por lo que la referencia tomará la forma de "(n.d./Año) " donde el Año es aquel en el cual el documento fue obtenido. Cuando se hace referencia a documentos que son susceptibles de ser cambiados en forma impredecible (la mayoría de las páginas web), el año debe estar seguido del mes y, si es posible, del día.Fecha de visita: En forma opcional, alguien puede querer especificar la fecha en que el documento fue bajado o visitado en la red, por si éste pudiera desaparecer o caducar en un corto plazo. Tales datos se ubican al final de la referencia, entre paréntesis y en el formato " (visitado Año, Mes Día)".
c) Títulos.- Generalmente el título de un documento de red se reconoce de inmediato. Sin embargo, hay que considerar algunas variaciones:Si el documento se recibe por correo electrónico, consideraremos como título el texto que aparece en Subject (o Tema). Si no hay texto, consideraremos al trabajo como no titulado.Si el documento aparece en una página web convencional (es decir, en formato HTML), el título puede ser tomado de la barra superior del navegador, pero si éste no presenta dicho título automáticamente, se puede encontrar buscando en la fuente del documento. Si el título escrito en el cuerpo del documento se diferencia sustancialmente del que está escrito en la barra superior, también debe ser enunciado y puesto después del primero, separado por un punto y coma.
d) Tipos de documento.- Hay muchos tipos de documentos y servicios disponibles en Internet. La naturaleza de un documento debe ser puesta entre corchetes inmediatamente después del título.Ejemplos de tipos de documentos son documentos en formato html, consultas en bases de datos, imágenes en formato .gif, .jpg u otro, archivos de sonido o de video, archivos FTP, etc.Todos aquellos documentos no son accesibles públicamente y que sólo pueden ser vistos por las personas que están suscritas a listas de correo, se tratarán como comunicaciones personales.
e) Información acerca de la publicación.- En el caso de Internet, la referencia a la publicación es la URL (vulgarmente, la dirección de la página web, es decir, la que comienza con http://www.....).Cada URL (Uniform Resource Locator, o localización original de la fuente) debe ser antecedido por la palabra clave "URL" seguida de un espacio. Un URL no puede terminar con un punto u otra puntuación. Asimismo, si un URL no cabe en el espacio de una línea, éste debe ser partido en el slash ("/"), dejándolo como último carácter de la línea.
Para consultar con más detalle las normas para referencias bibliográficas sobre material publicado en Internet, el lector puede remitirse a: American Psychological Association (APA) (n.d/1998) How to cite information from the Internet and the World Wide Web [Documento WWW] "http://www.apa.org/journals/webref.html"
Página 314 de 314
314


















