
Test Multietapa de Inteligencia Fluida
52
1 Informe de Investigación Test Multietapa de Inteligencia Fluida Manuel Martín-Fernández Vicente Ponsoda Julio Olea Pei-Chun Shih Javier Revuelta Universidad Autónoma de Madrid
Transcript of Test Multietapa de Inteligencia Fluida

1
Informe de Investigación
Test Multietapa de Inteligencia Fluida
Manuel Martín-Fernández
Vicente Ponsoda
Julio Olea
Pei-Chun Shih
Javier Revuelta
Universidad Autónoma de Madrid

i
Índice
Abstract 1 Introducción 2
Inteligencia Fluida 2 Test Multietapa 4 Objetivos 8
Estudio 1 9 Método 9 Participantes 9 Materiales 9 Procedimiento 13 Análisis de datos 14 Resultados 17 Análisis de los ítems 17 Fiabilidad 18 Evidencias de validez 19 Funcionamiento diferencial de los ítems 20 Conclusiones 22
Estudio 2 23 Método 23 Modelos 23 Diseño de la simulación 25 Análisis de datos 27 Resultados 27 Comparación de modelos 27 Resultados de la simulación 30 Conclusiones 31
Estudio 3 31 Método 32 Especificaciones 34 Análisis de datos 38 Resultados 38 Estructura del test 38 Información del FIMT 39 Conclusiones 41
Discusión 42 Referencias 45 Anexo I – Parámetros de los ítems 49 Anexo II – Módulos del FIMT 50

- 1 -
Abstract
The aim of this study is optimize the use of the fluid intelligente multistage test (FIMT)
items assembling a computerized multistage test, maximizing the test information for
people with high intelligence levels. The FIMT item bank is a pool of constructed
response progressive matrices items with strong constraints due to their isomorphic
character. First, an operative item bank was made, studying its psychometric properties,
such as the reliability and the validity sources, and testing the item constraints via DIF.
Then, two IRT models (polytomic and dichotomic) were tested with both empirical and
simulation studies. Finally, two multistage structures were built using automatic test
assembly and tested in order to determine the final form of the FIMT. Results show that
FIMT is valid, innovative and reliable test, ready to use in selection process contexts.
Resumen
En este trabajo se trata de optimizar al máximo los ítems de matrices de respuesta
construida de un banco inicial de ítems para construir con ellos el test multietapa de
inteligencia fluida (FIMT), un test multietapa informatizado lo más informativo posible
para los niveles altos de inteligencia. Para ello se construyó primero un banco de ítems
operativo y se estudiaron sus propiedades. En segundo lugar se estudió qué modelo de
la teoría de respuesta al ítem era más adecuado para puntuar a las personas a través de
estudios tanto empíricos como de simulación. Finalmente se probaron dos estructuras
multietapa, construidas mediante el ensamblaje automático de test, para decidir qué
forma debía presentar el FIMT, dando como resultado un test novedoso, preciso y
válido de inteligencia fluida, listo para administrarse en contextos de selección de
personal.

- 2 -
Introducción
El factor g o la capacidad cognitiva general se puede definir como la capacidad
que permite la resolución de problemas correctamente, la toma de decisiones rápidas y
correctas o la aplicación del razonamiento abstracto y los conocimientos adquiridos en
nuevas situaciones (Carroll, 1993). Se trata, en definitiva, de la capacidad de una
persona para aprender de forma rápida una tarea, habilidad o destreza, bajo condiciones
óptimas de instrucción. Es por ello unos de los mejores predictores del desempeño
laboral a nivel global (Schmidt y Hunter, 2004) y una de las capacidades más evaluadas
en los contextos de selección de personal a nivel europeo (Salgado, Anderson, Moscoso,
Bertua y de Fruyt, 2003). El Test Multietapa de Inteligencia Fluida (FIMT) es un test
informatizado de matrices progresivas de respuesta construida que mide uno de los
componentes centrales de este factor general de la inteligencia humana a través de una
estructura multietapa, un formato que aúna las mejores cualidades de una evaluación
adaptativa y de un control robusto tanto de los elementos presentados en el test como de
sus propiedades (Hendrickson, 2007).
Inteligencia Fluida
De acuerdo a las teorías más clásicas de la inteligencia, el factor general está
compuesto por la inteligencia fluida y la inteligencia cristalizada (Cattell, 1963; Horn,
1986). La inteligencia fluida es aquella capacidad que permite la resolución de
problemas que requieren el manejo de información novedosa que no depende de una
base explícita de conocimientos declarativos adquiridos, yendo más allá de la
información dada para percibir lo que no es inmediatamente obvio; formando
representaciones –no necesariamente verbales- que faciliten el manejo de problemas
complejos que involucren variables mutuamente dependientes (Raven, Raven y Court,
1998). La inteligencia cristalizada, en cambio, es aquella más vinculada a los aspectos
culturales y a los conocimientos adquiridos a través de la educación y la experiencia.
Si bien son muchas las pruebas y tareas que se utilizan para evaluar la
inteligencia fluida en los contextos de selección, las pruebas de analogías geométricas
(como las matrices progresivas) suponen una de las tareas centrales en la evaluación de
este constructo (Marshalek, Lohman y Snow, 1983; Snow, Kyllonen y Marshalek,
1984). Las matrices progresivas son problemas muy demandantes que requieren el
empleo de razonamiento abstracto, razonamiento deductivo e inducción de relaciones

- 3 -
(Carpenter, Just y Shell, 1990), por lo que resultan ideales para medir la inteligencia
fluida de forma rápida y precisa (Raven, Raven y Court 1998). Normalmente los ítems
de estas pruebas constan de una matriz de 3 × 3 casillas en la que falta la esquina
inferior derecha, y es la persona evaluada quien ha de deducir cuál de es la respuesta
correcta entre una serie de alternativas.
Según Primi (2001), cuando una persona se enfrenta a problemas de estas
características pasa por tres etapas fundamentales. En primer lugar sería necesario
hacerse una representación mental de las propiedades del problema, analizando
detenidamente qué reglas y atributos están presentes en el mismo. En segundo lugar hay
que reconocer el paralelismo –por analogía- entre estas reglas y la nueva situación para,
finalmente, llegar a la tercera etapa: la aplicación adecuada de las reglas para crear una
nueva solución que encaje con la casilla vacía de la matriz. Lo habitual en este tipo de
ítems es presentar la respuesta correcta junto a una serie de alternativas debajo de la
matriz, de modo que la tercera etapa incluye además la identificación de la solución
correcta entre un conjunto de distractores.
En los contextos de selección es habitual que se presenten las pruebas de
matrices progresivas junto a otro tipo de test que evalúan competencias más específicas
de la capacidad cognitiva general, con las que suelen estar fuertemente relacionadas
(Salgado y Peiro, 2008). El razonamiento abstracto, numérico y verbal son algunas de
las medidas clásicas que más estrechamente se relacionan con las pruebas de matrices
(Colom, Escorial, Shih y Privado 2007). Asimismo, también es frecuente encontrar
relaciones de menor intensidad entre los test de matrices progresivas y otras pruebas
más vinculadas a la inteligencia cristalizada como los test de comprensión verbal o las
pruebas de vocabulario (Colom, Abad, Quiroga, Shih y Flores-Mendoza, 2008).
En España, la capacidad cognitiva general no sólo es una de las variables más
evaluadas en los procesos de selección, sino que es de hecho el mejor predictor del
rendimiento laboral de los empleados (Salgado y Moscoso, 2008). El contexto laboral
actual exige a los trabajadores el aprendizaje de nuevas destrezas y la adquisición de
nuevos conocimientos a medida que evolucionan las nuevas tecnologías o las demandas
del mercado. En un entorno laboral tan flexible y en cambio constante, la capacidad
cognitiva general es una variable importante que conviene tener presente a la hora de
seleccionar a los mejores candidatos para un puesto de trabajo determinado.
Asimismo, dada la complejidad que pueden alcanzar los test de matrices
progresivas y la cantidad de información nueva que se maneja y que ha de tenerse

- 4 -
presente durante la resolución de estos problemas, no es sorprendente que distintos
estudios hayan puesto de manifiesto la estrecha relación entre la inteligencia fluida y la
memoria operativa (Ackerman, Beier, y Boyle, 2005; Colom, Flores-Mendoza et al.,
2005; Conway et al., 2002; Kane et al., 2004). Desde que Kyllonen y Christal (1990)
encontraran que el rendimiento en las tareas de memoria operativa o de trabajo estaba
fuertemente asociado con el rendimiento de las pruebas de inteligencia fluida (llegando
incluso a afirmar que las diferencias en la capacidad de razonamiento eran poco más
que la capacidad de memoria operativa), la relación entre ambos constructos ha sido
estudiada en profundidad. Sin embargo, Colom, et al. (2008) encontraron que las
relaciones entre el factor general de inteligencia y la memoria de trabajo desaparecen
cuando se tienen presentes otras variables en el modelo como la memoria a corto plazo,
la velocidad de procesamiento, el control atencional o el funcionamiento ejecutivo (la
capacidad de actualizar la información procesada).
El control atencional, entendido como la capacidad de mantener activas
representaciones mentales en presencia de distractores o fuentes de interferencia, es otra
de las variables tradicionalmente relacionadas con la inteligencia fluida (Engle, Kane y
Tuholski, 1999). No obstante, estudios recientes ponen de manifiesto que el control
atencional podría tratarse de un mediador entre la inteligencia fluida y la memoria de
trabajo (Unsworth, Fukuda, Awh y Vogel, 2014; Unsword, Spillers y Brewer, 2009).
Las relaciones entre la inteligencia fluida y estas otras variables son relevantes
de cara a la construcción de nuevas herramientas psicométricas como el FIMT, pues
suponen una fuerte evidencia de validez (véase Hambleton, Sireci y Zumbo, 2013; o en
castellano, Abad, Olea, Ponsoda y García, 2010).
En definitiva, las pruebas de matrices progresivas suponen un buen indicador de
la capacidad cognitiva general en los contextos de selección; más aún cuando se
combina con otro tipo de pruebas que evalúen capacidades más específicas relacionadas
con las funciones del puesto que se desea cubrir. Además, dada la estrecha relación
entre esta variable y el rendimiento laboral, es interesante contar durante el proceso
selectivo con herramientas psicológicas capaces de medir con precisión y de forma
adaptativa ese factor general de inteligencia.
Test Multietapa
Uno de los aspectos más novedosos que incorpora el FIMT es el modo en que
los ítems son presentados: a través de una estructura multietapa. Los test multietapa se

- 5 -
caracterizan por presentar conjuntos de ítems preconstruidos de forma adaptativa
(Hendrickson, 2007; Luecht y Sireci, 2011). El evaluado pasa así por distintos
conjuntos de ítems o módulos en función de su rendimiento en los anteriores, de una
manera muy similar a como se realizaría en un test adaptativo informatizado (TAI). No
obstante, a diferencia de los TAI, en un test multietapa se toman como unidad los
módulos en lugar de los ítems. La adaptación no tendría lugar por tanto entre ítems sino
entre módulos distribuidos en distintas etapas.
De este modo es posible aplicar módulos especialmente adecuados para personas
de distinto nivel de capacidad, de manera que el conjunto de ítems con una dificultad
más alta sea administrado en una nueva etapa a quienes hayan tenido un mayor
rendimiento en el módulo de la etapa anterior. Asimismo, los ítems de dificultad
moderada se aplicarían a aquellos evaluados con un rendimiento intermedio, y los ítems
de menor dificultad a los evaluados con un peor rendimiento en la etapa anterior.
Figura 1. Ejemplo del diseño de un test multietapa.
La figura 1 muestra un ejemplo de lo que sería un test multietapa de tres etapas.
Todos los evaluados tendrían que realizar un primer conjunto de ítems, denominado test
de ruta (módulo 1) en la primera etapa, y en función del resultado obtenido por cada
uno, pasarían a realizar un módulo de mayor o menor dificultad en la segunda etapa
(módulos 2, 3 o 4). Finalmente, el módulo administrado en la tercera etapa (módulos 5,

- 6 -
6 ó 7) dependerá a su vez del rendimiento de cada evaluado en la etapa anterior. Dado
que este test consta de tres etapas con un módulo en la primera y tres en la segunda y en
la tercera, se habla de un test multietapa 1-3-3 (Luecht y Sireci, 2011).
El hecho de que dos personas lleguen al mismo módulo de la tercera etapa no
implica necesariamente que hayan respondido al mismo test. Siguiendo el ejemplo
anterior, al módulo 5 llegarían aquellos evaluados cuyo rendimiento fuese intermedio en
el test de ruta y alto en el módulo 3 de la segunda etapa. Pero también podrían llegar al
módulo 5 aquellas personas con un rendimiento alto en el test de ruta y un rendimiento
alto en el módulo 2 de la segunda etapa. Por lo tanto es posible concatenar diferentes
módulos a través de cada etapa, estableciendo distintos recorridos o trayectorias dentro
de un mismo test multietapa.
A medida que se aumenta el número de etapas y de módulos por etapa aumenta
también la complejidad de la estructura multietapa del test, haciéndolo a su vez más
adaptativo para los evaluados (cuantos más módulos y etapas incorpore el test más
probable será que se adapte al nivel de quien lo realiza). No obstante, es necesario
encontrar un equilibrio entre la complejidad de la estructura y la adaptabilidad del test,
pues añadir muchas etapas puede dificultar seriamente la construcción del test sin
suponer prácticamente ningún beneficio a la precisión del mismo (Luecht y Nungester,
1998; Luecht, Nungester y Hadidi, 1996). Algo parecido sucede al añadir más módulos
por etapa, ya que llega un momento en el que tener más módulos no aporta gran cosa a
la estructura del test (Jodoin, Zenisky, y Hambleton, 2006; Wang, Fluegge, y Luecht,
2012). De hecho, en condiciones óptimas (con un banco de ítems elevado con el que
consstruir el test) parece que las estructuras sencillas (dos módulos por etapa) funcionan
igual de bien que estructuras más complicadas con el mismo número de etapas (Wang et
al., 2012). Por su parte, Armstrong et al. (2004) recomiendan no incorporar más de
cuatro módulos por etapa.
La forma más habitual de construir un test multietapa es a través del ensamblaje
automático de test (EAT) en conjunción con los modelos de la Teoría de Respuesta al
Ítem (TRI; Diao y Van der Linden, 2011; Van der Linden 2005; Melican et al., 2010).
El EAT consiste principalmente en convertir la construcción del test en un problema de
optimización binaria, de manera que añadiendo diferentes especificaciones (como el
contenido de los ítems, la longitud del test o la dificultad de un módulo) y fijando un
objetivo (normalmente maximizar la precisión del test) se llega a una solución óptima.
Y esa solución no es otra que los ítems que deben conformar los módulos de cada etapa

- 7 -
del test. De este modo es posible conocer las propiedades del test de antemano, sin
necesidad de administrarlo directamente con el formato multietapa.
El empleo de los modelos de TRI aporta además algunas ventajas adicionales al
EAT. En primer lugar, si se conocen los parámetros de los ítems se puede calcular la
precisión o información que proporciona cada ítem para cada nivel de rasgo θ
(inteligencia fluida, en el caso del FIMT). Y si se conoce la información de cada ítem
para el rasgo latente θ es posible tratar de maximizar la información final del test
mediante el EAT, imponiendo además el cumplimiento de otras especificaciones que
puedan resultar del interés, como el número de módulos por etapa o la dificultad de cada
uno de ellos.
Además, la TRI permite realizar la transición del módulo de una etapa al módulo
de la siguiente basándose en la estimación temporal del nivel de rasgo de los evaluados
(̂ ), de un modo muy similar a cómo se realiza en los TAI (Dallas, 2014). Al finalizar
cada módulo se hace una estimación del nivel de rasgo de cada evaluado teniendo en
cuenta las respuestas a los ítems presentados hasta ese momento (del módulo actual y de
los anteriores), y en función de ese nivel de rasgo se asigna un nuevo módulo..
En relación a los TAI, Hendrickson (2007) describe algunas de las ventajas
potenciales de los test multietapa. En primer lugar los test multietapa permiten un
mayor control sobre la exposición de los ítems atendiendo a criterios no estadísticos,
como el contenido, el orden de presentación o la estructura de los mismos. Asimismo, al
tratar a los módulos o conjuntos de ítems como una unidad es posible asegurar más
fácilmente el cumplimiento de algunas propiedades deseables en cada una de las partes
del test (como la unidimensionalidad o la independencia local entre los ítems). Además,
como el diseño de los módulos se hace previamente a la administración de los ítems, es
posible conocer –y revisar- las propiedades de cada uno de los test posibles, así como la
estructura de cada uno de ellos. Finalmente, los test multietapa simplifican tanto el
algoritmo de presentación de los ítems como la estimación de las puntuaciones finales
de los evaluados en el test.
Sin embargo, los test multietapa también tienen algunas limitaciones frente a los
TAI. En primer lugar, suelen requerir una mayor cantidad de ítems para conseguir
niveles de precisión similares a los obtenidos en los TAI. En segundo lugar, existe el
riesgo en los test multietapa de tan sólo dos etapas de que una mala clasificación en el

- 8 -
test de ruta comprometa la puntuación final de los evaluados. Por último, resulta difícil
realizar cambios puntuales en un ítem sin afectar al resto del módulo.
Objetivos
El propósito general de este trabajo es, por tanto, establecer un procedimiento
multietápico para optimizar la información del FIMT, prestando especial atención a los
niveles altos del rasgo latente θ, a partir de un banco de ítems inicial reducido y con
fuertes restricciones. El FIMT es una prueba que pretende aplicarse por vía telemática
en procesos de selección de personal y en contextos de evaluación psicológica en los
que el objetivo sea medir con precisión niveles altos de inteligencia. Para optimizar la
información del test será necesario: establecer un banco operativo de ítems de la mayor
longitud posible, estudiando qué ítems lo integrarán; decidir qué modelo psicométrico
(dicotómico o politómico) es más apropiado para puntuar a los sujetos; y estudiar qué
estructura multietapa es más conveniente para los ítems del FIMT. Además, para
conseguir una mayor precisión en la estimación del nivel de rasgo de los evaluados con
mejor rendimiento, se prolongará la longitud de los recorridos de mayor dificultad del
multietapa. Se obtendría así una mejor precisión para las personas con mayores
puntuaciones en las primeras etapas del test, a quienes responder a unos cuantos ítems
más no les debería de suponer un gran esfuerzo.
En concreto, este trabajo pretende dar respuesta a las siguientes preguntas:
1. ¿Cuál es la precisión del banco inicial y qué evidencias de validez se obtienen
respecto a la medición de la inteligencia fluida?
2. ¿Cuáles son las restricciones de presentación de los ítems y qué ítems pueden
formar parte del banco operativo definitivo?
3. ¿Cuál es el mejor modelo de la TRI para puntuar a los sujetos?
4. ¿Cuál es la estructura multietapa más adecuada para optimizar el objetivo
general?
Para hallar las respuestas a estas cuestiones se llevaron a cabo diversos estudios
(tanto empíricos como de simulación). El primer estudio empírico aborda precisamente
las dos primeras preguntas. En él se detalla el diseño y la construcción del test, el modo
en el que fue aplicado a través de subtests, y las propiedades psicométricas del banco de
ítems (precisión, evidencias de validez y estudio DIF entre las distintas versiones de un
mismo ítem). El segundo estudio da cuenta de la tercera pregunta mediante

- 9 -
procedimientos empíricos y de simulación, poniendo a prueba el ajuste de tanto
modelos polítomicos como dicotómicos con distintas restricciones. Una vez definido el
banco operativo y un modelo psicométrico a aplicar, se llevó a cabo un tercer estudio en
el que se pusieron a prueba diferentes estructuras multietapa con objeto de dar respuesta
a la última pregunta.
Estudio 1
El propósito de este primer estudio es conocer las propiedades estadísticas y
psicométricas de la totalidad del banco de ítems de respuesta construida inicial, así
como poner a prueba el carácter isomorfo de los ítems originales y sus clones, con
objeto de establecer un banco de ítems operativo sobre el que poder realizar estudios
posteriores sobre los que construir el FIMT. Para ello se detalla a continuación el
procedimiento seguido para administrar, diseñar y validar los ítems del banco inicial.
Método
Participantes
El banco inicial de ítems fue administrado a un total de 724 estudiantes
universitarios del segundo curso de la licenciatura de Psicología, de edades
comprendidas entre los 18 y los 30 años (M = 19.51, SD = 1.69) a través de seis subtests
distintos. Los evaluados fueron seleccionados mediante asignación aleatoria atendiendo
principalmente a la disponibilidad de los mismos. Además, del total de la muestra, 169
estudiantes accedieron a realizar otras pruebas de capacidad cognitiva (tanto de
inteligencia fluida como de inteligencia cristalizada), 271 accedieron a pasar por
diferentes pruebas de memoria operativa y 145 se mostraron conformes con realizar
distintas tareas de control atencional.
Materiales
Banco de ítems inicial. Los ítems del banco inicial fueron desarrollados por Pei-
Chun Shin, Vicente Ponsoda y Javier Revuelta, expertos en la evaluación psicológica de
la inteligencia y en psicometría de la Universidad Autónoma de Madrid, basándose en
la taxonomía de reglas propuesta por Carpenter et al. (1990) para ítems de matrices
progresivas. Por cada ítem original desarrollado, el banco inicial incorpora además dos

- 10 -
ítems isomorfos o clones en los que cambia alguno de los siguientes elementos del ítem
original: la forma de las figuras de los ítems, el color o la trama de las formas, o ambas.
Sin embargo, las reglas que se siguen para resolver el ítem original son exactamente las
mismas que las que han de seguirse para llegar a la solución de los clones. De este
modo cada ítem tiene tres versiones: el ítem original, una primer versión alternativa en
la que cambia alguna característica (primer clon) y una segunda versión alternativa en
la que cambia una segunda característica (segundo clon).
Además, los ítems del banco inicial son todos de respuesta construida, de
manera que es el propio evaluado quien ha de dibujar la respuesta utilizando una paleta
de herramientas con distintas tramas y colores para las celdillas que incorpora el propio
test.
Figura 2. Ítem de Ejemplo.
En la figura 2 se muestra uno de los ítems de ejemplo de la aplicación del banco
inicial. Como se observa, la casilla inferior derecha (compuesta a su vez por una matriz
de 4 × 4 celdillas) está en blanco. La persona que trate de resolver el ítem tendría
primero que analizar el problema y averiguar cuáles son las reglas que sigue para
aplicarlas a la nueva situación (la casilla en blanco) y concluir dibujando la que crea que
es la respuesta correcta. Para ello cada evaluado cuenta con una paleta de herramientas
dotada de una serie de tramas y colores bien diferenciados (a la derecha del ítem) que

- 11 -
puede colocar clicando en cada celdilla para dibujar la respuesta que considere
pertinente. El formato de respuesta construida aplicado a este tipo de ítems es un
procedimiento novedoso que permite extraer más información sobre la aproximación
que hace cada persona al problema que a través de un formato de elección múltiple.
El banco inicial cuenta con un total de 54 ítems (18 originales y 36 clones, dos
por cada ítem original). La puntuación que se puede obtener en cada ítem está
comprendida entre 0 y 16, o lo que es lo mismo, el número de celdillas de la matriz 4 ×
4 que han sido rellenadas correctamente. Con objeto de simplificar las puntuaciones de
cada ítem, se codificaron las respuestas de acuerdo a la siguiente clasificación:
− 1: Haber rellenado correctamente de 0 a 7 celdillas del ítem
− 2: Haber rellenado correctamente de 8 a 11 celdillas del ítem
− 3: Haber rellenado correctamente de 12 a 13 celdillas del ítem
− 4: Haber rellenado correctamente de 14 a 15 celdillas del ítem
− 5: Haber rellenado correctamente las 16 celdillas del ítem
Así, los evaluados que dibujen una respuesta más próxima a la correcta mayor
puntuación obtendrán en el ítem, permitiendo así un tratamiento politómico. Se optó
finalmente por esta categorización (que establece más puntos de corte según la respuesta
dibujada se aproxima a la respuesta correcta) ya que la mayor parte de las personas que
no respondían correctamente un ítem, tendían a tener bien rellenadas un gran número de
celdillas del mismo. De este modo cada ítem discrimina mejor entre aquellos evaluados
que han estado más próximos a la respuesta correcta. La puntuación directa de cada
participante sería, por tanto, el sumatorio de su puntuación en cada ítem presentado (de
1 a 5).
Salvo que se especifique lo contrario (como al utilizarse modelos psicométricos
dicotómicos), los ítems del banco de ítems inicial en este trabajo han recibido el
tratamiento politómico descrito con anterioridad.
Test de Matrices Progresivas de Raven. El Raven es una medida de
razonamiento abstracto (Raven, Raven y Court, 1998) compuesta por 36 ítems en orden
ascendente. Al igual que el FIMT, cada ítem consiste en una matriz 3 × 3 a la que le
falta la casilla inferior derecha. La tarea consiste en averiguar cuál es la respuesta
correcta de un conjunto de alternativas dado deduciendo los patrones que sigue
cada ítem. La puntuación de cada participante en el test es el número de ítems
acertados.

- 12 -
Test de Aptitudes Mentales Primarias (PMA). Se incluyeron dos pruebas de la
batería de aptitudes mentales primarias (Thurstone, 1938): la escala R, una tarea de
razonamiento lógico de 30 ítems en la que el evaluado debe deducir cuál es el siguiente
elemento de una serie de letras (como por ejemplo [a-b-a-b-a-b-a-b]) de una lista de
alternativas (las letras [a-b-c-d-e-f]) de las que sólo una es correcta; y la escala V, una
tarea de razonamiento verbal de 50 ítems en la que se presenta una palabra cuyo
significado debe comprarse con el de una lista de cuatro alternativas de las que sólo una
es correcta (por ejemplo, Robusto: delgado-gordo-corto-rudo). En ambas escalas la
puntuación de los participantes es el número de respuestas correctas obtenido.
Test de Aptitudes Diferenciales (DAT-5). Se emplearon las escalas de
razonamiento abstracto (DAT-AR), numérico (DAT-NR) y verbal (DAT-VR) del test
de aptitudes diferenciales (Bennett, Seashore, y Wesman, 1990). DAT-AR es un test de
series basado en figuras abstractas de 40 ítems de longitud. Cada ítem incluye cuatro
figuras que siguen una regla, y el evaluado tiene que elegir entre una figura que siga la
misma regla entre una lista de cinco alternativas. DAT-NR es una escala 40 ítems en la
que se plantea un problema matemático y ha de escogerse una respuesta de entre cinco
alternativas de la que sólo una es correcta (por ejemplo: 5 2 58P ; (a) 3, (b) 4, (c) 7,
(d) 9, (e) ninguna de las anteriores). Por su parte, DAT-VR es una test de razonamiento
verbal de 40 ítems consistentes en plantear un enunciado como una analogía que debe
ser completada de entre una lista de cinco alternativas de la que sólo una es correcta.
Cada alternativa tiene un par de palabras que encajan en los huecos de cada enunciado
(por ejemplo: (…) es al agua como comer es a (…); (a) viajar-conducir, (b) pie-
enemigo, (c) beber-pan, (d) chica-industria, (e) beber-enemigo). La puntuación total de
cada participante en cada escala es el sumatorio de las respuestas correctas.
Medidas de Memoria Operativa
Reading Span. Esta tarea consiste en confirmar si ciertas frases, presentadas en
una secuencia, tienen o no tienen sentido. Las palabras fueron tomadas la adaptación al
castellano de la prueba de Daneman y Carpenter (1980) (Elosúa, Gutiérrez, García-
Madruga, Luque, y Gárate, 1996). Cada ensayo incluye una frase que evaluar y una letra
mayúscula que recordar. Tan pronto como se evalúe la frase (si tiene o no sentido) se
presenta una nueva frase y una nueva la letra mayúscula. Al final de cada bloque
experimental los evaluados deben recordar las letras mayúsculas que han aparecido en
el orden correcto. La puntuación de cada participante es el número de series de letras
bien recordadas.

- 13 -
Computation Span. En esta tarea, desarrollada originalmente por Ackerman et
al. (2002), los participantes deben recordar una serie de letras mayúsculas mientras se
verifica si una ecuación matemática es o no correcta. Primero se presenta una ecuación
durante seis segundos (como: 10/2 + 4 = 8) y el evaluado debe decidir si la ecuación es
o no correcta. A continuación aparece una letra mayúscula durante un segundo y medio
que se debe recordar. Al final de cada bloque han de introducirse en el orden correcto
las letras presentadas entre cada ensayo. La puntuación de los participantes es el número
de veces que introducen bien la secuencia de letras.
.Dot Matrix. Esta tarea fue diseñada sobre la base de los trabajos de Miyake et
al. (2001). Los participantes resuelven primero una ecuación de primer orden en menos
de cuatro segundos y medio. A continuación aparece una matriz 5 × 5 con un punto en
su interior que debe memorizarse durante un segundo y medio. Después de cada par de
ecuaciones y matrices con punto aparece una matriz vacía en la que los participantes
deben colocar todos los puntos que recuerden de los ensayos anteriores. La puntuación
total de cada evaluado es el número de veces que se colocan bien todos los puntos en la
matriz vacía.
Medidas de Control Atencional
Flanker Task. Esta tarea se basa en los trabajos previos de Eriksen y Eriksen
(1974) e incluye tres tareas bien diferenciadas: numérica, verbal y espacial. En la tarea
numérica se presenta una serie de tres cifras y ha de decidirse, lo más rápido posible, si
la cifra central es par o impar. Las cifras que rodean al dígito central pueden ser
compatibles o incompatibles, es decir, todas del mismo tipo (pares o impares) o las dos
cifras que rodean a la central diferentes (si la central es par, las que las otras impares, y
viceversa). La tarea verbal, por su parte, es se plantea de la misma manera que la
numérica con la excepción de que aparecen letras en lugar de números y la decisión que
los participantes deben tomar es si son letras consonantes o vocales. Finalmente, la tarea
espacial requiere que el participante diga si una flecha horizontal apunta hacia la
izquierda o la derecha de un punto que aparece en la pantalla. La flecha, que de por sí ya
apunta hacia la izquierda o hacia la derecha) puede aparecer a ambos lados del punto.
En las tres pruebas la puntuación de cada evaluado es la suma del número de aciertos.
Procedimiento
Para la administración del banco de ítems inicial se empleó un diseño de anclaje.
Este tipo de diseños consisten en la presentación de todo el banco de ítems utilizando

- 14 -
distintas formas del test o subtests en las que se mantiene constante un determinado
número de ítems que funciona como punto de anclaje. De esta manera es posible
calibrar todo el banco de ítems sin tener que obligar a los evaluados a responder a todos
los ítems. El diseño de anclaje resultó especialmente propicio para esta primera
administración del test ya que precisamente permite tener en cuenta el carácter isomorfo
de los ítems. Tal y como se muestra en la tabla 1, los ítems fueron presentados a los
evaluados en seis subtests diferentes en las que tan sólo se incluye una única versión de
cada ítem.
Tabla 1.
Diseño de anclaje del FIMT.
Paralelamente se administró también a parte de la muestra el resto de las
pruebas. Se pasaron todas las pruebas durante un intervalo de dos horas, interrumpidas
por un breve descanso de diez minutos tras la primera hora.
Análisis de Datos
Para llevar a cabo el primer objetivo (conocer las propiedades psicométricas del
banco de ítems) se obtuvieron los estadísticos descriptivos de los ítems y se calcularon
los estadísticos de consistencia interna para cada una de los seis subtests en los que se
Subtest A Subtest B Subtest C Subtest D Subtest E Subtest F
Ítem 1 Original Clon 1 Clon 1 Clon 2 Clon 2 Original
Ítem 2 Original Clon 1 Clon 1 Clon 2 Clon 2 Original
Ítem 3 Original Clon 1 Clon 1 Clon 2 Clon 2 Original
Ítem 4 Original Clon 1 Clon 1 Clon 2 Clon 2 Original
Ítem 5 Original Clon 1 Clon 1 Clon 2 Clon 2 Original
Ítem 6 Original Clon 1 Clon 1 Clon 2 Clon 2 Original
Ítem 14 Original Clon 1 Clon 1 Clon 2 Clon 2 Original
Ítem 15 Original Clon 1 Clon 1 Clon 2 Clon 2 Original
Ítem 17 Original Clon 1 Clon 1 Clon 2 Clon 2 Original
Ítem 7 Original Original Clon 1 Clon 1 Clon 2 Clon 2
Ítem 8 Original Original Clon 1 Clon 1 Clon 2 Clon 2
Ítem 9 Original Original Clon 1 Clon 1 Clon 2 Clon 2
Ítem 11 Original Original Clon 1 Clon 1 Clon 2 Clon 2
Ítem 16 Original Original Clon 1 Clon 1 Clon 2 Clon 2
Ítem 19 Original Original Clon 1 Clon 1 Clon 2 Clon 2
Ítem 10 Original Original Clon 1 Clon 1 Clon 2 Clon 2
Ítem 12 Original Original Clon 1 Clon 1 Clon 2 Clon 2
Ítem 13 Original Original Clon 1 Clon 1 Clon 2 Clon 2
Ítem 18 Original Original Clon 1 Clon 1 Clon 2 Clon 2

- 15 -
administraron los ítems del banco inicial. Además se pusieron en relación las
puntuaciones totales de los sujetos en cada subtest con el resto de variables. Los ítems
del banco inicial se puntuaron para estos análisis en categorías ordenadas de 1 a 5, tal y
como se describe en los materiales.
Para cumplir con el segundo objetivo (obtener un banco de ítems operativo) fue
necesario poner a prueba las restricciones de administración de los ítems. Para
comprobar si dos ítems que siguen las mismas reglas están o no fuertemente
relacionados lo ideal sería realizar contrastes sobre la dependencia local de esos dos
ítems. Sin embargo, dado que en los subtests no se incluyen dos versiones de un mismo
ítem, es imposible realizar los análisis de dependencia local habituales. Así que para
poner a prueba el carácter isomorfo de los ítems, es decir, para contrastar si dos ítems
que siguen las mismas reglas no pueden presentarse juntos, se llevó a cabo un análisis
para detectar el funcionamiento diferencial de los ítems (DIF).
El DIF consiste en la aplicación de un conjunto de técnicas estadísticas que
permiten detectar si dos muestras de distintas poblaciones responden de manera
diferente a un mismo ítem. El objetivo habitual de estos análisis es contrastar si un
mismo ítem funciona o no de la misma manera entre dos grupos bien diferenciados
(como por ejemplo hombres y mujeres, o habitantes de distintos países). No obstante, en
el presente estudio se cuenta con dos muestras provenientes de la misma población
(estudiantes universitarios de Psicología) y lo que se busca es detectar si los ítems
originales funcionan de diferente manera al compararlos con sus clones. Es decir, el
objetivo no sería buscar diferencias de funcionamiento entre las muestras, sino entre los
propios ítems. De este modo, si se detecta DIF entre dos versiones de un mismo ítem, al
tratarse de dos muestras de la misma población, se asumiría que las diferencias de
funcionamiento se deben a los propios ítems, por lo que no deberían tratarse como
clones. En cambio, si no se encuentra DIF entre dos versiones de un mismo ítem, podría
mantenerse la hipótesis de que los ítems sí que son realmente isomorfos.
Con objeto de aplicar la mayor cantidad posible de métodos de detección de
DIF, los análisis realizados en esta segunda parte del estudio se llevaron a cabo
puntuando los ítems de manera dicotómica (0: error; 1: acierto), ya que las técnicas
disponibles de DIF para ítems politómicos son aún escasas. Así, si varios métodos
detectan que un ítem funciona de manera diferencial, podría asumirse que en realidad no
se trata de un ítem isomorfo.

- 16 -
Los métodos de detección de DIF no basados en la TRI fueron empleados en
este estudio fueron: Mantel-Haenszel (MH; Mantel y Haenszel, 1959, Holland &
Thayer, 1988), el conocido como estandarización (Dorans y Kulick, 1986), Breslow-
Day (BD; Breslow y Day, 1980) y el logístico (Swaminathan y Rogers, 1990). Los
métodos MH y la estandarización consisten en la comparación de las frecuencias de
aciertos obtenidas con las frecuencias de aciertos esperadas –si bien su formulación y la
distribución del estadístico de cada prueba es diferente-, y ambos métodos son
especialmente indicados para la detección de DIF uniforme. El método BD (que
compara las frecuencias de acierto esperadas con las obtenidas siguiendo otro
procedimiento), en cambio, funciona bastante bien para la detección de DIF no
uniforme. El método logístico funciona bien para ambos tipos de DIF y se basa en
modelar mediante regresión logística binaria cada ítem poniéndolo en relación con la
puntuación total obtenida, los grupos comparados y la interacción entre ambos. Así, si
el coeficiente de regresión asignado al grupo es significativo pero no la interacción se
trataría de un caso de DIF uniforme, mientras que si la interacción resultase significativa
se haría referencia a un caso de DIF no-uniforme.
Finalmente se aplicó un método de detección de DIF basado en la TRI que
funciona bastante bien para los casos tanto de DIF uniforme como no-uniforme: se trata
del método de Raju (1988, 1990). En esta técnica se compara la diferencia de las áreas
que las curvas características del ítem de cada grupo dejan debajo de sí.
Los criterios empleados para la detección de DIF en cada método fueron:
− MH: se considera DIF cuando el nivel de significación del estadístico MH sea
igual o inferior a α = 0.05.
− Estandarización: se considera DIF cuando el nivel de significación del
estadístico sea igual o inferior a α = 0.10.
− BD: se considera DIF cuando el nivel de significación del estadístico BD sea
igual o inferior a α = 0.05.
− Logístico: se considera DIF cuando el nivel de significación del coeficiente sea
igual o inferior a α = 0.05. Se emplearon los criterios de 2R de Nagelkerke de
Zumbo y Thomas (1997) para establecer el tipo de DIF.
− Raju: se considera DIF cuando el nivel de significación del estadístico Z
(obtenido entre la diferencia de las áreas que deja la CCI de cada grupo) sea
igual o inferior a α = 0.05.

- 17 -
En todos los métodos se utilizó el algoritmo de purificación hasta un máximo de
10 iteraciones.
Para poder llevar a cabo estos análisis se compararon los distintos subtest del
banco de ítems inicial. De este modo se realizan cuatro contrastes entre cada ítem y sus
clones mediante cinco métodos DIF diferentes (lo que da un total de veinte contrastes de
DIF al comparar las versiones de cada ítem entre sí). A su vez, cada ítem se compara
consigo mismo una vez por cada método DIF empleado (lo que da un total de cinco
contraste de DIF al comprar una versión de un ítem de un subtest con la misma versión
del ítem en otro subtest). Así, al comprar las diferentes versiones de un ítem de los
distintos subtests (original-clon1, original-clon2, clon1-clon2), lo que se obtiene es la
proporción de veces que se encuentra DIF en cada par de ítems comparados. Si se
compara esta proporción con la proporción de veces que se encuentra DIF al comparar
un ítem consigo mismo, es posible determinar si dos ítems funcionan de manera
diferencial dentro de la misma población.
Los análisis se llevaron a cabo utilizando el programa R statistics (R Core Team,
2014), utilizando los paquetes: psych (Revelle, 2015) para los análisis clásicos de
fiabilidad y difR (Magis, Beland y Raiche, 2013) para los análisis de funcionamiento
diferencial de los ítems.
Resultados
Análisis de los ítems
En general el banco posee ítems con diferentes niveles de dificultad (tabla 2),
con un buen número de ítems relativamente sencillos cuya media es cercana –o
ligeramente superior- al 4, por lo que la mayoría de los participantes han dado con la
respuesta correcta o han estado muy cerca de dibujarla correctamente, otro grupo de
ítems de dificultad intermedia (con medias en torno a 3) y un tercer conjunto de ítems
con mayor dificultad (con medias centradas alrededor de 2.5). Asimismo, la dispersión
de los ítems es buena (desviaciones típicas cercanas o superiores a 1), lo que indica que
hay heterogeneidad a la hora de responderlos.

- 18 -
Tabla 2.
Estadísticos descriptivos de los ítems
Ítem M SD Ítem M SD Ítem M SD
Original 1 4.29 1.4 Original 7 4 1 Clon1 13 2.73 1.63
Clon1 1 4.75 0.78 Clon1 7 3.68 1.03 Clon2 13 2.24 1.35
Clon2 1 4.64 0.92 Clon2 7 3.73 0.82 Original 13 3.55 1.27
Original 2 4.13 1.15 Original 8 3.28 1.37 Clon1 14 4.21 0.74
Clon1 2 4.39 1.05 Clon1 8 2.79 1.42 Clon2 14 4.2 0.77
Clon2 2 4.53 0.94 Clon2 8 2.76 1.44 Original 14 3.89 1.01
Original 3 4.65 0.92 Clon1 9 2.88 1.51 Clon1 15 4.58 0.75
Clon1 3 4.7 0.92 Clon2 9 3.39 1.59 Clon2 15 4.48 0.77
Clon2 3 4.67 0.89 Original 9 2.02 1.39 Original 15 4.6 0.75
Original 4 3.81 1.66 Clon1 10 2.62 1.17 Clon1 16 4.34 1.28
Clon1 4 3.92 1.64 Clon2 10 2.93 1.27 Clon2 16 4.14 1.37
Clon2 4 4.24 1.4 Original 10 3.39 1.2 Original 16 4.41 1.25
Original 5 4.13 1.34 Clon1 11 3.06 1.16 Clon1 17 3.5 1.44
Clon1 5 4.16 1.52 Clon2 11 3.07 1.19 Clon2 17 3.69 1.45
Clon2 5 3.72 1.6 Original 11 3.15 1.45 Original 17 3.29 1.29
Original 6 4.41 1.17 Clon1 12 3.48 0.76 Clon1 18 4.1 0.8
Clon1 6 3.84 1.16 Clon2 12 3.52 0.72 Clon2 18 3.96 0.85
Clon2 6 3.69 1.46 Original 12 3.85 1.26 Original 18 4.29 0.88
Fiabilidad
Una primera aproximación a la fiabilidad del total del banco de ítems inicial es a
través de las medidas clásicas de consistencia interna (tales como el α de Cronbach o el
coeficiente de las dos mitades de Guttman). Si bien es posible obtener indicadores de
precisión mucho más dinámicos al aplicar la TRI –que informan de lo fiable que es el
test para los diferentes niveles de capacidad de los evaluados-, estos primeros
indicadores clásicos ofrecen una perspectiva general de cómo ha funcionado el banco de
ítems en su conjunto.
Tabla 3.
Medidas de consistencia interna para cada forma del diseño.
α de Cronbach
Coeficiente de las
dos mitades
de Guttman
Subtest A .82 .83
Subtest B .79 .80
Subtest C .70 .71
Subtest D .72 .73
Subtest E .77 .77
Subtest F .82 .83

- 19 -
En la tabla 3 se aprecia que la consistencia interna de cada una de los seis
subtest administrados a los sujetos es relativamente alta (con valores que oscilan entre
.70 y .82), por lo que parece que la precisión alcanzada por el conjunto de los ítems es
adecuada.
Evidencias de validez
La principal evidencia de validez del banco de ítems inicial es su relación con
otras pruebas de inteligencia y de capacidades vinculadas a la misma. Dado que
paralelamente a los subtests del banco inicial se administraron otras pruebas de
inteligencia fluida, de inteligencia cristalizada, de memoria de trabajo y de control
atencional, es posible determinar en qué medida las puntuaciones de los subtests están
relacionadas con las puntuaciones en el resto de pruebas, obteniendo así evidencias de
validez convergente y discriminante. En la tabla 4 se muestran las correlaciones
obtenidas entre las puntuaciones directas del banco del FIMT y las otras pruebas y
tareas experimentales descritas en el método del presente estudio.
Tabla 4.
Correlaciones FIMT
FIMT
APM .47**
DAT5 – AR .52**
DAT 5 – NR .23**
DAT 5 – VR .39**
PMA – R .28**
PMA – V .12_
Reading span .29**
Computation span .30**
D matrix .42**
Control Atencional: Verbal -.11_
Control Atencional: Espacial -.27**
Control Atencional: Numérico .07_
Nota: **:
p < .001
Entre las pruebas de inteligencia, las puntuaciones de los subtests se relacionan
positiva y significativamente con la escala APM (Advanced Progressive Matrices) del
test del Raven (rxy = .47, t(165) = 6.88, p < .001), con las escalas de razonamiento
abstracto (rxy = .52, t(165) = 7.80, p < .001), de razonamiento verbal (rxy = .39, t(165) =
5.53, p < .001) y de razonamiento numérico (rxy = .23, t(165) = 3.03, p < .001) del

- 20 -
DAT5 y con el factor R (rxy = .28, t(165) = 3.80, p < .001) del PMA. Este último factor
evalúa las capacidades de razonamiento lógico dentro de este test. No obstante, no se
encontraron relaciones entre las puntuaciones en los susbtests y el factor V –que mide
comprensión verbal- del PMA (rxy = .12, t(165) = 1.53, p = .128). Las fuertes relaciones
del banco de ítems inicial con estas pruebas consolidadas dentro del ámbito de la
evaluación de la inteligencia, suponen una evidencia de validez convergente importante,
ya que las personas con altas puntuaciones en las diferentes formas del test tienden a
mostrar un buen desempeño en el resto de pruebas, en especial en aquellas más
vinculadas a la inteligencia fluida.
Asimismo, al poner en relación los resultados obtenidos en los subtests con las
medidas obtenidas en pruebas de memoria de trabajo, las correlaciones obtenidas son
algo más bajas, si bien significativas (rxy = .29, t(267) = 4.87, p < .001 en la tarea de
reading span; rxy = .30, t(267) = 5.18, p < .001 en la tarea de computation span; y rxy =
.41, t(267) = 7.62, p < .001 en la tarea dot matrix).
Finalmente, al relacionar las puntuaciones del banco de ítems inicial con las
pruebas de control atencional: o bien no se obtienen correlaciones significativas (rxy = -
.12, t(139) = -1.42, p = .158 en la tarea de capacidad atencional verbal; y rxy = -.15,
t(141) = -1.78, p = .077 en la tarea de control atencional numérica), o bien la relación es
negativa (rxy = -.27, t(142) = -3.33, p = .001 en la tarea de control atencional espacial).
Estos resultados suponen una evidencia de validez discriminante.
Funcionamiento diferencial de los ítems
Al comparar el funcionamiento de los ítems de un subtest con esos mismos ítems
en otro subtest, se obtiene la proporción de veces que se detecta DIF en el mismo ítem
entre dos muestras de la misma población (las tres primeras columnas de la tabla 5). En
general, la proporción de veces que los métodos empleados detectan DIF en un mismo
ítem es baja (M = 0.14, SD = 0.08), cercana a cero en casi todos los casos.
Tomando como referencia la media de estas proporciones se decidió que los
ítems ismorfos del banco inicial con una proporción media de DIF encontrado igual o
superior a 0.30 son susceptibles de funcionar diferencialmente en las dos muestras.
Nótese que 0.30 es justo el valor que está dos veces la desviación típica por encima de
la media de veces que se detecta DIF entre dos ítems idénticos.
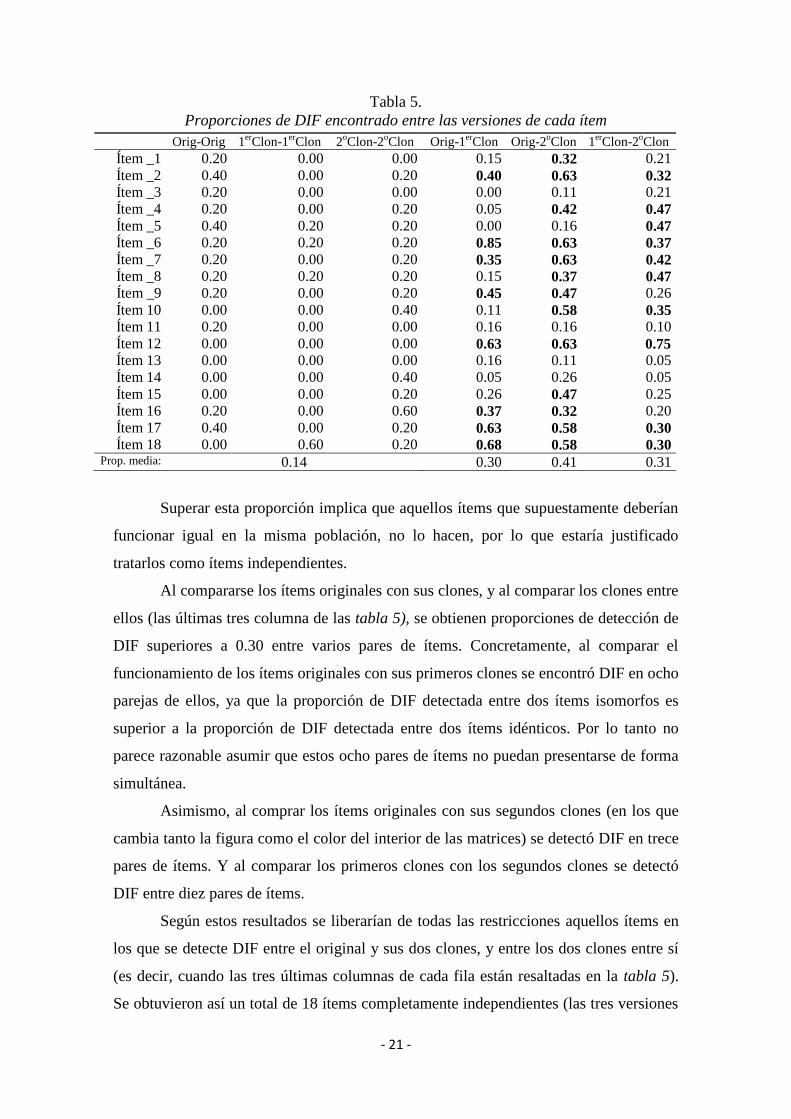
- 21 -
Tabla 5.
Proporciones de DIF encontrado entre las versiones de cada ítem
Orig-Orig 1
erClon-1
erClon 2
oClon-2
oClon Orig-1
erClon Orig-2
oClon 1
erClon-2
oClon
Ítem _1 0.20 0.00 0.00 0.15 0.32 0.21
Ítem _2 0.40 0.00 0.20 0.40 0.63 0.32
Ítem _3 0.20 0.00 0.00 0.00 0.11 0.21
Ítem _4 0.20 0.00 0.20 0.05 0.42 0.47
Ítem _5 0.40 0.20 0.20 0.00 0.16 0.47
Ítem _6 0.20 0.20 0.20 0.85 0.63 0.37
Ítem _7 0.20 0.00 0.20 0.35 0.63 0.42
Ítem _8 0.20 0.20 0.20 0.15 0.37 0.47
Ítem _9 0.20 0.00 0.20 0.45 0.47 0.26
Ítem 10 0.00 0.00 0.40 0.11 0.58 0.35
Ítem 11 0.20 0.00 0.00 0.16 0.16 0.10
Ítem 12 0.00 0.00 0.00 0.63 0.63 0.75
Ítem 13 0.00 0.00 0.00 0.16 0.11 0.05
Ítem 14 0.00 0.00 0.40 0.05 0.26 0.05
Ítem 15 0.00 0.00 0.20 0.26 0.47 0.25
Ítem 16 0.20 0.00 0.60 0.37 0.32 0.20
Ítem 17 0.40 0.00 0.20 0.63 0.58 0.30
Ítem 18 0.00 0.60 0.20 0.68 0.58 0.30 Prop. media: 0.14 0.30 0.41 0.31
Superar esta proporción implica que aquellos ítems que supuestamente deberían
funcionar igual en la misma población, no lo hacen, por lo que estaría justificado
tratarlos como ítems independientes.
Al compararse los ítems originales con sus clones, y al comparar los clones entre
ellos (las últimas tres columna de las tabla 5), se obtienen proporciones de detección de
DIF superiores a 0.30 entre varios pares de ítems. Concretamente, al comparar el
funcionamiento de los ítems originales con sus primeros clones se encontró DIF en ocho
parejas de ellos, ya que la proporción de DIF detectada entre dos ítems isomorfos es
superior a la proporción de DIF detectada entre dos ítems idénticos. Por lo tanto no
parece razonable asumir que estos ocho pares de ítems no puedan presentarse de forma
simultánea.
Asimismo, al comprar los ítems originales con sus segundos clones (en los que
cambia tanto la figura como el color del interior de las matrices) se detectó DIF en trece
pares de ítems. Y al comparar los primeros clones con los segundos clones se detectó
DIF entre diez pares de ítems.
Según estos resultados se liberarían de todas las restricciones aquellos ítems en
los que se detecte DIF entre el original y sus dos clones, y entre los dos clones entre sí
(es decir, cuando las tres últimas columnas de cada fila están resaltadas en la tabla 5).
Se obtuvieron así un total de 18 ítems completamente independientes (las tres versiones

- 22 -
de los ítems 2, 6, 7, 12, 17 y 18), 24 ítems parcialmente liberados (que conservan alguna
restricción) y 12 ítems isomorfos, que conservan las restricciones iniciales.
Conclusiones
De este primer estudio se derivan dos implicaciones importantes. La primera de
ellas pone de manifiesto que las propiedades psicométricas del banco de ítems inicial –
administrado en sus seis subtests diferentes- son adecuadas. La fiabilidad de cada una de
los subtests es moderadamente alta y los resultados obtenidos al relacionar las
puntuaciones de cada subtest con las otras pruebas proporcionan una sólida evidencia de
validez convergente y discriminante.
Las estrechas relaciones entre los resultados de las personas evaluadas mediante
los subtests del banco de ítems inicial y los resultados del test de Raven, la prueba de
matrices progresivas más utilizada a la hora de medir la capacidad cognitiva general,
supone una evidencia de validez convergente muy importante. Asimismo, las relaciones
entre las escalas de razonamiento abstracto, numérico y verbal del DAT-5 con los
resultados de los participantes en los subtests, apuntan en la misma dirección que
cuando se compraran los resultados de estas escalas con el Raven (Raven, et al., 1998).
Las correlaciones entre la escala de razonamiento abstracto del PMA con otras pruebas
de matrices también son significativas y positivas (Colom, et al. 2007), como sucede al
comparar los resultados obtenidos en esta escala con los obtenidos en los subtests del
banco de ítems del FIMT. Las relaciones entre otras pruebas de matrices progresivas
con la escala de comprensión verbal del PMA son en cambio más bajas (Colom, et al.
2008), lo que constituye una evidencia de validez discriminante en el caso de los ítems
del banco de ítems inicial, con los que la relación resultó más baja y no significativa.
A su vez, son varios los trabajos que ponen de manifiesto la relación entre las
tareas propias de la memoria de trabajo y la inteligencia fluida medida a través de tests
de matrices progresivas (Colom et al., 2008; Kyllonen & Christal, 1990) por lo que las
relaciones entre los ítems del banco inicial con las tareas más clásicas de memoria
operativa suponen una nueva evidencia del validez convergente para esta nueva
herramienta. Asimismo, las relaciones encontradas entre el banco de ítems inicial y las
medidas de control atencional son consistentes con estudios en los que tareas de este
tipo presentan correlaciones bajas y negativas con los resultados de los test de matrices
(Unsworth, Spillers y Brewer, 2009).

- 23 -
La segunda implicación de este primer estudio hace referencia al supuesto
carácter isomorfo de los ítems. Debido al diseño empleado durante la aplicación del
cuestionario no fue posible obtener datos para estudiar la dependencia local entre dos
versiones de un mismo ítem mediante los procedimientos habituales (ya que a ningún
participante se le presentó más de un ítem isomorfo). Es por ello por lo que se recurrió a
los métodos de detección de DIF como solución temporal al problema. Y los resultados
en este caso son claros: no todas las versiones de un mismo ítem funcionan de la misma
manera en dos muestras pertenecientes al mismo grupo normativo, por lo que a priori
tiene sentido asumir que ambas versiones son dos ítems bien diferenciados.
Esto permite ampliar el número de ítems que puede presentarse a un mismo
evaluado, pasando de un banco de ítems inicial con fuertes restricciones a un banco más
flexible y operativo con el que es posible estudiar distintas estructuras multietapa para el
FIMT. En los siguientes estudios se partirá de este banco de ítems operativo, en el que
se han liberado varios ítems de las restricciones de presentación que se asumieron
durante el diseño y la administración de los subtests.
Estudio 2
El objetivo de este estudio es encontrar el mejor modelo de la TRI para puntuar a
los evaluados, prestando especial a la información que los modelos proporcionan en los
niveles altos del rasgo latente θ y a las restricciones de los ítems isomorfos. Para ello se
pondrán a prueba diferentes modelos de la TRI (uno dicotómico y otro politómico) con
distintas restricciones y se optará por uno de ellos. Además, se realizará una simulación
para justificar el empleo del modelo elegido.
Método
Modelos
Para tratar las respuestas de manera dicotómica, se decidió aplicar el modelo
logístico de dos parámetros (Birnbaum, 1968), ya que no se espera que el efecto de las
respuestas al azar sea muy elevado en ítems de respuesta construida.
Este modelo viene definido por:
1(X 1)
1 exp( ( ))j
j i j
Pa b

- 24 -
donde (X 1)jP es la probabilidad de acertar el ítem j, θi es el nivel del rasgo
latente del evaluado i, bj es el parámetro de dificultad del ítem j y aj el parámetro de
discriminación del ítem j. Según este modelo la probabilidad de acertar uno de los ítems
depende del nivel de capacidad cognitiva general del sujeto, de la dificultad del ítem y
de lo discriminativo que sea.
Si los clones de un ítem original siguen las mismas reglas y tienen un patrón de
forma o un color parecido, entonces es razonable suponer que los dos clones comparten
algunas características entre sí, como su dificultad o su discriminación. Para poner esta
hipótesis a prueba se definieron tres modelos anidados a los que se les impusieron
diferentes restricciones. Estas restricciones responden al carácter isomorfo de los ítems
del banco operativo que no fueron liberados en el estudio anterior:
− Modelo 1: modelo de dos parámetros sin restricciones.
− Modelo 2: modelo de dos parámetros fijando al mismo valor los parámetros
de discriminación aj y dificultad bj de los clones de un mismo ítem.
− Modelo 3: modelo de dos parámetros fijando al mismo valor los parámetros
de discriminación aj de los clones de un mismo ítem.
− Modelo 4: modelo de dos parámetros fijando al mismo valor los parámetros
de dificultad bj de los clones de un mismo ítem.
Se modelaron además las respuestas de los participantes de acuerdo al modelo
politómico de respuesta graduada (Samejima, 1969) que tiene en cuenta las categorías
de respuesta del ítem miden el mismo rasgo y están ordenadas. Según este modelo, la
probabilidad de acertar un ítem se define como:
* *
1
*
( | ) ( ) ( )
1( ) ( | )
1 exp ( )
ij i k i k i
k i ij i
j i jk
P X k P P
P P X ka b
donde k es una de las categorías de respuesta posibles del ítem j (en este caso un
valor comprendido de uno a cinco, dada la codificación de los ítems), *( )k iP es la
probabilidad de obtener en el ítem la categoría k o una superior, i es el nivel de rasgo
del evaluado i, ja el parámetro de discriminación del ítem j y
jkb sería el parámetro de
posición –o dificultad- de la categoría k del ítem j. De acuerdo a este modelo, la
probabilidad de que una persona tenga un número determinado de celdillas bien

- 25 -
rellenadas (una de las k categorías) dependería de su capacidad cognitiva general, de la
dificultad y la discriminación del ítem.
Al igual que con el modelo de dos parámetros, se plantearon además tres
modelos anidados que responden a las mismas restricciones:
− Modelo 5: modelo de respuesta graduada sin restricciones.
− Modelo 6: modelo de respuesta graduada fijando al mismo valor los
parámetros de discriminación aj y dificultad bjk de los clones de un mismo
ítem.
− Modelo 7: modelo de respuesta graduada fijando al mismo valor los
parámetros de discriminación aj de los clones de un mismo ítem.
− Modelo 8: modelo de respuesta graduada fijando al mismo valor los
parámetros de dificultad bjk de los clones de un mismo ítem.
Diseño de la simulación
El modelo de respuesta graduada es una generalización del modelo de dos
parámetros. En este caso, además, la última categoría de respuesta del modelo
politómico (la categoría cinco, haber rellenado correctamente todas las celdillas de la
respuesta del ítem) coincide con el acierto del modelo dicotómico. No se esperan por lo
tanto grandes diferencias entre los parámetros de discriminación estimados de ambos
modelos. Sin embargo en los resultados se encontró que el modelo de dos parámetros
tendía a presentar mayores valores para los parámetros aj que el de respuesta graduada.
Esto hace a su vez que la información proporcionada por el modelo de dos parámetros
sea mayor para los valores altos del rasgo latente θ¸ lo cual no deja de ser una
circunstancia anómala.
Esta simulación se realizó con el propósito de determinar cuál es la proporción
de casos esperable en los que la función de información del modelo logístico de dos
parámetros tome valores superiores a los del modelo de respuesta graduada en los
niveles altos del rasgo latente θ cuando se utilizan las respuestas de los mismos sujetos.
Hipótesis. La hipótesis de este estudio de simulación es que la proporción de
casos en la que la información proporcionada por el modelo de dos parámetros para los
niveles altos de θ sea mayor que la información proporcionada por el modelo de
respuesta graduada debería de ser tendente a cero. Al ser modelo de respuesta graduada
una generalización del modelo logístico de dos parámetros y al coincidir la última
categoría politómica con el acierto del ítem en la codificación dicotómica, no deberían

- 26 -
de darse grandes diferencias en la información para los niveles altos de θ si el parámetro
de discriminación aj verdadero es el mismo.
Variables independientes. Para contrastar esta hipótesis se tuvieron presentes
dos variables independientes: (a) el modelo psicométrico con el que se estiman las
respuestas de los sujetos simulados (el logístico de dos parámetros o el de respuesta
graduada) y (b) los parámetros verdaderos con los que se generan las respuestas
(parámetros aleatorios o los parámetros estimados en el estudio empírico), dando como
resultado un total de cuatro condiciones (2 modelos × 2 tipos de parámetros
verdaderos).
Los parámetros aleatorios aj verdaderos se generaron a partir de una distribución
lognormal con μ = 0 y σ = 0.5, utilizando los mismos valores para las parejas de clones
isomorfas. Por su parte, los parámetros aleatorios bjk se generaron a partir de una
distribución normal con μ = -1 y σ = 1 para la categoría inferior (k = 1), y al valor de
cada parámetro se le sumó un incremento aleatorio de entre 0.25 y 0.75 para los
parámetros bjk siguientes. De este modo, cada parámetro bjk es mayor que el anterior
(bjk-1).
Variable dependiente. Como variable dependiente se utilizó la proporción del
número de casos en el que el sumatorio de la información del modelo de dos parámetros
es mayor que el sumatorio de la información del modelo de respuesta graduada para el
intervalo de theta comprendido entre θ = 1 y θ = 2. La idea es contrastar si la
proporción de casos en los que se da esta sobreestimación de los parámetros aj con los
parámetros estimados del banco operativo de ítems es la misma que cuando se utilizan
valores aleatorios para esos mismos parámetros.
Procedimiento.
Para la condición de parámetros verdaderos aleatorios se generaron 50 conjuntos
parámetros diferentes para el modelo de respuesta graduada. Se tuvieron en cuanta las
restricciones del modelo de respuesta graduada seleccionando, por lo que se forzaron a
distintas parejas de clones a tener los mismos parámetros. Con cada uno de estos
conjuntos de parámetros se generaron 100 matrices de respuesta una politómicas y otras
100 dicotómicas. A continuación se estimaron los parámetros de los ítems de cada
modelo para cada una de las 100 matrices de cada modelo y se comparó la cantidad de
veces que el modelo de dos parámetros proporciona más información para los niveles
altos de θ que el modelo de respuesta graduada.

- 27 -
Asimismo, para la condición que toma como parámetros verdaderos los
parámetros estimados empíricamente por el modelo de respuesta graduada, se generaron
otras 100 matrices de respuestas politómicas y 100 matrices más de respuestas
dicotómica. Se estiman después los parámetros de los ítems de cada una de las matrices
generadas y se comparó la cantidad de veces que se cumple la hipótesis.
Las matrices de respuestas politómicas se generaron para 723 sujetos simulados
utilizando los parámetros verdaderos pertinentes para cada condición. Para que las
condiciones de la simulación se adecuasen al máximo posible a las condiciones en las
que se recogieron los datos de los ítems, las respuestas de cada sujeto simulado se
obtuvieron de acuerdo al diseño de anclaje con el que se administraron las distintas
formas del test (es decir, cada fila de la matriz tiene respuesta para sólo 18 columnas).
Por su parte, las matrices de respuesta dicotómicas se obtuvieron recodificando las
matrices de respuesta politómicas (la categoría más alta del modelo de respuesta
graduada correspondería al 1, y todas las demás al 0).
Análisis de Datos
Tanto en la parte empírica como en la parte de simulación de este estudio,
cuando se ha estimado un modelo de la TRI se ha hecho en todos los casos a través del
algoritmo EM (Bock y Aiken, 1981).
Para comparar los distintos modelos anidados se utilizó la razón de
verosimilitudes (para una explicación detallada del procedimiento, véase Revuelta y
Ponsoda, 2005). Este análisis sirve para contrastar la hipótesis nula de que no hay
diferencias en el ajuste de dos modelos.
La simulación se llevó a cabo utilizando el programa R statistics (R Core Team,
2014), mientras que para realizar la distintas calibraciones de los ítems se empleó el
paquete mirt (Charlmers, 2012).
Resultados
Comparación de modelos
Al compararse las versiones anidadas del modelo logístico de dos parámetros
con el modelo con el modelo sin restricciones (tabla 6) a través del test de la razón de
verosimilitudes, se observa que no hay diferencias significativas en el ajuste entre
ambos modelos (G2 (9) = 9.014, p = .436), por lo que siguiendo el principio de

- 28 -
parsimonia, se decidió conservar el modelo con los parámetros de discriminación de los
clones fijados al mismo valor (modelo 3).
Tabla 6.
Comparación de modelos
Modelo Parámetros log. lik. G2 (con mod.1) gl p AIC BIC
Modelo Logístico de 2 Parámetros
1 104 -6620.26
13456.51 13951.67
2 85 -6634.72 28.931 18 0.049 13449.44 13862.07
3 94 -6624.76 9.014 9 0.436 13447.53 13901.42
4 94 -6628.75 17.072 9 0.048 13445.58 13909.48
Modelo de Respuesta Graduada
5 258 -13571.55
27659.1 28841.98
6 205 -13643.13 143.156 42 <.001 27718.26 28708.57
7 248 -13574.8 6.509 9 0.688 27647.61 28789.22
8 214 -13638.71 134.312 33 <.001 27727.41 28758.99
Algo muy parecido sucede al comparar las versiones anidadas del modelo de
respuesta graduada con el modelo sin restricciones. Al igual que con el modelo de dos
parámetros, se obtuvo que al restringir al mismo valor los parámetros de discriminación
aj de los clones del banco de ítems operativo, el modelo resultante ajusta tan bien como
el modelo sin restricciones (G2 (9) = 6.509, p = .688). Por ello se decidió conservar el
modelo 7 como el modelo de respuesta graduada.
A priori, las ventajas del modelo de respuesta graduada frente al modelo de dos
parámetros deberían de ser suficientes para justificar su elección: al añadir varias
categorías para los errores –cuantificando por tanto la magnitud de cada error-, se
obtiene mucha más información con cada ítem de la que se obtiene con el modelo de
dos parámetros, en especial para la parte baja del rasgo latente θ. Sin embargo, lo que se
encuentra es que la información ofrecida por el modelo de dos parámetros es superior
para los valores altos de θ en comparación con la ofrecida por el modelo de respuesta
graduada (figura 3).
Estos resultados anómalos se deben a que los parámetros aj de discriminación de
los ítems estimados con el modelo de dos parámetros tienden a ser más altos (M = 1.08,
SD = 0.36) que los parámetros aj estimados con el modelo de respuesta graduada (M =
0.95, SD = 0.34), lo que aumenta sensiblemente la información del test en los valores
altos del rasgo latente. En la figura 4 se ilustra precisamente cómo en aquellos ítems
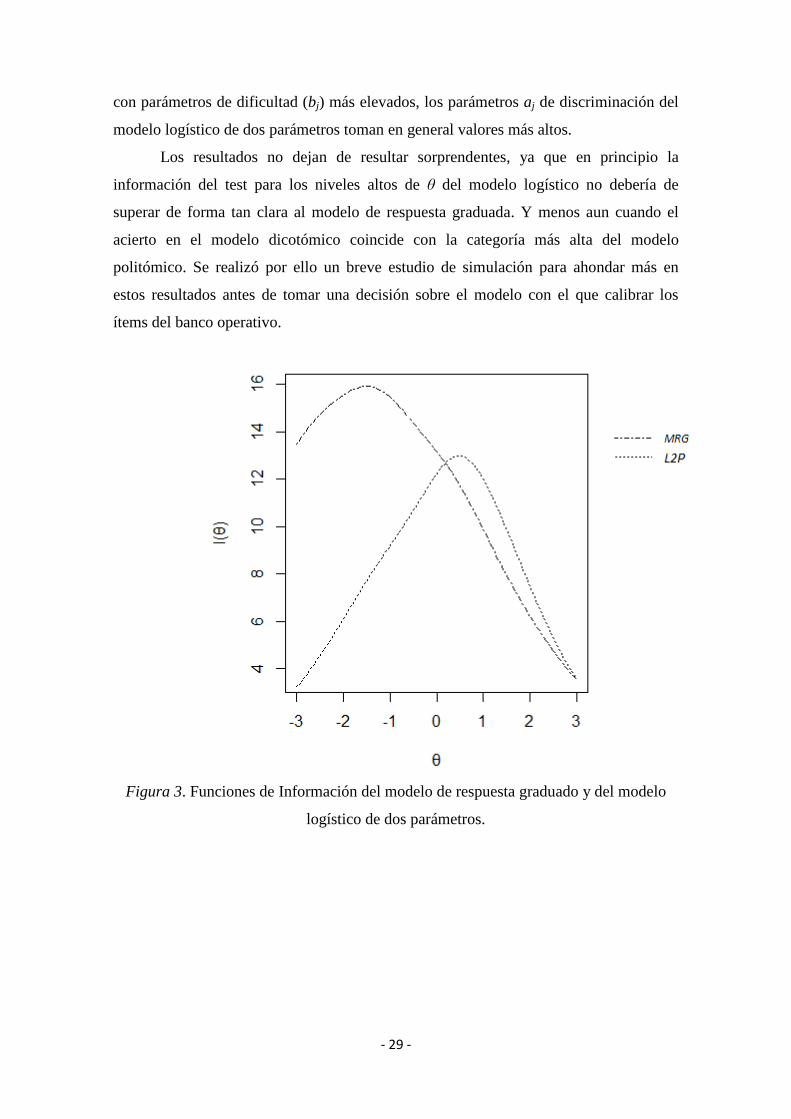
- 29 -
con parámetros de dificultad (bj) más elevados, los parámetros aj de discriminación del
modelo logístico de dos parámetros toman en general valores más altos.
Los resultados no dejan de resultar sorprendentes, ya que en principio la
información del test para los niveles altos de θ del modelo logístico no debería de
superar de forma tan clara al modelo de respuesta graduada. Y menos aun cuando el
acierto en el modelo dicotómico coincide con la categoría más alta del modelo
politómico. Se realizó por ello un breve estudio de simulación para ahondar más en
estos resultados antes de tomar una decisión sobre el modelo con el que calibrar los
ítems del banco operativo.
Figura 3. Funciones de Información del modelo de respuesta graduado y del modelo
logístico de dos parámetros.
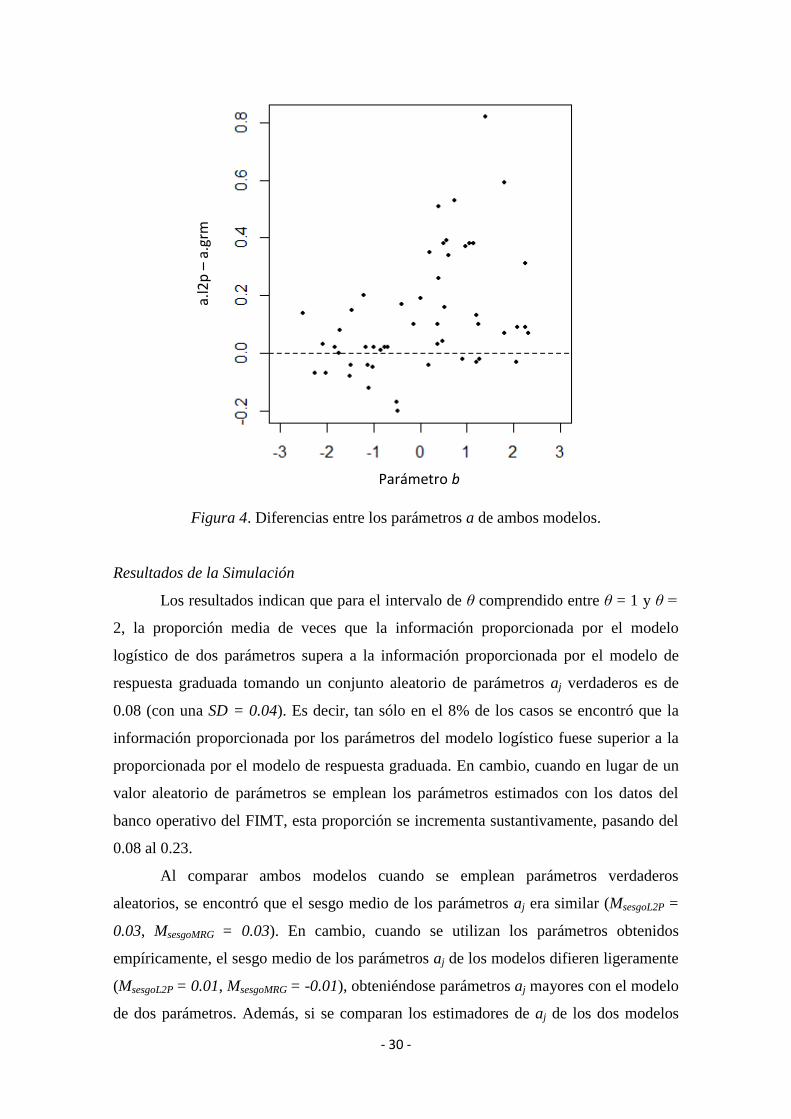
- 30 -
Figura 4. Diferencias entre los parámetros a de ambos modelos.
Resultados de la Simulación
Los resultados indican que para el intervalo de θ comprendido entre θ = 1 y θ =
2, la proporción media de veces que la información proporcionada por el modelo
logístico de dos parámetros supera a la información proporcionada por el modelo de
respuesta graduada tomando un conjunto aleatorio de parámetros aj verdaderos es de
0.08 (con una SD = 0.04). Es decir, tan sólo en el 8% de los casos se encontró que la
información proporcionada por los parámetros del modelo logístico fuese superior a la
proporcionada por el modelo de respuesta graduada. En cambio, cuando en lugar de un
valor aleatorio de parámetros se emplean los parámetros estimados con los datos del
banco operativo del FIMT, esta proporción se incrementa sustantivamente, pasando del
0.08 al 0.23.
Al comparar ambos modelos cuando se emplean parámetros verdaderos
aleatorios, se encontró que el sesgo medio de los parámetros aj era similar (MsesgoL2P =
0.03, MsesgoMRG = 0.03). En cambio, cuando se utilizan los parámetros obtenidos
empíricamente, el sesgo medio de los parámetros aj de los modelos difieren ligeramente
(MsesgoL2P = 0.01, MsesgoMRG = -0.01), obteniéndose parámetros aj mayores con el modelo
de dos parámetros. Además, si se comparan los estimadores de aj de los dos modelos
Parámetro b
a.l2
p –
a.g
rm
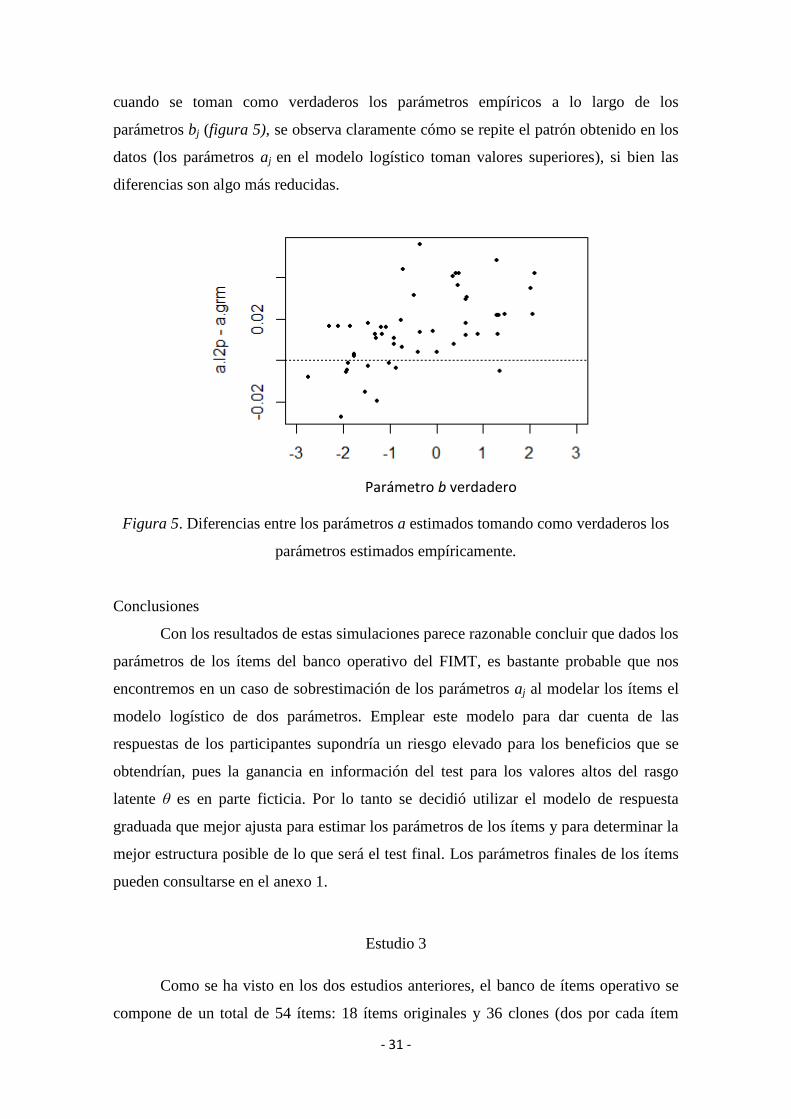
- 31 -
cuando se toman como verdaderos los parámetros empíricos a lo largo de los
parámetros bj (figura 5), se observa claramente cómo se repite el patrón obtenido en los
datos (los parámetros aj en el modelo logístico toman valores superiores), si bien las
diferencias son algo más reducidas.
Figura 5. Diferencias entre los parámetros a estimados tomando como verdaderos los
parámetros estimados empíricamente.
Conclusiones
Con los resultados de estas simulaciones parece razonable concluir que dados los
parámetros de los ítems del banco operativo del FIMT, es bastante probable que nos
encontremos en un caso de sobrestimación de los parámetros aj al modelar los ítems el
modelo logístico de dos parámetros. Emplear este modelo para dar cuenta de las
respuestas de los participantes supondría un riesgo elevado para los beneficios que se
obtendrían, pues la ganancia en información del test para los valores altos del rasgo
latente θ es en parte ficticia. Por lo tanto se decidió utilizar el modelo de respuesta
graduada que mejor ajusta para estimar los parámetros de los ítems y para determinar la
mejor estructura posible de lo que será el test final. Los parámetros finales de los ítems
pueden consultarse en el anexo 1.
Estudio 3
Como se ha visto en los dos estudios anteriores, el banco de ítems operativo se
compone de un total de 54 ítems: 18 ítems originales y 36 clones (dos por cada ítem
Parámetro b verdadero

- 32 -
original). El estudio 1 puso de manifiesto que no era razonable asumir en todos los
casos que las tríadas de ítems isomorfos funcionasen igual para la misma población
(hasta que se puedan realizar estudios de dependencia local). Por lo tanto, el test dispone
de un total de 18 ítems completamente independientes, que podrían presentarse de
forma simultánea aunque hubiesen sido diseñados como ítems isomorfos, más otros 36
ítems que tienen algún tipo de restricción en su administración. Estas restricciones son
distintas para cada tríada de ítems y condicionan la administración de los ítems del
banco operativo.
Teniendo esto presente y con los parámetros de los ítems ya estimados bajo el
modelo de respuesta graduada, es posible empezar a explorar distintas estructuras para
el FIMT a través del EAT.
En este tercer y último estudio se exploran mediante ensamblaje automático de
test (EAT) distintas estructuras multietapa para dar con la forma del FIMT que ofrezca
la mayor información posible para un intervalo relativamente amplio del rasgo latente θ,
especialmente para los valores altos del mismo. Se compara también la información del
test obtenida mediante este procedimiento con la que se obtendría al construir un test
mediante una selección aleatoria de ítems.
Método
Las dos estructuras multietapa puestas a prueba en este estudio se diferencian en
el número de módulos que emplean por etapa (figura 6). La primera de ellas se trata de
una estructura sencilla, con dos módulos de distinta dificultad en cada etapa posterior a
la primera (en adelante, estructura sencilla). La segunda estructura, en cambio, añade
tres módulos de diferente dificultad por etapa a partir de la primera (en adelante,
estructura compleja).
La estructura sencilla consta de tres etapas con un módulo inicial en la primera
de ellas y dos módulos en las etapas siguientes. Los evaluados pasarían primero por los
ítems ese módulo inicial o test de ruta y, dependiendo de su rendimiento, se enfrentarían
a un módulo de mayor o menor dificultad en la segunda etapa. Asimismo, una vez
respondidos los ítems de esta segunda etapa se presentaría en la tercera etapa un último
módulo de dificultad alta o baja, en función del desempeño de cada persona en el test.
De este modo, un evaluado que haya pasado el módulo de menor dificultad en la
segunda etapa, podría ser enviado al módulo de mayor dificultad en la tercera etapa si su
rendimiento es lo suficientemente alto.

- 33 -
Figura 6. Estructuras Sencilla y Compleja del FIMT
La estructura compleja se divide en tres etapas, con un test de ruta en la primera
y tres módulos de distinto grado de dificultad en la segunda y la tercera etapa. Los
evaluados responderían primero a los ítems del test de ruta y de nuevo, en función de su
rendimiento, realizarían un módulo de mayor o menor dificultad en la segunda etapa.
Finalmente, dependiendo de los resultados de los evaluados en la segunda etapa, se les
asignaría en la tercera un nuevo módulo de dificultad alta, intermedia o baja. En esta
estructura las personas que hayan respondido en la segunda etapa el módulo de máxima
dificultad (aquellas que obtuvieron un mejor rendimiento en el test de ruta), no podrán
ser enviadas en la tercera etapa al módulo de menor dificultad. Y viceversa: quienes
hayan respondido el módulo de menor dificultad en la segunda etapa (aquellos con un
peor rendimiento en el test de ruta), no podrán ser enviados al módulo de mayor
dificultad en la tercera etapa.
Estructura Compleja
Estructura Sencilla

- 34 -
En principio, la estructura compleja permitiría una administración de los ítems
más adaptativa, en la que la dificultad del test se ajustaría más fácilmente las
habilidades de cada evaluado que en la estructura sencilla. En cambio, la estructura
sencilla es mucho más fácil de implementar y emplea el menor número de ítems, lo que
permite un mejor aprovechamiento de los mismos.
Especificaciones
Para maximizar la información del FIMT a lo largo de todo el rasgo latente y,
muy especialmente, en la parte alta del mismo (y evaluar así con la mayor precisión
posible a las personas con una gran capacidad cognitiva general) se pusieron en práctica
dos estrategias durante la construcción de las dos estructuras del test multietapa. En
primer lugar, se permitió que se repitieran los ítems en aquellos módulos que no se
presentan simultáneamente, de manera que un mismo ítem puede aparecer en distintas
etapas siempre y cuando no sea administrado dos veces a la misma persona. Y en
segundo lugar se aumentó la longitud del módulo de mayor dificultad de la tercera etapa
añadiendo cinco ítems adicionales. Este módulo es en las dos estructuras el último
bloque de ítems que han de responder los evaluados con mejor rendimiento en el FIMT.
Así, las personas con un mejor rendimiento realizarían total de 20 ítems, pues se
entiende que para los evaluados con una mejor capacidad cognitiva general cinco ítems
más no supondrán un gran esfuerzo adicional.
Teniendo esto presente, las especificaciones necesarias para el EAT que se
plantearon para cada etapa son las siguientes:
Test de Ruta
max y
Sujeto a:
1 1
1
1
( ) , [ 1.75,1.75]
1c
J K
j k j k
j k
j
j V
J
j
j
I x y
x
x N
(1)
(2)
(3)
(4)

- 35 -
0,1
0.
jx
y
Para construir el test de ruta a través del EAT, hay que convertir primero la
construcción del test en un problema de optimización lineal. En este caso el objetivo
viene expresado en (1): maximizar la constante y. ¿Qué se consigue maximizando y?
Precisamente eso es lo que se expresa en (2), que la información total del test de ruta (o
la suma de la información de cada uno de los j ítems) sea máxima en el intervalo de θ
comprendido entre θ = -1.75 y θ = 1.75. Tal y como se establece en (5), jx es una
variable dicotómica que expresa si el ítem j es o no seleccionado para formar parte del
test de ruta. De esta manera se exploran todas las posibles combinaciones de ítems y se
selecciona aquella en la que la información del test sea mayor en el intervalo del rasgo
latente θ.
Pero además de buscar la máxima información posible, se deben cumplir
también las restricciones expresadas tanto en la ecuación (3), que impide presentar más
de un ítem isomorfo de forma simultánea (Vc expresa las parejas o grupos de j ítems del
banco operativo que no pueden presentarse a la vez en el mismo test), como en la
ecuación (4), que fija la longitud máxima del test de ruta a N1.
Por último se impone la restricción (6) que impide a la constante y tomar valores
negativos. Si la y pudiera tomar valores negativos daría igual qué ítems fuesen
seleccionados, ya que la constante tomaría el valor más pequeño posible para cumplir
con la restricción (2).
Segunda Etapa
max y
Sujeto a:
1 1
2
1
( ) , [ , ]
0prev
J K
j k j k l h
j k
J
j
j
j
j S
I x y
x N
x
(5)
(6)
(7)
(8)
(9)
(10)

- 36 -
1
0,1
0.
c
j
j V
j
x
x
y
Las especificaciones de los módulos de la segunda etapa son muy parecidas a las
del test de ruta, con una notable excepción: el intervalo de θ para el que se quiere
maximizar la información varía de un módulo a otro. El objetivo sigue siendo el mismo,
maximizar la constante y (7), de modo que en (8) lo que se busca es la combinación de
ítems que dé la máxima información posible para un intervalo determinado de θ. En el
caso de la estructura sencilla, cuando el módulo que se desea construir es el de menor
dificultad, entonces el intervalo de la función de información que se quiere maximizar
es el comprendido entre θl = -1.75 y θh = 0. Sin embargo, cuando ha de construirse el
módulo de dificultad alta, el intervalo es el comprendido entre θl = 0 y θh = 1.75.
En cambio, en la estructura compleja, cuando lo que se busca es construir es el
módulo de menor dificultad, entonces el intervalo de la función de información que se
ha de maximizar es el comprendido entre θl = -1.75 y θh = -1. Asimismo, cuando se
quiere construir el módulo de dificultad intermedia, el intervalo a maximizar es el
comprendido entre θl = -1 y θh = 1. Y por último, cuando se construye el módulo de
mayor dificultad el objetivo es maximizar la función de información entre θl = 1 y θh =
1.75.
Al igual que en el test de ruta, han de cumplirse algunas restricciones adicionales
durante la construcción de cada módulo. Las especificaciones (9) y (10) fijan,
respectivamente, la longitud del módulo igual a N2 e impiden que se presenten ítems
isomorfos. La especificación (10) impide que se añadan al módulo los ítems incluidos
en el conjunto Sprev (que no son más que los ítems seleccionados previamente en el
recorrido del multietapa, en este caso los ítems que componen el test de ruta).
Finalmente, las dos últimas restricciones –(12) y (13)- indican que xj se trata de
una variable dicotómica (de forma que si un ítem no se selecciona, multiplica por 0 el
valor de la información que aporta en la expresión (8)) y que la constante y debe tomar
valores positivos.
Tercera Etapa
max y
(14)
(11)
(12)
(13)

- 37 -
Sujeto a:
1 1
3 3 3
1
( ) , [ , ]
, 5 1.75
0
1
0,1
0.
prev
c
J K
j k j k l h
j k
J
j h
j
j
j S
j
j V
j
I x y y
x N N N
x
x
x
y
Las especificaciones de los módulos de la tercera etapa son prácticamente las
mismas que las de la segunda etapa. El único cambio relevante es el que expresa (16),
donde se establece que la longitud del módulo será 5 ítems mayor si el intervalo de θ
que se quiere maximizar es el comprendido entre θl = 0 y θh = 1.75 en la estructura
sencilla, o entre θl = 1 y θh = 1.75 en la estructura compleja. Por lo demás las
expresiones significan los mismo: (14) enuncia el objetivo del problema –maximizar y;
(15) que se busca maximizar la función de información del módulo en un intervalo
concreto del rasgo latente, que varía en función de la dificultad del módulo; (17) impide
que se incluyan los ítems que se han seleccionado previamente en el recorrido seguido;
(18) no deja que se presenten dos ítems isomorfos; y (19) y (20) que jx es una variable
dicotómica y que la constante y debe ser positiva.
Como se ha visto, las especificaciones del EAT necesarias para construir cada
una de las estructuras son exactamente las mismas, pues lo único que cambia es el
número de veces que se ejecuta el algoritmo de selección de ítems para cada etapa (dos
o tres veces, en función del número de módulos por etapa) y los puntos de los intervalos
en los que hay que maximizar la información. Siguiendo estas especificaciones es
posible crear módulos de distinta longitud en cada etapa de cada estructura, de manera
que no se presenten simultáneamente ítems isomorfos y que estén, además, ordenados
por dificultad (ya que cada módulo es más informativo para un intervalo determinado
del continuo del rasgo latente).
(15)
(16)
(17)
(18)
(19)
(20)

- 38 -
Análisis de datos
Para evaluar qué estructura multietapa era más apropiada se tuvieron en cuenta
la información total proporcionada por cada uno de los recorridos por los que puede
pasar un evaluado en cada estructura y el número de recorridos diferentes del test (ya
que es posible que dos evaluados que realicen distintos módulos acaben realizando los
mismos ítems). Se probaron además distintas configuraciones de módulos para cada
estructura. Las configuraciones difieren únicamente en la longitud de los módulos de
cada etapa, respetando siempre que la longitud final de los posibles recorridos del test
fuese de 15 ítems o de 20 en el caso de las personas con un mejor rendimiento.
Para obtener las medidas de información total se categorizó el continuo de θ en
121 puntos entre θ = -3 y θ = 3. La información total media se obtuvo promediando la
información total proporcionada por cada uno de los posibles recorridos de cada
estructura multietapa a lo largo de estos puntos de θ. Por su parte, el número total de
recorridos es el resultado de la comparación de los ítems que componen cada uno de las
distintas combinaciones posibles de módulos (cuatro en la estructura sencilla y siete en
la compleja).
Los análisis se llevaron a cabo utilizando el programa R statistics (R Core Team,
2014) y el paquete lpSolveAPI (Konis, 2014) para el EAT.
Resultados
Estructura del Test
Los resultados muestran que en general, para las distintas configuraciones
puestas a prueba, la estructura sencilla ofrece más información (tabla 7). Al promediar
los distintos recorridos posibles del multietapa, se encontró que la información
proporcionada por la estructura sencilla a lo largo del rasgo latente es siempre mayor. El
único caso en el que la estructura compleja da sistemáticamente más información que la
estructura sencilla es en los niveles bajos de θ, pues emplea módulos más informativos
para esos niveles.
Con respecto al número de recorridos diferentes generados mediante el EAT, se
encontró que en la estructura sencilla se construyen siempre cuatro recorridos distintos
dentro del test con independencia de la longitud de los módulos. Precisamente cuatro es
el número máximo de recorridos posibles, por lo que cada recorrido está compuesto por
al menos un ítem diferente. En cambio, en la estructura compleja el número de
recorridos distintos que se pueden construir utilizando los ítems del banco operativo
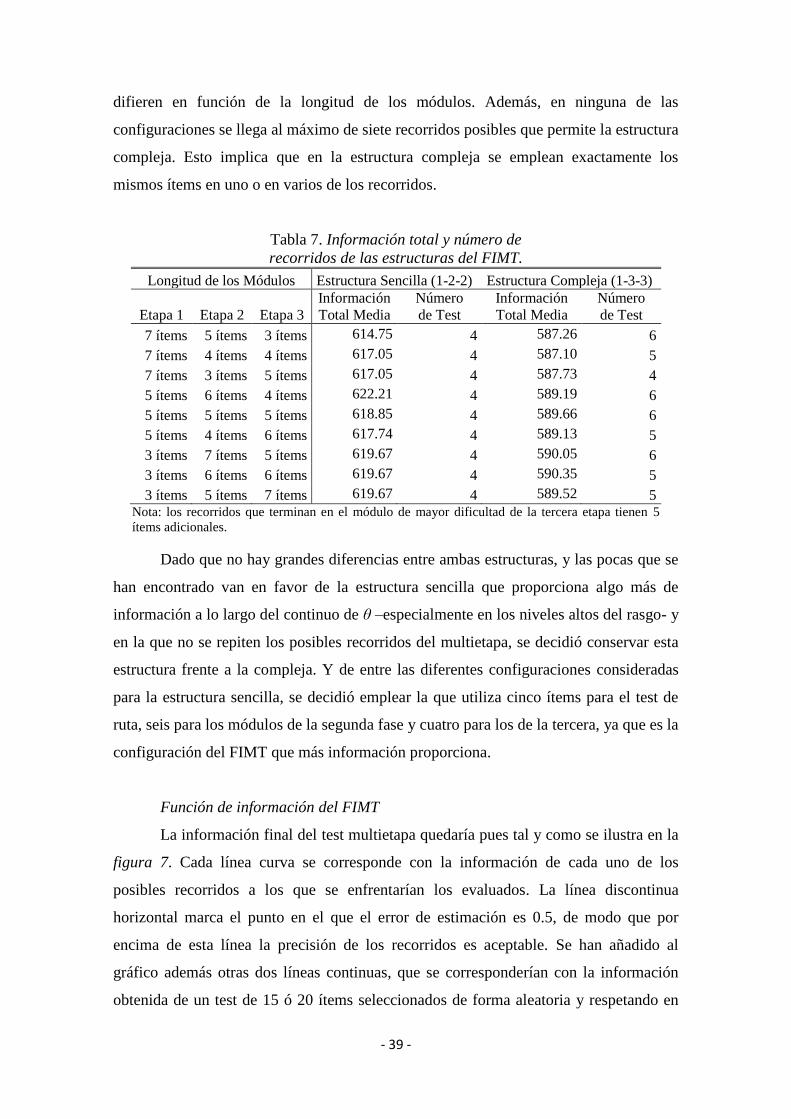
- 39 -
difieren en función de la longitud de los módulos. Además, en ninguna de las
configuraciones se llega al máximo de siete recorridos posibles que permite la estructura
compleja. Esto implica que en la estructura compleja se emplean exactamente los
mismos ítems en uno o en varios de los recorridos.
Tabla 7. Información total y número de
recorridos de las estructuras del FIMT.
Longitud de los Módulos Estructura Sencilla (1-2-2) Estructura Compleja (1-3-3)
Etapa 1 Etapa 2 Etapa 3
Información
Total Media
Número
de Test
Información
Total Media
Número
de Test
7 ítems 5 ítems 3 ítems 614.75 4 587.26 6
7 ítems 4 ítems 4 ítems 617.05 4 587.10 5
7 ítems 3 ítems 5 ítems 617.05 4 587.73 4
5 ítems 6 ítems 4 ítems 622.21 4 589.19 6
5 ítems 5 ítems 5 ítems 618.85 4 589.66 6
5 ítems 4 ítems 6 ítems 617.74 4 589.13 5
3 ítems 7 ítems 5 ítems 619.67 4 590.05 6
3 ítems 6 ítems 6 ítems 619.67 4 590.35 5
3 ítems 5 ítems 7 ítems 619.67 4 589.52 5 Nota: los recorridos que terminan en el módulo de mayor dificultad de la tercera etapa tienen 5
ítems adicionales.
Dado que no hay grandes diferencias entre ambas estructuras, y las pocas que se
han encontrado van en favor de la estructura sencilla que proporciona algo más de
información a lo largo del continuo de θ –especialmente en los niveles altos del rasgo- y
en la que no se repiten los posibles recorridos del multietapa, se decidió conservar esta
estructura frente a la compleja. Y de entre las diferentes configuraciones consideradas
para la estructura sencilla, se decidió emplear la que utiliza cinco ítems para el test de
ruta, seis para los módulos de la segunda fase y cuatro para los de la tercera, ya que es la
configuración del FIMT que más información proporciona.
Función de información del FIMT
La información final del test multietapa quedaría pues tal y como se ilustra en la
figura 7. Cada línea curva se corresponde con la información de cada uno de los
posibles recorridos a los que se enfrentarían los evaluados. La línea discontinua
horizontal marca el punto en el que el error de estimación es 0.5, de modo que por
encima de esta línea la precisión de los recorridos es aceptable. Se han añadido al
gráfico además otras dos líneas continuas, que se corresponderían con la información
obtenida de un test de 15 ó 20 ítems seleccionados de forma aleatoria y respetando en

- 40 -
todo momento las restricciones del banco operativo de ítems. En cualquiera de los dos
casos, es posible comprobar claramente las ventajas del EAT.
Figura 7. Función de información del FIMT y de dos test de ítems elegidos
aleatoriamente.
El recorrido bajo/bajo se corresponde con la información proporcionada por la
combinación de los ítems del test de ruta, el módulo de dificultad baja en la segunda
etapa y el módulo de dificultad baja en la tercera. Sería el recorrido seguido por aquellas
personas con un peor rendimiento en el FIMT, y es precisamente por ello por lo que la
precisión del test alcanza sus valores más altos en los valores bajos del rasgo latente θ.
Por su parte, el recorrido alto/bajo se corresponde con los ítems del test de ruta, el
módulo de dificultad alta en la segunda fase y de dificultad baja en la tercera. Sería el
test que se administraría a aquellas personas con un buen resultado en los primeros
ítems (de dificultad heterogénea) y con peores resultados en el módulo de dificultad alta
en la segunda fase. Proporciona menos información en los valores bajos de θ que el
itinerario anterior del FIMT, pero la caída de la función de información no es tan
abrupta en los valores intermedios y altos del rasgo latente.
Los otros dos recorridos se corresponderían a los test del FIMT ideados para
aquellas personas con un mejor rendimiento, y están compuestos por un total de 20
Recorrido Bajo/Alto
Recorrido Alto/Alto
Recorrido Alto/Bajo
Recorrido Bajo/Bajo
Test Aleatorio

- 41 -
ítems en lugar de tener la longitud de 15 de los dos anteriores. Este es el motivo por el
que la función de información de estos dos recorridos toma valores en general más altos
que los dos anteriores. El recorrido bajo/alto pertenece a la combinación de ítems del
test de ruta, el módulo de dificultad baja de la segunda etapa y de dificultad alta en la
tercera. Sería el realizado por aquellos evaluados que habiendo sacado un mal resultado
en el test de ruta, obtienen una buena puntuación en los ítems de la segunda etapa. Por
último, el recorrido alto/alto se correspondería con los ítems del test de ruta y los dos
módulos de dificultad alta en las etapas posteriores. Este sería el recorrido seguido por
las personas con mejor rendimiento en el FIMT.
Conclusiones
En este este estudio se ha tratado de dar con la mejor estructura posible para el
FIMT dado un banco de ítems reducido y con fuertes restricciones mediante la
aplicación del EAT. Si bien este procedimiento tiene una corta trayectoria en las
aplicaciones de medición y evaluación cognitiva, sus ventajas han quedado claramente
manifiestas en comparación con una selección de ítems aleatoria. Convertir la
composición de un test en un problema de optimización lineal resoluble permite llegar a
soluciones óptimas una vez se conocen las propiedades psicométricas del banco de
ítems.
La estructura sencilla ha sido en este caso la que mejor se ha adaptado a las
características del banco de ítems ya que era la estructura menos demandante. Al tener
el banco operativo un número de ítems reducido y una cantidad nada desdeñable de
restricciones de presentación, conseguir una estructura multietapa más flexible y
adaptativa no es una tarea sencilla. La estructura sencilla demandaba una menor
cantidad de ítems para el FIMT, y de entre las preguntas seleccionadas para formar
parte de cada módulo, se han empleado las más precisas e informativas. Este es el
motivo por el que la estructura sencilla proporciona mayor información: al utilizar en
conjunto menor cantidad de ítems del banco operativo, han de cumplirse menos
restricciones de presentación y se consigue así que cada recorrido esté formado por los
mejores ítems posibles. En cambio, al ampliar el número de módulos por etapa –como
sucede en la estructura compleja- es más probable que los mejores ítems acaben en los
módulos iniciales e impidan la presentación de buenos ítems en los módulos finales
debido a estas restricciones de presentación.

- 42 -
Otra de las desventajas de utilizar una estructura compleja con un banco de ítems
reducido –y en el que se flexibilizan las condiciones de administración-, es que al final
dos evaluados que sigan una ruta distinta a lo largo del multietapa, pueden terminar
respondiendo a los mismos ítems en un orden diferente. El caso más llamativo es el de
los sujetos que terminan en el módulo de máxima dificultad en la última etapa del
FIMT. A este módulo se puede llegar respondiendo mediante un buen rendimiento en el
módulo de dificultad alta en la segunda etapa del test, o bien a través de una buena
ejecución en el módulo de dificultad intermedia de esta misma segunda etapa. Como a
un mismo evaluado no se le pueden aplicar los mismos ítems, el FIMT le aplica a cada
sujeto los mejores ítems disponibles, que son curiosamente los ítems de mayor
dificultad no hayan sido presentados para cada sujeto en la etapa anterior. Es decir,
aquellas personas que respondieron correctamente en la segunda etapa a los ítems de
máxima dificultad responderán a los ítems de dificultad intermedia en la nueva etapa; y
quienes respondieron bien a los ítems de dificultad intermedia en la segunda etapa se
enfrentarán en la tercera a los ítems de dificultad alta. Es un problema del banco
operativo: si no abundan los ítems de dificultad elevada, al final se acaba “echando
mano” siempre de los mismos. Al emplear menos ítems, la estructura sencilla previene
que se den este tipo de casos a costa, eso sí, de perder algo de adaptabilidad en la
aplicación de los ítems.
En suma, gracias al empleo del ensamblaje automático de ítems se ha
conseguido dotar al FIMT de una estructura sólida que permite maximizar la precisión
del test a lo largo del continuo del rasgo latente con un número reducido de ítems, de
modo que puede adaptarse relativamente al nivel de capacidad de las personas que lo
realicen.
Discusión
El propósito principal de este trabajo era aprovechar al máximo un banco inicial
de ítems de matrices progresivas y darles un tratamiento riguroso y una forma puntera
que resultase atractiva para emplearse en contextos de selección de personal. A lo largo
de los diferentes estudios se ha pasado de un banco de ítems reducido y bastante
peculiar a un banco operativo de ítems con el que se ha construido el mejor test
multietapa posible.

- 43 -
Este es uno de los aspectos centrales del trabajo, pues supone un claro ejemplo
de cómo abordar la construcción de un test multietapa cuando el banco de ítems es
reducido y posee fuertes restricciones. En la literatura académica, las aplicaciones
empíricas del EAT para la construcción de los tests multietapa suelen aplicarse a un
conjunto inicial relativamente amplio de ítems (Dallas, 2014) o bien bajo condiciones
de simulación, para explorar y evaluar distintos aspectos sobre las estructuras
multietapa, cómo el número de ítems por módulo (Zheng et al., 2012) o el número de
módulos por etapa (Armstrong, 2002). En el FIMT, en cambio, se está en todo momento
en un contexto aplicado, en el que al partir de un banco de ítems reducido las
condiciones de ensamblaje del test multietapa no son las óptimas. Aun así, este trabajo
pone de manifiesto que es posible construir mediante EAT un test multietapa breve e
informativo bajo condiciones muy restrictivas.
Otro de las aportaciones principales de estos estudios es la aplicación de nuevas
metodologías al ámbito de la evaluación de la inteligencia. Las evidencias de validez
convergente y discriminante del banco inicial de ítems ponen de manifiesto que el
FIMT supone una buena herramienta para evaluar la inteligencia fluida. Además, FIMT
es el primer test de inteligencia fluida que utiliza el formato multietapa para
administrarse a los sujetos. Este formato, además de las ventajas técnicas presentadas en
la introducción, permite una aplicación de los ítems interesante. En primer lugar
posibilita combinar una administración telemática –a través de internet- de los ítems con
una administración presencial. Se podrían presentar las primeras etapas del FIMT a
distancia y, para aquellas personas con un mejor rendimiento, administrarse después la
última etapa de manera presencial, en un entorno más controlado. En segundo lugar,
debido al formato de respuesta de los ítems es muy improbable obtener una alta
puntuación en el FIMT dando respuestas poco elaboradas o al azar. Los ítems del test
son muy demandantes y requieren de los evaluados una atención constante para deducir
cuáles son las reglas y cuál la respuesta correcta. Por último, la implementación de un
test multietapa es mucho más sencilla –y barata- que la de un TAI, pues las veces que ha
estimarse la capacidad temporal de los sujetos y de decidirse qué ítems han de
presentarse a continuación es mucho más reducida.
La aplicación del modelo de respuesta graduada para modelar los ítems del
FIMT supone una ventaja potencial para prevenir posibles errores de clasificación.
Cuando el nivel de capacidad cognitiva general de un evaluado está próximo a uno de
los puntos de corte que determinan cuál es el siguiente módulo a realizar, es posible que

- 44 -
se le asigne a ese mismo evaluado un módulo que se aleje de su nivel. Sin embargo, el
modelo de respuesta graduada ofrece más información sobre las respuestas erróneas de
los evaluados que el modelo de logístico de dos parámetros. Por ello, en caso de que se
produzca un error de clasificación a la hora de estimar el nivel de capacidad temporal de
los sujetos tras la primera etapa, al finalizar los ítems de la segunda etapa es más
probable que se asigne al evaluado el módulo de dificultad más adecuado dadas sus
capacidades.
No obstante, durante el proceso de construcción del FIMT se han dado varias
dificultades. En primer lugar no se cuenta con evidencias suficientes para determinar si
dos ítems son o no realmente independientes. Los resultados de los análisis DIF
permiten asumir que no todos los ítems construidos con las mismas reglas funcionan
igual en la misma población, pero en ningún caso nos permiten determinar si las
puntuaciones de un ítem original están o no fuertemente relacionadas con las
puntuaciones de sus clones. Sería necesario por tanto realizar otras pruebas que
contrasten la dependencia local de los ítems que finalmente componen en FIMT.
Otra de las limitaciones que pueden plantearse para este trabajo es si el FIMT
puede considerarse realmente un test multietapa si se permite que se repitan los ítems en
los recorridos de las distintas etapas y que la longitud de los módulos sea variable.
Normalmente, al ensamblar un test multietapa, una vez que los ítems han sido asignados
a un módulo, estos ítems se sacan del banco y no pueden ser elegidos para formar parte
de otros módulos (Luecht y Sireci, 2011). En el caso del FIMT, si se cumpliera esta
restricción, la información final proporcionada por cada recorrido del test sería muy
baja, por lo que no podrían proporcionarse estimaciones precisas sobre el nivel de
capacidad cognitiva general de los evaluados.
Asimismo, otra de las restricciones más habituales es fijar la misma longitud
para los módulos de cada etapa. En el FIMT, en cambio, se consideró ampliar la
longitud del último módulo de mayor dificultad para obtener más información para las
personas con mayores niveles de capacidad cognitiva general a costa de aumentar
ligeramente el tiempo de aplicación de la prueba.
Sin embargo, el FIMT sí que sigue una estructura dividida en varias etapas. Y
cada una de sus etapas se divide a su vez en distintos módulos de diferente dificultad
que marcan la trayectoria de los evaluados dentro del test. Precisamente es este carácter
adaptativo y el control sobre los contenidos que deben aparecen en cada módulo lo que

- 45 -
hacen del FIMT el mejor test multietapa que se ha podido construir con el banco de
ítems operativo.
Referencias
Abad, F.J., Olea, J., Ponsoda, V. y García, C. (2011). Medición en Ciencias del
Comportamiento y de la Salud. Madrid: Síntesis.
Ackerman, P. L., Beier, M. E., y Boyle, M. O. (2002). Individual differences in working
memory within a nomological network of cognitive and perceptual speed
abilities. Journal of Experimental Psychology: General, 131, 567−589.
Ackerman, P. L., Beier, M. E., y Boyle, M. O. (2005).Working memory and
intelligence: The same or different constructs? Psychological Bulletin, 131, 30−
60.
Armstrong, R.D. (2002). Routing rules formultiple-formstructures. (Computerized
Testing ReportNo. 02-08.) Newtown, PA: LawSchool Admission Council.
Bennett, G. K., Seashore, H. G., y Wesman, A. G. (1990). Differential Aptitude Test.
Quinta Edición. Madrid: TEA.
Birnbaum, A. (1968). Some latent trait models and their use in inferring an examinee's
ability. In F. Lord y M. Novick, Statistical theories of mental test scores.
Reading: Mass. Addison-Wesley.
Bock, R. D., y Aitkin, M. (1981). Marginal maximum likelihood estimation of item
parameters: An application of the EM algorithm. Psychometrika, 46, 443–459.
Breslow, N. E., y Day, N. E. (1980). Statistical methods in cancer research: Vol. 1. The
analysis of case–control studies (Scientific Publication No. 32). Lyon, France:
International Agency for Research on Cancer.
Carpenter, P. A., Just, M. A., y Shell, P. (1990). What one intelligence test measures: a
theoretical account of the processing in the Raven Progressive Matrices
Test. Psychological review, 97(3), 404.
Carroll, J. B. (1993). Human cognitive abilities. Cambridge: Cambridge.
University Press. Cattell, R. B. (1963). Theory of fluid and crystallized intelligence: A
critical experiment. Journal of educational psychology, 54(1), 1.
Chalmers, R. P. (2012). mirt: A Multidimensional Item Response Theory Package for
the R Environment. Journal of Statistical Software, 48(6), 1-29.
Colom, R., Abad, F.J., Quiroga, M.A., Shih, P.C., Flores-Mendoza, C. (2008). Working
memory and intelligence are highly related constructs, but why?. Intelligence,
36, 584-606.
Colom, R., Escorial, S., Shih, P. C., & Privado, J. (2007). Fluid intelligence, memory
span, and temperament difficulties predict academic performance of young
adolescents. Personality and Individual differences, 42(8), 1503-1514.
Colom, R., Flores-Mendoza, C., Quiroga, M.Á., y Privado, J. (2005). Working memory
and general intelligence: The role of short-term storage. Personality and
Individual Differences, 39, 1005−1014.

- 46 -
Conway, A., Cowan, N., Bunting, M., Therriault, D., y Minkoff, S. (2002). A latent
variable analysis of working memory capacity, short-term memory capacity,
processing speed, and general fluid intelligence. Intelligence, 30, 163−183.
Dallas, A. (2014). The effects of routing and scoring within a computer adaptive multi-
stage framework. (Tesis doctoral inédita). Department of Psychology. University
of North Carolina.
Daneman, M., y Carpenter, P. A. (1980). Individual-differences in working memory and
reading. Journal of Verbal Learning and Verbal Behavior, 19, 450−466.
Diao, Q., y van der Linden, W. J. (2011). Automated test assembly using lp_solve
version 5.5 in R. Applied Psychological Measurement, 35, 398–409.
Dorans, N. J., y Kulick, E. (1986). Demonstrating the utility of the standardization
approach to assessing unexpected differential item performance on the
Scholastic Aptitude Test. Journal of Educational Measurement, 23, 355-368.
Elosúa, M. R., Gutiérrez, F., García-Madruga, J. A., Luque, J. L., y Gárate, M. (1996).
Adaptación española del “Reading Span Test”de Daneman y Carpenter [Spanish
standardization of the Reading Span Test]. Psicothema, 8, 383−395.
Engle, R. W., Tuholski, S. W., Laughlin, J. E., y Conway, A. R. A. (1999). Working
memory, short-term memory and general fluid intelligence: A latent-variable
approach. Journal of Experimental Psychology: General, 128, 309–331.
Eriksen, B. A., y Eriksen, C. W. (1974). Effects of noise letters upon the identification
of target letter in a non-search task. Perception and Psychophysics, 16, 143−149.
Hambleton, R. K., Sireci, S. G., y Zumbo, B. D. (2013). Psychometric methods and
practices. New York: Routledge.
Hendrickson, A. (2007). An NCME instructional module on multistage
testing.Educational Measurement: Issues and Practice, 26(2), 44-52.
Holland, P. W., y Thayer, D. T. (1988). Differential item performance and the Mantel–
Haenszel procedure. In H. Wainer y H. I. Braun (Eds.), Test validity (pp. 129-
145). Hillsdale, NJ: Lawrence Erlbaum Associates.
Horn, J. L. (1986). Theory of fluid and crystalized intelligence. En: R.J. Sternberg (Ed.),
Advances in the psychology of human intelligence (vol. 3, pp. 443-451).
Hillsdale, NJ: Lawrence Erlbaum Associates.
Jodoin, M. G., Zenisky, A., y Hambleton, R. K. (2006). Comparison of the sychometric
properties of several computer-based test designs for credentialing exams with
multiple purposes. Applied Measurement in Education, 19(3), 203–220.
Kane, M. J., Hambrick, D. Z., Tuholski, S. W., Wilhelm, O., Payne, T. W., y Engle, R.
W. (2004). The generality of working memory capacity: A latent-variable
approach to verbal and visuospatial memory span and reasoning. Journal of
Experimental Psychology: General, 133, 189−217.
Konis, K. (2014). lpSolveAPI: R Interface for lp_solve version 5.5.2.0. R package
version 5.5.2.0-14.
Kyllonen, P. C., y Christal, R. E. (1990). Reasoning ability is (little more than)
working-memory capacity?! Intelligence, 14, 389 – 433.

- 47 -
Luecht, R. M., y Nungester, R. J. (1998). Some practical examples of computer-
adaptive sequential testing. Journal of Educational Measurement, 35, 229–249.
Luecht, R. M., Nungester, R. J., y Hadidi, A. (1996). Heuristic-based CAT: Balancing
item information, content, and exposure. Paper presented at the annual meeting
of the National Council on Measurement in Education, New York, NY.
Luecht, R. M., y Sireci, S. (2011). A review of models for computer-based testing.
Research Report.
Magis, D., Beland, S. y Raiche, G. (2013). difR: Collection of methods to detect
dichotomous differential item functioning (DIF) in psychometrics. R package
version 4.5.
Mantel, N., y Haenszel, W. (1959). Statistical aspects of the analysis of data from
retrospective studies of disease. Journal of the National Cancer Institute, 22,
719-748.
Marshalek, B., Lohman, D. F., y Snow, R. E. (1983). The complexity continuum in the
radex and hierarchical models of intelligence. Intelligence,7(2), 107-127.
Melican, G. J., Breithaupt, K., y Zhang, Y. (2010). Designing and implementing a
multistage adaptive test: The Uniform CPA Examination. En W. J. van der
Linden y C. E. W. Glas (Eds.), Elements of adaptive testing (pp. 167–189). New
York: Springer.
Miyake, A., Friedman, N. P., Rettinger, D. A., Shah, P., y Hegarty, M. (2001). How are
visuospatial working memory, executive functioning, and spatial abilities
related? A latent-variable analysis. Journal of Experimental Psycholog: General,
130, 621−640.
Primi, R. (2001). Complexity of geometric inductive reasoning tasks: Contribution to
the understanding of fluid intelligence. Intelligence, 30(1), 41-70.
R Core Team (2014). R: A language and environment for statistical computing. R
Foundation for Statistical Computing, Vienna: Austria.
Raju, N. S. (1988). The area between two item characteristic curves. Psychometrika, 53,
495-502.
Raju, N. S. (1990). Determining the significance of estimated signed and unsigned areas
between two item response functions. Applied Psychological Measurement, 14,
197-207.
Raven, J., Raven, J. C., y Court, JH (1998). Manual for Raven’s progressive matrices
and vocabulary scales. Oxford, England: Oxford Psychologists Press/San
Antonio, TX: The Psychological Corporation.
Revelle, W. (2015) psych: Procedures for Personality and Psychological Research.
Northwestern University, Evanston, Illinois: USA.
Revuelta, J. y Ponsoda, V. (2005). Fundamentos de estadística. Segunda Edición.
Madrid: Ediciones de la UNED.
Salgado, J. F., Anderson, N., Moscoso, S., Bertua, C., De Fruyt, F., y Rolland, J. P.
(2003). A meta-analytic study of general mental ability validity for different
occupations in the European community. Journal of Applied Psychology, 88(6),
1068.

- 48 -
Salgado, J. F., y Peiro, J. M. (2008). Psicología del trabajo, las organizaciones y los
recursos humanos en España. Papeles del psicólogo, 29(1), 2-5.
Samejima, F. (1969). Estimation of latent ability using a response pattern of graded
scores. New York: Psychometric Society.
Schmidt, F. L., y Hunter, J. (2004). General mental ability in the world of work:
occupational attainment and job performance. Journal of personality and social
psychology, 86(1), 162.
Snow, R. E., Kyllonen, P. C., y Marshalek, B. (1984). The topography of ability and
learning correlations. Advances in the psychology of human intelligence, 2, 47-
103.
Swaminathan, H., y Rogers, H. J. (1990). Detecting differential item functioning using
logistic regression procedures. Journal of Educational Measurement, 27, 361-
370.
Thurstone, L. (1938). Primary mental abilities. Psychometric Monographs, 1.
Unsworth, N., Fukuda, K., Awh, E., y Vogel, E. K. (2014). Working memory and fluid
intelligence: Capacity, attention control, and secondary memory
retrieval. Cognitive psychology, 71, 1-26.
Unsworth, N., Spillers, G.J., y Brewer, G.A. (2009). Examining the relations among
working memory capacity, attention control, and fluid intelligence from a dual-
component framework. Psychology Science Quarterly, 4, 388-402.
van der Linden, W. J. (2005). Linear models for optimal test design. New York:
Springer.
Wang,X., Fluegge, L., y Luecht, R. (2012). A large-scale comparative study of the
accuracy and efficiency of ca-MST. Paper presented at the annual meeting of the
National Council on Measurement en Education, Vancouver, BC, Canada.
Zumbo, B. D., y Thomas, D. R. (1997). A measure of effect size for a model-based
approach for studying DIF. Prince George, Canada: University of Northern
British Columbia, Edgeworth Laboratory for Quantitative Behavioral Science.

- 49 -
Anexo I – Parámetros de los ítems
Se muestran a continuación los parámetros del banco operativo. Los ítems con tres parámetros
bj en lugar de cuatro son aquellos en los que se han colapsado la primera y la segunda categoría
de respuestas.
Núm. Ítem a b1 b2 b3 b4 Núm. Ítem a b1 b2 b3 b4
1 Original 1 1.13 -2.47 -1.64 -1.53 -1.48 28 Clon1 10 0.83 -2.68 0.38 2.07 2.46
2 Clon1 1 0.73 -6.20 -4.23 -3.90 -2.87 29 Clon2 10 0.83 -3.00 -0.34 1.47 1.92
3 Clon2 1 0.87 -5.15 -3.27 -2.76 -2.16 30 Original 10 1.30 -2.69 -1.59 0.64 0.83
4 Original 2 1.14 -3.93 -2.46 -0.77 -0.45 31 Clon1 11 1.15 -2.20 -0.83 0.47 2.21
5 Clon1 2 1.14 -3.81 -2.77 -1.27 -1.01 32 Clon2 11 1.15 -2.20 -0.68 0.41 2.36
6 Clon2 2 0.96 -5.01 -3.46 -1.86 -1.45 33 Original 11 1.35 -1.66 -0.39 -0.07 1.19
7 Original 3 1.29 -3.79 -2.77 -2.04 -1.83 34 Clon1 12* 0.16 -11.8 -1.95 21.51
—
8 Clon1 3 1.15 -3.47 -2.75 -2.30 -2.16 35 Clon2 12* 0.16 -13.8 -2.05 21.09 —
9 Clon2 3 1.15 -3.92 -3.00 -2.11 -1.92 36 Original 12 0.90 -6.61 -1.46 -0.72 0.17
10 Original 4 1.23 -1.43 -1.09 -0.86 -0.47 37 Clon1 13 0.58 -1.96 1.24 1.31 1.39
11 Clon1 4 0.98 -1.56 -1.41 -1.09 -0.71 38 Clon2 13 0.86 -1.07 1.66 2.01 2.17
12 Clon2 4 1.07 -2.26 -1.8 -1.46 -1.06 39 Original 13 0.96 -1.21 0.18 0.46 —
13 Original 5 1.17 -3.33 -1.56 -0.91 -0.89 40 Clon1 14 1.99 -3.11 -1.24 0.38 —
14 Clon1 5 0.67 -2.99 -2.01 -1.93 -1.74 41 Clon2 14 1.30 -4.85 -1.33 0.35 —
15 Clon2 5 0.69 -3.04 -1.03 -0.75 -0.51 42 Original 14 1.13 -2.33 -0.83 0.62 —
16 Original 6 1.21 -2.56 -2.45 -1.92 -1.06 43 Clon1 15 0.56 -8.69 -3.44 -1.89 —
17 Clon1 6 1.08 -2.99 -2.49 -0.35 0.48 44 Clon2 15 0.56 -8.01 -3.24 -1.03 —
18 Clon2 6 1.01 -2.04 -1.66 -0.49 0.19 45 Original 15 0.72 -7.16 -2.78 -1.77 —
19 Original 7 0.97 -4.17 -3.25 -1.20 0.55 46 Clon1 16 1.30 -2.63 -1.64 -1.3 -1.22
20 Clon1 7 0.92 -3.40 -0.28 1.29 — 47 Clon2 16 1.30 -2.53 -1.46 -0.91 -0.77
21 Clon2 7 0.79 -4.46 -4.17 -1.16 2.88 48 Original 16 1.50 -2.57 -1.74 -1.46 -1.39
22 Original 8 1.08 -3.06 -0.72 0.63 0.67 49 Clon1 17 0.60 -5.70 -0.77 0.01 0.42
23 Clon1 8 1.02 -1.63 -0.09 1.30 — 50 Clon2 17 0.60 -7.08 -0.92 -0.39 -0.20
24 Clon2 8 1.02 -1.56 0.09 1.34 1.37 51 Original 17 0.48 -5.27 -2.21 1.36 1.91
25 Clon1 9 1.10 -1.38 -0.03 0.62 1.17 52 Clon1 18 0.94 -3.55 -1.91 0.88 —
26 Clon2 9 0.75 -2.46 -0.63 -0.36 0.56 53 Clon2 18 0.94 -6.37 -3.41 -1.32 1.25
27 Original 9 0.78 0.01 1.75 2.10 2.66 54 Original 18 1.41 -4.65 -2.53 -1.77 -0.05
* El primer y el segundo clon del ítem 12 (número de ítem 34 y 35) no se incluyeron entre los ítems del banco operativo

- 50 -
Anexo II – Módulos del FIMT
Test de Ruta
Módulo 1. Clon1 8 (núm. 24), Clon1 9 (núm. 25), Original 10 (núm. 30),
Original 11 (núm. 33), Clon1 14 (núm. 40).
Segunda Etapa
Módulo 2. Clon1 6 (núm. 17), Clon1 7 (núm. 20), Clon1 10 (núm. 28),
Clon2 13 (núm. 38), Clon2 14 (núm. 41), Clon2 18 (núm. 53).
Módulo 3. Original 2 (núm. 4), Original 4 (núm. 10), Clon1 6 (núm. 17),
Clon2 14 (núm. 41), Clon2 16 (núm. 47), Original 18 (núm. 54).
Tercera Etapa
Módulo 4.
Recorrido Alto/Alto. Original 2 (núm. 4), Clon2 6 (núm18), Clon2 7 (núm. 21),
Clon2 9 (núm.26), Original 9 (núm. 27), Original 12 (núm. 36),
Clon1 13 (núm. 37), Original 13 (núm. 39), Original 18 (núm. 54).
Recorrido Bajo/Alto. Clon2 6 (núm18), Clon1 7 (núm. 20), Clon2 7 (núm. 21),
Original 9 (núm. 27), Clon1 10 (núm. 28), Original 12 (núm. 36),
Clon2 13(núm. 38), Original 13 (núm. 39).
Módulo 5.
Recorrido Alto/Bajo. Original 2 (núm. 4), Original 4 (núm. 10),
Clon2 16 (núm. 47), Original 18 (núm. 54).
Recorrido Bajo/Bajo. Original 5 (núm. 13), Clon2 6 (núm. 18),
Original 7 (núm. 19), Original 13 (núm. 39).


















