
Presentación estadistica para profesores
141
1 Es una ciencia que se ocupa de: recolectar, organizar, presentar, analizar e interpretar datos con el propósito de ayudar a una toma de decisiones más efectiva. Es una rama de las matemáticas, trata con métodos que sirven para obtener conclusiones de un conjunto de datos (población) basándose en una parte o porción representativa de la misma (muestra). ¿QUÉ ES ESTADÍSTICA?
description
Presentación en diapositivas sobre estadistica aplicada a los negocios y econoomia
Transcript of Presentación estadistica para profesores

1
Es una ciencia que se ocupa de: recolectar, organizar, presentar, analizar e interpretar datos con el propósito de ayudar a una toma de decisiones más efectiva.
Es una rama de las matemáticas, trata con métodos que sirven para obtener conclusiones de un conjunto de datos (población) basándose en una parte o porción representativa de la misma (muestra).
¿QUÉ ES ESTADÍSTICA?

2
1. Los datos se encuentran en todos los lados.
2. Las técnicas estadísticas se utilizan para la toma de
muchas decisiones que afectan nuestra vida.
3. Al Profesional, la estadística le ayudará a interpretar con
mayor eficiencia los resultados que se recopilaran de las
investigaciones y así podrá tomar decisiones.
¿POR QUÉ ESTUDIAR ESTADÍSTICA?

3
Las técnicas estadísticas se usan ampliamente por
personas en áreas de:
Comercialización,
Contabilidad,
Control de calidad,
Deportes,
Administración de hospitales, etcétera...
¿CAMPOS DE APLICACIÓN?

Es el conjunto de todos los elementos que estamos estudiando, ya sean compuestos de personas o de cosas acerca de los cuales intentamos sacar conclusiones.
Es la recolección completa de todas las observaciones de interés para el investigador.
¿Qué es Población?
La Cantidad total de estudiantes de la Facultad de Ciencias Administrativas es de 15,000.
Ejemplo:
4

Es una parte de la población que aislamos para estudiarla y obtener resultados.
Es la reunión de datos que se desea estudiar, obtenidos de una proporción reducida y representativa de la población.
¿Qué es Muestra?
De la población de 15,000 estudiantes de FCA Una muestra de esta población sería 12000 alumnos de la Modalidad Presencial.
El profesor de estadística desea conocer cuál es la edad promedio estimada de sus estudiantes.
Ejemplos:
5

Es la técnica para recoger una muestra a
partir de una población o un subgrupo de
esta. Permite inferir sobre la población
basándose en la información de la muestra.
¿Qué es Muestreo?
6
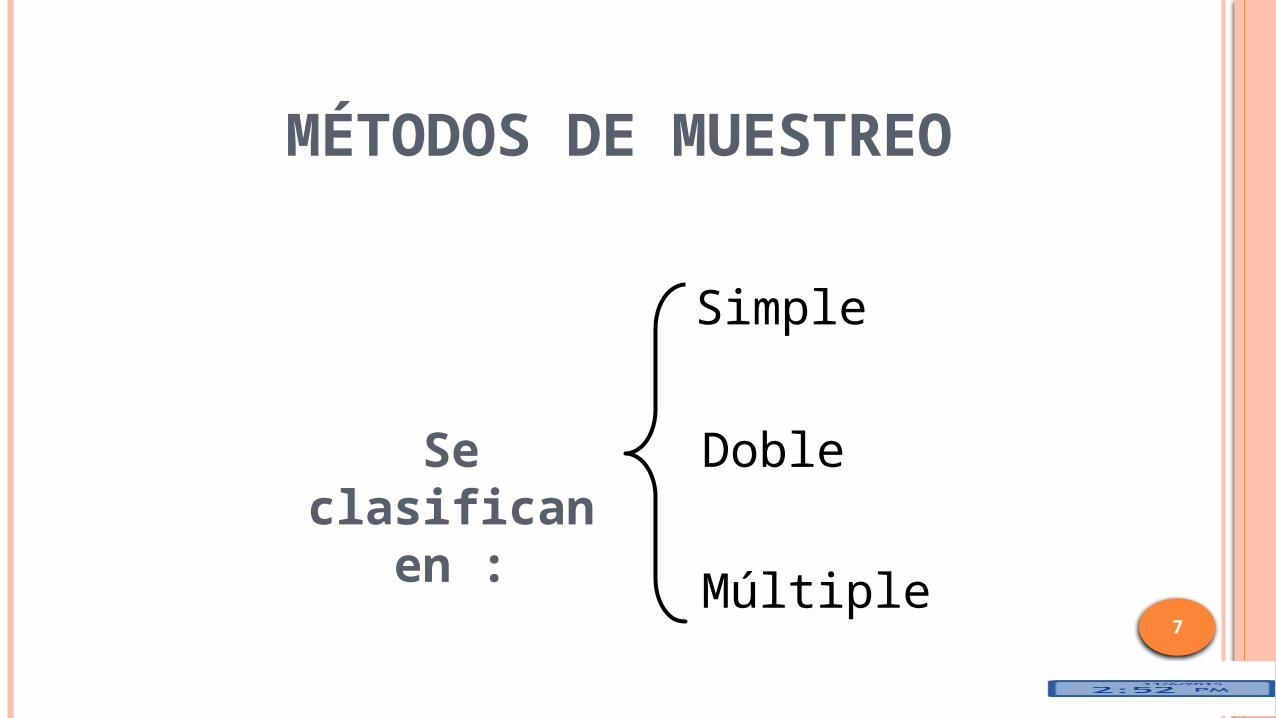
MÉTODOS DE MUESTREO
7
Se clasifican en :
Múltiple
Simple
Doble

Es cuando toma solamente una muestra de una
población dada para el propósito de inferencia
estadística.
Puesto que solamente una muestra es tomada, el
tamaño de muestra debe ser los suficientemente grande
para extraer una conclusión.
Muestreo Simple
8

Bajo este tipo de muestreo, cuando el resultado del estudio de la primera muestra no es decisivo, una segunda muestra es extraída de la misma población. Las dos muestras son combinadas para analizar los resultados.
Ejemplo: Al probar la calidad de un lote de productos manufacturados, si la primera muestra arroja una calidad muy alta, el lote es aceptado; si arroja una calidad muy pobre, el lote es rechazado. Solamente si la primera muestra arroja una calidad intermedia, será requerirá la segunda muestra.
Muestreo Doble
9

El procedimiento bajo este método es similar al expuesto en el muestreo doble, excepto que el número de muestras sucesivas requerido para llegar a una decisión es más de dos muestras.Los elementos de una muestra pueden ser seleccionados de dos maneras diferentes:
a. Basados en el juicio de una persona.
b. Selección aleatoria (al azar)
Muestreo Múltiple
10

11
Determinar cuál es población, y muestra.1) Los miembros del Colegio de Ingenieros Comerciales del
Ecuador.a) Respuesta: poblacionb) La cantidad de habitantes del Ecuador.c) Respuesta:poblaciond) Un estudio realizado a 50 miembros del Colegio de Espíritu
Santo.e) Respuesta : muestra
2) Cinco estudiantes fueron seleccionados como los mejores de su clase en la modalidad presencial de FCA.a) Respuesta: muestra
3) Se llevo acabo un censo para saber el nivel de conocimiento de los Docentes que laboran en la Facultad de Administracióna) Respuesta:población
EJERCICIOS

Un dato es cada uno de los valores que se a obtenido al realizar un estudio estadístico.
Son medidas, valores o características susceptibles de ser observados y contados.
¿Qué son Datos?
Son los valores que se han obtenido de la cantidad de estudiantes que hay en la Facultad de ciencias Administrativas es de 15,000.
Ejemplo:
12

13
Es cada una de las característica o cualidades que poseen los individuos de una población.
Puede tener diferentes valores en los distintos elementos de un conjunto.
Ejemplos:Variable estadística a una propiedad característica
de la población que estamos interesados en estudiar.El número de estudiantes aprobados en anatomía, el
color de los ojos, la renta familiar, etc...
¿QUÉ ES UNA VARIABLE?

TIPOS DE VARIABLE O DATOS
14
Se clasifican en :
Cuantitativos
Cualitativos

La característica o variable que se estudia no es numérica.
No se pueden medir y se describen con palabras.
¿Qué son Cualitativas o Atributos?
Razas de perro, estado civil de una persona, sexo, tipo de automóvil que se posee, lugar de nacimiento, color de los ojos, etc.
Ejemplo:
15

Ordenables: Aquellas que sugieren una ordenación.
Ejemplos: Grados de servidores de la Policía Nacional, el nivel de estudios, número de hijos, etc.
No ordenables: Aquellas que sólo admiten una mera ordenación alfabética, pero no establece orden por su naturaleza.
Ejemplos: El color del pelo, sexo, estado civil, etc.
Tipos de Cualitativas:
16

Se pueden medir y expresar con números.
La variable se puede registrar numéricamente.
¿Qué son Cuantitativas o Numéricos?
Saldo en una cuenta de cheques, minutos que faltan
para que termine la clase, número de niños en una
familia, número de goles en un partido de fútbol.
Ejemplos:
17

Discretas: Solo puede tomar valores aislados. Se
representa con un número natural. (Ejemplo: El número de
hermanos, número de sillas, etc.).
Continuas: Pueden tomar todos los valores de un intervalo.
Se representa con un número decimal. (Ejemplo: La estatura
de una persona, el peso de los estudiantes, etc.).
Tipos de Cuantitativas:
18

19
Defina cuáles son las variables cualitativas y cuantitativas.1. Una encuesta reveló sobre el estado civil de una población.
• R. cualitativa
2. Se llevó a cabo un concurso de perros de raza en Guayaquil. • R. Cualitativa
3. Comida Favorita.• R. cualitativa
4. Profesión que te gusta.• R. Cualitativa
5. Número de goles marcados por tu equipo favorito en la última temporada.• R. Ccuantitativatitativa
6. Número de alumnos de tu Instituto.• R. Cuantitativa
7. El color de los ojos de tus compañeros de clase.• R. Cualitativa
8. Coeficiente intelectual de tus compañeros de clase.• R. Cuantitativa
EJERCICIOS
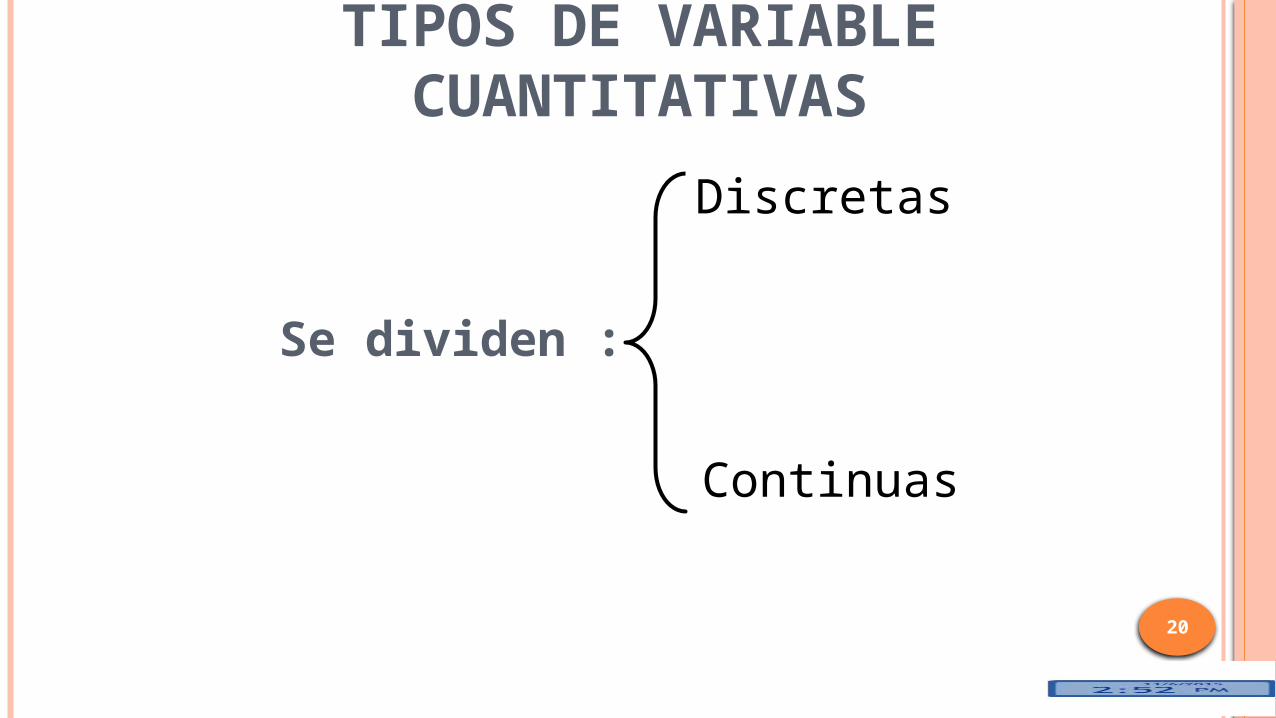
TIPOS DE VARIABLE CUANTITATIVAS
20
Se dividen :
Continuas
Discretas

Es aquella que toma valores aislados, es decir no admite valores intermedios entre 2 valores específicos.
Solo puede tomar valores enteros y un número finito.
Ejemplos: Número de hermanos, número de habitantes menores de edad, número de aulas de la Facultad de Educación Física Deportes y Recreación. (Ej: 10)
El número de habitaciones en una casa (Ej: 1,2,3,..., etc.).
Discretas
21

Es aquella que puede tomar valores comprendidos entre 2 números.
Pueden tomar cualquier valor dentro de un intervalo específico.
Ejemplos: Estatura de una persona: 1.73 ; 1.85; 1.77El tiempo de vuelo de Guayaquil a Japón: 14 horas y media.
Continuas
22

23
Defina: ¿Cuáles son las variables discretas y continuas?1) Número de acciones vendidas cada día en la Bolsa de Valores.
a) Respuesta: DdiscretasSCRETAS
2) Temperaturas registradas cada hora en un observatorio.a) Respuesta: continuasCONTINUA
3) Suma de puntos obtenidos en el lanzamiento de un par de dadosa) Respuesta: DdiscretasRETA
4) El diámetro de las ruedas de varios coches.a) Respuesta: CcontinuasTINUA
5) Número de hijos de 50 familias.a) Respuesta: DdiscretasRETA
6) Censo anual de los Ecuatorianos.a) Respuesta: DdiscretasCRETA
EJERCICIOS
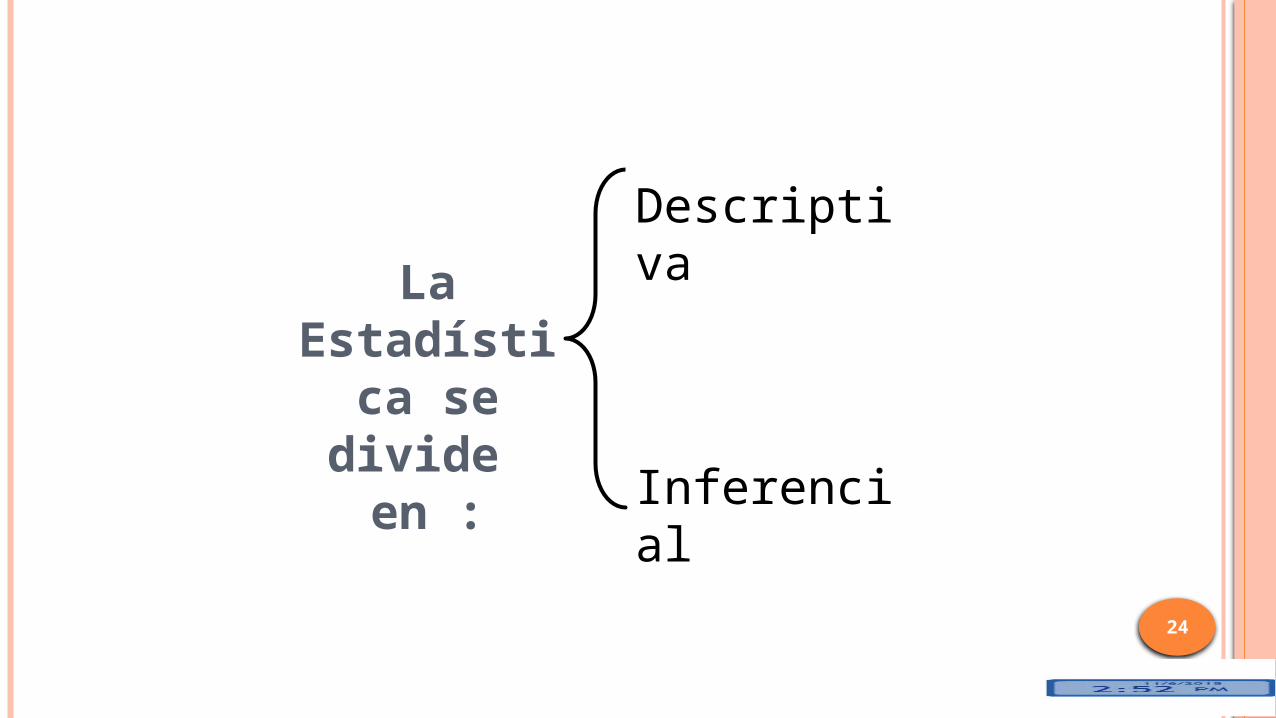
La Estadística se divide
en :
Descriptiva
Inferencial
24

25
Es una ciencia que analiza una serie de datos y la utilizamos para recolectar, organizar, resumir, presentar y analizar la información. Es la medida de relaciones entre 2 o más variables.
Se dedica exclusivamente al ordenamiento y tratamiento mecánico de la información para su presentación por medio de tablas y de representaciones gráficas, que son útiles para la explicación de la información.
EJEMPLO
En un sondeo de opinión se encontró que el 49% de las personas en una encuesta sabían el nombre del Presidente de Bolivia. La estadística “49” describe el número de cada 100 personas que saben la respuesta
ESTADÍSTICA DESCRIPTIVA

26
Se refiere a los estudios que se hacen sobre una parte de la población (Muestra), con el fin de obtener ( inferir) conclusiones sobre las características de interés de dicha población.
EJEMPLOS:
Las cadenas de TV monitorean la popularidad de sus programas contratando a empresas especializadas para muestrear las preferencias de los televidentes.El departamento de contabilidad de una empresa elegirá una muestra de facturas para verificar la exactitud de todas las facturas de la compañía.
ESTADÍSTICA INFERENCIAL

MEDIDAS DE TENDENCIA CENTRAL:
MEDIA, MEDIANA Y MODA

MEDIDAS DE TENDENCIA CENTRAL:
Este tipo de medidas nos permiten identificar y ubicar el punto (valor) alrededor del cual se tienden ha reunir los datos (“Punto central”).
NOTA: en las poblaciones se denominan parámetros y en las muestras se les denomina estimadores.

LA MEDIA
Es la suma de todos los valores observados, dividido por el número total de observaciones para obtener un promedio.
NOTA: es la mas sencilla y la mas utilizada.

EJEMPLOS= sumatoria µ = media N = número de elementos X = valores o datos
Calcule la media de los siguientes números:
10 , 11 , 12 , 12 , 13
1.Sumar las cantidades< 10 + 11 + 12 + 12 + 13 =58> 2. Dividir la suma por la cantidad de elementos<58/5> 3. El resultado es la media <11.6>
NOTA: este ejercicio se aplicó con datos desagrupados.

LA MEDIANA
Con esta medida podemos identificar el valor que se
encuentra en el centro de los datos, después que los
elementos han sido ordenados.

EJEMPLO
PAR
1,2,3,4,5,6
La mediana está entre 3 y 4.
IMPAR:
1,2,3,4,5
La mediana es el 3

LA MODA
La medida modal nos indica el valor que más veces se
repite dentro de los datos.
NOTA: en algunos casos pueden presentarse dos valores
que se repiten en igualdad de veces, por lo tanto puede ser
bimodal o multimodal.

EJEMPLOBuscar la moda de:
5 12 9 5 8 7 1
Como la moda es el número que más se repite, la moda es 5.
Buscar la moda de:
14 16 18 16 15 12 14 14 16 18 20 16 16
El 14 se repite 3 veces. El 18 se repite 2 veces. El 16 se repite 5 veces.
Por lo tanto, la moda es 16.
Buscar la moda de :
23 35 45 33 47 31 29 22
Como ningún número se repite, no tiene moda.

CONCLUSIÓN
En conclusión las Medidas de tendencia central, nos permiten identificar los valores más representativos de los datos, de acuerdo a la manera como se tienden a concentrar.
La Media nos indica el promedio de los datos; es decir, nos informa el valor que obtendría cada uno de los individuos si se distribuyeran los valores en partes iguales.
La Mediana por el contrario nos informa el valor que separa los datos en dos partes iguales, cada una de las cuales cuenta con el cincuenta porciento de los datos.
La Moda nos indica el valor que más se repite dentro de los datos.

MEDIDAS DE DISPERSION
• Varianza• Desviación estándar

Existen diversas medidas estadísticas de dispersión, pero muchos autores coinciden en que las principales son:
Rango
Varianza
Desviación estándar
Coeficiente de variación
MEDIDAS DE DISPERSIÓN

En algunos casos existen conjuntos de datos que tienen la misma media y la misma mediana, pero esto no refleja qué tan dispersos están los elementos de cada conjunto.
Ejemplo:Conjunto 1. 80, 90, 100, 110, 120Conjunto 2. 0, 50, 100, 150, 200
1005
1201101009080 Media
1005
200150100500 Media
Conjunto 1
Conjunto 2
Observa que para ambos conjuntos la Mediana es igual a 100. También nota que los datos del conjunto 2 están más dispersos con respecto a su media que los datos del conjunto 1.

Mide la amplitud de los valores de la muestra y se calcula por diferencia entre el valor más elevado (Límite superior) y el valor más bajo (Límite inferior).
RANGO
FÓRMULA
Ejemplo 1.
Ante la pregunta sobre número de hijos por familia, una muestra de 12 hogares, marcó las siguientes respuestas:
2 1 2 4 1 32 3 2 0 5 1
Calcula el rango de la variable
Solución.
MAX MINRango X X
5 0 5Rango

Ejemplo 2.
Hay dos conjuntos sobre la cantidad de lluvia (mm) en Taipei y Seúl en un año.
Calcula el rango en cada una de las ciudades.
Solución.
Aplicando la fórmula correspondiente tenemos:
Taipei
Seúl
305 66 239Rango mm mm mm
Ene Feb Mar Abr May Jun Jul Ago Sep Oct Nov DicTaipei 86 135 178 170 231 290 231 305 244 122 66 71Seúl 40 77 83 89 147 168 184 252 209 101 32 13
252 13 239Rango mm mm mm
En este caso se puede observar que el rango es el mismo para ambos casos aunque las cantidades sean diferentes.
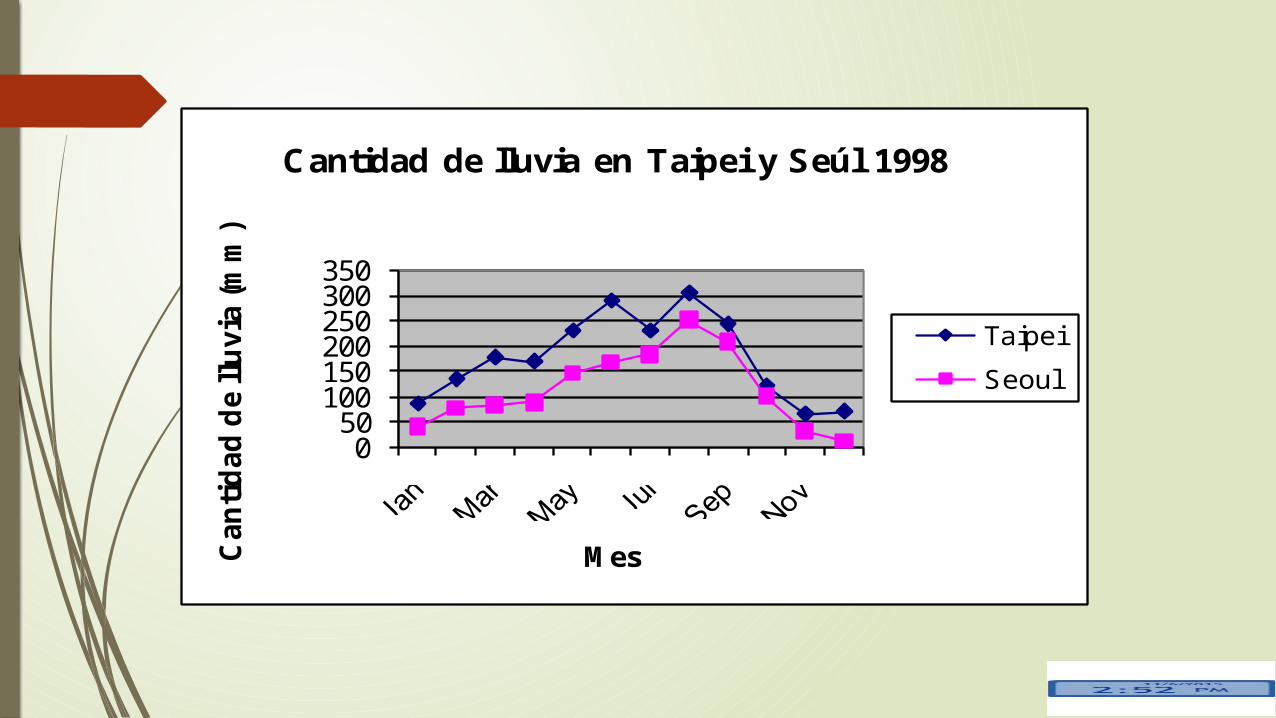
050
100150200250300350
Can
tid
ad
de llu
via
(m
m)
Mes
Cantidad de lluvia en Taipei y Seúl 1998
Taipei
Seoul

Mide la distancia existente entre los valores de la serie y la media. Se calcula como sumatoria de las diferencias al cuadrado entre cada valor y la media, multiplicadas por el número de veces que se ha repetido cada valor. La sumatoria obtenida se divide por el tamaño de la muestra.
VARIANZA (Datos no agrupados)
FÓRMULA
2
2 1
( )
1
n
ii
x xs
n
Muestral
Poblacional2
2 1
( )N
i xi
x
N

La varianza siempre será mayor que cero. Mientras más se aproxima a cero, más concentrados están los valores de la serie alrededor de la media. Por el contrario, mientras mayor sea la varianza, más dispersos están.
Ejemplo 1.
Calcula la varianza para los siguientes datos
2 1 2 4 1 3 2 3 2 0 5 1
Solución.
Primero es necesario obtener la media. En este caso
Ahora aplicamos la fórmula correspondiente
2.16x
2 2 2 2 2 2 2 2 2 2 2 22 (2 2.16) (1 2.16) (2 2.16) (4 2.16) (1 2.16) (3 2.16) (2 2.16) (3 2.16) (2 2.16) (0 2.16) (5 2.16) (1 2.16)
12 1s
2 21.6672
1.969711
s

Ejemplo 2.
A continuación se muestran dos conjuntos de datos obtenidos a partir de un experimento químico que realizaron dos estudiantes distintos. Calcular la varianza.
Volumen de ácido medido (cm^3)Estudiante A 8 12 7 9 3 10 12 11 12 14Estudiante B 7 6 7 15 12 11 9 9 13 11

También llamada desviación típica, es una medida de dispersión usada en estadística que nos dice cuánto tienden a alejarse los valores puntuales del promedio en una distribución.
Específicamente, la desviación estándar es "el promedio de la distancia de cada punto respecto del promedio". Se suele representar por una S o con la letra sigma,σ, según se calcule en una muestra o en la población.
Una desviación estándar grande indica que los puntos están lejos de la media, y una desviación pequeña indica que los datos están agrupados cerca de la media.
DESVIACIÓN ESTÁNDAR (Datos no agrupados)
FÓRMULAS2
1
( )
1
n
ii
x xs
n
N
xN
ixi
1
2)(
Muestral
Poblacional

Ejemplo 1.
Si retomamos el ejemplo 1 que corresponde a la varianza:
Calcula la desviación estándar para los siguientes datos
2 1 2 4 1 3 2 3 2 0 5 1
Solución.
Una vez que hemos calculado la media y la varianza, sólo resta calcular la raíz cuadrada de la varianza.
2.16x 2 21.66721.9697
11s 1.40341.9697S

Ejemplo 2.
Considerando nuevamente el segundo ejemplo que estudiaste para calcular la varianza, tenemos:
A continuación se muestran dos conjuntos de datos obtenidos a partir de un experimento químico que realizaron dos estudiantes distintos. Calcular la varianza.
Solución.
Una vez que has calculado la media y la varianza, es necesario calcular la desviación estándar a partir de la obtención de la raíz cuadrada de la varianza.
Estudiante A
Estudiante B
Volumen de ácido medido (cm 3̂)Estudiante A 8 12 7 9 3 10 12 11 12 14Estudiante B 7 6 7 15 12 11 9 9 13 11
2 91.69.16
10s
2 767.6
10s
026.316.9S
756.26.7S

Es una medida de dispersión que se utiliza para poder comparar las desviaciones estándar de poblaciones con diferentes medias y se calcula como cociente entre la desviación típica y la media.
COEFICIENTE DE VARIACIÓN
FÓRMULA
100%S
CVx
Muestral
Poblacional
100%CV

Ejemplo 1.
En dos cursos los promedios que sacaron sus alumnos fueron 6.1 y 4.3 y las desviaciones estándar respectivas fueron 0.6 y 0.45 respectivamente. ¿En qué curso hay mayor dispersión?
Solución
Para responder esto, debemos obtener el coeficiente de variación aplicando la fórmula
Claramente, el curso A tiene una dispersión menor que el B, pese a presentar una mayor desviación estándar.
%8.9%)100(1.66.0 ACV %4.10%)100(
3.4
45.0 BCV100%S
CVx

Cuando los datos están agrupados en tablas de frecuencias, el significado de las medidas de dispersión es el mismo, sin embargo la manera de calcularlas es diferente.
Enseguida se muestra la fórmula para la varianza, pero recuerda que la desviación estándar es igual a la raíz cuadrada de la primera.
VARIANZA Y DESVIACIÓN ESTÁNDAR (Datos agrupados)
FÓRMULA
11
)(1
2
12
1
2
2
nn
fx
xf
n
xxfs
k
i
k
iii
ii
k
iii
21
2
1
2
2)(
N
xf
N
xfk
iii
k
iii
Muestral
Poblacional
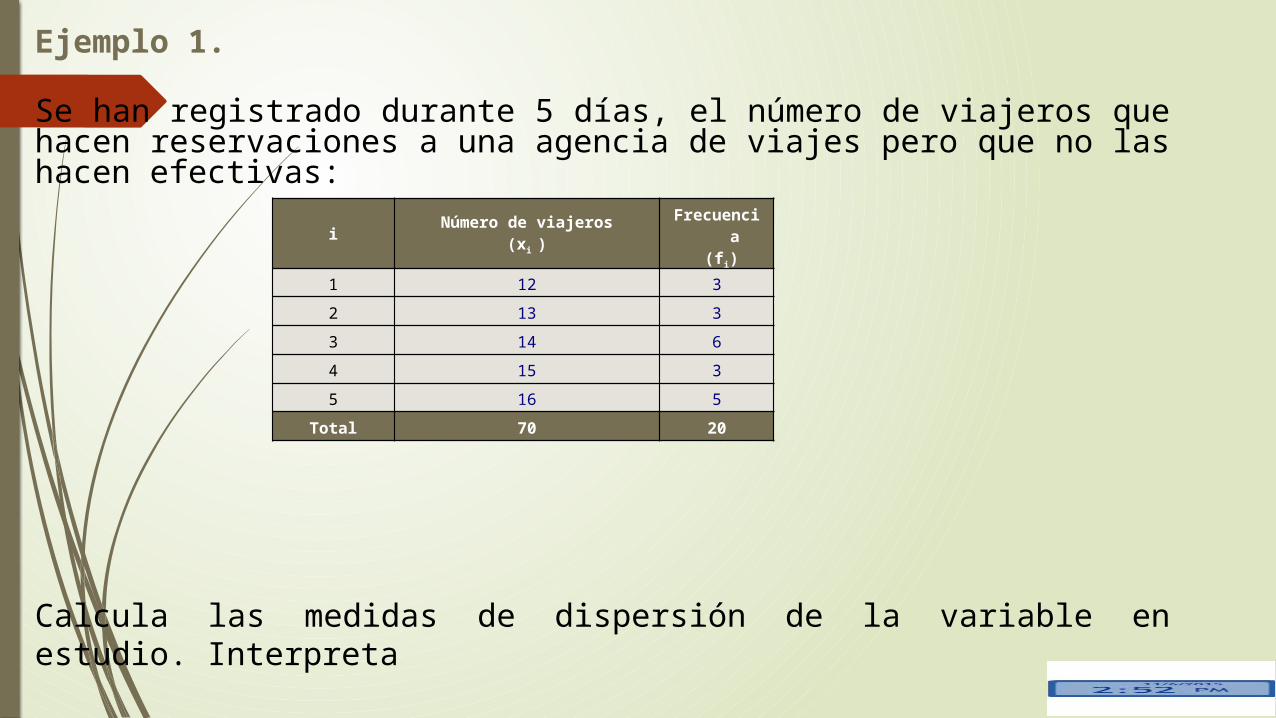
Ejemplo 1.
Se han registrado durante 5 días, el número de viajeros que hacen reservaciones a una agencia de viajes pero que no las hacen efectivas:
Calcula las medidas de dispersión de la variable en estudio. Interpreta
iNúmero de viajeros
(xi )Frecuencia
(fi)
1 12 3
2 13 3
3 14 6
4 15 3
5 16 5
Total 70 20

Medidas de posición
CUARTILES
DECILES
PERCENTILES

Medidas de posición
Análogos a la medianaPermiten fijar la posición de datos mayoresque una proporción determinada de casos
••
– Cuartiles (dividen la distribución en 4 partesiguales).
Deciles (dividen la distribución en 10 partes iguales).Percentiles (dividen la distribución en 100 partesiguales).
–
–

MEDIDAS DE POSICIÓN CUARTILIndicadores que dividen la distribución en partes iguales.Los cuartiles o cuantiles dividen a la distribución en cuatro partes iguales, cada una de estas partes posee la misma cantidad de observaciones.Se generan tres valores que dividen a la distribución;
••
•
– el primer cuartil Q1 (primera cuarta parte del conjunto de lasobservaciones)
el segundo cuartil Q2 (dos primeras cuartas partes de las observaciones, por lo que sería igual que hablar de la mediana)el tercer cuartil Q3 (contiene las tres primeras partes del conjunto deobservaciones)
–
–
4

55MEDIDAS DE POSICIÓN PERCENTIL
Función PERCENTIL.EXC(matriz; k)
Devuelve un valor numérico. El percentil es una medida de posición no central.
Argumento “matriz”. Contiene la referencia a un rango de celdas con valores numéricos ouna matriz de números.
Argumento “k”. Contiene un valor numérico mayor que 0 y menor que 1. Indica cuál es el valor de percentil que desea localizar.

56

Distribución De
Frecuencias
Para datos no agrupados
Para datos agrupados
57

58
Distribución de Frecuencias:
Es una ordenación de datos estadísticos representados en una tabla, organizados de ascendente a descendente.
La utilización de la distribución de frecuencias tiene como objetivo principal presentar los datos de una manera que facilite su comprensión e interpretación.
Método de Organización de los datos

¡Qué es clase?Son divisiones o categorías en las cuales se
agrupan un conjunto de datos ordenados con características comunes.
Una clase es un rango, grupo o intervalo de datos numéricos.
59

Límites de la clase Representan el tamaño de cada clase, determinadas por dos valores que son el
límite superior y el límite inferior.
60
Rango o Amplitud de la clase
• Es la diferencia entre el límite superior e inferior de la clase.

¿Qué es Frecuencia Absoluta?
Es el número de veces que aparece un determinado valor en un estudio estadístico. Se representa por fi.
Esta frecuencia tiene sentido calcularla para variables cuantitativas o cualitativas ordenables.
61

¿Qué es Frecuencia Absoluta Acumulada?
Son aquellas que se obtienen de las sumas sucesivas
de las ( fi ) que integran cada una de las clases de una
distribución de frecuencia de clase, esto se logra cuando
la acumulación de las frecuencias ( Fi )se realiza
tomando en cuenta la primera clase hasta alcanzar la
ultima.62

¿Qué es Frecuencia Relativa?
La frecuencia relativa porcentual se obtiene dividendo
la frecuencia absoluta y el número total de datos.
La frecuencia relativa se puede expresar en tantos por
ciento y se representa por hi.
63

¿Qué es Frecuencia Relativa Acumulada?
Es el resultado de la suma de los distintos valores de la frecuencia relativa, el total de estos valores nos dará como resultado la unidad o el 100%.
Una distribución de frecuencias relativas acumuladas expresa la frecuencia acumulada de cada clase en relación con toda la muestra. El proceso de acumulación puede basarse en un principio de <<o mas>> o <<menor que>>.
64

Distribución de Frecuencias No Agrupados
Se emplea si las variables toman un número pequeño de valores o la variable es discreta.
No se agrupan los valores en intervalos.
65

DISTRIBUCIÓN DE FRECUENCIAS PARA DATOS NO AGRUPADOS
Sea X la variable que representa el número de faltas de asistencia de los estudiantes del colegio 28 de mayo durante un año escolar. X genera el siguiente conjunto de los datos numéricos de 50 estudiantes de primer año:
3, 2, 3, 4, 1, 2, 3, 4, 3, 3, 3, 5, 6, 6, 5, 3, 4, 1, 2, 3, 2, 5, 1, 3, 3, 3, 2, 4, 1, 2, 2, 3, 3, 5, 5, 6, 3, 4, 4, 1, 2, 4, 3, 7, 7, 3, 7, 6, 5, 3.
66

DISTRIBUCIÓN DE FRECUENCIAS PARA DATOS NO AGRUPADOS
POBLACIÓN: La totalidad de los estudiantes del colegio 28 de mayo.
MUESTRA: 50 estudiantes de primer año.
TIPO DE VARIABLE: variable discreta.
Ordenemos los datos, representémoslos mediante una tabla de frecuencia.
LÍMITES DE CLASES: LI=1 LS=7
RANGO: LS - LI = 7-1= 6
67
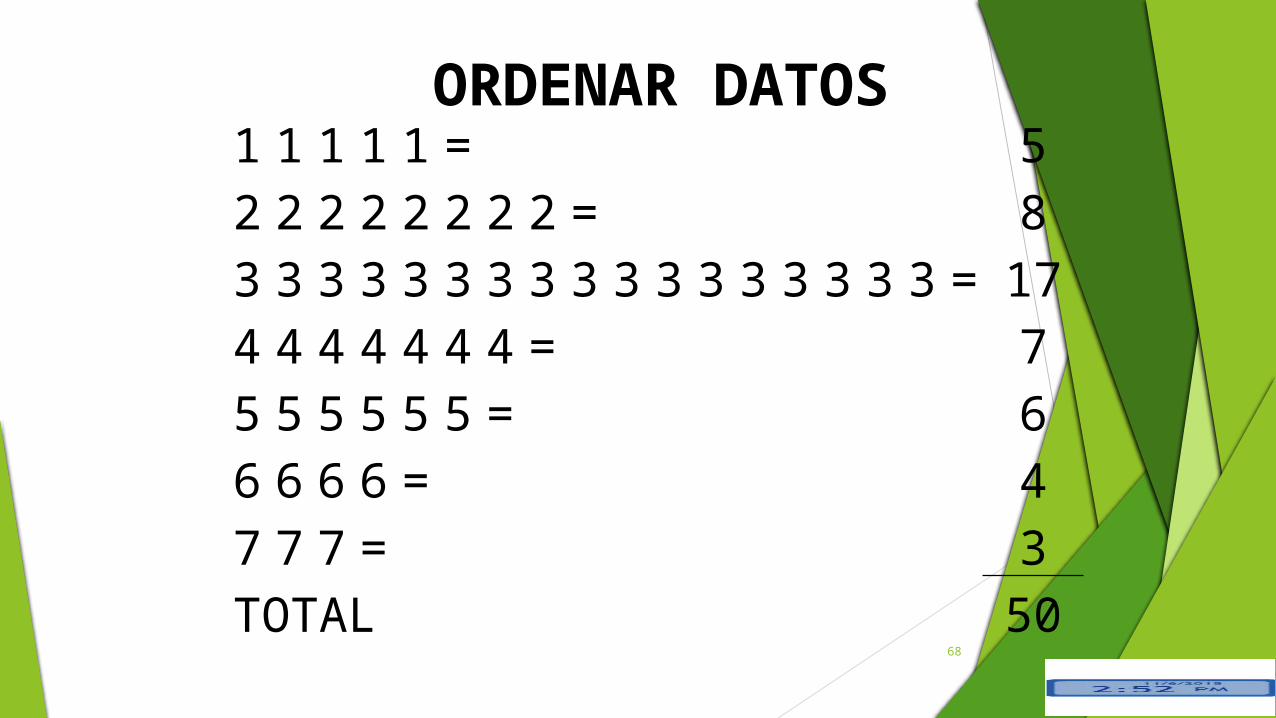
ORDENAR DATOS1 1 1 1 1 = 52 2 2 2 2 2 2 2 = 83 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 = 174 4 4 4 4 4 4 = 75 5 5 5 5 5 = 66 6 6 6 = 47 7 7 = 3TOTAL 50
68

Xi (Clases)
1
2
3
4
5
6
7
Total (n)
i
69
fi Frecuencia
absoluta
5
8
17
7
6
4
3
50
Fi
Frecuencia absoluta
acumulada
5
13
30
37
43
47
50
hi Frecuencia relativa
(fi/n)*100
10
16
34
14
12
8
6
100%
HiFrecuencia
relativa acumulada
(Fi/n) *100
10
26
60
74
86
94
100
DISTRIBUCIÓN DE FRECUENCIAS PARA DATOS NO AGRUPADOS

DISTRIBUCIÓN DE FRECUENCIAS PARA
DATOS NO AGRUPADOS
Sea X la variable que representa el número total que
recorre un jugador en un partido de fútbol. X
genera el siguiente conjunto de los datos numéricos:
8,6,7,5,3,2,4,6,2,1,7,4,6,7,8,3,9,1,6,7,5,1,9,8,7,4,5,6,8
,1,6,7,9,3,2,470
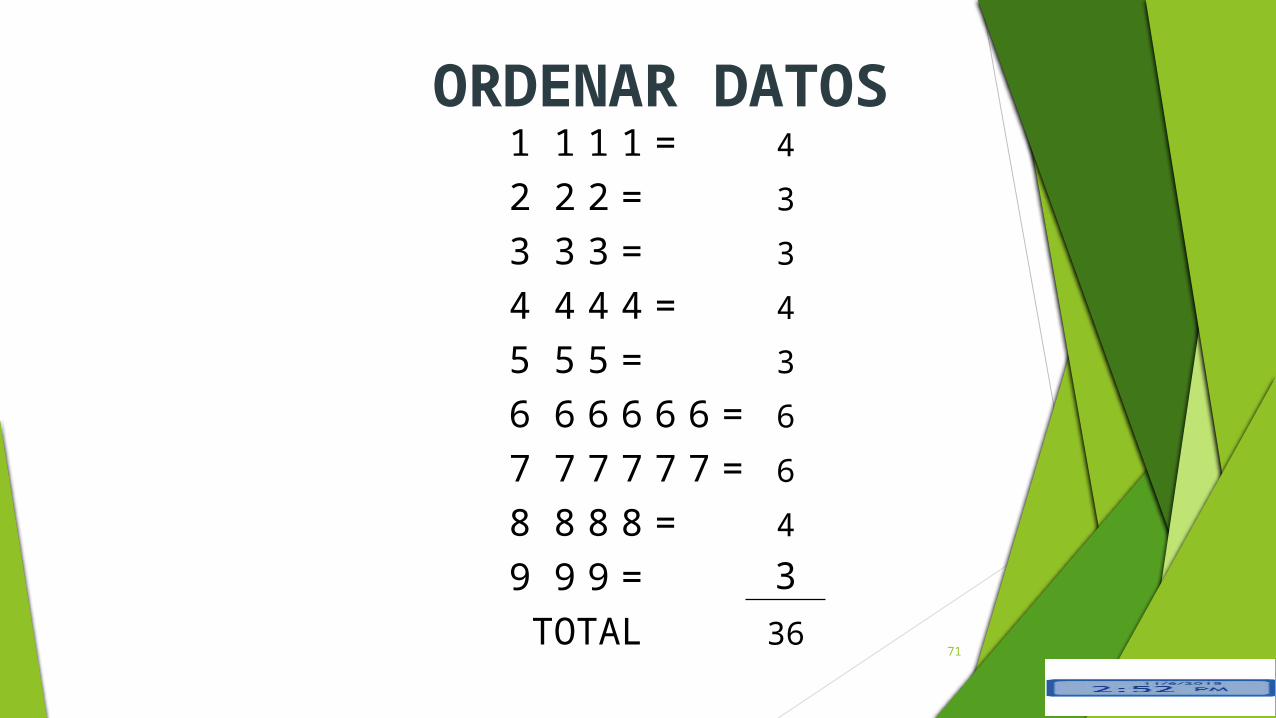
ORDENAR DATOS1 1 1 1 = 4
2 2 2 = 3
3 3 3 = 3
4 4 4 4 = 4
5 5 5 = 3
6 6 6 6 6 6 = 6
7 7 7 7 7 7 = 6
8 8 8 8 = 4
9 9 9 = 3TOTAL 36
71

DISTRIBUCIÓN DE FRECUENCIA PARA DATOS NO AGRUPADOS
Xi (Clases)
1
2
3
4
5
6
7
8
9
Total (n)
i
72
fi Frecuencia
absoluta
4
3
3
4
3
66
4
336
Fi
Frecuencia absoluta
acumulada
4
7
10
14
17
2329
33
36
hi Frecuencia
relativa
% (fi/n)*100
11
8
8
11
8
1717
11
9100%
HiFrecuencia relativa
acumulada
% (Fi/n) *100
11
19
27
38
46
6380
91
100

DISTRIBUCIÓN DE FRECUENCIAS PARA DATOS NO
AGRUPADOS
Sea X la variable que representa a nadadores durante una
competencia que se desarrolló en la piscina olímpica de la ciudad de
Guayaquil mostraron sus dominios en los diferentes estilos. X
genera el siguiente conjunto de datos numéricos:
9,6,7,5,8,2,10,4,6,2,3,4,6,2,8,9,5,6,10,7,9,9,10,2,10,6,7,8,3,9,10,2,10
73
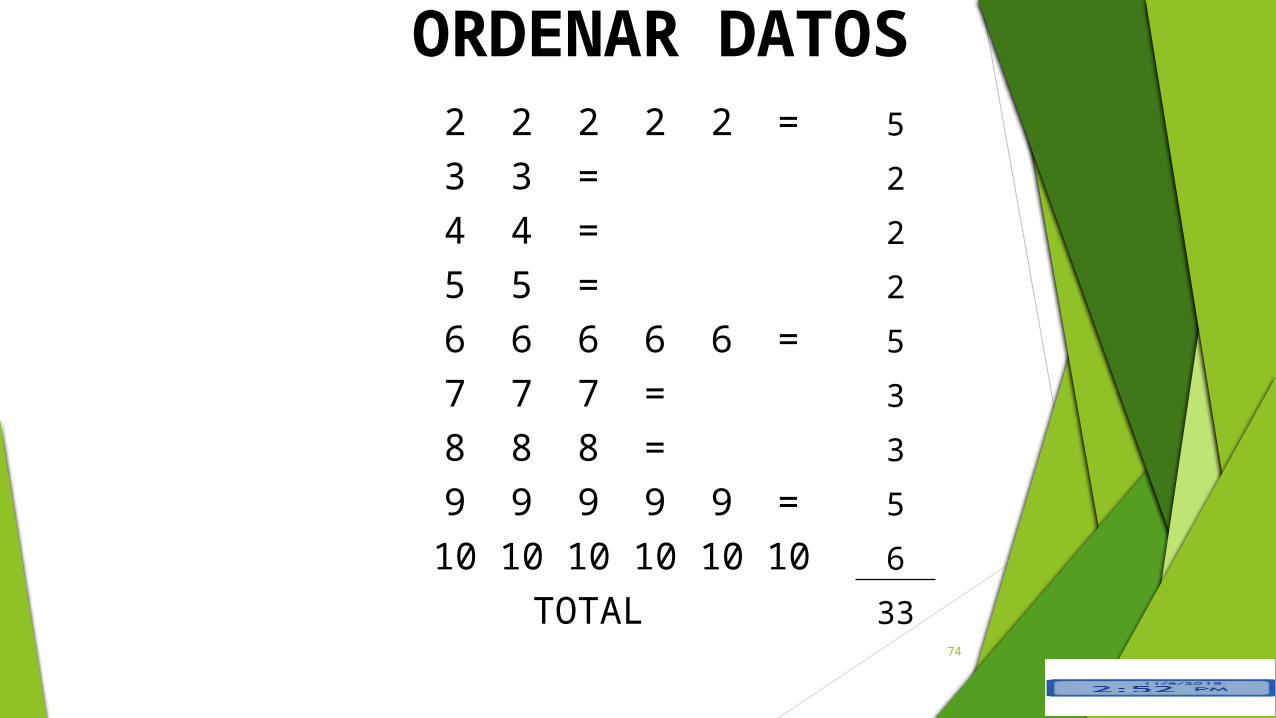
ORDENAR DATOS2 2 2 2 2 = 53 3 = 24 4 = 25 5 = 26 6 6 6 6 = 57 7 7 = 38 8 8 = 39 9 9 9 9 = 510 10 10 10 10 10 6
TOTAL 3374

DISTRIBUCIÓN DE FRECUENCIA PARA DATOS
NO AGRUPADOSXi
(clases)
fi Frecuencia
absoluta
Fi
Frecuencia absoluta
acumulada
hi Frecuencia
relativa
% (fi/n)*100
HiFrecuencia relativa
acumulada
% (Fi/n) *100
2 53 24 25 26 57 38 39 5
10 6Total (n) 33 100%
i
75

Distribución de Frecuencias Agrupadas
Conocida también como tabla con datos agrupados se emplea
si las variables toman un número grande de valores o la
variable es continua.
Se agrupan los valores en intervalos que tengan la misma
amplitud denominados clases. A cada clase se le asigna su
frecuencia correspondiente.76

77
Fórmula: 2c≥n
C= # de clases
n= # de Observaciones
Ejemplo de 50 datos:
Número de clases deseados
2c≥n 2c≥50 26≥50
2 43 84 165 326 647 1288 2569 51210 1024

78
1 2 = 2
2 2x2 = 4
3 2x2x2 = 8
4 2x2x2x2 = 16
5 2x2x2x2x2 = 32
6 2x2x2x2x2x2 = 64
7 2x2x2x2x2x2x2 = 128
8 2x2x2x2x2x2x2x2 = 256
9 2x2x2x2x2x2x2x2x2 = 512
10 2x2x2x2x2x2x2x2x2x2 = 1024
CÁLCULO DE TABLA

79
El intervalo de clases es el recorrido de los valores que se encuentran dentro de una clase. Para determinarlo se resta el limite inferior de una clase con el limite superior de la clase siguiente.
Para construir la tabla de frecuencias el intervalo de clases se puede determinar con ayuda de la expresión siguiente:
Intervalos de Clases
Ci =
Valor máximo
(LS)
- Valor mínimo (LI)
Número de clases deseados
(Nc)

80
Es el valor correspondiente al punto medio o mediano de un intervalo de clases, es la marca de clase y
su valor es igual a la mitad de la suma de los limites Inferior y Superior del intervalo de clase.
Marca de clase
Marca de claseo
Punto Medio de clase =
LI + LS2

81
Ejemplo de Marca de clase
Marca de clase =
LI + LS2
Clase Marca de Clase
50.15 - 59.74 54.9559.74 - 69.33 64.5469.33 - 78.92 74.1378.92 - 88.51 83.7288.51 - 98.10 93.31

DISTRIBUCIÓN DE FRECUENCIAS PARA DATOS
AGRUPADOSSea X la variables que representa la estatura de los jugadores del EMELEC. X genera el siguiente conjunto de los datos numéricos:
1.70
1.60
1.80
1.55
1.70
1.60
1.70
1.72
1.50
1.32
1.82
1.90
1.72
1.60
1.70
82

EJERCICIO 1:
1. Ordenarlos
1) 1.32
2) 1.50
3) 1.55
4) 1.60
5) 1.60
6) 1.60
7) 1.70
8) 1.70
9) 1.70
10) 1.72
11) 1.72
12) 1.80
13) 1.82
14) 1.90
15) 1.7083

EJERCICIO 1:
2. Determinar el límite inferior y superior
3. Determinar el número de clases
4. Determinar el intervalo o amplitud
LI= 1.32 LS= 1.90
2c≥n 2c≥15 24≥15
Ls - Li = 1.92 - 1.32Nc
Ci4
= 0.1584

EJERCICIO 1:5. Distribuir los datos en cada categoría o clase
Clase fi
Frecuencia absoluta
Fi
Frecuencia
absoluta acumulad
a
hi Frecuencia relativa
%
(fi/n)*100
HiFrecuencia relativa acumulad
a
% (Fi/n) *100
Marca de Clase
1.32 - 1.47 1 1 6.67
6.671.40
1.47 - 1.62 5 6 33.33
40.001.55
1.62 - 1.77 6 12 40.00
80.001.70
1.77 - 1.92 3 15 20.00
100.001.85
15 100.00
85
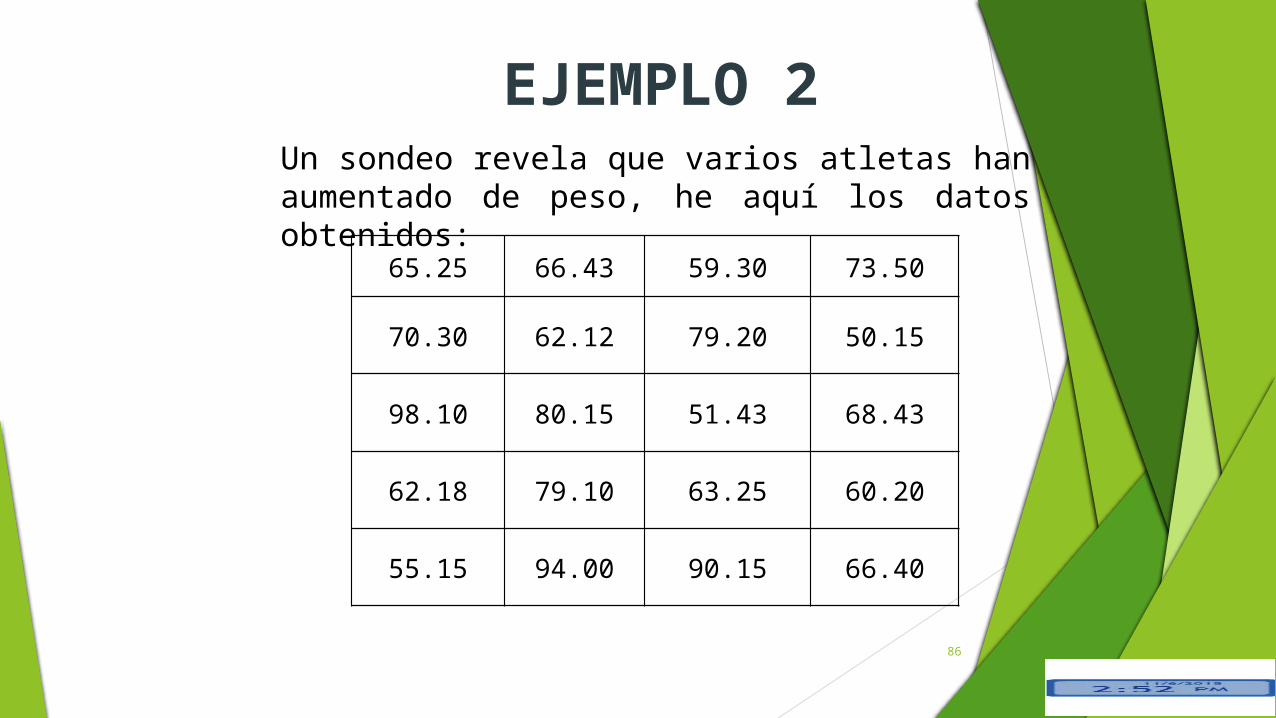
EJEMPLO 2Un sondeo revela que varios atletas han aumentado de peso, he aquí los datos obtenidos:
65.25 66.43 59.30 73.50
70.30 62.12 79.20 50.15
98.10 80.15 51.43 68.43
62.18 79.10 63.25 60.20
55.15 94.00 90.15 66.40
86
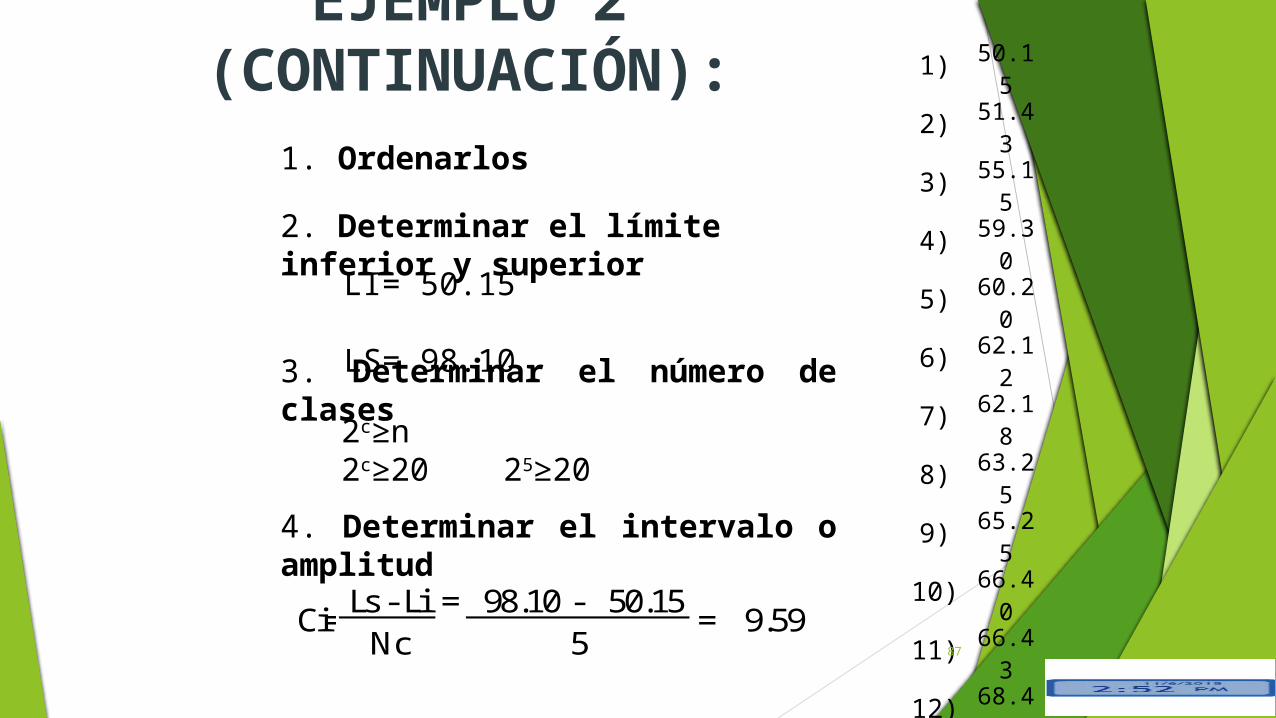
EJEMPLO 2 (CONTINUACIÓN): 1) 50.15
2) 51.433) 55.154) 59.305) 60.206) 62.127) 62.188) 63.259) 65.25
10) 66.4011) 66.4312) 68.4313) 70.3014) 73.5015) 79.1016) 79.2017) 80.1518) 90.1519) 94.0020) 98.10
1. Ordenarlos
2. Determinar el límite inferior y superior
3. Determinar el número de clases
4. Determinar el intervalo o amplitud
LI= 50.15 LS= 98.10
2c≥n 2c≥20 25≥20
Ls - Li = 98.10 - 50.15Nc
Ci=5
= 9.5987

EJEMPLO 2 (CONTINUACIÓN):
5. Distribuir los datos en cada categoría o clase
Clase fi
Frecuenciaabsoluta
Fi
Frecuencia absoluta acumulad
a
hi Frecuencia
relativa %
(fi/n)*100
HiFrecuencia
relativa acumulada
% (Fi/n) *100
Marca de Clase
50.15 - 59.74 4 4 20.00 20.00 54.9559.74 - 69.33 8 12 40.00 60.00 64.5469.33 - 78.92 2 14 10.00 70.00 74.1378.92 - 88.51 3 17 15.00 85.00 83.7288.51 - 98.10 3 20 15.00 100.00 93.31
20 100
88

A continuación se presenta el número de minutos y segundos que le toma a un grupo de futbolistas para ir desde su hogar hasta la cancha de entrenamiento,.
1. Ordenarlos2. Determinar el límite inferior y superior
3. Determinar el número de clases
4. Determinar el intervalo o amplitud
5. Distribuir los datos en cada categoría o clase
28.30 30.10 41.55 32.22 66.32 67.53 36.00
31.50 45.25 25.25 43.59 42.69 75.14 71.25
25.62 60.32 27.47 35.11 70.05 31.29 77.12
26.15 90.10 31.18 26.17 38.20 67.20 80.13
EJERCICIO 3
89

EJERCICIO 3 (CONTINUACIÓN):
1. Ordenarlos1) 25.25
2) 25.62
3) 26.15
4) 26.17
5) 27.47
6) 28.30
7) 30.10
8) 31.18
9) 31.29
10) 31.50
11) 32.22
12) 35.11
13) 36.00
14) 38.20
15) 41.55
16) 42.69
17) 43.59
18) 45.25
19) 60.32
20) 66.32
21) 67.20
22) 67.53
23) 70.05
24) 71.25
25) 75.14
26) 77.12
27) 80.13
28) 90.1090

EJERCICIO 3 (CONTINUACIÓN):
2. Determinar el límite inferior y superior
3. Determinar el número de clases
4. Determinar el intervalo o amplitud
LI= 25.25 LS= 90.10
2c≥n 2c≥25 25≥25
Ls - Li = 90.10 - 25.25Nc
Ci5
= 12.9791

EJERCICIO 3 (CONTINUACIÓN):
5. Distribuir los datos en cada categoría o clase
Clase fi
Frecuencia absoluta
Fi
Frecuencia absoluta
acumulada
hi Frecuencia
relativa
% (fi/n)*100
HiFrecuencia
relativa acumulada
%
(Fi/n) *100
Marca de Clase
25.25 - 38.25 14 14 50.00 50.00 31.7538.25 - 51.25 4 18 14.29 64.29 44.7551.25 - 64.25 1 19 3.57 67.86 57.7564.25 - 77.25 7 26 25.00 92.86 70.7577.25 - 90.25 2 28 7.14 100.00 83.75
28 100
92

GRÁFICOSHistogramas, polígono de frecuencias y ojiva
Otros gráficos
93

HIPOTESIS
Una hipótesis estadística es una proposición o supuesto sobre los parámetros de una o más poblaciones.

Un procedimiento que conduce a una decisión sobre una hipótesis en particular recibe el nombre de prueba de hipótesis. Los procedimientos de prueba de hipótesis dependen del empleo de la información contenida en la muestra aleatoria de la población de interés.

HIPOTESIS NULA
La hipótesis nula son, en un sentido, el reverso de las hipótesis de investigación. También constituyen proposiciones acerca de la relación entre variables solamente que sirven para refutar o negar lo que afirma la hipótesis de investigación. Por ejemplo, si la hipótesis de investigación propone: “Los adolescentes le atribuyen más impor tancia al atractivo físico en sus relaciones heterosexuales que las mujeres”, la nula postularía:
“Los jóvenes no le atribuyen más importancia al atractivo físico en sus relaciones heterosexuales que las adolescentes”.

La hipótesis alternativa, representada por H1, es la afirmación contradictoria a Ho, y ésta es la hipótesis del investigador.
Como su nombre lo indica, son posibilidades alternativas - ante las hipótesis de investigación y nula. Ofrecen otra descripción o explicación distintas a las que proporcionan estos tipos de hipótesis. Por ejemplo, si la hipótesis de investigación establece: “Esta silla es roja”, la nula afirmará: “Esta silla no es roja”, y podrían formularse una o más hipótesis alternativas: “Esta silla es azul”, “Esta silla es verde”, “Esta silla es amarilla”, etc. Cada una constituye una descripción distinta a las que proporcionan las hipótesis de investigación y nula.
Sólo pueden formularse cuando efectivamente hay otras posibilidades adicionales a las hipótesis de investiga ción y nula. De ser así, no pueden existir.
HIPOTESIS ALTERNATIVA

EJEMPLO:
98
La empresa Delicias y Mariscos del Ecuador desea lanzar un nuevo producto elaborado con atún que se denomina “XYZ” para medir la aprobación o percepción del consumidor respecto a este producto contratará a la empresa Margen y Asociados a fin de que realice las pruebas correspondientes. Esta empresa toma una muestra de 1960 posibles consumidores de los cuales 1176 después de probar el producto indicaron que estarán dispuestos a adquirirlo si se lanzara al mercado.
¿Cuál es la información que proporciona Margen y Asociados a la empresa productora de este novedoso bien?
¿Qué decisión tomará la empresa productora “XYZ” con respecto a la información y de qué tipo de estadística estamos hablando?
La decisión será de lanzar el producto al mercado y estamos hablando de una estadística inferencial.
1960 - 100 % 1176 x 1001176 - x
=1960
60 %
GRÁFICOS

REPRESENTACIONES GRÁFICAS
100
Las tres formas de gráficas más usadas son histogramas, polígonos de frecuencia y distribuciones de frecuencias acumuladas (ojiva).
Gráfica donde las clases se marcan en el eje horizontal (X) y las frecuencias de clase en el eje vertical (Y). Las frecuencias de clase se representan por las alturas de las barras y éstas se trazan adyacentes entre sí
Histograma

HISTOGRAMA
101
0
5
10
15
20
25
8
2317 18
84 2
Precios en miles
# v
eh
icu
los
Conjunto de barras Eje X - Limites de clase Eje Y - fi= Frecuencias no Acumuladas
Y
X

EJERCICIO DE HISTOGRAMA
102
Meses AsistentesEnero 100
Febrero 120Marzo 140Abril 80
Tabla de datos:
Público que asiste a un partido de fútbol.
Enero Febrero Marzo Abril0
60
120
180
100
120
140
80

EJERCICIO DE HISTOGRAMA
103
De los datos del ejemplo 1 obtenemos
Clase fi
Frecuencia absoluta
25.25 - 38.25 14
38.25 - 51.25 4
51.25 - 64.25 1
64.25 - 77.25 7
77.25 - 90.25 2
28
25.25 38.25 51.25 64.25 77.25 90.25 103.250
2
4
6
8
10
12
14
1614
4
1
7
2

POLÍGONO
104
Consiste en segmentos de línea que conectan los puntos formados por el punto medio de la clase y la frecuencia de clase.
El polígono se cierra con el eje X, agregando un intervalo de clase antes del inicial y otro a continuación del último.
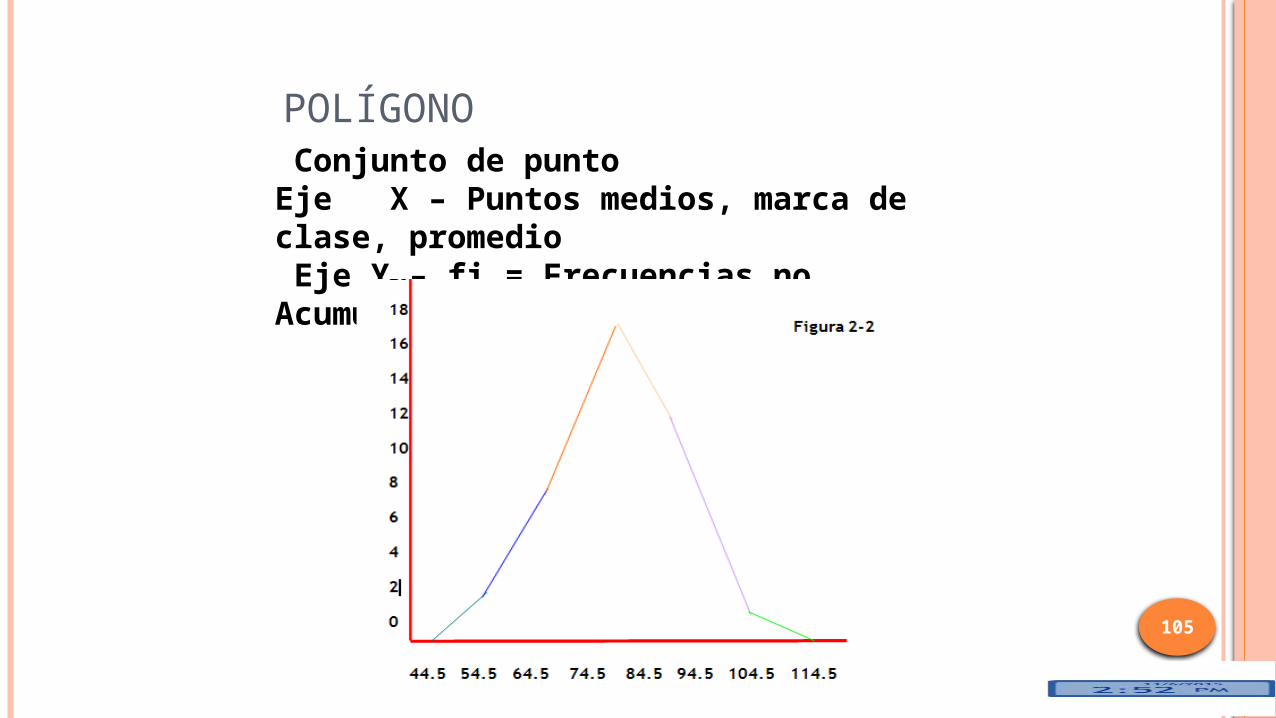
POLÍGONO
105
Conjunto de puntoEje X – Puntos medios, marca de clase, promedio Eje Y – fi = Frecuencias no Acumuladas
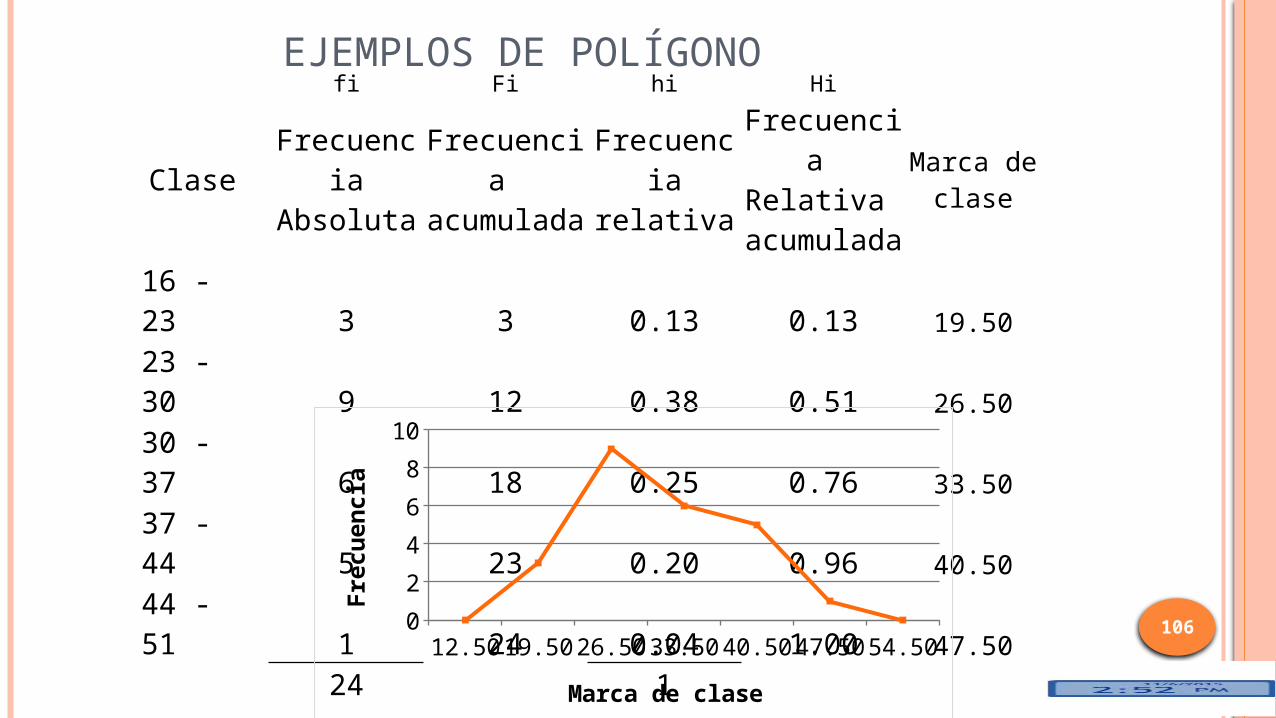
EJEMPLOS DE POLÍGONO
106
fi Fi hi Hi
Clase FrecuenciaAbsoluta
Frecuencia acumulada
Frecuenciarelativa
Frecuencia Relativa
acumulada
Marca de clase
16 - 23 3 3 0.13 0.13 19.5023 - 30 9 12 0.38 0.51 26.5030 - 37 6 18 0.25 0.76 33.5037 - 44 5 23 0.20 0.96 40.5044 - 51 1 24 0.04 1.00 47.50
24 1
12.50 19.50 26.50 33.50 40.50 47.50 54.500
2
4
6
8
10
Marca de clase
Fre
cu
en
cia

EJERCICIO EN CLASE
107
fi hi
Clase (PV) FrecuenciaAbsoluta Frecuencia
Relativa Punto Medio o Marca de clase
50 – 60 4 0.20 5560 – 70 5 0.25 6570 – 80 6 0.30 7580 – 90 2 0.10 85
90 - 100
3
0.15
95 20 1

OJIVA
108
Se usa para determinar cuántos o qué proporción de los valores de los datos es menor o mayor que cierto valor.
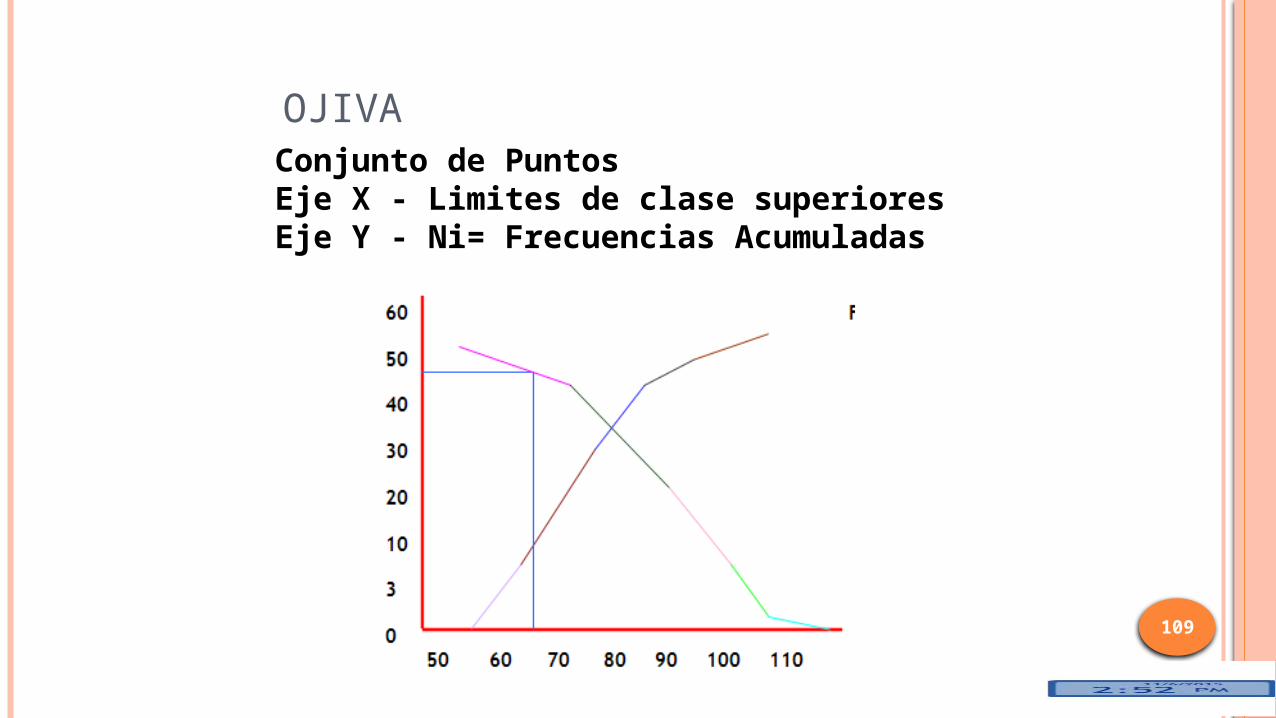
OJIVA
109
Conjunto de PuntosEje X - Limites de clase superioresEje Y - Ni= Frecuencias Acumuladas
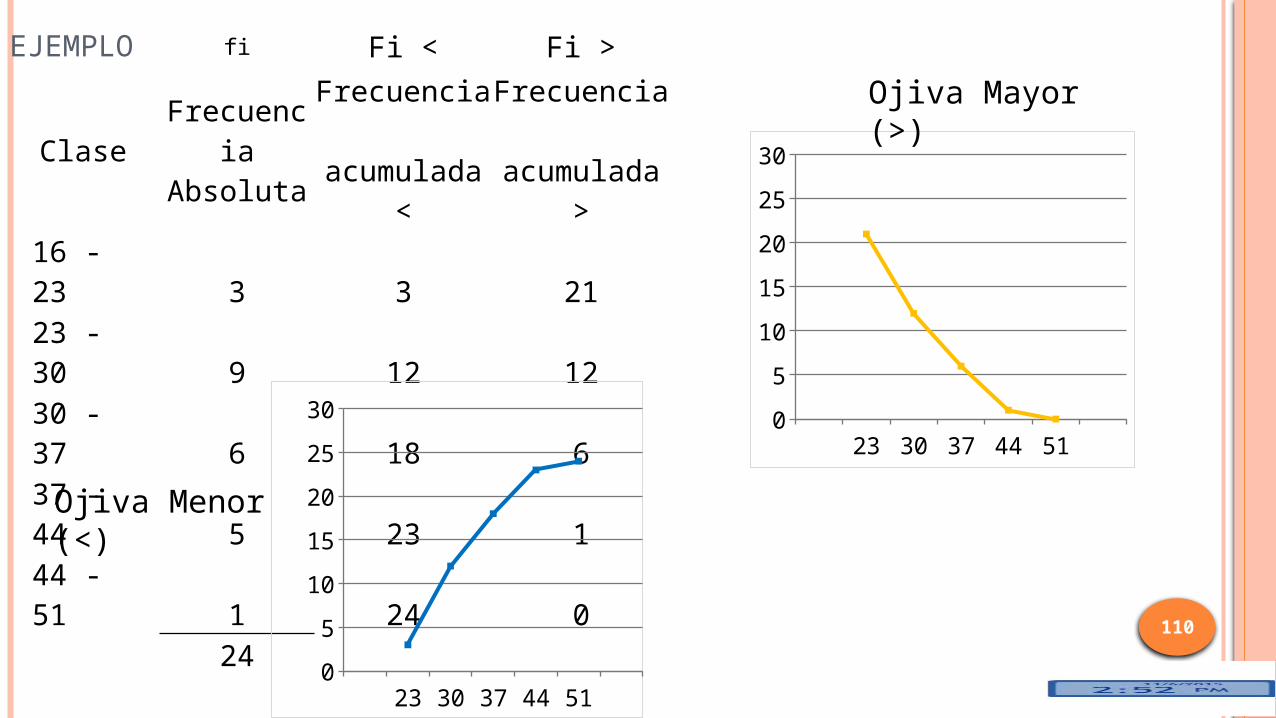
EJEMPLO
110
fi Fi < Fi >
Clase FrecuenciaAbsoluta
Frecuencia acumulada
<
Frecuencia acumulada
>16 - 23 3 3 2123 - 30 9 12 1230 - 37 6 18 637 - 44 5 23 144 - 51 1 24 0
24
23 30 37 44 510
5
10
15
20
25
30
23 30 37 44 510
5
10
15
20
25
30
Ojiva Mayor (>)
Ojiva Menor (<)

EJEMPLO
111
23 30 37 44 510
5
10
15
20
25
30
3
18
23 2423; 21
30; 12
37; 644; 1 51; 0
Las 2 Ojivas se intersectan en un punto M (30,12) tal que el número de mayores que y menores que son iguales; este punto es la mediana del número de casos observados
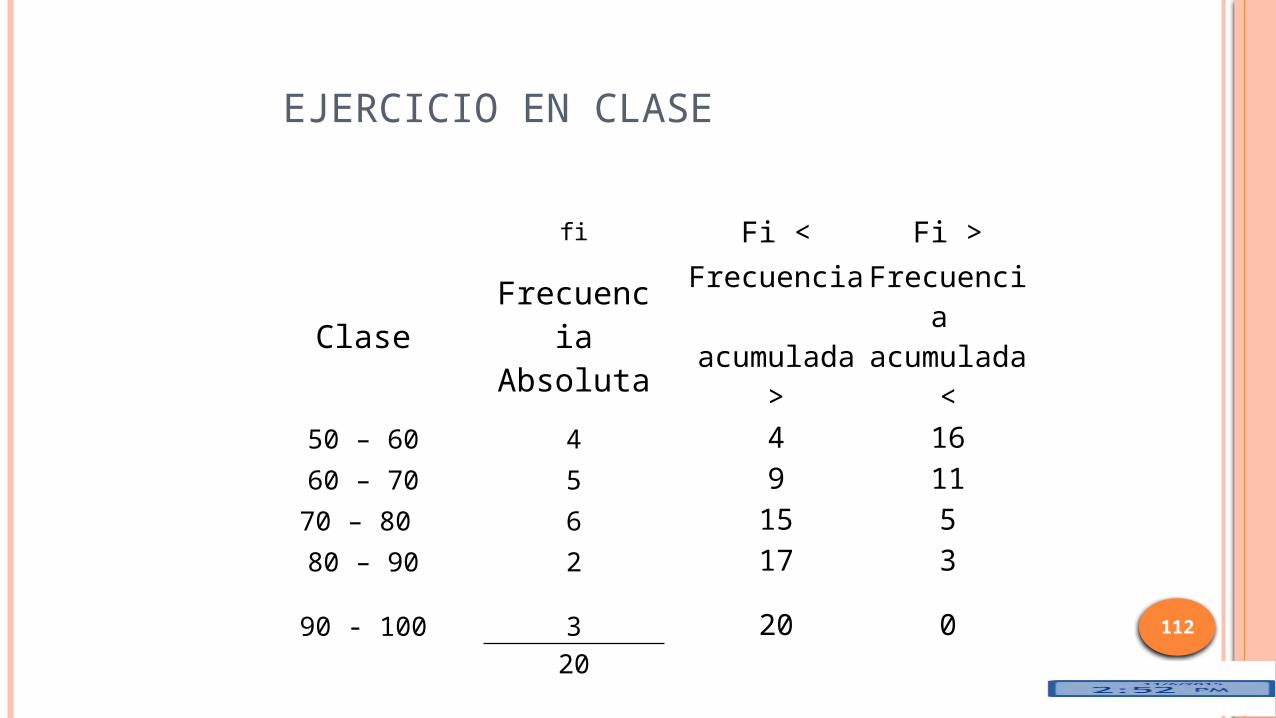
EJERCICIO EN CLASE
112
fi Fi < Fi >
Clase FrecuenciaAbsoluta
Frecuencia acumulada
>
Frecuencia acumulada
<50 – 60 4 4 1660 – 70 5 9 1170 – 80 6 15 580 – 90 2 17 3
90 - 100
3
20 0 20

CIRCULAR
113
Es en especial útil para desplegar una distribución de frecuencias relativas. Se divide un círculo de manera proporcional a la frecuencia relativa y las rebanadas representan los diferentes grupos.

CIRCULAR
114
48%
10%
13%
8%
9%
12%
Ventas
Menos de una vez al mesUna vez al mesUna vez a la semanaDos veces a la semana3 - 4 veces a la semanaTodos los dias
Ejercicio
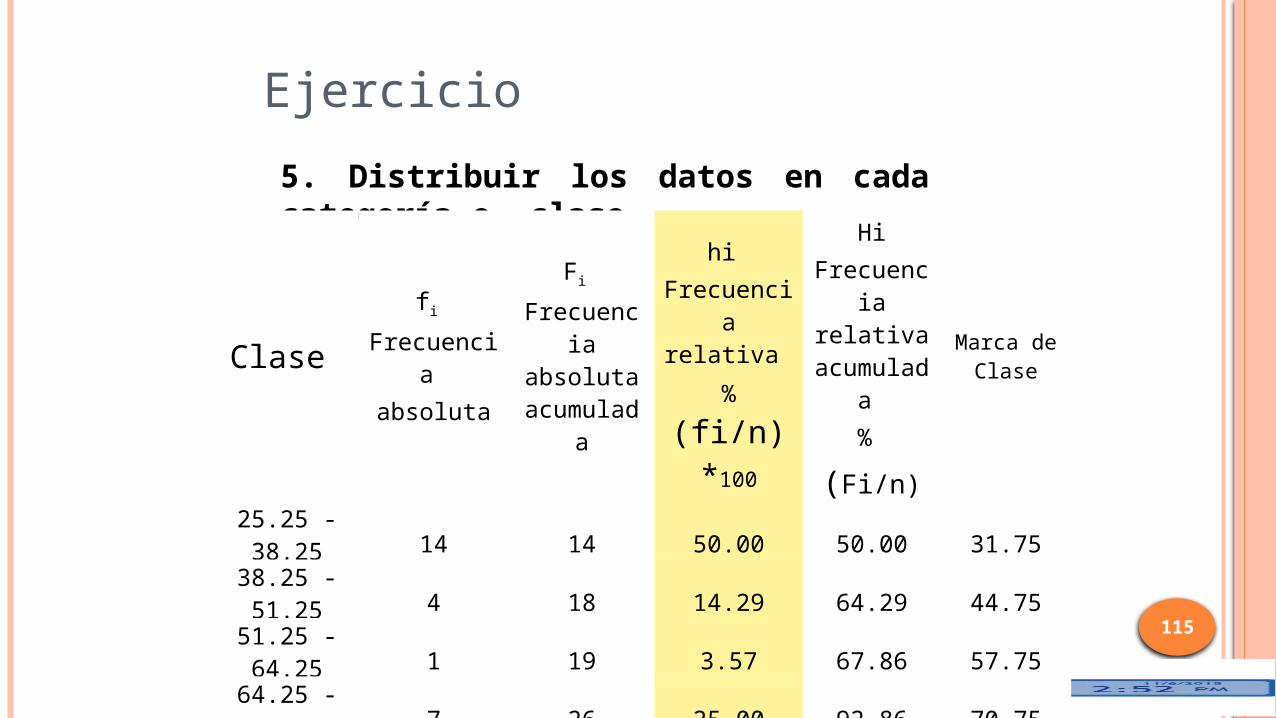
5. Distribuir los datos en cada categoría o clase
Clase fi
Frecuencia absoluta
Fi
Frecuencia absoluta
acumulada
hi Frecuencia
relativa %
(fi/n)*100
HiFrecuencia
relativa acumulada
%
(Fi/n) *100
Marca de Clase
25.25 - 38.25 14 14 50.00 50.00 31.75
38.25 - 51.25 4 18 14.29 64.29 44.75
51.25 - 64.25 1 19 3.57 67.86 57.75
64.25 - 77.25 7 26 25.00 92.86 70.75
77.25 - 90.25 2 28 7.14 100.00 93.75
28 100
115

LINEAL
116
Nos permite expresar unidades de tiempo en el eje horizontal

Año Homicidios
1986
21
1987
34
1988
26
1989
42
1990
37
1991
37
1992
44
1993
45
1994
40
1995
35
1996
30
1997
28
1998
25
1999
21
El periódico el Universo realizo un estudio del # de homicidios durante el periodo 1986 – 1999 en un sector de la ciudad de Guayaquil.Trace una gráfica de líneas para resumir los datos que correspondan a los últimos 14 años.
Fuente: El periódico el Universo Periodo 1986 – 1999 (Homicidios)
1986
1987
1988
1989
1990
1991
1992
1993
1994
1995
1996
1997
1998
1999
0
10
20
30
40
50
Homicidios
117
118
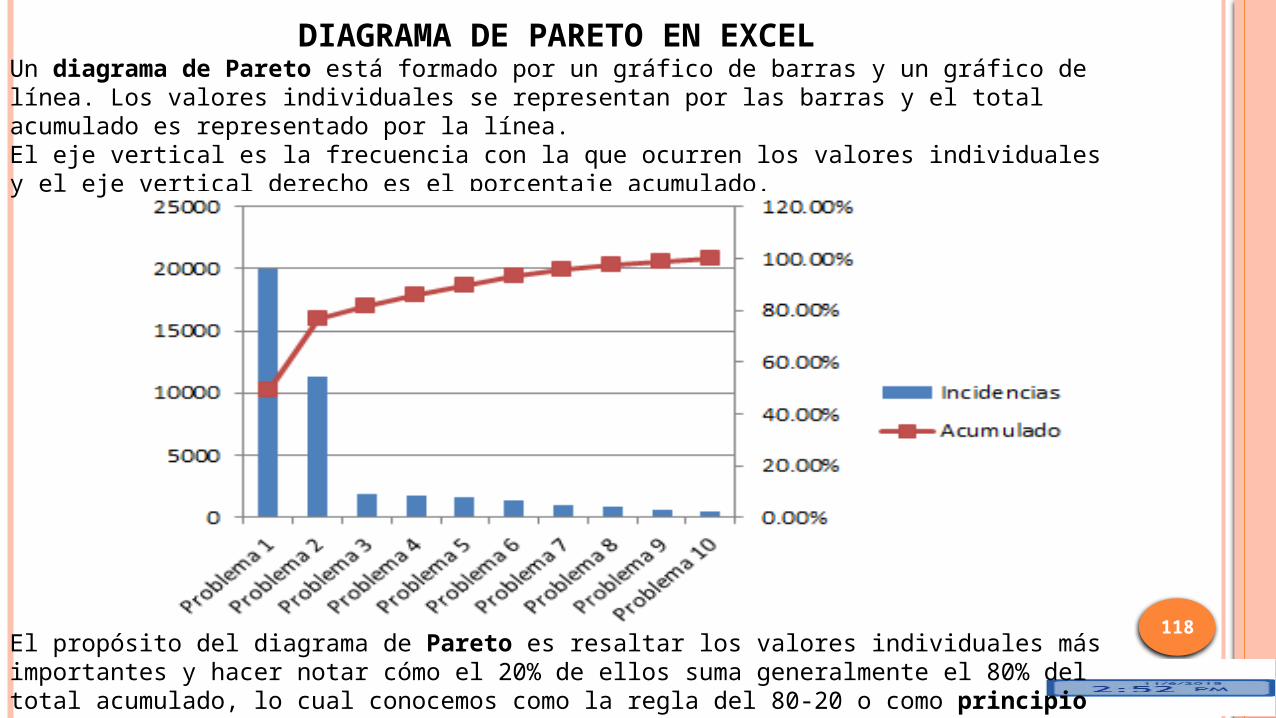
DIAGRAMA DE PARETO EN EXCELUn diagrama de Pareto está formado por un gráfico de barras y un gráfico de línea. Los valores individuales se representan por las barras y el total acumulado es representado por la línea.El eje vertical es la frecuencia con la que ocurren los valores individuales y el eje vertical derecho es el porcentaje acumulado.
El propósito del diagrama de Pareto es resaltar los valores individuales más importantes y hacer notar cómo el 20% de ellos suma generalmente el 80% del total acumulado, lo cual conocemos como la regla del 80-20 o como principio de Pareto. Para crear un diagrama de Pareto debemos preparar los datos.

FUNCIÓN COMBINAT
• Devuelve el número de combinaciones para un número determinado de elementos. Use COMBINAT para determinar el número total de grupos posibles para un número determinado de elementos. En esta función no importa el orden de los datos.

FÓRMULA MANUAL
• n! = n factorial donde n es el numero
• r!= r factorial donde r es el tamaño de la combinación y esto a su vez multiplicado por (n-r)! factorial.

SINTAXIS• La sintaxis de la función COMBINAT es la siguiente.
• La sintaxis de la función COMBINAT es la siguiente.
• Numero: es el número de elementos que forman el conjunto de los que se tomaran para la combinación, el parámetro es obligatorio.
• Tamaño: parámetro obligatorio y numérico, que representa el número de elementos de la combinación

FUNCIÓN PERMUTACIONES
• Una permutación es un conjunto o subconjunto de objetos o de sucesos en el que el orden de los objetos es importante.
• Difiere en esto de las combinaciones en las que el orden de los elementos no es significativo. Se utiliza esta función para los cálculos de probabilidad tipo sorteos.

TIPOS DE PERMUTACIONES
Hay dos tipos de permutaciones:
• Se permite repetir• Sin repetición
Existen dos tipos de permutaciones: Sin repeticiones y con repeticiones. Se refiere al hecho de que en el conjunto de objetos que se van a permutar haya o no cosas repetidas.

FÓRMULA MANUAL
• n! = n factorial donde n es el numero
• k!= k factorial donde k es el tamaño de la permutación.
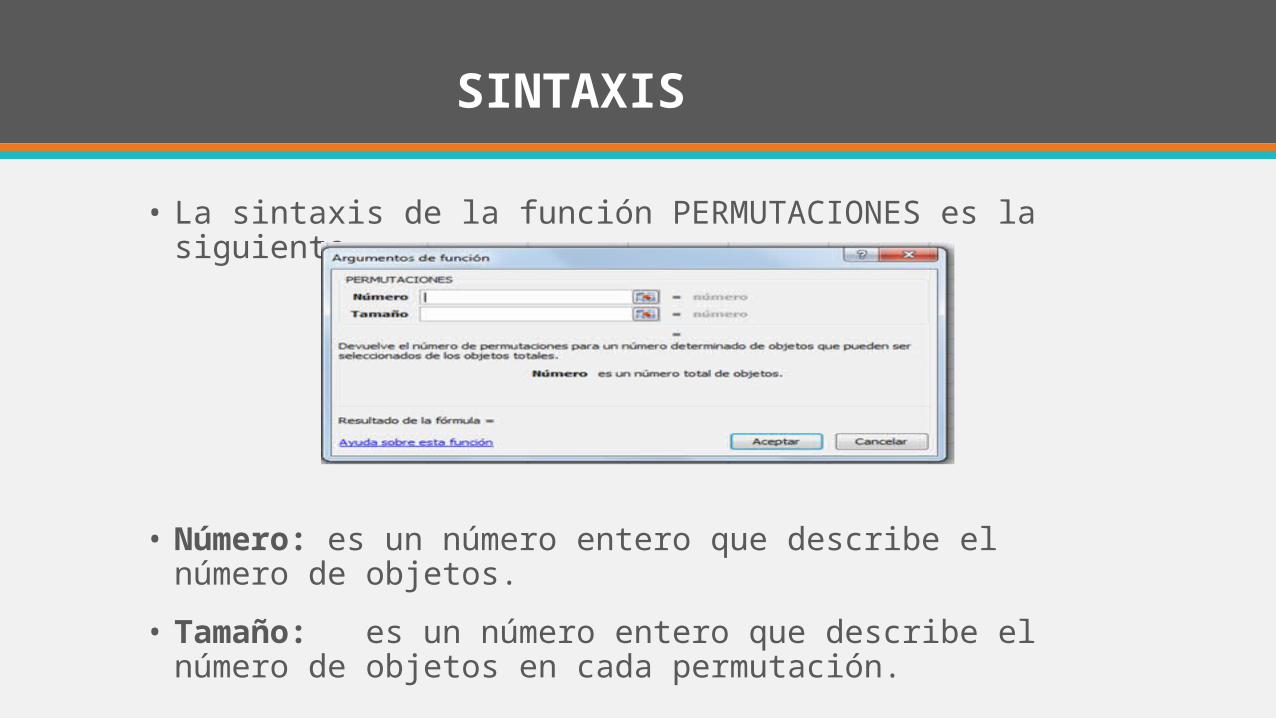
SINTAXIS
• La sintaxis de la función PERMUTACIONES es la siguiente.
• Número: es un número entero que describe el número de objetos.
• Tamaño: es un número entero que describe el número de objetos en cada permutación.

Consideraciones importantes sobre la función PERMUTACIONES
• Los argumentos deben ser números enteros, en caso contrario, Excel truncará los números.
• Si los argumentos número o tamaño no son numéricos, PERMUTACIONES devuelve el valor de error #¡VALOR!
• Si número ≤ 0 o si tamaño < 0, PERMUTACIONES devuelve el valor de error #¡NUM!
• Si número < tamaño, PERMUTACIONES devuelve el valor de error #¡NUM!

CONCLUSIÓN
• La combinación es todo arreglo de elementos en donde no nos interesa el lugar o posición que ocupa cada uno de los elementos que constituyen dicho arreglo.
• En cambio permutación es todo arreglo de elementos en donde nos interesa el lugar o posición que ocupa cada uno de los elementos que constituyen dicho arreglo.

UNIVERSIDAD DE GUAYAQUIL“Facultad de Ciencias Administrativas”
Carpeta de Computación
Módulo: Excel Aplicado a la Estadística
Tema: Distribución Binomial
Distribución Binomial NegativaIntegrantes:• Morales Aguirre Génesis• Jiménez Vásquez Angélica Docente: Alex Duque

Condiciones para una distribución binomial
Una distribución se denomina binomial cuando se cumplen las condiciones siguientes:
O El experimento aleatorio de base se repite n veces, y todos los resultados obtenidos son mutuamente independientes.
O En cada prueba se tiene una misma probabilidad de éxito (suceso A), expresada por p. Asimismo, existe en cada prueba una misma probabilidad de fracaso (suceso), que es igual a 1 - p.
O El objetivo de la distribución binomial es conocer la probabilidad de que se produzca un cierto número de éxitos. La variable aleatoria X, que indica el número de veces que aparece el suceso A (éxito), es discreta, y su recorrido es el conjunto {0, 1, 2, 3, ..., n}.
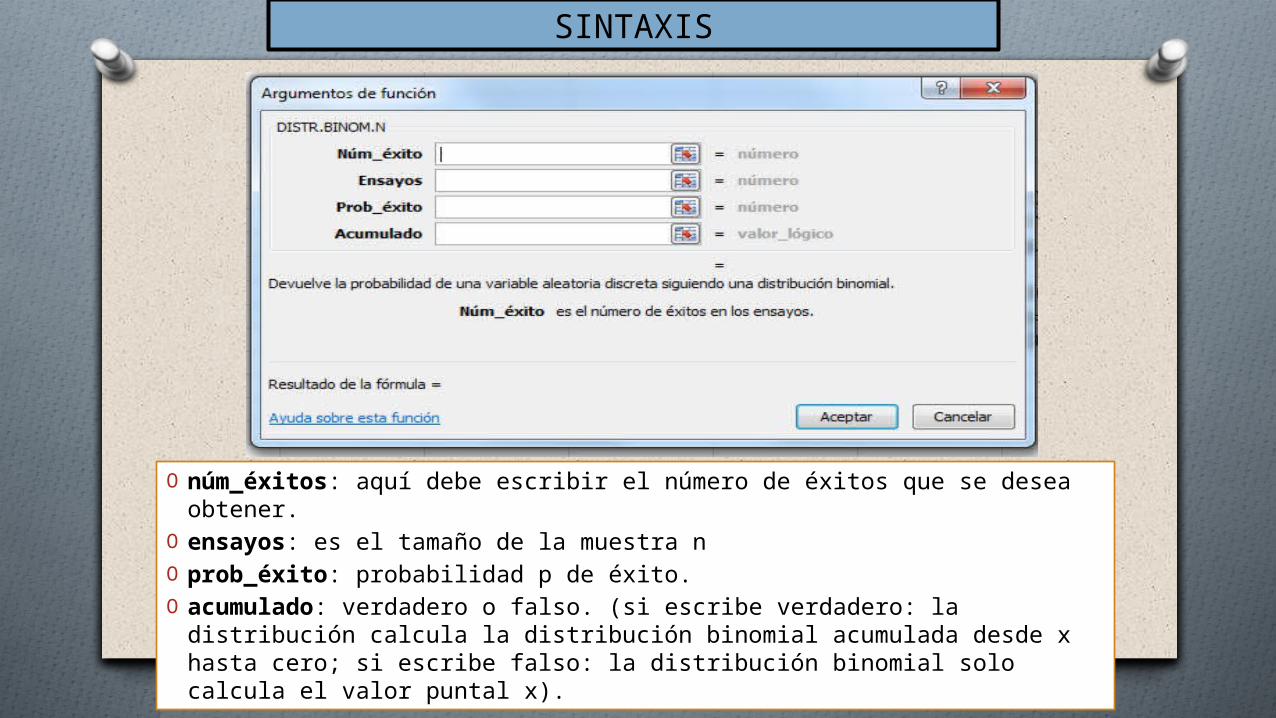
SINTAXIS
O núm_éxitos: aquí debe escribir el número de éxitos que se desea obtener.
O ensayos: es el tamaño de la muestra n O prob_éxito: probabilidad p de éxito. O acumulado: verdadero o falso. (si escribe verdadero: la distribución
calcula la distribución binomial acumulada desde x hasta cero; si escribe falso: la distribución binomial solo calcula el valor puntal x).

Por ejemplo si estamos interesado en encontrar la probabilidad binomial de n=3 ensayos de los cuales x=2 son éxitos con una probabilidad de acierto de p=0.40
b(x=2; n=3, p=0.40)= 0.2880. La probabilidad que eso ocurra es de 0.2880
EJEMPLO
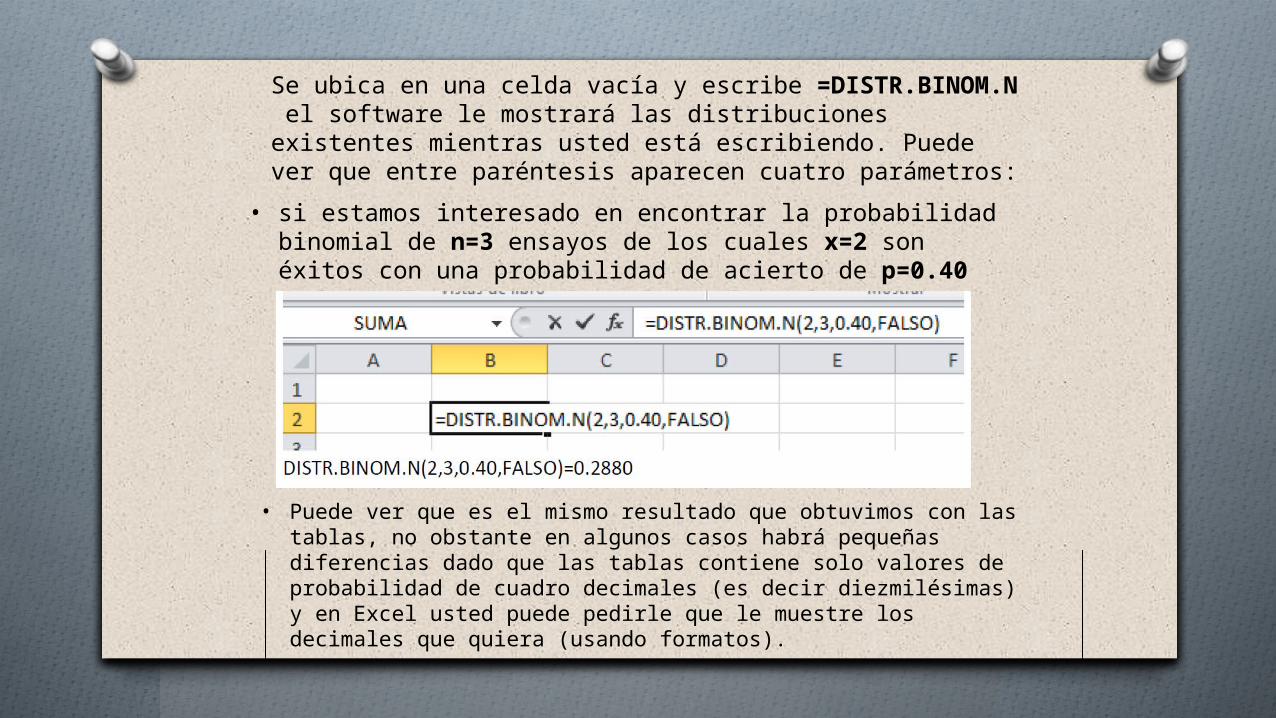
Se ubica en una celda vacía y escribe =DISTR.BINOM.N el software le mostrará las distribuciones existentes mientras usted está escribiendo. Puede ver que entre paréntesis aparecen cuatro parámetros:
• si estamos interesado en encontrar la probabilidad binomial de n=3 ensayos de los cuales x=2 son éxitos con una probabilidad de acierto de p=0.40
• Puede ver que es el mismo resultado que obtuvimos con las tablas, no obstante en algunos casos habrá pequeñas diferencias dado que las tablas contiene solo valores de probabilidad de cuadro decimales (es decir diezmilésimas) y en Excel usted puede pedirle que le muestre los decimales que quiera (usando formatos).

DISTRIBUCIÓN BINOMIAL NEGATIVA
DEFINICIÓN:
Devuelve la distribución binomial negativa.
Esta función es similar a la distribución binomial, con la excepción de que el número de éxitos es fijo y el número de ensayos es variable. Al igual que la distribución binomial, se supone que los ensayos son independientes.

APLICACIÓN EN EXCEL
DISTRIBUCIÓN BINOMIAL NEGATIVA(NEGBINOMDIST)
SINTAXIS
NEGBINOMDIST(núm_fracasos;núm_éxitos;prob_éxito) Núm_fracasos es el número de fracasos.Núm_éxitos es el número límite de éxitos.Prob_éxito es la probabilidad de obtener un éxito.

OBSERVACIONES
• Los argumentos núm_fracasos y núm_éxitos se truncan a enteros.• Si uno de los argumentos no es numérico, NEGBINOMDIST devuelve
el valor de error #¡VALOR!• Si el argumento prob_éxito < 0 o si probabilidad > 1,
NEGBINOMDIST devuelve el valor de error #¡NUM!.• Si los argumentos núm_fracasos < 0 o núm_éxitos < 1, la función
NEGBINOMDIST devuelve el valor de error #¡NUM!.

Dónde:
x es núm_fracasos, r es núm_éxitos, p es prob_éxito y q=1-p.
La ecuación para la distribución binomial negativa

DISTRIBUCIONES DE PROBABILIDAD:
Distribución de Poisson y Distribución Hipergeométrica

Distribución PoissonEs una distribución de probabilidad discreta que expresa la probabilidad que un determinado número de eventos ocurran en un determinado periodo de tiempo, dada una frecuencia media conocida e independientemente del tiempo discurrido desde el ultimo evento.=POISSON( x; Media; Acumulado)
X = es el número de sucesos.Media = es el valor numérico esperado.Acumulado = es un valor lógico que determina la forma de la distribución de probabilidad devuelta. Si el argumento acumulado es VERDADERO, POISSON devuelve la probabilidad de Poisson de que un suceso aleatorio ocurra un número de veces comprendido entre 0 y x inclusive; si el argumento acumulado es FALSO, la función devuelve la probabilidad de Poisson de que un suceso ocurra exactamente x veces.

Distribución HipergeometricaEs una de las distribuciones de probabilidad discreta. Esta distribución se utiliza para calcular la probabilidad de una selección aleatoria de un objeto sin repetición. Aquí, el tamaño de la población es el número total de objetos en el experimento.
=DISTR.HIPERGEOM(muestra_éxito;núm_de_muestra;población_éxito;núm_de_po
blación)
Muestra éxito = es el número de éxitos en la muestra.Núm_de_muestra = es el tamaño de la muestra.Población éxito = es el número de éxitos en la población.Núm_de_población = es el tamaño de la población.

ResumenLa distribución de probabilidad de una variable aleatoria es una función que asigna a cada suceso definido sobre la variable aleatoria LA PROBABILIDAD DE QUE DICHO SUCESO OCURRA.
DISTR.BINOM.N(núm_éxito;ensayos;prob_éxito;acumulado)
NEGBINOM.DIST(núm_fracasos; núm_éxitos;prob_éxito;acumulado)
Expresa la probabilidad de que haya un número de fracasos antes de que haya un número de éxitos.
Mide el número de éxitos en una secuencia de n ensayos independientes entre sí

ResumenLa distribución de probabilidad de una variable aleatoria es una función que asigna a cada suceso definido sobre la variable aleatoria LA PROBABILIDAD DE QUE DICHO SUCESO OCURRA.
Se utiliza para calcular la probabilidad de una selección aleatoria de un objeto sin repetición
DISTR.HIPERGEOM(muestra_éxito;núm_de_muestra;población_éxito;núm_de_población)
POISSON( x; Media; Acumulado)
Expresa la probabilidad que un determinado número de eventos ocurran en un determinado periodo de tiempo,


















