Métodos de Descomposición Lineal de las...
12
2. Métodos de Descomposición Lineal de las Observaciones 2.1. Introducción El avance tecnológico en los mecanismos de obtención de datos en multitud de materias ha provocado que la base de datos disponible sea muy extensa y contenga una mayor información que podría desembocar en la resolución del problema en estudio. Dicha información se encuentra latente esperada a ser descubierta pero dada la magnitud de la información, el análisis y la extracción de características se hace cada vez más difícil. La descomposición de estos datos originales en un nuevo conjunto, sin necesidad de pérdida de información relevante y sacando a la luz la información latente, parece de vital importancia. En este capítulo se estudiarán las técnicas de reducción de dimensión a través de la transformación de los datos originales en un nuevo conjunto o seleccionando un subconjunto de los mismos: Análisis de Componentes Principales (PCA), Descomposición en Valores Singulares (SVD) y Descomposición No Negativa de Matrices (NMF). Este capítulo está organizado de la siguiente forma: en la sección 2.2 se lleva a cabo el estudio del Análisis de Componentes Principales. Para tal fin se plantea el problema que supone PCA, se lleva a cabo la búsqueda de las Componentes Principales y se finaliza con un ejemplo que corrobora los resultados teóricos. En la sección 2.3 pasamos a estudiar la Descomposición en Valores Singulares empleada en la resolución del problema PCA. Tras un estudio de la descomposición y descomposición truncada de una matriz genérica se lleva a cabo un ejemplo numérico. En la sección 2.4 pasamos a estudiar el modelo básico de la Factorización No Negativa de Matrices. Acto seguido analizamos brevemente la NMF simétrica, semiortogonal, tri-NMF, multicapa y convolutiva, versiones particulares de la NMF básica. En los apartados siguientes se plantea un método para obtener la mejor solución posible de la NMF y se estudian algunos criterios de parada en los algoritmos iterativos empleados en el cálculo de la NMF. La sección 2.5 se corresponde con una revisión del capítulos y extracción de conclusiones. 13
Transcript of Métodos de Descomposición Lineal de las...

2.Métodos de Descomposición Lineal de las Observaciones
2.1. IntroducciónEl avance tecnológico en los mecanismos de obtención de datos en multitud de materias ha provocado que la base de datos disponible sea muy extensa y contenga una mayor información que podría desembocar en la resolución del problema en estudio. Dicha información se encuentra latente esperada a ser descubierta pero dada la magnitud de la información, el análisis y la extracción de características se hace cada vez más difícil.
La descomposición de estos datos originales en un nuevo conjunto, sin necesidad de pérdida de información relevante y sacando a la luz la información latente, parece de vital importancia. En este capítulo se estudiarán las técnicas de reducción de dimensión a través de la transformación de los datos originales en un nuevo conjunto o seleccionando un subconjunto de los mismos: Análisis de Componentes Principales (PCA), Descomposición en Valores Singulares (SVD) y Descomposición No Negativa de Matrices (NMF).
Este capítulo está organizado de la siguiente forma: en la sección 2.2 se lleva a cabo el estudio del Análisis de Componentes Principales. Para tal fin se plantea el problema que supone PCA, se lleva a cabo la búsqueda de las Componentes Principales y se finaliza con un ejemplo que corrobora los resultados teóricos. En la sección 2.3 pasamos a estudiar la Descomposición en Valores Singulares empleada en la resolución del problema PCA. Tras un estudio de la descomposición y descomposición truncada de una matriz genérica se lleva a cabo un ejemplo numérico. En la sección 2.4 pasamos a estudiar el modelo básico de la Factorización No Negativa de Matrices. Acto seguido analizamos brevemente la NMF simétrica, semiortogonal, tri-NMF, multicapa y convolutiva, versiones particulares de la NMF básica. En los apartados siguientes se plantea un método para obtener la mejor solución posible de la NMF y se estudian algunos criterios de parada en los algoritmos iterativos empleados en el cálculo de la NMF. La sección 2.5 se corresponde con una revisión del capítulos y extracción de conclusiones.
13

2.2. Análisis de Componentes PrincipalesEl principal objetivo del Análisis de Componentes Principales (PCA) [Jolliffe] [Hyvärinen] es reducir la dimensión de un conjunto de variables aleatorias manteniendo la mayor cantidad información posible. La utilidad del PCA radica en eliminar la redundancia de información existente, poder identificar las posibles variables latentes que se encuentran ocultas en la información original y el transformar las variables originales, normalmente correladas, en variables incorreladas para una mejor interpretación de los datos. Si las variables originales son independientes, el análisis PCA es irrelevante.
Esta reducción de la dimensión se logra a través de la transformación de dichas variables a través del álgebra lineal en un nuevo conjunto de variables denominadas Componentes Principales (Principal Components, PC). Estos Componentes o Factores Principales se corresponden con las direcciones en las que los datos tienen la máxima varianza. Además, dichos PC serán una combinación lineal de las variables originales, estarán incorrelados y ordenados de modo que los primeros contendrán la mayor parte de la información de los datos originales.
2.2.1. Planteamiento del Problema
Supongamos un vector X compuesto por p variables aleatorias:
X =[X
1,...,X
p]
t ,
donde cada variable Xi está compuesta por n observaciones Xi=[Xi,1,..., Xi,n] y existiendo la restricción n !p. A partir de este vector se pretende obtener otro
conjunto Y de variables aleatorias:
Y =[Y
1,..., Y
q]
t , donde q ! p
de forma que sean incorreladas entre sí y cuyas varianzas vayan decreciendo progresivamente. El error que se comete al transformar X en Y es menor cuanto mayor es el valor de q, siendo el error nulo en la igualdad q=p.
2.2.2. Obtención de las Componentes Principales
Una vez tenemos definido el problema vamos a ver la forma de llegar a la solución que nos ofrece la reducción de las dimensiones del problema y nos extrae características inherentes en el conjunto de datos originales.
En PCA, la matriz de datos originales X es centrada a partir de la extracción de la media de sus componentes:
X
c
i= X
i! E{X
i} ,
por lo que E{X} = 0 .
Sea RX=E{XXt} la matriz de correlaciones de la matriz X centrada. Puesto que RX es una matriz simétrica y definida positiva se puede demostrar que posee p autovalores reales y diferentes que garantizan que RX sea diagonalizable. Es decir,
se puede encontrar una matriz T invertible tal que:
2. Métodos de Descomposición Lineal de las Observaciones
14
(2.1)
(2.2)
(2.3)

R
X= T!T
"1
,
donde T=[T1,...,Tp]t es una matriz formada por los autovectores RX y
! = diag ["
1,...,"
p]una matriz diagonal formada por sus autovalores.
A continuación normalizamos los autovectores de la matriz T, redistribuimos los
valores !
i de la matriz ! de acuerdo con su magnitud, de forma que
!
i> !
j para
todo i < j , y rotamos de la misma manera las columnas de T.
Una vez tenemos preparada la matriz T estamos en disposición de obtener las
Componentes Principales. Si seleccionamos las q primeras columnas de la matriz T
y multiplicamos por la matriz de datos originales centrada X obtenemos la matriz
Y:
Y = T
(q)
tX =[Y
1,..., Y
q]
t,
denominada Variable de Componentes Principales. Cada Yi se denomina
Componente Principal y es una combinación lineal de las variables originales X.
2.2.3. Ejemplo de PCA
Para ver el procedimiento de forma numérica, consideremos el siguiente ejemplo
donde se tienen p=2 vectores de observaciones, X1 y X2, procedentes de dos
señales de voz.
Figura 2.1 Señales originales X1 (eje horizontal) y X2 (eje vertical).
La matriz de correlaciones para estas dos señales es:
Rx=
0.0901 0.0137
0.0137 0.2058
!
"#
$
%& .
Las matrices ! y T, obtenidas de la descomposición en autovalores y autovectores
de la matriz de correlaciones RX, son:
2.2 Análisis de Componentes Principales
15
(2.4)
(2.5)
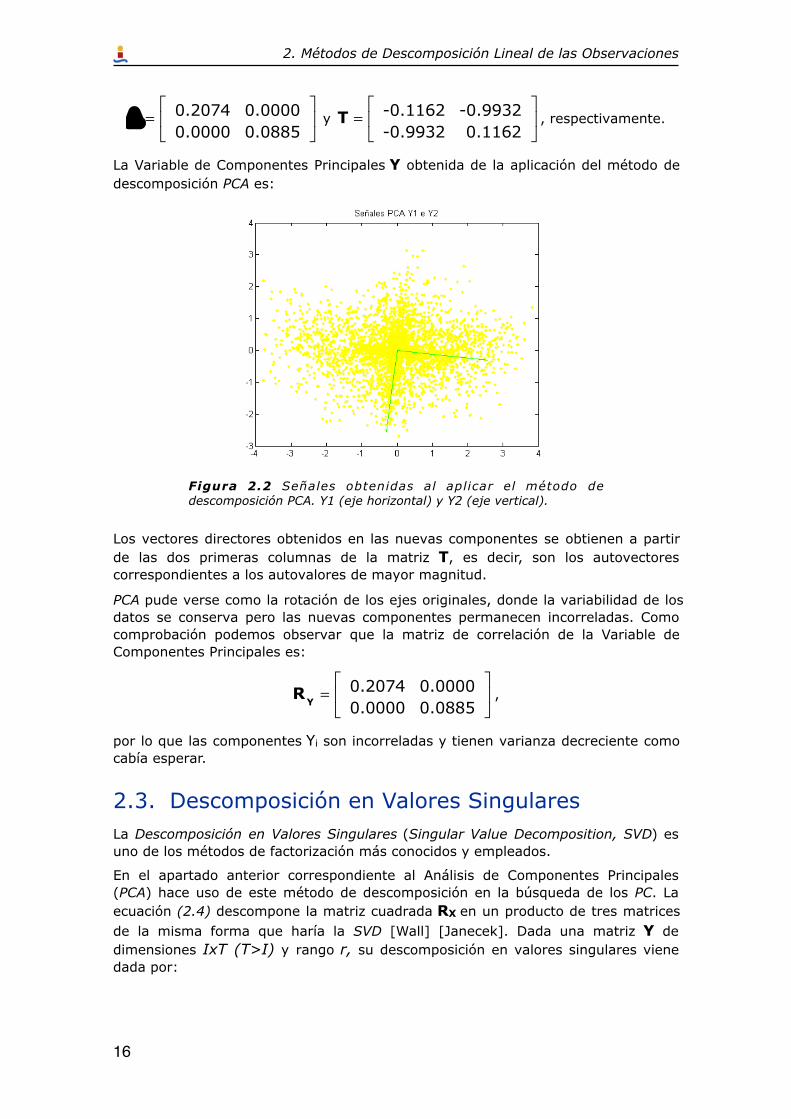
! =0.2074 0.0000
0.0000 0.0885
"
#$
%
&' y
T =-0.1162 -0.9932
-0.9932 0.1162
!
"#
$
%& , respectivamente.
La Variable de Componentes Principales Y obtenida de la aplicación del método de descomposición PCA es:
Figura 2.2 Señales obtenidas al aplicar el método de descomposición PCA. Y1 (eje horizontal) y Y2 (eje vertical).
Los vectores directores obtenidos en las nuevas componentes se obtienen a partir de las dos primeras columnas de la matriz T, es decir, son los autovectores correspondientes a los autovalores de mayor magnitud.
PCA pude verse como la rotación de los ejes originales, donde la variabilidad de los datos se conserva pero las nuevas componentes permanecen incorreladas. Como comprobación podemos observar que la matriz de correlación de la Variable de Componentes Principales es:
RY=
0.2074 0.0000
0.0000 0.0885
!
"#
$
%& ,
por lo que las componentes Yi son incorreladas y tienen varianza decreciente como cabía esperar.
2.3. Descomposición en Valores SingularesLa Descomposición en Valores Singulares (Singular Value Decomposition, SVD) es uno de los métodos de factorización más conocidos y empleados.
En el apartado anterior correspondiente al Análisis de Componentes Principales (PCA) hace uso de este método de descomposición en la búsqueda de los PC. La ecuación (2.4) descompone la matriz cuadrada RX en un producto de tres matrices de la misma forma que haría la SVD [Wall] [Janecek]. Dada una matriz Y de dimensiones IxT (T>I) y rango r, su descomposición en valores singulares viene dada por:
2. Métodos de Descomposición Lineal de las Observaciones
16

Y = U! Vt= "
jU
jV
j
t
j=1
J
! ,
donde la matriz U=[U1,...,UI]t de dimensiones IxI está compuesta por los I vectores singulares izquierdos, la matriz V=[V1,...,VT]t de dimensiones TxT está
compuesta por los T vectores singulares derechos, ! = diag ["
1,...,"
T] es una
matriz diagonal de dimensiones IxT cuyos elementos de la diagonal principal
representan a los valores singulares. Dichos valores son no negativos y están
ordenados de forma decreciente:
!
1" !
2" ... " !
J> !
J+1= !
J+2= ... = !
I= 0
y se obtienen como las raíces cuadradas de los autovalores de la matriz de
covarianza (1/T)YYt de dimensiones IxI.
El producto U
jV
j
t es una matriz IxT de rango unidad conocida como la autoimagen
j-éisma de Y. Además, los vectores singulares derechos e izquierdos son vectores
ortogonales ( U
i
tUj= !
ij y
V
i
tVj= !
ij), cumpliéndose UtU=VtV=I.
Figura 2.3 Descomposición en Valores Singulares (SVD). Los elementos no representados de la matriz diagonal ! son cero.
En multitud de aplicaciones es más práctico trabajar con una forma truncada de la
SVD donde únicamente se toman los P<J primeros valores singulares, por lo que:
Y ! U(P)
"(P)
V(P)
t= #
jU
jV
j
t
j=1
P
" ,
donde U(p)=[U1,...,Up]t tiene dimensiones IxP, V(p)=[V1,...,Vp]t tiene dimensiones
TxP y !
(P)= diag ["
1,...,"
P].
Esta descomposición no es una descomposición exacta de la matriz Y pero, según
el teorema de Eckart-Young es la mejor aproximación de rango P en términos del
error cuadrático medio.
Aunque esta descomposición es muy empleada su uso está limitado a
representaciones de datos en dos dimensiones por lo que en situaciones donde la
estructura de datos se compone de matrices de orden superior puede ser
insuficiente. Es necesario así utilizar descomposiciones de matrices o tensores con
el fin de mantener el significado físico de todas las componentes. Por ejemplo, en
estudios que engloban el estudio de múltiples sujetos los datos se agrupan en
2.3 Descomposición en Valores Singulares
17
(2.6)
(2.7)
(2.8)

estructuras de bloques de tres dimensiones. Si se analizara cada individuo por separado a partir de una cara del bloque multidimensional se perdería la información de la covarianza entre todos los sujetos en estudio, siendo la descomposición o factorización de matrices/tensores la solución natural al problema.
2.3.1. Ejemplo de SVD
En este apartado vamos a ver un ejemplo numérico de la descomposición SVD y de la reducción de la dimensión a través de la misma.
Partiendo de una matriz A de dimensiones [5,3], su Descomposición en Valores Singulares viene dada por:
Figura 2.4 SVD de la matriz A. La matriz U está compuesta por los 5 vectores singulares izquierdos; la matriz V por los 3 vectores singulares derechos; la matriz ! es diagonal y está formada por los
valores singulares.
Como era de esperar, las matrices U y V tienen dimensiones [5,5] y [3,3] respectivamente y están formadas a partir de los vectores singulares. Por otro lado, la matriz diagonal ! contiene en su diagonal principal los valores singulares
dispuestos en orden decreciente.
Si en vez de tomar los tres valores singulares nos quedamos con los dos mayores y eliminamos el de menor valor estamos ante la mejor aproximación de rango 2 en términos del error cuadrático medio:
Figura 2.5 SVD truncada de la matriz A. La matriz Up está compuesta por los 4 vectores singulares izquierdos; la matriz Vp por los 2 vectores singulares derechos; la matriz ! es diagonal y está
formada por los 2 valores singulares de mayor tamaño.
2.4. Factorización No Negativa de MatricesUno de los principales problemas de los mecanismos hasta ahora estudiados, PCA y SVD, radica en la interpretación de los datos obtenidos. La Factorización No Negativa de Matrices (NMF) mejora la interpretación y visualización de los mismos sin necesidad de perder sentido físico.
2. Métodos de Descomposición Lineal de las Observaciones
18

Así pues, la NMF permite reducir las dimensiones de los datos a la vez que hace
visibles ciertas características de los mismos que en un principio no podían ser
observadas.
La Factorización No Negativa de Matrices nace en 1999 a partir de los trabajos de
Lee y Seung [Lee] sobre la descomposición de imágenes a partir de elementos
reconocibles. La principal diferencia entre este método desarrollado y otros
métodos de factorización clásica se basa en la limitación de la no negatividad
impuesta al modelo. Esta condición que a priori parece muy restrictiva no es tal
para un gran número de campos de trabajo. Gracias a esta peculiaridad, se lleva a
cabo la representación de los datos a partir de combinaciones aditivas y nunca
substractivas, lo que se traduce en que cada una de las partes que conforman la
suma pueda ser considerado como parte de los datos originales. Otras técnicas de
factorización descomponen la matriz en una serie de matrices de cualquier signo
que lleva a una interpretación poco intuitiva y difícil.
2.4.1. El Modelo Básico NMF
El problema de la Factorización No Negativa de Matrices (NMF) puede describirse tal
que, dada una matriz Y de dimensiones IxT definida positiva (Y ! 0 o Yi,j! 0) y de
rango J (J !min(I,T)), se busca un par de matrices no negativas A=[A1,...,AJ] y
X=Bt=[B1,...,BJ]t que permitan factorizar Y de la mejor manera posible:
Y = AX +E = ABt+E ,
donde la matriz E representa el error cometido durante la factorización1. En caso de
obtenerse una descomposición exacta (E=0), la NMF pasa a denominarse
Factorización No Negativa de Rango (Nonnegative Rank Factorization, NRF).
Las matrices A y X tienen diferente sentido físico en las diferentes aplicaciones.
Para BSS A tiene el papel de matriz de mezcla mientras que X representa las
fuentes. En problemas de clustering A representa la matriz base mientras que X
denota la matriz de pesos. En el análisis acústico, A representa los parámetros
base, siendo cada columna de X las posiciones en las que el sonido está activo
[Cichocki02].
Por otro lado, podemos expresar el problema NMF a través de la suma del producto
externo de dos vectores:
Y = Aj
j=1
J
! !Bj+E = A
jj=1
J
! Bj
t+E ,
de forma que la matriz Y es construida a partir de la suma de matrices no
negativas de rango unidad A
jB
j
t.
2.4 Factorización No Negativa de Matrices
19
1 Dado que la notación que se está siguiendo a la hora definir una matriz es por columnas, con el fin de evitar una mayor complejidad en las expresiones resulta conveniente utilizar la
matriz B=Xt en lugar de la matriz X.
(2.9)
(2.10)

Figura 2.6 Modelo Bilineal de la NMF. La matriz Y es representada como una combinación lineal de matrices no negativas de rango unidad más un error desconocido.
De entre todas las posibles representaciones de la matriz Y, el menor número de matrices no negativas de rango unidad que reproducen la matriz Y se define como su rango no negativo, denotado como ran+(Y), cumpliéndose que:
ran(Y) ! ran
+(Y) ! min(I, T)
2.4.2. NMF: Casos Particulares
A parir del modelo básico NMF se pueden definir diferentes casos particulares según las propiedades que presenten las diferentes matrices implicadas [Cichocki02]:
! NMF simétrica. En el caso particular en el que A=B, la descomposición pasa a denominarse NMF-simétrica y cumple que:
Y = AAt+E
En caso de existir completa simetría (E=0) se dice que Y (IxI) es completamente positiva (CP) y el menor número de columnas de A (IxJ) que satisfacen Y=AAt se denomina rango-cp de la matriz Y, rancp(Y).
! NMF semiortogonal. La NMF semiortogonal se define del mismo modo que la NMF básica, con la particularidad de que alguna de las matrices A o X cumple la restricción:
AtA = I o XX
t= I
! Tri-NMF. La NMF de tres factores se define como:
Y = ASX +E ,
donde A tiene un tamaño IxJ, S tiene dimensiones JxR y X tiene dimensiones JxT.
Si no se impone restricción alguna a los factores (aparte de la no negatividad) estamos ante el caso de la NMF estándar si consideramos alguna de las transformaciones:
A ! AS o X ! SX .
Sin embargo, si aplicamos restricciones adicionales o nos encontramos ante situaciones particulares se pueden obtener mejores resultados que los que se podrían obtener mediante la NMF básica dado la estructura distribuida de este método. Por ejemplo, con este método de descomposición se disminuye el riesgo de converger hacia un mínimo local de la función de coste.
2. Métodos de Descomposición Lineal de las Observaciones
20
(2.11)
(2.12)
(2.13)
(2.14)
(2.15)

Figura 2.7 NMF de tres factores (Tri-NMF). El objetivo es, dada la matriz S, estimar las matrices A y X.
! NMF multicapa. La NMF multicapa puede verse como una generalización
de la Tri-NMF en la que la matriz A se reemplaza por un conjunto de
matrices (factores) dispuestas en cascada. Este modelo puede describirse
como:
Y = A(1)
A(2)!A
(L)X +E.
Dado que el modelo es lineal, todas los factores pueden reagruparse en
una única matriz A, sin embargo, la estructura distribuida de este modo
de descomposición sirve para mejorar las prestaciones de algunos
algoritmos NMF y mejorar el problema de los mínimos locales.
Figura 2.8 NMF multicapa. En este modelo la matriz A se encuentra distribuida a lo largo de las matrices factor A(i).
! NMF convolutiva. La NMF convolutiva (CNMF) es una extensión natural de
la NMF estándar. En este modelo se dispone de un conjunto de matrices
no negativas {A1,A2,...,AP-1} las cuales se relacionan con versiones
desplazadas de la matriz X:
Y = Yp+E =
p=0
P!1
" ApX
[p]+E
p=0
P!1
" ,
donde X[p]
representa la versión de X desplazada p columnas.
2.4 Factorización No Negativa de Matrices
21
(2.16)
(2.17)

Figura 2.9 NMF Convolutiva (CNMF). El objetivo es estimar las matriz X y el sistema convolutivo a través de las matrices no negativas Ap (p=1,...,P). Cada operador T indica un desplazamiento de las columnas de la matriz X.
2.4.3. Búsqueda de la Mejor Solución
A la hora de obtener las matrices A y X en la NMF estándar necesitamos una medida de similitud que nos permita medir la diferencia entre la matriz original Y y
la aproximación obtenida por el modelo NMF Y = AX . La medida más simple y utilizada se basa en la norma de Frobenius:
D
F(Y AX) =
1
2Y ! AX
F
2
,
Mediante esta función de coste no es posible la convergencia hacia una solución adecuada si intentamos optimizar ambas matrices a la vez. Por el contrario, esta función de coste es convergente de forma separada para la matriz A y X. Así pues, para minimizar el coste total se puede emplear el algoritmo ALS (Alternating Least Squares) que describimos a continuación:
1. Inicializamos A de forma aleatoria o mediante alguna estrategia determinista. El éxito de la solución alcanzada tras la aplicación del algoritmo NMF depende en gran medida de las condiciones iniciales que se impongan. Una mala elección de la matriz inicial da lugar a lentitud en la convergencia e incluso a incorrectas o que no aportan información alguna.
2. Estimamos X de la ecuación AtY = A
tAX de forma que:
min
X
DF(Y AX) =
1
2Y ! AX
F
2
, estando fijada la matriz A.
3. Imponemos un valor ! próximo a cero (típicamente 10-16) a todos los
elementos de la matriz X obtenida que sean menores que cero.
4. Estimamos A de la ecuación XYt= XX
tA
t de forma que:
2. Métodos de Descomposición Lineal de las Observaciones
22
(2.18)

min
A
DF(Y AX) =
1
2Y
t! X
tA
t
F
2
, estando fijada la X.
5. Imponemos un valor ! próximo a cero (típicamente 10-16) a todos los
elementos de la matriz A obtenida que sean menores que cero.
Este algoritmo no garantiza la convergencia hacia un mínimo global o hacia un
punto estacionario, sino que garantiza que la función de coste deja de decrecer.
2.4.4. Criterios de Parada
Existen multitud de criterios de parada para los algoritmos iterativos empleados en
la Factorización No Negativa de Matrices:
! La función de coste llega a un valor próximo a cero o por debajo de un
umbral establecido ! :
D
F(Y Y
(k)) = Y ! Y(k)
F
2
" #
! No se consigue mejora en la función de coste (o es muy pequeña) entre
varias iteraciones sucesivas:
DF
(k)!D
F
(k!1)
DF
(k)" #
! No se producen cambios (o son muy pequeños) en las matrices X y A.
! El número de iteraciones empleadas supera el límite preestablecido.
En la práctica, las iteraciones continúan hasta que se cumplen varios de los criterios
anteriormente mencionados.
2.5. Conclusiones
En este capítulo se abordaron los mecanismos de descomposición lineales más empleados a la hora de mejorar la visualización de los datos.
En un primer lugar analizamos cómo PCA consigue obtener una combinación lineal de las variables originales a través de la rotación de los ejes de coordenadas.
Posteriormente se analizó la SVD, herramienta empleada en la búsqueda de los PC, y ejecutamos un ejemplo donde se comprobó la mejor aproximación en términos del error cuadrático medio de la SVD truncada.
Para concluir con los mecanismos de descomposición lineales analizamos la NMF,
tanto básica como algunas de sus versiones. En algunas aplicaciones, la reducción de la dimensión es útil únicamente si la interpretación de los datos originales se sigue manteniendo en los datos obtenidos. En contraste con PCA o SVD, la NMF mejora la interpretación y visualización de los datos sin necesidad de perder el sentido físico de los mismos.
El problema de la Separación Ciega de Fuentes puede ser atacado desde diversos
frentes y en este capítulo se han introducido algunos de los mecanismos empleados
en el método ICA para la solución de este problema.
2.5 Conclusiones
23
(2.19)
(2.20)