
Tema 3 - UCM-Universidad Complutense de...
28
3. 3. Correlaci Correlaci ó ó n n 3-1 Tema 3 Tema 3 Correlaci Correlaci ó ó n n Introducción Coeficiente de correlación lineal de Pearson Coeficiente de correlación poblacional Contraste paramétrico clásico Transformación de Fisher Correlación bayesiana Test no paramétrico: Spearman Test no paramétrico: Kendall Test de permutaciones Correlaciones parciales Conclusiones Ejemplo: ley de Hubble
-
Upload
trinhxuyen -
Category
Documents
-
view
213 -
download
0
Transcript of Tema 3 - UCM-Universidad Complutense de...

3. 3. CorrelaciCorrelacióónn3-1
Tema 3Tema 3CorrelaciCorrelacióónn
IntroducciónCoeficiente de correlación lineal de PearsonCoeficiente de correlación poblacionalContraste paramétrico clásicoTransformación de FisherCorrelación bayesianaTest no paramétrico: SpearmanTest no paramétrico: KendallTest de permutacionesCorrelaciones parcialesConclusionesEjemplo: ley de Hubble
IntroducciónCoeficiente de correlación lineal de PearsonCoeficiente de correlación poblacionalContraste paramétrico clásicoTransformación de FisherCorrelación bayesianaTest no paramétrico: SpearmanTest no paramétrico: KendallTest de permutacionesCorrelaciones parcialesConclusionesEjemplo: ley de Hubble

3. 3. CorrelaciCorrelacióónn3-2
IntroducciIntroduccióónn
¿Para qué queremos buscar correlaciones?Para comprobar que nuestras medidas, o las de otros, son razonables.
Para contrastar una hipótesis.
Para intentar descubrir algo nuevo (salir a pescar).
¿Para qué queremos buscar correlaciones?Para comprobar que nuestras medidas, o las de otros, son razonables.
Para contrastar una hipótesis.
Para intentar descubrir algo nuevo (salir a pescar).
Primera lección:
Hacer siempre el diagrama de dispersión.
Si no vemos nada, no seguir.
Primera lecciPrimera leccióón:n:
Hacer siempre el diagrama de dispersión.
Si no vemos nada, no seguir.
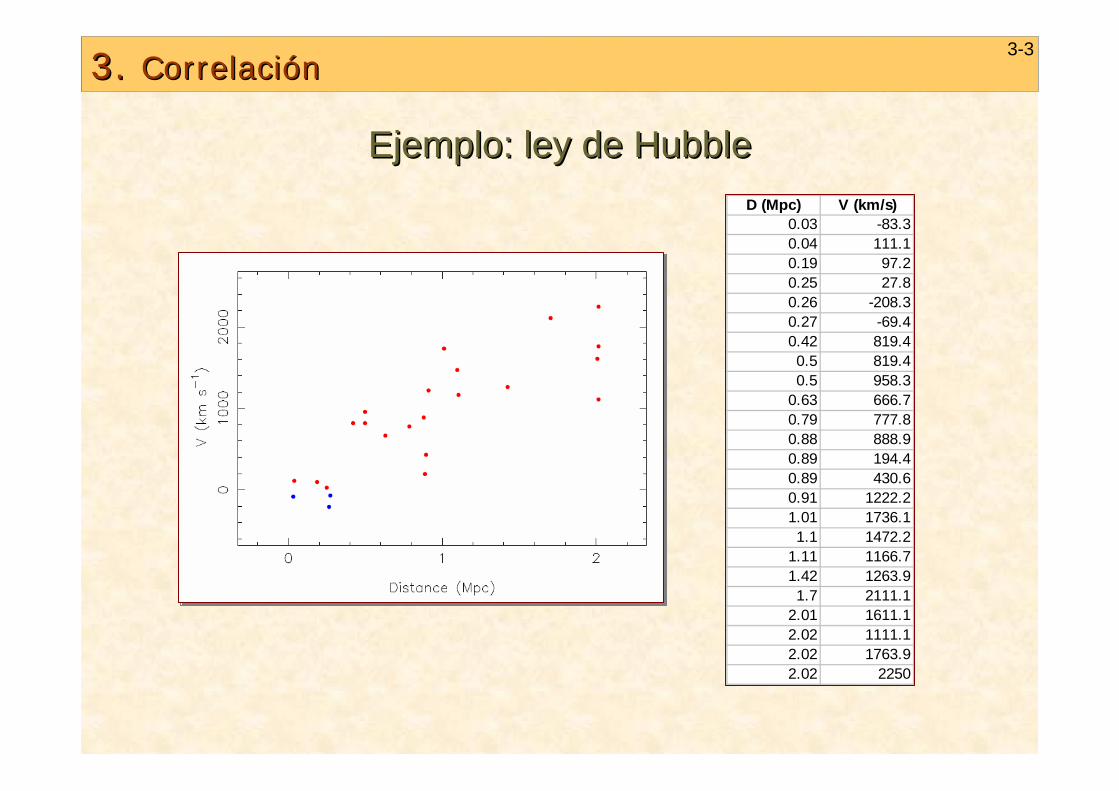
3. 3. CorrelaciCorrelacióónn3-3
Ejemplo: ley de Ejemplo: ley de HubbleHubbleD (Mpc) V (km/s)
0.03 -83.30.04 111.10.19 97.20.25 27.80.26 -208.30.27 -69.40.42 819.40.5 819.40.5 958.3
0.63 666.70.79 777.80.88 888.90.89 194.40.89 430.60.91 1222.21.01 1736.11.1 1472.2
1.11 1166.71.42 1263.91.7 2111.1
2.01 1611.12.02 1111.12.02 1763.92.02 2250

3. 3. CorrelaciCorrelacióónn3-4
Ejemplo: ley de Ejemplo: ley de HubbleHubbleD (Mpc) V (km/s)
0.03 -83.30.04 111.10.19 97.20.25 27.80.26 -208.30.27 -69.40.42 819.40.5 819.40.5 958.3
0.63 666.70.79 777.80.88 888.90.89 194.40.89 430.60.91 1222.21.01 1736.11.1 1472.2
1.11 1166.71.42 1263.91.7 2111.1
2.01 1611.12.02 1111.12.02 1763.92.02 2250
22
10
10
2
Procedimiento no paramétrico para “ver” rápidamente correlaciones: dividir el diagrama por las medianas y
contar el número de puntos en cada uno de los cuatro cuadrantes.

3. 3. CorrelaciCorrelacióónn3-5
IntroducciIntroduccióónnLos peligros de salir a pescar:
La correlación podría deberse a efectos de selección.
Los peligros de salir a pescar:La correlación podría deberse a efectos de selección.
Ejemplo: Luminosidades radio de radiofuentes 3CR en función del módulo de distancias (Sandage 1972)
La curva representa el límite de detección
Si la función de luminosidad decrece para objetos brillantes, no esperamos encontrar objetos cercanos brillantes.

3. 3. CorrelaciCorrelacióónn3-6
IntroducciIntroduccióónnLos peligros de salir a pescar:
La correlación podría deberse a efectos de selección.
Cuidado con los outliers (regla del pulgar)
Los peligros de salir a pescar:La correlación podría deberse a efectos de selección.
Cuidado con los outliers (regla del pulgar)
r = 0.26
r = 0.94r = 0.68
r = 0.41r = 0.88
r = 0.08

3. 3. CorrelaciCorrelacióónn3-7
IntroducciIntroduccióónnLos peligros de salir a pescar:
La correlación podría deberse a efectos de selección.
Cuidado con los outliers (regla del pulgar)
Cuidado con mezclar grupos de medidas no homogéneas
Los peligros de salir a pescar:La correlación podría deberse a efectos de selección.
Cuidado con los outliers (regla del pulgar)
Cuidado con mezclar grupos de medidas no homogéneas
r = 0.04
r = -0.20
r = 0.90

3. 3. CorrelaciCorrelacióónn3-8
IntroducciIntroduccióónnLos peligros de salir a pescar:
La correlación podría deberse a efectos de selección.
Cuidado con los outliers (regla del pulgar).
Cuidado con mezclar grupos de medidas no homogéneas.
Podría existir una correlación no lineal.
Los peligros de salir a pescar:La correlación podría deberse a efectos de selección.
Cuidado con los outliers (regla del pulgar).
Cuidado con mezclar grupos de medidas no homogéneas.
Podría existir una correlación no lineal.
r = -0.32

3. 3. CorrelaciCorrelacióónn3-9
IntroducciIntroduccióónnLos peligros de salir a pescar:
La correlación podría deberse a efectos de selección.
Cuidado con los outliers (regla del pulgar).
Cuidado con mezclar grupos de medidas no homogéneas.
Podría existir una correlación no lineal.
Una correlación no implica una relación causal (terceras variables).
Los peligros de salir a pescar:La correlación podría deberse a efectos de selección.
Cuidado con los outliers (regla del pulgar).
Cuidado con mezclar grupos de medidas no homogéneas.
Podría existir una correlación no lineal.
Una correlación no implica una relación causal (terceras variables).
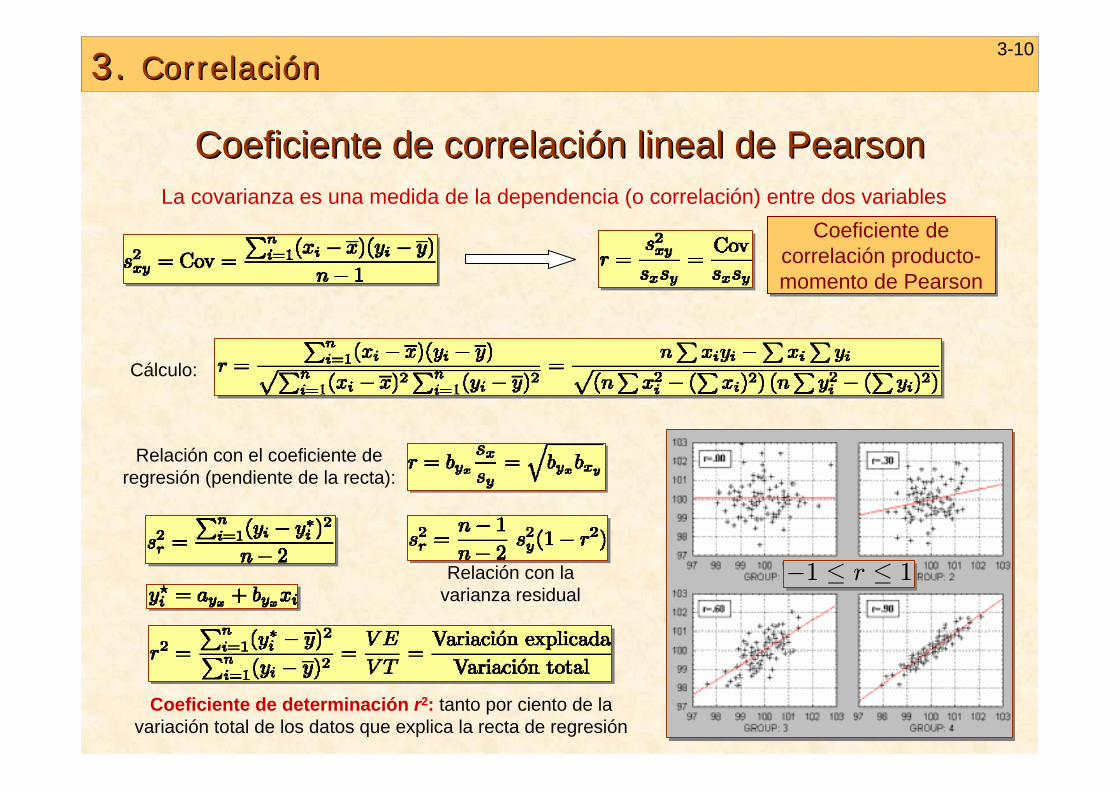
3. 3. CorrelaciCorrelacióónn3-10
Coeficiente de correlaciCoeficiente de correlacióón lineal de n lineal de PearsonPearson
−1 ≤ r ≤ 1
La covarianza es una medida de la dependencia (o correlación) entre dos variables
Coeficiente de correlación producto-momento de Pearson
Coeficiente de correlación producto-momento de Pearson
Cálculo:
Coeficiente de determinación r2: tanto por ciento de la variación total de los datos que explica la recta de regresión
Relación con el coeficiente de regresión (pendiente de la recta):
Relación con la varianza residual

3. 3. CorrelaciCorrelacióónn3-11
Coeficiente de correlaciCoeficiente de correlacióón poblacionaln poblacional
La función de densidad conjunta de X e Y sigue una distribución normal bivariada:
ρ : coeficiente de correlación poblacional
ρ : coeficiente de correlación poblacional
X e Y son independientes
Se supone que X e Y son variables aleatorias normales:
Para estimar ρ se usa el coeficiente de correlación muestral r
Pero sólo es válido si tanto X como Y son variables normales
SiX e Y no están correlacionadosTienen distribuciones con colas que caen rápidoN es grande (>500)

3. 3. CorrelaciCorrelacióónn3-12
Contraste Contraste paramparaméétricotrico clcláásicosico
H0 se acepta si:
(test de Fisher)
Bajo la hipótesis nula: sigue una distribución t de Studentcon N - 2 grados de libertad
Se usa r para estimar ρ
La desviación típica de r es:
O se determina el nivel de significación ppara poder rechazar H0 (probabilidad de que, si no hay correlación, se obtenga un valor de |r| igual o mayor al observado)
Para poder aplicar este método:
• Datos en una escala continua
• La relación entre X e Y ha de ser lineal
• Ambas variables siguen distribuciones normales
Para poder aplicar este método:
• Datos en una escala continua
• La relación entre X e Y ha de ser lineal
• Ambas variables siguen distribuciones normales

3. 3. CorrelaciCorrelacióónn3-13
TransformaciTransformacióón de n de FisherFisher
Hipotesis :
½H0 : ρ = ρ0H1 : ρ 6= ρ0
H0 se acepta si:
Hipotesis :
½H0 : ρ1 = ρ2H1 : ρ1 6= ρ2
H0 se acepta si:
Para muestras grandes (N ≥ 25)
es aprox. normal con:
Contraste para un valor determinado de ρ
Comparación de dos correlaciones

3. 3. CorrelaciCorrelacióónn3-14
Ejemplo: ley de Ejemplo: ley de HubbleHubbleScatterp lot: D vs. V
V = 44,173 + 918,52 * DCorre lation: r = ,83708
-0,2 0,0 0,2 0,4 0,6 0,8 1,0 1,2 1,4 1,6 1,8 2,0 2,2
D
-400
-200
0
200
400
600
800
1000
1200
1400
1600
1800
2000
2200
2400
V
95% confidence
Scatterp lot: D vs. VV = 44,173 + 918,52 * D
Corre lation: r = ,83708
-0,2 0,0 0,2 0,4 0,6 0,8 1,0 1,2 1,4 1,6 1,8 2,0 2,2
D
-400
-200
0
200
400
600
800
1000
1200
1400
1600
1800
2000
2200
2400
V
95% confidence
Histogram : DK-S d=,13052, p> .20; L i l l iefors p> .20
Expected Norm al
-0 ,5 0,0 0,5 1,0 1,5 2,0 2,5
X <= Category Boundary
0
1
2
3
4
5
6
7
8
9
10
No.
of o
bs.
Histogram : DK-S d=,13052, p> .20; L i l l iefors p> .20
Expected Norm al
-0 ,5 0,0 0,5 1,0 1,5 2,0 2,5
X <= Category Boundary
0
1
2
3
4
5
6
7
8
9
10
No.
of o
bs.
Histogram : VK-S d=,12192, p> .20; L i l l iefors p> .20
Expected Norm al
-500 0 500 1000 1500 2000 2500
X <= Category Boundary
0
1
2
3
4
5
6
7
8
No.
of o
bs.
Histogram : VK-S d=,12192, p> .20; L i l l iefors p> .20
Expected Norm al
-500 0 500 1000 1500 2000 2500
X <= Category Boundary
0
1
2
3
4
5
6
7
8
No.
of o
bs.

3. 3. CorrelaciCorrelacióónn3-15
Ejemplo: ley de Ejemplo: ley de HubbleHubbleHistogram : PAR_1
Expected Norm al
0,440,46
0,480,50
0,520,54
0,560,58
0,600,62
0,640,66
0,680,70
0,720,74
0,760,78
0,800,82
0,840,86
0,880,90
0,920,94
0,960,98
X < Category Boundary
0
20
40
60
80
100
120
140
160
180
No.
of o
bs.
Histogram : PAR_1 Expected Norm al
0,440,46
0,480,50
0,520,54
0,560,58
0,600,62
0,640,66
0,680,70
0,720,74
0,760,78
0,800,82
0,840,86
0,880,90
0,920,94
0,960,98
X < Category Boundary
0
20
40
60
80
100
120
140
160
180
No.
of o
bs.
103 simulaciones
106 simulaciones
Una buena estimación de la incertidumbre en r puede hacerse mediante BOOTSTRAP: se extraen con reemplazamiento muchas muestras aleatorias de tamaño N (se usa la muestra observada como población)
Una buena estimación de la incertidumbre en r puede hacerse mediante BOOTSTRAP: se extraen con reemplazamiento muchas muestras aleatorias de tamaño N (se usa la muestra observada como población)
Para calcular el nivel de significación habría que hacer simulaciones hasta obtener un valor de r = 0 (p=1/Nsimul)
Histograma de los valores de t en las 106 simulaciones

3. 3. CorrelaciCorrelacióónn3-16
CorrelaciCorrelacióón n bayesianabayesianaCálculo de la distribución de probabilidad del coeficiente de correlación poblacional ρ a partir de la verosimilitud de los datos. Hay que marginalizar para todos los parámetros no relevantes
Suponiendo una distribución normal bivariada y un prior uniforme para ρ:
Distribución de Jeffreys
A partir de la distribución de probabilidad se puede calcular ej: P(ρ > ρ0), P(ρ1 > ρ2), etc.
Ejemplo:
50 datos generados de una distribución t con 3 grados de libertad (colas extendidas) y ρ = 0.5
Excluyendo puntos con desviaciones mayores de 4σ
Método robusto pero dependiente de la distribución de probabilidad supuesta
ρmax=0.19
ρmax=0.44

3. 3. CorrelaciCorrelacióónn3-17
Ejemplo: ley de Ejemplo: ley de HubbleHubble
103 simulacionesMétodo bayesiano (test de Jeffrey)
La probabilidad de que ρ tenga un valor de 0 (no haya correlación) es muy pequeña.
Pero se ha supuesto una distribución normal

3. 3. CorrelaciCorrelacióónn3-18
TestTest no no paramparaméétricotrico: : SpearmanSpearmanSe ordenan de menor a mayor por separado los valores Xi e Yi de los datos y se sustituye cada uno por su número de orden (rango): xi, yi representan los rangos en X e Y para el par i
Coeficiente de correlación de rangos de SpearmanCoeficiente de correlación de rangos de Spearman
(se sustituye la distribución de probabilidad desconocida por una distribución uniforme entre 1 y N)
Interpretación similar al coeficiente de Pearson
H0 se acepta si:
En caso de empates, se asigna a todos los puntos empatados el valor de medio de los rangos que tendrían sin empates.
Fórmula más exacta para el caso de una alta
fracción de empates:
fk, gm: nº de empates por grupo

3. 3. CorrelaciCorrelacióónn3-19
TestTest no no paramparaméétricotrico: : SpearmanSpearmanPara muestras grandes (N > 30):
El estadístico: sigue una distribución t de Student con N-2 grados de libertad
rs tiende a una
VENTAJAS
No se asume una relación lineal entre las variables.
No se asume una distribución normal bivariada.
Es válido para muestras en las que no se pueden hacer medidas pero sí asignar rangos.
Es más robusto
INCONVENIENTES
Pérdida de información
La eficiencia es del 91% (para distribuciones normales, en el test de Fisher basta con un tamaño muestral un 91% menor para rechazar la hipótesis nula con el mismo nivel de significación)
VENTAJAS
No se asume una relación lineal entre las variables.
No se asume una distribución normal bivariada.
Es válido para muestras en las que no se pueden hacer medidas pero sí asignar rangos.
Es más robusto
INCONVENIENTES
Pérdida de información
La eficiencia es del 91% (para distribuciones normales, en el test de Fisher basta con un tamaño muestral un 91% menor para rechazar la hipótesis nula con el mismo nivel de significación)
En comparación con el test paramétrico clásico de Fisher:
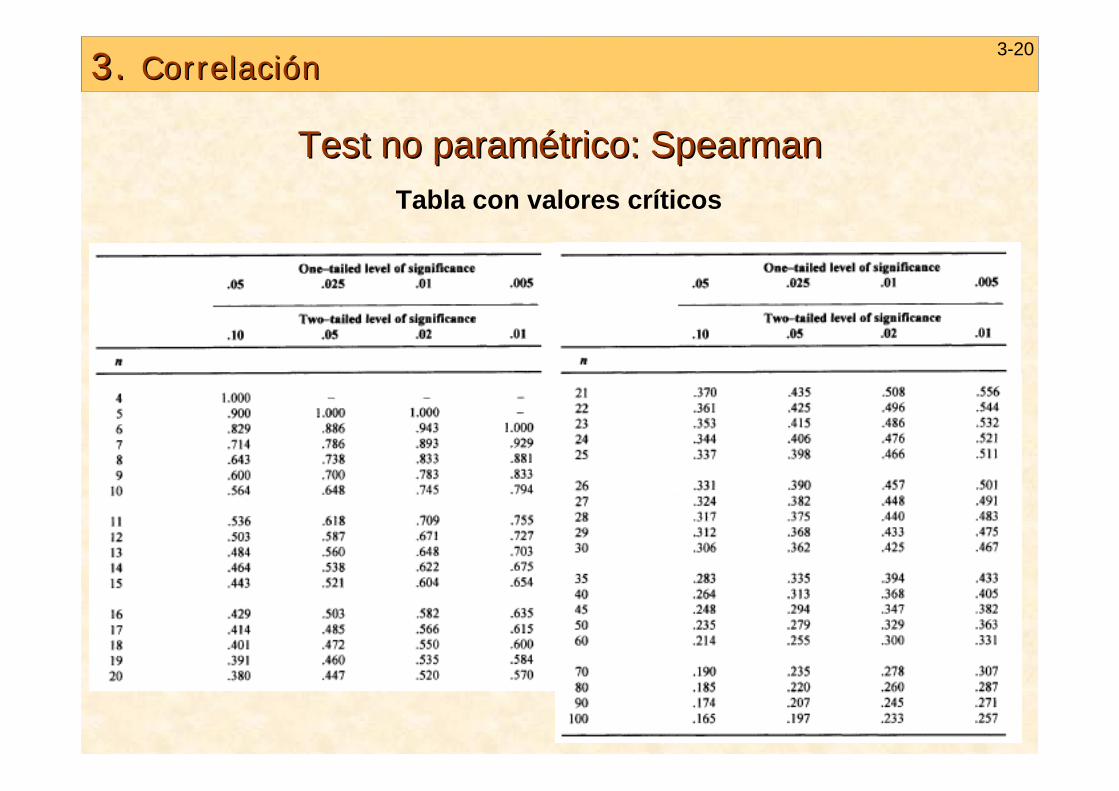
3. 3. CorrelaciCorrelacióónn3-20
TestTest no no paramparaméétricotrico: : SpearmanSpearmanTabla con valores críticos

3. 3. CorrelaciCorrelacióónn3-21
Ejemplo: ley de Ejemplo: ley de HubbleHubble
1,2
3,54,46,3
2,6
5,1
7,11.58.5,14
8.5,11.5
10,9
13.5,713.5,8
11,1012,13
15,17 18,16
17,19
16,21
19,18
20,2323,24
23,2221,20
23,15
Resultado de 106 simulaciones con BOOTSTRAPpara rs
Permite obtener una incertidumbre sobre el estadístico.
El resultado es muy seguro pues para ninguna simulación se obtiene rs≤ 0 (P < 10-6)
Método muy robusto

3. 3. CorrelaciCorrelacióónn3-22
TestTest no no paramparaméétricotrico: : KendallKendallMétodo aún más paramétrico que el de Spearman. En vez de comparar los rangos, sólo se calcula si una coordenada es mayor que la otra.
Coeficiente de correlación tau de KendallCoeficiente de correlación tau de Kendall
Interpretación: el coeficiente de Spearman es similar al de Fisher (fracción de la variación de los datos explicada por la correlación), mientras que el de Kendall indica la diferencia de la probabilidad de que las dos variables estén en el mismo orden menos la probabilidad de que estén en un orden diferente.
τ tiende rápidamente a una distribución normal con:(N > 10)
H0 se acepta si:
Más lento de calcular que el coeficiente de Spearman (excepto para datos agrupados en intervalos)
N datos (xi,yi) pares diferentes de puntosPar concordante (NC)
Par discordante (ND)
En el caso de empates: TX (nº de empates en la x )
TY (nº de empates en la y )

3. 3. CorrelaciCorrelacióónn3-23
TestTest no no paramparaméétricotrico: : KendallKendallTabla con
valores críticos

3. 3. CorrelaciCorrelacióónn3-24
Ejemplo: ley de Ejemplo: ley de HubbleHubble
Kendall Tau

3. 3. CorrelaciCorrelacióónn3-25
TestTest de permutacionesde permutacionesOtro método no paramétrico: Se extraen muestras de la muestra observada, del mismo tamaño, permutando aleatoriamente las asignaciones de las Ys a las Xs (sin reemplazamientos), y se calcula para cada muestra el valor del estadístico de prueba (ej. r, rs, τ, etc.). La distribución obtenida representa la distribución del estadístico en el caso de no correlación. Se compara el valor observado con dicha distribución.
Ejemplo: 20 datos no correlacionados
Funciones de distribución para 1000 permutaciones (de las 20! posibles)

3. 3. CorrelaciCorrelacióónn3-26
CorrelaciCorrelacióón parcialn parcialSI se sabe que una tercera (cuarta, etc.) variable (conocida) está afectando la correlación se puede eliminar su efecto.
Método paramétrico
Para una muestra de N datos con 3 variables:
Coeficiente de correlación parcial de primer orden
Para una muestra de N datos con 4 variables:
Coeficiente de correlación parcial de segundo orden
(coeficiente de correlación entre x1 y x2, manteniendo x3 y x4 constantes)
Con desviaciones típicas:
Se aplica el test t de Student

3. 3. CorrelaciCorrelacióónn3-27
Los métodos no paramétricos solucionan el problema de la distribución de probabilidad desconocida pero comparten las dificultades de los métodos no bayesianos (se basan en la comparación con la distribución bajo la hipótesis nula basada en observaciones hipotéticas)
El método bayesiano es más directo pero no soluciona el problema del desconocimiento de la distribución de probabilidad.
El método bayesiano proporciona resultados muy parecidos a usar el método de Fishercon simulaciones (bootstrap).
ConclusionesConclusiones
El análisis de correlación no indica cuál es la variable dependiente (fundamental para hacer un análisis de regresión).
Tampoco implica una relación causa-efecto.
El coeficiente de correlación por sí sólo no proporciona toda la información.
Ejemplo: cuarteto de Ascombe (mismo coeficiente de correlación y línea de regresión)

3. 3. CorrelaciCorrelacióónn3-28
PrPráácticacticaPosible correlación entre la abundancia relativa de C,N y la luminosidad (o masa) del cúmulo de galaxias
(Carretero et al., 2004, Ap.J. 609, L45)
0.400.300.390.400.450.480.610.43[CN/Fe]
2.011.971.801.220.310.300.150.08LX(1044 erg/s)
A1650A655ComaA2050A257VirgoA1238A279Cúmulo


















