
UNIVERSIDAD GRAN MARISCAL DE AYACUCHO … · Archivos de síntesis del SPSS. Análisis ... en las...
132
UNIVERSIDAD GRAN MARISCAL DE AYACUCHO DECANATO DE POSTGRADO MAESTRÍA EN EDUCACIÓN SUPERIOR MANUAL DE SPSS. Facilitador.: Realizado por Hamlet Mata Mata. Melania Araujo María Teresa Artís María E. Dávila Elizabeth Gómez Edith Guacaraán Barcelona, Enero de 2010
Transcript of UNIVERSIDAD GRAN MARISCAL DE AYACUCHO … · Archivos de síntesis del SPSS. Análisis ... en las...

UNIVERSIDAD GRAN MARISCAL DE AYACUCHO
DECANATO DE POSTGRADO
MAESTRÍA EN EDUCACIÓN SUPERIOR
MANUAL DE SPSS.
Facilitador.: Realizado por
Hamlet Mata Mata. Melania Araujo
María Teresa Artís
María E. Dávila
Elizabeth Gómez
Edith Guacaraán
Barcelona, Enero de 2010

CONTENIDO
Definición e historia del SPSS.
Características del SPSS.
Instalación del programa SPSS.
Estructura del SPSS.
Archivos de datos del SPSS.
Editor de Datos del SPSS.
Transformar datos mediante el SPSS.
Modificar Archivos de datos en el SPSS.
El Visor del SPSS.
Archivos de síntesis del SPSS.
Análisis Estadístico con el SPSS.
Solución de problemas estadísticas con el SPSS.
Problemas.

DEFINICIÓN E HISTORIA DE SPSS
El programa SPSS (Statistical Package for the Social Sciences) es un programa
estadístico informático que contiene un conjunto de potentes herramientas de tratamiento
de datos y análisis estadístico muy usado en las ciencias sociales y las empresas de
investigación de mercado. En la actualidad, la sigla se usa tanto para designar el programa
estadístico como la empresa que lo produce. Al igual que el resto de las aplicaciones que
usan como soporte el sistema operativo Windows, el SPSS funciona mediante menús
desplegables y cuadros de diálogos que facilitan el trabajo utilizando el puntero del ratón
Fue creado en 1968 por Norman H. Nie, C. Hadlai (Tex) Hull y Dale H. Bent. Entre
1969 y 1975 la Universidad de Chicago por medio de su National Opinión Research Center
estuvo a cargo del desarrollo, distribución y venta del programa. A partir de 1975
corresponde a SPSS Inc. Originalmente este programa fue creado para grandes
computadores. En 1970 se publica el primer manual de usuario del SPSS por Nie y Hall.
Este manual populariza el programa entre las instituciones de educación superior en EE.
UU. En 1984 sale la primera versión para computadores personales.
SPSS Inc. desarrolla un módulo básico del paquete estadístico SPSS, del que han aparecido
las siguientes versiones:
SPSS-X (para grandes servidores tipo UNIX)
SPSS/PC (1984, en DOS. Primera versión para computador portátil)
SPSS/PC+ (1986 (en DOS)
SPSS for Windows 6 (1992) / 6.1 para Macintosh
SPSS for Windows 7
SPSS for Windows 8
SPSS for Windows 9
SPSS for Windows 10 / for Macintosh 10 (2000)
SPSS for Windows 11 (2001) / for Mac OS X 11(2002)
SPSS for Windows 11.5 (2002)
SPSS for Windows 12 (2003)

SPSS for Windows 13 (2004): Permite por primera vez trabajar con múltiples bases
de datos al mismo tiempo.
SPSS for Windows 14 (2005)
SPSS for Macintosh 13 (2006)
SPSS for Windows 15 (2006)
SPSS for Windows 16 (Octubre de 2007): En la lista de usuarios de SPSS "SPSSX
(r) Discussion [SPSSX-L@LISTSERV. UGA. EDU]" varios funcionarios de la
empresa anunciaron previamente la salida de la versión 16 de este software. En ella
se incorporó una interfaz basada en Java que permite realizar algunas mejoras en las
facilidades de uso del sistema.
SPSS for Macintosh 16
SPSS for Linux 16
SPSS for Windows 17 (2008): Incorpora aportes importantes como el ser
multilenguaje, pudiendo cambiar de idioma en las opciones siempre que queramos.
También incluye modificaciones en el editor de sintaxis de forma tal que resalta las
palabras claves y comandos, haciendo sugerencias mientras se escribe. En este
sentido se aproxima a los sistemas IDE que se utilizan en programación
PASW Statistics 18 (anteriormente SPSS Statistics) tiene un análisis estadístico más
avanzado. Entre las nuevas características tenemos:
o Una nueva forma de implementar PASW Statistics
o Cada módulo puede ahora funcionar de forma autónoma o en conjunción
con otros módulos. PASW Statistics Base ya no es necesario en cada caso
porque las funciones como el acceso y gestión de los datos y los gráficos se
han añadido a cada módulo.
o Pruebas no paramétricas
o Permiten a los analistas estudiar las relaciones entre los datos que no están
normalmente distribuidos. Disponible en PASW Statistics Base.
o Mejora: PASW Custom Tables
o Realiza cálculos con datos incluso después de haberlos incluido en tablas
para crear nuevas categorías.
o Rendimiento mejorado

o Admite hardware cliente de 64 bits en plataformas Windows y Mac.
o Procesamiento más rápido
o Los procedimientos utilizados comúnmente se ejecutan ahora más rápido a
través de la compresión de datos en PASW Statistics Base Server.
o Comprobación de reglas en gráficos SPC
o Cuando se utilizan gráficos de control de procesos estadísticos, los usuarios
pueden comprobar las reglas no sólo en los gráficos primarios, sino en los
secundarios también.
CARACTERÍSTICAS DEL SPSS
El SPSS para Windows proporciona:
Editor de datos. Sistema versátil, similar a una hoja de cálculo, para definir, introducir,
editar y presentar datos.
Visor. El Visor permite examinar los resultados, mostrarlos y ocultarlos de forma selectiva,
modificar el orden de presentación en la pantalla y desplazar tablas y gráficos de gran
calidad entre SPSS y otras aplicaciones.
Tablas de pivote multidimensionales. Sus resultados cobrarán vida en las tablas pivotes
multidimensionales. Explora las tablas reorganizando las filas, las columnas y las capas.
Hace importantes descubrimientos que suelen quedar velados en los informes
convencionales. Compara fácilmente los grupos dividiendo la tabla de manera que aparezca
solamente un grupo cada vez.
Gráficos de alta resolución. Como funciones básicas de SPSS se incluyen gráficos de
sectores, gráficos de barras, histogramas, diagramas de dispersión y gráficos 3-D de alta
resolución y a todo color, entre muchos otros.
Acceso a bases de datos. Obtiene información de bases de datos mediante el Asistente para
bases de datos en lugar de utilizar consultas SQL de gran complejidad.
Transformaciones de los datos. Las funciones de transformación le ayudarán a preparar
los datos para el análisis. Puede crear fácilmente subconjuntos de datos, combinar
categorías y añadir, agregar, fusionar, segmentar y transponer archivos, entre muchas otras
posibilidades.

Distribución electrónica. Se pueden enviar informes por correo electrónico pulsando en un
botón o exportar tablas y gráficos en formato HTML para distribuirlos por Internet o dentro
de una Intranet.
Ayuda en pantalla. Los tutoriales ofrecen una introducción global ampliamente detallada,
los temas de la Ayuda sensible al contexto de los cuadros de diálogo guían a través de la
ejecución de tareas específicas, las definiciones de las ventanas emergentes para los
resultados de las tablas pivote explican los términos estadísticos y Estudios de casos
proporcionan ejemplos prácticos sobre cómo utilizar los procedimientos estadísticos y
cómo interpretar los resultados.
Lenguaje de comandos. Aunque la mayoría de las tareas se pueden llevar a cabo
simplemente situando el puntero del ratón en el lugar deseado y pulsando en el botón, SPSS
proporciona además un potente lenguaje de comandos que permite guardar y automatizar
muchas tareas comunes. El lenguaje de comandos también proporciona algunas
funcionalidades no incluidas en los menús y cuadros de diálogo. La documentación
completa sobre la sintaxis de comandos se instala automáticamente al mismo tiempo que
SPSS.
Entre las novedades de SPSS 13.0 se encuentran:
Gestión de datos
- El Asistente de fecha y hora facilita la realización de muchos cálculos con fechas y
horas, incluyendo el cálculo de la diferencia entre las fechas y la adición o
sustracción de una duración a partir de una fecha.
- Se puede añadir resultados agregados al archivo de datos de trabajo.
- Puede crear esquemas de recodificación automática coherentes para diversas
variables y archivos de datos.
- Los valores de cadena pueden tener hasta 32.767 bytes. Previamente, el límite era
de 255.
- Puede crear varios paneles en la Vista de datos del Editor de datos.
Gráficos
- Gráficos de barras 3-D.
- Pirámides de población.
- Gráficos de puntos.

- Gráficos con paneles.
Mejoras en los estadísticos
- Nueva opción Árbol de clasificación para generar modelos de árbol.
- Nuevo procedimiento MLG en la opción Muestras complejas.
- Nuevo procedimiento Regresión logística en la opción Muestras complejas.
- Nuevo procedimiento Correspondencia múltiple en la opción Categorías.
- Los estadísticos AIC y BIC se añaden a Regresión logística multinomial en la
opción Modelos de regresión y existe además la posibilidad de especificar el tipo de
estadístico utilizado para determinar la adición o eliminación de términos de modelo
al utilizar varios métodos de pasos sucesivos.
Resultados
- Panel de control del Sistema de gestión de resultados.
- Exportar resultados del Visor a PowerPoint. Si desea obtener más información,
consulte
- Más opciones de ordenación de resultados y la posibilidad de ocultar las categorías
de subtotal en Tablas personalizadas (opción Tablas).
- Resultados de las tablas pivote para Estimación curvilínea y Respuesta múltiple en
el sistema Base, todos los procedimientos de series temporales (incluyendo la
opción Tendencias), Kaplan-Meier y Tablas de mortalidad de la opción Modelos
avanzados y Regresión no lineal de la opción Modelos de regresión.
Sintaxis de comandos
- Controlar el directorio de trabajo con el nuevo comando CD.
- Controlar el tratamiento de errores en los archivos de sintaxis de comandos
incluidos con el nuevo comando INSERT.
- Utilizar el comando FILE HANDLE para definir las rutas de directorio.
Servidor de SPSS
- Puntuar los datos basados en modelos generados con muchos procedimientos de
SPSS.
- Trabajar con fuentes de bases de datos de forma más eficaz si se agrega u ordena
previamente los datos en la base de datos antes de leerlos en SPSS.

INSTALACIÓN DEL PROGRAMA SPSS 13 PASO A PASO.
1. Introducir el CD y seleccionar la opción 'Instalar SPSS'. Presione 'Siguiente'.
2. Seleccionar 'Lic de sede'. Presione 'Siguiente'.
3
.
3
.
3
3
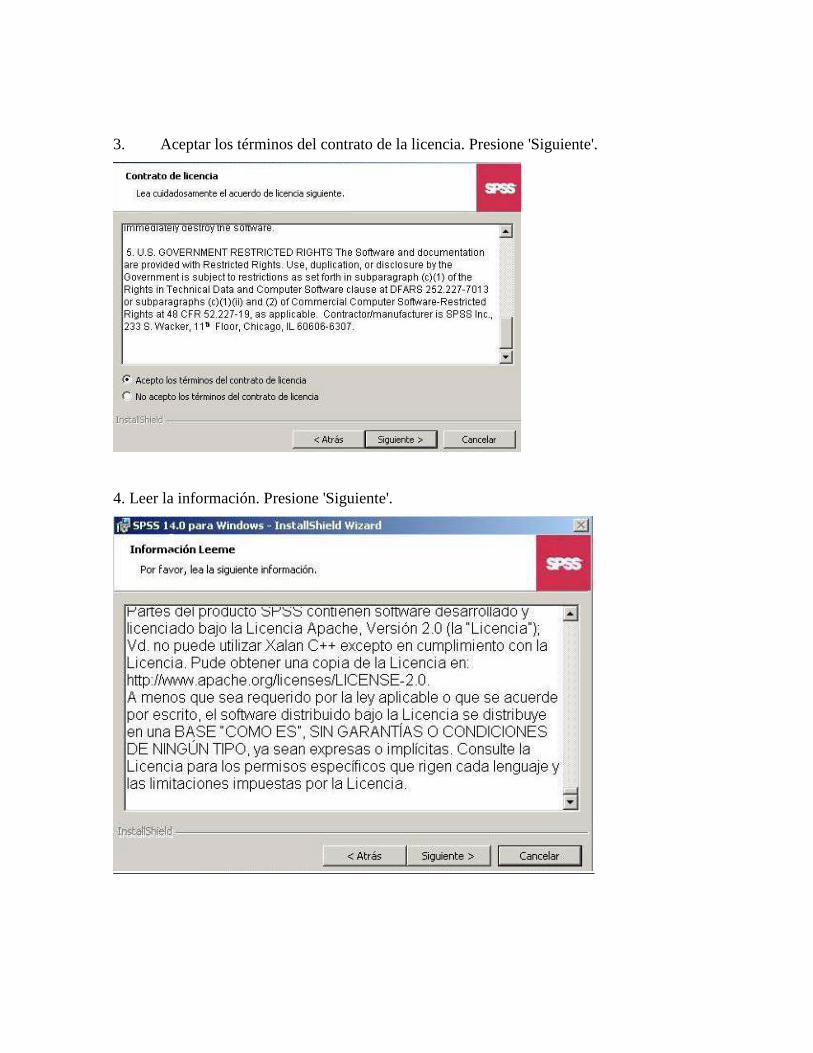
3. Aceptar los términos del contrato de la licencia. Presione 'Siguiente'.
4. Leer la información. Presione 'Siguiente'.
3
.
3
3
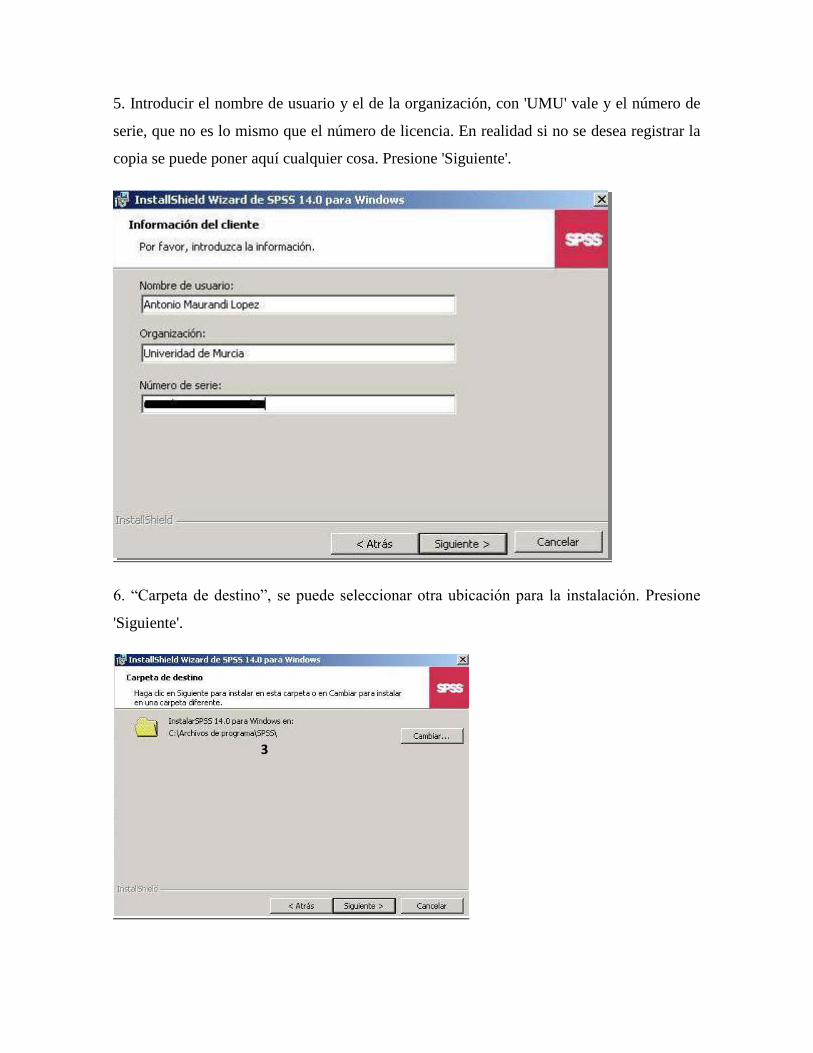
5. Introducir el nombre de usuario y el de la organización, con 'UMU' vale y el número de
serie, que no es lo mismo que el número de licencia. En realidad si no se desea registrar la
copia se puede poner aquí cualquier cosa. Presione 'Siguiente'.
6. “Carpeta de destino”, se puede seleccionar otra ubicación para la instalación. Presione
'Siguiente'.
3
3
3
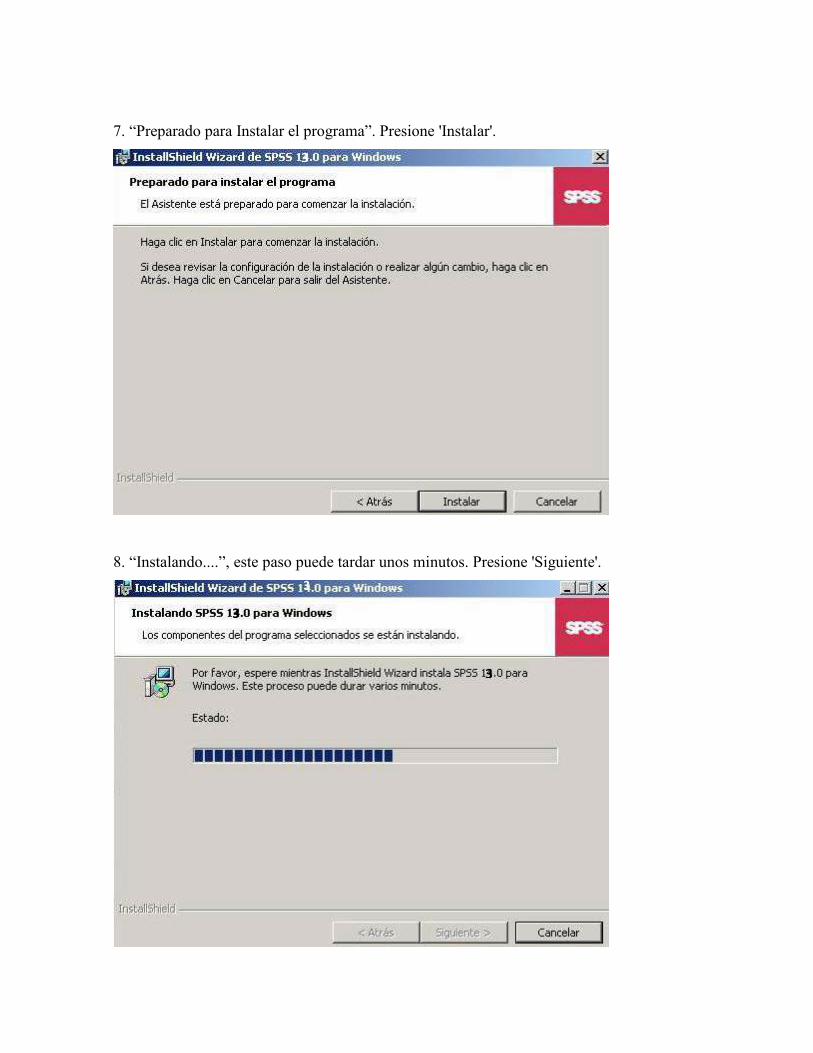
7. “Preparado para Instalar el programa”. Presione 'Instalar'.
8. “Instalando....”, este paso puede tardar unos minutos. Presione 'Siguiente'.
3
3
3
3
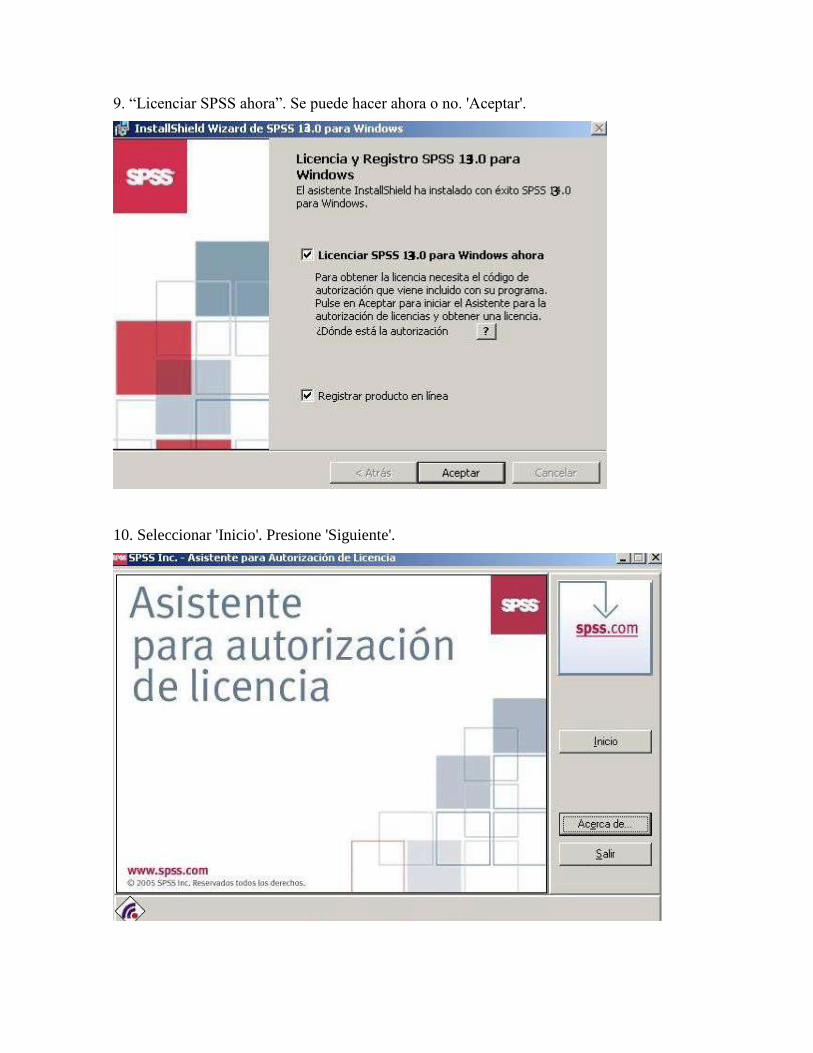
9. “Licenciar SPSS ahora”. Se puede hacer ahora o no. 'Aceptar'.
10. Seleccionar 'Inicio'. Presione 'Siguiente'.
3
3
3
3

11. Seleccionar la primera opción. Presione 'Siguiente'.
12. Introduzca un 'Código de Autorización' valido y presione 'Siguiente'.

13. Puede tardar unos instantes.
14. Finalmente Presione 'Finalizar'. Reinicie el producto SPSS.

ESTRUCTURA DEL SPSS
Como programa, el SPSS está organizado en base a comandos, que constituyen los
elementos de un lenguaje. Cada procedimiento tiene asociado una serie de comandos y con
la combinación de los mismos se puede elaborar un fichero de sintaxis para llevar a cabo
análisis estadísticos más complejos. Los ficheros de sintaxis se ejecutan directamente
mediante la opción Ejecutar Proceso dentro del menú Utilidades. A esta opción se la
denomina Proceso por lotes.
Subsecciones
1.1 Ventanas
1.2 Botones
1.3 Menú Principal
1.4 Iconos
o 1.4.1 Iconos de la Ventana Principal
o 1.4.2 Iconos del Visor
o 1.4.3 Iconos de la Ventana de Gráficos
1.5 Barra de Estado
1.6 Los Comandos
El programa tiene varios tipos de ventanas (las cuales permiten, por un lado, gestionar
la introducción de datos y decidir los análisis a realizar y, por otro lado, acceder a distintos
aspectos de la manipulación de los resultados generados. Todas ellas presentan sus propias
barras de herramientas que pueden ser, como en casi todas las aplicaciones del entorno
Windows, personalizadas a gusto del usuario.
Las dos ventanas principales son:
Editor de datos: Puede considerarse la ventana principal del programa pues se abre
automáticamente cuando se entra en el SPSS y se cierra cuando se termina con la
ejecución del mismo. Esta ventana cuenta con dos vistas diferentes: vista de datos
en la que se observan los datos a analizar y la vista de variables del archivo en la
que se observan las variables del fichero de datos con el conjunto de las

características que las definen. Sólo puede haber un fichero de datos abierto a un
tiempo. Contiene una barra de menús (un conjunto de menús despegables), una
barra de herramientas (serie de botones – íconos que facilitan el acceso rápido a
mucha de las funciones SPSS) y una barra de estado ( con información referente al
estado del programa) ver figura:
Visor de resultados: Recoge y muestra en el visor toda la información que se
genera de aplicar el programa, es decir, tablas, gráficos, estadísticos. Esta ventana se
abre de forma automática en el momento en el que se ejecuta el primer análisis. Si
bien pueden coexistir varios visores simultáneamente sólo hay uno activo en cada
momento y éste viene identificado con un signo . Desde la herramienta
utilidades se puede elegir una de ellas mediante la opción designar ventana
activa.
Los resultados del visor adoptan tres tipos de formatos básicos: tablas, gráficos y
textos. El SPSS dispone de un editor para cada uno de estos formatos:

o Editor de tablas pivote: Las tablas pivote son una potente (aunque
complicada) herramienta de gestión de tablas. Se puede editar el texto,
intercambiar filas y columnas, crear tablas multidimensionales, asignar
estilos prediseñados, etc.
o Editor de gráficos: Es otra potentísima herramienta de edición. Puede
modificar los gráficos cambiando cualquier aspecto del mismo: colores,
fuentes, tamaños, etiquetas intercambiar ejes, además de una elegante
herramienta de rotación de nubes de puntos 3-D en tiempo real.
o Editor de resultados de texto: Con este editor se pueden modificar los
resultados tipo texto como títulos, subtítulos y notas (fácilmente
identificables pues no están inmersos en una tabla). Es un simple editor
(similar al Wordpad) para cambiar aspectos básicos del texto. A destacar
sólo su útil acceso rápido al glosario de términos.
Las otras ventanas del programa SPSS son las siguientes:
El Borrador del Visor de resultados: Las tablas de resultados generadas pueden
observarse en modo texto sin poder editarlo.Es algo más rápido y ágil pero de una
apariencia bastante más austera.
Editor de sintaxis: Es la ventana en la que podemos escribir o pegar instrucciones
de programación en el lenguaje de SPSS para ser ejecutadas y obtener los resultados
correspondientes. Toda operación realizada con los distintos cuadros de diálogo del
SPSS tiene una traducción a un lenguaje de programación propio del programa.
Desde cualquier ventana donde se configura un análisis o cualquier operación sobre
los datos, se puede pegar dicha sintaxis a este editor. El botón pegar disponible en
los cuadros de diálogo siempre tienen el mismo efecto: convierte en sintaxis SPSS
las selecciones escogidas. Estas órdenes de programación pueden editarse
añadiendo incluso otras órdenes no contempladas en dichos cuadros de diálogo.
Como es de esperar, la programación del SPSS es una herramienta de gran utilidad
pero de gran complejidad.

Editor de procesos: Permite personalizar y automatizar algunas de las tareas que el
SPSS lleva a cabo en lo relacionado con el contenido del aspecto de las tablas de
resultado. Se utiliza para crear y modificar los procesos básicos
Cada una de las ventanas mencionadas anteriormente posee una barra de estado que,
como su nombre indica, proporciona información acerca de la situación en la que se
encuentra el programa (la mayoría del tiempo muestra el mensaje "SPSS El procesador está
preparado") pero además se muestra información acerca de si los datos están bajo algún
criterio de ponderación, segmentación o filtrado.
Ventana designada frente a ventana activa
Si tiene abiertas varias ventanas del Visor, los resultados se dirigirán hacia la
ventana designada del Visor. Si tiene abierta más de una ventana del Editor de sintaxis, la
sintaxis de comandos se pegará en la ventana designada del Editor de sintaxis. Las ventanas
designadas se distinguen por un signo de exclamación (!) rojo en la barra de estado y es
posible cambiarlas en cualquier momento. La ventana designada no debe confundirse con
la ventana activa, que es la ventana actualmente seleccionada, es decir la ventana sobre la
que se puede trabajar (contiene el cursor). Si tiene ventanas superpuestas, la ventana activa
es la que aparece en primer plano. Si abre una ventana, esa ventana se convertirá
automáticamente en la ventana activa y en la ventana designada.
CUADROS DE DIÁLOGO
La mayoría de las opciones de los menús acceden a un cuadro de diálogo cuando se
seleccionan. Este es otro tipo de ventana que el SPSS utiliza para que el usuario pueda
realizar cualquier actividad de la manera más sencilla posible, simplemente seleccionando y
haciendo clic con el puntero del ratón. Los cuadros de diálogo se utilizan para seleccionar
variables y opciones para el análisis.
Los cuadros de diálogo para los procedimientos estadísticos tienen normalmente dos
componentes básicos:

- Lista de variables de origen. Son un listado de todas las variables del archivo de
datos de trabajo. En la lista de origen sólo aparecen los tipos de variables que
permiten el procedimiento seleccionado. Pueden aparecer en orden alfabético o en
el orden en el que se encuentran en el editor de datos. La utilización de variables de
cadena corta y de cadena larga está restringida en muchos procedimientos.
- Listas de variables de destino. Una o varias listas que indican las variables
elegidas, las que se desean trabajar para realizar el análisis; un ejemplo son las listas
de variables dependientes e independientes.
Nombres y etiquetas de variable en las listas de los cuadros de diálogo
Es posible escoger entre la presentación de nombres de variable o de etiquetas de
variable en las listas de los cuadros de diálogo.
- Seleccione Opciones en el menú Edición de cualquier ventana: para determinar la
presentación de nombres o de etiquetas de variable,
- Elija Vista de variables en el Editor de datos: para definir o modificar las etiquetas
de variable,
- Utilice los nombres de los campos como etiquetas de variable: para los datos
importados de orígenes de bases de datos
- Sitúe el puntero sobre la etiqueta de la lista para verla completa: si las etiquetas son
largas,
- Muestre el nombre de la variable: si no se define ninguna etiqueta de variable.
Controles del cuadro de diálogo o Botones
Existen cinco controles estándares o comunes en la mayoría de los cuadros de diálogo,
estos son:
- Aceptar. Ejecuta el procedimiento y produce el cierre del cuadro de diálogo.
Después de seleccionar las variables y elegir las especificaciones adicionales, se
pulsa en Aceptar para ejecutar el procedimiento.
- Pegar. Genera la sintaxis de comandos a partir de las selecciones del cuadro de
diálogo y la pega en la ventana de sintaxis asignada. Posteriormente se pueden
personalizar los comandos con funciones adicionales que no se encuentran
disponibles en los cuadros de diálogo.

- Restablecer. Desactiva o limpia las variables en las listas de variables
seleccionadas y devuelve todas las especificaciones del cuadro de diálogo y los
subcuadros de diálogo al estado original
- Cancelar. Cancela los cambios de las selecciones del cuadro de diálogo desde la
última vez que se abrió y lo cierra. Durante una sesión se mantienen las selecciones
del cuadro de diálogo. El cuadro de diálogo retiene el último conjunto de
especificaciones hasta que se anulan.
- Ayuda. Ayuda contextual. Este botón le lleva a una ventana de Ayuda con
información sobre el cuadro de diálogo actual. También puede obtener ayuda sobre
los controles individuales del cuadro de diálogo pulsando en el botón derecho del
ratón.
Subcuadros de diálogo
Puesto que la mayoría de los procedimientos ofrecen un gran número de
posibilidades, un solo cuadro de diálogo no puede contener todas las opciones disponibles.
El cuadro de diálogo principal ofrece normalmente la información mínima que se requiere
para ejecutar un procedimiento. Las especificaciones adicionales se realizan en los
subcuadros de diálogo.
En el cuadro de diálogo principal, los controles (botones específicos) con puntos
suspensivos (...) después del nombre indican que se mostrará un subcuadro de diálogo.
MENÚ PRINCIPAL
Muchas de las tareas que desea realizar en SPSS comienzan por las selecciones de
menús. Cada ventana de SPSS tiene su propia barra de menús con los menús adecuados
para ese tipo de ventana. Los menús Analizar y Gráficos aparecen en todas las ventanas, lo
cual permite generar fácilmente nuevos resultados sin tener que cambiar de ventana.
En esta sección se comentan los submenús que se abren bajo cada una de las
opciones de la barra del menú principal, presente en todas las ventanas del SPSS.
- Archivo. Se utiliza para abrir, grabar, imprimir ficheros, y leer datos creados con el
SPSS o con otras aplicaciones, entre otras funciones.

- Edición. Contiene las habituales opciones de Windows para cortar, copiar, buscar y
recuperar datos y texto.
- Ver. Sirve para mostrar u ocultar la barra de herramientas, cambiar la fuente de las
letras, mostrar la cuadrícula, mostrar las etiquetas de valor, etc.
- Datos. Se utiliza para realizar cambios en el fichero de datos, tales como combinar
ficheros, trasponer variables y casos, agrupar casos para un análisis, etc. Dichos
cambios son temporales, a no ser que se grabe el fichero una vez realizados.
- Transformar. Se utiliza para realizar cambios en determinadas variables del fichero
de datos y también para crear nuevas variables basadas en los valores de variables
ya existentes. Cambios temporales hasta que se guarden en el archivo.
- Analizar.
Dentro de esta opción se encuentran todos los procedimientos estadísticos.
- Gráficos. Se utiliza para crear Gráficos de Barras, Histogramas, Diagramas de
sectores, Gráficos de Dispersión, etc.
- Utilidades.
Sirve para visualizar la información sobre el contenido del fichero de datos, del
fichero de parámetros, o definir grupos de variables.
- Ventana. Se usa para activar o desactivar los iconos, para cambiar el diseño de la
ventana de salida o la de sintaxis, o para cambiar el entorno que tiene definido por
defecto el SPSS.
Este menú abre una ventana de ayuda que contiene información sobre el uso de
cualquiera de las características o procedimientos del SPSS.
ICONOS
El SPSS como cualquier programa de Windows, tiene una serie de iconos que permiten
realizar ciertas operaciones, al pulsar con el botón izquierdo del ratón sobre el mismo sin
necesidad de utilizar los menús. Algunos iconos aparecen en casi todas las ventanas, pero
por lo general cada ventana presenta los suyos de manera específica. Entre los iconos
tenemos:

- Iconos de la Ventana Principal
Los iconos que aparecen en la ventana principal o de aplicación son los que
muestra la Figura. Su utilidad comenzando desde la izquierda hacia la derecha
es la siguiente:
Iconos de la Ventana Principal
- Abrir archivo. Muestra el cuadro de diálogo de la opción Abrir archivo para el tipo
de documento que esté en la ventana activa: de datos, de resultados, de sintaxis o de
gráficos.
- Guardar archivo. Guarda el fichero de la ventana que esté activa (base de datos
(.sav), análisis (.spo), sintaxis (.sps) o un gráfico (.sct)). Puede guardar el
documento completo o las líneas de texto seleccionadas. Si el fichero que se va a
guardar no tiene nombre muestra un cuadro de diálogo donde solicita el nombre, la
carpeta y la unidad donde se va a almacenar.
- Imprimir. Muestra el cuadro de diálogo de Imprimir para el tipo de documento que
esté en la ventana activa. En el caso de ficheros de resultados, sintaxis o datos, se
puede imprimir todo el documento, o sólo una parte seleccionada.
- Recuperar cuadros de diálogo. Muestran un listado con las operaciones más
recientes hechas con el SPSS, aunque no se hayan llevado a cabo en la última
sesión.
- Deshacer. Con dicho icono se deshace la última operación llevada a cabo.
- Ir a gráficos. Se utiliza para pasar de la ventana de datos a la de gráficos.
- Ir a caso. Sirve para desplazar el cursor a un caso concreto en el editor de datos.
- Variables. Muestra una ventana que contiene la lista de variables del fichero
cargado en el editor de datos y la información de la variable seleccionada. También
permite posicionar el cursor en dicha variable con sólo pulsar el botón IR A.

- Buscar. Se usa para buscar una cadena de caracteres en el editor de datos o en la
ventana de sintaxis. Una vez se ha pulsado el mismo se abre un cuadro con el
campo Buscar donde se ha de introducir dicha cadena, además de elegir entre los
botones BUSCAR HACIA ADELANTE y BUSCAR HACIA DETRÁS para
comenzar la búsqueda.
- Insertar caso. Al pulsar sobre este icono se inserta un caso por encima del caso en
que está posicionado el cursor.
- Insertar variable. Al hacer clic en este icono se inserta una variable a la izquierda
de la variable que contenga el cursor.
- Segmentar archivo. Se utiliza para dividir el archivo cargado en el editor de datos
atendiendo a las categorías de cierta variable, o mediante alguna condición, pero de
manera que los procedimientos estadísticos solicitados posteriormente a la
segmentación, se realicen por separado para cada grupo en que se ha dividido el
fichero.
- Ponderar casos. Sirve para indicar que alguna variable representa las frecuencias
absolutas de los valores y como tal debe considerarse a la hora de realizar cualquier
análisis posterior.
- Seleccionar casos. Sirve para elegir una muestra de casos de todo el archivo,
teniendo en cuenta alguna condición, de forma aleatoria, o indicando un rango de
valores.
- Etiquetas de valor. Conmuta entre los valores de las variables y las etiquetas de
valores en el editor de datos.
- Usar conjuntos. Abre un cuadro de diálogo donde se puede seleccionar los
conjuntos de variables que muestran los cuadros de diálogo y que se usan para
realizar los análisis estadísticos o transformaciones. Los conjuntos que trae por
defecto el SPSS son: ALLVARIABLES y NEWVARIABLES, pero se pueden crear
otros mediante la opción Definir Conjuntos dentro del menú Utilidades. Tras hacer
clic en este icono se abre un cuadro con un campo llamado Conjuntos en uso:
donde aparecen ALLVARIABLES y NEWVARIABLES. Si se quiere utilizar otro
conjunto distinto, se tendrán que extraer éstos de dicho campo.

Iconos del Visor
Las funciones de algunos de los iconos específicos del visor, como muestra la
Figura son:
Iconos del Visor
- Presentación preliminar. Se utiliza para ver como quedan los resultados dentro de
una página atendiendo al formato que tiene, por si quisiéramos corregirlos antes de
imprimirlos.
- Exportar. Se usa para exportar el fichero de resultados de forma que se pueda leer
o capturar con otra base de datos diferente.
- Ir a datos. Este icono se usa para activar la ventana del editor de datos y si está
minimizada la devuelve a su tamaño original. Cuando está seleccionado un punto en
un gráfico vinculado a los datos, al pulsar en este icono se activa el editor de datos,
y aparece resaltado el caso asociado con el punto seleccionado.
- Seleccionar los últimos resultados. Selecciona los resultados del último
procedimiento que se ha ejecutado.
- Designar ventana. Se utiliza para indicar el visor que recogerá los resultados que se
obtengan al ejecutar un procedimiento en aquellos casos donde haya varios visores
abiertos. La forma de hacerlo es colocando un signo de admiración al comienzo del
título de la ventana.
- Ascender. Sirve para subir los resultados a un nivel superior dentro de la tabulación
o numeración de los mismos.
- Degradar. Realiza el proceso inverso del icono anterior, es decir, baja los
resultados señalados un nivel dentro de la tabulación.
- Expandir. Muestra los resultados de un procedimiento recogidos bajo su título en el
fichero de resultados.

- Contraer. Este icono permite contraer los resultados asociados con un
procedimiento bajo su título. Se usa sobre todo, cuando el fichero de resultados es
muy grande y se quiere explorar para poder así reducir sus dimensiones.
- Mostrar. Se visualizan los resultados de un procedimiento que estaban ocultos.
- Ocultar. Este otro oculta los resultados seleccionados correspondientes a un
determinado procedimiento.
- Insertar encabezado. Sirve para introducir un encabezado en el fichero de
resultados.
- Insertar título. Te permite introducir un título en los resultados correspondientes a
un procedimiento.
- Insertar texto. Con este icono se puede colocar algún comentario en los resultados.
Iconos de la Ventana de Gráficos
Los iconos de la ventana de gráficos están destinados sobre todo a la modificación de los
gráficos.
Figura : Iconos de la Ventana de Gráficos
Su función comenzando por la izquierda es:
- Identificación de puntos. Se usa para identificar cualquier punto del gráfico con el
valor correspondiente. Haciendo clic sobre éste el cursor se convierte en un
cuadrado, y haciéndolo sobre el punto aparece el valor con que se corresponde.
- Trama de relleno. Abre una ventana para seleccionar el relleno a utilizar en el
gráfico.
- Color. Abre una ventana para seleccionar el color que deseamos usar en el gráfico.
- Marcador. Con éste icono seleccionamos la forma de la marca con que se dibuja el
gráfico.

- Estilos de línea. Permite cambiar la forma de las líneas usadas en los gráficos.
- Estilos de barra. Permite seleccionar el formato de la barra que se usa cuando se
trata de un diagrama de barras.
- Estilos de etiquetas de barra. Se usa para etiquetar las barras con los valores
numéricos que representan.
- Interpolación. Permite unir los puntos de un gráfico de dispersión mediante líneas
de diferente forma.
- Texto. Escoge el tamaño y la fuente del texto que aparecen en el gráfico.
- Rotación 3D. Lleva a cabo una rotación de los ejes y por tanto, del gráfico en el
caso tridimensional.
- Intercambiar ejes. Este icono nos permite intercambiar la colocación de los ejes.
- Desgajar sector. Con esta opción podemos extraer algún sector circular de un
diagrama de sectores.
- Romper líneas en valores perdidos. Sirve para cortar la línea del gráfico para
indicar los valores perdidos, en el caso de representaciones de variables que los
tengan.
- Opciones del gráfico. Abre una ventana para cambiar las opciones del gráfico.
- Activar/Desactivar modo de giro. Según se pulse o no activamos o desactivamos
la posibilidad de girar el gráfico.
BARRA DE ESTADO
La barra de estado que está situada en la parte inferior de cada ventana, es la forma en
que el sistema se comunica con el usuario y nos proporciona la siguiente información:
- Estado del comando o del procesador. Cuando el SPSS está ejecutando algún
procedimiento, la barra de estado indica el número de casos, o en caso contrario,
nos avisa de que el sistema está preparado. En los procedimientos que requieren
procesamientos iterativos se muestra el número de iteraciones. Cuando el
procesador del SPSS está inactivo, aparece el mensaje Procesado de SPSS para
Windows preparado

- Estado del filtro de casos. El mensaje filtrado indica que se ha seleccionado una
muestra aleatoria o un subconjunto de casos del fichero actual, por lo que en el
análisis que se vaya realizar, no se incluirán la totalidad de los casos del archivo.
- Estado de ponderación de casos. El mensaje ponderado indica que se está
utilizando una variable de frecuencias para ponderar el número de veces de los
casos en el análisis que se vaya a realizar.
- Estado de división o segmentación del archivo. El mensaje segmentado indica
que el fichero de datos se ha dividido en varios grupos para su análisis.
- Indicador de ventana designada: Las barras de estado de visor de resultados y del
Editor de sintaxis usan un signo de admiración rojo para indicar cuál de las
diferentes ventanas abiertas es la designada
LOS COMANDOS
Una forma de trabajar con el SPSS es a través del procesamiento por lotes, en el
cual se ejecutan uno tras otro los comandos que contiene un fichero de sintaxis, o al menos
los seleccionados.
Los comandos constan de palabras claves Keywords y de especificaciones. Las
primeras son los nombres de los comandos y subcomandos, y las segundas hacen referencia
a la información proporcionada por el usuario con el fin de adaptar la ejecución de la
instrucción a sus datos, objetivos y necesidades del proceso.
A la hora de crear un fichero de sintaxis para realizar cualquier procedimiento
estadístico, se han de tener en cuenta una serie de requisitos, ya que cada comando tiene un
formato específico. Así por ejemplo algunos comandos siempre deben aparecer en el
fichero de sintaxis, todos deben ir seguidos de punto, etc. No obstante, no vamos a entrar en
detalle, sino tan sólo comentar que existen tres tipos de comandos, según las diferentes
funciones que se desean realizar:
- Comandos de Operación. Indican al sistema la forma de operar, esto es, definen el
entorno de trabajo de una sesión del SPSS. Se ejecutan a medida que se introducen
en el sistema.

- Comandos de Definición y Manipulación de Datos. Proporcionan al sistema
información sobre los datos objeto del análisis, y sobre las modificaciones que sobre
ellos han de realizarse.
- Comandos de Procedimiento. Tienen por objeto el transformar los datos mediante
la carga y ejecución de los subprogramas correspondientes a los procesos a realizar.
ARCHIVOS DE DATOS
Los archivos de datos pueden tener diversidad de formatos, y este programa se diseñó
para trabajar con muchos de ellos, incluyendo:
Hojas de cálculo creadas con Lotus 1-2-3 y Excel.
Archivos de bases de datos creados con dBase y varios formatos SQL.
Archivos de texto delimitados por tabuladores y otros tipos de archivos de texto
ASCII.
Archivos de datos con formato SPSS creados en otros sistemas operativos.
Archivos de datos de SYSTAT.
Archivos de datos de SAS}
Apertura de un archivo de datos
Además de los archivos guardados en formato SPSS, puede abrir archivos de Excel, Lotus
1-2-3, dBASE y archivos delimitados por tabuladores sin necesidad de transformarlos a un
formato intermedio ni de introducir información sobre la definición de los datos.
Para abrir archivos de datos
Elija en los menús:
Archivo
Abrir
Datos...
En el cuadro de diálogo Abrir archivo, seleccione el archivo que desea abrir.
Pulse en Abrir.

Si lo desea, tiene la posibilidad de:
Leer los nombres de las variables de la primera fila en las hojas de cálculo y en los
archivos delimitados por tabuladores.
Especificar el rango de casillas que desee leer en los archivos de hojas de cálculo.
Especificar una hoja dentro de un archivo de Excel que desee leer (Excel 5 o versiones
posteriores).
Tipos de archivos de datos
SPSS. Abre archivos de datos guardados con formato SPSS, incluyendo SPSS para
Windows, Macintosh, UNIX y el producto SPSS/PC+ para DOS.
SPSS/PC+. Abre archivos de datos de SPSS/PC+.
SYSTAT. Abre archivos de datos de SYSTAT.
SPSS portátil. Abre archivos de datos guardados con formato SPSS portátil. El
almacenamiento de archivos en este formato lleva mucho más tiempo que guardarlos en
formato SPSS.
Excel. Abre archivos de Excel.
Lotus 1-2-3. Abre archivos de datos guardados en formato 1-2-3 en las versiones 3.0, 2.0 o
1A de Lotus.
SYLK. Abre archivos de datos guardados en formato SYLK (vínculo simbólico), un
formato utilizado por algunas aplicaciones de hoja de cálculo.

dBASE. Abre archivos con formato dBASE para dBASE IV, dBASE III o III PLUS, o
dBASE II. Cada caso es un registro. Las etiquetas de valor y de variable y las
especificaciones de valores perdidos se pierden si se guarda un archivo en este formato.
Nombre de archivo largo de SAS. Versión de 7-9 para SAS Windows, extensión larga.
Nombre de archivo corto de SAS. Versión de 7-9 para SAS Windows, extensión corta.
SAS v6 para Windows. Versión 6.08 de SAS para Windows y OS2.
SAS v6 para UNIX. Versión 6 de SAS para UNIX (Sun, HP, IBM).
Transporte de SAS. Archivo de transporte de SAS.
Texto. Archivo de texto ASCII.
EDITOR DE DATOS
El Editor de datos nos da un método práctico (como el de las hojas de cálculo) para crear y
editar archivos de datos. Cuando se inicia una sesión la ventana Editor de datos
automáticamente se abre.
El Editor de datos nos aporta dos vistas de los datos.
Vista de datos. Muestra los valores de datos reales o las etiquetas de valor
definidas.
Vista de variables. Muestra la información de definición de variable, que incluye
las etiquetas de la variable definida y de valor, tipo de dato (por ejemplo, de cadena,
fecha y numérico), nivel de medida (nominal, ordinal o de escala) y los valores
perdidos definidos por el usuario.

En ambas vistas, se puede añadir, modificar y eliminar la información contenida en el
archivo de datos.
Figura Vista de datos
Muchas de las funciones de la Vista de datos se parecen a las que se encuentran en
aplicaciones de hojas de cálculo. Sin embargo, existen varias diferencias importantes:
Las filas son casos. Cada fila representa un caso o una observación. Por ejemplo, cada
individuo que responde a un cuestionario es un caso.
Las columnas son variables. Cada columna representa una variable o una característica
que se mide. Por ejemplo, cada elemento en un cuestionario es una variable.
Las casillas contienen valores. Cada casilla contiene un único valor de una variable
para cada caso. La casilla es la intersección del caso y la variable. Las casillas sólo
contienen valores de datos. A diferencia de los programas de hoja de cálculo, las
casillas del Editor de datos no pueden contener fórmulas.
El archivo de datos es rectangular. Las dimensiones del archivo de datos vienen
determinadas por el número de casos y de variables. Pueden introducirse datos en
cualquier casilla. Si mete datos en una casilla fuera de los límites del archivo de datos
definido, el rectángulo de datos se extenderá para incluir todas las filas y columnas
situadas entre esa casilla y los límites del archivo. No hay casillas “vacías” en los
límites del archivo de datos. Para variables numéricas, las casillas vacías se asumen

como el valor perdido del sistema. Para variables de cadena, un espacio en blanco se
toma un valor válido.
Figura Vista de variables
La Vista de variables contiene descripciones de los atributos de cada variable del archivo de
datos. En la Vista de variables:
Las filas son variables.
Las columnas son atributos de las variables.
Se pueden añadir o eliminar variables, y modificar los atributos de las variables,
incluyendo:
Nombre de variable
Tipo de datos
Número de dígitos o caracteres
Número de decimales
Las etiquetas descriptivas de variable y de valor.
Valores perdidos definidos por el usuario
Ancho de columna.
Nivel de medida
Todos estos atributos se guardan al guardar el archivo de datos.

Además de la definición de propiedades de variables en la vista Variable, hay dos otros
métodos para definir las propiedades de variables:
El Asistente para la copia de propiedades de datos ofrece la opción de utilizar un
archivo de datos de SPSS como plantilla para definir los atributos de las variables y
del archivo del archivo de datos de trabajo. También puede utilizar las variables del
archivo de datos de trabajo como plantillas para el resto de las variables del archivo
de datos de trabajo. La opción Copiar propiedades de datos está disponible en el
menú Datos en la ventana Editor de datos.
La opción Definir propiedades de variables (también ofrecida en el menú Datos de la
ventana Editor de datos) explora los datos y muestra una lista con todos los valores de
datos únicos para las variables seleccionadas, indica los valores sin etiquetas y da una
función de etiquetas automáticas. Esta opción es especialmente válida para variables
categóricas que utilizan códigos numéricos para simbolizar las categorías (por
ejemplo, 0 = hombre, 1 = mujer).
Para visualizar o definir los atributos de las variables
Haga que el editor de datos sea la ventana activa.
Haga clic dos veces en un nombre de variable en la parte superior de la columna en la
Vista de datos o bien haga clic en la pestaña Vista de variables.
Para definir nuevas variables, coloque un nombre de variable en cualquier fila vacía.
Elija los atributos que desea definir o cambiar.
Nombres de variable
Para los nombres de variable se aplican las siguientes normas:
El nombre debe comenzar por una letra. Los demás caracteres pueden ser letras,
dígitos, puntos o los símbolos @, #, _ o $.
Los nombres de variable no pueden terminar en punto.
Se deben evitar los nombres de variable que finalizan con subrayado (para evitar
conflictos con las variables creadas automáticamente por algunos procedimientos).

La longitud del nombre no debe exceder los 64 bytes. Sesenta y cuatro bytes suelen
equivaler a 64 caracteres en idiomas de un solo byte (por ejemplo, inglés, francés,
alemán, español, italiano, hebreo, ruso, griego, árabe, tailandés) y 32 caracteres en los
idiomas de dos bytes (por ejemplo, japonés, chino, coreano).
No se pueden manejar espacios en blanco ni caracteres especiales (por ejemplo, !, ?, ‟
y *).
Cada nombre de variable debe ser único; no se permiten dobles.
Las palabras reservadas no se pueden utilizar como nombres de variable. Las palabras
reservadas son: ALL, AND, BY, EQ, GE, GT, LE, LT, NE, NOT, OR, TO, WITH.
Los nombres de variable se pueden definir combinando de cualquier forma caracteres
en mayúsculas y en minúsculas, esta distinción entre los dos tipos de letras se
conserva en lo que se refiere a la presentación.
Cuando es necesario separar los nombres largos de variables en varias líneas en los
resultados, SPSS intenta dividir las líneas aprovechando los subrayados, los puntos y
los cambios de minúsculas a mayúsculas.
Nivel de medida de variable
Puede especificar el nivel de medida como Escala (datos numéricos de una escala de
intervalo o de razón), Ordinal o Nominal. Los datos nominales y ordinales pueden ser de
cadena (alfanuméricos) o numéricos. La especificación de medida sólo tiene importancia
para:
procedimientos de los gráficos o de tablas personalizadas que identifican las
variables como de escala o categóricas. Las variables nominales y ordinales se
tratan como categóricas. (Las tablas personalizadas sólo están disponibles en el componente
adicional Tablas.)
Los archivos de datos con formato SPSS utilizados con AnswerTree.
Puede seleccionarse uno de los tres niveles de medida:
Escala. Los valores de los datos son numéricos en una escala de intervalo o de razón (por
ejemplo, edad o ingresos). Las variables de escala deben ser numéricas.

Ordinal. Los valores de datos simbolizan categorías con un cierto orden intrínseco (por
ejemplo, bajo, medio, alto; totalmente de acuerdo, de acuerdo, en desacuerdo, totalmente
en desacuerdo). Las variables ordinales pueden ser valores de cadena (alfanuméricos) o
numéricos que representen diversas categorías (por ejemplo, 1 = bajo, 2 = medio, 3 = alto).
Nota: Para variables de cadena ordinales, se asume que el orden alfabético de los valores de
cadena indica el orden correcto de las categorías. Por ejemplo, en una variable de cadena
cuyos valores sean bajo, medio, alto, se interpreta el orden de las categorías como alto,
bajo, medio (orden que no es el correcto). Generalmente, se puede indicar que es más fiable
utilizar códigos numéricos para representar datos ordinales.
Nominal. Los valores de datos representan categorías sin un orden intrínseco (por ejemplo,
categoría laboral o división de la compañía). Las variables nominales pueden ser valores de
cadena (alfanuméricos) o numéricos que representen diferentes
categorías (por ejemplo, 1 = hombre, 2 = mujer).
Figura Las variables categóricas y de escala en procedimientos de gráficos

Para los archivos de datos con formato SPSS elaborados en versiones anteriores de
productos de SPSS son aplicables las reglas siguientes:
Las variables de cadena (alfanuméricas) se establecen en nominales.
Las variables de cadena y numéricas con etiquetas de valor definidas se establecen
en ordinales.
Las variables numéricas sin etiquetas de valor definidas que no superen un número
específico de valores únicos se establecen en ordinales.
Las variables numéricas no etiquetadas de valores definidos que superen un número
especificado de valores únicos se establecen en variables de escala. Por defecto, el
número de valores únicos es de 24. Para cambiar el valor especificado, modifique
las opciones de los gráficos interactivos: en el menú Edición, elija opciones y pulse
en la pestaña Interactivo.
Tipo de variable
Especifica los tipos de datos de cada variable. Por defecto se asume que todas las variables
nuevas son numéricas. Se puede utilizar Tipo de variable para cambiar el tipo de datos. El
contenido del cuadro de diálogo Tipo de variable depende del tipo de datos escogidos. Para
algunos tipos de datos, hay cuadros de texto para el ancho y el número de decimales; para
otros, simplemente puede seleccionar un formato de una lista desplegable de ejemplos.
Figura :Cuadro de diálogo Tipo de variable
Los tipos de datos disponibles son los siguientes:

Numérico. Una variable cuyos valores son números. Los valores se muestran en formato
numérico estándar. El Editor de datos acepta valores numéricos en formato estándar o en
notación científica.
Coma. Una variable numérica cuyos valores se muestran con comas que delimitan cada
tres posiciones y con el punto como delimitador decimal. El Editor de datos acepta valores
numéricos para este tipo de variables con o sin comas, o bien en notación científica. Los
valores no pueden contener comas a la derecha del indicador decimal.
Punto. Una variable numérica cuyos valores se muestran con puntos que delimitan cada
tres posiciones y con la coma como delimitador decimal. El Editor de datos acepta valores
numéricos para este tipo de variables con o sin puntos, o bien en notación científica. Los
valores no pueden contener puntos a la derecha del indicador decimal.
Notación científica. Una variable numérica cuyos valores se muestran con una E
intercalada y un exponente con signo que representa una potencia de base diez. El Editor de
datos acepta para estas variables valores numéricos con o sin el exponente.
El exponente puede aparecer precedido por una E o una D con un signo opcional, o bien
sólo por el signo (por ejemplo, 123, 1,23E2, 1,23D2, 1,23E+2 e incluso 1,23+2).
Fecha. Una variable numérica cuyos valores se muestran en uno de los siguientes formatos
de fecha-calendario u hora-reloj. Seleccione un formato de la lista. Puede colocar las fechas
utilizando como delimitadores: barras, guiones, puntos, comas o espacios. El rango de siglo
para los valores de año de dos dígitos está establecido por la configuración de las Opciones
(en el menú Edición, seleccione Opciones y pulse en la pestaña Datos).
Moneda personalizada. Una variable numérica cuyos valores se muestran en uno de los
formatos de moneda personalizados que se hayan definido con antelación en la pestaña
Moneda del cuadro de diálogo Opciones. Los caracteres definidos en la moneda
personalizada no se pueden emplear en la introducción de datos pero sí se mostrarán en el
Editor de datos.

Cadena. Variable cuyos valores no son numéricos y, por lo tanto, no se utilizan en los
cálculos. Pueden contener cualquier carácter siempre que no se exceda la longitud definida.
Las mayúsculas y las minúsculas se consideran diferentes. También se le denomina
variable alfanumérica.
Para definir el tipo de variable
Pulse en el botón de la casilla Tipo para la variable que se quiere definir.
Seleccione el tipo de datos en el cuadro de diálogo Tipo de variable.
Formatos de entrada frente a formatos de presentación
Dependiendo del formato, la presentación de valores en la Vista de datos se puede
diferenciar del valor real que se ha introducido y almacenado en su interior.
A continuación, se proporcionan algunas normas generales:
Para formatos numéricos, de coma y de punto, se pueden colocar valores con
cualquier número de dígitos decimales (hasta 16) y el valor completo se almacena
internamente. La Vista de datos muestra sólo el número definido de dígitos
decimales y redondea los valores con más decimales. No obstante, el valor completo
se utiliza en todos los cálculos.
Para las variables de cadena, todos los valores se rellenan por la derecha hasta el
ancho máximo. Para una variable de cadena con un ancho de tres, un valor de No se
almacena internamente como ‟No ‟ y no es equivalente a ‟No‟.
Para formatos de fecha, se pueden utilizar guiones, barras, espacios, comas o puntos
como separadores entre valores de día, mes y año; se pueden incluir números,
abreviaciones de tres letras o nombres completos para el valor de mes. Las fechas
del formato general dd-mm-aa aparecen separadas por guiones y con abreviaciones
de tres letras para el mes. Las fechas del formato general dd/mm/aa y mm/dd/aa se
muestran con barras como separadores y números para el mes. Internamente, las
fechas se almacenan como el número de segundos transcurridos desde el 14 de
octubre de 1582.El rango de siglo para los valores de año de dos dígitos está

determinado por la configuración de las Opciones (en el menú Edición, seleccione
Opciones y pulse en la pestaña Datos).
Para formatos de hora, se pueden utilizar dos puntos, puntos o espacios como
separadores entre horas, minutos y segundos. Las horas se muestran separadas por
dos puntos. Internamente, las horas se almacenan como el número de segundos
transcurridos desde el 14 de octubre de 1582.
Etiquetas de variable
Puede asignar etiquetas de variable descriptivas de hasta 256 caracteres de longitud (128
caracteres en los idiomas de doble byte). Las etiquetas de variable pueden contener
espacios y caracteres reservados que no se admiten en los nombres de variable.
Para especificar etiquetas de variable
Haga que el editor de datos sea la ventana activa.
Pulse dos veces en un nombre de variable en la parte superior de la columna y en la
Vista de datos o bien pulse en la pestaña Vista de variables.
Escriba la etiqueta de variable descriptiva en la casilla Etiqueta para la variable.
Etiquetas de valor
Puede asignar etiquetas de valor descriptivas a cada valor de una variable. Esta posibilidad
es substancialmente útil si los archivos de datos manejan códigos numéricos para
representar categorías que no son numéricas (por ejemplo, códigos 1 y 2 para hombre y
mujer).
Las etiquetas de valor pueden tener hasta 60 caracteres.
Las etiquetas de valor no están utilizables para las variables de cadena larga (variables
de cadena de más de 8 caracteres).

Figura Cuadro de diálogo Etiquetas de valor
Para especificar etiquetas de valor
Pulse en el botón de la casilla Valores para la variable que se quiere definir.
Para cada valor, escriba el valor y una etiqueta.
Pulse en Añadir para introducir la etiqueta de valor.
Inserción de saltos de línea en etiquetas
Las etiquetas de valor y de variable se dividen automáticamente en varias líneas en los
gráficos y en las tablas pivote si el ancho de casilla o el área no es suficiente para mostrar la
etiqueta completa en una línea. Se pueden editar los resultados para insertar saltos de línea
manuales si se quiere dividir la etiqueta en otro punto.
También puede crear etiquetas de variable y de valor que siempre se dividan en puntos
especificados y se muestren en varias líneas:
Para etiquetas de variable, escoja la casilla Etiqueta de la variable en la Vista de
variables del Editor de datos.
Para etiquetas de valor, elija la casilla Valores correspondiente a la variable en la Vista
de variables del Editor de datos, haga clic en el botón que aparece en la casilla y,
seguidamente, seleccione la etiqueta que desea modificar en el cuadro de diálogo
Etiquetas de valor.
En el punto de la etiqueta en el que la desea dividir, escriba \n. El \n no aparece en las
tablas pivote ni en los gráficos; se asume como un carácter de salto de línea.
Valores perdidos

Valores perdidos define los valores de los datos definidos como perdidos por el usuario. A
menudo es útil para saber por qué se pierde información. Por ejemplo, puede desear
distinguir los datos perdidos porque un encuestado se niegue a responder de los datos
perdidos porque la pregunta no afecta a dicho encuestado. Los valores de datos
especificados como perdidos por el usuario aparecen marcados para un tratamiento especial
y se excluyen de la mayoría de los cálculos.
Figura Cuadro de diálogo Valores perdidos
Se pueden introducir hasta tres valores perdidos (individuales) de tipo discreto, un
rango de valores perdidos o un rango más un valor de tipo discreto.
Sólo pueden especificarse rangos para las variables numéricas.
No se pueden definir los valores perdidos para variables de cadena larga (variables de
cadena de más de ocho caracteres).
Valores perdidos para las variables de cadena. Son considerados válidos todos los
valores de cadena, incluidos los valores vacíos o nulos, al menos que se definan
explícitamente como perdidos. Para definir como perdidos los valores nulos o vacíos de una
variable de cadena, escriba un espacio en blanco en uno de los campos debajo de la
selección Valores perdidos discretos.
Para definir los valores perdidos

Haga clic en el botón de la casilla Perdido para la variable que se quiere definir.
Meta los valores o el rango de valores que representen los datos perdidos.
Ancho de columna
Puede especificarse un número de caracteres para el ancho de la columna. Los anchos de
columna también se pueden modificar en la Vista de datos haciendo clic y arrastrando los
bordes de las columnas.
Los formatos de columna afectan sólo a la presentación de valores en el Editor de datos. Al
cambiar el ancho de columna no se cambia el ancho definido de una variable. Si el ancho
real y definido de un valor es más ancho que la columna, aparecerán asteriscos (*) en la
ventana Vista de datos.
Alineación de la variable
La alineación controla la presentación de los valores de los datos y/o de las etiquetas de
valor en la Vista de datos. La alineación por defecto es a la derecha para las variables
numéricas y a la izquierda para las variables de cadena. Este arreglo sólo afecta a la
presentación en la Vista de datos.
Aplicación de atributos de definición de variables a varias variables
Una vez que se han definido los atributos de definición de variables correspondientes a una
variable, puede copiar uno o más atributos y aplicarlos a una o más variables.
Se manejan las operaciones básicas de copiar y pegar para aplicar atributos de definición de
variables. Tiene la posibilidad de:
Copiar un único atributo (por ejemplo, etiquetas de valor) y pegarlo en la misma casilla
de atributo para una o más variables.
Copiar todos los atributos de una variable y pegarlos en una o más variables.
Crear varias variables nuevas con todos los atributos de una variable copiada.
Aplicación de atributos de definición de variables a otras variables
Para aplicar atributos individuales de una variable definida:

En la Vista de variables, seleccione la casilla de atributos que quiere aplicar a otras
variables.
Elija en los menús:
Edición
Copiar
Escoja la casilla de atributos a la que quiere aplicar el atributo. Puede elegir varias
variables de destino.
Elija en los menús:
Edición
Pegar
Si pega el atributo en filas vacías, se crean nuevas variables con atributos por defecto
excepto para el atributo elegido.
Para aplicar todos los atributos de una variable definida:
En la Vista de variables, seleccione el número de fila para la variable con los atributos
que quiere utilizar. Se resaltará la fila entera.
Elija en los menús:
Edición
Copiar
Escoja los números de fila de las variables a la que desea aplicar los atributos. Puede
seleccionar varias variables de destino.
Seleccione en los menús:
Edición
Pegar
Generación de varias variables nuevas con los mismos atributos
En la Vista de variables, escoja el número de fila para la variable con los atributos que
quiere utilizar para la nueva variable. Se resaltará la fila entera.
Elija en los menús:
Edición
Copiar

Haga clic en el número de la fila vacía situada bajo la última variable definida en el
archivo de datos.
Elija en los menús:
Edición
Pegar variables...
Indique el número de variables que quiere crear.
Introduzca un prefijo y un número inicial para las nuevas variables. Los nombres de las
nuevas variables se compondrán del prefijo especificado, más un número secuencial
que comienza por el número indicado.
Introducción de datos
Se pueden introducir datos directamente en el Editor de datos de la Vista de datos. Se puede
introducir datos en cualquier orden. Asimismo, se pueden introducir datos por caso o por
variable, para áreas seleccionadas o para casillas individuales.
Se resaltará la casilla activa.
El nombre de la variable y el número de fila de la casilla activa aparecen en la esquina
superior izquierda del Editor de datos.
Cuando seleccione una casilla e introduzca un valor de datos, el valor se muestra en el
editor de casillas situado en la parte superior del Editor de datos.
Los valores de datos no se registran hasta que se pulsa Intro o se selecciona otra casilla.
Para introducir datos distintos de los numéricos, en primera instancia, se debe definir el
tipo de variable.
Si introduce un valor en una columna vacía, el Editor de datos creará de manera automática
una nueva variable y asignará un nombre de variable.

Figura Archivo de datos de trabajo en la Vista de datos
Para introducir datos numéricos
Seleccione una casilla en la Vista de datos.
Introduzca el valor de los datos. El valor se muestra en el editor de casillas situado en la
parte superior del Editor de datos.
Haga clic Intro o elija otra casilla para registrar el valor.
Para introducir datos no numéricos
Haga clic dos veces en un nombre de variable en la parte superior de la columna en la
Vista de datos o bien pulse en la pestaña Vista de variables.
Pulse en el botón de la casilla Tipo de la variable.
Elija el tipo de datos en el cuadro de diálogo Tipo de variable.
Haga clic en Aceptar.
Pulse dos veces en el número de fila o haga clic en la pestaña Vista de datos.
Meta en la columna los datos de la variable que se va a definir.
Para utilizar etiquetas de valor en la introducción de datos
Si las etiquetas de valor no aparecen en la Vista de datos, escoja en los menús:
Ver
Etiquetas de valor
Pulse en la casilla donde quiere introducir el valor.

Elija una etiqueta de valor en la lista desplegable.
De este modo se introducirá el valor y la etiqueta de valor se mostrará en la casilla.
Nota: Este método sólo funciona si ha definido etiquetas de valor para la variable.
Restricciones de los valores de datos en el Editor de datos
El ancho y el tipo de variable definidos determinan el tipo de valor que se puede introducir
en la casilla en la Vista de datos.
Si escribe un carácter no permitido por el tipo de variable definido, el Editor de datos
emitirá una señal acústica y el carácter no se introducirá.
Para variables de cadena, no se permiten los caracteres que sobrepasen el ancho
definido.
Para variables numéricas, se pueden introducir valores enteros que excedan el ancho
definido, pero el Editor de datos mostrará la notación científica o asteriscos en la casilla
para indicar que el valor es más ancho que el ancho definido. Para mostrar el valor de la
casilla, modifique el ancho definido de la variable. (Nota: Modificar el ancho de la
columna no afecta al ancho de la variable.)
Edición de datos
Con el Editor de datos es posible modificar los valores de datos en la Vista de datos de
muchas maneras. Tiene la posibilidad de:
Modificar los valores de datos.
Cortar, copiar y pegar valores de datos.
Añadir y eliminar casos.
Añadir y eliminar variables.
modificar el orden de las variables.
Para reemplazar o modificar un valor de datos
Para eliminar el valor anterior e introducir un valor nuevo:
En la Vista de datos, haga clic dos veces en la casilla. Su valor aparecerá en el editor de
casillas.

Edite el valor directamente en la casilla o en el editor de casillas.
Pulse Intro (o desplácese a otra casilla) para registrar el valor nuevo.
Cortar, copiar y pegar valores de datos
Puede cortar, copiar y pegar valores de casillas individuales o grupos de valores en el
Editor de datos. Tiene la posibilidad de:
Mover o copiar un único valor de casilla a otra casilla.
Mover o copiar un único valor de casilla en un grupo de casillas.
Mover o copiar los valores de un único caso (fila) en varios casos.
Mover o copiar los valores de una única variable (columna) en varias variables.
Mover o copiar un grupo de valores de casillas en otro grupo de casillas.
Conversión de datos para valores pegados en el Editor de datos
Si los tipos de variable definidos de las casillas de origen y de destino no son iguales, el
Editor de datos intentará convertir el valor. Si no es posible realizar la conversión, el valor
perdido del sistema se insertará en la casilla de destino.
Numérico o fecha a cadena. Los formatos numéricos (por ejemplo, numérico, dólar, de
punto o de coma) y de fechas se convierten en cadenas si se pegan en una casilla de
variable de cadena. El valor de cadena es el valor numérico tal como se muestra en la
casilla. Por ejemplo, para la variable con formato de dólar, el signo dólar que se muestra se
convierte en parte del valor de cadena. Los valores que sobrepasan el ancho de la variable
de cadena definida quedan cortados.
Cadena a numérico o fecha. Los valores de cadena que contienen caracteres admisibles
por el formato numérico o de fecha de la casilla de destino se convierten al valor numérico
o de fecha equivalente. Por ejemplo, un valor de cadena de 25/12/91 se convierte a una
fecha válida si el tipo de formato de la casilla de destino es uno de los formatos día-mes-

año, pero se convierte en perdido por el sistema si el tipo de formato de la casilla de destino
es uno de los formatos mes-día-año.
Fecha a numérico. Los valores de fecha y hora se convierten a un número de segundos si
la casilla de destino es uno de los formatos numéricos (por ejemplo, numérico, dólar, de
punto o de coma). Como las fechas se almacenan internamente como el número de
segundos transcurridos desde el 14 de octubre de 1582, la conversión de fechas a valores
numéricos puede generar números extremadamente grandes. Por ejemplo, la fecha 10/29/91
se convierte al valor numérico 12.908.073.600.
Numérico a fecha u hora. Los valores numéricos se convierten a fechas u horas si el valor
representa un número de segundos que puede producir una fecha u hora válidas. Para las
fechas, los valores numéricos menores de 86.400 se convierten al valor perdido del sistema.
Inserción de nuevos casos
Al introducir datos en una casilla de una fila vacía, se crea automáticamente un nuevo caso.
El Editor de datos inserta el valor perdido del sistema para el resto de las variables de dicho
caso. Si hay alguna fila vacía entre el nuevo caso y los casos existentes, las filas en blanco
también se convierten en casos nuevos con el valor perdido del sistema para todas las
variables. También puede insertar nuevos casos entre casos existentes.
Para insertar nuevos casos entre los casos existentes
En la Vista de datos, escoja cualquier casilla del caso (fila) debajo de la posición donde
desea insertar el nuevo caso.
Elija en los menús:
Datos
Insertar casos
Se inserta una fila nueva para el caso y todas las variables reciben el valor perdido del
sistema.
Inserción de nuevas variables

Al introducir datos en una columna vacía en la Vista de datos o en una fila vacía en la Vista
de variables se crea de forma automática una variable nueva con un nombre de variable por
defecto (el prefijo var y un número secuencial) y un tipo de formato de datos por defecto
(numérico). El Editor de datos inserta el valor perdido del sistema en todos los casos de la
variable nueva. Si hay columnas vacías en la Vista de datos o filas vacías en Vista de
variables entre la nueva variable y las variables existentes, estas columnas también se
transforman en nuevas variables con el valor perdido del sistema para todos los casos.
También se pueden insertar variables nuevas entre las variables existentes.
Para insertar nuevas variables entre variables existentes
Seleccione cualquier casilla de la variable a la derecha (Vista de datos) o debajo (Vista
de variables) de la posición donde desea insertar la nueva variable.
Elija en los menús:
Datos
Insertar variable
Se insertará una nueva variable con el valor perdido del sistema para todos los casos.
Para mover variables
Haga clic en el nombre de variable en la Vista de datos o en el número de fila de la
variable en la Vista de variables para elegirla.
Arrastre y suelte la variable en la nueva ubicación.
Si prefiere situar la variable entre dos variables existentes, en la Vista de datos ubique
la variable en la columna de variables a la derecha del lugar donde desea situar la
variable. En la Vista de variables, colóquela en la fila de variables por debajo del
lugar donde desea colocarla.
Para cambiar el tipo de datos
Puede cambiar el tipo de datos de una variable en cualquier momento utilizando el cuadro
de diálogo Tipo de variable en la Vista de variables y el Editor de datos intentará
transformar los valores existentes al nuevo tipo. Si esto no procede, se asignará el valor
perdido del sistema. Las reglas de conversión son las mismas que las del pegado de valores

de datos en una variable con distinto tipo de formato. Si el cambio del formato de los datos
puede generar la pérdida de las especificaciones de valores perdidos o de las etiquetas de
valor, el Editor de datos mostrará un cuadro de alerta solicitando confirmación para
continuar o cancelar la operación.
Ir a caso
Ir a caso va al número de caso (fila) especificado en el Editor de datos.
Figura Cuadro de diálogo Ir a caso
Para buscar un caso en el Editor de datos
Haga que el editor de datos sea la ventana activa.
Elija en los menús:
Datos
Ir a caso...
Meta el número de fila del Editor de datos para el caso.
Estado de selección de casos en el Editor de datos
Si ha escogido un subconjunto de casos pero no ha descartado los casos no seleccionados,
éstos se resaltarán en el Editor de datos con una línea diagonal (barra diagonal) atravesando
el número de fila.

Figura Casos filtrados en el Editor de datos
Editor de datos: Opciones de presentación
El menú Ver proporciona diferentes opciones de presentación para el Editor de datos:
Fuentes. Controla las características de fuentes de la presentación de datos.
Líneas de cuadrícula. Activa y desactiva la presentación de las líneas de cuadrícula.
Etiquetas de valor. Activa y desactiva la presentación de los valores reales de los datos y
las etiquetas de valor descriptivas definidas por el usuario. Esta opción sólo está a
disposición en la Vista de datos.
Uso de varias vistas
En la Vista de datos, puede crear varias vistas (paneles) mediante los divisores situados
sobre la barra de desplazamiento horizontal y a la derecha de la barra de desplazamiento
vertical.

Figura Divisores de paneles de Vista de datos
También puede utilizar el menú Ventana para insertar y eliminar divisores de paneles.
Para insertar divisores:
En la Vista de datos, elija en los menús:
Ventana
Dividir
Los divisores se insertan sobre y a la izquierda de la casilla elegida.
Si se ha escogido la casilla superior izquierda, los divisores se insertan para dividir la
vista actual alrededor de la mitad horizontal y verticalmente.
Si se selecciona una casilla diferente de la casilla superior de la primera columna, se
inserta un divisor de paneles horizontales sobre la casilla elegida.
Si se escoge una casilla distinta de la primera casilla de fila superior, se inserta un
divisor de paneles verticales a la izquierda de la casilla escogida.
Impresión en el Editor de datos
Los archivos de datos se imprimen tal y como aparece en la pantalla.
Se imprime la información que está en la vista actualmente mostrada. En la Vista de
datos, se imprimen los datos. En la Vista de variables, se imprime la información de
definición de los datos.
Las líneas de cuadrícula se imprimen si aparecen actualmente en la vista escogida

Las etiquetas de valor se imprimen si aparecen actualmente en la Vista de datos.
En caso contrario, se imprimirán los valores de datos reales.
Utilice el menú Ver en la ventana Editor de datos para mostrar u ocultar las líneas de
cuadrícula y para que se exhiban o no los valores de los datos y las etiquetas de valor.
Impresión del contenido del Editor de datos
Haga que el editor de datos sea la ventana activa.
Seleccione la pestaña de la vista que desea imprimir.
Elija en los menús:
Archivo
Imprimir..
TRANSFORMAR DATOS SPSS
Una de las principales ventajas de SPSS, radica en la capacidad de generar nueva
información a partir de los datos originales del archivo de trabajo. Esta propiedad nos
permite manipular la información incluida en las variables, ya sea para facilitar la
interpretación de los resultados, crear nuevas variables que compilen de forma general la
información de varias variables, crear nuevas variables que categoricen los datos de Escala
ó adecuar la información para que cumpla con los requerimientos de los procesos
estadísticos.
Para la modificación de la información SPSS cuenta con una serie de procedimientos, cuya
aplicación depende de las necesidades del análisis o del criterio del investigador. Dentro de
los métodos de transformación encontramos la Recodificación Automática, Categorizar
variables, Categorizador visual, Recodificar en las mismas variables, Recodificar en
distintas variables, Contar apariciones y Calcular [Fig.4-1].
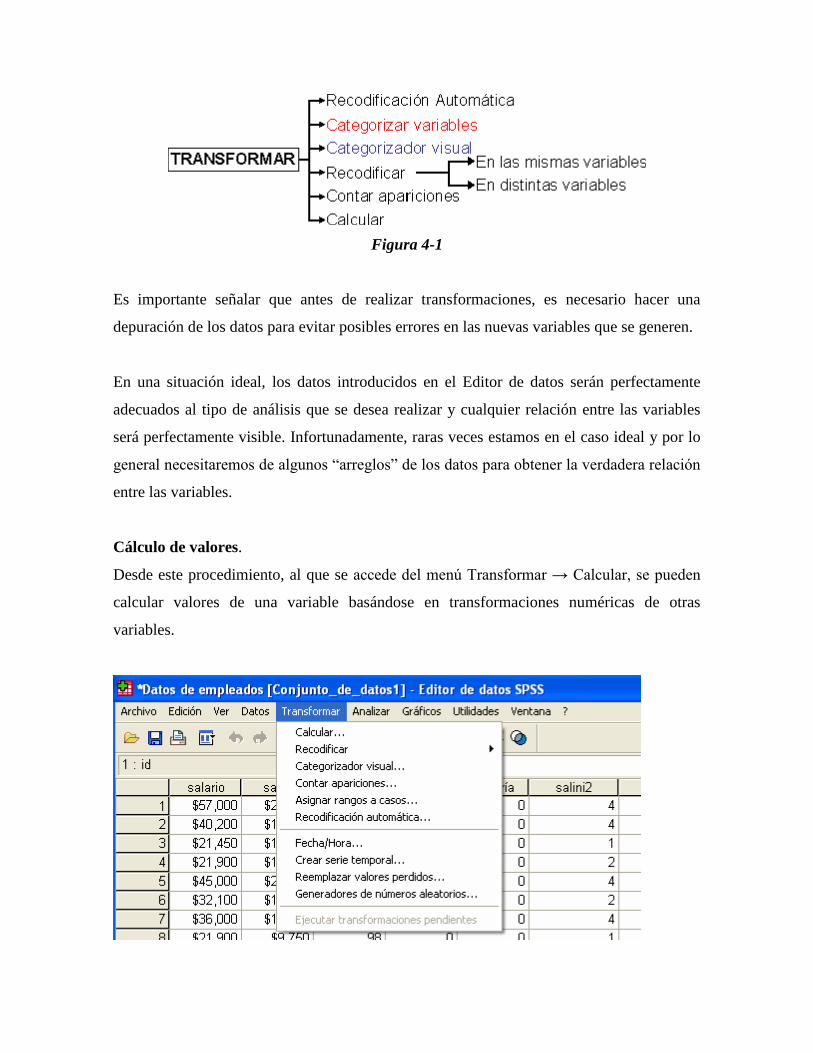
Figura 4-1
Es importante señalar que antes de realizar transformaciones, es necesario hacer una
depuración de los datos para evitar posibles errores en las nuevas variables que se generen.
En una situación ideal, los datos introducidos en el Editor de datos serán perfectamente
adecuados al tipo de análisis que se desea realizar y cualquier relación entre las variables
será perfectamente visible. Infortunadamente, raras veces estamos en el caso ideal y por lo
general necesitaremos de algunos “arreglos” de los datos para obtener la verdadera relación
entre las variables.
Cálculo de valores.
Desde este procedimiento, al que se accede del menú Transformar → Calcular, se pueden
calcular valores de una variable basándose en transformaciones numéricas de otras
variables.

Por ejemplo, el archivo de datos Datos de empleados.sav (incluido con el SPSS) contiene
una variable para la fecha de nacimiento de los encuestados (fechnac), sin embargo, no
contiene una variable para la edad actual del encuestado. Podemos crear una nueva variable
que sea la diferencia calculada entre la fecha actual y la fecha de nacimiento, que deberá ser
la edad aproximada, en este momento, del encuestado.
Para indicar al SPSS la definición de esa nueva variable, a la que llamaremos edad, hay que
entrar en el cuadro de diálogo calcular variable:
En el recuadro “variable de destino” se muestra el nombre de la variable que va a recibir el
valor calculado. Puede ser una variable existente o una nueva. Si es una nueva, el nombre
que le demos debe cumplir las normas de los nombres de variables en SPSS (en nuestro
ejemplo, es una variable nueva y la llamaremos edad). Las nuevas variables, por defecto se

consideran numéricas. Si se desea calcular una nueva variable de cadena o asignar etiquetas
a las variables, se pulsa el botón “Tipo y etiqueta…”
En el recuadro “expresión numérica” definimos la operación utilizada para calcular el valor
de la variable de destino. Esta expresión puede utilizar nombres de variables existentes,
constantes, operadores aritméticos y funciones (hay varias funciones preincorporadas,
incluyendo funciones aritméticas, funciones estadísticas, funciones de distribución y
funciones de cadena. En el panel de texto hallaremos una descripción de lo que hace cada
función y de los parámetros que necesita). Se puede teclear directamente la expresión en el
cuadro de texto y también se puede utilizar la calculadora, la lista de variables y la lista de
funciones para pegar elementos en la expresión. Para ello, pueden seleccionarse las
variables de la lista de la izquierda o la función y trasladarla a la expresión numérica
haciendo clic en el botón con punta de flecha. Los operadores y números se pasan a la
expresión haciendo clic en ellos con el ratón. Se recomienda poner paréntesis cada vez que
se incluya una operación para una variable. En nuestro ejemplo, como trabajaremos con
variables de tipo fecha, usaremos funciones para creación y cálculo de fechas y
completaremos los parámetros que necesita cada función.
Una vez definida la nueva variable se ejecuta la orden en el botón „Aceptar‟ y el resultado
aparece como una nueva columna al final del Editor de datos del SPSS.

También se pueden utilizar expresiones condicionales para aplicar conversiones a
subgrupos seleccionados de casos (para los que la expresión condicional es verdadera).
Para especificar la expresión condicional pulsamos en “Si…” que, a su vez, abre un cuadro
de diálogo como este:
Si, por ejemplo deseáramos realizar el cálculo anterior pero no para todos los empleados
sino sólo para aquellos con determinadas categorías laborales (catlab <5) y que hubieran
comenzado trabajando en la empresa con un determinado salario inicial (salini ≥ 12000),
que quizá sean los posibles candidatos “ideales” a una prejubilación elegiríamos lo anterior.
Contar apariciones
Para contar apariciones de los mismos valores en una lista de variables elegimos el
procedimiento Transformar→ Contar y se abre el siguiente cuadro de diálogo:
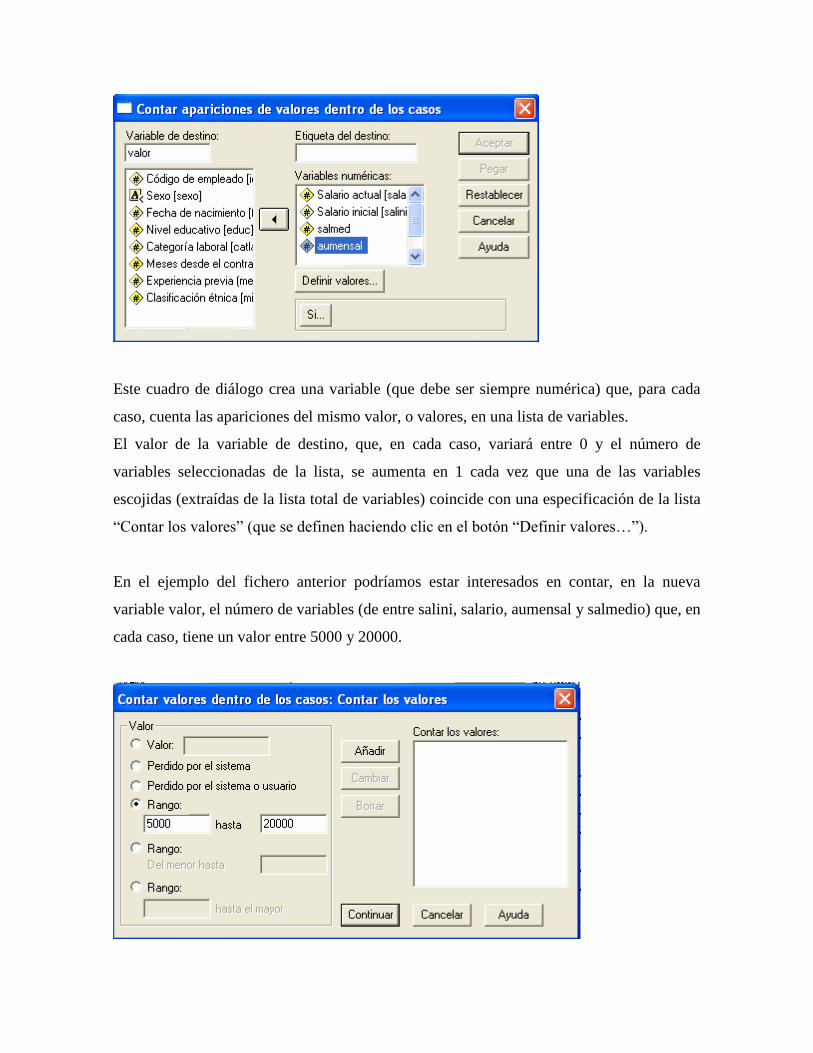
Este cuadro de diálogo crea una variable (que debe ser siempre numérica) que, para cada
caso, cuenta las apariciones del mismo valor, o valores, en una lista de variables.
El valor de la variable de destino, que, en cada caso, variará entre 0 y el número de
variables seleccionadas de la lista, se aumenta en 1 cada vez que una de las variables
escojidas (extraídas de la lista total de variables) coincide con una especificación de la lista
“Contar los valores” (que se definen haciendo clic en el botón “Definir valores…”).
En el ejemplo del fichero anterior podríamos estar interesados en contar, en la nueva
variable valor, el número de variables (de entre salini, salario, aumensal y salmedio) que, en
cada caso, tiene un valor entre 5000 y 20000.
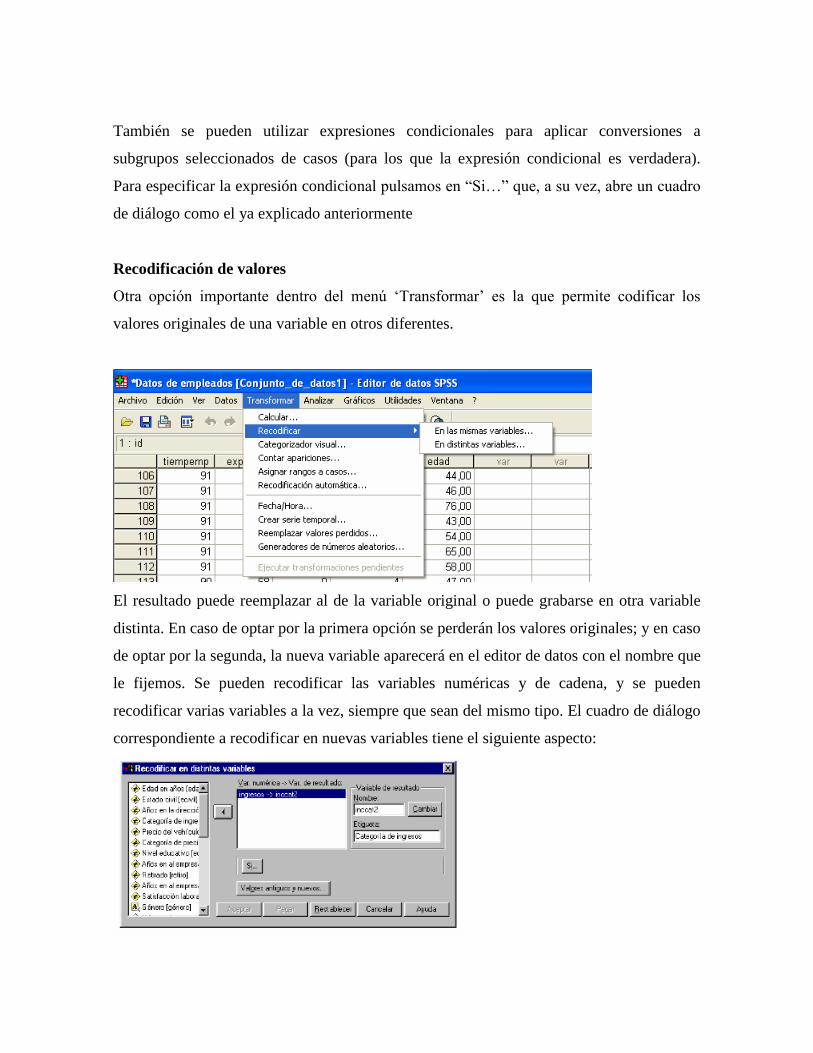
También se pueden utilizar expresiones condicionales para aplicar conversiones a
subgrupos seleccionados de casos (para los que la expresión condicional es verdadera).
Para especificar la expresión condicional pulsamos en “Si…” que, a su vez, abre un cuadro
de diálogo como el ya explicado anteriormente
Recodificación de valores
Otra opción importante dentro del menú „Transformar‟ es la que permite codificar los
valores originales de una variable en otros diferentes.
El resultado puede reemplazar al de la variable original o puede grabarse en otra variable
distinta. En caso de optar por la primera opción se perderán los valores originales; y en caso
de optar por la segunda, la nueva variable aparecerá en el editor de datos con el nombre que
le fijemos. Se pueden recodificar las variables numéricas y de cadena, y se pueden
recodificar varias variables a la vez, siempre que sean del mismo tipo. El cuadro de diálogo
correspondiente a recodificar en nuevas variables tiene el siguiente aspecto:

En el recuadro “Var. numérica -> Var. de resultado” se muestra cuál es la variable original
que se quiere recodificar y cómo se llamará la variable resultante. Supóngase que queremos
recodificar los valores de la variable ingresos (del fichero demo.sav) en las siguientes
cuatro categorías (hasta 25, de 25 a 50, de 50 a 75 y más de 75) definiendo una nueva
variable llamada cating2. Para ello trasladamos la variable ingresos al recuadro derecho.
En el recuadro “Nombre” hay que etiquetar a la variable resultado (por ejemplo cating2).
Finalmente hacemos clic en cambiar.
En el recuadro tiene que aparecer ingresos -> cating2. Para señalar los nuevos valores
seleccionamos la opción “valores antiguos y nuevos” y desde el cuadro de diálogo
correspondiente mostramos cada uno de ellos. Puesto que en nuestro ejemplo los valores
antiguos serán agrupados en intervalos, hay que utilizar la opción „Rango‟. Los valores
nuevos pueden ser numéricos o de cadena. Si desea recodificar una variable numérica en
una variable de cadena, también se deberá elegir “Las variables de resultado son cadenas”.
Por ejemplo, primera recodificación: valor antiguo: Rango del menor hasta 24,999; valor
nuevo: 1. Una vez especificado el cambio, se pulsa en „Añadir‟.
Hay que repetir la operación para cada uno de los cambios. El cuadro final tiene que tener
el siguiente aspecto:
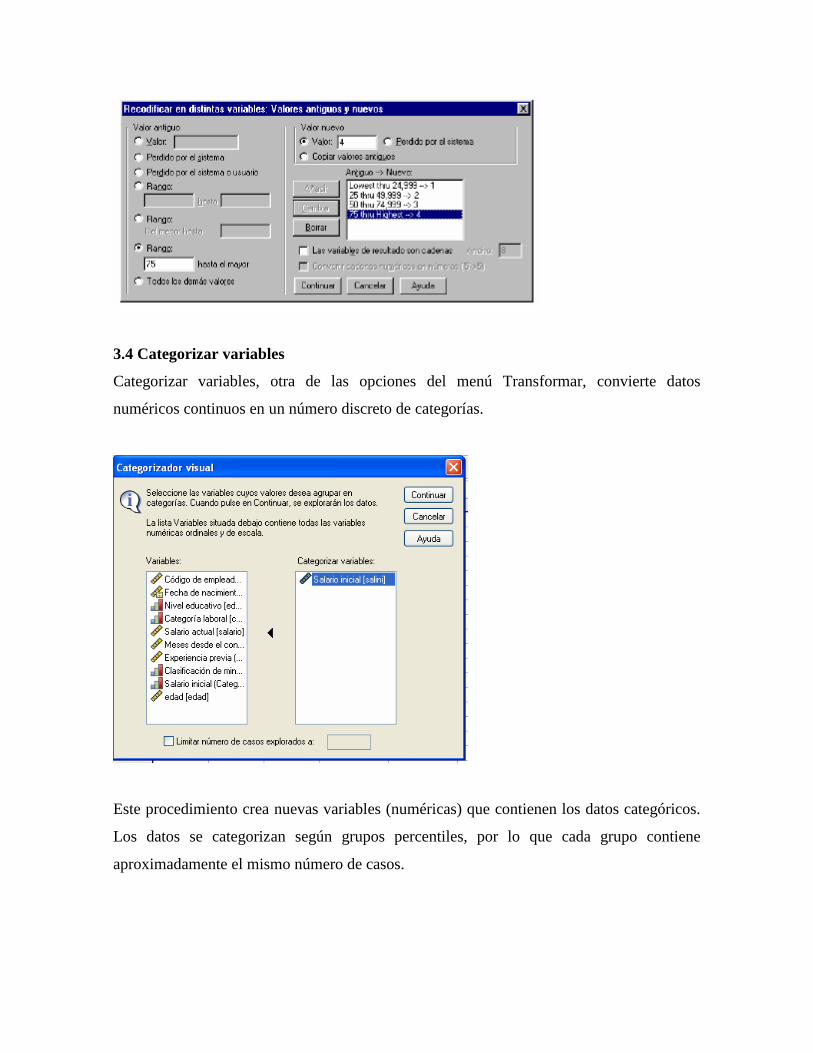
3.4 Categorizar variables
Categorizar variables, otra de las opciones del menú Transformar, convierte datos
numéricos continuos en un número discreto de categorías.
Este procedimiento crea nuevas variables (numéricas) que contienen los datos categóricos.
Los datos se categorizan según grupos percentiles, por lo que cada grupo contiene
aproximadamente el mismo número de casos.

Por ejemplo, la especificación de cuatro grupos asignará el valor 1 a los casos situados bajo
el percentil 25, 2 a los casos entre el percentil 25 y el 50, 3 a los casos situados entre el
percentil 50 y el 75 y 4 a los casos por encima del percentil 75.
Si, en el ejemplo de los datos de empleados, categorizamos la variable salini, en tres
grupos, crea la nueva variable nsalini, dividiendo los posibles valores de la variable en tres
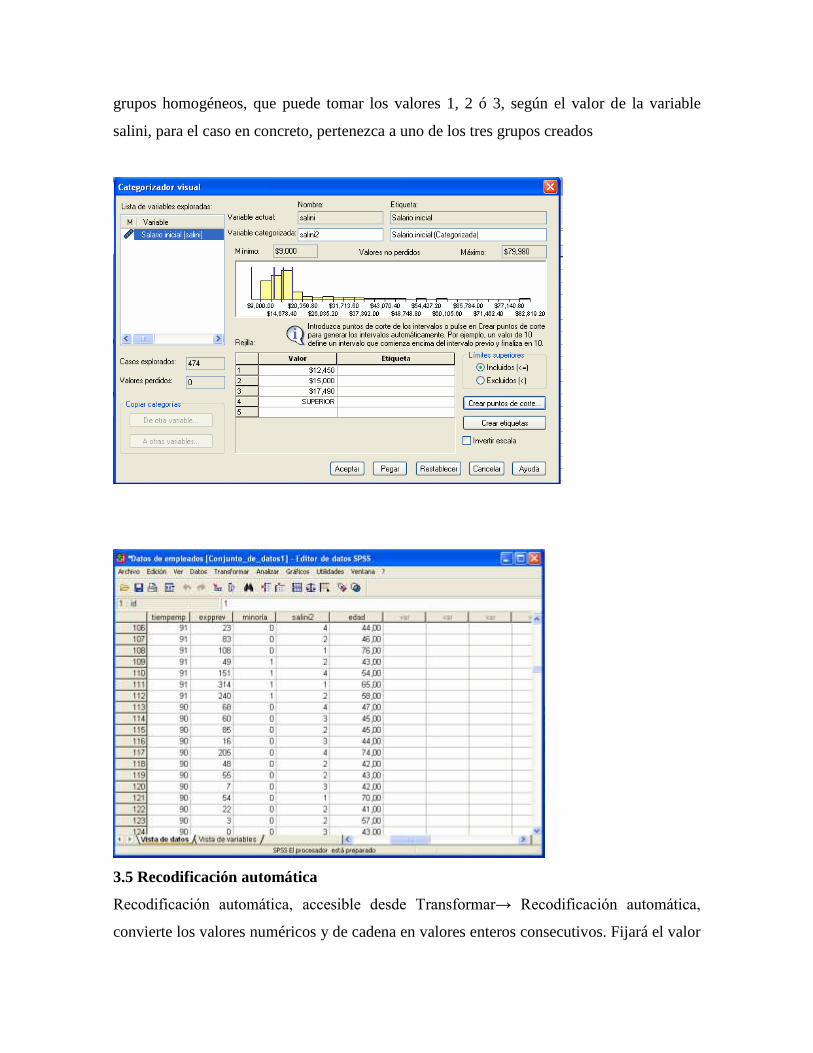
grupos homogéneos, que puede tomar los valores 1, 2 ó 3, según el valor de la variable
salini, para el caso en concreto, pertenezca a uno de los tres grupos creados
3.5 Recodificación automática
Recodificación automática, accesible desde Transformar→ Recodificación automática,
convierte los valores numéricos y de cadena en valores enteros consecutivos. Fijará el valor
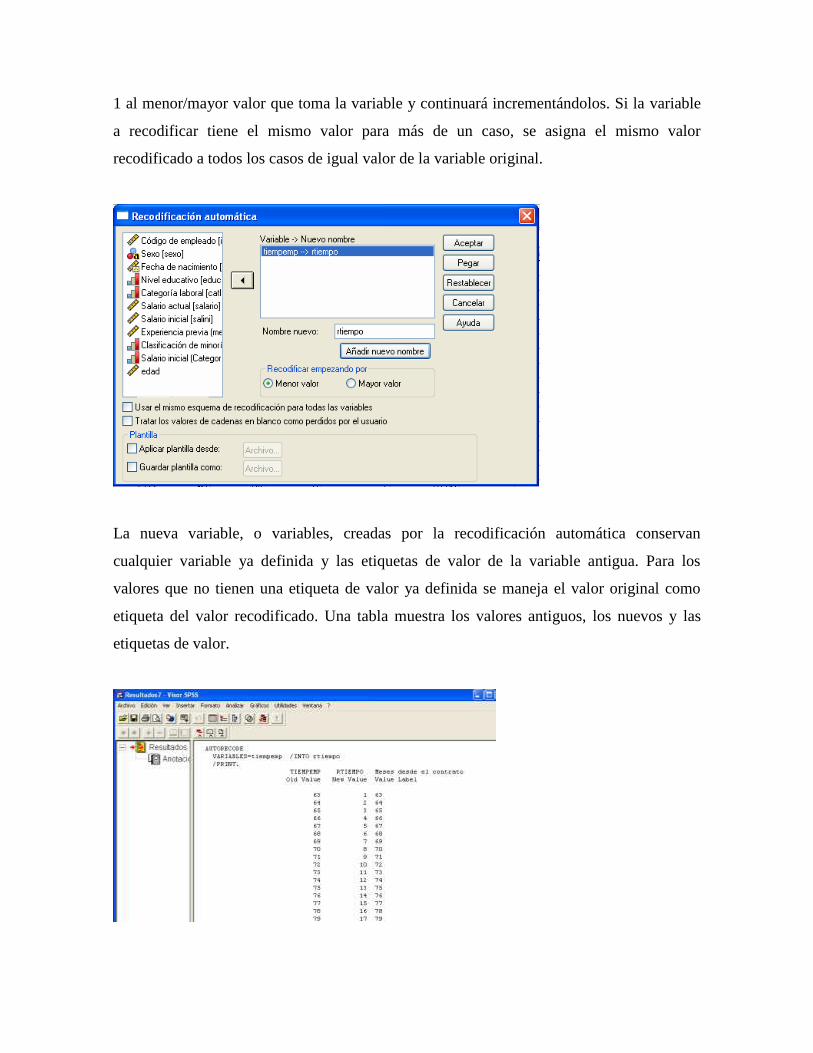
1 al menor/mayor valor que toma la variable y continuará incrementándolos. Si la variable
a recodificar tiene el mismo valor para más de un caso, se asigna el mismo valor
recodificado a todos los casos de igual valor de la variable original.
La nueva variable, o variables, creadas por la recodificación automática conservan
cualquier variable ya definida y las etiquetas de valor de la variable antigua. Para los
valores que no tienen una etiqueta de valor ya definida se maneja el valor original como
etiqueta del valor recodificado. Una tabla muestra los valores antiguos, los nuevos y las
etiquetas de valor.

Los valores de cadena se recodifican por orden alfabético, con las mayúsculas antes que las
minúsculas. Los valores perdidos se recodifican como valores perdidos mayores que
cualquier valor no perdido y manteniendo el orden. Por ejemplo, si la variable original
posee 10 valores no perdidos, el valor perdido mínimo se recodificará como 11, y el valor
11 será un valor perdido para la nueva variable.
TRANSFORMAR DATOS SPSS
Una de las principales ventajas de SPSS, radica en la capacidad de generar nueva
información a partir de los datos originales del archivo de trabajo. Esta propiedad nos
permite manipular la información incluida en las variables, ya sea para facilitar la
interpretación de los resultados, crear nuevas variables que compilen de forma general la
información de varias variables, crear nuevas variables que categoricen los datos de Escala
ó adecuar la información para que cumpla con los requerimientos de los procesos
estadísticos.
Para la modificación de la información SPSS cuenta con una serie de procedimientos, cuya
aplicación depende de las necesidades del análisis o del criterio del investigador. Dentro de
los métodos de transformación encontramos la Recodificación Automática, Categorizar
variables, Categorizador visual, Recodificar en las mismas variables, Recodificar en
distintas variables, Contar apariciones y Calcular [Fig.4-1].
Figura 4-1
Es importante señalar que antes de realizar transformaciones, es necesario hacer una
depuración de los datos para evitar posibles errores en las nuevas variables que se generen.

En una situación ideal, los datos introducidos en el Editor de datos serán perfectamente
adecuados al tipo de análisis que se desea realizar y cualquier relación entre las variables
será perfectamente visible. Infortunadamente, raras veces estamos en el caso ideal y por lo
general necesitaremos de algunos “arreglos” de los datos para obtener la verdadera relación
entre las variables.
Cálculo de valores.
Desde este procedimiento, al que se accede del menú Transformar → Calcular, se pueden
calcular valores de una variable basándose en transformaciones numéricas de otras
variables.
Por ejemplo, el archivo de datos Datos de empleados.sav (incluido con el SPSS) contiene
una variable para la fecha de nacimiento de los encuestados (fechnac), sin embargo, no
contiene una variable para la edad actual del encuestado. Podemos crear una nueva variable
que sea la diferencia calculada entre la fecha actual y la fecha de nacimiento, que deberá ser
la edad aproximada, en este momento, del encuestado.
Para indicar al SPSS la definición de esa nueva variable, a la que llamaremos edad, hay que
entrar en el cuadro de diálogo calcular variable:

En el recuadro “variable de destino” se muestra el nombre de la variable que va a recibir el
valor calculado. Puede ser una variable existente o una nueva. Si es una nueva, el nombre
que le demos debe cumplir las normas de los nombres de variables en SPSS (en nuestro
ejemplo, es una variable nueva y la llamaremos edad). Las nuevas variables, por defecto se
consideran numéricas. Si se desea calcular una nueva variable de cadena o asignar etiquetas
a las variables, se pulsa el botón “Tipo y etiqueta…”
En el recuadro “expresión numérica” definimos la operación utilizada para calcular el valor
de la variable de destino. Esta expresión puede utilizar nombres de variables existentes,
constantes, operadores aritméticos y funciones (hay varias funciones preincorporadas,
incluyendo funciones aritméticas, funciones estadísticas, funciones de distribución y
funciones de cadena. En el panel de texto hallaremos una descripción de lo que hace cada
función y de los parámetros que necesita). Se puede teclear directamente la expresión en el
cuadro de texto y también se puede utilizar la calculadora, la lista de variables y la lista de
funciones para pegar elementos en la expresión. Para ello, pueden seleccionarse las
variables de la lista de la izquierda o la función y trasladarla a la expresión numérica
haciendo clic en el botón con punta de flecha. Los operadores y números se pasan a la
expresión haciendo clic en ellos con el ratón. Se recomienda poner paréntesis cada vez que
se incluya una operación para una variable. En nuestro ejemplo, como trabajaremos con
variables de tipo fecha, usaremos funciones para creación y cálculo de fechas y
completaremos los parámetros que necesita cada función.
Una vez definida la nueva variable se ejecuta la orden en el botón „Aceptar‟ y el resultado
aparece como una nueva columna al final del Editor de datos del SPSS.
También se pueden utilizar expresiones condicionales para aplicar conversiones a
subgrupos seleccionados de casos (para los que la expresión condicional es verdadera).
Para especificar la expresión condicional pulsamos en “Si…” que, a su vez, abre un cuadro
de diálogo como este:
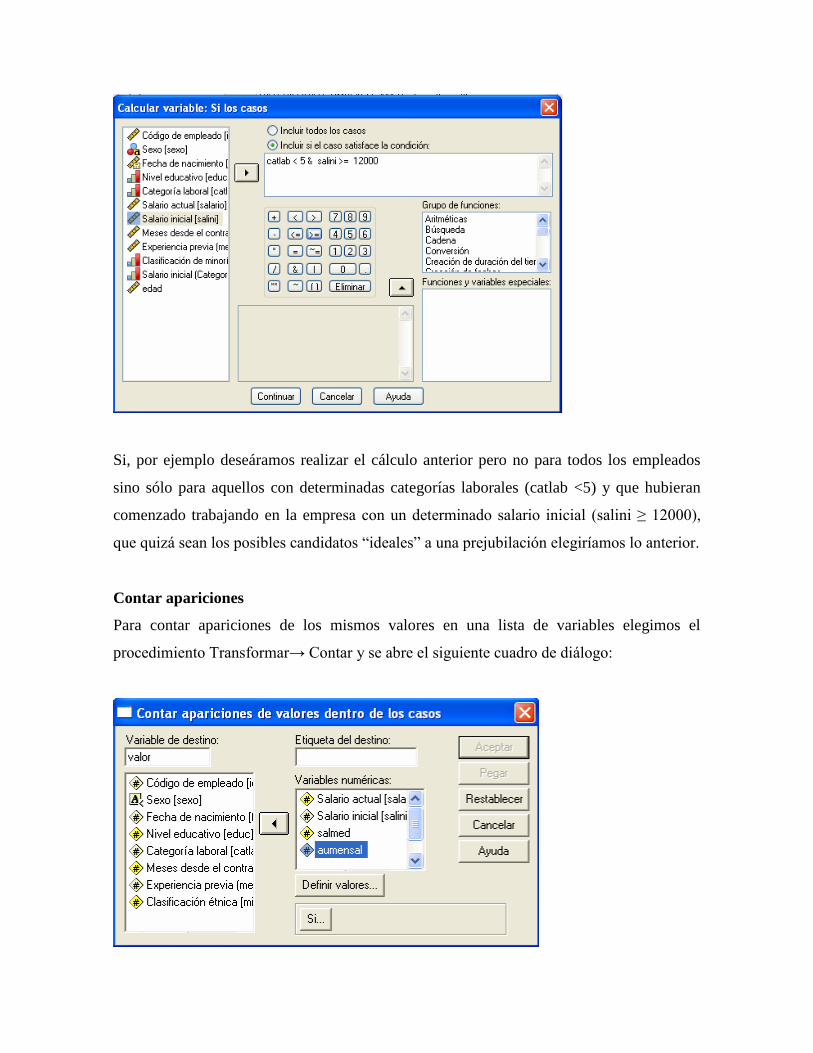
Si, por ejemplo deseáramos realizar el cálculo anterior pero no para todos los empleados
sino sólo para aquellos con determinadas categorías laborales (catlab <5) y que hubieran
comenzado trabajando en la empresa con un determinado salario inicial (salini ≥ 12000),
que quizá sean los posibles candidatos “ideales” a una prejubilación elegiríamos lo anterior.
Contar apariciones
Para contar apariciones de los mismos valores en una lista de variables elegimos el
procedimiento Transformar→ Contar y se abre el siguiente cuadro de diálogo:

Este cuadro de diálogo crea una variable (que debe ser siempre numérica) que, para cada
caso, cuenta las apariciones del mismo valor, o valores, en una lista de variables.
El valor de la variable de destino, que, en cada caso, variará entre 0 y el número de
variables seleccionadas de la lista, se aumenta en 1 cada vez que una de las variables
escojidas (extraídas de la lista total de variables) coincide con una especificación de la lista
“Contar los valores” (que se definen haciendo clic en el botón “Definir valores…”).
En el ejemplo del fichero anterior podríamos estar interesados en contar, en la nueva
variable valor, el número de variables (de entre salini, salario, aumensal y salmedio) que, en
cada caso, tiene un valor entre 5000 y 20000.
También se pueden utilizar expresiones condicionales para aplicar conversiones a
subgrupos seleccionados de casos (para los que la expresión condicional es verdadera).
Para especificar la expresión condicional pulsamos en “Si…” que, a su vez, abre un cuadro
de diálogo como el ya explicado anteriormente
Recodificación de valores
Otra opción importante dentro del menú „Transformar‟ es la que permite codificar los
valores originales de una variable en otros diferentes.
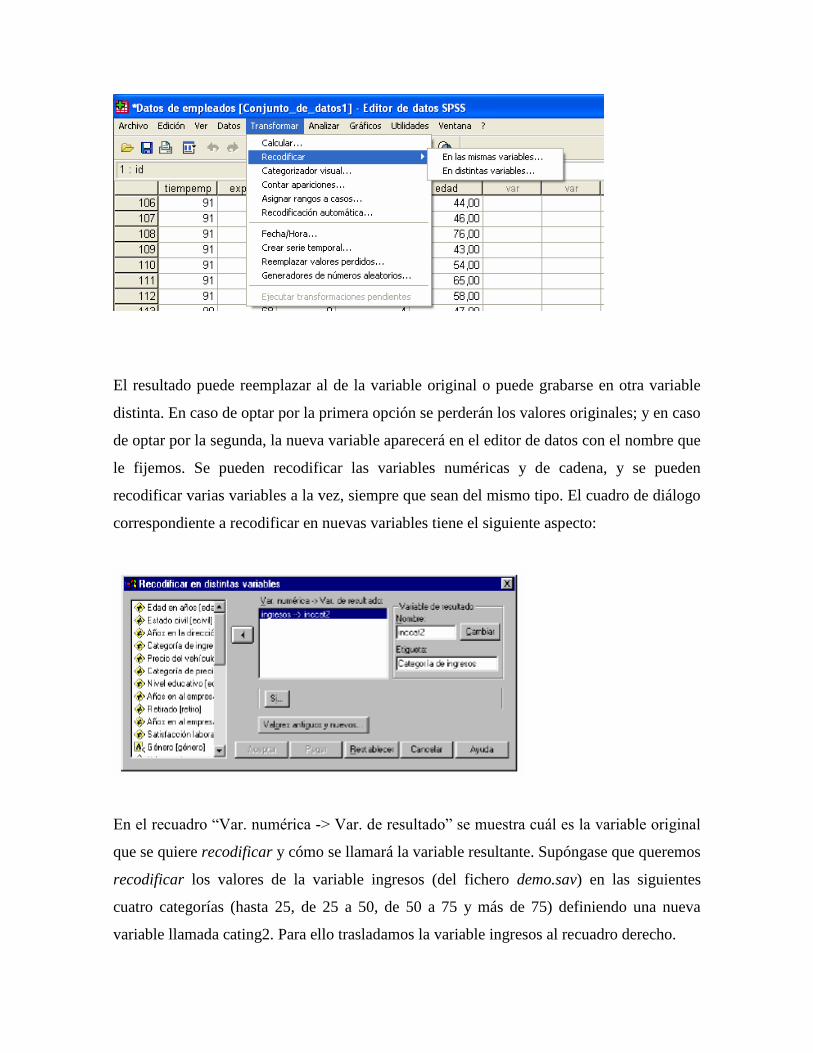
El resultado puede reemplazar al de la variable original o puede grabarse en otra variable
distinta. En caso de optar por la primera opción se perderán los valores originales; y en caso
de optar por la segunda, la nueva variable aparecerá en el editor de datos con el nombre que
le fijemos. Se pueden recodificar las variables numéricas y de cadena, y se pueden
recodificar varias variables a la vez, siempre que sean del mismo tipo. El cuadro de diálogo
correspondiente a recodificar en nuevas variables tiene el siguiente aspecto:
En el recuadro “Var. numérica -> Var. de resultado” se muestra cuál es la variable original
que se quiere recodificar y cómo se llamará la variable resultante. Supóngase que queremos
recodificar los valores de la variable ingresos (del fichero demo.sav) en las siguientes
cuatro categorías (hasta 25, de 25 a 50, de 50 a 75 y más de 75) definiendo una nueva
variable llamada cating2. Para ello trasladamos la variable ingresos al recuadro derecho.

En el recuadro “Nombre” hay que etiquetar a la variable resultado (por ejemplo cating2).
Finalmente hacemos clic en cambiar.
En el recuadro tiene que aparecer ingresos -> cating2. Para señalar los nuevos valores
seleccionamos la opción “valores antiguos y nuevos” y desde el cuadro de diálogo
correspondiente mostramos cada uno de ellos. Puesto que en nuestro ejemplo los valores
antiguos serán agrupados en intervalos, hay que utilizar la opción „Rango‟. Los valores
nuevos pueden ser numéricos o de cadena. Si desea recodificar una variable numérica en
una variable de cadena, también se deberá elegir “Las variables de resultado son cadenas”.
Por ejemplo, primera recodificación: valor antiguo: Rango del menor hasta 24,999; valor
nuevo: 1. Una vez especificado el cambio, se pulsa en „Añadir‟.
Hay que repetir la operación para cada uno de los cambios. El cuadro final tiene que tener
el siguiente aspecto:

3.4 Categorizar variables
Categorizar variables, otra de las opciones del menú Transformar, convierte datos
numéricos continuos en un número discreto de categorías.
Este procedimiento crea nuevas variables (numéricas) que contienen los datos categóricos.
Los datos se categorizan según grupos percentiles, por lo que cada grupo contiene
aproximadamente el mismo número de casos.
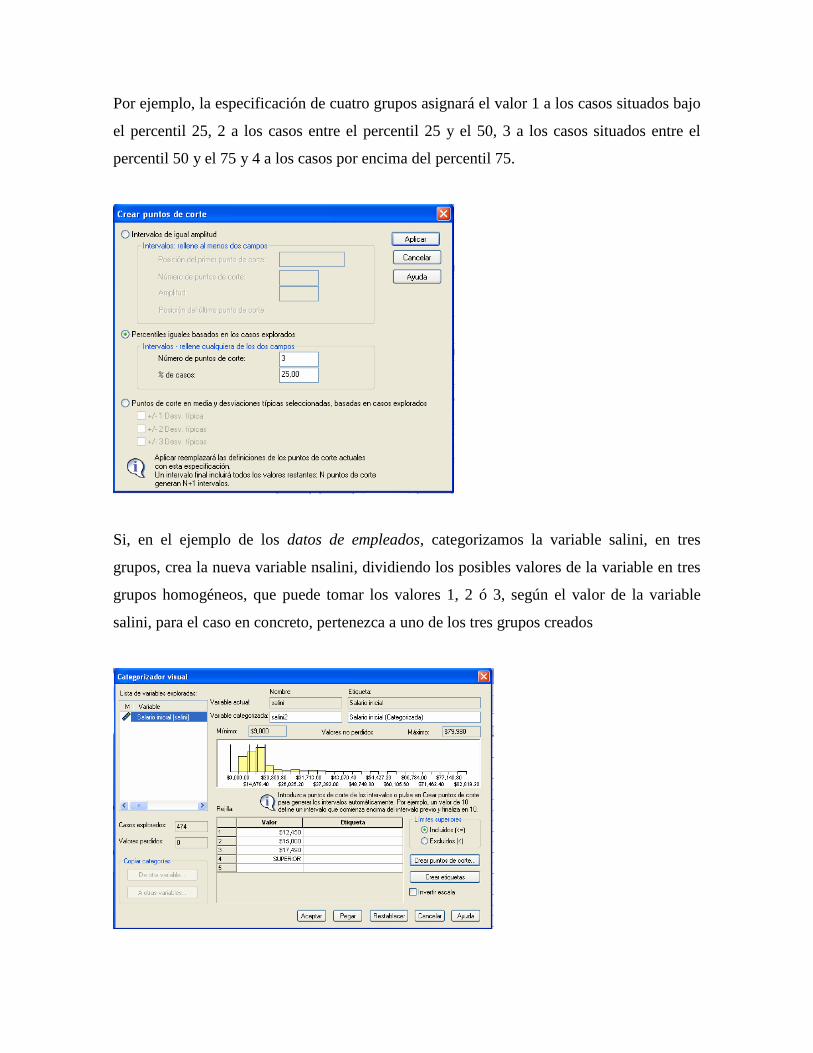
Por ejemplo, la especificación de cuatro grupos asignará el valor 1 a los casos situados bajo
el percentil 25, 2 a los casos entre el percentil 25 y el 50, 3 a los casos situados entre el
percentil 50 y el 75 y 4 a los casos por encima del percentil 75.
Si, en el ejemplo de los datos de empleados, categorizamos la variable salini, en tres
grupos, crea la nueva variable nsalini, dividiendo los posibles valores de la variable en tres
grupos homogéneos, que puede tomar los valores 1, 2 ó 3, según el valor de la variable
salini, para el caso en concreto, pertenezca a uno de los tres grupos creados
3.5 Recodificación automática
Recodificación automática, accesible desde Transformar→ Recodificación automática,
convierte los valores numéricos y de cadena en valores enteros consecutivos. Fijará el valor
1 al menor/mayor valor que toma la variable y continuará incrementándolos. Si la variable
a recodificar tiene el mismo valor para más de un caso, se asigna el mismo valor
recodificado a todos los casos de igual valor de la variable original.

La nueva variable, o variables, creadas por la recodificación automática conservan
cualquier variable ya definida y las etiquetas de valor de la variable antigua. Para los
valores que no tienen una etiqueta de valor ya definida se maneja el valor original como
etiqueta del valor recodificado. Una tabla muestra los valores antiguos, los nuevos y las
etiquetas de valor.
Los valores de cadena se recodifican por orden alfabético, con las mayúsculas antes que las
minúsculas. Los valores perdidos se recodifican como valores perdidos mayores que
cualquier valor no perdido y manteniendo el orden. Por ejemplo, si la variable original
posee 10 valores no perdidos, el valor perdido mínimo se recodificará como 11, y el valor
11 será un valor perdido para la nueva variable.
MODIFICACIÓN DEL ARCHIVO DE DATOS:
En algunas ocasiones es necesario cambiar o modificar la organización de un archivo
de datos y existen diversas maneras de realizar dichas modificaciones, por lo que se
comentarán las más utilizadas.
Añadir nuevas variables a un archivo de datos
Construir una variable a partir de otra

Recodificar variables
Separar o segmentar en grupos un archivo de datos
Seleccionar una Submuestra
Ordenar datos
Otras modificaciones
Añadir nuevas variables a un archivo de datos:
Para añadir una variable a un archivo de datos, se selecciona la columna que
queremos que quede a la derecha de la nueva variable dentro del archivo de datos. El
siguiente paso es elegir las opciones de la barra del menú principal:
Entonces aparecerá una nueva columna para la nueva variable. Se debe entonces
definir las características de la misma. Para ello, se pulsa en el botón VISTA DE
VARIABLES en la parte inferior de la pantalla, y se introducen directamente en la fila que
se corresponde con tal variable.
Construir una variable a partir de otra:
Una nueva variable se puede crear a partir de otra, mediante el resultado de una operación
aritmética, lógica o de una función de los valores de la variable inicial. De esta manera se
pueden generar muchísimas variables dependiendo de la transformación elegida. Para
realizar tal proceso seguiremos de manera consecutiva los siguientes pasos:
i)
En primer lugar se eligen seguidamente las opciones:

ii)
A continuación se abrirá una ventana en la que se han de rellenar los
siguientes campos:
Variable Destino:
Donde se coloca el nombre de la nueva variable.
Tipo y Etiqueta:
Aquí se especifica el tipo y la etiqueta de la nueva variable.
Expresión Numérica:
Aquí se recoge la transformación que se desea realizar sobre los datos. Esta
expresión puede contener operadores aritméticos, lógicos o una de las funciones que
aparecen en la lista que figura debajo de este campo. Esta lista contiene funciones
aritméticas, estadísticas, referentes a valores missing, de distribución y temporales.
Si:
Este es un botón que sirve para seleccionar los casos de la variable de partida
sobre los que se hace la modificación. Al pulsar sobre el mismo, se abre una
ventana en la que por defecto está activada la opción Incluir todos los casos, pero
si se desea, se pueden seleccionar aquellos casos que verifiquen una determinada
condición, eligiendo la opción Si el caso satisface la condición e incluyéndola en
este campo.
Para asignar un determinado valor a los valores perdidos de una variable se procede
a introducir en:

Variable Destino: su nombre,
Expresión Numérica: el valor a asignar, y pulsar el botón Si para completar el campo:
Si el caso satisface la condición: MISSING (nombre de la variable).
Entonces nos preguntará si queremos reemplazar la variable y en este caso, se elegirá
la opción ACEPTAR.
Recodificar Variables:
Es necesario recodificar una variable para realizar un análisis cuando por ejemplo, se
tiene que convertir una variable continua en categórica, o unir categorías de variables
discretas, etc. Para efectuar estas transformaciones se activa en el menú:
El sistema nos ofrece la posibilidad de almacenar los nuevos valores de la variable en
la misma o en otra diferente.
i) Si se elige la opción En las mismas variables, aparece una ventana con tres campos:
Variables: donde se especifican los nombres de las variables que se van a
recodificar. Si se seleccionan múltiples variables, todas deberán ser del mismo tipo
(numéricas o cadenas).
Si: botón que nos permite seleccionar los casos de la variable o variables para los
cuales se va a realizar la recodificación. Estos pueden ser todos, o los que verifiquen
una determinada condición.

Valores Antiguos y Nuevos: es un botón que abre un cuadro de diálogo donde se
introducen los valores a recodificar y los valores que los sustituirán.
ii) Si se elige la opción En distintas variables se muestra otra ventana con el siguiente
contenido:
Variable de Entrada Variable de Resultado: recoge la variable a
recodificar y la variable recodificada. La primera se selecciona de la lista de
variables a la izquierda de este campo, y la segunda se introduce directamente en
Variable de Resultado y después se pulsa el botón CAMBIAR para recogerla.
Etiqueta: aquí se puede especificar si se desea, una etiqueta para la variable
creada.
Los botones SI y VALORES ANTIGUOS Y NUEVOS tienen la misma
utilidad que en el caso de la recodificación en las mismas variables.
Separar o segmentar en grupos un archivo de datos:
Separar o segmentar un archivo consiste en dividirlo el grupos y para ello se deben
elegir las opciones:
Los subgrupos en que se divide la muestra, vienen determinados por una variable
cualitativa. Habrá entonces tantos grupos como categorías tenga dicha variable. Esto hará
que todos los análisis estadísticos que se soliciten posteriormente, se hagan de forma
separada para los casos dentro de cada grupo, a no ser que se indique lo contrario.
Para volver al estado inicial del archivo de datos y realizar los análisis estadísticos
con todos los datos de forma conjunta, se debe desactivar la segmentación de la manera
siguiente:

Para poder utilizar esta opción el archivo de datos debe estar ordenado por la variable
de agrupación, operación que el SPSS hace por defecto.
Seleccionar una Submuestra:
Algunas veces se quiere realizar un estudio estadístico considerando una muestra
aleatoria del total de casos del archivo de datos. Para ello, el SPSS resulta de gran utilidad
porque permite seleccionar un conjunto de casos utilizando diferentes criterios. En primer
lugar se debe seleccionar la opción del menú:
Entonces aparece un cuadro de diálogo con las siguientes posibilidades de selección de
submuestras.
a) Todos los casos: esta opción se usa cuando todos los casos de la muestra se necesitan
para el análisis, y está seleccionada por defecto.
b) Si se satisface la condición: al pulsar sobre el botón SI se abrirá un cuadro de diálogo
donde se puede introducir una expresión condicional (ejemplos: Zona = 2, Categoría= 1,
etc.), y se incluirán en el análisis todos los casos que cumplan esa condición.

c) Muestra aleatoria de Casos: al pulsar sobre el botón MUESTRA se abre un cuadro de
diálogo donde se puede indicar el tanto por ciento aproximado que se quiere seleccionar, o
el número exacto de casos a incluir.
d) Basándose en el rango del tiempo o de los casos: al entrar en esta opción se pedirá el
primer y el último caso a incluir. Si la variable es una fecha solicitará la fecha inicial y la
fecha final.
e) Usar variable de filtro: esta variable debe ser una variable numérica. Se seleccionarán
todos aquellos casos, que tengan un valor distinto de cero en tal variable.
Después de seleccionar los casos, el SPSS crea una variable en la columna final del
fichero llamada filter_$, que toma el valor uno en los casos seleccionados, y cero en los no
seleccionados.
Una vez establecido el criterio de selección, se puede decidir que hacer con los casos
no seleccionados. Se tienen dos opciones:
Filtrados: se filtran los casos no seleccionados, pero no desaparecen del archivo de
datos, sino que quedan tachados a la izquierda de cada fila. Para volver a retomar
todo el fichero de forma global no tenemos más que deshacer lo anterior mediante la
opción del menú:
y se elige Todos los casos. Desaparecen de esta forma todas las tachaduras de los
números de fila y cualquier estudio se hará sobre la muestra completa, pero la
variable filter_$ creada no desaparece.
Borrados: se eliminan los datos no seleccionados del archivo de datos.

Ordenar Datos:
Esta opción permite cambiar el orden de todos los casos del archivo, utilizando como
criterio una o más variables. Para ello se selecciona:
El cuadro de diálogo que se abre tiene un campo donde se introduce la variable o
variables según las cuales se quieren ordenar los datos, y la forma en que realizará la
ordenación: Ascendente o Descendente. Una vez completado el cuadro, se pulsa
ACEPTAR y se ordena el archivo de datos.
Otras modificaciones:
Unir Archivos:
Se muestra como unir los datos de dos o más archivos. Los archivos pueden combinarse
con las mismas variables pero con distintos casos, o con los mismos casos pero variables
diferentes.
Ponderar Casos:
Ponderar casos consiste en que un caso represente a más de in caso y para ello se hace
necesario utilizar una variable de ponderación. Si cada celda de una fila representa una
frecuencia, esto es, más de un caso, puede especificarse un factor de ponderación. Una vez
se aplica una variable de ponderación, ésta permanecerá activada hasta que se seleccione
una nueva o se desactive la actual.
EL VISOR DEL SPSS.
El Visor del SPSS muestra los resultados finales, e incluye tablas, gráficos,
estadísticas, etc., dependiendo de las indicaciones que nosotros le hayamos incluido. La

La Figura presenta la pantalla del visor de resultados.
Las figuras (a), (b) y (c) presentan todos los resultados obtenidos en el visor de resultados
del SPSS, de las dos variables con sus respectivos estadísticos y gráficos.
Figura a

Figura b

Figura C
Cuando tenemos los resultados, podemos copiar alguna tabla o gráfico que nos
interese, y pegarlo en otra aplicación, por ejemplo, en Word. El procedimiento para realizar
esto es muy sencillo, y se vislumbra en la figura tabla de frecuencia Ubicamos el puntero
del ratón sobre la tabla o gráfico que deseamos copiar, damos clic con el botón derecho y se
despliega un menú, entonces elegimos la opción copiar (o cortar) y con esto nos queda
guardada la tabla o el gráfico en el portapapeles, para pegarlo donde deseemos.

Figura
ARCHIVOS DE SINTAXIS DEL SPSS
Un archivo de sintaxis es simplemente un archivo de texto que contiene comandos.
Aunque es posible abrir una ventana de sintaxis y escribir comandos, suele ser más sencillo
permitir que el programa le ayude a construir un archivo de sintaxis a través de los
siguientes métodos:
Pegando la sintaxis de comandos desde los cuadros de diálogo
Copiando la sintaxis desde las a notaciones de los resultados
Copiando la sintaxis desde el archivo diario

En la ayuda en pantalla de un procedimiento determinado, pulse en el vínculo de
sintaxis de comandos que aparece en la lista de Temas relacionados para acceder a un
diagrama de sintaxis correspondiente al comando relevante. Si desea información detallada
sobre el lenguaje de comandos, consulte la referencia de sintaxis de comandos de SPSS
(SPSS Command Syntax Reference).
La documentación completa sobre la sintaxis de comandos se instala automáticamente al
mismo tiempo que SPSS. Para acceder a la documentación sobre la sintaxis:
E Elija en los menús:
Referencia de sintaxis de comandos
Reglas de la sintaxis
Recuerde las siguientes sencillas reglas al editar y escribir la sintaxis de los comandos:
Cada comando debe empezar en una línea nueva y terminar con un punto (.).
La mayoría de los subcomandos están separados por barras inclinadas (/). La barra
inclinada que precede al primer subcomando de un comando, generalmente es
opcional.
Los nombres de variable deben escribirse completos.
El texto incluido entre apóstrofos o comillas debe ir contenido en una sola línea.
Cada línea de la sintaxis de comando no puede exceder de 80 caracteres.
Debe utilizarse un punto (.) para indicar decimales, independientemente de la
configuración regional de Windows.
Los nombres de variable que terminen en un punto pueden causar errores en los
comandos creados por los cuadros de diálogo. No es posible crear nombres de
variable de este tipo en los cuadros de diálogo y en general deben evitarse.
La sintaxis de comandos no distingue las mayúsculas de las minúsculas y permite el uso de
abreviaturas de tres o cuatro letras en la mayoría de las especificaciones de los comandos.
Puede usar tantas líneas como desee para especificar un único comando.
Puede añadir espacios o líneas de separación en casi cualquier punto donde se permita
un único espacio en blanco, como alrededor de las barras inclinadas, los paréntesis,

los operadores aritméticos o entre los nombres de variable. Por ejemplo:
FREQUENCIES
VARIABLES=CATLAB SEXO
/PERCENTILES=25 50 75
/BARCHART.
y
freq var=catlab sexo /percent=25 50 75 /bar.
son alternativas aceptables que generan los mismos resultados.
Archivos INCLUDE
Para los archivos de comandos ejecutados mediante el comando INCLUDE, las reglas de
sintaxis son un poco diferentes:
Cada comando debe empezar en la primera columna de una línea nueva.
Las líneas de continuación deben estar sangradas al menos un espacio.
El punto del final del comando es opcional.
A menos que tenga archivos de comandos que ya utilizan el comando INCLUDE, debe
utilizar el comando INSERT en su lugar dado que puede adaptar los archivos de comandos
que se ajustan a los dos conjuntos de reglas. Si genera la sintaxis de comandos pegando las
selecciones del cuadro de diálogo en una ventana de sintaxis, el formato de los comandos es
apto para cualquier modo de operación. Consulte la referencia de sintaxis de comandos
(disponible en formato PDF en el menú Ayuda) si
desea obtener más información.
Pegar sintaxis desde cuadros de diálogo
La manera más fácil de construir un archivo de sintaxis de comandos es realizando las
selecciones en los cuadros de diálogo y pegar la sintaxis de las selecciones en una ventana
de sintaxis. Si pega la sintaxis en cada paso de un análisis largo, podrá generar un archivo
de trabajo que le permitirá repetir el análisis con posterioridad o ejecutar un trabajo
automatizado con la Unidad de producción.

En la ventana de sintaxis, puede ejecutar la sintaxis pegada, editarla y guardarla en un
archivo de sintaxis.
Nota: Si abre un cuadro de diálogo a partir de los menús de una ventana de proceso, el
código para ejecutar la sintaxis desde un proceso se pegará en la ventana de proceso.
Copia de la sintaxis desde las anotaciones de los resultados
Puede construir un archivo de sintaxis copiando la sintaxis de comandos de la anotación
que aparece en el Visor. Para usar este método debe seleccionar Mostrar comandos en
anotaciones en la configuración del Visor (menú Edición, Opciones, pestaña Visor) antes
de ejecutar el análisis. Todos los comandos aparecerán en el Visor junto con los resultados
del análisis.
En la ventana de sintaxis, puede ejecutar la sintaxis pegada, editarla y guardarla en un
archivo de sintaxis.
Edición de la sintaxis en un archivo diario
Por defecto, todos los comandos que se han ejecutado durante una sesión se graban en un
archivo de diario denominado spss.jnl (definido en Opciones en el menú Edición). Podrá
editar el archivo de diario y guardarlo como archivo de sintaxis, que podrá utilizar para
repetir un análisis ejecutado anteriormente, o bien ejecutarlo en un trabajo automatizado
con la Unidad de producción.
El archivo diario es un archivo de texto que puede editarse como cualquier otro archivo de
texto. Dado que los mensajes de error y las advertencias también se registran en el archivo
diario, junto con la sintaxis de comandos, deberá editar y eliminar los mensajes de error y
de advertencia que aparezcan antes de guardar el archivo de sintaxis. No obstante, tenga en
cuenta que los errores se deben solucionar o el trabajo no se podrá ejecutar correctamente.
Guarde el archivo diario editado con un nombre diferente. Puesto que el archivo
de diario se amplía o sobrescribe de forma automática en cada sesión, utilizar el
mismo nombre para un archivo de sintaxis y para un archivo de diario puede generar
resultados inesperados.

Para ejecutar la sintaxis de comandos
Resalte los comandos que desee ejecutar en la ventana de sintaxis.
Pulse en el botón Ejecutar (el triángulo que apunta hacia la derecha) en la barra de
herramientas del Editor de sintaxis.
Seleccione una de las opciones del menú Ejecutar.
! Todo. Ejecuta todos los comandos de la ventana de sintaxis.
Selección. Ejecuta los comandos seleccionados. Esto incluye los comandos
parcialmente resaltados.
Actual. Ejecuta el comando donde se encuentra el cursor.
Hasta el final. Ejecuta todos los comandos incluidos desde la posición actual del
cursor hasta el final del archivo de sintaxis de comandos.
El botón Ejecutar de la barra de herramientas del Editor de sintaxis ejecuta los comandos
seleccionados o el comando donde se encuentra el cursor si no hay nada seleccionado.
ANÁLISIS ESTADÍSTICO CON EL SPSS:
Cuando se va a realizar un análisis estadístico de una serie de datos se recomienda
hacer previamente una Estadística Descriptiva para obtener información de las variables a
analizar o simplemente para chequear posibles errores en los datos. Para realizar este
estudio se deben considerar:
- Análisis de Frecuencias.
- Análisis Exploratorio:
o Gráficos
o Estadísticos
-Tablas:
o Tablas Básicas
o Tablas de Frecuencias

Análisis de Frecuencias: El procedimiento Frecuencias permite obtener una descripción
de la distribución de la variable mediante:
- Tablas de Frecuencias.
- Histogramas y Gráficos de Barras.
- Cálculo de percentiles, Medidas de Tendencia Central y Medidas de Dispersión.
Para ejecutar este procedimiento se deben elegir las siguientes opciones:
A continuación se abre un cuadro de diálogo con los siguientes campos:
Variables: donde se introducen las variables que se van a analizar. Estas se
seleccionan de la lista que muestra el sistema, y después de marcarlas con el ratón se pulsa
el botón con una flecha hacia la derecha para llevarlas a este campo.
Mostrar tablas de frecuencias: esta opción está activada por defecto y hace que el
sistema construya las tablas de frecuencias de las variables seleccionadas, mostrándose los
valores de las variables, las frecuencias absolutas, los porcentajes sin incluir los valores
missing e incluyéndolos, y las frecuencias relativas acumuladas. En caso de que no se
quiera se deberá desactivar.
En la parte inferior del cuadro aparecen tres botones:
ESTADÍSTICOS: Este botón abre un cuadro donde se solicitan los estadísticos
descriptivos de las variables numéricas seleccionadas. Entre los estadísticos que permite el
sistema, se encuentran:

- Valores Percentiles:
Este cuadro recoge entre otros a:
. Los Cuartiles, los cuales son cuatro valores que dividen el conjunto total de datos en
cuatro partes iguales.
. Los puntos de corte para dividir el conjunto total de datos en un cierto número
específico de grupos iguales. Este número que se ha de introducir ha de estar entre 2 y 100.
Por defecto es 10, luego se trata de los deciles.
Los Percentiles se pueden solicitar indicando el porcentaje que se desea, y luego
pulsando el botón AÑADIR.
- Tendencia Central:
Entre las medidas de tendencia central que permite están la media, la mediana, y la
moda. También recoge la suma de los datos.
- Dispersión:
Permite seleccionar la desviación típica, la varianza, el rango, el máximo, el mínimo
y el error típico de la media.
- Distribución:
En este cuadro se solicitan los coeficientes de Asimetría y Curtosis.
En el caso de variables continuas, se puede pedir que los cálculos de las medidas se
realicen con los puntos medios de los intervalos, activando tal campo.
GRÁFICOS: Al pulsar este botón se abre un cuadro con las siguientes opciones:
- Gráficos de Barra: Propios de variables discretas o categóricas.
- Histograma: Adecuados para variables continuas. Sobre éstos se puede superponer
la función de densidad de la Normal, si se activa el campo Con curva normal.

- Gráficos de Sectores: Tanto para variables discretas como continuas.
Por defecto está activado el campo Ninguno. El sistema permite elegir los valores con
que se representa el gráfico sea bien con frecuencias o porcentajes.
FORMATO: Con este botón se puede cambiar el formato que presenta la tabla de
frecuencias. Las alternativas que muestra al activarlo son:
Ordenar por:
Entre las posibles formas a ordenar están:
- Valores Ascendentes: por defecto el sistema ordena la tabla de forma creciente
atendiendo a los valores de la variable a analizar.
- Valores Descendentes: en este caso, se ordena la tabla de forma decreciente según
los valores de la variable.
- Frecuencias Ascendentes: el orden se realiza de forma creciente, pero atendiendo a
los valores que toman las frecuencias.
- Frecuencias Descendentes: lo mismo que antes, pero de manera decreciente.
Múltiples Variables:
Aquí se recogen dos opciones:
- Comparar variables: se utiliza cuando se han seleccionado varias variables y se quiere
que los gráficos o tablas solicitados, aparezcan juntos para todas y poderlos comparar.
- Organizar resultados según variables: muestra todos los análisis para la primera variable,
luego para la segunda y así, sucesivamente.
También presenta un campo que permite suprimir las tablas correspondientes a
variables con más de un cierto número de categorías, número que se ha de indicar.

Análisis Exploratorio:
El procedimiento Explorar nos ofrece las posibilidades de representar gráficamente
los datos, examinar visualmente las distribuciones para varios grupos de datos, y realizar
pruebas de normalidad y homogeneidad sobre los mismos. Para ejecutarlo se debe
seleccionar:
Después de esto se abre un cuadro de diálogo con los siguientes campos y botones:
Dependientes: en este campo se introduce la variable o variables cuantitativas
que contiene los datos a analizar y de las que se quiere obtener los gráficos y/o
estadísticos.
Factores: aquí se indica la variable que sirve para dividir en grupos los datos.
Puede ser numérica o carácter de cadena corta.
Etiquetar los casos mediante: este campo se utiliza para etiquetar aquellos
valores atípicos en los diagramas de caja. La variable que se usa puede ser numérica
o carácter.
Gráficos: activando este campo y pulsando el botón GRÁFICOS, se abre una
ventana para seleccionar el gráfico a representar. Entre éstos se encuentran:
Diagramas de Caja; Descriptivos (Gráficos de Tallo y Hoja, e Histogramas);
Gráficos con prueba de Normalidad; y Gráficos de Dispersión por nivel con Prueba
de Levene.

Estadísticos: con este campo y su respectivo botón se abre una ventana donde
se pueden elegir una serie de medidas de tendencia central y de dispersión. Así
como una serie de estimadores robustos centrales, valores atípicos de los datos y
percentiles.
Ambos: en este punto se pueden seleccionar los botones tanto de GRÁFICOS
como de ESTADÍSTICOS.
Opciones: este botón sirve para controlar el tratamiento de los valores perdidos.
Las alternativas que presenta son:
Excluir casos según lista: para excluir de todos los análisis los valores
missing.
Excluir casos según pareja: para excluir los missing de las variables que
intervienen sólo en ese grupo, y no en otros.
Mostrar los valores perdidos: en este caso los valores perdidos para las variables
factor se tratan como una categoría diferente y todos los resultados se generan para esa
categoría adicional.
El SPSS es de gran utilidad en:
Gráficos
Estadísticos
Gráficos:
Tras el botón de GRÁFICOS se esconde una ventana con las siguientes opciones:
Diagrama de Caja:
Sirve para controlar la presentación de los diagramas de caja cuando existe más de
una variable dependiente. Opciones que presenta:

Niveles de los factores juntos: genera una presentación para cada variable
dependiente. En cada una se muestran diagramas de caja para cada uno de los grupos
definidos por un factor.
Dependientes juntas: genera una presentación para cada grupo definido por un
factor. En cada una se muestran juntos los diagramas de caja de cada variable dependiente.
Esta disposición es particularmente útil cuando las variables representan una misma
característica medida en momentos distintos.
Descriptivos:
Este apartado permite seleccionar Gráficos de Tallo y Hoja, e Histogramas.
Gráficos con Pruebas de Normalidad: Muestra los diagramas de probabilidad normal,
donde se representan los valores correspondientes a una distribución normal teórica
mediante una recta, y los puntos que se corresponden a las diferentes puntuaciones
observadas de los sujetos. También los gráficos de probabilidad sin tendencia, que recogen
las desviaciones de los sujetos respecto de la recta normal. Calcula también los estadísticos
de Kolmogorov-Smirnov y de Shapiro-Wilk para muestras con 50 o menos observaciones,
para contrastar la normalidad.
Dispersión por nivel con prueba de Levene: Sirve para representar los diagramas
de dispersión por nivel, en el caso de seleccionar algún factor. Junto con los mismos
muestra la pendiente de la recta de regresión y realiza la prueba de Levene sobre la
homogeneidad de varianzas. Si se realiza alguna transformación sobre los datos, las pruebas
de Levene se llevarán a cabo con los datos transformados. Dentro de este apartado se tienen
las siguientes opciones:
Estimación de potencia: Representa un gráfico de los logaritmos naturales de las
amplitudes intercuartil, respecto a los logaritmos naturales de las medianas de todas las
casillas, así como una estimación de la transformación de potencia necesaria para conseguir
varianzas iguales de los grupos.

Transformados: Genera gráficos de los datos transformados cuando se selecciona
una de las alternativas de potencia.
No transformados: Genera gráficos de los datos brutos, lo que equivale a una
potencia de 1.
Estadísticos:
Dentro de la ventana de ESTADÍSTICOS se encuentran:
Descriptivo: Por defecto muestra ciertas medidas de tendencia central, de dispersión
y de la forma de la distribución.
Las medidas de tendencia central indican la localización de los datos e incluyen la
media, la mediana y la media recortada al 5% (media aritmética calculada eliminando el
5% de las observaciones más bajas y el 5% de las más altas).
Las medidas de dispersión recogen la variabilidad de los datos y entre ellas están: los
errores típicos, la varianza, la desviación típica, el mínimo, el máximo, el rango y el rango
intercuartílico.
Las medidas de la forma de la distribución son: la asimetría y la curtosis junto con
sus errores típicos.
Construye además, el intervalo de confianza para la media a un nivel del 95%,
pudiendo especificarse otro.
Estimadores robustos centrales: Los estimadores se diferencian de las medidas de
tendencia central en las ponderaciones que se aplican a los casos. Aquí se encuentran: el
estimador M de Huber, el estimador en onda de Andrew, el estimador redescendente de
Hampel y el estimador biponderado de Tuckey.
Valores Atípicos: Muestra los cinco valores mayores y los cinco menores, con las
etiquetas de cada caso.

Percentiles: Muestra los valores de los percentiles 5, 10, 25, 50, 75, 90, y 95.
Tablas:
Tablas Básicas
Tablas de Frecuencias
Tablas Básicas
El procedimiento Tablas Básicas permite construir tablas que muestran estadísticos
de clasificación cruzados y de subgrupos. Se debe seleccionar:
se abre un cuadro de diálogo con los siguientes campos:
Resumir: las variables que se introducen en este campo son aquellas para las cuales
se calculan los estadísticos dentro de cada subgrupo, y se las denomina Variables Resumen.
Con todas las variables de la tabla se emplean los mismos estadísticos, que por defecto es la
media. La tabla muestra las etiquetas o los nombres de las variables resumen a lo largo de
la parte izquierda de la misma. En caso de no seleccionar variables resumen se muestran las
frecuencias.
Hacia abajo: es la primera dimensión de la tabla, y aquí se introducen las variables
que se quiere aparezcan por filas.

A través: se introduce en una segunda dimensión de la tabla que recoge la variable o
variables que irán en las columnas de la tabla.
Tablas Distintas: las variables de esta lista subdividen la tabla en capas o en grupos de
capas, de manera que sólo se puede ver una capa de la tabla cada vez. Una vez que se
muestre la tabla en el visor, podrá ver otras capas pulsando dos veces en la tabla y
moviéndose con las flechas del icono de pivoteado de capas. Dentro de la opción de tablas
distintas se pueden elegir entre:
Todas las combinaciones (anidadas): esto significa que se muestran las categorías de
una variable bajo cada una de las categorías de la variable anterior.
Cada una por separado (apiladas): en este caso, se muestran las categorías de cada
variable como un bloque. La apilación se puede entender como la extracción de tablas
diferentes y su unión en la misma presentación.
También aparecen en la ventana una serie de botones, entre los cuales están:
ESTADÍSTICOS:
En el caso de variables categóricas incluyen frecuencias y porcentajes para diferentes
partes de la tabla. Para las variables resumen incluyen medidas estándar de tendencia
central y variabilidad, además de percentiles, sumas y porcentajes sobre los casos válidos
para las distintas dimensiones de la tabla. Si no se seleccionan los estadísticos se asignará
por defecto la media para las tablas con variables resumen y frecuencias para las tablas sin
variables resumen. Al pulsar este botón se abre otra ventana con el siguiente contenido.
Estadísticos de casilla: ofrece una lista de los estadísticos que se mostrarán en la tabla

completa. Entre otros están frecuencias, % por filas, por columnas, estratos o global de la
tabla, estadísticos de tendencia central o variabilidad, etc.
- Se seleccionan y se pasan a este campo con el botón AÑADIR.
- Se pueden retirar con el botón BORRAR
- Para modificar su formato se seleccionan y luego se pulsa el botón CAMBIAR.
Formato y Etiqueta: puede elegir un formato de presentación, el ancho, el número de
decimales y una etiqueta para cada estadístico. Los formatos disponibles incluyen formatos
decimales, de porcentaje y de moneda preestablecidos.
Ordenación por el recuento en la casilla: reorganiza las casillas dentro de cada fila,
columna, o capa de la tabla en función de las frecuencias de las casillas.
DISEÑO:
Este botón abre otro cuadro con las siguientes alternativas:
Etiquetas de las variables resumidas: permite seleccionar la dimensión de las
etiquetas de las variables resumen.
Etiquetas de estadísticos: permite elegir la dimensión de las etiquetas de los
estadísticos.
Grupos en la dimensión de la variable resumida: proporciona la opción de anidar las

variables resumen bajo cada categoría de la variable de agrupamiento o anidar la variable
de agrupamiento bajo cada variable resumen.
Etiquetar los grupos sólo con las etiquetas de valor: elimina las etiquetas de las
variables de agrupamiento de la tabla. Las categorías se siguen identificando por las
etiquetas de valor o por los propios valores.
FORMATO:
Es el botón que sirve para indicar el aspecto de las casillas vacías y como aparecen
los estadísticos perdidos.
TÍTULOS:
Con este otro se puede especificar un título para el procedimiento, un pie de página
o incluso la fecha.
Tablas de Frecuencias
Este procedimiento se recomienda en aquellos casos en los que se quiere analizar los
resultados de una serie de variables, que tienen todas las mismas categorías de respuesta.
Por defecto, las variables forman las columnas y las categorías las filas. Cada casilla
muestra el número de casos de esa categoría. Si lo desea, puede seleccionar una o más
variables de agrupamiento. Para elegir el mismo seleccionamos:

entonces se abre un cuadro de diálogo similar al del procedimiento Tablas Básicas con los
campos:
Frecuencias para: este campo recoge aquellas variables con las mismas
categorías y de las cuales vamos a calcular las frecuencias.
En cada tabla: se introduce la variable de agrupamiento de las variables para
las que calculamos su frecuencia, y permite dividir cada tabla en columnas.
Tablas distintas: esta opción genera otra dimensión de agrupamiento de la
tabla, en capas. Si se divide en diferentes capas, sólo se mostrará una capa de la
tabla cada vez. Una vez que muestre la tabla en el Visor, podrá ver las otras capas
pulsando dos veces en la tabla y después con las flechas del icono de pivoteado de
capas. Si hay diversas variables de agrupamiento, puede elegir entre anidarlas o
apilarlas.
Al margen de estas opciones del cuadro de diálogo de entrada, se tienen los cuatro
botones que dan acceso a otros tantos subcuadros de diálogo. Puede también especificar
diferentes etiquetas, formatos de presentación, anchos y números de decimales para cada
estadístico que decide mostrar, y además, si está activada la ponderación de los casos,
puede solicitar recuentos no ponderados.
Estimación y Contrastes de Hipótesis:
El SPSS permite realizar comparaciones o diferencias de medias, tanto para muestras
independientes como para muestras dependientes (medidas repetidas o datos relacionados a
pares). También permite realizar una comparación entre la media de una variable y un valor
empírico. Este tipo de análisis se encuentra en:

Una vez hecho esto, se abre un cuadro de diálogo con una serie de opciones y se elige
el análisis estadístico que se desea aplicar:
Medias
Comparación con una Media Empírica
Comparación de muestras independientes
Comparación de muestras dependientes
Medias
El procedimiento Medias calcula las medias y estadísticos univariantes (la desviación
estándar, la varianza, la suma y el número de individuos), para uno o más grupos de sujetos.
Si lo desea también puede obtener el análisis de la varianza de un factor, la eta y las
pruebas de linealidad. Una vez seleccionada dicha opción aparece entonces una ventana
con los siguientes campos:
Dependientes: en este campo se introducen las variables de las que se quiere obtener
la media. Éstas se seleccionan de la lista que muestra la misma ventana.
Independientes: aquí se definen los grupos de sujetos, introduciendo aquellas
variables mediante las cuales se quiere agrupar las variables dependientes. Las variables
independientes se pueden especificar en distintas capas, y cada capa contener más de una
variable independiente. Si sólo se define una capa, se obtendrán las medias para cada uno
de los valores que tome la variable o variables independientes elegidas. Si se definen más
capas, se obtendrán las medias para cada grupo de sujetos, resultante de combinar cada
variable independiente de una capa con cada una de las otras capas.
Opciones: este botón abre otra ventana donde se pueden seleccionar una serie de
estadísticos como son la media, la mediana, la mediana agrupada, el error típico de la
media, el mínimo, el máximo, el rango, la desviación típica, la varianza, la curtosis, el error

típico de la curtosis, la asimetría, el error típico de la asimetría, la suma, etc. También se
muestran estadísticos de resumen para cada variable a través de todas las categorías.
Dentro de OPCIONES también se tiene la posibilidad de realizar un análisis de la
varianza con un factor, además de calcular la eta y la eta cuadrado (medidas de asociación)
para cada variable independiente de la primera capa. Para ello se ha de activar el campo
Tabla de anova y eta. La eta cuadrado representa la proporción de la varianza de la
variable dependiente que es explicada por la diferencia entre los grupos y se mide como la
razón de la suma de cuadrados entre grupos y la suma de cuadrados totales.
Por otro lado, activando el campo Contrastes de Linealidad se calcula el y el .
Estas medidas son apropiadas cuando se ordenan las categorías de la variable
independiente, para medir la bondad de ajuste a un modelo lineal.
Comparación con una Media Empírica
Supongamos que se desea contrastar si la media poblacional de una variable difiere
significativamente de una media prefijada, o si por el contrario, las diferencias pueden
considerarse debidas al azar, o al muestreo llevado a cabo, entonces se eligen las opciones:
Luego se abre una ventana con los siguientes campos:

Contrastar variables: es el campo donde se introducen las variables, cuya
media se quiere comparar con el valor prefijado.
Valor de Prueba: es el campo que recoge el valor específico con el que se
compara.
Opciones: este botón abre una ventana donde se especifica el nivel de
confianza para construir un intervalo de confianza para la media (por defecto es del
95%), y también aquí se indica la forma de tratar los valores missing, esto es,
Si se selecciona la opción Excluir casos según análisis, no entrarán en el análisis
aquellos casos que tengan valores missing en la variable que se está analizando.
Si se selecciona la opción Excluir casos según lista, no entrarán en el análisis
aquellos casos que tengan valores missing en alguna de las variables que figuran en
el campo Contrastar variables.
Comparación de muestras independientes:
Para comparar las medias de dos muestras aleatorias procedentes de dos poblaciones
normales e independientes, se utiliza el procedimiento Prueba T para muestras
independientes, y para ello, se selecciona:
Se abre una ventana con los siguientes campos:
Contrastar variables: donde se han de introducir las variables que se van a analizar,
es decir, aquellas variables sobre las que se va a contrastar si hay o no, diferencias
de grupos.

Variable de agrupación: aquí se debe introducir la variable que se utiliza para
definir los grupos de sujetos sobre los que se estudian las diferencias. Entonces el
sistema activa el botón DEFINIR GRUPOS y al presionarlo aparece una ventana
donde se introducen los valores de la variable que definen los dos grupos de sujetos
a comparar, o el valor de la variable que hará de corte para definir dichos grupos. Si
el valor de la variable para un individuo es menor o igual que el valor especificado,
el individuo pertenecerá al primer grupo, y en caso contrario, al segundo.
Opciones: presionando este botón se obtiene una ventana donde se especifica igual
que en la sección anterior el nivel de confianza para el intervalo y la forma de tratar
los valores missing.
Comparación de muestras dependientes:
Si se desea comparar las medias de dos muestras aleatorias procedentes de dos
poblaciones normales pero dependientes, se debe seleccionar las opciones:
Luego aparece una ventana con los siguientes campos:
Variables Relacionadas: donde se introducen los pares de variables que se van a
comparar. Se seleccionan las dos variables del campo Selecciones actuales, y se
trasladan a este campo pulsando el botón con un triángulo hacia la derecha. Este
proceso se repite para cada par de variables que se quieran comparar.
Opciones: este campo tiene la misma utilidad que en procedimientos anteriores.
Análisis de la Varianza:

Análisis de la Varianza con un sólo factor.
Análisis de la Varianza Multifactorial
Análisis de la Varianza con un sólo factor:
Esta es una prueba generalizada del contraste de medias para muestras con datos
independiente. Se comparan tres o más muestras independientes cuya clasificación viene
dada por la variable llamada Factor. La base de este procedimiento consiste en estudiar si
el Factor influye sobre la Variable Respuesta, y la forma de hacerlo es analizando como
varían los datos dentro de cada uno de los grupos en que clasifica el Factor a la
observaciones de la Variable Respuesta. Por ejemplo, supongamos que se quiere conocer
si existen diferencias significativas entre el tiempo diario de dedicación a la investigación
de los profesores, en función de la categoría que tienen. Para ello,se eligen las siguientes
opciones desde el menú principal:
y con esto se abre un cuadro de diálogo con los siguientes campos:
Dependientes: en este campo se introduce la variable respuesta a analizar. En
el ejemplo sería Tinvest (tiempo diario para la investigación).
Factor: aquí se introduce la variable de clasificación, que ha de ser categórica.
Para el ejemplo, se considera la Categoría de los profesores.
Además de los campos anteriores existen tres botones cuya utilidad es la siguiente:

CONTRASTES:
Con este botón se trata de averiguar si los valores promedios de la variable
dependiente para cada nivel del factor, siguen o no alguna tendencia determinada, lineal,
cuadrática, cúbica, de grado 4 ó 5. Además de poder realizar cualquier tipo de comparación
a priori, entre las medias de la variable respuesta para los niveles del factor que se elijan,
permite realizar hasta 10 contrastes diferentes, con 50 coeficientes en cada uno de ellos.
Para excluir algún grupo se le asigna el coeficiente 0.
POST HOC:
Este botón sirve para averiguar cuál o cuáles de los diferentes grupos o niveles del
factor son los que difieren entre sí, a través de una serie de pruebas diferentes (Contrastes a
posteriori).
OPCIONES:
Este botón sirve para mostrar una serie de estadísticos descriptivos para cada grupo
de la muestra o nivel del factor, el test de Levene para comprobar la homogeneidad de
varianzas entre los distintos grupos, un gráfico de las medias de cada grupo y la forma de
tratar los valores perdidos.
Se ejecuta el procedimiento con las variables indicadas anteriormente y se elige
dentro de OPCIONES la prueba de homogeneidad de varianzas, obteniéndose los siguientes
resultados.

Análisis de la Varianza Multifactorial
El procedimiento Modelo Lineal General Univariante proporciona un Análisis de
Regresión y un Análisis de la Varianza para una variable dependiente (respuesta) con uno o
más factores, o covariables. Los factores dividen la población en grupos. Con este
procedimiento se pueden investigar las interacciones entre los factores, así como los efectos
de los factores individuales, algunos de los cuales pueden ser aleatorios. Además se pueden
incluir los efectos de las covariables y las interacciones de las covariables con los factores.
Para el Análisis de Regresión, las variables independientes (predictoras) se especifican
como covariables.
Se consideran tanto los modelos balanceados como los que no. Esto es, un diseño es
balanceado si cada casilla del modelo contiene el mismo número de casos. Además de
contrastar las hipótesis, el procedimiento MLGU genera las estimaciones de los
parámetros.
También están disponibles en esta opción los contrastes a priori de uso más habitual.
Por otra parte, si en el análisis de la varianza global la F ha mostrado cierta significación, se
pueden emplear las pruebas Post Hoc para evaluar las diferencias entre las medias
especificadas. Las medias marginales estimadas ofrecen estimaciones de los valores de las
medias pronosticadas para las casillas del modelo; los Gráficos de Perfil de estas medias
(gráficos de interacciones) permiten observar fácilmente algunas de las relaciones entre los
factores.
Calcula los residuos, valores pronosticados, distancia de Cook, y valores de influencia
como variables nuevas para comprobar los supuestos, información toda ella que permite
guardar en un archivo de datos.

Para seleccionar este procedimiento se eligen las siguientes opciones desde el menú
principal:
Luego se abre un cuadro de diálogo con una serie de campos y botones. Entre los
campos están:
Dependientes: se recoge aquí la variable respuesta que se desea analizar.
Factores Fijos: se introducen aquellos factores cuyos efectos de los niveles se quieren
estudiar de manera precisa.
Factores Aleatorios: en este campo se colocan aquellos factores donde se selecciona de
forma aleatoria los niveles a estudiar, y luego se extrapolan los resultados al resto.
Covariables: se introducen las covariables, esto es, aquellas otras variables que guardan
relación con la variable respuesta y están medidas como la misma, en escala de intervalo o
de razón.
Ponderación MCP: permite especificar una variable para ponderar las observaciones de
forma diferente en un análisis de mínimos cuadrados ponderados (MCP). Esto se suele
hacer para compensar la distinta precisión de las medidas.
En cuanto a los botones, se tienen los siguientes:

a) MODELO:
Este botón esconde un cuadro con las siguientes opciones:
Especificar modelo. Por defecto está activa la opción Factorial Completo, la cual
considera los efectos principales de todos los factores, los efectos principales de todas las
covariables y todas las interacciones entre los factores. No contempla las interacciones
entre las covariables, ni de los factores con las covariables. Para especificar un determinado
conjunto de interacciones se ha de seleccionar el campo Personalizado. En este caso se
activan los campos:
Factores y Covariables: muestra una lista de los factores y las covariables,
etiquetando con F a los factores fijos, con C a las covariables y con R a los factores
aleatorios.
Modelo: depende de la naturaleza de los datos. Aquí mediante el campo Construir
término, se pueden elegir los efectos principales y las interacciones que sean de interés en
el análisis, y que se quieren contemplar en el modelo.
Suma de Cuadrados. Aquí se indica el método para calcular las sumas de cuadrados,
que por defecto es el Tipo III. Los otros tipos de sumas de cuadrados se utilizan según sea
un modelo balanceado o no, anidado o no, con o sin categorías o combinación de categorías
vacías. Así por ejemplo, si para alguna combinación de niveles el grupo está vacío se
recomienda utilizar la suma de cuadrados Tipo IV.
Incluir la intersección en el modelo: La intersección se incluye normalmente en el
modelo, pero ésta se puede excluir si se supone que los datos pasan por el origen.

b) CONTRASTES:
Este botón se usa para contrastar las diferencias entre los niveles de un factor. A los
contrastes de este tipo se les denomina Contrastes Planificados o a Priori. Se puede
especificar un contraste para cada factor en el modelo. Los contrastes representan las
combinaciones lineales de los parámetros.
El contraste de hipótesis se basa en la hipótesis nula , donde es la
matriz de coeficientes del contraste y es el vector de parámetros. Cuando se especifica
un contraste, el SPSS crea una matriz en la que las columnas correspondientes al factor
coinciden con el contraste. El resto de las columnas se corrigen para que la matriz sea
estimable. Los contrastes disponibles son:
Desviación: Compara las medias de los distintos niveles del factor, excepto la media de la
categoría de referencia, con la media global de la variable dependiente de todos los niveles.
Simples: Compara la media de cada nivel, excepto la del nivel de referencia con la media
del nivel de referencia.
Diferencia: Compara la media de cada nivel (excepto la del primero) con la media de todos
los niveles que le preceden.
Helmet: Compara la media de cada nivel (excepto la del último) con la media del resto de
los niveles que le siguen.
Repetida: Se compara la media de cada nivel del factor con la media del nivel que le
precede.
Polinomial: Cada factor es contrastado a través de un polinomio lineal, cuadrático, cúbico,
etc.

En los contrastes de desviación y contrastes simples, se puede determinar la categoría
de referencia pudiendo ser la primera o la última.
c) GRÁFICOS DE PERFIL:
Son gráficos de líneas en el que cada punto indica la media marginal estimada de una
variable dependiente (corregida respecto a las covariables) en un nivel de un factor. Los
niveles de un segundo factor se pueden utilizar para generar líneas diferentes, mientras que
cada nivel de un tercer factor se utilizaría para crear gráficos distintos. Permiten visualizar
la posible interacción entre factores. Si las líneas en el gráfico se cruzan existe interacción,
si por el contrario, las líneas son paralelas no la hay. También con ellos, se puede observar
la tendencia de los valores promedios de la variable dependiente para los distintos niveles
de cada factor.
Después de elegir los factores a representar, se debe pulsar el botón AÑADIR para
incluirlos en la lista de gráficos. En caso contrario, el sistema muestra un aviso.
d) POST HOC:
Una vez obtenidas las diferencias entre las medias, las pruebas de rango Post Hoc y
las comparaciones múltiples por parejas permiten determinar las medias que difieren. Las
comparaciones se realizan sobre valores sin corregir, y sólo se utilizan tales pruebas para
factores de efectos fijos.
e) GUARDAR:
Este botón abre un cuadro que permite guardar los valores pronosticados por el
modelo, los residuos y las medidas relacionadas como variables nuevas en el editor de
datos. Muchas veces, estas variables se pueden utilizar para examinar supuestos sobre los
datos. Dentro de este cuadro se tiene:

Valores pronosticados: los cuales son los pronosticados no tipificados y los errores
tipificados de los valores pronosticados. Si ha seleccionado una variable de ponderación
MCP, dispondrá así mismo de los valores pronosticados no tipificados ponderados.
Diagnósticos: son medidas para identificar casos con combinaciones pocos usuales de
valores para las variables independientes, y casos que puedan tener un gran impacto en el
modelo. Las opciones disponibles incluyen la distancia de Cook y los valores de influencia
no centrados.
Residuos: un residuo no tipificado es el valor real de la variable dependiente menos el valor
pronosticado por el modelo. También se encuentran disponibles residuos eliminados,
estudentizados y tipificados. Si ha seleccionado una variable de ponderación MCP, contará
además con residuos no tipificados ponderados.
Guardar en archivo nuevo las estimaciones del modelo: Para cada variable dependiente
habrá una fila de las estimaciones de los parámetros, una fila de valores de significación
para los estadísticos t de Student correspondientes a las estimaciones de los parámetros, y
una fila de grados de libertad.
f) OPCIONES:
El cuadro de diálogo que se abre al pulsar este botón contiene estadísticos opcionales.
Tales estadísticos se calculan utilizando un modelo de efectos fijos.
- Medias marginales estimada: Se trata de las medias marginales para cada grupo. Estas
medias se corrigen respecto a las covariables, si las hay.
Comparar los efectos principales: lleva a cabo comparaciones por parejas no
corregidas, entre las medias marginales estimadas para cualquier efecto principal del
modelo, tanto para los factores entre sujetos como para los de dentro de los sujetos. Este
elemento sólo se encuentra disponible si los efectos principales están seleccionados en la
lista de Mostrar las medias para.

Ajuste del Intervalo de Confianza: nos permite seleccionar un ajuste de menor
diferencia significativa (DMS), Bonferroni o Sidak para los intervalos de confianza y la
significación. Este elemento sólo estará disponible si se selecciona Comparar los efectos
principales.
- Mostrar: en este cuadro se recogen las siguientes opciones:
Estadísticos Descriptivos: entre los que se encuentran medias muéstrales, desviaciones
típicas y frecuencias para cada variable dependiente en todos los grupos.
Estimaciones del tamaño del efecto: ofrece un valor parcial de eta-cuadrado para cada
efecto y cada estimación de los parámetros. El estadístico eta-cuadrado describe la
proporción de variabilidad total atribuible a un factor.
Potencia observada: produce la potencia de la prueba cuando la hipótesis alternativa se ha
establecido basándose en el valor observado
Estimaciones de los parámetros: genera las estimaciones de los parámetros, los errores
típicos, las pruebas t de Student donde se contrastan los parámetros con el valor 0, los
intervalos de confianza y la potencia observada de la prueba.
Matriz de coeficientes de contraste: con ella se obtiene la matriz .
Las pruebas de homogeneidad: realiza el test de Levene para contrastar la igualdad de
varianzas para cada variable dependiente en todas las combinaciones de niveles de los
factores entre sujetos.
Diagramas de dispersión por nivel y Gráfico de los residuos: son útiles para comprobar
los supuestos sobre los datos. Estos elementos no están activos si no hay factores.
Gráficos de los residuos: produce un gráfico de los residuos observados respecto a
los pronosticados, y respecto a los tipificados para cada variable dependiente. Estos
gráficos son útiles para investigar el supuesto de varianzas iguales.

Falta de ajuste: para comprobar si el modelo puede describir de forma adecuada la
relación entre la variable dependiente y las variables independientes.
Función estimable general: permite construir pruebas de hipótesis personales
basadas en la función estimable general. Las filas en las matrices de coeficientes de
contraste son combinaciones lineales de la función estimable general.
- Nivel de significación: indica el nivel de significación usado en las pruebas Post Hoc y el
nivel de confianza empleado para construir intervalos de confianza. El valor especificado
también se utiliza para calcular la potencia observada para la prueba. Si especifica un nivel
de significación, el cuadro de diálogo mostrará el nivel asociado de los intervalos de
confianza.
SOLUCIÓN DE PROBLEMAS ESTADÍSTICOS CON EL SPSS.
Problema 1
Charlotte Mecklenburg Police Department
Situación
Uno de los 5 departamentos en el condado de Mecklenbur en Carolina del Norte, el
Departamento de Policía Charlotte-Mecklenburg (DPCM), ofrece un amplio rango de
servicios a los pobladores de la región, que son aproximadamente 650,000 residentes. El
Departamento emplea cerca de 2,000 personas y tiene un presupuesto de operación de más
de USD$ 127 millones.
Problema
El DPCM se dedica a resolver los problemas de la comunidad, los cuales dependen de la
colaboración que los ciudadanos tengan; esta agencia pretende desarrollar soluciones a
corto y largo plazo para eliminar el crimen y el desorden público. El reto del Departamento
es convencer a la comunidad de que los problemas existen actualmente y que su
participación es necesaria para que cualquier solución sea efectiva.

Con la ayuda de renombrados criminalogistas como lo son el Dr. Herman Goldstein y el
Dr. Clarke, expertos en soluciones situacionales, el Departamento ha podido identificar dos
áreas críticas en las cuales se desarrolla el crimen:
Robo a viviendas cerca de sitios en construcción
Robo de autos estacionados
Solución
Al utilizar SPSS, el DPCM completo su análisis de bases de datos las cuales documentaban
con múltiples variables estos problemas, y al mismo tiempo fueron capaces de medir la
satisfacción de los ciudadanos en cuanto al servicio prestado. Los resultados de este análisis
dieron como resultado que el involucramiento de los ciudadanos era necesario para
desarrollar medidas efectivas contra el crimen.
Resultados
Reducir el robo de viviendas en construcción
Identificar nuevas formas de reducir el robo autos en estacionamientos
Incrementar la satisfacción del los ciudadanos en cuanto al servicio prestado por el
Departamento
El DPCM tiene el compromiso de desarrollar políticas contra el crimen las cuales incluyan
la participación de los ciudadanos ya que es un problema de la comunidad en general. Esta
solución busca a largo plazo solucionar los crímenes identificando sus causas, educando a
la comunidad, y desarrollando soluciones en conjunto con los ciudadanos para eliminar las
causas de los crímenes.
La clave de esta solución es establecer una unión de trabajo entre el Departamento de
Policía, los ciudadanos y los organismos tanto públicos como privados.
“Para que las políticas contra el crimen funcionen es necesario que cada parte esté
involucrada”, según Amanda Neese, socio de investigación y planeación el DPCM,
“Nuestro trabajo es reducir el crimen, necesitamos educar a los ciudadanos para que ellos
se vuelvan parte de la solución”.

Si los ciudadanos pueden verse como parte de la solución, los oficiales de policía podrán
trabajar con la comunidad para desarrollar soluciones que eliminaran los problemas
radicalmente y no sólo darán soluciones temporales.
Brindar soluciones a la comunidad para reducir el robo de viviendas en construcción
Un ejemplo de solución de problemas situacionales es el robo de viviendas en construcción.
En años recientes, muchos constructores en el área de Charlotte-Mecklenburg han tenido
problemas con robos, particularmente de las casas en construcción.
El DPCM tiene evidencia la cual ha convencido a los constructores de que ellos son parte
de la solución para eliminar el problema en un futuro.
En conjunto con el Bureau de Investigación y Planeación (BIP) y el DPCM, y utilizando las
soluciones de SPSS encontraron evidencia suficiente para localizar cuándo se llevarían a
cabo los robos. Por ejemplo, el BIP fue capaz de demostrar que cuando los certificados de
ocupación eran altos, la tasa de robos iba en la misma proporción y que además cuando una
vivienda estaba desocupada y estaba a punto de ser habitada ésta tenía altas probabilidades
de ser robada.
Para disminuir los robos, el DPCM le propuso a los constructores que guardaran las
herramientas y las cosas que faltaban por instalar bajo llave para evitar que estas fueran
robadas; y que además era conveniente que mantuvieran el lugar bajo vigilancia.
Muchos constructores aceptaron las medidas y como resultado los robos disminuyeron.
Identificar nuevas maneras de reducir los robos de autos en estacionamientos
SPSS fue una pieza clave en convencer a la comunidad de participar en otro proyecto del
Departamento de Policía: reducir el robo de autos en estacionamientos “La solución más
eficiente en cuanto a costos a este problema es que los ciudadanos participen; ya que el
contratar nuevos policías está fuera del presupuesto” afirma Matthew White, gerente
administrativo de DPCM. “El problema es que los dueños de los estacionamientos no
quieren hacer un verdadero cambio; hasta que el Departamento de Policía les dé evidencias
sustanciales. Una vez que ellos lo vean en blanco y negro harán algo para cambiar esta

situación”.
Para presentar tal evidencia, el DPCM utilizó el software de SPSS para hacer análisis que
evaluó la relación de los robos con las variables de iluminación, cercas de protección y
circulación de vagabundos.
Con esta evidencia, el Departamento de Policía pudo educar a los dueños de los
estacionamientos y tomaron medidas preventivas que disminuían la probabilidad de robo.
“Los dueños de los estacionamientos cooperaron y estas medidas fueron exitosas” dice
Neese.
Incrementar la satisfacción de los ciudadanos con las nuevas políticas
Para comprender los resultados de esta acción conjunta, el DPCM lleva a cabo una vez por
año una encuesta de satisfacción. Envía 100 encuestas al azar a los ciudadanos de cada
distrito, con lo cual obtiene 1,200 encuestas.
“Creemos que la comunidad está haciendo un buen trabajo, por ejemplo, cuando les
preguntamos a los ciudadanos si están satisfechos con el servicio, el 82.6% contestan que sí
“, explica Neese. “Hay áreas en las cuales podemos mejorar; por ejemplo, cuando
preguntamos si tienen temor de su vecindario, el 52% contesta que sí; con lo cual nos
damos cuenta de que hay algunos vecindarios en los que se necesitan más oficiales”.
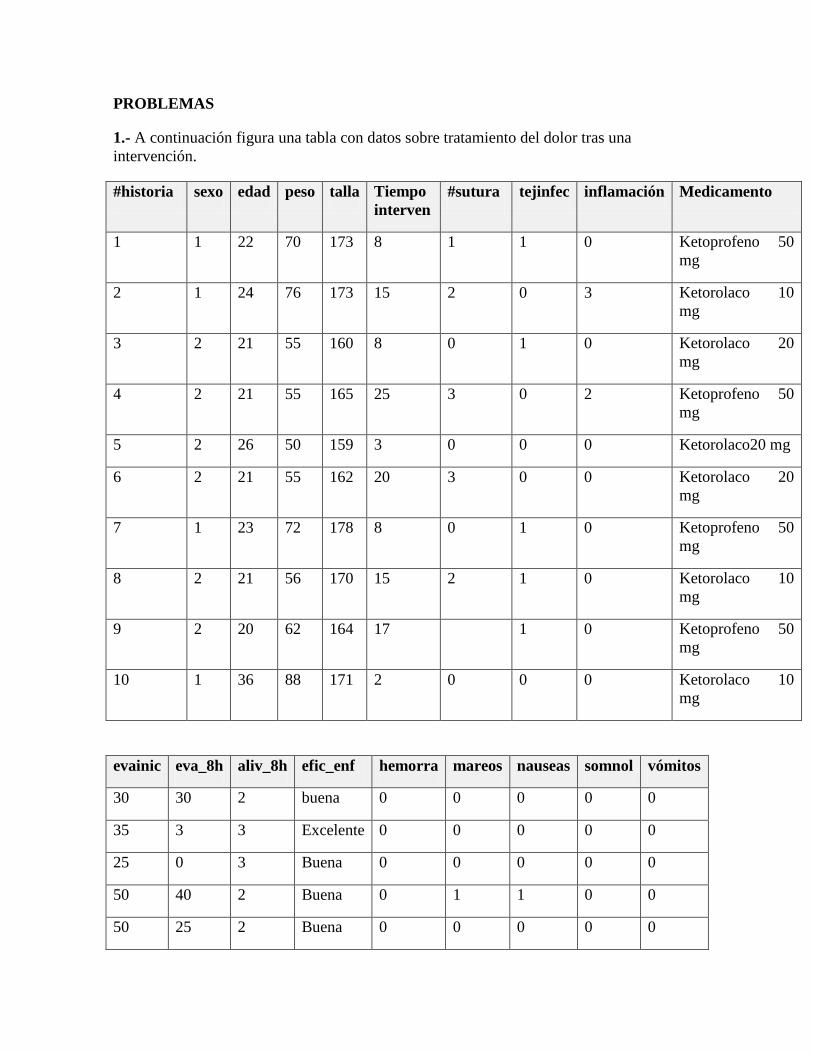
PROBLEMAS
1.- A continuación figura una tabla con datos sobre tratamiento del dolor tras una
intervención.
#historia sexo edad peso talla Tiempo
interven
#sutura tejinfec inflamación Medicamento
1 1 22 70 173 8 1 1 0 Ketoprofeno 50
mg
2 1 24 76 173 15 2 0 3 Ketorolaco 10
mg
3 2 21 55 160 8 0 1 0 Ketorolaco 20
mg
4 2 21 55 165 25 3 0 2 Ketoprofeno 50
mg
5 2 26 50 159 3 0 0 0 Ketorolaco20 mg
6 2 21 55 162 20 3 0 0 Ketorolaco 20
mg
7 1 23 72 178 8 0 1 0 Ketoprofeno 50
mg
8 2 21 56 170 15 2 1 0 Ketorolaco 10
mg
9 2 20 62 164 17 1 0 Ketoprofeno 50
mg
10 1 36 88 171 2 0 0 0 Ketorolaco 10
mg
evainic eva_8h aliv_8h efic_enf hemorra mareos nauseas somnol vómitos
30 30 2 buena 0 0 0 0 0
35 3 3 Excelente 0 0 0 0 0
25 0 3 Buena 0 0 0 0 0
50 40 2 Buena 0 1 1 0 0
50 25 2 Buena 0 0 0 0 0
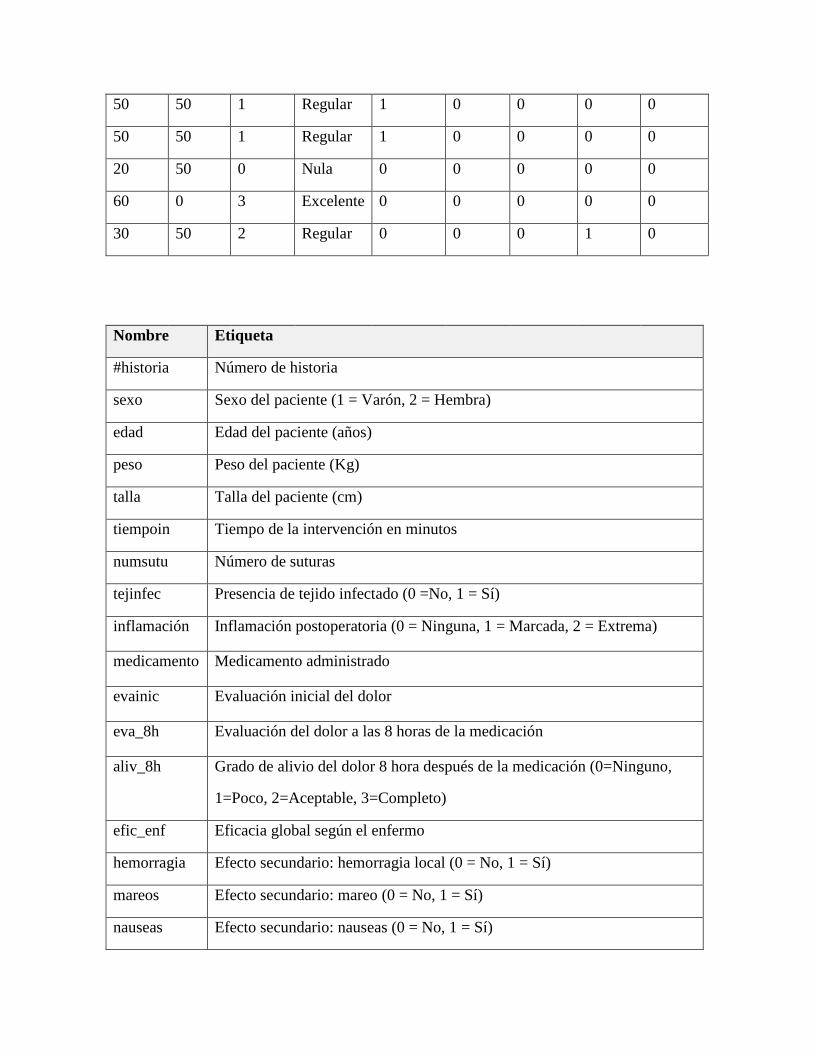
50 50 1 Regular 1 0 0 0 0
50 50 1 Regular 1 0 0 0 0
20 50 0 Nula 0 0 0 0 0
60 0 3 Excelente 0 0 0 0 0
30 50 2 Regular 0 0 0 1 0
Nombre Etiqueta
#historia Número de historia
sexo Sexo del paciente (1 = Varón, 2 = Hembra)
edad Edad del paciente (años)
peso Peso del paciente (Kg)
talla Talla del paciente (cm)
tiempoin Tiempo de la intervención en minutos
numsutu Número de suturas
tejinfec Presencia de tejido infectado (0 =No, 1 = Sí)
inflamación Inflamación postoperatoria (0 = Ninguna, 1 = Marcada, 2 = Extrema)
medicamento Medicamento administrado
evainic Evaluación inicial del dolor
eva_8h Evaluación del dolor a las 8 horas de la medicación
aliv_8h Grado de alivio del dolor 8 hora después de la medicación (0=Ninguno,
1=Poco, 2=Aceptable, 3=Completo)
efic_enf Eficacia global según el enfermo
hemorragia Efecto secundario: hemorragia local (0 = No, 1 = Sí)
mareos Efecto secundario: mareo (0 = No, 1 = Sí)
nauseas Efecto secundario: nauseas (0 = No, 1 = Sí)

somnolencia Efecto secundario: somnolencia (0 = No, 1 = Sí)
vómitos Efecto secundario: vómitos (0 = No, 1 = Sí)
Cree el fichero de datos SPSS correspondiente (definiendo las variables y grabando los
datos). Para la definición de las variables tenga en cuenta el tipo de datos y la etiqueta que
tiene cada variable (que se muestra arriba). Defina también etiquetas de valor cuando
corresponda.
Observación: Para practicar la edición de variables y datos, el alumno puede introducir
deliberadamente algunos errores en la definición de las variables y en la grabación de los
datos y, posteriormente, corregirlos. Por ejemplo, omitir una variable y cuando el fichero
esté construido, insertar dicha variable omitida con sus datos correspondientes. También
puede practicar cambiando el orden de las variables y los individuos, etc.
Guardar el fichero en el disco con el nombre datos_dolor.sav.
2.- Utilizando el fichero de datos del Ejercicio 1:
a) Calcular una nueva variable que contenga, para cada paciente, la talla en metros.
b) Idem, el IMC = (peso en Kg) / (talla en metros) **2.
c) Idem, la disminución en la evaluación del dolor a las 8 horas.
d) Idem, el número de efectos secundarios presentados en el paciente.
e) Obtener una nueva variable (por recodificación de aliv_8h) que exprese únicamente si el
alivio ha sido completo (aliv_8h=3) o no (poner etiqueta y etiquetas de valor).
f) Idem, con la variable inflamac para indicar si existe, o no, inflamación.
g) Obtener una nueva variable, por recodificación de efic_enf, con códigos 0, 1, 2, 3
(0=Nula, 1=Regular, 2=Buena, 3=Excelente). Colocarle etiqueta y etiquetas de valor
apropiadas.
El resto de los ejercicios se hace utilizando el fichero de datos osteo.sav
3.- Construya la tabla de frecuencias para el consumo de tabaco y para la presencia de
neuropatía, pero sólo para los varones.

Tabaco Frecuencias %
Si
No
Neuropatía Frecuencia %
No
Leve
Grave
5.- Construya gráficos apropiados para:
a) El valor tipificado de la densidad de masa ósea en el cuello del fémur.
b) Neuropatía en los varones.
c) Neuropatía por sexo (gráfico agrupado o compuesto)
d) El valor de calcio en los individuos con insuficiente ingesta de calcio (ingca = 2).
Observación: Todos los gráficos deben tener un título apropiado. Además, entre en el
Editor de gráficos y haga algún cambio en los rótulos o etiquetas y personalice el gráfico a
su gusto (colores,….).
6.- Calcule las siguientes medidas de síntesis para el nivel de calcio (variable ca) (global y
según la ingesta de calcio).

Nivel de calcio
Con ingesta
insuficiente de
calcio
Con ingesta
suficiente de calcio
Global
(toda la muestra)
Nº de casos
Media ( con 5 decimales)
Mediana
Moda
Desviación típica
Cuartil 1
Cuartil 3
Percentil 5
Percentil 95
7.- a) Recodifique las variables retin, nefro y neuro, obteniendo nuevas variables (retin2,
nefro2, y neuro2) en las que los códigos sean: 0 = ausencia, 1 = presencia.
b) A partir de estas nuevas variables, calcule otra variable que contenga el número de estas
complicaciones patológicas en cada paciente y obtenga su tabla de frecuencias.
Nº de complicaciones patológicas Frecuencia %
0
1
2
3
c) Obtener la misma tabla de frecuencias del apartado anterior, pero sólo para las mujeres
menores de 40 años.

Nº de complicaciones patológicas Frecuencia %
0
1
2
3
8.- Utilizando ordenar casos y/o seleccionar casos, escribir:
a) Los tres valores más pequeños de calcio (ca) entre las mujeres fumadoras.
b) Los valores de calcio (ca) de las tres mujeres con suficiente ingesta de calcio que tengan
menor edad.
______________ _______________ ______________
9.- Obtenga los valores tipificados del nivel de calcio (ca). Escriba el menor valor tipificado
de calcio entre los hombres del fichero, y el menor entre las mujeres del fichero.
Menor valor tipificado de ca
Hombres
Mujeres
Hacer una descriptiva de la densidad de masa ósea en el cuello del fémur (bmdcue) para
los
pacientes fumadores o bebedores.
n = media = mediana = desv. típica = p10 = p90 =
Problemas SPSS (Primera parte)
Soluciones
Nuevas variables creadas en el Ejercicio 2:
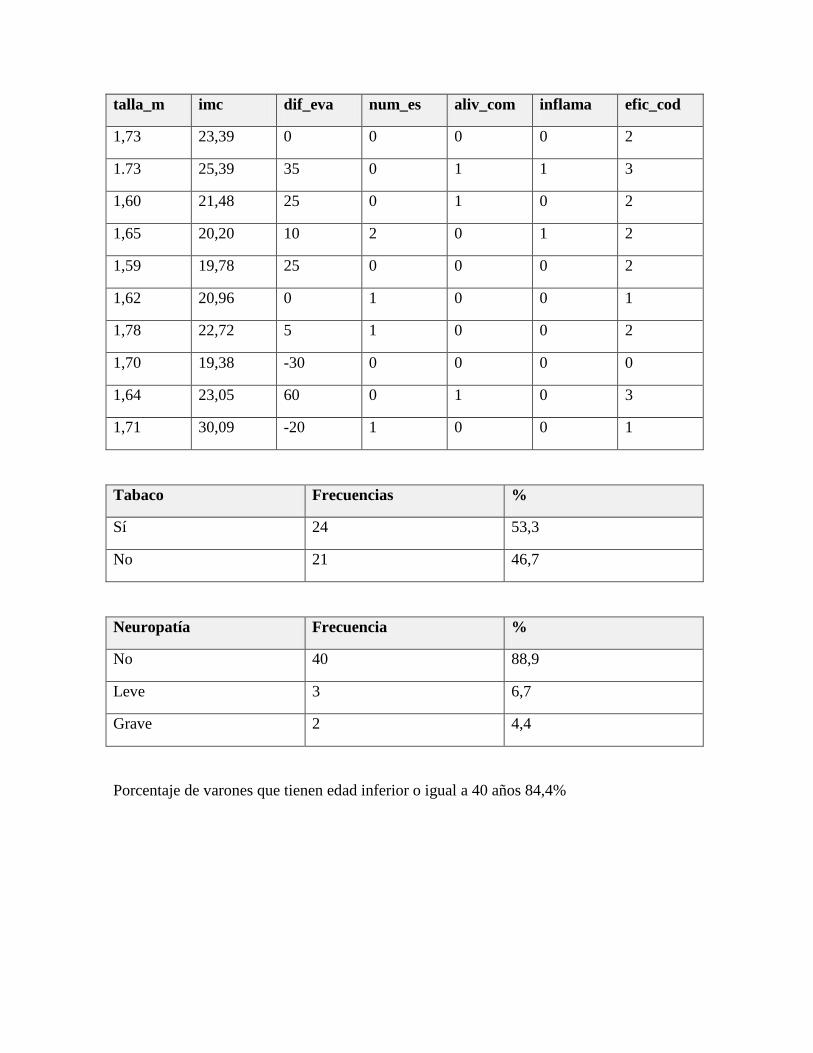
talla_m imc dif_eva num_es aliv_com inflama efic_cod
1,73 23,39 0 0 0 0 2
1.73 25,39 35 0 1 1 3
1,60 21,48 25 0 1 0 2
1,65 20,20 10 2 0 1 2
1,59 19,78 25 0 0 0 2
1,62 20,96 0 1 0 0 1
1,78 22,72 5 1 0 0 2
1,70 19,38 -30 0 0 0 0
1,64 23,05 60 0 1 0 3
1,71 30,09 -20 1 0 0 1
Tabaco Frecuencias %
Sí 24 53,3
No 21 46,7
Neuropatía Frecuencia %
No 40 88,9
Leve 3 6,7
Grave 2 4,4
Porcentaje de varones que tienen edad inferior o igual a 40 años 84,4%
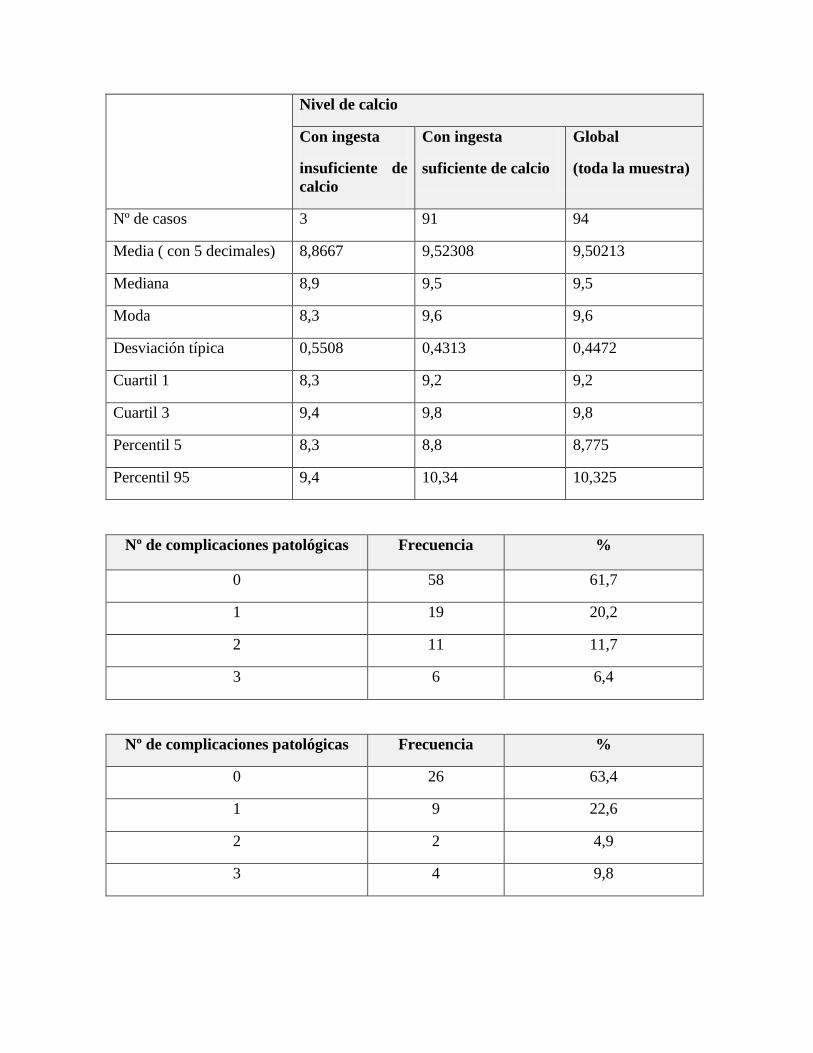
Nivel de calcio
Con ingesta
insuficiente de
calcio
Con ingesta
suficiente de calcio
Global
(toda la muestra)
Nº de casos 3 91 94
Media ( con 5 decimales) 8,8667 9,52308 9,50213
Mediana 8,9 9,5 9,5
Moda 8,3 9,6 9,6
Desviación típica 0,5508 0,4313 0,4472
Cuartil 1 8,3 9,2 9,2
Cuartil 3 9,4 9,8 9,8
Percentil 5 8,3 8,8 8,775
Percentil 95 9,4 10,34 10,325
Nº de complicaciones patológicas Frecuencia %
0 58 61,7
1 19 20,2
2 11 11,7
3 6 6,4
Nº de complicaciones patológicas Frecuencia %
0 26 63,4
1 9 22,6
2 2 4,9
3 4 9,8

8.- a) 8,6 8,8 8,9 b) 10,1 9,2 10,4
9.
Menor valor tipificado de ca
Hombres -2,6880
Mujeres -2,0172
10.- n = 61 media = 25,6492 mediana = 24,6 desv. típica = 13,0977 p10 = 12,32
p90 = 42,54
Problemas SPSS (Segunda parte)
* Todos los ejercicios se realizarán con los datos del fichero osteo.sav, salvo que se indique
lo contrario.
* En todos los ejercicios debe expresar la conclusión a la que se llegue.
Ejercicio 1.- Estudiar la normalidad de la variable creatinina (cr) y estimar su media
(estimación puntual y por intervalos). Hacerlo para todos los pacientes, y para varones y
mujeres por separado.
Ejercicio 2.- Calcule una estimación puntual de la proporción de retinopatías que se
presentan en este tipo de pacientes.
Ejercicio 3.- Igual que en el ejercicio anterior, pero para la proporción de pacientes que
tienen el nivel de fósforo (p) inferior a 3,4.
Ejercicio 4.- ¿Puede admitirse la hipótesis (Ho) de un 30% de osteoporóticos en el cuello
del fémur? Responder a la misma pregunta para el triángulo. (Nota: Se considera que hay
osteoporosis en un hueso cuando el valor tipificado de la masa ósea es inferior ó igual a
−2).
Ejercicio 5.- ¿La proporción de retinopatías graves difiere significativamente del 20% en
los pacientes con 15 o más años de evolución de la enfermedad (tevol≥15)?
Ejercicio 6.- a) Compare los valores medios de creatinina (cr) entre varones y mujeres.
b) Calcule el intervalo de confianza para la diferencia de valores medios de creatinina entre
ambos sexos. Comente el resultado en relación al del apartado anterior.
Ejercicio 7.- Considerando sólo a las mujeres y asumiendo la normalidad de la variable
hemoglobina glicoxilada (hba1c), compare los valores medios de hemoglobina entre: a)

fumadoras y no fumadoras; b) las que realizan actividad física y las que no la realizan; c)
las menores de 30 años y las de 30 ó más años.
Ejercicio 8.- Realice el ejercicio anterior, pero sin suponer la normalidad de la variable
hba1c. ¿Son las conclusiones las mismas que en el ejercicio anterior?.
Ejercicio 9.- Compare la presencia de retinopatía (catalogada como: No, Leve y Grave)
entre los pacientes que tienen 10 años ó menos de evolución de la enfermedad
(tevol) y los que tienen 11 años ó más. En cada uno de los dos grupos, ¿qué porcentaje de
pacientes no tienen retinopatías?
Ejercicio 10.- Asigne los valores cuantitativos 0, 1 y 2 a las categorías: No, Leve y
Grave, respectivamente, y resuelva el ejercicio anterior utilizando tests de comparación de
medias. Comente la conclusión en relación a la del ejercicio anterior.
Ejercicio 11.- Resuelva el Ejercicio 3 de la relación de problemas “Tests con dos
muestras” (Nota: Debe introducir los datos definiendo dos variables: sexo y PRL).
Ejercicio 12.- Considere los varones fumadores y compare el valor tipificado de la
densidad de masa ósea en el L24 (szl24) con el valor tipificado de la densidad de masa ósea
en el cuello del fémur (szcue), a) suponiendo la normalidad de
szl24−szcue. b) sin suponer la normalidad de szl24−szcue.
Ejercicio 13.- Recodifique las retinopatías y las nefropatías en presencia (código 1) y
ausencia (código 2). a) ¿Qué son más probables, las retinopatías o las nefropatías?
(Haga para ello la oportuna comparación de proporciones).b) ¿Qué porcentaje de pacientes
presentan ambas patologías?.c) ¿Qué porcentaje de pacientes presentan retinopatías?
Ejercicio 14.- Partiendo de la recodificación de las retinopatías hecha en el ejercicio
anterior, a) compare la proporción de retinopatías entre fumadores y no fumadores,
b) ¿cuáles son las proporciones de retinopatías en fumadores y no fumadores?.
Ejercicio 15.- Compruebe si a) el consumo de tabaco, b) el consumo de alcohol (cualquier
cantidad) y c) tener una edad superior a los 40 años, son factores de riesgo para padecer
nefropatía (recodificada como: presencia (código 1) y ausencia (código 2)). Calcule, en
cada caso, medidas de asociación y comente si es procedente su interpretación.
Ejercicio 16.- ¿La presencia de retinopatía está asociada a la presencia de neuropatía
(ambas catalogadas como No, Leve y Grave)? ¿Qué porcentaje de pacientes no presentan
ninguna de las dos patologías?

Ejercicio 17.- ¿El tener una retinopatía grave está asociada con el hecho de que el tiempo
de evolución de la enfermedad (tevol) sea de 15 años ó más? Calcule medidas de
asociación considerando tevol≥mayor o igual de 15 años como la presencia del factor de
riesgo. (Nota: debe recodificar la retinopatía en Grave (código 1) y No + Leve (código 2)).
Ejercicio 18.- Para los pacientes con suficiente ingesta de calcio (ingca = 1) construya el
gráfico de dispersión que relaciona la variable sztri (variable Y) con la imc (variable X)
¿Podemos admitir los supuestos de linealidad e igualdad de varianzas?
Colocar el número identificativo al punto (paciente) mas extremo; ¿cuál es?
Ejercicio 19.- Realice un estudio completo de regresión y correlación lineal (incluido el
gráfico de la nube de puntos) entre el valor tipificado de la densidad de masa ósea en el
cuello del fémur (szcue) (variable Y) y el nivel de fósforo (p) (variable X).
Ejercicio 20.- Resuelva los apartados a) y c) del ejercicio 1 de la relación de problemas
“Regresión y correlación”.
BIBLIOGRAFÍAS.
- Ramos, Carmen E.. Análisis Estadístico con SPSS.
http://nereida.deioc.ull.es/~pcgull/ihiu01/cdrom/spss/contenido/spss.html
- SPSS® 13.0 Base Manual del usuario Disponible en:
http://www.superiordepsicologia.com/archivos-esc/Invest-
Dra%20Moreno/manual_spss_13_espanol.pdf
- Esparza C. Cecilia. Introducción al programa SPSS 13.0. Disponible en.
http://www.scribd.com/doc/18957336/SPSS-Introduccion Consultado.. 09 enero
2010
- SPSS. Disponible en: http://es.wikipedia.org/wiki/SPSS

- Novedades de PASW Statistics 18. Disponible en:
http://www.spss.com/es/media/collateral/statistics/pasw-statistics-new.pdf
- González. Esther. Sesión práctica 3: Transformaciones de datos. Probabilidad y
estadística. Disponible en: http://www2.dis.ulpgc.es/~ii-pest/sesion3-spss.pdf
- Transformar datos o variables de spss - manual de spss en español. Disponible en:
http://www.spssfree.com/capitulo4.html
- Apoyo Estadístico. Servicio de Apoyo a la Investigación. Universidad de Murcia.
www.um.es/sai, sace-Ae-Instalacion-SPSS. Disponible en
http://www.um.es/ae/soloumu/pdfs/sace-Ae-Instalacion-SPSS13o14.pdf
- SPSS 10 Guía para el análisis de datos. Disponible en:
http://www2.uca.es/serv/ai/formacion/spss/Pantalla/verguia.pdf
- Ejercicios SPSS (Primera parte) y (segunda parte) disponible en
http://www.ugr.es/~bioest/medicina/prbspss.pdf
- Charlotte Mecklenburg Police Department. Disponible en:
http://www.spss.com/la/soluciones/Charlotte_Mecklenburg_Police_Department.htm
- Metodología. Análisis estadístico: SPSS (Manuales). Disponible en:
http://www.aristidesvara.com/metodologia/analisis/anali_05.htm
-


















