
Manual de Usuario Java
97
Facilitador: Ing. Luis Vargas L. 1 Curso de JAVA AVANZADO
-
Upload
elsner-boanerge-gonzalez-ortega -
Category
Documents
-
view
237 -
download
13
Transcript of Manual de Usuario Java

Facilitador: Ing. Luis Vargas L. 1
Curso de
JAVA
AVANZADO

Facilitador: Ing. Luis Vargas L. 2
Curso de programación
distribuida en JAVA
(versión 7, JDK 1.7.25)
Manual del alumno

Facilitador: Ing. Luis Vargas L. 3
INDICE
Contenido1. Introducción al curso .......................................................................................................... 4
2. Introducción ......................................................................................................................... 5
3. Enterprise java Beans...................................................................................................... 30
4. Java Persistence (API JPA)............................................................................................ 32
5. Hibernate ........................................................................................................................... 34
6. Servlets, Java Server Pages .......................................................................................... 50
7. Java Server Faces............................................................................................................ 56
8. Web Services .................................................................................................................... 61
9. Rest Web Services........................................................................................................... 66
10. Seguridad Java EE....................................................................................................... 71

Facilitador: Ing. Luis Vargas L. 4
1. Introducción al curso
1.1 Objetivo de este curso
En este curso vamos a ver como programar en la tecnología Java, lo cual le permitirá desarrollar y ejecutar aplicaciones Java en Arquitectura de N capas, que sean robustas y flexibles.
1.2 Manual del alumno
Este manual del alumno es una ayuda para el alumno, para que tenga un recuerdo del curso. Este manual contiene un resumen de las materias que se van a estudiar durante el curso, pero el alumno debería de tomar notas personales para completar este manual.
1.3 Ejercicios prácticos
Para captar mejor la teoría, se harán muchos ejercicios con los alumnos, para probar la teoría y verificar la integración de la materia.
También, el alumno podrá copiar sus códigos en una memoria USB al fin del curso para llevarse, con el fin de seguir la práctica en su hogar.

Facilitador: Ing. Luis Vargas L. 5
2. Introducción
Stack de tecnologías
La importancia de tener un stack de tecnología de base
A la hora de hacer un sistema (web en Java) para una aplicación empresarial, hay que tomar diversas decisiones -entre ellas de arquitectura-, las cuales no sólo enmarcarán la forma de trabajar; sino que además, harán más fácil (o no) el desarrollo del sistema. Ello puede deberse a la facilidad de la tecnología, al expertice del equipo de trabajo o bien, a la experiencia que se posea con ella. Otra cuestión relevante, es que dicha arquitectura tenga la capacidad de adaptarse a los “requerimientos no funcionales” de la solución a construir.
Es fundamental tener en consideración toda la configuración de los distintos componentes que definen el workbench, área de trabajo, la cual si bien puede variar ligeramente, para distintas aplicaciones; contemplará, definitivamente, los siguientes aspectos:
Área de trabajo y L&F (Look & Feel). Seguridad (log-in, permisos, etc.). Administración de usuarios, grupos y permisos. Auditoría y logueo. Reporting. Mecanismos de notificación (email, sms, chat). Mecanismo de persistencia y transaccionalidad.
Los componentes, anteriormente detallados, generalmente, son agnósticos al problema de negocio; y nuestros clientes, seguramente esperan que ellos estén allí: funcionando, como un derecho adquirido que el mismo mercado ha ido transformando e imponiendo como características básicas que ya no pueden no estar.
El problema que a mi entender, persiste de forma recurrente, es que en las organizaciones no se invierte en tener una plantilla (témplate) con dichos componentes pre-armados, lo que le permitiría así, estar preparados para comenzar un desarrollo cuánto antes. Por otro lado, funcionalidades que son comunes, a lo largo del tiempo en distintas aplicaciones –como por ejemplo, loguearse en la aplicación, manejo de usuarios, navegabilidad, etc.- son codificadas desde cero, una y otra vez, por distintas personas (¡o incluso por las mismas!); y por supuesto, con bugs que podrían haberse corregido si se hubiese utilizado como punto de partida dicha plantilla que ya tiene súper probados estas funcionalidades.

Facilitador: Ing. Luis Vargas L. 6
Arquitectura Multicapas
Cada capa compone un subsistema en el que se ubican clases con responsabilidades propias.
Instalación de JDK, IDE Eclipse, Glassfish y MySQLo Instalación de JDK
Lo primero que debemos hacer es instalar el “Java SE Development Kit” o “JDK” desde el sitio http://www.oracle.com, damos clic sobre el producto a descargar según la preferencia del sistema operativo que tengamos, como se muestra a continuación:

Facilitador: Ing. Luis Vargas L. 7
Una vez instalado, definimos nuestras variables de entorno (path y classpath) para su ejecución (propiedades del S.O.)
o Instalación IDE Eclipse
Descargamos el IDE desde el sitio oficial http://www.eclipse.org, cuando hayan terminado de descargar el archivo verán que es un zip y no tiene un instalador. Esto se debe a que el programa no hace falta instalarlo, lo colocan donde deseen (les recomiendo "C:/eclipse" )
o Instalación del Servidor Glassfish
Lo descargamos del sitio oficial: http://glassfish.java.net , cuando hayan terminado de descargar el archivo verán que es un zip y no tiene un instalador. Esto se debe a que el programa no hace falta instalarlo, lo colocan donde deseen (les recomiendo "C:/glassfish" )
o Instalación del MySQL
Lo descargamos del sitio oficial: http://dev.mysql.com , seguimos las instrucciones presentadas en el instalador para culminar con la instalación. Una vez instalado debemos de configurar nuestra BD siguiendo las instrucciones presentada.
Integración Maven y Eclipse
o Instalación plugin Maven
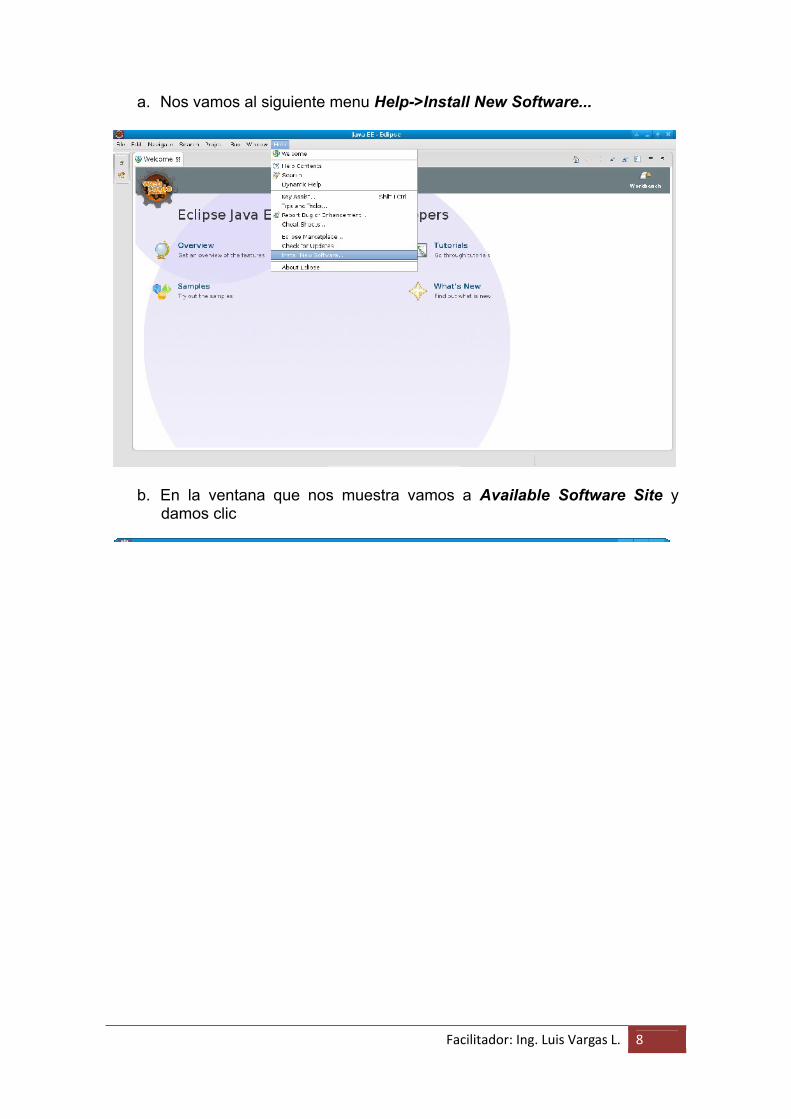
Facilitador: Ing. Luis Vargas L. 8
a. Nos vamos al siguiente menu Help->Install New Software...
b. En la ventana que nos muestra vamos a Available Software Site y damos clic
Facilitador: Ing. Luis Vargas L. 9
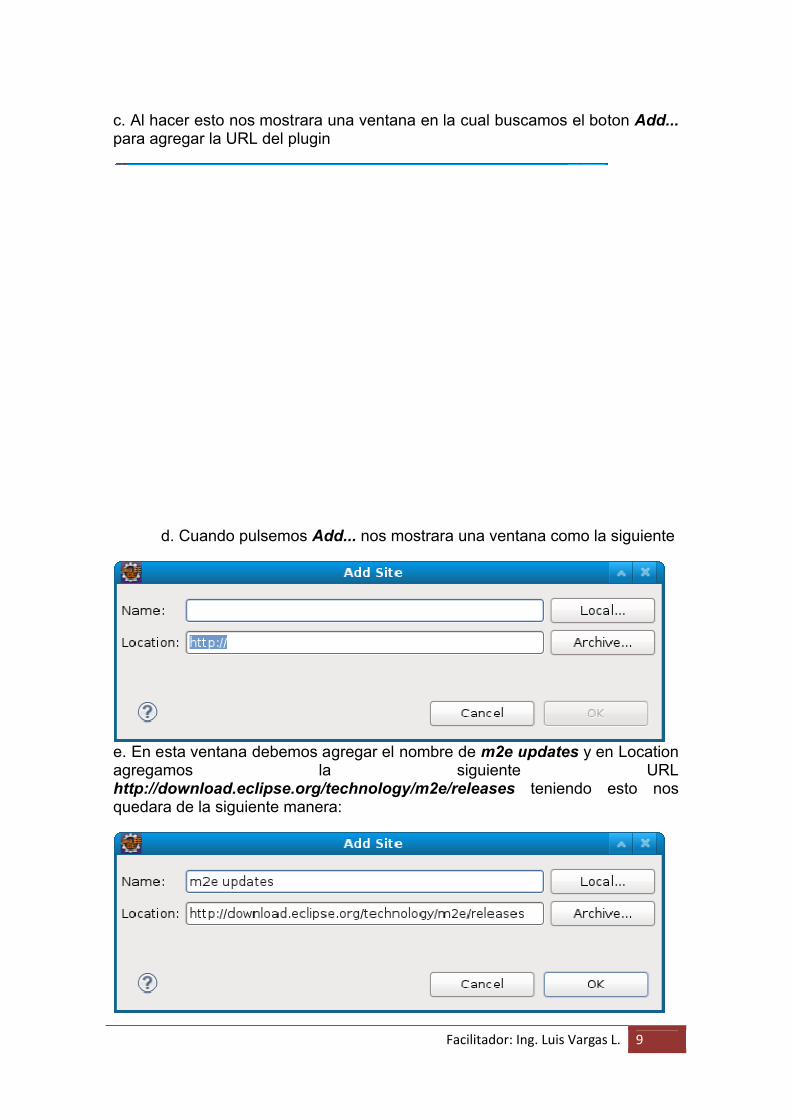
c. Al hacer esto nos mostrara una ventana en la cual buscamos el boton Add...para agregar la URL del plugin
d. Cuando pulsemos Add... nos mostrara una ventana como la siguiente
e. En esta ventana debemos agregar el nombre de m2e updates y en Location agregamos la siguiente URL http://download.eclipse.org/technology/m2e/releases teniendo esto nos quedara de la siguiente manera:

Facilitador: Ing. Luis Vargas L. 10
Ahora clic en OK y luego nos mostrara que ya esta agregado, y luego de esto nuevamente OK.
Luego en la ventana de instalación desplegamos la lista de selección y buscamos m2e updates -http://download.eclipse.org/technology/m2e/releases y lo seleccionamos.
Nota: Aqui surge un pequeño inconveniente, cuando tratamos de buscar lo anteriormente mencionado puede que no lo muestre, para ello lo que hacemos es dar cancelar y luego Help-->Install New Software... y cuando procedamos a buscarlo ya aparecerá.

Facilitador: Ing. Luis Vargas L. 11
f. Seleccionamos Maven Integration for Eclipse, y luego Next >

Facilitador: Ing. Luis Vargas L. 12
g. Next >
h. Aceptamos la licencia y pulsamos Finish

Facilitador: Ing. Luis Vargas L. 13
i. Inicia descargando e instalando el plugin y el siguiente paso es reiniciar Eclipse:
Aquí se concluye con la instalación solamente queda configurar el plugin m2e.

Facilitador: Ing. Luis Vargas L. 14
o Configuración del plugin Maven
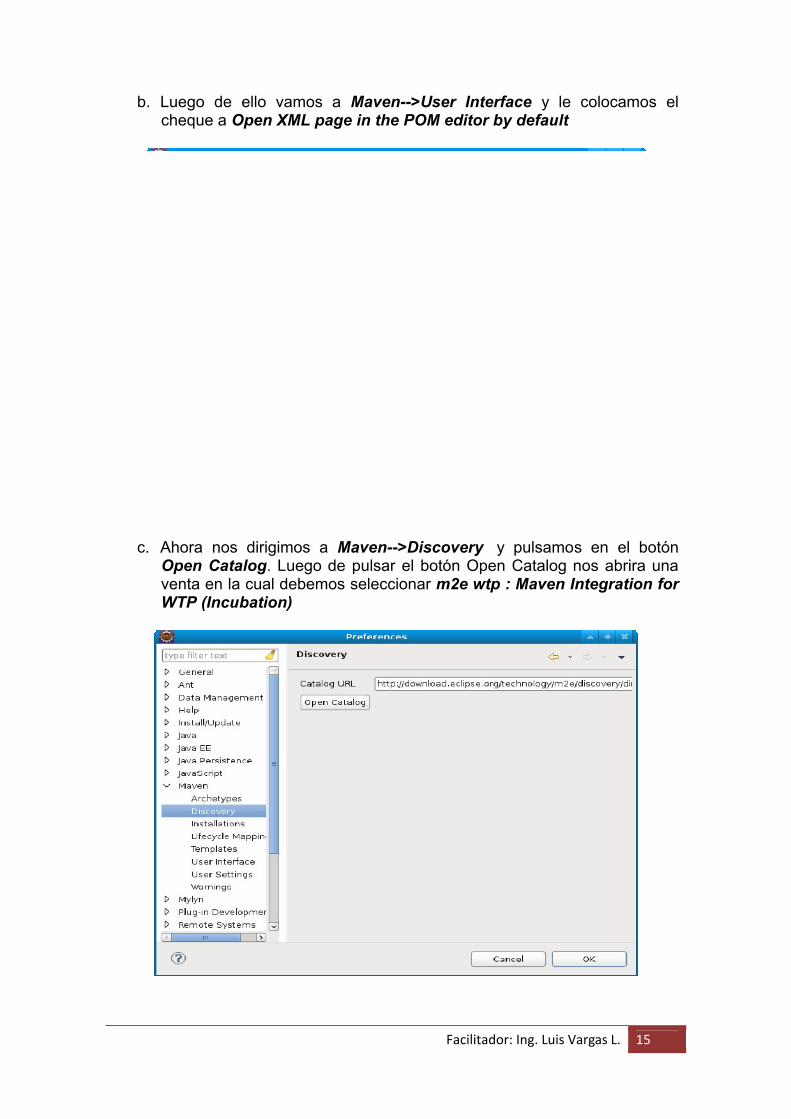
a. Para seguir con la configuración debemos ir a Window-->Preferences
Buscamos del lado izquierdo donde dice Maven, pulsamos sobre el, y seleccionamos lo siguiente:
Do not automatically update dependencies from remote repositories Download Artifact Sources Download Artifact JavaDoc Download repository index updates on startup
Facilitador: Ing. Luis Vargas L. 15
b. Luego de ello vamos a Maven-->User Interface y le colocamos el cheque a Open XML page in the POM editor by default
c. Ahora nos dirigimos a Maven-->Discovery y pulsamos en el botón Open Catalog. Luego de pulsar el botón Open Catalog nos abrira una venta en la cual debemos seleccionar m2e wtp : Maven Integration for WTP (Incubation)

Facilitador: Ing. Luis Vargas L. 16
d. Ya habiendo realizado lo anteriormente dicho nos mostrará una ventana de instalación y pulsamos Next >

Facilitador: Ing. Luis Vargas L. 17
e. Next ->
f. Aceptamos la licencia y pulsamos Finish
g. Para finalizar nos pedirá que reiniciemos Eclipse

Facilitador: Ing. Luis Vargas L. 18
creación de un proyecto web de Maven con Eclipse
Debemos ir a File-->New-->Other...
Buscamos la carpeta Maven y selccionamos Maven Project. Lo siguiente dar clic en el botón Next >
Next >

Facilitador: Ing. Luis Vargas L. 19
Buscamos en la columna de Artifact Id el que tenga el nombre de maven-archetype-webapp, cuando nos muestra la ventana por defecto esta seleccionado maven-archetype-quickstart, entonces solo bajamos 3posiciones y encontraremos la arquitectura para una aplicación web.
En esta parte es definir datos del proyecto
Group Id: En este caso coloque com.webapp, puedes colocar como gustes, si quieres, com.app.do, o web.app etc.
Artifact Id: Aqui deberá ir el nombre de la aplicación.
Facilitador: Ing. Luis Vargas L. 20
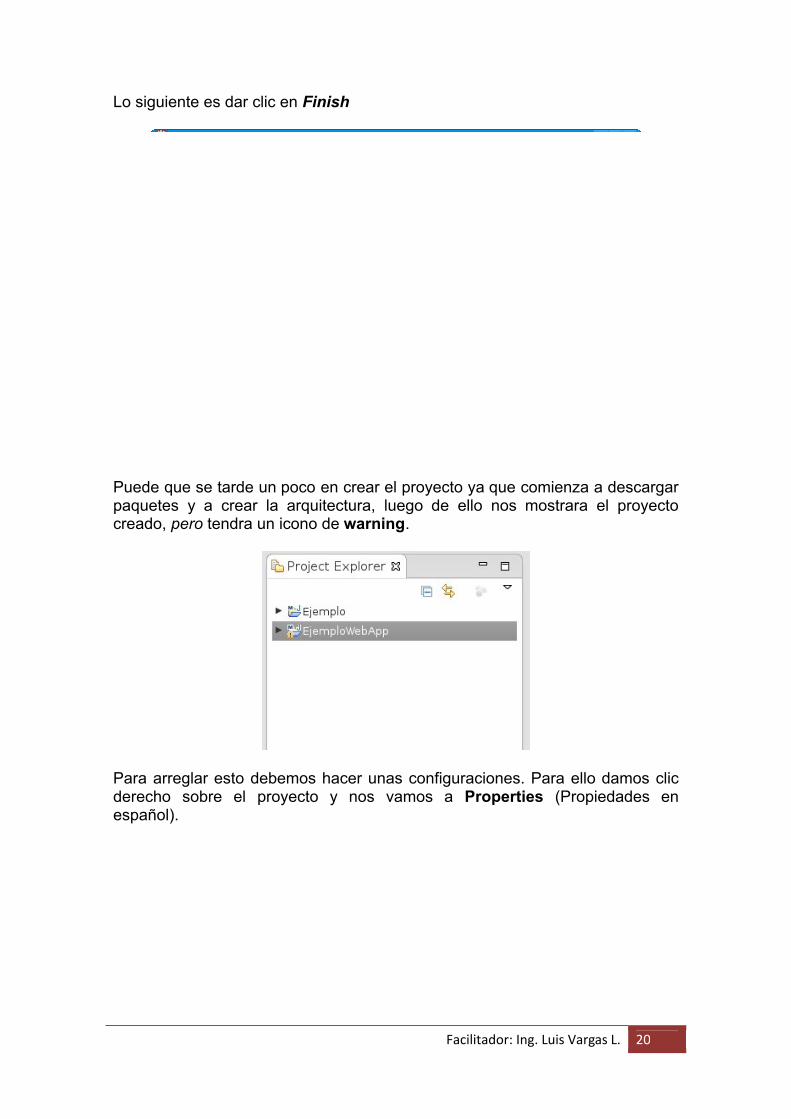
Lo siguiente es dar clic en Finish
Puede que se tarde un poco en crear el proyecto ya que comienza a descargar paquetes y a crear la arquitectura, luego de ello nos mostrara el proyecto creado, pero tendra un icono de warning.
Para arreglar esto debemos hacer unas configuraciones. Para ello damos clic derecho sobre el proyecto y nos vamos a Properties (Propiedades en español).
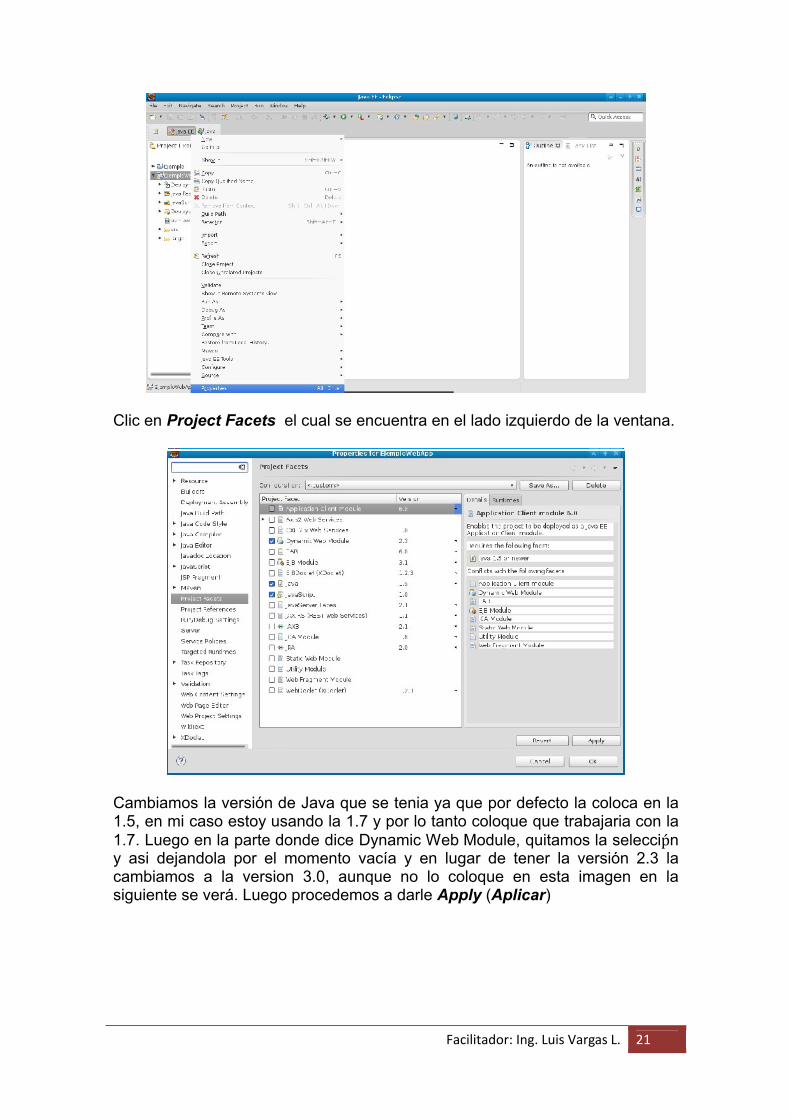
Facilitador: Ing. Luis Vargas L. 21
Clic en Project Facets el cual se encuentra en el lado izquierdo de la ventana.
Cambiamos la versión de Java que se tenia ya que por defecto la coloca en la 1.5, en mi caso estoy usando la 1.7 y por lo tanto coloque que trabajaria con la 1.7. Luego en la parte donde dice Dynamic Web Module, quitamos la selecciṕn y asi dejandola por el momento vacía y en lugar de tener la versión 2.3 la cambiamos a la version 3.0, aunque no lo coloque en esta imagen en la siguiente se verá. Luego procedemos a darle Apply (Aplicar)

Facilitador: Ing. Luis Vargas L. 22
Al haber realizado lo anterior procedemos a seleccionar la casilla de Dynamic Web Module en la version 3.0, esto es para que nos genere bien la parte del target y la creación de una carpeta WebContent (aunque luego la tendremos que eliminar). Siguiente paso es pulsar OK
Ya teniendo esto, vamos a nuestro proyecto y buscamos la carpeta WebContent y la eliminaremos.

Facilitador: Ing. Luis Vargas L. 23
Siguiente paso nuevamente clic derecho a nuestro proyecto y a Propiedades. Y buscamos la parte del lado izquierdo que dice Deployment Assembly. En la parte central en la columna Source seleccionamos el campo /WebContent y lo eliminamos con el botón Remove que aparece del lado derecho.
Siguiente es agregar un nuevo directorio, para ello pulsamos el botón Add... y nos mostrará la siguiente ventana, en la cual seleccionamos Folder y luego Next >

Facilitador: Ing. Luis Vargas L. 24
Seleccionamos la dirección webapp, que se desglosa de la siguiente manera src/main/webapp. Lo siguiente es pulsar Finish

Facilitador: Ing. Luis Vargas L. 25
Realizada la parte anterior, en la parte izquierda buscamos la opción Java Build Path (esta debajo de Deployment Assembly). Y en la parte central hay una pestaña llamada Libraries en esta parte debemos eliminar dos librerias la EAR Libraries y la Web App Libraries.
El siguiente paso es ir a la pestraña Order and Export y en esta parte seleccionamos todo y luego pulsamos OK.

Facilitador: Ing. Luis Vargas L. 26
Aquie vemos como queda el proyecto creado con Maven y sin el problema de warning.
Ya para finalizar, ejecutaremos el proyecto, para ello primero con Maven daremos un clean, para ello damos clic derecho en el proyecto luego Run As--> Maven clean

Facilitador: Ing. Luis Vargas L. 27
Luego un Maven Install para crear el war, para ello clic derecho en el proyecto Run As--> Maven install
Ahora nos toca ejecutar la aplicación, para ello nuevamente clic derecho en el proyecto Run As--> Run on Server
Al tratar de correrlo en un Servidor nos desplegara una lista de servidores luego de ello buscamos el servidor que deseamos en mi caso tengo instalado un Tomcat v7, por lo tanto este es el que seleccione. Luego pulsamos Next >

Facilitador: Ing. Luis Vargas L. 28
Aca si tenemos un tomcat instalado unicamente colocamos la dirección dedonde se encuentra en mi caso esta en /usr/share/apache-tomcat-7.0.32. En el campo del JRE, seleccionamos el que tenemos, en mi caso el JDK 1.7. Lo siguiente es dar clic en el botón Finish y si te mata la curiosidad :D da clic en siguiente Next >
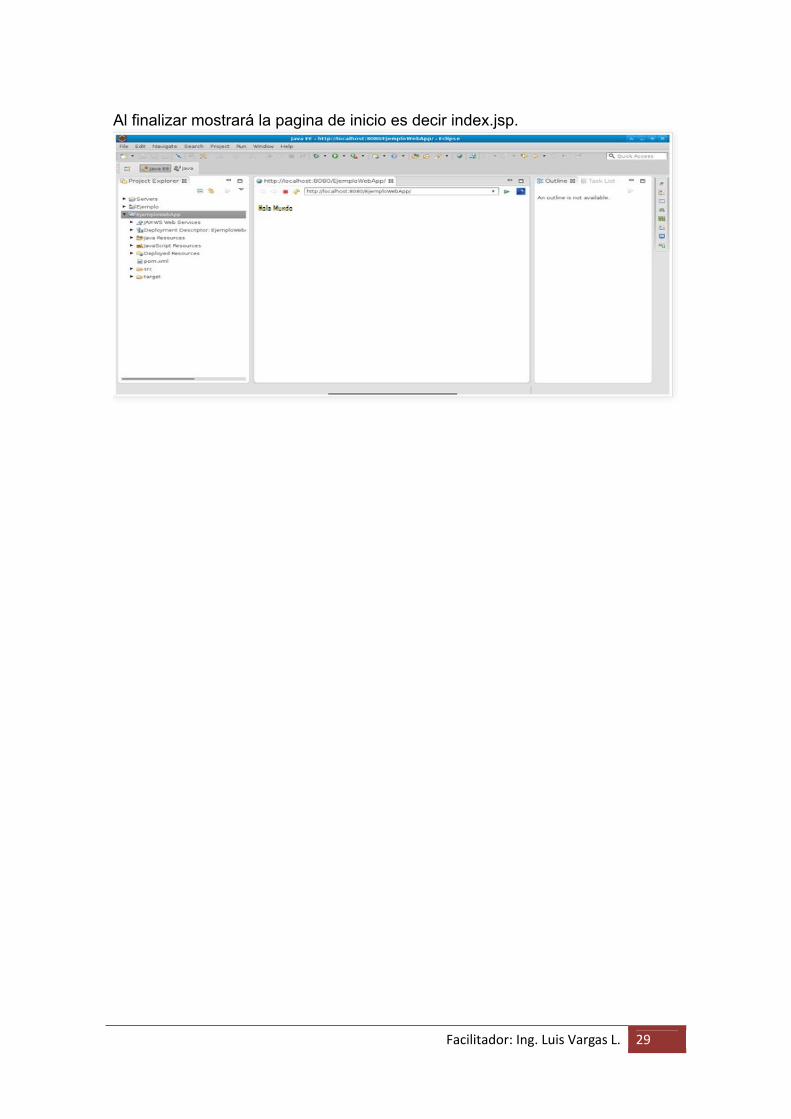
Facilitador: Ing. Luis Vargas L. 29
Al finalizar mostrará la pagina de inicio es decir index.jsp.

Facilitador: Ing. Luis Vargas L. 30
3. Enterprise java Beans
Introducción
EJB (Enterprise JavaBeans) es un modelo de programación que nos permite construir aplicaciones Java mediante objetos ligeros (como POJO's). Cuando construimos una aplicación, son muchas las responsabilidades que se deben tener en cuenta, como la seguridad, transaccionalidad, concurrencia, etc. El estandar EJB nos permite centrarnos en el código de la lógica de negocio del problema que deseamos solucionar y deja el resto de responsabilidades al contenedor de aplicaciones donde se ejecutará la aplicación.
Configuración y tipos de EJB
a. Message-Driven EJBs (EJBs dirigidos por mensajes)
- Permiten el procesamiento de mensajes (operaciones) de forma asíncrona (recepcióon y tratamiento de eventos JMS)
- Actúan como listeners (escuchadores) de eventos JMS (Java Message Service) Implementan el interfaz MessageListener
- Se "suscriben" a una cola (queue) quedando a la espera y se activan cuando se recibe un mensaje dirigido a dicha cola
o Esos mensajes JMS pueden ser enviados por cualquier componente de una
aplicación Java EE (clientes, componentes Web, otros EJBs)
o Los "clientes" de un Message-Driven EJB no invocan directamente sus métodos, simplemente envían mensajes JMS
b. Session EJBs (EJBs de sesión)
- Representan procesos de negocio (funcionalidades de la aplicación) implementan un interfaz de negocio (bussines interface)
- Gestionan la interacción con los "clientes" (objetos/procesos que hacen uso del componente) y encapsulan el flujo y manipulación de la información en el servidor
- Proporcionan a los "clientes" una "fachada" de los servicios proporcionados

Facilitador: Ing. Luis Vargas L. 31
por otros componentes disponibles en el servidor (patrón de diseño Facade)
- Ofrecen operaciones síncronas (peticióon-respuesta)
o Procesos de negocio ejecutados en respuesta a una solicitud del cliente
- Contenedor de EJBs crea e inicializa sus instancias (inyectándoleslas referencias necesarias) y las asigna a los "clientes" a medida que estos lo van requiriendo.
- En un instante de tiempo dado, sólo un "cliente" tiene acceso a los métodos de la instancia del EJB (control de concurrencia).
o Contenedor de EJBs garantiza que cada método del EJB se ejecuta dentro
de una transacción atómica
Inyección de Dependencia en Java EE
- Uso de la anotación @EJB acompañando al atributo donde se mantendrá la referencia al EJB.
o El tipo del atributo/referencia ser�a el nombre del interfaz de negocio que se desea invocar
o El contenedor usará el nombre por defecto del EJB (o el que se especique en el parámetro @EBJ(mappedName="...")) para consultar al servidor de nombres JNDI, inyectando en ese atributo la referencia encontrada
Empaquetamiento y Contenedores Empresariales
Como cualquier componente empresarial, los EJB también deben empaquetarse para ser desplegados en un servidor Java EE.

Facilitador: Ing. Luis Vargas L. 32
4. Java Persistence (API JPA)
Introducción
Java Persistence API (JPA) proporciona un estándar para gestionar datos relacionales en aplicaciones Java SE o Java EE, de forma que además se simplifique el desarrollo de la persistencia de datos.
Pero para entender JPA, tendremos que tener claro el concepto "persistencia". La persistencia o el almacenamiento permanente, es una de las necesidades básicas de cualquier sistema de información de cualquier tipo. En primer lugar, se propuso que el programa tratara los datos haciendo consultas directas a la base de datos. Después, se propuso trabajar con objetos, pero las bases de datos tradicionales no admiten esta opción.
Debido a esta situación, aparecieron los motores de persistencia, cuya función es traducir entre los dos formatos de datos: de registros a objetos y de objetos a registros. Persistir objetos Java en una base de datos relacional implica serializar un árbol de objetos Java en una base de datos de estructura tabular y viceversa. Esencial es la necesidad de mapear objetos Java para optimizar velocidad y eficiencia de la base de datos
En Java solucionamos problemas de negocio a través de objetos, los cuales tienen estado y comportamiento. Sin embargo, las bases de datos relacionales almacenan la información mediante tablas, filas, y columnas, de manera que

Facilitador: Ing. Luis Vargas L. 33
para almacenar un objeto hay que realizar una correlación entre el sistema orientado a objetos de Java y el sistema relacional de nuestra base de datos. JPA (Java Persistence API - API de Persistencia en Java) es una abstracción sobre JDBC que nos permite realizar dicha correlación de forma sencilla, realizando por nosotros toda la conversión entre nuestros objetos y las tablas de una base de datos. Esta conversión se llama ORM (Object Relational Mapping - Mapeo Relacional de Objetos), y puede configurarse a través de metadatos (mediante xml o anotaciones). Por supuesto, JPA también nos permite seguir el sentido inverso, creando objetos a partir de las tablas de una base de datos, y también de forma transparente. A estos objetos se le conoce como entidades (entities).
JPA establece una interface común que es implementada por un proveedor de persistencia de nuestra elección (como Hibernate, Eclipse, etc), de manera que podemos elegir en cualquier momento el proveedor que más se adecue a nuestras necesidades. Así, es el proveedor quién realiza el trabajo, pero siempre funcionando bajo la API de JPA.
Interfaces JPA
Los 4 tipos de interfaces de las que se compone JPA son:
- javax.persistence.Persistence: Contiene métodos estáticos de ayuda para obtener una instancia de Entity Manager Factory de una forma independiente al vendedor de la implementación de JPA. Una clase de inicialización que va proporcionar un método estático para la creación de una Entity Manager Factory.
- javax.persistence.EntityManagerFactory: La clase javax.persistence.Entity.Manager.Factory nos ayuda a crear objetos de EntityManager utilizando el patrón de diseño del Factory. Este objeto en tiempo de ejecución representa una unidad de persistencia particular. Generalmente va a ser manejado como un singleton y proporciona métodos para la creación de instancias EntityManager.
- javax.persistence.EntityManagerFactory: La clase javax.persistence.Entity es una anotación Java que se coloca a nivel de clases Java serializables y que cada objeto de una de estas clases anotadas representa un registro de una base de datos.
- javax.persistence.EntityManager: Es la interfaz principal de JPA utilizada para la persistencia de las aplicaciones. Cada Entity Manager puede realizar operaciones CRUD (Create, Read, Update, Delete) sobre un conjunto de objetos persistentes. Es un objeto único, no compartido que representa una unidad de trabajo particular

Facilitador: Ing. Luis Vargas L. 34
para el acceso a datos. Proporciona métodos para gestionar el ciclo de vida de las instancias entidad y para crear instancias Query.
- javax.persistence.Query: La interface javax.persistence.Query está implementada por cada vendedor de JPA para encontrar objetos persistentes manejando cierto criterio de búsqueda. JPA estandariza el soporte para consultas utilizando Java Persistence Query Language (JPQL) y Structured Query Language (SQL). Podemos obtener una instancia de Query desde una instancia de un Entity Manager.
- javax.persistence.EntityTransaction: Cada instancia de Entity Manager tiene una relación de uno a uno con una instancia de javax.persistence.EntityTransaction, permite operaciones sobre datos persistentes de manera que agrupados formen una unidad de trabajo transaccional, en el que todo el grupo sincroniza su estado de persistencia en la base de datos o todos fallan en el intento, en caso de fallo, la base de datos quedará con su estado original. Maneja el concepto de todos o ninguno para mantener la integridad de los datos.
5. Hibernate
Es una herramienta de Mapeo objeto-relacional (ORM) para la plataforma Java que facilita el mapeo de atributos entre una base de datosrelacional tradicional y el modelo de objetos de una aplicación, mediante archivos declarativos (XML) o anotaciones en los beans de las entidades que permiten establecer estas relaciones.
Para instalar las Hibernate Tools basta con ir a la página de descargas: http://www.hibernate.org/6.html y pinchar sobre el enlace “Download” de “Hibernate Tools”
Una vez descargado basta con descomprimirlo en el directorio del Eclipse (el mismo directorio donde se encuentra el ejecutable de Eclipse, por ejemplo, en Windows, eclipse.exe).
Si ahora arrancamos el Eclipse podemos comprobar, por ejemplo, que tenemos nuevas opciones en el asistente de creación (File -> New -> Other...)
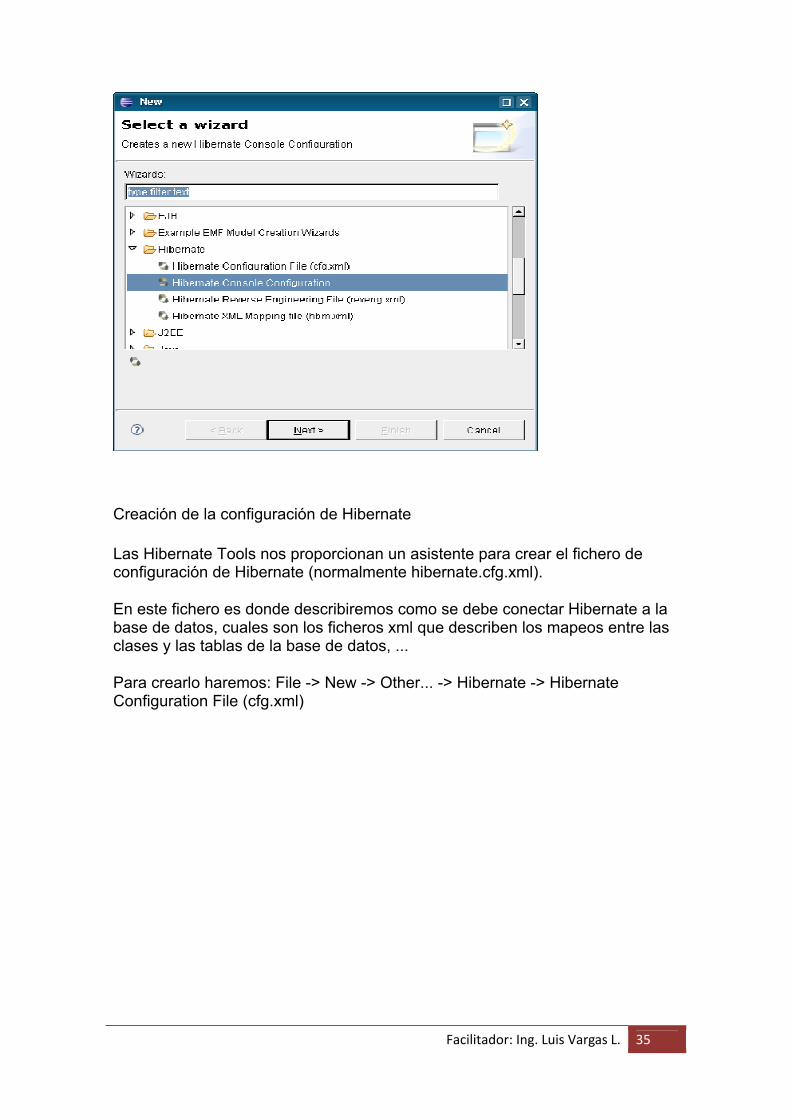
Facilitador: Ing. Luis Vargas L. 35
Creación de la configuración de Hibernate
Las Hibernate Tools nos proporcionan un asistente para crear el fichero de configuración de Hibernate (normalmente hibernate.cfg.xml).
En este fichero es donde describiremos como se debe conectar Hibernate a la base de datos, cuales son los ficheros xml que describen los mapeos entre las clases y las tablas de la base de datos, ...
Para crearlo haremos: File -> New -> Other... -> Hibernate -> Hibernate Configuration File (cfg.xml)

Facilitador: Ing. Luis Vargas L. 36
Le damos el nombre al fichero de configuración (normalmente hibernate.cfg.xml), e indicamos donde debe guardarlo. Deberá ser un directorio que en ejecución forme parte del classpath, para que la aplicación lo pueda localizar (si usamos Maven será el directorio src/main/resources).

Facilitador: Ing. Luis Vargas L. 37
Ahora indicamos el dialecto que debe usar Hibernate. El dialecto, básicamente, es el idioma que ha de hablar Hibernate con nuestra base de datos. También indicamos la clase del driver de acceso a la base de datos, la URL de conexión, el usuario y la password, ... y en definitiva toda la información para que Hibernate se pueda concatenar correctamente a nuestra base de datos.

Facilitador: Ing. Luis Vargas L. 38
Cuando demos a “Finish” se creará el fichero, que tendrá un aspecto similar (según los datos introducidos en la pantalla anterior) a:
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE hibernate-configuration PUBLIC"-//Hibernate/Hibernate Configuration DTD 3.0//EN""http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration><session-factory><property
name="hibernate.connection.driver_class">com.mysql.jdbc.Driver</property><property
name="hibernate.connection.url">jdbc:mysql://localhost:3306/AUTENTIA</property><property
name="hibernate.connection.username">autentia</property><property
name="hibernate.connection.password">autentia</property><property
name="hibernate.dialect">org.hibernate.dialect.MySQLInnoDBDialect</property></session-factory>
</hibernate-configuration>

Facilitador: Ing. Luis Vargas L. 39
Hibernate Console
Ahora vamos a crear la consola de Hibernate. La consola es el eje central de las Hibernate Tools, ya que cualquier otra operación que queramos hacer (generar código, lanzar sentencias HQL, ...) dependerán de la configuración de la consola.
Para crear una nueva configuración de la consola de Hibernate hacemos: File -> New -> Other... -> Hibernate -> Hibernate Console
Indicamos el nombre que le damos a esta configuración, el proyecto asociado, y el fichero de configuración donde está configurada nuestra conexión. Este fichero es el típico fichero “hibernate.cfg.xml” de configuración de Hibernate. Indicaremos el fichero de configuración que hemos creado en el punto anterior:

Facilitador: Ing. Luis Vargas L. 40
Antes de pulsar el botón “Finish”, pincharemos sobre la pestaña “Classpath”. Aquí vamos a indicar donde se encuentra el driver de la base de datos. Esto es muy importante, ya que de lo contrario las Hibernate Tools serán incapaces de conectarse con la base de datos.
Nótese que también tenemos activado “Include default classpath project”. Esto es necesario para que las Hibernate Tools sean capaces de encontrar nuestros .class, por ejemplo para poder lanzar sentencias HQL.
Ahora ya podemos pulsar el botón de “Finish”.

Facilitador: Ing. Luis Vargas L. 41
6. Generando código a partir de la base de datos
Ya estamos preparados para generar código a partir de las tablas creadas en nuestra base de datos. Para ello pulsamos sobre el nuevo icono (apareció al instalar las Hibernate Tools) que tenemos en la barra de herramientas (en la imagen aparece enmarcado en un rectángulo rojo):
Al pulsar sobre el icono, deberemos seleccionar la opción “Hibernate Code Generation......”
Nos aparece una ventana, donde en su lado izquierda aparece una zona en blanco. Sobre ella hay una barra de herramientas, pulsamos sobre el primer icono “New launch configuration”. Y ahora rellenamos los datos de la zona de la derecha:
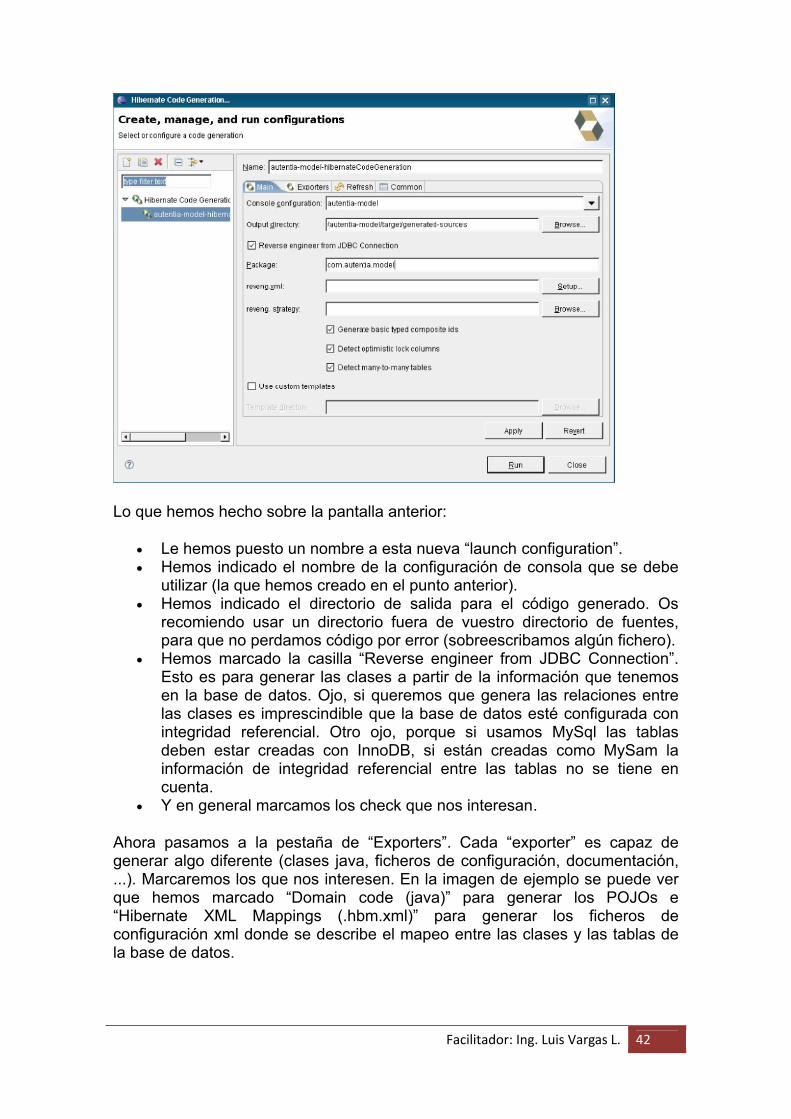
Facilitador: Ing. Luis Vargas L. 42
Lo que hemos hecho sobre la pantalla anterior:
Le hemos puesto un nombre a esta nueva “launch configuration”. Hemos indicado el nombre de la configuración de consola que se debe
utilizar (la que hemos creado en el punto anterior). Hemos indicado el directorio de salida para el código generado. Os
recomiendo usar un directorio fuera de vuestro directorio de fuentes, para que no perdamos código por error (sobreescribamos algún fichero).
Hemos marcado la casilla “Reverse engineer from JDBC Connection”. Esto es para generar las clases a partir de la información que tenemos en la base de datos. Ojo, si queremos que genera las relaciones entre las clases es imprescindible que la base de datos esté configurada con integridad referencial. Otro ojo, porque si usamos MySql las tablas deben estar creadas con InnoDB, si están creadas como MySam la información de integridad referencial entre las tablas no se tiene en cuenta.
Y en general marcamos los check que nos interesan.
Ahora pasamos a la pestaña de “Exporters”. Cada “exporter” es capaz de generar algo diferente (clases java, ficheros de configuración, documentación, ...). Marcaremos los que nos interesen. En la imagen de ejemplo se puede ver que hemos marcado “Domain code (java)” para generar los POJOs e “Hibernate XML Mappings (.hbm.xml)” para generar los ficheros de configuración xml donde se describe el mapeo entre las clases y las tablas de la base de datos.

Facilitador: Ing. Luis Vargas L. 43
En esta misma pantalla de los “Exportes” tenemos otra dos opciones:
Use Java 5 syntax: el código java generado usará la sintaxis List<Clase> para indicar el tipo de las colecciones.
Generate EJB3 annotations: Genera POJOs anotados según el estándar de EJB3. Esto es una alternativa a los ficheros xml de mapeo, de forma que, mediantes estas anotaciones, en el mismo POJO es donde se indica como se debe mapear con la base de datos. Estas anotaciones además de evitarnos mantener esos xml, tienen la ventaja de que son compatibles con las anoraciones de la nueva especificación 3 de EJBs (podríamos convertir nuestros POJOs en EJBs de forma casi directa, o usar nuestros POJOs con la capa de persistencia de EJB3 en vez de con Hibernate).
Sólo podemos usar estas opciones si tenemos una máquina virtual 5 o superior. Si es el caso, os lo recomiendo, la primera para detectar en compilación posibles problemas de tipos, y el segundo sobre todo por escribir y mantener menos ficheros.
Ahora ya podemos al botón “Run” para generar el código.
7. revenge.xml el fichero de la “venganza” ;)
Si observamos el código generado en el punto anterior podemos ver dos cosas:

Facilitador: Ing. Luis Vargas L. 44
Si nuestros identificadores en la base de datos son numéricos, los atributos correspondientes de los POJOs son tipos básicos (short, int, long).
Las relaciones de integridad referencial en la base de datos se han convertido en asociaciones bidireccionales en las clases (es decir, si tengo una relación 1:n tendré una clase “foo” con un atributo que hace referencia a la clase “bar”, y en la clase “bar” tendré una lista de objetos de “foo”).
Estas dos situaciones no son siempre recomendables:
En el caso de los identificadores es recomendable que siempre sean atributos nulables, de esta forma Hibernate es capaz de distinguir si la entidad ya existe en la base de datos o si se trata de una nueva entidad que habrá que añadir.
En el caso de las relaciones, no siempre es necesaria esa bidirecccionalidad, de hecho, estas asociaciones bidireccionales son el caso menos frecuente, ya que solemos hacer la navegación siempre en un sentido (por ejemplo de un pedido saco la lista de productos, pero de un producto no saco la lista de todos los pedidos donde aparece).
Para refinar este tipo de cosas podemos hacerlo a mano o usar el fichero revenge.xml. El uso de este fichero es recomendable ya que nos permite regenerar las clases sin perder los cambios.
Para crear este fichero, sobre la primera pantalla que veíamos al configurar el “launch configuration” vemos que hay un campo “revenge.xml” con un botón “Setup...”. Pulsamos este botón.
Le decimos que queremos crear un nuevo fichero “Create new...”.
Indicamos donde se debe guardar el fichero (debería ser un directorio que luego quede fuera de nuestra distribución).

Facilitador: Ing. Luis Vargas L. 45
Ahora seleccionamos la configuración de consola que creamos anteriormente y pulsamos sobre el botón “Refresh”. Con esto nos aparecerá a la izquierda nuestro esquema de la base de datos con las tablas, esto nos permite seleccionar las tablas de las que queremos generar código (por defecto lo que hicimos en el punto anterior genera código para todas las tablas del esquema).
Marcamos las que nos interesan y pulsamos sobre “Include...”. Veremos como pasan al lado de la derecha.

Facilitador: Ing. Luis Vargas L. 46
Pulsamos sobre “Finish” y volvemos a la pantalla de configuración de “launch configuration”. Podemos ver como ya aparece el nombre del fichero que acabamos de crear.

Facilitador: Ing. Luis Vargas L. 47
Ahora podemos localizar el fichero en nuestro explorador de paquetes de Eclipse y abrirlo. Veremos que nos aparece un editor específico, que nos permite, de forma más menos visual, modificar este fichero.
En la pestaña “Type Mappings” podemos indicar como se deben mapear las tipos de la base de datos con los tipos de Java. Por ejemplo, en esta sección podemos añadir un mapeo del tipo INTEGER de JDBC al tipo Java.lang.Integer de Java. Con esto solucionamos el tema de los identificadores numéricos, consiguiendo que sean nulables.
Si queremos que las relaciones de la base de datos no se conviertan en asociaciones bidireccionales, tendremos que modificar a mano fuente del

Facilitador: Ing. Luis Vargas L. 48
fichero revenge.xml (lamentablemente las Hibernate Tools todavía no soportan hacer esto de forma visual). Para ello podemos pinchar sobre la pestaña “Source”.
Un ejemplo de fichero sería el siguiente:
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE hibernate-reverse-engineering PUBLIC "-//Hibernate/Hibernate Reverse Engineering DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-reverse-engineering-3.0.dtd" ><hibernate-reverse-engineering><type-mapping><sql-type jdbc-type="INTEGER" hibernate-
type="java.lang.Integer"></sql-type></type-mapping><table-filter match-catalog="AUTENTIA" match-name="BuyCart"/><table-filter match-catalog="AUTENTIA" match-name="BuyCartProduct"/><table-filter match-catalog="AUTENTIA" match-name="Category"/><table-filter match-catalog="AUTENTIA" match-name="Product"/>
<table name="Product"><foreign-key constraint-name="fk_category_id"><set exclude="true"/></foreign-key>
</table><table name="BuyCartProduct"><foreign-key constraint-name="fk_product_id"><set exclude="true"/></foreign-key><foreign-key constraint-name="fk_buyCart_id"><many-to-one exclude="true"/></foreign-key>
</table></hibernate-reverse-engineering>
Vemos como tenemos los mapeos de los tipos de datos, las tablas que se tienen que usar al hacer la ingeniería inversa, y luego como se tienen que hacer las asociaciones.
En el ejemplo hay una relación 1:n entre la tabla “Category” y “Product”. De forma que por defecto se nos creará un atributo en la clase “Product” que apunta a la categoría correspondiente, y en la clase “Category” tendremos una lista de todos los productos que tienen esa categoría. Lo que estamos haciendo en el ejemplo es que esta asociación sea unidireccional de forma que desde la

Facilitador: Ing. Luis Vargas L. 49
clase “Product” podremos acceder a su categoría, pero desde la clase “Category” no podremos acceder a todos los productos.
Nótese que “fk_category_id” es el nombre de la “constraint” que hay en el campo de la tabla “Product” donde se guarda la clave ajena de la tabla “Category”. Mostramos el script de creación para aclarar este párrafo:
CREATE TABLE Category (id INTEGER UNSIGNED NOT NULL AUTO_INCREMENT,name VARCHAR(45) NOT NULL,description VARCHAR(255) NULL,PRIMARY KEY(id)
)engine=innodb default charset=utf8 collate=utf8_spanish_ci;CREATE TABLE Product (id INTEGER UNSIGNED NOT NULL AUTO_INCREMENT,categoryId INTEGER UNSIGNED NOT NULL,name VARCHAR(45) NULL,description VARCHAR(255) NULL,price INTEGER UNSIGNED NOT NULL,PRIMARY KEY(id),constraint fk_category_id foreign key (categoryId) references
Category (id))engine=innodb default charset=utf8 collate=utf8_spanish_ci;
Ahora, gracias al fichero revenge.xml podemos volver a generar las clases, pero esta vez el resultado obtenido se ajustará mucho más a nuestras necesidades.
El uso de Hibernate es muy recomendable para aislarnos de la base de datos y facilitarnos el acceso a la misma. Con herramientas como Hibernate Tools conseguimos facilitar mucho más el trabajo.

Facilitador: Ing. Luis Vargas L. 50
6. Servlets, Java Server Pages
Los servlets y Java Server Pages (JSPs) son dos métodos de creación de páginas web dinámicas en servidor usando el lenguaje Java. En ese sentido son similares a otros métodos o lenguajes tales como el PHP, los CGIs (common gateway interface), programas que generan páginas web en el servidor, o los ASP (Active Server Pages), un método específico de Microsoft. Sin embargo, se diferencian de ellos en otras cosas.
Para empezar, los JSPs y servlets se ejecutan en una máquina virtual Java, lo cual permite que, en principio, se puedan usar en cualquier tipo de ordenador, siempre que exista una máquina virtual Java para él. Cada servlet (o JSP, a partir de ahora lo usaremos de forma indistinta) se ejecuta en su propia hebra, es decir, en su propio contexto; pero no se comienza a ejecutar cada vez que recibe una petición, sino que persiste de una petición a la siguiente, de forma que no se pierde tiempo en invocarlo (cargar programa + intérprete). Su persistencia le permite también hacer una serie de cosas de forma más eficiente: conexión a bases de datos y manejo de sesiones, por ejemplo.
Los JSPs son en realidad servlets: un JSP se compila a un programa en Java la primera vez que se invoca, y del programa en Java se crea una clase que se empieza a ejecutar en el servidor como un servlet. La principal diferencia entre los servlets y los JSPs es el enfoque de la programación: un JSP es una página Web con etiquetas especiales y código Java incrustado, mientras que un servlet es un programa que recibe peticiones y genera a partir de ellas una página web
Ambos necesitan un programa que los contenga, y sea el que envíe efectivamente páginas web al servidor, y reciba las peticiones, las distribuya entre los servlets, y lleve a cabo todas las tareas de gestión propias de un servidor web.
Integración de Servlets y EJB
- Inyección de recursos de Java EE en un Web Bean

Facilitador: Ing. Luis Vargas L. 51
- Llamando a Web Bean desde un Servlet
- Llamada a un Web Bean desde un Message-Driven Bean
- endpoints JMS
- Empaquetamiento y despliegue.
Los Web Beans están totalmente integrados en un entorno de Java EE. Los Web Beans tienen acceso a recursos de Java EE y a contextos persistentes de JPA. Se pueden ser utilizar en expresiones Unificadas EL en páginas JSF y JSP. Pueden ser inyectados en algunos objetos, tales como Servlets y Message Driven Beans, los cuales no son Web Beans.
Inyección de recursos de Java EE en un Web Bean
Todos los Web Beans sencillos y empresariales pueden aprovechar la inyección de dependencia de Java EE utilizando@Resource, @EJB y @PersistenceContext. Ya hemos visto algunos ejemplos de esto, aunque no prestamos mucha atención en el momento.
@Transactional @Interceptor
public class TransactionInterceptor {
@Resource Transaction transaction;
@AroundInvoke public Object manageTransaction(InvocationContext ctx) { ...}
}@SessionScoped
public class Login {
@Current Credentials credentials;
@PersistenceContext EntityManager userDatabase;
...

Facilitador: Ing. Luis Vargas L. 52
}
Los @PostConstruct de Java EE y las llamadas de @PreDestroy también son compatibles con todos los Web Beans sencillos y empresariales. El método @PostConstruct es llamado después de realizar toda la inyección.
Hay una restricción para tener en cuenta aquí: @PersistenceContext(tipo=EXTENDIDO) no es compatible con Web Beans sencillos.
Llamando a Web Bean desde un Servlet
Es fácil utilizar un Web Bean desde un Servlet en Java EE 6. Simplemente inyecte el Web Bean mediante campo de Web Beans o Inyección de método inicializador.
public class Login extends HttpServlet {
@Current Credentials credentials;
@Current Login login;
@Override
public void service(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
credentials.setUsername( request.getAttribute("username") ):
credentials.setPassword( request.getAttribute("password") ):
login.login();
if ( login.isLoggedIn() ) {
response.sendRedirect("/home.jsp");
}
else {
response.sendRedirect("/loginError.jsp");
}

Facilitador: Ing. Luis Vargas L. 53
}
}
El cliente proxy de Web Beans cuida las invocaciones del método de enrutamiento desde el Servlet a las instancias correctas de Credenciales e Inicio de sesión para la petición y sesión HTTP actuales.
Llamada a un Web Bean desde un Message-Driven Bean
La inyección de Web Beans se aplica a todos los EJB, incluso cuando no están bajo el control del administrador de Web Bean (si fueron obtenidos por el JNDI o inyección utilizando @EJB, por ejemplo). En particular, se puede utilizar inyección de Web Beans en Message-Driven Beans que no sean considerados Web Beans porque no se puede inyectarlos.
Se pueden incluso utilizar enlaces de interceptor de Web Beans para Message-Driven Beans.
@Transactional @MessageDriven
public class ProcessOrder implements MessageListener {
@Current Inventory inventory;
@PersistenceContext EntityManager em;
public void onMessage(Message message) {
...
}
}
Así, la recepción de mensajes es superfácil en un entorno de Web Beans. No obstante, tenga en cuenta que no hay sesión o contexto de conversación disponible cuando se envía un mensaje a un Message-Driven Bean. Sólo los Web Beans @RequestScoped y @ApplicationScoped Web Beans están disponibles.
También es fácil enviar mensajes mediante Web Beans.

Facilitador: Ing. Luis Vargas L. 54
endpoints JMS
Enviar mensajes mediante JMS puede ser bastante complejo, debido al número de objetos diferentes que se tienen que manejar. Para colas tenemos Queue, QueueConnectionFactory, QueueConnection, QueueSession y QueueSender. Para temas tenemos Topic, TopicConnectionFactory, TopicConnection, TopicSession y TopicPublisher. Cada uno de estos objetos tiene su propio ciclo de vida y modelo de hilos de los cuales tenemos que preocuparnos.
Los Web Beans se encargan de eso por nosotros. Todo lo que se necesita es reportar la cola o tópico en web-beans.xml, especificando un tipo de enlace y conexión de fábrica.
<Queue>
<destination
>java:comp/env/jms/OrderQueue</destination>
<connectionFactory
>java:comp/env/jms/QueueConnectionFactory</connectionFactory>
<myapp:OrderProcessor/>
</Queue
>
<Topic>
<destination
>java:comp/env/jms/StockPrices</destination>
<connectionFactory
>java:comp/env/jms/TopicConnectionFactory</connectionFactory>
<myapp:StockPrices/>
</Topic
>

Facilitador: Ing. Luis Vargas L. 55
Ahora podemos inyectar Queue, QueueConnection, QueueSession o QueueSender para una cola, o Topic, TopicConnection, TopicSessionoTopicPublisher para un tema.
@OrderProcessor QueueSender orderSender;
@OrderProcessor QueueSession orderSession;
public void sendMessage() {
MapMessage msg = orderSession.createMapMessage();
...
orderSender.send(msg);
}@StockPrices TopicPublisher pricePublisher;
@StockPrices TopicSession priceSession;
public void sendMessage(String price) {
pricePublisher.send( priceSession.createTextMessage(price) );
}
El ciclo de vida de objetos JMS inyectados es controlado por el administrador deWeb Bean.
Empaquetamiento y despliegue.
Web Beans no define ningún despliegue especial de archivo. Se puede empaquetar Web Beans en JAR, EJB-JAR o WAR — cualquier ubicación de despliegue en la aplicación classpath. No obstante, cada archivo que contiene Web Beans debe incluir un archivo llamado web-beans.xml en META-INF o en el directorio WEB-INF. El archivo puede estar vacío. Los Web Beans desplegados en archivos que no tienen un archivo web-beans.xml no estarán disponibles para uso en la aplicación.
Para ejecución Java SE, los Web Beans pueden ser desplegados en cualquier lugar en el que los EJB se puedan implementar para ejecución por el contenedor Lite EJB incorporable. De nuevo, cada lugar debe contener un archivo web-beans.xml.

Facilitador: Ing. Luis Vargas L. 56
7. Java Server Faces
Introducción
Las empresas de hoy en día viven en un mundo global competitivo que necesitan aplicaciones para satisfacer las necesidades de negocio, que son cada vez más complejas. Con el avance de las tecnologías web y la Internet, se han abierto nuevas oportunidades para los desarrolladores de aplicaciones empresariales; permitiéndoles el uso de las nuevas tecnologías web en el desarrollo de aplicaciones mucho más robustas, escalables y con un mayor rendimiento. Algunas de las nuevas tecnologías que han surgido son: JavaServer Faces (JSF) que es la tecnología estándar de la edición empresarial de Java (Java Enterprise Edition, Java EE) para la creación deinterfaces de usuario en la web y que permite integrar otras tecnologías como las hojas de estilo en cascada (Cascade Style Sheet, CSS) que describen como se va a mostrar un documento, Ajax (Asynchronous JavaScript And XML); un modelo de desarrollo web para crear aplicaciones interactivas, JavaBeans empresariales (Enterprise JavaBeans, EJB) y el API (Application Programming Interface) de Java para el manejo de entidades persistentes (Java Persistence API, JPA) sobre bases de datos relacionales.
La Figura 1.1 muestra el conjunto de tecnologías de Java EE que pueden utilizarse para el desarrollo de aplicaciones web. Todas estas tecnologías serán descritas en este documento.
Java Server Faces [3, 4] (JSF) es un estándar de Java hacia la construcción deinterfaces de usuario para aplicaciones web que simplifican el desarrollo deaplicaciones web del lado del cliente, JSF está basado en la tecnología Java EE. En el 2009 se dio a conocer la nueva versión JSF 2.0, que contiene algunas características y/o mejoras con respecto a las versiones anteriores (JSF 1.0, JSF 1.1 y JSF 1.2) como son: Mejoras en la navegación: navegación condicional, inspección en tiempo de ejecución en las reglas de navegación. Control de excepciones: permite fácilmente la creación de una página de error que utiliza componentes JSF. Mejoras en la expresión del lenguaje: compatibilidad con métodos arbitrarios incluyendo el paso de parámetros. Validación: es una nueva especificación java desarrollada para la validación de

Facilitador: Ing. Luis Vargas L. 57
beans. Una página JSF utiliza la extensión *.xhtml, es decir, una combinación de XML con HTML y puede incluir componentes como CSS, JavaScript, entre otros.
La especificación de JSF define seis fases distintas en su ciclo de vida:1. Restauración de la vista: Crea un árbol de componentes en el servidor pararepresentar la información de un cliente.
2. Aplicar valores de la petición: Actualiza los valores del servidor con datosdel cliente.
3. Proceso de validación: Valida los datos del usuario y hace la conversión.
4. Actualización de valores del modelo: Actualiza el modelo del servidor connuevos datos.
5. Invocar la aplicación: Ejecutar cualquier lógica de aplicación para cumplircon la solicitud.
6. Procesar la respuesta: Guarda un estado y da una respuesta al cliente.
Características de JSF
o MVC: Implementa el patrón de diseño Modelo-Vista-Controladoro RAD: Desarrollo rápido de aplicaciones para Web.o Componentes de interfaz de usuario: ya cuenta desarrollados
componentes reutilizables listos para utilizarse.o Render –Kits: Los componentes pueden desplegarse no
solamente en navegadores Web, sino en dispositivos móviles u otros tipos de clientes.
o Extensibilidad: Es altamente extensible debido a su arquitectura.o Internacionalización: Las vistas pueden mostrarse en distintos
idiomas.
Nuevas características de JSF 2o Manejo de condiciones por default más inteligentes.o Manejo de anotaciones para varias configuraciones.o Soporte nativo para AJAX.o Soporte por default para Facelets.o Más componentes y validadores.
Ajax en JSF
JSF2 estandariza Asynchronous JavaScript y XML (Ajax) funcionalidad a través de bibliotecas de componentes JSF e introduce el f: tag ajax para proporcionar capacidades Ajax de una manera estándar. Ajax permite que las páginas de Internet para comunicarse de forma asíncrona con el servidor web y puede mejorar significativamente la experiencia del usuario.
El f: tag ajax añade capacidades Ajax para uno o más componentes JSF.

Facilitador: Ing. Luis Vargas L. 58
Puede estar anidada dentro de un solo componente de interfaz de usuario para permitir Ajax para ese componente, o se puede envolver alrededor de múltiples componentes para permitir el Ajax para muchos componentes.
El "ejecutar" y "render" atribuye especificar una lista delimitada por espacios de identificadores de los componentes que se deben incluidas en el envío de formularios y las actualizaciones de DOM para peticiones Ajax.
Ejemplo:
JSF Example
123456789101112131415
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html xmlns="http://www.w3.org/1999/xhtml" xmlns:f="http://java.sun.com/jsf/core" xmlns:h="http://java.sun.com/jsf/html"><h:head /><body><h:form> <h:commandButton value="Click"> <f:ajax render="message" listener="#{ajaxBean.handleEvent}" /> </h:commandButton> <h:outputText id="message" value="#{ajaxBean.message}" /></h:form></body></html>
Java Code
1234567891011121314151617
package com.mycompany;
import javax.faces.bean.ManagedBean;import javax.faces.bean.RequestScoped;import javax.faces.event.AjaxBehaviorEvent;
@ManagedBean@RequestScopedpublic class AjaxBean {
private String message;
public String getMessage() { return message; }
public void handleEvent(AjaxBehaviorEvent event) {

Facilitador: Ing. Luis Vargas L. 59
18192021
message = "Hello World"; }
}
Salida: Hello World
Integración JSF - PrimeFaces – AJAX - EJB y JPA.
Java Server Faces es un estándar dentro de la pila JEE (Java Enterprise Edition) que permite el desarrollo de la capa de presentación y control para aplicaciones Web.
JSF permite el desarrollo de aplicaciones Web en base a componentes y eventos. Aproximación típica para el desarrollo de aplicaciones interactivas en entornos de escritorio. De esta manera abandona la aproximación tradicional y más limitada de "petición/respuesta", en la que se trabaja básicamente con documentos y apuesta por el trabajo con pantallas de interacción.
Gracias a los componentes de JSF y Facelets es mucho más sencillo reutilizar piezas visuales (listas, controles, campos de entrada, ...) ya que estos se pueden "paquetizar" en forma de componentes por composición, que resultarán muy fáciles de usar en distintas partes de la aplicación, cómo si se tratara de un componente estándar.
Además, la idea de gestión de la interacción entre el usuario y la máquina en base a eventos, permite realizar interfaces de usuario mucho más ricas desde el punto de vista de la usabilidad, y simplifica el desarrollo de las mismas. Acercándose cada vez más las aplicaciones Web a las funcionalidades visuales típicamente ofrecidas por las aplicaciones de escritorio.
JSF se encuentra actualmente en su versión 2.x. Este nueva versión da soporte directamente a tecnología AJAX (Asynchronous JavaScript and XML), lo que la hace aún más atractiva, ya que gracias a AJAX se pueden actualizar partes de la página sin necesidad de hacer una petición completa al servidor. De esta forma se mejora el ancho de banda ya que por la red viajan menos datos, y se mejora la experiencia del usuario ya que se evitan incómodos parpadeos (al recargar la página completa) y se mejora la usabilidad haciendo las páginas más dinámicas.
Primefaces es una librería de componentes para JSF. Estos componentes aportan, frente a los componentes estándar de JSF, una abstracción para el uso de la tecnología AJAX ya soportada en JSF 2. Es decir, el desarrollador puede centrarse en la funcionalidad ofrecida sin tener que preocuparse del JavaScript que se ejecutará en el cliente o de que partes de la pantalla serán necesarias refrescar en respuesta de un evento en la interfaz de usuario.

Facilitador: Ing. Luis Vargas L. 60
No siendo Primefaces parte del estándar JEE, ahora es la única librería de componentes visuales que podemos decir que soporta de manera estable la versión 2 de JSF.
JPA (Java Persisence API) es un estándar de Java (JSR-220) que permite a los desarrolladores trabajar de forma sencilla con bases de datos relacionales. JPA permite la abstracción de la fuente de datos, permitiendo que el código sea portable entre distintos sistemas gestores de bases de datos: Oracle, DB2, MySQL, PostgresSQL, ...
Gracias a JPA el desarrollador se puede centrar en la lógica de negocio, olvidando los detalles de implementación la capa de acceso a datos. Esto permite realizar desarrollos más rápidos y más seguros.
Hibernate es un estándar de facto ampliamente aceptado y extendido en el mercado. Tanto que la implementación de referencia de JPA es el EntityManager de Hibernate.
En la medida de lo posible, tratamos de trabajar con la especificación, de modo que la implementación que usemos por entorno o servidor de aplicaciones debería ser trasparente. Una aplicación basada en JPA, aún usando Hibernate, sin salirse del estándar podría hacerse correr bajo el soporte de OpenJPA, por ejemplo.
No obstante lo anterior, si el proyecto lo requiere, podemos hacer uso de ciertas facilidades de Hibernate que no forman parte del estándar, pero imprimen una riqueza del lado de la capa de persistencia como el soporte para una caché de segundo nivel o la integración con un motor de indexación y recuperación de contenidos textuales como es Apache Lucene.
Subversion es un repositorio de código. Este tipo de servicios nos permiten guardar nuestro código y poder ver el histórico de cambios, hacer etiquetas (versiones) sobre un punto determinado, abrir nuevas ramas de desarrollo, ...
A día de hoy no se concibe un desarrollo sin usar este tipo de herramientas, ya que facilitan la colaboración entre desarrolladores (mientras más grande sea el equipo más se justifica la herramienta), sirve como backup (al igual que una base de datos, todo el código se almacena en un punto central, además de en las máquinas de cada desarrollador), permite identificar errores (cuando los test dejan de funcionar es muy sencillo ver todos los cambios que se hicieron entre el momento actual y la última subida al repositorio, ...
Otra alternativa a Subversion puede ser CVS. Este es otro servidor de control de versiones ampliamente extendido, pero el subversion aporta ciertas ventajas, como es el versionado de metadatos y directorios, y el ser capaz de identificar el estado de todo el repositorio en un punto determinado del tiempo con un solo identificador de revisión (de esta manera, sabiendo el número de revisión podemos obtener una foto completa de todo el repositorio en ese momento del tiempo).

Facilitador: Ing. Luis Vargas L. 61
Maven es una herramienta que permite automatizar el proceso de construcción y empaquetado del software.
Las herramientas del estilo del Maven son el complemento perfecto para el Subversion, ya que de no usarlas el proceso de compilación y empaquetado tendría que ser manual, y por lo tanto muy propenso a errores (qué pasa si la persona que normalmente lo hace no ha venido, o qué pasa si se olvida un paso, o ...).
Todos estos errores van a causar que hagamos instalaciones en preproducción, o incluso en producción, de sistemas para los que no somos capaces de identificar el código fuente. El gran problema de esta situación vendrá cuando alguno de nuestros clientes nos reporte una incidencia, y seamos incapaces de reproducirla en nuestro entorno debido a que no estamos trabajando con los mismos fuentes.
En Java, otra alternativa típica a Maven sería Ant. Se recomienda encarecidamente el Maven frente al Ant por las innumerables ventajas que aporta el primero. Por ejemplo, Maven da un ciclo de vida estándar para la construcción, pruebas, empaquetado, ... Maven trae de serie un sistema para la gestión de dependencias tanto directas como indirectas (esto es fundamental para saber contra que librerías estamos compilando nuestro código). También genera documentación, se integra con multitud de herramientas, ... y todo sin escribir una sola línea de script (el principal problema de Ant es que es un "lenguaje" de script y al final todo el mundo hace lo mismo pero de formas distintas, es decir, no hay dos scripts de Ant iguales).
8. Web Services
Introducción
Un servicio web, es un servicio ofrecido por una aplicación que expone su lógica a clientes de cualquier plataorma mediante una interfaz accesible a través de la red utilizando tecnologías (protocolos) estándar de Internet.
Por ejemplo, una aplicación como Access está formada por un conjunto de componentes que ofrecen una serie de servicios, como el acceso a datos, la impresión e informes, el diseño de tablas..
La idea de los servicios es la misma, aunque éstos no tienen por qué estar en el mismo ordenador que el cliente y además son accedidos a través de unservidor Web y de un modo independiente de la plataforma, utilizando protocolos estándar (HTTP, SOAP, WSDL UDDI).

Facilitador: Ing. Luis Vargas L. 62
Para crear un servicio web puede utilizarse cualquiera de los lenguajes, en nuestro caso utilizaremos la plataforma JAVA.
Una vez creado el servicio, para conseguir que sea accesible por los consumidores, es necesario describirlo utilizando un lenguaje estándar llamado WSDL (Web Service Description Language).
Los clientes del servicio podrán estar creados en cualquier lenguaje y ejecutarse sobre cualquier sistema operativo y hardware, lo único necesario es que sean capaces de obtener y entender la descripción WSDL de un servicio.
Un archivo WSDL es, en realidad, un archivo XML en el que se identifica el servicio y se indica el esquema para poder utilizarlo, así como el protocolo o protocolos que es posible utilizar.
Una vez dispone de esta información, el cliente puede comunicarse con el servicio utilizando protocolos como http o SOAP (SOAP añade invocación de métodos a http, aunque es posible hacerlo con peticiones HTTP-GET y/o HTTP-POST en lugar de SOAP).

Facilitador: Ing. Luis Vargas L. 63
Tipos
Remote Procedure Calls (RPC, Llamadas a Procedimientos Remotos): Los Servicios Web basados en RPC presentan una interfaz de llamada a procedimientos y funciones distribuidas, lo cual es familiar a muchos desarrolladores. Típicamente, la unidad básica de este tipo de servicios es la operación WSDL (WSDL es un descriptor del Servicio Web, es decir, el homologo del IDL para COM). Las primeras herramientas para Servicios Web estaban centradas en esta visión. Algunos lo llaman la primera generación de Servicios Web. Esta es la razón por la que este estilo está muy extendido. Sin embargo, ha sido algunas veces criticado por no ser débilmente acoplado, ya que suele ser implementado por medio del mapeo de servicios directamente a funciones específicas del lenguaje o llamadas a métodos. Muchos especialistas creen que este estilo debe desaparecer.
Arquitectura Orientada a Servicios (Service-oriented Architecture, SOA). Los Servicios Web pueden también ser implementados siguiendo los conceptos de la arquitectura SOA, donde la unidad básica de comunicación es el mensaje, más que la operación. Esto es típicamente referenciado como servicios orientados a mensajes.
Los Servicios Web basados en SOA son soportados por la mayor parte de desarrolladores de software y analistas. Al contrario que los Servicios Web basados en RPC, este estilo es débilmente acoplado, lo cual es preferible ya que se centra en el “contrato” proporcionado por el documento WSDL, más que en los detalles de implementación subyacentes.
REST (REpresentation State Transfer). Los Servicios Web basados en REST intentan emular al protocolo HTTP o protocolos similares mediante la restricción de establecer la interfaz a un conjunto conocido de operaciones
Documento WSDL
Un ejemplo de la estructura de un documento WSDL es el siguiente:
<?xml version="1.0"?>
<definitions>
<types> ... </types>
<message> ... </message>

Facilitador: Ing. Luis Vargas L. 64
<portType> ... </portType>
<binding> ... </binding>
</definitions>
Donde:
Elemento WSDL
Descripción
<?xml version=”1.0″>
Un documento WSDL es como cualquier documento XML y se basa en los esquemas, por lo que debe comenzar con dicha etiqueta.
<definitions>Comienzo del documento, este tag agrupa a todos los demás elementos
<types>Se definen los tipos de datos utilizados en los mensajes. Se utilizan los tipos definidos en la especificación de esquemas XML.
<message>
Se definen los métodos y parámetros para realizar la operación. Cada message puede consistir en una o más partes (parámetros). Las partes pueden ser de cualquiera de los tipos definidos en la sección anterior.
<portType>
Esta sección es la más importante, ya que definen las operaciones que pueden ser realizadas, y los mensajes que involucran (por ejemplo el mensaje de petición y el de respuesta).
<binding>Se definen el formato del mensaje y detalles del protocolo para cada portType.
En la etiqueta <definitions> podemos tener los siguientes atributos:
xmlnsc – Namespace al que pertenece el WSDL, http://schemas.xmlsoap.org/wsdl/
name – Podemos tener que el Servicio Web introduzca el nombre del propio servicio en el momento de crear el WSDL.
En realidad, se utiliza la etiqueta <service name=”MiServicioWeb”>para indicar el nombre del servicio, depende de la antigüedad del servicio y de la tecnología que se haya utilizado para crearlo.

Facilitador: Ing. Luis Vargas L. 65
Por tanto, dentro del árbol <service> podemos tener los siguientes atributos e hijos:
name – Como hemos dicho antes, éste atributo indica el nombre del Servicio Web.
<documentation> – Dentro del arbol del Servicio se puede abrir otra etiqueta para incluir una descripción del servicio.
<port> – Aquí se indica la dirección y el tipo de acceso de los Servicios Web. Podría ser:
1. SOAP con <soap:address location=”http://localhost:8082/MiServicio/Servicio1.wsdl” />
2. HTTP GET con <http:address location=”http://localhost:8082/MiServicio/wsdl/Servicio.jsp” />
API de JAXB
Java Architecture for XML Binding (JAXB) permite a los desarrolladores Java asignar clases de Java a representaciones XML. JAXB proporciona dos características principales: la capacidad de serializar las referencias de objetos Java a XML y la inversa, es decir, deserializar XML en objetos Java. En otras palabras, JAXB permite almacenar y recuperar datos en memoria en cualquier formato XML, sin la necesidad de implementar un conjunto específico de rutinas de carga y guardado de XML para la estructura de clases del programa. Es similar a xsd.exe y XmlSerializer en .NET Framework.
JAXB es particularmente útil cuando la especificación es compleja y cambiante. En tal caso, cambiar regularmente las definiciones de XML Schema para mantenerlas sincronizadas con las definiciones de Java puede llevar mucho tiempo y ser propenso a errores.
JAXB es una parte de la plataforma Java SE y una de las APIs de la plataforma Java EE, y es parte del Java Web Services Development Pack (JWSDP). También es uno de los fundamentos para WSIT. JAXB es parte de la versión 1.6 SE.
JAXB 1.0 fue desarrollado bajo el Java Community Process como JSR 31.1 A fecha de 2006, JAXB 2.0 está siendo desarrollado bajo JSR 222.2 Las implementaciones de referencia para estas especificaciones están disponibles bajo la licencia de código abierto CDDL en java.net.

Facilitador: Ing. Luis Vargas L. 66
9. Rest Web Services
REST (Representational State Transfer) es un estilo de arquitectura de software para sistemas hipermedias distribuidos tales como la Web. El término fue introducido en la tesis doctoral de Roy Fielding en 2000, quien es uno de los principales autores de la especificación de HTTP.
En realidad, REST se refiere estrictamente a una colección de principios para el diseño de arquitecturas en red. Estos principios resumen como los recursos son definidos y diseccionados. El término frecuentemente es utilizado en el sentido de describir a cualquier interfaz que transmite datos específicos de un domino sobre HTTP sin una capa adicional, como hace SOAP. Estos dos significados pueden chocar o incluso solaparse. Es posible diseñar un sistema software de gran tamaño de acuerdo con la arquitectura propuesta por Fielding sin utilizar HTTP o sin interactuar con la Web. Así como también es posible diseñar una simple interfaz XML+HTTP que no sigue los principios REST, y en cambio seguir un modelo RPC.
Cabe destacar que REST no es un estándar, ya que es tan solo un estilo de arquitectura. Aunque REST no es un estándar, está basado en estándares:
• HTTP
• URL
• Representación de los recursos: XML/HTML/GIF/JPEG/…
• Tipos MIME: text/xml, text/html, …
¿Cuál es la motivación de REST?
La motivación de REST es la de capturar las características de la Web que la han hecho tan exitosa.
Si pensamos un poco en este éxito, nos daremos cuenta que la Web ha sido la única aplicación distribuida que ha conseguido ser escalable al tamaño de Internet. El éxito lo debe al uso de formatos de mensaje extensibles y estándares, pero además cabe destacar que posee un esquema de direccionamiento global (estándar y extensible a su vez).
En particular, el concepto central de la Web es un espacio de URIs unificado. Las URIs permiten la densa red de enlaces que permiten a la Web que sea tan utilizada. Por tanto, ellos consiguen tejer una mega-aplicación.
Rafael Navarro Marset. Modelado, Diseño e Implementación de Servicios Web 2006-07 REST vs Web Services 5/19

Facilitador: Ing. Luis Vargas L. 67
Las URIs identifican recursos, los cuales son objetos conceptuales. La representación de tales objetos se distribuye por medio de mensajes a través de la Web. Este sistema es extremadamente desacoplado.
Estas características son las que han motivado para ser utilizadas como guía para la evolución de la Web.
¿Cuáles son los principios de REST?
El estilo de arquitectura subyacente a la Web es el modelo REST. Los objetivos de este estilo de arquitectura se listan a continuación:
• Escalabilidad de la interacción con los componentes. La Web ha crecido exponencialmente sin degradar su rendimiento. Una prueba de ellos es la variedad de clientes que pueden acceder a través de la Web: estaciones de trabajo, sistemas industriales, dispositivos móviles,…
• Generalidad de interfaces. Gracias al protocolo HTTP, cualquier cliente puede interactuar con cualquier servidor HTTP sin ninguna configuración especial. Esto no es del todo cierto para otras alternativas, como SOAP para los Servicios Web.
• Puesta en funcionamiento independiente. Este hecho es una realidad que debe tratarse cuando se trabaja en Internet. Los clientes y servidores pueden ser puestas en funcionamiento durante años. Por tanto, los servidores antiguos deben ser capaces de entenderse con clientes actuales y viceversa. Diseñar un protocolo que permita este tipo de características resulta muy complicado. HTTP permite la extensibilidad mediante el uso de las cabeceras, a través de las URIs, a través de la habilidad para crear nuevos métodos y tipos de contenido.
• Compatibilidad con componentes intermedios. Los más populares intermediaros son varios tipos de proxys para Web. Algunos de ellos, las caches, se utilizan para mejorar el rendimiento. Otros permiten reforzar las políticas de seguridad: firewalls. Y por último, otro tipo importante de intermediarios, gateway, permiten encapsular sistemas no propiamente Web. Por tanto, la compatibilidad con intermediarios nos permite reducir la latencia de interacción, reforzar la seguridad y encapsular otros sistemas.
REST logra satisfacer estos objetivos aplicando cuatro restricciones: • Identificación de recursos y manipulación de ellos a través de
representaciones. Esto se consigue mediante el uso de URIs. HTTP es un protocolo centrado en URIs. Los recursos son los objetos lógicos a los que se le envían mensajes. Los recursos no pueden ser directamente accedidos o modificados. Más bien se trabaja con representaciones de ellos. Cuando se utiliza un método PUT para enviar información, se coge como una representación de lo que nos gustaría que
Rafael Navarro Marset. Modelado, Diseño e Implementación de Servicios Web 2006-07 REST vs Web Services 6/19

Facilitador: Ing. Luis Vargas L. 68
el estado del recurso fuera. Internamente el estado del recurso puede ser cualquier cosa desde una base de datos relacional a un fichero de texto.
• Mensajes autodescriptivos. REST dicta que los mensajes HTTP deberían ser tan descriptivos como sea posible. Esto hace posible que los intermediarios interpreten los mensajes y ejecuten servicios en nombre del usuario. Uno de los modos que HTTP logra esto es por medio del uso de varios métodos estándares, muchos encabezamientos y un mecanismo de direccionamiento. Por ejemplo, las cachés Web saben que por defecto el comando GET es cacheable (ya que es side-effect-free) en cambio POST no lo es. Además saben como consultar las cabeceras para controlar la caducidad de la información. HTTP es un protocolo sin estado y cuando se utiliza adecuadamente, es posible es posible interpretar cada mensaje sin ningún conocimiento de los mensajes precedentes. Por ejemplo, en vez de logearse del modo que lo hace el protocolo FTP, HTTP envía esta información en cada mensaje.
• Hipermedia como un mecanismo del estado de la aplicación. El estado actual de una aplicación Web debería ser capturada en uno o más documentos de hipertexto, residiendo tanto en el cliente como en el servidor. El servidor conoce sobre le estado de sus recursos, aunque no intenta seguirle la pista a las sesiones individuales de los clientes. Esta es la misión del navegador, el sabe como navegar de recurso a recurso, recogiendo información que el necesita o cambiar el estado que el necesita cambiar.
En la actualidad existen millones de aplicaciones Web que implícitamente heredan estas restricciones de HTTP. Hay una disciplina detrás del diseño de sitios Web escalables que puede ser aprendida de los documentos de arquitectura Web o de varios estándares. Por otra parte, también es verdad que muchos sitios Web comprometen uno más de estos principios, como por ejemplo, seguir la pista de los usuarios moviéndose a través de un sitio. Esto es posible dentro de la infraestructura de la Web, pero daña la escalabilidad, volviendo un medio sin conexión en todo lo contrario. Los defensores de REST han creído que estas ideas son tan aplicables a los problemas de integración de aplicaciones como los problemas de integración de hipertexto. Fielding es bastante claro diciendo que REST no es la cura para todo. Algunas de estas características de diseño no serán apropiadas para otras aplicaciones. Sin embargo, aquellos que han decidido adoptar REST como un modelo de servicio Web sienten que al menos articula una filosofía de diseño con fortaleza, debilidades y áreas de aplicabilidad documentada.
¿Cómo sería un ejemplo de diseño basado en REST?
De nuevo tomaremos como ejemplo a la Web. La Web evidentemente es un ejemplo clave de diseño basado en REST, ya que muchos principios son la base de REST. Posteriormente mostraremos un posible ejemplo real aplicado a Servicios Web. Rafael Navarro Marset. Modelado, Diseño e Implementación de Servicios Web 2006-07 REST vs Web Services 7/19

Facilitador: Ing. Luis Vargas L. 69
La Web consiste del protocolo HTTP, de tipos de contenido, incluyendo HTML y otras tecnologías tales como el Domain Name System (DNS). Por otra parte, HTML puede incluir javascript y applets, los cuales dan soporte al code-on-demand, y además tiene implícitamente soporte a los vínculos. HTTP posee un interfaz uniforme para acceso a los recursos, el cual consiste de URIs, métodos, códigos de estado, cabeceras y un contenido guiado por tipos MIME.
Los métodos HTTP más importantes son PUT, GET,
POST y DELETE. Ellos suelen ser comparados con las
operaciones asociadas a la tecnología de base de datos,
operaciones CRUD: CREATE, READ, UPDATE, DELETE. Otras
analogías pueden también ser hechas como con el concepto de
copiar-y-pegar (Copy&Paste). Todas las analogías se
representan en la siguiente tabla: Acción
HTTP SQL Copy&Paste Unix Shell
Create PUT Insert Pegar > Read GET Select Copiar < Update POST Update Pegar
después >>
Delete DELETE Delete Cortar Del/rm
¿Qué pasará con REST?
Los negocios electrónicos van a necesitar algo más que tecnologías orientadas en RPC. Todos los negocios de cualquier lugar tendrán que estandarizar sus modelos de direccionamiento para exponer las interfaces en común a sus socios. SOAP no permite esto en si mismo, incluso confunde más que aclara. Para que los negocios interoperen sin programar manualmente de manera explícita enlaces a los socios, se necesitará estandarizar un modelo de direccionamiento, más que invertir en sistemas propietarios. REST proporciona un alto grado de estandarización. Por tanto, si los servicios Web basados en SOAP no consiguen implantar este mecanismo, no sobrevivirán y, por tanto, surgirá la era de los Servicios Web basados en REST.
¿Dónde es útil REST?
Tanto los arquitectos como los desarrolladores necesitan decidir cual es el estilo adecuado para las aplicaciones. En algunos casos es adecuado un diseño basado en REST, se listan a continuación:
• El servicio Web no tiene estado. Una buena comprobación de esto consistiría en considerar si la interacción puede sobrevivir a un reinicio del servidor.
• Una infraestructura de caching puede mejorar el rendimiento. Si los datos que el servicio Web devuelve no son dinámicamente generados y

Facilitador: Ing. Luis Vargas L. 70
pueden ser cacheados, entonces la infraestructura de caching que los servidores Web y los intermediarios proporcionan, pueden incrementar el rendimiento.
• Tanto el productor como el consumidor del servicio conocen el contexto y contenido que va a ser comunicado. Ya que REST no posee todavía (aunque hayamos visto una propuesta interesante) un modo estándar y formal de describir la interfaz de los servicios Web, ambas partes deben estar de acuerdo en el modo de intercambiar de información.
• El ancho de banda es importante y necesita ser limitado. REST es particularmente útil en dispositivos con escasos recursos como PDAs o teléfonos móviles, donde la sobrecarga de las cabeceras y capas adicionales de los elementos SOAP debe ser restringida.
• La distribución de Servicios Web o la agregación con sitios Web existentes puede ser fácilmente desarrollada mediante REST. Los desarrolladores pueden utilizar tecnologías como AJAX y toolkits como DWR (Direct Web Remoting) para consumir el servicio en sus aplicaciones Web.

Facilitador: Ing. Luis Vargas L. 71
10. Seguridad Java EE
Antes de nada vamos a dar una guía de buenas prácticas que es interesante conocer antes de empezar a construir aplicaciones para conseguir un trabajo lo más bueno posible.
No dar nunca nada por hecho ni en cuestiones de seguridad ni en cuestiones del flujo normal de la aplicación. Todo el riesgo que se corra debe ser por parte del usuario (no hay nada que hacer contra eso). Me explico, no supongamos que si le pido el nombre al usuario no me va a poner un número de teléfono. No se si sería una forma acertada de decirlo pero hay que pensar con pesimismo, en los peores casos, y por remotos que sean pueden ocurrir.
Siempre que usemos servicios externos estamos asumiendo riesgos añadidos. Podemos haber hecho una página web muy segura y muy bien construida, pero si incrustamos contenido externo nadie nos asegura que el contenido externo sea vulnerable a algún tipo de ataque.
La oscuridad no es seguridad. No poner un botón acceso a la administración no impide que se pueda acceder a ella. Ocultar nuestro código no debe ser parte de nuestra seguridad.
Principio del mínimo privilegio: El usuario del sistema debe tener únicamente los privilegios que necesita para llevar a cabo su actividad.
Fallar de manera segura: Hay que tratar de manera muy cuidadosa los fallos en la aplicación. Por poner un ejemplo, si se produce un fallo en la aplicación mientras se realizan tareas administrativas no debe seguir iniciada la sesión como administrador. Otro ejemplo, no debe mostrar en un fallo información técnica sobre el mismo al usuario del sistema. Si el usuario sabe datos acerca de nuestro sistema podría tener más fácil la búsqueda de vulnerabilidades.
Los riesgos
Ahora que hemos dado unos pequeños consejos sobre seguridad a la hora de la construcción de aplicaciones ya podemos pasar a explicar los riesgos que hay en las aplicaciones web. No vamos a ponernos a programar nada sin saber los riesgos existentes y el porque de las medidas que se toman para combatirlos.
Voy a nombrar aquí los riesgos que considero más importantes.
Inyección SQL: Consiste en intentar “engañar” al sistema para que realice peticiones contra la base de datos que no son las que han sido programadas y que podrían comprometer gravemente la base de datos o incluso mostrar al atacante toda la información de la misma.

Facilitador: Ing. Luis Vargas L. 72
Cross Site Scripting: El atacante intentará enviar información a nuestro servidor por medio de nuestros formularios u otros medios con la intención de que dicha información sea almacenada en nuestra base de datos y posteriormente sea mostrada a los demás usuarios del sistema. Un ejemplo sencillo: Un código JavaScript que borre el contenido de la página, si eso es mostrado a los demás usuarios de la aplicación verán siempre una página en blanco. Esto es un ejemplo sencillo, pero imaginarios que lo que se consigue introducir es un código que tome el control de los navegadores de los usuarios de la aplicación web.
Robo de sesión: Como sabemos HTTP es un protocolo sin estados, lo que significa que las credenciales o información de sesión deberá ir en cada petición; debido a esto dichos datos resultan muy expuestos. Un robo de estos datos podría tener como resultado que alguien se estuviera haciendo pasar por nosotros y realizando acciones con unos privilegios que nos pertenecen. Y tampoco hemos de olvidar que se pude robar la sesión intentando obtener nuestros credenciales de alguna manera (averiguar nuestra contraseña).
Acceso a URLs restringidas: Consiste en la observación de una URL e intentar cambiarla para intentar acceder a otras zonas. Estas es una de las razones por las que la seguridad a través de la ocultación no es efectiva.
Solucionando los problemas de seguridad
Ahora que ya hemos identificado y visto en que consisten los problemas que nos podemos encontrar en las aplicaciones web, o al menos lo más importantes y peligrosos vamos a ir uno por uno explicando como hemos de solucionarlos. Iremos primero a los dos últimos que son los más sencillos y en posteriores entradas explicaremos la solución a los dos primeros que son los más importantes de los cuatro y quiero dedicarles una entrada completa.
Robo de sesión
Ya hemos visto el riesgo que tiene el robo de una sesión. Podríamos decir de manera resumida que el peligro está en la exposición de los datos de sesión. En la ilustración de la presentación de seguridad que hice podemos ver una posible situación de robo de sesión.

Facilitador: Ing. Luis Vargas L. 73
Para solucionar este problema de seguridad hay que atenerse a varios aspectos de la seguridad: la autentificación y la sesión; para cada uno de ellos veremos varios aspectos importantes a cubrir para solucionar problemas con el robo de sesión.
La Autentificación
El más importante de todos. Usar SSL sobre HTTP (HTTPS) para transferir los datos y asegurarse de que el cifrado cubre los credenciales y el ID de sesión en todas las comunicaciones. De esta manera los datos de sesión de los que hablábamos siguen estando expuestos pero esta vez se encuentran cifrados, por lo que no se pueden usar. Alguien podría pensar: “¿Y si se obtiene la sesión y se rompe la encriptación?”, la respuesta es sencilla, y es que con los medios actuales para cuando hayas conseguido romper la encriptación esa sesión habrá dejado de existir.
Usar un sistema de autentificación simple, centralizado y estandarizado. Es mejor que usemos métodos de autentificación que nos proporcione el propio servidor de aplicaciones en vez de soluciones implementadas por nosotros, debido a que lo que implementa el servidor de aplicaciones es usado en muchos lugares y ha sido suficientemente probado. Por ejemplo los filtros de Java EE (que veremos posteriormente) o los métodos de autentificación que proporciona Java EE (no los he usado).

Facilitador: Ing. Luis Vargas L. 74
Posibilitar el bloqueo de autentificación después de un número determinado de intentos fallidos. Esto podría evitar ataques de fuerza bruta intentando averiguar la contraseña del usuario.
Implementar métodos seguros de recuperación de contraseñas: Es común que se intenten usar estos métodos para intentar ganar acceso a una cuenta del usuario, podemos ver una serie de consejos para implementar estos métodos. Pedir al usuario al menos tres datos o más, obligar a que responda preguntas de seguridad. La contraseña que recuperada deberá generarse de manera aleatoria (con una longitud de al menos 8 caracteres) y enviada al usuario por un canal diferente (E-mail); de esta forma si el atacante consiguió sortear los primeros pasos es difícil que logre sortear el canal usado para transmitir.
La Sesión
Usar los métodos de sesión que nos proporciona el servidor de aplicaciones que estemos usando, y digo esto por las mismas razones que aconsejé usar los métodos de autentificación que proporciona el servidor de aplicaciones. En este caso no estamos refiriendo a la sesión y a las cookies.
Asegurar que la operación de cierre de sesión realmente destruye dicha sesión. También fijar el periodo de expiración de la sesión (periodo de tiempo en el que no se realice ninguna acción bajo dicha sesión); por ejemplo para aplicaciones críticas de 2 a 5 minutos, mientras que para otras aplicaciones más comunes se podría usar de 15 a 30 minutos.
En el descriptor de despliegue podemos fijar la caducidad de la sesión en minutos.
XHTML
<session-config> <session-timeout>15</sessio</session-config>
1
2
3
<session-config>
<session-timeout>15</session-timeout>
</session-config>
Ahora que hemos visto las formas de evitar el robo de sesión; o al menos de manera teórica, ahora vamos a ver como se hacen esta serie de cosas en la práctica.

Facilitador: Ing. Luis Vargas L. 75
Hemos hablado de usar métodos proporcionados por el servidor de aplicaciones para realizar la autenticación usando filtros y la sesión. Vamos a ver en concreto como podría hacerse. En primer lugar habrá que comprobar si los datos de usuario son correctos y posteriormente se podría hacer algo como añadir algún parámetro a la sesión indicando que esta autenticada. Voy a simplificar mucho un código para que nos centremos en lo fundamental.
Java
if (passw ord.equals(user.getPa //Se añade a la sesión un boo request.getSession().setAttri
1
2
3
4
5
6
7
if (password.equals(user.getPass()) == true) {
//Se añade a la sesión un boolean indicando que está autentificado
request.getSession().setAttribute("auth", true);
//Se añade a la sesión el identificador del usuario
request.getSession().setAttribute("usuario", user.getMail());
}
Respecto a bloquear el inicio de sesión después de un número determinado de intentos fallidos podría ser tan fácil como añadir a la sesión el número de intentos fallidos y en el caso de que superen un determinado número no ejecutar ningún mecanismo de autenticación ni mostrar el formulario de login, únicamente habría que lanzar un timer para desbloquear el inicio de sesión pasado un tiempo.
Java
protected void starTimer(f inal H //Tarea que se lanzará cuand TimerTask timerTask = new T
1
2
3
4
protected void starTimer(final HttpSession sesion) {
//Tarea que se lanzará cuando el Timer la ejecute
TimerTask timerTask = new TimerTask() {

Facilitador: Ing. Luis Vargas L. 76
5
6
7
8
9
10
11
12
13
14
@Override
public void run() {
sesion.invalidate();
}
};
Timer timer = new Timer ();
//El tiempo esta en milisegundos y se lanza la tarea que definimos anteriormente
timer.schedule(timerTask, 600000);
}
Luego, para comprobar este parámetro (el que se ha añadido a la sesión para comprobar si se ha autentificado o no) sería factible usar filtros para todas las URLs para las que se necesite permiso y en ellos comprobar si existe el parámetro añadido en la sesión o no.
Lo primero de todo en el descriptor de despliegue (web.xml) hemos de configurar el filtro. Definiremos el filtro para un patrón de URL, en este caso todas las estén dentro del directorio /admin. Como sabemos los filtros actúan ante las peticiones de cliente para los patrones de URL para los que estén definidos. ¿Es esto del todo cierto? Pues no, en Java EE 6 esto ha cambiado un poco y podemos especificar que un filtro se ejecute sin necesidad de que el cliente haga una petición, simplemente con que el servidor haga una redirección porque así lo especifique el código (repito, sin que el cliente tenga nada que ver y sin que sepa nada de esa redirección). Podemos hacer esto mediante las sentencias que he dejado resaltadas.
XHTML
<!-- Filtro de zona privada--><filter> <filter-name>AdminFilter</filte <filter-class>control.admin.Ad
1
2
3
<!-- Filtro de zona privada-->
<filter>
<filter-name>AdminFilter</filter-name>

Facilitador: Ing. Luis Vargas L. 77
4
5
6
7
8
9
10
11
12
13
14
<filter-class>control.admin.AdminFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>AdminFilter</filter-name>
<url-pattern>/admin/*</url-pattern>
<dispatcher>REQUEST</dispatcher>
<dispatcher>FORWARD</dispatcher>
<dispatcher>INCLUDE</dispatcher>
<dispatcher>ERROR</dispatcher>
</filter-mapping>
Ahora veremos la clase que implementa el filtro y veremos que es a la misma clase a la que se hace referencia en el descriptor de despliegue. En ella simplemente se comprueba la existencia de los parámetros que se añadieron a la sesión en el proceso de autenticación. Los nombres de las variables son claros por lo que no he hecho comentarios, me parece que se ve claro el objetivo del código
Unicamente comentar que un Servlet no es exclusivo de una aplicación web, un ServletHttp es una clase de Servlet especial por así decirlo, de ahí que con el ServletRequest que nos da el filtro no podamos obtener la sesión y por eso necesitamos la primera línea del método doFilter en la que se hace un casting.
Java
package control.admin;
import java.io.IOException;
1
2
3
4
package control.admin;
import java.io.IOException;
import javax.servlet.Filter;

Facilitador: Ing. Luis Vargas L. 78
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
import javax.servlet.FilterChain;
import javax.servlet.FilterConfig;
import javax.servlet.RequestDispatcher;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.http.HttpServletRequest;
/**
* @author Juan Díez-Yanguas Barber
*/
public class AdminFilter implements Filter {
@Override
public void doFilter(ServletRequest request, ServletResponse response,FilterChain chain) throws IOException, ServletException {
//Obtenemos un HttpServletRequest con un casting
HttpServletRequest requestMod = ((HttpServletRequest) request);
if (isPermited(requestMod) == false){
requestMod.getSession().setAttribute("requestedPage",requestMod.getRequestURL().toString());
RequestDispatcher noPermited =request.getRequestDispatcher("/WEB-INF/paginasError/restricted.jsp");
noPermited.forward(request, response);
}else{
//Continua la secuencia de ejecución normal
chain.doFilter(request, response);
}

Facilitador: Ing. Luis Vargas L. 79
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
}
private boolean isPermited(HttpServletRequest request) {
if (request.getSession().getAttribute("auth") == false ||request.getSession().getAttribute("usuario") == null) {
return false;
} else{
return true;
}
}
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void destroy() {
}
}
Ahora veremos como cerrar la sesión de la manera más correcta. Lo más correcto sería destruir la sesión, de esta manera nuestra sesión dejará de existir a todos los efectos. Para ello usaremos la siguiente sentencia, cuya función es destruir la sesión. La podríamos usar por ejemplo en un Servlet encargado del cierre de sesión.
Java
request.getSession().invalidate(

Facilitador: Ing. Luis Vargas L. 80
1 request.getSession().invalidate();
Respecto al tema de las contraseñas voy a dedicar al final de esta entrada un apartado donde explicaré como trabajar correctamente con ellas.
Acceso a URLs restringidas
Como ya hemos visto en el apartado teórico sobre este problema la seguridad a través de la ocultación no sirve de nada. Si por ejemplo para la parte pública se usara un patrón de URL /public el atacante podría pensar que la parte privada pudiera ser /admin o cosas parecidas, con no dar a conocer el detalle de ese directorio no es suficiente, hay que protegerlo.
Como a estas alturas supondremos no hay que hacer nada especial si se ha realizado lo anterior, es decir, si hemos realizado una autenticación y un control de sesión correctos. Con el uso de los filtros podríamos solucionar este problema perfectamente.
Se que es un problema que a la vista parece bastante evidente y con una solución sencilla; pero mientras siga apareciendo como uno de los problemas más graves de seguridad será porque no está tan bien solucionado aunque sea evidente el problema y la solución.
Trabajando correctamente con contraseñas
Las contraseñas son un dato delicado, la palabra secreta que usa el usuario para acceder a su cuenta en el sitio web, algo suyo y personal. Por este motivo únicamente el usuario debería conocer su contraseña. Ahora bien, si solo conoce él la contraseña… ¿Cómo la comprobamos cuando inicie sesión? Vamos a ver que si que es posible hacerlo sin conocer la contraseña; lo haremos usando una huella digital MD5 o SHA1 (he puesto los enlaces en inglés, me parecían más completos).
En definitiva estos dos son los algoritmos más usados para la generación de huellas digitales, consistentes en crear una suma siempre de igual longitud independientemente del tamaño del mensaje y con la particularidad de que no se puede volver al mensaje original a partir del mensaje encriptado; pero un mismo mensaje siempre genera el mismo código.
Java
//Método para generar la huella public static String generateMD5 try { //Cambiando MD5 por SHA
1 //Método para generar la huella MD5

Facilitador: Ing. Luis Vargas L. 81
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
public static String generateMD5Signature(String input) {
try {
//Cambiando MD5 por SHA-1 podríamos obtener la huella usando este otro algoritmo
MessageDigest md = MessageDigest.getInstance("MD5");
byte[] huella = md.digest(input.getBytes());
return transformaAHexadecimal(huella);
} catch (NoSuchAlgorithmException ex) {
Logger.getLogger(Tools.class.getName()).log(Level.SEVERE,
"No se ha encontrado el algoritmo MD5", ex);
return "-1";
}
}
//Método para transformar el array de bytes en una cadena hexadecimal
private static String transformaAHexadecimal(byte buf[]) {
StringBuilder strbuf = new StringBuilder(buf.length * 2);
for (int i = 0; i < buf.length; i++) {
if (((int) buf[i] & 0xff) < 0x10) {
strbuf.append("0");
}
strbuf.append(Long.toString((int) buf[i] & 0xff, 16));
}
return strbuf.toString();
}
A sabiendas de lo anterior podríamos darnos cuenta de que si en vez de guardar la contraseña de los usuarios guardamos la huella digital de la misma podremos verificar su identidad cuando él inicie sesión, y no tendremos su

Facilitador: Ing. Luis Vargas L. 82
contraseña guardada ni modo alguno de obtenerla. Lo que habrá que hacer es obtener la huella de su contraseña cuando el usuario la introduzca y la compararemos con la huella que nosotros teníamos guardada.
Así estaremos protegiendo al usuario; si nuestra base de datos se viese comprometida y llegamos a tener guardadas las contraseñas todos nuestros usuarios estarían expuestos, mientras que de esta manera que explico esto no ocurriría.
¿Es este método infalible? Pues no, existen tablas de huellas de palabras clave que se suelen usar, ya se sabe que no solemos ser bastante ocurrentes poniendo las palabras clave (solemos usar 1234, password, etc…), así que si disponen de una tabla de este tipo podrían obtener las contraseñas a partir de las huellas de nuestra base de datos comprometida (si bien no obtendrán todas, alguna seguro que sí).
Pues bien, aún con estos problemas nos quedan armas a usar. Si en vez de guardar las huellas de las contraseñas, guardamos las huellas de las contraseñas sumado con algo más. Si obtienen el mensaje que formó esa huella con una tabla de esas obtendrían la contraseña más eso que añadimos nosotros, luego no obtienen la contraseña. Y esto podría admitir muchas variaciones, como poner caracteres por enmedio de la contraseña, al final, al principio, lo que se añada a la contraseña podría ser tan complejo como desearamos. Pero sin olvidarse que al comprobar la contraseña habrá que hacer el mismo proceso.
Vamos a ver un ejemplo sencillo, mostraremos como se introduce lacontraseña cuando el usuario se registra y como se comprueba cuando inicia sesión. En este caso vamos a añadir al final de la contraseña el nombre de usuario del sistema (Podría haber problemas si se cambiara el nombre de usuario en la máquina, pero no me voy a centrar en eso ahora, esto pretende ser solo un ejemplo ilustrativo).
Java
String pass = request.getParampass = Tools.generateMD5Signa
1
2
String pass = request.getParameter("pass");
pass = Tools.generateMD5Signature(pass +System.getProperty("user.name"));
Veamos ahora el proceso de comprobación (user será el usuario que tenemos guardado ya en la base de datos y del cual tenemos su huella de la contraseña más el añadido).

Facilitador: Ing. Luis Vargas L. 83
Java
String pass = request.getParamif (Tools.generateMD5Signature //Contraseña correcta} else {
1
2
3
4
5
6
String pass = request.getParameter("pass");
if (Tools.generateMD5Signature(password +System.getProperty("user.name")).equals(user.getPass()) == true) {
//Contraseña correcta
} else {
//Contraseña incorrecta
}
Ahora la cuestión viene cuando hacemos un método para recuperar la contraseña, no la podemos recuperar de forma alguna, no la hemos guardado. Por lo tanto, lo que habrá que hacer es generar una nueva y asignarla al usuario y mandarle la nueva contraseña por correo.
Java
//Como argumento la longitud deString new Pass = RandomStringString new PassHash = Tools.ge//Asignar new PassHash al usua
1
2
3
4
//Como argumento la longitud de la contraseña
String newPass = RandomStringUtils.randomAlphanumeric(19);
String newPassHash = Tools.generateMD5Signature(newPass +System.getProperty("user.name"));
//Asignar newPassHash al usuario
Inyección SQL
Comenzaremos hablando por el primero de los riesgos de seguridad que se comentaban en la entrada anterior. Para hacer un breve recordatorio veíamos que se trataba de intentar comprometer de alguna manera la base de datos de la aplicación.

Facilitador: Ing. Luis Vargas L. 84
Para ello, se suelen usar los formularios de las páginas web tratando de cerrar en ellos una consulta SQL e iniciando otra a continuación; dicho esto enviardirectamente los datos de los formularios hacia una consulta SQL no es una buena práctica. Veremos en este apartado una serie de buenas prácticas que deberíamos llevar a cabo para evitar la inyección SQL.
Uso de PreparedStatements
En primer lugar una muy buena práctica es cambiar el uso de los Statements por los PreparedStatements. Este tipo de Statement obliga a que la consulta tenga exactamente la estructura que se indica, y no deja que se cambie la estructura de la misma o se cierre una consulta y se abra otra nueva. También lleva a cabo un escapado de caracteres, puesto que podrías poner de nombre “O’Donnell” y no habría problema alguno en poner la comilla simple. Ni que decir tiene que también podríamos evitar la inyección SQL usando procedimientos almacenados.
Para hacer una consulta con un PreparedStatement lo primero que se hace es indicar la estructura de la consulta dejando los parámetros marcados con una interrogación “?” y posteriormente se irá indicando que son cada una de esas interrogaciones y su tipo de dato. Y gracias a que se indica el tipo de dato, Java ya se encarga de poner las comillas que hagan falta dependiendo del tipo de dato. Veremos que hay muchos métodos set dependiendo del tipo de dato a introducir.
Veamos un ejemplo. En el ejemplo se muestra un método sencillo para hacer un insert en la base de datos . He puesto el método completo para que también se observe una buena estructura para un método de este tipo. Siguiendo esta estructura es la mejor manera de asegurarse de que todos los recursos van a ser liberados en cualquier caso, tanto si se produce un error como si la ejecución es normal. Voy a explicar al final de esta entrada en que consiste ese método cerrarConexionYStatement (), ya que considero que es un punto importante a tener en cuenta para ahorrarnos unas cuantas líneas de código.
Java
public boolean addUser(Usuario Connection conexion = null; boolean exito = false; PreparedStatement insert = n
1
2
3
4
public boolean addUser(Usuario user) {
Connection conexion = null;
boolean exito = false;
PreparedStatement insert = null;

Facilitador: Ing. Luis Vargas L. 85
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
try {
conexion = pool.getConnection();
//Definir la estructura de la consulta
insert = conexion.prepareStatement("INSERT INTO " + nameBD +".Usuarios VALUES (?,?,?,?,?)");
//Indicamos cada uno de los parámetros
insert.setString(1, user.getMail());
insert.setString(2, user.getNombre());
insert.setString(3, user.getDir());
insert.setString(4, user.getPass());
//Incluso si no encontramos un método set para incluir un tipo de dato se puede personalizar como en este caso
insert.setObject(5, user.getPermisos(), java.sql.Types.CHAR, 1);
int filasAfectadas = insert.executeUpdate();
if (filasAfectadas == 1) {
exito = true;
}
} catch (SQLException ex) {
logger.log(Level.SEVERE, "Error insertando usuario", ex);
} finally {
cerrarConexionYStatement(conexion, insert);
}
return exito;
}
En el código de la tienda online podemos encontrar numerosos métodos de este estilo y se pueden ver ejemplos en los que se use un ResultSet e incluso

Facilitador: Ing. Luis Vargas L. 86
algún ejemplo en el que se realizan varias transacciones dependientes entre si y se realizan rollbacks y commits manualmente.
Hay que comentar que aunque no se vea siempre se realizan commits en todos los métodos, solo que por el hecho de ser consultas simples la conexión realiza los commit de manera automática, pero esto se puede cambiar como se puede ver en el código de la tienda online.
Java
conexion.setAutoCommit(false)
1 conexion.setAutoCommit(false);
Realizar validaciones con expresiones regulares
¿Esto es todo lo que podemos hacer? Pues no, podemos usar como medida de apoyo una validación de todos los datos de entrada de los usuarios en los formularios. Para realizar esta validación usaremos la librería que nos proporciona OWASP que se hace denominar ESAPI.
Y ahora como es lógico veremos como usar esta librería y configurarla. En primer lugar hemos de bajar el paquete que nos proporcionan en el que se incluye en jar de ESAPI y todas las librerías que requiere ESAPI para funcionar (carpeta libs del paquete descargado). Hemos de añadir todas esas librerías a nuestro proyecto.
Una cosa importante. Entre las librerías requeridas es posible que se incluya la librería de servlets. Esa librería no la debéis de incluir en el proyecto puesto que es una versión más antigua de los Servlets y cambian métodos como por ejemplo la forma de acceder al contexto de la aplicación, por lo que nos interesa conservar la especificación de Servlets moderna que tenga nuestro servidor de aplicaciones.
La siguiente parte importante son los ficheros de configuración que necesita ESAPI para funcionar: ESAPI.properties y validation.properties. Podemos encontrar una plantilla de cada uno de los ficheros en el paquete descargado en configuration/.esapi.
La siguiente tarea es colocar los ficheros de configuración en un lugar adecuado para que se reconozcan. ESAPI buscará los ficheros en varios lugares en el orden en el que indico a continuación. Encontraremos esta información en la página de ESAPI o de la manera que lo he hecho yo que es mirando la consola del servidor de aplicaciones.

Facilitador: Ing. Luis Vargas L. 87
INFO: Not found in 'org.ow asp.esapi.readable: /Applications/NetBeans/glassfis
1
2
3
4
INFO: Not found in 'org.owasp.esapi.resources' directory or file not readable:/Applications/NetBeans/glassfish-3.1/glassfish/domains/domain1/ESAPI.properties
INFO: Not found in SystemResource Directory/resourceDirectory:.esapi/ESAPI.properties
INFO: Not found in 'user.home' (/Users/Usuario) directory:/Users/Usuario/esapi/ESAPI.properties
INFO: Attempting to load ESAPI.properties via the classpath.
En mi caso me pareció lo más cómodo incluirlo en el classpath. Para ello cree en la raiz del proyecto una carpeta llamada setup, que por otra parte es estándar que los proyectos web puedan tener esta carpeta para archivos de configuraciones, y posteriormente se ha de añadir dicha carpeta al classpath del proyecto.

Facilitador: Ing. Luis Vargas L. 88
Una vez que hemos colocado los archivos en su lugar comenzaremos configurando cada uno de ellos. Lo que se va a configurar en estos ficheros principalmente serán las expresiones regulares que se van a usar para validar cada uno de los campos que deseemos.
El primer fichero que hemos nombrado, ESAPI.properties es un fichero que en lo que a nosotros nos concierne no hemos de tocar nada, la librería se sirve de él para hacer sus operaciones; nuestras personalizaciones irán en el segundo fichero nombrado. Pero no está de más echar un ojo al fichero para ver las validaciones que ya incluye y se verá que incluye validación para Email y alguna otra cosa más. Mirándolo también veremos cual es la forma de las expresiones regulares que admite.
Ahora pasemos al segundo fichero en el que hemos de configurar las expresiones regulares que consideremos necesarias. Para ello hemos de poner una clave y una atributo; al estilo de un fichero de propiedades. La clave será siempre Validator.Campo, siendo Campo lo que usaremos posteriormente para referirnos a esa expresión regular.
Esto no pretende ser un tutorial sobre como crear expresiones regulares, sin embargo haré algunas anotaciones. Si alguien necesita más ayuda con el tema puede preguntar y no tendré problema alguno en resolver sus dudas.
El símbolo “^” indica el inicio de la cadena, mientras que el símbolo “$” indica el final de la cadena. Es bueno escapar caracteres como el guión y el punto puesto que el guión se usa para indicar un rango y el punto significa cualquier cosa. Otra anotación importante es que a la hora de poner caracteres regionales debéis ponerlos con su correspondiente código en UTF-16; si no se hace de esta manera después puede que no funcione correctamente. Se puede encontrar una tabla de correspondencia básica en la wikipedia. Por ejemplo, si se quiere poner una ‘a’ acentuada “á” se debe poner así \u00e1.
Si tenéis problemas con las expresiones regulares hay una web que podéis usar que puede resultar interesante. También se puede usar un software específico para expresiones regulares que nos puede ayudar a crearlas en unos sencillos pasos y también nos ayudará a crearlas. Su nombre es RegexBuddy y RegexMagic. El primero de ellos es sobretodo para aprender y verificar expresiones regulares mientras que el segundo está orientado a su creación.
Veamos ahora un pequeño ejemplo que son las que usé yo para la tienda online. Decir que no hace falta crear expresiones regulares para números porque tiene su verificación a parte que ya veremos.
Java
Validator.Pss=^[A-Za-z0-9._$%Validator.Name=^[A-Z][a-zA-Z -Validator.Adress=^[A-Z][a-zA-ZValidator.NameDescProd=^[A-Z

Facilitador: Ing. Luis Vargas L. 89
1
2
3
4
Validator.Pss=^[A-Za-z0-9._$%&/()= -#@áÁéÉíÍóÓúÚüÜñÑ]+$
Validator.Name=^[A-Z][a-zA-Z -áÁéÉíÍóÓúÚüÜñÑ]+$
Validator.Adress=^[A-Z][a-zA-Z0-9\-\ \,ºáÁéÉíÍóÓúÚüÜñÑ]+\ [0-9]{5}\-[A-Z][A-Za-z\ \-áÁéÉíÍóÓúÚüÜñÑ]+$
Validator.NameDescProd=^[A-Za-z0-9.,-_ @#%&=áÁéÉíÍóÓúÚüÜñÑ¿?¡!]+$
Una vez que estos ficheros han quedado correctamente configurados pasaremos ha explicar como han de usarse dentro de nuestra aplicación.
Veamos por ejemplo un método para validar un nombre usando la expresión regular que hicimos para validar un nombre. He dejado comentados cada uno de los argumentos necesarios y también se encuentra disponible el javadoc en la página de los repositorios del proyecto o en el paquete descargado; por ejemplo puede existir un argumento más para que la cadena de caracteres se pase a forma canónica antes de ser validada.
Java
public static String validateName Validator validador = ESAPI.v //Nombre a referirse, entrada return validador.getValidInput
1
2
3
4
5
public static String validateName(String input) throws IntrusionException,ValidationException {
Validator validador = ESAPI.validator();
//Nombre a referirse, entrada, nombre de la expresión regular, máxima longitud, permitir nulo o no
return validador.getValidInput("Nombre", input, "Name", 100, false);
}
El método devuelve la cadena validada y en caso de error hay dos tipos de excepciones, ValidationException es lanzada cuando simplemente no se ha pasado la validación, mientras que IntrusionException se lanza cuando se cree de manera muy clara que ha ocurrido un intento de ataque.
El primer argumento es un nombre para nuestro uso personal que posteriormente lo usará si hay un error para indicar donde ha ocurrido. Y el nombre de la expresión regular ha de ser el mismo que dimos en el fichero de propiedades, de esta manera se elige con que expresión regular se desea validar una entrada.

Facilitador: Ing. Luis Vargas L. 90
Como dije no hace falta crear expresiones regulares para los números puesto que usan validaciones a parte. Veamos un ejemplo.
Java
public static int validateNumber( Validator validador = ESAPI.v //Nombe para referirse, entra return validador.getValidInteg
1
2
3
4
5
public static int validateNumber(String input) throws IntrusionException,ValidationException {
Validator validador = ESAPI.validator();
//Nombe para referirse, entrada, mínimo, máximo, permitir nulo o no
return validador.getValidInteger("Entero", input, 0, 999999, false);
}
Como se puede ver en el ejemplo validar un número es tremendamente sencillo sin tener siquiera la necesidad de especificar una expresión regular para la validación de los mismos.
Ahora veremos un ejemplo de como usar estas validaciones dentro de nuestra aplicación.
Java
try { String name = Tools.validateN} catch (IntrusionException ex) request.setAttribute("resultad
1
2
3
4
5
6
7
try {
String name = Tools.validateName(request.getParameter("name"));
} catch (IntrusionException ex) {
request.setAttribute("resultados", "Detectada una intrusión");
Tools.anadirMensaje(request, ex.getUserMessage());
} catch (ValidationException ex) {
request.setAttribute("resultados", "Error en el formulario");

Facilitador: Ing. Luis Vargas L. 91
8
9
Tools.anadirMensaje(request, ex.getUserMessage());
}
Escapar las entradas de usuario
ESAPI también nos permitirá escapar las entradas del usuario para introducirlas en la base de datos; pero la verdad es que usando PreparedStatements este paso no sería necesario, y en caso de querer hacerlo habría que hacerlo después de pasar la validación por expresiones regulares puesto que al escapar una cadena se van a incluir nuevos caracteres como la contrabarra “\”. Veamos a continuación un ejemplo sencillo para escapar las entradas preparado especialmente para MySQL (ESAPI proporciona métodos de escape para MySQL y para Oracle si no recuerdo mal).
Java
protected String scapeUserEntr Encoder encod = ESAPI.enco return encod.encodeForSQL(}
1
2
3
4
protected String scapeUserEntries (String input){
Encoder encod = ESAPI.encoder();
return encod.encodeForSQL(newMySQLCodec(MySQLCodec.MYSQL_MODE), input);
}
Recomiendo que partiendo de los ejemplos y explicaciones que se han dejado aquí se eche un vistazo al javadoc de ESAPI puesto que contiene opciones bastante interesantes. Entre ellas tiene una forma de hacer validaciones seguidas poniendo los errores en una lista para hacer todo el conjunto de validaciones seguidas sin detenerse por el fallo de alguna de ellas.
Cross Site Scripting (XSS)
Ahora que hemos visto como evitar las inyecciones SQL veremos ahora las formas de evitar Cross Site Scripting, que a modo de resumen a lo que se comentó en el capítulo anterior se podría decir que el fin que se persigue con este tipo de ataques es introducir alguna información en la base de datos para que posteriormente sea mostrada a otros usuarios. La información que se suele introducir serán scripts que persiguen realizar alguna actividad ilegítima.

Facilitador: Ing. Luis Vargas L. 92
De la misma manera que en el apartado anterior se validaban las entradas de los usuarios para evitar la inyección SQL realizando esa validación es evidente que se puede evitar también el XSS.
Aunque el problema puede venir de un caso en el que no queramos usar una expresión regular para validar, por ejemplo un campo de comentarios para el usuario en el que se permite cualquier caracter. En este caso lo que habrá que hacer es buscar etiquetas html sospechosas como script, pero… ¿realmente vale con buscar este tipo de etiquetas? Pues la respuesta es que no, porque si se usa otra codificación ya no van a aparecer así las etiquetas. A continuación veremos una buena forma de validar las entradas para evitar el XSS.
El problema de las codificaciones
Lo primero veamos el problema de las codificaciones. En el siguiente ejemplo ambas líneas son equivalentes.
XHTML
<script>alert("Este sitio es un pe%3C%2Ftitle%3E%3Cscript%3E
1
2
<script>alert("Este sitio es un peligro");</script>
%3C%2Ftitle%3E%3Cscript%3Ealert%28%22%A1Este+Sitio+es+un+peligro%21%22%29%3C%2Fscript%3E
Ahora si vemos que no se puede proteger simplemente buscando etiquetas html ¿no?. Por lo tanto lo primero que habrá que hacer es pasar la cadena a una forma canónica.
Obtener la forma canónica de una cadena consiste en convertir toda la cadena a una codificación conocida y admitida para que de esta manera se eviten problemas en la posterior validación.
Usando AntiSamy para validar entradas en HTML
ESAPI también nos proporciona soluciones para todos los problemas comentados mediante un módulo llamado AntiSamy. Este se encarga de procesar código html y verificar si está permitido o por el contrario es un posible intento de intrusión, para ello usa un fichero xml de configuración en el que se especificarán con detalle las etiquetas html permitidas y no permitidas; también será posible especificar que tipo de propiedades de CSS se pueden usar.
El archivo xml de configuración de AntiSamy se puede colocar donde nosotros queramos, aunque, obviamente no sería una buena medida colocarlo en un directorio que sea accesible publicamente. En mi caso lo he colocado en el

Facilitador: Ing. Luis Vargas L. 93
mismo sitio que los archivos de configuración de ESAPI, que si recordamos estaban en la carpeta setup que habíamos añadido al classpath.
En la página del proyecto de AntiSamy es posible encontrar varios archivos de configuración de ejemplo, de más a menos restrictivos. Lo mejor es partir de alguno de estos archivos y en caso de querer modificarlos hacerlo observando las directivas que ya contiene puesto que no es una tarea sencilla hacer un archivo de estos desde cero, por ello nos proporcionan varios ejemplos. También hay un ejemplo en su página de descargas muy interesante pensado para enviar datos al servidor que provienen de un TextArea con TinyMCE (Librería JQuery para dotar a un TextArea de un editor con WYSIWYG).
Ahora que hemos visto lo referente al fichero de configuración ya estamos en disposición de poner un ejemplo de un método que valida una entrada HTML. Este método que muestro a continuación valida una entrada que se le pasa como argumento y lanza una IntrusionException si la validación no ha pasado, dicha excepción la he lanzado yo para detectar los errores puesto que la librería no lanza excepciones ante una validación fallida, sino que anota los errores que han ocurrido y también tiene la posibilidad de eliminar aquello que no es válido según la configuración que hayamos hecho en el fichero xml.
Es importante ver también que como anoto en los comentarios antes de pasar la validación se obtiene la forma canónica del String usando un método que nos proporciona ESAPI. Y finalmente observar como se ha indicado donde esta el fichero xml de configuración, que se ha realizado usando el classpath y obteniendo su flujo de entrada.
Java
public static void validateHTML( try { //No se admite una entrada if (input.isEmpty() == true)
1
2
3
4
5
6
7
8
public static void validateHTML(String input) {
try {
//No se admite una entrada vacía
if (input.isEmpty() == true) {
throw new IntrusionException("No se admite el campo vacío", "");
}
//Se obtiene el archivo de configuración a través del classpath
Policy politica =Policy.getInstance(Tools.class.getResource("/antisamy-tinymce-1.4.4.xml"));

Facilitador: Ing. Luis Vargas L. 94
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
AntiSamy validator = new AntiSamy();
//Antes de analizar la cadena es convertida en su forma canónica
//ESAPI.encoder().canonicalize(input)
CleanResults cr = validator.scan(ESAPI.encoder().canonicalize(input),politica);
//Si ha ocurrido un error se lanza una excepción indicando el error
if (cr.getNumberOfErrors() != 0) {
throw new IntrusionException("Ha introducido código HTML que no está permitido",
cr.getErrorMessages().get(0).toString());
}
} catch (PolicyException ex) {
Logger.getLogger(Tools.class.getName()).log(Level.SEVERE,ex.getMessage());
} catch (ScanException ex) {
Logger.getLogger(Tools.class.getName()).log(Level.SEVERE,ex.getMessage());
}
}
Anexo – Cerrar Conexiones, Statements y ResultSets. Varargs en java
En este apartado vamos a ver una buena manera de hacer esos métodos que decíamos para cerrar las conexiones y Statments. Aquí el problema viene de hacer un método que nos sirva para todos los métodos de la clase manejadora de la base de datos. No van a tener todos los métodos un Statement o un ResultSet, pueden tener varios de cada uno.
Se puede pensar en hacer métodos que reciban listas de Statements, pero estaríamos a lo mejor escribiendo líneas construyendo esas listas en cada método, líneas que se supone intentamos ahorrarnos. Pues bien java tiene algo llamado varargs para facilitarnos esta tarea, aunque internamente este construyendo listas el caso es que no tenemos que construirlas nosotros.

Facilitador: Ing. Luis Vargas L. 95
Lo único que hemos de hacer es colocar en la cabecera de los métodos de cierre unos puntos suspensivos detrás del tipo de dato. El argumento que vaya con varargs debe ser el último y debe haber solo uno (esto es debido a que sino java no tiene forma de saber los tipos de datos de los argumentos). Posteriormente dentro del método podemos recorrer los elementos con un bucle for-each, como si de un lista normal se tratara (que es de hecho lo que hace internamente como ya he dicho).
Java
private void cerrarConexionYSt try { conexion.close(); } catch (SQLException ex) {
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
private void cerrarConexionYStatement(Connection conexion, Statement...statements) {
try {
conexion.close();
} catch (SQLException ex) {
logger.log(Level.SEVERE, "Error al cerrar una conexión a la base de datos", ex);
} finally {
for (Statement statement : statements) {
if (statement != null) {
try {
statement.close();
} catch (SQLException ex) {
logger.log(Level.SEVERE, "Error al cerrar un statement", ex);
}
}
}
}
}

Facilitador: Ing. Luis Vargas L. 96
19
20
21
22
23
24
25
26
27
28
29
private void cerrarResultSet(ResultSet... results) {
for (ResultSet rs : results) {
if (rs != null) {
try {
rs.close();
} catch (SQLException ex) {
logger.log(Level.SEVERE, "Error al cerrar un resultset", ex);
}
}
}
}
Estos métodos podrían admitir toda una serie de llamadas no dependiendo del número de Statement o ResultSet.
Java
cerrarConexionYStatement(concerrarConexionYStatement(con
cerrarResultSet(rs);
1
2
3
4
5
cerrarConexionYStatement(conexion, select);
cerrarConexionYStatement(conexion, deleteHistorialCarros,deleteProdCarro);
cerrarResultSet(rs);
cerrarResultSet(consultaDatosCarro, rs);
Como podemos suponer nos hemos ahorrado bastantes líneas en cada uno de los métodos, ahora como máximo habrá dos líneas en cada método para cerrar los recursos independientemente del número de recursos que haya.

Facilitador: Ing. Luis Vargas L. 97
















