
Serializar objetos vinculados
12
Serializar objetos vinculados Serializar objetos vinculados: Para que un programa java pueda convertir un objeto en un montón de bytes y pueda luego recuperarlo, el objeto necesita ser Serializable. Al poder convertir el objeto a bytes, ese objeto se puede enviar a través de red, guardarlo en un fichero, y después reconstruirlo al otra lado de la red, leerlo del fichero Como resulta muy útil la propiedad de serializar a la vez conjuntos de objetos vinculados, veremos un ejemplo, muy sencillo, en el cual se serializa un objeto HashMap y luego se recuperan sus elementos, que son de tipos distintos. SerializarHashMap.java
-
Upload
maryrem-flores -
Category
Documents
-
view
35 -
download
5
Transcript of Serializar objetos vinculados

Serializar objetos vinculados
Serializar objetos vinculados: Para que un programa java pueda convertir un objeto en un montón de bytes y pueda luego recuperarlo, el objeto necesita ser Serializable. Al poder convertir el objeto a bytes, ese objeto se puede enviar a través de red, guardarlo en un fichero, y después reconstruirlo al otra lado de la red, leerlo del fichero Como resulta muy útil la propiedad de serializar a la vez conjuntos de objetos vinculados, veremos un ejemplo, muy sencillo, en el cual se serializa un objeto HashMap y luego se recuperan sus elementos, que son de tipos distintos. SerializarHashMap.java



DeserializarHashMap.java
Cuando un byte no basta: comunicaciones en un mundo plurilingüe. Las dos superclases raíz vistas hasta ahora y sus subclases trabajan directamente con bytes. A menudo se precisa utilizar caracteres en lugar de bytes. Cuando un carácter corresponde a un byte, es decir, cuando se almacena un carácter en un solo byte, leer bytes corresponde a leer caracteres. Eso ocurre, por ejemplo en las codificaciones US-ASCII e ISO Latin-1. Sin embargo, cuando un carácter requiere más de un byte para ser almacenado (como sucede con los caracteres asiáticos, por ejemplo), las clases anteriores son inútiles: desconocen cómo codificar o decodificar caracteres que ocupen más de un byte. Todos los métodos de las clases anteriores que manipulan texto a partir de flujos de bytes asumen una codificación ISO Latin 1 (US-ASCII es un subconjunto suyo). Las subclases de las clases abstractas java.io.Reader y java.io.Writer permiten trabajar directamente con flujos de caracteres Unicode, esto es, con flujos de datos basados en caracteres Unicode.
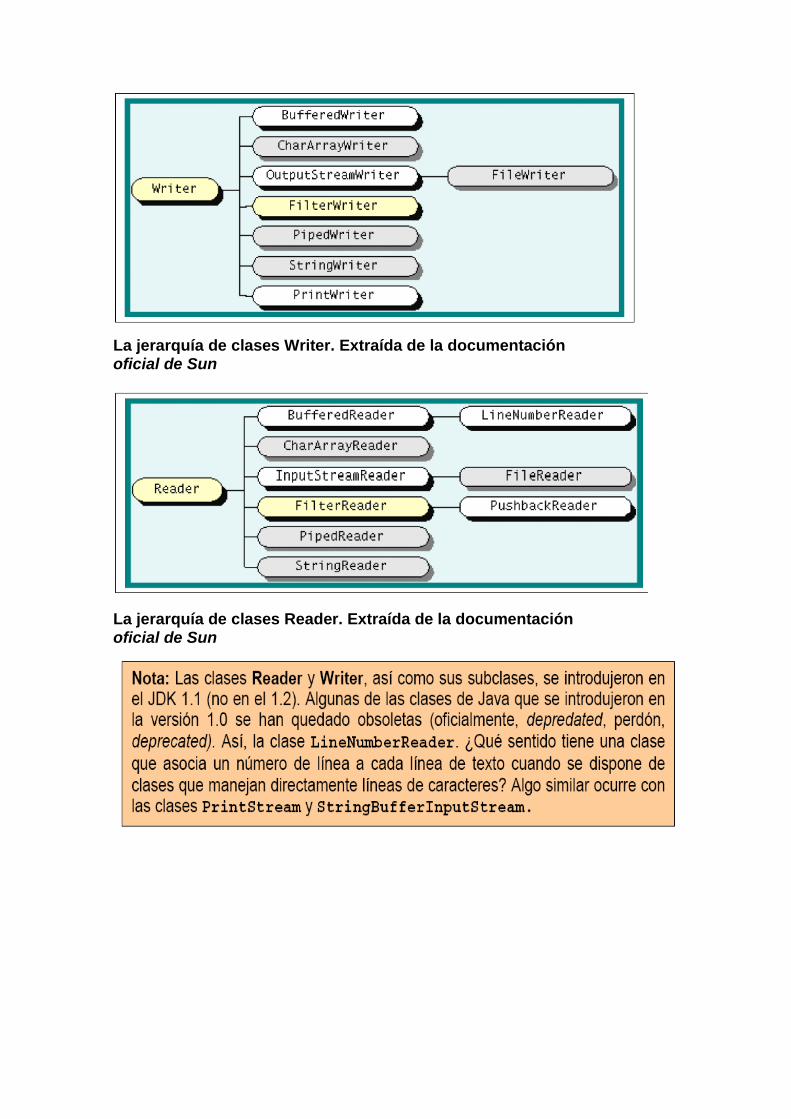
La jerarquía de clases Writer. Extraída de la documentación oficial de Sun
La jerarquía de clases Reader. Extraída de la documentación oficial de Sun

La primera codificación oficial de caracteres para ordenadores fue la codificación US-ASCII. Es una codificación de 7 bits, aunque se use un byte u octeto para representar cada carácter. De los ocho bits que forman un octeto, se usa uno como dígito de control (por ejemplo, para comprobar posibles errores en las comunicaciones). Esta codificación permite sólo 128 caracteres (de 0 a 127), suficientes para el inglés; pero insuficientes para el español o el alemán, y completamente insuficientes para idiomas como chino, coreano o japonés. Incluso codificaciones que usan un byte completo para cada carácter (como la ISO 8859-1 o ISO Latin 1) son incapaces de representar alfabetos asiáticos, hebreos o cirílicos.

En resumen, las clases Reader y Writer proporcionan métodos similares a
los de InputStream y OutputStream; pero orientados a caracteres, en lugar
de a bytes. Especificando la codificación deseada, estas clases saben en qué caracteres deben convertir los bytes, y viceversa. Para concretar ideas, supongamos que se quiere leer un archivo grabado usando la codificación ISO 8859-5 (que incluye el alfabeto cirílico) y que se desea grabarlo, mediante Internet, en un sistema ruso que trabaja con UTF-8. El código necesario se muestra aquí:
Lo que hace exactamente las clases no resulta relevante para el ejemplo (se explicarán más adelante); pero sí la estructura del código: Lectura y decodificación Codificación y escritura Si el sistema que lee el archivo estuviera configurado como ASCII o ISO Latin 1 y no se especificara la codificación que debe usarse para la lectura, todos los caracteres que no correspondieran a caracteres ASCII o ISO Latin 1 aparecerían equivocados. En consecuencia, los datos que se grabarían en el archivo del sistema ruso carecerían de sentido. El resultado de leer, usando la configuración por defecto de mi sistema (ISO Latin 1), un archivo con caracteres cirílicos codificado con ISO 8859-5 y de

transformarlo en un archivo UTF-8 se muestra a continuación. La primera captura de pantalla corresponde al archivo original; la segunda, al transformado. En resumen Para enviar datos a través de una red o almacenarlos en un archivo hay que manejar una codificación que el receptor sepa interpretar. De nada sirve Internet si los receptores reciben garabatos. Usar siempre la codificación por defecto del sistema es incorrecto: las aplicaciones así escritas se comportarán de distinto modo en distintos sistemas.
Para conseguir que un lenguaje sea respetado por todos los estándares hay que hacer los primeros basándose en ese lenguaje. En esto de los estándares, como en tantas cosas de la vida, gana quien llega primero.
3.5. La clase java.io.InputStreamReader
Esta subclase de Reader modela un flujo de entrada basado en bytes como un
flujo de caracteres, también de entrada. Los bytes se leen de un InputStream
y se convierten en caracteres, de acuerdo con la codificación especificada en el
constructor. Proporciona métodos de lectura (public int read(), public
int read(char[] array, int offset, int longitud)) que permiten
leer bytes y convertirlos en caracteres, según la codificación usada (si no se especifica ninguna, se toma por defecto la que corresponde al sistema operativo). Cada vez que se llama a uno de los dos métodos de lectura, se lee uno o más octetos del flujo de bytes sobre el cual se ha construido. Los dos constructores más usados de esta clase son public InputStreamReader(InputStream entrada)
public InputStreamReader(InputStream entrada, String
codificacion) throws UnsupportedEncodingException
Para leer caracteres se usan dos métodos read(): public int read() throws IOException
public int read(char[] buffer, int offset, int longitud)
throws IOException
La siguiente línea lee la entrada estándar y la convierte en caracteres Unicode: InputStreamReader entradaCaracteres = new InputStreamReader(
System.in);
Al haberse usado el primer constructor, se toma como codificación la usada en la máquina. En un ordenador europeo o estadounidense, lo normal es que sea

Cp1252 o ISO 8859-1 (ISO Latin 1). En una máquina ubicada en China, por ejemplo, lo lógico es que se use MS936, GB18030, EUC_CN o GBK. En una máquina china cabe esperar que se manipulen archivos con datos escritos en chino mandarín y que se use un sistema operativo que permita trabajar con caracteres chinos; si se intentara usar una codificación ISO Latin 1, los bytes de los archivos (codificados para representar caracteres chinos) se intentarían convertir en caracteres europeos. Resultado: el programador recibiría, días después, comentarios como "Creo que he cometido algún error al manejar su excelente programa. ¿Sería tan amable de echarle un vistazo cuando pueda? No es urgente: habré cometido algún error" (a los chinos no occidentalizados les es casi imposible manifestar abiertamente desacuerdo con un interlocutor). El lector puede imaginarse los comentarios que sufriría el programador en cualquier país menos educado (o más franco, según se mire). En el siguiente código se lee la entrada estándar y se convierte en caracteres Unicode, según la codificación internacional para caracteres griegos: InputStreamReader entradaCaracteres = new InputStreamReader(
System.in, "ISO-8859-7");
Cada vez que se llame a un método read(), se leerán los caracteres que
correspondan –según la codificación ISO 8859-7– a los bytes introducidos desde el teclado. Otro ejemplo: si se quiere convertir un archivo escrito con la codificación ISO 8859-5 (usada para caracteres cirílicos) en caracteres Unicode, de modo que sean manipulables por los programas Java, habrá que usar código similar a éste: FileInputStream archivo = new FileInputStream("ruso.txt");
InputStreamReader entradaCaracteres = new InputStreamReader(
archivo, " ISO-8859-5");
Para leer el primer carácter cirílico de ruso.txt y mostrarlo en pantalla, se podría
escribir esto:char c = (char) entradaCaracteres.read(); System.out.println(c);
En un sistema con fuentes cirílicas, se mostraría el primer carácter (por ejemplo)
.
Dado un objeto InputStreamReader, puede obtenerse el nombre de la
codificación de caracteres que se está usando mediante el método public String
getEncoding(). Veamos un ejemplo: InputStreamReader entradaCaracteres = new
InputStreamReader(System.in);
System.out.println("Codificación ": +
entradaCaracteres.getEncoding());

La única subclase de InputStreamReader es FileReader, que permite leer
archivos de texto usando la codificación por defecto del sistema. Esta clase proporciona una interfaz de flujos de caracteres para leer archivos de texto usando la codificación por defecto. Uno de sus constructores es éste: public FileReader(String nombreArchivo) throws
FileNotFoundException
Este constructor crea un objeto FileReader que lee, usando la codificación
por defecto del sistema, del archivo denotado por nombreArchivo.
3.6. La clase java.io.OutputStreamWriter
Esta subclase de Writer modela un flujo de salida basado en bytes como un
flujo de caracteres, también de salida. Proporciona métodos de escritura
(public void
write(); public void write(char[] array, int offset, int
longitud); public void write(String cadena, int offset, int
longitud)) que permiten escribir en un OutputStream los bytes que resultan
de codificar los caracteres, de acuerdo con la codificación especificada en el constructor (si no se especifica ninguna, se toma por defecto la del sistema). Cada vez que se llama a uno de los tres métodos de escritura, se obtienen los bytes (o el byte) que corresponden al carácter o al grupo de caracteres que se introduce como argumento; pero los bytes no se escriben inmediatamente en el
flujo de salida: permanecen en un buffer. El método public void flush()
se encarga de hacer que se escriban cuando se le llama, este lleno o no el buffer. Los dos constructores más usados de esta clase son public OutputStreamWriter(OutputStream salida)
public OutputStreamWriter(OuputStream salida, String
codificacion) throws UnsupportedEncodingException
En el siguiente código: OutputStreamWriter salidaCaracteres = new
OutputStreamWriter(
System.out, "ASCII");
cada vez que se llame a un método write(), seguido de un flush(), se
escribirán en el flujo estándar de salida los bytes que correspondan, según la privilegiada codificación US-ASCII, a los caracteres introducidos dentro del
argumento de write().
Si, por ejemplo, se quiere escribir en un archivo codificado con el juego de
caracteres ISO-8859-5 (cirílico), se puede usar FileOutputStream fis = new FileOutputStream("ruso.txt");
OutputStreamWriter salidaCaracteres = new
OutputStreamWriter(
archivo, "ISO-8859-5");
Para escribir la letra rusa _ en el flujo de salida se necesita este código: char c = (char) 1174; // también se podría usar el código
// Unicode del carácter
salidaCaracteres.write(c);
Para obtener el nombre de la codificación usada en un OutputStreamWriter,
se usa el método public String getEncoding().

La única subclase de OutputStreamWriter es FileWriter, que permite
escribir en archivos de texto mediante la codificación por defecto del sistema. Esta clase proporciona una interfaz de flujos de caracteres para escribir en archivos de texto mediante la codificación por defecto. Uno de sus constructores
tiene esta forma: public FileWriter(String nombreArchivo, boolean anyadir)
throws IOException
Este constructor crea un objeto FileWriter que escribe en el archivo al que
se refiere nombreArchivo usando la codificación por defecto del sistema. El
parámetro anyadir indica si los datos deben añadirse a un archivo ya existente
(true) o si debe eliminarse el archivo que ya existía (false).
3.7. La clase java.io.BufferedReader
Esta subclase de la superclase raíz Reader decora los objetos Reader
añadiéndoles la posibilidad de usar buffers, lo que mejora la eficiencia. Esta clase
incorpora un nuevo método: public String readLine() throws
IOException, que permite leer líneas de texto desde un archivo de texto
Siempre que se vaya a procesar el contenido de archivos de texto es convenienteusar esta clase. Para ver un ejemplo de su uso, vamos a considerar
un archivo cualquiera.txt, ubicado en el directorio donde debe ejecutase la
clase LeerArchivo.
LeerArchivo.java

Una manera muy visual de entender las clases de E/S de Java es imaginar que
son ríos (la palabra filtro de las clases FilterXXX sólo me hace pensar en
filtros de café y en filtros pasabanda, pasabaja, etc). Un objeto como
BufferedReader es como un río con un cauce más grueso que el de un objeto
InputStreamReader. Así pues, el río InputStreamReader cabe dentro del
río BufferedReader. Cada vez que un río es engullido dentro de otro, este
último le proporciona más caudal (es decir, más funciones o funciones más especializadas), pero sigue usando el caudal del engullido (sus métodos).

![Estatica [1] Cuerpos Vinculados](https://static.fdocuments.es/doc/165x107/55c1ec4cbb61eb4d158b462e/estatica-1-cuerpos-vinculados.jpg)
















