Sistemas Distribuidos I Conceptos de Sistemas Distribuidos y Arquitectura.
Upload
jhon-fredy-salazarCategory
view
324download
6
UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA
PROGRAMA DE INGENIERÍA DE SISTEMAS
302090 – SISTEMAS DISTRIBUIDOS
GERARDO GRANADOS ACUÑA (Director Nacional)
EDUARDO ZAPATA ZAPATA Acreditador
BUCARAMANGA Julio de 2009

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
ASPECTOS DE PROPIEDAD INTELECTUAL Y VERSIONAMIENTO
El presente módulo fue diseñado en el año 2006 por el Ing. Gerardo Granados Acuña, docente de la UNAD, y ubicado en el CEAD de Bucaramanga, el Ing. Granados Ingeniero de Sistemas y Especialista en Telecomunicaciones; se ha desempeñado como tutor de la UNAD desde el 2004 hasta el año 2009 y ha sido catedrático de diversas Universidades de Santander.
El presente módulo ha tenido dos actualizaciones, desarrolladas por el mismo ing. Granados en los años 2007 y 2008. Las actualizaciones han estado principalmente enfocadas a incluir nuevos tópicos que han adquirido mayor importancia dentro del desarrollo de los sistemas distribuidos, tales como los agentes inteligentes, las bases de datos distribuidas, la web semántica y el middleware.
Este mismo año el Ing. EDUARDO ZAPATA ZAPATA, tutor del CEAD Ocaña, apoyó el proceso de revisión de estilo del módulo y dio aportes disciplinares, didácticos y pedagógicos en el proceso de acreditación de material didáctico desarrollado en el mes de JULIO de 2009.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
INTRODUCCIÓN
Anualmente el Instituto Tecnológico de Massachussets (MIT), el más reconocido centro de investigación a nivel mundial, presenta una lista de las diez tecnologías de mayor futuro, y, para satisfacción de quienes comienzan a trabajar con el presente módulo, en los últimos años se han destacado tres innovadoras tecnologías: las redes de sensores inalámbricos, los sistemas de computación distribuida y el almacenamiento distribuido. Todas estas tecnologías forman parte integral del campo de los Sistemas Distribuidos (SD) y es así, que muchas de las aplicaciones y avances tecnológicos de nuestra sociedad se han visto acelerados por la evolución de las tecnologías de información distribuida y, como ejemplo característico, tenemos a Internet, la mayor red de información distribuida a nivel mundial.
Lo expuesto hasta aquí, apunta a reconocer la importancia de los Sistemas Distribuidos como un elemento fundamental, que deben conocer y aplicar los profesionales que trabajan en el desarrollo de las ciencias de la información y en especial de quienes implementan y utilizan aplicaciones basadas en las tecnologías de la información y de las comunicaciones.
Los SD son una evolución de los sistemas centralizados los cuales, con el surgimiento de las redes de información, se vieron en la necesidad de expandir su alcance y cobertura. Debido a ello, emergieron conceptos como sistemas operativos distribuidos, memoria distribuida, almacenamiento distribuido y aplicaciones distribuidas, entre otros.
Muchas de las facilidades de nuestra vida diaria están siendo soportadas por SD. Por citar algunos casos tenemos que el uso de la tecnología de comunicación celular se fundamenta en una red distribuida de células de procesamiento de llamadas, los sistemas de cajeros electrónicos se apoyan en bases de datos distribuidas y el correo electrónico es un sistema distribuido de almacenamiento y envío de información. Además de lo anterior, tenemos innumerables aplicaciones que usan sistemas distribuidos y que serán la base de la computación móvil (ubicua), la computación distribuida y los servicios web, tecnologías revolucionarias que serán parte de la transformación de nuestra sociedad.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
El curso de Sistemas Distribuidos ofrecido por la Facultad de Ciencias Básicas e Ingenierías de la UNAD, tiene asignados 3 créditos académicos y corresponde al campo de formación Electivo del Programa de Ingeniería de Sistemas. Tiene un carácter metodológico pues se espera que el estudiante asimile los elementos conceptuales y los aplique en la formulación de su proyecto utilizando tecnología computacional.
A través del desarrollo de las diferentes unidades temáticas se pretende que el estudiante adquiera los fundamentos conceptuales de los SD, su uso y los requerimientos para su desarrollo. También se busca que el estudiante adquiera las destrezas necesarias para formular, planear y ejecutar proyectos que involucren tecnologías de SD.
El presente módulo se ha estructurado en tres unidades temáticas que abarcan los aspectos más relevantes e implícitos en el campo de los SD. Estas unidades son en su orden: fundamentos de sistemas distribuidos, arquitectura de un sistema distribuido y aplicaciones distribuidas.
En la primera unidad se abordan los aspectos conceptuales necesarios para iniciar el estudio de los SD. Se presentan los componentes de un sistema distribuido, las principales características así como los tipos de sistemas distribuidos.
La segunda unidad expone los elementos claves que conforman la arquitectura de un sistema distribuido. Se analizan los modelos de sistemas distribuidos (cliente/servidor, P2P, componentes), el concepto de middleware (lógica de la mediación) y los aspectos de diseño y seguridad en sistemas distribuidos.
El módulo finaliza con una unidad destinada a presentar las principales aplicaciones distribuidas. Se estudian el sistema operativo distribuido CORBA, los sistemas de archivos distribuidos, los servicios web y otras aplicaciones distribuidas como el sistema de nombres de dominio (DNS) y los sistemas de gestión distribuida.
Teniendo en cuenta que la mayoría de los desarrollos en las tecnologías que soportan los SD, tienen su origen en los países industrializados y en especial en los países angloparlantes, se han incluido los términos en inglés de uso común para referirse a las tecnologías que se utilizan en los SD. Es por ello que se encontrarán expresiones como middleware, router, kernel, backbone, cluster, mainframe, host, applet, socket y muchas otras que están referenciadas a largo del módulo, con la consideración de haber incluido la traducción correspondiente y un glosario de ampliación de conceptos al final del módulo.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Además, considerando la cantidad de siglas, abreviaturas y acrónimos que constantemente se manejan al profundizar en los diversos tópicos de los SD, se ha incluido un glosario de siglas con aproximadamente ochenta (80) ítems con su correspondiente traducción. Todo lo anterior con el fin de familiarizar y facilitar el uso de los términos, así como evitar emplear tiempo valioso en búsquedas externas.
Para dar una mayor claridad a los temas tratados, en el presente módulo se han incluido más de cien (100) figuras ilustrativas, tanto importadas como de autoría personal, con su correspondiente explicación dentro del texto.
Se espera que las múltiples experiencias que se realicen a lo largo del curso cumplan con las expectativas planteadas en éste módulo didáctico, de forma que al finalizar, el estudiante se sienta con las bases teóricas y metodológicas que le permitan formular, realizar o hacer parte de grupos de trabajo que implementen SD.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
INDICE DE CONTENIDO
Página
UNIDAD 1. FUNDAMENTOS DE SISTEMAS DISTRIBUIDOS 12 CAPITULO 1: COMPONENTES DE UN SISTEMA DISTRIBUIDO 14 Lección 1: Introducción y Conceptos 14 Lección 2: Objetivos de un Sistema Distribuido 16 Lección 3: Comunicación en los Sistemas Distribuidos 18 Lección 4: Ventajas y desventajas de los Sistemas Distribuidos 28
CAPITULO 2: CARACTERIZACIÓN DE LOS SISTEMAS DISTRIBUIDOS 30 Lección 5: Heterogeneidad 30 Lección 6: Extensibilidad 33 Lección 7: Seguridad 35 Lección 8: Escalabilidad 37 Lección 9: Tratamiento de fallos 40 Lección 10: Concurrencia 42 Lección 11: Transparencia 42 CAPITULO 3: TIPOS DE SISTEMAS DISTRIBUIDOS 46 Lección 12: Internet 46 Lección 13: Intranet 48 Lección 14: Computación móvil y ubicua 50 Lección 15: Computación Distribuida 53 UNIDAD 2. ARQUITECTURA DE UN SISTEMA DISTRIBUIDO 60 CAPITULO 1: MODELOS DE SISTEMAS DISTRIBUIDOS 62 Lección 1: Modelo Cliente/Servidor 62 Lección 2: Tipos de arquitecturas cliente-servidor 66 Lección 3: Redes Igual – Igual (P2P) 72 Lección 4: Modelos de Componentes 78 CAPITULO 2: MIDDLEWARE 81 Lección 5: Fundamentos de Middleware 81 Lección 6: Componentes Middleware 84 Lección 7: Servicios Middleware 85 Lección 8: Ventajas y campos de aplicación del Middleware 87

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
CAPITULO 3: ASPECTOS DE DISEÑO DE UN SISTEMA DISTRIBUIDO 89 Lección 9: Comunicación entre procesos 89
Lección 10: Comunicación entre procesos en plataformas UNIX – LINUX® 95 Lección 11: Objetos distribuidos e invocación remota 101
CAPITULO 4: ASPECTOS DE SEGURIDAD EN UN SISTEMA DISTRIBUIDO 106 Lección 12: Políticas de Seguridad, Mecanismos de Protección 108 Lección 13: Criptografía 113 Lección 14: Seguridad con Cortafuegos 118 Lección 15: Servidor proxy 125 UNIDAD 3. APLICACIONES DISTRIBUIDAS 131 CAPITULO 1: SISTEMAS OPERATIVOS DISTRIBUIDOS - CORBA 133 Lección 1: Fundamentos de CORBA 133 Lección 2: Características de CORBA 135 Lección 3: Los servicios y componentes de CORBA 139 Lección 4: Introducción a IDL 142 CAPITULO 2: SISTEMAS DE ARCHIVOS DISTRIBUIDOS 148 Lección 5: Características de los Sistemas de Archivos 149 Lección 6: Requisitos del sistema de archivos distribuidos 152 Lección 7: Arquitectura del servicio de archivos 155 Lección 8: Sistema de archivos de red de SUN (NFS) 158 CAPITULO 3: SERVICIOS WEB 168
Lección 9: Arquitectura y tecnologías básicas de los servicios web 170 Lección 10: Implementación de los servicios web 178 Lección 11: Tendencias en servicios web – web semántica 180 CAPITULO 4: OTRAS APLICACIONES DISTRIBUIDAS 181 Lección 12: Fundamentos de DNS 181 Lección 13: IPv6 – El Direccionamiento del Futuro 187 Lección 14: Introducción a la Gestión Distribuida 189 Lección 15: Sistema de Gestión Distribuida 193 Glosario de Acrónimos 203 Glosario de Términos 207 Fuentes Documentales 215

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
LISTADO DE GRÁFICOS Y FIGURAS
Pág.
Figura 1. Sistema Distribuido 15
Figura 2. Sistema Distribuido Multimedia 16
Figura 3. Sincronización en Red 18
Figura 4. Fallos Independientes 18
Figura 5. Agentes 20
Figura 6. Agentes Móviles 25
Figura 7. Agentes de Recuperación de Información 26
Figura 8. Googlebot 29
Figura 9. Heterogeneidad de Sistemas Distribuidos 32
Figura 10. Heterogeneidad y Código Móvil 33
Figura 11. Extensibilidad en un Sistema Distribuido 34
Figura 12. Seguridad 37
Figura 13. Crecimiento de Internet en los últimos años 38
Figura 14. Red Internet 48
Figura 15. Red Intranet 50
Figura 16. Dispositivos móviles en un Sistema Distribuido 51
Figura 17. Velocidad de los procesadores 54
Figura 18. Usos de la Computación Distribuida 55
Figura 19. Ejemplo de Computación Distribuida 56

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Figura 20. Comunicación Cliente/Servidor 63
Figura 21. Procesos Cliente/Servidor 64
Figura 22. Paso de Mensajes 68
Figura 23. Arquitectura Cliente/Servidor Monolítica 68
Figura 24. Arquitectura Cliente/Servidor de dos capas 69
Figura 25. Arquitectura Cliente/Servidor de tres capas 71
Figura 26. Modelo Peer-to-Peer 73
Figura 27. Redes P2P centralizadas 75
Figura 28. Redes P2P Descentralizadas 76
Figura 29. Redes P2P hibridas 77
Figura 30. Operación Tabla Hash 78
Figura 31. Modelo de componentes de SUN 80
Figura 32. Modelo de componentes distribuidos de Microsoft 81
Figura 33. Middleware 82
Figura 34. Middleware y APIs 83
Figura 35. Sistema distribuido visto como Middleware 84
Figura 36. Comunicación entre Procesos 90
Figura 37. Sistema Cliente/Servidor con Paso de Mensajes 92
Figura 38. API para protocolos en Internet 93
Figura 39. Sockets 95
Figura 40. Operación de los protocolos TCP y UDP 96
Figura 45. Conectores usados para Datagramas 98
Figura 46. Conectores usados para Flujos 100
Figura 47. Operación RPC 102
Figura 48. Operación de Java® RMI 105
Figura 49. Evolución de las Necesidades de Seguridad 107

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Figura 50. Amenazas a la Seguridad 108
Figura 51. Emisor, Receptor e Intruso 110
Figura 52. Ataques a la seguridad 113
Figura 53. Criptografía 114
Figura 54. Modelo de Criptografía 115
Figura 55. Algoritmo PGP 117
Figura 56. Cortafuegos (Firewall) 120
Figura 57. Cortafuegos con Filtrado de Paquetes 122
Figura 58. Cortafuegos en combinación con pasarela de aplicación 124
Figura 59. Servidor Proxy 127
Figura 60. Código generado en CORBA 139
Figura 61. Categorías de Interfaz OMA. 140
Figura 62. Componentes de CORBA 142
Figura 63. El Papel de IDL 144
Figura 64. Encapsulamiento IDL 145
Figura 65. Desarrollo IDL con Java® 145
Figura 66. Desarrollo IDL con c++ 146
Figura 67. Ejemplo de interfaz IDL 146
Figura 68. Desarrollo de aplicaciones con CORBA 147
Figura 69. CORBA, Java® y la WEB 148
Figura 70. Estructura del registro de atributos de un archivo 150
Figura 71. Módulos de un sistema de archivos 151
Figura 72. Operaciones del sistema de archivo de LINUX®-UNIX 152
Figura 73. Arquitectura del Servicio de Archivos 156
Figura 74. Operaciones del servicio de archivos plano 158
Figura 75. Arquitectura NFS 160

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Figura 76. Apuntador de archivo 161
Figura 77. Operaciones del Servidor NFS (simplificado) 164
Figura 78. Sistemas de archivos loc. y remotos accesibles desde un cliente NFS 166
Figura 79. Niveles de Aplicaciones Web 169
Figura 80. Interacción de Aplicaciones Web con Objetos Distribuidos 170
Figura 81. Protocolos de Servicios Web 181
Figura 82. Operación del Protocolo SOAP – RPC 174
Figura 83. Ejemplo de Mensaje SOAP 174
Figura 84. Operación SOAP – Proceso cliente 175
Figura 85. Operación SOAP – Proceso Servidor 175
Figura 86. Elementos WSDL 176
Figura 87. Integración WSDL - UDDI 177
Figura 88. Ejemplo de WSFL 178
Figura 89. Ejemplo de Servicios Web 179
Figura 90. Consulta en Web Semántica 181
Figura 91. Rango de Direcciones IPv4 183
Figura 92. Base de datos DNS vs Sistema de Archivos LINUX®-UNIX 183
Figura 93. Leyendo nombres en DNS y LINUX®-UNIX 184
Figura 94. Lista de dominios de nivel superior 185
Figura 95. Administración y delegación de un dominio 186
Figura 96. Zonas DNS 187
Figura 97. Operación DNS 188
Figura 98. IPv6 encapsulado en IPv4 189
Figura 99. Gestión Distribuida 190
Figura 100. Sistema de Gestión Distribuida 194
Figura 101. Arquitectura del Software de Gestión Distribuida 196

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
UNIDAD 1
Nombre de la Unidad FUNDAMENTOS DE SISTEMAS DISTRIBUIDOS Introducción La presente unidad se compone de tres capítulos
introductorios, organizados de tal manera que se inicie con un conjunto de definiciones básicas y poco a poco se incremente el nivel de complejidad. En el primer capítulo se analizan los principales componentes de un sistema distribuido y en particular aspectos como la concurrencia, la sincronización y manejo de fallas. Además se presenta el concepto de agente y su importancia en un sistema distribuido. El siguiente capitulo expone de manera detallada las siete (7) principales características de un sistema distribuido: heterogeneidad, extensibilidad, seguridad, escalabilidad, tratamiento de fallos, concurrencia y transparencia. Cada uno de estas características se apoya en diversas definiciones y ejemplos. La unidad finaliza con un capítulo explicativo de los diferentes tipos y ejemplos de sistemas distribuidos. Se detallan sistemas como internet e intranet y se indican los fundamentos tanto para la computación móvil, como para la computación distribuida, estas últimas con un desarrollo y una evolución sin precedentes en nuestra sociedad actual. Bienvenido a esta primera unidad y espero que sus contenidos sean de interés para su desarrollo profesional en este campo de las ciencias de la información.
Justificación Al igual que con cualquier nuevo tema, para abordar el conocimiento de los Sistemas Distribuidos debemos hacerlo a partir de los fundamentos. Sólo así se obtendrán las bases necesarias para ir profundizando en este tema tan interesante.
Intencionalidades Formativas
Que el estudiante describa los componentes fundamentales de un sistema distribuido, su relación y su finalidad, partiendo de la ejemplificación de diversos

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
sistemas distribuidos con diferentes orientaciones y su comparación con los fundamentos teóricos estudiados. Que el estudiante conozca e identifique de manera clara el concepto, propiedades y características de un sistema distribuido, aplicados a una organización, a través del análisis de las diversas aplicaciones, tecnologías y servicios de comunicación que se utilizan. Que el estudiante comprenda la importancia de los sistemas distribuidos para el desarrollo de la sociedad a través plataformas como internet, intranet, computación móvil y computación distribuida.
Denominación de capítulos
Cap. 1. Componentes de un Sistema Distribuido Cap. 2. Caracterización de los Sistemas Distribuidos Cap. 3. Tipos de Sistemas Distribuidos

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
CAPITULO 1: COMPONENTES DE UN SISTEMA DISTRIBUIDO
Introducción
En ésta primera unidad se abordan los aspectos conceptuales necesarios para iniciar el estudio de los SD. Se presentan los componentes de un sistema distribuido, las principales características así como los tipos de sistemas distribuidos.
Lección 1: Introducción y Conceptos 1
Un Sistema Distribuido consiste en una colección de computadores autónomos enlazados por una red y equipadas con un sistema de software distribuido que luce a los usuarios como si fuera en sistema único y centralizado.
Figura 1. Sistema Distribuido
Fuente: COULOURIS George, SISTEMAS DISTRIBUIDOS, Addison Wesley, Madrid, 2001, 3ª Ed.
1 COULOURIS George, DOLLIMORE Jean y KINDBERG Tim (2001): “SISTEMAS DISTRIBUIDOS – Conceptos y Diseño”. Pearson – Addison Wesley.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Este tipo de sistemas se poseen las siguientes características intrínsecas:
� Cada uno de los componentes trabajan en forma concurrente (interactúan simultáneamente).
� Los componentes pueden fallar de manera independiente sin ocasionar un fallo general.
� No existe un reloj global que sincronice los procesos que se ejecutan en el sistema.
� Los componentes no comparten memoria. Los sistemas distribuidos están por todas partes. Internet (considerado un gran sistema distribuido) permite que los usuarios de todo el mundo accedan a sus servicios donde quiera que estén situados. La mayoría de empresas administran una intranet, que provee servicios locales y servicios de Internet a los usuarios locales y habitualmente proporciona servicios a otros usuarios de Internet. Es posible construir pequeños sistemas distribuidos con computadores portátiles y otros dispositivos computacionales pequeños conectados a una red inalámbrica.
Figura 2. Sistema Distribuido Multimedia
Fuente: Autor
En la figura 2 se presenta un sistema distribuido multimedia típico capaz de soportar una variedad de aplicaciones como conferencias, accesos a secuencias almacenadas de vídeo y difusión de radio y televisión digitales. En este sistema, distribuido y abierto, las aplicaciones multimedia2 pueden ser iniciadas y utilizadas sin anuncio previo. Pueden coexistir varias aplicaciones en la misma red e incluso en la misma estación de trabajo, para lo cual se debe garantizar que todas las aplicaciones serán capaces de obtener la cantidad de recursos necesaria en los momentos requeridos, incluso cuando otras aplicaciones estén compitiendo por esos recursos. 2 Aplicaciones como Multimedia basada en web, telefonía de red y conferencias de audio, Servicios de vídeo bajo demanda, etc.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Lección 2: Objetivos de un Sistema Distribuido
La compartición de recursos es el principal factor que motiva la construcción de sistemas distribuidos. Recursos como impresoras, archivos, páginas web o registros de bases de datos se administran mediante servidores del tipo apropiado. Por ejemplo, los servidores web administran páginas y otros recursos web. Los recursos son accedidos por clientes, por ejemplo, los clientes de los servidores web se llaman normalmente browsers o navegadores web.
Además de compartir recursos, un sistema distribuido tiene como finalidad atender los siguientes aspectos que regularmente se presentan en una red:
1. Concurrencia
En una red de computadores, la ejecución de programas concurrentes es la norma. Yo puedo realizar mi trabajo en mi computador, mientras tú realizas tu trabajo en el tuyo, compartiendo recursos como páginas web o archivos, cuando es necesario. La capacidad del sistema para manejar recursos compartidos se puede incrementar añadiendo más recursos (por ejemplo, computadores) a la red. La coordinación de programas que comparten recursos y se ejecutan de forma concurrente es también un aspecto importante de cualquier sistema distribuido.
2. Inexistencia de reloj global
Cuando los programas necesitan cooperar coordinan sus acciones mediante el intercambio de mensajes. La coordinación estrecha depende a menudo de una idea compartida del instante en el que ocurren las acciones de los programas. Pero resulta que hay límites a la precisión con lo que los computadores en una red pueden sincronizar sus relojes (Figura 3), ya que no hay una única noción global del tiempo correcto. Esto es una consecuencia directa del hecho que la única comunicación se realiza enviando mensajes a través de la red.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Figura 3. Sincronización en Red
Fuente: Autor
3. Fallos independientes
Todos los sistemas informáticos pueden fallar y los diseñadores de sistemas tienen la responsabilidad de planificar las consecuencias de posibles fallos. Los sistemas distribuidos pueden fallar de muy diversas formas. Los fallos en la red producen el aislamiento de los computadores conectados al Sistema Distribuido, pero eso no significa que detengan su ejecución. De hecho, los programas que se ejecutan en ellos pueden no ser capaces de detectar cuando la red ha fallado o está excesivamente lenta (Figura 4).
Figura 4. Fallos Independientes
Fuente: Autor
De forma similar, la caída de un servidor o la terminación inesperada de un programa en alguna parte del sistema (crash) no se da a conocer inmediatamente a los demás componentes con los que se comunica. En un sistema distribuido

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
cada componente del sistema puede fallar independientemente, permitiendo que los demás continúen su ejecución.
Lección 3: Comunicación en los Sistemas Distribuido s
Por ser de gran importancia para el esquema de comunicación entre los elementos de un sistema distribuido, se hará una profundización en el concepto de Agente y sus diversas connotaciones.
1. Agentes 3
Uno de los elementos claves para la comunicación en un Sistema Distribuido es el Agente. La palabra “Agente ” se refiere a todo ente que posee la habilidad, capacidad y autorización para actuar en nombre de otro (Figura 5). A diario, los “agentes humanos ” asisten a las personas en tareas que requieren recursos especializados o conocimiento específico en un dominio. Por ejemplo, una secretaria atiende y resuelve situaciones en nombre de su jefe: administra la agenda, coordina las reuniones, recibe a los visitantes. El usuario “delega ” en el agente una o varias tareas que debe llevar a cabo quedando a la espera de los resultados. Dichas tareas son a menudo fáciles de especificar, pero - en algunos casos – complejas de realizar.
Los investigadores en el campo de los agentes computacionales han dado varias definiciones al término, cada uno desde su óptica particular, fundamentada básicamente en la línea de investigación en la cual trabajan (Inteligencia Artificial, Ingeniería de Software, Sistemas Autónomos, Sistemas Distribuidos). A continuación se presentan algunas definiciones:
Wooldridge y Jennings4 definen agente como “un programa autocontenido capaz de controlar su proceso de toma de decisiones y de actuar, basado en la percepción de su ambiente, en persecución de uno o varios objetivos”.
3 TOLOSA, Gabriel Hernan (1999). “Tecnología de agentes de software”, Brasília, v. 28, n. 3, p. 302-309.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Figura 5. Agentes
Fuente: Autor
Según Nwana5, “el término agente se refiere a un componente de software y/o hardware que es capaz de actuar para poder ejecutar tareas en nombre de un usuario”.
Pattie Maes6 del laboratorio de Inteligencia Artificial del MIT (Massachusetts Institute of Technology / Instituto Tecnológico de Massachusetts) definió a los agentes autónomos como “sistemas computacionales que habitan en algún ambiente dinámico y complejo, sensando su estado y actuando autónomamente, llevando a cabo una serie de objetivos o tareas para los cuales fueron diseñados”.
Nicholas Negroponte, director del Media Lab del MIT, hizo la observación que el futuro de la computación será de “delegar a “ y no de “manipular “ computadores. Dentro de este marco el término agente se redefine para cada aplicación que persiga dicho objetivo.
4 JENNINGS, N.; WOOLDRIDGE, M. “Agent Technology - Foundations, Applications, and Markets”. Springer-UNICOM. 1998 5 NWANA, H. “Software Agents: An Overview”. Knowledge Engineering Review. Cambridge University Press. v.3, p.1- 40. 1996 6 MAES, P. “Modeling Adaptive Autonomous Agents”. Artificial Life Journal, v.1, n. 1&2, p.135-162. MIT Press. 1994

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
2. Propiedades de los agentes
Con base en todas las definiciones anteriores es posible extraer algunas características que requieren los agentes: deben ser parte de un ambiente, deben poder monitorear (sensar) su entorno y actuar sobre el, y deben responder según los objetivos para los cuales fueron diseñados. Deben –entonces – poseer una serie de atributos o propiedades que lo definen como agente7.
Autonomía: Capacidad de actuar sin la intervención directa de una persona o de otro agente. Un agente debe poder controlar sus propias acciones y estado interno. Una vez que el usuario activa el agente indicando algún objetivo de alto nivel, éste actúa independientemente, seleccionando estrategias y monitoreando el progreso en busca de la meta. Si falla con una estrategia, usa otra, pero sin intervención humana o con la mínima indispensable.
Habilidad Social: Un agente debe ser comunicativo. Debe tener habilidad para interactuar con otros agentes o incluso con alguna persona, para solicitar información o bien para exponer los resultados obtenidos de la ejecución de las tareas planeadas. La naturaleza de la comunicación depende del tipo de agente con quien se comunique (humanos o no), en ambos casos debe establecer un protocolo común de intercambio de información entre ambas partes. Los agentes deben poseer algún tipo de interfaz para comunicarse con sus usuarios. Dicha interfaz puede establecerse simplemente mediante el envío de mensajes por correo electrónico o puede ser todo lo sofisticada que se desee (lo ideal es proveer una interfaz más antropomórfica para los agentes).
Reactividad: Se refiere al hecho de que un agente debe poder sensar el estado del ambiente dentro del cual se encuentra inmerso y -en función de esto- actuar, respondiendo de manera adecuada a cambios producidos en el mismo. Los efectos producidos pueden modificar el estado de su entorno. Por ejemplo, un agente de filtrado de correo electrónico está sensando su ambiente, alerta a la llegada de nuevos mensajes. La llegada de un nuevo mensaje (cambio en el medio) produce que el agente responda de acuerdo a las tareas asignadas.
Orientación por objetivos: Un agente no sólo debe actuar por cambios detectados en el medioambiente, sino que debe “trabajar ” en función de los objetivos para los cuales fue diseñado y las tareas que le fueron delegadas en cada momento. Un agente busca permanentemente satisfacer su agenda interna. En las aplicaciones convencionales, cuando un usuario ejecuta un comando, se
7 WOOLDRIDGE, M.; JENNINGS, N. “Software Agents”. IEE Review, p.17-20. 1996.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
activa un proceso que se ejecuta por determinado tiempo, algunos solicitan datos al usuario, retornan resultados y así sucesivamente. Esta es una visión pasiva de computación, ya que la motivación viene de parte del usuario. En un modelo basado en agentes, el proceso es auto-motivado, es decir, el agente busca satisfacer cierto estado interno con mínima intervención humana. Por ejemplo, un agente recuperador de archivos tiene especificada una tarea. El agente debe intentar permanentemente satisfacer la tarea que le fue delegada con base en las estrategias de búsqueda y recuperación con las cuales fue construido, hasta cumplir con el objetivo.
Continuidad temporal: Un agente es un proceso temporalmente continuo. A diferencia de un programa convencional del cual se conoce su inicio y fin, un agente debe ejecutarse hasta que se haya alcanzado con el conjunto de objetivos solicitados, o bien, mientras su ciclo perdure y su usuario no desee detenerlo. La continuidad temporal es la propiedad que da “vida ” al agente, posibilitando que se mantenga alerta a una solicitud o a algún cambio en el medio. El ciclo de vida de un agente depende de sus características, de las tareas que realice y de los deseos de su usuario en cuanto al tiempo durante el cual el agente debe ejecutarse.
Movilidad: Es la capacidad de un agente de “viajar ” por las redes de computadores, de nodo a nodo, en busca de los recursos que le permitan cumplir con su agenda. El término “viajar ” se refiere a que en un determinado instante de tiempo el agente detiene su ejecución, almacena su estado interno y se dirige a otro sitio dentro de una red de computadores (tanto el código del agente como su estado) para luego continuar con su ejecución en la nueva ubicación. Los recursos a los que puede acceder pueden ser de software o hardware. Por ejemplo, un agente puede ir en busca de una base de datos que se encuentra en cierta máquina o bien ejecutarse remotamente haciendo uso del procesador y memoria del equipo destino.
3. Clasificación de los Agentes
Los agentes pueden clasificarse de varias maneras, teniendo en cuenta algunas de las propiedades que poseen o bien haciendo hincapié en alguna en particular. De esta manera puede armarse un árbol taxonómico que abarque todas las combinaciones de propiedades y tareas que se quieran.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Partiendo de lo anterior, se presenta la siguiente clasificación de los agentes de acuerdo con la función u objetivo principal del mismo8:
• Agentes de interfaz • Agentes colaborativos • Agentes móviles • Agentes de recuperación de información
Agentes de interfaz
Un agente de interfaz es un software cuasi-inteligente que asiste a un usuario cuando interactúa con una o más aplicaciones. La motivación es que se les pueda delegar tareas aburridas y laboriosas. Son asistentes personales que reducen el trabajo por la sobrecarga de información, como por ejemplo el filtrado de los mensajes de correo electrónico o la recuperación de archivos de Internet. Esta categoría de agentes apoyan y proveen asistencia a su usuario. El agente observa y monitorea las acciones que toma el usuario en la interfaz, aprende nuevos atajos, y sugiere mejores formas de hacer las tareas. La idea es que el agente pueda adaptarse a las preferencias y hábitos de sus usuarios. Enfatizan la autonomía y el aprendizaje para llevar a cabo tareas para sus dueños y trabajan en el mismo ambiente que éstos.
A su vez, los agentes de interfaz pueden encontrarse subdivididos debido a diferentes tareas para las cuales son construidos. Las más comunes son:
� Asistentes : Trabajan realizando tareas típicas como el manejo de la agenda. Estos agentes ayudan al usuario a planificar las reuniones. Sus acciones incluyen negociar, aceptar o rechazar reuniones.
� Filtros : Su tarea principal es la de analizar información según un conjunto de reglas dadas por el usuario. La aplicación típica es el filtrado de mensajes de correo electrónico.
� Guías : Asisten a los usuarios en el uso de una aplicación. Estos agentes monitorean las acciones de los usuarios e intentan sugerir qué pasos realizar para alcanzar el objetivo. Algunos ayudan a navegar por la Web.
Agentes colaborativos
Los agentes colaborativos constituyen un sistema multiagentes, es decir existe mas de un agente dedicado a satisfacer los requerimientos de sus usuarios. Para
8 BERNEY, B. Software “Agents – A Review”. Manchester Metropolitan University. 1996

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
ello es necesario contar con esquemas de comunicación entre agentes que posibiliten la cooperación y el intercambio de conocimiento. Además, deben poseer un alto grado de autonomía para actuar interactuando con sus pares.
La motivación detrás de la construcción de agentes colaborativos es que los sistemas construidos con unidades relativamente simples proveen mayor funcionalidad que un ente mayor, pudiendo extender la funcionalidad del sistema mas allá de las capacidades de uno de sus miembros.
Además, estas arquitecturas posibilitan contar con mayor confiabilidad (debido a la redundancia) y mayor velocidad (debido al paralelismo) en el sistema conjunto. Las áreas de aplicación de este tipo de agentes incluyen:
� Resolución de problemas demasiado grandes. � Interconexión de múltiples sistemas. � Manejo de información proveniente de fuentes distribuidas.
Agentes Móviles
Los agentes móviles son procesos capaces de “viajar ” por una red de computadores, interactuando con hosts9 externos, recolectando información en nombre de su dueño y retornando a “casa ” luego de completar las tareas establecidas (Figura 6). Los agentes forman un nivel de abstracción más para el usuario, detrás del cual se encuentran soluciones a cuestiones técnicas en algunos casos complicadas. Una de estas cuestiones es la distribución, es decir, como manejar recursos computacionales distribuidos. Con la idea de agentes móviles los recursos distribuidos no son completamente ocultados al usuario pero tampoco completamente expuestos10. La noción de movilidad viene del objetivo de reducir el tráfico innecesario dentro de una red, con lo que se pueden reducir los costos de comunicación. Además, al aportar una nueva forma de computación distribuida posibilita el mejor aprovechamiento de los recursos de la red y permite que los usuarios tengan acceso a una cantidad mayor de recursos. Por ejemplo, debido a que las sesiones en busca de un recurso determinado ciertas veces son largas, la idea de agentes móviles provee una solución. Un usuario delega la tarea de búsqueda de información a un agente, establece una comunicación con la red y “envía” al agente a cumplir con su misión. La próxima vez que el usuario se conecte, el agente “retorna ” con los resultados obtenidos.
9 Anfitrión. Máquina conectada a una red de computadores y que tiene un nombre de equipo (Hostname). Puede ser un computador, un servidor de archivos, un dispositivo de almacenamiento por red, una máquina de fax, impresora, etc. 10 WILLIAM, J. “ BOTS and other Internet Beasties”. Sams.Net Publisihing. First Edition. 1996

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Figura 6. Agentes Móviles
Fuente: Autor
Para soportar la movilidad, debe existir una infraestructura de transporte que mueva el código del agente de una ubicación a otra. Además, se debe contar con un entorno de ejecución de agentes, donde los agentes “viven ”, compuesto por todas los computadores que los proveen. Finalmente, para construir sistemas con agentes móviles es necesario resolver algunas cuestiones fundamentales tales como:
� Transporte: Cómo se mueven de lugar en lugar? � Ejecución: Cómo ejecutar el agente de forma remota? � Autenticación: Cómo saber si el agente es quien dice ser y a quién representa? � Privacidad: Cómo asegurar que el agente mantenga resguardado su estado
interno? � Seguridad: Cómo protegerlo de virus? Cómo prevenir que el agente entre en
bucles infinitos o falle?
Agentes de recuperación de información
El objetivo principal de los agentes dedicados específicamente a la recuperación de información es obtener información por el usuario (Figura 7). La motivación para su construcción es que con el crecimiento vertiginoso de Internet, la cantidad de información accesible supera la cantidad de tiempo disponible para analizarla. Un adagio popular en Internet dice: “Nos estamos sumergiendo en información pero hambrientos de conocimiento”.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Las tecnologías de la información han expandido los horizontes de los usuarios en cuanto a las formas de generar y acceder a la misma. Pero esta amplia variedad de información distribuida plantea desafíos en cuanto a las formas de manejar su complejidad y heterogeneidad.
Figura 7. Agentes de Recuperación de Información
Fuente: Autor
Hoy en día, la información se produce en múltiples contextos, se difunde por medios muy variados y se utiliza en todas partes. El rápido crecimiento de la cantidad de documentos en Internet (especialmente en la web) presenta la dificultad de poder acceder a la información relevante.
Se produce así el fenómeno conocido como “sobrecarga de información ”, entonces se trata de mejorar, pero no eliminar, el problema específico de la sobrecarga y administración de la información. Además, existe el problema que debido al gran volumen de información disponible, se mezclan el ruido o desperdicio con la información útil o necesaria, lo que determina la gran dificultad de hallar lo que realmente resulta de interés para las personas.
Las soluciones actuales a este problema se basan en la construcción de motores de búsqueda, con mecanismos de indexación de documentos, combinados con interfaces de consulta apropiadas a esta tarea, o bien, índices manuales multi-nivel (o directorios), los cuales presentan clasificaciones de los documentos según el criterio de sus autores. Ambas técnicas poseen debilidades visibles. Los primeros, son muy propensos a “recuperar ” demasiada cantidad de documentos

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
“no deseables ” ya que trabajan (básicamente) mediante técnica de búsqueda de la ocurrencia de los términos buscados en los documentos. Por otra parte, los índices manuales, solamente tienen “parte ” de los posibles documentos, debido al alto costo que posee la recuperación, manipulación y clasificación manual de los mismos. La motivación es poder diseñar una técnica que permita describir los cientos de millones de documentos disponibles de manera precisa, creando un índice de alta calidad, con una forma eficaz y eficiente de acceder a éste (ya sea de manera manual o automática). Una de las soluciones posible se basa en los agentes de recuperación de información. Estos agentes pueden asistir a un usuario novato en la formulación de consultas avanzadas, en base a sus necesidades de información. Además, permiten acceder e integrar fuentes heterogéneas y manejar diferentes tipos formatos de información.
Los agentes de recuperación de información poseen métodos para permitir el rápido acceso y recuperación de información relevante. Tienen la tarea de administrar, manipular y juntar información de fuentes distribuidas. Pueden tener mecanismos de búsqueda y navegación flexibles y algoritmos de clasificación poderosos. El objetivo es construir agentes capaces de “armar ” un diario personalizado, sabiendo dónde buscar, cómo encontrar lo buscado y cómo armarlo luego. Los agentes se presentan como una herramienta muy útil en la tarea de resolver el problema de la sobrecarga de información, debido a que éstos pueden realizar sus tareas mucho más rápido que las personas y, además, se encuentran disponibles las veinticuatro horas.
4. Ejemplos de Agentes
Para dar claridad acerca concepto de agente software, se describen dos ejemplos de amplia utilización en las plataformas computacionales distribuidas:
Los agentes de biblioteca.
Un interesante ámbito de aplicación de los agentes de recuperación de información son las bibliotecas. Las colecciones de información pública almacenadas en formato electrónico han aumentado considerablemente, por lo cual las bibliotecas deben incorporar este formato como una alternativa a las publicaciones tradicionales. Dentro de este ámbito, los agentes de recuperación de información pueden resultar de gran utilidad como asistentes de los

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
bibliotecarios, manejando los grandes volúmenes de material electrónico almacenado. Dado un contexto de búsqueda (según la petición de material por parte de un usuario), el bibliotecario puede recurrir a un agente para que lo asista en las tareas de buscar, clasificar y filtrar la información solicitada. Con base en una solicitud, el agente puede recurrir a estrategias para seleccionar las bases de datos donde buscar y cómo categorizar los documentos encontrados. Además, pueden colaborar con el bibliotecario en el desarrollo de las siguientes actividades:
� Recuperar información de fuentes distribuidas (Internet) � Realizar consultas con distintas estrategias � Generar reportes detallados y/o resumidos � Mantener estadísticas de solicitudes/búsqueda/utilidad � Crear perfiles de usuarios, con base en sus áreas temáticas o preferencias de
material
En los próximos años, es impensable una biblioteca que no incorpore asistentes digitales. La diversidad de soportes, formatos, idiomas, motores de consulta, etc, están a disposición de los usuarios con la finalidad de brindar una mayor calidad de servicio informativo, pero él usuario debe abstraerse de cuestiones tecnológicas que lo dispersen de sus objetivos principales. Esta última cuestión es la que tienden a realizar los asistentes o agentes de bibliotecas, operando como interfaces inteligentes entre el usuario y las tecnologías de información.
Googlebot 11.
Un Googlebot es un agente distribuido (robot de búsqueda) usado por Google. Colecciona documentos desde la web, para construir una base de datos para el motor de búsqueda Google.
Si un webmaster12 no quiere que su página sea descargada por un Googlebot, el puede insertar un texto llamado robots.txt , el cual puede hacer que Googlebot (y otros robots de información) no investiguen esa página.
Googlebot tiene dos versiones, deepbot y freshbot. Deepbot investiga profundamente, tratando de seguir cualquier enlace en esa página, además de poner está página en el caché, y dejarla disponible para Google. Freshbot investiga la web buscando por contenido nuevo, visitando sitios que cambian
11 http://es.wikipedia.org/wiki/Google 12 Persona responsable del matenimiento y administración de un sitio Web.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
frecuentemente. Idealmente, el freshbot visita la página de un periódico todos los días, mientras que la de una revista cada semana, o cada 15 días.
Figura 8. Googlebot
Fuente: http://www.gugologia.hpg.ig.com.br/GoogleBot.gif
Googlebot descubre enlaces a otras páginas, y se dirige hacia ellos también, así puede abarcar toda la web fácilmente.
Lección 4: Ventajas y desventajas de los Sistemas D istribuidos
En general, los sistemas distribuidos exhiben algunas ventajas sobre los sistemas centralizados. Las principales se describen enseguida:
• Economía : El cociente precio/desempeño de la suma del poder de los procesadores separados contra el poder de uno solo centralizado es mejor cuando están distribuidos.
• Velocidad : Relacionado con el punto anterior, la velocidad sumada es muy superior.
• Confiabilidad: Si una sola máquina falla, el sistema total sigue funcionando.
• Crecimiento: El poder total del sistema puede irse incrementando al añadir pequeños sistemas, lo cual es mucho más difícil en un sistema centralizado y caro.
• Distribución: Algunas aplicaciones requieren de por sí una distribución física.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Por otro lado, los sistemas distribuidos también exhiben algunas ventajas sobre sistemas aislados. Estas ventajas son:
• Compartir datos: Un sistema distribuido permite compartir datos más fácilmente que los sistemas aislados, que tendrían que duplicarlos en cada nodo para lograrlo.
• Compartir dispositivos: Un sistema distribuido permite acceder dispositivos desde cualquier nodo en forma transparente, lo cual es imposible con los sistemas aislados. El sistema distribuido logra un efecto sinergético.
• Comunicaciones: La comunicación persona a persona es factible en los sistemas distribuidos, en los sistemas aislados no.
• Flexibilidad: La distribución de las cargas de trabajo es factible en el sistema distribuido, se puede incrementar el poder de cómputo.
Así como los sistemas distribuidos exhiben grandes ventajas, también se pueden identificar algunas desventajas, algunas de ellas tan serias que han frenado la producción comercial de sistemas operativos en la actualidad. El problema más importante en la creación de sistemas distribuidos es el software; los problemas de compartición de datos y recursos son tan complejos que los mecanismos de solución generan mucha sobrecarga al sistema haciéndolo ineficiente. El revisar y validar, por ejemplo, quiénes tienen acceso a algunos recursos y quiénes no, el aplicar los mecanismos de protección y registro de permisos consume demasiados recursos. En general, las soluciones presentes para estos problemas están aún en sus comienzos.
Otros problemas de los sistemas distribuidos surgen debido a la concurrencia y al paralelismo. Tradicionalmente las aplicaciones son creadas para computadores que ejecutan secuencialmente, de manera que el identificar secciones de código “paralelizable ” es un trabajo “arduo ”, pero necesario para dividir un proceso grande en sub-procesos y enviarlos a diferentes unidades de procesamiento para lograr la distribución. Con la concurrencia se deben implantar mecanismos para evitar las condiciones de competencia, las postergaciones indefinidas, el ocupar un recurso y estar esperando otro, las condiciones de espera circulares y, finalmente, los "abrazos mortales "13 (deadlocks). Estos problemas de por sí se presentan en los sistemas multiusuarios o multitareas, y su tratamiento en los sistemas distribuidos es aún más complejo, y por lo tanto, necesita de algoritmos más complejos con la inherente sobrecarga esperada.
13 Una condición de error que se produce cuando dos programas o dispositivos están esperando por una señal del otro para poder continuar con el procesamiento.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
CAPITULO 2: CARACTERIZACIÓN DE LOS SISTEMAS DISTRIBUIDOS 14
Introducción
Al momento de implementar un sistema distribuido deben tenerse en cuenta una serie de factores que lo caracterizan, como lo son la heterogeneidad de componentes, la extensibilidad, la seguridad, el tratamiento de fallos, la escalabilidad, la concurrencia y la transparencia, entre otros. A continuación se presenta de manera detallada que comprende cada una de estas características mencionadas.
Lección 5: Heterogeneidad
Un sistema distribuido permite que los usuarios accedan a servicios y ejecuten aplicaciones sobre un conjunto heterogéneo de redes y computadores. Esta heterogeneidad (es decir, variedad y diferencia) comprende los siguientes cinco (5) aspectos:
• Redes. • Hardware de computadores. • Sistemas operativos. • Lenguajes de programación. • Implementaciones de diferentes desarrolladores.
La heterogeneidad (Figura 9) se aplica también a los tipos de datos manejados, como los enteros, los cuales pueden representarse de diferente forma en diferentes clases de hardware. Hay que tratar con estas diferencias de representación si se van a intercambiar mensajes entre programas que se ejecutan en diferente hardware.
14 COULOURIS George, DOLLIMORE Jean y KINDBERG Tim (2001): “SISTEMAS DISTRIBUIDOS – Conceptos y Diseño”. Pearson – Addison Wesley.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Figura 9. Heterogeneidad de Sistemas Distribuidos
Fuente: http://www.programacion.com/cursos/acscorba/i/Xbill.png
Adicional, las llamadas para intercambiar mensajes en plataformas LINUX® o UNIX son diferentes de las llamadas en plataformas WINDOWS®, por lo tanto hay que tener en cuenta estas diferencias si se desea que los programas escritos en diferentes lenguajes de programación sean capaces de comunicarse entre ellos.
El problema de la heterogeneidad plantea que los programas escritos por diferentes programadores no podrán comunicarse entre sí a menos que utilicen estándares comunes, por ejemplo, para la comunicación en red, la representación de datos elementales y estructuras de datos en mensajes. Para que esto ocurra es necesario concertar y adoptar estándares como por ejemplo los protocolos de Internet (TCP/IP)15.
Heterogeneidad y código móvil
El término código móvil se emplea para referirse al código que puede ser enviado desde un computador a otro y ejecutarse en éste último (Figura 10), por eso los applets16 de Java®17 son un ejemplo de ello. Dado que el conjunto de
15 TCP/IP son las abreviaturas de los protocolos más utilizados en Internet. El protocolo de control de transmisión (TCP) y el protocolo de Internet (IP). 16 Componente de software que corre en el contexto de otro programa, por ejemplo un navegador web. El applet debe correr en un contenedor, que es proporcionado por un programa anfitrión, mediante un plugin, o

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
instrucciones de un computador depende del hardware, el código de nivel de máquina adecuado para ejecutarse en un tipo de computador no es adecuado para ejecutarse en otro tipo. Por ejemplo, los usuarios de PCs envían a veces archivos ejecutables agregados a los correos electrónicos para ser ejecutados por el destinatario, pero el receptor bien pudiera no ser capaz de ejecutarlo, por ejemplo, sobre un Macintosh® o un computador con LINUX®.
Figura 10. Heterogeneidad y Código Móvil
Fuente: http://www.code-magazine.com/ArticleImage.aspx
La aproximación de máquina virtual provee un modo de crear código ejecutable sobre cualquier hardware: el compilador de un lenguaje concreto genera código para una máquina virtual en lugar de código apropiado para un hardware particular, por ejemplo el compilador Java® produce código para la máquina virtual Java®, la cual sólo necesita ser implementada una vez para cada tipo de máquina con el fin de poder lanzar programas Java®. Sin embargo, la solución Java® no se puede aplicar de modo general a otros lenguajes. en aplicaciones como teléfonos celulares que soportan el modelo de programación por applets. A diferencia de un programa, un applet no puede correr de manera independiente, ofrece información gráfica y a veces interactua con el usuario, típicamente carece de sesión y tiene privilegios de seguridad restringidos. Un applet normalmente lleva a cabo una función muy específica que carece de uso independiente. Un applet es un código Java® que carece de un método main, por eso se utiliza principalmente para el trabajo de páginas web, ya que es un pequeño programa que es utilizado en una página HTML y representado por una pequeña pantalla gráfica dentro de ésta. 17 Lenguaje de programación orientado a objetos desarrollado por James Gosling y sus compañeros de Sun Microsystems al inicio de la década de 1990. A diferencia de los lenguajes de programación convencionales, que generalmente están diseñados para ser compilados a código nativo, Java® es compilado en un bytecode que es ejecutado (usando normalmente un compilador JIT), por una máquina virtual Java®. El lenguaje en sí mismo toma mucha de su sintaxis de C y C++, pero tiene un modelo de objetos mucho más simple y elimina herramientas de bajo nivel como punteros.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Lección 6: Extensibilidad
La extensibilidad de un sistema de computación es la característica que determina si el sistema puede ser extendido y reimplementado en diversos aspectos (Figura 11). La extensibilidad de los sistemas distribuidos se determina en primer lugar por el grado en el cual se pueden añadir nuevos servicios de compartición de recursos y ponerlos a disposición para el uso por una variedad de programas cliente.
Para hablar de extensibilidad es importante que la documentación de las interfaces software clave de los componentes de un sistema esté disponible para los desarrolladores de software. Es decir, que las interfaces clave estén publicadas. Este procedimiento es similar a una estandarización de las interfaces, aunque a menudo va mas allá de los procedimientos oficiales de estandarización, que por lo demás suelen ser lentos y complicados.
El desafío para los diseñadores es hacer frente a la complejidad de los sistemas distribuidos que constan de muchos componentes diseñados por personas diferentes.
Figura 11. Extensibilidad en un Sistema Distribuido
Fuente: Autor
Los diseñadores de los protocolos de Internet presentaron una serie de documentos denominados “Solicitudes de Comentarios ” (RFC / Request For Comments), cada una de los cuales se conoce por un número. Las

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
especificaciones de los protocolos de Internet fueron publicadas en esta serie a principios de los años ochenta, seguido por especificaciones de aplicaciones que corrieran sobre ellos, tales como transferencia de archivos, correo electrónico y TELNET a mediados de los años ochenta. Esta práctica continúa y forma la base de la documentación técnica sobre Internet, que incluye discusiones así como especificaciones de protocolos18. Así, la publicación de los protocolos originales de comunicación de Internet ha posibilitado que se construyera una enorme variedad de sistemas y aplicaciones sobre Internet. Los documentos RFC no son el único modo de publicación. Por ejemplo, la documentación del Sistema Operativo Distribuido CORBA19 está publicada a través de una serie de documentos técnicos, incluyendo una especificación completa de las interfaces de sus servicios a través del Grupo de Administración Abierto (OMG / Open Management Group)20.
Estándares abiertos
La extensibilidad de un sistema distribuido se destaca por el hecho de ser un “Sistema Abierto ” o de utilizar estándares abiertos. Gracias a esto, los sistemas pueden ser extendidos en el nivel hardware mediante la inclusión de computadores a la red y en el nivel software por la introducción de nuevos servicios y la reimplementación de los antiguos, posibilitando a los programas de aplicación la compartición de recursos. Otro beneficio más, citado a menudo, de los sistemas abiertos es su independencia de proveedores concretos.
Los Estándares abiertos son especificaciones disponibles públicamente para lograr una tarea específica. Al permitir a todos el obtener e implementar el estándar, pueden incrementar compatibilidad entre varios componentes de hardware y software, ya que cualquiera con el conocimiento técnico necesario y recursos puede construir productos que trabajen con productos de otros vendedores, los cuales compartan en su diseño base el estándar (aunque los poseedores de las patentes pueden imponer cargos o otros términos de licencia en las implementaciones del estándar). Ejemplos de estándares abiertos son:
• GSM �Sistema Global para Comunicaciones Móviles especificado por 3GPP21 • HTML/XHTML22
�Especificación de W3C23 para formato de documentos estructurados
18 Se pueden obtener copias de estos documentos en http://www.ietf.org 19 Estándar que facilita las comunicaciones entre aplicaciones distribuidas orientadas a objetos sin considerar el lenguaje de programación en que ellas fueron escritas y la plataforma hardware en la cual se ejecutan. 20 http://www.omg.org 21 http://www.3gpp.org 22 Lenguaje de marcación de Hipertexto (Hiper-Text Markup Language)

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
• IP24�Especificación de la IETF25 para transmitir paquetes de datos en una red)
Con base en lo anterior se puede concluir lo siguiente: • Los sistemas abiertos se caracterizan porque sus interfaces están publicadas. • Los sistemas distribuidos abiertos se basan en la providencia de un
mecanismo de comunicación uniforme e interfaces públicas para acceder a recursos compartidos.
• Los sistemas distribuidos abiertos pueden construirse con hardware y software heterogéneo, posiblemente de diferentes proveedores. Sin embargo, la conformidad con el estándar publicado de cada componente debe contrastarse y verificarse cuidadosamente si se desea que el sistema trabaje correctamente.
Lección 7: Seguridad
Entre los recursos de información que se ofrecen y se mantienen en los sistemas distribuidos, muchos tienen un alto valor intrínseco para sus usuarios. Por esto su seguridad es de considerable importancia (Figura 12). La seguridad de los recursos de información tiene tres componentes: confidencialidad (protección contra el descubrimiento por individuos no autorizados); integridad (protección contra la alteración o corrupción); y disponibilidad (protección contra interferencia con los procedimientos de acceso a los recursos).
Si se tiene en cuenta lo anterior, el permitir un acceso libre a todos los recursos de una intranet lleva asociados riesgos contra la seguridad. Aunque se pueda emplear un cortafuegos (firewall)26 para disponer una barrera alrededor de una intranet, restringiendo el tráfico que pudiera entrar y salir, es muy difícil asegurar el uso apropiado de los recursos por usuarios del interior de la intranet.
En un sistema distribuido, los clientes envían peticiones de acceso a datos administrados por servidores, lo que trae consigo enviar información en los mensajes por la red. Por ejemplo:
• Un médico puede solicitar acceso a los datos hospitalarios de un paciente o enviar modificaciones sobre ellos.
23 http://w3.org 24 Ver glosario 25 http://www.ietf.org/) 26 En todo el módulo se utilizará la palabra cortafuegos (ver glosario) a cambio del término Firewall. Un cortafuegos es un elemento de hardware o software utilizado en una red de computadores para prevenir algunos tipos de comunicaciones prohibidos según las políticas de red que se hayan definido en función de las necesidades de la organización responsable de la red.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
• En comercio electrónico y banca, los usuarios envían su número de tarjeta de crédito a través de Internet.
Figura 12. Seguridad
Fuente: KUROSE James, REDES DE COMPUTADORES, Addison Wesley, Madrid, 2004, 2ª Ed.
En ambos casos, el reto se encuentra en enviar información sensible en un mensaje, por la red, de forma segura. Pero la seguridad no sólo es cuestión de ocultar los contenidos de los mensajes, también consiste en conocer con certeza la identidad del usuario u otro agente en nombre del cual se envía el mensaje. En el primer ejemplo, el servidor necesita conocer que el usuario es realmente un médico y en el segundo, el usuario necesita estar seguro de la identidad de la tienda o del banco con el que está tratando. El segundo reto consiste en identificar un usuario remoto u otro agente correctamente. Ambos desafíos pueden lograrse a través de técnicas de encriptación desarrolladas al efecto.
Sin embargo, aún existen dos desafíos de seguridad que no han sido atendidos a cabalidad: los ataques de denegación del servicio (DoS / Denial of Service)27 y el código móvil.
Ataques de denegación de servicio : Este problema de seguridad ocurre cuando un usuario desea obstaculizar un servicio por alguna razón. Esto se obtiene al bombardear el servicio con un número suficiente de peticiones inútiles de modo que los usuarios serios sean incapaces de utilizarlo.
Seguridad del código móvil: el código móvil necesita ser tratado con cuidado. Suponga que alguien recibe un programa ejecutable adherido a un correo electrónico: los posibles efectos al ejecutar el programa son impredecibles; por ejemplo, pudiera parecer que presentan un interesante dibujo en la pantalla
27 Tipo de ataque hecho por un usuario a un sistema de computación para saturarlo con consultas y evitar que ofrezca uno o varios servicios.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
cuando en realidad están interesados en el acceso a los recursos locales, o quizás pueda ser parte de un ataque de denegación de servicio.
Lección 8: Escalabilidad
Los sistemas distribuidos operan efectiva y eficientemente en muchas escalas diferentes, desde pequeñas intranets a Internet. Se dice que un sistema es escalable si su capacidad de procesamiento puede crecer añadiendo nodos adicionales:
� Aumenta el rendimiento con un número creciente de nodos (idealmente de forma lineal).
� El tiempo de respuesta decrece (o se mantiene constante o crece lentamente) con un número creciente de nodos.
� La fiabilidad el sistema aumenta con número creciente de nodos (idealmente de forma logarítmica).
Internet proporciona un ejemplo de un sistema distribuido en el que el número de computadores y servicios experimenta un dramático incremento. La figura 13 muestra las estadísticas de crecimiento de Internet, por áreas geográficas, con respecto al crecimiento de la población mundial durante los últimos años28.
Figura 13. Crecimiento de Internet en los últimos años
Fuente: http://www.isoc.org
28 http://info.isoc.org

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
El diseño de los sistemas distribuidos escalables presenta los siguientes retos:
1. Control del coste de los recursos físicos
Según crece la demanda de un recurso, debiera ser posible extender el sistema, a un coste razonable, para satisfacerla. Por ejemplo, la frecuencia con la que se accede a los archivos de una intranet suele crecer con el incremento del número de usuarios y computadores. Debe ser posible añadir servidores para evitar el embotellamiento que aparece cuando un solo servidor de archivos ha de manejar todas las peticiones de acceso a éstos. En general, para que un sistema con (n) usuarios fuera escalable, la cantidad de recursos físicos necesarios para soportarlo debiera ser como máximo O(n), es decir proporcional a (n). Por ejemplo, si un solo servidor de archivos pudiera soportar 20 usuarios, entonces 2 servidores del mismo tipo tendrán capacidad para 40 usuarios. Aunque parezca una meta obvia, no es tan fácil lograrlo en la práctica.
2. Control de las pérdidas de prestaciones
Considere la administración de un conjunto de datos cuyo tamaño es proporcional al número de usuarios o recursos del sistema, sea por ejemplo la tabla con la relación de nombres de dominio de computadores y sus direcciones Internet sustentado por el Sistema de Nombres de Dominio (DNS / Domain Name System)29, que se emplea principalmente para averiguar nombres DNS tales como www.unad.edu.co . Los algoritmos que emplean estructuras jerárquicas se comportan mejor frente al crecimiento de la escala que los algoritmos que emplean estructuras lineales. Pero incluso con estructuras jerárquicas un incremento en tamaño trae consigo pérdidas en prestaciones: el tiempo que lleva acceder a datos estructurados jerárquicamente es O(log n), donde (n) es el tamaño del conjunto de datos. Para que un sistema sea escalable, la máxima pérdida de prestaciones no debiera ser peor que esta medida.
3. Prevención de desbordamiento de recursos softwar e
Un ejemplo de pérdida de escalabilidad se muestra en el tipo de número usado para las direcciones Internet (direcciones de computadores en Internet). A finales
29 Sistema de direccionamiento distribuido que traduce el nombre de un servidor web en una dirección IP. Facilita el uso de Internet ya que no hay necesidad de aprender o recordar las direcciones IP (Ej: 172.18.4.5)

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
de los años setenta, se decidió emplear para esto 32 bits (formato de direccionamiento IPv430), pero este tipo de direccionamiento para Internet se desbordará probablemente al comienzo de la década del año 2010. Por esta razón, la nueva versión del protocolo emplea direcciones Internet de 128 bits (formato de direccionamiento IPv631). A pesar de ello, para ser justos con los primeros diseñadores de Internet, no hay una solución idónea para este problema. Es difícil predecir la demanda que tendrá que soportar un sistema con años de anticipación. Además, sobredimensionar para prever el crecimiento futuro pudiera ser peor que la adaptación a un cambio cuando se hace necesario; las direcciones Internet grandes ocupan espacio extra en los mensajes, y en la memoria de los computadores.
4. Evitar cuellos de botella de prestaciones
En general, para evitar cuellos de botella de prestaciones, los algoritmos deberían ser descentralizados. Ilustramos este punto aludiendo al predecesor del Sistema de Nombres de Dominio en el cual la tabla de nombres se alojaba en un solo archivo maestro que podía descargarse a cualquier computador que lo necesitara. Esto funcionaba bien cuando sólo había unos cientos de computadores en Internet, pero pronto se convirtió en un serio cuello de botella de prestaciones y de administración. El Sistema de Nombres de Dominio eliminó este cuello de botella particionando la tabla de nombres entre servidores situados por todo Internet y siendo administrados localmente. Algunos recursos compartidos son accedidos con mucha frecuencia; por ejemplo, puede que muchos usuarios accedan a la misma página web, causando un declive de las prestaciones. Una forma de optimizar lo anterior es mediante el empleo de caché y replicación puede mejorar las prestaciones de los recursos que estén siendo muy fuertemente utilizadas.
Idealmente, el software de sistema y aplicación no tiene por qué cambiar cuando la escala del sistema se incremente, pero esto es difícil de conseguir. La cuestión del escalado de un sistema es un tema dominante en el desarrollo de sistemas distribuidos.
30 Versión 4 del Protocolo IP. Esta fue la primera versión del protocolo que se implementó extensamente, y forma la base de Internet. IPv4 usa direcciones de 32 bits, limitándola a 232 = 4.294.967.296 direcciones únicas, muchas de las cuales están dedicadas a redes locales (LANs). 31 Para una ampliación de IPv6 vea capítulo 4 de la unidad 3 del presente módulo

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Lección 9: Tratamiento de fallos
Los sistemas computacionales a veces fallan. Cuando aparecen fallos en el hardware o el software, los programas pueden producir resultados incorrectos o pueden parar antes de haber completado el cálculo pedido. Los fallos en un sistema distribuido son parciales; es decir, algunos componentes fallan mientras otros siguen funcionando. Consecuentemente, el tratamiento de fallos es particularmente difícil. Entre las principales técnicas para tratar fallos se encuentran las siguientes:
1. Detección de fallos
Algunos fallos son detectables. Por ejemplo, se pueden utilizar sumas de comprobación (checksums) para detectar datos corruptos en un mensaje o un archivo. Por otra parte, los sistemas que trabajan con el protocolo IP tienen algoritmos para detectar errores en los datos transmitidos.
2. Enmascaramiento de fallos
Algunos fallos que han sido detectados pueden ocultarse o atenuarse. Dos ejemplos de ocultación de fallos son:
• Los mensajes pueden retransmitirse cuando falla la recepción. • Los archivos con datos pueden escribirse en una pareja de discos de forma
que si uno está deteriorado el otro seguramente está en buen estado. • Simplemente eliminar un mensaje corrupto es un ejemplo de atenuar un fallo
(pudiera retransmitirse de nuevo). 3. Tolerancia de fallos
La mayoría de los servicios en Internet exhiben fallos; es posible que no sea práctico para ellos pretender detectar y ocultar todos los fallos que pudieran aparecer en una red tan grande y con tantos componentes. Sus clientes pueden diseñarse para tolerar ciertos fallos, lo que implica que también los usuarios tendrán que tolerarlos generalmente. Por ejemplo, cuando un visualizador web no puede contactar con un servidor web no hace que el cliente tenga que esperar indefinidamente mientras hace sucesivos intentos; informa al usuario del problema, dándole la libertad de intentarlo más tarde.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
4. Recuperación frente a fallos
La recuperación implica el diseño de software en el que, tras una caída del servidor, el estado de los datos pueda reponerse o “reversarse ” (roll back) a una situación anterior. En general, cuando aparecen fallos los cálculos realizados por algunos programas se encontrarán incompletos y al actualizar datos permanentes (archivos e información ubicada en almacenamiento persistente) pudiera encontrarse en un estado inconsistente.
5. Redundancia
Puede lograrse que los servicios toleren fallos mediante el empleo redundante (duplicidad) de componentes. Considere los siguientes ejemplos:
• Siempre debe haber al menos dos rutas diferentes entre cualesquiera dos encaminadotes (routers)32 en Internet.
• En el Sistema de Nombres de Dominio, cada tabla de nombres se encuentra replicada en dos servidores diferentes.
• Una base de datos puede encontrarse replicada en varios servidores para asegurar que los datos siguen siendo accesibles tras el fallo de cualquier servidor concreto; los servidores pueden diseñarse para detectar fallos entre sus iguales; cuando se detecta algún error en un servidor se redirigen los clientes a los servidores restantes.
Los sistemas distribuidos proporcionan un alto grado de disponibilidad frente a los fallos del hardware. La disponibilidad de un sistema mide la proporción de tiempo en que está utilizable. Cuando falla algún componente del sistema distribuido sólo resulta afectado el trabajo relacionado con el componente defectuoso. Así como cuando un computador falla el usuario puede desplazarse a otro, también puede iniciarse un proceso de servicio en otra ubicación.
32 Del inglés Router. Dispositivo hardware o software de interconexión de redes de computadores que opera en la capa tres (nivel de red) del modelo OSI. Este dispositivo interconecta segmentos de red o redes enteras. Hace pasar paquetes de datos entre redes tomando como base la información de la capa de red. El router toma decisiones lógicas con respecto a la mejor ruta para el envío de datos a través de una red interconectada y luego dirige los paquetes hacia el segmento y el puerto de salida adecuados.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Lección 10: Concurrencia
Tanto los servicios como las aplicaciones proporcionan recursos que pueden compartirse entre los clientes en un sistema distribuido. Existe por lo tanto una posibilidad de que varios clientes intenten acceder a un recurso compartido a la vez. Por ejemplo, una estructura de datos que almacena artículos de un determinado Proveedor puede ser accedida muy frecuentemente cuando se ofertan descuentos o gangas.
El proceso que administra un recurso compartido puede atender las peticiones de cliente una por una en cada momento, pero esta aproximación limita el ritmo de producción del sistema Por esto los servicios y aplicaciones permiten, usualmente, procesar concurrentemente múltiples peticiones de los clientes. Más concretamente, suponga que cada recurso se encapsula en un objeto y que las invocaciones se ejecutan en hilos de ejecución concurrentes (threads)33. En este caso es posible que varios threads estuvieran ejecutando concurrentemente el contenido de un objeto, en cuyo caso las operaciones en el objeto pueden entrar en conflicto entre sí y producir resultados inconsistentes. Por ejemplo, sean dos ofertas que concurren a una subasta como «Pérez: 122$» y «Rodríguez: 111$» y las operaciones correspondientes se entrelazan sin control alguno, estas ofertas se pueden almacenar como «Pérez: 111$» y «Rodríguez: 122$».
La moraleja de esta historia es que cada objeto que represente un recurso compartido en un sistema distribuido debe responsabilizarse de garantizar que opera correctamente en un entorno concurrente. De este modo cualquier programador que recoge una implementación de un objeto que no está concebido para su aplicación en un entorno distribuido, debe realizar las modificaciones necesarias para que su uso sea seguro en un entorno concurrente.
Para que un objeto sea seguro en un entorno concurrente, sus operaciones deben sincronizarse de forma que sus datos permanezcan consistentes. Esto puede lograrse mediante el empleo de técnicas conocidas como los semáforos, que se usan en la mayoría de los sistemas operativos.
Lección 11: Transparencia
Se define transparencia como la ocultación, al usuario y al programador de aplicaciones, de la separación de los componentes en un sistema distribuido, de forma que se perciba el sistema como un todo más que como una colección de
33 Ver Glosario.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
componentes independientes. Las implicaciones de la transparencia son de gran calado en el diseño del software del sistema. El Modelo de Referencia para el Procesamiento Distribuido Abierto (RM-ODP: Reference Model for Open Distri-buted Processing) de la Organización Internacional de Estándares (ISO 1992) identifican ocho formas de transparencia.
• Transparencia de acceso que permite acceder a los recursos locales y remotos empleando operaciones idénticas.
• Transparencia de ubicación que permite acceder a los recursos sin conocer su localización.
• Transparencia de concurrencia que permite que varios procesos operen concurrentemente sobre recursos compartidos sin interferencia mutua.
• Transparencia de replicación que permite utilizar múltiples ejemplares de cada recurso para aumentar la fiabilidad y las prestaciones sin que los usuarios y los programadores de aplicaciones necesiten su conocimiento.
• Transparencia frente a fallos que permite ocultar los fallos, dejando que los usuarios y programas de aplicación completen sus tareas a pesar de fallos del hardware o de los componentes software.
• Transparencia de movilidad que permite la reubicación de recursos y clientes en un sistema sin afectar la operación de los usuarios y los programas.
• Transparencia de prestaciones que permite reconfigurar el sistema para mejorar las prestaciones según varía su carga.
• Transparencia al escalado que permite al sistema y a las aplicaciones expandirse en tamaño sin cambiar la estructura del sistema o los algoritmos de aplicación.
Las dos más importantes son la transparencia de acceso y la transparencia de ubicación; su presencia o ausencia afecta principalmente a la utilización de recursos distribuidos. A veces se les da el nombre conjunto de transparencia de red.
Como aclaración de la transparencia de acceso, considere una interfaz gráfica de usuario basada en carpetas, donde los contenidos de las carpetas se observan igual ya sean éstas locales o remotas. Otro ejemplo pudiera ser el de una interfaz de programación de aplicaciones (API)34 para archivos que emplea las mismas
34 Del inglés Application Programming Interface (Interfaz de Programación de Aplicaciones). Conjunto de especificaciones de comunicación entre componentes software. Representa un método para conseguir abstracción en la programación, generalmente (aunque no necesariamente) entre los niveles o capas inferiores y los superiores del software. Uno de los principales propósitos de una API consiste en proporcionar un conjunto de funciones de uso general, por ejemplo, para dibujar ventanas o iconos en la pantalla. De esta

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
operaciones para acceder a éstos ya sean locales o remotos. Como ejemplo de carencia de transparencia de acceso, considere un sistema distribuido que no permite acceder a los archivos de un computador remoto a menos que se emplee el programa FTP (File Transfer Protocol / Protocolo de Transferencia de Archivos).
Los nombres de recursos web o URLs35 son transparentes a la ubicación dado que la parte del URL que identifica el nombre del dominio del servidor web se refiere a un nombre de computador en un dominio, más que a una dirección en Internet. Sin embargo, un URL no es transparente a la movilidad, porque una página web dada no puede moverse a un nuevo lugar en un dominio diferente sin que todos los enlaces anteriores a esta página sigan apuntando a la página original.
En general, los identificadores como los URLs que incluyen los nombres de dominio en los computadores contravienen la transparencia de replicación. Aunque el DNS permite que un nombre de dominio se refiera a varios computadores, sólo se escoge uno de ellos cuando se utiliza un nombre. Ya que un esquema de replicación generalmente necesita ser capaz de acceder a todos los computadores del grupo, sería necesario acceder a cada entrada del DNS por nombre.
Como ilustración de la presencia de transparencia de red, considere el uso de una dirección de correo electrónico como [email protected] . La dirección consta de un nombre de usuario y un nombre de dominio. Observe que a pesar de que los programas de correo aceptan nombres de usuario para usuarios locales, añaden el nombre del dominio. El envío de correo a un usuario no implica el conocimiento de su ubicación física en la red. Tampoco el procedimiento de envío de un mensaje de correo depende de la ubicación del receptor. En resumen, el correo electrónico en Internet proporciona ambas cosas: transparencia de ubicación y transparencia de acceso (en definitiva, transparencia de red).
La transparencia frente a fallos puede ilustrarse también en el contexto del correo electrónico, el cual eventualmente se envía, incluso aunque los servidores o los enlaces de comunicaciones fallen. Los fallos se enmascaran intentando retransmitir los mensajes hasta que se envían satisfactoriamente, incluso si lleva varios días. Para ilustrar la transparencia a la movilidad, considere el caso de los forma, los programadores se benefician de las ventajas de la API haciendo uso de su funcionalidad, evitándose el trabajo de programar todo desde el principio. 35 Del inglés Uniform Resource Locator (localizador uniforme de recurso). Es una secuencia de caracteres, de acuerdo a un formato estándar, que se usa para nombrar recursos, como documentos e imágenes en Internet, por su localización. El URL es la cadena de caracteres con la cual se asigna una dirección única a cada uno de los recursos de información disponibles en la Internet. Existe un URL único para cada página de cada uno de los documentos de la World Wide Web. Ejemplo: http://es.wikipedia.org:80/wiki/data

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
teléfonos móviles. Supongamos que ambos, el emisor y el receptor, viajan en tren por diferentes partes del país, moviéndose de un entorno (célula) a otro. Veamos al terminal del emisor como un cliente y al terminal del receptor como un recurso. Los dos usuarios telefónicos no perciben el desplazamiento de sus terminales (el cliente y el recurso) entre dos células.
La transparencia oculta y difumina anónimamente los recursos que no son relevantes directamente para la tarea entre manos de los usuarios y programadores de aplicaciones. Por ejemplo, en general es deseable que el uso de ciertos dispositivos físicos sea intercambiable. Por ejemplo, en un sistema multiprocesador, la identificación del procesador en que se ejecuta cada proceso es irrelevante. Aún puede que la situación sea otra: por ejemplo, un viajero que conecta un computador portátil a una red local, en cada oficina que visita hace uso de servicios locales como el correo, utilizando diferentes servidores en cada ubicación. Incluso dentro de un edificio, es normal preparar las cosas para imprimir cada documento en una impresora concreta: generalmente la más próxima. También para un programador que desarrolla programas paralelos, no todos los procesadores son anónimos. Él o ella pudiera estar interesado en qué procesadores utilizar para la tarea, o al menos cuántos y su topología de interconexión.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
CAPITULO 3: TIPOS DE SISTEMAS DISTRIBUIDOS 36
Introducción
La motivación para construir y utilizar sistemas distribuidos tiene su origen en un deseo de compartir recursos. El término recurso es un poco abstracto, pero caracteriza bien el rango de cosas que pueden ser compartidas de forma útil en un sistema de computadores conectados en red. Éste se extiende desde los componentes hardware como los discos y las impresoras hasta las entidades de software definidas como archivos, bases de datos y objetos de datos de todos los tipos. Incluye la secuencia de imágenes que sale de una cámara de vídeo digital y la conexión de audio que representa una llamada de teléfono móvil.
Dependiendo del acceso, la configuración y el tipo de información que se transmite se pueden tener muchos tipos de sistemas distribuidos. Para reforzar los conceptos vistos hasta aquí se presentan, de manera detallada, cuatro tipos de sistemas distribuidos de gran uso actualmente. Ellos son Internet, Intranet, Computación móvil y Computación Distribuida.
Lección 12: Internet
Internet es una vasta colección de redes de computadores de diferentes tipos, las cuales se encuentran interconectadas. La figura 14 muestra una porción típica de Internet. Programas ejecutándose en los computadores conectados a ella interactúan mediante paso de mensajes, empleando un medio común de comunicación. El diseño y la construcción de los mecanismos de comunicación Internet (los protocolos Internet) es una realización técnica fundamental, que permite que un programa que se está ejecutando en cualquier parte dirija mensajes a programas en cualquier otra parte.
36 COULOURIS George, DOLLIMORE Jean y KINDBERG Tim (2001): “SISTEMAS DISTRIBUIDOS – Conceptos y Diseño”. Pearson – Addison Wesley.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Figura 14. Red Internet
Fuente: COULOURIS George, SISTEMAS DISTRIBUIDOS, Addison Wesley, Madrid, 2001, 3ª Ed.
Internet es también un sistema distribuido muy grande. Permite a los usuarios, donde quiera que estén, hacer uso de servicios como el World Wide Web37,38. El conjunto de servicios es abierto, puede ser extendido por la adición de servidores y nuevos tipos de servicios. La figura 14 nos muestra una colección de intranets, subredes gestionadas por compañías y otras organizaciones. Los proveedores de servicios de Internet (ISP / Internet Service Providers) son empresas que proporcionan enlaces de módem y otros tipos de conexión a usuarios individuales y pequeñas organizaciones, permitiéndoles el acceso a servicios desde cualquier parte de Internet, así como proporcionando servicios como correo electrónico y páginas web. Las intranets están enlazadas conjuntamente por conexiones troncales (backbones)39. Una conexión o red troncal es un enlace de red con una gran capacidad de transmisión, que puede emplear conexiones de satélite, cables de fibra óptica y otros circuitos de gran ancho de banda.
En Internet hay disponibles servicios multimedia, que permiten a los usuarios el acceso a datos de audio y vídeo, incluyendo música, radio y canales de televisión, así como mantener videoconferencias. La capacidad de Internet para manejar los requisitos especiales de comunicación de los datos multimedia es actualmente
37 La World Wide Web, comúnmente llamada Web o WWW, nace a principios de los años 90, aunque sus orígenes se remontan a mucho tiempo antes, ya que es fruto de la confluencia de la teoría hipertextual y de las redes de computadores. Fue creada por Tim Berners-Lee del Centro Europeo de Física Nuclear (CERN) con el objetivo de servir como herramienta para la búsqueda y transmisión de información entre los científicos del mundo. 38 Berners-Lee, T., Caillaiau, R., Luotonen, A., Nielse, H., Secret, A. (1994): "The World Wide Web". Communications of the ACM, Vol. 37, Nº 8. Agosto 1994. pp 76-82). 39 Porción de la red que administra el tráfico de alto volumen. El backbone puede conectar varias sedes o edificios de una organización, así como las pequeñas redes LAN que posea.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
bastante limitada porque no proporciona la infraestructura necesaria para reservar capacidad de la red para flujos individuales de datos.
Lección 13: Intranet
Una intranet es una porción de Internet que es administrada separadamente, y que tiene un límite que puede ser configurado para hacer cumplir políticas de seguridad local. La figura 15 muestra una intranet típica. Está compuesta de varias redes de área local (LANs / Local Area Networks)40 enlazadas por conexiones backbone. La configuración de red de una intranet particular es responsabilidad de la organización que la administra y puede variar ampliamente, desde una LAN en un único sitio a un conjunto de LANs conectadas perteneciendo a ramas de la empresa u otra organización en diferentes países.
Una intranet está conectada a Internet por medio de un encaminador (router), lo que permite a los usuarios hacer uso de servicios de otro sitio como el Web o el correo electrónico. Permite también acceder a los servicios que ella proporciona a los usuarios de otras intranets. Muchas organizaciones necesitan proteger sus propios servicios frente al uso no autorizado por parte de usuarios maliciosos de cualquier lugar. Por ejemplo, una empresa no desea que la información segura esté accesible para los usuarios de organizaciones competidoras, y un hospital no desea que los datos sensibles de los pacientes sean revelados. Las empresas también quieren protegerse a sí mismas de que programas nocivos, como los virus, entren y ataquen los computadores de la intranet y posiblemente destruyan datos valiosos.
El papel del cortafuegos es proteger una intranet impidiendo que entren o salgan mensajes no autorizados. Un cortafuegos se implementa filtrando los mensajes que entran o salen, por ejemplo de acuerdo con su origen o destino. Un cortafuegos podría permitir, por ejemplo, sólo aquellos mensajes relacionados con el correo electrónico o el acceso web para entrar o salir de la intranet que protege.
40 Del inglés Local Area Network, Red de Área Local. Una red local es la interconexión de varios computadores y periféricos. Su extensión esta limitada físicamente a un edificio o a un entorno de unos pocos kilómetros.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Figura 15. Red Intranet
Fuente: COULOURIS George, SISTEMAS DISTRIBUIDOS, Addison Wesley, Madrid, 2001, 3ª Ed.
Algunas organizaciones no desean conectar sus redes internas a Internet. Por ejemplo, la policía y otras agencias para la seguridad y la vigilancia de la ley prefieren disponer de algunas redes internas que están aisladas del mundo exterior, y el Servicio Nacional de Salud ha tomado la opción de que los datos médicos sensibles relacionados con los pacientes sólo pueden ser protegidos adecuadamente manteniéndolos en una red interna separada físicamente. Algunas organizaciones militares desconectan sus redes internas de Internet en tiempos de guerra. Pero incluso dichas organizaciones desean beneficiarse del amplio rango de aplicaciones y software de sistemas que emplean los protocolos de Internet. La solución que se adopta en tales organizaciones es realizar una intranet como se ha indicado, pero sin conexiones a Internet. Tal intranet puede prescindir de cortafuegos, o, dicho de otro modo, disponer del cortafuegos más efectivo posible, la ausencia de cualquier conexión física a Internet.
Los principales temas relacionados con el diseño de componentes para su uso en intranets son:
• Los servicios de archivos son necesarios para permitir a los usuarios compartir datos.
• Los cortafuegos tienden a impedir el acceso legítimo a servicios, cuando se precisa compartir recursos entre usuarios externos e internos, los cortafuegos deben ser complementados con el uso de mecanismos de seguridad más refinados.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
• El coste de instalación y mantenimiento del software es una cuestión importante. Estos costes pueden ser reducidos utilizando arquitecturas de sistema como redes de computadores y clientes ligeros.
Lección 14: Computación móvil y ubicua
Si hay un hecho relevante y característico de nuestra sociedad actual es la aparición y rápida difusión de dispositivos móviles (teléfonos móviles, PDAs41, portátiles, etc) los cuales nos acompañan en todo momento debido a su reducido tamaño (Figura 16). Estos dispositivos tienen capacidad de cómputo y además pueden comunicarse con otros elementos sin necesidad de conexiones físicas, gracias a protocolos inalámbricos como GPRS42, UMTS43, WLAN44 y Bluetooth®45.
Figura 16. Dispositivos móviles en un Sistema Distribuido
Fuente: COULOURIS George, SISTEMAS DISTRIBUIDOS, Addison Wesley, Madrid, 2001, 3ª Ed.
Las aplicaciones software de estos pequeños dispositivos deben de adaptarse a las restricciones de memoria, procesamiento y de comunicación intermitente y de calidad cambiante que les caracteriza. El paradigma de computación distribuida que mejor se adapta a todas estas características es lo que se denomina Agente y de esta manera es que se desarrollan ampliamente los sistemas de computación móvil y ubicua. De acuerdo con lo anterior es que han evolucionado las plataformas de agentes móviles en dispositivos limitados, y de la mano una serie 41 Asistente Personal Digital (Personal Digital Assistant) 42 Paquete General de Servicios Radiales (General Packet Radio Service) 43 Sistema de Telecomunicaciones Móviles Universal (Universal Mobile Telecommunications System) 44 Red de Área Local Inalámbrica (Wireless Local Area Network) 45 Bluetooth® es la norma que define un estándar global de comunicación inalámbrica de corto alcance que posibilita la transmisión de voz y datos entre diferentes equipos mediante un enlace por radiofrecuencia.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
de servicios básicos que deben ser proporcionados para los entornos móviles. Por lo general la mayoría de aplicaciones distribuidas para plataformas móviles se están desarrollando en lenguaje Java® el cual se caracteriza por su alta portabilidad.
Entre los servicios básicos que debe proporcionar una plataforma de agentes distribuidos para computación móvil, se encuentran los siguientes:
• Servicios de comunicación: La mayoría de plataformas de agentes que se han desarrollado emplean mecanismos de computación distribuida complejos como RMI46, CORBA, etc. Debido a las limitaciones de los dispositivos móviles (capacidad de procesamiento, memoria), estas soluciones son inviables. Por lo tanto se deben emplear otros métodos de comunicación que sean más ligeros, aunque no proporcionen tantas facilidades.
• Servicios de descubrimiento y anuncio: Las plataformas deben de
conocerse unas a otras, y además deben de saber qué tipo de servicios complementarios ofrecen para poder beneficiarse de ellos. Existen varios protocolos de descubrimiento, como SLP47, Jini48, SSDP49 de UPnP50 y SDP51 de Bluetooth®, la mayoría de ellos centralizan en un único elemento la información de estos servicios.
• Servicios de seguridad: Uno de los principales frenos a la utilización de
agentes móviles en aplicaciones comerciales es la seguridad, por lo tanto es uno de los temas que es necesario analizar en mayor profundidad. Las principales propuestas se centran en que el servicio de seguridad se proporcione a través de tarjetas inteligentes, algo bastante habitual en este tipo de dispositivos, como en el caso de los teléfonos móviles.
La utilización de la tecnología de agentes distribuidos en sistemas de computación móvil permite adaptarse a estas limitaciones de los equipos para proporcionar mejores servicios a los usuarios finales y mejorar las prestaciones de la red, debido a que:
46 Invocación de Método Remoto (Remote Method Invocation) 47 Protocolo de Localización de Servicios (Service Location Protocol) 48 Mecanismo para conectar servicios distribuidos dentro de una red Java 49 Protocolo Simple de Descubrimiento de Servicio (Simple Service Discovery Protocol) 50 Enchufe y Ejecute Universal (Universal Plug and Play) 51 Protocolo de Descripción de Sesión (Session Description Protocol)

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
� Los agentes que proporcionan un servicio pueden enviarse dinámicamente y bajo demanda a los propios usuarios.
� Los agentes permiten realizar distribuciones de tareas para realizar actividades de gestión, siendo los propios agentes quienes recopilen los datos y los procesen localmente en la parte del dispositivo móvil.
� La autonomía de los agentes permite que se realicen tareas de forma asíncrona.
� Los agentes pueden realizar gran parte del procesamiento de forma local, por lo que se conseguiría una reducción importante del tráfico en la red.
� Los agentes permiten una mayor independencia de la disponibilidad de la red, ya que su capacidad de movilidad les permite migrar a otros nodos de la red.
Algunas de las aplicaciones de la tecnología de sistemas distribuidos en sistemas de telefonía móvil de tercera generación son:
� Tareas de gestión de red, siguiendo una tendencia ya explorada en redes fijas, pero que tiene mayor interés en redes móviles debido a que las propias características de los agentes móviles se adaptan a las limitaciones de los sistemas inalámbricos.
� Desarrollo del VHE (Virtual Home Environment / Entorno de Hogar Virtual), que
permitirá la personalización y portabilidad de los servicios de los usuarios independientemente de la red que le dé servicio y del dispositivo que empleen en el acceso. Asociamos la implementación del VHE con un agente móvil, que permitirá configurar el servicio para adaptarse a las preferencias del usuario y a las características del dispositivo, y además será el encargado de crear el propio perfil de usuario analizando su comportamiento y su posición.
Además de los beneficios indicados como parte de un sistema de telefonía móvil, un dispositivo con una plataforma de agentes puede proporcionar al usuario mayores servicios de valor añadido si se integra como parte de entornos de computación ubicua. El usuario desde su dispositivo móvil puede controlar su entorno: La intensidad de las luces, el aire acondicionado, etc. como si fuera un mando a distancia universal que se autoconfigura según el ambiente en el que se encuentre. También es posible beneficiarse de otros servicios que ofrezcan los dispositivos que están en su entorno mas próximo, como por ejemplo: mandar documentos a la impresora, enviar sus transparencias al portátil que tiene conectado el VideoBeam, etc. Todo esto de una manera casi “mágica ” e invisible al usuario, porque son los agentes que se ejecutan sobre los dispositivos móviles los que sabrán que tareas hay que realizar para alcanzar el objetivo final.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Lección 15: Computación Distribuida 52
La computación distribuida, computación en grilla o informática en rejilla, es un nuevo modelo para resolver problemas de computación masiva utilizando un gran número de computadores organizados en racimos incrustados en una infraestructura de telecomunicaciones distribuida.
Figura 17. Velocidad de los Procesadores
Fuente: http://rd13doc.cern.ch/Notes/003/t1.2.pdf
La informática en grilla (grid computing) consiste en compartir recursos heterogéneos (basadas en distintas plataformas, arquitecturas de equipos y programas, lenguajes de programación), situados en distintos lugares y pertenecientes a diferentes dominios de administración sobre una red que utiliza estándares abiertos. Dicho brevemente, consiste en virtualizar los recursos informáticos. Para ello se aprovecha la gran capacidad que están teniendo los procesadores y en especial los utilizados en equipos personales (Figura 17).
La computación en grilla ha sido diseñada para resolver problemas demasiado grandes para cualquier simple supercomputadora, mientras se mantiene la flexibilidad de trabajar en múltiples problemas más pequeños. Por lo tanto, la computación distribuida es naturalmente un entorno multiusuario; por ello, las
52 http://www.grid.org

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
técnicas de autorización segura son esenciales antes de permitir que los recursos informáticos sean controlados por usuarios remotos.
1. Características de la Computación Distribuida
En entorno de computación distribuida en grilla se caracteriza principalmente por contar con los siguientes elementos:
� Servidores y clientes con conexión a una red (Internet). � Conexión altamente confiable 7/24 (7 días a la semana, 24 horas al día) � Compartición de recursos (hardware, software, datos, dispositivos de
almacenamiento, etc.) � Desarrollo de procesos de manera transparente a los usuarios. � Alta capacidad de cálculo global. 2. Aplicaciones de la Computación Distribuida
Actualmente la computación en grilla se esta utilizando en macroproyectos relacionados con: servicios financieros, bioinformática, sismología y geofísica, astronomía y astrofísica, diseño mecánico, simulación de procesos, análisis de elementos finitos, rendering53 y visualización digital, etc. (Figura 18)
Figura 18. Usos de la Computación Distribuida
Fuente: Revista Investigación y Ciencia, Mayo, 2002.
53 Proceso de cálculo complejo desarrollado por un computador y destinado a generar una imagen 3D o secuencia de imágenes 3D.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
3. Como opera la Computación Distribuida
Las dos principales entidades en un entorno de computación distribuida son el servidor y muchos clientes. El servidor se considera un computador central que genera “paquetes de trabajo ” los cuales son enviados a los clientes. Estos últimos realizan las tareas descritas en el paquete y una vez hayan finalizado, el paquete de trabajo junto con los resultados son regresados al servidor.
Figura 19. Ejemplo de Computación Distribuida
Fuente: Revista Investigación y Ciencia, Mayo, 2002.
Una variante de la computación en grilla es la computación de ciclos redundantes, también conocida como “computación zombi ”, el cual es el método empleado por aplicaciones como Seti@Home54 (búsqueda de vida extraterrestre), consistente en que un servidor o grupo de servidores distribuyen trabajo de procesamiento a un grupo de computadores voluntarias (con capacidad de procesamiento no utilizada). Básicamente, cuando se deja un computador encendido, pero sin utilizarlo, la capacidad de procesamiento se desperdicia por lo general en algún protector de pantalla; este tipo de procesamiento distribuido utiliza el computador cuando no lo necesitamos, aprovechando al máximo la capacidad de procesamiento.
54 http:// setiathome.berkeley.edu

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
4. Ventajas de la Computación Distribuida 55
Los computadores y el acceso a la red son económico s: Los computadores personales actuales tienen una potencia superior a los primeros mainframes56, además de tener mucho menos tamaño y precio.
Compartición de recursos: La arquitectura de la computación distribuida refleja la arquitectura de computación de las organizaciones modernas. Cada organización mantiene de forma independiente los computadores y recursos locales, mientras permite compartir recursos a través de la red.
Escalabilidad: En la computación monolítica57, los recursos disponibles están limitados por la capacidad de un computador. Por el contrario, la computación distribuida proporciona escalabilidad, debido a que permite incrementar el número de recursos compartidos según la demanda.
Tolerancia a fallos: Al contrario que la computación monolítica, la computación distribuida permite que un recurso pueda ser replicado con el fin de dotar al sistema de tolerancia a fallos, de tal forma que proporcione disponibilidad de dicho recurso en presencia de fallos.
5. Desventajas de la Computación Distribuida
Múltiples puntos de fallo: Hay más puntos de fallo en la computación distribuida. Ya que múltiples computadores están implicados en la computación distribuida, y todos son dependientes de la red para su comunicación, el fallo de uno o más computadores, o uno o más enlaces de red, puede suponer problemas para un sistema de computación distribuida.
Aspectos de seguridad: En un sistema distribuido hay más posibilidad de ocurrencia de ataques. Mientras que en un sistema centralizado los recursos están bajo el control de una administración única, en un sistema distribuido la gestión es descentralizada y frecuentemente implica a un gran número de organizaciones independientes.
55 http://www.infor.uva.es/~fdiaz/so/ 56 Ordenador central. Es un computador grande, potente y costoso usado principalmente por una gran compañía para el procesamiento de una gran cantidad de datos; por ejemplo, para el procesamiento de transacciones bancarias.
57 Para ampliar este concepto véase el numeral 1.1.3.1 en la Unidad 2

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Actividades de Autoevaluación de la UNIDAD
� ¿Qué es un sistema de video por demanda a través de Internet?. Describa alguno de los productos existentes para vídeo por demanda a través de Internet. Encuentre alguno de los sitios web de empresas del negocio de video por demanda a través de Internet. ¿Se puede considerar un sistema de por video por demanda como sistema distribuido?
� Cada vez son más comunes en el mercado los computadores sin disco local,
denominados estaciones Diskless, Thin Clients, Network Computers o Network Stations. Son computadores con CPU, memoria, dispositivos de E/S y un adaptador de red de área local. Diseñar un sistema informático que permita dar soporte a estos computadores (boot, carga de aplicaciones, almacenamiento de datos), y encuadrarlo dentro de uno o varios de los modelos de sistemas distribuidos estudiados. Compararlo con un sistema centralizado de computadores con pantallas. ¿Dónde está la diferencia?
� Para que sirve el archivo robots.txt?, como el archivo robots.txt controla el acceso a un
sitio web?, donde se ubica robots.txt dentro de un sitio?, como se prueba si el archivo robots.txt está funcionando en un sitio web?.
� Que tipo de agente es y que funciones ejecutan los siguientes Agentes: Websailor,
Virtual Mattie (UNIX), VisitorBot y Web Watcher. � Revisar la aplicación distribuida Wikipedia. Principalmente en la organización de la
información y en la plataforma Hardware (http://es.wikipedia.org/wiki/Wikipedia). � Para cada uno de los siguientes servicios, indique ¿ por que se pueden considerar
como sistemas distribuidos ¿ a. Monitorización de la carga de mercancías a transportar por un vehículo en camino
entre almacenes y tiendas. b. Una sala de chat. c. Una subasta on-line. d. Un servicio que permita a su universidad proporcionar información de los cursos a
los estudiantes. La información se actualiza frecuentemente. � Un programa servidor escrito en un lenguaje (por ejemplo C++) proporciona un objeto
BURBUJA al que se pretende que accedan clientes que pudieran estar escritos en un lenguaje diferente (por ejemplo Java®). Los computadores clientes y servidores pueden tener un hardware diferente, pero todas están conectadas a Internet. Describa los problemas debidos a cada uno de los cinco aspectos de la heterogeneidad que necesitan resolverse para posibilitar que un objeto cliente invoque un método sobre el objeto servidor.
� Indague acerca de las principales características de los siguientes estándares
abiertos: TCP, Bluetooth®, PNG y XML. Para qué se utiliza el estándar?, qué entidad a nivel mundial promueve actualmente su difusión?, en qué tipo de aplicaciones se utiliza? y cuáles son sus perspectivas futuras?

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
� Explique el objetivo del modelo de referencia OSI de la ISO para la interconexión de los sistemas abierto y esboce la función de cada capa. En lo posible utilice gráficos descriptivos.
� Proponga cinco tipos de recursos hardware y cinco tipos de recursos software o de
datos que puedan compartirse útilmente. Proponga ejemplos de su uso compartido tal y como ocurre en la práctica en los sistemas distribuidos.
� ¿Cómo podrían sincronizarse los relojes de dos computadores unidos por una red
local, sin hacer uso de una referencia temporal externa? ¿Qué factores limitarían la precisión del procedimiento propuesto? ¿Cómo podrían sincronizarse los relojes de un mayor número de computadores conectados a Internet?. Discuta la precisión de éste procedimiento.
� Un usuario llega a una estación de ferrocarril que no conoce, portando un PDA capaz
de conectarse a una red inalámbrica. Sugiera cómo podría proporcionársele al usuario información sobre los servicios locales y las comodidades en la estación, sin necesidad de insertar el nombre de la estación o sus características. ¿Qué dificultades técnicas hay que superar?
� Tome World Wide Web como ejemplo para ilustrar el concepto de compartición de
recursos, cliente y servidor. Los recursos en World Wide Web y otros servicios se direccionan mediante URL. ¿Qué significan las siglas URL? Proporcione ejemplos de tres tipos de recursos web a los que pueda darse un nombre URL.
� Qué es un enrutador (router) y cuales son sus principales funciones? Qué función
cumplen los algoritmos de vector distancia y estado de enlace dentro de Internet? Analice si una red de routers se puede considerar un Sistema Distribuido.
� Suponga que quiere construir una red en su casa que incluya un router con una
conexión a Internet y cinco adaptadores sin cable a Ethernet. Encuentre productos específicos que convengan a sus necesidades, y proporcione su precio.
� Qué es un protocolo de descubrimiento y como opera? Establezca un paralelo entre
los protocolos de descubrimiento SLP, Jini, Saludation, SSDP de UPnP y SDP de Bluetooth®.
� Realice un paralelo incluyendo las principales características en torno a (3) de las
siguientes plataformas software para sistemas de computación distribuida. Plaformas: Condor, Sun Grid Environment (SGE), GridSystems, CactusCode, Globus, Unicore, OAR GRID.
� Consultar la página (http://www.distributed.net/) la cual corresponde a un proyecto a
nivel mundial de computadores en malla para realizar procesos distribuidos. Indague acerca del objetivo y principales componentes de este sistema distribuido. Inscríbase y participe. Es una experiencia muy interesante para hacer parte de un proyecto de computación distribuida.
� Con ayuda de dibujos describa la estructura de lo siguiente:
(a) Direcciones IP (b) Datagramas IP

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Identifique claramente cada campo y explique su función basado en el protocolo IP.
� Explique las aplicaciones para las cuales está diseñado el protocolo UDP. Con base en un dibujo, identifique los campos que componen la cabecera de un datagrama de usuario y explique su función.
� Mediante un dibujo, muestre los campos que componen la cabecera de un segmento
de TCP y explique la función de cada campo. � Investigue acerca de la computación distribuida de los proyectos seti@home
[http://setiathome.berkeley.edu] y genome@home [http://genomeathome.stanford.edu]. Escoja uno de ellos. Escriba un informe para (a) explicar el objetivo del proyecto, (b) explicar cómo se lleva a cabo la computación en el sistema distribuido, y (c) explicar qué hay que hacer para participar en el proyecto.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
UNIDAD 2
Nombre de la Unidad ARQUITECTURA DE UN SISTEMA DISTRIBUIDO
Introducción El primer capítulo presenta los tres principales modelos de los sistemas distribuidos: el modelo cliente / servidor, ampliamente utilizado en muchas aplicaciones actuales y que está en permanente evolución, el modelo de redes igual a igual (P2P) que ha tenido una amplia expansión con el auge de internet, y el modelo de componentes, utilizado en arquitecturas de mayor complejidad y como base de las plataformas Java y Microsoft. Como elemento característico de los sistemas distribuidos, surge el concepto de “Middleware”, la capa de software que se ubica entre el sistema operativo y las aplicaciones de los usuarios. Debido a su especial importancia se estudia ampliamente en el segundo capítulo. En el tercer capítulo se detallan los aspectos de diseño de un sistema distribuido, considerando entre otros las comunicaciones entre procesos, el paso de mensajes, los conceptos de socket, datagrama y stream y sus aplicaciones tanto en comunicaciones para plataformas P2P como en sistemas UNIX-LINUX, y en aplicaciones Java. La unidad finaliza con un capitulo dedicado al aspecto de la seguridad en los sistemas distribuidos, tan indispensable para la implementación de los mismos. Se estudian las políticas y los mecanismos de seguridad, los principales factores de seguridad al igual que los diversos tipos de amenazas y ataques. Se recomienda, de manera especial, que analice cada uno de los ejemplos presentados y desarrolle la mayor parte de los ejercicios planteados en cada unidad.
Justificación Para ahondar apropiadamente en el dominio de un tema es necesario conocer sus respectivas características intrínsecas y los sistemas distribuidos no son la

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
excepción. Es por ello, que ésta unidad se orienta en profundizar acerca de la arquitectura de un sistema distribuido.
Intencionalidades Formativas
Que el estudiante conozca los fundamentos y componentes de las diversas arquitecturas de sistemas distribuidos y determine su campo de aplicación. Que el estudiante comprenda la importancia de la lógica de la mediación (middleware) como elemento fundamental para incorporar en la implementación de cualquier sistema distribuido moderno. Que el estudiante determine los elementos claves relacionados con los aspectos de diseño y seguridad que requiere un sistema distribuido.
Denominación de capítulos
Cap. 1. Modelos de Sistemas Distribuidos Cap. 2. Middleware Cap. 3. Aspectos de Diseño de un sistema distribuido Cap. 4. Aspectos de Seguridad en un sistema distribuido

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
CAPITULO 1: MODELOS DE SISTEMAS DISTRIBUIDOS
Introducción
Éste primer capítulo presenta los tres principales modelos de los sistemas distribuidos: el modelo cliente / servidor, ampliamente utilizado en muchas aplicaciones actuales y que está en permanente evolución, el modelo de redes igual a igual (P2P) que ha tenido una amplia expansión con el auge de internet, y el modelo de componentes, utilizado en arquitecturas de mayor complejidad y como base de las plataformas Java y Microsoft.
Lección 1: Modelo Cliente/Servidor
El término Cliente/Servidor fue utilizado inicialmente en los ochentas para denominar computadores personales (PCs / Personal Computers) en una red. El modelo Cliente/Servidor (Figura 20) es una arquitectura de software que posee una infraestructura modular basada en mensajes para mejorar la usabilidad, flexibilidad, interoperatividad y escalabilidad en comparación con los modelos centralizados.
Figura 20. Comunicación Cliente/Servidor
Fuente: COULOURIS George, SISTEMAS DISTRIBUIDOS, Addison Wesley, Madrid, 2001, 3ª Ed.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Un cliente se define como un “solicitador de servicios ” y un servidor se define como un “proveedor de servicios ”. En el entorno Cliente/Servidor el cliente está relacionado con las funciones de presentación de datos junto con actividades lógicas de validación y verificación local, mientras que el servidor desarrolla actividades relacionadas con búsqueda y recuperación de resultados en sus bases de datos.
Desde un punto de vista más técnico los clientes (o programas que representan entidades que necesitan servicios) y los servidores (o programas que proporcionan servicios) son objetos separados y se comunican a través de una red de comunicaciones para realizar una o varias tareas de forma conjunta.
De manera mas detallada, el cliente se caracteriza por desarrollar las siguientes funciones:
• Mantener y procesar todo el dialogo con el usuario • Manejo de pantallas • Menús e interpretación de comandos • Entrada de datos y validación • Procesamiento de ayudas y recuperación de errores
El servidor por su parte se caracteriza por cumplir con las siguientes funciones:
• Acceso, almacenamiento y organización de datos • Actualización de datos almacenados • Administración de recursos compartidos • Ejecución de toda la lógica para procesar una transacción • Procesamiento común de elementos del servidor (datos, capacidad de CPU,
almacenamiento en disco, capacidad de impresión, manejo de memoria y comunicación)
Figura 21. Procesos Cliente/Servidor
Fuente: COULOURIS George, SISTEMAS DISTRIBUIDOS, Addison Wesley, Madrid, 2001, 3ª Ed.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
El modelo Cliente/Servidor asigna roles diferentes a los dos procesos que colaboran:
• El servidor interpreta el papel de proveedor de servicio, esperando de forma pasiva la llegada de peticiones.
• El cliente invoca determinadas peticiones al servidor y aguarda sus respuestas
Desde una concepción simple, el modelo Cliente/Servidor proporciona una abstracción eficiente para facilitar servicios de red. Muchos servicios de Internet dan soporte a aplicaciones Cliente/Servidor, por ejemplo: HTTP58, DNS, FTP, etc.
1. Características
El empleo de la arquitectura Cliente/Servidor se basa en las siguientes propiedades características:
• Protocolos asimétricos: hay una relación muchos a uno entre los clientes y un servidor. Los clientes siempre inician un diálogo mediante la solicitud de un servicio. Los servidores esperan pasivamente por las solicitudes de los clientes.
• Encapsulación de servicios: El servidor es un especialista, cuando se le
entrega un mensaje solicitando un servicio, el determina cómo conseguir hacer el trabajo. Los servidores se pueden actualizar sin afectar a los clientes en tanto que la interfaz pública de mensajes que se utilice por ambos lados, permanezca sin cambiar.
• Integridad: el código y los datos de un servidor se mantienen centralizados, lo
que origina que el mantenimiento sea más barato y la protección de la integridad de datos compartidos. Al mismo tiempo, los clientes mantienen su independencia y autonomía.
• Transparencia de localización: el servidor es un proceso que puede residir
en la misma máquina que el cliente o otra una máquina diferente de la red. El software Cliente/Servidor habitualmente oculta la localización de un servidor a los clientes mediante la redirección de servicios. Un programa puede actuar tanto como cliente, como servidor o como cliente y servidor simultáneamente.
58 Protocolo de Transferencia de Hipertexto (Hiper-Text Transfer Protocol)

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
• Intercambios basados en mensajes: Los clientes y servidores son procesos débilmente acoplados que pueden intercambiar solicitudes de servicios y respuestas utilizando mensajes.
• Modularidad, diseño extensible: el diseño modular de una aplicación
Cliente/Servidor permite que la aplicación sea tolerante a fallos. � En sistemas tolerantes a fallos, los fallos pueden ocurrir sin causar la
caída de la aplicación completa. � En una aplicación Cliente/Servidor tolerante a fallos, uno o más
servidores pueden fallar sin parar el sistema total mientras que los servicios proporcionados por los servidores caídos estén disponibles en otros servidores activos.
� Otra ventaja de la modularidad es que una aplicación Cliente/Servidor puede responder automáticamente al incremento o decremento de la carga del sistema mediante la incorporación o eliminación de uno o más servicios o servidores.
• Independencia de la plataforma: el software Cliente/Servidor “ideal ” es
independiente del hardware o sistemas operativos, permitiendo al programador mezclar plataformas de clientes y servidores. El entorno de explotación de clientes y servidores puede ser sobre diferentes plataformas, con el fin de optimizar el tipo de trabajo que cada uno desempeña.
• Código reutilizable: La implementación de un mismo servicio puede utilizarse
en varios servidores. • Escalabilidad: Los sistemas Cliente/Servidor pueden ser escalados horizontal
o verticalmente. El escalado horizontal significa añadir o eliminar estaciones clientes con un ligero impacto en el rendimiento mientras que el escalado vertical significa la migración a una máquina servidora más grande y rápida o la incorporación de nuevas máquinas servidoras.
• Separación de la funcionalidad del Cliente/Servidor : El modelo
Cliente/Servidor es una relación entre procesos que se ejecutan en la misma o en máquinas separadas. Un proceso servidor es un proveedor de servicios. Un cliente es un consumidor de servicios. El modelo cliente servidor proporciona una clara separación de funciones.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
• Recursos compartidos: un servidor puede proporcionar servicios a muchos clientes al mismo tiempo, y regular el acceso de éstos a un conjunto de recursos compartidos
2. Tipos de Servidores
Los principales tipos de servidores encontrados en la arquitectura cliente/Servidor son:
• Servidores de archivos: los clientes hacen solicitudes de archivos al servidor y esto representa una forma de compartir archivos en una red (repositorios de documentos, imágenes, programas, etc.)
• Servidores de bases de datos: las aplicaciones del cliente mandan
solicitudes SQL59 al servidor. El servidor devuelve el resultado de la consulta. • Servidores de transacciones: el cliente invoca procedimientos remotos o
transacciones (conjunto de instrucciones SQL) sobre la base de datos. Los datos intercambiados son: Cliente � servidor: solicitud Servidor � cliente: mensaje de resultado
• Servidores groupware: intercambio de información semiestructurada: texto, imágenes, u otros (Lotus Notes®, Microsoft Exchange®). Hace uso exhaustivo del e-mail.
• Servidores de aplicaciones web: Los clientes solicitan información Web a los
servidores. La solicitud es por nombre y el protocolo es HTTP. Hay objetos web y toda clase de aplicaciones nuevas.
Lección 2: Tipos de arquitecturas cliente-servidor
Los orígenes del modelo Cliente/Servidor se basan en los sistemas de paso de mensajes (Figura 22). Los datos, representados en forma de mensajes, se intercambian entre dos procesos, un emisor y un receptor:
• Un proceso envía un mensaje que representa una petición. El mensaje se entrega a un receptor, que procesa la petición y envía un mensaje como respuesta. En secuencia, la réplica puede disparar posteriores peticiones, que llevan a nuevas respuestas, y así, sucesivamente.
59 Lenguaje de Consulta Estructurado (Structured Query Language) usado en Bases de Datos.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Figura 22. Paso de Mensajes
Fuente: Autor
• Las operaciones básicas necesarias para dar soporte al paradigma de paso de mensajes son enviar y recibir . Para comunicaciones orientadas a conexión, también se necesitan las operaciones conectar y desconectar
De acuerdo con la complejidad de la arquitectura utilizada, los sistemas Cliente/Servidor se clasifican en arquitecturas monolíticas, arquitecturas de dos capas y arquitecturas de tres capas.
1. Arquitecturas Cliente/Servidor Monolíticas (1 ca pa)
La industria de la Tecnología de la Información ha puesto en práctica una forma muy sencilla de computación Cliente/Servidor desde la aparición inicial de los mainframe (Figura 23).
Figura 23. Arquitectura Cliente/Servidor Monolítica
Fuente: Autor
En esa configuración un host mainframe (microcomputador) y un terminal “tonto ” directamente conectado con el mainframe puede verse como un modelo Cliente/Servidor de una capa.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
2. Arquitecturas Cliente/Servidor de dos capas
El cliente se comunica directamente con un servidor de bases de datos. La aplicación o lógica de negocio bien reside en el cliente, o en el servidor de base de datos en la forma de procedimientos almacenados (Figura 24).
Un primer modelo Cliente/Servidor de dos capas comenzó a emerger con las aplicaciones desarrolladas para redes LAN a finales de los 80 y principios de los 90. Estas aplicaciones se basaban en técnicas sencillas de compartición de archivos, implementadas mediante lenguajes del tipo xBase60.
Figura 24. Arquitectura Cliente/Servidor de dos capas
Fuente: Autor
Posteriormente se añadió más complejidad a la arquitectura de dos capas y es así como surgieron los conceptos de “cliente grueso ” (robusto) y “servidor grueso ”.
Cliente grueso
Inicialmente, en el modelo de dos capas intervienen equipos que no tienen la característica de mainframe (un servidor de archivos en red) y un cliente grueso inteligente, donde se hace la mayor parte del procesamiento (Figura 24). Esta configuración no es fácilmente escalable en sistemas de gran, e incluso medio, tamaño (50 o más clientes conectados). Entonces el Interfaz Gráfico de Usuario (GUI, Graphical User Interface) emerge como el entorno dominante para las
60 xBase se refiere genéricamente a los lenguajes derivados a partir del lenguaje de dBase: dBase®, FoxPro®, Clipper®, Paradox®, etc.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
aplicaciones de escritorio y con él, emerge un nuevo enfoque en el planteamiento inicial de la arquitectura de dos capas. El servidor de archivos en red de propósito general se reemplaza por un servidor de bases de datos especializado.
Esto modelo origina la aparición de nuevas herramientas de desarrollo: Powerbuilder®, VisualBasic y Delphi®, por citar algunas donde la mayor parte del procesamiento tiene lugar aún en los clientes “gruesos ”, pero ahora la información se hace llegar al cliente utilizando SQL para realizar peticiones al servidor de base de datos, que simplemente informa del resultado de las consultas.
Es importante considerar los siguientes aspectos al utilizar “clientes gruesos ”:
• Cuanto más complicada la aplicación, más “grueso ” pasa a ser el cliente y más potente debe ser el hardware que debe soportarlo.
• El coste de adecuar la tecnología del cliente pasa a ser prohibitivo y puede frustrar la abordabilidad de las aplicaciones.
• Además, la carga de la red utilizando este tipo de clientes es muy grande, de modo que el ancho efectivo de la red (y por lo tanto del número de usuarios que pueden utilizarla) se reduce.
Servidor Grueso
Una configuración alternativa cliente “fino ” � Servidor “grueso ” es otra aproximación utilizada en la arquitectura de dos capas. En este caso el cliente invoca procedimientos almacenados en el servidor de base de datos. El modelo del Servidor grueso tiene un mejor rendimiento “grueso ” porque aunque la carga de red es todavía pesada, es más ligera que en la aproximación del cliente grueso.
El inconveniente de esta aproximación es que el uso de procedimientos almacenados hace depender el desarrollo excesivamente del software del vendedor. Otro inconveniente se deriva del hecho de que los procedimientos están almacenados conjuntamente con los datos y cada base de datos que contiene el procedimiento debe modificarse cuando cambia la lógica de la aplicación. En grandes bases de datos distribuidas esto puede conducir a una administración tediosa. En ambos caso, se utiliza un protocolo de transporte de bases de datos (como SQL-net) para llevar las transacciones de un extremo a otro, que generalmente resulta ser un proceso “pesado ”. No importa que modelo particular se utilice, los sistemas de dos capas no se ajustan bien cuando se manejan aproximadamente 100 usuarios.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
3. Arquitecturas Cliente/Servidor de tres capas
Una generación más moderna de la arquitectura Cliente/Servidor añade una capa intermedia (middle tier). En la arquitectura de tres capas (en general, en la arquitectura multicapa) el cliente implementa la lógica de presentación (cliente fino), el servidor(es) de aplicación implementan la lógica de negocio y los datos residen en uno (o varios) servidor(es) de bases de datos (Figura 25).
Una arquitectura multicapa se define por tanto por las siguientes tres capas de componentes:
• Un componente front-end que es el responsable de proporcionar la lógica de presentación.
• Un componente back-end que proporciona acceso a servicios dedicados, tales
como un servidor de bases de datos. • Un componente que hace las funciones de capa intermediaria (middl tier) que
permite a los usuarios compartir y controlar la lógica de negocio mediante su aislamiento de la aplicación real.
Figura 25. Arquitectura Cliente/Servidor de tres capas
Fuente: Autor

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Una arquitectura multicapa aumenta la arquitectura Cliente/Servidor tradicional mediante la introducción de una o más componentes intermedios. El sistema cliente interactúa con la capa intermedia vía un protocolo estándar como HTTP o RPC61.
La capa intermedia interactúa con el servidor de datos (back-end) mediante protocolos de bases de datos estándar tales como SQL, ODBC y JDBC. Esta capa intermedia contiene la mayor parte de la lógica de la aplicación, traduciendo las llamadas del cliente en consultas (u otras acciones) a la base de datos y traduciendo los datos provenientes de la base de datos en datos del cliente para devolvérselos.
Este emplazamiento de la lógica de negocio sobre el servidor de aplicaciones proporciona escalabilidad y aislamiento de la lógica de negocio con el fin de manejar rápidamente los cambios necesarios de ésta. Además, este hecho permite ampliar las opciones en lo que se refiere a la elección de un software propietario de bases de datos.
La arquitectura de 3 capas se puede extender a <n> capas cuando la capa intermedia soporta conexiones a diferentes tipos de servicios (no sólo servicios de almacenamiento de datos), integrándolos y acoplándolos al cliente y entre ellos
Otras ventajas de la arquitectura Cliente/Servidor multicapa son:
• Cambios en la interfaz de usuario o en la lógica de la aplicación son muy independientes entre sí, permitiendo a la aplicación evolucionar fácilmente para satisfacer los nuevos requisitos.
• Los cuellos de botella de la red de comunicaciones se minimizan porque la capa de aplicación no transmite datos extras al cliente, sólo lo que necesite para llevar a cabo la tarea.
• Cuando se requieren cambios en la lógica de negocio, sólo debe actualizarse el servidor. En la arquitectura de dos capas, cada cliente debe ser modificado cuando cambia la lógica.
• El cliente está aislado de la base de datos y las operaciones de red. El cliente
puede acceder fácil y rápidamente sin saber dónde están los datos o cuántos servidores se están utilizando.
61 Llamada a Procedimiento Remoto (Remote Procedure Call)

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
• Las conexiones de bases de datos se pueden agrupar y, por tanto, compartidas por varios usuarios, lo que reduce considerablemente el coste asociado a las licencias por usuario.
• La organización es independiente de la base de datos, porque la capa de datos
se escribe utilizando SQL estándar que es independiente de la plataforma.
• La lógica de la aplicación se puede utilizar un lenguaje estándar como Java®, C o COBOL.
Lección 3: Redes Igual – Igual (P2P)
En el modelo de sistemas distribuidos igual – igual (P2P / Peer-to-Peer) los procesos participantes interpretan los mismos papeles, con idénticas capacidades y responsabilidades (lo que sugiere interacciones directas entre las partes). Por ejemplo, los sistemas web para compartir archivos varios como son Napster62 y Kazaa63.
Figura 26. Modelo Peer-to-Peer
Fuente: Autor
De acuerdo con la figura 26, cada participante puede solicitar una petición a cualquier otro participante y recibir una respuesta. Mientras que el modelo Cliente/Servidor es un modelo ideal para servicios centralizados de red, el modelo P2P resulta más apropiado para aplicaciones como mensajería instantánea, transferencia de archivos, video-conferencia y trabajo colaborativo. 62 http://www.napster.com 63 http://www.kazaa.com

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
1. Fundamentos
Las redes peer-to-peer se denominan redes informáticas “entre iguales ” y se refieren a redes que no tienen clientes y servidores fijos, sino una serie de nodos que se comportan simultáneamente como clientes y como servidores de los demás nodos de la red. Este modelo de red contrasta con el modelo Cliente/Servidor el cual se rige de una arquitectura rígida donde no hay distribución de tareas entre sí, solo una simple comunicación entre un usuario y una terminal donde el cliente y el servidor no pueden cambiar de roles.
Uno de los principales servicios ofrecido por las plataformas P2P es compartir archivos. Los archivos compartidos son almacenados y entregados por los diferentes usuarios del la plataforma de red P2P. Usualmente cada usuario que forma parte de una aplicación de red P2P comparte sus archivos a otros usuarios y tiene acceso a los archivos compartidos por otros usuarios.
El modelo P2P se basa principalmente en la filosofía de que todos los usuarios deben compartir, conocida como filosofía P2P la cual es aplicada en algunas redes P2P en forma de un sistema enteramente meritocrático en donde "el que más comparta, más privilegios tiene y más acceso dispone de manera más rápida a más contenido". Con este sistema se pretende asegurar la disponibilidad del contenido compartido, ya que de lo contrario no sería posible la subsistencia de una red P2P.
Aquellos usuarios que no comparten contenido en una red P2P, se les denomina “sanguijuelas ” (leechers), los cuales muchas veces representan una amenaza para la disponibilidad de recursos en una red P2P debido a que solo consumen recursos sin reponer lo que consumen, por ende podrían agotar los recursos compartidos de una red P2P y atentar contra la estabilidad de la misma.
2. Clasificación de las redes P2P 64
De acuerdo con el grado de centralización de la información, las redes P2P se clasifican en centralizadas, descentralizadas y mixtas.
64 http://es.wikipedia.org/wiki/P2P

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
2.1 Redes P2P centralizadas
Este tipo de red P2P, se basa en una arquitectura monolítica donde todas las transacciones se hacen a través de un único servidor que sirve de punto de enlace entre dos nodos, y que a la vez almacena y distribuye el contenido desde sus servidores (Figura 27). Tiene la ventaja de tener una administración muy dinámica y una disposición más permanente de contenido, pero también tiene desventajas como la muy limitada privacidad de los usuarios, y la constante amenaza de depender de un solo servidor, ya que como todo depende de un solo sitio en particular, al verse involucrado en situaciones legales una red de este tipo, es muy fácil desactivarla en su totalidad, además de los enormes costos de mantenimiento que requiere un servidor de este tipo sin mencionar el enorme coste de banda ancha que implica.
Figura 27. Redes P2P centralizadas
Fuente: http://www.infor.uva.es/~fdiaz/sd/doc/SD_TE01_20060227.pdf
Una red P2P centralizada reúne las siguientes características:
• Se rige bajo un único servidor que sirve como punto de enlace entre nodos y como almacenista de contenido, el cual distribuye a petición de los nodos.
• Todas las comunicaciones (como las peticiones y enrutamientos entre nodos)
dependen exclusivamente de la existencia del servidor.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Algunos ejemplos de este tipo de red P2P son Napster y Audiogalaxy65.
2.2. Redes P2P "puras" o totalmente descentralizada s
Las redes P2P de este tipo son las más comunes, siendo las mas versátiles al no requerir de un gestionamiento central de ningún tipo, lo que permite una reducción de la necesidad de usar un servidor central, por lo que se opta por los mismos usuarios como nodos de esas conexiones y también como almacenistas de esa información (Figura 28). En otras palabras, todas las comunicaciones son directamente de usuario a usuario con ayuda de un nodo (que es otro usuario) quien permite enlazar esas comunicaciones.
Figura 28. Redes P2P descentralizadas
Fuente: http://www.infor.uva.es/~fdiaz/sd/doc/SD_TE01_20060227.pdf
Las redes P2P descentralizadas poseen las siguientes características:
• Los nodos actúan como cliente y servidor. • No existe un servidor central que maneje las conexiones de red. • No hay un router central que sirva como nodo y administre direcciones.
65
http://www.audiogalaxy.com

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Algunos ejemplos de una red P2P "pura " son: Ares Galaxy66, Gnutella67, Freenet68 y Gnutella269.
2.3. Redes P2P híbridas, semi-centralizadas o mixta s
En este tipo de red, se puede observar la interacción entre un servidor central que sirve como hub70 (concentrador) y administra los recursos de banda ancha, enrutamientos y comunicación entre nodos pero sin saber la identidad de cada nodo y sin almacenar información alguna, por lo que el servidor no comparte archivos de ningún tipo a ningún nodo (Figura 29). Tiene la peculiaridad de funcionar de ambas maneras, es decir, puede incorporar más de un servidor que gestione los recursos compartidos, pero también en caso de que el o los servidores que gestionan todo caigan, el grupo de nodos sigue en contacto a través de una conexión directa entre ellos mismos con lo que es posible seguir compartiendo y descargando más información en ausencia de los servidores.
Figura 29. Redes P2P hibridas
Fuente: http://www.infor.uva.es/~fdiaz/sd/doc/SD_TE01_20060227.pdf
66 http://aresgalaxy.sourceforge.net 67 http://www.gnutella.com 68 http://freenetproject.org 69 http://www.gnutella2.com 70 Equipo de redes que permite conectar entre sí otros equipos y retransmite los paquetes que recibe desde cualquiera de ellos a todos los demás.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Las redes P2P Hibridas tienen las siguientes características: • Tienen un servidor central que guarda información en espera y responde a
peticiones para esa información. • Los nodos son responsables de hospedar la información (pues el servidor
central no almacena la información), lo que permite al servidor central reconocer los recursos que se desean compartir, y para poder descargar esos recursos compartidos a los equipos que lo solicitan.
• Las terminales de enrutamiento son direcciones usadas por el servidor, que son administradas por un sistema de índices para obtener una dirección absoluta.
Algunos ejemplos de una red P2P híbrida son Bittorrent71 y eMule.
2.4 Arquitectura P2P
Los sistemas P2P para compartir recursos se basan en la utilización de Tablas Hash Distribuidas (THD) que permiten indizar la información de muchos recursos (archivos, programas, documentos, canciones, etc). Básicamente una THD realiza las funciones de una tabla hash almacenando parejas (clave, valor) y recuperando un valor si se tiene la respectiva clave (Figura 30). Lo fundamental de las THD es que las búsquedas se realizan en diferentes máquinas (nodos de la red P2P) y en un entorno dinámico (con nodos ingresando y dejando frecuentemente la red). Las THD se almacenan como listas circulares doblemente enlazadas donde cada nodo.
Figura 30. Operación Tabla Hash
Fuente: Autor
71 http://www.torrents.to

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Lección 4: Modelos de Componentes
Una última arquitectura de los modelos de Sistemas Distribuidos, son los modelos de componentes que se incorporan como la base de algunos sistemas operativos de red. Un modelo de componentes se caracteriza por:
� Definir la forma de las interfaces de sus componentes. � Determinar los mecanismos de composición y comunicación entre ellos. � Especificar la forma en la que se proveen los servicios (seguridad, comercio,
impresión, autenticación, etc.) � Reutilización de componentes para el desarrollo acelerado de aplicaciones.
Los modelos de componentes de mayor difusión mundial y que serán analizados en los siguientes párrafos son: el modelo de componente Sun (J2EE72) y el modelo de componentes de Microsoft.
1. Modelo de Componentes de Sun
El modelo de componentes de Sun (J2EE) se caracteriza por utilizar el estándar javabeans, el cual define los beans73 como los componentes del modelo. Los beans que utiliza el modelo se caracterizan por que: � Son componentes software reutilizables que pueden ser manipuladas de forma
visual por herramientas de desarrollo de aplicaciones. � Poseen funcionalidades muy distintas: botón, hoja de cálculo, etc. Los EJBs proporcionan un modelo de componentes distribuido estándar para el lado del servidor. El objetivo de los Enterprise beans (EJB) es dotar al programador de un modelo que le permita abstraerse de los problemas generales de una aplicación empresarial (concurrencia, transacciones, persistencia, seguridad, etc.) para centrarse en el desarrollo de la lógica de negocio en sí. El hecho de estar basado en componentes permite que éstos sean flexibles y sobre todo reutilizables.
72 Edición Empresarial del paquete Java (Java 2 Enterprice Edition). Comprenden un conjunto de especificaciones y funcionalidades orientadas al desarrollo de aplicaciones empresariales. 73 Componentes de software reutilizables que se puedan manipular visualmente en una herramienta de construcción

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Figura 31. Modelo de Componentes de SUN
Fuente: www.it.uc3m.es/mcfp/docencia/si/material/10_ccm.pdf
2. Modelo de Componentes de Microsoft
En plataformas Microsoft WINDOWS® se suele designar a COM (Component Objetc Model / Modelo de Objetos Componentes) como un modelo de programación orientada a objetos que trabaja entre diferentes lenguajes, DLLs y programas. Define un sistema para crear objetos que se ejecutan no solo sobre un computador sino sobre un amplio rango de computadores. COM soporta diferentes lenguajes y compiladores y su OOP (object oriented programming / programación orientada a objetos) se ejecuta a nivel de sistema operativo.
DCOM (Distributed Component Object Model / Modelo Distribuido de Objetos Componentes) es una forma de distribuir objetos a través de una red. Con DCOM se pueden crear objetos que se ejecutan en uma gran variedad de servidores y que pueden ser llamados desde lenguajes como Delphi®, Visual Basic®, C++ o desde aplicaciones como Word, Excel, etc.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Figura 32. Modelo de componentes distribuidos de Microsoft
Fuente: www.it.uc3m.es/mcfp/docencia/si/material/10_ccm.pdf

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
CAPITULO 2: MIDDLEWARE
Introducción
Como elemento característico de los sistemas distribuidos, surge el concepto de “Middleware”, la capa de software que se ubica entre el sistema operativo y las aplicaciones de los usuarios. Debido a su especial importancia se estudia ampliamente en el siguiente capítulo.
Lección 5: Fundamentos de Middleware
En un Sistema Distribuido, el middleware (lógica de la mediación) es un software de conectividad que permite ofrecer un conjunto de servicios que hacen posible el funcionamiento de aplicaciones distribuidas sobre plataformas heterogéneas. Como se muestra en la figura 33, el middleware funciona como una capa de abstracción de software distribuida que se sitúa entre las capas de aplicaciones y las capas inferiores (sistema operativo y red).
Figura 33. Middleware
Fuente: Autor

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
El middleware permite abstraer las funciones de un sistema distribuido, de la complejidad y heterogeneidad de las redes de comunicaciones subyancentes, así como de los sistemas operativos y lenguajes de programación, proporcionando una API (Application Programming Interface / Interfaz de Programación de Aplicaciones) para la fácil programación y manejo de aplicaciones distribuidas (Figura 34). Dependiendo del problema a resolver y de las funciones necesarias se requieren diferentes tipos de servicios de middleware.
Figura 34. Middleware y APIs
Fuente: http://www.infor.uva.es/~fdiaz/sd/doc/SD_TE01_20060227.pdf
El Middleware es fundamental para:
• Migrar las aplicaciones monolíticas basadas en mainframes a aplicaciones Cliente/Servidor.
• Soportar la comunicación entre procesos a través de plataformas heterogéneas.
Según se aprecia en la figura 35, los servicios del middleware son una capa de software distribuida, que se localiza entre la aplicación y la plataforma concreta sobre la que se implementa la aplicación (Sistema Operativo + Red).
Los servicios del middleware proporcionan un conjunto de APIs más funcional que el sistema operativo y los servicios de red para permitir a una aplicación:

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Figura 35. Sistema distribuido visto como Middleware
Fuente: Autor.
• Localización transparente a través de la red, proporcionando interacción con otra aplicación o servicio.
• Ser independiente de los servicios de red. • Ser fiable y disponible. • Ser escalable, en el sentido de poder aumentar su capacidad sin pérdida de
funcionalidad.
Funciones Middleware
Las aplicaciones middleware realizan las siguientes funciones:
• Ocultar la distribución: middleware maneja el hecho de que una aplicación esté compuesta de muchas partes interconectadas ejecutándose en ubicaciones distribuidas.
• Ocultar la heterogeneidad: middleware oculta o hace transparente al usuario diversas plataformas de sistemas operativos, protocolos de comunicación y dispositivos hardware.
• Proveer interfaces uniformes y estándares de alto n ivel: tanto a los desarrolladores como a los integradores de aplicaciones, de tal manera que las aplicaciones sean fácilmente desarrolladas, reusadas, transportadas y puedan interoperar correctamente.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
• Suministrar un conjunto de servicios comunes : para realizar varias actividades de propósito general con el fín de evitar duplicar esfuerzos y facilitar la colaboración entre aplicaciones.
Lección 6: Componentes Middleware
El middleware esta compuesto de agentes de software que generalmente actúan entre el sistema operativo y las aplicaciones, con la finalidad de proveer comunicación entre diferentes aplicaciones en un sistema distribuido. Las funciones que realiza el middleware dentro de un cluster de servidores (datacenter74) son:
• Una interfaz única de acceso al sistema, denominada SSI75, la cual genera la sensación al usuario de que utiliza un único computador muy potente.
• Herramientas para la optimización y mantenimiento del sistema: migración de
procesos, checkpoint-restart (congelar uno o varios procesos, mudarlos de servidor y continuar su funcionamiento en el nuevo host), balanceo de carga, tolerancia a fallos, etc.
• Escalabilidad: debe poder detectar automáticamente nuevos servidores
conectados al cluster para proceder a su utilización.
Existen diversos tipos de middleware, como por ejemplo: MOSIX76, OpenMOSIX77, Condor78, OpenSSI79, etc.
El middleware recibe los trabajos entrantes al cluster y los redistribuye de manera que el proceso se ejecute más rápido y el sistema no sufra sobrecargas en un servidor. Esto se realiza mediante políticas definidas en el sistema
74 Centro de datos. Ubicación donde se concentran todos los recursos necesarios para el procesamiento de información de una organización. Dichos recursos consisten esencialmente en unas dependencias debidamente acondicionadas, computadores y redes de comunicaciones. 75 Imagen Particular del Sistema (Single System Image). Es una propiedad de un sistema que oculta la naturaleza heterogénea y distribuida de los recursos, y los presenta a los usuarios y a las aplicaciones como un recurso computacional unificado y sencillo 76 http://www.mosix.org 77 http://openmosix.sourceforge.net 78 http://www.cs.wisc.edu/condor 79 http://openssi.org

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
(automáticamente o por un administrador) que le indican dónde y cómo debe distribuir los procesos, por un sistema de monitorización, el cual controla la carga de cada CPU y la cantidad de procesos en él.
El middleware también debe poder migrar procesos entre servidores con distintas finalidades:
• Balancear la carga: si un servidor está muy cargado de procesos y otro está ocioso, pueden transferirse procesos a este último para liberar de carga al primero y optimizar el funcionamiento.
• Mantenimiento de servidores: si hay procesos corriendo en un servidor que necesita mantenimiento o una actualización, es posible migrar los procesos a otro servidor y proceder a desconectar del cluster al primero.
• Priorización de trabajos: en caso de tener varios procesos corriendo en el cluster, pero uno de ellos de mayor importancia que los demás, puede migrarse este proceso a los servidores que posean más o mejores recursos para acelerar su procesamiento.
Lección 7: Servicios middleware
Dentro de los principales servicios que se pueden ofrecer con una plataforma middleware se encuentran los siguientes:
Administración de Objetos : Soporta desde simples tipos de datos hasta grandes volúmenes de información. Administración de Documentos : Usa el servicio de administración de objetos y además nombra y organiza documentos. Soporta el lenguaje de fórmulas (lenguaje de script para construir aplicaciones de usuarios). Seguridad: soporta encripción, firmas digitales y control de acceso discrecional. Indexamiento: Suministra acceso indexado tanto a resúmenes como a contenidos completos de documentos. Opera con herramientas de recuperación basadas en contenido y descriptores de documentos.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Mensajería: soporta direccionamiento y transporte de correos, incluyendo direccionamientos a grupos de nombres y nombres jerárquicamente organizados. Eventos: Soportar notificación dinámica a través de mensajes de correo o registro de Bitácora (Log). Registro (Logging): Para auditar eventos. Nombrado: Soporta enlaces Cliente/Servidor y lo integra con servicios de transporte y seguridad. Administración del Sistema: Soporta control de administración desde consolas remotas. Además de lo anterior, los siguientes componentes podrían ser servicios Middleware: • Administración de Presentaciones: Administrador de formas, administrador
de gráficos, enlazador de hipermedios y administrador de impresión. • Computación : Ordenamientos, servicios matemáticos de cálculos, servicios de
internacionalización (para manipulación de alfabetos y caracteres). • Administración de la Información: Servidor de Directorios, Administrador de
Logs, administrador de archivos, administrador de registros, sistemas de bases de datos relacionales, sistemas de bases de datos orientadas a objetos, administrador de bodegas de datos.
• Comunicaciones: Mensajería Peer-to-Peer (P2P), Llamadas a procesos
remotos (RPC), colas de mensajes, correo electrónico, intercambio electrónico de datos (EDI).
• Administración de Sistemas: Servicio de notificación de eventos, servicios de
contabilidad, administrador de la configuración de dispositivos, administrador de instalación de software, detector de fallas, coordinador de recuperaciones.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Lección 8: Ventajas y campos de aplicación del midd leware
Entre las principales ventajas que se obtienen al utilizar el middleware se encuentran:
� Simplifica el proceso de desarrollo de aplicaciones al independizar los entornos propietarios.
� Permite la interconectividad de los diferentes Sistemas de Información de una
organización.
� Proporciona mayor control del negocio al poder contar con información procedente de distintas plataformas sobre el mismo soporte.
� Facilita el desarrollo desistemas complejos con diferentes tecnologías y
arquitecturas.
Dentro de los inconvenientes más importantes se destacan la mayor carga de máquina necesaria para que puedan funcionar.
Los sistemas middleware tienen un amplio rango de aplicaciones, de los cuales se describirán los más importantes:
Migración de los Sistemas Host. Reingeniería de Apl icaciones Toda aplicación empresarial debería diseñarse en base a módulos intermedios middleware encargados de la comunicación entre el ordenador personal y el host. Con el uso de middleware se puede desarrollar una aplicación sin tener en cuenta los futuros cambios tecnológicos que puedan sufrir los sistemas host. Si el sistema host cambia, o las aplicaciones de host se migran a plataformas de ordenadores personales, todo lo que se necesita es un nuevo módulo middleware. La interfaz de usuario, la lógica y el código interno permanecen sin cambios. Por ejemplo, si el equipo lógico del sistema host se traslada desde el mainframe a una base de datos de plataforma PC ejecutándose en un servidor de archivos, sólo hay que sustituir el módulo de middleware de forma que realice llamadas SQL. Interconectividad Uno de los usos más importantes de las herramientas de middleware es la de facilitar la interconectividad de los diferentes sistemas de una organización integrando las diferentes islas de información departamentales.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Arquitectura orientada a objetos distribuidos El concepto de middleware permite también independizar los servicios proporcionados por diferentes objetos que se encuentran en una red proporcionando una red de objetos independientes e interconectados entre sí. Arquitectura cliente/servidor La utilización de middleware permite desarrollar aplicaciones en arquitectura cliente servidor independizando los servidores y clientes, facilitando la interrelación entre ellos y evitando dependencias de tecnologías propietarias.
Como se puede apreciar, la tecnología emergente middleware está constituyéndose en una plataforma fundamental para la operación de los sistemas en las organizaciones. En el capítulo uno de la tercera unidad se realizará una exposición detallada de uno de los sistmas Middleware de mayor uso actualmente, el sistema operativo distribuido CORBA.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
CAPITULO 3: ASPECTOS DE DISEÑO DE UN SISTEMA DISTRI BUIDO
Introducción
El desarrollo e implementación de un Sistema Distribuido requiere tener muy en cuenta los aspectos de diseño, entre los que se destacan los diferentes métodos de comunicación entre procesos, la utilización de APIs, el diseño de sockets y las estructuras de los mensajes.
Lección 9: Comunicación entre procesos
La comunicación entre procesos (Figura 36) es un conjunto de técnicas para el intercambio de datos entre dos o más hilos80 en uno o más procesos. Los procesos pueden estar en ejecución en un computador o en dos o más computadores conectados en red.
Figura 36. Comunicación entre Procesos
Fuente: Autor
Las técnicas de comunicación entre procesos son divididas en métodos para: paso de mensajes, sincronización, memoria compartida y llamada de procedimiento remoto (RPC / Remote procedure call). A continuación se presentan los diferentes
80 Es un proceso concurrente que es parte de un proceso mayor o de un programa. En un sistema operativo multitarea, un simple programa puede tener varios hilos, todos ejecutándose al mismo tiempo. Ejemplo: Una parte de un programa puede estar haciendo un cálculo mientras que otra parte está dibujando un gráfico.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
métodos de comunicación entre procesos y los sistemas operativos en los cuales operan:
Método de CEP Suministrado por los Sistemas Operativos
Archivo Todos los Sistemas Operativos
Señal UNIX, LINUX®, WINDOWS® con la librería C Runtime
Socket WINDOWS®, UNIX, LINUX®
Pipe / canal UNIX, LINUX®
Semáforo UNIX, LINUX®
Memoria Compartida UNIX, LINUX®
Paso de Mensajes Java® RMI, CORBA
Mapeo de Memoria UNIX, LINUX®, WINDOWS® mediante APIs
Cola de Mensajes WINDOWS®, UNIX, LINUX®
Buzón de Correo WINDOWS®, UNIX, LINUX®
1. Paso de mensajes
El paso de mensajes (Figura 37) es una técnica empleada en programación concurrente para aportar sincronización entre procesos y permitir la exclusión mutua, de manera similar a como se hace con los semáforos, monitores, etc. Los elementos principales que intervienen en el paso de mensajes son el proceso que envía, el que recibe y el mensaje.
Dependiendo de la confiabilidad del mensaje la técnica de paso de mensajes es:
� No Fiable: El mensaje puede llegar una vez, más de una vez, ninguna vez (por ejemplo, UDP81).
� Fiable: El mensaje llega exactamente una vez (por ejemplo, TCP82).
81 Protocolo del nivel de transporte basado en el intercambio de datagramas. Permite el envío de datagramas a través de la red sin que se haya establecido previamente una conexión, ya que el propio datagrama incorpora suficiente información de direccionamiento en su cabecera.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Figura 37. Sistema Cliente/Servidor con Paso de Mensajes
Fuente: Autor
� Ordenación FIFO: Se garantiza que los mensajes se entregan al receptor en el orden en el que fueron enviados por el emisor (por ejemplo, TCP).
2. API para protocolos en Internet: UDP, TCP
La interfaz del programa de aplicación (API) para UDP proporciona una abstracción del tipo paso de mensajes, la forma más simple de comunicación entre procesos (Figura 38). Esto hace que el proceso emisor pueda transmitir un mensaje simple al proceso receptor. Los paquetes independientes que contienen estos mensajes se llaman “datagramas ”83. Tanto en Java® como en cada API UNIX, el emisor especifica el destino utilizando un zócalo, conector o “socket ” (una referencia indirecta a un puerto particular utilizada por el proceso destino en el computador destino).
82 Protocolo del nivel de transporte basado en el intercambio de flujo de datos. Muchos programas dentro de una red de datos compuesta por computadores pueden usar TCP para crear conexiones entre ellos a través de las cuales enviarse datos. El protocolo garantiza que los datos serán entregados en su destino sin errores y en el mismo orden en que se transmitieron. También proporciona un mecanismo para distinguir distintas aplicaciones dentro de una misma máquina, a través del concepto de puerto. 83 Fragmento de paquete que es enviado con la suficiente información como para que la red pueda simplemente encaminar el fragmento hacia el computador receptor, de manera independiente a los fragmentos restantes.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Figura 38. API para protocolos en Internet
Fuente: Autor
La interfaz del programa de aplicación de TCP proporciona la abstracción de un flujo (stream) de dos direcciones entre pares de procesos. La información intercambiada consiste en un flujo de ítems de datos sin límites entre mensajes. Los flujos son un bloque básico para la construcción de la comunicación productor-consumidor. Un productor y un consumidor forman un par de procesos en los cuales el papel del primero es producir ítems de datos y el papel del segundo es consumirlos. Los ítems de datos enviados por el productor al consumidor se colocan en una cola a su llegada hasta que el consumidor esté en disposición de recibirlos. El consumidor debe esperar cuando no haya datos disponibles. El productor debe esperar si se llena el almacenamiento utilizado para guardar la cola con los ítems de datos.
3. Características de la comunicación entre proceso s84
Para que un proceso se pueda comunicar con otro, el proceso envía un mensaje (una secuencia de bytes) a un destino y otro proceso en el destino recibe el mensaje. Esta actividad implica la comunicación de datos desde el proceso emisor al proceso receptor y puede implicar además la sincronización de los dos procesos. A continuación se resaltan las características más importantes de la comunicación entre procesos:
3.1 Comunicación síncrona y asíncrona
A cada destino de mensajes se asocia una cola. Los procesos emisores producen mensajes que son añadidos a las colas remotas mientras que los procesos receptores eliminan mensajes de las colas locales. La comunicación entre los procesos emisor y
84 COULOURIS George, DOLLIMORE Jean y KINDBERG Tim (2001): “SISTEMAS DISTRIBUIDOS – Conceptos y Diseño”. Pearson – Addison Wesley.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
receptor puede ser síncrona o asíncrona. En la forma síncrona , los procesos receptor y emisor se sincronizan con cada mensaje. En este caso, tanto envía como recibe son operaciones bloqueantes. A cada envía producido, el proceso emisor se bloquea hasta que se produce el correspondiente recibe. Cuando se invoca un recibe, el proceso se bloquea hasta que llega un mensaje.
En la forma de comunicación asíncrona , la utilización de la operación envía es no bloqueante, de modo que el proceso emisor puede continuar tan pronto como el mensaje haya sido copiado en el búfer local, y la transmisión del mensaje se lleva a cabo en paralelo con el proceso emisor. La operación recibe puede tener variantes bloqueantes y no bloqueantes. En la variante no bloqueante, el proceso receptor sigue con su programa después de invocar la operación recibe, la cual proporciona un búfer que es llenado en un segundo plano, pero el proceso debe ser informado por separado de que su búfer ha sido llenado, ya sea por el método de encuesta o mediante una interrupción.
3.2 Destinos de los mensajes
En los protocolos Internet, los mensajes son enviados a direcciones construidas por pares (dirección Internet, puerto local)85. Un puerto local es el destino de un mensaje dentro de un computador, especificado como un número entero. Un puerto tiene exactamente un receptor pero puede tener muchos emisores. Los procesos pueden utilizar múltiples puertos desde los que recibir mensajes. Cualquier proceso que conozca el número de puerto apropiado puede enviarle un mensaje. Generalmente, los servidores hacen públicos sus números de puerto para que sean utilizados por los clientes.
Si el cliente utiliza una dirección Internet fija para referirse a un servicio, entonces ese servicio debe ejecutarse siempre en el mismo computador para que la dirección se considere válida.
3.3 Fiabilidad
85 Un ejemplo puede ser direccion: 192.168.6.45 puerto: 23 � Notación 192.168.6.45:23

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Una comunicación fiable se puede manejar en términos de validez e integridad. En lo que concierne a la propiedad de validez, se dice que un servicio de mensajes punto a punto es fiable si se garantiza que los mensajes se entregan a pesar de poder dejar caer o perder un número razonable de ellos. Por el contrario, puede decirse que un servicio de mensajes punto a punto es no fiable si no se garantiza la entrega de los mensajes ante la pérdida o eliminación incluso de un solo paquete. Respecto a la integridad, los mensajes deben llegar sin corromperse ni duplicarse.
3.4 Ordenación
Algunas aplicaciones necesitan que los mensajes sean entregados en el orden de su emisión, esto es, en el orden en el que fueron transmitidos por el emisor. La entrega de mensajes desordenados, por esas aplicaciones, es considerada como un fallo.
4. Sockets
Ambas formas de comunicación (UDP y TCP) utilizan la abstracción de sockets 86, que proporciona los puntos extremos de la comunicación entre procesos. Los sockets (conectores) se originan en UNIX BSD aunque están presentes en la mayoría de las versiones de UNIX, incluido LINUX® y también WINDOWS® NT y Macintosh® OS. La comunicación entre procesos consiste en la transmisión de un mensaje entre un conector de un proceso y un conector de otro proceso, según se muestra en la figura 39.
Figura 39. Sockets
86 Mecanismo de comunicación entre procesos. Socket designa un concepto abstracto por el cual dos programas (posiblemente situados en computadores distintos) pueden intercambiarse cualquier flujo de datos, generalmente de manera fiable y ordenada. Un socket queda definido por un protocolo, por una dirección IP y un número de puerto. Ejemplo: ftp://201.45.23.45:21

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Fuente: COULOURIS George, SISTEMAS DISTRIBUIDOS, Addison Wesley, Madrid, 2001, 3ª Ed.
Para los procesos receptores de mensajes, su conector debe estar asociado a un puerto local y a una de las direcciones Internet del computador donde se ejecuta. Los mensajes enviados a una dirección de Internet y a un número de puerto concretos, sólo pueden ser recibidos por el proceso cuyo conector esté asociado con esa dirección y con ese puerto.
Figura 40. Operación de los protocolos TCP y UDP
Fuente: Autor
Los procesos pueden utilizar un mismo conector tanto para enviar como para recibir mensajes. Cada computador permite un gran número (216) de puertos posibles, que pueden ser usados por los procesos locales para recibir mensajes. Cada proceso puede utilizar varios puertos para recibir mensajes, pero un proceso no puede compartir puertos con otros procesos del mismo computador. No obstante, cualquier cantidad de procesos puede enviar mensajes a un mismo puerto. Cada conector se asocia con un protocolo concreto, que puede ser UDP o TCP.
Lección 10: Comunicación entre procesos en platafor mas UNIX – LINUX®
Las operaciones básicas (primitivas) para la comunicación entre procesos para platformas LINUX® – UNIX son proporcionadas como llamadas al sistema e implementadas como una capa sobre los protocolos TCP y UDP. Los destinos de los mensajes se especifican como direcciones de conectores; una dirección de conector consta de una dirección Internet y un número de puerto local.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
El proceso de comunicación se desarrolla de la siguiente manera: los mensajes se colocan en una cola en el conector emisor hasta que el protocolo de red (IP) los transmite, y allí permanecen hasta que llega el correspondiente reconocimiento, si es que el protocolo así lo requiere. Cuando llega un mensaje, se coloca en una cola en el conector receptor hasta que el proceso destinatario realiza la correspondiente llamada al sistema para recogerlo.
Cualquier proceso puede crear un conector para utilizarlo en la comunicación con otro proceso. Esto se realiza invocando a la llamada al sistema socket, cuyos argumentos especifican el dominio de comunicación (normalmente Internet), el tipo (datagrama o flujo) y en algunas ocasiones un protocolo particular. El protocolo (por ejemplo, TCP o UDP) es seleccionado normalmente por el sistema dependiendo de si el tipo de comunicación es de datagramas o de flujos.
Antes de poder comunicar un par de procesos, el receptor debe enlazar su descriptor de conector con una dirección de conector. El emisor también debe enlazar su descriptor de conector con una dirección de conector si necesita responder. Para este propósito se utiliza la llamada al sistema bind; cuyos argumentos son el descriptor del conector y una referencia a una estructura que contiene la dirección del conector con la que se va a ligar el conector. Una vez que un conector está ligado a una dirección, ésta no puede cambiar.
Algunas direcciones son públicas en el sentido de que pueden ser utilizadas como destinos por cualquier proceso. Después de que un proceso ha ligado su conector a una dirección de conector, el conector puede ser apuntado indirectamente por otro proceso refiriéndose a la dirección de conector apropiada. Cualquier proceso, por ejemplo un servidor que planea recibir mensajes a través de su conector, debe primero enlazar ese conector a una dirección de conector y hacer que la dirección sea conocida por los potenciales clientes.
A continuación se presentan de manera breve los elementos claves de comunicación de datagramas (protocolo UDP) y de comunicación con flujos (protocolos TCP)

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
1. Comunicación de Datagramas
Para poder enviar datagramas, se identifica el par de conectores (emisor y receptor) cada vez que se realiza una comunicación. Esto se logra en el proceso emisor utilizando su descriptor de conector local y la dirección del conector receptor cada vez que envía un mensaje.
Figura 45. Conectores usados para Datagramas
Fuente: COULOURIS George, SISTEMAS DISTRIBUIDOS, Addison Wesley, Madrid, 2001, 3ª Ed.
El proceso de comunicación con datagramas representado en la figura 45 se describe a continuación:
Ambos procesos utilizan la llamada socket para crear un conector y conseguir un descriptor para él. El primer argumento de socket especifica el dominio de comunicación como el dominio Internet, y el segundo argumento indica que se va a necesitar una comunicación de datagramas. El último argumento de la llamada socket puede utilizarse para especificar un protocolo particular, pero si se pone a cero produce que el sistema seleccione el protocolo adecuado (UDP en este caso).
Ambos procesos, entonces, utilizan la llamada bind para enlazar sus conectores a las direcciones de conector. El proceso emisor enlaza su conector a una dirección de conector dada por cualquier puerto local libre. El proceso receptor enlaza su conector a una dirección de conector que contiene un puerto de servidor que debe ser conocido por el emisor.
El proceso emisor utiliza la llamada sendto, con argumentos que especifican el socket a través del cual va a ser enviado el mensaje, el mensaje mismo y (una referencia a la estructura que contiene) la dirección del conector destino. La llamada sendto pasa el mensaje a las capas subyacentes UDP e IP y devuelve el

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
número de bytes enviados. Como hemos solicitado un servicio de datagramas, el mensaje es transmitido a su destino sin acuse de recibo.
El proceso receptor utiliza la llamada recvfrom con argumentos que especifican el conector local en el que se recibe el mensaje, las direcciones de memoria en las que se almacena el mensaje y (una referencia a la estructura que contiene) la dirección de conector del conectar emisor. La llamada recvfrom toma el primer mensaje en la cola del conector, o si la cola está vacía espera a que llegue uno.
La comunicación se produce exclusivamente cuando un sendto en un proceso dirige su mensaje al conector utilizado por recvfrom en otro proceso. En una comunicación cliente-servidor, no existe necesidad de que los servidores tengan conocimiento previo de las direcciones de los conectores de los clientes, ya que la operación recvfrom proporciona la dirección del emisor con cada mensaje que entrega.
2. Comunicación de Flujos
Antes de utilizar el protocolo de Flujos, dos procesos deben establecer una conexión entre sus pares de conectares. Una vez que un par de conectores han sido conectados, pueden utilizarse para transmitir datos en ambas o en cualquier dirección. Esto es, se comportan como Flujos en los que cualquier dato disponible se lee inmediatamente en el mismo orden en que fue escrito. Sin embargo, existe una cola limitada en el conector receptor y el receptor se bloquea si la cola está vacía; y el emisor se bloquea si la cola está llena.
Para la comunicación entre clientes y servidores, los clientes solicitan conexiones y los servidores que escuchan esas peticiones las aceptan.
El proceso de comunicación con datagramas representado en la figura 46 se describe a continuación:
El servidor, o proceso en escucha, utiliza primero la operación socket para crear un conector de flujo y después la operación bind para enlazar su conector a la dirección del conector de servidor. El segundo argumento de la llamada al sistema socket es SOCK_FLUJO, para indicar que se requiere una comunicación de Flujos. El tercer argumento se deja a cero, de modo que se seleccione el protocolo TCP/IP de forma automática. Utiliza la operación listen para escuchar en su conector las peticiones de conexión de los clientes. El segundo argumento de

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
listen especifica el número máximo de peticiones de conexión que admite la cola de espera de ese conector.
Figura 46. Conectores usados para Flujos
Fuente: COULOURIS George, SISTEMAS DISTRIBUIDOS, Addison Wesley, Madrid, 2001, 3ª Ed.
El servidor utiliza la llamada al sistema accept para aceptar una conexión solicitada por un cliente y obtener un nuevo conector para la comunicación con el cliente. El conector original continúa en uso para aceptar futuras peticiones de conexión de otros clientes.
El proceso cliente utiliza la operación socket para crear un conector de flujo y entonces utiliza la llamada al sistema connect para solicitar una conexión a través de la dirección de conector del proceso en escucha. Como la llamada al sistema connect enlaza automáticamente el conector con una dirección de conector, no es necesario un enlace previo.
Después de que se ha establecido una conexión, ambos procesos pueden utilizar las operaciones write y read en sus respectivos conectores para enviar y recibir secuencias de bytes a través de la conexión. La operación write es similar a la operación de escritura en archivos. Especifica el mensaje a enviar al conector. Confía el mensaje a los protocolos TCP/IP subyacentes y devuelve el número de bytes enviados. La operación read recibe caracteres en su búfer y devuelve el número de bytes recibidos.
3. Comunicación en plataformas P2P - Sistemas de Me nsajes
Los Sistemas de Mensajes proporcionan un método de comunicación entre aplicaciones o componentes software y son utilizados principalmente para el desarrollo de aplicaciones P2P donde cliente del sistema puede enviar y recibir

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
mensajes de cualquier otro cliente. Cada cliente se conecta a un agente del sistema de mensajes que proporciona facilidades para crear, enviar, recibir y leer mensajes. Los sistemas de mensajes habilitan comunicaciones entre procesos distribuidos con un bajo acoplamiento.
Un componente envía un mensaje a un destino y el receptor puede recuperar un mensaje de un destino. Sin embargo, el emisor y el receptor no tienen porqué estar disponibles al mismo tiempo para poder comunicarse, de hecho, el emisor no necesita conocer nada sobre el receptor, ni el receptor conocer nada sobre el emisor. El emisor y receptor sólo necesitan conocer que formato de mensaje y qué destino utilizar. Esta es una diferencia frente a modelos de comunicación distribuidos fuertemente acoplados, como por ejemplo la Invocación Remota de Métodos, que requieren que la aplicación conozca los métodos remotos.
4. Características y utilización
Cualquier sistema de mensajes posee las siguientes propiedades características:
• Soporta el reparto asíncrono de mensajes, es decir, repartir los mensajes cuando lleguen los clientes, sin necesidad de que tengan que solicitar los mensajes para recibirlos.
• Es un sistema fiable, es decir, tener la posibilidad de garantizar que un
mensaje sólo se reparte una, y sólo una, vez. Aunque parecido en la filosofía al sistema de correo electrónico, su uso está orientado a comunicar aplicaciones o componentes software en lugar de interconectar personas o aplicaciones con personas.
La utilización de los Sistemas de Mensajes es adecuada cuando se dan las siguientes circunstancias:
• Se requiere que los componentes no dependan de la información acerca de otras interfaces de componentes, de forma que los componentes puedan reemplazarse fácilmente.
• Se requiere que la aplicación se ejecute independientemente de si todos los
componentes están activos y ejecutándose simultáneamente. • El modelo de negocio de la aplicación permite que un componente envíe
información a otro y pueda seguir operando sin recibir una respuesta inmediata.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Con el fin de clarificar los conceptos se presenta la siguiente situación que se da en el mundo del automóvil:
Un fabricante de automóviles utiliza un componente software para gestionar su inventario de automóviles fabricados. Cuando el número de unidades de un determinado modelo baja de una determinada cantidad, el “componente inventario ” puede enviar un mensaje al “componente fábrica ”, solicitando la fabricación de más coches. El componente fábrica puede enviar mensajes a los “componentes suministradores ” de piezas para obtener las piezas necesarias en la fabricación de nuevos coches. Los componentes asociados a los suministradores de piezas pueden enviar mensajes a sus propios inventarios y departamentos de pedidos para actualizar su inventario, y si llega el caso, solicitar pedidos a sus Proveedores. Tanto la fábrica como los suministradores de piezas pueden enviar mensajes al “componente de contabilidad ” para actualizar sus cuentas. La empresa puede comunicar su catálogo de productos actualizados al departamento de ventas
Lección 11: Objetos distribuidos e invocación remot a
Un sistema Distribuido sofisticado debe proporcionar los mecanismos necesarios para permitir la comunicación entre objetos distribuidos. En este ítem se presentan dos metodologías ampliamente usadas: RPC y Java RMI.
1. LINUX®/UNIX RPC87
Las Llamadas a Procedimientos Remotos (RPC / Remote Procedure Call) constituyen una infraestructura del modelo cliente-servidor que incrementan lo siguiente:
• Interoperabilidad (capacidad de dos o más sistemas o componentes software para intercambiar información y utilizar la información que has sido intercambiada).
• Portabilidad (facilidad con la que un sistema o componente Software puede
transferirse de un entorno Hardware o Software a otro).
87 http://www.chuidiang.com/cLINUX®/rpc/rpc.html

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
• Flexibilidad (facilidad con la que un sistema o componente Software puede modificarse de modo que pueda utilizarse en otras aplicaciones o entornos para los que fue expresamente diseñado (de una aplicación, permitiendo que ésta se distribuya sobre múltiples plataformas heterogéneas).
La utilización de RPC reduce la complejidad del desarrollo de aplicaciones que comprenden múltiples sistemas operativos y protocolos de red mediante el aislamiento del desarrollador de los detalles de la plataforma subyacente (cuando se utiliza RPC, las invocaciones a funciones son las interfaces del programador).
Operación RPC
Para acceder a la porción de código del servidor remoto de una aplicación, las RPC o invocaciones especiales a funciones, son insertadas dentro de la porción de código del cliente (Figura 47).
Figura 47. Operación RPC
Fuente: http://www.infor.uva.es/~fdiaz/sd/doc/SD_TE01_20060227.pdf
Cuando se compila la aplicación, el compilador genera un programa “stub ” local para el lado cliente y un “stub ” remoto para la parte servidora de la aplicación. Son a estos stubs a los que se les invoca cuando la aplicación requiere una función remota y, habitualmente, soportan llamadas síncronas entre el cliente y el servidor (análogas a una invocación en modo local).

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Mediante el uso de RPC, se reduce la complejidad asociada al desarrollo de un procesamiento distribuido, gracias a dotar a una invocación remota de la misma semántica que una invocación en modo local. Sin embargo, RPC incrementa el grado de participación del desarrollador de la aplicación, como consecuencia de la naturaleza maestro-esclavo del Mecanismo. Además, RPC incrementa la flexibilidad de una arquitectura, permitiendo a un cliente emplear una invocación a una función para acceder a un servidor en un sistema remoto.
RPC permite que el componente remoto sea accesible sin necesidad de conocer su dirección de red o cualquier otra información de bajo nivel.
La mayoría de las implementaciones de RPC utilizan un protocolo solicitud-respuesta síncrono (esquema call/wait) que implica el bloqueo del cliente hasta que el servidor satisface su solicitud.
Ejemplo
En plataformas LINUX®-UNIX es posible tener en ejecución un programa en C con varias funciones que pueden ser llamadas desde otros programas. Estos otros programas pueden estar ejecutándose en diversos computadores conectados en red.
Se supone, por ejemplo, que se tiene un computador muy potente en cálculo matemático y otro con un buen display para gráficos. Se desea hacer un programa con mucho cálculo y con unos gráficos "sofisticados ". Ninguno de los dos computadores cumple con ambos requisitos. Una solución, utilizando RPC (Llamada a procedimientos remotos), consiste en programar las funciones matemáticas en el computador de cálculo y publicar dichas funciones. Estas funciones podrán ser llamadas por el computador gráfico, pero se ejecutarán en el computador de cálculo. Por otro lado, se realizan los gráficos en el computador gráfico y cuando se requiera algún cálculo, se invocan las funciones del computador de cálculo.
Al programa con las funciones se le llama "servido r". Al programa que llama a esas funciones se le llama "cliente ". Normalmente el servidor está siempre en ejecución y a la espera de que algún cliente llame a alguna de sus funciones. Cuando el cliente llama a una función del servidor, la función se ejecuta en el servidor y el cliente detiene su ejecución hasta que el servidor termina.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
En el código del programa servidor básicamente hay que seguir los siguientes pasos:
• Codificar las funciones que van a ser llamadas siguiendo un determinado mecanismo.
• Informar al sistema operativo (UNIX-LINUX®) de un nombre, una versión y funciones que publica.
• Dejar en un bucle infinito esperando que alguien llame a alguna de sus funciones.
Mientras que el programa cliente debe:
• Establecer una conexión con el servidor. • Llamar a las funciones. • Cerrar la conexión con el servidor.
2. Java® RMI
Java® RMI (Remote Method Invocation / Invocación de Método Remoto) es el mecanismo ofrecido en Java® que permite a un procedimiento (método, clase, aplicación) poder ser invocado remotamente (Figura 48). Una de las ventajas al diseñar un procedimiento con RMI es interoperabilidad, ya que RMI forma parte de todo JDK (Java® Development Kit / Kit de Desarrollo de Java®), y por lo tanto, cualquier plataforma que tenga acceso a un JDK también tiene acceso a estos procedimientos.
Figura 48. Operación de Java® RMI
Fuente: Autor

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Por medio de RMI, un programa Java® (servidor), pone uno de los objetos que maneja, accesible desde red, de forma que otros programas Java® en red (clientes) pueden invocar métodos de este objeto.
Cuando un cliente Java® le pide al servidor un objeto e invoca a uno de sus métodos, el código de dicho método se ejecuta en el servidor. El código del cliente queda en espera de que el servidor termine de ejecutar el método y devuelva un resultado.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
CAPITULO 4: ASPECTOS DE SEGURIDAD DE UN SISTEMA DIS TRIBUIDO88
Introducción
La seguridad y protección en los sistemas distribuidos debe ser implementada con el objetivo de proteger la información contra acceso, uso no autorizado, y contra modificación o destrucción de datos almacenados/transmitidos por un sistema computacional.
El la figura 49 se resume la evolución de las necesidades de seguridad en los sistemas de computadores desde su aparición con los sistemas de compartición de datos hasta el día de hoy con el advenimiento de los sistemas distribuidos abiertos de carácter global.
Figura 49. Evolución de las Necesidades de Seguridad
1965 – 1975 1975-1989 1990-1999 1999-Actualmente
Plataformas Computadores multiusuario de tiempo compartido
Sistemas distribuidos basados en redes locales
Internet, servicios de área extensa
Internet + dispositivos móviles
Recursos compartidos
Memoria, archivos
Servicios locales (p. ej.: NFS), redes locales
e-mail, lugares web, comercio Internet
Objetos distribuidos, código móvil
Requisitos de seguridad
Identificación y autenticación de usuario
Protección de servicios
Seguridad robusta para transacciones comerciales
Control de acceso para objetos individuales, código móvil seguro
Entorno de gestión de la seguridad
Autoridad única, base de datos de autorización única (p. ej.: /etc/passwd)
Autoridad única, delegación, bases de datos de autorización replicadas (p. e).: NIS)
Muchas autoridades, sin autoridad en la red, en general
Autoridades por actividad, grupos con responsabilidades compartidas
88 http://exa.unne.edu.ar/depar/areas/informatica/SistemasOperativos/MonogSO/SEG02.html

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Fuente: COULOURIS George, SISTEMAS DISTRIBUIDOS, Addison Wesley, Madrid, 2001, 3ª Ed.
Existen varios elementos que complican la aplicación de formas o esquemas para dar seguridad dentro de un sistema. Estos elementos están presentes en función del tipo de seguridad y los objetivos que se desean proteger, he aquí algunos:
• Compartición de datos y objetos, así como todas las posibilidades de acceso remoto.
• Valor incremental de la información que se transmite. • Desarrollo de nuevas tecnologías que facilitan la posibilidad de accesos (o
ataques) en un sistema distribuido. El intruso puede llevar a cabo alguna de las siguientes violaciones:
o Liberación no autorizada de información (tomar ventaja). o Modificación no autorizada de información (alterar información). o Denegar sin autorización en servicios.
• Aplicación de redes dinámicas de los niveles de administración de dominios. • Cambios constantes de los niveles de administración de dominios. • Diferentes protocolos de comunicación. • Incremento de los alcances con ambiente de crecimiento rápido (mala
planeación).
Hay una necesidad apremiante de medidas para garantizar la privacidad, integridad y disponibilidad de recursos en los sistemas distribuidos. Los ataques contra la seguridad toman las formas de escuchas, suplantación, modificación y denegación de servicio (Figura 50).
Figura 50. Amenazas a la Seguridad
Fuente: Autor

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
En todos aquellos sistemas de computadores, donde existan objetivos potenciales para ataques maliciosos o con fines de diversión hay que incluir medidas de seguridad. Especialmente para sistemas que traten con transacciones financieras, confidenciales, clasificadas u otra información cuyo secreto e integridad sea crítica.
Lección 12: Políticas de Seguridad, Mecanismos de Protección, Factores de Seguridad
La necesidad de proteger la integridad y la privacidad de la información, y otros recursos que pertenecen a individuos y organizaciones, conjuga ambos mundos: el físico y el digital.
En el mundo físico, las organizaciones adoptan políticas de seguridad para poder compartir recursos dentro de unos límites especificados. Las políticas de seguridad se hacen cumplir con la ayuda de los mecanismos de protección.
En el mundo electrónico, la distinción entre políticas de seguridad y los mecanismos de protección también es importante: sin ella, seria difícil determinar si un sistema particular es seguro.
1. Políticas de Seguridad
Se refiere a todos las normas que son implementadas adicionalmente a los mecanismos para incrementar las posibilidades de integridad de los sistemas. Por ejemplo cambiar el password de un sistema periódicamente.
2. Mecanismos de Protección
Se refiere a todos los mecanismos que deben ser implementados para proporcionar seguridad en los sistemas, pueden ser operaciones y procesos que

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
permitan restringir accesos dentro de los sistemas. Por ejemplo la instalación de un cortafuegos89 empresarial.
Las políticas de seguridad son independientes de la tecnología empleada, así como el instalar una cerradura en una puerta no garantiza la seguridad del edificio a menos que haya una política de uso (por ejemplo. que la puerta esté cerrada cuando no esté vigilada). Los mecanismos de seguridad que se describen no garantizan, por sí mismos, la seguridad de un sistema. Por ello es importante tener en cuenta que tanto las políticas como los mecanismos son fundamentales para implementar la seguridad.
3. Factores de Seguridad
Para comprender los factores involucrados en la seguridad de un sistema distribuido se usará el ejemplo representado en la figura 51.
Figura 51. Emisor, Receptor e Intruso
Fuente: KUROSE James, REDES DE COMPUTADORES, Addison Wesley, Madrid, 2004, 2ª Ed.
Alicia y Roberto, que quieren comunicarse de forma segura. ¿Qué significa esto exactamente?. Realmente, Alicia quiere que únicamente Roberto sea capaz de entender el mensaje que ella le ha enviado, incluso aunque se estén comunicando sobre un medio inseguro, en el que un intruso (Gertrudis, la intrusa) pudiera interceptarlo, leerlo o realizar conjeturas sobre qué es lo que se transmite entre Alicia y Roberto. Roberto también quiere estar seguro de que el mensaje que recibe de Alicia fue enviado en efecto por Alicia, y Alicia quiere eso segura de que la persona con quien está comunicándose es en realidad Roberto. Alicia y Roberto 89 Para empliar este concepto ver glosario de términos.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
también desean estar seguros de que el contenido de sus mensajes no es alterado durante su tránsito. Dadas estas premisas, se pueden identificar las propiedades deseadas de una comunicación segura:
3.1 Confidencialidad
Únicamente el emisor y el receptor deseado deben ser capaces de entender el contenido del mensaje transmitido. Como los oyentes ocultos pueden interceptar el mensaje, se requiere necesariamente que el mensaje sea encriptado de algún modo (disfrazados sus datos) para que el mensaje interceptado no pueda ser desencriptado (entendido) por un interceptador.
3.2 Autenticación
Roberto, como emisor y receptor, debería ser capaz de confirmar la identidad de la otra parte involucrada en la comunicación para asegurarse de que la otra parte es en efecto quién o lo que parece. La comunicación cara a cara resuelve este problema fácilmente mediante el reconocimiento visual. Cuando las entidades en comunicación intercambian mensajes sobre un medio donde no pueden ver a la otra parte, la autenticación no es tan simple. ¿Por qué, por ejemplo, debería usted creerse que un correo electrónico que contiene una cadena de caracteres que dice que el correo viene de un amigo proviene en realidad de tal amigo? Si alguien le llama por teléfono diciendo que es de su banco, le pide su número de cuenta, el número de identificación personal (PIN / Personal Identification Number), y los balances de cuenta para efectuar una verificación, ¿le daría usted esa información por teléfono?.
3.3 Integridad del mensaje y no repudio
Incluso si el emisor y el receptor son capaces de autenticarse entre ellos, también querrán estar seguros de que el contenido de sus comunicaciones no es alterado durante la transmisión, ya sea maliciosamente o por accidente. Para proporcionar

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
tal integridad de mensaje se pueden utilizar extensiones de las técnicas de suma de comprobación.
3.4 Disponibilidad y control de acceso
La apremiante necesidad de seguridad en las redes se ha hecho dolorosamente patente en los últimos años a partir de numerosos ataques de denegación de servicio (DoS / Denial-of-Service)90, que han conseguido que una red, un host u otra pieza de la infraestructura de la red dejaran de ser utilizables por sus legítimos usuarios; quizá los más notorios de estos ataques DoS han sido los perpretados contra sitios web de empresas de alto nivel. Por lo tanto, un requisito de las comunicaciones seguras debe ser en primer lugar que la comunicación pueda darse (que los chicos malos no puedan impedir que la infraestructura sea utilizada por sus legítimos usuarios). El hecho de que determinados usuarios estén legitimados y otros no, conduce naturalmente hacia la noción de control de acceso (asegurar que las entidades que deseen acceder a los recursos puedan hacerlo sólo si poseen los derechos de acceso apropiados y ejecutan sus accesos de un modo bien definido).
4. Amenazas y ataques a la seguridad
Todo sistema de información y en especial un sistema distribuido, debido a la heterogeneidad de sus componentes, es propenso a las amenazas y ataques a su seguridad. Algunos ataques son obvios; por ejemplo, en la mayoría de los tipos de redes locales es fácil construir y lanzar un programa sobre un computador conectado para que obtenga copias de los mensajes transmitidos entre otros computadores. Otras amenazas son más sutiles; si los clientes fallan en autenticar los servidores, un programa podría situarse a sí mismo en lugar del auténtico servidor de archivos y así obtener copias de información confidencial que los clientes, inconscientemente, envían para su almacenamiento.
90 Para empliar este concepto ver glosario de términos.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
La principal meta de la seguridad es restringir el acceso a la información y los recursos de modo que sólo tengan acceso aquellos principales autorizados. Las amenazas de seguridad caen en tres amplias clases:
• Fuga. La adquisición de información por receptores no autorizados. • Alteración. La modificación no autorizada de información. • Vandalismo. Interferencia con el modo de operación adecuado de un sistema,
sin ganancia alguna para el perpetrador.
Los ataques en los sistemas distribuidos (Figura 52) dependen de la obtención de acceso a los canales de comunicación existentes o del establecimiento de canales nuevos que se suplantan a las conexiones (se emplea el término canal para hacer alusión a cualquier mecanismo de comunicación entre procesos).
Figura 52. Ataques a la seguridad
Fuente: Autor
Los métodos de ataque (Figura 52) pueden clasificarse más aún en función del modo en que se abusa del canal:
� Interrupción: destruye la información o la inutiliza. Ataca la disponibilidad. � Interceptación: Obtiene acceso a información. Ataca la confidencialidad. � Modificación: Modifica la información. Ataca la integridad. � Suplantación : Falsifica la información. Ataca la autenticidad.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
La mayoría de los ataques a los sistemas distribuidos parten de la exposición de sus canales de comunicación y sus interfaces. Para muchos sistemas, éstos son los únicos ataques que se deben considerar y que no se derivan de los errores humanos. Los mecanismos de seguridad no pueden proteger contra una clave de acceso mal elegida o mal custodiada.
Lección 13: Criptografía
La criptografía que etimológicamente, procede de la raíz griega kriptón (oculto), y de grafía (escritura) significa "escritura oculta " y se puede definir como la disciplina que estudia los principios, métodos y medios de ocultar la información contenida en un mensaje. Es practicada por los criptógrafos.
La idea fundamental en que se basa la criptografía es permitir que dos entidades, ya sean usuarios o aplicaciones, puedan enviarse mensajes por un canal que puede ser intervenido por una tercera entidad, de modo que sólo los destinatarios autorizados puedan leer los mensajes (Figura 53).
Figura 53. Criptografía
Fuente: Autor
La criptografía proporciona la base de la autenticación de mensajes así como del secreto y la integridad. Para explotarla es preciso utilizar protocolos de seguridad diseñados cuidadosamente. La selección de algoritmos criptográficos y la administración de claves son puntos críticos para la efectividad, prestaciones y usabilidad de los mecanismos de seguridad. La criptografía de clave pública facilita la distribución de claves criptográficas pero sus prestaciones son

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
inadecuadas para la encriptación de datos masivos. La criptografía de clave secreta es más adecuada para tareas de encriptación masiva.
Como técnica, la criptografía provee un incremento en la protección de los sistemas en eventos o lugares donde se maneja información no autorizada y que puede estar disponible para los impulsos. Permite que una pieza de información sea convertida a una forma encriptada antes de que sea almacenada o transmitida por un canal de comunicación.
1. Modelo de criptografía
La Encriptación es una operación primitiva (a bajo nivel) empleada por la criptografía y que se efectúa sobre datos para convertirlos a una representación que no tenga significado para cualquier otra entidad, únicamente para el receptor designado (Figura 54).
La encriptación está asociada con la transformación de un mensaje inteligible (M: Texto Plano) a una forma no inteligible (C: Texto Cifrado) con la ayuda de una clave secreta (KE) antes de que sea colocada en un medio inseguro.
Figura 54. Modelo de Criptografía
Fuente: KUROSE James, REDES DE COMPUTADORES, Addison Wesley, Madrid, 2004, 2ª Ed.
La encriptación se define como una función matemática (algoritmo) de la siguiente forma:
C = E (M,KE) = EKE (M)
donde E es el Algoritmo de Encriptación.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Un algoritmo de desencriptación (D) debe tener la propiedad de que el dato original (M) pueda ser recuperado de su forma encriptada si se conoce el valor de su llave (KD) .
M = D (C,KD) = DKD (C)
donde D= Función decriptadora.
La protección de un sistema de encriptación es medida por el grado de dificultad que presente para encontrar la clave utilizada. Entre más complejo sea el método de encriptado utilizado, le es más difícil a otras personas descifrar el mensaje.
2. Tipos de Criptografía
A continuación se relacionan los nombres de los algoritmos de encriptado mas famosos y a manera de ejemplo se explicaran dos, PGP91 y RSA92.
� DES (Data Encryption Standard / Estandar de Encripción de Datos) � Triple-DES (3des) � IDEA (International Data Encryption Algorithm / Algoritmo de Encripción de
Datos Internacional) � RC-2 Y RC-4 � Skipjack93 � AES (Advanced Encryption Standard / Estandar de Encripción Avazado) � Algoritmo RSA (Rivest-Shamir-Adleman) � Algoritmo ElGamal (De origen Israelí) � PGP
3. Software de Encriptamiento PGP
PGP (Pretty Good Privacy / Privacidad Bastante Buena), en su versión 2.6.3i (internacional) se convirtió a mediados de la década de los 90 en un estándar de hecho. La principal característica de éste software es su amplia utilización para cifrar todo tipo de datos en entornos WINDOWS®, UNIX y LINUX®. Su orientación principal es el cifrado de los datos y la firma digital en correo electrónico. Los algoritmos básicos que usa PGP son:
91 Privacidad Bastante Buena (Pretty Good Privacy) 92 Algoritmo Rivest-Shamir-Adleman 93 Algoritmo de cifrado-descifrado. de llave simétrica (se usa la misma llave para encriptar-descencriptar)

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
• IDEA94 para cifrar con sistema de clave secreta. • RSA para intercambio de claves y firma digital. • MD595 para obtener la función hash de la firma digital y para recuperar la clave
privada asimétrica y el cifrado local.
El método de cifrado utilizado por PGP se muestra a continuación (Figura 55).
Figura 55. Algoritmo PGP
Fuente: Autor
En origen, el mensaje o archivo que se desea proteger va pasando por diferentes bloques que lo van transformando:
• PGP solicita una frase de paso (contraseña): ésta debe ser lo suficientemente larga como para evitar ataques por combinaciones.
• Se aplica el algoritmo de resumen MD5 a esa contraseña, generando así una
clave de 128 bits (clave local). • Con esa clave, PGP cifra el documento con el algoritmo IDEA y le pone como
extensión (.pgp). • Como una opción, permite luego hacer un borrado físico del archivo en claro.
94 En criptografía el Algoritmo Internacional de Encriptamiento de Datos (IDEA) es un cifrado de bloque diseñado por Xuejia Lai y James L. Massey de ETH-Zurich y descrito por primera vez en 1991. 95 En criptografía, MD5 (acrónimo de Message-Digest Algorithm 5 / Algoritmo de Resumen del Mensaje 5) es un algoritmo de reducción criptográfico de 128 bits ampliamente usado. El código MD5 fue diseñado por Ronald Rivest en 1991. Durante el año 2004 fueron divulgados ciertos defectos de seguridad, lo que hará que en un futuro cercano se cambie de este sistema a otro más seguro.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
• En la recepción se realiza el proceso inverso, con lo que se obtiene el mensaje
original, asegurando los requerimientos buscados.
El acceso al texto en claro sólo es posible si se conoce una clave o contraseña que es la frase de paso usada al cifrar.
Es importante tener en cuenta que si después de cifrar el archivo, se borra físicamente el texto en claro (operación que realiza una grabación de unos y ceros aleatorios en la zona de almacenamiento del disco) entonces será imposible recuperarlo si olvida la contraseña.
4. Algoritmo Rivest-Shamir-Adleman (RSA)
En febrero de 1978 Ron Rivest, Adi Shamir y Leonard Adleman proponen un algoritmo de cifrado de clave pública: RSA.
El algoritmo RSA se fundamenta en el hecho de que la factorización de números primos es un problema de resolución computacionalmente difícil.
El algoritmo RSA está descrito en infinidad de sitios96 y es extremadamente simple:
Primero es necesario calcular las claves:
Encontrar dos números primos grandes (de 100 cifras o más), p y q.
Los valores p y q no se hacen públicos.
Definir n (conocido como módulo) como: n = pq
Definir z como: z = (p-1)(q-1)
Encontrar un número primo aleatorio e menor que el módulo y tal que e y z sean primos entre sí.
Determinar un valor d tal que se cumpla que (e d - 1) es divisible entre z (d
existe y es único).
96 http://es.wikipedia.org/wiki/RSA, http://daniellerch.com/sources/doc/algoritmo_rsa.html

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
El cifrado del mensaje M se obtendrá según la siguiente operación: C = M e (mod n)
Y el descifrado mediante la siguiente: M = C d (mod n)
Por tanto, la clave pública estará constituida por el par (n,e), mientras que la
clave privada la constituirán (n,d).
Ejemplo:
Lección 14: Seguridad con Cortafuegos
Un cortafuegos “es un elemento de hardware o software utilizado en una red de computadores para prevenir algunos tipos de comunicaciones prohibidos según las políticas de red que se hayan definido en función de las necesidades de la organización responsable de la red”. Su modo de funcionar es definido por la recomendación RFC-297997, la cual define las características de comportamiento y requerimientos de interoperabilidad”98
La idea principal de un cortafuegos (Figura 56) es crear un punto de control de la entrada y salida de tráfico de una red. Un cortafuegos correctamente configurado es un sistema adecuado para añadir protección a una instalación informática, pero en ningún caso debe considerarse como suficiente. La Seguridad informática abarca más ámbitos y más niveles de trabajo y protección.
97 http://www.ietf.org/rfc/rfc2979.txt 98 http://es.wikipedia.org/wiki/Cortafuegos

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Figura 56. Cortafuegos (Firewall)
Fuenter: Autor
Los cortafuegos son un tipo de seguridad muy efectiva en redes e intentan prevenir los ataques de usuarios externos a la red interna. Tienen múltiples propósitos:
• Restringir la entrada a usuarios a puntos cuidadosamente controlados. • Restringir los permisos de los usuarios a puntos cuidadosamente controlados. • Prevenir los ataques.
Un cortafuegos es a menudo instalado en el punto donde la red interna se conecta con Internet. Todo tráfico externo de Internet hacia la red interna pasa a través del cortafuegos, así puede determinar si dicho tráfico es aceptable, de acuerdo a sus políticas de seguridad.
Lógicamente un cortafuegos es un separador, un analizador, un limitador. La implementación física varía de acuerdo al lugar. A menudo, un Cortafuegos es un conjunto de componentes de hardware - un router, un host, una combinación de routers, computadores y redes con software apropiado. Rara vez es un simple objeto físico. Usualmente esta compuesto por múltiples partes y alguna de esas partes puede realizar otras tareas.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
La conexión de Internet también forma parte del cortafuegos. Un cortafuegos es vulnerable, él no protege de la gente que está dentro de la red interna. El cortafuegos trabaja mejor si se complementa con una defensa interna. Un Cortafuegos es la forma más efectiva de conectar una red a Internet y proteger su red. Los cortafuegos también tienen otros usos. Por ejemplo, se pueden usar para dividir partes de un sitio que tienen distintas necesidades de seguridad.
1. Objetivos de Seguridad de un Cortafuegos
Los cortafuegos son un mecanismo de seguridad pero toda implementación de protección con cortafuegos debe incluir una política de seguridad. Los objetivos de la política de seguridad de un cortafuegos incluyen todos o algunos de aspectos los enumerados a continuación:
Control de servicios: para determinar qué servicios en los hosts internos son accesibles desde el exterior y para rechazar cualquier otra petición de servicio. También se controlan las peticiones de servicios al exterior y sus respuestas. Estas acciones de filtrado pueden basarse en el contenido de los paquetes IP y en las peticiones TCP y UDP que contienen. Por ejemplo, las peticiones HTTP pueden rechazarse a menos que sean dirigidas al host que albergue el servidor web oficial.
Control del comportamiento: para prevenir comportamientos que infrinjan las políticas de la organización, sean antisociales o no tengan un propósito legítimo y, por lo tanto, sean sospechosos de formar parte de un ataque. Algunas de estas acciones de filtrado pueden ser aplicadas a nivel IP o a nivel TCP, pero otras pueden requerir la interpretación de mensajes al más alto nivel. Por ejemplo, filtrar un ataque de spam99 en el correo electrónico puede necesitar examinar la dirección del remitente en la cabecera del mensaje o incluso el contenido del mismo.
Control de usuarios: la organización puede querer distinguir entre sus usuarios, permitiéndoles algún acceso a servicios exteriores pero inhibiendo a otros hacer lo mismo. Un ejemplo de control de usuarios, que quizás sea más aceptable socialmente que otros, es impedir que se pueda instalar software excepto a aquellos que son miembros del equipo de administradores de sistemas, para prevenir infecciones de virus o para mantener estándares de software. Este ejemplo en concreto puede ser difícil de llevar a cabo en la práctica sin llegar a impedir el uso del Web por los usuarios normales.
99 Ver ampliación del término en el glosario

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Otro ejemplo de control de usuarios es la gestión de los accesos telefónicos y de otras conexiones proporcionadas a los usuarios que se encuentran ausentes. Si el cortafuegos es también el host de las conexiones vía módem, puede autentificar los usuarios en el momento de conectarse y requerir el uso de un canal seguro para las comunicaciones (para prevenir la escucha, y el enmascaramiento y otros ataques en las conexiones externas).
Las dos principales aproximaciones usadas para construir Cortafuegos hoy son:
• Filtrado de paquetes. • Pasarelas de Aplicación
2. Filtrado de Paquetes
El sistema de filtrado de paquetes (Figura 57) encamina paquetes entre los host internos y los externos, pero de manera selectiva. Permite bloquear cierto tipo de paquetes de acuerdo con la política de seguridad de la red.
Figura 57. Cortafuegos con Filtrado de Paquetes
Autor: COULOURIS George, SISTEMAS DISTRIBUIDOS, Addison Wesley, Madrid, 2001, 3ª Ed.
El tipo de enrutamiento usado para filtrar paquetes en un Cortafuegos es conocido como "screening router ". Se puede selectivamente rutear paquetes desde o hacia su sitio:
• Bloquear todas las conexiones que entran desde sistemas externos, excepto las conexiones SMTP100 (solo recibirá mails).
• Bloquear todas las conexiones (puertos) que provienen de un determinado
lugar que se considera peligroso.
100 Protocolo Simple de Transferencia de Correo (Simple Mail Transfer Protocol)

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
• Permitir servicio de Mail y FTP, pero bloqueando servicios peligrosos como TFTP101, RPC, servicios "r" (rlogin102, rsh103, etc), etc.
Para entender como se filtra un paquete, se necesita conocer la diferencia entre enrutamiento ordinario y screening router. Un enrutamiento ordinario simplemente mira la dirección destino de cada paquete y elige el mejor camino que él conoce hacia la dirección destino. La decisión sobre como atender el paquete se basa solamente en el destino del paquete. En screening router, mira el paquete más detalladamente. Además de determinar si el paquete puede ser ruteado o nó a la dirección destino, determina si debe o nó debe ser ruteado de acuerdo con la política de seguridad. La comunicación entre la red interna y externa tiene una enorme responsabilidad. Realizar el enrutamiento y la decisión de rutear es la única protección al sistema. Si la seguridad falla, la red interna queda expuesta. Un screening router puede permitir o denegar un servicio, pero no puede proteger operaciones individuales dentro del servicio.
Casi todos los dispositivos actuales de filtro de paquetes (routers de selección o compuertas de filtro de paquetes) operan de la siguiente forma:
El criterio de filtro de paquete debe almacenarse para los puertos del dispositivo para filtro de paquetes. El criterio de filtro de paquetes se conoce como reglas de filtro de paquetes.
Cuando un paquete llega al puerto, los encabezados de los paquetes se analizan. La mayoría de los filtros los campos sólo en los encabezados IP, TCP o UDP. Las reglas del filtro de paquete se almacenan en un orden específico. Cada regla se aplica al paquete en el mismo orden en que la regla del filtro de paquetes se almacenó. Si una regla bloquea la transmisión o recepción del paquete, el paquete no se acepta. Si una regla permite la transmisión o recepción de un paquete, el paquete sigue su camino. Si un paquete no satisface ninguna regla, es bloqueado. Es decir aquello que no esté expresamente permitido, se prohíbe, por lo tanto, debe observar que es importante colocar las reglas en orden correcto. Un error común al configurar las reglas del filtro de paquetes es hacerlo en desorden. Si dichas reglas se colocan en un orden equivocado, podría terminar denegando servicios válidos, mientras que permitiría los servicios que deseaba denegar.
101 Protocolo de Transferencia de Archivos Trivial (Trivial File Transfer Protocol) 102 Utilidad que permite establecer una sesión de terminal remota con un host en internet. Trabaja con TCP/IP. 103 Comando que utiliza el servicio rlogin y tiene el problema de que la información se transmite sin cifrar.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
3. Pasarela de Aplicación
En los ejemplos anteriores, se ha explicado que el filtrado a nivel de paquetes permite realizar un filtrado sobre las cabeceras IP y TCP/UDP, incluyendo las direcciones IP, los servicios TCP/IP y los números de puerto, por ejemplo, se ha explicado que el filtrado basado en una combinación de direcciones IP y números de puerto puede permitir que los clientes internos salgan utilizando Telnet, pero impide que los clientes externos hagan Telnet hacia dentro. Pero, ¿qué sucede si una organización desea proporcionar servicio de Telnet a conjunto restringido de usuarios internos (en oposición a direcciones IP)? ¿Y si organización quiere que tales usuarios privilegiados se autentiquen a sí mismos antes de permitirles crear sesiones Telnet hacia el mundo exterior? Tales tareas están más allá de las capacidades de un cortafuegos de filtrado de paquetes. En efecto, la información sobre la identidad de los usuarios internos no se incluye en las cabeceras IP/TCP/UDP, sino en los datos de nivel de aplicación.
Para poder conseguir una seguridad a nivel de aplicación, los cortafuegos deben combinar el filtrado de paquetes con las pasarelas de aplicación. Las pasarelas de aplicación miran más allá de las cabeceras IP/TCP/UDP, y toman decisiones basadas en los datos de aplicación.
Figura 58. Cortafuegos en combinación con pasarela de aplicación
Fuente: KUROSE James, REDES DE COMPUTADORES, Addison Wesley, Madrid, 2004, 2ª Ed.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Una pasarela de aplicación (Figura 58) es un servidor de aplicación específico a través del cual deben pasar todos los datos de aplicación (entrantes y salientes). Varias pasarelas de aplicación pueden ejecutarse sobre el mismo host, pero cada pasarela es un servidor separado con sus propios procesos.
Para dar algunas nociones sobre las pasarelas de aplicación, se presenta un cortafuegos que permite sólo a un conjunto restringido de usuarios hacer Telnet hacia el exterior al tiempo que impide que los clientes externos puedan hacer Telnet hacia el interior. Tal política puede ser ejecutada implementando una combinación de filtrado de paquetes (en un router) y una pasarela de aplicación Telnet, tal y como se muestra en la figura 58.
El filtro del router es configurado para bloquear todas las conexiones Telnet, excepto aquéllas que se originen en la dirección IP de la pasarela de aplicación. Tal configuración del filtro obliga a todas las conexiones salientes a pasar por la pasarela de aplicación. Considere ahora un usuario interno que desea realizar un Telnet hacia el mundo exterior. En primer lugar, el usuario debe iniciar una sesión Telnet con la pasarela de aplicación. Una aplicación que se ejecuta sobre la pasarela, la cual escucha sesiones Telnet entrantes, pide al usuario una identificación y una contraseña. Cuando el usuario proporciona esta información, la pasarela de aplicación comprueba si el usuario tiene permiso para realizar Telnet hacia el exterior. Si no lo tiene, la conexión Telnet del usuario interno es finalizada por la pasarela. Si el usuario tiene permiso, entonces:
(a) la pasarela solicita al usuario el nombre del host externo al que quiere conectarse.
(b) establece una sesión Telnet entre la pasarela y el host externo. (c) hace de intermediario ente los datos que llegan al usuario y salen hacia al host
externo.
Así, la pasarela de aplicación Telnet no sólo realiza la autorización de usuario, sino que actúa al mismo tiempo como servidor y como cliente Telnet, pasando la información entre el usuario y el servidor Telnet remoto. Hay que destacar que el filtro permite el paso (b), porque la pasarela inicia la conexión Telnet hacia el mundo exterior.
Las redes internas a menudo tienen múltiples pasarelas de aplicación (por ejemplo, pasarelas para Telnet, HTTP, FTP, y correo electrónico). De hecho, el servidor de correo de una organización y la caché web son pasarelas de aplicación.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Las pasarelas de aplicación también presentan inconvenientes. Primero, se necesita una pasarela de aplicación para cada aplicación. Segundo, existe una penalización en las prestaciones, ya que todos los datos han de pasar por la pasarela. Esto se convierte en un problema, especialmente cuando múltiples usuarios o aplicaciones están utilizando la misma máquina de pasarela.
Finalmente, se debe realizar una cierta cantidad de trabajo de configuración extra; a saber:
� El software del cliente debe saber cómo contactar con la pasarela en lugar de hacerlo con el servidor externo cuando el usuario realiza una petición, y debe saber cómo indicarle a la pasarela de aplicación el servidor externo al que ha de conectarse, o
� El usuario debe conectarse explícitamente con el servidor externo a través de la pasarela de aplicación.
Concluimos esta sección mencionando que los cortafuegos no son la panacea para todos los problemas de seguridad. Introducen una relación entre el grado de comunicación con el mundo exterior y el nivel de seguridad. Como los cortafuegos no pueden impedir la falsificación de las direcciones IP y de los números de puerto, utilizan a menudo una política de todo o nada (por ejemplo, prohibiendo todo el tráfico UDP). Las pasarelas también tienen agujeros en el software, que permiten que los atacantes penetren en ellas. Finalmente, los cortafuegos son incluso menos efectivos si las comunicaciones generadas internamente pueden alcanzar el mundo exterior sin pasar a través del cortafuegos, como en el caso de las comunicaciones inalámbricas.
Lección 15: Servidor P roxy 104
Proxy es un sistema intermediario (Figura 59) entre los hosts internos de una red y los hosts de Internet de forma tal que reciba las requisiciones de unos y se las pase a los otros, previa verificación de accesos y privilegios. Este sistema puede correr en hosts "dual-homed " o hosts "bastion" los cuales serán llamados Servidores Proxy.
104 Hace referencia a un programa o dispositivo que realiza una acción en representación de otro. La finalidad más habitual es la del servidor proxy, que sirve para permitir el acceso a Internet a todos los equipos de una organización cuando sólo se puede disponer de un único equipo conectado, esto es, una única dirección IP.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Figura 59. Servidor Proxy
Fuente: KUROSE James, REDES DE COMPUTADORES, Addison Wesley, Madrid, 2004, 2ª Ed.
Los sistemas Proxy son efectivos solo si se utilizan junto a métodos de restricción de tráfico IP entre clientes y servidores reales. De este modo, un cliente no puede "saltarse " el servidor Proxy para comunicarse con un servidor real utilizando este protocolo.
1. Funcionamiento
El programa cliente del usuario se comunica con el servidor Proxy enviando pedido de conexión con un servidor real. El servidor Proxy evalúa esta requisición y decide si se permite la conexión. Si el servidor Proxy permite la conexión, envía al servidor real la solicitud recibida desde el cliente. De este modo, un servidor Proxy se ve como "Servidor " cuando acepta pedidos de clientes y como "cliente " cuando envía solicitudes a un servidor real. Una vez que establecida la comunicación entre un cliente y un servidor real, el servidor Proxy actúa como un retransmisor pasando comandos y respuestas de un lado a otro. Un punto importante a tener en cuenta en este tipo de conexión es que es totalmente transparente. Un usuario nunca se entera de que existe un "intermediario " en la conexión que ha establecido.
La comunicación entre el programa cliente y el servidor Proxy puede realizarse de dos formas distintas:
Custom Client Software (Software adaptado por el cliente ): El cliente debe saber como opera el servidor Proxy, como contactarlo, como pasar la información

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
al servidor real, etc. Se trata de un software cliente estándar que ha sido modificado para que cumpla ciertos requerimientos.
Custom User Procedures ( Procedimientos adaptados por el usuario ): El usuario utiliza un cliente estándar para conectarse con un servidor Proxy y usa diferentes procedimientos (comandos del servidor Proxy) para pasar información acerca del servidor real al cual quiere conectarse. El servidor Proxy realiza la conexión con el servidor real.
2. Tipos de servidores Proxy
Servidor Proxy de Aplicación: Es un servidor que conoce sobre una aplicación en particular y provee servicios proxy para ella. Entiende e interpreta comandos de un protocolo en particular. Con este tipo de servidores es necesario contar con uno de ellos para cada servicio. Recibe también el nombre de servidor Dedicado.
Servidor Proxy de Circuito: Crea un circuito virtual entre el cliente y el servidor real sin interpretar el protocolo de la aplicación. Son llamados Proxies Genéricos.
3. Ventajas
Permite a los usuarios acceder a los servicios de Internet ocultando totalmente la red interna. Permite un buen servicio de logs a nivel de cada aplicación. Debido a que todo el tráfico pasa a través del servidor Proxy se puede registrar gran cantidad de información con fines de auditoria y seguridad. El servidor Proxy de Circuito provee soporte para un conjunto grande de protocolos.
4. Desventajas
A menudo se requiere la modificación del software cliente. Hay software que esta disponible solo para ciertas plataformas: Por ejemplo: GATEWAY es un paquete Proxy para FTP y TELNET de SUN que corre solo sobre SUN. La disponibilidad de estos tipos de paquetes a menudo no es inmediata.
En el caso de servidores Proxy de Aplicación se requiere un servidor Proxy para cada servicio. Algunos servicios no son viables para trabajar con servidores Proxy (por ejemplo, talk). El uso de servidores Proxy introduce algún retardo en las comunicaciones. Los servidores Proxy de circuitos no brindan control específico sobre las aplicaciones.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Actividades de Autoevaluación de la UNIDAD 2
� Cómo es el proceso de establecimiento de una conexión Cliente/Servidor mediante el protocolo TCP/IP?
� Diseñe y describa un protocolo del nivel de aplicación para ser usado entre un cajero
automático y el computador central del banco. El protocolo debe permitir que se verifique la tarjeta y la clave del usuario, que se consulte el balance de la cuenta (que se mantiene en el computador central), y que se realicen reintegros de una cuenta (es decir, dinero reintegrado al usuario). Las entidades del protocolo deben ser capaces de resolver el problema tan común de que no haya suficiente dinero en la cuenta para cubrir el reintegro. Especifique el protocolo listando los mensajes intercambiados y la acción tomada por el cajero automático o el computador central del banco ante la transmisión o recepción de mensajes. Esboce la operación de su protocolo para el caso de un reintegro sencillo sin errores, utilizando un diagrama de estados.
� Suponga que está descargando archivos MP3 utilizando algún sistema de
compartición de archivos entre iguales (P2P). El cuello de botella en Internet es su enlace de acceso residencial, que es un enlace 128 kpbs full-duplex. Mientras está descargando MP3, otros diez usuarios empiezan de repente a cargar archivos MP3 desde su computador. Asumiendo que su computador es muy potente y que estas cargas y descargas no suponen ningún esfuerzo (CPU, I/O a disco, etc.), ¿harán las cargas simultáneas (que también pasan a través de su enlace cuello de botella) que se ralenticen sus descargas? ¿Por qué, o por qué no?
� Investigar acerca de la arquitectura y el esquema de funcionamiento de Napster para
compartir archivos de música. Este sitio ofrecía un esquema centralizado o distribuido y por qué?. Cuál fue la razón para que este sitio de red fuera sancionado y sus servicios suspendidos? (Ayuda: http://www.napster.com/)
� Se dice que algunos sistemas P2P vienen con software tipo malware, spyware o
adware. Qué significan estos términos y en que se diferencian? Cómo penetran estos software en el computador? Mediante que mecanismos podemos prevenir la llegada de este tipo de software, a nuestras redes o equipos?
� Seleccione dos (2) de los siguientes sistemas distribuidos con arquitectura P2P.
EMULE, GNUTELLA, KAZAA, FREENET, ARES GALAXY
Haga un cuadro comparativo e indique como es el funcionamiento de los sistemas, qué componentes se instalan, tamaño, áreas del disco que acceden, protocolo utilizado y tipo de puertos que usan, cómo opera la aplicación distribuida para recuperar información, que sistemas requieren servidor central y cuales no?.
� Que son los sistemas P2M, cual es su filosofía de trabajo, como es su arquitectura y funcionamiento. Indique el URL de sistemas P2M en uso actualmente tanto en inglés como en español.
� El sistema telefonía entre pares por Internet llamado SKYPE bajo que modelo de red
P2P puede catalogarse de acuerdo con el grado de centralización. Justifique su respuesta.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
� Practica: Diseñar un monitor API basado en WINDOWS®, para controlar el proceso de los equipos en una sala de cuidados intensivos.
� Establezca un paralelo entre las siguientes herramientas middleware:
SMARTSOCKETS, RENDEZVOUS, MAGICBUS.
� Uno de los principales problemas que tiene que tratar cualquier middleware que comunique computadores de distinto tipo es la transparencia del formato de representación interno de los datos en cada componente de la red. Estudiar las ventajas e incovenientes de cada una de estas tres posibles alternativas en distintas situaciones de sistemas distribuidos:
a. Convertir todos los datos al formato interno de uno de los componentes de la red. b. Convertir todos los datos a un formato intermedio de intercambio. c. No realizar ninguna conversión en el middleware, y dejar que cada aplicación
realice las conversiones que considere oportunas. � Un determinado sistema distribuido requiere que cada servidor autentifique la
conexión de sus clientes mediante la introducción de un identificador de usuario y una contraseña. Supuesto que posee un middleware genérico, diseñar sobre él un servicio que permita a las aplicaciones clientes realizar una validación única de usuario y contraseña, independientemente del número de servicios que sea necesario utilizar.
� Enumere los tres principales componentes software que pueden fallar cuando un
proceso cliente invoca un método en un objeto servidor, proporcionando un ejemplo del fallo de cada clase. Sugiera cómo pueden construirse los componentes para que toleren sus fallos mutuamente.
� Practica: Confeccionar dos programas, que se ejecutarán en dos máquinas LINUX®,
de tal manera que uno reciba secuencias de caracteres y devuelva la misma secuencia al programa que las envió. Por cada cadena deberá imprimir en la consola local, la fecha, hora y longitud de la cadena recibida. A su vez el segundo programa deberá enviar secuencias de caracteres, y recibir las mismas de vuelta (echo), dichas respuestas se deberán imprimir en la consola local. Los datos se tomarán en forma interactiva desde la consola local.
� El host A está enviando un archivo enorme al host B sobre una conexión TCP. Sobre
esta conexión nunca se pierde ningún paquete ni expiran los temporizadores. La tasa de transmisión del enlace que conecta el host A a Internet es de R bps. Suponga que el proceso en el host A es capaz de enviar datos por su socket TCP a una tasa de S bps, con S = 10 • R. Suponga además que el almacén de recepción de TCP es lo suficientemente grande como para almacenar el archivo entero, y que el almacén de envío sólo puede albergar un uno por ciento del archivo. ¿Qué podría impedir que el proceso en el host A continuara pasando datos a su socket TCP a la tasa 5? ¿El control de flujo TCP, el control de congestión TCP, o algo más? Detalle la explicación.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
� Busque los números de puertos bien conocidos a través de la página web http://www.iana.org/assignments/port-numbers. Cuál es el número de puerto asignado a cada uno de estos servicios: (a) FTP, (b) telnet, (c) SMTP, y (d) World Wide Web HTTP? ¿Estos servicios están disponibles utilizando TCP, UDP, o ambos? Qué servicios están asociados a los puertos 13 y 17 respectivamente?
� En lugar de utilizar el esquema de Internet que usa el número de puerto del protocolo como parte de la dirección para la entrega de datos a un proceso en una determinada máquina, considere un esquema alternativo donde el proceso se localiza utilizando un identificador de proceso único (PID), de forma que el sistema operativo UNIX se encarga de asignar dicho identificador a cada proceso activo. Obsérvese que el PID se asigna de forma dinámica a cada proceso cuando se crea, de forma que no es posible conocer a priori el identificador del proceso. Además, el rango de valores para los PID varía de un sistema a otro. ¿Cuáles son los problemas, si existen, de este esquema de direcciones?
� Investigue acerca de las políticas y mecanismos de seguridad de dos empresas de su
elección. � Describa algunas formas en las que es vulnerable el correo electrónico a la
indiscreción, suplantación, modificación, repetición y denegación del servicio. Sugiera métodos por los que se pudiera proteger el correo electrónico contra cada una de éstas formas de ataque.
� Traduzca el documento RFC-2979 el cual define las características de
comportamiento y requerimientos de interoperabilidad para los cortafuegos de Internet. Plantea dichos requerimientos como un paso inicial necesario para hacer consistente el comportamiento de los cortafuegos en distintas plataformas, de acuerdo con las prácticas aceptadas del protocolo IP. (Ayuda: http://www.ietf.org/rfc/rfc2979.txt)
� Utilice el algotimo RSA para el cifrado y descifrado de la palabra "SECRETO"
(empleando código ASCII), tome valores pequeños de los parámetros para simplificar los cálculos: p=3, q=11 y d=7.
� Cómo podría enviarse un correo electrónico a una lista de receptores utilizando PGP o
un esquema similar? � Que es un Proxy caché y que ventajas representa su instalación en una empresa
donde los empleados utilizan Internet frecuentemente. Elabore un cuadro de herramientas Proxy-Cache para plataformas LINUX® y WINDOWS® 2003 SERVER.
� Supóngase que los nodos A, B, y C pueden atacar a la misma LAN de difusión (a
través de sus adaptadores). Si A envía miles de datagramas IP a B encapsulando con cada marco dirigido a la LAN la dirección de B, ¿procesará estos marcos el adaptador de C? Si lo hace, ¿pasará el adaptador de C los datagramas IP en estos marcos a C (es decir, el nodo padre del adaptador)? ¿Cómo cambiarían sus respuestas si A enviara marcos con la dirección de difusión de la LAN?

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
UNIDAD 3
Nombre de la Unidad APLICACIONES DISTRIBUIDAS Introducción Esta unidad se dedica a presentar un selecto grupo de
aplicaciones distribuidas, analizando en primer lugar los sistemas operativos distribuidos y en especial el sistema CORBA, detallando sus elementos intrínsecos y la importancia de su aplicación en las organizaciones para tomar ventaja de los ambientes distribuidos. El siguiente capítulo se enfoca en el análisis de los sistemas de archivos distribuidos y su amplia utilización en entornos informáticos heterogéneos. Se estudia en particular el sistema NFS (Network File System) de Sun gracias a su flexibilidad y amplia acogida. Debido a las inmensas perspectivas futuras que tienen los Servicios Web, se dedica el tercer capitulo para su estudio. Se presentan en detalle, aspectos como el uso de tecnologías como XML, SOAP, WSDL, UDDI, WSFL y la web semántica. La unidad finaliza con un capitulo dedicado al conocimiento en profundidad del sistema de nombres de dominio (DNS) y de los sistemas de gestión distribuida, tan necesarios para tener un control centralizado de cada unos de los componentes de un sistema distribuido.
Justificación Las diversas aplicaciones de los sistemas distribuidos están revolucionando el uso que se hace de los elementos informáticos y a su vez están marcando la pauta para cada una de las tecnologías emergentes, en especial las relacionadas con las aplicaciones multimedia, los sistemas de comunicaciones móviles, los servicios de búsqueda en Internet, y la computación distribuida, entre otros.
Intencionalidades Formativas
Que el estudiante conozca los aspectos intrínsecos de los principales tipos de aplicaciones distribuidas a fin de que puedan servirle de base para el planteamiento de nuevas aplicaciones.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Que el estudiante exprese en forma verbal los requerimientos para la conformación de grupos de trabajo, los roles, y las diferentes etapas que se requieren para la implementación de un sistema distribuido, teniendo en cuenta la información consultada al respecto y su conocimiento de las arquitecturas. Que el estudiante determine y sustente la aplicación de los sistemas distribuidos según su arquitectura, tendencias y perspectivas, usando estrategias que le faciliten el acceso a la información, obtención de fuentes bibliográficas y el fomento del espíritu investigativo.
Denominación de capítulos
Cap. 1. Sistemas Operativos Distribuídos - CORBA Cap. 2. Sistemas de Archivos Distribuidos Cap. 3. Servicios WEB Cap. 4. Otras Aplicaciones Distribuidas

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
CAPITULO 1: SISTEMAS OPERATIVOS DISTRIBUIDOS - CORB A
Introducción
Al extender el concepto de administración de recursos e interfaces con el usuario, hacia computadores de memoria compartida se forma un sistema Operativo Distribuido, el cual consiste en varios computadores autónomos conectados por una red de comunicaciones. Un sistema operativo distribuido se ejecuta sobre un sistema distribuido haciendo creer a los usuarios que se trata de un sistema centralizado. Teniendo en cuenta el creciente auge del sistema CORBA como base de los Sistemas Operativos Distribuidos, se analizará en el presente capítulo.
Lección 1: Fundamentos de CORBA
Se define a CORBA105 como una especificación de Sistema Operativo Distribuido y representa la sigla Common Object Request Broker Architecture (Arquitectura de Mediador de Peticiones a Objetos Comunes). Es un estándar que establece una plataforma de desarrollo de sistemas distribuidos facilitando la invocación de métodos remotos bajo un paradigma orientado a objetos. El desarrollo de CORBA está controlado por el Grupo de Administración de Objetos (OMG / Object Management Group)106 que define las APIs, el protocolo de comunicaciones y los mecanismos necesarios para permitir la interoperabilidad entre diferentes aplicaciones escritas en diversos lenguajes y ejecutadas en múltiples plataformas, lo que es fundamental en computación distribuida. Debido al carácter “abierto ” de CORBA, un objeto creado en UNIX puede ser llamado por programas ejecutándose en plataformas MAC®, WINDOWS®, LINUX®, etc.
105 http://www.ietf.org/rfc/rfc2714.txt 106 http://www.omg.org

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
1. Por que usar CORBA
La principal razón por la cual CORBA es importante, es que la mayoría de los negocios de hoy viven en un mundo conectado por redes de computadores y en el cual los usuarios necesitan compartir información. Esta información puede venir de aplicaciones stand-alone (monousuario) de múltiples plataformas heterogéneas de hardware y software, y solo unas pocas de estas aplicaciones están diseñadas para interoperar con otras aplicaciones en sus propias plataformas. Y si lo anterior ocurre, únicamente pueden interoperar con muy pocas aplicaciones.
Integrar aplicaciones y sistemas aislados no es fácil y se requieren convertidores entre formatos de datos y protocolos de comunicación. Esto requiere una solución personalizada que consume tiempo y es costosa debido al número de diferentes aplicaciones que necesitan ser conectadas. Es imposible reusar componentes de software que han sido escritos para plataformas incompatibles. Además los componentes no interoperan eficientemente con soluciones de integración propietarias dado que las aplicaciones no fueron diseñadas teniendo en cuenta la interoperatividad. Una pobre integración lleva a una ineficiencia organizacional que se manifiesta en datos redundantes y múltiples pasos de conversión de los mismos. Estos procesos son costosos, consumen tiempo y son propensos al error. Desde la perspectiva de los usuarios, la pobre integración resulta en la constante necesidad de aprender de aplicaciones dispares ya que sus propias habilidades no pueden ser transferidas de un sistema a otro.
Por ejemplo, los administradores para tomar sus decisiones, necesitan ser capaces de reunir datos a partir de varias fuentes sobre la red (gráficos del dpto. de mercadeo, hojas de cálculo del departamento de finanzas, datos de contabilidad, etc), incluyendo tanto datos actuales como históricos. O como ocurre en las grandes compañías, las cuales a menudo tienen sistemas que han estado evolucionando por varias décadas incluyendo mainframes, PCs, LANs, WANs107, y múltiples sistemas de administración de bases de datos. Estos sistemas ejecutan un conjunto variado de aplicaciones en diversos sistemas operativos (UNIX, NOVELL®, LINUX®, WINDOWS®, MAC® etc). Los cambios frecuentes en el entorno de software debido a las nuevas necesidades de los negocios, nuevas tecnologías y cambios organizacionales pueden ser realizados más eficientemente en un entorno integrado.
107 Ver terminos ampliados en el glosario

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
2. Perspectiva tecnológica
Técnicamente se define a CORBA como una especificación middleware para una librería de Software � el Mediador de Peticiones a Objetos (ORB / Object Request Broker / ORB), con interfaces de objetos estandarizadas que permiten a los objetos software “hablar ” unos con otros a través de una red de una manera “bien definida ”. Además CORBA automáticamente aplica un amplio rango de útiles servicios para comunicaciones y lo más atractivo es que todo esto lo hace “ampliamente transparente ” al programador de aplicaciones. Una vez se inicializa el ORB, todos los objetos CORBA pueden ser invocados como objetos de software normales.
El término genérico para objetos como CORBA es middleware (software que reside entre una aplicación y los trabajos inherentes del sistema anfitrión (host) de la aplicación). El middleware aísla las aplicaciones de los detalles y complejidades de bajo nivel del software de manera que el desarrollador de la aplicación sólo tiene que tratar con una simple API. El middleware maneja otros detalles tales como mediar la comunicación para objetos remotos. En lugar de codificar para sistemas operativos o interfaces de bajo nivel, el desarrollador de aplicaciones puede usar el middleware para trabajar en un alto nivel con la aplicación.
Lección 2: Características de CORBA
CORBA es un middleware de comunicaciones ya que aísla la aplicación de los detalles del kernel de comunicaciones y desde la perspectiva técnica su arquitectura presenta las siguientes características de diseño:
1. Transparencia
CORBA oculta, al programador de aplicaciones, muchas de las dificultades inherentes de la computación de objetos distribuidos. Todas las invocaciones de métodos en objetos remotos son manejadas transparentemente por CORBA. Para el programador de aplicaciones todas las llamadas a objetos serán invocaciones locales, y no necesita saber donde están localizados los objetos en la red.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Además, CORBA automáticamente suministra un número de útiles servicios para comunicaciones de red, tales como procesamiento de transacciones o nombrado (naming). La mayoría de estos servicios pueden ser comprados como paquetes de software añadidos (add-on) y pueden ser instalados dentro del ORB para añadir la funcionalidad requerida a CORBA.
El hecho de que CORBA sea ampliamente transparente en el nivel de Aplicación, simplifica la programación de aplicaciones en sistemas distribuidos y, por lo tanto, puede reducir los costos de desarrollo de aplicaciones. Igualmente, los programadores de aplicaciones no requieren ser especialistas en CORBA para usarlo.
2. Independencia de Plataforma
CORBA tiene su propio lenguaje para describir interfaces de objetos, llamado Lenguaje de Definición de Interfaces (IDL / Interface Definition Language) el cual puede ser compilado en una variedad de lenguajes de programación y plataformas. De esta manera, las interfaces CORBA son independientes del lenguaje de programación usado para implementar los objetos cliente y servidor. Por ejemplo, es posible tener interfaces CORBA para un navegador (browser) basado en Java® del lado cliente, una aplicación PC basadas en C++, y una aplicación LINUX® basada en C del lado servidor. Todos estos objetos software pueden ser conectados a través de este ambiente heterogéneo con CORBA debido a que todas las interfaces de objetos tienen una representación IDL. CORBA también provee sus propios protocolos de comunicación, los cuales se ejecutan en la cima de una variedad de protocolos de red convencionales (Por ejemplo: TCP/IP)
3. Portabilidad
CORBA es una solución apropiada para evitar los costos de desarrollo innecesarios ya que muchos objetos software pueden ser reusados en varias partes del sistema. Esto es debido a que CORBA provee los mecanismos para acceder todos los objetos a través de las fronteras de plataformas y lenguajes de programación, lo cual significa que el software no necesita ser llevado a diferentes lenguajes de programación o plataformas.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
4. Integración
CORBA permite la integración de componentes de software de varias fuentes. Por ejemplo, un código Java® en un cliente web puede usar información de una base de datos servidor en un entorno LINUX®. La mayoría de las grandes empresas tienen un gran número de sistemas heredados con información crítica del negocio, los cuales no pueden ser llevados a modernos sistemas debido a incompatibilidades de formatos de datos y de protocolos de comunicación. En la práctica, la solución CORBA a este problema es su mayor atractivo, y muchas compañías desarrollan “envolturas ” (wrappers) CORBA para proveer una interfaz IDL a sus sistemas heredados.
5. Interoperatividad
La idea central detrás de CORBA es “que objetos en ejecución, en cumplimiento con productos CORBA de diferentes vendedores es posible”, debido a que CORBA especifica sus propios protocolos de comunicación y lenguajes de definición de interfaces estandarizados. Por lo tanto todos los productos que cumplan con el estándar CORBA deben ser capaces de interoperar.
6. Localización Transparente
CORBA hoy requiere ser capaz de soportar aplicaciones móviles, por ejemplo en entornos inalámbricos con dispositivos móviles donde a menudo los servidores cambian su ubicación. Estos objetos son comúnmente llamados nómadas y los “servicios de nombrado ” CORBA así como su mecanismo de invocación transparente a la localización, ofrecen los medios para ubicarlos.
7. Escalabilidad
CORBA fue ideado para soportar entornos con un gran número de objetos y usuarios potenciales. Por lo tanto la arquitectura CORBA no coloca restricciones al crecimiento tanto en el número de objetos como de usuarios en el sistema. De igual manera CORBA facilita la migración de plataformas pequeñas centralizadas a grandes entornos distribuidos.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
En un sentido general CORBA "envuelve " el código escrito en otro lenguaje en un paquete que contiene información adicional sobre las capacidades del código que contiene, y sobre cómo llamar a sus métodos. Los objetos que resultan pueden entonces ser invocados desde otro programa (u objeto CORBA) desde la red.
La figura 60 muestra como el código generado es usado dentro de la infraestructura CORBA:
Figura 60. Código generado en CORBA
Fuente: http://en.wikipedia.org/wiki/CORBA
Por lo general el lado del servidor tiene un adaptador de código portable que redirige todas las llamadas, o bien se a los servidores locales (para balancear la carga) o a servidores remotos.
Arquitectura de Gestión de Objetos de OMG
En 1989, el Grupo de Administración de Objetos (OMG / Object Management Group), el cual es actualmente el consorcio de software más grande del mundo (con mas de 800 miembros), fue creado para atender los problemas de desarrollo de aplicaciones distribuidas portables para sistemas heterogéneos. La filosofía era desarrollar un producto con abstracciones de alto nivel para ocultar detalles de bajo nivel. Es así como se produjo la primera especificación denominada Arquitectura de Administración de Objetos (OMA / Object Management Architecture) y su núcleo la especificación CORBA.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
OMA utiliza el Modelo de Referencia para proveer las categorías de interfaces, que son las agrupaciones generales para las categorías de objetos. La figura 61 muestra todas las categorías de interfaces que son conceptualmente enlazadas por un Mediador de Peticiones a Objetos (ORB / Object Request Broker). Generalmente un ORB habilita la comunicación entre Clientes y Objetos, activando transparentemente aquellos objetos que no están en ejecución al momento de recibir las solicitudes. Además, el ORB suministra una interfaz que puede ser usada directamente por los clientes así como por los objetos.
Figura 61. Categorías de Interfaz OMA.
Fuente: Autor
Lección 3: Los servicios y componentes de CORBA
1. Servicios de CORBA
Los servicios de objetos son construcciones de bloques de software orientados horizontalmente que son fundamentales para el desarrollo de aplicaciones distribuidas CORBA y dan las bases para la interoperatividad de aplicaciones. Además son independientes del dominio y proveen la funcionalidad para las aplicaciones CORBA de tal manera que los desarrolladores de aplicaciones pueden “llamar ” funciones de servicios de objetos sin necesidad de “escribir ” y

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
“llamar ” sus propias funciones de servicios de objetos privadas. La Especificación de Servicios de Objetos Comunes CORBA, desarrollada por OMG define múltiples servicios CORBA, de los cuales los más representativos serán descritos a continuación:
Servicio de Nombres: Provee la habilidad de enlazar un Nombre a un Objeto dentro de un contexto de nombrado (como un directorio Telefónico). El contexto de nombrado, usado para localizar un objeto en la red, es un objeto que contiene un conjunto de enlaces a nombres donde cada nombre es único.
Servicio de Eventos: Suministra interacciones asíncronas entre objetos anónimos. Soporta eventos asíncronos y no requiere un servidor centralizado. Los proveedores pueden generar eventos sin conocer la identidad de los consumidores y los consumidores pueden recibir eventos desconociendo las identidades de los proveedores.
Servicio de Ciclo de Vida: Trata con la vida, muerte y reubicación de objetos. Define las operaciones para copiar, mover y remover grafos de objetos relacionados.
Servicio de Transacción de Objetos: Define las interfaces que permiten que múltiples objetos distribuidos cooperen con el fin de proveer atomicidad108. Estas interfaces habilitan a los objetos a realizar “commit ” (acometer) todas las transacciones o “rollback ” (reversar) las mismas en presencia de alguna falla. Este servicio soporta múltiples modelos de transacción, así como la interoperabilidad entre diferentes modelos de programación y diferentes sistemas, incluyendo la capacidad de tener un servicio de transacción interoperando con otro en diferentes ORB.
Servicio de Control de Concurrencia: Habilita a múltiples clientes para acceder de manera coordinada a los recursos compartidos. El uso concurrente de los recursos es regulado con semáforos y cada semáforo se asocia con un recurso y un cliente particular.
Servicio de Licenciamiento: Suministra un mecanismo para que los productores controlen el uso de su propiedad intelectual. Los productores pueden implementar el servicio de licenciamiento de acuerdo con sus propias necesidades y las necesidades de los clientes. La tendencia actual es hacia el “licenciamiento de componentes ” en el cual los componentes tendrán que ser escritos para que
108 Una operación atómica es una operación que se ejecuta de forma indivisible, sin que se puedan observar estados intermedios en su ejecución.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
automáticamente se registren con “administradores de licencias ”. Este servicio permite medir el uso de los componentes y tarificar los mismos de manera flexible.
Servicio de Consultas: Permite a los usuarios y objetos invocar consultas en otras colecciones de objetos. Las consultas son declaraciones con sus respectivo atributos, que estructuradas en lenguajes procedimentales como SQL.
Servicio de Tiempo: Habilita a los usuarios a obtener el tiempo actual junto con un error estimado asociado a el. Determina el orden en que los eventos ocurrieron y computa el intervalo entre dos eventos. Mantener una noción única de tiempo es importante para ordenar los eventos en Sistemas de Objetos Distribuidos.
Servicio de Colecciones: Permite al usuario manipular objetos en “grupo” . Las colecciones son grupos de objetos que soportan algunas operaciones y exhiben comportamientos específicos que están relacionados a la naturaleza de las colecciones en lugar del tipo de objetos que ellas contienen. Ejemplos de colecciones son conjuntos, colas, pilas, listas y árboles binarios.
Servicio de Seguridad: Comprende los servicios de identificación y autenticación, autorización y control de acceso, seguridad y auditoria, seguridad de comunicación y administración.
2. Componentes de CORBA
La figura 62 ilustra los principales componentes de CORBA, los cuales se describen brevemente a continuación:
Figura 62. Componentes de CORBA
Fuente: http://jair.lab.fi.uva.es/~jperez/corba.pdf

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Cabo del Cliente ( Client Stub ): Cada cabo representa una operación sobre un objeto invocada por un cliente. El cliente está ligado al cabo de manera estática. Mediante esta interfaz el cliente invoca los servicios de los objetos conocidos en tiempo de compilación. La invocación se hace sobre un objeto local ya que el cabo es un proxy del servidor remoto.
Esqueleto de la Implementación (Implementation Skeleton ): Cada esqueleto proporciona una interfaz dependiente del lenguaje de la implementación del objeto, mediante la cual el ORB invoca las operaciones ofrecidas por dicho objeto. Equivale al cabo del lado del servidor.
Invocación Dinámica ( Dynamic Invocation): Es una interfaz mediante la cual un cliente puede construir e invocar dinámicamente operaciones sobre los objetos. Cuando los objetos invocados no se conocen en tiempo de compilación, es posible en tiempo de ejecución localizar el servicio deseado y construir la invocación pasando los parámetros requeridos.
Adaptador de Objetos ( Object Adapter ): Atiende la gestión de los recursos específicos del servidor. Facilita a las implementaciones de los objetos el acceso a los servicios del ORB, como la generación de referencias, y así mismo al ORB la realización de acciones sobre los objetos, como activación y desactivación, invocación de operaciones, etc.
Interfaz del ORB ( ORB Interface ): Es la interfaz para las operaciones del ORB comunes a todos los objetos. Por ejemplo, una referencia hacia un objeto puede ser convertida en una cadena de caracteres y viceversa.
Lección 4: Introducción a IDL
CORBA utiliza el lenguaje de definición de interfaces (IDL / Interface Definition Language) para especificar los interfaces con los servicios que los objetos ofrecerán. CORBA puede especificar a partir de este IDL la interfaz a un lenguaje determinado (Figura 63), describiendo cómo los tipos de dato CORBA deben ser utilizados en las implementaciones del cliente y del servidor. Implementaciones estándar existen para Ada, C, C++, Smalltalk, Java®. Perl y Python.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Figura 63. El Papel de IDL
Fuente: http://www.infor.uva.es/~fdiaz/so/IDL.pdf
IDL ofrece la sintaxis necesaria para definir los métodos que se desean invocar remotamente. Una vez creada esta interfaz se debe pasar por un compilador de interfaces que generará el proxy o stub cliente y el skeleton o stub servidor.
Al compilar una interfaz en IDL se genera código para el cliente y el servidor (el implementador del objeto). El código del cliente sirve para poder realizar las llamadas a métodos remotos. Es el conocido como Cabo (stub), el cual incluye un proxy (representante) del objeto remoto en el lado del cliente. El código generado para el servidor consiste en unos Esqueletos (skeletons) que el desarrollador tiene que rellenar para implementar los métodos del objeto.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Figura 64. Encapsulamiento IDL
Fuente: http://www.infor.uva.es/~fdiaz/so/IDL.pdf
Figura 65. Desarrollo IDL con Java®
Fuente: http://www.infor.uva.es/~fdiaz/so/IDL.pdf
El compilador IDL genera el cabo (stub) del lado del cliente y el esqueleto (skeleton) del lado del servidor. Esto puede hacerse en cualquier lenguaje soportado por el compilador, y además el cliente y el servidor no están obligados a utilizar el mismo lenguaje de programación. Finalmente, se agrega el código del servidor, es decir, el código correspondiente a la interfaz definida en IDL.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Figura 66. Desarrollo IDL con c++
Fuente: http://www.infor.uva.es/~fdiaz/so/IDL.pdf
Figura 67. Ejemplo de interfaz IDL
Fuente: http://www.infor.uva.es/~fdiaz/so/IDL.pdf

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Corba y Aplicaciones 109
La figura 68 ilustra el desarrollo de aplicaciones utilizando CORBA. El proceso empieza por la definición de las clases servidoras mediante el IDL, que es específico para CORBA.
Figura 68. Desarrollo de aplicaciones con CORBA
Fuente: http://jair.lab.fi.uva.es/~jperez/corba.pdf
El lenguaje Java® ha venido también a revolucionar las aplicaciones distribuidas con su aportación de código transportable (Figura 69). Java® se asocia perfectamente con la Web logrando una gran sinergia.
CORBA puede complementar estas tecnologías aportando la capacidad de hacer interoperar componentes escritos en diferentes lenguajes de programación e instalados sobre plataformas heterogéneas. CORBA puede aumentar así las opciones para construir las arquitecturas distribuidas abriendo la vía del futuro.
109 Si desea conocer las implementaciones CORBA existentes vea http://www.puder.org/CORBA/matrix/
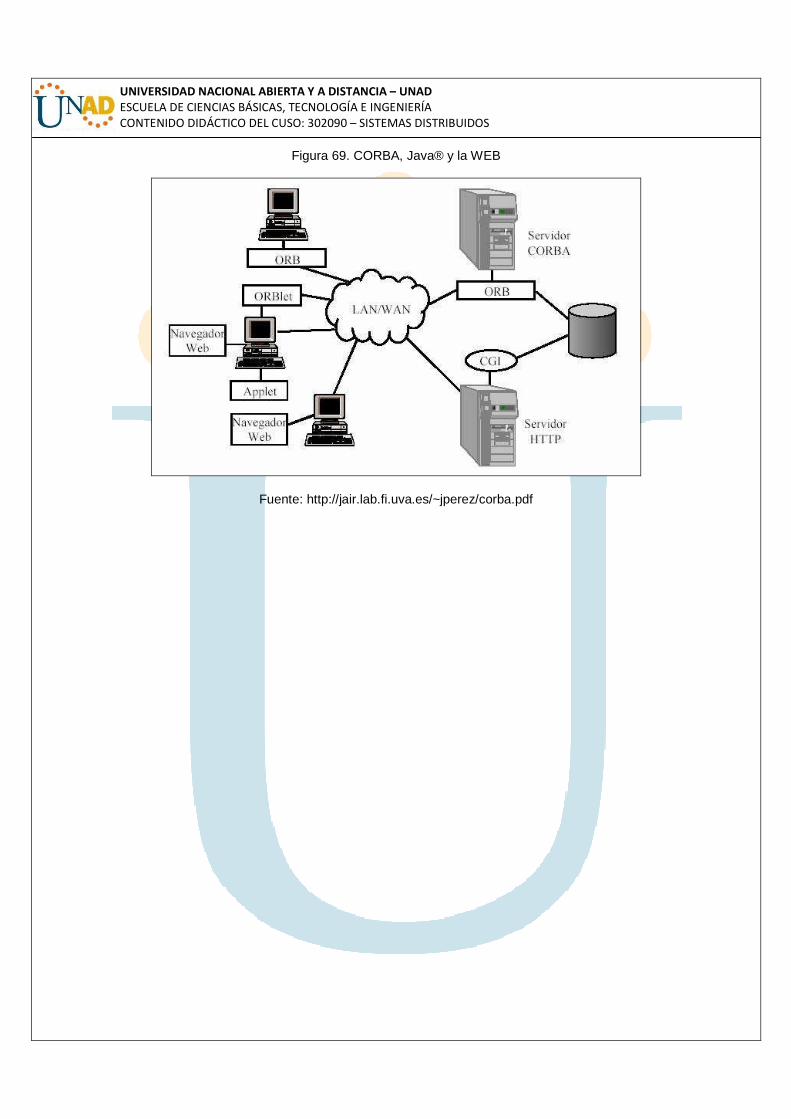
UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Figura 69. CORBA, Java® y la WEB
Fuente: http://jair.lab.fi.uva.es/~jperez/corba.pdf

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
CAPITULO 2: SISTEMAS DE ARCHIVOS DISTRIBUIDOS 110
Introducción
Los sistemas de archivos distribuidos soportan la compartición de información en forma de archivos a través de Internet. Un servicio de archivos bien diseñado proporciona acceso a los archivos almacenados en un servidor con prestaciones y fiabilidad semejantes (y en algunos casos mejor) que la de archivos almacenados en discos locales. Un sistema de archivos distribuidos permite a los programas almacenar y acceder a archivos remotos del mismo modo que si fueran locales, permitiendo a los usuarios que accedan a archivos desde cualquier computador en una intranet.
Un servicio de archivos permite a los programas almacenar y acceder a los archivos remotos del mismo modo que se hace con los locales, permitiendo a los usuarios acceder a sus archivos desde cualquier computador de una intranet. La concentración de almacenamiento persistente en unos pocos servidores reduce la necesidad de almacenamiento en disco local y (más importante) permite economizar la gestión y el archivo de datos persistentes pertenecientes a una organización. Otros servicios, como el servicio de nombres, el servicio de autenticación de usuarios y el servicio de impresión, pueden ser implementados más fácilmente si hacen llamadas al servicio de archivos, que satisface sus necesidades de almacenamiento permanente. Los servidores web dependen de los sistemas de archivos para el almacenamiento de las páginas web que sirven. En organizaciones que operan con servidores web para acceso externo e interno vía una intranet, los servidores web suelen almacenar y acceder al material desde un sistema de archivos local distribuido.
110 COULOURIS George, DOLLIMORE Jean y KINDBERG Tim (2001): “SISTEMAS DISTRIBUIDOS – Conceptos y Diseño”. Pearson – Addison Wesley.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Lección 5: Características de los Sistemas de Archi vos
Los sistemas de archivos son responsables de la organización, almacenamiento, recuperación, nominación (nombrado), compartición y protección de los archivos. Proporcionan una interfaz de programación característica de la abstracción de archivo, liberando a los programadores de la preocupación por los detalles de la asignación y la disposición del almacenamiento. Los archivos se almacenan en discos y otros medios de almacenamiento no volátiles.
Los archivos contienen datos y atributos. Los datos consisten en una secuencia de elementos de datos (normalmente bytes de 8 bits), donde cualquier porción de ésta es accesible mediante operaciones de lectura y escritura. Los atributos se alojan como un único registro que contiene información como la longitud del archivo, marcas de tiempo, tipo del archivo, identidad del propietario y listas de control de acceso.
En la figura 70 se aprecia una estructura típica del registro de atributos.
Figura 70. Estructura del registro de atributos de un archivo
Tamaño del Archivo
Marca temporal de creación
Marca temporal de lectura
Marca temporal de escritura
Marca temporal de atributos
Contador de referencias
Propietario
Tipo de Archivo
Lista de control de acceso
Fuente: COULOURIS George, SISTEMAS DISTRIBUIDOS, Addison Wesley, Madrid, 2001, 3ª Ed.
Los atributos resaltados son administrados por el sistema de archivos y no son modificables habitualmente desde los programas del usuario.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Los sistemas de archivos están diseñados para almacenar y gestionar gran número de archivos, con posibilidades de crear, nombrar y borrar archivos. La nomenclatura de los archivos está respaldada por la utilización de directorios. Un directorio es un archivo, a menudo de un tipo especial, que relaciona los nombres en texto con los identificadores internos de los archivos. Los directorios pueden incluir los nombres de otros directorios derivando en el esquema familiar de nomenclatura jerárquica de archivos y los nombres de ruta, tanto para los archivos en LINUX®, UNIX como para otros sistemas operativos. Los sistemas de archivo tienen también la responsabilidad del control de acceso a los archivos, restringiendo el acceso a los mismos de acuerdo con las autorizaciones de los usuarios y el tipo de acceso solicitado (lectura, actualización, ejecución y demás).
El término metadato se utiliza a menudo para referirse a toda la información extra almacenada por un sistema de archivos, que es necesaria para la gestión de los mismos. Incluye los atributos de los archivos, los directorios y todas las demás informaciones persistentes empleadas por el sistema de archivos.
La figura 71 muestra una estructura típica de niveles para la implementación de un sistema de archivos no distribuido en un sistema operativo convencional.
Figura 71. Módulos de un sistema de archivos
Módulo de directorio Relaciona nombres de acuerdo con los ID de archivos
Módulo de archivos Relaciona ID de archivos con archivos concretos
Módulo de control de acceso Comprueba los permisos para una operación (lectura, escritura) solicitada
Módulo de acceso a archivos Lee o escribe datos o atributos de un archivo
Módulo de bloques Accede y asigna bloques de disco
Módulo de dispositivo Entrada/Salida de disco y búferes
Fuente: COULOURIS George, SISTEMAS DISTRIBUIDOS, Addison Wesley, Madrid, 2001, 3ª Ed.
Cada nivel depende sólo de los niveles que se encuentran debajo de él. La implementación de un servicio de archivos distribuidos requiere todos los componentes indicados, junto a componentes adicionales para ocuparse de la comunicación cliente-servidor y de la nomenclatura y ubicación de los archivos distribuidos.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Operaciones en el sistema de archivos
La figura 72 ilustra las principales operaciones básicas (primitivas) sobre archivos, que están disponibles para aplicaciones en sistemas LINUX®-UNIX. Ésas son las llamadas del sistema que implementa el núcleo (kernel), los programadores de aplicaciones normalmente acceden a ellas a través de bibliotecas de procedimientos, como la librería estándar de entrada-salida de C o las clases archivo de Java®.
Figura 72. Operaciones del sistema de archivo de LINUX®-UNIX
desarchivo = open(nombre, modo) Abre un archivo existente con un nombre determinado.
desarchivo = creat(nombre, modo) Crea un archivo nuevo con un nombre determinado.
Ambas operaciones devuelven un descriptor de archivo que referencia el archivo abierto. El modo es read, write u otro.
estado = close(desarchivo) Cierra el archivo abierto desarchivo .
recuento = read(desarchivo, búfer, n) Transfiere n bytes del archivo referenciado por desarchivo sobre búfer .
recuento = write(desarchivo, búfer, n) Transfiere n bytes al archivo referenciado por desarchivo desde búfer .
Ambas operaciones retornan el número de bytes transferidos realmente y adelanta el apuntador de lectura-escritura.
pos = Iseekf(desarchivo ,despl, desde) Desplaza el puntero de lectura-escritura hasta despl.
(relativo o absoluto, dependiendo del valor de desde ).
estado = unlink(nombre) Elimina el nombre de archivo de la estructura de directorios. Si e! archivo no tuviera otros nombres, sería también eliminado.
estado = Iink(nombre1, nombre2)
Añade un nombre nuevo (nombre2 ) a un archivo (nombre1 ).
estado = stat(nombre, búfer) Obtiene los atributos de archivo del archivo nombre sobre búfer .
Fuente: COULOURIS George, SISTEMAS DISTRIBUIDOS, Addison Wesley, Madrid, 2001, 3ª Ed.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Se presentan estas primitivas como una indicación de las operaciones que se espera que los servicios de archivo soporten. Las operaciones de LINUX®-UNIX se basan en un modelo de programación en el que se almacena cierta información del estado de un archivo, por el sistema de archivos, para cada programa que lo use. El sistema registra una lista de los archivos abiertos actualmente con un apuntador de lectura-escritura para cada uno, que proporciona la posición en el archivo en la que se aplicará la siguiente operación de lectura o escritura.
El sistema de archivos es responsable de aplicar el control de acceso para los archivos. En sistemas de archivos locales como en LINUX®-UNIX, esto se hace cada vez que se abre un archivo, comprobando los derechos permitidos para la identidad del usuario mediante la lista de control de acceso contra el modo de acceso solicitado en la llamada del sistema open . Si los derechos concuerdan con el modo, el archivo es abierto y el modo se almacena en la información del estado del archivo abierto.
Lección 6: Requisitos del sistema de archivos distr ibuidos
Muchos de los requisitos y potenciales obstáculos en el diseño de servicios distribuidos fueron ya observados en los primeros desarrollos de sistemas de archivos distribuidos. Inicialmente ofrecían transparencia de acceso y transparencia de ubicación, los requisitos de prestaciones, escalabilidad, control de concurrencia, tolerancia a fallos y seguridad surgieron y se fueron satisfaciendo en fases posteriores del desarrollo. A continuación se presentan los principales requisitos a considerar para el desarrollo de un sistema de archivos distribuidos.
1. Transparencia
El servicio de archivos es el servicio más fuertemente cargado en una intranet, por lo que su funcionalidad y prestaciones son críticas. El diseño debe balancear la flexibilidad y escalabilidad que se derivan de la transparencia frente a la complejidad del software y las prestaciones. Las siguientes formas de transparencia son parcial o totalmente tratadas por los actuales servicios de archivos:
� Transparencia de acceso: los programas del cliente no deben preocuparse de la distribución de los archivos. Se proporciona un conjunto sencillo de operaciones para el acceso a archivos locales y remotos. Los programas

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
escritos para trabajar sobre archivos locales serán capaces de acceder a los archivos remotos sin modificación.
� Transparencia de ubicación: los programas del cliente deben ver un espacio de nombres de archivos uniforme. Los archivos o grupos de archivos pueden ser reubicados sin cambiar sus nombres de ruta, y los programas de usuario verán el mismo espacio de nombres en cualquier parte que sean ejecutados.
� Transparencia de movilidad: ni los programas del cliente ni las tablas de administración de sistema en los nodos cliente necesitan ser cambiados cuando se mueven los archivos. Esta movilidad de archivos permite que archivos o, más comúnmente, conjuntos o volúmenes de archivos puedan ser movidos, ya sea por los administradores del sistema o automáticamente.
� Transparencia de prestaciones: los programas cliente deben continuar funcionando satisfactoriamente mientras la carga en el servicio varíe dentro de un rango especificado.
� Transparencia de escala: el servicio puede ser aumentado por un crecimiento incremental para tratar con un amplio rango de cargas y tamaños de redes.
2. Actualizaciones concurrentes de archivos
Los cambios en un archivo por un cliente no deben interferir con la operación de otros clientes que acceden o cambian simultáneamente el mismo archivo. Este es el tema conocido del control de concurrencia. La necesidad de control de concurrencia para el acceso a datos compartidos en muchas aplicaciones está ampliamente aceptada y las técnicas para su implementación son conocidas, aunque muy costosas. La mayoría de los servicios de archivos actuales siguen los estándares de UNIX moderno proporcionando bloqueo consultivo u obligatorio a nivel de archivo o registro.
3. Replicación de archivos
En un servicio de archivos que soporta replicación, un archivo puede estar representado por varias copias de su contenido en diferentes ubicaciones. Esto tiene dos beneficios, permite que múltiples servidores compartan la carga de proporcionar un servicio a los clientes que acceden al mismo conjunto de archivos, mejorando la escalabilidad del servicio y mejorando la tolerancia a fallos, permitiendo a los clientes localizar otro servidor que mantiene una copia del archivo cuando uno ha fallado. Muy pocos servicios de archivos soportan totalmente la replicación, pero la mayoría soportan la caché local de archivos o porciones de archivos, una forma limitada de replicación.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
4. Heterogeneidad del hardware y del sistema operativo
Las interfaces del servicio deben estar definidas de modo que el software del cliente y el servidor pueden estar implementados por diferentes sistemas operativos y computadores. Este requisito es un aspecto importante de la extensibilidad.
5. Tolerancia a fallos
El papel central de un servicio de archivos en los sistemas distribuidos hace que sea esencial que el servicio continúe funcionando aun en el caso de fallos del cliente y del servidor. Afortunadamente un diseño moderadamente tolerante a fallos es inmediato para servidores sencillos. Los servidores pueden ser sin estado111, por lo que pueden ser reiniciados y el servicio restablecido después de un fallo sin necesidad de recuperar el estado previo. La tolerancia a la desconexión o fallos del servidor precisa de replicación de los archivos.
6. Consistencia
Los sistemas de archivos convencionales, como los que se proporcionan en UNIX, ofrecen una semántica de actualización de una copia. Esto se refiere a un modelo para acceso concurrente a archivos, en el que el contenido del archivo visto por todos los procesos que acceden o actualizan a un archivo dado, es aquel que ellos verían si existiera un única copia del contenido del archivo. Cuando los archivos están replicados, o en la caché, en diferentes lugares, hay un retardo inevitable en la propagación de las modificaciones hechas en un lugar hacia los otros lugares que mantienen copias, y esto puede producir alguna desviación de la semántica de una copia.
7. Seguridad
Virtualmente todos los sistemas de archivos proporcionan mecanismos de control de acceso basados en el uso de listas de control de acceso. En sistemas de archivos distribuidos, hay una necesidad de autenticar las solicitudes del cliente por lo que el control de acceso en el servidor está basado en identificar al usuario
111 Un servidor sin estado es aquel que no recuerda la historia de peticiones anteriores realizadas por los clientes.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
correcto y proteger el contenido de los mensajes de solicitud y respuesta con firmas digitales y (opcionalmente) encriptación de datos secretos.
8. Eficiencia
Un servicio de archivos distribuidos debe ofrecer posibilidades con la misma potencia y generalidad que las que se encuentran en los sistemas de archivos convencionales y deben proporcionar un nivel de prestaciones comparable.
Las técnicas utilizadas para la implementación de los servicios de archivo son una parte importante del diseño de sistemas distribuidos. Un sistema de archivos distribuidos debe proporcionar un servicio que sea comparable con, o mejor que, los sistemas de archivos locales en prestaciones y fiabilidad. Debe ser adecuado para administrar, proporcionando operaciones y herramientas que permitan a los administradores del sistema instalar y operar el sistema convenientemente.
Lección 7: Arquitectura del servicio de archivos
El alcance de la extensibilidad y configurabilidad se mejora si el servicio de archivos se estructura en tres componentes, un servicio de archivos plano, un servicio de directorio y un módulo cliente. Los módulos relevantes y sus relaciones se ven en la figura 73.
Figura 73. Arquitectura del Servicio de Archivos
Fuente: COULOURIS George, SISTEMAS DISTRIBUIDOS, Addison Wesley, Madrid, 2001, 3ª Ed.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
El servicio de archivos plano y el servicio de directorio exportan cada uno una interfaz, para su uso por los programas del cliente y sus interfaces RPC, consideradas conjuntamente, proporcionan un conjunto global de operaciones para acceso a archivos. El módulo cliente proporciona una interfaz de programación sencilla con operaciones sobre archivos semejantes a las encontradas en los sistemas de archivos convencionales. El diseño es abierto en el sentido que pueden utilizarse diferentes módulos cliente para implementar diferentes interfaces de programación, simulando las operaciones sobre archivos de una variedad de diferentes sistemas operativos y optimizando las prestaciones para diferentes configuraciones de hardware del cliente y el servidor. La división de las responsabilidades entre los módulos puede definirse como sigue:
1. Servicio de archivos planos
El servicio de archivos planos está relacionado con la implementación de operaciones en el contenido de los archivos. Se utilizan identificadores únicos de archivos (UFID / Unique File IDentifiers ) para referirse a los archivos en todas las solicitudes de operaciones del servicio de archivos plano. La división de responsabilidades entre el servicio de archivos y el servicio de directorio, está basada en la utilización de UFID. Cada UFID es una secuencia larga de bits elegidas de forma que cada archivo tiene un UFID que es único entre todos los archivos en un sistema distribuido. Cuando el servicio de archivos planos recibe una solicitud para crear un archivo, genera un nuevo UFID para él y lo devuelve al solicitante.
2. Servicio de directorio
El servicio de directorio proporciona una transformación entre nombres de texto para los archivos y sus UFID. Los clientes pueden obtener el UFID de un archivo indicando su nombre de texto al servicio de directorio. El servicio de directorio proporciona las funciones necesarias para generar directorios, para añadir nuevos nombres de archivo a los directorios y para obtener UFID desde los directorios. Es un cliente del servicio de archivos plano, sus archivos de directorio están almacenados en archivos del servicio de archivos plano. Cuando se adopta un esquema jerárquico de nominación de archivos, como en UNIX, los directorios mantienen referencias a otros directorios.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
3. Módulo cliente
En cada computador cliente se ejecuta un módulo de cliente, que integra y extiende las operaciones del servicio de archivos plano y el servicio de directorio bajo una interfaz de programación de aplicaciones sencilla, que estará disponible para los programas a nivel de usuario en los computadores cliente. Por ejemplo, en máquinas UNIX, se debe proporcionar un módulo cliente que emula el conjunto total de operaciones UNIX sobre archivos, interpretando los nombres compuestos de archivos UNIX mediante reiteradas solicitudes al servicio de directorio. El módulo cliente mantiene también información sobre las ubicaciones en la red del proceso servidor de archivos planos y del proceso servidor de directorio. Finalmente el módulo cliente puede jugar un papel importante consiguiendo unas prestaciones satisfactorias mediante la implementación de una caché de los bloques de archivos utilizados recientemente en el cliente.
4. Interfaz del servicio de archivos plano
La figura 74 contiene una definición de la interfaz para un servicio de archivos planos. Es la interfaz RPC utilizada por los módulos cliente. No es utilizada directamente por los programas a nivel de usuario. Un IdArchivo es inválido si el archivo a que se refiere no está presente en el servidor que procesa la solicitud o si sus permisos de acceso son inapropiados para la operación solicitada. Todos los procedimientos de la interfaz excepto Crea lanzan excepciones si el argumento IdArchivo contiene un UFID inválido o el usuario no tiene los derechos de acceso suficientes.
Figura 74. Operaciones del servicio de archivos plano
Lee(IdArchivo,i,n) � Datos
- lanza MalaPosición
Si 1 ≤ i ≤ Tamaño(Archivo): Lee una secuencia de hasta n elementos del archivo, partiendo del elemento i y la devuelve en Datos.
Escribe(IdArchivo,i,Datos)
- lanza MalaPosición
Si 1 ≤ i ≤ Tamaño(Archivo): Escribe una secuencia de datos sobre el archivo, partiendo del elemento i, y extendiendo el archivo si es preciso.
Crea() � Id Archivo Crea un nuevo archivo de tamaño 0 y obtiene un UFID para él.
Elimina(IdArchivo) Elimina el archivo del almacén de archivos
DameAtributos(IdArchivo) � Atrib Obtiene los atributos del archivo
PonAtributos(IdArchivo, Atrib) Pone los atributos del archivo

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Autor: COULOURIS George, SISTEMAS DISTRIBUIDOS, Addison Wesley, Madrid, 2001, 3ª Ed.
Las operaciones más importantes son las de lectura y escritura. Tanto la operación de lectura como la de escritura necesitan un parámetro i especificando una posición en el archivo. La operación de lectura copia la secuencia de n elementos de datos comenzando en el elemento i del archivo especificado en Datos que se devuelve entonces al cliente.
La operación Escribe copia la secuencia de elementos de datos de Datos en el archivo especificado comenzando en el elemento i, reemplazando el contenido anterior del archivo en la posición correspondiente y extendiendo el archivo si es necesario.
Crea crea un archivo nuevo, vacío y devuelve el UFID que se ha generado. Elimina borra el archivo especificado.
DameAtributos y PonAtributos permiten a los usuarios acceder al registro de los atributos. DameAtributos está disponible generalmente para cualquier usuario que acceda al archivo. El acceso a la operación PonAtributos suele estar restringida normalmente al servicio de directorio que accede al archivo. Los valores de la longitud y de las partes de marcas de tiempo del registro de atributos no son afectados por PonAtributos, son mantenidos por el servicio de archivos planos.
Lección 8: Sistema de archivos de red de SUN (NFS)
El sistema de archivos de red NFS (Network File System) fue desarrollado por la empresa Sun Microsystems y es un sistema de archivos distribuidos que opera en las plataformas LINUX® y UNIX. La figura 75 representa la arquitectura de NFS de Sun.
Todas las implementaciones de NFS soportan el protocolo de NFS: un conjunto de llamadas a procedimientos remotos que proporcionan el medio para que los clientes realicen operaciones en un almacén de archivos remotos. El protocolo NFS es independiente del sistema operativo pero fue desarrollado originalmente

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
para su utilización en redes de sistemas UNIX. Al emerger LINUX®, adopto éste sistema como estándar.
Figura 75. Arquitectura NFS
Fuente: COULOURIS George, SISTEMAS DISTRIBUIDOS, Addison Wesley, Madrid, 2001, 3ª Ed.
El módulo servidor NFS reside en el núcleo de cada computador que actúa como un servidor NFS. Las solicitudes que se refieren a archivos en un sistema de archivos remoto se traducen en el módulo cliente a operaciones del protocolo NFS y después se trasladan al módulo servidor NFS en el computador que mantiene el sistema de archivos relevante.
Los módulos cliente y servidor NFS se comunican utilizando llamadas a procedimientos remotos. El sistema RPC de SUN, se desarrolló para su uso en NFS. Puede configurarse para utilizar UDP o TCP, y el protocolo NFS es compatible con ambos. Incluye un servicio de enlace que permite a los clientes encontrar los servicios de una máquina a partir del nombre. La interfaz RPC para el servidor NFS es abierta: cualquier proceso puede enviar solicitudes a un servidor NFS. Si las solicitudes son válidas e incluyen credenciales válidas del usuario, serán ejecutadas. El envío de credenciales firmadas del usuario puede requerirse como una característica adicional de seguridad, como lo puede ser la encriptación de los datos para privacidad e integridad.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
A continuación se destacan las principales características del sistema NFS:
1. Sistema de archivos virtuales
La figura 75 expone claramente que NFS proporciona acceso transparente: los programas del usuario pueden realizar operaciones sobre los archivos locales o remotos sin distinción. Otros sistemas de archivos distribuidos pueden considerar que permiten las llamadas al sistema de UNIX, y si lo hacen, podrían integrarse de la misma forma.
La integración se obtiene mediante un módulo de sistema de archivos virtual (VFS / Virtual File System), que ha sido añadido al kernel de UNIX para distinguir entre archivos remotos y locales y para traducir los identificadores de archivo, independientes de UNIX, utilizados por NFS en los identificadores de archivo internos utilizados en UNIX y otros sistemas de archivos. En resumen, VFS mantiene la pista de los sistemas de archivos que están actualmente disponibles tanto local como remotamente, pasa cada solicitud al módulo del sistema local apropiado (el sistema de archivos UNIX, el módulo cliente NFS o el módulo de servicio de otro sistema de archivos).
Los identificadores de archivo utilizados en NFS se llaman apuntadores de archivo (Figura 76). Un apuntador de archivo es opaco para los clientes y contiene toda la información que necesita el servidor para distinguir un archivo individual. En las implementaciones UNIX de NFS, el apuntador de archivo se deriva del número de i-nodo del archivo, añadiendo dos campos extra como sigue (el número de i-nodo de un archivo UNIX es un número que sirve para identificar y localizar el archivo en el sistema de archivos en el que está almacenado):
Figura 76. Apuntador de archivo
Identificador del filesystem
Número de i-nodo del archivo
Número de generación de i-nodos
Fuente: Autor

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
NFS adopta el filesystem (volumen)112 montable de UNIX como la unidad de agrupación de archivos definida en la sección precedente. El campo identificador del volumen es un número único que se reserva para cada volumen cuando se crea (y en la implementación UNIX se almacena en el superbloque del sistema de archivos). La generación del número de i-nodo es necesaria porque en el sistema de archivos normal de UNIX los números de i-nodo se reutilizan después de la eliminación del archivo. En las extensiones VFS al sistema de archivos UNIX, se almacena un número de generación con cada archivo y se incrementa cada vez que se reutiliza el número de i-nodo (por ejemplo, en una llamada creat del sistema UNIX). El cliente obtiene el primer apuntador de archivo para un sistema de archivos remotos cuando lo monta. Los apuntadores de archivos se pasan del servidor al cliente en los resultados de las operaciones lookup, create y mkdir (consultar la figura 77) y del cliente al servidor en la lista de argumentos de todas las operaciones del servidor.
La capa del sistema de archivos virtual tiene una estructura VFS por cada sistema de archivos montado y un v-nodo por archivo abierto. Una estructura VFS relaciona un sistema de archivos remoto con el directorio local en el que está montado. El v-nodo contiene un indicador para mostrar si el archivo es local o remoto. Si el archivo es local, el v-nodo contiene una referencia al índice del archivo local (un i-nodo en una implementación UNIX). Si el archivo es remoto, contiene un apuntador al archivo remoto.
2. Integración del cliente
El cliente NFS juega el papel descrito para el módulo cliente en el modelo arquitectónico, proporcionado una interfaz idónea para su uso por programas de aplicación convencionales. Pero a diferencia del módulo cliente del modelo, emula la semántica de las primitivas del sistema de archivos estándar de UNIX de forma precisa y está integrado con el núcleo UNIX. Está integrado con el núcleo y no proporcionado como una librería para cargar en los procesos clientes de modo que:
� Los programas de usuario pueden acceder a los archivos mediante llamadas del sistema de UNIX sin recompilación o recarga.
112 El término filesystem (volumen) se refiere al conjunto de archivos mantenidos en un dispositivo de almacenamiento o partición.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
� Un único módulo cliente sirve a todos los procesos del nivel del usuario, con una caché compartida de los bloques utilizados recientemente.
� La clave de encriptación utilizada para autenticar las ID del usuario pasadas al servidor (ver más adelante) puede retenerse en el núcleo, previniendo la impersonación por clientes a nivel de usuario.
El módulo cliente de NFS coopera con el sistema de archivos virtual en cada máquina cliente. Funciona de una manera semejante al sistema de archivos convencional de UNIX, transfiriendo bloques de archivos hacia y desde el servidor y haciendo caching113 de los bloques en la memoria local cuando es posible. Comparte el mismo búfer de caché que el utilizado por el sistema de entrada-salida local. Pero puesto que varios clientes en diferentes máquinas pueden acceder simultáneamente al mismo archivo remoto, se plantea un nuevo y significativo problema de consistencia de caché.
3. Control de acceso y autenticación
A diferencia del sistema de archivos convencional UNIX, el servidor NFS es sin estado y no mantiene archivos abiertos en nombre de sus clientes. Por lo tanto el servidor debe comprobar la identidad del usuario frente a los atributos de acceso del archivo en cada solicitud, para ver si el usuario tiene permiso de acceso al archivo de la forma solicitada. El protocolo Sun RPC requiere que los clientes envíen la información de autenticación del usuario (por ejemplo, los convencionales 16 bits de la ID del usuario y del grupo de UNIX) con cada solicitud y ésta se comprueba frente a los permisos de acceso en los atributos del archivo. En aras de mejorar la seguridad de NFS, Recientemente, se ha integrado Kerberos 114 en Sun NFS para proporcionar una solución más fuerte y completa a los problemas de autenticación y seguridad del usuario.
113 Técnica consistente en duplicar datos de otros originales, con la propiedad de que los datos originales son costosos de acceder, normalmente en tiempo, respecto a la copia en el caché. Cuando se accede por primera vez a un dato, se hace una copia en el caché; los accesos siguientes se realizan a dicha copia, haciendo que el tiempo de acceso aparente al dato sea menor. 114 Kerberos es un protocolo de autentificación de red. Está diseñado para suministrar una potente autentificación para aplicaciones cliente/servidor usando criptografía secret-key. Una versión gratuita de este protocolo está disponible en el Massachusetts Institute of Technology (http://web.mit.edu/kerberos/).

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
4. Interfaz del servidor NFS
En la figura 77 se ve una representación simplificada de la interfaz RPC proporcionada por el servidor NFS (definida en RFC-1813115). Las operaciones NFS de acceso al archivo read, write, getattr y setattr son casi idénticas a las operaciones Lee, Escribe, DameAtributos y PonAtributos definidas en el modelo de servicio de archivos planos (Figura 69).
Figura 77. Operaciones del Servidor NFS (simplificado)
lookup(aadir, nombre) � aa, atrib Devuelve el apuntador del archivo y los atributos para el archivo nombre en el directorio aadir.
create(aadir, nombre, atrib) � aanuevo, atrib
Crea un nuevo archivo nombre en el directorio aadir con los atributos atrib y devuelve el nuevo apuntador de archivo y sus atributos.
remove(aadir, nombre) � estado Elimina el archivo nombre del directorio aadir.
getattr(aa) � atrib Devuelve los atributos del archivo aa. (Igual que la llamada UNIX stat.)
setattr(aa) � atrib Establece los atributos (modo, ID usuario, ID grupo, tamaño, tiempo de acceso y tiempo de modificación de un archivo). Si se pone el tamaño a 0 se trunca el archivo.
read(aa, despl, conteo) � atrib, datos Devuelve hasta conteo bytes de datos desde el archivo, comenzando en despl. También devuelve los atributos más recientes del archivo.
write(aa, despl, conteo, datos) � atrib Escribe conteo bytes de datos sobre el archivo, comenzando en despl. También devuelve los atributos del archivo tras la operación de escritura.
rename(aadir, nombre, destaadir, destnombre)� estado
Cambia el nombre del archivo nombre del directorio aadir en destnombre del directorio destaadir.
link(nuevoaadir, nuevonombre, aadir, nombre) � estado
Crea una entrada nuevonombre en el directorio nuevoaadir que se refiere al archivo nombre en el directorio aadir.
symlink(nuevoaadir, nuevonombre, texto) � estado
Crea una entrada nuevonombre en el directorio nuevoaadir, con un enlace simbólico con el valor texto. El servidor no interpreta texto pero crea un archivo de enlace simbólico para alojarlo.
115 http://www.ietf.org/rfc/rfc1813.txt

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
readlink(aa) � texto Devuelve el texto asociado con el archivo de enlace simbólico identificado por aa.
Medir(aadir, nombre, atrib) � nuevoaa, atrib
Crea un nuevo directorio nombre con los atributos atrib y devuelve el nuevo apuntador de archivo (nuevoaa) y sus atributos.
rmdir(aadir, nombre) � estado Elimina el directorio vacío nombre del directorio padre aadir. Falla si el directorio no está vacío.
readdir(aadir, cookie, conteo) � entradas Devuelve conteo bytes de entradas de directorio desde el directorio aadir. Cada entrada contiene un nombre de archivo, un apuntador a archivo, y un puntero opaco a la siguiente entrada del directorio, denominado cookie (galletita). cookie se emplea en las siguientes llamadas a readdir para comenzar la lectura desde la siguiente entrada. Si se pone el valor de cookie a 0, lee desde la primera entrada.
statfs(aa) � estadosf Devuelve información sobre el sistema de archivos (tal como tamaño de bloque, número de bloques libres y demás) para el sistema de archivos que contiene el archivo aa.
Fuente: COULOURIS George, SISTEMAS DISTRIBUIDOS, Addison Wesley, Madrid, 2001, 3ª Ed.
Las operaciones de archivo y directorio están integradas en un único servicio, la creación e inserción de nombres de archivo en directorios se realiza en una única operación create que toma el nombre del nuevo archivo y el apuntador de archivo del directorio destino (aadir) como argumentos. Las otras operaciones NFS sobre directorios son create, remove, rename, link, sym-link, readlink, mkdir, rmdir, readdir y statfs.
5. Servicio de montado
El montado de los sub-árboles de los sistemas de archivos remotos por los clientes está soportado por un proceso de servicio de montado separado que se ejecuta a nivel de usuario en cada computador servidor NFS. En cada servidor, hay un archivo con un nombre bien conocido (/etc/exports) conteniendo los nombres de los sistemas de archivos locales que están disponibles para montado remoto. Se asocia una lista de acceso con cada nombre del sistema de archivos indicando qué máquinas están autorizadas para montar el sistema de archivos.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Los clientes utilizan una versión modificada del comando mount de UNIX para solicitar el montado de un sistema de archivos remoto, especificando el nombre de la máquina remota, el nombre de la ruta de un directorio en el sistema de archivos remoto y el nombre local con el que va a ser montado. El directorio remoto puede ser cualquier sub-árbol del sistema de archivos remoto solicitado, permitiendo a los clientes montar cualquier parte del sistema de archivos remoto.
El comando mount modificado comunica con el proceso del servicio de montado en la máquina remota, utilizando un protocolo de montado. Éste es un protocolo RPC e incluye una operación que toma un nombre de ruta de directorio y devuelve el asidero de archivo del directorio especificado si el cliente tiene permiso de acceso para el sistema de archivos relevante. La ubicación (dirección IP y número de puerto) del servidor y el asidero de archivo para el directorio remoto se pasan a la capa VFS y al cliente NFS.
La figura 78 muestra un cliente con dos almacenes de archivos montados remotamente. Los nodos gente y usuarios en los sistemas de archivos en el Servidor 1 y Servidor 2 están montados sobre los nodos estudiantes y personal en el almacén de archivos local del cliente. El significado de esto es que programas que se ejecuten en cliente pueden acceder a archivos en Servidor 1 y Servidor 2 utilizando nombres de ruta como /usr/estudiantes/jon y /usr/personal/ana.
Figura 78. Sistemas de archivos locales y remotos accesibles desde un cliente NFS
Fuente: COULOURIS George, SISTEMAS DISTRIBUIDOS, Addison Wesley, Madrid, 2001, 3ª Ed.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
6. Fortalezas de NFS
NFS de Sun se ajusta fuertemente al modelo de arquitectura de un sistema de archivos distribuidos. NFS soporta hardware y sistemas operativos heterogéneos. La implementación del servidor NFS es sin estado, permitiendo a los clientes y servidores recuperar la ejecución después de un fallo sin necesidad de ningún procedimiento de recuperación. La migración de archivos o sistemas de archivos no está soportada, excepto en el nivel de intervención manual para reconfigurar las directivas de montado después de un movimiento de un sistema de archivos a una nueva ubicación.
Los otros aspectos de diseño de NFS y las ventajas que con ellos se consiguen, se presentan a continuación:
Transparencia de acceso: el módulo cliente NFS proporciona una interfaz de programación de aplicación para los procesos locales que es idéntica a la interfaz del sistema operativo local. Por tanto en un cliente UNIX-LINUX®, los accesos a archivos remotos se realizan utilizando llamadas al sistema normales de UNIX. No se precisa modificar los programas existentes para poder trabajar correctamente con archivos remotos.
Transparencia de ubicación: cada cliente establece un espacio de nombres de archivo añadiendo directorios montados en volúmenes remotos sobre su espacio local de nombres. Los sistemas de archivos han de ser exportados por el nodo que los mantiene y montados remotamente por un cliente antes que ellos puedan ser accedidos por procesos ejecutándose en el cliente (Figura 78). El punto de la jerarquía de nombres del cliente donde aparece montado remotamente un sistema de archivos lo determina el cliente, por tanto NFS no fuerza un espacio de nombres de archivo único a través de la red; cada cliente ve un conjunto de sistemas de archivos remotos que es determinado localmente, y los archivos remotos pueden tener diferentes nombres de ruta en diferentes clientes, pero se puede establecer un espacio de nombres uniforme en cada cliente mediante las tablas de configuración apropiadas, logrando el objetivo de transparencia de ubicación.
Transparencia de movilidad: los volúmenes (en el sentido UNIX-LINUX®, esto es, subárboles de archivos) pueden ser reubicados entre servidores, pero las tablas de montado remoto en cada cliente deben ser actualizadas separadamente para permitir a los clientes el acceso al sistema de archivos en su nueva ubicación, por lo que la transparencia de migración no está totalmente conseguida en NFS.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Escalabilidad: las cifras de prestaciones publicadas muestran que se pueden construir servidores NFS que mantengan cargas reales muy grandes, de una manera eficiente y beneficiosa. Se pueden incrementar las prestaciones de un único servidor mediante la adición de procesadores, discos y controladores. Cuando los límites de esos procesos son alcanzados, hay que instalar servidores adicionales y los sistemas de archivos deben ser reubicados entre ellos.
Replicación de archivos: los almacenes de archivos de sólo lectura pueden ser replicados en varios servidores NFS, pero NFS no soporta la replicación de archivos actualizables. El Servicio de Información de Red de Sun (NIS / Network Information Service) es un servicio separado disponible para su uso con NFS que soporta la replicación de bases de datos sencillas organizadas como pares clave-valor (por ejemplo, los archivos del sistema UNIX /etc/passwd y /etc/hosts). NIS proporcionan un almacén compartido para información del sistema que cambia infrecuentemente y no requiere que las actualizaciones ocurran simultáneamente en todos los sitios.
Heterogeneidad del hardware y del sistema operativo : NFS ha sido implementado para casi todos los sistemas operativos y plataformas hardware conocidos y está soportado por una variedad de sistemas de archivos.
Tolerancia a fallos: cuando un servidor falla, el servicio que proporciona se suspende hasta que se reinicia el servidor, pero una vez que ha sido reiniciado los procesos cliente a nivel de usuario proceden desde el punto en el que fue interrumpido el servicio sin darse cuenta del fallo. El fallo de un computador cliente o de un proceso a nivel de usuario en un cliente no tiene efecto sobre ningún servidor que el pueda estar utilizando, puesto que los servidores no mantienen el estado en nombre de sus clientes.
Seguridad: las necesidades de seguridad en NFS sólo emergen al conectar la mayoría de las intranets con Internet. La integración de Kerberos116 con NFS fue un salto fundamental hacia delante. Otros desarrollos recientes incluyen la opción de utilizar una implementación RPC segura (RPCSEC- GSS, documentada en RFC-2203117) para la autenticación y la privacidad y seguridad de los datos transmitidos con las operaciones de lectura y escritura.
Eficiencia: las prestaciones medidas de varias implementaciones de NFS y su amplia adopción para uso en situaciones que generan cargas muy pesadas son indicaciones claras de la eficiencia con la que puede ser implementado el protocolo NFS. 116 Ver concepto ampliado en el glosario. 117 http://www.ietf.org/rfc/rfc2203.txt

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
CAPITULO 3: SERVICIOS WEB
Introducción
En los apartados anteriores se ha hecho gran énfasis en la distribución de la “lógica de la aplicación ” sobre la red mediante tecnologías distribuidas como CORBA, DCOM y RMI.
La evolución de los entornos Web en las Organizaciones ha llevado a replantear la distribución de la “lógica de la aplicación ” sobre la WEB y es así como surge el concepto de Servicios Web, el cual es considerado como una enorme API de servicios (Web de Componentes).
Los Servicios Web tienen una especial aplicación en los siguientes entornos:
• Empresas de Valor Agregado (B2B / Business to Business, Negocio a Negocio) • Sistemas distribuidos sobre Internet
Figura 79. Niveles de Aplicaciones Web
Fuente: Autor

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Figura 80. Interacción de Aplicaciones Web con Objetos Distribuidos
Fuente: Autor
Los Servicios Web son una arquitectura distribuida en evolución que usan sus propias interfaces programas-programa, protocolos y servicios de registro de tal manera que posibilitan que aplicaciones de diferentes plataformas tecnológicas puedan utilizar “servicios ” de otras aplicaciones.
Un Servicio Web se aprovecha de la especificación de XML118, para definir tanto su descripción como los mensajes que recibe y produce. Algunas de sus características son:
� Interconecta aplicaciones distribuidas sobre Internet. � Utiliza protocolos Web estándar como HTTP, XML. � Semánticamente “encapsula ” funcionalidades discretas. � Se utiliza en sistemas débilmente acoplados con componentes reutilizables. � Dado que todas las comunicaciones se realizan en XML, los Servicios Web no
dependen de sistemas operativos específicos. De acuerdo con esto Java® puede hablar con ASP119, WINDOWS® con LINUX®, etc.
118 Lenguaje de Marcación Extensible (eXtensible Markup Language) 119 Servidor de Páginas Activo (Active Server Pages)

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Lección 9: Arquitectura y tecnologías básicas de lo s servicios web
La estructura de un Servicio Web está basada en una arquitectura de protocolos con funciones específicas según la figura 81.
Figura 81. Protocolos de Servicios Web
Fuente: http://bmrc.berkeley.edu/research/publications/1996/104/WS.pdf
A continuación se presentan de manera detallada cada uno de los componentes de la arquitectura basada en Servicios WEB.
1. XML
XML (eXtensible Markup Language / Lenguaje de Marcación Extensible).
Es un estándar en evolución que ha establecido un marco heterogéneo para compartir información sobre la Web. XML ha sufrido una evolución desde la simple representación de información estructurada hasta la posibilidad de compartir procesos.
1.1. Características
La tecnología XML para desarrollo de Servicios Web presenta las siguientes características:

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
� Puede ser leído tanto por máquinas como por personas (XML es texto, lo que permite que los expertos puedan depurar los archivos XML fácilmente con herramientas universales como el vi 120 o cualquier editor de texto).
� Los documentos XML siguen unas reglas de generación sencillas pero bien definidas que les hace fácilmente procesables y le permiten el intercambio de información sobre Internet.
� Utiliza el conjunto de caracteres UNICODE121, lo que facilita la internacionalización.
� Ayuda a descongestionar Internet, ya que gran parte del procesamiento se puede hacer en el cliente.
� XML Facilita encontrar lo que se está buscando: exactitud y agilidad. � Es Independiente de medio: para publicar contenidos en múltiples formatos. � Es Independiente de fabricante y de plataforma: para poder utilizar cualquier
herramienta estándar. � Permite que cualquier lenguaje creado con él puede ser analizado
sintácticamente por un procesador tan pequeño que puede ser incluido en un navegador Web.
� No es compatible con HTML, pero los documentos HTMLv4.0 son fácilmente convertibles a XML.
1.2. Documentos XML
Todo documento XML se caracteriza por utilizar marcado descriptivo, de manera que utiliza las etiquetas que delimitan una porción del documento y dicen lo que es. Los documentos comienzan con la instrucción de procesamiento:
<?xml version="1.0" ?>
que los identifican como documentos XML.
Ejemplo: Un correo electrónico
<?xml version="1.0" ?>
<!doctype email system "http://www.sitio.es/DTDs/em ail.dtd">
120 Vi es el editor de texto estándar utilizado en el sistema UNIX. 121 Código de caracteres de 16-Bits (definido por la norma ISO 10646) el cual soporta un máximo de 65536 caracteres y muy superior a los 256 que soporta el código ASCII.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
<email id="E1X108">
<head>
<from>
<name>Jesús Vegas</name>
<address>[email protected]</address>
</from>
<to>
<name>Fulanito</name>
<address>[email protected]</address>
</to>
<subject>Introducción a XML</subject>
</head>
<body>
<p>Este es el guión de la conferencia sobre XML.
Mira a ver qué te parece. Saludos, jvegas.</p>
<attach encoding="mime" name="ixml.html" />
</body>
</email>
2. SOAP
SOAP (Simple Access Object Protocol / Protocolo Simple de Acceso a Objeto)
Es un protocolo de aplicación simple y extensible basado en mensajes, que permite el intercambio de información estructurada y tipeada, entre aplicaciones en un entorno distribuido.
SOAP no define el uso de un protocolo de transporte como FTP o SMTP. El contenido del mensaje SOAP es independiente del protocolo que lo transporte. Debido a que HTTP es el protocolo de transporte más popular de Internet, SOAP describe una convención a usar cuando el transporte se realiza mediante HTTP.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
SOAP – RPC corresponde al protocolo usado para el transporte del mensaje SOAP. (Figura 82).
• La invocación RPC se mapea al request de HTTP. • La respuesta RPC se mapea al response de HTTP.
Figura 82. Operación del Protocolo SOAP – RPC
Fuente: http://bmrc.berkeley.edu/research/publications/1996/104/WS.pdf
Para realizar una invocación RPC es necesaria la siguiente información (Fig. 78):
Figura 83. Ejemplo de Mensaje SOAP
Fuente: http://bmrc.berkeley.edu/research/publications/1996/104/WS.pdf
• El URL del receptor del mensaje. • El nombre del procedimiento o método. • Los parámetros del procedimiento o método. Operación de SOAP Las figuras 84 y 85 describen paso a paso la operación del protocolo SOAP en un entorno distribuido:

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Figura 84. Operación SOAP – Proceso cliente
Fuente: http://bmrc.berkeley.edu/research/publications/1996/104/WS.pdf
Figura 85. Operación SOAP – Proceso Servidor
Fuente: http://bmrc.berkeley.edu/research/publications/1996/104/WS.pdf

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
3. WSDL
(Web Services Description Language / Lenguaje de descripción de Servicios Web)
Es un documento XML que describe la interfaz semántica y administración de llamada al Servicio Web. Las operaciones y mensajes se describen en forma abstracta y después se enlazan a un protocolo de red y a un formato de mensaje concreto.
Los elementos característicos de WSDL se presentan en la figura 86 y se describen a continuación:
Figura 86. Elementos WSDL
Fuente: Autor
� Mensajes (Message): Definición abstracta y escrita de los datos que se están comunicando.
� Tipos de Puerto (Port Type): Conjunto abstracto de las operaciones admitidas por uno o más puntos finales.
� Tipos (Type): Contenedor de definiciones del tipo de datos.
� Operaciones (Operations): Acción solicitada al servicio.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
� Enlaces (Binding 122): Especificación del protocolo y del formato de datos para un tipo de puerto determinado.
� Puertos (Port): Punto Final = Dirección de Red + Enlace (Binding)
� Servicios (Services): Colección de Puntos finales relacionados.
4. UDDI
(Universal Description, Discovery and Integration / Descripción Universal, Descubrimiento e Integración). Es una especificación usada para descubrir registros distribuidos de Servicios Web. Opera como un directorio en red para descubrir Servicios web. Como se aprecia en la figura 87 todos los Servicios web que la empresa ofrece deben determinarse a través de UDDI.
Figura 87. Integración WSDL - UDDI
Fuente: http://bmrc.berkeley.edu/research/publications/1996/104/WS.pdf
122 Proceso de establecer comunicaciones entre el driver del protocolo del dispositivo y el driver de la tarjeta de interfaz de red (NIC).

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
5. WSFL
(Web Services Flow Language / Lenguaje de Flujo de Servicios Web). Se trata de un sencillo lenguaje basado en XML y diseñado para representar flujos de Servicios Web que faciliten la creación de Orquestaciones de estos servicios.
Se define como orquestación de Servicios Web al concepto de recoger un conjunto de servicios para ofrecer una solución que se adapta a algún proceso de negocio.
Figura 88. Ejemplo de WSFL
Fuente: Autor
Según la figura 88, las actividades son las tareas a realizar mientras que los proveedores de servicios son los encargados de realizar dichas actividades.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Lección 10: Implementación de los servicios web
Al diseñar un Servicio Web se debe considerar lo siguiente: • El Servicio Web debe tener una interfaz pública definida en una gramática
común en XML, la interfaz debe describir todos los métodos disponibles a los clientes y especificar la “firma ” para cada método.
• Todo Servicio Web debe tener una forma de publicarse, debe existir una forma
de localizar el servicio y localizar su interfaz pública. Esto se realiza con UDDI (Universal Description Discovery and Integration / Descripción Universal Descubrimiento e Integración)
• Interoperabilidad entre ambientes de desarrollo: Tradicionalmente el
webmaster123 de una empresa debía decidir en que ambiente de desarrollo trabajar (“me voy por Java”, “me voy por Microsoft”, “me voy por Oracle”) y una vez decido ese ambiente de desarrollo se producía “un matrimonio ” con dicha plataforma. Al emplear Servicios Web se pueden desarrollar e integrar aplicaciones en plataformas heterogéneas.
A manera de conclusión se presenta un ejemplo ilustrativo (Figura 89) acerca de una plataforma operativa de Servicios Web:
Figura 89. Ejemplo de Servicios Web
Fuente: Autor
123 Persona responsable del matenimiento y administración de un sitio Web.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Se instala en Internet una agencia de viajes virtual cuya función es elaborar el mejor “paquete turístico ” a partir de un conjunto de condiciones (destinos, hoteles, precios, etc).
Una vez dadas las condiciones, en la agencia virtual se generan agentes inteligentes que indagan en la Web y reúnen toda la información necesaria para realizar el viaje.
Servicios web versus sistemas distribuidos tradicionales
Los Servicios Web presentan algunas diferencias sobre los sistemas distribuidos tradicionales:
• Escaso Acoplamiento: El cliente no necesita conocer nada acerca de la implementación del servicio al que está accediendo.
• Independencia del lenguaje de programación: El Servidor y el cliente no necesitan estar escritos en el mismo lenguaje.
• Independencia del modo de transporte: SOAP puede funcionar sobre múltiples protocolos de transporte como por ejemplo HTTP, HTTPS124, BEEP, JABBER, IIOP125, SMTP, FTP.
• Múltiples modos de invocación : Los Servicios Web soportan tanto invocación estática como invocación dinámica.
• Múltiples estilos de comunicación: Los Servicios Web soportan tanto comunicación síncrona (RPC) como comunicación asíncrona (Mensajería).
• Extensibilidad: Al estar basados en XML, los Servicios Web son fáciles de adaptar, extender y personalizar.
124 Protocolo de Transferencia de Hipertexto Seguro (Secure Hiper-Text Transfer Protocol) 125 Internet Inter-ORB Protocol . Parte de la arquitectura CORBA que permite la interacción sobre redes TCP/IP reemplazando al protocolo HTTP.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Lección 11: T endencias en servicios web – web semántica 126
La Web semántica es la idea de añadir metadatos semánticos a la World Wide Web. Esas informaciones adicionales —describiendo el contenido, el significado y la relación de los datos— deben ser dadas de manera formal, así que es posible evaluarlas automáticamente por máquinas. El destino es mejorar la World Wide Web ampliando la interoperabilidad entre los sistemas informáticos y reduciendo la mediación de operadores humanos.
Figura 90. Consulta en Web Semántica
Fuente: Autor
En la figura 90 se presenta un ejemplo simplificado de lo que puede llegar a ser una consulta en web semántica. Mediante una interfaz amigable se realiza una pregunta en lenguaje natural indagando acerca de los pediatras en Bucaramanga que atienden por el seguro social. El sistema a través de un entramado de datos distribuidos realiza la búsqueda y entrega la información solicitada.
Según Tim Berners-Lee (padre de la Web actual) la web semántica es una visión futura para “disponer datos en la Web definidos y enlazados de forma que puedan ser utilizados por las máquinas no solamente para visualizarlos sino también para: automatizar tareas, integrar y reutilizar datos entre aplicaciones”
126 http://es.wikipedia.org/wiki/Web_semantica

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
CAPITULO 4: OTRAS APLICACIONES DISTRIBUIDAS
Introducción
La presente unidad finaliza con un capitulo dedicado al conocimiento en profundidad del sistema de nombres de dominio (DNS) y de los sistemas de gestión distribuida, tan necesarios para tener un control centralizado de cada unos de los componentes de un sistema distribuido.
Lección 12: Fundamentos de DNS
El Sistema de Nombres de Dominio (del Inglés DNS / Domain Name System) es una base de datos distribuida y jerárquica que almacena información asociada a nombres de dominio en redes como Internet. Aunque como base de datos el DNS es capaz de asociar distintos tipos de información a cada nombre, los usos más comunes son la asignación de nombres de dominio a direcciones IP y la localización de los servidores de correo electrónico de cada dominio.
Actualmente el direccionamiento IP se basa en el protocolo IPv4 (Figura 91) en el cual cada dirección tiene una estructura A.A.A.A donde cada A corresponde a un valor entre 0 y 255. Todo equipo asociado a Internet o a una Intranet posee una dirección IP que determina su ubicación en la red. Debido a lo complicado que resulta el manejo de Internet con base en las direcciones IP, se utilizan los nombres de equipos con su correspondiente dominio.
Por ejemplo, es más útil referirse al servidor de la Asociación de Ingenieros de Sistemas de Colombia como www.acis.edu.co que mediante la dirección IPv4: 201.19.45.6, y es en esta facilidad de manejo en la que el sistema DNS representa un papel fundamental.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Figura 91. Rango de Direcciones IPv4
Fuente: Autor
La asignación de nombres a direcciones IP es ciertamente la función más conocida de los protocolos DNS. Por ejemplo, si la dirección IP del sitio FTP de time.co es 200.64.128.4, la mayoría de la gente llega a este equipo especificando ftp.time.co y no la dirección IP. Además de ser más fácil de recordar, el nombre es más fiable. La dirección numérica podría cambiar por muchas razones, sin que tenga que cambiar el nombre.
1. Estructura de DNS
La estructura de la base de datos DNS es similar a la estructura de los sistemas LINUX®-UNIX (Figura 92).
Figura 92. Base de datos DNS vs Sistema de Archivos LINUX®-UNIX
Fuente: Autor

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
La base de datos o el sistema de archivos son dibujados como árboles invertidos con el nodo raíz en la cima. Cada nodo en el árbol tiene una etiqueta textual, la cual identifica el nodo relativo a su padre. Por ejemplo, para el nodo bin la etiqueta seria \usr\bin .
Según la figura 92, la base de datos DNS se denomina el Espacio de Nombres de Dominio y cualquier subárbol de esta estructura se denomina Dominio. A su vez un dominio puede estar formado por subárboles que se denominan Subdominios y estos se componen de hosts (los cuales se ubican en las hojas del árbol).
Cada nodo es también la raíz de un nuevo subárbol del árbol general. Cada uno de estos subárboles representa una partición de la base de datos general del directorio en el sistema UNIX-LINUX® o un dominio en el sistema DNS. Cada directorio o dominio puede ser dividido subsecuentemente en particiones llamadas Subdominios en DNS (como subdirectorios en LINUX®).
Cada dominio tiene un nombre único al igual que cada directorio. En DNS el nombre de dominio es la secuencia de etiquetas desde el nodo raíz del dominio al raíz del árbol total, como puntos (.) separando las etiquetas (Figura 93).
Figura 93. Leyendo nombres en DNS y LINUX®-UNIX
Fuente: Autor

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
2. Componentes de un nombre de dominio
Un nombre de dominio usualmente consiste en dos o más partes (técnicamente etiquetas), separadas por puntos cuando se las escribe en forma de texto. Por ejemplo, www.LINUX-malaga.org.es o www.hp.com .
A la etiqueta ubicada más a la derecha se le llama dominio de nivel superior (del inglés Top Level Domain). Como org en www.LINUX-malaga.org o com en www.hp.com .
La siguiente es una lista de los dominios de nivel superior registrados en Internet:
Figura 94. Lista de dominios de nivel superior
Dominio Area
.aero Industria del transporte aéreo
.biz Negocios
.com Fines comerciales
.coop Cooperativas
.info Información
.museum Museos
.name Nombres de personas
.net Infraestructura de red
.org Organizaciones
.pro Profesionales
.gov Gobiernos y Entidades Públicas
.edu Educación
.mil Milicias (Ejército, Armada, Fuerza Aérea)
.int Internacional, para organizaciones como la ONU
.travel Páginas de la industria de viajes
Fuente: Autor

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Cada etiqueta a la izquierda especifica una subdivisión y corresponde a un subdominio. Nótese que subdominio expresa dependencia relativa, no dependencia absoluta. En teoría, esta subdivisión puede tener hasta 127 niveles, y cada etiqueta contener hasta de 63 caracteres, pero restringido a que la longitud total del nombre del dominio no exceda los 255 caracteres, aunque en la práctica los dominios son casi siempre mucho más cortos.
Finalmente, la parte más a la izquierda del dominio suele expresar el nombre de la máquina (en inglés hostname). El resto del nombre de dominio simplemente especifica la manera de crear una ruta lógica a la información requerida. Por ejemplo, el dominio es.Wikipedia.org tendría el nombre de la máquina "es", aunque en este caso no se refiere a una máquina física en particular.
3. Delegación
La responsabilidad del manejo de cada subdominio es distribuida a través de diferentes organizaciones (Figura 95).
Figura 95. Administración y delegación de un dominio
Fuente: Autor
Por ejemplo, una organización llamada Educase administra el dominio edu (educativo) pero delega la responsabilidad del dominio Unad.edu a la Universidad Nacional Abierta y a Distancia.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
La UNAD puede crear una nueva zona (una porción del espacio de nombre administrada autónomamente) llamada cs. (Figura 96)
Figura 96. Zonas DNS
Fuente: Autor
La zona unad.edu es ahora independiente de la zona más general edu , y contiene todos los nombres de dominio que finalizan en unad.edu . La zona edu , por otra parte contiene sólo nombres de dominio que finalizan en edu pero no están en zonas delegadas tales como unad.edu.
Unad.edu puede además ser dividido en en subdominios tales como cs.unad.edu, y algunos de estos subdominios pueden ser en si mismos zonas separadas si los administradores de unad.edu quieren delegar la responsabilidad de ellos a otras organizaciones. Si cs.unad.edu es una zona separada, la zona unad.edu no contiene nombres de dominio que finalicen en cs.unad.edu y de esta forma se mantienen nombres único de manera distribuida.
Los nombres de dominio son usados como índices en la base de datos DNS, la cual contiene la información tanto de hosts como de subdominios. Se dice que un dominio contiene aquellos hosts y subdominios cuyos nombres de dominio están dentro del subárbol del dominio.
4. Operación DNS
Para la operación práctica del sistema DNS se utilizan dos componentes principales (Figura 97):

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Figura 97. Operación DNS
Fuente: Autor
Los clientes DNS (full resolvers): un programa cliente DNS que se ejecuta en el computador del usuario (estación) y que genera peticiones DNS de resolución de nombres a un servidor de nombres de dominio (Por ejemplo: ¿Qué dirección IP corresponde a nombre.dominio?);
Los Servidores de Nombres de Dominio: que contestan las peticiones de los clientes, los servidores recursivos tienen la capacidad de reenviar la petición a otro servidor (servidor DNS de otro dominio) si no disponen de la dirección solicitada.
Lección 13: IPv6 – El Direccionamiento del Futuro
IPv6 es la versión 6 del Protocolo de Internet (Internet Protocol), un estándar del nivel de red encargado de dirigir y encaminar los paquetes a través de una red. IPv6 está destinado a sustituir al estándar IPv4, cuyo límite en el número de direcciones de red admisibles está empezando a restringir el crecimiento de Internet y su uso, especialmente en China, India, y otros países asiáticos densamente poblados. Pero el nuevo estándar mejorará el servicio globalmente; por ejemplo, proporcionando a futuras celdas telefónicas y dispositivos móviles

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
con sus direcciones propias y permanentes. Al día de hoy se calcula que las dos terceras partes de las direcciones que ofrece IPv4 ya están asignadas.127
Ipv4 soporta 4.294.967.296 (4,294 × 109) direcciones de red diferentes, un número inadecuado para dar una dirección a cada persona del planeta, y mucho menos para cada coche, teléfono, PDA o tostadora; mientras que IPv6 soporta 340.282.366.920.938.463.463.374.607.431.768.211.456 (3,4 x 1038 ó 340 sextillones) direcciones -- cerca de 4,3 x 1020 (430 trillones) direcciones por cada pulgada cuadrada (6.7 x 1017 ó 670 mil billones direcciones/mm²) de la superficie de la tierra.
Figura 98. IPv6 encapsulado en IPv4
Fuente: COULOURIS George, SISTEMAS DISTRIBUIDOS, Addison Wesley, Madrid, 2001, 3ª Ed.
La adopción de IPv6 ha sido frenada por la traducción de direcciones de red (NAT / Network Address Translation), que alivia parcialmente el problema de la falta de direcciones IP. Pero NAT hace difícil o imposible el uso de algunas aplicaciones P2P, como son voz sobre IP (VoIP) y juegos multiusuario. Además, NAT rompe con la idea originaria de Internet donde todos pueden conectarse con todos. Actualmente, el gran acelerador para la aplicación de la tecnología IPv6 es la capacidad de ofrecer nuevos servicios, como la movilidad, calidad del servicio (QoS / Quality of Service), privacidad, etc. El gobierno de los Estados Unidos ha ordenado el despliegue de IPv6 por todas sus agencias federales para el año 2008.
IPv6 y el Sistema de Nombres de Dominio
Las direcciones IPv6 se representan en el Sistema de Nombres de Dominio (DNS) mediante registros AAAA (también llamados registros de quad-A, por analogía con los registros A para IPv4)
127 http://es.wikipedia.org/w/index.php?title=Ipv6

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
El concepto de AAAA fue una de las dos propuestas al tiempo que la arquitectura IPv6 estaba siendo diseñada. La otra propuesta utilizaba registros A6 y otras innovaciones como las etiquetas de cadena de bits (bit-string labels) y los registros DNAME.
Mientras que la idea de AAAA es una simple generalización del DNS IPv4, la idea de A6 fue una revisión y puesta a punto del DNS para ser más genérico, y de ahí su complejidad.
La RFC-3363128 recomienda utilizar registros AAAA hasta tanto se pruebe y estudie exhaustivamente el uso de registros A6.
Lección 14: Introducción a la Gestión Distribuida
La gestión distribuida definida por ISO (Internacional Organization for Standarization / Organización Internacional de Estándares)129, describe una arquitectura de gestión OSI (Open Systems Interconnection / Interconexión de Sistemas Abierto) cuya función es permitir supervisar (monitorear) y controlar una red de datos.
Figura 99. Gestión Distribuida
Fuente: Autor
128 http://rfc.net/rfc3363.html. Representing Internet Protocol version 6 (IPv6) Addresses in the Domain Name System (DNS). R. Bush, A. Durand, B. Fink, O. Gudmundsson, T. Hain. August 2002. 129 Normativas ISO/ITU-T: X.700/ISO 7498-4, X.701/ISO 10040.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
La gestión distribuida se encuentra dividida en cinco categorías de servicios de administración:
1. Administración de fallos
Detección, diagnóstico y corrección de los fallos de la red y de las condiciones de error. Incluye:
• Notificación de fallos • Sondeo periódico en busca de mensajes de error • Establecimiento de alarmas • Corrección de fallos (posiblemente en forma automática).
Los usuarios esperan estar informados del estado de la red, incluyendo suspensión de procesos por actividades de mantenimiento programadas y no programadas. Cuando algo falla, es importante, tan rápido como sea posible: Determinar exactamente cual es el fallo
• Aislar el resto de la red del fallo para que continúe funcionando sin interferencias
• Reconfigurar o modificar la red de manera que se minimice el impacto del fallo en las operaciones de la organización
• Reparar o sustituir los componentes que han fallado.
2. Administración del Desempeño (Prestaciones)
Se define como la evaluación (medida) del comportamiento de los elementos de la red. Para poder efectuar este análisis es preciso mantener un histórico con datos estadísticos y de configuración. La gerencia del desempeño permite:
• Obtener tasas de utilización y error de los dispositivos de la red • Proporcionar un nivel constante de desempeño, asegurando que los
dispositivos tengan suficiente capacidad.
Las redes modernas están compuestas de muchos componentes que se comunican y comparten datos y recursos. La efectividad de una aplicación

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
depende cada vez más de unas prestaciones adecuadas de la red. Entre los interrogantes que pueden plantearse en este aspecto se encuentran:
• ¿Cuál es el nivel de utilización de la capacidad? • ¿Hay excesivo tráfico? • ¿Las prestaciones se han reducido a niveles inaceptables? • ¿Hay cuellos de botella? • ¿Está aumentando el tiempo de respuesta?
Para esta gestión hay que identificar los valores relevantes a monitorizar de la red y definir los parámetros de medición adecuados. Esto permite obtener estadísticas que ayuden a mantener las prestaciones adecuadas (eliminar cuellos de botella reconfigurando rutas o ampliando líneas, etc.)
3. Administración de contabilidad
Determinación de los costos asociados a la utilización de los recursos y administrar y regular dichos costos manteniendo un nivel de desempeño aceptable. En muchas organizaciones, diferentes divisiones, centros de gasto o proyectos, son facturados por el uso de los servicios de red. Aun cuando esto no ocurra, es necesario mantener información sobre el uso de los recursos de red por usuarios o tipos de usuarios:
• Determinados usuarios pueden estar abusando de sus privilegios de acceso y cargar la red afectando a los demás usuarios.
• Los usuarios pueden hacer un uso ineficiente de la red, y el gestor puede ayudar a cambiar procedimientos para aumentar la efectividad.
• Conocer en detalle las actividades de los usuarios es muy útil para planificar el crecimiento adecuado de la red.
4. Administración de seguridad
Implica las tareas relacionadas con el control de accesos no autorizados y daños tanto a los recursos de la red como a la información manejada (datos privados). La protección de la red incluye aspectos como:

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
• Mantenimiento y distribución de claves cifradas y otras autorizaciones o controles de acceso a la información.
• Monitorización y control del acceso a los computadores de la red y a parte o
toda la información de la información de gestión de los nodos de la red. • Registros (logs): recolección, almacenamiento y procesamiento de registros de
auditoría y seguridad. • Gestión (definir, lanzar/parar) las facilidades de registro.
5. Administración de Configuración
La gestión de configuración se refiere al monitoreo o seguimiento de los cambios en el tiempo con respecto a la configuración inicial de los dispositivos de la red y comprende una serie de facilidades mediante las cuales se realizan las siguientes funciones:
• Iniciación y desactivación de cualquier elemento de la red. • Definición o cambio de parámetros de configuración. • Recogida de información de estado actual de cualquier elemento.
Los modernos elementos físicos y lógicos (por ejemplo, el controlador de dispositivos de un sistema operativo) de una red se pueden configurar para realizar diversas tareas. Un dispositivo se puede configurar por ejemplo para ser un nodo final, un router o ambas cosas. Una vez elegido el papel de cada dispositivo el gestor debe elegir el software adecuado y los atributos y valores para ese dispositivo. La configuración también se encarga de inicializar y apagar adecuadamente parte de la red, tanto de manera manual como automática.
Los usuarios a veces quieren o necesitan estar informados acerca del estado de los componentes y recursos de la red. Por ello cuando se hacen cambios en la red, se les debe informar. Esta reconfiguración puede ser debida a labores de rutina o necesidades del usuario. Antes de reconfigurar, el usuario quiere conocer como van a quedar las cosas (por ejemplo, si les cambia el sistema operativo de su máquina). Este modelo de administración OSI posee una arquitectura del tipo

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
cliente-servidor y se utiliza ampliamente en los protocolos de gestión de red SNMP130 y CMIP131.
Lección 15: Sistema de Gestión Distribuida
Un sistema de gestión distribuida es una colección de herramientas para monitorización y control compuesto por (Figura 100):
• Una única interfaz de operador con un completo conjunto de comandos para realizar la mayoría de las tareas de gestión. Está diseñado para ver la red completa como una arquitectura unificada, con direcciones y etiquetas asignadas a cada punto y a los atributos específicos de cada elemento y enlace del sistema.
Figura 100. Sistema de Gestión Distribuida
Fuente: Autor
• Un conjunto mínimo de equipamiento separado. La mayoría del software y hardware de gestión está incorporado en el equipamiento existente. El software
130 Protocolo Simple de Gestión de Red (Simple Network Management Protocol). Ver información adicional en el glosario. 131 Protocolo de Gestión de Información Común (Common Management Information Protocol)

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
utilizado en realizar tareas de gestión reside en los computadores y procesadores de comunicaciones (hubs, bridges132, routers, etc.)
Como se puede apreciar en la figura 100, los elementos activos de la red envían regularmente información de estado al centro de control de red. Cada nodo contiene un conjunto de software relacionado con la gestión y llamado Entidad de Administración de Red (EAR), el cual realiza las siguientes tareas:
• Recoge estadísticas de actividades de comunicaciones y actividades de red • Almacena estadísticas localmente • Responde a comandos del centro de control de red, como:
o Enviar estadísticas al centro de control de red o Cambiar un parámetro (por ejemplo, un temporizador usado en un
protocolo) o Proporcionar información de estado (por ejemplo, valores de
parámetros, enlaces activos) o Generar tráfico artificial para realizar pruebas.
Cada nodo con un EAR se suele denominar agente y al menos un nodo de la red es el nodo de gestión de red o gestor (manager). El nodo gestor, además del EAR, incluye una colección de software denominada la Aplicación de Administración de Red (AAR), la cual realiza las siguientes tareas: • Incluye una interfaz de operador para permitir a usuarios autorizados gestionar
la red. • Responde a comandos del usuario mostrando información y/o enviando
comandos a los EAR de la red. Esta comunicación se realiza mediante un protocolo de gestión de red a nivel de aplicación de manera similar a cualquier otra aplicación distribuida.
Normalmente por motivos de seguridad se suelen tener dos o más nodos de gestión de red. Todos menos uno no hacen nada o sólo recogen estadísticas. Si el principal falla, se usa uno de los otros.
132 Dispositivo hardware usado para conectar Redes de Area Local de manera que ellas puedan intercambiar datos. Pueden operar con redes que usan diferentes protocolos o sistemas de cableado.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
1. Arquitectura del Software de Gestión Distribuida
La funcionalidad del software en un agente o gestor varía mucho dependiendo de la funcionalidad de la plataforma y sus capacidades de gestión. En general el software se puede dividir en tres categorías:
� Software de presentación al usuario � Software de gestión de red � Software de soporte de gestión de red (gestión de base de datos y
comunicaciones).
La siguiente figura muestra una visión genérica de esta arquitectura software.
Figura 101. Arquitectura del Software de Gestión Distribuida
Fuente: Autor

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Software de presentación al usuario: Proporciona la interacción entre el usuario (gestor) y el software de gestión de red. Siempre reside en el gestor de red para monitorizar y controlar la red. A veces es útil un software de este tipo en un agente para pruebas, depuración y gestionar algunos parámetros de manera local.
Una de las claves de este software es proporcionar una interfaz de usuario unificada. La interfaz debe ser la misma para cualquier nodo, independientemente del vendedor. Esto permite gestionar una red heterogénea con un mínimo entrenamiento. Como desventaja puede presentarse sobrecarga de información. Una gran cantidad de información está disponible al gestor. Son necesarias herramientas de presentación que organicen, resuman y simplifiquen esta información tanto como sea posible. Es preferible información gráfica que textual o tabular.
Software de Gestión de Red: Este software puede ser muy simple, como SNMP133 o complejo, como CMIP. El cuadro central de la figura 101 muestra una arquitectura compleja que refleja la arquitectura de OSI y de sistemas propietarios típicos. El software tiene tres niveles:
• Aplicaciones: Proporciona servicios de interés de los usuarios, por ejemplo podrían corresponder con las áreas de OSI: fallos, costes, etc.
• Elementos: Las pocas aplicaciones son soportadas por un número mayor de
elementos que implementas funciones más primitivas y más de propósito general, tal como generar alarmas o resumir estadísticas. Son elementos básicos normalmente compartidos por varias aplicaciones. Esta organización sigue los principios tradicionales de diseño modular y reutilización de software.
• Servicio de transporte de datos: Es el protocolo utilizado para intercambiar
información de gestión entre gestores y agentes y una interfaz de servicio para los elementos. Esta interfaz proporciona funciones muy primitivas como obtener una información, dar un valor a un parámetro o generar una notificación.
Software de soporte de gestión de red: Para realizar sus funciones el software de gestión de red necesita acceder a los gestores y agentes remotos, así como a la base de información de gestión local (MIB / Management Information Base), la cual es una sencilla base de datos con información de los recursos del sistema distribuido.
133 http://www.ietf.org/rfc/rfc1351.txt

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
La MIB local de un agente contiene información sobre gestión, incluyendo información de la configuración y comportamiento del nodo y parámetros que pueden utilizarse para controlar la operación del nodo. La MIB de un gestor contiene la información de su agente y un resumen de la información de los agentes que controla.
El módulo de acceso ala MIB consiste en un software básico de acceso a archivos que permite acceder a la MIB. Además puede ser necesario que convierta la información del formato de la MIB local a un formato estandarizado utilizado por el sistema de gestión.
La comunicación con otros nodos (agentes y gestores) es soportada por la torre de protocolos, como pueden ser TCP/IP. Es decir, la arquitectura de comunicaciones soporta el protocolo de gestión, que está en el nivel de aplicación.
2. Beneficios de la gestión de red distribuida
La gestión distribuida mantiene la capacidad de un control centralizado, ofreciendo ventajas adicionales:
• El tráfico de gestión de red disminuye. • Ofrece mayor escalabilidad. Añadir capacidad de gestión consiste simplemente
en instalar otra estación de bajo coste en el lugar deseado. • El uso de múltiples estaciones de gestión elimina el único punto de fallo que
existe en los esquemas centralizados.
A continuación se presentan las principales herramientas de gestión (de dominio público) existentes en Internet134:
Ipmonitor: http://www.ipmonitor.com/
LanSurveyor: http://www.neon.com/LSwin.html
NimBus: http://www.nimsoft.com/netman/index.shtml
N-Vision: http://www.n-able.com/products/N-vision/
InterMapper: http://www.intermapper.com/
134 http://www.slac.stanford.edu/~cottrell/tcom/nmtf-tools.html

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Netcrunch: http://www.adremsoft.com/netcrunch/
SolarWinds Orion: http://www.solarwinds.net/
Airwave: http://www.airwave.com/ (monitoreo de redes Wi-Fi)
VitalNet: http://www.lucent.com/products/solution/0,,CTID+2020-STID+10439-SOID+1335-LOCL+1,00.html redes hibridas (cableadas e inalámbricas)
Whatsup: http://www.ipswitch.com/Products/WhatsUp/

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Actividades de Autoevaluación de la UNIDAD
� Practica: Descargar de Internet la herramienta freeware VBOrb (http://www.martin-both.de/vborb.html), con la cual usted puede escribir Clientes y Servidores CORBA Visual Basic®. Los clientes CORBA pueden llamar métodos de objetos remotos escritos en cualquier lenguaje y los Servidores CORBA pueden responder con métodos de sus objetos locales. Por ejemplo, puede escribir su servidor en Java® usando JavaORB (http://dog.team.free.fr/index_javaorb.html) y su cliente en Visual Basic® usando VBOrb.
� Investigar acerca del Sistema Operativo PLAN 9, en desarrollo por los laboratorios
Bell. Porqué se dice que será el sucesor de UNIX?, En cuáles plataformas se ejecuta?, Como se denominan los recursos?, Qué protocolo de comunicación utiliza?. Cómo es la estructura del sistema de archivos? (link: http://plan9.bell-labs.com/plan9/).
� Práctica: Usando Java, escriba una aplicación para un prototipo de un sistema de
consultas de opinión. Asúmase que sólo se va a encuestar un tema. Los entrevistados pueden responder sí, no o ns/nc. Escriba una aplicación servidora, que acepte los votos, guarde la cuenta (en memoria), y proporcione las cuentas actuales a aquellos que estén interesados.
a. Escriba el archivo de interfaz primero. Debería proporcionar métodos remotos para
aceptar una respuesta a la encuesta, proporcionando los recuentos actuales (ejemplo: 10 sí, 2 no, 5 ns/nc) sólo cuando el cliente lo requiera.
b. Diseñe e implemente un servidor que (i) exporte los métodos remotos, y (ii) mantenga información de estado (las cuentas).
c. Diseñe e implemente una aplicación cliente que proporcione una interfaz de usuario para aceptar una respuesta y/o una petición, y para interactuar con el servidor apropiadamente a través de la invocación de métodos remotos.
d. Pruebe la aplicación ejecutando dos o más clientes en máquinas diferentes (preferiblemente en plataformas diferentes).
e. Entregue los listados de los archivos, que deben incluir los archivos fuente (el archivo de interfaz, los archivos del servidor y los archivos del cliente) y un archivo LÉEME que explique los contenidos y las interrelaciones de los archivos fuente, así como el procedimiento para ejecutar el trabajo.
� Investigar como operan los servicios de licenciamiento en plataformas LINUX® y
WINDOWS® 2003 server. � Practica: Utilizar la aplicación MOUNT para poder acceder a un sistema de distribuido
de archivos, en plataformas LINUX®/UNIX. � Investigar para que se usan los comandos LINUX®/UNIX: showmount y umount,
indicar los parámetros y ejemplos. � Investigar los usos y aplicaciones de la especificación WEBNFS. � Investigar que características se han mejorado con las versiones NSFv3 y NSFv4.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
� Investigar acerca de los sistemas de archivos distribuidos Coda y Andrew File System (AFS): Con cuáles sistemas operativos trabajan, Capacidad, Estructura (volúmenes, archivos), Operaciones de lectura/escritura, caching, Seguridad, etc.
� Realice un resumen acerca del sistema de Archivos LUSTRE. Con que Sistema
Operativo Trabaja, quién lo desarrolló y que tipo de licencia utiliza, que estructura de almacenamiento posee, que aplicaciones lo usan actualmente. Cual es el URL del Sitio principal de LUSTRE.
� Investigar que es la especificación SAMBA y que papel cumple con el manejo de
archivos en diferentes plataformas. � En el contexto de las aplicaciones basadas en la Web, ¿qué papel juega cada uno de
los siguientes lenguajes/protocolos? HTML, MIME, XML, HTTP, CGI. � Cuando un servidor HTTP envía el contenido de un documento a un cliente en el cuerpo
de la respuesta, utiliza la línea de cabecera Content-Lenght para especificar la longitud en bytes del cuerpo. Para los documentos estáticos la longitud en bytes la proporciona el sistema de ficheros. Pero para páginas web generadas dinámicamente, tales como las generadas por un script CGI, la longitud debe ser determinada en tiempo de ejecución. Para una página web generada dinámicamente, ¿cómo puede saber el servidor web la longitud del contenido especificado en la cabecera Content-Lenght? Recuerde que las líneas de cabecera aparecen antes que el cuerpo en la respuesta HTTP.
� Investigue acerca de la función, principales características y usos de los protocolos
BEEP, JABBER, IIOP y HTTPS. � Mencione los protocolos asociados al sistema de nombre de dominio DNS. Elabore un
dibujo de una organización representativa de estos protocolos en relación con un sistema cliente, un servidor y un servidor de nombres de dominio. Bosqueje la secuencia de mensajes que se intercambian entre estos protocolos para obtener la dirección TCP/IP del servidor. Que numero de puerto utiliza el servicio DNS?
� Práctica: Utilice el comando “traceroute ” en WINDOWS® y LINUX® para encontrar la
ruta seguida por un equipo en Internet para alcanzar un destino determinado. Revise las principales opciones del comando. La operación del comando requiere un procesamiento distribuido?
� Práctica: Realice un “traceroute ” entre fuente y destino en el mismo continente y a
tres horas diferentes del día. a. Encuentre la media y la desviación estándar de los retardos en cada una de las
tres horas. b. Encuentre el número de routers en el recorrido en cada una de las tres horas.
¿Cambian los recorridos durante cualquiera de las horas? c. Intente identificar el número de redes ISP por las que pasan los paquetes
Traceroute desde la fuente al destino. Los routers con nombres similares y con direcciones IP semejantes deben ser considerados como parte del mismo ISP. En tus experimentos, ¿se producen retardos grandes en las interfaces colegas entre ISP adyacentes?

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
d. Repita lo anterior para una fuente y un destino en diferentes continentes. Comparar, los resultados intracontinente e intercontinentes.
� Investigue en que consiste el sistema de directorios X.500 y en relación con dicho
sistema explique con ayuda de ejemplos el significado de los siguientes términos: a. Árbol de información de directorio b. Nombre distinguido relativo c. Nombre distinguido d. Seudónimo
� A partir de la siguiente lista de tipos de servidores DNS (Bind, PowerDNS, MaraDNS,
djbdns, pdnsd, MyDns) seleccione tres (3) y realice un cuadro comparativo con cuatro (4) características representativas.
� Cúal es la lista de dominios por distribución geográfica?. Qué significa la sigla ccTLD?.
Cuáles son los dominios geográficos asignados pero sin uso, los dominios retirados y los dominios reservados?. (Ayuda: http://es.wikipedia.org/wiki/CcTLD).
� Práctica: (en grupos) Instale un servidor BIND en LINUX®. Use direcciones ejemplo y
documente el proceso. Instale el servicio DNS en la plataforma WINDOWS® 2003 Server. Use direcciones ejemplo y documente el proceso.
� Indique como es el proceso para registrar un dominio en Internet desde Colombia.
Documente como haría desde nuestro país para registrar el dominio www.diezmicosenunpalo.org .
� Investigue:
� Qué función tienen las organizaciones ICANN (http://www.icann.org/) y IANA(http://www.iana.org/) en la asignación de nombres de dominios y números en Internet?.
� Qué diferencias existen entre dominios genéricos y dominios territoriales?. � Cuales son los dominios genéricos patrocinados y los dominios genéricos no
patrocinados?. � Explique el concepto de registrador de dominios
(http://es.wikipedia.org/wiki/Registrador_de_dominios) y los principales registradores acreditados en el mundo (http://www.icann.org/registrars/accredited-list.html)
Ayuda: Utilice wikipedia (http://es.wikipedia.org)
� Investigue acerca de Internet II (I2), porqué se caracteriza con respecto al direccionamiento y al sistema de nombres de dominios?.
� Lea el RFC-3531 (Un método flexible para Administrar la Asignación de Bits de un
bloque de direcciones IPv6) del sitio (http://www.rfc-es.org/rfc/rfc3531-es.txt). Realice un resumen y elabore un ejemplo descriptivo.
� Investigue en qué se diferencian una dirección MAC y una dirección de LOOPBACK?.
Qué formato emplean y para qué se utilizan?

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
� Investigue acerca del uso del comando NSLOOKUP (Hace consultas interactivas a Servidores que corren un DNS). � Qué formatos y opciones utiliza (indique ejemplos representativos)? � Qué tipo de información se puede recopilar acerca de un Host en la red? � Utilice NSLOOKUP para encontrar un servidor Web que tenga múltiples
direcciones IP. ¿Tiene el servidor web de la UNAD múltiples direcciones IP?
� Realice un paralelo entre los protocolos de gestión de red SNMP y CMIP. � Realice un paralelo entre las siguientes herramientas de gestión distribuida (para
redes heterogéneas) basadas en el protocolo SNMP: OpenView de Hewlett-Packard, Spectrum de Aprisma, Solstice de Sun.
� Investigue acerca de la herramienta de monitoreo WAN PingER (función, instalación,
operación) (Ayuda: http://www-iepm.slac.stanford.edu/pinger/) � Practica: Diseñar una herramienta que permita detectar la presencia de direcciones
IPs duplicadas en una red. (Tenga en cuenta las direcciones físicas de las tarjetas de red � Direcciones MAC).
� Practica: Diseñar un software que mediante una interfaz de tipo gráfico haga uso de la
utilidad “ping ” para determinar la presencia de un equipo IP en la red y despliegue la información de respuesta. Utilice principalmente las plataformas LINUX® y WINDOWS®.
� Investigue acerca de la función de los “demonios ” de monitoreo presentes en los
sistemas UNIX-LINUX®: inetd, syslogd � Investigue cuáles son los comandos, utilidades o servicios utilizados en las
plataformas LINUX®, WINDOWS® 2003 y UNIX para realizar las siguientes funciones de monitoreo: � Determinar la carga/utilización de la CPU � Indicar el número de procesos en ejecución y usuarios activos � Indicar las estadísticas de tráfico de las tarjetas de red � Indicar el tamaño de las particiones / filesystems � Mostrar los logs (bitácoras) de errores y avisos del sistema
� Practica: Instalar y configurar una herramienta de monitoreo de red basada en SNMP. Herramienta de monitoreo NetLogger para entornos LINUX® (http://www-didc.lbl.gov/NetLogger)
Nota: Netlogger reune información a partir de los agentes de monitoreo y escribe la información (eventos) en un formato estándar apropiado para un procesamiento posterior. Los agentes de monitoreo se ejecutan en cada uno de los recursos (hosts) y transmiten la información al proceso “netlogd ” que se ejecuta en el equipo de administración. En este equipo, mediante la utilidad “nlv ” se pude ver el registro de eventos en tiempo real. Netlogger maneja APIs en c, c++, Java®, phyton.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
GLOSARIO DE ACRÓNIMOS
AAR Aplicación de Administración de Red
AFS Sistema de Archivos Andrew (Andrew File System)
API Interfaz de Programación de Aplicaciones (Application Program Interfase)
ASP Servidor de Páginas Activo (Active Server Pages)
B2B Negocio a Negocio (Business to Business)
BSD Distribución de Software Berkeley (Berkeley Software Distribution)
CMIP Protocolo de Gestión de Información Común (Common Management Information Protocol)
COM Modelo de Objetos Componentes (Component Object Model)
CORBA Arquitectura de Mediador de Peticiones a Objetos Comunes (Common Object Request Broquer Architecture)
DCOM Modelo Distribuido de Objetos Componentes (Distributed Component Object Model)
DES Estandar de Encripción de Datos (Data Encryption Standard)
DNS Sistema de Nombres de Dominio (Domain Name System)
DoS Denegación del Servicio (Denial of Service)
EAR Entidad de Administración de Red
EDI Intercambio Electrónico de Datos (Electronic Data Interchange)
FTP Protocolo de Transferencia de Archivos (File Transfer Protocol)
GPRS Paquete General de Servicios Radiales (General Packet Radio Service)
GSM Sistema Global para las comunicaciones Móviles (Global System Mobile)
GUI Interfaz Gráfica de Usuario (Graphical User Interface)

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
HTML Lenguaje de Marcación de Hipertexto (Hiper-Text Markup Language)
HTTP Protocolo de Transferencia de Hipertexto (Hiper-Text Transfer Protocol)
HTTPS Protocolo de Transferencia de Hipertexto Seguro (Secure Hiper-Text Transfer Protocol)
IANA Autoridad para Números Asignados de Internet (Internet Assigned Numbers Authority)
ICANN Corporación Internet para Nombres y Números Asignados (Internet Corporation for Assigned Names and Numbers)
IDEA Algoritmo Internacional de Encriptamiento de Datos (International Data Encryption Algorithm)
IDL Lenguaje de Definición de Interfaz (Interfaz Definition Language)
IEEE Instituto de Ingenieros Electricos y Electronicos (Institute of Electrical and Electronics Engineers)
IETF Grupo de Trabajo en Ingeniería de Internet (Internet Engineering Task Force)
IP Protocolo de Internet (Internet Protocol)
ISO Organización Internacional de Estándares (Internacional Standard Organization)
ISP Proveedor de Servicios de Internet (Internet Service Provider)
J2EE Edición Empresarial del paquete Java (Java 2 Enterprice Edition)
JDBC Conectividad Java de Base de Datos (Jave DataBase Connectivity)
JDK Kit de Desarrollo de Java (Java Development Kit)
JVM Máquina Virtual de Java (Java Virtual Machine)
LAN Red de Área Local (Local Area Network)
MAC Control de Acceso al Medio (Media Access Control)
MIB Base de datos de Información de Gestión (Management Information Base)
MIT Instituto Tecnológico de Massachusetts (Massachusetts Institute of Technology)
MOM Middleware Orientado a Mensajes / (Message Oriented Middleware)
NAT Traducción de Direcciones de Red (Network Address Translation)

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
NFS Sistema de Archivos de Red (Network File System)
ODBC Conectividad Abierta de Base de Datos (Open DataBase Connectivity)
OMA Arquitectura de Administración de Objetos (Object Management Architecture)
OMG Grupo de Administración Abierto (Open Management Group)
ORB Mediador de Peticiones a Objetos (Object Request Broker)
OSI Interconexión de Sistemas Abiertos (Open Systems Interconnection)
P2P Igual a Igual (Peer to Peer)
PDA Asistente Personal Digital (Personal Digital Assistant)
PGP Privacidad Bastante Buena (Pretty Good Privacy)
PIN Número de Identificación Personal (Personal Identification Number)
PNG Gráficos de Red Portable (Portable Network Graphics)
QoS Calidad del Servicio
RFC Solicitudes por Comentarios (Request for Comments)
RMI Invocación de Método Remoto (Remote Method Invocation)
RPC Llamada a Procedimiento Remoto (Remote Procedure Call)
RSA Algoritmo Rivest-Shamir-Adleman
SDP Protocolo de Descripción de Sesión (Session Description Protocol)
SLP Protocolo de Localización de Servicios (Service Location Protocol)
SMTP Protocolo Simple de Transferencia de Correo (Simple Mail Transfer Protocol)
SNMP Protocolo Simple de Gestión de Red (Simple Network Management Protocol)
SOAP Protocolo Simple de Acceso a Objeto (Simple Access Object Protocol)
SQL Lenguaje de Consulta Estructurado (Structured Query Language)
SSDP Protocolo Simple de Descubrimiento de Servicio (Simple Service Discovery Protocol)
SSI Imagen Particular del Sistema (Single System Image)
TCP Protocolo de Control de Transmisión (Transmisión Control Protocol)

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
TFTP Protocolo de Transferencia de Archivos Trivial (Trivial File Transfer Protocol)
UDDI Descripción Universal, Descubrimiento e Integración (Universal Description, Discovery and Integration)
UDP Protocolo de Datagrama de Usuario (User Datagram Protocol)
UFID Identificador Único de Archivo (Unique File IDentifier)
UMTS Sistema de Telecomunicaciones Móviles Universal (Universal Mobile Telecommunications System)
UPnP Enchufe y Ejecute Universal (Universal Plug and Play)
UPS Sistema Ininterrumpible de Energia (Uninterrumpible Power System)
URL Localizador Uniforme de Recursos (Uniform Resource Locator)
VFS Sistema Virtual de Archivos (Virtual File System)
VHE Entorno de Hogar Virtual (Virtual Home Environment)
W3C Consorcio World Wide Web (World Wide Web Consortium)
WAN Red de Área Extensa (Wide Area Network)
WLAN Red de Área Local Inalámbrica (Wireless Local Area Network)
WSDL Lenguaje de Descripción de Servicios Web (Web Services Description Language)
WSFL Lenguaje de Flujo de Servicios Web (Web Services Flow Language)
XML Lenguaje de Marcación Extensible (eXtensible Markup Language)

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
GLOSARIO DE TERMINOS
Alarma Indicador. Señal asincrónica generada por un dispositivo o software para indicar la ocurrencia de un evento previamente definido grave.
API (del inglés Application Programming Interface / Interfaz de Programación de Aplicaciones). Conjunto de especificaciones de comunicación entre componentes software. Representa un método para conseguir abstracción en la programación, generalmente (aunque no necesariamente) entre los niveles o capas inferiores y los superiores del software. Uno de los principales propósitos de una API consiste en proporcionar un conjunto de funciones de uso general, por ejemplo, para dibujar ventanas o iconos en la pantalla. De esta forma, los programadores se benefician de las ventajas de la API haciendo uso de su funcionalidad, evitándose el trabajo de programar todo desde el principio. Las APIs asimismo son abstractas: el software que proporciona una cierta API generalmente es llamado la implementación de esa API.
ASP (del inglés Active Server Pages / Servidor de Páginas Activo). Es una tecnología del lado servidor de Microsoft para páginas web generadas dinámicamente, que ha sido comercializada como un anexo a Internet Information Server (IIS). ASP ha pasado por cuatro iteraciones mayores, ASP 1.0 (distribuido con IIS 3.0), ASP 2.0 (distribuido con IIS 4.0), ASP 3.0 (distribuido con IIS 5.0) y ASP.NET (parte de la plataforma .NET de Microsoft). Las versiones pre-.NET se denominan actualmente (desde 2002) como ASP clásico.
Backbone Porción de la red que administra el tráfico de alto volumen. El backbone puede conectar varias sedes o edificios de una organización, así como las pequeñas redes LAN que posea.
Caching Técnica consistente en duplicar datos de otros originales, con la propiedad de que los datos originales son costosos de acceder, normalmente en tiempo, respecto a la copia en el caché. Cuando se accede por primera vez a un dato, se hace una copia en el caché; los accesos siguientes se realizan a dicha copia, haciendo que el tiempo de acceso aparente al dato sea menor.
Cliente Computador que accede a recursos y servicios brindados por otro llamado Servidor, generalmente en forma remota.
Cliente También llamado modelo cliente-servidor, es una forma de dividir y especializar programas y equipos de cómputo a fin de que la tarea que cada

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
/Servidor uno de ellos realizada se efectúe con la mayor eficiencia, y permita simplificarlas. En esta arquitectura la capacidad de proceso está repartida entre el servidor y los clientes.
Cluster Racimo. Se aplica a los conjuntos o conglomerados de computadores construidos utilizando componentes de hardware comunes y, la mayor parte de las veces, software libre. Ellos juegan hoy en día un papel importante en la solución de problemas de las ciencias, las ingenierías y del comercio moderno.
Computación distribuida
Es la rama de las Ciencias Computacionales que estudia la ejecución de un algoritmo por medio de varios sitios, dispersos geográficamente, que comparten recursos.
Computación en malla
(del inglés Grid computing, computación en grilla o informática en rejilla). Es un nuevo modelo para resolver problemas de computación masiva utilizando un gran número de computadores organizados en racimos incrustados en una infraestructura de telecomunicaciones distribuida.
Cortafuegos (del inglés Firewall). Elemento de hardware o software utilizado en una red de computadores para prevenir algunos tipos de comunicaciones prohibidos según las políticas de red que se hayan definido en función de las necesidades de la organización responsable de la red.
Datagrama Fragmento de paquete que es enviado con la suficiente información como para que la red pueda simplemente encaminar el fragmento hacia el computador receptor, de manera independiente a los fragmentos restantes. Esto puede provocar una recomposición desordenada o incompleta del paquete en el computador destino. La estructura de un datagrama es: cabecera y datos.
Datacenter Centro de Datos. Ubicación donde se concentran todos los recursos necesarios para el procesamiento de información de una organización. Dichos recursos consisten esencialmente en unas dependencias debidamente acondicionadas, computadores y redes de comunicaciones.
DCOM (del inglés Distributed Component Object Model / Modelo de Objetos Componentes distribuidos). Es la propuesta de Microsoft hacia un modelo de componentes que soporte la reutilización y facilite la evolución de las aplicaciones existentes, enfocada por supuesto a la plataforma WINDOWS®.
DoS (del inglés Denial of Service / Denegacion del Servicio). Es un ataque a un sistema de ordenadores o red que causa que un servicio o recurso sea innaccesible a los usuarios legítimos. Normalmente provoca la pérdida de la conectividad de la red por el consumo del ancho de banda de la red de la víctima o sobrecarga de los recursos computacionales del sistema de la víctima. Se genera mediante la saturación de los puertos con flujo de información, haciendo que el servidor se sobrecargue y no pueda seguir prestando servicios, por eso se le dice "denegación", pues hace que el servidor no de abasto a la cantidad de usuarios. Esta técnica es usada por los llamados crackers para dejar fuera de servicio a servidores objetivo.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Enrutador (del inglés Router). Dispositivo hardware o software de interconexión de redes de computadores que opera en la capa tres (nivel de red) del modelo OSI. Este dispositivo interconecta segmentos de red o redes enteras. Hace pasar paquetes de datos entre redes tomando como base la información de la capa de red. El router toma decisiones lógicas con respecto a la mejor ruta para el envío de datos a través de una red interconectada y luego dirige los paquetes hacia el segmento y el puerto de salida adecuados.
Granja de Servidores
(del inglés Farm Server). Grupo de servidores, normalmente mantenidos por una empresa o universidad para ejecutar tareas que van más allá de la capacidad de una sóla máquina corriente, como alternativa, generalmente más económica, a un supercomputador. También hace posible la distribución de tareas, de forma que el sistema gana cierta tolerancia a fallos, ya que si uno de los servidores se estropea, el sistema continúa trabajando, notando únicamente una pérdida de rendimiento.
GUI (del inglés Graphical User Interface, Interfaz gráfica de usuario). Método para facilitar la interacción del usuario con el computador a través de la utilización de un conjunto de imágenes y objetos pictóricos (iconos, ventanas, etc.) además de texto. Surge como evolución de la línea de comandos de los primeros sistemas operativos y es pieza fundamental en un entorno gráfico.
Hilo (del Inglés Thread). Es un proceso concurrente que es parte de un proceso mayor o de un programa. En un sistema operativo multitarea, un simple programa puede tener varios hilos, todos ejecutándose al mismo tiempo. Ejemplo: Una parte de un programa puede estar haciendo un cálculo mientras que otra parte está dibujando un gráfico. Ver Proceso.
Host Anfitrión. Máquina conectada a una red de computadores y que tiene un nombre de equipo (Hostname). Puede ser un computador, un servidor de archivos, un dispositivo de almacenamiento por red, una máquina de fax, impresora, etc. Este nombre ayuda al administrador de la red a identificar las máquinas sin tener que memorizar una dirección IP para cada una de ellas.
Hub Concentrador. Equipo de redes que permite conectar entre sí otros equipos y retransmite los paquetes que recibe desde cualquiera de ellos a todos los demás. Los hubs han dejado de ser utilizados, debido al gran nivel de colisiones y tráfico de red que propician.
Interfaz Punto, área, o la superficie a lo largo de la cual dos cosas de naturaleza distinta convergen. Por extensión, se denomina interfaz a cualquier medio que permita la interconexión de dos procesos diferenciados con un único propósito común. Se conoce como Interfaz Física a los medios utilizados para la conexión de un computador con el medio de transporte de la red. Esto puede ser un módem, una tarjeta de red, un puerto serie, enlace infrarrojo, una conexión inalámbrica, etc. Se utiliza esta expresión para no referirse a ningún medio o tipo de conexión en concreto, así se refiere al dispositivo por el cual se accede a la red de forma genérica.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
IP (del inglés Internet Protocol, Protocolo de Internet). Protocolo no orientado a conexión usado tanto por el origen como por el destino para la comunicación de datos a través de una red de paquetes conmutados. Los datos en una red basada en IP son enviados en bloques conocidos como paquetes o datagramas (en el protocolo IP estos términos se suelen usar indistintamente). En particular, en IP no se necesita ninguna configuración antes de que un equipo intente enviar paquetes a otro con el que no se había comunicado antes.
IPv4 Versión 4 del Protocolo IP (Internet Protocol). Esta fue la primera versión del protocolo que se implementó extensamente, y forma la base de Internet. IPv4 usa direcciones de 32 bits, limitándola a 232 = 4.294.967.296 direcciones únicas, muchas de las cuales están dedicadas a redes locales (LANs). Por el crecimiento enorme que ha tenido del Internet (mucho más de lo que esperaba, cuando se diseñó IPv4), combinado con el hecho de que hay desperdicio de direcciones en muchos casos, ya hace varios años se vio que escaseaban las direcciones IPv4. Esta limitación ayudó a estimular el impulso hacia IPv6, que esta actualmente en las primeras fases de implementación, y se espera que termine reemplazando a IPv4.
Java® Lenguaje de programación orientado a objetos desarrollado por James Gosling y sus compañeros de Sun Microsystems al inicio de la década de 1990. A diferencia de los lenguajes de programación convencionales, que generalmente están diseñados para ser compilados a código nativo, Java® es compilado en un bytecode que es ejecutado (usando normalmente un compilador JIT), por una máquina virtual Java®. El lenguaje en sí mismo toma mucha de su sintaxis de C y C++, pero tiene un modelo de objetos mucho más simple y elimina herramientas de bajo nivel como punteros.
Kerberos Kerberos es un protocolo de autentificación de red. Está diseñado para suministrar una potente autentificación para aplicaciones cliente/servidor usando criptografía secret-key. Una versión gratuita de este protocolo está disponible en el Massachusetts Institute of Technology.
http://web.mit.edu/kerberos/
Kernel (del Inglés Núcleo). En informática, el núcleo (también conocido en español con el anglicismo kernel, de raíces germánicas como kern) es la parte fundamental de un sistema operativo. Es el software responsable de facilitar a los distintos programas acceso seguro al hardware del computador o en forma más básica, es el encargado de gestionar recursos, a través de servicios de llamada al sistema. Como hay muchos programas y el acceso al hardware es limitado, el núcleo también se encarga de decidir qué programa puede hacer uso de un dispositivo de hardware y durante cuanto tiempo, lo que se conoce como multiplexado.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
LAN (del inglés Local Area Network, Red de Área Local). Una red local es la interconexión de varios computadores y periféricos. Su extensión esta limitada físicamente a un edificio o a un entorno de unos pocos kilómetros. Su aplicación más extendida es la interconexión de computadores personales y estaciones de trabajo en oficinas, fábricas, etc; para compartir recursos e intercambiar datos y aplicaciones. En definitiva, permite que dos o más máquinas se comuniquen. El término red local incluye tanto el hardware como el software necesario para la interconexión de los distintos dispositivos y el tratamiento de la información.
LINUX® Denominación de un sistema operativo y el nombre de un núcleo. Es uno de los paradigmas del desarrollo de software libre (y de código abierto), donde el código fuente está disponible públicamente y cualquier persona, con los conocimientos informáticos adecuados, puede libremente estudiarlo, usarlo, modificarlo y redistribuirlo.
Mainframe Ordenador central. Es un computador grande, potente y costoso usado principalmente por una gran compañía para el procesamiento de una gran cantidad de datos; por ejemplo, para el procesamiento de transacciones bancarias.
MIB (del inglés Management Information Base, Base de información de administración). Es un esquema o un modelo que contiene la orden jerárquica de todos los objetos manejados en un sistema distribuido. Cada objeto manejado en un MIB tiene un identificador único. El identificador incluye el tipo (tal como contador, secuencia o dirección), el nivel de acceso (tal como read/write), restricciones del tamaño, y la información del tipo de objeto.
Middleware Lógica de la Mediación. Capa de programas que oculta a los desarrolladores de aplicaciones distribuidas los detalles de la plataforma física incluyendo su heterogeneidad. Gracias a ella, el entorno de ejecución aparenta ser un sistema uniforme. Los desarrolladores pueden concentrarse en los aspectos relevantes de la aplicación, la cual puede ser implantada en cualquier plataforma sobre la que se instale la lógica de mediación.
OMG (del inglés Object Management Group, Grupo de Gestión de Objetos). Es un consorcio dedicado al cuidado y el establecimiento de diversos estándares de tecnologías orientadas a objetos, tales como UML, XMI, CORBA. Además es una organización NO lucrativa que promueve el uso de tecnología orientada a objetos mediante guías y especificaciones para tecnologías orientadas a objetos. El grupo está formado por compañías y organizaciones de software como lo son: Hewlett-Packard (HP), IBM, Sun Microsystems, Apple Computer. (http://www.omg.org/)
ORB (del inglés Object Request Broker, Mediador de Peticiones a Objetos). Es el nombre que recibe una capa de software (también llamada middleware) que permite a los objetos realizar llamadas a métodos situados en máquinas remotas, a través de una red. Maneja la transferencia de estructuras de datos, de manera que sean compatibles entre los dos objetos.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
P2P (del inglés Peer-to-Peer, igual a igual). Es una red que no tiene clientes y servidores fijos, sino una serie de nodos que se comportan simultáneamente como clientes y como servidores de los demás nodos de la red.
Proceso Es un concepto manejado por el sistema operativo que consiste en el conjunto formado por: (a) Las instrucciones de un programa destinadas a ser ejecutadas por el microprocesador, (b) Su estado de ejecución en un momento dado, esto es, los valores de los registros de la CPU para dicho programa, (c) Su memoria de trabajo, es decir, la memoria que ha reservado y sus contenidos. En los sistemas operativos multihilo, un proceso consta de uno o más hilos, la memoria de trabajo (compartida por todos los hilos) y la información de planificación. Cada hilo consta de instrucciones y estado de ejecución. Además en estos sistemas es posible crear tanto hilos como procesos. La diferencia estriba en que un proceso solamente puede crear hilos para sí mismo y en que dichos hilos comparten toda la memoria reservada para el proceso.
Proxy Hace referencia a un programa o dispositivo que realiza una acción en representación de otro. La finalidad más habitual es la del servidor proxy, que sirve para permitir el acceso a Internet a todos los equipos de una organización cuando sólo se puede disponer de un único equipo conectado, esto es, una única dirección IP.
RFC (del inglés Request For Comments, Solicitud para comentarios). Es un conjunto de notas técnicas y organizativas donde se describen los estándares o recomendaciones de Internet. En el caso de la informática, están hechos para hacer compatibles los programas entre sí y que se pueda usar diferente software para la misma función. Definen protocolos y lenguajes, se garantiza la interoperabilidad entre sistemas si ambos cumplen el mismo RFC. (ver http://rfc.net/rfc-index.html)
RMI (del inglés Remote Method Invocation / Invocación Remota de Métodos). Es una Interfaz para Programación de Aplicaciones que permite que un objeto que reside en una máquina virtual de Java® pueda invocar un método de un objeto servidor que reside en otra máquina virtual. Se orienta específicamente a aplicaciones escritas totalmente en Java®.
RPC (del inglés Remote Procedure Call, Llamada a Procedimiento Remoto). Es un protocolo que permite a un programa de computador ejecutar código en otra máquina remota sin tener que preocuparse por las comunicaciones entre ambos. El protocolo fue propuesto inicialmente por Sun Microsystems como un gran avance sobre los sockets usados hasta el momento. De esta manera el programador no tenía que estar pendiente de las comunicaciones, estando éstas encapsuladas dentro de las RPC.
Semáforo Es una variable especial protegida (o tipo abstracto de datos) que constituye el método clásico para restringir o permitir el acceso a recursos compartidos (por ejemplo, un recurso de almacenamiento) en un entorno de procesamiento distribuido.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
Servidor Computador en el que se ejecuta un programa que realiza alguna tarea en beneficio de otras aplicaciones llamadas clientes, tanto si se trata de un computador central (mainframe), un minicomputador, un computador personal, un PDA o un sistema integrado; sin embargo, hay computadores destinados únicamente a proveer los servicios de estos programas.
Sincronización Técnica que permite operar simultáneamente dos aplicaciones de ya sea mediante secciones críticas, semáforos o paso de mensajes, para garantizar la exclusión mutua en las zonas del código en las que sea necesario.
SNMP (del inglés Simple Network Management Protocol, Protocolo Simple de administración de red). Es un protocolo de la capa de aplicación que facilita el intercambio de información de administración entre dispositivos de red. Es parte de la suite de protocolos TCP/IP. SNMP permite a los administradores supervisar el desempeño de la red, buscar y resolver sus problemas, y planear su crecimiento.
Socket Mecanismo de comunicación entre procesos. Socket designa un concepto abstracto por el cual dos programas (posiblemente situados en computadores distintos) pueden intercambiarse cualquier flujo de datos, generalmente de manera fiable y ordenada. Un socket queda definido por una dirección IP, un protocolo y un número de puerto. Ejemplo: ftp://201.45.23.45:21
Spam Mensajes no solicitados, habitualmente de tipo publicitario, enviados en cantidades masivas. Aunque se puede hacer por distintas vías, la más utilizada entre el público en general es la basada en el correo electrónico. Otras tecnologías de internet que han sido objeto de spam incluyen grupos de noticias usenet, motores de búsqueda, wikis y blogs. El spam también puede tener como objetivo los teléfonos móviles (a través de mensajes de texto) y los sistemas de mensajería instantánea.
Switch Conmutador. Dispositivo de interconexión de redes de computadores que opera en la capa 2 (nivel de enlace de datos) del modelo OSI (Open Systems Interconection). Un switch interconecta dos o más segmentos de red, pasando datos de un segmento a otro, de acuerdo con la dirección de destino de los datagramas en la red. Un switch en el centro de una red en estrella. Los switches se utilizan cuando se desea conectar múltiples redes, fusionándolas en una sola. Dado que funcionan como un filtro en la red, mejoran el rendimiento y la seguridad de las LANs.
TCP (del inglés Transmission Control Protocol, Protocolo de Control de Transmisión). Protocolo que fue creado entre los años 1973 - 1974 (por Vint Cerf y Robert Kahn) es uno de los protocolos fundamentales en Internet. Muchos programas dentro de una red de datos compuesta por computadores pueden usar TCP para crear conexiones entre ellos a través de las cuales enviarse datos. El protocolo garantiza que los datos serán entregados en su destino sin errores y en el mismo orden en que se transmitieron. También proporciona un mecanismo para distinguir distintas aplicaciones dentro de una misma máquina, a través del concepto de puerto.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
UDP (del Inglés User Datagram Protocol, protocolo de datagrama de usuario). Protocolo del nivel de transporte basado en el intercambio de datagramas. Permite el envío de datagramas a través de la red sin que se haya establecido previamente una conexión, ya que el propio datagrama incorpora suficiente información de direccionamiento en su cabecera. Tampoco tiene confirmación, ni control de flujo, por lo que los paquetes pueden adelantarse unos a otros; y tampoco sabemos si ha llegado correctamente, ya que no hay confirmación de entrega o de recepción. Su uso principal es para protocolos como DHCP, BOOTP, DNS y demás protocolos en los que el intercambio de paquetes de la conexión/desconexión son mayores, o no son rentables con respecto a la información transmitida, así como para la transmisión de audio y vídeo en tiempo real, donde no es posible realizar retransmisiones por los estrictos requisitos de retardo que se tiene en estos casos.
UNIX Sistema operativo portable, multitarea y multiusuario. Desde el punto de vista técnico, UNIX se refiere a una familia de sistemas operativos que comparten unos criterios de diseño e interoperabilidad en común. Esta familia incluye más de 100 sistemas operativos desarrollados a lo largo de 20 años.
URL (del Inglés Uniform Resource Locator, localizador uniforme de recurso). Es una secuencia de caracteres, de acuerdo a un formato estándar, que se usa para nombrar recursos, como documentos e imágenes en Internet, por su localización. El URL es la cadena de caracteres con la cual se asigna una dirección única a cada uno de los recursos de información disponibles en la Internet. Existe un URL único para cada página de cada uno de los documentos de la World Wide Web.
Ejemplo: http://es.wikipedia.org:80/wiki/data
WAN (del inglés Wide Area Network, Red de área amplia). Tipo de red de computadores capaz de cubrir distancias desde unos 100 hasta unos 1000 km, proveyendo de servicio a un país o un continente. Un ejemplo de este tipo de redes sería RedIRIS, Internet o cualquier red en la cual no estén en un mismo edificio todos sus miembros (sobre la distancia hay discusión posible). Muchas WAN son construidas por y para una organización o empresa particular y son de uso privado, otras son construidas por los proveedores de Internet (ISP) para proveer de conexión a sus clientes.
WINDOWS® Nombre de una familia de sistemas operativos privativos desarrollados por la empresa de software Microsoft Corporation. Todos ellos tienen en común el estar basados en una interfaz gráfica de usuario apoyada en el paradigma de ventanas (de ahí su nombre en inglés).

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
FUENTES DOCUMENTALES
LIBROS
SISTEMAS DISTRIBUIDOS – Conceptos y Diseño. COULOURIS George, DOLLIMORE Jean y KINDBERG Tim, Pearson – Addison Wesley, Madrid, 2001, 3ª Ed.
SISTEMAS OPERATIVOS MODERNOS, TANENBAUM, Andrew S., Prentice – Hall, Madrid, 2003, 2ª Ed.
REDES DE COMPUTADORES, TANENBAUM, Andrew S., Prentice – Hall, Madrid, 2003, 4ª Ed.
REDES DE COMPUTADORES – Un enfoque descendente basado en Internet. KUROSE James F. y ROSS Keith W., Pearson – Addison Wesley, Madrid, 2004, 2ª Ed.
COMUNICACIONES Y REDES DE COMPUTADORES. STALLINGS, William, Prentice-Hall, Madrid, 2000. 2ª Ed.
COMUNICACIÓN DE DATOS, REDES DE COMPUTADORES Y SISTEMAS ABIERTOS, HALSALL, Fred, Pearson – Addison Wesley, México, 1998, 4ª Ed.
DISTRIBUTED COMPUTING: Fundamentals, Simulations and Advanced Topics, ATTIYA, Hagit y WELCH, Jennifer, John Wiley & Sons, New Jersey, 2004.
MIDDLEWARE NETWORKS: Concept, Design and Deployment of Internet Infrastructure, LERNER, Michach y Vanecek George, Kluwer Academic Publishers, New York, 2002.
TOOLS AND ENVIRONTMENTS FOR PARALLEL AND DISTRIBUTED COMPUTING, HARIRI, Salim y PARASAR, Manish, John Wiley & Sons, New Jersey, 2004
ADVANCED COMPUTER ARCHITECTURE AND PARALLEL PROCESSING, EL-REWINI, Hesham y ADB-EL-BARR, Mostafa, John Wiley & Sons, New Jersey, 2005
FUNDAMENTALS OF DISTRIBUTED OBJECT SYSTEMS: The CORBA Perspective, TARI, Zahir y BUKHRES, Omran, John Wiley & Sons, New Jersey, 2001
DEVELOPING SECURE DISTRIBUTED SYSTEMS WITH CORBA. LANG, Ulrich y SCHREINER, Rudolf, Artech House, Norwood, 2002.

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
A NETWORKING APPROACH TO GRID COMPUTING, MINOLI, Daniel, John Wiley & Sons, New Jersey, 2005.
GRID COMPUTING: Making the Global Infrastructure a Reality, BERMAN, Frank, HEY, Anthony y Fox Geoffrey, John Wiley & Sons, England, 2005.
ARTÍCULOS
LA RED SEMÁNTICA. Tim Berners Lee y Hames Hendler en INVESTIGACIÓN Y CIENCIA, págs. 39-47, Julio 2001
EL SUPERODENADOR BEUWOLF. William Hargrove y Thomas Sterling en INVESTIGACIÓN Y CIENCIA, págs. 4-12, Octubre 2001
INFORMATIZACIÓN DEL HOGAR. W. Wayt Gibss en INVESTIGACIÓN Y CIENCIA, págs. 16-21, Abril 2002
EL COMPUTADOR MUNDIAL. DAVID P. Anderson y John Kubiatowicz en INVESTIGACIÓN Y CIENCIA, págs. 68-75, Mayo 2002
LA MALLA: COMPUTACIÓN SIN LÍMITES. Ian Foster en INVESTIGACIÓN Y CIENCIA, págs. 60-67, Junio 2003
NUEVOS BUSCADORES EN LA RED. Javed Mostaza en INVESTIGACIÓN Y CIENCIA, págs. 61-57, Abril 2005
SITIOS WEB
http://rfc.net/rfc-index.html
Servidor donde residen los documentos Internet RFC (Request for Comments)
http://www.wikipedia.org
Sistema distribuido de información de referencia en múltiples idiomas
http://www.disc-conference.org/
Simposio internacional sobre teoría, diseño, análisis, implementación y aplicación de redes y Sistemas Distribuidos.
http://www.omg.org
Grupo de Gestión de Objetos. Definió las especificaciones de UML, XML, CORBA

UNIVERSIDAD NACIONAL ABIERTA Y A DISTANCIA – UNAD
ESCUELA DE CIENCIAS BÁSICAS, TECNOLOGÍA E INGENIERÍA CONTENIDO DIDÁCTICO DEL CUSO: 302090 – SISTEMAS DISTRIBUIDOS
http://www.distributedcomputing.info/projects.html
Portal de acceso a los principales proyectos de computación distribuida en desarrollo a nivel mundial
http://www.grid.org
http://www.grid5000.org
http://www.gridsystems.com
Portales Web dedicados a la Computación en malla. (Grid Computing)
http://www.infor.uva.es/~fdiaz/sd/doc/java2.pdf
Tutorial completo sobre JAVA.
LIBROS ELECTRÓNICOS
http://info.borland.com/techpubs/jbuilder/jbuilderx/spanish/viewordownloadpdf.html
Borland Corporation. “Guía del desarrollador de Servicios Web”. 2004.
ftp://jano.unicauca.edu.co/cursos/SistDistrib/Corba/1-intro.pdf
Introduccion a los Sistemas Distribuidos. PEREZ C., José Raul (ITESM)
http://www.cs.ucl.ac.uk/staff/jon/ods/ods.html
Libro en línea “Open Distributed Systems” de Jon Crowcroft
http://www.cdk3.net/
Libro en línea “Distributed Systems: Concepts and Design. 3th Edition” de George Coulouris, Jean Dollimore y Tim Kindberg
REVISTAS ELECTRÓNICAS
http://www.computer.org/portal/site/Internet//
Revista. IEEE Internet Computing (Magazine).
Revista. IEEE Transactions on Parallel and Distributed Systems
http://www.elsevier.com/wps/find/journaldescription.cws_home/622895/description
Revista. IEEE Transactions on Parallel and Distributed Systems (Journal)