

Presentación de PowerPoint - Iniciofisica.cab.cnea.gov.ar/gpgpu/images/charlas/partec... · •...
52
PARTE C – Programación II 3EAGPGPU 3EAGPGPU Pablo Ezzatti CUDA Básico
Transcript of Presentación de PowerPoint - Iniciofisica.cab.cnea.gov.ar/gpgpu/images/charlas/partec... · •...

PARTE C – Programación II 3EAGPGPU
3EAGPGPU
Pablo Ezzatti
CUDA Básico

PARTE C – Programación II 3EAGPGPU
Parte C

PARTE C – Programación II 3EAGPGPU
Contenido
• Continuamos programando
• Acceso Coalesced a Memoria Global
• Memoria compartida
• Reduce
• Algunas recomendaciones de performance

PARTE C – Programación II 3EAGPGPU
Continuamos programando

PARTE C – Programación II 3EAGPGPU
Programación en CUDA
Lanzamiento del kernel (2)
// configuración de la ejecución
int bloques = N / 128;
dim3 tamGrid(1, bloques); //Grid dimensión
dim3 tamBlock(1, 128, 1); //Block dimensión
// lanzamiento del kernel
MatrixSumKernel<<<tamGrid, tamBlock>>>( M, Md, Nd);
Hay que hacer cambios en el Kernel !!!!

PARTE C – Programación II 3EAGPGPU
Programación en CUDA
Kernel (2)
// Suma por columnas de una matriz
__global__ void SumaColMatrizKernel(int M, float* Md, float* Nd){
//
float Pvalue = 0;
int aux = blockIdx.y*blockDim.y + threadIdx.y;
int aux2 = aux*M;
for (int k = 0; k < M; ++k) {
Pvalue = Pvalue + Md[aux2+k];
}
Nd[aux] = Pvalue;
}

PARTE C – Programación II 3EAGPGPU
Programación en CUDA
Vamos a la máquina 2
• Trasladar los códigos para hacer el kernel 2.
• Compilar.
• Ejecutar.

PARTE C – Programación II 3EAGPGPU
Programación en CUDA
// configuración de la ejecución
int bloques = N / 128;
dim3 tamGrid(1, bloques); //Grid dimensión
dim3 tamBlock(1, 128, 1); //Block dimensión
// lanzamiento del kernel
MatrixSumKernel<<<tamGrid, tamBlock>>>( M, Md, Nd);
// Suma por columnas de una matriz
__global__ void SumaColMatrizKernel(int M, float* Md, float* Nd){
//
float Pvalue = 0;
int aux = blockIdx.y*blockDim.y + threadIdx.y;
int aux2 = aux*M;
for (int k = 0; k < M; ++k) {
Pvalue = Pvalue + Md[aux2+k];
}
Nd[aux] = Pvalue;
}

PARTE C – Programación II 3EAGPGPU
Programación en CUDA
Lanzamiento del kernel (3)
// configuración de la ejecución
int chunk = 32;
dim3 tamGrid(1, N); //Grid dimensión
dim3 tamBlock(M/chunk,1,1); //Block dimensión
// lanzamiento del kernel
SumaColMatrizKernel<<<tamGrid, tamBlock>>>(M, Md, Nd);

PARTE C – Programación II 3EAGPGPU
Programación en CUDA
Vamos a la máquina 3
• Hacer el kernel 3 utilizando atomicAdd().
atomicAdd(float* address, float val);
• Compilar.
• Ejecutar.

PARTE C – Programación II 3EAGPGPU
Programación en CUDA
Kernel (3)
// Suma por columnas de una matriz
__global__ void SumaColMatrizKernel(int M, float* Md, float* Nd){
//
float Pvalue = 0;
int aux = blockIdx.y*M + threadIdx.x*(M/blockDim.x);
int aux2 = aux + (M/blockDim.x);
for (int k = aux; k < aux2; ++k) {
Pvalue = Pvalue + Md[k];
}
atomicAdd(&(Nd[blockIdx.y]), Pvalue);
}
atomicAdd() funciona a partir de compute capabilities 2.0 !!!

PARTE C – Programación II 3EAGPGPU
Programación en CUDA
Lanzamiento del kernel (4a - 40)
// configuración de la ejecución
int chunk = 32;
dim3 tamGrid(1, N/chunk); //Grid dimensión
dim3 tamBlock(M/chunk,chunk,1); //Block dimensión
// lanzamiento del kernel
SumaColMatrizKernel<<<tamGrid, tamBlock>>>(M, N, Md, Nd);
Si quiero otro balance

PARTE C – Programación II 3EAGPGPU
Programación en CUDA
Kernel (4a-40)
// Suma por columnas de una matriz
__global__void SumaColMatrizKernel (int M,int N,float*Md,float* Nd){
//
float Pvalue = 0;
int aux = blockIdx.y* (N/gridDim.y)*M + threadIdx.y*M+
threadIdx.x * (M/blockDim.x);
int aux2 = aux + (M/blockDim.x);
for (int k = aux; k < aux2; ++k) {
Pvalue = Pvalue + Md[k];
}
atomicAdd(&(Nd[blockIdx.y*(N/gridDim.y)+threadIdx.y]), Pvalue);
}

PARTE C – Programación II 3EAGPGPU
Programación en CUDA
Vamos a la máquina 4
• Que pasa si tenemos más de 1024 columnas y filas ?!
• Hacer un kernel 4 que cubra esta problemática.
• Compilar.
• Ejecutar.

PARTE C – Programación II 3EAGPGPU
Programación en CUDA
Lanzamiento del kernel (4)
// configuración de la ejecución
int chunk = 32;
dim3 tamGrid(chunk, N/chunk); //Grid dimensión
dim3 tamBlock(M/chunk,1,1); //Block dimensión
// lanzamiento del kernel
SumaColMatrizKernel<<<tamGrid, tamBlock>>>(M, N, Md, Nd);
Si tengo más de 1024 filas:

PARTE C – Programación II 3EAGPGPU
Programación en CUDA
Kernel (4)
// Suma por columnas de una matriz
__global__void SumaColMatrizKernel (int M,int N,float*Md,float* Nd){
//
float Pvalue = 0;
int aux = blockIdx.y* (N/gridDim.y)*M + blockIdx.x*M+
threadIdx.x * (M/blockDim.x);
int aux2 = aux + (M/blockDim.x);
for (int k = aux; k < aux2; ++k) {
Pvalue = Pvalue + Md[k];
}
atomicAdd(&(Nd[blockIdx.y*(N/gridDim.y)+ blockIdx.y]), Pvalue);
}

PARTE C – Programación II 3EAGPGPU
Acceso Coalesced a Memoria Global

PARTE C – Programación II 3EAGPGPU
Acceso Coalesced a Memoria Global
• El acceso a memoria global es por segmentos.
• Incluso cuando solamente se quiere leer una palabra.
• Si no se usan todos los datos de un segmento, se está desperdiciando ancho de banda.
• Los segmentos están alineados a múltiplos de 32, 64 o 128 bytes.
• El acceso no alineado es más costoso que el acceso alineado.
• Simplificando ….
hilos consecutivos tienen que acceder a espacios de memoria consecutivos !

PARTE C – Programación II 3EAGPGPU
Acceso Coalesced a Memoria Global
• Coalesced access:
– Según Merriam-Webster “to unite into a whole” (unir en un todo).
– Podríamos traducirlo como acceso unido o fusionado.
• Cada solicitud de acceso a memoria global de un warp:
– se parte en dos solicitudes
– una para cada half-warp
– ambas solicitudes son atendidas (issued) independientemente.
• Los accesos a memoria de hilos de un half-warp se fusionan en una o más transacciones según características que dependen de las compute capability de la tarjeta.

PARTE C – Programación II 3EAGPGPU
Acceso Coalesced a Memoria Global
• Compute capabilities 2.x:
– Las transacciones a memoria global son cacheadas.
– Hay un caché L1 para cada multiprocesador y un caché L2 compartido por todos los multiprocesadores.
– La misma memoria física se usa como memoria compartida y caché L1 (se puede configurar 48 KB y 16 KB o 16 KB y 48 KB).
– El tamaño del caché L2 es 768 KB.
– Los accesos a memoria caché en L1 y L2 usan transacciones de 128 bytes.
– Los accesos a memoria caché solamente en L2 usan transacciones de 32 bytes.

PARTE C – Programación II 3EAGPGPU
Acceso Coalesced a Memoria Global
• Compute capabilities 2.x:
– Si el tamaño de la palabra es de 8 bytes, se realizan dos solicitudes de 128 bytes, una para cada half-warp.
– Si el tamaño de la palabra es de 16 bytes, se realizan cuatro solicitudes de 128 bytes, una para cada quarter-warp.
– Cada solicitud se particiona en cache-lines.
– Si se produce un miss, se accede a la memoria global.
– Los hilos pueden acceder a las palabras en cualquier orden, incluso a las mismas palabras.
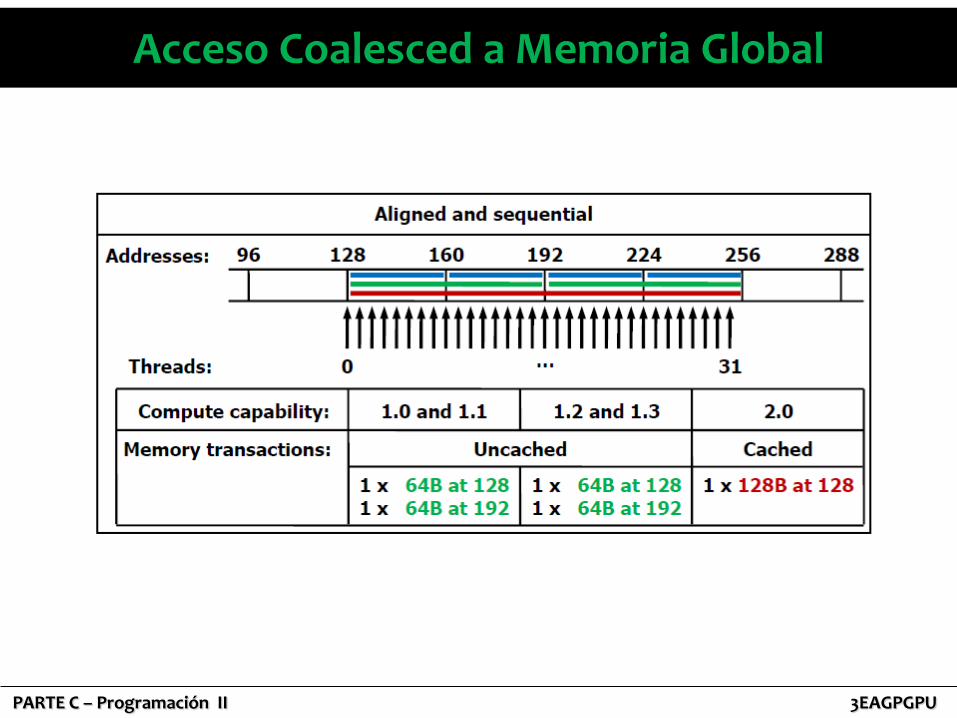
PARTE C – Programación II 3EAGPGPU
Acceso Coalesced a Memoria Global

PARTE C – Programación II 3EAGPGPU
Acceso Coalesced a Memoria Global

PARTE C – Programación II 3EAGPGPU
Acceso Coalesced a Memoria Global
PARTE C – Programación II 3EAGPGPU
Acceso Coalesced a Memoria Global
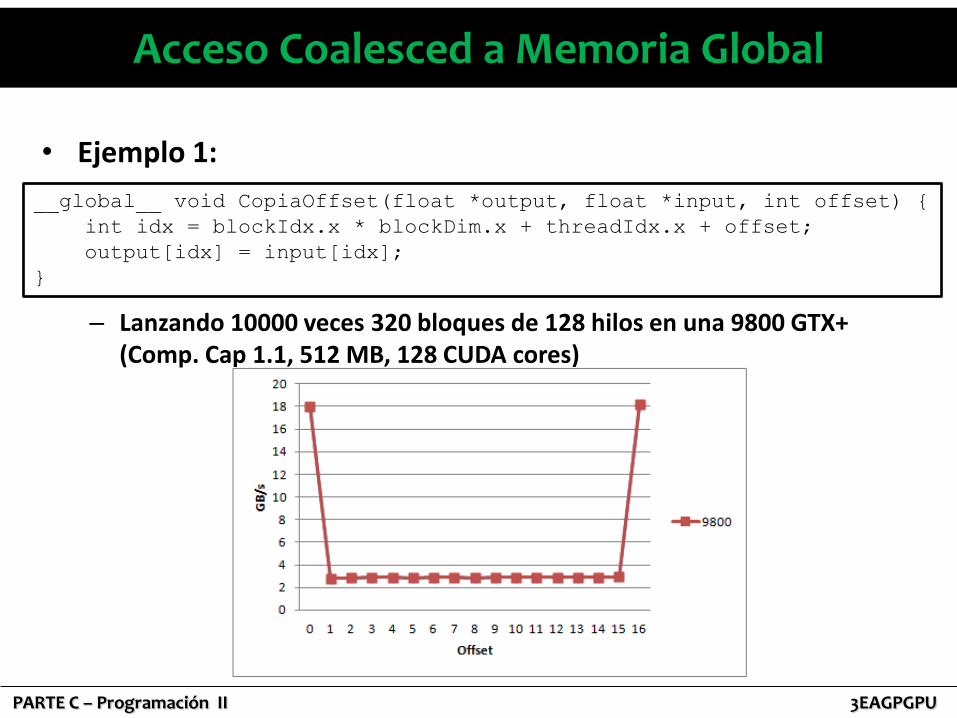
• Ejemplo 1:
– Lanzando 10000 veces 320 bloques de 128 hilos en una 9800 GTX+ (Comp. Cap 1.1, 512 MB, 128 CUDA cores)
__global__ void CopiaOffset(float *output, float *input, int offset) {
int idx = blockIdx.x * blockDim.x + threadIdx.x + offset;
output[idx] = input[idx];
}
PARTE C – Programación II 3EAGPGPU
Acceso Coalesced a Memoria Global
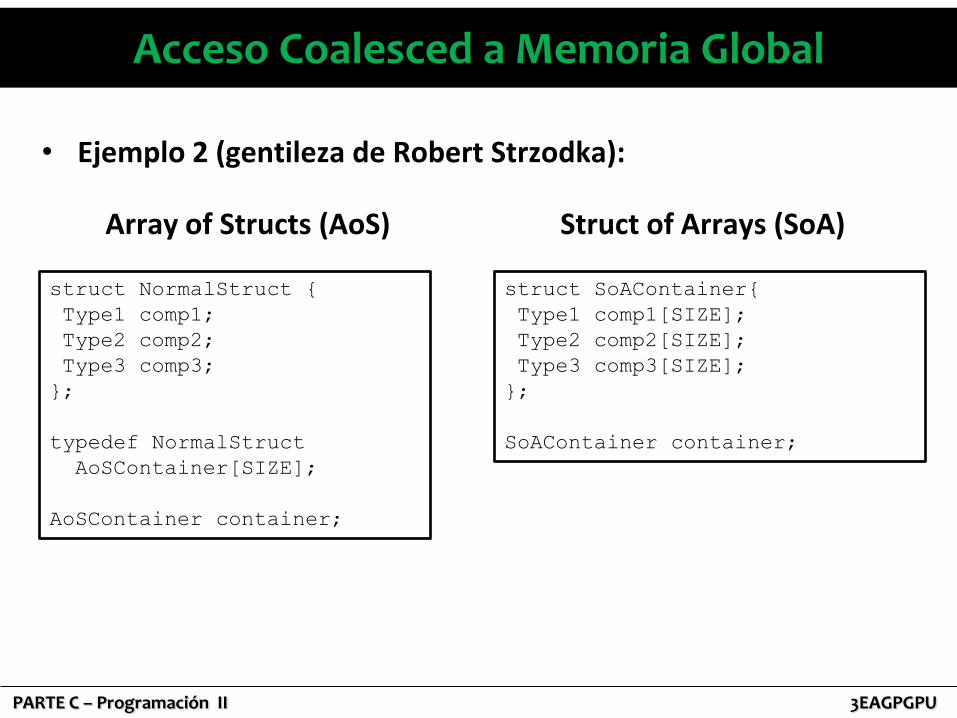
• Ejemplo 2 (gentileza de Robert Strzodka):
struct NormalStruct {
Type1 comp1;
Type2 comp2;
Type3 comp3;
};
typedef NormalStruct
AoSContainer[SIZE];
AoSContainer container;
Array of Structs (AoS)
struct SoAContainer{
Type1 comp1[SIZE];
Type2 comp2[SIZE];
Type3 comp3[SIZE];
};
SoAContainer container;
Struct of Arrays (SoA)

PARTE C – Programación II 3EAGPGPU
Acceso Coalesced a Memoria Global
• Ejemplo 2 (gentileza de Robert Strzodka):
container[1].comp3;
container[2].comp3;
container[3].comp3;
container[4].comp3;
Array of Structs (AoS):
Struct of Arrays (SoA): container.comp3[1];
container.comp3[2];
container.comp3[3];
container.comp3[4];

PARTE C – Programación II 3EAGPGPU
Acceso Coalesced a Memoria Global
Vamos a la máquina 5
• Apliquemos la idea de acceso coalesced al kernel 3 !!, haciendo un kernel 5
• Compilar.
• Ejecutar.

PARTE C – Programación II 3EAGPGPU
Acceso Coalesced a Memoria Global
Lanzamiento del kernel (5)
// configuración de la ejecución
Int chunk=32;
dim3 tamGrid(1, N); //Grid dimensión
dim3 tamBlock(M/chunk,1,1); //Block dimensión
// lanzamiento del kernel
SumaColMatrizKernel<<<tamGrid, tamBlock>>>(M, N, Md, Nd);

PARTE C – Programación II 3EAGPGPU
Acceso Coalesced a Memoria Global
Kernel (5)
// Suma por columnas de una matriz
__global__void SumaColMatrizKernel (int M,int N,float*Md,float* Nd){
//
float Pvalue = 0;
int aux = blockIdx.y* M + threadIdx.x;
for (int k = aux; k < M+aux; k += blockDim.x) {
Pvalue = Pvalue + Md[k];
}
atomicAdd(&(Nd[blockIdx.y]), Pvalue);
}

PARTE C – Programación II 3EAGPGPU
Memoria Compartida

PARTE C – Programación II 3EAGPGPU
Memoria Compartida
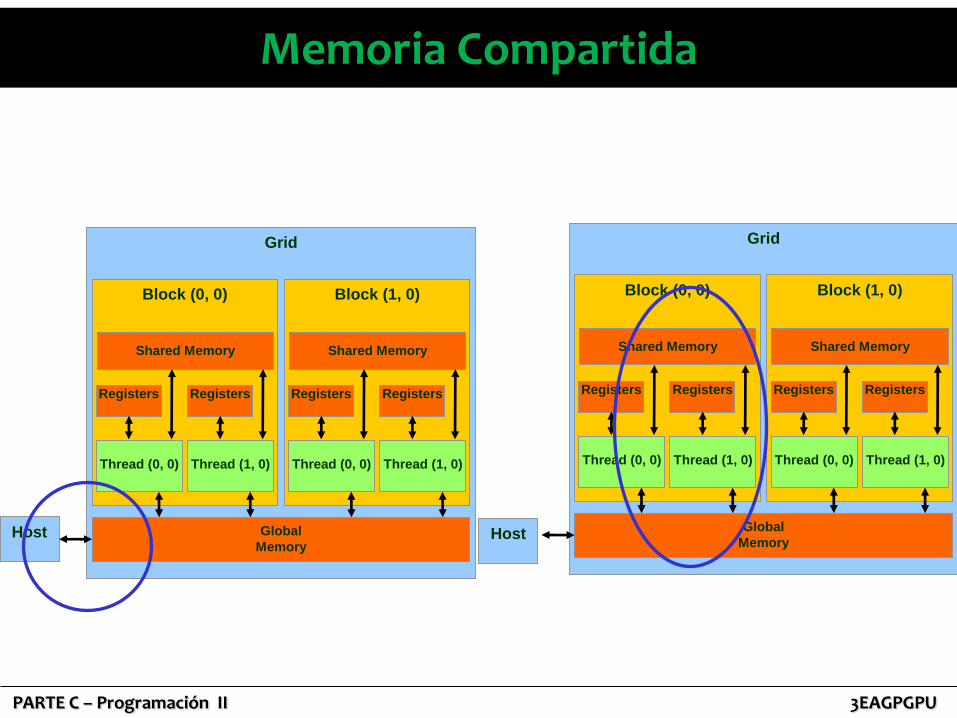
• Es cientos de veces más rápida que la memoria global.
• Puede usarse como una especie de caché para reducir los accesos a memoria global.
• Permite que los hilos de un mismo bloque puedan cooperar.
• Se puede usar para evitar accesos no coalesced a la memoria global:
– Los datos se guardan en forma intermedia en la memoria compartida.
– Se reordena el acceso a los datos para que cuando se copien de memoria compartida a memoria global el acceso sea coalesced.
PARTE C – Programación II 3EAGPGPU
Grid
Global
Memory
Block (0, 0)
Shared Memory
Thread (0, 0)
Registers
Thread (1, 0)
Registers
Block (1, 0)
Shared Memory
Thread (0, 0)
Registers
Thread (1, 0)
Registers
Host
Memoria Compartida
Grid
Global
Memory
Block (0, 0)
Shared Memory
Thread (0, 0)
Registers
Thread (1, 0)
Registers
Block (1, 0)
Shared Memory
Thread (0, 0)
Registers
Thread (1, 0)
Registers
Host

PARTE C – Programación II 3EAGPGPU
Memoria Compartida
Vamos a la máquina 6
• Hagamos un kernel (kernel 6) que utilice memoria compartida para sumar matrices
__shared __float Nds[DIMBLOCKX];
__syncthreads();
• Compilar.
• Ejecutar.

PARTE C – Programación II 3EAGPGPU
Memoria Compartida
Lanzamiento del kernel memoria compartida
// configuración de la ejecución
int chunk = 32;
dim3 tamGrid(1, N); //Grid dimensión
dim3 tamBlock(M/chunk,1,1); //Block dimensión
// lanzamiento del kernel
SumaColMatrizKernel<<<tamGrid, tamBlock>>>(M, Md, Nd);

PARTE C – Programación II 3EAGPGPU
Memoria Compartida
__global__ void SumaColMatrizKernel(int M, float* Md, float* Nd){
__shared __float Nds[DIMBLOCKX];
float Pvalue = 0;
int aux = blockIdx.y*M + threadIdx.x*(M/blockDim.x);
int aux2 = aux + (M/blockDim.x);
for (int k = aux; k < aux2; ++k) {
Pvalue = Pvalue + Md[k];
}
Nds[threadIdx.x] = Pvalue;
__syncthreads();
if (threadIdx.x == 0){
for (int i = 1; i < blockDim.x; ++i) {
Nds[0] = Nds[0]+Nds[i];
}
Nd[blockIdx.y] = Nds[0];
}
}

PARTE C – Programación II 3EAGPGPU
Reduce

PARTE C – Programación II 3EAGPGPU
Reduce
• Reducción en paralelo de la suma.
• Los datos se copian inicialmente de la memoria global a la memoria compartida.
• Solamente se realiza la primera etapa de la reducción.
• La suma de subtotales podría ser en:
- GPU: haciendo más etapas de reducción.
- CPU: transfiriendo a CPU los resultados intermedios y haciendo una iteración en CPU.

PARTE C – Programación II 3EAGPGPU
Reduce
• Para declarar la memoria compartida se puede usar una constante:
• Para declarar la memoria compartida se puede hacer en forma dinámica con extern:
__global__ void reduction(float * output, float * input) { extern __shared__ float intermedio[];
…
};
reduction <<<N_BLOCK,CANT_HILOS,
CANT_HILOS*sizeof(float)>>> (output,input);
#define CANT_HILOS 128
__global__ void reduction(float * output, float * input) {
__shared__ float intermedio[CANT_HILOS];
…
};
reduction <<<N_BLOCK,CANT_HILOS>>> (output,input);

PARTE C – Programación II 3EAGPGPU
Reduce
Primer enfoque

PARTE C – Programación II 3EAGPGPU
Reduce Primer enfoque
__global__ void reduction(float * output, float * input){
extern __shared__ float intermedio[];
int step = 1;
int idx = blockIdx.x * blockDim.x + threadIdx.x;
intermedio[threadIdx.x] = input[idx];
__syncthreads();
while (step < blockDim.x) {
if (threadIdx.x%(2*step)==0)
intermedio[threadIdx.x] =
intermedio[threadIdx.x] + intermedio[threadIdx.x + step];
__syncthreads();
step = step * 2;
}
__syncthreads();
if (threadIdx.x==0)
output[blockIdx.x] = intermedio[0];
}

PARTE C – Programación II 3EAGPGPU
Reduce
Primer enfoque
• Bloques 5000
• Hilos 128
• Ejecutado en loop 5000 x 128 veces en una 9800 GTX+ (Comp. Cap 1.1, 512 MB, 128 CUDA cores – una reliquia !-), el tiempo de ejecución es aproximadamente 505 s.
• La implementación tiene varios problemas.
• El más importante es la divergencia de warps.
PARTE C – Programación II 3EAGPGPU
Reduce
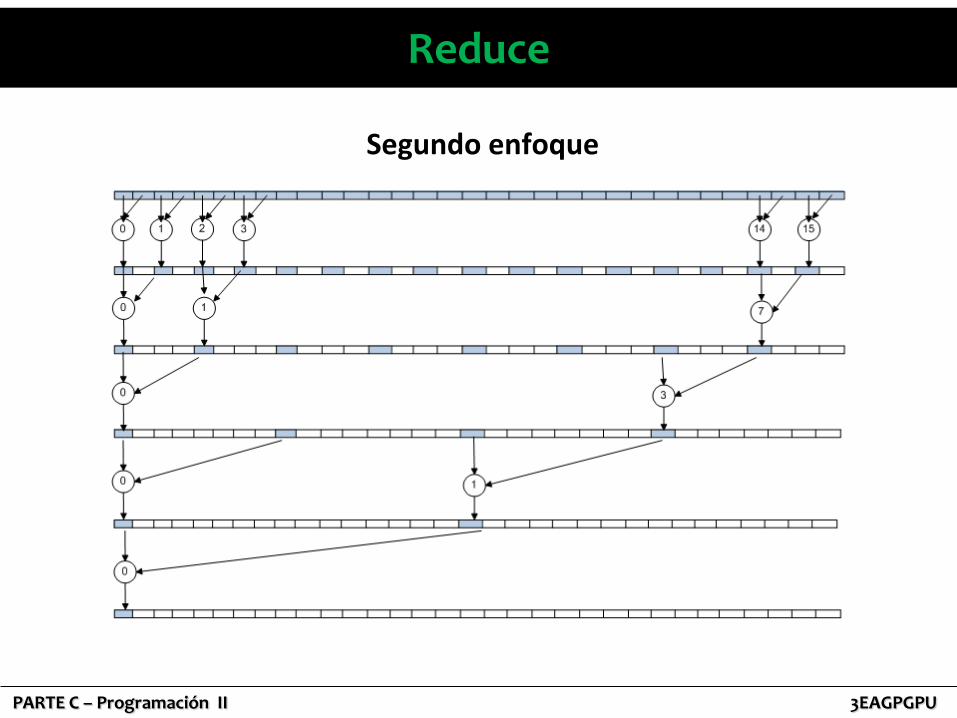
Segundo enfoque

PARTE C – Programación II 3EAGPGPU
Reduce Segundo enfoque
__global__ void reduction(float * output, float * input){
extern __shared__ float intermedio[];
int step = 1;
int idx = blockIdx.x * blockDim.x + threadIdx.x;
intermedio[threadIdx.x] = input[idx];
__syncthreads();
while (step < blockDim.x) {
if (threadIdx.x < blockDim.x/step)
intermedio[2*step*threadIdx.x] =
intermedio[2*step*threadIdx.x]+intermedio[2*step*threadIdx.x+step];
__syncthreads();
step = step * 2;
}
__syncthreads();
if (threadIdx.x==0)
output[blockIdx.x] = intermedio[0];
}
PARTE C – Programación II 3EAGPGPU
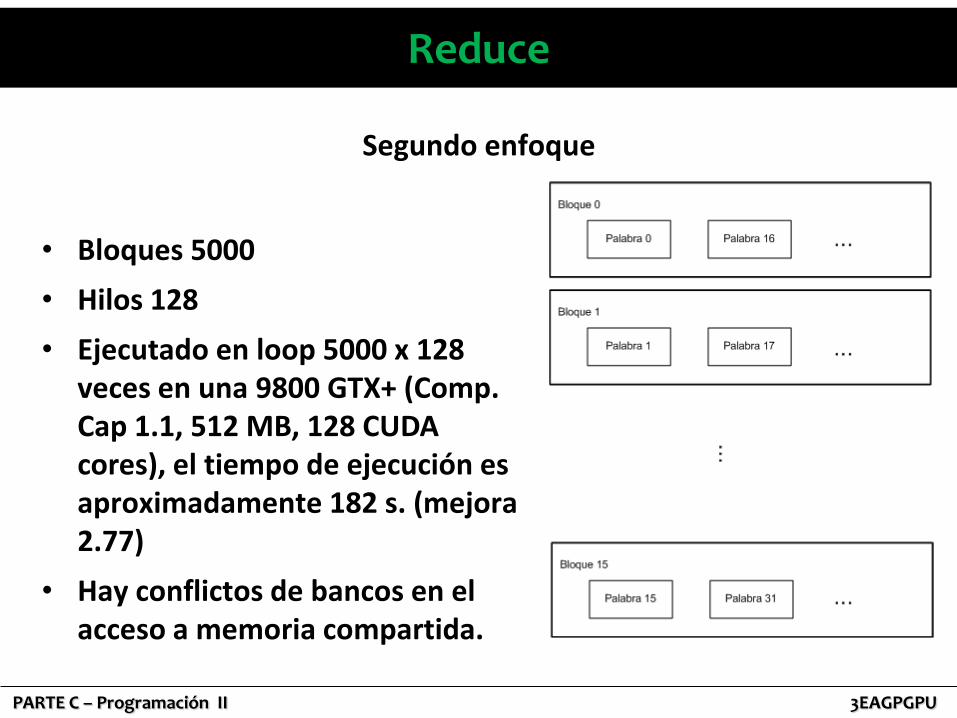
Reduce
• Bloques 5000
• Hilos 128
• Ejecutado en loop 5000 x 128 veces en una 9800 GTX+ (Comp. Cap 1.1, 512 MB, 128 CUDA cores), el tiempo de ejecución es aproximadamente 182 s. (mejora 2.77)
• Hay conflictos de bancos en el acceso a memoria compartida.
Segundo enfoque
PARTE C – Programación II 3EAGPGPU
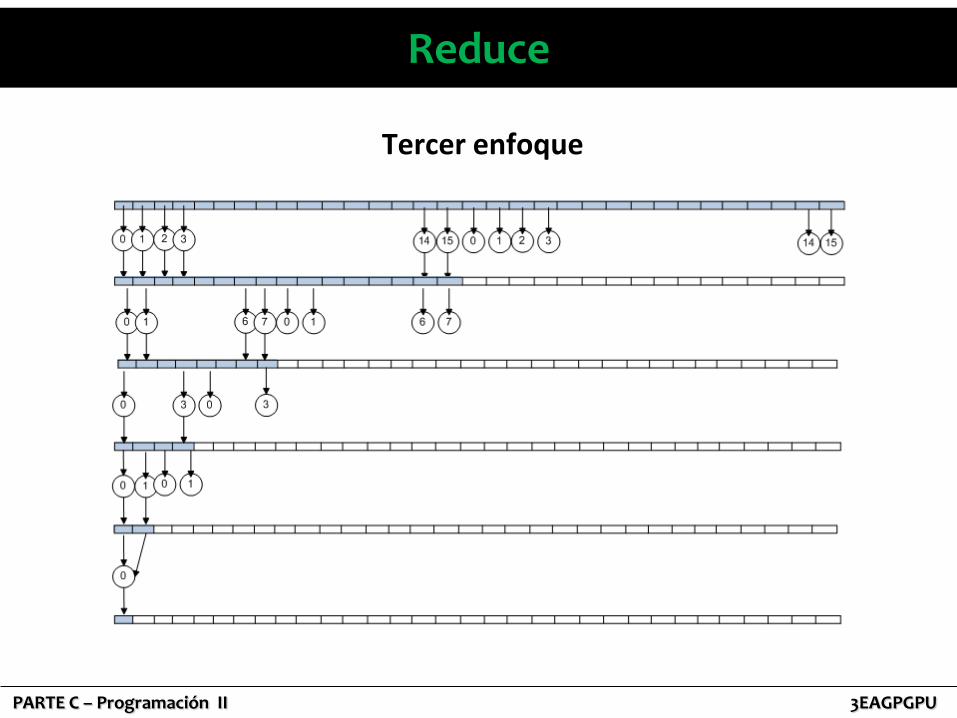
Reduce
Tercer enfoque

PARTE C – Programación II 3EAGPGPU
Reduce
Tercer enfoque __global__ void reduction(float * output, float * input){
extern __shared__ float intermedio[];
int idx = blockIdx.x * blockDim.x + threadIdx.x;
intermedio[threadIdx.x] = input[idx];
__syncthreads();
int i = blockDim.x/2;
while (i != 0) {
if (threadIdx.x < i)
intermedio[threadIdx.x] =
intermedio[threadIdx.x] + intermedio[threadIdx.x + i];
__syncthreads();
i = i / 2;
}
__syncthreads();
if (threadIdx.x==0)
output[blockIdx.x] = intermedio[0];
}

PARTE C – Programación II 3EAGPGPU
Reduce
• Bloques 5000
• Hilos 128
• Ejecutado en loop 5000 x 128 veces en una 9800 GTX+ (Comp. Cap 1.1, 512 MB, 128 CUDA cores), el tiempo de ejecución es aproximadamente 153 s. (mejora 3.30).
Tercer enfoque

PARTE C – Programación II 3EAGPGPU
Reduce
Otras optimizaciones …
• loop unrolling
• leer más de una palabra de la memoria global
• lower occupancy

PARTE C – Programación II 3EAGPGPU
Algunas recomendaciones adicionales sobre performance

PARTE C – Programación II 3EAGPGPU
Algunas recomendaciones adicionales sobre performance
• Evitar la divergencia de hilos dentro de un warp.
• El número de bloques debe ser mayor al número de multiprocesadores:
- De forma de mantener a todos los multiprocesadores ocupados.
- Para permitir ocultar latencias cuando un bloque está trancado con un __syncthreads() debe ser mayor al doble del número de multiprocesadores.
• El número de hilos por bloque debe ser un múltiplo de 32 (tamaño de warp).


















