
Redes bayesianas para inferir integridad ecológica · 2014-11-11 · Redes bayesianas para inferir...
81
UNIVERSIDAD VERACRUZANA Redes Bayesianas para inferir integridad ecológica en los ecosistemas mexicanos. TRABAJO RECEPCIONAL Reporte de aplicación QUE COMO REQUISITO PARCIAL PARA OBTENER EL DIPLOMA DE ESTA ESPECIALIZACIÓN PRESENTA: Liliana Areli Sánchez Parra DIRIGE: Dr. Nicandro Cruz Ramírez CO - DIRIGE: Dr. Octavio Miguel Pérez Maqueo XALAPA, VER., agosto 2014 FACULTAD DE ESTADÍSTICA E INFORMÁTICA ESPECIALIZACIÓN EN MÉTODOS ESTADÍSTICOS
Transcript of Redes bayesianas para inferir integridad ecológica · 2014-11-11 · Redes bayesianas para inferir...

UNIVERSIDAD VERACRUZANA
Redes Bayesianas para inferir integridad ecológica en
los ecosistemas mexicanos.
TRABAJO RECEPCIONAL
Reporte de aplicación
QUE COMO REQUISITO PARCIAL PARA OBTENER EL
DIPLOMA DE ESTA ESPECIALIZACIÓN
PRESENTA:
Liliana Areli Sánchez Parra
DIRIGE:
Dr. Nicandro Cruz Ramírez
CO - DIRIGE:
Dr. Octavio Miguel Pérez Maqueo
XALAPA, VER., agosto 2014
FACULTAD DE ESTADÍSTICA E INFORMÁTICA
ESPECIALIZACIÓN EN MÉTODOS ESTADÍSTICOS

Redes bayesianas para inferir integridad ecológica
EME - UV
Redes Bayesianas para inferir integridad ecológica en los
ecosistemas mexicanos.
Liliana Areli Sánchez Parra
Xal1 – 36 – 1213
FEI_EME_397

Redes bayesianas para inferir integridad ecológica
EME - UV
Agradecimientos
Al Dr. Octavio Pérez Maqueo porque desde aquella vez que nos recibió en
el INECOL, nos permitió adentrarnos a sus proyectos. También por
contagiarme el interés por las Redes Bayesianas y de su entusiasmo. Por
todo el apoyo brindado, la paciencia y sobretodo el conocimiento
impartido. Por aquella presentación aterradora en la CONABIO y a todo el
equipo de ROBIN en general.
Al Dr. Nicandro Cruz Ramírez por haber aceptado dirigir mi trabajo, dado
que ya comenzaba a correr el tiempo, por todo los paper’s y material que
me proporciono así como la resolución de dudas.
A la coordinación de la EME y sobre todo a la Dra. María Luisa Hernández
Maldonado, por todo el apoyo durante todo el año de este programa. Por
aceptarme y por ser lectora de este trabajo, por guiarme en el proceso de
titulación y los consejos dados.
Finalmente a mi familia por todo el apoyo y paciencia que siempre me han
tenido, y a Dios por darme la vida y ayudarme día a día.

Redes bayesianas para inferir integridad ecológica
EME - UV
Resumen
Con nuestra vida se daña nuestro planeta, tan solo con un cambio se ve
afectado el ecosistema y todo lo que en él habita, se habla de la desaparición de
especies vegetales y animales. Existe mucho interés en encontrar la manera de
medir la integridad de los ecosistemas, pero antes una definición para ésta
característica deseable. En nuestro país investigadores de dos instituciones
colaboran en un proyecto internacional para encontrar relaciones entre
variables y de esta manera inferir que tanto los ecosistemas de México son
íntegros.
Se recurre a las Redes Bayesianas para determinar las relaciones
probabilistas, es una técnica relativamente nueva que consta de dos partes:
una gráfica y las tablas de probabilidades. Pertenece a la minería de datos por
lo que se pueden manejar bases de datos muy grandes y combinan los
principios de la teoría de grafos, teoría de la probabilidad, la informática y la
estadística, ya que las dependencias entre variables se estiman utilizando
métodos estadísticos y computacionales.
En este trabajo se presentan estructuras generadas mediante algoritmos de
búsqueda y se finaliza eligiendo una red para cada una de las dos bases
empleadas y tomadas del Inventario Nacional Forestal y de Suelos, mediante
criterios de información.

Redes bayesianas para inferir integridad ecológica
EME - UV
Tabla de contenido
1. INTRODUCCIÓN .................................................................................................................................. 1
1.1 MARCO CONTEXTUAL ........................................................................................................................... 1
1.2 ANTECEDENTES ................................................................................................................................... 3
1.3 PLANTEAMIENTO DEL PROBLEMA ............................................................................................................. 5
1.4 JUSTIFICACIÓN .................................................................................................................................... 6
1.5 OBJETIVOS ......................................................................................................................................... 7
Objetivo general .................................................................................................................................. 7
Objetivos específicos............................................................................................................................ 7
2. TEORÍA DE LA PROBABILIDAD ............................................................................................................. 8
2.1 PROBABILIDAD CONJUNTA Y MARGINAL ................................................................................................... 10
2.2 PROBABILIDAD CONDICIONAL................................................................................................................ 10
2.3 INDEPENDENCIA CONDICIONAL .............................................................................................................. 11
2.4 TEOREMA DE BAYES ........................................................................................................................... 11
2.5 ESPERANZA MATEMÁTICA .................................................................................................................... 14
3. MÉTRICAS ......................................................................................................................................... 16
3.1 MDL.............................................................................................................................................. 17
3.2 ENTROPÍA ........................................................................................................................................ 18
3.3 CRITERIOS DE SELECCIÓN: AIC Y BIC ...................................................................................................... 20
4. REDES BAYESIANAS........................................................................................................................... 22
4.1 DEFINICIÓN ...................................................................................................................................... 22
4.2 APRENDIZAJE DE LOS PARÁMETROS ........................................................................................................ 25
4.2.1 Aprendizaje de la estructura ................................................................................................ 28
4.2.2 Aprendizaje de variables latentes ......................................................................................... 29
4.3 INFERENCIA EN UNA RED BAYESIANA....................................................................................................... 32
4.4 CLASIFICACIÓN .................................................................................................................................. 33
4.4.1 Métodos de evaluación ........................................................................................................ 33
5. MATERIALES & MÉTODOS................................................................................................................. 35
5.1 DESCRIPCIÓN DE LAS BASES DE DATOS ..................................................................................................... 35
5.2 ALGORITMOS QUE APRENDEN LA ESTRUCTURA DE LA RED BAYESIANA A PARTIR DE DATOS. .................................... 38
5.2.1 Hill Climbing (ascenso de colinas) ......................................................................................... 38

Redes bayesianas para inferir integridad ecológica
EME - UV
5.2.2 K2 ........................................................................................................................................ 39
5.2.3 Simulated annealing (recocido simulado) ............................................................................. 40
5.2.4 Tabú Search (búsqueda tabú) ............................................................................................... 41
5.2.5 TAN (Naïve Bayes Aumentado a Árbol) ................................................................................. 42
6. METODOLOGÍA Y RESULTADOS. ....................................................................................................... 44
6.1 METODOLOGÍA ................................................................................................................................. 44
6.2 RESULTADOS .................................................................................................................................... 45
7. CONCLUSIONES Y TRABAJO FUTURO ................................................................................................ 48
8. BIBLIOGRAFÍA ................................................................................................................................... 49
9. ANEXOS .............................................................................................................................................. 1
9.1 RESULTADOS (COMPLETOS) .................................................................................................................... 1
9.2 USANDO WEKA ............................................................................................................................... 13

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
1
1. Introducción
1.1 Marco Contextual
Según la Real Academia Española, algo es íntegro cuando no carece de
ninguna de sus partes1. Pero, ¿cómo se mide la integridad en los seres vivos, en
los ecosistemas y espacios de nuestro entorno? Intuitivamente, se podría
pensar que en un estado de integridad debería estar toda especie vegetal y
animal según la caracterización del ecosistema. Sin embargo la medición de
integridad no es tan sencilla como se señala a continuación, dado que se trata
de una variable latente.
Un análisis de la literatura en la materia muestra que no existe una
definición única y objetiva de integridad ecológica. Hasta ahora se ha recurrido
a conceptos como el de estabilidad o resiliencia para describir en la teoría
ecológica las respuestas de los ecosistemas a los factores de tensión (Kay, 1991).
Sin embargo existen algunas definiciones que se han propuesto en distintas
fuentes.
Groves define la integridad ecológica como la capacidad de un sistema de
mantener comunidades bióticas2 y una organización funcional comparable con
los hábitats naturales (sin disturbios antropogénicos) (Groves, 2003). Por otro
lado, (Angermaier, 1994) la define como la habilidad de un ecosistema de
1 Consulta en línea 2014 http://lema.rae.es/drae/srv/search?key=%C3%ADntegro
2 Conjunto de poblaciones que viven en un hábitat o zona definida que puede ser amplia o reducida. Las interacciones de los diversos tipos de organismos conservan la estructura y función de la comunidad y brindan la base para la regularización ecológica de la sucesión en la misma. Consultado en http://ecologiasomosnaturaleza.blogspot.mx/2007/04/comunidades-biticas.html

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
2
perpetuar su funcionamiento siguiendo su camino natural de evolución y de
poder recuperarse tras una perturbación3.
La enciclopedia de la salud y ecología la define como la protección y
restauración de los sistemas ecológicos del planeta Tierra, prestando particular
atención al mantenimiento de la diversidad ecológica. También como la
protección de todos los seres vivos evitando por todos los medios su destrucción.
(Biblioteca educación y salud, 2002). Si bien es difícil contar con una definición
única de integridad ecológica es posible tratar de encontrar indicadores sobre
una condición deseable (integra) de los ecosistemas. Por tanto, en este trabajo y
de acuerdo con Equihua et al (Equihua Z., Miguel; García A., N; Pérez M,
Octavio; Benítez Badillo, G; Kolb, M; Schmidt, M; Equihua Benítez, J; Maeda,
P) se considera que la integridad ecológica constituye un atributo subyacente
no medible directamente (como lo serían la salud o la inteligencia humanas por
ejemplo).
A nivel nacional se cuenta con una gran cantidad de información que
puede ser utilizada en la evaluación de integridad. Se tienen variables
contenidas en el Inventario Nacional Forestal (INFyS), el cual tiene un rico
acervo de datos y es operado por la Comisión Nacional Forestal (CONAFOR).
Este instrumento está basado en un esquema de muestreo constituido por una
retícula espaciada entre 5 y 20 km sobre el territorio nacional. Incluye 57 tipos
de vegetación (Serie IV de INEGI) y tres grandes grupos de uso del suelo
(agricultura, ganadería y urbanización). En el protocolo de medición vigente el
INFyS produce datos sobre la estructura y estado de la vegetación así como de
la riqueza de especies en un conjunto de más de 200 variables.
Aparentemente, existe un dilema por parte de los expertos en ecología ya
que la formulación de políticas públicas orientadas hacia la sustentabilidad
3 Ejemplos de perturbaciones naturales son el fuego, las avalanchas de nieve, fenómenos meteorológicos extremos (vientos intensos, temperaturas anormalmente altas o bajas), inundaciones y deposición de partículas, las plagas de insectos, las enfermedades y algunos mamíferos.

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
3
requiere de forma urgente evaluar sus impactos económicos, sociales y
ambientales (Boulanger, P., y T. Bréchet, 2005). Como respuesta, se ha optado
por usar índices que “denotan” una condición de integridad ante las dificultades
que se han encontrado distintos autores por medir esta característica desde un
enfoque determinista.
Como se mencionó se cuenta con una gran cantidad de información que
puede ser utilizada en la evaluación de integridad. A través del proyecto
internacional llamado ROBIN (Role Of Biodiversity In climate change
mitigatioN), en colaboración con el Instituto de Ecología, y la Comisión
Nacional para el Conocimiento y Uso de la Biodiversidad (CONABIO), haciendo
uso de la metodología bayesiana se pretende modelar patrones de dependencia
entre un conjunto de variables (contenidas en el Inventario Nacional Forestal).
1.2 Antecedentes
A lo largo de las décadas se le ha dado mayor importancia a la
preservación de los ecosistemas en su forma natural. No obstante, fue en la
década de los 60s cuando comenzó a ser utilizado el término de “integridad”. Se
dice que algo es íntegro cuando existe garantía de la exactitud de la
información frente a la alteración, pérdida o destrucción, ya sea de forma
accidental o con base en un propósito determinado.
En 1975 bajo la organización de la Agencia de Protección al Ambiente de
los Estados Unidos (EPA por sus siglas en inglés) se discutió el concepto de
integridad, como referencia a ser una “característica deseable de los
ecosistemas” así como su “principio cultural o moral”. Como resultado de lo
anterior, existe una amplia gama de interpretaciones sobre lo que significa
integridad. No obstante, existía el consenso de que era necesario asegurar la

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
4
integridad ecológica en la práctica.
Ulanowicz publicó que nunca se puede decir que los ecosistemas están
completos ya que hay cambios en ellos que conducen a una condición madura
congruente con el entorno físico prevaleciente (Ulanowicz, 1990).
Para mediados de los 90s el concepto de integridad ecológica así como el
de integridad ecosistémica, fueron mencionados en un gran número de
instrumentos regulatorios en EUA (Navarrete, 2001). En México ha ocurrido
algo semejante en relación con el manejo de los ecosistemas o las consecuencias
de la intervención humana en ellos. Se le concibe como un referente o bien
como una meta para el manejo con criterios de sustentabilidad.
De acuerdo con (Westra, 2000) un tema importante en biología de la
conservación es conocer qué requerimientos espaciales son necesarios para
mantener los ecosistemas nativos. No sólo en términos de superficie sino
también en cuanto a la configuración espacial necesaria de modo que su
ocurrencia combinada constituya un elemento de integridad ecológica.
Para promover la transición hacia formas sostenibles de vida y una
sociedad global con base en un marco ético compartido ampliamente. Dicho
marco establecido en la Carta de la Tierra incluye el respeto y el cuidado de la
comunidad de vida, la integridad ecológica, los derechos humanos universales,
el respeto a la diversidad, la justicia económica, la democracia y una cultura de
paz. La Carta de la Tierra es un documento internacional y todos los países
pueden firmarlo y de esta manera comprometerse. En la Carta de la Tierra
(Mackey, 2005) se menciona que la integridad ecológica es el funcionamiento
permanente saludable o apropiado de los ecosistemas a escala global y local, así
como a su provisión continua de recursos renovables y servicios ambientales.
De esta forma los procesos naturales que sostienen la integridad ecológica de
los ecosistemas incluyen la evolución de nuevas especies y la dispersión de

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
5
especies existentes de flora y fauna y sus propágulos4.
En el proyecto ROBIN (antes mencionado) se manifiesta que la
biodiversidad juega un papel importante en el bienestar humano. En este
sentido, la pérdida de biodiversidad podría considerarse como una de las
principales fuerzas mundiales del cambio ambiental. Para arrojar luz sobre el
papel de la biodiversidad en la mitigación del cambio climático en los procesos
de los ecosistemas, este proyecto analiza la relación entre ésta y la provisión de
servicios ambientales dentro de un contexto socio-ecológico que considera por
ejemplo, el impacto de varias políticas relacionadas con la actividad humana.
Como parte de este proyecto, investigadores del INECOL y de la
CONABIO han propuesto el uso de redes bayesianas para evaluar la integridad
de los distintos ecosistemas presentes. Resultados preliminares se basan en
redes automáticas utilizando el clasificador Naïve. Este es el modelo más
simple de clasificación con redes bayesianas, ya que asume independencia
entre todos los atributos dada una clase, además existen otras propuestas
basadas en opinión de expertos utilizando distintas fuentes de información.
1.3 Planteamiento del problema
Como se ha mencionado la integridad es una característica deseable en
todos los ecosistemas, sin embargo poder decir si existe y en qué grado es un
proceso muy complejo. Si bien existen propuestas de redes basadas en
opiniones de expertos y con otras fuentes de información, mediante este trabajo
se proponen distintas redes para encontrar las relaciones entre variables y de
esta forma evaluar la integridad ecológica haciendo uso de distintos algoritmos
4 Propágulo (del latín propagulum) en biología es cualquier germen, parte o estructura de un organismo (planta, hongo o bacteria), producido sexual o asexualmente, capaz de desarrollarse separada para dar lugar a un nuevo organismo idéntico al que le formó.1 2 Es decir, es cualquier estructura de reproducción y propagación biológica. Consulta en línea en http://es.wikipedia.org/wiki/Prop%C3%A1gulo

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
6
de búsqueda y determinar la mejor red en base a los criterios de información. A
partir de esto surgen las siguientes preguntas:
¿Cómo saber cuándo un ecosistema es integro? ¿Cuáles son las variables
que lo determinan? ¿Se podrían reducir algunos recursos en la medición de
variables y emplearlos en mejorar la medida de otras?
A nivel nacional el principal objetivo de los distintos instrumentos
normativos mexicanos en materia ambiental se enfocan a la conservación de los
ecosistemas, la vida silvestre y sus hábitats. El plan Nacional de Desarrollo
correspondiente convoca a detener la pérdida y degradación de ecosistemas y
lograr un uso sustentable del capital natural.
1.4 Justificación
Si se asume que la integridad es una condición valiosa y medible de un
sistema biológico, el concepto da oportunidad para conjuntar las
preocupaciones de la ciencia y la política pública. La pérdida de integridad
interfiere con los procesos del ecosistema y al modificar su funcionamiento
altera las formas de producción de los servicios ecosistémicos que éste provee.
Se pretende con las redes bayesianas tener mayor claridad para identificar la
relación entre variables que mejor contribuyan a identificar condiciones de
integridad ecológica.
En México actualmente se hacen grandes esfuerzos por preservar los
ecosistemas en un estado alto de conservación. Este trabajo proporcionará
información relevante para las instituciones que tiene la responsabilidad de
realizar acciones en pro de la conservación de los ecosistemas. Lo anterior a
través de colaborar en la construcción de medidas sobre integridad que les

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
7
permitan diseñar y optimizar las estrategias de conservación y desarrollo.
1.5 Objetivos
Objetivo general
Crear una red bayesiana a través de distintos algoritmos para identificar la
estructura de las variables que definen a un ecosistema íntegro y que aporte
información útil para la toma de decisiones dentro de los esfuerzos que se
hacen para la preservación de los ecosistemas.
Objetivos específicos
a) Proponer una estructura de red bayesiana obtenida a partir de datos que
evalúen integridad ecológica.
b) Comparar esta red con otras propuestas existentes (incluida Naive o
ingenua).

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
8
2. Teoría de la probabilidad
La probabilidad es un método por el cual se obtiene la frecuencia de un
acontecimiento determinado mediante la realización de un experimento
aleatorio, del que se conocen todos los resultados posibles, bajo
condiciones estables. La Teoría de la Probabilidad nos permite la obtención de
modelos aleatorios o estocásticos mediante los cuales podremos conocer, en
términos de probabilidad el comportamiento de los fenómenos aleatorios
(Montes S, 2007).
Se considera el siguiente fenómeno aleatorio: lanzar un dado y observar el
número de puntos en la cara. Lo cual da lugar a un resultado de entre un
conjunto de posibles resultados, los cuales pueden ser . Este
conjunto de posibles resultados recibe el nombre de espacio muestral. Si se
considera alguna característica en común de los posibles resultados se habla de
un suceso, (Degroot, 1988). La
probabilidad de que la cara del dado tenga un número par sería
.
De manera más formal, la probabilidad de aparición de un suceso de un
total de casos posibles sería y se define como la razón entre el número de
ocurrencias en que dicho suceso es cierto y el número total de casos posibles
:
⁄
Esta definición tiene el problema de que las frecuencias sólo son exactas
en el límite de infinitas repeticiones (De Finetti, 1989).
La probabilidad es una herramienta que nos permitirá modelar nuestro
conocimiento aproximado sobre un suceso.
En 1993, el matemático ruso Andrei N. Kolmogorov estableció un conjunto

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
9
de axiomas (N. Kolmogorov, 1956), que deben satisfacerse para que podamos
determinar consistentemente la probabilidad sobre unos sucesos (García F. J.,
2009), dichos axiomas son:
Primer axioma: la probabilidad de un suceso es un número real no
negativo, es decir:
Segundo axioma: la probabilidad del espacio muestral es 1:
Tercer axioma: si son un conjunto de sucesos mutuamente
excluyentes, entonces la probabilidad de que al menos uno de estos
sucesos ocurra, es la suma de las probabilidades individuales:
∑( )
De estos axiomas hay una serie de propiedades que se pueden deducir:
Normalización:
Monotonicidad: si entonces
Inclusión – Exclusión: dado cualquier par de subconjuntos y de ,
se cumple siempre la siguiente igualdad:
Para cualquier suceso
Como y su complementario son dos sucesos disjuntos, es decir,
podemos deducir que
Antes de comenzar a describir las probabilidades conjunta y condicional es
necesario describir la distribución de probabilidad de una variable aleatoria ,
esta es una función que asigna a cada evento definido sobre la variable

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
10
aleatoria una probabilidad. La distribución de probabilidad describe el rango de
valores de la variable aleatoria así como la probabilidad de que el valor de la
variable aleatoria esté dentro de un subconjunto de dicho rango (García F. J.,
2009).
2.1 Probabilidad conjunta y marginal
Sea la distribución de probabilidad conjunta sobre
es decir
Entonces la distribución de probabilidad marginal sobre la i-ésima variable se
obtiene mediante la siguiente fórmula:
∑
2.2 Probabilidad condicional
Sean y dos variables que toman valores en y tales que ( )
. Entonces la probabilidad condicional de dado viene dada
por
| |

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
11
Por lo tanto, la distribución de probabilidad conjunta de y puede obtenerse
como:
|
2.3 Independencia condicional
Sean tres conjuntos disjuntos de variables. Se dice que es
condicionalmente independiente de dado que conocemos , si y solo si para
se verifica que
| |
De lo contrario se dice que son condicionalmente dependientes dado
. Cuando son condicionalmente independientes dado se nota como
| .
2.4 Teorema de Bayes
En la teoría de la probabilidad el Teorema de Bayes se expresa como la
probabilidad condicional de un suceso aleatorio dado en términos de la
distribución de probabilidad condicional del suceso dado y la distribución de
probabilidad marginal de sólo . La capacidad de vincular la probabilidad de
dado , con la de dado , a veces es llamado también teorema de las causas.
(Mesa P., 2011).
Este teorema nos permite representar la probabilidad condicionada |
mediante la siguiente expresión (García F. J., 2009).

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
12
| |
Teniendo en cuenta que ∑ y que | ,
podemos representar el teorema de Bayes usando la siguiente expresión:
| |
∑ |
De la ecuación anterior se puede distinguir:
La probabilidad se denomina probabilidad marginal, a priori o
inicial de puesto que puede ser obtenida antes de conocer la
evidencia, es decir, no tiene en cuenta ninguna información acerca de
.
La probabilidad | es la probabilidad posterior, a posteriori, o
condicional de puesto que después de conocer la evidencia, es decir,
depende del valor .
La probabilidad | se le llama verosimilitud y es la probabilidad de
la observación dado .
Un ejemplo (Carreño S, 2006) de la aplicación de este teorema es la
siguiente:
Imaginemos que, por ejemplo, nos interesa conocer cuál será la probabilidad
de que un paciente con resultado positivo en la prueba de la diabetes sea
realmente diabético, sabiendo que dicha prueba presenta errores de detección.
Un esquema nos será muy útil para calcular su probabilidad:

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
13
Ilustración 1 Ejemplo del diagnóstico de diabetes
Para el ejemplo anterior, la prevalencia de la diabetes es de alrededor del
4%, de lo que se extrae que el 96% de los individuos no son diabéticos. Además,
dicha prueba diagnóstica correctamente al 80% de los pacientes diabéticos (el
20% restante obtiene valores erróneos), mientras que lo hace correctamente en
el 90% de los pacientes no diabéticos (aparece un resultado positivo cuando
debería ser negativo en el 10% de los no diabéticos, se le conoce como falso
negativo).
Lo que nos interesa es conocer los resultados positivos que provienen de
pacientes diabéticos, de entre todos los que son diabéticos. Por tanto, según el
teorema de Bayes, la probabilidad de que un paciente sea diabético (D) cuando
el test sale positivo (+) sería la probabilidad de que el diagnóstico positivo sea
correcto, de entre todas las posibilidades de que sea positivo sustituyendo en la
fórmula del teorema, se obtiene lo siguiente:
| |
( | ) |
De este modo se observa que a pesar de haber obtenido un resultado
positivo en la prueba, solo existe un 25% de posibilidades de que el paciente sea
R. Positivo
R. Negativo
R. Positivo
R. Negativo
No Diabético
Diabético
Población
Diagnóstico Prueba

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
14
diabético.
El teorema de Bayes es válido en todas las aplicaciones de la teoría de la
probabilidad. Sin embargo, hay una controversia sobre el tipo de probabilidades
que emplea. En ciertas condiciones, los partidarios de la estadística tradicional
sólo admiten probabilidades basadas en experimentos repetibles y que tengan
una confirmación empírica mientras que los llamados estadísticos bayesianos
permiten probabilidades subjetivas.
No elaboramos más aquí sobre la teoría bayesiana por no usarla en este
trabajo, sin embargo se sugiere consultar (López de Castilla Vásquez, 2011).
2.5 Esperanza matemática
Una variable aleatoria es discreta si existe una sucesión de
números reales tales que
∑
El valor esperado para variables aleatorias discretas, se define como:
Sea una variable discreta con la notación anterior, y llamemos
diremos que existe el valor esperado, la media o la
esperanza matemática si la serie es convergente (Ortega, 2009).
∑| |
En ese caso, el valor esperado se denota y se define mediante la
serie

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
15
∑
Ejemplo
Sea el resultado de lanzar un dado, entonces toma valores
con probabilidad uniforme en este conjunto. Por lo tanto
∑
∑
En este caso el valor esperado no es un valor posible de la variable aleatoria.

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
16
3. Métricas
Hay distintas métricas, la mayoría pueden ser agrupadas en dos categorías:
bayesianas y basadas en medidas de información (García F. J., 2009).
Las métricas bayesianas (L. Buntine, 1994) buscan la estructura que
maximiza la probabilidad de una red condicionada a la base de datos |
usando para ello la fórmula de Bayes.
| |
El término representa la distribución a priori de cada estructura
candidata, y | llamada evidencia, es la verosimilitud muestral promedio
que puede calcularse bajo ciertas suposiciones (diferentes suposiciones dan
lugar a diferentes métricas) (García F. J., 2009).
Las métricas basadas en teoría de la información representan otra
opción para medir el ajuste del grafo dirigido acíclico al conjunto de datos
(Bouckaert, 1993). Están basadas en conceptos de la teoría de la codificación e
información.
En la codificación de un mensaje se trata de reducir lo más posible el
número de elementos necesarios para representarlos atendiendo a su
probabilidad de ocurrencia esto es, los mensajes más frecuentes tienen códigos
cortos y los mensajes menos frecuentes tendrán códigos largos. El principio de
mínima longitud de descripción (Rissanen, 1978) (o MDL, del inglés Mínimum
Description Length), selecciona la codificación que conduce a una mínima
longitud en la codificación de los mensajes. En el caso de las redes bayesianas,
modelos muy complejos serán aquellos donde los nodos estén densamente
conectados (el caso extremo sería un grafo completo) y serán redes muy
precisas, bastante ajustadas a los datos. No obstante, redes tan complejas

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
17
suponen serios problemas de comprensión, computación y sobre ajuste, por lo
que se buscan redes más simples aunque menos precisas (García F. J., 2009).
3.1 MDL
El comportamiento esperado para la métrica MDL consiste en que
comienza con un valor x, y a medida que se van incrementando relaciones entre
variables (arcos), la complejidad del modelo va incrementando y el valor de
MDL se decrementa hasta llegar a su valor mínimo, lo que significa que MDL
ha encontrado el mejor modelo con el mejor balance entre bondad de ajuste y
complejidad. La bondad de ajuste se define como el ajuste que toman los datos
en relación con una estructura de red Bayesiana propuesta, dicha de otra
manera, es la precisión con la que los datos pueden ser representados con la
estructura de red (Domínguez Sánchez, 2009).
La idea principal en la que se basa el principio MDL es el considerar
equivalente el aprendizaje con el descubrimiento de regularidades (Gutiérrez
Fragoso, 2007) (semejanzas entre datos). Entre más datos existan, habrá mayor
certeza en los resultados y mayor posibilidad de encontrar regularidades en los
datos (aunque puede no haberlas). A mayor cantidad de regularidades, mucho
mayor será la comprensión de los datos. Entre mayor sea la comprensión de los
datos, mayor será el aprendizaje obtenido a partir de ellos. Entre mayor sea el
aprendizaje obtenido, menor será el valor de la entropía o incertidumbre. Se
entiende por entropía como el grado de certeza en cuanto a la aceptación de
una hipótesis, por tanto, entre mayor aprendizaje se obtenga a partir de los
datos, disminuirá la incertidumbre y por ende, tendremos mayor certeza en
cuanto a nuestras inferencias (Domínguez Sánchez, 2009).

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
18
La ecuación para MDL es la siguiente:
|
Donde representa los datos, denota los parámetros del modelo,
representa la dimensión del modelo y es una noción de complejidad, es el
tamaño de la muestra y es una constante que no depende de sino de , el
cual es un término que representa el número de variables.
∑
Representa la longitud de la descripción de la estructura de la red
Bayesiana y se define por la siguiente ecuación:
∑ | |
Donde | | denota la cardinalidad de los padres de en la red Bayesiana
(Grünwald, 2005).
3.2 Entropía
Este término aparece en algunas otras teorías, pero en el ámbito de la
teoría de información se utiliza para medir la incertidumbre de una fuente de
información.
La entropía asociada a la variable aleatoria es un número que depende
directamente de la distribución de probabilidad de e indica como es de
predictible el resultado del proceso sujeto a incertidumbre o experimento.
Desde un punto de vista matemático cuanto más plana sea la distribución de
probabilidad más difícil será acertar cuál de las posibilidades se dará en cada

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
19
instancia. Una distribución es plana (tiene alta entropía) cuando todos los
valores de tienen probabilidades similares, mientras que es poco plana
cuando algunos valores de son mucho más probables que otros (se dice que la
función es más puntiaguda en los valores más probables). En una distribución
de probabilidad plana (con alta entropía) es difícil poder predecir cuál es el
próximo valor de que va a presentarse, ya que todos los valores de son
igualmente probables (Rodríguez-Caballero, 2012).
Shannon ofrece una definición de entropía que satisface las siguientes
afirmaciones:
La medida de información debe ser proporcional (continua). Es decir, el
cambio pequeño en una de las probabilidades de aparición de uno de los
elementos de la señal debe cambiar poco la entropía.
Si todos los elementos de la señal son equiprobables a la hora de
aparecer, entonces la entropía será máxima.
La información que aporta un determinado valor de una variable
aleatoria discreta se define como:
A pesar del signo negativo de la última expresión, la información
siempre tiene signo positivo.
La entropía determina el límite máximo al que se puede comprimir un
mensaje usando un enfoque símbolo a símbolo sin ninguna pérdida de
información (demostrado analíticamente por Shannon), el límite de compresión
(en bits) es igual a la entropía multiplicada por el largo del mensaje. También
es una medida de la información promedio contenida en cada símbolo del
mensaje. Su cálculo se realiza a partir de su distribución de probabilidad
mediante la siguiente fórmula:

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
20
( ) ∑ (
) ∑
Propiedades de la entropía:
1. . Es decir, la entropía H está acotada superiormente
(cuando es máxima) y no supone perdida de información.
2. Dado un procesos con posibles resultados con probabilidades
relativas , la función es máxima en el caso de que
⁄
3. Dado un proceso con posibles resultados con probabilidades
relativas , la función , es nula en el caso de que
para cualquier .
3.3 Criterios de selección: AIC y BIC
Una de las características de los modelos estadísticos es la parsimonia, es
decir, que un modelo sea fácil de interpretar y que contenga pocos parámetros.
Los índices más comunes son:
Criterio de inferencia de Akaike (AIC (del inglés Akaike Information
Criterion)): Existen dos formas de calcular este índice para comparar
conjuntos de MCL. El índice propuesto originalmente por Akaike
(Akaike, 1974), está basado en el logaritmo de la función de
verosimilitud, . Un procedimiento alternativo , está basado en el
estadístico . Se tiene:
Donde es el número de parámetros independientes estimados y son

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
21
los correspondientes grados de libertad. La decisión está basada en elegir
el modelo con el mínimo o .
Criterio Bayesiano de Schwarz (BIC (del inglés Bayesian Information
Criterion)) una crítica al criterio anterior, es el hecho de que no
considera explícitamente el tamaño de muestra . Schwarz (Schwarz,
1978) utiliza el BIC para desarrollar una medida consistente
asintóticamente basada en el logaritmo de la función de verosimilitud ,
el número de parámetros independientes a ser estimados , y el tamaño
muestral. Una versión alternativa puede ser calculada utilizando
y los grados de libertad correspondientes .
El criterio de selección es igual al anterior.
Como regla, el tiende a seleccionar modelos menos complejos (con
menos número de parámetros) que el . En el contexto del modelo de clases
latentes, investigaciones empíricas (Lin & Dayton, 1997) sugieren que se debe
preferir utilizar el a menos que el tamaño muestral sea de varios cientos de
casos o los modelos estimados estén basados en un número relativamente
pequeño de parámetros, en cuyo caso es preferible utilizar el índice .
Cuando se tienen valores pequeños en los índices, implica que un modelo es
parsimonioso.

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
22
4. Redes Bayesianas
4.1 Definición
Las redes bayesianas también conocidas como redes de creencias (o redes
de Bayes para abreviar), pertenecen a la familia de los modelos gráficos
probabilistas (GMS) (Ruggeri, Faltin, & Kenett, 2007). Estas estructuras
gráficas se utilizan para representar el conocimiento acerca de un dominio
incierto. En particular, cada nodo en el gráfico representa una variable
aleatoria, mientras que los arcos o aristas entre los nodos representan
dependencias probabilistas entre las correspondientes variables aleatorias. Los
nodos se clasifican en nodos padre y nodos hijo, en donde el nodo padre es aquel
donde inicia un arco y los nodos hijos son aquellos hacia los que va dirigido
dicho arco (Domínguez Sánchez, 2009).
Una red probabilista tiene al menos un nodo raíz (sin padre alguno) y un
nodo terminal (sin hijo alguno).
Ilustración 2 Componentes de una red bayesiana
Por lo tanto, las redes bayesianas combinan los principios de la teoría de
grafos, teoría de la probabilidad, la informática y la estadística, ya que las
dependencias entre variables se estiman utilizando métodos estadísticos y
Nodos Arcos o aristas

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
23
computacionales (Ruggeri, Faltin, & Kenett, 2007).
Las redes bayesianas o modelos bayesianos son gráficos probabilistas que
representan un conjunto de variables aleatorias y sus dependencias
condicionales a través de la topología y un conjunto de tablas de probabilidad
condicional. La topología es la parte grafica del modelo y está conformada por
dos elementos descritos en la figura anterior, y las tablas probabilistas son
aquellas en las que se almacenan los valores de probabilidad condicional para
cada nodo.
Las redes bayesianas están dentro de las técnicas de clasificación, son
grafos dirigidos acíclicos cuyos nodos representan variables aleatorias en el
sentido de Bayes: las mismas pueden ser cantidades observables, variables
latentes, parámetros desconocidos o hipótesis.
En la siguiente ilustración se observa que la imagen (a) es un clico,
imagen (b) y (c) no lo son (Lauritzen & Spiegelhalter, 1988).
Ilustración 3 Ejemplos de Redes Bayesianas
En 1985 Judea Pearl (Pearl, 1985) propuso el término «red bayesiana» para
representar e inferir en sistemas inteligentes, teniendo en cuenta las siguientes
características:

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
24
La naturaleza subjetiva de la información de entrada.
La confianza en el condicionamiento de Bayes como la base para
actualizar la información.
La distinción entre los modos de razonamiento casual y evidencial.
A fines de la década de 1980 los textos “Probabilistic Reasoning in
Intelligent Systems” y “Probabilistic Reasoning in Expert Systems”
sintetizaron las propiedades de las Redes Bayesianas y ayudaron a su
establecimiento como un campo de estudio.
Las redes bayesianas se pueden interpretar de dos formas (Morales &
González, 2012):
Distribución de probabilidad: Representa la distribución de la
probabilidad conjunta de las variables representadas en la red.
Ilustración 4 Ejemplo de distribución de probabilidad
| | | | |
Base de reglas: Cada arco representa un conjunto de reglas que asocian
las variables involucradas, Si .
Dichas reglas están cuantificadas por las probabilidades respectivas.
Esta técnica busca determinar relaciones probabilistas que expliquen un
G
A
F
D C
B
E

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
25
fenómeno y es aplicado en aquellos casos que son de carácter predictivo y
diagnóstico. Es decir, el razonamiento probabilista o propagación de
probabilidades consiste en difundir los efectos de la evidencia por medio de la
red para conocer la probabilidad a posteriori de las variables. Dicho de otra
forma a determinadas variables (conocidas) se les otorga una probabilidad y
con base a esto se obtiene una probabilidad posterior.
4.2 Aprendizaje de los parámetros
Una red bayesiana constituye un dispositivo potente para el razonamiento
probabilista. Pero ¿Cómo se construye una red bayesiana? Existen tres
enfoques para de determinar la topología de una red Bayesiana, es decir, las
relaciones de dependencia entre las variables relevantes involucradas en un
problema dado: de forma manual o tradicional, de forma automática y el
enfoque Bayesiano que puede ser visto como una combinación de los dos
anteriores (Cruz Ramírez, 2001).
En muchos casos, la estructura y la asignación de probabilidades de una
red bayesiana son dadas a través de la opinión de expertos ayudado por el
ingeniero del conocimiento, forma manual o tradicional. El experto humano
plasma su conocimiento dibujando la red con las relaciones de dependencia e
independencia condicional entre las variables involucradas en un problema
determinado. Aunque ésta es una tarea bastante difícil y tardada, la
construcción de la estructura realizada de esta forma puede pensarse como la
determinación de las relaciones entre las variables de una manera causal. Sin
embargo, en muchos de los casos, el mismo experto no tiene bien definidas las
relaciones de dependencia relevantes entre las variables del problema. Esto
significa que si dos variables están conectadas, se piensa que la primera es la

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
26
causa de la segunda (Jiménez, 2003). Debido al gran volumen de datos con los
que se trabaja, es de enorme interés proporcionarles a estos expertos
herramientas que adquieran este tipo de conocimiento de forma automática a
partir de datos de ejemplos del problema en cuestión, para que de esta manera
tengan una herramienta de soporte para la decisión (Hernández Orallo, Ferri
Ramírez, & Ramírez Quintana, 2004).
La forma automática o de aprendizaje a partir de datos consiste en definir
la red probabilista a partir de datos almacenados en bases de datos en lugar de
obtener el conocimiento directamente del experto. Este tipo de aprendizaje
ofrece la posibilidad de inducir la estructura gráfica de la red a partir de los
datos observados y de definir las relaciones entre los nodos basándose también
en dichos casos.
Obtener una red Bayesiana a partir de datos es un proceso de aprendizaje
que se divide en dos etapas: el aprendizaje estructural y el aprendizaje
paramétrico (Césari, 2006). La primera de ellas, consiste en obtener la
estructura de la red bayesiana, es decir, las relaciones de dependencia e
independencia entre las variables involucradas (se verá con detalle más
adelante). La segunda etapa, tiene como finalidad obtener las probabilidades a
priori y condicionales requeridas a partir de una estructura dada.
A continuación se presenta un ejemplo de Red Bayesiana automática o
aprendizaje (Ruiz Reina, 2006).

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
27
Ilustración 5 Ejemplo diagnóstico caries
En esta red observamos que:
Caries es una causa directa de Dolor y Huecos
Dolor y Huecos son condicionalmente independientes dada Caries
Tiempo es independiente de las otras variables
La combinación de ambas posibilidades (enfoque bayesiano), permite
orientar al experto y al ingeniero del conocimiento para afianzar o corregir su
percepción del dominio. Se puede optar por obtener el modelo de forma manual,
a través de la ayuda de expertos humanos y aplicar alguno de los algoritmos de
aprendizaje para la obtención de las probabilidades. Por otro lado, también se
puede aprender la red a partir de una base de datos y posteriormente realizar
una depuración refinando la estructura y los parámetros con la ayuda de
expertos humanos (García D. , 2010).

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
28
4.2.1 Aprendizaje de la estructura
Es una etapa del aprendizaje automático, en la cual se buscan las
relaciones cualitativas entre las variables del problema, el conjunto de redes
bayesianas con nodos es de orden súper-exponencial5 (Robinson, 1977), con lo
que un recorrido exhaustivo por dicho conjunto con el fin de encontrar la mejor
red candidata no es factible en la mayoría de los casos.
Podemos realizar la siguiente clasificación de las estrategias de aprendizaje con
base a la técnica utilizada para obtener la parte cualitativa de la red.
Basadas en pruebas de Independencia: son métodos que utilizan criterios
de independencia entre variables, para obtener la estructura que mejor
representa el conjunto de independencias que se deducen de los datos.
Métricas + búsqueda: son paradigmas de aprendizaje que se basan en el
criterio de bondad del ajuste de una estructura a los datos. Utilizando
dicho criterio se realiza un proceso de búsqueda entre las estructuras
candidatas, dando como resultado aquella estructura que mejor se ajuste
a los datos.
Híbridos: son modelos que combinan ideas de las anteriores técnicas.
La idea subyacente en el segundo tipo de métodos, es encontrar el grafo que
mejor represente los datos, utilizando el menor número de arcos posibles, es
decir, la calidad de cada grafo candidato se cuantifica mediante algún tipo de
medida o métrica. Dicha medida es utilizada por algún algoritmo de búsqueda
para encontrar las mejores soluciones desde el punto de vista de la medida
utilizada. Por lo tanto, estos métodos se caracterizan tanto por lo métrica usada
como por el algoritmo de búsqueda (García F. J., 2009).
5 El número de grafos dirigidos acíclicos posibles para nodos sería ∑
Por ejemplo,

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
29
4.2.2 Aprendizaje de variables latentes
El Análisis de Clases (o variables) Latentes (ACL) es una técnica de
reciente desarrollo, esta se puede aplicar en diversas áreas, principalmente se
utiliza en estudios de mercado, en investigaciones científicas, sociales,
educativas entre otras.
Esta técnica permite estudiar identifica y define grupos de una muestra en
estudio, por medio del principio de Independencia Condicional, esta prueba nos
asegura que cada grupo es diferente de los restantes, metodología que trabaja
con dos tipos de variables (Sánchez Parra, 2012):
Las primeras se llaman indicadoras, son las variables que se han
observado, esta variable sirve para definir o medir la variable latente
(Vermunt y Magdison, 2000).
Las segundas variables se llaman latentes, son aquellas variables que no
son directamente observadas o cuantificadas y se construyen a partir de
otras variables (Vermunt y Magdison, 2000).
El ACL es una técnica estadística que permite estudiar la existencia de una
o varias variables latentes a partir de un conjunto de variables indicadoras
observadas y definir, a partir de sus clases, una clasificación o topología de los
datos con los que se trabaja. (Pérez & Fajardo, 2001)
El diseño estadístico de clases latentes permite construir una variable nominal
no observada; es decir, una variable latente con k categorías, las cuales
representan a cada una de las clases identificadas en la población bajo estudio
(Reyes, 2009).
El Modelo de Clases Latentes (MCL) es una técnica estadística que
permite estudiar la existencia de una o varias variables latentes a partir de un
conjunto de variables explicativas observadas, este modelo puede parametrizar

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
30
de dos formas distintas, por probabilidades condicionadas entre las variables o
mediante un modelo log-lineal (Goodman, 1974).
Supóngase que se tiene un conjunto de variables indicadoras ,
con un número de categorías . Por otro lado, sea una variable latente
con un total de clases. Las ecuaciones básicas del modelo de clases latentes
son:
∑
Donde
| | | | |
Representa la probabilidad de estar en la celda de la
distribución conjunta
Es la probabilidad de pertenecer a la clase latente .
| Es la probabilidad de tener un patrón de respuesta concreta dado .
Son probabilidades condicionadas.
Como se observa que las variables son estadísticamente independientes
dentro de cada clase latente (Pérez & Fajardo, 2001).
Por tanto, los parámetros del modelo de clases latentes son las
probabilidades condicionadas | | | | y las probabilidades de las clases
latentes que estarán sometidas a las siguientes restricciones:
∑ |
∑ |
∑ |
∑ |
Y

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
31
∑
Los primeros métodos que se utilizaban para resolver un MCL se basaba
en cálculos matriciales y en sistemas de ecuaciones lineales, lo cual traía como
consecuencia una enorme cantidad de cálculos y gran consumo de tiempo y
recursos computacionales, en la actualidad se utilizan procedimientos
numéricos iterativos para obtener las soluciones a las ecuaciones de
verosimilitud, lo cual disminuye la complejidad del proceso de estimación.
Para las estimaciones máximo-verosímiles de los parámetros de un
modelo de clases latentes se utilizan varios métodos, lo más usados son el
algoritmo de Newton-Raphson y el algoritmo EM (Dempster, Laird, & Rubin,
1977). En este trabajo se hace uso de este último algoritmo.
Goodman en 1974 (Goodman, 1974) propone un proceso iterativo de estimación
que consta de los siguientes pasos:
1. Esperanza se calculan todos los valores esperados dados los valores
observados y los “actuales” parámetros del modelo.
2. Maximización se maximiza la función de verosimilitud de todos los
datos a partir de los valores esperados calculadas en el paso 1. Esto
implica el cálculo de estimaciones actualizadas de los parámetros del
modelo como si no faltaran datos. Las iteraciones continúan hasta que se
alcanza la convergencia.
Así finalmente, se obtienen las estimaciones máximo-verosímiles
| | | |
A partir de las que es posible calcular las probabilidades
∑

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
32
El siguiente paso en el análisis es asignar cada individuo a las diferentes
clases de la variable latente , para ello se calcula la probabilidad condicionada
de que un individuo que se sitúe en las categorías de las variables
indicadoras , pertenezca a la clase de la variable de la siguiente
manera:
|
∑
Dada esta probabilidad, la regla de asignación es mediante la
probabilidad modal, es decir, los individuos situados en la celda de la
tabla serán asignados a aquella clase latente cuya | sea mayor. Como
vemos se utiliza un proceso bayesiano para realizar dicha asignación (Reyes,
2009).
4.3 Inferencia en una red Bayesiana
Se entiende por inferencia cuando deducimos algo tomando en cuenta el
contexto o las otras opciones presentes, se puede llegar a alguna conclusión
teniendo en cuenta la incertidumbre.
De manera más formal Inferencia se refiere a obtener conclusiones
basadas en premisas, es decir basada en una nueva información, permitiendo
realizar predicciones en caso de intervenciones que se hagan en base a las
nuevas probabilidades (Roche B., 2002).
La inferencia es el proceso de introducción de nuevas observaciones y
calcular las nuevas probabilidades que tendrán las variables, dicho proceso
consiste en calcular la probabilidad a posteriori | de un conjunto de
variables después de obtener un conjunto de observaciones (donde es

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
33
la lista de variables observadas e es la lista correspondiente de los valores
observados para esas variables) (Felgaer, 2005).
4.4 Clasificación
Al construir clasificadores debemos cuantificar de alguna manera qué tan
buenos o malos son, existen distintos criterios de evaluarlos puede ser el tiempo
que se tarda en construirlo, la interpretabilidad del modelo obtenido, la
sencillez del modelo o diferencias respecto al original; sin embargo es la
precisión que posee el modelo la característica que más importante se considera
(García F. J., 2009).
4.4.1 Métodos de evaluación
La precisión de un clasificador es la probabilidad con la que se clasifica
correctamente un caso seleccionado al azar (Kohavi, 1996), o también lo
podemos ver como el número de casos clasificados correctamente entre el
número total de elementos.
Además de ser la medida más aceptada para la evaluación de un
clasificador, la precisión es utilizada en algunos procedimientos para guiar la
construcción (García F. J., 2009). Existen varias formas de obtener su valor,
una de éstas y a la que se recurre en esta investigación es la validación

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
34
cruzada.
Validación cruzada de k-hojas (k-fold cross validation) (Stone, 1974). Se
puede ver como una generalización del criterio de re muestreo. Hacemos k
particiones del conjunto de datos mutuamente excluyentes y de igual tamaño. k
- 1 conjuntos se utilizan para construir el clasificador y se valida con el
conjunto restante. Este paso se efectúa k veces y la estimación de la precisión
del clasificador se obtiene como la medida de las k mediciones realizadas.
El algoritmo de inducción es probado k veces de la siguiente manera: en
la primera iteración el algoritmo es entrenado con los subconjuntos y
probado con el subconjunto ; en la segunda iteración, el algoritmo se entrena
con los subconjuntos y se prueba con el subconjunto y así
sucesivamente. El número total de clasificaciones correctas de las k iteraciones
se divide por el tamaño completo del conjunto de datos para obtener la
estimación de la exactitud en este método (Jiménez, 2003).
∑ ( )
Donde ( ) denota la proposición construida por el modelo \ en el
conjunto , la cual es asignada a la etiqueta y probada en el conjunto
es el tamaño total de conjunto de datos . Si de lo contrario
. Lo anterior quiere decir que la función de pérdida usada para
calcular la exactitud del con el método cross-validation es una función de
pérdida 0/1, lo cual considera un costo igual para una clasificación errónea.
Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
35
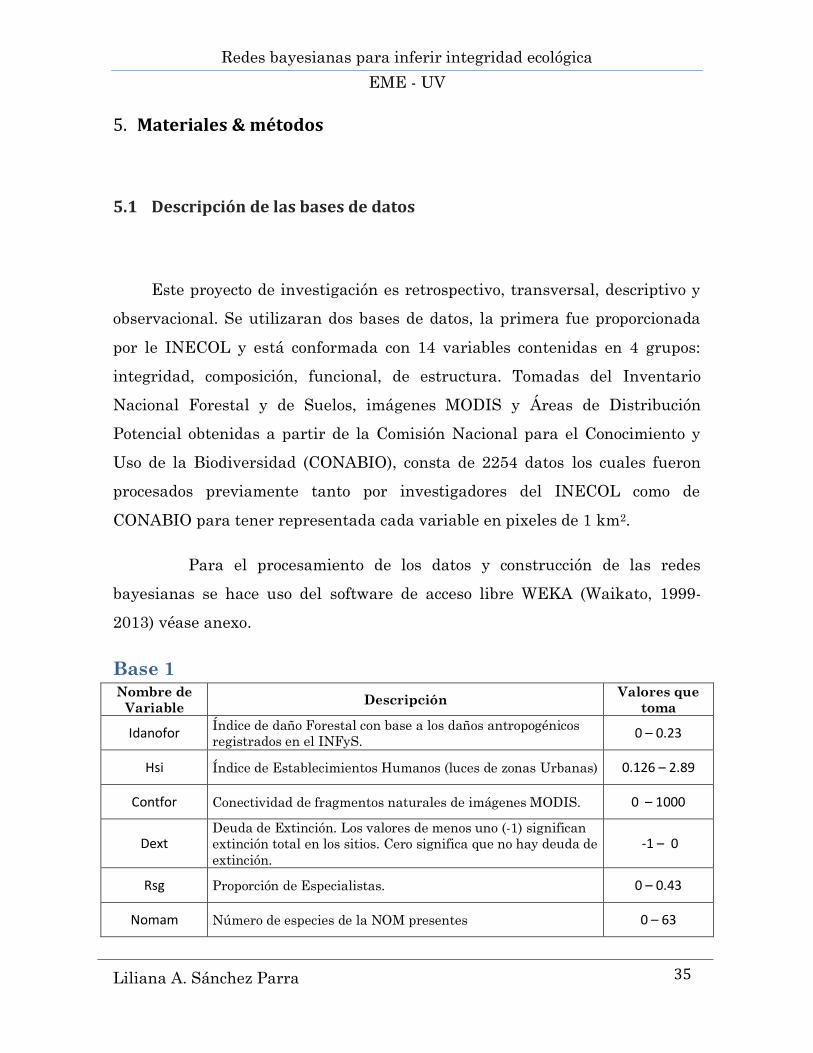
5. Materiales & métodos
5.1 Descripción de las bases de datos
Este proyecto de investigación es retrospectivo, transversal, descriptivo y
observacional. Se utilizaran dos bases de datos, la primera fue proporcionada
por le INECOL y está conformada con 14 variables contenidas en 4 grupos:
integridad, composición, funcional, de estructura. Tomadas del Inventario
Nacional Forestal y de Suelos, imágenes MODIS y Áreas de Distribución
Potencial obtenidas a partir de la Comisión Nacional para el Conocimiento y
Uso de la Biodiversidad (CONABIO), consta de 2254 datos los cuales fueron
procesados previamente tanto por investigadores del INECOL como de
CONABIO para tener representada cada variable en pixeles de 1 km2.
Para el procesamiento de los datos y construcción de las redes
bayesianas se hace uso del software de acceso libre WEKA (Waikato, 1999-
2013) véase anexo.
Base 1 Nombre de
Variable Descripción
Valores que
toma
Idanofor Índice de daño Forestal con base a los daños antropogénicos
registrados en el INFyS. 0 – 0.23
Hsi Índice de Establecimientos Humanos (luces de zonas Urbanas) 0.126 – 2.89
Contfor Conectividad de fragmentos naturales de imágenes MODIS. 0 – 1000
Dext Deuda de Extinción. Los valores de menos uno (-1) significan
extinción total en los sitios. Cero significa que no hay deuda de
extinción.
-1 – 0
Rsg Proporción de Especialistas. 0 – 0.43
Nomam Número de especies de la NOM presentes 0 – 63
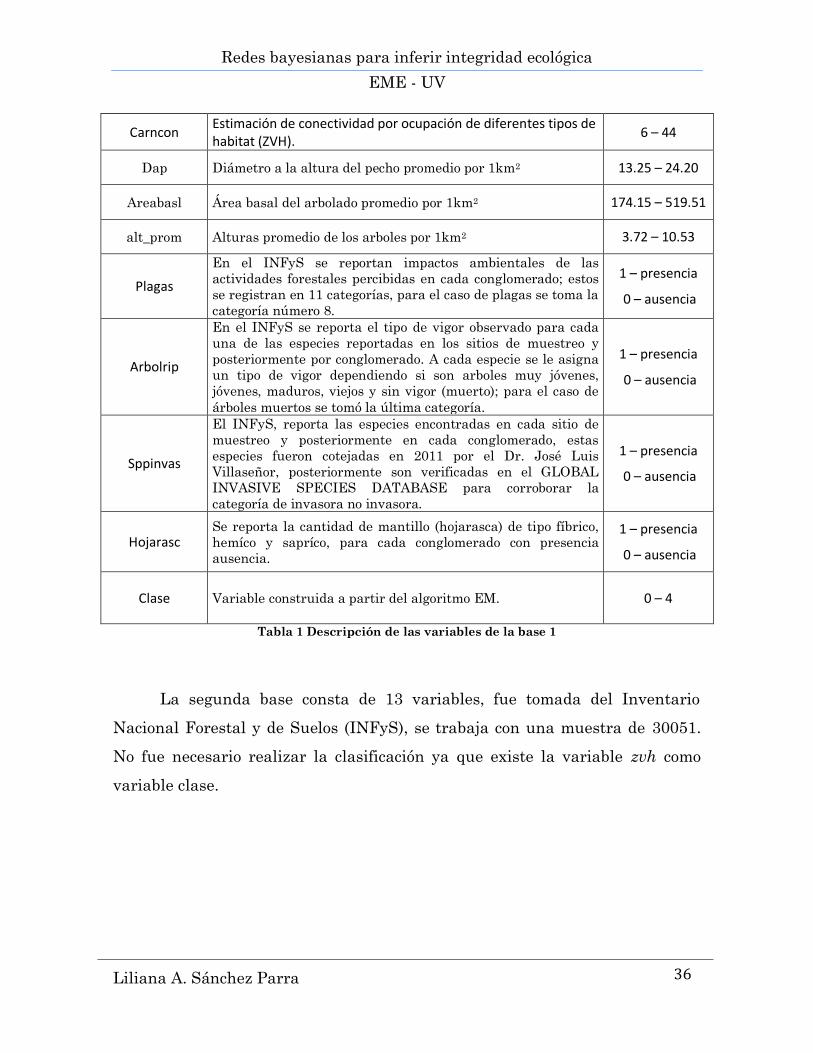
Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
36
Carncon Estimación de conectividad por ocupación de diferentes tipos de habitat (ZVH).
6 – 44
Dap Diámetro a la altura del pecho promedio por 1km2 13.25 – 24.20
Areabasl Área basal del arbolado promedio por 1km2 174.15 – 519.51
alt_prom Alturas promedio de los arboles por 1km2 3.72 – 10.53
Plagas
En el INFyS se reportan impactos ambientales de las
actividades forestales percibidas en cada conglomerado; estos
se registran en 11 categorías, para el caso de plagas se toma la
categoría número 8.
1 – presencia
0 – ausencia
Arbolrip
En el INFyS se reporta el tipo de vigor observado para cada
una de las especies reportadas en los sitios de muestreo y
posteriormente por conglomerado. A cada especie se le asigna
un tipo de vigor dependiendo si son arboles muy jóvenes,
jóvenes, maduros, viejos y sin vigor (muerto); para el caso de
árboles muertos se tomó la última categoría.
1 – presencia
0 – ausencia
Sppinvas
El INFyS, reporta las especies encontradas en cada sitio de
muestreo y posteriormente en cada conglomerado, estas
especies fueron cotejadas en 2011 por el Dr. José Luis
Villaseñor, posteriormente son verificadas en el GLOBAL
INVASIVE SPECIES DATABASE para corroborar la
categoría de invasora no invasora.
1 – presencia
0 – ausencia
Hojarasc Se reporta la cantidad de mantillo (hojarasca) de tipo fíbrico,
hemíco y sapríco, para cada conglomerado con presencia
ausencia.
1 – presencia
0 – ausencia
Clase Variable construida a partir del algoritmo EM. 0 – 4
Tabla 1 Descripción de las variables de la base 1
La segunda base consta de 13 variables, fue tomada del Inventario
Nacional Forestal y de Suelos (INFyS), se trabaja con una muestra de 30051.
No fue necesario realizar la clasificación ya que existe la variable zvh como
variable clase.
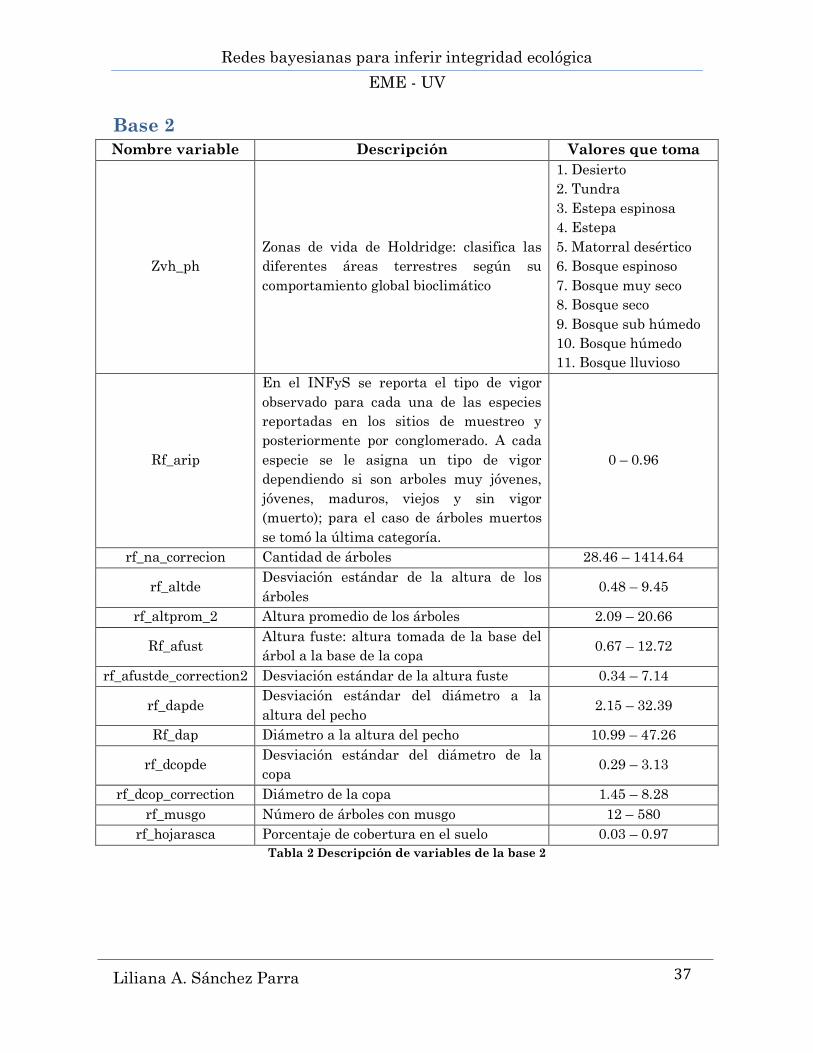
Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
37
Base 2
Nombre variable Descripción Valores que toma
Zvh_ph
Zonas de vida de Holdridge: clasifica las
diferentes áreas terrestres según su
comportamiento global bioclimático
1. Desierto
2. Tundra
3. Estepa espinosa
4. Estepa
5. Matorral desértico
6. Bosque espinoso
7. Bosque muy seco
8. Bosque seco
9. Bosque sub húmedo
10. Bosque húmedo
11. Bosque lluvioso
Rf_arip
En el INFyS se reporta el tipo de vigor
observado para cada una de las especies
reportadas en los sitios de muestreo y
posteriormente por conglomerado. A cada
especie se le asigna un tipo de vigor
dependiendo si son arboles muy jóvenes,
jóvenes, maduros, viejos y sin vigor
(muerto); para el caso de árboles muertos
se tomó la última categoría.
0 – 0.96
rf_na_correcion Cantidad de árboles 28.46 – 1414.64
rf_altde Desviación estándar de la altura de los
árboles 0.48 – 9.45
rf_altprom_2 Altura promedio de los árboles 2.09 – 20.66
Rf_afust Altura fuste: altura tomada de la base del
árbol a la base de la copa 0.67 – 12.72
rf_afustde_correction2 Desviación estándar de la altura fuste 0.34 – 7.14
rf_dapde Desviación estándar del diámetro a la
altura del pecho 2.15 – 32.39
Rf_dap Diámetro a la altura del pecho 10.99 – 47.26
rf_dcopde Desviación estándar del diámetro de la
copa 0.29 – 3.13
rf_dcop_correction Diámetro de la copa 1.45 – 8.28
rf_musgo Número de árboles con musgo 12 – 580
rf_hojarasca Porcentaje de cobertura en el suelo 0.03 – 0.97
Tabla 2 Descripción de variables de la base 2

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
38
5.2 Algoritmos que aprenden la estructura de la red bayesiana a partir
de datos.
A continuación se presentan los algoritmos de búsqueda utilizados en esta
investigación, sin embargo existen más para continuar con lo descrito en la
sección 4.2.1
5.2.1 Hill Climbing (ascenso de colinas)
Se trata simplemente de un bucle que continuamente mueve en la dirección
para incrementar el valor. El algoritmo no mantiene un árbol de búsqueda, por
lo que la estructura de datos de nodo sólo tiene que registrar el estado y su
evaluación, que denotamos por valor. Un refinamiento importante es que
cuando hay más de un mejor sucesor para elegir, el algoritmo puede seleccionar
entre ellos al azar. Esta política simple tiene tres inconvenientes conocidos.
Máximos locales: un máximo local, en oposición a un máximo global, es
un pico que es más bajo que el pico más alto en el espacio de estados.
Una vez en un máximo local, el algoritmo se detiene a pesar de que la
solución puede estar lejos de ser satisfactoria.
Mesetas: una meseta es un área del espacio de estado, donde la función
de evaluación es esencialmente plana. La búsqueda realiza una
caminata aleatoria. Dado que el algoritmo realiza una búsqueda al azar,
un sucesor podría encontrarse en esta área.
Cresta: una cresta puede tener lados con fuertes pendientes, por lo que
la búsqueda llega a la parte superior de la cresta con facilidad. A menos
que suceda que los operadores que se mueven directamente a lo largo de
la parte superior de la cresta, la búsqueda puede oscilar desde de lado a

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
39
lado, haciendo pocos progresos.
En cada caso, el algoritmo llega a un punto en el que se está haciendo
ningún progreso. Si esto sucede, una cosa obvia a hacer es empezar de nuevo
desde un punto de partida diferente. Se reinicia aleatoriamente y en escalada
hace precisamente esto: que lleva a cabo una serie de allanamientos en
escalada desde inicial generada aleatoriamente estados, ejecutando cada uno
hasta que se detiene o hace ningún progreso discernible. Guarda el mejor
resultado encontrado tan lejos de cualquiera de la búsqueda. Se puede utilizar
un número fijo de iteraciones, o puede continuar hasta que el resultado mejor
guardado no ha sido mejorado para un cierto número de iteraciones.
Es evidente que si se permite suficientes iteraciones, el re arranque al azar
en escalada eventualmente encontrará la solución óptima. El éxito de este
algoritmo depende mucho de la forma del espacio "superficie" del estado si sólo
hay unos pocos máximos locales, el re-arranque al azar de escalada encuentra
una buena solución muy rápidamente (Norvig, 1995).
Ilustración 6 Hill climbing
5.2.2 K2
Este algoritmo fue desarrollado por Cooper y Herskovits en 1992 (Cooper
& Herskovits, 1992). Se trata de un algoritmo de búsqueda, muy rápido que

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
40
optimiza la probabilidad de la red dada la base de datos. En realidad lo que
hace este algoritmo es encontrar el conjunto de padres más probables,
utilizando la métrica Bayesiana, que mide precisamente la probabilidad de la
estructura dado los datos. La heurística de este algoritmo se basa en un
ordenamiento topológico 6que tiene que ser especificado por el usuario.
El funcionamiento del algoritmo inicia con la red más simple, es decir,
una red sin arcos, y supone que los nodos se encuentran ordenados. Para cada
variable, el algoritmo añade a su conjunto de padres, el nodo menor de la
variable que conduce a un máximo de incremento de la calidad correspondiente
a la medida de calidad elegida para el proceso de búsqueda. El proceso se
repite hasta que no se incrementa la calidad, o se llega a una red completa
(Sánchez S., 2009).
5.2.3 Simulated annealing (recocido simulado)
Es un algoritmo de Hill-Climbing (UPC, 2012) estocástico (elegimos un
sucesor de entre todos los posibles según una distribución de probabilidad, el
sucesor podría ser peor). Hacemos paseos aleatorios por el espacio de soluciones
Inspirado en el proceso físico de enfriamiento controlado (cristalización,
templado de metales).
Se calienta un metal/disolución a alta temperatura y se enfría
progresivamente de manera controlada Si el enfriamiento es adecuado se
obtiene la estructura de menor energía (mínimo global).
Debemos identificar los elementos del problema con los del problema físico
Temperatura parámetro de control
Energía calidad de la solución
6 Ordenamiento topológico de un grafo acíclico G dirigido es una ordenación lineal de todos los nodos de G que conserva la unión entre vértices del grafo G original. La condición que el grafo no contenga ciclos es importante, ya que no se puede obtener ordenación topológica de grafos que contengan ciclos. http://es.wikipedia.org/wiki/Ordenaci%C3%B3n_topol%C3%B3gica

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
41
Función de aceptación permite decidir si escoger un nodo sucesor
Función de la temperatura y la diferencia de calidad entre la solución
actual y la solución candidata. A menor temperatura menor probabilidad de
elegir sucesores peores.
Estrategia de enfriamiento número de iteraciones a realizar, como bajar
la temperatura y cuantos sucesores explorar para cada paso de
temperatura.
A continuación se muestra el algoritmo
Ilustración 7 Algoritmo Simulated Annealing
5.2.4 Tabú Search (búsqueda tabú)
La búsqueda tabú se basa en la premisa de que la resolución de
problemas, debe incorporar la memoria adaptativa y exploración sensible7. La
función de adaptación de la memoria permite la aplicación de procedimientos
que son capaces de buscar el espacio, la solución económica y efectiva. El
énfasis en la exploración de respuesta en la búsqueda tabú, ya sea en una
aplicación determinista o probabilista, se deriva de la suposición de que una
7 se concentra en buscar buenas características de las soluciones

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
42
mala elección estratégica puede producir más información que una buena
elección al azar (Glover, 1997).
En otras palabras, este algoritmo clasifica algunos movimientos y los
introduce en una lista tabú: los movimientos que se encuentran aquí no serán
posibles de realizar. Enfrenta el problema de ciclos impidiendo temporalmente
movimientos que podrían hacer volver a una solución que ha sido revisada. En
una lista se guardan los movimientos prohibidos y en cada iteración se elige el
mejor movimiento no tabú. Se agregan a la lista los movimientos no factibles.
Ilustración 8 Algoritmo Tabú search8
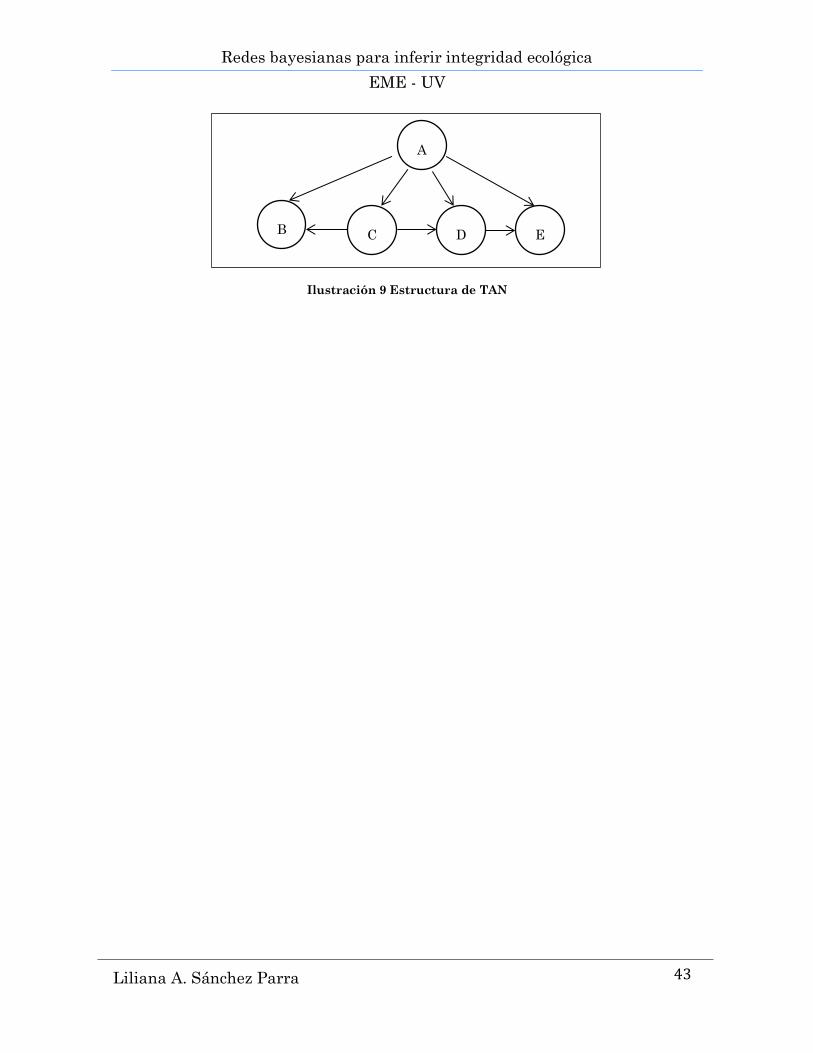
5.2.5 TAN (Naïve Bayes Aumentado a Árbol)
El algoritmo TAN es un algoritmo de aprendizaje para clasificadores de
redes Bayesianas, es llamado así por sus siglas en inglés Tree Augmented
Naive Bayes (Jiménez, 2003). Hace uso de la clasificación Naïve Bayes y agrega
arcos entre los atributos, este algoritmo hace que sus componentes formen un
árbol. El atributo clase o salida es el único padre de cada nodo de la red Naïve
Bayes y el algoritmo considera agregar un segundo padre a cada nodo (Sánchez
S., 2009).
La estructura para representar a una red Bayesiana TAN es como la que
se muestra en la figura siguiente.
8 Tomado de (Hernández-Díaz, Guerrero Casas, Caballero Fernandez, & Molina Luque, 2006)
Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
43
Ilustración 9 Estructura de TAN
A
B C D E

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
44
6. Metodología y resultados.
6.1 Metodología
Como primera etapa fue la obtención de las bases de datos, por parte de
las personas del INECOL. Se realizó la exploración de la base, con lo cual se
observa que no existen datos faltantes, y se convirtió a formato .csv para poder
trabajarlos en Weka. Para el caso de la base 1, mediante el algoritmo EM
(véase sección 4.2.2) se construyó la variable latente “clase”, con niveles del 0 al
4.
Comienza un proceso iterativo en el que mediante los algoritmos se
encuentran las distintas estructuras y relaciones probabilistas entre las
variables, además de incluir la consulta de los ecólogos expertos para la toma
de decisiones en cuanto a la creación de estas redes, y de ésta manera
encontrar una red adecuada que modele el fenómeno de manera confiable.
Se calculan los criterios de información de cada estructura obtenida por
cada algoritmo, y mediante estos elegir la red Bayesiana más parsimoniosa.
Bases Búsqueda de
estructuras
Algoritmo
EM
Exploración
datos
Determinar red
adecuada
Ilustración 10 Pasos realizados para el desarrollo de las pruebas
Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
45
6.2 Resultados
En esta parte se presenta solo el resultado así como las interpretaciones
de una red, las demás se incluyen en la parte de anexos. Después de esto, se
presenta una tabla resumiendo los valores así como el porcentaje de
correcta clasificación.
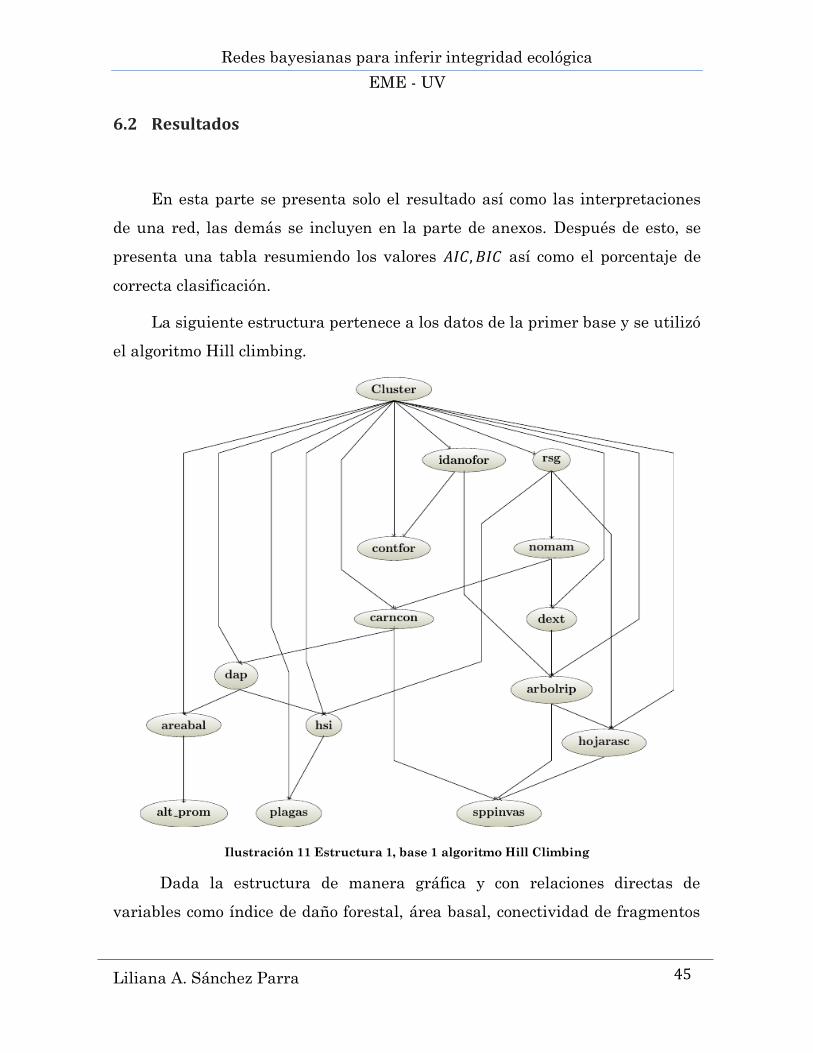
La siguiente estructura pertenece a los datos de la primer base y se utilizó
el algoritmo Hill climbing.
Ilustración 11 Estructura 1, base 1 algoritmo Hill Climbing
Dada la estructura de manera gráfica y con relaciones directas de
variables como índice de daño forestal, área basal, conectividad de fragmentos

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
46
naturales y diámetro a la altura del pecho, indican mayor probabilidad de que
la clasificación sea en el clúster 3.
Ilustración 12 Probabilidad de pertenecer al Cluster, estructura 1
Con el logaritmo Hill climbing, se observa que se clasificó correctamente
el 93% de los casos, se calcula un valor log score Bayes igual a -23398.60, y
según la matriz de confusión se tiene que el clúster 3, es el que mayor cantidad
de datos clasificó correctamente.
Hill climbing – false – 10000 – false Log Score Bayes: -23398.60317310535 Log Score BDeu: -30552.750398087293 Log Score MDL: -29260.869018823156 Log Score ENTROPY: -24022.836846239872 Log Score AIC: -25379.836846239872 Correctly Classified Instances 93.0759 %
=== Confusion Matrix ===
a b c d e <-- classified as 333 20 1 0 0 | a = cluster0 16 336 16 3 0 | b = cluster1 0 21 523 0 0 | c = cluster2 0 5 0 542 37 | d = cluster3 0 0 0 37 363 | e = cluster4
Tabla 3 Resultados con algoritmo Hill Climbing
A continuación se presenta el resumen de ambas bases y los resultados
según los algoritmos usados así como los criterios de información.
Base 1
Algoritmo AIC BIC % correcta clasificación
Hill Climbing -25379.84 -23398.60 93.1
k2 -24915.16 -23562.14 93.7
Simulated Annealing -25663.81 -23462.45 93.3
Tabú search -24383.23 -23555.74 94.2
TAN -24813.51 -23558.23 94.5 Tabla 4 Criterios de selección de acuerdo a los algoritmos empleados: Base 1
De acuerdo a lo descrito en la sección 3.3, en este caso es preferible
utilizar el ya que se tiene una muestra grande de datos. Sin embargo en la
tabla se presenta también el .
De los algoritmos usados el Hill Climbing es el que presenta el menor, y

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
47
clasificó de manera correcta el 93.1% de los datos. Ahora bien, si utilizáramos
el la estructura seleccionada sería la construida bajo el algoritmo Tabú
search.
Base 2
Algoritmo AIC BIC % correcta clasificación
Hill Climbing -914620.13 -741699.19 73.49
K2 -982342.56 -751713.07 73.15
Simulated Annealing -883392.86 -747316.56 72.72
Tabú search -811707.69 -747125.46 72.73
TAN -811884.66 -742331.83 73.55 Tabla 5 Criterios de selección de acuerdo a los algoritmos empleados: Base 2
Para los datos de la base 2, se observa que existe un comportamiento igual
en los criterios de selección, el BIC elige a Hill Climbing, mientras que AIC a Tabú
search.

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
48
7. Conclusiones y trabajo futuro
De acuerdo a los objetivos y las preguntas del planteamiento del problema
se encontró que:
Mediante redes bayesianas y con los algoritmos utilizados se generó una red
para cada base de datos, seleccionando la mejor mediante los criterios de
información, con las cuales se determinaron las relaciones probabilistas y se
observó que la mayoría de ellas se relacionan directamente.
Como se mencionó para ambas bases se elige la estructura creada con el
algoritmo Hill climbing, se podría decir que se adecua bien a este tipo de datos.
Sólo con la primera base se puede llegar a un acuerdo con los expertos para
evaluar la integridad ya que se creó la variable Cluster, con la que se puede
tomar los valores como escala, en el caso se la segunda, se podrá evaluar en qué
medida están relacionadas las variables de acuerdo al tipo de ecosistema (zvh).
Este trabajo proporcionará información relevante con las relaciones
probabilistas encontradas, será trabajo de los expertos evaluar la importancia y
pertinencia biológicamente de éstas. Si bien no se lograron algunos objetivos, se
presenta como un inicio de análisis.
Se planea seguir con la evaluación de cada una de las estructuras de los
expertos así como las relaciones probabilistas desde sus conocimientos
expertos. Además del cálculo de las tablas de probabilidad.

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
49
8. Bibliografía
Akaike, H. (1974). A new look at the statistical model identification. Automatic
control, IEEE Transactions on 19(6), 716-723.
Angermaier, P. (1994). Does Biodiversity include artificial diversity?
Conservation Biology.
Biblioteca educación y salud. (2002). Enciclopedia de la ecología y la salud.
España: Safeliz, S. L.
Bouckaert, R. (1993). Belief networks construction using the minimum
description length principle. Symbolic and Quantitative Approaches to
Reasoning and Uncertainty, Lecture Notes in Computer Science., 747, 47-
48.
Boulanger, P., y T. Bréchet. (2005). Models for policy-making in sustainable
development: The state of the art and perspectives for research.
Ecological Economics 55, 337-350.
Carreño S, Á. (Diciembre de 2006). Recuperado el Diciembre de 2013, de
http://www.seden.org/files/7-CAP%207.pdf
Césari, M. I. (2006). Nivel de significación estadística para el aprendizaje de
una red bayesiana. Mendoza: ITBA.
Cooper, G., & Herskovits, E. (1992). A bayesian method fot the induction of
probabilistic networks from data. Machine Learning, 9, 309-347.
Cruz Ramírez, N. (2001). Building Bayesian Networks From Data: a Constraint
Based Approach. Ph D Thesis. Department of Psychology. The
University of Sheffield.
De Finetti, B. (1989). Probabilism: A critical essay on the theory of probability
and on the value of science. Erkenntnis, 31.

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
50
Degroot, M. (1988). Probabilidad y estadística. EUA: ADDISON-WESLEY
IBEROAMERICA.
Dempster, A., Laird, N., & Rubin, D. (1977). Maximum Likelihood from
Incomplete Data via the EM Algorithm. Journal of the Royal Statistical
Society., 39(1), 1-38.
Domínguez Sánchez, F. (2009). Evaluación empírica del comportamiento de
MDL en el aprendizaje de redes Bayesianas para Minería de datos.
México: Tesis de Licenciatura. Universidad Veracruzana. Facultad de
Estadística e Informática.
Equihua Z., Miguel; García A., N; Pérez M, Octavio; Benítez Badillo, G; Kolb,
M; Schmidt, M; Equihua Benítez, J; Maeda, P. (s.f.). Integridad ecológica
como indicador de la calidad ambiental. (A. V.-P. C. Gonzalez-Zuarth,
Ed.) Bioindicadores: guardianes de nuestro futuro ecológico.
Felgaer, P. (2005). Optimización de Redes Bayesianas basado en técnicas de
aprendizaje por inducción. Buenos Aires, Argentina: Tesis de grado en
Ingeniería Informática, Facultad de Ingeniería, Universidad de Buenos
Aires.
García, D. (2010). Desarrollo de un entorno de usuario para aplicación de redes
bayesianas dinámicas a problemas de fusión de información. Madrid:
Tesis de licenciatura. Universidad Carlos III de Madrid.
García, F. J. (2009). Modelos bayesianos para la clasificación supervisada.
Aplicaciones al análisis de datos de expresión genética. Granada, España:
Tesis Doctotal, Universidad de Granada.
Glover, F. y. (1997). Tabu Search. Boston: Kluwer Academic Publishers.
Goodman. (1974). Exploraty latent analysis using both identificable and
inidentificable models. Biometrika.

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
51
Groves, C. R. (2003). Drafting a conservation Blueprint: a practitioner's guide
to planing for Biodiversity. Washington: Island Press.
Grünwald, P. (2005). A tutorial inroduction to the Minimun Description Length
Principle. (P. Grünwald, I. Myung, & M. Pitt, Edits.) Advances in
Minimum Description Length: Theory and Applications.
Gutiérrez Fragoso, K. (2007). Anáisis del compportamiento de MDL en el
contexto del aprendizaje de la estructura de redes Bayesianas a partir de
datos. Veracruz, México: Departamento de Inteligencia Artificial,
Universidad Veracruzana. Tesis para obtener el grado de Maestra en
Inteligencia Artificial.
Hernández Orallo, J., Ferri Ramírez, C., & Ramírez Quintana, J. (2004).
Introducción a la minería de datos. PEARSON EDUCACIÓN.
Hernández-Díaz, A., Guerrero Casas, F., Caballero Fernandez, R., & Molina
Luque, J. (2006). Algoritmo Tabú para un problema de distribución de
espacios. Métodos cuantitativos para la economía y la empresa, 25-37.
Jiménez, J. L. (2003). BayesN: Un Algoritmo para Aprender Redes Bayesianas
Clasificadoras a partir de datos. Xalapa, Veracruz: Tesis de maestría.
Universidad Veracruzana. Facultad de Física e Inteligencia Artificial.
Kay, J. J. (1991). A nonequilibrium thermodynamic framework for discussing
ecosystem integrity. Environmental Management.
Kohavi, R. (1996). Wrappers for performance enhancement and oblivious
decision graphs. Stanford, CA, USA: Tesis doctoral, Stanford University.
L. Buntine, W. (1994). Operations for learning with graphical models. Journal
of Artificial Intelligence Research.(2), 159-225.
Lauritzen, S., & Spiegelhalter, D. (1988). Local computations wilh probabililics
on graphical structures and their application to expert systems. Journal

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
52
of the Royal Statistical Society, 157-224.
Lin, T. S., & Dayton, C. M. (1997). Model-selection information criteria for
nonnested latent class models. Journal of Educational and Behavioral
Statistics(22), 249-264.
López de Castilla Vásquez, C. (19 de Octubre de 2011). Recuperado el
Noviembre de 2013, de
http://tarwi.lamolina.edu.pe/~clopez/Estadistica%20Bayesiana/Estadistic
a_Bayesiana.pdf
Mackey, B. (2005). Carta de la tierra en acción. Ámsterdam, Los Países Bajos:
KIT Publishers.
Mesa P., e. a. (2011). Recuperado el Diciembre de 2013, de
http://www.urosario.edu.co/urosario_files/38/38e60ea0-497e-4197-913d-
e156ae0bb084.pdf
Montes S, F. (2007). Introducción a la probabilidad. Valencia: Universidad de
Valencia, Departamento de Estadística e Investigación Operativa.
Morales, E., & González, J. (Enero de 2012). Aprendizaje bayesiano. INAOE.
N. Kolmogorov, A. (1956). Foundations of the theory of probability (2 ed.). New
York: Chelsea Publishing Company.
Navarrete, M. (2001). A historical overview of the ecological.
Norvig, S. J. (1995). Artificial Intelligence, A Modern Approach. New Jersey:
Prentice-Hall.
Ortega, J. (2009). Capítulo 6. Esperanza matemática. Guanajuato, México.
Pearl, J. (1985). Recuperado el Diciembre de 2013, de
http://es.wikipedia.org/wiki/Red_de_inferencia
Pérez, J., & Fajardo, M. (2001). Determinación de la lealtad de voto mediante

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
53
un modelo de clases latentes. Estadística española, 147(43), 89-103.
Reyes, Y. (2009). Introducción al análisis de clases latentes. Xalapa, Veracruz,
México: Tesis de licenciatura, Facultad de Estadística e Informática,
Universidad Veracruzana.
Rissanen, J. (1978). Modelling by the shortest data description. Automatica 14,
465-471.
Robinson, R. W. (1977). Counting unlabeled acyclic digraphs. Combinatorial
mathematics V: Proceedings of the Fifth Australian Conference, 28-43.
Roche B., D. (2002). Métodos para obtener conocimiento utilizando redes
Bayesianas y procesos de aprendizaje con algoritmos evolutivos. Sevilla,
Eapaña: Tesis Doctoral. Universidad de Sevilla, Departamento de
Lenguajes y Sistemas Informáticos.
Rodríguez-Caballero, C. (2012). Entropía y teoría de la información.
Econometría I. (U. Facultad de Ciencias, Ed.) México.
Ruggeri, F., Faltin, F., & Kenett, R. (2007). Encyclopedia of Statistics in
Quality & Reliability: Bayesian Networks. Wiley & Sons.
Ruiz Reina, J. (2006). Recuperado el Diciembre de 2013, de
http://www.cs.us.es/cursos/ia2-2005/temas/tema-08.pdf
Sánchez Parra, L. (2012). Análisis sobre la percepción, conocimientos y
prácticas de riesgo en relación con el VIH y SIDA de consumidores de
drogas que asisten a Centros de Tratamiento en el Estado de Veracruz.
Xalapa, Veracruz, México: Tesis de licenciatura, Facultad de Estadística
e Informática, Universidad Veracruzana.
Sánchez S., D. (2009). Evaluación del comportamiento de Clasificadores
basados en Redes Bayesianas. Xalapa, Veracruz, México: Tesis para
obtener el grado de licenciado en Informática. Facultad de Estadística e

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
54
Informática. Universidad Veracruzana.
Schwarz, G. (1978). Estimating the dimension of a model. Annals of Statistics
6, 461-464.
Stone, M. (1974). Cross Validatory choice and assessment of statistical
predictions. Journal of the Royal Statistical Society B 36(1), 111-147.
Ulanowicz, R. E. (1990). Ecosystem integrity and network theory. Edwards y
H. A. Higashi.
UPC. (2012). Departament de Llenguatges i Sistemes Informàtics. Recuperado
el agosto de 2014, de Búsqueda Local:
http://www.lsi.upc.edu/~bejar/ia/transpas/teoria/2-BH3-
Busqueda_local.pdf
Vermunt y Magdison. (2000). Latent gold 4.0 user's guide. Nueva York:
Statistical Innovations.
Waikato, U. d. (1999-2013). Patente nº Version 3.6.10 . Nueva Zelanda.
Westra, L. P. (2000). Ecological integrity and the aims of the global integrity
project. Island Press: Washington, DC.

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
1
9. Anexos
9.1 Resultados (completos)
En la sección 6.2 se presentan los resultados del primer algoritmo, Hill
climbing. A continuación se presentan las estructuras, probabilidad de
clasificación así como tabla de resultados de cada uno de los demás algoritmos.
Algoritmo K2
Ilustración 13 Estructura 2, base 1 algoritmo K2
Ilustración 14 Probabilidad de pertenecer al Cluster, estructura 2

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
2
K2 - false – 10000 – false LogScore Bayes: -23562.136961983902 LogScore BDeu: -28516.442440905295 LogScore MDL: -28001.10477652969 LogScore ENTROPY: -23836.155097666495 LogScore AIC: -24915.155097666502 Correctly Classified Instances 93.6973 %
=== Confusion Matrix ===
a b c d e <-- classified as 331 22 1 0 0 | a = cluster0 15 340 15 1 0 | b = cluster1 0 15 529 0 0 | c = cluster2 0 5 0 556 23 | d = cluster3 0 0 0 45 355 | e = cluster4
Tabla 6 Resultados con algoritmo K2
Algoritmo Simulated Annealing
Ilustración 15 Estructura 3, base 1 algoritmo Simulated Annealing
Ilustración 16 Probabilidad de pertenecer al Cluster, estructura 3

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
3
Tabla 7 Resultados con algoritmo Simulated Annealing
Algoritmo Tabú search
Ilustración 17 Estructura 4, base 1 algoritmo Tabú search
Ilustración 18 Probabilidad de pertenecer al Cluster, estructura 4
Simulated Annealing - false– false LogScore Bayes: -23462.453977319026 LogScore BDeu: -31289.523440510202 LogScore MDL: -29893.759509092393 LogScore ENTROPY: -24184.80624214273 LogScore AIC: -25663.806242142724 Correctly Classified Instances 93.3422 %
=== Confusion Matrix ===
a b c d e <-- classified as 329 24 1 0 0 | a = cluster0 16 339 12 4 0 | b = cluster1 0 21 523 0 0 | c = cluster2 0 5 0 543 36 | d = cluster3 0 0 0 31 369 | e = cluster4

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
4
Ilustración 19 Resultados con algoritmo Tabú search
Algoritmo TAN
Ilustración 20 Estructura 5, base 1 algoritmo TAN
Ilustración 21 Probabilidad de pertenecer al Cluster, estructura 5
Tabú search - false– false LogScore Bayes: -23555.73888413739 LogScore BDeu: -26658.780952017503 LogScore MDL: -26410.977202515976 LogScore ENTROPY: -23674.23084263275 LogScore AIC: -24383.23084263275 Correctly Classified Instances 94.1855 %
=== Confusion Matrix ===
a b c d e <-- classified as 333 19 2 0 0 | a = cluster0 15 340 14 2 0 | b = cluster1 0 14 530 0 0 | c = cluster2 0 5 0 554 25 | d = cluster3 0 0 0 35 365 | e = cluster4
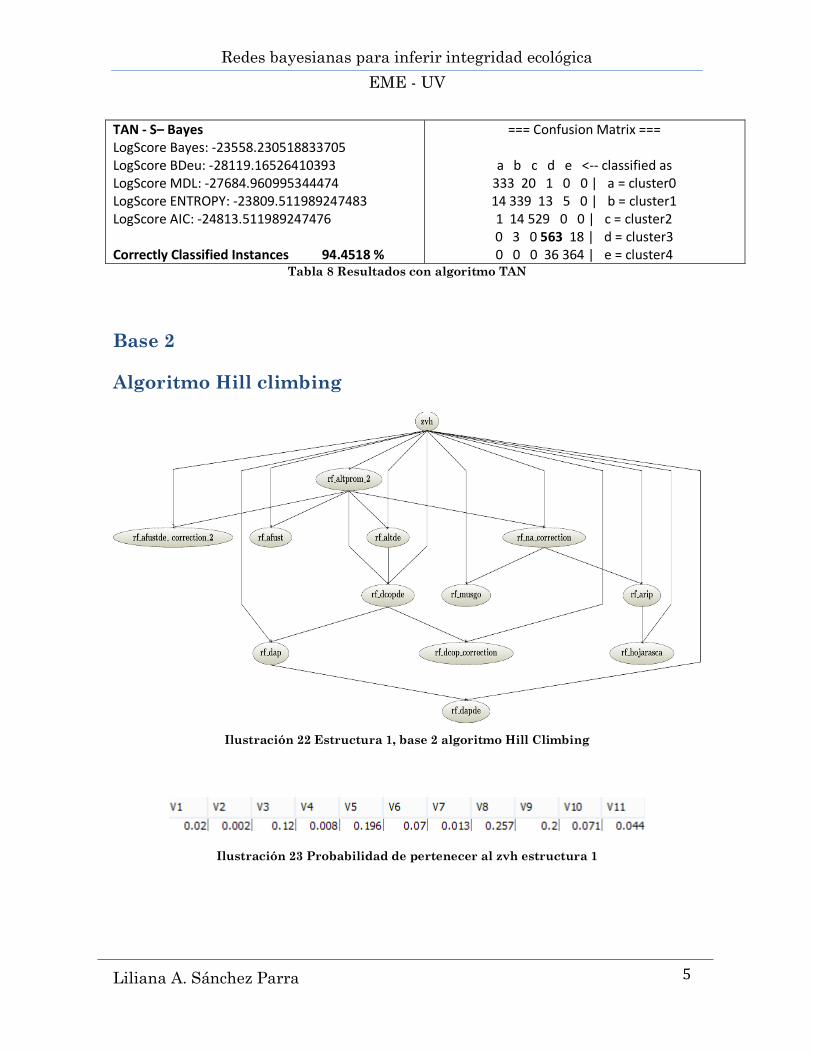
Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
5
Tabla 8 Resultados con algoritmo TAN
Base 2
Algoritmo Hill climbing
Ilustración 22 Estructura 1, base 2 algoritmo Hill Climbing
Ilustración 23 Probabilidad de pertenecer al zvh estructura 1
TAN - S– Bayes LogScore Bayes: -23558.230518833705 LogScore BDeu: -28119.16526410393 LogScore MDL: -27684.960995344474 LogScore ENTROPY: -23809.511989247483 LogScore AIC: -24813.511989247476 Correctly Classified Instances 94.4518 %
=== Confusion Matrix ===
a b c d e <-- classified as 333 20 1 0 0 | a = cluster0 14 339 13 5 0 | b = cluster1 1 14 529 0 0 | c = cluster2 0 3 0 563 18 | d = cluster3 0 0 0 36 364 | e = cluster4

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
6
Hill climbing – false – 10000 – false LogScore Bayes: -741699.1910544233 LogScore BDeu: -1513892.9755854046 LogScore MDL: -1240425.4366588404 LogScore ENTROPY: -836213.1262494246 LogScore AIC: -914620.1262494408 Correctly Classified Instances 73.4908 %
=== Confusion Matrix ===
a b c d e f g h i j k <-- classified as 40 0 0 0 0 0 0 0 0 0 10 | a = V2
0 4943 59 0 0 426 6 237 212 5 0 | b = V5 0 9 6187 948 7 198 102 79 0 48 144 | c = V8
3 0 993 4119 204 5 1 2 0 6 677 | d = V9 2 0 1 54 993 0 0 0 0 0 270 | e = V11
1 282 324 16 2 2763 3 150 1 52 2 | f = V3 0 7 124 4 0 16 166 60 1 0 0 | g = V7
0 492 158 2 0 299 72 1063 7 7 0 | h = V6 0 202 0 0 0 16 0 3 388 0 0 | i = V1 0 0 41 6 0 77 0 0 0 125 0 | j = V4
7 0 69 393 362 0 0 0 0 0 1297 | k = V10 Tabla 9 Resultados con algoritmo Hill Climbing

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
7
Algoritmo K2
Ilustración 24 Estructura 2, base 2 algoritmo K2
Ilustración 25 Probabilidad de pertenecer a ZVH, estructura 2
K2 – false – 10000 – false LogScore Bayes: -751713.0678051873 LogScore BDeu: -1794866.5042554142 LogScore MDL: -1415059.8158636456 LogScore ENTROPY: -878206.5609655143 LogScore AIC: -982342.5609655415 Correctly Classified Instances 73.1481 %

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
8
=== Confusion Matrix ===
a b c d e f g h i j k <-- classified as 33 0 0 0 0 0 0 0 0 0 17 | a = V2
0 4952 72 10 0 433 20 241 149 11 0 | b = V5 1 13 6145 913 10 320 91 65 0 14 150 | c = V8
2 1 983 4154 138 1 0 0 0 4 727 | d = V9 0 0 2 73 965 0 0 0 0 0 280 | e = V11
1 294 392 8 0 2698 5 144 6 46 2 | f = V3 0 9 125 5 1 21 163 54 0 0 0 | g = V7
0 468 177 3 0 315 66 1063 5 3 0 | h = V6 0 195 3 1 0 13 0 17 374 3 3 | i = V1 0 4 73 2 0 69 0 2 1 98 0 | j = V4
9 0 98 380 304 0 0 0 0 1 1336 | k = V10 Tabla 10 Resultados con algoritmo K2

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
9
Algoritmo Simulated Annealing
Ilustración 26 Estructura 3, base 2 algoritmo Simulated Annealing
Ilustración 27 Probabilidad de pertenecer a ZVH, estructura 3
Simulated Annealing– false– false LogScore Bayes: -747316.5603340995 LogScore BDeu: -1339555.003229849 LogScore MDL: -1148543.1248765974 LogScore ENTROPY: -819582.8595020369 LogScore AIC: -883392.8595020572 Correctly Classified Instances 72.7221 %

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
10
=== Confusion Matrix ===
a b c d e f g h i j k <-- classified as 29 0 0 0 2 0 0 0 0 0 19 | a = V2
0 5044 48 0 1 373 9 233 174 6 0 | b = V5 0 10 6127 955 8 205 111 102 2 45 157 | c = V8
1 1 984 4119 184 1 1 0 1 4 714 | d = V9 0 0 1 63 970 0 0 0 1 0 285 | e = V11
0 329 304 17 2 2713 4 178 0 46 3 | f = V3 0 14 141 6 0 24 151 41 0 1 0 | g = V7
0 541 157 1 0 364 64 950 5 18 0 | h = V6 0 236 0 0 0 7 0 3 362 1 0 | i = V1 0 0 40 6 1 85 0 3 0 113 1 | j = V4
8 0 91 385 368 0 0 0 1 0 1275 | k = V10 Tabla 11 Resultados con algoritmo Simulated Annealing
Algoritmo Tabú search
Ilustración 28 Estructura 4, base 2 algoritmo Tabú search
Ilustración 29 Probabilidad de pertenecer a ZVH, estructura 4

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
11
Tabú Search– false - 10000– false LogScore Bayes: -747125.4574814732 LogScore BDeu: -1009911.9749531187 LogScore MDL: -943480.8518110849 LogScore ENTROPY: -779995.6937550211 LogScore AIC: -811707.693755022 Correctly Classified Instances 72.7255 %
=== Confusion Matrix ===
a b c d e f g h i j k <-- classified as 39 0 0 0 1 0 0 0 0 0 10 | a = V2
0 4901 59 1 0 424 7 251 241 4 0 | b = V5 3 6 6148 918 9 192 101 106 0 58 181 | c = V8
5 0 1045 3951 189 2 0 6 0 7 805 | d = V9 0 0 1 40 999 0 0 0 0 0 280 | e = V11
1 300 332 13 2 2716 4 161 1 61 5 | f = V3 0 7 118 5 0 20 175 53 0 0 0 | g = V7
0 470 155 4 0 312 80 1068 4 7 0 | h = V6 0 194 1 0 0 9 1 10 394 0 0 | i = V1 0 0 49 3 0 75 0 0 0 121 1 | j = V4
7 0 71 338 370 0 0 0 0 0 1342 | k = V10 Ilustración 30 Resultados con algoritmo Tabú search
Algoritmo TAN
Ilustración 31 Estructura 5, base 2 algoritmo TAN

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
12
Ilustración 32 Probabilidad de pertenecer a ZVH, estructura 5
TAN– false - 10000– false LogScore Bayes: -742331.8334505183 LogScore BDeu: -1023802.95231424 LogScore MDL: -952845.2059700268 LogScore ENTROPY: -777961.6597813366 LogScore AIC: -811884.6597813367 Correctly Classified Instances 73.5541 %
=== Confusion Matrix ===
a b c d e f g h i j k <-- classified as 32 0 0 1 0 0 0 0 0 0 17 | a = V2
0 4907 52 0 1 401 8 292 223 3 1 | b = V5 4 7 6309 811 8 178 88 107 0 33 177 | c = V8 1 0 1068 3987 190 7 2 2 0 3 750 | d = V9
0 0 3 52 998 0 0 0 0 0 267 | e = V11 0 301 279 6 3 2776 3 167 4 55 2 | f = V3
0 4 124 7 0 18 166 58 0 1 0 | g = V7 0 449 133 2 0 323 78 1108 4 3 0 | h = V6
0 204 0 0 0 11 1 21 371 1 0 | i = V1 0 0 58 2 0 78 0 0 0 109 2 | j = V4
7 0 120 307 354 0 0 0 0 0 1340 | k = V10 Tabla 12 Resultados con algoritmo TAN

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
13
9.2 Usando WEKA
Como se mencionó en la es un software de uso libre y se puede descargar
http://www.cs.waikato.ac.nz/ml/weka/. La siguiente es la pantalla inicial, se
mostraran los pasos para reproducir los resultados aquí mostrados.
Después de elegir Explorer aparece la siguiente pantalla, en esta se carga la
base de datos y aparece una pequeña descripción del comportamiento, también
se puede elegir las variables que se usaran y remover las demás, y/o aplicar
Es la opción que permite
llevar a cabo la ejecución de
los algoritmos de análisis
implementados sobre los
ficheros de entrada, una
ejecución independiente por
cada prueba. En esta opción
se trabajaron los resultados.
Esta opción permite definir
experimentos más complejos, con
objeto de ejecutar uno o varios
algoritmos sobre uno o varios
conjuntos de datos de entrada, y
comparar estadísticamente los
resultados
Es una novedad de WEKA 3-4 que permite
llevar a cabo las mismas acciones del
"Explorer", con una configuración
totalmente gráfica, inspirada en
herramientas de tipo "data-flow" para
seleccionar componentes y conectarlos en
un proyecto de minería de datos, desde
que se cargan los datos, se aplican
algoritmos de tratamiento y análisis,
hasta el tipo de evaluación deseada.
Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
14
algún filtro.
Estadísticas
descriptivas.
Se puede observar la distribución de los datos
de acuerdo a la variable clase, si es que existe.
Filtros que se pueden
seleccionar, para
discretizar, re muestrear,
etc.
Cargar base de datos,
pueden leer archivos .arff,
.csv entre otros

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
15
De las opciones que se tienen en la parte superior:
Preprocess: selección de la fuente de datos y preparación (filtrado).
Clasify: Facilidades para aplicar esquemas de clasificación, entrenar
modelos y evaluar su precisión
Cluster: Algoritmos de agrupamiento
Associate: Algoritmos de búsqueda de reglas de asociación
Select Attributes: Búsqueda supervisada de subconjuntos de atributos
representativos
Visualize: Herramienta interactiva de presentación gráfica en 2D.
Proceso para crear variable latente.
Una vez seleccionada la base de datos en la sección de Preprocess, pasamos a
la sección de Cluster. En la imagen pequeña se observa la lista de algoritmos
disponibles para hacer los Cluster, en este trabajo se utilizó EM. Una vez
seleccionado el algoritmo, oprimir Start.

Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
16
En el caso de la base 1, en donde se crea la variable clase, se debe
guardar e incluir en la base para cargarla de nuevo.
1
2
Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
17
Una vez incluida en la base de datos, se procede a generar las
estructuras mediante los algoritmos. Se realiza en la sección de “Classify”. En
choose se elige BayesNet.
Elegir el algoritmo
BayesNet
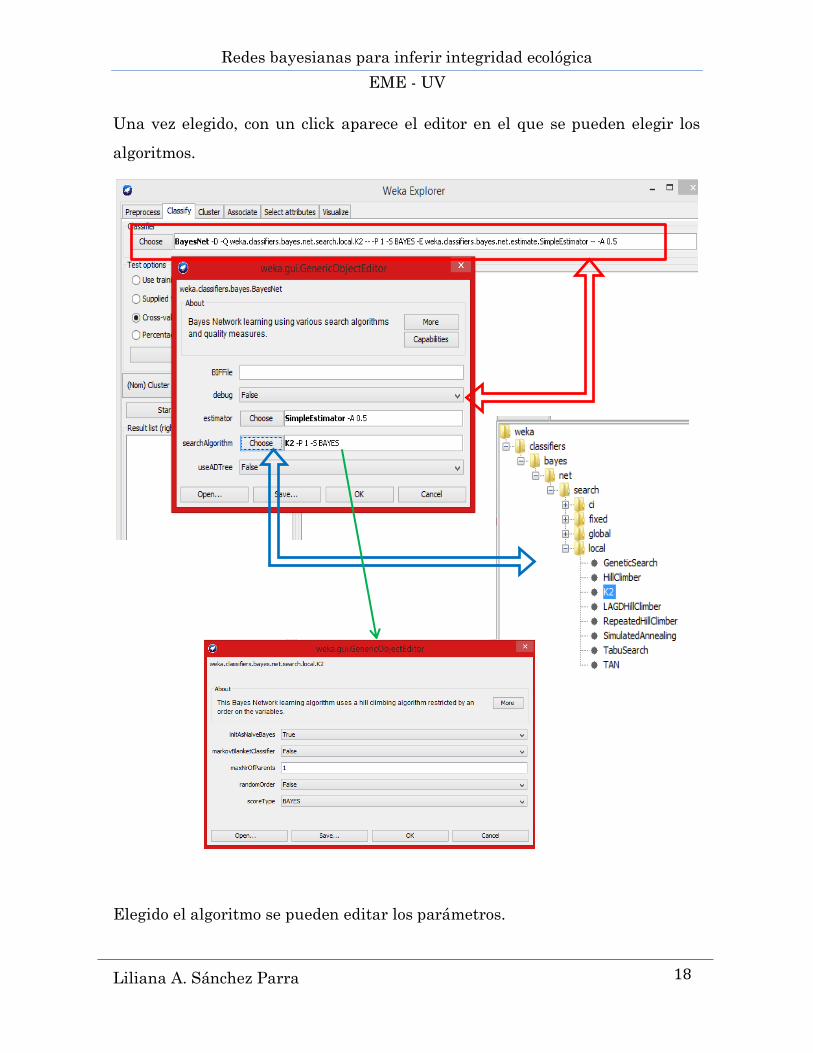
Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
18
Una vez elegido, con un click aparece el editor en el que se pueden elegir los
algoritmos.
Elegido el algoritmo se pueden editar los parámetros.
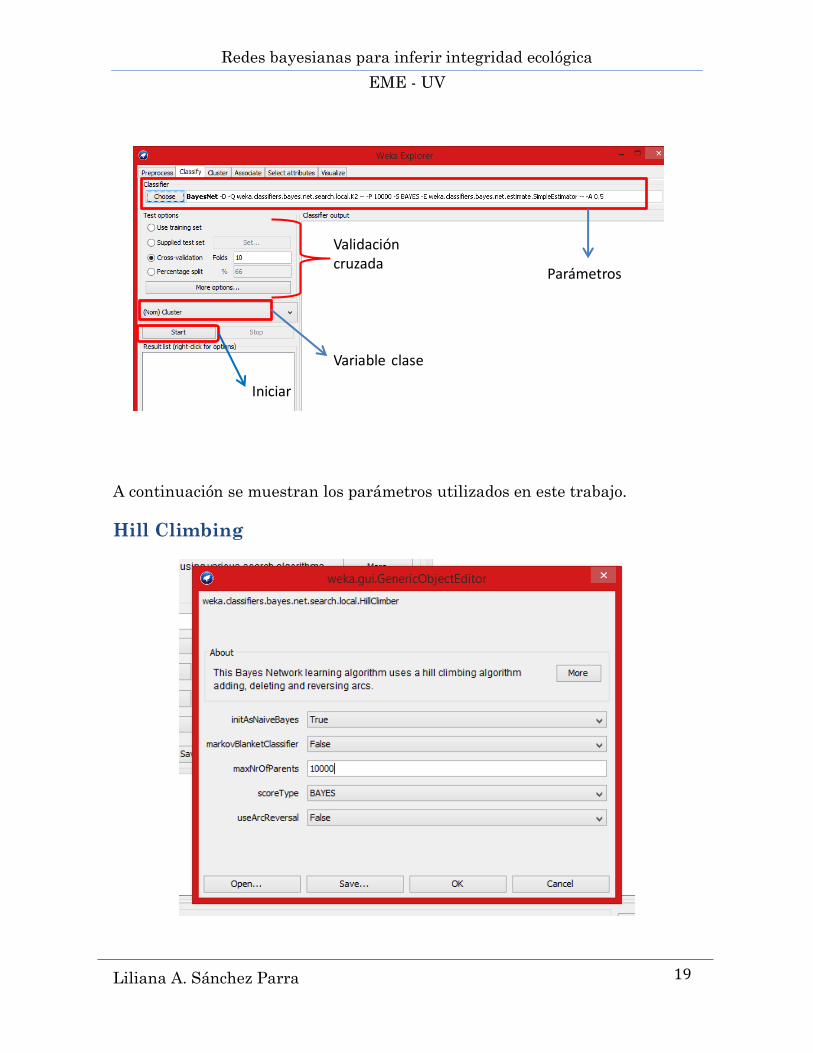
Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
19
A continuación se muestran los parámetros utilizados en este trabajo.
Hill Climbing
Validación cruzada
Variable clase
Iniciar
Parámetros
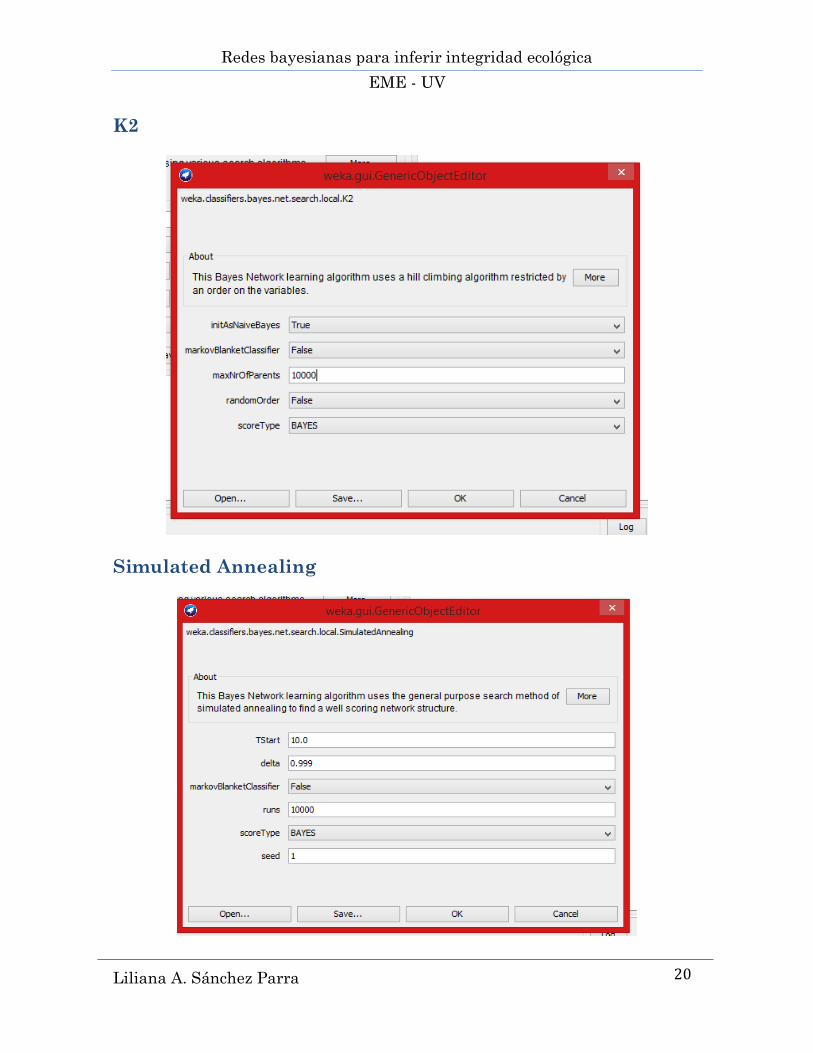
Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
20
K2
Simulated Annealing
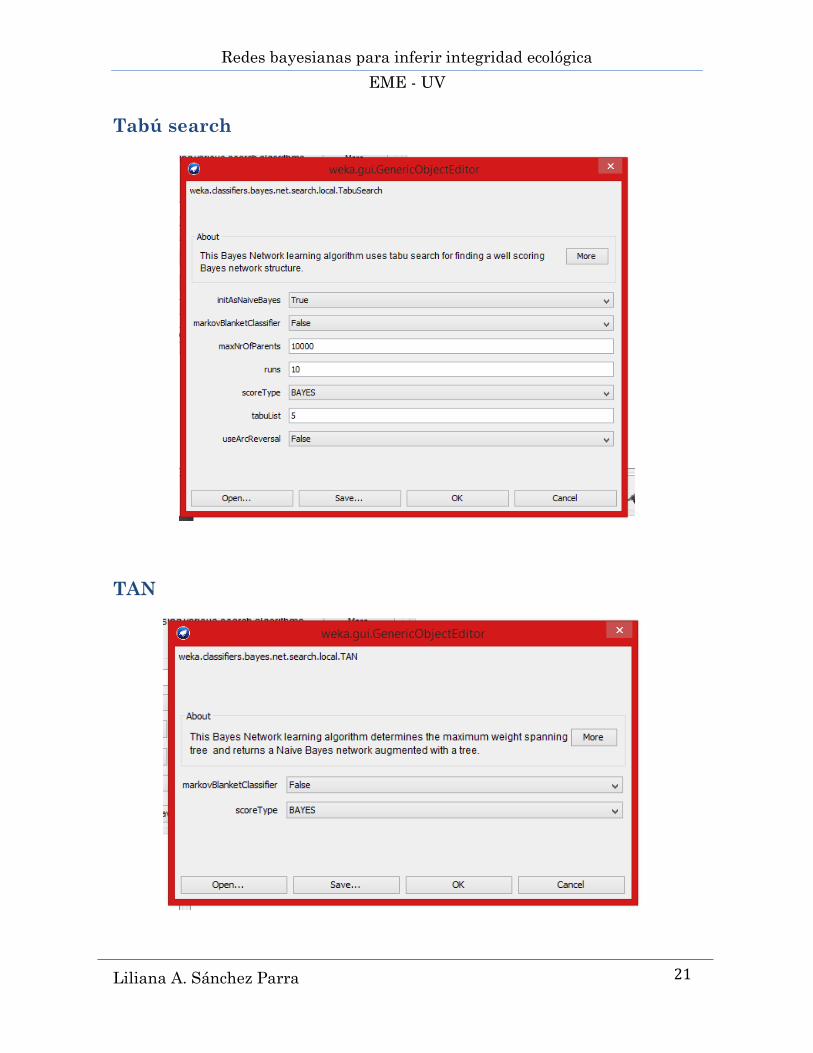
Redes bayesianas para inferir integridad ecológica
EME - UV
Liliana A. Sánchez Parra
21
Tabú search
TAN







![Sesión 12: Redes Bayesianas – Aprendizaje “Preferiría ...Sesión 12: Redes Bayesianas – Aprendizaje “Preferiría descubrir una ley causal que ser rey de Persia” [Democritus]](https://static.fdocuments.es/doc/165x107/604586f563b0d04c961fbaba/sesin-12-redes-bayesianas-a-aprendizaje-aoepreferira-sesin-12-redes.jpg)










