







Idiomas
Páginas
Jurídico


PROYECTO INTEGRADO
MONTAJE DE INFRAESTRUCTURADE MÁQUINAS EN
ALTA DISPONIBILIDADVIRTUALIZADA
administración de sistemasinformáticos en red
safa ntra sra de los reyes
rafael carlos garrido fernández
gerardo acosta luque
1

Índice del proyectoINTRODUCCIÓN..................................................................................................................3
¿QUÉ ES UN CLÚSTER?..............................................................................................................3
ALTA DISPONIBILIDAD.....................................................................................................5
SOLUCIONES DE ALTA DISPONIBILIDAD..............................................................................5
CARACTERÍSTICAS.....................................................................................................................6
PLANTEAMIENTO DE LA PRÁCTICA..............................................................................8
SOLUCIÓN PREVISTA PARA LA PRÁCTICA............................................................................9
ESQUEMA DE RED.....................................................................................................................11
SOFTWARE..................................................................................................................................12
DESARROLLO PASO A PASO DE LA PRÁCTICA..........................................................15
CONCLUSIONES................................................................................................................28
INFORMACIÓN CONSULTADA.......................................................................................29
2

INTRODUCCIÓN
Esta es la documentación del proyecto integrado del módulo de formación
profesional de Administración de Sistemas Informáticos y Redes, correspondiente
a los cursos 2013/2014 y 2014/2015, realizado por Rafael Carlos Garrido
Fernández y Gerardo Acosta Luque. El proyecto fue ideado por el profesor José
Antonio Díaz y se entregó a los alumnos en el mes de Marzo de 2015, la defensa
del proyecto tendrá lugar el 17 de Junio del mismo año.
Actualmente existe una demanda desde empresas, organismos públicos,
colegios, universidades, etc... de servicios que requieren su disponibilidad las 24
horas del día, 7 días a la semana y 365 días al año. Para que esa alta
disponibilidad de ese determinado servicio sea factible se necesitan adoptar una
serie de soluciones tanto hardware como software. Una de las soluciones más
empleadas es la del clúster de servidores, que es el método del que va a tratar
este proyecto integrado.
El proyecto consiste en la realización de un clúster de alta disponibilidad de
máquinas virtuales utilizando para ello software libre, ofreciendo algún tipo de
servicio y que cuando uno de los nodos del clúster sufra un fallo, el servidor siga
funcionando como si nada hubiera pasado.
¿QUÉ ES UN CLÚSTER?
Un clúster es un conjunto de ordenadores, que unidos mediante una red, se
comportan como un solo ordenador, es decir, físicamente son varias computadoras
pero lógicamente funcionan como una sola.
Un clúster puede estar configurado de varias formas, en función de las
necesidades que se tengan y por tanto del rendimiento que se quiera obtener del
clúster para cubrir esas necesidades. Un clúster puede cumplir con las siguientes
características:
3

• Alta disponibilidad
• Alto rendimiento
• Balanceo de carga
• Escalabilidad
Para que el clúster funcione correctamente necesita una serie de
componentes que son los que hacen que funcione.
Nodos:
Los nodos pueden ser ordenadores de escritorio o servidores, de hecho se puede
establecer un clúster con cualquier tipo de máquina.
Sistema operativo:
Este debe de tener un entorno multiusuario, cuanto más fácil sea el manejo del
sistema menores problemas tendremos.
Conexiones de Red:
Las conexiones utilizadas en este tipo de sistema pueden ser muy variadas, se
pueden utilizar desde simples conexiones Ethernet con placas de red comunes o
sistemas de alta velocidad como Fast Ethernet, Gigabit Ethernet, Myrinet,
Infiniband, SCI, etc.
Middleware:
El middleware es el software que actúa entre el sistema operativo y las
aplicaciones y que brinda al usuario la experiencia de estar utilizando una única
super máquina. Este software provee una única interfaz de acceso al sistema,
denominada SSI (Single System Image). Optimiza el sistema y provee
herramientas de mantenimiento para procesos pesados como podrían ser
migraciones, balanceo de carga, tolerancia de fallos, etc.
Es posible configurar el clúster de dos maneras, en función de lo que
necesitemos de el y de lo que queramos que haga cada uno de los nodos que lo
componen:
4

• Modo Activo/Pasivo: en este modo existe un nodo maestro, que es el que
tiene instalado todo el software y donde corren los servicios en un primer
momento, y un segundo (o más) esclavo que es el que entra en
funcionamiento cuando el nodo maestro deja de funcionar. Este modo se
utiliza cuando queremos realizar un clúster de alta disponibilidad.
• Modo Activo/Activo: en este modo los recursos se encuentran en todos los
nodos del clúster, los cuales funcionan por igual, logrando un balanceo de
carga para responder a las peticiones que se realicen al clúster. Este modo
se utiliza cuando queremos implementar un clúster de alto rendimiento.
ALTA DISPONIBILIDAD
Dentro de los distintos tipos de configuraciones que puede tener un clúster,
nos vamos a centrar en la que nos interesa a nosotros en este caso, que es el
clúster de alta disponibilidad.
La alta disponibilidad (High availability en inglés o HA por sus siglas en inglés),
consiste en dotar a una infraestructura hardware o software de la capacidad de
permanecer el mayor tiempo ininterrumpido posible en funcionamiento, de forma
que el usuario no deje de disponer de los servicios que ofrezca dicha
infraestructura.
SOLUCIONES DE ALTA DISPONIBILIDAD
Existen diversas opciones de software mediante el cual implementar un
clúster de alta disponibilidad, nosotros vamos a nombrar y a explicar aquellos que
son de libre distribución, que es lo que se nos pide en el enunciado del proyecto.
En esta lista se incluyen aquellos que en la actualidad se siguen utilizando y de
los cuales hemos encontrado información, otros muchos quedaron en el olvido y
5

en desuso, ellos son:
• Pacemaker
• Corosync
• Keepalived
• Linux Virtual Server
• Wackamole
CARACTERÍSTICAS
Pacemaker:
-Controla y administra los recursos que nos ofrece el clúster.
-Verifica el estado de los nodos, para que en caso de que uno no este
operativo, inmediatamente disponer de otro de los nodos del clúster.
-Se complementa con Corosync.
-Se puede administrar mediante diferentes interfaces:
-CRM:La más común. Proporciona interfaz de comandos (CLI) con una sintaxis
muy simplificada pero con una gran potencia.
-DMC: Herramienta gráfica escrita en Java. Puede simplificar bastante las
tareas de mantenimiento de un cluster de alta disponibilidad.
-Cibadmin: Programa CLI de edición directa del "cib.xml" con sintaxis muy
compleja.
Corosync:
-Proporciona servicios de infraestructura de clustering (comunicación y
pertenencia) a sus clientes. Esto permite a los clientes conocer la disponibilidad y
los procesos de los demás nodos del clúster.
6

-Proporciona comunicación entre los nodos, para que continuamente se
conozca el estado de los demás nodos.
-Se complementa con Pacemaker.
-Su función básica es la de comunicar los nodos entre ellos, Pacemaker
administra los nodos y sus recursos y Corosync los comunica, van de la mano
siempre.
Keepalived:
-Se puede configurar para eliminar servidores de la cola del clúster si éste
deja de responder.
-Implementa mediante protocolo VRRPv2 un módulo para recoger información
adicional del clúster.
-Permite balancear la carga, con una configuración diferenciada entre un nodo
maestro (principal) y un nodo secundario (de backup)
-Es un servicio complementario a Linux Virtual Server encargado de supervisar
el estado del clúster y proporcionarle alta disponibilidad.
Linux Virtual Server:
-Solución para gestionar balanceo de carga en Linux.
-Se usa para desarrollar clústers de alto rendimiento con escalabilida,
confiabilidad y robustez.
-Actualmente, la labor principal del proyecto LVS es desarrollar un sistema IP
avanzado de balanceo de carga por software (IPVS), balanceo de carga por
software a nivel de aplicación y componentes para la gestión de clústers.
Wackamole:
-Solo es capaz de gestionar las direcciones ips virtuales en un clúster, es poco
configurable y no es válido para todos los tipos de clústers.
-Se quedó obsoleto por su poca flexibilidad y por su falta de actualización para
atender nuevas necesidades.
7

PLANTEAMIENTO DE LA PRÁCTICA
Supongamos que los dos alumnos hemos decidido tras unas infructuosas
prácticas intentar ganarnos un sueldo creando una página web para dotarla de
contenido que genere un buen número de visitas y de esa forma atraer el interés
por publicitarse en nuestra web. Lo primero que necesitamos es un sitio donde
alojar nuestra web, por lo tanto teóricamente debemos contratar un hosting de
alojamiento, pero hay un problema, no tenemos ni un duro. Ese problema nos
lleva a pensar en montar nuestro propio servidor web, pero claro, no disponemos
por supuesto de un servidor con un hardware potente y que nos asegure que el
servicio estará operativo a pesar de posibles fallos, ¿Qué hacemos entonces?
¿existe algún tipo de alternativa para dar un servicio sin tener que asumir un
costo y dejarlo en manos de terceros? ¿es posible hacer eso ofreciendo un servicio
ininterrumpido? Pues sí, es posible.
Debido a nuestra situación económica precaria no podemos permitirnos el
pagar un hosting para alojar la web, por lo tanto hemos decidido reciclar varios
ordenadores que teníamos por ahí tirados y montarnos nuestro propio servidor
web gracias a las enseñanza de nuestro querido profesor Alex Tolón. Si queremos
que nuestra web este siempre operativa necesitamos de alguna manera garantizar
siempre su funcionamiento por lo que decidimos montar un clúster de alta
disponibilidad con cuatro viejos ordenadores que estaban a punto de pasar al
paraíso del punto limpio. Como dijimos antes nuestra ausencia de dinero es
importante, así que ni nos podemos plantear el pagar por un software que nos
permita implementar el clúster, así que acudimos al software libre en donde
siempre encontramos algo para todo lo que se necesite en el mundo de la
informática
8

SOLUCIÓN PREVISTA PARA LA PRÁCTICA
En el contexto real de la práctica vamos a utilizar cuatro máquinas virtuales,
como nodos del clúster, en cada uno de los cuales instalaremos el mismo sistema
operativo, el mismo servicio y el mismo software que nos permita dotar de alta
disponibilidad al clúster.
Este clúster funcionará en una red interna dentro de un ordenador, para evitar
así cualquier tipo de conflicto IP dentro del aula cuando realicemos las prácticas
los días que corresponden y el día de la defensa del proyecto.
El cliente que se utilizará para acceder a la web será nuestro propio
ordenador portátil usando un navegador web.
Nuestro ordenador portátil, en el cual se desarrollará la práctica,tiene las
siguientes características:
9
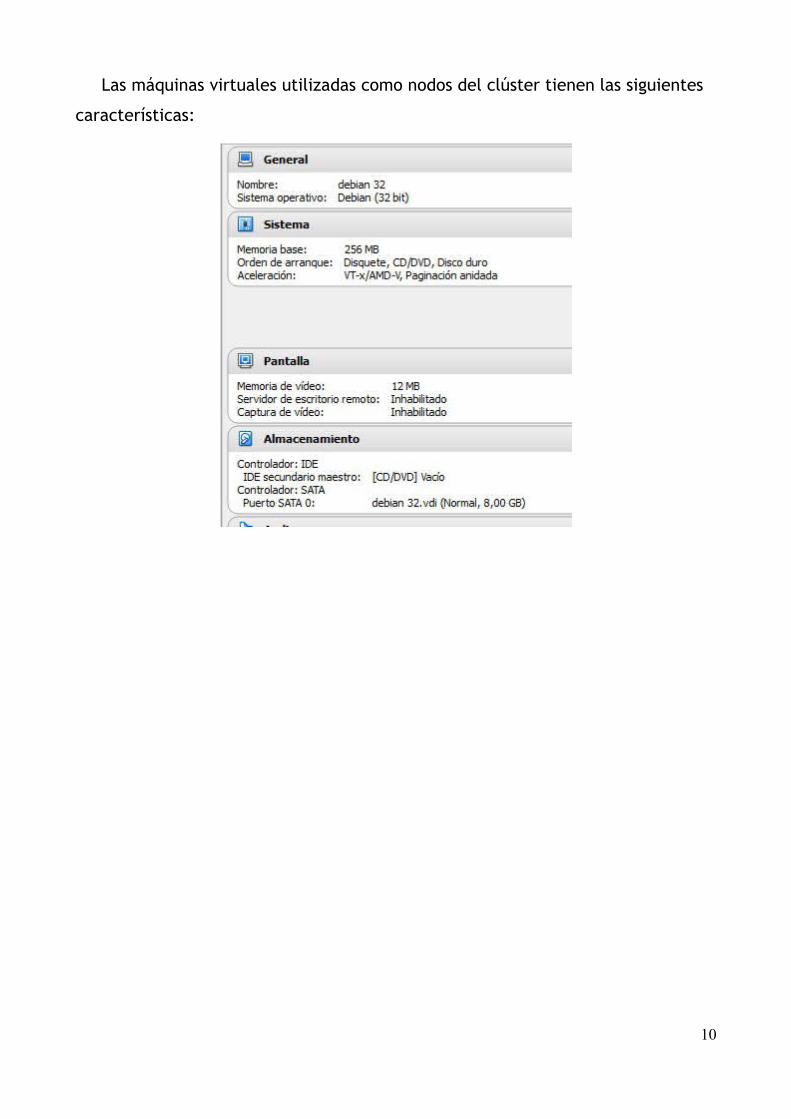
Las máquinas virtuales utilizadas como nodos del clúster tienen las siguientes
características:
10

ESQUEMA DE RED
El esquema de red real que montaremos para el proyecto, será el siguiente:
Podemos observar la lan que creamos en nuestro portátil, el que contienen las
máquinas virtuales que ejercen como nodos del clúster, cuya ip virtual es a la que
se conectan los clientes del servicio, web en este caso, que son ordenadores que
se encuentran en el aula del instituto. Los hostname de cada nodo figuran arriba
de cada uno de ellos con su ip, hemos querido darles nombres de personas para
identificarlos fácilmente y darles un toque personal. No es un esquema detallado
al 100% con toda la topología de red que hay en el centro, pero sirve para tener
una idea de lo que hemos montado.
El esquema hipotético del proyecto llevado a cabo en un entorno real, no
virtualizado, sería este otro:
11

Podemos ver el clúster con sus respectivos nodos, en este caso equipos físicos
reales, que se encuentran dentro de una LAN doméstica y cuya salida a Internet
requiere de una dirección ip fija para posibilitar el acceso a la web desde el
exterior. Al igual que en el esquema anterior sería posible hacer un análisis más
detallado y pormenorizado, pero consideramos que no es relevante para el
objetivo de la práctica.
SOFTWARE
Debian: Como sistema operativo vamos a utilizar en todos los nodos del clúster
esta distribución basada en Linux. Es un sistema operativo GNU basado en
software libre que nos parece que por sus características es ideal para
implementarlo en los nodos del clúster. Requiere de muy pocos recursos y nos
12

ofrece lo que necesitamos: Simpleza y comodidad a la hora de configurar y
administrar nuestros recursos.
Pacemaker: La elección de Pacemaker es por un mero motivo funcional, es el
único software de clústerización con documentación y soporte disponible en la
actualidad, con lo cual la elección era clara.
Corosync: Igual que con Pacemaker, uno va de la mano del otro y es la opción
más segura y con mayores posibilidades de funcionar.
Apache: Es un servidor web http de código abierto, el cual sabemos configurar
y administrar, por ello consideramos que es el adecuado. El motivo de usar el
servicio web para desarrollar este proyecto sobre alta disponibilidad no es otro
que el de considerar que es uno de los servicios más visuales que existen y que a
la hora de comprobar si el servicio esta funcionando o no basta con ver si la
página web se puede ver o no se puede ver desde el cliente. ¿Podríamos haber
elegido otro servidor más complejo? Sí, pero consideramos que usar otro servidor
u otra plataforma nos haría perdernos en caminos que no nos conducirían al
verdadero objetivo de este proyecto, ya que nuestros conocimientos en dicha
materia son pocos debido a nuestro tipo de formación.
13

Rsync: Es una aplicación que se usa en sistemas Linux que nos permite
sincronizar archivos y directorios tanto en modo local como en red. Cuando
comprobamos la cantidad de ficheros y carpetas que debíamos replicar en los
nodos del clúster buscamos la forma de hacerlo lo más fácil posible, así que
pensamos en esta herramienta tremendamente útil y que aprendimos a usar en
este curso.
14

DESARROLLO PASO A PASO DE LA PRÁCTICA
Lo primero para realizar la práctica es configurar las máquinas virtuales que
vamos a utilizar como nodos del clúster. Nos ahorramos la explicación
pormenorizada de la instalación del sistema operativo y de la máquina en sí,
disponemos de una maquina virtual a modo de patrón, con las características
indicadas anteriormente y que clonaremos cuatro veces para obtener los cuatro
nodos que necesitamos. La plataforma de virtualización que usamos es
Virtualbox.
15

Entramos en cada una de las máquinas y cambiamos su hostname, ya que al
ser clonadas todas tienen el mismo: Se cambia en la ruta /etc/hostname
Como el clúster virtualizado lo vamos a realizar dentro de un solo host físico,
mediante una red interna, no tendremos salida a internet, con lo cual las
instalaciones de software las hacemos antes de configurar el direccionamiento ip
en cada una de las máquinas virtuales.
De tal modo lo primero de todo es instalar el software que vamos a necesitar
en cada una de las máquinas virtuales que compondrán el clúster, así que
instalamos rsync, apache, corosync y pacemaker desde la consola de comandos de
cada nodo.
16

Antes de nada actualizamos los repositorios con el comando apt-get update
Luego procedemos a la instalación de lo anteriormente mencionado en cada
uno de los nodos.
En el siguiente paso configuramos los parámetros de red de cada máquina
virtual, configurando el adaptador de red en modo red interna, una red interna
que hemos llamado “cluster”. Esto lo hacemos para no afectar a la red del aula y
para no tener que ir cambiando de subred en función del sitio en el que
trabajemos, llegados a este punto no necesitamos acceder a internet, por lo que
no tendremos problemas en ese sentido.
17

Cambiamos la dirección ip, máscara y puerta de enlace.
Realizamos los mismos pasos en cada nodo y comprobamos con el comando
ifconfig que todo es correcto.
18

Editamos el archivo /etc/hosts del nodo principal (rafa), con las direcciones ip
y sus correspondientes hostname de cada nodo para poder identificarlos en
nuestra red.
Ahora para evitar tener que ir cambiando cada uno de estos archivos en cada
nodo, vamos a hacer uso de la herramienta rsync, con la que podemos copiar y
sincronizar archivos entre equipos de una misma red. La transferencia se realiza
mediante ssh por lo que generamos una llave en el nodo principal y la pasamos al
resto de nodos, de esta forma cada vez que queramos conectar vía ssh o realizar
una transferencia con rsync, como es nuestro caso, no nos pedirá la contraseña.
19

Una vez que cada uno de los nodos secundarios tiene la llave del nodo
principal, podemos copiar archivos con rsync, así que copiamos el archivo hosts
en cada nodo con la siguiente sintaxis.
Comenzamos la configuración de apache, para habilitar nuestra página web,
pero antes de configurar nada vamos a copiar la carpeta que contiene la web a
todos los nodos desde el nodo principal usando rsync.
El primer archivo que vamos a modificar es el que se encuentra en esta ruta
/etc/apache2/sites-available/default, en el que indicamos la ruta donde se
encuentra la página que queremos mostrar y el ServerName.
20

Una vez que hemos modificado el archivo en el nodo principal, volvemos a
pasarlo a los secundarios con rsync.
Habilitamos el nuestro sitio web ejecutando el comando a2ensite desde el
directorio sites-available, que crea un enlace simbólico en el directorio sites-
enabled.
Ahora es el turno de echar a andar corosync y pacemaker, para lo cual el
primer paso será crear el archivo de autentificación de corosync en el nodo
principal del clúster.
21

Otorgamos permisos de escritura a la carpeta de corosync en cada uno de los
nodos.
Ahora podemos pasar el archivo llave a todos los nodos del clúster desde el
principal.
Editamos el archivo de configuración de corosync para indicar la red en la que
va a trabajar el clúster, la ruta de dicho archivo es /etc/corosync/corosync.conf
22

Como en pasos anteriores, pasamos este archivo vía rsync a los nodos
secundarios.
Para que el sistema reconozca el demonio de corosync, debemos modificar el
archivo /etc/default/corosync como vemos.
De nuevo lo pasamos por rsync a los nodos secundarios.
Comprobamos que todo es correcto reiniciando el servicio corosync en cada
uno de los nodos.
Utilizando el comando crm status comprobamos el estado del clúster, vemos
como reconoce y muestra online los cuatro nodos que hay en la red que indicamos
anteriormente.
23

Ahora procedemos a dar el que probablemente sea el paso más importante
dentro de la configuración de nuestro clúster, que es la configuración de la ip
virtual que utilizaremos para dar el servicio que queremos que ofrezca nuestro
clúster, en nuestro caso una página web.
Antes de configurar la ip virtual, debemos deshabilitar el mecanismo de
STONITH (Shot The Other Node In The Head), que se usa para para un nodo que
esté dando problemas, sino lo desactivamos no podremos configurar la ip virtual,
así que tecleamos el siguiente comando.
Ahora sí podemos proceder a la configuración de la ip virtual, para lo cual nos
situamos en el nodo principal, a partir de ahora no será necesario tocar nada más
en los secundarios, y tecleamos el siguiente comando.
24

Si hacemos ping desde cualquiera de los nodos a la nueva ip virtual,
comprobamos como responde como si de cualquier equipo de nuestra red se
tratase.
El siguiente paso es indicar el orden en que pacemaker y corosync irán
comprobando la disponibilidad de los servidores.
Si toda la configuración ha sido correcta y no hay ningún tipo de fallo al
teclear el comando crm configure show nos mostrará todos los parámetros del
clúster como a continuación.
25

Ahora solo nos queda comprobar que todo lo hecho hasta ahora es correcto
comprobando el funcionamiento real del clúster y del servidor desde un cliente.
Desde la barra del navegador del cliente ponemos la dirección ip virtual que
creamos para el clúster y vemos el resultado.
26

Accedemos sin problemas a la página web que aloja nuestro clúster, pero lo
interesante está en comprobar que ocurre si uno de los nodos se cae, por lo que
vamos manualmente a desconectar el nodo principal mediante el comando crm
node standby rafa
Comprobamos el estado del clúster con el comando crm_mon y vemos que el
nodo principal (rafa) no esta online, sino en standby.
A pesar de ello la web se sigue mostrando sin problemas por lo que el clúster
cumple su función y todo se ha desarrollado correctamente.
27

CONCLUSIONES
Nuestras conclusiones tras la realización del proyecto son muy positivas,
puesto que nuestros conocimientos sobre la alta disponibilidad eran muy bajos, ya
que durante la realización de nuestros estudios, solamente se han dado conceptos
sobre ella muy por encima. Hemos aprendido bastante sobre el mundo de los
clúster y de lo importante que pueden llegar a ser de cara a ofrecer redundancia
y seguridad. También valoramos más positivamente el uso del software libre al
comprobar que no le debe de envidiar nada a soluciones de pago y que
comprobamos como es posible llevar a cabo un proyecto de este tipo, que si bien
no es de gran importancia y envergadura, puede solucionarnos una necesidad
puntual y ofrecernos la posibilidad de desarrollar una idea de negocio abaratando
los costes de manera importante.
Nos ha parecido un proyecto interesante de desarrollar, dado que a ambos
componentes del grupo nos interesa la administración de servicios y de recursos.
El hecho de que varias máquinas puedan comunicarse entre ellas y funcionar
como una sola es algo genial, son cosas que hace unos años eran posibles hacerlas
solo en ciertos ambientes y a base de muchísimo dinero, sin embargo hoy, en el
año 2015, dos estudiantes con sus propios medios son capaces de poner en
marcha algo que hace no más de diez años ni siquiera se podrían plantear hacer
dos jóvenes sin medios para ello.
28

INFORMACIÓN CONSULTADA
http://es.wikipedia.org/wiki/Alta_disponibilidad
http://es.wikipedia.org/wiki/Clúster_(informática)
http://es.wikipedia.org/wiki/Clúster_de_alta_disponibilidad
http://enunlugardealcala.blogspot.com.es/2013/03/ha-cluster-de-apache2-
con-pacemaker-y.html
http://www.keepalived.org/
http://es.wikipedia.org/wiki/Linux_Virtual_Server
http://11870.com/2e5e/2009/04/29/wackamole-alta-disponibilidad-con-
balanceo-de-carga/
http://linux.descargarvista.com/wackamole-2.1.3.zip/332146
http://debian-comunicacion.blogspot.com.es/2011/10/cluster-web-alta-
disponibilidad_03.html
http://eltallerdelbit.com/followsymlinks-apache-options/
http://clusterlabs.org/wiki/Debian_Lenny_HowTo
http://clusterlabs.org/doc/en-US/Pacemaker/1.1-plugin/html-
single/Clusters_from_Scratch/index.html#idm140457876882496
29
Top Related