
LOS ERRORES DE MUESTREO EN LAS - decon.edu.uydecon.edu.uy/network/C/medinac.pdf · mial bajo un...
29
LOS ERRORES DE MUESTREO EN LAS ENCUESTAS COMPLEJAS: USOS Y ABUSOS DE LA INFORMACIÓN Fernando Medina H. 1 Resumen 2 Las investigaciones por muestreo han logrado gran aceptación en las últimas décadas y actualmente su uso se ha generalizado a empresas públicas y privadas, así como a centros de inves- tigación y organismos internacionales. Sin embargo, esto ha propiciado su uso irracional ya que son pocas las personas que conocen las restriccio- nes que imponen a los datos los pro- cedimientos aplicados para la selec- ción de la muestra. De hecho, toda vez que los resultados han sido difundidos y la base de datos se pone a disposi- ción de los investigadores y tomado- res de decisiones, la mayor parte de éstos hacen caso omiso de las limita- ciones de la información y se dedican a formular hipótesis de comportamien- to y a diseñar opciones de política, sin corrobar si las afirmaciones que reali- zan tienen validez estadística. Asimis- mo, existen restricciones en el uso de los métodos clásicos de inferencia y análisis estadístico ya que estas téc- nicas se basan en el supuesto de que las observaciones provienen de una muestra aleatoria simple extraída sin reemplazo y con igual probabilidad, lo cual no coincide con la forma en que se seleccionan las observaciones en las encuestas complejas. En este tra- bajo se analizan algunas de las limita- ciones que imponen a los datos los diseños de muestras complejas y se calculan los errores de muestreo utili- zando información generada a partir de encuestas realizadas por países de Hispanoamérica. Palabras Clave: Diseños de muestras complejas; encuestas; ponderadores; errores de muestreo; varianza; estrati- ficación; conglomerados; efecto de di- seño; estimadores. 1. Introducción La utilización de las encuestas por muestreo como una herramienta útil para generar información ha cobrado gran relevancia en las últimas déca- das. De hecho, parecería que la credi- bilidad de las afirmaciones que se hacen sobre el comportamiento de un determinado fenómeno aumentan en la medida en que al público se le hace saber que la información se generó por medio de una investigación por mues- treo la cual se argumenta que es “re- presentativa y confiable al 95%”. 1 Asesor Regional en Estadísticas Sociales. División de Estadística y Proyecciones Eco- nómicas de la Comisión Económica para Amé- rica Latina y el Caribe (CEPAL). Las opiniones expresadas, son responsabili- dad del autor y no corresponden necesaria- mente con las de la institución en donde cola- bora. ([email protected]) 2 Este trabajo se presentará en la reunión de la Asociación Internacional de Estadísticos de Encuestas(IASS) y la Asociación Internacio- nal de Estadísticas Oficiales(IAOS), organiza- da por el Instituto Internacional de Estadística(ISI), Statistics Canada y el Insti- tuto Nacional de Estadística, Geografía e In- formática de México(INEGI), en la ciudad de Aguascalientes, México del 1 al 4 de septiem- bre de 1998.
Transcript of LOS ERRORES DE MUESTREO EN LAS - decon.edu.uydecon.edu.uy/network/C/medinac.pdf · mial bajo un...

LOS ERRORES DEMUESTREO EN LASENCUESTASCOMPLEJAS: USOS YABUSOS DE LAINFORMACIÓN
Fernando Medina H. 1
Resumen 2
Las investigaciones por muestreo hanlogrado gran aceptación en las últimasdécadas y actualmente su uso se hageneralizado a empresas públicas yprivadas, así como a centros de inves-tigación y organismos internacionales.Sin embargo, esto ha propiciado suuso irracional ya que son pocas laspersonas que conocen las restriccio-nes que imponen a los datos los pro-cedimientos aplicados para la selec-ción de la muestra. De hecho, toda vezque los resultados han sido difundidosy la base de datos se pone a disposi-ción de los investigadores y tomado-res de decisiones, la mayor parte deéstos hacen caso omiso de las limita-ciones de la información y se dedicana formular hipótesis de comportamien-
to y a diseñar opciones de política, sincorrobar si las afirmaciones que reali-zan tienen validez estadística. Asimis-mo, existen restricciones en el uso delos métodos clásicos de inferencia yanálisis estadístico ya que estas téc-nicas se basan en el supuesto de quelas observaciones provienen de unamuestra aleatoria simple extraída sinreemplazo y con igual probabilidad, locual no coincide con la forma en quese seleccionan las observaciones enlas encuestas complejas. En este tra-bajo se analizan algunas de las limita-ciones que imponen a los datos losdiseños de muestras complejas y secalculan los errores de muestreo utili-zando información generada a partirde encuestas realizadas por países deHispanoamérica.
Palabras Clave : Diseños de muestrascomplejas; encuestas; ponderadores;errores de muestreo; varianza; estrati-ficación; conglomerados; efecto de di-seño; estimadores.
1. Introducción
La utilización de las encuestas pormuestreo como una herramienta útilpara generar información ha cobradogran relevancia en las últimas déca-das. De hecho, parecería que la credi-bilidad de las afirmaciones que sehacen sobre el comportamiento de undeterminado fenómeno aumentan enla medida en que al público se le hacesaber que la información se generó pormedio de una investigación por mues-treo la cual se argumenta que es “re-presentativa y confiable al 95%”.
1 Asesor Regional en Estadísticas Sociales.División de Estadística y Proyecciones Eco-nómicas de la Comisión Económica para Amé-rica Latina y el Caribe (CEPAL).Las opiniones expresadas, son responsabili-dad del autor y no corresponden necesaria-mente con las de la institución en donde cola-bora. ([email protected])
2 Este trabajo se presentará en la reunión dela Asociación Internacional de Estadísticos deEncuestas(IASS) y la Asociación Internacio-nal de Estadísticas Oficiales(IAOS), organiza-da por el Instituto Internacional deEstadística(ISI), Statistics Canada y el Insti-tuto Nacional de Estadística, Geografía e In-formática de México(INEGI), en la ciudad deAguascalientes, México del 1 al 4 de septiem-bre de 1998.

A pesar de ser práctica común quediversas organizaciones nacionales einternacionales participen en la pla-neación y apoyen el desarrollo de en-cuestas, se considera pertinente eva-luar la manera en que éstas se pro-yectan y analizan planteando las si-guientes preguntas:
i) Se diseñan las encuestas en for-ma adecuada?
Se determina el tamaño de muestraóptimo, se aplican procedimientos ro-bustos de estratificación, se asigna lamuestra de manera adecuada en losestratos;
ii) Los resultados obtenidos se in-terpretan de manera correcta?
La inferencia estadística está basadaen el diseño muestral); y
iii) Las relaciones de causalidad quese prueban y las recomendacionesde política que se formulan tienenvalidez estadística?
Es estadísticamente válida la inferen-
cia basada en modelos de comporta-miento.
Tratando de contribuir a dar respues-ta a estas preguntas, el objetivo deeste trabajo se centra en evaluar losaspectos técnicos que se consideranmás importantes y que debieran serel foco de atención de los estadísticosde encuestas, pero sobre todo paralos usuarios de la información en lafase de interpretación y utilización delos resultados para la formulación dehipótesis de comportamiento y el di-seño de políticas en el ámbito social yeconómico.
2. Determinación del tamaño demustra óptimo
Para determinar el número de unida-des que formarán parte de la muestralas expresiones propuestas suponenque la unidad ejecutora de la encues-ta cuenta con antecedentes acerca dela(s) varianza(s) de la(s) variable(s)que se desean estudiar3. Así, cuandointeresa estimar una proporción bino-mial bajo un esquema de selección
aleator io simple (MAS ) Cochran(1953),suponiendo normalidad en ladistribución del parámetro, propusouna expresión para calcular el tama-ño de muestra (n=t2pq/d 2) que se uti-liza con mucha frecuencia y tambiéncon alguna ligereza4. En el caso deque no se tenga ninguna informaciónacerca de la varianza del parámetrode interés -lo cual sucede frecuente-mente- la práctica aconseja asumir unvalor de p=.5 (“worts case”) el cualmaximiza la variabilidad del estimador(pq=.25) y genera un tamaño de mues-tra que en apariencia garantiza la pre-cisión deseada5.
Como dan cuenta diversas investiga-ciones (Tortota,1978; Angers,1979;Thompson,1987 y Medina,1998) estamanera de proceder no es del todo
3 Esta forma de proceder llevaría a suponerque la encuesta sólo desea obtener estima-ciones de una variable sin considerar que prác-ticamente todas las encuestas son de propó-sitos múltiples.
4 En los diseños poliétapicos y multipropósi-tos, el tamaño de muestra obtenido se multi-plica por un factor que se analizará más de-lante y que se denomina comúnmente comoefecto de diseño(efd).

apropiada, ya que en la realidad eshabitual que la variable de interés ten-ga una distribución multinomial. Eneste sentido, además de que el pro-cedimiento sugerido por Cochran pue-de subestimar en forma importante eltamaño de la muestra, tampoco per-mite fijar en forma simultánea un co-eficiente de confianza para todas lascategorías en que se distribuye la va-riable de estudio lo cual inhibe al in-vestigador sobre la posibilidad de con-trolar la precisión deseada de las esti-maciones.
Es evidente que en la práctica cotidia-na las encuestas que se realizan sonde propósitos múltiples. De esta for-ma, para determinar el tamaño demuestra óptimo se deben considerartodas las variables de interés de talsuerte que el número de observacio-nes seleccionadas garantice que seminimice la varianza de los estimado-res en forma simultánea o se puedaconocer el nivel de la variabilidad paraun monto de presupuesto asignado.Para resolver este problema en la lite-ratura se han propuesto algunos al-goritmos de optimización no lineal que
permiten calcular el tamaño de mues-tra óptimo (Kokan,1963, Kokan yKhan,1967 y Medina, op.cit. para ejem-plificar su uso).
Cuando la selección de las unidadesde observación y análisis se realiza envarias etapas es necesario aplicar téc-nicas de estratificación y conglomera-ción adecuadas que permitan identifi-car a las unidades de estudio, lo cualincrementa la varianza del estimadorasí como el número de seleccionesque se deben obtener para garantizarla eficiencia del diseño en términos devarianza mínima6.
En este sentido, decidir sobre el totalde observaciones a seleccionar sedebe apoyar en criterios objetivos quefijen prioridades sobre las variables deinterés, la precisión y confiabilidaddeseada, los dominios analíticos quese formarán, el método para la selec-ción de la muestra, los indicadoresderivados que se desean calcular, asícomo los costos que involucra la iden-tificación de las unidades de marco.Para encuestas de propósitos múlti-ples se sugiere utilizar algoritmos que
permitan encontrar el tamaño óptimode la muestra por estrato que minimi-ce la variabilidad de los estimadoresen forma simultánea (Kokan y Khan,op.cit.).
Es muy usual que no se disponga deinformación sobre la varianza de lasvariables de estudio, ya que la mayo-ría de las Oficinas Nacionales de Es-tadística no la calculan ni publican deforma rutinaria. Asimismo, tampoco es
5 Para los casos en que se desean obtenerestimadores de medias y totales es necesarioconocer la variabilidad asociada a la variablede interés, por lo que proceder como si se tra-tara de estimar una proporción es incorrecto.Así, si se decide estimar el tamaño de mues-tra utilizando la expresión para proporciones,se debe estar consciente que el error de mues-treo se incrementará sin que exista la posibili-dad de evaluar su repercusión en la varianzade los estimadores.
6 Es importante recordar que la muestra nodepende del tamaño de la población a excep-ción de su efecto en el factor de correcciónpor finitud(CPF) en el caso de que este seconsidere. Además, hay que recordar que eltamaño de la muestra es inversamente pro-porcional al cuadrado del error estándar , porlo que para lograr una reducción de k vecessu nivel se requiere incrementar la muestra enun factor k2.

habitual que se realicen estudios pilo-to a gran escala que generen informa-ción confiable que pueda ser utilizadacomo insumo para determinar el tama-ño de muestra óptimo. De esta mane-ra, se deben buscar alternativas desolución que permitan planear en-cuestas con información limitada.
2.1. El efecto de diseño y el errorestándar del estimador
Para tratar de resolver la situación quese presenta en el cálculo del tamañode muestra en encuestas complejas,en donde no se cuenta con informa-ción sobre la varianza de la(s)variable(s) de interés, Kish (1979pp.302-309) propuso una manera desolucionar el problema definiendo unfactor de ajuste que a partir de unamuestra aleatoria simple MAS permi-te aproximarse al número de seleccio-nes necesarias para que un diseño deconglomerados proporcione la mismavarianza. El factor se conoce como elefecto de diseño (efdk) y se define pormedio de:
efdk = Varc(y) / (1-f) S 2/n (1)
en donde Varc(y) representa la varian-
za de la variable de interés en el dise-ño de conglomerados y (1-f) S2/n ladel esquema de selección aleatoria,de tal forma que:
Varc(y)= (1-f) S 2/n * efd
k (2)
Según Kish (op.cit.), “este extenso fac-tor apunta a resumir las diversas com-plejidades en el diseño de una mues-tra, sobre todo los de conglomeracióny estratificación”. Asimismo, este au-tor señala que una mejor aproximacióna la varianza S2 del estimador se lograpor medio de:
S2 = s2 [1+(efdk-1)/n] (3)
De (3) se observa que s2 será unabuena aproximación a S2 cuandoefd
k=1. Es común que en los diseños
estratificados el efdk<1 ya que los pro-
cedimientos de estratificación tiendena reducir la varianza del estimadordebido a la homogeneidad que se lo-gra al interior de los grupos formados.Lo contrario sucede en el caso de di-seños de conglomerados en dondegeneralmente se observa que efd
k>1,
lo cual estaría indicando que el efectode conglomeración tiende a incremen-tar la varianza y por lo tanto es nece-sario aumentar el tamaño de muestraobtenido bajo un esquema aleatoriosimple a fin de lograr la precisión de-seada7.
En caso de que los conglomeradossean en promedio de igual tamaño elefecto de diseño se puede expresarpor medio de:
efdk =[1+r (M-1)] (4)
efdk=[1+r (M-1)] (5)
en donde M y M representan el tama-ño del conglomerado y el tamaño pro-medio respectivamente, y r se inter-preta como el coeficiente de correla-
7 Una interpretación adecuada del factor pro-puesto por Kish sería la siguiente. Cuando nose conoce la varianza de la variable de interésen un diseño complejo, pero si se dispone deuna aproximación bajo un esquema aleatoriosimple, entonces se calcula el tamaño demuestra bajo este esquema y luego se ajustamultiplicándolo por el efecto de diseño. De estaforma, el nuevo número de observaciones ga-rantiza la misma varianza que un esquema deselección MAS.

ción intraconglomerados y se puedecalcular por medio de8:
r = [åmi åM
j ¹ j (X
ij - X)(X
ij - X)] / [m(M- 1) M s2] (6)
y m y ‘M representan el número deconglomerados en la población y eltamaño medio del conglomerado res-pectivamente, mientras que
s2= (M M -1)S2 / M M.
La varianza del estimador se puedeescribir en términos del efd
k como se
muestra a continuación:
Vc(x) = (1-f) S2 [1 + (M -1) r] nM (7)
lo cual permite comparar la varianzade un diseño aleatorio simple sin re-emplazo (MASSR) con la que se ob-tiene de un esquema de selección porconglomerados (DC), lo que se pue-de interpretar como una medida de laeficiencia relativa del diseño.
Es evidente que se desea que los con-glomerados mantengan baja correla-ción entre sus elementos lo cual selogra cuando r = - 1/(M- 1), por lo que
en este caso tanto la varianza del es-timador como el efd
k son iguales a
cero. Por otra parte, el caso más des-favorable se presenta cuando r ® +1lo cual induce a un incremento site-mático en la varianza y en esta situa-ción todos los elementos son igualespor lo que el efecto de diseño asumi-ría un valor igual al tamaño promediodel conglomerado, de modo que lavarianza será tan grande como la delas unidades elementales (efd
k= M).
En el caso de que r = 0 significaríaque la variable está completamentedistribuida al azar, por lo que el efectode diseño es igual a uno (efd
k=1) y
tanto el esquema de selección MAScomo el de conglomerados DC gene-rarían la misma varianza9.
El término (M - 1)r debe interpretarsecomo el aumento que se genera en lavarianza del estimador por haber se-leccionado n conglomerados de tama-ño M en lugar de nM unidades ele-mentales10. Con esta información seestá en condiciones de analizar cuáles el efecto de un diseño de mues-tra complejo en el error estándar delestimador ^q.
Una manera de responder esta pre-gunta se logra al comparar las varian-zas obtenidas por los dos diseños: elverdadero, que para una encuestahabitual corresponde a un esquemade selección estratificado y de conglo-merados (DC), y uno hipotético gene-rado por una selección MASSR (Skin-ner,1989).
8 La expresión (5) es la que se utiliza con ma-yor frecuencia ya que en la práctica es usualque los conglomerado sean en promedio delmismo tamaño y el coeficiente de correlaciónde derive de la siguiente expresión r = [(efd k
- 1)] / (M -1).
9 A pesar de que los conglomerados estén bienmezclados en las situaciones prácticas el co-eficiente de correlación intraconglomerados (r)tiende a ser mayor que cero, por lo que el va-lor del efdk puede ser considerable en la medi-da de que el tamaño del conglomerado seamuy grande.
10 Es normal que al interior de los conglomera-dos las unidades tengan un cier to parecido(r>0), por lo que se espera que el diseño deconglomerados genere menor precisión. Sinembargo, es posible encontrar situaciones enque la correlación entre los elementos seanegativa (r<0 ) lo cual significaría que el mues-treo por conglomerados fue más preciso queun MAS.

Como fue señalado, Kish (op. cit.) pro-puso comparar la eficiencia relativa deldiseño complejo DC respecto a la va-rianza del MASSR definiendo el fac-tor conocido como efecto de diseño:
efdk(^q)= Var
DC(^q) / Var
MAS( ^q) (8)
Skinner (op. cit.), señala que esta me-dida es apropiada cuando se deseancomparar dos diseños alternativos; sinembargo, toda vez que se realizó laencuesta y si se aplicó un esquemadiferente al MASSR resulta irrelevan-te hacer la comparación propuesta porKish (efd
k), ya que los datos fueron
generados por un mecanismo de se-lección compleja y poco o nada tienenque ver con un proceso de selecciónaleatorio y sin reemplazo.
La intención de Kish al proponer el efdk
fue medir el efecto de la varianza so-bre el valor del estimador del paráme-tro ^q; sin embargo, para los fines deuna encuesta compleja es más impor-tante conocer cuál es el efecto del di-seño de muestra sobre el estimadorde la varianza. Siguiendo a Skinner(op.cit.), sea
v0
= ^varMAS
(^q) un estimador de lavarianza del estimador del parámetrobajo un esquema de selección MAS(asumiendo que las observacionesson independientes e idénticamentedistribuidas iid)11. De esta manera, elefecto de un diseño complejo sobre elestimador de la varianza se puedeevaluar al comparar la distribución dev
0 con la varianza del diseño v
DC lo cual
se interpreta como el sesgo de esti-mación.
sesgo(v0) = E
DC(v
0) - Var
DC(^q) (9)
A fin de lograr congruencia con la pro-puesta de Kish, (9) se puede expre-sar en términos relativos lo cual dalugar a la definición del factor efmeque se refiere al efecto en la varianzadel estimador debido a una mala es-pecificación en el diseño de la mues-tra (“misspecification effect, meff ”) pro-puesto en Skinner (op. cit.):
efme(^q , v0)= Var
DC(^q) / E
DC(v
0) (10)
En este caso, VarDC
(^q) representa lavarianza observada en el diseño,mientras que E
DC(v
0) es el valor espe-
rado de la varianza de un diseño MAS-
SR y el efme( ^q,v0) se interpreta como
un factor que evalúa qué tanto v0 tien-
de a subestimar o sobreestimar la va-rianza verdadera var(^q) tal que;
< 1 si el sesgo(v0) > 0
efme(^q , v0) = 1 si el sesgo(v
0) = 0
> 1 si el sesgo(v0) < 0(11)
En los diseños estratificados y de con-glomerados con tamaños de muestraapropiados se tiene que la E
DC(v
0) »
VarMAS
(^q) por lo que se puede esta-blecer una relación entre los factoresde ajuste mencionados12 ;efd
k(̂ q) = efme(^q, v
0)= var
DC(̂ q) / E
DC(v
0) (12)
11 Por ejemplo, para el caso de una proporciónv0= p (1-p).
12 En Skinner (op.cit.) se presentan expresio-nes para el cálculo del efd para diseños polie-tápicos y multivariados que llevan a la defini-ción de una matriz V0 de efectos de diseño deun vector de parámetros q.

2.2. El tamaño de muestra efectivo
Determinar el error de muestreo de unestimador es importante por las si-guientes razones: i) Es necesario co-nocer la precisión y confiabilidad es-tadística de los datos generados; ii) Sedebe evaluar la eficiencia estadísticadel diseño de muestra aplicado; y iii)Para generar información útil que pue-da ser aprovechada para planear fu-turas investigaciones por muestreo.
A pesar de que la mayor parte de losestadísticos de encuestas ponen granénfasis en minimizar los errores demuestreo, no hay que olvidar que tam-bién existen errores de no muestreoque afectan la calidad de los datos loscuales deben ser reducidos a partir dela supervisión y control de las activi-dades de diseño conceptual y del tra-bajo de campo.
A partir del efecto de diseño es posi-ble derivar otras expresiones que sonde gran utilidad práctica: el denomina-do factor de diseño fdd y el tamañoefectivo de muestra ne. El factor de di-seño se define como;
fdd = efdk 1/2 (13)
y es muy importante para la interpre-tación de la precisión de los estima-dores y se utiliza fundamentalmentecomo un factor de ajuste para corregirel error estándar del estimador y lalongitud de los intervalos de confian-za (Verma et. al., 1980).
Por su parte, Kish (1965) definió eltamaño efectivo de muestra como;
ne= n
0 /efd
k (14)
el cual puede ser interpretado comola cantidad de información contenidaen una muestra. Por ejemplo, para unefd
k=1.30 en una muestra de conglo-
merados de tamaño nDC
=10,000 ho-gares, el tamaño efectivo indica quesólo se requeriría de n
e=7,692 hoga-
res para estimar el parámetro q con lamisma precisión deseada a partir deun esquema aleatorio simple13.
Es bien sabido que los errores de es-timación y las pruebas de significan-cia juegan un papel fundamental en
el análisis de los resultados de unaencuesta ya que permiten, entre otrascosas, contrastar las hipótesis delcomportamiento de una poblaciónante un determinado fenómeno de in-terés.
Los errores de muestreo son muy di-ferentes cuando se trata de estimarestadísticas descriptivas a nivel pobla-cional que cuando éstas se calculanpara dominios de estudio específicos.Asimismo, la pruebas de significanciapermiten establecer relaciones de cau-salidad y formular recomendacionesde política, por lo que su validaciónestadística es fundamental para de-terminar la confiabilidad y precisión delas aseveraciones que se realizan so-bre una variable de interés.
A pesar de que esto es muy impor-tante, es muy frecuente que investi-gadores y analistas pasen por alto estehecho y utilicen la información sin pre-
13 El concepto de tamaño efectivo de muestrano debe ser confundido con el mismo términoque se utiliza para señalar al número de uni-dades diferentes que se eligen en una mues-tra con reemplazo.

guntarse si los supuestos en que sebasan los modelos que aplican secumplen con la muestra observada.Los paquetes de cómputo más utili-zados y convencionales (SAS, SPSS,entre otros) no consideran esta situa-ción, y las rutinas de cálculo que tie-nen disponibles para efectuar inferen-cia estadística y estimar modelos decausalidad, asumen que las observa-ciones provienen de una muestra alea-toria simple extraída sin reemplazo,situación que no se cumple en el casode los diseños de muestra complejos.En este sentido, el efecto de diseñoedf
k debe tenerse presente al momen-
to de interpretar los resultados de lasencuestas, y de manera especialcuando se calculan los errores demuestreo de los estimadores. A conti-nuación se presentan dos fases tradi-cionales de la inferencia estadística endonde el diseño de una muestra com-pleja tiene incidencia en la precisiónde los resultados de la encuesta.
Suponga que se han procesado losresultados de la investigación y sedesea calcular un intervalo de confian-za para un conjunto de estimadores
de interés. Se utiliza un paquete decómputo convencional el cual asumeque la muestra se extrajo en formaaleatoria y sin reemplazo, por lo quese considera una muestra de n obser-vaciones independientes e idéntica-mente distribuidas (iid).
La expresión tradicional para calcularintervalos de confianza para un pará-metro ^q parte de suponer que;
t0 = (^q - q)/v
01/2 ~ N(0,1) (15)
de tal suerte que un intervalo al 95%de confianza se obtiene por medio de;
C0= {q ê t0 ê < 1.96} = ( q̂ - 1.96 v01/2, ^q + 1.96 v0
1/2)
(16)
La pregunta que se debe responderes: cuál es el efecto del diseño demuestra sobre los supuestos enque se basa la construcción del in-tervalo de confianza propuesto en(16). Bajo un diseño de conglomera-dos se puede asumir que ^q es inses-gado y tiene una distribución normal;es decir
^qDC
~ N [q, varDC
(^q)] (17)
Para muestras grandes el valor de v0
se aproxima a EDC
(v0) de tal forma que
la distribución de t0 ~ (^q - q)/ E
DC(v
0)1/2,
por lo que de la ecuación (16) se tie-ne que:
t0DC ~ N [0, var DC(^q)/ EDC(v0)] = N [0, efd k(^q,v0)]
(18)
En esta situación el efecto de diseñose puede interpretar como un factor quemide los cambios en la varianza delestimador basados en el valor del es-tadístico t
0. De esta manera, cuando
= 1 C0 es correcto
edfk> 1 C
0 es muy pequeño
< 1 C0 es muy amplio
(19)
En términos prácticos cuando se dis-pone de un estimador del efd
k un in-
tervalo de confianza al 95% se puedecalcular por medio de14:
C0*= (^q - 1.96 (v0 efd k)1/2 , ^q +1.96(v0efd k)
1/2)
(20)

Por otra parte, en caso de que se de-see comprobar la significancia de al-gún parámetro de interés(^q), la teo-ría estadística convencional estable-ce que bajo el supuesto de normali-dad la hipótesis simple H
0:q=0 se re-
chaza si T0=(^q - q)/v
01/2 se ubica en la
región crítica (de rechazo) de una dis-tribución normal estandarizada. Parauna prueba de dos colas a un 95% deconfianza se tiene que:
H0 se rechaza si ê T
0 ê > 1.96 bajo H
0
(21)
Sin embargo, bajo un diseño de mues-tra complejo;
T’0 = T
0 / efd
k1/2 = (^q - q) /( v
0 efd
k)1/2
(22)
2.3. Un ejemplo real15
A continuación se evalúan los resulta-dos de una encuesta a fin de tratar decumplir los siguientes objetivos: i) Evi-denciar la manera en que se altera elerror de estimación cuando se consi-dera el diseño de la muestra; ii) Mos-
trar como se incrementan los erroresde muestreo cuando se ajustan por elefecto de diseño(efd
k); iii) Indicar como
crecen los errores en los estimadoresa consecuencia de que en el diseñode muestra no se tuvieron las precau-ciones para determinar el número deobservaciones necesarias. iv) Eviden-ciar los riesgos de mala interpretaciónque se enfrentan por el hecho de quelos usuarios no validan la confiabilidadestadística de la información en losdominios de estudio que se forman.
En términos generales se puede se-ñalar que la información utilizada co-rresponde a una encuesta realizadapor algún país de la región y se pla-neó con el objetivo central de estimarla tasa de desocupación abierta(TDA),pero que tiene como objetivo secun-dario -y tal vez esto es lo más impor-tante- caracterizar el ámbito laboral dediferentes regiones del país utilizan-do un modelo teórico que supone laexistencia de un mercado laboral seg-mentado. Para el cálculo del tamañode muestra se utilizó la expresión pro-puesta por Cochran (op. cit.) suponien-do una distribución binomial del pará-
metro de interés y se fijó la precisión yun error máximo esperado.
Se deseaban generar estimacionespara el área urbana de la capital delpaís, así como para cada una de laszonas urbanas de las cabeceras mu-nicipales de los departamentos másimportantes; y por agregación se po-drían obtener estimaciones para elconjunto urbano. Además de la clasi-ficación tradicional que permite iden-tificar a los desocupados abiertos, elmarco conceptual utilizado establecey define diversas modalidades de des-ocupación y subutilización de la fuer-za de trabajo, por lo que se consideró
14 En Kish (1979) se ejemplifica que calcularun intervalo de confianza conforme a la expre-sión (16) equivale a utilizar la siguiente expre-sión: y ± ( t’ / Ö efdk) ( s Ö efdk / n). Para una t=2y un Ö efdk =1.5, entonces t’= 2/ 1.5=1.34, y enconsecuencia se tendría un incremento en larazón del error del 5% al 9%.
15 Los resultados presentados correspondena una encuesta real efectuada en algún paísde Hispanoamérica, y el único objetivo de pre-sentar resultados es con el ánimo de ejempli-ficar los errores que se pueden cometer por elmal uso de la información y la utilización delos datos para efectos distintos a los que mo-tivaron la realización de la investigación.

de interés disponer de una caracteri-zación de la población económica-mente activa ubicada en las diversascategorías de estudio16, así como delas variables socieodemográficas yeconómicas que condicionan la utili-zación de la mano de obra17.
Para la elaboración del diseño de lamuestra se definieron como unidadesprimarias de muestreo (UPM’s) lascabeceras municipales de los depar-tamentos del país, mientras que lasunidades de segunda etapa (USM’s)se formaron a partir de segmentos deviviendas. En ambos casos, la selec-ción de las observaciones que forma-ron parte de la muestra se hizo asig-nando igual probabilidad a todas lasunidades ya que aparentemente nohabía diferencias considerables en sutamaño.
Se trata de una encuesta que se reali-za en forma continua y que permite ge-nerar información para estudiar la evo-lución del mercado de trabajo en la zonaurbana del país, y de manera particularsobre los niveles de desocupación ysubutilización de la fuerza de trabajo.
En la tabla 1 se presentan resultadosde los totales expandidos para distin-tas variables interés, los cuales fue-ron estimados utilizando el paquetePC CARP el cual considera en susrutinas de cálculo la estructura del di-seño de la muestra (efecto de estrati-ficación y conglomeración) y las dife-rentes probabilidades de selección delas observaciones18.
En todos los casos los coeficientes devariación(CV) estimados son menoresal 10%. Sin embargo, se aprecia queen la medida que las categorías enque se distribuye la población ocupa-da presentan frecuencias más bajas,el error del estimador se incrementapasando el CV de 1.24% para el totalde población, al 8.31% que correspon-de al caso de los aspirantes a obtenerun empleo.
Asimismo, se debe observar que losmayores valores en el efecto de dise-ño se presentaron en las subclases endonde la homogeneidad de las obser-vaciones es mayor. Por ejemplo, co-rrespondió un efd
k= 9.8 en la catego-
ría de aspirantes a conseguir un em-
16 La clasificación utilizada corresponde a laque recomienda la Organización Internacionaldel Trabajo(OIT) para el estudio de la desocu-pación y el comportamiento del mercado la-boral.
17 Además, y ante falta de información actuali-zada, es frecuente que estas encuestas seutilicen para realizar estimaciones de pobrezalo cual le impone restricciones adicionales alos objetivos de la investigación, tamaños demuestra y precisión de los estimadores.
18 Es importante señalar que el PC CARP utili-za para los cálculos de la varianza el métododel conglomerado último propuesto por Han-sen et. al.(1963), por lo que es necesario iden-tificar la unidades primarias de muestreo ydefinir un ponderador para cada una de lasobservaciones. Por las características del di-seño muestral, el factor de expansión se calcu-ló a partir del cociente entre una estimación depoblación proyectada para un año determina-do, entre el total de observaciones en muestra.
pleo lo que indicaría un valor alto enel coeficiente de correlación intracon-glomerados y conlleva a que se incre-mente la varianza del diseño de mues-tra respecto a una selección aleato-ria. En este caso, el valor del coeficien-te de correlación intraconglomeradosestimado fue r = 0.1086 lo cual evi-dencia la relación que existe entre lasobservaciones19.

En las categoría de activos, ocupados(con valores en el efdk mayores de 2) y
en la de los ocupados plenos, se percibe una mayor heterogeneidad intracon-glomerados, y en este caso los valores de r fueron 0.0225, 0.0188 y 0.0163respectivamente, lo cual contribuyó a disminuir la varianza del estimador y se
Tabla 1
Coeficiente de Variación y Efecto de Diseño para Estimadores de TotalesArea Urbana del País
VARIABLE ESTIMADOR ERROR COEF. DE EFECTO DE COEF. DE
DEL TOTAL ESTÁNDAR VARIACIÓN DISEÑO VARIAC.*
AJUSTADO
Población Total 1’352,960 16,733.20 1.2368 **** ****Activos 639,703 9,271.82 1.4494 3.3852 2.6667Ocupados 572,802 8,486.60 1.4816 2.8957 2.5212 Plenos 375,236 6,274.02 1.6720 1.9277 2.3214 Subocupados 198,706 Invisibles 108,531 3,858.63 3.5553 1.9807 5.0036 Visibles 90,175 3,831.52 4.2490 2.3163 6.4667Desocupados 66,901 3,059.73 4.5735 1.9550 6.3947 Cesantes 51,896 2,621.14 5.0508 1.8282 6.8292 Aspirantes 15,005 1,246.60 8.3079 1.3908 9.7978Inactivos 713,256 11,085.70 1.5542 4.8393 3.4190 Con Exper. 36,765 2,155.11 5.8619 1.7245 7.6979 Sin Exper. 676,491 10,737.50 1.5872 4.5266 3.3769
* Corresponde al valor que se obtiene al multiplicar el error estándar del estimador por la raíz
cuadrada del efecto de diseño.
reflejó en los valores bajos observa-dos en el coeficiente de variación (CV).
También se debe señalar que el ver-dadero error del estimador se deter-mina al considerar en el cálculo de lavarianza el factor de ajuste que seobtiene por medio de la raíz cuadradadel efecto de diseño (Öefd ). Así, esevidente que debido a que para todaslas variables el efd
k>1 se observa que
el coeficiente de variación ajustado porel diseño de muestra (CV*= CV * Öefd )se incrementa, y para el caso de laspersonas que se clasificaron en la ca-tegoría de aspirantes su valor creceen el entorno del 10% y para los inac-tivos con experiencia se ubicó en 7.7%
Asimismo, a fin de ilustrar como cam-bian los límites del intervalo de con-fianza al considerar el efecto del dise-ño sobre la varianza del estimador, acontinuación se presentan los resul-
19 Es importante recordar que para efectos delcálculo de la varianza, se sugiere que se man-tengan correlaciones intraconglomerados muybajas, con objeto de que el valor del efd k seacercano a la unidad. Es decir, se busca que eldiseño de conglomerados no incremente demanera artificial la varianza del estimador.

tados obtenidos para algunas de lasvariables analizadas.
Total de Activos:693,703 ± 18,173 sin ajuste y693,703 ± 33,436 ajustados por efd
k ;
Total de Inactivos:713,256 ± 21,728 sin ajuste y713,256 ± 47,798 ajustados por efd
k.
En el caso de los activos existe unadiferencia absoluta de15,263 perso-nas en los límites calculados por am-bos procedimientos, lo cual podría re-presentar una diferencia poco impor-tante. Por otra parte, en el caso de losinactivos los resultados ajustados evi-dencian una diferencia de más de dosveces el valor de los límites obtenidosin ajustar el error estándar del esti-mador, lo cual permite apreciar la re-levancia de estimar en forma apropia-da el error de muestreo.
Para el caso de los desocupados setiene que la encuesta estima que66,901 personas se consideraron ensituación de desocupación abierta conuna diferencia de ± 5,997 personas
según el error estándar del estimador.Sin embargo, cuando en los cálculosse incorpora el efecto de diseño loslímites cambian y se observa una di-ferencia de ± 8,385 personas. Si sedecide diseñar acciones de política apartir de la puesta en marcha de unprograma emergente de empleo queinvolucre a toda la población desocu-pada (en este caso se debiera consi-derar como techo presupuestario el lí-mite superior del intervalo de confian-za), es evidente que los recursos quese requieren invertir son diferentes enlos casos señalados. De hecho, la di-ferencia absoluta de 2,388 personasdesempleadas establece una diferen-cia significativa en el presupuesto quese debiera asignar para la operacióndel programa.
Siguiendo a Kish (1979) se enfatizaque el trabajar de la manera tradicio-nal (expresión (16)) supone que tantoel valor de tablas (t) obtenido de la dis-tribución normal estandarizada comoel error estándar del estimador, seafectan por la raíz cuadrada del efec-to de diseño (y ± t’ [s Ö efd
k / n] en
donde t’ = t / Ö efdk ). En el caso que
nos ocupa para obtener un intervaloal 95% de confianza (a=5%) se sabeque t=1.96; por lo que para el total deactivos se tiene que Öefd
k =1.8399 y
t’=1.0653 lo cual significa que el errorde estimación se incrementa del 5%al 14.5%; es decir, aumenta más denueve puntos porcentuales sin que elanalista se percate de esta situacióny en sus conclusiones continúe afir-mando que el intervalo de confianzaque contiene el verdadero valor delparámetro corresponde a un a=5%.
En este análisis los valores del errorde muestreo con y sin efd
k pueden pa-
recer menores para aquellos que tra-bajan los métodos convencionales decálculo; sin embargo, el hecho de quelas diferencias no sean tan grandes sedebe, en parte, a que se trabaja a unnivel de agregación en donde el tama-ño de muestra es suficiente para ga-rantizar una precisión adecuada20. Sin
20 En la encuesta que se utilizó para ejemplifi-car los conceptos aquí presentados, existendepartamentos en donde los errores de esti-mación para algunas variables de interés sonmayores y por lo tanto las diferencias en loslímites de los intervalos de confianza son másnotables.

embargo, un análisis detallado de losdatos permite observar que en la cate-goría de personas que se clasificaroncomo aspirantes a ocupar un puestoen el mercado de trabajo, sólo se ubi-caron 212 observaciones lo cual deno-ta que cualquier intento por desagre-gar este tamaño de muestra podríaconducir a resultados erróneos de in-terpretación. Es decir, no es posible si-quiera intentar conocer a nivel desagre-gado la rama de actividad a la cualdesearía insertarse esta subpoblación.
Asimismo, 60 de las 212 observacio-nes registradas (28.3%) se concentra-ron en la capital del país, mientras queen 10 municipios se reportaron menosde 10 casos y en uno de ellos no seobtuvo ninguna observación, lo cualrompe con la lógica de selección de lamuestra ya que los municipios se de-finieron como UPM’s y se espera quetodos contribuyan en la formación delestimador del área urbana del país.
Un comportamiento similar se observóen la distribución muestral de la cate-goría de subempleados visibles. Eneste caso se dispone de 1,241 perso-
nas que se ubicaron en esta situación,de las cuales el 31.7% se concentróen la capital del país. Asimismo, exis-ten 6 municipios en donde el tamañode muestra reportado fue menor a trein-ta observaciones y en uno de ellos sólose registraron dos casos.
Situaciones como la descrita se pre-sentan en algunas otras de las cate-gorías de análisis, lo cual debe obli-gar a los usuarios a reflexionar sobrela confiabilidad estadística que puedetenerla información desagregadacuando ésta se pretende utilizar paraformular hipótesis de comportamien-to o establecer acciones de políticapara grupos de población específicos.La encuesta cumple sus propósitospara estimar con precisión la tasa dedesocupación abierta (TDA) a niveldepartamental y para la zona urbanadel país, pero presenta limitacionespara caracterizar el mercado de tra-bajo a nivel municipal, y evidentemen-te tiene escasa capacidad de uso paraestablecer modelos de comportamien-to y formular relaciones de causalidadentre las variables que explican la con-formación del mercado laboral.
Sin embargo, a pesar de la evidenciaeste tipo de situaciones frecuentemen-te se pasan por alto y muchos analis-tas actúan como si la información re-cabada fuera lo suficientemente con-fiable para inferir sobre el comporta-miento de la población en su conjuntoy abusan de la bondad de los datos almomento de elaborar sus análisis ydiseñar alternativas de políticas.
Es obvio que el no considerar la es-tructura del diseño de la muestra in-crementa el error cuadrático medio delos estimadores, sin que los analistastengan capacidad de controlar el efec-to que esto puede tener en las con-clusiones derivadas de sus análisis.
En la tabla 2 se presentan para el áreaurbana del país los resultados de al-gunas tasas que son de gran utilidadpara analizar el comportamiento delmercado de trabajo. Se observa quecuando el error de muestreo se ajustópor el efecto de diseño, la mayor va-riabilidad observada es menor al 6%la cual corresponde al estimador de latasa de desocupación abierta (TDA).Esta situación confirma la confiabilidad

Tabla 2
Coeficiente de Variación y Efecto de Diseño para Estimadoresde Tasas Area Urbana del País
Variable Estimador Error Coef. de Efecto de Coef. deTasa en % Estándar Variación % Diseño Variación
AjustadoPEA/PO10 47.2818 .004286 0.9066 1.3244 1.0433PEI/PO10 52.7182 .004286 0.8131 1.3244 0.9357PEA/PEI 89.6877 .015423 1.7197 1.3244 1.9791OCUP/PEA 89.5419 .004384 0.4896 1.7435 0.6464PLE/OCUP 65.5088 .007646 1.1672 1.9683 1.6375DESO/PEA 10.4581 .004384 4.1919 1.7435 5.5350INAS/PEI 94.8455 .002921 0.3080 1.6528 0.5090
PEA Población Económicamente ActivaPO10 Población en edad de trabajar de 10 y más añosPEI Población Económicamente InactivaOCUP OcupadosPLE Ocupados PlenosDESO DesocupadosINAS Inactivos sin experiencia
Los intervalos de confianza para losestimadores de algunas tasas de in-terés se presentan a continuación:
Tasa Neta de Participación: 47.28 ± 0.84 sin ajuste y ± 0.97
con ajuste;
Tasa de Ocupación: 65.51 ± 0.86 sin ajuste y ± 1.13
con ajuste;
Tasa de Desocupación Abierta:10.46 ± 0.86 sin ajuste y ± 1.13
con ajuste .
Cuando no se considera el factor deajuste la tasa de desocupación abier-ta puede tener un valor máximo de11.3%, mientras que cuando se afec-ta por el efecto de diseño el valor deeste indicador se incrementa y puedeinvolucrar hasta 11.6% de la fuerza detrabajo, lo cual para todo efecto prác-tico no resulta significativo.
A fin de conocer el error en que seincurre por no considerar en el proce-so de estimación las características deldiseño de la muestra, en la tabla 3 se
de la información a este nivel de agregación y corrobora que el total de obser-vaciones logradas es suficiente para satisfacer la precisión deseada.

presentan resultados obtenidos pordiversas alternativas de cálculo.
En primera instancia se observa queno existen diferencias significativas enlos valores de las tasas estimadas conlos datos ponderados y sin ponderar,debido a que a partir de una proyec-ción de población (y utilizando un es-timador de razón) se definieron facto-res de expansión constantes por de-partamento; es decir, se tuvieronmuestras autoponderadas a ese nivelgeográfico21 .
Tabla 3
Error Estándar para Estimadores de Tasas Area Urbana del País
Variable Estimador Error Est. Error Est.2 Estimador Error Est. EstimadorError Est.
PCCARP1 PCCARP PCCARP SASP3 SASP SASSP4 SASSP5
Tasa Neta
de Partic. 47.28 .004286 .004932 47.41 .003725 47.28 .003725
Tasa de
Ocupac. 89.54 .004384 .005789 89.54 .003317 89.54 .003316
Tasa de
Desocup 10.46 .004900 .006470 10.46 .003317 10.46 .003316
Abierta
1 Corresponde a los resultados considerando la estructura del diseño de mues-tra y los ponderadores de las observaciones.2 Ajustado por el efecto de diseño que calcula la rutina incluida en el PC CARP.3 Corresponde a los resultados ponderados calculados con el SAS.4 Corresponde a los resultados sin ponderar calculados con el SAS.5 El error estándar calculado por el SAS (pq/Ön) se considera una aproxima-ción a la varianza verdadera basada en el teorema del límite central para mues-tras grandes (Kakwani,1990). Sin embargo, a pesar de este hecho se nota queal no considerar la estructura del diseño se subestima el error de muestreo delestimador.
21 A pesar de que esta es una práctica común,es claro que esta forma de actuar limita la ca-pacidad de uso de las encuestas. Esto signifi-ca que en aquellas organizaciones que asig-nan recursos permanentes para la actualiza-ción del marco tienen la oportunidad, en cadalevantamiento, de poner al día la cartografía ylos pesos relativos de las unidades de selec-ción lo cual permite generar estimaciones depoblación alternativas en períodos intercensa-les. Sin embargo, las que por razones de faltade presupuesto no realizan esta actividad sedeben conformar con trabajar con estimado-res de razón lo cual puede llegar a ocasionarseveras inconsistencias entre las estimacionesderivadas de las muestras y los censos.

Por otra parte, se observa que existela tendencia general a subestimar elverdadero error de muestreo cuandoen la rutina de estimación no se con-sideran las restricciones impuestas porel diseño de la muestra ni las diferen-tes probabilidades de selección de lasobservaciones.
Los problemas de tamaño de muestraque se señalaron en párrafos anterio-res se agravan y complican las capa-cidades de explotación de la informa-ción, en la medida que se desagre-gan los datos y el análisis se efectúapara dominios de estudio más espe-cíficos, en donde los tamaño de mues-tra resultan insuficientes para garanti-zar una adecuada precisión de losestimadores, así como de los estadís-ticos utilizados para la contrastaciónde hipótesis.
En la tabla 4 se presentan estimacio-nes de algunas variables de interéspara el área urbana de la capital delpaís. A pesar que se registra informa-ción para el total de subocupados vi-sibles, aspirantes a conseguir un em-pleo y de cesantes, en unidades de
Tabla 4
Coeficiente de Variación y Efecto de Diseño para Estimadoresde Totales Area Urbana de la Capital del país
Variable Estimador Error Coef. De Efecto de Coef. Dede Totales Estándar Variación% Diseño Variación
AjustadoPLENOS 230,620 5,155.2 2.2353 1.4363 2.6789INVISIBLE 52,326 2,998.94 5.7313 1.6162 7.2862VISIBLE 44,916 2,865.62 6.3799 1.7018 8.3227CESANTE 31,806 2,309.88 7.2624 1.5340 8.9948ASPIRAN. 6,840 950.33 13.894 1.1683 15.0177INAC/EXP. 18,924 17,833.5 9.4237 1.5107 11.5827INAS/EXP 393,528 83,795.0 2.1239 3.1674 3.7799
ACTIVOS 365,370 6,453.89 1.7664 1.8856 2.4256INACTIVO 412,452 8,473.15 2.0543 3.2501 3.7035OCUPADO 326,724 5,975.91 1.8290 1.6530 2.3515DESOCUP. 38,646 2,635.75 6.8202 1.6591 8.7848
PLENOS »Activos Plenos INAC »Inactivo con ExperienciaINVISIBLE »Subempelados Invisibles INACSIN »Inactivos sin ExperienciaVISIBLE »Subempelados Visibles INACTIVO »InactivosCESANTE »Desocupados Abiertos OCUPADO »OcupadosASPIRANTE»Aspirante a ocupado DESOCUP »Desocupados
millar, cualquier intento por desagregar esta información y formular hipótesis decomportamiento debiera obligar al usuario a observar que los valores muestra-les para esas categorías fueron 394, 279 y 60 casos respectivamente.

Esto significa que las particiones quese quieran forman con los datos de-ben considerar este hecho, a fin deprever que los tamaños de muestraobservados garanticen que los esta-dísticos de prueba converjan a las dis-tribuciones teóricas que se utilizanpara calcular intervalos de confianzay contrastar hipótesis.
Los resultados obtenidos al compararalgunos procedimientos de cálculopara la parte urbana de la capital delpaís se presentan en la tabla 5. Al igualque en el análisis realizado para elárea urbana en su conjunto, se confir-ma la tendencia de los paquetes deuso convencional a subestimar el ver-dadero error de muestreo.
A fin de ejemplificar la situación deaquellos dominios de estudio en losque se enfrentan mayores limitacionesen relación al tamaño de muestra, latabla 6 presenta información sobre losresultados obtenidos para una de lasprovincias del país.
En este caso los valores muestralespara las variables subempleados visi-
Tabla 5
Error Estándar para Estimadores de Tasas Area Urbanade la Capital del País
Variable Estimador Error Est. Error Est.2 Estimador Error Est. EstimadorError Est.
PCCARP1 PCCARP PCCARP SASP3 SASP SASSP4 SASSP5
Tasa Neta
de Partic. 46.97 .006313 .008116 46.97 .006043 46.97 .006043
Tasa de
Ocupac. 89.42 .006732 .010264 89.42 .005433 89.42 ..005433
Tasa de
Desocup 10.58 .006732 .010264 10.57 .005433 10.58 .005433Abierta
1 Corresponde a los resultados considerando la estructura del diseño de mues-tra y los ponderadores.2 Ajustado por el efecto de diseño que calcula la rutina incluida en el PC CARP.3 Corresponde a los resultados ponderados calculados con el SAS.4 Corresponde a los resultados sin ponderar calculados con el SAS.5 El error estándar calculado por el SAS (pq/Ön) se considera una aproximacióna la varianza verdadera basada en el teorema del límite central para muestrasgrandes (Kakwani,1990). Sin embargo, a pesar de este hecho se nota que alno considerar la estructura del diseño se subestima el error de muestreo delestimador.
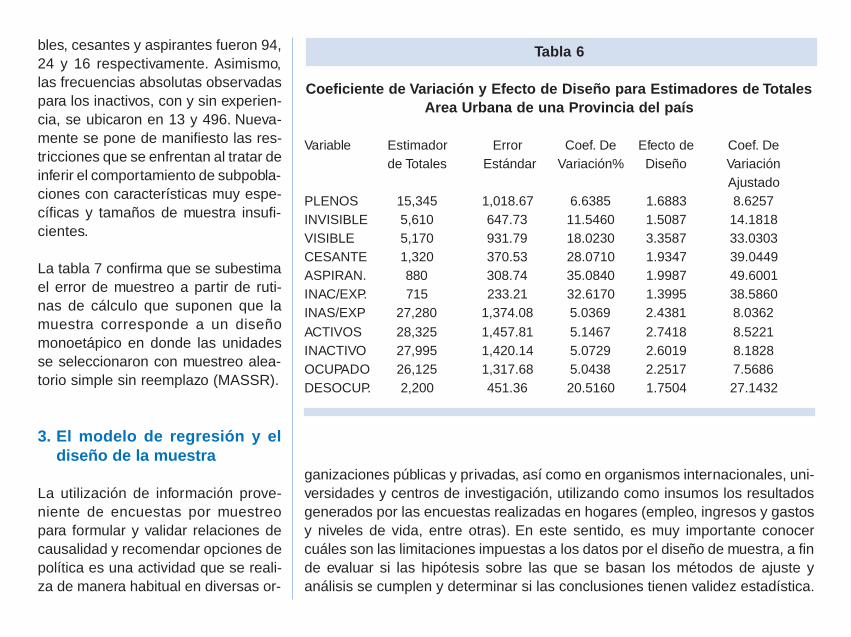
bles, cesantes y aspirantes fueron 94,24 y 16 respectivamente. Asimismo,las frecuencias absolutas observadaspara los inactivos, con y sin experien-cia, se ubicaron en 13 y 496. Nueva-mente se pone de manifiesto las res-tricciones que se enfrentan al tratar deinferir el comportamiento de subpobla-ciones con características muy espe-cíficas y tamaños de muestra insufi-cientes.
La tabla 7 confirma que se subestimael error de muestreo a partir de ruti-nas de cálculo que suponen que lamuestra corresponde a un diseñomonoetápico en donde las unidadesse seleccionaron con muestreo alea-torio simple sin reemplazo (MASSR).
3. El modelo de regresión y eldiseño de la muestra
La utilización de información prove-niente de encuestas por muestreopara formular y validar relaciones decausalidad y recomendar opciones depolítica es una actividad que se reali-za de manera habitual en diversas or-
Tabla 6
Coeficiente de Variación y Efecto de Diseño para Estimadores de TotalesArea Urbana de una Provincia del país
Variable Estimador Error Coef. De Efecto de Coef. Dede Totales Estándar Variación% Diseño Variación
AjustadoPLENOS 15,345 1,018.67 6.6385 1.6883 8.6257INVISIBLE 5,610 647.73 11.5460 1.5087 14.1818VISIBLE 5,170 931.79 18.0230 3.3587 33.0303CESANTE 1,320 370.53 28.0710 1.9347 39.0449ASPIRAN. 880 308.74 35.0840 1.9987 49.6001INAC/EXP. 715 233.21 32.6170 1.3995 38.5860INAS/EXP 27,280 1,374.08 5.0369 2.4381 8.0362
ACTIVOS 28,325 1,457.81 5.1467 2.7418 8.5221INACTIVO 27,995 1,420.14 5.0729 2.6019 8.1828OCUPADO 26,125 1,317.68 5.0438 2.2517 7.5686DESOCUP. 2,200 451.36 20.5160 1.7504 27.1432
ganizaciones públicas y privadas, así como en organismos internacionales, uni-versidades y centros de investigación, utilizando como insumos los resultadosgenerados por las encuestas realizadas en hogares (empleo, ingresos y gastosy niveles de vida, entre otras). En este sentido, es muy importante conocercuáles son las limitaciones impuestas a los datos por el diseño de muestra, a finde evaluar si las hipótesis sobre las que se basan los métodos de ajuste yanálisis se cumplen y determinar si las conclusiones tienen validez estadística.

Tal vez una de las técnicas estadísti-cas a las que se recurre con mayor fre-cuencia para explicar la relación queexiste entre un conjunto de variablessea el análisis de regresión. En estasección se realiza una evaluación delos supuestos en que se basa la apli-cación de esta técnica así como de lasrepercusiones en su uso, por el hechode que la mayor parte de las muestrasque se analizan en el ámbito socieco-nómico provienen de encuestas efec-tuadas a partir de diseños de muestramultietápicos y estratificados.
Es bien sabido que a partir del mode-lo de regresión es posible corroborarsi existe dependencia lineal entre unvector de variables explicativas oindependientes(
~x) y una variable y
denominada dependiente la cual seasume con distribución normal.
La expresión que relaciona la variabley con el vector
~x se expresa por me-
dio de una combinación lineal de pa-rámetros desconocidos y las variablesindependientes;
yi = x0 b0 + x1i b1 + x2i b2 + ... + xpi bi + ei; i = 1, ... , n(23)
1 Corresponde a los resultados considerando la estructura del diseño de mues-tra y los ponderadores.2 Ajustado por el efecto de diseño que calcula la rutina incluida en el PC CARP.3 Corresponde a los resultados ponderados calculados con el SAS.4 Corresponde a los resultados sin ponderar calculados con el SAS.5 El error estándar calculado por el SAS (pq/ Ön) se considera una aproxi-mación a la varianza verdadera basada en el teorema del límite centralpara muestras grandes (Kakwani,1990). Sin embargo, a pesar de este he-cho se nota que al no considerar la estructura del diseño se subestima elerror de muestreo del estimador.
Tabla 7
Error Estándar para Estimadores de Tasas Area Urbana para unaProvincia del País
Variable Estimador Error Est. Error Est.2 Estimador Error Est. EstimadorError Est.
PCCARP1 PCCARP PCCARP SASP3 SASP SASSP4 SASSP5
Tasa Neta
de Partic. 5.29 .015574 .041363 50.29 .015632 59.29 .015632
Tasa de
Ocupac. 92.84 .014578 .015399 92.23 .0118056 92.23 .0118056
Tasa de
Desocup 7.77 .014578 ..015399 7.77 .0118056 7.77 .0118056Abierta

en donde las bi‘s son los parámetros
que se desean estimar y se establececomo hipótesis que el término de errore
i tiene una distribución normal con
media cero y varianza constante (ei ~
N [0, s2]). Asimismo, se asume que loserrores no están correlacionados y quelas observaciones son independientese idénticamente distribuidas (iid) y queprovienen de una muestra aleatoriacon una cierta distribución de proba-bilidad.
En términos matriciales (23) se pue-de expresar como;
E (Y/X=x) = a + Xt b + e(24)
La estimación de la ecuación (24) pormedio del método de mínimos cuadra-dos ordinarios (MCO) genera la solu-ción:
^b = (XtX)-1 XtY (25)
a partir de suponer que los datos pro-vienen de una muestra aleatoria se-leccionada sin reemplazo (MASSR) yque no están relacionados con el di-
seño de la muestra. Sin embargo, estesupuesto no se cumple en la realidadya que el efecto de conglomeracióngenera correlación entre los errores(Kish y Frankel, 1974), por lo que esnecesario establecer algunas conside-raciones cuando los datos provienende encuestas complejas.
El método de estimación MCO supo-ne que V(e / X)= s2 I en donde I repre-senta la matriz identidad; sin embar-go, la realidad indica que V(e / X)= s2 V(con V¹I) por lo que se debe buscarun método alternativo y adecuado deestimación.
A partir de lo anterior se puede afir-mar que no se verifica la hipótesis deindependencia del término de error(Sul,E. et. al.,1994) por lo que los esti-madores y sus varianzas son sesga-dos, lo cual tiene consecuencias en elcálculo de intervalos de confianza yen las expresiones para obtener losestadísticos de prueba que se utilizanpara la constrastación de hipótesis.
Una expresión del vector estimador deparámetros
~^b para el caso de pro-
babilidades desiguales de selecciónse obtiene por medio de:
^b* = (Xt D -1 X)-1 Xt D -1 Y (26)
en donde la matriz Xt D -1X tiene unelemento å
s X
ij X
ik/ p
i , y la sumatoria
se extiende sobre las n unidades queforman parte de la muestra y D repre-senta una matriz con las probabilida-des de selección incluidas en la dia-gonal22 .
De igual forma se afirma que la va-rianza del vector (
~^b):
VMCO
(b) = [n0(n
0 -k)] -1 å e2
t V-1
xx
(27)
puede ser inconsistente aún en el casode que la muestra sea aleatoria sim-ple debido a la presencia de hetero-
22 De acuerdo con Kish y Frankel (1974), laestimación de (26) se puede lograr por los si-guientes tres métodos para estimar la varian-za del estimador para muestras repetidas detamaño n provenientes de encuestas comple-jas: Expansión de serie de Taylor ST, Replica-ciones Repetidas y Balanceadas RRB y Repli-caciones con Jacknife RJ.

cedasticidad en los datos, mientrasque un estimador de la varianza de^b* se calcula como:
^V(^b*) = (Xt D -1 X)-1 s2 23
(28)
Por la forma de la expresión (23) unaalternativa para resolver el problemade estimar de manera apropiada (24)consiste en utilizar el método de míni-mos cuadrados ponderados (MCP)(Fuller,1975; Holt et. al.,1980 y Shahet. al., 1977) y como alternativas posi-bles se proponen el método de míni-mos cuadrados generalizados (MCG)y el de máxima verosimilitud (MV) (Holtet. al. op. cit.). En este sentido, el pon-derador es el inverso de la probabili-dad de selección de la observación(factor de expansión) o un factor ajus-tado por no respuesta y postestratifi-cación (Sul et. al., op. cit.)24 .
Esta forma de proceder no considerala posible correlación que exista entreel término de error y su efecto sobrela varianza del estimador. De hecho,la correlación entre los errores aleato-rios tiene un efecto mínimo sobre el
estimador de los parámetros el cualpuede ser ignorado.
3.1. Ejemplo real
Suponga que a partir de los datos deuna encuesta de empleo se quiereestudiar la relación que existe entre lacondición de ocupación de un indivi-duo y algunas variables sociodemo-gráficas como la edad, los años de es-tudio y el sexo, la cual se desea mo-delar a partir de definir una relaciónlineal entre las variables.
cond. de ocupación = f(edad, años de estudio, sexo)
(29)
Utilizando el modelo de regresión li-neal simple se desea estimar el valorde los parámetros bi, así como su errorestándar y corroborar su significanciaestadística.
condocu= b1 + b
2 edad + b
3 edu + b
4 sexo + e
(30)
Los resultados para distintos métodosde estimación se presentan en la ta-bla 825 .
Como se puede observar existen pe-queñas diferencias entre los valoresde los parámetros estimados por elmétodo de MCO y los obtenidos cuan-do las observaciones se ponderan uti-lizando el factor de expansión y elmétodo de MCP. De hecho, se presen-ta una total coincidencia entre los re-sultados generados utilizando el PCCARP, considerando el factor de ex-pansión y la estructura del diseño demuestra, y aquellos que se producen
23 Esta expresión no corresponde a la propues-ta por Kish y Frankel (op cit.); sin embargo, enel caso de que no se detecte la presencia deheterocedasticidad en los datos, la estimaciónpropuesta para estimar la varianza de los es-timadores es una buena aproximación(Holt et.al. op. cit.)
24 Los procedimientos de postestratificaciónhan sido analizados por Holt y Smith (1989)quienes han concluido que se pueden consi-derar como técnicas robustas de estimación.En su trabajo ellos demuestran que, contrarioa lo que se supone habitualmente, las mues-tras autoponderadas generan estimadoressesgados para la media y la postestratifica-ción permite solucionar este problema.
25 Los datos utilizados para la estimación delmodelo son reales y se obtuvieron de una en-cuesta de empleo realizada por una OficinaNacional de Estadística de la región.

a partir del SAS y un método de esti-mación que considera únicamente elfactor de expansión26 .
Lo que se debe enfatizar es el hechoque el error estándar del estimador sesubestima siempre que no se consi-dera el diseño de la muestra y los pon-deradores, y aún en la situación enque se ponderan los resultados peroel esquema de selección de la mues-tra no se tiene en cuenta27 .
Esto significa que a pesar de que seaplique un método de estimación queinvolucre las distintas probabilidadesde selección de las observaciones, esposible que persista subestimación delerror del estimador.
26 Los parámetros b1, b2 y b3 resultaron estadís-ticamente distintos de cero, mientras que b4 notiene significancia estadística lo cual indica quepara este conjunto de datos el sexo de la per-sona no ayuda a explicar la condición de activi-dad de la población en edad de trabajar.
27 Resultados similares fueron obtenidos porSue, et. al.(1989), para una investigación querelacionaba el índice de masa corporal condistintas variables sociodemográficas.
TABLA 8
Estimadores y su Error Estándar por diferentesMétodos de Estimación
Parámetro Estimador Error1 Estimador Error2 Estimador Error3
b1
.869483 .016124 .862701 .012760 .869484 .012450b
2.002139 .000272 .002348 .000224 .002139 .000221
b3
-.003405 .001298 -.003333 .001256 -.003405 .001233b
4-.000814 .006116 -.004796 .005969 -.000814 .005799
1 Corresponde al estimado considerando el factor de expansión y la estructuradel diseño de la muestra y utilizando para la estimación el PC CARP.2 Corresponde al estimado por Mínimos Cuadrados Ordinarios con SAS.3 Corresponde al estimado sin considerar el diseño de la muestra, pero estima-do por Mínimos Cuadrados ponderados con el SAS.
TABLA 9
EFECTO DE DISEÑO PARA LOS PARÁMETROS DEL MODELO ESTIMADO
Parámetro Efecto de Diseño
b1 1.2636b2 1.2143b3 1.0334b4 1.0246

Es evidente que en el caso ilustradono se generan mayores problemas deinferencia debido a las ligeras discre-pancias observadas en las estimacio-nes del error; sin embargo, en la litera-tura abundan los casos en donde lasdiferencias pueden ser considerablesy conllevan a asumir conclusiones erró-neas por el mal manejo de los datos(Skinner op. cit. y Holt et. al. op. cit.).
Una aproximación al efecto de conglo-meración sobre la varianza de los pa-rámetros estimados se presenta en latabla 9 el cual se puede interpretarcomo el porcentaje de subestimaciónque existe en el estimador del errorestándar al considerar a las observa-ciones como una muestra aleatoriaseleccionada sin reemplazo.
4. La estimación del efecto dediseño y el uso de los ponde-radores
Se ha evidenciado que para hacer unuso adecuado de la información esnecesario que los usuarios conozcanlos detalles del método de estratifica-
ción utilizado y el procedimiento que seaplicó para la selección de la muestra,a fin de estar en condiciones de calcu-lar los factores de expansión así comopara estimar el efecto del diseño sobrela varianza de los estimadores.
La realidad parece indicar que sonpocas las organizaciones que calcu-lan errores de muestreo y el efecto dediseño para las distintas variables deinterés casi nunca se conoce. En estesentido, los usuarios -las mayoría delas veces con poco conocimiento so-bre métodos de análisis de encuestascomplejas- no le dan importancia aeste hecho lo cual puede llevar a ma-los usos de la información.
La única manera de sensibilizar a losusuarios sobre los riesgos que repre-senta hacer caso omiso de las espe-cificaciones del diseño de la muestray las limitaciones de desagregación delos datos, es que las Oficinas Nacio-nales de Estadística publiquen demanera regular estimaciones de loserrores de muestreo y del efecto dediseño, y además acompañen las ba-ses de datos con la información nece-
saria para que los analistas especiali-zados tengan la posibilidad de calcu-lar la magnitud del error de estimaciónpara dominios de estudio específicosque no se consideraron entre los ob-jetivos del diseño muestral y evalúensu confiabilidad estadística.
Como es muy difícil que esta situaciónideal se logre concretar en el corto pla-zo, tal vez sería suficiente incorporaren las bases de datos la mínima infor-mación necesaria para lograr aproxi-maciones al efecto de diseño.
Para el cálculo del efdk se requiere al
menos identificar a las unidades deprimera etapa de selección(UPM). Esdecir, para una encuesta estratificadase debiera disponer como mínimo dela información que permita ubicar elestrato y la UPM de procedencia delas observaciones. En el caso de quesólo una UPM se haya seleccionado -como sucede en algunos diseños- esevidente que en este caso su identifi-cación coincide con la del estrato.
Si no se conoce el estrato de proce-dencia el efd
k se puede calcular como

si se tratara de un diseño de conglo-merados en la medida que sea posi-ble identificar el segmento al cual per-tenecen las observaciones. Asimismo,para un diseño de muestra estratifica-do se debe asegurar que al menosexistan dos UPM’s seleccionadas porestrato ya que en caso contrario noes posible estimar la varianza. En lasituación de que sólo un conglomera-do haya sido seleccionado por estra-to, se sugiere formar seudoestratospara lo cual el analista requiere con-tar con un buen conocimiento del di-seño de muestra.
A fin de ejemplificar los procedimien-tos sugeridos a continuación se pre-sentan los resultados obtenidos alestimar errores y efectos de diseñopara algunas variables de interés. Losdatos utilizados corresponden a unaencuesta de empleo realizada por unpaís de la región que tiene por objeti-vo central estimar la tasa de desocu-pación abierta (TDA) respecto a lapoblación económicamente activa(PEA). Las unidades de observaciónse seleccionaron a partir de un diseñoestratificado (cuatro estratos) en tres
fases. Para las dos primeras etapas, laprobabilidad de selección fue propor-cional a una medida de tamaño, mien-tras que las unidades de última etapa(segmentos de viviendas) se eligieroncon muestreo aleatorio simple.
Para evaluar el efecto que tiene la se-lección multietápica y la estratificaciónde la unidades primarias en el errorestándar del estimador se probaron lassiguientes alternativas de diseño: i) Enel primer caso (D1) se utilizaron lasobservaciones muestrales simulandoque la información se obtuvo pormuestreo aleatorio simple de elemen-tos. ii) Otra opción (D2) fue utilizar lasagrupaciones de viviendas de últimaetapa para estimar el error y efecto dediseño asumiendo un esquema alea-torio simple de conglomerados. iii) Sesuprimió la información de la primeraetapa de selección y sólo se conside-raron las unidades de segunda y ter-cera fase(D3). iv) Por último, se traba-jó con el diseño de muestra trietápicoaplicado para la realización de la en-cuesta (D4).
En todos los casos los cálculos se rea-
lizaron utilizando el PC CARP y seestimaron totales y proporciones (pro-medios en el caso del ingreso) a finde analizar los cambios observados enel efecto de diseño como consecuen-cia de incorporar etapas adicionalesen la selección de la muestra.
Un primer comentario que se deberealizar es que al igual que lo que seobserva en muchas de las encuestasde empleo que se realizan en la re-gión, el ingreso de las personas estásubestimado ya que sólo correspon-de a lo que declaran percibir los ocu-pados por concepto de sueldos y sa-larios del trabajo remunerado. Asimis-mo, se señala que para los cálculosse eliminaron aquellos registros endonde no se consignó ninguna res-puesta(10.7%) (código de no especi-ficado), pero si se consideraron loscasos que repor taron cero ingre-sos(5.6%), lo cual es posible que inci-da en la calidad de los resultados.
En la tabla 10 se presentan los resul-tados obtenidos para los totales esti-mados de algunas variables de inte-rés. En teoría se esperaría que el efec-

to de diseño se incrementara para to-das las variables en la medida que seincorporan subsecuentes etapas deselección de la muestra según lo ob-tenido en otras investigaciones simi-lares (Verma et.al. op.cit.). En este sen-tido, al pasar de la opción D1 a D2 seregistró un aumento en el efd
K, com-
portamiento que se mantuvo entre lasopciones D2 y D3 (a excepción de loobservado en el ingreso total). Porejemplo, en la categoría ocupados elaumento fue del 32%, mientras quepara el total de desocuapdos abiertosel incremento fue del 13.9%.
Sin embargo, esta tendencia crecientese revirtió al comparar los resultadosde las opciones D3 y D4. Por ejemplo,para la categoría ocupados el efd
k dis-
minuyó 9.3%, mientras que en el casode los desempleado se redujo 6.4%.
En el caso del ingreso continuó el com-portamiento errático que ya había sidoidentificado, a pesar de que el coefi-ciente de variación estimado para estavariable (2.48%) fue menor al obser-vado para el total de desocupados elcual se ubicó en 5.0%.
Por su parte, los resultados obtenidos para las tasas y promedios evidencia uncomportamiento más acorde con lo esperado. En efecto, en el caso de la tasaneta de participación (TNP) y la de desocupación abierta (TDA), el valor delefecto de diseño muestra una tendencia creciente en la medida que se incre-menta en número de etapas para la selección de la muestra.
Conforme a los datos que se presentan en la tabla 12 se observó un incremen-to del 45% en la varianza de la TNP por el hecho de estimar los datos a partir deun diseño de muestra bietápico en lugar de un esquema de conglomerados.
TABLA 10
EFECTO DE DISEÑO PARA TOTALES DE VARIABLES DE INTERÉS
Variable Estimador1 Efecto de Efecto de Efecto de Efecto dedel Total Diseño D1. Diseño D2 Diseño D3 Diseño D4
Ocupados 5’363,210 1.0000 2.2292 2.9452 2.6715
Desocup. Abiertos 423,655 1.0000 1.3361 1.5213 1.4244
Ingreso 877,5622 1.0000 2.1590 1.6098 1.6509
1 Los estimadores de totales fueron los mismos para ambos procedimientos.
2 En millones de unidades.

Asimismo, se corrobora que una eta-pa más de selección no tiene una in-cidencia importante en la varianza delestimador ya que el aumento registra-do en el efd
k no alcanza ni un punto
porcentual(0.16%).
Los resultados observados en la TDAmuestran un comportamiento similar;sin embargo, en este caso el aumen-to en varianza por pasar de un diseñode conglomerados D2 a un esquemade selección bietápico D3 es del 9.2%,mientras que incorporar una etapamás de muestreo en el proceso deestimación (pasar de D3 a D4) sóloincrementa el error en 0.25%.
En el caso del ingreso promedio delos ocupados se mantuvo el compor-tamiento errático que se había eviden-ciado para el estimador del total, y enesta situación también se observó unerror de muestreo inferior al registra-do para la tasa de desocupación abier-ta; es decir, los coeficientes de varia-ción reportados fueron 2.2% y 4.8%respectivamente.
Los efectos de diseño verdaderos, que
1 Los estimadores de totales fueron los mismos para ambos procedimientos.
2 En unidades.
TABLA 12INCREMENTO PORCENTUAL EN EL EFECTO DE DISEÑO
PARA TASAS DE INTERÉS
Variable Estimador1
del Total D1. D3/D2 D4/D3 D4/D2Tasa Netade Ocupación 48.61 1.0000 45.12 0.16 45.35Tasa de Desocup.Abierta 3.84 1.0000 9.24 0.25 9.51IngresoPromedio 795.472 1.0000 (-36.1) 0.09 (-36.0)
1 Los estimadores de totales fueron los mismos para ambos procedimientos.
2 En unidades.
TABLA 11EFECTO DE DISEÑO PARA TASAS DE INTERÉS
Variable Estimador1 Efecto de Efecto de Efecto de Efecto dedel Total Diseño D1. Diseño D2 Diseño D3 Diseño D4
Tasa Netade Ocupación 48.61 1.0000 1.0126 1.4695 1.4719Tasa de Desocup.Abierta 3.84 1.0000 1.2151 1.3274 1.3307IngresoPromedio 795.472 1.0000 2.1921 1.4008 1.4022

que se definieron en los objetivos cen-trales de la investigación.
iv) Las encuestas de empleo, ingresosy gastos, demográficas y de niveles devida, entre otras, tienen restriccionesnaturales en su capacidad explicativalas cuales están impuestas por los ob-jetivos de las mismas, así como por lavariable de diseño y los tamaños demuestra utilizados. Se sugiere a losanalistas realizar una evaluación esta-dística de los resultados y elegir méto-dos de análisis que consideren entresus rutinas de cálculo las limitacionesque impone el diseño de la muestra,como una etapa previa a la formula-ción de modelos de causalidad, con-clusiones y recomendaciones de ac-ciones de política.
v) Si una encuesta de propósitos múl-tiples no se diseñó de manera ade-cuada en relación con la aplicación deun procedimiento de estratificación yconglomeración robusto, así como ladeterminación del tamaño óptimo demuestra, es muy probable que la con-fiabilidad de los datos no sea la ade-cuada por lo que en el análisis de los
corresponden al esquema que se uti-lizó para la selección de la muestra D4,son muy parecidos entre sí y mues-tran valores bastante aceptables locual haría suponer un nivel muy bajode correlación de las observacionesentre conglomerados. De hecho, losvalores del coeficiente de correlaciónintraclase r fueron 0.1179, 0.0827 y0.1005 para la tasa neta de participa-ción, tasa de desocupación abierta yel ingreso medio, respectivamente.
5. Conclusiones
i) Cualquier resultado generado pormedio de una encuesta está sujeto aun error de estimación, el cual se re-quiere conocer para determinar la con-fiabilidad estadística de los datos. Ade-más, en la medida que se relajan lasrestricciones impuestas por el diseñoy se desagreguen los datos, la proba-bilidad de que el número de observa-ciones resulte insuficiente aumenta ypor lo tanto disminuye la precisión delos resultados.
ii) La estructura del diseño de mues-
tra afecta la varianza de los estimado-res. Esta situación se afirma ya quemientras que el proceso de estratifi-cación ayuda a disminuir la varianza,la conglomeración y las diferentes pro-babilidades de selección de las obser-vaciones incrementa la variabilidad delos estimadores. De hecho, tambiéncontribuye a incrementar la varianzael tamaño promedio del conglomera-do ya que guarda estrecha relacióncon el error estándar, por lo que todosestos elementos se deben controlardurante la etapa del diseño muestral.
iii) Prácticamente todas las encuestasque realizan las Oficinas Nacionalesde Estadística de los países de la re-gión corresponden a diseños de mues-tra complejos. En este sentido, se su-giere incorporar en las publicacionesde resultados estimaciones de loserrores de muestreo y del efecto dediseño, a fin de que los usuarios co-nozcan la magnitud del error y confia-bilidad de las estimaciones. Asimismo,se debe ser más enfático y advertirsobre los riesgos que se enfrentan porla utilización de los resultados de laencuesta, para fines diferentes a los

resultados se debieran asumir las pre-cauciones necesarias.
vi) Los objetivos de la investigación,el tamaño de muestra y el esquemade selección le imponen restriccionesa los datos que deben ser considera-das durante la etapa de análisis de lainformación. Así, en caso de que nose respeten los aspectos señaladosexiste el riesgo de que la inferenciaque se realice carezca de significan-cia estadística.
vii) Los usuarios de los datos debenenfrentar la etapa de análisis con pru-dencia y hacerse asesorar por perso-nas que conozcan el diseño de lamuestra y que manejen los conceptosde la inferencia estadística en el casode encuestas complejas. De lo contra-rio, es probable que algunas de lasformulaciones de política que reco-mienden carezcan de confiabilidadestadística.
viii)El no considerar el diseño de lamuestra en el análisis de los resulta-dos, significa que se subestima el errorde muestreo y se obtiene intervalos
de confianza imprecisos que puedenllevar a asumir conclusiones erróneasrespecto a los estadísticos de pruebaque se utilizan para contrastar la sig-nificancia estadística de parámetrosde interés, así como de los que seobtienen a partir del ajuste de un mo-delo econométrico.

Referencias Bibliográficas
Angers,C.(1979).“Sample Size Estima-tion for Multinomial Populations”.TheAmerican Statistician”. Vol. 33, No.3,163-164.
Bankier,M.D.(1988).“Power Allocation:Determinig Sample Size for Subnatio-nal Areas”. American Statistician,vol.42,No.3,174-177.Cochran,W.G.(1953).”Sampling Tech-nics”. John Wiley & Sons, Inc.
Fuller,W.A.(1975).“Regression Analy-sis for Sample Surveys”.Sankhyã,37(Series C), 117-132.
Holt,D. and T.M.F.Smith(1979).”PostStratifi-cation”.Journal of the Royal Sta-tistical Society 142 (Series A), 33-46.
Holt,D., T.M.F.Smith and P.D. Winter(1980).”Regression Analysis of Datafrom Complex Surveys”. Journal of theRoyal Statistical Society,143 (SeriesA), 174-487.
Kish,L. and Frankel,M.R. (1974).”Infe-rence from Complex Samples” (with
Discussion).Journal of the Royal Sta-tistical Society. (Series B),vol. 36,1-37.
Kish,L.(1979).”Muestreo de Encues-tas”. Editorial Trillas, México, D.F..
Kakwani,N.(1990).”Testing for the Sig-nificance of Poverty Differences”.WorldBank.Living Standar MeasurementStudy, Working Papers No. 62.
Kokan,A.R.(1963).“Optimum Alloca-tion in Multivariate Surveys”.Journal ofthe Royal Statistical Society(Series A),vol. 126, 557-565.
Kokan,A.R. and Khan,S.(1967). “Opti-mum Allocation in MultivariateSurveys:An Analytical Solution”. Jour-nal of the Royal Statistical Society (Se-ries B), vol. 29. 115-125.
Medina,F.(1988).”Tamaño Óptimo deMuestra en Encuestas de PropósitosMúltiples”. CEPAL, Memoria del TallerRegional sobre Planificación de En-cuestas en Hogares, Santiago de Chi-le, agosto, 1998.
Skinner,C.J.(1989). “Analysis of Com-
plex Surveys”. Chapter 2, Introductionto Part A., Edited by C.J. Skinner, D.Holt and T.M.F. Smith.John Wiley andSons Ltd., 23-58.
Sul,E., N.Forthofer, R. and J. Loromier,R.(1994).“Analyzing Complex SurveyData”.Sage University Papers onQuantitative Applications in the SocialScience, Num. 71,Beverly Hills:SagePubns.
Thompson,S.K.(1987).”Sample Sizefor Estimating Proportions”.The Ame-rican Statistician, vol.41, No.1, 42-46.
Tortora,R.D.(1978). “A Note on Sam-ple Size Estimation for MultinomialPopulations”. The American Statisti-cian, vol. 32, No. 3, 100-102.
Verma, V., Scott, C. andO’Muircheartaigh (1980). “Sample De-signs and Samplig Errors for the WorldFertility Survey”. (With Discussion).Journal of the Royal Statistical Socie-ty (Series A), vol. 143, 431-473.


















