
Tema 4: Inferencia Estadística - ugr.esmvargas/Tema4.pdf · •Si el tamaño de muestra es...
41
1 Tema 4: Inferencia Estadística •El objetivo es efectuar una generalización de los resultados de la muestra a la población. Inferir o adivinar el comportamiento de la población a partir del conocimiento de una muestra. •Para ello es necesario conocer las distribuciones de probabilidad de ciertas funciones de las muestras que constituyen variables aleatorias asociadas al experimento aleatorio: selección de una muestra al azar de una población. •Estas variables aleatorias denominadas estadísticos muestrales , porque se basan en el comportamiento de las muestras, asignan a cada muestra del espacio muestral, constituido por todas la muestras posibles, un número real que es un resumen estadístico de la muestra . Por ejemplo, media de la muestra. •El esquema siguiente resume visualmente la situación: Dada una población formada por un número N grande de elementos, donde se observa la variable X, se extrae al azar una muestra de tamaño n (n<N). •Tanto en la población como en la muestra podemos resumir los valores de la variable X observada. Los valores resumen se denominan parámetros en la población y estadísticos en las muestras. Notaremos con U a un estadístico o resumen muestral determinado.
Transcript of Tema 4: Inferencia Estadística - ugr.esmvargas/Tema4.pdf · •Si el tamaño de muestra es...

1
Tema 4: Inferencia Estadística•El objetivo es efectuar una generalización de los resultados de la muestraa la población. Inferir o adivinar el comportamiento de la población a partirdel conocimiento de una muestra.
•Para ello es necesario conocer las distribuciones de probabilidad de ciertasfunciones de las muestras que constituyen variables aleatorias asociadasal experimento aleatorio: selección de una muestra al azar de una población.
•Estas variables aleatorias denominadas estadísticos muestrales , porque se basan en el comportamiento de las muestras, asignan a cada muestra del espacio muestral, constituido por todas la muestras posibles, un número realque es un resumen estadístico de la muestra . Por ejemplo, media de la muestra.
•El esquema siguiente resume visualmente la situación: Dada una población formada por un número N grande de elementos, donde se observa la variableX, se extrae al azar una muestra de tamaño n (n<N).
•Tanto en la población como en la muestra podemos resumir los valores de la variable X observada. Los valores resumen se denominan parámetros en la población y estadísticos en las muestras. Notaremos con U a un estadísticoo resumen muestral determinado.

2
Distribuciones Muestrales
Población X variable aleatoria
x4
x2 x20
x1
x15x8
x7
x6
x3x2
x5
xi
xj
…
Muestra
x1,x2,x3,…,xn
Resumen de X en la muestra:Estadísticos: media, varianza, …
Resumen de X en la Población:Parámetros: media, varianza, …
Población formada por todas lasmuestras posibles de tamaño nU variable aleatoria muestral(Estadísticos de las muestras: resúmenes de los valores de X en las muestras.)
x4
x2
x20
x1
x15
x8
x6
x3x2
x5
xi
xj…
Resumen de los estadísticos muestrales:media, varianza, …
x2
x4x2
xh
x2x2
x2
….
…
U1 U2
UiUj
U5
3
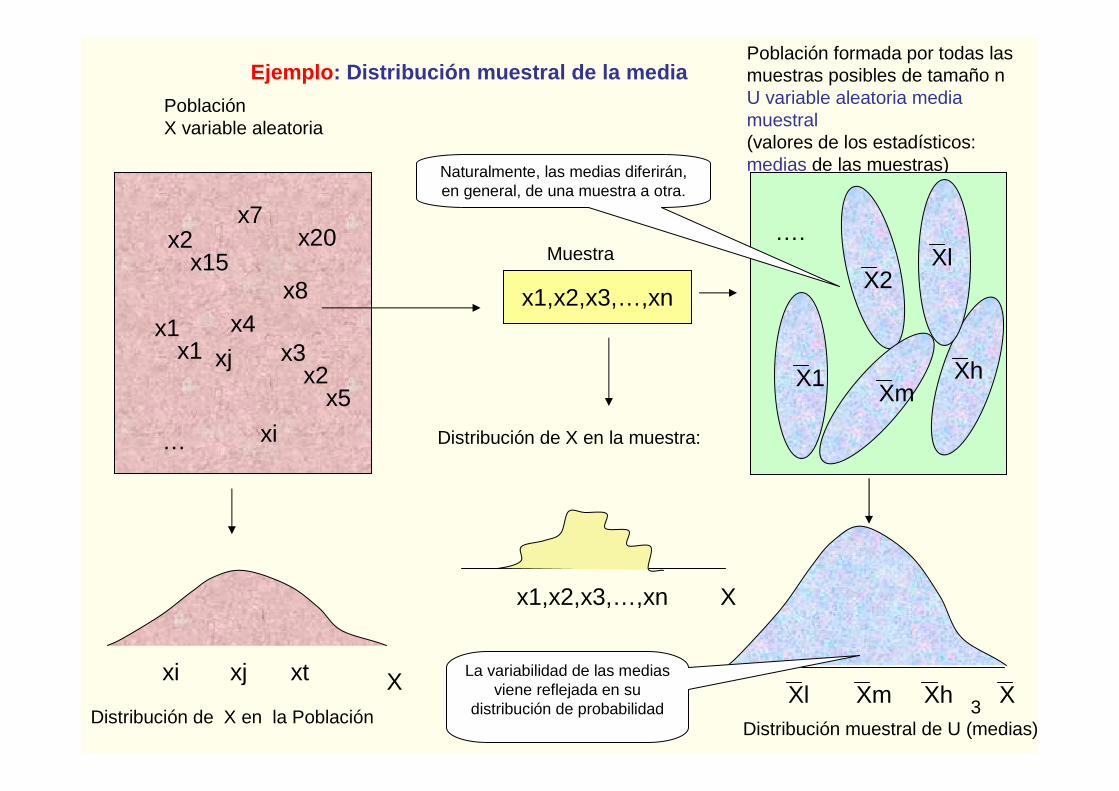
Ejemplo : Distribución muestral de la media
Población X variable aleatoria
x4
x2 x20
x1
x15x8
x7
xj
x3x2
x5
xi
xj
…
Muestra
x1,x2,x3,…,xn
Distribución de X en la muestra:
Distribución de X en la Población
Población formada por todas lasmuestras posibles de tamaño nU variable aleatoria media muestral(valores de los estadísticos: medias de las muestras)
x4
Distribución muestral de U (medias)
….
X
X
XXhXmXlxi
x1
xt
x1,x2,x3,…,xn
Xm
X2
X1 Xh
Xl
Naturalmente, las medias diferirán, en general, de una muestra a otra.
La variabilidad de las medias viene reflejada en su
distribución de probabilidad

4
Distribuciones Muestrales•Resumiendo: •Dada una población y el experimento aleatorio consistente en seleccionar unamuestra de dicha población, se define la variable aleatoria U (estadístico muestral)como una aplicación que asigna a cada muestra, m, un resumen estadístico determinado,U(m). Esta nueva variable aleatoria U tiene una distribución de probabilidad denominada distribución muestral de U .
U : E R
m=(x1, x2, …,xn) U(m)=estadístico muestral
•Su comportamiento dependerá del que tenga X en la población y del tamañode las muestras.
•Utilidad:Estaremos interesados en conocer su comportamiento probabilístico, porque estonos permitirá hacer inferencias acerca del comportamiento de la población.
•A veces nos resultará útil conocer su esperanza matemática y/o su varianza.

5
Distribuciones Muestrales•Casos particulares de distribuciones muestrales:
U=total muestral=t : E R
m=(x1, x2, …,xn)
•Se verifica que el estadístico muestral t es también normal con las siguientes mediay desviación típica:
Además, si el tamaño de la muestra es suficientemente grande (n>30), t se distribuye normalmente, aunque X en la población no sea normal.
Total muestral
∑=
==n
i
XitmU1
)(
Sea una población P y X la variable aleatoria observada, cuya distribución esNormal
),( σµNX →
),( 2
1
σµ nnNXitn
i
→=∑=

6
Distribuciones Muestrales•Casos particulares de distribuciones muestrales:
U=media muestral : E R
m=(x1, x2, …,xn)
•Se verifica que el estadístico muestral media es también normal con las siguientes media y desviación típica:
Además, si el tamaño de la muestra es suficientemente grande (n>30), se distribuye normalmente, aunque X en la población no sea normal.
Media muestral
n
XiXmU
n
i∑
=== 1)(
Sea una población P y X la variable aleatoria observada, cuya distribución esNormal
),( σµNX →
),(1
nN
n
XiX
n
i σµ→=∑
=
7
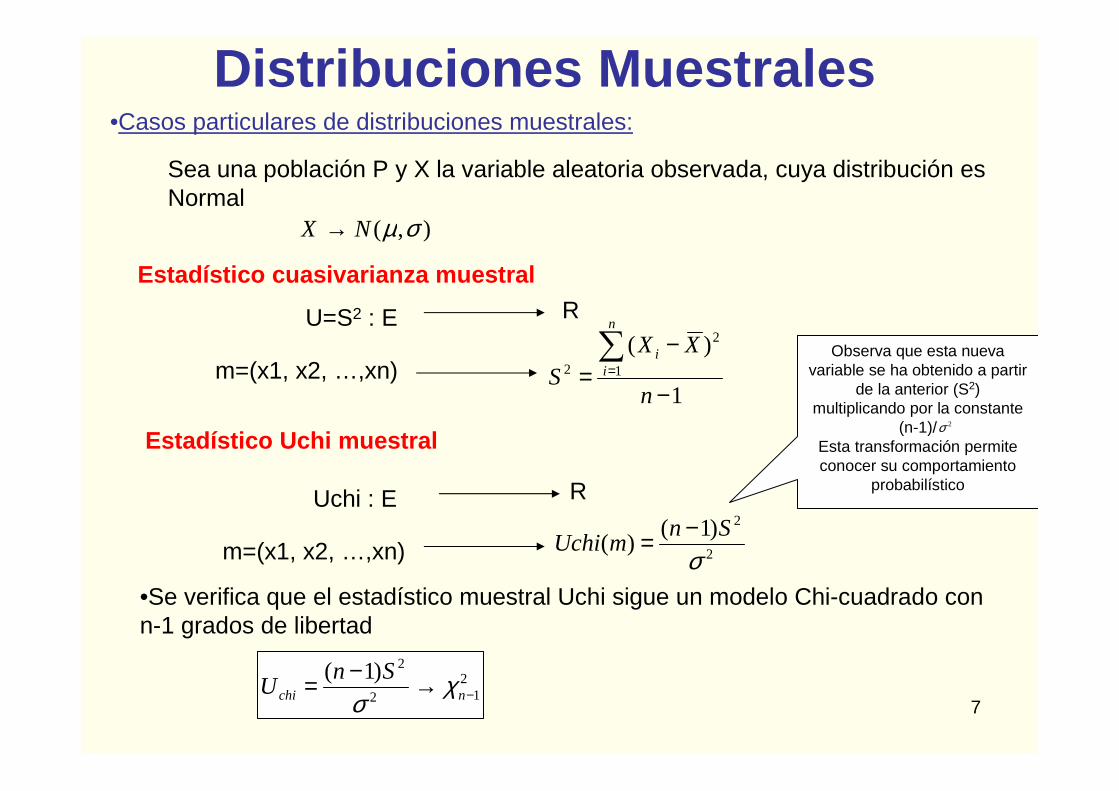
Distribuciones Muestrales•Casos particulares de distribuciones muestrales:
U=S2 : E R
m=(x1, x2, …,xn)
•Se verifica que el estadístico muestral Uchi sigue un modelo Chi-cuadrado conn-1 grados de libertad
Estadístico cuasivarianza muestral
1
)(1
2
2
−
−=∑
=
n
XXS
n
ii
Sea una población P y X la variable aleatoria observada, cuya distribución esNormal
),( σµNX →
212
2)1(−→−= nchi
SnU χ
σ
Uchi : E R
m=(x1, x2, …,xn)
Estadístico Uchi muestral
2
2)1()(
σSn
mUchi−=
Observa que esta nueva variable se ha obtenido a partir
de la anterior (S2) multiplicando por la constante
(n-1)/ Esta transformación permite conocer su comportamiento
probabilístico
2σ

8
Distribuciones Muestrales•Casos particulares de distribuciones muestrales:
Ut,v : E R
m=(x1, x2, …,xn)
•Se verifica que el estadístico muestral Ut,v sigue un modelo t de Student conn-1 grados de libertad
Estadístico Ut,v (función de los estadísticos media y cuasivarianza)
n
SX
U t
µυ
−=,
Sea una población P y X la variable aleatoria observada, cuya distribución esNormal
),( σµNX →
1,
)(−→−= nt t
n
SX
Uµ
υ
Observa que esta nueva variable se ha obtenido a partir
de los estadísticos media y cuasidesviación típica (S)
Esta transformación permite conocer su comportamiento
probabilístico

9
Distribuciones Muestrales•Casos particulares de distribuciones muestrales:
Ut : E R
m=(x1, x2, …,xn)
•Se verifica que el estadístico muestral Ut sigue un modelo Binomial
∑=
==n
i
XitUt1
Sea una población P y X la variable aleatoria observada, cuya distribución esuna Bernoulli: X=0 con probabilidad q=P(fracaso) y X=1 con probabilidad p=P(éxito)Se sabe que E(X)=p y V(X)=pq
),( pnBUt →
Observa que esta variable refleja el total de éxitos (1’s)
en la muestra entre el total de selecciones n. Es un caso
particular de total muestral t, ya visto. Observa que es
también la variable binomial
Estadístico Ut=t=total de éxitos en la muestra
E(Ut)=npV(Ut)=npq
•Para tamaños de muestra suficientemente grandes se aproxima a una normal

10
Distribuciones Muestrales•Casos particulares de distribuciones muestrales:
Up : E R
m=(x1, x2, …,xn)
•Si el tamaño de muestra es suficientemente grande (n>30)se verifica que el estadístico muestral Up sigue un modelo normal
éxitosdeproporciónn
Xi
n
UtUp
n
i ===∑
=1
Sea una población P y X la variable aleatoria observada, cuya distribución esuna Bernoulli: X=0 con probabilidad q=P(fracaso) y X=1 con probabilidad p=P(éxito)Se sabe que E(X)=p y V(X)=pq
),(n
pqpNUp →
Observa que esta variable refleja la proporción de éxitos
(1’s) en la muestra entre el total de selecciones n. Es un
caso particular de media muestral , ya visto.
Estadístico Up=proporción de éxitos en la muestra

11
• Supondremos una población formada por solo N=3 elementos. Por ejemplo 3 niños. Se observa la variable X=edad. Consideremos la selección con reemplazamiento de todas las muestras posibles de tamaño n=2.
• Población niños: {A, B, C} Edad: 2, 3 y 4 años respectivamente.
• El espacio muestral formado por todas las muestras posibles
• E={AA, AB, AC, BA, BB, BC, CA, CB, CC}
• Estadístico muestral U=media muestral
Ejemplo simple de simulación del proceso de generac ión de una Distribución Muestralde la Media
U=media muestral : E R
m=(x1, x2, …,xn)n
XiXmU
n
i∑
=== 1)(

12
Ejemplo simple de simulación del proceso de generac ión de una Distribución Muestralde la Media (continuación)
U=media muestral : E R
(AA) 22
22 =+=X
(AB) 5,22
32 =+=X
(BA)
32
42 =+=X(AC)
(BB)
(CA)
(BC) 5,32
43 =+=X
(CB)
32
33 =+=X
(CC) 42
44 =+=X
5,22
32 =+=X
32
42 =+=X
5,32
43 =+=X

13
Ejemplo simple de simulación del proceso de generac ión de una Distribución Muestralde la Media (continuación)
Distribución muestral de la media
U=media P(U)
2 1/9
2,5 2/9
3 3/9
3,5 2/9
4 1/9
X=Edad P(X)
2 1/3
3 1/3
4 1/3
Distribución de X=Edad en la población
Comprueba que la esperanza de X en la población coincide con la esperanza de la variable media muestral, U, y que la varianza de U es igual al cociente entre la Varianza de X y el tamaño de la muestra (2).
E(X)=3Varianza(X)=2/3

14
Ejemplo: Distribución Muestral de la Media
Observa que en la práctica se selecciona una muestra de la población y se efectúa un resumen de dicha muestra mediante el cálculo de un estadístico muestral que nos interese. Por ejemplo media de la muestra, desviación típica, mediana, etc.
Si conociéramos el comportamiento que tienen todos los posibles valores del esta-dístico muestral que nos interesa (su modelo de probabilidad), podríamos saberqué probabilidad hay de que el valor de nuestra muestra esté comprendida en undeterminado intervalo.
Ejemplo:
Se ha seleccionado una muestra al azar de 50 mujeres de una población de mayoresde 18 años. Se desconoce la talla media de la población, pero en la muestra se ha observado que la media de las 50 tallas es 1,60 m. Si se sabe por otros estudios que
la desviación típica en la población es de 3 ,3 cm, determina la probabilidad de que lamedia de la población no difiere en más de 1 cm de la de la muestra.

15
Ejemplo: Distribución Muestral de la Media
Ejemplo (continuación):
),(1
nN
n
XiX
n
i σµ→=∑
=
Se sabe que para tamaños de muestra grandes la media muestral se distribuyesegún un modelo normal.
)4667,0,()50
3,3,( µµ NNX ≡→Sustituyendo
µ X
1 cm
)14,214,2()4667,0
1
4667,0
1(
)11()1|)(|
≤≤−=≤≤−=
+≤≤−=<−
ZPZP
XPXP µµµ

16
Ejemplo: Distribución Muestral de la Media
Ejemplo 2
)10,500( ==→ σµNX
Se sabe que los pesos de los paquetes de cierto artículo en una cadena deproducción se distribuyen normalmente con media 500 gr y desviación típica 10 gr
Se selecciona una muestra de 100 paquetes de la producción y se observa que la media de éstos es de 530 gr ¿es coherente este resultado con la hipótesis de que
se distribuyen normalmente con media y desviación típica 500 y 10, respectivamente.
)1,500()100
10,500( NNX ≡→
Si la hipótesis es cierta, entonces habrá que admitir
500=µ )530( ≥X
0)30()1
500530()530( =≥=−≥=≥ ZPZPXP
La probabilidad de observar un suceso tan extremoo más (530 gr) es igual a
530
17
Ejemplo: Distribución Muestral de la Media
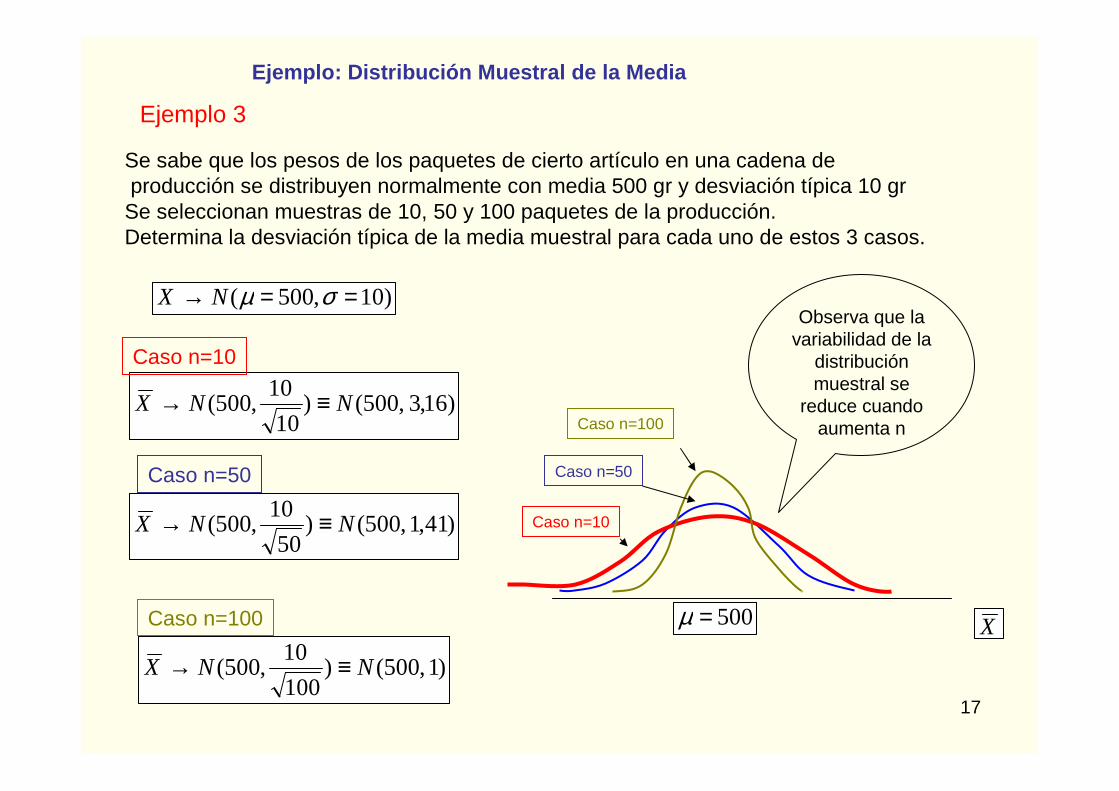
Ejemplo 3
)10,500( ==→ σµNX
Se sabe que los pesos de los paquetes de cierto artículo en una cadena deproducción se distribuyen normalmente con media 500 gr y desviación típica 10 gr
Se seleccionan muestras de 10, 50 y 100 paquetes de la producción.Determina la desviación típica de la media muestral para cada uno de estos 3 casos.
)16,3,500()10
10,500( NNX ≡→
500=µ X
Caso n=10
)41,1,500()50
10,500( NNX ≡→
Caso n=50
)1,500()100
10,500( NNX ≡→
Caso n=100
Observa que la variabilidad de la
distribución muestral se
reduce cuando aumenta n
Caso n=10
Caso n=50
Caso n=100

18
Ejemplo: Distribución Muestral de la proporción
Ejemplo 4
)5,0,1( =→ pBX
En unas elecciones un determinado candidato asegura que tiene ganadosal menos el 50% de los votos. En un sondeo previo a las elecciones se obtuvo una muestra de 500 votantes y 160 se mostraron favorables al candidato ¿es coherente con la hipótesis del candidato el resultado obtenido en la muestra?
Si la hipótesis fuese cierta, entonces habría que admitir que la proporción muestral se distribuye según
5,0=p
0)04,8()0224,0
5,032,0()32,0( =−≤=−≤=≤ ZPZPUP p
La probabilidad de observar un suceso tan extremo o más al obtenido Up=160/500=0,32 es
Up
)0224,0,5,0()500
5,05,0,5,0(),( NN
n
pqpNUp ≡⋅≡→
32,0)32,0( ≤Up

19
Estimacion puntual y por Intervalo
•El objetivo es efectuar una generalización de los resultados de la muestraa la población. Inferir o adivinar el comportamiento de la población a partirdel conocimiento de una muestra. En general nos interesará conocer algún parámetro determinado de la población (media, varianza, proporción, etc.)
•Para ello es necesario conocer las distribuciones de probabilidad de ciertasfunciones de las muestras que constituyen variables aleatorias asociadasal experimento aleatorio, selección de una muestra al azar de una población.
•Esta variable aleatoria es un estadístico muestral , y su distribuciónes la distribución muestral
•Podemos distinguir entre estimación puntual y por intervalo•Estimación puntual : se proporciona un solo valor numérico del parámetrodesconocido.Estimación por intervalo : se proporciona un intervalo dentro del cual se afirmaque se encuentra el parámetro desconocido con una confianza dada. El nivelde confianza expresa en términos de probabilidad el grado de seguridad que tenemos al afirmar que el intervalo incluirá al parámetro.

20
Estimacion puntual y por Intervalo
Definición de estimador
Dado un parámetro un estimador del parámetro, que notaremos con , es un estadístico muestral que se emplea para conocer el parámetro
θ θ̂
El valor concreto que tome para la muestra seleccionada se denominaestimación puntual de θ
Es deseable que los estimadores presenten ciertas propiedades tales como insesgadez (la esperanza o media del estimador coincide con el parámetro estimado); eficiencia (dados dos estimadores insesgados es más eficiente elde menor varianza), entre otras.
La elección del estimador adecuado dependerá de estas propiedades
A veces se usa como estimador el mismo resumen estadístico que define el parámetro. Por ejemplo, como estimador de la media de la población se usa la media de la muestra; de la proporción en la población, la de la muestra; de la varianza en la población, la de la muestra. Pero no siempre es esta la mejor elección. Por ejemplo, la cuasivarianza muestral es mejor estimador de la varianza de la población desde el punto de vista de la insesgadez.

21
Ejemplo: Estimador de la media de una población
Población: X variable aleatoria
Muestra seleccionada
x1,x2,x3,…,xn
Distribución de X en la Población
Distribución muestral de medias
X
XXmuestra
Estimador:Estadístico muestral media muestral
Estimación:Media de la muestra Xmuestra
Valor de la variable
Inferencia
µ

22
Estimacion puntual y por Intervalo
Intervalo de confianza para la media con conocidaµ σ
)1( α−Dado un nivel de confianza podemos encontrar en la distribución los valores que encierran en el centro de la distribución un área (probabilidad) igual
Sea una población sobre la que se observa una variable aleatoria X con distribución ),( σµNX →
Usaremos como estimador de la media poblacional la media muestral. Sabemos que
),(n
NXσµ→
Por tanto, la variable estandarizada sigue un modelo N(0,1):
)1,0(N
n
XZ →−= σ
µ
)1( α−
)1( α−
2/αz− 2/αz
2/α2/α
=≤−≤−=≤≤−=− )()(1 2/2/2/2/ αααα σµα z
n
XzPzZzP
Z

23
Estimacion puntual y por Intervalo
Intervalo de confianza para la media con conocida (continúa)µ σ
)1( α−
2/αz− 2/αz
2/α2/α
=≤−≤−=≤≤−=− )()(1 2/2/2/2/ αααα σµα z
n
XzPzZzP
Z
=+−≤−≤−−=≤−≤−= )()( 2/2/2/2/n
zXn
zXPn
zXn
zPσµσσµσ
αααα
)( 2/2/n
zXn
zXPσµσ
αα +≤≤−=
El intervalo de confianza para la media al nivel )1( α−
+−n
zXn
zXσσ
αα 2/2/ ,

24
Estimacion puntual y por Intervalo
Ejemplo: Intervalo de confianza para la media con conocidaµ σ
El intervalo de confianza para la media al nivel )1( α−
+−n
zXn
zXσσ
αα 2/2/ ,
Se ha seleccionado una muestra de 25 viviendas de un barrio. Se sabe que la superficie de éstas se distribuye normalmente con media desconocida y varianza 49. Estime el valor medio de la superficie por vivienda en dicho barrio a un nivel de confianza del 95%, sabiendo que la media observada en las 25 viviendas de la muestra fue de 102,5m2.
+−25
796,15,102,
25
796,15,102

25
Estimacion puntual y por Intervalo
Intervalo de confianza para la media con desconocidaµ σ
)1( α−Dado un nivel de confianza podemos encontrar en la distribución los valores que encierran en el centro de la distribución un área (probabilidad) igual
Sea una población sobre la que se observa una variable aleatoria X con distribución ),( σµNX →
Usaremos como estimador de la media poblacional la media muestral. Sabemos que
)1( α−
)1( α−
2/αt− 2/αt
2/α2/α
=≤−≤−=≤≤−=− − )()(1 2/2/2/12/ ααααµα t
n
sX
tPtttP n
t de Studen con n-1 g.l
el estadístico muestral Ut,v sigue un modelo t de Student con n-1 grados de libertad
1,
)(−→−= nt t
n
SX
Uµ
υ

26
Estimacion puntual y por Intervalo
Intervalo de confianza para la media con desconocida (continúa)µ σ
=≤−≤−=≤≤−=− − )()(1 2/2/2/12/ ααααµα t
n
sX
tPtttP n
=+−≤−≤−−=≤−≤−= )()( 2/2/2/2/n
stX
n
stXP
n
stX
n
stP αααα µµ
)( 2/2/n
stX
n
stXP αα µ +≤≤−=
El intervalo de confianza para la media al nivel )1( α−
+−n
stX
n
stX 2/2/ , αα
)1( α−
2/αt− 2/αt
2/α2/α
t de Studen con n-1 g.l
Donde s es la cuasivarianza muestral1
)(1
2
−
−=∑
=
n
Xxs
n
ii
Nota: cuando el tamaño muestral es grande la t de Student se aproxima a una normal

27
Estimacion puntual y por Intervalo
Ejemplo: Intervalo de confianza para la media con desconocidaµ σ
El intervalo de confianza para la media al nivel )1( α−
Se ha seleccionado una muestra de 25 viviendas de un barrio. Se sabe que la superficie de éstas se distribuye normalmente con media y varianza desconocidas. Estime el valor medio de la superficie por vivienda en dicho barrio a un nivel de confianza del 95%, sabiendo que la media y la varianza observadas en la muestra fueron de 102,5 y 64, respectivamente.
+−n
stX
n
stX 2/2/ , αα
667,666424
25)(
12 ==
−= muestraVar
n
nS
165,8667,666424
25 ===S
+−25
165,8064,25,102,
25
165,8064,25,102

28
Estimacion puntual y por Intervalo
Intervalo de confianza para la proporción p
)1( α−Dado un nivel de confianza podemos encontrar en la distribución los valores que encierran en el centro de la distribución un área (probabilidad) igual
Sea una población sobre la que se observa una variable aleatoria X con distribución ),1( pBX →
Usaremos como estimador de la proporción poblacional la proporción muestral. Sabemos que
)1( α−
el estadístico muestral Up sigue un modelo normal para muestras suficientemente grandes
),(n
pqpNUp →
)1,0(N
n
pq
pUZ p →
−=
De modo equivalente
)1( α−
2/αz− 2/αz
2/α2/α
=≤−
≤−=≤≤−=− )()(1 2/2/2/2/ ααααα z
n
pq
pUzPzZzP p
Z

29
Estimacion puntual y por Intervalo
Intervalo de confianza para la proporción
)1( α−
2/αz− 2/αz
2/α2/α
Z
=+−≤−≤−−=≤−≤−= )()( 2/2/2/2/ n
pqzUp
n
pqzUP
n
pqzpU
n
pqzP ppp αααα
)( 2/2/ n
pqzUp
n
pqzUP pp αα +≤≤−=
El intervalo de confianza para p al nivel )1( α−
−+
−−
n
UUzU
n
UUzU pp
ppp
p
)1(,
)1(2/2/ αα
=≤−
≤−=≤≤−=− )()(1 2/2/2/2/ ααααα z
n
pq
pUzPzZzP p
Observa que se ha sustituido p por su estimador, dado que este es
desconocido

30
Estimacion puntual y por Intervalo
Ejemplo: Intervalo de confianza para la proporción
El intervalo de confianza para p al nivel )1( α−
−+
−−
n
UUzU
n
UUzU pp
ppp
p
)1(,
)1(2/2/ αα
En un centro escolar se ha seleccionado una muestra al azar de 120 padres de alumnos para estimar la proporción de éstos que ayudan en las tareas escolares a sus hijos. De entre los 120 seleccionados 97 respondieron afirmativamente. Obtenga un intervalo de confianza del 80% para estimar la proporción de padres del centro que ayudan a sus hijos.
197,01
803,0120
97
=−
==
p
p
u
u
−+−−120
)803,01(803,028,1803,0,
120
)803,01(803,028,1803,0
[ ] )849,0,757,0(046,0803,0,046,0803,0 =+−

31
Estimacion puntual y por Intervalo
Intervalo de confianza para la varianza de una población
)1( α−Dado un nivel de confianza podemos encontrar en la distribución los valores que encierran en el centro de la distribución un área (probabilidad) igual
Sea una población sobre la que se observa una variable aleatoria X con distribución ),( σµNX →
Usaremos como estimador de la varianza poblacional la cuasivarianza muestral. Sabemos que
)1( α−
)1( α−
22/1 αχ −
2/α2/α
=≤−≤=≤≤=− −− ))1(
()(1 22/2
22
2/12
2/2
2/1 αααα χσ
χχχα SnPUP chi
Chi-cuadrado con n-1 g.l
el estadístico muestral Uchi sigue un modelo Chi-cuadrado con n-1 grados de libertad
212
2)1(−→−= nchi
SnU χ
σ 1
)(1
2
2
−
−=∑
=
n
XXS
n
ii
donde
22/αχ

32
)1( α−
22/1 αχ −
2/α2/α
=≤−≤=≤≤=− −− ))1(
()(1 22/2
22
2/12
2/2
2/1 αααα χσ
χχχα SnPUP chi
Chi-cuadrado con n-1 g.l22/αχ
Estimacion puntual y por IntervaloIntervalo de confianza para la varianza
))1()1(
()1
)1(
1(
22/
22
22/1
2
22/
2
2
22/1 αααα χ
σχχ
σχ
SnSnP
SnP
−≥≥−=≥−
≥=−−
El intervalo de confianza para la varianza al nivel )1( α−
−−
−2
2/1
2
22/
2 )1(,
)1(
αα χχSnSn

33
Estimacion puntual y por IntervaloEjemplo: Intervalo de confianza para la varianza
El intervalo de confianza para la varianza al nivel )1( α−
( )991,56,756,1558,6
786,26)115(,
8,23
786,26)115( =
−−
−−
−2
2/1
2
22/
2 )1(,
)1(
αα χχSnSn
( )608,66,259,1463,5
786,26)115(,
3,26
786,26)115( =
−−
Se desea estimar la variabilidad resultante en los pesos de una máquina de empaquetado. Se ha seleccionado una muestra de 15 paquetes cuyos pesos presentan una varianza iguala 25 gramos. Estime la varianza con la que trabaja la máquina a un nivel de confianza dela) 90%b) 95%
786,262514
15var
12 ==
−=
n
ns

34
Contraste de hipótesis•Una hipótesis es una afirmación, juicio o enunciado sobre el comportamiento de unapoblación.
•El contraste de hipótesis tiene como objetivo decidir si se rechaza o no la hipótesis nulaplanteada.
•La decisión se basa en el resultado obtenido en la muestra de trabajo. Si este resultado es coherente con la hipótesis planteada, ésta no puede rechazarse; si por el contrario, los resultadosno son coherentes con la hipótesis, se rechaza.
•Ejemplos de contrastes de hipótesis comunes son los efectuados sobre los valores de los parámetros. Por ejemplo:
H0: la media poblacional es superior o igual a 50Se denomina hipótesis nula y se nota con H0. A la alternativa se nota con H1: la media es inferior a 50.
•Para el contraste de hipótesis se utilizan determinados estadísticos muestrales , de los que seconoce su comportamiento probabilístico bajo la hipótesis nula. De este modo, el valor resultantedel estadístico para la muestra de trabajo, representa un valor de la distribución muestral.
Si el resultado es poco probable bajo la hipótesis nula, se asumirá que ha ocurrido un suceso raroy por tanto sospechoso bajo esta hipótesis, lo que conlleva el rechazo.
•El procedimiento consiste en dividir el rango de valores del estadístico muestral, cuya distribuciónde probabilidad se conoce bajo la hipótesis nula, en dos regiones: una que representa valorespocos coherentes con la hipótesis, que se denomina zona de rechazo, y otra, que representa elresto de los valores posibles de la variable muestral, denominada zona de aceptación.

35
Contraste de hipótesisContraste de hipótesis sobre la media de una población
Dada una población sobre la que se observa una variable X, tal que ),( σµNX →
00 : µµ =H
Se desea constrastar
Frente a
01 : µµ ≠H
Si se asume que H0 es cierta, entonces también es cierto que el estadístico muestralmedia muestral se distribuye según el modelo siguiente:
),( 0n
NXσµ→
Se divide el rango de valores posibles de esta variable muestral en dos zonas. Observa que la zona no coherente con la hipótesis nula H0 es la formada por los valores más alejados del valor 0µ
El tamaño de la zona de rechazo está relacionado con el valor de la probabilidad de que la variable muestral tome valores en dicha zona. Y representa la probabilidad rechazar H0 siendo cierta (error tipo I). Se denomina nivel de significación y se nota con . α
)1,0(0 N
n
XZ →−= σ
µDe modo equivalente

36
αDado un nivel de significación podemos encontrar en la distribución los valores que constituyen la zonade rechazo (menos coherentes con la hipótesis nula).
)1( α−
2/αz− 2/αz
2/α2/α
Z
Contraste de hipótesisContraste de hipótesis sobre la media de una población (continúa)
0
)1,0(0 N
n
XZ →−= σ
µ
observa que valores muy altos o muy bajos de Z indican que la media muestralse aleja de
RECHAZO RECHAZOaceptación
Reglas del contraste
Observa que una vez fijadas las reglas del contraste, la decisión es clara:Si el valor de la media de la muestra de trabajo cae en la zona roja se rechaza la hipótesis nulaEn caso contrario, se acepta.
00 : µµ =H
0µ

37
Otro modo de tomar la decisión es mediante el conocimiento de la probabilidad de que ocurra un suceso tanraro o más que el obtenido en la muestra. Es decir, mediante el p-valor o significación asociado al resultado de la muestra de trabajo.
2/αz− 2/αz
2/α2/α
Z
Contraste de hipótesisContraste de hipótesis sobre la media de una población (continúa)
0
|)| |ZP(|iónsignificac ovalor -p Zmuestra>=
α>>= |)| |ZP(|signif. ovalor -p Zmuestra
RECHAZO RECHAZOaceptación
Observa que hay dos posibilidades: Zmuestra cae en zona roja o no cae en zona roja.
2/αz− 2/αz
2/α2/α
Z0
RECHAZO RECHAZOaceptación
Zmuestra
-Zmuestra
Zmuestra
-Zm
uest
ra
α<>= |)| |ZP(|signif. ovalor -p Zmuestra
Observa que cuando el valor del estadístico en la muestra de trabajo cae en la zona de aceptación, el p-valor es mayor que alfa. Cuando el estadístico de la muestra cae en la zona de rechazo, el p-valor es menor que alfa.Por tanto la decisión también puede tomarse simplemente comparando el p-valor o significación con alfa

38
Tablas de Contingencia: Contraste de Independencia Chi-cuadrado
∑∑= =
−=
p
i
q
j ij
ijij
t
tn
1 1
22 )(
χ
Hipótesis nula (H0): Las variables X e Y son independientes
Hipótesis alternativa (H1): Las variables X e Y no son independientes
Si las variables son independientes, entonces el estadístico chi-cuadrado
Sigue un modelo Chi-cuadrado con (p-1)(q-1) g.l.
Supongamos que el gráfico define su comportamiento probabilístico. Señalemos en el mismo, aquella zona que representa un suceso “raro”, cuando se asume la independencia. Observa que bajo independencia esperamos que las frecuencias observadas, nij, no difieran “demasiado” de las teóricas, y por tanto, el valor del estadístico observado en la muestra no debería ser “muy grande”. Es coherente que definamos como valores raros para chi-cuadrado, por ejemplo, el 5% de los más altos.
0Aceptación Rechazo
2χ
05,0=α
2αχ
Percentil 95: Valor de la variable que deja el 5% de los más altosa la derecha

39
Tablas de Contingencia: Contraste de Independencia Chi-cuadrado
2muestraχ
2αχ
H0: Las variables X e Y son independientesH1: Las variables X e Y no son independientes
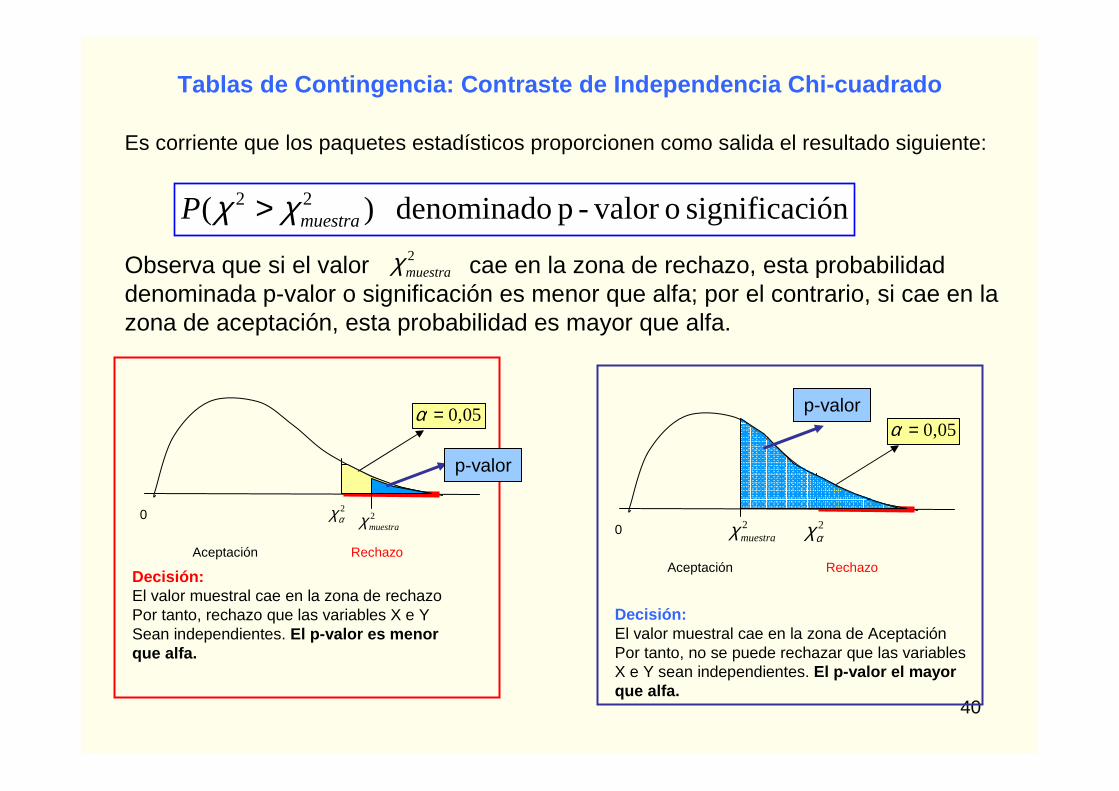
Si las variables son independientes, entonces el valor del estadístico chi-cuadrado calculado para la muestra, obtenida de esa población ¿cómo crees que es más probable que sea, alto o bajo ?Lógicamente si se asume H0, esperaremos encontrar un valor bajo dePor tanto la decisión será:Rechazar H0 si el valor de chi-cuadrado en la muestra es alto, porque la ocurrencia de este suceso nos hará sospechar de la veracidad de la hipótesis nula. Aceptaremos Ho, si dicho valor no es alto.
0
Aceptación Rechazo
2muestraχ
05,0=α
2αχ0
Aceptación Rechazo
2muestraχ
05,0=α
Decisión:El valor muestral cae en la zona de rechazoPor tanto, rechazo que las variables X e YSean independientes
Decisión:El valor muestral cae en la zona de AceptaciónPor tanto, no se puede rechazar que las variables X e Y sean independientes
40
Tablas de Contingencia: Contraste de Independencia Chi-cuadrado
2muestraχ
2αχ 2
muestraχ
Es corriente que los paquetes estadísticos proporcionen como salida el resultado siguiente:
0
Aceptación Rechazo
05,0=α
2αχ0
Aceptación Rechazo
2muestraχ
05,0=α
Decisión:El valor muestral cae en la zona de rechazoPor tanto, rechazo que las variables X e YSean independientes. El p-valor es menor que alfa.
Decisión:El valor muestral cae en la zona de AceptaciónPor tanto, no se puede rechazar que las variables X e Y sean independientes. El p-valor el mayor que alfa.
iónsignificac ovalor -p denominado )( 22muestraP χχ >
Observa que si el valor cae en la zona de rechazo, esta probabilidaddenominada p-valor o significación es menor que alfa; por el contrario, si cae en la zona de aceptación, esta probabilidad es mayor que alfa.
p-valor
p-valor

41
Tablas de Contingencia: Contraste de Independencia Chi-cuadrado
Hipótesis nula (H0): Las variables X e Y son independientes
Hipótesis alternativa (H1): Las variables X e Y no son independientes
Resumiendo: la decisión puede tomarse observando el p-valor o significacióndel estadístico chi-cuadrado.
iónsignificac ovalor -p )( 22 => muestraP χχ
Si el p-valor es menor que alfa: Rechazo que las h ipótesis sean independientes
Si el p-valor es mayor que alfa: No se puede recha zar que las hipótesissean independientes
Nota : observa que el p-valor es la probabilidad de que la variable tome valores másextremos que el observado en la muestra, cuando se asume la hipótesis nula. Si esta probabilidad es “baja” estamos ante un suceso “raro” y sospecharemos de lahipótesis. Por eso la rechazamos.


















