Presentacion seminario 6
20
Seminario VI: Análisis exploratorio de datos Tablas de frecuencias, resúmenes numéricos y gráficos ELENA RAMÍREZ CALERO.
-
Upload
elena-ramirez-calero -
Category
Internet
-
view
117 -
download
0
Transcript of Presentacion seminario 6

Seminario VI: Análisis exploratorio de datos
Tablas de frecuencias, resúmenes numéricos y
gráficosELENA RAMÍREZ CALERO.

En esta ocasión, seguimos trabajando
con R.
La primera tarea a realizar es:
Selecciona dos variables cualitativas-
factor del fichero
“activossalud.RData”, descríbelas en
tablas de frecuencias e interpreta al
menos 3 aspectos en relación a la
distribución de las mismas.
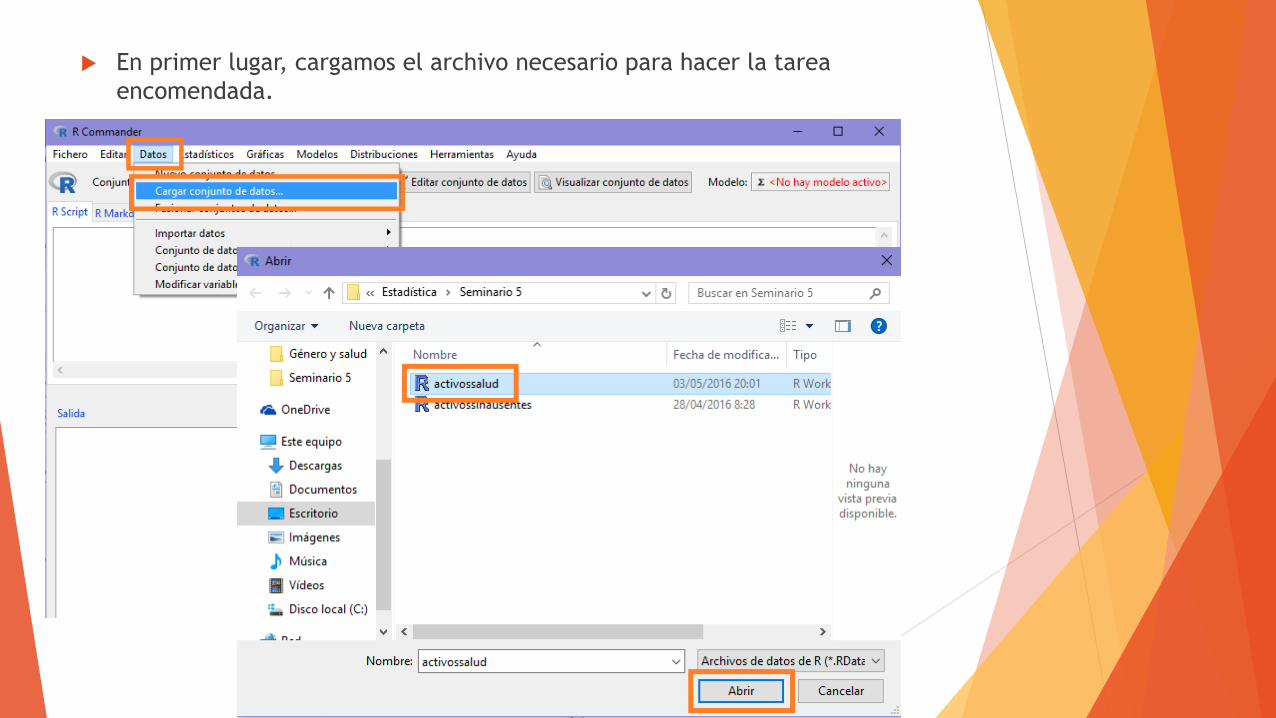
En primer lugar, cargamos el archivo necesario para hacer la tarea
encomendada.

Para seleccionar las variables que queremos, nos situamos en R y seguimos los
siguientes pasos: estadísticos-resúmenes-distribución de frecuencias.
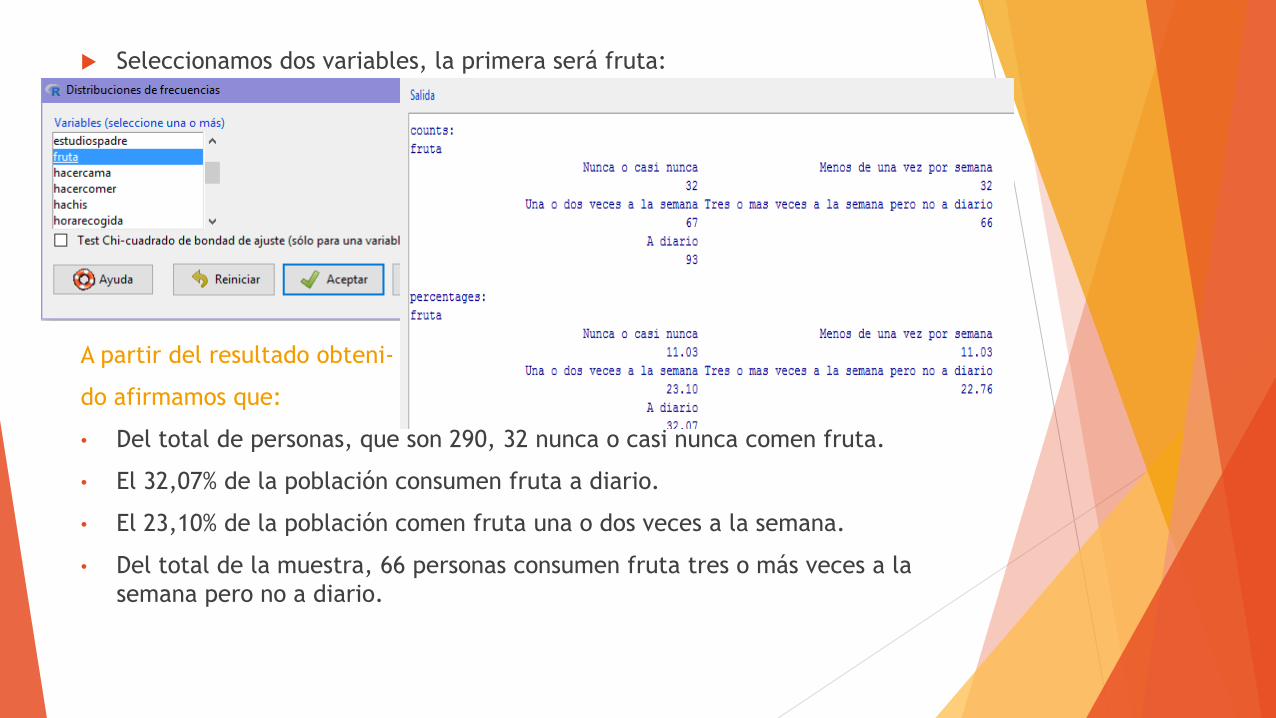
Seleccionamos dos variables, la primera será fruta:
A partir del resultado obteni-
do afirmamos que:
• Del total de personas, que son 290, 32 nunca o casi nunca comen fruta.
• El 32,07% de la población consumen fruta a diario.
• El 23,10% de la población comen fruta una o dos veces a la semana.
• Del total de la muestra, 66 personas consumen fruta tres o más veces a la
semana pero no a diario.

La segunda variable elegida es hacer la cama, de esto deducimos:
• Que del total, 291, 185 personas hacen su cama a diario.
• Que un 13,75% hacen la cama solo los fines de semana.
• Que 3 personas no hacen nunca la cama.
• Que un 3,44% hacen su cama dos o tres veces entre semana.

EJERCICIO 2:
Selecciona dos variables numéricas
del fichero “activossalud.RData”, y
mediante resúmenes numéricos
describe e interpreta la
distribución de las mismas.
Variables elegidas: peso y altura.

Para llegar a la selección de variables, seguimos los siguientes pasos:
estadísticos-resúmenes- resúmenes numéricos.
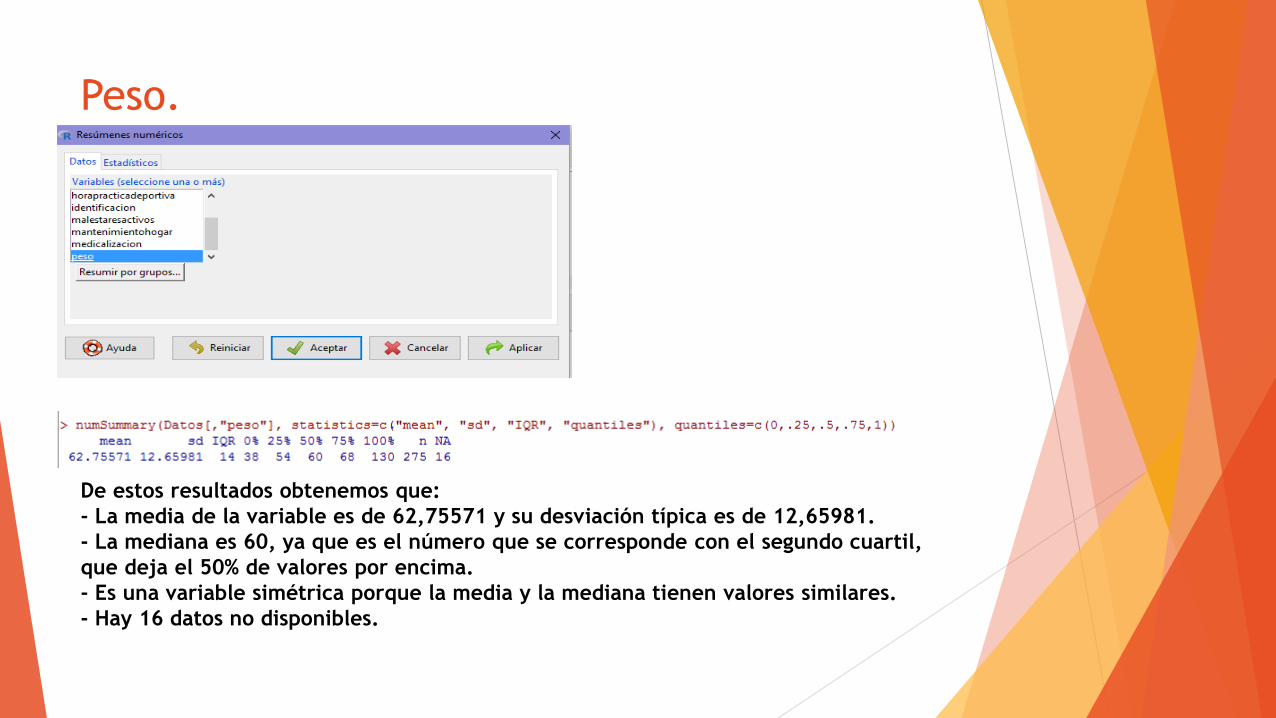
Peso.
De estos resultados obtenemos que:
- La media de la variable es de 62,75571 y su desviación típica es de 12,65981.
- La mediana es 60, ya que es el número que se corresponde con el segundo cuartil,
que deja el 50% de valores por encima.
- Es una variable simétrica porque la media y la mediana tienen valores similares.
- Hay 16 datos no disponibles.

ALTURA.
Gracias a estos datos, obtenemos que:
- La media de la variable es de 1,667; la desviación típica es de 0,08078101.
- Hay un único dato del que no se conoce información.
- La mediana es el valor 1,655, esta cifra coincide con el segundo cuartil, que divide a la
variable en dos partes.
- La variable es simétrica porque hay poca diferencia entre la media y la mediana.

TERCER EJERCICIO.
Debes realizar al menos un
gráfico de cada tipo con
variables adecuadamente
seleccionadas del fichero
“activossalud.RData”, describe
e interpreta la distribución los
mismos.

Los diferentes tipos de gráficos son:
GRÁFICOS DE SECTORES.
GRÁFICOS DE BARRAS.
HISTOGRAMAS.
DIAGRAMAS DE CAJAS.
LOS DOS PRIMEROS SE UTILIZAN SOBRE TODO PARA
REPRESENTAR VARIABLES CUALITATIVAS.
LOS DOS ÚLTIMOS SE USAN PARA REPRESENTAR LAS VARIABLES
CUANTITATIVAS.

GRÁFICA DE SECTORES.
Variables seleccionada: práctica de deporte.

Se deduce de este gráfico que algo más de la
mitad de las personas de la muestra practican
deporte, mientras que alrededor de un 45% no lo
practica nunca.
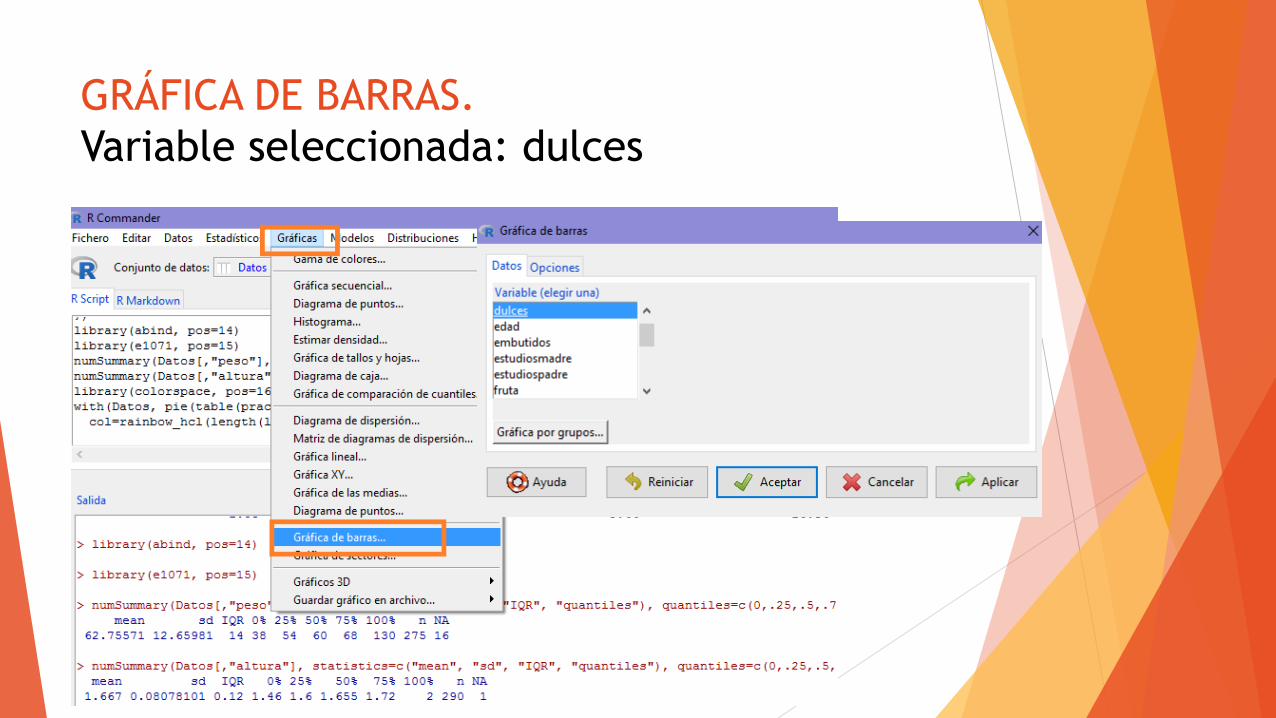
GRÁFICA DE BARRAS.
Variable seleccionada: dulces

Con el gráfico, comprobamos que la mayor parte de las personas (más
de 80) toman dulces menos de una vez a la semana, este valor está
muy seguido de cerca por las personas que toman dulces una o dos
veces a la semana (80). En el medio está la gente que toma dulces
tres o más veces a las semana (50). Las posibilidades con menos
personas son: las que no toman dulces nunca (40) y las que los toman
a diario (20).

HISTOGRAMA. Variable seleccionada: hora de práctica deportiva.

Del histograma deducimos que la mayoría de las
personas practica deporte en las primeras horas
del día. A partir de las 10, pocas personas lo
practican. La variable se aleja de la normal.
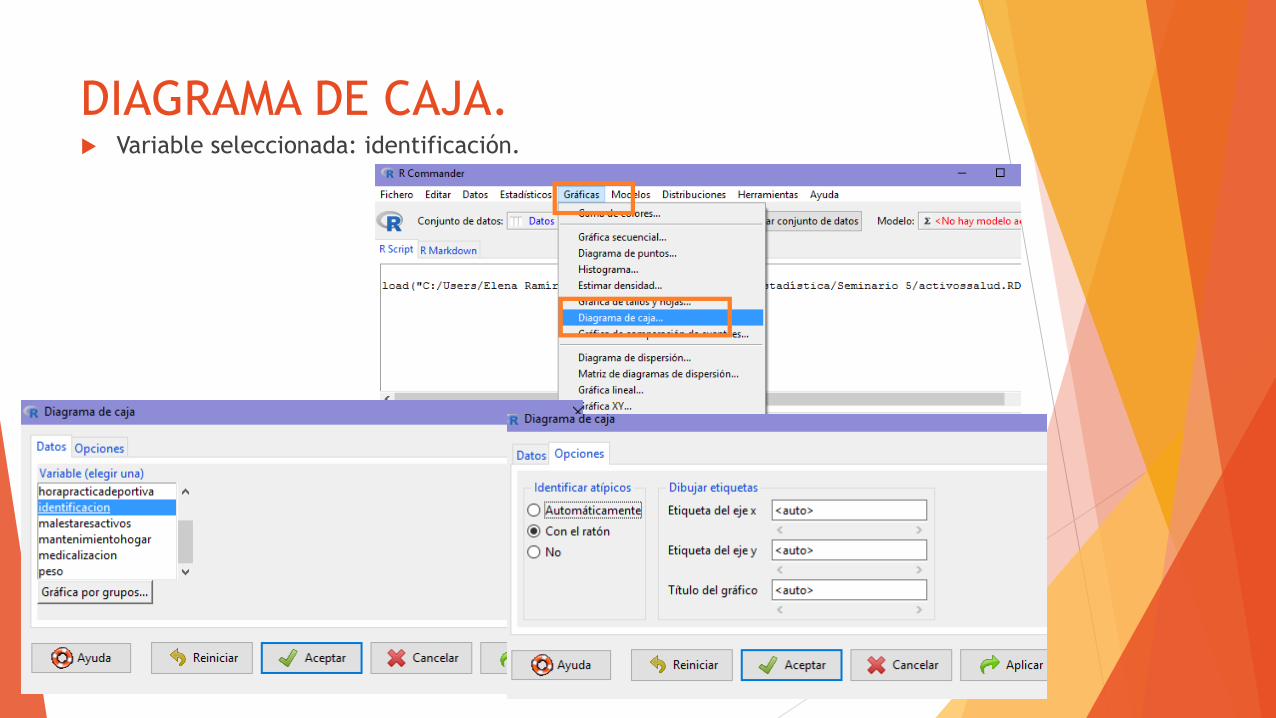
DIAGRAMA DE CAJA. Variable seleccionada: identificación.

Observamos que es
una variable simétrica
ya que la media y la
mediana coinciden o
están muy próximas.
Los datos se
distribuyen de forma
similar.