
SISTEMAS INFORMÁTICOS DE TIEMPO REALel1orlom/docs/STRtema6.pdf · Fiabilidad y Tolerancia a Fallos...
23
SISTEMAS EN TIEMPO REAL Fiabilidad y Tolerancia a Fallos en Sistemas en Tiempo Real Manuel Agustín Ortiz López Área de Arquitectura y Tecnología de Computadores Departamento de Arquitectura de Computadores, Electrónica y Tecnología Electrónica Universidad de Córdoba Córdoba a 17 de enero de 2006
Transcript of SISTEMAS INFORMÁTICOS DE TIEMPO REALel1orlom/docs/STRtema6.pdf · Fiabilidad y Tolerancia a Fallos...

SISTEMAS EN TIEMPO REAL
Fiabilidad y Tolerancia a Fallos en Sistemas en Tiempo Real
Manuel Agustín Ortiz López Área de Arquitectura y Tecnología de Computadores Departamento de Arquitectura de Computadores, Electrónica y Tecnología Electrónica Universidad de Córdoba
Córdoba a 17 de enero de 2006


Índice
Fiabilidad y Tolerancia a Fallos en Sistemas en Tiempo Real
• Índice:
1. Introducción 2. Fiabilidad y fallos
2.1. Definiciones y clasificación de los fallos 2.2. Prevención de fallos 2.3. Tolerancia a fallos 2.4. Redundancia
3. Redundancia del software 3.1. Programación de N-versiones 3.2. Estrategia de bloques de recuperación en la tolerancia a fallos
software
4. Medición y predicción de la fiabilidad de software
Sistemas en Tiempo Real
Manuel Ortiz. Universidad de Córdoba Página 1

Sistemas en Tiempo Real
Manuel Ortiz. Universidad de Córdoba Página 2

Introducción
1. Introducción • El tema que iniciamos está basado en los trabajos de Anderson
y Lee(1990) y en la bibliografía recomendada, la cual a su vez,
hace referencia continua a estos trabajos.
• Los requisitos de fiabilidad y seguridad de los sistemas de
tiempo real son mucho más estrictos que los de un sistema
informático de propósito general. Existen tres causas que
provocan un fallo un sistema en tiempo real:
Errores en una especificación inadecuada.
Defectos en alguno de los componentes, tanto componentes
hardware como software.
Por efectos del entorno.
Sistemas en Tiempo Real
Manuel Ortiz. Universidad de Córdoba Página 3

Sistemas en Tiempo Real
Manuel Ortiz. Universidad de Córdoba Página 4

Fiabilidad y Fallos
2. Fiabilidad y Fallos.[Krisna,96][Burns, 03]
2.1. Definiciones y clasificación de los fallos • Fiabilidad es una medida del éxito de que el sistema se
comporta de acuerdo a una especificación.
• Fallo. Cuando el comportamiento del sistema se desvía del
especificado, se dice que el sistema tiene un fallo.
• Las definiciones de fiabilidad y fallo están relacionadas con el
comportamiento externo del sistema. Los fallos son el
resultado de problemas internos que se manifiestan
externamente.
• Un error es la consecuencia de un fallo del sistema y una
avería es un efecto del error en un servicio que da el sistema.
• Los tipos de fallo se clasifican como:
Fallos transitorios. Un fallo transitorio comienza en un instante de
tiempo concreto se mantiene durante algún período y luego
desaparece. Ejemplo de este tipo de fallos suelen darse en los
componentes hardware debidos a alguna interferencia externa y se
mantiene mientras se mantiene la interferencia. Muchos de los fallos
de los sistemas de comunicaciones son transitorios.
Fallos permanentes. Son fallos que comienzan en un instante de
tiempo y permanece hasta que se repara el sistema.
Fallos intermitentes. Son fallos transitorios que ocurren de vez en
cuando. Ejemplo de este tipo de fallos suelen darse en componentes
hardware sensibles a la temperatura, cuando se calienta demasiado
Sistemas en Tiempo Real
Manuel Ortiz. Universidad de Córdoba Página 5

fallan y cuando se enfrían vuelven a funcionar fallando de nuevo
cuando se calientan.
• Independientemente de la clasificación anterior los fallos se
suelen clasificar también de acuerdo a su comportamiento
temporal (fallos de tiempo) y su comportamiento de acuerdo a
las salidas que provocan (fallos de valor). La siguiente figura
muestra como se clasifican estos modos de fallo:
• Con la clasificación anterior un sistema puede fallar, en el
dominio del tiempo, de la siguiente manera:
Fallo descontrolado. El sistema produce errores descontrolados
tanto en el dominio de valor como del tiempo, incluido los fallos de
improvisación.
Fallo de retraso. El sistema produce servicios correctos en el
dominio de valor, pero sufre errores de retraso en el tiempo.
Fallo de silencio. El sistema deja de producir servicios debidos a
fallos de omisión provocando en el resto del sistema fallos de
omisión.
Sistemas en Tiempo Real
Manuel Ortiz. Universidad de Córdoba Página 6

Fallo de parada. Similar al fallos de silencio pero informa a otros
sistemas que tiene fallo de silencio.
Fallo controlado. El sistema falla según una forma especificada.
Sin fallos. El sistema produce servicios correctos tanto en el dominio
del valor como del tiempo.
Sistemas en Tiempo Real
Manuel Ortiz. Universidad de Córdoba Página 7

2.2. Prevención de fallos • La prevención de fallos se refiere al intento de impedir
cualquier posibilidad de fallo antes de que el sistema esté
operativo. Para ello es necesario evitar y eliminar los fallos
durante la etapa de diseño. Para evitar los fallos se actúa tanto
en el hardware como en el software.
• Hardware:
Utilización de los componentes más fiables dentro de las
restricciones de coste/prestaciones.
Utilización de técnicas refinadas para la interconexión y ensamblado
de componentes.
Aislamiento del hardware para evitar interferencias.
• Software:
Especificaciones de requisitos rigurosas e incluso formales.
Utilización de probadas metodologías de diseño.
Utilización de lenguajes que faciliten la abstracción de datos y la
modularidad.
Uso de herramientas de ingeniería de software para ayuda a la
manipulación de los componentes software.
• La segunda parte en la prevención de fallos consiste en su
intento de eliminación, para ello el sistema se somete a un
conjunto de pruebas lo más exhaustivas posibles.
Sistemas en Tiempo Real
Manuel Ortiz. Universidad de Córdoba Página 8

2.3. Tolerancia a Fallos • A pesar de todas las técnicas y pruebas de verificación los
componentes hardware y software pueden fallar, y dado que
muchas veces no es posible su mantenimiento y reparación se
hace necesario recurrir a la idea de tolerancia a fallos.
• Un sistema puede proporcionar distintos niveles de tolerancia a
fallos:
Tolerancia total frente a fallos. El sistema continua en presencia de
fallos sin una pérdida significativa de funcionalidad o de
prestaciones, aunque por un período limitado.
Degradación controlada. El sistema continua en operación en
presencia de errores, aunque con una funcionalidad parcial durante la
reparación.
Fallo seguro. El sistema cuida de su integridad durante el fallo
aceptando una parada temporal de su funcionamiento.
• El nivel de tolerancia de un sistema dependerá de la aplicación,
y aunque teóricamente los sistemas críticos deben tener
tolerancia total frente a fallos, la realidad es que la mayoría
admiten una degradación controlada.
• La tolerancia a fallos consta de cuatro fases:
Detección de errores
Confinamiento y valoración de los daños
Recuperación del error
Tratamiento del fallo y continuación del servicio
Sistemas en Tiempo Real
Manuel Ortiz. Universidad de Córdoba Página 9

• Detección de errores. Se pueden identificar dos clases
técnicas de detección de errores:
Detección por el entorno de ejecución del programa:
Detectados por el hardware próximo al procesador. Por ejemplo ,
“la detección de una instrucción ilegal”, “salto a una dirección
inválida”, ”violación de la protección”, etc.
Detectados por el sistema soporte del lenguaje de programación
de tiempo real. Por ejemplo “referencia a un apuntador nulo”,
“valor fuera de rango”, etc.
Detección por la aplicación. Los errores los detecta la propia
aplicación:
Comprobación de réplicas, como la programación de N-versiones
que se verá posteriormente.
Comprobaciones temporales. Por ejemplo a través del “watch-dog
timer”. El componente software debe resetear el contador antes de
que se desborde de forma continúa indicando así que funciona de
forma “correcta”. Estas comprobaciones temporales no aseguran
que esté funcionando correctamente desde el punto de vista
lógico pero si al menos “funciona a tiempo”.
Comprobaciones inversas. En aquellos componentes que tengan
una relación uno a uno con la salidas, se puede tomar la salida y
calcular la entrada que corresponde a esta salida y comprobarla
con la entrada del sistema.
Códigos de comprobación. Se utilizan sobre todo para comprobar
la integridad de los datos. Es lo que habitualmente llamamos
”CheckSum”.
Sistemas en Tiempo Real
Manuel Ortiz. Universidad de Córdoba Página 10

Comprobaciones estructurales. Se utilizan para comprobar la
integridad de los objetos como listas o colas. En este caso se trata
de comprobar si por ejemplo los punteros no está corruptos, o
comprobar si el número de elementos del objeto es el correcto.
• Confinamiento y valoración de los daños. Cuando ocurre un
error en un componente, este error puede transmitir una
información errónea a todo el sistema. Se trata de construir
cortafuegos para evitar la propagación del error.
• Recuperación del error. Una vez detectado el fallo y valorado
el daño que haya podido producir hay que recuperar el error.
Existe dos estrategias para la recuperación: recuperación hacia
delante y recuperación hacia atrás. Ejemplos de la recuperación
hacia delante son los códigos autocorrectores como el código
Hamming o la utilización de punteros redundantes en las listas
enlazadas. Un ejemplo de recuperación hacia atrás es la
estrategia de bloques de recuperación que se tratará más
adelante en este tema.
• Tratamiento del fallo y continuación del servicio. Aunque se
haya localizado el problema y recuperado el error, puede que el
fallo se vuelva a producir. El tratamiento de los fallos se divide
en dos fases: la localización del fallo y la recuperación del
sistema. En el caso del hardware puede bastar con cambiar el
componente, en el caso del software puede que baste con
instalar una nueva versión del software. Sin embargo existen
sistemas que no pueden parar y el programa deberá ser Sistemas en Tiempo Real
Manuel Ortiz. Universidad de Córdoba Página 11

modificado mientras se está ejecutando, este es un problema
bastante complejo que no estudiaremos en este tema.
Sistemas en Tiempo Real
Manuel Ortiz. Universidad de Córdoba Página 12

2.4. Redundancia
• Todas las técnicas que se utilizan para conseguir la tolerancia a
fallos se basan en añadir elementos redundantes que detecten y
recuperen los fallos. Estos elementos son innecesarios en el
funcionamiento normal del sistema, por lo que se trata de
minimizar la redundancia y maximizar la fiabilidad dentro de
los costes y tamaño del sistema.
• Existen varias clasificaciones de redundancia dependiendo de
los elementos hardware o software considerados y de la
terminología utilizada. A continuación repasaremos
brevemente la redundancia hardware dejando la redundancia
software para los siguientes capítulos.
Redundancia hardware
• En el caso de los elementos hardware, se distingue entre la
redundancia estática o enmascarada y la redundancia dinámica.
En el caso de la redundancia estática, los componentes se utilizan
dentro de un sistema para ocultar los efectos de los fallos. Un
ejemplo es la redundancia triple modular TMR (caso particular de la
N-modular redundancy en el que N=3). La TMR consiste en tener
tres componentes idénticos y unos circuitos que comparan
continuamente la salida y en el caso de que alguna difiera de las otras
dos, se bloquea la salida.
Sistemas en Tiempo Real
Manuel Ortiz. Universidad de Córdoba Página 13
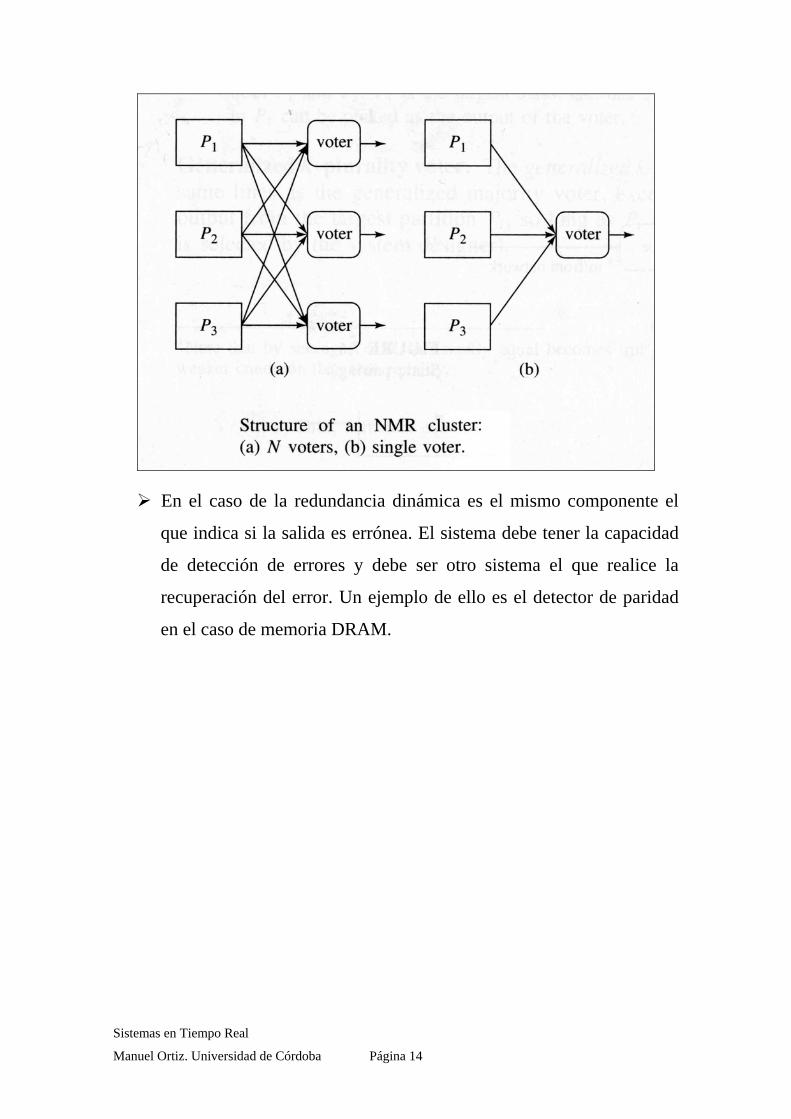
En el caso de la redundancia dinámica es el mismo componente el
que indica si la salida es errónea. El sistema debe tener la capacidad
de detección de errores y debe ser otro sistema el que realice la
recuperación del error. Un ejemplo de ello es el detector de paridad
en el caso de memoria DRAM.
Sistemas en Tiempo Real
Manuel Ortiz. Universidad de Córdoba Página 14

Redundancia del software
3. Redundancia del software.[Krisna, 96][Burns, 03] • La realización de software tolerante a fallos está emergiendo
actualmente y está en su fase inicial. Dado que el software no
se degrada, la tolerancia a fallos en el software está basada en
la búsqueda de errores de diseño. Como es sabido es imposible
escribir un programa largo sin cometer errores. La práctica
indica que la tasa de fallos software es mayor que la tasa de
fallos hardware en un aplicación compleja.
• La redundancia en software en la búsqueda de errores de
diseño tiene dos enfoques distintos. Uno de ellos es similar a la
redundancia enmascarada del hardware denominada
programación de N-versiones y el otro se basa en la detección
y recuperación de errores que es análogo a la redundancia
dinámica del hardware en el sentido de que se activan los
procedimientos de recuperación después de que se ha detectado
el error.
Sistemas en Tiempo Real
Manuel Ortiz. Universidad de Córdoba Página 15

Redundancia del software
3.1. Programación de N-versiones
• La programación de N-versiones se basa en la generación
independiente de N programas funcionalmente equivalentes.
Una vez diseñados los programas se ejecutan de forma
independiente y un programa director va comparando los
resultados.
• En la programación de N-versiones se supone que se ha podido
especificar completamente y sin ambigüedad una aplicación y
que los programas se han escrito independientemente y por
tanto deben fallar de forma independiente. Esta suposición
supone que se deben utilizar lenguajes y entornos diferentes
para evitar errores debidos a la implementación el lenguaje. Si
se utiliza el mismo lenguaje deben utilizarse compiladores y
procesadores de distintos fabricantes. Por ejemplo para el
boeing 777 se escribió un único programa en ADA pero se
utilizaron tres compiladores y procesadores distintos.
Sistemas en Tiempo Real
Manuel Ortiz. Universidad de Córdoba Página 16
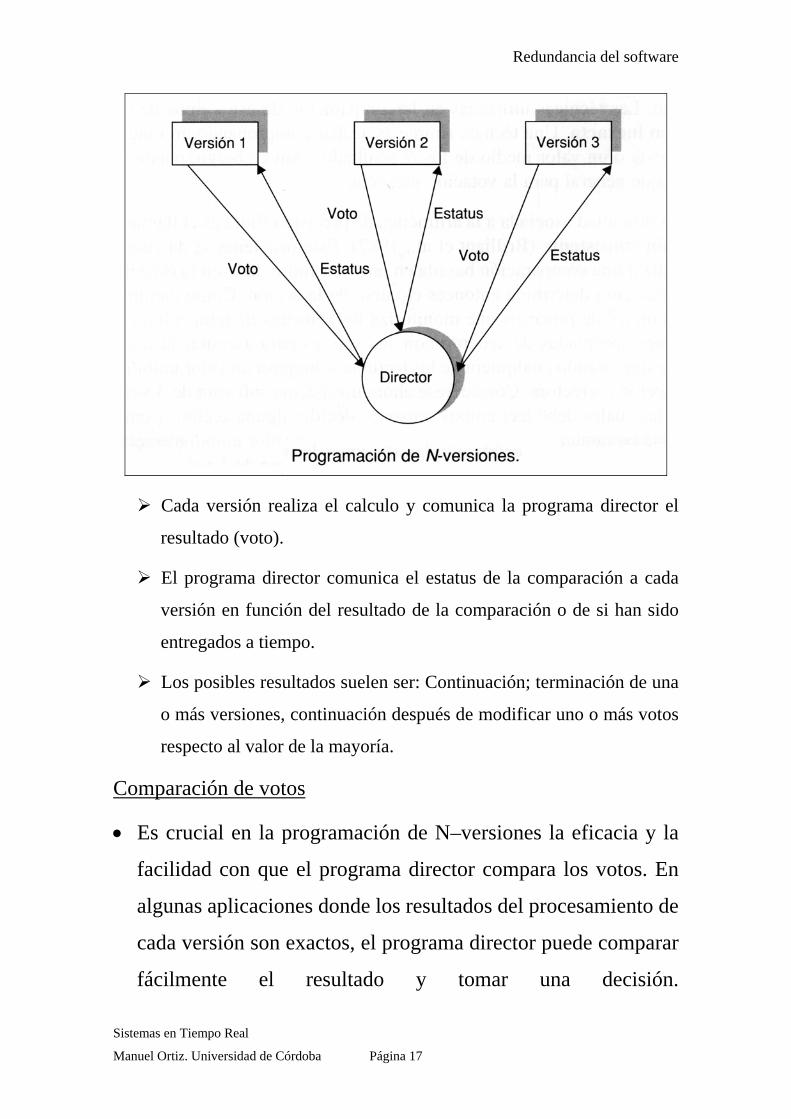
Redundancia del software
Cada versión realiza el calculo y comunica la programa director el
resultado (voto).
El programa director comunica el estatus de la comparación a cada
versión en función del resultado de la comparación o de si han sido
entregados a tiempo.
Los posibles resultados suelen ser: Continuación; terminación de una
o más versiones, continuación después de modificar uno o más votos
respecto al valor de la mayoría.
Comparación de votos • Es crucial en la programación de N–versiones la eficacia y la
facilidad con que el programa director compara los votos. En
algunas aplicaciones donde los resultados del procesamiento de
cada versión son exactos, el programa director puede comparar
fácilmente el resultado y tomar una decisión.
Sistemas en Tiempo Real
Manuel Ortiz. Universidad de Córdoba Página 17

Redundancia del software
Desafortunadamente en la mayoría de las aplicaciones dicha
comparación no resulta tan fácil. Para ahondar en este aspecto
de la comparación de votos se puede consultar la bibliografía
recomendada y los trabajos de Anderson y Lee del año 1990.
Sistemas en Tiempo Real
Manuel Ortiz. Universidad de Córdoba Página 18

Redundancia del software
3.2. Estrategia de bloques de recuperación en la tolerancia a fallos software • La programación N-versiones se le considera el equivalente
software a la redundancia estática en hardware ya que cada
versión tiene una relación fija con el director y siempre entra
en funcionamiento se hayan producidos fallos o no. En el caso
de la redundancia dinámica los componentes redundantes solo
entran en funcionamiento cuando se ha detectado un error
• Cabe decir que la estrategia de bloques de recuperación no está
implementada en ningún lenguaje de programación comercial
solo se han desarrollado algunos sistemas experimentales.
• Los bloques de recuperación (propuestos por Horning et al.,
1974) son bloques en el sentido habitual de los lenguajes de
programación, excepto que en la entrada del bloque se
encuentra un punto de recuperación automático, y en la salida
se encuentra un test de aceptación.
• El test de aceptación se utiliza para comprobar que el sistema
se encuentra dentro de un estado aceptable después de la
ejecución del bloque. Si el test de aceptación falla, provoca que
el programa sea restaurado al punto de recuperación del
principio del bloque y se ejecuta otro módulo alternativo. Si de
nuevo falla el test de aceptación se ejecuta de nuevo otro
módulo y así alternativamente. Si falla todos los módulos
entonces el bloque falla. La siguiente figura muestra Sistemas en Tiempo Real
Manuel Ortiz. Universidad de Córdoba Página 19
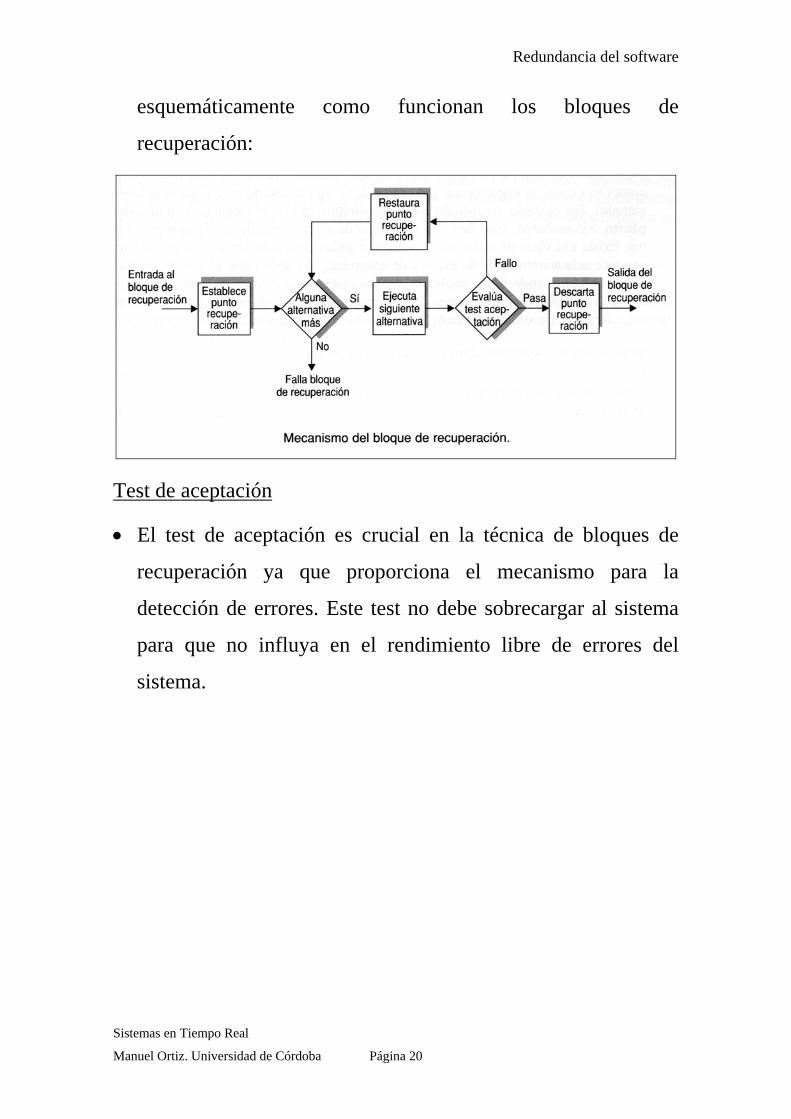
Redundancia del software
esquemáticamente como funcionan los bloques de
recuperación:
Test de aceptación • El test de aceptación es crucial en la técnica de bloques de
recuperación ya que proporciona el mecanismo para la
detección de errores. Este test no debe sobrecargar al sistema
para que no influya en el rendimiento libre de errores del
sistema.
Sistemas en Tiempo Real
Manuel Ortiz. Universidad de Córdoba Página 20

Medición y predicción de la fiabilidad de software
4. Medición y predicción de la fiabilidad de software. [Burns, 03]
• La fiabilidad del software se considera como la probabilidad de
que un programa funcione correctamente en un entorno
concreto y durante un periodo de tiempo. Se han propuesto
varios modelos para estimar la fiabilidad y calidad del
software, los cuales se pueden clasificar en:
Modelos de crecimiento de la fiabilidad del software. Estos modelos
intentan predecir la fiabilidad de un programa basándose en su
historial de errores
Modelos estadísticos. Estiman la fiabilidad del software mediante la
respuesta exitosa o fallida en determinados casos de prueba
aleatorios.
Sistemas en Tiempo Real
Manuel Ortiz. Universidad de Córdoba Página 21


















