Replicacion y Alta Disponibilidad en Postgresql
43
Mecanismos de Replicación y Alta Disponibidad en PostgreSQL Álvaro Hernández Tortosa <[email protected]>
-
Upload
enrique-herrera-noya -
Category
Documents
-
view
26 -
download
6
description
Tutorial de Instalación de postgresql en Alta disponibilidad y con replicación
Transcript of Replicacion y Alta Disponibilidad en Postgresql

Mecanismos de Replicacióny Alta Disponibidad en PostgreSQLÁlvaro Hernández Tortosa <[email protected]>

Acerca de mí
● Álvaro Hernández Tortosa <[email protected]>● Fundador y Director Técnico en NOSYS● ¿Qué hacemos en NOSYS?
✔ Formación, consultoría y desarrollo de software con PostgreSQL (y Java)✔ Partners de EnterpriseDB✔ Formación avanzada en Java con Javaspecialists.eu: Java Master Course y Java Concurrency Course✔ Partners de Amazon AWS. Formación y consultoría en AWS
● Twitter: @ahachete● LinkedIn: http://es.linkedin.com/in/alvarohernandeztortosa/

Conceptos básicos
● Disponibilidad: que un sistema esté accesible, esto es, que se pueda conectar a él y operar con normalidad.
● Alta disponibilidad: sistema indisponible un porcentaje muy bajo del tiempo (típicamente < 0,05%). Casi siempre requiere que no haya SPOFs.
● Clustering: que un conjunto de máquinas individuales formen un sistema distribuido, esto es, se comporten como un todo.No confundir con el cluster de PostgreSQL (una instancia)

Conceptos básicos (II)
● Replicación: técnica que permite transmitir el estado (datos) de un servidor a otro(s) de manera que todos terminen con una copia del estado. Puede ser:
Síncrona/asíncrona Total/parcial (sólo una parte del estado se replica)
● Sharding o escalado horizontal: técnica para dividir una carga de trabajo entre diversos nodos. Si no es transparente, el sistema no se comporta como un todo.
● Consistencia eventual: garantía de una relación de causalidad en los eventos pero no que éstos sepropaguen inmediatamente

Alta disponibilidad
http://www.xtium.com/blog/on-cloud-9-but-how-many-nines-do-i-need

Alta Disponibilidad y Capacidad de Recuperación
● Disponibilidad y Capacidad de Recuperación son dos cosas distintas
●Las tablas eliminadas y actualizaciones erróneas son mucho más comunes de lo que se piensa
● El archivado continuo (PITR, “Recuperación Point in Time”) es el mejor mecanismo para recuperarse de este tipo de fallos.
● Las técnicas de Alta Disponibilidad están dirigidas a Escenarios de Fallos de Sistemas o Sitios.

Mecanismos de Alta Disponibilidad
1. Externos a la base de datos:a. Almacenamiento compartido en red (SAN)b. DRBDc. Clustering (a nivel de S.O.)
2. A nivel de base de datosa. pgpool b. Log shippingc. Replicación

Mecanismos externos a la BB.DD.
1. Ventajas generales:a. No tienen impacto (arrastre) sobre la base de datosb. Tienen un RTO muy bajoc. Tienen un RPO cero
2. Inconvenientes generales: Sólo dos nodos Configuración estrictamente activo-pasivo Distancia LAN No ofrece funcionalidades adicionales como ayuda
al backup, PITR, etc
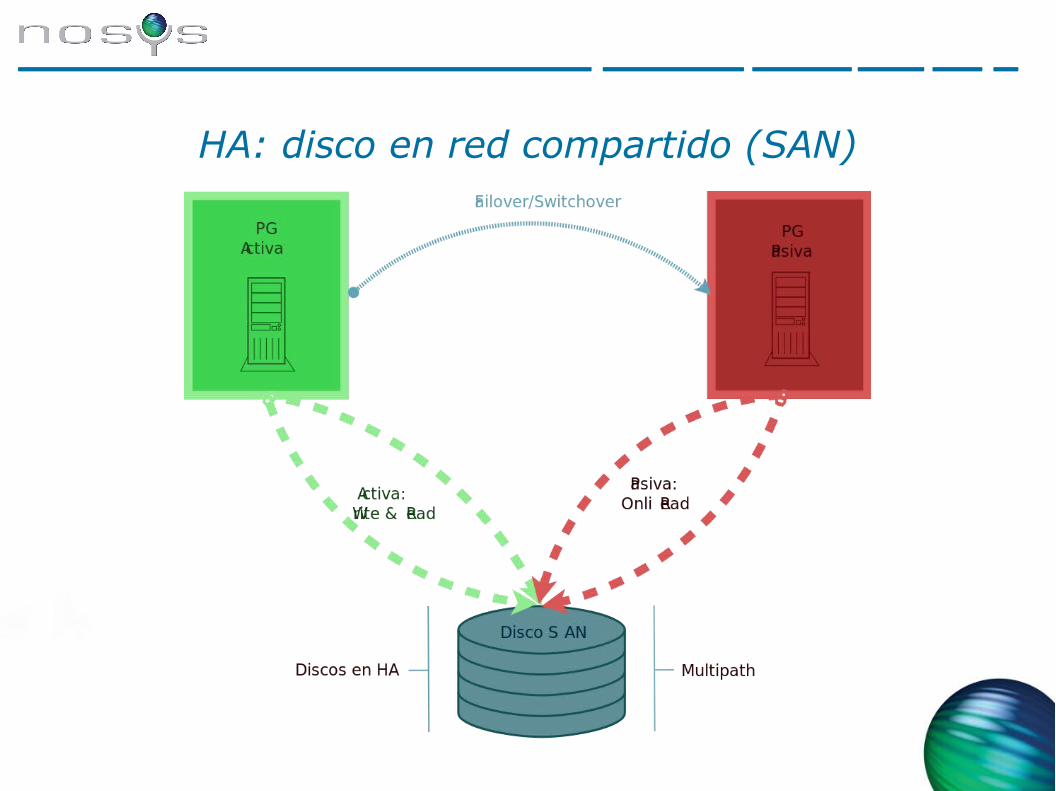
HA: disco en red compartido (SAN)

HA: disco en red compartido (SAN)
● Ventajas:➔ Transparente a la base de datos➔ Permite un RTO muy bajo
● Inconvenientes:➔ Configuración activo-pasivo ➔ Coste elevado➔ Sólo dos nodos➔ Es necesario un mecanismo para levantar el servicio en el nodo secundario➔ Requiere/utiliza multipath
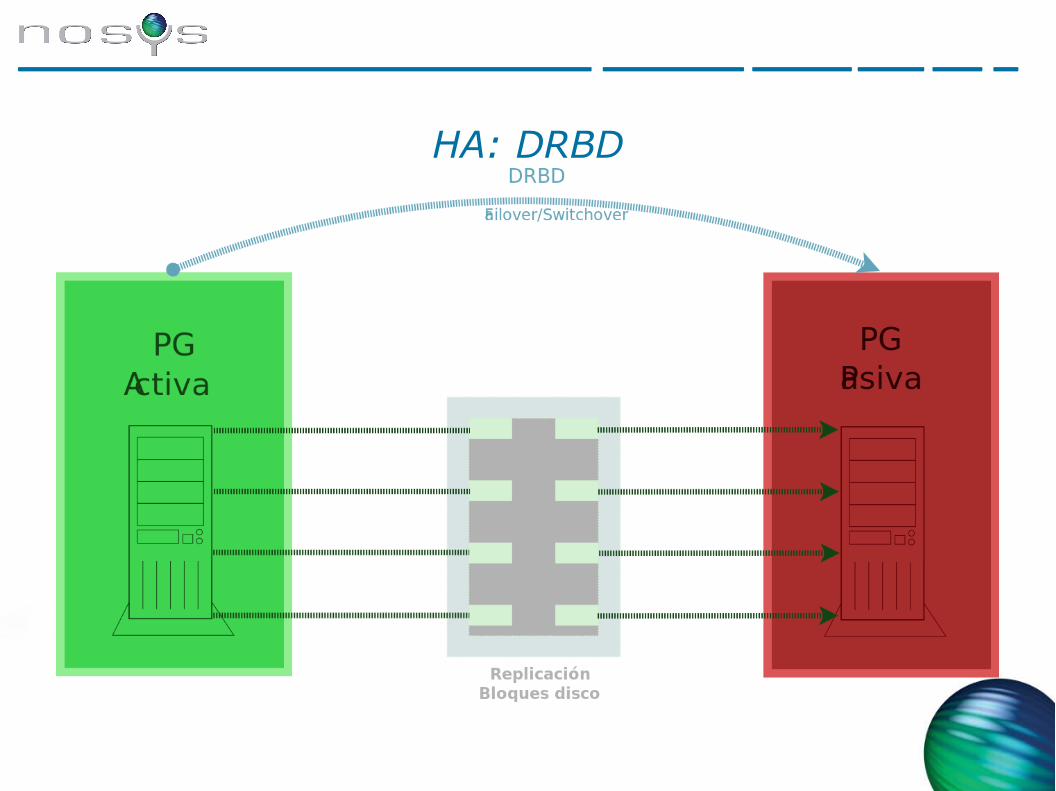
HA: DRBD

HA: DRBD
● Ventajas e inconvenientes: los mismos que el disco compartido en red salvo el coste, no requiere hardware dedicado.
● Es open source y muy eficiente
● Replica los volúmenes de disco de forma asíncrona, síncrona o semi-síncrona
● Puede dar lugar a configuraciones muy interesantes, como por ejemplo replicar de un volumen efímero de AWS a un EBS lento (con cuidado)

HA: Clustering a nivel de S.O.
● Técnica casi en desuso
● Requiere soporte del S.O.
● Permite que dos máquinas se comporten como una única. Requiere una IP virtual.
● Configuración activo-pasivo

HA: pgpool
● Hace de pooling de conexiones (como pgbouncer)
● Si un servidor cae, la conexión con pgpool no, y sirve carga a los demás
● Entiende la replicación (core o Slony) y divide r/w entre los servidores esclavo(s)/maestro
● Permite ejecutar scripts ante eventos de HA
● Tiene un modo de HA para no ser SPOF

HA: WAL shipping
● WAL shipping es la técnica para enviar registros de WAL de un servidor maestro de postgres a otro(s), esclavo(s), de forma que el(los) esclavo(s) están continuamente reproduciendo los segmentos de WAL, según llegan, y por lo tanto contienen una copia de la base de datos maestra.
● Se basa en archivado continuo: cada vez que se rota un fichero de WAL (de pg_xlog), archivado continuo lo copia al directorio externo (archive_command). Este fichero externo se copia a la base de datos esclava (el mecanismo es independiente de la base de datos: NFS, cp, rsync, etc) y ésta lo reproduce y aplica los cambios.
● Está disponible desde PostgreSQL 8.2.

HA: WAL shipping (II)
● La réplica está continuamente en modo recuperación, aplicando los ficheros de WAL que reciba.
●Requiere un proceso de copia (síncrono o asíncrono) pero externo a la base de datos.
● Hay una ventana de pérdida de datos, suma de: Tiempo de rotación del fichero de WAL (controlado por
checkpoint_timeout, checkpoint_segments, checkpoint_completion_target).
Tiempo de transmisión/copia del fichero rotado y archivado a la base de datos esclava.
● Es un mecanismo extremadamente sencillo.

Replicación
http://www.flickr.com/photos/86624586@N00/10177597/

● La replicación es la transmisión de información derivada de las modificaciones de estado, de una base de datos a otra.
● Todas las operaciones que modifiquen el estado de la base de datos se transmiten (transformadas o no) a otra base de datos, que “replica” las operaciones, de forma que ambas bases de datos tengan la misma información.
● La replicación permite alcanzar objetivos como:✔ Alta disponibilidad (caída del maestro)✔ Backups “calientes” (backup con poca o cero recuperación
necesaria)✔ Disponer de una copia en otro lugar
geográfico
Replicación
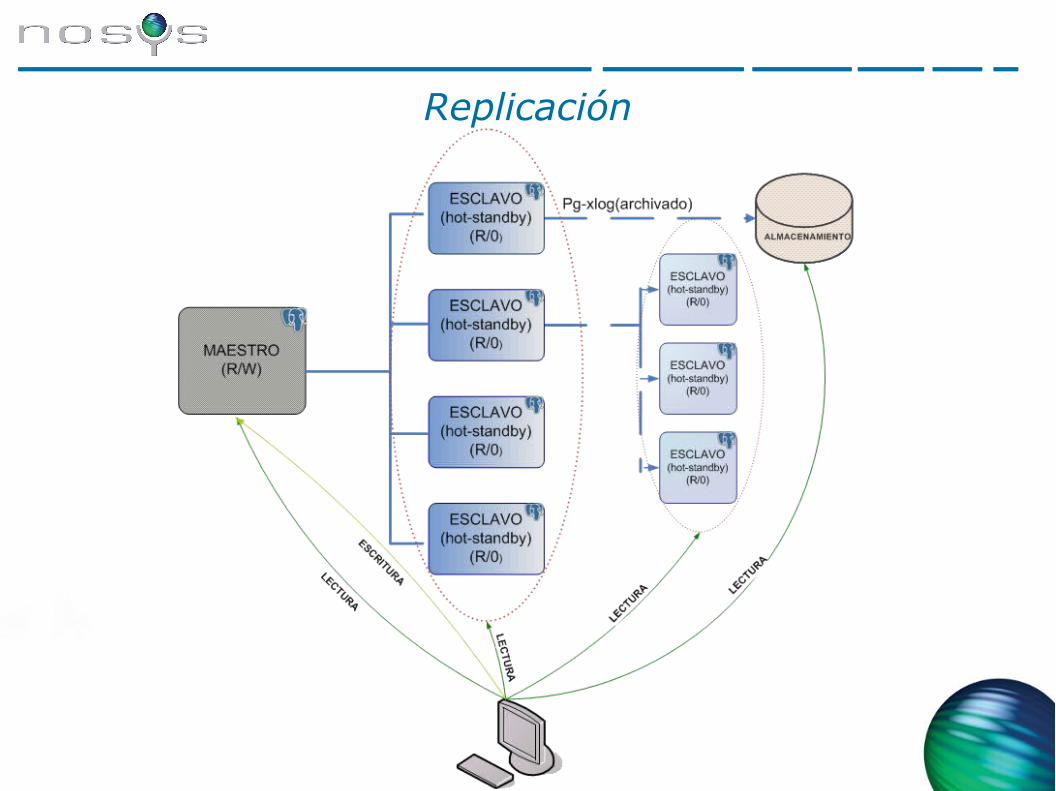
Replicación

● Cada operación DML ejecuta un trigger (acción en respuesta a un evento de la base de datos) que genera una representación del cambio (SQL, JSON, formato binario, etc) y la envía a la base de datos remota.
● Típicamente utiliza una cola para almacenar los cambios, a un ritmo potencialmente diferente del de envío a la base de datos remota (modelo productor-consumidor): asincronía
● Dado que los triggers se instalan por el software en las tablas, se puede seleccionar un subconjunto arbitrario de la(s) tabla(s) de la base(s) de datos que se quieren replicar.
Replicación basada en triggers

● Postgres ya dispone de un formato nativo de representación de los cambios en la base de datos: el WAL (Write-Ahead Log).
● Dado que el WAL ya se genera (sí o sí) para garantizar la durabilidad de la base de datos, no supone más overhead
● Postgres además sabe cómo interpretar estos registros (proceso de recuperación, wal writer, checkpoint) por lo que la implementación es muy sencilla.
● Los registros de WAL pueden enviarse a la réplica por ficheros (WAL shipping) o por la red (streaming)
Replicación basada en WAL

● Impacto en el maestro (overhead): trigger es alto (10-15%) y en WAL es bajo (1-3%).
● Latencia de la replicación: baja/muy baja en WAL, baja/media/alta en trigger.
● Posibilidad de seleccionar subconjuntos de bases de datos y/o tablas (y secuencias) a replicar: WAL no, trigger sí.
● Adecuación a entornos MAN/alta latencia/canales ruidosos: WAL establece canales TCP/IP permanentemente abiertos, y es muy sensible; trigger funciona mucho mejor.
● Integración core de PostgreSQL: WAL sí, trigger no.
Trigger vs. WAL

● Hot standby permite que una base de datos postgres en modo recuperación acepte consultas de sólo lectura durante dicho proceso de recuperación. Disponible desde PostgreSQL 8.4
● Abre la puerta a escalabilidad horizontal de las consultas de lectura en un esquema de replicación.
● No es “trivial”: ¿qué sucede si mientras una query larga se ejecuta en un esclavo llega un DML de DROP TABLE? Se puede retrasar la aplicación del cambio o cancelar la query.
● Permite tener esclavos retrasados para solucionarfallos humanos.
Hot standby

● El primer paso es activar archivado continuo (repaso):[postgresql.conf]wal_level = archivearchive_mode = onarchive_command = 'test ! -f /path/dir/archivado/%f && cp %p /path/dir/archivado/%f'
[require restart de la base de datos]
● Configurar un mecanismo para que todos los ficheros en /path/dir/archivado/ estén disponibles en la máquina del esclavo. P.ej. directorio compartido en local o por NFS.
● Opcionalmente, forzar tiempo máximo de archivado:archive_timeout = 300
Configuración de WAL shipping

● Realizar un backup base del maestro y copiarlo al esclavo (pg_start_backup + rsync/equivalente + pg_stop_backup).
● Crear recovery.conf en el esclavo:[recovery.conf]restore_command = 'cp /path/dir/esclavo/%f %p'standby_mode = on
● Iniciar el esclavo. Se podrá comprobar en los logs que comienza primero a recuperar la base de datos a partir del backup, y que posteriormente entra en un bucle continuo de esperar a que aparezcan nuevos ficheros WALy aplicarlos.
Configuración de WAL shipping (II)

● Sea con WAL shipping o con streaming replication (a continuación), se puede (o no) configurar hot standby para que el esclavo acepte consultas de sólo lectura:
[postgresql.conf maestro]wal_level = hot_standby
[postgresql.conf esclavo]hot_standby = onmax_standby_archive_delay = 30s
● El parámetro wal_level es ignorado en el esclavo (no genera WALs). Los parámetros hot_standby y max_standby_archive_delay son ignorados en el maestro. Así que el mismo postgresql.conf puede usarse para ambos.
Configuración de hot standby

LOG: database system was interrupted; last known up at 2013-09-26 12:12:49 CEST
LOG: entering standby mode
LOG: database system was not properly shut down; automatic recovery in progress
LOG: redo starts at 0/2000028
LOG: record with zero length at 0/2003600
LOG: consistent recovery state reached at 0/2003600
LOG: database system is ready to accept read only connections
LOG: restored log file "000000010000000000000002" from archive
LOG: restored log file "000000010000000000000003" from archive
cp: /tmp/archived/000000010000000000000004: No such file or directory
cp: /tmp/archived/000000010000000000000004: No such file or directory
[...]
LOG: restored log file "000000010000000000000004" from archive
cp: /tmp/archived/000000010000000000000005: No such file or directory
cp: /tmp/archived/000000010000000000000005: No such file or directory
[...]
WAL shipping + hot standby: logs en el esclavo

● WAL shipping tiene dos inconvenientes:➔ Hasta que un WAL no rota, no se copiará y procesará al esclavo,
por lo que hay una ventana de potencial pérdida de datos.➔ Requiere interacción con un mecanismo externo para la copia de los
ficheros.
● Para resolverlos, en 9.0 se introdujo Streaming Replication (SR), que copia los registros de WAL (según se produzcan, no cuando rote el fichero) a las bases de datos esclavas a través de la red (streaming).
● El overhead es muy bajo: los esclavos se comportan como una conexión más a la base de datos para obtener los WAL.
Streaming Replication

● Por defecto, SR es asíncrono (el COMMIT en el maestro no espera a que los esclavos hayan recibido los registros WAL).
● Normalmente, la latencia de replicación (que determina la máxima pérdida de datos) es muy baja (inferior al segundo)
● Desde 9.1 se soporta también modo síncrono (el COMMIT en maestro sólo se produce cuando todos los esclavos han recibido -no necesariamente replicado- los registros de WAL). El modo síncrono se puede seleccionar por cada tx. En modo síncrono no hay nunca pérdida de datos.
● Desde 9.3 se soporta replicación en cascada (un esclavo puede servir de “maestro” de envío de registros de WAL).
Streaming Replication (II)

● Si la sincronización maestro/esclavo(s) se desfasa mucho, puede suceder que el esclavo se “desconecte” (si los segmentos de WAL que se deben enviar por streaming al esclavo, éste no los ha consumido, y en el maestro se reciclan, ya no se le podrán enviar). En este caso, es necesario comenzar de nuevo (backup base).
● SR es compatible con WAL shipping (y es la configuración recomendada): postgres puede aplicar los registros de WAL independientemente de donde vengan (sea de la red o de ficheros archivados). Así, si la red cae o se reciclan segmentos en el maestro, se podrán seguir aplicando de ficheros archivados sin que se desconecte el esclavo.
Streaming Replication (III)

●Realizar un backup base del maestro al esclavo.
●Opcionalmente, configurar archivado continuo.
[postgresql.conf maestro]wal_level = hot_standbymax_wal_senders = X # número máx esclavoswal_keep_segments = Y # número de segmentos WAL a # conservar (desconexiones)
[postgresql.conf esclavo]hot_standby = onmax_standby_streaming_delay = 30shot_standby_feedback = on # previene conflictos
Configuración SR asíncrono

[recovery.conf]primary_conninfo = “host=ip port=5432 user=...”
standby_mode = on
●La replicación se realiza mediante conexiones a la bbdd de los esclavos al maestro que requieren permisos especiales.
● Es necesario un usuario con privilegios de “replication” (CREATE USER … WITH REPLICATION).
● Además, hace falta una entrada específica en pg_hba, con conexiones a la base de datos llamada replication:[pg_hba.conf]host replication user ip/mask trust/md5
Configuración SR asíncrono (II)

● Se puede consultar en cada máquina cuál es el último registro de WAL creado, enviado y recibido:
[maestro]SELECT pg_current_xlog_location();
[esclavo]select pg_last_xlog_receive_location(); # recibidoselect pg_last_xlog_replay_location(); # aplicado
● Desde PostgreSQL 9.2:SELECT * FROM pg_stat_replication;
Monitorización básica SR asíncrono

● Replication slots: permite segmentar la replicación pendiente en los esclavos de forma que puedan reconectarse sin necesidad de backup base ni archivado continuo.http://blog.2ndquadrant.com/postgresql-9-4-slots/
● Time delayed standbys: permite aplicar un retraso en el nodo esclavo para aplicar la replicación. Esto permite recuperar fácilmente errores humanos (borrados accidentales, por ejemplo).http://www.depesz.com/2013/12/20/waiting-for-9-4-allow-time-delayed-standbys-and-recovery/
SR en 9.4

● Replicación lógica, pero no basada en triggers, sino en decoding del WAL.
● Incluida en el core de postgres en 9.5 ó 10. Las características básicas internas van a estar ya en 9.4.
● Además, va a implementar BRD: Bi-Directional Replication (esto es, maestro-maestro).
No pretende lograr un cluster (conjunto que se comporta como un todo), sino sistemas separados (aunque interconectados). Permite escala geográfica
http://wiki.postgresql.org/wiki/BDR_Project
BDR en 9.5/10

● Dos o más nodos: uno Activo(RW), varios Pasivos Permite tener diferentes versiones al tiempo
● Replicación de Datos basada en trigger tabla a tabla Overhead alto: más del 10% en el Activo(RW) Compleja de instalar/configurar y mantener
● Distacia máxima entre nodos: todo el mundo
● Soportado desde PostgreSQL 8.3
Slony

●Ventajas Seleccionable para objetos de la base de datos
individuales Posibilidad de replicación en cualquier lugar del mundo Posibilidad de mantener la disponibilidad a través de
actualizaciones de software No se necesitan requerimientos hardware adicionales
●Inconvenientes Pérdida potencial de algunos datos (retardo) Proporciona opciones de Alta Disponibilidad y
Recuperación en caso de Desastres La recuperación de Errores Comunes es posible
mediante el uso de aplicación diferida de cambios●Futuro
Se está considerando la replicación por logs
Slony (II)

●Maestro/Esclavo asíncrono Se puede usar para mejorar el rendimiento de usuarios
dispersos geográficamente Alta disponibilidad
●Limitaciones importantes No se detectan ni propagan cambios en DDL Las tablas replicadas deben tener índices únicos No se replican BLOBs No permite varios maestros No se puede detectar un fallo de nodo
Slony (III)

● Dos maestros o maestro-esclavo(s)
● Asíncrona
● Basado en replicación vía triggers. Escrito en PERL
● Handler de conflictos estándar o a medida
● Funciona desde PostgreSQL 8.1
Bucardo

● Similar a Slony, replicación basada en triggers maestro-esclavo(s)
● Utiliza PgQ, un sistema de colas para PostgreSQL muy bueno
● Parte del paquete skytools (al igual que PgQ), desarrollado y usado por Microsoft (perdón, Skype)
● Programado en Python
Londiste

● Clustering puro de bases de datos. Escala en escritura y lectura.
● Soporta transacciones multi-nodo: es una base de datos global.
● Permite tanto replicar tablas como distribuirlas (aumentar fiabilidad o rendimiento).
● Es un proyecto aparte de postgres, pero se expone con el mismo interfaz que postgres. Es también software libre.
● La arquitectura es compleja y escala hasta un número limitado de nodos.
● El rendimiento es bastante bueno
Postgres-XC
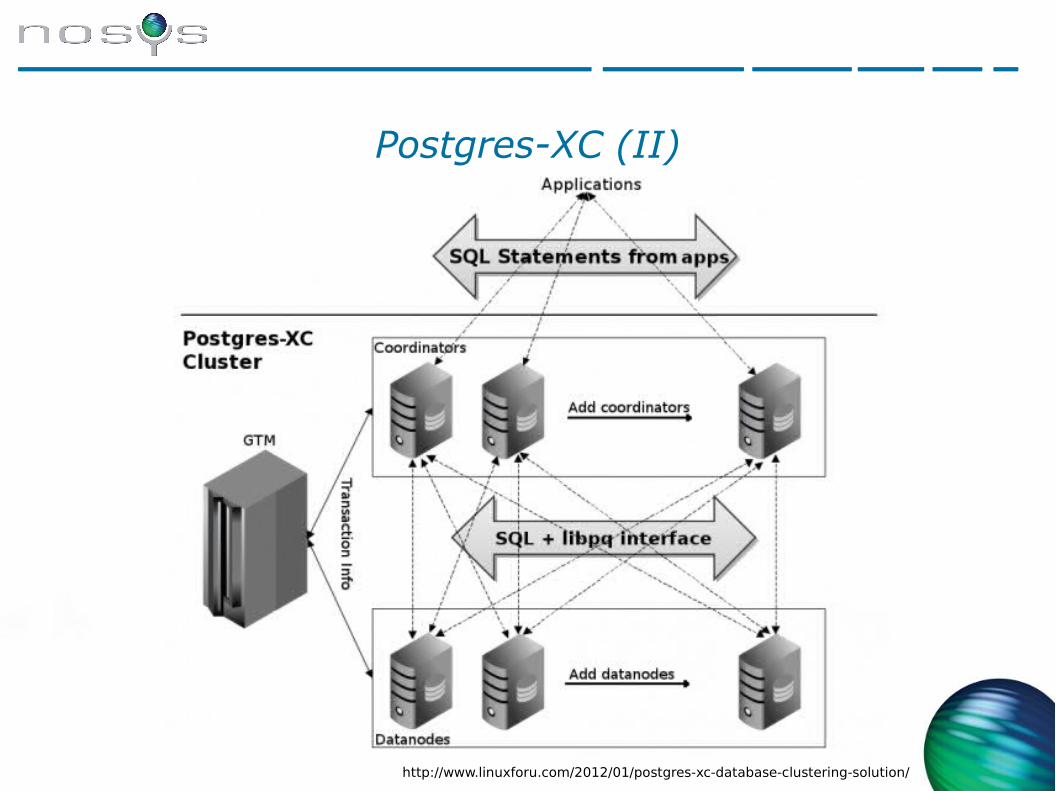
Postgres-XC (II)
http://www.linuxforu.com/2012/01/postgres-xc-database-clustering-solution/
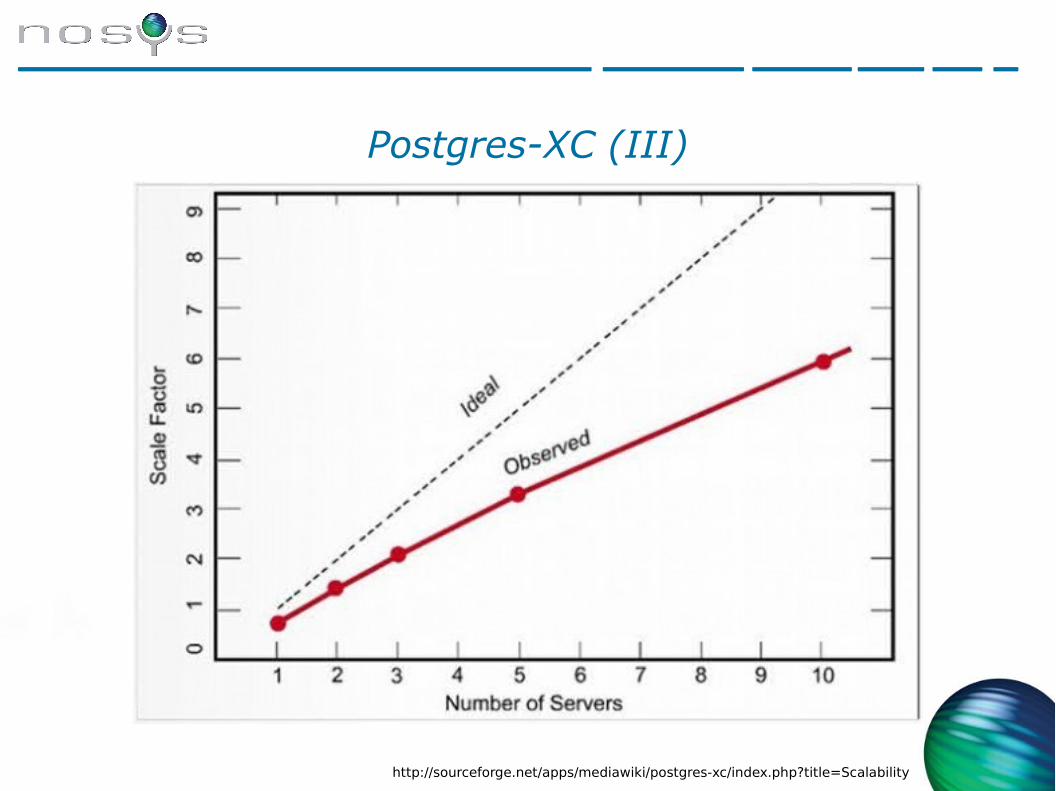
Postgres-XC (III)
http://sourceforge.net/apps/mediawiki/postgres-xc/index.php?title=Scalability