
Tareas de la minería de datos: clasificación
25
Tareas de la minería de datos: clasificación PF-5028 Minería de datos Prof. Braulio José Solano Rojas UCR
Transcript of Tareas de la minería de datos: clasificación

Tareas de la minería de datos: clasificación
PF-5028 Minería de datosProf. Braulio José Solano Rojas
UCR

Tareas de la minería de datos: clasificación
● Clasificación (discriminación)● Empareja o asocia datos a grupos predefinidos
(aprendizaje supervisado).● Encuentra modelos (funciones) que describen y
distinguen clases o conceptos para futuras predicciones.
● Probablemente la tarea más familiar y más popular de la minería de datos.
2 de 26

Tareas de la minería de datos: clasificación
● Ejemplos de aplicación: Calificación de crédito (credit scoring), reconocimiento de imágenes y patrones, diagnóstico médico, detección de fallos en aplicaciones industriales, clasificar tendencias de mercados financieros, ...
● Métodos: Análisis discriminante, árboles de decisión, reglas de clasificación, redes neuronales.
3 de 26

Tareas de la minería de datos: clasificación
● Ejemplo simple:● En EE.UU. los maestros clasifican a los estudiantes
en A, B, C, D o F según sus notas. Utilizando simplemente límites (60, 70, 80, 90), las siguientes clasificaciones son posibles:
90 <= nota A80 <= nota <= 90 B70 <= nota <= 80 C60 <= nota < 70 DNota < 60 F
4 de 26

Clasificación contra predicción
● En alguna literatura de minería de datos se considera a la clasificación como el emparejamiento contra clases (etiquetas de valores), mientras que la predicción está asociada a valores continuos. Es decir, en el conjunto de entrenamiento la variable objetivo es una variable continua.
● Finalmente, clasificación y predicción vienen siendo lo mismo, aunque se pueden hacer la diferenciación según el tipo de variable.
5 de 26
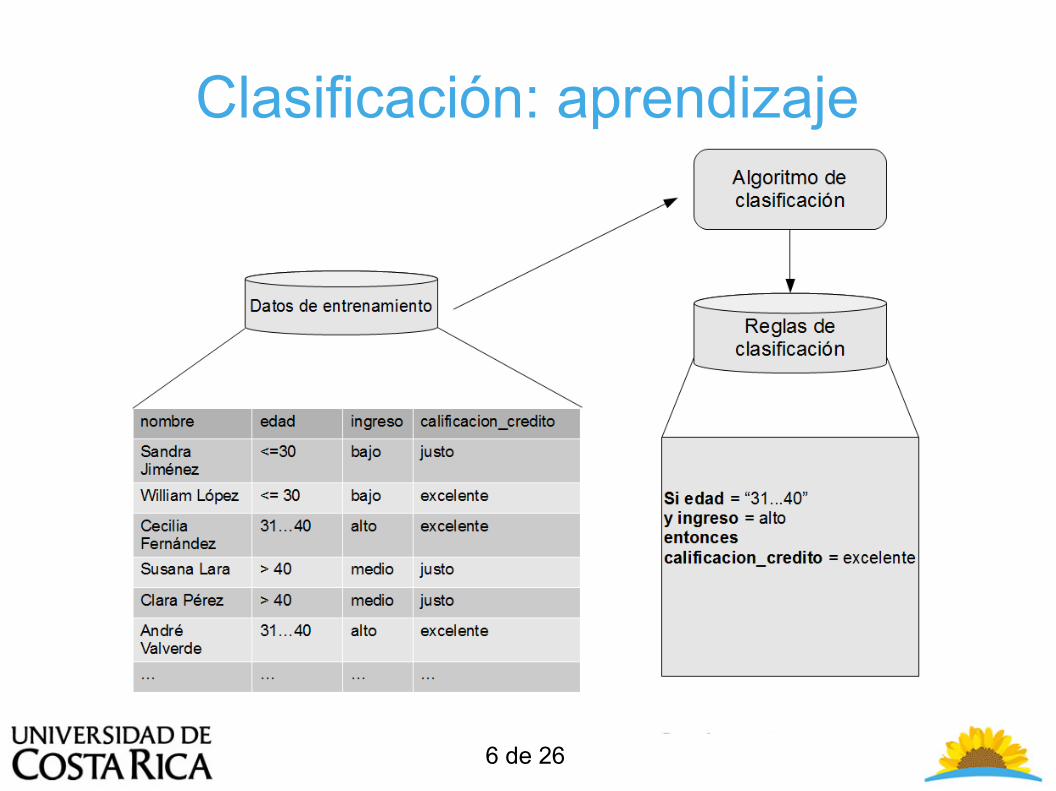
Clasificación: aprendizaje
6 de 26
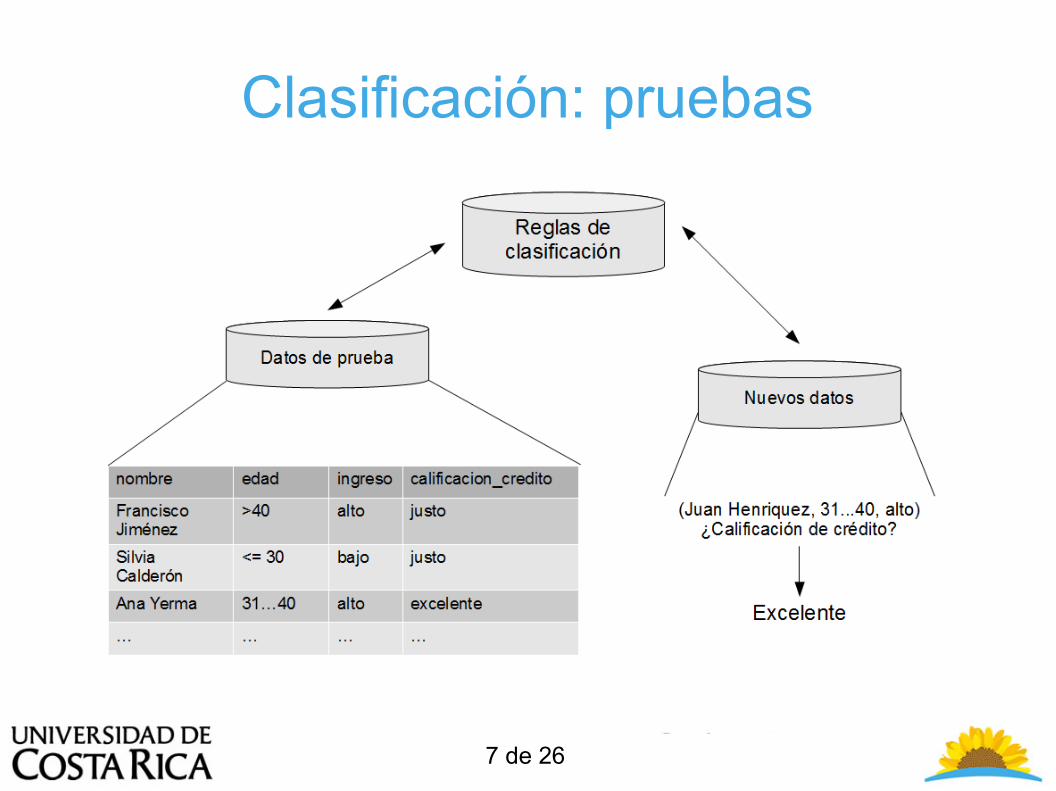
Clasificación: pruebas
7 de 26

Preparación de los datos para clasificación y predicción
● Limpieza de los datos● Tratamiento del ruido y de valores faltantes.
● Análisis de relevancia● Algunos atributos en los datos pueden ser
irrelevantes o redundantes. Eliminar dichos atributos mejora la eficiencia y la eficacia.
● Transformación de datos● Se pueden hacer generalizaciones de los datos a
conceptos de mayor nivel. También se pueden normalizar los datos.
8 de 26

Evaluación de métodos de clasificación
● Precisión en la predicción● Capacidad de predecir correctamente.
● Eficiencia● Costos computacionales.
● Robustez● Habilidad para funcionar con ruido y ausencia de
ciertos valores.● Escalabilidad
● Habilidad para trabajar con grandes cantidades de datos.
● Interpretabilidad● Entendimiento y comprensión que brinda.
9 de 26

Clasificación: definición formal
● Dada una base de datos D = {t1, t
2, …, t
n} de
tuplas (elementos, registros) y un conjunto de clases C = {C
1, …, C
m}, el problema de
clasificación trata de definir un mapeo f : D → C donde cada t
i se asigna a una clase. Una clase
Cj contiene precisamente aquellas tuplas
mapeadas a ella; esto es, Cj = { t
i | f(t
i) = C
j,
1<=i<=n y ti ϵ D }.
10 de 26

Clasificación: algoritmos
● Estadísticos● Regresión simple, regresión múltiple, bayes, ...
● Distancia● k vecinos más cercanos, ...
● Árboles de decisión● ID3, C4.5, CART, ...
● Redes neuronales● Retropropagación, ...
● Reglas● Reglas de asociación, ...
11 de 26

Clasificación por inducción de árboles de decisión
● El aprendizaje por árboles de decisión es un método comúnmente utilizado en minería de datos. El objetivo es crear un modelo que prediga el valor de una variable objetivo basándose en varias variables de entrada. Se muestra un ejemplo en las dos filminas siguientes. Cada nodo interior corresponde a a una de las variables de entrada. Hay aristas hacia un hijo para cada uno de los posibles valores de dicha variable de entrada. Cada hoja representa un valor de la variable objetivo dados los valores de las variables entrada representadas por el camino de la raíz a la hoja.
12 de 26
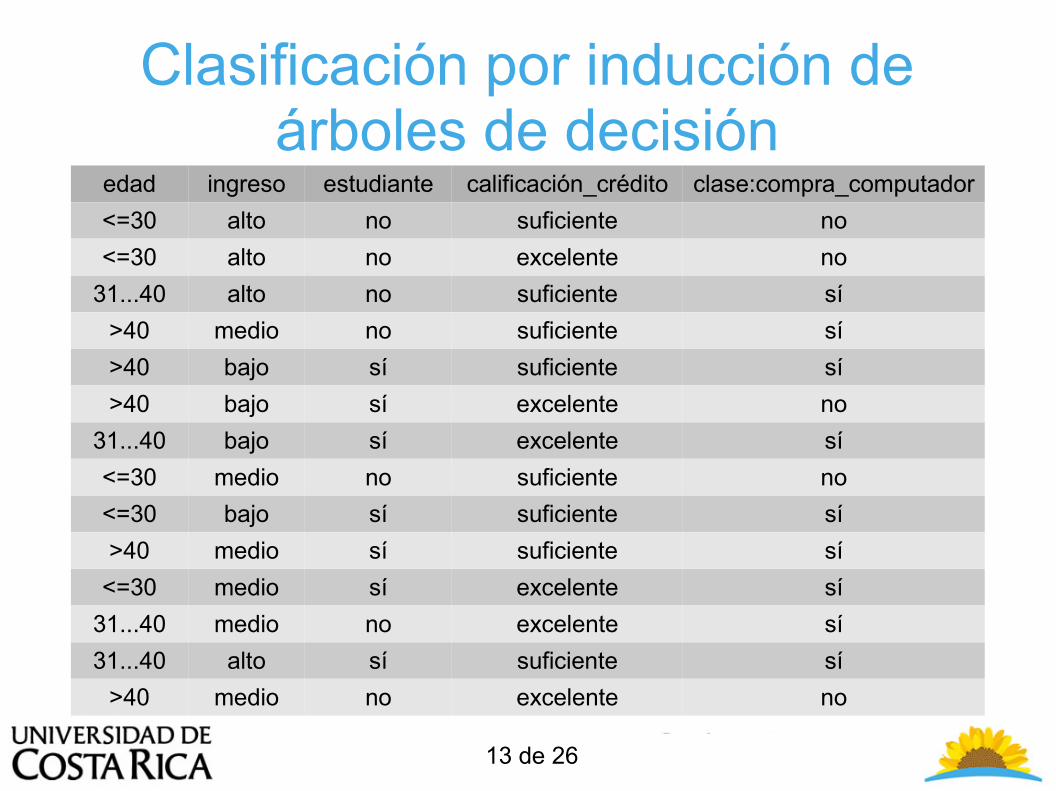
Clasificación por inducción de árboles de decisión
edad ingreso estudiante calificación_crédito clase:compra_computador
<=30 alto no suficiente no
<=30 alto no excelente no
31...40 alto no suficiente sí
>40 medio no suficiente sí
>40 bajo sí suficiente sí
>40 bajo sí excelente no
31...40 bajo sí excelente sí
<=30 medio no suficiente no
<=30 bajo sí suficiente sí
>40 medio sí suficiente sí
<=30 medio sí excelente sí
31...40 medio no excelente sí
31...40 alto sí suficiente sí
>40 medio no excelente no
13 de 26

Clasificación por inducción de árboles de decisión
14 de 26

Clasificación por inducción de árboles de decisión
● Un árbol puede ser “aprendido” separando el conjunto fuente en subconjuntos basados en una prueba de valor de atributo. Este proceso es repetido en cada subconjunto derivado de una manera recursiva llamada particionamiento recursivo. La recursión termina cuando el subconjunto en un nodo tiene para todos sus miembros el mismo valor de la variable objetivo o cuando separar ya no agrega valor a la predicción.
15 de 26

Clasificación por inducción de árboles de decisión
● Los datos vienen en registros de la forma:
(x,Y) = (x1, x
2, x
3, ..., x
k, Y)
● La variable dependiente Y es la variable objetivo que se está tratando de explicar, clasificar o generalizar. El vector x está compuesto de las variables de entrada x
1, x
2,
x3, etc., que son usadas para la tarea de
minería.
16 de 26

Clasificación por inducción de árboles de decisión
17 de 26

Clasificación por los k vecinos más cercanos (KNN)
● Esquema de clasificación común, basado en el uso de medidas de distancia. Es un tipo de “aprendizaje por analogía”.
● La técnica asume que el conjunto completo de entrenamiento incluye no sólo los datos sino también la clasificación deseada.
● Los datos de entrenamiento son entonces el modelo.
18 de 26

Clasificación por los k vecinos más cercanos (KNN)
● Cuando se va a clasificar un nuevo elemento (t) se determina su distancia contra todos los elementos en el conjunto de entrenamiento.
● Luego sólo se consideran los K elementos más cercanos al nuevo elemento (t).
● El nuevo elemento (t) es entonces clasificado en la clase mayoritaria de los vecinos cercanos.
19 de 26

Clasificación por los k vecinos más cercanos (KNN)
● De manera más formal:● El conjunto de entrenamiento es descrito por
atributos numéricos n-dimensionales.
● Cada individuo representa un punto en un espacio n-dimensional.
● Así, el conjunto de entrenamiento es almacenado en un espacio patrón n-dimensional.
● Cuando se clasifica un individuo nuevo se busca en el espacio patrón los k individuos más cercanos al nuevo individuo.
20 de 2620 de 26
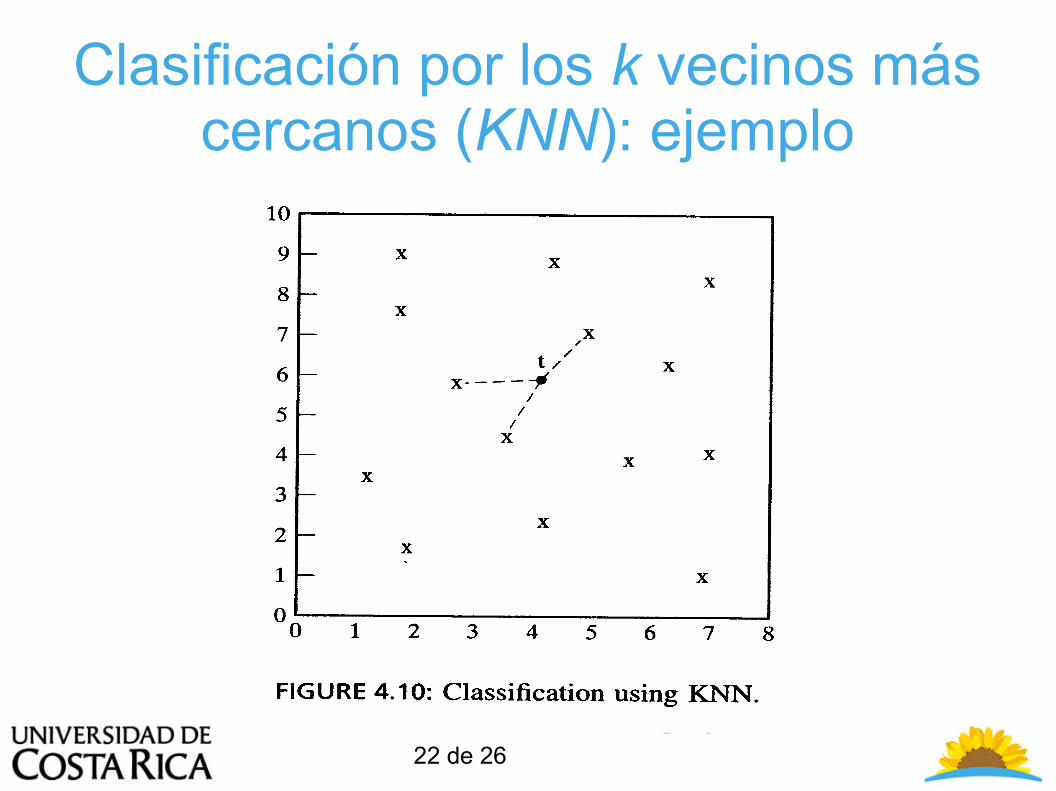
Clasificación por los k vecinos más cercanos (KNN): ejemplo
22 de 26

Clasificación por los k vecinos más cercanos (KNN): algoritmo
23 de 26

Clasificación por los k vecinos más cercanos (KNN)
● La técnica KNN es muy sensible a la escogencia de k. Una regla práctica es k menor o igual a la raíz del número de elementos de entrenamiento.
● Los clasificadores de vecinos más cercanos son aprendizaje basados en instancia o aprendizaje flojo (lazy learning). Tienen mayor eficiencia en el entrenamiento. Sin embargo, los costos computacionales pueden ser caros en la clasificación si los individuos de entrenamiento (el modelo) son muchos.
24 de 26

Clasificación por redes neuronales
● Ver artículos.

¡Gracias por su atención!
¿Preguntas?


















