







Idiomas
Páginas
Jurídico


Factores de Rendimiento en Entornos Multicore
César Allande Álvarez
Computer Architecture & Operating Systems Department (CAOS)Barcelona SpainBarcelona, Spain
Director: Eduardo César Galobardes
14 de julio de 2010

Índice
• Introducción
• ObjetivosObjetivos
• Desarrollo del Estudio
• Análisis y Experimentación
• ConclusionesConclusiones
• Trabajo actual y Líneas abiertas
Cesar.Allande@ .uab.es

Introducción
¿Q é?• ¿Qué?– Integración de sistemas multicore en HPC
• ¿Por qué?Mejora de eficiencia rendimiento y consumo– Mejora de eficiencia, rendimiento y consumo
• ¿Cómo?• ¿Cómo?– Sintonizando aplicaciones paralelas
• Teniendo en cuenta el modelo de programaciónTeniendo en cuenta el modelo de programación• Teniendo en cuenta la arquitectura• Considerando el patrón de comportamiento de la aplicación
Cesar.Allande@ .uab.es

Introducción – ¿ Multicore en HPC ?
• Multicore está implantado en HPC
4%
3%
0%1%
1% Top 500 ‐ Supercomputers June 2010
45%
Number of Cores per processor
single core
/45%
46%
dual / 2 core
4 core
6 core6 core
8 cores
9 cores (8+1)
Cesar.Allande@ .uab.es
12 cores

Introducción
• La potencia de los ordenadores se duplica cada dosaños, reduciendo además su coste.Ley de Moore
• El incremento de velocidad de un programa utilizandomúltiples procesadores en computación distribuida
á li i d l f ió i l d lLey de Amdahl
• Cualquier problema suficientemente grande puedeLey de
está limitada por la fracción secuencial del programa
• Cualquier problema suficientemente grande puedeser eficientemente paralelizado
Ley de Gustafson
• Se debe incrementar el tamaño del recurso solamentesi por cada 1% de aumento del área se obtiene almenos un 1% de mejora de rendimiento del core
Kill Rule
Cesar.Allande@ .uab.es
j

Introducción – Taxonomía multicore
Arquitectura
Procesador
Arquitectura• Multicore vs. Manycore• Homogénea / Heterogénea
Core
ncipal
g / gInterconexión• Comunicación
ia Prin • Topología
Acceso a Memoria compartidaó í
CoreMem
or • Sección Crítica• TransaccionalModelos de programaciónCoreM Modelos de programación• Paralelismo de datos• Paralelismo funcional
Cesar.Allande@ .uab.es
• Paralelismo funcional

Introducción – Taxonomía multicore
Arquitectura
Procesador
Arquitectura• Multicore vs. Manycore• Homogénea / HeterogéneaArquitectura
Core
ncipal
g / gInterconexión• Comunicación
•Escalabilidad‐ cores + complejos (multicore)+ l j ( )
ia Prin • Topología
Acceso a Memoria compartidaó í
+ cores ‐ complejos (manycore)
•Tipos de cores (funcionalidad)
CoreMem
or • Sección Crítica• TransaccionalModelos de programación
HomogéneosIntel Core
H t éCoreM Modelos de programación• Paralelismo de datos• Paralelismo funcional
HeterogéneosPPE & SPE (PowerXCell)
Cesar.Allande@ .uab.es
• Paralelismo funcional
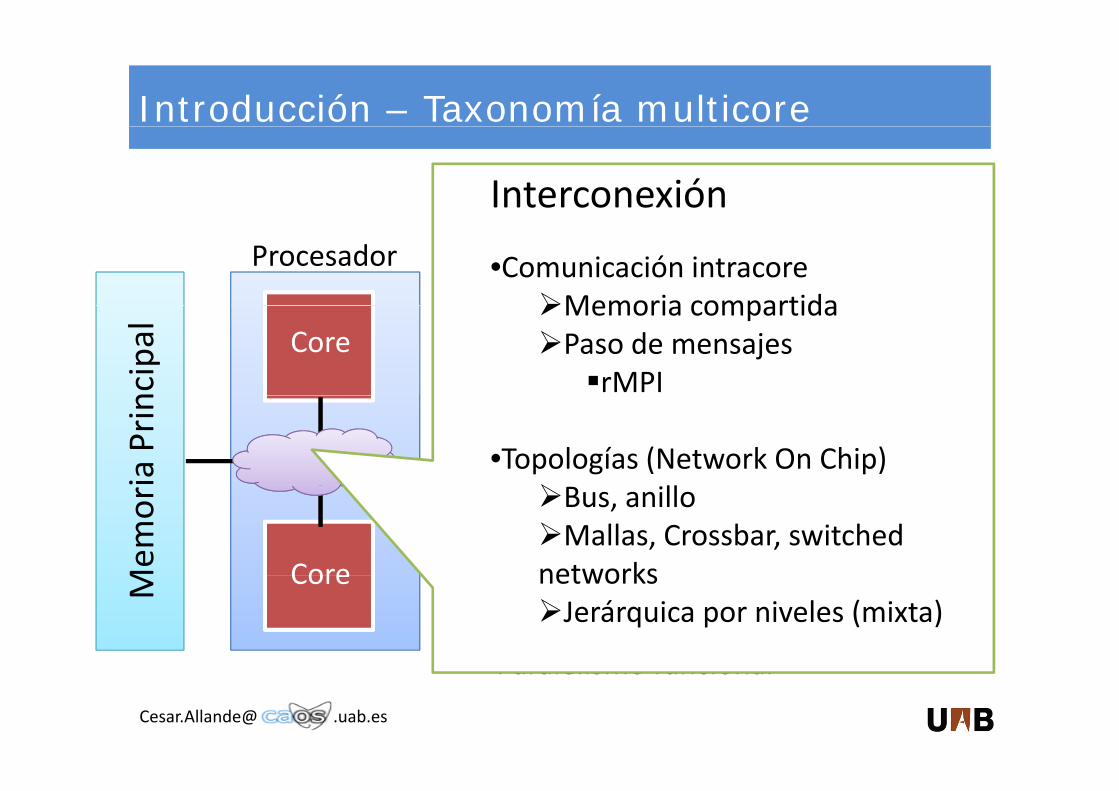
Introducción – Taxonomía multicore
ArquitecturaInterconexiónProcesador
Arquitectura• Multicore vs. Manycore• Homogénea / Heterogénea
•Comunicación intracoreMemoria compartida
Core
ncipal
g / gInterconexión• Comunicación
Memoria compartidaPaso de mensajes
rMPI
ia Prin • Topología
Acceso a Memoria compartidaó í
•Topologías (Network On Chip)ll
CoreMem
or • Sección Crítica• TransaccionalModelos de programación
Bus, anilloMallas, Crossbar, switched
networksCoreM Modelos de programación• Paralelismo de datos• Paralelismo funcional
networksJerárquica por niveles (mixta)
Cesar.Allande@ .uab.es
• Paralelismo funcional
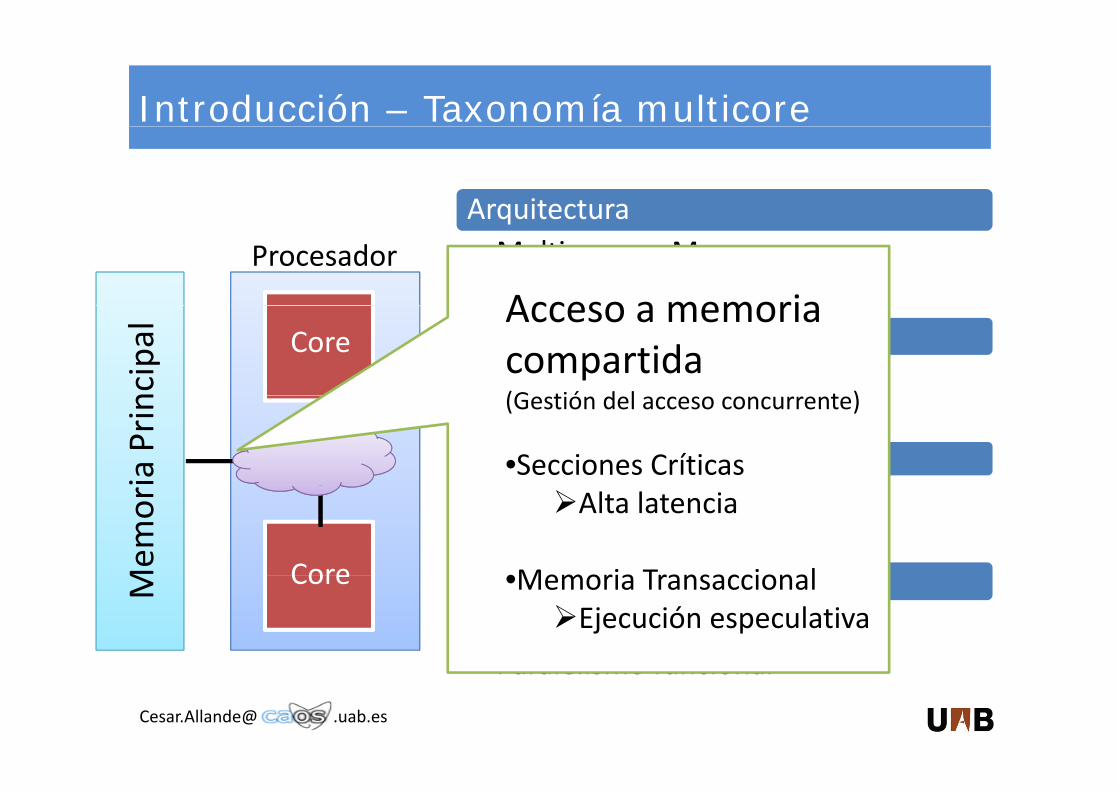
Introducción – Taxonomía multicore
Arquitectura
Procesador
Arquitectura• Multicore vs. Manycore• Homogénea / HeterogéneaAcceso a memoria
Core
ncipal
g / gInterconexión• Comunicación
Acceso a memoria compartida (G tió d l t )
ia Prin • Topología
Acceso a Memoria compartidaó í
(Gestión del acceso concurrente)
•Secciones Críticas
CoreMem
or • Sección Crítica• TransaccionalModelos de programación
Alta latencia
•Memoria TransaccionalCoreM Modelos de programación• Paralelismo de datos• Paralelismo funcional
•Memoria TransaccionalEjecución especulativa
Cesar.Allande@ .uab.es
• Paralelismo funcional

Introducción – Taxonomía multicore
ArquitecturaArquitectura• Homogénea / Heterogénea• (‐cores+complex)vs(+cores‐complex)
Procesador Paradigmas de programación( p ) ( p )
Interconexión• Topología
Core
ncipal •Paralelismo de datos
•Unidad: thread• ComunicaciónAcceso a Memoria
ó í
ia Prin •Gestión: nivel de S.O. o usuario
•Ejemplos: Pthreads, OpenMP 2.5
• Sección Crítica• TransaccionalSoft areCoreM
emor •Paralelismo funcional
•Unidad:tarea Software• Threads• Tasks
CoreM •Gestión: DAGs •Ejemplos: Cilk, OpenMP v3.0, *Ss
Cesar.Allande@ .uab.es
• Tasks

CAOS
Cesar.Allande@ .uab.es

Definir un marco de trabajo acotado
Paradigma de programación paralelabasado en OpenMP v2.5
Paralelismo de datos
Herramientas de acceso concurrente a memoria
Planificación de threads a nivel de Sistema Operativo
Procesadores homogéneosDual(2 cores)
memoria compartida jerárquica
L2 unificada (2MB)
L1 datos e instrucciones (32KB)
Asociatividad por bloques (8 vías)
Cesar.Allande@ .uab.es

Objetivosj
Objetivos
• Identificar factores de rendimientoE di d l á i i bl d• Estudio de los parámetros sintonizables de una API multicoreE t di d l t ó d t i t d• Estudio del patrón de comportamientos de una aplicación y evaluación de los factores de rendimientorendimiento
Cesar.Allande@ .uab.es

Desarrollo del Estudio
Detectar factores de Selección de Herramientas deAnálisis OpenMP de GNU
Detectar factores de rendimiento en
OpenMP
Aplicaciones Paralelas y
Experimentación
Herramientas de medición de rendimiento
ProfilersCompilador GCC
conversión pragmas a
llamadas libgomp
Scheduling• Static•Dynamic•Guided
Segmentación imágenes RMI
• Paralelismo de grano grueso
Profilers•ompp
Librería libgomp (OpenMP
•Guided
Acceso memoria •Critical•Atomic
Multiplicación de matrices
runtime)
ib í
•Atomic•Reduction
Localidad de los datos
de matrices
Multiplicación
Contadores Hardware• PAPI
Librerías POSIX Thread
datos•Afinidad•Chunksize
pde matrices por
bloques
Cesar.Allande@ .uab.es

Análisis I - factor de rendimentoplanificación de la carga de trabajo
Schedulingplanificación de la carga de trabajo • Static
•Dynamic•Guided
Gestión de planificación de la carga de trabajo
• La sintonización de las políticas de balanceo de carga puede ser determinante para el rendimiento de la aplicación
Cesar.Allande@ .uab.es

Análisis I – Scheduling I (static) Schedulingg ( )WorkLoad = Iteraciones / Num Threads
•Static•Dynamic•Guided
Core 1
Core 2
Core 3
Core 4
Cesar.Allande@ .uab.es Tiempo
Core 4

Análisis I – Scheduling II (dynamic) Schedulingg ( y )WorkLoad = Chunksize (1)
• Static•Dynamic•Guided
Core 1
Core 2
Core 3
Core 4
Cesar.Allande@ .uab.es Tiempo
Core 4

Análisis I – Scheduling III (guided) Schedulingg (g )WorkLoad = Remaining iterations / Num Threads
•Static•Dynamic•Guided
Core 1
Core 2
Core 3
Core 4
Cesar.Allande@ .uab.es Tiempo
Core 4

Experimentación Ischeduling segmentación RMI (I)
Schedulingscheduling - segmentación RMI (I)
T. Ejecución ‐ (umbral de precisión 0.001)imagen RMI ‐ rMCI‐JBC 12 dat
• Static•Dynamic•Guided
6
imagen RMI rMCI JBC_12.dat
4
5
s
3
Segund
os
1
2
S
00 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 52 54 56 58 60 62 64 66 68 70 72 74 76 78 80 82 84 86 88 90
Nú d
Cesar.Allande@ .uab.es
Número de corte

Experimentación I scheduling segmentación RMI (II)
Schedulingscheduling - segmentación RMI (II)
Segmentación de imágenes carga desbalanceada (convergencia)
• Static•Dynamic•Guided
120
140
carga desbalanceada (convergencia)
80
100
120
os
60
80
Segund
o
static
dynamic
20
40 guided
01 2 4 8 16
Número de Threads
Cesar.Allande@ .uab.es
Número de Threads

Experimentación I scheduling segmentación RMI (II)
Schedulingscheduling - segmentación RMI (II)
Segmentación de imágenes carga desbalanceada (convergencia)
• Static•Dynamic•Guided
7,2%
4,2% 3,5%7,4%73
74
75
3,2%
3,5%, %
1,5% 0,20 0471
72
73
os 1,5% 0,04
69
70
Segund
o
static
dynamic
66
67
68 guided
65
66
2 4 8 16Nú d Th d
Cesar.Allande@ .uab.es
Número de Threads

Experimentación I scheduling segmentación RMI (III)
Schedulingscheduling - segmentación RMI (III)
T. Ejecución ‐ Distribución ‐ (145 iteraciones)imagen RMI ‐ rMCI‐JBC 12 dat
• Static•Dynamic•Guided
25
imagen RMI rMCI JBC_12.dat
15
20
s
10
15
Segund
o
5
00 2 4 6 8 1012141618202224262830323436384042444648505254565860626466687072747678808284868890
Número de corte
Cesar.Allande@ .uab.es
Número de corte

Experimentación I scheduling segmentación RMI (IV)
Schedulingscheduling - segmentación RMI (IV)
Segmentación de imágen carga desbalanceada (límite 145 iteraciones)
• Static•Dynamic•Guided
350
400
carga desbalanceada (límite 145 iteraciones)
250
300
os
150
200
Segund
o
static
dynamic
50
100guided
01 2 4 8 16
Número de Threads
Cesar.Allande@ .uab.es
Número de Threads

Experimentación I scheduling segmentación RMI (IV)
Schedulingscheduling - segmentación RMI (IV)
Segmentación de imágen ‐ Overheadcarga desbalanceada (límite 145 iteraciones)
• Static•Dynamic•Guided
43.4%
300
carga desbalanceada (límite 145 iteraciones)
21,78% 21,80%3,95%
0.65% 3.41% ‐0.1%0 02%
200
250
os 0.02%
100
150
Segund
o
static
dynamic
50
100guided
02 4 8 16
Número de Threads
Cesar.Allande@ .uab.es
Número de Threads

Análisis II - factor de rendimientoacceso concurrente a memoria
Acceso memoria acceso concurrente a memoria •Critical
•Atomic•Reduction
l d ó d
Sincronización de hilos
• El mecanismo de sincronización de acceso a memoria compartida genera una sobrecarga que afecta al rendimiento
Cesar.Allande@ .uab.es
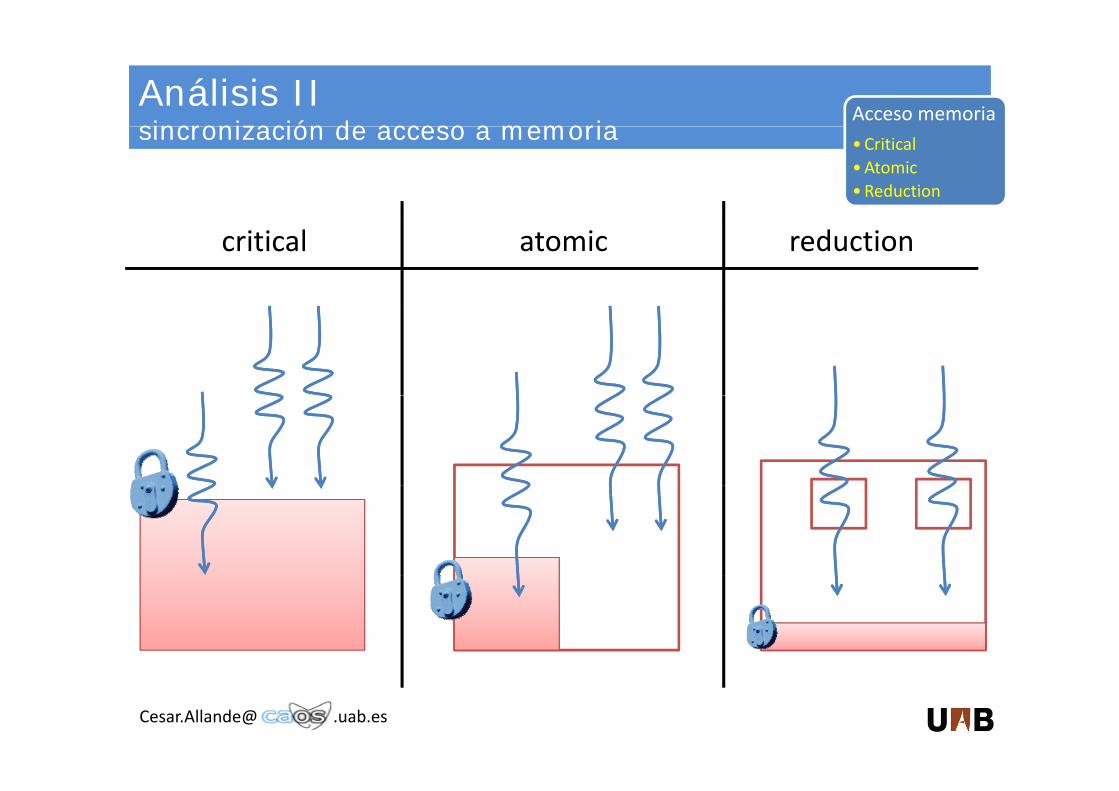
Análisis IIsincronización de acceso a memoria
Acceso memoria sincronización de acceso a memoria •Critical
•Atomic•Reduction
critical atomic reduction
Cesar.Allande@ .uab.es

Experimentación IIsincronización Mat Mul (400x400)
Acceso memoria sincronización – Mat. Mul. (400x400)
10
T. Ejecución ‐Multiplicación de Matrices (400x400)•Critical•Atomic•Reduction
8
9
10
6
7
dos
critical
3
4
5
Segund critical
reduction
atomic
serie
1
2
3 serie
01 2 4 8 16 32
Número de threads
Cesar.Allande@ .uab.es
Número de threads

Experimentación IIsincronización Mat Mul (400x400)
Acceso memoria sincronización – Mat. Mul. (400x400) •Critical
•Atomic•Reduction
0,7
T. Ejecución ‐Multiplicación de Matrices (400x400)
0,6
0,7
0,4
0,5
dos
d ti
0,3Segund reduction
serie
especulativo
id l
0,1
0,2 ideal
01 2 4 8 16 32
Cesar.Allande@ .uab.es
Número de threads

Análisis III - factor de rendimientolocalidad espacial y temporal
Localidad de los localidad espacial y temporal datos
•Afinidad•Chunksize
j á i d i dif i l
Localidad de los datos
• Las estructuras jerárquicas de memoria con diferentes niveles de latencia y etapas de acceso a los datos se benefician de la localidad espacial y temporal
Cesar.Allande@ .uab.es

Análisis III - Localidad de los datos Localidad de los datos•Afinidad•Chunksize
L1 L1 L1 L1L1 L1 L1 L1
Cesar.Allande@ .uab.es
Análisis III - Localidad de los datos Localidad de los datos•Afinidad•Chunksize
L1 L1 L1 L1L1 L1 L1 L1
Cesar.Allande@ .uab.es

Análisis III - Localidad de los datos Localidad de los datos•Afinidad•Chunksize
L1 L1 L1 L1L1 L1 L1 L1
Cesar.Allande@ .uab.es

Análisis III - Localidad de los datos Localidad de los datos•Afinidad•Chunksize
L1 L1 L1 L1L1 L1 L1 L1
Cesar.Allande@ .uab.es

Análisis III - Localidad de los datos Localidad de los datos•Afinidad•Chunksize
L1 L1 L1 L1L1 L1 L1 L1
Cesar.Allande@ .uab.es

Experimentación IIIlocalidad datos Mat Mul x Bloques
Localidad de los localidad datos – Mat.Mul x Bloques datos
•Afinidad•ChunksizeMultiplcación de Matrices por Bloques
Tiempo total de ejecución
12
14
Tiempo total de ejecución
8
10
dos
4
6
Segun
Tiempo Exec.
0
2
01024 X 1024 (serie)
512 x 512
256 x 256
128 x 128
64 x 64 32 x 32 16 x 16 8 x 8 4 x 4 2 x 2 1 x 1
1 4 16 64 256 1024 4096 16384 65536 262144 1048576
Cesar.Allande@ .uab.es
Tamaño del bloque / Número de bloques

Experimentación IIIlocalidad datos Mat Mul x Bloques
Localidad de los localidad datos – Mat.Mul x Bloques
1,00E+08
Fallos de Cache L2, L1 Datos y L1 Instruccionesdatos•Afinidad•Chunksize
1,00E+06
1,00E+07
Caché
1,00E+04
1,00E+05
Fallo
s de
1,00E+02
1,00E+03
úmero de
Caché L1 Datos
Caché L2 unificada
Caché L1 Instrucciones
1,00E+00
1,00E+01
1024 X 512 x 256 x 128 x 64 x 64 32 x 32 16 x 16 8 x 8 4 x 4 2 x 2 1 x 1
Nú
1024 X 1024 (serie)
512 x 512
256 x 256
128 x 128
64 x 64 32 x 32 16 x 16 8 x 8 4 x 4 2 x 2 1 x 1
1 4 16 64 256 1024 4096 16384 65536 262144 1048576
T ñ d l bl / Nú d bl
Cesar.Allande@ .uab.es
Tamaño del bloque / Número de bloques

Experimentación IIIlocalidad datos Mat Mul x Bloques
Localidad de los localidad datos – Mat.Mul x Bloques datos
•Afinidad•Chunksize
• Modificación del algoritmo para ajustar el acceso a datos para 2 niveles de cachép
• Bloques de 64x64 elem (256 KB), ajuste L2
• Sub‐bloques de 2x2 elem.(4KB), ajuste L1.q ( ), j
Cesar.Allande@ .uab.es

Experimentación IIIl lid d d t M t M l Bl ( j )
Localidad de los localidad datos – Mat.Mul x Bloques (mejora)
matriz Cdatos•Afinidad•Chunksize
matriz A matriz B
Cesar.Allande@ .uab.es
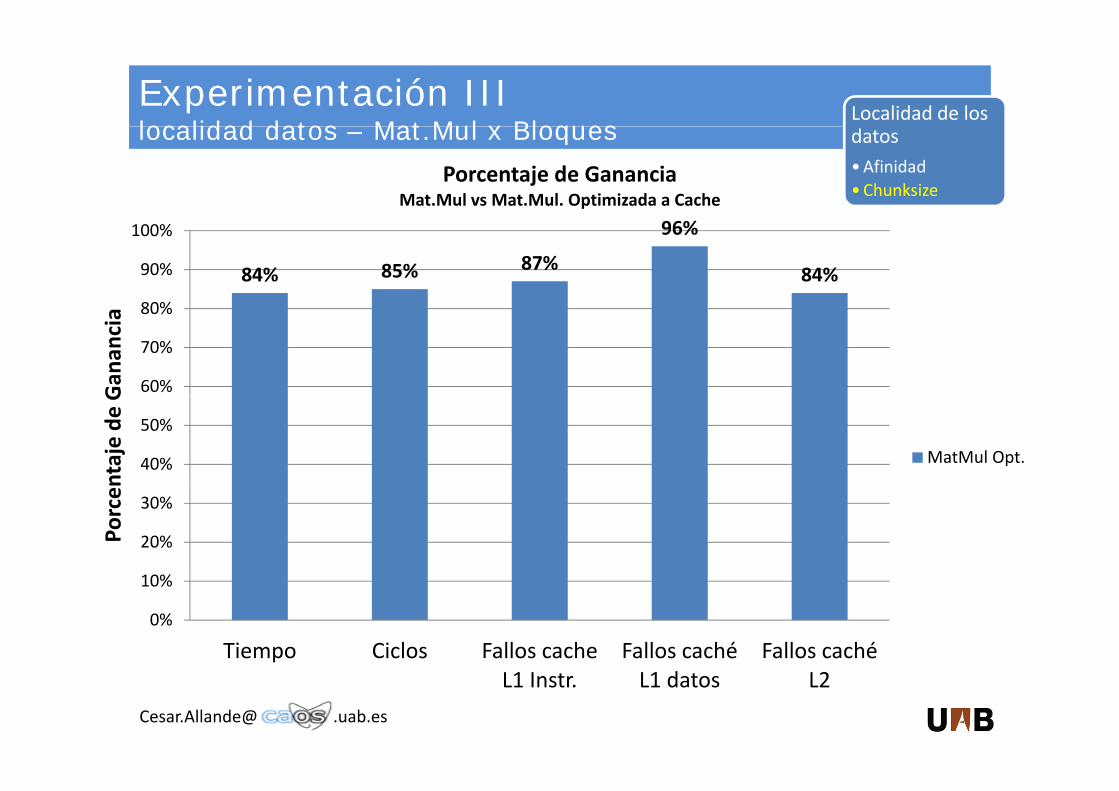
Experimentación IIIlocalidad datos Mat Mul x Bloques
Localidad de los localidad datos – Mat.Mul x Bloques
Porcentaje de GananciaMat.Mul vs Mat.Mul. Optimizada a Cache
datos•Afinidad•Chunksize
84% 85% 87%
96%
84%
80%
90%
100%
60%
70%
80%
Gan
ancia
40%
50%
ntaje de
G
MatMul Opt.
10%
20%
30%
Porcen
0%
10%
Tiempo Ciclos Fallos cache Fallos caché Fallos caché
Cesar.Allande@ .uab.es
L1 Instr. L1 datos L2

Conclusiones (I)( )
S h t di d f t d di i t• Se han estudiado factores de rendimiento para un entorno multicore
• Se ha estudiado la implementación GNU OpenMP que ha permitido detectar factores deque ha permitido detectar factores de rendimiento del modelo de programación
• Se ha analizado el patrón de comportamiento de varias aplicaciones y se ha evaluado el impactovarias aplicaciones, y se ha evaluado el impacto de sintonizar factores de rendimiento
Cesar.Allande@ .uab.es

Conclusiones (II)( )
S h d li d l d b j• Scheduling de la carga de trabajo. – Sintonización: dificultad moderada.N h id j l di i t difi d– No se ha conseguido mejorar el rendimiento modificando el tipo de planificación para diferentes cargas de trabajo
• Static. Poca adaptación con carga desbalanceadap g• Guided y Dinamic. Consiguen balanceo de carga
• Sincronismo de acceso concurrente a memoria. – Sintonización: depende de la funcionalidad.– Los primitivas ofrecen diferente latencia y flexibilidad– Existe un overhead en la utilización de OpenMP.
Cesar.Allande@ .uab.es

Conclusiones (III)( )
• Localidad de los datos– Sintonización: dificultad alta
– Efectuando un cambio en la granularidad de los datos por fuerza bruta no se ha conseguido unadatos por fuerza bruta, no se ha conseguido una mejora significativa
Sintonizando la aplicación para hacer un ajuste en– Sintonizando la aplicación para hacer un ajuste en los dos niveles de caché, se ha conseguido una ganancia de 6x (respecto a la versión paralelaganancia de 6x. (respecto a la versión paralela previa)
Cesar.Allande@ .uab.es

Trabajo actual y Líneas abiertasj y
T b j t l• Trabajo actual– Ejecución en un entorno Quad (o más cores), para evaluar el
rendimiento en la definición de grupos afines en una jerarquía d d lde memoria modular
• Líneas abiertasLíneas abiertas– Continuar con el estudio de impacto de los factores que afectan
al rendimientoEstudiar la posibilidad de alterar parámetros de la aplicación de– Estudiar la posibilidad de alterar parámetros de la aplicación de forma dinámica para mejorar su rendimiento
– Estudiar los factores que será necesario monitorizar para d t t l bl d di i tdetectar los problemas de rendimiento
– Sentar las bases que permitan definir un modelo de rendimiento para entornos multicore
Cesar.Allande@ .uab.es

¡ Gracias por vuestra atención !
Cesar.Allande@ .uab.es

Experimentación IVlocalidad datos Mat Mul x Bloques
Localidad de los localidad datos – Mat.Mul x Bloques datos
•Afinidad•Chunksize
Tam Bloque Tiempo CiclosCache L1
Fallos Instr.Cache L1
Fallos DatosCache L2
Fallos
64x 64 6,24 seg. 1,62E+10 3,86E+03 3,40E+07 4,79E+05
64 x 64 opt. 0,956 seg. 2,42E+09 4,75E+02 1,10E+06 7,41E+04
Cesar.Allande@ .uab.es
Top Related