
1. GENERALIDADES DEL DISEÑO DE BASES DE …dis.unal.edu.co/~icasta/consejero/BD_dise_ICF.pdf ·...
52
Documento en preparación. Ing. Ismael Castañeda Fuentes Página 1 1. GENERALIDADES DEL DISEÑO DE BASES DE DATOS RELACIONALES 1.1 Ingeniería de software • El diseño de bases de datos es un subproblema de la Ingeniería de Software. • Clases de software: ◊ Científico ◊ Ingeniería ◊ Tiempo real ◊ Soporte a la toma de decisiones ◊ Operacional Ejemplo: sistema que captura diariamente las transacciones en una organización, controlando depósitos, cambios de políticas, estado de los inventarios, ventas y personal. Estos sistemas son críticos en cualquier organización y si se cae el sistema, estará temporalmente fuera de los negocios. • Dos dimensiones de la Ingeniería de Software: ◊ Ciclo de vida Fases del proyecto a través del tiempo ◊ Disciplina Componentes del software en sí mismo 1.1.1 El ciclo de vida 1. Definición del alcance en términos de los objetivos de la organización. 2. Identificación de requerimientos a través de entrevistas y revisión bibliográfica. 3. Análisis de los requerimientos dados en las especificaciones del diseño. 4. Diseño esquemático y detallado. 5. Construcción del software y las bases de datos. 6. Prueba e instalación del sistema. 7. Mantenimiento y ampliación repitiendo las fases anteriores. 1.1.2 Disciplinas • Datos. Típicamente representados por objetos y relaciones entre ellos. • Procesos. Parte dinámica del software. En el diseño se representa mediante diagramas de flujo, diagramas organizacionales, lenguajes 3GL, ... • Reglas del negocio. Reglas que deben cumplir los procesos y los datos para que representen estados válidos del mundo real (ejemplo: reglas para integridad referencial). • Presentación. Manera de presentar al usuario pantallas e informes escritos.
Transcript of 1. GENERALIDADES DEL DISEÑO DE BASES DE …dis.unal.edu.co/~icasta/consejero/BD_dise_ICF.pdf ·...

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 1
1. GENERALIDADES DEL DISEÑO DE BASES DE DATOS RELACIONALES
1.1 Ingeniería de software • El diseño de bases de datos es un subproblema de la Ingeniería de Software.
• Clases de software:
◊ Científico ◊ Ingeniería ◊ Tiempo real ◊ Soporte a la toma de decisiones ◊ Operacional Ejemplo: sistema que captura diariamente las transacciones en una organización, controlando
depósitos, cambios de políticas, estado de los inventarios, ventas y personal. Estos sistemas son críticos en cualquier organización y si se cae el sistema, estará
temporalmente fuera de los negocios.
• Dos dimensiones de la Ingeniería de Software: ◊ Ciclo de vida Fases del proyecto a través del tiempo ◊ Disciplina Componentes del software en sí mismo
1.1.1 El ciclo de vida 1. Definición del alcance en términos de los objetivos de la organización. 2. Identificación de requerimientos a través de entrevistas y revisión bibliográfica. 3. Análisis de los requerimientos dados en las especificaciones del diseño. 4. Diseño esquemático y detallado. 5. Construcción del software y las bases de datos. 6. Prueba e instalación del sistema. 7. Mantenimiento y ampliación repitiendo las fases anteriores.
1.1.2 Disciplinas • Datos. Típicamente representados por objetos y relaciones entre ellos. • Procesos. Parte dinámica del software. En el diseño se representa mediante diagramas de flujo, diagramas
organizacionales, lenguajes 3GL, ... • Reglas del negocio. Reglas que deben cumplir los procesos y los datos para que representen estados válidos del mundo real
(ejemplo: reglas para integridad referencial). • Presentación. Manera de presentar al usuario pantallas e informes escritos.

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 2
• Documentación. Manuales de referencia, Guía del usuario, Diccionario de datos, tutoriales, ...
1.1.3 Esquema de trabajo en Ingeniería de Software
1.1.4 Datos/Análisis Un diagrama Entidad/Relación, es un ejemplo de cómo la disciplina de Datos está presente en la fase de análisis de la Ingeniería de Software. • Diagramas Entidad/Relación
◊ Documento original de Peter Peen y Chan Chen ◊ Metodología Case de Barker
1.1.5 Reglas/Análisis Las reglas que se deben cumplir en una institución • Expresadas en lenguaje natural
1.1.6 Proceso/Construcción • Sentencias SQL
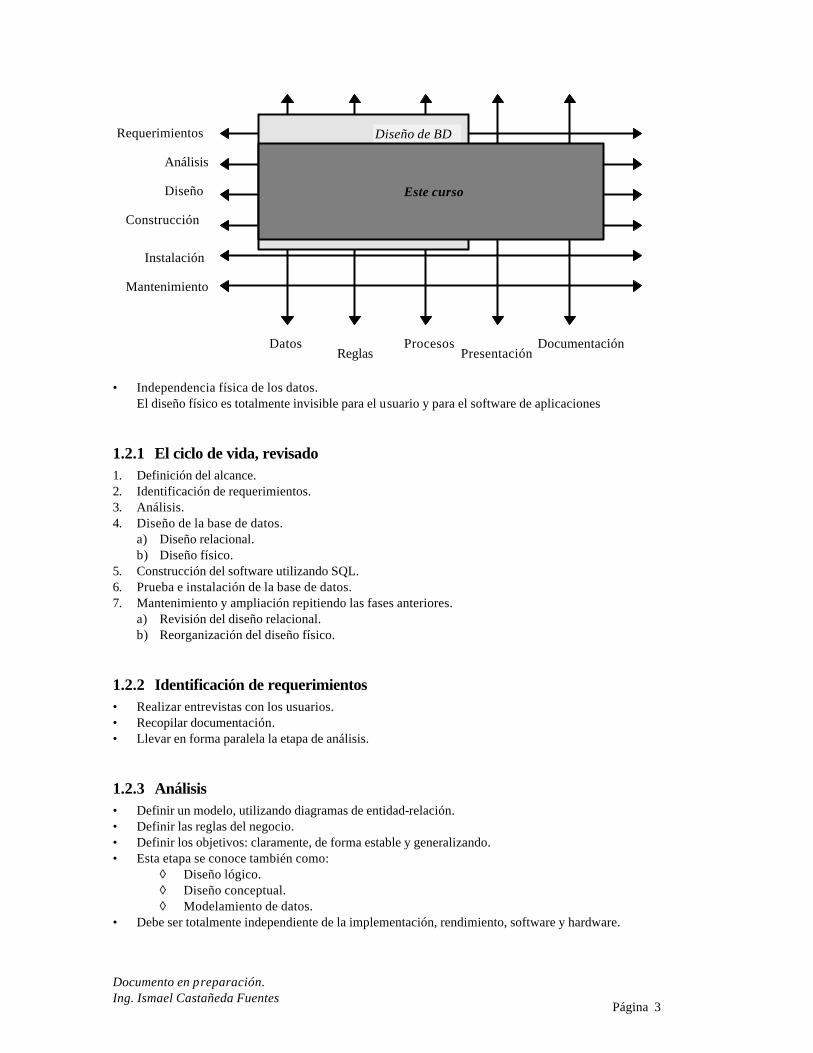
1.2 Diseño de Bases de datos
Requerimientos
Análisis
Diseño
Construcción
Instalación
Mantenimiento
DatosReglas
ProcesosPresentación
Documentación
Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 3
• Independencia física de los datos. El diseño físico es totalmente invisible para el usuario y para el software de aplicaciones
1.2.1 El ciclo de vida, revisado 1. Definición del alcance. 2. Identificación de requerimientos. 3. Análisis. 4. Diseño de la base de datos. a) Diseño relacional. b) Diseño físico. 5. Construcción del software utilizando SQL. 6. Prueba e instalación de la base de datos. 7. Mantenimiento y ampliación repitiendo las fases anteriores. a) Revisión del diseño relacional. b) Reorganización del diseño físico.
1.2.2 Identificación de requerimientos • Realizar entrevistas con los usuarios. • Recopilar documentación. • Llevar en forma paralela la etapa de análisis.
1.2.3 Análisis • Definir un modelo, utilizando diagramas de entidad-relación. • Definir las reglas del negocio. • Definir los objetivos: claramente, de forma estable y generalizando. • Esta etapa se conoce también como:
◊ Diseño lógico. ◊ Diseño conceptual. ◊ Modelamiento de datos.
• Debe ser totalmente independiente de la implementación, rendimiento, software y hardware.
Diseño de BD
Este curso
Requerimientos
Análisis
Diseño
Construcción
Instalación
Mantenimiento
DatosReglas
ProcesosPresentación
Documentación

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 4
1.2.4 Diseño relacional • Definir tablas, columnas y llaves. • Objetivos:
◊ Reducir la redundancia para simplificar la administración de los datos y asegurar integridad. ◊ Buscar comportamiento satisfactorio.
• A veces llamado: diseño lógico.
1.2.5 Diseño físico • Especifica la organización interna de las tablas en los discos del computador (estructuras de
almacenamiento, manejo de índices, asignación de tablas a dispositivos, ...).
1.3 Problemas al diseñar bases de datos • Cuáles son las entidades? • Cuáles son las relaciones? • Cuáles son los atributos?
1.3.1 Problemas de relatividad La naturaleza del análisis es altamente sujetivo.

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 5
1.3.2 Problema de datos compartidos en L
1.3.3 Problema de llaves artificiales • Cómo se identifican de manera única cada fila de una tabla?
◊ Natural, utilizando la información de varias columnas (Ejemplo: Proveedor, Parte, Fecha). ◊ Artificial, utilizando una columna (Ejemplo: Código).
1.3.4 Problema de los datos tipo vector
EN FORMA DE FILA
# año
civil
eléctrica
mecánica
química
sistemas
1995 1430 1020 2050 2570 500 1996 1870 990 1630 1200 380
PROGRAMADOR
VENDEDOR
NombreSalario
DeptoComisión
Meta

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 6
EN FORMA DE COLUMNA
# año
# carrera
alumnos
1995 civil 1430 1995 eléctrica 1020 1995 mecánica 2050 1995 química 2570 1995 sistemas 500 1996 civil 1870 1996 eléctrica 990 1996 mecánica 1630 1996 química 1200 1996 sistemas 380
1.3.5 Administración de la base de datos • El administrador de la base de datos.
◊ Una o varias personas, dependiendo del tamaño de la organización. ◊ Enfocadosa una base de datos específica o a un motor específico de bases de datos. ◊ Encargado de:
∗ Diseñar las bases de datos. ∗ Rediseñar las bases de datos. ∗ Construir las bases de datos. ∗ Reponder por la seguridad, integridad y disponibilidad de los datos. ∗ Hacer monitoreo. ∗ Chequear el rendimiento. ∗ Hacer el ajuste de los parámetros generales de comportamiento.
• El administrador de los datos.
◊ Responsable de los datos, a nivel global. ◊ Responsable de proporcionar las vistas necesarias de los datos a los usuarios. ◊ De importancia especial en la fase de análisis.
• El diccionario de datos.
◊ Sitio donde se encuentra la documentación relacionada con el análisis, diseño y construcción de las bases de datos.
◊ También denominado: ∗ Metabase de datos. ∗ Repositorio. ∗ Enciclopedia. ∗ Directorio. ∗ Catálogo.
1.3.6 Tipos de diccionarios • Dinámicos. Están en línea con el motor de bases de datos y el sistema en producción. • Activos. Están en línea únicamente con las herramientas de desarrollo (CASE). • Pasivos. Están fuera de línea, utilizados sólo para documentación.

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 7
1.3.7 Diccionarios estándar • ANSI Information Resource Dictionary System (IRDS). • ISO IRDS. • IBM Repository (AD/Cycle). • DEC A tools Integration Standard (CDD+).

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 8
2. ANÁLISIS BÁSICO • Modelo Entidad Relación de Peter Peen y Chan Chen. • Case Designer de Barker. • Nissjen’s Information Analysis Methodology (NIAM). • Objects-oriented approaches. • Ventajas del modelo Entidad Relación:
◊ Cercano al lenguaje natural: una Entidad es como un Sustantivo, una Relación es como un Verbo y un Atributo es como una frase proposicional. Esto hace que sea relativamente sencillo convertir una entrevista en un modelo de datos.
◊ La mayoría de las herramientas CASE lo han adoptado.
2.1 Entidades • Entidad: Cualquier cosa de interés sobre la que podemos decir algo.
◊ Persona. ◊ Lugar. ◊ Objeto. ◊ Actividad. ◊ Evento.
• Nombre de la Entidad: Escrito en mayúsculas. • Tipo de Entidad: conjunto de cosas. • Instancia de una Entidad: una cosa individual. • Una Entidad generalmente se convierte en una tabla en el diseño de bases de datos relacionales.
2.1.1 Descubrir y documentar Entidades:
E1 Identificar Entidades en las Entrevistas • Las Entidades siempre son sustantivos, pero no todos los sustantivos son Entidades. • Ignore sustantivos que:
◊ Se refieren a datos específicos. ◊ No son significativos para el estudio.
• No confunda una forma, con la información contenida en ella.
E2 Clasificar la Entidades Se hará más adelante.
E3 Determinar la llave primaria • La llave primaria debe identificar de manera inequívoca una instancia de una entidad. • Características obligatorias:
◊ Valor único. ◊ Valor siempre conocido.
• Características deseables: ◊ Valor estable. ◊ Valor controlado por el administrador de los datos. ◊ Disponible para todos los usuarios. ◊ Desprovisto de información descriptiva.

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 9
• Si no encuentra una buena llave primaria, invéntese una. • Si no la descubre:
◊ Pregunte al usuario cómo identifica la Entidad. ◊ Reconsidere la Entidad. Posiblemente no es una cosa sino corresponde a un dato o no
es importante en esa lugar de estudio o está pobremente definida.
E4 Colocar nombres a las Entidades ♦ Utilizar un sustantivo en singular. ♦ Escribir el sustantivo en letras mayúsculas. ♦ Elaborar una lista de sinónimos en el diccionario. ♦ Eliminar homónimos.
E5 Escribir una descripción de cada Entidad ♦ Describir en forma significativa y con frases completas. ♦ Incluir ejemplos y contraejemplos.
2.2 Relaciones • Relación: Asociación entre entidades. • Nombre de la Relación: Escrita en mayúsculas. Se puede escribir utilizando una frase asociando dos entidades. Ejemplo: EMPLEADO-ASIGNADO_A-PROYECTO. • Instancia de una Relación: caso particular. Ejemplo: Juan Arias - asignado_a - Urrá II. • Una Relación generalmente tiene llaves foráneas en el diseño de bases de datos relacionales.
2.2.1 Descubrir y documentar Relaciones:
R1 Identificar Relaciones en las Entrevistas • Las Relaciones son verbos, pero no todos los verbos son Relaciones. • Ignore verbos que:
◊ Describan procesos mas que datos. ◊ No son significativos para el estudio.
• Descubra y documente relaciones implícitas.
R2 Clasificar la Relaciones Se hará más adelante.
R3 Determinar la cardinalidad
MÁXIMA CARDINALIDAD La máxima cardinalidad de una relación es la respuesta a las siguientes preguntas: Cúantos Referencia_Entidad_1_p verbo_de_la_relación Referencia_Entidad_2_s? Cúantos Referencia_Entidad_2_p verbo_de_la_relación Referencia_Entidad_1_s? La respuesta correcta, depende de las políticas de la Empresa. Respuestas posibles:

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 10
• Muchos a Uno. Ejemplo: EMPLEADO-TRABAJA_EN-DEPARTAMENTO. Cúantos Empleados trabajan en un Departamento? Muchos. En cúantos Departamentos trabaja un Empleado? Al menos uno (a la vez). • Uno a Uno. Ejemplo: EMPLEADO-ADMINISTRA-DEPARTAMENTO. Cúantos Empleados administran un Departamento? Al menos uno (a la vez). Cúantos Departamentos administra un Empleado? Al menos uno (a la vez). • Muchos a Muchos. Ejemplo: EMPLEADO-ASIGNADO_A-PROYECTO. Cúantos Empleados están asignados a un Proyecto? Muchos. En cúantos Proyectos está aasignado un Empleado? Muchos. MÍNIMA CARDINALIDAD La mínima cardinalidad de una relación es la respuesta a las siguientes preguntas: Cúantos Referencia_Entidad_1_p tiene verbo_de_la_relación Referencia_Entidad_2_s? Cúantos Referencia_Entidad_2_p tiene verbo_de_la_relación Referencia_Entidad_1_s? La respuesta correcta, depende de las políticas de la Empresa. Respuestas posibles:
◊ Cero a Cero. ◊ Cero a Uno. ◊ Uno a Uno.
Esta información es particularmente importante cuando se convierten relaciones en columnas de un diseño de bases de datos relacional.
R4 Colocar nombres a las Relaciones ♦ Utilizar un verbo (en lo posible). ♦ Escribir el nombre en letras mayúsculas. ♦ Elaborar una lista de sinónimos en el diccionario. ♦ Eliminar homónimos. ♦ Incluir los nombres de las entidades (aunque se pueden suprimir en casos obvios).
R5 Escribir una descripción de cada Relación ♦ Describir en forma significativa y con frases completas. ♦ Incluir ejemplos y contraejemplos.
2.3 Atributos • Atributo: Describe una propiedad (o característica) de una Entidad o de una Relación. • Padre del Atributo: Nombre de Entidad a la que pertenece el Atributo. • El nombre del Atributo se escribe en minúsculas. Ejemplo: color. • Instancia de una Atributo: caso particular. Ejemplo: verde. • Los atributos generalmente se convierten en Columnas de una Tabla en un diseño de bases de datos
relacionales.

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 11
2.3.1 Descubrir y documentar Atributos:
A1 Identificar Atributos en las Entrevistas • Las Atributos son sustantivos que se refieren específicamente a datos. Ejemplo: nombre, fecha,
cantidad, código).
A2 Tipo de dato • Incluye los siguientes aspectos:
◊ Nombre. ◊ Característica asociada para su manejo (entero, flotante, caracter, ...). ◊ Espacio para su almacenamiento. ◊ Valores válidos. ◊ Reglas que deben cumplir. ◊ Valor por omisión.
• Tipos de datos compuestos. Varios tipos de datos relacionados encerrados en un paréntesis. Ejemplo: fecha = ( año, mes, día ) • Se debe elaborar una lista de todos los tipos de datos.
A3 Determinar la cardinalidad • Los atributos tienen máxima y mínima cardinalidad. Responden respectivamente a las preguntas:
◊ Cúantos Referencia_al_Atributo_p puede tener Referencia_al_padre? Respuestas posibles:
∗ Al menos uno. ∗ Muchos.
◊ Cúantos Referencia_al_Atributo_p tiene que Referencia_al_padre? Respuestas posibles:
∗ Al menos uno. ∗ Ninguno.
Ejemplo: teléfono Cúantos teléfonos puede tener un Empleado? Muchos. Cuantos teléfonos tiene que tener un Empleado? Cero. • Terminología:
◊ Singular: Para máxima cardinalidad en uno. ◊ Plural: Para máxima cardinalidad en muchos. ◊ Opcional: Para mínima cardinalidad en cero. ◊ Requerido: Para mínima cardinalidad en uno.
A4 Colocar nombres a las Atributos ♦ Utilizar un nombre significativo. ♦ Escribir el nombre en letras minúsculas. ♦ Omitir el nombre del padre si es único (no hay dos o más entidades con el mismo nombre de un
atributo). ♦ Utilizar los calificativos de:
◊ Cero.

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 12
◊ Uno. ◊ Muchos.
♦ Elaborar una lista de los tipos de datos. ♦ Documentar los sinónimos. ♦ Eliminar homónimos.
A5 Escribir una descripción de cada Atributo ♦ Describir en forma significativa y con frases completas. ♦ Incluir ejemplos y contraejemplos. ♦ Especificar conceptos asociados: unidades de moneda, peso, distancia, tiempo, ...

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 13
3. ANÁLISIS AVANZADO Familiarizados con las técnicas del diseño básico, se denominan técnicas avanzadas aquellas que permiten el manejo de problemas especiales al elaborar el modelo. Primero se verán clases especiales de entidades, relaciones y atributos, y luego técnicas que permitan manejar datos que reflejan condiciones del pasado o del futuro.
3.1 Entidades
3.1.1 Entidades dependientes • Entidad dependiente: Aquella entidad que no puede existir si no existe una entidad denominada padre. • La dependencia siempre se expresa como una relación al padre (generalmente muchos a uno). • La llave primaria de la entidad dependiente tiene por lo menos dos partes. Siempre incluye la llave primaria
de la entidad padre y uno o más atributos que la describen.
3.1.2 Sub-entidad • Sub-entidad: Aquella entidad que es un subconjunto de otra entidad denominada superentidad. • Las sub-entidades se crean cuando existen entidades que presentan características especiales para los
atributos.
3.1.3 Herencia • La llave primaria, los atributos y relaciones de una superentidad aplican a todas las sub-entidades. • El contrario es falso. • Las sub-entidades siempre heredan los atributos y relaciones de su super-entidad. • Las sub-entidades heredan la llave primaria de la super-entidad.
3.1.4 Relación ES-UN • Siempre existe una relación ES-UN entre una sub-entidad y su super-entidad. • La cardinalidad siempre es:
◊ máximo 1-1 ◊ mínimo 1-0
3.1.5 Descubrir y documentar Entidades:
E2 Clasificar la Entidades • Entidad dependiente. Si no puede existir si no existe una entidad padre. • Sub-entidad. La entidad es un subconjunto de una super-entidad.
E3 Determinar la llave primaria ♦ La llave primaria de una entidad dependiente incluye la llave primaria de la entidad padre y otros
atributos que la describen.

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 14
◊ La llave primaria de uns sub-entidad la hereda de la super-entidad.
E7 Crear Super-entidades con entidades similares Entidades similares son las que tienen atributos comunes. ♦ Asignar atributos comunes a la super-entidad y los atributos especiales a las sub-entidades. ♦ Buscar una llave primaria artificial, si es del caso.
E8 Determinar clases y clasificar atributos • Clase: grupo de sub-entidades mutuamente excluyentes. • Cada clase corresponde a un atributo de clasificación de la super-entidad. • Una super-entidad puede tener varias clases no relacionadas.
3.2 Relaciones • Una relación N-ária es la que involucra más de dos entidades.
3.2.1 Relaciones triples vs. Tres relaciones binarias • Una relación triple es diferente de tres relaciones binarias:
Empleado
Actividad
Proyecto
Juan Carlos Operador Plan 1 Juan Carlos Administrador Plan 32 José Vicente Operador Plan 32
Empleado
Actividad
Empleado
Proyecto
Actividad
Proyecto
Juan Carlos Operador Juan Carlos Plan 1 Operador Plan 1 Juan Carlos Administrador Juan Carlos Plan 32 Administrador Plan 32 José Vicente Operador José Vicente Plan 32 Operador Plan 32
Empleado
Actividad
Proyecto
Juan Carlos Operador Plan 1 Juan Carlos Administrador Plan 32 José Vicente Operador Plan 32 Juan Carlos Operador Plan 32
3.2.2 Relaciones recursivas: • Relación recursiva: Aquella que hace asociaciones con la misma entidad. Ejemplo: EMPLEADO-SUPERVISAR-EMPLEADO

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 15
• Documentar las actividades asociadas con la primera y segunda entidad de la relación. Ejemplo: Supervisor, Subordinado.
3.2.3 Descubrir y documentar Relaciones:
R2 Clasificar la Relaciones ♦ Identificar las relaciones N-árias. ♦ Distinguir una relación triple de tres relaciones binarias. ♦ Documentar las actividades asociadas a entidades en relaciones recursivas.
R7 Eliminar relaciones indirectas Una relación indirecta es redundate a las otras relaciones. ♦ Excluir las relaciones indirectas del modelo de datos. Si la relación indirecta es muy importante para
algunos usuarios, se puede documentar, pero no implementarla en el diseño de la base de datos relacional.
R8 No confundir relaciones con entidades o atributos • Atributos que hacen referencia a entidades son relaciones (cuando un atributo concuerda con la
llave primaria de otra entidad, ella realmente es una relación). • Si la llave primaria de una entidad contiene la llave primaria de otra, ella es una relación.
3.3 Atributos • Intuitivamente se puede decir quien es la entidad padre de un Atributo. Si no se está seguro se puede mirar:
◊ El posesivo de un sustantivo.
EMPLEADO DEPARTAMENTO DIVISIÓN
ASIGNADO_A
TRABAJA_EN A_TRAVÉS_DE

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 16
Ejemplo: De quién es el salario? Salario del empleado. ◊ Nombre del verbo. Ejemplo: Quién tiene salario? El empleado tiene salario. ◊ Una frase. Ejemplos: Fecha de iniciación del proyecto. El estudiante tiene código.
3.3.1 Descubrir y documentar Atributos:
A1 Identificar Atributos en las Entrevistas ♦ Verificar la entidad o relación padre. ♦ Mirar el posesivo de un sustantivo, el nombre de un verbo o una frase.
A7 Reasignar atributos indirectos • Atributos indirectos realmente no son una propiedad de su padre. • Atributo indirecto es igual a un caso especial de relación indirecta.
A7 Documentar las fórmulas ♦ Atributos derivados: Aquellos que resultan de una operación en la que participan otros atributos. Ejemplo: valor_a_pagar = sueldo + bonificaciones - deducciones ♦ Atributo primitivo: el que se debe dar en forma directa. ♦ Documentar las fórmulas, especialmente si el atributo es importante o si su deducción es
complicada. ♦ Consderar la eliminación de atributos derivados.
A9 Convertir atributos opcionales en sub-entidades Atributo opcional: cuando su mínima cardinalidad es cero. Los atributos se consideran opcionales porque:
◊ A veces no se conocen. ◊ A veces no aplican.
♦ Crear una sub-entidad cuando un atributo opcional de una entidad signifique que no aplica, pero
no cuando signifique no conocido.
3.4 Datos históricos La mayoría de entidades, relaciones y atributos reflejan estados actuales, pero en algunos casos es necesario considerar hechos que estan relacionados con fechas.
E6 Considerar estados pasados o futuros ♦ Incluir un atributo de fecha asociado con un hecho. ♦ Incluir un atributo de fecha asociado con el inicio de un estado continuo ♦ Incluir los atributos de fecha inicial y fecha final asociados con estados segmentados ♦ Documentar los estados pasados y futuros en la descripción.

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 17
R6 Considerar estados pasados o futuros ♦ Incluir un atributo de fecha asociado con un hecho. ♦ Incluir un atributo de fecha asociado con el inicio de un estado continuo ♦ Incluir los atributos de fecha inicial y fecha final asociados con estados segmentados ♦ Documentar los estados pasados y futuros en la descripción.
A6 Considerar estados pasados o futuros ♦ Formar una característica compuesta por el atributo y la fecha cuando un caso de un atributo es de
tipo histórico, pero no los demás. ♦ Documentar los estados pasados y futuros en la descripción.
3.5 Contenido del diccionario • Entidades:
◊ Nombre. ◊ Sinónimos. ◊ Descripción. ◊ Llave primaria. ◊ Padre (si es dependiente). ◊ Super-entidad, clase, atributo de clasificación (si es subconjunto). ◊ Volúmen (número de instancias esperadas).
• Relaciones: ◊ Nombre. ◊ Sinónimos. ◊ Descripción. ◊ Cardinalidad (máxima y mínima). ◊ Identificación del rol de cada entidad (si es recursiva). ◊ Volúmen (número de instancias esperadas).
• Atributos: ◊ Nombre. ◊ Sinónimos. ◊ Entidad o relación padre. ◊ Descripción (incluyendo unidades). ◊ Cardinalidad (singular/plural, opcional/requerida). ◊ Tipo de dato:
∗ Nombre. ∗ Característica asociada para su manejo (entero, flotante, caracter, ...). ∗ Valores válidos. ∗ Reglas. ∗ Valor por omisión.
◊ Explicación de las fórmulas.
3.6 Análisis de datos • Determinar datos y reglas independientemente de procesos, rendimiento y presentación. • Dar las especificaciones que se dan para una aplicación y para el modelo general (corporativo).

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 18
MUNDO REAL DATOS
REQUERIMIENTOSMODELO
ENTIDAD-RELACIÓNMODELO
DBMSMODELO
FISICO
Jerárquico
Relacional
Red
Por objetos

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 19
4. BASES DE DATOS RELACIONALES
4.1 Definiciones • Elemental: Organización tabular de datos donde se permiten operaciones con restricción, proyección y
encadenamiento (join). • Práctica: Sistema que suporta SQL. • General: Sistema que se acomoda a los principios del modelo relacional.
4.2 El modelo relacional • Estructura de datos:
◊ Tablas. ◊ Filas. ◊ Columnas. ◊ Tipos de datos. ◊ Valores nulos. ◊ Vistas.
• Operadores (según Codd): ◊ Restricción. ◊ Proyección. ◊ Encadenamiento (join). ◊ Unión. ◊ Diferencia. ◊ Intersección. ◊ Producto. ◊ División.
• Reglas de integridad: ◊ Llave primaria. ◊ Llaves foráneas. ◊ Integridad a nivel de entidad. ◊ Integridad referencial.
Las anteriores tres partes corresponden a los tres componentes de ingeniería de software:
◊ Información. ◊ Procesos. ◊ Integridad.
4.3 Estructura de datos
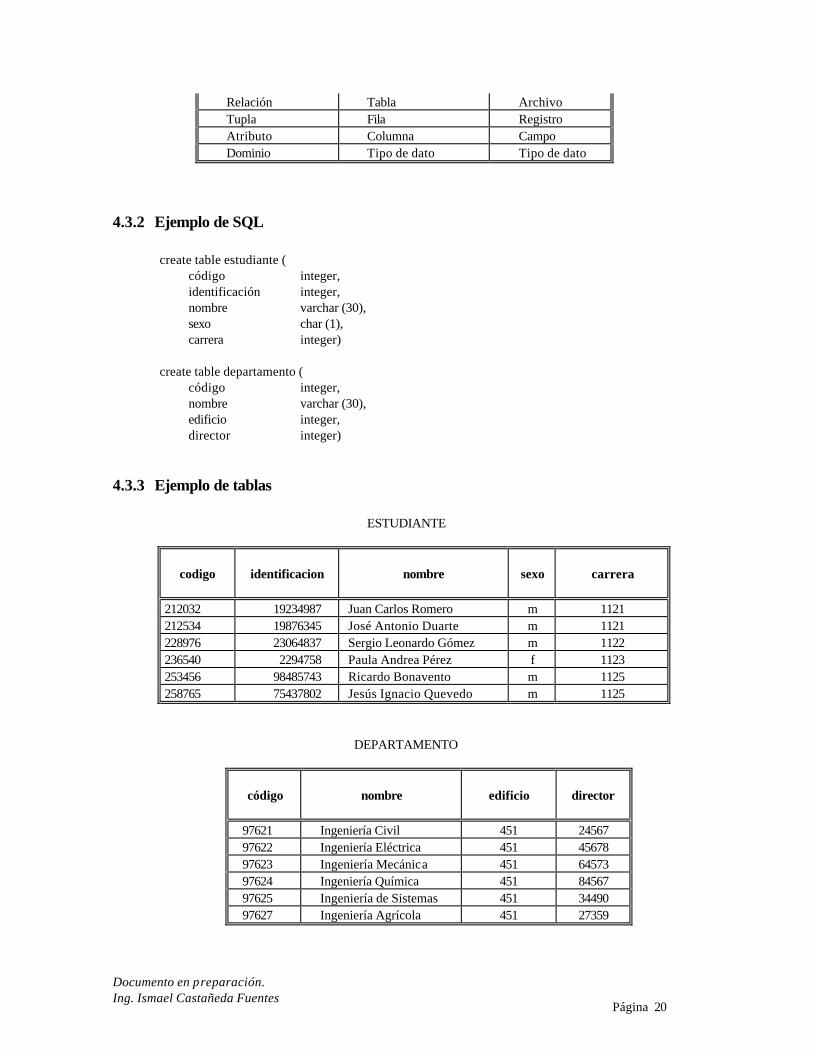
4.3.1 Terminología
TÉRMINOS EQUIVALENTES
FORMAL
(Codd)
COMÚN
FÍSICO
Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 20
Relación Tabla Archivo Tupla Fila Registro Atributo Columna Campo Dominio Tipo de dato Tipo de dato
4.3.2 Ejemplo de SQL create table estudiante (
código integer, identificación integer, nombre varchar (30), sexo char (1), carrera integer)
create table departamento (
código integer, nombre varchar (30), edificio integer, director integer)
4.3.3 Ejemplo de tablas
ESTUDIANTE
codigo
identificacion
nombre
sexo
carrera
212032 19234987 Juan Carlos Romero m 1121 212534 19876345 José Antonio Duarte m 1121 228976 23064837 Sergio Leonardo Gómez m 1122 236540 2294758 Paula Andrea Pérez f 1123 253456 98485743 Ricardo Bonavento m 1125 258765 75437802 Jesús Ignacio Quevedo m 1125
DEPARTAMENTO
código
nombre
edificio
director
97621 Ingeniería Civil 451 24567 97622 Ingeniería Eléctrica 451 45678 97623 Ingeniería Mecánica 451 64573 97624 Ingeniería Química 451 84567 97625 Ingeniería de Sistemas 451 34490 97627 Ingeniería Agrícola 451 27359

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 21
4.3.4 Definición formal de Tabla • Una tabla está compuesta de un encabezado y un cuerpo. • El encabezado de una tabla es un conjunto fijo de columnas C1 , ... Cn y tipos de datos D1 , ... Dn • El cuerpo de una tabla es un conjunto variable de filas { (C1 : V1 ) . . . (Cn : Vn ) } donde todos los valores Vi son del tipo de datos Di
4.3.5 Alcance de la definición • Las filas y columnas no tienen un determinado orden. • No tiene sentido tener filas o filas duplicadas. • Por cada celda (intersección de fila y columna) sólo debe existir un valor (tablas normalizadas).
4.3.6 Facilidades de los tipos de datos • Incluyen el concepto de representación física (entero, real, caracter, decimal). • El usuario puede definir:
◊ Sus propios tipos de datos (por ejemplo: grados). ◊ Un valor por omisión. ◊ El conjunto de valores válidos. ◊ Reglas de validación. ◊ Tipos de datos compuestos o complejos (por ejemplo: fecha, polígono, área). ◊ Funciones (por ejemplo: área (polígono).
• Chequeo automático (por ejemplo para compatibilidad de tipos de datos en expresiones).
4.4 Valores nulos (null) • Null: es un símbolo especial, independiente del tipo de dato, que significa deconocido o no aplica. • El resultado al hacer una operación con uno de los siguientes operadores: < = > + - * / , en el cual uno o
ambos operandos es nulo el resultado es nulo. • Tablas de verdad que incluyen el concepto de nulo: AND VERDADERO FALSO NULO VERDADERO Verdadero Falso Nulo FALSO Falso Falso Falso NULO Nulo Falso Nulo OR VERDADERO FALSO NULO VERDADERO Verdadero Verdadero Verdadero FALSO Verdadero Falso Nulo NULO Verdadero Nulo Nulo X NOT (X) VERDADERO Falso FALSO Verdadero NULO Nulo

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 22
4.4.1 Nulo sin sentido • Dos valores null son diferentes en la expresión: “null = null” • Dos valores null tiene el mismo significado en sentencias con SELECT DISTINCT y GROUP BY. • Los operadores aritméticos no son distributivos sobre funciones SQL. Ejemplo: Select sum (salario + comisión) from pago Select sum (salario) + sum (comisión) from pago
4.4.2 Valores por omisión • El valor por omisión es el valor ‘normal’ de un tipo de datos. • El valor por omisión es más predecible que el valor null. • El valor ‘normal’ de un tipo de dato representa:
◊ Valor estándar. ◊ Valor desconocido. ◊ No aplica.
• Problemas con los valores por omisión: ◊ Todos los valores son significativos. ◊ Posibles errores al utilizar funciones SQL. ◊ No se pueden eliminar nulos del SQL.
• Usar valores por omisión para tipos de datos de caracteres. • Usar valores por omisión para tipos de datos numéricos cuando las funciones SQL sean importantes.
4.5 Operadores • El modelo relacional tiene ocho operadores:
◊ Restricción. ◊ Proyección. ◊ Encadenamiento (join). ◊ Unión. ◊ Diferencia. ◊ Intersección. ◊ Producto. ◊ División.
• Los operadores son la base del algebra relacional, implementada en el SQL. • El resultado, al aplicar estos operadores, siempre se coloca en una tabla. • Ejemplos:
◊ Restricción: select * from estudiante where código > 250000 ◊ Proyección: select código, nombre from estudiante ◊ Encadenamiento (join): select * from estudiante, carrera where estudiante.cod_car = carrera.codigo ◊ Restricción + Proyección: select código, nombre from estudiante where código > 250000 ◊ Proyección + Encadenamiento: select código, nombre, nom_carrera from estudiante, carrera where estudiante.cod_car = carrera.codigo
4.6 Reglas de integridad Definiciones: • Llave: Columna o columnas utilizadas para identificar filas. • Llave sencilla: Llave que utiliza una columna. • Llave compuesta: Llave que utiliza dos o más columnas. • Índice: Columna o columnas utilizadas para identificar y/o localizar filas.

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 23
Clase de llaves en el modelo relacional: • Primaria. • Foránea. • Candidata. • Alterna.
4.6.1 Llave primaria • Llave primaria: es la que identifica de manera inequívoca una fila. • Características de la llave primaria:
◊ Valor único. ◊ No puede tener valores de tipo nulo. ◊ Es mínima, es decir, utiliza el mínimo de columnas necesarias para asegurar unicidad.
• Si se utilizan valores nulos, las consultas pueden fallar.
4.6.2 Llave foránea • Llave foránea: Columna o columnas que se refieren a la llave primaria de otra tabla. • Características de la llave foránea:
◊ Deben tener el mismo tipo de datos. ◊ Deben tener características iguales.
• Una llave primaria puede contener llaves foráneas.
4.6.3 Reglas de integridad • Las llaves primarias deben tener valores únicos. • Integridad a nivel de entidad: todas las columnas de una llave primaria deben ser diferentes de nulos. • Integridad referencial: El valor de una llave foránea debe concordar con uno de los valores contenidos en
la correspondiente llave primaria. • Las reglas de llaves foráneas especifican la manera como se debe mantener la integridad referencial.
4.6.4 Reglas para inserción/actualización de llaves foráneas • Automática: Si el valor de una llave foránea no concuerda con una llave primaria se crea una llave primaria con ese valor. • Restringida: No se puede colocar un valor como llave foránea si no hay concordancia con las llaves primarias. • Nulificación: Colaca en nulo una llave foránea nueva (solamente para inserción). • Por omisión: Colaca el valor por omisión a una llave foránea nueva (solamente para inserción).
4.6.5 Reglas para actualización/borrado de llaves primarias • Cascada: Al borrar una llave primaria se borran todas las llaves foráneas concordantes. Al actualizar una llave primaria se actualizan todas las llaves foráneas concordantes. • Restingido: No se puede borrar una llave primaria si existe cualquier concordancia con llaves foráneas. • Nulificación: Al actualizar/borrar una llave primaria todas las llaves foráneas concordantes se dejan con valor nulo. • Por omisión: Al actualizar/borrar una llave primaria todas las llaves foráneas concordantes

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 24
se dejan con el valor por omisión.
4.7 Vistas • Tabla(s) base: Existen físicamente y sus filas están almacenados en la base de datos. • Vista:
◊ Físicamente sólo existe su estructura. ◊ Puede tomar toda la información de otra(s) tabla(s) base. ◊ Puede tomar sólo algunas filas/columnas de otra(s) tabla(s) base. ◊ Puede tener columnas calculadas. ◊ Puede tener información resultante de operaciones de encadenamiento de tablas base. ◊ Las operaciones de inserción, actualización y borrado operan sobre la(s) tabla(s) base y
generalmente son operaciones restringidas en los DBMS.
4.7.1 El modelo relacional Con respecto a los componentes de la ingeniería de software: • Estructura de datos: Tablas, columnas, filas, tipos de datos, nulos. • Operadores: Restricción, proyección, encadenamiento, unión, diferencia, intersección, producto y división. • Integridad: Llaves primarias, llaves foráneas, integridad a nivel de entidad e integridad referencial.
4.7.2 Ventajas del modelo relacional • Sólida fundamentación teórica (teoría de conjuntos, lógica y algebra relacional). Esto significa que el modelo es cohesivo, predecible y teóricamente sólido. • Independencia física de los datos. Sólo se definen tablas con columnas y filas. • Los resultados siempre se obtienen en tablas. Se tiene más productividad que tratarlos como simples filas. • La estructura de datos es sencilla, intuitiva y uniforme. Programadores o usuarios finales pueden manipular tablas. Cualquier cosa puede llevarse a una tabla, inclusive los resultados de una consulta.
4.8 SQL Ver cuidadosamente en los DBMS la implementación de: • Tipos de datos del sistema. • Tipos de datos del usuario. • Valores por omisión. • Reglas. • Asignación de valores por omisión y/o reglas a los tipos de datos. • Manejo de las llaves primarias y foráneas. • Manejo de índices. • Manejo de la integridad a nivel de entidad. • Manejo de la integridad referencial. • Manejo de activadores (triggers).

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 25
5. DISEÑO RELACIONAL BÁSICO
5.1 Entidades a tablas En el diseño básico relacional cada entidad se convierte en una tabla.
T1 Entidades independientes a tablas independientes ♦ La llave primaria no contiene llaves foráneas.
T2 Entidades dependientes a tablas dependientes ♦ La llave foránea encadena a la tabla padre. ♦ La llave primaria contiene la llave foránea y otra(s) columna(s). ♦ Reglas para llaves foráneas:
◊ No se permiten valores nulos o por omisión. ◊ Borrado en cascada o restringido.
T3 Sub-entidades a sub-tablas ♦ La llave foránea se encadena con la super-tabla. ♦ La llave primaria es la llave foránea. ♦ Reglas para las llaves foráneas
◊ No se permiten valores nulos o por omisión. ◊ Borrado en cascada o restringido.
♦ Hacer clasificación por columnas en la super-tabla (recomendado). ◊ Elimina la necesidad de ver datos en sub-tablas. ◊ Redundante para datos en sub-tablas.
5.2 Relaciones a llaves foráneas • Nombre de la llave foránea = Nombre de la llave primaria (con calificador si es necesario). • Utilizar nombres significativos.
K1 Relaciones 1-n. Colocar la llave foránea en el lado de muchos ♦ Las llaves foráneas deben ser singulares (deben ser tablas normalizadas).
K2 Relaciones 1-1. Colocar la llave foránea en la tabla con menos filas ♦ Reduce o elimina valores nulos.
K3 Relaciones n-n a tablas asociada ♦ Las dos llaves foráneas se refieren las dos tablas relacionadas. ♦ La llave primaria se compone de las llaves foráneas y puede incluir una o más columnas
adicionales. ♦ Reglas para las llaves foráneas

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 26
◊ No se permiten valores nulos o por omisión. ◊ Borrado en cascada o restringido.
K4 Relaciones n-árias a tabla asociada ♦ Comportamiento como el caso de relaciones n-n excepto que la llave primaria contine por lo menos
n llaves foráneas.
5.3 Atributos a columnas • Atributos singulares pasan como columnas. • Tipos de datos compuestos pasan como varias columnas (depende del DBMS).
C1 Atributos plurales a tablas dependientes ♦ La llave foránea encadena a la tabla padre. ♦ La llave primaria contiene la llave foránea y el atributo plural. ♦ Reglas para las llaves foráneas
◊ No se permiten valores nulos o por omisión. ◊ Borrado en cascada.
C2 Especificar NOT NULL para atributos y relaciones tipo ‘requerido’ ♦ ‘Requerido’ = mínima cardnalidad 1 = columna con opción not null. ♦ Especificar not null a:
◊ La columna que representa el atributo tipo ‘requerido’. ◊ Llave foránea que representa la relación tipo ‘requerido’. ◊ Todas las columnas llave primaria, siempre.
♦ Desaprobar valores por omisión que signifiquen desconocido o no aplica.
C3 Forzar valores únicos para atributos utilizando índices ♦ Los índices hacen más lentas las operaciones de adición, modificación y borrado. ♦ Definir las llaves primarias como índices con la opción de valor único (depende del DBMS).
C4 Atributos de relaciones van con la llave foránea ♦ Para relaciones 1-1 y 1-n, colocar el atributo en la tabla que contiene la llave foránea. ♦ Para relaciones n-n y n-árias, colocar el atributo en la tabla asociada.
5.4 Clase de tablas
TABLA
REPRESENTA
LLAVE PRIMARIA
Independiente Entidad independiente Sin llave foráneas Sub-tabla Sub-entidad Una llave foránea

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 27
Dependiente Entidad dependiente Atributo plural
Una llave foránea y columna(s) adicional(es)
Asociada Relación muchos a muchos Relaciones n-árias
Dos o n llaves foráneas y opcionalmente otras columnas.
5.5 Diseño básico vs. Diseño avanzado • Diseño básico no tiene en cuenta el rendimiento. • Diseño avanzado tiene en cuenta alternativas y hace afinamiento.

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 28
6. FORMAS NORMALES
6.1 Redundancia • En bases de datos relacionales es necesario la repetición de valores. • Redundancia es la repstición de un hecho (asunto, caso, ...). • La redundancia puede dar mejor rendimiento, pero generalmente no es deseable. • La siguiente tabla tiene información redundante:
ASIGNACIÓN # empleado cargo # proyecto rol rata e1 Programador p1 Supervisor 6000.00 e1 Programador p2 Investigador 4500.00 e1 Programador p3 Auxiliar 3850.00 e2 Operador p3 Supervisor 6000.00 e3 Analista p3 Supervisor 6000.00 Existe redundancia en la información:
− e1 es programador. − El supervisor tiene una rata de 6000
6.1.1 Problemas de la redundancia • Inconsistencia de datos. • Anomalias en la actualización. • Rendimiento bajo (analizar actualización vs consulta). • Descontrol en los procedimientos que hacen mantenimiento de datos. Los activadores (triggers pueden manejar las anomalías e inconsistencias, pero sigue el bajo rendimiento y
la complejidad permanece.
6.1.2 Formas normales • Forma normal: Estructura de tablas que reducen la redundancia. • Existen muchas formas normales, pero seis son la de mayor importancia práctica: 1FN, 2FN, 3FN, BCFN,
4FN y 5FN. Cada una de esta formas normales es más potente (menos redundancia) que la anterior. • Las formas normales más altas se obtiene por descomposición, se convierte una tabla en tablas más
pequeñas, sin perder información.
6.2 Primera forma normal - 1FN • Una tabla está en primera forma normal cuando en cada celda existe sólo un valor. • Por definición, en un sistema relacional todas las tablas deben estar en 1FN. • Generalmente se habla de una tabla normalizada cuando está en 1FN. • Tablas en 1FN pueden tener redundancia. • Ejemplo de tabla no normalizada:

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 29
ASIGNACIÓN # empleado cargo # proyecto rol rata
e5 Programador
p1
Supervisor Investigador Auxiliar
6000.00 4500.00 3850.00
e7 Operador p3 Supervisor 6000.00 e8 Analista p3 Supervisor 6000.00
6.3 Segunda forma normal - 2FN • Segunda forma normal: Es una tabla que debe estar en 1FN y donde cada columna no llave debe depender
totalmente de la llave primaria (las columnas no llave no pueden depender parcialmente de la llave principal).
• Ejemplo: en la siguiente tabla se tiene que cargo sólo depende parcialmente de la llave principal, por lo tanto no está en 2FN:
ASIGNACIÓN_1
# empleado cargo # proyecto rol rata e1 Programador p1 Supervisor 6000.00 e1 Programador p2 Investigador 4500.00 e1 Programador p3 Auxiliar 3850.00 e2 Operador p3 Supervisor 6000.00 e3 Analista p3 Supervisor 6000.00 • La tabla del ejemplo anterior se puede llevar a 2FN descomponiéndola en otras tablas. Ejemplo:
ASIGNACIÓN_1A # empleado # proyecto rol rata e1 p1 Supervisor 6000.00 e1 p2 Investigador 4500.00 e1 p3 Auxiliar 3850.00 e2 p3 Supervisor 6000.00 e3 p3 Supervisor 6000.00
ASIGNACIÓN_2A # empleado cargo e1 Programador e2 Operador

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 30
e3 Analista • Las tablas en 2FN pueden tener redundancia. En el ejemplo anterior la información ‘supervisor tiene una rata de 6000’ es redundante.
6.4 Tercera forma normal - 3FN • Tercera forma normal: Es una tabla que está en 2FN y donde cada columna no llave depende directamente
de la llave primaria • Ejemplo: la tabla ASIGNACIÓN_1 se puede tener en 3FN así: ASIGNACIÓN_A1
# empleado # proyecto rol e1 p1 Supervisor e1 p2 Investigador e1 p3 Auxiliar e2 p3 Supervisor e3 p3 Supervisor ASIGNACIÓN_A2 ASIGNACIÓN_A3
# rol rata # empleado cargo Supervisor 6000.00 e1 Programador Investigador 4500.00 e2 Operador Auxiliar 3850.00 e3 Analista • Las tablas en 3FN pueden tener redundancia.
T4 Verificar que las tablas están en 3FN
6.5 Forma normal de Boyce-Codd - BCFN
6.5.1 Dependencia funcional • Si c1 y c2 son columnas de la tabla T, se dice que c2 depende de c1 si para cada valor de c1 siempre se
asocia un mismo valor en c2. • También se puede decir que: Si c1 y c2 son columnas de la tabla T, se dice que c2 depende de c1 si la
relación de c1 a c2 es singular y requerida. • Dependencia funcional no es lo mismo que dependencia de existencia.

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 31
6.5.2 Llaves candidatas • Llave candidata: Cualquier columna o grupo de columnas que identifiquen de manera única una fila. • Cualquiera de las llaves candidatas se puede elegir como llave primaria. • Una vez elegida la llave primara las demás llaves candidatas se denominan llaves alternas.
6.5.3 Fallas en la definición 3FN • La definición de 3FN generalmenta es buena en términos prácticos pero presenta dos fallas:
◊ Sólo controla columnas no llaves y no mira problemas con llaves compuestas. ◊ Se abre en tablas con llaves alternas.
• Ejemplo: Si se tiene la entidad ESTUDIANTE con atributos: código, cédula, nombre y estado_civil, con llave primaria código, entonces cada instancia también depende de la llave alterna cédula, lo cual viola la definición de 3FN.
6.5.4 Determinante (columna determinante) • Una columna es determinante cuando un valor de otra columna depende del valor de esa. • Un determinante puede ser compuesto.
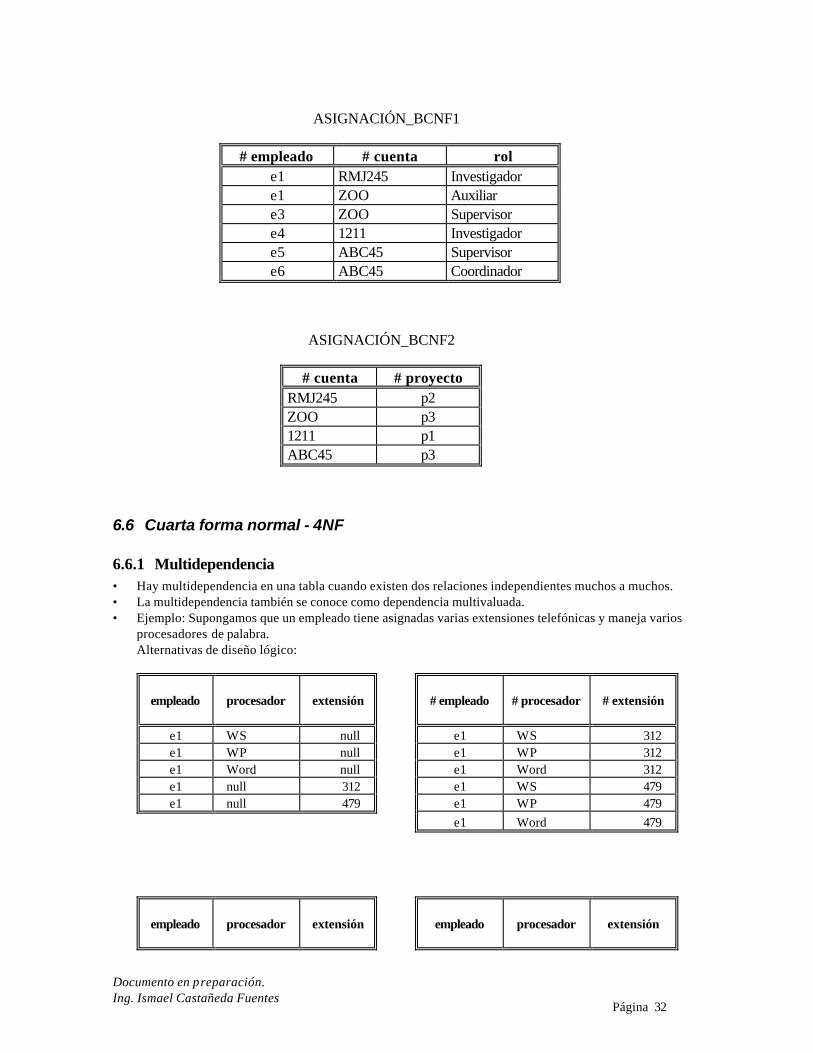
6.5.5 BCNF • La forma normal Boyce-Codd es una tabla donde cada determinante es llave candidata. • Ejemplo: ASIGNACIÓN_3FN
# empleado # proyecto cuenta rol e1 p2 RMJ245 Investigador e1 p3 ZOO Auxiliar e3 p3 ZOO Supervisor e4 p1 1211 Investigador e5 p3 ABC45 Supervisor e6 p3 ABC45 Coordinador
La anterior tabla: ∗ Está en 3FN. ∗ Tiene información redundante: proyecto depende de cuenta. ∗ Se puede hacer análisis de determinante y llave candidata:
Determinante
Determinada
Llave candidata
empleado, proyecto cuenta rol
Sí
cuenta proyecto No ∗ Se puede eliminar la redundancia por descomposición y obtener tablas BCNF:
Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 32
ASIGNACIÓN_BCNF1
# empleado # cuenta rol e1 RMJ245 Investigador e1 ZOO Auxiliar e3 ZOO Supervisor e4 1211 Investigador e5 ABC45 Supervisor e6 ABC45 Coordinador ASIGNACIÓN_BCNF2
# cuenta # proyecto RMJ245 p2 ZOO p3 1211 p1 ABC45 p3
6.6 Cuarta forma normal - 4NF
6.6.1 Multidependencia • Hay multidependencia en una tabla cuando existen dos relaciones independientes muchos a muchos. • La multidependencia también se conoce como dependencia multivaluada. • Ejemplo: Supongamos que un empleado tiene asignadas varias extensiones telefónicas y maneja varios
procesadores de palabra. Alternativas de diseño lógico:
empleado
procesador
extensión
# empleado
# procesador
# extensión
e1 WS null e1 WS 312 e1 WP null e1 WP 312 e1 Word null e1 Word 312 e1 null 312 e1 WS 479 e1 null 479 e1 WP 479 e1 Word 479
empleado
procesador
extensión
empleado
procesador
extensión

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 33
e1 WS null e1 WS 312 e1 null 479 e1 WP 479 e1 Word 479 e1 Word null e1 WP 312
Las tablas anteriores están en BCNF pero presentan redundancia y anomalías cuando se van a actualizar.
6.6.2 4NF • La cuarta forma normal es una tabla que está en 3FN y no contiene relaciones independientes de muchos a
muchos. • Ejemplo:
# empleado
# procesador
# empleado
# extensión
e1 WS e1 312 e1 WP e1 479 e1 Word
6.7 Quinta forma normal - 5NF
6.7.1 Dependencia cíclica • Generalmente ocurre en relaciones n-árias donde las relaciones muchos a muchos son dependientes. • Ejemplo:
Si un empleado e1 tiene asignada la actividad a1 y el empleado e1 está asignado al proyecto p1 y el proyecto p1 requiere de la actividad a1 entonces el empleado e1 debe estar asignado al proyecto p1 con la actividad a1.
• Usualmente estas relaciones n-árias no se pueden descomponer. • Ejemplo:
Empleado
Actividad
Proyecto
Juan Carlos Operador Plan 1 Juan Carlos Administrador Plan 32 José Vicente Operador Plan 32
Empleado
Actividad
Empleado
Proyecto
Actividad
Proyecto
Juan Carlos Operador Juan Carlos Plan 1 Operador Plan 1 Juan Carlos Administrador Juan Carlos Plan 32 Administrador Plan 32

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 34
José Vicente Operador José Vicente Plan 32 Operador Plan 32
Empleado
Actividad
Proyecto
Juan Carlos Operador Plan 1 Juan Carlos Administrador Plan 32 José Vicente Operador Plan 32 Juan Carlos Operador Plan 32
6.7.2 5NF • La quinta forma normal es una tabla que está en 4FN y no contiene dependencias cíclicas, excepto para el
caso trivial entre llaves candidatas. • 5NF básicamente es de interés académico. • Matemáticamente se ha demostrado que 5NF es la última forma normal.
6.8 Definiciones formales Si A, B y C son columnas (probablemente compuestas) de la tabla T:
6.8.1 Dependencia funcional • B es funcionalmente dependiente de A si y solamente si para cada valor de A en T siempre se asocia
exactamente con el mismo valor de B. • B es totalmente dependiente de A si y solamente si B es funcionalmente dependiente de A, pero no sobre
cualquier subconjunto propio de columnas de A. • La columna A es determinante cuando cualquier columna de T es totalmente dependiente de A.
6.8.2 Multidependencia
• a1, a2, ... an son subconjuntos del conjunto de columnas de una tabla T.
• Proyección de T sobre a1: Proyección de T a una tabla que incluye cada columna de a1 y no otras.
• T satisface la dependencia cíclica sobre a1, a2, ... an si y solamente si T es el encadenamiento (join) de
su proyección sobre a1, a2, ... an. • Dependencia funcional es un caso especial de multidependencia. • Multidependencia es un caso especial de dependencia cíclica.
6.8.3 Formas normales • Primera: Los dominios de cada columna solamente contienen valores atómicos. • Segunda: Tabla en 1NF y cada columna no llave es funcionalmente dependiente de toda la llave primaria. • Tercera: Tabla en 2NF y no hay dependencias funcionales indirectas de columnas no llave sobre la llave
primaria. • Boyce-Codd: Cada determinante es una llave candidata. • Cuarta: Tabla en BCNF y cada multidependencia es actualmente una dependencia funcional. • Quinta: Cada dependencia cíclica está sobre las llaves candidatas.

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 35

Documento en preparación. Ing. Ismael Castañeda Fuentes
Página 36
7. DISEÑO RELACIONAL AVANZADO Elaboradas las tablas y verificadas que están en 3FN generalmente sigue el diseño de pequeñas tablas que se crean para hacer encadenamientos (joins) cuando se van a hacer cierto tipo de preguntas y degradan el rendimiento. Hasta este momento se han dejado de lado consideraciones para elaborar diseños alternos que den mejor rendimiento o simplifiquen la base de datos. En el dieño relacional avanzado se identifican esas alternativas, se evalúan mirando el mercado y se afinan las tablas. Como en el diseño relacional avanzado se atiende especialmente el rendimiento, primero se miran las preguntas críticas. Las preguntas críticas son aquellas que significan muy alto volúmen, alta frecuencia de uso o que exigen excelente tiempo de respuesta. Estas preguntas son el punto de partida y de referencia para mirar el rendimiento y plantear alternativas. Se van a considerar siete problemas importantes: llaves artificiales, datos compartidos en L, relaciones 1-1, datos en forma de vector, columnas sobrecargadas, sobrenormalización y desnormalización.
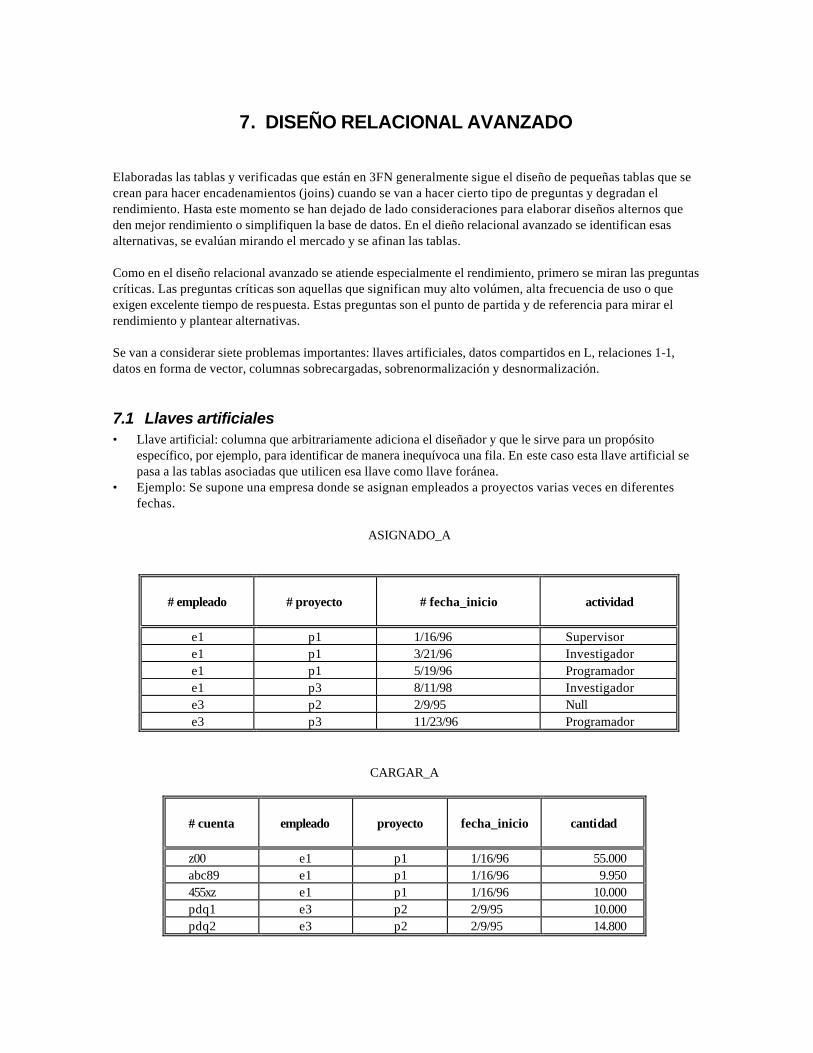
7.1 Llaves artificiales • Llave artificial: columna que arbitrariamente adiciona el diseñador y que le sirve para un propósito
específico, por ejemplo, para identificar de manera inequívoca una fila. En este caso esta llave artificial se pasa a las tablas asociadas que utilicen esa llave como llave foránea.
• Ejemplo: Se supone una empresa donde se asignan empleados a proyectos varias veces en diferentes fechas.
ASIGNADO_A
# empleado
# proyecto
# fecha_inicio
actividad
e1 p1 1/16/96 Supervisor e1 p1 3/21/96 Investigador e1 p1 5/19/96 Programador e1 p3 8/11/98 Investigador e3 p2 2/9/95 Null e3 p3 11/23/96 Programador CARGAR_A
# cuenta
empleado
proyecto
fecha_inicio
cantidad
z00 e1 p1 1/16/96 55.000 abc89 e1 p1 1/16/96 9.950 455xz e1 p1 1/16/96 10.000 pdq1 e3 p2 2/9/95 10.000 pdq2 e3 p2 2/9/95 14.800

En la tabla ASIGNADO_A la llave primaria es: empleado, proyecto, fecha_inicio. Por conveniencia el diseñador puede inventarse una columna llamada código con característica de llave artificial, quedando así el ejemplo:
ASIGNADO_A
# código
empleado
proyecto
fecha_inicio
actividad
c1 e1 p1 1/16/96 Supervisor c2 e1 p1 3/21/96 Investigador c3 e1 p1 5/19/96 Programador c4 e1 p3 8/11/98 Investigador c5 e3 p2 2/9/95 Null c6 p3 p3 11/23/96 Programador CARGAR_A
# cuenta
código
cantidad
z00 c1 55.000 abc89 c1 9.950 455xz c5 10.000 pdq1 c5 10.000 pdq2 c5 14.800
7.1.1 Ventajas de las llave artificiales • Cuando una llave primaria en forma natural tiene nulos, al seleccionar una llave artificial se le puede dar la
característica de no nulo. • A las llaves artificiales generalmente se les asigna un valor entero o un mnemónico fácil de manipular. • Los índices sobre llaves artificiales ocupan menos espacio físico y generalmente son más eficientes. • Las llaves artificiales son estables y se les puede controlar (a veces un concepto de la llave primaria
natural puede perder significado, por ejemplo en la columna fecha_inicio del ejemplo anterior). • Las llaves artificiales eliminan redundancia al escribirlas como llaves foráneas.
7.1.2 Desventajas de las llave artificiales • A veces no tienen significado alguno para el usuario final y hacen más difícil el acceso directo a las tablas. • Se aumenta el número de columnas de una tabla. • Hay que hacer más encadenamientos (joins) cuando se traen o actualizan datos.
K5 Considerar llaves artificiales como llaves primarias Cuando: • Hay muchas llaves foráneas.

• La llave primaria natural tiene el caso de valores: ◊ Tipo nulo. ◊ No únicos. ◊ Inestables. ◊ Complejos. ◊ Poco significativos.
Lo deseable para una llave primaria es: • Que sea estable. • Corta y sencilla. • Sin información descriptiva. • Familiar para los usuarios finales. La complejidad de una llave primaria se puede mirar desde dos aspectos: • Relacional: por ejemplo que tenga muchos caracteres o que tenga muchas columnas y por lo tanto
ser incómoda. • Físico: Cantidad de espacio que se necesita para su manejo interno y su eficiencia. Por ejemplo la
cantidad de espacio que se necesita para utilizarla como un índice o como llave foránea.
7.2 Datos compartidos en L
7.2.1 Supertablas Tabla donde se tiene toda la información en columnas. Ventajas de las supertablas: • Se necesitan menos encadenamientos (joins) • Se necesitan menos llaves foráneas. • Se necesitan menos tablas. • Ejemplo:
EMPLEADO
empleado
. . .
actividad
depto
proc_pal
nivel
zona
comisión
e1 . . . Secretaria d3 Word Básico null null e2 . . . Vendedor d2 null null Centro 242.000 e3 . . . Vendedor d2 null null Sur null e4 . . . Portero d1 null null null null e5 . . . Secretaria d2 WP Intermedio null null e6 . . . Secretaria d3 WS Avanzado null null
7.2.2 Subtablas En varias tablas se tiene la información. Ventajas de las subtablas: • Se aplica menos veces el concepto de nulo o no aplica. • Generalmente necesitan menos espacio físico para su almacenamiento. • Son más estables y flexibles.
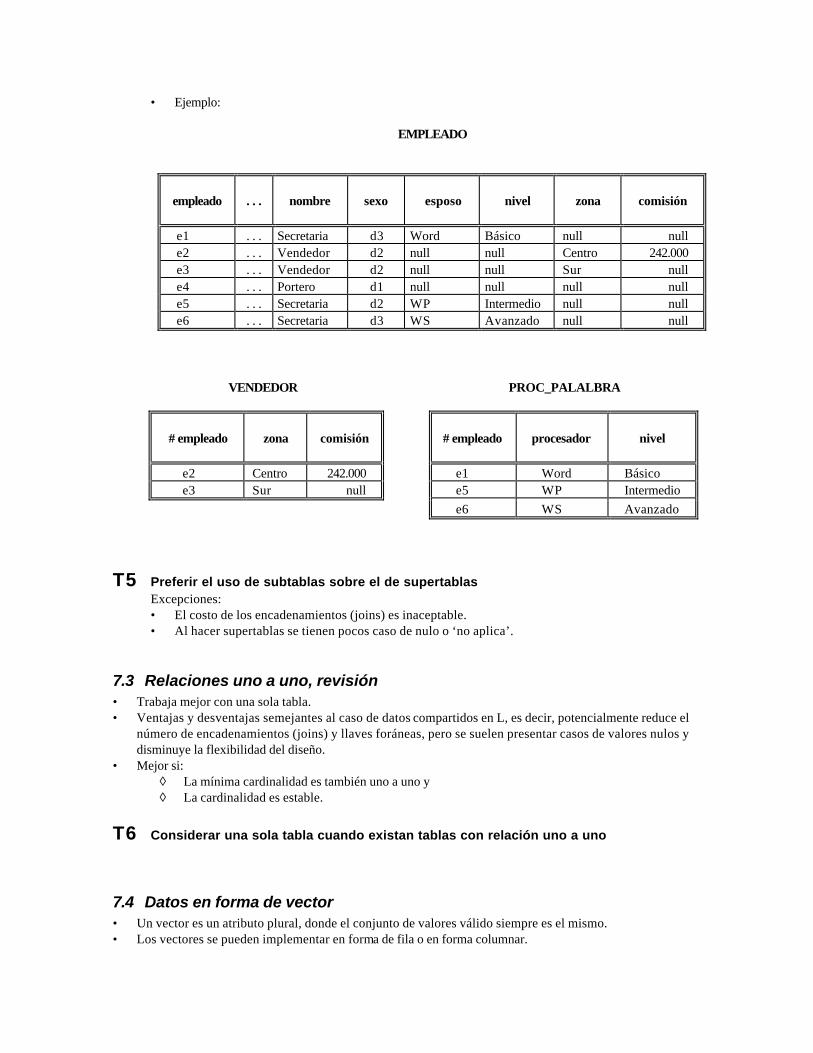
• Ejemplo: EMPLEADO
empleado
. . .
nombre
sexo
esposo
nivel
zona
comisión
e1 . . . Secretaria d3 Word Básico null null e2 . . . Vendedor d2 null null Centro 242.000 e3 . . . Vendedor d2 null null Sur null e4 . . . Portero d1 null null null null e5 . . . Secretaria d2 WP Intermedio null null e6 . . . Secretaria d3 WS Avanzado null null VENDEDOR PROC_PALALBRA
# empleado
zona
comisión
# empleado
procesador
nivel
e2 Centro 242.000 e1 Word Básico e3 Sur null e5 WP Intermedio e6 WS Avanzado
T5 Preferir el uso de subtablas sobre el de supertablas Excepciones: • El costo de los encadenamientos (joins) es inaceptable. • Al hacer supertablas se tienen pocos caso de nulo o ‘no aplica’.
7.3 Relaciones uno a uno, revisión • Trabaja mejor con una sola tabla. • Ventajas y desventajas semejantes al caso de datos compartidos en L, es decir, potencialmente reduce el
número de encadenamientos (joins) y llaves foráneas, pero se suelen presentar casos de valores nulos y disminuye la flexibilidad del diseño.
• Mejor si: ◊ La mínima cardinalidad es también uno a uno y ◊ La cardinalidad es estable.
T6 Considerar una sola tabla cuando existan tablas con relación uno a uno
7.4 Datos en forma de vector • Un vector es un atributo plural, donde el conjunto de valores válido siempre es el mismo. • Los vectores se pueden implementar en forma de fila o en forma columnar.
• Normalmente se utiliza la implementación columnar. • No se debe utilizar la implementación en forma de filas cuando no es razonable el número de filas. • De hecho es el mismo caso que se presenta cuando se elabora el diseño básico: los atributos plurales se
llevan a tablas dependientes. • Ventajas del diseño utilizando la forma de filas:
◊ Generalmente ocupa mucho menos espacio de almacenamiento, es decir, es más compacta. ◊ La cantidad de trabajo, desde el punto de vista físico, es menor. ◊ Se necesitan menos tablas (cuando existen otros atributos singulares). ◊ Es la forma natural de presentar informes al usuario final.
• Ventajas del diseño utilizando la forma columnar: ◊ Es la forma natural como trabaja el modelo relacional. ◊ La mayoría de los atributos plurales se deben llevar a forma columnar, es decir, utilizando tablas
dependientes. ◊ Más fácil de mantener, sobretodo cuando el vector cambia de longitud. ◊ Presenta ventajas cuando hay casos de valores nulos. ◊ Los procedimientos y/o funciones imp lementados por los DBMS generalmente trabajan mejor,
porque existe una mejor compatibilidad. Además las sentencias SQL son más sencillas y la probabilidad de error que comete el usuario al escribirlas es menor.
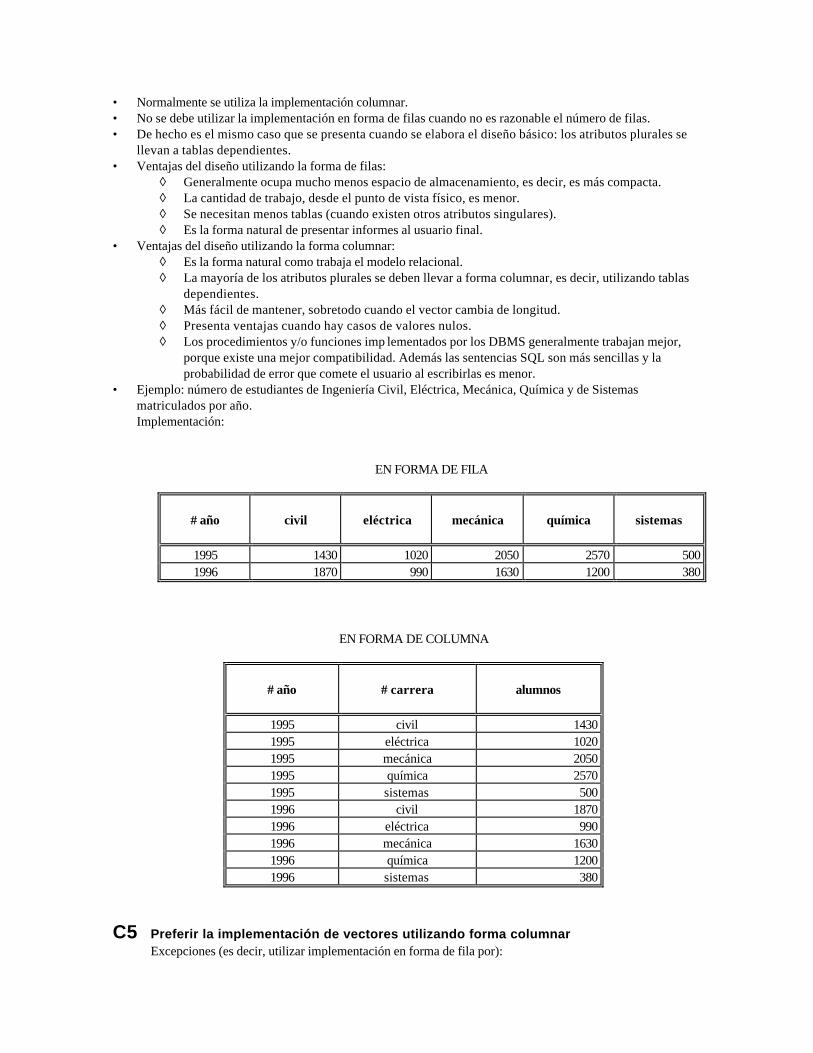
• Ejemplo: número de estudiantes de Ingeniería Civil, Eléctrica, Mecánica, Química y de Sistemas matriculados por año.
Implementación:
EN FORMA DE FILA
# año
civil
eléctrica
mecánica
química
sistemas
1995 1430 1020 2050 2570 500 1996 1870 990 1630 1200 380 EN FORMA DE COLUMNA
# año
# carrera
alumnos
1995 civil 1430 1995 eléctrica 1020 1995 mecánica 2050 1995 química 2570 1995 sistemas 500 1996 civil 1870 1996 eléctrica 990 1996 mecánica 1630 1996 química 1200 1996 sistemas 380
C5 Preferir la implementación de vectores utilizando forma columnar Excepciones (es decir, utilizar implementación en forma de fila por):

◊ Tamaño físico. ◊ Acceso del usuario. ◊ Número de tablas.
7.5 Sobrecarga de columnas • Columna sobrecargada: cuando en una columna existen dos o más atributos. • Existen tres casos importantes de columnas sobrecargadas: alternación, codificación y traslape.
7.5.1 Atributos alternos • Dos o más atributos se alternan en diferentes filas de una columna. • Es posible que columnas definidas así conduzcan a resultados que cualitativamente no tienen significado
o sean erróneamente interpretados. • La aparición de este tipo de columnas reflejan fallas de la etapa de análisis. • Tener valores no comparables en una columna son causa de errores. • Emplear nombres distintos de columnas para representar atributos diferentes y considerar la posibilidad
de utilizar subtablas. • En caso de utilizar supertablas, se definen tantas columnas como atributos diferentes se tengan y se
preveé la utilización de valores nulos donde no aplique (los nulos son indeseables, pero son preferibles a tener atributos alternos).
• Ejemplo: En la tabla ATR_ALT que se muestra, aparece una columna identificada como cantidad. Para los programadores significa la cantidad de líneas de código producidas por ellos en un mes y Para los vendedores significa la cantidad en pesos vendidos en un mes. En este caso cantidad es un homónimo para representar dos cosas diferentes. No tendría significado hacer cálculos como suma o promedio sobre esta columna. Una posible solución sería definir dos atributos: uno para líneas_de_código y otro para
cantidad_en_pesos y asignárselos a las subentidades PROGRAMADOR y VENDEDOR. Otras soluciones posibles serían: definir dos subtablas separadas o crear una supertabla con valores nulos en los sitios donde no aplica el concepto.
ATR_ALT
# empleado
ocupación
cantidad
e1 Programador 2550 e2 Programador 1820 e3 Vendedor 300.000 e4 Programador 3278 e5 Vendedor 450.782
7.5.2 Atributos codificados • Atributos con significado codificado no son claros, especialmente para programadores y usuarios. • En atributos codificados generalmente se encuentran dos o más atributos en una sola columna. • Se utiliza concatenación o codificación. • Son esquemas incómodos y propensos a errores. • Los programadores y usuarios deben entenderlos muy bien para codificarlos y decodificarlos
apropiadamente. • Se presta para que en casos críticos, se empiecen a tomar medidas de excepción (poco aconsejables).

• Es una buena solución, cuando en la columna que se aplica codificación sólo existe un atributo (pensando en ahorro de espacio en dispositivos para almacenamiento de datos).
• No es una solución deseable si la columna que se codifica tiene inmersos dos o más atributos. • Ejemplos:
◊ De columna concatenada: En la columna descripción se desea representar la combinación de características de transmisión
de un vehículo y características de la caja de cambios: CONCATENADA
descripción
4ruedas/4velocidades 4ruedas/5velocidades 4ruedas/automática 2ruedas/4velocidades
◊ De columna codificada: En la columna empleado se desea representar en tres posiciones digitales lo siguiente:
Último dígito para representar el tipo de contrato, así: si es par quiere decir que trabaja a comisión y si es impar que trabaja a salario fijo.
Primer y segundo dígito para un número secuencial. CODIFICADA
empleado
325 672 744 827
◊ Caso crítico: Supongamos que en caso anterior más del sesenta por ciento (60%) son empleados a comisión.
Entonces se decide que todos los empleados con código mayor que .... son a comisión (hay que aplicar un caso de excepción).
7.5.3 Valores traslapados • Se presenta el caso de valores traslapados cuando en una columna existen valores que no son
mutuamente excluyentes. • Valores traslapados es equivalente a implementar atributos plurales como singulares. • Ejemplo: En la columna estado se quiere representar el estado en que está un estudiante en la universidad:
estudiante con matrícula de honor, becario, con préstamo beca. Podemos observar que un estudiante puede simultáneamente tener uno o más de esos estados. ESTUDIANTE

# código
. . . . .
estado
212432 . . . . . Matrícula de honor 233922 . . . . . Becario 243475 . . . . . Con préstamo beca 253963 . . . . . Becario 274937 . . . . . Becario • Implementar atributos plurales en tablas dependientes FORMA_COLUMNAR
# código
estado
212432 Matrícula de honor 212432 Becario 212432 Con préstamo beca 253963 Becario 274937 Becario • Si el atributo plural es un vector, considerar una tabla con solución en forma de fila. FORMA_DE_FILA
# código
matr_honor
becario
con_préstamo
212432 sí sí sí 253963 no sí no 274937 no sí no
7.6 Tratamiento general para columnas sobrecargadas • Añadir una columna por cada atributo, cargar y actualizar el software. • Separar información codificada en columnas separadas. • Borrar la(s) columna(s) sobrecargada(s) y derivarla como sea necesario. Si no es derivable de la
información codificada en columnas, se deben mantener ambas. Esto causa redundancia pero es preferible al hecho de tener que constantemente codificar y decodificar.
C6 Evitar columnas con atributos alternos, codificados o traslapados
7.7 Sobrenormalización • Descomponer tablas más allá de lo requerido por 3FN, para obtener mejor rendimiento. • Pregunta: Qué nivel de sobrenormalización optimiza el rendimiento de una consulta crítica? Respuesta muy difícil de contestar en términos generales.

EMPLEADO_1 EMPLEADO_2 # empleado nombre apellido #empleado cargo depto e1 Alejandro López e1 programador c3 e2 Carolina Torres e2 vendedor c2 e3 Leonardo Mahecha e3 vendedor c2 e4 Sergio Sandoval e4 investigador c1 e5 Johana Pastrana e5 programador c3 e6 Cesar Valencia e6 programador c3 EMPLEADO_3 # empleado no_identificación sexo esposo e1 19’422.375 masculino e2 e2 79’395.883 femenino e1 e3 3’684.844 masculino nulo e4 3’573.531 masculino nulo e5 33’738.218 femenino e6 e6 43’894.824 masculino e5
7.7.1 Consideraciones para sobrenormalizar • Existen datos poco importantes en una tabla crítica. • Existen columnas que tienen amplia información descriptiva. • Una fila ocupa más de una unidad física de asignación. • En el caso de datos compartidos en L, estrictamente hablando, es un caso particular de
sobrenormalización: la subtabla y la supertabla son soluciones en 3 FN. • Utilizar subtablas puede ser el resultado de descomponer tablas más allá de 3FN. • La sobrenormalización puede potencialmente dar mejor rendimiento. Considerar siguientes casos:
◊ Concurrencia (acceso simultáneo): cuando dos o más usuarios acceden al mismo tiempo a una tabla y al menos uno de ellos está actualizando una fila los otros no pueden trabajarla.
Si los usuarios están accediendo columnas diferentes, una posible solución para evitar conflictos y dar mejor rendimiento es separar atributos en tablas diferentes.
◊ Frecuencia de las consultas. ◊ Columnas pocas veces consultadas. ◊ Actualización de datos.
• Sobrenormalizar no es sinónimo de redundancia. • El rendimiento es el que fija el mejor nivel de sobrenormalización. • Primero ver exhaustivamente soluciones a nivel físico. Generalmente corregir un error a nivel físico es más sencillo que uno de orden lógico.
T7 Sobrenormalizar para buscar rendimiento, cuando sea necesario
7.8 Desnormalización • Significa unir subtablas en tablas con el objeto de evitar encadenamientos (joins). • Se termina en 1FN ó 2FN. • Introduce redundancia.

• Puede presentar problemas al actualizar datos. Por tal razón tratar de elaborar las actualizaciones sobre tablas que estén mínimo en 3FN.
• Es una solución muy controvertible. • Aceptada cuando de otra forma no se obtiene el mínimo rendimiento exigido. • Desnormalizar selectivamente: los problemas de rendimiento usualmente están localizados en unas pocas
tablas. • Primero ver exhaustivamente soluciones a nivel físico.
T8 Desnormalizar para buscar rendimiento, como último recurso
7.9 Tablas snapshopt • Por razones de rendimiento se puede considerar el uso de tablas snapshopt. • Una tabla snapshopt es una tabla que tiene la imagen de un cierto instante de otra tabla. • La tabla snapshopt es fija en el tiempo, es decir, no debe ser actualizable. • Se puede duplicar muchas veces (replicar) para muchos usuarios. • Cada usuario la puede utilizar para tareas críticas. • Aquí la redundancia no es problema.
7.10 Documentación • En todos los casos anteriores hay que documentar apropiadamente explicando las conveniencias. • Se debe prever un plan de contingencia en caso de anomalías.

8. DISEÑO FÍSICO
8.1 Alcance • Para mejorar aspectos del diseño relacional avanzado. • Planteado como de tipo introductorio para un estudio más exhaustivo. • Para clarificar algunos aspectos del diseño relacional. • Para aprender algunas diferencias, por ejemplo entre llaves e índices. • Para entender aspectos de independencia física de los datos. • Para cubrir aspectos que son invisibles para las aplicaciones y los usuarios. • Para dar soluciones a problemas de rendimiento Mejorando:
◊ Operaciones de entrada/salida a disco. ◊ Utilización de la memoria principal. ◊ Utilización de CPU. ◊ Tráfico en los buses. ◊ Tráfico en la red.
Evitando: ◊ Cuellos de botella. ◊ Bloqueos indeseados. ◊ Competencias indeseadas (por la utilización de recursos). ◊ Respuestas lentas.
8.2 Lista de operaciones críticas • Elaborar lista con las operaciones críticas. Considerar:
◊ Alto volúmen. ◊ Tiempo aceptable para respuesta. ◊ Frecuencia de uso. ◊ Tipo de acceso:
∗ Consulta. ∗ Actualización. ∗ Adición. ∗ Borrado.
◊ Tipo de ejecución: ∗ Batch. ∗ Interactivo.
◊ Tipo de presentación de resultados: ∗ Aleatorio. ∗ Ordenados.
◊ Tablas accedidas: ∗ Una. ∗ Varias (con operaciones de encadenamiento, joins).
◊ Filas recuperadas: ∗ Una. ∗ Varias.

8.3 Índices • Definidos para hacer una determinada presentación de información. • Generalmente la secuencia lógica de valores se presenta ordenado según su valor aritmético o su posición
en el diccionario. • La secuencia física, depende de la manera como los organice el DBMS. En el caso de Sybase, la secuencia física de filas de una tabla tiene que ver con:
La secuencia lógica de páginas en el disco, y La secuencia física de filas en la página.
• Columna tipo cluster: aquella donde la secuencia lógica de valores concuerda con la secuencia física de filas.
TABLA ORDENADA PÁGINA 0 PÁGINA 1 PÁGINA 2 . . . 100 Diego 115 Marleny 135 Juan 102 Jorge 117 Gladys 140 Adriana 103 Fernando 119 Richard 153 Rosa 110 Nubia 120 Cristian 177 Marina 111 Néstor 128 Allison 189 Pilar
8.3.1 Índice tipo cluster • Índice sobre un columna: Los valores de la columna están almacenados ordenadamente con apuntadores a la fila que contiene el
correspondiente valor. • Índice compuesto: índice definido sobre varias columnas. • Índice tipo cluster: índice sobre una columna tipo cluster. • Índice tipo no cluster: índice sobre una columna no organizada (tipo no cluster).
8.3.2 Índice denso • Índice denso: contiene una entrada por cada fila de la tabla. • Índice no denso: contiene una entrada por cada página de la tabla. • Los índices no cluster son necesariamente densos. • Los índices no densos ocupan menos espacio y el acceso a datos es más rápido.
8.3.3 Índice organizado en forma de árbol • Generalmente los índices se encuentran organizados en forma de árbol para accesos más rápidos. • En índices densos organizados en forma de árbol se tiene la siguiente relación para hacer estimativos:
R = ( P / W ) ̂L Donde:
R Número de filas en la tabla. P Tamaño de la página de índices (en bytes). W Tamaño del índice (en bytes, incluyendo lo ocupado por el apuntador). L Número de niveles del índice.

Ejemplo:
Tamaño de página: 2000 bytes. Tamaño del índice: 10 bytes. Número de niveles: 3 Entonces el número de filas que puede manejar es: 8’000.000 R = ( 2000 / 10 ) ^ 3 = 8’000.000
• En índices no densos se tiene un nivel menos que en índices densos, para la misma tabla. • En la práctica, índices densos organizados en forma de árbol tienen por lo menos tres niveles. • Generalmente, uno o dos niveles se encuentran en memoria. Esto hace que la localización se haga con un
buen tiempo de respuesta.
8.4 Diseño para índices tipo cluster • Solamente se puede tener un índice tipo cluster por tabla. • Índices tipo cluster en Sybase:
◊ El nivel más bajo está encadenado al superior para acceso secuencial. ◊ No densos
• El rompimiento de índices son siempre de la misma longitud (árboles beta). • La inserción o actualización puede causar la apertura de una página, la cual se puede propagar a través de
los índices y crear un nuevo nivel.
8.4.1 Características de rendimiento • Los índices tipo cluster son efectivos para:
◊ Consultas ordenadas. ◊ Consultas con respuesta de muchas filas. ◊ Consultas a una fila. ◊ Acceso a un valor parcial del índice.
• Robusto para tablas que crecen. • Sobrecarga para operaciones que impliquen ajuste, inserción o actualización de índices.
8.4.2 Tablas sin índice tipo cluster • Las nuevas filas se insertan al final de la tabla. • Espacio de filas borradas no se recupera hasta cuando exista reorganización. • Preferido para tablas temporales o “pequeñas”. • Poco efectivas en tablas “grandes” o “medianas” para alcanzar:
◊ Una fila. ◊ Respuesta ordenada.
P2 Crear para cada tabla un índice tipo cluster (usualmente sobre la llave primaria)
8.5 Diseño para índices tipo no cluster • En una tabla se pueden tener varios índices tipo no cluster. • Operaciones sobre columnas que no tienen índice tipo cluster debe hacerse a través de tablas de
búsqueda o por medio de índices no cluster. • Hit radio: porcentaje de filas seleccionadas en una consulta. También denominado filter o selectivity.

• Los índices no cluster son efectivos cuando el porcentaje de filas seleccionadas en una consulta (hit radio) es bajo.
• Aconsejable en columnas: ◊ Con característica de llave foránea. ◊ Que aparezcan en claúsualas WHERE del SQL, especialmente en columnas utilizadas para
encadenamiento (joins). • Los índices de tamaño pequeño son más compactos, tienen menos niveles y son más eficientes. • La longitud de un índice generalmente está limitada. • Tener buen juicio para definir el número de índices tipo no cluster en una tabla.
P3 Crear índices tipo no cluster (considerar las columnas definidas como llaves foráneas)

9. REGLAS DE CODD Reglas publicadas por E.F. Codd en octubre de 1985 en la revista COMPUTERWORLD. Acogidas prácticamente por todos los proveedores de DBMS de tipo relacional.
9.1 Regla 0 Un paquete de base de datos relacional debe estar en capacidad de manejar totalmente la base de datos a través de sus capacidades relacionales.
9.2 Regla 1 - Regla de información Toda la información en paquetes de base de datos relacionales deben estar representadas explícitamente en niveles lógicos como valores en tablas.
9.3 Regla 2 - Acceso garantizado A cada valor en la base de datos relacional se debe garantizar su acceso lógico a través de una combinación del nombre de la tabla, valor de la llave primaria y nombre de columna.
9.4 Regla 3 - Valores nulos Se debe permitir el uso de valores nulos (diferentes de valores por omisión) para representar en forma sistemática valores “no conocidos” o “no alicables” (independientes del dominio).
9.5 Regla 4 - Catálogo relacional dinámico en línea La descripción de bases de datos debe representarse en niveles lógicos de tablas, tal como si fueran datos ordinarios.
9.6 Regla 5 - Sublenguaje de datos comprensivo Debe existir al menos un lenguaje (1) cuyas sentencias se expresen por medio de una sintaxis bien definida y (2) que sea comprensible (que soporte definición de datos, definición de vistas, manejo de datos, reglas de integridad, autorización y límites de transacción).
9.7 Regla 6 - Actualización de vistas Todas las vistas que son teóricamente actualizables también deben ser actualizables por el sistema.
9.8 Regla 7 - Nivel de operaciones El nivel de procesamiento aplica no solo a la recuperación de información sino también para operaciones de inserción, actualización y borrado.

9.9 Regla 8 - Independencia física de datos Programas de aplicación o actividades terminales permanecen (lógicamente) intactas cuando los cambios se hacen en memoria o por métodos de acceso.
9.10 Regla 9 - Independencia lógica de datos Programas de aplicación o actividades terminales permanecen (lógicamente) intactas cuando los cambios se hacen en la información almacenada en la base de datos (para posible ampliación).
9.11 Regla 10 - Independencia de integridad Las reglas de integridad deben poderse definir utilizando el sublenguaje de datos relacional y deben poderse almacenar en el catálogo (no en los programas de aplicación).
9.12 Regla 11 - Independencia de distribución Programas de aplicación o actividades terminales permanecen (lógicamente) intactas cuando se hace la distribución inicial de datos o cuando los datos se redistribuyen.
9.13 Regla 12 - No subversión Las reglas de integridad expresadas a nivel del lenguaje relacional no pueden ser cambiadas por lenguajes de bajo nivel.


















