MUESTREO - Dr. Ing. Luz Davalos Z. · Consiste en dividir la población en n estratos, compuestos...
38
1. Mostrar los beneficios del muestreo 2. Analizar los tipos de muestreo 3. Aplicar las fórmulas de muestreo para poblaciones finitas e infinitas MUESTREO
Transcript of MUESTREO - Dr. Ing. Luz Davalos Z. · Consiste en dividir la población en n estratos, compuestos...

1. Mostrar los beneficios del muestreo
2. Analizar los tipos de muestreo
3. Aplicar las fórmulas de muestreo para poblaciones finitas e infinitas
MUESTREO

MUESTREO
Una paso fundamental para realizar un estudio estadístico del
mercado es obtener unos resultados confiables y que puedan ser
aplicables. No obstante resulta casi imposible o impráctico llevar a
cabo algunos estudios sobre toda una población, por lo que la
solución es llevar a cabo el estudio basándose en un subconjunto de
ésta denominada muestra.
Sin embargo, para que los estudios tengan la validez y confiabilidad
buscada es necesario que esta muestra, posea algunas características
específicas que permitan, al final, generalizar los resultados hacia la
población en total. Esas características tienen que ver principalmente
con el tamaño de la muestra y con la manera de obtenerla.

POBLACIÓN, es el conjunto de unidades (personas, empresas y
familias, etc.) de las cuales se desea información las poblaciones pueden
ser finitas o infinitas. Se pueden considerar infinitas aquellas formadas
por más de 5000 unidades.
MARCO MUESTRAL, es la fuente de información, es la base de datos
de la cual se extrae la muestra para analizar el comportamiento de la
población, Por ejemplo el listado de las 100 empresas más grandes de
Bolivia, la ciudad de Oruro, etc.
MUESTRA, es una parte de las unidades de la población a partir de la
cual se realizan las inferencias.
Nota: En el caso de tomar en cuenta a todos los elementos de una
población el estudio se denomina CENSO (de opinión, población ,etc.).

TIPOS DE MUESTREO
Muestreo no probabilístico
• Los elementos de la muestra se seleccionan siguiendo criterios determinados por el investigador siempre procurando la representatividad de la muestra
Muestreo probabilístico
• Todos los individuos o elementos de la población tienen la misma probabilidad de ser incluidos en la muestra extraída, asegurándonos la representatividad de la misma

A. MUESTREO NO PROBABILÍSTICO
Este tipo de muestreo se utiliza cuando el probabilístico
resulta muy costoso, teniendo presente que no sirve para
hacer inferencias puesto que no existe certeza de que la
muestra extraída tenga representatividad, puesto que no
todos los elementos de la población tiene la misma
probabilidad de ser seleccionados.

A.1 MUESTREO DISCRECIONAL
Los elementos de la muestra son seleccionados por el investigador de
acuerdo a criterios que él considera de aporte para el estudio.
Ejemplo: Seleccionar a cajeros de un banco en un estudio sobre el
comportamiento del usuario ante el pago de impuestos.
A.2 MUESTREO CAUSAL O INCIDENTAL
Los elementos de la muestra son seleccionados directa o
intencionadamente de acuerdo a la facilidad de acceso
Ejemplo: Un profesor universitario frecuentemente utilizará a sus
estudiantes para integrar muestras.

A.3 POR CUOTAS O CUPOS Presupone un buen conocimiento de los segmentos o estratos
de la población y selecciona a los elementos o individuos más representativos de cada segmento (estrato).
Primero. Se realiza una clara división por segmentos (estratos)
Segundo. A cada cuota se aplica un muestreo discrecional
Ejemplo: Seleccionar 20 estudiantes de la carrera de ingeniería industrial, que ya hayan cursado el noveno semestre de la carrera y que tengan promedio arriba del 65 por ciento. Se eligen a los primeros 20 que cumplan con estas condiciones.

A.4 SNOW BALL
Algunos elementos seleccionados de la muestra conducen a
otros y estos a otros hasta conseguir una muestra adecuada en
tamaño.
Ejemplo: Realizar estudios con poblaciones marginales, tipos de
enfermos, especialistas, etc.

B. MUESTREO PROBABILÍSTICO
Todos los individuos o elementos de la población tienen la
misma probabilidad de ser incluidos en la muestra extraída,
asegurándonos la representatividad de la misma

B.1 MUESTREO ALEATORIO SIMPLE
Todos los elementos de la población tienen la misma
probabilidad de ser seleccionados en la muestra y esta
probabilidad es conocida.
Este tipo de muestreo es más recomendable, pero resulta
mucho más difícil de llevarse a cabo y, por lo tanto, es más
costoso. Para seleccionar una muestra de este tipo se
requiere tener en forma de lista todos los elementos que
integran la población investigada y utilizar tablas de números
aleatorios.

EJEMPLO
A un grupo de 100 personas se les numera de uno a cien y se
depositan en una urna 100 bolitas a su vez numeradas de uno
a cien. Para obtener una muestra aleatoria simple de 20
elementos, tendríamos que sacar 20 bolitas numeradas de la
urna que nos seleccionarán en forma completamente al azar a
los 20 elementos escogidos para que opinen sobre un nuevo
producto.

B.2 MUESTREO ALEATORIO SISTEMÁTICO
Es susceptible de ser más preciso que el muestreo aleatorio simple.
Se elige un primer elemento del universo y luego se van escogiendo
otros elementos igualmente espaciados a partir del primero.
Consiste en dividir la población en n estratos, compuestos de k
unidades.
Ejemplo: a partir de una lista de 100 establecimientos de comestibles,
deseamos seleccionar una muestra probabilística de 20 tiendas. La
forma de hacerlo sería:
Dividir 100 entre 20 para obtener 5 que es el salto sistemático
Extraer un número al azar entre 1 y 5. Supóngase que es el número 2
el cual corresponde al primer elemento seleccionado.
Se incluyen en la muestra de establecimientos numerados: 2, 7, 12, 17,
22,…..,97.

B.3 MUESTREO POR ZONAS (ciudades)
Es ideal cuando se desea que las entrevistas se apliquen en áreas
representativas del fenómeno a estudiar, en un área determinada. Esta zona
puede ser una ciudad, un barrio, etc. Se procede por etapas:
Primera etapa: selección de manzanas en un mapa. Se necesita un plano de la
ciudad que se investigará.
Segunda etapa: eliminar del plano las manzanas no destinadas a casa habitación:
como parques, iglesias, tiendas e industrias.
Tercera etapa: Se enumera cada manzana de las que restan en el plano con un
criterio uniforme para no alterar la aleatoriedad. Al mismo tiempo se determinar
el número de manzanas que estarán en la muestra.
Una vez realizados estos pasos se encuentra un número promedio de viviendas
por manzana
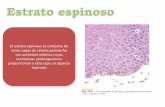
Ejemplo: Se desea realizar un estudio en las familias de una ciudad, en esta
ciudad existen cerca de 5,000 manzanas disponibles y 200,000 hogares, con
un promedio de 40 familias por manzana.
Se fija un “salto” mínimo de hogares para hacer cada entrevista. Un salto
es el número de casas que se dejarán de visitar después de cada encuesta.
A mayor salto, mayor dispersión de la muestra y mayor representatividad,
pero mayor costo. Se recomiendan saltos no menores de 4 ni mayores de
10 casas. Se puede utilizar un salto promedio de 8.
Se determina el tamaño de la muestra. Suponiendo que la muestra es de
800 hogares entrevistados, se tiene:
40 hogares por manzana/8 (salto)
Entrevistaré 5 hogares por manzana
200.000/5000
Tengo que sortear
160 manzanas
Con fórmulas

El número de manzanas que se deben dejar de visitar después de haber encuestado una manzana, se obtiene de la siguiente forma: si se precisa 160 manzanas
Se obtiene un número aleatorio entre 1 y 32 = 25
Primera manzana…………….25
Salto sistemático……..32
Segunda manzana………….....57
Salto sistemático……..32
Tercera manzana…………..…89
Etc.
Se localizan las manzanas en el mapa y se procede a la encuesta.
5000/160=31,25

B.4 MUESTREO ALEATORIO ESTRATIFICADO
Se aplica cuando la población no es homogénea con relación a la
característica que se desea estudiar: clases sociales, regiones, sexo,
grupos de edad. En este caso la población queda dividida en
estratos o grupos y el muestreo debe hacerse de tal forma que
todos esos grupos queden representados.
Para determinar el tamaño de la muestra en cada estrato, sobre
todo si la estratificación es por niveles de ingreso y por regiones, se
puede utilizar dos métodos:

Cálculo proporcional al tamaño del estrato. En este caso existe
una relación proporcional entre el tamaño del estrato y el
número de elementos que aporta a la muestra. Cuanto mayor
sea el estrato, mayor será el tamaño de la muestra seleccionada.
Cálculo desproporcional al tamaño del estrato. Este tipo de
cálculo se utiliza para no tener muestras excesivamente grandes
en los estratos de mayor tamaño y muestras demasiado pequeñas
que no permitan un análisis mayor en los estratos de menor
tamaño. Muchas veces, los productos a investigar tienen su
mayor demanda en los estratos más pequeños.

Ejemplo: Se desea realizar una investigación acerca de las actitudes,
preferencias y hábitos de consumo de las madres de familia y los niños
para un nuevo tipo de galleta en el mercado no obstante es evidente que
este estudio debe enfocarse más hacia los niveles socioeconómicos altos,
ya que son quienes pueden hacer frente a un precio Premium del 20%.
Suponga que la muestra total es de 500 encuestas en la ciudad del estudio.
Considerando los porcentajes de hogares en cada estrato socioeconómico
en un muestreo probabilístico con cálculo proporcional obtendríamos:
Sin embargo, este número de entrevistas por estrato no permitiría mayor
análisis y desvirtuaría los objetivos de la investigación en los estratos altos,
solo 40 entrevistas de 500.
Es el 8% de 500
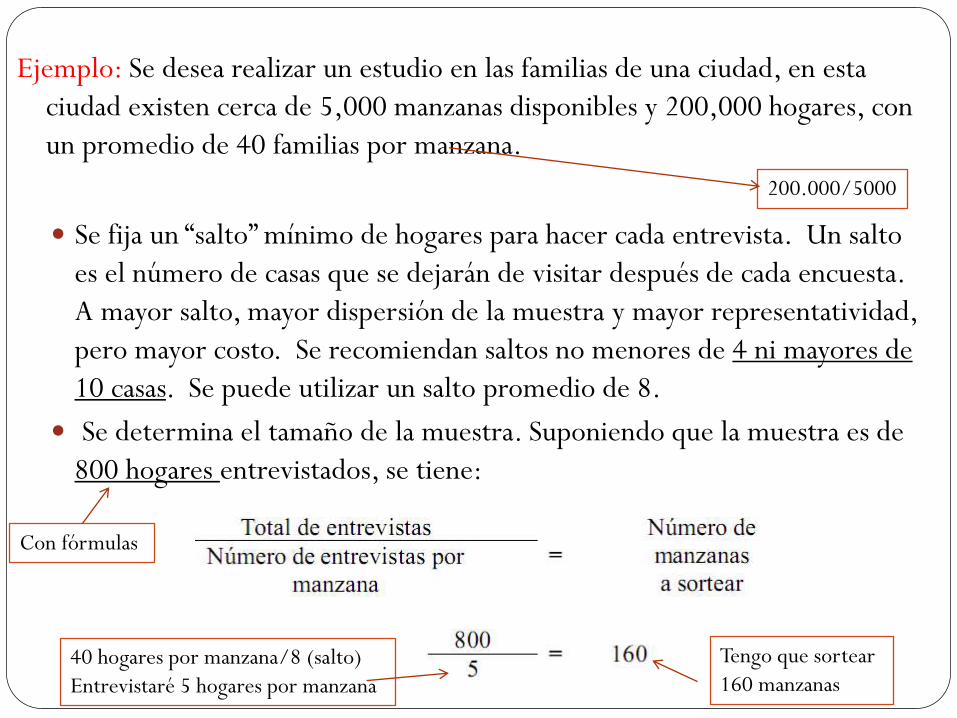
Aquí se deberá calcular el tamaño de cada muestra mediante el método desproporcional, analizando el comportamiento de la característica para cada estrato y haciendo una estimación de su distribución en la muestra total.
Es evidente que si se aplica el muestreo directamente proporcional al tamaño del estrato, al intentar investigar la probabilidad de pago de un precio Premium, la investigación se ve muy limitada, precisamente por el tamaño del estrato. Al considerar la probabilidad estimada de posesión del producto, se podrá explorar mejor el fenómeno.
Prueba piloto o
criterio de expertos

TAMAÑO DE LA MUESTRA
El objetivo del muestreo es estimar características de la
población, con base en la información contenida en una
muestra. La teoría de muestreo permite desarrollar métodos
de selección de muestras que proporcionen, al menor costo
posible y con la suficiente exactitud la información necesaria
para los propósitos establecidos.
Para calcular el tamaño de una muestra hay que tomar en
cuenta tres factores:

1. El nivel de confianza es el porcentaje de seguridad que existe para generalizar los resultados obtenidos. Esto quiere decir que un porcentaje del 100% equivale a que no existe ninguna duda para generalizar resultados e implica estudiar a la totalidad de los casos de la población. Para evitar un costo muy alto para el estudio se busca un porcentaje de confianza menor. Comúnmente en las investigaciones sociales se busca alrededor de 95%. Es un área debajo de la curva normal.
2. El error o porcentaje de error equivale a elegir una probabilidad de aceptar una hipótesis que sea falsa como si fuera verdadera, o la inversa: rechazar a hipótesis verdadera por considerarla falsa. Al igual que en el caso de la confianza, si se quiere eliminar el riesgo del error y considerarlo como 0%, entonces la muestra es del mismo tamaño que la población, por lo que conviene correr un cierto riesgo de equivocarse. Comúnmente se aceptan entre el 4% y el 6% como error, tomando en cuenta de que no son complementarios la confianza y el error.

3. La variabilidad es la probabilidad (o porcentaje) con el que se
aceptó y se rechazó la hipótesis que se quiere investigar en alguna
investigación anterior o en un ensayo previo a la investigación actual. El
porcentaje con que se aceptó tal hipótesis se denomina variabilidad
positiva y se denota por p, y el porcentaje con el que se rechazó la
hipótesis es la variabilidad negativa, denotada por q.
Hay que considerar que p y q son complementarios, es decir, que su
suma es igual a la unidad: p+q=1. Además, cuando se habla de la
máxima variabilidad, en el caso de no existir antecedentes sobre la
investigación (no hay otras o no se pudo aplicar una prueba previa),
entonces los valores de variabilidad es p=q=0.5.

EN RESUMEN: Cuando deseamos estimar el tamaño de una muestra, debemos conocer los
siguientes aspectos:
a) El nivel de confianza o seguridad (1 - α). El nivel de confianza prefijado da
lugar a un coeficiente (Zα). Por ejemplo para una seguridad del 95%, Zα =
1.96, para una seguridad del 99%, Zα = 2.58. (Estos valores provienen de
las tablas de la distribución normal Z)
b) La precisión que deseamos para el estudio es decir el máximo error
muestral entre 4% y el 6%
c) Una idea del valor aproximado del parámetro que queremos medir. Esta
idea se puede obtener revisando la literatura, por estudio pilotos previos.
En caso de no tener dicha información utilizaremos el valor p = 0.5 (50%).
Una consideración clave para una investigación es la cantidad de información
con la que se cuente; específicamente se pueden tener dos casos:
desconocer la población del fenómeno estudiado, o bien, conocerla.

Cálculo del Tamaño de la Muestra
desconociendo el Tamaño de la Población.
La fórmula para calcular el tamaño de muestra cuando se
desconoce el tamaño de la población es la siguiente: Es la constante que depende del nivel de confianza
que asignemos. El nivel de confianza indica la
probabilidad de que los resultados de nuestra
investigación sean ciertos: con un 95,5 % de confianza
yo puedo asegurar que la información obtenida con
esta muestra corresponde a la realidad.
Es el error muestral deseado. El error muestral es la
diferencia que puede haber entre el resultado que
obtenemos preguntando a una muestra de la población y
el que obtendríamos si preguntáramos al total de ella Z = nivel de confianza
p = probabilidad de éxito
q = probabilidad de fracaso
d = precisión (error muestral máximo admisible)

Ejemplo 1: si los resultados de una encuesta dicen que 100 personas comprarían un producto y tenemos un error muestral (d) del 5% comprarán entre 95 y 105 personas.
Ejemplo 2: si hacemos una encuesta de satisfacción a los empleados con un error muestral (d) del 3% y el 60% de los encuestados se muestran satisfechos significa que entre el 57% y el 63% (60% +/- 3%) del total de los empleados de la empresa lo estarán.
Ejemplo 3: si los resultados de una encuesta electoral indicaran que un partido iba a obtener el 55% de los votos y el error estimado fuera del 3%, se estima que el porcentaje real de votos estará en el intervalo 52-58% (55% +/- 3%).

Ejemplo: ¿A cuántas familias tendríamos que estudiar para conocer la preferencia del mercado en cuanto a una marca de shampoo para bebé, si se desconoce la población total?
Seguridad = 95%; Precisión = 3%;
Probabilidad de éxito = de un estudio piloto realizado a 50 personas el 95% (alto %) pudieron responder; si no tuviésemos ninguna idea de dicha proporción utilizaríamos el valor p = 0.5 (50%) que maximiza el tamaño muestral.
Entonces:
Zα² = 1.962 (ya que la seguridad es del 95%)
p = 0.95 (tiene la característica de interés)
q = 1 – p (en este caso 1 – 0.95 = 0.05)
d = precisión (en este caso deseamos un 3%)
Se requeriría encuestar a no menos de 203 familias para poder tener una seguridad
del 95%
q p

Ejemplo: ¿Cómo hubiera cambiando el ejemplo anterior, si se desconoce la
proporción esperada?
Cuando se desconoce la probabilidad de éxito esperada, se tiene que utilizar el criterio (p = q = 0.5), lo cual maximiza el tamaño de muestra de la siguiente
manera:
Z α²= 1.962 (ya que la seguridad es del 95%)
p = Probabilidad de éxito(en este caso 50% = 0.5)
q = 1 – p (en este caso 1 – 0.5 = 0. 5)
d = precisión (en este caso deseamos un 3%) quedando como resultado:
Se requeriría encuestar a no menos de 1068 familias para poder tener una seguridad del 95%

Cálculo del Tamaño de la Muestra
conociendo el Tamaño de la Población. La fórmula para calcular el tamaño de muestra cuando se conoce el tamaño
de la población es la siguiente:
Donde:
N = tamaño de la población
Z = nivel de confianza,
p = probabilidad de éxito
q = probabilidad de fracaso
d = precisión (error máximo admisible)

Ejemplo: ¿A cuántas familias tendríamos que estudiar para conocer la preferencia del mercado en cuanto a una marca de shampoo para bebé, si se conoce que el número de familias con bebés en el sector de interés es de 15,000?
Seguridad = 95%;
Precisión = 3%;
Probabilidad de éxito= asumimos que puede ser próxima al 95%; si no tuviese ninguna idea de dicha proporción utilizaríamos el valor p = 0.5 (50%) que maximiza el tamaño muestral.
Se requeriría encuestar a no menos de 200 familias para poder tener una seguridad del 95%

Ejemplo: ¿Cómo hubiera cambiando el ejemplo anterior, si se desconoce la
proporción esperada?
Si se desconoce la probabilidad de éxito esperada, se tendría que utilizar el criterio conservador (p = q = 0.5), lo cual maximiza el tamaño de muestra de la siguiente manera:
Zα² = 1.962 (ya que la seguridad es del 95%)
p = Probabilidad de éxito(en este caso 50% = 0.5)
q = 1 – p (en este caso 1 – 0.5 = 0. 5)
d = precisión (en este caso deseamos un 3%) quedando como resultado:
Se requeriría encuestar a no menos de 997 familias para poder tener una seguridad del 95%

EL NIVEL DE SEGURIDAD EN EL
MUESTREO
Según diferentes seguridades, el coeficiente de Zα varía así:
Si la seguridad fuese del 90% el coeficiente Zα sería 1.645
Si la seguridad fuese del 95% el coeficiente Zα sería 1.96
Si la seguridad fuese del 97.5% el coeficiente Zα sería 2.24
Si la seguridad fuese del 99% el coeficiente sería Zα 2.576
Si los recursos del investigador son limitados, debe recordar que a
medida que se disminuya el nivel de seguridad, se permitirá una
mayor incertidumbre en el estudio de investigación, lo cual a su
vez permitirá al investigador trabajar con un número de muestra
más reducido, sacrificando la confiabilidad de los resultados.

EJEMPLO Los investigadores de una empresa de productos de aseo personal
desean a aplicar una encuesta en la ciudad de Bellavista para conocer las preferencias de consumo de una nueva crema aftershave. Su principal duda es el número de personas que deberán encuestar para realizar su investigación. Por lo que le han solicitado determinar:
1.- La población meta. El elemento y unidad muestral.
2.- El marco muestral y el estrato.
3.- El tipo de muestreo más adecuado.
4.- La distribución y el tamaño de la muestra a utilizar.
1. Tomar en cuenta que la población meta estará compuesta solo por varones mayores de 18 años.
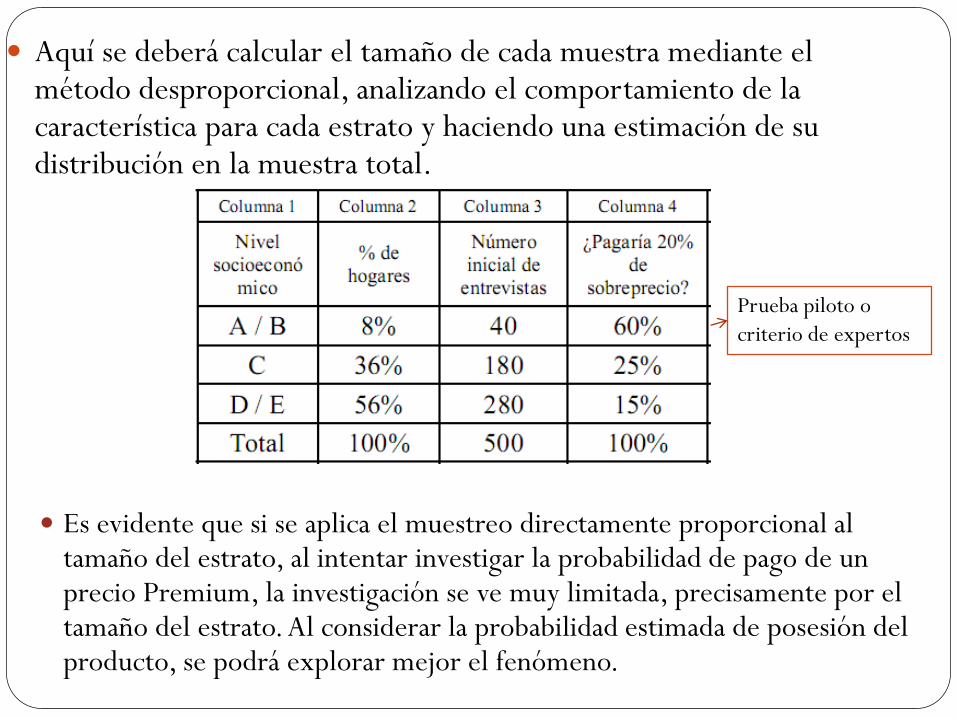
Edades |Nivel A |Nivel B |Nivel C
De 18 a 25 años |58,000 |89,000 |113,000
De 26 a 30 años |123,000 |234,000 |567,000
+ de 30 años |215,000 |450,000 |600,000
Total |396,000 |773,000 |1,280,000
POBLACIÓN DE VARONES EN BELLAVISTA
Como la población meta estará compuesta solo por varones mayores de 18
años en este caso coincide que cada persona de sexo masculino del distrito de
Bellavista, mayor de 18 años, será el elemento muestral y la unidad de
muestra.
El marco muestral para obtener los datos de la población meta, será el listado
anual de distribución poblacional que emite el INSTITUTO NACIONAL DE
ESTADÍSTICA
El estrato está conformado por los varones mayores de 18 años de los niveles
socioeconómicos A, B, C.
Todos ellos
son unidades
de muestreo
Ej. Elemento pueden ser determinadas empresas y
la unidad el responsable de compras
Niveles socioeconómicos

La técnica de muestreo más conveniente es el muestreo
aleatorio estratificado por ser el de uso más frecuente cuando
queremos una primera aproximación de mercado. A través de
este podremos seleccionar las unidades de muestra al azar, según
la distribución poblacional, definida por las características de
control. Es decir, estableceremos cuotas según sexo, edad y nivel
socio económico. Variables importante por la naturaleza de la
investigación.
Para empezar, sumamos las columnas de cada nivel
socioeconómico, para luego obtener los porcentajes de cada una,
en base al total neto de varones.
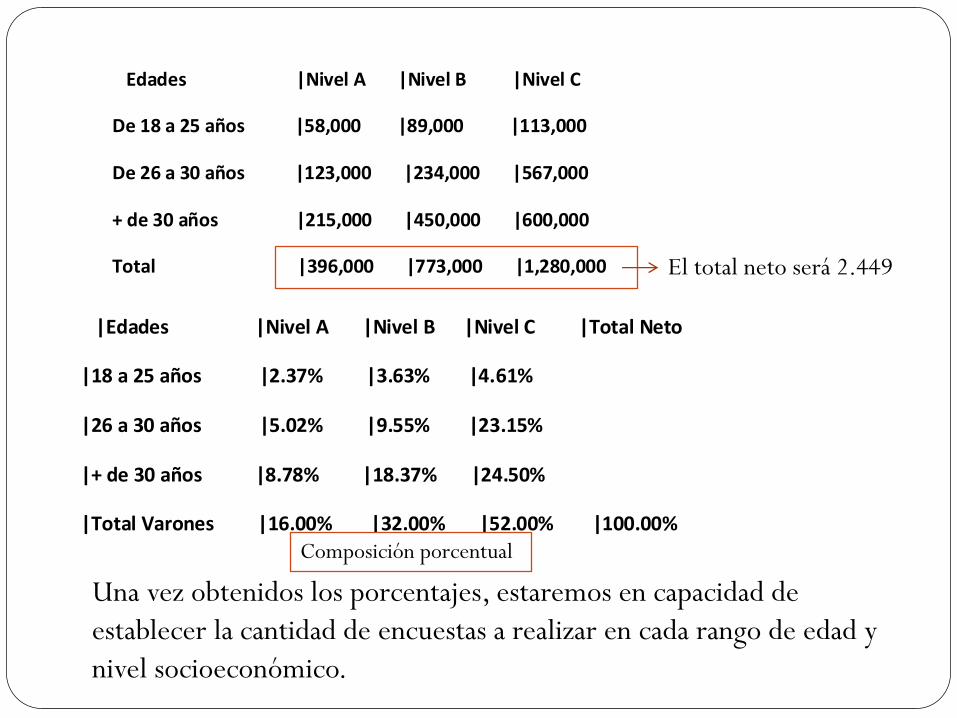
Edades |Nivel A |Nivel B |Nivel C
De 18 a 25 años |58,000 |89,000 |113,000
De 26 a 30 años |123,000 |234,000 |567,000
+ de 30 años |215,000 |450,000 |600,000
Total |396,000 |773,000 |1,280,000 El total neto será 2.449
|Edades |Nivel A |Nivel B |Nivel C |Total Neto
|18 a 25 años |2.37% |3.63% |4.61%
|26 a 30 años |5.02% |9.55% |23.15%
|+ de 30 años |8.78% |18.37% |24.50%
|Total Varones |16.00% |32.00% |52.00% |100.00%
Una vez obtenidos los porcentajes, estaremos en capacidad de
establecer la cantidad de encuestas a realizar en cada rango de edad y
nivel socioeconómico.
Composición porcentual

Nivel de confianza α = 0.95
Distribución normal estandarizada z =1.96
Si tiene características de interés p =0.60
No tiene características de interés q =0.40
Error d =0.05
Tamaño de la población N =2,449
Luego procederemos a calcular el tamaño de muestra de acuerdo con
los datos y la fórmula correspondiente.
Indica la probabilidad de que los resultados
de nuestra investigación sean ciertos: un 95
% de confianza
Es la diferencia que puede haber entre el
resultado que obtenemos preguntando a una
muestra de la población y el que obtendríamos
si preguntáramos al total de ella
=2257,93/7,04=321 encuestas
De un estudio piloto previo
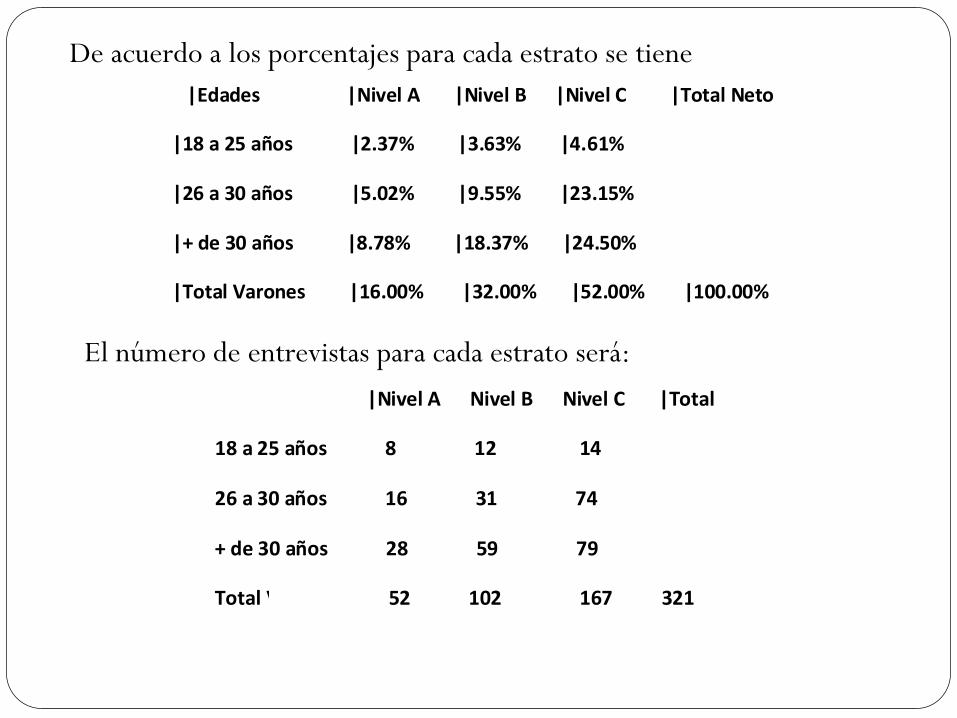
|Edades |Nivel A |Nivel B |Nivel C |Total Neto
|18 a 25 años |2.37% |3.63% |4.61%
|26 a 30 años |5.02% |9.55% |23.15%
|+ de 30 años |8.78% |18.37% |24.50%
|Total Varones |16.00% |32.00% |52.00% |100.00%
|Nivel A Nivel B Nivel C |Total
18 a 25 años 8 12 14
26 a 30 años 16 31 74
+ de 30 años 28 59 79
Total Varones 52 102 167 321
De acuerdo a los porcentajes para cada estrato se tiene
El número de entrevistas para cada estrato será:

EJERCICIOS 1. Determinar el tamaño de la muestra para realizar una encuesta
para conocer el nivel de satisfacción de clientes con un
determinado modelo de coche del que hemos vendido 10.000
unidades (N), en la que queremos una confianza del 95%,
deseamos un error muestral del 5% y consideramos que el 50%
tiene la característica de interés
2. Determinar el tamaño de la muestra para conocer las
preferencias de las personas de un país en relación a un
determinado programa de televisión. Si la población del país es
de 40 millones de personas, estimamos que tiene la característica
de interés el 20% de la población, queremos una confianza del
95% y estamos dispuestos a asumir un error muestral del 4%