
Modelado de Datos -...
21
UNIVERSIDAD DE CARABOBO FACULTAD EXPERIMENTAL DE CIENCIAS Y TECNOLOGÍA DEPARTAMENTO DE COMPUTACIÓN BASES DE DATOS Valencia - Edo. Carabobo Modelo De Datos Jerárquico y De Red. Elaborado por: Camargo Danny C.I 17.257.550 Peña Bernardo C.I 12.245.499 Romero Haydée C.I. 15.865.688 Prof.: Bena Leung Sección 01 Valencia; 07 de Marzo del 2005
Transcript of Modelado de Datos -...

UNIVERSIDAD DE CARABOBO FACULTAD EXPERIMENTAL DE CIENCIAS Y TECNOLOGÍA
DEPARTAMENTO DE COMPUTACIÓN BASES DE DATOS
Valencia - Edo. Carabobo
Modelo De Datos Jerárquico y De Red.
Elaborado por: Camargo Danny C.I 17.257.550 Peña Bernardo C.I 12.245.499
Romero Haydée C.I. 15.865.688 Prof.: Bena Leung
Sección 01
Valencia; 07 de Marzo del 2005

1. Modelado de Datos: Ya se han explicado con anterioridad los conceptos de Archivos y de Base
de Datos, sus ventajas, debilidades y diferencias entre cada uno. Para describir la estructura de una BD es necesario definir el concepto de
modelo de datos, “es el enfoque utilizado para la representación de las entidades y sus características dentro de la base de datos, semántica asociada a los datos y restricciones de consistencia”.
1.1 Tipos de modelos de Datos
Los diversos modelos de datos se dividen en tres grupos: • modelos lógicos basados en objetos • modelos lógicos basados en registros • modelos físicos de datos
1.1.1 Modelos lógicos basados en objetos
Los modelos lógicos basados en objetos se usan para describir datos en el nivel conceptual y de visión. Se caracterizan porque proporcionan capacidad de estructuración bastante flexible y permiten especificar restricciones de datos explícitamente. Hay muchos modelos diferentes, y aparecerán más. Algunos de los más conocidos son el modelo entidad-relación (E/R), el orientado a objetos, el binario, el semántico de datos, el infológico y el modelo funcional de datos. El modelo entidad-relación ha ganado aceptación y se utiliza ampliamente en la práctica, el modelo orientado a objetos incluye muchos conceptos del anterior, y esta ganado aceptación rápidamente.
1.1.1.1 Modelo Entidad-Relación (E/R) El modelo de datos entidad-relación se basa en una percepción de
un mundo real que consiste en una colección de objetos básicos llamados entidades, y relaciones entre estos objetos. Una entidad es un objeto distinguible de otros por medio de un conjunto de atributos. Por ejemplo, en la fig. 1.1, los atributos número y saldo describen una cuenta particular. Una relación es una asociación entre varias entidades. En la fig. 1.1, una relación CtaCli asocia a un cliente con cada cuenta que posee. El conjunto de todas las entidades del mismo tipo y relaciones del mismo tipo se denomina conjunto de entidades y conjunto de relaciones.

CalleCiudad
Cliente CtaCli Cuenta
Número SaldoNombre
Fig 1.1
CalleCiudad
Cliente CtaCli Cuenta
Número SaldoNombreCalle
Ciudad
Cliente CtaCli Cuenta
Número SaldoNombre
Fig 1.1 1.1.1.2 Modelo Orientado a Objetos
Al igual que el modelo E/R, el modelo orientado a objetos se basa en una colección de objetos. Un objeto contiene valores acumulados en variables dentro de él, y estos valores son objetos por si mismos. Así, los objetos contienen objetos a un nivel de anidamiento arbitrario. Un objeto también contiene partes de código que operan sobre el objeto, que se denominan métodos.
Los objetos que contienen los mismos tipos de valores y los mismos
métodos se agrupan en clases. Una clase puede se vista como una definición de tipo para objetos.
La única forma en la que un objeto puede acceder a los datos de otro
objeto es invocando a un método de ese otro objeto. Esto se llama envío de un mensaje al objeto. Así, la interfaz de llamada de los métodos de un objeto define su parte visible externamente, la parte interna del objeto (las variables de instancia y el código de método) no son visibles externamente. El resultado es dos niveles de abstracción de datos.
Algunos autores definen estos modelos como “modelos semánticos”. 1.1.2 Modelos lógicos basados en registros
Los modelos lógicos basados en registros se utilizan para describir datos en los modelos conceptual y físico. A diferencia de los modelos lógicos basados en objetos, se usan para especificar la estructura lógica global de la BD y para proporcionar una descripción a nivel más alto de la implementación.
Los modelos basados en registros se llaman así porque la BD está
estructurada en registros de formato fijo de varios tipos. Cada tipo de registro define un número fijo de campos, o atributos, y cada campo normalmente es de longitud fija. La estructura más rica de estas BD a menudo lleva a registros de longitud variable en el nivel físico.
Los modelos basados en registros no incluyen un mecanismo para la
representación directa de código de la BD, en cambio, hay lenguajes separados que se asocian con el modelo para expresar consultas y actualizaciones.

Los tres modelos de datos más aceptados son los modelos relacional, de red y jerárquico. El modelo relacional ha ganado aceptación por encima de los otros.
1.1.2.1 Modelo relacional El modelo relacional representa los datos y sus relaciones mediante
tablas bidimensionales, que contienen datos tomados de los dominios correspondientes.
Nombre Calle Ciudad Número Número Saldo
Juan Perez Comercio Valencia 500 500 500.000,00Juan Perez Comercio Valencia 99 99 60.000.000,00Luis Yepez 48 Barquisimeto 752 752 85.623,52
María Guerrero Humbolt Caracas 45 45 450.000,00Luis Yepez 48 Barquisimeto 99
1.1.2.2 Modelo de red El modelo de red está formado por colecciones de registros,
relacionados mediante punteros o ligas en grafos arbitrarios.
500 500.000
1.1.2.3 Modelo jerárquico El modelo jerárquico es similar al modelo de red, los datos y las
relaciones se representan mediante registros y enlaces. Se diferencia del modelo de red en que los registros están organizados como colecciones de árboles.
Juan Perez Valencia Comercio
99 60.000.000 Luis Yepez Barquisimet
o48
752 85.623,52 Ma Guerrero Caracas Humbolt
45 450.000

Juan Perez
Comercio Valencia
Luis Yepez
Ma Guerrero
Barquisimeto
48 Humbolt
Los modelos relacionales se diferencian de los modelos de red y jerárquico en que no usan punteros o enlaces. En cambio, el modelo relacional conecta registros mediante los valores que éstos contienen. Esta libertad del uso de punteros permite que se defina una base matemática formal. Algunos autores definen estos modelos como "modelos de datos clásicos". 1.1.3 Modelos físico de datos
Los modelos físicos de datos se usan para describir datos en el nivel más bajo. Hay muy pocos de modelos físicos de datos en uso, siendo los más conocidos el modelo unificador y de memoria de elementos.
1.2 Objetivos del modelo de datos
Los objetivos del modelo de datos son dos: 1.2.1 Formalización:
El modelado de datos permite definir formalmente las estructuras permitidas y sus restricciones a fin de representar los datos y también establece las bases para un lenguaje de datos.
1.2.2 Diseño:
El modelo de datos es uno de los elementos básicos (Herramienta obligada) para el desarrollo de la metodología de diseño de la base de datos.
Caracas
500 500.000
99 60.000.000
752 85.623,52
45 500.000 500 450.000

1.3 Elementos del modelo de datos
Los diferentes modelos de datos comparten, aunque con diferentes nombres y notaciones, unos elementos comunes, componentes básicos de la representación de la realidad que realizan. Estos componentes se identifican gracias a la clasificación, y pueden identificarse conceptos estáticos y conceptos dinámicos.
1.3.1 Conceptos estáticos Los conceptos estáticos corresponden a:
1.3.1.1 Objeto: cualquier entidad con existencia independiente sobre
el que almacenan datos. Puede ser simple o compuesto. 1.3.1.2 Relación: asociación entre objetos.
1.3.1.3 Restricción estática: propiedad estática del mundo real que
no puede expresarse con los anteriores, ya que sólo se da en la base de datos; suele corresponder a valores u ocurrencias, y puede ser sobre atributos, entidades y relaciones.
1.3.1.4 Objeto compuesto: definidos como nuevos objetos dentro de
la base de datos, tomando como punto de partida otros existentes, mediante mecanismos de agregación y asociación.
1.3.1.5 Generalización: se trata de relaciones de subclase entre
objetos, es decir, parte de las características de diferentes entidades pueden resultar comunes entre ellas.
1.3.2 Conceptos dinámicos Por su parte, los conceptos dinámicos responden a:
1.3.2.1 Operación: acción básica sobre objetos o relaciones (crear, modificar, eliminar...).
1.3.2.2 Transacción: conjunto de operaciones que deben ejecutarse
en su conjunto obligatoriamente.
1.3.2.3 Restricción dinámica: propiedades del mundo real que restringen la evolución en el tiempo de la base de datos.

2. Modelo de Datos de Red 2.1 Historia
Las estructuras y construcciones del lenguaje para el modelo de red fueron definidas por el comité CODASYL (Conference on Data Systems Languages: Conferencia sobre lenguajes para sistemas de datos), por lo que suele denominársele modelo de red CODASYL. El modelo de red original se dio a conocer en 1971 en un informe publicado por el Grupo de trabajo sobre bases de datos (Data Base Task Group, DBTG) de CODASYL, este modelo se conoce como Modelo DBTG; en 1978 y 1984 se incorporaron nuevos conceptos.
2.2 Estructuras de una Base de Datos de Red
Una base de datos de red está formada por una colección de registros, los cuales están conectados entre sí por medio de enlaces. Las estructuras de datos básicas en este modelo son los registros y los conjuntos.
Un registro es la unidad mínima de manejo de datos en un sistema
de bases de datos de red, es una colección de campos (atributos), cada uno de los cuales contiene solamente almacenado un solo valor. Los registros se clasifican en tipos de registros, cada uno de los cuales describe la estructura de un grupo de registros que almacenan el mismo tipo de información. Cada registro posee un nombre y cada elemento de información (atributo) aparte de poseer un nombre, también posee un formato (tipo de dato).
En el modelo de red es posible definir elementos de información
complejos: vector y grupo repetitivo. Un vector es un elemento de información que puede tener múltiples valores en un solo registro. Un grupo repetitivo permite incluir un conjunto de valores compuestos para un campo en un solo registro.
Los elementos de información antes mencionados se denominan
elementos de información reales, porque sus valores se almacenan realmente en los registros. También es posible definir elementos de información virtuales (derivados), cuyos valores no se almacenan realmente en los registros, en vez de ello, se derivan de los elementos de información reales mediante algún procedimiento definido específicamente para tal fin.
Una aplicación de base de datos común tiene muchos tipos de registro, hasta varios centenares. Para representar los vínculos entre los registros, el modelo de red proporciona la construcción de modelado llamada tipo de conjuntos.

Un tipo de conjuntos es una descripción de un vínculo 1:N entre dos tipos de registros. Una representación diagramático común de los tipos de conjuntos es la llamada diagrama de Bachean. Cada definición dsew tipos de conjuntos consta de tres elementos básicos:
- Un nombre para el tipo de conjuntos. - Un tipo de registros propietarios. - Un tipo de registros miembro.
DEPTO_CARRERA
DEPARTAMENTO
NombreD … …
DEPARTAMENTO
NombreD … …
Registros
Ejemplo de un tipo de conjunto y de tipos de registro.
En el ejemplo el tipo de conjuntos se llama DEPTO_CARRERA, DEPARTAMENTO es el tipo de registros propietario y ESTUDIUANTE es el tipo de registros miembro. Esto representa el vínculo 1:N entre los departamentos académicos y los estudiantes que cursan una carrera en esos departamentos.
En la base de datos habrá muchas ocurrencias de conjunto
(ejemplares de conjunto) que corresponderán a un tipo de conjuntos. Cada ejemplar relaciona un registro del tipo de registros propietario con el conjunto de registros del tipo de registros miembro relacionado con él. Cada ocurrencia de conjunto se compone de:
- Un registro propietario del tipo de registros propietario. - Cero o más registros relacionados del tipo de registros miembro.
Un registro del tipo de registros miembro no puede ocurrir en más de
una ocurrencia de conjunto de un tipo de conjuntos particular, esto mantiene la restricción de que un tipo de conjuntos representa un vínculo de 1:N.. En el ejemplo, un registro ESTUDIANTE puede estar relacionado cuando más con un DEPARTAMENTO de carrera y, por tanto, es miembro de cuando más una ocurrencia de conjunto del tipo de conjuntos DEPTO_CARRERA.

En el modelo de red un ejemplar conjunto se diferencia del conjunto
matemático debido a que el ejemplar de conjunto tiene un elemento distinguido (el registro propietario) y en el conjunto matemático no hay distinción entre los elementos; además en el modelo de red los registros miembro están ordenados, mientras que en el conjunto matemático no existe ningún tipo de orden.
2.3 Tipos Especiales de Conjuntos
Existen dos tipos especiales de conjuntos en el modelo original de CODASYL: los conjuntos propiedad del sistema y los conjuntos multimiembro. Luego se incorporó un tercer tipo: llamado conjunto recursivo.
2.3.1 Conjuntos Propiedad del Sistema (Singulares)
Es un conjunto sin tipo de registros propietario, en este caso el sistema gestor de base de datos actúa como un tipo de registro propietario “virtual” especial en el que sólo hay una ocurrencia de registro. Los conjuntos singulares sirven como puntos de entrada a la base de datos a través de los registros del tipo de registros miembro especificado. También sirven para ordenar los registros de un tipo de registros dado mediante los criterios de ordenamiento del conjunto.
2.3.2 Conjuntos Multimiembro
Se utilizan en casos en los que los registros miembro de un conjunto pueden pertenecer más de un tipo de registros. Los registros miembros en una ocurrencia de conjunto de un tipo de conjuntos multimiembro pueden contener registros de cualquier combinación de tipos de registros miembro.
DEPARTAMENTO
EMP_ADMVO EMP_TECNICO EMP_GERENCIAL
EMP_DEPTO
Ejemplo de un Conjunto Multimiembro

2.3.3. Conjuntos Recursivos Es un tipo de conjuntos en el que al mismo tipo de registros
desempeña el papel tanto de propietario como de miembro. En el modelo CODASYL original estaban prohibidos los conjuntos recursivos debido a su dificultad de implementación. En los conjuntos recursivos, el mismo registro puede ser propietario de una ocurrencia de conjunto y miembro de otra, si ambas ocurrencias de conjuntos son del mismo tipo de conjuntos. Se acostumbra a representarlos con un tipo de registros de enlaces (ficticio) adicional. Esta técnica se usa para representar vínculos de 1:N y de N:M.
EMPLEADO
SUPERVISION
SUPERVISADO SUPERVISOR
Ejemplo de Conjunto Recursivo
2.4 Representación Almacenada de Ejemplares de Conjuntos
Los ejemplares de conjuntos suelen representarse como anillos (listas enlazadas circulares) que enlazan el registro propietario con todos los registros miembro del conjunto, esto se conoce también como cadena circular. En esta representación el SGBD cuenta con un campo especial, llamado campo de tipo, que tiene un valor distinto (asignado por el SGDB) para cada tipo de registros. Al examinar el campo de tipo, el sistema puede saber si el registro es el propietario del ejemplar de conjunto o es uno de los registros miembro, este campo es invisible al usuario.
Además del campo de tipo, el SGBD asigna automáticamente a cada
tipo de registros un campo apuntador por cada tipo de conjuntos en el que participa como propietario o como miembro. Podemos considerar que este apuntador está rotulado con el nombre del tipo de conjunto correspondiente, así el sistema mantiene internamente la correspondencia entre estos apuntadores y sus tipos de conjuntos.
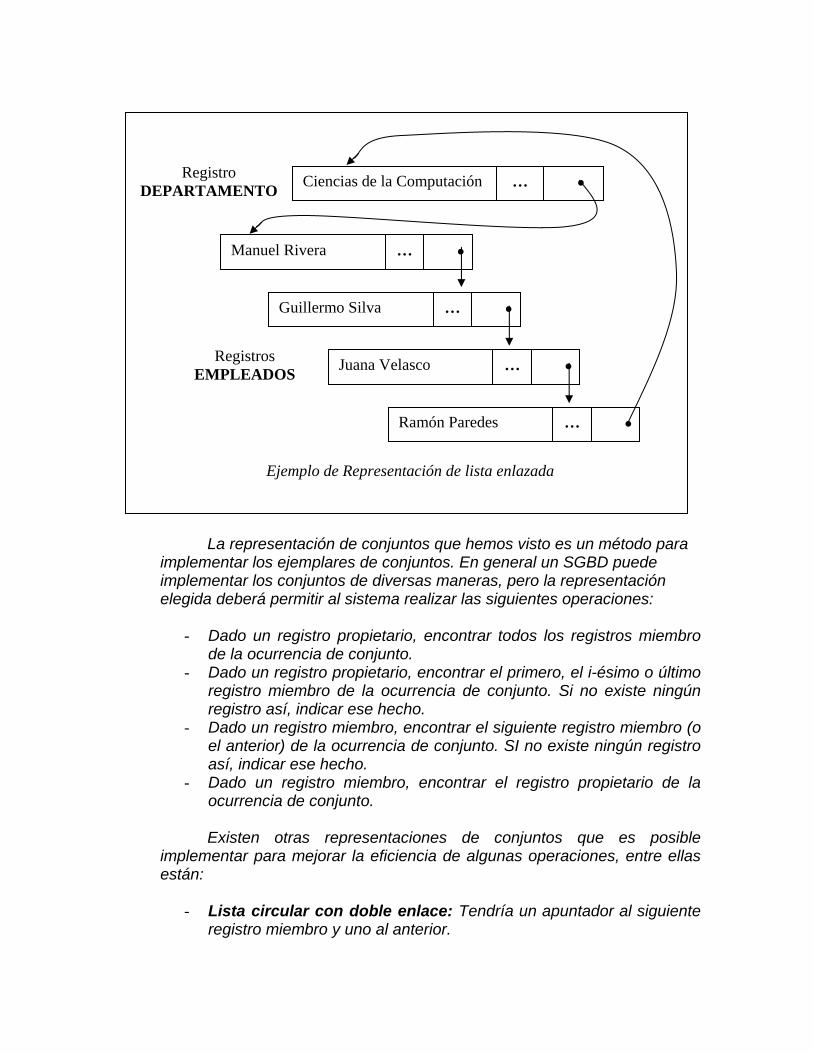
Ciencias de la Computación … •
Manuel Rivera … •
Guillermo Silva … •
Juana Velasco … •
Ramón Paredes … •
Registro DEPARTAMENTO
Registros EMPLEADOS
Ejemplo de Representación de lista enlazada
La representación de conjuntos que hemos visto es un método para implementar los ejemplares de conjuntos. En general un SGBD puede implementar los conjuntos de diversas maneras, pero la representación elegida deberá permitir al sistema realizar las siguientes operaciones:
- Dado un registro propietario, encontrar todos los registros miembro
de la ocurrencia de conjunto. - Dado un registro propietario, encontrar el primero, el i-ésimo o último
registro miembro de la ocurrencia de conjunto. Si no existe ningún registro así, indicar ese hecho.
- Dado un registro miembro, encontrar el siguiente registro miembro (o el anterior) de la ocurrencia de conjunto. SI no existe ningún registro así, indicar ese hecho.
- Dado un registro miembro, encontrar el registro propietario de la ocurrencia de conjunto.
Existen otras representaciones de conjuntos que es posible
implementar para mejorar la eficiencia de algunas operaciones, entre ellas están:
- Lista circular con doble enlace: Tendría un apuntador al siguiente registro miembro y uno al anterior.

- Apuntador al propietario: Puede utilizarse con la lista enlazada o con la doblemente enlazada, para cada tipo de conjuntos, se incluye un apuntador directo al propietario adicional en el tipo de registros miembro.
- Registros miembros contiguos: En vez de estar enlazados por apuntadores, los registros miembros se colocan físicamente uno al lado del otro, casi siempre seguida del registro propietario.
- Arreglo de apuntadores: Un arreglo de apuntadores se almacena junto con el registro propietario, el i-ésimo elemento del arreglo apunta al i-ésimo registro miembro de la ocurrencia de conjunto.
- Representación indizada: Se guarda un índice pequeño con el registro propietario por cada ocurrencia de conjunto. Cada entrada del índice contiene un valor de un campo clave de indización y un apun dor al registro miembro que tiene ese valor en dicho campo.
Empleo de
Por d
dos tipos daparecer envínculo 1:1 restringir qumiembro, es
Un v
con un solode este tipadicionales.enlace (fict
EMNU
2.5 Restr
Aparconjuntos, emiembros d
ta
conjuntos para representar vínculos 1:1 y N:M
efinición un tipo de conjuntos representa un vínculo 1:N entre e registros. Esto significa que un registro miembro sólo puede una ocurrencia del conjunto. Cuando se quiere representar un entre dos tipos de registros con un tipo de conjuntos, se debe e cada ocurrencia de conjunto sólo pueda tener un registro to debe comprobarlo el programador.
ínculo N:M entre dos tipos de registros no puede representarse tipo de conjuntos. La forma correcta de representar un vínculo o es utilizando dos tipos de conjuntos y un tipo de registros Este tipo de registros adicional se llama tipo de registros de icios).
PLEADOMEROE …
EMPLEADO…NUMEROE
E T P TTRABAJA E
HORAS
icciones en el Modelo de Red
te de las restricciones estructurales de los tipos de registros y de stán las restricciones de comportamiento que se aplican a los e los conjuntos (o al comportamiento de dichos miembros)

cuando se realizan operaciones de inserción, eliminación y actualización con esos conjuntos.
Para determinar estas restricciones durante el diseño de la base de
datos hay que conocer cómo deberá comportarse un conjunto cuando se inserten registros miembro o cuando se eliminen registros miembro o propietario. Estas restricciones se especifican al SGBD cuando se declara la estructura de la base de datos.
• Opciones (restricciones) de inserción de conjuntos
Las restricciones de inserción sobre la pertenencia a conjuntos, especifican lo que sucede cuando se inserta en la base de datos un registro nuevo que es de un tipo de registros miembro. Hay dos opciones de inserción:
- AUTOMATIC: El nuevo registro se conecta automáticamente a una ocurrencia de conjunto apropiada cuando se inserta el registro.
- MANUAL: El nuevo registro no se conecta a ninguna ocurrencia de conjunto. Se puede conectar luego explícitamente (manualmente) el registro a una ocurrencia de conjunto.
• Opciones (restricciones) de retención en conjuntos
Las restricciones de retención especifican si un registro de un tipo de registros miembro puede existir en la base de datos por sí solo o siempre debe estar relacionado con un propietario como miembro de algún ejemplar de conjunto. Hay tres opciones de retención: - OPTIONAL: Un registro miembro puede existir por sí solo sin ser
miembro de ninguna ocurrencia del conjunto. Se le puede conectar y desconectar de las ocurrencias de conjunto a voluntad.
- MANDATORY: Ningún registro miembro puede existir por sí solo, siempre debe ser miembro de una ocurrencia de conjunto. Se le puede reconectar en una sola operación de una ocurrencia de conjunto a otra.
- FIXED: Al igual que en MANDATORY, ningún registro miembro puede existir por sí solo. Una vez insertado en una ocurrencia de conjunto queda fijo, no se le puede reconectar a otra ocurrencia de conjunto

3. Modelo de Datos Jerárquico.
3.1. Definición
Una base de datos jerárquica consiste en una colección de registros que se conectan entre si por medio de enlaces. Cada registro es una colección de campos (atributo) que contienen un solo valor cada uno de ellos. Un enlace se conoce como una unión o asociación entre dos registros exclusivamente.
Es un modelo muy rígido en el que las diferentes entidades de las que está
compuesta una determinada situación, se organizan en niveles múltiples de acuerdo a una estricta relación PADRE/HIJO, de manera que un padre puede tener más de un hijo, todos ellos localizados en el mismo nivel, y un hijo únicamente puede tener un padre situado en el nivel inmediatamente superior al suyo.
Las entidades se denominan en el caso particular del modelo jerárquico
SEGMENTOS, mientras que los atributos reciben el nombre de CAMPOS. Los segmentos, se organizan en niveles de manera que en un mismo nivel
estén todos aquellos segmentos que dependen de un segmento de nivel inmediatamente superior.
El contenido de un registro específico puede repetirse en varios sitios (en el mismo árbol o en varios árboles).
La repetición de los registros tiene dos desventajas principales:
* Puede producirse una inconsistencia de datos * El desperdicio de espacio.
Una base de datos jerárquica está formada por una colección o bosque de árboles disjuntos.
3.2. Características De La Estructura Jerárquica.
Los segmentos, en función de su situación en el árbol y de sus características, pueden denominarse como:
* Segmento Padre: Es aquél que tiene descendientes, todos ellos
localizados en el mismo nivel.
* Segmento Hijo: Es aquél que depende de un segmento de nivel superior. Todos los hijos de un mismo padre están en el mismo nivel del árbol.

* Segmento Raíz: El segmento raíz de una base de datos jerárquica es aquel padre que no tiene padres. La raíz siempre es única y ocupa el nivel superior del árbol.
La relación PADRE/HIJO en la que se apoyan las bases de dato jerárquicas,
determina que el camino de acceso a los datos sea ÚNICO; este camino, denominado CAMINO SECUENCIA JERÁRQUICA, comienza siempre en una ocurrencia del segmento raíz y recorre la base de datos de arriba a abajo, de izquierda a derecha y por último de adelante a atrás.
La estructura del modelo de datos jerárquico es un caso particular de la del modelo en red, con fuertes restricciones adicionales derivadas de que las asociaciones del modelo jerárquico deben formar un árbol ordenado, es decir, un árbol en el que el orden de los nodos es importante.
El esquema es una estructura arborescente compuesta de nodos, que representan las entidades, enlazados por arcos, que representan las asociaciones o interrelaciones entre dichas entidades.
Una estructura jerárquica, tiene las siguientes características:
-. El árbol se organiza en un conjunto de niveles. -. El nodo raíz, el más alto de la jerarquía, se corresponde con el nivel 0. -. Los arcos representan las asociaciones jerárquicas entre dos entidades y
no tienen nombre, ya que no es necesario porque entre dos conjuntos de datos sólo puede haber una interrelación.
-. Mientras que un nodo de nivel superior (padre) puede tener un número ilimitado de nodos de nivel inferior (hijos), al nodo de nivel inferior sólo le puede corresponder un único nodo de nivel superior. en otras palabras, un progenitor o padre puede tener varios descendientes o hijos, pero un hijo sólo tiene un padre.
-. Todo nodo, a excepción del nodo raíz, ha de tener obligatoriamente un padre.
-. Se llaman hojas los nodos que no tienen descendientes. -. Se llama altura al número de niveles de la estructura jerárquica. -. Se denomina momento al número de nodos. -. El número de hojas del árbol se llama peso. -. Sólo están permitidas las interrelaciones 1:1 ó 1:N -. Cada nodo no terminal y sus descendientes forman un subárbol, de forma
que un árbol es una estructura recursiva.
El árbol se suele recorrer en preorden; es decir, raíz, subárbol izquierdo y subárbol derecho.
Entre las restricciones propias de este modelo se pueden resaltar: -. Cada árbol debe tener un único segmento raíz. -. No puede definirse más de una relación entre dos segmentos
dentro de un árbol.

-. No se permiten las relaciones reflexivas de un segmento consigo mismo.
-. No se permiten las relaciones N:M. -. No se permite que exista un hijo con más de un padre. -. Para cualquier acceso a la información almacenada, es obligatorio
el acceso por la raíz del árbol, excepto en el caso de utilizar un índice secundario.
-. El árbol debe recorrer siempre de acuerdo a un orden prefijado: el camino jerárquico.
-. La estructura del árbol, una vez creada, no se puede modificar.
3.3. Estructuras De Base De Datos Jerárquica.
Departamento
NombreD NúmeroD NombreGte Fecha
Proyecto Empleado
3.3.1.1 Vínculos Padre / Hijo (VPH): en ésta sección tocamos dos puntos importantes que son registros o colección de valores de campos que proporcionan información sobre una entidad o un ejemplar de vínculo; y vínculo padre / hijo, este tipo de vínculo es 1:N entre dos tipos de registros. El tipo de registros del lado 1 se denomina tipo de registro padre y el del lado N se denomina tipo de registro hijo del tipo de VPH.
NombreE LugarP NombreP NumeroP Dirección FechaINIC
Este esquema tiene tres tipos de registros y dos tipos de VPH. Los tres tipos de registros son: Departamento, Empleado y Proyecto; y lo dos tipo de VPH son: Departamento, Empleado y Departamento, Proyecto.
Cada ocurrencia del tipo de VPH (Departamento, Empleado) relaciona un registro del departamento con los registros de los múltiples empleados que pertenecen a ese departamento. Una ocurrencia del tipo de VPH (Departamento, Proyecto) relaciona un

registro de departamento con los registros de los proyectos controlados por ese departamento.
2.3.1.2 Propiedades De Los Esquemas Jerárquicos:
-. Un tipo de registro, la raíz del esquema jerárquico, no
participa como tipo de registro hijo en ningún tipo de VPH.
-. Todo tipo de registros, con excepción de la raíz, participa como tipo de registros hijos en uno y solo un tipo de VPH.
-. Un tipo de registros puede participar como tipo de registros
padres en cualquier cantidad (cero o más) de tipos de VPH.
- . Un tipo de registros que no participa como tipo de registros padre en ningún tipo de VPH se denomina hoja del esquema jerárquico.
-. Si un tipo de registros participa como padre en más de un
tipo de VPH, entonces sus tipos de registros hijos están ordenados. El orden se visualiza, por convención, de izquierda a derecha en los diagramas jerárquicos.
2.3.1.3 Árboles De Ocurrencias Jerárquicas:
Un árbol de ocurrencia se puede definir como el subárbol de
un registro cuyo tipo es del tipo de registro raíz.
Cada ocurrencia jerárquica es una estructura de árbol que además de cumplir con lo antes señalado, el mismo contiene todas las ocurrencias de registros hijo del registro raíz, todas las ocurrencias de registros hijo dentro de los VPH de cada uno de los registros hijos del registro raíz, y así sucesivamente, hasta los registros de los tipos de registros hojas.
La raíz de un árbol de ocurrencia es una solo ocurrencia del
registro del tipo de registros raíz. Puede haber un número variable de ocurrencias de cada tipos de registros no raíz, y cada una de ellas debe tener un registro padre en el árbol de ocurrencia.
3.3.1.4 Problemas De Datos Jerárquico:
El modelo de datos jerárquico presenta importantes
inconvenientes, que provienen principalmente de su rigidez, la cual deriva de la falta de capacidad de las organizaciones jerárquicas para representar sin redundancias ciertas estructuras muy difundidas en la realidad, como son las interrelaciones reflexivas y N:M.

Además de este problema, existe otro importante inconveniente en este tipo de solución como es la no conservación de las simetrías naturales existentes en el mundo real.
Las actualizaciones en las bases de datos jerárquicas pueden
también originar problemas, debido a las restricciones inherentes al modelo:
-. Toda alta, a no ser que corresponda a un nodo raíz, debe
tener un padre. Por ejemplo, sería imposible insertar en la base de datos profesor, alumno; un alumno que aún no tuviera asignado profesor.
Se podría resolver el problema creando un padre ficticio para
este registro, pero con ello se complicaría la labor del usuario de la base de datos, que tendría, cuando deseara conectar el registro a su padre real, que eliminarlo de la base de datos y volver a introducirlo ligado a su verdadero padre además, el sistema no podría distinguir entre padre ficticio y real y cuando contara el número de profesores de la base de datos nos daría uno más
-. La baja de un registro implica que desaparezca todo el
subárbol que tiene dicho registro como nodo raíz, con lo que pueden desaparecer datos importantes que convendría conservar en la base de datos.
Como se describió anteriormente, en las relaciones muchos a muchos se requerían la repetición de datos para conservar la organización de la estructura del árbol de la base de datos.
La repetición de la información genera 2 grandes problemas:
• La actualización puede generar inconsistencia de los datos. • Se genera un desperdicio considerable de espacio.
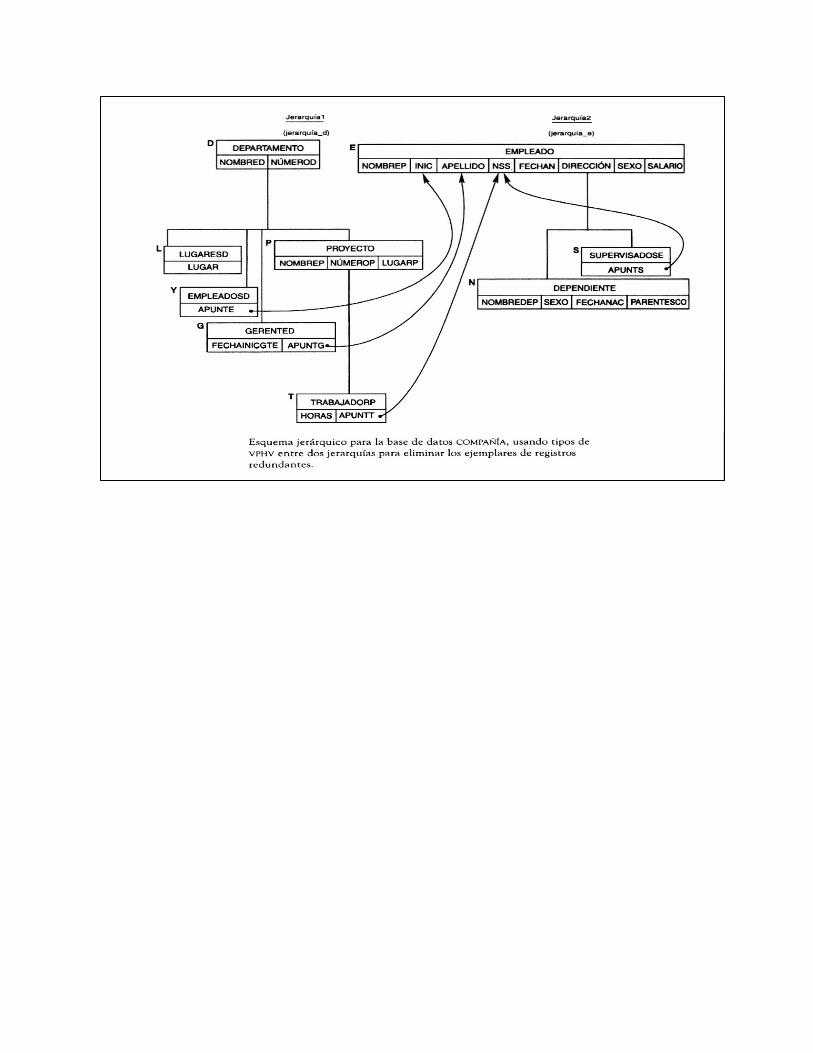
Para solventar estos problemas se introdujo el concepto de registro virtual, el cual no contiene datos almacenados, si no un puntero lógico a un registro físico determinado.
Cuando se va a repetir un registro en varios árboles de la base de datos, se mantiene una sola copia de ese registro en uno de los árboles y empleamos en los otros registros la utilización de un registro virtual que contiene la dirección del registro físico original.

Proyecto Empleado Proyecto
ApuntP
Representación del vínculo N:M con Padre virtual Proyecto.
Empleado
Apunte
Representación del vínculo N:M con Padre virtual Empleado.
3.3.1.5 Restricciones de Integridad en el Modelo Jerárquico
1) Ninguna ocurrencia de registro, con excepción de la raíz, puede existir si no esta relacionado con una ocurrencia de registro padre. Esto tiene las siguientes implicaciones:
-. Ningún registro hijo puede insertarse si no esta enlazado a un registro padre.
-. Un registro hijo se puede eliminar independientemente de su
padre; pero la eliminación de un padre causa automáticamente la eliminación de todos sus registros hijos y descendientes.
-. Un apuntador en un registro hijo virtual debe apuntar a una
ocurrencia real de un registro padre virtual. No debe permitirse la eliminación de un registro en tanto existan apuntadores a él en registros hijo virtuales, lo que lo convierte en un registro padre virtual.
2) Si un registro hijo tiene dos o más registros padre del mismo tipo de
registros, el registros hijo debe duplicarse una vez bajo cada registro padre.
3) Un registro hijo que tenga dos o más registros padre de diferentes
tipos de registros solo puede tener un padre real; todos los demás deben representarse como padre virtuales.

Bibliografía.
Hhttep://www3.uji.es/~mmarques/f47/apun/node79.htmlHHhttp://www.itlp.edu.mx/publica/tutoriales/basedat1/temas6.htmHHhttp://alarcos.inf-cr.uclm.es/doc/bda/doc/trab/T0001_IGarcia.pdfHHhttp://www.itlp.edu.mx/publica/tutoriales/basedat1/temas1.htmHELMASRI, R,; NAVATHE, S.;Sistema de Base De Datos (2º Edición). Addison Wesley Longman de Mexico.


















