
Trabajo Arquitectura
36
2 INSTITUTO TECNOLOGICO DE ORIZABA Programa Educativo Arquitectura de computadoras Estudiante Paola Alejandra Silva García Docente Rossana Graciela Trejo Pacheco Trabajo Reporte de la Unidad 1 Hora 10:00 – 11:00 am
-
Upload
paola-silva-garcia -
Category
Documents
-
view
229 -
download
0
description
Resumen unidad 1
Transcript of Trabajo Arquitectura

2
INSTITUTO TECNOLOGICO DE ORIZABA
Programa Educativo
Arquitectura de computadoras
Estudiante
Paola Alejandra Silva García
Docente
Rossana Graciela Trejo Pacheco
Trabajo
Reporte de la Unidad 1
Hora
10:00 – 11:00 am
Grupo
5g6A

2
INTRODUCCION
En el siguiente trabajo se recopilan los temas correspondientes a la unidad número 1, de la asignatura Arquitectura de Computadoras.
La arquitectura de computadoras es el diseño conceptual y la estructura operacional fundamental de un sistema que conforma una computadora. Es decir, es un modelo y una descripción funcional de los requerimientos y las implementaciones de diseño para varias partes de una computadora, con especial interés en la forma en que la unidad central de proceso (CPU) trabaja internamente y accede a las direcciones de memoria.
La arquitectura de una computadora explica la situación de sus componentes y permite determinar las posibilidades de un sistema informático, con una determinada configuración, para que pueda realizar las operaciones para las que se va a utilizar. La arquitectura básica de cualquier ordenador completo está formado por solo 5 componentes básicos: procesador, memoria RAM, disco duro, dispositivos de entrada/salida y software.

2
INDICE
1.1 Modelos de Arquitecturas de cómputo
1.1.1 Arquitecturas Clásicas
1.1.2 Arquitecturas Segmentadas
1.1.3 Arquitecturas de Multiprocesamiento
1.2 Análisis de los componentes
1.2.1 CPU
1.2.1.1 Arquitecturas
1.2.1.2 Tipos
1.2.1.3 Características
1.2.1.4 Funcionamiento
1.2.2 Memoria
1.2.2.1 Conceptos básicos del manejo de la memoria
1.2.2.2 Memoria Principal Semiconductora
1.2.2.3 Memoria Cache
1.2.3 Manejo de la Entrada/Salida
1.2.3.1 Módulos de Entrada/Salida
1.2.3.2 Entrada/Salida Programada
1.2.3.3 Entrada/Salida mediante interrupciones
1.2.3.4 Acceso directo a Memoria
1.2.3.5 Canales y Procesadores de Entrada/Salida
Página 5
Página 5
Página 9
Página 11
Página 12
Página 12
Página 12
Página 16
Página 16
Página 17
Página 21
Página 22
Página 22
Página 22
Página 23
Página 23
Página24
Página 24
Página 25
Página 25
2
1.2.4 Buses
1.2.4.1 Tipos de Buses
1.2.4.2 Estructura de los Buses
1.2.4.3 Jerarquía de los Buses
1.2.5 Interrupciones
Bibliografía
Página 26
Página 26Página 27
Página 28
Página 30
Página 31

2
1.1 Modelos de Arquitecturas de Cómputo
Existen tres modelos de Arquitectura de computadora que son: la clásica, la segmentada y la de multiprocesamiento. La arquitectura de computadoras es el diseño conceptual y la estructura operacional fundamental de un sistema de computadora. Es decir, es un modelo y una descripción funcional de los requerimientos y las implementaciones de diseño para varias partes de una computadora. También suele definirse como la forma de seleccionar e interconectar componentes de hardware para crear computadoras según los requerimientos de funcionalidad, rendimiento y costo.
1.1.1 Arquitecturas ClásicasEstas arquitecturas se desarrollaron en las primeras computadoras electromecánicas y de tubos de vacío. Aun son usadas en procesadores empotrados de gama baja y son la base de la mayoría de las arquitecturas modernas.
Arquitectura Mauchly-Eckert (Von Newman) Esta arquitectura fue utilizada en la computadora ENIAC. Consiste en una unidad central de proceso que se comunica a través de un solo bus con un banco de memoria en donde se almacenan tanto los códigos de instrucción del programa, como los datos que serán procesados por este. Esta arquitectura es la más empleada en la actualidad ya, que es muy versátil. Ejemplo de esta versatilidad es el funcionamiento de los compiladores, los cuales son programas que toman como entrada un archivo de texto conteniendo código fuente y generan como datos de salida, el código maquina que corresponde a dicho código fuente (Son programas que crean o modifican otros programas). Estos datos de salida pueden ejecutarse como un programa posteriormente ya que se usa la misma memoria para datos y para el código del programa.

2
La principal desventaja de esta arquitectura, es que el bus de datos y direcciones único se convierte en un cuello de botella por el cual debe pasar toda la información que se lee de o se escribe a la memoria, obligando a que todos los accesos a esta sean secuenciales. Esto limita el grado de paralelismo (acciones que se pueden realizar al mismo tiempo) y por lo tanto, el desempeño de la computadora. Este efecto se conoce como el cuello de botella de Von Newman En esta arquitectura apareció por primera vez el concepto de programa almacenado. Anteriormente la Procesador Memoria Principal Almacena el programa y los datos Entrada y salida Bus principal Registros ALU Unidad de Control secuencia de las operaciones era dictada por el alambrado de la unidad de control, e cambiarla implicaba un proceso de re cableado laborioso, lento (hasta tres semanas) y propenso a errores. En esta arquitectura se asigna un código numérico a cada instrucción. Dichos códigos se almacenan en la misma unidad de memoria que los datos que van a procesarse, para ser ejecutados en el orden en que se encuentran almacenados en memoria. Esto permite cambiar rápidamente la aplicación de la computadora y dio origen a las computadoras de propósito general.
Arquitectura Harvard Esta arquitectura surgió en la universidad del mismo nombre, poco después de que la arquitectura Von Newman apareciera en la universidad de Princeton. Al igual que en la arquitectura Von Newman, el programa se almacena como un código numérico en la memoria, pero no en el mismo espacio de memoria ni en el mismo formato que los datos. Por ejemplo, se pueden almacenar las instrucciones en doce bits en la memoria de programa, mientras los datos de almacenan en 8 bits en una memoria aparte.
El hecho de tener un bus separado para el programa y otro para los datos permite que se lea el código de operación de una instrucción, al mismo tiempo

2
se lee de la memoria de datos los operados de la instrucción previa. Así se evita el problema del cuello de botella de Von Newman y se obtiene un mejor desempeño. En la actualidad la mayoría de los procesadores modernos se conectan al exterior de manera similar a a la arquitectura Von Newman, con un banco de memoria masivo único, pero internamente incluyen varios niveles de memoria cache con bancos separados en cache de programa y cache de datos, buscando un mejor desempeño sin perder la versatilidad.
Arquitectura vectorial El encadenamiento aumenta la velocidad de proceso, pero aún se puede mejorar añadiendo técnicas como el supersescalado. Esta técnica permite hacer paralelas las mismas etapas sobre instrucciones diferentes. Un procesador superescalar puede ejecutar más de una instrucción a la vez. Para esto es necesario que existan varias unidades aritmético-lógicas, de punto flotante y de control. El proceso que sigue el micro es transparente al programa, aunque el compilador puede ayudar analizando el código y generando un flujo de instrucciones optimizado. Veamos cómo se ejecutarían las instrucciones en un procesador superescalar de que tiene duplicadas las subunidades que lo componen:
Aunque esto mejora la velocidad global del sistema, los conflictos de datos crecen. Si antes las instrucciones se encontraban muy próximas, ahora se
ejecutan simultáneamente Esto hace necesario un chequeo dinámico para detectar y resolver los posibles conflictos.
Arquitectura pipe-line Paralelismo Temporal: Pipe-Line “Lineal”

2
La arquitectura pipe-line se aplica en dos lugares de la maquina, en la CPU y en la UAL. Veamos en qué consiste el pipe-line y tratemos de entender porque el pipe-line mejora el rendimiento de todo el sistema.
Veamos una CPU no organizada en pipe-line:
Si se trata de una instrucción a ser ejecutada por la ALU podemos decir que la CPU realiza a lo largo del ciclo de maquina estas 5 tareas. Una vez que termina de ejecutar una instrucción va a buscar otra y tarda en ejecutarla un tiempo T, es decir cada T segundos ejecuta una instrucción.
Ya hemos mencionado que una de las formas de lograr operaciones concurrentes en un procesador se utilizan dos técnicas básicas: paralelismo y pipelining.
El paralelismo conseguía la concurrencia multiplicando la estructura del hardware tantas veces como sea posible, de modo que las diferentes etapas del proceso se ejecuten simultáneamente.
Pipelining consiste en desdoblar la función a realizarse en varias partes, asignándole al hardware correspondiente a cada una de las partes también llamadas etapas. Así como el agua fluye a través de una tubería (pipeline) las instrucciones o datos fluyen a través de las etapas de un computador digital pipeline a una velocidad que es independiente de la longitud de la tubería (numero de etapas del pipeline) y depende solamente de la velocidad a la cual los datos e instrucciones pueden ingresar al pipeline.

2
Esta velocidad a su vez depende del tiempo que tarde el dato en atravesar una etapa. Este tiempo puede ser significativo ya que el computador no solo desplaza los datos o instrucciones de etapa en etapa sino que en cada una de ellas se realiza alguna operación sobre los mismos. Como ejemplo en el caso de las instrucciones tendremos operaciones de búsqueda, decodificación y ejecución.
1.1.2 Arquitecturas SegmentadasLas arquitecturas segmentadas o con segmentación del cauce buscan mejorar el desempeño realizando paralelamente varias etapas del ciclo de instrucción al mismo tiempo. El procesador se divide en varias unidades funcionales independientes y se dividen entre ellas el procesamiento de las instrucciones. Para comprender mejor esto, supongamos que un procesador simple tiene un ciclo de instrucción sencillo consistente solamente en una etapa de búsqueda del código de instrucción y en otra etapa de ejecución de la instrucción. En un procesador sin segmentación del cauce, las dos etapas se realizarían de manera secuencial para cada una de las instrucciones, como lo muestra la siguiente figura
En un procesador con segmentación del cause, cada una de estas etapas se asigna a una unidad funcional diferente, la búsqueda a la unidad de búsqueda y la ejecución a la unidad de ejecución. Estas unidades pueden trabajar en

2
forma paralela en instrucciones diferentes. Estas unidades se comunican por medio de una cola de instrucciones en la que la unidad de búsqueda coloca los códigos de instrucción que leyó para que la unidad de ejecución los tome de la cola y los ejecute. Esta cola se parece a un tubo donde las instrucciones entran por un extremo y salen por el otro. De esta analogía proviene el nombre en inglés: Pipelining o entubamiento. En general se divide al procesador segmentado en una unidad independiente por cada etapa del ciclo de instrucción.
Completando el ejemplo anterior, en un procesador con segmentación, la unidad de búsqueda comenzaría buscando el código de la primera instrucción en el primer ciclo de reloj. Durante el segundo ciclo de reloj, la unidad de búsqueda obtendría el código de la instrucción 2, mientras que la unidad de ejecución ejecuta la instrucción 1 y así sucesivamente. La siguiente figura muestra este proceso.
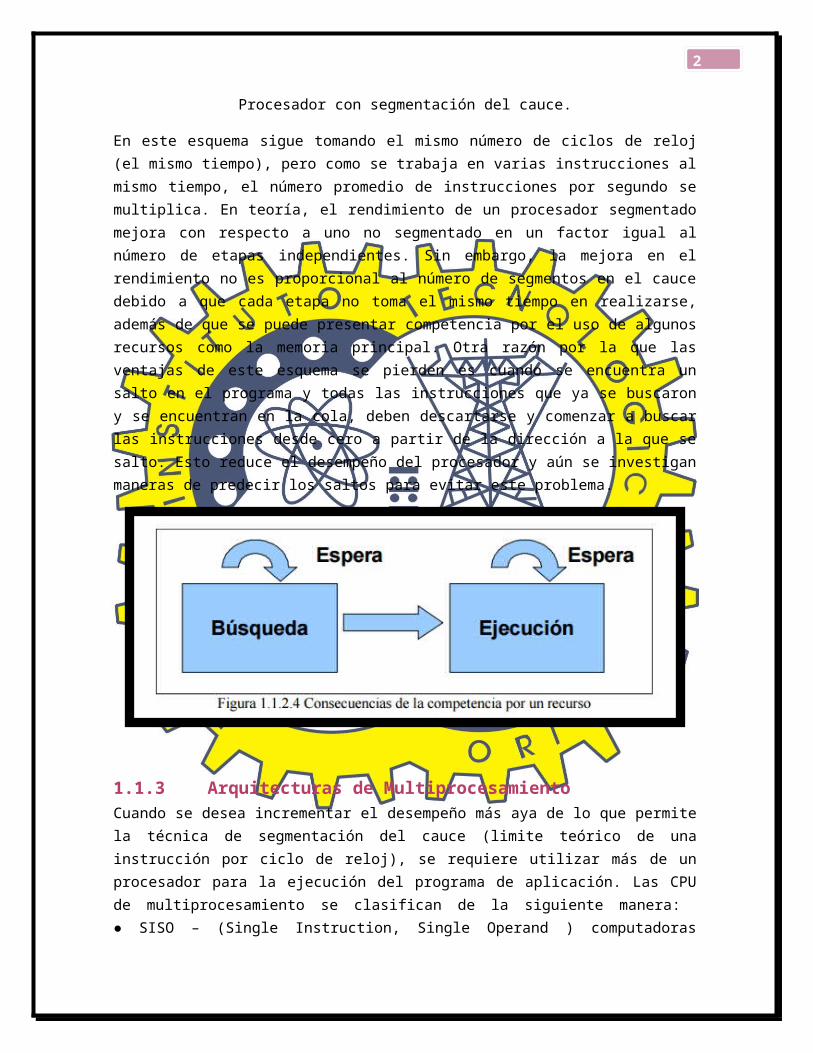
Procesador con segmentación del cauce.
En este esquema sigue tomando el mismo número de ciclos de reloj (el mismo tiempo), pero como se trabaja en varias instrucciones al mismo tiempo, el número promedio de instrucciones por segundo se multiplica. En teoría, el rendimiento de un procesador segmentado mejora con respecto a uno no segmentado en un factor igual al número de etapas independientes. Sin

2
embargo, la mejora en el rendimiento no es proporcional al número de segmentos en el cauce debido a que cada etapa no toma el mismo tiempo en realizarse, además de que se puede presentar competencia por el uso de algunos recursos como la memoria principal. Otra razón por la que las ventajas de este esquema se pierden es cuando se encuentra un salto en el programa y todas las instrucciones que ya se buscaron y se encuentran en la cola, deben descartarse y comenzar a buscar las instrucciones desde cero a partir de la dirección a la que se salto. Esto reduce el desempeño del procesador y aún se investigan maneras de predecir los saltos para evitar este problema.
1.1.3 Arquitecturas de MultiprocesamientoCuando se desea incrementar el desempeño más aya de lo que permite la técnica de segmentación del cauce (limite teórico de una instrucción por ciclo de reloj), se requiere utilizar más de un procesador para la ejecución del programa de aplicación. Las CPU de multiprocesamiento se clasifican de la siguiente manera: ● SISO – (Single Instruction, Single Operand ) computadoras independientes ● SIMO – (Single Instruction, Multiple Operand ) procesadores vectoriales● MISO – (Multiple Instruction, Single Operand ) No implementado ● MIMO – (Multiple Instruction, Multiple Operand ) sistemas SMP, Clusters Procesadores vectoriales – Son computadoras pensadas para aplicar un mismo algoritmo numérico a una serie de datos matriciales, en especial en la simulación de sistemas físicos complejos, tales como simuladores para predecir el clima, explosiones atómicas, reacciones químicas complejas, etc., donde los datos son representados como grandes números de datos en forma matricial sobre los que se deben se aplicar el mismo algoritmo numérico. En los sistemas SMP (Simetric Multiprocesesors), varios procesadores comparten la misma memoria principal y periféricos de I/O, Normalmente conectados por un bus común. Se conocen como simétricos, ya que ningún procesador toma el papel de maestro y los demás de esclavos, sino que todos tienen derechos
2
similares en cuanto al acceso a la memoria y periféricos y ambos son administrados por el sistema operativo.
Los Clusters son conjuntos de computadoras independientes conectadas en una red de área local o por un bis de interconexión y que trabajan cooperativamente para resolver un problema. Es clave en su funcionamiento contar con un sistema operativo y programas de aplicación capaces de distribuir el trabajo entre las computadoras de la red.
1.2 Análisis de Componentes
1.2.1 CPULa unidad central de procesamiento, UCP o CPU (por el acrónimo en inglés de central processing unit), o simplemente el procesador o microprocesador, es el componente del computador y otros dispositivos programables, que interpreta las instrucciones contenidas en los programas y procesa los datos. Los CPU proporcionan la característica fundamental de la computadora digital (la programabilidad) y son uno de los componentes necesarios encontrados en las computadoras de cualquier tiempo, junto con el almacenamiento primario y los dispositivos de entrada/salida. Se conoce como microprocesador el CPU que es manufacturado con circuitos integrados. Desde mediados de los años 1970, los microprocesadores de un solo chip han reemplazado casi totalmente todos los tipos de CPU, y hoy en día, el término "CPU" es aplicado usualmente a todos los microprocesadores.
1.2.1.1 ArquitecturasAdemás de las arquitecturas clásicas mencionadas anteriormente, en la actualidad han aparecido arquitecturas híbridas entre la Von Newman y la Harvard, buscando conservar la flexibilidad, pero mejorando el rendimiento. El cambio más importante de los últimos años en diseño de las computadoras de los últimos años se dio durante los años 1980, con la aparición de la corriente de diseño conocida como computadoras de conjunto reducido de instrucciones (RISC, por sus siglas en ingles). Esta escuela pretende aplicar un enfoque totalmente distinto al tradicional hasta entonces, que pasó a conocerse como computadoras de conjunto complejo de instrucciones (CISC) para diferenciarla de la nueva tendencia. La tendencia tradicional, representada por las arquitecturas CISC (Complex Instruction Set Computers) se caracterizan por tener un número amplio de instrucciones y modos de direccionamiento. Se implementan instrucciones especiales que realizan funciones complejas, de manera que un programador puede encontrar con seguridad, una instrucción especial que realiza en hardware la función que el necesita. El número de

2
registros del CPU es limitado, ya que las compuertas lógicas del circuito integrado se emplean para implementar las secuencias de control de estas instrucciones especiales. Al investigar las tendencias en la escritura de software científico y comercial al inicio de los 80, ya se pudo observar que en general ya no se programaba mucho en ensamblador, sino en lenguajes de alto nivel, tales como C. Los compiladores de lenguajes de alto nivel no hacían uso de las instrucciones especiales implementadas en los procesadores CISC, por lo que resultaba un desperdicio de recursos emplear las compuertas del circuito de esta forma. Por lo anterior, se decidió que era mejor emplear estos recursos en hacer que las pocas instrucciones que realmente empleaban los compiladores se ejecutaran lo más rápidamente posible. Así surgió la escuela de diseño RISC (Reduced Instruction Set Computers) donde solo se cuenta con unas pocas instrucciones y modos de direccionamiento, pero se busca implementarlos de forma muy eficiente y que todas las instrucciones trabajen con todos los modos de direccionamiento. Además, se observo que una de las tareas que tomaban más tiempo en ejecutarse en lenguajes de alto nivel, era el pasar los parámetros a las subrutinas a través de la pila. Como la forma más rápida de hacer este paso es por medio de registros del CPU, se busco dotarlo con un amplio número de registros, a través de los cuales se pueden pasar dichos parámetros. Tanto la miniaturización como la estandarización de los CPU han aumentado la presencia de estos dispositivos digitales en la vida moderna mucho más allá de las aplicaciones limitadas de máquinas de computación dedicadas. Los microprocesadores modernos aparecen en todo, desde automóviles, televisores, neveras, calculadoras, aviones, hasta teléfonos móviles o celulares, juguetes, entre otros.
Arquitectura interna del CPULa CPU contiene un conjunto de localidades de almacenamiento temporal de datos de alta velocidad llamada registro. Algunos de los registros están dedicados al control, y solo la unidad de control tiene acceso a ellos. Los registros restantes son los registros de uso general y el programador es el usuario que tiene acceso a ellos.
Dentro del conjunto básico de registros de control se deben incluir a los siguientes:
Contador de programa (PC).
Registro de direcciones de la memoria (MAR).
Registro de datos (RD).
Registro de instrucciones (ER).
Palabra de estado de programa (PSW).

2
(PC): La función del PC consiste en seguir la pista de la instrucción por buscar (capturar) en el siguiente ciclo de maquina, por lo tanto contiene la dirección de la siguiente instrucción por ejecutar.El PC es modificado dentro del ciclo de búsqueda de la instrucción actual mediante la suma de una constante. El numero que se agrega al PC es la longitud de una instrucción en palabras.
Por lo tanto, si una instrucción tiene una palabra de longitud se agrega 1 al PC, si una instrucción tiene dos palabras de largo se agrega 2, y así sucesivamente.
Registro de direcciones de la memoria (MAR): funciona como registro de enlace entre la CPU y el canal de direcciones. Cuando se logra el acceso a la memoria la dirección es colocada en el MAR por la unidad de control y ahí permanece hasta que se completa la transacción. El numero de bit que hay en el MAR es igual al del canal de direcciones.
La diferencia que existe entre el PC y el MAR es que durante el ciclo de ejecución de una instrucción, el PC y el MAR sirven al mismo fin. Sin embargo, muchas de las instrucciones de la maquina hacen referencia a la memoria y operan con los datos que están en ella. Como la dirección de los datos suele ser diferente de la instrucción siguiente se necesita el MAR.
Registro de datos: la función del RD consiste en proporcionar un área de almacenamiento temporal (memoria intermedia, acumulada o buffer) de datos que se intercambian entre la PCU y la memoria. Los datos pueden ser instrucciones (obtenidos en el ciclo de ejecución) o datos del operando (obtenidos en el ciclo de ejecución). Debido a su conexión directa con el canal de datos el RD contiene el mismo numero de bit que dicho canal.
Registro de instrucciones (ER): es un registro que conserva el código de operación de la instrucción en todo el ciclo de la maquina. El código es empleado por la unidad de control de la CPU para generar las señales apropiadas que controla le ejecución de la instrucción. La longitud del ER es la longitud en bit del código de operación.
Palabra de estado de programa (PSW): la palabra de estado o condición de programa almacena información pertinente sobre el programa que este ejecutándose. Por ejemplo al completarse una función de la unidad aritmética lógica se modifica un conjunto de bit llamados códigos (o señales de condición). Estos bit especifican si el resultado de una operación aritmética fue 0 o negativo o si el resultado se desbordó.

2
El programa puede verificar estos bit en las instrucciones siguientes cambiar en forma condicional su flujo de control según su valor.
Además el PSW contiene bit que hacen posible que la computadora responda a solicitudes de servicio asincrónicas generadas por dispositivos de Entrada-Salida, o condiciones de error interno. Estas señales se denominan interrupciones.
Los registros restantes que se pueden encontrar en un microprocesador son de uso general. Estos se utilizan para almacenar información en forma temporal. También retienen operandos que participan en operaciones de la ULA.
Algunas veces el conjunto de instrucciones de la computadora y el esquema de direccionamiento de la arquitectura restringe el uso de alguno de estos registros.
Si bien en todas las maquinas la información contenida en el registro puede manipularse como datos ordinarios durante la ejecución de algunas instrucciones los datos se utilizan en forma explícita para decidir una dirección de la memoria. La ventaja de usar registros para retener datos de operaciones es la velocidad.
1.2.1.2 TiposLos primeros CPU fueron diseñados a la medida como parte de una computadora más grande, generalmente una computadora única en su especie. Sin embargo, este costoso método de diseñar los CPU a la medida, para una aplicación particular, ha desaparecido en gran parte y se ha sustituido por el desarrollo de clases de procesadores baratos y estandarizados adaptados para uno o muchos propósitos. Esta tendencia de estandarización comenzó generalmente en la era de los transistores discretos, computadoras centrales, y microcomputadoras, y fue acelerada rápidamente con la popularización del circuito integrado (IC), éste ha permitido que sean diseñados y fabricados CPU más complejos en espacios pequeños (en la orden de milímetros).

2
Los CPUs modernos pueden clasificarse de acuerdo a varias características, tales como: el tamaño del ALU o del Bus de conexión al exterior (8, 16, 32, 64 bits), si tienen cauce segmentado o no segmentado, si con tipo CISC o RISC, Von Newman o Harvard y si solo tienen instrucciones enteras o implementan también instrucciones de punto flotante.
1.2.1.3 CaracterísticasLas características más importantes a considerar al escoger un CPU para usarlo en una aplicación, son: •Modelo del programador (Conjunto de registros que el programador puede utilizar), forman el modelo mental del CPU que el programador utiliza al programar en ensamblador. •Conjunto de instrucciones que puede ejecutar el CPU •Modos de direccionamiento que pueden usarse para obtener los operandos de las instrucciones. •Ciclo de instrucción (el conjunto de pasos que realiza el CPU para procesar cada instrucción) •Buses de interconexión, usados para que el CPU lea y escriba a la memoria y a los dispositivos de entrada y salida.
Desde mediados de los años 1970, los microprocesadores de un solo chip han reemplazado casi totalmente todos los tipos de CPU, y hoy en día, el término "CPU" es aplicado usualmente a todos los microprocesadores.
1.2.1.4 Funcionamiento (ALU, unidad de control, Registros y buses internos)
Debido a la gran variedad de CPU disponibles comercialmente, se explicara el funcionamiento de un unidad central de proceso imaginaria muy simple, pero que resume el funcionamiento básico de la mayoría de los CPUs. Este CPU es similar a las primeras computadoras existentes en los años 1950s. Esta computadora contara con una memoria de 4096 palabras de 16 bits cada una. Esto corresponde a un bus de direcciones de 12 bits y un bus de datos de 16 bits). En cada localidad de memoria se podrá almacenar un entero de 16 bits o el código de una instrucción, también de 16 bits. Todos los CPU tienen como función principal la ejecución de un programa acorde a la aplicación del mismo. Un programa es un conjunto de instrucciones almacenadas de acuerdo al orden en que deben ejecutarse. Por lo tanto, toda computadora debe ser capaz de procesar las instrucciones de su programa en un ciclo de instrucción, consistente en un número de etapas que varia con cada CPU, pero que tradicionalmente han sido tres:

2
1-Búsqueda del código de Instrucción. Esta consiste en leer de la memoria cual será la siguiente instrucción a ejecutar, la cual esta almacenada en forma de un código numérico que indica cual de todas las operaciones que puede realizar el CPU será la siguiente y con que operandos se ejecutara. 2- Decodificación. Consiste en tomar el código numérico e identificar a cuál de las operaciones que puede realizar el CPU corresponde dicho código. El proceso contrario, la codificación, consiste en conociendo la instrucción, determinar el número que la va a representar. Esta etapa usualmente se realiza con un decodificador binario. 3- Ejecución. En esta etapa se lleva a cabo la operación sobre los datos que se vallan a procesar. En general, la unidad de control (CU) genera las señales de control necesarias para llevar los datos a las entradas de la Unidad Aritmética Lógica, la cual efectuará las operaciones aritméticas y lógicas. Posteriormente, la unidad de control generara las señales de control necesarias para transferir la salida de la Unidad Aritmética Lógica al registro donde serán almacenados los resultados para su uso posterior.
Es importante recordar que cada instrucción del programa se almacena en memoria como un número binario. Este número se conoce como código de instrucción, y usualmente se divide en al menos dos campos: un código de operación (Opcode) y un número que representa al operando u operandos de la instrucción. En el caso de la computadora imaginaria que estamos estudiando, se almacena cada instrucción en una de las 4096 palabras de memoria de 16 bits cada una. Se utiliza un formato de un solo operando, con un segundo operando en el acumulador cuando es necesario. Los cuatro bits más significativos de los dieciséis bits de la palabra se dedican a almacenar el código de operación. Los doce bits menos significativos se dedican a almacenar la dirección del operando.

2
La siguiente tabla resume los códigos de operación de la computadora de ejemplo.

2
Las partes del CPU de la computadora imaginaria son: ACC – Acumulador, se usará para almacenar uno de los operandos y el resultado de varias de las instrucciones MAR – (Memory Address Register) Registro de dirección de memoria, selecciona a que localidad de memoria se va a leer o a escribir. MBR – (Memory Bus Register) Registro de bus de memoria. A través de él se lee y se escriben los datos. PC – (Program Counter) El contador de programa almacena la dirección de la siguiente instrucción a buscar. Por esta razón también es conocido como apuntador de instrucciones. IR - Registro de instrucción, guarda el código de la instrucción que se esta ejecutando.
Flags – Registro de Banderas, agrupa a todas las banderas de la ALU en un registro, en el caso de nuestra computadora imaginaria, las banderas disponibles serán: Z – Bandera de Cero, se pone en uno cuando todos los bits del resultado son cero; O – Sobreflujo, se pone en uno cuando el resultado de la última operación se sale de el rango de los números de 16 bits con signo; C – Acarreo, se enciende cuando el resultado de la última operación se sale del rengo de los números de 16 bits sin signo.

2
Como se explico anteriormente, el funcionamiento del CPU se basa en los pasos del ciclo de instrucción, consistentes en búsqueda, decodificación y ejecución de la instrucción. Comenzaremos revisando los pasos correspondientes a la búsqueda de la instrucción. El registro PC contiene la dirección de la localidad de memoria que contiene el código de instrucción de la siguiente instrucción a ejecutar. Como la etapa de búsqueda consistirá básicamente en leer este código y almacenarlo en el registro IR para su posterior uso en las etapas de decodificación y ejecución, el contenido de PC se copia al MAR para poder leer esa localidad de memoria. Se lee la memoria y el resultado de dicha lectura se copia del MBR al IR. Finalmente, se incrementa el PC para que en el siguiente ciclo de instrucción se lea la instrucción de la localidad de memoria consecutiva. Resumiendo estas operaciones en lenguaje de transferencia de registros: MAR<-PC IR<-[MAR] PC<-PC+1 En la etapa de decodificación simplemente se separan los códigos de operación de los operandos. Por ejemplo, la instrucción LOAD 023h se codificaría como 0023h, siendo 0h el código de operación y 023h el operando. Además, la unidad de control deberá identificar que al opcode 0 corresponde a la instrucción LOAD para que en la siguiente etapa se realicen las operaciones correspondientes a esta instrucción. En cuanto a la etapa de ejecución, los pasos realizados en esta etapa varían dependiendo del código de operación leído en la etapa de búsqueda. Por ejemplo, si el código leído es un 0, que corresponde con una instrucción LOAD, la etapa de ejecución consistirá en copiar la parte de la dirección del operando en el registro MAR para poder leer la localidad en donde se encuentra el operando. Se lee el operando de memoria y el dato

2
leído se copia del MBR al acumulador. Resumiendo dichas operaciones en lenguaje de transferencia de registros se tiene: MAR<-IR(M) //IR(M) representa los bits del registro IR que almacenan la dirección del operando ACC<-MBR Para el código de operación 2, correspondiente a la instrucción ADD, también se transfiere la dirección del operando al MAR y se lee el contenido de la memoria, pero en vez de enviarse directamente del MBR al acumulador, se envía al ALU para que se sume con el contenido del acumulador y posteriormente se almacene el resultado de la suma en el acumulador. Resumiendo en lenguaje de transferencia de registros: MAR<-IR(M) //IR(M) representa los bits del registro IR que almacenan la dirección del operando ACC<-ACC+MBR La columna operación de la Tabla 1.2.1.4.1 proporciona un resumen el lenguaje de transferencia de registros de las operaciones correspondientes a cada código de operación.
1.2.2 MemoriaEn informática, la memoria (también llamada almacenamiento) se refiere a parte de los componentes que forman parte de una computadora. Son dispositivos que retienen datos informáticos durante algún intervalo de tiempo. Las memorias de computadora proporcionan una de las principales funciones de la computación moderna, la retención o almacenamiento de información. Es uno de los componentes fundamentales de todas las computadoras modernas que, acoplados a una unidad central de procesamiento (CPU por su sigla en inglés, central processing unit), implementa lo fundamental del modelo de computadora de Arquitectura de von Neumann, usado desde los años 1940. Dispositivo basado en circuitos que posibilitan el almacenamiento limitado de información y su posterior recuperación. Las memorias suelen ser de rápido acceso, y pueden ser volátiles o no volátiles. La clasificación principal de memorias son RAM y ROM. Estas memorias son utilizadas para almacenamiento primario.
1.2.2.1 Conceptos básicos del manejo de la memoriaSe produce bajo el control directo y continuo del programa que solicita la operación de E/S. tanto en la entrada y salida programada como con interrupciones, el procesador es responsable de extraer los datos de la memoria en una salida, y almacenar los datos en la memoria principal. El problema con la E/S es que el procesador tiene que esperar un tiempo considerable hasta que el modulo en cuestión esté preparado para recibir o transmitir datos

2
1.2.2.2 Memoria Principal SemiconductoraLa memoria de semiconductor usa circuitos integrados basados en semiconductores para almacenar información. Un chip de memoria de semiconductor puede contener millones de minúsculos transistores o condensadores. Existen memorias de semiconductor de ambos tipos: volátiles y no volátiles. En las computadoras modernas, la memoria principal consiste casi exclusivamente en memoria de semiconductor volátil y dinámica, también conocida como memoria dinámica de acceso aleatorio o más comúnmente RAM, su acrónimo inglés. Con el cambio de siglo, ha habido un crecimiento constante en el uso de un nuevo tipo de memoria de semiconductor no volátil llamado memoria flash. Dicho crecimiento se ha dado, principalmente en el campo de las memorias fuera de línea en computadoras domésticas. Las memorias de semiconductor no volátiles se están usando también como memorias secundarias en varios dispositivos de electrónica avanzada y computadoras especializadas y no especializadas.
1.2.2.3 Memoria CacheEn informática, la caché es la memoria de acceso rápido de una computadora, que guarda temporalmente las últimas informaciones procesadas.
La memoria caché es un búfer especial de memoria que poseen las computadoras, que funciona de manera similar a la memoria principal, pero es de menor tamaño y de acceso más rápido. Es usada por el microprocesador para reducir el tiempo de acceso a datos ubicados en la memoria principal que se utilizan con más frecuencia. La caché es una memoria que se sitúa entre la unidad central de procesamiento (CPU) y la memoria de acceso aleatorio (RAM) para acelerar el intercambio de datos. Cuando se accede por primera vez a un dato, se hace una copia en la caché; los accesos siguientes se realizan a dicha copia, haciendo que sea menor el tiempo de acceso medio al dato. Cuando el microprocesador necesita leer o escribir en una ubicación en memoria principal, primero verifica si una copia de los datos está en la caché; si es así, el microprocesador de inmediato lee o escribe en la memoria caché, que es mucho más rápido que de la lectura o la escritura a la memoria principal.
1.2.3 Manejo de Entrada/Salida.En computación, entrada/salida, también abreviado E/S o I/O (del original en inglés input/output), es la colección de interfaces que usan las distintas unidades funcionales (subsistemas) de un sistema de procesamiento de información para comunicarse unas con otras, o las señales (información) enviadas a través de esas interfaces. Las entradas son las señales recibidas por la unidad, mientras que las salidas son las señales enviadas por ésta. El término puede ser usado para describir una acción; "realizar una entrada/salida" se refiere a ejecutar una operación de entrada o de salida. Los

2
dispositivos de E/S los usa una persona u otro sistema para comunicarse con una computadora. De hecho, a los teclados y ratones se los considera dispositivos de entrada de una computadora, mientras que los monitores e impresoras son vistos como dispositivos de salida de una computadora. Los dispositivos típicos para la comunicación entre computadoras realizan las dos operaciones, tanto entrada como salida, y entre otros se encuentran los módems y tarjetas de red.
1.2.3.1 Módulos de Entrada/SalidaEn primer término hablaremos de los dispositivos de entrada, que como su nombre lo indica, sirven para introducir datos (información) a la computadora para su proceso. Los datos se leen de los dispositivos de entrada y se almacenan en la memoria central o interna. Los dispositivos de entrada convierten la información en señales eléctricas que se almacenan en la memoria central. Los dispositivos de entrada típicos son los teclados, otros son: lápices ópticos, palancas de mando (joystick), CD-ROM, discos compactos (CD), etc. Hoy en día es muy frecuente que el usuario utilice un dispositivo de entrada llamado ratón que mueve un puntero electrónico sobre una pantalla que facilita la interacción usuario-máquina.
Los módulos de entrada y salida están conectados con el procesador y la memoria principal, y cada uno controla uno o más dispositivos externos. La arquitectura de E/S es su interfaz con el exterior, esta arquitectura se diseña de manera que permita una forma sistemática de controlar las interacciones con el mundo exterior y proporcione al sistema operativo la información que
necesita para gestionar la actividad de E/S.
1.2.3.2 Entrada/Salida ProgramadaLos dispositivos de Entrada y Salida permiten la comunicación entre la computadora y el usuario.
Se produce bajo el control directo y continuo del programa que solicita la operación de E/S. tanto en la entrada y salida programada como con interrupciones, el procesador es responsable de extraer los datos de la memoria en una salida, y almacenar los datos en la memoria principal. El problema con la E/S es que el procesador tiene que esperar un tiempo considerable hasta que el modulo en cuestión esté preparado para recibir o transmitir datos.

2
1.2.3.3 Entrada/Salida mediante interrupcionesEl programa genera una orden de E/S y después continúa ejecutándose hasta que el hardware lo interrumpe para indicar que la operación ha concluido. La entrada y salida con interrupciones, aunque es más eficiente que la sencilla, también requiere la intervención activa del procesador para transferir los datos entre la memoria y el módulo de E/S.
El módulo de E/S interrumpirá al CPU para solicitar su servicio cuando esté preparado para intercambiar datos. El CPU ejecuta la transferencia de datos y después continúa con el procesamiento previo. Se pueden distinguir dos tipos: E/S síncrona y E/S asíncrona E/S Síncrona: cuando la operación de E/S finaliza, el control es retornado al proceso que la generó. La espera por E/S se lleva a cabo por medio de una instrucción wait que coloca al CPU en un estado ocioso hasta que ocurre otra interrupción. Aquellas máquinas que no tienen esta instrucción utilizan un loop. Este loop continúa hasta que ocurre una interrupción transfiriendo el control a otra parte del sistema de operación. Sólo se atiende una solicitud de E/S por vez. El sistema de operación conoce exactamente que dispositivo está interrumpiendo. Esta alternativa excluye procesamiento simultáneo de E/S. E/S Asíncrona: retorna al programa usuario sin esperar que la operación de E/S finalice. Se necesita una llamada al sistema que le permita al usuario esperar por la finalización de E/S (si es requerido). También es necesario llevar un control de las distintas solicitudes de E/S. Para ello el sistema de operación utiliza una tabla que contiene una entrada por cada dispositivo de E/S (Tabla de Estado de Dispositivos). La ventaja de este tipo de E/S es el incremento de la eficiencia del sistema. Mientras se lleva a cabo E/S, el CPU puede ser usado para procesar o para planificar otras E/S. Como la E/S puede ser bastante lenta comparada con la velocidad del CPU, el sistema hace un mejor uso de las facilidades.
1.2.3.4 Acceso directo a MemoriaEl acceso directo a memoria (DMA, del inglés direct memory access) permite a cierto tipo de componentes de una computadora acceder a la memoria del sistema para leer o escribir independientemente de la unidad central de procesamiento (CPU) principal. Muchos sistemas hardware utilizan DMA, incluyendo controladores de unidades de disco, tarjetas gráficas y tarjetas de sonido. DMA es una característica esencial en todos los ordenadores modernos, ya que permite a dispositivos de diferentes velocidades comunicarse sin someter a la CPU a una carga masiva de interrupciones. Una transferencia DMA consiste principalmente en copiar un bloque de memoria de un dispositivo a otro. En lugar de que la CPU inicie la transferencia, la transferencia se lleva a cabo por el controlador DMA. Un ejemplo típico es

2
mover un bloque de memoria desde una memoria externa a una interna más rápida. Tal operación no ocupa al procesador y, por ende, éste puede efectuar otras tareas. Las transferencias DMA son esenciales para aumentar el rendimiento de aplicaciones que requieran muchos recursos. Cabe destacar que aunque no se necesite a la CPU para la transacción de datos, sí se necesita el bus del sistema (tanto bus de datos como bus de direcciones), por lo que existen diferentes estrategias para regular su uso, permitiendo así que no quede totalmente acaparado por el controlador DMA. El acceso directo a memoria es simplemente eso, un acceso a memoria que se crea al particionar la memoria en bloques del mismo tamaño.
1.2.3.5 Canales y Procesadores de Entrada/SalidaEl canal de E/S es una extensión del concepto de DMA. Un canal de E/S tiene la capacidad de ejecutar instrucciones de E/S, lo que da un control total sobre las operaciones de E/S. Las instrucciones de E/S se almacenan en la memoria principal y serán ejecutadas por un procesador de propósito específico en el mismo canal de E/S.
Un canal selector controla varios dispositivos de velocidad elevada y en un instante dado, se dedica a transferir datos a uno de esos dispositivos, es decir el canal de entrada y salida selecciona un dispositivo y efectúa la transferencia de datos. Cada dispositivo o pequeño grupo de dispositivos es manejado por un controlador o módulo de E/S, así el canal de entrada y salida se utiliza en lugar de la CPU para controlar estos controladores de E/S. Un canal multiplexor puede manejar la entrada y salida de varios dispositivos al mismo tiempo. Para dispositivos de velocidad reducida, un multiplexor de byte acepta o transmite caracteres tan rápido como es posible a varios dispositivos.
1.2.4 BusesEn arquitectura de computadores, el bus (o canal) es un sistema digital que transfiere datos entre los componentes de una computadora o entre computadoras. Está formado por cables o pistas en un circuito impreso, dispositivos como resistores y condensadores además de circuitos integrados. En los primeros computadores electrónicos, todos los buses eran de tipo paralelo, de manera que la comunicación entre las partes del computador se hacía por medio de cintas o muchas pistas en el circuito impreso, en los cuales cada conductor tiene una función fija y la conexión es sencilla requiriendo únicamente puertos de entrada y de salida para cada dispositivo. La tendencia en los últimos años se hacia uso de buses seriales como el USB, Firewire para comunicaciones con periféricos reemplazando los buses paralelos, incluyendo el caso como el del microprocesador con el chipset en la placa base. Esto a

2
pesar de que el bus serial posee una lógica compleja (requiriendo mayor poder de cómputo que el bus paralelo) a cambio de velocidades y eficacias mayores. Existen diversas especificaciones de que un bus se define en un conjunto de características mecánicas como conectores, cables y tarjetas, además de protocolos eléctricos y de señales.
1.2.4.1 Tipos de BusesBus paralelo.- Es un bus en el cual los datos son enviados por bytes al mismo tiempo, con la ayuda de varias líneas que tienen funciones fijas. La cantidad de datos enviada es bastante grande con una frecuencia moderada y es igual al ancho de los datos por la frecuencia de funcionamiento. En los computadores ha sido usado de manera intensiva, desde el bus del procesador, los buses de discos duros, tarjetas de expansión y de vídeo, hasta las impresoras.
Bus serial.-En este los datos son enviados, bit a bit y se reconstruyen por medio de registros o rutinas de software. Está formado por pocos conductores y su ancho de banda depende de la frecuencia. Es usado desde hace menos de 10 años en buses para discos duros, unidades de estado sólido, tarjetas de expansión y para el bus del procesador.
Multiplexados y no multiplexados o dedicados.- Los multiplexados realizan diferentes funciones en función de las necesidades del momento. Ejemplo: bus compartido para direcciones y datos ahorro en Hardware y por lo tanto en costos. Tipos de Buses
Centralizados y distribuidos.- Necesidad de determinar qué elemento transmite y cuál recibe. Generalmente existe administración centralizada por la CPU o procesador.
Síncronos y asíncronos (temporización).- Cómo ocurren los diferentes eventos (comienzo, fin,...) implicados en la transmisión de información. Utilización de una señal de reloj (comunicación síncrona) o unas líneas de protocolo (comunicación asíncrona).

2
1.2.4.2 Estructuras de los BusesEstructura de un bus:
Líneas de datos Líneas de dirección Líneas de control
Datos: Llevan datos y también comandos para los dispositivos de entrada /salida. Su amplitud influye en el rendimiento del bus Relacionado con el tamaño de palabra del sistema
Direcciones: Llevan direcciones de memoria en acceso a memoria, o permiten seleccionar un dispositivo conectado al bus. Su amplitud determina el espacio de direcciones tanto de memoria como entrada / salida
Control: Son señales de control de acceso y uso del bus. Arbitraje del bus Sincronización de las comunicaciones Reloj del sistema

2
1.2.4.3 Jerarquías de Buses
Jerarquía.- Tendencia a utilizar múltiples buses debido a la:
Degradación del rendimiento a medida que aumenta el número de dispositivos colgados al bus. "Cuello de botella" de las comunicaciones debido a los tiempos de espera para acceder al bus.
Por ellos se introducen múltiples buses basando la jerarquía en los requerimientos de comunicación de los dispositivos: Bus local: Conecta al procesador con la cache y con algún dispositivo e/s muy rápido. Bus del sistema: Conecta al procesador (a través de la cache) con la memoria del sistema y con un segundo nivel de dispositivos de velocidad media. Bus de expansión: Se conecta al bus del sistema y hace de interfaz entre este y los dispositivos más lentos

2
1.2.5 InterrupcionesEn el contexto de la informática, una interrupción (del inglés Interrupt Request, también conocida como petición de interrupción) es una señal recibida por el procesador de un ordenador, indicando que debe "interrumpir" el curso de ejecución actual y pasar a ejecutar código específico para tratar esta situación. Una interrupción es una suspensión temporal de la ejecución de un proceso, para pasar a ejecutar una subrutina de servicio de interrupción, la cual, por lo general, no forma parte del programa, sino que pertenece al sistema operativo o al BIOS). Una vez finalizada dicha subrutina, se reanuda la ejecución del programa. Las interrupciones surgen de la necesidad que tienen los dispositivos periféricos de enviar información al procesador principal de un sistema informático. La primera técnica que se empleó para esto fue el polling, que consistía en que el propio procesador se encargara de sondear los dispositivos periféricos cada cierto tiempo para averiguar si tenía pendiente alguna comunicación para él. Este método presentaba el inconveniente de ser muy ineficiente, ya que el procesador consumía constantemente tiempo y recursos en realizar estas instrucciones de sondeo. El mecanismo de interrupciones fue la solución que permitió al procesador desentenderse de esta problemática, y delegar en el dispositivo periférico la responsabilidad de comunicarse con él cuando lo necesitara. El procesador, en este caso, no sondea a ningún dispositivo, sino que queda a la espera de que estos le avisen (le "interrumpan") cuando tengan algo que comunicarle (ya sea un evento, una transferencia de información, una condición de error, etc.).

2
BIBLIOGRAFIAhttp://es.slideshare.net/CynthiaRamirez3/unidad-1-arquitectura
http://itcv-arquitectura-de-computadoras.blogspot.mx/2014/11/12-analisis-de-los-componentes.html
http://arquitecturadecomputadorasunidades.blogspot.mx/2013/05/1-unidad-de-arquitecturas-de-computo.html
http://es.wikipedia.org/wiki/Arquitectura_Harvard
http://html.rincondelvago.com/computadores_arquitectura-harvard-pipeline-vectorial.html
http://www.itpn.mx/recursosisc/5semestre/arquitecturadecomputadoras/Unidad%20I.pdf
http://tics-arquitectura.blogspot.mx/2012/03/modelos-de-arquitecturas-de-computo.html


















