
Recomenda ci ó n d e l u g ares p ara red es so ci al es b ...
97
Universidad Nacional del Centro de la Provincia de Buenos Aires Facultad de Ciencias Exactas Recomendación de lugares para redes sociales basadas en ubicación Trabajo final de la carrera Ingeniería en Sistemas Pablo Barrenechea Sebastián Claudio Troccoli Director de Tesis Daniela Godoy Tandil 2017
Transcript of Recomenda ci ó n d e l u g ares p ara red es so ci al es b ...

Universidad Nacional del Centro de la Provincia de Buenos Aires Facultad de Ciencias Exactas
Recomendación de lugares para redes sociales basadas en ubicación
Trabajo final de la carrera Ingeniería en Sistemas
Pablo Barrenechea Sebastián Claudio Troccoli
Director de Tesis
Daniela Godoy
Tandil 2017

Índice de Contenido
Capítulo 1: Introducción 9
1.1. Motivación 9
1.2. Problema a resolver 11
1.3. Trabajo Propuesto 12
1.4. Organización del Trabajo 13
Capítulo 2: Marco Teórico 14
2.1. Redes sociales basadas en ubicación 14
2.2. Sistemas de recomendación 15
2.2.1. Sistemas de recomendación en RSBU 16
2.3. Filtrado Colaborativo 17
2.3.1. Filtrado Colaborativo basado en memoria 18
2.3.1.1. Algoritmos de Similitud 21
2.3.1.1.1. Correlación de Pearson 21
2.3.1.1.2. Similitud del coseno 22
2.3.2. Filtrado Colaborativo basado en modelos 23
2.3.2.1. Factorización de Matrices 23
2.3.2.2. Modelos de Factorización de matrices 26
2.3.2.2.1. Descomposición de valores singulares 26
2.3.2.2.2. Descomposición de valores singulares con feedback implícito 27
2.5. Evaluación de Sistemas de Recomendación 28
2.5.1. Métodos de decisión 28
2.5.1.1. Precision 29
2.5.1.2. Recall / Exhaustividad 29
2.5.1.3. Valor-F (F1 Score o F-Measure en inglés) 30
2.5.2. Métodos estadísticos 30
1

2.5.2.1. Root Mean Square Error (RMSE) 30
2.5.2.2. Mean Absolute Error(MAE) 31
2.6. Análisis de Sentimiento 31
2.7. TF IDF 32
2.8. Antecedentes 33
2.8.1. Síntesis de trabajos realizados anteriormente 33
2.8.2. Ventajas y desventajas de los trabajos estudiados 34
Capítulo 3: Enfoque propuesto 36
3.1. Visión preliminar 36
3.2. Representación inicial de la información 37
3.3. Solución propuesta 39
3.4 Casos de estudio 41
3.4.1. Variables a analizar 42
Capítulo 4: Diseño e implementación 43
4.1. Investigación de Frameworks para filtrado colaborativo 43
4.1.1. Crab 43
4.1.2. Racoon 44
4.1.3. Django-Recommends 44
4.1.4. Apache Mahout 45
4.1.4.1. Características de Mahout 45
4.1.4.2. Arquitectura de Mahout 46
4.1.5. Criterio de selección del framework 47
4.1.5.1. Comparativa basada en atributos de calidad 48
4.1.5.2. Comparativa basada en características 48
4.1.5.3. Comparativa basada en factores externos 48
4.2. Arquitectura del sistema 49
4.2.1. Modelo de datos 51
4.2.2. Refinador de información 53
2

4.2.3. Constructor de Preferencias 55
4.2.3.1. Detección de preferencias personales 57
4.2.3.2. Uso del Sentimiento como preferencia 59
4.2.3.3. Detección de expertos locales 61
4.2.4. Evaluador de Recomendaciones 64
4.2.4.1. Recomendador Base 66
4.2.4.2. Comparación de árboles de usuarios 66
4.2.4.3. Ratings Inferidos 68
4.2.4.4. Factorización de Matrices 71
4.2.4.5. Evaluación de resultados 73
4.2.5. Servicio de Recomendación 73
Capítulo 5: Pruebas y resultados 76
5.1. Conjunto de datos 76
5.2. Configuración del conjunto de datos 78
5.3. Experimentos realizados 79
5.3.1. Experimentos realizados utilizando número de checkins 81
5.3.1.1 Resultados 81
5.3.1.2 Análisis de los Resultados Obtenidos 81
5.3.2 Experimentos realizados utilizando análisis de sentimiento 83
5.3.2.1 Resultados 83
5.3.2.2 Análisis de los Resultados Obtenidos 84
5.4. Comparación de ambas series de experimentos 85
Capítulo 6: Conclusiones 89
6.1. Conclusiones 89
6.2. Trabajos Futuros 89
Bibliografía 91
3

Índice de Figuras Capítulo 1: Introducción
1.1 Checkins Foursquare entre Agosto 2011 y Marzo 2015 10
Capítulo 2: Marco Teórico
2.1 Diferentes capas de una RSBU 14
2.2 Sistema de recomendación no personalizado 16
2.3 Sistema de recomendacion User-User 19
2.4 Cálculo de preferencia de un ítem i para un usuario u en un sistema User-User 19
2.5 Sistema de recomendación Item-Item 20
2.6 Cálculo de preferencias para un usuario u en un sistema Item-Item 21
2.7 Ejemplo de modelos de factor latente en LBSN 27
Capítulo 3: Enfoque propuesto
3.1 Escenario de uso del sistema de recomendación 37
3.2 Entidades presentes en un sistema de RSBU 38
3.3 Arquitectura general de la solución propuesta 40
Capítulo 4: Diseño e implementación
4.1 Arquitectura general de Apache Mahout 47
4.2 Vista global de la arquitectura del Sistema de Recomendación 50
4.3 Modelo de datos relacional utilizado 52
4.4 Arquitectura del sistema. Componente Refinador de Información 53
4.5 Arquitectura del sistema. Constructor de preferencias 56
4.6 Generación de las preferencias del usuario 57
4.7 Sentimiento de los distintos tips 60
4.8 Identificación de expertos locales 63
4.9 Funcionamiento de Recommender Evaluator 64
4.10 Funcionamiento de Base Recommender 66
4

4.11 Funcionamiento de Inferred Ratings 68
4.12 Algoritmo PACS 69
4.13 Elementos en la factorización de matrices 72
4.14 Servicio de recomendación 74
4.15 Respuesta del servicio de recomendación 75
Capítulo 5: Pruebas y resultados
5.1 Demografía de visitas 77
5.2 Comparación de tips, lugares y usuarios antes y después de optimizarlos 79
5.3 RMSE y MAE para los experimentos en Los Ángeles y Nueva York 82
5.4 F1 - Score para los experimentos en las ciudades de Los Ángeles y Nueva York 82
5.5 RMSE y MAE para los experimentos con sentimiento en Los Ángeles y Nueva York 84
5.6 F1 - Score para los experimentos en las ciudades de Los Ángeles y Nueva York 85
5.7 Mejores recomendadores para RMSE y MAE para cada medida de ranking 86
5.8 Mejores recomendadores para F1 para cada medida de ranking 86
5

Índice de Ecuaciones Capítulo 2: Marco Teórico
2.1 Coeficiente de correlación de Pearson 22
2.2 Similitud del coseno entre x e y 23
2.3 Cálculo de la matriz R 24
2.4 Modelo de Factorización de matrices básico 24
2.5 Minimización del error cuadrado regularizado 25
2.6 Tendencia usuario-ítem 26
2.7 Factorización de Matrices básico con desviaciones 26
2.8 Dimensión de una matriz SVD 26
2.9 Vector de preferencias de un usuario u 27
2.10 Normalización del vector de preferencias 27
2.11 Vector de atributos de un usuario u 27
2.12 Calificación con SVD ++ 28
2.13 Cálculo de la Precisión 29
2.14 Cálculo de la Exhaustividad o Recall 29
2.15 Cálculo del Valor-F o F-Measure 30
2.16 Cálculo de Root Mean Square Error 31
2.17 Cálculo de Mean Absolute Error 31
2.18 Cálculo de Frecuencia de Términos (TF) 32
2.19 Cálculo de Frecuencia Inversa de Términos (IDF) 33
Capítulo 4: Diseño e implementación
4.1 Preferencia de un usuario por una categoría 58
4.2 Preferencia de un usuario por una categoría 61
4.3 Función signo 61
4.4 Función escalón de Heaviside 61
6

4.5 Calidad de los lugares visitados por un usuario (1) y calidad del lugar (2) 63
4.6 Valor mínimo de preferencia para un nivel 67
4.7 Entropía para un nivel L 67
4.8 Similitud entre dos árboles 67
4.9 Calificación inferida de un usuario u a un lugar v 70
7

Índice de Tablas
Capítulo 4: Diseño e implementación
4.1 Comparativa de herramientas soporte realizada por atributos de calidad 48
4.2 Comparativa de herramientas soporte realizada por características de las mismas 48
4.3 Comparativa de herramientas soporte realizada por factores externos 49
Capítulo 5: Pruebas y resultados
5.1 Distribución de los distintos datos en las ciudades de Los Ángeles y Nueva York 77
5.2 Distribución de los distintos datos en las ciudades de Los Ángeles y Nueva York 78
5.3 Resultados obtenidos usando el nro de checkins como medida de ranking 81
5.4 Resultados obtenidos utilizando el sentimiento como medida de ranking
83
8

Capítulo 1: Introducción
“Se definen a las Redes Sociales como un conjunto bien delimitado de actores
-individuos, grupos, organizaciones, comunidades, sociedades globales, etc.- vinculados unos
a otros a través de una relación o un conjunto de relaciones sociales, las cuales pueden ser
diversas, como amistades, relaciones laborales, afectivas, entre otras. [1] “
Los avances tecnológicos recientes relacionados con la determinación de posiciones
de los objetos en el mundo han creado una mejora notable en los servicios ofrecidos por las
redes sociales, permitiendo a los usuarios compartir su ubicación y relacionarla con el
contenido que desean publicar. Llamamos a estas redes sociales: Redes sociales basadas en
ubicación (En inglés Locations Based Social Networks).
1.1. Motivación
En los últimos años, las redes sociales han experimentado un gran incremento tanto
en cantidad de usuarios que hacen uso de ellas, como en cantidad de información que
comparten.
Hoy en día no solo ayudan a conectar a distintas personas a mantener contacto con
familiares a través del mundo como actualmente hace Facebook, sino que además han
surgido redes sociales con propósitos especializados como es el caso de Foursquare, donde
los usuarios registran visitas a lugares alrededor del mundo y a su vez recomiendan los
mismos a otros miembros de la misma red.
Todo esto sucede en tiempo real y es así como mediante diferentes portales que
ofertan las distintas redes sociales, en donde expresar un ideal, un sentimiento o
sencillamente el estado de ánimo, se convierte una acción virtual en algo que permite la
relación real con el mundo [31].
Probablemente uno de los factores más importantes en el aumento de usuarios de
estas redes sea el incremento exponencial de personas que disponen de dispositivos móviles.
Este fenómeno les permite a los usuarios una mayor facilidad para compartir su ubicación
geográfica instantáneamente. Además, toda esta información nueva disponible supone un
aumento potencial de las posibilidades de publicidad y consumo. Estas facilidades son
9
utilizadas por Foursquare, por ejemplo, en el que un usuario puede opinar sobre la visita a un
lugar visitado (o checkin ) con solo un click.
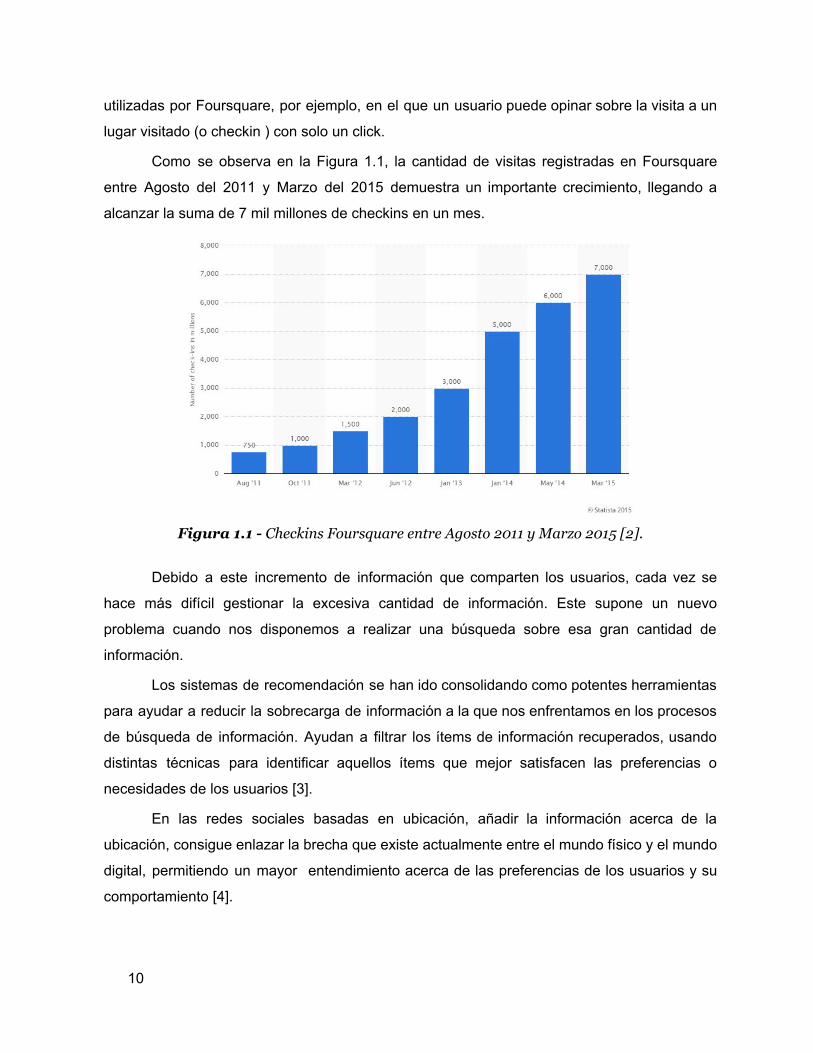
Como se observa en la Figura 1.1, la cantidad de visitas registradas en Foursquare
entre Agosto del 2011 y Marzo del 2015 demuestra un importante crecimiento, llegando a
alcanzar la suma de 7 mil millones de checkins en un mes.
Figura 1.1 - Checkins Foursquare entre Agosto 2011 y Marzo 2015 [2].
Debido a este incremento de información que comparten los usuarios, cada vez se
hace más difícil gestionar la excesiva cantidad de información. Este supone un nuevo
problema cuando nos disponemos a realizar una búsqueda sobre esa gran cantidad de
información.
Los sistemas de recomendación se han ido consolidando como potentes herramientas
para ayudar a reducir la sobrecarga de información a la que nos enfrentamos en los procesos
de búsqueda de información. Ayudan a filtrar los ítems de información recuperados, usando
distintas técnicas para identificar aquellos ítems que mejor satisfacen las preferencias o
necesidades de los usuarios [3].
En las redes sociales basadas en ubicación, añadir la información acerca de la
ubicación, consigue enlazar la brecha que existe actualmente entre el mundo físico y el mundo
digital, permitiendo un mayor entendimiento acerca de las preferencias de los usuarios y su
comportamiento [4].
10

Dentro de los servicios que puede ofrecer una red social basada en ubicación, el
servicio de recomendación de puntos de interés es una de las características más
importantes. Este servicio es muy utilizado por los usuarios para encontrar lugares de interés
cercanos, así como para ser asistido en sitios desconocidos. Además, le permite a las
compañías publicitar anuncios en base a la presencia física de los usuarios y generar ingresos
para la red social en cuestión [5].
1.2. Problema a resolver
Como se mencionó en el apartado anterior, las redes sociales son una fuente de
información muy poderosa. En el caso particular de las redes sociales basadas en ubicación o
RSBU, cada vez son más los lugares registrados en las mismas y por consiguiente,
potenciales recomendaciones a los distintos usuarios. No obstante, el crecimiento exponencial
de la información generada por las interacciones de los usuarios hace que sea necesario la
clasificación.
La finalidad de este trabajo es la implementación de un sistema de recomendación
híbrido que haciendo uso de la información extra que nos proveen las redes sociales basadas
en ubicación, sea capaz de recomendar puntos de interés a los usuarios de una forma
efectiva. Para ello utilizaremos un conjunto de datos de la Red Social Foursquare que posee
información de la actividad de los usuarios en las ciudades de Los Ángeles y Nueva York.
Para lograr esto, el problema puede ser descompuesto en dos partes:
1. Modelar las preferencias del usuario usando el conjunto de datos escogido.
2. Proveer a cada usuario una lista de lugares que se adapten a sus preferencias
personales.
1) Modelar las preferencias del usuario :
Esta tarea consiste en lograr asignarle a los usuarios un valor de preferencia asociado
a los distintos lugares. Se pueden inferir preferencias de distintas maneras. Por ejemplo, si un
usuario registra un considerable número de visitas a un lugar determinado, el sistema podría
inferir que es de su agrado. Otro caso, podría no tener en cuenta el lugar en sí, pero si la
11

categoría del mismo como por ejemplo, un usuario que registre varias visitas restaurantes de
comida china seguramente tenga una preferencia por ese tipo de lugares.
Haciendo uso de su historial de visitas y revisiones u opiniones otorgadas a cada lugar,
analizaremos el contexto del comportamiento de los usuarios en el conjunto de datos y se
modelarán sus preferencias.
2) Proveer una lista de lugares útiles :
El objetivo de esta tarea es el de recomendar a los usuarios una lista de lugares
basándose en las preferencias personales obtenidas anteriormente.
Para esto se analizarán, compararán y evaluarán diferentes técnicas utilizadas en los
sistemas de recomendación, como lo son la factorización de matrices y el filtrado colaborativo.
1.3. Trabajo Propuesto
La propuesta que realizamos, está basada en el estudio de Sistemas de
Recomendación existentes y estudios realizados acerca de Redes Sociales Basadas en
Ubicación y cómo explotar sus características.
De las ventajas y desventajas de cada Sistema de Recomendación estudiado, surge la
iniciativa de crear un Sistema de Recomendación que sea capaz de:
● Explotar la información extraída de los tips de los usuarios haciendo uso de análisis de
sentimiento.
● Recomendar lugares basándose en la ubicación de un usuario, haciendo uso de la
recomendación asociada a expertos locales.
● Encontrar estrategias de recomendación relacionadas con el arranque en frío.
● Utilizar la información de las categorías de los lugares para modelar las preferencias
de los usuarios y encontrar usuarios con gustos similares.
● Realizar recomendaciones mediante distintas técnicas existentes: Filtrado colaborativo
basado en usuarios y Factorización de Matrices.
Una vez implementadas dichas características, el sistema será capaz de extraer
métricas que muestren el rendimiento de las distintas soluciones.
12

Ninguno de los trabajos anteriormente estudiados, posee todas estas características
juntas. Es por eso que añadiendo estas características incrementalmente se podrá crear un
Sistema de Recomendación que resuelva el problema contemplando una porción mayor del
contexto.
1.4. Organización del Trabajo
En esta sección se detalla la estructura general del presente trabajo, brindando una
breve descripción de los temas que se abordan en cada capítulo.
En el Capítulo 2, denominado Marco Teórico, se presentan los fundamentos teóricos
utilizados en esta investigación así como también trabajos existentes utilizados como punto de
referencia. Dentro de los fundamentos teóricos, se describen y explican las principales
definiciones y conceptos relacionados a las Redes sociales basadas en ubicación y los
Sistemas de Recomendación.
Una vez presentados dichos conceptos teóricos, abordaremos a lo largo del Capítulo 3
detalles respecto de las investigaciones realizadas, el diseño propuesto y los componentes
que conforman la implementación del Sistema de Recomendación.
El capítulo 4 presenta el diseño e implementación elegido para llevar a cabo la
solución final al problema. El mismo presenta un detalle de herramientas analizadas para
llevar a cabo la implementación junto con la presentación de los distintos componentes de
arquitectura y sus responsabilidades.
El Capítulo 5 estará dedicado al desarrollo de los distintos experimentos utilizados para
la evaluación del Sistema de Recomendación. Tomando como entrada un conjunto de datos
obtenido de la red social Foursquare y distintas configuraciones del Sistema de
Recomendación, se evaluarán las salidas con distintas métricas que serán de utilidad para
medir la calidad de los resultados obtenidos.
El capítulo 6 contiene el análisis y la interpretación de los resultados provistos por el
capítulo 5 así como también conclusiones del trabajo y tareas futuras que enriquecerán el
trabajo realizado.
13

Capítulo 2: Marco Teórico
El presente capítulo tiene como objetivo describir los principales conceptos y
definiciones que le darán contexto al trabajo.
2.1. Redes sociales basadas en ubicación
Cuando hablamos de redes sociales basadas en ubicación, de aquí en adelante
RSBU, no solo estamos hablando de añadir la ubicación a una red social existente para que
los usuarios de la misma puedan compartir información acerca de su ubicación, sino también
de una nueva estructura social compuesta por personas unidas por la interdependencia
derivada de su ubicación en el mundo físico, y los contenidos que comparten, tales como
fotos, videos y textos.
En estas redes, la ubicación física consiste en el instante de ubicación de un individuo
en un momento dado y el historial de ubicaciones que un individuo ha acumulado en un cierto
período. Además, la interdependencia incluye no sólo que dos personas co-ocurren en la
misma ubicación física o comparten historias similares de localización, sino también el
conocimiento adquirido, por ejemplo, los intereses comunes, el comportamiento y actividades,
inferidas a partir de la ubicación de un individuo (historial) y los datos clasificados por las
distintas ubicaciones [6].
14

Figura 2.1: Diferentes capas de una RSBU [8] .
La figura 2.1 nos da una vista global de las diferentes redes contenidas en una típica
RSBU, en la que el agregado de las ubicaciones crea nuevas relaciones y correlaciones.
La capa geográfica contiene información acerca del historial de checkins de los
usuarios que ocurren dentro de una línea de tiempo, mientras que la capa social contiene
información de relación entre los usuarios, y por último, la capa de contenido consiste en los
tips de los usuarios publicados en cada lugar [7].
2.2. Sistemas de recomendación
Los sistemas de recomendación (SR), son diseñados para recomendar ítems a
usuarios en varias situaciones como los sitios de compra online, citas o redes sociales. Dado
que la cantidad de opciones es muy amplia, los SR han sido indispensables para ayudar a los
usuarios a filtrar items que no les resultan de interés, y reducir el tiempo en la toma de
decisiones [9].
Cada SR intenta predecir los ítems que un usuario considerará más relevantes y útiles.
Si bien este concepto es común en todos los tipos de SR, la manera en que un SR calcula
relevancia y utilidad varía.
15

La cantidad y el tipo de datos disponibles sobre los distintos componentes del SR,
como usuarios, objetos y preferencias a menudo dictan cómo se calcula la relevancia y la
utilidad y el impacto en última instancia en la selección del algoritmo de recomendación.
Por ejemplo, cuando se escasea de datos sobre un usuario, un sistema de
recomendación no personalizado puede ser el algoritmo indicado. Un sistema de
recomendación no personalizado se basará en los datos de un total de ítems populares entre
todos los usuarios y generará una lista con los N ítems más populares dentro de SR (Figura
2.2).
Figura 2.2: Sistema de recomendación no personalizado [24].
Como es de apreciarse, estos algoritmos no proveen recomendaciones personalizadas
o diferentes a los distintos usuarios. Tampoco están basadas en el pasado o las preferencias
de los mismos. En cambio, el SR asume que un ítem que es del agrado de la mayoría de
usuarios será del agrado para un usuario genérico.
En resumen, un SR no personalizado proporciona una interfaz simple y eficaz para
proporcionar recomendaciones a los usuarios cuando se carecen de las preferencias
anteriores o los datos que tenemos son insuficientes. Este problema es conocido como cold
start o arranque en frío.
2.2.1. Sistemas de recomendación en RSBU
16

Los sistemas de recomendación en RSBU han comenzado hace unos pocos años, y
los ítems principalmente recomendados son lugares, etiquetas y amigos:
● La recomendación de lugares apunta a recomendar un conjunto de lugares a los
usuarios, basandose los intereses del mismo.
Este tipo de recomendación, ha tenido un rol muy importante en las RSBU ya que no
solo asiste a los usuarios para visitar nuevos lugares, sino que también ayuda a las
RSBU a generar ingresos ofreciendo servicios inteligentes de publicidades basadas en
la ubicación.
● La recomendación de etiquetas tiene como fin, enriquecer el significado semántico de
los lugares para facilitar el desarrollo de sistemas de recomendación utilizando esas
etiquetas. Por lo general, se utilizan los patrones temporales para recomendar
etiquetas. Por ejemplo, un bar puede ser visitado frecuentemente entre las 11:00 pm y
la 1:00 am, mientras que un restaurante puede tener más visitas entre las 12:00 pm y
las 6:00pm. Por lo tanto, podrían asignarles etiquetas diferentes acorde a la franja
horaria en la que son mayormente visitados.
● La recomendación de amigos analiza los patrones similares (Por ejemplo: hábitos de
compra, intereses comunes, trayectorias de viaje, etc.) entre un usuario objetivo y otros
usuarios, y luego recomienda usuarios con mayor cantidad de patrones similares.
En el presente trabajo, nos dedicaremos a plantear soluciones relacionadas solamente
con la recomendación de lugares.
2.3. Filtrado Colaborativo
En los últimos años, un algoritmo conocido como Filtrado Colaborativo se ha vuelto
una constante dentro de las implementaciones de los SR.
Esta técnica analiza las relaciones entre los usuarios y las interdependencias entre los
productos para identificar nuevas asociaciones entre usuarios e ítems.
Los sistemas de recomendación basados en filtrado colaborativo, a menudo están
compuestos de varios componentes conocidos como usuarios, artículos, preferencias /
calificaciones.
17

● Ítems: objetos que son recomendados al usuario, tales como productos, noticias, etc..
Estos pueden ser caracterizados por su respectiva metadata que incluye títulos, tags, o
keywords. Por ejemplo, las noticias pueden ser clasificadas por categoría, las
canciones por artistas y género musical y las peliculas por genero y director. En
nuestro caso, aplicaría a los lugares y la metadata estaría relacionada con la categoría
del lugar, la ubicación, etc.
● Usuarios: Son las personas a las cuales van dirigidas las recomendaciones.
Generalmente necesitan de asistencia para elegir un ítem dentro del contexto de una
aplicación (como lo pueden ser Netflix o Foursquare) y utilizan este tipo de sistemas
para estar mejor informados y así, hipotéticamente, tomar la decisión más acertada.
Un modelo de usuario puede construirse incrementalmente con el tiempo, con el fin de
mejorar las recomendaciones para un usuario en particular. Para esto sus acciones e
interacciones son almacenadas dentro del SR, generando como resultado un perfil del
mismo.
● Preferencias/Calificaciones: Las preferencias se pueden interpretar como la opinión
de un usuario con respecto a un ítem. Generalmente se representan mediante ratings,
es decir, el usuario puntúa el ítem en cuestión. Se podría decir entonces que el rating
es un tipo de preferencia explícita que representa la relación entre un usuario y un ítem
perteneciente al SR.
Los sistemas de filtrado colaborativo pueden ser divididos en dos, los basados en
memoria y los basados en modelo.
2.3.1. Filtrado Colaborativo basado en memoria
Este método utiliza las evaluaciones explícitas de los usuarios respecto a los ítems
para generar recomendaciones. El objetivo es relacionar a un usuario y sus preferencias,
comparándolo con otros usuarios del sistema y para construir grupos de usuarios similares.
Este grupo es llamado vecindario y es utilizado para generar recomendaciones basadas en
gustos de usuarios parecidos.
Si existen datos acerca de las preferencias de un usuario en un modelo de sistemas
de recomendación, es posible hacer recomendaciones personalizadas basadas en similitudes
de los gustos o preferencias de usuario. En este caso, estaríamos bajo la presencia de un SR
de filtrado colaborativo User-User donde las correlaciones se pueden identificar entre los
18

diferentes usuarios en función de las preferencias del pasado que son similares con el fin de
hacer predicciones sobre lo que a cada usuario le va a gustar en el futuro.
Si dos personas han evaluado muchos items de manera similar en el pasado, pueden
ser considerados en el mismo vecindario.
Generalmente, un vecindario de usuarios similares es construido por un SR y se utiliza
para ayudar a recomendar artículos.
A diferencia de los SR no personalizados, los SR de filtrado colaborativo User-User
son específicos para cada usuario y se adaptarán a medida que los mismos ingresen nuevos
ratings/preferencias [9] .
Figura 2.3: Sistema de recomendacion User-User [24].
Pseudocódigo para estimar preferencias de usuario en sistemas User-User
19

Figura 2.4: Cálculo de preferencia de un ítem i para un usuario u en un sistema User-User [24]
Dentro de la categoría de los SR de filtrado colaborativo también existen los
denominados SR Item-Item. En estos sistemas, las similitudes entre los distintos ítems
evaluados por el usuario son utilizadas para realizar las recomendaciones. En lugar de
construir un vecindario y recomendar basándose en usuarios similares, las correlaciones se
realizan entre las preferencias de los ítems que ha calificado el usuario.
Por ejemplo, si quisiéramos recomendar un nuevo items al usuario u , se recolectan
todos los ítems por los que u tiene preferencia y son comparados con todos los ítems i usando
un algoritmo de similitud. La premisa es que a u se le recomendarán ítems que son similares a
los que u ya había calificado positivamente en el pasado.
Los sistemas de recomendación Item-Item pueden ser ventajosos ya que la escala de
los ítems es menor. Por ejemplo, los ítems tienden a crecer a un ritmo más lento que los
usuarios y adicionalmente son menos propensos a cambios (a comparación de los usuarios
que son muy cambiantes)[24].
20

Figura 2.5: Sistema de recomendación Item-Item [24]
Pseudocódigo para estimar preferencias de usuario en sistemas Item-Item
Figura 2.6: Cálculo de preferencias para un usuario u en un sistema Item-Item [24]
2.3.1.1. Algoritmos de Similitud
21

En los algoritmos de clasificación previamente mencionados existe un patrón en
común: el cálculo de la similitud entre los diferentes ítems o usuarios. Para esto existen
diferentes algoritmos, de los cuales se pueden mencionar los siguientes: Correlación de
Pearson, Coeficiente de Tanimoto y Similitud del Coseno, entre otros.
2.3.1.1.1. Correlación de Pearson
El coeficiente de correlación de Pearson determina la similitud entre dos usuarios o
ítems midiendo la tendencia de las dos series de preferencias que se mueven juntas de una
manera proporcional y lineal. Se trata de encontrar la desviación para cada uno de los
usuarios o ítems respecto a su calificación promedio al tiempo que también se identifican
dependencias lineales entre dos usuarios o ítems.
Se calcula de la siguiente manera:
Ecuación 2.1: Coeficiente de correlación de Pearson
donde w y u son los usuarios o ítems de los cuales se quiere saber la relación.
Interpretación
El valor del índice de correlación varía en el intervalo [-1,1]:
● Si r = 1, existe una correlación positiva perfecta. El índice indica una dependencia total
entre las dos variables denominada relación directa: cuando una de ellas aumenta, la
otra también lo hace en proporción constante.
● Si 0 < r < 1, existe una correlación positiva.
● Si r = 0, no existe relación lineal. Pero esto no necesariamente implica que las
variables son independientes: pueden existir todavía relaciones no lineales entre las
dos variables.
● Si -1 < r < 0, existe una correlación negativa.
22

● Si r = -1, existe una correlación negativa perfecta. El índice indica una dependencia
total entre las dos variables llamada relación inversa: cuando una de ellas aumenta, la
otra disminuye en proporción constante.
Si bien la correlación de Pearson es una buena medida para relacionar distintos
elementos también existen casos en los que no es tan efectiva. Por ejemplo, no tiene en
cuenta el número de preferencias que se solapan. Supongamos dos usuarios que evaluaron
10 ítems de manera similar (suponiendo la evaluación en valores numéricos pero no
idénticos), estos usuarios tendrán menos similitud que dos usuarios que solo evaluaron dos
ítems pero de manera casi idéntica [26].
2.3.1.1.2. Similitud del coseno
Otro de los métodos más populares para encontrar similitudes dentro del marco del
filtrado colaborativo es la función de similitud del coseno. La misma consiste en la medida
de similitud entre dos vectores derivados del coseno del ángulo formado entre ellos [36].
Dentro del plano del trabajo actual, cada vector representará a un usuario del
sistema y sus coordenadas, las preferencias por los distintos ítems. De este modo, cuando
se quiera calcular la similitud entre dos usuarios, se calculará el coseno entre los mismos.
Por consiguiente, el enfoque que define la similitud del coseno entre dos usuarios x e
y queda conformado de la siguiente manera:
Ecuación 2.2: Similitud del coseno entre x e y [37].
2.3.2. Filtrado Colaborativo basado en modelos
El filtrado colaborativo basado en modelos construye un modelo basado en las
evaluaciones de los usuarios que se utilizará para realizar las nuevas recomendaciones.
23

Entre los algoritmos de FC basados en modelos más conocidos se encuentran las
Redes Bayesianas, los modelos de clustering y modelos semánticos latentes como
descomposición de valores singulares, análisis de componente principal y factorización de
matrices [13].
2.3.2.1. Factorización de Matrices
La mayoría de los modelos de factorización de matrices, son basados en el modelo del
factor latente. La factorización de Matrices se la conoce como la aproximación más precisa
para reducir el problema de la escasez de información en los conjuntos de datos.
Las técnicas basadas en el modelo de Índice Semántico Latente y Valor Singular de
descomposición usualmente son combinadas.
Valor Singular de descomposición y análisis de componente principal son técnicas bien
establecidas para identificar factores latentes en el campo de recuperación de información con
filtrado colaborativo. Estos métodos se han vuelto populares recientemente por combinar una
buena escalabilidad con una precisión predecible. También ofrecen mucha flexibilidad
modelando varias aplicaciones de la vida real.
En primer lugar, tenemos un conjunto de usuarios U, un conjunto de ítems I y R será la
matriz de tamaño U x I que contiene todos los ratings que el usuario ha asignado a los ítems.
En este caso, las características latentes serían descubiertas. El objetivo es encontrar 2
matrices P ( de tamaño U x К ) y Q ( de tamaño I x К) tales que su producto se aproxime a R:
Ecuación 2.3: Cálculo de la matriz R
De esta forma, la Factorización de Matrices modela uniendo usuarios e ítems a un espacio de
factor latente conjunto de dimensionalidad f, de tal forma que las interacciones entre usuarios
e ítems son modeladas como productos internos en dicho espacio.
Cada ítem I es asociado a un vector y cada usuario u es asociado con un vector
.
Dado un item i, los elementos de miden el grado en el que el ítem posee esos factores.
24

Dado un usuario u, los elementos de miden el factor de interés que el usuario tiene en
ítems que se corresponden con esos factores, otra vez, positivo o negativo.
El resultado del producto entre captura la interacción entre un usuario u y un ítem i,
dicho de otra forma sería el interés general del usuario u en las características del ítem.
Esta aproximación es definida como:
Ecuación 2.4: Modelo de Factorización de matrices básico
Para aprender los vectores y , el sistema minimiza el error cuadrado
regularizado en el conjunto de ratings con:
Ecuación 2.5: Minimización del error cuadrado regularizado
Aquí, K es un conjunto de pares (u,i) para el que es conocido en el conjunto de
entrenamiento. La constante λ controla el factor de regularización y es usualmente
determinado por validación cruzada.
25

Figura 2.7: Ejemplo de modelos de factor latente en LBSN [30].
La figura 2.7 muestra un ejemplo simplificado bidimensional (f=2) de un modelo de
factor latente dentro de una LBSN. Las dimensiones plasmadas en la gráfica son hipotéticas y
nos muestran el espacio donde los diferentes ítems pueden ser ubicados en función de las
características atracción turística o no turística y horario diurno o nocturno.
La Ecuación 2.6 intenta capturar la interacción entre usuarios e ítems que producen
diferentes calificaciones. Sin embargo, la variación de las calificaciones observadas está
ligada a los efectos de los usuarios y los ítems. Por ejemplo, el filtrado colaborativo exhibe
tendencias sistemáticas de usuarios que otorgan calificaciones más altas que otros.
Por lo tanto, sería imprudente explicar el total de las calificaciones como la interacción
entre los vectores y . El sistema intentará identificar la porción de estas tendencias con
la información verdadera del conjunto de datos.
Esta tendencia para cada para usuario-item será calculada como:
Ecuación 2.6: Tendencia usuario-ítem
Donde μ será el rating promedio general, los parámetros bu y bi indicarán las
desviaciones promedio observadas para el usuario u e item i, respectivamente.[12]
26

Añadiendo esta información a la ecuación 2.4, obtenemos:
Ecuación 2.7: Factorización de Matrices básico con desviaciones
2.3.2.2. Modelos de Factorización de matrices
A continuación se describirán algunos de los modelos de factorización de matrices más
utilizados.
2.3.2.2.1. Descomposición de valores singulares (SVD)
La DVS es una técnica para la reducción de dimensionalidad de un conjunto de datos.
La clave en una DVS es encontrar un espacio de característica dimensional baja.
DVS de una matriz A (tamaño m x n) tiene la forma:
V D(A) ΣVS = T
Ecuación 2.8: Dimensión de una matriz SVD
Donde, U y V son matrices ortogonales respectivamente de tamaño m x m y n x n.
Σ es una matriz ortogonal singular con elementos no negativos de tamaño m x n.
Una matriz U de tamaño m x m es llamada ortogonal si es igual a una matriz
identidad de m x m. Los elementos de la diagonal en Σ (σ1, σ2, σ3, …… σn), son llamados
valores singulares de la matriz A. Usualmente, los valores singulares son ubicados en orden
descendente dentro de Σ. Los vectores columna de U y V son llamados los vectores
singulares a izquierda y derecha respectivamente [14].
2.3.2.2.2. Descomposición de valores singulares con feedback implícito (SVD ++ )
A menudo, un sistema debe tratar con el problema de arranque en frío, donde muchos
de los usuarios poseen solo unas pocas calificaciones, creando una gran dificultad para
identificar sus preferencias. Una manera de tratar este problema es incorporando información
de una fuente de datos adicional acerca de los usuarios. Los sistemas de recomendación
pueden usar el feedback implícito para obtener calificaciones extras acerca de los usuarios.
27

Por simplicidad, consideraremos una caso de feedback implícito booleano. N(u)
denotará un conjunto de elementos para cada usuario u expresado como una preferencia
implícita.
Aquí, un nuevo conjunto de factores de elementos son necesarios, donde se tiene el
ítem i asociado con xi ∈ f. En consecuencia, el conjunto de preferencias que un usuario
mostró por ítems en N(u) es representada por el vector:
Ecuación 2.9: Vector de preferencias de un usuario u
Normalizar la suma es a menudo un beneficio:
Ecuación 2.10: Normalización del vector de preferencias
Otra fuente de información es conocer atributos de los usuarios, por ejemplo, por ubicación
geográfica. Otra vez, por simplicidad consideraremos atributos booleanos donde al usuario u
le corresponde un conjunto de atributos A(u), que describen datos personales del mismo tales
como localidad, edad, género, etc. El vector de factores A Ya ∈ f corresponde a cada atributo
que describe al usuario:
Ecuación 2.11: Vector de atributos de un usuario u
El modelo de factorización de matrices deberá integrar todas las fuentes descritas como una
mejora de la representación de los intereses del usuario en la ecuación x.h, dando como
resultado:
Ecuación 2.12: Calificación con SVD ++ [12]
28

2.5. Evaluación de Sistemas de Recomendación
Evaluar el rendimiento de los algoritmos de recomendación no es trivial. Primero
porque diferentes algoritmos pueden ser mejores o peores dependiendo del conjunto de datos
elegido. También los objetivos del sistema de recomendación pueden ser diversos. Un
sistema puede diseñarse para estimar con exactitud el puntaje que daría un usuario a un
elemento, mientras otro puede tener como principal objetivo el no proporcionar
recomendaciones erróneas. Es decir, puede haber múltiples tipos de medidas: que las
recomendaciones cubran todo el espectro de elementos del conjunto (cobertura), que no se
repitan, que sean explicables, etc.. Sin embargo, el principal objetivo de un sistema de
recomendación, que es la satisfacción del usuario, no es directamente cuantificable.
En cualquier caso las medidas de precisión pueden dar una primera idea de cuan
bueno es el algoritmo del sistema de recomendación.
Existen dos tipos de métodos de evaluación: de decisión y estadísticos.
2.5.1. Métodos de decisión
Evalúan cómo de efectivo es un sistema de predicción ayudando al usuario a
seleccionar los elementos mayor calidad, es decir con qué frecuencia el sistema de
recomendación efectúa recomendaciones correctas. Para ello asumen que el proceso de
predicción es binario: o el elemento recomendado agrada al usuario o no lo agrada. Sin
embargo en la práctica se plantea el problema de evaluar esto. Una posible solución es la de
dividir el conjunto de datos en dos conjuntos, entrenamiento y test. Se trabaja con con el
conjunto de entrenamiento y posteriormente se evalúa el resultado comparando las
recomendaciones proporcionadas con las del conjunto de test. Aun siendo a veces útil esta
técnica, hay que tener en cuenta que los resultados dependen fuertemente del porcentaje de
elementos relevantes que el usuario haya votado. La más conocida de estas métricas es la de
“Precision and Recall”.
2.5.1.1. Precision
29

La precisión es calculada entre el número de documentos relevantes recuperados y el
número de documentos recuperados. Acorde con la definición se tiene la siguiente expresión:
Ecuación 2.13: Cálculo de la Precisión
De esta forma, cuanto más se acerque el valor de la precisión al valor nulo, mayor será
el número de documentos recuperados que no se consideren relevantes. Si por el contrario, el
valor de la precisión es igual a uno, se entenderá que todos los documentos recuperados son
relevantes. Esta forma de entender la precisión introduce el concepto de ruido informativo y de
silencio informativo [10].
2.5.1.2. Recall / Exhaustividad
Esta métrica viene a expresar la proporción de documentos relevantes recuperados,
comparado con el total de los documentos que son relevantes existentes en la base de datos,
con total independencia de que éstos, se recuperen o no. La ecuación en este caso se
expresa como:
Ecuación 2.14: Cálculo de la Exhaustividad o Recall
Si el resultado de esta fórmula arroja como valor 1, se tendrá la exhaustividad máxima
posible, y esto viene a indicar que se ha encontrado todo documento relevante que residía en
la base de datos, por lo tanto no se tendrá ni ruido, ni silencio informativo: siendo la
recuperación de documentos entendida como perfecta. Por el contrario en el caso que el valor
de la exhaustividad sea igual a cero, se tiene que los documentos obtenidos no poseen
relevancia alguna [10].
30

2.5.1.3. Valor-F (F1 Score o F-Measure en inglés)
Al aumentar el Recall (la proporción de elementos relevantes) disminuimos la
precisión, por lo cual hay un compromiso entre ambas métricas [32]. Valor-F intenta hacer un
balance entre ambas métricas y se la define como:
Ecuación 2.15: Cálculo del Valor-F o F-Measure
Si β es igual a uno, se le está dando la misma ponderación (o importancia) a la
Precisión que a la Exhaustividad, si β es mayor que uno la Exhaustividad será más
importante, mientras que si es menor que uno, la Precisión será más relevante [33].
2.5.2. Métodos estadísticos
Los métodos estadísticos intentan medir la desviación que existe entre los valores
reales del conjunto de datos y los valores predichos por el algoritmo. Estos algoritmos son
utilizados cuando lo que deseamos medir es la calidad del valor asignado en la
recomendación.
Los algoritmos más utilizados son Root Mean Square Error y Mean Absolute Error.
2.5.2.1. Root Mean Square Error (RMSE)
El RMSE es frecuentemente utilizado para medir la diferencia entre los valores
predichos por un modelo y los valores reales observados.
RMSE se calcula hallando la raíz cuadrada de las desviaciones cuadráticas medias
entre el rating estimado para un usuario y el rating real [11].
Ecuación 2.16: Cálculo de Root Mean Square Error
31

2.5.2.2. Mean Absolute Error(MAE)
MAE se obtiene calculando el promedio de la desviación absoluta entre el rating
estimado para un usuario y el rating real. Expresado matemáticamente, se define como:
Ecuación 2.17: Cálculo de Mean Absolute Error
2.6. Análisis de Sentimiento
El análisis de sentimiento es un campo de investigación en el área de minería de textos
y está relacionado con el tratamiento computacional de las opiniones, sentimiento y
subjetividad de los textos [17].
El análisis de sentimientos utiliza las técnicas de procesamiento de texto en lenguaje
natural, análisis de texto y lingüística computacional para clasificar documentos en función de
la polaridad de la opinión que expresa su autor [16].
Esta información de alto nivel puede ser utilizada en muchas aplicaciones como el
análisis de comentarios de los clientes, negocios, recomendaciones personalizadas, etc.
Con la moda de las redes sociales, el análisis de sentimiento, nos trae un
entendimiento más profundo acerca de las redes sociales disponibles. Micro-blogs como
Twitter proveen una gran cantidad de datos, que pueden ser usados para descubrir el
sentimiento colectivo respecto a diversos temas. Muchas aplicaciones pueden ser construidas
para medir la tendencia en elecciones políticas, investigación de opiniones de consumo de
ciertas marcas, detección de contenidos virales, etc.
En las redes sociales basadas en ubicación este tipo de análisis aplicado a los tips de
los usuarios, puede ser utilizado para investigar el impacto que posee en la movilidad de los
usuarios [18].
32

2.7. TF IDF Tf-idf, del inglés term frequency - inverse document frequency es una medida de
pesaje comúnmente utilizada en recuperación de información y minería de texto.
Este peso es una medida estadística utilizada para evaluar la relevancia de una
palabra para un documento en una colección. La importancia aumenta proporcionalmente al
número de veces que una palabra aparece en el documento, pero es compensada por la
frecuencia de la palabra a través de toda la colección de documentos. Las variaciones del
esquema de ponderación tf-idf suelen ser utilizadas por los motores de búsqueda como una
herramienta central para anotar y clasificar la relevancia de un documento dada una consulta
del usuario [27].
Normalmente, el tf-idf está compuesto por dos términos donde el primero (TF) calcula
la Frecuencia de Término normalizada. Esto es el número de veces que una palabra aparece
en un documento, dividida por el número total de palabras en ese documento. El segundo
término es la Frecuencia Inversa de Documento (IDF), computada como el logaritmo del
número de documentos que se tienen en la colección dividido por el número de documentos
donde aparece el término específico [27].
En resumen, tenemos que TF mide la frecuencia con que un término aparece en un
documento. Como cada documento tiene una longitud diferente, es posible que un término
aparezca mucho más veces en documentos largos que en documentos más cortos. Por lo
tanto, el término frecuencia es a menudo dividido por la longitud del documento (es decir, el
número total de términos en el documento) como una forma de normalización:
TF(t) = f(t,d) / T(d)
Ecuación 2.18: Cálculo de Frecuencia de Términos (TF)
Donde la función f(t) cuenta la cantidad de veces que el término t aparece en un
documento d y T(d) cuenta la cantidad de términos que tiene el documento d.
Asimismo, IDF mide la importancia de un término. Mientras se calcula TF, todos los
términos se consideran igualmente importantes. Sin embargo, se sabe que ciertos términos,
como "es", "de" y "eso" (también denominados stop words), pueden aparecer muchas veces
33

pero tienen poca importancia. Por lo tanto, se tiene que bajar la relevancia de términos
frecuentes, mientras que se tienen que escalar los menos frecuentes. Esto se realiza
mediante el siguiente cálculo:
IDF (t) = log (D / f(t) )
Ecuación 2.19: Cálculo de Frecuencia Inversa de Terminos (IDF)
Donde D es el número total de documentos y f(t) es una función que cuenta cuantos
documentos tienen el término t consigo.
2.8. Antecedentes
En esta sección, se expondrán distintos trabajos relacionados con Sistemas de
Recomendación a los que se le ha dado mayor relevancia para desarrollar las soluciones
propuestas en el presente trabajo. Además se realizó una síntesis de dichos trabajos, donde
se expusieron sus ventajas y desventajas. Por último, se presentará una comparación entre
los mismos.
2.8.1. Síntesis de trabajos realizados anteriormente
● A Sentiment-Enhanced Personalized Location Recommendation System: En este
trabajo se presenta un sistema de recomendación híbrido que modela las preferencias
de los usuarios combinando información extraída del historial de check-ins, los tips,
que son procesados haciendo uso de técnicas de análisis de sentimiento, y las
relaciones de los usuarios dentro de la red social. Para la recomendaciones de lugares
se utiliza un algoritmo de Factorización de Matrices con distintas configuraciones. Por
ejemplo, dentro de las distintas configuraciones, en principio se utiliza únicamente
información del historial de check-ins, luego se añade análisis de sentimiento e
información de los tips y por último, se hace uso de las relaciones entre los usuarios.
● Location-based and Preference-Aware Recommendation Using Sparse Geo-Social Networking Data: En este trabajo, se presenta un sistema de
recomendación que sugiere lugares considerando la ubicación y preferencias del
34

usuario. Para generar recomendaciones, este sistema tiene en cuenta las preferencias
personales del usuario (que son obtenidas del historial de check-ins) y las opiniones
sociales, que son obtenidas de los expertos locales. Es por esto que el recomendador
es capaz de recomendar lugares a los usuarios que visitan una ciudad en la que jamás
han estado anteriormente. El sistema precomputa y extrae información de los expertos
locales de cada área para cada categoría en una ciudad utilizando el historial de todos
los usuarios en dicha región y la información asociada a las categorías de los lugares.
El recomendador infiere las calificaciones haciendo uso de un algoritmo de filtrado
colaborativo con algoritmos de similitud propios (que comparan las categorías favoritas
de los usuarios) y utilizando la información de los expertos locales en la región que se
desea recomendar.
● Matrix Factorization Techniques for Recommender Systems: Dentro de los
trabajos estudiados, se desea resaltar también el estudio realizado acerca de los
sistemas de recomendación realizado por una de las empresas más exitosas en la
actualidad, Netflix. En este trabajo se explican los conceptos teóricos de la técnica de
factorización de matrices así como también los beneficios que esta posee sobre las
tácticas más comunes de filtrado colaborativo como la basadas en cercanía de vecinos
(como lo son el Filtrado Colaborativo User-User o Item-User).
2.8.2. Ventajas y desventajas de los trabajos estudiados
A Sentiment-Enhanced Personalized Location Recommendation System
Ventajas: En este trabajo se quiere destacar la importancia de la información de contexto
añadida a la hora de realizar recomendaciones. Utilizando análisis de sentimiento, se
consigue modelar información muy importante acerca de la preferencia del usuario hacia un
lugar.
Desventajas : El algoritmo de recomendación no tiene en cuenta la posición en la que se encuentra
un usuario. Esta información suele ser muy útil, ya que los usuarios tienden a ir a lugares
próximos frecuentemente, y rara vez se dirigen a lugares alejados.
35

Dentro de los experimentos efectuados, aparece como línea base un filtrado
colaborativo que no tiene información acerca de su configuración (algoritmo de similitud
utilizado, basado en usuarios o items,etc.).
Location-based and Preference-Aware Recommendation Using Sparse Geo-Social Networking Data
Ventajas :
Este sistema de recomendación contempla el lugar en el que el usuario se encuentra
para recomendar lugares. El sistema de recomendación, realiza cálculo de preferencias
implícitas, lo cual facilita las recomendaciones en conjuntos de datos con alto grado de
esparcimiento. El algoritmo contempla una estrategia de recomendación para lugares en los
cuales no se posee información del usuario gracias a una técnica que logra combinar las
preferencias del usuario con la popularidad de los lugares disponibles para visitar.
Desventajas :
No utiliza el contenido de los tips como información adicional para generar las
recomendaciones.
El trabajo no contempla utilizar información de las relaciones entre los usuarios.
Matrix Factorization Techniques for Recommender Systems:
Ventajas :
Los sistemas de recomendación basados en factorización de matrices resuelven mejor
el problema de la escasez de datos. Actualmente Netflix usa esta técnica para recomendar
películas a usuarios.
Desventajas :
La técnica de matrix factorization es difícil de comprender e implementar que las
técnicas de filtrado colaborativo más comunes .
36

Capítulo 3: Enfoque propuesto
En esta sección se describe una visión preliminar del escenario de aplicación real del
recomendador. Consecuentemente a eso, se va a dar una vista general a la solución
propuesta, sobre los trabajos pasados que se han utilizado como referencia y cuál fue la
arquitectura resultante. También, se describirán brevemente cuáles fueron los experimentos
realizados para luego explicarlos en detalle en capítulos posteriores.
3.1. Visión preliminar
La figura 3.1 describe un escenario de aplicación del recomendador en donde existe
una aplicación móvil distribuida entre los distintos usuarios que interactúan en el marco de la
red social en cuestión, y otra aplicación que almacena toda la información generada por los
mismos integrantes de la red social que se utiliza luego para cálculo y la generación de
sugerencias. El hecho de que la aplicación utilizada por los miembros de la red social sea
móvil no es aleatorio, de hecho, uno de los principios de una red LBSN es que la misma
movilidad de los usuarios afecta directamente a las recomendaciones que el sistema debe
brindar. En otras palabras, es una de las claves para el funcionamiento más eficiente del
sistema de recomendación debido a la facilidad de acceso a las coordenadas geográficas de
un determinado usuario.
El uso de la aplicación es simple, el usuario posicionado en una determinada
coordenada geográfica consulta al sistema por lugares que podrían ser de su agrado.
Consecuentemente, se envian sus coordenadas a la aplicación centralizada y haciendo uso
de su ubicación sumado a la información histórica de sus visitas almacenada previamente, se
le recomienda sitios de interés en base a sus preferencias. Nótese que el sistema cuenta con
información previamente cargada de las características, como pueden ser la ubicación
geográfica o bien la categoría, de los lugares a los que concurren los distintos usuarios.
Posteriormente a esto, existe una capa de presentación, representada con un mapa,
en donde el usuario puede observar las recomendaciones brindadas por el sistema. Desde la
interfaz de la aplicación el usuario puede ver, entre otras cosas, dónde se encuentran
ubicados geoespacialmente para identificar la distancia y la categoría de dicho lugar.
37
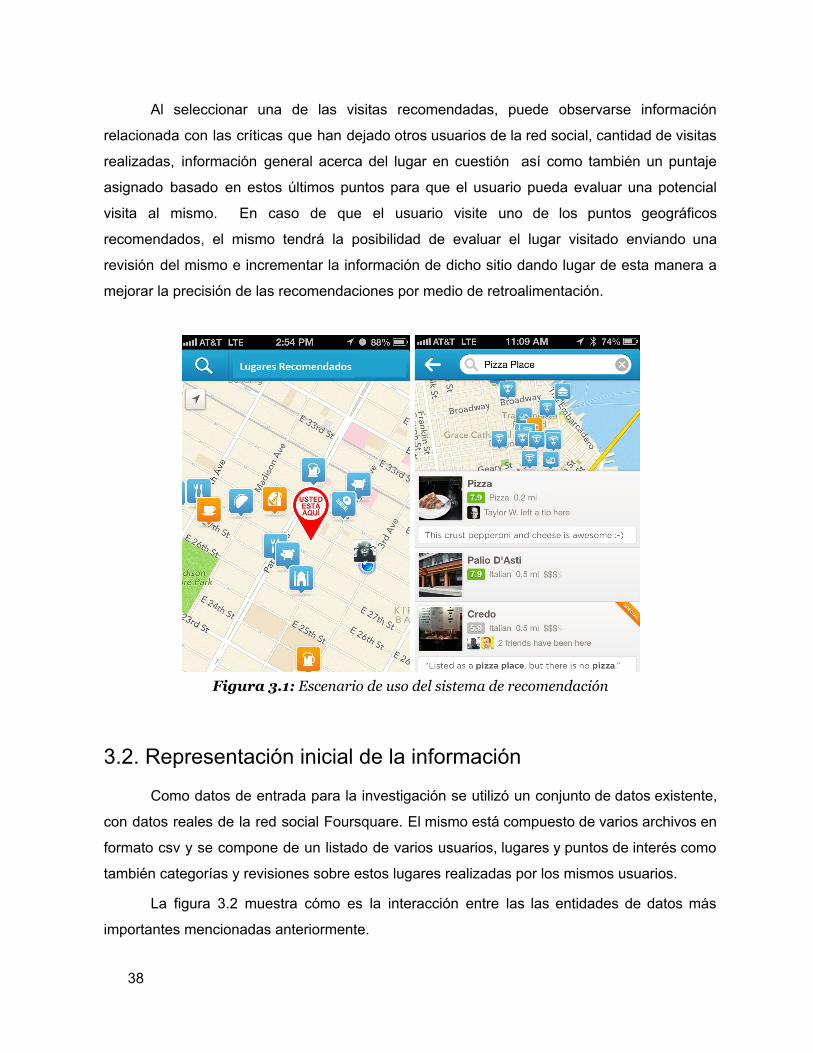
Al seleccionar una de las visitas recomendadas, puede observarse información
relacionada con las críticas que han dejado otros usuarios de la red social, cantidad de visitas
realizadas, información general acerca del lugar en cuestión así como también un puntaje
asignado basado en estos últimos puntos para que el usuario pueda evaluar una potencial
visita al mismo. En caso de que el usuario visite uno de los puntos geográficos
recomendados, el mismo tendrá la posibilidad de evaluar el lugar visitado enviando una
revisión del mismo e incrementar la información de dicho sitio dando lugar de esta manera a
mejorar la precisión de las recomendaciones por medio de retroalimentación.
Figura 3.1: Escenario de uso del sistema de recomendación
3.2. Representación inicial de la información
Como datos de entrada para la investigación se utilizó un conjunto de datos existente,
con datos reales de la red social Foursquare. El mismo está compuesto de varios archivos en
formato csv y se compone de un listado de varios usuarios, lugares y puntos de interés como
también categorías y revisiones sobre estos lugares realizadas por los mismos usuarios.
La figura 3.2 muestra cómo es la interacción entre las las entidades de datos más
importantes mencionadas anteriormente.
38

Figura 3.2: Entidades presentes en un sistema de RSBU
Como se puede observar, los usuarios se relacionan con los lugares compartiendo su
ubicación geográfica registrando su visita a cualquier lugar perteneciente a la red social. Para
su facilidad de uso, cada lugar cuenta consigo información acerca de las coordenadas
geográficas en las que está ubicado, ciudad a la que pertenece, entre otras características.
También es necesario destacar que cada vez que un usuario realiza una visita a algún sitio
tiene la opción de dejar una reseña del mismo, a fin de brindar más información a otros
potenciales visitantes.
Los sitios de interés, también poseen categorías que describen el tipo de lugar al que
se hace referencia. Este es un atributo de mucho valor para el propósito de la recomendación,
ya que refleja información directa acerca de los gustos del usuario. Resulta difícil encontrar
usuarios que concurran al mismo lugar, debido a la cantidad de lugares registrados y además
a la variedad de ubicaciones de los usuarios dentro de la red. Utilizando la información de las
categorías se puede modelar la similitud entre los usuarios en una mayor cantidad de casos.
Con respecto a las categorías, las mismas están representadas mediante un árbol de
jerarquía en donde los nodos más cercanos a la raíz representan una descripción más
genérica del lugar. Por consiguiente, los nodos más cercanos a las hojas, son una
especialización de las mismas. En resumen, las categorías que serán hojas dentro del árbol
de la jerarquía serán las que contienen la granularidad más fina. Por ejemplo, la categoría
“Comida” incluye a las categorías “Comida China” o “Comida Italiana”.
39

3.3. Solución propuesta
A continuación se mostrará a grandes rasgos cuál fue la solución propuesta para la
problemática en cuestión. En principio, se tienen que satisfacer dos necesidades muy
marcadas como son la recomendación de sitios de interés a usuarios finales y la efectividad
de las recomendaciones de los mismos. Para el primer punto, esto significa un servicio que
pueda responder a la solicitud de usuarios finales. Respecto al segundo punto, la calidad de
las recomendaciones es de vital importancia, con lo cual también se tiene la necesidad de
evaluar la precisión y eficacia de distintas implementaciones.
La figura 3.3 nos da una visión general que explica el funcionamiento del sistema. La
entrada del sistema es la información presentada en el apartado anterior, no obstante, para
que ese conjunto de datos sea funcional al propósito de la investigación, debe ser pre
procesado y optimizado. Esto significa, eliminar datos que no aportan información alguna o
generan ruido, como pueden ser usuarios que no registran ninguna visita, lugares que no
fueron visitados, ciudades que tienen muy poca actividad (es decir, visitas de usuarios), etc.,
para reducir el nivel de ruido de la información. Consecuentemente, también tiene un efecto
positivo en la performance del sistema, ya que al reducir el volumen de datos, menor será la
cantidad de procesamiento.
El siguiente paso, es la migración del conjunto de datos de entrada a una base de
datos relacional, haciendo uso de una serie de transformaciones que serán explicadas con
mayor nivel de detalle en el siguiente capítulo. De momento, lo que se tiene que comprender
es que partiendo de un conjunto de datos con información sin proceso alguno, existe un
componente dentro de la arquitectura del sistema que aplica sucesivos procesos sobre la
misma con el fin de facilitar su uso para los algoritmos de recomendación.
Todo ese proceso es realizado por un componente del sistema que se puede observar
en la figura 3.3 bajo el nombre de Sistema de Recomendación . Como se ve en dicha figura, el
mismo es un sistema que puede ser replicado en distintas máquinas y de esta manera escalar
horizontalmente con el fin de permitir procesamiento en paralelo en caso de ser necesario. Si
bien para el marco de esta investigación no es algo necesario, el sistema está preparado para
una mayor demanda de proceso.
40

Como se mencionó anteriormente, las modificaciones aplicadas a la información dada
serán almacenadas en una base de datos. La misma será compartida a través de todas las
réplicas del Sistema de Recomendación y también por todos los demás módulos
pertenecientes al sistema.
El paso siguiente a la transformación y almacenamiento de la información es la
implementación de distintos algoritmos y técnicas de recomendación que serán evaluadas
posteriormente, con el fin de determinar la eficacia de sus resultados.
Dentro de las técnicas implementadas, se utilizaron algoritmos como filtrado
colaborativo basado en usuarios y factorización de matrices, aplicando en algunos casos
mejoras o personalizaciones que se ajustaban mejor a la problemática en concreto.
En resumen, la arquitectura dispone de un componente llamado Sistema de
Recomendación , el cual tiene distintas responsabilidades:
● Pre procesar la información existente.
● Recomendar de sitios de interés para los distintos usuarios.
● Evaluar la calidad de las recomendaciones provistas.
Figura 3.3: Arquitectura general de la solución propuesta
41

Adicionalmente, la figura 3.3 contiene otro componente llamado API de
recomendación . Este componente funciona como comunicación entre los usuarios finales de
la aplicación y el sistema de recomendación implementado. En otras palabras, es la manera
que tienen los usuarios finales de la aplicación para pedir o acceder a las recomendaciones
que el sistema puede brindar. En este caso se implementó una capa sobre los sistemas de
recomendación implementados y una API REST para poder enviar las recomendaciones en
un formato apto para el procesamiento desde una aplicación móvil. En este caso, la
información se devuelve en formato de XML. En el capítulo 4 se hablará más en detalle acerca
de este módulo, pero de manera resumida, el propósito de este módulo es el de proveer un
medio de acceso a la información generada por el módulo Sistema de Recomendación para
los usuarios finales.
3.4 Casos de estudio
Por último, los restantes capítulos del documento hacen referencia a los experimentos
realizados utilizando la implementación provista en el capítulo 4, el análisis de los resultados
obtenidos así como también la presentación de posibles trabajos a realizar en un futuro.
Para la materialización de los distintos experimentos se utilizó un set de datos
perteneciente a la red social Foursquare, dentro de los cuales se pueden encontrar un listado
completo de lugares con su ubicación geográfica y su categoría, un listado de revisiones de
los lugares realizada por los mismos usuarios de la red social y un conjunto de usuarios. Del
mismo se utilizaron los datos de dos ciudades, Nueva York y Los Ángeles.
Una vez elegido el conjunto de datos a utilizar se va a proceder con distintas pruebas,
a fin de evaluar cuál es la más conveniente dependiendo de distintas variables de entrada:
rankeo de lugares, algoritmos de recomendación y el cálculo de similitud.
Cada una de las pruebas será evaluada utilizando las métricas mencionadas en el
capítulo 2 que son MAE, RMSE, precisión, recall y f-score.
Posteriormente a esto se va a realizar un análisis de los resultados obtenidos, con el
fin de identificar los distintos comportamientos de la aplicación desarrollada.
Finalmente, se van a mencionar potenciales mejoras a realizar, teniendo como objetivo
la continuidad del presente trabajo.
42

3.4.1. Variables a analizar
Como se mencionó en la sección anterior, los experimentos a realizar se basan en la
combinación de distintas variables y cómo reaccionará el sistema ante los cambios de las
mismas.
En principio, lo primero que se intentó conseguir fue medir la preferencia de un
usuario por un lugar determinado y la discretización de la misma. Para cumplir con este
objetivo se analizaron dos alternativas. La primera consiste en contar la cantidad de veces
que un usuario visitó un lugar dado. La segunda no solo tiene en cuenta la cantidad de
veces que un miembro de la red social visitó un sitio sino que además se tuvo en cuenta el
análisis de sentimiento de cada visita.
Siguiendo con la mención de las distintas variables de los experimentos, tal vez la
más importante sea la técnica de recomendación utilizada. En este caso se utilizaron dos
técnicas distintas como lo son el filtrado colaborativo basado en usuarios y la factorización
de matrices.
Por último, se sabe que los algoritmos de filtrado colaborativo tienen una fuerte
dependencia de otra función que es la que calcula la similitud entre ítems o usuarios.
Existen maneras muy variadas de calcular la similitud y para los fines de la investigación
se utilizaron el Coeficiente de correlación de Pearson, la similitud del Coseno y la
comparación de árboles de preferencias de los usuarios.
.
43

Capítulo 4: Diseño e implementación
El presente capítulo tiene como objetivo explicar en detalle la solución aplicada a la
problemática presentada, comenzando por nombrar las herramientas que se utilizaron como
ayuda o soporte para lograr el objetivo así como también la descripción de todos los
componentes de arquitectura diseñados.y su relación con otros trabajos realizados
previamente.
4.1. Investigación de Frameworks para filtrado colaborativo Para la realización del Sistema de recomendación se analizaron distintos frameworks y
herramientas que implementan los distintos algoritmos de filtrado colaborativo. Finalmente se
eligió Apache Mahout por ser la alternativa que escalaba mejor para grandes cantidades de
datos y por la variedad de características disponibles como integración con Apache Hadoop,
variedad de algoritmos de recomendación y facilidad de uso, entre otras.
A continuación se listan los componentes evaluados en conjunto con una explicación
de porqué se eligieron o se descartaron.
4.1.1. Crab
Crab es un motor de recomendación flexible y rápido escrito en el lenguaje Python.
Crab nos provee la implementación de una gran cantidad de algoritmos de filtrado
colaborativo integrados también con librerías o paquetes de índole científica utilizados por la
comunidad de desarrolladores Python. El motor tiene como objetivo proporcionar un amplio
conjunto de componentes a partir de los cuales se puede construir un sistema de
recomendación personalizado utilizando la implementación de los distintos algoritmos [20].
Dentro de las características de Crab, se destaca lo siguiente:
● Implementación de algoritmos de filtrado colaborativo basados en ítems y en usuarios.
● Evaluación de recomendadores.
● Soporte para APIs REST
● Implementado en un lenguaje muy descriptivo y fácil de usar como Python.
44

Si bien Crab provee varias cosas útiles, luego de varias pruebas de concepto se
decidió descartarlo por los siguientes motivos:
● Pobre performance. Ante una cantidad de datos superior, el sistema no tiene un tiempo
de respuesta razonable. En algunos casos pasan horas hasta tener una respuesta.
● Proyecto descontinuado. El proyecto no recibe soporte desde hace un par de años.
4.1.2. Racoon
Otra alternativa que se analizó fue Racoon, una herramienta de filtrado colaborativo
escrita con el framework Node.js y que utiliza Redis como mecanismo de caché.
Dentro de las características de Racoon, se puede mencionar que utiliza el algoritmo
de los N vecinos más cercanos para generar las recomendaciones. Este módulo es útil para
cualquier sistema con una base de datos de usuarios, una base de datos de productos /
películas / artículos y el deseo de dar a sus usuarios la capacidad de evaluar ítems y recibir
recomendaciones basadas en usuarios similares. Se puede emparejar con cualquier base de
datos, ya que no realiza un seguimiento de cualquier información de usuario / elemento
además de un ID único [21].
En resumen, las principales ventajas que se observaron fueron las siguientes:
● Independencia de la bases de datos. Se puede usar cualquier motor de base de datos,
inclusive distinto paradigma (relacionales o no relacionales).
● Caché incorporada. La herramienta ya viene integrada con Redis.
No obstante, las desventajas son grandes:
● Proyecto descontinuado.
● Ausencia de un módulo que evalúe los distintos algoritmos de recomendación.
● No funciona para versiones más actuales de Node.js.
4.1.3. Django-Recommends
Continuando con la evaluación de las distintas herramientas, se encontró algo más
completo que los anteriores llamado Django-Recommends, escrito en el lenguaje Python
utilizando el framework Django, como su nombre lo indica.
45

Django-Recommends se presenta como una herramienta bastante superior a las
presentadas anteriormente teniendo como base un framework bastante aceptado por la
comunidad de desarrolladores Python y presentando mayor cantidad de características.
Podemos mencionar las siguientes ventajas:
● Mayor cantidad de algoritmos implementados.
● Buena performance cuando se dispone de grandes cantidades de datos.
● Soporte. La documentación de este proyecto es superior a las que pertenecen a las
herramientas previamente presentadas.
En contrapartida, se encontraron los siguientes inconvenientes:
● Difícil instalación y configuración en plataformas que no sean Unix.
● Gran cantidad de dependencias externas.
4.1.4. Apache Mahout
Finalmente, el último componente analizado fue Apache Mahout. El mismo es un
proyecto de código abierto, escrito en el lenguaje Java, que se utiliza principalmente para la
creación de algoritmos de aprendizaje automático escalables [22]. Implementa técnicas de
aprendizaje automático populares, tales como:
● Recomendación
● Clasificación
● La agrupación (en inglés, Clustering)
Adicionalmente Mahout se integra fácilmente con otro sistema muy utilizado para el
almacenamiento de grandes cantidades de datos llamado Hadoop. Hadoop es un marco de
código abierto de Apache que permite almacenar y procesar grandes volúmenes de datos en
un entorno distribuido a través de grupos de ordenadores que utilizan modelos de
programación simples. Pensando en una aplicación que deba escalar en un futuro, parece ser
una opción bastante favorable.
4.1.4.1. Características de Mahout
46

Las características primitivas de Apache Mahout se enumeran a continuación.
● Los algoritmos de Mahout se escriben en la parte superior de Hadoop, por lo que
funciona bien en entornos distribuidos. Mahout utiliza la biblioteca Apache Hadoop
para escalar de manera efectiva en HDFS.
● Mahout permite a las aplicaciones analizar grandes conjuntos de datos de manera
eficaz y en poco tiempo.
● Incluye múltiples algoritmos de Filtrado Colaborativo basados en vecindarios como
basados en Usuario-Usuario, Ítem-Usuario e implementaciones de los distintos
algoritmos de similitud.
● Incluye algoritmos de Filtrado Colaborativo basados en modelos de factor latente
como la factorización de matrices y distintas implementaciones para hallar dichos
factores.
● Incluye implementaciones para evaluar los sistemas de recomendación.
4.1.4.2. Arquitectura de Mahout
El siguiente diagrama muestra la relación entre los distintos componentes de Apache
Mahout, considerando el escenario de un sistema de recomendación basado en usuarios. En
un sistema basado en ítems la interacción es similar exceptuando que no hay ningún
algoritmo para la conformación de un vecindario.
Observando la figura 4.1 se puede notar que existen cuatro capas principales en
sistema:
● Aplicación externa: Sistema de recomendación final, que utiliza los distintos
componentes de Apache Mahout.
● Recomendador: Es el núcleo de Mahout. Recibe como entrada un conjunto de datos y
produce recomendaciones sobre los mismos.
● Modelo de datos: Contiene la información de las preferencias de los distintos usuarios
del sistema.
● Almacenamiento fìsico: Donde se guarda la información.Puede ser una base de
datos relacional, no relacional, un sistema de archivos, etc..
47

Figura 4.1: Arquitectura general de Apache Mahout [23].
4.1.5. Criterio de selección del framework
Luego de realizar un análisis exhaustivo de las distintas herramientas, se determinó
que Apache Mahout era la que más soporte brindaba para resolver la problemática planteada.
Para la elección se tuvieron en cuenta varios factores:
● La herramienta cumple con mayor cantidad de atributos de calidad.
● Las características de la herramienta son suficientes para continuar con el desarrollo y
la investigación.
48

● La herramienta se ajusta a otros factores externos como pueden ser el conocimiento
en la tecnología de los desarrolladores o bien la cantidad de documentación acerca de
la misma.
A continuación se muestran unas tablas que comparan los distintos componentes
según los criterios mencionados.
4.1.5.1. Comparativa basada en atributos de calidad
Herramienta Performance Escalabilidad Portabilidad Usabilidad
Apache Mahout Si Si Si Si
Django Recommends
Si Si No No
Crab No No No Si
Raccon Si Si Si No
Tabla 4.1: Comparativa de herramientas soporte realizada por atributos de calidad
4.1.5.2. Comparativa basada en características
Herramienta Posee sistema de cache Implementa algoritmos de filtrado colaborativo
Evalúa efectividad de algoritmos
Apache Mahout Si Si Si
Django Recommends
Si Si Si
Crab No Si No
Raccon Si Si No
Tabla 4.2: Comparativa de herramientas soporte realizada por características de las
mismas
4.1.5.3. Comparativa basada en factores externos
Herramienta Conocimiento del lenguaje por parte de los Documentación
49
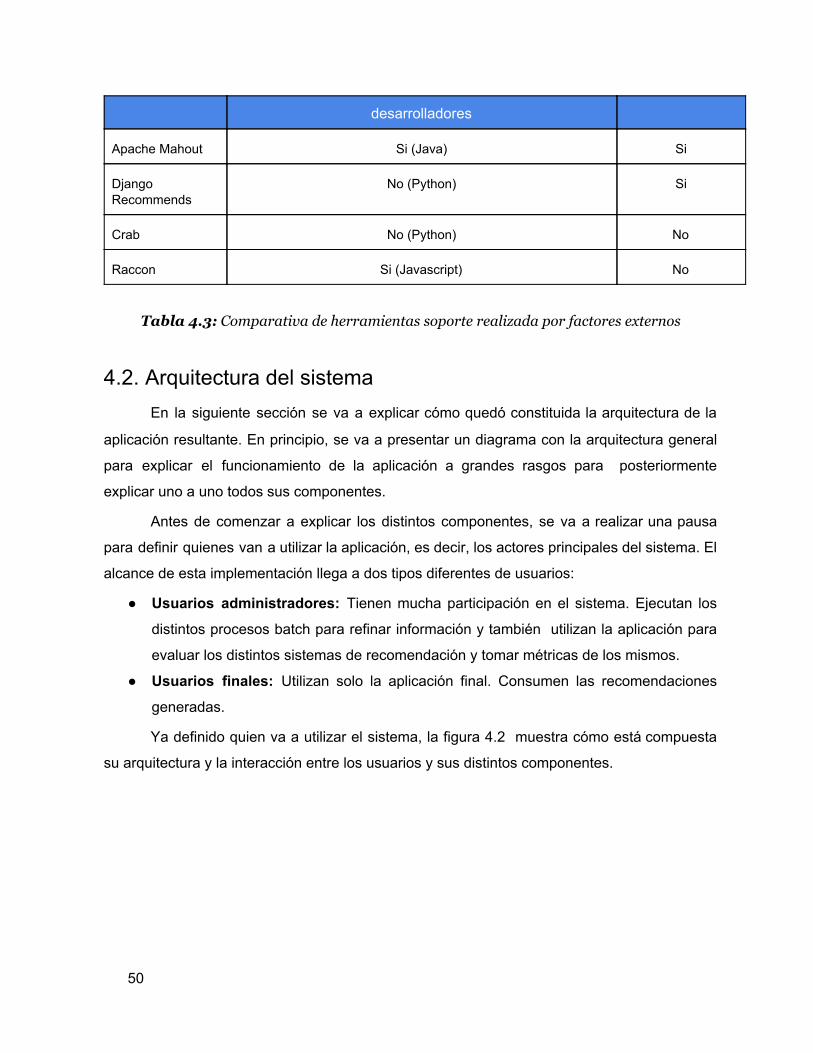
desarrolladores
Apache Mahout Si (Java) Si
Django Recommends
No (Python) Si
Crab No (Python) No
Raccon Si (Javascript) No
Tabla 4.3: Comparativa de herramientas soporte realizada por factores externos
4.2. Arquitectura del sistema En la siguiente sección se va a explicar cómo quedó constituida la arquitectura de la
aplicación resultante. En principio, se va a presentar un diagrama con la arquitectura general
para explicar el funcionamiento de la aplicación a grandes rasgos para posteriormente
explicar uno a uno todos sus componentes.
Antes de comenzar a explicar los distintos componentes, se va a realizar una pausa
para definir quienes van a utilizar la aplicación, es decir, los actores principales del sistema. El
alcance de esta implementación llega a dos tipos diferentes de usuarios:
● Usuarios administradores: Tienen mucha participación en el sistema. Ejecutan los
distintos procesos batch para refinar información y también utilizan la aplicación para
evaluar los distintos sistemas de recomendación y tomar métricas de los mismos.
● Usuarios finales: Utilizan solo la aplicación final. Consumen las recomendaciones
generadas.
Ya definido quien va a utilizar el sistema, la figura 4.2 muestra cómo está compuesta
su arquitectura y la interacción entre los usuarios y sus distintos componentes.
50

Figura 4.2: Vista global de la arquitectura del Sistema de Recomendación
Para comenzar, como se puede observar en la figura, todos los componentes tienen
una conexión en común con una capa de almacenamiento de datos, en donde se pueden
encontrar todas las entidades que conforman el modelo de datos del sistema. Para esta parte
en cuestión se optó por utilizar una base de datos relacional por la simplicidad de uso de la
51

misma pero se podría tener el mismo resultado utilizando bases de datos no relacionales
como pueden ser Mongo DB o Cassandra.
El motor de base de datos escogido fue Postgres SQL. Postgres es un poderoso
sistema de base de datos relacional de código abierto. Cuenta con más de 15 años de
desarrollo activo y una arquitectura probada que le ha valido una sólida reputación de
fiabilidad, integridad de datos y corrección. Se ejecuta en todos los principales sistemas
operativos, incluyendo Linux, UNIX y Windows y permite escalar a grandes cantidades de
datos [7].
Siguiendo con la vista general de la arquitectura, existen tres componentes que
consolidan el núcleo del sistema de recomendación implementado que son:
● Refinador de Información: Provee una interfaz de comandos a los usuarios
administradores para realizar distintas transformaciones a los datos de entrada.
● Evaluador de recomendaciones: Provee distintas métricas a los usuarios
administradores con el fin de evaluar el funcionamiento de los distintos
recomendadores implementados.
● Constructor de Preferencias: Calcula las preferencias de los usuarios por las
categorías pertenecientes al sistema dentro de las distintas ciudades.
Es importante mencionar que los tres componentes mencionados poseen autonomía
propia, por lo que pueden ser desplegados en distintas computadoras o servidores en
inclusive, dependiendo del uso de la aplicación, los tres pueden ser replicados las veces que
se quiera para poder escalar horizontalmente.
Finalmente, existe un módulo adicional llamado Servicio de Recomendación que define
una interfaz por medio de una API REST para devolver las distintas recomendaciones
realizadas para los usuarios finales.
4.2.1. Modelo de datos
En el apartado anterior mencionamos la existencia de una capa de datos. En la misma
se almacenan todas las entidades de datos pertenecientes al sistema y que son necesarias
para todos los componentes dentro de la arquitectura.
Para poder proveer una solución a la problemática planteada se encontró la necesidad
de definir las siguientes entidades:
52

● Venue: Contiene toda la información relacionada a los lugares dentro del sistema,
como pueden ser las coordenadas geográficas, la ciudad a la cual pertenece o el
nombre del sitio.
● User: Entidad que representa a los usuarios del sistema.
● Category: Información de las categorías de lugares en el sistema como pueden ser
Museos, Bares, Restaurantes, etc..
● Venue_Category: Representa la relación entre las entidades Venue y Category. Un
registro de venue puede estar asociado con múltiples registros de category.
● Tips: Representa las visitas y las críticas que han otorgado los usuarios a los distintos
lugares. Un usuario puede realizar múltiples visitas. También es necesario aclarar que
un usuario puede visitar varias veces el mismo lugar.
A continuación, se muestra la constitución final del modelo de datos.
Figura 4.3: Modelo de datos relacional utilizado
53
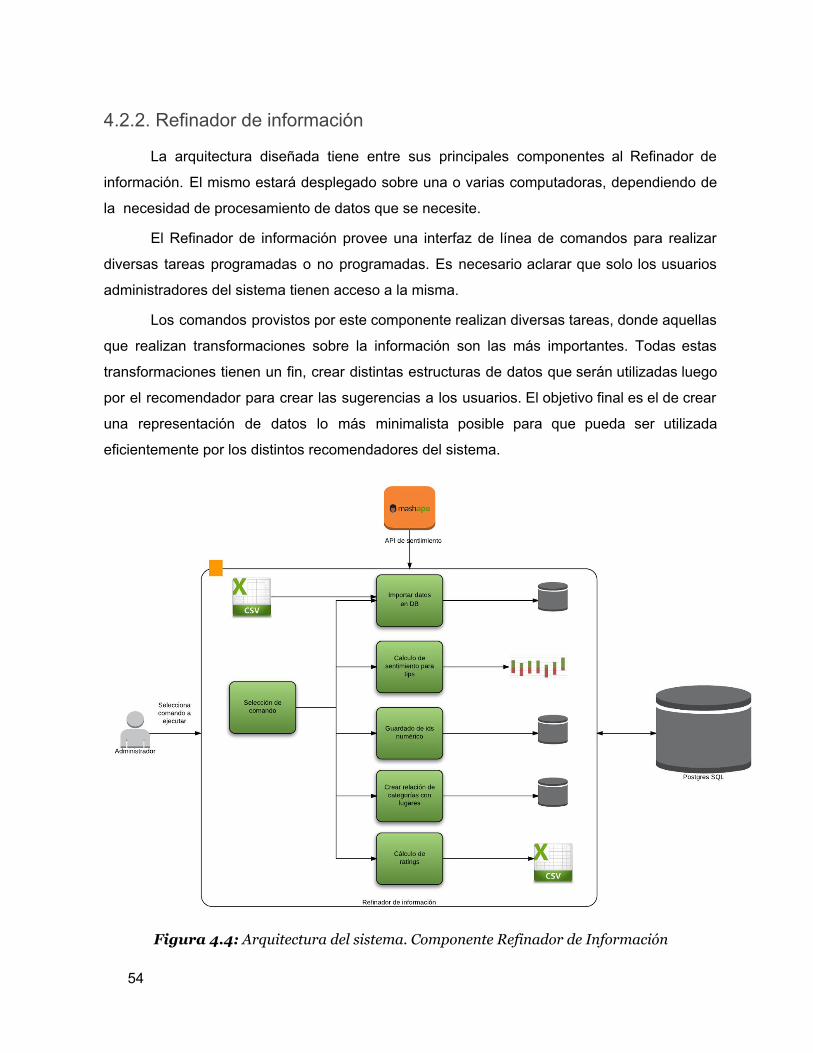
4.2.2. Refinador de información
La arquitectura diseñada tiene entre sus principales componentes al Refinador de
información. El mismo estará desplegado sobre una o varias computadoras, dependiendo de
la necesidad de procesamiento de datos que se necesite.
El Refinador de información provee una interfaz de línea de comandos para realizar
diversas tareas programadas o no programadas. Es necesario aclarar que solo los usuarios
administradores del sistema tienen acceso a la misma.
Los comandos provistos por este componente realizan diversas tareas, donde aquellas
que realizan transformaciones sobre la información son las más importantes. Todas estas
transformaciones tienen un fin, crear distintas estructuras de datos que serán utilizadas luego
por el recomendador para crear las sugerencias a los usuarios. El objetivo final es el de crear
una representación de datos lo más minimalista posible para que pueda ser utilizada
eficientemente por los distintos recomendadores del sistema.
Figura 4.4: Arquitectura del sistema. Componente Refinador de Información
54

Además de las transformaciones de datos, como se observa en la figura 4.4, hay
diversos procesos disponibles en la línea de comandos que pueden ejecutarse. A
continuación, se explica en detalle qué acción realiza cada comando:
● Importar datos en base de datos: Uno de los inconvenientes encontrados en el
conjunto de datos que se utilizó para el experimento fue el formato del mismo, csv (del
inglés, comma separated values). Si bien el formato es bastante intuitivo, tiene
bastantes limitaciones para su uso, como por ejemplo la poca tolerancia a fallos de
mantener un archivo de texto o la inserción de nuevos datos. Para esto, se implementó
un proceso que transforma los archivos de formato csv pertenecientes al conjunto de
datos en tablas dentro de una base de datos relacional. De este modo, se pueden
utilizar las bondades de las bases de datos relacionales como pueden ser la creación
de vistas, triggers y demás características.
● Guardado de ids numérico: Este proceso se encarga de transformar los
identificadores de los lugares (que inicialmente se encuentran en formato de hash) a
identificadores numéricos. También tiene como objetivo crear las relaciones
correspondientes apuntando a los nuevos identificadores. Esto es necesario para
poder asociar nuestra información de lugares con Items en Mahout, ya que este
framework solo acepta identificadores numéricos para los Ítems. Dentro de las ventajas
de utilizar ids numéricos está la posibilidad de crear índices de estos campos en la
base de datos, incrementando la eficiencia al momento de querer acceder a un
registro.
● Crear relación de categorías con lugares: Otra desventaja del conjunto de datos de
entrada, era la relación de los distintos lugares y las categorías de los mismos. Como
ya se vio anteriormente en el apartado 4.2.1, un lugar puede tener varias categorías.
En principio, cada lugar contenía un campo que conformado de una lista de
identificadores de categorías separados por coma. El problema de esto era la
complejidad para realizar búsquedas por categoría. Este proceso tuvo como fin la
creación de una tabla donde cada registro asocia un lugar con una categoría,
simplificando el proceso de datos por medio de una simple sentencia JOIN .
● Cálculo de sentimiento para tips: Cada visita registrada en la base datos contiene
una revisión textual realizada por el visitante. Si bien la revisión no tiene un valor
numérico, mediante el cálculo de sentimiento (calcular si el usuario está hablando
55

positivamente, negativamente o de forma neutral acerca del lugar ) podemos tener una
representación numérica bastante cercana a la realidad. Para ello se desarrolló un
proceso que para visita registrada se calcule el sentimiento de la revisión. Para el
cálculo se utilizaron los servicios ofrecidos por Mashape (https://www.mashape.com/).
Mashape nos provee un gran conjunto de servicios en la nube, del los cuales este
proceso utiliza únicamente el servicio de sentimiento
(https://market.mashape.com/vivekn/sentiment-3).
Este servicio de sentimiento examina las palabras individuales y algunas secuencias
cortas de palabras (n-gramas) y las compara con un modelo probabilístico. El modelo
probabilístico fue construído por Mashape sobre un conjunto de datos de prueba con
críticas acerca de películas en IMDb [29].
● Cálculo de ratings: Debido a la inexistencia de calificaciones de usuarios en el
conjunto de datos de entrada, se tomó como solución alternativa calcular las
calificaciones de los usuarios como la suma de la cantidad de veces que una persona
visita un lugar, normalizando ese número para tener una cota superior (se utilizó el
número 5, como actualmente se utiliza en la valoración por estrellas).
4.2.3. Constructor de Preferencias
Siguiendo con la descripción de los distintos componentes de la arquitectura, se va a
describir el funcionamiento del Constructor de Preferencias.
Este componente de la arquitectura tiene como objetivo la construcción de distintas
estructuras de datos con el fin de indicar las preferencias personales de los usuarios para las
distintas categorías existentes dentro de una ciudad. Un ejemplo de esto podría ser que el
usuario Juan Gómez prefiere ir a restaurantes italianos en la ciudad de Mar del Plata. La
salida de este módulo es la conformación de un grupo de “expertos” en determinadas
categorías pertenecientes a una ciudad. Posteriormente estos usuarios serán un punto de
referencia al momento de recomendar lugares que pertenezcan a una categoría dada (bar,
restaurante, museo, etc.) situados en una ubicación geoespacial determinada.
Para la creación de este modelo, nos hemos basado en el análisis de las preferencias
de los usuarios tanto individual como grupalmente dentro de la red social.
56

Las actividades de este componente son muchas y de complejidad muy variada. Existe
una fase inicial de puntuación o pesaje de las categorías del sistema. Para todos los casos,
esta puntuación se realiza utilizando el algoritmo TF-idf. Dentro de estos cálculos, se pueden
mencionar los siguientes:
● Obtención de preferencias de un usuario para las diferentes categorías. En este
procedimiento, a cada usuario se le asigna un peso basado en el cantidad de visitas
que posee para cada categría.
● Obtención de preferencias de un usuario para las diferentes categorías, para una
ciudad dada. Similar al anterior, pero con el detalle de que se agrupa por ciudad por el
siguiente motivo: el usuario va a tener mayor cantidad de visitas en su ciudad de
origen, y por consiguiente, ser considerado un experto local.
● Generar jerarquía de categorías. En este caso, se calcula el peso para una categoría
sin distinción de usuario o ciudad. Esta información resulta útil para saber cual es la
preferencia a nivel global de los usuarios del sistema.
● Además del cálculo de relevancia para los tipos de lugares, existe un proceso posterior
a esto que se encarga de generar expertos locales. Esta información es de vital
importancia para los módulos que se ejecutarán posterior a este. La generación de
este grupo de usuarios se va a explicar más adelante, en este capítulo.
La figura 4.5 muestra cómo es el proceso de generación de los distintos expertos locales.
57
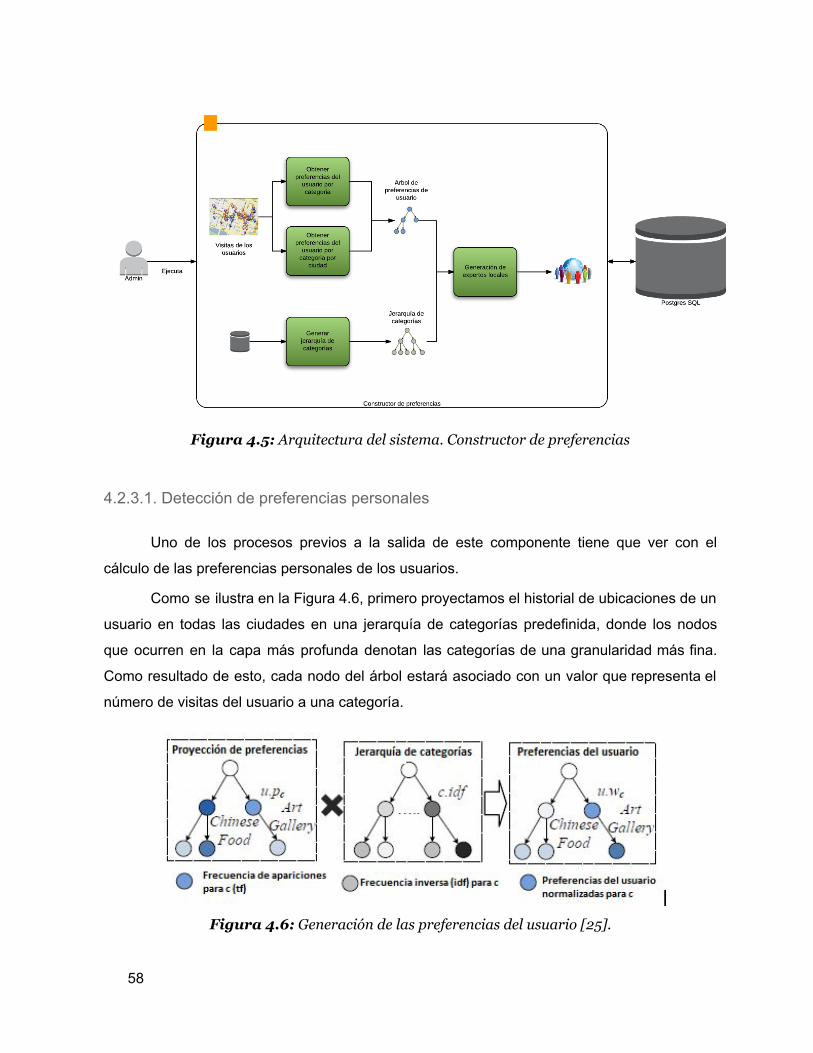
Figura 4.5: Arquitectura del sistema. Constructor de preferencias
4.2.3.1. Detección de preferencias personales
Uno de los procesos previos a la salida de este componente tiene que ver con el
cálculo de las preferencias personales de los usuarios.
Como se ilustra en la Figura 4.6, primero proyectamos el historial de ubicaciones de un
usuario en todas las ciudades en una jerarquía de categorías predefinida, donde los nodos
que ocurren en la capa más profunda denotan las categorías de una granularidad más fina.
Como resultado de esto, cada nodo del árbol estará asociado con un valor que representa el
número de visitas del usuario a una categoría.
Figura 4.6: Generación de las preferencias del usuario [25].
58

La motivación de este paso es ganar precisión en el caso de categorías que tengan
gran cantidad de niveles. Por ejemplo, se puede identificar a un usuario cuya preferencia por
los lugares de categoría “restaurantes” sea alta y su vez la distribución de visitas de este
usuario puede ser equitativa en categorías de granularidad más fina tales como “restaurante
italiano”, “restaurante chino” o “asador criollo”. Del mismo modo, otro usuario de la red social
puede mostrar una afinidad similar por la categoría restaurantes pero al momento de ver la
granularidad de las subcategorías puede ser que la distribución está concentrada solo en
“restaurante italiano”.
Como segundo paso de este proceso, se calcula el valor de TF-IDF para cada nodo presente
en la jerarquía. Para poder utilizar dicho algoritmo, se realiza el siguiente mapeo:
● El historial de ubicaciones del usuario se considera un documento.
● Las categorías se consideran términos dentro del documento.
De todo esto, se puede intuir que un usuario visitará más lugares correspondientes a
un tipo en especial si el mismo usuario tiene una preferencia por ello.
Además, si un usuario visita las ubicaciones de una categoría que rara vez es visitada
por otras personas, el usuario podría tener un gusto de esta categoría mucho más prominente.
Por ejemplo, el número de visitas a restaurantes es generalmente mayor al que otras
categorías como “Museo de historia”. Esto no significa que el alimento sea el primer interés de
toda la gente, más bien sería una necesidad para muchas personas. Sin embargo, si
encontramos un usuario visita museos con mucha frecuencia, el usuario puede estar
verdaderamente interesado en este tipo de visitas [25] .
Retomando el cálculo de las preferencias de los usuarios por una categoría, tenemos
la siguiente ecuación:
Ecuación 4.1: Preferencia de un usuario por una categoría
Donde la primera parte de la ecuación representa la frecuencia de una categoría c en
el histórico de visitas de un usuario u y la segunda parte denota el valor IDF para c .
59

La ecuación presentada se compone de los siguientes términos:
● |{u.vi : vi.c = c′}| : es el número de visitas de un usuario u a una categoría c’.
● u.V: es el número total de visitas del usuario u.
● |{uj :c′ 2 uj .C}|: cuenta el número de usuarios que han visitado lugares de categoría c’
dentro del conjunto de usuarios del sistema.
Volviendo a la figura 4.6, se puede ver cómo Chinese food dejó de ser la primera
preferencia del usuario. Este proceso realizado ayuda a detectar mejor los intereses de los
usuarios, teniendo además las siguientes ventajas:
● Reduce el problema de que distintos usuarios tengan distinto volumen de visitas.
● Permite el cálculo de similitud entre usuarios que no comparten ninguna historia de
ubicación física, por ejemplo, que viven en diferentes ciudades.
4.2.3.2. Uso del Sentimiento como preferencia
En la sección anterior explicamos cómo se establecen las preferencias de un usuario
en particular utilizando el algoritmo TF - IDF, teniendo como premisa que si un lugar era
visitado por una persona una gran cantidad de veces, era de su preferencia. Si bien es una
presunción totalmente válida, existe otra variante que se puede utilizar al momento de medir
las preferencias de la persona. Dado que el conjunto de datos utilizado, además de poseer el
registro de la visita, tiene consigo un texto que es la revisión o crítica del lugar realizada por el
usuario. Calculando el sentimiento sobre esa revisión se puede obtener, además de la visita,
un valor numérico que representa la satisfacción del usuario con el lugar.
Para el cálculo de sentimiento se utiliza uno de los comandos provistos por el
componente Refinador de Información (visto en la sección 4.2.2). El sentimiento se compone
de dos valores:
● Sentimiento, que puede ser positivo, indicado en el sistema con el valor 1, negativo, de
valor -1, e informativo o neutro con valor 0.
● La intensidad de sentimiento, que es un valor que oscila entre 0 y 100. Cuanto más
cerca de 0, más neutro será el texto analizado y cuanto más cerca de 100 más positivo
o negativo. Esto se basa en la idea de que teniendo dos afirmaciones de igual
sentimiento (negativo o positivo) una tenga mayor peso que otra. Por ejemplo, en el
caso de un hospedaje en un hotel no será lo mismo si el usuario escribe
negativamente acerca del servicio de desayuno o si además del servicio de desayuno
60

no quedó conforme con la atención en la recepción. Si bien ambas afirmaciones son
negativas, la segunda representa una crítica más fuerte que la primera.
A continuación, se detalla cómo se utiliza el sentimiento automático como medida de
preferencia. Para ello se va a utilizar el número de check-ins y los puntajes obtenidos del
servicio de sentimiento sobre los tips.
De igual manera que con el valor de preferencia anterior, se utilizará una escala de 1 a
5 para representar la preferencia de un usuario por un lugar, donde 1 es el grado de
preferencia más bajo y 5 el más alto.
La figura 4.7 ilustra cómo varían los valores de sentimiento para los distintos lugares
dentro de la red social, donde el eje de las abscisas representa el valor de sentimiento y el de
las ordenadas la cantidad de visitas realizadas. En ese gráfico, los valores de sentimiento
fueron normalizados para entrar en el rango de -1 a 1, multiplicando a cada tip por su valor de
sentimiento (1, o -1), según corresponda.
Figura 4.7: Sentimiento de los distintos tips [18]
Como el puntaje de sentimiento extraído de las críticas contiene información más
precisa acerca de los gustos del usuario, debería considerarse junto con el número de visitas,
para personalizar aún más las preferencias de los usuarios.
Como paso siguiente, se va a intentar combinar el número de visitas realizadas a un
lugar junto con el sentimiento de ese lugar a través de todas sus visitas. Para ello, primero se
definirá un criterio de fusión que ayude a resolver el conflicto entre los valores de una y otra.
Para definir este criterio se asume lo siguiente:
61

● Una visita a un lugar no revela información suficiente acerca de lo que el usuario siente
allí. En este caso, el sentimiento expresado por la crítica ingresada en dicho lugar dará
información más precisa de la preferencia final del usuario.
Por ejemplo, si un usuario deja una revisión muy positiva (calificación 5) en un lugar
visitado en una sola ocasión (calificación 1), la calificación final será 5.
● Los usuarios que visitan un lugar al menos 2 veces, usualmente tienen alguna
preferencia por dicho lugar. El sentimiento adjunto a los tips del usuario en ese tipo de
lugar podría tener un impacto sobre la preferencia final. En este caso, el valor de
sentimiento es usado para modificar la preferencia establecida por la cantidad de
check-ins. Por ejemplo, cuando un usuario tiene una preferencia de check-in de 3
puntos en un lugar y deja un tip muy negativo (1 punto), la calificación de preferencia
final será 2.
De los puntos presentados anteriormente se de deduce la ecuación 4.2:
Ecuación 4.2: Preferencia de un usuario por una categoría
Donde Pc y Ps es la calificación establecida para la matriz de preferencia de check-ins y
sentimiento, respectivamente.
H(x) es la función escalón de Heaviside y la función sgn se define como:
Ecuación 4.3: función signo
Ecuación 4.4: función escalón de Heaviside
Basándonos en estas premisas y el criterio de fusión, construimos una matriz de
preferencias híbrida que combina información de check-ins y sentimiento extraído de los tips.
62

4.2.3.3. Detección de expertos locales
De acuerdo a lo presentado en la figura anterior (4.5), se observa claramente que la
salida de este componente tiene que ver con la detección de los expertos locales. Los tres
procesos previos tienen como objetivo ajustar la información para que esto suceda.
Para identificar los expertos locales de una categoría como por ej. “Comida China” y
“Shopping”, este componente calcula la experiencia de un usuario en cada categoría en
diferentes ciudades. Esto es realizado basándose en la información encapsulada del historial
de visitas de los usuarios a cada categoría de lugar. En pocas palabras, este proceso
descubre que tipo de lugares son los preferidos de un usuario dentro de la red social.
Se asume que los expertos locales de cada categoría pueden encontrar lugares de
mejor calidad en sus respectivas categorías. Además, el uso de estos expertos locales
permite ignorar algunos usuarios que poseen muy poca información (y conocimiento) en una
categoría dada. El objetivo de esto último es reducir la complejidad temporal de los distintos
algoritmos al momento de efectivizar la evaluación de los mismos. El proceso de evaluación
de algoritmos es extenso y costoso, con lo que cualquier optimización que se pueda realizar
tiene su grado de importancia.
En el método presentado, primero se agrupan todas las visitas de cada usuario por
ciudad y categoría. Esto tiene una explicación, la experiencia de los usuarios varía en
términos geográficos. Por ejemplo, un usuario podría saber cuales son los mejores
restaurantes de “Comida China” existentes en la ciudad de Nueva York, por ser habitante o
visitante frecuente, pero no tener información acerca de cuáles restaurantes visitar en la
ciudad de Los Ángeles.
Como resultado de esta agrupación, cada ciudad tiene un número N de matrices de
preferencia. La dimensión de las matrices es de N x M, donde N es el número de categorías
en el sistema y M es la cantidad de usuarios de la red social. La matriz se completa con un
valor de preferencia que consiste en el número de visitas que un usuario ha efectuado a un
determinado tipo de lugar. Para no realizar este cálculo cada vez que se necesita esta
información, se aplicaron vistas en la base de datos, donde con una simple consulta SQL se
puede obtener la matriz requerida.
63

El siguiente, es un ejemplo de una de las vistas que se utilizan en el sistema. La misma
calcula la cantidad de visitas que realiza un usuario, agrupada por categoría y por la ciudad en
la que se realiza.
CREATE VIEW user_category_city_chekins as SELECT u.id_user, v.city,
vc.category, count(1) as total
FROM users u
INNER JOIN tips t on ( t.id_user = u.id_user )
INNER JOIN venue v on (t.venue_id = v.id)
INNER JOIN venue_category vc on ( vc.venue_id = v.id )
GROUP BY u.id_user, v.city, vc.category
ORDER BY total DESC;
Figura 4.8: Identificación de expertos locales
En la figura 4.8 vemos como este modelo considera una visita individual a un lugar
como un link directo de un usuario a un lugar. Cada usuario tiene un puntaje de autoridad (en
el marco de este trabajo, puede ser la cantidad de veces que visitó ese lugar o bien utilizando
la ponderación propuesta en la sección 4.2.3.2, con cálculo de sentimiento incluído. Ese lugar,
posee una o más categorías asociadas. La suma del valor de autoridad para todos los lugares
pertenecientes a esa categoría dentro de una ciudad denota su conocimiento para cada
categoría indicando su nivel de preferencia.
64

Así, la gente que ha visitado los lugares de mayor calidad en una región, es más
probable que tengan mayor conocimiento acerca de la región. Sucesivamente, un lugar
visitado por muchas personas de mayor conocimiento en una región, es más probable que
sea un lugar de mayor calidad.
Como resultado de esto, obtenemos las ecuaciones 1 y 2. El conocimiento de un
usuario puede ser representado por la suma de la calidad de los lugares visitados por el
usuario, y la calidad de un lugar puede ser representada por la suma del conocimiento de los
usuarios que han visitado el lugar.
Ecuación 4.5: Calidad de los lugares visitados por un usuario (1) y calidad del lugar (2)
4.2.4. Evaluador de Recomendaciones
Continuando con el detalle de los componentes de la arquitectura diseñada, es el turno
de explicar en detalle cómo funciona uno de los módulos más importantes, el Evaluador de
Recomendaciones. El mismo tiene como objetivo medir la eficiencia y el comportamiento de
los distintos algoritmos de recomendación sobre distintos escenarios de entrada. Con esto
último, se podrá saber bajo determinadas circunstancias cuáles son los algoritmos ofrece
mejores recomendaciones.
Si bien este módulo puede funcionar de manera autónoma, tiene una fuerte
dependencia con el módulo Constructor de Preferencias mencionado anteriormente, ya que
muchas de las entradas que posee este módulo, como pueden ser el cálculo de las
preferencias de los usuarios, van a ser utilizadas como distintos escenarios de pruebas.
En la figura 4.9 se puede ver como funciona este módulo a alto nivel.
65

Figura 4.9: Funcionamiento de Evaluador de Recomendaciones
En principio, va a ser un usuario de tipo administrador el que va a lanzar la ejecución
del componente. El mismo ingresa datos al sistema como pueden ser la ciudad (obligatorio) y,
si se quisiera hacer un experimento más detallado, una coordenada de referencia en conjunto
con un radio. El objetivo de esto es acotar la cantidad de lugares logrando así mejorar la
performance del sistema. Si bien es algo secundario, como ya se mencionó anteriormente, la
evaluación del recomendador es un proceso costoso en lo que a complejidad temporal se
refiere, es por eso que además de la eficacia del recomendador, la performance también será
una variable a considerar.
El paso siguiente es la elección del algoritmo a utilizar. Como se ve en la figura 4.9,
existen tres módulos que se encargan de realizar las distintas recomendaciones. Uno de los
tres será escogido por el usuario administrador para su posterior evaluación. Cabe destacar
que para poder materializar la implementación de los mismos se utilizó Apache Mahout como
herramienta soporte. Respecto a las opciones a elegir, se disponen de las siguientes:
● Recomendador Base: En este caso se implementó un algoritmo de filtrado
colaborativo basado en usuarios, pudiendo utilizar una función de similitud como el
coeficiente de correlación de Pearson, la similitud del coseno o cualquier otra
66

implementación de la función de similitud. Este módulo utiliza implementaciones
realizadas por Mahout, por lo tanto es utilizado como línea base para comparar
resultados. Esta línea base, es un punto de referencia para medir cuán bien o mal
responden el resto de las implementaciones.
● Ratings Inferidos: Para este componente también se utilizó filtrado colaborativo
basado en usuarios pero con algunas variantes. Primero, se implementó una solución
más a medida de la problemática particular que consiste en la selección de usuarios
candidatos basado en las preferencias calculadas por el módulo Constructor de
Preferencias. Además de esto, debido a la escasa correlación de usuarios dentro del
conjunto de datos, se llevó a cabo el cálculo de calificación de lugares. Este módulo es
el encargado de inferir la calificación que un usuario le asignaría a un lugar. Las dos
mejoras realizadas serán explicadas en detalle en la sección 4.2.4.3.
● Factorización de Matrices: Para este caso particular se decidió cambiar el enfoque y
evaluar un algoritmo completamente diferente. Se utilizaron algoritmos de factorización
de matrices adaptados para la problemática. Además de la implementación
convencional del algoritmo de Factorización de Matrices, se ofrece la posibilidad de
ejecutar la evaluación sobre una modificación del mismo que será explicada más
adelante en la sección 4.2.4.3.
4.2.4.1. Recomendador Base
El primer recomendador implementado fue el Recomendador Base (RB). Como se
mencionó anteriormente, el objetivo de este módulo es el de establecer una línea base para
tener un punto de comparación para las posteriores implementaciones.
El componente está conformado íntegramente por componentes de Apache Mahout,
como lo son el algoritmo de filtrado colaborativo o el cálculo de similitud de usuario realizado
utilizando tanto el coeficiente de correlación de Pearson, la similitud del coseno o cualquier
otra implementación de algoritmo de similitud.
La figura 4.10 muestra el funcionamiento de RB. Como se puede apreciar, permite la
elección de la función de similitud a utilizar como paso previo a la ejecución del filtrado
colaborativo.
67

Figura 4.10: Funcionamiento del Recomendador Base
4.2.4.2. Comparación de árboles de usuarios
Como segunda implementación realizada, se construyó un componente muy similar al
RB implementado en la sección anterior pero utilizando una función de similitud personalizada
que consiste en la comparación de árboles n-arios pertenecientes a los distintos usuarios
registrados en el sistema, donde cada nivel del mismo está formado por una granularidad de
una categoría o clasificación de un sitio y siendo el valor de cada nodo un valor numérico que
representa la preferencia de un usuario por dicha categoría.
La similitud entre dos árboles estará dada por la suma de las similitudes entre cada
nivel del árbol, donde los niveles más profundos representan un mayor peso debido a la
granularidad de las categoría. La similitud entre dos niveles iguales de diferentes árboles de
preferencias es medida por las siguientes características:
La primera característica es la cantidad de nodos superpuestos y el mínimo valor de
preferencia del nodo en esa categoría:
Ecuación 4.6: valor mínimo de preferencia para un nivel
Cuantos más nodos superpuestos haya, 2 usuarios serán más similares. La segunda,
es la entropía de cada nivel, que puede capturar efectivamente la diversidad de las
preferencias de los usuarios (como se muestra en la ecuación 4.7),
68

Ecuación 4.7: Entropía para un nivel l
Donde H(u,l) es la entropía del usuario en el nivel l y P(c) es la probabilidad de que u
haya visitado un lugar en la categoría c en sus datos históricos. Finalmente, la similitud entre 2
árboles puede ser calculada como :
Ecuación 4.8: Similitud entre dos árboles
Donde β es una peso que varía según la importancia que le demos al nivel de
profundidad del árbol, en nuestro caso utilizamos la función para que dicha importancia 2l
varíe exponencialmente.
Resumiendo, 2 usuarios son probablemente más similares cuando:
● Comparten mayor cantidad de nodos con grandes pesos de preferencia.
● La diferencia entre cada nivel de entropía es pequeña.
● Los nodos son ubicados superpuestos están ubicados en los niveles más profundos
del árbol.
4.2.4.3. Ratings Inferidos
Para esta implementación en particular, previo a la ejecución del algoritmo de filtrado
colaborativo y su posterior ejecución, se introdujeron algunas mejoras al conjunto de datos
dado. La figura 4.11 muestra el funcionamiento general de este módulo y cuales son los pasos
previos que se utilizan para mejorar la calidad de las recomendaciones.
69

Figura 4.11: Funcionamiento de Ratings Inferidos
El primer paso que se realiza es la selección de candidatos basados en preferencias o
PACS (del inglés, Preference Aware Candidate Selection ), presente en la figura.
Este componente, selecciona un conjunto de expertos locales y lugares pertenecientes a un
área específica utilizando el algoritmo de selección de candidatos, garantizando así que el
número de lugares seleccionados no exceda el de un parámetro K y la distribución de los
expertos locales seleccionados encajen con las preferencias del usuario.
70

Figura 4.12: Algoritmo PACS [7].
Dado un punto P en el que el usuario se encuentra y un rango R especificado por el
mismo, el algoritmo tomará los V’ lugares dentro del radio y los U usuarios que hayan visitado
lugares en V ’ (Línea 1 y 2).
Luego inicia el proceso de selección de expertos locales recorriendo los nodos del
árbol de preferencias del individuo (que representan categorías) desde sus hojas, moviéndose
hacia arriba si la cantidad de lugares requerida aún no es cumplida.
Esta estrategia soluciona el problema del arranque en frío, ya que no depende tanto de
del conocimiento del usuario en dicha región, sino que se basa en el conocimiento de los
expertos locales y su similitud con ellos para recomendar.
Cuando se seleccionan lugares en un nivel del árbol, escogemos el nodo con menor
valor wmin. Después, calculamos un valor K = | u.wc / wmin |, donde u.wc es la preferencia del
71

usuario u para una categoría c, para decidir el número de expertos locales que se
seleccionarán de la categoría y se seleccionarán los top-k usuarios con mayor autoridad en
dicha categoría, añadiendoles al conjunto E de candidatos expertos.
Los lugares visitados dentro de R por los usuarios en E serán añadidos a V.
El punto de corte del algoritmo será cuando se consiga la cantidad suficiente de lugares
requerida en V .
El algoritmo mejora significativamente la eficiencia, ya que no necesita computar la
similitud entre el usuario y el resto de los usuarios dentro del área.
De esta forma, también son excluídos los usuarios que tienen poco conocimiento en
dicha región.
Una vez ejecutado el algoritmo PACS, se aplica una segunda mejora que consiste en
el cálculo de calificación de lugares. Esta parte del sistema infiere la calificación que un
usuario le asignaría a un lugar si lo visitara.
Para esto, primero calculamos la función de similitud de usuario, vista en la sección
4.2.4.2, entre el individuo en cuestión y cada experto local (seleccionado por el algoritmo
PACS).
Luego, ubicamos los expertos locales y lugares candidatos seleccionados por el
Algoritmo en la matriz de preferencias, que será el modelo a utilizar por el algoritmo de filtrado
colaborativo basado en usuario para inferir calificaciones del usuario a lugares candidatos.
La idea detrás del filtrado colaborativo es que los usuarios similares califican los ítems
similarmente.
Como los usuarios normalmente no dejan calificaciones explícitas en los lugares, hasta
ahora se ha utilizado el número de visitas a un determinado lugar como una calificación
explícita. El feedback implícito favorece a solucionar el problema de la dispersidad de los
datos, ya que cumple el rol de completar la matriz de calificaciones que le sirve como entrada
al algoritmo.
La calificación de un usuario u a un lugar v es calculada como:
Ecuación 4.9: calificación inferida de un usuario u a un lugar v
72

Donde v(u′, v) hace referencia al número de visitas de un usuario (u’,v).
La función Sim(u,u’) es la comparación de los árboles de los usuarios u y u’,
mencionada anteriormente en la sección 4.2.4.2. Así es como se generan recomendaciones
para un usuario dado. Por último, el sistema deberá encargarse de retornar los N lugares con
las clasificaciones calculadas de mayor valor.
4.2.4.4. Factorización de Matrices
Otra de las técnicas utilizadas para el recomendador fue la de factorización de
matrices. Como mencionamos anteriormente, en el Capítulo 2, esta técnica está basada en
feedback implícito, lo cual ayuda a resolver el problema de la dispersión de los datos.
Para implementar esta técnica, se utilizaron componentes existentes provistos por
Apache Mahout. Los mismos se pueden utilizar implementando una interfaz para construir un
recomendador basado en factorización de matrices. La idea detrás de esto es la de proyectar
los usuarios e ítems dentro de un espacio de características de dimensión f , e intentar
optimizar los vectores y , de modo tal que el resultado de sea lo más cercano
posible a R como se ha descrito en el Capítulo 2, en la Ecuación 2.2.
Siguiendo con los detalles de implementación, para lograr tener esta técnica
funcionando se realizaron dos implementaciones diferentes. La primera consiste en la
Descomposición de Valores Singulares, de ahora en adelante SVD, y la segunda
Descomposición de Valores Singulares utilizando feedback implícito (SVD++).
La primer solución, hace uso de la implementación básica de Mahout, donde lo único
que debemos pasarle como parámetro es el modelo de datos a utilizar y el método calcula los
valores de P y Q haciendo uso de la distribución normal de Gauss.
Si bien Apache Mahout cuenta además con una implementación del algoritmo SVD++,
la misma no acepta como parámetros las características de los usuarios e ítems y se basa en
el método de factorización del algoritmo del gradiente descendente (AGD), que utiliza valores
aleatorios entre 0 y 1 para inicializar los vectores .
Debido a esto, la segunda implementación surge de la imposibilidad de utilizar las
categorías dentro de la dimensión de características en el método de factorización SVD++.
Por lo que esta nueva solución consta de una adaptación al método SVD++ para que los
73

vectores P y Q sean generados haciendo uso de la información de los usuarios y lugares
respectivamente. Finalmente la dimensión f estará dada por el listado de las categorías del
conjunto de datos.
Figura 4.13: Elementos en la factorización de matrices
Como se aprecia en la figura, R es la matriz de preferencia de los usuarios y los lugares.
Dentro de P, están los valores que representan la preferencia de los usuarios por cada
categoría, y dicho valor será extraído de la base de datos haciendo uso de la estructura de
datos generada para calcular los expertos locales que era calculada mediante la realización
de TF-IDF.
La matriz Q, estará dada por el listado de las categorías que poseen los distintos
lugares. El valor ubicado en dicha posición contendrá un 0 si la categoría no se encuentra
relacionada al lugar o un 1 si la categoría se haya presente.
Las matrices P y Q serán entregadas a una redefinición de la clase SVD++. La nueva
definición de SVD++ será modificada para tomar los valores de dichas matrices en lugar de
utilizar la distribución de Gauss para inferir los ratings y así utilizar los valores asociados a las
características de los usuarios y lugares.
74

Con esta nueva implementación, se dispondrá de un recomendador que utilice las
categorías de los lugares y el grado de asociación a cada usuario para generar
recomendación con el método de factorización de matrices.
4.2.4.5. Evaluación de resultados
Para finalizar con la descripción del Evaluador de Recomendaciones, como se ve en la
figura 4.9, existe un último paso que es la evaluación de resultados. La salida de este módulo
es un reporte con diferentes métricas aplicadas a las recomendaciones brindadas por un
recomendador elegido previamente.
Este módulo está íntegramente basado en métodos de evaluación implementados por
Apache Mahout. La lista de métricas utilizadas fue la siguiente:
● Precisión
● Recall
● F1 Score
● Mean Absolute Error (MAE)
● Mean Square Root Error (MSRE)
4.2.5. Servicio de Recomendación
La función principal de este componente es la de, dado un usuario, retorna un listado
de N lugares recomendados que el sistema ha calculado que serán de su interés.
Para cumplir con esta función, se optó por utilizar el patrón de arquitectura
cliente/servidor, implementando una interfaz REST del lado del servidor. Representational
State Transfer (REST) es una técnica de diseño de software que adopta una arquitectura
cliente-servidor en la cual los servicios web son vistos como recursos y pueden ser
identificados por las URLs [19]. La elección de este paradigma se basa en desacoplar
totalmente la consulta y/o obtención de recomendaciones con la presentación de los mismos.
De esta manera, podemos integrar distintas aplicaciones que utilicen el mismo sistema de
recomendación. Un caso común por estos días es una aplicación móvil y otra aplicación web.
75

Figura 4.14: Servicio de Recomendación
Como se puede observar en la figura 4.14, un grupo de usuarios solicitan
recomendaciones al sistema. Se envian sus coordenadas geoespaciales, se obtiene una lista
de lugares cercanos y por último, utilizando algún algoritmo de recomendación se envía una
lista con posibles puntos de interés para el usuario final.
El servicio REST implementado recibe tres parámetros para poder hacer efectiva la
recomendación:
● Coordenadas geoespaciales: se utilizan para que la recomendación sea más
precisa. Con esto se quiere evitar que se recomienden lugares de interés que estén
demasiado lejos del usuario.
● Algoritmo a utilizar: Si bien es transparente al usuario final, el sistema dispone de
distintos algoritmos para la recomendación y tiene la opción de cambiar de algoritmo
cuando sea solicitado.
● Identificador del usuario: Un número que identifica al usuario dentro del sistema.
La siguiente imagen muestra la respuesta del sistema luego de una solicitud de un
usuario. El formato de la misma es en XML.
76

Figura 4.15: Respuesta del Servicio de Recomendación
77

Capítulo 5: Pruebas y resultados
El siguiente capítulo consta de una serie de experimentos realizados que tienen como
objetivo medir la eficacia de las recomendaciones en los distintos recomendadores
implementados para conocer cuales de estos otorgan recomendaciones más útiles a los
usuarios.
Para esto, se evaluaron diversos casos de estudio que consisten en distintas
configuraciones para el sistema de recomendación que estarán dadas por combinaciones de
las transformaciones realizadas sobre el conjunto de datos de entrada, elección de distintos
algoritmos de recomendación y elección del algoritmo de similitud de usuarios.
Finalmente los distintos experimentos darán como resultado una serie de métricas
como Precisión, Recall, RMSE y MAE. Luego, los resultados obtenidos serán comparados y
analizados para medir la eficacia de cada configuración.
5.1. Conjunto de datos
Para la materialización de los distintos experimentos se utilizó un conjunto de datos
provisto por el siguiente sitio http://www.public.asu.edu/~hgao16/recsys2014.html,
perteneciente a la Universidad Estatal de Arizona. El mismo contiene datos pertenecientes a
la red social Foursquare, dentro de los cuales se pueden encontrar un listado completo de
lugares con su ubicación geográfica y su categoría, un listado de revisiones de los lugares
realizada por los mismos usuarios de la red social y un conjunto de usuarios.
Por políticas de privacidad de las redes sociales basadas en ubicación, no es posible
obtener información acerca de la identidad de los usuarios, es por eso que, en el conjunto de
datos, los usuarios fueron traducidos a un identificador numérico para mantener su identidad
en el anonimato.
Este conjunto de datos posee información acerca de lugares visitados por usuarios en
las ciudades de Nueva York y Los Ángeles.
Un detalle fundamental del conjunto de datos escogido, es que este no posee
información de los checkins de los usuarios, pero por otro lado, si ofrece información de las
revisiones que los usuarios han dejado en los distintos lugares.
78

Estas revisiones poseen ventajas en relación a los checkins de los usuarios, ya que
nos dan mayor información respecto de los intereses del usuario. Un usuario puede haber
registrado una visita a un lugar sin haber hecho algo trascendente en él. No obstante, el dejar
una crítica o revisión, usualmente indica que el usuario ha llevado alguna actividad
trascendente allí. De hecho, como ya se mencionó en los capítulos anteriores, el sistema
puede ser configurado para realizar un cálculo de sentimiento sobre todas las revisiones de
los usuarios con el fin de establecer otra escala de calificaciones que será analizada como
caso de estudio en el presente capítulo.
La Tabla 5.1, muestra en detalle información acerca de la cantidad de usuarios, tips y
lugares para ambas ciudades que posee el conjunto de datos escogido.
Los Angeles Nueva York
Tips 163.969 423.442
Usuarios 501.940 716.776
Lugares 215.614 206.416
Tabla 5.1: Distribución de los distintos datos en las ciudades de Los Ángeles y Nueva York
Observando las cantidades de información descritas en la tabla, y una representación
geográfica de cómo se encuentran distribuidas las visitas en las 2 ciudades (Figura 5.1),
podemos observar una mayor densidad de información en la ciudad de Nueva York.
Figura 5.1: Demografía de visitas (izq: Los Ángeles; der: Nueva York) [25].
79
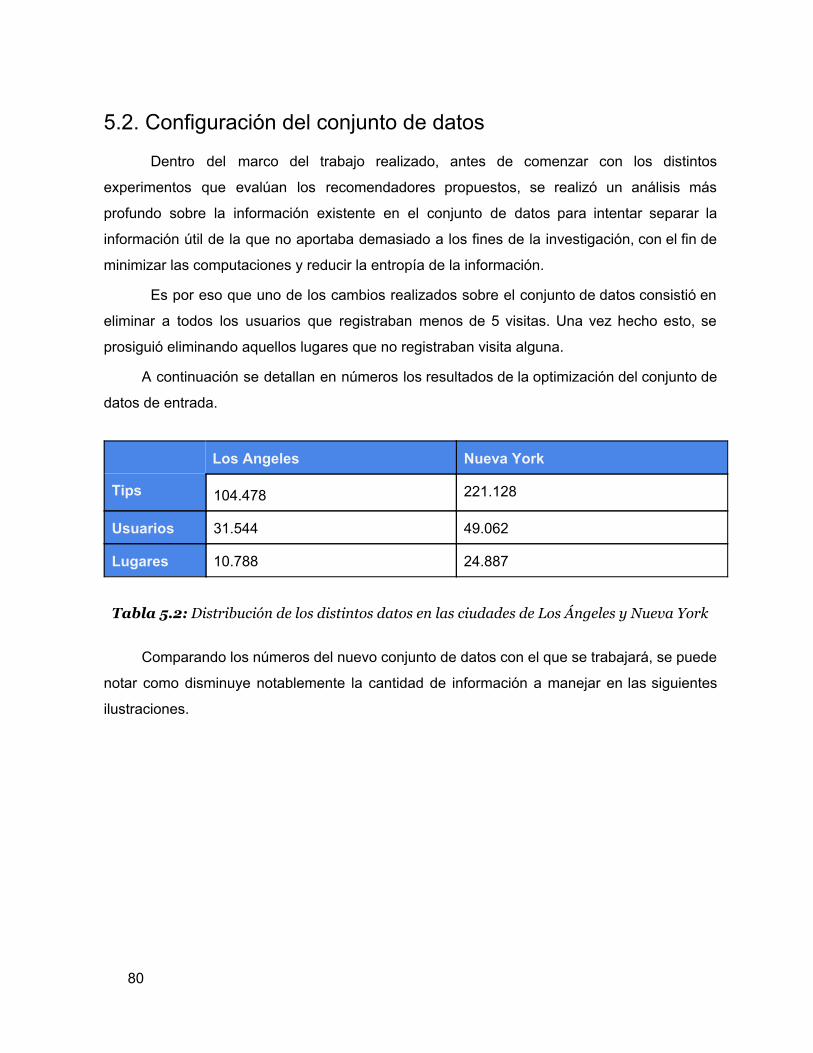
5.2. Configuración del conjunto de datos
Dentro del marco del trabajo realizado, antes de comenzar con los distintos
experimentos que evalúan los recomendadores propuestos, se realizó un análisis más
profundo sobre la información existente en el conjunto de datos para intentar separar la
información útil de la que no aportaba demasiado a los fines de la investigación, con el fin de
minimizar las computaciones y reducir la entropía de la información.
Es por eso que uno de los cambios realizados sobre el conjunto de datos consistió en
eliminar a todos los usuarios que registraban menos de 5 visitas. Una vez hecho esto, se
prosiguió eliminando aquellos lugares que no registraban visita alguna.
A continuación se detallan en números los resultados de la optimización del conjunto de
datos de entrada.
Los Angeles Nueva York
Tips 104.478 221.128
Usuarios 31.544 49.062
Lugares 10.788 24.887
Tabla 5.2: Distribución de los distintos datos en las ciudades de Los Ángeles y Nueva York
Comparando los números del nuevo conjunto de datos con el que se trabajará, se puede
notar como disminuye notablemente la cantidad de información a manejar en las siguientes
ilustraciones.
80

Figura 5.2: Comparación de tips, lugares y usuarios antes y después de optimizarlos.
5.3. Experimentos realizados
A continuación se detallan las distintas pruebas realizadas sobre el conjunto de datos
de entrada. Es necesario mencionar que las pruebas se encuentran divididas por la medida de
rankeo utilizada. Para la primer serie de experimentos se utilizó una medida de preferencias
basada en la cantidad de visitas que un usuario realizó a un lugar, y, para la segunda serie,
se tuvo en cuenta no solo la cantidad de visitas, sino que también se utilizó el valor asociado
al sentimiento del usuario por un lugar basándose en las revisiones hechas como se explicó
en el apartado 4.2.3.2.
81

Luego, los mejores resultados obtenidos de cada serie de experimentos, serán
comparados para deducir si al añadir información del sentimiento se obtiene algún beneficio
en la calidad de las recomendaciones.
Por otra parte, para el cálculo de la Precisión y Recall, se tuvo en cuenta un conjunto
de 5 lugares a recomendar para cada usuario. También es importante mencionar que para
cada medida de evaluación se utilizó el promedio de la métrica luego de correr 10 iteraciones
cada escenario seleccionado.
La serie de recomendadores a evaluar es la siguiente:
● Un Recomendador Base (RB), que representará al recomendador más sencillo de
todos. RB posee un algoritmo de similitud del coseno para los usuarios y la elección de
recomendaciones mediante la técnica de Filtrado Colaborativo basado en usuarios tal
como se ha descrito en el capítulo 4.2.4.1. Es necesario aclarar que además de esta
función de similitud se utilizó el Coeficiente de Correlación de Pearson, mencionado en
el capítulo 2, aunque se descartó debido a que la poca similitud entre los usuarios para
construir un vecindario hace que el algoritmo no pueda recomendar lugares en una
gran cantidad de casos.
● El segundo recomendador evaluado es el que utiliza como función de similitud la
comparación de árboles de usuario (UTC), provista en el capítulo 4.2.4.2. Este
recomendador intenta mejorar los resultados de RB modificando solo la función de
similitud, la técnica de recomendación continúa siendo filtrado colaborativo.
● El tercero de los recomendadores a evaluar, es el recomendador de Ratings Inferidos
(RRI). Este recomendador posee el mismo algoritmo de recomendación y similitud que
UTC, pero añade al archivo de preferencias de entrada un conjunto de ratings inferidos
haciendo uso de la implementación descrita en el capítulo 4.2.4.3.
● El cuarto recomendador a evaluar utiliza la técnica de Matrix Factorization (MF) para
generar las recomendaciones. La implementación de este método fue detallada en el
capítulo 4.2.4.4.
● El último recomendador del cual queremos observar su eficacia, es la variación
propuesta al método Matrix Factorization, que utiliza información de las categorías
para calcular los ratings implícitos tal cual como se explicó en el apartado 4.2.4.4.
Llamaremos a este recomendador MFC.
82

5.3.1. Experimentos realizados utilizando número de checkins
A continuación se muestran los resultados obtenidos utilizando el número de checkins
como medida de preferencia.
La medida propuesta para este experimento es calificar el valor de preferencia de los
usuarios de 1 a 5, siendo 1 el valor de preferencia si el usuario ha visitado una vez el lugar, 2
si lo ha visitado 2 veces, así sucesivamente hasta 5, que es el valor de preferencia de un
usuario que ha visitado un lugar 5 o más veces.
5.3.1.1 Resultados Recomendador Conj. de Datos RMSE MAE Precision Recall F1 Score
RB
New York 0.7770 0.5631 0.0095 0.0062 0.0075
Los Angeles 0.5874 0.5402 0.0239 0.0091 0.0132
UTC
New York 0.5284 0.2654 0.1024 0.0059 0.0112
Los Angeles 0.5512 0.3803 0.0715 0.0055 0.0103
RRI
New York 0.5922 0.3097 0.33880 0.3159 0.3269
Los Angeles 0.8852 0.5496 0.3438 0.3202 0.3316
MF
New York 0.5987 0.3444 0.02000 0.0200 0.0200
Los Angeles 0.7089 0.4009 0.02834 0.0283 0.0283
MFC
New York 0.5717 0.3630 0.0268 0.0268 0.0268
Los Angeles 0.6372 0.3845 0.0378 0.0378 0.0378
Tabla 5.3: Resultados obtenidos usando el nro de checkins como medida de ranking
5.3.1.2 Análisis de los Resultados Obtenidos
El siguiente apartado muestra una serie de visualizaciones de los resultados
obtenidos. Se puede observar cada métrica utilizada y la variación de la misma a lo largo
de los distintos recomendadores en las ciudades de Nueva York y Los Ángeles.
83
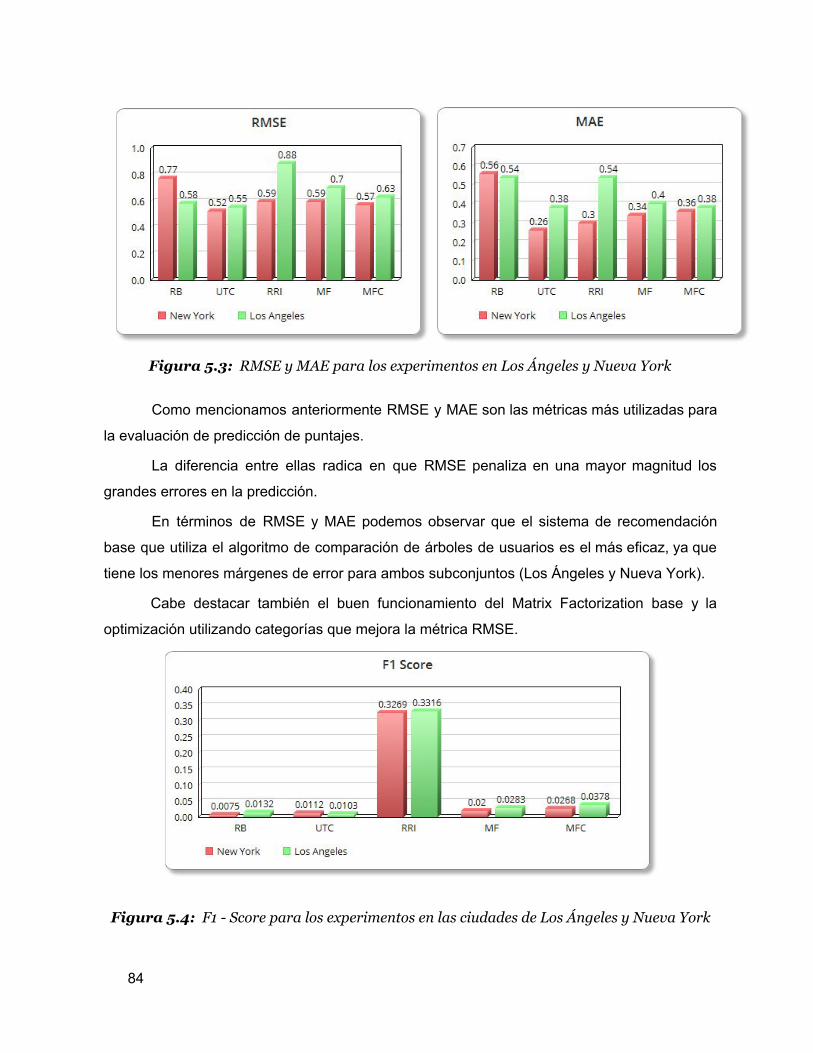
Figura 5.3: RMSE y MAE para los experimentos en Los Ángeles y Nueva York
Como mencionamos anteriormente RMSE y MAE son las métricas más utilizadas para
la evaluación de predicción de puntajes.
La diferencia entre ellas radica en que RMSE penaliza en una mayor magnitud los
grandes errores en la predicción.
En términos de RMSE y MAE podemos observar que el sistema de recomendación
base que utiliza el algoritmo de comparación de árboles de usuarios es el más eficaz, ya que
tiene los menores márgenes de error para ambos subconjuntos (Los Ángeles y Nueva York).
Cabe destacar también el buen funcionamiento del Matrix Factorization base y la
optimización utilizando categorías que mejora la métrica RMSE.
Figura 5.4: F1 - Score para los experimentos en las ciudades de Los Ángeles y Nueva York
84

En la figura 5.4 se observan los resultados obtenidos para la métrica F1 Score o
Valor-F, y lo más destacado es el alto rendimiento del recomendador con ratings inferidos.
Este comportamiento está dado por la mayor cantidad de calificaciones implícitas utilizadas
como entrada, que da como resultado una Matriz de preferencias más densa.
También observamos como el recomendador propuesto MFC mejora los resultados
obtenidos por MF al añadirle información de las categorías para calcular el feedback implícito.
Por último, analizando todas las métricas evaluadas puede concluirse que el
recomendador base es el que peor resultados de MAE y F1-score otorga, lo que nos hace
notar que todas las mejoras aplicadas que se realizaron y probaron mejoraron en mayor o
menor medidas los resultados obtenidos por el recomendador más simple de todos. Este
recomendador solo ha rendido mejor que algunos otros de los recomendadores propuestos en
la ciudad de Los Ángeles, al calcular el RMSE.
5.3.2 Experimentos realizados utilizando análisis de sentimiento
A continuación se muestran los resultados obtenidos utilizando el número de checkins
y el sentimiento analizado como medida de preferencia.
La medida propuesta para este experimento es calificar el valor de preferencia de los
usuarios de 1 a 5 usando los cálculos explicados en el capítulo 4.2.3.2.
5.3.2.1 Resultados Recomendador Conj. de Datos RMSE MAE Precision Recall F1 Score
RB
New York 0.8641 0.6992 0.0043 0.0041 0.0042
Los Angeles 0.9718 0.6219 0.0101 0.0071 0.0083
UTC
New York 0.7126 0.5618 0.0021 0.0021 0.0021
Los Angeles 0.7390 0.5866 0.0072 0.0056 0.0063
RRI
New York 0.8441 0.5483 0.0021 0.0021 0.0021
Los Angeles 0.7364 0.5822 0.0051 0.0048 0.0049
MF
New York 0.8159 0.5813 0.0131 0.0131 0.0131
Los Angeles 0.8571 0.5945 0.0215 0.0215 0.0215
MFC
New York 0.7672 0.5926 0.0285 0.0285 0.0285
Los Angeles 0.8153 0.5969 0.0496 0.0496 0.0496
85

Tabla 5.4: Resultados obtenidos usando el nro de checkins y el sentimiento analizado como
medida de ranking
5.3.2.2 Análisis de los Resultados Obtenidos
Al igual que en el análisis anterior se presentan una serie de visualizaciones que
permiten analizar y comparar más fácilmente las métricas obtenidas luego de evaluar los
experimentos.
Figura 5.5: RMSE y MAE para los experimentos con sentimiento en las ciudades de Los Ángeles y Nueva York
Como se observa en la figura 5.5, para la métrica RMSE el recomendador que
mejores resultados nos entrega es el UTC. Y el recomendador que peor efectividad posee
a la hora de predecir calificaciones es el Recomendador Baseline (RB).
Observando los resultados de MAE obtenidos podemos ver como el RRI es el que
arroja mejores predicciones, y con resultados muy similares se encuentra también el
recomendador UTC. Nuevamente, el que peor efectividad muestra es el recomendador
Baseline.
86

Figura 5.6: F1 - Score para los experimentos en las ciudades de Los Ángeles y Nueva York
Al momento de observar los resultados obtenidos para la métrica F1, nos encontramos
con que los algoritmos implementados con factorización de matrices otorgan las mejores
predicciones.
El recomendador MFC es el que mejores recomendaciones genera y contrariamente el
recomendador RRI es el que peor F1 alcanza.
5.4. Comparación de ambas series de experimentos
El siguiente apartado tiene el objetivo de comparar los distintos recomendadores
presentados en la sección anterior, para identificar el recomendador y el modelo de
preferencia de usuarios que otorga las mejores predicciones.
Siguiendo el análisis deducido para los experimentos anteriores, compararemos los
resultados obtenidos por los recomendadores con mejor rendimiento para cada métrica y
medida de ranking.
Para las métrica RMSE y MAE se tomará el recomendador UTC como referencia con
ambas medidas de rankeo, ya que este recomendador es el que mejores predicciones otorga
en cada uno de los experimentos.
87
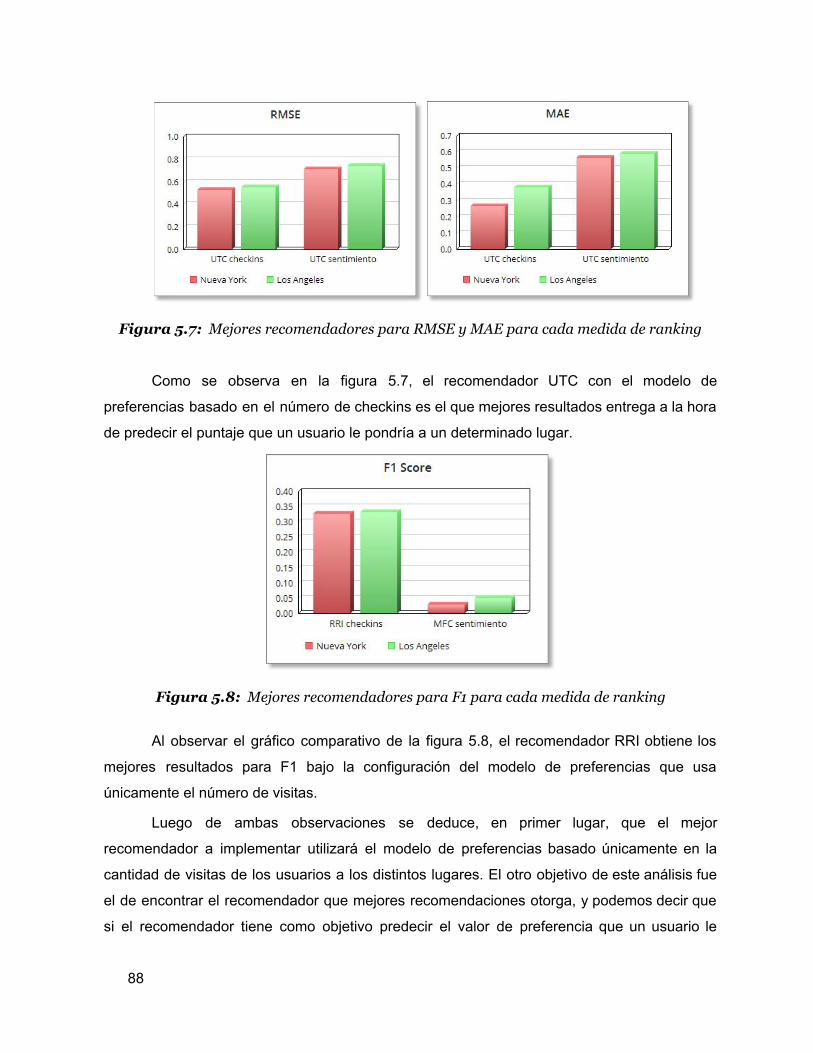
Figura 5.7: Mejores recomendadores para RMSE y MAE para cada medida de ranking
Como se observa en la figura 5.7, el recomendador UTC con el modelo de
preferencias basado en el número de checkins es el que mejores resultados entrega a la hora
de predecir el puntaje que un usuario le pondría a un determinado lugar.
Figura 5.8: Mejores recomendadores para F1 para cada medida de ranking
Al observar el gráfico comparativo de la figura 5.8, el recomendador RRI obtiene los
mejores resultados para F1 bajo la configuración del modelo de preferencias que usa
únicamente el número de visitas.
Luego de ambas observaciones se deduce, en primer lugar, que el mejor
recomendador a implementar utilizará el modelo de preferencias basado únicamente en la
cantidad de visitas de los usuarios a los distintos lugares. El otro objetivo de este análisis fue
el de encontrar el recomendador que mejores recomendaciones otorga, y podemos decir que
si el recomendador tiene como objetivo predecir el valor de preferencia que un usuario le
88

pondría a un lugar, el recomendador UTC es el que otorga los mejores resultados, pero por
otro lado, si lo que queremos encontrar son solamente lugares que le sean de interés a un
usuario, RRI sería la mejor solución para dicho problema.
89

Capítulo 6: Conclusiones
Finalmente, en el siguiente capítulo se van a presentar las conclusiones de la
investigación realizada que incluye un análisis profundo de las distintas pruebas realizadas
basadas en la implementación provista.
Por otro lado, también se van a mencionar distintas alternativas para la potencial
continuación del trabajo realizado.
6.1. Conclusiones En este trabajo, se demostró cómo modelar las preferencias del usuario y que clase de
recomendador implementar para generar un recomendador de lugares utilizando
información de una RSBU.
Se mostró como aprovechar la información espacial y semántica para estimar las
preferencias de los usuarios. Además, se hicieron diversos análisis y desarrollos de
distintos recomendadores que intentarían encontrar recomendaciones a los usuarios
utilizando distintos algoritmos de similitud y técnicas de recomendación.
Finalmente, se realizó una serie de experimentos sobre la información modelada y se
analizó y comparó el resultado de los mismos.
Las evaluaciones entre los distintos recomendadores implementados dieron como
resultado que el recomendador que mejor rendimiento posee a la hora de predecir el
puntaje que un usuario le dará a un lugar, es el recomendador que usa como algoritmo de
similitud la función UTC (descrita en la sección 4.2.4.2 ), y a la hora de predecir lugares
que resultan de interés al usuario o no, el recomendador que hace uso de ratings inferidos
(RRI) fue quien obtuvo mejores resultados.
Otra de los factores importantes a destacar es cómo los distintos recomendadores
implementados que aplican alguna mejora sobre el recomendador base siempre mejoran
su efectividad.
También es útil resaltar cómo al mejorar el algoritmo de Matrix Factorization provisto
por Mahout, se consiguieron mejores resultados.
90

Por último, se pudo concluir que añadiendo información del sentimiento aplicado a las
revisiones para modelar las preferencias del usuario, no se mejoran los resultados
respecto de modelar las preferencias haciendo uso solamente de la cantidad de veces que
un usuario visitó un lugar.
6.2. Trabajos Futuros
En el desarrollo del presente trabajo se ha puesto énfasis principalmente en la calidad
de las recomendaciones realizadas por parte del sistema. Para ello se han utilizado premisas
del comportamiento de las personas dentro de las redes sociales basadas en ubicación,
hechos como el historial de visitas de los usuarios, el contenido de los tips dejados en los
distintos lugares y las categorías de los lugares.
Para concluir con el presente trabajo, se presentan algunos posibles trabajos futuros
que podrían desarrollarse en base al mismo:
● Investigar el efecto de los patrones temporales para generar recomendaciones.
Dentro de este análisis se encuentran los patrones secuenciales y los patrones
periódicos:
○ Los patrones secuenciales hacen referencia al orden en el que los lugares son
visitados. Por ejemplo: Visitar un bar luego de trabajar. Ir a un café luego de
visitar un aeropuerto. Por lo general, situaciones como esta son modeladas
haciendo uso de Modelos de Markov.
○ Los patrones periódicos hacen referencia al momento en el que son realizadas
las acciones. En este caso, se intentaría modelar la preferencia de los usuarios
por visitar lugares similares en determinados horarios y días. Por ejemplo: Los
viernes por la noche algunos usuarios tienden a ir a cenar.
Existen trabajos relacionados con este tema en los cuales basarse como por
ejemplo “Exploring Temporal Effects for Location Recommendation on
Location-Based Social Networks” escrito por Huiji Gao, Jiliang Tang, Xia Hu, y
Huan Liu.
● Investigar el efecto de los lazos sociales para generar recomendaciones.
En el trabajo Influence and correlation in social networks (Anagnostopoulos, Kumar, y
Mahdian, 2008) sugiere considerar relación entre los lazos sociales y el movimiento de
91

las personas, ya que este último usualmente se ve afectado por el contexto social,
como visitar amigos, salir con compañeros de trabajo, viajar siguiendo las
recomendaciones de amigos, etc. [35]
Actualmente el informe Exploring Social-Historical Ties on Location-Based Social
Networks (Huiji Gao, Jiliang Tang, y Huan Liu ) trata estas ideas.
● Investigar la efectividad de las recomendaciones al acotar el rango de movilidad sobre
la ubicación actual de un usuario dado. En este caso, se parte con la premisa de que el
usuario tiene un interés inmediato en realizar la visita a un lugar que esté dentro de sus
preferencias, por lo que la distancia del mismo al resultado recomendado resulta de
vital interés. En otras palabras, la probabilidad de que un usuario visite un sitio lejano
es baja. Si bien se sabe que en estos casos el sistema de recomendación retornará
resultados en menor tiempo, se debe intentar mantener la efectividad del mismo. En
este caso, basado en el trabajo realizado, previo a consultar por posibles
recomendaciones, se deben filtrar los lugares que superan una distancia a convenir de
la ubicación actual del usuario.
● Recomendaciones para un momento del día en particular. Este caso tiene como
objetivo analizar qué lugares pueden llegar a ser de interés para usuario basado en su
historial de visitas pero en un momento del día determinado (mañana, tarde o noche,
por ejemplo). La premisa se formula basada en que un usuario puede manifestar
interés por ciertas categorías en base a lo que acostumbra hacer por las mañanas, por
ejemplo, pero las mismas pueden perder efectividad si las recomendaciones son
solicitadas en otro momento del día.
92

Bibliografía [1] Freeman, L. (2004). The development of social network analysis . A Study in the Sociology
of Science. Empirical Press.
[2] Number of check-ins by registered members on Foursquare locations from August 2011 to
March 2015 (in millions). Statista. Recuperada el 12/05/2016
( http://www.statista.com/statistics/253838/number-of-check-ins-on-foursquare/)
[3] Porcel, C., Viedma, E. H., & Hidalgo, L. (2004). Sistemas de recomendaciones:
herramientas para el filtrado de información en Internet . Hipertext. net, (2), 22.
[4] Bao, J., Zheng, Y., Wilkie, D., & Mokbel, M. (2015). Recommendations in location-based
social networks: a survey . GeoInformatica, 19(3), 525-565.
[5] Wang, H., Terrovitis, M., & Mamoulis, N. (2013, November). Location recommendation in
location-based social networks using user check-in data. In Proceedings of the 21st ACM
SIGSPATIAL International Conference on Advances in Geographic Information Systems (pp.
374-383). ACM.
[6] Zheng, X., Xie, X..(2011) Location-Based Social Networks . Microsoft Research.
Recuperado el 12/05/2016 ( http://research.microsoft.com/en-us/projects/lbsn/ )
[7] Henriquez, N., Iglesias, A., Amaris, L., & Ropain, Y. (2017). Postgresql una alternativa
efectiva en las empresas. Revista Investigación y Desarrollo en TIC, 4(1).
[8] Gao, H., & Liu, H. (2014). Data analysis on location-based social networks. In Mobile social
networking (pp. 165-194). Springer New York. (2014)
[9] Nieto, S. M. G. (2007). Filtrado colaborativo y sistemas de recomendación . Inteligencia en
Redes de Comunicaciones. Madrid.[Links].
[10] Gómez Díaz, R. (2003), La evaluación en recuperación de la información en línea .
"Hipertext.net", núm. 1. Recuperada el 02/07/2016
(https://www.upf.edu/hipertextnet/numero-1/evaluacion_ri.html#7)
[11] Avazpour, I., Pitakrat, T., Grunske, L., & Grundy, J. (2014). Dimensions and metrics for
evaluating recommendation systems . In Recommendation systems in software engineering
(pp. 245-273). Springer Berlin Heidelberg.
93

[12] Koren, Y., Bell, R., & Volinsky, C. (2009). Matrix factorization techniques for recommender
systems . Computer, 42(8).
[13]Girase, S., & Mukhopadhyay, D. (2015). Role of Matrix Factorization Model in Collaborative
Filtering Algorithm: A Survey. arXiv preprint arXiv:1503.07475.
[14] Polat H., Du W. (2005) SVD-based collaborative filtering with privacy. ACM SAC
Symposium, pp. 791-795.
[15] Jolliffe I.T. (2002) Principal Component Analysis . Series: Springer Series in Statistics, 2nd
ed., Springer, NY, 2002, XXIX, 487 p. 28 illus. ISBN 978-0-387-95442-4
[16] Turney, P. (2002). Thumbs Up or Thumbs Down? Semantic Orientation Applied to
Unsupervised Classification of Reviews . Proceedings of the Association for Computational
Linguistics. pp. 417–424.
[17] Medhat W., Hassan, A. and Korashy, H. (2014) Sentiment analysis algorithms and
applications: A survey. Ain Shams Engineering Journal. 5 (4), pp. 1093–1113
[18] Yang D., Zhang D., Yu Z. & Wang Z..(2013) A sentiment-enhanced personalized location
recommendation system. In Proceedings of the 24th ACM Conference on Hypertext and Social
Media(HT’13), pages 119–128. ACM.
[19] Palacios Aguilar, P., & Ynga Palacios, C. (2015). Propuesta de implementación de un
marco de trabajo para el desarrollo de aplicaciones Android . Universidad Peruana de Ciencias
Aplicadas (UPC).
[20] Melo B., Caraciolo M.,Caspirro R., Rodrigo Vieira, (2010) Crab: A recommender system in
Python (https://github.com/muricoca/crab)
[21] Morita G. (2013) - A Collaborative Filtering Recommendation Engine for Node.js utilizing
Redis (https://www.npmjs.com/package/raccoon)
[22] W3ii.com (2016). Mahout: Introducción. W3ii.com. Recuperado el 25/09/2016
(http://www.w3ii.com/es/mahout/mahout_introduction.html)
[23] Apache Software Foundation. (2014). Recommender Documentation . Apache Software
Foundation. Recuperado el 16/05/2016
(https://mahout.apache.org/users/recommender/recommender-documentation.html)
[24] Casinelli P.. (2014) Evaluating and Implementing Recommender Systems As Web
Services Using Apache Mahout
94

[25] Bao J., Zheng Y., Wilkie D. & Mokbel M.. (2012). Location-based and preference-aware
recommendation using sparse geo-social networking data . In Proceedings of the 20th ACM
SIGSPATIAL Conference on Advances in Geographic Information Systems. ACM, 199–208.
[26] Edwards, A. L.. (1976) The Correlation Coefficient. Ch. 4 in An Introduction to Linear
Regression and Correlation. San Francisco, CA: W. H. Freeman, pp. 33-46.
[27] Rajaraman, A. & Ullman, J. D. (2011). "Data Mining". Mining of Massive Datasets , pp.
1–17
[28] Schein A., Popescul A., Ungar L. & Pennock D.. (2002). Methods and Metrics for
Cold-Start Recommendations . Proceedings of the 25th Annual International ACM SIGIR
Conference on Research and Development in Information Retrieval (SIGIR 2002). New York
City, New York: ACM. pp. 253–260.
[29] Mashape Inc. (2015) Sentiment Api Documentation . Recuperada el 20/11/2016
(https://market.mashape.com/vivekn/sentiment-3)
[30] Berjani B. & Strufe T.. (2011). A recommendation system for spots in location-based
online social networks . In 4th Workshop on Social Network Systems.
[31] Esparza, E. (2016) El fenómeno de las redes sociales . informador.mx. Recuperada el
28/11/2016
(http://www.informador.com.mx/suplementos/2009/158058/6/el-fenomeno-de-las-redes-sociale
s.htm)
[32] Parra, D., & Sahebi, S. (2013). Recommender systems: Sources of knowledge and
evaluation metrics. In Advanced Techniques in Web Intelligence-2 (pp. 149-175). Springer
Berlin Heidelberg.
[33] Powers D.M.W. . (2011). Evaluation: From precision, recall and f-measure to roc,
informedness, markedness & correlation. Flinders University, South Australia, Australia :
Bioinfo Publications.
[34] Cheng C., Yang H., Lyu M. & King I.. (2013) . Where you like to go next: successive
point-of-interest recommendation. IJCAI '13 Proceedings of the Twenty-Third international joint
conference on Artificial Intelligence, pp. 2605-2611.
[35] Gao H., Tang J., & Liu H.. (2012). Exploring Social-Historical Ties on Location-Based
Social Networks . Sixth International AAAI Conference on Weblogs and Social Media.
95

[36] Rajendra, Qing W, Raj JD. (2015). Recommending news articles using cosine similarity
function. Warwick Business School Journal. 2015; 1–8.
[37] Ricci F., Rokach L. & Shapira B..(2011) Introduction to Recommender Systems
Handbook, Recommender Systems Handbook , Springer, 2011, pp. 1-35
96


















