
Trabajo Fin de Título - Paloma Cuesta Uría
39
UNIVERSIDAD AUTÓNOMA DE MADRID ESCUELA POLITÉCNICA SUPERIOR Experto en Big Data y Data Science: ciencia e ingeniería de datos TRABAJO FIN DE TÍTULO ¿CUÁNTO VALE EL CLIENTE? UNA ALTERNATIVA AL MODELO DE PARETO. Paloma Cuesta Uría Tutor: José Ramón Dorronsoro Íbero Agosto 2016
-
Upload
paloma-cuesta-uria -
Category
Documents
-
view
89 -
download
7
Transcript of Trabajo Fin de Título - Paloma Cuesta Uría

UNIVERSIDAD AUTÓNOMA DE MADRID
ESCUELA POLITÉCNICA SUPERIOR
Experto en Big Data y Data Science: ciencia e ingeniería de datos
TRABAJO FIN DE TÍTULO
¿CUÁNTO VALE EL CLIENTE?
UNA ALTERNATIVA AL MODELO DE PARETO.
Paloma Cuesta Uría
Tutor: José Ramón Dorronsoro Íbero
Agosto 2016


¿CUÁNTO VALE EL CLIENTE?
UNA ALTERNATIVA AL MODELO DE PARETO.
AUTOR: Paloma Cuesta Uría
TUTOR: José Ramón Dorronsoro Íbero
Escuela Politécnica Superior
Universidad Autónoma de Madrid
Agosto de 2016

Resumen
En una economía moderna basada en los servicios, el análisis del comportamiento del cliente y la relación
con la empresa, juega un papel crucial en la optimización de costes en pro del beneficio y crecimiento
sostenible de las compañías. La necesidad de optimizar la cuantificación de los retornos de la inversión en
marketing, toman sentido e importancia en un momento de incertidumbre creciente pero también de
desarrollo de nuevas y mejoradas técnicas de extracción de la información y análisis del comportamiento
del consumidor. El diagnóstico se vuelve cada vez más complejo, pero a la vez, las empresas tienen cada
vez más información sobre ese feed-back del cliente, existiendo la posibilidad creciente de personalizarlo.
Es por ello, que aparecen nuevos nichos analíticos para enriquecer esta panorámica.
Nuestro estudio se centrará en intentar calcular el valor del cliente para la empresa en el largo plazo,
también conocido como CLTV (Customer Lifetime Value), o LCV, concepto clave en marketing y
estrategia de negocio, pero también como materia de estudio en numerosas investigaciones académicas.
Es un valor cuantificable que monetiza la relación con el cliente basándose en el valor presente de los
flujos de esa relación, extrayéndose de ello conclusiones importantes en torno al retorno y compensación
de esa inversión.
En el caso de una empresa de telecomunicaciones o de un banco, se asocia directamente con el estudio de
la rentabilidad para la compañía de la permanencia del cliente en el largo plazo.
De ello se desprende la idea de que no todos ellos son rentables para la empresa o al menos, no a todos
hay que dedicarle la misma fuerza de ventas.
También se intuye que su modelización debería emplear el cruce de técnicas predictivas como el estudio
del abandono, la segmentación por clustering, predicciones de frecuencias de uso del servicio y en
general, procesos inductivos de análisis para descubrir relaciones y patrones ya presentes en los datos.
Cabe señalar, aunque no es objeto de esta primera aproximación, que el modelo se puede beneficiar
también de técnicas econométricas, entre otras, que optimizan y complementan bien algunos resultados.
Centrándonos en nuestro enfoque, para su implementación en Python, se utilizará el modelo BD/NBD1,
como alternativa paramétrica al modelo de Pareto/NBD2 para un primer ajuste inicial.
Posteriormente, se emplearán varios métodos tales como la matriz de frecuencias o la creación de
rankings de nuestros clientes en base a su histórico de compras para visualizar algunos de los conceptos
estudiados.
En suma, el objeto de este TFT, no es otro que el de hacer una aproximación conceptual y primera
aplicación práctica con Python para intentar visualizar y predecir el comportamiento de nuestros clientes a
la vez que evaluamos la calidad de nuestro modelo.
1 O modelo Beta – Geometric/NBD que es una pequeña variación al modelo de Pareto. Lo iremos referenciando y explicando más en
detalle a lo largo de toda la memoria. 2 Desarrollado por Schmittlein y otros (1987), también llamado SMC.

Agradecimientos
Pienso en todo y todos los que han hecho posible que yo
esté aquí hoy. En ocasiones son una serie de aparentes
casualidades concatenadas que cuando se dan cita, sólo cabe
agradecer infinitamente a la mano que definitivamente las ejecuta.
Ellos saben quiénes son, o no.

ÍNDICE
1. Introducción 1
2. Estado del Arte 2
3. Planteamiento del Modelo 3
3.1. Fundamentos del Modelo CLV 3
3.2. El Modelo de Pareto/NBD. 4
3.3. Supuestos del Modelo BG/NBD. 6
4. Desarrollo del modelo 7
4.1. Desarrollo del Modelo a nivel individual. 7
4.1.1. Derivación de la Función de Probabilidad. 7
4.1.2. Derivación de P (X (t)=x). 8
4.1.3. Derivación de E [X (t)] 8
4.2. Desarrollo del modelo para un individuo aleatorio. 9
5. Aplicación empírica. 10
6. Conclusiones y trabajo futuro 22
6.1. Conclusiones 22
6.2. Trabajo futuro 22
7. Referencias 25
8. Anexos 27
8.1. Manual de instalación 27
8.2. Manual del programador 27
8.3. Apéndice matemático 30
8.3.1. Derivada de 𝑬[𝑿(𝒕)] 30
8.3.2. Derivada de 𝑬𝒀𝒕𝑿 = 𝒙, 𝒕𝒙, 𝑻 31

1
1. Introducción La obtención, evaluación y análisis de información útil para el negocio, no sólo financiera o contable,
juega un papel crucial en la nueva estrategia empresarial. La necesidad creciente de contabilizar el
marketing en un momento de reducción de beneficios debido a la competencia y la coyuntura económica
actual, plantean nuevos retos para las compañías. Ante la conciencia de la diversidad de la demanda,
surgen nuevas necesidades de conocimiento y trato con el cliente. Se deduce que no todos los clientes son
iguales, y no todos son igual de valiosos para las compañías.
El presente trabajo tendrá como objetivo principal acercarse a una visión integral en el desarrollo y
análisis de un modelo. Se introducirá el planteamiento matemático que lo sustenta, se relacionará
directamente con el código y finalmente se expondrán los resultados de negocio que se pretenden
investigar.
La elección del tema pasa por lo expositivo y lo didáctico, pero también es una primera aproximación a
una temática que une lo académico con lo empresarial, en un momento clave donde se necesitan y
complementan los dos mundos, abriendo nuevas perspectivas y oportunidades.
La utilización del modelo concreto BG/NBD que se expondrá viene justificada por su facilidad de
implementación computacional y busca ser un acercamiento al modelo de Pareto, pero de una forma más
accesible, y contando con una librería3 de reciente creación.
Las motivaciones principales que me llevaron a elegir investigar este tema concreto fueron una clara
percepción de la convergencia futura de técnicas no paramétricas con técnicas paramétricas que quería
empezar a investigar desde los modelos más antiguos. Consideré prioritario tener una visión global, para
ir acercándome poco a poco desde diferentes perspectivas. Aunque a priori, se podría pensar que no
encaja del todo con el objeto de este título, si lo hace en tanto en cuanto exige un conocimiento previo de
ciertas herramientas como Python, y entra dentro de los campos de analytics, visualización y data mining
con orientación directa al business intelligence.
Otro punto que me llamó la atención fue pensar en los motivos que podría tener el MIT para desarrollar
una librería en el 2014 cuando podría pensarse que es un modelo “obsoleto”, o demasiado complejo. Pero
no lo es tanto. De hecho, una vez desplegado parece sencillo.
Pero el argumento definitivo fue la atención empresarial que este modelo en general sigue despertando,
que puedo ver y experimentar a diario. Y que no dudo que todavía tiene mucho recorrido, porque por
encima de todo, su esencia es el estudio del consumo.
3 La excelente librería Lifetimes-0.2.0.0 desarrollado por Cam Davidson-Pilon, y con licencia del MIT, Copyright del 2015 se puede
encontrar en < https://github.com/CamDavidsonPilon/lifetimes > que nos proporcionará prácticamente todo el material que
necesitaremos para ésta primera aproximación.

2
Todo lo anterior unido al inicio de una nueva era en el tratamiento, monitorización y análisis de los datos,
hacen resurgir este tema como concepto clave y fácilmente alcanzable para las compañías. El futuro se
acerca, y se intuye que sólo es el comienzo de una larga e interesante andadura. Lo mejor está por venir.
2. Estado del Arte El Customer Lifetime Value (CLV) es un concepto muy estudiado tanto en el ámbito empresarial como en
el académico. Compañías como IBM, ING, Harrah´s, Capital One, LL Bean, por poner algunos ejemplos,
utilizan continuamente esta herramienta para medir el éxito de su negocio. Fue un tema que ganó
popularidad en los años 90 y ya entonces estaba siendo muy analizado en la academia.
Concretamente, el modelo en el que se basa el núcleo de este estudio, es el Modelo de Pareto/NBD en un
marco teórico propuesto por Schmittlein entre otros, en 1987, llamado también SMC.
Aunque las preguntas fundamentales serán las mismas (qué clientes son los más valiosos para la
empresa, cómo distribuir los recursos, etc.) y en muchos casos la metodología subyacente sea similar
(modelos de riesgo de retención de los clientes con distribuciones binomiales negativas), hay muchas
perspectivas de investigación abiertas.
Algunos investigadores han preferido un horizonte temporal aleatorio o CLV esperado
(Reinartz y Kumar 2000; Thomas 2001) mientras que otros han centrado sus esfuerzos en un
horizonte temporal infinito (Fader, Hardie, y Lee 2005; Gupta, Lehmann, y Stuart 2004). Gupta
y Lehmann (2005) demostraron que trabajar con el CLV esperado, suele tender a sobreestimar
los resultados significativamente.
Es importante señalar que la mayoría de las aproximaciones al modelo ignoran la competencia
por la falta de datos, al menos hasta el momento. Lo que es muy probable que empiece a
cambiar, si no lo está haciendo ya.
Por otra parte, la actualización del modelo depende de las características del tipo de mercado (o
mercados) en el que se desenvuelva el estudio. La elasticidad de la oferta y demanda, que
puedan hacer que por ejemplo los márgenes o la retención puedan variar en un periodo corto de
tiempo, harán necesario recalcular el CLV con más frecuencia.
Algunos modelos se han desarrollado en torno a la construcción de tres modelos separados para
el estudio de la adquisición, retención y margen de beneficio del cliente para la empresa.
Mientras que otros modelos combinan dos de estos tres componentes. Por ejemplo, Thomas
(2001) y Reinartz, Thomas y Kumar (2005) estudiaron la adquisición y retención del cliente en
un mismo modelo. Como veremos a continuación Fader, Hardie, y Lee (2005) estudiaron lo
que llamarán recency y frecuency por un lado, y su valor monetario por otro.

3
Nos encontraremos con los Modelos RFM (Recency, Frecuency, Monetary Value), modelos
probabilísticos, modelos econométricos, modelos de persistencia, modelos informáticos y
modelos de difusión y crecimiento de los datos (Diffussion/Growth models).
Cabe destacar los modelos informáticos o más correctamente Computer Science Models.
Mientras que los modelos paramétricos provenientes de la teoría económica (como la teoría de
la utilidad) son fáciles de entender e interpretar, pero tienen menos capacidad predictiva
demostrada. Tales son algunos modelos de riesgo, logit o probit.
Por otra parte, el desarrollo de la estadística no paramétrica para machine learning disfruta
ahora de una acogida mayor dadas las nuevas técnicas de data mining. Algunos ejemplos
pueden incluir redes neuronales, árboles de decisión, modelos spline-based tales como
generalized additive models (GAM), multivariate adaptative regresión splines (MARS) y
modelos SVM.
Está claro que la combinación de varios de ellos también es una posibilidad, en ocasiones más
que recomendable. Todos ellos darían para un análisis y comparación realmente interesante,
pero que no es objeto de esta memoria por el momento.
3. Planteamiento del Modelo
3.1. Fundamentos del Modelo CLV
Se define Customer Lifetime Value (CLV) como el valor presente de los beneficios obtenidos por
un cliente durante el ciclo de vida de su relación con la empresa. Su cálculo puede ser similar a la
contabilización de los cash flows financieros. Aunque hay dos diferencias fundamentales. En
primer lugar, el CLV se define y calcula a nivel individual, y/o por segmentos de clientes. No se
trabaja con valores medios. Además, a diferencia de los valores financieros, se incorpora a la
competencia. Existe y se calcula la posibilidad de que el cliente se vaya a la competencia en un
futuro.
Una definición genérica e introductoria en donde se visualiza bien esta similitud con los cash
flows, podría ser la siguiente (Gupta, Lehmann and Stuart 2004; Reinartz and Kumar 2003)
𝐶𝐿𝑉 = ∑(𝑝𝑡−𝑐𝑡)𝑟𝑡
(1+𝑖)𝑡𝑇𝑡=0 − 𝐴𝐶 (1a)
donde
𝑝𝑡 = precio que paga el cliente en un momento determinado del tiempo t
𝑐𝑡 = coste directo de dar servicio al cliente en un tiempo t
𝑖 = tasa de descuento de coste del capital para la empresa
𝑟𝑡 = probabilidad de que el cliente vuelva a comprar o de que esté “vivo” en un tiempo t.
𝐴𝐶 = coste de adquisición
𝑇 = horizonte temporal para estimar el CLV

4
Esta es una de las formulaciones más simples, que creemos es interesante como aproximación
conceptual. Aunque no será objeto de este análisis.
A partir de aquí nos centraremos en el Modelo de Pareto/NBD.
3.2. El Modelo de Pareto/NBD.
El modelo de Pareto/NBD, fue desarrollado por Schmittlein y otros, en 1987. También conocido
como SMC, analiza el comportamiento del consumidor en base a su consumo reiterado, en un
contexto no contractual. Del análisis se desprenden la probabilidad, condicionada a su histórico
de compras, de que un cliente permanezca activo, así como el número de transacciones esperadas
para un cliente aleatorio.
La función hipergeométrica Gaussiana es una de las partes centrales del modelo.
𝐹1(𝑎, 𝑏; 𝑐; 𝑧)=∑(𝑎)𝑗(𝑏)𝑗
(𝑐)𝑗
𝑧𝑗
𝑗!∞𝑗=0 , 𝑐 ≠ 0, −1, −2, …,
En el anexo desarrollamos esto algo más en detalle.
El modelo de Pareto/NBD está basado en cinco supuestos básicos:
(1) Mientras está activo, el número de transacciones realizadas por un cliente en un periodo de
tiempo t, se distribuye como una Poisson con media 𝜆𝑡.
(2) Por lo tanto, la probabilidad de observar x transacciones en un intervalo de tiempo (0, t] se
muestra como
𝑃(𝑋(𝑡) = 𝑥|𝜆) =(𝜆𝑡)𝑥𝑒−𝜆𝑡
𝑥! , 𝑥 = 0, 1, 2 …
Esto es equivalente a suponer que el intervalo de tiempo entre cada transacción se distribuye
como una exponencial con tasa de transacción λ,
𝑓(𝑡𝑗 − 𝑡𝑗−1|𝜆) = 𝜆𝑒−𝜆(𝑡𝑗−𝑡𝑗−1), 𝑡𝑗 > 𝑡𝑗−1 > 0,
donde 𝑡𝑗 es el momento de la compra j.
(3) La heterogeneidad en la tasa de transacción de los clientes λ, sigue una distribución Gamma
con forma (shape parameter) 𝑟 y escala (scale parameter) 𝛼.
𝑔(𝜆|𝑟, 𝛼) =𝛼𝑟𝜆𝑟−1𝑒−𝜆𝛼
Г(𝑟)
(4) Cada cliente tiene un ciclo de vida indeterminado (lifetime) de longitud 𝜏, tras el que se
considerará inactivo. El momento en el que el cliente se transforma en inactivo se distribuye
como una exponencial con tasa de abandono 𝜇.
𝑓(Г|𝜇) = 𝜇𝑒−𝜇Г

5
(5) La heterogeneidad en las tasas de abandono de los clientes sigue una distribución Gamma con
forma 𝑠 y escala 𝛽.
𝑔(𝜇 |𝑠) =𝛽𝑠𝜇𝑠−1𝑒−𝜇𝛽
Г(𝑟)
(6) La tasa de transacción 𝜆 y de abandono μ, varían independientemente de los consumidores.
Además, tanto el modelo de Pareto/NBD como el modelo BG/NBD sólo requerirán dos datos del
histórico de compras de cada cliente: la fecha de su última transacción, parámetro que llamaremos
recency, y el número de transacciones hechas en un tiempo determinado, definido como frecuency
(frecuencia de compra).
La notación será (𝑋 = 𝑥, 𝑡𝑥 , 𝑇) donde 𝑥 es el número de transacciones observadas en el periodo
(0, 𝑇] y 𝑡𝑥(0 < 𝑡𝑥 ≤ 𝑇 ) es el tiempo de la última transacción.
Usando estas dos estadísticas agregadas clave, con el modelo SMC podemos extraer conclusiones
económicas para un número significativo de KPIs (Key Performance Indicators) tales como:
𝐸[𝑋(𝑡)] como las compras esperadas en un periodo de tiempo de longitud 𝑡 para lo que es
necesario calcular el volumen de transacciones esperadas para la base de clientes a lo largo
del tiempo.
𝑃(𝑋(𝑡) = 𝑥) la probabilidad de observar 𝑥 transacciones en un periodo de tiempo de
longitud 𝑡.
𝐸[𝑌 (𝑡)|𝑋 = 𝑥, 𝑡𝑥 , 𝑇] es el número esperado de transacciones en el periodo (𝑇, 𝑇 + 𝑡] para
un cliente con comportamiento determinado (𝑥, 𝑡𝑥 , 𝑇).
La función de probabilidad asociada con el modelo de Pareto/NBD es compleja e implica varios
análisis de la función hipergeométrica Gaussiana y exige muchos cálculos desde el punto de
vista computacional. Además, la precisión de los procesos numéricos para evaluar esta función
son claves, incluso por encima de los parámetros pudiendo causar problemas importantes
buscando optimizar la función de máxima probabilidad.
Reinartz y Kumar (2003) publicaron sus resultados sobre esta implementación, con reconocida
carga computacional utilizando técnicas de estimación de máxima verosimilitud (Standard
Maximum Likelihood Estimation o MLE).
Schmittlein y Peterson (1994) propusieron un método de estimación en tres pasos que, aunque
más simple que el MLE, es difícil de implementar y no cumple con los principios básicos del
MLE.
El modelo que se presenta a continuación es fácilmente implementable y cumple con las
condiciones probabilísticas del MLE. La estimación de los parámetros no requiere ningún
software especializado ni funciones matemáticas demasiado complejas.

6
3.3. Supuestos del Modelo BG/NBD.
Este modelo está basado en el Modelo de Pareto/NBD con la única diferencia de cómo y cuándo
determinar si un cliente está inactivo. El Modelo temporal de Pareto supone que el abandono del
cliente puede ocurrir en cualquier momento del tiempo, independientemente de las compras
realizadas.
Más formalmente, el modelo BG/NBD está basado en los siguientes cinco supuestos (el primer
y segundo supuesto son coincidentes con el modelo SMC):
(1) El número de transacciones realizadas por un cliente mientras está activo en un periodo
de tiempo t, se distribuye como una Poisson con media 𝜆𝑡.
Por lo tanto, la probabilidad de observar x transacciones en un intervalo de tiempo (0, t]
se muestra como
𝑃(𝑋(𝑡) = 𝑥|𝜆) =(𝜆𝑡)𝑥𝑒−𝜆𝑡
𝑥! , 𝑥 = 0, 1, 2 …
Esto es equivalente a suponer que el intervalo de tiempo entre cada transacción se
distribuye como una exponencial con tasa de transacción λ, por ejemplo,
𝑓(𝑡𝑗 − 𝑡𝑗−1|𝜆) = 𝜆𝑒−𝜆(𝑡𝑗−𝑡𝑗−1), 𝑡𝑗 > 𝑡𝑗−1 > 0,
donde 𝑡𝑗 es el momento de la compra j.
(2) La heterogeneidad en la tasa de transacción de los clientes, 𝜆, sigue una distribución
gamma con forma 𝑟 y escala 𝛼.
𝑓( 𝜆| 𝑟, 𝛼) =∝𝑟𝜆𝑟−1𝑒−𝜆𝛼
𝛤(𝑟) , 𝜆 > 0 (1)
(3) Después de una transacción cualquiera, un cliente se convierte en inactivo con
probabilidad 𝑝. Por lo tanto, el punto en el que un cliente abandona se distribuye a lo
largo de varias transacciones de acuerdo a una distribución geométrica (“desplazada”)
cuya función de probabilidad será
𝑃(𝑐𝑙𝑖𝑒𝑛𝑡𝑒 𝑖𝑛𝑎𝑐𝑡𝑖𝑣𝑜 𝑖𝑛𝑚𝑒𝑑𝑖𝑎𝑡𝑎𝑚𝑒𝑛𝑡𝑒 𝑑𝑒𝑠𝑝𝑢é𝑠 𝑑𝑒 𝑙𝑎 𝑐𝑜𝑚𝑝𝑟𝑎 𝑗) = 𝑝(1 − 𝑝)𝑗−1,
𝑗 = 1, 2, 3 …
(4) La heterogeneidad en p sigue una distribución de densidad beta de la forma
𝑓( 𝑝| 𝑎, 𝑏) =𝑝𝑎−1(1−𝑝)𝑏−1
𝐵(𝑎,𝑏) , 0 ≤ 𝑝 ≤ 1 (2)
donde 𝐵(𝑎, 𝑏) es la función Beta que puede expresarse en términos de funciones
Gamma:
𝐵(𝑎, 𝑏) =𝛤(𝑎) + 𝛤(𝑏)
𝛤(𝑎 + 𝑏)

7
(5) La tasa de transacción λ, y la probabilidad de abandono 𝑝 varía con independencia de
los clientes.
4. Desarrollo del modelo
4.1. Desarrollo del Modelo a nivel individual.
4.1.1. Derivación de la Función de Probabilidad.
Consideremos un cliente que ha realizado x transacciones en el periodo (0, 𝑇] ocurridas en
diferentes momentos 𝑡1, 𝑡2, … , 𝑡𝑥:
0 𝑡1 𝑡2 𝑡𝑥 𝑇
… ….
Derivaremos la función de probabilidad a nivel individual de la siguiente manera:
La probabilidad de que la primera transacción ocurra en el momento 𝑡1 tiene una
probabilidad exponencial estándar igual a 𝜆𝑒−𝜆𝑡1.
La probabilidad de que la segunda transacción ocurra en el momento 𝑡2 tiene una
probabilidad exponencial estándar igual a (1 − 𝑝)𝜆𝑒−𝜆(𝑡2−𝑡1).
Esto continúa para las siguientes transacciones hasta que:
La probabilidad de que la transacción 𝑥 ocurra en el momento 𝑡𝑥 es la probabilidad de
permanecer activo en el momento 𝑡𝑥−1 que sería igual a
(1 − 𝑝)𝜆𝑒−𝜆(𝑡𝑥−𝑡𝑥−1).
Por último, la probabilidad de no observar ninguna compra en (𝑡𝑥, 𝑇] es la probabilidad de
que el cliente permanezca inactivo en 𝑡𝑥 más la probabilidad de que permanezca activo pero
que no haya hecho compras en ese intervalo, que es igual a
𝑝 + (1 − 𝑝)𝑒−𝜆(𝑇−𝑡𝑥)
Por lo tanto,
ℒ(𝜆, 𝑝|𝑡1, 𝑡2, … , 𝑡𝑥 , 𝑇) =
𝜆𝑒−𝜆𝑡1(1 − 𝑝)𝜆𝑒𝜆(𝑡2−𝑡1) … (1 − 𝑝)𝜆𝑒𝜆(𝑡𝑥−𝑡𝑥−1). {𝑝 + (1 − 𝑝)𝑒−𝜆(𝑇−𝑡𝑥)}
= 𝑝(1 − 𝑝)𝑥−1 𝜆𝑥 𝑒−𝜆𝑡𝑥 + (1 − 𝑝)𝑥 𝜆𝑥𝑒−𝜆𝑇
Como hemos apuntado antes, para el Modelo de Pareto/NBD, tampoco se necesitarán los
momentos de las compras. Será suficiente con un sumatorio del histórico de las mismas.
(𝑋 = 𝑥, 𝑡𝑥 , 𝑇).

8
De la misma manera que el Modelo SMC, suponemos que todos los clientes están activos en el
momento del periodo de observación. Por lo tanto, la función de probabilidad para que un cliente
no haga ninguna compra en el periodo (0, 𝑇] es la recurrente función exponencial.
ℒ(𝜆|𝑋 = 0, 𝑇) = 𝑒−𝜆𝑇
Por tanto, la función de probabilidad individual será:
ℒ(𝜆, 𝑝|𝑋 = 𝑥, 𝑇) = (1 − 𝑝)𝑥 𝜆𝑥𝑒−𝜆𝑇 + 𝛿𝑥>0𝑝(1 − 𝑝)𝑥−1𝜆𝑥 𝑒−𝜆𝑡𝑥 , (3)
donde 𝛿𝑥>0 = 1 si 𝑥 > 0, en caso contrario es 0.
4.1.2. Derivación de P (X (t)=x).
Considerando las variables aleatorias 𝑋(𝑡) como el número de transacciones que ocurren en un
periodo de tiempo de longitud 𝑡 (empezando en el tiempo 0), y 𝑇𝑥 como el tiempo de la
transacción 𝑥, tenemos que 𝑋(𝑡) ≥ 𝑥 ⇔ 𝑇𝑥 ≤ 𝑡.
Derivando una expresión como 𝑃(𝑋(𝑡) = 𝑥), subrayaremos la relación existente entre el número
de eventos y los periodos entre dichos eventos.
Entonces,
𝑃(𝑋(𝑡) = 𝑥) = 𝑃(𝑐𝑙𝑖𝑒𝑛𝑡𝑒 𝑎𝑐𝑡𝑖𝑣𝑜 𝑑𝑒𝑠𝑝𝑢é𝑠 𝑑𝑒 𝑙𝑎 𝑐𝑜𝑚𝑝𝑟𝑎 𝑥) . 𝑃(𝑇𝑥 ≤ 𝑡 𝑦 𝑇𝑥+1 > 𝑡) + 𝛿𝑥>0
. 𝑃(𝑐𝑙𝑖𝑒𝑛𝑡𝑒 𝑖𝑛𝑎𝑐𝑡𝑖𝑣𝑜 𝑑𝑒𝑠𝑝𝑢é𝑠 𝑑𝑒 𝑙𝑎 𝑐𝑜𝑚𝑝𝑟𝑎 𝑥) . 𝑃(𝑇𝑥 ≤ 𝑡)
Bajo el supuesto de que el tiempo entre las transacciones se distribuye como una exponencial
𝑃(𝑇𝑥 ≤ 𝑡 𝑦 𝑇𝑥+1 > 𝑡) que es simplemente la probabilidad de Poisson en la que 𝑋(𝑡) = 𝑥 y
𝑃(𝑇𝑥 ≤ 𝑡). Por tanto,
𝑃(𝑋(𝑡) = 𝑥|𝜆, 𝑝) = (1 − 𝑝)𝑥 (𝜆𝑡)𝑥𝑒−𝜆𝑡
𝑥!+ 𝛿𝑥>0 𝑝(1 − 𝑝)𝑥−1 [1 − 𝑒−𝜆𝑡 ∑
(𝜆𝑡)𝑗
𝑗!𝑥−1𝑗=0 ] (4)
4.1.3. Derivación de E [X (t)]
Dado que el número de transacciones se distribuye como una Poisson, 𝐸[𝑋(𝑡)] es simplemente
𝜆𝑡 si el cliente está activo en 𝑡. Para un cliente que se convierte en inactivo en
𝜏 ≤ 𝑡, el número de transacciones esperadas en el periodo (0, 𝜏] es λ𝜏.
En cualquier caso, ¿cuál es la probabilidad de que un cliente llegue a ser inactivo en 𝜏?
Condicionado a λ y 𝑝,
𝑃(𝜏 > 𝑡) = 𝑃(𝑎𝑐𝑡𝑖𝑣𝑜 𝑒𝑛 𝑡| 𝜆, 𝑝) = ∑(1 − 𝑝)𝑗(𝜆𝑡)𝑗𝑒−𝜆𝑡
𝑗!
∞
𝑗=0
= 𝑒−𝜆𝑝𝑡
Esto implica que el momento del abandono se daría como 𝑔(𝜏|𝜆, 𝑝) = 𝜆𝑝𝑒−𝜆𝑝𝜏
(el modelo de Pareto considera independiente el abandono y la tasa de transacción)
Por lo tanto, el número de transacciones esperado en un periodo de longitud 𝑡 aparece como

9
𝐸(𝑋(𝑡)|𝜆, 𝑝) = 𝜆𝑡 𝑃(𝜏 > 𝑡) + ∫ 𝜆𝜏𝑔(𝜏|𝜆, 𝑝) 𝑑𝜏𝑡
0=
1
𝑝−
1
𝑝𝑒−𝜆𝑝𝑡 (5)
4.2. Desarrollo del modelo para un individuo aleatorio.
Todas las expresiones desarrolladas debajo están condicionadas a la tasa de transacción λ, y la
probabilidad de abandono 𝑝, ambas son no observadas.
Para derivar las expresiones equivalentes para un cliente elegido aleatoriamente, tomamos los
resultados esperados a nivel individual por encima de las distribuciones combinadas para λ y 𝑝,
como vemos en (1) y (2). Esto nos da los siguientes resultados.
Tomando el valor esperado de (3) por encima de la distribución de λ y 𝑝 se obtiene la siguiente
expresión de la función de probabilidad para un cliente aleatorio con histórico de compras
(𝑋 = 𝑥, 𝑡𝑥 , 𝑇):
ℒ(𝑟, 𝛼, 𝑎, 𝑏|𝑋 = 𝑥, 𝑡𝑥 , 𝑇) =
=𝐵(𝑎,𝑏+𝑥)
𝐵(𝑎,𝑏)
Г(𝑟+𝑥)𝛼𝑟
Г(𝑟)(𝛼+𝑇)𝑟+𝑥 + 𝛿𝑥>0𝐵(𝑎+1,𝑏+𝑥−1)
𝐵(𝑎,𝑏)
Г(𝑟+𝑥)𝛼𝑟
Г(𝑟)(𝛼+𝑡𝑥)𝑟+𝑥 (6)
Los cuatro parámetros del modelo BG/NBD (𝑟, 𝛼, 𝑎, 𝑏) pueden estimarse por el método de
máxima verosimilitud de la siguiente manera. Suponemos que tenemos una muestra de N
clientes, donde el cliente 𝑖 tiene 𝑋𝑖 = 𝑥𝑖, transacciones en el período (0, 𝑇], con la última
transacción que tiene lugar en 𝑡𝑥𝑖. La función de probabilidad logarítmica sería,
ℒℒ(𝑟, 𝛼, 𝑎, 𝑏) = ∑ ln[ℒ(𝑟, 𝛼, 𝑎, 𝑏|𝑋𝑖 = 𝑥𝑖 , 𝑡𝑥𝑖, 𝑇𝑖)]𝑁
𝑖=1 (7)
Esto se puede maximizar utilizando técnicas de optimización estándar.
Tomando el valor esperado de (4) por encima de la distribución de λ y 𝑝, resulta la siguiente
expresión para la probabilidad de compras observadas en un período de tiempo t:
𝑃(𝑋(𝑡) = 𝑥 | 𝑟, 𝛼, 𝑎, 𝑏) =
=𝐵(𝑎, 𝑏 + 𝑥)
𝐵(𝑎, 𝑏)
Г(𝑟 + 𝑥)
Г(𝑟)𝑥!(
𝛼
𝛼 + 𝑡)
𝑟
(𝑡
𝛼 + 𝑡)
𝑡
+𝛿𝑥>0𝐵(𝑎+1,𝑏+𝑥−1)
𝐵(𝑎,𝑏)[1 − (
𝛼
𝛼+𝑡)
𝑟
{∑Г(𝑟+𝑗)
Г(𝑟)𝑗!
𝑥−1𝑗=0 (
𝑡
𝛼+𝑡)
𝑗
}] (8)
Finalmente, tomando el valor esperado de (5) por encima de la distribución de λ y 𝑝 resulta la
siguiente expresión para un número esperado de compras en un período de tiempo de longitud t:
𝐸(𝑋(𝑡) = 𝑥 | 𝑟, 𝛼, 𝑎, 𝑏) =𝑎+𝑏−1
𝑎−1[1 − (
𝛼
𝛼+𝑡)
𝑟𝐹2 1 (𝑟, 𝑏; 𝑎 + 𝑏 − 1;
𝑡
𝛼+𝑡)] (9)
Donde 𝐹2 1 es la función hipergeométrica Gaussiana (ver anexo).

10
Advertir que esta expresión final necesita una evaluación individual para la función
hipergeométrica Gaussiana, pero es importante subrayar que este valor esperado se utiliza sólo
después de que la función de probabilidad se haya maximizado. una evaluación individual para
la función hipergeométrica Gaussiana para un conjunto dado de parámetros es relativamente
directa, y se puede acercar mucho a una serie polinomial, incluso en un entorno como el de
Microsoft Excel.
En tanto en cuanto el modelo BG/NBD se utilice en predicciones basadas en el análisis del
cliente necesitamos obtener una expresión para el valor esperado de las transacciones en un
período de tiempo futuro de longitud 𝑡 para una observación del histórico individual de los
clientes (𝑋 = 𝑥, 𝑡𝑥 , 𝑇).
La expresión final resultante sería la siguiente:
𝐸(𝑌(𝑡)|𝑋 = 𝑥, 𝑡𝑥 , 𝑇, 𝑟, 𝛼, 𝑎, 𝑏) =
𝑎+𝑏+𝑥−1
𝑎+1[1−(
𝛼+𝑇
𝛼+𝑇+𝑡)
𝑟+𝑥+ 𝐹2 1(𝑟+𝑥,𝑏+𝑥;𝑎+𝑏+𝑥−1;
𝑡
𝛼+𝑇+𝑡) ]
1+𝛿𝑥>0 𝑎
𝑏+𝑥−1 (
𝛼+𝑇
𝛼+𝑡𝑥)
𝑟+𝑥 (10)
Una vez más este valor esperado requiere una evaluación individual de la función
hipergeométrica Gaussiana para cualquier cliente de interés. Es una tarea relativamente sencilla
porque es simple aritmética.
5. Aplicación empírica.
En nuestro estudio, exploraremos el rendimiento del modelo BG/NBD usando datos de las
compras de los CDs en la tienda online CDNOW. El dataset completo se enfoca en un grupo de
clientes nuevos que hicieron su primera compra en el primer cuatrimestre de 1997 hasta junio de
1998, durante los cuales 23.570 personas estudiadas se compraron cerca de 163.000 CDs en el
primer cuatrimestre del año 97 después de su primera ocasión de compra (ver Fader y Hardie
2001 para más detalles sobre este dataset4). Para los objetivos de este análisis, tomaremos sólo
una parte de esos datos.
Calibraremos el modelo usando los datos de las transacciones repetidas para la muestra de 2357
clientes sobre la primera mitad del periodo de 78 semanas y las compras predichas de las
siguientes 39. Nótese que para el cliente 𝑖(𝑖 = 1, … , 2357), ya conocemos la longitud del
periodo de tiempo durante el cual podía haber comprado (𝑇𝑖 =39-momento de la primera
4 Fader, Peter S., Bruce G. S. Hardie (2001). Forecasting repeat sales at CDNOW: A case study, Part 2 of 2. Interfaces 31
(May-June) S94-S107.

11
compra), el número de compras que ha hecho en ese periodo (𝑥𝑖) y el momento en el que repitió
su última compra (𝑡𝑥).
Es importante señalar que nos estamos centrando en el número de transacciones, de compras, no
en el número de productos (cds, en este caso), vendidos.
En nuestro notebook de Python, se analizará la actividad o inactividad del consumidor final,
basándonos en un tiempo finito: al cabo de un tiempo concreto la relación con el cliente
"morirá". El objetivo será tratar de predecir la frecuencia con la que un potencial cliente visitará
nuestra web. Estudiando el histórico de compras, trataremos de predecir la repetición de una
compra, el abandono de una aplicación, y calcular el CLTV.
Para esta primera parte se importarán las librerías necesarias más comunes tales como numpy,
spicy matplotlib y pandas. Pero antes que nada la librería lifetimes, de la que iremos hablando a
lo largo de esta memoria (ver anexo de instalación).
import numpy as np
import scipy as sp
import matplotlib.pyplot as plt
import pandas as pd
%matplotlib inline
La librería Lifetimes jugará un papel fundamental en todo nuestro análisis, de la que extraemos
una muestra del dataset comentado cdnow.
from lifetimes.datasets import load_cdnow
data = load_cdnow(index_col=[0])
print data.head()
ID Frequency Recency T
1 2 30.43 38.86
2 1 1.71 38.86
3 0 0.00 38.86
4 0 0.00 38.86
5 0 0.00 38.86
Tabla 1: Muestra del dataset cdnow_customers
En la Tabla 1 observamos una pequeña muestra del dataset cdnow_customers en la que
observamos los datos con los que vamos a trabajar en esta primera parte.
La frecuencia de compra de los clientes (calculado como el total menos 1).

12
T el tiempo que lleva el cliente en la empresa, en una unidad de tiempo cualquiera
(una semana, en nuestro caso). Es igual al tiempo transcurrido entre la primera y la
última compra total.
Recency es el momento de la última compra. Es la diferencia entre la primera y la
última compra individual. Nótese que 1 compra tiene una recency de 0. Lo
notaremos como 𝑡𝑥 .
Observamos por ejemplo como en la tabla 1, el cliente 1, ha repetido 2 veces su compra,
lleva más de 38 semanas con nosotros y hace 30 semanas que no nos visita para adquirir
nada. Al contrario que el cliente 2 que hace una semana realizó su última compra.
Como se ha comentado anteriormente, utilizaremos el Modelo BG/NBD, una variación del
modelo de Pareto que implementamos con el código que sigue.
from lifetimes import BetaGeoFitter
# similar API to scikit-learn and lifelines.
bgf = BetaGeoFitter(penalizer_coef=0.0)
bgf.fit(data['frequency'], data['recency'], data['T'])
print bgf
<lifetimes.BetaGeoFitter:
fitted with 2357 subjects, r: 0.24, alpha: 4.41, a: 0.79, b: 2.43>
Comprobamos que tenemos un dataset de 2357 filas cuyos 4 parámetros clave
comentados (𝑟, 𝛼, 𝑎 𝑦 𝑏) tienen los valores que observamos arriba (0.24, 4.41, 0.79, 2.43).
Matriz de Frecuencias
A continuación, pongamos un ejemplo. Un cliente ha realizado compras durante tres semanas
seguidas, y después de eso, desaparece. Se considera que las probabilidades de que vuelva a
comprar son bajas. Por otra parte, un cliente que compra periódicamente bajo un espacio de
tiempo más dilatado, pero regular (1 vez al trimestre, por ejemplo), se considera activo.
Podemos visualizar esta relación usando la Matriz de Frecuencias, que calcula el número de
transacciones esperadas de un cliente en el próximo período, dado su recency (edad de la última
compra) y frecuencia (número de compras repetidas).
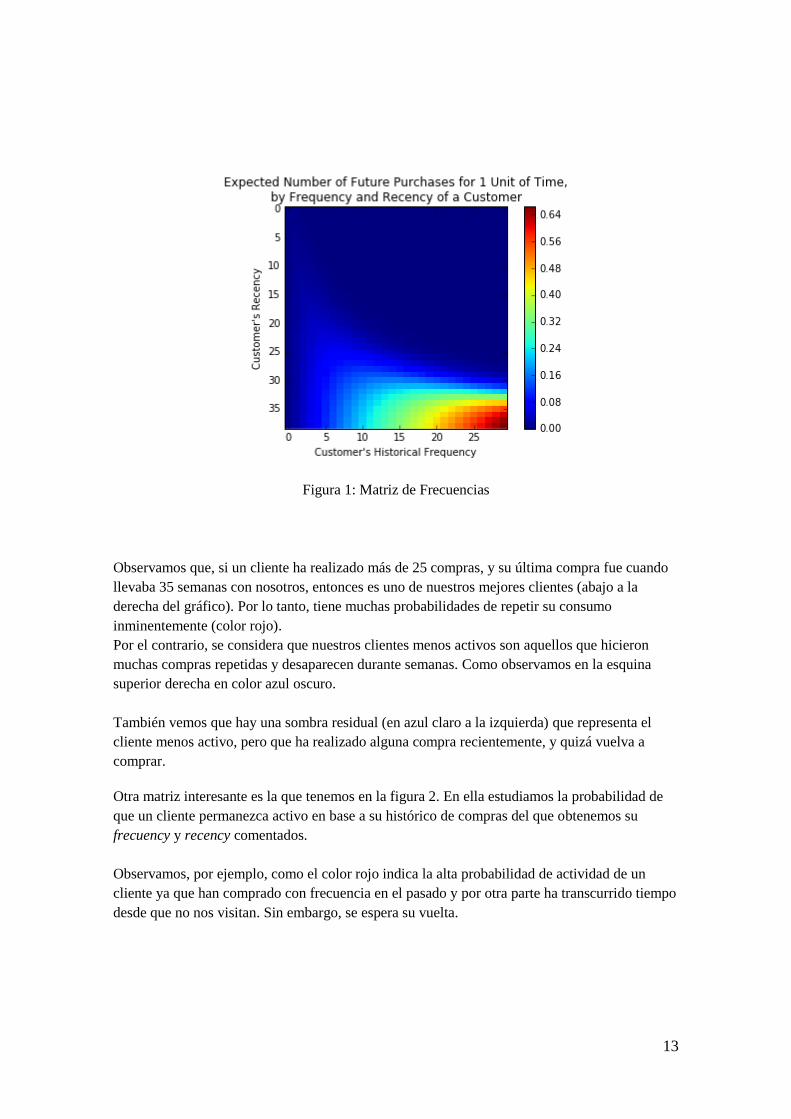
13
Figura 1: Matriz de Frecuencias
Observamos que, si un cliente ha realizado más de 25 compras, y su última compra fue cuando
llevaba 35 semanas con nosotros, entonces es uno de nuestros mejores clientes (abajo a la
derecha del gráfico). Por lo tanto, tiene muchas probabilidades de repetir su consumo
inminentemente (color rojo).
Por el contrario, se considera que nuestros clientes menos activos son aquellos que hicieron
muchas compras repetidas y desaparecen durante semanas. Como observamos en la esquina
superior derecha en color azul oscuro.
También vemos que hay una sombra residual (en azul claro a la izquierda) que representa el
cliente menos activo, pero que ha realizado alguna compra recientemente, y quizá vuelva a
comprar.
Otra matriz interesante es la que tenemos en la figura 2. En ella estudiamos la probabilidad de
que un cliente permanezca activo en base a su histórico de compras del que obtenemos su
frecuency y recency comentados.
Observamos, por ejemplo, como el color rojo indica la alta probabilidad de actividad de un
cliente ya que han comprado con frecuencia en el pasado y por otra parte ha transcurrido tiempo
desde que no nos visitan. Sin embargo, se espera su vuelta.
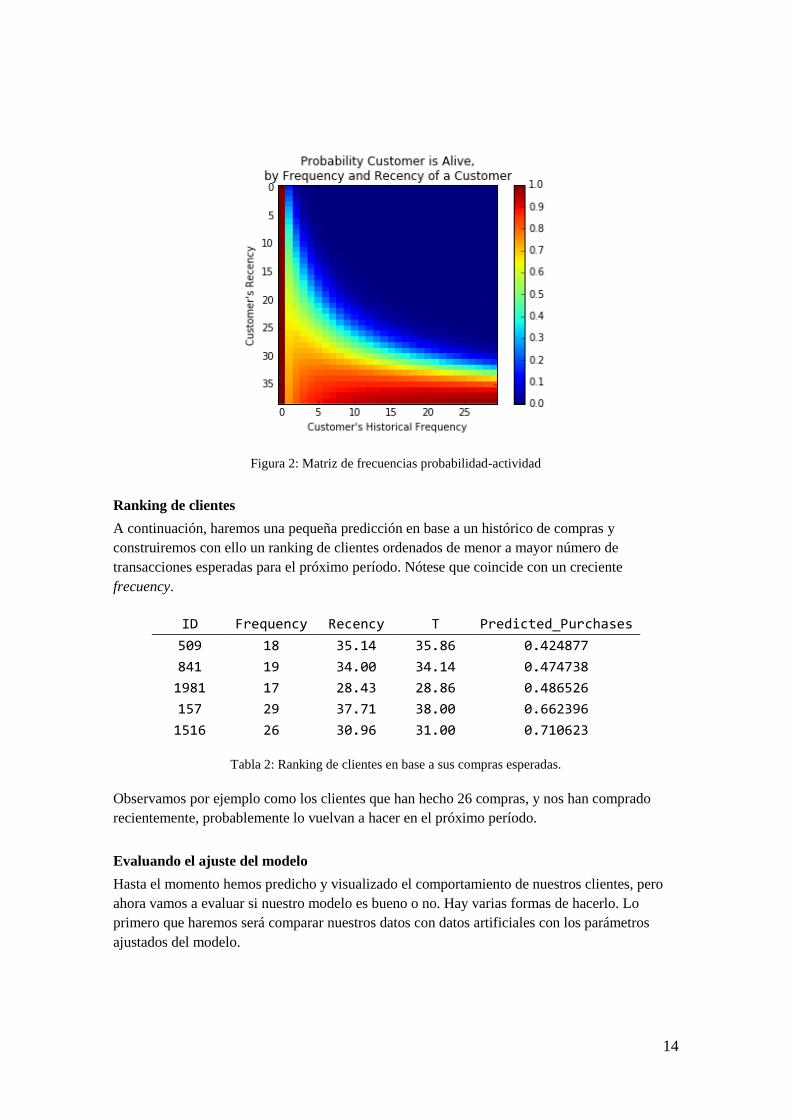
14
Figura 2: Matriz de frecuencias probabilidad-actividad
Ranking de clientes
A continuación, haremos una pequeña predicción en base a un histórico de compras y
construiremos con ello un ranking de clientes ordenados de menor a mayor número de
transacciones esperadas para el próximo período. Nótese que coincide con un creciente
frecuency.
ID Frequency Recency T Predicted_Purchases
509 18 35.14 35.86 0.424877
841 19 34.00 34.14 0.474738
1981 17 28.43 28.86 0.486526
157 29 37.71 38.00 0.662396
1516 26 30.96 31.00 0.710623
Tabla 2: Ranking de clientes en base a sus compras esperadas.
Observamos por ejemplo como los clientes que han hecho 26 compras, y nos han comprado
recientemente, probablemente lo vuelvan a hacer en el próximo período.
Evaluando el ajuste del modelo
Hasta el momento hemos predicho y visualizado el comportamiento de nuestros clientes, pero
ahora vamos a evaluar si nuestro modelo es bueno o no. Hay varias formas de hacerlo. Lo
primero que haremos será comparar nuestros datos con datos artificiales con los parámetros
ajustados del modelo.
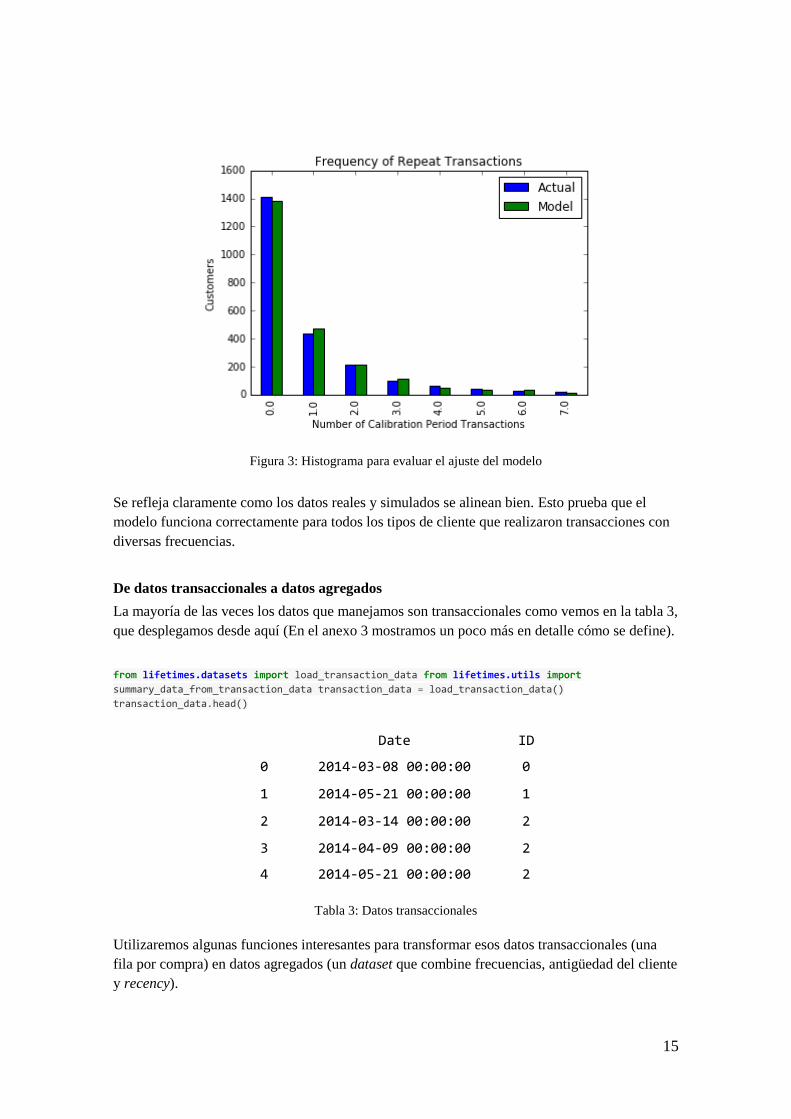
15
Figura 3: Histograma para evaluar el ajuste del modelo
Se refleja claramente como los datos reales y simulados se alinean bien. Esto prueba que el
modelo funciona correctamente para todos los tipos de cliente que realizaron transacciones con
diversas frecuencias.
De datos transaccionales a datos agregados
La mayoría de las veces los datos que manejamos son transaccionales como vemos en la tabla 3,
que desplegamos desde aquí (En el anexo 3 mostramos un poco más en detalle cómo se define).
from lifetimes.datasets import load_transaction_data from lifetimes.utils import
summary_data_from_transaction_data transaction_data = load_transaction_data()
transaction_data.head()
Date ID
0 2014-03-08 00:00:00 0
1 2014-05-21 00:00:00 1
2 2014-03-14 00:00:00 2
3 2014-04-09 00:00:00 2
4 2014-05-21 00:00:00 2
Tabla 3: Datos transaccionales
Utilizaremos algunas funciones interesantes para transformar esos datos transaccionales (una
fila por compra) en datos agregados (un dataset que combine frecuencias, antigüedad del cliente
y recency).

16
Lo haremos con el siguiente código.
bgf.fit(summary['frequency'], summary['recency'], summary['T'])
# <lifetimes.BetaGeoFitter: fitted with 5000 customers, a: 1.85, alpha: 1.86, r: 0.16, b: 3.18>
Del que resultan los nuevos parámetros para el nuevo ajuste del modelo.
<lifetimes.BetaGeoFitter: fitted with 5000 subjects,
r: 0.16, alpha: 1.86, a: 1.85, b: 3.18>
Que nos ayudarán para desplegar un nuevo dataset de datos agregados.
ID Frequency Recency T
0 0 0 298
1 0 0 224
2 6 142 292
3 0 0 147
4 2 9 183
Tabla 4: Nuevos datos agregados transformados
Predicciones del cliente individual
Basándonos en el histórico de compras del cliente, haremos una predicción las futuras compras.
t = 10 #Predicción de compras para los próximos 10 periodos
individual = summary.iloc[20]
# La función de abajo es un alias de `bfg.conditional_expected_number_of_purchases_up_to_time`
bgf.predict(t, individual['frequency'], individual['recency'], individual['T'])
0.057651166220182973
En el ejemplo, la probabilidad de que un individuo vuelva a repetir la compra en base a los
nuestros parámetros comentados (t, frecuency, recency y T) es de 0.05765.
Probabilidad de actividad
Dado un histórico de compras del cliente, podemos calcular su probabilidad de estar activo, de
acuerdo al modelo que acabamos de entrenar. A continuación, el ejemplo.
from lifetimes.plotting import plot_history_alive
id = 35 # Cliente 35
days_since_birth = 200 # Con 200 días de antigüedad en relación con la empresa
sp_trans = transaction_data.ix[transaction_data['id'] == id]
plot_history_alive(bgf, days_since_birth, sp_trans, 'date')
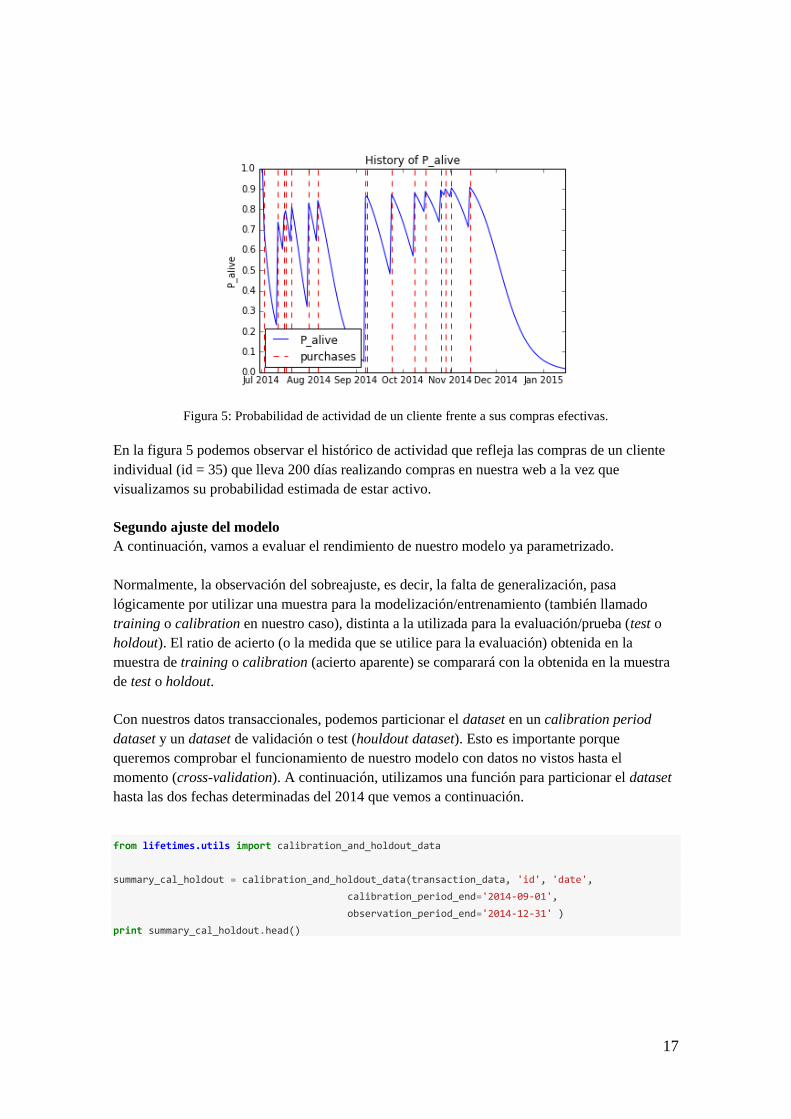
17
Figura 5: Probabilidad de actividad de un cliente frente a sus compras efectivas.
En la figura 5 podemos observar el histórico de actividad que refleja las compras de un cliente
individual (id = 35) que lleva 200 días realizando compras en nuestra web a la vez que
visualizamos su probabilidad estimada de estar activo.
Segundo ajuste del modelo
A continuación, vamos a evaluar el rendimiento de nuestro modelo ya parametrizado.
Normalmente, la observación del sobreajuste, es decir, la falta de generalización, pasa
lógicamente por utilizar una muestra para la modelización/entrenamiento (también llamado
training o calibration en nuestro caso), distinta a la utilizada para la evaluación/prueba (test o
holdout). El ratio de acierto (o la medida que se utilice para la evaluación) obtenida en la
muestra de training o calibration (acierto aparente) se comparará con la obtenida en la muestra
de test o holdout.
Con nuestros datos transaccionales, podemos particionar el dataset en un calibration period
dataset y un dataset de validación o test (houldout dataset). Esto es importante porque
queremos comprobar el funcionamiento de nuestro modelo con datos no vistos hasta el
momento (cross-validation). A continuación, utilizamos una función para particionar el dataset
hasta las dos fechas determinadas del 2014 que vemos a continuación.
from lifetimes.utils import calibration_and_holdout_data
summary_cal_holdout = calibration_and_holdout_data(transaction_data, 'id', 'date',
calibration_period_end='2014-09-01',
observation_period_end='2014-12-31' )
print summary_cal_holdout.head()

18
A partir de aquí, vemos como particiona el dataset en dos subconjuntos con sus respectivas
recency y frecuency para nuestras pruebas. Es sólo la cabecera, pero nos sirve para visualizar lo
que hacemos. En general, se tratará de general muestras de training y test lo suficientemente
amplias como para garantizar que la evaluación en ambas es confiable.
ID Frequency_Cal Recency_Cal T_Cal Frequency_Holdout Duration_Holdout
0 0 0 177 0 121
1 0 0 103 0 121
2 6 142 171 0 121
3 0 0 26 0 121
4 2 9 62 0 121
Tabla 5: Dataset dividido en calibration period dataset y houldout dataset.
from lifetimes.plotting import plot_calibration_purchases_vs_holdout_purchases
bgf.fit(summary_cal_holdout['frequency_cal'], summary_cal_holdout['recency_cal'], summary_cal_ho
ldout['T_cal'])
plot_calibration_purchases_vs_holdout_purchases(bgf, summary_cal_holdout)
Salvando las limitaciones y el riesgo que supone la utilización de una única muestra de
entrenamiento y otra de validación, comprobamos que nuestro modelo predice bastante bien
frente a nuestros datos de prueba.
Figura 4: Evaluación de la capacidad predictiva de nuestro modelo.
En la figura 4, estamos comparando las compras reales del conjunto de test con sus compras
predichas, y evaluando si se ajustan bien. Parece que, para compras elevadas, difieren más (de la
quinta a la sexta compra), el modelo pierde capacidad predictiva.

19
Estimando el Customer Life Time Value
Hasta este momento no hemos tenido en cuenta el valor económico de cada compra y nos hemos
enfocado principalmente en la existencia de estas transacciones. Para estimar esto podemos usar
el submodelo Gamma-Gamma. Pero primero necesitamos crear datos agregados de datos
transaccionales que también contengan valores económicos de estas transacciones (por ejemplo,
beneficios o ingresos). En la tabla 6 apreciamos mejor esa transformación. Más detalles del código
asociado en el anexo.
from lifetimes.datasets import load_summary_data_with_monetary_value
summary_with_money_value = load_summary_data_with_monetary_value()
summary_with_money_value.head()
returning_customers_summary = summary_with_money_value[summary_with_money_value['frequency']>0]
returning_customers_summary.head()
Customer_id Frequency Recency T Monetary_value
1 2 30.43 38.86 22.35
2 1 1.71 38.86 11.77
6 7 29.43 38.86 73.74
7 1 5.00 38.86 11.77
9 2 35.71 38.86 25.55
Tabla 6: Nuevo dataset transformado
El submodelo Gamma-Gamma5 y el supuesto de independencia
El modelo que vamos a usar para estimar para el CLV para nuestra base de datos de clientes se
llama submodelo Gamma-Gamma, que es necesario para incluir los valores monetarios que
expondremos a continuación. El submodelo Gamma-Gamma supone que no hay relación entre
el valor monetario y la frecuencia de compra. En la práctica, vamos a comprobar primero si el
coeficiente de correlación de Pearson entre los dos vectores se aproxima a cero para poder usar
este modelo.
returning_customers_summary[['monetary_value', 'frequency']].corr()
Monetary_value Frequency
Monetary_value 1.000000 0.113884
Frequency 0.113884 1.000000
Tabla 7: Coeficiente de correlación entre el valor monetario y la frecuencia de compra.
5 Fader, Peter S., Bruce G. S. Hardie (2013). The Gamma-Gamma Model of Monetary Value <http://brucehardie.com/notes/025/>

20
Confirmamos que no hay relación entre el precio de los bienes de nuestro dataset y su frecuencia
de compra. Parece que el precio determina poco la compra. Obviamente esto sería muy
característico del tipo de bien que estudiamos. Para este caso concreto, la correlación es muy baja.
A partir de aquí, entrenaremos nuestro submodelo Gamma-Gamma y trataremos de predecir el
valor esperado medio de nuestros clientes.
from lifetimes import GammaGammaFitter
ggf = GammaGammaFitter(penalizer_coef = 0)
ggf.fit(returning_customers_summary['frequency'],
returning_customers_summary['monetary_value'])
print ggf
<lifetimes.GammaGammaFitter: fitted with 946 subjects, p: 6.25, q: 3.74, v: 15.45>
De los 2357 individuos en nuestro dataset, 946 hicieron como mínimo una compra, y es con los
que hemos trabajado para concluir que, por el método de máxima verosimilitud, los valores de
los tres parámetros de nuestro modelo (p, q, 𝛾) son (6.25, 3.74, 15.45) respectivamente. Una vez
que tenemos nuestro modelo Gamma-Gamma parametrizado, procedemos a calcular el CLV
que debe de exponerse en unidades monetarias.
print ggf.conditional_expected_average_profit(
summary_with_money_value['frequency'],
summary_with_money_value['monetary_value']
).head()
customer_id CLV
1 24.658617
2 18.911481
3 35.171002
4 35.171002
5 35.171002
Dty6pe: float64
Tabla 8: Beneficio medio esperado por cliente o CLV
En la tabla 8 obtenemos el CLV por cliente para la empresa de nuestro dataset.
Ahora ya podemos mostrar el resultado del valor medio del CLV de nuestros clientes (averange
Customer Lifetime Value) como sigue.

21
print "Expected conditional average profit: %s, Average profit: %s" % (
ggf.conditional_expected_average_profit(
summary_with_money_value['frequency'],
summary_with_money_value['monetary_value']
).mean(),
summary_with_money_value[summary_with_money_value['frequency']>0]['monetary_value'].mean()
)
Expected conditional average profit: 35.2529582528, Average profit: 35.078551797
Resultando un beneficio medio esperado por cliente de 35.25 unidades monetarias, y un
beneficio medio de 35.07 u.m. Lo que los aproxima mucho, concluyendo con la fiabilidad de la
predicción.
Para hacer una comparación entre los dos métodos, ahora vamos a calcular el CLV total usando
el método de DFC (discounted cash flows) ajustado para el coste del capital con una tasa de
descuento de 0.7.
Recordamos la primera fórmula al inicio (1a), que utilizaremos para hacer una rápida
comparación entre dos métodos muy distintos. También lo son sus resultados.
𝐶𝐿𝑉 = ∑(𝑝𝑡−𝑐𝑡)𝑟𝑡
(1+𝑖)𝑡𝑇𝑡=0 − 𝐴𝐶 (1a)
# Reajuste del modelo BG para los datos agregados con valor monetario
bgf.fit(summary_with_money_value['frequency'], summary_with_money_value['recency'], summary_with
_money_value['T'])
print ggf.customer_lifetime_value(
bgf, #Modelo a usar para predecir el número de compras futuras
summary_with_money_value['frequency'],
summary_with_money_value['recency'],
summary_with_money_value['T'],
summary_with_money_value['monetary_value'],
time=12, # meses
discount_rate=0.7
).head(10)

22
Customer_ID CLV
1 27.535073
2 3.568359
3 6.598023
4 6.598023
5 6.598023
6 210.596295
7 5.294988
8 6.598023
9 32.905050
10 6.598023
Tabla 9: CLV por el método de DFC.
En la tabla 9 observamos el Customer Lifetime Value en valores monetarios para cada cliente,
con el método del DFC. Así, observamos que hay significativas diferencias entre los valores de
unos clientes y otros. Como ya hemos ido diciendo a lo largo de toda esta memoria: no todos los
clientes son iguales.
6. Conclusiones y trabajo futuro
6.1. Conclusiones
Con un ajuste correcto, el modelo BG/NBD se presta también a una buena capacidad de
generalización para la evaluación del Customer Litetime Value, con diversas métricas
empresariales. Aunque no hay que perder de vista que la segmentación de los clientes se realiza
en base a un histórico de compras siempre, como el utilizado método RFM (Recency,
Frecuency, Monetary Value). Esta segmentación puede y en la mayoría de ocasiones está
dirigida a objetivos de marketing diferentes (Elsner y otros 2004) e implica por ello ciertas
cuestiones que hay que tener en cuenta también, tales como el sesgo de endogeneidad (Shugan
2004) y el sesgo de selección de la muestra.
A pesar de todo, es un modelo muy bueno, con poca competencia hasta la fecha en contextos no
contractuales, donde las oportunidades de transacción para los clientes son continuas, y una vez
que el cliente se convierte en inactivo, la relación con la empresa expira.
6.2. Trabajo futuro
Estas son algunas líneas abiertas sobre las que se está trabajando en torno al Customer Lifetime
Value.
Más allá de los datos transaccionales
Uno de los retos principales para esta temática serán las limitaciones de los datos
transaccionales, de los cuales las empresas coleccionan cantidades ingentes, y a los que se
debería extraer valor.

23
Por un lado, los datos transaccionales son una base muy buena para un estudio de cross-selling
en marketing, y al mismo tiempo no arrojan luz sobre las causas inherentes de ese consumo, las
motivaciones del cliente o la competencia.
Desde el business intelligence se estudia la oferta, pero, ¿es tan representativa de la demanda?
Entender las causas inherentes del consumo es la gran pregunta, y aún sin formularla, está
presente en todo momento.
Los datos de encuestas que al fin y al cabo siempre serán muestrales, son difíciles de incluir o
fusionar con datos transaccionales que son mucho más representativos. Wagner y Wedel 6 están
investigando en esa línea.
Evolución de un cliente a un portfolio de clientes
Decisiones localmente óptimas, como podrían ser la adquisición y mantenimiento del cliente, en
muchos casos son globalmente subóptimas en lo que a decisiones empresariales estratégicas se
refiere. Por ejemplo, el valor esperado del cliente demandante de servicios financieros, quizá a
priori se considere más valioso para la empresa si tiene alta propensión al riesgo. Sin embargo,
los mercados financieros valorarán más a la entidad que tenga una cartera de clientes más
diversificada.
Dhar y Glazer7 han avanzado en esta dirección. En general hay mucha documentación financiera
sobre la optimización del Portfolio. Es precisamente uno de los retos principales que se intuye
desde el principio, inherente en toda esta memoria.
Micro-modelos vs macro-modelos
La utilización conjunta de micro-modelos junto con macro-modelos presenta dificultades de
integración conjunta en cuanto a diferencia de variables, pero sobre todo de escala. Percival y
Walden8 investigan sobre esta reconciliación necesaria.
Hay mucho que añadir en este apartado, pero no será objeto de este Trabajo de Fin de Título.
Actualmente las empresas tienen una gran cantidad de datos de las operaciones con sus clientes.
Y el desarrollo de modelos para el estudio de esos datos aumenta de forma exponencial, por lo
reveladores que resultan para el estudio del comportamiento de la demanda.
6 Wagner, K & Wedel, M, de Rosa, F. & Mazzon, J.A. (2003), Cross-Selling through Database Marketing: A Mixed Data Factor Analyzer for
Data Augmentation and Prediction, International Journal of Research in Marketing, 20 (March), 45–65.
7 Dhar, Ravi and Rashi Glazer (2003), Hedging Customers, Harvard Business Review, 81 (5), 3-8. 8 Percival, D.B. and A. T. Walden (2000), Wavelet methods for Time Series Analysis. Cambridge, UK: Cambridge University Press.

24
A pesar de todo, debemos de rendirnos a las limitaciones de esos datos, que al fin y al cabo son
en su mayoría, datos de compras. Pueden resultar datos significativos en un contexto de estudio
de cross-selling para el análisis de la cesta de la compra, pero será prácticamente imposible
descubrir la casuística inherente a esas compras.
Hasta ahora los esfuerzos del Business Intelligence se han concentrado en los datos más fiables
que tenían: el estudio de sus ventas. Pero ¿qué pasa con la demanda, con el cliente? ¿Y con la
competencia? ¿Cómo se relacionan entre sí? ¿Cómo extraer, seguir y modelizar esos datos?
Para completar el puzzle, hay que entender al cliente. Y ese es un reto mucho mayor que está
sobre la mesa.

25
7. Referencias Abramowitz, M. & Stegun I.A. (eds.) (1972), Handbook of Mathematical Functions, New York: Dover
Publications.
Andrews, G. E., Askey R., & Roy R. (1999), Special Functions, Cambridge: Cambridge University Press.
Dhar, R. & Glazer R. (2003), Hedging Customers, Harvard Business Review, 81 (5), 3-8.
Elsner, R., Krafft, M. & Huchzermeier, A. (2004), Optimizing Rhenania’s direct maketing business
through dynamic multilevel modeling (DMLM) in a multicatalog environment. Marketing Sci. 23(2) 192-
206
Fader, P. S. & Hardie, B. G. (2005), A Note on Deriving the Pareto/NBD Model and Related Expressions.
http://brucehardie.com/notes/009/, 2005
Fader, P. S., Hardie, B. G., & Lee, K. L. (2005a), A Note on Implementing the Pareto/NBD Model in
MATLAB. http://brucehardie.com/notes/008/, 2005c.
Fader, P. S., Hardie, B. G., & Lee, K. L. (2003), “Counting Your Customers” the Easy Way: An
Alternative to the Pareto/NBD Model, Marketing Science, 24(2):275-284, 2005b.
Fader, P. S. & Hardie, B. G. (2001), Forecasting repeat sales at CDNOW: A case study, Part 2 of 2.
Interfaces 31 (May-June) S94-S107.
Fader, P. S. & Hardie, B. G. (2013). The Gamma-Gamma Model of Monetary Value.
<http://brucehardie.com/notes/025/>
Fader, P. S., Hardie, B. G., & Lee, K. L. (2005), RFM and CLV: Using iso-value curves for customer
base analysis. Journal of Marketing Research, 42(4), 415-430.
Glady, N., Baesens B. & Croux C. A modified Pareto/NBD approach for predicting customer lifetime
value. Departament of Decision Sciences and Information Management. Faculty of Economics and
Applied Economics. Katholieke Universiteit Leuven.
Gupta, S., Hassens, D. Hardie, B. & others (2005), Modeling Customer Lifetime Value. Journal of
Service Research, Vol. 9, No. 2, November 2006 139-155.
Gupta, S. & Lehmann, D. R. (2005), Managing Customers as Investments. Philadelphia: Wharton School
Publishing.
McCarthy, D. & Wadsworth E. (2014), Buy ’Til You Die - A Walkthrough.

26
Reinartz, W. & Kumar, V. (2000), On the profitability of long-life customers in a non-contractual setting:
An empirical investigation and implications for marketing. J. Marketing 64 (October) 17-35.
Reinartz, W. & Kumar, V.(2003), The Impact of Customer Relationship Characteristics on
Profitable Lifetime Duration. J. Marketing 67 (January) 77-99.
Reinartz, W., Thomas, J. & Kumar, V. (2005), Balancing Acquisition & Retention Resources to
Maximize Customer Profitability. Journal of Marketing, 69 (1), 69-79.
Schmittlein, D. C., Morrison, D.G. & Colombo, R. (1987), Counting Your Customers: Who Are They
and What Will They Do Next? Management Science, Vol. 33, No. 1 (Jan., 1987), pp. 1–24.
Shugan, S. M. (2004), Endogeneity in marketing decision models. Marketing Sci. 23(1) 1-3.
Thomas, J. (2001), A Metodology for Linking Customer Acquisition to Customer Retention, Journal
of Marketing Research, 38 (2), 262-68.
Wagner, K. Ramaswami, S. & Srivastava R. (1991), Applying Latent Trait Analysis in the Evaluation
of Prospects for Cross-Selling of Financial Services, International Journal of Research in Marketing,
8, 329-49.
Wagner, K & Wedel, M. (2003), List Augmentation with Model Based Multiple Implementation: A
Case of Study Using a Mixed- Outcome Factor Model. Statistica Neerlandica, 57 (1), 46-57.
Wagner, K & Wedel, M, de Rosa, F. & Mazzon, J.A. (2003), Cross-Selling through Database Marketing:
A Mixed Data Factor Analyzer for Data Augmentation and Prediction, International Journal of Research
in Marketing, 20 (March), 45–65.

27
8. Anexos
8.1. Manual de instalación
La instalación de la librería lifetimes, previa a la ejecución del notebook de Python con el que se
han trabajado estos resultados, se realiza desde el terminal en Linux con el comando: pip install lifetimes
A partir de aquí, su ejecución no debería de plantear demasiados problemas funcionando bien
para las diversas versiones de Python.
8.2. Manual del programador
Agradecemos y señalamos con especial énfasis el código de Lifetimes-0.2.0.0 desarrollado por
Cam Davidson-Pilon, y con licencia del MIT, Copyright del 2015, que nos ha posibilitado el
despliegue del notebook de Python de nuestro modelo.
Es un código largo, pero a la vez limpio y directo, en el que se puede leer si cabe con más
claridad que el propio planteamiento matemático, que en ocasiones puede resultar denso. He
aquí una pequeña muestra de ese código. Destacamos algunas partes interesantes.
summary_data_from_transaction_data transformará datos transaccionales con determinada forma
customer_id, datetime [, monetary_value], a datos de la forma
customer_id, frequency, recency, T [, monetary_value].
Lo vemos con algunos comentarios del autor.
def summary_data_from_transaction_data(transactions, customer_id_col, datetime_col, monetary_val
ue_col=None, datetime_format=None,
observation_period_end=datetime.today(), freq='D'):
¨Parameters:
transactions: a Pandas DataFrame.
customer_id_col: the column in transactions that denotes the customer_id
datetime_col: the column in transactions that denotes the datetime the purchase was made.
monetary_value_col: the columns in the transactions that denotes the monetary value of the transaction
Optional, only needed for customer lifetime value estimation models.
observation_period_end: a string or datetime to denote the final date of the study. Events
after this date are truncated.
datetime_format: a string that represents the timestamp format. Useful if Pandas can't understand
the provided format.
freq: Default 'D' for days, 'W' for weeks, 'M' for months... etc. Full list here:
http://pandas.pydata.org/pandas-docs/stable/timeseries.html#dateoffset-objects ¨
observation_period_end = pd.to_datetime(observation_period_end, format=datetime_format).to_p
eriod(freq)
# Etiqueta todas las transacciones repetidas
repeated_transactions = find_first_transactions(
transactions,

28
customer_id_col,
datetime_col,
monetary_value_col,
datetime_format,
observation_period_end,
freq
)
# Cuenta todos los pedidos por cliente.
customers = repeated_transactions.groupby(customer_id_col, sort=False)[datetime_col].agg(['m
in', 'max', 'count'])
# Al restar uno del “count”, se ignora el primer pedido del cliente
customers['frequency'] = customers['count'] - 1
customers['T'] = (observation_period_end - customers['min'])
customers['recency'] = (customers['max'] - customers['min'])
summary_columns = ['frequency', 'recency', 'T']
if monetary_value_col:
# Crea un índice de todas las compras iniciales
first_purchases = repeated_transactions[repeated_transactions['first']].index
#Por “nan” el valor monetario de las primeras compras, se excluirá del cálculo del valor medio.
repeated_transactions.loc[first_purchases, monetary_value_col] = np.nan
customers['monetary_value'] = repeated_transactions.groupby(customer_id_col)[monetary_va
lue_col].mean().fillna(0)
summary_columns.append('monetary_value')
return customers[summary_columns].astype(float)
En otro apartado, también vemos como importa los modelos que ya hemos visto que utilizamos
para nuestro análisis: Beta-Geometric, Gamma-Gamma y el Modelo de Pareto/NBD.
from .estimation import BetaGeoFitter, ParetoNBDFitter, GammaGammaFitter, ModifiedBetaGeoFitter
from .version import __version__
__all__ = ['BetaGeoFitter', 'ParetoNBDFitter', 'GammaGammaFitter', 'ModifiedBetaGeoFitter']
Por ejemplo, para nuestro modelo Beta Geometric comentado lo escribe así:
def beta_geometric_nbd_model(T, r, alpha, a, b, size=1): # Parámetros
"""
Generate artificial data according to the BG/NBD model.
Parameters:
T: scalar or array, the length of time observing new customers.
r, alpha, a, b: scalars, represening parameters in the model. See [1]
size: the number of customers to generate
Returns:

29
DataFrame, with index as customer_ids and the following columns:
'frequency', 'recency', 'T', 'lambda', 'p', 'alive', 'customer_id'
"""
if type(T) in [float, int]:
T = T * np.ones(size)
else:
T = np.asarray(T)
probability_of_post_purchase_death = stats.beta.rvs(a, b, size=size)
lambda_ = stats.gamma.rvs(r, scale=1. / alpha, size=size)
columns = ['frequency', 'recency', 'T', 'lambda', 'p', 'alive', 'customer_id']
df = pd.DataFrame(np.zeros((size, len(columns))), columns=columns)
for i in range(size):
p = probability_of_post_purchase_death[i]
l = lambda_[i]
times = []
next_purchase_in = stats.expon.rvs(scale=1. / l)
alive = True
while (np.sum(times) + next_purchase_in < T[i]) and alive:
times.append(next_purchase_in)
next_purchase_in = stats.expon.rvs(scale=1. / l)
alive = np.random.random() > p
times = np.array(times).cumsum()
df.ix[i] = len(times), np.max(times if times.shape[0] > 0 else 0), T[i], l, p, alive, i
return df.set_index('customer_id')
El Modelo de Pareto/NBD sería
def pareto_nbd_model(T, r, alpha, s, beta, size=1):
"""
Generate artificial data according to the Pareto/NBD model.
Parameters:
T: scalar or array, the length of time observing new customers.
r, alpha, s, beta: scalars, representing parameters in the model. See [2]
size: the number of customers to generate, equal to size of T if T is
an array.
Returns:
DataFrame, with index as customer_ids and the following columns:
'frequency', 'recency', 'T', 'lambda', 'mu', 'alive', 'customer_id'
"""
if type(T) in [float, int]:
T = T * np.ones(size)
else:
T = np.asarray(T)

30
lambda_ = stats.gamma.rvs(r, scale=1. / alpha, size=size)
mus = stats.gamma.rvs(s, scale=1. / beta, size=size)
columns = ['frequency', 'recency', 'T', 'lambda', 'mu', 'alive', 'customer_id']
df = pd.DataFrame(np.zeros((size, len(columns))), columns=columns)
for i in range(size):
l = lambda_[i]
mu = mus[i]
time_of_death = stats.expon.rvs(scale=1. / mu)
times = []
next_purchase_in = stats.expon.rvs(scale=1. / l)
while np.sum(times) + next_purchase_in < min(time_of_death, T[i]):
times.append(next_purchase_in)
next_purchase_in = stats.expon.rvs(scale=1. / l)
times = np.array(times).cumsum()
df.ix[i] = len(times), np.max(times if times.shape[0] > 0 else 0), T[i], l, mu, time_of_
death > T[i], i
return df.set_index('customer_id')
Aquí están los datasets que se han utilizado.
import lifetimes.estimation as estimation
from lifetimes.datasets import load_cdnow, load_summary_data_with_monetary_value
cdnow_customers = load_cdnow()
cdnow_customers_with_monetary_value = load_summary_data_with_monetary_value()
Todo esto y más, está disponible en la librería Lifetimes.
8.3. Apéndice matemático
En el siguiente apéndice, derivaremos las expresiones para 𝐸[𝑋(𝑡)] y 𝐸[𝑌(𝑡)|𝑋 = 𝑥, 𝑡𝑥 , 𝑇]. El
elemento principal de estas derivadas es la integral de Euler para la función hipergeométrica
Gaussiana:
𝐹2 1(𝑎,𝑏;𝑐;𝑧) =1
B(b,c−b)∫ 𝑡𝑏−1(1 − 𝑡)𝑐−𝑏−11
0(1 − 𝑧𝑡)−𝑎𝑑𝑡 , 𝑐 > 𝑏.
8.3.1. Derivada de 𝑬[𝑿(𝒕)]
Para llegar a esta expresión, para un cliente elegido aleatoriamente, necesitaremos calcular antes
el valor esperado de la ecuación (5) en las distribuciones de λ y 𝑝.
En primer lugar, la esperanza con respecto a λ resulta

31
𝐸[𝑋(𝑡)| 𝑟, 𝛼, 𝑝] =1
𝑝−
𝛼𝑟
𝑝(𝛼 + 𝑝𝑡)𝑟
El próximo paso será obtener la esperanza de lo anterior respecto a 𝑝. Primero calculamos,
∫1
𝑝 𝑝𝑎−1(1 − 𝑝)𝑏−1
𝐵(𝑎, 𝑏)𝑑𝑝 =
𝑎 + 𝑏 − 1
𝑎 − 1
1
0
A continuación, deducimos
∫𝛼𝑟
𝑝(𝛼 + 𝑝𝑡)𝑟
𝑝𝑎−1(1 − 𝑝)𝑏−1
𝐵(𝑎, 𝑏)
1
0
𝑑𝑝 = 𝛼𝑟1
𝐵(𝑎, 𝑏)∫ 𝑝𝑎−2(1 − 𝑝)𝑏−1(𝛼 + 𝑝𝑡)−𝑟𝑑𝑝
1
0
,
Si tenemos en cuenta que 𝑞 = 1 − 𝑝 (que implica que 𝑑𝑝 = −𝑑𝑞), entonces,
= (𝛼
𝛼 + 𝑡)
𝑟 1
𝐵(𝑎, 𝑏)∫ 𝑞𝑏−1(1 − 𝑞)𝑎−2 (1 −
𝑡
𝛼 + 𝑡 𝑞)
−𝑟
𝑑𝑝 1
0
Recordando que la integral de Euler para la función hipergeométrica Gaussiana es
= (𝛼
𝛼 + 𝑡)
𝑟 𝐵(𝑎 − 1, 𝑏)
𝐵(𝑎, 𝑏)𝐹2 1 (𝑟, 𝑏; 𝑎 + 𝑏 − 1;
𝑡
𝛼 + 𝑡)
Se deduce que,
𝐸(𝑋(𝑡)|𝑟, 𝛼, 𝑎, 𝑏) =𝑎 + 𝑏 − 1
𝑎 − 1[1 − (
𝛼
𝛼 + 𝑡)
𝑟
] 𝐹2 1 (𝑟, 𝑏; 𝑎 + 𝑏 − 1;𝑡
𝛼 + 𝑡)
8.3.2. Derivada de 𝑬(𝒀(𝒕)|𝑿 = 𝒙, 𝒕𝒙, 𝑻)
Consideramos que la variable aleatoria 𝑌(𝑡) representa el número de transacciones realizadas en
un periodo (𝑇, 𝑇 + 𝑡]. El objetivo será calcular la esperanza condicionada 𝐸(𝑌(𝑡)|𝑋 = 𝑥, 𝑡𝑥, 𝑇)
al número de transacciones esperadas en el periodo (𝑇, 𝑇 + 𝑡] para un cliente con un historial
de compras 𝑋 = 𝑥, 𝑡𝑥 , 𝑇.
Si el cliente está activo en el periodo 𝑇, se deduce de la fórmula (5) en la que,
𝐸(𝑌(𝑡)|𝜆, 𝑝) =1
𝑝−
1
𝑝𝑒−𝜆𝑝𝑡 (A1)
¿Cuál es la probabilidad de que un cliente esté activo en 𝑻?
Dado nuestro supuesto de que todos los clientes están activos en el principio del periodo
observado, un cliente no puede abandonar antes de haber hecho su primera compra; por tanto,
𝑃(𝑐𝑙𝑖𝑒𝑛𝑡𝑒 𝑎𝑐𝑡𝑖𝑣𝑜 𝑒𝑛 𝑇|𝑋 = 0, 𝑇, 𝜆, 𝑝) = 1
Para el caso en el que las compras se hicieron en el periodo (0, 𝑇], la probabilidad de que un
cliente con un histórico de compras (𝑋 = 𝑥, 𝑡𝑥 , 𝑇) aun esté activo en 𝑇, condicionado a λ y 𝑝, es
simplemente la probabilidad de que no abandonara en 𝑡𝑥 y de que no hiciera ninguna compra en

32
(𝑡𝑥 , 𝑇], dividida por la probabilidad de no hacer compras en el mismo periodo. Recordando que
esta segunda probabilidad es simplemente la probabilidad de que un cliente se convierta en
inactivo en 𝑡𝑥, más la probabilidad de que permanezca activo pero que no haya hecho compras
en ese intervalo, obtenemos
𝑃(𝑐𝑙𝑖𝑒𝑛𝑡𝑒 𝑎𝑐𝑡𝑖𝑣𝑜 𝑒𝑛 𝑇|𝑋 = 𝑥, 𝑡𝑥 , 𝑇, 𝜆, 𝑝) =(1 − 𝑝)𝑒−𝜆(𝑇−𝑡𝑥)
𝑝 + (1 − 𝑝)𝑒−𝜆(𝑇−𝑡𝑥) .
Multiplicando lo anterior por (1−𝑝)𝑥−1𝜆𝑥𝑒−𝜆𝑡𝑥
(1−𝑝)𝑥−1𝜆𝑥𝑒−𝜆𝑡𝑥 , obtenemos
𝑃(𝑐𝑙𝑖𝑒𝑛𝑡𝑒 𝑎𝑐𝑡𝑖𝑣𝑜 𝑒𝑛 𝑇|𝑋 = 𝑥, 𝑡𝑥 , 𝑇, 𝜆, 𝑝) =(1−𝑝)𝑥𝜆𝑥𝑒−𝜆𝑇
ℒ(𝜆, 𝑝|𝑋 = 𝑥, 𝑡𝑥 , 𝑇) , (A2)
donde ℒ(𝜆, 𝑝|𝑋 = 𝑥, 𝑡𝑥, 𝑇) proviene de (3).
(Obsérvese que cuando 𝑥 = 0, la expresión obtenida en (A2) es igual a 1.)
Multiplicando (A1) y (A2), obtenemos
𝐸(𝑌(𝑡)|𝑋 = 𝑥, 𝑡𝑥 , 𝑇, 𝜆, 𝑝)
=(1−𝑝)𝑥𝜆𝑥𝑒−𝜆𝑇 (
1
𝑝−
1
𝑝𝑒−𝜆𝑝𝑡
𝑝)
ℒ(𝜆, 𝑝|𝑋 = 𝑥, 𝑡𝑥, 𝑇)
=𝑝−1(1−𝑝)𝑥𝜆𝑥𝑒−𝜆𝑇−𝑝−1(1−𝑝)𝑥𝜆𝑥𝑒−𝜆(𝑇+𝑝𝑡)
ℒ(𝜆, 𝑝|𝑋 = 𝑥, 𝑡𝑥, 𝑇) . (A3)
(Nótese que esto se reduce a (A1) cuando 𝑥 = 0. De este resultado se desprende la idea de que
un cliente que no hizo ninguna compra en el periodo (0, 𝑇], se asume como activo en el
momento 𝑇).
Como la tasa de transacción 𝜆 y la probabilidad de abandono 𝑝 son inapreciables,
calculamos la esperanza 𝐸(𝑌(𝑡)|𝑋 = 𝑥, 𝑡𝑥 , 𝑇) para un cliente aleatorio, tomando el valor
esperado de (A3) en la distribución de λ y 𝑝 y actualizándolo con la nueva información de
𝑋 = 𝑥, 𝑡𝑥 , 𝑇:
𝐸(𝑌(𝑡)|𝑋 = 𝑥, 𝑡𝑥 , 𝑇, 𝑟, 𝛼, 𝑎, 𝑏)
= ∫ ∫ 𝐸(𝑌(𝑡)|𝑋 = 𝑥, 𝑡𝑥 , 𝑇, 𝜆, 𝑝)∞
0
1
0· 𝑓(𝜆, 𝑝|𝑟, 𝛼, 𝑎, 𝑏, 𝑋 = 𝑥, 𝑡𝑥 , 𝑇)𝑑𝜆𝑑𝑝 . (A4)
Por el teorema de Bayes, la siguiente distribución de λ y 𝑝 sería
𝑓(𝜆, 𝑝|𝑟, 𝛼, 𝑎, 𝑏, 𝑋 = 𝑥, 𝑡𝑥, 𝑇)
=ℒ(𝜆, 𝑝|𝑋 = 𝑥, 𝑡𝑥, 𝑇)𝑓(𝜆,𝑝|𝑋=𝑥,𝑡𝑥,𝑇)𝑓(𝑝|𝑎,𝑏)
ℒ(𝑟, 𝛼, 𝑎, 𝑏|𝑋 = 𝑥, 𝑡𝑥, 𝑇) . (A5)

33
Sustituyendo (A3) y (A5) en (A4), obtenemos
𝐸(𝑌(𝑡)|𝑋 = 𝑥, 𝑡𝑥 , 𝑇, 𝑟, 𝛼, 𝑎, 𝑏) =𝐴−𝐵
ℒ(𝑟, 𝛼, 𝑎, 𝑏|𝑋 = 𝑥, 𝑡𝑥, 𝑇) (A6)
Donde
𝐴 = ∫ ∫ 𝑝−1(1 − 𝑝)𝑥𝜆𝑥𝑒−𝜆𝑇𝑓(𝜆|𝑟, 𝛼)∞
0
1
0
𝑓(𝑝|𝑎, 𝑏)𝑑𝜆𝑑𝑝
=𝐵(𝑎−1,𝑏+𝑥)
𝐵(𝑎,𝑏)
𝛤(𝑟+𝑥)𝛼𝑟
𝛤(𝑟)(𝛼+𝑇)𝑟+𝑥 (A7)
Y
𝐵 = ∫ ∫ 𝑝−1(1 − 𝑝)𝑥𝜆𝑥𝑒−𝜆(𝑇+𝑝𝑡)𝑓(𝜆|𝑟, 𝛼)∞
0
1
0
𝑓(𝑝|𝑎, 𝑏)𝑑𝜆𝑑𝑝
= ∫𝑝𝑎−2(1 − 𝑝)𝑏+𝑥−1
𝐵(𝑎, 𝑏) {∫
𝛼𝑟𝜆𝑟+𝑥−1𝑒−𝜆(𝛼+𝑇+𝑝𝑡)
𝛤(𝑟) 𝑑𝜆
∞
0
} 𝑑𝑝1
0
=𝛤(𝑟 + 𝑥)𝛼𝑟
𝛤(𝑟)𝐵(𝑎, 𝑏)∫ 𝑝𝑎−2(1 − 𝑝)𝑏+𝑥−1(𝛼 + 𝑇 + 𝑝𝑡)−(𝑟+𝑥)𝑑𝑝
1
0
Si se considera que 𝑞 = 1 − 𝑝 (que implica que 𝑑𝑝 = −𝑑𝑞)
=𝛤(𝑟 + 𝑥)𝛼𝑟
𝛤(𝑟)𝐵(𝑎, 𝑏)(𝛼 + 𝑇 + 𝑡)𝑟+𝑥 · ∫ 𝑞𝑏+𝑥−11
0
(1 − 𝑞)𝑎−2 (1 −𝑡
𝛼 + 𝑇 + 𝑡𝑞)
−(𝑟+𝑥)
𝑑𝑞
junto con la integral de Euler para la función hipergeométrica Gaussiana,
=𝐵(𝑎−1,𝑏+𝑥)
𝐵(𝑎,𝑏)
𝛤(𝑟+𝑥)𝛼𝑟
𝛤(𝑟)(𝛼+𝑇)𝑟+𝑥 · 𝐹2 1 (𝑟 + 𝑥, 𝑏 + 𝑥; 𝑎 + 𝑏 + 𝑥 − 1;𝑡
𝛼+𝑇+𝑡) . (A8)
Sustituyendo (6), (A7) y (A8) en (A6) y simplificando, obtenemos
𝐸(𝑌(𝑡)|𝑋 = 𝑥, 𝑡𝑥 , 𝑇, 𝑟, 𝛼, 𝑎, 𝑏)
𝑎 + 𝑏 + 𝑥 − 1𝑎 − 1 [1 − (
𝛼 + 𝑇𝛼 + 𝑇 + 𝑡)
𝑟+𝑥
𝐹2 1 (𝑟 + 𝑥, 𝑏 + 𝑥; 𝑎 + 𝑏 + 𝑥 − 1;𝑡
𝛼 + 𝑇 + 𝑡)]
1 + 𝛿𝑥>0𝑎
𝑏 + 𝑥 − 1(
𝛼 + 𝑇𝛼 + 𝑡𝑥
)𝑟+𝑥 .
Dado que el objeto de esta memoria no es el desarrollo matemático, les instamos a que
completen sus dudas si las hubiere, en las notas más completas de este desarrollo concreto de
Fader y Hardie9.
9 Fader, Peter S. and Bruce G.S. Hardie (2005), A Note on Deriving the Pareto/NBD Model and Related Expressions.
http://brucehardie.com/notes/009/, 2005


















