{v1,v - IQCCstark.udg.edu/~perico/docencia/curs_07_08/TC_QTC_0708.pdf ·
91
Técnicas Computacionales, Curso 2007-2008. Pedro Salvador 1 2.1- Nociones de Álgebra lineal No entraremos en detalle ni en definiciones demasiado formales sino que veremos únicamente aquellos conceptos que necesitaremos durante el curso. 2.1.1 Espacios vectoriales Un espacio vectorial es una estructura algebraica que incluye dos tipos de elementos que cumplen una serie de propiedades y axiomas. Éstos elementos son los escalares y los vectores. En general, los escalares serán el conjunto de números reales o complejos. Los vectores son objetos abstractos que cumplen una serie de propiedades y no tienen porque ser únicamente los vectores geométricos que conocemos. El término vector también se usa para describir entidades como matrices, polinomios o funciones. Por ejemplo, los vectores que se usan en mecánica cuántica son funciones. 2.1.2 Combinación lineal, independencia lineal y base Supongamos un conjunto de N vectores de un espacio vectorial determinado { } N v v v ,..., , 2 1 . Una combinación lineal de dichos elementos se define como la suma siguiente ∑ = + + N i i i N N v a v a v a v a ... 2 2 1 1 donde a 1 , a 2 ,.., a n son escalares. El conjunto de N vectores es linealmente independiente si se cumple que 0 = ∑ N i i i v a únicamente cuando a 1 = a 2 =...= a n = 0. Esto implica que ningún vector del conjunto { } N v v v ,..., , 2 1 puede expresarse como combinación lineal de los demás. El conjunto de vectores será un conjunto generador del espacio vectorial si cualquier vector w que pertenezca al espacio vectorial puede expresarse como combinación lineal de ellos
Transcript of {v1,v - IQCCstark.udg.edu/~perico/docencia/curs_07_08/TC_QTC_0708.pdf ·

Técnicas Computacionales, Curso 2007-2008. Pedro Salvador
1
2.1- Nociones de Álgebra lineal
No entraremos en detalle ni en definiciones demasiado formales sino que veremos
únicamente aquellos conceptos que necesitaremos durante el curso.
2.1.1 Espacios vectoriales
Un espacio vectorial es una estructura algebraica que incluye dos tipos de elementos
que cumplen una serie de propiedades y axiomas. Éstos elementos son los escalares y
los vectores.
En general, los escalares serán el conjunto de números reales o complejos.
Los vectores son objetos abstractos que cumplen una serie de propiedades y no tienen
porque ser únicamente los vectores geométricos que conocemos. El término vector
también se usa para describir entidades como matrices, polinomios o funciones. Por
ejemplo, los vectores que se usan en mecánica cuántica son funciones.
2.1.2 Combinación lineal, independencia lineal y base
Supongamos un conjunto de N vectores de un espacio vectorial determinado
{ }Nvvv ,...,, 21 .
Una combinación lineal de dichos elementos se define como la suma siguiente
∑=++N
iiiNN vavavava ...2211
donde a1, a2,.., an son escalares.
El conjunto de N vectores es linealmente independiente si se cumple que
0=∑N
iiiva
únicamente cuando a1 = a2 =...= an = 0.
Esto implica que ningún vector del conjunto { }Nvvv ,...,, 21 puede expresarse como
combinación lineal de los demás.
El conjunto de vectores será un conjunto generador del espacio vectorial si cualquier
vector w que pertenezca al espacio vectorial puede expresarse como combinación lineal
de ellos

Técnicas Computacionales, Curso 2007-2008. Pedro Salvador
2
∑=++=N
iiiNN vavavavaw ...2211 .
Además, si esta combinación es única el conjunto generador será una base del espacio.
En este caso, los vectores del conjunto serán además linealmente independientes.
Los coeficientes escalares a1, a2,.., an serán las componentes del vector w en la base.
El numero de vectores de una base determina la dimensión del espacio vectorial. En
realidad, los espacios vectoriales pueden ser de dimensión finita o infinita1. El conjunto
de todos los vectores de n componentes reales conforma el espacio vectorial Rn, cuya
dimensión es precisamente n.
Por ejemplo, para el espacio Euclidiano tridimensional, R3. el conjunto de vectores
{(1,2,3), (0,1,2), (−1,1/2,3), (1,1,1)},
son generadores del espacio pero no son base, porque no son linealmente
independientes. Una base del espacio la forman los vectores
{(1,0,0), (0,1,0), (0,0,1)}.
Sin embargo, los vectores
{(1,0,0), (0,1,0), (1,1,0)}
no son generadores (ni base) de R3 porque los vectores cuya tercera componente sea
diferente de cero no pueden expresarse como combinación lineal de ellos.
2.1.3 Producto escalar
Aparte de las propiedades propias del espacio vectorial se define también un producto
interno que permite introducir las nociones de distancia, ángulo y norma, llamado
producto escalar.
Un producto escalar debe cumplir también una serie de propiedades y de hecho su
definición depende del tipo de espacio vectorial.
Para el espacio vectorial Rn se define el producto escalar entre dos vectores como
1 En los espacios que intervienen en la mecánica cuántica, Espacios de Hilbert, los vectores son
funciones definidas sobre el cuerpo complejo que cumplen una serie de condiciones y la dimensión del
espacio es infinita.

Técnicas Computacionales, Curso 2007-2008. Pedro Salvador
3
∑=++==⋅n
iiinn
T vwvwvwvwvwvw ...2211
es decir, la suma de los productos de las componentes de los vectores.
A partir del producto escalar de un vector con sigo mismo
22)( vwvvN
ii
rrr ==⋅ ∑
encontramos el concepto de norma
( ) 21vvv rrr ⋅=
Diremos que un vector esta normalizado cuando su norma es la unidad
1=vr
Se demuestra también que el producto escalar entre dos vectores también cumple
αcosvwvw =⋅
donde α es el ángulo que forman ambos vectores. Por tanto, cuando dos vectores son
ortogonales entre si, su producto escalar se anula
vwsivw rrrr ⊥=⋅ 0
Si los vectores de una base { }ivr son ortogonales ente si y están normalizados diremos
que la base es ortonormal o que está ortonormalitzada.
Podemos escribir ambas condiciones al mismo tiempo usando la función delta de
Kronecker
ijji vv δ=⋅ rr
donde
⎩⎨⎧
=≠
=jiji
ij 10
δ

Técnicas Computacionales, Curso 2007-2008. Pedro Salvador
4
2.1.4 Matrices: propiedades y operaciones
Definiciones y propiedades elementales
Una matriz es una tabla rectangular de (generalmente) números que pueden ser sumados
o multiplicados. Las líneas horizontales de números se llaman filas y las verticales
columnas. Decimos matriz de dimensión n x m a una matriz compuesta por n filas y m
columnas.
Dada una matriz A de dimensión n x m , representamos el elemento que ocupa la y-
ésima fila y j-ésima columna como Aij o bien A(y,j).
Un vector no es mas que una matriz donde una de las dimensiones es 1. Así, un vector
fila es una matriz de dimensión 1 x m y un vector columna una matriz de dimensión
n x 1.
Suma de matrices
Dadas dos matrices de dimensión n x m, A y B, podemos definir su suma C = A + B
como la matriz de dimensión n x m los elementos de la cual vienen dados por la suma
de los elementos correspondientes de las matrices A y B tal que
jiBAC ijijij ,∀+=
Para poder sumar dos matrices, éstas deben tener las mismas dimensiones. La matriz
resultante tendrá también las mismas dimensiones.
Producto de matriz por escalar
Dada una matriz A cualquiera y un escalar α definimos el producto escalar de α por A,
B = α·A como el producto de α por cada elemento de la matriz A de manera que
jiAB ijij ,∀=α
Producto de matrices
El producto matricial entre dos matrices A y B solamente se puede llevar a cabo cuando
el numero de columnas de la matriz A es igual al número de filas de la matriz B. En tal
caso, sea una matriz A de dimensión n x m y una matriz B de dimensión m x p tenemos
que el producto matricial A·B es otra matriz C de dimensión m x p , los elementos de la
cual vienen dados por
pjmiBABABABACn
kkjiknjinjijiij ,1,1...2211 ∈∀∧∈∀=+++= ∑

Técnicas Computacionales, Curso 2007-2008. Pedro Salvador
5
El producto de matrices no es conmutativo, por tanto, en general
A·B ≠ B·A
De hecho, en el ejemplo anterior el producto B·A no es ni siquiera posible ya que el
número de filas de B no coincide con el número de columnas de A.
Tipos de matrices :
Matriz cuadrada
Matriz donde el número de filas es igual al número de columnas. El producto entre dos
matrices cuadradas es otra matriz cuadrada. Con matrices cuadradas los productos
matriciales A·B y B·A son posibles, a pesar de que, en general, no dan el mismo
resultado.
Matriz simétrica
Una matriz cuadrada A es simétrica si cumple que
jiAA jiij ,∀=
Cuando los elementos de la matriz están definidos en el cuerpo complejo se define
matriz hermítica como
jiAA jiij ,* ∀=
donde *jiA representa el conjugado complejo del elemento de matriz.
Matriz diagonal
Una matriz cuadrada A es diagonal si los elementos de fuera de la diagonal principal son
cero
jiAij ≠∀= 0
Matriz identidad
La matriz identidad es una matriz cuadrada diagonal donde los elementos de la diagonal
principal son la unidad. Por tatnto, podemos escribir sus elementos a partir de una delta
de Kronecker
ijijI δ=
La matriz identidad hace el papel de elemento neutro para el producto matricial. Es
decir, el producto de una matriz cuadrada por la matriz identidad de dimensión

Técnicas Computacionales, Curso 2007-2008. Pedro Salvador
6
adecuada (y viceversa) da como resultado la propia matriz.
A·I = I·A = A
Matriz transpuesta
Dada una matriz A de dimensión n x m , definimos su matriz transpuesta, AT, que será
de dimensión m x n, intercambiando sus filas y columnas,
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
nmmm
n
n
T
nmnn
m
m
aaa
aaaaaa
A
aaa
aaaaaa
A
...............
...
...
...............
...
...
21
22212
12111
21
22221
11211
Por tanto, podemos escribir
jiAA jiTij ,∀=
Para una matriz simétrica se cumple que
A = AT
Por otro lado, en general
(AT)T = A
(A + B)T = AT + BT
(A·B)T = BT· AT
Por tanto, el producto de una matriz cualquiera por su transpuesta resulta en una matriz
simétrica
B = AT·A → BT = (AT·A)T = AT·(A T)T= AT·A =B
Cuando los elementos de la matriz están definidos en el cuerpo complejo se definen los
elementos de la matriz adjunta como
jiAA jiij ,* ∀=+
En este caso, para una matriz hermítica se cumple que
A = A+

Técnicas Computacionales, Curso 2007-2008. Pedro Salvador
7
Matriz Inversa
Dada una matriz cuadrada A de dimensión n, se define su matriz inversa A-1 como la
matriz que cumple que
A-1·A = A·A-1·= I
donde I es la matriz identidad de dimensión n. La matriz inversa A-1 es única y en
general
(A-1)-1 = A
(A·B)-1 = B-1· A-1
Matriz singular
Una matriz es singular cuando no existe su matriz inversa, es decir, cuando no es
invertible. Cuando el determinante de una matriz cuadrada es cero (vide infra) la matriz
es singular.
Matriz ortogonal
Una matriz cuadrada U es ortogonal cuando su transpuesta es su propia inversa, por
tanto
U-1 = UT·
Si dos matrices A y B son ortogonales, su producto es también una matriz ortogonal.
Una matriz es ortogonal si y solo si sus vectores columna son ortonormales, es decir,
cuando éstos forman una base ortonormalitzada.
Cuando los elementos de la matriz están definidos en el cuerpo complejo tenemos que
una matriz cuadrada es unitaria cuando su adjunta es su propia inversa.
V-1 = V+·
Traza de una matriz
Se define la traza de una matriz cuadrada de dimensión n como la suma de los
elementos de su diagonal principal
∑=N
iiiAAtr )(

Técnicas Computacionales, Curso 2007-2008. Pedro Salvador
8
Determinante de una matriz
El determinante de una matriz cuadrada no es mas que una función que aplicada a la
matriz retorna un escalar (número)
det(A) = α
Cuando el determinante de una matriz es cero la matriz es singular (no invertible).
También indica que una o más filas o columnas de la matriz se puede expresar como
combinación lineal de las otras; por tanto, indica dependencia lineal de los vectores fila
o columna que componen la matriz.
Se cumplen las propiedades siguientes
det(AB) = det(A) det(B) = det (BA)
det(AT) = det(A)
det(U) = 1
Además
• Si se intercambian dos filas o columnas de una matriz su determinante cambia
de signo
• Multiplicando una fila o columna por un escalar α multiplica el valor del
determinante por α
• Añadir un múltiplo de una fila o columna a otra no afecta al valor del
determinante
En secciones siguientes veremos como se obtiene el determinante de una matriz
cuadrada.
2.5 Cambio de base.
Dadas dos bases de vectores { }iwr y { }iwr de un espacio vectorial Rn, podemos escribir
cada vector de la base { }iwr como combinación lineal de los vectores de la base { }iwr .
⎪⎪⎭
⎪⎪⎬
⎫
+++=
+++=+++=
nnnnnn
nn
nn
vavavaw
vavavawvavavaw
rrrr
rrrr
rrrr
......
......
2211
22221212
12121111
Los coeficientes de la combinación lineal se pueden escribir en forma de una matriz,
que representa la matriz de cambio de base.

Técnicas Computacionales, Curso 2007-2008. Pedro Salvador
9
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
nnnn
n
n
aaa
aaaaaa
A
...............
...
...
21
22221
11211
Podemos escribir el proceso de cambio de base de la manera siguiente
AVW ⋅=
donde W y V son matrices que contienen, en columnas, las componentes de los vectores
de las bases { }iwr y { }iwr , respectivamente.
( )⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
≡≡
nnnn
n
n
n
www
wwwwww
wwwW
...............
...
...
...;;;
21
22221
11211
21rrr
Por tanto, podemos escribir
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
nnnn
n
n
nnnn
n
n
nnnn
n
n
aaa
aaaaaa
vvv
vvvvvv
www
wwwwww
...............
...
...
...............
...
...
...............
...
...
21
22221
11211
21
22221
11211
21
22221
11211

Técnicas Computacionales, Curso 2007-2008. Pedro Salvador
10
2.2.- Resolución de sistemas de ecuaciones lineales.
2.2.1. Algoritmo de resolución de sistemas de ecuaciones lineales por el método de Gauss-Jordan
Partimos de un sistema de N ecuaciones lineales con N incógnitas (x1,x2,...,xN).
⎪⎪⎭
⎪⎪⎬
⎫
=+++
=+++=+++
NNNNNN
NN
NN
bxa...xaxa...
bxa...xaxabxa...xaxa
2211
22222121
11212111
(1)
donde los elementos aij y bi corresponden a los coeficientes y términos independientes
de las ecuaciones. Podemos escribir la expresión (1) en forma matricial de manera que
bAx = (2)
donde
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
NNNNNN
N
N
x...xx
x
b...bb
b
a...aa............
a...aaa...aa
A 2
1
2
1
21
22221
11211
(3)
El algoritmo de Gauss-Jordan se basa en sustituir ecuaciones (filas de la matriz A y
elementos del vector de términos independientes b) por combinaciones lineales de
ecuaciones del propio sistema (entre filas de la matriz A) de tal manera que
conseguimos transformar la matriz A en una matriz diagonal.
Vamos a ver como funciona. El objetivo es, tomando una de las ecuaciones (filas de A)
como referencia (eqref) , sustituir las otras ecuaciones (eqk) por una combinación lineal
del tipo
refkeqeqeq refkk ≠∀×+⇐ α' (4)
de tal manera que se consiga eliminar de la eqk la dependencia con la variable de

Técnicas Computacionales, Curso 2007-2008. Pedro Salvador
11
referencia (hacer cero el elemento correspondiente de la columna ref en A). Para ello se
escoge de manera adecuada el factor α para cada fila k.
En forma matricial, esto implica que si hemos escogido la primera fila de A como
referencia, sustituimos cada una de las otras filas por combinaciones lineales tales que
hagan que el elemento Ak1 se anule. Es decir, pretendemos conseguir que en la primera
columna de la matriz A todos los elementos sean cero excepto el primero (el de la fila de
referencia). Se puede comprobar fácilmente que si sustituimos la segunda de las
ecuaciones por la combinación lineal
111
2122 eq
aaeqeq' ×⎟⎟
⎠
⎞⎜⎜⎝
⎛+⇐ (5)
la nueva eq2 tendrá la forma
'bx'a...x'ax NN 1121210 =+++ (6)
Si lo hacemos para todas las ecuaciones (excepto la de referencia) tendremos un
sistema de ecuaciones equivalente al original
'bx'A = (7)
donde tanto la matriz de los coeficientes como el vector de términos independientes
habrán cambiado a la forma
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
'b...
'b'b
'b
'a...'a............
'a...'a'a...'aa
'A
NNNN
N
N
2
1
2
222
11211
0
0
(8)
Si tomamos ahora como fila de referencia la segunda y repetimos el proceso para todas
las demás filas (incluida la primera, que fue referencia en el paso anterior) el sistema
quedaría de la forma

Técnicas Computacionales, Curso 2007-2008. Pedro Salvador
12
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
''b...
''b''b
'b
''a...............
''a...'a''a...a
''A
NNN
N
N
2
1
222
111
00
00
(9)
Vemos que en este segundo paso hemos generado ceros en la segunda columna (excepto
para la segunda fila), mientras que los cero de la primera columna generados en el paso
anterior se mantienen (esto es así porque la segunda fila de referencia ya tiene un cero
en la primera columna, por lo que al llevar a cabo la combinación lineal correspondiente
para las demás filas su primer elemento no se ve modificado).
Por tanto, si repetimos el proceso consecutivamente para cada fila de la matriz A
conseguiremos finalmente tener un sistema de ecuaciones equivalente al original pero
con las matrices de coeficientes y de términos independientes de la forma
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
finalN
final
final
final
finalNN
finalfinal
b...
bb
b
a...............
...a
...a
A 2
1
22
11
00
0000
(10)
Ahora, cada ecuación depende únicamente de una variable y por tanto la solución del
sistema es trivial
finalNN
finalN
Nfinal
final
final
final
abx,...,
abx,
abx ===
22
22
11
11 (11)
Visualmente, si dividimos cada ecuación final por el coeficiente correspondiente a la
variable de que depende cada una tenemos que la matriz de coeficientes es la matriz
identidad de la dimensión del problema.

Técnicas Computacionales, Curso 2007-2008. Pedro Salvador
13
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=≡
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
finalNN
finalN
finalfinal
final
finalfinal
ab
abab
xbA...
1...00............0...00...01
222
111
(10)
En este punto, el vector de términos independientes coincide con la solución del
sistema de ecuaciones.
El algoritmo en pseudocodigo para este proceso seria el siguiente
do Por cada fila de referencia i
do Por las demás filas k (k ≠ i)
⎪⎪
⎭
⎪⎪
⎬
⎫
⎟⎟⎠
⎞⎜⎜⎝
⎛−⇐
∀⎟⎟⎠
⎞⎜⎜⎝
⎛−⇐
iii
kikk
ijii
kikjkj
baab'b
jaaaa'a
end do
end do
iabx final
ii
finali
i ∀=
Internamente, las modificaciones de la matriz de coeficientes y de términos
independientes se pueden guardar en las posiciones de memoria de las propias matrices
iniciales por lo que se sobrescriben sus valores iniciales. De esta manera no se necesita
definir ninguna matriz o vector auxiliar para llevar a cabo el proceso de Gauss-Jordan.

Técnicas Computacionales, Curso 2007-2008. Pedro Salvador
14
Otras consideraciones
• Debemos procurar de que los elementos de la diagonal de la matriz A (akk) deben ser
diferentes de cero, de lo contrario α no seria calculable. Si al principio se detectara
este problema (a11 = 0), entonces la primera fila de referencia debería ser otra donde
(ak1 ≠ 0). Por otro lado, dado que la matriz A se va modificando conforme vamos
avanzando el proceso de eliminación, cada vez que debamos escoger una fila de
referencia deberemos comprobar que el elemento de la diagonal principal no se
anula, y si es así, intercambiar esta fila por otra de las que no ha sido utilizada
anteriormente como referencia para seguir con el proceso. Si se llega a un punto
en que ninguna de las ecuaciones restantes cumple dicha condición entonces querría
decir que el sistema no es compatible (no tiene solución).
Para una discusión mas detallada ver la sección de Pivoteo Parcial.
• Fíjense que para calcular el factor α se utilizan los elementos de la matriz de
coeficientes antes de ser transformada .O sea que puesto que tenemos que
ijii
kikjkj a
aaa'a ⎟⎟
⎠
⎞⎜⎜⎝
⎛−⇐
conforme vamos recalculando los nuevos elementos de la fila k (para cada columna
j; 'kja ), eventualmente sobrescribiremos el valor aki (cuando j=i). Esto implicaría
utilizar para una misma fila dos factores α diferentes, ii
ki
aa
=α para j ≤ i y ii
ki
aa '
=α
para j > i). Para evitarlo debemos calcular el valor de α y guardarlo en una variable
antes de aplicar las sustituciones oportunas.
• Una manera de hacer más sencillo el algoritmo es definir la matriz ampliada
siguiente
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
NNNNN
N
N
b...bb
||||
a...aa............
a...aaa...aa
2
1
21
22221
11211

Técnicas Computacionales, Curso 2007-2008. Pedro Salvador
15
donde la columna de términos independientes se ha añadido a la matriz cuadrada de
coeficientes. De esta manera la matriz A ahora tendría dimensiones N x(N+1) y
tendríamos todos los efectos que )N(ii ab 1+≡
Esto quiere decir que podriamos recalcular los elementos de la matriz de
coeficientes y el vector de terminos independientes de una vez haciendo
⎪⎭
⎪⎬⎫
+=⎟⎟⎠
⎞⎜⎜⎝
⎛−⇐ 11 N,ja
aaa'a ij
ii
kikjkj

Técnicas Computacionales, Curso 2007-2008. Pedro Salvador
16
2.2.2. La técnica del pivoteo en el algoritmo de Gauss-Jordan
El algoritmo de eliminación Gaussiana tal y como lo hemos visto es bastante inestable y
comporta una serie de problemas. Entre ellos, el más evidente es cuando nos
encontramos con que un elemento de la diagonal de la matriz de coeficientes
(inicialmente o según la vamos transformando) es cero (o un número muy pequeño, del
orden de la precisión de la máquina).
La estrategia de pivoteo combinada con el escalado nos puede ayudar a diseñar un
algoritmo mas estable y de aplicación general.
Recordemos que el algoritmo de Gauss-Jordan resuelve un sistema de ecuaciones
lineales del tipo,
bAx = (1)
o más de uno simultáneamente (algoritmo de inversión matricial)
1−≡= AXIAX (1)
mediante la aplicación de operaciones básicas que consisten en sustituir una fila de A
por una combinación lineal entre ella misma y otra que se elige como pivote. Se puede
ver facilmente que el hecho de realizar este tipo de operación no afecta al resultado
siempre y cuando apliquemos la misma operación al vector/matriz de términos
independentes, es decir a la derecha de la eq. (1) o (2).
Así mismo, hay otras operaciones elementales que podemos realizar y que no nos afecta
a la solución de las eq (1) o (2): el intercambio de filas o columnas.
Intercambiar dos filas de A y las correspondientes de b o I no afecta a la solución del
sistema ya que solo implica cambiar el orden en que se escriben las N ecuaciones.
Si se intercambian dos columnas entonces debemos ir con cuidado ya que el resultado
final del sistema se verá alterado a menos que realicemos los mismos intercambios
entre las filas del vector (x) o matriz (X) de soluciones.
La técnica de pivoteo implica realizar estas operaciones con el fin de seleccionar el
mejor elemento de la diagonal que se utilizará para llevar a cabo el proceso de

Técnicas Computacionales, Curso 2007-2008. Pedro Salvador
17
eliminación de Gauss-Jordan. El uso del intercambio de filas únicamente recibe el
nombre de pivoteo parcial (partial pivoting), mientras que si se aplica a demás el
intercambio de columnas estaremos aplicando pivoteo total (full pivoting).
Con el pivoteo parcial conseguiremos fácilmente a) evitar divisiones per cero y b)
determinar si el sistema es incompatible o la matriz es singular (no tiene inversa).
Lo que haremos será escoger la fila de referencia siempre como aquella (disponible)
que presente un valor más grande (en valor absoluto) en el elemento situado en la
columna donde pretendemos generar los ceros. Así, si pretendemos generar ceros en
la primera columna elegiremos como fila de referencia aquella cuyo primer elemento
sea mayor en valor absoluto. Si ésta fila no corresponde con la primera, procederemos al
intercambio de los valores de la fila escogida de la matriz ampliada por los de la
primera, y procederemos seguidamente al proceso de eliminación. El paso siguiente es
el de generar ceros en la segunda columna de la matriz ampliada. Para ellos
escogeremos como fila de referencia aquella que presente un elemento mayor en valor
absoluto en la segunda columna, exceptuando la fila primera, que acababa de ser
usada como fila de referencia. Esto es así porque si volviéramos a usar como referencia
una fila anterior perderíamos los cero que habíamos generado previamente en columnas
anteriores.
Por tanto, siempre debemos buscar la nueva fila de referencia para generar ceros
en la columna i entre las i, i+1 ,..., n filas disponibles.
La ventaja de este proceso es que, si se llega a un punto en el que no hay ninguna fila
disponible con un valor diferente de cero en la columna en la que se pretenden generar
ceros podemos asegurar que el sistema no es compatible (o bien que la matriz no tiene
inversa).
Por otro lado, si en un sistema de ecuaciones multiplicáramos una de las ecuaciones por
un factor de 106 la solución no se verá afectada, y esto provocaría que, casi con total
seguridad, esta ecuación pasaría a ser la primera referencia para el proceso de
eliminación. Normalmente se combina la técnica del pivoteo parcial con la del
escalado, según la cual se escalan las ecuaciones originales del sistema de manera que
los coeficientes de las mismas sean comparables entre si. Una manera de hacerlo es
dividir los coeficientes de cada ecuación por el elemento máximo (en valor absoluto)
de cada una.

Técnicas Computacionales, Curso 2007-2008. Pedro Salvador
18
Ejemplo
Encontrar el polinomio interpolador de 3er orden que pasa por los puntos (-1,0), (3,2),
(0,-4), (-3,2).
Debemos plantear un sistema de ecuaciones del tipo
yi = a xi3 + b xi
2 +c xi +d ∀ i,
en este caso:
0 = a (-1)3 + b (-1)2 +c(-1) +d
2 = a 33 + b 32 +c 3 +d
-4 = a 03 + b 02 +c 0 +d
2 = a (-3)3 + b (-3)2 +c(-3) +d
Así pues, debemos resolver el sistema de ecuaciones lineales siguiente:
0 = -a + b -c +d
2 = 27a + 9b +3c +d
-4 = d
2 = -27a + 9b -3c +d
y en forma matricial
-1 1 –1 1 0
27 9 3 1 2
0 0 0 1 -4
-27 9 -3 1 2
Si aplicáramos Gauss-Jordan sin pivoteo parcial tendríamos:
Generando ceros en columna 1
-1.00000 1.00000 -1.00000 1.00000 0.00000
0.00000 36.00000 -24.00000 28.00000 2.00000
0.00000 0.00000 0.00000 1.00000 -4.00000
0.00000 -18.00000 24.00000 -26.00000 2.00000
Generando ceros en columna 2
-1.00000 0.00000 -0.33333 0.22222 -0.05556
0.00000 36.00000 -24.00000 28.00000 2.00000
0.00000 0.00000 0.00000 1.00000 -4.00000
0.00000 0.00000 12.00000 -12.00000 3.00000
No es posible generar ceros en la columna 3 debido a la presencia de un cero en el elemento

Técnicas Computacionales, Curso 2007-2008. Pedro Salvador
19
correspondiente de la diagonal y el algoritmo falla.
Solo si aplicamos un algoritmo más robusto incluyendo pivoteo parcial (intercambiando
filas) podemos solucionar el problema, llegando a la solución final:
1.0000000 0.0000000 0.0000000 0.0000000 0.4166667
0.0000000 1.0000000 0.0000000 0.0000000 0.6666667
0.0000000 0.0000000 1.0000000 0.0000000 -3.7500000
0.0000000 0.0000000 0.0000000 1.0000000 -4.0000000
y por tanto el polinomio interpolador que buscábamos es
f(x) = 0.4166667 x3 + 0.6666667 x2 -3.7500000 x -4.0000000
En este caso particular el problema se puede solucionar sin pivoting. Solo debemos
introducir las ecuaciones en un orden diferente. Cual? A pesar de ello, no podemos
encontrar a menudo casos donde independientemente del orden inicial de las ecuaciones
necesitemos implementar pivoting para llegar a la solución.

Tècniques Computacionals, Curs 2007-2008. Pedro Salvador
2.3.- Inversió de Matrius
2.3.1 Algorisme general d’inversió de matrius quadrades
Partim d’una matriu quadrada, A, de dimensions N×N i volem determinar la seva matriu
inversa, A-1, és a dir la matriu amb la que es compleix
IAAAA == −− 11 (1)
De fet, podríem plantejar el problema de trobar la matriu inversa com la resolució de N
sistemes d’equacions del tipus
N,ibAx ii 1=∀= (2)
on
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
1
00
0
10
0
01
21 ...b,...,
...b,
...b N
(3)
Si escrivim l’eq (2) de la següent manera
[ ] [ ]4342143421
I
N
A
N b,...,b,bx,...,x,xA 21211
=−
(4)
podem veure fàcilment que els vectors xi corresponen a les columnes de la matriu
inversa
1

Tècniques Computacionals, Curs 2007-2008. Pedro Salvador
[ ]⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
==−
NNNN
N
N
N
x...xx............
x...xxx...xx
x,...,x,xA
21
22221
11211
211
(4)
Podem trobar la inversa de la matriu resolent les N equacions simultàniament construint
la següent matriu auxiliar
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
1000010001
21
22221
11211
...
.........
...
...
||||
a...aa............
a...aaa...aa
B
NNNN
N
N
(5)
que construïm a partir de la matriu original, A, i la matriu identitat , I.
Ara, l’algorisme per determinar la matriu inversa és anàleg al de Gauss-Jordan per la
resolució de sistemes d’equacions que hem vist prèviament.
L’objectiu és, mitjançant la tècnica de l’eliminació Gaussiana, transformar el primer
bloc de la matriu en la matriu identitat. És a dir, el que farem és substituir files de la
matriu B per combinacions lineals de files de la pròpia matriu de tal manera que
aconseguim transformar el primer bloc de la matriu en una matriu diagonal.
Posteriorment, dividim cada fila per l’element de la diagonal del primer bloc per tal
d’aconseguir la matriu identitat. Arribats a aquest punt, al segon bloc de la matriu B hi
trobarem la matriu inversa que estàvem buscant.
2

Tècniques Computacionals, Curs 2007-2008. Pedro Salvador
Per tant l’algorisme serà, pràcticament, anàleg al de Gauss-Jordan, amb la diferència
que la matriu sobre la que fem les transformacions tindrà 2N columnes
do Per cada fila de referència i do Per totes les altres files k (k≠i)
[ ]⎭⎬⎫
∈∀⎟⎟⎠
⎞⎜⎜⎝
⎛−⇐ N,ja
aaa'a ij
ii
kikjkj 21 !Apliquem Gauss-Jordan
end do end do do Per cada fila i
[ ]⎭⎬⎫
∈∀⇐ N,jaa
aii
ijij 21 !Dividim cada fila per aconseguir
!matriu diagonal al primer bloc end do
( ) Nj'jaa 'ijij+=∧≡−1
!Elements de la matriu inversa
Anàlogament al mètode de Gauss-Jordan, ens podem trobar amb zeros a la diagonal (del
primer bloc de la matriu B), que implicarien eventualment una divisió per zero. Aquests
elements nuls podem existir inicialment a la matriu A, o bé aparèixer a mesura que la
matriu original es va transformant. Tant en un cas com en un altre, podem evitar el
problema simplement seleccionant una altra fila de referència (veure pivotatge)
3

Tècniques Computacionals, Curs 2007-2008. Pedro Salvador
2.4.- Equacions seculars
2.4.1. Definicions
Les equacions seculars, o equacions de valors i vectors propis, son potser les equacions
matricials més importants i les seves aplicacions son il·limitades en el camp de l’àlgebra
lineal.
Suposem que tenim una matriu quadrada A de dimensió N i un vector columna v de la
mateixa dimensió. El resultat de multiplicar la matriu pel vector
wvA rr = (1)
serà una altre vector w, de la mateixa dimensió.
Direm que el vector v és un vector propi o eigenvector de la matriu A si es compleix
que
vvA rr λ= (2)
o bé desenvolupant el producte de matriu per vector
NivvAN
kikik ,1=∀=∑ λ (3)
a on λ és un escalar. És a dir, si el resultat de multiplicar una matriu per un vector
columna dona un múltiple d’aquest,
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
NNNNNNN
N
N
v
vv
v
vv
v
vv
AAA
AAAAAA
............
..................
2
1
2
1
2
1
21
22221
11211
λ
λ
λλ
(4)
el vector serà un vector propi de la matriu. Per tant, els vectors propis d’una matriu són
aquells que quan son transformats (multiplicats) per la matriu no canvien la seva
direcció.
1

Tècniques Computacionals, Curs 2007-2008. Pedro Salvador
Per altra banda, l’escalar λ rep el nom de valor propi o eigenvalor associat al vector
propi.
Fixeu-vos que en una equació del tipus (2)-(4), les incògnites son tant el vector propi
(cada component) com el valor propi associat, el que provoca que la seva resolució, és a
dir, el procés de determinar valors i vectors propis no sigui trivial.
Els vectors propis d’una matriu A no estan únicament definits en el sentit de que si v és
un vector propi de A amb valor propi λ, un múltiple del vector v també serà vector propi
i tindrà associat el mateix valor propi. Si definim el vector w con un múltiple de v
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
==
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
NN v
vv
v
w
ww
w
α
αα
α......
2
1
2
1
rr
(5)
i comprovem si és vector propi a partir de l’eq (2)
wvvvAvAwA rrrrrr λαλαλαα ===== )()( (6)
veiem que en efecte es compleix la condició, on hem fet servir les propietats del
producte d’una matriu o vector per un escalar. Podem veure-ho també desenvolupant el
producte de la matriu pel vector, tal i com hem fet a l’equació (3)
Niw
vvvAvAwA
i
N
ki
N
kikikkik
N
kkik
,1=∀=
=====∑ ∑∑λ
λααλαα
(7)
Així doncs, sempre podrem multiplicar un vector propi per un escalar i el resultat
seguirà essent un vector propi amb el mateix vector propi. No considerem però que
aquest nou vector sigui un altre vector propi diferent, és a dir, una altra solució de l’eq.
(2). A la pràctica això vol dir que podem triar la longitut (mòdul) de cada vector propi.
Normalment s’escullen de manera que la seva norma sigui la unitat, és a dir,
normalitzats.
Ara veurem algunes propietats i teoremes importants pel cas particular de les matrius
simètriques.
2

Tècniques Computacionals, Curs 2007-2008. Pedro Salvador
2.4.2. Propietats
a) Una matriu quadrada i simètrica A de dimensió N sempre serà diagonalitzable,
és a dir, tindrà N vectors propis amb els seus valors propis corresponents. Per tant, l’eq.
(2) tindrà N solucions diferents
NivvA iii ,1=∀= rr λ (8)
on el subíndex i ara fa referència a vectors diferents i no a la component i del vector.
Podem escriure en una sola equació matricial totes les solucions possibles de la forma
Λ= XXA (9)
a on la matriu X és una matriu quadrada de dimensió N que conté en les seves columnes
els vectors propis de A.
( )⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
==
NNNN
N
N
N
vvv
vvvvvv
vvvX
...............
...
...
...
21
22221
11211
21rrr
(10)
Per altra banda, la matriu Λ és una matriu diagonal i conté a la diagonal principal els
corresponents valors propis associats a cada vector propi (columna de la matriu X)
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=Λ
Nλ
λλ
...00............0...00...0
2
1
(11)
i en el mateix ordre. Per tant, λ1 és el valor propi del vector propi v1, λ2 és el valor propi
del vector propi v2, etc...
Les matrius i X Λ no son úniques en el sentit que les seves columnes es poden reordenar
de manera arbitrària. Tot i això, si les columnes de X apareixen en un ordre determinat,
el mateix ha de ser per les de la matriu Λ, de manera que per un determinat vector propi
que es trobi a la columna k de la matriu X, el seu corresponent valor propi ha d’ocupar
3

Tècniques Computacionals, Curs 2007-2008. Pedro Salvador
precisament la columna k de la matriu diagonal Λ.
b) El conjunt de vectors propis diferents { }ivr formen una base de vectors de
dimensió N.
Per tant, els vectors propis són linealment independents entre sí.
c) Els vectors propis associats a valors propis diferents són ortogonals entre si.
Suposem que v i w son vectors propis de la matriu A amb valors propis λ i τ,
respectivament.
wwAvvA rrrr τλ == (12)
A partir de la primera equació anterior podem escriure
vwvwvAw TTT rrrrrr λλ == (13)
multiplicant a un cantó i altre de la igualtat pel vector w transposat (filera).
Fent el mateix a partir de la segona, en aquest cas multiplicant per l’esquerra pel vector
v transposat tenim
wvwAv TT rrrr τ= (14)
Transposant ara a un canto i altre de l’equació (14)
( ) ( )TTTT wvwAv rrrr τ= (15)
i aplicant les propietats del transposat del producte i de les matrius simètriques
vwvAwvAw TTTT rrrrrr τ== (16)
Comparant les equacions (13) i (16)
vwvw TT rrrr τλ = (17)
podem veure que si τ ≠ λ llavors forçosament
0=vwT rr,
és a dir que el producte escalar entre els dos vectors propis s’anul·la, i per tant són
ortogonals entre si.
d) Una combinació lineal entre dos o més vectors propis que tenen un mateix valor
propi associat és també vector propi i amb el mateix valor propi.
4

Tècniques Computacionals, Curs 2007-2008. Pedro Salvador
Segons l’equació (17), en el cas de que τ = λ la ortogonalitat dels respectius vectors
propis no esta assegurada. De fet, quan els valors propis són degenerats (coincideixen)
els vectors propis no estan definits únicament i qualsevol combinació lineal entre ells
compleix també la condició de vector propi. Per veure-ho simplement definim un nou
vector com a combinació lineals dels altres dos
wvx rrr βα += (18)
on α i β són escalars, i comprovem que en efecte és també vector propi de A
( ) xwvwvwAvAwvAxA
rrr
rrrrrrr
λβαλλβαλβαβα
=+==+=+=+= )(
(19)
i amb el mateix valor propi.
Així, quan hi hagi degeneració podrem combinar linealment entre sí els vectors propis
que comparteixen el mateix valor propi de tal manera que els vectors resultants siguin
ortogonals entre si.
Per tant, la conclusió final és que conjunt de vectors propis d’una matriu quadrada i
simètrica es poden triar de manera que formin una base ortogonalitzada de l’espai.
Això vol dir que el producte escalar entre diferents vectors propis s’anul·la, mentre que
el producte escalar entre un vector propi i ell mateix serà la unitat, perquè l’escollim
normalitzat. Per tant, podem escriure
ijjT
i vv δ=rr (20)
En l’eq. (9) hem vist que els vectors propis ocupen les columnes de la matriu X. Si la
multipliquem per la esquerra per ella mateix transposada el resultat és precisament la
matriu que conté el productes escalars entre tots els vectors propis.
( )⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
NT
NT
NT
N
NTTT
NTTT
N
TN
T
T
T
vvvvvv
vvvvvvvvvvvv
vvv
v
vv
XX
rrrrrr
rrrrrr
rrrrrr
rrr
r
r
r
...............
...
...
......
21
22212
12111
212
1
(21)
5

Tècniques Computacionals, Curs 2007-2008. Pedro Salvador
Llavors, segons l’eq. (20), el resultat del producte matricial és la matriu identitat
IXX T =
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
1...00............0...100...01
(22)
i per tant, les matrius X que contenen els vectors propis d’una matriu simètrica són
matrius unitàries. Com veurem més endavant, aquest fet fa que el procés de
diagonalització es pugui fer servir com a pas previ per a la determinació de inverses de
matrius, determinants, funcions de matrius, etc...
6
perico
Highlight

Tècniques Computacionals, Curs 2007-2008. Pedro Salvador
2.4.3 Algorisme de diagonalització de matrius pel mètode de les rotacions elementals de Jacobi.
Partim d’una matriu quadrada (N×N) i simètrica A. L’objectiu és resoldre l’equació
matricial següent
Λ= XAX (1)
on X és una matriu unitària (tal que XT = X-1) i Λ és una matriu diagonal.
La matriu diagonal conté a la seva diagonal principal els N valors propis de la matriu
original A, mentre que les columnes de la matriu X són els N vectors propis
corresponents.
Per tant, amb les matrius X i Λ , multiplicant per un costat o altre a ambdós costats de
l’eq. (1) per XT obtenim les igualtats següents
TXXA Λ≡ (2)
o bé
AXX T≡Λ (3)
Veiem ara com podem resoldre l’eq (1), és a dir, trobar la matriu diagonal Λ és i la
matriu de transformació, X, aplicant l’anomenat mètode de les rotacions de Jaboi.
L’algorisme de Jacobi es basa en l’ús de matrius elementals de rotació, .
Aquestes son matrius unitàries (com X) que tenen la forma següent
)(R pq α
q
p
....cos..sin..
..................
sin..cos................
....
....
)(R
qp
pq
⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜
⎝
⎛
−
=
1000000000000100000000000010000001
αα
ααα
Si ens fixem, la matriu és gairebé la matriu identitat, I, amb només quatre )(R pq α
7
perico
Highlight

Tècniques Computacionals, Curs 2007-2008. Pedro Salvador
elements de la matriu modificats, precisament els corresponents a les fileres i columnes
a què fan referència els superíndexos pq .
Veiem amb un exemple què fan aquests tipus de matrius. Suposem que tenim un punt P
en l’espai 2D que ve donat per les coordenades P(x, y). En coordenades polars tindríem
)sin(ry)rcos(x
αα
==
a on r i α representen el mòdul i angle respecte l’eix de les x, respectivament. Si
realitzen una rotació del vector en el pla de θ graus en el sentit de les agulles del rellotge
arribarem a un altre punt del pla que vindrà donat per altres coordenades P’(x’,y’)
x
y
(x,y)
θ
α
(x’,y’ )
x
y
(x,y)
θ
α
(x’,y’ )
Escrivint-lo en funció de les seves coordenades polars i fent ús de relacions
trigonomètriques conegudes i de l’expressió en coordenades polars del punt original
podem escriure
ycosθxsinθ)sinθcosαcosθr(sinαθ)sin(αry'ysinθxcosθ)sinθsinαcosθr(cosαθ)rcos(αx'
+−=−=−=+=+=−=
En forma matricial tindrem
⎟⎟⎠
⎞⎜⎜⎝
⎛⎟⎟⎠
⎞⎜⎜⎝
⎛=⎟⎟
⎠
⎞⎜⎜⎝
⎛yx
cossin-inscos
yx
θθθθ
''
XRX )(' θ=
Per tant, la matriu R(θ) representa la rotació de θ graus en el sentit de les agulles del
rellotge.
Es pot comprovar que en un espai 3D, la mateixa rotació d’un punt repecte l’eiz z (és a
dir, en el pla xy) vindria donada per la matriu,
8

Tècniques Computacionals, Curs 2007-2008. Pedro Salvador
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛
1000cosθsinθ-0sinθcosθ
per tant ja poden intuir que la matriu és una generalització en un cas
multidimensional a on la rotació de α graus es dona en el pla pq , i per tant només afecta
a les coordenades p i q del punt.
)(R pq α
Una de les propietats de les matrius unitàries és que el producte entre dues matrius
unitàries qualsevol és també una matriu unitària. Per tant, podem representar una rotació
complexa com una sèrie de rotacions elementals, i la matrius unitària que correspon a
aquesta rotació complexa serà el producte de les respectives matrius de les rotacions
elementals de què consta.
Tenint en compte això, l’estratègia que segueix l’algorisme de Jacobi és la següent:
Amb una matriu de rotació escollida escaientment, transformem la matriu
inicial A de tal manera que
)(αpqRR ≡
ARRA T=' (4)
La nostra matriu A ha canviat (ara és A’). Degut a la forma particular de les matrius de
rotació (gairebé son la matriu identitat), els canvis només afectaran a les files i
columnes p i q de la matriu original A. En concret, anem a veure com canvia l’element
A(p,q). Desenvolupant el producte matricial de les tres matrius anteriors tenim
[ ][ ] [ qqqqpqqp
Tpqqqpqpqpp
Tpp
kqqkqpqkp
Tpk
lklqkl
Tpkpq
RARARRARAR
RARARRARA
+++=
=+==
]∑∑
,'
(5)
Substituint els elements de la matriu de rotació R tenim
)cos(A)AA()sin(
sincosAsinAcosAsincosA'A
pqqqpp
qqqppqpppq
αα
αααααα
222
22
−−=
=−−+=
(6)
on hem fet servir la relació , donat que A és simètrica. qppq AA =
9

Tècniques Computacionals, Curs 2007-2008. Pedro Salvador
Per tant tenim una expressió per la forma final de l’element p,q de la matriu
transformada en funció de l’angle de rotació α. El que farem es trobar l’angle α tal
que provoca que l’element p,q de la matriu A’ esdevingui zero. És a dir, imposant
que A’pq= 0 tenim
⎟⎟⎠
⎞⎜⎜⎝
⎛
−=
−=⇒=
qqpp
pq
qqpp
pqpq
AAA
AAA
A
2arctan
21
2)2tan()2cos(
2)2sin(
α
ααα
(7)
Per tant, si fem la transfomació donada per l’eq (4) per aquest angle α, aconseguirem
que l’element A’pq (i per simetria l’ A’qp) sigui zero.
Si la matriu A’ resultés ser diagonal, l’eq (4) seria equivalent a l’eq (3) i per tant ja
hauríem resolt el problema: la matriu de rotació R seria la matriu X i la matriu diagonal
A’ seria Λ.
Excepte en algun cas particular (matrius 2x2), això no serà així. Tanmateix podríem dir
que la matriu A’ està, en principi, més a prop de ser diagonal ja que hem aconseguit
anular alguns dels seus elements.
L’estratègia és tornar a aplicar una altra vegada la transformació sobre la matriu
transformada A’ amb una altra matriu de rotació per tal d’aconseguir anular un altre
element, i així successivament fins que tots els elements de fora de la diagonal fossin
zero (o suficientment petits).
Així, en anar aplicant rotacions successives tindrem
k
''A
'A
TTTk R...RARRR...R
4434421321 2112≅Λ
(8)
fins arribar a tenir una matriu diagonal.
Comparant l’eq.(8) amb la (3) poden veure fàcilment que la matriu de transformació X
que estem buscant
kR...RRX 21≅ (9)
seria el resultat del producte matricial de les successives rotacions que hem anat fent (i
en aquest ordre!).
10

Tècniques Computacionals, Curs 2007-2008. Pedro Salvador
La pregunta és: com escollim la matriu de rotació? El que farem és, en cada iteració
(transformació), determinar l’element de fora de la diagonal de la nostra matriu amb
un valor absolut més gran (per tant més diferent al nostre objectiu, el zero). La fila i
columna on es trobi aquest element determinarà el valor de p i q de la matriu de rotació,
mentre que l’eq (7) ens donarà l’angle tal que fa que l’element target s’anul·li en fer la
transformació.
Malauradament, quan es fa un transformació com la de l’eq (4), no només l’element Apq
canvia sinó que tots els elements de les files i columnes p i q també canvien. Per tant,
no podem esperar que amb un nombre determinat de transformacions aconseguim
diagonalitzar la matriu, excepte en el cas trivial d’una matriu 2x2. De tota manera, es
pot demostrar que aconseguirem el nostre objectiu si en cada iteració realitzem la
transformació de manera que anul·lem l’element més gran fora de la diagonal, i per tant
això és el que farem.
Per dur a terme la transfomació de l’eq (4) en cada iteració cal fer un producte matricial
de tres matrius. Tot i això, donada la simplicitat de les matrius de rotació, és més fàcil
determinar de quina manera canvien els elements de la matriu A desprès de la
transformació i introduir aquests canvis directament, en comptes de realitzar el producte
matricial. Amb un anàlisi anàleg al de les eq. (5) i (6) es troba que
{
qpiAAAA
AAAA
AAAAA
AAAAA
AA
iqipqiiq
iqippiip
pqqqppqqqq
pqqqpppppp
qppq
,cossin''
sincos''
2sinsin)('
2sinsin)('
0''
2
2
≠∀⎪⎩
⎪⎨⎧
+−⇐=
+⇐=
⎪⎩
⎪⎨⎧
−−+=
+−−=
==
αα
αα
αα
αα
(10)
Per tant el que fem amb l’algorisme de Jacobi és recalcular els elements de la matriu A
que canvien en cada iteració (per tant, sobreescrivim la matriu original)
Finalment, hem vist que la matriu X es troba com a producte de les matrius de rotació
11

Tècniques Computacionals, Curs 2007-2008. Pedro Salvador
de cada transformació. Seria molt més eficient computacionalment el anar multiplicant
les matrius de rotació en cada iteració que no pas guardar-les totes i multiplicar-les al
final. Per tant, en cada iteració hauríem de fer el producte acumulatiu amb la nova
matriu. Però, tenint en compte l’estructura d’aquestes matrius, ens resulta encara més
eficient fer el mateix que amb la matriu A , és a dir, determinar quins elements de R1
canvien i de què manera quan es fes el producte X’ = R2 R1 i guardar-ho, per en la
següent iteració multiplicar-ho per R3 i així successivament
Es pot demostrar que si fem el producte X’ = R pq(α) X, els únics elements diferents
entre les matrius X’ i X es troben a les fileres p i q i la seva relació és la següent
iXXX
XXX
iqipiq
iqipip∀
⎪⎩
⎪⎨⎧
+−=
+=
αα
αα
cossin'
sincos' (11)
Només hem de vigilar amb la primera iteració, on la matriu X’ seria directament la
matriu R1. Tanmteix, podem fer servir l’eq. (11) en qualsevol cas si inicialitzem la
matriu X con a matriu identitat, I, ja que X = R1 I = R1.
12
perico
Highlight

Tècniques Computacionals, Curs 2007-2008. Pedro Salvador
Per tant, el mètode de Jacobi es podria resumir amb l’algorisme següent
llegir matriu A
Inicialitzar matriu X a identitat
set toler
ilog=0
iter=0
do mentre (ilog=0)
trobar l’element maxim de fora de la diagonal (offdiag) i posició :fila p, columna q
if (offdiag>toler o maxim nombre d’iteracions exhaurit)
determinar l’angle de rotació α
recalcular els nous elements de A (equacions 10)
Apq=Aqp=0
App, Aqq
Aip, Aiq ∀i≠p,q
recalcular els elements de la matriu X (equacions 11)
Xip, Xiq
else
ilog=1
end if
iter = iter + 1
end do
escriure X i A
fi
13

Tècniques Computacionals, Curs 2007-2008. Pedro Salvador
Exemple 1:
Matriu topològica per a la molècula de ciclobutè:
0.0000 1.0000 0.0000 1.0000 1.0000 0.0000 1.0000 0.0000 0.0000 1.0000 0.0000 1.0000 1.0000 0.0000 1.0000 0.0000
Tolerància: 1.0e-6
Resultats:
Matriu després de la iteració 1: -1.0000 0.0000 -0.7071 0.7071 0.0000 1.0000 0.7071 0.7071 -0.7071 0.7071 0.0000 1.0000 0.7071 0.7071 1.0000 0.0000
Iter 2 -1.0000 0.0000 -1.0000 0.0000 0.0000 1.0000 0.0000 1.0000 -1.0000 0.0000 -1.0000 0.0000 0.0000 1.0000 0.0000 1.0000
Iter 3 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000 0.0000 1.0000 0.0000 0.0000 -2.0000 0.0000 0.0000 1.0000 0.0000 1.0000
Iter 4 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 -2.0000 0.0000 0.0000 0.0000 0.0000 2.0000
Matriu diagonal final:
0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 -2.0000 0.0000 0.0000 0.0000 0.0000 2.0000
Matriu de vectors propis (X)
0.5000 0.5000 0.5000 0.5000 -0.5000 0.5000 -0.5000 0.5000 -0.5000 -0.5000 0.5000 0.5000 0.5000 -0.5000 -0.5000 0.5000
Error: (Element més gran de fora de la diagonal) 5.55E-17
14

Tècniques Computacionals, Curs 2007-2008. Pedro Salvador
Exemple 2:
Matriu topològica per a la molècula de benzè:
0.0000 1.0000 0.0000 0.0000 0.0000 1.0000 1.0000 0.0000 1.0000 0.0000 0.0000 0.0000 0.0000 1.0000 0.0000 1.0000 0.0000 0.0000 0.0000 0.0000 1.0000 0.0000 1.0000 0.0000 0.0000 0.0000 0.0000 1.0000 0.0000 1.0000 1.0000 0.0000 0.0000 0.0000 1.0000 0.0000
Tolerància: 1.0e-6
Matriu diagonal final (després de 32 iteracions):
-1.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 -2.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 -1.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 2.0000
Matriu de vectors propis (X)
0.5136 0.5026 0.4082 -0.2841 0.2638 0.4082 -0.4852 0.4974 -0.4082 0.2932 0.3129 0.4082 -0.0284 -0.0053 0.4082 0.5773 -0.5767 0.4082 0.5136 -0.5026 -0.4082 0.2841 0.2638 0.4082 -0.4852 -0.4974 0.4082 -0.2932 0.3129 0.4082 -0.0284 0.0053 -0.4082 -0.5773 -0.5767 0.4082
Error: (Element més gran de fora de la diagonal) 9.7 E-7
15

Tècniques Computacionals, Curs 2007-2008. Pedro Salvador
Altres consideracions:
Cal tenir en compte que els valors propis d’una matriu són únics (tot i que poden ser
degenerats), però la matriu Λ no és única ja que els valors propis es poden ordenar de
manera arbitrària a la diagonal principal. Per tant, hom pot arribar a una matriu diagonal
diferent a les que aquí es donen, però només pel que fa a l’ordre de les columnes. Tot i
això, si les columnes de la matriu diagonal es troben en un altre ordre, el mateix ha de
ser amb les columnes de la matriu de vectors propis.
Un altre factor a tenir en compte és que, com hem vist en la secció 1, els vectors propis
associat s a valors propis iguals (degenerats) no estan definits de manera única, de
manera que qualsevol combinació lineal entre vectors propis associats a un mateix valor
propi degenerat són també vectors propis vàlids.
Aplicat a l’exemple anterior de la matriu topològica del benzè això vol dir que podríem
substituir les columnes 2 i 4 de la matriu X per qualsevol combinació lineal entre elles
(sempre i quan els dos vectors columna finals siguin linealment independents). El
mateix succeeix per les columnes 1 i 5 de la mateixa matriu o per les columnes 1 i 2 de
la matriu X de l’exemple 1.
16
perico
Highlight

1
2.5 Aplicacions de la diagonalització de matrius quadrades simètriques
Ja hem vist que, si tenim una matriu quadrada (N×N) i simètrica A, i resolem l’equació
secular següent
Λ= XAX (1)
podem escriure l’eq (1) com
TXXA Λ≡ (2)
on X és una matriu unitària (tal que XT = X-1) i Λ és una matriu diagonal.
Ara veurem com el fet de poder expressar la nostra matriu original A en funció de les
matrius X i Λ ens permetrà determinar-ne fàcilment la seva matriu inversa, determinant,
etc...
2.5.1. Determinant d’una matriu
Calcular el determinat d’una matriu de manera directa és força costos a més de
relativament difícil d’implementar. Tanmateix, tenint en compte que
)Bdet()Adet()ABdet( = (3)
i si fem servir l’eq (2) i el fet que la matriu X és unitària tenim
)det()det()Idet()det()XXdet()det()Xdet()Xdet(
)Xdet()det()Xdet()Adet(TT
T
Λ=Λ==Λ=Λ=
=Λ=
(3)

2
Per tant, El determinat de la nostra matriu original A és igual que el de la matriu
diagonal Λ. Però en el cas d’una matriu diagonal el determinat és trivial
∏==Λi
iN...)det( λλλλ 21 (5)
És a dir, el determinant és simplement el productori dels valors propis de la matriu.
En el cas que la matriu no sigui simètrica, podem determinar de manera similar el valor
absolut del seu determinant. Primer de tot, definim una nova matriu S així
AAS T= (6)
Es pot demostrar fàcilment que aquesta nova matriu és simètrica. Per tant, es
diagonalitzable i llavors
Σ= ZSZ , o bé
TZZS Σ= (7)
on Z és una matriu unitària i Σ una matriu diagonal. Aleshores tenim que, donat que el
determinat d’una matriu i el de la seva transposta són equivalents (intercanviar files per
columnes no afecta el determinant) i aplicant l’eq. (3)
2)Adet()Adet()Adet()det()Sdet( T ==Σ= (8)
i per tant
)Sdet()Adet( = (9)

3
2.5.2 Matriu Inversa
En aquest cas podem trobar la matriu inversa d’una matriu simètrica quadrada utilitzant
la relació (2). Tenim
TTT XXXX)XX(A 11111 −−−−−− Λ=Λ=Λ= (10)
on hem fet servir les propietats de la inversa del producte de matrius.
Per tant, si sabéssim la inversa de la matriu diagonal Λ, podríem determinar igualment
la inversa de A fent el producte matricial TXX 1−Λ . Tot i que pot semblar més
complicat, el càlcul de la matriu inversa d’una matriu diagonal és trivial. Es pot veure
fàcilment que la inversa d’una matriu diagonal és també una matriu diagonal a on els
elements de la diagonal no son més que la inversa dels elements de la diagonal de la
matriu original, és a dir ,
( )kk
kk Λ=Λ− 11
(11)
Així, l’expressió pels elements de la matriu inversa queda simplement
( ) ( ) ( ) ( ) ( )
∑
∑∑∑
Λ=
=Λ=Λ= −−−
k kk
jkik
kkj
Tkkik
k llj
Tklikij
XX
XXXXA 111
(12)
A partir de l’equació anterior veiem que una condició per a què una matriu sigui
invertible (no singular) és que tots el valors propis de la matriu siguin diferent de
zero.

4
2.5.3 Potències d’una matriu
La diagonalització ens simplifica molt el càlcul de les potències de matrius. Per
exemple, anem a veure com determinar el quadrat de A. Aplicant l’eq. (2) tenim
T
T
I
TTT
XX
X)XX(X)XX)(XX(AAA
2
2
Λ=
=ΛΛ=ΛΛ==43421
(13)
Per tant només cal determinar el quadrat de la matriu diagonal. Un altre cop, donada la
forma de la matriu diagonal el càlcul és immediat
( )( ) 22
2 0
iiiiiik
kiikii
ijiik
kjikij
Λ=ΛΛ=ΛΛ=Λ
=ΛΛ=ΛΛ=Λ
∑
∑
(14)
Com es pot veure a l’expressió anterior, el quadrat d’una matriu diagonal Λ és també
una matriu diagonal, on els elements de la diagonal són els quadrats dels elements de la
matriu original.
En el cas d’una potència qualsevol k
TkT
I
T
I
T
TTTk
XXX...)XX()XX(X)XX)...(XX)(XX(A...AAA
Λ=ΛΛΛ
=ΛΛΛ==
4342143421 (15)
on els elements de la matriu Λk és calculen simplement a partir dels elements de la
matriu diagonal
( ) ( )kiiiik Λ=Λ (16)

5
De fet, la diagonalització permet determinar no només potències de matrius sinó
qualsevol funció en general d’una matriu.
Per exemple, podem fer la exponencial d’una matriu A com
TA XXee Λ= (17)
essent la matriu Λe una matriu diagonal amb elements
( ) iiee iiΛΛ = (18)
2.5.4 Ortonormalització d’una base de vectors
Suposem que tenim un conjunt de N vectors linealment independents de dimensió N.
Amb aquests podem formar una matriu quadrada on les columnes de la matriu siguin
cadascun dels vectors.
)x...xx(X N21≡ (19)
Aquest conjunt de vectors (base) seria ortonormal si es complís que
⎪⎭
⎪⎬⎫
≠∀=
∀=
jixx
ixx
jT
i
iT
i
0
1
(20)
és a dir que el producte escalar entre dos vectors diferents fos zero, i la norma de cada
vector fos la unitat. En forma matricial això equival a que es compleixi1
IXX T ≡ (21)
Suposem, però, que en un cas general, el nostre conjunt de vectors no és ortonormal.
1 Per tant podem dir que una base és ortonormal si la matriu dels vectors és unitària

6
Llavors tindríem
ISXX T ≠≡ (22)
on S rep el nom de matriu de la mètrica, i conté tots el productes escalars entre els
vectors. La pregunta és, com podem aconseguir un conjunt ortonormalitzat de vectors a
partir del conjunt que disposem? És a dir, com podem trobar un conjunt de vectors que
la seva matriu de la mètrica sigui la matriu identitat?
Anem a veure-ho. Primer definim una altra matriu transformada, Z, com
21−= XSZ (23)
utilitzant la matriu 21−S (arrel quadrada de la matriu de la mètrica S).
Comprovem ara que la nova matriu Z conte vectors ortonormals en columnes
( ) ( ) ( )( ) 2121
21212121
−−
−−−−
=
===
SSS
XSXSXSXSZZT
TTTT
(24)
La matriu S, per construcció, és simètrica i per tant serà diagonalitzable. Podem
expressar tant S com 21−S (una potència de S) com
⎩⎨⎧
Σ=Σ=
⇒Σ=−− T
T
UUSUUS
USU2121 (25)
i llavors substituint en (24) tenim
( ) ( ) ( )( ){ { IUUUUUUUUUU
UUUUUUSSSZZTT
I
T
I
T
I
T
TTTTTT
==ΣΣΣ=ΣΣΣ=
=ΣΣΣ==−−−−
−−−−
4342121212121
21212121
(26)

7
on hem fet servir el fet que la transposada d’una matriu diagonal és ella mateixa i que
els elements del producte de matrius diagonals és el producte dels elements de la
diagonal de les respectives matrius.
Hem demostrat que la matriu Z conté vectors ortonormals, que és el que buscàvem. Així
doncs, per ortogonalitzar el nostre conjunts de vector inicial, X, només cal multiplicar la
matriu per la dreta per l’arrel quadrada de la matriu de la mètrica del conjunt de vectors
inicial
( )Tiótransfomac UUXXSZX 2121 −− Σ==⎯⎯⎯⎯ →⎯ (27)
i aquesta darrera la podem trobar a partir la diagonalització de la matriu de la mètrica.
Aquest procés rep el nom de ortogonalització de Löwdin i ´s’utilitza freqüentment en el
camp de la Química Quàntica.

Técnicas Computacionales, Curso 2007-2008. Pedro Salvador
3.1 - Ajuste de curvas e interpolación El ajuste de curvas es un proceso mediante el cual, dado un conjunto de N pares de
puntos {xi, yi} (siendo x la variable independente e y la dependiente), se determina una
función matemática f(x) de tal manera que la suma de los cuadrados de la diferencia
entre la imagen real y la correspondiente obtenida mediante la función ajustada en cada
punto sea mínima:
⎟⎠
⎞⎜⎝
⎛−= ∑
N
iii xfy 2))((minε
Generalmente, se escoge una función genérica f(x) en función de uno o más parámetros
y se ajusta el valor de estos parametros de la manera que se minimice el error
cuadrático, ε. La forma más típica de esta función ajustada es la de un polinomio de
grado M; obteniendose para M = 1 un ajuste lineal (o regresión lineal),
xaaxf 10)( +=
para M = 2 un ajuste parabólico, 2
210)( xaxaaxf ++=
etc..
Por otro lado podemos tener un conjunto de datos multidimensionales; es decir, un
conjunto de N puntos en un espacio k+1-dimensional del tipo { xi(1), xi
(2), ..., xi(k),... yi,}.
La función que ajustaremos a estos puntos será una función de k variables
y = f(x(1) (2) (k), x ,..., x )
El ajuste multidimensional más sencillo es considerar una dependencia lineal de la
función respecto a cada una de las variables de que depende; es decir, ajustando una
funcion del tipo )()2(
2)1(
10)()2()1( ...),...,,( k
kk xaxaxaaxxxf ++++=
de tal manera que se minimice el error cuadrático respecto al conjunto de parámetros
{a , a0 1,..,ak}. Es lo que se conoce como ajuste o regresión multilineal.
En esta sección veremos que el ajuste lineal, el de un polinomio de grado M y el ajuste
multilineal se pueden expresar dentro de un mismo formalismo de manera que las
respectivas soluciones al problema se pueden determinar mediante algoritmos
prácticamente análogos.
1

Técnicas Computacionales, Curso 2007-2008. Pedro Salvador
3.1.1. Regresión lineal
Supongamos que tenemos un conjunto de N puntos en el plano {xi, yi}. El objetivo es
determinar la ecuación de la recta tal que minimiza el error cuadrático
⎟⎠
⎞⎜⎝
⎛−−=⎟
⎠
⎞⎜⎝
⎛−= ∑∑
N
iii
N
i
calcii xaayyy 2
102 )(min)(minε
(ordenada al origen) y arespecto a los parámetros a (pendiente). 0 1
Matemáticamente:
0222)(2 10100
=−−=−−=∂∂ ∑∑∑
N
ii
N
ii
N
iii xaNayxaay
aε
0222)(2 21010
1
=−−=−−=∂∂ ∑∑∑∑
N
ii
N
ii
N
iii
N
iiii xaxayxxxaay
aε
Simplificando las ecuaciones anteriores vemos que se debe cumplir que
∑∑ =+N
ii
N
ii yxaNa 10
∑∑∑ =+N
iii
N
ii
N
ii yxxaxa 2
10
o bien, dividiendo ambas ecuaciones por el numero total de puntos e introduciendo
valores medios
xyxaxa
yxaa
=+
=+2
10
10
En forma matricial, podemos escribir
⎟⎟⎠
⎞⎜⎜⎝
⎛=⎟⎟
⎠
⎞⎜⎜⎝
⎛⎟⎟⎠
⎞⎜⎜⎝
⎛xyy
aa
xxx
1
02
1
por lo que determinar los parámetros de la recta se resume a resolver el sistema de
ecuaciones lineales de dos ecuaciones y dos incógnitas anterior.
2

Técnicas Computacionales, Curso 2007-2008. Pedro Salvador
Algoritmo general matricial
Consideremos ahora el mismo problema desde otra perspectiva. Vamos a suponer que
los N puntos pueden pasar exactamente por la recta que buscamos. En este caso,
plantearíamos el siguiente sistema N de ecuaciones con 2 incógnitas
⎪⎪⎩
⎪⎪⎨
⎧
=+
=+=+
NN yxaa
yxaayxaa
10
2210
1110
...
o bien, en forma matricial
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=⎟⎟⎠
⎞⎜⎜⎝
⎛
⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛
NN y
yy
aa
x
xx
...1
......11
2
1
1
02
1
yxA rr =⋅
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
Ny
yy
y...
2
1
r
⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛
=
Nx
xx
A
1......
11
2
1
⎟⎟⎠
⎞⎜⎜⎝
⎛=
1
0
aa
xr
Como ya hemos visto, una manera directa de resolver los sistemas de ecuaciones
expresados en forma matricial es la de multiplicar por la izquierda a ambos lados de la
igualdad por la inversa de la matriz de coeficientes. sin embargo, en este caso, al tener
mas ecuaciones que incógnitas, la matriz de coeficientes, A, no es una matriz cuadrada
(tendrá dimensión N × 2) por lo que no esta definida su inversa. Una posible estrategia a
seguir es multiplicar la ecuación matricial anterior por la transpuesta de la matriz de
coeficientes (el producto de una matriz por su transpuesta es siempre una matriz
cuadrada y simétrica) de manera que tendremos
yAxAA TT rr ⋅=⋅⋅ yAz T rr ⋅= AAS T ⋅=
El sistema de N ecuaciones y dos incógnitas inicial lo hemos condensado en otro
sistema de dos ecuaciones y dos incógnitas dado por
zxS rr =⋅
Ahora bien, la matriz S es una matriz cuadrada de dimensión 2×2 y simétrica por lo que
es invertible así que podemos escribir
yASxSS T rr ⋅⋅=⋅⋅ −− 11
y por tanto, el vector que buscamos nos quedaría de la forma
yASx T rr ⋅⋅= −1
3

Técnicas Computacionales, Curso 2007-2008. Pedro Salvador
Ahora bien, representa esta estrategia una solución diferente al problema de la que
hemos deducido anteriormente mediante minimización del error cuadrático?
Veremos a continuación que no es el caso.
A partir de la estructura de la matriz A, el producto de su transpuesta por ella misma
resulta en
⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛
=⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛
⎟⎟⎠
⎞⎜⎜⎝
⎛=⋅
∑∑
∑
==
=N
ii
N
ii
N
ii
N
N
T
xx
xN
x
xx
xxxAA
1
2
1
12
1
21
1......
11
...1...11
Del mismo modo, el producto de AT por el vector de términos independientes queda
⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛
=
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
⎟⎟⎠
⎞⎜⎜⎝
⎛=⋅=
∑
∑
=
=N
iii
N
ii
N
N
T
yx
y
y
yy
xxxyAz
1
12
1
21 ......1...11rr
por lo que la ecuación matricial 2×2 anterior la podemos escribir mas explicitamente
como
⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛
=⎟⎟⎠
⎞⎜⎜⎝
⎛
⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛
∑
∑
∑∑
∑
=
=
==
=N
iii
N
ii
N
ii
N
ii
N
ii
yx
y
aa
xx
xN
1
1
1
0
1
2
1
1 .
Dividiendo cada ecuación por N y utilizando la notación típica para el valor medio
llegamos a
⎟⎟⎠
⎞⎜⎜⎝
⎛=⎟⎟
⎠
⎞⎜⎜⎝
⎛⎟⎟⎠
⎞⎜⎜⎝
⎛xyy
aa
xxx
1
02
1
que es exactamente el mismo sistema de ecuaciones al que habíamos llegado
anteriormente imponiendo la condición de mínimo error cuadrático.
Así pues, podemos plantear el siguiente algoritmo para el ajuste lineal
a) Lectura de los N pares de valores {xi, yi} y construcción de las matriz A y vector y.
b) Construcción de la transpuesta de la matriz A: AT
c) Construcción de la matriz S mediante el producto matricial ATA
d) Construcción del vector z mediante el producto matriz por vector ATy -1e) Inversión de matriz S: S
f) Producto matriz por vector S-1 z para obtener el vector de soluciones final.
4

Técnicas Computacionales, Curso 2007-2008. Pedro Salvador
A priori puede parecer un algoritmo demasiado complicado para un problema tan
simple como la regresión lineal, para el que existen fórmulas directas de
implementación sencilla. Sin embargo, vamos a ver que podemos extender este
algoritmo de manera trivial a otro tipo de ajustes.
5

Técnicas Computacionales, Curso 2007-2008. Pedro Salvador
3.1.2. Ajuste polinómico por mínimos cuadrados.
De manera análoga al caso lineal, el objetivo es determinar la ecuación del polinomio de
grado M que minimiza el error cuadrático
⎟⎠
⎞⎜⎝
⎛−−−−=⎟
⎠
⎞⎜⎝
⎛−= ∑∑
N
i
MiMiii
N
i
calcii xaxaxaayyy 22
2102 )...(min)(minε
, a ,... arespecto a los parámetros M +1 parámetros a0 1 M .
Por ejemplo, para un ajuste parabólico (M = 2), la condición de mínimo del error
cuadrático lleva a las ecuaciones siguientes:
02222)(2 2210
2210
0
=−−−=−−−=∂∂ ∑∑∑∑
N
ii
N
ii
N
ii
N
iiii xaxaNayxaxaay
aε
02222)(2 32
210
2210
1
=−−−=−−−=∂∂ ∑∑∑∑∑
N
ii
N
ii
N
ii
N
iii
N
iiiii xaxaxayxxxaxaay
aε
02222)(2 42
31
20
222210
2
=−−−=−−−=∂∂ ∑∑∑∑∑
N
ii
N
ii
N
ii
N
iii
N
iiiii xaxaxayxxxaxaay
aε
Procediendo de manera análoga al caso lineal llegamos a que la determinación de los
parámetros del polinomio pasa por la resolución de un sistema de ecuaciones de la
forma:
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛=
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛
⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛
yxxyy
aaa
xxxxxxxx
22
1
0
432
32
21
Para el caso general de un polinomio de grado M ya podemos intuir que la solución
vendrá dada por un sistema de ecuaciones lineales de dimensión (M+1) ×(M+1) de la
forma
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
+
+
yx
xyy
a
aa
xxx
xxxxx
MM
MMM
M
M
.........
..................1
1
0
21
12
Una manera de implementar el ajuste polinomial general es la de escribir un
6

Técnicas Computacionales, Curso 2007-2008. Pedro Salvador
subprograma (función) general de la forma
⎟⎠
⎞⎜⎝
⎛≡→ ∑
=
N
i
qi
pi
qp yxN
yxyxqpNf1
1),,,,( rr
para determinar todos los promedios de potencias de x y productos de éstas por y que
aparecen en la matriz de coeficientes y de términos independientes.
3),,0,3,(
),,1,1,(),,0,1,(
xyxNf
xyyxNfxyxNf
→
→
→
rr
rr
rr
Sin embargo, es mucho mas sencillo aplicar el algoritmo general matricial descrito
anteriormente para el caso lineal. Ahora, para el ajuste de un polinomio de grado M
plantearíamos un sistema N de ecuaciones con M+1 incógnitas (incluyendo el término
independiente)
⎪⎪
⎩
⎪⎪
⎨
⎧
=++++
=++++
=++++
NMNMNN
MM
MM
yxaxaxaa
yxaxaxaa
yxaxaxaa
......
...
...
2210
22222210
11212110
o bien, en forma matricial
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
NMMN
MN
M
NN y
yy
a
aa
x
xx
xx
xxxx
............1.........1...1...1
2
1
1
01
2
222
211
yxA rr =⋅
Así pues, una vez construida la matriz A de dimensión N × M + 1 y el vector de
coeficientes y a partir de los N pares de puntos {xi, yi}, simplemente aplicamos los
pasos b) a f) descritos anteriormente.
Un algoritmo general de ajuste de una función polinómica debería solicitar únicamente:
a) el numero de total de pares de puntos de que disponemos, N, y
b) el grado del polinomio que se pretende ajustar, M
A partir de aquí, deberemos definir en nuestro programa la matriz de coeficientes A de
dimensión N × M + 1 y el vector de coeficientes y de dimensión N. Los diferentes pasos
7

Técnicas Computacionales, Curso 2007-2008. Pedro Salvador
del algoritmo requieren el uso de la matriz transpuesta (de dimensión M + 1 × N), la
matriz resultante del producto de la transpuesta de A por ella misma y su inversa (de
dimensión M+1 × M+1 ambas) y el vector transformado por la transpuesta de A (de
dimensión M + 1), así como el vector de soluciones, de dimensión M + 1.
8

Técnicas Computacionales, Curso 2007-2008. Pedro Salvador
3.1.3. Regresión multilineal
El algoritmo matricial anterior se puede adaptar de manera sencilla para el caso de la
regresión multilineal.
En este caso disponemos de un conjunto de datos multidimensionales; es decir, un
conjunto de N puntos en un espacio k+1-dimensional del tipo { xi(1), xi
(2), ..., xi(k),... yi,}.
La función que ajustaremos a estos puntos será del tipo )()2(
2)1(
10)()2()1( ...),...,,( k
kk xaxaxaaxxxf ++++=
Si planteamos el sistema de ecuaciones N ecuaciones con k incógnitas para la solución
exacta tendremos
⎪⎪
⎩
⎪⎪
⎨
⎧
=++++
=++++
=++++
Nk
NkNN
kk
kk
yxaxaxaa
yxaxaxaa
yxaxaxaa
)()2(2
)1(10
2)(
2)2(
22)1(
210
1)(
1)2(
12)1(
110
......
...
...
o bien, en forma matricial
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
Nkk
N
kN
k
NN y
yy
a
aa
x
xx
xx
xxxx
............1.........1...1...1
2
1
1
0
)(
)(
)(1
)2()1(
)2(2
)1(2
)2(1
)1(1
yxA rr =⋅
donde las columnas de la matriz de coeficientes A corresponden simplemente a los N
valores de entrada de cada dimensión o categoría (incluyendo una columna extra de “1”
relativa al término independiente).
En este punto podemos aplicar el algoritmo matricial general exactamente de la misma
manera que lo haríamos para ajustar un polinomio de grado k a un conjunto de N pares
de puntos.
9

Técnicas Computacionales, Curso 2007-2008. Pedro Salvador
3.1.4. Coeficiente de determinación
El coeficiente de determinación, R2, definido entre 0 y 1, nos da una idea de la bondad
del ajuste, de manera que para valores cercanos a 1 el ajuste es perfecto mientras que
para valores cercanos a cero indica inexistencia de relación entre x e y con el modelo de
ajuste propuesto.
El coeficiente R2 viene dado por la relación entre la varianza de los datos explicada con
el modelo y la varianza de los datos experimentales. En concreto
( )
( )∑
∑
−
−= N
ii
N
i
calci
yy
yyR
2
2
2
ydonde representa el valor medio de los valores de la variable independiente e
los valores calculados para cada punto usando el modelo ajustado a los datos.
calciy
La implementación computacional de este índice es muy sencilla una vez ajustado el
modelo tras resolver el sistema de ecuaciones que plantea el algoritmo matricial general.
En el caso de la regresión lineal, el coeficiente de determinación tiene la misma
expresión que el coeficiente de regresión r2, que indica también cómo de
correlacionadas estadísticamente están las variables aleatorias x e y . Es importante ver
que ambos coeficientes tiene significados e interpretaciones diferentes y que, salvo en el
caso de la regresión lineal, no coinciden.
Así, se puede comprobar que para el caso de la regresión lineal este índice coincide con
el coeficiente de regresión, definido a partir de la relación entre la covarianza de las
variables aleatorias x e y y el producto de la raíz cuadrada de las varianzas individuales
(desviación típica) de ambas variables, con el fin de obtener un parámetro adimensional
( )( ) yx
XYCov
yyxx
yxxyrσσ
)(2222=
−−
−=
Como se puede ver, el valor de este coeficiente es independiente del modelo ajustado,
ya que únicamente indica la relación estadística entre el conjuntos de datos.
10
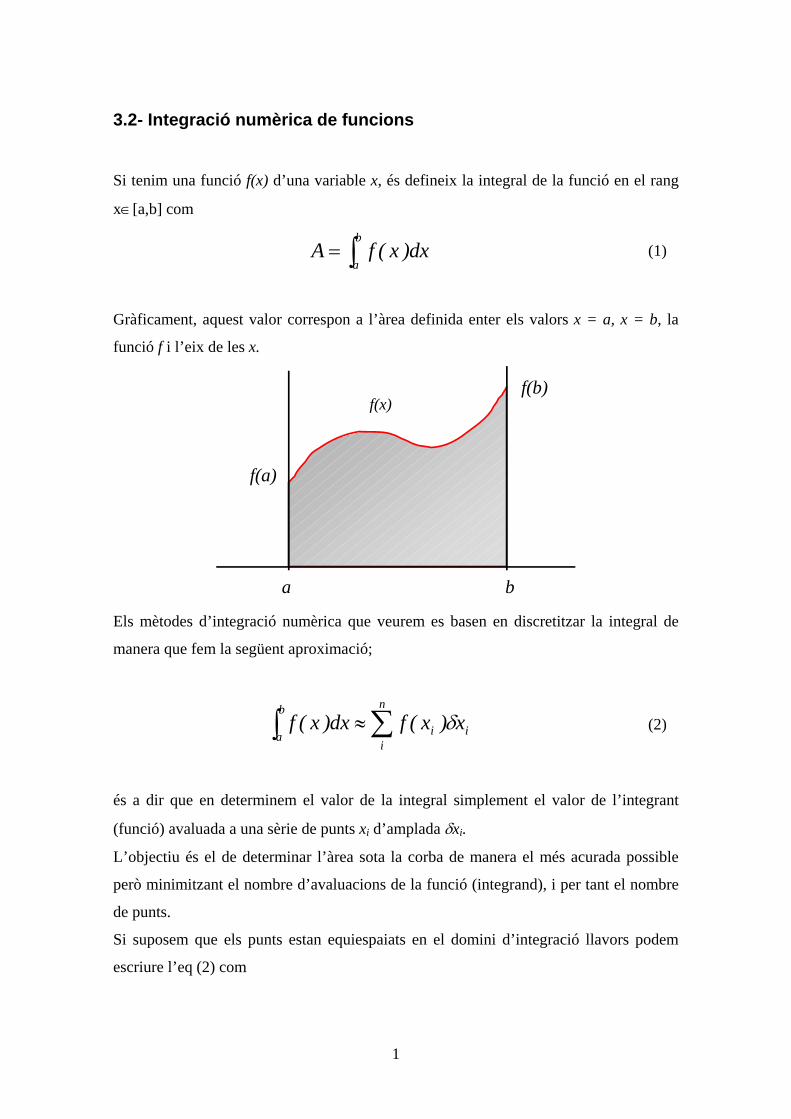
1
3.2- Integració numèrica de funcions
Si tenim una funció f(x) d’una variable x, és defineix la integral de la funció en el rang
x∈[a,b] com
∫=b
adx)x(fA (1)
Gràficament, aquest valor correspon a l’àrea definida enter els valors x = a, x = b, la
funció f i l’eix de les x.
a b
f(a)
f(b)f(x)
Els mètodes d’integració numèrica que veurem es basen en discretitzar la integral de
manera que fem la següent aproximació;
∑∫ ≈n
iii
b
ax)x(fdx)x(f δ (2)
és a dir que en determinem el valor de la integral simplement el valor de l’integrant
(funció) avaluada a una sèrie de punts xi d’amplada δxi.
L’objectiu és el de determinar l’àrea sota la corba de manera el més acurada possible
però minimitzant el nombre d’avaluacions de la funció (integrand), i per tant el nombre
de punts.
Si suposem que els punts estan equiespaiats en el domini d’integració llavors podem
escriure l’eq (2) com
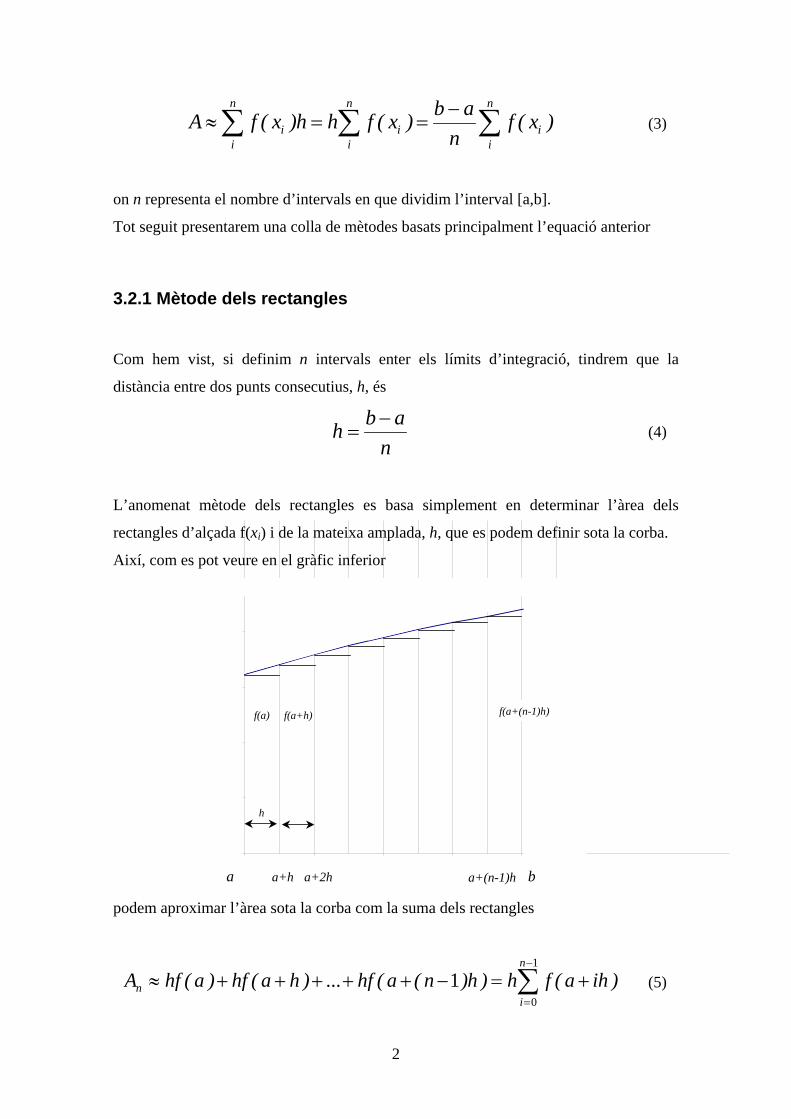
2
∑ ∑ ∑−==≈
n
i
n
i
n
iiii )x(f
nab)x(fhh)x(fA (3)
on n representa el nombre d’intervals en que dividim l’interval [a,b].
Tot seguit presentarem una colla de mètodes basats principalment l’equació anterior
3.2.1 Mètode dels rectangles
Com hem vist, si definim n intervals enter els límits d’integració, tindrem que la
distància entre dos punts consecutius, h, és
nabh −
= (4)
L’anomenat mètode dels rectangles es basa simplement en determinar l’àrea dels
rectangles d’alçada f(xi) i de la mateixa amplada, h, que es podem definir sota la corba.
Així, com es pot veure en el gràfic inferior
f(a)
b
h
a+h a+2h a+(n-1)h
f(a+h)
a
f(a+(n-1)h)
podem aproximar l’àrea sota la corba com la suma dels rectangles
∑−
=
+=−+++++≈1
01
n
in )iha(fh)h)n(a(hf...)ha(hf)a(hfA (5)
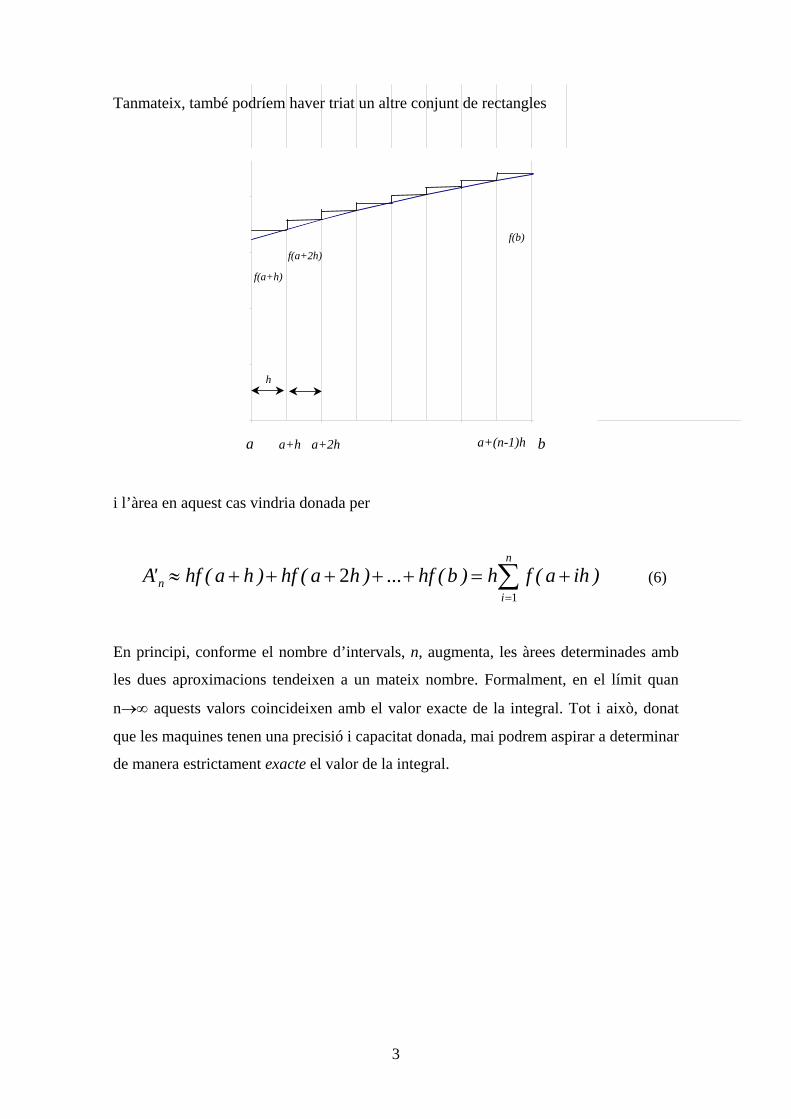
3
Tanmateix, també podríem haver triat un altre conjunt de rectangles
a b
h
a+h a+2h a+(n-1)h
f(a+h)
f(a+2h)
f(b)
i l’àrea en aquest cas vindria donada per
∑=
+=+++++≈n
in )iha(fh)b(hf...)ha(hf)ha(hf'A
1
2 (6)
En principi, conforme el nombre d’intervals, n, augmenta, les àrees determinades amb
les dues aproximacions tendeixen a un mateix nombre. Formalment, en el límit quan
n→∞ aquests valors coincideixen amb el valor exacte de la integral. Tot i això, donat
que les maquines tenen una precisió i capacitat donada, mai podrem aspirar a determinar
de manera estrictament exacte el valor de la integral.
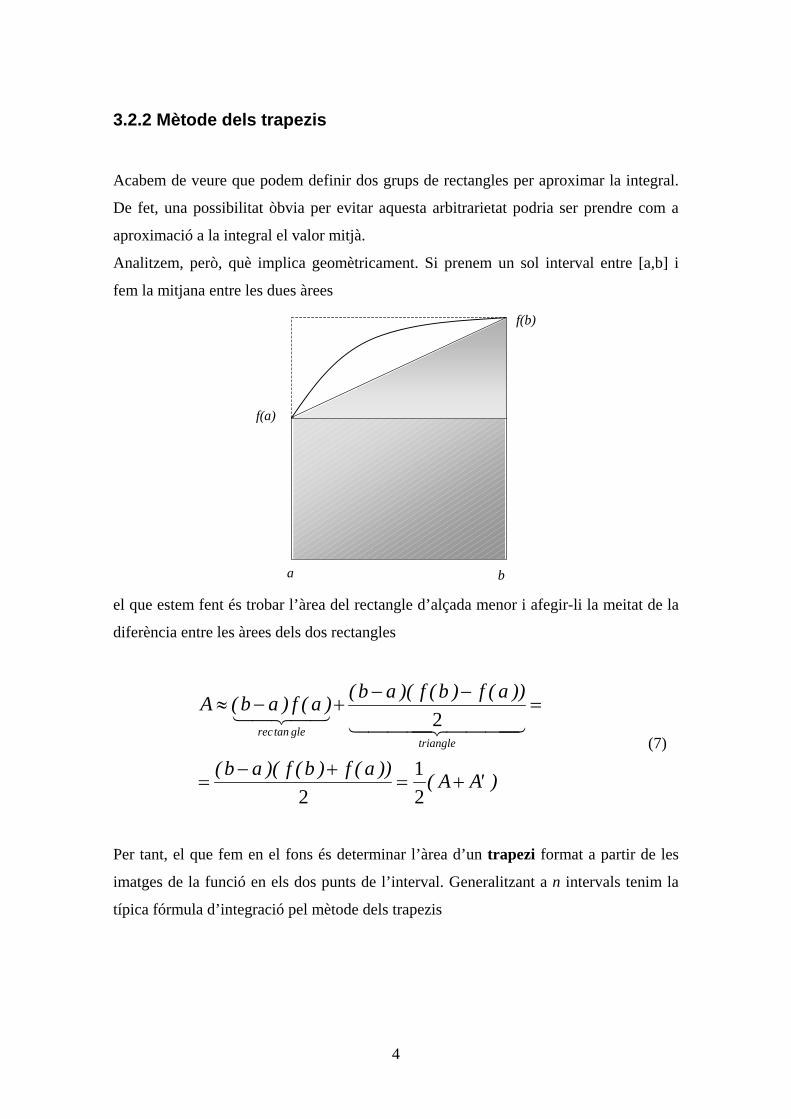
4
3.2.2 Mètode dels trapezis
Acabem de veure que podem definir dos grups de rectangles per aproximar la integral.
De fet, una possibilitat òbvia per evitar aquesta arbitrarietat podria ser prendre com a
aproximació a la integral el valor mitjà.
Analitzem, però, què implica geomètricament. Si prenem un sol interval entre [a,b] i
fem la mitjana entre les dues àrees
a b
f(a)
f(b)
el que estem fent és trobar l’àrea del rectangle d’alçada menor i afegir-li la meitat de la
diferència entre les àrees dels dos rectangles
)'AA())a(f)b(f)(ab(
))a(f)b(f)(ab()a(f)ab(A
trianglegletanrec
+=+−
=
=−−
+−≈
21
2
2 4444 34444 2143421
(7)
Per tant, el que fem en el fons és determinar l’àrea d’un trapezi format a partir de les
imatges de la funció en els dos punts de l’interval. Generalitzant a n intervals tenim la
típica fórmula d’integració pel mètode dels trapezis

5
[ ]
[ ]
⎟⎠
⎞⎜⎝
⎛+++=
=++++++
+−+++++=+=
∑−
=
1
12
2
22
122
1
n
i
nntrapn
)iha(f)b(f)a(fh
)b(f...)ha(f)ha(fh
)h)n(a(f...)ha(f)a(fh)'AA(A
(8)
Fixeu-vos que per trobar l’àrea en necessitem avaluar la funció en n+1 punts.
Arribats a aquest punt ens hem de preocupar ara per la pressió dels resultats que podem
obtenir. En principi (veure més endavant), conforme augmentem el nombre d’intervals
hauríem de ser capaços de trobar el valor de la integral amb més precisió. Una manera
obvia de determinar la pressió amb la que estem treballant és la de comparar el resultat
obtingut amb un nombre determinat d’intervals amb el que obtenim augmentant-ne el
nombre d’intervals. Tanmateix, tenint en compte que un dels objectius per qüestions
computacionals és el de calcular la imatge de la funció en el mínim nombre de punts,
hem de trobar una manera intel·ligent d’augmentar el nombre d’intervals.
La idea consisteix simplement en doblar el nombre de punts però de tal manera que
podem aprofitar els n+1 punts anteriors. Això ho farem subdividint en dos els intervals
existents.
Tot seguit veurem les avantatges d’aquesta tècnica. Primer de tot, anomenarem k a
l’ordre del càlcul, que es relaciona amb el nombre d’intervals, n, de la següent manera
,..,,kn k 2102 == (9)
Definim Tk com l’aproximació de trapezis d’ordre k, que correspon un càlcul realitzat
amb 2k intervals
⎟⎠
⎞⎜⎝
⎛+++= ∑
−
=
1
12
2
n
ik
kk )iha(f)b(f)a(fhT (10)
Òbviament, la mida del interval (hk, distància entre punts) depèn de l’ordre. El què és
més important, però, és la relació entre la mida de dos intervals d’ordres consecutius
perico
Highlight
perico
Highlight

6
11 21
221
2 −− =−
=−
= kkkk hababh (11)
És a dir que si augmentem l’ordre del càlcul en una unitat estarem dividint per dos la
mida de l’interval.
Amb la nomenclatura anterior i prenent l’eq (8) anem a veure les expressions per als
primers ordres. Per un interval (k = 0)
( ))b(f)a(fhT +=20
0 (12)
Per dos (k =1):
( ))ha(f)b(f)a(fhT 11
1 22
+++= (13)
Per quatre (k = 2):
( ))ha(f)ha(f)ha(f)b(f)a(fhT 2222
2 322222
+++++++= (14)
Fixem-nos, però , que podem escriure l’expressió (13) com
( )
)ha(fhT)ha(fh))b(f)a(f(h
)ha(f)b(f)a(fhT
110110
11
1
21
221
22
++=+++=
=+++=
(15)
Similarment, per l’expressió (14)
( )
))ha(f)ha(f(hT
))ha(f)ha(f(h))ha(f)b(f)a(f(h
)ha(f)ha(f)ha(f)b(f)a(fhT
ha
2221
22221
2222
2
321
32222
1
322222
1
++++=
=+++++++=
=+++++++=
+321 (16)
De fet, es pot veure que en un cas general tenim la relació següent

7
senari)iha(fhTTn
ikkkk ∈++= ∑
−
=−
1
112
1 (17)
L’avantatge d’aquest mètode es que un cop calculada la integral per un determinat ordre
k, l’aproximació corresponent al següent ordre (k+1) només necessita avaluar la funció
als punts centrals de cada interval. Això és així perquè doblem el nombre d’intervals i
per tant si incrementem el nombre d’intervals d’una altra manera (per exemple passar de
50 a 70) hauríem de recalcular la funció en tots (o gran part) dels punts.
Això ens permet dissenyar un algorisme força intel·ligent per determinar la integral amb
una precisió determinada. Bàsicament en calculem el valor per un ordre determinat i el
comparem amb el trobat amb un ordre una unitat inferior. Si la diferència entre els dos
valors és suficientment petita per poder considerar-lo convergit, acabarem. En cas
contrari en determinarem la integral amb un ordre més a partir de la formula (17) i així
successivament. L’algorisme podria ser, per exemple
Definir interval d’integració, a,b Definir ordre màxim de càlcul, kmax
Definir tolerància, toler
( ))b(f)a(fhT +=20
0
k = 1 fer mentre k menor que kmax i error més gran que toler n = 2k h = (b-a)/n
senari)iha(fhTTn
inou ∈++= ∑
−
=
1
102
1
error = abs(Tnou-T0) T0 = Tnou end do si k no és igual a kmax llavors Integral=Tnou end if
A banda d’això, el fet de definir el nombre d’intervals d’aquesta manera ens permet
relacionar la tècnica dels trapezis amb una altra molt més acurada: el mètode de
Simpson.
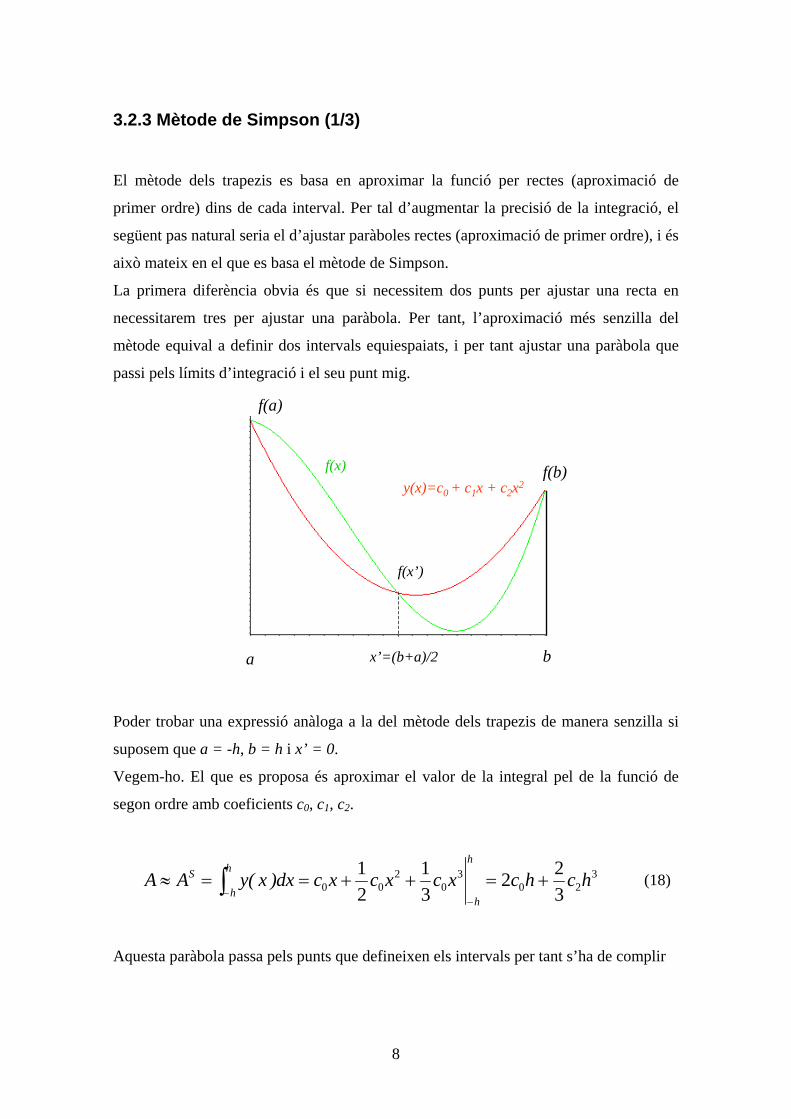
8
3.2.3 Mètode de Simpson (1/3)
El mètode dels trapezis es basa en aproximar la funció per rectes (aproximació de
primer ordre) dins de cada interval. Per tal d’augmentar la precisió de la integració, el
següent pas natural seria el d’ajustar paràboles rectes (aproximació de primer ordre), i és
això mateix en el que es basa el mètode de Simpson.
La primera diferència obvia és que si necessitem dos punts per ajustar una recta en
necessitarem tres per ajustar una paràbola. Per tant, l’aproximació més senzilla del
mètode equival a definir dos intervals equiespaiats, i per tant ajustar una paràbola que
passi pels límits d’integració i el seu punt mig.
a b
f(a)
f(b)
x’=(b+a)/2
f(x’)
y(x)=c0 + c1x + c2x2
f(x)
Poder trobar una expressió anàloga a la del mètode dels trapezis de manera senzilla si
suposem que a = -h, b = h i x’ = 0.
Vegem-ho. El que es proposa és aproximar el valor de la integral pel de la funció de
segon ordre amb coeficients c0, c1, c2.
320
30
200 3
2231
21 hchcxcxcxcdx)x(yAA
h
h
h
h
S +=++==≈−
−∫ (18)
Aquesta paràbola passa pels punts que defineixen els intervals per tant s’ha de complir

9
⎪⎭
⎪⎬
⎫
=++=
+−=−
0
2210
2210
0 c)(fhchcc)h(f
hchcc)h(f
(19)
Si resolem el sistema tenim
22
22
0
202
202
0
h)(f)h(f)h(fc
hc)(f)h(f)h(f
)(fc
−+−=⇒
⇒+=+−
=
(20)
I substituint en l’expressió (18) arribem a l’expressió
( ))(f)h(f)h(fh
hh
)(f)h(f)h(fh)(fAS
043
202
3202 3
2
++−=
=−+−
+=
(21)
Finalment, si desfem el canvi anterior tenim l’expressió general final
( ))ha(f)b(f)a(fhAS +++= 43 (22)
Podem definir més intervals per millorar-ne la precisió. Tanmateix, el pas següent seria
definir quatre intervals, i no tres. De fet, es pot veure fàcilment que el nombre
d’intervals ha de ser parell, sinó ens quedaria un últim interval amb només dos punts
disponibles per ajustar una paràbola.
En el cas de quatre intervals, tindrem
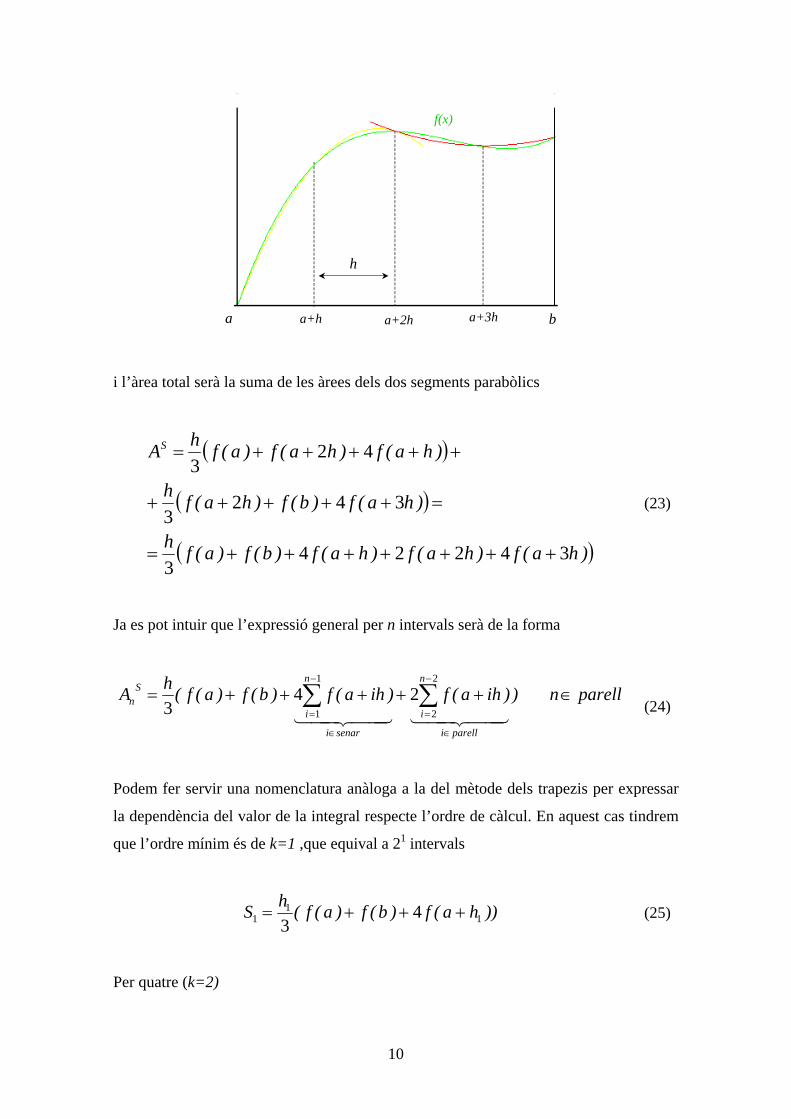
10
a b
f(x)
h
a+h a+2h a+3h
i l’àrea total serà la suma de les àrees dels dos segments parabòlics
( )
( )
( ))ha(f)ha(f)ha(f)b(f)a(fh
)ha(f)b(f)ha(fh
)ha(f)ha(f)a(fhAS
342243
3423
423
+++++++=
=+++++
+++++=
(23)
Ja es pot intuir que l’expressió general per n intervals serà de la forma
parelln))iha(f)iha(f)b(f)a(f(hA
parelli
n
i
senari
n
i
Sn ∈+++++=
∈
−
=
∈
−
=∑∑
44344214434421
2
2
1
124
3 (24)
Podem fer servir una nomenclatura anàloga a la del mètode dels trapezis per expressar
la dependència del valor de la integral respecte l’ordre de càlcul. En aquest cas tindrem
que l’ordre mínim és de k=1 ,que equival a 21 intervals
))ha(f)b(f)a(f(hS 11
1 43
+++= (25)
Per quatre (k=2)

11
))ha(f)ha(f)ha(f)b(f)a(f(hS 2222
2 342243
+++++++= (26)
Si analitzem l’expressió (25) podem veure que
321
34
31
34
6
34
3
011010
21
11
31
0
111
1
010
TTT)TT(T
)ha(fh))b(f)a(f(h
)ha(fh))b(f)a(f(hS
TTT
−+=−+=
=+++=
=+++≡
−
43421444 3444 21 (27)
i, de fet, fent el mateix per l’expressió (26)
321
34
31
33422
231
122121
21
22221
2
121
TTT)TT(T
))ha(f)ha(f(h))ha(f)b(f)a(f(hS
TTT
−+=−+=
=+++++++≡
−
4444 34444 21444444 344444 21
(28)
Per tant, podríem dir que en un cas general
,...,,nTTTS kkkk 321
31 =
−+= − (29)
Existeix doncs una relació clara entre el mètode de Simpson i el dels trapezis.
Si coneixem el valor de la integral calculat amb el mètode dels trapezis amb dos
ordres de càlcul consecutius, k i k-1, podem determinar fàcilment el valor pel
mètode de Simpson d’ordre k mitjançant la senzilla regla donada en l’equació
anterior.

12
Exemple numèric
Veiem els resultats d’aplicar els mètodes que hem vist fins ara a la integral
∫ −−
5
1
2
1dx
exx
k Tk (trapezis) Sk (Simpson)
0 (1) -53.50313616
1 (2) -45.69469062 -43.09187544
2 (4) -43.77193365 -43.13101465
3 (8) -43.29300082 -43.13335655
4 (16) -43.17337456 -43.13349914
5 (32) -43.14347464 -43.13350800
6 (64) -43.13600007 -43.13350855
7 (128) -43.13413146 -43.13350859
8 (256) -43.13366431 -43.13350859
... ...
16 (65536) -43.13350859
Exacte -43.13350859 En parèntesi el nombre d’intervals
Podem veure que mentre que amb el mètode dels trapezis necessitem 216 punts per
obtenir la precisió desitjada, amb Simpson la convergència és molt millor.
Pel que fa a la implementació del mètode, només ens caldrà modificar lleugerament
l’algorisme previ proposat pel mètode dels trapezis. Ara, tot i que no seria estrictament
necessari, el que farem serà emmagatzemar en un vector els resultats de la integració
per trapezis fins a l’ordre desitjat. Un cop disposem d’aquests nombres, podrem obtenir
els resultats amb el mètode de Simpson simplement aplicant l’eq (29).
En aquest cas ens podria resultar útil que el primer índex del vector fos el zero, enlloc
de ú. Per aconseguir això haurem de declarar el vector com
DIMENSION T(0:MAXDIM)
i llavors podrem escriure
T(0)=(b-a)*(f(a)+f(b))

13
3.2.4 Mètode de Romberg
Si hem deduït les expressions per la integració de segments parabòlics (Simpson) a
partir dels valors obtinguts a partir de segments lineals (trapezis), ens podríem plantejar
si a partir dels resultats amb el mètode de Simpson podem arribar a les expressions que
obtindríem d’ajustar segments polinòmics d’ordre més alt. La resposta és sí.
Mitjançant anàlisis anàlegs als descrit anteriorment, es pot demostrar que
,...,kCCCD
,...,kSSSC
kkkk
kkkk
4363
3215
1
1
=−
+=
=−
+=
−
−
(30)
essent Ck i Dk les expressions per a la integral aproximada a partir de segments
polinòmics d’ordre 4 (mètode de Cotes) i 8, respectivament.
Si utilitzem ara la nomenclatura següent
mk
kk
kk
kk
T
CotesCT
SimpsonST
trapecioTT
→≡
→≡
→≡
2
1
0
(31)
on k representa l’ordre del càlcul (relacionat amb el nombre d’intervals) i m l’ordre
d’aproximació del polinomi interpolador (primer, segon, quart, vuitè...), es pot veure
que es compleix
14
11
11
−−
+=−
−−
−m
mk
mkm
km
kTTTT (32)
El mètode de Romberg no és més que la generalització natural de l’esquema anterior
fins a un ordre arbitrari, m.
Fixeu-vos que podem obtenir la integral aproximada amb un ordre de Romberg m i 2k
intervals només amb els valors obtinguts amb un 2k i 2k-1 intervals i un ordre m-1.
La manera més fàcil d’aplicar el mètode és mitjançant la construcció de la anomenada
perico
Highlight

14
Taula de Romberg que es presenta a continuació
mk
mkkk
m
TT...TT............
T...TT...TT
TTT
110
13
13
03
12
02
11
01
00
−
− (33)
La primera columna correspon a les integrals calculades amb el mètode dels trapezis
amb ordre creixent. Les següents columnes corresponen als valors calculats amb els
mètodes de Simpson, Cotes, etc..., però obtinguts, en última instància, únicament a
partir dels valors de la primer columna.
Això vol dir que, amb el mateix cost computacional (no ens cal avaluar la funció en més
punts, només combinar linealment els valors ja obtinguts) d’un càlcul amb el mètode
dels trapezis d’ordre k, aplicant la Taula de Romberg podem obtenir un resultat d’ordre
de Romberg fins a k, el que equival a una integració a partir de segments polinòmics
d’ordre 2k!
Veiem l’efecte en la precisió de la integral de l’exemple anterior
k m=0 m=1 m=2 m=3
0 (1) 53.50313616
1 (2) 45.69469062 43.09187544
2 (4) 43.77193365 43.13101465 43.13362394
3 (8) 43.29300082 43.13335655 43.13351268 43.13351091
4 (16) 43.17337456 43.13349914 43.13350865 43.13350859
5 (32) 43.14347464 43.13350800 43.13350859 43.13350859
6 (64) 43.13600007 43.13350855 43.13350859 43.13350859
7 (128) 43.13413146 43.13350859 43.13350859 43.13350859
Exacte -43.13350859
Ara, amb només 16 intervals aconseguim la precisió desitjada si anem fins a ordre 3 en
la sèrie de Romberg. Òbviament, sempre hi ha la opció de deduir les equacions
corresponents a un mètode amb un polinomi interpolador d’ordre suficientment gran,
implementar el mètode i determinar el valor de la integral directament. L’esquema

15
anterior, no obstant, és més senzill i flexible, ja que permet assolir de manera econòmica
i sistemàtica la precisió desitjada, que pot variar segons les nostres necessitats
computacionals.
Pel que fa a l’algorisme, no serà gaire diferent al del mètode dels trapezis. En aquest
cas, l’opció més senzilla és la d’emmagatzemar la taula de Romberg conforme l’anem
generant. Aquest procés s’haurà de dur a terme per columnes. és a dir, primer caldrà
determinar, fins a un ordre k les aproximacions corresponents al mètode dels trapezis i,
a partir d’elles determinar les corresponents aproximacions per Simpson. Tot seguit, els
valors per Cotes a partir dels de Simpson i així successivament fins a l’ordre de
Romberg màxim, m (m ≤ k).
Definir interval d’integració, a,b Definir ordre màxim de càlcul, kmax Definir ordre màxim de Romberg, mmax
( ))b(f)a(fab),(T +−
=2
00
do k=1 fins kmax n = 2k h = (b-a)/n
senari)iha(fh),k(T),k(Tn
i
∈++−= ∑−
=
1
1
01210
end do do m =1,mmax
14
1111−
−−−−+−= m
)m,k(T)m,k(T)m,k(T)m,k(T
end do escriure T end

16
3.2.5 Anàlisi d’errors i pèrdua de precisió
L’anàlisi d’errors següent ens ajudarà a veure la importància del mètode de Romberg a
la vegada que les seves limitacions
Anem a considerar de nou el mètode dels trapezis. Com hem discutit abans, el què fem
es substituir la integral de la funció en cada interval per la d’un polinomi de primer
ordre (recta)
Per tant podem dir que dins l’interval
)x(Oxcc)x(f 210 ++≈ (33)
on el terme d’error O(xn) vol dir que s’ignoren els termes d’ordre igual o superior a n.
Per tant, també vol dir que l’aproximació és exacta per funcions polinomques
d’ordre inferior a n, en aquest cas una recta
Tanmateix, el que acabem fent és integrar aquesta funció aproximada de manera que
l’error integrat és de l’ordre
)x(O)x(Ob
a
32 =∝ ∫ε (34)
L’estimació de l’error en un cas general, amb n intervals la podem escriure com
⎟⎠⎞
⎜⎝⎛∝⎟
⎠⎞
⎜⎝⎛ −−
=∝ ∑∑ 2
33 1
nO)
nab(O
nab)h(Oh
ii
ε (35)
És a dir, en cada interval l’error és de l’ordre de k , o bé 1/n3 ,però com que s’acumula
per n intervals l’error final serà de l’ordre de 1/n2.
A més, el fet clau de l’aproximació dels trapezis és que es pot demostrar que l’error de
l’aproximació, que comença com hem vist en l’ordre 1/n2 és, de fet, únicament
parell expressat en potències de 1/n.
Això vol dir que si d’alguna manera aconseguim eliminar el terme principal d’error, el
nostre mètode passaria a tenir un error de l’ordre de 1/n4 , el que implicaria que la
integració seria exacta per polinomis d’ordre 3.

17
Com ho podem aconseguir? Suposem que avaluem la integral amb n intervals. L’error
seria 21 nn ∝ε . Si ara doblem el nombre de punts tindrem
⎟⎠⎞
⎜⎝⎛∝⎟⎟
⎠
⎞⎜⎜⎝
⎛∝ 222 4
121
n)n(nε (36)
Llavors, si fem la combinació
⎟⎠⎞
⎜⎝⎛∝− 422
131
34
nnn εε (36)
es pot veure com el terme principal d’error es cancel·la, quedant el següent, que, com
hem dit abans no contindria ordre senar en 1/n.
A més, és fàcil veure que aquesta combinació correspon, de fet, a la descrita en l’eq (29)
pel mètode de Simpson. És a dir, que en passar de trapezis a Simpson en disminuïm
l’error en dos ordres de magnitud, el que implica no només una major precisió sinó una
convergència millor.
Una altra conseqüència immediata és el fet que, tot i basar-se en segments parabòlics, el
mètode de Simpson és exacte per polinomis d’ordre 3.
Ja pots intuir ara la base del mètode de Romberg. El que s’aconsegueix és eliminar els
termes d’error fins a ordre 1/n2(m+1), on m es l’ordre de la sèrie de Romberg. Per tant, el
mètode de Cotes (m=2) té un error de l’ordre 1/n6, la següent columna de la taula 1/n8 i
així successivament.
Fixa’t en les conseqüències d’aquest fet. Per exemple, la integració exacta d’un
polinomi d’ordre 10 és podria aconseguir aplicant Romberg fins a ordre m=4. I
per poder aplicar-ho només en necessitem saber els aproximacions a la integral pel
mètode dels trapezis fent servir 20, 21, 22, 23 i 24 intervals! Curiós, no?
Hi ha, però, un altre factor que no hem tingut en compte fins ara i es que cal tenir
presents els errors d’arrodoniment. La computadora, com ja sabem té una precisió
limitada. En FORTRAN aquesta depèn també del tipus de dada. Les dades tipus REAL
tenen 8 xifres significatives, mentre que les REAL*8 (double precision) en tenen el
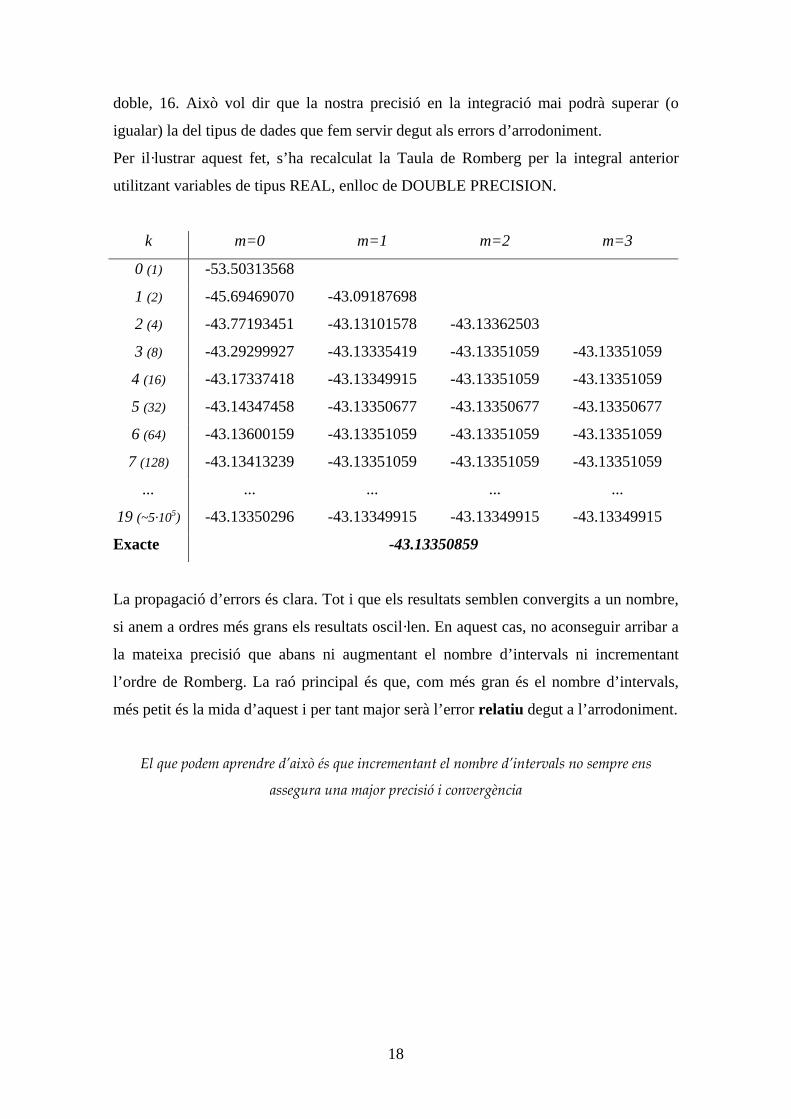
18
doble, 16. Això vol dir que la nostra precisió en la integració mai podrà superar (o
igualar) la del tipus de dades que fem servir degut als errors d’arrodoniment.
Per il·lustrar aquest fet, s’ha recalculat la Taula de Romberg per la integral anterior
utilitzant variables de tipus REAL, enlloc de DOUBLE PRECISION.
k m=0 m=1 m=2 m=3
0 (1) -53.50313568
1 (2) -45.69469070 -43.09187698
2 (4) -43.77193451 -43.13101578 -43.13362503
3 (8) -43.29299927 -43.13335419 -43.13351059 -43.13351059
4 (16) -43.17337418 -43.13349915 -43.13351059 -43.13351059
5 (32) -43.14347458 -43.13350677 -43.13350677 -43.13350677
6 (64) -43.13600159 -43.13351059 -43.13351059 -43.13351059
7 (128) -43.13413239 -43.13351059 -43.13351059 -43.13351059
... ... ... ... ...
19 (~5·105) -43.13350296 -43.13349915 -43.13349915 -43.13349915
Exacte -43.13350859
La propagació d’errors és clara. Tot i que els resultats semblen convergits a un nombre,
si anem a ordres més grans els resultats oscil·len. En aquest cas, no aconseguir arribar a
la mateixa precisió que abans ni augmentant el nombre d’intervals ni incrementant
l’ordre de Romberg. La raó principal és que, com més gran és el nombre d’intervals,
més petit és la mida d’aquest i per tant major serà l’error relatiu degut a l’arrodoniment.
El que podem aprendre d’això és que incrementant el nombre d’intervals no sempre ens
assegura una major precisió i convergència

19
3.2.6 Integració numèrica de funcions: Integrals impròpies
Fins ara hem assumit que l’integrand era una funció que es comportava bé, amb uns
límits d’integració ben definits. En realitat, ens podem trobar amb certs casos on els
mètodes descrits amb anterioritat fallaran.
En distingirem de varis tipus i en veurem quines tècniques podem fer servir per
solucionar-ho.
Límits d’integració no avaluables
En aquest cas, el problema és que no podem determinar la imatge de la funció al/als
límits d’integració. I no podem determinar aquest valor a) perquè no és finit, o b) perquè
no és determinable numèricament.
Exemples típics poden ser les integrals següent1:
11
0−=∫ dx)xln( (1)
85193710
.dxx
)xsin(=∫
π
(2)
En el primer cas la imatge del límit inferior tendeix a -∞, mentre que en el segon tenim
una indeterminació del tipus 0/0. En aquest cas, aplicant l’Hôpital es pot veure que el
seu valor és 1, però mai podrem determinar-ho numèricament. En altres paraules, si el
programa arriba a un càlcul del tipus 0/0 l’algorisme serà inestable (dependent de les
opcions de compilació i del compilador mateix potser que fins i tot s’aturi).
Pel que fa a la resta de l’interval d’integració, no presenta cap problema.
Per tant, l’únic problema és que no podem avaluar la funció en un dels extrems de
l’interval d’integració. La solució podria ser intentar trobar una fórmula que no en
depengués dels valors de la funció als intervals, i això és el que farem.
1 Obviament, només cal preocuparse per integrals que tenen un valor finit. Si una integral divergeix no cal
intentar trobar el valor numèricament!

20
Partirem de l’expressió per al mètode dels trapezis d’ordre k
⎟⎟⎠
⎞⎜⎜⎝
⎛+++= ∑
−
=
1
12
2
kn
ik
kk )iha(f)b(f)a(fhT (3)
on la mida del interval (hk, distància entre punts) depèn de l’ordre de manera que
121
−= kk hh (4)
Amb les expressions 3 i 4 podem escriure la corresponent a l’ordre k-1.
⎟⎟⎠
⎞⎜⎜⎝
⎛+++=
=⎟⎟⎠
⎞⎜⎜⎝
⎛+++=
∑
∑−
=
−
=−
−−
−
−
1
1
1
11
11
1
1
22
22
k
k
n
ikk
n
ik
kk
)hia(f)b(f)a(fh
)iha(f)b(f)a(fhT
(5)
Es pot veure fàcilment que si prenem la combinació 2Tk – Tk-1
senari)iha(fh
)hia(f)iha(fhTT
k
kk
n
ikk
n
ik
n
ikkkk
∈+=
=⎟⎟⎠
⎞⎜⎜⎝
⎛+−+=−
∑
∑∑−
=
−
=
−
=−
−
1
1
1
1
1
11
2
22221
(6)
arribem a una expressió on no apareixen els valors de la funció en els límits
d’integració. A més, si suposem que Tk , conforme augmenta k, convergeix al valor de la
integral, això vol dir que
kkkkk TTTTT ≈−→≈ −− 11 2 (7)
i així, les eq (3) i (6) tendeixen al mateix valor.
Les expressions que no depenen del valor de la funció als límits d’integració (6)

21
s’anomenen fórmules obertes i, de fet, es poden deduir de manera similar expressions
anàlogues pel mètode del Simpson, etc...
Límits d’integració no finits
Aquest és el cas d’integrals impròpies del tipus
∫∫ ∞−
∞ a
adx)x(fdx)x(f (8)
Es presenten dos tipus de problemes. El primer és que no podem representar
numèricament l’infinit. Per tant, hauríem d’aproximar el límit d’integració per un
nombre suficientment gran. Aquesta aproximació serà, en general, força bona donat que
una condició per a que el valor d’una integral d’aquest tipus convergeixi és que la
funció tendeixi a zero als límits no finits. Per tant, tenim que la contribució al valor de la
integral per a valors de x suficientment grans (o petits) serà menyspreable. Fixeu-vos
que en el cas anterior, l’efecte és ben be el contrari. És al voltant de la discontinuïtat (on
la funció es fa no finita) on hi ha una major contribució al valor de la integral. És per
això que es sol recórrer a formules obertes.
L’altre problema és que, tot i aproximar l’infinit numèricament (1012, etc) , l’interval
d’integració és extremadament gran, pel que caldria avaluar la funció en un gran
nombre de punts a fi que la distància enter intervals sigui suficientment petita.
El que es pot fer en aquests casos és un mapping de la funció i intervals d’integració
originals en uns altres, amb la obvia restricció de que l’àrea sota la corba sigui
exactament la mateixa.
Farem el següent canvi de variable
⎪⎪⎭
⎪⎪⎬
⎫
−=
=
dxx
dt
xt
2
1
1
(9)
Si ho substituïm a l’expressió de la integral tindrem, per exemple

22
∫∫∫ ⎟⎠⎞
⎜⎝⎛=⎟
⎠⎞
⎜⎝⎛−≡
a/
b/
b/
a/
b
adt
tf
tdt
tf
tdx)x(f
1
1 2
1
1 2
1111 (10)
Amb això, hem passat d’avaluar la integral dins un interval infinit x∈[a,∞] a un interval
t∈[0,1/a]. Òbviament, la funció a integrar ha canviat. Aquesta tècnica del “mapeig” no
és útil només en cas de límits d’integració no finits, sinó que pot servir en molts casos
per escurçar l’interval d’integració a fi d’obtenir una millor precisió amb menys punts.
Fixeu-vos, però, que solucionem la presència de l’interval infinit, però introduïm una
discontinuïtat, ja que no podem avaluar la imatge de la nova funció per t = 0. Això
també implica que no podem fer aquest canvi de variable per escurçar un interval
d’integració quan els respectius límits d’integració canvien de signe (passaríem pel zero
i ens trobaríem amb la discontinuïtat a l’interior de l’interval!).
Podem evitar aquest problema utilitzant formules obertes o bé prenent com a límit
d’integració original un nombre suficientment gran (o petit).
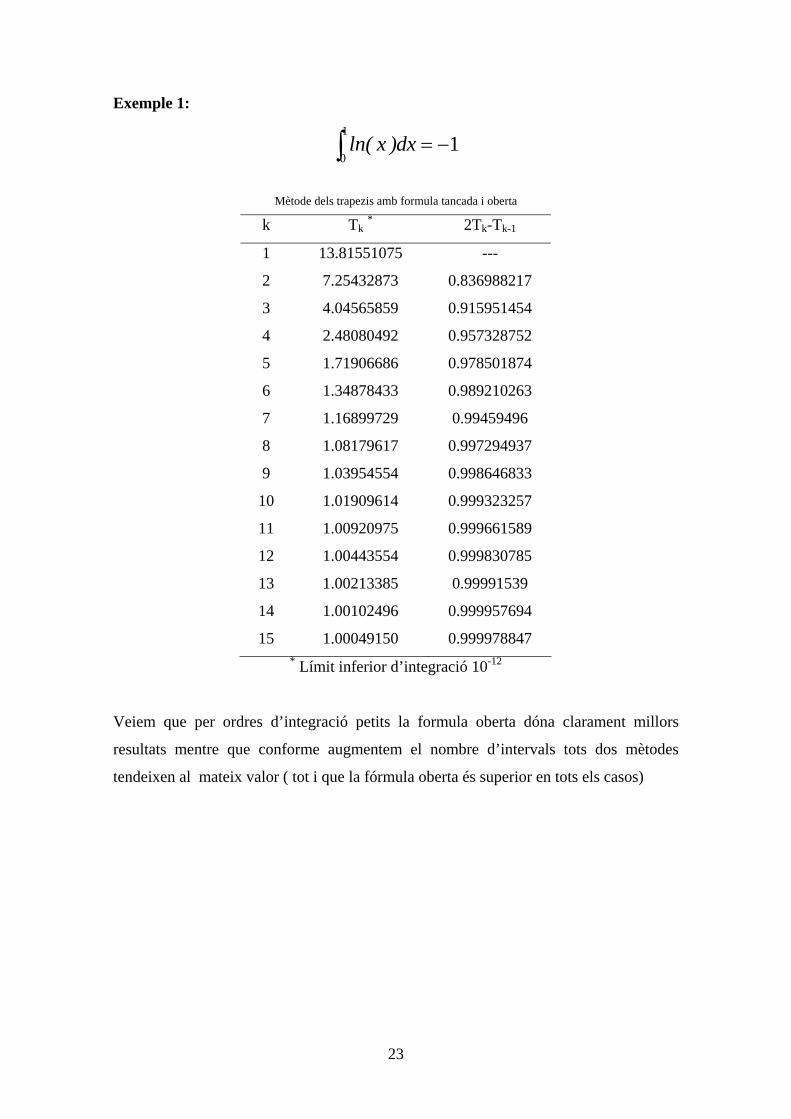
23
Exemple 1:
11
0−=∫ dx)xln(
Mètode dels trapezis amb formula tancada i oberta
k Tk * 2Tk-Tk-1
1 13.81551075 ---
2 7.25432873 0.836988217
3 4.04565859 0.915951454
4 2.48080492 0.957328752
5 1.71906686 0.978501874
6 1.34878433 0.989210263
7 1.16899729 0.99459496
8 1.08179617 0.997294937
9 1.03954554 0.998646833
10 1.01909614 0.999323257
11 1.00920975 0.999661589
12 1.00443554 0.999830785
13 1.00213385 0.99991539
14 1.00102496 0.999957694
15 1.00049150 0.999978847 * Límit inferior d’integració 10-12
Veiem que per ordres d’integració petits la formula oberta dóna clarament millors
resultats mentre que conforme augmentem el nombre d’intervals tots dos mètodes
tendeixen al mateix valor ( tot i que la fórmula oberta és superior en tots els casos)

24
Exemple 2:
∫∞
∞− +dx
x211
El valor exacte d’aquesta integral impròpia és π. Per tal de determinar-ne el valor
numèricament tenim el problema de dos límits d’integració no finits. No poden aplicar
directament la transformació (10) per raons òbvies. Tanmateix podríem plantejar-nos
trobar el valor de la integral a partir de
∫∫∫∞
∞−
∞
∞− ++
+≡
+ 0 2
0
22 11
11
11 dx
xdx
xdx
x
El problema ara és que el mapeig de l’eq (10) tornaria a donar un límit d’integració
infinit, ja que el un dels límits original és el 0. Per tant, podríem descomposar novament
la integral en
∫∫∫∫∞
−
−
∞−
∞
∞− ++
++
+≡
+ 1 2
1
1 2
1
22 11
11
11
11 dx
xdx
xdx
xdx
x
i aplicar la tècnica del mapeig i posterior formula oberta a la primera i tercera de les
integrals, mentre que la segona no comporta cap problema addicional.
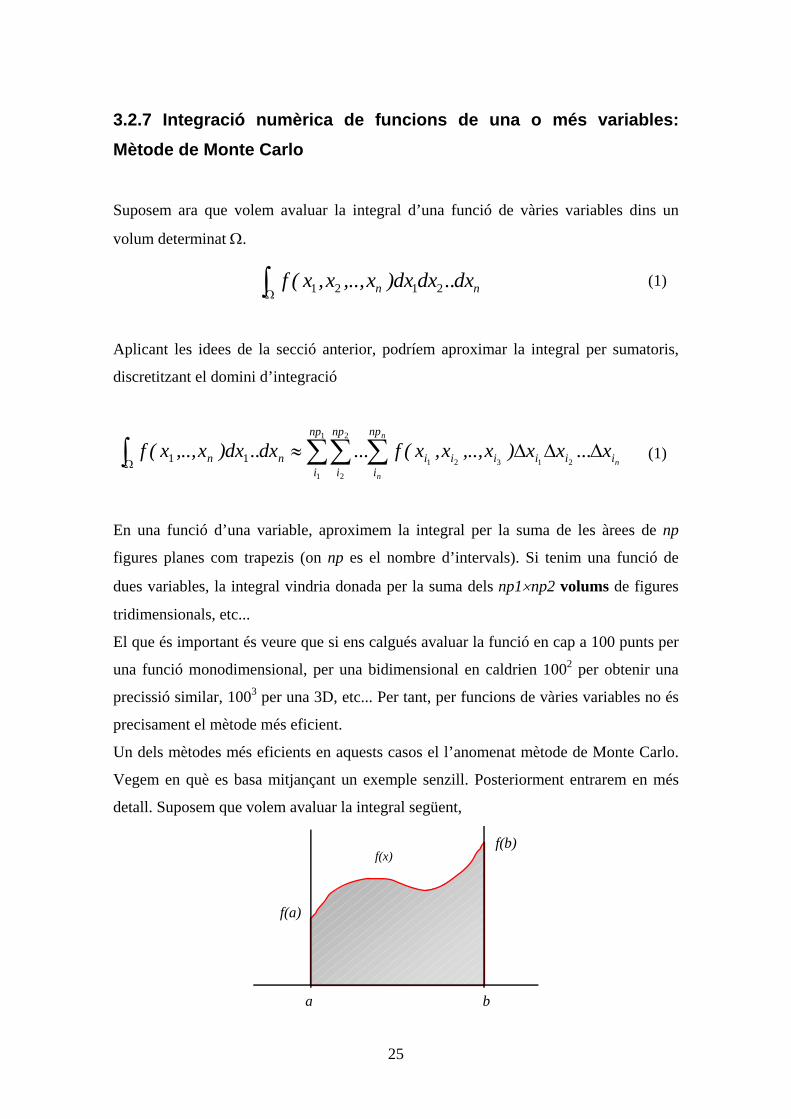
25
3.2.7 Integració numèrica de funcions de una o més variables: Mètode de Monte Carlo
Suposem ara que volem avaluar la integral d’una funció de vàries variables dins un
volum determinat Ω.
∫Ω nn dx..dxdx)x,..,x,x(f 2121 (1)
Aplicant les idees de la secció anterior, podríem aproximar la integral per sumatoris,
discretitzant el domini d’integració
n
n
n
ii
np
i
np
i
np
iiiiinn x...xx)x,..,x,x(f...dx..dx)x,..,x(f ΔΔΔ≈∑∑ ∑∫Ω 2
1
1
2
2
132111 (1)
En una funció d’una variable, aproximem la integral per la suma de les àrees de np
figures planes com trapezis (on np es el nombre d’intervals). Si tenim una funció de
dues variables, la integral vindria donada per la suma dels np1×np2 volums de figures
tridimensionals, etc...
El que és important és veure que si ens calgués avaluar la funció en cap a 100 punts per
una funció monodimensional, per una bidimensional en caldrien 1002 per obtenir una
precissió similar, 1003 per una 3D, etc... Per tant, per funcions de vàries variables no és
precisament el mètode més eficient.
Un dels mètodes més eficients en aquests casos el l’anomenat mètode de Monte Carlo.
Vegem en què es basa mitjançant un exemple senzill. Posteriorment entrarem en més
detall. Suposem que volem avaluar la integral següent,
a b
f(a)
f(b)f(x)
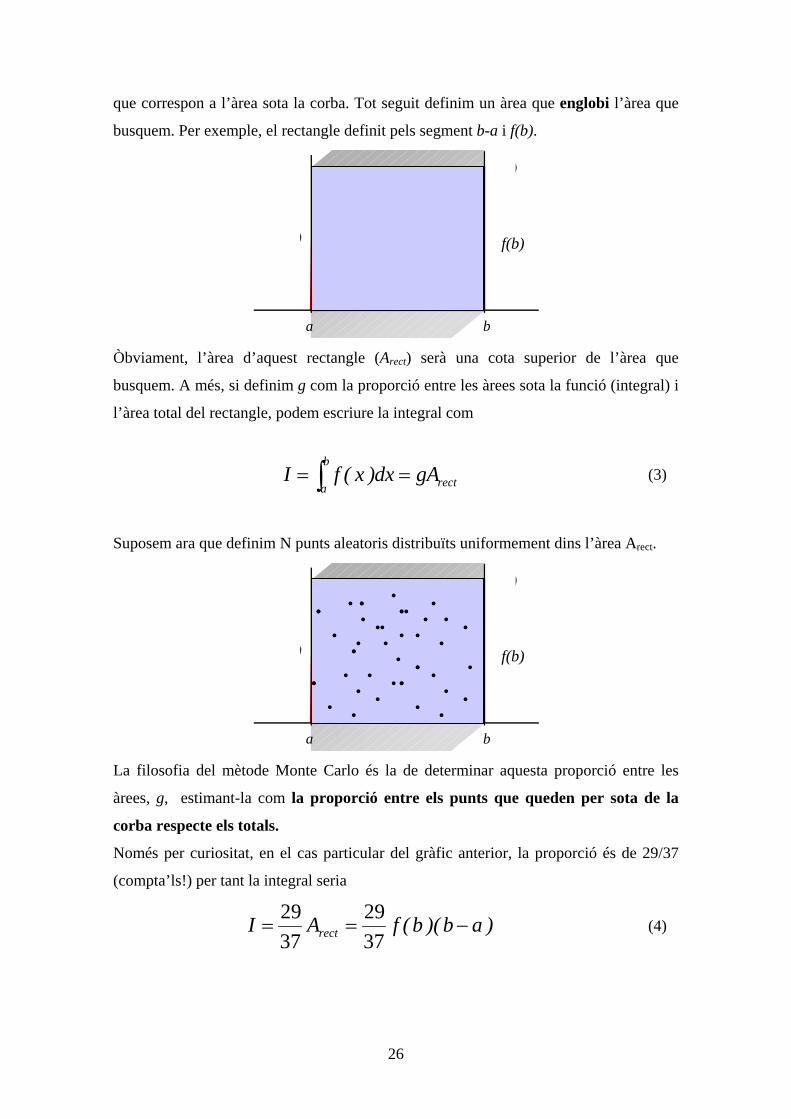
26
que correspon a l’àrea sota la corba. Tot seguit definim un àrea que englobi l’àrea que
busquem. Per exemple, el rectangle definit pels segment b-a i f(b).
a b
f(a)
f(b)f(x)
f(b)
Òbviament, l’àrea d’aquest rectangle (Arect) serà una cota superior de l’àrea que
busquem. A més, si definim g com la proporció entre les àrees sota la funció (integral) i
l’àrea total del rectangle, podem escriure la integral com
rect
b
agAdx)x(fI == ∫ (3)
Suposem ara que definim N punts aleatoris distribuïts uniformement dins l’àrea Arect.
a b
f(a)
f(b)f(x)
f(b)..
.. ...
..
..
.. ...
..
.. ...
..
.. ...
..
.. ...
..
.. ...
La filosofia del mètode Monte Carlo és la de determinar aquesta proporció entre les
àrees, g, estimant-la com la proporció entre els punts que queden per sota de la
corba respecte els totals.
Només per curiositat, en el cas particular del gràfic anterior, la proporció és de 29/37
(compta’ls!) per tant la integral seria
)ab)(b(fAI rect −==3729
3729
(4)

27
Mètodes Monte Carlo
En general, el teorema en què és basen els mètodes Monte Carlo és el que ens diu que la
integral d’una funció en un volum multidimensional V, dins el qual escollim N punts
(x1,..., xN) de manera aleatòria i uniforme, es pot expressar com
( )∫
−±≈
V NffVfVfdV
22
(5)
on
∑∑ ==N
ii
N
ii )x(f
Nf)x(f
Nf 22 11
(6)
representen les mitjanes aritmètiques de la funció i el quadrat de la mateixa, i el segon
terme de l’eq (5) representa una estimació de l’error (desviació standard).
A partir d’aquest teorema podem plantejar-nos dues maneres de determinar una integral
multidimensional. Escollirem un o altra bàsicament en funció de la regió d’integració,
és a dir segons aquesta es pugui “samplejar” fàcilment o no.
Vegem-ho amb un exemple:
Exemple 1
Volem determinar la integral següent
∫ ∫− −
+−1
1
1
1
22
dxdye )yx(
En aquest cas, la regió d’integració és simple; ve definida pels intervals x∈[-1,1] i y∈[-
1,1], és a dir, per un quadrat d’àrea 2×2 = 4. Segons les eq (5)-(6), si avaluem la funció
en N punts aleatoris uniformement distribuïts dins la regió d’integració (quadrat) i en
determinem el valor mitjà, f , el valor de la integral serà
ffVdxdye )yx( 41
1
1
1
22
=≈∫ ∫− −
+−
De vegades, però, la regió d’integració no es tan simple, i pot resultar difícil obtenir una
distribució uniforme de punts per tal de determinar la mitjana de la funció a integrar.

28
El que fem és tractar de trobar un volum multidimensional (regió d’integració) conegut,
W, que contingui la regió d’integració original, V. Posteriorment, generem els N
nombres aleatoris dins aquest volum W , tot determinant per cada punt si pertany a la
regió d’integració, V. En cas negatiu, el punt no es pren per determinar el valor mig de
la funció dins l’interval, f (de fet és com considerar que la funció es fa zero en els
punts de fora de l’interval d’integració....). Finalment, el producte del valor mitjà de la
funció, f , pel volum “samplejat” ,W, ens donarà el valor de la integral.
Exemple 2
Per exemple, imaginem ara que volem determinar l’integral de la funció
)yx(e22 +−
en un interval circular de radi R al voltant del centre de coordenades2. Com a volum W
podríem prendre simplement un quadrat de costat 2R centrat a l’eix de coordenades
x
y
R
Cada punt aleatori dins W, pi , vindrà donat per les seves coordenades (xi, yi). Aquest
punt pertanyerà també a la regió d’integració, V, si xi2+ yi
2 ≤ R2. Llavors, per cada punt
generat caldrà comprovar si es compleix la inequació anterior per tal de tenir-ho en
compte. És clar que els punts “no vàlids” tenen el seu efecte: l’eq (5) ens diu que l’error
estimat serà major (en aquest cas el volum serà W, essent W > V).
Existeix encara una manera més intuïtiva d’aplicar la tècnica de Monte Carlo. Aquest
2 En aquest cas un canvi de variable a coordenades polars seria molt més eficient, però es tracta només
d’un exemple.

29
pot ser el cas, per exemple, de determinar el volum de figures 3D complexes.
La manera de fer en aquest cas seria una generalització de l’esquema presentat a l’inici
del tema. En aquest cas es tractaria de trobar un volum multidimensional conegut, W,
que contingui el volum3 (integral) que busquem, V. Es generen els N nombres aleatoris
dins aquest volum es determinen quants d’aquest punts es troben dins el volum V. La
relació entre aquests punts “vàlids” i els totals ens donarà la relació entre els volums V i
W, i per tant V, que és el que busquem
Exemple 3
Per exemple, podem determinar el volum d’una esfera de radi R (com pots imaginar hi
ha mill maneres més eficients de fer-ho).
En aquest cas, el volum W podria ser el d’un cub de costat 2R, és a dir 8R3. Cada punt
aleatori dins W, pi , vindrà donat per les seves coordenades, en aquest cas (xi, yi, zi). En
aquest cas, el punt pertanyerà també al volum que busquem, V, si xi2+ yi
2 + zi2≤ R2.
Finalment V vindrà donat simplement pel producte de W per la fracció de punts que
han caigut dins el volum que buscàvem.
De fet, la funció 2D en coordenades cartesianes que defineix la superfície de l’esfera i
que integrada ens dóna el volum és simplement f(x,y)=R2 - xi2- yi
2. Pots aplicar Monte
Carlo de manera anàloga a l’exemple 2 per tal de determinar-ne el volum per
integració de f(x,y). Sol: En surt la meitat, no? Per què?
3 Un volum N dimensional sempre es pot entendre com la integral d’una funció N-1 dimensional. Tot i
això, de vegades no és senzill trobar l’equació matemàtica que descriu la forma de l’objecte i que
integrada ens donaria el seu volum.

30
3.2.8. Generació de nombres aleatoris en FORTRAN
El FORTRAN 77 standard no té cap funció o subrutina intrinseca que generi nombres
aleatoris. Existeixen algunes funcions no standard com, ran, rand o srand que son
proveïdes de fet pel propi compilador i que funcionen en entorns de hardware específic
(no PC’s... supercomputadors tipus IBM, Sillicon Graphics, CRAY, etc..).
El FORTRAN90 si que inclou subrutines intrínseques standard per generar nombres
aleatoris i, donat que de fet fem servir un compilador de FORTRAN95, les utilitzarem
com si fossin part del FORTRAN 77.
Per generar un nombre aleatori i emmagatzemar-lo en una variable de tipus REAL, x,
farem simplement
call random_number(x)
Cal tenir en compte que la sentència anterior ens genera un nombre aleatori només
dins l’interval [0,1]. Això no és cap restricció, si volem un nombre aleatori dins
l’interval [a,b] , a < b, només cal realitzar la transformació següent
x = x*(b - a) + a
Amb el factor multiplicatiu expandim/contraiem el rang inicial (una unitat) a la mida
desitjada, mentre que afegint a aconseguim ajustar el valor mínim possible que es pot
generar al menor valor de l’interval, en aquest cas a.
Per generar nombres aleatoris en un volum multidimensional caldrà determinar
cadascuna de les components del punt de manera aleatòria, mitjançant successives
crides a la subrutina.
Per exemple, per un punt dins un volum 3D donat per les components (x,y,z) caldrà fer
call random_number(x)
call random_number(y)
call random_number(z)
Val a dir també que cal incialitzar el generador de nombres aleatoris per tal de no
obtenir sempre la mateixa seqüència. Això es pot fer cridant a una altra subrutina
intrínseca un sol cop abans de començar a generar els nombres aleatoris . La
subrutina en qüestió es diu random_seed i pot ser cridada sense arguments. En concret
call random_seed( )

31
3.2.7 Quadratures Gaussianes
De forma general, els mètodes d’integració numèrica que hem vist es basen en
discretitzar la integral a calcular de manera que
∑∫ ≈n
iii
b
axwxfdxxf )()()(
És a dir, determinem el valor de la integral simplement a partir de productes del valor de
la funció avaluada a una sèrie de punts xi i amb uns pesos w(xi), tal que w(xi) >0.
En el cas del mètode dels rectangles aquests pesos corresponen a les amplades
d’aquests. En el cas de mètodes una mica més elaborats com Simpson aquests pesos
prenen diferents valors segons el valor de xi. Així, recordant la fórmula de Simpson per
n intervals
parelln))iha(f)iha(f)b(f)a(f(hA
parelli
n
i
senari
n
i
Sn ∈+++++=
∈
−
=
∈
−
=∑∑
44344214434421
2
2
1
124
3
podem veure que per x = a i x = b el pes corresponent és de h/3, on h és l’amplada de
l’interval. En canvi, pels punts x = a + ih, essent i senar, el pes és de 4h/3, mentre que
quan i pren valors parells el pes és de 2h/3.
Veiem doncs que el pes de cada punt que s’utilitza per aproximar la integral pot variar,
de manera que hi ha punts que potencialment hi contribueixen més al valor de la
integral numèrica.
En el cas del mètode de trapezis, Simpson i en definitiva el mètode de Romberg els
punts a on cal avaluar la funció (i determinar el pes corresponent) venen determinats pel
nombre d’intervals que escollim aplicar i pel rang d’integració de la funció. Això és així
per què cal utilitzar intervals de mateixa amplada.

32
El mètode de la Quadratura Gaussiana elimina aquesta restricció i proposa una
estratègia per tal de determinar de manera òptima tant la posició dels punts a on cal
avaluar la funció com els seus pesos corresponents. Il·lustrarem la estratègia amb un
exemple:
Suposem que volem aproximar el valor de la integral d’una funció en l’interval [-1,1]
fent servir només dos punts d’integració (n = 2), x0 i x1. Això vol dir que volem
aproximar la integral per
)()()()()( 1100
1
1xwxfxwxfdxxf +≈∫−
Com veurem més endavant el fet que la quadratura estigui definida per a integrals en el
rang [-1,1] no suposa cap problema i sempre podrem extendre la formulació a qualsevol
rang.
Així doncs, tenim que determinar quatre paràmetres, els dos punts de integració {x0 , x1}
i valor dels pesos corresponents {w(x0), w(x1)}. Per fer-ho imposarem la condició de que
la integral sigui exacta per qualsevol polinomi de grau 2n-1, és a dir de grau 3 en aquest
cas. Per tant
)()()()(322 110020
1
1
33
2210 xwxfxwxfaadxxaxaxaa +=+=+++∫−
i substituint per la expressió del polinomi
( ) ( ) 2013
132
1211003
032
02010 322)()( aaxwxaxaxaaxwxaxaxaa +=+++++++
Aquesta condició dóna lloc a quatre equacions de la formar
2)()( 10 =+ xwxw
0)()( 1100 =+ xwxxwx
32)()( 1
210
20 =+ xwxxwx
0)()( 13
103
0 =+ xwxxwx

33
Es pot veure fàcilment com les solucions en aquest cas son
1)()( 10 == xwxw 31
31
10 =−= xx
Per tant, hem demostrat que
⎟⎠⎞
⎜⎝⎛+⎟
⎠⎞
⎜⎝⎛−=∫− 3
13
1)(1
1ffdxxf
essent f(x) un polinomi qualsevol de grau 3.
Es pot demostrar que una quadratura de n punts proporciona integrals exactes dins
l’interval [-1,1] per a polinomis de grau 2n-1 o inferior.
De fet, es demostra també que els punts {x0, x1, ..., xn-1} d’una quadratura de n punts
corresponen als zeros del polinomi ortogonal de Legendre de grau n,
( )
( )
( )...
3303581
3521
1321
1
244
33
22
1
0
+−=
−=
−=
==
xxP
xxP
xP
xPP
Polinomis de Legendre
mentre que els pesos corresponents es poden obtenir a partir de l’expressió
∫− −=
1
1
)()('
1)( dxxxxP
xPxw
k
n
knk

34
Val a dir que la quadratura que acabem de veure no és la única quadratura que existeix.
En un cas més general la integral es pot representar introduint una funció W(x) de
manera que
∫b
adxxfxW )()(
El cas a = -1, b = 1 i W(x) = 1 correspon al cas que hem vist anteriorment,i dona lloc a
l’anomenada Quadratura de Gauss-Legendre. Altres casos particulars queden recollits a
la taula següent.
Interval W(x) Polinomis ortogonals associats Quadratura
[-1,1] 21 x− Chebyshev Gauss-Chebyshev
[0,∞) xe− Laguerre Gauss-Laguerre
(-∞,∞) 2xe− Hermite Gauss-Hermite
Límits d’integració
Per poder aplicar la integració numèrica mitjançant una quadratura gaussiana cal
expressar primer la integral general entre els límits [a,b] com a una integral en el rang
[-1,1]. Això es pot fer fàcilment mitjançant un canvi de variable. Per exemple si
definim una relació lineal amb la nova variable
( )
( )⎪⎪⎩
⎪⎪⎨
⎧
−=
++−=
dtabdx
abtabx
2
2)(
llavors podem veure que l’aproximació a la integral queda de la forma
∑∫∫ ⎟⎠⎞
⎜⎝⎛ +
+−−
≈⎟⎠⎞
⎜⎝⎛ +
+−−
=−
iii
b
a
abtabftwabdtabtabfabdxxf22
)(2222
)(1
1

35
Fixa’t que de fet també podem interpretar aquest resultat com que la transformació
lineal també fa variar els pesos corresponents de forma que
)(2
)( ii xwabtw −=
Altres transformacions no lineals son també possibles i de fet s’han de fer servir per
extendre els límits d’integració a l’infinit. Per exemple, fent
( )⎪⎪⎩
⎪⎪⎨
⎧
−=
−+
=
dtt
rdr
ttrr
20
0
12
11
podem escriure la integral següent com
dtt
rttrfdrrf 2
01
1 00 )1(2
11)(
−⎟⎠⎞
⎜⎝⎛
−+
= ∫∫ −
∞
El paràmetre r0 controla el mapeig entre tots dos rangs d’integració. És facil veure que
els punts de la quadratura en el rang [-1,0) mostregen els valors de r entre 0 i r0. Així es
pot escollir el valor de r0 segons la forma de la funció que es vol integrar.
Per altra banda l’aproximació numèrica a la integral queda de la forma
∑∫ −⎟⎟⎠
⎞⎜⎜⎝
⎛−+
≈−
⎟⎠⎞
⎜⎝⎛
−+
−i
iii
i twtr
ttrfdt
tr
ttrf )(
)1(2
11
)1(2
11
20
0201
1 0
i podem fer la associació
)()1(
2)(' 20
kk
k rwtrtw
−≡ i )
11
()( 0k
kk t
trftf
−+
=
però també

36
)()(' kk rwtw ≡ i 20
0 )1(2
)11
()(kk
kk t
rtt
rftf−−
+=
La primera opció sembla més natural i així doncs considerem que es recalculen els
pesos de la quadratura original per tal d’adaptar-los al nou rang d’integració (en realitat
al nou diferencial de volum).